<kernel v5.4>
스케줄러 코어
스케줄러 코어와 각각의 스케줄러들은 다음과 같이 구성되어 있다.
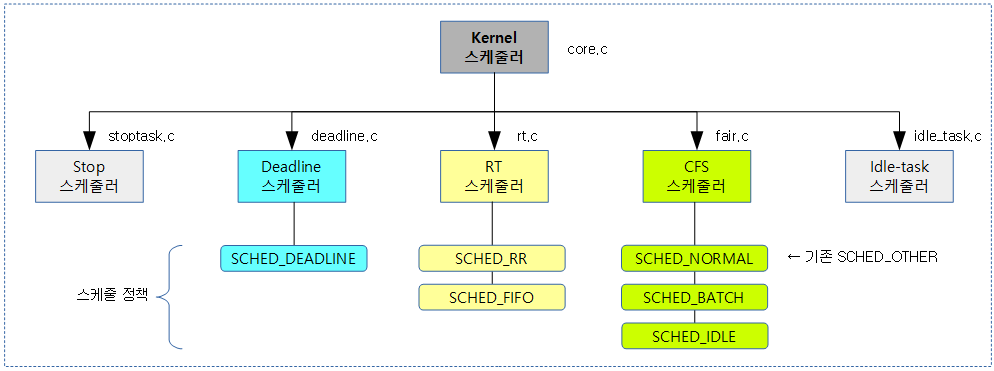
스케줄러 Operations
스케줄러 코어는 여러 개의 스케줄러들과 연동되어 사용하는데, 직접 각 스케줄러의 함수를 호출하지 않고, 다음 sched_class 구조체를 통해 현재 5가지의 스케줄러와 인터페이스하여 사용하고 있다.
각 스케줄러의 operation을 담당하는 후크 함수들은 다음과 같이 구성되어 있다.

sched_class 구조체
kernel/sched/sched.h
struct sched_class {
const struct sched_class *next;
#ifdef CONFIG_UCLAMP_TASK
int uclamp_enabled;
#endif
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task)(struct rq *rq, struct task_struct *p, bool preempt);
void (*check_preempt_curr)(struct rq *rq, struct task_struct *p, int flags);
/*
* Both @prev and @rf are optional and may be NULL, in which case the
* caller must already have invoked put_prev_task(rq, prev, rf).
*
* Otherwise it is the responsibility of the pick_next_task() to call
* put_prev_task() on the @prev task or something equivalent, IFF it
* returns a next task.
*
* In that case (@rf != NULL) it may return RETRY_TASK when it finds a
* higher prio class has runnable tasks.
*/
struct task_struct * (*pick_next_task)(struct rq *rq,
struct task_struct *prev,
struct rq_flags *rf);
void (*put_prev_task)(struct rq *rq, struct task_struct *p);
void (*set_next_task)(struct rq *rq, struct task_struct *p);
#ifdef CONFIG_SMP
int (*balance)(struct rq *rq, struct task_struct *prev, struct rq_flags *rf);
int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags);
void (*migrate_task_rq)(struct task_struct *p, int new_cpu);
void (*task_woken)(struct rq *this_rq, struct task_struct *task);
void (*set_cpus_allowed)(struct task_struct *p,
const struct cpumask *newmask);
void (*rq_online)(struct rq *rq);
void (*rq_offline)(struct rq *rq);
#endif
void (*task_tick)(struct rq *rq, struct task_struct *p, int queued);
void (*task_fork)(struct task_struct *p);
void (*task_dead)(struct task_struct *p);
/*
* The switched_from() call is allowed to drop rq->lock, therefore we
* cannot assume the switched_from/switched_to pair is serliazed by
* rq->lock. They are however serialized by p->pi_lock.
*/
void (*switched_from)(struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio);
unsigned int (*get_rr_interval)(struct rq *rq,
struct task_struct *task);
void (*update_curr)(struct rq *rq);
#define TASK_SET_GROUP 0
#define TASK_MOVE_GROUP 1
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_change_group)(struct task_struct *p, int type);
#endif
};
- (*next)
- 현재 스케줄러에서 더 이상 진행할 수 없을 때, 다음으로 진행할 스케줄링 클래스를 지정한다.
- 각각의 스케줄러들은 다음 순서대로 지정된다.
- stop -> deadline -> rt -> cfs -> stop
- 각각의 스케줄러들은 다음 순서대로 지정된다.
- 현재 스케줄러에서 더 이상 진행할 수 없을 때, 다음으로 진행할 스케줄링 클래스를 지정한다.
- uclamp_enabled
- uclamp min, max 사용 여부를 지정한다.
- (*enqueue_task)
- 태스크가 실행 가능한(러너블) 상태가 되어 스케줄러가 관리하는 런큐에 엔큐할 때 호출된다.
- (*dequeue_task)
- 태스크가 실행 가능하지 않은 상태가 되어 스케줄러가 관리하는 런큐로부터 디큐할 때 호출된다.
- (*yield_task)
- yield() 함수를 실행하여 현재 태스크를 스케줄 아웃하고, 다음 태스크에 양보할 때 호출된다.
- (*yield_to_task)
- 이 스케줄러의 지정한 태스크로 양보할 때 호출된다.
- (*check_preempt_curr)
- 이 스케줄러의 현재 동작 중인 태스크를 선점할 수 있는지 체크하여 선점 필요 시 리스케줄링 요청 표식을 한다.
- (*pick_next_task)
- 해당 스케줄러의 내부 자료 구조로부터 실행할 다음 태스크를 선택할 때 호출된다.
- (*put_prev_task)
- 실행중인 태스크를 다시 해당 스케줄러의 내부 자료 구조에 넣을 때 호출된다.
- (*set_next_task)
- 태스크의 스케줄링 클래스나 태스크 그룹을 바꿀때 호출된다.
- (*balance)
- 로드 밸런싱 필요 여부를 확인하기 위해 호출된다.
- 현재 스케줄러를 포함하여 상위 스케줄러에서 동작 중인 태스크가 있는 경우 1을 반환한다.
- (*select_task_rq)
- 태스크가 실행될 cpu의 런큐를 선택할 때 호출된다.
- (*migrate_task_rq)
- 태스크를 마이그레이션 할 때 호출된다.
- (*task_woken)
- 태스크가 깨어날 때 사용할 cpu의 런큐를 지정할 때 호출된다.
- (*set_cpus_allowed)
- 태스크에 사용될 cpu 마스크를 지정할 때 호출된다.
- (*rq_online)
- 런큐를 온라인 상태로 변경할 때 호출된다.
- (*rq_offline)
- 런큐를 오프라인 상태로 변경할 떄 호출된다.
- (*task_tick)
- 스케줄 틱이 발생될 때 호출된다.
- hrtick이 사용될 때 queued=1로 호출된다.
- 일반 고정 스케줄틱이 사용될 때 queued=0으로 호출된다.
- 스케줄 틱이 발생될 때 호출된다.
- (*task_fork)
- fork한 태스크를 스케줄러가 관리하는 런큐에 엔큐할 떄 호출된다.
- (*task_dead)
- 지정한 태스크를 dead 처리하기 위해 런큐에서 디큐할 때 호출된다.
- (*switched_from)
- 스케줄러 스위칭 전에 기존 실행 중인 스케줄러에서 동작했었던 태스크를 detach할 때 호출된다.
- (*switched_to)
- 스케줄러 스위칭 후에 새로 실행 할 스케줄러에 태스크를 attach할 때 호출된다.
- (*prio_changed)
- 태스크의 우선 순위를 변경할 때 호출된다.
- (*get_rr_interval)
- 라운드 로빈 인터벌 타임 값을 알아올 때 호출된다.
- (*update_curr)
- 현재 실행 중인 태스크의 런타임을 갱신할 때 호출된다.
- (*task_change_group)
- 태스크의 태스크 그룹(cgroup)을 변경할 때 호출된다.
- type이 0일 때 태스크 그룹을 설정한다.
- type이 1일 때 태스크 그룹을 이동한다.
- 태스크의 태스크 그룹(cgroup)을 변경할 때 호출된다.
우선 순위
우선 순위는 다음과 같은 값들을 사용하며, 숫자의 크기와 우선 순위가 각각 다름에 주의해야 한다.
- NICE
- -20(highest) ~ 19(lowest)까지 cfs 태스크에서 사용한다.
- PRIORITY (유저 우선 순위)
- 0(lowest) ~ 139(highest)까지 rt 및 cfs 태스크에서 사용한다.
- RT PRIORITY (유저 rt 우선 순위)
- 1(lowest) ~ 99(highest)까지 rt 태스크에서 사용한다.
- 다음에서 사용한다.
- p->rt_priority
- 커널 우선 순위
- 0(highest) ~ 139(lowest)까지 rt 및 cfs 태스크에서 사용한다.
- 다음에서 사용한다.
- p->static_prio
- p->normal_prio
- p->prio
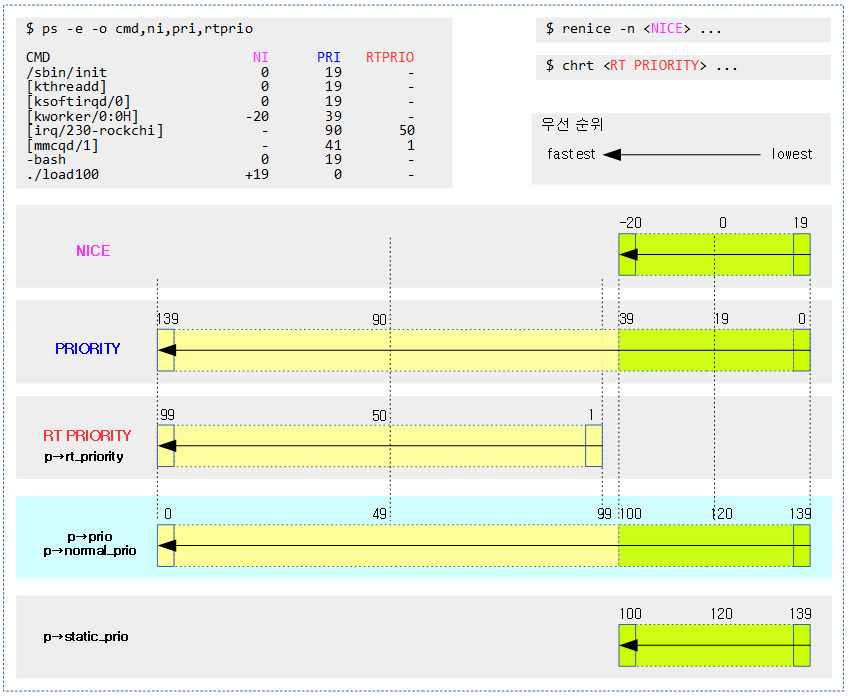
다음 ps 툴에서 보여주는 값을 확인한다.
