스케줄러 초기화
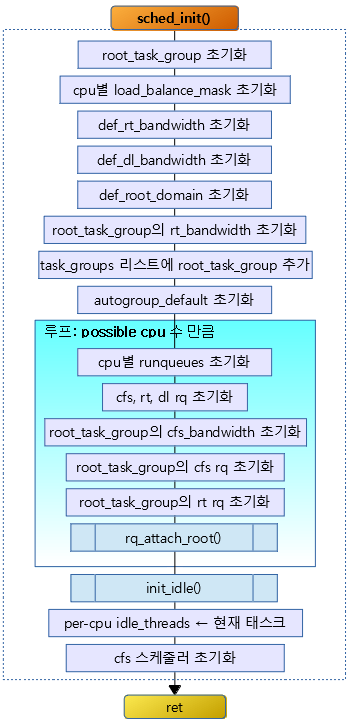
다음 그림은 sched_init() 함수의 간략한 처리 흐름도이다.
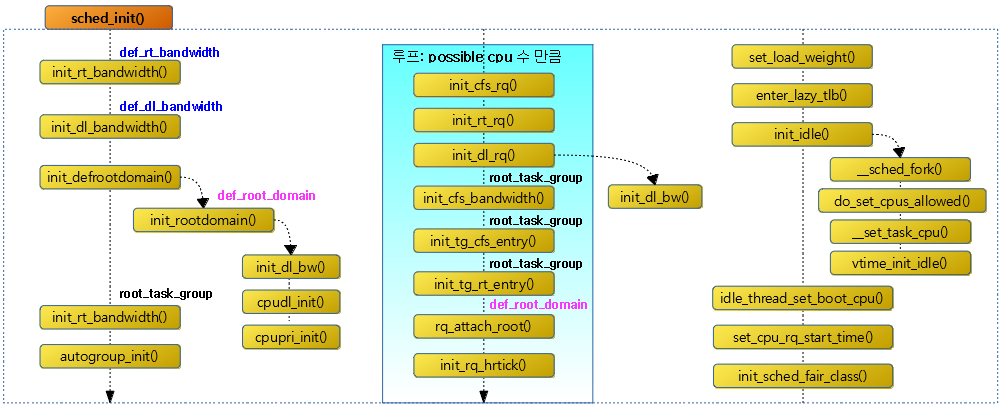
다음 그림은 sched_init() 함수 내부에서 다른 함수들과의 호출 관계 흐름을 보여준다.
sched_init()
함수의 소스 라인이 길어서 5개로 나누었다.
kernel/sched/core.c – (1/5)
void __init sched_init(void)
{
int i, j;
unsigned long alloc_size = 0, ptr;
#ifdef CONFIG_FAIR_GROUP_SCHED
alloc_size += 2 * nr_cpu_ids * sizeof(void **);
#endif
#ifdef CONFIG_RT_GROUP_SCHED
alloc_size += 2 * nr_cpu_ids * sizeof(void **);
#endif
if (alloc_size) {
ptr = (unsigned long)kzalloc(alloc_size, GFP_NOWAIT);
#ifdef CONFIG_FAIR_GROUP_SCHED
root_task_group.se = (struct sched_entity **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
root_task_group.cfs_rq = (struct cfs_rq **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
#endif /* CONFIG_FAIR_GROUP_SCHED */
#ifdef CONFIG_RT_GROUP_SCHED
root_task_group.rt_se = (struct sched_rt_entity **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
root_task_group.rt_rq = (struct rt_rq **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
#endif /* CONFIG_RT_GROUP_SCHED */
}
#ifdef CONFIG_CPUMASK_OFFSTACK
for_each_possible_cpu(i) {
per_cpu(load_balance_mask, i) = (cpumask_var_t)kzalloc_node(
cpumask_size(), GFP_KERNEL, cpu_to_node(i));
}
#endif /* CONFIG_CPUMASK_OFFSTACK */
init_rt_bandwidth(&def_rt_bandwidth,
global_rt_period(), global_rt_runtime());
init_dl_bandwidth(&def_dl_bandwidth,
global_rt_period(), global_rt_runtime());
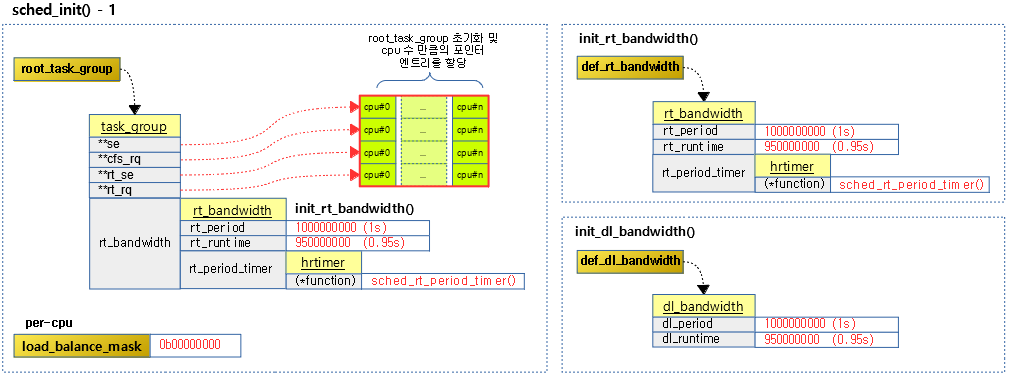
cfs 그룹 스케줄링을 위해 cpu 수 만큼 루트 태스크 그룹용 스케줄 엔티티들과 cfs 런큐의 포인터 배열을 할당받아 준비한다. rt 그룹 스케줄링도 동일하게 준비한다. 그리고 디폴트 rt 및 디폴트 dl 밴드폭을 초기화한다.
- 코드 라인 6~13에서 cfs 그룹 스케줄링을 위해 cpu 수 만큼의 sched_entity 포인터 배열과 cfs_rq 포인터 배열을 할당받는다. 또한 rt 그룹 스케줄링을 위해 같은 방법으로 준비한다.
