<kernel v5.4>
EAS(Energy Aware Scheduling)
모바일 시스템으로 인해 에너지 절약에 대한 요구, 터치에 대한 빠른 application의 빠른 응답 성능, 그리고 높은 성능 유지 등에 대한 사용자의 요구가 매우 높은데, 기존의 커널 스케줄러 만으로는 각각의 세 항목들을 동시에 만족시키기란 매우 어려운 상황이었다. 이에 대한 시장의 요구를 반영한 솔루션이 안드로이드 진영에서 먼저 시작되어 EAS를 탄생시켰고, 메인 라인 커널에도 업스트림되었다.
- 참고로 3 가지 항목을 동시(at a time)에 높일 수 없다. 그런 것이 가능할 수는 없다. 다만 환경 조건에 따라 어느 한 쪽에 더 힘을 준다.
- PM에서 절전을 하는 것 이외에 스케줄러 분야에서는 빠른 응답과 높은 성능 위주로 코드가 튜닝되어 왔는데, EAS 출현 후 에너지 효율에 대해 더 강력한 로직들이 추가되었다.

1) 에너지 효율을 달성하기 위해 전력 관리(Power Management) 기술 중 하나인 cpuidle과 관련하여 빅/리틀 클러스터 개념이 탄생되었고 다음과 같이 세 종류의 마이그레이션에 대한 운용 개념이 탄생되었고, 최근의 모바일 시스템은 빅/미디엄/리틀 클러스터를 동시에 사용하는 HMP 방식으로 추세가 바뀌었다. 또한 cpufreq(DVFS)를 통해 에너지 이득을 얻고자 하였다.
- 클러스터 운용
- Clustered switching (Cluster migration)
- 클러스터 단위로 빅/리틀 선택 운용
- In-kernel switcher (CPU migration)
- cpu core 단위로 빅/리틀 선택 운용
- HMP(Heterogeneous multi-processing) 운용
- 그냥 동시에 같이 운용하고, EAS를 통해 에너지 와 성능에 대해 적절한 cpu를 선택하는 스케줄 방법을 사용한다.
- Clustered switching (Cluster migration)
- DVFS 운용
- cpu의 유틸 로드에 따라 코어의 주파수를 여러 단계로 변화시켜 절전하는 시스템을 채용하였다.
2) 빠른 응답을 달성하기 위해 안드로이드 진영에서는 32ms 단위로 절반씩 deacy되는 특성을 가진 PELT를 WALT로 바꾸어 로드의 상향에 대해 4배, 하향에 대해 8배를 가진 특성을 사용하여 응답성을 높이고, uclamp를 통해 특정 application의 EAS를 통해 적절한 core를 찾아 빠르게 운용된다.
3) 높은 성능을 달성하기 위해 EAS는 빅/리틀 코어에 대해 필요 시 빅 코어에 대한 선택을 강화하였다.
- 태스크의 유틸 로드가 리틀로 마이그레이션 시 capacity 부족으로 인한 misfit 판정 시 리틀로의 마이그레이션을 제한한다.
- uclamp를 통해 특정 application이 동작 시 유틸 로드 범위를 제한하는 것으로 성능을 위한 빅 클러스터 또는 절전을 위한 리틀 클러스터를 조금 더 선택할 수 있도록 도와준다.
EAS component
다음 그림은 EAS를 구성하는 component들을 보여준다. 이들은 모바일 분야에서 치열하게 연구되어 계속 추가되고 있고, 일부는 새로운 기술로 대체되고 있다. (퀄컴, 삼성, 구글, ARM사에서 주도적으로 경쟁하였고 근래에는 서로의 장점을 모아 거의 유사해지고 있다.)
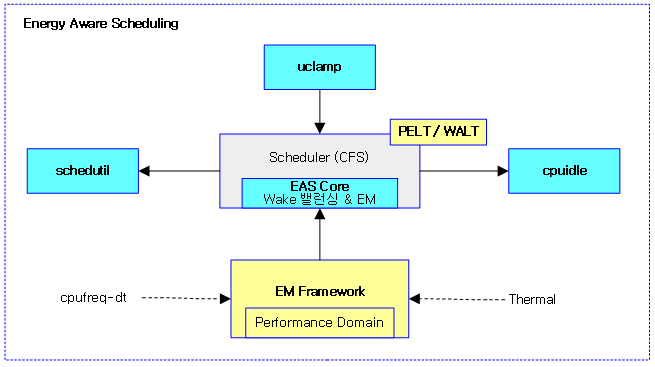
- EAS Core
- 스케줄러 내에서 에너지 모델로 동작하는 Task Placement 로직
- WALT 또는 PELT
- Schedutil
- 스케줄러 결합된 새로운 CPUFreq(DVFS) based governor
- CPUIdle
- 스케줄러 결합된 새로운 CPUIdle based governor
- UtilClamp(uclamp)
- Task Placement와 schedutil에 영향을 준다.
- 기존 SchedTune을 대체하여 사용한다.
Wake 밸런싱과 EA Task Placement
빅/리틀 클러스터를 가진 시스템처럼 Asymetric cpu capacity를 사용하는 시스템에서 깨어난 태스크가 Wake 밸런싱 과정에서 어떠한 cpu에서 동작해야 유리한지 알아본다.
- 에너지(J)
- 파워(W) = ————————–
- 시간(second)
- 명령어(instruction)
- 성능(performance) = ——————————
- 시간(second)
- 파워(W) 에너지(J) / 시간(second) 에너지(J)
- ———– = ————————————————– = —————————— = EAS의 목적
- 성능(P) 명령어(instruction) / 시간(second) 명령어(instruction)
EAS의 경우 성능은 높을 수록 좋고, 파워는 낮을 수록 좋으므로 EAS의 값이 작을 수록 좋다.
- EAS는 빅/리틀 시스템처럼 asym cpu capacity가 적용된 시스템에서만 동작할 수 있게 하였다.
- 참고: sched/topology: Disable EAS on inappropriate platforms (2018, v5.0-rc1)
- EAS는 SMT 시스템에서 동작시킬 수 없게 하였다.
- 참고: sched/topology: Don’t enable EAS on SMT systems (2020, v5.7-rc1)
다음 그림은 wake 밸런스에 의해 깨어날 cpu를 찾는 과정을 보여준다. 깊게 잠든 C2 idle 상태의 cpu 보다 살짝 잠든 WFI 상태의 cpu를 선택하는 모습을 보여준다.
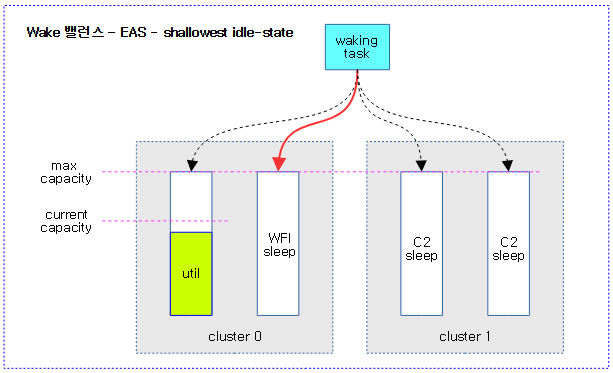
다음 그림은 wake 밸런스에 의해 깨어날 cpu를 찾는 과정을 보여주며, DVFS가 영향을 주는 과정을 보여준다.

에너지 효과적인 cpu 찾기
find_energy_efficient_cpu()
kernel/sched/fair.c -1/2-
/* * find_energy_efficient_cpu(): Find most energy-efficient target CPU for the * waking task. find_energy_efficient_cpu() looks for the CPU with maximum * spare capacity in each performance domain and uses it as a potential * candidate to execute the task. Then, it uses the Energy Model to figure * out which of the CPU candidates is the most energy-efficient. * * The rationale for this heuristic is as follows. In a performance domain, * all the most energy efficient CPU candidates (according to the Energy * Model) are those for which we'll request a low frequency. When there are * several CPUs for which the frequency request will be the same, we don't * have enough data to break the tie between them, because the Energy Model * only includes active power costs. With this model, if we assume that * frequency requests follow utilization (e.g. using schedutil), the CPU with * the maximum spare capacity in a performance domain is guaranteed to be among * the best candidates of the performance domain. * * In practice, it could be preferable from an energy standpoint to pack * small tasks on a CPU in order to let other CPUs go in deeper idle states, * but that could also hurt our chances to go cluster idle, and we have no * ways to tell with the current Energy Model if this is actually a good * idea or not. So, find_energy_efficient_cpu() basically favors * cluster-packing, and spreading inside a cluster. That should at least be * a good thing for latency, and this is consistent with the idea that most * of the energy savings of EAS come from the asymmetry of the system, and * not so much from breaking the tie between identical CPUs. That's also the * reason why EAS is enabled in the topology code only for systems where * SD_ASYM_CPUCAPACITY is set. * * NOTE: Forkees are not accepted in the energy-aware wake-up path because * they don't have any useful utilization data yet and it's not possible to * forecast their impact on energy consumption. Consequently, they will be * placed by find_idlest_cpu() on the least loaded CPU, which might turn out * to be energy-inefficient in some use-cases. The alternative would be to * bias new tasks towards specific types of CPUs first, or to try to infer * their util_avg from the parent task, but those heuristics could hurt * other use-cases too. So, until someone finds a better way to solve this, * let's keep things simple by re-using the existing slow path. */
static int find_energy_efficient_cpu(struct task_struct *p, int prev_cpu)
{
unsigned long prev_delta = ULONG_MAX, best_delta = ULONG_MAX;
struct root_domain *rd = cpu_rq(smp_processor_id())->rd;
unsigned long cpu_cap, util, base_energy = 0;
int cpu, best_energy_cpu = prev_cpu;
struct sched_domain *sd;
struct perf_domain *pd;
rcu_read_lock();
pd = rcu_dereference(rd->pd);
if (!pd || READ_ONCE(rd->overutilized))
goto fail;
/*
* Energy-aware wake-up happens on the lowest sched_domain starting
* from sd_asym_cpucapacity spanning over this_cpu and prev_cpu.
*/
sd = rcu_dereference(*this_cpu_ptr(&sd_asym_cpucapacity));
while (sd && !cpumask_test_cpu(prev_cpu, sched_domain_span(sd)))
sd = sd->parent;
if (!sd)
goto fail;
sync_entity_load_avg(&p->se);
if (!task_util_est(p))
goto unlock;
for (; pd; pd = pd->next) {
unsigned long cur_delta, spare_cap, max_spare_cap = 0;
unsigned long base_energy_pd;
int max_spare_cap_cpu = -1;
/* Compute the 'base' energy of the pd, without @p */
base_energy_pd = compute_energy(p, -1, pd);
base_energy += base_energy_pd;
for_each_cpu_and(cpu, perf_domain_span(pd), sched_domain_span(sd)) {
if (!cpumask_test_cpu(cpu, p->cpus_ptr))
continue;
/* Skip CPUs that will be overutilized. */
util = cpu_util_next(cpu, p, cpu);
cpu_cap = capacity_of(cpu);
if (!fits_capacity(util, cpu_cap))
continue;
/* Always use prev_cpu as a candidate. */
if (cpu == prev_cpu) {
prev_delta = compute_energy(p, prev_cpu, pd);
prev_delta -= base_energy_pd;
best_delta = min(best_delta, prev_delta);
}
/*
* Find the CPU with the maximum spare capacity in
* the performance domain
*/
spare_cap = cpu_cap - util;
if (spare_cap > max_spare_cap) {
max_spare_cap = spare_cap;
max_spare_cap_cpu = cpu;
}
}
/* Evaluate the energy impact of using this CPU. */
if (max_spare_cap_cpu >= 0 && max_spare_cap_cpu != prev_cpu) {
cur_delta = compute_energy(p, max_spare_cap_cpu, pd);
cur_delta -= base_energy_pd;
if (cur_delta < best_delta) {
best_delta = cur_delta;
best_energy_cpu = max_spare_cap_cpu;
}
}
}
빅/리틀 처럼 asym cpucapacity를 사용하는 도메인에서 @p태스크가 마이그레이션할 에너지 효과적인(절약 가능한) cpu를 찾아 반환한다. @prev_cpu를 반환할 수도 있고, asym cpucapacity가 아니거나 오버유틸 중인 경우 -1을 반환한다. (pd들 중 가장 낮은 에너지를 사용하는 도메인에서 가장 높은 spare를 가진 cpu를 찾는다)
- 코드 라인 11~13에서 perf domain이 없거나 overutilized 된 경우 fail 레이블을 통해 -1을 반환한다.
