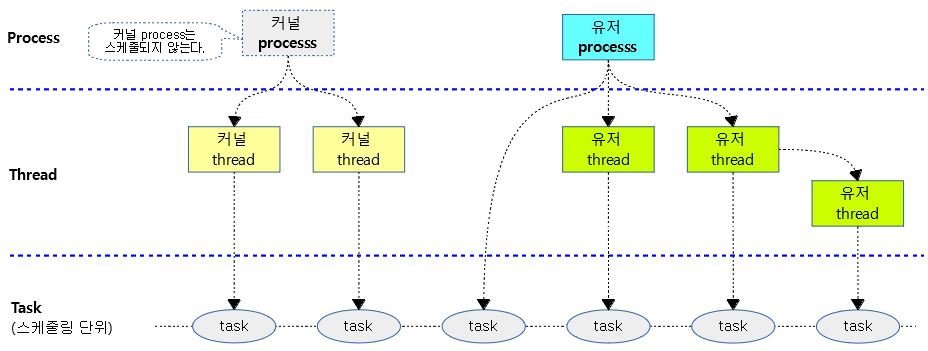
태스크란?
- 프로세스
- 일반적인 정의는 프로그램이 실행중인 상태이다.
- OS 커널이 부트업되어 준비된 경우 유저 레벨에서 디스크로부터 application을 로드하여 자원(메모리, 파일, 페이징, 시그널, 스택, …)을 할당하여 동작시킬 수 있는 최소 단위이다.
- 유저 레벨에서 요청하여 OS 커널이 준비하고 생성한다.
- 특별히 OS 커널은 그 자체가 하나의 커널 프로세스라고도 할 수 있다.
- 커널 프로세스는 부트업타임에 생성되고 종료 직전까지 소멸되지 않으며 스케줄링 단위에는 포함되지 않는 특성으로 인해 존재 유무가 확연히 드러나지 않는다.
- 스레드
- 일반적인 정의는 프로세스에서 실행 단위만 분리한 상태이다.
- 이 때문에 경량 프로세스 (LWP, Light-Weight Process)로도 불린다.
- 참고: 메인스트림 OS로 레벨업「리눅스 커널2.6」| ZDnet Korea
- 아키텍처를 다루는 문서에서 사용하는 스레드는 하드웨어 스레드를 의미하며 명령들을 수행할 수 있는 최소단위 장치인 core 또는 virtual core이다.
- 예) core 당 2개의 하이퍼 스레드(x86에서의 virtual core)를 가진 4 core의 하드웨어 스레드는 총 8개이다.
- OS 레벨에서의 스레드는 Process 내부에서 생성되는 더 작은 단위의 소프트웨어 스레드를 의미한다.
- 커널 코드에서는 사용위치에 따라 스레드가 하드웨어 스레드를 의미할 수도 있고 소프트웨어 스레드를 의미할 수도 있으므로 적절히 구분해서 판단해야 한다.
- 리눅스 버전 2.6에서 전적으로 커널이 스레드를 관리하고 생성한다. 따라서 이 기준으로 설명하였다.
- 최종적으로 Red-hat팀이 개발한 NPTL(Native POSIX Thread Library)을 채용하였다.
- 유저 스레드라고 불려도 커널이 생성하여 관리하는 것에 주의해야 한다. 리눅스 커널 2.6 이전에는 프로세스를 clone하여 사용하거나 유저 라이브러리를 통해 만들어 사용한 진짜 유저 스레드이다.
- 참고: Native POSIX Thread Library | Wikipedia
- 프로세스가 할당 받은 자원을 공유하여 사용할 수 있다. 단 스택 및 TLS(Thread Local Storage) 영역은 공유하지 않고 별도로 생성한다.
- 유저 스레드는 유저 프로세스 또는 상위 스레드로 부터 생성된다.
- 특별히 커널 스레드는 유저 레벨이 아닌 OS 커널 레벨에서만 생성 가능하다.
- 일반적인 정의는 프로세스에서 실행 단위만 분리한 상태이다.
- 태스크
- 프로세스나 스레드를 리눅스에서 스케줄링 할 수 있는 최소 단위가 태스크이다.
- 유저 태스크에서 스케줄링에 대한 비율을 조정하는 경우 nice 값을 사용하여 각 태스크의 time slice를 산출해낸다.
- 내부 자료 구조에서는 task_struct가 태스크를 나타내고 그 내부에 스케줄 엔티티 구조체를 포함하며 이 스케줄 엔티티를 사용하여 time slice를 계산한다.
- 태스크에는 스케줄러별로 사용할 수 있도록 3 개의 스케줄 엔티티인 sched_entity, sched_rt_entity 및 sched_dl_entity가 있다.
- cgroup을 사용한 그룹 스케줄링을 하는 경우에는 스케줄 엔티티가 태스크 그룹(group scheduling)에 연결되어 time slice를 계산한다.
- 내부 자료 구조에서는 task_struct가 태스크를 나타내고 그 내부에 스케줄 엔티티 구조체를 포함하며 이 스케줄 엔티티를 사용하여 time slice를 계산한다.
- 유닉스와 다르게 리눅스의 경우 별도의 설정이 없는 경우 프로세스와 스레드가 동일한 태스크 표현을 사용하고 스케줄링 비율은 동일하다.
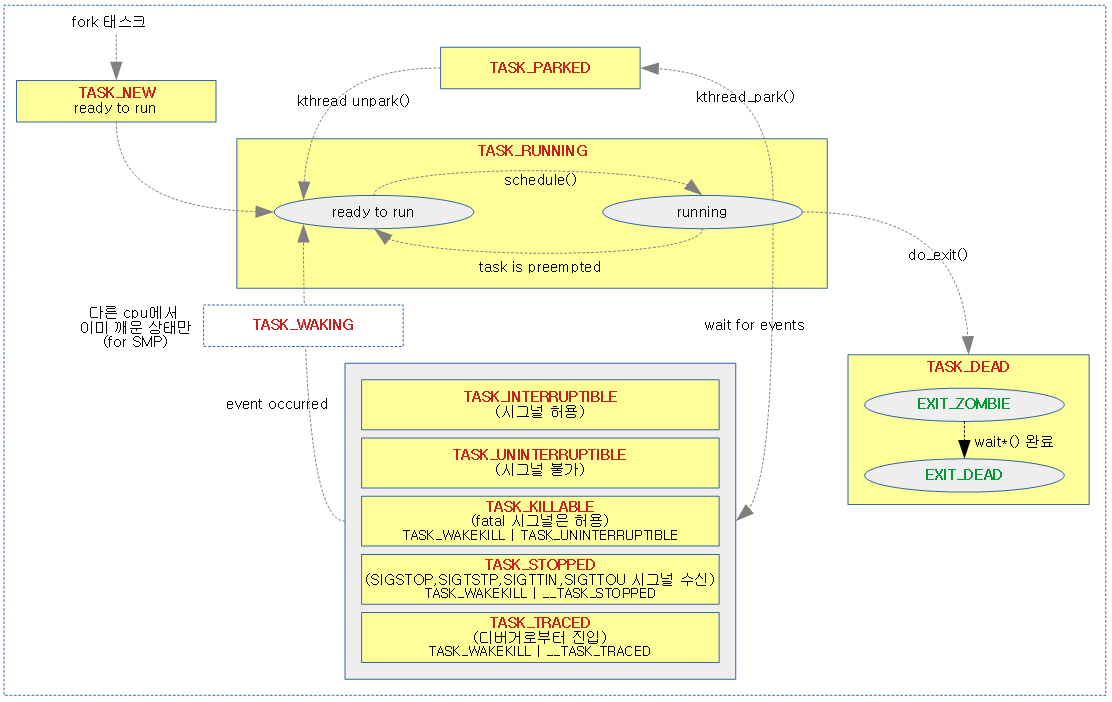
태스크 상태
태스크마다 상태를 나타내는 플래그가 있다. 다음과 같이 두 종류의 플래그를 사용하며 각각은 다음과 같다.
