<kernel v5.4>
Load Balance
CFS 로드 밸런싱을 위한 관련 componet들은 다음과 같다.

로드밸런싱에 진입하는 방법은 다음과 같이 5가지가 있다. passive 밸런싱은 태스크 상태의 변화에 따라 동작한다. periodic 밸런싱은 dynamic하게 변화하는 밸런싱 인터벌에 따라 호출되어 동작한다. Fork, Exec, Wake 밸런싱은 현재 동작시키고자하는 태스크의 대상 cpu를 결정하기 위해 idlest cpu를 찾아 동작하는 구조이다. 그리고 나머지 idle 밸런싱과 periodic 밸런싱은 busiest cpu를 찾고 그 cpu의 런큐에 위치한 태스크를 가져(pull migration)와서 동작시키는 구조이다.
- Passive Balancing
- Fork Balancing
- 태스크 생성 시 태스크를 부모 태스크가 실행되던 cpu에서 수행할 지 아니면 다른 cpu로 마이그레이션할 지 결정한다.
- 가능하면 캐시 친화력이 있는 cpu나 idle cpu를 선택하고 그렇지 않은 경우 cpu 로드가 적은 cpu의 런큐로 마이그레이션한다.
- wake_up_new_task() 함수에서 SD_BALANCE_FORK 플래그를 사용하여 호출한다.
- Exec Balancing
- 태스크 실행 시 태스크를 기존 실행되던 cpu에서 수행할 지 아니면 다른 cpu로 마이그레이션할 지 결정한다.
- 가능하면 캐시 친화력이 있는 cpu나 idle cpu를 선택하고 그렇지 않은 경우 cpu 로드가 적은 cpu의 런큐로 마이그레이션한다.
- 다른 cpu로 마이그레이션 할 때 migrate 스레드를 사용한다.
- sched_exec() 함수에서 SD_BALANCE_EXEC 플래그를 사용한다.
- Wake Balancing
- idle 태스크가 깨어났을 때 깨어난 cpu에서 수행할 지 아니면 다른 idle cpu로 마이그레이션할 지 결정한다.
- try_to_wake_up() 함수에서 SD_BALANCE_WAKE 플래그를 사용한다.
- Idle Balancing
- cpu가 idle 상태에 진입한 경우 가장 바쁜 스케줄 그룹의 가장 바쁜 cpu에서 태스크를 가져올지 결정한다.
- idle_balance() 함수에서 SD_BALANCE_NEWIDLE 플래그를 사용한다.
- Fork Balancing
- Periodic Balancing
- 주기적인 스케줄 틱을 통해 밸런싱 주기마다 리밸런싱 여부를 체크하여 결정한다.
- 로드밸런스 주기는 1틱 ~ max_interval(초기값 0.1초)까지 동적으로 변한다.
- SD_LOAD_BALANCE 플래그가 있는 스케줄 도메인의 스케줄 그룹에서 오버로드된 태스크를 찾아 현재 cpu로 pull 마이그레이션 하여 로드를 분산한다.
- 스케줄 틱 -> raise softirq -> run_rebalance_domains() -> rebalance_domains() 호출 순서를 가진다.
- active 로드 밸런싱
- 주기적인 스케줄 틱을 통해 리밸런싱 여부를 체크하여 결정하지만 특정 상황에서 몇 차례 실패하는 경우 이 방법으로 전환한다.
- buesiest cpu에서 이미 러닝 중인 태스크를 migration하기 위해서는 active 로드 밸런싱을 사용한다.
- 대상 cpu의 cpu stopper 스레드(stop 스케줄러를 사용하므로 가장 우선 순위가 높다)를 깨워 그 cpu 런큐에서 동작하는 cpu stopper 스레드를 제외한 하나의 태스크를 dest 런큐로 push 마이그레이션한다.
- 주기적인 스케줄 틱을 통해 리밸런싱 여부를 체크하여 결정하지만 특정 상황에서 몇 차례 실패하는 경우 이 방법으로 전환한다.
- 주기적인 스케줄 틱을 통해 밸런싱 주기마다 리밸런싱 여부를 체크하여 결정한다.
다음 그림은 CFS 로드 밸런스에 대한 주요 함수 흐름을 보여준다.

SCHED softirq
로드 밸런싱을 위한 sched softirq 호출
trigger_load_balance()
kernel/sched/fair.c
/* * Trigger the SCHED_SOFTIRQ if it is time to do periodic load balancing. */
void trigger_load_balance(struct rq *rq)
{
/* Don't need to rebalance while attached to NULL domain */
if (unlikely(on_null_domain(rq)))
return;
if (time_after_eq(jiffies, rq->next_balance))
raise_softirq(SCHED_SOFTIRQ);
nohz_balancer_kick();
}
현재 시각이 밸런싱을 체크할 시각이 지났으면 sched 소프트인터럽트를 호출한다. 또한 nohz idle을 지원하는 경우 nohz kick이 필요한 경우 수행한다.
- 코드 라인 4~5에서 아직 런큐에 스케줄링 도메인이 지정(attach)되지 않은 경우 함수를 빠져나간다.
- 코드 라인 7~8에서 밸런싱 체크할 시각이 지난 경우 sched softirq를 호출한다.
- 코드 라인 10에서 nohz 밸런싱 주기마다 수행한다.
sched softirq 루틴
다음 그림은 스케줄 틱마다 active 로드밸런싱을 수행할 때 호출되는 함수들의 흐름을 보여준다.

run_rebalance_domains()
kernel/sched/fair.c
/* * run_rebalance_domains is triggered when needed from the scheduler tick. * Also triggered for nohz idle balancing (with nohz_balancing_kick set). */
static __latent_entropy void run_rebalance_domains(struct softirq_action *h)
{
struct rq *this_rq = this_rq();
enum cpu_idle_type idle = this_rq->idle_balance ?
CPU_IDLE : CPU_NOT_IDLE;
/*
* If this CPU has a pending nohz_balance_kick, then do the
* balancing on behalf of the other idle CPUs whose ticks are
* stopped. Do nohz_idle_balance *before* rebalance_domains to
* give the idle CPUs a chance to load balance. Else we may
* load balance only within the local sched_domain hierarchy
* and abort nohz_idle_balance altogether if we pull some load.
*/
if (nohz_idle_balance(this_rq, idle))
return;
/* normal load balance */
update_blocked_averages(this_rq->cpu);
rebalance_domains(this_rq, idle);
}
CFS 로드 밸런스 softirq를 통해 이 함수가 호출된다. 스케줄 도메인이 로드밸런싱을 할 주기에 이른 경우에 한해 이를 수행한다.
- 코드 라인 4~5에서 현재 런큐의 idle_balance 값이 있는 경우, 즉 idle 중인 경우 CPU_IDLE 타입으로 idle이 아닌 경우에는 CPU_NOT_IDLE 타입을 선택한다.
- 코드 라인 15~16에서 다른 cpu에서 요청받은 nohz 밸런싱을 시도한다
- trigger_load_balance() -> nohz_balancer_kick() -> kick_ilb() 함수에서 IPI를 통해 nohz idle 중인 cpu를 깨울 때 깨울 cpu의 런큐에 NOHZ_KICK_MASK 플래그가 설정하여 요청한다.
- 코드 라인 19~20에서 blocked 평균을 갱신한 후 nohz 밸런싱이 아닌 일반 적인 로드 밸런싱을 호출하여 동작한다.
rebalance_domains()
kernel/sched/fair.c -1/2-
/* * It checks each scheduling domain to see if it is due to be balanced, * and initiates a balancing operation if so. * * Balancing parameters are set up in init_sched_domains. */
static void rebalance_domains(struct rq *rq, enum cpu_idle_type idle)
{
int continue_balancing = 1;
int cpu = rq->cpu;
unsigned long interval;
struct sched_domain *sd;
/* Earliest time when we have to do rebalance again */
unsigned long next_balance = jiffies + 60*HZ;
int update_next_balance = 0;
int need_serialize, need_decay = 0;
u64 max_cost = 0;
rcu_read_lock();
for_each_domain(cpu, sd) {
/*
* Decay the newidle max times here because this is a regular
* visit to all the domains. Decay ~1% per second.
*/
if (time_after(jiffies, sd->next_decay_max_lb_cost)) {
sd->max_newidle_lb_cost =
(sd->max_newidle_lb_cost * 253) / 256;
sd->next_decay_max_lb_cost = jiffies + HZ;
need_decay = 1;
}
max_cost += sd->max_newidle_lb_cost;
if (!(sd->flags & SD_LOAD_BALANCE))
continue;
/*
* Stop the load balance at this level. There is another
* CPU in our sched group which is doing load balancing more
* actively.
*/
if (!continue_balancing) {
if (need_decay)
continue;
break;
}
- 코드 라인 8에서 밸런싱에 사용할 시각으로 최대값의 의미를 갖는 60초를 대입한다.
- 코드 라인 14에서 최상위 스케줄 도메인까지 순회한다.
- 코드 라인 19~25에서 1초에 한 번씩 sd->next_decay_max_lb_cost를 1%씩 decay 한다.
- 코드 라인 27~28에서 스케줄 도메인에 SD_LOAD_BALANCE 플래그가 없는 경우 skip 한다.
- 코드 라인 35~39에서 밸런싱에 성공하여 continue_balancing(초기값=1)이 설정되어 있지 않으면 need_decay 값에 따라 설정된 경우 skip하고 그렇지 않은 경우 루프를 벗어난다.
kernel/sched/fair.c -2/2-
interval = get_sd_balance_interval(sd, idle != CPU_IDLE);
need_serialize = sd->flags & SD_SERIALIZE;
if (need_serialize) {
if (!spin_trylock(&balancing))
goto out;
}
if (time_after_eq(jiffies, sd->last_balance + interval)) {
if (load_balance(cpu, rq, sd, idle, &continue_balancing)) {
/*
* The LBF_DST_PINNED logic could have changed
* env->dst_cpu, so we can't know our idle
* state even if we migrated tasks. Update it.
*/
idle = idle_cpu(cpu) ? CPU_IDLE : CPU_NOT_IDLE;
}
sd->last_balance = jiffies;
interval = get_sd_balance_interval(sd, idle != CPU_IDLE);
}
if (need_serialize)
spin_unlock(&balancing);
out:
if (time_after(next_balance, sd->last_balance + interval)) {
next_balance = sd->last_balance + interval;
update_next_balance = 1;
}
}
if (need_decay) {
/*
* Ensure the rq-wide value also decays but keep it at a
* reasonable floor to avoid funnies with rq->avg_idle.
*/
rq->max_idle_balance_cost =
max((u64)sysctl_sched_migration_cost, max_cost);
}
rcu_read_unlock();
/*
* next_balance will be updated only when there is a need.
* When the cpu is attached to null domain for ex, it will not be
* updated.
*/
if (likely(update_next_balance)) {
rq->next_balance = next_balance;
#ifdef CONFIG_NO_HZ_COMMON
/*
* If this CPU has been elected to perform the nohz idle
* balance. Other idle CPUs have already rebalanced with
* nohz_idle_balance() and nohz.next_balance has been
* updated accordingly. This CPU is now running the idle load
* balance for itself and we need to update the
* nohz.next_balance accordingly.
*/
if ((idle == CPU_IDLE) && time_after(nohz.next_balance, rq->next_balance))
nohz.next_balance = rq->next_balance;
#endif
}
}
- 코드 라인 1에서 스케줄 도메인의 밸런스 주기(jiffies)를 알아온다.
- 이 함수에는 CPU_IDLE 또는 CPU_NOT_IDLE 플래그 둘 중 하나로 요청된다.
- CPU_NOT_IDLE 상태인 경우 도메인의 밸런스 주기에 32배의 busy_factor(느린 밸런싱 주기)가 반영된다.
- 코드 라인 3~7에서 모든 cpu에서 누마 밸런싱을 위해 요청이 온 경우 시리얼하게 처리를 하기 위해 락을 획득한다. 실패하는 경우 skip 한다.
- NUMA 도메인들은 SD_SERIALIZE 플래그를 가지고 있다. 이 도메인에서 밸런싱 작업을 할 때 다른 cpu들에서 밸런싱을 하기 위해 진입하면 경쟁을 회피하기 위해 skip 하고 다음 밸런싱 인터벌 후에 다시 시도한다.
- 코드 라인 9~20에서 현재 시각이 순회 중인 도메인의 밸런싱 주기를 지나친 경우 로드 밸런싱을 수행한다. 그리고 밸런스 인터벌을 다시 갱신한다.
- 코드 라인 24~27에서 next_balance은 각 도메인의 last_balance + interval 값 중 최소치를 갱신해둔다.
- 코드 라인 29~36에서 need_decay가 설정된 경우 max_idle_balance_cost를 갱신한다.
- 코드 라인 44~59에서 갱신해둔 최소 next_balance로 런큐의 next_balance를 설정한다. CPU_IDLE로 진입한 경우엔 다음 주기 보다 nohz의 밸런싱 주기가 더 멀리 있는 경우 next_balance 주기도 동일하게 갱신한다.
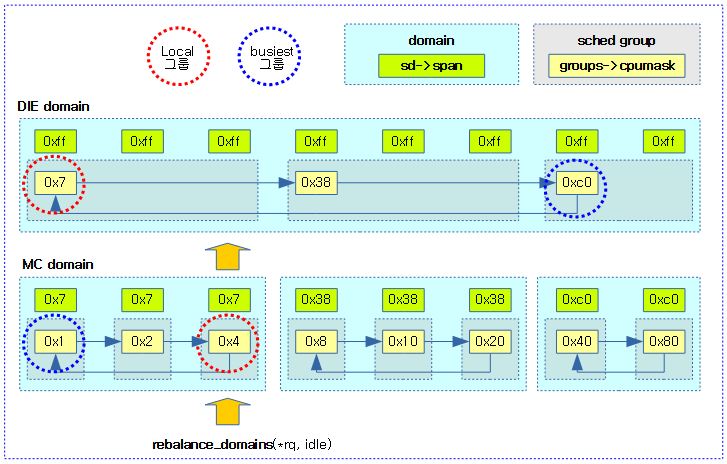
다음 그림은 특정 cpu의 런큐에 대해 최하위 스케줄 도메인부터 최상위 스케줄 도메인까지 로드 밸런스를 수행하는 모습을 보여준다.
- 각 스케줄 도메인에서 cpu#2가 포함된 스케줄 그룹이 로컬 그룹이고, 다른 비교 대상 그룹들과 밸런싱을 비교한다.
도메인의 밸런싱 주기
도메인의 밸런싱 인터벌(sd->balance_interval)은 다음과 같은 값으로 변화한다.
- 밸런싱 주기의 단위는 틱(tick)이며 최소 주기부터 시작한다.
- 최소 밸런싱 주기(sd->min_interval)는 해당 도메인의 cpu수 만큼이다.
- 따라서 도메인 레벨이 위로 올라갈 수록 밸런싱 주기는 길어진다.
- 최대 밸런싱 주기(sd->max_interval)는 최소 주기의 2배이다.
도메인의 다음 밸런싱 시각(rq->next_balance)은 다음과 같이 결정된다.
- 밸런싱으로 인한 오버 헤드를 적게 하기 위해 cpu가 not-idle 상태에서는 밸런싱 주기의 32배를 곱하여 사용하고, idle 상태인 경우에는 밸런싱 주기 그대로 사용한다.
- active 밸런싱을 수행한 경우에 다음 밸런싱 시각은 결정한 밸런싱 주기의 2배를 사용한다.
get_sd_balance_interval()
kernel/sched/fair.c
static inline unsigned long
get_sd_balance_interval(struct sched_domain *sd, int cpu_busy)
{
unsigned long interval = sd->balance_interval;
if (cpu_busy)
interval *= sd->busy_factor;
/* scale ms to jiffies */
interval = msecs_to_jiffies(interval);
interval = clamp(interval, 1UL, max_load_balance_interval);
return interval;
}
요청한 스케줄링 도메인의 밸런스 주기(jiffies)를 알아오는데 cpu_busy인 경우 로드밸런싱을 천천히 하도록 busy_factor를 곱하여 적용한다.
- 코드 라인 4~7에서 스케줄 도메인의 밸런스 주기를 알아온 후 인수 cpu_busy가 설정된 경우 busy_factor(디폴트: 32)를 곱한다.
- interval 값은 도메인 내 cpu 수로 시작하기 때문에 cpu가 많은 시스템에서 32배를 곱하면 매우 큰 수가 나온다. 따라서 이 값은 커널 v5.10-rc1에서 16으로 줄인다.
- 참고: sched/fair: Reduce busy load balance interval (2020, v5.10-rc1)
- interval 값은 도메인 내 cpu 수로 시작하기 때문에 cpu가 많은 시스템에서 32배를 곱하면 매우 큰 수가 나온다. 따라서 이 값은 커널 v5.10-rc1에서 16으로 줄인다.
- 코드 라인 10~13에서 ms 단위로된 밸런스 주기를 jiffies 단위로 변경하고 1 ~ max_load_balance_interval(초기값 0.1초)로 제한한 후 반환한다.
로드 밸런스
load_balance()
load_balance() 함수는 현재 cpu 로드와 스케줄링 도메인내의 가장 바쁜 cpu 로드와 비교하여 불균형 상태이면 밸런스 조절을 위해 가장 바쁜 cpu의 태스크를 현재 cpu로 마이그레이션해온다. (Pull migration) 만일 바쁜 cpu의 태스크가 동작 중이어서 가져올 수 없으면 바쁜 cpu에서 cpu stopper를 깨워 하나의 태스크를 요청한 cpu 쪽으로 마이그레이션하도록 한다. (Push migration)
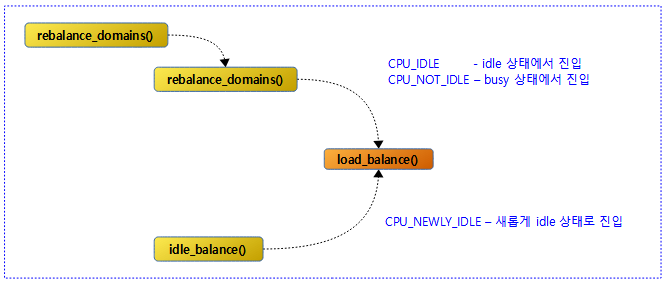
load_balance() 함수에 진입 시 사용되는 cpu_idle_type은 다음과 같이 3가지가 있다.
- CPU_IDLE
- 스케줄틱에 의해 주기적 로드밸런스 조건에서 진입 시, 현재 cpu의 런큐가 idle 중이다.
- SD_LOAD_BALANCE 플래그를 가진 스케줄 도메인 만큼 loop를 돈다.
- { env.dst = 현재 idle cpu <- env.src = 검색한 busiest cpu }
- CPU_NOT_IDLE
- 스케줄틱에 의해 주기적 로드밸런스 조건에서 진입 시, 현재 cpu의 런큐에서 어떤 태스크가 동작 중이다.
- SD_LOAD_BALANCE 플래그를 가진 스케줄 도메인 만큼 loop를 돈다.
- { env.dst = 현재 busy cpu <- env.src = 검색한 busiest cpu }
- CPU_NEWLY_IDLE
- 패시브 로드밸런스 조건으로, 런큐에서 마지막 동작하던 어떤 태스크가 dequeue되어 idle 진입 직전에 이 함수에 진입하였다.
- SD_LOAD_BALANCE & SD_BALANCE_NEWIDLE 플래그를 가진 스케줄 도메인 만큼 loop를 돌며 마이그레이션 성공하거나 런큐에 1 개 이상의 태스크가 동작할 때 stop 한다.
- { env.dst = 현재 new idle cpu <- env.src = 검색한 busiest cpu }
다음 그림은 3 가지 cpu_idle_type에 대해 진입하는 루트를 보여준다.
즉, 위와 같은 조건일 때에 인자로 요청한 스케줄 도메인에 포함된 cpu들과 현재 cpu 간에 뷸균형 로드가 발견되면 가장 바쁜 cpu의 태스크를 현재 cpu로 가져오는 것으로 로드밸런싱을 수행한다.
도메인내에서 가장 바쁜 cpu를 찾는 알고리즘은 다음과 같다.
- 첫 번째, find_busiest_group() 함수를 통해 도메인에서 가장 바쁜(busiest) 그룹을 찾는다.
- cpu 그룹의 로드 값에 그룹 평균 cpu capacity를 나누어 비교한다.
- 예) 다음 두 그룹의 로드는 고성능 및 저성능 그룹 각각 동일하다.
- 그룹A) 그룹로드=1035, 그룹 capacity =2070
- 그룹B) 그룹로드=430, 그룹 capacity =860
- 두 번째, find_busiest_queue() 함수를 통해 가장 바쁜(busiest) 그룹에서 가장 바쁜 cpu를 찾는다.
- cpu의 로드 값에 cpu capacity를 나누어 비교한다.
- 예) 다음 두 cpu의 로드는 고성능 및 저성능 cpu 각각 동일하다.
