<kernel v4.0>
런큐 로드 평균 – rq->cpu_load[] 산출 – (1, 2, 4, 8, 16 ticks)
cpu 로드 밸런스에 사용하였던 이 방법은 커널 v5.3-rc1에서 제거되었다.
- 참고: sched/fair: Remove the rq->cpu_load[] update code (2019, v5.3-rc1)
런큐 로드 평균 (1 tick ~ 16 ticks)
- 매 tick 마다 평균 cpu 로드를 산출하여 rq->cpu_load[5]에 저장하고 로드밸런스를 위해 사용된다.
- rq->cpu_load[]에 5개의 cpu 로드가 저장되는데 각각의 기간은 2배씩 커진다.
- cpu_load[0] <- 1 tick 기간
- cpu_load[1] <- 2 ticks 기간
- cpu_load[1] <- 4 ticks 기간
- cpu_load[3] <- 8 ticks 기간
- cpu_load[4] <- 16 ticks 기간
- “/proc/sched_debug” 파일을 확인하여
# cat /proc/sched_debug Sched Debug Version: v0.11, 4.4.11-v7+ #888 ktime : 4393169013.219659 sched_clk : 4393169057.443466 cpu_clk : 4393169057.443935 jiffies : 439286901 sysctl_sched .sysctl_sched_latency : 18.000000 .sysctl_sched_min_granularity : 2.250000 .sysctl_sched_wakeup_granularity : 3.000000 .sysctl_sched_child_runs_first : 0 .sysctl_sched_features : 44859 .sysctl_sched_tunable_scaling : 1 (logaritmic) cpu#0 .nr_running : 0 .load : 0 .nr_switches : 145928196 .nr_load_updates : 57706792 .nr_uninterruptible : -324009 .next_balance : 439.286901 .curr->pid : 0 .clock : 4393169054.864143 .clock_task : 4393169054.864143 .cpu_load[0] : 81 .cpu_load[1] : 41 .cpu_load[2] : 21 .cpu_load[3] : 11 .cpu_load[4] : 6
update_cpu_load_active()
kernel/sched/proc.c
/*
* Called from scheduler_tick()
*/
void update_cpu_load_active(struct rq *this_rq)
{
unsigned long load = get_rq_runnable_load(this_rq);
/*
* See the mess around update_idle_cpu_load() / update_cpu_load_nohz().
*/
this_rq->last_load_update_tick = jiffies;
__update_cpu_load(this_rq, load, 1);
calc_load_account_active(this_rq);
}
요청한 런큐의 cpu 로드 active를 갱신한다.
- 코드 라인 6에서 런큐의 load 평균 값을 알아온다.
- 코드 라인 10에서 현재 시각(jiffies)으로 cpu 로드가 산출되었음을 기록한다.
- 코드 라인 11에서 cpu 로드를 산출한다.
- 코드 라인 13에서 5초 간격으로 전역 calc_load_tasks 값을 갱신한다.
- 매 스케줄 tick 마다 nr_active를 산출하지 않기 위해 5초 간격으로 nr_active를 산출하여 그 차이 값 만큼만 calc_load_tasks에 반영한다.
다음 그림은 런큐의 cpu 로드가 산출되기 위해 처리되는 흐름을 보여준다.
