<kernel v5.4>
Scheduler -3- (PELT-1)
리눅스 커널은 다음과 같이 시스템 운영 환경에 따라 스케줄러와 로드 추적을 구분하여 적용하고 있다.
- SMP(Symmetric Multi Processing) 시스템
- 스케줄러로 내장 커널 스케줄러를 사용한다.
- PELT(Per-Entity Load Tracking)를 구성하여 사용한다.
- AMP(Asymmetric Multi Processing) or HMP(Heterogeneous multi-processing) 시스템
- 모바일 기기를 만드는 안드로이드 진영의 각 칩셋사에서 여러 모델을 시험적으로 사용하고 있고, 현재 가장 우수한 성능을 나타내는 조합은 다음과 같다.
- 스케줄러로 IKS(In-Kernel Switcher), GTS(Global Task Scheduling) 또는 EAS(Energy Aware Scheduler)를 사용하여 왔는데, 최근에는 EAS 만 사용한다.
- EAS는 메인 라인 커널 v5.0에 적용되었고, CONFIG_ENERGY_MODEL 커널 옵션을 사용한다.
- 참고:
- PM: Introduce an Energy Model management framework (2018, v5.0-rc1)
- EAS Development for Mainline Linux | ARM
- Scheduling for Android devices (2016) | LWN.net
WALT(Window Assisted Load Tracking)
- 안드로이드 모바일 시스템을 위해 도입된 WALT는 PELT와 같이 사용할 수도 있고, 독립적으로 사용할 수도 있다.
- 태스크의 로드 상승 및 하강에 대한 변화는 PELT에 비해 약 4배 정도 빠르게 상승하고, 하강은 8배 더 빠르다.
- EAS(Energy Aware Scheduler) + schedutil이 기본적으로 같이 사용된다.
- 참고:
- sched: Introduce Window Assisted Load Tracking (2016) | LWN.net
- WALT vs PELT | Redux
Big/Little SoC
big/little migration을 위한 H/W 모델에 다음과 같은 것들이 사용된다.
- 클러스터 마이그레이션 사용 모델
- 클러스터들 중 하나만 사용되는 모델로, 오래된 big/little SoC 들에서 사용되었다.
- CPU 마이그레이션 사용 모델
- IKS(In-Kernel Switcher)를 통해 cpu별로 big/little cpu를 선택하여 가동하는 모델이다.
- HMP(Heterogeneous Multi-Processing) 사용 모델
- 가장 강력한 모델로 동시에 모든 프로세스를 사용하는 모델로, 최근 SoC들이 사용되는 방식이다.
PELT(Per-Entity Load Tracking)
- 용도
- 로드 밸런스
- 그룹 스케줄링
- sched util governor에서 주파수 선택
- EAS(Energy Aware Scheduler) 에서 태스크의 cpu 선정
- 커널 v3.8부터 다음 로드 평균을 산출하여 엔티티별 로드를 추적할 수 있다.
- 로드 합계 및 평균 (load sum & average)
- 로드밸런스에서 task를 다른 cpu로 이동시킬지 여부를 결정하기 위해 엔티티별 로드를 비교할 때 사용하는 값.
- runnable% * load weight
- 러너블 합계 및 평균(runnable sum & average)
- 작업 대기 시간을 추적하기 위해 사용됨.
- 엔티티가 cpu에서 러너블(curr + 엔큐) 상태로 있었던 기간 평균
- 커널 v5.7-rc1에서 기존 runnable load sum & avg가 삭제됨
- 참고: sched/pelt: Remove unused runnable load average (2020, v5.7-rc1)
- 커널 v5.7-rc1에서 runnable sum & avg가 새로 추가됨.
- 참고: sched/pelt: Add a new runnable average signal (2020, v5.7-rc1)
- 유틸 로드 합계 및 평균(util load sum & average)
- 엔티티가 cpu에서 수행한 기간 평균
- running% * 1024
- 유틸 추정치 로드 합계 및 평균 (util_est load sum & average)
- 빅 태스크가 약각 오랜 시간 슬립하였다가 깨어난 경우 슬립한 기간만큼 로드값이 decay되어 매우 낮아지면서 다시 런큐에 등록될 때 로드가 현저하게 적어 cpu freq가 낮게 배정되어 출발하는 이슈가 있다. 때문에 이러한 문제를 개선하기 위해 태스크가 슬립하여 deaueue되는 순간의 util 로드를 기억해두었다가, 다시 사용시 재계산된 util 로드와 비교하여 최대 값을 적용한 것이 util_est 로드이다.
- 로드 합계 및 평균 (load sum & average)
- 스케줄 틱마다 그리고 태스크의 엔티티에 변화(enqueue, dequeue, migration 등)가 생길 때마다 갱신한다.
- 로드 값은 1 period 단위 기간인 2^20ns(약 1024us) 마다 decay되며, 32번째 단위 시간이 될 때 정확히 절반으로 줄어드는 특성을 가진다.
커널의 PELT를 위한 지수 평활 계수는 다음과 같다.
- 지수 함수 모델 k = a * (b ^ n)
- a=1, b=0.5^(1/n)), n=32 또는 a=1, b=2^(-1/n), n=32
- k=0.5^(1/32) 또는 k=2^(-1/32)
- k 값은 32번 decay할 때 절반으로 줄어드는 특징이 있다. (k^32=0.5)
- k = 0.97857206…
- 지수 평활 계수 k를 사용하여 로드 값은 다음과 같이 산출된다.
- cpu 로드 값 = 기존 cpu 로드 값 * k + 새 cpu 로드 값 * (1 – k)
엔티티들의 로드 합계와 평균을 구할 때마다 전체 엔티티를 스캔하는 방식은 많은 코스트를 사용해야 하므로 이러한 방법은 사용하지 않는다. 다음과 같은 타이밍에 엔티티들의 합과 평균을 구한다.
- 스케줄 틱
- 스케줄 틱마다 현재 러닝 중인 엔티티의 로드 합계와 평균을 갱신한다.
- 엔티티의 변화
- 엔티티의 attach/detach/migration 등 이벤트마다 해당 엔티티의 로드 합계와 평균을 갱신한다.
엔티티의 로드 합계와 평균을 산출한 후에는 다음 순서로 누적하고 상위에 보고한다.
- 1단계: 엔티티 accumulate
- 엔티티들의 로드를 모아 해당 cfs 런큐로 누적(accumulate)
- 2단계: 상위 cfs 런큐 propagation
- 최하위 cfs 런큐부터 최상위 cfs 런큐까지 전파(propagation)
- 2단계에서는 cfs 런큐를 대변하는 그룹 엔티티의 로드값을 먼저 갱신한 후에 상위 cfs 런큐에 propagation을 하도록 2단계로 나뉘어 수행한다.
- 3단계: 태스크 그룹 contribution
- per-cpu cfs 런큐의 로드를 태스크 그룹으로 글로벌 로드 값으로 변화분 기여(atomic add)
로드 평균 추적
로드 평균 추적을 위해 해당 태스크의 pid가 필요하다. 아래 bash 태스크의 pid를 알아온 후 cgroup 유저 세션의 tasks에 포함되었는지 확인해본다.
# ps
PID TTY TIME CMD
471 ttyAMA0 00:00:00 login
760 ttyAMA0 00:00:00 bash
791 ttyAMA0 00:00:00 ps
# cat /sys/fs/cgroup/cpu/user.slice/user-0.slice/session-1.scope/tasks
471
760
949
다음은 /proc/<pid> 디렉토리에 진입한 후 해당 태스크의 스케줄 statistics 정보를 확인한다.
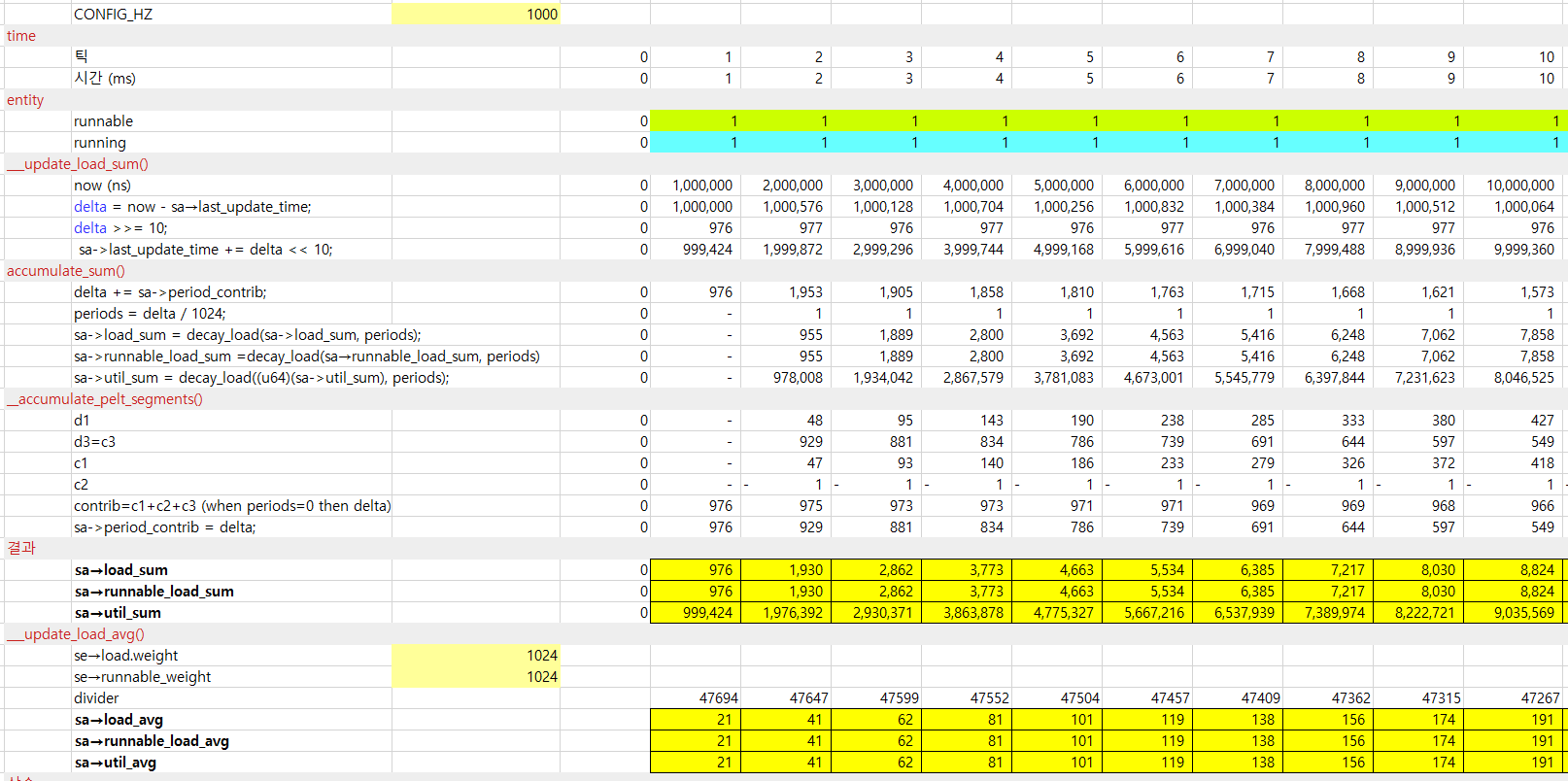
# cd /proc/760 # cat /proc/760$ cat schedstat 503102081 13905504 293 # cat /proc/760/sched full_load (760, #threads: 1) ------------------------------------------------------------------- se.exec_start : 3989409.638984 se.vruntime : 17502.410171 se.sum_exec_runtime : 783.958340 se.nr_migrations : 1 nr_switches : 1016 nr_voluntary_switches : 935 nr_involuntary_switches : 81 se.load.weight : 1048576 se.runnable_weight : 1048576 se.avg.load_sum : 7971 se.avg.runnable_load_sum : 7971 se.avg.util_sum : 8163624 se.avg.load_avg : 167 se.avg.runnable_load_avg : 167 se.avg.util_avg : 167 se.avg.last_update_time : 3989409638400 se.avg.util_est.ewma : 53 se.avg.util_est.enqueued : 167 policy : 0 prio : 120 clock-delta : 292 mm->numa_scan_seq : 0 numa_pages_migrated : 0 numa_preferred_nid : -1 total_numa_faults : 0 current_node=0, numa_group_id=0 numa_faults node=0 task_private=0 task_shared=0 group_private=0 group_shared=0
다음 명령을 사용하면 모든 태스크의 스케줄 statistics 정보를 한 번에 알아볼 수 있다. (소숫점 이상은 밀리세컨드이다.)