- cpu A) cpu 로드=1535, 그룹 capacity =1535
- cpu B) cpu 로드=430, 그룹 capacity =430
kernel/sched/fair.c -1/5-
/* * Check this_cpu to ensure it is balanced within domain. Attempt to move * tasks if there is an imbalance. */
static int load_balance(int this_cpu, struct rq *this_rq,
struct sched_domain *sd, enum cpu_idle_type idle,
int *continue_balancing)
{
int ld_moved, cur_ld_moved, active_balance = 0;
struct sched_domain *sd_parent = sd->parent;
struct sched_group *group;
struct rq *busiest;
struct rq_flags rf;
struct cpumask *cpus = this_cpu_cpumask_var_ptr(load_balance_mask);
struct lb_env env = {
.sd = sd,
.dst_cpu = this_cpu,
.dst_rq = this_rq,
.dst_grpmask = sched_group_cpus(sd->groups),
.idle = idle,
.loop_break = sched_nr_migrate_break,
.cpus = cpus,
.fbq_type = all,
.tasks = LIST_HEAD_INIT(env.tasks),
};
cpumask_copy(cpus, cpu_active_mask);
schedstat_inc(sd, lb_count[idle]);
redo:
if (!should_we_balance(&env)) {
*continue_balancing = 0;
goto out_balanced;
}
group = find_busiest_group(&env);
if (!group) {
schedstat_inc(sd, lb_nobusyg[idle]);
goto out_balanced;
}
busiest = find_busiest_queue(&env, group);
if (!busiest) {
schedstat_inc(sd, lb_nobusyq[idle]);
goto out_balanced;
}
BUG_ON(busiest == env.dst_rq);
schedstat_add(sd->lb_imbalance[idle], env.imbalance);
env.src_cpu = busiest->cpu;
env.src_rq = busiest;
- 코드 라인 10에서 per-cpu 로드 밸런스 cpu 마스크의 포인터를 가져온다.
- 코드 라인 12~22에서 로드밸런스 환경 정보를 담고 있는 env를 준비한다.
- 로드 밸런스에 사용할 lb_env 구조체 각 항목의 설명은 이 글의 마지막에 위치한다.
- 코드 라인 24에서 스케줄 도메인 @sd에 소속된 cpu들과 런큐가 동작 중인(cpu_active_mask) cpu들 둘 다 만족하는 cpu들을 알아온다.
- 코드 라인 26에서 idle 타입에 따른 스케줄링 도메인의 lb_count[] 카운터를 1 증가시킨다.
- 코드 라인 28~32에서 redo: 레이블이다. 이미 밸런싱 상태인 경우 out_balanced 레이블로 이동하여 함수를 빠져나간다.
- 코드 라인 34~38에서 busiest 그룹이 없는 경우 로드밸런싱을 할 필요가 없으므로 idle 타입에 따른 스케줄 도메인의 lb_nobusyg[] 카운터를 1 증가 시키고 out_balanced 레이블로 이동하여 함수를 빠져 나간다.
- 코드 라인 40~44에서 그룹내에서 busiest 런큐가 없는 경우 역시 로드밸런싱을 할 필요가 없으므로 idle 타입에 따른 스케줄 도메인의 lb_nobusyq[] 카운터를 1 증가 시키고 out_balanced 레이블로 이동하여 함수를 빠져 나간다.
- 코드 라인 48에서 스케줄링 도메인의 lb_imbalance[idle] stat에 env.imbalance 값을 추가한다.
- 코드 라인 50~51에서 src_cpu와 src_rq에 busiest cpu와 busiest 런큐 정보를 대입한다.
kernel/sched/fair.c -2/5-
ld_moved = 0;
if (busiest->nr_running > 1) {
/*
* Attempt to move tasks. If find_busiest_group has found
* an imbalance but busiest->nr_running <= 1, the group is
* still unbalanced. ld_moved simply stays zero, so it is
* correctly treated as an imbalance.
*/
env.flags |= LBF_ALL_PINNED;
env.loop_max = min(sysctl_sched_nr_migrate, busiest->nr_running);
more_balance:
rq_lock_irqsave(busiest, &rf);
update_rq_clock(busiest);
/*
* cur_ld_moved - load moved in current iteration
* ld_moved - cumulative load moved across iterations
*/
cur_ld_moved = detach_tasks(&env);
/*
* We've detached some tasks from busiest_rq. Every
* task is masked "TASK_ON_RQ_MIGRATING", so we can safely
* unlock busiest->lock, and we are able to be sure
* that nobody can manipulate the tasks in parallel.
* See task_rq_lock() family for the details.
*/
rq_unlock(busiest, &rf);
if (cur_ld_moved) {
attach_tasks(&env);
ld_moved += cur_ld_moved;
}
local_irq_restore(rf.flags);
if (env.flags & LBF_NEED_BREAK) {
env.flags &= ~LBF_NEED_BREAK;
goto more_balance;
}
- 코드 라인 2~10에서 busiest 런큐에 2개 이상의 러닝 태스크가 있는 경우 최대 반복 횟수로 busiest의 러닝 태스크 수를 대입하되 sysctl_sched_nr_migrate(디폴트 32)로 제한한다. 태스크들을 디태치하기 전에 태스크를 하나도 옮길 수 없는 의미의 LBF_ALL_PINNED 플래그를 초기값으로 대입한다. 이 플래그는 태스크들 중 하나라도 마이그레이션할 수 있을때 제거된다.
- busiest 런큐에 1개의 태스크가 있는 경우 해당 태스크가 이미 동작 주이므로 pull migration해올 수 없다. 이 경우 자동으로 ld_moved는 0이고, 이후 루틴에서 active 밸런싱을 통해 push migration을 시도한다.
- 코드 라인 12~14에서 more_balance: 레이블이다. bisiest 런큐 락을 획득한 후 런큐 클럭을 갱신한다.
- 코드 라인 20~30에서 마이그레이션할 태스크들을 env->src_rq에서 detach하고 그 수를 cur_ld_moved에 대입한 후 런큐 락을 해제한다.
- cur_ld_moved
- 현재 migration을 위해 detach한 태스크 수가 대입된다.
- ld_moved
- migration된 태스크 수가 누적된다.
- cur_ld_moved
- 코드 라인 32~35에서 detach한 태스크들을 env->dst_rq에 attach하고 ld_moved에 그 수를 더한다.
- 코드 라인 39~42에서 LBF_NEED_BREAK 플래그가 설정된 경우 이 플래그를 제거한 후 다시 more_balance 레이블로 다시 이동하여 더 처리하도록 한다.
- loop
- 현재 migration 시도 횟수가 담긴다.
- loop_max까지 시도하며, 중간에 loop_break 횟수에 도달하는 경우 loop_break 횟수를 누적시키고 다시 시도한다.
- loop_max
- busiest 그룹에서 동작 중인 태스크 수가 설정되고, sysctl_sched_nr_migrate(디폴트=32) 이하로 제한된다.
- “/proc/sys/kernel/sched_latency_ns”로 한 번의 밸런싱 호출을 처리할 때 migration 태스크의 최대 수를 제한할 수 있다.
- loop_break
- sched_nr_migrate_break(디폴트로 32)부터 시작하여 32개씩 증가한다.
- 태스크 수가 32개를 초과하는 경우 인터럽트를 너무 오랫동안 막고 migration 하는 것을 방지하기 위해 중간에 한 번씩 인터럽트를 열고 닫아줄 목적으로 사용한다. (interrupt latency를 짧게 유지하도록)
- loop
kernel/sched/fair.c -3/5-
. /*
* Revisit (affine) tasks on src_cpu that couldn't be moved to
* us and move them to an alternate dst_cpu in our sched_group
* where they can run. The upper limit on how many times we
* iterate on same src_cpu is dependent on number of cpus in our
* sched_group.
*
* This changes load balance semantics a bit on who can move
* load to a given_cpu. In addition to the given_cpu itself
* (or a ilb_cpu acting on its behalf where given_cpu is
* nohz-idle), we now have balance_cpu in a position to move
* load to given_cpu. In rare situations, this may cause
* conflicts (balance_cpu and given_cpu/ilb_cpu deciding
* _independently_ and at _same_ time to move some load to
* given_cpu) causing exceess load to be moved to given_cpu.
* This however should not happen so much in practice and
* moreover subsequent load balance cycles should correct the
* excess load moved.
*/
if ((env.flags & LBF_DST_PINNED) && env.imbalance > 0) {
/* Prevent to re-select dst_cpu via env's cpus */
cpumask_clear_cpu(env.dst_cpu, env.cpus);
env.dst_rq = cpu_rq(env.new_dst_cpu);
env.dst_cpu = env.new_dst_cpu;
env.flags &= ~LBF_DST_PINNED;
env.loop = 0;
env.loop_break = sched_nr_migrate_break;
/*
* Go back to "more_balance" rather than "redo" since we
* need to continue with same src_cpu.
*/
goto more_balance;
}
/*
* We failed to reach balance because of affinity.
*/
if (sd_parent) {
int *group_imbalance = &sd_parent->groups->sgc->imbalance;
if ((env.flags & LBF_SOME_PINNED) && env.imbalance > 0)
*group_imbalance = 1;
}
/* All tasks on this runqueue were pinned by CPU affinity */
if (unlikely(env.flags & LBF_ALL_PINNED)) {
cpumask_clear_cpu(cpu_of(busiest), cpus);
/*
* Attempting to continue load balancing at the current
* sched_domain level only makes sense if there are
* active CPUs remaining as possible busiest CPUs to
* pull load from which are not contained within the
* destination group that is receiving any migrated
* load.
*/
if (!cpumask_subset(cpus, env.dst_grpmask)) {
env.loop = 0;
env.loop_break = sched_nr_migrate_break;
goto redo;
}
goto out_all_pinned;
}
}
- 코드 라인 20~36에서 아직 불균형 상태이면서 LBF_DST_PINNED 플래그가 설정되어있는 경우, 즉 하나 이상의 태스크들이 목적하는(dest) cpu를 허용하지 않아 마이그레이션을 하지못한 경우이다. 따라서 dst cpu가 선택되지 않도록 막고 대체 cpu를 dst cpu로 지정한 후 LBF_DST_PINNED 플래그를 클리어한다. 그리고 loop 카운터를 리셋한 후 다시 처음부터 시작하도록 more_balance 레이블로 이동한다.
- 코드 라인 41~46에서 부모 도메인이 아직 불균형 상태이면서 태스크들 중 일부가 마이그레이션 되지 못하고 남아 있는 경우라 LBF_SOME_PINNED 플래그가 설정되어 있는 상태이다. 이 때엔 cpu affinity 문제로 밸런싱을 못하였으므로 다음 부모 스케줄링 도메인에서 밸런싱을 시도할 때 이를 알리기 위해 부모 스케줄링 도메인의 첫 스케줄 그룹 imbalance 값을 1로 변경한다.
- 코드 라인 49~65에서 낮은 확률로 LBF_ALL_PINNED 플래그가 설정되어 현재 런큐에 있는 모든 태스크의 마이그레이션이 불가능한 상태이다. 이러한 경우 busiest cpu를 제거하고, dst cpu로 사용할 수 있는 cpu가 남아 있는 경우 loop 카운터를 리셋하고 다시 redo 레이블로 이동하여 계속 처리하게 한다. dst cpu로 사용할 수 있는 cpu가 하나도 남지 않게 되면 out_all_pinned 레이블로 이동한 후 함수를 빠져나간다.
kernel/sched/fair.c -4/5-
. if (!ld_moved) {
schedstat_inc(sd, lb_failed[idle]);
/*
* Increment the failure counter only on periodic balance.
* We do not want newidle balance, which can be very
* frequent, pollute the failure counter causing
* excessive cache_hot migrations and active balances.
*/
if (idle != CPU_NEWLY_IDLE)
sd->nr_balance_failed++;
if (need_active_balance(&env)) {
unsigned long flags;
raw_spin_lock_irqsave(&busiest->lock, flags);
/* don't kick the active_load_balance_cpu_stop,
* if the curr task on busiest cpu can't be
* moved to this_cpu
*/
if (!cpumask_test_cpu(this_cpu, busiest->curr->cpus_ptr)) {
raw_spin_unlock_irqrestore(&busiest->lock,
flags);
env.flags |= LBF_ALL_PINNED;
goto out_one_pinned;
}
/*
* ->active_balance synchronizes accesses to
* ->active_balance_work. Once set, it's cleared
* only after active load balance is finished.
*/
if (!busiest->active_balance) {
busiest->active_balance = 1;
busiest->push_cpu = this_cpu;
active_balance = 1;
}
raw_spin_unlock_irqrestore(&busiest->lock, flags);
if (active_balance) {
stop_one_cpu_nowait(cpu_of(busiest),
active_load_balance_cpu_stop, busiest,
&busiest->active_balance_work);
}
/*
* We've kicked active balancing, reset the failure
* counter.
*/
sd->nr_balance_failed = sd->cache_nice_tries+1;
}
} else
sd->nr_balance_failed = 0;
- 코드 라인 1~2에서 마이그레이션한 태스크가 하나도 없는 경우 스케줄링 도메인의 lb_failed[idle] 카운터를 1 증가시킨다.
- 코드 라인 9~10에서 CPU_NEWLY_IDLE이 아닌 경우 스케줄링 도메인의 nr_balance_failed 카운터를 1 증가시킨다.
- 코드 라인 12~15에서 active 로드 밸런싱 조건을 만족하게 되면 busiest 스핀 락을 획득한다.
- nr_balance_failed > cache_nice_tries+2인 경우 true가 된다.
- 코드 라인 21~26에서 현재 cpu가 busiest의 현재 태스크에 허가된 cpu가 아닌 경우 모든 태스크들을 옮길 수 없게 되었으므로 LBF_ALL_PINNED 플래그를 추가한 후 out_one_pinned 레이블로 이동하여 함수를 빠져나간다.
- 코드 라인 33~44에서 busiest 런큐의 active_balance를 1로 설정하고 태스크를 이동해올 목적지 cpu로 this_cpu(dest cpu)를 지정한 후 busiest cpu에서 push migration하도록 의뢰한다.
- stop 스케줄러에서 동작하는 cpu stopper 스레드(“migration%d” 커널스레드)는 active_load_balance_cpu_stop() 함수를 호출하는데 busiest cpu에서 동작 중인 cpu stopper 스레드를 제외한 나머지 태스크들 중 하나를 선택하여 rq->push_cpu 쪽으로 마이그레이션 한다.
- 코드 라인 50에서 스케줄링 도메인의 nr_balance_failed에 cache_nice_tries+1 값을 대입한다.
- 코드 라인 52~53에서 로드 밸런스로 옮겨진 태스크가 있는 경우 스케줄링 도메인의 nr_balance_failed 통계를 0으로 리셋한다.
kernel/sched/fair.c -5/5-
if (likely(!active_balance) || voluntary_active_balance(&env)) {
/* We were unbalanced, so reset the balancing interval */
sd->balance_interval = sd->min_interval;
} else {
/*
* If we've begun active balancing, start to back off. This
* case may not be covered by the all_pinned logic if there
* is only 1 task on the busy runqueue (because we don't call
* detach_tasks).
*/
if (sd->balance_interval < sd->max_interval)
sd->balance_interval *= 2;
}
goto out;
out_balanced:
/*
* We reach balance although we may have faced some affinity
* constraints. Clear the imbalance flag only if other tasks got
* a chance to move and fix the imbalance.
*/
if (sd_parent && !(env.flags & LBF_ALL_PINNED)) {
int *group_imbalance = &sd_parent->groups->sgc->imbalance;
if (*group_imbalance)
*group_imbalance = 0;
}
out_all_pinned:
/*
* We reach balance because all tasks are pinned at this level so
* we can't migrate them. Let the imbalance flag set so parent level
* can try to migrate them.
*/
schedstat_inc(sd, lb_balanced[idle]);
sd->nr_balance_failed = 0;
out_one_pinned:
ld_moved = 0;
/*
* newidle_balance() disregards balance intervals, so we could
* repeatedly reach this code, which would lead to balance_interval
* skyrocketting in a short amount of time. Skip the balance_interval
* increase logic to avoid that.
*/
if (env.idle == CPU_NEWLY_IDLE)
goto out;
/* tune up the balancing interval */
if (((env.flags & LBF_ALL_PINNED) &&
sd->balance_interval < MAX_PINNED_INTERVAL) ||
sd->balance_interval < sd->max_interval)
sd->balance_interval *= 2;
out:
return ld_moved;
}
- 코드 라인 1~15에서 밸런스 주기를 조정하고 out 레이블로 이동한다. 높은 확률로 active_balance가 실행된 적이 없는 경우 스케줄링 도메인의 밸런스 주기에 최소 주기를 대입하고, 실행된 적이 있는 경우 밸런스 주기를 최대 밸런스 주기를 넘지 않을 때에만 두 배로 증가시킨다.
- 코드 라인 17~28에서 out_balanced: 레이블이다. 이미 밸런스가 잡힌 경우 진입하는데, all pinned 설정이 아닌 경우 부모 스케줄링 도메인의 첫 스케줄링 그룹 imbalance 값을 0으로 리셋한다.
- 코드 라인 30~38에서 out_all_pinned 레이블이다. 스케줄링 도메인의 lb_balanced[idle] 카운터를 1 증가시키고 nr_balance_failed를 0으로 리셋한다.
- 코드 라인 40~50에서 ld_moved를 0으로 리셋하고, cpu가 처음 idle 상태에 진입하였던 경우 out 레이블로 이동하고 함수를 빠져나간다.
- 코드 라인 53~56에서 LBF_ALL_PINNED 플래그가 설정되었고 밸런스 주기가 MAX_PINNED_INTERVAL(512) 및 max_interval 이내인 경우 밸런스 주기를 2배로 높인다.
- 코드 라인 57~58에서 out: 레이블이다. 로드밸런싱으로 인해 마이그레이션한 태스크 수를 반환한다.
다음 그림은 DIE domain에서 cpu#2가 포함된 로컬 그룹과 다른 그룹들을 비교하여 busiest group를 찾은 후 그에 소속된 cpu들 사이에서 buest queue를 찾는 모습을 보여준다.

밸런스 필요 체크
should_we_balance()
kernel/sched/fair.c
static int should_we_balance(struct lb_env *env)
{
struct sched_group *sg = env->sd->groups;
int cpu, balance_cpu = -1;
/*
* Ensure the balancing environment is consistent; can happen
* when the softirq triggers 'during' hotplug.
*/
if (!cpumask_test_cpu(env->dst_cpu, env->cpus))
return 0;
/*
* In the newly idle case, we will allow all the CPUs
* to do the newly idle load balance.
*/
if (env->idle == CPU_NEWLY_IDLE)
return 1;
/* Try to find first idle CPU */
for_each_cpu_and(cpu, group_balance_mask(sg), env->cpus) {
if (!idle_cpu(cpu))
continue;
balance_cpu = cpu;
break;
}
if (balance_cpu == -1)
balance_cpu = group_balance_cpu(sg);
/*
* First idle CPU or the first CPU(busiest) in this sched group
* is eligible for doing load balancing at this and above domains.
*/
return balance_cpu == env->dst_cpu;
}
로드 밸런스를 하여도 되는지 여부를 반환한다.
- 코드 라인 10~11에서 env->cpus 들에 dst_cpu가 없으면 로드 밸런싱을 하지 않도록 0을 반환한다.
- 코드 라인 17~18에서 cpu가 처음 idle 진입한 경우 항상 true(1)를 반환하여 로드밸런싱을 시도하게 한다.
- pull 마이그레이션을 시도하는 현재 cpu가 idle 상태에서 진입한 경우 항상 밸런스를 허용한다.
- 코드 라인 21~30에서 첫 스케줄 그룹의 밸런스 마스크에 속한 cpu들과 env->cpus 둘 모두 포함된 cpu들을 대상으로 순회하며 첫 idle cpu를 찾는다. 만일 못 찾은 경우 스케줄링 그룹의 첫 번째 cpu를 알아온다.
- 코드 라인 36에서 알아온 cpu가 env->dst_cpu인지 여부를 반환한다.
- pull 마이그레이션을 시도하는 현재 cpu가 busy cpu 상태에서 진입한 경우 dst cpu가 idle 상태이거나, 첫 그룹 밸런스 마스크의 첫 번째 cpu인 경우 밸런스를 허용한다.
- 참고로 처음 밸런싱 시도시에는 this cpu가 dst cpu이지만 특정 태스크가 this cpu를 허용하지 않는 경우 두 번째 시도에서는 dst cpu가 다른 cpu로 바뀐다.
다음 그림은 busy 상태에서 밸런스를 시도할 수 있는 cpu를 보여준다.
- 3 가지 case가 있지만 그림에는 1)과 3)의 case만 표현하였다.
- 1) idle 상태에서는 어떠한 cpu도 밸런스를 시도할 수 있다.
- 2) busy cpu의 경우 dst cpu가 첫 그룹 밸런스 마스크의 첫 번째 idle cpu인 경우에만 밸런스를 시도한다.
- 3) 위의 2)번 케이스에서 idle cpu가 하나도 찾을 수 없는 경우 첫 그룹의 밸런스 마스크 중 첫 번째 cpu만 밸런스를 시도할 수 있다.

도메인내 가장 바쁜 그룹 및 cpu 찾기
도메인 내 가장 바쁜 그룹 찾기
find_busiest_group()
kernel/sched/fair.c -1/2-
/******* find_busiest_group() helpers end here *********************/ /** * find_busiest_group - Returns the busiest group within the sched_domain * if there is an imbalance. * * Also calculates the amount of runnable load which should be moved * to restore balance. * * @env: The load balancing environment. * * Return: - The busiest group if imbalance exists. */
static struct sched_group *find_busiest_group(struct lb_env *env)
{
struct sg_lb_stats *local, *busiest;
struct sd_lb_stats sds;
init_sd_lb_stats(&sds);
/*
* Compute the various statistics relavent for load balancing at
* this level.
*/
update_sd_lb_stats(env, &sds);
if (sched_energy_enabled()) {
struct root_domain *rd = env->dst_rq->rd;
if (rcu_dereference(rd->pd) && !READ_ONCE(rd->overutilized))
goto out_balanced;
}
local = &sds.local_stat;
busiest = &sds.busiest_stat;
/* ASYM feature bypasses nice load balance check */
if (check_asym_packing(env, &sds))
return sds.busiest;
/* There is no busy sibling group to pull tasks from */
if (!sds.busiest || busiest->sum_nr_running == 0)
goto out_balanced;
/* XXX broken for overlapping NUMA groups */
sds.avg_load = (SCHED_CAPACITY_SCALE * sds.total_load)
/ sds.total_capacity;
/*
* If the busiest group is imbalanced the below checks don't
* work because they assume all things are equal, which typically
* isn't true due to cpus_ptr constraints and the like.