- 코드 라인 19~23에서 빅/리틀 같이 asym cpucapacity 도메인이 없거나 해당 도메인을 포함하여 상위 도메인에 @prev_cpu가 속해있지 않으면 fail 레이블을 통해 -1을 반환한다.
- 코드 라인 25~36에서 perf 도메인을 순회하며 compute_energy() 함수를 통해 태스크를 마이그레이션 후 소비할 에너지를 추정한 값을 알아와서 base_energy_pd 대입하고, 이를 base_energy에 누적한다.
- 코드 라인 43~46에서 perf 도메인과 스케줄 도메인에 양쪽에 포함된 cpu들을 순회하며 태스크가 지원하지 않는 cpu들과 overutilized된 cpu들은 skip 한다.
- 태스크 p가 cpu로 마이그레이션한 후를 예측한 cpu의 유틸을 알아와서 util에 대입하고, 이 값이 cpu의 capacity 이내에서 동작할 수 없으면 skip 한다.
- 코드 라인 49~53에서 순회 중인 cpu에 @prev_cpu인 경우는 언제나 대상이 되어 @prev_cpu로 compute_energy() 함수를 통해 반환된 값에서 base_energy_pd를 뺀 차이를 prev_delta에 대입한다. 그 후 이 값은 best_delta와 비교하여 작은 값을 best_delta로 갱신한다.
- 코드 라인 59~63에서 cpu에 남은 capacity 여분이 max_spare_cap보다 큰 경우 이를 갱신한다.
- perf 도메인내에서 가장 spare가 높은 cpu를 일단 찾아놓는다.
- 코드 라인 67~74에서 capacity 여분이 가장 큰 cpu가 새로운 cpu로 결정된 경우 태스크를 max_spare_cap_cpu로 마이그레이션할 때의 추정되는 에너지 소비량을 알아와서 base_energy_pd를 뺀 후 cur_delta에 대입한다. 이 값이 best_delta 보다 작을 때엔 best_delta로 이 값을 갱신한다.
- perf 도메인들 중 가장 낮은 에너지를 소모하는 perf 도메인인을 찾는다. 그 후 위에서 결정한 가장 spare가 높은 cpu를 반환한다.
kernel/sched/fair.c -2/2-
unlock:
rcu_read_unlock();
/*
* Pick the best CPU if prev_cpu cannot be used, or if it saves at
* least 6% of the energy used by prev_cpu.
*/
if (prev_delta == ULONG_MAX)
return best_energy_cpu;
if ((prev_delta - best_delta) > ((prev_delta + base_energy) >> 4))
return best_energy_cpu;
return prev_cpu;
fail:
rcu_read_unlock();
return -1;
}
- 코드 라인 8~9에서 @prev_cpu로 결정된 경우가 아니면 best_energy_cpu를 반환한다.
- 코드 라인 11~12에서 best_energy_cpu가 @prev_cpu보다 6% 이상의 에너지 절약이 되는 경우 best_energy_cpu를 반환한다.
- 코드 라인 14에서 그냥 @prev_cpu를 반환한다.
- 코드 라인 16~19에서 fail: 레이블이다. -1을 반환한다.
마이그레이션 후 에너지 추정
compute_energy()
kernel/sched/fair.c
/* * compute_energy(): Estimates the energy that @pd would consume if @p was * migrated to @dst_cpu. compute_energy() predicts what will be the utilization * landscape of @pd's CPUs after the task migration, and uses the Energy Model * to compute what would be the energy if we decided to actually migrate that * task. */
compute_energy(struct task_struct *p, int dst_cpu, struct perf_domain *pd)
{
struct cpumask *pd_mask = perf_domain_span(pd);
unsigned long cpu_cap = arch_scale_cpu_capacity(cpumask_first(pd_mask));
unsigned long max_util = 0, sum_util = 0;
int cpu;
/*
* The capacity state of CPUs of the current rd can be driven by CPUs
* of another rd if they belong to the same pd. So, account for the
* utilization of these CPUs too by masking pd with cpu_online_mask
* instead of the rd span.
*
* If an entire pd is outside of the current rd, it will not appear in
* its pd list and will not be accounted by compute_energy().
*/
for_each_cpu_and(cpu, pd_mask, cpu_online_mask) {
unsigned long cpu_util, util_cfs = cpu_util_next(cpu, p, dst_cpu);
struct task_struct *tsk = cpu == dst_cpu ? p : NULL;
/*
* Busy time computation: utilization clamping is not
* required since the ratio (sum_util / cpu_capacity)
* is already enough to scale the EM reported power
* consumption at the (eventually clamped) cpu_capacity.
*/
sum_util += schedutil_cpu_util(cpu, util_cfs, cpu_cap,
ENERGY_UTIL, NULL);
/*
* Performance domain frequency: utilization clamping
* must be considered since it affects the selection
* of the performance domain frequency.
* NOTE: in case RT tasks are running, by default the
* FREQUENCY_UTIL's utilization can be max OPP.
*/
cpu_util = schedutil_cpu_util(cpu, util_cfs, cpu_cap,
FREQUENCY_UTIL, tsk);
max_util = max(max_util, cpu_util);
}
return em_pd_energy(pd->em_pd, max_util, sum_util);
}
태스크 @p가 @dst_cpu로 마이그레이션 후 @pd가 소비할 에너지를 추정한 값을 반환한다.
- 코드 라인 3~4에서 perf 도메인에 소속한 cpu들 중 첫 cpu의 scale 적용된 cpu capacity를 알아온다.
- 코드 라인 17~18에서 perf 도메인에 소속한 cpu들 중 online cpu를 순회하며 태스크가 dst_cpu로 마이그레이션 한 후 cpu의 유틸을 예상해온 값을 util_cfs에 대입한다.
- 코드 라인 27~28에서 순회 중인 cpu에 대해 에너지 산출을 위한 유효 유틸을 알아와서 sum_util에 추가한다.
- 코드 라인 37~39에서 순회 중인 cpu에 대해 주파수를 선택하기 위한 유효 유틸을 알아와서 cpu_util에 대입하고, max_util도 갱신한다. 단 산출된 유효 유틸은 태스크의 uclamp 된 값으로 제한된다.
- 코드 라인 42에서 perf 도메인의 cpu들이 소모할 에너지 추정치를 알아와서 반환한다.
schedutil_cpu_util()
kernel/sched/cpufreq_schedutil.c
/*
* This function computes an effective utilization for the given CPU, to be
* used for frequency selection given the linear relation: f = u * f_max.
*
* The scheduler tracks the following metrics:
*
* cpu_util_{cfs,rt,dl,irq}()
* cpu_bw_dl()
*
* Where the cfs,rt and dl util numbers are tracked with the same metric and
* synchronized windows and are thus directly comparable.
*
* The cfs,rt,dl utilization are the running times measured with rq->clock_task
* which excludes things like IRQ and steal-time. These latter are then accrued
* in the irq utilization.
*
* The DL bandwidth number otoh is not a measured metric but a value computed
* based on the task model parameters and gives the minimal utilization
* required to meet deadlines.
*/
unsigned long schedutil_cpu_util(int cpu, unsigned long util_cfs,
unsigned long max, enum schedutil_type type,
struct task_struct *p)
{
unsigned long dl_util, util, irq;
struct rq *rq = cpu_rq(cpu);
if (!IS_BUILTIN(CONFIG_UCLAMP_TASK) &&
type == FREQUENCY_UTIL && rt_rq_is_runnable(&rq->rt)) {
return max;
}
/*
* Early check to see if IRQ/steal time saturates the CPU, can be
* because of inaccuracies in how we track these -- see
* update_irq_load_avg().
*/
irq = cpu_util_irq(rq);
if (unlikely(irq >= max))
return max;
/*
* Because the time spend on RT/DL tasks is visible as 'lost' time to
* CFS tasks and we use the same metric to track the effective
* utilization (PELT windows are synchronized) we can directly add them
* to obtain the CPU's actual utilization.
*
* CFS and RT utilization can be boosted or capped, depending on
* utilization clamp constraints requested by currently RUNNABLE
* tasks.
* When there are no CFS RUNNABLE tasks, clamps are released and
* frequency will be gracefully reduced with the utilization decay.
*/
util = util_cfs + cpu_util_rt(rq);
if (type == FREQUENCY_UTIL)
util = uclamp_util_with(rq, util, p);
dl_util = cpu_util_dl(rq);
/*
* For frequency selection we do not make cpu_util_dl() a permanent part
* of this sum because we want to use cpu_bw_dl() later on, but we need
* to check if the CFS+RT+DL sum is saturated (ie. no idle time) such
* that we select f_max when there is no idle time.
*
* NOTE: numerical errors or stop class might cause us to not quite hit
* saturation when we should -- something for later.
*/
if (util + dl_util >= max)
return max;
/*
* OTOH, for energy computation we need the estimated running time, so
* include util_dl and ignore dl_bw.
*/
if (type == ENERGY_UTIL)
util += dl_util;
/*
* There is still idle time; further improve the number by using the
* irq metric. Because IRQ/steal time is hidden from the task clock we
* need to scale the task numbers:
*
* max - irq
* U' = irq + --------- * U
* max
*/
util = scale_irq_capacity(util, irq, max);
util += irq;
/*
* Bandwidth required by DEADLINE must always be granted while, for
* FAIR and RT, we use blocked utilization of IDLE CPUs as a mechanism
* to gracefully reduce the frequency when no tasks show up for longer
* periods of time.
*
* Ideally we would like to set bw_dl as min/guaranteed freq and util +
* bw_dl as requested freq. However, cpufreq is not yet ready for such
* an interface. So, we only do the latter for now.
*/
if (type == FREQUENCY_UTIL)
util += cpu_bw_dl(rq);
return min(max, util);
}
@cpu에 대한 유효 유틸을 산출한다. 산출 타입에 FREQUENCY_UTIL(주파수 설정 목적) 및 ENERGY_UTIL(에너지 산출 목적) 타입을 사용한다.
- 코드 라인 8~11에서 uclamp를 지원하는 않는 커널 옵션이고, FREQUENCY_UTIL 타입으로 rt 태스크가 동작 중인 경우 최대 성능을 위해 최대 에너지가 필요하므로 @max 값을 반환한다.
- 코드 라인 18~20에서 irq 유틸이 max를 초과하는 경우 최대 성능을 위해 @max 값을 반환한다.
- 코드 라인 34~36에서 @util_cfs 및 rt 유틸을 더하고, FREQUENCY_UTIL 타입인 경우 @p 태스크에 설정된 uclamp를 적용한다.
- 코드 라인 38~50에서 dl 유틸을 알아오고, util과 더한 값이 @max를 초과하는 경우도 @max를 반환한다.
- 코드 라인 56에서 ENERGY_UTIL 타입인 경우 util 값에 dl_util도 추가한다.