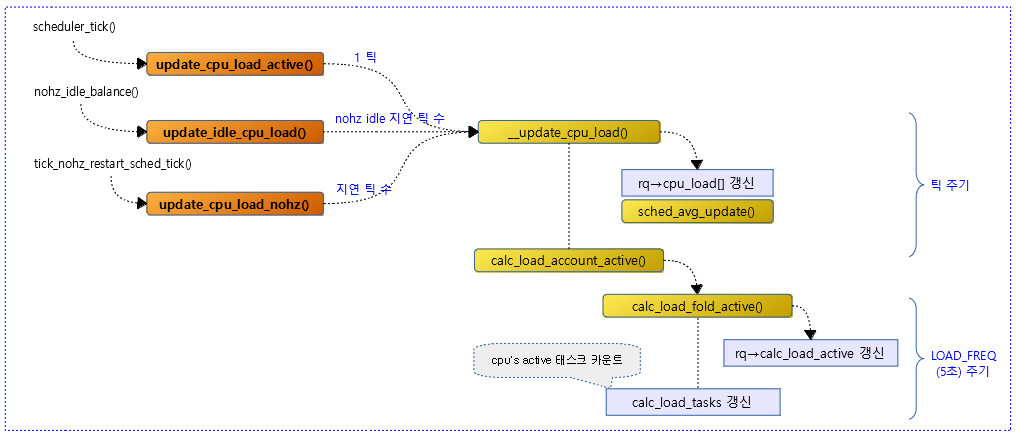
get_rq_runnable_load()
kernel/sched/proc.c
#ifdef CONFIG_SMP
static inline unsigned long get_rq_runnable_load(struct rq *rq)
{
return rq->cfs.runnable_load_avg;
}
#else
static inline unsigned long get_rq_runnable_load(struct rq *rq)
{
return rq->load.weight;
}
#endif
런큐의 로드 평균 값을 반환한다.
- enqueue_entity_load_avg(), dequeue_entity_load_avg(), update_entity_load_avg() 함수 등에서 cfs 태스크들의 load 평균이 산출된다.
__update_cpu_load()
kernel/sched/proc.c
/*
* Update rq->cpu_load[] statistics. This function is usually called every
* scheduler tick (TICK_NSEC). With tickless idle this will not be called
* every tick. We fix it up based on jiffies.
*/
static void __update_cpu_load(struct rq *this_rq, unsigned long this_load,
unsigned long pending_updates)
{
int i, scale;
this_rq->nr_load_updates++;
/* Update our load: */
this_rq->cpu_load[0] = this_load; /* Fasttrack for idx 0 */
for (i = 1, scale = 2; i < CPU_LOAD_IDX_MAX; i++, scale += scale) {
unsigned long old_load, new_load;
/* scale is effectively 1 << i now, and >> i divides by scale */
old_load = this_rq->cpu_load[i];
old_load = decay_load_missed(old_load, pending_updates - 1, i);
new_load = this_load;
/*
* Round up the averaging division if load is increasing. This
* prevents us from getting stuck on 9 if the load is 10, for
* example.
*/
if (new_load > old_load)
new_load += scale - 1;
this_rq->cpu_load[i] = (old_load * (scale - 1) + new_load) >> i;
}
sched_avg_update(this_rq);
}
jiffies 기반 tick 마다 런큐의 cpu 로드를 갱신한다.
- 코드 라인 11에서 nr_load_updates 카운터를 1 증가시킨다. (단순 카운터)
- 코드 라인 14에서 cpu_load[0]에는 load 값을 100% 반영한다.
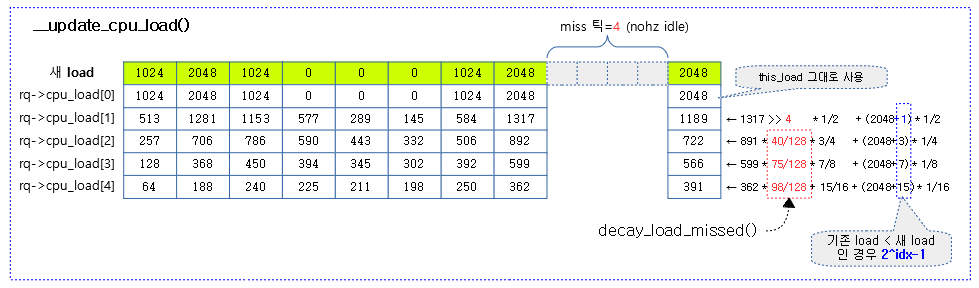
- 코드 라인 15에서 cpu_load[1] ~ cpu_load[4]까지 갱신하기 위해 루프를 돈다. 루프를 도는 동안 scale 값은 2, 4, 8, 16과 같이 2배씩 커진다.