- task->state
- TASK_RUNNING
- 다음과 같이 두 종류로 나뉜다.
- 태스크가 cpu에서 동작 중이다. (running on cpu)
- 태스크가 런큐에서 실행 준비 중이다. (ready to run)
- 다음과 같이 두 종류로 나뉜다.
- TASK_INTERRUPTIBLE
- 태스크가 슬립되었고, 시그널을 받아들일 수 있는 상태이다.
- TASK_UNINTERRUPTIBLE
- 태스크가 슬립되었고, 시그널에 의해 방해받지 않는 상태이다.
- TASK_WAKEKILL 플래그와 같이 사용될 때에는 fatal signal인 SIGKILL은 받을 수 있다.
- 중요한 일을 시그널의 방해 없이 슬립 상태에서 기다릴 때 사용한다.
- 예) 블럭 디바이스 데이터를 버퍼에 옮기는 작업의 완료를 기다릴때 사용한다.
- 태스크가 슬립되었고, 시그널에 의해 방해받지 않는 상태이다.
- TASK_STOPPED
- 태스크가 다음 시그널을 받아 중단된 상태이다.
- 유저가 보낸 SIGSTOP 시그널 요청을 받았다. 이는 유저가 보낸 SIGCONT 시그널로 계속할 수 있다.
- foreground에서 SIGTSTP(^Z) 시그널 요청을 받았다.
- background에서 SIGTTIN 시그널 요청을 받았다.
- background에서 SIGTTOUT 시그널 요청을 받았다.
- 태스크가 다음 시그널을 받아 중단된 상태이다.
- TASK_TRACED
- 태스크가 디버거 요청에 의해 중단된 상태이다.
- TASK_KILLABLE
- TASK_WAKEKILL 과 TASK_UNINTERRUPTIBLE 두 개 상태가 조합되었다.
- uninterruptible 상태이지만 오직 fatal signal인 SIGKILL 요청을 받을 수 있는 상태이다.
- TASK_WAKEKILL
- fatal signal인 SIGKILL 요청을 받을 수 있는 플래그로, 단독으로 사용하진 않는다.
- TASK_PARKED
- ktrhead_create()로 생성된 per-cpu 커널 스레드를 대상으로 슬립 상태의 전환을 수행할 수 있는 특별한 관리 방법이다.
- kthread_park()로 슬립하고 kthread_unpark()로 꺠어날 수 있다.
- TASK_RUNNING
- task->exit_state
- EXIT_ZOMBIE
- 태스크가 종료될 때 사용하는 두 개의 상태 중 첫 번째 상태이다.
- 부모 태스크가 wait*() 관련 함수를 통해 자식 태스크의 정보를 수집하기 직전까지 이 상태를 유지한다.
- EXIT_DEAD
- 태스크가 종료될 때 사용하는 두 개의 상태 중 마지막 상태이다.
- 부모 태스크가 wait*() 관련 함수를 통해 자식 태스크의 정보를 수집완료 하였으므로 자식 태스크가 소멸하는 중인 상태이다.
- EXIT_ZOMBIE
다음 그림은 태스크 상태 전환 다이어그램이다.
멀티태스킹 (time slice, virtual runtime)
동시에 2개의 태스크를 하나의 CPU에서 구동을 시키면 이론적으로는 그 CPU에서 50%의 파워로 2 개의 태스크그가 동시에 병렬로 동작해야 하는데 실제 하드웨어 CPU는 한 번에 하나의 태스크 밖에 수행할 수 없으므로 시간을 분할(time slice) 한 그 가상 시간(virtual runtime) 만큼 교대로 수행을 하여 만족시킨다.
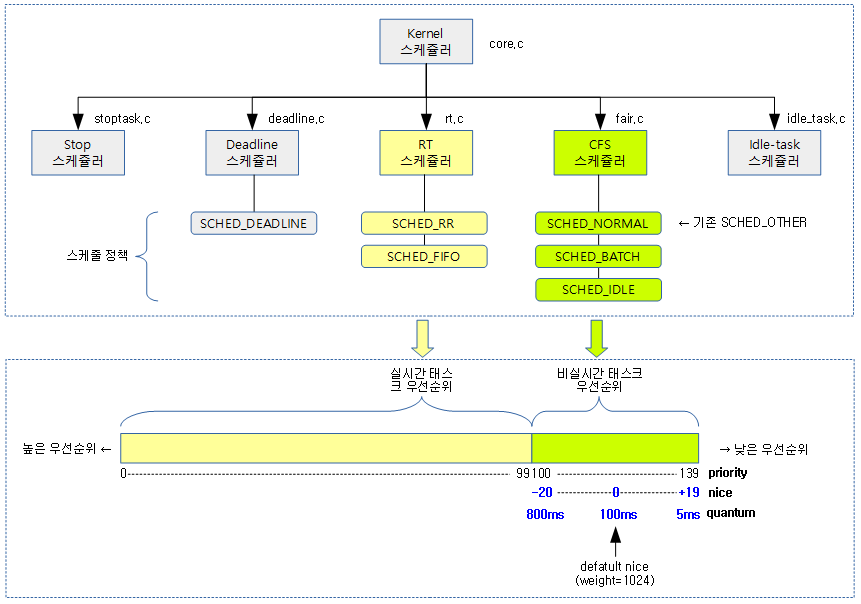
우선순위
Priority
- 커널에서 분류하여 사용하는 우선순위로 0~139까지 총 140 단계가 있다.