- 코드 라인 67~68에서 irq 스케일 적용한 유틸을 산출한다.
- task 클럭에는 irq 타임이 제거된 상태이다. 따라서 @max에서 irq을 뺀 나머지 capacity로 유틸을 곱하고 그 후 다시 irq를 추가한다.
- 코드 라인 81~82에서 FREQUENCY_UTIL 타입인 경우 dl 밴드위드에 설정한 최소 유틸이 필요하므로 이 값도 util에 추가한다.
- 코드 라인 84에서 산출된 유틸을 반환한다. 단 @max 값을 초과하지 못하게 제한한다.
에너지 소비량 추정
em_pd_energy()
include/linux/energy_model.h
/** * em_pd_energy() - Estimates the energy consumed by the CPUs of a perf. domain * @pd : performance domain for which energy has to be estimated * @max_util : highest utilization among CPUs of the domain * @sum_util : sum of the utilization of all CPUs in the domain * * Return: the sum of the energy consumed by the CPUs of the domain assuming * a capacity state satisfying the max utilization of the domain. */
static inline unsigned long em_pd_energy(struct em_perf_domain *pd,
unsigned long max_util, unsigned long sum_util)
{
unsigned long freq, scale_cpu;
struct em_cap_state *cs;
int i, cpu;
/*
* In order to predict the capacity state, map the utilization of the
* most utilized CPU of the performance domain to a requested frequency,
* like schedutil.
*/
cpu = cpumask_first(to_cpumask(pd->cpus));
scale_cpu = arch_scale_cpu_capacity(cpu);
cs = &pd->table[pd->nr_cap_states - 1];
freq = map_util_freq(max_util, cs->frequency, scale_cpu);
/*
* Find the lowest capacity state of the Energy Model above the
* requested frequency.
*/
for (i = 0; i < pd->nr_cap_states; i++) {
cs = &pd->table[i];
if (cs->frequency >= freq)
break;
}
/*
* The capacity of a CPU in the domain at that capacity state (cs)
* can be computed as:
*
* cs->freq * scale_cpu
* cs->cap = -------------------- (1)
* cpu_max_freq
*
* So, ignoring the costs of idle states (which are not available in
* the EM), the energy consumed by this CPU at that capacity state is
* estimated as:
*
* cs->power * cpu_util
* cpu_nrg = -------------------- (2)
* cs->cap
*
* since 'cpu_util / cs->cap' represents its percentage of busy time.
*
* NOTE: Although the result of this computation actually is in
* units of power, it can be manipulated as an energy value
* over a scheduling period, since it is assumed to be
* constant during that interval.
*
* By injecting (1) in (2), 'cpu_nrg' can be re-expressed as a product
* of two terms:
*
* cs->power * cpu_max_freq cpu_util
* cpu_nrg = ------------------------ * --------- (3)
* cs->freq scale_cpu
*
* The first term is static, and is stored in the em_cap_state struct
* as 'cs->cost'.
*
* Since all CPUs of the domain have the same micro-architecture, they
* share the same 'cs->cost', and the same CPU capacity. Hence, the
* total energy of the domain (which is the simple sum of the energy of
* all of its CPUs) can be factorized as:
*
* cs->cost * \Sum cpu_util
* pd_nrg = ------------------------ (4)
* scale_cpu
*/
return cs->cost * sum_util / scale_cpu;
}
perf 도메인의 cpu들이 소모할 에너지 추정치를 알아온다. @max_util은 도메인의 cpu들 중 가장 큰 유틸, @sum_util 에는 도메인의 전체 유틸을 전달한다.
- 코드 라인 13~16에서 perf 도메인의 첫 cpu의 capacity와 @max_util 값으로 pd 테이블을 통해 적절한 주파수를 알아온다.
- 코드 라인 22~26에서 위에서 찾은 주파수를 초과하는 cpu가 실제 지원하는 주파수가 담긴 cs(em_cap_state 구조체)를 알아온다.
- 코드 라인 70에서 cs->cost * @sum_util / pd 도메인내 첫 cpu의 scale된 cpu capacity를 반환한다.
map_util_freq()
include/linux/sched/cpufreq.h
static inline unsigned long map_util_freq(unsigned long util,
unsigned long freq, unsigned long cap)
{
return (freq + (freq >> 2)) * util / cap;
}
freq 1.25배 * util/cap을 반환한다.
마이그레이션 후 유틸 예측
cpu_util_next()
kernel/sched/fair.c
/* * Predicts what cpu_util(@cpu) would return if @p was migrated (and enqueued) * to @dst_cpu. */
static unsigned long cpu_util_next(int cpu, struct task_struct *p, int dst_cpu)
{
struct cfs_rq *cfs_rq = &cpu_rq(cpu)->cfs;
unsigned long util_est, util = READ_ONCE(cfs_rq->avg.util_avg);
/*
* If @p migrates from @cpu to another, remove its contribution. Or,
* if @p migrates from another CPU to @cpu, add its contribution. In
* the other cases, @cpu is not impacted by the migration, so the
* util_avg should already be correct.
*/
if (task_cpu(p) == cpu && dst_cpu != cpu)
sub_positive(&util, task_util(p));
else if (task_cpu(p) != cpu && dst_cpu == cpu)
util += task_util(p);
if (sched_feat(UTIL_EST)) {
util_est = READ_ONCE(cfs_rq->avg.util_est.enqueued);
/*
* During wake-up, the task isn't enqueued yet and doesn't
* appear in the cfs_rq->avg.util_est.enqueued of any rq,
* so just add it (if needed) to "simulate" what will be
* cpu_util() after the task has been enqueued.
*/
if (dst_cpu == cpu)
util_est += _task_util_est(p);
util = max(util, util_est);
}
return min(util, capacity_orig_of(cpu));
}
태스크 @p를 @cpu에서 @dst_cpu로 마이그레이션한 후를 예측한 @cpu의 유틸을 반환한다.
- 코드 라인 3~4에서 태스크가 소속된 cfs 런큐의 유틸 평균을 알아와 util에 대입한다.
- 코드 라인 12~15에서 태스크가 @cpu에서 @dst_cpu로 마이그레이션 하므로 태스크의 cpu와 두 cpu가 관련된 경우 로드를 빼거나 추가해야 한다.
- 태스크의 cpu가 @cpu이고, @dst_cpu와 @cpu가 다른 경우 util에서 태스크의 유틸 평균을 뺀다. (양수로 제한)
- 태스크의 cpu가 @cpu가 아니면서 @dst_cpu와 @cpu가 같은 경우 util에 태스크의 유틸 평균을 추가한다.
- 코드 라인 17~30에서 UTIL_EST feature를 사용하는 경우 태스크의 cpu와 @dst_cpu가 같은 경우 cfs 런큐의 util_est에서 태스크의 util_est를 더한 후 이 값을 util과 비교하여 최대값으로 util을 갱신한다.
- 매우 짧은 시간 실행되는 태스크의 경우 1ms 단위로 갱신되는 PELT 시그널을 사용한 유틸 로드가 적을 수 있다. 따라서 태스크의 디큐 시마다 산출되는 추정 유틸(estimated utilization)과 기존 유틸 중 큰 값을 사용해야 cpu 간의 더 정확한 유틸 비교를 할 수 있다.
- 참고: sched/fair: Update util_est only on util_avg updates (2018, v4.17-rc1)
- 코드 라인 32에서 산출한 util 값이 기존 @cpu의 capacity를 초과하면 안되도록 제한하여 반환한다.
남은 여유 capacity
capacity_spare_without()
kernel/sched/fair.c
static unsigned long capacity_spare_without(int cpu, struct task_struct *p)
{
return max_t(long, capacity_of(cpu) - cpu_util_without(cpu, p), 0);
}
태스크가 사용중인 유틸을 제외한 cpu에 남은 여유 capacity를 반환한다.
- cpu의 capacity – 태스크가 cpu에 기여한 유틸 로드를 제외한 cpu의 유틸 로드
cpu_util_without()
kernel/sched/fair.c
/* * cpu_util_without: compute cpu utilization without any contributions from *p * @cpu: the CPU which utilization is requested * @p: the task which utilization should be discounted * * The utilization of a CPU is defined by the utilization of tasks currently * enqueued on that CPU as well as tasks which are currently sleeping after an * execution on that CPU. * * This method returns the utilization of the specified CPU by discounting the * utilization of the specified task, whenever the task is currently * contributing to the CPU utilization. */
static unsigned long cpu_util_without(int cpu, struct task_struct *p)
{
struct cfs_rq *cfs_rq;
unsigned int util;
/* Task has no contribution or is new */
if (cpu != task_cpu(p) || !READ_ONCE(p->se.avg.last_update_time))
return cpu_util(cpu);
cfs_rq = &cpu_rq(cpu)->cfs;
util = READ_ONCE(cfs_rq->avg.util_avg);
/* Discount task's util from CPU's util */
lsub_positive(&util, task_util(p));
/*
* Covered cases:
*
* a) if *p is the only task sleeping on this CPU, then:
* cpu_util (== task_util) > util_est (== 0)
* and thus we return:
* cpu_util_without = (cpu_util - task_util) = 0
*
* b) if other tasks are SLEEPING on this CPU, which is now exiting
* IDLE, then:
* cpu_util >= task_util
* cpu_util > util_est (== 0)
* and thus we discount *p's blocked utilization to return:
* cpu_util_without = (cpu_util - task_util) >= 0
*
* c) if other tasks are RUNNABLE on that CPU and
* util_est > cpu_util
* then we use util_est since it returns a more restrictive
* estimation of the spare capacity on that CPU, by just
* considering the expected utilization of tasks already
* runnable on that CPU.
*
* Cases a) and b) are covered by the above code, while case c) is
* covered by the following code when estimated utilization is
* enabled.
*/
if (sched_feat(UTIL_EST)) {
unsigned int estimated =
READ_ONCE(cfs_rq->avg.util_est.enqueued);
/*
* Despite the following checks we still have a small window
* for a possible race, when an execl's select_task_rq_fair()
* races with LB's detach_task():
*
* detach_task()
* p->on_rq = TASK_ON_RQ_MIGRATING;
* ---------------------------------- A
* deactivate_task() \
* dequeue_task() + RaceTime
* util_est_dequeue() /
* ---------------------------------- B
*
* The additional check on "current == p" it's required to
* properly fix the execl regression and it helps in further
* reducing the chances for the above race.
*/
if (unlikely(task_on_rq_queued(p) || current == p))
lsub_positive(&estimated, _task_util_est(p));
util = max(util, estimated);
}
/*
* Utilization (estimated) can exceed the CPU capacity, thus let's
* clamp to the maximum CPU capacity to ensure consistency with
* the cpu_util call.
*/
return min_t(unsigned long, util, capacity_orig_of(cpu));
}
태스크가 cpu에 기여한 로드가 있는 경우 그 로드를 제외한 cpu의 유틸 로드를 반환한다.
- 코드 라인 7~8에서 태스크가 동작했었던 cpu가 아닌 경우 @cpu의 런큐에는 태스크가 기여한 유틸 로드가 없다. 따라서 이러한 경우 cpu의 유틸 로드를 반환한다. 또한 태스크의 로드 평균을 한 번도 갱신한 적이 없는 새 태스크인 경우도 마찬가지이다.
- 코드 라인 10~14에서 @cpu의 유틸에서 태스크의 유틸을 뺀다.
- 코드 라인 42~67에서 UTIL_EST feature를 사용하는 경우 유틸과 cfs 런큐의 추정 유틸 둘 중 큰 값을 사용한다. 추정 유틸 값도 태스크가 이미 런큐에 있거나 현재 태스크와 동일한 경우 태스크의 추정 유틸을 뺀 값을 사용한다.