*/
if (busiest->group_type == group_imbalanced)
goto force_balance;
/*
* When dst_cpu is idle, prevent SMP nice and/or asymmetric group
* capacities from resulting in underutilization due to avg_load.
*/
if (env->idle != CPU_NOT_IDLE && group_has_capacity(env, local) &&
busiest->group_no_capacity)
goto force_balance;
/* Misfit tasks should be dealt with regardless of the avg load */
if (busiest->group_type == group_misfit_task)
goto force_balance;
요청한 로드밸런스 환경을 사용하여 태스크를 끌어오기 위해 가장 바쁜 스케줄 그룹을 찾아온다.
- 코드 라인 6에서 로드 밸런스에 사용하는 스케줄 도메인 통계 sds를 초기화하는데 sds.busiest_stat->group_type을 group_other로 초기화한다.
- 코드 라인 12에서 로드 밸런스를 위해 스케줄 도메인 통계 sds를 갱신한다.
- 코드 라인 14~19에서 EAS(Energy Aware Scheduler)가 enable된 경우 performance 도메인이 가동 중이고 오버 유틸되지 않은 경우 밸런스가 필요없으므로 out_balanced 레이블로 이동한다.
- EAS에서는 도메인내에 오버 유틸된 cpu가 하나라도 있어야 밸런싱을 시도한다.
- 코드 라인 21~22에서 local 및 busiest에 대한 통계를 관리하기 위해 지정해둔다.
- 코드 라인 25~26에서 asym packing 도메인(SMT를 사용하는 POWER7 칩은 0번 hw thread가 1번보다 더 빠르므로 0번 hw trhead가 idle 상태로 변경되는 시점에서 1번 hw thread에서 동작 중인 태스크를 0번으로 옮기는 것이 성능면에서 효율적이다)을 사용하는 cpu인 경우 보다 빠른 코어로 migration을 하는 것이 좋다고 판단되어 sds.busiest 그룹을 반환한다.
- 코드 라인 29~30에서 끌어 당겨올 busiest 그룹이 없거나 busiest 그룹에서 동작하는 cfs 태스크가 하나도 없는 경우 out_balanced 레이블로 이동한다.
- 코드 라인 33~34 도메인의 전체 로드에서 전체 capacity를 나누어 도메인 로드 평균을 구한다.
- 코드 라인 41~42에서 태스크가 특정 cpu로 제한되어 그룹 간의 로드 평균을 비교하는 일반적인 방법을 사용할 수 없는 상황이다. 이렇게 busiest 그룹이 불균형 밸런스 타입으로 분류된 경우 불균형 상태로 분류하여 force_balance 레이블로 이동 후 calculate_imbalance() 함수를 통해 기 선정된 busiest 그룹의 불균형 값을 산출한다.
- 밸런싱 시 태스크의 일부를 마이그레이션(LBF_SOME_PINNED ) 할 수 없었던 경우 상위 도메인 첫 그룹 capacity의 imbalance 값에 1을 대입하여 그룹 불균형 상태를 감지하도록 설정한다.
- 코드 라인 48~50에서 idle 및 newidle 상태에서 진입하였고, 로컬 그룹이 충분한 capacity를 가졌고, busiest 그룹이 capacity가 부족한 상황이면 이 busiest 그룹을 불균형 상태로 분류하여 무조건 밸런싱이 필요한 상황이므로 force_balance 레이블로 이동한다.
- 코드 라인 53~54에서 busiest 그룹이 misfit_task 상태로 분류된 경우 이 역시 busiest 그룹을 불균형 상태로 분류하여 무조건 밸런싱이 필요한 상황이므로 force_balance 레이블로 이동한다.
kernel/sched/fair.c -2/2-
/*
* If the local group is busier than the selected busiest group
* don't try and pull any tasks.
*/
if (local->avg_load >= busiest->avg_load)
goto out_balanced;
/*
* Don't pull any tasks if this group is already above the domain
* average load.
*/
if (local->avg_load >= sds.avg_load)
goto out_balanced;
if (env->idle == CPU_IDLE) {
/*
* This CPU is idle. If the busiest group is not overloaded
* and there is no imbalance between this and busiest group
* wrt idle CPUs, it is balanced. The imbalance becomes
* significant if the diff is greater than 1 otherwise we
* might end up to just move the imbalance on another group
*/
if ((busiest->group_type != group_overloaded) &&
(local->idle_cpus <= (busiest->idle_cpus + 1)))
goto out_balanced;
} else {
/*
* In the CPU_NEWLY_IDLE, CPU_NOT_IDLE cases, use
* imbalance_pct to be conservative.
*/
if (100 * busiest->avg_load <=
env->sd->imbalance_pct * local->avg_load)
goto out_balanced;
}
force_balance:
/* Looks like there is an imbalance. Compute it */
env->src_grp_type = busiest->group_type;
calculate_imbalance(env, &sds);
return env->imbalance ? sds.busiest : NULL;
out_balanced:
env->imbalance = 0;
return NULL;
}
- 코드 라인 5~34에서 다음 조건들 중 하나라도 걸리는 경우 밸런싱을 할 필요없어 포기하기 위해 out_balanced 레이블로 이동한다.
- 로컬 그룹의 평균 로드가 선택한 busiest 그룹의 평균 로드보다 크거나 같다.
- 로컬 그룹의 평균 로드가 도메인의 평균 로드보다 더 크거나 같다.
- idle 상태에서 진입하였고, busiest 그룹이 오버 로드된 상태가 아니고, 로컬 그룹의 idle cpu가 busiest 그룹에 비해 2개 이상 더 많지 않을 때이다.
- not-idle 또는 new idle 상태로 진입한 경우 로컬 그룹의 로드가 busiest 그룹보다 더 로드가 큰 경우이다.
- 밸런싱에는 오버헤드가 있으므로 로컬 값에 imbalance_pct 비율만큼 더 가중치를 줘서 약간의 차이일 때에는 밸런싱을 하지 못하게 한다.
- imbalance_pct 비율은 SMT는 110%, MC는 117%, 그 외 도메인의 경우 125%의 가중치를 사용한다. 이 값이 클 수록 로컬에 더 가중치를 주어 밸런싱을 억제하게 한다.
- imbalance_pct 비율은 커널 v5.10-rc1에서 디폴트로 117%로 줄여, DIE나 NUMA 도메인에서도 이 값을 사용하게 한다.
- 참고: sched/fair: Reduce minimal imbalance threshold (2020, v5.10-rc1)
- 코드 라인 36~40에서 force_balance 레이블이다. imbalance를 산출하고, 그 후 결정된 busiest 스케줄 그룹을 반환한다.
- 코드 라인 42~44에서 busiest 그룹을 찾지 못했다. 밸런싱을 포기하도록 null을 반환한다.
그룹 내 가장 바쁜 cpu 찾기
find_busiest_queue()
kernel/sched/fair.c -1/2-
/* * find_busiest_queue - find the busiest runqueue among the CPUs in the group. */
static struct rq *find_busiest_queue(struct lb_env *env,
struct sched_group *group)
{
struct rq *busiest = NULL, *rq;
unsigned long busiest_load = 0, busiest_capacity = 1;
int i;
for_each_cpu_and(i, sched_group_span(group), env->cpus) {
unsigned long capacity, load;
enum fbq_type rt;
rq = cpu_rq(i);
rt = fbq_classify_rq(rq);
/*
* We classify groups/runqueues into three groups:
* - regular: there are !numa tasks
* - remote: there are numa tasks that run on the 'wrong' node
* - all: there is no distinction
*
* In order to avoid migrating ideally placed numa tasks,
* ignore those when there's better options.
*
* If we ignore the actual busiest queue to migrate another
* task, the next balance pass can still reduce the busiest
* queue by moving tasks around inside the node.
*
* If we cannot move enough load due to this classification
* the next pass will adjust the group classification and
* allow migration of more tasks.
*
* Both cases only affect the total convergence complexity.
*/
if (rt > env->fbq_type)
continue;
/*
* For ASYM_CPUCAPACITY domains with misfit tasks we simply
* seek the "biggest" misfit task.
*/
if (env->src_grp_type == group_misfit_task) {
if (rq->misfit_task_load > busiest_load) {
busiest_load = rq->misfit_task_load;
busiest = rq;
}
continue;
}
스케줄 그룹내에서 가장 busy한 워크 로드(러너블 로드 평균 / cpu capacity)를 가진 cpu 런큐를 반환한다.
- 코드 라인 8에서 스케줄 그룹 소속 cpu들과 env->cpus 들 양쪽에 포함된 cpu들을 대상으로 순회한다.
- 코드 라인 34~35에서 NUMA 밸런싱을 사용하는 시스템의 경우 런큐의 fbq 타입이 env->fbq_type 보다 큰 경우 skip 한다.
- NUMA 밸런싱을 사용하지 않는 경우 런큐의 fbq 타입은 항상 regular(0)이므로 skip 하지 않는다.
- fbq_type은 NUMA 시스템에서만 갱신되며 update_sd_lb_stats() 함수를 통해 도메인 통계를 산출한 후에 이루어진다.
- 코드 라인 41~48에서 빅/리틀 클러스터가 운영되는 asym 도메인에서 misfit task 로드를 관리하는데 소스 그룹 타입이 group_misfit_task 타입이고, 런큐의 misfit_task_load가 busiest_load보다 커서 갱신할 때 이 그룹을 busiest 그룹으로 선택한다. 이 후 다음 그룹을 계속한다.
kernel/sched/fair.c -2/2-
capacity = capacity_of(i);
/*
* For ASYM_CPUCAPACITY domains, don't pick a CPU that could
* eventually lead to active_balancing high->low capacity.
* Higher per-CPU capacity is considered better than balancing
* average load.
*/
if (env->sd->flags & SD_ASYM_CPUCAPACITY &&
capacity_of(env->dst_cpu) < capacity &&
rq->nr_running == 1)
continue;
load = cpu_runnable_load(rq);
/*
* When comparing with imbalance, use cpu_runnable_load()
* which is not scaled with the CPU capacity.
*/
if (rq->nr_running == 1 && load > env->imbalance &&
!check_cpu_capacity(rq, env->sd))
continue;
/*
* For the load comparisons with the other CPU's, consider
* the cpu_runnable_load() scaled with the CPU capacity, so
* that the load can be moved away from the CPU that is
* potentially running at a lower capacity.
*
* Thus we're looking for max(load_i / capacity_i), crosswise
* multiplication to rid ourselves of the division works out
* to: load_i * capacity_j > load_j * capacity_i; where j is
* our previous maximum.
*/
if (load * busiest_capacity > busiest_load * capacity) {
busiest_load = load;
busiest_capacity = capacity;
busiest = rq;
}
}
return busiest;
}
- 코드 라인 1~12에서 SD_ASYM_CPUCAPACITY 플래그를 사용하는 빅리틀 유형의 도메인이고, 산출한 capacity가 dst cpu의 capacity 보다 크고, 런큐에 태스크가 1개만 잘 동작하고 있으므로 이 때에는 skip 한다.
- 1개의 태스크가 빅 cpu에서 동작할 때 평균 로드 분산을 위해 active 밸런싱을 통해 리틀 cpu로 옮기기 보다는 그냥 빅 cpu에서 계속 동작하는 것이 더 좋기 때문에 밸런싱을 하지 않는다.
- 코드 라인 14~23에서 순회 중인 cpu의 런큐에서 busiest 그룹의 imbalance 값보다 더 높은 러너블 로드로 rt/dl/irq 방해없이 cfs 태스크가 잘 동작하는 경우 밸런싱을 하지 않도록 skip 한다.
- 태스크가 1개만 동작하고 러너블 로드 값이 env->imbalance 값보다 크며 rt/dl/irq 등의 유틸로 인해 cfs capacity가 감소하지 않은 경우 skip 한다.
- 코드 라인 36~40에서 마지막으로 이제 실제 러너블 로드 값을 비교하여 busiest 런큐를 갱신한다.
- cpu 스케일 적용하여 순회 중인 cpu의 로드 값과 busiest cpu의 로드를 서로 비교하여 busiest를 갱신한다.
- 당연히 처음 루프에서는 무조건 갱신한다.
- 코드 라인 43에서 가장 바쁜 cpu 런큐를 반환한다.
스케일 적용된 cpu 로드 비교
예) 두 개의 cpu capacity는 A=1024, B=480이고, 동일한 200의 로드를 가지는 경우 누가 busy cpu일까?
- 19.5%(A: 200/1204) < 41.7%(B: 200/480)
예) 두 개의 cpu capacity는 A=1024, B=480이고, 각각 A=400, B=200의 로드를 가지는 경우 누가 busy cpu일까?
- 39.1%(A: 400/1024) < 41.7%(B: 200/480)
로드밸런스 통계
스케줄링 도메인 로드밸런스 통계 갱신
update_sd_lb_stats()
kernel/sched/fair.c -1/2-
/** * update_sd_lb_stats - Update sched_domain's statistics for load balancing. * @env: The load balancing environment. * @sds: variable to hold the statistics for this sched_domain. */
static inline void update_sd_lb_stats(struct lb_env *env, struct sd_lb_stats *sds)
{
struct sched_domain *child = env->sd->child;
struct sched_group *sg = env->sd->groups;
struct sg_lb_stats *local = &sds->local_stat;
struct sg_lb_stats tmp_sgs;
bool prefer_sibling = child && child->flags & SD_PREFER_SIBLING;
int sg_status = 0;
#ifdef CONFIG_NO_HZ_COMMON
if (env->idle == CPU_NEWLY_IDLE && READ_ONCE(nohz.has_blocked))
env->flags |= LBF_NOHZ_STATS;
#endif
do {
struct sg_lb_stats *sgs = &tmp_sgs;
int local_group;
local_group = cpumask_test_cpu(env->dst_cpu, sched_group_span(sg));
if (local_group) {
sds->local = sg;
sgs = local;
if (env->idle != CPU_NEWLY_IDLE ||
time_after_eq(jiffies, sg->sgc->next_update))
update_group_capacity(env->sd, env->dst_cpu);
}
update_sg_lb_stats(env, sg, sgs, &sg_status);
if (local_group)
goto next_group;
/*
* In case the child domain prefers tasks go to siblings
* first, lower the sg capacity so that we'll try
* and move all the excess tasks away. We lower the capacity
* of a group only if the local group has the capacity to fit
* these excess tasks. The extra check prevents the case where
* you always pull from the heaviest group when it is already
* under-utilized (possible with a large weight task outweighs
* the tasks on the system).
*/
if (prefer_sibling && sds->local &&
group_has_capacity(env, local) &&
(sgs->sum_nr_running > local->sum_nr_running + 1)) {
sgs->group_no_capacity = 1;
sgs->group_type = group_classify(sg, sgs);
}
if (update_sd_pick_busiest(env, sds, sg, sgs)) {
sds->busiest = sg;
sds->busiest_stat = *sgs;
}
next_group:
/* Now, start updating sd_lb_stats */
sds->total_running += sgs->sum_nr_running;
sds->total_load += sgs->group_load;
sds->total_capacity += sgs->group_capacity;
sg = sg->next;
} while (sg != env->sd->groups);
로드 밸런스를 위한 스케줄 도메인 통계 sd_lb_stats를 갱신한다.
- 코드 라인 11~12에서 no hz로 처음 진입한 경우 LBF_NOHZ_STATS 플래그를 추가한다.
- 코드 라인 15~32에서 스케줄 그룹을 순회하며 그룹 통계를 갱신한다. 만일 dst cpu가 포함된 스케줄 그룹은 로컬 그룹으로 지정하고, next_group 레이블로 이동한다. 또한 new-idle 상태로 진입한 경우가 아니고 갱신 주기가 도달한 경우 그룹 capacity도 갱신한다.
- update_group_capacity() 참고: Scheduler -14- (Scheduling Domain 2) | 문c
- 코드 라인 44~49에서 child 도메인에 SD_PREFER_SIBLING 플래그가 있는 도메인이면서 로컬 그룹의 capacity가 여유가 있고 순회 중인 그룹의 태스크 수가 로컬 그룹의 태스크 수보다 2개 이상 더 많은 경우에 한해 그룹 타입을 group_overloaded 상태로 변경한다.
- 코드 라인 51~54에서 순회 중인 그룹 중 busiest 그룹을 선택하고 busiest 통계를 갱신한다.
- 코드 라인 56~63에서 next_group 레이블이다. 전체 그룹의 로드를 누적하고 다음 그룹 루프를 돈다.
kernel/sched/fair.c -2/2-
#ifdef CONFIG_NO_HZ_COMMON
if ((env->flags & LBF_NOHZ_AGAIN) &&
cpumask_subset(nohz.idle_cpus_mask, sched_domain_span(env->sd))) {
WRITE_ONCE(nohz.next_blocked,
jiffies + msecs_to_jiffies(LOAD_AVG_PERIOD));
}
#endif
if (env->sd->flags & SD_NUMA)
env->fbq_type = fbq_classify_group(&sds->busiest_stat);
if (!env->sd->parent) {
struct root_domain *rd = env->dst_rq->rd;
/* update overload indicator if we are at root domain */
WRITE_ONCE(rd->overload, sg_status & SG_OVERLOAD);
/* Update over-utilization (tipping point, U >= 0) indicator */
WRITE_ONCE(rd->overutilized, sg_status & SG_OVERUTILIZED);
trace_sched_overutilized_tp(rd, sg_status & SG_OVERUTILIZED);
} else if (sg_status & SG_OVERUTILIZED) {
struct root_domain *rd = env->dst_rq->rd;
WRITE_ONCE(rd->overutilized, SG_OVERUTILIZED);
trace_sched_overutilized_tp(rd, SG_OVERUTILIZED);
}
}
- 코드 라인 2~7에서 LBF_NOHZ_AGAIN 플래그를 가지고 도메인에 no hz idle cpu들을 모두 포함한 경우 nohz.next_blocked 시각을 32ms 후의 시각으로 설정한다.
- 코드 라인 10~11에서 누마 스케줄 도메인인 경우 busiest 그룹에서 fbq 타입을 알아와서 지정한다.
- 코드 라인 13~21에서 마지막 도메인을 진행 중인 경우 dst 런큐의 루트도메인에 overload 및 overutilized 여부를 갱신한다.
- 코드 라인 22~27에서 마지막 도메인이 아니고 overutilized 된 경우에만 루트도메인에 overload 및 overutilized를 SG_OVERUTILIZED(2) 값으로 갱신한다.
다음 그림은 sd_lb_stats 구조체에 도메인 통계 및 local/busiest 그룹에 대한 통계를 산출하는 모습을 보여준다.

스케줄링 그룹 로드밸런스 통계 갱신
update_sg_lb_stats()
kernel/sched/fair.c
/** * update_sg_lb_stats - Update sched_group's statistics for load balancing. * @env: The load balancing environment. * @group: sched_group whose statistics are to be updated. * @sgs: variable to hold the statistics for this group. * @sg_status: Holds flag indicating the status of the sched_group */
static inline void update_sg_lb_stats(struct lb_env *env,
struct sched_group *group,
struct sg_lb_stats *sgs,
int *sg_status)
{
int i, nr_running;
memset(sgs, 0, sizeof(*sgs));
for_each_cpu_and(i, sched_group_span(group), env->cpus) {
struct rq *rq = cpu_rq(i);
if ((env->flags & LBF_NOHZ_STATS) && update_nohz_stats(rq, false))
env->flags |= LBF_NOHZ_AGAIN;
sgs->group_load += cpu_runnable_load(rq);
sgs->group_util += cpu_util(i);
sgs->sum_nr_running += rq->cfs.h_nr_running;
nr_running = rq->nr_running;
if (nr_running > 1)
*sg_status |= SG_OVERLOAD;
if (cpu_overutilized(i))
*sg_status |= SG_OVERUTILIZED;
#ifdef CONFIG_NUMA_BALANCING
sgs->nr_numa_running += rq->nr_numa_running;
sgs->nr_preferred_running += rq->nr_preferred_running;
#endif
/*
* No need to call idle_cpu() if nr_running is not 0
*/
if (!nr_running && idle_cpu(i))
sgs->idle_cpus++;
if (env->sd->flags & SD_ASYM_CPUCAPACITY &&
sgs->group_misfit_task_load < rq->misfit_task_load) {
sgs->group_misfit_task_load = rq->misfit_task_load;
*sg_status |= SG_OVERLOAD;
}
}
/* Adjust by relative CPU capacity of the group */
sgs->group_capacity = group->sgc->capacity;
sgs->avg_load = (sgs->group_load*SCHED_CAPACITY_SCALE) / sgs->group_capacity;
if (sgs->sum_nr_running)
sgs->load_per_task = sgs->group_load / sgs->sum_nr_running;
sgs->group_weight = group->group_weight;
sgs->group_no_capacity = group_is_overloaded(env, sgs);
sgs->group_type = group_classify(group, sgs);
}
로드 밸런스를 위한 스케줄 그룹 통계 sg_lb_stats를 갱신한다.
- 코드 라인 8에서 먼저 출력 인수로 지정된 스케줄 그룹 통계 @sgs를 모두 0으로 초기화한다.
- 코드 라인 10에서 스케줄 그룹에 포함한 cpu들과 env->cpus로 요청한 cpu들 둘 모두에 포함된 cpu들에 대해 순회한다.
- 코드 라인 13~14에서 LBF_NOHZ_STATS 플래그 요청이 있는 경우 no hz 관련 블럭드 로드가 있는 경우 블럭드 로드 관련 통계를 갱신하고 LBF_NOHZ_AGAIN 플래그를 추가한다.
- 코드 라인 16~18에서 그룹에 속한 cpu의 러너블 로드, 유틸 및 cfs 태스크 수 등을 그룹 통계에 누적시킨다.