- CONFIG_FAIR_GROUP_SCHED
- cgroup의 cfs 그룹 스케줄링을 지원하는 커널 옵션
- CONFIG_RT_GROUP_SCHED
- cgroup의 rt 그룹 스케줄링을 지원하는 커널 옵션
- CONFIG_FAIR_GROUP_SCHED
- 코드 라인 15~22에서 cfs 그룹 스케줄링을 위해 root_task_group.se와 root_task_group.cfs_rq에 위에서 할당받은 cpu 수 만큼의 포인터 배열을 각각 지정한다.
- 코드 라인 23~30에서 rt 그룹 스케줄링을 위해 root_task_group.rt_se와 root_task_group.rt_rq에 위에서 할당받은 cpu 수 만큼의 포인터 배열을 각각 지정한다.
- 코드 라인 32~37에서 cpumask offstack을 위해 load_balance_mask에 cpu 수 만큼의 cpu 비트맵을 할당받아 대입한다.
- CONFIG_CPUMASK_OFFSTACK
- cpu 수가 많은 경우 시스템에서 스택오버 플로우를 방지하기 위해 스택 대신 dynamic 메모리를 할당받아 cpu 비트맵으로 사용한다.
- DEFINE_PER_CPU(cpumask_var_t, load_balance_mask);
- CONFIG_CPUMASK_OFFSTACK
- 코드 라인 39~42에서 디폴트 rt 밴드폭 및 디폴트 dl 밴드폭을 초기화한다.
- rt 밴드폭과 dl 밴드폭은 95%로 rt 스케줄러와 dl 스케줄러가 점유할 수 있는 비율은 최대 95%까지 가능하다.
다음 그림은 루트 태스크 그룹 및 디폴트 rt 밴드폭 및 디폴트 dl 밴드폭을 초기화하는 과정을 보여준다.
kernel/sched/core.c – (2/5)
#ifdef CONFIG_SMP
init_defrootdomain();
#endif
#ifdef CONFIG_RT_GROUP_SCHED
init_rt_bandwidth(&root_task_group.rt_bandwidth,
global_rt_period(), global_rt_runtime());
#endif /* CONFIG_RT_GROUP_SCHED */
#ifdef CONFIG_CGROUP_SCHED
list_add(&root_task_group.list, &task_groups);
INIT_LIST_HEAD(&root_task_group.children);
INIT_LIST_HEAD(&root_task_group.siblings);
autogroup_init(&init_task);
#endif /* CONFIG_CGROUP_SCHED */
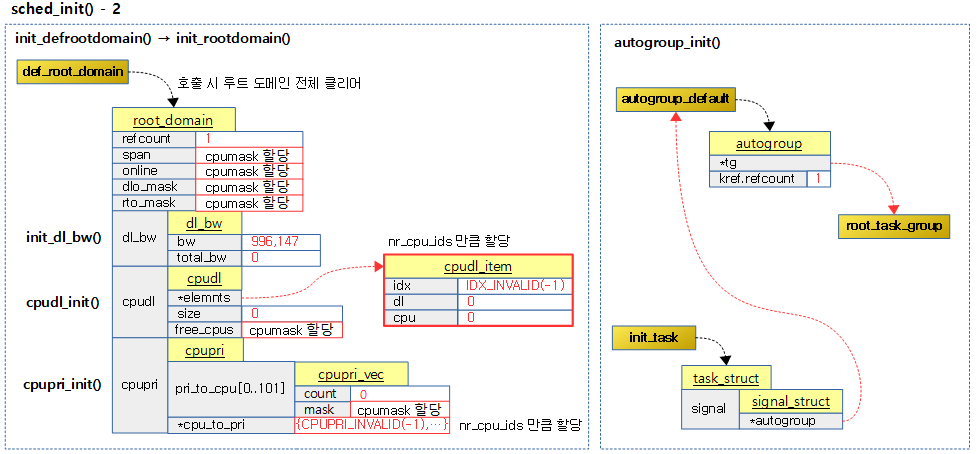
루트 도메인을 초기화한다. rt 그룹 스케줄링을 위해 루트 태스크 그룹의 rt 밴드폭도 초기화한다. 루트 태스크 그룹 및 오토그룹도 초기화한다.
- 코드 라인 1~3에서 smp 시스템인 경우 루트 도메인을 초기화한다.
- 코드 라인 5~8에서 rt 그룹 스케줄링을 위해 루트 태스크 그룹의 rt 밴드폭을 초기화한다.
- 코드 라인 10~15에서 cgroup 스케줄링을 위해 루트 태스크 그룹의 리스트에 전역 태스크 그룹을 추가하고 children, sibling 등의 리스트를 초기화한다. 마지막으로 autogroup을 초기화한다.
다음 그림은 디폴트 루트 도메인과 오토 그룹을 초기화하는 과정을 보여줍니다.
kernel/sched/core.c – (3/5)
. for_each_possible_cpu(i) {
struct rq *rq;
rq = cpu_rq(i);
raw_spin_lock_init(&rq->lock);
rq->nr_running = 0;
rq->calc_load_active = 0;
rq->calc_load_update = jiffies + LOAD_FREQ;
init_cfs_rq(&rq->cfs);
init_rt_rq(&rq->rt, rq);
init_dl_rq(&rq->dl, rq);
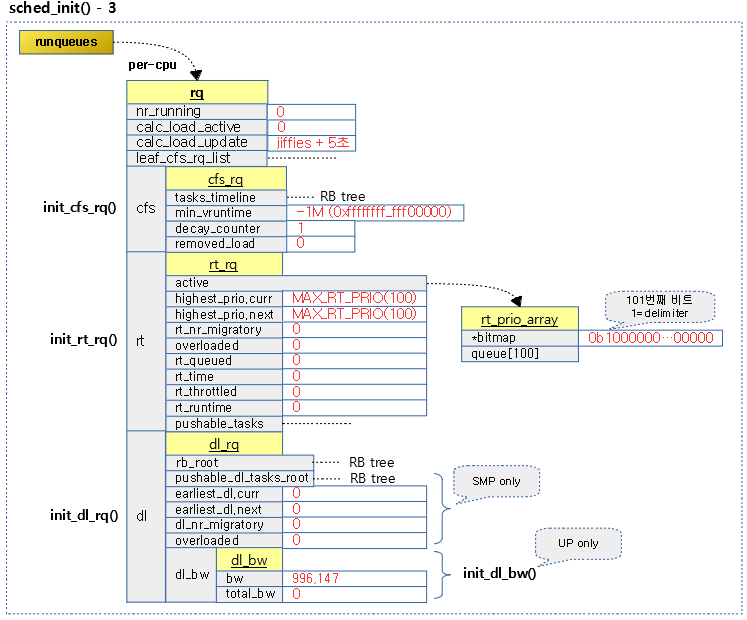
cpu 수 만큼 루프를 돌며 cfs 런큐, rt 런큐, dl 런큐들을 초기화한다.
