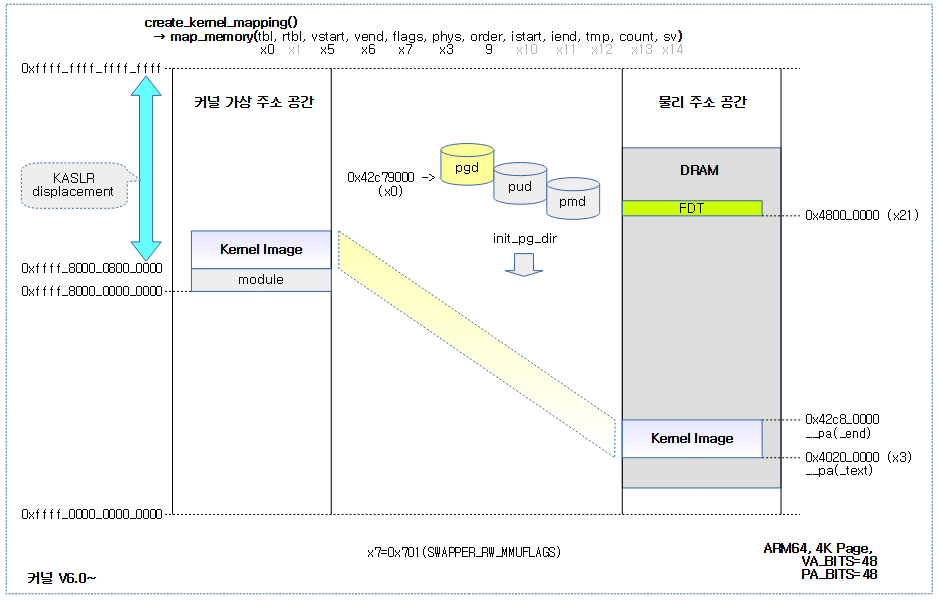
<kernel v5.4>
Scheduler -3- (PELT-2)
PELT Migration Propagation
kernel/sched/fair.c
/* * When on migration a sched_entity joins/leaves the PELT hierarchy, we need to * propagate its contribution. The key to this propagation is the invariant * that for each group: * * ge->avg == grq->avg (1) * * _IFF_ we look at the pure running and runnable sums. Because they * represent the very same entity, just at different points in the hierarchy. * * Per the above update_tg_cfs_util() is trivial and simply copies the running * sum over (but still wrong, because the group entity and group rq do not have * their PELT windows aligned). * * However, update_tg_cfs_runnable() is more complex. So we have: * * ge->avg.load_avg = ge->load.weight * ge->avg.runnable_avg (2) * * And since, like util, the runnable part should be directly transferable, * the following would _appear_ to be the straight forward approach: * * grq->avg.load_avg = grq->load.weight * grq->avg.runnable_avg (3) * * And per (1) we have: * * ge->avg.runnable_avg == grq->avg.runnable_avg * * Which gives: * * ge->load.weight * grq->avg.load_avg * ge->avg.load_avg = ----------------------------------- (4) * grq->load.weight * * Except that is wrong! * * Because while for entities historical weight is not important and we * really only care about our future and therefore can consider a pure * runnable sum, runqueues can NOT do this. * * We specifically want runqueues to have a load_avg that includes * historical weights. Those represent the blocked load, the load we expect * to (shortly) return to us. This only works by keeping the weights as * integral part of the sum. We therefore cannot decompose as per (3). * * Another reason this doesn't work is that runnable isn't a 0-sum entity. * Imagine a rq with 2 tasks that each are runnable 2/3 of the time. Then the * rq itself is runnable anywhere between 2/3 and 1 depending on how the * runnable section of these tasks overlap (or not). If they were to perfectly * align the rq as a whole would be runnable 2/3 of the time. If however we * always have at least 1 runnable task, the rq as a whole is always runnable. * * So we'll have to approximate.. :/ * * Given the constraint: * * ge->avg.running_sum <= ge->avg.runnable_sum <= LOAD_AVG_MAX * * We can construct a rule that adds runnable to a rq by assuming minimal * overlap. * * On removal, we'll assume each task is equally runnable; which yields: * * grq->avg.runnable_sum = grq->avg.load_sum / grq->load.weight * * XXX: only do this for the part of runnable > running ? * */
엔티티의 마이그레이션 시 엔티티가 PELT 계층 구조에 가입/탈퇴할 때 그 기여도를 전파(propagate)해야 한다. 이 전파의 핵심은 불변성이다.
- 다음 약자를 혼동하지 않도록 한다.
- tg: 태스크 그룹 (struct task_group *)
- ge: 그룹 엔티티 (struct sched_entity *)
- grq: 그룹 cfs 런큐 (struct cfs_rq *)
- (1) ge->avg == grq->avg
- 그룹을 대표하는 그룹 엔티티의 로드 통계와 그룹 cfs 런큐의 통계는 같다.
- 순수(pure) 러닝 합계와 순수(pure) 러너블 합계를 검토한다. 왜냐하면 그들은 계층의 서로 다른 지점에서 매우 동일한 엔티티를 표현하고 있기 때문이다.
- update_tg_cfs_util()은 간단하게 러닝 합계를 상위로 복사한다.
- 복사한 값은 서로 다른 PELT 계층 구조에서 윈도우가 정렬되어 있지 않기 때문에 약간 다르므로 잘못되었다.
- 추후 커널 v5.8-rc1에서 그룹 엔티티와 그룹 cfs 런큐 사이의 PELT window를 정렬하여 약간의 잘못된 점을 바로 잡았다.
- 참고: sched/pelt: Sync util/runnable_sum with PELT window when propagating (2020, v5.8-rc1)
- (2) ge->avg.load_avg = ge->load.weight * ge->avg.runnable_avg
- 그룹 엔티티의 로드 평균은 그룹 엔티티의 러너블 평균에 가중치(weight)를 곱한 값이다.
- (3) grq->avg.load_avg = grq->load.weight * grq->avg.runnable_avg
- util과 마찬가지로, 러너블 파트는 직접 이전할 수 있어야 하므로 직선적 전진 접근방식이 될 것이다
- (4) ge->avg.load_avg = ge->load.weight * grq->avg.load_avg / grq->load.weight
- (2)번 수식을 사용하고 싶지만, 엔티티의 러너블 평균 대신 (3)번과 같이 cfs 런큐의 러너블 평균을 사용한다.
- (1) 번에서 말한 것처럼 ge->avg.runnable_avg == grq->avg.runnable_avg 이다. 이를 이용하여 (4)번 수식이 성립한다.
다만 위의 접근식에는 다음과 같은 잘못된 점이 있다.
- historical weights는 중요하지 않지만 cfs 런큐는 순수한 러너블 로드를 산출할 수 없어 historical weights를 고려한다는 점
- cfs 런큐의 historical weights를 포함하는 로드 평균은 블럭드 로드(uninterruptible 상태의 슬립 태스크지만 금방 깨어날거라 예상)를 포함한다는 점 때문에 (3)번으로 해결할 수 없다. 산술적으로 슬립상태의 태스크를 로드로 계산해야 하므로 정확히 산출할 수 없다.
- 또 다른 이유로 러너블 기간이 얼마나 중복되는지를 정확히 알 수 없다.
- 러너블이 0-sum 엔티티가 아니다.
- 각각 2/3가 러너블한 2개의 작업이 포함된 rq를 상상해 보자. 그런 다음, rq 자체는 이러한 작업의 러너블 섹션이 어떻게 겹치는지에 따라 2/3와 1 사이의 어느 곳에서나 실행될 수 있다(또는 그렇지 않다). 만약 전체적으로 rq를 완벽하게 정렬한다면, 그 시간의 2/3가 실행될 수 있을 것이다.
- 최소 하나의 실행 가능한 작업을 가지고 있다면, rq 전체는 항상 러너블 상태이다.
그래서 제약 조건을 주면 :
- ge->avg.running_sum <= ge->avg.runnable_sum <= LOAD_AVG_MAX
- 러너블을 추가 시 최소한의 중복(overlap)을 가정한다.
- 얼마 기간이 겹쳤는지 모른다. 이러한 경우에는 최소한의 중복(overlap) 기간만을 사용한다.
- 제거시 각 작업을 동일하게 실행할 수 있다고 가정한다.
- grq-> avg.runnable_sum = grq-> avg.load_sum / grq-> load.weight
다음 그림은 그룹 엔티티와 cfs 런큐의 로드 평균에 대해 이론적으로 동일하다는 것을 보여준다.
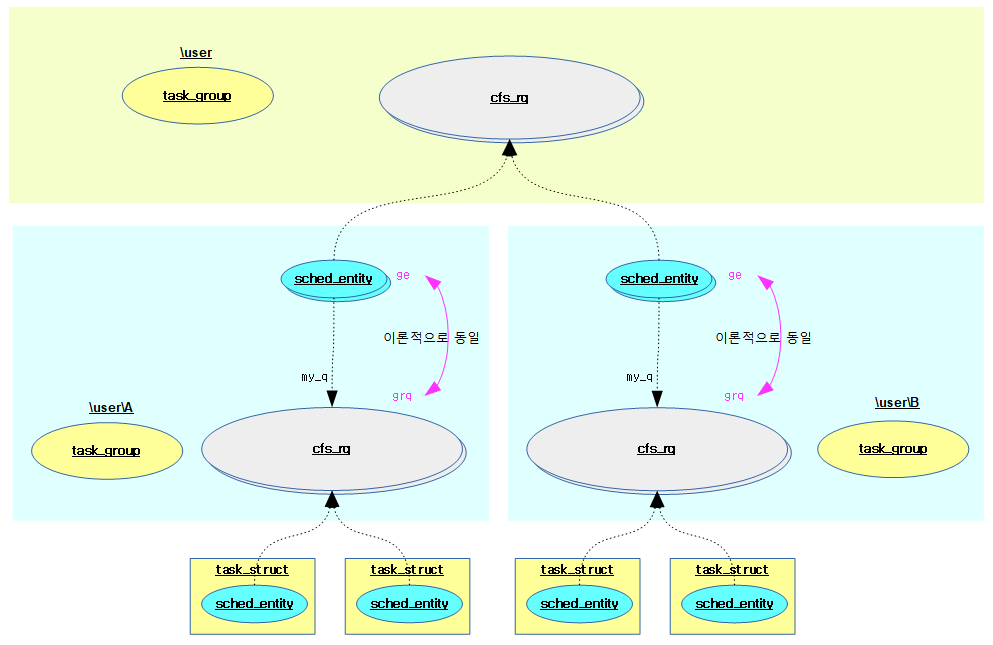
다음은 그룹 엔티티와 cfs 런큐의 로드 평균이 실제로는 약간 다른 것을 보여준다.
cfs_rq[5]:/B .exec_clock : 143287629.494567 .MIN_vruntime : 0.000001 .min_vruntime : 143287628.829813 .max_vruntime : 0.000001 .spread : 0.000000 .spread0 : -625159177.736145 .nr_spread_over : 0 .nr_running : 1 .load : 1024 .load_avg : 1004 .runnable_load_avg : 1004 .util_avg : 459 .removed_load_avg : 0 .removed_util_avg : 0 .tg_load_avg_contrib : 1007 .tg_load_avg : 1007 .throttled : 0 .throttle_count : 0 .se->exec_start : 1193546377.026124 .se->vruntime : 179287288.570602 .se->sum_exec_runtime : 143287629.494567 .se->statistics.wait_start : 0.000000 .se->statistics.sleep_start : 0.000000 .se->statistics.block_start : 0.000000 .se->statistics.sleep_max : 0.000000 .se->statistics.block_max : 0.000000 .se->statistics.exec_max : 1.007417 .se->statistics.slice_max : 10.040917 .se->statistics.wait_max : 22.002458 .se->statistics.wait_sum : 5636994.599562 .se->statistics.wait_count : 19461708 .se->load.weight : 1024 .se->avg.load_avg : 1007 .se->avg.util_avg : 460
다음 그림은 태스크가 있는 태스크 그룹내에서 로드 평균을 관리하는 모습을 보여준다.
- 엔티티 —(add)—> cfs 런큐 —(sum)—> 태스크 그룹
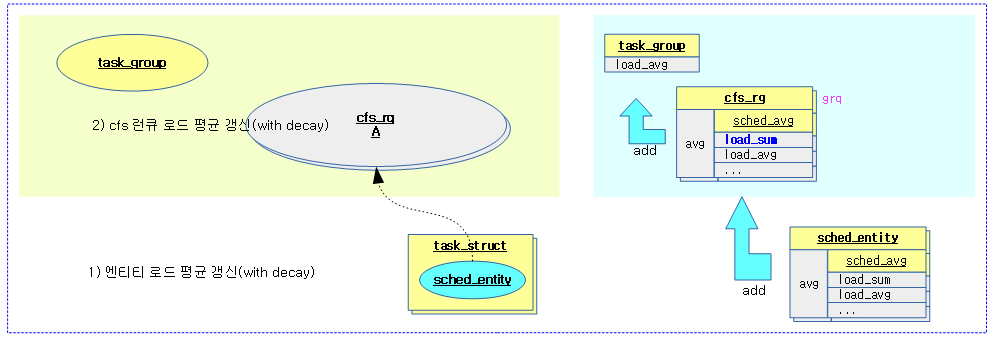
다음 그림은 attach 또는 detach 태스크 시 상위로 러너블 합계를 전파하기 위해 설정하는 모습을 보여준다.