# cat /proc/sched_debug
(...생략...)
runnable tasks:
S task PID tree-key switches prio wait-time sum-exec sum-sleep
-----------------------------------------------------------------------------------------------------------
S systemd 1 128.556417 1435 120 0.000000 2532.278466 0.000000 0 0 /init.scope
S kthreadd 2 9007.043581 110 120 0.000000 38.206758 0.000000 0 0 /
I rcu_gp 3 7.075165 3 100 0.000000 0.017792 0.000000 0 0 /
I rcu_par_gp 4 8.587139 3 100 0.000000 0.023918 0.000000 0 0 /
I kworker/0:0H 6 372.048163 8 100 0.000000 6.427459 0.000000 0 0 /
I mm_percpu_wq 8 14.188365 3 100 0.000000 0.024208 0.000000 0 0 /
S ksoftirqd/0 9 9072.934585 312 120 0.000000 30.653868 0.000000 0 0 /
S migration/0 11 0.000000 73 0 0.000000 30.741958 0.000000 0 0 /
S cpuhp/0 12 337.602512 13 120 0.000000 1.789666 0.000000 0 0 /
I kworker/0:1 21 9068.975793 653 120 0.000000 173.940206 0.000000 0 0 /
S kauditd 23 64.560835 2 120 0.000000 0.137958 0.000000 0 0 /
S oom_reaper 24 70.621792 2 120 0.000000 0.060960 0.000000 0 0 /
I writeback 25 74.666295 2 100 0.000000 0.059208 0.000000 0 0 /
S kcompactd0 26 74.680295 2 120 0.000000 0.063125 0.000000 0 0 /
I kintegrityd 77 173.140036 2 100 0.000000 0.056583 0.000000 0 0 /
I blkcg_punt_bio 79 179.192415 2 100 0.000000 0.067375 0.000000 0 0 /
I tpm_dev_wq 80 179.207188 3 100 0.000000 0.095500 0.000000 0 0 /
I ata_sff 81 179.208301 3 100 0.000000 0.158208 0.000000 0 0 /
I devfreq_wq 83 179.225743 3 100 0.000000 0.162542 0.000000 0 0 /
I kworker/u5:0 86 218.072428 3 100 0.000000 0.827083 0.000000 0 0 /
I xprtiod 87 218.102147 2 100 0.000000 0.223708 0.000000 0 0 /
S kswapd0 146 243.631141 3 120 0.000000 0.045208 0.000000 0 0 /
I nfsiod 147 231.757201 3 100 0.000000 0.177042 0.000000 0 0 /
I xfsalloc 148 237.636886 3 100 0.000000 0.097125 0.000000 0 0 /
I kworker/0:1H 155 9042.378580 127 100 0.000000 89.291426 0.000000 0 0 /
I kworker/0:3 187 5836.456951 50 120 0.000000 0.949960 0.000000 0 0 /
S systemd-udevd 207 676.417929 890 120 0.000000 762.019973 0.000000 0 0 /autogroup-13
Ssystemd-network 240 10.659505 54 120 0.000000 89.746452 0.000000 0 0 /autogroup-21
S acpid 257 3.489799 8 120 0.000000 8.382792 0.000000 0 0 /autogroup-22
S gdbus 271 115.518683 38 120 0.000000 9.789205 0.000000 0 0 /autogroup-24
S rsyslogd 272 22.666138 29 120 0.000000 51.687122 0.000000 0 0 /autogroup-27
S rtkit-daemon 273 16.551777 19 121 0.000000 17.856413 0.000000 0 0 /autogroup-28
S rtkit-daemon 275 56.491989 225 120 0.000000 34.801951 0.000000 0 0 /autogroup-28
S rtkit-daemon 276 0.000000 111 0 0.000000 16.475375 0.000000 0 0 /autogroup-28
S systemd-logind 279 3.639090 143 120 0.000000 73.653134 0.000000 0 0 /autogroup-32
S NetworkManager 283 207.003587 235 120 0.000000 343.688449 0.000000 0 0 /autogroup-35
S gmain 328 222.841799 236 120 0.000000 58.477883 0.000000 0 0 /autogroup-35
S polkitd 301 34.343594 84 120 0.000000 34.283501 0.000000 0 0 /autogroup-37
S gmain 306 18.460635 5 120 0.000000 0.291958 0.000000 0 0 /autogroup-37
S bash 760 2480.890766 941 120 0.000000 2141.409558 0.000000 0 0 /user.slice/user-0.slice/session-1.scope
S ntpd 771 128.569616 776 120 0.000000 300.594067 0.000000 0 0 /autogroup-53
I kworker/u4:0 800 9013.026954 461 120 0.000000 24.093421 0.000000 0 0 /
I kworker/u4:1 847 9073.130002 56 120 0.000000 8.608543 0.000000 0 0 /
cpu#0
.nr_running : 0
.nr_switches : 33262
.nr_load_updates : 0
.nr_uninterruptible : 3
.next_balance : 4295.902295
.curr->pid : 0
.clock : 4040095.934379
.clock_task : 4021572.724115
.avg_idle : 8881345
.max_idle_balance_cost : 5154074
cfs_rq[0]:/user.slice/user-0.slice/session-1.scope
.exec_clock : 0.000000
.MIN_vruntime : 0.000001
.min_vruntime : 17534.518299
.max_vruntime : 0.000001
.spread : 0.000000
.spread0 : -15804.041501
.nr_spread_over : 0
.nr_running : 0
.load : 0
.runnable_weight : 0
.load_sum : 2658005
.load_avg : 56
.runnable_load_sum : 415
.runnable_load_avg : 0
.util_sum : 2647676
.util_avg : 55
.util_est_enqueued : 0
.removed.load_avg : 0
.removed.util_avg : 0
.removed.runnable_sum : 0
.tg_load_avg_contrib : 56
.tg_load_avg : 1080
.se->exec_start : 4021516.525783
.se->vruntime : 20945.789828
.se->sum_exec_runtime : 17480.214425
.se->load.weight : 156022
.se->runnable_weight : 2
.se->avg.load_sum : 2592
.se->avg.load_avg : 8
.se->avg.util_sum : 2647676
.se->avg.util_avg : 55
.se->avg.runnable_load_sum : 2592
.se->avg.runnable_load_avg : 0
(...생략...)
스케줄 틱
scheduler_tick()
kernel/sched/core.c
/* * This function gets called by the timer code, with HZ frequency. * We call it with interrupts disabled. */
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
struct rq_flags rf;
sched_clock_tick();
rq_lock(rq, &rf);
update_rq_clock(rq);
curr->sched_class->task_tick(rq, curr, 0);
(...생략...)
}
스케줄 틱마다 런타임 처리 및 로드 평균 산출 등의 처리를 수행하고, 로드 밸런스 주기가 된 경우 SCHED softirq를 호출한다.
- 코드 라인 3~5에서 현재 cpu의 런큐 및 현재 태스크를 알아온다.
- 코드 라인 8에서 x86 및 ia64 아키텍처에 등에서 사용하는 unstable 클럭을 사용하는 중이면 per-cpu sched_clock_data 값을 현재 시각으로 갱신한다.
- 코드 라인 10에서 런큐 정보를 수정하기 위해 런큐 락을 획득한다.
- 코드 라인 12에서 런큐 클럭 값을 갱신한다.
- rq->clock, rq->clock_task, rq->clock_pelt 클럭등을 갱신한다.
- 코드 라인 13에서 현재 태스크의 스케줄링 클래스에 등록된 (*task_tick) 콜백 함수를 호출한다.
- task_tick_fair(), task_tick_rt(), task_tick_dl()
스케줄링 클래스별 틱 처리
- Real-Time 스케줄링 클래스
- task_tick_rt()
- Deadline 스케줄링 클래스
- task_tick_dl()
- Completly Fair 스케줄링 클래스
- task_tick_fair()
- Idle-Task 스케줄링 클래스
- task_tick_idle() – 빈 함수
- Stop-Task 스케줄링 클래스
- task_tick_stop() – 빈 함수
task_tick_fair()
kernel/sched/fair.c
/* * scheduler tick hitting a task of our scheduling class. * * NOTE: This function can be called remotely by the tick offload that * goes along full dynticks. Therefore no local assumption can be made * and everything must be accessed through the @rq and @curr passed in * parameters. */
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
(...생략...)
