<kernel v5.4>
NUMA 밸런싱
NUMA 밸런싱을 시작하면 동작 중인 태스크가 사용하는 메모리 페이지들을 주기적으로 NUMA hinting faults가 발생하도록 언매핑한다. 초당 약 256MB 공간을 처리할 수 있는 주기(period)를 사용하고, 메모리 공간을 상향 이동하며 NUMA 표식(PROT_NONE 매핑 속성)을 사용한채로 언매핑한다. 그 후 특정 태스크가 이 영역에 접근하는 경우 NUMA 표식된 채로 NUMA hinting faults가 발생한다. 이를 통해 각 태스크가 어떤 cpu 노드 또는 메모리 노드에 액세스를 하는지 그 빈도를 누마 faults로 기록하고, 이 값을 사용하여 물리 메모리 페이지를 다른 노드로 마이그레이션하여 사용하거나, 아니면 태스크 자체를 다른 노드로 마이그레이션할 수 있는 선택을 할 수 있도록 도움을 준다.
NUMA 밸런싱을 위해 사용되는 다음 항목들을 알아본다.
- 태스크별 NUMA Scan
- NUMA hinting fault
- fault score 수집
- NUMA 밸런싱
- page 마이그레이션이 필요한 조건
- 태스크 마이그레이션이 필요한 조건
태스크별 NUMA Scan
- NUMA 시스템에선 태스크가 생성될 때 마다 NUMA 스캔을 준비 한다.
- NUMA 스캔
- 태스크가 사용하는 가상 메모리 영역(VMA)들을 물리메모리와 단절 시키도록 언매핑한다.
- 언매핑시 PROT_NONE 속성을 사용한다.
- MMU H/W는 언매핑 상태로 인식
- Linux 커널 S/W는 fault 발생시 NUMA 스캔 용도로 언매핑하였다는 것을 알아내기 위해 사용
- VMA 스캐닝은 초당 최대 256MB의 양으로 제한한다.
- 스캔을 허용하지 않는 VMA들
- migrate 불가능
- MOF(Migrate On Fault) 미지원
- Hugetlb
- VM_MIXEDMAP 타입
- readonly 파일 타입(라이브러리 등)
- 참고: NUMA 스캔이 시작되는 콜백 함수
- task_numa_work()
NUMA Hinting Fault
어떤 노드에서 동작하는 태스크가 Numa 스캔 용도로 언매핑한 메모리에 접근하다 fault가 발생하였을 때 이를 NUMA Hinting fault라고 한다. fault가 발생한 경우 어떠한 노드에서 요청되었는지를 구분하여 faults(접근) 횟수를 몇 가지 필드에 기록하고, 이 값들이 관리되어 노드별 액세스 빈도를 추적하는데 이를 fault score라고 한다. 이 fault score는 해당 태스크와 누마 그룹(ng)으로 나누어 동시에 관리한다. 페이지가 단일 태스크에의해 접근되어 사용되는 경우 해당 태스크의 fault score를 활용하지만, 페이지가 공유 메모리 또는 스레드간에 공유되어 접근되는 공유 페이지인 경우 이들 태스크를 묶어 누마 그룹(ng) 단위로 fault score를 누적하여 활용한다.
- 참고: NUMA Hinting fault로 시작 함수
- do_numa_page()
fault score 수집 및 관리 방법은 다음과 같다.
- 기본적으로 faults 발생 시마다 태스크에서 2가지 방법으로 관리한다.
- p->numa_faults_locaility[]에 local 노드 fault인지 remote 노드 fault인지를 구분하여 단순 증가시켜 누적시킨다.
- p->numa_faults[]에 fault가 발생한 노드별로 나누어 관리하지만, 그 외에도 추가적으로 다음과 같이 3가지(총 8개) 타입으로 분류하여 관리한다.
- faults score로 읽어내어 사용하는 mem 노드/cpu 노드 구분
- NUMA_MEM, NUMA_CPU
- 아래 단순 누적된 buf 수를 바로 사용하여 누적하지 않고 절반만 누적시켜 사용한다.
- memless 노드를 가지는 NUMA 시스템을 위해 cpu 노드와 mem 노드를 구분하였다.
- 단순 누적용 BUF 구분
- NUMA_MEMBUF, NUMA_CPUBUF
- 공유 페이지 구분을 위해 private/share로 구분
- priv=0, priv=1
- 누마 스캔 주기를 결정하기 위해서만 사용한다.
- faults score로 읽어내어 사용하는 mem 노드/cpu 노드 구분
- 누마 그룹의 경우 p->numa_faults[]같이 노드별로 나누어 관리하지만 buf 는 제외시킨 2가지(총 4개) 타입으로만 분류하여 ng->faults[]에서 관리한다.
- faults score로 읽어내어 사용하는 mem 노드/cpu 노드
- NUMA_MEM, NUMA_CPU
- 공유 페이지 구분을 위해 private/share로 구분
- priv=0, priv=1
- 누마 스캔 주기를 결정하기 위해서만 사용하며, task_scan_max() 함수에서 반환되는 max 주기가 shared 페이지 비율만큼 비례하여 커진다.
- faults score로 읽어내어 사용하는 mem 노드/cpu 노드
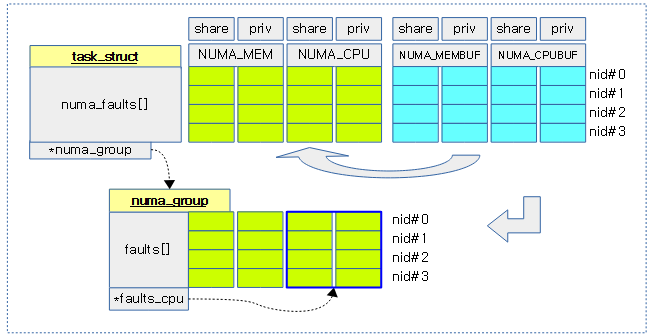
다음 그림은 태스크의 numa_faults[] 와 누마 그룹의 faults[] 값이 관리되는 모습을 보여준다.
- faults_cpu 포인터는 NUMA_CPU 배열을 직접가리킨다.
- 누마 그룹에서 NUMA_MEMBUF 및 NUMA_CPUBUF 관련 faults 항목이 없음을 유의한다.
- 하늘색 BUF 항목은 fault 발생시마다 누적되며, 누마 스캔 주기 시마다 이 값들을 읽어 내어 연두색 부분으로 옮겨 반영을 한 후 클리어된다.
- 하늘색 BUF 값이 연두색 기존 값에 반영될 때 다음 값 만큼씩 누적한다.
- 하늘색 BUF 값 – 연두색 기존 값의 절반
예 1) 기존 fault값 0에서 BUF fault 값이 계속 10이 발생한 경우 새 값이 기존 값의 절반을 뺀 차이만큼씩 증가하여 누적되는 것을 알 수 있다.
- 1st: 0 += 10 – 0/2 = 10
- 2nd: 10 += 10 – 10/2 = 15
- 3rd: 15 += 10 – 15/2 = 18
- 4th: 18 += 10 – 18/2 = 19
- 5th: 19 += 10 – 19/2 = 20
- 6th: 20 += 10 – 20/2 = 20
- 7th: 동일 반복
예 2) 기존 fault값 20에서 BUF fault 값이 계속 0이 발생한 경우 절반씩 줄어드는 것을 알 수 있다.
- 1st: 20 += 0 – 20/2 = 10
- 2nd: 10 += 0 – 10/2 = 5
- 3rd: 5 += 0 – 5/2 = 3
- 4th: 3 += 0 – 3/2 = 2
- 5th: 2 += 0 – 2/2 = 1
- 6th: 1 += 0 – 1/2 = 1
- 7th: 동일 반복
페이지 migration 조건
태스크가 실행되는 노드가 아닌 노드에 위치한 페이지에 접근 시 태스크 마이그레이션 조건에 앞서 먼저 다음과 같은 조건인 경우 수행한다.
- 하나의 task 가 page 에 연속해서 fault가 발생하는 경우
- 누마 그룹(ng)이 있는 태스크의 경우에만 dst node 가 src node보다 3배 이상 fault score가 높을 때
- 메모리 리스 노드 시스템에서 메모리를 가지고 있는 노드가 가지고 있지 않는 노드 보다 1.33배 이상 fault score가 높을 때
다음 그림은 4개의 노드를 가진 누마 시스템에서 메모리 리스(memless) 노드를 가진 누마 시스템과의 비교를 보여준다.
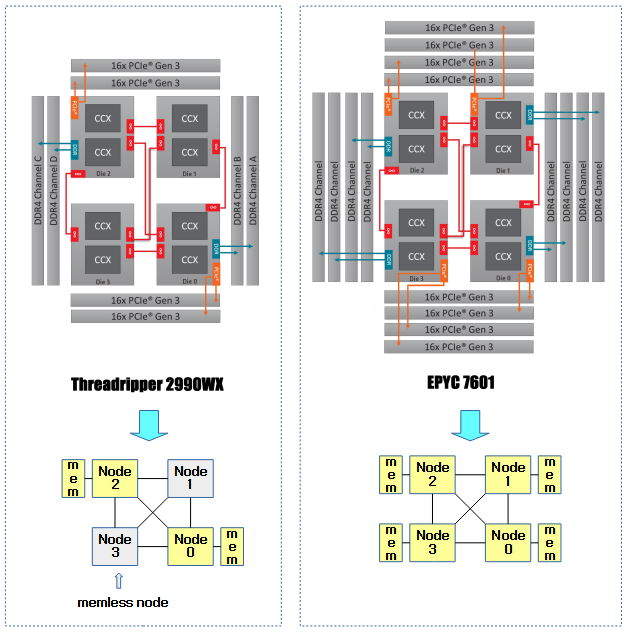
태스크 migration 조건
- 태스크가 이동이 되는 경우는 최대 fault score를 가진 노드가 우선 노드로 채택된다.
- 이 우선 노드에서 best cpu로 migrate 또는 swap 둘 중 액세스 성능, 로드 성능 뿐 아니라 태스크 affinity 및 캐시 지역성을 모두 고려하여 정한다.
- 만일 우선 노드에서 best cpu를 찾지 못하는 경우 다른 노드들을 대상으로 시도한다.
NUMA 메모리 Fault score
다음 그림과 같이 누마 그룹의 weight와 태스크의 weight 두 기준에 대한 함수 호출관계를 보여준다.
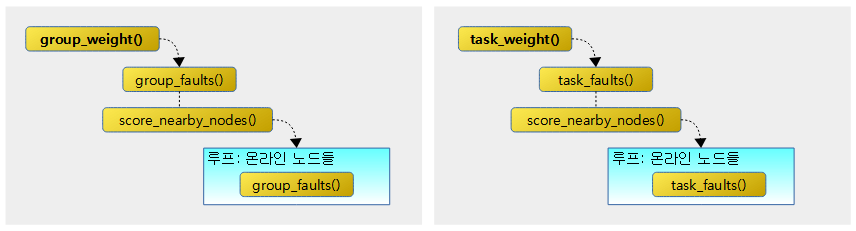
group_weight()
kernel/sched/fair.c
static inline unsigned long group_weight(struct task_struct *p, int nid,
int dist)
{
struct numa_group *ng = deref_task_numa_group(p);
unsigned long faults, total_faults;
if (!ng)
return 0;
total_faults = ng->total_faults;
if (!total_faults)
return 0;
faults = group_faults(p, nid);
faults += score_nearby_nodes(p, nid, dist, false);
return 1000 * faults / total_faults;
}
태스크의 누마 그룹에 누적된 메모리 faults 값을 해당 누마 그룹의 전체 faults에 대한 가중치 값으로 변환하여 알아온다. (1000 = 100%)
- 코드 라인 4~8에서 태스크가 가리키는 누마 그룹이 없으면 0을 반환한다.
- 코드 라인 10~13에서 누마 그룹의 전체 faults 값이 0인 경우 함수를 빠져나간다.
- 코드 라인 15에서 누마 그룹에서 관리하고 있는 @nid 노드의 faults 값을 알아온다.
- 코드 라인 16에서 누마 그룹에서 관리하고 있는 faults에 대해 @nid 노드를 중심으로 전체 노드에 대한 faults 값을 거리별로 반비례 누적시킨 후 알아온 score 값을 faults에 추가한다.
- 코드 라인 18에서 누마 그룹의 전체 faults에 대해 알아온 faults의 비율을 0~1000 사이 값으로 반환한다.
다음 그림은 특정 노드의 faults 값과 다른 노드들의 faults를 score로 변환한 값의 전체 faults에 대한 비율을 산출하는 과정을 보여준다.