- 코드 라인 1~5에서 cpu 수만큼 루프를 돌며 해당 cpu용 런큐를 선택하고 락을 획득한다.
- 코드 라인 6에서 nr_running에 0을 대입하여 현재 런큐에서 active하게 돌고 있는 태스크의 수를 0으로 초기화한다.
- 코드 라인 7에서 calc_load_active에 0을 대입하여 active 로드 값을 0으로 초기화한다.
- 코드 라인 8에서 다음 로드 갱신 주기를 현재 시각 + LOAD_FREQ(5초) 후로 설정한다.
- 코드 라인 9~11에서 cfs, rt 및 dl 런큐를 초기화한다.
다음 그림은 cpu 수 만큼 루프를 돌며 각각의 런큐를 초기화하고 내부의 cfs, rt 및 dl 런큐를 초기화하는 과정을 보여준다.
kernel/sched/core.c – (4/5)
#ifdef CONFIG_FAIR_GROUP_SCHED
root_task_group.shares = ROOT_TASK_GROUP_LOAD;
INIT_LIST_HEAD(&rq->leaf_cfs_rq_list);
/*
* How much cpu bandwidth does root_task_group get?
*
* In case of task-groups formed thr' the cgroup filesystem, it
* gets 100% of the cpu resources in the system. This overall
* system cpu resource is divided among the tasks of
* root_task_group and its child task-groups in a fair manner,
* based on each entity's (task or task-group's) weight
* (se->load.weight).
*
* In other words, if root_task_group has 10 tasks of weight
* 1024) and two child groups A0 and A1 (of weight 1024 each),
* then A0's share of the cpu resource is:
*
* A0's bandwidth = 1024 / (10*1024 + 1024 + 1024) = 8.33%
*
* We achieve this by letting root_task_group's tasks sit
* directly in rq->cfs (i.e root_task_group->se[] = NULL).
*/
init_cfs_bandwidth(&root_task_group.cfs_bandwidth);
init_tg_cfs_entry(&root_task_group, &rq->cfs, NULL, i, NULL);
#endif /* CONFIG_FAIR_GROUP_SCHED */
rq->rt.rt_runtime = def_rt_bandwidth.rt_runtime;
#ifdef CONFIG_RT_GROUP_SCHED
init_tg_rt_entry(&root_task_group, &rq->rt, NULL, i, NULL);
#endif
for (j = 0; j < CPU_LOAD_IDX_MAX; j++)
rq->cpu_load[j] = 0;
rq->last_load_update_tick = jiffies;
#ifdef CONFIG_SMP
rq->sd = NULL;
rq->rd = NULL;
rq->cpu_capacity = SCHED_CAPACITY_SCALE;
rq->post_schedule = 0;
rq->active_balance = 0;
rq->next_balance = jiffies;
rq->push_cpu = 0;
rq->cpu = i;
rq->online = 0;
rq->idle_stamp = 0;
rq->avg_idle = 2*sysctl_sched_migration_cost;
rq->max_idle_balance_cost = sysctl_sched_migration_cost;
INIT_LIST_HEAD(&rq->cfs_tasks);
rq_attach_root(rq, &def_root_domain);
#ifdef CONFIG_NO_HZ_COMMON
rq->nohz_flags = 0;
#endif
#ifdef CONFIG_NO_HZ_FULL
rq->last_sched_tick = 0;
#endif
#endif
init_rq_hrtick(rq);
atomic_set(&rq->nr_iowait, 0);
}
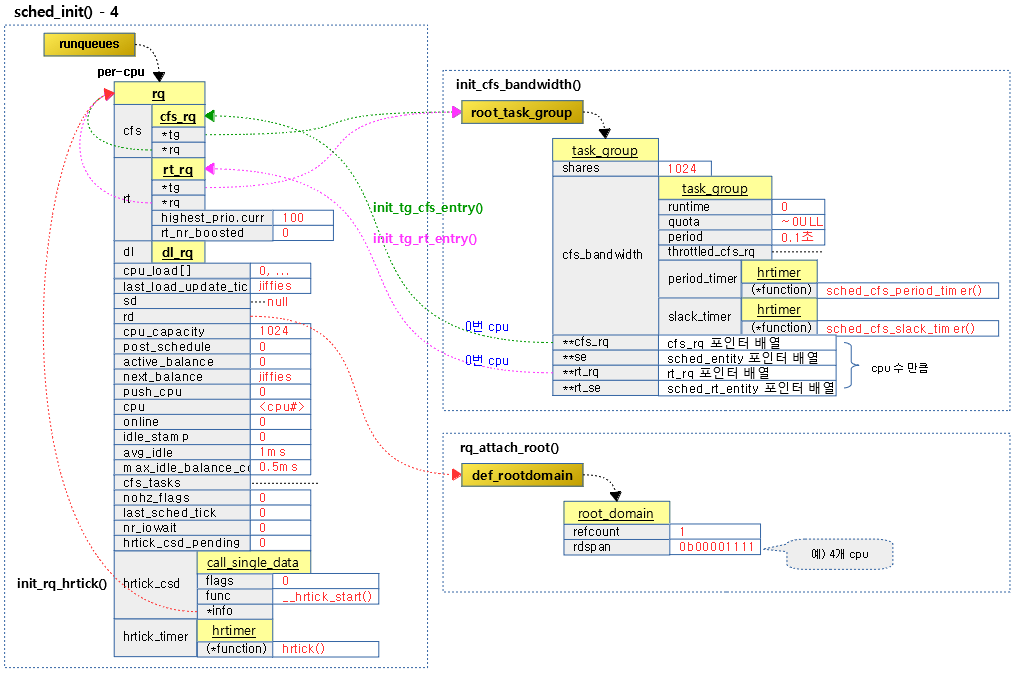
계속해서 cpu 수 만큼 루프를 돌며 런큐 및 다음 항목들을 초기화한다.