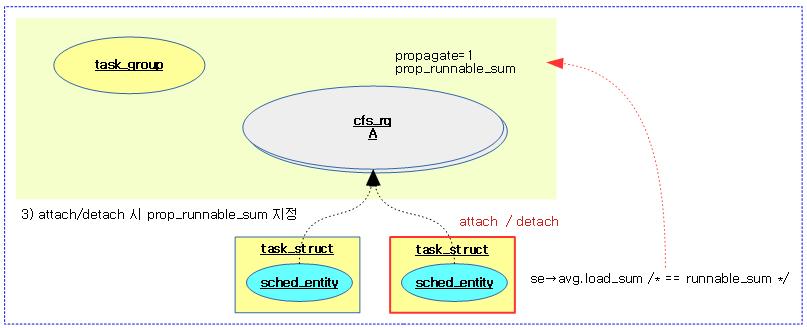
다음 그림은 attach 또는 detach 태스크되는 그룹의 상위 그룹에서 그룹 엔티티와 cfs 런큐의 로드 평균이 갱신되는 과정을 보여준다.
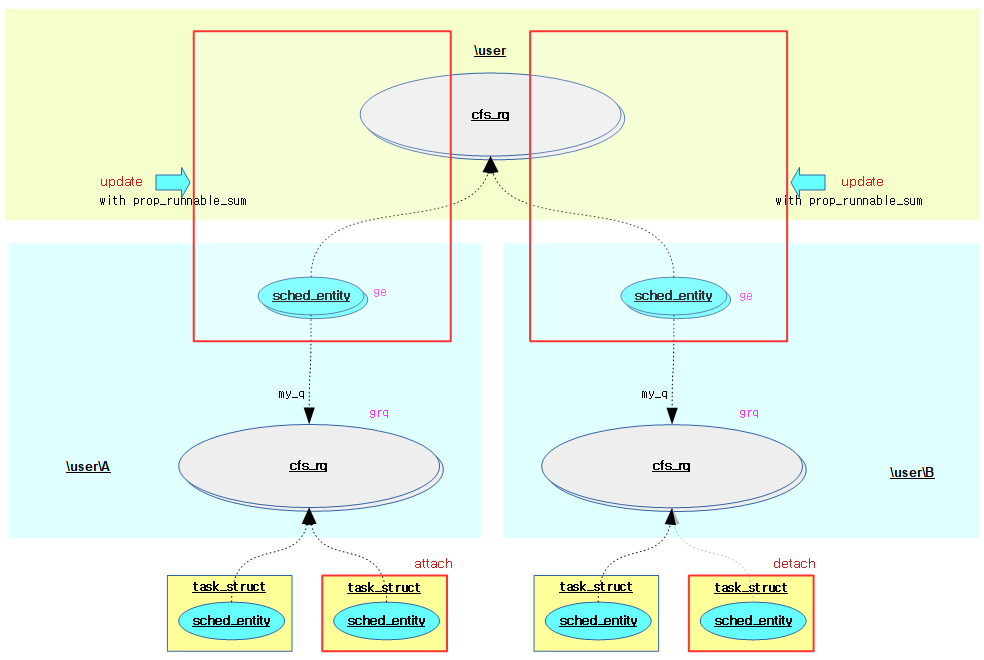
다음 그림은 attach/detach된 엔티티의 +-load_sum을 상위 cfs 런큐로 전파(propagate)한 후 변화된 로드에 대해 그룹 엔티티 및 cfs 런큐의 로드 평균들을 재산출하는 경로를 보여준다.
- attach_entity_load_avg() 또는 detach_entity_load_avg()
- attach/detach된 엔티티의 load_sum을 —–> 소속 cfs 런큐의 prop_runnable_sum에 기록해둔다.
- update_tg_cfs_runnable()
- 정규 그룹 엔티티 갱신시 하위의 그룹 cfs 런큐에서 전파 값을 읽어온 후 그룹 엔티티 및 cfs 런큐의 로드 평균들을 재산출한다.
태스크 그룹 유틸 갱신
update_tg_cfs_util()
kernel/sched/fair.c
static inline void
update_tg_cfs_util(struct cfs_rq *cfs_rq, struct sched_entity *se, struct cfs_rq *gcfs_rq)
{
long delta = gcfs_rq->avg.util_avg - se->avg.util_avg;
/* Nothing to update */
if (!delta)
return;
/*
* The relation between sum and avg is:
*
* LOAD_AVG_MAX - 1024 + sa->period_contrib
*
* however, the PELT windows are not aligned between grq and gse.
*/
/* Set new sched_entity's utilization */
se->avg.util_avg = gcfs_rq->avg.util_avg;
se->avg.util_sum = se->avg.util_avg * LOAD_AVG_MAX;
/* Update parent cfs_rq utilization */
add_positive(&cfs_rq->avg.util_avg, delta);
cfs_rq->avg.util_sum = cfs_rq->avg.util_avg * LOAD_AVG_MAX;
}
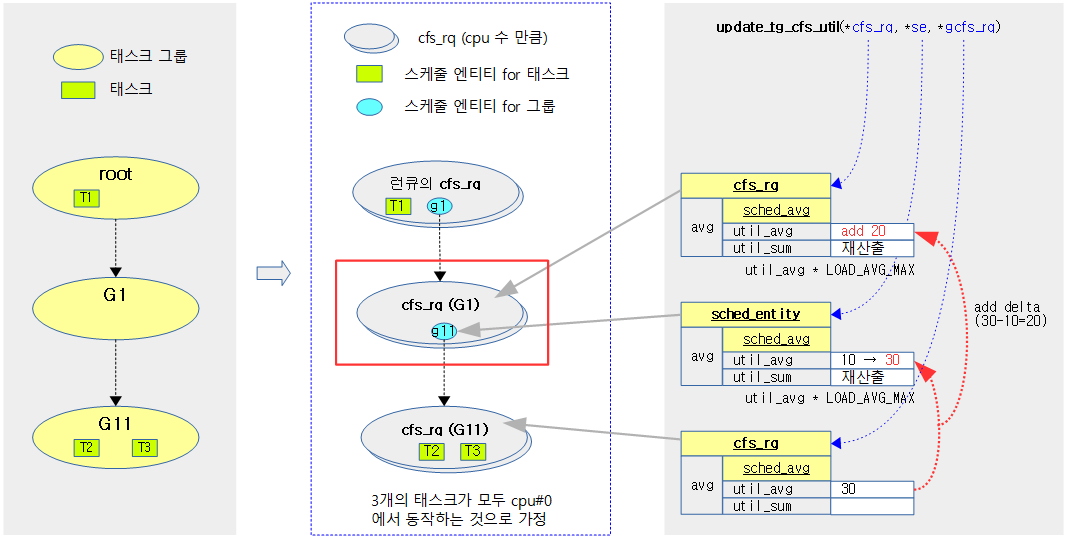
태스크 그룹 유틸을 갱신한다. (새 엔티티 attach 후 상위 태스크 그룹(그룹 엔티티 및 cfs 런큐) 갱신을 위해 진입하였다.)
- 코드 라인 4에서 그룹 cfs 런큐 @gcfs_rq의 유틸 평균에서 그룹 엔티티 @se의 유틸 평균을 뺀 delta를 구한다.
- 코드 라인 7~8에서 변화가 없으면 그냥 함수를 빠져나간다.
- 코드 라인 19에서 새 그룹 엔티티의 유틸 평균은 그룹 cfs 런큐의 유틸 평균을 그대로 사용한다.
- PELT 윈도우는 그룹 cfs 런큐와 그룹 엔티티간에 정렬되어 있지 않지만 추후 다음과 같이 패치되어 정렬되게 한다.
- 참고: sched/pelt: Sync util/runnable_sum with PELT window when propagating (2020, v5.8-rc1)
- PELT 윈도우는 그룹 cfs 런큐와 그룹 엔티티간에 정렬되어 있지 않지만 추후 다음과 같이 패치되어 정렬되게 한다.
- 코드 라인 20에서 새 그룹 엔티티의 유틸 합계를 갱신한다.
- 유틸 합계 = 유틸 평균 * 최대 로드 평균 기간
- 코드 라인 23에서 그룹 엔티티의 부모 cfs 런큐의 유틸 평균에 delta를 추가한다.
- 코드 라인 24에서 그룹 엔티티의 부모 cfs 런큐의 유틸 합계를 갱신한다.
- 유틸 합계 = 유틸 평균 * 최대 로드 평균 기간
다음 그림은 태스크 그룹에 대한 유틸을 산출하는 과정을 보여준다.
러너블 합계 상위 전파(propagate)
propagate_entity_load_avg()
kernel/sched/fair.c
/* Update task and its cfs_rq load average */
static inline int propagate_entity_load_avg(struct sched_entity *se)
{
struct cfs_rq *cfs_rq, *gcfs_rq;
if (entity_is_task(se))
return 0;
gcfs_rq = group_cfs_rq(se);
if (!gcfs_rq->propagate)
return 0;
gcfs_rq->propagate = 0;
cfs_rq = cfs_rq_of(se);
add_tg_cfs_propagate(cfs_rq, gcfs_rq->prop_runnable_sum);
update_tg_cfs_util(cfs_rq, se, gcfs_rq);
update_tg_cfs_runnable(cfs_rq, se, gcfs_rq);
trace_pelt_cfs_tp(cfs_rq);
trace_pelt_se_tp(se);
return 1;
}
attach/detach에 따라 러너블 로드의 상위 전파를 위한 값이 있으면 이를 현재 그룹 엔티티와 cfs 런큐에 반영하고, 상위에도 전파한다. 전파할 값이 있어 갱신된 경우 1을 반환하고, 전파할 값이 없어 갱신하지 않은 경우 0을 반환한다.
- 코드 라인 6~7에서 태스크용 엔티티인 경우 이 함수를 수행할 필요가 없으므로 0을 반환한다.
- 코드 라인 9~11에서 그룹 cfs 런큐에 propagate가 설정되지 않은 경우 0을 반환한다.
- 코드 라인 13에서 먼저 그룹 cfs 런큐에서 propagate를 클리어하고, 상위 cfs 런큐에 prop_runnable_sum을 전파한다.
- 코드 라인 15에서 그룹 엔티티와 cfs 런큐에서 util 로드를 갱신한다.
- 코드 라인 16에서 그룹 엔티티와 cfs 런큐에서 로드 및 러너블 로드를 갱신한다.
- 코드 라인 21에서 갱신을 하였으므로 1을 반환한다.
add_tg_cfs_propagate()
kernel/sched/fair.c
static inline void add_tg_cfs_propagate(struct cfs_rq *cfs_rq, long runnable_sum)
{
cfs_rq->propagate = 1;
cfs_rq->prop_runnable_sum += runnable_sum;
}
엔티티가 attach/detach 되거나 최상위 태스크 그룹까지 러너블 합계를 전파하도록 요청한다.
- 추후 update_tg_cfs_runnable() 함수에서 이 값을 읽어들여 사용한다. 읽어들인 후에는 이 값은 0으로 변경된다.
태스크 그룹 러너블 갱신
update_tg_cfs_runnable()
kernel/sched/fair.c
static inline void
update_tg_cfs_runnable(struct cfs_rq *cfs_rq, struct sched_entity *se, struct cfs_rq *gcfs_rq)
{
long delta_avg, running_sum, runnable_sum = gcfs_rq->prop_runnable_sum;
unsigned long runnable_load_avg, load_avg;
u64 runnable_load_sum, load_sum = 0;
s64 delta_sum;
if (!runnable_sum)
return;
gcfs_rq->prop_runnable_sum = 0;
if (runnable_sum >= 0) {
/*
* Add runnable; clip at LOAD_AVG_MAX. Reflects that until
* the CPU is saturated running == runnable.
*/
runnable_sum += se->avg.load_sum;
runnable_sum = min(runnable_sum, (long)LOAD_AVG_MAX);
} else {
/*
* Estimate the new unweighted runnable_sum of the gcfs_rq by
* assuming all tasks are equally runnable.
