<kernel v4.0>
PELT: Per-Entity Load Tracking
커널 v5.4에 대한 최근 글은 다음을 참고한다.
엔티티 로드 평균을 산출하는 update_entity_load_avg() 함수는 다음과 같은 함수에서 호출된다.
- enqueue_entity_load_avg()
- cfs 런큐에 태스크가 엔큐될 때
- dequeue_eneity_load_avg()
- cfs 런큐에서 태스크가 디큐될 때
- put_prev_entity()
- 현재 동작 중인 태스크를 런큐의 대기로 돌려질 때
- entity_tick()
- 스케줄 틱마다 호출될 때
엔큐 시 엔티티 로드 평균 산출
enqueue_entity_load_avg()
kernel/sched/fair.c
/* Add the load generated by se into cfs_rq's child load-average */
static inline void enqueue_entity_load_avg(struct cfs_rq *cfs_rq,
struct sched_entity *se,
int wakeup)
{
/*
* We track migrations using entity decay_count <= 0, on a wake-up
* migration we use a negative decay count to track the remote decays
* accumulated while sleeping.
*
* Newly forked tasks are enqueued with se->avg.decay_count == 0, they
* are seen by enqueue_entity_load_avg() as a migration with an already
* constructed load_avg_contrib.
*/
if (unlikely(se->avg.decay_count <= 0)) {
se->avg.last_runnable_update = rq_clock_task(rq_of(cfs_rq));
if (se->avg.decay_count) {
/*
* In a wake-up migration we have to approximate the
* time sleeping. This is because we can't synchronize
* clock_task between the two cpus, and it is not
* guaranteed to be read-safe. Instead, we can
* approximate this using our carried decays, which are
* explicitly atomically readable.
*/
se->avg.last_runnable_update -= (-se->avg.decay_count)
<< 20;
update_entity_load_avg(se, 0);
/* Indicate that we're now synchronized and on-rq */
se->avg.decay_count = 0;
}
wakeup = 0;
} else {
__synchronize_entity_decay(se);
}
/* migrated tasks did not contribute to our blocked load */
if (wakeup) {
subtract_blocked_load_contrib(cfs_rq, se->avg.load_avg_contrib);
update_entity_load_avg(se, 0);
}
cfs_rq->runnable_load_avg += se->avg.load_avg_contrib;
/* we force update consideration on load-balancer moves */
update_cfs_rq_blocked_load(cfs_rq, !wakeup);
}
엔티티 로드 평균을 갱신한다.
- 코드 라인 15~32에서 낮은 확률로 decay_count가 0이하인 경우 avg.last_runnable_update에서 음수 decay_count 만큼의 ms 단위의 기간을 감소시키고 decay_count는 0으로 변경한다. 그리고 엔티티 로드 평균을 구하고 wakeup 요청을 0으로 한다.
- 처음 태스크가 fork된 경우 decay_count 값은 0이하 이다.
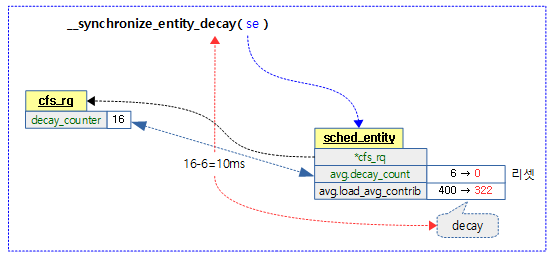
- 코드 라인 33~35에서 스케줄 엔티티의 decay_count가 0을 초과한 경우 엔티티 decay를 동기화시킨다.
- 스케줄 엔티티의 로드 평균 기여를 ‘cfs 런큐의 decay_counter – 스케줄 엔티티의 avg.decay_count’ 만큼 decay 한다.
- 코드 라인 38~41에서 decay_count가 0을 초과하였었고, 인수wakeup 요청이 있는 경우 migrate된 태스크들은 blocked 로드에서 기여 값을 감소시키고 엔티티 로드 평균을 구한다.
- 코드 라인 43에서 스케줄 엔티티에 있는 로드 평균 기여를 cfs 런큐의 러너블 로드 평균에 추가한다
- 코드 라인 45에서 블럭드 로드를 갱신하고 러너블 평균과 더해 cfs 런큐의 tg_load_contrib와 태스크 그룹의 load_avg 에 추가한다.
rq_clock_task()
kernel/sched/sched.h
static inline u64 rq_clock_task(struct rq *rq)
{
lockdep_assert_held(&rq->lock);
return rq->clock_task;
}
런큐의 clock_task 를 반환한다.
__synchronize_entity_decay()
kernel/sched/fair.c
/* Synchronize an entity's decay with its parenting cfs_rq.*/
static inline u64 __synchronize_entity_decay(struct sched_entity *se)
{
struct cfs_rq *cfs_rq = cfs_rq_of(se);
u64 decays = atomic64_read(&cfs_rq->decay_counter);
decays -= se->avg.decay_count;
se->avg.decay_count = 0;
if (!decays)
return 0;
se->avg.load_avg_contrib = decay_load(se->avg.load_avg_contrib, decays);
return decays;
}
스케줄 엔티티의 로드 평균 기여를 cfs 런큐의 decay_counter – 스케줄 엔티티의 avg.decay_count 만큼 decay 한다.
- 코드 라인 5~10에서 cfs 런큐의 decay_counter에서 스케줄 엔티티의 decay_count 값을 뺀다. 스케줄 엔티티의 decay_count 값은 0으로 리셋한다. 적용할 decays 값이 없으면 결과 값을 0으로 함수를 빠져나간다.
- 코드 라인 12에서 스케줄 엔티티의 load_avg_contrib를 decays 만큼 decay한다.
- 코드 라인 14에서 decays 값으로 함수를 빠져나간다.
다음 그림은 cfs 런큐에 소속된 하나의 스케줄 엔티티에 대해 decay할 기간을 적용시킨 모습을 보여준다.
디큐 시 엔티티 로드 평균 산출
dequeue_entity_load_avg()
kernel/sched/fair.c
/*
* Remove se's load from this cfs_rq child load-average, if the entity is
* transitioning to a blocked state we track its projected decay using
* blocked_load_avg.
*/
static inline void dequeue_entity_load_avg(struct cfs_rq *cfs_rq,
struct sched_entity *se,
int sleep)
{
update_entity_load_avg(se, 1);
/* we force update consideration on load-balancer moves */
update_cfs_rq_blocked_load(cfs_rq, !sleep);
cfs_rq->runnable_load_avg -= se->avg.load_avg_contrib;
if (sleep) {
cfs_rq->blocked_load_avg += se->avg.load_avg_contrib;
se->avg.decay_count = atomic64_read(&cfs_rq->decay_counter);
} /* migrations, e.g. sleep=0 leave decay_count == 0 */
}
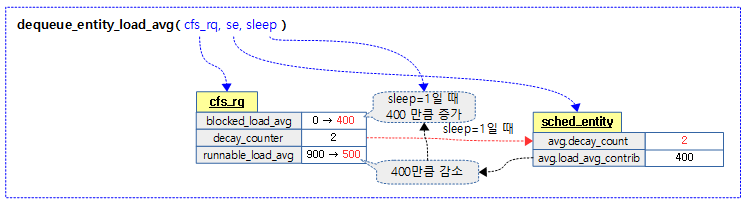
스케줄 엔티티가 디큐되면서 수행할 로드 평균을 갱신한다. cfs 런큐의 러너블 로드 평균에서 스케줄 엔팉티의 로드 평균 기여를 감소시키고 인수 sleep=1 요청된 경우 cfs 런큐의 블럭드 로드 평균에 추가한다.
- 코드 라인 10~12에서 디큐 관련 산출을 하기 전에 먼저 스케줄 엔티티의 로드 평균을 산출하고 블럭드 로드 평균까지 갱신한다.
- 코드 라인 14에서 cfs 런큐의 러너블 로드 평균을 스케줄 엔티티의 로드 평균 기여분만큼 감소시킨다.
- 코드 라인 15~18에서 인수 sleep=1인 경우 감소 시킨 기여분을 cfs 런큐의 블럭드 로드 평균에 추가하고 cfs 런큐의 decay_counter를 스케줄 엔티티에 복사한다.
다음 그림은 dequeue_eneity_load_avg() 함수의 처리 과정을 보여준다.
Idle 관련 엔티티 로드 평균 산출
idle 상태로 진입하거나 빠져나올 때마다 러너블 평균을 산출한다.
idle_enter_fair()
kernel/sched/fair.c
/*
* Update the rq's load with the elapsed running time before entering
* idle. if the last scheduled task is not a CFS task, idle_enter will
* be the only way to update the runnable statistic.
*/
void idle_enter_fair(struct rq *this_rq)
{
update_rq_runnable_avg(this_rq, 1);
}
idle 상태로 진입하기 전에 러너블 평균을 갱신한다.
idle_exit_fair()
kernel/sched/fair.c
/*
* Update the rq's load with the elapsed idle time before a task is
* scheduled. if the newly scheduled task is not a CFS task, idle_exit will
* be the only way to update the runnable statistic.
*/
void idle_exit_fair(struct rq *this_rq)
{
update_rq_runnable_avg(this_rq, 0);
}
idle 상태에서 빠져나오면 러너블 평균을 갱신하고 그 값을 태스크 그룹에도 반영한다.