- 코드 라인 74에서 유틸 값을 반환하되 @cpu의 오리지날 capacity보다 큰 경우에는 clamp 한다.
cpu_util()
kernel/sched/fair.c
/** * Amount of capacity of a CPU that is (estimated to be) used by CFS tasks * @cpu: the CPU to get the utilization of * * The unit of the return value must be the one of capacity so we can compare * the utilization with the capacity of the CPU that is available for CFS task * (ie cpu_capacity). * * cfs_rq.avg.util_avg is the sum of running time of runnable tasks plus the * recent utilization of currently non-runnable tasks on a CPU. It represents * the amount of utilization of a CPU in the range [0..capacity_orig] where * capacity_orig is the cpu_capacity available at the highest frequency * (arch_scale_freq_capacity()). * The utilization of a CPU converges towards a sum equal to or less than the * current capacity (capacity_curr <= capacity_orig) of the CPU because it is * the running time on this CPU scaled by capacity_curr. * * The estimated utilization of a CPU is defined to be the maximum between its * cfs_rq.avg.util_avg and the sum of the estimated utilization of the tasks * currently RUNNABLE on that CPU. * This allows to properly represent the expected utilization of a CPU which * has just got a big task running since a long sleep period. At the same time * however it preserves the benefits of the "blocked utilization" in * describing the potential for other tasks waking up on the same CPU. * * Nevertheless, cfs_rq.avg.util_avg can be higher than capacity_curr or even * higher than capacity_orig because of unfortunate rounding in * cfs.avg.util_avg or just after migrating tasks and new task wakeups until * the average stabilizes with the new running time. We need to check that the * utilization stays within the range of [0..capacity_orig] and cap it if * necessary. Without utilization capping, a group could be seen as overloaded * (CPU0 utilization at 121% + CPU1 utilization at 80%) whereas CPU1 has 20% of * available capacity. We allow utilization to overshoot capacity_curr (but not * capacity_orig) as it useful for predicting the capacity required after task * migrations (scheduler-driven DVFS). * * Return: the (estimated) utilization for the specified CPU */
static inline unsigned long cpu_util(int cpu)
{
struct cfs_rq *cfs_rq;
unsigned int util;
cfs_rq = &cpu_rq(cpu)->cfs;
util = READ_ONCE(cfs_rq->avg.util_avg);
if (sched_feat(UTIL_EST))
util = max(util, READ_ONCE(cfs_rq->avg.util_est.enqueued));
return min_t(unsigned long, util, capacity_orig_of(cpu));
}
cpu의 유틸 로드 값을 반환한다.
- 코드 라인 6~7에서 cpu의 cfs 런큐에서 유틸 로드 평균을 알아온다.
- 코드 라인 9~10에서 런큐에서 태스크가 1ms 미만으로 동작하는 경우 유틸 로드가 정확히 반영되지 않아 실제보다 작은 값이 사용될 수 있다. 따라서 UTIL_EST feature를 사용하는 경우 태스크의 디큐마다 갱신되는 예상 유틸 로드와 비교하여 큰 값을 사용하면 조금 더 정확한 유틸 로드를 알아낼 수 있다.
- 코드 라인 12에서 유틸 값을 반환하되 @cpu의 오리지날 capacity보다 큰 경우에는 clamp 한다.
EAS enable 여부
sched_energy_enabled()
kernel/sched/sched.h
static inline bool sched_energy_enabled(void)
{
return static_branch_unlikely(&sched_energy_present);
}
EAS(Energy Aware Scheduling) 기능이 enabled 상태인지 여부를 반환한다.
- sysctl을 통한 EAS enable
- echo 1 > /proc/sys/kernel/sched_energy_aware
- 참고: sched/topology: Introduce a sysctl for Energy Aware Scheduling (2019, v5.1-rc1)
Performance Domain
기존 스케줄링 도메인의 계층 구조는 캐시 기반으로 구성되어 있다. 그러나 EAS를 사용하려면 플랫폼에 대한 더 많은 정보를 알아야 하며 특히 캐시기반과 무관하게 cpu들 포함시킬 수 있는 performance 도메인이 구성되어야 할 때가 있다. pd(performance domain)는 리스트로 연결되어 루트 도메인에 attach 된다. 여러 개의 루트 도메인을 사용하는 경우 각 루트 도메인에서 사용하는 pd의 멤버 cpu는 서로 중복되면 안된다.
- 참고: sched/topology: Reference the Energy Model of CPUs when available (2018, v5.0-rc1)
다음 그림과 같이 ARM Cortex-A75 아키텍처에서 멀티플 파티션을 구성할 수 있음을 보여준다.
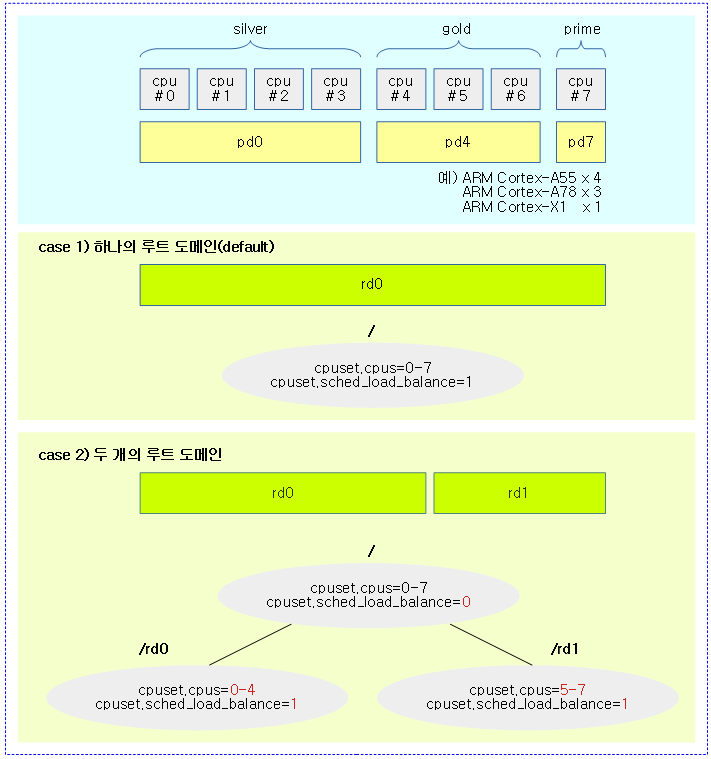
다음 그림은 performance domain을 구성한 예를 간단히 보여준다.
- 두 개의 루트 도메인(rd)에 리스트 연결용 pd4가 중복됨을 볼 수 있다.
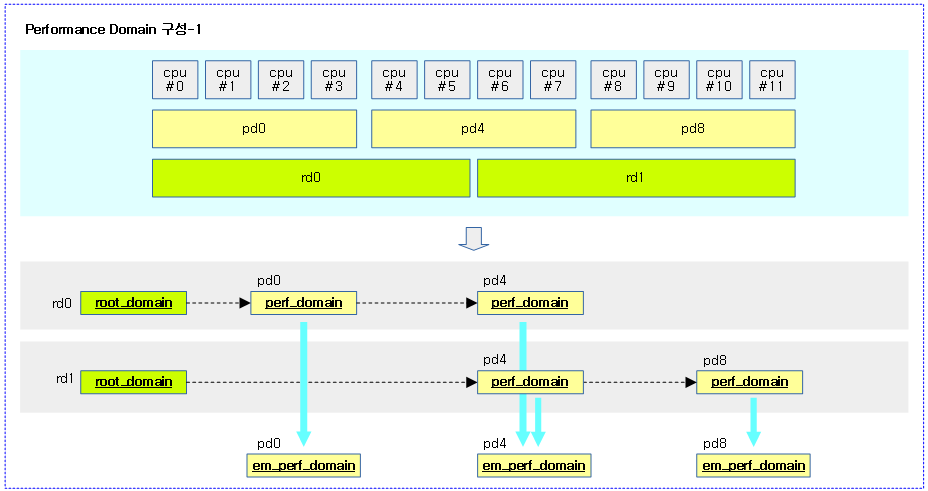
다음 그림은 performance domain을 구성한 예를 조금 더 자세히 구조체 레벨에서 보여준다.
- 실제 데이터를 관리하는 에너지 모델 pd(em_perf_domain)는 중복되지 않고 pd 숫자만큼만 만들어진다.
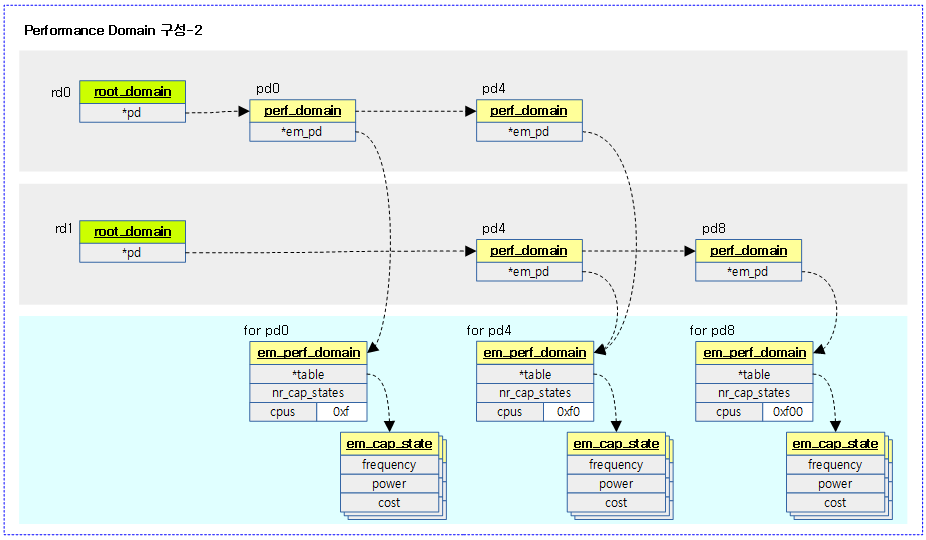
다음 그림은 여러 개의 루트 도메인을 구성한 경우 EAS를 사용한 wake-up 밸런싱에서 pd들이 루트 도메인들에 포함되는 모습을 볼 수 있다.
- performance 도메인은 디바이스 트리를 통해서 결정되고, 루트 도메인은 cgroup 설정으로 지정할 수 있다.
- 두 개의 루트 도메인 예를 보면
- cpu0~4는 wake-up 밸런싱에서 pd0~pd4에 소속한 cpu 0~6까지의 cpu를 선택할 수 있음을 보여준다.
- cpu5~7은 wake-up 밸런싱에서 pd4~pd7에 소속한 cpu 4~7까지의 cpu를 선택할 수 있음을 보여준다.
“sched_energy_aware” proc
sched_energy_aware_handler()
kernel/sched/topology.c
int sched_energy_aware_handler(struct ctl_table *table, int write,
void __user *buffer, size_t *lenp, loff_t *ppos)
{
int ret, state;
if (write && !capable(CAP_SYS_ADMIN))
return -EPERM;
ret = proc_dointvec_minmax(table, write, buffer, lenp, ppos);
if (!ret && write) {
state = static_branch_unlikely(&sched_energy_present);
if (state != sysctl_sched_energy_aware) {
mutex_lock(&sched_energy_mutex);
sched_energy_update = 1;
rebuild_sched_domains();
sched_energy_update = 0;
mutex_unlock(&sched_energy_mutex);
}
}
return ret;
}
에너지 모델을 enable/disable하고 스케줄 도메인을 재구성한다.
- 코드 라인 6~7에서 CAP_SYS_ADMIN capability가 없으면 권한이 없으므로 -EPERM을 반환한다.
