<kernel v5.4>
Group Scheduling 관리
그룹 스케줄링은 cgroup의 cpu 서브시스템을 사용하여 구현하였고 각 그룹은 태스크 그룹(struct task_group)으로 관리된다.
- 참고로 그룹 스케줄링(스케줄 그룹)과 유사한 단어인 스케줄링 그룹(sched_group)은 로드 밸런스에서 사용하는 점에 유의한다.
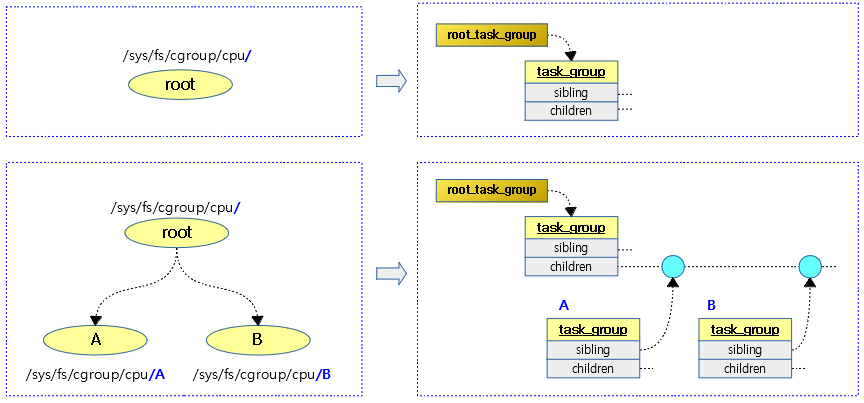
다음 그림은 태스크 그룹간 계층도를 보여준다.
- cgroup 디렉토리의 계층 구조
- task_group 에서의 계층 구조
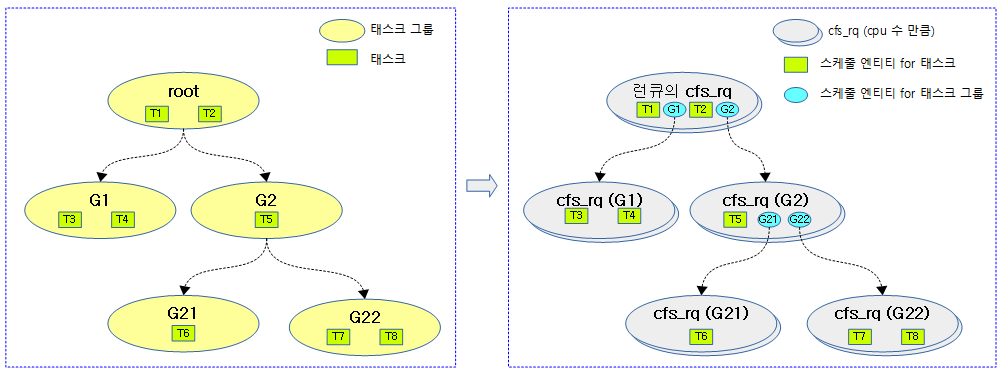
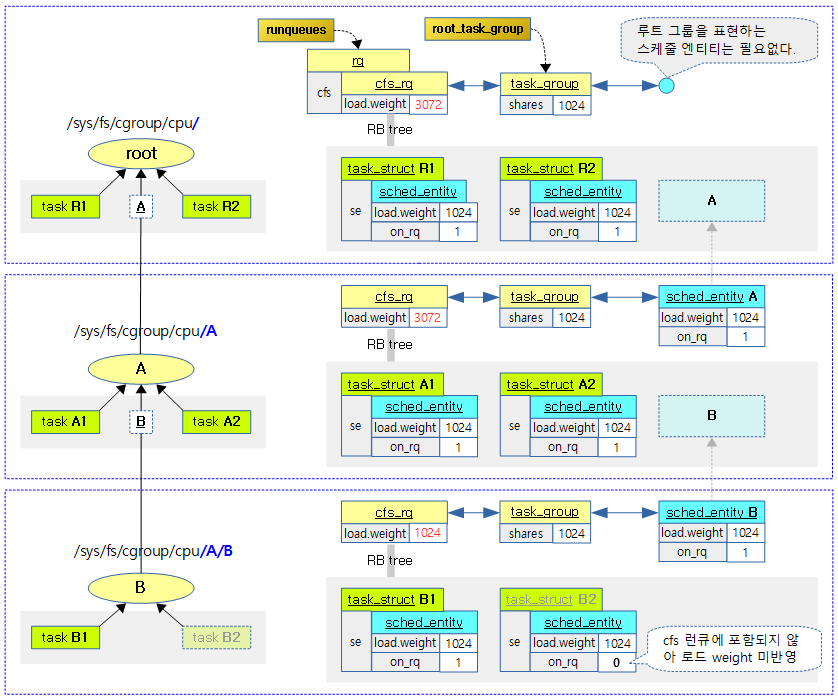
다음 그림은 태스크 그룹에 태스크 및 스케줄 엔티티가 포함된 모습을 보여준다.
다음 그림은 cfs 런큐들이 cpu 만큼 있음을 보여준다.