}
현재 태스크에 대한 스케줄 틱 처리를 수행한다.
- 코드 라인 6~9에서 최상위 그룹 엔티티까지 스케줄 틱에 대한 로드 평균 등의 산출을 수행한다.
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq);
/*
* Ensure that runnable average is periodically updated.
*/
update_load_avg(cfs_rq, curr, UPDATE_TG);
update_cfs_group(curr);
(...생략...)
}
스케줄 틱에 대해 현재 엔티티에 대한 로드 평균 등을 갱신한다.
- 코드 라인 7에서 런타임 등에 대해 처리한다.
- 코드 라인 12에서 요청한 엔티티의 로드 평균을 갱신한다.
- 코드 라인 13에서 그룹 엔티티 및 cfs 런큐에 대해 로드 평균을 갱신한다.
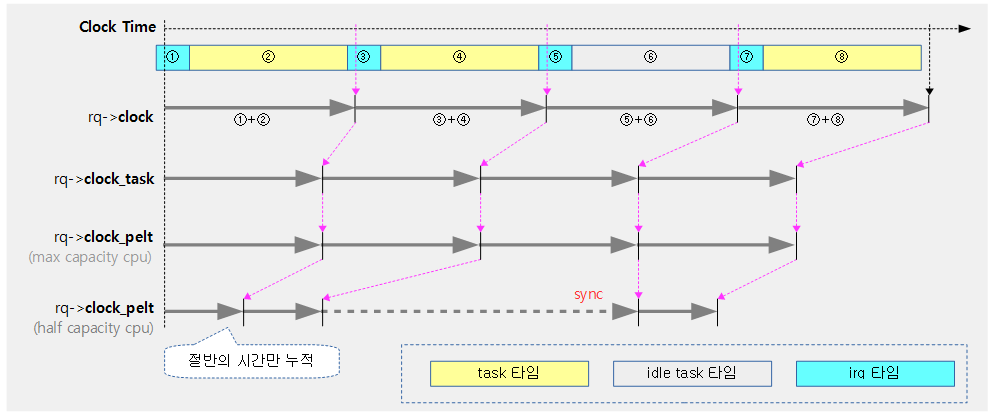
런큐 클럭
런큐에는 다음과 같은 3가지 클럭이 사용된다.
- rq->clock
- 갱신할 때 마다 정확히 절대 스케줄 클럭을 사용하여 런타임을 누적한다.
- rq->clock_task
- irq 처리 및 vCPU 처리에 사용된 시간을 제외하고 순수하게 현재 cpu가 태스크에 소모한 런타임을 누적한다.
- rq->clock 보다 약간 느리게 간다.
- rq->clock_pelt
- clock_task에 누적되는 시간에 cpu capacity를 적용하여 누적시킨 런타임이다.
- big little 시스템에서 big cpu들이 1024(1.0)을 적용될 경우 little cpu들은 더 적은 capacity를 반영한다.
- 또한 cpu frequency 모드에 따른 성능 갭도 반영한다.
- 런큐가 idle 상태인 경우에는 항상 rq->clock_task에 동기화된다.
- clock_task에 누적되는 시간에 cpu capacity를 적용하여 누적시킨 런타임이다.
위의 3가지 런큐 클럭은 다음 순서로 갱신한다.
- update_rq_clock() -> update_rq_clock_task() -> update_rq_clock_pelt()
다음 그림은 3가지 런큐 클럭에 대한 차이를 보여준다.
- rq->clock_task는 이전 타임의 irq 타임 + task 타임을 반영한다.
런큐 클럭 조회
rq_clock()
kernel/sched/sched.h
static inline u64 rq_clock(struct rq *rq)
{
lockdep_assert_held(&rq->lock);
assert_clock_updated(rq);
return rq->clock;
}
런큐의 clock을 를 반환한다.
rq_clock_task()
kernel/sched/sched.h
static inline u64 rq_clock_task(struct rq *rq)
{
lockdep_assert_held(&rq->lock);
return rq->clock_task;
}
런큐의 clock_task 를 반환한다.
rq_clock_pelt()
kernel/sched/pelt.h
static inline u64 rq_clock_pelt(struct rq *rq)
{
lockdep_assert_held(&rq->lock);
assert_clock_updated(rq);
return rq->clock_pelt - rq->lost_idle_time;
}
런큐의 clock_pelt를 반환한다.
cfs_rq_clock_pelt()
kernel/sched/pelt.h
/* rq->task_clock normalized against any time this cfs_rq has spent throttled */
static inline u64 cfs_rq_clock_pelt(struct cfs_rq *cfs_rq)
{
if (unlikely(cfs_rq->throttle_count))
return cfs_rq->throttled_clock_task - cfs_rq->throttled_clock_task_time;
return rq_clock_pelt(rq_of(cfs_rq)) - cfs_rq->throttled_clock_task_time;
}
런큐의 clock_pelt에서 cfs 런큐의 스로틀 시간을 뺀 시간을 반환한다. 이 클럭으로 로드 평균을 구할 때 사용한다.
- cfs bandwidth를 설정하여 사용할 때 스로틀 시간에 관련된 다음 변수들이 있다.
- 스로틀이 시작되면 cfs_rq->throttled_clock_task는 rq->clock_task로 동기화된다.
- 스로틀이 종료되면 cfs_rq->throttled_clock_task_time에는 스로틀한 시간만큼을 누적시킨다.
런큐 클럭들의 갱신
update_rq_clock()
kernel/sched/core.c
void update_rq_clock(struct rq *rq)
{
s64 delta;
lockdep_assert_held(&rq->lock);
if (rq->clock_update_flags & RQCF_ACT_SKIP)
return;
#ifdef CONFIG_SCHED_DEBUG
if (sched_feat(WARN_DOUBLE_CLOCK))
SCHED_WARN_ON(rq->clock_update_flags & RQCF_UPDATED);
rq->clock_update_flags |= RQCF_UPDATED;
#endif
delta = sched_clock_cpu(cpu_of(rq)) - rq->clock;
if (delta < 0)
return;
rq->clock += delta;
update_rq_clock_task(rq, delta);
}
나노초로 동작하는 런큐 클럭을 갱신한다. (스케줄 틱 및 태스크(또는 엔티티)의 변동시 마다 호출된다)
- 코드 라인 7~8에서 skip 요청을 받아들인 경우이다. 이때엔 런큐 클럭을 갱신하지 않고 그냥 함수를 빠져나간다.
- 코드 라인 16~18에서 런큐 클럭이 갱신된 시간과 스케쥴 클럭의 시간 차이 delta를 얻어온다. 시간이 흐르지 않은 경우 클럭 갱신 없이 함수를 빠져나간다.
- 코드 라인 19에서 런큐 클럭에 delta를 추가하여 갱신한다.
- 코드 라인 20에서 rq->clock_task에 @delta를 전달하여 반영한다. (일부 시간이 빠짐)
update_rq_clock_task()
kernel/sched/core.c
static void update_rq_clock_task(struct rq *rq, s64 delta)
{
/*
* In theory, the compile should just see 0 here, and optimize out the call
* to sched_rt_avg_update. But I don't trust it...
*/
s64 __maybe_unused steal = 0, irq_delta = 0;
#ifdef CONFIG_IRQ_TIME_ACCOUNTING
irq_delta = irq_time_read(cpu_of(rq)) - rq->prev_irq_time;
/*
* Since irq_time is only updated on {soft,}irq_exit, we might run into
* this case when a previous update_rq_clock() happened inside a
* {soft,}irq region.
*
* When this happens, we stop ->clock_task and only update the
* prev_irq_time stamp to account for the part that fit, so that a next
* update will consume the rest. This ensures ->clock_task is
* monotonic.
*
* It does however cause some slight miss-attribution of {soft,}irq
* time, a more accurate solution would be to update the irq_time using
* the current rq->clock timestamp, except that would require using
* atomic ops.
*/
if (irq_delta > delta)
irq_delta = delta;
rq->prev_irq_time += irq_delta;
delta -= irq_delta;
#endif
#ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING
if (static_key_false((¶virt_steal_rq_enabled))) {
steal = paravirt_steal_clock(cpu_of(rq));
steal -= rq->prev_steal_time_rq;
if (unlikely(steal > delta))
steal = delta;
rq->prev_steal_time_rq += steal;
delta -= steal;
}
#endif
rq->clock_task += delta;
#ifdef CONFIG_HAVE_SCHED_AVG_IRQ
if ((irq_delta + steal) && sched_feat(NONTASK_CAPACITY))
update_irq_load_avg(rq, irq_delta + steal);
#endif
update_rq_clock_pelt(rq, delta);
}
나노초로 동작하는 rq->clock_task를 갱신한다. 커널 옵션들의 사용 유무에 따라 rq->clock과 동일할 수도 있고, irq 처리 및 vCPU에 사용된 시간을 빼고 순수하게 현재 cpu에서 동작한 태스크 시간만을 누적할 수 있다.
- 코드 라인 9~32에서 irq 처리에 사용된 시간을 측정하기 위한 CONFIG_IRQ_TIME_ACCOUNTING 커널 옵션을 사용한 경우 인자로 전달받은 @delta 값을 그대로 사용하지 않고 irq 처리에 사용된 시간은 @delta에서 뺴고 순수 태스크 런타임만을 적용하도록 한다.
- 코드 라인 33~44에서 CONFIG_PARAVIRT_TIME_ACCOUNTING 커널 옵션을 사용한 경우 vCPU에서 소모한 시간을 빼고 현재 cpu에서 사용된 시간만을 적용하도록 한다.
- 코드 라인 46에서 rq->clock_task에 변화(약간 감소)된 delta 시간을 누적시킨다.
- 코드 라인 48~51에서 irq 처리에 사용된 시간으로 로드 평균을 갱신한다.
- CONFIG_HAVE_SCHED_AVG_IRQ 커널 옵션은 위의 두 커널 옵션 중 하나라도 설정된 SMP 시스템에서 enable된다.
- 코드 라인 52에서 rq->clock_pelt에 @delta를 전달하여 반영한다. (cpu capacity 및 frequency에 따라 @delta 값이 증감된다.)