deref_task_numa_group()
kernel/sched/fair.c
/* * For functions that can be called in multiple contexts that permit reading * ->numa_group (see struct task_struct for locking rules). */
static struct numa_group *deref_task_numa_group(struct task_struct *p)
{
return rcu_dereference_check(p->numa_group, p == current ||
(lockdep_is_held(&task_rq(p)->lock) && !READ_ONCE(p->on_cpu)));
}
태스크에 지정된 누마 그룹을 알아온다.
group_faults()
kernel/sched/fair.c
static inline unsigned long group_faults(struct task_struct *p, int nid)
{
struct numa_group *ng = deref_task_numa_group(p);
if (!ng)
return 0;
return ng->faults[task_faults_idx(NUMA_MEM, nid, 0)] +
ng->faults[task_faults_idx(NUMA_MEM, nid, 1)];
}
태스크가 가리키는 누마 그룹에 누적된 @nid의 메모리 폴트 값을 알아온다.
- 코드 라인 5~6에서 태스크에 누마 그룹이 설정되지 않은 경우 0을 반환한다.
- 코드 라인 8~9에서 누마 그룹의 NUMA_MEM의 해당 노드의 두 개 faults[] stat을 더해서 반환한다.
task_faults_idx()
kernel/sched/fair.c
/* * The averaged statistics, shared & private, memory & CPU, * occupy the first half of the array. The second half of the * array is for current counters, which are averaged into the * first set by task_numa_placement. */
static inline int task_faults_idx(enum numa_faults_stats s, int nid, int priv)
{
return NR_NUMA_HINT_FAULT_TYPES * (s * nr_node_ids + nid) + priv;
}
태스크에서 요청한 누마 @nid의 요청한 타입의 폴트 수를 알아온다. @priv가 0인 경우 shared stat, 1인 경우 private 카운터 값을 반환한다.
- 예) 4개의 노드, NUMA_CPU stat, nid=2, priv=0
- 인덱스 = 2 * (1 * 4 + 2) + 0 = 12
- 예) 4개의 노드, NUMA_CPU stat, nid=3, priv=0
- 인덱스 = 2 * (1 * 4 + 3) + 0 = 14
task_weight()
kernel/sched/fair.c
/* * These return the fraction of accesses done by a particular task, or * task group, on a particular numa node. The group weight is given a * larger multiplier, in order to group tasks together that are almost * evenly spread out between numa nodes. */
static inline unsigned long task_weight(struct task_struct *p, int nid,
int dist)
{
unsigned long faults, total_faults;
if (!p->numa_faults)
return 0;
total_faults = p->total_numa_faults;
if (!total_faults)
return 0;
faults = task_faults(p, nid);
faults += score_nearby_nodes(p, nid, dist, true);
return 1000 * faults / total_faults;
}
태스크에서 관리하고 있는 누마 faults 값을 태스크의 전체 faults에 대한 가중치 값으로 변환하여 알아온다. (1000 = 100%)
- 코드 라인 6~7에서 태스크의 누마 메모리 faults가 0인 경우 0을 반환한다.
- 코드 라인 9~12에서 태스크의 전체 누마 faults 값이 0인 경우 0을 반환한다.
- 코드 라인 14에서 태스크가 관리하고 있는 누마 faults에 대해 @nid 노드에 해당하는 faults 값을 알아온다.
- 코드 라인 15에서 태스크에 관리하고 있는 누마 faults에 대해 @nid 노드를 중심으로 다른 노드들에 대한 faults 값을 거리별로 반비례 누적시킨 후 score로 알아온 값을 faults에 추가한다.
- 코드 라인 17에서 태스크의 전체 누마 faults에 대해 알아온 faults의 비율을 0~1000 사이 값으로 반환한다.
task_faults()
kernel/sched/fair.c
static inline unsigned long task_faults(struct task_struct *p, int nid)
{
if (!p->numa_faults)
return 0;
return p->numa_faults[task_faults_idx(NUMA_MEM, nid, 0)] +
p->numa_faults[task_faults_idx(NUMA_MEM, nid, 1)];
}
태스크에 누적된 @nid의 메모리 폴트 값을 알아온다.
- faults[] 배열은 2개의 타입 x 노드 수 x 2개와 같은 방법으로 구성되어 있다.
- faults[4][nid][2]
- 4개의 타입은 다음과 같다.
- NUMA_MEM(0), NUMA_CPU(1)
- faults[] 값들은 시간에 따라 exponential decay 된다.
다음 그림은 group_faults() 함수와 task_faults() 함수가 faults 데이터를 가져오는 곳을 보여준다.
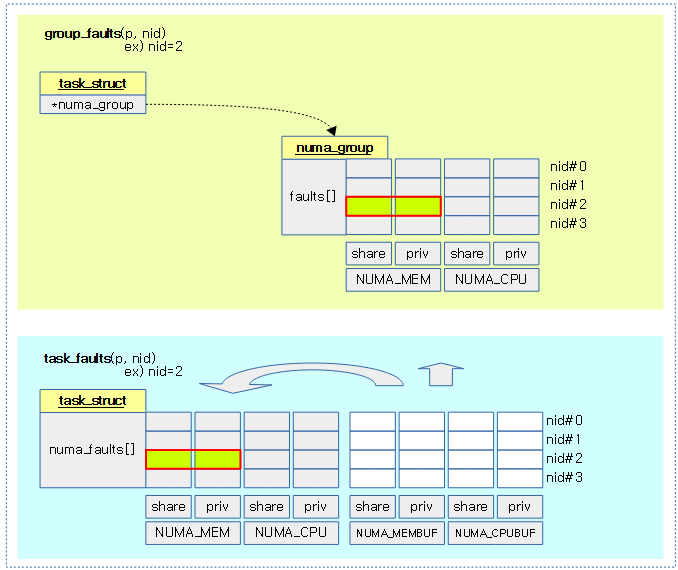
태스크의 특정 노드에 대한 faults score 산출
score_nearby_nodes()
kernel/sched/fair.c
/* Handle placement on systems where not all nodes are directly connected. */
static unsigned long score_nearby_nodes(struct task_struct *p, int nid,
int maxdist, bool task)
{
unsigned long score = 0;
int node;
/*
* All nodes are directly connected, and the same distance
* from each other. No need for fancy placement algorithms.
*/
if (sched_numa_topology_type == NUMA_DIRECT)
return 0;
/*
* This code is called for each node, introducing N^2 complexity,
* which should be ok given the number of nodes rarely exceeds 8.
*/
for_each_online_node(node) {
unsigned long faults;
int dist = node_distance(nid, node);
/*
* The furthest away nodes in the system are not interesting
* for placement; nid was already counted.
*/
if (dist == sched_max_numa_distance || node == nid)
continue;
/*
* On systems with a backplane NUMA topology, compare groups
* of nodes, and move tasks towards the group with the most
* memory accesses. When comparing two nodes at distance
* "hoplimit", only nodes closer by than "hoplimit" are part
* of each group. Skip other nodes.
*/
if (sched_numa_topology_type == NUMA_BACKPLANE &&
dist >= maxdist)
continue;
/* Add up the faults from nearby nodes. */
if (task)
faults = task_faults(p, node);
else
faults = group_faults(p, node);
/*
* On systems with a glueless mesh NUMA topology, there are
* no fixed "groups of nodes". Instead, nodes that are not
* directly connected bounce traffic through intermediate
* nodes; a numa_group can occupy any set of nodes.
* The further away a node is, the less the faults count.
* This seems to result in good task placement.
*/
if (sched_numa_topology_type == NUMA_GLUELESS_MESH) {
faults *= (sched_max_numa_distance - dist);
faults /= (sched_max_numa_distance - LOCAL_DISTANCE);
}
score += faults;
}
return score;
}
태스크에 대해 @nid 노드를 중심으로 전체 노드에 대한 faults 값을 거리별로 반비례 누적시킨 후 score로 반환한다. 백본 타입의 누마 토플로지를 사용하는 경우 @max_dist 이상은 skip 한다. @task가 1인 경우 태스크에서 관리하고 있는 numa faults 값을 사용하고, 0인 경우 태스크가 가리키는 누마 그룹에서 관리하고 있는 faults를 사용한다. (0=누마 direct 방식, score가 클 수록 fault가 더 많다. @nid와 더 가까운 노드들은 더 중요하므로 faults 값을 더 많이 반영한다)
- 코드 라인 12~13에서 full 메시 형태로 모든 노드가 연결되어 있는 경우 score 0을 반환한다.
- 코드 라인 19~28에서 온라인 노드를 순회하며 요청한 노드 @nid와의 거리가 가장 멀거나 같은 노드인 경우는 skip 한다.
- 코드 라인 37~39에서 누마 토플로지가 백플레인 타입이면서 @nid와의 거리가 @maxdist 이상인 노드의 경우는 skip 한다.
- 코드 라인 42~45에서 순회 중인 노드의 태스크의 누마 메모리 fault를 알아온다.
- 코드 라인 55~58에서 누마 토플로지가 glueless 타입인 경우 다음과 같이 거리가 멀리 있을수록 faults 비율을 반비례하게 줄여 적용한다.즉 멀리있는 노드 끼리의 메모리 faults는중요하지않지만 가까이 있는 노드끼리의 메모리 faults는 더 중요하게 판단한다는 의미이다.
- (최대 distance – 순회 중인 노드의 distance)
- = faults * —————————————————–
- (최대 distance – 10)
- 코드 라인 60~63에서 faults를 score에 누적시키고, 모든 노드에 대해 누적이 완료되면 score를 반환한다.
다음 그림은 특정 태스크가 사용하는 누마 그룹의 노드 0번에 대한 메모리 faults score를 산출하는 모습을 보여준다.

누마 밸런싱
다음 그림은 태스크에 대한 누마 밸런싱이 시작한 후 누마 스캔을 통해 누마 페이지로 변경하고, 태스크가 누마 페이지에 접근할 때의 함수 호출 과정을 보여준다.
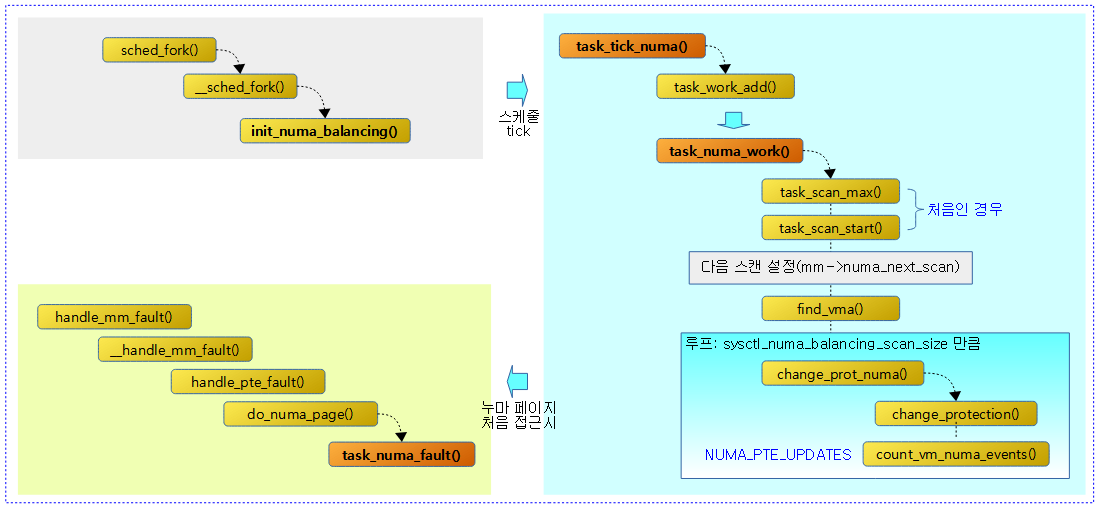
태스크에 대한 NUMA 밸런싱 초기화
init_numa_balancing()
kernel/sched/fair.c
void init_numa_balancing(unsigned long clone_flags, struct task_struct *p)
{
int mm_users = 0;
struct mm_struct *mm = p->mm;
if (mm) {
mm_users = atomic_read(&mm->mm_users);
if (mm_users == 1) {
mm->numa_next_scan = jiffies + msecs_to_jiffies(sysctl_numa_balancing_scan_delay);
mm->numa_scan_seq = 0;
}
}
p->node_stamp = 0;
p->numa_scan_seq = mm ? mm->numa_scan_seq : 0;
p->numa_scan_period = sysctl_numa_balancing_scan_delay;
/* Protect against double add, see task_tick_numa and task_numa_work */
p->numa_work.next = &p->numa_work;
p->numa_faults = NULL;
RCU_INIT_POINTER(p->numa_group, NULL);
p->last_task_numa_placement = 0;
p->last_sum_exec_runtime = 0;
init_task_work(&p->numa_work, task_numa_work);
/* New address space, reset the preferred nid */
if (!(clone_flags & CLONE_VM)) {
p->numa_preferred_nid = NUMA_NO_NODE;
return;
}
/*
* New thread, keep existing numa_preferred_nid which should be copied
* already by arch_dup_task_struct but stagger when scans start.
*/
if (mm) {
unsigned int delay;
delay = min_t(unsigned int, task_scan_max(current),
current->numa_scan_period * mm_users * NSEC_PER_MSEC);
delay += 2 * TICK_NSEC;
p->node_stamp = delay;
}
}
태스크에 대한 NUMA 밸런싱을 초기화한다.