- priority 값이 작을수록 높은 우선순위로 time slice를 많이 받는다.
- 0~99까지 100 단계는 RT 스케줄러에서 사용한다.
- 100~139까지의 40단계는 CFS 스케줄러에서 사용한다.
- Nice로 변환되는 영역이다.
- deadline 태스크는 RT나 CFS 태스크들과 달리 우선순위가 없고 항상 RT나 CFS 태스크들보다 우선 처리한다.
Nice
- POSIX 표준이 지정하였다. 일반적인 태스크에서 지정할 수 있는 -20 ~ +19 까지 총 40단계가 있다.
- nice 값이 가장 작은 -19가 우선 순위가 더 높고 time slice를 많이 받는다.
- priority 값으로 변환 시 100 ~ 139의 우선순위를 갖는다.
- RT 스케줄러에서 사용하는 priority 0 ~ 99값보다 커서 RT 스케줄러보다는 항상 낮은 우선 순위를 갖는다.
- root 권한이 아닌 유저로 프로세스나 스레드가 생성되면 스케줄링 단위인 태스크의 nice 값은 0으로 시작된다.
- 2003년에 +19 레벨의 time slice는 1ms(1 jiffy)와 동일하게 설정을 하였으나 그 후 HZ=1000인 시스템(데스크탑)에서 time slice가 너무 적어 5ms로 변경하였다.
스케줄러
커널에 디폴트로 5개의 스케줄러가 준비되어 있고 사용자 태스크는 스케줄 정책을 선택하는 것으로 각각의 스케줄러를 선택할 수 있다. 단 stop 스케줄러 및 Idle-task 스케줄러는 커널이 자체적으로만 사용하므로 사용자들은 선택할 수 없다. 스케줄러별 처리 우선 순위는 아래 스케줄러 순서대로 동작한다. 단 RT 스케줄러의 경우 CFS 스케줄러에 5%(디폴트)의 시간 배분을 양보하여 RT 태스크에 의해 CFS 태스크가 고사(Starvation)되는 것을 막는다.
- Stop 스케줄러
- Deadline 스케줄러
- RT 스케줄러
- CFS 스케줄러
- Idle Task 스케줄러
스케줄러 경쟁
태스크가 각각의 스케줄러들에 등록되면 가장 먼저 처리할 스케줄러가 가장 먼저 처리할 스케줄러는 Stop이고, 우선 순위는
스케줄 정책
- SCHED_DEADLINE
- 태스크를 deadline 스케줄러에서 동작하게 한다.
- SCHED_RR
- 같은 우선 순위의 태스크를 default 0.1초 단위로 round-robin 방식을 사용하여 RT 스케줄러에서 동작하게 한다.
- SCHED_FIFO
- 태스크를 FIFO(first-in first-out) 방식으로 RT 스케줄러에서 동작하게 한다.
- SCHED_NORMAL
- 태스크를 CFS 스케줄러에서 동작하게 한다.
- SCHED_BATCH
- 태스크를 CFS 스케줄러에서 동작하게 한다. 단 SCHED_NORMAL과는 다르게 yield를 회피하여 현재 태스크가 최대한 처리를 할 수 있게 한다.
- SCHED_ILDE
- 태스크를 CFS 스케줄러에서 가장 낮은 우선순위로 동작하게 한다. (nice 19보다 더 느리다. nice=20이란 것은 없지만 이와 같다고 생각하면 된다.)
- 주의: 이 정책을 사용한다고 idle 스케줄러로 진입시키는 것이 아니다.
- 태스크를 CFS 스케줄러에서 가장 낮은 우선순위로 동작하게 한다. (nice 19보다 더 느리다. nice=20이란 것은 없지만 이와 같다고 생각하면 된다.)
CFS 스케줄러
- nice(-20 ~ +19) 우선 순위 태스크는 nice 값에 따른 weight를 태스크에 배정하고 각 태스크들의 weight 비율만큼 timeslice를 배정받아 태스크들이 교대로(context siwthching) 동작한다.
- linux v2.6.23부터 사용하기 시작하였다.
- 태스크마다 virtual 런타임이 주어지고 이를 RB 트리에서 관리한다.
- p->se.vruntime을 키로 소팅된다.
- CFS 이전의 기존 스케줄러에 사용하던 active, expired 배열은 더이상 cfs 스케줄러에서 사용하지 않는다.
- 3가지 스케줄 정책에서 사용된다.
- SCHED_NORMAL
- SCHED_BATCH
- SCHED_IDL
- cfs 직전에 사용한 O(1) 스케줄러는 jiffies나 hz 상수에 의존하여 ms 단위를 사용한 것에 반해 cfs 스케줄러는 ns 단위로 설계되었다.
- 더 이상 통계적 방법을 사용하지 않고 주어진 런타임 시간의 마감(deadline) 방식으로 관리한다.
- CFS bandwidth 기능을 사용할 수 있다.
- 예) ksoftirqd나 high 우선 순위 워크큐의 워커로 동작하는 kworker 태스크들은 CFS 스케줄러에서 nice -20(nice중 가장 우선 순위가 높다)으로 동작한다.
리얼타임(RT) 스케줄러
- RT 태스크마다 priority(0~99, 0이 가장 빠름) 가 지정되는데, 우선순위에 따라 RT 태스크들끼리 경쟁 시 가장 우선 순위가 높은 RT 태스크를 먼저 처리하고, 처리를 완료한 후에 그 다음 우선순위의 RT 태스크를 수행한다.
- priority 51번과 52번이 경쟁하는 경우 51번 우선 순위의 태스크가 동작하는 중에는 52번으로 task context switch 하지 않는다. 즉 자신 보다 낮은 우선 순위의 RT 태스크에는 양보하지 않는다. 다만 cfs 스케줄러가 동작할 수 있도록 디폴트로 5%(1초 – sched_rt_runtime_us)의 시간 분할을 cfs 태스크에게 양보한다.
- sched_rt_period_us
- 실행 주기 결정 (초기값: 1000000 = 1초)
- 이 값을 매우 작은 수로 하는 경우 시스템이 처리에 응답할 수 없다.
- hrtimer보다 작은 경우 등
- sched_rt_runtime_us
- 실행 시간 결정 (초기값: 950000 = 0.95초)
- 전체 스케줄 타임을 100%로 가정할 때 95%에 해당하는 시간을 RT 스케줄러가 이용할 수 있다.
- 동일한 우선 순위의 RT 태스크에서 task context switching 여부를 결정할 수 있는 2가지 스케줄 정책을 선택할 수 있다.
- SCHED_FIFO
- cfs 스케줄러에서 사용하는 weight 값 및 time slice라는 개념이 없다. 먼저 동작된 RT 태스크는 스스로 슬립하거나 태스크가 종료되기 전까지 계속 동작한다.