- PRI
- = 139 – p->prio
- RTPRIO
- = p->rt_priority
- = 99 – p->normal_prio
$ ps -e -o cmd,ni, pri,rtprio CMD NI PRI RTPRIO /sbin/init 0 19 - [kthreadd] 0 19 - [ksoftirqd/0] 0 19 - [kworker/0:0H] -20 39 - [rcu_sched] 0 19 - [rcu_bh] 0 19 - [migration/0] - 139 99 <- p->prio = 0(highest) [watchdog/0] - 139 99 [cfinteractive] - 139 99 [rpciod] -20 39 - [kvm_arch_timer] -20 39 - [kvm-irqfd-clean] -20 39 - [kswapd0] 0 19 - [vmstat] -20 39 - [irq/230-rockchi] - 90 50 [vcodec] -20 39 - [bioset] -20 39 - [nvme] -20 39 - [spi32766] 0 19 - [fusb302_wq] -20 39 - [irq/26-mmc1] - 90 50 [mmcqd/1] - 41 1 /lib/systemd/systemd-udevd 0 19 - -bash 0 19 - ./load0 -20 39 - ./load100 +19 0 - <- p->prio = 139(lowest)
NICE 우선 순위 변경
다음과 같이 3가지 구성에 대해 nice 우선 순위를 변경할 수 있다.
- 태스크(process)
- 태스크 그룹(process group)
- 유저
renice
다음은 renice 유틸리티의 사용방법이다.
$ renice Usage: renice [-n] <priority> [-p|--pid] <pid>... renice [-n] <priority> -g|--pgrp <pgid>... renice [-n] <priority> -u|--user <user>... Alter the priority of running processes. Options: -n, --priority <num> specify the nice increment value -p, --pid <id> interpret argument as process ID (default) -g, --pgrp <id> interpret argument as process group ID -u, --user <name>|<id> interpret argument as username or user ID -h, --help display this help and exit -V, --version output version information and exit For more details see renice(1).
다음 그림은 NICE 우선 순위를 변경할 때의 함수 호출 관계를 보여준다.

우선 순위 관리
다음과 같이 태스크에는 우선 순위 관련하여 4개의 멤버 변수로 관리한다. RT 태스크의 경우 러닝 중에 PI(Priority Inversion) Problem을 회피하기 위해 PI 태스크의 우선 순위만큼 부스트하여 우선 순위가 상승하였다가 다시 돌아온다. 이렇게 운영 중에 우선 순위가 변할 수 있으므로 상속되는 태스크에 부스트된 우선 순위를 상속하지 않게 하기 위해 p->normal_prio를 사용하여 관리한다. 일반 cfs 태스크로만 운영하는 경우 아래의 p->static_prio, p->prio 및 p->normal_prio는 동일한 값을 유지한다.
p->static_prio
- 유저가 nice 값을 사용하여 cfs 태스크에 static하게 지정한 커널 우선 순위이다.
- cfs 태스크: 100~139
- 지정 전의 태스크들은 부모 태스크로부터 상속된다.
- 참고로 kthread_create_worker() API를 사용하여 만드는 태스크들(dl, rt, cfs)은 디폴트 값으로 nice 0를 사용하는 cfs 스케줄러를 사용하는 kthreadd(pid=2)를 통해 만들어진다. 따라서 nice 0에 대응하는 priority 120 값을 상속받는다.
p->prio
- 현재 운영되는 커널 우선 순위로 rt 및 cfs 태스크를 위해 0~139까지 사용된다.
- rt 태스크의 경우 PI boost로 인해 러닝 중에 커널 우선 순위가 상승할 수도 있다.
- fork 된 태스크는 부모 태스크로부터 우선 순위를 상속받지만, RT 태스크의 경우엔 부스트된 부모 태스크의 우선 순위를 상속 받지 않기 위해 부모 태스크의 normal_prio 값을 상속받는다.
p->normal_prio
- 커널 우선 순위이다.
- deadline 태스크의 경우 -1
- rt 태스크의 경우 0~99
- cfs 태스크의 경우 100~139
- 처음 부모 태스크로부터 상속된다.
- 부스트된 우선 순위가 아닌 원래 설정된 priority로 되돌아올 때 사용할 우선 순위로 시스템이 운영 중 스스로 값을 바꾸지 않는다.
- rt -> cfs 스케줄러로 변경되는 경우 cfs 태스크에서 사용하는 p->static_prio 값을 가져와 사용한다. (디폴트: 120)
- cfs -> rt 스케줄러로 변경하는 경우 아래 p->rt_priority 값도 전달받는다. 이 값을 변환(99 – p->rt_priority)하여 사용한다.
p->rt_priority
- 유저가 rt 태스크에 static하게 지정한 rt 유저 우선 순위이다.
- rt 유저 우선 순위 1~99 값은 커널 우선 순위와 다르게 숫자가 높을 수록 우선 순위가 높아지도록 사용된다.
- 유저가 chrt 유틸리티 등으로 지정한 유저 rt 우선 순위 값은 sched_setscheduler() syscall 이후 커널의 sys_sched_setscheduler() 함수를 통해 p->rt_priority에 그 값 그대로 설정되고, p->normal_prio에는 98 ~ 0 값으로 변환되어 사용된다.
CFS 태스크의 우선 순위 변경
유저가 nice 및 renice 유틸리티 등으로 지정한 nice 값을 setpriority() syscall 이후 커널의 set_user_nice() 함수를 통해 cfs 태스크의 중간 우선 순위 값인 120을 더해 p->static_prio에 저장한다.
- -20 ~ 19 범위의 nice 우선 순위는 커널 우선 순위 100 ~ 139로 변경하여 다음 멤버 변수에 저장한다.
- p->static_prio
- p->normal_prio
- p->prio
다음은 태스크 하나의 우선 순위를 변경하는 예를 보여준다.
$ ps PID TTY TIME CMD 11636 pts/1 00:00:00 bash 11675 pts/1 00:40:25 load100 11740 pts/1 00:00:00 ps $ renice -n -2 -p 11675 11675 (process ID) old priority 0, new priority -2
다음은 유저에 해당하는 모든 태스크의 우선 순위를 변경하는 예를 보여준다.
$ who root ttyFIQ0 2020-08-24 14:39 linaro tty7 2020-08-24 14:39 (:0) jake pts/0 2020-09-14 10:31 (172.17.1.111) $ renice -n -3 -u jake 1000 (user ID) old priority 0, new priority -3
RT 태스크의 우선 순위 변경
rt 태스크의 경우 cfs 태스크 처럼 nice나 renice 툴로 간단히 우선 순위를 바꾸는 경로를 사용하지 않고, 스케줄러를 지정하는 sched_setscheduler() API를 통해 우선 순위도 바꿀 수 있다.
유저가 chrt 유틸리티로 지정한 rt 유저 우선 순위 값(1~99)을 sched_setscheduler() syscall 이후 커널의 sched_setscheduler() 함수를 통해 다음의 멤버 변수에 설정한다.
- p->rt_priority
- 전달 받은 값 그대로 설정한다.
- p->normal_prio
- 전달 받은 값을 변환(99 – p->rt_priority)하여 설정한다.
- p->prio
- 전달 받은 값을 변환(99 – p->rt_priority)하여 설정한다.
다음은 rt 태스크의 우선 순위를 변경하는 방법을 보여준다.
$ chrt Show or change the real-time scheduling attributes of a process. Set policy: chrt [options] <priority> <command> [<arg>...] chrt [options] --pid <priority> <pid> Get policy: chrt [options] -p <pid> Policy options: -b, --batch set policy to SCHED_BATCH -d, --deadline set policy to SCHED_DEADLINE -f, --fifo set policy to SCHED_FIFO -i, --idle set policy to SCHED_IDLE -o, --other set policy to SCHED_OTHER -r, --rr set policy to SCHED_RR (default) Scheduling options: -R, --reset-on-fork set SCHED_RESET_ON_FORK for FIFO or RR -T, --sched-runtime <ns> runtime parameter for DEADLINE -P, --sched-period <ns> period parameter for DEADLINE -D, --sched-deadline <ns> deadline parameter for DEADLINE Other options: -a, --all-tasks operate on all the tasks (threads) for a given pid -m, --max show min and max valid priorities -p, --pid operate on existing given pid -v, --verbose display status information -h, --help display this help and exit -V, --version output version information and exit For more details see chrt(1). $ ps -e -o pid,cmd,nice,pri,rtprio | grep watchdog 10 [watchdog/0] - 139 99 11 [watchdog/1] - 139 99 16 [watchdog/2] - 139 99 21 [watchdog/3] - 139 99 26 [watchdog/4] - 139 99 31 [watchdog/5] - 139 99 184 [dhd_watchdog_th] 0 19 - 1799 grep watchdog 0 19 - $ chrt -f --pid 98 11 <- 유저 rt 우선 순위를 99에서 98로 1단계 내림 $ ps -e -o pid,cmd,nice,pri,rtprio | grep watchdog 10 [watchdog/0] - 139 99 11 [watchdog/1] - 138 98 16 [watchdog/2] - 139 99 21 [watchdog/3] - 139 99 26 [watchdog/4] - 139 99 31 [watchdog/5] - 139 99 184 [dhd_watchdog_th] 0 19 - 1803 grep watchdog 0 19 -
다음 그림은 policy 및 rt 유저 우선 순위를 지정하여 스케줄러 속성을 지정하는 과정을 보여준다. 이 과정에서 rt 태스크의 우선 순위를 변경할 수 있다.