*/
if (scale_load_down(gcfs_rq->load.weight)) {
load_sum = div_s64(gcfs_rq->avg.load_sum,
scale_load_down(gcfs_rq->load.weight));
}
/* But make sure to not inflate se's runnable */
runnable_sum = min(se->avg.load_sum, load_sum);
}
/*
* runnable_sum can't be lower than running_sum
* Rescale running sum to be in the same range as runnable sum
* running_sum is in [0 : LOAD_AVG_MAX << SCHED_CAPACITY_SHIFT]
* runnable_sum is in [0 : LOAD_AVG_MAX]
*/
running_sum = se->avg.util_sum >> SCHED_CAPACITY_SHIFT;
runnable_sum = max(runnable_sum, running_sum);
load_sum = (s64)se_weight(se) * runnable_sum;
load_avg = div_s64(load_sum, LOAD_AVG_MAX);
delta_sum = load_sum - (s64)se_weight(se) * se->avg.load_sum;
delta_avg = load_avg - se->avg.load_avg;
se->avg.load_sum = runnable_sum;
se->avg.load_avg = load_avg;
add_positive(&cfs_rq->avg.load_avg, delta_avg);
add_positive(&cfs_rq->avg.load_sum, delta_sum);
runnable_load_sum = (s64)se_runnable(se) * runnable_sum;
runnable_load_avg = div_s64(runnable_load_sum, LOAD_AVG_MAX);
delta_sum = runnable_load_sum - se_weight(se) * se->avg.runnable_load_sum;
delta_avg = runnable_load_avg - se->avg.runnable_load_avg;
se->avg.runnable_load_sum = runnable_sum;
se->avg.runnable_load_avg = runnable_load_avg;
if (se->on_rq) {
add_positive(&cfs_rq->avg.runnable_load_avg, delta_avg);
add_positive(&cfs_rq->avg.runnable_load_sum, delta_sum);
}
}
하위 그룹 cfs 런큐에서 전파 받은 러너블 합계가 있는 경우 그룹 엔티티 및 cfs 런큐의 로드 평균을 갱신한다.
- 코드 라인 4~12에서 그룹 cfs 런큐에서 전파 받은 러너블 섬을 알아온 후 클리어해둔다. 이 값이 0이면 갱신이 필요 없으므로 그냥 함수를 빠져나간다.
- 전파 받은 gcfs_rq->prop_runnable_sum이 존재하는 경우 하위 그룹에서 엔티티가 attach(양수) 또는 detach(음수)된 상황이다.
attach/detach 엔티티로부터 propagate된 러너블 합계를 사용한 로드들 산출
- 코드 라인 14~20에서 하위 그룹에서 엔티티가 attach되어 전파 받은 러너블 합계에 현재 그룹 엔티티의 로드 합계를 추가한다. 단 이 값이 최대치 LOAD_AVG_MAX를 넘을 수는 없다.
- attach: runnable_sum = gcfs_rq->prop_runnable_sum + se->avg.load_sum
- 엔티티의 러너블 합계 증가 시 최고 LOAD_AVG_MAX를 초과할 수 없다.
- runnable_sum <= LOAD_AVG_MAX(47742)
- attach: runnable_sum = gcfs_rq->prop_runnable_sum + se->avg.load_sum
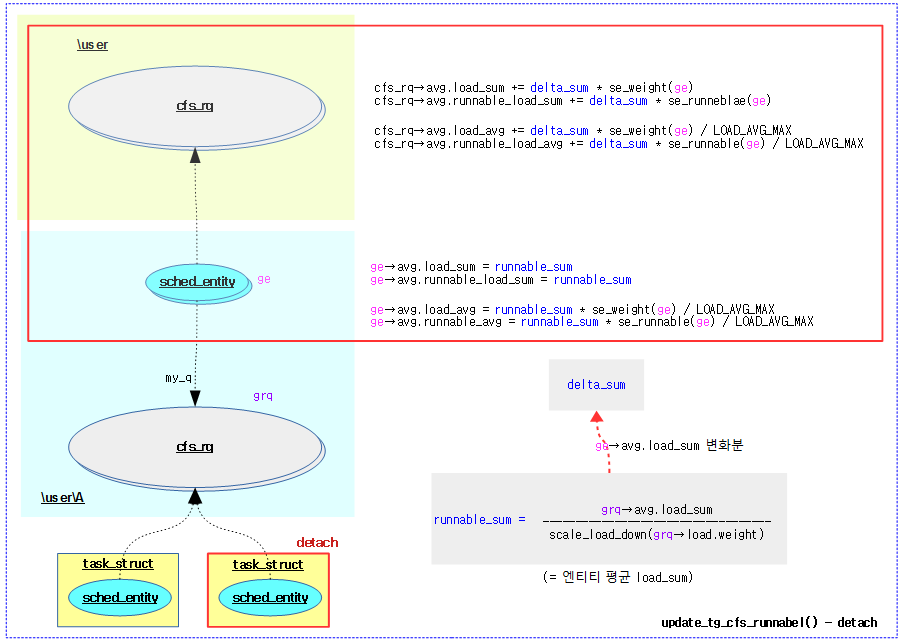
- 코드 라인 21~33에서 하위 그룹에서 엔티티가 detach되어 전파 받은 러너블 섬이 음수이면 이 값을 사용하지 않는다. 대신 하위 그룹 런큐에서 엔티티 평균 러너블 합계를 사용한다.
- 그룹 cfs 런큐의 로드 합계를 그룹 cfs 런큐의 로드 weight 값으로 나눈 값으로 대략적인 러너블 합계를 구한다. 단 이 값은 엔티티의 로드 합보다 더 커질 수는 없다.(detach되었는데 더 커지는 상황은 어울리지 않는다.)
- detach: runnable_sum = gcfs_rq->avg.load_sum / scale_load_down(gcfs_rq->load.weight)
- 엔티티의 러너블 합계 감소 시 엔티티의 로드 합계보다 작아질 수 없다.
- se->avg.load_sum <= runnable_sum
- 코드 라인 41~42에서 그룹에서 엔티티의 유틸 합계를 SCHED_CAPACITY_SHIFT(10) 비트만큼 스케일을 낮춰 러닝 합계를 구한다. 단 이 값은 러너블 합계보다 작지 않아야 한다.
- running_sum = se->avg.util_sum >> 10
- runnable_sum이 running_sum보다 작을 수는 없으므로 클립한다.
- running_sum <= runnable_sum
- running_sum = se->avg.util_sum >> 10
- 코드 라인 44~45에서 attach/detach 상황을 포함한 runnable_sum이 구해졌으므로 먼저 다음과 같이 runnable_sum에 엔티티의 로드 weight을 곱하여 반영된 로드 합계를 산출하고, 로드 평균은 최대 로드 평균 기간으로 나누어 산출한다.
- load_sum(weight 반영 상태) = se_weight(se) * runnable_sum
- load_avg = load_sum / LOAD_AVG_MAX(최대 로드 평균 기간)
그룹 엔티티에 새 로드 합계와 평균 반영
- 코드 라인 47~48에서 attach/detach 상황에서 산출한 로드 합계와 평균으로 기존 엔티티의 로드합계와 평균 사이의 차이(delta) 값을 구한다.
- delta_sum(weight 반영 상태) = load_sum – se_weight(se) * se->avg.load_sum
- delta_avg = load_avg – se->avg.load_avg
- 코드 라인 50~51에서 엔티티에 새롭게 산출된 로드 합계(weight 제거된)와 평균을 대입한다.
- se->avg.load_sum = runnable_sum
- se->avg.load_avg = load_avg
cfs 런큐에 엔티티 로드 변화분(delta)을 반영
- 코드 라인 52~53에서 cfs 런큐의 로드 평균과 로드 합계에 위에서 산출한 델타 평균과 합계를 추가한다.
- cfs_rq->avg.load_sum(weight 반영 상태) += delta_sum
- cfs_rq->avg.load_avg += delta_avg
그룹 엔티티에 러너블 로드 합계와 평균 반영
- 코드 라인 55~56에서 러너블 로드 합계와 평균을 산출한다.
- runnable_load_sum(weight 반영 상태) = se->runnable(se) * runnable_sum
- runnable_load_avg = runnable_load_sum / LOAD_AVG_MAX(최대 로드 평균 기간)
- 코드 라인 57~58에서 재산출된 러너블 로드 합계와 평균에서 기존 엔티티의 러너블 로드 합계와 평균 사이의 차이(delta) 값을 구한다.
- delta_sum = runnable_load_sum – se_weight(se) * se->avg.runnable_load_sum
- delta_avg = runnable_load_avg – se->avg.runnable_load_avg
- 코드 라인 60~61에서 엔티티의 러너블 로드 합계 및 평균에 산출해둔 러너블 로드 합계와 러너블 로드 평균을 대입한다.
- se->avg.runnable_load_sum(weight 미반영 상태) = runnable_sum
- se->avg.runnable_load_avg = runnable_load_avg
cfs 런큐에 러너블 로드 합계와 평균 변화분 추가
- 코드 라인 63~66에서 엔티티가 런큐에 있어 러너블 상태인 경우 cfs 런큐의 러너블 로드 합계와 평균에 위에서 산출해둔 델타 합계와 평균을 추가한다.
- cfs_rq->avg.runnable_load_sum += delta_sum
- cfs_rq->avg.runnable_load_avg += delta_avg
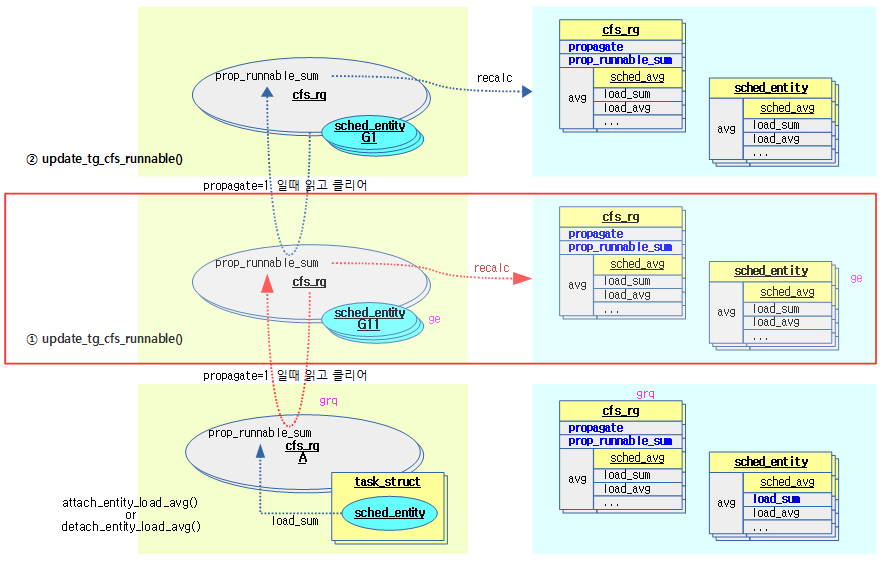
다음 그림은 엔티티 attach 상황에서 상위 그룹의 로드 평균을 갱신하는 과정을 보여준다.
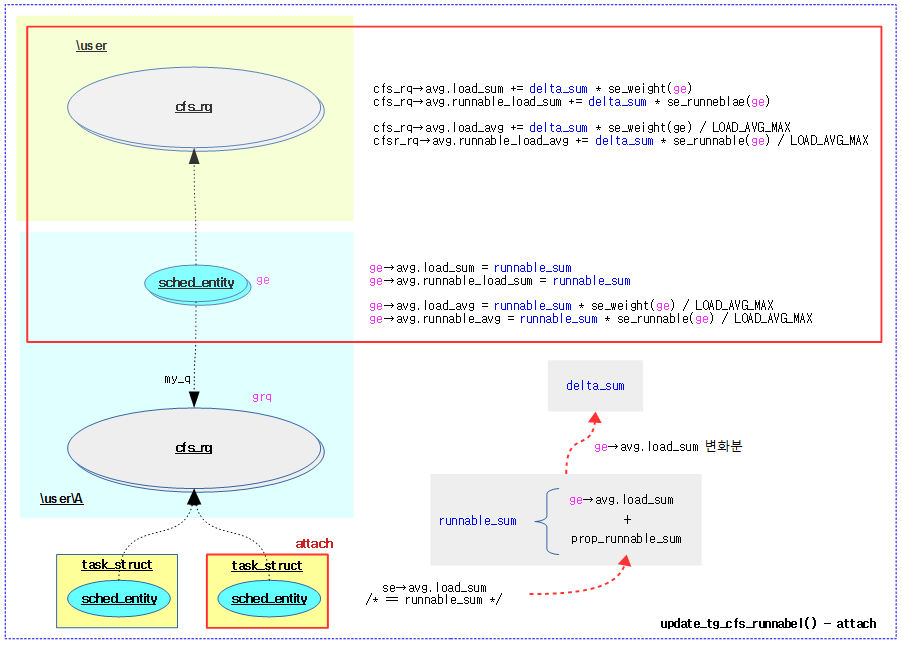
다음 그림은 엔티티 attach 상황에서 상위 그룹의 로드 평균을 갱신하는 과정을 보여준다.
태스크용 엔티티 -> CFS 런큐 -> 그룹 엔티티의 로드 관계
/* * sched_entity: * * task: * se_runnable() == se_weight() * * group: [ see update_cfs_group() ] * se_weight() = tg->weight * grq->load_avg / tg->load_avg * se_runnable() = se_weight(se) * grq->runnable_load_avg / grq->load_avg * * load_sum := runnable_sum * load_avg = se_weight(se) * runnable_avg * * runnable_load_sum := runnable_sum * runnable_load_avg = se_runnable(se) * runnable_avg * * XXX collapse load_sum and runnable_load_sum * * cfq_rq: * * load_sum = \Sum se_weight(se) * se->avg.load_sum * load_avg = \Sum se->avg.load_avg * * runnable_load_sum = \Sum se_runnable(se) * se->avg.runnable_load_sum * runnable_load_avg = \Sum se->avg.runable_load_avg */
엔티티:
태스크용 엔티티:
- se_runnable() == se_weight()
- 태스크용 엔티티는 러너블과 러닝 비율이 항상 같으므로 러너블 가중치와 로드 가중치가 항상 같다.