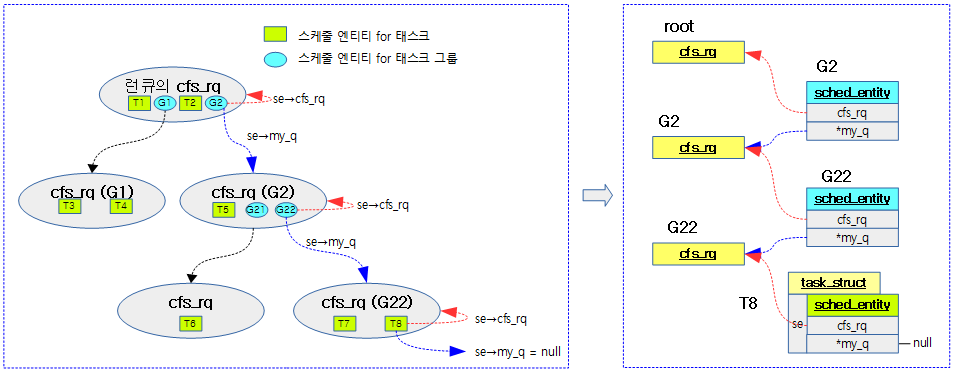
다음 그림은 스케줄 엔티티의 부모 관계를 보여준다.

다음 그림은 스케줄 엔티티의 cfs_rq 및 my_q가 어떤 cfs_rq를 가리키는지 보여준다.
태스크 그룹 생성 – (1)
cpu_cgroup_css_alloc()
kernel/sched/core.c
static struct cgroup_subsys_state *
cpu_cgroup_css_alloc(struct cgroup_subsys_state *parent_css)
{
struct task_group *parent = css_tg(parent_css);
struct task_group *tg;
if (!parent) {
/* This is early initialization for the top cgroup */
return &root_task_group.css;
}
tg = sched_create_group(parent);
if (IS_ERR(tg))
return ERR_PTR(-ENOMEM);
return &tg->css;
}
요청한 cpu cgroup에 연결된 태스크 그룹의 하위에 새 태스크 그룹을 생성한다.
- 코드 라인 4에서 요청한 cpu cgroup에 연결된 태스크 그룹을 알아온다.
- 코드 라인 7~10에서 태스크 그룹이 null인 경우 루트 태스크 그룹을 반환한다.
- 코드 라인 12~14에서 태스크 그룹의 child에 새 태스크 그룹을 생성하고 태스크 그룹 내부의 cfs 스케줄 그룹과 rt 스케줄 그룹을 초기화한다.
cpu cgroup 서브시스템이 설정된 커널인 경우 커널이 초기화되면서 cgroup_init_subsys() 함수에서 루트 태스크 그룹은 초기화된다. 그 밑으로 새 태스크 그룹을 생성할 때 다음과 같이 디렉토리를 생성하는 것으로 새 태스크 그룹이 생성된다.
/$ cd /sys/fs/cgroup/cpu /sys/fs/cgroup/cpu$ sudo mkdir A /sys/fs/cgroup/cpu$ ls cgroup.clone_children cpu.rt_runtime_us cpuacct.stat cpuacct.usage_percpu_user cgroup.procs cpu.shares cpuacct.usage cpuacct.usage_sys cpu.cfs_period_us cpu.stat cpuacct.usage_all cpuacct.usage_user cpu.cfs_quota_us cpu.uclamp.max cpuacct.usage_percpu notify_on_release cpu.rt_period_us cpu.uclamp.min cpuacct.usage_percpu_sys tasks
위의 주요 설정 항목들은 다음과 같다. cgroup 공통 항목들의 설명은 제외한다.
- cpu.cfs_periods_us
- cfs 밴드위드의 기간(periods)을 설정한다.
- 디폴트 값은 100,000 us 이고, 최대 값은 1,000,000 us(1초)이다.
- cpu.cfs_quota_us
- cfs 밴드위드의 quota를 설정한다.
- 디폴트 값은 -1로 이는 동작하지 않는 상태이다.
- cpu.rt_period_us
- rt 밴드위드의 기간(periods)를 설정한다.
- 디폴트 값은 100,000 us이다.
- cpu.rt_runtime_us
- rt 밴드위드의 런타임을 설정한다.
- 디폴트 값은 0으로 동작하지 않는 상태이다.
- cpu.shares
- cfs 스케줄러에서 사용하는 shares 비율이다.
- 디폴트 값은 nice-0의 로드 weight에 해당하는 1024 이다. 이 값이 클 수록 cpu 유틸을 높일 수 있다.
- cpu.stat
- 다음과 같은 rt 밴드위드 statistics 값 들을 보여준다.
- nr_periods, nr_throttled, throttled_time
- 다음과 같은 rt 밴드위드 statistics 값 들을 보여준다.
- cpu.uclamp.max
- cpu 유틸 값을 상한을 제한하는 용도인 uclamp 최대 값이다.
- 서로 다른 여러 개의 core를 가진 시스템에서 사용된다. 이 태스크 그룹에 동작하는 태스크들은 아무리 높은 cpu 유틸을 기록해도 이 제한 값을 초과하지 못하므로 low performance cpu에서 동작할 확률이 높아진다.
- 디폴트 값은 max(100%)이다.
- cpu.uclamp.min
- cpu 유틸 값의 하한을 제한하는 용도인 uclamp 최소 값이다.
- 서로 다른 여러 개의 core를 가진 시스템에서 사용된다. 이 태스크 그룹에 동작하는 태스크들은 일을 거의 하지 않아도 이 제한 값을 넘기게 되므로 high performance cpu에서 동작할 확률이 높아진다.
- 이 값이 높아질 수록 이 태스크 그룹에 해당하는 태스크들은 high performance cpu에서 동작하게 된다.