- cfs 밴드폭
- 루트 태스크 그룹의 cfs 엔트리 및 rt 엔트리
- 각종 cpu 로드, 상태 및 통계 정보
- 런큐의 루트 도메인에 디폴트 루트 도메인 설정
- hrtick이 준비된 경우 초기화
- 코드 라인 1~3에서 cfs 그룹 스케줄링을 위해 루트 태스크 그룹의 shares 값을 nice 0 로드값(32비트 시스템에서 1024)으로 초기 지정한다. leaf_cfs_rq_list를 초기화한다.
- #define ROOT_TASK_GROUP_LOAD NICE_0_LOAD
- #define NICE_0_LOAD SCHED_LOAD_SCALE
- #define SCHED_LOAD_SCALE (1L << SCHED_LOAD_SHIFT)
- #define SCHED_LOAD_SHIFT (10 + SCHED_LOAD_RESOLUTION)
- SCHED_LOAD_RESOLUTION 값은 32비트 시스템은 0이고 64비트 시스템은 10이다.
- 코드 라인 23에서 루트 태스크 그룹의 cfs 밴드폭을 초기화한다.
- 코드 라인 24에서 cfs 런큐의 태스크 그룹에 디폴트 태스크 그룹을 지정하고 다음 항목들을 초기화한다.
- 태스크 그룹의 cfs 런큐 및 스케줄 엔티티 설정
- cfs 그룹 스케줄링을 사용하지 않는 경우 런큐의 runtime_enable에 0을 대입하여 디폴트로 스로틀링하지 않게 한다.
- 코드 라인 27에서 런큐의 rt_runtime에 디폴트 rt 밴드폭의 런타임을 대입한다.
- 코드 라인 28~30에서 rt 그룹 스케줄링을 위해 rt 런큐의 태스크 그룹에 디폴트 태스크 그룹을 지정하고 다음 항목을 초기화한다.
- 태스크 그룹의 rt 런큐 및 스케줄 엔티티 설정
- 코드 라인 32~33에서 CPU_LOAD_IDX_MAX(5)개로 이루어진 cpu_load[] 배열을 0으로 초기화한다.
- 이 배열은 향후 각 tick의 배수 단위로 산출된 cpu 로드 평균 값을 갖는다.
- cpu_load[0] = 1 tick 현재 cpu 로드
- cpu_load[1] = 2 ticks 기간 cpu 로드
- cpu_load[2] = 4 ticks 기간 cpu 로드
- cpu_load[3] = 8 ticks 기간 cpu 로드
- cpu_load[4] = 16 ticks 기간 cpu 로드
- 코드 라인 35에서 위 cpu_load[]가 산출된 최종 시각(jiffies) 값을 대입한다.
- 코드 라인 37~39에서 smp 시스템인 경우 런큐의 스케줄 도메인 및 루트 도메인으로null을 대입한다.
- 코드 라인 40에서 런큐의 cpu_capacity 값으로 SCHED_CAPACITY_SCALE(1024) 값을 대입한다.
- #define SCHED_CAPACITY_SCALE (1L << SCHED_CAPACITY_SHIFT)
- #define SCHED_CAPACITY_SHIFT 10
- 코드 라인 42~44까지 로드밸런싱에 사용하는 멤버들을 0으로 초기화하고 다음 밸런스 시각을 현재 시각(jiffies)로 설정한다.
- 코드 라인 45~46에서 현재 런큐의 cpu를 지정하고 online 되지 않음으로 설정한다.
- 코드 라인 47~49에서 idle_stamp를 0으로 설정하고 max_idle_balance_cost는 스케줄 마이그레이션 코스트 값과 동일하게 하고 avg_idle은 그 두 배로 설정한다.
- 디폴트 sysctl_sched_migration_cost = 500000UL;
- 코드 라인 51에서 런큐의 cfs_tasks 리스트를 초기화한다.
- 코드 라인 53에서 런큐의 루트 도메인으로 디폴트 루트 도메인을 연결한다.
- 코드 라인 54~56에서 nohz를 지원하는 시스템인 경우 nohz_flags를 0으로 초기화한다.
- 코드 라인 57~59에서 nohz full을 지원하는 시스템인 경우 마지막 스케줄 틱 값에 0을 대입한다.
- 코드 라인 61에서 hrtick이 지원되는 시스템인 경우 런큐의 hrtick을 준비한다.
- 코드 라인 62에서 런큐의 iowait 카운터를 0으로 초기화한다.
다음 그림은 계속하여 cpu 수 만큼 루프를 돌며 각각의 런큐를 초기화하고 cfs 밴드폭, 태스크 그룹 cfs 엔트리, 태스크 그룹 rt 엔트리 및 디폴트 루트 도메인을 초기화하는 모습을 보여보여준다.
kernel/sched/core.c – (5/5)
set_load_weight(&init_task);
#ifdef CONFIG_PREEMPT_NOTIFIERS
INIT_HLIST_HEAD(&init_task.preempt_notifiers);
#endif
/*
* The boot idle thread does lazy MMU switching as well:
*/
atomic_inc(&init_mm.mm_count);
enter_lazy_tlb(&init_mm, current);
/*
* During early bootup we pretend to be a normal task:
*/
current->sched_class = &fair_sched_class;
/*
* Make us the idle thread. Technically, schedule() should not be
* called from this thread, however somewhere below it might be,
* but because we are the idle thread, we just pick up running again
* when this runqueue becomes "idle".