- 코드 라인 20~21에서 4개 배열에 있는 기존 cpu 로드값들은 지연 틱 값에 의해 미리 준비된 테이블의 값을 참고하여 decay load 값으로 산출된다.
- decay_load = old_load * miss 틱을 사용한 decay factor
- 코드 라인28~29에서 새 로드가 기존 로드보다 큰 경우에 한하여 즉, 로드가 상승되는 경우 올림을 할 수 있도록 새 로드에 scale-1을 추가한다.
- 코드 라인 31에서 기존 로드에 (2^i-1)/2^i 의 비율을 곱하고 새 로드에 1/(2^i) 비율을 곱한 후 더한다.
- i=1:
- cpu_load[1] = decay_load * 1/2 + new_load * 1/2
- i=2:
- cpu_load[2] = decay_load * 3/4 + new_load * 1/4
- i=3:
- cpu_load[3] = decay_load * 7/8 + new_load * 1/8
- i=4
- cpu_load[4] = decay_load * 15/16 + new_load * 1/16
- i=1:
- 코드 라인 34에서 런큐의 age_stamp와 rt_avg 값을 갱신한다.
다음 그림은 cpu_load[]를 산출하는 식이다.
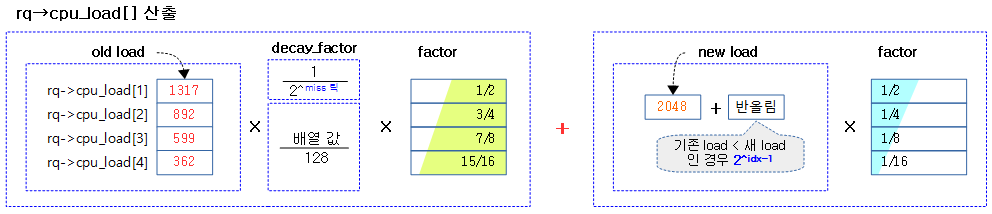
다음 그림은 런큐의 cpu_load[] 값이 매 tick 마다 변화되는 모습을 보여준다.
decay_load_missed()
kernel/sched/proc.c
/*
* Update cpu_load for any missed ticks, due to tickless idle. The backlog
* would be when CPU is idle and so we just decay the old load without
* adding any new load.
*/
static unsigned long
decay_load_missed(unsigned long load, unsigned long missed_updates, int idx)
{
int j = 0;
if (!missed_updates)
return load;
if (missed_updates >= degrade_zero_ticks[idx])
return 0;
if (idx == 1)
return load >> missed_updates;
while (missed_updates) {
if (missed_updates % 2)
load = (load * degrade_factor[idx][j]) >> DEGRADE_SHIFT;
missed_updates >>= 1;
j++;
}
return load;
}
nohz idle 기능이 동작하여 tick이 발생하지 않은 횟수를 사용하여 미리 계산된 테이블에서 load 값을 산출한다.
- 코드 라인 11~12에서 miss 틱이 없는 경우 그냥 load 값을 그대로 반환한다.
- 코드 라인 14~15에서 miss 틱이 idx 순서대로 8, 32, 64, 128 값 이상인 경우 너무 작은 load 값을 반영해봤자 미미하므로 load 값으로 0을 반환한다.
- 코드 라인 17~18에서 인덱스 값이 1인 경우 load 값을 miss 틱 만큼 우측으로 쉬프트한다.
- 코드 라인 20~26에서 missed_updates 값의 하위 비트부터 설정된 경우 이 위치에 해당하는 테이블에서 값을 곱하고 128로 나눈다.