- 디폴트 값은 0이다.
다음 그림은 sched_create_group() 함수의 호출 관계를 보여준다.
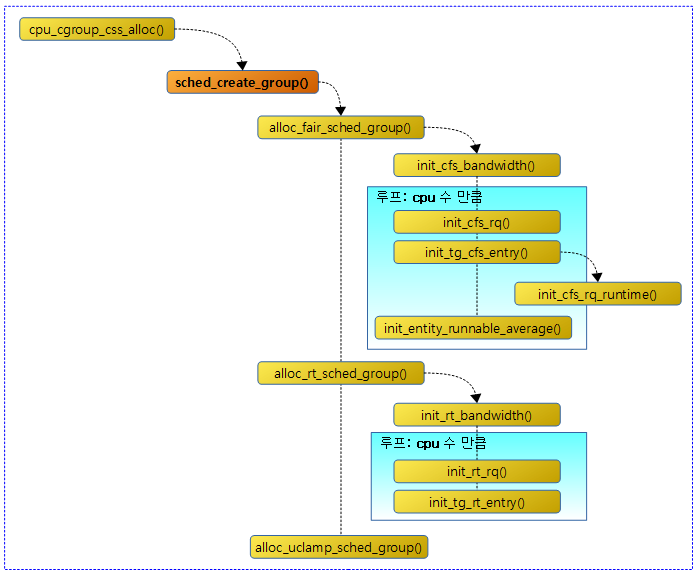
sched_create_group()
kernel/sched/core.c
/* allocate runqueue etc for a new task group */
struct task_group *sched_create_group(struct task_group *parent)
{
struct task_group *tg;
tg = kmem_cache_alloc(task_group_cache, GFP_KERNEL | __GFP_ZERO);
if (!tg)
return ERR_PTR(-ENOMEM);
if (!alloc_fair_sched_group(tg, parent))
goto err;
if (!alloc_rt_sched_group(tg, parent))
goto err;
alloc_uclamp_sched_group(tg, parent);
return tg;
err:
sched_free_group(tg);
return ERR_PTR(-ENOMEM);
}
요청한 cpu cgroup의 child에 태스크 그룹을 생성하고 그 태스크 그룹에 cfs 스케줄 그룹과 rt 스케줄 그룹을 할당하고 초기화한다.
- 코드 라인 6~8에서 태스크 그룹 구조체를 할당한다.
- 코드 라인 10~11에서 태스크 그룹에 cfs 스케줄 그룹을 할당하고 초기화한다.
- 코드 라인 13~14에서 태스크 그룹에 rt 스케줄 그룹을 할당하고 초기화한다.
- 코드 라인 16에서 태스크 그룹에 uclamp 디폴트 값을 할당한다.
- 코드 라인 18에서 생성하고 초기화한 태스크 그룹을 반환한다.
다음 그림은 sched_create_group() 함수를 호출하여 태스크 그룹을 생성할 때 태스크 그룹에 연결되는 cfs 런큐, 스케줄 엔티티, rt 런큐, rt 스케줄 엔티티를 보여준다.
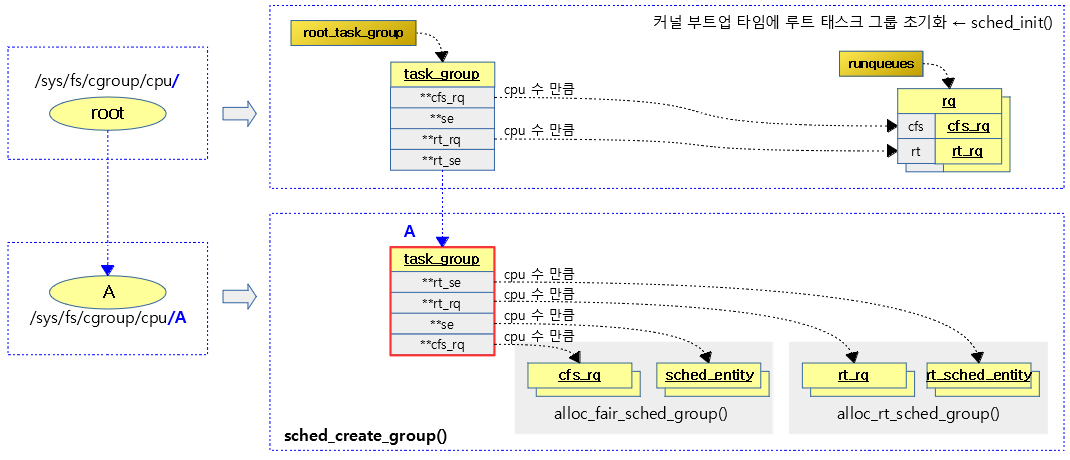
태스크 그룹 생성 – (2) CFS 스케줄 그룹 할당
alloc_fair_sched_group()
kernel/sched/core.c
int alloc_fair_sched_group(struct task_group *tg, struct task_group *parent)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se;
int i;
tg->cfs_rq = kzalloc(sizeof(cfs_rq) * nr_cpu_ids, GFP_KERNEL);
if (!tg->cfs_rq)
goto err;
tg->se = kzalloc(sizeof(se) * nr_cpu_ids, GFP_KERNEL);
if (!tg->se)
goto err;
tg->shares = NICE_0_LOAD;
init_cfs_bandwidth(tg_cfs_bandwidth(tg));
for_each_possible_cpu(i) {
cfs_rq = kzalloc_node(sizeof(struct cfs_rq),
GFP_KERNEL, cpu_to_node(i));
if (!cfs_rq)
goto err;
se = kzalloc_node(sizeof(struct sched_entity),
GFP_KERNEL, cpu_to_node(i));
if (!se)
goto err_free_rq;
init_cfs_rq(cfs_rq);
init_tg_cfs_entry(tg, cfs_rq, se, i, parent->se[i]);
init_entity_runnable_average(se);
}
return 1;
err_free_rq:
kfree(cfs_rq);
err:
return 0;
}
태스크 그룹에 cfs 스케줄 그룹을 할당하고 초기화한다. 성공인 경우 1을 반환한다.