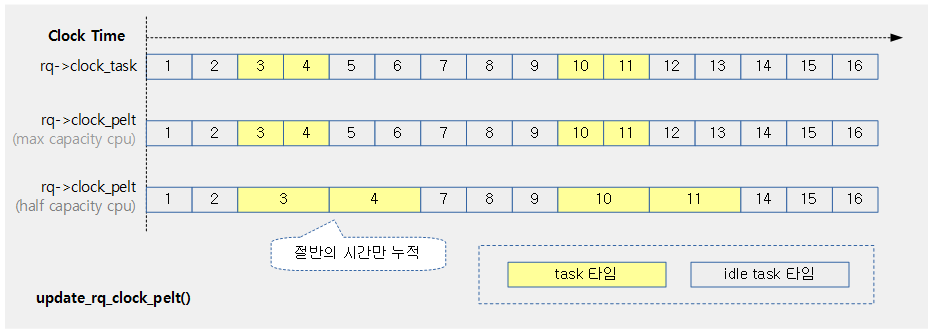
update_rq_clock_pelt()
kernel/sched/pelt.h
/* * The clock_pelt scales the time to reflect the effective amount of * computation done during the running delta time but then sync back to * clock_task when rq is idle. * * * absolute time | 1| 2| 3| 4| 5| 6| 7| 8| 9|10|11|12|13|14|15|16 * @ max capacity ------******---------------******--------------- * @ half capacity ------************---------************--------- * clock pelt | 1| 2| 3| 4| 7| 8| 9| 10| 11|14|15|16 * */
static inline void update_rq_clock_pelt(struct rq *rq, s64 delta)
{
if (unlikely(is_idle_task(rq->curr))) {
/* The rq is idle, we can sync to clock_task */
rq->clock_pelt = rq_clock_task(rq);
return;
}
/*
* When a rq runs at a lower compute capacity, it will need
* more time to do the same amount of work than at max
* capacity. In order to be invariant, we scale the delta to
* reflect how much work has been really done.
* Running longer results in stealing idle time that will
* disturb the load signal compared to max capacity. This
* stolen idle time will be automatically reflected when the
* rq will be idle and the clock will be synced with
* rq_clock_task.
*/
/*
* Scale the elapsed time to reflect the real amount of
* computation
*/
delta = cap_scale(delta, arch_scale_cpu_capacity(cpu_of(rq)));
delta = cap_scale(delta, arch_scale_freq_capacity(cpu_of(rq)));
rq->clock_pelt += delta;
}
clock_pelt는 실행중인 @delta 시간을 cpu 성능에 따라 반감된 시간을 반영한다. 런큐가 idle 상태인 경우에는 clock_task 시각으로 동기화시킨다.
- 코드 라인 3~7에서 런큐가 idle 상태인 경우 rq->clock_pelt는 rq->clock_task에 동기화된다.
- 코드 라인 25에서 @delta 시간에서 cpu capacity 만큼 반감시킨다.
- full capacity 상태인 경우 반감되지 않는다.
- 코드 라인 26에서 다시 한 번 frequency 성능만큼 반감시킨다.
- full frequency로 동작하는 상태인 경우 반감되지 않는다.
- 코드 라인 28에서 위에서 cpu 성능(capacity 및 frequency)에 따라 감소된 delta를 rq->clock_pelt에 반영한다.
다음 그림은 rq->clock_pelt에 서로 다른 cpu capacity가 적용된 시간이 반영되는 모습을 보여준다.
엔티티 로드 평균 갱신
엔티티 로드 평균을 산출하는 update_load_avg() 함수는 다음과 같은 함수에서 호출된다.
- entity_tick()
- 스케줄 틱마다 호출될 때
- enqueue_task_fair()
- cfs 런큐에 태스크가 엔큐될 때
- dequeue_task_fair()
- cfs 런큐에 태스크가 디큐될 때
- enqueue_entity()
- cfs 런큐에 엔티티가 엔큐될 때
- dequeue_entity()
- cfs 런큐에서 엔티티가 디큐될 때
- set_next_entity()
- cfs 런큐의 다음 엔티티가 선택될 때
- put_prev_entity()
- 현재 동작 중인 엔티티를 런큐의 대기로 돌려질 때
- update_blocked_averages()
- blocked 평균을 갱신할 때
- propagate_entity_cfs_rq()
- cfs 런큐로의 전파가 필요할 때
- detach_entity_cfs_rq()
- cfs 런큐로부터 엔티티를 detach할 때
- attach_entity_cfs_rq()
- cfs 런큐로 엔티티를 attach할 때
- sched_group_set_shares()
- 그룹에 shares를 설정할 때
엔티티 로드 weight과 러너블 로드 weight
64비트 시스템에서는 엔티티에 대한 로드 weight과 러너블 로드 weight 값을 10비트 더 정확도를 올려 처리하기 위해 스케일 업(<< 10)한다.
- 32비트 시스템
- nice 0 엔티티에 대한 se->load_weight = 1,024
- 64비트 시스템
- nice 0 엔티티에 대한 se->load_weight = 1,024 << 10 = 1,048,576
se_weight()
kernel/sched/sched.h
static inline long se_weight(struct sched_entity *se)
{
return scale_load_down(se->load.weight);
}
엔티티 로드 weight을 스케일 다운하여 반환한다.
se_runnable()
kernel/sched/sched.h
static inline long se_runnable(struct sched_entity *se)
{
return scale_load_down(se->runnable_weight);
}
엔티티 러너블 로드 weight을 스케일 다운하여 반환한다.
틱 마다 스케줄 엔티티에 대한 PELT 갱신과 preemption 요청 체크
스케줄 틱마다 호출되는 scheduler_tick() 함수와 hr 틱마다 호출되는 hrtick() 함수는 현재 curr에서 동작하는 태스크의 스케줄러의 (*task_tick) 후크 함수를 호출한다. 예를 들어 현재 런큐의 curr가 cfs 태스크인 경우 task_tick_fair() 함수가 호출되는데 태스크와 관련된 스케줄 엔티티부터 최상위 스케줄 엔티티까지 entity_tick() 함수를 호출하여 PELT와 관련된 함수들을 호출한다. 그리고 스케줄 틱으로 호출된 경우 preemption 요청 여부를 체크하여 리스케줄 되는 것에 반해, hrtimer에 의해 정확히 러닝 타이밍 소진시 HR 틱이 발생되어 호출되는 경우에는 무조건 리스케줄 요청한다.
- 함수 호출 경로 예)
- 스케줄 틱: scheduler_tick() -> task_tick_fair() -> entity_tick()
- entity_tick() 함수를 호출할 때 인수 queued=0으로 호출된다.
- HR 틱: hrtick() -> task_tick_fair() -> entity_tick()
- entity_tick() 함수를 호출할 때 인수 queued=1로 호출된다.
- 스케줄 틱: scheduler_tick() -> task_tick_fair() -> entity_tick()
- 참고: Scheduler -6- (CFS Scheduler) | 문c
엔티티의 로드 평균 갱신
다음 그림은 update_load_avg() 함수의 호출 과정을 보여준다.
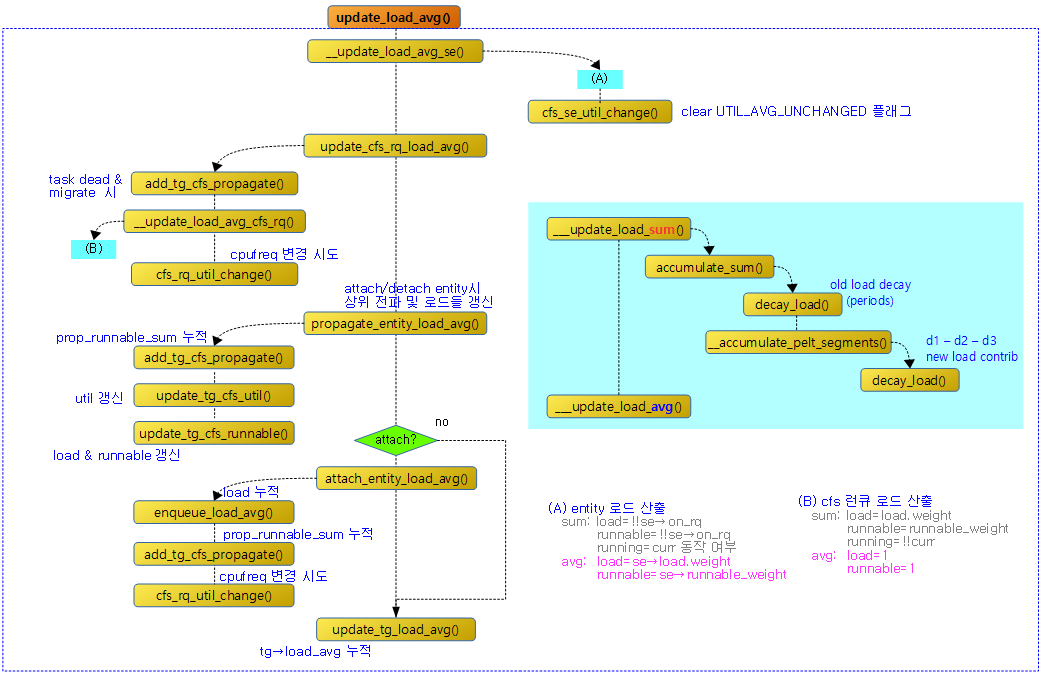
update_load_avg()
kernel/sched/fair.c
/* Update task and its cfs_rq load average */
static inline void update_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
u64 now = cfs_rq_clock_pelt(cfs_rq);
int decayed;
/*
* Track task load average for carrying it to new CPU after migrated, and
* track group sched_entity load average for task_h_load calc in migration
*/
if (se->avg.last_update_time && !(flags & SKIP_AGE_LOAD))
__update_load_avg_se(now, cfs_rq, se);
decayed = update_cfs_rq_load_avg(now, cfs_rq);
decayed |= propagate_entity_load_avg(se);
if (!se->avg.last_update_time && (flags & DO_ATTACH)) {
/*
* DO_ATTACH means we're here from enqueue_entity().
* !last_update_time means we've passed through
* migrate_task_rq_fair() indicating we migrated.
*
* IOW we're enqueueing a task on a new CPU.
*/
attach_entity_load_avg(cfs_rq, se, SCHED_CPUFREQ_MIGRATION);
update_tg_load_avg(cfs_rq, 0);
} else if (decayed && (flags & UPDATE_TG))
update_tg_load_avg(cfs_rq, 0);
}
엔티티의 로드 평균 등을 갱신한다.