그룹 엔티티:
- update_cfs_group() -> calc_group_shares() – (3)번 참고:
- grq->load_avg
- se_weight() = tg->weight * ————————–
- tg->load_avg
- grq->runnable_load_avg
- se_runnable() = se_weight(se) * ————————————
- grq->load_avg
- load_sum := runnable_sum
- 태스크 엔티티등의 러너블 로드에 변화가 생길 때 상위 그룹에 러너블 합계를 전파한다. 상위 그룹에서는 전파한 러너블 합계 값을 더해 이 값을 적용한다. 단 이 값은 LOAD_AVG_MAX ~ running_sum 범위에서 clamp 한다.
- 참고: update_tg_cfs_runnable()
- load_avg = se_weight(se) * runnable_avg
- runnable_sum
- runnable_avg = —————————–
- LOAD_AVG_MAX
- runnable_load_sum := runnable_sum
- 로드 합계와 동일하게 러너블 로드 합계에도 적용한다.
- runnable_load_avg = se_runnable(se) * runnable_avg
- 러너블 로드 평균은 그룹 엔티티의 러너블 가중치와 runnable_avg를 곱하여 산출한다.
CFS 런큐:
- load_sum = \Sum se_weight(se) * se->avg.load_sum
- cfs 런큐에 엔큐된 엔티티들의 가중치와 로드 합계를 곱한 값들을 모두 더한 값이다.
- load_avg = \Sum se->avg.load_avg
- cfs 런큐에 엔큐된 엔티티들의 로드 평균을 모두 더한 값이다.
- runnable_load_sum = \Sum se_runnable(se) * se->avg.runnable_load_sum
- cfs 런큐에 엔큐된 엔티티들의 러너블 가중치와 러너블 로드 합계를 곱한 값들을 모두 더한 값이다.
- runnable_load_avg = \Sum se->avg.runable_load_avg
- cfs 런큐에 엔큐된 엔티티들의 러너블 로드 평균을 모두 더한 값이다.
다음 그림은 루트 그룹에 두 개의 하위 그룹 A, B를 만들고 다음과 같은 설정을 하였을 때 예상되는 cpu utilization을 보고자 한다.
- A 그룹
- cpu.shares=1024 (default)
- nice 0 태스크 (no sleep)
- B 그룹
- cpu.shares=2048
- nice -10 태스크 (no sleep)
- nice -13 태스크 (no sleep)
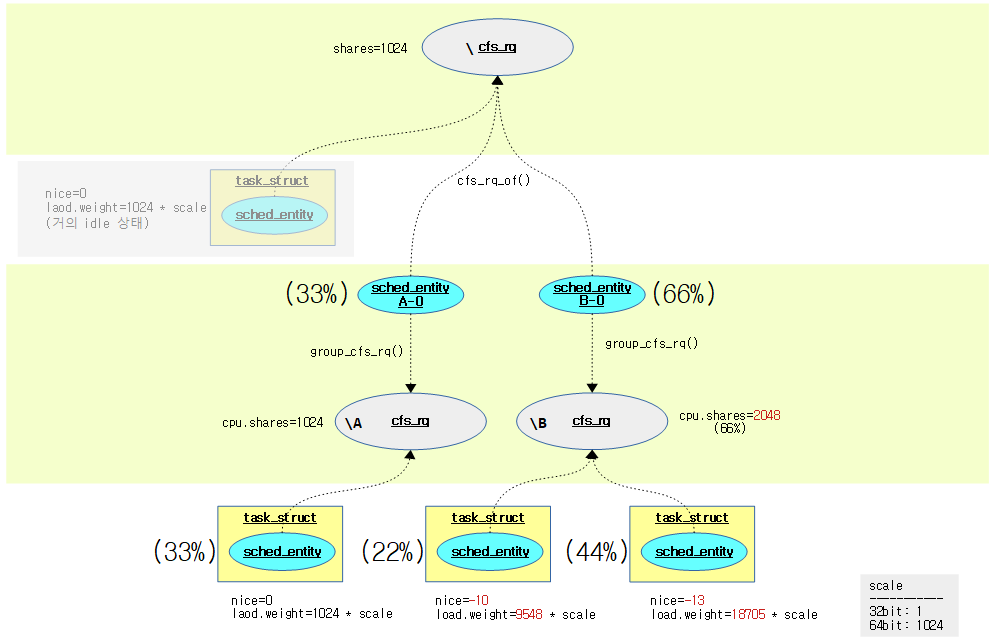
다음 그림은 A 그룹에서 1개의 태스크만을 가동하였을 때 load 평균등을 알아본다.

다음 그림은 A, B 그룹에서 각각 1개의 태스크를 가동하였을 때 load 평균등을 알아본다.

다음 그림은 A 그룹에 1개의 태스크, B 그룹에 2개의 태스크를 가동하였을 때 load 평균등을 알아본다.
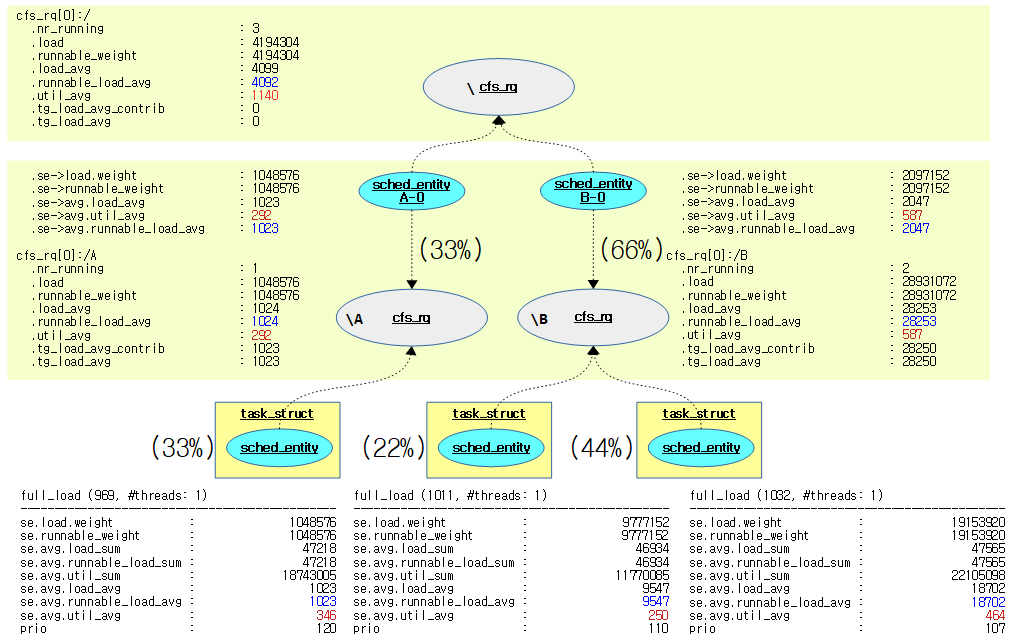
실제 평균은 다음과 같이 확인할 수 있다.
- 실제 다른 프로세스들이 약간 동작하고 있음을 감안하여야 한다.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND ---------------------------------------------------------------------------- 1032 root 7 -13 1608 324 256 R 41.3 0.0 0:21.67 full_load 969 root 20 0 1608 356 288 R 31.3 0.0 29:24.63 full_load 1011 root 10 -10 1608 368 304 R 21.0 0.0 6:52.56 full_load
태스크 그룹 로드 평균 갱신
update_tg_load_avg()
kernel/sched/fair.c
/** * update_tg_load_avg - update the tg's load avg * @cfs_rq: the cfs_rq whose avg changed * @force: update regardless of how small the difference * * This function 'ensures': tg->load_avg := \Sum tg->cfs_rq[]->avg.load. * However, because tg->load_avg is a global value there are performance * considerations. * * In order to avoid having to look at the other cfs_rq's, we use a * differential update where we store the last value we propagated. This in * turn allows skipping updates if the differential is 'small'. * * Updating tg's load_avg is necessary before update_cfs_share(). */
static inline void update_tg_load_avg(struct cfs_rq *cfs_rq, int force)
{
long delta = cfs_rq->avg.load_avg - cfs_rq->tg_load_avg_contrib;
/*
* No need to update load_avg for root_task_group as it is not used.
*/
if (cfs_rq->tg == &root_task_group)
return;
if (force || abs(delta) > cfs_rq->tg_load_avg_contrib / 64) {
atomic_long_add(delta, &cfs_rq->tg->load_avg);
cfs_rq->tg_load_avg_contrib = cfs_rq->avg.load_avg;
}
}
태스크 그룹 로드 평균을 갱신한다.
- 코드 라인 3에서 cfs 런큐의 로드 평균과 지난번 마지막에 태스크 그룹에 기록한 로드 평균의 차이를 delta로 알아온다.
- 코드 라인 8~9에서 루트 태스크 그룹의 로드 평균은 사용하지 않으므로 산출하지 않고 함수를 빠져나간다.
- 코드 라인 11~14에서 cfs 로드 평균이 일정량 이상 변화가 있는 경우에만 태스크 그룹의 로드 평균에 추가한다. 태스크 그룹에 기록해둔 값은 다음 산출을 위해 cfs_rq->tg_load_avg_contrib에 기록해둔다.
- cfs 런큐의 tg_load_avg_contrib 값의 1/64보다 델타 값이 큰 경우 또는 @force 요청이 있는 경우 다음과 같이 갱신한다.
- 델타 값을 cfs 런큐가 가리키는 태스크 그룹의 로드 평균에 추가한다.
- cfs 런큐의 tg_load_avg_contrib 는 cfs 런큐의 로드 평균으로 싱크한다.
tg->load_avg
태스크 그룹의 로드 평균은 cpu별로 동작하는 cfs 런큐들의 로드 평균을 모두 모아 반영한 글로벌 값이다.
cfs_rq->tg_load_avg_contrib
태스크 그룹에 대한 이 cfs 런큐 로드 평균의 기여분이다.
- cfs 런큐의 로드 평균을 태스크 그룹에 추가한 후에, 이 멤버 변수에도 저장해둔다.
- 이 값은 다음 갱신 시의 cfs 런큐의 로드 평균과 비교하기 위해 사용된다.
tg->load_avg 갱신 조건
글로벌인 태스크 그룹의 로드 평균 값을 변경하려면 atomic 연산을 사용해야 하는데 빈번한 갱신은 성능을 떨어뜨린다. 따라서 다음 조건에서만 갱신을 허용한다.
- delta = 이번 cfs 런큐의 로드 평균과 지난번 태스크 그룹에 기여한 cfs 런큐의 로드 평균의 절대 차이 값
- 지난번 cfs 런큐의 로드 평균을 태스크 그룹에 기여한 값의 1/64 보다 큰 변화(delta)가 있을 경우에만 갱신한다.
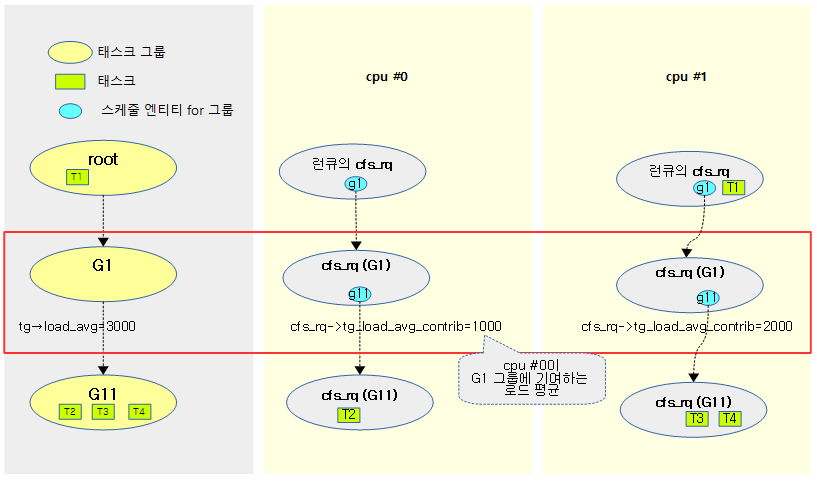
다음 그림은 각 cpu의 cfs 런큐가 태스크 그룹에 기여하는 로드 평균을 보여준다.