- 코드 라인 7~9에서 tg->cfs_rq에 cpu 수 만큼 cfs 런큐를 가리키는 포인터를 할당한다.
- 코드 라인 10~12에서 tg->se에 cpu 수 만큼 스케줄 엔티티를 가리키는 포인터를 할당한다.
- 코드 라인 14에서 shares 값으로 기본 nice 0의 load weight 값인 NICE_0_LOAD(1024)를 대입한다.
- 64비트 시스템에서는 조금 더 정밀도를 높이기 위해 2^10 scale을 적용하여 NICE_0_LOAD 값으로 1K(1024) * 1K(1024) = 1M (1048576)를 사용한다.
- 코드 라인 16에서 cfs 대역폭을 초기화한다.
- 코드 라인 18~27에서 cpu 수 만큼 루프를 돌며 cfs 런큐 및 스케줄 엔티티를 할당받는다.
- 코드 라인 29에서 할당받은 cfs 런큐를 초기화한다.
- 코드 라인 30에서 태스크 그룹에 할당받은 cfs 런큐와 cfs 스케줄 엔티티를 연결시키고 cfs 엔트리들을 초기화한다.
- 코드 라인 31에서 엔티티 러너블 평균을 초기화한다.
- 코드 라인 34에서 성공 값 1을 반환한다.
다음 그림은 alloc_rt_sched_group() 함수를 통해 태스크 그룹이 이 함수에서 생성한 cfs 런큐와 스케줄 엔티티가 연결되고 초기화되는 모습을 보여준다.
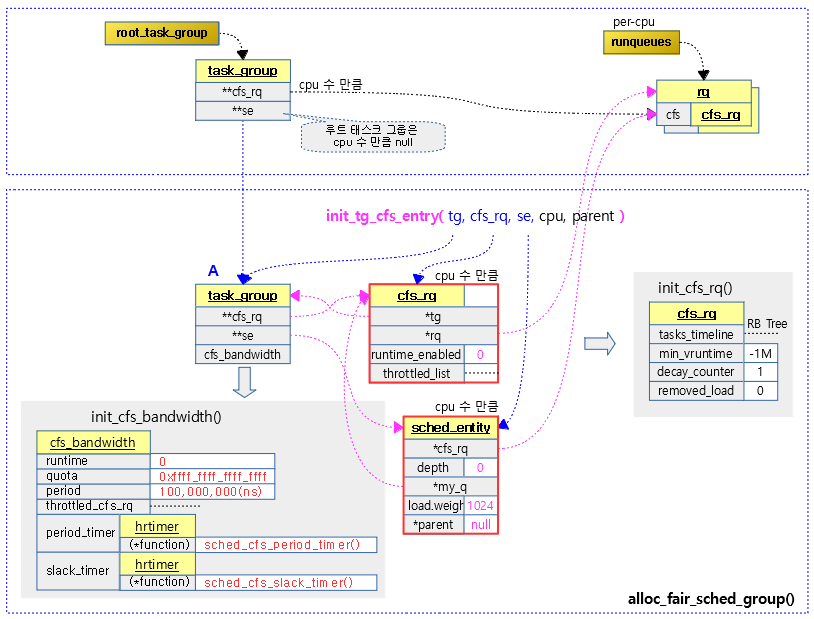
다음 그림은 CFS 런큐 <-> 태스크 그룹 <-> 스케줄 엔티티간의 연관 관계를 보여준다.
- 하위 태스크 그룹 하나가 스케줄 엔티티 하나에 대응하고 다른 태스크의 스케줄 엔티티와 동등하게 cfs 런큐에 큐잉되어 있음을 알 수 있다.
태스크 그룹의 cfs 스케줄 엔티티 초기화
init_tg_cfs_entry()
kernel/sched/fair.c
void init_tg_cfs_entry(struct task_group *tg, struct cfs_rq *cfs_rq,
struct sched_entity *se, int cpu,
struct sched_entity *parent)
{
struct rq *rq = cpu_rq(cpu);
cfs_rq->tg = tg;
cfs_rq->rq = rq;
init_cfs_rq_runtime(cfs_rq);
tg->cfs_rq[cpu] = cfs_rq;
tg->se[cpu] = se;
/* se could be NULL for root_task_group */
if (!se)
return;
if (!parent) {
se->cfs_rq = &rq->cfs;
se->depth = 0;
} else {
se->cfs_rq = parent->my_q;
se->depth = parent->depth + 1;
}
se->my_q = cfs_rq;
/* guarantee group entities always have weight */
update_load_set(&se->load, NICE_0_LOAD);
se->parent = parent;
}
태스크 그룹에 cfs 런큐 및 cfs 스케줄 엔티티를 연결시키고 cfs 엔트리들을 초기화한다.