- 코드 라인 4에서 cpu 성능이 적용된 런큐의 pelt 시각을 알아온다.
- 코드 라인 11~12에서 SKIP_AGE_LOAD 플래그가 없는 경우 엔티티의 로드 평균을 갱신한다.
- 코드 라인 14에서 cfs 런큐의 로드/유틸 평균을 갱신하고 decay 여부를 알아온다.
- 코드 라인 15에서 cfs 런큐에 태스크가 attach/detach할 때 전파(propagate) 표시를 하여 다음 update에서 변경 사항을 상위 수준(cfs 런큐 및 엔티티)으로 전파하기 위해 cfs 런큐의 로드 등을 엔티티에 복사한다.그리고 decay 여부도 알아온다.
- 참고: sched/fair: Propagate load during synchronous attach/detach (2016, v4.10-rc1)
- 코드 라인 17~27에서 태스크를 마이그레이션한 이후 엔티티에서 처음인 경우 로드 평균을 추가하고, 태스크 그룹 로드 평균을 갱신한다.
- 처음 마이그레이션된 경우 last_update_time은 0으로 클리어되어 있다.
- 코드 라인 29~30에서 decay 된 경우에 한해 태스크 그룹 로드 평균도 갱신한다.
스케줄 엔티티에 대한 로드 합계 및 평균을 산출
__update_load_avg_se()
kernel/sched/pelt.c
int __update_load_avg_se(u64 now, struct cfs_rq *cfs_rq, struct sched_entity *se)
{
if (___update_load_sum(now, &se->avg, !!se->on_rq, !!se->on_rq,
cfs_rq->curr == se)) {
___update_load_avg(&se->avg, se_weight(se), se_runnable(se));
cfs_se_util_change(&se->avg);
trace_pelt_se_tp(se);
return 1;
}
return 0;
}
새롭게 반영해야 할 로드를 엔티티 로드 합계에 추가하고 그 과정에서 decay한 적이 있으면 로드 평균도 재산출한다. 반환 되는 값은 로드 평균의 재산출 여부이다. (로드 합계의 decay가 수행된 경우 로드 평균도 재산출되므로 1을 반환한다.)
- 코드 라인 3~4에서 새롭게 반영해야 할 로드를 엔티티의 로드 합계에 추가하고, 그 과정에서 decay 한 적이 있으면
- 코드 라인 6에서 로드 평균을 재산출한다.
- 코드 라인 7~9에서 avg->util_est.enqueued의 UTIL_AVG_UNCHANGED 플래그가 설정되어 있는 경우 제거하여 로드 평균이 재산출되었음을 인식하게 한다. 그런 후 decay 하여 로드 평균이 재산출 되었음을 의미하는 1을 반환한다.
- 코드 라인 12에서 decay 없어서 로드 평균이 재산출 되지 않았음을 의미하는 0을 반환한다.
cfs_se_util_change()
kernel/sched/pelt.h
/* * When a task is dequeued, its estimated utilization should not be update if * its util_avg has not been updated at least once. * This flag is used to synchronize util_avg updates with util_est updates. * We map this information into the LSB bit of the utilization saved at * dequeue time (i.e. util_est.dequeued). */ #define UTIL_AVG_UNCHANGED 0x1
static inline void cfs_se_util_change(struct sched_avg *avg)
{
unsigned int enqueued;
if (!sched_feat(UTIL_EST))
return;
/* Avoid store if the flag has been already set */
enqueued = avg->util_est.enqueued;
if (!(enqueued & UTIL_AVG_UNCHANGED))
return;
/* Reset flag to report util_avg has been updated */
enqueued &= ~UTIL_AVG_UNCHANGED;
WRITE_ONCE(avg->util_est.enqueued, enqueued);
}
avg->util_est.enqueued의 UTIL_AVG_UNCHANGED 플래그가 설정되어 있는 경우 제거하여 로드 평균이 재산출되었음을 인식하게 한다.
로드 합계 및 평균 산출
로드 합계 산출
___update_load_sum()
kernel/sched/pelt.c
/*
* We can represent the historical contribution to runnable average as the
* coefficients of a geometric series. To do this we sub-divide our runnable
* history into segments of approximately 1ms (1024us); label the segment that
* occurred N-ms ago p_N, with p_0 corresponding to the current period, e.g.
*
* [<- 1024us ->|<- 1024us ->|<- 1024us ->| ...
* p0 p1 p2
* (now) (~1ms ago) (~2ms ago)
*
* Let u_i denote the fraction of p_i that the entity was runnable.
*
* We then designate the fractions u_i as our co-efficients, yielding the
* following representation of historical load:
* u_0 + u_1*y + u_2*y^2 + u_3*y^3 + ...
*
* We choose y based on the with of a reasonably scheduling period, fixing:
* y^32 = 0.5
*
* This means that the contribution to load ~32ms ago (u_32) will be weighted
* approximately half as much as the contribution to load within the last ms
* (u_0).
*
* When a period "rolls over" and we have new u_0`, multiplying the previous
* sum again by y is sufficient to update:
* load_avg = u_0` + y*(u_0 + u_1*y + u_2*y^2 + ... )
* = u_0 + u_1*y + u_2*y^2 + ... [re-labeling u_i --> u_{i+1}]
*/
static __always_inline int
___update_load_sum(u64 now, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u64 delta;
delta = now - sa->last_update_time;
/*
* This should only happen when time goes backwards, which it
* unfortunately does during sched clock init when we swap over to TSC.
*/
if ((s64)delta < 0) {
sa->last_update_time = now;
return 0;
}
/*
* Use 1024ns as the unit of measurement since it's a reasonable
* approximation of 1us and fast to compute.
*/
delta >>= 10;
if (!delta)
return 0;
sa->last_update_time += delta << 10;
/*
* running is a subset of runnable (weight) so running can't be set if
* runnable is clear. But there are some corner cases where the current
* se has been already dequeued but cfs_rq->curr still points to it.
* This means that weight will be 0 but not running for a sched_entity
* but also for a cfs_rq if the latter becomes idle. As an example,
* this happens during idle_balance() which calls
* update_blocked_averages()
*/
if (!load)
runnable = running = 0;
/*
* Now we know we crossed measurement unit boundaries. The *_avg
* accrues by two steps:
*
* Step 1: accumulate *_sum since last_update_time. If we haven't
* crossed period boundaries, finish.
*/
if (!accumulate_sum(delta, sa, load, runnable, running))
return 0;
return 1;
}
로드 합계들을 구한다. 그리고 decay 여부를 반환한다.
- 코드 라인 7에서 현재 시각에서 last_update_time 시각까지의 차이를 delta로 알아온다.
- 코드 라인 12~15에서 unstable한 TSC 클럭을 사용하는 아키텍처등에서는 초기에 delta가 0보다 작아지는 경우도 발생한다. 이러한 경우에는 last_update_time만 현재 시각으로 갱신하고 그냥 0을 반환한다.
- 코드 라인 21~23에서 나노초 단위인 delta를 PELT가 로드 값 산출에 사용하는 마이크로초 단위로 바꾸고, 이 값이 0인 경우 그냥 0을 반환한다.
- 코드 라인 25에서 last_update_time에 마이크로초 이하를 절삭한 나노초로 변환하여 저장한다. PELT의 로드 산출에는 항상 마이크로초 이하의 나노초들은 적용하지 않고 보류한다.
- 코드 라인 36~37에서 @load 값이 0인 경우 runnable과 running에는 0을 반환한다.
- 코드 라인 46~47에서 delta 기간의 새 로드를 반영하여 여러 로드들의 합계들을 모두 구한다. 로드 합계 산출 후 기존 로드합계의 decay가 이루어지지 않은 경우 0을 반환한다.
- 코드 라인 49에서 로드 산출에 decay 하였으므로 1을 반환한다. (decay가 되면 이 함수 이후에 산출된 로드 합계를 사용하여 로드 평균을 재산출해야 한다.)
period
PELT 시간 단위 기준은 다음과 같은 특성을 가진다.
- PELT 클럭 값들은 ns 단위이다.
- PELT 연산에 사용하는 시간 단위는 1024(ns)로 정렬하여 사용하고, 약 1(us)이다.
- Period 단위는 1024 * 1024(ns)로 정렬하여 사용하고, 약 1(ms)이다.
- Decay는 보통 Period 단위로 정렬된
다음 그림은 pelt와 관련된 시간 단위들을 시각적으로 표현하였다.

다음 그림은 ___update_load_sum() 함수에서 Step 1 구간의 Old 로드의 decay 부분 산출 과정을 보여준다.
- decay 구간은 1024us 단위마다 수행하며, 각 구간마다 decay 적용률이 반영될때 현재 시각에 가까운 구간일 수록 더 높게 로드값을 반영하는 것을 알 수 있다.
- Old 로드를 산출하는 Step 1 과정에서는 now가 있는 끝 구간의 짤린 부분을 제외하고, Olt 로드를 3 periods 구간만큼만 decay 한다.
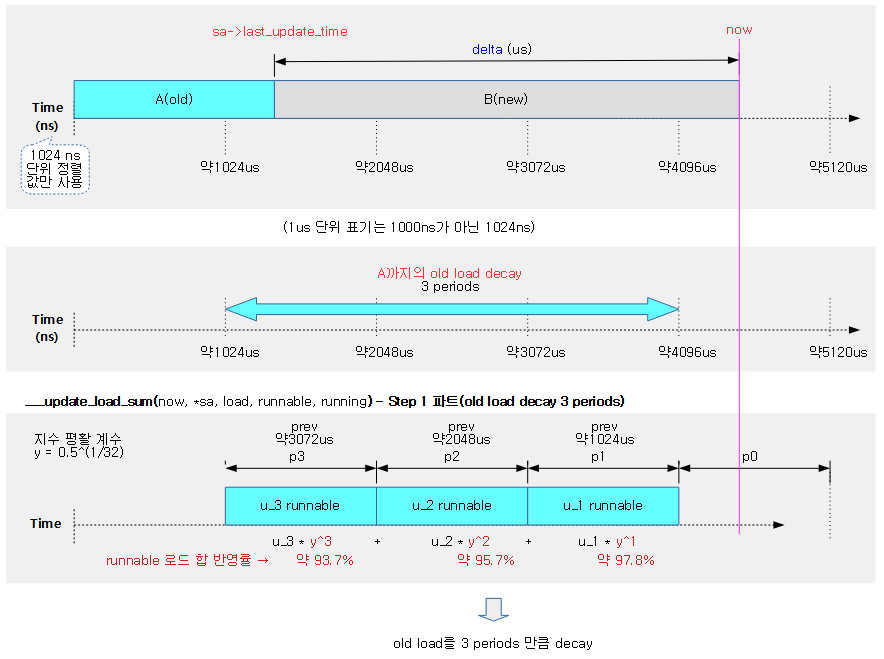
다음 그림은 ___update_load_sum() 함수에서 Step 2 구간의 New 로드의 decay 부분 산출 과정을 보여준다.