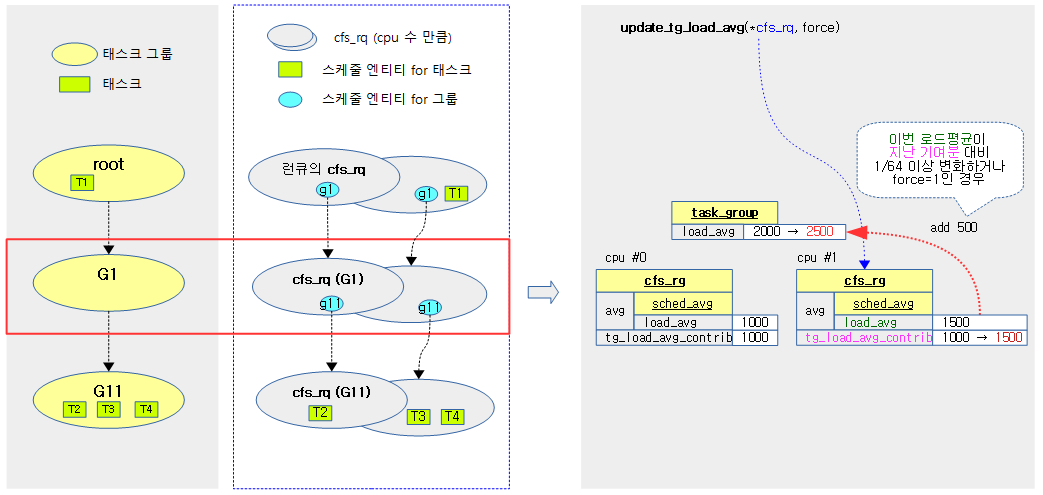
다음 그림은 update_tg_load_avg() 함수가 요청한 cfs 런큐의 로드 평균을 태스크 그룹의 로드 평균에 추가하는 과정을 보여준다.
그룹 엔티티 갱신
update_cfs_group()
kernel/sched/fair.c
/* * Recomputes the group entity based on the current state of its group * runqueue. */
static void update_cfs_group(struct sched_entity *se)
{
struct cfs_rq *gcfs_rq = group_cfs_rq(se);
long shares, runnable;
if (!gcfs_rq)
return;
if (throttled_hierarchy(gcfs_rq))
return;
#ifndef CONFIG_SMP
runnable = shares = READ_ONCE(gcfs_rq->tg->shares);
if (likely(se->load.weight == shares))
return;
#else
shares = calc_group_shares(gcfs_rq);
runnable = calc_group_runnable(gcfs_rq, shares);
#endif
reweight_entity(cfs_rq_of(se), se, shares, runnable);
}
태스크 그룹에 설정된 shares(디폴트: 1024) 값에 cfs 런큐 로드 비율을 적용하여 그룹 엔티티의로드 weight을 재산출하여 갱신한다.
- 코드 라인 3~7에서 그룹 엔티티의 그룹 cfs 런큐를 알아온다.
- 코드 라인 9~10에서 그룹 cfs 런큐가 스로틀 중인 경우 함수를 빠져나간다.
그룹 엔티티의 로드 weight 재산출
- 코드 라인 13~16에서 UP 시스템에서 태스크 그룹의 shares 값과 스케줄 엔티티의 로드 값이 동일하면 최대치를 사용하는 중이므로 함수를 빠져나간다.
- 코드 라인 18에서 SMP 시스템에서 설정된 태스크 그룹의 shares 값을 전체 cpu 대비 해당 cpu의 cfs 런큐가 가진 가중치(weight) 비율만큼 곱하여 반환한다.
- 해당 cpu의 cfs 런큐에 load.weight
- shares = tg->shares = ———————————————
- 태스크 그룹의 weight
- 코드 라인 19에서 위에서 산출된 shares를 해당 cfs 런큐의 로드 평균 대비 러너블 로드 평균 비율만큼 곱하여 runnable 값으로 알아온다.
- 그룹 cfs 런큐의 러너블 로드 평균
- runnable = shares * 비율 = ——————————————
- 그룹 cfs 런큐의 로드 평균
- 코드 라인 22에서 산출된 shares 및 runnable 값으로 그룹 엔티티의 로드 weight과 러너블 로드 weight 값을 재계산한다
Shares에 따른 그룹 엔티티 로드 weight 산출
calc_group_shares()
kernel/sched/fair.c
/* * All this does is approximate the hierarchical proportion which includes that * global sum we all love to hate. * * That is, the weight of a group entity, is the proportional share of the * group weight based on the group runqueue weights. That is: * * tg->weight * grq->load.weight * ge->load.weight = ----------------------------- (1) * \Sum grq->load.weight * * Now, because computing that sum is prohibitively expensive to compute (been * there, done that) we approximate it with this average stuff. The average * moves slower and therefore the approximation is cheaper and more stable. * * So instead of the above, we substitute: * * grq->load.weight -> grq->avg.load_avg (2) * * which yields the following: * * tg->weight * grq->avg.load_avg * ge->load.weight = ------------------------------ (3) * tg->load_avg * * Where: tg->load_avg ~= \Sum grq->avg.load_avg * * That is shares_avg, and it is right (given the approximation (2)). * * The problem with it is that because the average is slow -- it was designed * to be exactly that of course -- this leads to transients in boundary * conditions. In specific, the case where the group was idle and we start the * one task. It takes time for our CPU's grq->avg.load_avg to build up, * yielding bad latency etc.. * * Now, in that special case (1) reduces to: * * tg->weight * grq->load.weight * ge->load.weight = ----------------------------- = tg->weight (4) * grp->load.weight * * That is, the sum collapses because all other CPUs are idle; the UP scenario. * * So what we do is modify our approximation (3) to approach (4) in the (near) * UP case, like: * * ge->load.weight = * * tg->weight * grq->load.weight * --------------------------------------------------- (5) * tg->load_avg - grq->avg.load_avg + grq->load.weight * * But because grq->load.weight can drop to 0, resulting in a divide by zero, * we need to use grq->avg.load_avg as its lower bound, which then gives: * * * tg->weight * grq->load.weight * ge->load.weight = ----------------------------- (6) * tg_load_avg' * * Where: * * tg_load_avg' = tg->load_avg - grq->avg.load_avg + * max(grq->load.weight, grq->avg.load_avg) * * And that is shares_weight and is icky. In the (near) UP case it approaches * (4) while in the normal case it approaches (3). It consistently * overestimates the ge->load.weight and therefore: * * \Sum ge->load.weight >= tg->weight * * hence icky! */
이 모든 작업은 우리 모두가 싫어하는 global 합계를 포함하는 계층적 비율에 가깝다.
즉, 그룹 엔티티의 가중치(weight)는 태스크 그룹에 설정된 weight 곱하기 전체 cpu 중 해당 cpu의 그룹 런큐 가중치 비율만큼으로 다음 수식과 같다.
- grq->load.weight
- (1) ge->load.weight = tg->weight * ——————————–
- \Sum grq->load.weight
- 해당 cpu의 그룹 런큐->load.weight
- = tg->weight * ——————————————————-
- 전체 cpu들의 그룹 런큐->load.weight 총합
위와 같이 전체 cpu의 그룹 런큐 가중치(weight)를 모두 합하는 것은 매우 비싼 코스트이다. 어짜피 평균은 천천히 움직이므로 대략 산출하는 것이 값싸고, 더 안정적이다. 그래서 위의 그룹 런큐의 load.weight 대신 그룹 런큐의 로드 평균으로 대체한다.
- (2) grq->load.weight -> grq->avg.load_avg
결과는 다음과 같다.
- grq->avg.load_avg
- (3) ge->load.weight = tg->weight * —————————
- tg->load_avg
- 해당 cpu의 그룹 런큐 로드 평균
- = tg->weight * ——————————————-
- 태스크 그룹의 로드 평균
여기: tg->load_avg ~= \Sum grq->avg.load_avg
태스크 그룹의 로드 평균에는 이미 모든 cpu의 그룹 런큐에서 일정량 이상의 큰 변화들은 집계된다.(적은 변화는 성능을 위해 추후 모아 변화량이 커질때에만 처리한다.)
그런데 평균은 느린 문제가 있다. 이로 인해 경계 조건에서 과도 현상이 발생한다. 구체적으로, 그룹이 idle 상태이고 하나의 작업을 시작하는 경우이다. cpu의 grq-> avg.load_avg가 쌓이는 데 시간이 걸리고 지연 시간이 나빠진다.
이제 특별한 경우 (1)번 케이스는 다음과 같이 축소한다.
-
grq->load.weight - (4) = tg->weight * ————————– = tg->weight
-
grq->load.weight
위의 시나리오에선 다른 모든 cpu가 idle 상태일 때 합계가 축소된다. 그래서 다음과 같이 UP(Uni Processor) 케이스에서 (4)에 접근하도록 다음과 같이 근사값 (3)을 수정하였다.
- grq->load.weight
- (5) = tg->weight * ——————————————————————–
- tg->load_avg – grq->avg.load_avg + grq->load.weight
그러나 grq-> load.weight이 0으로 떨어질 수 있고 결과적으로 0으로 나눌 수 있으므로 grq-> avg.load_avg를 하한값으로 사용해야 한다.
- grq->load.weight
- (6) = tg->weight * —————————–
- tg_load_avg’
- tg_load_avg’ = tg->load_avg – grq->avg.load_avg + max(grq->load.weight, grq->avg.load_avg)
UP(Uni Processor)의 경우 (4)번 방식을 사용하고, 정상적인 경우 (3)번 방식을 사용한다. ge-> load.weight를 지속적으로 과대 평가하므로 다음과 같다.
- \Sum ge->load.weight >= tg->weight
static long calc_group_shares(struct cfs_rq *cfs_rq)
{
long tg_weight, tg_shares, load, shares;
struct task_group *tg = cfs_rq->tg;
tg_shares = READ_ONCE(tg->shares);
load = max(scale_load_down(cfs_rq->load.weight), cfs_rq->avg.load_avg);
tg_weight = atomic_long_read(&tg->load_avg);
/* Ensure tg_weight >= load */
tg_weight -= cfs_rq->tg_load_avg_contrib;
tg_weight += load;
shares = (tg_shares * load);
if (tg_weight)
shares /= tg_weight;
/*
* MIN_SHARES has to be unscaled here to support per-CPU partitioning
* of a group with small tg->shares value. It is a floor value which is
* assigned as a minimum load.weight to the sched_entity representing
* the group on a CPU.
*
* E.g. on 64-bit for a group with tg->shares of scale_load(15)=15*1024
* on an 8-core system with 8 tasks each runnable on one CPU shares has
* to be 15*1024*1/8=1920 instead of scale_load(MIN_SHARES)=2*1024. In
* case no task is runnable on a CPU MIN_SHARES=2 should be returned
* instead of 0.
*/
return clamp_t(long, shares, MIN_SHARES, tg_shares);
}
태스크 그룹의 shares 값을 전체 cpu 대비 해당 cpu의 cfs 런큐가 가진 가중치(weight) 비율만큼 곱하여 반환한다.
- 코드 라인 4~6에서 그룹 런큐가 소속된 태스크 그룹에 설정된 shares 값을 알아온다.
- 예) 루트 태스크 그룹의 디폴트 share 값(/sys/fs/cgroup/cpu/cpu.shares) = 1024
- 코드 라인 8~18에서 다음 수식과 같이 shares 값을 산출한다.
- max(grq->load.weight, grq->avg.load_avg)
- = tg->shares * ———————————————————————————————————–
- tg->load_avg – grq->tg_load_avg_contrib + max(grq->load.weight, grq->avg.load_avg)
- 코드 라인 32에서 산출한 shares 값은 MIN_SHARES(2) ~ tg->shares 범위를 벗어나는 경우 clamp하여 반환한다.
예) tg->shares=1024, cpu#0의 qrq->load.weight=1024, cpu#1의 qrq->load.weight=2048
- cpu#0: 1024 * 1024 / 3072 = 341
- cpu#1: 1024 * 2048 / 3072 = 682
Shares에 따른 그룹 엔티티 러너블 weight 재산출
/* * This calculates the effective runnable weight for a group entity based on * the group entity weight calculated above. * * Because of the above approximation (2), our group entity weight is * an load_avg based ratio (3). This means that it includes blocked load and * does not represent the runnable weight. * * Approximate the group entity's runnable weight per ratio from the group * runqueue: * * grq->avg.runnable_load_avg * ge->runnable_weight = ge->load.weight * -------------------------- (7) * grq->avg.load_avg * * However, analogous to above, since the avg numbers are slow, this leads to * transients in the from-idle case. Instead we use: * * ge->runnable_weight = ge->load.weight * * * max(grq->avg.runnable_load_avg, grq->runnable_weight) * ----------------------------------------------------- (8) * max(grq->avg.load_avg, grq->load.weight) * * Where these max() serve both to use the 'instant' values to fix the slow * from-idle and avoid the /0 on to-idle, similar to (6). */
위 함수에서 산출한 그룹 엔티티 가중치(weight)를 기반으로 그룹 엔티티의 유효 러너블 가중치(weight)를 산출한다.
위의 근사치 (2)번을 이유로, 그룹 엔티티 가중치(weight)는 (3)의 로드 평균 기반 비율이다. 이는 러너블 가중치(weight)를 나타내게 한 게 아니라, blocked 로드를 포함함을 의미한다. (가중치 비율이 아닌 로드 평균 비율을 사용하면 러너블과 blocked 로드 둘다 포함한다.)
그룹 런큐별 그룹 엔티티의 러너블 가중치(weight)를 대략적으로 산출한다.