- 코드 라인 20~22에서 cfs 태스크가 2 개 이상 동작하는 경우 출력 인자 @sg_status에 SG_OVERLOAD 플래그를 추가한다.
- 코드 라인 24~25에서 순회 중인 cpu의 capacity를 초과하는 유틸 상태인 경우 출력 인자 @sg_status에 SG_OVERUTILIZED 플래그를 추가한다.
- 코드 라인 28~29에서 순회 중인 cpu의 numa 관련 태스크 수를 그룹 통계에 누적시킨다.
- 누마 태스크 수 및 누마 우선 노드에서 동작 중인 태스크 수
- 코드 라인 34~35에서 순회 중인 cpu가 idle 상태인 경우 그룹 내 idle cpu 수를 나타내는 idle_cpus 카운터를 1 증가시킨다.
- 코드 라인 37~41에서 빅 리틀 클러스터(DIE 도메인) 처럼 도메인 내에 다른 cpu capacity를 가진 그룹을 가진 도메인이면서 group_misfit_task_load 보다 큰 순회 중인 cpu의 misfit_task_load가 더 큰 경우 group_misfit_task_load를 갱신하고 출력 인자 @sg_status에 SG_OVERLOAD 플래그를 추가한다.
- 코드 라인 45~46에서 먼저 sgs->group_capacity에 스케줄 그룹의 capacity 값을 대입한다. 그런 후 sgs_avg_load에는 그룹 로드 * (1024 / 그룹 capacity)를 대입한다.
- 코드 라인 48~49에서 그룹 내 동작 중인 태스크가 있는 경우 태스크당 로드를 산출한다.
- 코드 라인 51에서 먼저 sgs->group_weight에 스케줄 그룹의 weight를 대입한다.
- 코드 라인 53~54에서 그룹이 오버로드된 상태인 지 여부와 그룹 타입을 알아온다.
- 오버로드 상태인 경우 그룹 타입으로 group_overloaded가 지정되고, 그렇지 않은 경우 그 외의 그룹 타입을 판정해온다.
update_nohz_stats()
kernel/sched/fair.c
static bool update_nohz_stats(struct rq *rq, bool force)
{
#ifdef CONFIG_NO_HZ_COMMON
unsigned int cpu = rq->cpu;
if (!rq->has_blocked_load)
return false;
if (!cpumask_test_cpu(cpu, nohz.idle_cpus_mask))
return false;
if (!force && !time_after(jiffies, rq->last_blocked_load_update_tick))
return true;
update_blocked_averages(cpu);
return rq->has_blocked_load;
#else
return false;
#endif
}
nohz 런큐에 대해 블럭드 로드가 있는 경우 블럭드 로드 관련 통계를 갱신한다. @force가 0인 경우 틱이 변경된 경우에만 갱신되며, @force가 1인 경우 언제나 갱신한다.
- 코드 라인 6~7에서 런큐에 블럭드 로드가 없는 경우 false를 반환한다.
- 코드 라인 9~10에서 요청한 런큐의 cpu가 nohz 중인 cpu가 아닌 경우 false를 반환한다.
- 코드 라인 12~13에서 @force 요청이 없는 경우 블럭드 로드가 갱신된 틱과 현재 틱이 같은 경우 중복 갱신을 피하기 위해 true를 반환한다.
- 코드 라인 15~17에서 블럭드 로드 평균을 갱신하고 블럭드 로드 여부를 반환한다.
가장 바쁜 그룹 여부 체크
update_sd_pick_busiest()
kernel/sched/fair.c
/** * update_sd_pick_busiest - return 1 on busiest group * @env: The load balancing environment. * @sds: sched_domain statistics * @sg: sched_group candidate to be checked for being the busiest * @sgs: sched_group statistics * * Determine if @sg is a busier group than the previously selected * busiest group. * * Return: %true if @sg is a busier group than the previously selected * busiest group. %false otherwise. */
static bool update_sd_pick_busiest(struct lb_env *env,
struct sd_lb_stats *sds,
struct sched_group *sg,
struct sg_lb_stats *sgs)
{
struct sg_lb_stats *busiest = &sds->busiest_stat;
/*
* Don't try to pull misfit tasks we can't help.
* We can use max_capacity here as reduction in capacity on some
* CPUs in the group should either be possible to resolve
* internally or be covered by avg_load imbalance (eventually).
*/
if (sgs->group_type == group_misfit_task &&
(!group_smaller_max_cpu_capacity(sg, sds->local) ||
!group_has_capacity(env, &sds->local_stat)))
return false;
if (sgs->group_type > busiest->group_type)
return true;
if (sgs->group_type < busiest->group_type)
return false;
if (sgs->avg_load <= busiest->avg_load)
return false;
if (!(env->sd->flags & SD_ASYM_CPUCAPACITY))
goto asym_packing;
/*
* Candidate sg has no more than one task per CPU and
* has higher per-CPU capacity. Migrating tasks to less
* capable CPUs may harm throughput. Maximize throughput,
* power/energy consequences are not considered.
*/
if (sgs->sum_nr_running <= sgs->group_weight &&
group_smaller_min_cpu_capacity(sds->local, sg))
return false;
/*
* If we have more than one misfit sg go with the biggest misfit.
*/
if (sgs->group_type == group_misfit_task &&
sgs->group_misfit_task_load < busiest->group_misfit_task_load)
return false;
asym_packing:
/* This is the busiest node in its class. */
if (!(env->sd->flags & SD_ASYM_PACKING))
return true;
/* No ASYM_PACKING if target CPU is already busy */
if (env->idle == CPU_NOT_IDLE)
return true;
/*
* ASYM_PACKING needs to move all the work to the highest
* prority CPUs in the group, therefore mark all groups
* of lower priority than ourself as busy.
*/
if (sgs->sum_nr_running &&
sched_asym_prefer(env->dst_cpu, sg->asym_prefer_cpu)) {
if (!sds->busiest)
return true;
/* Prefer to move from lowest priority CPU's work */
if (sched_asym_prefer(sds->busiest->asym_prefer_cpu,
sg->asym_prefer_cpu))
return true;
}
return false;
}
요청한 스케줄 그룹이 기존에 선택했었던 busiest 스케줄 그룹보다 더 바쁜지 여부를 반환한다.
- 1) 빅->리틀: misfit & 로컬 보다 작은 capacity로 인한 거절
- 2) 그룹 타입이 큰 경우 허용, 작은 경우 거절
- 3) 그룹 타입이 같고 평균 로드가 적은 경우 거절
- 4) 빅->리틀: 소스 capacity 충분하여 거절 또는 misfit task 로드가 적어 거절
- 5) asym packing: busy 진입 또는 dst cpu가 더 빠른 cpu시 허용
- 6) 마지막으로 항상 허용
- 코드 라인 6에서 busiest 스케줄 그룹의 통계와 비교하기 위해 알아온다.
- 코드 라인 14~17에서 group_misfit_task 그룹 타입이면서 그룹이 다음 조건에 해당하면 false를 반환한다.
- 그룹이 로컬 그룹보다 작은 cpu capacity를 가졌다.
- 그룹이 충분한 capacity를 가지지 못하였다.
- 코드 라인 19~20에서 요청한 그룹 타입이 busiest 그룹 타입보다 큰 경우 요청한 그룹 타입이 더 바쁘다고 판단하여 true(1)를 반환한다.
- 그룹 타입은 4 가지로 group_other(0), group_misfit_task(1), group_imbalanced(2) 및 group_overloaded(3)가 있다.
- 코드 라인 22~23에서 요청한 그룹 타입이 busiest 그룹 타입보다 작은 경우 요청한 그룹 타입이 더 바쁘지 않다고 판단하여 false(0)를 반환한다.
- 코드 라인 25~26에서 동일한 그룹 타입인 경우는 평균 로드를 비교하여 요청한 그룹이 기존 busiest 그룹보다 작거나 같으면 false(0)를 반환한다.
- 코드 라인 28~29에서 스케줄 도메인이 빅리틀 같은 SD_ASYM_CPUCAPACITY 플래그가 없는 경우 sym_packing 레이블로 이동한다.
- 코드 라인 37~39에서 그룹에서 동작 중인 태스크 수가 그룹내 cpu 수 이하이고 로컬 그룹이 비교 그룹보다 작은 capacity를 가진 경우 false를 반환한다.
- 코드 라인 44~46에서 요청한 그룹이 group_misfit_task 그룹 상태이고 busiest 그룹의 group_misfit_task_load 값 보다 작은 경우 false를 반환한다.
- 코드 라인 48~51에서 asym_packing: 레이블이다. SD_ASYM_PACKING(현재 powerpc 아키텍처 및 x86의 ITMT 지원 아키텍처에서 사용) 플래그를 사용하지 않는 경우 true를 반환한다.
- 코드 라인 54~55에서 cpu가 busy 상태에서 진입한 경우 true를 반환한다.
- 코드 라인 61~72에서 요청한 스케줄 그룹에서 동작 중인 태스크가 있고, 더 높은 capacity를 가진 hw thread로 이동하는 것이 좋을 때엔 다음 조건을 만족하는 경우 true를 반환하고, 그 외의 경우 false를 반환한다.
- busiest 그룹이 아직 결정되지 않았을 때
- busiest 그룹이 선택한 cpu보다 dst cpu로 이동하는 것이 좋을 때
다음 그림은 도메인내의 스케줄 그룹을 순회하며 busiest 그룹을 선택하여 갱신하는 모습을 보여준다.

Overload & Overutilized & Misfit-Task-Load
빅/리틀 아키텍처처럼 asym cpu capacity를 사용하는 스케줄 도메인 간 로드밸런싱을 사용할 때 태스크 로드가 빅 프로세스에서 문제 없이 동작하였지만 리틀 프로세스로 옮겨갈 때 cpu capacity가 부족해지는데 이를 판단하기 위해 다음과 같은 상태 구분을 한다.
- overloaded
- 로드가 초과된 오버 로드 상태이다.
- 스케줄 그룹에는 group_no_capacity가 설정된다.
- 루트 도메인에는 SG_OVERLOAD 플래그가 추가된다.
- overutilized
- 낮은 성능의 cpu로 전환 시 유틸이 초과된 오버 유틸 상태이다.
- 루트 도메인에는 SG_OVERUTILIZED 플래그가 추가된다.
- misfit_task_load
- 빅/리틀 클러스터가 채용된 시스템에서 태스크의 유틸이 매우 높은 경우 빅 클러스터에서 최대의 성능을 높일 수 있도록 하였다.
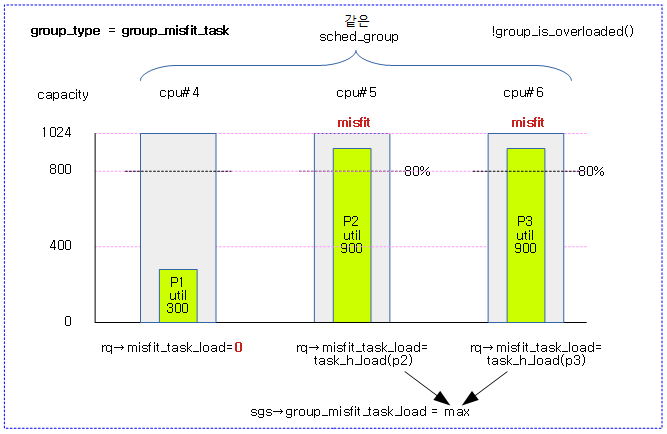
- 리틀 클러스터와 같이 낮은 성능의 cpu로 전환 시 해당 런큐는 misfit_task 상태가 되고 rq->misfit_task_load에는 태스크의 로드 값이 담긴다. 또한 해당 cpu가 포함된 스케줄 그룹에 대해서는 그 그룹에 속한 rq->misfit_task_load 중 가장 큰 값이 sgs->group_misfit_task_load에 담긴다.
- misfit 상태가 아닌 경우 0을 가진다.
Misfit 상태 갱신
update_misfit_status()
kernel/sched/fair.c
static inline void update_misfit_status(struct task_struct *p, struct rq *rq)
{
if (!static_branch_unlikely(&sched_asym_cpucapacity))
return;
if (!p) {
rq->misfit_task_load = 0;
return;
}
if (task_fits_capacity(p, capacity_of(cpu_of(rq)))) {
rq->misfit_task_load = 0;
return;
}
rq->misfit_task_load = task_h_load(p);
}
요청한 태스크의 유틸을 런큐의 cpu capacity로 충분히 처리할 수 있는지 misfit 로드를 갱신한다. (misfit 상태인 경우 rq->misfit_task_load에 태스크 로드 값이 대입되고, 그렇지 않은 경우 0으로 클리어된다)
- 코드 라인 3~4에서 asym cpu capcity를 사용하지 않는 시스템인 경우 함수를 빠져나간다.
- 코드 라인 6~9에서 태스크가 주어지지 않은 경우 런큐의 misfit_task_load 값은 0으로 클리어한 후 함수를 빠져나간다.
- 코드 라인 11~14에서 태스크가 런큐가 동작하는 cpu의 capacity 이내에서 처리할 수 있는 경우 런큐의 misfit_task_load 값을 0으로 클리어한 후 함수를 빠져나간다.
- 코드 라인 16에서 cpu capacity가 부족한 상태라는 것을 표시하기 위해 태스크 로드를 런큐의 misfit_task_load에 대입한다.
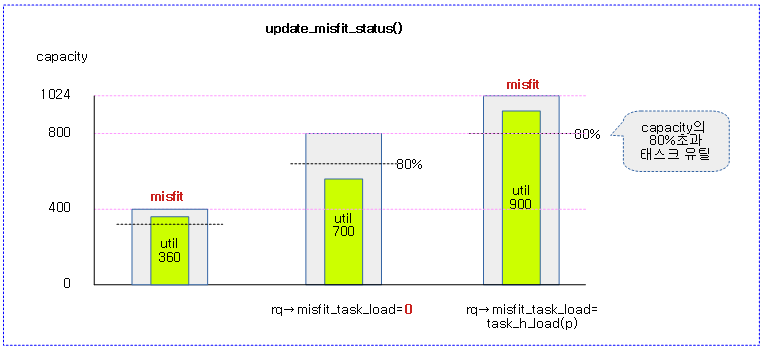
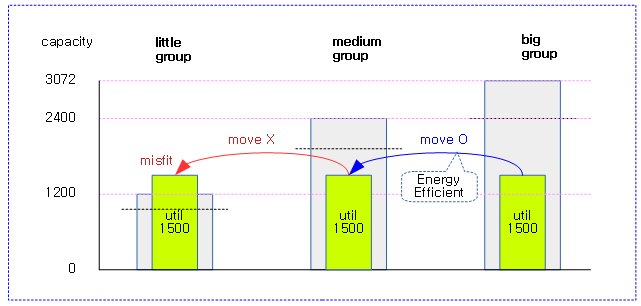
다음 그림은 그룹내 misfit 태스크의 로드 중 가장 큰 로드를 group_misfit_task_load에 갱신하는 모습을 보여준다.
- update_sg_lb_stats() 참조
다음 그림은 그룹간 busiest 그룹의 비교 시 유틸을 담기에 그룹 capacity가 부족한 경우를 보여준다.
task_fits_capacity()
kernel/sched/fair.c
static inline int task_fits_capacity(struct task_struct *p, long capacity)
{
return fits_capacity(task_util_est(p), capacity);
}
요청한 태스크의 유틸(125% 적용)이 @capacitiy에 충분히 적합한지 여부를 반환한다. (1=적합, 0=부적합)
check_misfit_status()
kernel/sched/fair.c
/* * Check whether a rq has a misfit task and if it looks like we can actually * help that task: we can migrate the task to a CPU of higher capacity, or * the task's current CPU is heavily pressured. */
static inline int check_misfit_status(struct rq *rq, struct sched_domain *sd)
{
return rq->misfit_task_load &&
(rq->cpu_capacity_orig < rq->rd->max_cpu_capacity ||
check_cpu_capacity(rq, sd));
}
런큐가 misfit 상태이면서 다른 cpu보다 낮은 성능을 가졌거나 cpu가 rt/dl/irq 등의 유틸로 인해 cfs capacity 가 압박을 받고 있는지 여부를 반환한다. (1=misfit 및 압박 상태, 0=압박 받지 않는 상태)
- 런큐가 misfit 상태이고 다른 cpu 보다 작은 cpu capacity를 가졌거나, cpu가 압박(rt/dl/irq로 인해 cfs에 대한 cpu capacity가 줄어든 상태) 중인 경우 1을 반환한다.
check_cpu_capacity()
kernel/sched/fair.c
/* * Check whether the capacity of the rq has been noticeably reduced by side * activity. The imbalance_pct is used for the threshold. * Return true is the capacity is reduced */
static inline int
check_cpu_capacity(struct rq *rq, struct sched_domain *sd)
{
return ((rq->cpu_capacity * sd->imbalance_pct) <
(rq->cpu_capacity_orig * 100));
}
rt/dl/irq 등의 유틸로 인해 해당 cpu의 cfs capacity가 감소했는지 여부를 알아온다.
- 요청한 런큐의 cfs 성능을 나타내는 cpu capacity에 도메인의 imbalance_pct 만큼의 스레졸드를 적용하였을 때 해당 cpu의 오리지날 capacity 보다 작아졌는지 여부를 알아온다. 1=스레졸드 이상 감소. 0=스레졸드 미만 감소
- side activity 란?
- rt, dl, irq 등의 유틸 로드
다음 그림은 해당 cpu의 cfs capacity가 감소되었는지 여부를 판단하는 모습을 보여준다.

group_smaller_max_cpu_capacity()
kernel/sched/fair.c
/* * group_smaller_max_cpu_capacity: Returns true if sched_group sg has smaller * per-CPU capacity_orig than sched_group ref. */
static inline bool
group_smaller_max_cpu_capacity(struct sched_group *sg, struct sched_group *ref)
{
return fits_capacity(sg->sgc->max_capacity, ref->sgc->max_capacity);
}
스케줄 그룹 @sg의 max_capacity가 스케줄 그룹 @ref의 것 보다 작은지 여부를 반환한다. (1=@sg가 작다)
- sg->sgc->max_capacity * 125% < ref->sgc->max_capacity
group_smaller_min_cpu_capacity()
kernel/sched/fair.c
/* * group_smaller_min_cpu_capacity: Returns true if sched_group sg has smaller * per-CPU capacity than sched_group ref. */
static inline bool
group_smaller_min_cpu_capacity(struct sched_group *sg, struct sched_group *ref)
{
return fits_capacity(sg->sgc->min_capacity, ref->sgc->min_capacity);
}
스케줄 그룹 @sg의 min_capacity가 스케줄 그룹 @ref의 것 보다 작은지 여부를 반환한다. (1=@sg가 작다)
- sg->sgc->min_capacity * 125% < ref->sgc->min_capacity
fits_capacity()
kernel/sched/fair.c
/* * The margin used when comparing utilization with CPU capacity. * * (default: ~20%) */
#define fits_capacity(cap, max) ((cap) * 1280 < (max) * 1024)
요청한 @cap에 125%를 적용한 값이 @max값 이내인지 여부를 반환한다. (1=보통, 0=capacity 초과)
Overutilized 상태 갱신
update_overutilized_status()
kernel/sched/fair.c
static inline void update_overutilized_status(struct rq *rq)
{
if (!READ_ONCE(rq->rd->overutilized) && cpu_overutilized(rq->cpu)) {
WRITE_ONCE(rq->rd->overutilized, SG_OVERUTILIZED);
trace_sched_overutilized_tp(rq->rd, SG_OVERUTILIZED);
}
}
런큐의 유틸이 cpu capacity를 초과하는 오버 유틸 상태인 경우 런큐가 가리키는 루트 도메인에 오버 유틸 상태를 갱신한다.
cpu_overutilized()
kernel/sched/fair.c
static inline bool cpu_overutilized(int cpu)
{
return !fits_capacity(cpu_util(cpu), capacity_of(cpu));
}
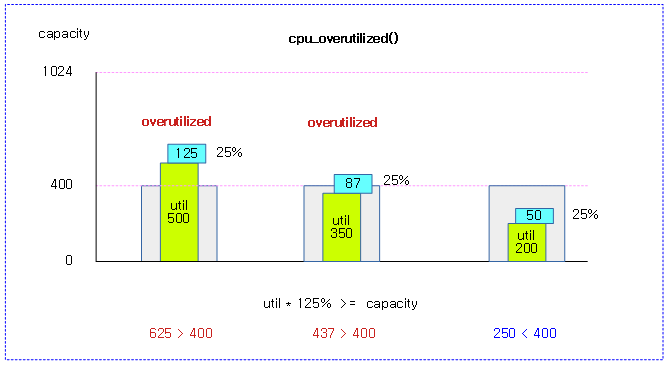
cpu capacity를 초과하는 유틸 여부를 반환한다. (1=초과)
- 현재 cpu의 유틸 * 125%가 현재 cpu의 capacity를 초과하면 오버 유틸 상태가 된다.