*/
init_idle(current, smp_processor_id());
calc_load_update = jiffies + LOAD_FREQ;
#ifdef CONFIG_SMP
zalloc_cpumask_var(&sched_domains_tmpmask, GFP_NOWAIT);
/* May be allocated at isolcpus cmdline parse time */
if (cpu_isolated_map == NULL)
zalloc_cpumask_var(&cpu_isolated_map, GFP_NOWAIT);
idle_thread_set_boot_cpu();
set_cpu_rq_start_time();
#endif
init_sched_fair_class();
scheduler_running = 1;
}
현재 부트업 태스크를 초기화하고 마지막으로 cfs 스케줄러를 준비하는 것으로 스케줄러가 준비되었다.
- 코드 라인 1에서 현재 부트업 태스크인 init_task의 로드 weight을 초기화한다.
- static_prio 값을 nice 레벨의 prio로 변환하고 이의 weight 값을 대입한다.
- 태스크의 스케줄 정책이 SCHED_IDLE인 경우에는 weight 값을 가장 느린 WEIGHT_IDLEPRIO(3)으로 설정한다.
- 코드 라인 3~5에서 init_task의 preempt_notifiers 리스트를 초기화한다.
- 코드 라인 10~11에서 부트업 idle 스레드는 init_mm의 mm_count를 1증가 시키고 lazy MMU 스위칭을 하게 한다.
- arm & arm64 커널은 현재 lazy tlb를 지원하지 않는다.
- 코드 라인 16에서 처음 부트업 중인 현재 태스크의 스케줄러를 cfs 스케줄러로 설정한다.
- 코드 라인 24에서 현재 cpu에서 부트업 태스크를 idle 스레드로 설정하고 또한 idle 스케줄러를 지정한다.
- 코드 라인 26에서 전역 calc_load_update에 jiffies + LOAD_FREQ(5초)를 대입한다.
- 코드 라인 28~29에서 smp 시스템인 경우 임시 스케줄 도메인의 cpu 비트맵을 zero 값으로 할당받는다.
- 코드 라인 31~32에서 cpu_isolated_map이 지정되지 않은 경우 cpu_isolated_map이라는 cpu 비트맵을 zero 값으로 할당받는다.
- 코드 라인 33에서 현재 태스크를 현재 cpu에 해당하는 전역 per-cpu idle_threads 값에 대입한다.
- per_cpu(idle_threads, smp_processor_id()) = current;
- 코드 라인 34에서 현재 런큐의 age_stamp에 현재 스케줄 클럭을 대입한다.
- 코드 라인 36~38에서 cfs 스케줄러를 초기화한 후 스케줄러가 동작중임을 알린다.
디폴트 루트 도메인
디폴트 루트 도메인 초기화
init_defrootdomain()
kernel/sched/core.c
static void init_defrootdomain(void)
{
init_rootdomain(&def_root_domain);
atomic_set(&def_root_domain.refcount, 1);
}
디폴트 루트 도메인을 초기화하고 참조 카운터를 1로 설정한다.
init_rootdomain()
kernel/sched/core.c
static int init_rootdomain(struct root_domain *rd)
{
memset(rd, 0, sizeof(*rd));
if (!alloc_cpumask_var(&rd->span, GFP_KERNEL))
goto out;
if (!alloc_cpumask_var(&rd->online, GFP_KERNEL))
goto free_span;
if (!alloc_cpumask_var(&rd->dlo_mask, GFP_KERNEL))
goto free_online;
if (!alloc_cpumask_var(&rd->rto_mask, GFP_KERNEL))
goto free_dlo_mask;
init_dl_bw(&rd->dl_bw);
if (cpudl_init(&rd->cpudl) != 0)
goto free_dlo_mask;
if (cpupri_init(&rd->cpupri) != 0)
goto free_rto_mask;
return 0;
free_rto_mask:
free_cpumask_var(rd->rto_mask);
free_dlo_mask:
free_cpumask_var(rd->dlo_mask);
free_online:
free_cpumask_var(rd->online);
free_span:
free_cpumask_var(rd->span);
out:
return -ENOMEM;
}
요청한 루트 도메인을 초기화한다.
- 코드 라인 3에서 루트 도메인 구조체를 모두 0으로 초기화한다.
- 코드 라인 5~12에서 루트 도메인의 cpumask 용도의 멤버 span, online, dlo_mask, rto_mask를 할당받는다.
- 코드 라인 14에서 루트 도메인의 dl_bw를 초기화한다.
- UP 시스템에서는 dl 스케줄러의 cpu 밴드폭 비율로 최대 95%를 할당하게 한다.
- 하나의 core만을 가진 시스템에서 dl 태스크가 최대 점유할 수 있는 cpu 비율을 제한하여 rt나 cfs 스케줄러가 조금이라도 동작할 수 있게 한다.
- SMP 시스템에서는 dl 스케줄러의 cpu 밴드폭 비율을 100%(무한대 설정) 사용할 수 있게 한다.
- 코드 라인 15~16에서 dl 스케줄러에서 로드밸런스 관리를 위해 루트 도메인의 cpudl을 초기화한다.