- grq->avg.runnable_load_avg
- (7) ge->runnable_weight = ge->load.weight * —————————————–
- grq->avg.load_avg
- max(grq->avg.runnable_load_avg, grq->runnable_weight)
- (8) = ge->load.weight * —————————————————————————
- max(grq->avg.load_avg, grq->load.weight)
- idle로 시작하는 느림을 교정
- idle 상태에서 0으로 나누는 문제
calc_group_runnable()
kernel/sched/fair.c
static long calc_group_runnable(struct cfs_rq *cfs_rq, long shares)
{
long runnable, load_avg;
load_avg = max(cfs_rq->avg.load_avg,
scale_load_down(cfs_rq->load.weight));
runnable = max(cfs_rq->avg.runnable_load_avg,
scale_load_down(cfs_rq->runnable_weight));
runnable *= shares;
if (load_avg)
runnable /= load_avg;
return clamp_t(long, runnable, MIN_SHARES, shares);
}
@shares를 전체 cpu 대비 해당 cpu의 러너블 비율만큼 곱한 runnable 값을 반환한다.
- 코드 라인 5~13에서 다음과 같이 runnable 값을 산출한다.
- max(grq->avg.runnable_avg, grq->runnable.weight)
- = shares * ———————————————————————
- max(grq->avg.load_avg, grq->load.weight)
- 코드 라인 15에서 산출한 runnable 값은 MIN_SHARES(2) ~ @shares 범위를 벗어나는 경우 clamp하여 반환한다.
그룹 엔티티의 weight 재설정
reweight_entity()
kernel/sched/fair.c
static void reweight_entity(struct cfs_rq *cfs_rq, struct sched_entity *se,
unsigned long weight, unsigned long runnable)
{
if (se->on_rq) {
/* commit outstanding execution time */
if (cfs_rq->curr == se)
update_curr(cfs_rq);
account_entity_dequeue(cfs_rq, se);
dequeue_runnable_load_avg(cfs_rq, se);
}
dequeue_load_avg(cfs_rq, se);
se->runnable_weight = runnable;
update_load_set(&se->load, weight);
#ifdef CONFIG_SMP
do {
u32 divider = LOAD_AVG_MAX - 1024 + se->avg.period_contrib;
se->avg.load_avg = div_u64(se_weight(se) * se->avg.load_sum, divider);
se->avg.runnable_load_avg =
div_u64(se_runnable(se) * se->avg.runnable_load_sum, divider);
} while (0);
#endif
enqueue_load_avg(cfs_rq, se);
if (se->on_rq) {
account_entity_enqueue(cfs_rq, se);
enqueue_runnable_load_avg(cfs_rq, se);
}
}
엔티티의 로드 및 러너블 weight 값을 재설정한다.
엔티티의 기존 가중치 관련 빼기
- 코드 라인 4~10에서 엔티티가 cfs 런큐에 존재하는 경우 cfs 런큐에서 기존 가중치 및 로드등을 빼기 위해 다음을 수행한다.
- 엔티티가 현재 러닝 중인 경우 현재 엔티티에 대해 로드 등을 갱신한다.
- cfs 런큐에서 엔티티의 기존 가중치를 뺀다.
- cfs 런큐에서 엔티티의 기존 러너블 가중치를 뺀다.
- 코드 라인 11에서 cfs 런큐에서 엔티티의 기존 로드 합계 및 평균을 뺀다.
엔티티의 새 가중치 재설정
- 코드 라인 13~14에서 엔티티에 인자로 전달 받은 새 @runnable과 @weight를 적용한다.
엔티티의 새 가중치 더하기
- 코드 라인 18~22에서 엔티티의 새 가중치로 로드 평균과 러너블 평균을 재산출한다.
- 코드 라인 26에서 cfs 런큐에 새 가중치 값을 가진 엔티티의 로드 합계 및 평균을 더한다.
- 코드 라인 27~30에서 엔티티가 cfs 런큐에 존재하는 경우 cfs 런큐에 새 가중치 및 로드등을 더하기 위해 다음을 수행한다.
- cfs 런큐에 엔티티의 새 가중치를 더한다.
- cfs 런큐에 엔티티의 새 러너블 가중치를 더한다.
update_load_set()
kernel/sched/fair.c
static inline void update_load_set(struct load_weight *lw, unsigned long w)
{
lw->weight = w;
lw->inv_weight = 0;
}
로드 weight 걊을 설정하고 inv_weight 값은 0으로 리셋한다.
엔큐 & 디큐 엔티티 시 PELT
엔큐 엔티티
enqueue_entity()
kernel/sched/fair.c
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
(...생략...)
/*
* When enqueuing a sched_entity, we must:
* - Update loads to have both entity and cfs_rq synced with now.
* - Add its load to cfs_rq->runnable_avg
* - For group_entity, update its weight to reflect the new share of
* its group cfs_rq
* - Add its new weight to cfs_rq->load.weight
*/
update_load_avg(cfs_rq, se, UPDATE_TG | DO_ATTACH);
update_cfs_group(se);
enqueue_runnable_load_avg(cfs_rq, se);
account_entity_enqueue(cfs_rq, se);
(...생략...)
}
엔티티를 cfs 런큐에 엔큐한다.
- 코드 라인 13에서 요청 엔티티를 갱신한다.
- UPDATE_TG 플래그는 태스크 그룹까지 갱신을 요청한다.
- DO_ATTACH 플래그는 migration에 의해 attach된 태스크가 있는 경우 이의 처리를 요청한다.
- 코드 라인 14에서 그룹 엔티티 및 cfs 런큐를 갱신한다.
- 코드 라인 15에서 엔큐할 엔티티의 로드 평균 등을 cfs 런큐에 추가한다.
- 코드 라인 16에서 cfs 런큐에 엔티티가 엔큐될 때의 account를 처리한다.
엔큐 엔티티 시 로드 평균
enqueue_load_avg()
kernel/sched/fair.c
static inline void
enqueue_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
cfs_rq->avg.load_avg += se->avg.load_avg;
cfs_rq->avg.load_sum += se_weight(se) * se->avg.load_sum;
}
엔티티 로드 평균을 cfs 런큐에 추가한다.
- 코드 라인 4에서 엔티티 로드 평균을 cfs 런큐에 추가한다.
- 코드 라인 5에서 엔티티의 weight에 로드 합계를 곱해 cfs 런큐에 추가한다.
엔큐 엔티티 시 러너블 로드 평균
enqueue_runnable_load_avg()
kernel/sched/fair.c
static inline void
enqueue_runnable_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
cfs_rq->runnable_weight += se->runnable_weight;
cfs_rq->avg.runnable_load_avg += se->avg.runnable_load_avg;
cfs_rq->avg.runnable_load_sum += se_runnable(se) * se->avg.runnable_load_sum;
}
엔티티 러너블 로드 평균을 cfs 런큐에 추가한다.
- 코드 라인 4에서 엔티티 러너블 weight를 cfs 런큐에 추가한다.
- 코드 라인 6에서 엔티티 러너블 로드 평균을 cfs 런큐에 추가한다.
- 코드 라인 7에서 엔티티 러너블 수와 러너블 로드 합계를 곱해 cfs 런큐에 추가한다.
엔큐 엔티티 시 account
account_entity_enqueue()
kernel/sched/fair.c
static void
account_entity_enqueue(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
update_load_add(&cfs_rq->load, se->load.weight);
#ifdef CONFIG_SMP
if (entity_is_task(se)) {
struct rq *rq = rq_of(cfs_rq);
account_numa_enqueue(rq, task_of(se));
list_add(&se->group_node, &rq->cfs_tasks);
}
#endif
cfs_rq->nr_running++;
}
cfs 런큐에 엔티티가 엔큐될 때의 account를 처리한다.
- 코드 라인 4에서 cfs 런큐에 엔티티의 로드를 추가한다.
- 코드 라인 6~11에서 태스크용 엔티티가 enqueue된 경우 런큐의 NUMA 카운터를 갱신하고, 태스크를 런큐의 cfs_tasks 리스트에 추가한다.
- 코드 라인 13에서 cfs 런큐에서 엔티티 수를 담당하는 nr_running 카운터를 1 증가시킨다.
account_numa_enqueue()
kernel/sched/fair.c
static void account_numa_enqueue(struct rq *rq, struct task_struct *p)
{
rq->nr_numa_running += (p->numa_preferred_nid != NUMA_NO_NODE);
rq->nr_preferred_running += (p->numa_preferred_nid == task_node(p));
}
태스크가 enqueue된 경우에 호출되며, 런큐의 NUMA 카운터를 갱신한다.
- rq->nr_numa_running++ (태스크의 권장 누마 노드가 지정된 경우에만)
- rq->nr_preferred_running++ (태스크의 노드가 권장 누마 노드와 동일한 경우에만)
디큐 엔티티
dequeue_entity()
kernel/sched/fair.c
static void
dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
(...생략...)
/*
* When dequeuing a sched_entity, we must:
* - Update loads to have both entity and cfs_rq synced with now.
* - Subtract its load from the cfs_rq->runnable_avg.
* - Subtract its previous weight from cfs_rq->load.weight.
* - For group entity, update its weight to reflect the new share
* of its group cfs_rq.
*/
update_load_avg(cfs_rq, se, UPDATE_TG);
dequeue_runnable_load_avg(cfs_rq, se);
(...생략...)
account_entity_dequeue(cfs_rq, se);
(...생략...)
update_cfs_group(se);
(...생략...)
}
엔티티를 cfs 런큐로부터 디큐한다.
- 코드 라인 13에서 요청 엔티티를 갱신한다.
- UPDATE_TG 플래그는 태스크 그룹까지 갱신을 요청한다.
- 코드 라인 14에서 디큐할 엔티티의 로드 평균 등을 cfs 런큐로부터 감산한다.
- 코드 라인 16에서 cfs 런큐로부터 엔티티가 디큐될 때의 account를 처리한다.
- 코드 라인 18에서 그룹 엔티티 및 cfs 런큐를 갱신한다.
디큐 엔티티 시 로드 평균
dequeue_load_avg()
kernel/sched/fair.c
static inline void
dequeue_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
sub_positive(&cfs_rq->avg.load_avg, se->avg.load_avg);
sub_positive(&cfs_rq->avg.load_sum, se_weight(se) * se->avg.load_sum);
}
엔티티 로드 평균만큼을 cfs 런큐에서 감소시킨다.
- 코드 라인 4에서 엔티티 로드 평균만큼을 cfs 런큐에서 감소시킨다.
- 코드 라인 5에서 엔티티의 weight에 로드 합계를 곱한 만큼을 cfs 런큐에서 감소시킨다.
디큐 엔티티 시 러너블 로드 평균
dequeue_runnable_load_avg()
kernel/sched/fair.c
static inline void
dequeue_runnable_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
cfs_rq->runnable_weight -= se->runnable_weight;
sub_positive(&cfs_rq->avg.runnable_load_avg, se->avg.runnable_load_avg);
sub_positive(&cfs_rq->avg.runnable_load_sum,
se_runnable(se) * se->avg.runnable_load_sum);
}
엔티티 러너블 로드 평균만큼을 cfs 런큐에서 감소시킨다.
- 코드 라인 4에서 엔티티 러너블 weight 만큼을 cfs 런큐에서 감소시킨다.
- 코드 라인 6에서 엔티티 러너블 로드 평균 만큼을 cfs 런큐에서 감소시킨다.
- 코드 라인 7~8에서 엔티티 러너블 수와 러너블 로드 합계를 곱한 만큼을 cfs 런큐에서 감소시킨다.
디큐 엔티티 시 account
account_entity_dequeue()
kernel/sched/fair.c
static void
account_entity_dequeue(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
update_load_sub(&cfs_rq->load, se->load.weight);
#ifdef CONFIG_SMP
if (entity_is_task(se)) {
account_numa_dequeue(rq_of(cfs_rq), task_of(se));
list_del_init(&se->group_node);
}
#endif
cfs_rq->nr_running--;
}
cfs 런큐에 엔티티가 디큐될 때의 account를 처리한다.
- 코드 라인 4에서 엔티티의 로드 weight 값을 cfs 런큐에서 차감한다.
- 코드 라인 6~9에서 태스크용 엔티티의 경우 런큐의 누마 관련 카운터 값을 감소시키고, 런큐의 cfs_tasks 리스트에서 태스크를 제거한다.
- 코드 라인 11에서 cfs 런큐에서 엔티티 수를 담당하는 nr_running을 1 감소시킨다.
account_numa_dequeue()
kernel/sched/fair.c
static void account_numa_dequeue(struct rq *rq, struct task_struct *p)
{
rq->nr_numa_running -= (p->numa_preferred_nid != NUMA_NO_NODE);
rq->nr_preferred_running -= (p->numa_preferred_nid == task_node(p));
}
태스크가 디큐된 경우에 호출되며, 런큐의 NUMA 카운터를 갱신한다.
- rq->nr_numa_running– (태스크의 권장 누마 노드가 지정된 경우에만)
- rq->nr_preferred_running– (태스크의 노드가 권장 누마 노드와 동일한 경우에만)
Attach & Detach 엔티티 시 PELT
Attach 엔티티
attach_entity_cfs_rq()
kernel/sched/fair.c
static void attach_entity_cfs_rq(struct sched_entity *se)
{
(...생략...)