다음 그림은 스레졸드 125%가 주어진 cpu 유틸이 capacity를 초과하는 여부를 3가지 예로 보여준다.
group_is_overloaded()
kernel/sched/fair.c
/* * group_is_overloaded returns true if the group has more tasks than it can * handle. * group_is_overloaded is not equals to !group_has_capacity because a group * with the exact right number of tasks, has no more spare capacity but is not * overloaded so both group_has_capacity and group_is_overloaded return * false. */
static inline bool
group_is_overloaded(struct lb_env *env, struct sg_lb_stats *sgs)
{
if (sgs->sum_nr_running <= sgs->group_weight)
return false;
if ((sgs->group_capacity * 100) <
(sgs->group_util * env->sd->imbalance_pct))
return true;
return false;
}
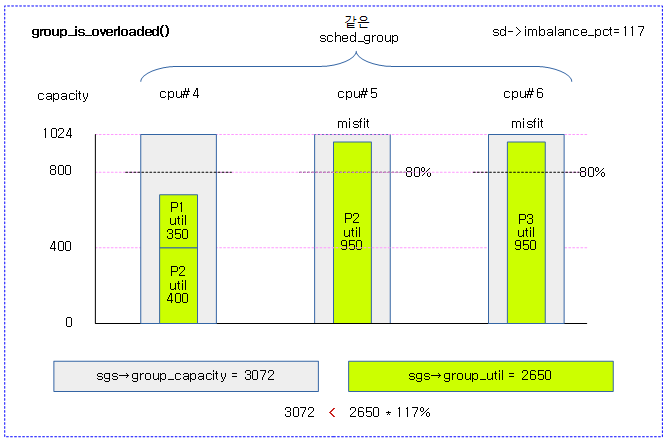
그룹 유틸이 오버 로드된 상태인지 여부를 반환한다. (1=오버 로드)
- 코드 라인 4~5에서 그룹에서 동작 중인 태스크 수가 그룹에 속한 cpu 수보다 작은 경우 오버 로드되지 않은 상태로 false를 반환한다.
- 코드 라인 7~11에서 imbalance_pct를 적용한 그룹 유틸이 그룹 capacity를 초과하는 경우 오버 로드 상태인 true를 반환한다. 그렇지 않은 경우 false를 반환한다.
다음 그림은 그룹내 cpu 런큐의 유틸 * 스레졸드가 그룹 capactiy를 초과하여 group_overloaded 타입이 된 모습을 보여준다.
Group 및 fbq 타입
그룹 타입
그룹 타입은 다음과 같이 4 종류로 구분되며 숫자가 클 수록 우선 순위가 높다. 로드 밸런스를 위해 그룹 간에 밸런싱 비교를 하는데 먼저 그룹 타입을 비교하고, 그 후 그룹 타입이 서로 동일한 경우에 그룹 로드 값을 비교한다.
- group_other(0)
- 그룹은 보통 상태이다.
- group_misfit_task(1)
- 그룹에 유틸이 큰 misfit task가 있는 상태이다. (빅 클러스터에서 동작시켜 최대 성능)
- group_imbalanced(2)
- 태스크에 cpu 제한을 두어 마이그레이션이 제한되어 그룹이 불균형 상태에서 밸런싱을 해야하는 상태이다.
- 그룹간에 일반적인 밸런싱을 하는 경우 태스크의 cpu 제한에 의해 의도치 않게 특정 그룹에 태스크가 오버 로드될 수 있는 상황을 막기 위함이다.
- group_overloaded(3)
- 그룹에 로드가 초과된 상태이다.
group_classify()
kernel/sched/fair.c
static inline enum
group_type group_classify(struct sched_group *group,
struct sg_lb_stats *sgs)
{
if (sgs->group_no_capacity)
return group_overloaded;
if (sg_imbalanced(group))
return group_imbalanced;
if (sgs->group_misfit_task_load)
return group_misfit_task;
return group_other;
}
그룹 상태를 분류하여 반환한다.
- 코드 라인 5~6에서 그룹 통계에서 capacity 부족 상태이면 group_overloaded 상태를 반환한다.
- 코드 라인 8~9에서 일부 태스크들이 특정 cpu를 허용하지 않아 그룹간 밸런싱을 하는 것이 오히려 문제가 되는 경우이다. 이렇게 별도의 그룹 불균형 상태로 밸런싱을 해야할 때 group_imbalanced 상태를 반환한다.
- 코드 라인 11~12에서 group_misfit_task_load가 있는 경우 group_misfit_task 상태를 반환한다.
- 코드 라인 14에서 그 외의 경우 group_other 상태를 반환한다.
그룹 불균형
두 개의 그룹에서 4개의 태스크를 동작시킬 때 p->cpus_ptr 을 통해 다음 4개의 cpu만을 허용시키면 그룹 관점에서 밸런싱을 수행하면 각 그룹에서 두 개의 태스크들을 수행시켜 밸런싱이 이루어질 것이다.
- cpu { 0 1 2 3 } { 4 5 6 7 }
- cpus_ptr * * * *
조건을 바꿔 p->cpus_ptr 을 통해 다음 4개의 cpu만을 허용시키면 그룹 관점에서 밸런싱을 수행하면 3번 cpu에서는 오버로드되어 2개의 태스크가 동작해야 하고, 나머지 456 cpu 중 하나는 idle 상태가 되는 의도치 않은 결과를 얻게된다. 따라서 이러한 그룹 불균형 상태를 인지하여 그룹 불균형 상태에서 밸런싱을 하는 방법이 필요해졌다.
- cpu { 0 1 2 3 } { 4 5 6 7 }
- cpus_ptr * * * *
그룹 불균형 detect
하위 도메인에서 일부 태스크가 cpu affinity 문제로 migration이 실패(LB_SOME_PINNED)하는 경우 상위 도메인 첫 그룹에 그룹 불균형 상태를 기록한다. 상위 도메인에서는 이러한 시그널이 있으면 해당 그룹을 busiest 그룹 후보로 인식하고, calculate_imbalance() 함수와 find_busiest_group() 두 함수에서 일반적인 균형 조건 중 일부를 피해 효과적인 그룹 불균형을 생성하도록 허락한다.
sg_imbalanced()
kernel/sched/fair.c
/*
* Group imbalance indicates (and tries to solve) the problem where balancing
* groups is inadequate due to ->cpus_ptr constraints.
*
* Imagine a situation of two groups of 4 CPUs each and 4 tasks each with a
* cpumask covering 1 CPU of the first group and 3 CPUs of the second group.
* Something like:
*
* { 0 1 2 3 } { 4 5 6 7 }
* * * * *
*
* If we were to balance group-wise we'd place two tasks in the first group and
* two tasks in the second group. Clearly this is undesired as it will overload
* cpu 3 and leave one of the CPUs in the second group unused.
*
* The current solution to this issue is detecting the skew in the first group
* by noticing the lower domain failed to reach balance and had difficulty
* moving tasks due to affinity constraints.
*
* When this is so detected; this group becomes a candidate for busiest; see
* update_sd_pick_busiest(). And calculate_imbalance() and
* find_busiest_group() avoid some of the usual balance conditions to allow it
* to create an effective group imbalance.
*
* This is a somewhat tricky proposition since the next run might not find the
* group imbalance and decide the groups need to be balanced again. A most
* subtle and fragile situation.
*/
static inline int sg_imbalanced(struct sched_group *group)
{
return group->sgc->imbalance;
}
그룹 불균형 상태 여부를 반환한다. (1=태스크가 특정 cpu로의 이동이 제한된 그룹 불균형 상태로 밸런싱을 해야하는 상황이다. 0=그룹 불균형 상태가 아니므로 일반적인 그룹간 밸런싱을 수행한다.)
fbq(find busiest queue) 타입
fbq 타입은 NUMA 밸런싱을 위해 사용되며 런큐나 그룹에서 3가지 타입으로 분류된다.
- regular(0)
- 누마 태스크들이 없을 수 있다.
- remote(1)
- 모든 태스크가 누마 태스크이고, 일부는 preferred 노드가 아닌 wrong 노드에서 동작한다.
- buesiest queue를 찾을 때 제외한다.
- all(2)
- 모든 태스크가 preferred 노드에서 동작하는 누마 태스크이다.
- 레귤러 및 리모트를 구분하지 않는다.
fbq_classify_group()
kernel/sched/fair.c
#ifdef CONFIG_NUMA_BALANCING
static inline enum fbq_type fbq_classify_group(struct sg_lb_stats *sgs)
{
if (sgs->sum_nr_running > sgs->nr_numa_running)
return regular;
if (sgs->sum_nr_running > sgs->nr_preferred_running)
return remote;
return all;
}
#else
static inline enum fbq_type fbq_classify_group(struct sg_lb_stats *sgs)
{
return all;
}
#endif
그룹의 fbq 타입을 반환한다. regular(0), remote(1), all(2) 타입을 구분하여 반환한다. 단 UMA 시스템에서는 all(2) 만을 반환한다.
fbq_classify_rq()
kernel/sched/fair.c
#ifdef CONFIG_NUMA_BALANCING
static inline enum fbq_type fbq_classify_rq(struct rq *rq)
{
if (rq->nr_running > rq->nr_numa_running)
return regular;
if (rq->nr_running > rq->nr_preferred_running)
return remote;
return all;
}
#else
static inline enum fbq_type fbq_classify_rq(struct rq *rq)
{
return regular;
}
#endif
런큐의 fbq 타입을 반환한다. regular(0), remote(1), all(2) 타입을 구분하여 반환한다. 단 UMA 시스템에서는 regular(0) 만을 반환한다.
ASYM 패킹 마이그레이션 필요 체크
check_asym_packing()
kernel/sched/fair.c
/** * check_asym_packing - Check to see if the group is packed into the * sched domain. * * This is primarily intended to used at the sibling level. Some * cores like POWER7 prefer to use lower numbered SMT threads. In the * case of POWER7, it can move to lower SMT modes only when higher * threads are idle. When in lower SMT modes, the threads will * perform better since they share less core resources. Hence when we * have idle threads, we want them to be the higher ones. * * This packing function is run on idle threads. It checks to see if * the busiest CPU in this domain (core in the P7 case) has a higher * CPU number than the packing function is being run on. Here we are * assuming lower CPU number will be equivalent to lower a SMT thread * number. * * Return: 1 when packing is required and a task should be moved to * this CPU. The amount of the imbalance is returned in env->imbalance. * * @env: The load balancing environment. * @sds: Statistics of the sched_domain which is to be packed */
static int check_asym_packing(struct lb_env *env, struct sd_lb_stats *sds)
{
int busiest_cpu;
if (!(env->sd->flags & SD_ASYM_PACKING))
return 0;
if (env->idle == CPU_NOT_IDLE)
return 0;
if (!sds->busiest)
return 0;
busiest_cpu = sds->busiest->asym_prefer_cpu;
if (sched_asym_prefer(busiest_cpu, env->dst_cpu))
return 0;
env->imbalance = sds->busiest_stat.group_load;
return 1;
}
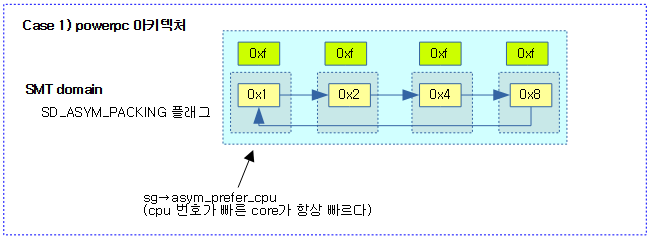
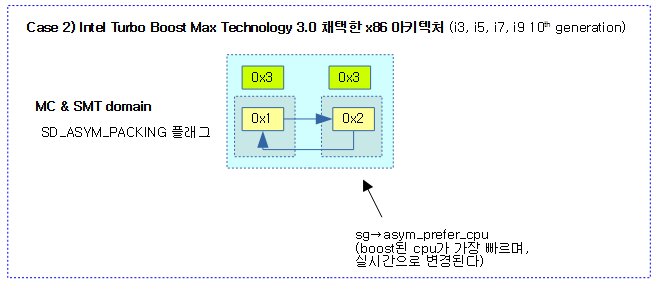
asym packing 도메인에서 더 빠른 코어로의 migration이 필요한지 여부를 반환한다. SMT를 사용하는 POWER7 칩은 0번 hw thread가 1번보다 더 빠르므로 0번 hw trhead가 idle 상태로 변경되는 시점에서 1번 hw thread에서 동작 중인 태스크를 0번으로 옮기는 것이 성능면에서 효율적이다. 최근엔 x86에서도 특정 core를 boost하는 기술을 사용한다.
- 코드 라인 5~6에서 SD_ASYM_PACKING 플래그를 사용하지 않는 스케줄링 도메인은 0을 반환한다.
- SD_ASYM_PACKING 플래그는 POWER7(powerpc) 및 ITMT(Intel Turbo Boost Max Technology 3.0)를 지원하는 x86의 일부 아키텍처에서만 사용한다.
- POWER7 아키텍처의 경우 SMT 스레드들 중 작은 번호의 스레드를 사용하는 것을 권장한다. 작은 번호의 스레드를 사용하여야 코어 리소스를 덜 공유하여 더 높은 성능을 낸다.
- 코드 라인 8~9에서 busy 상태에서 진입한 경우 0을 반환한다. idle 상태에서만 asym 패킹 마이그레이션을 한다.
- 코드 라인 11~12에서 busiest 스케줄 그룹이 없는 경우 0을 반환한다.
- 코드 라인 14~16에서 busiest cpu보다 dest cpu가 더 성능이 좋은 경우 0을 반환한다.
- 코드 라인 18~20에서 그룹 로드를 env->imbalance에 대입하고 asym 밸런싱을 위해 1을 반환한다.
다음 그림과 같이 asym packing을 사용하는 도메인에서는 idle 상태인 빠른 cpu로 태스크를 옮겨 최대 성능을 얻어낼 수 있다.

sched_asym_prefer()
kernel/sched/sched.h
static inline bool sched_asym_prefer(int a, int b)
{
return arch_asym_cpu_priority(a) > arch_asym_cpu_priority(b);
}
asym 패킹에서 @a cpu가 @b cpu 보다 더 우선 순위가 높은지 여부를 알아온다.
- ASYM PACKING을 지원하는 SMT 도메인에서 cpu간에 우선 순위가 존재한다.
- POWERPC의 경우 cpu 번호가 가장 낮은 경우 우선 순위가 높다.
- ITMT를 지원하는 x86 아키텍처의 경우 부스트 되는 경우가 있어 우선 순위가 실시간으로 바뀐다.
arch_asym_cpu_priority() – Generic
kernel/sched/fair.c
int __weak arch_asym_cpu_priority(int cpu)
{
return -cpu;
}
현재 cpu의 우선 순위를 반환한다. cpu 번호가 낮을 수록 우선 순위가 높아진다.
- ITMT를 지원하는 x86 아키텍처를 제외한 나머지 아키텍처들은 모두 generic 코드를 사용한다.
다음 그림은 powerpc 아키텍처에서 hw thread를 사용하는데 SMT 도메인에서 앞 core가 항상 더 빠름을 보여준다.
다음 그림은 ITMT를 채택한 x86 아키텍처가 MC 및 SMT 도메인에서 boost된 cpu가 더 빠름을 보여준다.
불균형 산출
calculate_imbalance()
kernel/sched/fair.c
/** * calculate_imbalance - Calculate the amount of imbalance present within the * groups of a given sched_domain during load balance. * @env: load balance environment * @sds: statistics of the sched_domain whose imbalance is to be calculated. */
static inline void calculate_imbalance(struct lb_env *env, struct sd_lb_stats *sds)
{
unsigned long max_pull, load_above_capacity = ~0UL;
struct sg_lb_stats *local, *busiest;
local = &sds->local_stat;
busiest = &sds->busiest_stat;
if (busiest->group_type == group_imbalanced) {
/*
* In the group_imb case we cannot rely on group-wide averages
* to ensure CPU-load equilibrium, look at wider averages. XXX
*/
busiest->load_per_task =
min(busiest->load_per_task, sds->avg_load);
}
/*
* Avg load of busiest sg can be less and avg load of local sg can
* be greater than avg load across all sgs of sd because avg load
* factors in sg capacity and sgs with smaller group_type are
* skipped when updating the busiest sg:
*/
if (busiest->group_type != group_misfit_task &&
(busiest->avg_load <= sds->avg_load ||
local->avg_load >= sds->avg_load)) {
env->imbalance = 0;
return fix_small_imbalance(env, sds);
}
/*
* If there aren't any idle CPUs, avoid creating some.
*/
if (busiest->group_type == group_overloaded &&
local->group_type == group_overloaded) {
load_above_capacity = busiest->sum_nr_running * SCHED_CAPACITY_SCALE;
if (load_above_capacity > busiest->group_capacity) {
load_above_capacity -= busiest->group_capacity;
load_above_capacity *= scale_load_down(NICE_0_LOAD);
load_above_capacity /= busiest->group_capacity;
} else
load_above_capacity = ~0UL;
}
/*
* We're trying to get all the CPUs to the average_load, so we don't
* want to push ourselves above the average load, nor do we wish to
* reduce the max loaded CPU below the average load. At the same time,
* we also don't want to reduce the group load below the group
* capacity. Thus we look for the minimum possible imbalance.
*/
max_pull = min(busiest->avg_load - sds->avg_load, load_above_capacity);
/* How much load to actually move to equalise the imbalance */
env->imbalance = min(
max_pull * busiest->group_capacity,
(sds->avg_load - local->avg_load) * local->group_capacity
) / SCHED_CAPACITY_SCALE;
/* Boost imbalance to allow misfit task to be balanced. */
if (busiest->group_type == group_misfit_task) {
env->imbalance = max_t(long, env->imbalance,
busiest->group_misfit_task_load);
}
/*
* if *imbalance is less than the average load per runnable task
* there is no guarantee that any tasks will be moved so we'll have
* a think about bumping its value to force at least one task to be
* moved
*/
if (env->imbalance < busiest->load_per_task)
return fix_small_imbalance(env, sds);
}
busiest 그룹이 불균형하여 진입했고, 정확히 불균형 값을 계산해본다.
- 코드 라인 9~16에서 busiest 그룹이 group_imbalanced(1) 타입인 경우 태스크의 cpu 허용 제한으로 인해 일반적인 그룹간의 평균 로드로만 밸런싱을 비교하면 안되는 상황이다. busiest 그룹의 태스크 당 로드 값 load_per_task 을 도메인 평균 로드 sds->avg_load 이하로 제한한다.
- 코드 라인 24~29에서 busiest 그룹이 group_misfit_task 타입이 아니고 다음 두 조건 중 하나에 해당하면 일단 imbalance를 0으로 클리어한 후 조금 더 깊이 산출하기 위해 fix_small_imabalnce() 함수를 통해 minor한 imbalance 값을 다시 산출한다.
- busiest 그룹의 평균 로드가 도메인의 평균 로드보다 작은 경우
- local 그룹의 평균 로드가 도메인의 평균 로드보다 큰 경우
- 코드 라인 34~43에서 busiest 및 local 그룹 모두 group_overloaded(2) 타입인 경우 즉, idle cpu들이 없는 경우 load_above_capacity 값을 다음과 같이 준비한다.
- 그룹에서 동작 중인 태스크 * 1024이 busiest 그룹의 capacity를 초과하는 만큼만 (nice-0 weight(1024) / group capacity) 비율만큼 적용한다. 초과분이 없는 경우 ~0UL 값을 대입한다.
- 코드 라인 52에서 max_pull 값을 산출하는데 busiest 그룹의 평균 로드가 도메인의 평균 로드를 초과한 차이와 load_above_capacity 값 중 작은 값으로 한다.
- 코드 라인 55~58에서 얼마나 불균형한지 imbalance 값을 아래 두 값 중 작은 값으로 산출한다.
- 이미 산출해둔 max_pull 값에 busiest 그룹의 capacity 값을 곱한 값과
- 도메인의 평균 로드에서 local 그룹의 평균 로드를 뺀 차이분을 ( group_capacity / 1024) 비율로 곱한 값
- 코드 라인 61~63에서 만일 그룹 타입이 group_misfit_task 인 경우에는 산출된 imbalance 보다 더 높은 busiest->group_misfit_task_load 인 경우 이 값으로 갱신한다.
- 코드 라인 72~73에서 최종 산출된 imbalance 값 보다 busiest 그룹의 태스크 당 로드 값이 큰 경우 fix_small_imabalnce() 함수를 통해 minor한 imbalance 값을 다시 산출한다.
작은 불균형 산출
fix_small_imbalance()
kernel/sched/fair.c
/** * fix_small_imbalance - Calculate the minor imbalance that exists * amongst the groups of a sched_domain, during * load balancing. * @env: The load balancing environment. * @sds: Statistics of the sched_domain whose imbalance is to be calculated. */
static inline
void fix_small_imbalance(struct lb_env *env, struct sd_lb_stats *sds)
{
unsigned long tmp, capa_now = 0, capa_move = 0;
unsigned int imbn = 2;
unsigned long scaled_busy_load_per_task;
struct sg_lb_stats *local, *busiest;
local = &sds->local_stat;
busiest = &sds->busiest_stat;
if (!local->sum_nr_running)
local->load_per_task = cpu_avg_load_per_task(env->dst_cpu);
else if (busiest->load_per_task > local->load_per_task)
imbn = 1;
scaled_busy_load_per_task =
(busiest->load_per_task * SCHED_CAPACITY_SCALE) /
busiest->group_capacity;
if (busiest->avg_load + scaled_busy_load_per_task >=
local->avg_load + (scaled_busy_load_per_task * imbn)) {
env->imbalance = busiest->load_per_task;
return;
}
/*
* OK, we don't have enough imbalance to justify moving tasks,
* however we may be able to increase total CPU capacity used by
* moving them.
*/
capa_now += busiest->group_capacity *
min(busiest->load_per_task, busiest->avg_load);
capa_now += local->group_capacity *
min(local->load_per_task, local->avg_load);
capa_now /= SCHED_CAPACITY_SCALE;
/* Amount of load we'd subtract */
if (busiest->avg_load > scaled_busy_load_per_task) {
capa_move += busiest->group_capacity *
min(busiest->load_per_task,
busiest->avg_load - scaled_busy_load_per_task);
}
/* Amount of load we'd add */
if (busiest->avg_load * busiest->group_capacity <
busiest->load_per_task * SCHED_CAPACITY_SCALE) {
tmp = (busiest->avg_load * busiest->group_capacity) /
local->group_capacity;
} else {
tmp = (busiest->load_per_task * SCHED_CAPACITY_SCALE) /
local->group_capacity;
}
capa_move += local->group_capacity *
min(local->load_per_task, local->avg_load + tmp);
capa_move /= SCHED_CAPACITY_SCALE;
/* Move if we gain throughput */
if (capa_move > capa_now)
env->imbalance = busiest->load_per_task;
}
local 그룹과 busiest 그룹의 로드 비교가 쉽지 않은 상화에서 이 함수가 호출되었다. busiest 그룹의 태스크 하나에 해당하는 로드를 local 그룹으로 마이그레이션한 상황을 가정하여 마이그레이션 후 성능이 더 올라가는 경우 imbalnce 값으로 busiest 그룹의 태스크 하나에 해당하는 로드 값을 지정한다.