- 코드 라인 18~19에서 rt 스케줄러에서 로드밸런스 관리를 위해 루트 도메인의 cpupri를 초기화한다.
init_dl_bw()
kernel/sched/deadline.c
void init_dl_bw(struct dl_bw *dl_b)
{
raw_spin_lock_init(&dl_b->lock);
raw_spin_lock(&def_dl_bandwidth.dl_runtime_lock);
if (global_rt_runtime() == RUNTIME_INF)
dl_b->bw = -1;
else
dl_b->bw = to_ratio(global_rt_period(), global_rt_runtime());
raw_spin_unlock(&def_dl_bandwidth.dl_runtime_lock);
dl_b->total_bw = 0;
}
cpu가 1개 밖에 없는 up 시스템에서는 dl 스케줄러 요청 사항에 대해 100% cpu 밴드폭을 할당하지 않고 제한을 시키기 위해 디폴트 dl 밴드폭 사용 비율을 설정한다. (정수 1M=100%이며, 디폴트 비율은 95%가 설정된다.)
- 코드 라인 5~6에서 글로벌 rt runtime 값이 무한대 값 RUNTIME_INF(0xffffffff_ffffffff)인 경우 bw에 -1을 대입한다.
- 코드 라인 7~8에서 그 외의 경우 글로벌 rt runtime << 20 / 글로벌 rt period 값을 대입한다.
- 예) 글로벌 값으로 period=1,000,000,000이고 runtime=950,000,000일 때 결과 값은 996,147이고 이 값은 996,147 / 1M인 95%에 해당한다.
- 코드 라인 10에서 total 밴드폭을 0으로 초기화한다.
global_rt_runtime()
kernel/sched/sched.h
static inline u64 global_rt_runtime(void)
{
if (sysctl_sched_rt_runtime < 0)
return RUNTIME_INF;
return (u64)sysctl_sched_rt_runtime * NSEC_PER_USEC;
}
글로벌 rt 런타임 값을 나노초 단위로 반환한다.
- 코드 라인 3~4에서 sysctl_sched_rt_runtime 값이 0보다 작게 설정된 경우 무한대 값 RUNTIME_INF(0xffffffff_ffffffff)을 반환한다.
- sysctl_sched_rt_runtime의 디폴트 값은 950,000 (us)이다.
- 코드 라인 6에서 us초 단위의 sysctl_sched_rt_runtime을 나노초 단위로 바꾸어 반환한다.
global_rt_period()
kernel/sched/sched.h
static inline u64 global_rt_period(void)
{
return (u64)sysctl_sched_rt_period * NSEC_PER_USEC;
}
글로벌 rt 런타임 값을 나노초 단위로 반환한다.
- us초 단위의 sysctl_sched_rt_runtime을 나노초 단위로 바꾸어 반환한다.
- sysctl_sched_rt_period의 디폴트 값은 1,000,000 (us)이다.
to_ratio()
kernel/sched/core.c
unsigned long to_ratio(u64 period, u64 runtime)
{
if (runtime == RUNTIME_INF)
return 1ULL << 20;
/*
* Doing this here saves a lot of checks in all
* the calling paths, and returning zero seems
* safe for them anyway.
*/
if (period == 0)
return 0;
return div64_u64(runtime << 20, period);
}
runtime 비율을 1M 곱한 정수로 반환한다. (runtime / period 비율 결과를 1M를 곱한 정수로 바꿔서 반환한다.)
- 코드 라인 3~4에서 runtime이 무한대 값 RUNTIME_INF(0xffffffff_ffffffff)인 경우 1M를 반환한다. (100%)
- 코드 라인 11~12에서 period 값이 0인 경우 0을 반환한다. (0%)
- 코드 라인 14에서 runtime << 1M / period 값을 반환한다.
- 예) 글로벌 값으로 period=1,000,000,000이고 runtime=950,000,000일 때 결과 값은 996,147이고 이 값은 996,147 / 1M인 95%에 해당한다.
cpudl_init()
kernel/sched/cpudeadline.c
/*
* cpudl_init - initialize the cpudl structure
* @cp: the cpudl max-heap context
*/
int cpudl_init(struct cpudl *cp)
{
int i;
memset(cp, 0, sizeof(*cp));
raw_spin_lock_init(&cp->lock);
cp->size = 0;
cp->elements = kcalloc(nr_cpu_ids,
sizeof(struct cpudl_item),
GFP_KERNEL);
if (!cp->elements)
return -ENOMEM;
if (!zalloc_cpumask_var(&cp->free_cpus, GFP_KERNEL)) {
kfree(cp->elements);
return -ENOMEM;
}
for_each_possible_cpu(i)
cp->elements[i].idx = IDX_INVALID;
return 0;
}
dl 스케줄러에서 로드밸런스 관리를 위해 cpudl 구조체를 초기화한다.
- 코드 라인 9에서 cpudl 구조체 내부를 모두 0으로 클리어한다.
- 코드 라인 11에서 멤버 size에 0을 대입한다.
- 코드 라인 13~17에서 cpu 수 만큼 cpudl_item 구조체를 할당받아 멤버 elemenents에 대입한다.
- 코드 라인 19~22에서 멤버 free_cpus에 cpu 비트맵을 할당한다.
- 코드 라인 24~25에서 cpu 수 만큼 멤버 elements[].idx 값에 IDX_INVALID(-1) 값으로 초기화한다.
cpupri_init()
kernel/sched/cpupri.c
/**
* cpupri_init - initialize the cpupri structure
* @cp: The cpupri context
*
* Return: -ENOMEM on memory allocation failure.
*/
int cpupri_init(struct cpupri *cp)
{
int i;
memset(cp, 0, sizeof(*cp));
for (i = 0; i < CPUPRI_NR_PRIORITIES; i++) {
struct cpupri_vec *vec = &cp->pri_to_cpu[i];
atomic_set(&vec->count, 0);
if (!zalloc_cpumask_var(&vec->mask, GFP_KERNEL))
goto cleanup;
}
cp->cpu_to_pri = kcalloc(nr_cpu_ids, sizeof(int), GFP_KERNEL);
if (!cp->cpu_to_pri)
goto cleanup;
for_each_possible_cpu(i)
cp->cpu_to_pri[i] = CPUPRI_INVALID;
return 0;
cleanup:
for (i--; i >= 0; i--)
free_cpumask_var(cp->pri_to_cpu[i].mask);
return -ENOMEM;
}
rt 스케줄러에서 로드밸런스 관리를 위해 cpupri 구조체를 초기화한다.