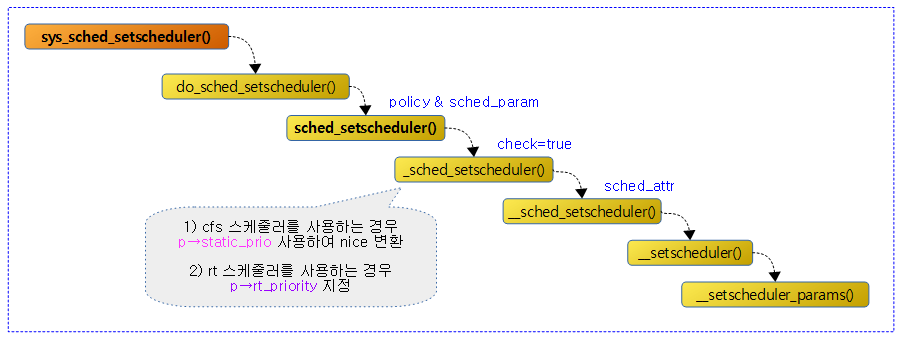
RT 스레드 생성 및 우선 순위 지정
다음 코드 예는 SCHED_FIFO policy와 유저 rt 우선 순위 99(highest)로 RT 스레드를 생성하는 예를 보여준다.
static struct kthread_worker *foo_kworker;
int foo_thread_init(void)
{
int err;
struct sched_param param = { .sched_priority = MAX_RT_PRIO - 1,};
foo_kworker = kthread_create_worker(0, "foo");
if (IS_ERR(foo_kworker)) {
pr_err("Failed to create foo kworker\n");
return PTR_ERR(foo_kworker);
}
sched_setscheduler(foo_kworker->task, SCHED_FIFO, ¶m);
}
UCLAMP
특정 프로세스의 유틸 로드 평균을 uclamp min ~ max 범위내에서만 산출되도록 제한한다. 즉 실제보다 더 크게 하거나 작게 제한할 수 있다.
- 디폴트 값은 제한하지 않도록 min 값은 0이고, max 값은 100이다. (0~100%)
- /sys/fs/cgroup/cpu/XXX/cpu.uclamp.{min,max}
- 0 ~ max
- /proc/sys/kernel/sched_util_clamp_util_{min,max}
- 1024
- /sys/fs/cgroup/cpu/XXX/cpu.uclamp.{min,max}
- 서버나 데스크탑 보다는 절전을 위한 안드로이드 등의 모바일 시스템에서 활용하기 좋다.
- 예) 만일 중요한 GUI 등의 forground 프로세스를 항상 고성능 cpu에서 동작하게 하려면 min 값을 높은 값으로 지정한다.
- 예) 저성능 cpu에서 돌려도 될만한 백그라운드 프로세스에 대해서는 max 값을 낮은 값으로 지정한다.
- 커널 옵션
- CONFIG_UCLAMP_TASK=y
- CONFIG_UCLAMP_TASK_CGROUP=y
- 참고:
- UtilClamp usage on Android | Android – 다운로드 pdf
- Scheduler utilization clamping (2018) | LWN.net
- sched/uclamp: Add CPU’s clamp buckets refcounting (2019, v5.3-rc1)
- sched/uclamp: Add system default clamps (2019, v5.3-rc1)
- sched/uclamp: Add a new sysctl to control RT default boost value (2020, v5.9-rc1)
스케줄 틱
다음과 같이 커널에서 사용하는 두 개의 틱의 호출 과정을 알아본다.
- 정규 스케줄 틱
- HR 틱
정규 스케줄 틱
scheduler_tick()
kernel/sched/core.c
/* * This function gets called by the timer code, with HZ frequency. * We call it with interrupts disabled. */
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
struct rq_flags rf;
sched_clock_tick();
rq_lock(rq, &rf);
update_rq_clock(rq);
curr->sched_class->task_tick(rq, curr, 0);
calc_global_load_tick(rq);
psi_task_tick(rq);
rq_unlock(rq, &rf);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
}
스케줄 틱마다 런타임 처리 및 로드 평균 산출 등의 처리를 수행하고, 로드 밸런스 주기가 된 경우 SCHED softirq를 호출한다.
- 코드 라인 3~5에서 현재 cpu의 런큐 및 현재 태스크를 알아온다.
- 코드 라인 8에서 x86 및 ia64 아키텍처에 등에서 사용하는 unstable 클럭을 사용하는 중이면 per-cpu sched_clock_data 값을 현재 시각으로 갱신한다.
- 코드 라인 10에서 런큐 정보를 수정하기 위해 런큐 락을 획득한다.
- 코드 라인 12에서 런큐 클럭 값을 갱신한다.
- rq->clock, rq->clock_task, rq->clock_pelt 클럭등을 갱신한다.
- 코드 라인 13에서 현재 태스크의 스케줄링 클래스에 등록된 (*task_tick) 콜백 함수를 호출한다.
- task_tick_fair(), task_tick_rt(), task_tick_dl()
- 코드 라인 14에서 글로벌 로드를 갱신한다.
- 코드 라인 15에서 psi 요청 태스크가 등록된 psi 그룹의 stat 을 매 틱마다 갱신한다.
- 코드 라인 17에서 런큐 락을 해제한다.
- 코드 라인 22에서 현재 cpu의 런큐가 idle 상태인지 확인하여 rq->idle_balance에 대입한다.
- 코드 라인 23에서 매 틱마다 로드 밸런스를 할 타이밍인지 체크하여 수행하게 한다.
hrtick 호출
hrtick()
kernel/sched/core.c
/* * High-resolution timer tick. * Runs from hardirq context with interrupts disabled. */
static enum hrtimer_restart hrtick(struct hrtimer *timer)
{
struct rq *rq = container_of(timer, struct rq, hrtick_timer);
WARN_ON_ONCE(cpu_of(rq) != smp_processor_id());
raw_spin_lock(&rq->lock);
update_rq_clock(rq);
rq->curr->sched_class->task_tick(rq, rq->curr, 1);
raw_spin_unlock(&rq->lock);
return HRTIMER_NORESTART;
}
런큐 클럭을 갱신하고 현재 태스크에 동작 중인 스케줄러의 (*task_tick) 후크 함수를 호출한다.
- 각각의 스케줄러에서 사용되는 함수는 다음과 같다.
- task_tick_rt()
- task_tick_dl()
- task_tick_fair()
- task_tick_idle()
- task_tick_stop()
hrtick 만료 시각 설정
hrtick_start()
kernel/sched/core.c
/* * Called to set the hrtick timer state. * * called with rq->lock held and irqs disabled */
void hrtick_start(struct rq *rq, u64 delay)
{
struct hrtimer *timer = &rq->hrtick_timer;
ktime_t time;
s64 delta;
/*
* Don't schedule slices shorter than 10000ns, that just
* doesn't make sense and can cause timer DoS.
*/
delta = max_t(s64, delay, 10000LL);
time = ktime_add_ns(timer->base->get_time(), delta);
hrtimer_set_expires(timer, time);
if (rq == this_rq()) {
__hrtick_restart(rq);
} else if (!rq->hrtick_csd_pending) {
smp_call_function_single_async(cpu_of(rq), &rq->hrtick_csd);
rq->hrtick_csd_pending = 1;
}
}
delta 만료 시간으로 런큐의 hrtick 타이머를 가동시킨다. 런큐가 현재 cpu인 경우 hrtimer를 곧바로 설정하고 그렇지 않은 경우 IPI call을 통해 hrtick에 대한 hrtimer를 설정한다.
- 코드 라인 11~12에서 요청한 delta 값이 10000ns(10us) 보다 작지 않도록 교정하고 현재 시각에 더해 만료 시각 time을 산출한다.
- 코드 라인 14에서 hrtimer에 만료 시각 time을 설정한다.
- 코드 라인 16~17에서 요청 런큐가 현재 cpu에서 동작중인 경우 곧바로 hrtick에 대한 hrtimer를 가동시킨다.
- 만료 시간이 되면 init_rq_hrtick()에서 초기화 설정해둔 hrtick() 함수가 호출된다.
- 코드 라인 18~21에서 런큐에서 hrtick_csd_pending 상태가 아니면 hrtick에 대한 IPI 호출을 수행하고 런큐의 hrtick_csd_pending을 1로 설정한다.
- init_rq_hrtick()에서 초기화 설정해둔 __hrtick_start() 함수가 IPI 호출 시 동작된다.
hrtick IPI 호출
__hrtick_start()
kernel/sched/core.c
/* * called from hardirq (IPI) context */
static void __hrtick_start(void *arg)
{
struct rq *rq = arg;
raw_spin_lock(&rq->lock);
__hrtick_restart(rq);
rq->hrtick_csd_pending = 0;
raw_spin_unlock(&rq->lock);
}
다른 cpu로부터 IPI 호출을 받아 동작되는 이 함수에서는 런큐의 hrtick을 리프로그램한다.
- 코드 라인 6에서 런큐의 hrtick을 리프로그램한다.
- 코드 라인 7에서 런큐의 hrtick_csd_pending에 0을 대입하여 hrtick에 대한 call single data IPI 가 처리되었음을 알린다.
태스크 Fork
sched_fork()
kernel/sched/core.c
/* * fork()/clone()-time setup: */
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
unsigned long flags;
__sched_fork(clone_flags, p);
/*
* We mark the process as NEW here. This guarantees that
* nobody will actually run it, and a signal or other external
* event cannot wake it up and insert it on the runqueue either.