- SCHED_RR
- 같은 우선 순위의 태스크가 존재하는 경우 0.1초(디폴트) 단위로 라운드 로빈 방식으로 순회(task context switching)하며 동작한다.
- SCHED_FIFO
- 0번부터 99번까지 100개의 우선 순위 리스트 배열로 관리된다.
- RT bandwidth 기능을 사용할 수 있다.
- 예) migration, threaded irq 및 watchdog 태스크들은 rt 스케줄러에서 동작한다.
Deadline 스케줄러
사용자가 지정할 수 있는 스케줄러 중 가장 우선순위를 갖는 스케줄러이다. 규칙적으로 동작해야 하는 audio, video 프레임 재생 및 pwm 드라이버를 위해 준비하였는데 아직 잘 활용되고 있지 않다.
- 1가지 스케줄 정책에서 사용된다.
- SCHED_DEADLINE
- deadline은 RB 트리에서 관리한다.
런큐
- 각각의 CPU 마다 하나 씩 사용된다.
- 런큐에는 각 스케쥴러들이 동작한다.
- 런큐 하위에 cfs 런큐, rt 런큐, deadline 런큐가 하위에 존재한다.
- CPU에 배정할 태스크들이 스케줄 엔티티 형태로 런큐에 enqueue 된다.
- current 태스크를 제외한 태스크들이 엔큐된다.
- nr_current = current 태스크 + 엔큐된 태스크들 수 이다.
- 태스크가 처음 실행될 때 가능하면 부모 태스크가 위치한 런큐에 enqueue 된다.
- 같은 cpu에 배정되는 경우 캐시 친화력이 높아서 성능이 향상된다.
다음 그림은 런큐에 포함된 각 스케줄러들이 태스크들을 관리할 때 사용되는 주요 자료 구조를 보여준다.
- stop 스케줄러와, idle 스케줄러는 커널이 내부적으로 관리하는 용도로 사용되며 아래 그림에는 포함시키지 않았다.

커널과 실수(Floating Point)
리눅스 커널은 성능을 필요로 하는 루틴이 매번 반복되는 경우에는 실수 연산 성능을 향상시키기 위해 다음과 같은 테크닉등을 사용한다.
- 실수(float) 연산 명령 대신 정수(int) 연산 명령을 사용하기 위해 실수 값을 이진화 정수로 변환하여 사용한다.
- 복잡한 계산을 미리 산출해둔 테이블로 만들어 사용한다.
- 미리 산출해둔 테이블을 위해 어느 정도 테이블 범위가 제한되어야 한다.
- 예) 입력 n값이 0~3으로 한정된 경우 어떠한 수식(factor)을 반영한 테이블
- x[0] = 1024
- x[1] = 820
- x[2] = 655
- 곱셈(mult) 후 시프트(shift) 연산 명령을 사용하여 느린 정수(int) 나눗셈 연산도 대체한다.
- inline 함수를 사용하여 인수 전달에 사용되는 시간 절약을 절약한다. 대신 이 함수를 호출하는 곳이 많은 경우 코드 사이즈가 비례하게 커진다.
리눅스 커널에서 실수(Floating Point) 연산 명령
리눅스 커널 코드에서 실수(Floating Point)를 사용하는 경우의 처리 방법은 다음과 같다.
- 컴파일러가 이러한 커널 코드를 빌드하면 실수 연산용 코프로세서(Coprocess)가 사용하는 어셈블리 코드를 만들지 않도록 한다.
- 컴파일러는 실수 처리를 위해 컴파일러가 라이브러리로 제공하는 실수 라이브러리를 사용한다.
- 이 실수 라이브러리에는 정수만을 사용하는 범용 레지스터와 명령들로만 구현되어 있다.
- 그 외에 커널은 유저 태스크가 실수 코드를 수행하면 이 명령의 수행이 불가능한 경우 명령(instruction) fault를 발생시키는데, 커널이 이를 emulation 하도록 하는 실수 라이브러리도 포함되어 있다.
- 단 예외적으로, FPU 및 GPU 등의 드라이버가 직접 실수(Floating Point) 명령을 사용할 수도 있다.
- 초창기 대부분의 컴퓨터 시스템에는 실수 연산용 코프로세서 유닛이 없거나 빈 소켓인 채로 사용되었다.
- 코프로세서가 장착되었다 하더라도 시스템마다 성능이크게 달랐다. 그리고 단순 곱셈과 나눗셈에서의 실수 명령은 정수 명령의 처리보다는 항상 처리 사이클이 더 많아 느렸고 현재도 동일하다. 따라서 리눅스 커널은 처음 코어 설계에서 실수(Floating Point) 연산용 Coprocess를 배제하는 코드만을 사용하도록 강제하였다.
이진화 정수
실수를 정수로 만들어 사용할 때에는 소숫점 이하 단위의 정확도를 높이기 위해 정확도에 따른 정수를 만들어 사용한다.
- 예) 10진화 정수
- 10 진수에서 실수 1을 -> 정밀도 1.000 까지 취급하기 위해서는 실수 1에 1000(10^3)을 곱하여 사용한다.
- 예) 이진화 정수
- 2 진수에서 실수 1을 -> 정밀도 1.000 까지 취급하기 위해서는 실수 1에 0b10000000000(2^10)을 곱하여 사용한다.
Mult & Shift
곱셈(mult)과 시프트(shift) 연산 명령을 사용하여 느린 정수(int) 나눗셈 명령을 대체하는 방법을 알아본다.
- 수식
- X / Y ——(대체)—–> X * mult >> shift
- 예) X를 Y(820)로 나누고 싶은 경우
- Y(820)를 inverse한 1/Y(1/820) 값을 이진화 정수 값으로로 기억해둔다.
- 사용할 정밀도(shift=32)를 결정하면, 이진화 정수 값(mult)은 다음과 같이 결정된다.
- mult = (2^32) * 1/820 = (2^32) / 820 = 5,237,765
- 결국 X * mult(5,237,765) >> shift(32) 한 방법으로 나눗셈 연산을 대체할 수 있다.
- 이와 같은 기법은 커널의 여러 루틴에서 사용된다.
- 예: Timer -10- (Timekeeping) | 문c
CFS Runtime(Time Slice) & Virtual Runtime
CFS 태스크 Runtime 산출
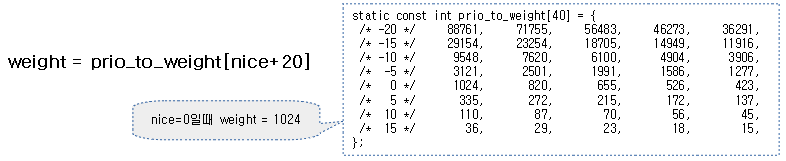
Nice별 가중치(weight)
time slice를 산출하기 위해 각 cfs 태스크에 부여된 nice 우선순위 값에 따라서 각 cfs 태스크의 가중치(weight) 값이 부여된다.