- 코드 라인 7~8에서 cfs 런큐의 태스크 그룹 및 런큐를 지정한다.
- 코드 라인 11에서 cfs 런큐의 스로틀링 runtime을 초기화한다.
- 코드 라인 12에서 태스크 그룹의 cfs 런큐 및 스케줄링 엔티티를 지정한다.
- 코드 라인 15~16에서 스케줄링 엔티티가 지정되지 않은 경우 함수를 빠져나간다.
- 디폴트 그룹 초기화 호출 시에는 스케줄링 엔티티가 null이다.
- 코드 라인 18~20에서 부모가 지정되지 않은 경우 스케줄링 엔티티의 cfs 런큐는 런큐의 cfs 런큐를 사용하고 depth를 0으로 한다.
- 코드 라인 21~24에서 부모가 지정된 경우 스케줄링 엔티티의 cfs 런큐는 부모의 my_q를 지정하고 depth 값은 부모 값보다 1 증가시켜 사용한다.
- 코드 라인 26에서 스케줄링 엔티티의 my_q에 cfs 런큐를 대입한다.
- 코드 라인 28에서 스케줄링 엔티티의 로드값을 일단 nice 0에 해당하는 로드 weight 값인 1024를 대입한다.
- 코드 라인 29에서 스케줄링 엔티티의 부모를 지정한다.
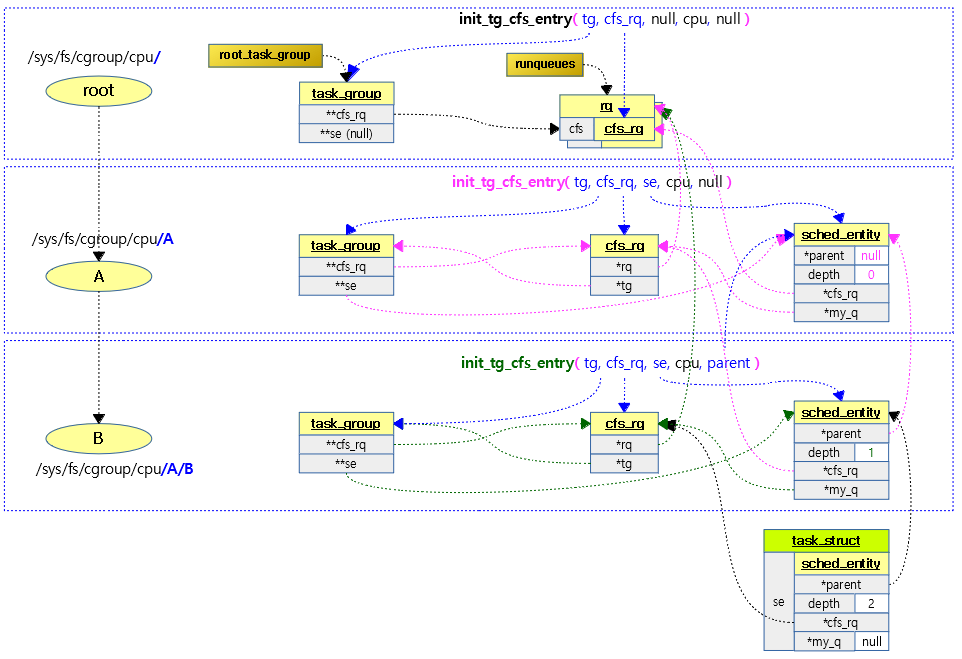
다음 그림은 루트 태스크 그룹부터 하위 태스크 그룹까지 init_tg_cfs_entry() 함수를 각각 호출할 때 서로 연결되는 모습을 보여준다.
- init_tg_cfs_entry() 함수와는 관계없지만 태스크 내부에 있는 스케줄 엔티티가 해당 태스크 그룹에 연결된 모습도 참고바란다.
- init_tg_cfs_entry() 함수 내부에서 다음 두 함수를 호출하여 처리하지만 그림에는 표현하지 않았다.
- init_cfs_rq_runtime() -> runtime_enable=0, throttled_list 초기화
- update_load_set() -> load.weight=1024, load.inv_weight=0으로 초기화
init_cfs_rq_runtime()
kernel/sched/fair.c
static void init_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
cfs_rq->runtime_enabled = 0;
INIT_LIST_HEAD(&cfs_rq->throttled_list);
}
cfs 런큐의 스로틀링 runtime을 초기화한다.
- 코드 라인 3에서 cfs 런큐의 runtime_enabled 값에 0을 대입하여 cfs 대역폭의 런타임 산출을 disable로 초기화한다.
- 코드 라인 4에서 throttled_list를 초기화한다.
update_load_set()
kernel/sched/fair.c
static inline void update_load_set(struct load_weight *lw, unsigned long w)
{
lw->weight = w;
lw->inv_weight = 0;
}
로드 weight 값을 설정한다. inv_weight 값은 0으로 일단 초기화한다.