*/
p->state = TASK_NEW;
/*
* Make sure we do not leak PI boosting priority to the child.
*/
p->prio = current->normal_prio;
uclamp_fork(p);
/*
* Revert to default priority/policy on fork if requested.
*/
if (unlikely(p->sched_reset_on_fork)) {
if (task_has_dl_policy(p) || task_has_rt_policy(p)) {
p->policy = SCHED_NORMAL;
p->static_prio = NICE_TO_PRIO(0);
p->rt_priority = 0;
} else if (PRIO_TO_NICE(p->static_prio) < 0)
p->static_prio = NICE_TO_PRIO(0);
p->prio = p->normal_prio = __normal_prio(p);
set_load_weight(p, false);
/*
* We don't need the reset flag anymore after the fork. It has
* fulfilled its duty:
*/
p->sched_reset_on_fork = 0;
}
if (dl_prio(p->prio))
return -EAGAIN;
else if (rt_prio(p->prio))
p->sched_class = &rt_sched_class;
else
p->sched_class = &fair_sched_class;
init_entity_runnable_average(&p->se);
/*
* The child is not yet in the pid-hash so no cgroup attach races,
* and the cgroup is pinned to this child due to cgroup_fork()
* is ran before sched_fork().
*
* Silence PROVE_RCU.
*/
raw_spin_lock_irqsave(&p->pi_lock, flags);
/*
* We're setting the CPU for the first time, we don't migrate,
* so use __set_task_cpu().
*/
__set_task_cpu(p, smp_processor_id());
if (p->sched_class->task_fork)
p->sched_class->task_fork(p);
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
#ifdef CONFIG_SCHED_INFO
if (likely(sched_info_on()))
memset(&p->sched_info, 0, sizeof(p->sched_info));
#endif
#if defined(CONFIG_SMP)
p->on_cpu = 0;
#endif
init_task_preempt_count(p);
#ifdef CONFIG_SMP
plist_node_init(&p->pushable_tasks, MAX_PRIO);
RB_CLEAR_NODE(&p->pushable_dl_tasks);
#endif
return 0;
}
- 코드 라인 5에서 fork된 태스크의 cfs, dl 및 rt 스케줄링 엔티티의 멤버 값들과 numa 밸런싱 관련 값들을 초기화한다.
- 코드 라인 11에서 처음 태스크가 fork될 때 TASK_NEW 상태로 시작한다.
- 코드 라인 16에서 PI(Priority Inversion) 문제를 회피하기 위해 부모 태스크가 boosting 상태의 우선 순위로 변경되어 운영하고 있는 경우가 있으므로, 부스팅 되기 직전에 원래 사용하던 우선 순위를 사용해야 한다.
- 코드 라인 18에서 fork된 태스크의 uclamp 설정이 동작되지 않게 한다. 만일 fork된 태스크의 스케줄러 설정을 reset 요청한 경우 uclamp 값을 min=0, max=100으로 초기화한다. 단 rt 태스크의 경우 min 값을 100으로 설정하여 항상 부스팅한다.
- 코드 라인 23~39에서 fork된 태스크의 스케줄러 설정을 reset 요청한 경우에 대해 부모의 priority/policy를 사용하지 않고, 디폴트 priority/policy 값을 사용하게 한다.
- 코드 라인 41~42에서 dl 태스크의 경우 -EAGAIN 값을 반환한다.
- 코드 라인 43~46에서 태스크가 사용할 스케줄러(rt, cfs)를 지정한다.
- 태스크에 설정된 prio 값에 따라 rt 또는 cfs 스케줄러를 지정한다.
- 코드 라인 48에서 엔티티의 로드 및 러너블 로드 평균을 설정된 가중치(scale_load_down(load.weight))값으로 초기화한다.
- 코드 라인 57~65에서 태스크에 대해 spin 락을 획득한 채로 태스크가 사용할 cpu로 현재 cpu를 지정하고, 스케줄러의 (*task_fork) 후크 함수를 호출하여 런큐에 엔큐하도록 한다.
- 코드 라인 68~69에서 태스크의 sched_info를 초기화한다.
- 코드 라인 72에서 태스크가 러닝(running) 상태에 있음을 표시하는 on_cpu를 0으로 초기화한다.
- 코드 라인 74에서 preempt 카운터를 초기화한다.
- 코드 라인 76에서 rt 태스크의 마이그레이션에 사용할 pushabnle_tasks를 초기화한다.
- 코드 라인 77에서 deadline 태스크의 마이그레이션에 사용할 pushable_dl_tasks를 초기화한다.
- 코드 라인 79에서 정상 값 0을 반환한다.
__sched_fork()
kernel/sched/core.c
/* * Perform scheduler related setup for a newly forked process p. * p is forked by current. * * __sched_fork() is basic setup used by init_idle() too: */
static void __sched_fork(unsigned long clone_flags, struct task_struct *p)
{
p->on_rq = 0;
p->se.on_rq = 0;
p->se.exec_start = 0;
p->se.sum_exec_runtime = 0;
p->se.prev_sum_exec_runtime = 0;
p->se.nr_migrations = 0;
p->se.vruntime = 0;
INIT_LIST_HEAD(&p->se.group_node);
#ifdef CONFIG_FAIR_GROUP_SCHED
p->se.cfs_rq = NULL;
#endif
#ifdef CONFIG_SCHEDSTATS
/* Even if schedstat is disabled, there should not be garbage */
memset(&p->se.statistics, 0, sizeof(p->se.statistics));
#endif
RB_CLEAR_NODE(&p->dl.rb_node);
init_dl_task_timer(&p->dl);
init_dl_inactive_task_timer(&p->dl);
__dl_clear_params(p);
INIT_LIST_HEAD(&p->rt.run_list);
p->rt.timeout = 0;
p->rt.time_slice = sched_rr_timeslice;
p->rt.on_rq = 0;
p->rt.on_list = 0;
#ifdef CONFIG_PREEMPT_NOTIFIERS
INIT_HLIST_HEAD(&p->preempt_notifiers);
#endif
#ifdef CONFIG_COMPACTION
p->capture_control = NULL;
#endif
init_numa_balancing(clone_flags, p);
}
fork된 태스크의 cfs, dl 및 rt 스케줄링 엔티티의 멤버 값들과 numa 밸런싱 관련 값들을 초기화한다. 이 태스크는 현재 태스크에서 새롭게 fork되었으며 다음 두 곳 함수에서 호출되어 사용된다.
- kernel/fork.c – copy_process() 함수 -> sched_fork() 함수
- kernel/sched/core.c – init_idle() 함수
- 코드 라인 3에서 on_rq를 0으로 초기화한다. 태스크가 아직 런큐에 엔큐되지 않았음을 의미한다.
- 코드 라인 5에서 se.on_rq를 0으로 초기화한다. 엔티티가 아직 cfs 런큐에 엔큐되지 않았음을 의미한다.
- 코드 라인 6~11에서 cfs 스케줄링 엔티티 값들을 초기화한다.
- 코드 라인 14에서 그룹 스케줄링을 위해 엔티티가 소속된 cfs 런큐를 null로 초기화한다.
- 코드 라인 19에서 엔티티 통계 값을 초기화한다.
- 코드 라인 22에서 dl 스케줄링 엔티티의 rb_node를 클리어하여 dl 스케줄러의 RB 트리에 태스크가 하나도 대기하지 않음을 의미한다.
- 코드 라인 23~24에서 dl 태스크 타이머와 inactive 태스크 타이머를 초기화한다.
- 코드 라인 25에서 dl 엔티티용 파라미터들을 초기화한다.
- 코드 라인 27에서 rt 엔티티용 run_list를 초기화한다.
- 코드 라인 28~31에서 rt 엔티티용 파라미터들을 초기화한다.
- 코드 라인 34에서 현재 태스크에서 preemption이 발생되면 preempt_notifiers에 등록된 함수들을 동작시키게 하기 위해 preempt_notifiers 리스트를 초기화한다.
- 코드 라인 38에서 compaction에서 사용할 capture_control 구조체 포인터를 null로 초기화한다.
- 코드 라인 40에서 numa 밸런싱에서 사용할 값들을 초기화한다.
init_dl_task_timer()
kernel/sched/deadline.c
void init_dl_task_timer(struct sched_dl_entity *dl_se)
{
struct hrtimer *timer = &dl_se->dl_timer;
hrtimer_init(timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL_HARD);
timer->function = dl_task_timer;
}
dl 엔티티의 태스크 timer를 초기화하고 만료 시 호출될 함수를 지정한다.
init_dl_inactive_task_timer()
kernel/sched/deadline.c
void init_dl_inactive_task_timer(struct sched_dl_entity *dl_se)
{
struct hrtimer *timer = &dl_se->inactive_timer;
hrtimer_init(timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL_HARD);
timer->function = inactive_task_timer;
}
dl 엔티티의 inactive 태스크 timer를 초기화하고 만료 시 호출될 함수를 지정한다.
__dl_clear_params()
kernel/sched/core.c
void __dl_clear_params(struct task_struct *p)
{
struct sched_dl_entity *dl_se = &p->dl;
dl_se->dl_runtime = 0;
dl_se->dl_deadline = 0;
dl_se->dl_period = 0;
dl_se->flags = 0;
dl_se->dl_bw = 0;
dl_se->dl_density = 0;
dl_se->dl_throttled = 0;
dl_se->dl_yielded = 0;
dl_se->dl_non_contending = 0;
dl_se->dl_overrun = 0;
}
dl 엔티티용 파라메터들을 초기화한다.
태스크 깨우기
다음 그림은 wake_up_process() 함수 이후의 호출 관계를 보여준다.