/* Synchronize entity with its cfs_rq */
update_load_avg(cfs_rq, se, sched_feat(ATTACH_AGE_LOAD) ? 0 : SKIP_AGE_LOAD);
attach_entity_load_avg(cfs_rq, se, 0);
update_tg_load_avg(cfs_rq, false);
propagate_entity_cfs_rq(se);
}
마이그레이션 또는 새 태스크의 로드를 cfs 런큐에 attach 하여 cfs 런큐 및 태스크 그룹의 로드들을 갱신한다.
- 코드 라인 5에서 엔티티의 로드 평균 등을 갱신한다.
- 단 ATTACH_AGE_LOAD feature가 없는 경우 엔티티의 로드 평균 갱신만 skip 하고 cfs 런큐의 로드 평균 및 propagation 등은 수행한다.
- 코드 라인 6에서 엔티티 attach 시 CFS 런큐에 로드 평균을 추가한다.
- 코드 라인 7에서 cfs 런큐의 로드가 추가되었으므로 태스크 그룹에 대한 로드 평균도 갱신한다.
- 코드 라인 8에서 최상위 그룹 엔티티까지 전파된 러너블 로드를 추가하여 각 그룹을 재산출한다.
attach 엔티티 시 로드 평균
attach_entity_load_avg()
kernel/sched/fair.c
/** * attach_entity_load_avg - attach this entity to its cfs_rq load avg * @cfs_rq: cfs_rq to attach to * @se: sched_entity to attach * @flags: migration hints * * Must call update_cfs_rq_load_avg() before this, since we rely on * cfs_rq->avg.last_update_time being current. */
static void attach_entity_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
u32 divider = LOAD_AVG_MAX - 1024 + cfs_rq->avg.period_contrib;
/*
* When we attach the @se to the @cfs_rq, we must align the decay
* window because without that, really weird and wonderful things can
* happen.
*
* XXX illustrate
*/
se->avg.last_update_time = cfs_rq->avg.last_update_time;
se->avg.period_contrib = cfs_rq->avg.period_contrib;
/*
* Hell(o) Nasty stuff.. we need to recompute _sum based on the new
* period_contrib. This isn't strictly correct, but since we're
* entirely outside of the PELT hierarchy, nobody cares if we truncate
* _sum a little.
*/
se->avg.util_sum = se->avg.util_avg * divider;
se->avg.load_sum = divider;
if (se_weight(se)) {
se->avg.load_sum =
div_u64(se->avg.load_avg * se->avg.load_sum, se_weight(se));
}
se->avg.runnable_load_sum = se->avg.load_sum;
enqueue_load_avg(cfs_rq, se);
cfs_rq->avg.util_avg += se->avg.util_avg;
cfs_rq->avg.util_sum += se->avg.util_sum;
add_tg_cfs_propagate(cfs_rq, se->avg.load_sum);
cfs_rq_util_change(cfs_rq, flags);
trace_pelt_cfs_tp(cfs_rq);
}
엔티티 attach 시 CFS 런큐에 로드 평균을 추가한다.
- 코드 라인 3에서 divider는 로드 평균 산출에 사용할 기간을 구한다.
- 코드 라인 12에서 엔티티의 cfs 런큐의 last_update_time을 엔티티에 대입한다.
- 코드 라인 13에서 cfs 런큐의 decay하지 않은 period_contrib를 엔티티에 대입한다.
- 코드 라인 21에서 엔티티의 유틸 평균에 기간 divider를 곱하여 유틸 합계를 구한다.
- 코드 라인 23~27에서 엔티티의 로드 합계에 로드 평균 * 기간 divider / weight 결과를 대입한다.
- 코드 라인 29에서 러너블 로드 합계에도 로드 합계를 대입한다.
- 코드 라인 31에서 cfs 런큐에 로드 평균을 추가한다.
- 코드 라인 32~33에서 cfs 런큐의 유틸 합계 및 평균에 엔티티의 유틸 합계 및 평균을 추가한다.
- 코드 라인 35에서 태스크 그룹에 대한 전파를 한다.
- 코드 라인 37에서 유틸 값이 바뀌면 cpu frequency 변경 기능이 있는 시스템의 경우 주기적으로 변경한다.
Detach 엔티티
detach_entity_cfs_rq()
kernel/sched/fair.c
static void detach_entity_cfs_rq(struct sched_entity *se)
{
struct cfs_rq *cfs_rq = cfs_rq_of(se);
/* Catch up with the cfs_rq and remove our load when we leave */
update_load_avg(cfs_rq, se, 0);
detach_entity_load_avg(cfs_rq, se);
update_tg_load_avg(cfs_rq, false);
propagate_entity_cfs_rq(se);
}
마이그레이션에 의해 cfs 런큐로부터 엔티티를 detach 한다.
- 코드 라인 6에서 엔티티의 로드 평균 등을 갱신한다.
- 코드 라인 7에서 엔티티 detach 시 CFS 런큐로부터 로드 평균을 감산한다.
- 코드 라인 8에서 cfs 런큐에 로드가 감소하였으므로 태스크 그룹에 대한 로드 평균도 갱신한다.
- 코드 라인 9에서 최상위 그룹 엔티티까지 전파하여 각 그룹의 로드 평균을 재산출한다.
Detach 엔티티 시 로드 평균
detach_entity_load_avg()
kernel/sched/fair.c
/** * detach_entity_load_avg - detach this entity from its cfs_rq load avg * @cfs_rq: cfs_rq to detach from * @se: sched_entity to detach * * Must call update_cfs_rq_load_avg() before this, since we rely on * cfs_rq->avg.last_update_time being current. */
static void detach_entity_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
dequeue_load_avg(cfs_rq, se);
sub_positive(&cfs_rq->avg.util_avg, se->avg.util_avg);
sub_positive(&cfs_rq->avg.util_sum, se->avg.util_sum);
add_tg_cfs_propagate(cfs_rq, -se->avg.load_sum);
cfs_rq_util_change(cfs_rq, 0);
trace_pelt_cfs_tp(cfs_rq);
}
엔티티 detach 시 CFS 런큐에 로드 평균을 감소시킨다.
- 코드 라인 3에서 엔티티 로드 평균만큼을 cfs 런큐에서 감소시킨다.
- 코드 라인 4에서 엔티티 유틸 평균만큼을 cfs 런큐에서 감소시킨다.
- 코드 라인 5에서 엔티티 유틸 합계 만큼을 cfs 런큐에서 감소시킨다.
- 코드 라인 7에서 태스크 그룹에 대한 전파를 한다.
- 코드 라인 9에서 유틸 값이 바뀌면 cpu frequency 변경 기능이 있는 시스템의 경우 주기적으로 변경한다.
엔티티 로드 평균 제거
remove_entity_load_avg()
kernel/sched/fair.c
/* * Task first catches up with cfs_rq, and then subtract * itself from the cfs_rq (task must be off the queue now). */
static void remove_entity_load_avg(struct sched_entity *se)
{
struct cfs_rq *cfs_rq = cfs_rq_of(se);
unsigned long flags;
/*
* tasks cannot exit without having gone through wake_up_new_task() ->
* post_init_entity_util_avg() which will have added things to the
* cfs_rq, so we can remove unconditionally.
*/
sync_entity_load_avg(se);
raw_spin_lock_irqsave(&cfs_rq->removed.lock, flags);
++cfs_rq->removed.nr;
cfs_rq->removed.util_avg += se->avg.util_avg;
cfs_rq->removed.load_avg += se->avg.load_avg;
cfs_rq->removed.runnable_sum += se->avg.load_sum; /* == runnable_sum */
raw_spin_unlock_irqrestore(&cfs_rq->removed.lock, flags);
}
cfs 런큐에서 엔티티의 로드를 감소시키도록 요청하고, 추후 cfs 로드 평균을 갱신할 때 효과를 본다.
- 코드 라인 12에서 엔티티 로드 평균을 동기화한다.
- 코드 라인 14~19에서 cfs 런큐의 removed에 엔티티의 유틸/로드 평균 및 로드 합계를 추가한다.
sync_entity_load_avg()
kernel/sched/fair.c
/* * Synchronize entity load avg of dequeued entity without locking * the previous rq. */
static void sync_entity_load_avg(struct sched_entity *se)
{
struct cfs_rq *cfs_rq = cfs_rq_of(se);
u64 last_update_time;
last_update_time = cfs_rq_last_update_time(cfs_rq);
__update_load_avg_blocked_se(last_update_time, se);
}
엔티티 로드 평균을 동기화한다.
유틸 변경에 따른 cpu frequency 변경
cfs_rq_util_change()
kernel/sched/fair.c
static inline void cfs_rq_util_change(struct cfs_rq *cfs_rq, int flags)
{
struct rq *rq = rq_of(cfs_rq);
if (&rq->cfs == cfs_rq || (flags & SCHED_CPUFREQ_MIGRATION)) {
/*
* There are a few boundary cases this might miss but it should
* get called often enough that that should (hopefully) not be
* a real problem.
*
* It will not get called when we go idle, because the idle
* thread is a different class (!fair), nor will the utilization
* number include things like RT tasks.
*
* As is, the util number is not freq-invariant (we'd have to
* implement arch_scale_freq_capacity() for that).
*
* See cpu_util().
*/
cpufreq_update_util(rq, flags);
}
}
유틸 값이 바뀌면 cpu frequency를 바꿀 수 있는 기능을 가진 런큐인 경우 cpu frequency를 변경 시도를 한다.
cpufreq_update_util()
kernel/sched/sched.h
/** * cpufreq_update_util - Take a note about CPU utilization changes. * @rq: Runqueue to carry out the update for. * @flags: Update reason flags. * * This function is called by the scheduler on the CPU whose utilization is * being updated. * * It can only be called from RCU-sched read-side critical sections. * * The way cpufreq is currently arranged requires it to evaluate the CPU * performance state (frequency/voltage) on a regular basis to prevent it from * being stuck in a completely inadequate performance level for too long. * That is not guaranteed to happen if the updates are only triggered from CFS * and DL, though, because they may not be coming in if only RT tasks are * active all the time (or there are RT tasks only). * * As a workaround for that issue, this function is called periodically by the * RT sched class to trigger extra cpufreq updates to prevent it from stalling, * but that really is a band-aid. Going forward it should be replaced with * solutions targeted more specifically at RT tasks. */
static inline void cpufreq_update_util(struct rq *rq, unsigned int flags)
{
struct update_util_data *data;
data = rcu_dereference_sched(*per_cpu_ptr(&cpufreq_update_util_data,
cpu_of(rq)));
if (data)
data->func(data, rq_clock(rq), flags);
}
유틸 평균이 바뀌면 cpu frequency를 바꿀 수 있도록 해당 후크 함수를 호출한다.
- 각 드라이버에서 hw 특성으로 인해 cpu frequency를 변경하는 cost가 있어 각각의 정책에 따라 최소 수ms 또는 수십~수백 ms 주기마다 frequency를 설정한다.
- cpufreq_add_update_util_hook() API 함수를 사용하여 후크 함수를 등록하고, 현재 커널에 등록된 후크 함수들은 다음과같다.
- 기본 cpu frequency governors util
- kernel/sched/cpufreq_schedutil.c – sugov_start()
- CPUFREQ governors 서브시스템
- drivers/cpufreq/cpufreq_governor.c – dbs_update_util_handler()
- 인텔 x86 드라이버
- drivers/cpufreq/intel_pstate.c – intel_pstate_update_util_hwp() 또는 intel_pstate_update_util()
- 기본 cpu frequency governors util
기타
entity_is_task()
kernel/sched/sched.h
/* An entity is a task if it doesn't "own" a runqueue */ #define entity_is_task(se) (!se->my_q)
스케줄 엔티티가 태스크인지 여부를 반환한다.
- 태스크인 경우 se->cfs_rq를 사용하고 태스크 그룹을 사용하는 경우 se->my_q를 사용한다.
group_cfs_rq()
kernel/sched/fair.c
/* runqueue "owned" by this group */
static inline struct cfs_rq *group_cfs_rq(struct sched_entity *grp)
{
return grp->my_q;
}
스케줄 엔티티의 런큐를 반환한다.