Case 1) 평균 로드를 비교 (busiest > 로컬 + 1개의 scaled busiest 태스크 로드 추가(1개의 local 태스크 로드보다 작거나 같은 경우에만))
- 코드 라인 12~13에서 local 그룹의 sum_nr_running 값이 주어지지 않은 경우 로컬 그룹의 태스크당 로드 값으로 dst cpu의 태스크 당 로드 평균 값을 산출해와서 사용한다.
- dst cpu 로드 * (1/n 개 태스크)를 산출해온다. 태스크가 없으면 0을 반환한다.
- 코드 라인 14~15에서 태스크당 로드가 busiest 그룹 > local 그룹인 경우 로컬 그룹에 busiest 그룹의 태스크 하나를 migration하는 조건에 사용할 배율(imbn)이 반영되지 못하게 2 배에서 1 배로 떨어뜨린다.
- 코드 라인 17~19에서 busiest 그룹의 태스크 하나에 해당하는 로드를 스케일 적용한 값을 scaled_busy_load_per_task에 담는다.
- busiest 그룹의 태스크 당 로드 값 * 1024 / group capacity 비율
- 코드 라인 21~25에서 busiest 그룹 평균 로드 > local 그룹 평균 로드 + scaled_busy_load_per_task(imbn이 2인 경우에만)인 경우 busiest의 태스크당 로드 값을 imbalance에 대입하고 함수를 빠져나간다.
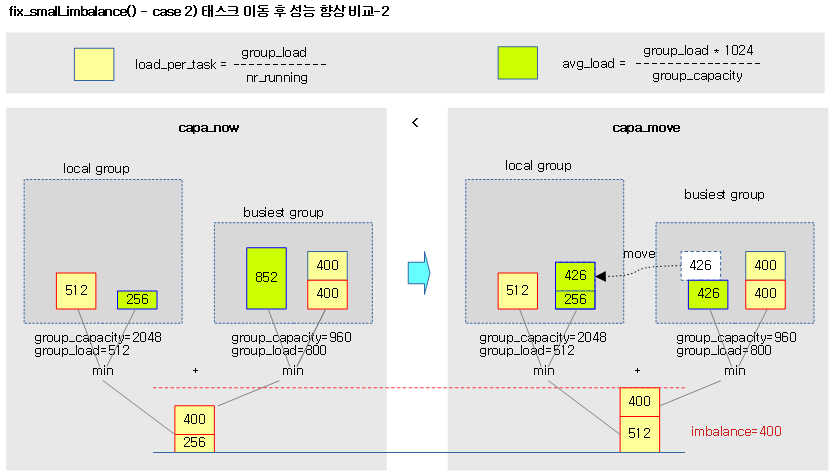
Case 2) busiest 태스크 1개 로드를 local로 옮겼다고 가정할 때 더 좋은 성능(태스크 이동 후 양쪽 로드 합계를 더해 로드 평균이 커진 경우이다.)
- 코드 라인 33~37에서 태스크를 옮기기에 충분한 imbalance 값이 없다. 그렇지만 태스크를 이동하여 사용되는 전체 cpu capcaity를 증가시키면 가능해질 수도 있다. 이하 코드에서 capa_now와 capa_move를 구해 비교할 계획이다. capa_now는 다음과 두 값을 더 해 산출한다.
- busiest 그룹의 capacity * min(태스크당 로드, 평균 로드) / 1024
- local 그룹의 capacity * min(태스크당 로드, 평균 로드) / 1024
- 코드 라인 40~44에서 busiest 그룹의 평균 로드가 scale 적용된 busiest 그룹의 태스크당 로드보다 큰 경우 capa_move에 다음을 더한다.
- busiest 그룹의 capacity * min(태스크당 로드, 평균 로드-스케일 적용 태스크당 로드) / 1024
- 코드 라인 47~54에서 busied 그룹의 로드 평균 * capacity < 태스크당 로드 * 1024인 경우 여부에 따라 tmp 값을 구한다.
- 참: tmp = busiest 로드 평균 * (busiest 그룹 capacity / 로컬 그룹 capacity)
- 거짓: busiest 그룹의 태스크당 로드 * (1024 / 로컬 그룹 capacity)
- 코드 라인 55~56에서 다음 값을 capa_move에 추가한다.
- 로컬 그룹 capacity * min(로컬 태스크당 로드, 로컬 로드 평균 + tmp) / 1024
- 코드 라인 60~61에서 태스크를 옮겼을 때가 더 유리한 경우 imbalance에 busiest 그룹의 태스크당 로드 평균을 대입한다.
다음 그림은 case 1)의 busiest의 로드 평균이 local의 로드 평균 보다 큰 경우를 보여준다.
- 두 그룹의 태스크당 로드를 비교하여 우측 그림과 같이 busiest가 같거나 작은 경우에는 1개의 태스크를 local 그룹의 로드 평균에 더해 비교한다.
- 우측 아래의 예에서는 imbalance를 결정하지 못해 case 2)로 게속 판단을 해야 한다.

다음 그림은 case 2) busiest 그룹의 태스크 1개 로드 scale 적용하여 local 그룹으로 옮겼을 때의 두 그룹 로드 평균 합이 커지지 않아 imbalnace 결정을 하지 못한 모습을 보여준다.
- 항상 1개 태스크 로드와 로드 평균 중 가장 작은 값을 사용한다.

다음 그림은 case 2) busiest 그룹의 태스크 1개 로드 scale 적용하여 local 그룹으로 옮겼을 때의 두 그룹 로드 평균 합이 커져 imbalnace 값으로 busiest 그룹의 1 개 태스크 로드로 결정하는 모습을 보여준다.
디태치 & 어태치 태스크들
디태치 태스크들
detach_tasks()
kernel/sched/fair.c -1/2-
/* * detach_tasks() -- tries to detach up to imbalance weighted load from * busiest_rq, as part of a balancing operation within domain "sd". * * Returns number of detached tasks if successful and 0 otherwise. */
static int detach_tasks(struct lb_env *env)
{
struct list_head *tasks = &env->src_rq->cfs_tasks;
struct task_struct *p;
unsigned long load;
int detached = 0;
lockdep_assert_held(&env->src_rq->lock);
if (env->imbalance <= 0)
return 0;
while (!list_empty(tasks)) {
/*
* We don't want to steal all, otherwise we may be treated likewise,
* which could at worst lead to a livelock crash.
*/
if (env->idle != CPU_NOT_IDLE && env->src_rq->nr_running <= 1)
break;
p = list_first_entry(tasks, struct task_struct, se.group_node);
env->loop++;
/* We've more or less seen every task there is, call it quits */
if (env->loop > env->loop_max)
break;
/* take a breather every nr_migrate tasks */
if (env->loop > env->loop_break) {
env->loop_break += sched_nr_migrate_break;
env->flags |= LBF_NEED_BREAK;
break;
}
if (!can_migrate_task(p, env))
goto next;
load = task_h_load(p);
if (sched_feat(LB_MIN) && load < 16 && !env->sd->nr_balance_failed)
goto next;
if ((load / 2) > env->imbalance)
goto next;
detach_task(p, env);
list_add(&p->se.group_node, &env->tasks);
detached++;
env->imbalance -= load;
소스 런큐의 cfs_tasks 리스트에 있는 태스크들을 디태치하여 env->tasks 리스트에 넣어온다. 반환되는 값으로 디태치한 태스크 수를 알아온다.
- 코드 라인 10~11에서 env->imbalance가 0 이하이면 밸런싱할 필요가 없으므로 0을 반환한다.
- 코드 라인 13~21에서 src 런큐의 cfs_tasks 리스트에 처리할 태스크가 없을 때까지 루프를 돌며 앞에서 부터 태스크를 하나씩 가져온다. 단 idle 상태로 진입한 경우에는 소스 런큐 태스크가 1개 이하인 경우에는 루프를 벗어난다.
- 코드 라인 23~26에서 루프 카운터를 증가시키고 loop_max를 초과하면 루프를 벗어난다.
- loop_max 값은 busiest cpu에서 동작중인 태스크의 수이며, 최대 sysctl_sched_nr_migrate(디폴트: 32)개로 제한된다.
- 코드 라인 29~33에서 루프 카운터가 loop_break를 초과하는 경우에는 LBF_NEED_BREAK 플래그를 설정한채 루프를 벗어난다.
- 이 경우 이 함수를 호출한 load_balance() 함수로 돌아간 후 unlock 후 다시 처음부터 lock을 다시 잡고 시도하게된다. loop_max가 매우 클 경우 lock을 잡고 한번에 처리하는 개수가 크면 시간이 너무 많이 소요되므로 이를 loop_break 단위로 나누어 처리하도록 한다.
- 코드 라인 35~36에서 태스크를 마이그레이션 할 수 없으면 next 레이블로 이동하여 태스크를 리스트의 뒤로 옮긴다음 계속 루프를 돈다.
- 코드 라인 38에서 태스크의 로드 평균 기여값을 알아온다.
- 코드 라인 40~41에서 LB_MIN feature를 사용하고 로드가 16보다 작고 도메인에 밸런싱이 실패한 적이 없으면 next 레이블로 이동하여 리스트의 뒤로 옮긴다음 계속 루프를 돈다. 즉 너무 작은 로드는 마이그레이션하지 않으려할 때 사용한다.
- 디폴트로 LB_MIN feature를 사용하지 않는다.
- 코드 라인 43~44에서 로드 값의 절반이 imbalance보다 큰 경우 next 레이블로 이동하여 리스트의 뒤로 옮긴다음 계속 루프를 돈다. 즉 2 개 이상의 태스크들 중 로드의 절반 이상을 차지하는 태스크는 마이그레이션 하지 않는다.
- 코드 라인 46~50에서 태스크를 detach하고 env->tasks 리스트에 추가한다. env->imbalance에 로드 값을 감소시킨다.
kernel/sched/fair.c -2/2-
#ifdef CONFIG_PREEMPT
/*
* NEWIDLE balancing is a source of latency, so preemptible
* kernels will stop after the first task is detached to minimize
* the critical section.
*/
if (env->idle == CPU_NEWLY_IDLE)
break;
#endif
/*
* We only want to steal up to the prescribed amount of
* weighted load.
*/
if (env->imbalance <= 0)
break;
continue;
next:
list_move_tail(&p->se.group_node, tasks);
}
/*
* Right now, this is one of only two places we collect this stat
* so we can safely collect detach_one_task() stats here rather
* than inside detach_one_task().
*/
schedstat_add(env->sd, lb_gained[env->idle], detached);
return detached;
}
- 코드 라인 1~9에서 preempt 커널 옵션을 사용하고 NEWIDLE 밸런싱이 수행중인 경우 하나만 처리하고 루프를 벗어난다.
- 코드 라인 15~16에서 imbalance가 0 이하인 경우 루프를 벗어난다. 즉 로드를 더 뺄 imbalance 값이 없는 경우 그만 처리한다.
- 코드 라인 18에서 계속 순회한다.
- 코드 라인 19~21에서 next 레이블에 도착하면 태스크를 소스 런큐의 cfs_tasks 리스트의 후미로 옮긴다.
- 코드 라인 28~30에서 lb_gained[] 통계를 갱신하고 detached된 수를 반환한다.
detach_task()
kernel/sched/fair.c
/* * detach_task() -- detach the task for the migration specified in env */
static void detach_task(struct task_struct *p, struct lb_env *env)
{
lockdep_assert_held(&env->src_rq->lock);
deactivate_task(env->src_rq, p, DEQUEUE_NOCLOCK);
set_task_cpu(p, env->dst_cpu);
}
태스크를 소스 런큐에서 디태치하고, 디태치한 태스크에 dst_cpu를 지정한다.
task_h_load()
kernel/sched/fair.c
#ifdef CONFIG_FAIR_GROUP_SCHED
static unsigned long task_h_load(struct task_struct *p)
{
struct cfs_rq *cfs_rq = task_cfs_rq(p);
update_cfs_rq_h_load(cfs_rq);
return div64_ul(p->se.avg.load_avg_contrib * cfs_rq->h_load,
cfs_rq_load_avg(cfs_rq) + 1);
}
#else
static unsigned long task_h_load(struct task_struct *p)
{
return p->se.avg.load_avg_contrib;
}
#endif
태스크의 로드 평균 기여값을 반환한다. 만일 그룹 스케줄링을 사용하는 경우 태스크의 로드 평균 기여에 cfs 런큐의 h_load 비율을 곱하고 러너블 로드 평균으로 나누어 반환한다.
- 코드 라인 4~6에서 요청한 태스크의 cfs 런큐부터 최상위 cfs 런큐까지 h_load를 갱신한다.
- 코드 라인 7~8에서 태스크의 로드 평균 기여에 cfs 런큐의 h_load 비율을 곱하고 러너블 로드 평균으로 나누어 반환한다.
다음 그림은 요청한 태스크의 로드 평균 기여를 산출하는 모습을 보여준다.
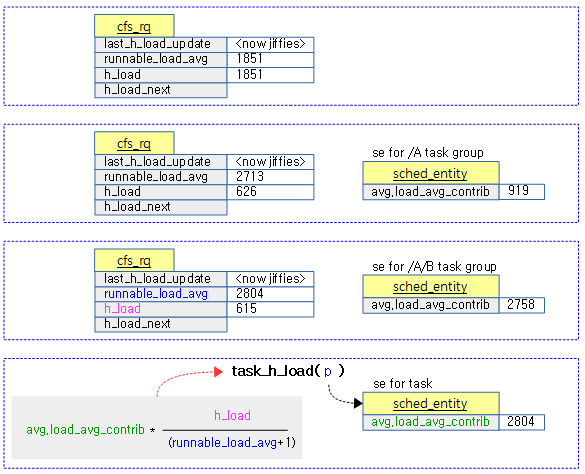
update_cfs_rq_h_load()
kernel/sched/fair.c
/* * Compute the hierarchical load factor for cfs_rq and all its ascendants. * This needs to be done in a top-down fashion because the load of a child * group is a fraction of its parents load. */
static void update_cfs_rq_h_load(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct sched_entity *se = cfs_rq->tg->se[cpu_of(rq)];
unsigned long now = jiffies;
unsigned long load;
if (cfs_rq->last_h_load_update == now)
return;
WRITE_ONCE(cfs_rq->h_load_next, NULL);
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
WRITE_ONCE(cfs_rq->h_load_next, se);
if (cfs_rq->last_h_load_update == now)
break;
}
if (!se) {
cfs_rq->h_load = cfs_rq_load_avg(cfs_rq);
cfs_rq->last_h_load_update = now;
}
while ((se = cfs_rq->h_load_next) != NULL) {
load = cfs_rq->h_load;
load = div64_ul(load * se->avg.load_avg,
cfs_rq_load_avg(cfs_rq) + 1);
cfs_rq = group_cfs_rq(se);
cfs_rq->h_load = load;
cfs_rq->last_h_load_update = now;
}
}
요청한 cfs 런큐부터 최상위 까지의 h_load를 갱신한다.
- 코드 라인 8~9에서 이미 마지막 h_load가 갱신된 시각(jiffies)이면 함수를 빠져나간다.
- 코드 라인 11에서 요청한 cfs 런큐를 대표하는 엔티티의 cfs 런큐 h_load_next에 null을 대입한다. h_load_next는 스케줄 엔티티를 top down으로 연결시키기 위해 잠시 사용되는 변수이다.
- 코드 라인 12~17에서 요청한 cfs 런큐를 대표하는 엔티티부터 최상위 엔티티까지 순회하며 순회중인 스케줄 엔티티의 cfs 런큐 h_load_next 에 스케줄 엔티티를 대입한다. 만일 순회 중 h_load가 갱신되어 있으면 순회를 중단한다.
- 코드 라인 19~22에서 순회가 중단되지 않고 끝까지 수행되었거나 최상위 cfs 런큐로 요청된 경우 cfs 런큐의 h_load에 러너블 로드 평균을 대입하고 h_load 갱신이 완료된 현재 시각을 대입한다.
- 코드 라인 24~31에서 엔티티를 top down으로 순회를 한다. h_load 값에 로드 평균 기여를 곱한 후 러너블 로드로 나누어 h_load를 갱신한다. 그 후 갱신된 시각에 현재 시각을 대입한다.
다음 그림은 h_load 값이 산출되는 모습을 보여준다.
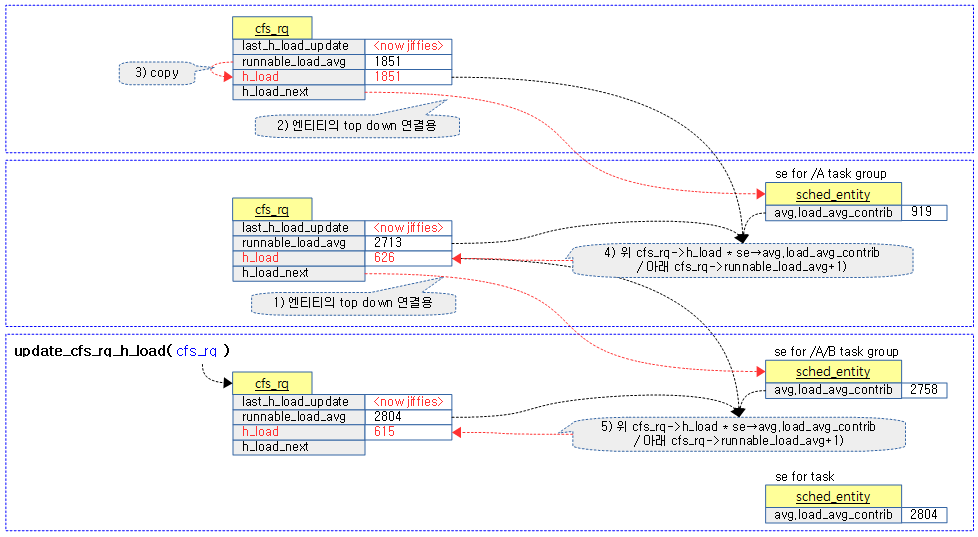
어태치 태스크들
attach_tasks()
kernel/sched/fair.c
/* * attach_tasks() -- attaches all tasks detached by detach_tasks() to their * new rq. */
static void attach_tasks(struct lb_env *env)
{
struct list_head *tasks = &env->tasks;
struct task_struct *p;
struct rq_flags rf;
rq_lock(env->dst_rq, &rf);
update_rq_clock(env->dst_rq);
while (!list_empty(tasks)) {
p = list_first_entry(tasks, struct task_struct, se.group_node);
list_del_init(&p->se.group_node);
attach_task(env->dst_rq, p);
}
rq_unlock(env->dst_rq, &rf);
}
디태치한 태스크들을 모두 dst 런큐에 어태치한다.
attach_task()
kernel/sched/fair.c
/*
* attach_task() -- attach the task detached by detach_task() to its new rq.
*/
static void attach_task(struct rq *rq, struct task_struct *p)
{
lockdep_assert_held(&rq->lock);
BUG_ON(task_rq(p) != rq);
p->on_rq = TASK_ON_RQ_QUEUED;
activate_task(rq, p, 0);
check_preempt_curr(rq, p, 0);
}
태스크를 요청한 런큐에 어태치한다. 그런 후 preemption 조건을 만족하면 요청 플래그를 설정한다.
Active 밸런스
load_balance() 함수에서 pull migration에서 가져올 수 없는 태스크가 있었다. busiest 런큐에서 러닝 중인 태스크를 마이그레이션할 수 없는데, 이를 active 밸런스를 사용하여 동작 중인 태스크의 로드밸런싱을 가능하게 한다.
다음 그림은 태스크가 하나도 마이그레이션되지 않았을 대 active 밸런싱을 호출하여 수행하는 과정을 보여준다.