- 코드 라인 6~12에서 유저 태스크의 경우 mm_users가 1인 경우 다음 누마 스캔 시각(numa_next_scan)을 sysctl_numa_balancing_scan_delay(디폴트 1초) 시간 후에 수행하도록 설정한다.
- 코드 라인 13~23에서 태스크의 numa 관련 멤버들을 초기화한다. 누마 스캔 주기(numa_scan_period)는 sysctl_numa_balancing_scan_delay(디폴트 1초)로 지정한다.
- 코드 라인 26~29에서 가상 주소 공간을 부모 태스크로 부터 clone하여 새로운 가상 주소 공간을 사용하는 태스크의 경우 새로운 누마 밸런싱을 위해 누마 우선 노드 지정을 클리어한다.
- 코드 라인 35~42에서 유저 태스크의 경우 p->node_stamp에 위에서 설정한 누마 스캔 주기(numa_scan_period) * mm_users 시간 + 2 틱을 나노초로 대입한다.
스케줄 틱에서 호출
task_tick_numa()
kernel/sched/fair.c
static void task_tick_numa(struct rq *rq, struct task_struct *curr)
{
struct callback_head *work = &curr->numa_work;
u64 period, now;
/*
* We don't care about NUMA placement if we don't have memory.
*/
if (!curr->mm || (curr->flags & PF_EXITING) || work->next != work)
return;
/*
* Using runtime rather than walltime has the dual advantage that
* we (mostly) drive the selection from busy threads and that the
* task needs to have done some actual work before we bother with
* NUMA placement.
*/
now = curr->se.sum_exec_runtime;
period = (u64)curr->numa_scan_period * NSEC_PER_MSEC;
if (now > curr->node_stamp + period) {
if (!curr->node_stamp)
curr->numa_scan_period = task_scan_start(curr);
curr->node_stamp += period;
if (!time_before(jiffies, curr->mm->numa_next_scan))
task_work_add(curr, work, true);
}
}
정기 스케줄 틱을 통해 호출되며 cfs 태스크의 누마 메모리 faults를 스캔한다.
- 코드 라인 9~10에서 유저 태스크가 아니거나 종료 중이거나 또 다른 워크가 존재하는 경우 함수를 빠져나간다.
- 코드 라인 18~28에서 태스크의 총 실행 시간 기준 numa_scan_period 주기를 초과한 경우이다. node_stamp는 주기만큼 추가하고, 처음인 경우 누마 스캔 주기(numa_scan_period)를 누마 그룹으로 부터 scan 주기를 알아와 설정한다. 다음 스캔 시각(numa_next_scan)을 넘긴 경우 p->task_works 리스트에 누마 워크를 추가한다.
- 추가된 work는 커널에서 유저로 복귀 시 다음과 같은 경로로 호출되어 실행된다.
- arch/arm64/entry.S – work_pending: 레이블 -> do_notify_resume() -> do_signal() -> get_signal() -> task_work_run() 함수에서 펜딩 워크들이 호출되어 실행된다.
- 추가된 work는 커널에서 유저로 복귀 시 다음과 같은 경로로 호출되어 실행된다.
누마 스캔 작업
task_numa_work()
kernel/sched/fair.c -1/2-
/* * The expensive part of numa migration is done from task_work context. * Triggered from task_tick_numa(). */
static void task_numa_work(struct callback_head *work)
{
unsigned long migrate, next_scan, now = jiffies;
struct task_struct *p = current;
struct mm_struct *mm = p->mm;
u64 runtime = p->se.sum_exec_runtime;
struct vm_area_struct *vma;
unsigned long start, end;
unsigned long nr_pte_updates = 0;
long pages, virtpages;
SCHED_WARN_ON(p != container_of(work, struct task_struct, numa_work));
work->next = work;
/*
* Who cares about NUMA placement when they're dying.
*
* NOTE: make sure not to dereference p->mm before this check,
* exit_task_work() happens _after_ exit_mm() so we could be called
* without p->mm even though we still had it when we enqueued this
* work.
*/
if (p->flags & PF_EXITING)
return;
if (!mm->numa_next_scan) {
mm->numa_next_scan = now +
msecs_to_jiffies(sysctl_numa_balancing_scan_delay);
}
/*
* Enforce maximal scan/migration frequency..
*/
migrate = mm->numa_next_scan;
if (time_before(now, migrate))
return;
if (p->numa_scan_period == 0) {
p->numa_scan_period_max = task_scan_max(p);
p->numa_scan_period = task_scan_start(p);
}
next_scan = now + msecs_to_jiffies(p->numa_scan_period);
if (cmpxchg(&mm->numa_next_scan, migrate, next_scan) != migrate)
return;
/*
* Delay this task enough that another task of this mm will likely win
* the next time around.
*/
p->node_stamp += 2 * TICK_NSEC;
start = mm->numa_scan_offset;
pages = sysctl_numa_balancing_scan_size;
pages <<= 20 - PAGE_SHIFT; /* MB in pages */
virtpages = pages * 8; /* Scan up to this much virtual space */
if (!pages)
return;
누마 스캔 주기마다 동작하는 cost가 높은 작업으로 태스크의 vma 영역을 NUMA hinting fault가 발생하도록 매핑을 변경한다. 한 번 처리할 때마다 sysctl_numa_balancing_scan_size 만큼씩 영역을 처리한다. 매 스캔 시마다 스캔할 영역은 그 전 위치를 기억하여 다음 스캔 시 사용한다.
- 코드 라인 23~24에서 이미 태스크가 종료가 진행 중인 경우 함수를 빠져나간다.
- 코드 라인 26~29에서 다음 누마 스캔 시각(numa_next_scan)가 설정되지 않은 경우 현재 시각에 sysctl_numa_balancing_scan_delay(디폴트 1초)를 추가하여 설정한다.
- 코드 라인 34~36에서 누마 스캔 시각이 지나지 않은 경우 함수를 빠져나간다.
- 코드 라인 38~41에서 누마 스캔 주기(numa_scan_period)가 설정되지 않은 경우 numa_scan_period_max와 numa_scanm_period를 초기 설정한다.
- 코드 라인 43~45에서 다음 누마 스캔 시각(numa_next_scan)에 현재 시각 + 누마 스캔 주기(numa_scan_period)로 설정한다. 만일 다른 cpu 등에서 이 값을 먼저 교체한 경우 현재 cpu는 처리를 양보하기 위해 함수를 빠져나간다.
- 코드 라인 51에서 p->node_stamp에 2 틱 만큼의 시간을 추가한다.
- 코드 라인 53~58에서 스캔을 시작할 주소와 누마 스캔 사이즈를 알아와서 바이트 단위로 변경하여 pages에 대입한다. 이 함수가 호출되어 한 번에 처리할 영역 사이즈이다. 그리고 이 값의 8배를 virtpages에 대입하는데, 역시 한 번 처리할 때마다 사용할 스캔 영역의 크기이다.
kernel/sched/fair.c -2/2-
if (!down_read_trylock(&mm->mmap_sem))
return;
vma = find_vma(mm, start);
if (!vma) {
reset_ptenuma_scan(p);
start = 0;
vma = mm->mmap;
}
for (; vma; vma = vma->vm_next) {
if (!vma_migratable(vma) || !vma_policy_mof(vma) ||
is_vm_hugetlb_page(vma) || (vma->vm_flags & VM_MIXEDMAP)) {
continue;
}
/*
* Shared library pages mapped by multiple processes are not
* migrated as it is expected they are cache replicated. Avoid
* hinting faults in read-only file-backed mappings or the vdso
* as migrating the pages will be of marginal benefit.
*/
if (!vma->vm_mm ||
(vma->vm_file && (vma->vm_flags & (VM_READ|VM_WRITE)) == (VM_READ)))
continue;
/*
* Skip inaccessible VMAs to avoid any confusion between
* PROT_NONE and NUMA hinting ptes
*/
if (!(vma->vm_flags & (VM_READ | VM_EXEC | VM_WRITE)))
continue;
do {
start = max(start, vma->vm_start);
end = ALIGN(start + (pages << PAGE_SHIFT), HPAGE_SIZE);
end = min(end, vma->vm_end);
nr_pte_updates = change_prot_numa(vma, start, end);
/*
* Try to scan sysctl_numa_balancing_size worth of
* hpages that have at least one present PTE that
* is not already pte-numa. If the VMA contains
* areas that are unused or already full of prot_numa
* PTEs, scan up to virtpages, to skip through those
* areas faster.
*/
if (nr_pte_updates)
pages -= (end - start) >> PAGE_SHIFT;
virtpages -= (end - start) >> PAGE_SHIFT;
start = end;
if (pages <= 0 || virtpages <= 0)
goto out;
cond_resched();
} while (end != vma->vm_end);
}
out:
/*
* It is possible to reach the end of the VMA list but the last few
* VMAs are not guaranteed to the vma_migratable. If they are not, we
* would find the !migratable VMA on the next scan but not reset the
* scanner to the start so check it now.
*/
if (vma)
mm->numa_scan_offset = start;
else
reset_ptenuma_scan(p);
up_read(&mm->mmap_sem);
/*
* Make sure tasks use at least 32x as much time to run other code
* than they used here, to limit NUMA PTE scanning overhead to 3% max.
* Usually update_task_scan_period slows down scanning enough; on an
* overloaded system we need to limit overhead on a per task basis.
*/
if (unlikely(p->se.sum_exec_runtime != runtime)) {
u64 diff = p->se.sum_exec_runtime - runtime;
p->node_stamp += 32 * diff;
}
}
- 코드 라인 3~8에서 mm 내에서 누마 스캔할 가상 주소가 포함된 vma를 알아온다. vma가 발견되지 않은 경우 시작 주소를 0으로 변경하고, vma로 mmap 매핑의 처음을 사용한다.
- 코드 라인 9~30에서 vma를 순회하며 다음 경우에 한하여 skip 한다.(누마밸런싱은 페이지의 migration과 함께 한다)
- migratable(페이지 이동) 하지 않은 vma 영역
- migration 시 fault 되도록 정책(MPOL_F_MOF)된 vma 영역이 아닌 경우
- hugetlb 페이지 영역
- VM_MIXEDMAP 플래그를 사용한 영역으로 struct page 및 pure PFN 페이지가 포함가능한 영역
- vma->vm_mm 이 지정되지 않은 경우
- read only 파일 매핑인 경우
- rwx(read/write/excute)가 하나도 설정되지 않은 영역
- 코드 라인 32~55에서 순회 중인 vma 영역의 끝까지 페이지 매핑 protection을 PAGE_NONE으로 변경하여 NUMA hinting fault를 유발할 수 있게 한다. 매핑 변경이 성공한 경우 해당 vma 영역은 sysctl_numa_balancing_scan_size 에서 감소시키고, 스캔 영역 크기는 최대 sysctl_numa_balancing_scan_size의 8배 크기로 제한한다.
- 코드 라인 58~68에서 out: 레이블이다. vma 영역을 모두 처리하지 않은 경우 다음 스캔 시작 지점을 해당 vma의 끝 주소부터 시작하게 설정해 둔다. vma 영역 모두 끝난 경우 다시 처음 부터 시작될 수 있게 리셋한다.
- 코드 라인 77~80에서 이 함수가 처리되는 동안 태스크의 총 실행 누적 시간이 변경된 경우 그 차이분 만큼의 32배를 곱해 p->node_stamp에 기록한다.
reset_ptenuma_scan()
kernel/sched/fair.c
static void reset_ptenuma_scan(struct task_struct *p)
{
/*
* We only did a read acquisition of the mmap sem, so
* p->mm->numa_scan_seq is written to without exclusive access
* and the update is not guaranteed to be atomic. That's not
* much of an issue though, since this is just used for
* statistical sampling. Use READ_ONCE/WRITE_ONCE, which are not
* expensive, to avoid any form of compiler optimizations:
*/
WRITE_ONCE(p->mm->numa_scan_seq, READ_ONCE(p->mm->numa_scan_seq) + 1);
p->mm->numa_scan_offset = 0;
}
누마 스캔 시작 주소를 0으로 리셋한다.
NUMA fault 영역으로 변경
change_prot_numa()
mm/mempolicy.c
/* * This is used to mark a range of virtual addresses to be inaccessible. * These are later cleared by a NUMA hinting fault. Depending on these * faults, pages may be migrated for better NUMA placement. * * This is assuming that NUMA faults are handled using PROT_NONE. If * an architecture makes a different choice, it will need further * changes to the core. */
unsigned long change_prot_numa(struct vm_area_struct *vma,
unsigned long addr, unsigned long end)
{
int nr_updated;
nr_updated = change_protection(vma, addr, end, PAGE_NONE, 0, 1);
if (nr_updated)
count_vm_numa_events(NUMA_PTE_UPDATES, nr_updated);
return nr_updated;
}
vma 영역의 가상 주소 @addr ~ @end 범위를 NUMA hinging fault가 발생하게 PROT_NONE 매핑 속성으로 변경한다.