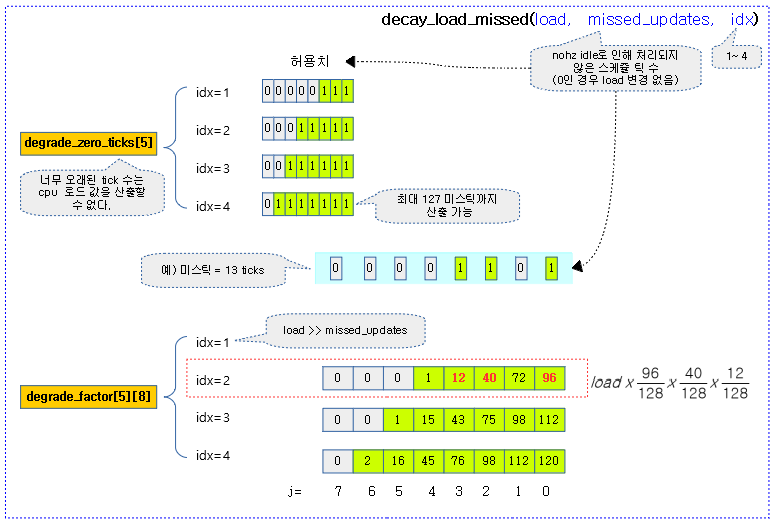
다음 그림은 idx=2, miss 틱=13이 주어졌고 이에 해당하는 decay 로드 값을 구하는 모습을 보여준다.
/*
* The exact cpuload at various idx values, calculated at every tick would be
* load = (2^idx - 1) / 2^idx * load + 1 / 2^idx * cur_load
*
* If a cpu misses updates for n-1 ticks (as it was idle) and update gets called
* on nth tick when cpu may be busy, then we have:
* load = ((2^idx - 1) / 2^idx)^(n-1) * load
* load = (2^idx - 1) / 2^idx) * load + 1 / 2^idx * cur_load
*
* decay_load_missed() below does efficient calculation of
* load = ((2^idx - 1) / 2^idx)^(n-1) * load
* avoiding 0..n-1 loop doing load = ((2^idx - 1) / 2^idx) * load
*
* The calculation is approximated on a 128 point scale.
* degrade_zero_ticks is the number of ticks after which load at any
* particular idx is approximated to be zero.
* degrade_factor is a precomputed table, a row for each load idx.
* Each column corresponds to degradation factor for a power of two ticks,
* based on 128 point scale.
* Example:
* row 2, col 3 (=12) says that the degradation at load idx 2 after
* 8 ticks is 12/128 (which is an approximation of exact factor 3^8/4^8).
*
* With this power of 2 load factors, we can degrade the load n times
* by looking at 1 bits in n and doing as many mult/shift instead of
* n mult/shifts needed by the exact degradation.
*/
#define DEGRADE_SHIFT 7
static const unsigned char
degrade_zero_ticks[CPU_LOAD_IDX_MAX] = {0, 8, 32, 64, 128};
idx별로 miss 틱에 대한 반영 비율을 적용할 지 여부를 확인하기 위한 테이블이다.
- miss 틱 수가 idx에 따른 테이블 값 이상으로 오래된 경우 기존 load 값을 사용할 필요 없다.
- 예) idx=2, miss 틱=33인 경우 기존 cpu 로드 값을 0으로 간주하게 한다.
static const unsigned char
degrade_factor[CPU_LOAD_IDX_MAX][DEGRADE_SHIFT + 1] = {
{0, 0, 0, 0, 0, 0, 0, 0},
{64, 32, 8, 0, 0, 0, 0, 0},
{96, 72, 40, 12, 1, 0, 0},
{112, 98, 75, 43, 15, 1, 0},
{120, 112, 98, 76, 45, 16, 2} };
idx 별로 miss 틱에 대한 decay_load를 구하기 위한 테이블이다. (각 값은 x/128에 해당하는 분자 값이다.)
- 예) idx=2, miss 틱=6, load=1024 일 때
- 분모가 128이고, miss 틱에 대한 비트에 해당하는 72와 40에 해당하는 분자 값을 사용한다.
- decay_load = 1024 * 72/128 * 40/128 = 1024 * 2880 / 16384 = 180
평균 스케쥴 갱신
sched_avg_update()
kernel/sched/core.c
void sched_avg_update(struct rq *rq)
{
s64 period = sched_avg_period();
while ((s64)(rq_clock(rq) - rq->age_stamp) > period) {
/*
* Inline assembly required to prevent the compiler
* optimising this loop into a divmod call.