틱 마다 스케줄 엔티티에 대한 PELT 갱신과 preemption 요청 체크
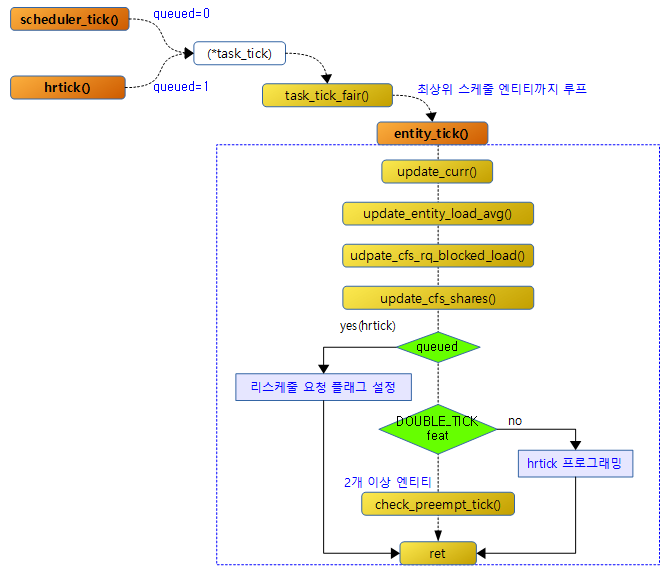
스케줄 틱마다 호출되는 scheduler_tick() 함수와 hr 틱마다 호출되는 hrtick() 함수는 현재 curr에서 동작하는 태스크의 스케줄러의 (*task_tick) 후크 함수를 호출한다. 예를 들어 현재 런큐의 curr가 cfs 태스크인 경우 task_tick_fair() 함수가 호출되는데 태스크와 관련된 스케줄 엔티티부터 최상위 스케줄 엔티티까지 entity_tick() 함수를 호출하여 PELT와 관련된 함수들을 호출하고 스케줄 틱으로 호출된 경우 리스케줄 여부를 체크하고 hr 틱으로 호출되는 경우 무조건 리스케줄 요청한다.
- 함수 호출 경로 예)
- 스케줄 틱: scheduler_tick() -> task_tick_fair() -> entity_tick()
- entity_tick() 함수를 호출할 때 인수 queued=0으로 호출된다.
- hr 틱: hrtick() -> task_tick_fair() -> entity_tick()
- entity_tick() 함수를 호출할 때 인수 queued=1로 호출된다.
- 스케줄 틱: scheduler_tick() -> task_tick_fair() -> entity_tick()
다음 그림은 entity_tick()에 대한 함수 흐름을 보여준다.
entity_tick()
kernel/sched/fair.c
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq);
/*
* Ensure that runnable average is periodically updated.
*/
update_entity_load_avg(curr, 1);
update_cfs_rq_blocked_load(cfs_rq, 1);
update_cfs_shares(cfs_rq);
#ifdef CONFIG_SCHED_HRTICK
/*
* queued ticks are scheduled to match the slice, so don't bother
* validating it and just reschedule.
*/
if (queued) {
resched_curr(rq_of(cfs_rq));
return;
}
/*
* don't let the period tick interfere with the hrtick preemption
*/
if (!sched_feat(DOUBLE_TICK) &&
hrtimer_active(&rq_of(cfs_rq)->hrtick_timer))
return;
#endif
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr);
}
이 함수는 스케줄 틱 또는 hr 틱을 통해 호출되며 인수로 요청한 엔티티에 대한 로드(PELT) 갱신과 preemption 필요를 체크한다.
- 코드 라인 7에서 PELT 관련 산출을 하기 전에 사전 준비를 위해 인수로 요청한 스케줄 엔티티의 런타임 통계들을 갱신한다.
- 코드 라인 12에서 엔티티의 로드 평균 기여값을 갱신한다.
- 코드 라인 13에서 스케줄 엔티티가 포함된 cfs 런큐의 러너블 로드와 블럭드 로드를 합하여 기여분을 cfs 런큐와 tg에 갱신한다.
- 코드 라인 14에서 shares * 비율(tg에서 cfs 런큐의 로드 기여값이 차지하는 일정 비율)을 사용하여 스케줄 엔티티의 weight을 갱신하고 cfs 런큐의 로드 weight도 갱신한다.
- 코드 라인 16~24에서 hrtick을 사용하는 커널에서 hrtick() 함수를 통해 호출된 경우 인수 queued=1로 진입한다. 이 때에는 무조건 리스케줄 요청을 하고 함수를 빠져나간다.
- 코드 라인 28~30에서 DOUBLE_TICK feature를 사용하지 않는 경우 hrtick을 프로그래밍한다.
- rpi2: DOUBLE_TICK 기능을 사용하지 않는다.
- 코드 라인 33~34에서 이 루틴은 hrtick을 제외한 스케줄 틱을 사용할 때에만 진입되는데 러너블 태스크가 2개 이상인 경우 preemption 체크를 수행한다.
스케줄 엔티티의 러너블 로드 평균 갱신
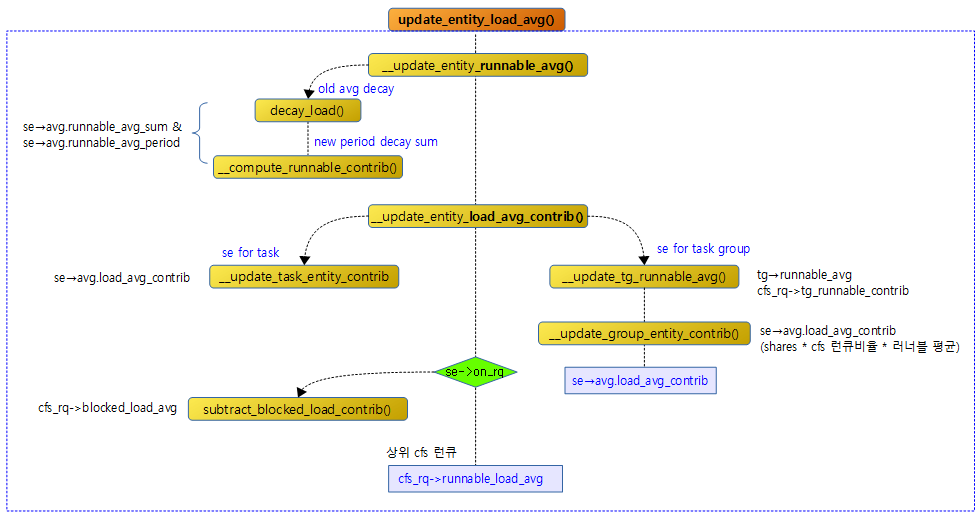
update_entity_load_avg()
kernel/sched/fair.c
/* Update a sched_entity's runnable average */
static inline void update_entity_load_avg(struct sched_entity *se,
int update_cfs_rq)
{
struct cfs_rq *cfs_rq = cfs_rq_of(se);
long contrib_delta;
u64 now;
/*
* For a group entity we need to use their owned cfs_rq_clock_task() in
* case they are the parent of a throttled hierarchy.
*/
if (entity_is_task(se))
now = cfs_rq_clock_task(cfs_rq);
else
now = cfs_rq_clock_task(group_cfs_rq(se));
if (!__update_entity_runnable_avg(now, &se->avg, se->on_rq))
return;
contrib_delta = __update_entity_load_avg_contrib(se);
if (!update_cfs_rq)
return;
if (se->on_rq)
cfs_rq->runnable_load_avg += contrib_delta;
else
subtract_blocked_load_contrib(cfs_rq, -contrib_delta);
}
스케줄 엔티티에 대한 러너블 로드 평균을 갱신한다. 인수로 cfs 런큐까지 갱신 요청하는 경우 기여도를 계산하여 cfs 런큐의 러너블 로드 평균도 갱신한다.
- a) 스케줄 엔티티에 대한 러너블 로드 평균을 산출하기 위한 러너블 평균합(runnable_avg_sum) 및 러너블 평균 기간(runnable_avg_periods) 산출
- 기존 러너블 평균합을 decay 시킨 값을 old라고 하고,
- 산정할 기간을 decay한 값을 new라고 할 때
- se->avg.runnable_avg_sum에는
- 스케줄 엔티티에 대해 러너블 상태(러닝 포함)의 태스크에 대해서는 new + old 값을 반영하고, 러너블 상태가 아닌 태스크에 대해서는 old 값만 반영한다.
- 추후 커널 소스에서는 러닝 상태를 별도로 관리한다.
- se->avg.runnable_avg_periods에는
- 스케줄 엔티티의 상태와 관계 없이 new + old 값을 반영한다.
- b) cfs 런큐의 러너블 로드 평균 갱신
- se->avg.load_avg_contrib
- 코드 라인 13~16에서 스케줄 엔티티가 태스크인 경우 now에 스케줄 엔티티가 가리키는 cfs 런큐의 클럭 태스크 값을 대입하고 그렇지 않은 경우 태스크 그룹용 cfs 런큐의 클럭 태스크 값을 대입한다.
- 외부에서 최상위 스케줄 엔티티까지 순회하며 이 함수를 호출하는 경우 가장 하위 cfs 런큐를 두 번 호출한다.
- 코드 라인 18~19에서 엔티티 러너블 평균 갱신을 수행하고 실패한 경우 함수를 빠져나간다.
- 코드 라인 21에서 엔티티 로드 평균 기여값을 갱신하고 그 delta 값을 controb_delta에 대입한다.
- 코드 라인 23~24에서 인수 update_cfs_rq가 0인 경우 함수를 빠져나간다.
- 코드 라인 26~29에서 스케줄 엔티티가 런큐에 있는 경우 러너블 로드 평균 값에 contrib_delta 값을 더하고 그렇지 않은 경우 blocked 로드 기여 값에 contrib_delta 값을 추가한다.
다음 그림은 __update_entity_load_avg() 함수가 스케줄 엔티티의 러너블 평균을 구하는 모습을 보여준다.