새 태스크의 유틸 평균 초기화
post_init_entity_util_avg()
kernel/sched/fair.c
/* * With new tasks being created, their initial util_avgs are extrapolated * based on the cfs_rq's current util_avg: * * util_avg = cfs_rq->util_avg / (cfs_rq->load_avg + 1) * se.load.weight * * However, in many cases, the above util_avg does not give a desired * value. Moreover, the sum of the util_avgs may be divergent, such * as when the series is a harmonic series. * * To solve this problem, we also cap the util_avg of successive tasks to * only 1/2 of the left utilization budget: * * util_avg_cap = (cpu_scale - cfs_rq->avg.util_avg) / 2^n * * where n denotes the nth task and cpu_scale the CPU capacity. * * For example, for a CPU with 1024 of capacity, a simplest series from * the beginning would be like: * * task util_avg: 512, 256, 128, 64, 32, 16, 8, ... * cfs_rq util_avg: 512, 768, 896, 960, 992, 1008, 1016, ... * * Finally, that extrapolated util_avg is clamped to the cap (util_avg_cap) * if util_avg > util_avg_cap. */
void post_init_entity_util_avg(struct task_struct *p)
{
struct sched_entity *se = &p->se;
struct cfs_rq *cfs_rq = cfs_rq_of(se);
struct sched_avg *sa = &se->avg;
long cpu_scale = arch_scale_cpu_capacity(cpu_of(rq_of(cfs_rq)));
long cap = (long)(cpu_scale - cfs_rq->avg.util_avg) / 2;
if (cap > 0) {
if (cfs_rq->avg.util_avg != 0) {
sa->util_avg = cfs_rq->avg.util_avg * se->load.weight;
sa->util_avg /= (cfs_rq->avg.load_avg + 1);
if (sa->util_avg > cap)
sa->util_avg = cap;
} else {
sa->util_avg = cap;
}
}
if (p->sched_class != &fair_sched_class) {
/*
* For !fair tasks do:
*
update_cfs_rq_load_avg(now, cfs_rq);
attach_entity_load_avg(cfs_rq, se, 0);
switched_from_fair(rq, p);
*
* such that the next switched_to_fair() has the
* expected state.
*/
se->avg.last_update_time = cfs_rq_clock_pelt(cfs_rq);
return;
}
attach_entity_cfs_rq(se);
}
fork된 새 태스크가 동작할 cfs 런큐의 로드 평균을 사용하여 태스크의 유틸 평균에 대한 초기값을 결정한다.
- 코드 라인 6에서 요청한 태스크가 동작 중인 cpu의 scale 적용된 capacity를 알아온다.
- big/little 클러스터에서 big cpu는 최대 값인 1024
- 코드 라인 7~17에서 알아온 capacity와 cfs 런큐의 유틸 평균과의 차이 절반을 cap에 대입하고, 이 cap이 0보다 큰 경우 다음과 같이 처리한다.
- cfs 런큐의 유틸 평균이 0인 경우
- 그룹 엔티티의 유틸 평균 = cap
- cfs 런큐의 유틸 평균이 0보다 큰 경우 다음과 같이계산하고 최대 값은 cap으로 제한한다.
- 엔티티의 유틸 평균 = cfs 런큐 유틸 평균 * 그룹 엔티티의 weight / cfs 런큐 로드 평균
- cfs 런큐의 유틸 평균이 0인 경우
- 코드 라인 19~32에서 cfs 태스크가 아닌 경우엔 엔티티의 통계 갱신 시각을 현재 pelt 클럭으로 갱신하고 함수를 빠져나간다.
- 코드 라인 34에서 cfs 태스크인 경우 엔티티의 로드를 cfs 런큐에 attach 하여 cfs 런큐 및 태스크 그룹의 로드들을 갱신한다.
구조체
sched_avg 구조체
include/linux/sched.h
/* * The load_avg/util_avg accumulates an infinite geometric series * (see __update_load_avg() in kernel/sched/fair.c). * * [load_avg definition] * * load_avg = runnable% * scale_load_down(load) * * where runnable% is the time ratio that a sched_entity is runnable. * For cfs_rq, it is the aggregated load_avg of all runnable and * blocked sched_entities. * * [util_avg definition] * * util_avg = running% * SCHED_CAPACITY_SCALE * * where running% is the time ratio that a sched_entity is running on * a CPU. For cfs_rq, it is the aggregated util_avg of all runnable * and blocked sched_entities. * * load_avg and util_avg don't direcly factor frequency scaling and CPU * capacity scaling. The scaling is done through the rq_clock_pelt that * is used for computing those signals (see update_rq_clock_pelt()) * * N.B., the above ratios (runnable% and running%) themselves are in the * range of [0, 1]. To do fixed point arithmetics, we therefore scale them * to as large a range as necessary. This is for example reflected by * util_avg's SCHED_CAPACITY_SCALE. * * [Overflow issue] * * The 64-bit load_sum can have 4353082796 (=2^64/47742/88761) entities * with the highest load (=88761), always runnable on a single cfs_rq, * and should not overflow as the number already hits PID_MAX_LIMIT. * * For all other cases (including 32-bit kernels), struct load_weight's * weight will overflow first before we do, because: * * Max(load_avg) <= Max(load.weight) * * Then it is the load_weight's responsibility to consider overflow * issues. */
struct sched_avg {
u64 last_update_time;
u64 load_sum;
u64 runnable_load_sum;
u32 util_sum;
u32 period_contrib;
unsigned long load_avg;
unsigned long runnable_load_avg;
unsigned long util_avg;
struct util_est util_est;
} ____cacheline_aligned;
- last_update_time
- 마지막 갱신된 시각(ns)이 저장되는데, us 단위로 내림 정렬된 값이 저장된다.
- 예) 갱신 시각이 1025ns 라면 저장되는 값은 1024ns 이다.
- 태스크 마이그레이션으로 인해 엔티티가 cfs 런큐에 attach/detach된 경우 이 값은 0으로 리셋된다.
- 마지막 갱신된 시각(ns)이 저장되는데, us 단위로 내림 정렬된 값이 저장된다.
- load_sum
- 로드 합계
- 러너블 상태와 블럭드(uninterruptible sleep에 대해서도 로드가 추가) 상태의 기간 합계이다.
- runnable_load_sum
- 러너블 로드 합계
- 러너블(curr + rb 트리에서 대기) 상태의 기간 합계이다.
- util_sum
- 엔티티 또는 cfs 런큐가 running(실제 cpu를 잡고 수행한) 상태였던 기간 합계
- period_contrib
- 로드는 산출시마다 1024us 기간(period)마다 decay하는 방식을 사용하는데, 현재 시각이 period-0 구간에서 로드에 기여한 값을 저장해둔다.
- 즉 로드 산출시마다 0us ~ 1023 us 값이 저장된다.
- load_avg
- 로드 평균
- = runnable% * scale_load_down(load)
- runnable% = cfs 런큐에서 runnable한 시간 비율로 0~100%까지이다.
- runnable과 blocked 엔티티들을 모두 합친 비율이다.
- scale_load_down(load) = 10bit 정밀도의 이진화 정수 로드 값
- runnable% = cfs 런큐에서 runnable한 시간 비율로 0~100%까지이다.
- 엔티티 가중치와 frequency 스케일링이 러너블 타임에 곱해져서 적용된다.
- cfs 런큐에서 사용될 떄 이 값은 그룹 스케줄링에서 사용된다.
- runnable_load_avg
- 러너블 로드 평균
- cfs 런큐에서 사용될 떄 이 값은 로드 밸런스에서 사용된다.
- util_avg
- 유틸 평균
- = running% * SCHED_CAPACITY_SCALE(1024)
- running% = 하나의 cpu에서 러닝중인 엔티티의 시간 비율로 0~100%까지이다.
- cpu effiency와 frequency 스케일링이 러닝 타임에 곱해져서 적용된다.
- 엔티티에서 사용될 때 이 값은 EAS(Energy Aware Scheduler)에서 에너지 효과적인 cpu를 선택하는 용도로 사용된다.
- cfs 런큐에서 사용될 때 이 값은 schedutil governor에서 주파수 선택 시 사용된다.
- util_est
- max(util_avg, util_avg@dequeue)
- 빅 태스크가 오랜 시간 슬립하였다가 깨어난 경우 슬립한 기간만큼 util 로드값이 decay되어 매우 낮아지면서 다시 런큐에 등록될 때 로드가 현저하게 적어 cpu freq가 낮게 배정되어 출발하는 이슈가 있다. 때문에 이러한 문제를 개선하기 위해 태스크가 슬립하여 deaueue되는 순간의 util 로드를 기억해두었다가, 다시 사용시 재계산된 util 로드와 비교하여 최대 값을 적용한 것이 util_est 로드이다.
태스크용 엔티티
- load.weight
- nice 우선 순위에 따른 로드 가중치(weight)
- 예) nice 0 태스크
- 1048576 (64비트 시스템의 경우 10bit scale-up)
- 예) nice -10 태스크
- 9777152 (64비트 시스템의 경우 10bit scale-up)
- runnable_weight
- load.weight와 동일
- load_sum & load_avg
- 예) nice 0 태스크
- load_sum = 46,872
- load_avg = load_sum * se_weight() / LOAD_AVG_MAX = 1,005
- 예) nice -10 태스크
- load_sum = 47,742
- load_avg = load_sum / se_weight() / LOAD_AVG_MAX = 9,483
- 예) nice 0 태스크
- runnable_load_sum & runnable_load_avg
- 태스크용 엔티티의 경우 load_sum & load_avg와 동일하다.
- util_sum & util_avg
- 예) 3개의 nice 0 태스크, 1 개의 nice-10 태스크
- nice 0 태스크
- util_sum = 6,033,955
- util_avg = util_sum / 약 LOAD_AVG_MAX = 126
- nice -10 태스크
- util_sum = 36,261,788
- util_avg = util_sum / 약 LOAD_AVG_MAX = 759
- nice 0 태스크
- 예) 3개의 nice 0 태스크, 1 개의 nice-10 태스크
그룹 엔티티
예) A 그룹, cpu.shares=1024, 3개의 nice 0 태스크, 1 개의 nice-10 태스크, UP
- load.weight
- load.weight=12,922,880
- runnable_weight
- runnable_weight=12,922,880
- load_sum & load_avg
- load_sum = 598,090,350
- load_avg = 12,620
- runnable_sum & runnable_avg
- load_sum & load_avg와 비슷하다.
- util_sum & util_avg
- util_sum = 48529673
- util_avg = util_sum / 약 LOAD_AVG_MAX = 1024 (100%)
cfs 런큐
예) A 그룹, cpu.shares=1024, 3개의 nice 0 태스크, 1 개의 nice-10 태스크, UP
- load.weight
- 예) load.weight = 12,922,880
- runnable_weight
- 예) runnable_weight = 12,922,880
- load_sum & load_avg
- 예) load_sum = 12,903,424
- 예) load_avg = load_sum / se_weight() = 12601
- .runnable_load_sum & runnable_load_avg
- load_sum & load_avg와 비슷하다.
- util_sum & util_avg
- 예) util_sum =48,529,673
- 예) util_avg = util_sum / LOAD_AVG_MAX = 1024 <- A 그룹내에서 util 로드를 이 cpu가 모두 다 사용하는 상태이다.
task_group 구조체
kernel/sched/sched.h
/* Task group related information */
struct task_group {
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each CPU */
struct sched_entity **se;
/* runqueue "owned" by this group on each CPU */
struct cfs_rq **cfs_rq;
unsigned long shares;
#ifdef CONFIG_SMP
/*
* load_avg can be heavily contended at clock tick time, so put
* it in its own cacheline separated from the fields above which
* will also be accessed at each tick.
*/
atomic_long_t load_avg ____cacheline_aligned;
#endif
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
struct task_group *parent;
struct list_head siblings;
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
#ifdef CONFIG_UCLAMP_TASK_GROUP
/* The two decimal precision [%] value requested from user-space */
unsigned int uclamp_pct[UCLAMP_CNT];
/* Clamp values requested for a task group */
struct uclamp_se uclamp_req[UCLAMP_CNT];
/* Effective clamp values used for a task group */
struct uclamp_se uclamp[UCLAMP_CNT];
#endif
};
- css
- cgroup 서브시스템 상태
- rcu
- 미사용?
- list
- 전역 task_groups 리스트에 연결될 때 사용하는 노드이다.
- *parent
- 부모 태스크 그룹
- siblings
- 부모 태스크 그룹의 children 리스트에 연결될 떄 사용된다.
- children
- 자식 태스크 그룹들이 연결될 리스트이다.
- cfs_bandwidth
- cfs 관련 밴드폭 정보
- cfs 그룹 스케줄링 관련
- **se
- cpu 수 만큼 그룹용 cfs 스케줄 엔티티가 할당되어 연결된다.
- **cfs_rq
- cpu 수 만큼 cfs 런큐가 할당되어 연결된다.
- shares
- 그룹에 적용할 로드 weight 비율
- load_avg
- cfs 런큐의 로드 평균을 모두 합한 값으로 결국 그룹 cfs 런큐들의 로드 평균을 모두 합한 값이다.
- **se
- rt 그룹 스케줄링 관련
- **rt_se
- cpu 수 만큼 그룹용 rt 스케줄 엔티티가 할당되어 연결된다.
- **rt_rq
- cpu 수 만큼 rt 런큐가 할당되어 연결된다.
- rt_bandwidth
- cfs 관련 밴드폭 정보
- **rt_se
- autogroup 관련
- *autogroup
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT-1) | 문c
- Scheduler -3a- (PELT-2) | 문c – 현재 글
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- Update on big.LITTLE scheduling experiments | ARM – 다운로드 pdf
- Per-entity load tracking | LWN.net
- Load tracking in the scheduler | LWN.net
- Scheduler Load tracking update and improvement | Vincent Guittot, Linaro connect 2017 – 다운로드 pdf