- 코드 라인 9~19에서 sched_energy_present가 동작 중이면 sysctl_sched_energy_aware로 기록한 값이 변경된 경우 스케줄 도메인을 재구성하며 그 동안 sched_energy_update를 1로 유지한다.
- “/proc/sys/kernel/sched_energy_aware”
rebuild_sched_domains()
kernel/sched/topology.c
void rebuild_sched_domains(void)
{
get_online_cpus();
percpu_down_write(&cpuset_rwsem);
rebuild_sched_domains_locked();
percpu_up_write(&cpuset_rwsem);
put_online_cpus();
}
스케줄 도메인들을 재구성한다.
rebuild_sched_domains_locked()
kernel/sched/topology.c
/* * Rebuild scheduler domains. * * If the flag 'sched_load_balance' of any cpuset with non-empty * 'cpus' changes, or if the 'cpus' allowed changes in any cpuset * which has that flag enabled, or if any cpuset with a non-empty * 'cpus' is removed, then call this routine to rebuild the * scheduler's dynamic sched domains. * * Call with cpuset_mutex held. Takes get_online_cpus(). */
static void rebuild_sched_domains_locked(void)
{
struct sched_domain_attr *attr;
cpumask_var_t *doms;
int ndoms;
lockdep_assert_cpus_held();
percpu_rwsem_assert_held(&cpuset_rwsem);
/*
* We have raced with CPU hotplug. Don't do anything to avoid
* passing doms with offlined cpu to partition_sched_domains().
* Anyways, hotplug work item will rebuild sched domains.
*/
if (!top_cpuset.nr_subparts_cpus &&
!cpumask_equal(top_cpuset.effective_cpus, cpu_active_mask))
return;
if (top_cpuset.nr_subparts_cpus &&
!cpumask_subset(top_cpuset.effective_cpus, cpu_active_mask))
return;
/* Generate domain masks and attrs */
ndoms = generate_sched_domains(&doms, &attr);
/* Have scheduler rebuild the domains */
partition_and_rebuild_sched_domains(ndoms, doms, attr);
}
스케줄 도메인들을 재구성한다.
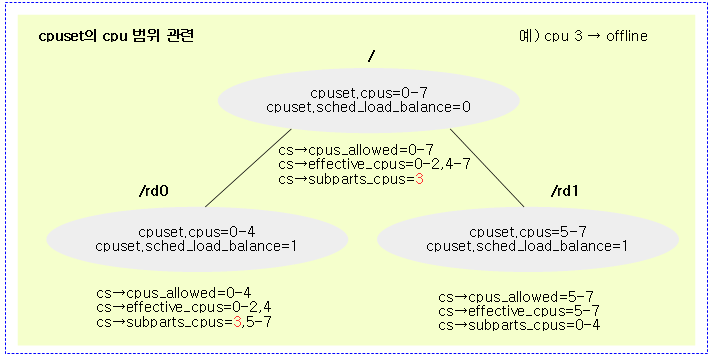
cpuset cpu 범위 관련
- cpus_allowed
- cpuset.cpus에서 지정한 cpu들에 대한 비트마스크
- effective_cpus
- cpuset.cpus에서 지정한 cpu들 중 online cpu에 대한 비트마스크
- subpart_cpus
- 부모 effective_cpus 중 현재 effective_cpus에 없는 cpu들에 대한 비트마스크 (offline 포함)
다음 그림과 같이 cpuset.cpus를 통해 설정된 cpu들의 범위를 확인할 수 있다.
generate_sched_domains()
kernel/cgroup/cpuset.c -1/2-
/* * generate_sched_domains() * * This function builds a partial partition of the systems CPUs * A 'partial partition' is a set of non-overlapping subsets whose * union is a subset of that set. * The output of this function needs to be passed to kernel/sched/core.c * partition_sched_domains() routine, which will rebuild the scheduler's * load balancing domains (sched domains) as specified by that partial * partition. * * See "What is sched_load_balance" in Documentation/admin-guide/cgroup-v1/cpusets.rst * for a background explanation of this. * * Does not return errors, on the theory that the callers of this * routine would rather not worry about failures to rebuild sched * domains when operating in the severe memory shortage situations * that could cause allocation failures below. * * Must be called with cpuset_mutex held. * * The three key local variables below are: * cp - cpuset pointer, used (together with pos_css) to perform a * top-down scan of all cpusets. For our purposes, rebuilding * the schedulers sched domains, we can ignore !is_sched_load_ * balance cpusets. * csa - (for CpuSet Array) Array of pointers to all the cpusets * that need to be load balanced, for convenient iterative * access by the subsequent code that finds the best partition, * i.e the set of domains (subsets) of CPUs such that the * cpus_allowed of every cpuset marked is_sched_load_balance * is a subset of one of these domains, while there are as * many such domains as possible, each as small as possible. * doms - Conversion of 'csa' to an array of cpumasks, for passing to * the kernel/sched/core.c routine partition_sched_domains() in a * convenient format, that can be easily compared to the prior * value to determine what partition elements (sched domains) * were changed (added or removed.) * * Finding the best partition (set of domains): * The triple nested loops below over i, j, k scan over the * load balanced cpusets (using the array of cpuset pointers in * csa[]) looking for pairs of cpusets that have overlapping * cpus_allowed, but which don't have the same 'pn' partition * number and gives them in the same partition number. It keeps * looping on the 'restart' label until it can no longer find * any such pairs. * * The union of the cpus_allowed masks from the set of * all cpusets having the same 'pn' value then form the one * element of the partition (one sched domain) to be passed to * partition_sched_domains(). */
static int generate_sched_domains(cpumask_var_t **domains,
struct sched_domain_attr **attributes)
{
struct cpuset *cp; /* top-down scan of cpusets */
struct cpuset **csa; /* array of all cpuset ptrs */
int csn; /* how many cpuset ptrs in csa so far */
int i, j, k; /* indices for partition finding loops */
cpumask_var_t *doms; /* resulting partition; i.e. sched domains */
struct sched_domain_attr *dattr; /* attributes for custom domains */
int ndoms = 0; /* number of sched domains in result */
int nslot; /* next empty doms[] struct cpumask slot */
struct cgroup_subsys_state *pos_css;
bool root_load_balance = is_sched_load_balance(&top_cpuset);
doms = NULL;
dattr = NULL;
csa = NULL;
/* Special case for the 99% of systems with one, full, sched domain */
if (root_load_balance && !top_cpuset.nr_subparts_cpus) {
ndoms = 1;
doms = alloc_sched_domains(ndoms);
if (!doms)
goto done;
dattr = kmalloc(sizeof(struct sched_domain_attr), GFP_KERNEL);
if (dattr) {
*dattr = SD_ATTR_INIT;
update_domain_attr_tree(dattr, &top_cpuset);
}
cpumask_and(doms[0], top_cpuset.effective_cpus,
housekeeping_cpumask(HK_FLAG_DOMAIN));
goto done;
}
csa = kmalloc_array(nr_cpusets(), sizeof(cp), GFP_KERNEL);
if (!csa)
goto done;
csn = 0;
rcu_read_lock();
if (root_load_balance)
csa[csn++] = &top_cpuset;
cpuset_for_each_descendant_pre(cp, pos_css, &top_cpuset) {
if (cp == &top_cpuset)
continue;
/*
* Continue traversing beyond @cp iff @cp has some CPUs and
* isn't load balancing. The former is obvious. The
* latter: All child cpusets contain a subset of the
* parent's cpus, so just skip them, and then we call
* update_domain_attr_tree() to calc relax_domain_level of
* the corresponding sched domain.
*
* If root is load-balancing, we can skip @cp if it
* is a subset of the root's effective_cpus.
*/
if (!cpumask_empty(cp->cpus_allowed) &&
!(is_sched_load_balance(cp) &&
cpumask_intersects(cp->cpus_allowed,
housekeeping_cpumask(HK_FLAG_DOMAIN))))
continue;
if (root_load_balance &&
cpumask_subset(cp->cpus_allowed, top_cpuset.effective_cpus))
continue;
if (is_sched_load_balance(cp) &&
!cpumask_empty(cp->effective_cpus))
csa[csn++] = cp;
/* skip @cp's subtree if not a partition root */
if (!is_partition_root(cp))
pos_css = css_rightmost_descendant(pos_css);
}
rcu_read_unlock();
for (i = 0; i < csn; i++)
csa[i]->pn = i;
ndoms = csn;
스케줄 도메인을 생성한다.
- 코드 라인 13에서 cgroup의 top cpuset에 있는 “cpuset.sched_load_balance” 설정 값 여부에 따라 해당 cpu들이 싱글 스케줄 도메인에 소속되어 로드 밸런스에 참여한다. (디폴트=1)
- 위의 값이 1인 경우 cgroup의 “cpuset.cpus”에 속한 cpu들이 기본 로드 밸런스에서 동작한다. (디폴트=모든 cpu) 위의 값이 0인 경우 기본 로드 밸런스에서 제외된다. 이 때에는 별도의 파티션 도메인을 만들 때 구성원으로 참여 시킬 수 있다.
- 코드 라인 20~35에서 별도의 서브 파티션이 없는 경우 해당 cpu들을 대상으로 로드 밸런싱에 참여하게 하도록 싱글 스케줄 도메인을 구성한 후 done 레이블로 이동한다.
- 코드 라인 37~39에서 이미 생성된 cpuset 수 만큼 cpuset 구조체 포인터를 할당하여 csa에 대입한다.
- 코드 라인 43~44에서 싱글 스케줄 도메인이 포함되는 경우 첫 번째 csa[0]는 top cpuset을 가리키게 한다.
- 코드 라인 45~67에서 cpuset들을 대상으로 child 우선 방향으로 순회하며 다음 cpuset들은 제외한다.
- top cpuset인 경우
- 순회 중인 cpuset에 cpu들을 지정하였으면서, 로드 밸런싱이 설정되지 않았거나 “isolcpus=” 커널 파라미터로 지정된 cpu들로 다 사용할 수 있는 cpu가 없는 경우
- 루트에서 로드 밸런싱이 동작하면서 지정한 cpu들은 모두 루트의 effective cpu들에 포함된 경우
- 코드 라인 69~71에서 순회 중인 cpuset이 기본 로드 밸런싱이 설정되었고 effective_cpus들이 있는 경우 해당 cpuset을 csa[]에 추가한다.
- 코드 라인 74~75에서 cpuset이 파티션 루트가 아닌 하위 cpuset들은 한꺼번에 skip 한다.
- 코드 라인 79~81에서 위 루프에서 지정하여 사용가능한 csa[]->pn에 일련번호를 0부터 대입하고, 도메인의 수를 결정한다.
kernel/cgroup/cpuset.c -2/2-
restart:
/* Find the best partition (set of sched domains) */
for (i = 0; i < csn; i++) {
struct cpuset *a = csa[i];
int apn = a->pn;
for (j = 0; j < csn; j++) {
struct cpuset *b = csa[j];
int bpn = b->pn;
if (apn != bpn && cpusets_overlap(a, b)) {
for (k = 0; k < csn; k++) {
struct cpuset *c = csa[k];
if (c->pn == bpn)
c->pn = apn;
}
ndoms--; /* one less element */
goto restart;
}
}
}
/*
* Now we know how many domains to create.
* Convert <csn, csa> to <ndoms, doms> and populate cpu masks.
*/
doms = alloc_sched_domains(ndoms);
if (!doms)
goto done;
/*
* The rest of the code, including the scheduler, can deal with
* dattr==NULL case. No need to abort if alloc fails.