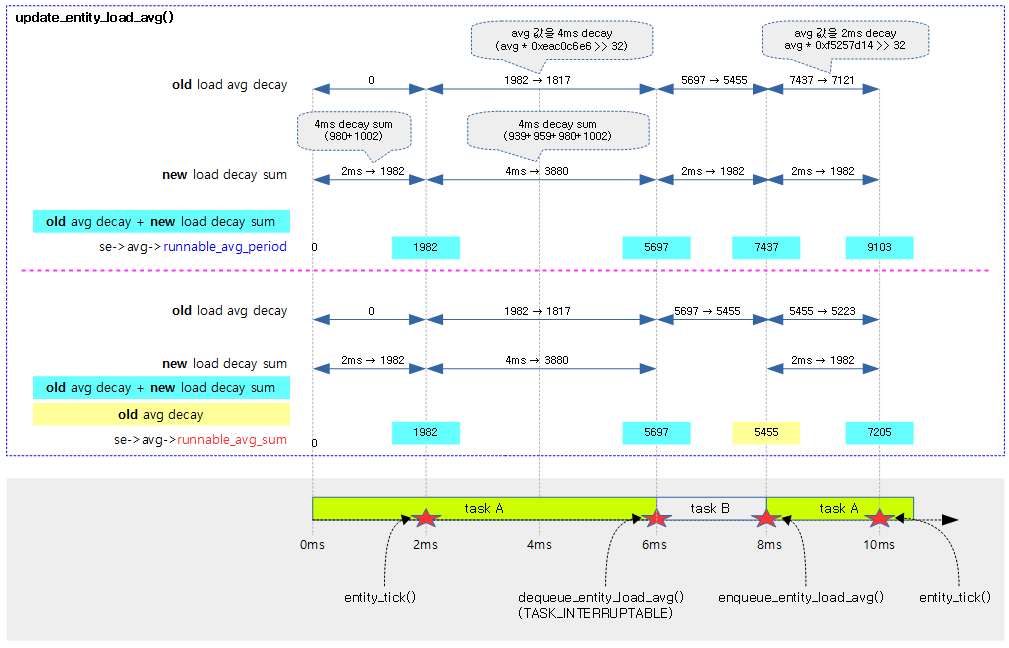
다음 그림은 스케줄 틱이 동작할 때 entity_tick() 함수에서 update_entity_load_avg() 함수를 호출할 때 동작하는 모습을 보여준다.
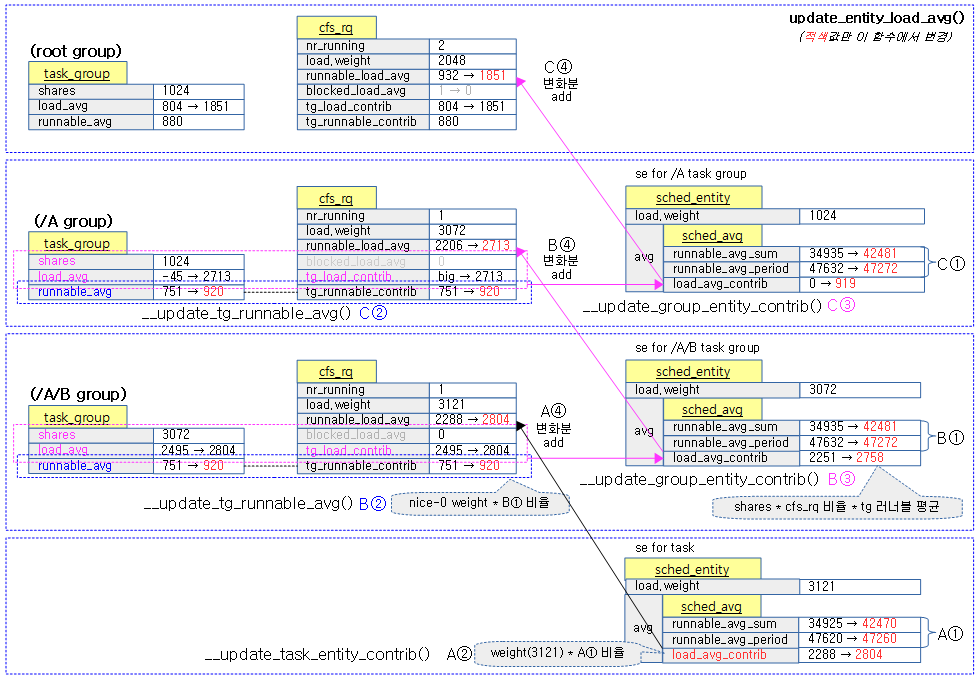
entity_is_task()
kernel/sched/fair.c
/* An entity is a task if it doesn't "own" a runqueue */ #define entity_is_task(se) (!se->my_q)
스케줄 엔티티가 태스크인지 여부를 반환한다.
- 태스크인 경우 se->cfs_rq를 사용하고 태스크 그룹을 사용하는 경우 se->my_q를 사용한다.
cfs_rq_clock_task()
kernel/sched/fair.c
/* rq->task_clock normalized against any time this cfs_rq has spent throttled */
static inline u64 cfs_rq_clock_task(struct cfs_rq *cfs_rq)
{
if (unlikely(cfs_rq->throttle_count))
return cfs_rq->throttled_clock_task;
return rq_clock_task(rq_of(cfs_rq)) - cfs_rq->throttled_clock_task_time;
}
스로틀 카운트가 있는 경우 cfs->throttled_clock_task를 반환하고 그렇지 않은 경우 cfs_rq->clock_task에서 스로틀 클럭 태스크 시간을 뺀 값을 반환한다.
group_cfs_rq()
kernel/sched/fair.c
/* runqueue "owned" by this group */
static inline struct cfs_rq *group_cfs_rq(struct sched_entity *grp)
{
return grp->my_q;
}
스케줄 엔티티의 런큐를 반환한다.
update_rq_runnable_avg()
kernel/sched/fair.c
static inline void update_rq_runnable_avg(struct rq *rq, int runnable)
{
__update_entity_runnable_avg(rq_clock_task(rq), &rq->avg, runnable);
__update_tg_runnable_avg(&rq->avg, &rq->cfs);
}
엔티티 러너블 평균을 산출하고 태스크 그룹에 반영한다.
스케줄 엔티티의 러너블 평균합 갱신
__update_entity_runnable_avg()
kernel/sched/fair.c
/*
* We can represent the historical contribution to runnable average as the
* coefficients of a geometric series. To do this we sub-divide our runnable
* history into segments of approximately 1ms (1024us); label the segment that
* occurred N-ms ago p_N, with p_0 corresponding to the current period, e.g.
*
* [<- 1024us ->|<- 1024us ->|<- 1024us ->| ...
* p0 p1 p2
* (now) (~1ms ago) (~2ms ago)
*
* Let u_i denote the fraction of p_i that the entity was runnable.
*
* We then designate the fractions u_i as our co-efficients, yielding the
* following representation of historical load:
* u_0 + u_1*y + u_2*y^2 + u_3*y^3 + ...
*
* We choose y based on the with of a reasonably scheduling period, fixing:
* y^32 = 0.5
*
* This means that the contribution to load ~32ms ago (u_32) will be weighted
* approximately half as much as the contribution to load within the last ms
* (u_0).
*
* When a period "rolls over" and we have new u_0`, multiplying the previous
* sum again by y is sufficient to update:
* load_avg = u_0` + y*(u_0 + u_1*y + u_2*y^2 + ... )
* = u_0 + u_1*y + u_2*y^2 + ... [re-labeling u_i --> u_{i+1}]
*/
static __always_inline int __update_entity_runnable_avg(u64 now,
struct sched_avg *sa,
int runnable)
{
u64 delta, periods;
u32 runnable_contrib;
int delta_w, decayed = 0;
delta = now - sa->last_runnable_update;
/*
* This should only happen when time goes backwards, which it
* unfortunately does during sched clock init when we swap over to TSC.
*/
if ((s64)delta < 0) {
sa->last_runnable_update = now;
return 0;
}
/*
* Use 1024ns as the unit of measurement since it's a reasonable
* approximation of 1us and fast to compute.
*/
delta >>= 10;
if (!delta)
return 0;
sa->last_runnable_update = now;
엔티티 러너블 평균을 산출한다.
- rq->runnable_avg_sum
- 태스크가 런큐에 있거나 동작중 일때의 러너블 평균 합
- runnable load.on_rq=1
- rq->runnable_avg_period
- 태스크의 동작 유무와 관련 없이 러너블 평균 기간
- 코드 라인 37에서 현재 시각 now에서 마지막 러너블 업데이트 갱신 시각을 뺀 값을 delta에 대입한다.
- 코드 라인 42~45에서 delta가 음수인 경우 시간이 거꾸로 되돌려 졌다고 판단하고 예외 케이스로 last_runnable_update를 갱신하고 함수를 빠져나온다.
- 부트업 타임에 발생할 가능성이 있다.
- 코드 라인 51~53에서 PELT(Per Entity Load Tracking)의 스케쥴링 시간 처리 최소 단위는 1024ns(1us)이다 따라서 delta를 최소 단위 us단위로 바꾸고 만일 1us도 안되는 경우 함수를 빠져나간다.
- 코드 라인 54에서 last_runnable_update에 현재 시각(ns)을 기록한다.
/* delta_w is the amount already accumulated against our next period */
delta_w = sa->runnable_avg_period % 1024;
if (delta + delta_w >= 1024) {
/* period roll-over */
decayed = 1;
/*
* Now that we know we're crossing a period boundary, figure
* out how much from delta we need to complete the current
* period and accrue it.
*/
delta_w = 1024 - delta_w;
if (runnable)
sa->runnable_avg_sum += delta_w;
sa->runnable_avg_period += delta_w;
delta -= delta_w;
/* Figure out how many additional periods this update spans */
periods = delta / 1024;
delta %= 1024;
sa->runnable_avg_sum = decay_load(sa->runnable_avg_sum,
periods + 1);
sa->runnable_avg_period = decay_load(sa->runnable_avg_period,
periods + 1);
/* Efficiently calculate \sum (1..n_period) 1024*y^i */
runnable_contrib = __compute_runnable_contrib(periods);
if (runnable)
sa->runnable_avg_sum += runnable_contrib;
sa->runnable_avg_period += runnable_contrib;
}
/* Remainder of delta accrued against u_0` */
if (runnable)
sa->runnable_avg_sum += delta;
sa->runnable_avg_period += delta;
return decayed;
}
PELT(Per-Entity Load Tracking)에 사용되는 러너블 평균 합계(sa->runnable_avg_sum)와 러너블 평균 기간(sa->runnable_avg_period)을 갱신한다.
- 코드 라인 2에서 기존 산출된 평균 기간 runnable_avg_period를 1024us(약 1ms) 단위로 잘라 남는 기간을 delta_w에 대입한다.
- 코드 라인 3~5에서 delta와 delta_w 값이 1ms 이상인 경우 decay 처리 한다.