- New 로드를 산출하는 Step 2 과정에서는 last_update_time 이후의 기간을 모두 decay 한다.
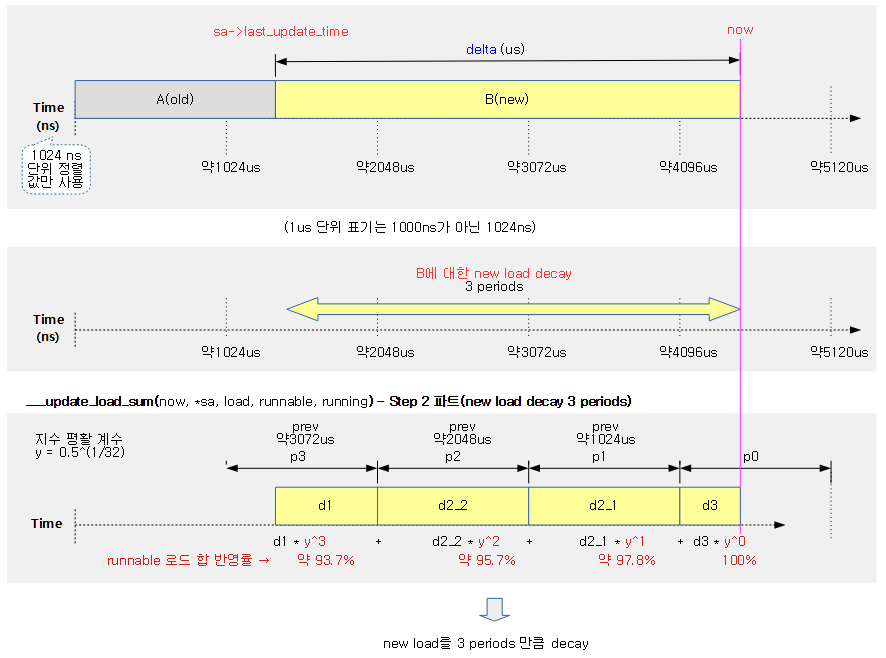
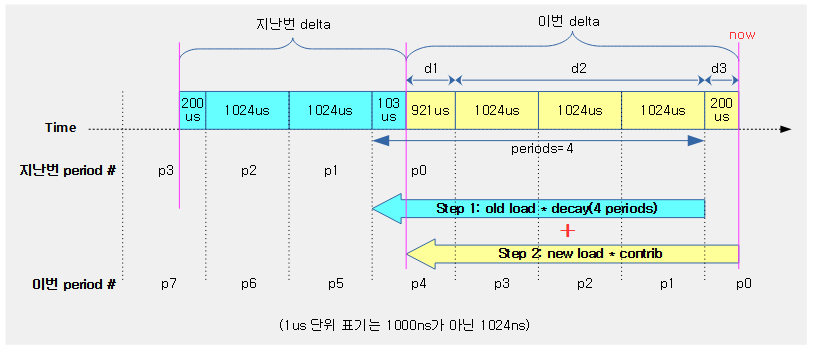
다음 그림의 예는 직접 기간을 정해 산출할 수 있도록 하였다.
- Step 1부분의 Old 로드에 decay 반영하고
- Step 2 부분의 New 로드에 decay 반영하여
- 두 값을 더하여 로드를 산출하는 모습을 보여준다.
예) old 로드 합계=20000, new 로드 값=2048로 최종 로드를 구해본다.
- Step 1) decay_load(old 로드 합계, periods)
- = decay_load(20000, 4)
- Step 2) new 로드 * __accumalate_pelt_segments(periods, d1, d3)
- 2048 * __accumalate_pelt_segments(4, 921, 200)
accumulate_sum()
kernel/sched/pelt.c
/* * Accumulate the three separate parts of the sum; d1 the remainder * of the last (incomplete) period, d2 the span of full periods and d3 * the remainder of the (incomplete) current period. * * d1 d2 d3 * ^ ^ ^ * | | | * |<->|<----------------->|<--->| * ... |---x---|------| ... |------|-----x (now) * * p-1 * u' = (u + d1) y^p + 1024 \Sum y^n + d3 y^0 * n=1 * * = u y^p + (Step 1) * * p-1 * d1 y^p + 1024 \Sum y^n + d3 y^0 (Step 2) * n=1 */
static __always_inline u32
accumulate_sum(u64 delta, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u32 contrib = (u32)delta; /* p == 0 -> delta < 1024 */
u64 periods;
delta += sa->period_contrib;
periods = delta / 1024; /* A period is 1024us (~1ms) */
/*
* Step 1: decay old *_sum if we crossed period boundaries.
*/
if (periods) {
sa->load_sum = decay_load(sa->load_sum, periods);
sa->runnable_load_sum =
decay_load(sa->runnable_load_sum, periods);
sa->util_sum = decay_load((u64)(sa->util_sum), periods);
/*
* Step 2
*/
delta %= 1024;
contrib = __accumulate_pelt_segments(periods,
1024 - sa->period_contrib, delta);
}
sa->period_contrib = delta;
if (load)
sa->load_sum += load * contrib;
if (runnable)
sa->runnable_load_sum += runnable * contrib;
if (running)
sa->util_sum += contrib << SCHED_CAPACITY_SHIFT;
return periods;
}
마이크로초 단위의 @delta 기간 동안 새 @load를 반영한 여러 로드 합계 및 평균들을 산출한다. 반환되는 값은 decay에 사용한 기간 수이다.
- 코드 라인 5에서 contrib 값은 1024us 미만에서만 사용되는 값이다. 여기서 delta가 1024us 미만일 경우에만 사용하기 위해 delta를 contrib에 미리 대입한다.
- 코드 라인 8에서 인자로 전달받은 @delta에 기존 갱신 타임에 1024us 미만이라 decay를 하지 않은 마이크로 단위의 기간 잔량 sa->period_contrib를 추가한다.
- 코드 라인 9에서 1024us 단위로 decay하기 위해 delta를 1024로 나눈다.
- 커널에서 하나의 period는 정확히 1024us이다. 그런데 사람은 오차를 포함하여 약 1ms라고 느끼면 된다.
- 코드 라인 14~18에서 Step 1 루틴으로 과거 값을 먼저 decay 한다. 즉 기존 load_sum, runnable_load_sum 및 util_sum 값들을 periods 만큼 decay 한다.
- old 로드는 1024us 단위로 정렬하여 decay하므로 나머지에 대해서는 decay하지 않는다.
- 코드 라인 23~25에서 Step 1에서 decay하여 산출한 로드 값에 Step 2의 새로운 로드를 반영하기 위해 기여분(contrib)을 곱하여 산출한다.
- 새 로드 값 = old 로드 * decay + new 로드 * contrib
- decay_load(old 로드, 1024us 단위 기간 수) + new 로드 * __accumulate_pelt_segments()
- 새 로드 값 = old 로드 * decay + new 로드 * contrib
- 코드 라인 27에서 1024us 단위 미만이라 decay 처리하지 못한 나머지 마이크로초 단위의 delta를 sa->period_contrib에 기록해둔다. 이 값은 추후 다음 갱신 기간 delta에 포함하여 활용한다.
- 코드 라인 29~32에서 기존 로드 합계를 decay한 값에 새 load * contrib를 적용하여 로드합계를 산출한다.
- 코드 라인 33~34에서 util_sum 값의 경우 1024 * contrib를 추가하여 산출한다.
- 코드 라인 36에서 1024us 단위로 decay 산출한 기간 수(periods)를 반환한다.
기여분(contrib)
기여분은 최대 로드 기간인 LOAD_AVG_MAX(47748)를 초과할 수 없다.
- avg.load_sum += load * contrib
- 예) 기여분(contrib) = LOAD_AVG_MAX * 10% = 4774
- avg.runnable_load_sum += runnable * contrib
- avg.util_sum += contrib * 1024
로드 감쇠
decay_load()
kernel/sched/pelt.c
/* * Approximate: * val * y^n, where y^32 ~= 0.5 (~1 scheduling period) */
static u64 decay_load(u64 val, u64 n)
{
unsigned int local_n;
if (unlikely(n > LOAD_AVG_PERIOD * 63))
return 0;
/* after bounds checking we can collapse to 32-bit */
local_n = n;
/*
* As y^PERIOD = 1/2, we can combine
* y^n = 1/2^(n/PERIOD) * y^(n%PERIOD)
* With a look-up table which covers y^n (n<PERIOD)
*
* To achieve constant time decay_load.
*/
if (unlikely(local_n >= LOAD_AVG_PERIOD)) {
val >>= local_n / LOAD_AVG_PERIOD;
local_n %= LOAD_AVG_PERIOD;
}
val = mul_u64_u32_shr(val, runnable_avg_yN_inv[local_n], 32);
return val;
}
로드 값 @val을 @n 기간(1024us) 에 해당하는 감쇠 비율로 줄인다. n=0인 경우 감쇠 없는 1.0 요율이고, n=32인 경우 절반이 줄어드는 0.5 요율이다.
- 코드 라인 5~6에서 기간 @n이 2016(32 * 63)을 초과하는 경우 많은 기간을 감쇠시켜 산출을 하더라도 0이 되므로 성능을 위해 연산 없이 곧장 0으로 반환한다.
- 코드 라인 9에서 기간 @n을 32비트 타입으로 변환한다.
- 코드 라인 18~21에서 기간 @n은 32 단위로 절반씩 줄어든다. 따라서 기간 @n이 32 이상인 경우 val 값을 n/32 만큼 시프트하고, local_n 값은 32로 나눈 나머지를 사용한다.
- 코드 라인 23~24에서 미리 계산해둔 decay 요율을 inverse 형태로 담은 runnable_avg_yN_inv[]테이블에서 local_n 인덱스에 해당하는 mult 값을 val에 곱하고 정밀도 32비트를 우측 시프트하여 반환한다.