- PROT_NONE 매핑 속성
- NUMA 밸런싱을 위해 강제로 액세스 불가능 형태로 바꾸어 이 페이지에 처음 접근할 때에 한하여 numa fault가 발생하게 한다.
NUMA 페이지 접근
다음 그림은 태스크가 누마 페이지에 접근하여 faults 통계를 갱신하고 밸런싱을 하는 함수 호출과정을 보여준다.
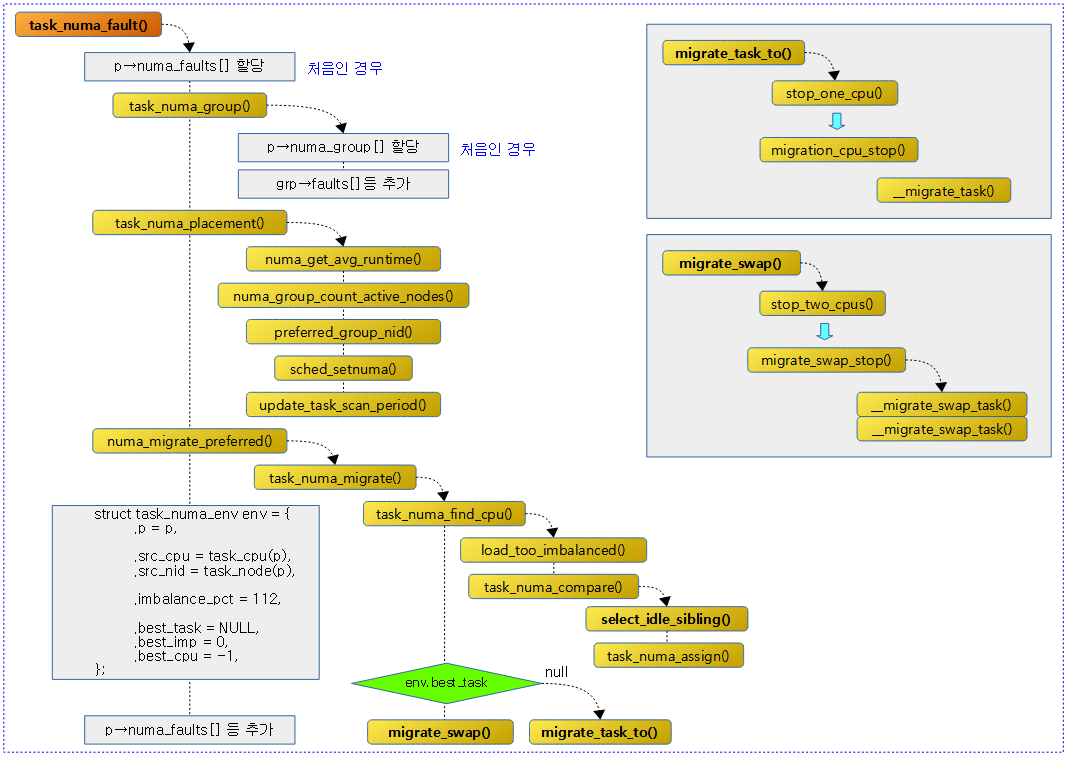
NUMA faults 동작
task_numa_fault()
fault 핸들러 handle_mm_fault() -> __handle_mm_fault() -> handle_pte_fault() -> do_numa_page() 함수로 부터 진입된다.
kernel/sched/fair.c
/* * Got a PROT_NONE fault for a page on @node. */
void task_numa_fault(int last_cpupid, int mem_node, int pages, int flags)
{
struct task_struct *p = current;
bool migrated = flags & TNF_MIGRATED;
int cpu_node = task_node(current);
int local = !!(flags & TNF_FAULT_LOCAL);
struct numa_group *ng;
int priv;
if (!static_branch_likely(&sched_numa_balancing))
return;
/* for example, ksmd faulting in a user's mm */
if (!p->mm)
return;
/* Allocate buffer to track faults on a per-node basis */
if (unlikely(!p->numa_faults)) {
int size = sizeof(*p->numa_faults) *
NR_NUMA_HINT_FAULT_BUCKETS * nr_node_ids;
p->numa_faults = kzalloc(size, GFP_KERNEL|__GFP_NOWARN);
if (!p->numa_faults)
return;
p->total_numa_faults = 0;
memset(p->numa_faults_locality, 0, sizeof(p->numa_faults_locality));
}
/*
* First accesses are treated as private, otherwise consider accesses
* to be private if the accessing pid has not changed
*/
if (unlikely(last_cpupid == (-1 & LAST_CPUPID_MASK))) {
priv = 1;
} else {
priv = cpupid_match_pid(p, last_cpupid);
if (!priv && !(flags & TNF_NO_GROUP))
task_numa_group(p, last_cpupid, flags, &priv);
}
/*
* If a workload spans multiple NUMA nodes, a shared fault that
* occurs wholly within the set of nodes that the workload is
* actively using should be counted as local. This allows the
* scan rate to slow down when a workload has settled down.
*/
ng = deref_curr_numa_group(p);
if (!priv && !local && ng && ng->active_nodes > 1 &&
numa_is_active_node(cpu_node, ng) &&
numa_is_active_node(mem_node, ng))
local = 1;
/*
* Retry to migrate task to preferred node periodically, in case it
* previously failed, or the scheduler moved us.
*/
if (time_after(jiffies, p->numa_migrate_retry)) {
task_numa_placement(p);
numa_migrate_preferred(p);
}
if (migrated)
p->numa_pages_migrated += pages;
if (flags & TNF_MIGRATE_FAIL)
p->numa_faults_locality[2] += pages;
p->numa_faults[task_faults_idx(NUMA_MEMBUF, mem_node, priv)] += pages;
p->numa_faults[task_faults_idx(NUMA_CPUBUF, cpu_node, priv)] += pages;
p->numa_faults_locality[local] += pages;
}
누마 hinting fault가 발생하고 마이그레이션 후에 이 함수가 호출되었다. 이 함수에서는 numa fault 관련 통계들을 증가시킨다.
- 코드 라인 10~11에서 누마 밸런싱이 설정되지 않은 경우 함수를 빠져나간다.
- 코드 라인 14~15에서 유저 태스크가 아닌 경우 함수를 빠져나간다.
- 코드 라인 18~28에서 처음에 한하여 태스크에 numa_faults[]를 할당하고, total_numa_faults 및 numa_faults_locality[]를 클리어한다.
- 4 가지 타입 * 노드 수 * 2 (private|shared) 만큼 배열을 할당한다.
- 코드 라인 34~40에서 priv 값을 다음과 같이 설정한다.
- 처음 접근 시 priv=1
- 처음 접근이 아닌 경우 priv 값은 태스크에 설정된 pid가 lastcpupid와 같은 pid 사용 여부이다. 단 priv가 0이고 TNF_NO_GROUP 플래그를 사용하는 경우 누마 그룹을 통해 priv를 알아온다.
- 코드 라인 48~52에서 priv가 0이고 리모트 노드에서 누마 그룹의 active 노드가 2개 이상이며, mem_node와 cpu_node가 모두 active 상태인 경우 local에 1을 대입한다.
- 코드 라인 58~61에서 현재 시각이 numa_migrate_retry 시각을 넘긴 경우 태스크를 preferred 노드로 옮기는 것을 재시도한다.
- 코드 라인 63~64에서 TNF_MIGRATED 플래그를 사용한 경우 numa_pages_migrated에 페이지 수를 추가한다.
- 코드 라인 65~66에서 TNF_MIGRATE_FAIL 플래그를 사용한 경우 numa_faults_locality[2]에 페이지 수를 추가한다.
- numa_faults_locality[]
- 0=remote
- 1=local
- 2=failed to migrate
- numa_faults_locality[]
- 코드 라인 68~70에서 numa_faults[]에 페이지 수를 추가하여 갱신하고, numa_faults_locality[]의 로컬에도 페이지 수를 추가한다.
task_numa_group()
kernel/sched/fair.c -1/2-
static void task_numa_group(struct task_struct *p, int cpupid, int flags,
int *priv)
{
struct numa_group *grp, *my_grp;
struct task_struct *tsk;
bool join = false;
int cpu = cpupid_to_cpu(cpupid);
int i;
if (unlikely(!deref_curr_numa_group(p))) {
unsigned int size = sizeof(struct numa_group) +
4*nr_node_ids*sizeof(unsigned long);
grp = kzalloc(size, GFP_KERNEL | __GFP_NOWARN);
if (!grp)
return;
refcount_set(&grp->refcount, 1);
grp->active_nodes = 1;
grp->max_faults_cpu = 0;
spin_lock_init(&grp->lock);
grp->gid = p->pid;
/* Second half of the array tracks nids where faults happen */
grp->faults_cpu = grp->faults + NR_NUMA_HINT_FAULT_TYPES *
nr_node_ids;
for (i = 0; i < NR_NUMA_HINT_FAULT_STATS * nr_node_ids; i++)
grp->faults[i] = p->numa_faults[i];
grp->total_faults = p->total_numa_faults;
grp->nr_tasks++;
rcu_assign_pointer(p->numa_group, grp);
}
rcu_read_lock();
tsk = READ_ONCE(cpu_rq(cpu)->curr);
if (!cpupid_match_pid(tsk, cpupid))
goto no_join;
grp = rcu_dereference(tsk->numa_group);
if (!grp)
goto no_join;
my_grp = deref_curr_numa_group(p);
if (grp == my_grp)
goto no_join;
/*
* Only join the other group if its bigger; if we're the bigger group,
* the other task will join us.
*/
if (my_grp->nr_tasks > grp->nr_tasks)
goto no_join;
/*
* Tie-break on the grp address.
*/
if (my_grp->nr_tasks == grp->nr_tasks && my_grp > grp)
goto no_join;
/* Always join threads in the same process. */
if (tsk->mm == current->mm)
join = true;
/* Simple filter to avoid false positives due to PID collisions */
if (flags & TNF_SHARED)
join = true;
/* Update priv based on whether false sharing was detected */
*priv = !join;
if (join && !get_numa_group(grp))
goto no_join;
rcu_read_unlock();
if (!join)
return;
누마 hinting faults을 통해 누마 마이그레이션에 대한 누마 faults 관련 stat을 갱신한다. 만일 요청한 태스크 @p가 처음 접근한 경우엔 태스크에 누마 그룹을 생성한다. 출력 인자 @priv에 1이 단일 접근인 경우이고, 0이 출력되면 공유 접근한 상태이다.
- 코드 라인 10~34에서 처음인 경우 태스크에 누마 그룹을 할당한 후 내부 멤버들을 초기화한다. 또한 누마 그룹내 faults[] 배열을 할당하고 역시 초기화한다.
- 코드 라인 36~61에서 다음에 해당하는 경우 no_join 레이블을 통해 함수를 빠져나간다.
- 현재 cpu에서 동작 중인 태스크와 cpupid의 pid가 서로 다른 경우
- 현재 태스크의 누마 그룹이 지정되지 않은 경우
- 현재 태스크의 누마 그룹과 요청한 태스크의 누마 그룹이 서로 같은 경우
- 현재 태스크의 누마 그룹에서 동작 중인 태스크의 수 보다 요청한 태스크의 그룹에서 동작 중인 태스크의 수 보다 큰 경우
- 현재 태스크의 누마 그룹에서 동작 중인 태스크의 수와 요청한 태스크의 그룹에서 동작 중인 태스크의 수가 동일한 경우 두 그룹의 주소를 비교하여 요청한 태스크의 그룹 주소가 더 큰 경우
- 코드 라인 64~69에서 다음의 경우에 한해 join=true로 설정한다.
- 현재 태스크와 요청한 태스크의 프로세스가 동일한 경우
- TNF_SHARED 플래그를 사용한 경우
- 코드 라인 72에서 출력 인자 *priv에는 join의 반대 값을 대입한다.
- 코드 라인 74~75에서 join=true일 때 현재 태스크의 그룹의 참조 카운터를 1 증가시킨다.
- 코드 라인 79~80에서 join=false인 경우 함수를 빠져나간다.
kernel/sched/fair.c -2/2-
BUG_ON(irqs_disabled());
double_lock_irq(&my_grp->lock, &grp->lock);
for (i = 0; i < NR_NUMA_HINT_FAULT_STATS * nr_node_ids; i++) {
my_grp->faults[i] -= p->numa_faults[i];
grp->faults[i] += p->numa_faults[i];
}
my_grp->total_faults -= p->total_numa_faults;
grp->total_faults += p->total_numa_faults;
my_grp->nr_tasks--;
grp->nr_tasks++;
spin_unlock(&my_grp->lock);
spin_unlock_irq(&grp->lock);
rcu_assign_pointer(p->numa_group, grp);
put_numa_group(my_grp);
return;
no_join:
rcu_read_unlock();
return;
}
- 코드 라인 2에서 현재 태스크의 누마 그룹과 요청한 태스크의 그룹 둘 모두 한꺼번에 스핀락을 건다.