- PELT에서 1 스케쥴링(1ms)이 지나면 과거 로드에 그 기간만큼 decay 요율을 곱해서 산출한다.
- 코드 라인 12에서 1024(약 1ms) PELT 스케쥴링 단위에서 delta_w를 빼면 남은 기간(us)이 산출된다. 이를 다시 delta_w에 대입한다.
- 코드 라인 13~15에서 sa->runnable_avg_sum 및 sa->runnable_avg_period에 delta_w 값을 추가하여 PELT 스케줄링 최소 단위로 정렬하게 한다. 만일 인수 runnable이 0인 경우에는 sa->runnable_avg_sum은 갱신하지 않는다.
- 코드 라인 17에서 delta 값에서 방금 처리한 delta_w를 감소시킨다.
- 코드 라인 20~21에서 delta에 몇 개의 1ms 단위가 있는지 그 횟수를 periods에 대입한다. 이 값은 decay 횟수로 사용된다. 그리고 delta 값도 나머지 값만 사용한다.
- 코드 라인 23~24에서 sa->runnable_avg_sum에 periods+1 만큼의 decay 횟수를 적용하여 다시 갱신한다.
- 코드 라인 25~26에서 sa->runnable_avg_period에 periods+1 만큼의 decay 횟수를 적용하여 다시 갱신한다.
- 코드 라인 29~32에서 runnable_contrib를 산출하여 sa->runnable_avg_sum 및 runnable_avg_period에 더해 갱신한다. 만일 인수 runnable이 0인 경우에는 sa->runnable_avg_sum은 갱신하지 않는다.
- 코드 라인 36~40에서 남은 delta를 sa->runnable_avg_sum 및 runnable_avg_period에 더해 갱신하고 decay 여부를 반환한다. 만일 인수 runnable이 0인 경우에는 sa->runnable_avg_sum은 갱신하지 않는다.
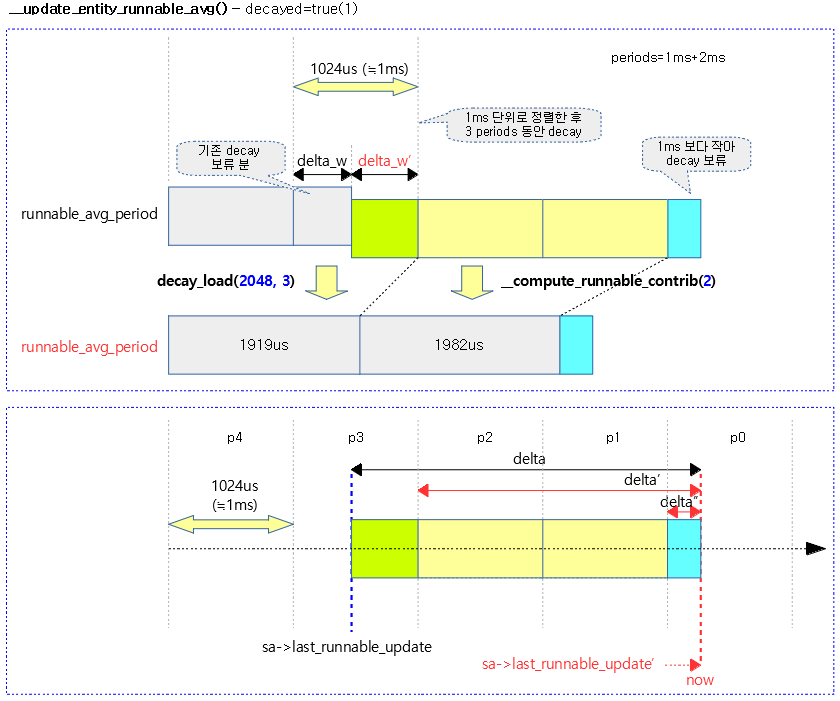
다음 그림은 갱신 기간이 1ms가 못되어 decay를 수행하지 않는 경우의 모습을 보여준다.

다음 그림은 갱신 기간이 1ms를 초과하여 decay를 수행하는 경우의 모습을 보여준다.
기존(old) 평균의 감소(decay)
기존 로드 값에 대해 ms 단위의 지나간 기간 만큼의 감쇠 비율(decay factor)로 곱한다. decay 요율은 ‘y^32 = 0.5’를 사용하는데 32ms 이전의 값은 0.5의 감쇠 비율(decay factor)을 사용한다. 이러한 경우 기존 로드 값이 512라고 할 때 4ms의 기간이 지나 감소된 로드 값은 y^4가 된다. 먼저 y에 대한 값을 계산해 보면 y=0.5^(1/32) = 0.978572… 가 산출된다. 이제 결정된 y 값을 사용하여 4ms 기간이 지난 감쇠 비율(decay factor)을 계산해 보면 ‘0.5^(1/32)^4 = 0.917004… ‘와 같이 산출된다. 결국 ‘512 * 0.91700404 = 469’라는 로드 값으로 줄어든다. 리눅스는 소수 표현을 사용하지 않으므로 빠른 연산을 하기 위해 ms 단위의 기간별로 미리 산출해둔 감쇠 비율을 32bit shift 값을 사용한 정수로 mult화 시켜 미리 테이블로 만들어 두고 활용한다. (0.91700404 << 32 = 0xeac0c6e6)
기존 로드 평균 값에 대해 ms 단위의 지나간 기간 만큼 감소(decay)한다.
- 예) val=0x64, 기간 n=0~63(ms)일 때 산출되는 값들의 변화
- 산출 식: ((val >> (n / 32)) * 테이블[n % 32]) >> 32
- 1 = (0x64 * 0xfa83b2da) >> 32 = 0x61
- 2 = (0x64 * 0xf5257d14) >> 32 = 0x5f
- …
- 31 = (0x64 * 0x82cd8698) >> 32 = 0x33
- 32 = (0x32 * 0xffffffff) >> 32 = 0x31
- 33 = (0x32 * 0xfa83b2da) >> 32 = 0x30
- 34 = (0x32 * 0xf5257d14) >> 32 = 0x2f
- …
- 63 = (0x32 * 0x82cd8698) >> 32 = 0x19
decay_load()
kernel/sched/fair.c
/*
* Approximate:
* val * y^n, where y^32 ~= 0.5 (~1 scheduling period)
*/
static __always_inline u64 decay_load(u64 val, u64 n)
{
unsigned int local_n;
if (!n)
return val;
else if (unlikely(n > LOAD_AVG_PERIOD * 63))
return 0;
/* after bounds checking we can collapse to 32-bit */
local_n = n;
/*
* As y^PERIOD = 1/2, we can combine
* y^n = 1/2^(n/PERIOD) * y^(n%PERIOD)
* With a look-up table which covers y^n (n<PERIOD)
*
* To achieve constant time decay_load.
*/
if (unlikely(local_n >= LOAD_AVG_PERIOD)) {
val >>= local_n / LOAD_AVG_PERIOD;
local_n %= LOAD_AVG_PERIOD;
}
val *= runnable_avg_yN_inv[local_n];
/* We don't use SRR here since we always want to round down. */
return val >> 32;
}
로드 값 val을 n 기간(ms) 에 해당하는 감소 비율로 줄인다. n=0인 경우 1.0 요율이고, n=32인 경우 0.5 요율이다.
- 코드 라인 9~10에서 n이 0인 경우 val 값을 그대로 사용하는 것으로 반환한다. (요율 1.0)
- 코드 라인 11~12에서 n이 1356(32 * 63)을 초과하는 경우 너무 오래된 기간이므로 0을 반환한다.
- 코드 라인 24~27에서 n이 32 이상인 경우 val 값을 n/32 만큼 시프트 하고 n 값은 32로 나눈 나머지를 사용한다.
- 코드 라인 29~31에서 미리 계산해둔 테이블에서 n 인덱스에 해당하는 값을 val에 곱하고 32비트 우측 시프트하여 반환한다.
미리 만들어진 PELT용 decay factor
kernel/sched/fair.c
/*
* We choose a half-life close to 1 scheduling period.
* Note: The tables below are dependent on this value.
*/
#define LOAD_AVG_PERIOD 32
#define LOAD_AVG_MAX 47742 /* maximum possible load avg */
#define LOAD_AVG_MAX_N 345 /* number of full periods to produce LOAD_MAX_AVG */
/* Precomputed fixed inverse multiplies for multiplication by y^n */
static const u32 runnable_avg_yN_inv[] = {
0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6,
0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85,
0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581,
0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9,
0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80,
0x85aac367, 0x82cd8698,
};
32ms까지 decay될 요율(factor)이 미리 계산되어 있는 runnable_avg_yN_inv[] 테이블은 나눗셈 연산을 하지 않게 하기 위해 decay 요율마다 mult 값이 다음 수식으로 만들어졌다.
- n 번째 요율을 계산하는 수식(32bit shift 적용):
- ‘y^n’은 실수 요율이고 커널에서 사용하기 위해 32비트 shift를 적용하여 정수로 바꾼다.
- ‘y^k * 2^32’ 수식을 사용한다. (단 y^32=0.5)
- y값을 먼저 구해보면
- y=0.5^(1/32)=0.97852062…
- 인덱스 값 n에 0부터 32까지 사용한 결과 값은? (테이블 구성은 0~31 까지)
- 인덱스 n에 0을 주면 y^0 * 2^32 = 0.5^(1/32)^0 * (2^32) = 1.0 << 32 = 0x1_0000_0000 (32bit로 구성된 테이블 값은 0xffff_ffff 사용)
- 인덱스 n에 1 을 주면 y^1 * 2^32 = 0.5^(1/32)^1 * (2^32) = 0.97852062 << 32 = 0xfa83_b2db
- 인덱스 n에 2을 주면 y^2 * 2^32 = 0.5^(1/32)^2 * (2^32) = 0.957603281 << 32 = 0xf525_7d15
- …
- 인덱스 n에 31을 주면 y^2 * 2^32 = 0.5^(1/32)^31 * (2^32) = 0.510948574 << 32 = 0x82cd_8698
- 인덱스 n에 32을 주면 y^2 * 2^32 = 0.5^(1/32)^31 * (2^32) = 0.5 << 32 = 0x7fff_ffff
- ‘y^n’은 실수 요율이고 커널에서 사용하기 위해 32비트 shift를 적용하여 정수로 바꾼다.