*/
dattr = kmalloc_array(ndoms, sizeof(struct sched_domain_attr),
GFP_KERNEL);
for (nslot = 0, i = 0; i < csn; i++) {
struct cpuset *a = csa[i];
struct cpumask *dp;
int apn = a->pn;
if (apn < 0) {
/* Skip completed partitions */
continue;
}
dp = doms[nslot];
if (nslot == ndoms) {
static int warnings = 10;
if (warnings) {
pr_warn("rebuild_sched_domains confused: nslot %d, ndoms %d, csn %d, i %d, apn %d\n",
nslot, ndoms, csn, i, apn);
warnings--;
}
continue;
}
cpumask_clear(dp);
if (dattr)
*(dattr + nslot) = SD_ATTR_INIT;
for (j = i; j < csn; j++) {
struct cpuset *b = csa[j];
if (apn == b->pn) {
cpumask_or(dp, dp, b->effective_cpus);
cpumask_and(dp, dp, housekeeping_cpumask(HK_FLAG_DOMAIN));
if (dattr)
update_domain_attr_tree(dattr + nslot, b);
/* Done with this partition */
b->pn = -1;
}
}
nslot++;
}
BUG_ON(nslot != ndoms);
done:
kfree(csa);
/*
* Fallback to the default domain if kmalloc() failed.
* See comments in partition_sched_domains().
*/
if (doms == NULL)
ndoms = 1;
*domains = doms;
*attributes = dattr;
return ndoms;
}
- 코드 라인 1~22에서 restart: 레이블이다. cpuset들에서 effective_cpus가 중첩되는 도메인을 제거한 수를 알아낸다.
- csn 수 만큼 i, j, k 이터레이터를 가진 3 중첩 루프를 사용한다.
- 처음 i, j로 2 중첩 루프를 돌면서 csa[i]->pn 값과 csn[j]->pn 값이 다르고 csa[i]->effiective_cpus와 csa[j]->effective_cpus가 중첩되는 경우에 한해 k로 3 중첩 루프를 돌면서 j, k에 해당하는 pn이 같을 때 k에 해당하는 pn에 i에 해당하는 pn 값으로 대입한다. 그 후 도메인 수(ndoms)를 감소시키고 restart: 레이블로 이동하여 다시 시작한다.
- 코드 라인 28~37에서 중첩 도메인을 제거한 최종 결정된 도메인 수 만큼 도메인 마스크와 도메인 속성을 할당한다.
- 코드 라인 39~78에서 원래 도메인 수(csn)만큼 nslot으로 1차 순회하고, 다시 nslot부터 원래 도메인 수까지(csn) 2차 순회하며 같은 pn에 대해 effective_cpus를 더해 update_domain_attr_tree() 함수를 호출한다.
- 한 번 생성한 파티션은 다시 만들지 않도록 pn에 -1을 대입한다.
- 코드 라인 81~92에서 done: 레이블이다. 임시로 만들어 사용했던 csa[] 배열을 할당 해제하고, 출력 인자 *domains에 결정된 도메인 수만큼 중복된 도메인을 합친 cpu 마스크를 반환하고, 출력인자 *dattr에는 결정된 도메인 수만큼의 도메인 속성을 반환한다.
- 코드 라인 93에서 최종 결정된 도메인 수를 반환한다.
다음 그립은 generate_sched_domains() 함수에서 오버랩된 cpu를 가진 도메인을 묶어 도메인 수를 줄인 과정을 보여준다.

update_domain_attr_tree()
kernel/cgroup/cpuset.c
static void update_domain_attr_tree(struct sched_domain_attr *dattr,
struct cpuset *root_cs)
{
struct cpuset *cp;
struct cgroup_subsys_state *pos_css;
rcu_read_lock();
cpuset_for_each_descendant_pre(cp, pos_css, root_cs) {
/* skip the whole subtree if @cp doesn't have any CPU */
if (cpumask_empty(cp->cpus_allowed)) {
pos_css = css_rightmost_descendant(pos_css);
continue;
}
if (is_sched_load_balance(cp))
update_domain_attr(dattr, cp);
}
rcu_read_unlock();
}
도메인 속성 @dattr을 @root_cs 이하 모든 cpuset에 적용한다.
- 코드 라인 8~14에서 @root_cs 이하 child 우선으로 순회하며 지정된 cpu가 없는 경우 skip 한다.
- “cpuset.cpus”
- 코드 라인 16~17에서 로드 밸런싱이 설정된 cpuset인 경우 도메인 속성을 갱신한다.
- “cpuset.sched_load_balance”
partition_and_rebuild_sched_domains()
kernel/sched/topology.c
static void
partition_and_rebuild_sched_domains(int ndoms_new, cpumask_var_t doms_new[],
struct sched_domain_attr *dattr_new)
{
mutex_lock(&sched_domains_mutex);
partition_sched_domains_locked(ndoms_new, doms_new, dattr_new);
rebuild_root_domains();
mutex_unlock(&sched_domains_mutex);
}
분할된 스케줄 도메인들과 루트 도메인들을 재구성한다.
partition_sched_domains()
kernel/sched/topology.c
/* * Call with hotplug lock held */
void partition_sched_domains(int ndoms_new, cpumask_var_t doms_new[],
struct sched_domain_attr *dattr_new)
{
mutex_lock(&sched_domains_mutex);
partition_sched_domains_locked(ndoms_new, doms_new, dattr_new);
mutex_unlock(&sched_domains_mutex);
}
분할된 스케줄 도메인들을 재구성한다.
partition_sched_domains_locked()
kernel/sched/topology.c -1/2-
/* * Partition sched domains as specified by the 'ndoms_new' * cpumasks in the array doms_new[] of cpumasks. This compares * doms_new[] to the current sched domain partitioning, doms_cur[]. * It destroys each deleted domain and builds each new domain. * * 'doms_new' is an array of cpumask_var_t's of length 'ndoms_new'. * The masks don't intersect (don't overlap.) We should setup one * sched domain for each mask. CPUs not in any of the cpumasks will * not be load balanced. If the same cpumask appears both in the * current 'doms_cur' domains and in the new 'doms_new', we can leave * it as it is. * * The passed in 'doms_new' should be allocated using * alloc_sched_domains. This routine takes ownership of it and will * free_sched_domains it when done with it. If the caller failed the * alloc call, then it can pass in doms_new == NULL && ndoms_new == 1, * and partition_sched_domains() will fallback to the single partition * 'fallback_doms', it also forces the domains to be rebuilt. * * If doms_new == NULL it will be replaced with cpu_online_mask. * ndoms_new == 0 is a special case for destroying existing domains, * and it will not create the default domain. * * Call with hotplug lock and sched_domains_mutex held */
void partition_sched_domains_locked(int ndoms_new, cpumask_var_t doms_new[],
struct sched_domain_attr *dattr_new)
{
bool __maybe_unused has_eas = false;
int i, j, n;
int new_topology;
lockdep_assert_held(&sched_domains_mutex);
/* Always unregister in case we don't destroy any domains: */
unregister_sched_domain_sysctl();
/* Let the architecture update CPU core mappings: */
new_topology = arch_update_cpu_topology();
if (!doms_new) {
WARN_ON_ONCE(dattr_new);
n = 0;
doms_new = alloc_sched_domains(1);
if (doms_new) {
n = 1;
cpumask_and(doms_new[0], cpu_active_mask,
housekeeping_cpumask(HK_FLAG_DOMAIN));
}
} else {
n = ndoms_new;
}
/* Destroy deleted domains: */
for (i = 0; i < ndoms_cur; i++) {
for (j = 0; j < n && !new_topology; j++) {
if (cpumask_equal(doms_cur[i], doms_new[j]) &&
dattrs_equal(dattr_cur, i, dattr_new, j)) {
struct root_domain *rd;
/*
* This domain won't be destroyed and as such
* its dl_bw->total_bw needs to be cleared. It
* will be recomputed in function
* update_tasks_root_domain().
*/
rd = cpu_rq(cpumask_any(doms_cur[i]))->rd;
dl_clear_root_domain(rd);
goto match1;
}
}
/* No match - a current sched domain not in new doms_new[] */
detach_destroy_domains(doms_cur[i]);
match1:
;
}
n = ndoms_cur;
if (!doms_new) {
n = 0;
doms_new = &fallback_doms;
cpumask_and(doms_new[0], cpu_active_mask,
housekeeping_cpumask(HK_FLAG_DOMAIN));
}
/* Build new domains: */
for (i = 0; i < ndoms_new; i++) {
for (j = 0; j < n && !new_topology; j++) {
if (cpumask_equal(doms_new[i], doms_cur[j]) &&
dattrs_equal(dattr_new, i, dattr_cur, j))
goto match2;
}
/* No match - add a new doms_new */
build_sched_domains(doms_new[i], dattr_new ? dattr_new + i : NULL);
match2:
;
}
분할된 스케줄 도메인들을 재구성한다.
- 코드 라인 11에서 “/proc/sys/kernel/sched_domain” 디렉토리를 등록 해제한다.
- 코드 라인 14에서 cpu topology 변경 여부를 알아온다. (1=변경)
- 코드 라인 16~27에서 두 번째 인자 doms_new가 지정되지 않은 경우 isolcpus를 제외한 active cpu들로 1개의 도메인을 할당한다. doms_new가 지정된 경우 도메인 수로 첫 번째 인자 ndoms_new 에서 받은 값을 사용한다.
- 코드 라인 30~51에서 기존 동작 중인 도메인들을 순회하며 토플로지 변경이 있으면 기존 도메인을 detach한 후 제거한다. 만일 토플로지 변경이 없으면 기존 도메인들 중 기존 cpu와 속성이 같은 경우 detach 및 제거하지 않고 루트 도메인의 dl 밴드위드만 클리어하고, 다른 경우에만 기존 도메인을 detach한 후 제거한다.
- 코드 라인 53~59에서 새로운 도메인이 요청되지 않은 경우 isolcpus를 제외한 active cpu들로 구성하는 1개의fallback_doms을 지정한다.
- 코드 라인 62~72에서 새 도메인들을 순회하며 토플로지 변경이 있으면 도메인을 새로 만든다. 만일 토플로지 변경이 없으면 기존 도메인들 중 cpu 및 속성이 같은 경우 새로 만들지 않고,다른 경우에만 도메인을 새로 만든다.
kernel/sched/topology.c -2/2-
#if defined(CONFIG_ENERGY_MODEL) && defined(CONFIG_CPU_FREQ_GOV_SCHEDUTIL)
/* Build perf. domains: */
for (i = 0; i < ndoms_new; i++) {
for (j = 0; j < n && !sched_energy_update; j++) {
if (cpumask_equal(doms_new[i], doms_cur[j]) &&
cpu_rq(cpumask_first(doms_cur[j]))->rd->pd) {
has_eas = true;
goto match3;
}
}
/* No match - add perf. domains for a new rd */
has_eas |= build_perf_domains(doms_new[i]);
match3:
;
}
sched_energy_set(has_eas);
#endif
/* Remember the new sched domains: */
if (doms_cur != &fallback_doms)
free_sched_domains(doms_cur, ndoms_cur);
kfree(dattr_cur);
doms_cur = doms_new;
dattr_cur = dattr_new;
ndoms_cur = ndoms_new;
register_sched_domain_sysctl();
}
- 코드 라인 3~15에서 EAS를 위해 새 도메인 수 만큼 순회하며 다음의 EAS 동작 변경으로 인한 스케줄 도메인 변경이 진행 중인 경우 perf 도메인을 만든다. 만일 스케줄 도메인 변경이 진행중이 아닌 경우 새 도메인들 중 cpu들이 같고 첫 번째 cpu의 perf 도메인도 이미 있는 경우 perf 도메인을 만들지 않고, 그 외의 경우 perf 도메인을 새로 만든다.