- 코드 라인 4~12에서 4 종류의 누마 fault stats를 순회하며 태스크의 누마 faults 값을 이동시키고, tatal_faults와 nr_tasks 수도 이동시킨다. (요청한 태스크의 누마 그룹 -> 현재 태스크의 누마 그룹)
- 코드 라인 14~15에서 두 스핀락을 해제한다.
- 코드 라인 19~20에서 요청한 태스크의 누마 그룹 참조 카운터를 1 감소시킨 후 정상적으로 함수를 빠져나간다.
- 코드 라인 22~24에서 no_join: 레이블이다. 함수를 빠져나간다.
numa_is_active_node()
kernel/sched/fair.c
static bool numa_is_active_node(int nid, struct numa_group *ng)
{
return group_faults_cpu(ng, nid) * ACTIVE_NODE_FRACTION > ng->max_faults_cpu;
}
누마 그룹 @ng의 faults 통계를 보고 누마 노드 @nid에 대한 활성화 여부를 반환한다.
- faults 수 * 3배한 값이 누마 그룹 @ng의 max_faults_cpu보다 큰지 여부를 반환한다.
ACTIVE_NODE_FRACTION
kernel/sched/fair.c
/* * A node triggering more than 1/3 as many NUMA faults as the maximum is * considered part of a numa group's pseudo-interleaving set. Migrations * between these nodes are slowed down, to allow things to settle down. */ #define ACTIVE_NODE_FRACTION 3
최적의 누마 노드로 태스크 이동
task_numa_placement()
kernel/sched/fair.c -1/2-
static void task_numa_placement(struct task_struct *p)
{
int seq, nid, max_nid = NUMA_NO_NODE;
unsigned long max_faults = 0;
unsigned long fault_types[2] = { 0, 0 };
unsigned long total_faults;
u64 runtime, period;
spinlock_t *group_lock = NULL;
struct numa_group *ng;
/*
* The p->mm->numa_scan_seq field gets updated without
* exclusive access. Use READ_ONCE() here to ensure
* that the field is read in a single access:
*/
seq = READ_ONCE(p->mm->numa_scan_seq);
if (p->numa_scan_seq == seq)
return;
p->numa_scan_seq = seq;
p->numa_scan_period_max = task_scan_max(p);
total_faults = p->numa_faults_locality[0] +
p->numa_faults_locality[1];
runtime = numa_get_avg_runtime(p, &period);
/* If the task is part of a group prevent parallel updates to group stats */
ng = deref_curr_numa_group(p);
if (ng) {
group_lock = &ng->lock;
spin_lock_irq(group_lock);
}
- 코드 라인 16~18에서 누마 스캔 시퀀스에 변동이 없으면 함수를 빠져나간다.
- 코드 라인 19~20에서 바뀐 누마 스캔 시퀀스를 갱신하고, 누마 스캔 주기 최대치를 갱신한다.
- 코드 라인 22~23에서 태스크에 대한 numa_faults_locality 값을 알아온다. (remote + local)
- 코드 라인 24에서 태스크의 지난 누마 placement 사이클 동안의 런타임을 알아오고 period에는 기간을 알아온다.
- 평균 런타임은 runtime / period를 해야 알 수 있다.
- 코드 라인 27~31에서 태스크에 대한 누마 그룹이 있는 경우 그룹 스핀 락을 획득한다.
kernel/sched/fair.c -2/2-
/* Find the node with the highest number of faults */
for_each_online_node(nid) {
/* Keep track of the offsets in numa_faults array */
int mem_idx, membuf_idx, cpu_idx, cpubuf_idx;
unsigned long faults = 0, group_faults = 0;
int priv;
for (priv = 0; priv < NR_NUMA_HINT_FAULT_TYPES; priv++) {
long diff, f_diff, f_weight;
mem_idx = task_faults_idx(NUMA_MEM, nid, priv);
membuf_idx = task_faults_idx(NUMA_MEMBUF, nid, priv);
cpu_idx = task_faults_idx(NUMA_CPU, nid, priv);
cpubuf_idx = task_faults_idx(NUMA_CPUBUF, nid, priv);
/* Decay existing window, copy faults since last scan */
diff = p->numa_faults[membuf_idx] - p->numa_faults[mem_idx] / 2;
fault_types[priv] += p->numa_faults[membuf_idx];
p->numa_faults[membuf_idx] = 0;
/*
* Normalize the faults_from, so all tasks in a group
* count according to CPU use, instead of by the raw
* number of faults. Tasks with little runtime have
* little over-all impact on throughput, and thus their
* faults are less important.
*/
f_weight = div64_u64(runtime << 16, period + 1);
f_weight = (f_weight * p->numa_faults[cpubuf_idx]) /
(total_faults + 1);
f_diff = f_weight - p->numa_faults[cpu_idx] / 2;
p->numa_faults[cpubuf_idx] = 0;
p->numa_faults[mem_idx] += diff;
p->numa_faults[cpu_idx] += f_diff;
faults += p->numa_faults[mem_idx];
p->total_numa_faults += diff;
if (ng) {
/*
* safe because we can only change our own group
*
* mem_idx represents the offset for a given
* nid and priv in a specific region because it
* is at the beginning of the numa_faults array.
*/
ng->faults[mem_idx] += diff;
ng->faults_cpu[mem_idx] += f_diff;
ng->total_faults += diff;
group_faults += ng->faults[mem_idx];
}
}
if (!ng) {
if (faults > max_faults) {
max_faults = faults;
max_nid = nid;
}
} else if (group_faults > max_faults) {
max_faults = group_faults;
max_nid = nid;
}
}
if (ng) {
numa_group_count_active_nodes(ng);
spin_unlock_irq(group_lock);
max_nid = preferred_group_nid(p, max_nid);
}
if (max_faults) {
/* Set the new preferred node */
if (max_nid != p->numa_preferred_nid)
sched_setnuma(p, max_nid);
}
update_task_scan_period(p, fault_types[0], fault_types[1]);
}
- 코드 라인 2~8에서 온라인 노드를 순회하고, 다시 그 내부에서 누마 hint fault 타입 수(private, shared)만큼 순회한다.
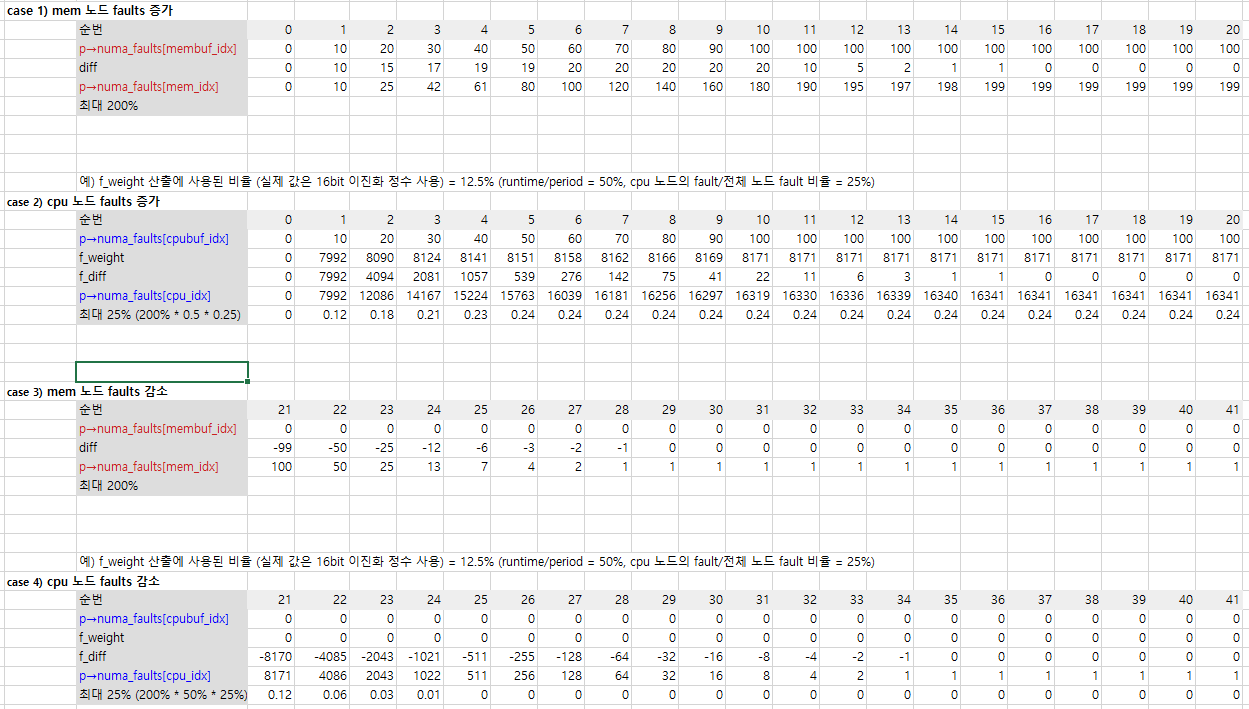
- 코드 라인 17~19에서 태스크에 대한 누마 faults들 중 membuf에서 mem의 절반을 뺀 값을 diff에 대입하고, 순회 중인 fault 타입의 임시 배열 fault_types[]에 membuf의 값을 추가하고, membuf는 클리어한다.
- p->numa_faults[mem_idx] 값은 p->numa_faults[membuf_idx] 값의 200%로 제한된다.
- 코드 라인 28~30에서 f_weight에는 p->numa_faults[cpubuf_idx] 값을 16비트 이진화 정수로 변환(normalization)한 후 다음 두 비율을 적용한다.
- 누마 placement 사이클 동안의 평균 런타임 비율 (runtime / period)
- 전체 노드 fault 중 numa_faults[cpubuf_idx] 비율 (p->numa_faults[cpu_idx] / total_faults + 1)
- 코드 라인 31~32에서 증감 시킬 f_diff 값은 산출한 f_weight – 기존 p->numa_faults[cpu_idx]의 절반을 적용한다. 그 후 p->numa_faults[cpubuf_idx]는 클리어한다.
- 코드 라인 34~37에서 mem_idx 및 cpu_idx의 p->numa_faults[] 값에 diff 및 f_diff 값을 추가하고, 이렇게 누적된 p->numa_faults[mem_idx] 값을 faults에 다시 누적하고, p->total_numa_fuautls에 diff를 누적한다.
- 코드 라인 38~50에서 누마 그룹의 faults, faults_cpu, total_faults 들에 대해서도 diff 만큼 추가하고, group_faults에는 ng->faults[mem_idx]를 누적시킨다.
- 코드 라인 53~61에서 max_faults와 max_nid를 갱신한다.
- 코드 라인 64~68에서 누마 그룹의 최대 faults 수와 active 노드 수를 갱신하고, 태스크에 가장 적합한 우선 노드를 알아와서 max_nid에 대입한다.
- 코드 라인 70~74에서 태스크의 우선 노드로 max_nid를 지정한다.
- 코드 라인 76에서 태스크의 누마 스캔 주기의 증/감을 갱신한다.
다음은 numa faults 값의 증감시 변화되는 값을 보여준다.
- faults가 10씩 증가될때와, 0이된 후 decay되는 값을 보여준다.
numa_get_avg_runtime()
kernel/sched/fair.c
/* * Get the fraction of time the task has been running since the last * NUMA placement cycle. The scheduler keeps similar statistics, but * decays those on a 32ms period, which is orders of magnitude off * from the dozens-of-seconds NUMA balancing period. Use the scheduler * stats only if the task is so new there are no NUMA statistics yet. */
static u64 numa_get_avg_runtime(struct task_struct *p, u64 *period)
{
u64 runtime, delta, now;
/* Use the start of this time slice to avoid calculations. */
now = p->se.exec_start;
runtime = p->se.sum_exec_runtime;
if (p->last_task_numa_placement) {
delta = runtime - p->last_sum_exec_runtime;
*period = now - p->last_task_numa_placement;
/* Avoid time going backwards, prevent potential divide error: */
if (unlikely((s64)*period < 0))
*period = 0;
} else {
delta = p->se.avg.load_sum;
*period = LOAD_AVG_MAX;
}
p->last_sum_exec_runtime = runtime;
p->last_task_numa_placement = now;
return delta;
}
태스크 @p의 지난 누마 placement 사이클 동안의 런타임을 알아온다. 출력 인자 *period에는 지난 누마 placement 사이클이 담긴다.
- 코드 라인 5~6에서 태스크의 이번 스케줄 실행 시각과 총 누적 실행 시간을 알아온다.
- p->exec_start는 태스크가 스케줄되거나, 매 스케줄 틱마다 현재 시각(런큐 클럭)으로 갱신한다.
- p->se.sum_exec_runtime에는 스케줄 틱마다 태스크의 총 누적 실행 시간이 담겨있다.
- 코드 라인 8~18에서 task_numa_placement 함수를 통해 갱신된 적이 있는지 여부에 따라 다음과 같이 처리한다.