새(new) 기간에 대한 기여 감소 합계(decay sum)
기존 값이 ms 단위의 지나간 기간 만큼 감쇠 비율(decay factor)을 사용하여 산출한 것에 반해 새 로드 값은 1 ms 단위의 각각의 지나간 기간에 대해 적용한 감쇠 비율을 곱한 값을 모두 더해 산출한다. 예를 들어 3ms의 기간이 흐른 로드 값은 ‘1024*y^3 + 1024*y^2 + 1024*y’ = ‘959 + 980 + 1002 = 2941’이다. (y 값은 ‘0.5^(1/32) = 0.97857206…;) 즉 1ms에 해당하는 1024us의 값이 3ms가 지나면 959us로 작아졌음을 알 수 있다. 리눅스는 빠른 산출을 위해 각 기간 별로 산출된 감쇠 비율에 대한 총합(deacy sum)을 테이블로 만들어 사용한다.
__compute_runnable_contrib()
kernel/sched/fair.c
/*
* For updates fully spanning n periods, the contribution to runnable
* average will be: \Sum 1024*y^n
*
* We can compute this reasonably efficiently by combining:
* y^PERIOD = 1/2 with precomputed \Sum 1024*y^n {for n <PERIOD}
*/
static u32 __compute_runnable_contrib(u64 n)
{
u32 contrib = 0;
if (likely(n <= LOAD_AVG_PERIOD))
return runnable_avg_yN_sum[n];
else if (unlikely(n >= LOAD_AVG_MAX_N))
return LOAD_AVG_MAX;
/* Compute \Sum k^n combining precomputed values for k^i, \Sum k^j */
do {
contrib /= 2; /* y^LOAD_AVG_PERIOD = 1/2 */
contrib += runnable_avg_yN_sum[LOAD_AVG_PERIOD];
n -= LOAD_AVG_PERIOD;
} while (n > LOAD_AVG_PERIOD);
contrib = decay_load(contrib, n);
return contrib + runnable_avg_yN_sum[n];
}
인수로 받은 1ms 단위 기간의 수 n 만큼 러너블 평균에 기여할 누적값을 산출하여 반환한다.
- y^32=0.5일 때, 1024 * sum(y^n)에 대한 결과 값을 산출하되 미리 계산된 테이블을 이용한다.
- 스케쥴링 기간 n은 ms 단위이며 결과는 us단위로 반환된다.
- 343ms 이상은 최대 47742us 값을 반환한다.
- 코드 라인 12~13에서 n이 32 이하인 경우 미리 계산된 테이블을 사용하여 곧바로 결과 값을 반환한다.
- 예) n=2 -> 1982
- 코드 라인 14~15에서 n이 LOAD_AVG_MAX_N(345) 이상인 경우 최대치인 47742를 반환한다.
- 코드 라인 18~20에서 루프를 돌 때마다 contrib를 절반으로 감소시키며 contrib에 최대치인 테이블 최대치인 23371을 더한다.
- 코드 라인 22~23에서 LOAD_AVG_PERIOD(32) 만큼씩 n을 줄이며 32를 초과하는 경우 계속 루프를 돈다.
- 코드 라인 25~26에서 마지막으로 contrib를 가지고 n 만큼 decay한 후 n 번째 테이블 값을 더해 반환한다.
다음과 같이 다양한 조건에서 결과값을 알아본다.
- n=0
- =runnable_avg_yN_sum[0] =0
- n=1
- =runnable_avg_yN_sum[1] =1002
- n=2
- =runnable_avg_yN_sum[2] =1982
- n=10
- =runnable_avg_yN_sum[10] =9103
- n=32
- =runnable_avg_yN_sum[32] =23371
- n=33
- =decay_load(23371, 1) + runnable_avg_yN_sum[1] = 22870 + 1002 = 23872
- n=100
- = decay_load(23371 + 23371/2 + 23371/4, 4) + runnable_avg_yN_sum[4] = decay_load(40898, 4) + 3880 = 37503 + 3880 = 41383
- n=343
- =decay_load(23371 + 23371/2, 23371/4, 23371/8 + 23371/16 + 23371/32, + 23371/64 + 23371/128 + 23371/256 + 23371/512, 23) + runnable_avg_yN_sum[23] = decay_load(23371 + 11685 + 5842 + 2921 + 1460 + 730 + 365 + 182 + 91 + 45, 4) + 3880 = decay_load(46692, 23) + 18340 = 28371 + 18340 = 46711
- n >= 344
- =47742 (max)
미리 만들어진 PELT용 decay factor sum
kernel/sched/fair.c
/*
* Precomputed \Sum y^k { 1<=k<=n }. These are floor(true_value) to prevent
* over-estimates when re-combining.
*/
static const u32 runnable_avg_yN_sum[] = {
0, 1002, 1982, 2941, 3880, 4798, 5697, 6576, 7437, 8279, 9103,
9909,10698,11470,12226,12966,13690,14398,15091,15769,16433,17082,
17718,18340,18949,19545,20128,20698,21256,21802,22336,22859,23371,
};
runnable_avg_yN_sum[] 테이블은 다음 수식으로 만들어졌다.
- ‘sum(y^k) { 1<=k<=n } y^32=0.5’은 실수 요율이고 커널에서 사용하기 위해 정수로 바꾸기 위해 산출된 값에 12bit shift를 적용한다.
- 1024 * Sum(y^k) { 1<=k<=n } y^32=0.5
- y값을 먼저 구해보면
- y=0.5^(1/32)=0.97852062…
- 인덱스 값 n에 1부터 31까지 사용한 결과 값은?
- sum(1024 * y^1) { 1<=k<=1 } = 1024 * (y^1) = 1002
- sum(1024 * y^2) { 1<=k<=2 } =1024 * (y^1 + y^2) = 1002 + 980 = 1,982
- sum(1024 * y^3) { 1<=k<=3 } =1024 * (y^1 + y^2 + y^3) = 1,002 + 980 + 959=2,941
- …
- sum(1024 * y^32)=1024 * (y^1 + y^2 + y^3 + … + y^32) = 1,002 + 980 + 959 + … + 512=23,371
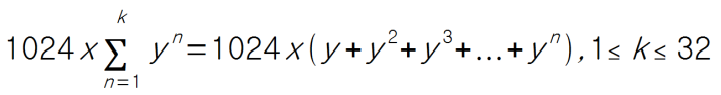
스케줄링 엔티티 로드 평균 기여 갱신
스케줄링 엔티티의 러너블 로드 평균 값과 러너블 로드 기간의 decay 산출이 완료된 후 아래 함수가 호출된다. 여기에서는 엔티티가 태스크용인지 태스크 그룹용인지에 따라 처리하는 방법이 나뉜다.
- 태스크용 스케줄 엔티티의 경우 se->avg.load_avg_contrib 값을 산출할 때 로드 weight과 러너블 기간 비율을 곱하여 산출한다.
- = weight * 러너블 기간 비율(러너블 평균 합 / 러너블 기간 합)
- = se->load.weight * se->avg.runnable_avg_sum / (se->avg.runnable_avg_period+1)
- 태스크 그룹용 스케줄 엔티티의 경우 태스크 그룹에 기여하는 정도를 알아보기 위해 nice-0의 weight를 사용하여 러너블 기간 비율을 곱하여 산출한다.
- = nice-0용 weight * 러너블 기간 비율(러너블 평균 합 / 러너블 기간 합)
- = 1024 * se->avg.runnable_avg_sum / (se->avg.runnable_avg_period+1)
__update_entity_load_avg_contrib()
kernel/sched/fair.c
/* Compute the current contribution to load_avg by se, return any delta */
static long __update_entity_load_avg_contrib(struct sched_entity *se)
{
long old_contrib = se->avg.load_avg_contrib;
if (entity_is_task(se)) {
__update_task_entity_contrib(se);
} else {
__update_tg_runnable_avg(&se->avg, group_cfs_rq(se));
__update_group_entity_contrib(se);
}
return se->avg.load_avg_contrib - old_contrib;
}
스케줄링 엔티티의 로드 평균 기여값을 갱신하고 그 변화값을 반환한다.
- 코드 라인 4에서 스케줄링 엔티티의 로드 평균 기여 값을 old_contrib에 보관해둔다.
- 코드 라인 6~7에서 태스크용 스케줄 엔티티인 경우 스케줄 엔티티의 로드 평균 기여값을 갱신한다.
- 코드 라인 8~11에서 태스크 그룹용 스케줄 엔티티인 경우 스케줄 엔티티의 태스크 그룹용 로드 평균 기여값을 갱신한다.
- 코드 라인 13에서 스케줄링 엔티티의 로드 평균 기여 값의 변화값을 반환한다.
스케줄링 엔티티 로드 평균 기여 갱신 – a) for 태스크용 se
__update_task_entity_contrib()
kernel/sched/fair.c
static inline void __update_task_entity_contrib(struct sched_entity *se)
{
u32 contrib;
/* avoid overflowing a 32-bit type w/ SCHED_LOAD_SCALE */
contrib = se->avg.runnable_avg_sum * scale_load_down(se->load.weight);
contrib /= (se->avg.runnable_avg_period + 1);
se->avg.load_avg_contrib = scale_load(contrib);
}
태스크용 스케줄 엔티티의 로드 평균 기여값을 다음과 같이 산출한다.
- avg.load_avg_contrib = load.weight * avg.runnable_avg_sum / (avg.runnable_avg_period + 1)
다음 그림은 위의 태스크용 스케줄 엔티티의 로드 평균 기여값 산출 과정을 보여준다.

스케줄링 엔티티 로드 평균 기여 갱신 – b) for 태스크 그룹용 se
__update_tg_runnable_avg()
kernel/sched/fair.c
/*
* Aggregate cfs_rq runnable averages into an equivalent task_group
* representation for computing load contributions.