- nice가 0인 cfs 태스크에 대한 가중치(weight) 값을 실수 1.0으로 정하였다.
- 관련 구현 코드는 1.0이라는 실수(Floating Point) 연산을 사용하지 않고, 대신 이진화 정수 값을 사용한다.
- 32비트 시스템에서의 이진화 정수 값으로 정밀도에 해당하는 shift 값은 10을 사용하여 1024(2^10)가 된다.
- 64비트 시스템에서는 위의 값에 정밀도를 더 높이기 위해 scale(1024)을 곱하여 1,048,576(2^20)을 사용한다.
먼저 nice 우선 순위에 따라 미리 산출해둔 가중치 테이블을 알아본다.
- 중간 우선 순위인 nice 0 값을 가진 태스크의 가중치는 1024이고, 가장 느린 nice 19 값을 가진 태스크의 가중치는 15이다.
- 아래 테이블에 나오지 않았지만 idle 스케줄러에서 사용하는 idle 태스크의 경우 time slice를 가장 적게 받는 3을 사용한다. 가장 느린 cfs 태스크의 가중치가 15보다 느린 것을 알 수 있다.
- nice 값의 우선 순위 1 변화시에 25%의 가중치(weight)가 변화되도록 설계되었고, 그 이유는 바로 아래에서 설명한다.
kernel/sched/core.c – sched_prio_to_weight[]
weight 변화량
동작 중인 태스크가 2개 일때 기준으로 nice 값이 1씩 감소할 때마다 10%의 time slice 배정을 더 받을 수 있도록 25%씩 weight 값이 증가된다. 단 3개 이상의 태스크를 비교할 때에는 10%가 아닌 7.6%가 증가된 time slice 배정을 한다.
아래 그림과 같이 weight가 25% 증가 시 실제 cpu 점유율이 기존에 비해 증가되는 폭을 확인할 수 있다.
- 2개 기준일때 10% 증가, 3개 기준일 때 7.6% 증가
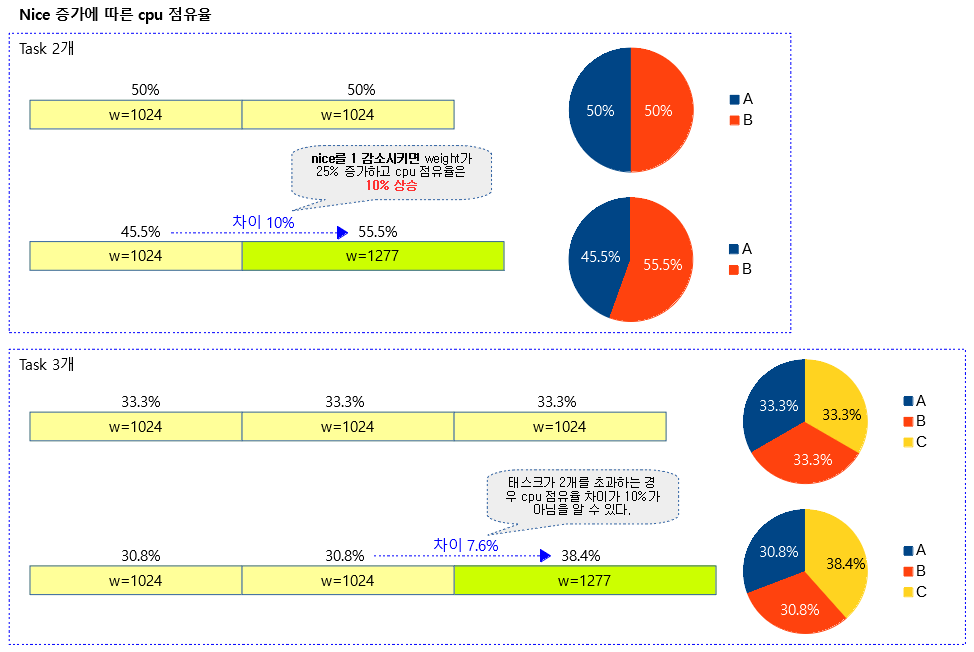
다음 그림은 5개의 task에 대해 각각의 nice 값에 따른 weight 값과 그 비율을 산출하였다.

CFS 태스크 inverse weight
다음 테이블은 nice 값을 사용하여 inverse weighted mult 값을 미리 산출해둔 테이블이다. 32비트 정확도를 사용하여 만들었다.
- 성능향상을 목적으로 커널은 x / weight = y와 같은 산술식을 사용하여야 할 때 나눗셈을 피해서, 아래 테이블 값을 사용한 x * wmult >> 32로 y 값을 산출한다.
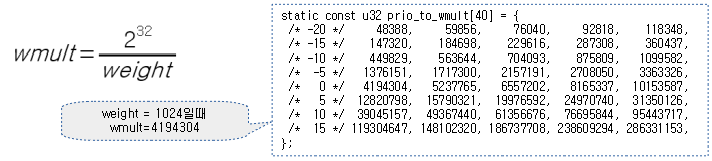
CFS 런큐
스케줄링 latency 와 스케일 정책
런큐에서 동작하는 태스크들이 실시간 동시에 동작하는 것처럼 보이게 하기 위해 기간을 두고 반복을 한다. 이 때 한 바퀴 돌 기간인 periods(ns)를 산출하기 위한 관련 변수들은 다음과 같다. 자세한 설명은 그 다음 스케줄링 latency 산출식부터 살펴본다.
- rq->nr_running
- 런큐에서 동작중인 태스크 수
- current 태스크 + 런큐에 엔큐된 태스크 수
- factor
- 스케일링 정책에 따른 비율이다. 이 정책에 따라 cpu 수에 따른 비율 적용 factor 값을 결정한다. (rpi2: factor=3)
- cpu 수에 따라 periods 산출에 영향을 준다. cpu가 많아지면 cpu 수 만큼 비례하게 할 것인지, 아니면 2log()를 사용하여 점진적으로 비율을 줄여 나갈 것인지 아니면 cpu 수와 관계 없이 사용할 것인지를 지정한다.
- 3가지 정책이 사용되며 아래 별도 항목에서
- sched_latency_ns
- 최소 스케줄 기간(periods)으로 디폴트 값(6000000) * factor(3) = 18000000(ns)
- “/proc/sys/kernel/sched_latency_ns”
- sched_min_granularity
- 태스크에 대한 최소 스케쥴 기간으로 디폴트 값(750000) * factor(3) = 2250000(ns)
- task context switching이 빈번해서 효율이 떨어질 수 있으므로 태스크에 배정될 타임 슬라이스는 이 값보다 작게 배정하지 않는다.