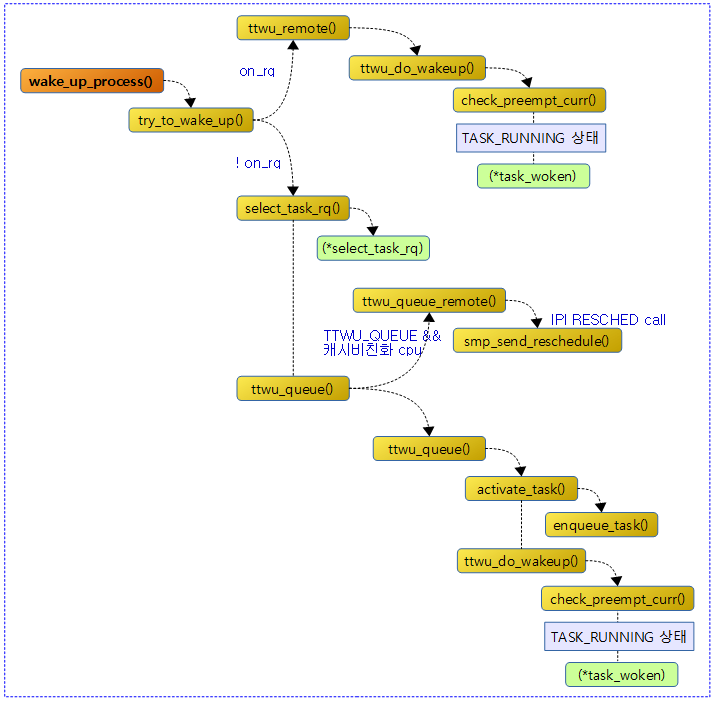
wake_up_process()
kernel/sched/core.c
/** * wake_up_process - Wake up a specific process * @p: The process to be woken up. * * Attempt to wake up the nominated process and move it to the set of runnable * processes. * * Return: 1 if the process was woken up, 0 if it was already running. * * This function executes a full memory barrier before accessing the task state. */
int wake_up_process(struct task_struct *p)
{
WARN_ON(task_is_stopped_or_traced(p));
return try_to_wake_up(p, TASK_NORMAL, 0);
}
EXPORT_SYMBOL(wake_up_process);
요청한 태스크가 TASK_INTERRUPTIBLE 또는 TAKS_UNINTERRUPTIBLE 상태인 경우 깨운다. 깨운 경우 1을 반환하고, 이미 깨어나 동작 중인 경우 0을 반환한다.
- #define TASK_NORMAL (TASK_INTERRUPTIBLE | TAKS_UNINTERRUPTIBLE )
try_to_wake_up()
kernel/sched/core.c – 1/2
/** * try_to_wake_up - wake up a thread * @p: the thread to be awakened * @state: the mask of task states that can be woken * @wake_flags: wake modifier flags (WF_*) * * If (@state & @p->state) @p->state = TASK_RUNNING. * * If the task was not queued/runnable, also place it back on a runqueue. * * Atomic against schedule() which would dequeue a task, also see * set_current_state(). * * This function executes a full memory barrier before accessing the task * state; see set_current_state(). * * Return: %true if @p->state changes (an actual wakeup was done), * %false otherwise. */
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
unsigned long flags;
int cpu, success = 0;
preempt_disable();
if (p == current) {
/*
* We're waking current, this means 'p->on_rq' and 'task_cpu(p)
* == smp_processor_id()'. Together this means we can special
* case the whole 'p->on_rq && ttwu_remote()' case below
* without taking any locks.
*
* In particular:
* - we rely on Program-Order guarantees for all the ordering,
* - we're serialized against set_special_state() by virtue of
* it disabling IRQs (this allows not taking ->pi_lock).
*/
if (!(p->state & state))
goto out;
success = 1;
cpu = task_cpu(p);
trace_sched_waking(p);
p->state = TASK_RUNNING;
trace_sched_wakeup(p);
goto out;
}
/*
* If we are going to wake up a thread waiting for CONDITION we
* need to ensure that CONDITION=1 done by the caller can not be
* reordered with p->state check below. This pairs with mb() in
* set_current_state() the waiting thread does.
*/
raw_spin_lock_irqsave(&p->pi_lock, flags);
smp_mb__after_spinlock();
if (!(p->state & state))
goto unlock;
trace_sched_waking(p);
/* We're going to change ->state: */
success = 1;
cpu = task_cpu(p);
/*
* Ensure we load p->on_rq _after_ p->state, otherwise it would
* be possible to, falsely, observe p->on_rq == 0 and get stuck
* in smp_cond_load_acquire() below.
*
* sched_ttwu_pending() try_to_wake_up()
* STORE p->on_rq = 1 LOAD p->state
* UNLOCK rq->lock
*
* __schedule() (switch to task 'p')
* LOCK rq->lock smp_rmb();
* smp_mb__after_spinlock();
* UNLOCK rq->lock
*
* [task p]
* STORE p->state = UNINTERRUPTIBLE LOAD p->on_rq
*
* Pairs with the LOCK+smp_mb__after_spinlock() on rq->lock in
* __schedule(). See the comment for smp_mb__after_spinlock().
*/
smp_rmb();
if (p->on_rq && ttwu_remote(p, wake_flags))
goto unlock;
태스크의 상태가 요청한 state 마스크에 포함된 경우 태스크를 깨운다. 깨운 경우 1을 반환하고, 이미 깨어나 동작 중인 경우 0을 반환한다.
- 코드 라인 8~29에서 요청한 태스크가 현재 동작 중인 태스크인 경우 다음과 같이 처리한다.
- 러닝 상태가 아닌 경우 이미 꺠어 있는 상태이므로 먼저 러닝 상태로 변경하고 함수를 빠져나가기 위해 success=1로 변경하고 out 레이블로 이동한다.
- 이미 러닝 상태인 경우엔 꺠울 필요 없으므로 그냥 함수를 빠져나가기 위해 out 레이블로 이동한다.
- 코드 라인 37~40에서 스핀락을 획득하고, 다시 상태를 확인해보아 이미 러닝 상태인 경우 깨울 필요 없으므로 unlock 레이블로 이동한다.
- 코드 라인 45에서 잠들어 있는 태스크를 깨울 예정이므로 미리 success=1로 변경해둔다.
- 코드 라인 46에서 슬립전에 동작하던 cpu를 알아온다.
- 코드 라인 68~70에서 태스크가 이미 런큐에 있는 경우 기존 태스크가 슬립해 있었던 cpu의 런큐에서 태스크를 깨우고 러닝 상태로 바꾼다음 out 레이블로 이동한다.
kernel/sched/core.c – 2/2
#ifdef CONFIG_SMP
/*
* Ensure we load p->on_cpu _after_ p->on_rq, otherwise it would be
* possible to, falsely, observe p->on_cpu == 0.
*
* One must be running (->on_cpu == 1) in order to remove oneself
* from the runqueue.
*
* __schedule() (switch to task 'p') try_to_wake_up()
* STORE p->on_cpu = 1 LOAD p->on_rq
* UNLOCK rq->lock
*
* __schedule() (put 'p' to sleep)
* LOCK rq->lock smp_rmb();
* smp_mb__after_spinlock();
* STORE p->on_rq = 0 LOAD p->on_cpu
*
* Pairs with the LOCK+smp_mb__after_spinlock() on rq->lock in
* __schedule(). See the comment for smp_mb__after_spinlock().
*/
smp_rmb();
/*
* If the owning (remote) CPU is still in the middle of schedule() with
* this task as prev, wait until its done referencing the task.
*
* Pairs with the smp_store_release() in finish_task().
*
* This ensures that tasks getting woken will be fully ordered against
* their previous state and preserve Program Order.
*/
smp_cond_load_acquire(&p->on_cpu, !VAL);
p->sched_contributes_to_load = !!task_contributes_to_load(p);
p->state = TASK_WAKING;
if (p->in_iowait) {
delayacct_blkio_end(p);
atomic_dec(&task_rq(p)->nr_iowait);
}
cpu = select_task_rq(p, p->wake_cpu, SD_BALANCE_WAKE, wake_flags);
if (task_cpu(p) != cpu) {
wake_flags |= WF_MIGRATED;
psi_ttwu_dequeue(p);
set_task_cpu(p, cpu);
}
#else /* CONFIG_SMP */
if (p->in_iowait) {
delayacct_blkio_end(p);
atomic_dec(&task_rq(p)->nr_iowait);
}
#endif /* CONFIG_SMP */
ttwu_queue(p, cpu, wake_flags);
unlock:
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
out:
if (success)
ttwu_stat(p, cpu, wake_flags);
preempt_enable();
return success;
}
- 코드 라인 34에서 태스크가 로드에 기여를 하는지 여부를 알아온다.
- frozen 태스크가 아니고 noload 없는 uniterruptible 상태의 태스크는 로드에 기여한다.
- 코드 라인 35에서 태스크를 TASK_WAKING 상태로 바꾼다.
- 코드 라인 37~40에서 태스크가 in_iowait 상태이면 io_wait 상태를 해제한다.
- 코드 라인 42~47에서 태스크가 깨어날 cpu를 알아온다. 만일 태스크의 슬립전 cpu가 아닌 다른 cpu를 선택한 경우 WF_MIGRATED 플래그를 추가하고, psi 정보를 전달한 후 태스크에 선택한 cpu를 기록한다.
- 코드 라인 58에서 태스크를 알아온 cpu의 런큐에서 깨운다.
- 코드 라인 59~60에서 unlock 레이블이다. 스핀락을 복구한다.
- 코드 라인 61~63에서 out 레이블이다. wakeup이 성공한 경우 관련 stat을 갱신한다.
- 코드 라인 64~66에서 preemption을 다시 enable하고 success 상태를 반환한다.