*/
static inline void __update_tg_runnable_avg(struct sched_avg *sa,
struct cfs_rq *cfs_rq)
{
struct task_group *tg = cfs_rq->tg;
long contrib;
/* The fraction of a cpu used by this cfs_rq */
contrib = div_u64((u64)sa->runnable_avg_sum << NICE_0_SHIFT,
sa->runnable_avg_period + 1);
contrib -= cfs_rq->tg_runnable_contrib;
if (abs(contrib) > cfs_rq->tg_runnable_contrib / 64) {
atomic_add(contrib, &tg->runnable_avg);
cfs_rq->tg_runnable_contrib += contrib;
}
}
cfs 런큐와 태스크 그룹용 스케줄 엔티티의 러너블 평균 기여값을 산출한다. 단 변화분이 절대값이 기존 값의 1/64을 초과하는 경우에만 갱신한다. 태스크 그룹은 cpu별로 동작하는 cfs 런큐의 tg_runnable_contrib를 모두 합한 값이다. 이렇게 산출된 러너블 평균은 이어진 다음 함수에서 사용된다.
- cont = sa->runnable_avg_sum * 1024 / (sa->runnable_avg_period + 1) – cfs_rq->tg_runnable_contrib
- tg->runnable_avg = cont
- cfs_rq->tg_runnable_contrib += cont

__update_group_entity_contrib()
kernel/sched/fair.c
static inline void __update_group_entity_contrib(struct sched_entity *se)
{
struct cfs_rq *cfs_rq = group_cfs_rq(se);
struct task_group *tg = cfs_rq->tg;
int runnable_avg;
u64 contrib;
contrib = cfs_rq->tg_load_contrib * tg->shares;
se->avg.load_avg_contrib = div_u64(contrib,
atomic_long_read(&tg->load_avg) + 1);
/*
* For group entities we need to compute a correction term in the case
* that they are consuming <1 cpu so that we would contribute the same
* load as a task of equal weight.
*
* Explicitly co-ordinating this measurement would be expensive, but
* fortunately the sum of each cpus contribution forms a usable
* lower-bound on the true value.
*
* Consider the aggregate of 2 contributions. Either they are disjoint
* (and the sum represents true value) or they are disjoint and we are
* understating by the aggregate of their overlap.
*
* Extending this to N cpus, for a given overlap, the maximum amount we
* understand is then n_i(n_i+1)/2 * w_i where n_i is the number of
* cpus that overlap for this interval and w_i is the interval width.
*
* On a small machine; the first term is well-bounded which bounds the
* total error since w_i is a subset of the period. Whereas on a
* larger machine, while this first term can be larger, if w_i is the
* of consequential size guaranteed to see n_i*w_i quickly converge to
* our upper bound of 1-cpu.
*/
runnable_avg = atomic_read(&tg->runnable_avg);
if (runnable_avg < NICE_0_LOAD) {
se->avg.load_avg_contrib *= runnable_avg;
se->avg.load_avg_contrib >>= NICE_0_SHIFT;
}
}
태스크 그룹용 스케줄 엔티티의 로드 평균 기여값을 갱신한다.
- 코드 라인 9~11에서 태스크 그룹용 로드 기여값과 shares를 곱하고 태스크 그룹용 로드 평균+1로 나눈 값을 se->avg.load_avg_contrib에 대입한다.
- 코드 라인 36~40에서 태스크 그룹의 러너블 평균이 nice-0 weight 값인 1024보다 작은 경우에 한해 이 값을 nice-0 weight에 대한 비율로 바꾼 후 위에서 산출한 값을 곱하여 갱신한다.
- se->avg.load_avg_contrib *= runnable_avg / 1024
다음 그림은 태스크 그룹용 스케줄 엔티티의 로드 평균 기여값을 산출하는 수식이다.

스케줄링 엔티티 블럭드 로드 갱신
update_cfs_rq_blocked_load()
kernel/sched/fair.c
/*
* Decay the load contributed by all blocked children and account this so that
* their contribution may appropriately discounted when they wake up.
*/
static void update_cfs_rq_blocked_load(struct cfs_rq *cfs_rq, int force_update)
{
u64 now = cfs_rq_clock_task(cfs_rq) >> 20;
u64 decays;
decays = now - cfs_rq->last_decay;
if (!decays && !force_update)
return;
if (atomic_long_read(&cfs_rq->removed_load)) {
unsigned long removed_load;
removed_load = atomic_long_xchg(&cfs_rq->removed_load, 0);
subtract_blocked_load_contrib(cfs_rq, removed_load);
}
if (decays) {
cfs_rq->blocked_load_avg = decay_load(cfs_rq->blocked_load_avg,
decays);
atomic64_add(decays, &cfs_rq->decay_counter);
cfs_rq->last_decay = now;
}
__update_cfs_rq_tg_load_contrib(cfs_rq, force_update);
}
blocked 로드 평균을 업데이트한다. blocked_load_avg에서 removed_load 만큼을 감소시킨 값을 ms 단위로 decay할 기간만큼 decay 한다.
- 코드 라인 7에서 현재 클럭 태스크의 시각을 ms 단위로 변환하여 now에 대입한다.
- 코드 라인 10~12에서 now와 최종 decay 시각과의 차이를 decays에 대입한다. 만일 decays가 0이고 force_update 요청이 없는 경우 함수를 빠져나간다.
- 코드 라인 14~18에서 removed_load가 있는 경우 0으로 대입하고 기존 값을 blocked 로드 평균에서 감소시킨다.
- 코드 라인 20~25에서 decays 기간이 있는 경우 blocked_load_avg 값을 decays 만큼 decay 시킨 후 decay_counter에 decays를 추가하고 현재 갱신 시각 now를 last_decay에 저장한다.
- 코드 라인 27에서 태스크 그룹용 로드 평균 기여를 갱신한다.
다음 그림은 blocked_load_avg – removed_load 값을 10ms decay 하는 모습을 보여준다.

subtract_blocked_load_contrib()
kernel/sched/fair.c
static inline void subtract_blocked_load_contrib(struct cfs_rq *cfs_rq,
long load_contrib)
{
if (likely(load_contrib < cfs_rq->blocked_load_avg))
cfs_rq->blocked_load_avg -= load_contrib;
else
cfs_rq->blocked_load_avg = 0;
}
blocked 로드 평균에서 요청한 로드 기여값을 감소시킨다. 만일 0보다 작아지는 경우 0을 대입한다.
__update_cfs_rq_tg_load_contrib()
kernel/sched/fair.c
static inline void __update_cfs_rq_tg_load_contrib(struct cfs_rq *cfs_rq,
int force_update)
{
struct task_group *tg = cfs_rq->tg;
long tg_contrib;
tg_contrib = cfs_rq->runnable_load_avg + cfs_rq->blocked_load_avg;
tg_contrib -= cfs_rq->tg_load_contrib;
if (!tg_contrib)
return;
if (force_update || abs(tg_contrib) > cfs_rq->tg_load_contrib / 8) {
atomic_long_add(tg_contrib, &tg->load_avg);
cfs_rq->tg_load_contrib += tg_contrib;
}
}
태스크 그룹용 로드 평균 기여를 갱신한다.
- tmp = cfs_rq->runnable_load_avg + cfs_rq->blocked_load_avg – cfs_rq->tg_load_contrib
- cfs_rq->tg_load_contrib = tmp
- tg->load_avg = tmp
다음 그림은 태스크 그룹용 스케줄 엔티티의 로드 평균과 로드 기여값을 갱신하는 모습을 보여준다.
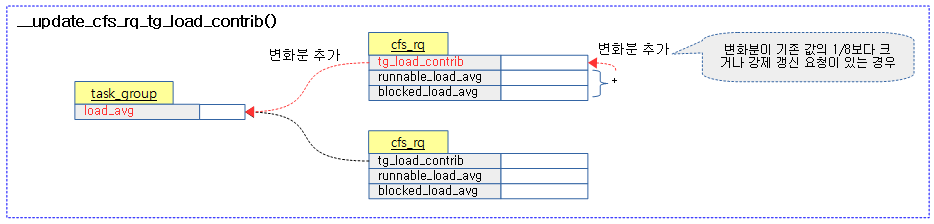
CFS Shares 갱신으로 인한 로드 weight 재반영
kernel/sched/fair.c
update_cfs_shares()
static void update_cfs_shares(struct cfs_rq *cfs_rq)
{
struct task_group *tg;
struct sched_entity *se;
long shares;
tg = cfs_rq->tg;
se = tg->se[cpu_of(rq_of(cfs_rq))];
if (!se || throttled_hierarchy(cfs_rq))
return;
#ifndef CONFIG_SMP
if (likely(se->load.weight == tg->shares))
return;
#endif
shares = calc_cfs_shares(cfs_rq, tg);
reweight_entity(cfs_rq_of(se), se, shares);
}
태스크 그룹의 shares 값에 대한 cfs 런큐의 로드 비율을 적용하여 스케줄 엔티티, cfs 런큐 및 런큐등의 로드 weight을 갱신한다.
- 코드 라인 7~8에서 cfs 런큐로 태스크 그룹 및 스케줄 엔티티를 알아온다.
- 코드 라인 9~10에서 스케줄 엔티티가 없거나 cfs 런큐가 스로틀된 경우 함수를 빠져나간다.
- 코드 라인 11~14에서 UP 시스템에서 태스크 그룹의 shares 값과 스케줄 엔티티의 로드 값이 동일하면 최대치를 사용하는 중이므로 함수를 빠져나간다.
- 코드 라인 15에서 태스크 그룹의 cfs shares 값에 cfs 런큐 로드 비율이 반영된 로드 weight 값을 산출한다
- 코드 라인 17에서 산출된 shares 값으로 스케줄 엔티티의 로드 weight 값을 재계산한다.
calc_cfs_shares()
kernel/sched/fair.c
static long calc_cfs_shares(struct cfs_rq *cfs_rq, struct task_group *tg)
{
long tg_weight, load, shares;
tg_weight = calc_tg_weight(tg, cfs_rq);
load = cfs_rq->load.weight;
shares = (tg->shares * load);
if (tg_weight)
shares /= tg_weight;
if (shares < MIN_SHARES)
shares = MIN_SHARES;
if (shares > tg->shares)
shares = tg->shares;
return shares;
}
태스크 그룹의 cfs shares 값에 대한 cfs 런큐 로드 비율이 반영된 로드 weight 값을 산출한다. (태스크 그룹의 shares * cfs 런큐 로드 weight / 태스크 그룹 weight)
- 코드 라인 5에서 태스크 그룹의 weight 값을 tg_weight에 대입한다.