태스크 그룹 생성 – (3) RT 스케줄 그룹 할당
alloc_rt_sched_group()
kernel/sched/core.c
int alloc_rt_sched_group(struct task_group *tg, struct task_group *parent)
{
struct rt_rq *rt_rq;
struct sched_rt_entity *rt_se;
int i;
tg->rt_rq = kzalloc(sizeof(rt_rq) * nr_cpu_ids, GFP_KERNEL);
if (!tg->rt_rq)
goto err;
tg->rt_se = kzalloc(sizeof(rt_se) * nr_cpu_ids, GFP_KERNEL);
if (!tg->rt_se)
goto err;
init_rt_bandwidth(&tg->rt_bandwidth,
ktime_to_ns(def_rt_bandwidth.rt_period), 0);
for_each_possible_cpu(i) {
rt_rq = kzalloc_node(sizeof(struct rt_rq),
GFP_KERNEL, cpu_to_node(i));
if (!rt_rq)
goto err;
rt_se = kzalloc_node(sizeof(struct sched_rt_entity),
GFP_KERNEL, cpu_to_node(i));
if (!rt_se)
goto err_free_rq;
init_rt_rq(rt_rq, cpu_rq(i));
rt_rq->rt_runtime = tg->rt_bandwidth.rt_runtime;
init_tg_rt_entry(tg, rt_rq, rt_se, i, parent->rt_se[i]);
}
return 1;
err_free_rq:
kfree(rt_rq);
err:
return 0;
}
태스크 그룹에 rt 스케줄 그룹을 할당하고 초기화한다. 성공인 경우 1을 반환한다.
- 코드 라인 7~9에서 tg->rt_rq에 cpu 수 만큼 rt 런큐를 가리키는 포인터를 할당한다.
- 코드 라인 10~12에서 tg->rt_se에 cpu 수 만큼 rt 스케줄 엔티티를 가리키는 포인터를 할당한다.
- 코드 라인 14~15에서 rt 대역폭을 초기화한다.
- 코드 라인 17~26에서 cpu 수 만큼 루프를 돌며 rt 런큐 및 rt 스케줄 엔티티를 할당받는다.
- 코드 라인 29에서 할당받은 rt 런큐를 초기화한다.
- 코드 라인 30에서 할당받은 rt 스케줄 엔티티를 초기화한다.
- 코드 라인 33에서 성공 값 1을 반환한다.
다음 그림은 alloc_rt_sched_group() 함수를 통해 태스크 그룹이 이 함수에서 생성한 rt 런큐와 rt 스케줄 엔티티가 연결되고 초기화되는 모습을 보여준다.
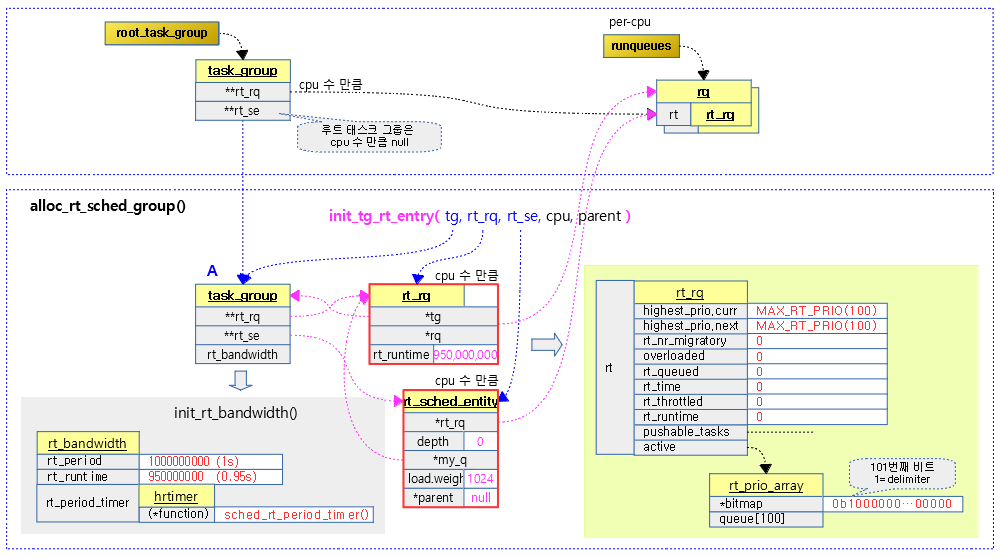
태스크 그룹의 rt 스케줄 엔티티 초기화
init_tg_rt_entry()
kernel/sched/rt.c
void init_tg_rt_entry(struct task_group *tg, struct rt_rq *rt_rq,
struct sched_rt_entity *rt_se, int cpu,
struct sched_rt_entity *parent)
{
struct rq *rq = cpu_rq(cpu);
rt_rq->highest_prio.curr = MAX_RT_PRIO;
rt_rq->rt_nr_boosted = 0;
rt_rq->rq = rq;
rt_rq->tg = tg;
tg->rt_rq[cpu] = rt_rq;
tg->rt_se[cpu] = rt_se;
if (!rt_se)
return;
if (!parent)
rt_se->rt_rq = &rq->rt;
else
rt_se->rt_rq = parent->my_q;
rt_se->my_q = rt_rq;
rt_se->parent = parent;
INIT_LIST_HEAD(&rt_se->run_list);
}
태스크 그룹에 rt 런큐 및 rt 스케줄 엔티티를 연결시키고 rt 엔트리들을 초기화한다.
- 코드 라인 7에서 rt 런큐의 highest_prio.curr에 MAX_RT_PRIO(100)으로 초기화한다.
- 코드 라인 8에서 rt_nr_boosted 값을 0으로 초기화한다.
- 코드 라인 9~10에서 rt 런큐의 태스크 그룹 및 런큐를 지정한다.
- 코드 라인 12~13에서 태스크 그룹의 rt 런큐 및 rt 스케줄링 엔티티를 지정한다.
- 코드 라인 15~16에서 rt 스케줄링 엔티티가 지정되지 않은 경우 함수를 빠져나간다.