- “/proc/sys/kernel/sched_min_granularity_ns”
- sched_wakeup_granularity_ns
- 태스크의 wakeup 기간으로 디폴트 값(1000000) * factor(3) = 3000000(ns)
- “/proc/sys/kernel/sched_wakeup_granularity_ns”
- sched_nr_latency
- sched_latency_ns를 사용할 수 있는 태스크 수
- 이 값은 sched_latency_ns / sched_min_granularity 으로 자동 산출된다.
스케줄링 latency 산출식
산출은 nr_running와 sched_nr_latency를 비교한 결과에 따라 다음 두 가지 중 하나로 결정된다.
- sysctl_sched_latency(18ms) <- 조건: nr_running <= sched_nr_latency(8)
- sysctl_sched_min_granularity(2.25ms) * nr_running <- 조건: nr_running > sched_nr_latency(8)
다음 그림은 rpi2(cpu:4) 시스템에서 하나의 cpu에 태스크가 5개 및 10개가 구동될 떄 각각의 스케줄링 기간을 산출하는 모습을 보여준다.
- 태스크가 일정 수 이하일 경우에는 산출된 스케줄링 latency를 그대로 periods로 사용한다.
- 태스크가 일정 수를 초과하면 산출된 스케줄링 latency에 태스크들을 배치할 때 태스크에 대한 최소 스케쥴 기간( sched_min_granularity)이 보장되지 않기 때문에 최소 스케쥴 기간( sched_min_granularity) * 태스크 수를 하여 periods를 산출한다.

cpu 수에 따른 스케일링 정책
스케일링 정책에 따른 비율이며 cpu 수에 따른 스케일 latency에 변화를 주게된다.
- SCHED_TUNABLESCALING_NONE(0)
- 항상 1을 사용하여 스케일이 변하지 않게 한다.
- SCHED_TUNABLESCALING_LOG(1)
- 1 + ilog2(cpus)과 같이 cpu 수에 따라 변화된다. (디폴트)
- rpi2: cpu=4개이고 이 옵션을 사용하므로 factor=3이 적용되어 3배의 스케일을 사용한다.
- SCHED_TUNABLESCALING_LINEAR(2)
- online cpu 수로 8 단위로 정렬하여 사용한다. (8, 16, 24, 32, …)
태스크별 Runtime(Time Slice)
개별 태스크에 배정된 런타임 시간을 산출한다.
- 런큐별 스케줄링 latency 1 주기 기간을 각 태스크의 weight 비율별로 나눈다.
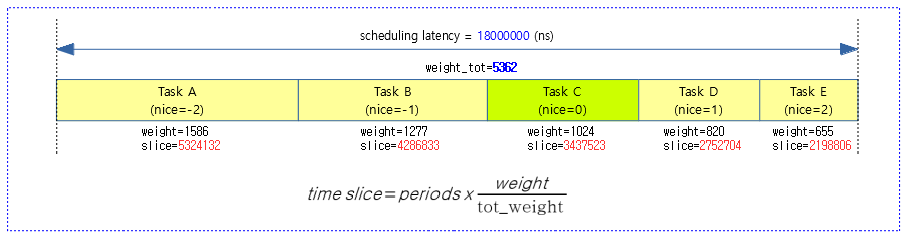
태스크별 VRuntime
태스크의 vruntime(virtual runtime)은 개별 태스크 실행 시간을 누적시킨 값을 런큐의 RB 트리에 배치하기 위해 로드 weight을 반비례하게 적용한 값이다. (우선 순위가 높을 수록 누적되는 weight 값을 반대로 작게하여 vruntime에 추가하므로 RB 트리에서 먼저 우선 처리될 수 있게 한다)
- 증가될 vruntime 값은 nice 0 태스크에 대해 주어지는 런타임값과 동일하다.
- 예) 6ms 주기에서 하나의 nice 0 태스크가 동작하는 경우 태스크에 주어지는 런타임 값은 6ms이고, vruntime 값도 6ms 이다.
- 예) 6 ms 주기에서 두 개의 nice 0 태스크가 동작하는 경우 각 태스크에 주어지는 런타임 값은 6ms 주기의 절반인 3ms이고, vruntime 값도 3ms 이다.
- 현재 태스크의 실행을 중단시키고 task context switch를 하는 경우 현재 태스크를 vruntime 만큼 뒤로 옮겨 놓는다. 이렇게 옮겨 놓고 즉 CFS 런큐의 RB Tree 내에서 다음 수행할 태스크는 각 태스크의 vruntime이 가장 빠른 태스크로 선정한다. 즉 next 태스크를 선정하는 기준으로 사용한다.
- 모든 태스크에 동일한 vruntime이 산출되는데 현재 태스크의 런타임이 소모되면 태스크에 대한 vruntime 값은 다음과 같이 갱신된다.
- curr->vruntime += 산출된 vruntime
- 해당 태스크의 vruntime 값은 산출된 vruntime 만큼 뒤로 옮긴다.
누적시 추가될 virtual runtime slice는 다음과 같이 산출된다.
vruntime slice = time slice * wieght-0 / weight
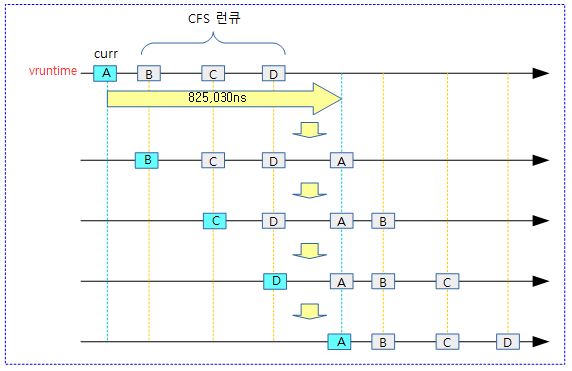
다음 그림은 nice 값이 각각 다른 4개의 태스크에 대해 vruntime을 구한 결과를 보여준다.
- nice 0 값을 가진 Task B의 경우 런타임 값과 vruntime 값이 동일함을 알 수 있다.