- 갱신된 적이 있으면 태스크의 총 누적 실행 시간에서 지난 갱신 되었던 총 실행 시간을 뺀 delta 값을 알아오고, 출력 인자 *period에는 현재 시각에서 지난 갱신 시각을 뺀 기간을 반환한다.
- 갱신된 적이 없으면 태스크의 로드 합을 delta에 담고, 출력 인자 *perido에 전체 기간(LOAD_AVG_MAX)를 담는다.
- 코드 라인 20~21에서 처음 알아온 runtime과 now를 갱신한다.
- 코드 라인 23에서 delta 실행 시간을 반환한다.
numa_group_count_active_nodes()
kernel/sched/fair.c
/* * Find out how many nodes on the workload is actively running on. Do this by * tracking the nodes from which NUMA hinting faults are triggered. This can * be different from the set of nodes where the workload's memory is currently * located. */
static void numa_group_count_active_nodes(struct numa_group *numa_group)
{
unsigned long faults, max_faults = 0;
int nid, active_nodes = 0;
for_each_online_node(nid) {
faults = group_faults_cpu(numa_group, nid);
if (faults > max_faults)
max_faults = faults;
}
for_each_online_node(nid) {
faults = group_faults_cpu(numa_group, nid);
if (faults * ACTIVE_NODE_FRACTION > max_faults)
active_nodes++;
}
numa_group->max_faults_cpu = max_faults;
numa_group->active_nodes = active_nodes;
}
@numa_group의 max_faults_cpu와 active_nodes를 갱신해온다.
- 코드 라인 6~10에서 모든 온라인 노드들을 순회하며 @numa_group의 faults들 중 가장 큰 값을 max_faults에 알아온다.
- 코드 라인 12~16에서 모든 온라인 노드들을 순회하며 @numa_group의 faults에 액티브 비율(3배)을 적용한 값이 max_faults를 초과하는 노드들의 수를 active_nodes에 알아온다.
- 가장 접근이 많은 노드의 1/3이 넘는 노드들의 수가 avtive_nodes로 지정된다.
- 이 값이 2 이상인 경우 2개 이상의 메모리 노드에 분산되어 많이 사용됨을 알 수 있다.
- 코드 라인 18~19에서 @numa_group의 max_faults_cpu와 active_nodes를 갱신한다.
태스크에 적절한 우선 노드 찾기
preferred_group_nid()
kernel/sched/fair.c -1/2-
/* * Determine the preferred nid for a task in a numa_group. This needs to * be done in a way that produces consistent results with group_weight, * otherwise workloads might not converge. */
static int preferred_group_nid(struct task_struct *p, int nid)
{
nodemask_t nodes;
int dist;
/* Direct connections between all NUMA nodes. */
if (sched_numa_topology_type == NUMA_DIRECT)
return nid;
/*
* On a system with glueless mesh NUMA topology, group_weight
* scores nodes according to the number of NUMA hinting faults on
* both the node itself, and on nearby nodes.
*/
if (sched_numa_topology_type == NUMA_GLUELESS_MESH) {
unsigned long score, max_score = 0;
int node, max_node = nid;
dist = sched_max_numa_distance;
for_each_online_node(node) {
score = group_weight(p, node, dist);
if (score > max_score) {
max_score = score;
max_node = node;
}
}
return max_node;
}
태스크에 가장 적절한 누마 우선 노드를 알아온다. 누마 노드 타입에 따라 다음과 같이 알아온다.
- direct 노드 타입의 경우 @nid를 반환한다.
- glueless mesh 노드 타입의 경우 모든 노드에서 태스크 @p에 대한 그룹 weight가 가장 큰 노드를 선택한다.
- backplain 노드 타입의 경우 가장 큰 distance부터 시작하여 노드들 중 다른 노드들과의 그룹 faults가 가장 큰 노드를 선택한다. 그룹 faults가 없는 경우 다음 distance를 진행한다.
- 코드 라인 7~8에서 누마 direct 노드 타입의 경우 인자로 전달받은 @nid를 우선 노드로 사용하기 위해 반환한다.
- 코드 라인 15~29에서 누마 glueless mesh 노드 타입의 경우 태스크 @p와 각 노드 간에 그룹 weight가 가장 큰 노드를 우선 노드로 사용하기 위해 반환한다.
kernel/sched/fair.c -2/2-
/*
* Finding the preferred nid in a system with NUMA backplane
* interconnect topology is more involved. The goal is to locate
* tasks from numa_groups near each other in the system, and
* untangle workloads from different sides of the system. This requires
* searching down the hierarchy of node groups, recursively searching
* inside the highest scoring group of nodes. The nodemask tricks
* keep the complexity of the search down.
*/
nodes = node_online_map;
for (dist = sched_max_numa_distance; dist > LOCAL_DISTANCE; dist--) {
unsigned long max_faults = 0;
nodemask_t max_group = NODE_MASK_NONE;
int a, b;
/* Are there nodes at this distance from each other? */
if (!find_numa_distance(dist))
continue;
for_each_node_mask(a, nodes) {
unsigned long faults = 0;
nodemask_t this_group;
nodes_clear(this_group);
/* Sum group's NUMA faults; includes a==b case. */
for_each_node_mask(b, nodes) {
if (node_distance(a, b) < dist) {
faults += group_faults(p, b);
node_set(b, this_group);
node_clear(b, nodes);
}
}
/* Remember the top group. */
if (faults > max_faults) {
max_faults = faults;
max_group = this_group;
/*
* subtle: at the smallest distance there is
* just one node left in each "group", the
* winner is the preferred nid.
*/
nid = a;
}
}
/* Next round, evaluate the nodes within max_group. */
if (!max_faults)
break;
nodes = max_group;
}
return nid;
}
- 코드 라인 11~18에서 누마 백플레인 노드 타입인 경우이다. 로컬을 제외한 리모트 최장거리부터 최단거리까지 1씩 줄여가며 순회하며 누마 디스턴스에 사용하지 않는 거리들은 skip 한다.
- 예) 30, 29, 28, … 11 까지 감소하며 누마 디스턴스인 30, 25, 20, 15을 제외하고는 skip 한다.
- 코드 라인 20~32에서 누마 온라인 노드들을 대상으로 순회하며 순회하는 노드가 다른 노드들과의 거리가 dist 보다 작을 때 태스크에 대한 그룹 faults를 누적하고, 누적한 그룹을 this_group에 마크하고, nodes에서는 제거한다.
- 코드 라인 35~44에서 max_faults를 갱신하고, 갱신한 노드를 nid에 대입하고, 마크된 this_group을 max-group에 대입한다.
- 코드 라인 47~49에서 max-faults가 0인 경우 함수를 빠져나가고, 존재하는 경우 nodes에 max_group을 대입하고, 다음 distance를 진행하도록 한다.
- 코드 라인 51에서 태스크가 가장 많은 접근(max_faults)을 기록한 nid 노드를 반환한다.
누마 스캔 주기 증/감 갱신
update_task_scan_period()
kernel/sched/fair.c
/* * Increase the scan period (slow down scanning) if the majority of * our memory is already on our local node, or if the majority of * the page accesses are shared with other processes. * Otherwise, decrease the scan period. */
static void update_task_scan_period(struct task_struct *p,
unsigned long shared, unsigned long private)
{
unsigned int period_slot;
int lr_ratio, ps_ratio;
int diff;
unsigned long remote = p->numa_faults_locality[0];
unsigned long local = p->numa_faults_locality[1];
/*
* If there were no record hinting faults then either the task is
* completely idle or all activity is areas that are not of interest
* to automatic numa balancing. Related to that, if there were failed
* migration then it implies we are migrating too quickly or the local
* node is overloaded. In either case, scan slower
*/
if (local + shared == 0 || p->numa_faults_locality[2]) {
p->numa_scan_period = min(p->numa_scan_period_max,
p->numa_scan_period << 1);
p->mm->numa_next_scan = jiffies +
msecs_to_jiffies(p->numa_scan_period);
return;
}
/*
* Prepare to scale scan period relative to the current period.
* == NUMA_PERIOD_THRESHOLD scan period stays the same
* < NUMA_PERIOD_THRESHOLD scan period decreases (scan faster)
* >= NUMA_PERIOD_THRESHOLD scan period increases (scan slower)
*/
period_slot = DIV_ROUND_UP(p->numa_scan_period, NUMA_PERIOD_SLOTS);
lr_ratio = (local * NUMA_PERIOD_SLOTS) / (local + remote);
ps_ratio = (private * NUMA_PERIOD_SLOTS) / (private + shared);
if (ps_ratio >= NUMA_PERIOD_THRESHOLD) {
/*
* Most memory accesses are local. There is no need to
* do fast NUMA scanning, since memory is already local.
*/
int slot = ps_ratio - NUMA_PERIOD_THRESHOLD;
if (!slot)
slot = 1;
diff = slot * period_slot;
} else if (lr_ratio >= NUMA_PERIOD_THRESHOLD) {
/*
* Most memory accesses are shared with other tasks.
* There is no point in continuing fast NUMA scanning,
* since other tasks may just move the memory elsewhere.
*/
int slot = lr_ratio - NUMA_PERIOD_THRESHOLD;
if (!slot)
slot = 1;
diff = slot * period_slot;
} else {
/*
* Private memory faults exceed (SLOTS-THRESHOLD)/SLOTS,
* yet they are not on the local NUMA node. Speed up
* NUMA scanning to get the memory moved over.
*/
int ratio = max(lr_ratio, ps_ratio);
diff = -(NUMA_PERIOD_THRESHOLD - ratio) * period_slot;
}
p->numa_scan_period = clamp(p->numa_scan_period + diff,
task_scan_min(p), task_scan_max(p));
memset(p->numa_faults_locality, 0, sizeof(p->numa_faults_locality));
}
태스크 @p의 NUMA 스캔 주기를 증/감하여 갱신한다. 누마 로컬 또는 private 접근 비율이 스레졸드(70%) 이상인 증가되어 스캔 주기가 길어지고, 반대로 누마 리모트 또는 shared의 접근 비율이 스레졸드(70%) 이상인 경우 감소되어 스캔 주기는 짧아진다.
- 코드 라인 8~9에서 리모트 및 로컬 누마 노드로의 접근 수를 알아온다.
- 코드 라인 18~26에서 아직 접근된 수가 없거나 마이그레이션 실패한 경우가 있으면 누마 스캔 주기를 2배 증가시키고, 다음 스캔 시각을 결정한 후 함수를 빠져나간다.
- 코드 라인 34에서 누마 스캔 주기를 NUMA_PERIOD_SLOTS(10) 단위로 올림 정렬한 값을 period_slot에 담는다.
- 코드 라인 35에서 로컬/리모트 중 로컬 접근 비율을 구한다.
- 코드 라인 36에서 private/shared 중 private 접근 비율을 구한다.
- 코드 라인 38~65에서 누마 스캔 주기를 증감 시킬 diff 값을 다음과 같이 구한다.
- private 비율 >= 70%일 때 초과 값을 period_slot에 곱한다. (증가)
- local 비율 >= 70% 초과 값을 period_slot에 곱한다. (증가)
- local 비율 또는 private 비율 중 큰 값에서 스레졸드 값을 뺀 후 period_slot에 곱한다. (음수 -> 감소)
- 코드 라인 67~68에서 누마 스캔 주기에 diff를 반영한다.(증/감)
- 코드 라인 69에서 numa_faults_locality[]를 0으로 클리어한다.
누마 우선 노드로의 마이그레이션
numa_migrate_preferred()
kernel/sched/fair.c
/* Attempt to migrate a task to a CPU on the preferred node. */
static void numa_migrate_preferred(struct task_struct *p)
{
unsigned long interval = HZ;
/* This task has no NUMA fault statistics yet */
if (unlikely(p->numa_preferred_nid == NUMA_NO_NODE || !p->numa_faults))
return;
/* Periodically retry migrating the task to the preferred node */
interval = min(interval, msecs_to_jiffies(p->numa_scan_period) / 16);
p->numa_migrate_retry = jiffies + interval;
/* Success if task is already running on preferred CPU */
if (task_node(p) == p->numa_preferred_nid)
return;
/* Otherwise, try migrate to a CPU on the preferred node */
task_numa_migrate(p);
}
누마 우선 노드로 태스크를 마이그레이션 시도한다.
- 코드 라인 7~8에서 낮은 확률로 태스크의 우선 노드가 설정되지 않았거나 누마 밸런싱용 fault 통계가 아직 시작되지 않은 경우 함수를 빠져나간다.
- 코드 라인 11~12에서 최대 1초 이내의 누마 스캔 주기 /16을 현재 시각에서 추가하여 태스크의 numa_migrate_retry에 대입한다.
- 코드 라인 15~16에서 이미 태스크가 누마 우선 노드를 사용 중이면 함수를 빠져나간다.