- 디폴트 그룹 초기화 호출 시에는 rt 스케줄링 엔티티가 null이다.
- 코드 라인 18~21에서 부모가 지정되지 않은 경우 rt 스케줄링 엔티티의 rt 런큐는 런큐의 rt 런큐를 사용하고, 부모가 지정된 경우 부모의 my_q를 사용한다.
- 코드 라인 23에서 rt 스케줄링 엔티티의 my_q에 rt 런큐를 대입한다.
- 코드 라인 24에서 rt 스케줄링 엔티티의 부모를 지정한다.
- 코드 라인 25에서 rt 스케줄링 엔티티의 run_list를 초기화한다.
다음 그림은 루트 태스크 그룹부터 하위 태스크 그룹까지 init_tg_rt_entry() 함수를 각각 호출할 때 서로 연결되는 모습을 보여준다.
- init_tg_rt_entry() 함수와는 관계없지만 태스크 내부에 있는 스케줄 엔티티가 해당 태스크 그룹에 연결된 모습도 참고바란다.
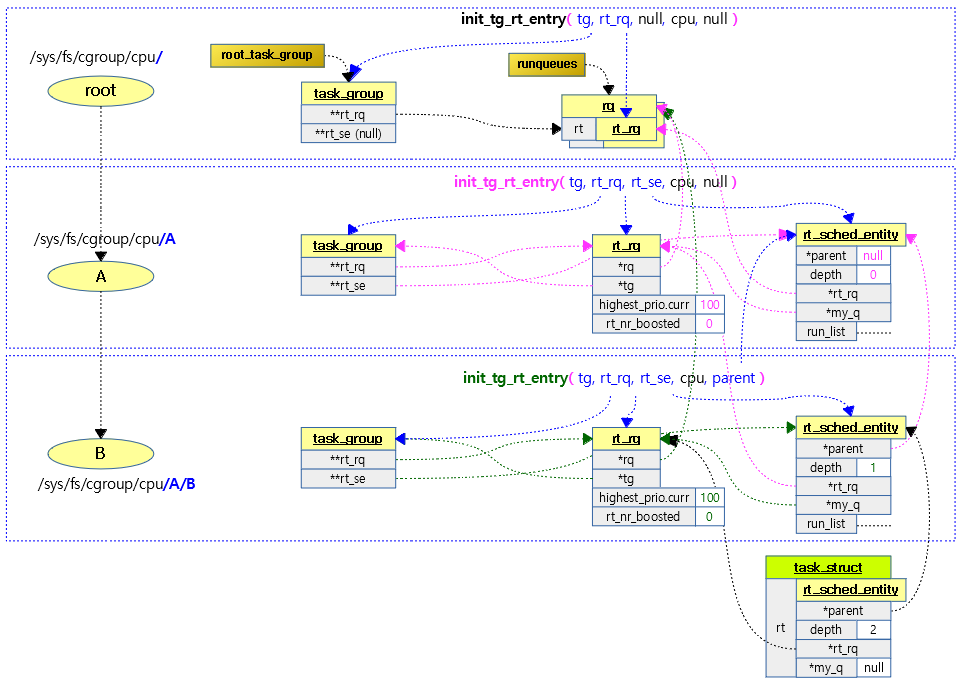
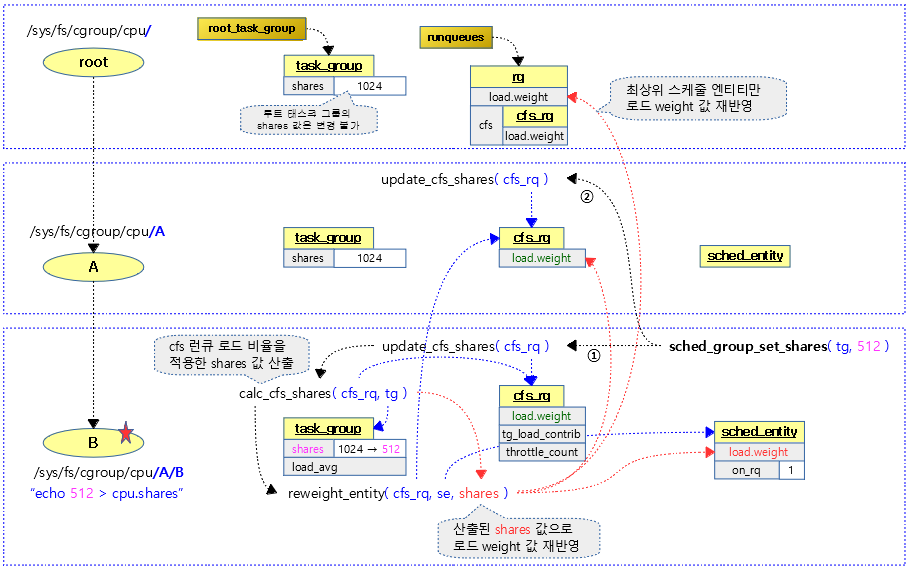
CFS shares 설정
sched_group_set_shares()
kernel/sched/fair.c
int sched_group_set_shares(struct task_group *tg, unsigned long shares)
{
int i;
/*
* We can't change the weight of the root cgroup.