- 코드 라인 11에서 cpupri 구조체 내부를 모두 0으로 클리어한다.
- 코드 라인 13~19에서 CPUPRI_NR_PRIORITIES(102) 개 만큼 루프를 돌며 pri_to_cpu[]->count에 0을 대입하고 pri_to_cpu[]->mask에 cpumask를 할당받아 대입한다.
- 코드 라인 21~26에서 멤버 cpu_to_pri에 cpu 수 만큼 int 배열을 할당받아 지정하고 각각의 값으로 CPUPRI_INVALID(-1)를 대입한다.
디폴트 루트 도메인에 런큐 attach
rq_attach_root()
kernel/sched/core.c
static void rq_attach_root(struct rq *rq, struct root_domain *rd)
{
struct root_domain *old_rd = NULL;
unsigned long flags;
raw_spin_lock_irqsave(&rq->lock, flags);
if (rq->rd) {
old_rd = rq->rd;
if (cpumask_test_cpu(rq->cpu, old_rd->online))
set_rq_offline(rq);
cpumask_clear_cpu(rq->cpu, old_rd->span);
/*
* If we dont want to free the old_rd yet then
* set old_rd to NULL to skip the freeing later
* in this function:
*/
if (!atomic_dec_and_test(&old_rd->refcount))
old_rd = NULL;
}
atomic_inc(&rd->refcount);
rq->rd = rd;
cpumask_set_cpu(rq->cpu, rd->span);
if (cpumask_test_cpu(rq->cpu, cpu_active_mask))
set_rq_online(rq);
raw_spin_unlock_irqrestore(&rq->lock, flags);
if (old_rd)
call_rcu_sched(&old_rd->rcu, free_rootdomain);
}
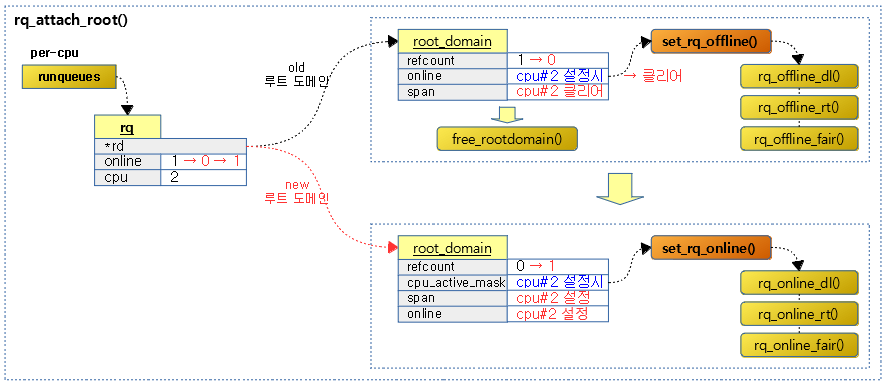
런큐에 루트 도메인을 연결한다.
- 코드 라인 8~9에서 루트 도메인이 지정된 경우 현재 런큐의 루트 도메인을 old_rd에 대입한다.
- 코드 라인 11~14에서 기존 루트 도메인에 런큐의 cpu가 online 상태였었던 경우 런큐를 offline으로 바꾸도록 각 스케줄러의 런큐를 offline으로 바꾸도록 해당 후크 함수들을 호출한다. 그리고 online 및 span의 해당 cpu 비트를 클리어한다.
- 코드 라인 21~22에서 기존 루트 도메인의 참조 카운터를 감소시키고 그 값이 0이 되면 old_rd에 null을 대입한다.
- 코드 라인 25~26에서 요청한 런큐의 루트 도메인 참조 카운터를 1 증가시키고 런큐의 루트 도메인을 지정한다.
- 코드 라인 28~30에서 루트도메인의 span cpu 마스크에서 요청 런큐의 cpu에 해당하는 비트를 설정한다. 만일 cpu_active_mask에 런큐의 cpu에 해당하는 비트가 설정된 경우 런큐를 online 상태로 바꾸도록 각 스케줄러의 런큐를 online으로 바꾸도록 해당 후크 함수들을 호출한다. 그리고 online의 해당 cpu 비트를 설정한다.
- 코드 라인 34~35에서 기존 루트 도메인을 rcu 방식을 사용하여 할당 해제하게한다.
다음 그림은 런큐의 루트도메인이 교체되는 모습을 보여준다.
루트 도메인 할당 해제
free_rootdomain()
kernel/sched/core.c
static void free_rootdomain(struct rcu_head *rcu)
{
struct root_domain *rd = container_of(rcu, struct root_domain, rcu);
cpupri_cleanup(&rd->cpupri);
cpudl_cleanup(&rd->cpudl);
free_cpumask_var(rd->dlo_mask);
free_cpumask_var(rd->rto_mask);
free_cpumask_var(rd->online);
free_cpumask_var(rd->span);
kfree(rd);
}
rcu에 연결된 루트 도메인을 할당 해제한다.
cpupri_cleanup()
kernel/sched/cpupri.c
/**
* cpupri_cleanup - clean up the cpupri structure
* @cp: The cpupri context
*/
void cpupri_cleanup(struct cpupri *cp)
{
int i;
kfree(cp->cpu_to_pri);
for (i = 0; i < CPUPRI_NR_PRIORITIES; i++)
free_cpumask_var(cp->pri_to_cpu[i].mask);
}
cpupri 멤버 cpu_to_pri에 할당된 메모리를 할당해제하고 102번 루프를 돌며 pri_to_cpu[].mask에 할당된 cpu 마스크를 를 할당 해제한다.
cpudl_cleanup()
kernel/sched/cpudeadline.c
/*
* cpudl_cleanup - clean up the cpudl structure
* @cp: the cpudl max-heap context
*/
void cpudl_cleanup(struct cpudl *cp)
{
free_cpumask_var(cp->free_cpus);
kfree(cp->elements);
}
cpudl 멤버 free_cpus에 할당된 cpu 마스크를 할당해제하고 elements에 할당된 메모리도 할당 해제한다.