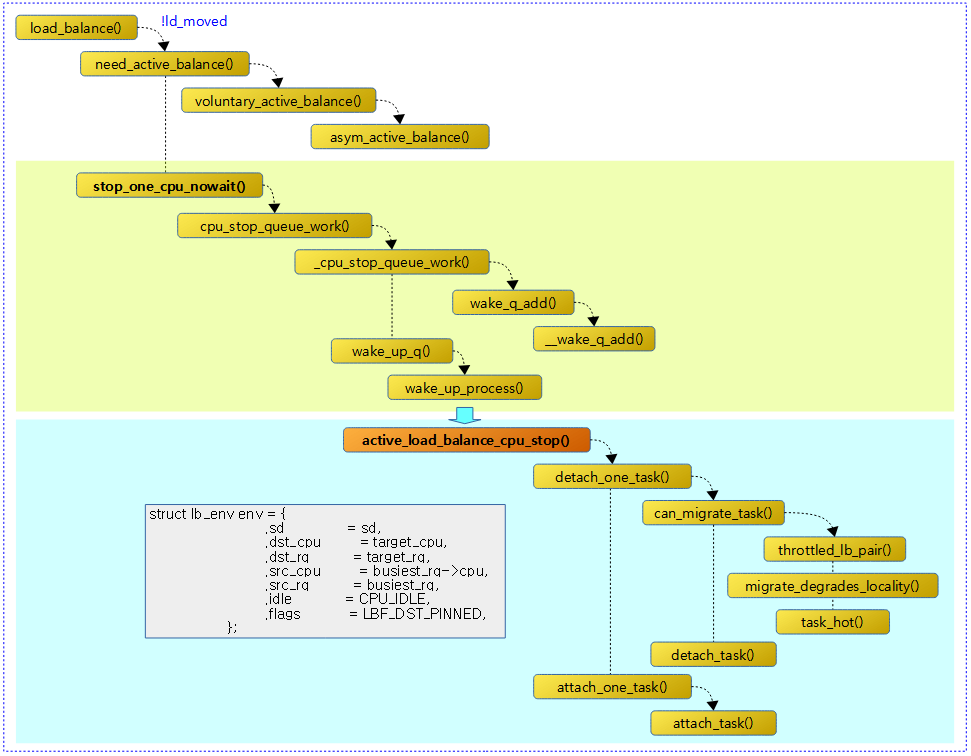
need_active_balance()
kernel/sched/fair.c
static int need_active_balance(struct lb_env *env)
{
struct sched_domain *sd = env->sd;
if (voluntary_active_balance(env))
return 1;
return unlikely(sd->nr_balance_failed > sd->cache_nice_tries+2);
}
active 로드 밸런싱이 필요한지 여부를 반환한다. (nr_balance_failed > cache_nice_tries+2인 경우 1)
- 코드 라인 5~6에서 active 밸런싱이 필요한 특수한 케이스가 있으면 1을 반환한다.
- 코드 라인 8에서 낮은 확률로 로드밸런스 실패 횟수가 cache_nice_tries+2 보다 큰 경우 1을 반환한다.
voluntary_active_balance()
kernel/sched/fair.c
static inline bool
voluntary_active_balance(struct lb_env *env)
{
struct sched_domain *sd = env->sd;
if (asym_active_balance(env))
return 1;
/*
* The dst_cpu is idle and the src_cpu CPU has only 1 CFS task.
* It's worth migrating the task if the src_cpu's capacity is reduced
* because of other sched_class or IRQs if more capacity stays
* available on dst_cpu.
*/
if ((env->idle != CPU_NOT_IDLE) &&
(env->src_rq->cfs.h_nr_running == 1)) {
if ((check_cpu_capacity(env->src_rq, sd)) &&
(capacity_of(env->src_cpu)*sd->imbalance_pct < capacity_of(env->dst_cpu)*100))
return 1;
}
if (env->src_grp_type == group_misfit_task)
return 1;
return 0;
}
active 밸런싱이 필요한 특수한 케이스가 있으면 1을 반환한다.
- 코드 라인 6~7에서 asym packing 도메인에서 dst_cpu가 src cpu보다 우선 순위가 높은 경우 1을 반환한다.
- 코드 라인 15~20에서 cpu가 idle 또는 new idle 상태에서 진입하였고, 소스 런큐에서 cfs 태스크 1 개만 동작할 때 다음 조건인 경우 1을 반환한다.
- rt,dl,irq 유틸 등으로 소스 런큐의 cpu에 대한 cfs capacity가 감소되었고, imbalance_pct 비율을 소스 cpu에 적용하더라도 dst cpu의 capacity가 더 높은 경우 1을 반환한다.
- 코드 라인 22~25에서 소스 그룹이 group_misfit_task이면 1을 반환하고, 그 외의 경우 0을 반환한다.
asym_active_balance()
kernel/sched/fair.c
static inline bool
asym_active_balance(struct lb_env *env)
{
/*
* ASYM_PACKING needs to force migrate tasks from busy but
* lower priority CPUs in order to pack all tasks in the
* highest priority CPUs.
*/
return env->idle != CPU_NOT_IDLE && (env->sd->flags & SD_ASYM_PACKING) &&
sched_asym_prefer(env->dst_cpu, env->src_cpu);
}
cpu가 busy가 아닌 상태에서 진입하였고, asym packing 도메인에서 dst_cpu가 src cpu보다 우선 순위가 높은 경우 여부를 반환한다.
stop_one_cpu_nowait()
kernel/stop_machine.c
/** * stop_one_cpu_nowait - stop a cpu but don't wait for completion * @cpu: cpu to stop * @fn: function to execute * @arg: argument to @fn * @work_buf: pointer to cpu_stop_work structure * * Similar to stop_one_cpu() but doesn't wait for completion. The * caller is responsible for ensuring @work_buf is currently unused * and will remain untouched until stopper starts executing @fn. * * CONTEXT: * Don't care. * * RETURNS: * true if cpu_stop_work was queued successfully and @fn will be called, * false otherwise. */
bool stop_one_cpu_nowait(unsigned int cpu, cpu_stop_fn_t fn, void *arg,
struct cpu_stop_work *work_buf)
{
*work_buf = (struct cpu_stop_work){ .fn = fn, .arg = arg, };
return cpu_stop_queue_work(cpu, work_buf);
}
@cpu를 멈추고 인자로 받은 @fn 함수가 동작하게 한다. 종료 결과 없이 요청한다.
- 현재 커널 소스에서 인수로 사용되는 함수는 active_load_balance_cpu_stop() 함수와 watchdog_timer_fn() 함수에서 사용된다.
- 이 함수를 통해 busiest cpu의 태스크를 push_cpu로 옮기게 한다.
active_load_balance_cpu_stop()
kernel/sched/fair.c -1/2-
/* * active_load_balance_cpu_stop is run by the CPU stopper. It pushes * running tasks off the busiest CPU onto idle CPUs. It requires at * least 1 task to be running on each physical CPU where possible, and * avoids physical / logical imbalances. */
static int active_load_balance_cpu_stop(void *data)
{
struct rq *busiest_rq = data;
int busiest_cpu = cpu_of(busiest_rq);
int target_cpu = busiest_rq->push_cpu;
struct rq *target_rq = cpu_rq(target_cpu);
struct sched_domain *sd;
struct task_struct *p = NULL;
struct rq_flags rf;
rq_lock_irq(busiest_rq, &rf);
/*
* Between queueing the stop-work and running it is a hole in which
* CPUs can become inactive. We should not move tasks from or to
* inactive CPUs.
*/
if (!cpu_active(busiest_cpu) || !cpu_active(target_cpu))
goto out_unlock;
/* Make sure the requested CPU hasn't gone down in the meantime: */
if (unlikely(busiest_cpu != smp_processor_id() ||
!busiest_rq->active_balance))
goto out_unlock;
/* Is there any task to move? */
if (busiest_rq->nr_running <= 1)
goto out_unlock;
/*
* This condition is "impossible", if it occurs
* we need to fix it. Originally reported by
* Bjorn Helgaas on a 128-CPU setup.
*/
BUG_ON(busiest_rq == target_rq);
/* Search for an sd spanning us and the target CPU. */
rcu_read_lock();
for_each_domain(target_cpu, sd) {
if ((sd->flags & SD_LOAD_BALANCE) &&
cpumask_test_cpu(busiest_cpu, sched_domain_span(sd)))
break;
}
busiest cpu의 태스크 하나를 idle cpu로 옮긴다.
- 코드 라인 17~18에서 busiest cpu 및 target cpu가 active 상태가 아닌 경우 함수를 빠져나간다.
- 코드 라인 21~23에서 낮은 확률로 busiest cpu가 현재 cpu가 아니거나 busiest 런큐의 active_balance가 해제된 경우 out_unlock 레이블로 이동하여 마이그레이션을 포기한다.
- 코드 라인 26~27에서 busiest 런큐에서 동작 중인 태스크가 한 개 이하인 경우 out_unlock 레이블로 이동하여 마이그레이션을 포기한다.
- 코드 라인 38~42에서 target cpu의 스케줄 도메인을 순회하며 로드 밸런스가 허용된 도메인에 busiest cpu가 포함되어 있는 경우 이 도메인을 통해 밸런싱을 하기 위해 루프를 벗어난다.
kernel/sched/fair.c -2/2-
if (likely(sd)) {
struct lb_env env = {
.sd = sd,
.dst_cpu = target_cpu,
.dst_rq = target_rq,
.src_cpu = busiest_rq->cpu,
.src_rq = busiest_rq,
.idle = CPU_IDLE,
/*
* can_migrate_task() doesn't need to compute new_dst_cpu
* for active balancing. Since we have CPU_IDLE, but no
* @dst_grpmask we need to make that test go away with lying
* about DST_PINNED.
*/
.flags = LBF_DST_PINNED,
};
schedstat_inc(sd->alb_count);
update_rq_clock(busiest_rq);
p = detach_one_task(&env);
if (p) {
schedstat_inc(sd->alb_pushed);
/* Active balancing done, reset the failure counter. */
sd->nr_balance_failed = 0;
} else {
schedstat_inc(sd->alb_failed);
}
}
rcu_read_unlock();
out_unlock:
busiest_rq->active_balance = 0;
rq_unlock(busiest_rq, &rf);
if (p)
attach_one_task(target_rq, p);
local_irq_enable();
return 0;
}
- 코드 라인 1~29에서 높은 확률로 밸런싱 가능한 도메인을 찾은 경우 alb_count 카운터를 증가시키고 busiest 런큐의 클럭을 갱신 한 후 busiest cpu 에서 태스크를 디태치해온다. 디태치한 경우 alb_pushed 카운터를 증가시키고 그렇지 못한 경우 alb_failed 카운터를 증가시킨다.
- 코드 라인 31~40에서 out_unlock: 레이블이다. busiest 런큐의 avtive_balance에 0을 대입하고 target cpu에 디태치 했었던 태스크를 어태치하고 0 값으로 함수를 마친다.
detach_one_task()
kernel/sched/fair.c
/* * detach_one_task() -- tries to dequeue exactly one task from env->src_rq, as * part of active balancing operations within "domain". * * Returns a task if successful and NULL otherwise. */
static struct task_struct *detach_one_task(struct lb_env *env)
{
struct task_struct *p, *n;
lockdep_assert_held(&env->src_rq->lock);
list_for_each_entry_reverse(p,
&env->src_rq->cfs_tasks, se.group_node) {
if (!can_migrate_task(p, env))
continue;
detach_task(p, env);
/*
* Right now, this is only the second place where
* lb_gained[env->idle] is updated (other is detach_tasks)
* so we can safely collect stats here rather than
* inside detach_tasks().
*/
schedstat_inc(env->sd, lb_gained[env->idle]);
return p;
}
return NULL;
}
src 런큐에서 동작하는 태스크들 중 마이그레이션 가능한 태스크 하나를 디태치하고 반환한다.
- 코드 라인 7~10에서 src 런큐에서 동작하는 태스크들을 역방향 순회하며 마이그레이션 할 수 없는 태스크는 skip 한다.
- 코드 라인 12~21에서 태스크를 디태치하고 lb_gained[]의 stat 카운터를 증가시키고 태스크를 반환한다.
- 코드 라인 23에서 디태치를 못한 경우 null을 반환한다.
attach_one_task()
kernel/sched/fair.c
/* * attach_one_task() -- attaches the task returned from detach_one_task() to * its new rq. */
static void attach_one_task(struct rq *rq, struct task_struct *p)
{
struct rq_flags rf;
rq_lock(rq, &rf);
update_rq_clock(rq);
attach_task(rq, p);
rq_unlock(rq, &rf);
}
요청한 태스크를 어태치한다. (런큐에 엔큐)
마이그레이션 가능 여부 체크
can_migrate_task()
kernel/sched/fair.c
/* * can_migrate_task - may task p from runqueue rq be migrated to this_cpu? */
static
int can_migrate_task(struct task_struct *p, struct lb_env *env)
{
int tsk_cache_hot;
lockdep_assert_held(&env->src_rq->lock);
/*
* We do not migrate tasks that are:
* 1) throttled_lb_pair, or
* 2) cannot be migrated to this CPU due to cpus_allowed, or
* 3) running (obviously), or
* 4) are cache-hot on their current CPU.
*/
if (throttled_lb_pair(task_group(p), env->src_cpu, env->dst_cpu))
return 0;
if (!cpumask_test_cpu(env->dst_cpu, tsk_cpus_allowed(p))) {
int cpu;
schedstat_inc(p, se.statistics.nr_failed_migrations_affine);
env->flags |= LBF_SOME_PINNED;
/*
* Remember if this task can be migrated to any other cpu in
* our sched_group. We may want to revisit it if we couldn't
* meet load balance goals by pulling other tasks on src_cpu.
*
* Also avoid computing new_dst_cpu if we have already computed
* one in current iteration.
*/
if (!env->dst_grpmask || (env->flags & LBF_DST_PINNED))
return 0;
/* Prevent to re-select dst_cpu via env's cpus */
for_each_cpu_and(cpu, env->dst_grpmask, env->cpus) {
if (cpumask_test_cpu(cpu, tsk_cpus_allowed(p))) {
env->flags |= LBF_DST_PINNED;
env->new_dst_cpu = cpu;
break;
}
}
return 0;
}
태스크를 마이그레이션해도 되는지 여부를 반환한다.
- 코드 라인 15~16에서 태스크가 존재하는 태스크 그룹의 src 또는 dest cpu의 cfs 런큐가 스로틀 중인 경우 0을 반환한다.
- 코드 라인 18~46에서 dst cpu들 중 태스크에 허락된 cpu가 없는 경우 nr_failed_migrations_affine stat을 증가시키고 LBF_SOME_PINNED 플래그를 설정하고 0을 반환한다. 만일 dst_grpmask가 비어있지 않으면서 LBF_DST_PINNED 플래그가도 설정되지 않은 경우 env->cpus를 순회하며 태스크가 허용하는 cpu에 한하여 LBF_DST_PINNED 플래그를 설정하고 new_dst_cpu에 cpu를 대입하고 0을 반환한다.
/* Record that we found atleast one task that could run on dst_cpu */
env->flags &= ~LBF_ALL_PINNED;
if (task_running(env->src_rq, p)) {
schedstat_inc(p, se.statistics.nr_failed_migrations_running);
return 0;
}
/*
* Aggressive migration if:
* 1) destination numa is preferred
* 2) task is cache cold, or
* 3) too many balance attempts have failed.
*/
tsk_cache_hot = migrate_degrades_locality(p, env);
if (!tsk_cache_hot == -1)
tsk_cache_hot = task_hot(p, env);
if (tsk_cache_hot <= 0 ||
env->sd->nr_balance_failed > env->sd->cache_nice_tries) {
if (tsk_cache_hot == 1) {
schedstat_inc(env->sd, lb_hot_gained[env->idle]);
schedstat_inc(p, se.statistics.nr_forced_migrations);
}
return 1;
}
schedstat_inc(p, se.statistics.nr_failed_migrations_hot);
return 0;
}
- 코드 라인 2에서 LBF_ALL_PINNED 플래그를 제거한다.
- 코드 라인 4~7에서 src 런큐에서 태스크가 러닝 중이면 nr_failed_migrations_running stat을 증가시키고 0을 반환한다.
- 코드 라인 15~17에서 태스크가 cache hot 상태이거나 numa 밸런싱을 하는 경우 locality가 저하되는지 여부를 확인한다.
- cache-hot을 유지하는 경우 마이그레이션을 하지 않는다.
- numa 밸런싱을 사용하지 않는 경우 migrate_degrades_locality() 함수의 결과는 항상 false(0)이다.
- 코드 라인 19~26에서 numa 밸런싱을 하는 경우 locality가 상승하거나 태스크가 cache hot 상태가 아니거나 밸런싱 실패가 cache_nice_tries 보다 많은 경우 마이그레이션을 할 수 있다고 1을 반환한다. 태스크가 캐시 hot 상태인 경우 lb_hot_gained[] 및 nr_forced_migrations stat 을 증가시킨다.
- 코드 라인 28~29에서 nr_failed_migrations_hot stat을 증가시키고 0을 반환한다.
소스 및 목적 cpu의 스로틀 여부
throttled_lb_pair()
kernel/sched/fair.c
/* * Ensure that neither of the group entities corresponding to src_cpu or * dest_cpu are members of a throttled hierarchy when performing group * load-balance operations. */
static inline int throttled_lb_pair(struct task_group *tg,
int src_cpu, int dest_cpu)
{
struct cfs_rq *src_cfs_rq, *dest_cfs_rq;
src_cfs_rq = tg->cfs_rq[src_cpu];
dest_cfs_rq = tg->cfs_rq[dest_cpu];
return throttled_hierarchy(src_cfs_rq) ||
throttled_hierarchy(dest_cfs_rq);
}
태스크 그룹에 대한 src 또는 dest cpu의 cfs 런큐가 스로틀되었는지 여부를 반환한다.
throttled_hierarchy()
kernel/sched/fair.c
/* check whether cfs_rq, or any parent, is throttled */
static inline int throttled_hierarchy(struct cfs_rq *cfs_rq)
{
return cfs_bandwidth_used() && cfs_rq->throttle_count;
}
요청한 cfs 런큐가 스로틀되었는지 여부를 반환한다.
마이그레이션 후 locality 저하 여부 체크
migrate_degrades_locality()
kernel/sched/fair.c
/* * Returns 1, if task migration degrades locality * Returns 0, if task migration improves locality i.e migration preferred. * Returns -1, if task migration is not affected by locality. */
static int migrate_degrades_locality(struct task_struct *p, struct lb_env *env)
{
struct numa_group *numa_group = rcu_dereference(p->numa_group);
unsigned long src_weight, dst_weight;
int src_nid, dst_nid, dist;
if (!static_branch_likely(&sched_numa_balancing))
return -1;
if (!p->numa_faults || !(env->sd->flags & SD_NUMA))
return -1;
src_nid = cpu_to_node(env->src_cpu);
dst_nid = cpu_to_node(env->dst_cpu);
if (src_nid == dst_nid)
return -1;
/* Migrating away from the preferred node is always bad. */
if (src_nid == p->numa_preferred_nid) {
if (env->src_rq->nr_running > env->src_rq->nr_preferred_running)
return 1;
else
return -1;
}
/* Encourage migration to the preferred node. */
if (dst_nid == p->numa_preferred_nid)
return 0;
/* Leaving a core idle is often worse than degrading locality. */
if (env->idle == CPU_IDLE)
return -1;
dist = node_distance(src_nid, dst_nid);
if (numa_group) {
src_weight = group_weight(p, src_nid, dist);
dst_weight = group_weight(p, dst_nid, dist);
} else {
src_weight = task_weight(p, src_nid, dist);
dst_weight = task_weight(p, dst_nid, dist);
}
return dst_weight < src_weight;
}
NUMA 밸런싱을 사용하는 경우 태스크의 마이그레이션이 locality를 저하시키는지 여부를 반환한다. 1인 경우 locality가 저하되므로 마이그레이션 권장하지 않는다. 0인 경우에는 locality가 상승하는 경우이므로 마이그레이션을 권장한다. -1인 경우 영향이 없거나 모르는 경우이다. (NUMA 밸런싱을 사용하지 않는 경우 항상 -1이다)
- 코드 라인 7~8에서 NUMA 밸런싱이 사용되지 않는 경우 -1을 반환한다.
- /proc/sys/kernel/numa_balancing
- 코드 라인 10~11에서 태스크의 누마 폴트가 없거나 NUMA 도메인이 아닌 경우 -1을 반환한다.
- 코드 라인 13~17에서 src 노드와 dst 노드가 같은 경우 -1을 반환한다.
- 코드 라인 20~25에서 태스크의 선호 노드가 소스 노드인 경우이다. 소스 런큐에서 동작 중인 태스크가 리모트 노드도 있는 경우 locality가 나빠지므로 1을 반환하고, 그렇지 않은 경우 locality 영향 없는 -1을 반환한다.
- 코드 라인 28~29에서 태스크의 선호 노드가 dst 노드인 경우 locality가 좋아지므로 0을 반환한다.
- 코드 라인 32~33에서 idle 상태에서 진입한 경우 -1을 반환한다.
- 코드 라인 35~44에서 태스크가 dst 노드의 폴트 수 보다 src 노드의 폴트 수가 큰지 여부를 반환한다.
- dst < src 인 경우 1 (locality 저하)
- dst >= src인 경우 0 (locality 증가)
태스크의 캐시 hot 상태 여부
task_hot()
kernel/sched/fair.c
/* * Is this task likely cache-hot: */
static int task_hot(struct task_struct *p, struct lb_env *env)
{
s64 delta;
lockdep_assert_held(&env->src_rq->lock);
if (p->sched_class != &fair_sched_class)
return 0;
if (unlikely(task_has_idle_policy(p))
return 0;
/*
* Buddy candidates are cache hot:
*/
if (sched_feat(CACHE_HOT_BUDDY) && env->dst_rq->nr_running &&
(&p->se == cfs_rq_of(&p->se)->next ||
&p->se == cfs_rq_of(&p->se)->last))
return 1;
if (sysctl_sched_migration_cost == -1)
return 1;
if (sysctl_sched_migration_cost == 0)
return 0;
delta = rq_clock_task(env->src_rq) - p->se.exec_start;
return delta < (s64)sysctl_sched_migration_cost;
}
태스크가 cache-hot 상태인지 여부를 반환한다. (hot 상태인 경우 가능하면 마이그레이션 하지 않고 이 상태를 유지하게 한다)
- 코드 라인 7~8에서 cfs 태스크가 아닌 경우 0을 반환한다.
- 코드 라인 10~11에서 태스크가 SCHED_IDLE policy를 사용하는 경우 0을 반환한다.
- 코드 라인 15~19에서 CACHE_HOT_BUDDY feature를 사용하면서 dst 런큐에서 동작 중인 태스크가 있고 이 태스크가 next 및 last 버디에 모두 지정된 경우 1을 반환한다.
- CACHE_HOT_BUDDY feature는 디폴트로 true이다.
- 혼자 열심히 잘 돌고 있으므로 방해하면 안된다. 마이그레이션하면 캐시만 낭비된다.