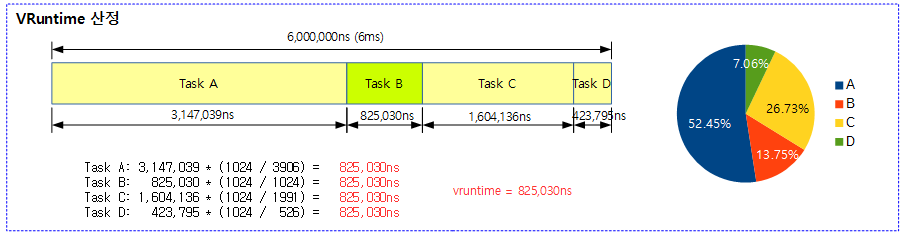
다음 그림은 4개의 태스크가 idle 없이 계속 실행되는 경우 각 태스크의 vruntime은 산출된 vruntime slice 만큼 계속 누적되어 실행되는 모습을 보여준다.
- 주의: HRTICK(디폴트=no)이 동작하고, preemption 요청 RT 태스크들이 없다고 가정한 상태에서 각 태스크에 동일한 기회가 주어지는 상황에 대해 이해를 돕기 위한 그림이다. 실제 HRTICK이 동작하지 않는 상태에서는 아래 그림과 같이 동작하지 않고 런타임이 적은 Task D의 경우 정규 스케줄 틱에서 실제 자신의 런타임보다 더 많은 시간을 실행하므로 런타임이 큰 Task A와 같은 기회를 갖지는 못한다.
cfs_rq->min_vruntime
cfs 런큐에 새로운 태스크 또는 슬립되어 있다가 깨어나 엔큐되는 경우 vruntime이 0부터 시작하게되면 이러한 태스크의 vruntime이 가장 낮아 이 태스크에 실행이 집중되고 다른 태스크들은 cpu 타임을 얻을 수 없는 상태가 된다. (starvation problem) 따라서 이러한 것을 막기 위해서 cfs 런큐에 새로 진입할 때 min vruntime 값을 기준으로 사용하게 하였다.
- cfs_rq->min_vruntime 값은 현재 태스크와 cfs 런큐에 대기중인 태스크들 중 가장 낮은 수가 스케줄 틱 및 필요 시마다 갱신되어 사용된다.
- cfs 런큐에 진입 시에 min_vruntime 값을 더해서 사용하고 cfs 런큐에서 빠져나갈 때에는 min_vruntime 값만큼 감소시킨다.
- 태스크가 슬립하거나 다른 cpu의 런큐로 옮기기 위해 이 cpu의 런큐에서 디큐되는데 이 cpu의 런큐의 min_vruntime 뺀 delta 값만을 보관한다.
- 태스크가 깨어나거나 다른 cpu의 런큐에서 이 cpu의 런큐에 엔큐될 때에는 태스크의 보관된 delta vruntime 값에 현재 런큐의 min_vruntime 값을 추가한다.
- cfs 런큐에 진입 시에 vruntime에 대해 약간의 규칙을 사용한다.
- 새 태스크가 cfs 런큐에 진입
- min_vruntime 값 + vruntime slice를 더해 사용
- fork된 child 태스크가 먼저 실행되는 옵션을 사용한 경우 현재 태스크가 우선 처리되도록 vruntime과 swap한다.
- idle 태스크가 깨어나면서 cfs 런큐에 진입
- min_vruntime 값 사용
- 기타 여러 이유로 cfs 런큐에 진입(태스크 그룹내 이동, cpu migration, 스케줄러 변경)
- 새 태스크가 cfs 런큐에 진입
다음 그림은 min_vruntime이 vruntime이 가장 낮은 curr 태스크가 사용하는 vruntime 값으로 갱신되는 모습을 보여준다.
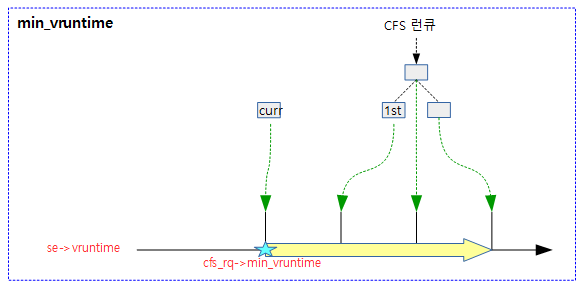
태스크의 vruntime 값은 런큐에서 디큐하고 엔큐할 때 해당 런큐의 min_vruntime을 기준으로 하는 것을 보여준다.

CFS Group Scheduling
- cgroup의 cpu 서브시스템을 사용하여 커널 v2.6.24에서 소개되었다.
- 계층적 스케줄 그룹(TG: Task Group)을 설정하여 사용자 프로세스의 utilization을 조절할 수 있다.
- 태스크의 로드 weight 값을 관리하기 위해 스케줄 엔티티를 사용하는데 태스크용 스캐줄 엔티티와 태스크 그룹용 스케줄 엔티티(tg->se[])로 나뉜다.
- 스케줄 그룹의 CFS bandwidth 기능을 사용하면 배정받은 시간 범위내에서의 utilization 마저도 조절할 수 있다.
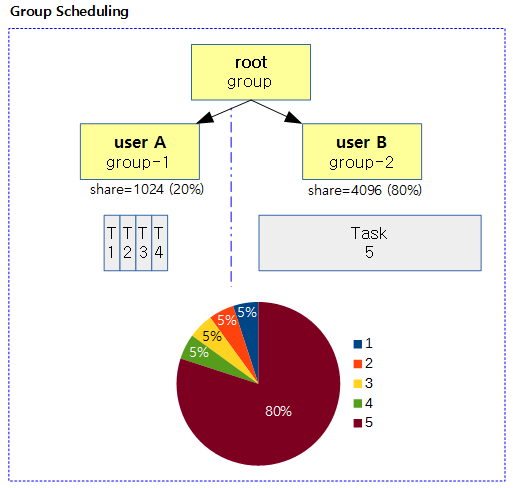
다음 그림은 그룹 스케줄링의 유/무에 대해 비교를 하였다.
- 좌측은 cfs 스케줄러가 설계한대로 태스크에 주어진 우선 순위가 동일하면 각 태스크에 공평(fair)하게 런타임이 배정된다.
- 우측은 cgroup을 적용하여 유저별로 우선 순위를 동일하게 적용하면 각 유저에 공평(fair)하게 런타임이 배정된다.
- 우측의 경우 루트 그룹을 만들고 그 아래에 두 개의 스케줄 그룹을 만들면 디폴트로 각각 하위 두 그룹이 50%씩 utilization을 나누게 된다.
- 태스크 그룹을 사용하는 경우 각 태스크 그룹마다 cpu 수 만큼 cfs 런큐가 있고 그 그룹에 속한 태스크나 태스크 그룹은 각각의 스케줄 엔티티로 본다.
- 우측의 경우 5개의 태스크용 스케줄 엔티티가 모두 1024의 weight 값을 갖는다고 가정할 때 root 그룹은 2개의 그룹용 스케줄 엔티티에 대한 분배를 결정하고, 각 group에서는 그룹에 소속된 task용 스케줄 엔티티에 대한 분배를 결정한다.