- 코드 라인 19에서 태스크를 마이그레이션 시도한다.
task_numa_migrate()
kernel/sched/fair.c -1/2-
static int task_numa_migrate(struct task_struct *p)
{
struct task_numa_env env = {
.p = p,
.src_cpu = task_cpu(p),
.src_nid = task_node(p),
.imbalance_pct = 112,
.best_task = NULL,
.best_imp = 0,
.best_cpu = -1,
};
unsigned long taskweight, groupweight;
struct sched_domain *sd;
long taskimp, groupimp;
struct numa_group *ng;
struct rq *best_rq;
int nid, ret, dist;
/*
* Pick the lowest SD_NUMA domain, as that would have the smallest
* imbalance and would be the first to start moving tasks about.
*
* And we want to avoid any moving of tasks about, as that would create
* random movement of tasks -- counter the numa conditions we're trying
* to satisfy here.
*/
rcu_read_lock();
sd = rcu_dereference(per_cpu(sd_numa, env.src_cpu));
if (sd)
env.imbalance_pct = 100 + (sd->imbalance_pct - 100) / 2;
rcu_read_unlock();
/*
* Cpusets can break the scheduler domain tree into smaller
* balance domains, some of which do not cross NUMA boundaries.
* Tasks that are "trapped" in such domains cannot be migrated
* elsewhere, so there is no point in (re)trying.
*/
if (unlikely(!sd)) {
sched_setnuma(p, task_node(p));
return -EINVAL;
}
env.dst_nid = p->numa_preferred_nid;
dist = env.dist = node_distance(env.src_nid, env.dst_nid);
taskweight = task_weight(p, env.src_nid, dist);
groupweight = group_weight(p, env.src_nid, dist);
update_numa_stats(&env.src_stats, env.src_nid);
taskimp = task_weight(p, env.dst_nid, dist) - taskweight;
groupimp = group_weight(p, env.dst_nid, dist) - groupweight;
update_numa_stats(&env.dst_stats, env.dst_nid);
/* Try to find a spot on the preferred nid. */
task_numa_find_cpu(&env, taskimp, groupimp);
- 코드 라인 3~14에서 태스크의 마이그레이션을 위해 관련 함수에서 인자 전달 목적으로 사용될 구조체 내에 태스크를 소스로 구성한다.
- 코드 라인 31~45에서 태스크의 cpu에 대한 누마 스케줄 도메인이 여부에 따라 다음과 같이 수행한다.
- 있을 때 imbalance_pct의 100% 초과분을 절반으로 줄인다.
- 없을 때 태스크의 누마 우선 노드만을 지정한 후 -EINVAL 값을 반환한다.
- 코드 라인 47에서 dst_nid에 태스크의 누마 우선 노드를 지정한다.
- 코드 라인 48~51에서 소스 노드측의 러너블 로드와 capacity를 알아온다.
- 코드 라인 52~54에서 데스트 노드측의 러너블 로드와 capacity를 알아온다.
- 코드 라인 57에서 데스트 노드내에서 가장 적절한 cpu를 찾는다.
kernel/sched/fair.c -2/2-
/*
* Look at other nodes in these cases:
* - there is no space available on the preferred_nid
* - the task is part of a numa_group that is interleaved across
* multiple NUMA nodes; in order to better consolidate the group,
* we need to check other locations.
*/
ng = deref_curr_numa_group(p);
if (env.best_cpu == -1 || (ng && ng->active_nodes > 1)) {
for_each_online_node(nid) {
if (nid == env.src_nid || nid == p->numa_preferred_nid)
continue;
dist = node_distance(env.src_nid, env.dst_nid);
if (sched_numa_topology_type == NUMA_BACKPLANE &&
dist != env.dist) {
taskweight = task_weight(p, env.src_nid, dist);
groupweight = group_weight(p, env.src_nid, dist);
}
/* Only consider nodes where both task and groups benefit */
taskimp = task_weight(p, nid, dist) - taskweight;
groupimp = group_weight(p, nid, dist) - groupweight;
if (taskimp < 0 && groupimp < 0)
continue;
env.dist = dist;
env.dst_nid = nid;
update_numa_stats(&env.dst_stats, env.dst_nid);
task_numa_find_cpu(&env, taskimp, groupimp);
}
}
/*
* If the task is part of a workload that spans multiple NUMA nodes,
* and is migrating into one of the workload's active nodes, remember
* this node as the task's preferred numa node, so the workload can
* settle down.
* A task that migrated to a second choice node will be better off
* trying for a better one later. Do not set the preferred node here.
*/
if (ng) {
if (env.best_cpu == -1)
nid = env.src_nid;
else
nid = cpu_to_node(env.best_cpu);
if (nid != p->numa_preferred_nid)
sched_setnuma(p, nid);
}
/* No better CPU than the current one was found. */
if (env.best_cpu == -1)
return -EAGAIN;
best_rq = cpu_rq(env.best_cpu);
if (env.best_task == NULL) {
ret = migrate_task_to(p, env.best_cpu);
WRITE_ONCE(best_rq->numa_migrate_on, 0);
if (ret != 0)
trace_sched_stick_numa(p, env.src_cpu, env.best_cpu);
return ret;
}
ret = migrate_swap(p, env.best_task, env.best_cpu, env.src_cpu);
WRITE_ONCE(best_rq->numa_migrate_on, 0);
if (ret != 0)
trace_sched_stick_numa(p, env.src_cpu, task_cpu(env.best_task));
put_task_struct(env.best_task);
return ret;
}
- 코드 라인 8에서 태스크의 누마 그룹을 알아온다.
- 코드 라인 9~12에서 best_cpu를 찾지 못하였거나 2개 이상의 active 누마 그룹이 있는 경우 모든 온라인 노드를 순회한다. 단 소스 노드와 누마 우선 노드는 skip 한다.
- 코드 라인 14~19에서 두 소스 노드와 데스트 노드가 백플레인 타입으로 연결되었고 두 노드간의 거리가 env.dist가 아닌 경우 소스 노드에 대한 taskweight과 groupweight을 구한다.
- 코드 라인 22~25에서 순회 중인 노드에 대한 태스크 weight과 순회 중인 노드에 대한 그룹 weight 둘 다 0보다 작은 경우는 skip 한다.
- 코드 라인 27~30에서 순회 중인 노드의 러너블 로드와 capacity를 구한 후 idlest cpu를 찾아 env->best_cpu에 알아온다.
- 코드 라인 42~50에서 태스크의 누마 그룹이 있는 경우 마이그레이트 할 cpu를 찾은 경우 해당 노드, 못 찾은 경우 원래 소스 노드로 태스크의 우선 노드를 결정한다.
- 코드 라인 53~54에서 마이그레이트할 best cpu를 찾지 못한 경우 -EAGAIN을 반환한다.
- 코드 라인 56~63에서 env.best_task가 지정되지 않은 경우 best cpu로 태스크를 마이그레이션한 후 그 결과를 갖고 함수를 빠져나간다.
- 코드 라인 65~71에서 두 개의 태스크를 서로 교체한 후 그 결과를 갖고 함수를 빠져나간다.
update_numa_stats()
kernel/sched/fair.c
/* * XXX borrowed from update_sg_lb_stats */
static void update_numa_stats(struct numa_stats *ns, int nid)
{
int cpu;
memset(ns, 0, sizeof(*ns));
for_each_cpu(cpu, cpumask_of_node(nid)) {
struct rq *rq = cpu_rq(cpu);
ns->load += cpu_runnable_load(rq);
ns->compute_capacity += capacity_of(cpu);
}
}
누마 stat을 갱신한다. 해당 노드의 러너블 로드와 capacity를 알아온다.
- 코드 라인 5에서 누마 stat을 모두 0으로 클리어한다.
- 코드 라인 6~11에서 @nid 노드에 대한 cpu들을 순회하며 러너블 로드와 capacity를 누적한다.
태스크를 누마 이동할 cpu 찾기
task_numa_find_cpu()
kernel/sched/fair.c
static void task_numa_find_cpu(struct task_numa_env *env,
long taskimp, long groupimp)
{
long src_load, dst_load, load;
bool maymove = false;
int cpu;
load = task_h_load(env->p);
dst_load = env->dst_stats.load + load;
src_load = env->src_stats.load - load;
/*
* If the improvement from just moving env->p direction is better
* than swapping tasks around, check if a move is possible.
*/
maymove = !load_too_imbalanced(src_load, dst_load, env);
for_each_cpu(cpu, cpumask_of_node(env->dst_nid)) {
/* Skip this CPU if the source task cannot migrate */
if (!cpumask_test_cpu(cpu, env->p->cpus_ptr))
continue;
env->dst_cpu = cpu;
task_numa_compare(env, taskimp, groupimp, maymove);
}
}
태스크를 누마 이동할 cpu를 찾아온다. cpu는 env->best_cpu에 알아오고, 교체할 태스크는 env->best_task에 알아온다.
- 코드 라인 8~10에서 태스크가 마이그레이션된 후의 로드 값을 결정한다.
- 마이그레이션될 데스트 노드에 태스크 로드를 추가하고,
- 마이그레이션할 소스 노드에서는 태스크 로드를 감소시킨다.
- 코드 라인 16에서 마이그레이션 후의 소스 노드와 데스트 노드 간의 로드가 차이가 적은지 여부를 maymove에 대입한다.
- 코드 라인 18~25에서 데스트 노드의 cpu들을 순회하고 태스크가 지원하는 cpu에 대해서만 로드를 비교하여 idlest cpu를 찾아 env->best_cpu에 기록한다.
load_too_imbalanced()
kernel/sched/fair.c
static bool load_too_imbalanced(long src_load, long dst_load,
struct task_numa_env *env)
{
long imb, old_imb;
long orig_src_load, orig_dst_load;
long src_capacity, dst_capacity;
/*
* The load is corrected for the CPU capacity available on each node.
*
* src_load dst_load
* ------------ vs ---------
* src_capacity dst_capacity
*/
src_capacity = env->src_stats.compute_capacity;
dst_capacity = env->dst_stats.compute_capacity;
imb = abs(dst_load * src_capacity - src_load * dst_capacity);
orig_src_load = env->src_stats.load;
orig_dst_load = env->dst_stats.load;
old_imb = abs(orig_dst_load * src_capacity - orig_src_load * dst_capacity);
/* Would this change make things worse? */
return (imb > old_imb);
}
태스크를 마이그레이션 했을 때의 소스 로드와 데스트 로드의 차이 값과 태스크를 마이그레이션 하기 전의 오리지날 소스 로드와 오리지날 데스트 로드의 차이를 비교한 결과를 반환한다. (1=마이그레이션 후가 더 불균형 상태, 0=마이그레이션 후 밸런스 상태)
- 코드 라인 15~18에서 소스 로드와 데스트 로드에 노드 capacity 비율을 적용한 두 값의 차이를 imb에 대입한다.
- 코드 라인 20~23에서 오리지날 소스 로드와 오리지날 데스트 로드에 노드 capacity 비율을 적용한 두 값의 차이를 old_imb에 대입한다.
- 코드 라인 26에서 마이그레이션 후의 imb가 마이그레이션 전의 old_imb보다 큰 경우 오히려 더 불균형 상태로 판단되어 1을 반환하고, 그렇지 않은 경우 이미 밸런스로 판단하여 0을 반환한다.
task_numa_compare()
kernel/sched/fair.c -1/2-
/* * This checks if the overall compute and NUMA accesses of the system would * be improved if the source tasks was migrated to the target dst_cpu taking * into account that it might be best if task running on the dst_cpu should * be exchanged with the source task */
static void task_numa_compare(struct task_numa_env *env,
long taskimp, long groupimp, bool maymove)
{
struct numa_group *cur_ng, *p_ng = deref_curr_numa_group(env->p);
struct rq *dst_rq = cpu_rq(env->dst_cpu);
long imp = p_ng ? groupimp : taskimp;
struct task_struct *cur;
long src_load, dst_load;
int dist = env->dist;
long moveimp = imp;
long load;
if (READ_ONCE(dst_rq->numa_migrate_on))
return;
rcu_read_lock();
cur = rcu_dereference(dst_rq->curr);
if (cur && ((cur->flags & PF_EXITING) || is_idle_task(cur)))
cur = NULL;
/*
* Because we have preemption enabled we can get migrated around and
* end try selecting ourselves (current == env->p) as a swap candidate.
*/
if (cur == env->p)
goto unlock;
if (!cur) {
if (maymove && moveimp >= env->best_imp)
goto assign;
else
goto unlock;
}
/*
* "imp" is the fault differential for the source task between the
* source and destination node. Calculate the total differential for
* the source task and potential destination task. The more negative
* the value is, the more remote accesses that would be expected to
* be incurred if the tasks were swapped.
*/
/* Skip this swap candidate if cannot move to the source cpu */
if (!cpumask_test_cpu(env->src_cpu, cur->cpus_ptr))
goto unlock;
/*
* If dst and source tasks are in the same NUMA group, or not
* in any group then look only at task weights.