- “/proc/sys/kernel/sched_energy_aware”
- 코드 라인 16에서 EAS를 enable/disable 시키고 다음과 같은 로그 중 하나를 출력한다.
- “sched_energy_set: starting EAS”
- “sched_energy_set: stopping EAS”
- 코드 라인 20~23에서 기존 도메인들과 속성들을 할당 해제한다.
- 코드 라인 24~26에서 새 도메인과 속성 정보를 전역 변수에 지정한다.
- 코드 라인 28에서 “/proc/sys/kernel/sched_domain” 디렉토리를 등록한다.
build_perf_domains()
kernel/sched/topology.c
static bool build_perf_domains(const struct cpumask *cpu_map)
{
int i, nr_pd = 0, nr_cs = 0, nr_cpus = cpumask_weight(cpu_map);
struct perf_domain *pd = NULL, *tmp;
int cpu = cpumask_first(cpu_map);
struct root_domain *rd = cpu_rq(cpu)->rd;
struct cpufreq_policy *policy;
struct cpufreq_governor *gov;
if (!sysctl_sched_energy_aware)
goto free;
/* EAS is enabled for asymmetric CPU capacity topologies. */
if (!per_cpu(sd_asym_cpucapacity, cpu)) {
if (sched_debug()) {
pr_info("rd %*pbl: CPUs do not have asymmetric capacities\n",
cpumask_pr_args(cpu_map));
}
goto free;
}
for_each_cpu(i, cpu_map) {
/* Skip already covered CPUs. */
if (find_pd(pd, i))
continue;
/* Do not attempt EAS if schedutil is not being used. */
policy = cpufreq_cpu_get(i);
if (!policy)
goto free;
gov = policy->governor;
cpufreq_cpu_put(policy);
if (gov != &schedutil_gov) {
if (rd->pd)
pr_warn("rd %*pbl: Disabling EAS, schedutil is mandatory\n",
cpumask_pr_args(cpu_map));
goto free;
}
/* Create the new pd and add it to the local list. */
tmp = pd_init(i);
if (!tmp)
goto free;
tmp->next = pd;
pd = tmp;
/*
* Count performance domains and capacity states for the
* complexity check.
*/
nr_pd++;
nr_cs += em_pd_nr_cap_states(pd->em_pd);
}
/* Bail out if the Energy Model complexity is too high. */
if (nr_pd * (nr_cs + nr_cpus) > EM_MAX_COMPLEXITY) {
WARN(1, "rd %*pbl: Failed to start EAS, EM complexity is too high\n",
cpumask_pr_args(cpu_map));
goto free;
}
perf_domain_debug(cpu_map, pd);
/* Attach the new list of performance domains to the root domain. */
tmp = rd->pd;
rcu_assign_pointer(rd->pd, pd);
if (tmp)
call_rcu(&tmp->rcu, destroy_perf_domain_rcu);
return !!pd;
free:
free_pd(pd);
tmp = rd->pd;
rcu_assign_pointer(rd->pd, NULL);
if (tmp)
call_rcu(&tmp->rcu, destroy_perf_domain_rcu);
return false;
}
1개의 도메인에 해당하는 @cpu_map 비트마스크 멤버로 perf 도메인들을 구성한다. (1개의 도메인내에 파티션이 하나 이상 존재할 수 있다.)
- 코드 라인 10~11에서 다음 EAS 기능이 disable된 경우 free 레이블로 이동한다.
- “/proc/sys/kernel/sched_energy_aware”
- 코드 라인 14~20에서 빅/리틀 같은 asym cpu capacity 도메인이 없는 경우 EAS 기능을 동작시킬 수 없으므로 정보를 출력한 후 free 레이블로 이동한다.
- 코드 라인 22~25에서 cpu_map 비트마스크에 설정된 cpu 비트만큼 순회하며 해당 cpu가 멤버인 perf 도메인이 이미 만들어져 있는 경우 skip 한다.
- 코드 라인 27~29에서 cpufreq policy를 가져온다. 만일 schedutil이 활성화되지 않아 가져올 수 없으면 EAS를 사용하지 못하므로 free 레이블로 이동한다.
- 코드 라인 30~37에서 policy의 governor가 schedutil인 경우에만 EAS를 사용할 수 있다. 따라서 schedutil이 아닌 경우 free 레이블로 이동한다.
- 코드 라인 40~44에서 perf 도메인을 만들고 리스트 연결한다.
- 코드 라인 50~52에서 perf 도메인 수를 증가시키고, em_pd의 cap_states 수를 증가시키고 계속 순회한다.
- 코드 라인 55~59에서 만일 너무 많은 pd가 구성되는 경우 에너지모델이 너무 복잡해지므로 free 레이블로 이동한다.
- (cap state 수 + cpu 수) * pd 수 > 2048개
- 코드 라인 61에서 pd 정보를 디버그 출력한다.
- 코드 라인 64~67에서 rcu를 사용하여 루트 도메인의 기존 domain은 제거하고, 새롭게 생성한 perf 도메인을 지정한다.
- 코드 라인 69에서 pd 생성 여부를 반환한다.
- 코드 라인 71~78에서 free: 레이블이다. pd를 제거하고, 루트 도메인이 null pd를 지정하게한 후 false를 반환한다.
EM_MAX_COMPLEXITY
kernel/sched/topology.c
/* * EAS can be used on a root domain if it meets all the following conditions: * 1. an Energy Model (EM) is available; * 2. the SD_ASYM_CPUCAPACITY flag is set in the sched_domain hierarchy. * 3. the EM complexity is low enough to keep scheduling overheads low; * 4. schedutil is driving the frequency of all CPUs of the rd; * * The complexity of the Energy Model is defined as: * * C = nr_pd * (nr_cpus + nr_cs) * * with parameters defined as: * - nr_pd: the number of performance domains * - nr_cpus: the number of CPUs * - nr_cs: the sum of the number of capacity states of all performance * domains (for example, on a system with 2 performance domains, * with 10 capacity states each, nr_cs = 2 * 10 = 20). * * It is generally not a good idea to use such a model in the wake-up path on * very complex platforms because of the associated scheduling overheads. The * arbitrary constraint below prevents that. It makes EAS usable up to 16 CPUs * with per-CPU DVFS and less than 8 capacity states each, for example. */
#define EM_MAX_COMPLEXITY 2048
(cap state 수 + cpu 수) * pd 수가 2048개를 초과하는 경우 너무 복잡하여 EAS를 사용할 수 없다.
pd_init()
kernel/sched/topology.c
static struct perf_domain *pd_init(int cpu)
{
struct em_perf_domain *obj = em_cpu_get(cpu);
struct perf_domain *pd;
if (!obj) {
if (sched_debug())
pr_info("%s: no EM found for CPU%d\n", __func__, cpu);
return NULL;
}
pd = kzalloc(sizeof(*pd), GFP_KERNEL);
if (!pd)
return NULL;
pd->em_pd = obj;
return pd;
}
performance 도메인을 할당하고 초기화한 후 반환한다.
find_pd()
kernel/sched/topology.c
static struct perf_domain *find_pd(struct perf_domain *pd, int cpu)
{
while (pd) {
if (cpumask_test_cpu(cpu, perf_domain_span(pd)))
return pd;
pd = pd->next;
}
return NULL;
}
performance 도메인들 내에 속한 @cpu를 찾는다.
- performance 도메인들은 리스트로 연결되어 있다.
Perf 도메인의 EM(Energy Model) 추가
다음은 cpufreq 디바이스 드라이버 초기화 루틴을 통해 dev_pm_opp_of_register_em() 함수를 호출하여 perf 도메인의 em을 추가한 경로 예를 본다.
- cpufreq_init() – drivers/cpufreq/cpufreq-dt.c
- dev_pm_opp_of_register_em()
- em_register_perf_domain()
- dev_pm_opp_of_register_em()
em_register_perf_domain()
kernel/power/energy_model.c
/** * em_register_perf_domain() - Register the Energy Model of a performance domain * @span : Mask of CPUs in the performance domain * @nr_states : Number of capacity states to register * @cb : Callback functions providing the data of the Energy Model * * Create Energy Model tables for a performance domain using the callbacks * defined in cb. * * If multiple clients register the same performance domain, all but the first * registration will be ignored. * * Reteturn 0 on success */
int em_register_perf_domain(cpumask_t *span, unsigned int nr_states,
struct em_data_callback *cb)
{
unsigned long cap, prev_cap = 0;
struct em_perf_domain *pd;
int cpu, ret = 0;
if (!span || !nr_states || !cb)
return -EINVAL;
/*
* Use a mutex to serialize the registration of performance domains and
* let the driver-defined callback functions sleep.
*/
mutex_lock(&em_pd_mutex);
for_each_cpu(cpu, span) {
/* Make sure we don't register again an existing domain. */
if (READ_ONCE(per_cpu(em_data, cpu))) {
ret = -EEXIST;
goto unlock;
}
/*
* All CPUs of a domain must have the same micro-architecture
* since they all share the same table.
*/
cap = arch_scale_cpu_capacity(cpu);
if (prev_cap && prev_cap != cap) {
pr_err("CPUs of %*pbl must have the same capacity\n",
cpumask_pr_args(span));
ret = -EINVAL;
goto unlock;
}
prev_cap = cap;
}
/* Create the performance domain and add it to the Energy Model. */
pd = em_create_pd(span, nr_states, cb);
if (!pd) {
ret = -EINVAL;
goto unlock;
}
for_each_cpu(cpu, span) {
/*
* The per-cpu array can be read concurrently from em_cpu_get().
* The barrier enforces the ordering needed to make sure readers
* can only access well formed em_perf_domain structs.
*/
smp_store_release(per_cpu_ptr(&em_data, cpu), pd);
}
pr_debug("Created perf domain %*pbl\n", cpumask_pr_args(span));
unlock:
mutex_unlock(&em_pd_mutex);
return ret;
}
EXPORT_SYMBOL_GPL(em_register_perf_domain);
perf 도메인의 em을 등록한다.
- 코드 라인 8~9에서 인자들이 0인 경우 -EINVAL 에러를 반환한다.
- 코드 라인 17~22에서 @span 비트마스크의 cpu들을 순회하며 em_data에 이미 값이 지정된 경우 -EEXIST 에러를 반환한다.
- 코드 라인 28~36에서 순회 중인 cpu들의 cpu capacity가 서로 다른 경우 -EINVAL 에러를 반환한다.
- 코드 라인 39~43에서 em perf 도메인을 생성하고 em들을 추가한다.
- 코드 라인 45~52에서 @span 비트마스크의 cpu들을 순회하며 em_data에 pd를 지정한다.
- 코드 라인 54~58에서 pd 생성에 대한 디버그 출력을한 후 결과 값을 반환한다. (성공 시 0)
performance 도메인은 다음과 같이 디바이스 트리를 통해서 생성된다.
- pd0 – little cpu x 2
- cluster_a53_opp_table 노드 생략
- pd1 – big cpu x 2
- cluster_a57_opp_table 노드 생략
cpus {
#address-cells = <1>;
#size-cells = <0>;
cpu0: cpu@100 {
device_type = "cpu";
compatible = "arm,cortex-a53";
operating-points-v2 = <&cluster_a53_opp_table>;
...
};
cpu1: cpu@101 {
device_type = "cpu";
compatible = "arm,cortex-a53";
operating-points-v2 = <&cluster_a53_opp_table>;
...
};
cpu2: cpu@0 {
device_type = "cpu";
compatible = "arm,cortex-a57";
operating-points-v2 = <&cluster_a57_opp_table>;
...
};
cpu3: cpu@1 {
device_type = "cpu";
compatible = "arm,cortex-a57";
operating-points-v2 = <&cluster_a57_opp_table>;
...