- 코드 라인 6에서 cfs 런큐의 로드 weight 값을 load에 대입한다.
- 코드 라인 8~10에서 태스크 그룹의 shares 값과 load를 곱한 후 태스크 그룹의 weight 값으로 나눈다.
- tg->shares * cfs_rq->load.weight / tg_weight
- 코드 라인 12~17에서 산출된 share 값이 최소 shares(2)보다 작지 않도록 제한하고 태스크 그룹의 shares 값보다 크지 않도록 제한하고 반환한다.
- 2 <= 계산된 shaers <= tg->shares
다음 그림은 태스크 그룹의 shares 값에 대하여 태스크 그룹 대비 cfs 런큐의 로드기여 비율을 반영하여 산출한다.
- UP 시스템에서는 태스크 그룹 대비 cfs 런큐의 로드 weight 비율을 반영하지 않는다. 따라서 태스크 그룹의 shares 값을 100% 반영한다.
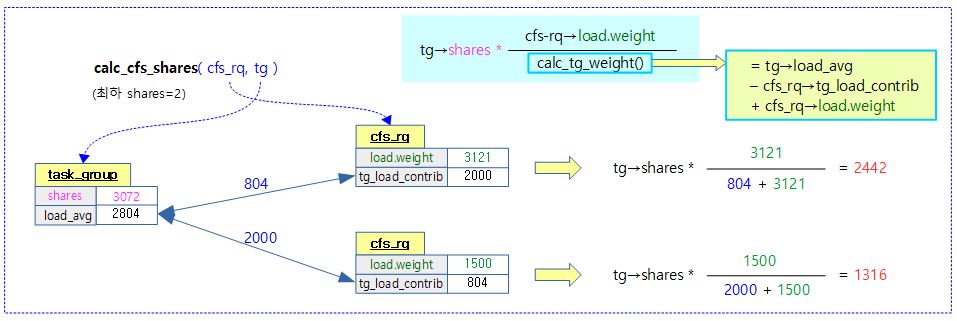
calc_tg_weight()
kernel/sched/fair.c
static inline long calc_tg_weight(struct task_group *tg, struct cfs_rq *cfs_rq)
{
long tg_weight;
/*
* Use this CPU's actual weight instead of the last load_contribution
* to gain a more accurate current total weight. See
* update_cfs_rq_load_contribution().
*/
tg_weight = atomic_long_read(&tg->load_avg);
tg_weight -= cfs_rq->tg_load_contrib;
tg_weight += cfs_rq->load.weight;
return tg_weight;
}
태스크 그룹의 로드 평균 값을 읽어와서 cfs 런큐의 태스크 그룹 로드 기여 값을 감소시키고 다시 cfs 런큐의 로드 weight 값을 더한 후 반환한다.
- tg->load_avg – cfs_rq->tg_load_contrib + cfs_rq->load.weight
로드 weight 재설정
reweight_entity()
kernel/sched/fair.c
static void reweight_entity(struct cfs_rq *cfs_rq, struct sched_entity *se,
unsigned long weight)
{
if (se->on_rq) {
/* commit outstanding execution time */
if (cfs_rq->curr == se)
update_curr(cfs_rq);
account_entity_dequeue(cfs_rq, se);
}
update_load_set(&se->load, weight);
if (se->on_rq)
account_entity_enqueue(cfs_rq, se);
}
스케줄 엔티티의 로드 weight 값을 변경 시킨다. 스케줄 엔티티가 cfs 런큐에서 이미 동작중인 경우 cfs 런큐와 런큐의 로드 값을 다음 예와 같이 조정한다.
- 예) se->load.weight 값이 5000 -> 6024로 변경되는 경우
- cfs_rq->load -= 5000 -> cfs_rq->load += 6024
- rq->load -= 5000 -> rq->load += 6024 (최상위 스케줄 엔티티인 경우)
- 코드 라인 4~7에서 요청한 스케줄 엔티티가 런큐에 있고 cfs 런큐에서 지금 돌고 있는 중이면 현재 태스크의 런타임 통계를 갱신한다.
- 코드 라인 8에서 스케줄 엔티티의 로드 weight 값을 cfs 런큐에서 감소시킨다. 또한 최상위 스케줄 엔티티인 경우 런큐의 로드 weight 값을 동일하게 감소시킨다.
- 코드 라인 11에서 스케줄 엔티티의 로드 weight 값을 갱신한다.
- 코드 라인 13~14에서 요청한 스케줄 엔티티가 런큐에 있는 경우 스케줄 엔티티의 로드 weight 값을 cfs 런큐에 추가한다. 또한 최상위 스케줄 엔티티인 경우 런큐의 로드 weight 값에 동일하게 추가한다.
로드 weight이 재산출되야 하는 상황들을 알아본다.
- 태스크 그룹의 shares 값을 변경 시 sched_group_set_shares() -> 변경할 그룹부터 최상위 그룹까지 반복: update_cfs_shares() -> reweight_entity()에서 사용된다.
- 요청 스케줄 엔티티가 엔큐될 때 enqueue_entity() -> update_cfs_shares() -> reweight_entity()
- 요청 스케줄 엔티티가 디큐될 때 enqueue_entity() -> update_cfs_shares() -> reweight_entity()
다음 그림은 스케줄 엔티티의 로드 weight 값이 변경될 때 관련된 cfs 런큐 및 런큐값도 재산출되는 과정을 보여준다.
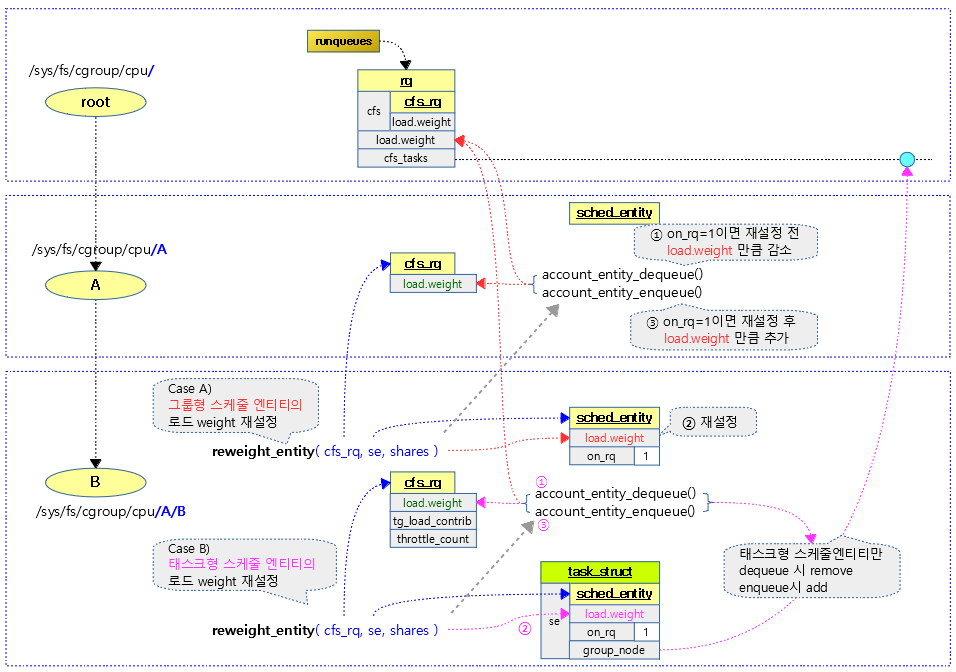
update_load_set()
kernel/sched/fair.c
static inline void update_load_set(struct load_weight *lw, unsigned long w)
{
lw->weight = w;
lw->inv_weight = 0;
}
로드 weight 걊을 설정하고 inv_weight 값은 0으로 리셋한다.
Account Entity Enqueue & Dequeue
account_entity_enqueue()
kernel/sched/fair.c
static void
account_entity_enqueue(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
update_load_add(&cfs_rq->load, se->load.weight);
if (!parent_entity(se))
update_load_add(&rq_of(cfs_rq)->load, se->load.weight);
#ifdef CONFIG_SMP
if (entity_is_task(se)) {
struct rq *rq = rq_of(cfs_rq);
account_numa_enqueue(rq, task_of(se));
list_add(&se->group_node, &rq->cfs_tasks);
}
#endif
cfs_rq->nr_running++;
}
cfs 런큐에 스케줄 엔티티의 로드를 추가한다. 부모 스케줄 엔티티가 없으면 cfs 런큐가 속한 런큐의 로드에도 추가한다.
- 코드 라인 4에서 cfs 런큐에 스케줄 엔티티의 로드를 추가한다.
- 코드 라인 5~6에서 부모 스케줄 엔티티가 없으면 cfs 런큐가 속한 런큐의 로드에도 추가한다.
- 코드 라인 8~13에서 smp 시스템에서 태스크용 스케줄 엔티티인 경우 NUMA 시스템을 위해 런큐의 nr_numa_running 및 nr_preferred_running을 갱신한다. 그런 후 런큐의 cfs_tasks 리스트에 se->group_node를 추가한다.
- 코드 라인 15에서 런큐의 nr_running 카운터를 1 증가시킨다.
스케줄 엔티티가 cfs 런큐에 엔큐되는 경우 관련 값들을 추가한다.
- 코드 라인 4에서 스케줄 엔티티의 로드 weight 값을 cfs 런큐에 추가한다.
- 코드 라인 5~6에서 최상위 스케줄 엔티티인 경우 런큐에도 추가한다.
- 코드 라인 7~14에서 태스크 타입 스케줄 엔티티인 경우 누마 관련 값도 증가시키고 스케줄 엔티티를 런큐의 cfs_tasks 리스트에 추가한다.