런큐에 있는 태스크 깨우기
ttwu_remote()
kernel/sched/core.c
/* * Called in case the task @p isn't fully descheduled from its runqueue, * in this case we must do a remote wakeup. Its a 'light' wakeup though, * since all we need to do is flip p->state to TASK_RUNNING, since * the task is still ->on_rq. */
static int ttwu_remote(struct task_struct *p, int wake_flags)
{
struct rq *rq;
int ret = 0;
rq = __task_rq_lock(p);
if (task_on_rq_queued(p)) {
/* check_preempt_curr() may use rq clock */
update_rq_clock(rq);
ttwu_do_wakeup(rq, p, wake_flags);
ret = 1;
}
__task_rq_unlock(rq);
return ret;
}
태스크가 이미 런큐에 있는 경우 태스크를 TASK_RUNNING 상태로 바꾸고 preemption 가능한지 체크한다. 런큐에 태스크가 있었으면 1을 반환한다.
ttwu_do_wakeup()
kernel/sched/core.c
/* * Mark the task runnable and perform wakeup-preemption. */
static void ttwu_do_wakeup(struct rq *rq, struct task_struct *p, int wake_flags,
struct rq_flags *rf)
{
check_preempt_curr(rq, p, wake_flags);
p->state = TASK_RUNNING;
trace_sched_wakeup(p);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken) {
/*
* Our task @p is fully woken up and running; so its safe to
* drop the rq->lock, hereafter rq is only used for statistics.
*/
rq_unpin_lock(rq, rf);
p->sched_class->task_woken(rq, p);
rq_repin_lock(rq, rf);
}
if (rq->idle_stamp) {
u64 delta = rq_clock(rq) - rq->idle_stamp;
u64 max = 2*rq->max_idle_balance_cost;
update_avg(&rq->avg_idle, delta);
if (rq->avg_idle > max)
rq->avg_idle = max;
rq->idle_stamp = 0;
}
#endif
}
태스크를 러너블(TASK_RUNNING) 상태로 변경하고 wake-up preemption을 수행한다.
- 코드 라인 4에서 preemption이 필요하면 리스케줄 요청을 하도록 체크한다.
- 코드 라인 5에서 태스크를 TASK_RUNNING 상태로 바꾼다.
- 코드 라인 9~17에서 해당 태스크의 스케줄러에 해당하는 task_woken에 연결된 함수를 호출한다.
- dl 및 rt 스케줄러만 관련 함수를 제공한다.
- task_woken_dl()
- 다른 dl 태스크가 동작 중이고 요청한 dl 태스크가 동작 중이 아닌 경우 밸런싱을 위해 필요 시 push 한다.
- task_woken_rt()
- 다른 rt 태스크가 동작 중이고 요청한 rt 태스크가 동작 중이 아닌 경우 밸런싱을 위해 필요 시 push 한다.
- task_woken_dl()
- dl 및 rt 스케줄러만 관련 함수를 제공한다.
- 코드 라인 19~29에서 idle 동안의 시간과 기존 avg_idle의 차이 기간의 1/8만 avg_idle에 추가한다. 단 max_idle_balance_cost의 2배를 초과하지 못하게 제한한다.
update_avg()
kernel/sched/core.c
static void update_avg(u64 *avg, u64 sample)
{
s64 diff = sample - *avg;
*avg += diff >> 3;
}
avg += (sample – avg) / 8 를 산출한다.
런큐에 없는 태스크를 깨우기
ttwu_queue()
kernel/sched/core.c
static void ttwu_queue(struct task_struct *p, int cpu, int wake_flags)
{
struct rq *rq = cpu_rq(cpu);
struct rq_flags rf;
#if defined(CONFIG_SMP)
if (sched_feat(TTWU_QUEUE) && !cpus_share_cache(smp_processor_id(), cpu)) {
sched_clock_cpu(cpu); /* Sync clocks across CPUs */
ttwu_queue_remote(p, cpu, wake_flags);
return;
}
#endif
rq_lock(rq, &rf);
update_rq_clock(rq);
ttwu_do_activate(rq, p, wake_flags, &rf);
rq_unlock(rq, &rf);
}
태스크를 요청한 cpu의 런큐에서 깨운다.
- 코드 라인 7~11에서 TTWU_QUEUE(디폴트=true) feature가 설정되었고 요청한 cpu와 현재 cpu가 같은 캐시를 공유하지 않으면 요청한 cpu의 런큐의 wake_list에 태스크를 추가하고 IPI를 통해 해당 cpu에 wakeup 요청을 한다.
- 코드 라인 14~17에서 현재 cpu에서 직접 해당 cpu의 런큐 락을 획득한 후 태스크를 런큐에 엔큐한다. 그런 후 태스크를 러닝 상태로 변경한 후 wake-up preemption을 수행한다.
ttwu_queue_remote()
kernel/sched/core.c
static void ttwu_queue_remote(struct task_struct *p, int cpu, int wake_flags)
{
struct rq *rq = cpu_rq(cpu);
p->sched_remote_wakeup = !!(wake_flags & WF_MIGRATED);
if (llist_add(&p->wake_entry, &cpu_rq(cpu)->wake_list)) {
if (!set_nr_if_polling(rq->idle))
smp_send_reschedule(cpu);
else
trace_sched_wake_idle_without_ipi(cpu);
}
}
태스크를 리모트 cpu에서 깨운다.
- 코드 라인 5에서 태스크에 remote wakeup 여부를 기록한다.
- 태스크가 원래 슬립했었던 cpu가 아닌 다른 cpu에서 깨워졌는지 여부가 기록된다.
- 코드 라인 7~12에서 태스크를 wake_list에 추가하고 IPI를 통해 해당 cpu에 리스케줄 요청한다.
ttwu_do_activate()
kernel/sched/core.c
static void
ttwu_do_activate(struct rq *rq, struct task_struct *p, int wake_flags,
struct rq_flags *rf)
{
int en_flags = ENQUEUE_WAKEUP | ENQUEUE_NOCLOCK;
lockdep_assert_held(&rq->lock);
#ifdef CONFIG_SMP
if (p->sched_contributes_to_load)
rq->nr_uninterruptible--;
if (wake_flags & WF_MIGRATED)
en_flags |= ENQUEUE_MIGRATED;
#endif
activate_task(rq, p, en_flags);
ttwu_do_wakeup(rq, p, wake_flags, rf);
}
태스크를 런큐에 엔큐하고 러너블 상태로 변경한 후 wake-up preemption을 수행한다.
- 코드 라인 4에서 런큐 엔큐시 사용할 플래그를 지정한다.
- 코드 라인 6에서 런큐 락을 획득한다.
- 코드 라인 9~10에서 로드에 참여하는 uninterruptible 태스크인 경우 nr_uninterruptible을 1 감소시킨다.
- 코드 라인 12~13에서 슬립 했었던 cpu가 아니라 다른 cpu에서 깨워지는 경우 ENQUEUE_MIGRATED 플래그를 추가한다.
- 코드 라인 16에서 태스크를 런큐에 엔큐하여 동작시킨다.
- 코드 라인 17에서 태스크를 러너블(TASK_RUNNING) 상태로 변경하고 wake-up preemption을 수행한다.
다음 스케줄할 태스크 선택
pick_next_task()
kernel/sched/core.c
/* * Pick up the highest-prio task: */
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in the fair class we can
* call that function directly, but only if the @prev task wasn't of a
* higher scheduling class, because otherwise those loose the
* opportunity to pull in more work from other CPUs.
*/
if (likely((prev->sched_class == &idle_sched_class ||
prev->sched_class == &fair_sched_class) &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto restart;
/* Assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, rf);
return p;
}
restart:
#ifdef CONFIG_SMP
/*
* We must do the balancing pass before put_next_task(), such
* that when we release the rq->lock the task is in the same
* state as before we took rq->lock.
*
* We can terminate the balance pass as soon as we know there is
* a runnable task of @class priority or higher.
*/
for_class_range(class, prev->sched_class, &idle_sched_class) {
if (class->balance(rq, prev, rf))
break;
}
#endif
put_prev_task(rq, prev);
for_each_class(class) {
p = class->pick_next_task(rq, NULL, NULL);
if (p)
return p;
}
/* The idle class should always have a runnable task: */
BUG();
}
다음 스케줄할 최우선 순위의 태스크를 알아온다. (stop -> dl -> rt -> fair -> idle 스케줄러 순)
- 코드 라인 13~26에서 높은 확률로 idle 상태였거나 cfs 태스크만 동작하는 경우 cfs 스케줄러의 pick_next_task() 함수를 호출하여 다음 처리할 태스크를 반환한다.처리할 태스크가 없는 경우 idle 태스크를 반환한다. 만일 낮은 확률로 RETRY_TASK 결과를 가져온 경우 restart 레이블로 이동한다.
- 코드 라인 27~40에서 stop 스케줄러부터 idle 스케줄 클래스까지 순서대로 돌며 (*balance) 루틴을 수행하여 true인 경우 다음 클래스는 무시하고 루프를 빠져나온다.
- 코드 라인 52에서 기존 태스크를 런큐에 다시 엔큐한다.
- 코드 라인 54~58에서 stop 스케줄러부터 idle 스케줄 클래스까지 순서대로 돌며 다음 태스크를 가져와서 반환한다.
- 코드 라인 61에서 이 라인으로 내려오는 일이 없다.
다음 그림은 런큐에서 태스크가 수행될 때의 스케줄 순서를 보여준다.
- 마지막 idle-task 스케줄러 이전까지 수행시킬 task가 없는 경우 부트 프로세스 중에 처음 사용했던 idle 태스크가 사용된다.

activate & deactivate 태스크
엔큐 및 디큐 플래그들
다음은 태스크의 엔큐에 사용되는 플래그들이다.
- ENQUEUE_WAKEUP
- 슬립된 태스크를 외부에서 깨웠을 때 사용된다.
- ENQUEUE_RESTORE
- save/restore 페어로 사용되며 설정 변경으로 인해 다시 엔큐할 때 사용된다.
- ENQUEUE_MOVE
- save/restore 페어와 같이 사용되며 태스크 그룹을 이동하여 엔큐할 때 사용된다.