*/
cur_ng = rcu_dereference(cur->numa_group);
if (cur_ng == p_ng) {
imp = taskimp + task_weight(cur, env->src_nid, dist) -
task_weight(cur, env->dst_nid, dist);
/*
* Add some hysteresis to prevent swapping the
* tasks within a group over tiny differences.
*/
if (cur_ng)
imp -= imp / 16;
} else {
/*
* Compare the group weights. If a task is all by itself
* (not part of a group), use the task weight instead.
*/
if (cur_ng && p_ng)
imp += group_weight(cur, env->src_nid, dist) -
group_weight(cur, env->dst_nid, dist);
else
imp += task_weight(cur, env->src_nid, dist) -
task_weight(cur, env->dst_nid, dist);
}
if (maymove && moveimp > imp && moveimp > env->best_imp) {
imp = moveimp;
cur = NULL;
goto assign;
}
/*
* If the NUMA importance is less than SMALLIMP,
* task migration might only result in ping pong
* of tasks and also hurt performance due to cache
* misses.
*/
if (imp < SMALLIMP || imp <= env->best_imp + SMALLIMP / 2)
goto unlock;
- 코드 라인 3~10에서 env->p 태스크의 누마 그룹이 있는 경우 @groupimp, 없는 경우 @taskimp를 imp 및 moveimp에 대입한다.
- 코드 라인 13~14에서 누마 마이그레이션이 진행 중인 경우 함수를 빠져나간다.
- 코드 라인 17~19에서 dst 런큐에서 동작 중인 태스크가 이미 종료 중이거나 idle 상태인 경우 cur에 null을 대입한다.
- 코드 라인 25~26에서 cur가 env->p와 동일한 경우 unlock 레이블로 이동한다.
- 코드 라인 28~33에서 cur가 없는 경우 @maymove 이면서 moveimp 가 env->best_imp 이상인 경우 assign 레이블로 이동하고, 그렇지 않은 경우 unlock 레이블로 이동한다.
- 코드 라인 43~44에서 src cpu가 cur 태스크가 허용하는 cpu에 없는 경우 unlock 레이블로 이동한다.
- 코드 라인 50~71에서 cur 태스크와 env->p가 같은 누마 그룹에 있을 때와 그렇지 않을 때의 imp 값은 다음과 같이 산출한다.
- 같은 경우 @task_imp + 소스 노드에서의 cur 태스크 weight – 데스트 노드에서의 cur 태스크 비중을 구한 후 1/16 만큼 감소시킨다.
- 다른 경우 소스 노드에서의 cur 그룹 weight – 데스트 노드에서의 cur 그룹 weight을 imp에 추가한다. 만일 하나라도 그룹이 없으면 소스 노드에서의 cur 태스크 weight – 데스트 노드에서의 cur 태스크 weight을 imp에 추가한다.
- 코드 라인 73~77에서 @maymove이고 moveimp가 imp나 env->best_imp보다 더 큰 경우 imp에 moveimp를 대입하고, cur에 null을 대입한 후 assign 레이블로 이동한다.
- 코드 라인 85~86에서 마이그레이션으로 서로 ping-pong 하지 못하게 누마 importance 값이 너무 작은 경우 unlock 레이블로 이동한다.
kernel/sched/fair.c -2/2-
/*
* In the overloaded case, try and keep the load balanced.
*/
load = task_h_load(env->p) - task_h_load(cur);
if (!load)
goto assign;
dst_load = env->dst_stats.load + load;
src_load = env->src_stats.load - load;
if (load_too_imbalanced(src_load, dst_load, env))
goto unlock;
assign:
/*
* One idle CPU per node is evaluated for a task numa move.
* Call select_idle_sibling to maybe find a better one.
*/
if (!cur) {
/*
* select_idle_siblings() uses an per-CPU cpumask that
* can be used from IRQ context.
*/
local_irq_disable();
env->dst_cpu = select_idle_sibling(env->p, env->src_cpu,
env->dst_cpu);
local_irq_enable();
}
task_numa_assign(env, cur, imp);
unlock:
rcu_read_unlock();
}
- 코드 라인 4~6에서 env->p 태스크의 로드에서 cur 태스크의 로드를 뺀 로드를 load에 대입하고, 이 값이 0인 경우 assign 레이블로 이동한다.
- 코드 라인 8~12에서 태스크를 마이그레이션 후에 로드가 더 불균형해지는 경우 마이그레이션을 포기하도록 unlock 레이블로 이동한다.
- 코드 라인 14~28에서 assign: 레이블이다. cur가 없는 경우 env->dst_cpu에 idle cpu를 찾아오되 env->dst_cpu, env->src_cpu 및 캐시 공유 도메인 내 cpu들 순으로 처리한다.
- 코드 라인 30에서 누마 best cpu, task 및 imp를 지정한다.
- 코드 라인 31~32에서 unlock: 레이블이다. rcu read 락을 해제한 후 함수를 빠져나간다.
task_numa_assign()
kernel/sched/fair.c
static void task_numa_assign(struct task_numa_env *env,
struct task_struct *p, long imp)
{
struct rq *rq = cpu_rq(env->dst_cpu);
/* Bail out if run-queue part of active NUMA balance. */
if (xchg(&rq->numa_migrate_on, 1))
return;
/*
* Clear previous best_cpu/rq numa-migrate flag, since task now
* found a better CPU to move/swap.
*/
if (env->best_cpu != -1) {
rq = cpu_rq(env->best_cpu);
WRITE_ONCE(rq->numa_migrate_on, 0);
}
if (env->best_task)
put_task_struct(env->best_task);
if (p)
get_task_struct(p);
env->best_task = p;
env->best_imp = imp;
env->best_cpu = env->dst_cpu;
}
누마 마이그레이션용 best cpu, task 및 imp를 지정한다.
- 코드 라인 4~8에서 dst_cpu가 이미 누마 마이그레이션이 진행 중인 경우 함수를 빠져나간다.
- 코드 라인 14~17에서 best_cpu를 처음 결정하는 경우 누마 마이그레이션 진행중 표시를 제거한다.
- 코드 라인 19~20에서 기존에 설정되었던 best_task의 참조는 1 감소시킨다.
- 코드 라인 21~24에서 태스크 @p를 best_task로 지정한다.
- 코드 라인 25~26에서 @imp를 best_imp로 지정하고, dst_cpu를 best_cpu로 지정한다.
구조체
task_struct 구조체 (NUMA 밸런싱 부분)
include/linux/sched.h
struct task_struct {
...
#ifdef CONFIG_NUMA_BALANCING
int numa_scan_seq;
unsigned int numa_scan_period;
unsigned int numa_scan_period_max;
int numa_preferred_nid;
unsigned long numa_migrate_retry;
/* Migration stamp: */
u64 node_stamp;
u64 last_task_numa_placement;
u64 last_sum_exec_runtime;
struct callback_head numa_work;
/*
* This pointer is only modified for current in syscall and
* pagefault context (and for tasks being destroyed), so it can be read
* from any of the following contexts:
* - RCU read-side critical section
* - current->numa_group from everywhere
* - task's runqueue locked, task not running
*/
struct numa_group __rcu *numa_group;
/*
* numa_faults is an array split into four regions:
* faults_memory, faults_cpu, faults_memory_buffer, faults_cpu_buffer
* in this precise order.
*
* faults_memory: Exponential decaying average of faults on a per-node
* basis. Scheduling placement decisions are made based on these
* counts. The values remain static for the duration of a PTE scan.
* faults_cpu: Track the nodes the process was running on when a NUMA
* hinting fault was incurred.
* faults_memory_buffer and faults_cpu_buffer: Record faults per node
* during the current scan window. When the scan completes, the counts
* in faults_memory and faults_cpu decay and these values are copied.
*/
unsigned long *numa_faults;
unsigned long total_numa_faults;
/*
* numa_faults_locality tracks if faults recorded during the last
* scan window were remote/local or failed to migrate. The task scan
* period is adapted based on the locality of the faults with different
* weights depending on whether they were shared or private faults
*/
unsigned long numa_faults_locality[3];
unsigned long numa_pages_migrated;
#endif /* CONFIG_NUMA_BALANCING */
...
}
- numa_scan_seq
- 누마 스캔 주기마다 증가되는 시퀀스
- numa_scan_period
- 누마 스캔 주기
- numa_scan_period_max
- 누마 스캔 최대 주기
- numa_preferred_nid
- 누마 우선 노드
- numa_migrate_retry
- 누마 migration 재시도 수
- node_stamp
- 다음 누마 스캔 시각이 담긴다.
- last_task_numa_placement
- 누마 placement 지난 갱신 시각
- last_sum_exec_runtime
- 누마 placement용 누적 실행 시간
- numa_work
- 누마 밸런싱 work이 담기는 callback head
- *numa_group
- 누마 그룹 구조체를 가리킨다.
- *numa_faults
- 다음 4 종류의 영역이 있고, 각각 노드별 및 private/shared 별 누마 faults 값이 담긴다. (예: 6 개의노드인 경우 배열은 4 * 6 * 2 = 48개가 할당된다)
- faults_memory
- 메모리 노드에 대한 누마 faults의 exponential decay 된 값이 누적된다.
- faults_cpu
- cpu 노드에 대한 누마 faults의 exponential decay 된 값이 누적된다.
- faults_memory_buffer
- 메모리 노드에 대한 누마 faults가 누적되고, 스캔 윈도우 주기마다 클리어된다.
- faults_cpu_buffer
- cpu 노드에 대한 누마 faults가 누적되고, 스캔 윈도우 주기마다 클리어된다.
- faults_memory
- 다음 4 종류의 영역이 있고, 각각 노드별 및 private/shared 별 누마 faults 값이 담긴다. (예: 6 개의노드인 경우 배열은 4 * 6 * 2 = 48개가 할당된다)
- total_numa_faults
- 누마 faults의 exponential decay 된 값이 누적된다.
- numa_faults_locality[3]
- 다음과 같이 노드 지역성별로 numa faults 값이 담기며, 누마 스캔 주기마다 클리어된다.
- remote
- local
- failed to migrate
- 다음과 같이 노드 지역성별로 numa faults 값이 담기며, 누마 스캔 주기마다 클리어된다.
- numa_pages_migrated
- 누마 마이그레이션 페이지 수
numa_group 구조체
kernel/sched/fair.c
struct numa_group {
refcount_t refcount;
spinlock_t lock; /* nr_tasks, tasks */
int nr_tasks;
pid_t gid;
int active_nodes;
struct rcu_head rcu;
unsigned long total_faults;
unsigned long max_faults_cpu;
/*
* Faults_cpu is used to decide whether memory should move
* towards the CPU. As a consequence, these stats are weighted
* more by CPU use than by memory faults.
*/
unsigned long *faults_cpu;
unsigned long faults[0];
};
- refcount
- 태스크들의 누마 그룹에 대한 참조 카운터
- nr_tasks
- 이 누마 그룹에 조인한 태스크 수
- gid
- 그룹 id
- active_nodes
- 페이지가 일정 부분 액세스를 하는 노드 수로 노드들 중 faults 수가 max_faults의 1/3 이상인 노드 수이다.
- rcu
- total_faults
- 이 그룹의 전체 numa faults
- 태스크의 numa 밸런싱 참여 시 추가되고, 태스크가 종료될 때 태스크의 누마 faults가 감소한다.
- max_faults_cpu
- *faults_cpu
- faults[]
- 누마 faults로 태스크에 저장되는 것과 동일하게 4 종류의 영역에 각각 노드별 및 private/shared 별로 numa faults 값이 담긴다.
numa_stats 구조체
kernel/sched/fair.c
/* Cached statistics for all CPUs within a node */
struct numa_stats {
unsigned long load;
/* Total compute capacity of CPUs on a node */
unsigned long compute_capacity;
};
- load
- 노드 내 cpu들의 러너블 로드 합계
- compute_capacity
- 노드 내 cpu들의 scaled cpu capactiy 합계
task_numa_env 구조체
kernel/sched/fair.c
struct task_numa_env {
struct task_struct *p;
int src_cpu, src_nid;
int dst_cpu, dst_nid;
struct numa_stats src_stats, dst_stats;
int imbalance_pct;
int dist;
struct task_struct *best_task;
long best_imp;
int best_cpu;
};
- *p
- 마이그레이션 할 태스크
- src_cpu
- 소스 cpu
- src_nid
- 소느 노드 id
- dst_cpu
- 데스트(목적지) cpu
- dst_nid
- 데스트(목적지) 노드 id
- src_stats
- 소스 노드의 러너블 로드와 scaled cpu capacity가 담긴다.
- dst_stats
- 데스트(목적지) 노드의 러너블 로드와 scaled cpu capacity가 담긴다.
- imbalance_pct
- 불균형 스레졸드 값(100 이상 = 100% 이상)
- dist
- 노드 distance
- *best_task
- swap할 best 태스크
- best_imp
- 중요(importance)도
- best_cpu
- 마이그레이션할 최적의 cpu
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- Automatic NUMA Balancing | Red Hat & HP – 다운로드 pdf