- 코드 라인 21~22에서 sysctl_sched_migration_cost가 -1로 설정된 경우 마이그레이션을 하지 못하도록 1을 반환한다.
- “/proc/sys/kernel/sched_migration_cost_ns”의 디폴트 값은 500,000(ns)이다.
- 코드 라인 23~24에서 sysctl_sched_migration_cost가 0으로 설정된 경우 항상 마이그레이션 하도록 0을 반환한다.
- 코드 라인 26~28에서 실행 시간이 sysctl_sched_migration_cost보다 작은지 여부를 반환한다.
- 실행 시간이 극히 적을 때 마이그레이션하면 캐시만 낭비하므로 마이그레이션을 하지 못하도록 1을 반환한다.
Schedule Features
# cat /sys/kernel/debug/sched_features GENTLE_FAIR_SLEEPERS START_DEBIT NO_NEXT_BUDDY LAST_BUDDY CACHE_HOT_BUDDY WAKEUP_PREEMPTION ARCH_CAPACITY NO_HRTICK NO_DOUBLE_TICK LB_BIAS NONTASK_CAPACITY TTWU_QUEUE NO_FORCE_SD_OVERLAP RT_RUNTIME_SHARE NO_LB_MIN
- feature를 설정하는 방법
- echo HRTICK > sched_features
- feature를 클리어하는 방법
- echo NO_HRTICK > sched_features
구조체
lb_env 구조체
kernel/sched/fair.c
struct lb_env {
struct sched_domain *sd;
struct rq *src_rq;
int src_cpu;
int dst_cpu;
struct rq *dst_rq;
struct cpumask *dst_grpmask;
int new_dst_cpu;
enum cpu_idle_type idle;
long imbalance;
/* The set of CPUs under consideration for load-balancing */
struct cpumask *cpus;
unsigned int flags;
unsigned int loop;
unsigned int loop_break;
unsigned int loop_max;
enum fbq_type fbq_type;
enum group_type src_grp_type;
struct list_head tasks;
};
- *sd
- 로드밸런싱을 수행할 스케줄링 도메인
- *src_rq
- source 런큐
- src_cpu
- source cpu
- dst_cpu
- dest cpu
- *dst_rq
- dest 런큐
- *dst_grpmask
- dest 그룹의 cpu 마스크
- new_dst_cpu
- 태스크의 cpu 허용 제한으로 인해 dst cpu로 마이그레이션이 불가능할 때 dest 그룹내 다른 cpu 중 하나를 선택한 후 재시도할 때 이 값을 dst_cpu로 대입할 목적으로 사용된다.
- idle
- idle 타입
- CPU_IDLE
- 정규 틱에서 cpu가 idle 상태일 때 밸런싱 시도한 경우
- CPU_NOT_IDLE
- 정규 틱에서 cpu가 idle 상태가 아닐 때 밸런싱 시도한 경우
- CPU_NEWLY_IDLE
- 새롭게 cpu가 idle 상태가 되었을 때 밸런싱 시도한 경우
- CPU_IDLE
- idle 타입
- imbalance
- 로드밸런싱이 필요한 강도만큼 수치가 설정된다.
- 이 값이 클 수록 불균형 상태이므로 로드밸런싱 확률이 높아진다.
- *cpus
- 로드 밸런싱에 고려되는 cpu들에 대한 cpu mask
- flags
- LBF_ALL_PINNED(0x01)
- 모든 태스크들을 마이그레이션 하지 못하는 상황이다.
- LBF_NEED_BREAK(0x02)
- loop_break 단위로 나누기 위해 마이그레이션 루프에서 잠시 빠져나온 후 다시 시도한다.
- LBF_DST_PINNED(0x04)
- 목적 cpu로 마이그레이션을 할 수 없는 상황이다.
- LBF_SOME_PINNED(0x08)
- 일부 태스크가 마이그레이션을 할 수 없는 상황이다.
- src cpu의 런큐에서 러닝 중인 태스크등은 pull migration을 할 수 없다. 이러한 경우 active 밸런싱의 push migration을 사용한다.
- LBF_ALL_PINNED(0x01)
- loop
- migration 진행 중인 내부 카운터
- 태스크 하나의 마이그레이션을 시도할 때마다 증가된다.
- loop_break
- loop가 이 값에 도달하면 루프를 멈추었다가 다시 시도한다.
- loop_max
- loop가 이 값에 도달하면 중지한다.
- 대상 cpu에서 동작중인 태스크들의 수로 지정되고, 최대 수는 sysctl_sched_nr_migrate(디폴트 32)개로 제한된다.
- fbq_type
- find busiest queue 타입이고 설명은 본문에 기술하였다.
- regular(0)
- remote(1)
- all(2)
- find busiest queue 타입이고 설명은 본문에 기술하였다.
- src_grp_type
- 소스 그룹 타입이고 설명은 본문에 기술하였다.
- group_other(0)
- group_misfit_task(1)
- group_imbalanced(2)
- group_overloaded(3)
- 소스 그룹 타입이고 설명은 본문에 기술하였다.
- tasks
- 로드밸런싱할 태스크 리스트
sd_lb_stats 구조체
kernel/sched/fair.c
/* * sd_lb_stats - Structure to store the statistics of a sched_domain * during load balancing. */
struct sd_lb_stats {
struct sched_group *busiest; /* Busiest group in this sd */
struct sched_group *local; /* Local group in this sd */
unsigned long total_running;
unsigned long total_load; /* Total load of all groups in sd */
unsigned long total_capacity; /* Total capacity of all groups in sd */
unsigned long avg_load; /* Average load across all groups in sd */
struct sg_lb_stats busiest_stat;/* Statistics of the busiest group */
struct sg_lb_stats local_stat; /* Statistics of the local group */
};
로드 밸런싱 중에 사용되며 특정 도메인에 대한 로드 밸런스 통계를 표현한다.
- *busiest
- 도메인내 busiest 스케줄 그룹을 가리킨다.
- *local
- 도메인내 현재 비교 중인 로컬 스케줄 그룹을 가리킨다.
- tatal_running
- 도메인내에 동작 중인 태스크 수
- total_load
- 도메인에 포함된 모든 그룹의 로드 합
- total_capacity
- 도메인에 포함된 모든 그룹의 capacity 합
- avg_load
- 도메인에 포함된 모든 그룹의 로드 평균
- busiest_stat
- busiest 그룹 통계
- local_stat
- 로컬 그룹 통계
sg_lb_stats 구조체
kernel/sched/fair.c
/* * sg_lb_stats - stats of a sched_group required for load_balancing */
struct sg_lb_stats {
unsigned long avg_load; /*Avg load across the CPUs of the group */
unsigned long group_load; /* Total load over the CPUs of the group */
unsigned long load_per_task;
unsigned long group_capacity;
unsigned long group_util; /* Total utilization of the group */
unsigned int sum_nr_running; /* Nr tasks running in the group */
unsigned int idle_cpus;
unsigned int group_weight;
enum group_type group_type;
int group_no_capacity;
unsigned long group_misfit_task_load; /* A CPU has a task too big for its capacity */
#ifdef CONFIG_NUMA_BALANCING
unsigned int nr_numa_running;
unsigned int nr_preferred_running;
#endif
};
로드 밸런싱 중에 사용되며 sd_lb_stats 구조체 내에 포함되어 사용되며, 특정 그룹에 대한 로드 밸런스 통계를 표현한다.
- avg_load
- 그룹 로드 평균
- group_load
- 그룹에 포함된 cpu들의 로드 합
- load_per_task
- 태스크 당 로드로 다음과 같이 구해진다.
- group_load / sum_nr_running
- 태스크 당 로드로 다음과 같이 구해진다.
- group_capacity
- 그룹에 포함된 cpu들의 capacity 합
- group_util
- 그룹에 포함된 cpu들의 util 합
- sum_nr_running
- 그룹에서 동작 중인 태스크들의 합
- idle_cpus
- 그룹에서 idle 중인 cpu들 수
- group_weight
- 그룹에 포함된 cpu들 수
- group_type
- 그룹 타입이고 설명은 본문에 기술하였다.
- group_other
- group_misfit_task
- group_imbalanced
- group_overloaded
- 그룹 타입이고 설명은 본문에 기술하였다.
- group_no_capacity
- capacity 부족으로 로드 밸런싱이 필요 여부. (1=capacity 부족)
- group_misfit_task_load
- 그룹에 포함된 cpu들의 misfit_task_load 합
- nr_numa_running
- 그룹 내 권장 노드가 아닌 다른 노드에서 동작 중인 태스크의 수
- nr_preferred_running
- 그룹 내 누마 권장 노드에서 동작 중인 태스크의 수
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c – 현재 글
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
안녕하세요?
문영일님 블로그를 통해 스케줄러 공부에 많은 도움을 받고 있는 개발자중 한명입니다. 정말 감사드리고요.
최근 pelt를 비롯한 linux의 load tracking mechanism을 공부하던중 의문이 나는 부분이 있어서 문의를 좀드립니다.
find_busiest_group에서 imbalance를 판단할 때 해당 sched_domain내의 각 sched_group의 stat을 계산할 때 보면
sched_group별로 group_load 와 group_capacity를 구한뒤 group_load/group_capacity 로 avg_load를 구한뒤 각
group의 avg_load를 비교하여 busiest를 찾아내고 있는데요.
제가 궁금한 부분은 group_load를 왜 group_capacity로 나누는가 하는 점입니다. 아시겠지만, group_capacity는
architecture에 따른 performace 차이가 반영되어 있는 factor잖아요? 예를 들면 big, little 구조 같은 곳에서 똑같은
current freq, current max freq, max freq으로 돌더라도 big cluster의 core가 좀더 performance가 높을 수 있는
그런 차이를 감안할때 사용되는 factor이며, 말씀드렷듯이 big cluster의 capacity가 little보다 크게 계산이 될텐데요.
avg_load를 비교할 때는 이게 곱해지는 것이 맞지 않나 하는 생각이 듭니다.
왜냐하면 예를 들어 bigLITTLE 구조를 감안했을을때 freq 관련 조건등은 모두 동일하다고 가정하면 little에서 10ms를
돈 task와 big에서 10ms를 돈 task의 각각의 load는 상식적으로 big에서의 10ms가 더 크다고 보는게 맞을거라 생각합니다.
왜냐하면 big에서는 동일 clock조건에서도 performace가 little보다 더 좋을 것인데도 10ms 돌았다는 것은 그 task가
little에서 돈다면 더 많은 시간을 소요할 것이기 때문이죠. 그런 관점에서 little과 big에서 10ms를 돈 load를 구했을때는
capacity감안 전에는 둘이 동일한 값을 가질테지만, capacity factor를 고려할때 곱해주어야만 big에서 수행된 task의 load가
더 크게 되는데, 지금 kernel에서는 이걸 반대로 나누고 있기 때문에 big의 load가 더 작게되는 결과가 나오는데, 이건 잘못된게
아닐까요?
시간이 되시면 고견을 좀 부탁드리겠습니다.
감사합니다.
안녕하세요? 로드밸런싱에 대해 아주 깊은 곳까지 분석하고 계시는군요. 반갑습니다.
이 정도로 분석을 하실 정도면 이미 잘 알고 계실 내용이지만 본문의 load_balance() 함수에서 내용을 약간 보충하여 설명하였습니다. 보충한 내용을 여기 댓글에서 언급해봅니다.
load_balance() 함수는 현재 cpu 로드와 스케줄링 도메인내의 가장 바쁜 cpu 로드와 비교하여 불균형 상태이면 밸런스 조절을 위해 가장 바쁜 cpu의 태스크를 마이그레이션합니다.
load_balance() 함수에 진입 시 사용되는 cpu_idle_type은 다음과 같이 3가지가 있습니다.
– CPU_IDLE: 스케줄틱에 의해 주기적 로드밸런스 조건으로 진입 시, 현재 cpu의 런큐가 idle 중이다.
– CPU_NOT_IDLE: 스케줄틱에 의해 주기적 로드밸런스 조건으로 진입 시, 현재 cpu의 런큐에서 어떤 태스크가 동작 중이다.
– CPU_NEWLY_IDLE: 패시브 로드밸런스 조건으로, 런큐에서 마지막 동작하던 어떤 태스크가 dequeue되어 idle 진입 직전에 이 함수에 진입하였다.
즉, 위와 같은 조건일 때에 인자로 요청한 스케줄 도메인 안의 cpu들과 현재 cpu 간에 뷸균형 로드가 발견되면 가장 바쁜 cpu의 태스크를 현재 cpu로 가져오는 것으로 로드밸런싱을 수행합니다.
도메인내에서 가장 바쁜 cpu를 찾는 알고리즘은
– 첫 번째, find_busiest_group() 함수를 통해 도메인에서 가장 바쁜(busiest) 그룹을 찾습니다.
– 두 번째, find_busiest_queue() 함수를 통해 가장 바쁜(busiest) 그룹에서 가장 바쁜 cpu를 찾습니다.
지금부터는 궁금하신 내용에 대해 말씀드리겠습니다.
가장 바쁜 cpu를 비교할 때에는 개발자님이 생각하신 것과 동일합니다. 로드 값에 cpu capacity를 곱하여 비교합니다. 동일한(우선순위, 러닝 타임) 태스크를 고성능 cpu와 저성능 cpu에서 동작시키는 경우 고성능 cpu에서 더 많은 코드가 동작하지만, 로드 값은 서로 동일합니다. 이 값을 그대로 비교하면 안되기 때문에 당연히 각각의 cpu capacity를 곱한 값으로 비교하여야 정확한 비교가 가능합니다.
그러나 가장 바쁜 그룹을 선택하는 경우에는 그렇지 않습니다. 여기서 키포인트는 고성능과 저성능을 가리지 않고 그들의 평균 로드만을 사용하여 비교합니다. 즉 저성능 cpu 그룹에서 평균 60% 로드와 고성능 cpu 그룹에서 평균 50% 로드를 비교하는 경우 저성능 cpu 그룹이 더 바쁘다고 판단합니다.
도움이 되시길 바랍니다. ^^
안녕하세요? 문영일님
답변 주셔서 너무 감사드립니다.
답변해 주신 내용에 대해서 2가지 더 여쭙고 싶은게 있는데요.
그중에 한가지만 더 여쭙고, 그 내용을 듣고, 더불어 두번째 것도 여쭙고 싶습니다.
먼저 여쭐 내용은 find_busiest_queue()에 대해서 언급하신 내용인데요.
“가장 바쁜 cpu를 비교할 때에는 개발자님이 생각하신 것과 동일합니다. 로드 값에 cpu capacity를 곱하여 비교합니다.”
의 내용인데, 분석시 처음에는 저도 find_busiest_queue()에서는 find_busiest_group()과 달리 이상하게도 capacity를 곱한다고 생각했었는데, 자세히 보니 아닌 것으로 판단됩니다.
아마도 곱한다고 생각하시는 이유는
wl * busiest_capacity > busiest_load * capacity
이 부분일 것으로 생각이 되는데, 자세히 보면 저 조건문은 다음과 동일합니다.
wl / capacity > busiest_load / busiest_capacity
즉 loop을 통해 방문중인 cpu의 wl를 capacity로 나누어 계산한 avg load가 현재까지 기록되어 있는 busiest_load를 busiest_capacity로 나누어 계산한 avg load보다 크면 busiest_load, busiest_capacity를 갱신하는 내용이기 때문에 결론적으로 여기서에서 비교시에 load를 capacity 로 나눈 값으로 이용하고 있고, find_busiest_group에서와 group간 비교할때 avg load를 산출해 내는 방법과 차이는 없다고 생각합니다. 이 부분은 어떻게 생각하시는 지요?
오류를 잡아주셔서 감사합니다.
제가 처음 분석할 때에는 정확히 글을 썻었는데, 시간이 지난 후 개발자님이 말씀하신 함수 소스를 다시 볼 때 착각을 했습니다.
find_busiest_queue() 함수에서 다음 예)를 보였었던것과 같이 로드 값에 capacity를 곱하는 것이 아니라 로드 값에 capacity를 나누어 비교합니다.
결국 그룹이나 queue(cpu)나 동일하게 로드 값에 capacity를 나누어 비교합니다.
예) 두 개의 cpu capacity가 A=1535, B=430과 같이 다른 경우 각각 A=700, B=197의 워크로드를 가지는 경우 누가 busy cpu일까?
-> 45.6%(A: 700/1535) < 45.8%(B: 430/197)
안녕하세요,
저는 문영일님의 블로그를 통해 스케줄러 공부를 하고 있는 어느 시스템 개발자 입니다. 먼저 블로그를 통해 많이 배워갈 수있는 것에 대해 너무 감사드립니다.
한가지 너무 이해가 안되는 부분이 있어 질문을 남깁니다.
그냥 load balancing과 active load balancing에 대해 너무 잘 설명해 주셨는데,
ld_moved가 0인 detach를 몇몇 상황에서 실패한경우 active load balancing을 수행한다고 생각했는데, 함수를 따라가다 보니 active_load_balance_cpu_stop 함수 에서
cpu == 현재 cpu 라고 하는 점에서 어쩔 수 없이 run queue는 같아지지 않나 생각이들었으나 만약 그럴경우 커널 패닉이 발생하는 코드를 볼 수 있었습니다.
전체적으로 제가 이해를 잘 못한 것 같습니다.
본격 적인 질문으로는
언제 active load balancing을 수행하게 되나요?
특정상황이라는게 자기자신이 제일 바쁜 cpu일때도 포함되는게 맞을까요?
감사합니다.
P.S
오탈자가 있는것 같아 남깁니다 🙂
load_balance 함수 첫 부분 중
그룹A) 그룹로드=1035, 그룹 capacity =3070
그룹B) 그룹로드=430, 그룹 capacity =860
3070 -> 2070
안녕하세요?
“if (!ld_moved) {” 라인까지 진행하였다는 것은, 로드가 불균형한(imbalance) 상태라 busiest cpu의 런큐에 포함된 태스크 중 1개 이상을 현재 cpu의 런큐로 옮기려고 합니다. 그런데 busiest cpu의 런큐에 있는 태스크 중 하나도 detach 하지 못하여 ld_moved 값이 0인 상황입니다.
ld_moved가 0인 이유는 1개의 태스크도 detach를 못 한 경우입니다. 즉 detach_tasks() 함수에서 busiest cpu의 런큐에 속한 태스크들을 iteration 하며 can_migrate_task() 함수를 사용하여 태스크의 migration 가능한지 여부를 확인한 후, detach를 진행하는데 하나도 migration 할 태스크가 없는 경우입니다.
can_migrate_task() 함수 내부의 주석 원문을 살펴보면 다음과 같이 설명하고 있습니다.
/*
* We do not migrate tasks that are:
* 1) throttled_lb_pair, or
* 2) cannot be migrated to this CPU due to cpus_ptr, or
* 3) running (obviously), or
* 4) are cache-hot on their current CPU.
*/
migration을 하지 않는 이유를 쉽게 설명해 드리면,
1) 태스크가 두 개의 cpu 사이를 핑퐁 하는 것을 막기 위한 경우,
2) pin 된 상태로 migration이 금지된 상태의 cpu인 경우,
3) busiest cpu의 태스크 중 현재 동작 중인 태스크인 경우,
4) migration을 하는 경우 캐시 등 locality를 이유로 성능이 떨어지는 경우 등이 있습니다.
—————-
Q) 언제 active load balancing을 수행하게 되나요?
A) 불균형 로드 상태에서 migration이 불가능한 상태가 반복되면, need_active_balance() 함수에서 결과를 보고 busiest cpu에서 주도적으로 로드 밸런싱을 하도록 하게 합니다.
이 동작을 active load balancing이라고 합니다.
need_active_balance() 함수에서는 2개의 조건을 봅니다.
1) busiest cpu에서 1개의 cfs 태스크가 열심히 동작 중
2) 자주 실패한 경우(실패 횟수가 성공 횟수+2보다 더 많다)
Q) 특정상황이라는 게 자기 자신이 제일 바쁜 cpu일 때도 포함되는 게 맞을까요?
A) 아니오. 특정 상황은 위의 답변과 같은 상태입니다.
오탈자는 수정하였습니다.
감사합니다.
친절한 답변 너무 감사드립니다! 🙂
그렇다면,
39 if (active_balance) {
40 stop_one_cpu_nowait(cpu_of(busiest),
41 active_load_balance_cpu_stop, busiest,
42 &busiest->active_balance_work);
43 }
이 부분에서 인자로 busiest cpu가 들어가는 모습을 볼 수 있는데 stop_one_cpu_nowait() 함수 내부에서 진행되는 조건문
if(cpu == smp_processor_id())
에서는 현재 CPU가 아닐 경우 false를 return 하게 되는데요, 만약 가장 바쁜 cpu(busiest cpu)가 아닐 경우 work queue에 등록하지 못하는 것 으로 이해를 하였고
코드 설명 중 “코드 라인 39~42에서 active 밸런스를 처음 동작 시켰으면 busiest cpu가 현재 cpu인 경우에 한해 active 밸런싱을 하라고 busiest cpu에 스케줄 의뢰한다”
이 부분은 어떻게 이해를 하면 좋을까요!
항상 감사드립니다!
stop_one_cpu_nowait() 함수가 두 개 있습니다.
보시고 계신 함수는 SMP가 아닌 설정입니다. SMP는 다음 함수로 진행하셔야 합니다.
bool stop_one_cpu_nowait(unsigned int cpu, cpu_stop_fn_t fn, void *arg,
struct cpu_stop_work *work_buf)
{
*work_buf = (struct cpu_stop_work){ .fn = fn, .arg = arg, };
return cpu_stop_queue_work(cpu, work_buf);
}
감사합니다.
아, 제가 그 부분을 놓친 것 같습니다..!
큰 도움이 되었습니다. 정말 너무 감사합니다!
좋은 하루되세요. ^^