- 우측의 경우 root 그룹에 2 개의 task가 추가로 실행되는 경우 root 그룹은 총 4개의 스케줄 엔티티에 대한 분배를 수행한다. (태스크 그룹용 스케줄 엔티티 2개 + 태스크용 스케줄 엔티티 2개)
- group-1에 해당하는 각 태스크는 6.25%를 할당받는다.
- group-2에 해당하는 태스크는 25%를 할당받는다.
- 그림에는 표현되지 않았지만 루트 그룹에 새로 추가된 task 6와 task 7은 각각 25%를 할당받는다.

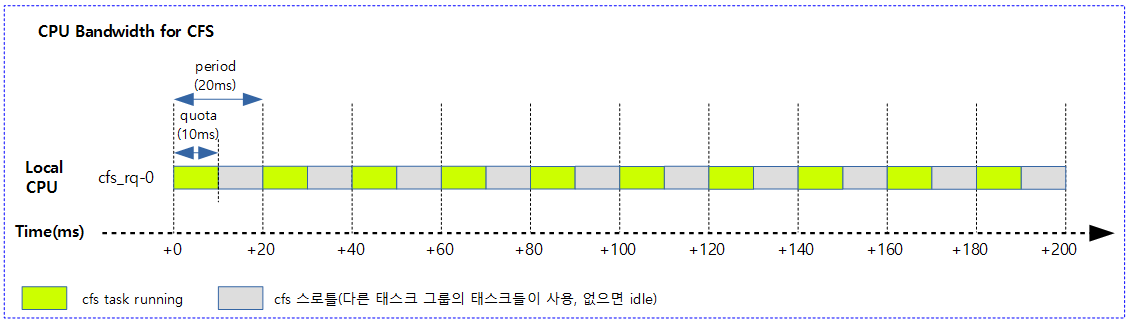
다음 그림은 그룹 스케줄링을 적용 시 time slice 적용 비율이 변경된 것을 보여준다.
- 루트 그룹 밑에 두 개의 태스크 그룹을 만들고 각각 20%, 80%에 해당하는 share 값을 설정한 경우 그 그룹 아래에서 동작하는 태스크들의 utilization을 다음과 같이 확인할 수 있다.
CPU Bandwidth for CFS
태스크 그룹에 할당된 time slice를 모두 사용하지 않고 일정 비율만 사용하게 한다. 이렇게 시간 점유를 안하는 구간을 cfs 스로틀링이라고 하는데, 이 때 다른 태스크 그룹에 타임 슬라이스를 양보하게 된다. 양보할 태스크들마저 없는 경우 idle 한다.
다음 그림은 어느 한 태스크 그룹에 소속된 cfs 태스크의 절반을 스로틀링하도록 설정한 모습을 보여준다. (1개 core를 사용한 시스템 예를 보여준다)
CFS Scheduling Domain
스케줄링 그룹(sched_group)에 많은 cpu 로드가 발생하면 각 스케줄링 도메인을 통해 로드 밸런스를 수행하게 한다.
- 계층적 구조를 통해 cpu affinity에 합당한 core를 찾아가도록 한다.
스케줄링 도메인은 디바이스 트리 및 MPIDR 레지스터를 참고하여 cpu가 on/off 될 때마다 cpu topology를 변경하고 이를 통해 스케줄링 도메인을 구성한다.
- 디바이스 트리 + MPIDR 레지스터 -> cpu on/off -> cpu topology 구성 변경 -> 스케줄링 도메인
cpu 토플로지의 단계는 다음과 같다.
- cluster
- core
- thread
스케줄링 도메인의 단계는 다음과 같다.
- DIE 도메인
- cpu die (package)
- MC 도메인
- 멀티 코어
- SMT 도메인
- 멀티 스레드(H/W)
다음 그림은 스케줄링 도메인과 스케줄링 그룹을 동시에 표현하였다. (arm 문서 참고)
- 참고로 아래 그림의 스케줄링 그룹(sched_group)과 그룹 스케줄링(task_group)은 다른 기능이므로 주의한다.

참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- CPU bandwidth control for CFS | Google Paul Turner, IBM Bharata B Rao, Google Nikhil Rao – 다운로드 pdf
- CFS bandwidth control | LWN.net – 한글 번역 | KERNELMSG
- CFS Bandwidth Control | kernel.org
- cfs scheduling 1 & cfs group scheduling (1) | 솔개가하늘을가르네
- Linux 3.2 – CFS CPU bandwidth (english version) | Christophe Blaess
- integrating the scheduler and cpufreq | Linaro connect – 다운로드 pdf
- CFS 소스 코드 분석 | 어린아이
- linux kernel 강좌 1 – CFS ( Completely Fair Scheduler ) 스케쥴러 | 토리
- 리눅스 커널 내부구조 스터디[ chapter 3] | 이즈리얼
- [CFS] cfs 정리 | NZCV
- [Linux] Completely Fair Scheduler | F/OSS
- cfs 스케줄러 | 솔개가하늘을가르네
- Load balance in Linux source level bottom-up analysis | Mad for Simplicity
- CPU bandwidth control for CFS | P. Turner, B. B. Rao, N. Rao – 다운로드 pdf
- Evaluation of CPU cgroup | Fujitsu – 다운로드 pdf
- Task Management | 백승재 – 다운로드 pdf
감사합니다 정말 많은 도움이 됐습니다.
응원해주셔서 감사합니다.
즐거운 하루되세요. ^^
찾던 내용인데 정리가 깔끔하게 되어 있네요. 정말 감사드립니다.
응원 감사합니다. 좋은 하루되세요~
안녕하세요, 커널 글 덕분에 많은 도움이 되고 있습니다.
한가지 질문이 있는데 task state machine에서 TASK_RUNNING을 보면, task가 preemption되는 경우에도 TASK_RUNNIGN state가 유지되는 이유가 있는건가요?
State만 생각해보면, TASK_STOPPED나 다른 state로 transition되어야할 것 같아서요.
안녕하세요? 휴가를 다녀오느라 게을러져 질문이 있었는지 몰랐었습니다. ^^;
TASK_RUNNING 상태는 현재 돌고 있다는 의미로 설계가 된 것이 아니라,
실행 가능한 상태라는 의미로 설계되었습니다.
따라서 현재 돌고 있거나(curr), preemption 되어 런큐에서 대기중일 때에도
TASK_RUNNING 상태를 유지하고 있습니다.
다른 state를 하나 만들어 전이 되어도 좋을 것 같지만, 처음 설계가 위와 같아서 그대로 유지하고 있다고 판단하고 있습니다.
감사합니다.
헷갈렸던 부분인데 설명 감사합니다!
좋은 하루되세요. ^^