};
}
em_create_pd()
kernel/power/energy_model.c -1/2-
static struct em_perf_domain *em_create_pd(cpumask_t *span, int nr_states,
struct em_data_callback *cb)
{
unsigned long opp_eff, prev_opp_eff = ULONG_MAX;
unsigned long power, freq, prev_freq = 0;
int i, ret, cpu = cpumask_first(span);
struct em_cap_state *table;
struct em_perf_domain *pd;
u64 fmax;
if (!cb->active_power)
return NULL;
pd = kzalloc(sizeof(*pd) + cpumask_size(), GFP_KERNEL);
if (!pd)
return NULL;
table = kcalloc(nr_states, sizeof(*table), GFP_KERNEL);
if (!table)
goto free_pd;
/* Build the list of capacity states for this performance domain */
for (i = 0, freq = 0; i < nr_states; i++, freq++) {
/*
* active_power() is a driver callback which ceils 'freq' to
* lowest capacity state of 'cpu' above 'freq' and updates
* 'power' and 'freq' accordingly.
*/
ret = cb->active_power(&power, &freq, cpu);
if (ret) {
pr_err("pd%d: invalid cap. state: %d\n", cpu, ret);
goto free_cs_table;
}
/*
* We expect the driver callback to increase the frequency for
* higher capacity states.
*/
if (freq <= prev_freq) {
pr_err("pd%d: non-increasing freq: %lu\n", cpu, freq);
goto free_cs_table;
}
/*
* The power returned by active_state() is expected to be
* positive, in milli-watts and to fit into 16 bits.
*/
if (!power || power > EM_CPU_MAX_POWER) {
pr_err("pd%d: invalid power: %lu\n", cpu, power);
goto free_cs_table;
}
table[i].power = power;
table[i].frequency = prev_freq = freq;
/*
* The hertz/watts efficiency ratio should decrease as the
* frequency grows on sane platforms. But this isn't always
* true in practice so warn the user if a higher OPP is more
* power efficient than a lower one.
*/
opp_eff = freq / power;
if (opp_eff >= prev_opp_eff)
pr_warn("pd%d: hertz/watts ratio non-monotonically decreasing: em_cap_state %d >= em_cap_state%dd
\n",
cpu, i, i - 1);
prev_opp_eff = opp_eff;
}
em perf 도메인을 생성한다.
- 코드 라인 6에서 em 정보는 @span 비트마스크의 첫 번째 cpu를 사용한다.
- 코드 라인 11~12에서 em data 콜백에 (*active_power) 후크 함수가 지정되지 않은 경우 null을 반환한다.
- 코드 라인 14~20에서 em_perf_domai과 @nr_state 만큼의 테이블을 생성한다.
- 코드 라인 23~33에서 @nr_states 만큼 순회하며 (*active_power) 후크 함수를 통해 pd 도메인의 첫 번째 cpu에 대한 첫 번째 opp 데이터의 power(mW) 및 frequency(khz) 정보를 알아온다.
- 코드 라인 39~42에서 frequency 테이블은 항상 증가하여야 한다. 만일 frequency가 증가되지 않은 경우 에러를 출력하고 free_cs_table 레이블로 이동한다.
- 코드 라인 48~51에서 power 값은 1~0xffff까지 사용한다. 만일 범위 밖인 경우 에러를 출력하고 free_cs_table 레이블로 이동한다.
- 코드 라인 53~54에서 테이블에 power와 frequency를 추가한다.
- 코드 라인 62~67에서 operating performance point effective 값을 구한다. (freq / power) 이 값이 감소되지 않는 경우 경고 메시지를 출력한다.
kernel/power/energy_model.c -2/2-
/* Compute the cost of each capacity_state. */
fmax = (u64) table[nr_states - 1].frequency;
for (i = 0; i < nr_states; i++) {
table[i].cost = div64_u64(fmax * table[i].power,
table[i].frequency);
}
pd->table = table;
pd->nr_cap_states = nr_states;
cpumask_copy(to_cpumask(pd->cpus), span);
em_debug_create_pd(pd, cpu);
return pd;
free_cs_table:
kfree(table);
free_pd:
kfree(pd);
return NULL;
}
- 코드 라인 2~6에서 @nr_states 만큼 순회하며 각 테이블의 cost 값을 산출한다.
- 최대 주파수
- cost = power(mW) * ———————–
- 주파수
- 코드 라인 8~10에서 em perf 도메인에 테이블과 @nr_states 및 @span 정보를 대입한다.
- 코드 라인 12에서 em perf 도메인을 위한 sysfs를 생성한다.
- 코드 라인 14에서 생성된 em perf 도메인을 반환한다.
주파수와 파워 알아오기
_get_cpu_power()
drivers/opp/of.c
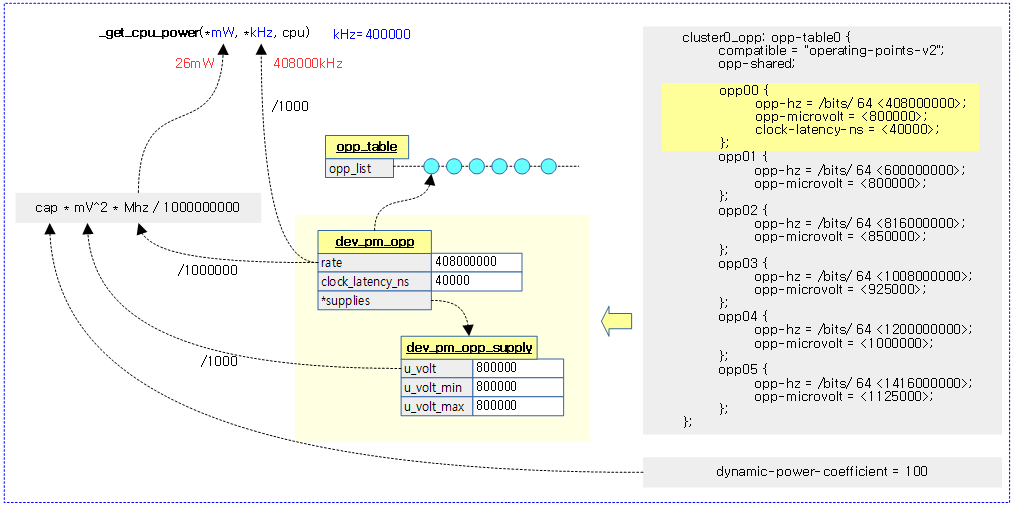
/* * Callback function provided to the Energy Model framework upon registration. * This computes the power estimated by @CPU at @kHz if it is the frequency * of an existing OPP, or at the frequency of the first OPP above @kHz otherwise * (see dev_pm_opp_find_freq_ceil()). This function updates @kHz to the ceiled * frequency and @mW to the associated power. The power is estimated as * P = C * V^2 * f with C being the CPU's capacitance and V and f respectively * the voltage and frequency of the OPP. * * Returns -ENODEV if the CPU device cannot be found, -EINVAL if the power * calculation failed because of missing parameters, 0 otherwise. */
static int __maybe_unused _get_cpu_power(unsigned long *mW, unsigned long *kHz,
int cpu)
{
struct device *cpu_dev;
struct dev_pm_opp *opp;
struct device_node *np;
unsigned long mV, Hz;
u32 cap;
u64 tmp;
int ret;
cpu_dev = get_cpu_device(cpu);
if (!cpu_dev)
return -ENODEV;
np = of_node_get(cpu_dev->of_node);
if (!np)
return -EINVAL;
ret = of_property_read_u32(np, "dynamic-power-coefficient", &cap);
of_node_put(np);
if (ret)
return -EINVAL;
Hz = *kHz * 1000;
opp = dev_pm_opp_find_freq_ceil(cpu_dev, &Hz);
if (IS_ERR(opp))
return -EINVAL;
mV = dev_pm_opp_get_voltage(opp) / 1000;
dev_pm_opp_put(opp);
if (!mV)
return -EINVAL;
tmp = (u64)cap * mV * mV * (Hz / 1000000);
do_div(tmp, 1000000000);
*mW = (unsigned long)tmp;
*kHz = Hz / 1000;
return 0;
}
@khz를 포함하는 바로 상위의 주파수에 해당하는 cpu 파워를 알아온다. (입력 인자: @cpu, @mw, 출력 인자: @mw, @khz)
- 코드 라인 12~14에서 cpu 디바이스가 없으면 -ENODEV 에러를 반환한다.
- 코드 라인 16~18에서 cpu 노드 정보를 가져온다.
- 코드 라인 20~23에서 “dynamic-power-coefficient” 속성을 읽어와서 cap에 담아둔다.
- cpu의 에너지 효율로 리틀 cpu보다 빅 cpu의 값이 더 크다.
- 코드 라인 25~28에서 요청한 주파수로 인접 상위 opp 데이터를 찾아온다.
- 코드 라인 30~33에서 opp 데이터에서 volatage를 알아와서 mV로 변환한다.
- 코드 라인 35~36에서 mW로 변환한다.
- mW = cap * mV^2 * Mhz / 1000000000
- 코드 라인 38~39에서 변환한 mW를 출력인자에 대입한다. 또한 주파수도 Khz로 변환하여 출력인자에 대입한다.
- 코드 라인 41에서 성공 값 0을 반환한다.
다음 그림은 _get_cpu_power() 함수를 통해 요청한 주파수를 포함한 상위 인접 opp 데이터에서 mW 및 kHz를 알아오는 과정을 보여준다.
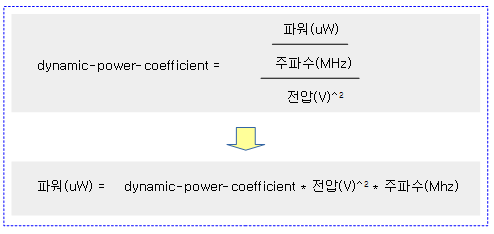
dynamic-power-coefficient 속성
디바이스트리의 cpu 노드에서 사용하는 “dynamic-power-coefficient” 속성값은 다음과 같이 산출되고, opp 데이터(전압, 주파수)에서 이 값을 곱해 파워(uW)를 알아내기 위해 사용된다.
Energy Model Sysfs
다음은 2개의 perf 도메인을 구성한 모습을 보여준다.
/sys/devices/system/cpu/energy_model
. ├── pd0
. │ ├── cost
. │ ├── cpus
. │ ├── frequency
. │ └── power
. └── pd4
. ├── cost
. ├── cpus
. ├── frequency
. └── power
OPP(Operating Performance Point)
다음 그림은 rk3399chip을 사용하는 rock960 보드의 opp 관련 디바이스 트리로부터 cost를 산출한 모습을 보여준다.
- cpu 4개의 리틀 클러스터(약 400M, 600M, 800M, 1G, 1.2G, 1.4Ghz)
- cpu 2개의 빅 클러스터(약 400M, 600M, 800M, 1G, 1.2G, 1.4G, 1.6G, 1.8Ghz)

참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c – 현재 글
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- Energy Aware Scheduling | Linux.org
- Energy Aware Scheduling (EAS) progress update (2015) | Linaro
- Energy Aware Scheduling on Android | Todd Kjos(Google) & Robin Randhawa(ARM) – 다운로드 pdf
- EAS overview and Integration Guide | ARM – 다운로드 pdf
- EAS – Energy Aware Scheduler | VitalyWool, KonsulkoGroup – 다운로드 pdf
- UtilClamp usage on Android | Android – 다운로드 pdf
- UTILIZING A BIG.LITTLETM SOLUTION IN AUTOMOTIVE (2018) | YOSHIYUKI ITO(RENESAS) – 다운로드 pdf