*/
if (!tg->se[0])
return -EINVAL;
shares = clamp(shares, scale_load(MIN_SHARES), scale_load(MAX_SHARES));
mutex_lock(&shares_mutex);
if (tg->shares == shares)
goto done;
tg->shares = shares;
for_each_possible_cpu(i) {
struct rq *rq = cpu_rq(i);
struct sched_entity *se;
struct rq_flags rf;
/* Propagate contribution to hierarchy */
raw_spin_lock_irqsave(&rq->lock, rf);
update_rq_clock(rq);
for_each_sched_entity(se) {
update_load_avg(cfs_rq_of(se), se, UPDATE_TG);
update_cfs_group(se);
}
raw_spin_unlock_irqrestore(&rq->lock, &rf);
}
done:
mutex_unlock(&shares_mutex);
return 0;
}
요청한 태스크 그룹의 cfs shares 값을 설정한다.
- 코드 라인 8~9에서 태스크 그룹의 첫 번째 스케줄 엔티티가 null인 경우 -EINVAL 에러를 반환한다.
- 루트 태스크그룹의 스케줄 엔티티 포인터들은 null로 설정되어 있다.
- 코드 라인 11~17에서 shares 값이 MIN_SHARES(2) ~ MAX_SHARES(256K) 범위에 들도록 조절하고 태스크 그룹에 설정한다. 만일 기존 shares 값에 변화가 없으면 변경 없이 그냥 성공(0)을 반환한다.
- 코드 라인 18~25에서 possible cpu 수 만큼 순회하며 런큐 및 태스크 그룹에서 스케줄 엔티티를 알아온 후 런큐 락을 획득한 후 런큐 클럭을 갱신한다.
- 코드 라인 26~29에서 계층 구조의 스케줄 엔티티들에 대해 현재 스케줄 엔티티부터 최상위 스케줄 엔티티까지 로드 평균 및 shares 값을 갱신하게 한다.
kernel/sched/sched.h
/* * A weight of 0 or 1 can cause arithmetics problems. * A weight of a cfs_rq is the sum of weights of which entities * are queued on this cfs_rq, so a weight of a entity should not be * too large, so as the shares value of a task group. * (The default weight is 1024 - so there's no practical * limitation from this.) */ #define MIN_SHARES (1UL << 1) #define MAX_SHARES (1UL << 18)
CFS shares 값 범위(2 ~ 256K)
다음 그림은 태스크 그룹에 설정한 shares 값이 스케줄 엔트리, cfs 런큐 및 런큐의 로드 weight 값에 재반영되는 모습을 보여준다.
구조체
task_group 구조체
kernel/sched/sched.h
/* Task group related information */
struct task_group {
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each CPU */
struct sched_entity **se;
/* runqueue "owned" by this group on each CPU */
struct cfs_rq **cfs_rq;
unsigned long shares;
#ifdef CONFIG_SMP
/*
* load_avg can be heavily contended at clock tick time, so put
* it in its own cacheline separated from the fields above which
* will also be accessed at each tick.
*/
atomic_long_t load_avg ____cacheline_aligned;
#endif
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
struct task_group *parent;
struct list_head siblings;
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
#ifdef CONFIG_UCLAMP_TASK_GROUP
/* The two decimal precision [%] value requested from user-space */
unsigned int uclamp_pct[UCLAMP_CNT];
/* Clamp values requested for a task group */
struct uclamp_se uclamp_req[UCLAMP_CNT];
/* Effective clamp values used for a task group */
struct uclamp_se uclamp[UCLAMP_CNT];
#endif
};
- css
- cgroup 인터페이스
- **se
- cpu 수 만큼의 스케줄링 엔티티들이다.
- cpu별 해당 태스크 그룹을 대표하는 스케줄링 엔티티이다.
- **cfs_rq
- cpu 수 만큼의 cfs 런큐들이다.
- cpu별 해당 태스크 그룹에 대한 cfs 런큐이다.
- shares
- 태스크 그룹에 소속된 cfs 태스크들이 다른 그룹과의 cpu 로드 점유 비율을 설정한다.
- 루트 태스크 그룹의 shares 값은 변경할 수 없다. (“/sys/fs/cgroup/cpu/cpu.shares”)
- 하위 태스크 그룹의 shares 값을 설정하여 사용한다.
- load_avg
- 로드 평균
- **rt_se
- cpu 수 만큼의 rt 스케줄링 엔티티들이다.
- cpu별 해당 태스크 그룹을 대표하는 스케줄링 엔티티이다.
- **rt_rq
- cpu 수 만큼의 rt 런큐들이다.
- cpu별 해당 태스크 그룹에 대한 rt 런큐이다.
- rt_bandwidth
- rt 밴드폭
- 디폴트로 rt 태스크가 최대 cpu 점유율의 95%를 사용할 수 있게한다.
- *parent
- 상위 태스크 그룹을 가리킨다.
- 루트 태스크 그룹에서는 null 값을 담는다.
- siblings
- 형재 태스크 그룹들을 담는다.
- children
- 하위 태스크 그룹을 담는다.
- *autogroup
- tty 로긴된 유저쉘에 대해 자동으로 태스크 그룹을 만들때 사용한다.
- cfs_bandwidth
- 태스크 그룹에 소속된 cfs 태스크들의 cpu 점유 비율을 결정하게 한다. (스로틀 등)
- uclamp_pct[]
- 유저가 요청한 clamp min, max의 백분률이 저장된다.
- ucmap_req[]
- 태스크 그룹을 위해 요청된 clamp 밸류들이다.
- uclamp[]
- 동작 중인 clamp min, max 설정 값이다.
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c – 현재 글
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c