* See __iter_div_u64_rem() for another example of this.
*/
asm("" : "+rm" (rq->age_stamp));
rq->age_stamp += period;
rq->rt_avg /= 2;
}
}
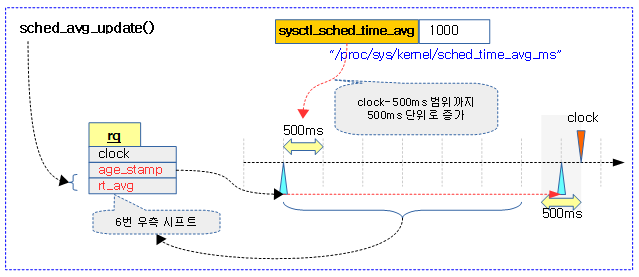
런큐의 age_stamp와 rt_avg 값을 갱신한다.
- 코드 라인 3에서 평균 스케줄 타임(ns)의 절반을 가져와서 period에 대입한다.
- 코드 라인 5~14에서 런큐 클럭에서 age_stamp를 뺀 간격이 period보다 큰 경우에 한해 계속 루프를 돌며 age_stamp를 period만큼 더하고 rt_avg 값은 절반으로 나눈다.
sched_avg_period()
kernel/sched/sched.h
static inline u64 sched_avg_period(void)
{
return (u64)sysctl_sched_time_avg * NSEC_PER_MSEC / 2;
}
평균 스케줄 타임(ns)의 절반을 가져온다.
5초 간격으로 active 태스크 수 산출
calc_load_account_active()
kernel/sched/proc.c
/*
* Called from update_cpu_load() to periodically update this CPU's
* active count.
*/
static void calc_load_account_active(struct rq *this_rq)
{
long delta;
if (time_before(jiffies, this_rq->calc_load_update))
return;
delta = calc_load_fold_active(this_rq);
if (delta)
atomic_long_add(delta, &calc_load_tasks);
this_rq->calc_load_update += LOAD_FREQ;
}
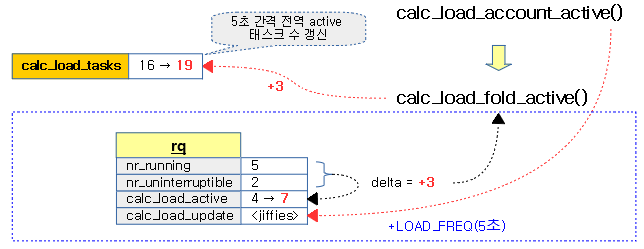
로드 산출 주기(5초) 간격으로 active 태스크 수를 전역 calc_load_tasks에 갱신한다.
- 코드 라인 9~10에서 지정된 5초 만료시간이 안된 경우 함수를 빠져나간다.
- 코드 라인 12~14에서 기존 active 태스크 수와 현재 산출한 active 태스크 수의 차이를 알아와서 calc_load_tasks에 추가하여 갱신한다.
- 코드 라인 16에서 다음 산출할 시간을 위해 5초를 더한다.
다음 그림은 런큐의 active 태스크 수를 런큐와 전역 변수에 갱신하는 것을 보여준다.
calc_load_fold_active()
kernel/sched/proc.c
long calc_load_fold_active(struct rq *this_rq)
{
long nr_active, delta = 0;
nr_active = this_rq->nr_running;
nr_active += (long) this_rq->nr_uninterruptible;
if (nr_active != this_rq->calc_load_active) {
delta = nr_active - this_rq->calc_load_active;
this_rq->calc_load_active = nr_active;
}
return delta;
}
요청한 런큐의 기존 active 태스크 수와 현재 산출한 active 태스크 수의 차이를 산출한다.
- 코드 라인 5~6에서 요청한 런큐의 active 태스크 수를 알아온다.
- 코드 라인 8~13에서 런큐의 calc_load_active와 다른 경우 이 값을 갱신하고 그 차이를 delta 값으로 하여 반환한다.
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c – 현재 글
- PELT(Per-Entity Load Tracking) – v4.0 | 문c