- ENQUEUE_NOCLOCK
- 엔큐 시 런큐 클럭을 갱신하지 않게 한다.
- ENQUEUE_HEAD
- 엔큐 시 런큐의 앞부분에 위치하게 한다.
- ENQUEUE_REPLENISH
- 밴드위드 사용으로 인해 스로틀된 태스크가 다시 런타임 보충되어 엔큐되는 상황에서 사용된다.
- ENQUEUE_MIGRATED
- 태스크가 다른 cpu의 런큐에 migrate되어 엔큐하는 상황에서 사용된다.
다음은 태스크의 디큐에 사용되는 플래그들이다.
- DEQUEUE_SLEEP
- 태스크의 슬립으로 인해 디큐되는 상황에서 사용된다.
- DEQUEUE_SAVE
- save/restore 페어로 사용되며 설정 변경으로 인해 잠시 디큐한다.
- DEQUEUE_MOVE
- save/restore 페어와 같이 사용되며 태스크 그룹을 이동하기 위해 디큐할 때 사용된다.
- DEQUEUE_NOCLOCK
- 엔큐시 런큐 클럭을 갱신하지 않게 한다.
activate_task()
kernel/sched/core.c
void activate_task(struct rq *rq, struct task_struct *p, int flags)
{
if (task_contributes_to_load(p))
rq->nr_uninterruptible--;
enqueue_task(rq, p, flags);
p->on_rq = TASK_ON_RQ_QUEUED;
}
태스크를 런큐에 추가한다.
- 로드 기여중인 uninterruptible 태스크인 경우 런큐의 nr_uninterrtible 카운터를 감소시킨다.
task_contributes_to_load()
include/linux/sched.h
#define task_contributes_to_load(task) ((task->state & TASK_UNINTERRUPTIBLE) != 0 && \
(task->flags & PF_FROZEN) == 0 && \
(task->state & TASK_NOLOAD) == 0)
uninterruptible 태스크 상태이면서 suspend 된 것은 아닌 경우 true를 반환한다.
- 시스템 suspend 시 frozen 플래그가 설정된다.
- uninterruptible 태스크가 forzen 플래그와 noload 상태가 없어야 로드 기여 상태가 된다.
enqueue_task()
kernel/sched/core.c
static void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
{
if (!(flags & ENQUEUE_NOCLOCK))
update_rq_clock(rq);
if (!(flags & ENQUEUE_RESTORE)) {
sched_info_queued(rq, p);
psi_enqueue(p, flags & ENQUEUE_WAKEUP);
}
uclamp_rq_inc(rq, p);
p->sched_class->enqueue_task(rq, p, flags);
}
태스크를 런큐에 추가한다.
- 런큐 클럭을 갱신시키고 요청 태스크의 스케줄러에 있는 (*enqueue_task) 후크에 연결된 함수를 호출하여 런큐에 추가한다.
- 각 스케줄러마다 다음의 함수를 호출한다.
- stop 스케줄러 – enqueue_task_stop()
- deadline 스케줄러 – enqueue_task_dl()
- rt 스케줄러 – enqueue_task_rt()
- cfs 스케줄러 – enqueue_task_fair()
- idle 스케줄러 – enqueue_task_idle()
deactivate_task()
kernel/sched/core.c
void deactivate_task(struct rq *rq, struct task_struct *p, int flags)
{
p->on_rq = (flags & DEQUEUE_SLEEP) ? 0 : TASK_ON_RQ_MIGRATING;
if (task_contributes_to_load(p))
rq->nr_uninterruptible++;
dequeue_task(rq, p, flags);
}
태스크를 런큐에서 제거한다.
- 로드 기여중인 uninterruptible 태스크인 경우 런큐의 nr_uninterrtible 카운터를 증가시킨다.
dequeue_task()
kernel/sched/core.c
static void dequeue_task(struct rq *rq, struct task_struct *p, int flags)
{
if (!(flags & DEQUEUE_NOCLOCK))
update_rq_clock(rq);
if (!(flags & DEQUEUE_SAVE)) {
sched_info_dequeued(rq, p);
psi_dequeue(p, flags & DEQUEUE_SLEEP);
}
uclamp_rq_dec(rq, p);
p->sched_class->dequeue_task(rq, p, flags);
}
태스크를 런큐에서 제거한다.
- 런큐 클럭을 갱신시키고 요청 태스크의 스케줄러에 있는 (*dequeue_task) 후크에 연결된 함수를 호출한다.
- 각 스케줄러마다 다음의 함수를 호출한다.
- stop 스케줄러 – dequeue_task_stop()
- deadline 스케줄러 – dequeue_task_dl()
- rt 스케줄러 – dequeue_task_rt()
- cfs 스케줄러 – dequeue_task_fair()
- idle 스케줄러 – dequeue_task_idle()
기타
스케줄링 클래스 변경
__sched_setscheduler() 에서 스케줄 클래스를 변경하거나 우선 순위를 변경할 때 check_class_changed() 함수를 호출한다.
check_class_changed()
- (*switched_from)
- (*switched_to)
- (*prio_changed)
preemption 체크
check_preempt_curr()
- (*check_preempt_curr)
실행 가능 cpu 설정
do_set_cpus_allowed()
- (*set_cpus_allowed)
실행 cpu 변경
set_task_cpu()
- (*migrate_task_rq)
새 태스크 실행
wake_up_new_task()
- (*select_task_rq)
- (*task_woken)
태스크 킬
finish_task_switch()
- (*task_dead)
실행 도메인을 통해 선택한 cpu에서 태스크 실행(execve)
sched_exec()
- (*select_task_rq)
- migration_cpu_stop() -> 디큐 -> cpu 지정 -> 엔큐
태스크의 총 실행시간 조회
task_sched_runtime()
- (*update_curr)
- 현재 실행 중인 경우 정확한 산정을 위해 현재 까지 실행한 시간을 추가하기 위해 위의 후크를 통해 현재 태스크의 런타임 갱신을 요청한다.
다음 태스크에 양보
태스크는 러닝 상태를 유지하여 런큐에서 디큐되지 않은 채로 리스케줄한다. 현재 태스크가 cfs 태스크인 경우 리스케줄 시 현재 태스크는 가능한한 제외한다.
- 현재 태스크가 cfs 태스크인 경우 skip 버디에 지정되어 pick_next_task()에서 리스케줄 시 선택되지 않게 한다.
sys_sched_yield()
- (*yield_task)
지정된 태스크에 양보
태스크는 러닝 상태를 유지하여 런큐에서 디큐되지 않은 채로 지정한 태스크로 리스케줄한다. 현재 태스크가 cfs 태스크인 경우 리스케줄 시 현재 태스크는 가능한한 제외한다.
- cfs 태스크인 경우 현재 태스크는 skip 버디에 지정되어 pick_next_task()에서 리스케줄 시 선택되지 않게 한다.
- cfs 태스크인 경우 지정된 태스크는 next 버디에 지정되어 pick_next_task()에서 리스케줄 시 선택되도록 한다.
yield_to()
- (*yield_to_task)
RR 인터벌 조회
round robin rt 태스크인 경우 rr 인터벌을 반환한다. (디폴트=100ms) cfs 태스크인 경우엔 해당 태스크의 time slice 값을 반환한다.
sched_rr_get_interval()
- (*get_rr_interval)
Migrate 태스크
migrate_tasks()
- (*put_prev_task)
태스크 그룹 변경
sched_change_group()
- (*task_change_group)
런큐 선택
select_task_rq()
- (* select_task_rq)
- 참고: Scheduler -14- (Load Balance 2) | 문c
Wait for Blocked I/O
wait queue와 wait event에 대한 내용은 별도의 페이지에서 분석하기로 하고 관련된 문서는 다음을 먼저 참고한다.
- 참고: 6.2장 Blocking I/O | Linux Device Drivers, 3rd Edition
스케줄러 Features
sched_feat() 매크로
kernel/sched/sched.h
/* * Each translation unit has its own copy of sysctl_sched_features to allow * constants propagation at compile time and compiler optimization based on * features default. */
#define SCHED_FEAT(name, enabled) \
(1UL << __SCHED_FEAT_##name) * enabled |
static const_debug __maybe_unused unsigned int sysctl_sched_features =
#include "features.h"
0;
#undef SCHED_FEAT
#define sched_feat(x) !!(sysctl_sched_features & (1UL << __SCHED_FEAT_##x))
kernel/sched/features.h
/* * Only give sleepers 50% of their service deficit. This allows * them to run sooner, but does not allow tons of sleepers to * rip the spread apart. */ SCHED_FEAT(GENTLE_FAIR_SLEEPERS, true) /* * Place new tasks ahead so that they do not starve already running * tasks */ SCHED_FEAT(START_DEBIT, true) /* * Prefer to schedule the task we woke last (assuming it failed * wakeup-preemption), since its likely going to consume data we * touched, increases cache locality. */ SCHED_FEAT(NEXT_BUDDY, false) /* * Prefer to schedule the task that ran last (when we did * wake-preempt) as that likely will touch the same data, increases * cache locality. */ SCHED_FEAT(LAST_BUDDY, true) /* * Consider buddies to be cache hot, decreases the likelyness of a * cache buddy being migrated away, increases cache locality. */ SCHED_FEAT(CACHE_HOT_BUDDY, true) /* * Allow wakeup-time preemption of the current task: */ SCHED_FEAT(WAKEUP_PREEMPTION, true) SCHED_FEAT(HRTICK, false) SCHED_FEAT(DOUBLE_TICK, false) /* * Decrement CPU capacity based on time not spent running tasks */ SCHED_FEAT(NONTASK_CAPACITY, true) /* * Queue remote wakeups on the target CPU and process them * using the scheduler IPI. Reduces rq->lock contention/bounces. */ SCHED_FEAT(TTWU_QUEUE, true) /* * When doing wakeups, attempt to limit superfluous scans of the LLC domain. */ SCHED_FEAT(SIS_AVG_CPU, false) SCHED_FEAT(SIS_PROP, true) /* * Issue a WARN when we do multiple update_rq_clock() calls * in a single rq->lock section. Default disabled because the * annotations are not complete. */ SCHED_FEAT(WARN_DOUBLE_CLOCK, false) #ifdef HAVE_RT_PUSH_IPI /* * In order to avoid a thundering herd attack of CPUs that are * lowering their priorities at the same time, and there being * a single CPU that has an RT task that can migrate and is waiting * to run, where the other CPUs will try to take that CPUs * rq lock and possibly create a large contention, sending an * IPI to that CPU and let that CPU push the RT task to where * it should go may be a better scenario. */ SCHED_FEAT(RT_PUSH_IPI, true) #endif SCHED_FEAT(RT_RUNTIME_SHARE, true) SCHED_FEAT(LB_MIN, false) SCHED_FEAT(ATTACH_AGE_LOAD, true) SCHED_FEAT(WA_IDLE, true) SCHED_FEAT(WA_WEIGHT, true) SCHED_FEAT(WA_BIAS, true) /* * UtilEstimation. Use estimated CPU utilization. */ SCHED_FEAT(UTIL_EST, true)
다음과 같은 스케줄러 feature들이 있다. (디폴트: 주황색=true, 파란색=false)
- GENTLE_FAIR_SLEEPERS
- 슬립 후 깨어나는 태스크에 대해 스케줄 레이턴시의 절반 만큼 더 빨리 실행할 수 있도록 한다. (50% 보너스)
- 이 기능을 disable하면 저가형(low-end) 디바이스에서 응답성이 좋아진다.