미리 만들어진 PELT용 decay factor
kernel/sched/fair.c
static const u32 runnable_avg_yN_inv[] __maybe_unused = {
0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6,
0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85,
0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581,
0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9,
0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80,
0x85aac367, 0x82cd8698,
};
#define LOAD_AVG_PERIOD 32
#define LOAD_AVG_MAX 47742
약 32ms(1024us * 32)까지 decay될 요율(factor)이 미리 계산되어 있는 runnable_avg_yN_inv[] 테이블은 나눗셈 연산을 하지 않게 하기 위해 decay 요율마다 mult 값이 다음 수식으로 만들어졌다.

- n 번째 요율을 계산하는 수식(32bit shift 적용):
- ‘y^n’은 항상 1.0 이하의 실수 값이다. 이 값에 32비트 정밀도를 적용하여 이진화 정수화한다.
- ‘y^k * 2^32’ 수식을 사용한다. (단 y^32=0.5)
- y값을 먼저 구해보면
- y=0.5^(1/32)=0.97852062…
- 인덱스 값 n에 0부터 32까지 사용한 결과 값은? (테이블 구성은 0~31 까지)
- 인덱스 n에 0을 주면 y^0 * 2^32 = 0.5^(1/32)^0 * (2^32) = 1.0 << 32 = 0x1_0000_0000 (32bit로 구성된 테이블 값은 0xffff_ffff 사용)
- 인덱스 n에 1 을 주면 y^1 * 2^32 = 0.5^(1/32)^1 * (2^32) = 0.97852062 << 32 = 0xfa83_b2db
- 인덱스 n에 2을 주면 y^2 * 2^32 = 0.5^(1/32)^2 * (2^32) = 0.957603281 << 32 = 0xf525_7d15
- …
- 인덱스 n에 31을 주면 y^2 * 2^32 = 0.5^(1/32)^31 * (2^32) = 0.510948574 << 32 = 0x82cd_8698
- 인덱스 n에 32을 주면 y^2 * 2^32 = 0.5^(1/32)^31 * (2^32) = 0.5 << 32 = 0x7fff_ffff
- ‘y^n’은 항상 1.0 이하의 실수 값이다. 이 값에 32비트 정밀도를 적용하여 이진화 정수화한다.
__accumulate_pelt_segments()
kernel/sched/pelt.c
static u32 __accumulate_pelt_segments(u64 periods, u32 d1, u32 d3)
{
u32 c1, c2, c3 = d3; /* y^0 == 1 */
/*
* c1 = d1 y^p
*/
c1 = decay_load((u64)d1, periods);
/*
* p-1
* c2 = 1024 \Sum y^n
* n=1
*
* inf inf
* = 1024 ( \Sum y^n - \Sum y^n - y^0 )
* n=0 n=p
*/
c2 = LOAD_AVG_MAX - decay_load(LOAD_AVG_MAX, periods) - 1024;
return c1 + c2 + c3;
}
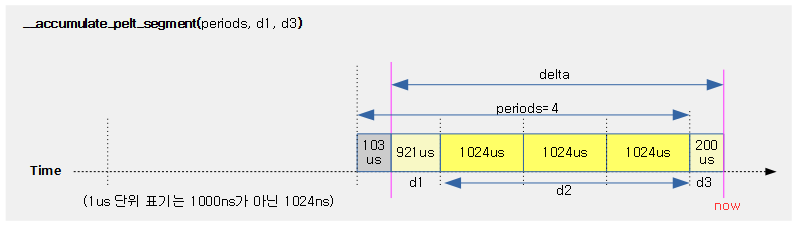
새 로드에 곱하여 반영할 기여율(contrib)을 반환한다. 기여율을 산출하기 위해 @periods는 새 로드가 decay할 1024us 단위의 기간 수이며, 처리할 기간의 1024us 정렬되지 않는 1024us 미만의 시작 @d1 구간과 1024us 미만의 마지막 d3 구간을 사용한다.
- 코드 라인 3에서 1024us 미만의 d3 구간은 y^0 구간을 적용받으므로 d3 * y^0 = d3이다. 그러므로 기여분에 그대로 d3 값을 사용하기 위해 c3에 대입한다.
- 코드 라인 8에서 d1 구간에 대해 @periods 만큼 decay를 수행하여 c1을 구한다.
- 코드 라인 19에서 d2 구간을 decay 하기 위한 변형된 수식을 사용하여 c2를 구한다.
- 코드 라인 21에서 c1 + c2 + c3 한 값을 반환한다. 이 값은 새 로드에 곱하여 기여율(contrib)로 사용될 예정이다.
예) 새 로드 값=3072(3.0), periods=32, d1=512, d3=768인 경우 기여분(contrib)은?
- y = 0.5^(1/32) = 0.978572…
- c1 = d1 * y^periods = 500 * (0.5^(1/32))^32 = 250
- c2 = 1024 * (y^1 + … + y^(periods-1)) = 22870
- = 1024 * ((y ^ 0 + … + y^inf) – (y^periods + … + y^inf) – (y^0))
- = 1024 * (y ^ 0 + … + y^inf) – 1024 * (y^periods + … + y^inf) – 1024 * y^0
- = 47742 – decay_load(47742, 32) – 1024
- = 47742 – 24359 – 1024 = 23336
- c3 = 750
- return = 256 + 22870 + 768 = 23894
- 전체 로드 기간 LOAD_AVG_MAX(47742) 대비 50%를 기여분(contrib)으로 반환한다.
다음 그림은 새 로드가 반영될 때 사용할 기여분(contrib)을 산출할 때 사용되는 구간들을 보여준다.
로드 평균 산출
___update_load_avg()
kernel/sched/pelt.c
static __always_inline void
___update_load_avg(struct sched_avg *sa, unsigned long load, unsigned long runnable)
{
u32 divider = LOAD_AVG_MAX - 1024 + sa->period_contrib;
/*
* Step 2: update *_avg.
*/
sa->load_avg = div_u64(load * sa->load_sum, divider);
sa->runnable_load_avg = div_u64(runnable * sa->runnable_load_sum, divider);
WRITE_ONCE(sa->util_avg, sa->util_sum / divider);
}
@sa의 로드, 러너블 로드 및 유틸 평균들을 재산출한다.
- 코드 라인 4에서 divider 값은 decay를 고려했을 떄의 최대 기간 값을 사용해야 하고, 이번 산출에서 decay에 반영하지 못할 기간은 제외해야 한다. LOAD_AVG_MAX는 모든 decay 로드 값을 더했을 때 최대값이 될 수 있는 값으로 이 값을 사용하여 최대 기간으로 사용한다. 그래서 어떤 로드 합계 / divider가 새 로드에 반영할 비율이 된다. 그런데 decay 산출할 때 마다 1024us 미만의 기간은 decay를 하지 않아야 하므로 최대 기간에서 빼야한다. 이렇게 제외시켜야할 기간은 다음과 같다.
- 1024(us) – 기존 산출에서 decay 하지 않은 값(sa->period_contrib) = 새 산출에서 decay 하지 않아 제외 시켜야 할 값
- 지난 산출에서 3993(921+1024+1024+1024+921)us 의 시간 중 3 기간에 대한 3072 us를 decay 하는데 사용하였고, 921 us는 사용하지 않았다. 이번 산출에서는 그 기존 분량은 decay에 사용하고, 나머지 103us는 decay에 사용하지 않는 기간이된다.
- 참고: sched/cfs: Make util/load_avg more stable (2017, v
- 1024(us) – 기존 산출에서 decay 하지 않은 값(sa->period_contrib) = 새 산출에서 decay 하지 않아 제외 시켜야 할 값
- 코드 라인 9~10에서 @load 및 @runnable에 이 함수 진입 전에 산출해둔 로드 섬들을 divider로 나눈 비율을 곱하여 적용한다.
- @load가 0일 때 로드 평균은 0으로 리셋되고, @runnable이 0일 때 역시 러너블 로드 평균도 0으로 리셋된다.
- 참고: sched/cfs: Make util/load_avg more stable (2017, v4.13-rc1)
- 코드 라인 11에서 유틸 평균은 유틸 합계를 divider로 나눈 값으로 갱신한다.
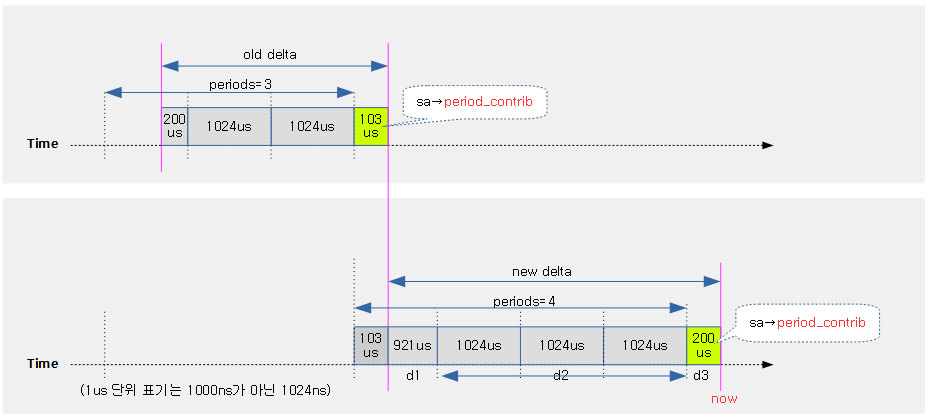
sa->period_contrib
period_contrib는 지난번 decay 되지 않았던 1 period(1024*1024us) 미만의 시간을 저장해둔다.
다음 그림은 period_contrib에 대한 정확한 위치를 보여준다.
LOAD_AVG_MAX
LOAD_AVG_MAX 값은 1 periods에서 사용하는 단위 1024us에 로드가 있을 때 이 값을 1024(1.0을 10비트 이진화정수로 사용한 값)라고 가정하고 이 값을 무한대 periods 기간 n번까지 decay한 값을 모두 더했을 때 나올 수 있는 최대 값으로 로드 평균 산출을 위한 최대 산출 기간으로 사용한다.
- n=∞(무한)
- 평활 계수 y를 32번 감쇠할 때 0.5일때, y 값의 산출은 다음과 같다.