- 코드 라인 15에서 cfs 런큐의 nr_running을 1 증가시킨다.
account_numa_enqueue()
kernel/sched/fair.c
static void account_numa_enqueue(struct rq *rq, struct task_struct *p)
{
rq->nr_numa_running += (p->numa_preferred_nid != -1);
rq->nr_preferred_running += (p->numa_preferred_nid == task_node(p));
}
태스크가 엔큐되고 선호하는 누마 노드로 추가된 경우 다음의 값을 1씩 증가시킨다.
- rq->nr_numa_running++ (태스크의 권장 누마 노드가 지정된 경우에만)
- rq->nr_preferred_running++ (태스크의 노드가 권장 누마 노드와 동일한 경우에만)
다음 그림은 스케줄 엔티티의 로드 weight 값을 런큐 및 cfs 런큐에 증감시키는 상황을 보여준다.
- 태스크형 스케줄 엔티티의 경우 cfs_tasks 리스트에 추가/삭제되는 것도 알 수 있다.
- 런큐의 load.weight 증감은 최상위 엔티티의 load.weight에 대해서만 해당한다.
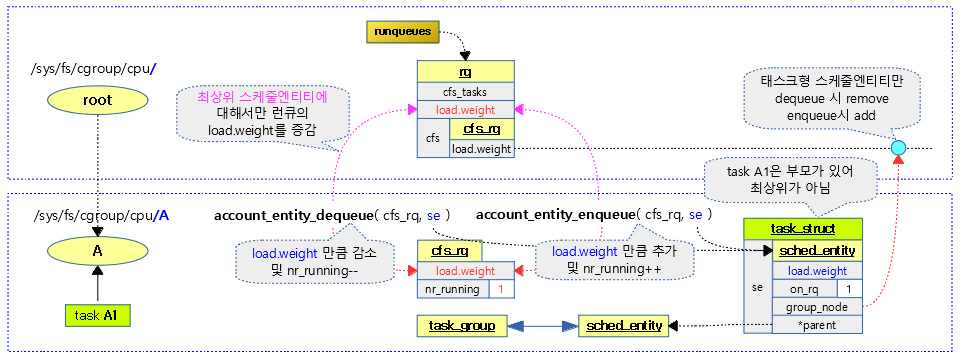
account_entity_dequeue()
kernel/sched/fair.c
static void
account_entity_dequeue(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
update_load_sub(&cfs_rq->load, se->load.weight);
if (!parent_entity(se))
update_load_sub(&rq_of(cfs_rq)->load, se->load.weight);
if (entity_is_task(se)) {
account_numa_dequeue(rq_of(cfs_rq), task_of(se));
list_del_init(&se->group_node);
}
cfs_rq->nr_running--;
}
스케줄 엔티티가 cfs 런큐에서 디큐되는 경우 관련 값들을 감소시킨다.
- 코드 라인 4에서 스케줄 엔티티의 로드 weight 값을 cfs 런큐에서 감소시킨다.
- 코드 라인 5~6에서 최상위 스케줄 엔티티인 경우 런큐에서도 감소시킨다.
- 코드 라인 7~10에서 태스크 타입 스케줄 엔티티인 경우 누마 관련 값을 감소시키고, 런큐의 cfs_tasks 리스트에서 스케줄 엔티티를 제거하고 초기화한다.
- 코드 라인 11에서 cfs 런큐의 nr_running을 1 감소시킨다.
account_numa_dequeue()
kernel/sched/fair.c
static void account_numa_dequeue(struct rq *rq, struct task_struct *p)
{
rq->nr_numa_running -= (p->numa_preferred_nid != -1);
rq->nr_preferred_running -= (p->numa_preferred_nid == task_node(p));
}
태스크가 디큐되고 선호하는 누마 노드로 추가된 경우 다음의 값을 1씩 감소시킨다.
- rq->nr_numa_running– (태스크의 권장 누마 노드가 지정된 경우에만)
- rq->nr_preferred_running– (태스크의 노드가 권장 누마 노드와 동일한 경우에만)
엔큐 & 디큐 시 엔티티 로드 평균 산출
enqueue_entity_load_avg()
kernel/sched/fair.c
/* Add the load generated by se into cfs_rq's child load-average */
static inline void enqueue_entity_load_avg(struct cfs_rq *cfs_rq,
struct sched_entity *se,
int wakeup)
{
/*
* We track migrations using entity decay_count <= 0, on a wake-up
* migration we use a negative decay count to track the remote decays
* accumulated while sleeping.
*
* Newly forked tasks are enqueued with se->avg.decay_count == 0, they
* are seen by enqueue_entity_load_avg() as a migration with an already
* constructed load_avg_contrib.
*/
if (unlikely(se->avg.decay_count <= 0)) {
se->avg.last_runnable_update = rq_clock_task(rq_of(cfs_rq));
if (se->avg.decay_count) {
/*
* In a wake-up migration we have to approximate the
* time sleeping. This is because we can't synchronize
* clock_task between the two cpus, and it is not
* guaranteed to be read-safe. Instead, we can
* approximate this using our carried decays, which are
* explicitly atomically readable.
*/
se->avg.last_runnable_update -= (-se->avg.decay_count)
<< 20;
update_entity_load_avg(se, 0);
/* Indicate that we're now synchronized and on-rq */
se->avg.decay_count = 0;
}
wakeup = 0;
} else {
__synchronize_entity_decay(se);
}
/* migrated tasks did not contribute to our blocked load */
if (wakeup) {
subtract_blocked_load_contrib(cfs_rq, se->avg.load_avg_contrib);
update_entity_load_avg(se, 0);
}
cfs_rq->runnable_load_avg += se->avg.load_avg_contrib;
/* we force update consideration on load-balancer moves */
update_cfs_rq_blocked_load(cfs_rq, !wakeup);
}
스케줄 엔티티가 엔큐될 때 로드 평균을 갱신한다.
- 코드 라인 15~16에서 낮은 확률로 스케줄 엔티티의 decay_count가 0이하인 경우 스케줄 엔티티의 avg.last_runnable_update를 현재 시각(clock_task)으로 갱신한다.
- 코드 라인 17~31에서 decay_count가 음수인 경우 스케줄 엔티티의 avg.last_runnable_update(ns)를 decay_count(ms) 만큼 이전으로 감소시킨다. 그리고 update_entity_load_avg()를 호출하여 로드 평균을 갱신하고 decay_count는 0으로 초기화한다.
- 코드 라인 33~35에서 스케줄 엔티티의 decay_count가 0을 초과한 경우 스케줄 엔티티의 로드 평균 기여를 ‘cfs 런큐의 decay_counter – 스케줄 엔티티의 avg.decay_count’ 만큼 decay 한다.
- 코드 라인 38~41에서 decay_count가 0을 초과하였었고 인수 wakeup=1이 주어진 경우 블럭드로드 기여를 감소시키고 다시 update_entity_load_avg()를 호출하여 로드 평균을 갱신한다.
- 코드 라인 43에서 스케줄 엔티티에 있는 로드 평균 기여를 cfs 런큐의 러너블 로드 평균에 추가한다.
- 코드 라인 45에서 블럭드 로드를 갱신하고 러너블 평균과 더해 cfs 런큐의 tg_load_contrib와 태스크 그룹의 load_avg 에 추가한다.
구조체
sched_avg 구조체
include/linux/sched.h
struct sched_avg {
/*
* These sums represent an infinite geometric series and so are bound
* above by 1024/(1-y). Thus we only need a u32 to store them for all
* choices of y < 1-2^(-32)*1024.
*/
u32 runnable_avg_sum, runnable_avg_period;
u64 last_runnable_update;
s64 decay_count;
unsigned long load_avg_contrib;
};
- runnable_avg_sum
- 러너블 로드라 불리며 러너블(curr + rb 트리에서 대기) 타임 평균을 합하였다.
- runnable_avg_period
- Idle 타임을 포함한 전체 시간 평균을 합하였다.
- last_runnable_update
- 러너블 로드를 갱신한 마지막 시각
- decay_count
- 트래킹 migration에 사용하는 엔티티 decay 카운터로 슬립되어 엔티티가 cfs 런큐를 벗어난 시간을 decay하기 위해 사용된다.
- load_avg_contrib
- 평균 로드 기여(weight * runnable_avg_sum / (runnable_avg_period+1))
- 태스크용 스케줄 엔티티에서는 엔티티의 load.weight이 러너블 평균 비율로 곱하여 산출된다.
- 태스크 그룹용 스케줄 엔티티에서는 shares 값이 tg에 대한 cfs 비율 및 로드 비율 등이 적용되어 산출된다.
task_group 구조체
kernel/sched/sched.h
/* task group related information */
struct task_group {
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each cpu */
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
struct cfs_rq **cfs_rq;
unsigned long shares;
#ifdef CONFIG_SMP
atomic_long_t load_avg;
atomic_t runnable_avg;
#endif
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
struct task_group *parent;
struct list_head siblings;
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
};
- css
- cgroup 서브시스템 상태
- rcu
- list
- *parent
- 부모 태스크 그룹
- siblings
- 현재 태스크들
- children
- 자식 태스크 그룹
- cfs_bandwidth
- cfs 그룹 스케줄링 관련
- **se
- 각 cpu에서 이 그룹에 연결된 스케줄 엔티티(cpu 수 만큼)
- **cfs_rq
- 각 cpu에서 이 그룹에 연결된 cfs 런큐
- shares
- 그룹에 적용할 로드 weight 비율
- load_avg
- cfs 런큐의 로드 평균을 모두 합한 값으로 결국 스케줄 엔티티의 로드 평균 기여값을 모두 합한 값이다.
- runnable_avg
- cfs 런큐의 러너블 평균을 모두 합한 값으로 결국 스케줄 엔티티의 러너블 평균을 모두 합한 값이다.
- **se
- rt 그룹 스케줄링 관련
- **rt_se
- 각 cpu에서 이 그룹에 연결된 rt 스케줄 엔티티(cpu 수 만큼)
- **rt_rq
- 각 cpu에서 이 그룹에 연결된 rt 런큐
- rt_bandwidth
- **rt_se
- autogroup 관련
- *autogroup
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c – 현재 글