- 참고: sched: Implement a gentler fair-sleepers feature (2009, v2.6.32-rc1)
- START_DEBIT
- 새(fork) 태스크에 대해 한 타임(스케줄 레이턴시) 뒤에서 실행하도록 한다.
- 새 태스크가 이미 실행 중인 태스크를 방해하지 못하게 한다.
- 참고: Improving scheduler latency (2010) | LWN.net
- NEXT_BUDDY
- 캐시 지역성을 높이기 위해 깨어난 태스크를 다음 스케줄 시 우선 처리한다.
- LAST_BUDDY
- 캐시 지역성을 향상시키기 위해 웨이크 업 preemption이 성공하면 preemption 직전에 실행된 작업 옆에 둔다.
- CACHE_HOT_BUDDY
- 캐시 지역성을 높이기 위해 마이그레이션 할 작업을 항상 캐시 hot 상태로 판단한다. (다른 cpu로의 마이그레이션 비율을 축소시킨다)
- WAKEUP_PREEMPTION
- 헤비 로드를 갖는 시스템에서 이 옵션을 disable하면 preemption을 하지 않도록 하여 성능을 높일 수 있다. 단 반응성이 떨어진다.
- HRTICK
- hrtick을 사용하면 태스크마다 주어지는 런타임을 hrtimer를 사용하여 틱을 만들어낸다.
- DOUBLE_TICK
- 정규 틱과 hrtick을 동시에 운영하게 한다.
- NONTASK_CAPACITY
- 런큐 클럭 갱신 시 마다 irq 시간에 PELT를 적용하여 IRQ 유틸을 트래킹할 수 있게 한다.
- 참고: sched/irq: Add IRQ utilization tracking (2018, v4.19-rc1)
- 기존 NONTASK_POWER에서 이름을 바꾸었다.
- 참고: sched: Rename capacity related flags (2014, v3.16-rc1)
- 런큐 클럭 갱신 시 마다 irq 시간에 PELT를 적용하여 IRQ 유틸을 트래킹할 수 있게 한다.
- TTWU_QUEUE
- 캐시 지역성을 높이기 위해서 태스크가 로컬 cpu가 아닌 다른 cpu에서 깨어나야 할 때 IPI를 사용하는 리모트 큐의 사용 여부를 결정한다.
- 이 기능을 사용하면서 깨어날 태스크가 로컬 캐시를 공유하지 않는 cpu인 경우 IPI를 통해 원격 cpu 런큐에 태스크를 깨운다.
- 이 기능을 사용하지 않거나 현재 cpu가 깨어나야 할 cpu가 서로 로컬 캐시를 공유하는 경우 다음과 같이 기존 wakeup 방법을 사용한다.
- 로컬 cpu가 리모트 cpu의 런큐락을 획득하고 직접 enqueue한 후 preempt 요청한다.
- SIS_AVG_CPU
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. wake 밸런싱에서 cpu의 평균 idle 시간(rq->avg_idle)이 스케줄 도메인의 wakeup cost(sd->avg_scan_cost)에 비해 너무 짧은 경우 밸런싱을 방지한다.
- 참고: sched/fair: Make select_idle_cpu() more aggressive (2017, v4.11)
- SIS_PROP
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. wake 밸런싱에서 sibling cpu를 스캔할 수를 제한한다.
- span_avg(avg_idle * 도메인 소속 cpu 수) / avg_cost
- 참고: sched/core: Implement new approach to scale select_idle_cpu() (2017, v4.13-rc1)
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. wake 밸런싱에서 sibling cpu를 스캔할 수를 제한한다.
- WARN_DOUBLE_CLOCK
- 참고: sched/core: Add WARNING for multiple update_rq_clock() calls (2017, v4.12-rc1)
- RT_PUSH_IPI
- 참고: sched/rt: Use IPI to trigger RT task push migration instead of pulling (2015, v4.1-rc1)
- RT_RUNTIME_SHARE
- SMP 시스템에서 RT 그룹 스케줄링을 사용할 때 런타임이 부족해진 경우 다른 cpu로 부터 빌려올 수 있게 한다.
- 이 기능은 빌려오는 런타임때문에 cfs 태스크의 기아(starving) 현상이 발생할 수 있어 커널 v5.10-rc1에서 디폴트 값을 disable 하였다.
- LB_MIN
- 참고: sched: Fix more load-balancing fallout (2012, v3.4-rc5)
- ATTACH_AGE_LOAD
- 참고: sched/fair: Make the entity load aging on attaching tunable (2015, v4.4-rc1)
- WA_IDLE
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. 태스크의 기존 cpu가 캐시 친화 idle인 경우 약간의 성능을 개선하기 위해 밸런싱을 방지한다.
- 참고: sched/core: Fix wake_affine() performance regression (2017, v4.14-rc5)
- WA_WEIGHT
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. 태스크의 기존 cpu와 현재 cpu간의 러너블 로드가 작은 쪽으로 밸런싱을 수행하게 한다. 이렇게 하여 약간의 성능을 개선한다.
- 참고: sched/core: Address more wake_affine() regressions (2017, v4.14-rc5)
- WA_BIAS
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. 위의 WA_WEIGHT 기능을 사용할 때 태스크의 기존 cpu 로드에 약간의 바이어스(sd->imbalance_pct의 100% 초과분 절반)를 추가하여 this cpu 쪽으로 조금 더 유리한 선택이되게 한다.
- UTIL_EST
- EAS를 사용한 wake 밸런싱에서 관련 기능이다. 매우 짧은 시간 실행되는 태스크의 경우 1ms 단위로 갱신되는 PELT 시그널을 사용한 유틸 로드가 적을 수 있다. 따라서 태스크의 디큐 시마다 산출되는 추정 유틸(estimated utilization)과 기존 유틸 중 큰 값을 사용해야 cpu 간의 더 정확한 유틸 비교를 할 수 있다.
- 참고: sched/fair: Update util_est only on util_avg updates (2018, v4.17-rc1)
참고: Tweak Kernel’s Task Scheduler to Boost Performance on Android [Part 2] (2018) | DroidViews.com
다음은 qemu에서 동작중인 커널 v5.4의 스케줄러 feature들 예를 보여준다.
$ cat /sys/kernel/debug/sched_features GENTLE_FAIR_SLEEPERS START_DEBIT NO_NEXT_BUDDY LAST_BUDDY CACHE_HOT_BUDDY WAKEUP_PREEMPTION NO_HRTICK NO_DOUBLE_TICK NONTASK_CAPACITY TTWU_QUEUE NO_SIS_AVG_CPU SIS_PROP NO_WARN_DOUBLE_CLOCK RT_PUSH_IPI RT_RUNTIME_SHARE NO_LB_MIN ATTACH_AGE_LOAD WA_IDLE WA_WEIGHT WA_BIAS UTIL_EST
다음은 rpi4 시스템에서 동작중인 커널 v4.19의 스케줄러 feature들 예를 보여준다.
$ cat /sys/kernel/debug/sched_features GENTLE_FAIR_SLEEPERS START_DEBIT NO_NEXT_BUDDY LAST_BUDDY CACHE_HOT_BUDDY WAKEUP_PREEMPTION NO_HRTICK NO_DOUBLE_TICK LB_BIAS NONTASK_CAPACITY TTWU_QUEUE NO_SIS_AVG_CPU SIS_PROP NO_WARN_DOUBLE_CLOCK RT_PUSH_IPI RT_RUNTIME_SHARE NO_LB_MIN ATTACH_AGE_LOAD WA_IDLE WA_WEIGHT WA_BIAS UTIL_EST
다음은 rock960 시스템에서 동작중인 커널 v4.4의 스케줄러 feature들 예를 보여준다.
$ cat /sys/kernel/debug/sched_features GENTLE_FAIR_SLEEPERS START_DEBIT NO_NEXT_BUDDY LAST_BUDDY CACHE_HOT_BUDDY WAKEUP_PREEMPTION NO_HRTICK NO_DOUBLE_TICK LB_BIAS NONTASK_CAPACITY TTWU_QUEUE RT_PUSH_IPI NO_FORCE_SD_OVERLAP RT_RUNTIME_SHARE NO_LB_MIN ATTACH_AGE_LOAD ENERGY_AWARE
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c – 현재 글
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- Process Scheduling | Alessandro Pellegrini (2019) – 다운로드 pdf