- y^32=0.5
- y=0.5^(1/32)
- = 약 0.97852
- 엑셀식: =POWER(0.5, 1/32)
예) decay 총합 = y^0 + y^1 + y^2 + y^3 + … + y^n = 1 + 0.978572 + 0.957603 + 0.937084 + … 0.0000 = 약 46.668046
- 1ms 단위의 로드 값 1024를 계속 n번 만큼 decay 한 수를 합하면? (소숫점을 이진화 정수 40bit 정밀도의 엑셀 사용 시)
- = 1024 * y^0 + 1024 * y^1 + 1024 * y^2 + 1024 * y^3 + … + 1024 * y^n
- = 1024 * (y^0 + y^1 + y^2 + y^3 + … + y^n) =
- = 1024 + 1002 + 980 + 959 + … + 0
- = 47579
- 커널의 경우 위의 값과는 다른 결과 값 47742를 사용하는데, 다음 소스를 참고 할 수 있다.
- 47742라는 값을 추적하기 위해 y 값에 double 자료형으로 사용하여 정밀도를 높였고, 정수의 연산을 위해 32비트 이진화 정수형을 사용하고, 결과는 long 자료형을 사용하였다.
- deacy를 346(n=0 ~ 345)번 진행하는 동안 계속 new load에 대한 1024를 계속 더했다.
- 참고: Documentation/scheduler/sched-pelt.c
다음 그림은 LOAD_AVG_MAX에 대한 값을 산출하는 과정을 보여준다.
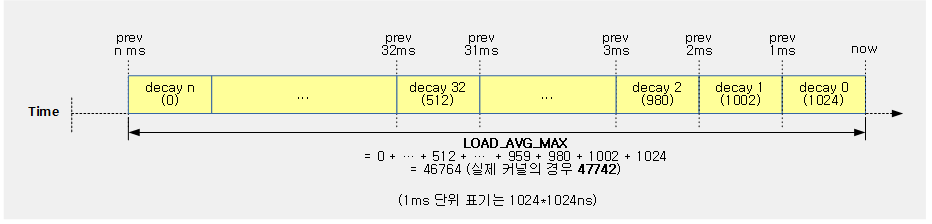
다음과 같이 로드 값 1024를 y^n(1부터 32까지) 누적한 값을 산출해본다. (sum=23,382)
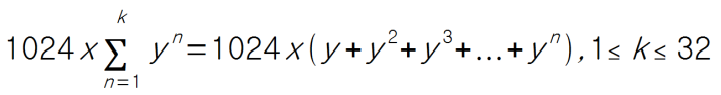
로드 평균 산출시 LOAD_AVG_MAX 대신 실제 사용하는 값?
load_sum 값으로 실제 load_avg를 산출하기 위해서는 간단히 다음과 같은 수식을 사용한다.
- load_avg = load_sum / LOAD_AVG_MAX
그러나 PELT의 경우 periods 기간을 1024us 단위로 잘라 사용하다 보니 산출하는 시점의 시각이 1024us 단위에 정확히 맟춰지지 않는다. 때문에 로드 합계에 사용된 기간만을 정확히 사용해야 하므로 LOAD_AVG_MAX 에서 로드 합계에 관여하지 않은 기간이 발생하는 P0 구간에서 미래 시간인 1024 – sa->period_contrib 값을 빼준다.
- divider = LOAD_AVG_MAX – 1024 + sa->load_sum
- load_avg = load_sum / divider
다음 그림은 divider를 산출하는 과정을 보여준다.

다음 그림은 ___update_load_avg() 함수가 하는 일에서 로드 평균만 산출하는 과정을 보여준다.

다음 그림은 태스크용 엔티티의 로드 평균을 산출한 값들이다.
- 1000HZ 틱을 10번 진행하였을 때의 로드 합계 및 평균을 보여준다.
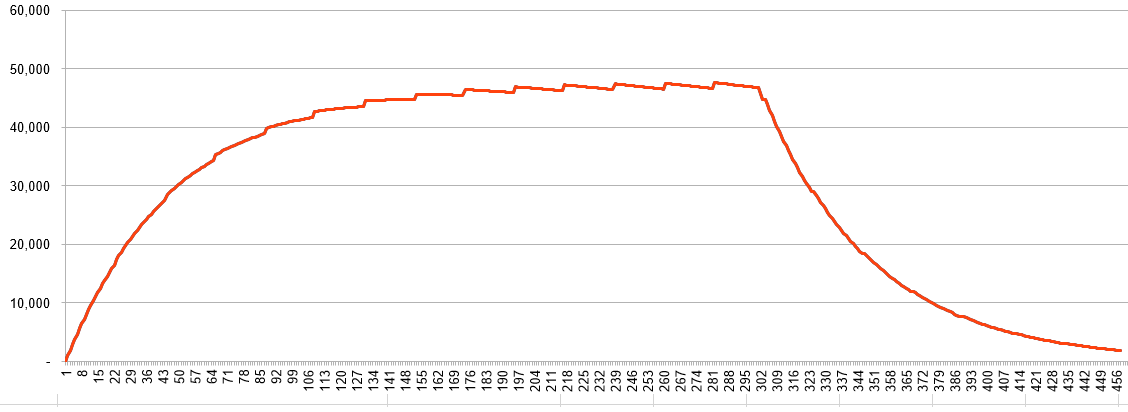
다음 그림은 위의 조건으로 태스크용 엔티티의 로드 합계를 456틱까지 진행한 모습을 보여준다.
- 201틱부터 ruunning을 0으로 하여 유틸 로드를 하향시켰다.
- util_sum은 단위가 scale up(1024)되어 아래 그래프에는 표현하지 않았다.
- 301틱부터 runnable을 0으로 하여 로드 및 러너블 로드를 하향시켰다.
- 빨간색은 load_sum 및 runnable_sum
cfs 런큐 로드 평균 갱신
엔티티의 로드 평균을 구했으면 다음은 cfs 런큐로 로드를 모으고 이에 대한 cfs 런큐 로드 평균을 구해야 한다.
update_cfs_rq_load_avg()
kernel/sched/fair.c
/** * update_cfs_rq_load_avg - update the cfs_rq's load/util averages * @now: current time, as per cfs_rq_clock_pelt() * @cfs_rq: cfs_rq to update * * The cfs_rq avg is the direct sum of all its entities (blocked and runnable) * avg. The immediate corollary is that all (fair) tasks must be attached, see * post_init_entity_util_avg(). * * cfs_rq->avg is used for task_h_load() and update_cfs_share() for example. * * Returns true if the load decayed or we removed load. * * Since both these conditions indicate a changed cfs_rq->avg.load we should * call update_tg_load_avg() when this function returns true. */
static inline int
update_cfs_rq_load_avg(u64 now, struct cfs_rq *cfs_rq)
{
unsigned long removed_load = 0, removed_util = 0, removed_runnable_sum = 0;
struct sched_avg *sa = &cfs_rq->avg;
int decayed = 0;
if (cfs_rq->removed.nr) {
unsigned long r;
u32 divider = LOAD_AVG_MAX - 1024 + sa->period_contrib;
raw_spin_lock(&cfs_rq->removed.lock);
swap(cfs_rq->removed.util_avg, removed_util);
swap(cfs_rq->removed.load_avg, removed_load);
swap(cfs_rq->removed.runnable_sum, removed_runnable_sum);
cfs_rq->removed.nr = 0;
raw_spin_unlock(&cfs_rq->removed.lock);
r = removed_load;
sub_positive(&sa->load_avg, r);
sub_positive(&sa->load_sum, r * divider);
r = removed_util;
sub_positive(&sa->util_avg, r);
sub_positive(&sa->util_sum, r * divider);
add_tg_cfs_propagate(cfs_rq, -(long)removed_runnable_sum);
decayed = 1;
}
decayed |= __update_load_avg_cfs_rq(now, cfs_rq);
#ifndef CONFIG_64BIT
smp_wmb();
cfs_rq->load_last_update_time_copy = sa->last_update_time;
#endif
if (decayed)
cfs_rq_util_change(cfs_rq, 0);
return decayed;
}
cfs 런큐의 로드/유틸 평균을 갱신한다.
- 코드 라인 7~29에서 cfs 런큐에서 엔티티가 detach되었을 때 cfs 런큐에서 로드 합계 및 평균을 직접 감산시키지 않고, cfs_rq->removed에 로드/유틸 평균 및 로드 합계 등을 감소시켜달라고 요청해두었었다. 성능을 높이기 위해 cfs 런큐의 락을 획득하지 않고 removed를 이용하여 atomic 명령으로 갱신한다. 다음은 cfs 로드 평균 갱신 시에 다음과 같이 처리한다.
- cfs 런큐의 removed에서 이 값들을 로컬 변수로 읽어오고 0으로 치환한다.
- cfs 런큐의 로드/유틸 합계와 평균에서 이들을 감소시킨다.
- cfs 런큐에 러너블 합계를 전파하기 위해 추가한다.
- 코드 라인 31에서 cfs 런큐의 로드 평균을 갱신한다.
- 코드 라인 38~39에서 유틸 값이 바뀌면 cpu frequency 변경 기능이 있는 시스템의 경우 주기적으로 변경한다.
__update_load_avg_cfs_rq()
kernel/sched/pelt.c
int __update_load_avg_cfs_rq(u64 now, struct cfs_rq *cfs_rq)
{
if (___update_load_sum(now, &cfs_rq->avg,
scale_load_down(cfs_rq->load.weight),
scale_load_down(cfs_rq->runnable_weight),
cfs_rq->curr != NULL)) {
___update_load_avg(&cfs_rq->avg, 1, 1);
trace_pelt_cfs_tp(cfs_rq);
return 1;
}
return 0;
}
cfs 런큐의 로드 합계 및 평균을 갱신한다. 반환 되는 값은 cfs 런큐의 로드 평균의 재산출 여부이다.
- 코드 라인 3~6에서 cfs 런큐의 로드 합계를 갱신한다. 그 과정에서 decay 한 적이 있으면
- 코드 라인 8~10에서 cfs 런큐의 로드 평균을 갱신하고, 1을 반환한다.
- 코드 라인 13에서 decay 없어서 cfs 런큐의 로드 평균이 재산출 되지 않았음을 의미하는 0을 반환한다.
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c – 현재 글
- Scheduler -3a- (PELT-2) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- Update on big.LITTLE scheduling experiments | ARM – 다운로드 pdf
- big.LITTLE technology – 다운로드 ppt
- Per-entity load tracking | LWN.net
- Load tracking in the scheduler | LWN.net
- Scheduler Load tracking update and improvement | Vincent Guittot, Linaro connect 2017 – 다운로드 pdf