오토 그룹 초기화
autogroup_init()
kernel/sched/auto_group.c
void __init autogroup_init(struct task_struct *init_task)
{
autogroup_default.tg = &root_task_group;
kref_init(&autogroup_default.kref);
init_rwsem(&autogroup_default.lock);
init_task->signal->autogroup = &autogroup_default;
}
자동 그룹 스케줄링을 지원하는 커널에서 디폴트 오토 그룹으로 루트 태스크 그룹을 지정한다.
- 코드 라인 3에서 디폴트 오토그룹의 태스크 그룹으로 루트 태스크 그룹을 지정한다.
- 코드 라인 6에서 init_task의 오토그룹으로 디폴트 오토 그룹을 지정한다.
cfs, rt, dl 런큐 초기화
init_cfs_rq()
kernel/sched/fair.c
void init_cfs_rq(struct cfs_rq *cfs_rq)
{
cfs_rq->tasks_timeline = RB_ROOT;
cfs_rq->min_vruntime = (u64)(-(1LL << 20));
#ifndef CONFIG_64BIT
cfs_rq->min_vruntime_copy = cfs_rq->min_vruntime;
#endif
#ifdef CONFIG_SMP
atomic64_set(&cfs_rq->decay_counter, 1);
atomic_long_set(&cfs_rq->removed_load, 0);
#endif
}
cfs 런큐의 구조체를 초기화한다.
- 코드 라인 3에서 tasks_timeline은 스케줄링 엔티티의 vruntime 값으로 정렬될 RB 트리로 이 값을 RB_ROOT로 지정한다.
- 코드 라인 4에서 min_vruntime 값으로 0xffff_ffff_fff0_0000 (-1M)를 지정한다.
- 코드 라인 8~11에서 smp 시스템인 경우 decay_counter에 1을 대입하고 removed_load에 0을 대입한다.
init_rt_rq()
kernel/sched/rt.c
void init_rt_rq(struct rt_rq *rt_rq, struct rq *rq)
{
struct rt_prio_array *array;
int i;
array = &rt_rq->active;
for (i = 0; i < MAX_RT_PRIO; i++) {
INIT_LIST_HEAD(array->queue + i);
__clear_bit(i, array->bitmap);
}
/* delimiter for bitsearch: */
__set_bit(MAX_RT_PRIO, array->bitmap);
#if defined CONFIG_SMP
rt_rq->highest_prio.curr = MAX_RT_PRIO;
rt_rq->highest_prio.next = MAX_RT_PRIO;
rt_rq->rt_nr_migratory = 0;
rt_rq->overloaded = 0;
plist_head_init(&rt_rq->pushable_tasks);
#endif
/* We start is dequeued state, because no RT tasks are queued */
rt_rq->rt_queued = 0;
rt_rq->rt_time = 0;
rt_rq->rt_throttled = 0;
rt_rq->rt_runtime = 0;
raw_spin_lock_init(&rt_rq->rt_runtime_lock);
}
rt 런큐의 구조체를 초기화한다.
- 코드 라인 6~10에서 rt 런큐의 우선 순위 큐를 초기화한다. 100개의 우선 순위 수 만큼 active->quque[] 리스트를 초기화하고 bitmap을 클리어한다.
- 코드 라인 12에서 마지막 101번째 비트맵 비트에 구분자 역할로 사용하기 위해 1을 설정한다.
- 코드 라인 15~16에서 highest_prio.curr 및 next에 MAX_RT_PRIO(100) 우선 순위 값을 대입한다.
- 코드 라인 17~18에서 rt_nr_migratory, overloaded 값에 0을 대입한다.
- 코드 라인 19에서 pushable_tasks 리스트를 초기화한다.
- 코드 라인 22에서 rt_queued에 0을 대입하여 현재 큐잉된 태스크가 없음을 나타낸다.
- 코드 라인 24~26에서 rt_time, rt_throttled, rt_runtime 값을 0으로 초기화하다.
init_dl_rq()
kernel/sched/deadline.c
void init_dl_rq(struct dl_rq *dl_rq, struct rq *rq)
{
dl_rq->rb_root = RB_ROOT;
#ifdef CONFIG_SMP
/* zero means no -deadline tasks */
dl_rq->earliest_dl.curr = dl_rq->earliest_dl.next = 0;
dl_rq->dl_nr_migratory = 0;
dl_rq->overloaded = 0;
dl_rq->pushable_dl_tasks_root = RB_ROOT;
#else
init_dl_bw(&dl_rq->dl_bw);
#endif
}
dl 런큐의 구조체를 초기화한다.
- 코드 라인 3에서 rb_root는 스케줄링 엔티티의 vruntime 값으로 정렬될 RB 트리로 이 값을 RB_ROOT로 지정한다
- 코드 라인 7에서 earliest_dl.curr 및 next의 값으로 0을 대입하여 큐잉된 태스크가 없음을 나타낸다.
- 코드 라인 9~10에서 dl_nr_migratory, overloaded 값에 0을 대입한다.
- 코드 라인 11에서 pushable_dl_tasks_root RB 트리를 초기화한다.
- 코드 라인 13에서 UP 시스템인 경우 dl 밴드폭 비율을 설정한다.
hrtick 초기화
init_rq_hrtick()
kernel/sched/core.c
static void init_rq_hrtick(struct rq *rq)
{
#ifdef CONFIG_SMP
rq->hrtick_csd_pending = 0;
rq->hrtick_csd.flags = 0;
rq->hrtick_csd.func = __hrtick_start;
rq->hrtick_csd.info = rq;
#endif
hrtimer_init(&rq->hrtick_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
rq->hrtick_timer.function = hrtick;
}
런큐용 hrtick을 초기화한다.
- 코드 라인 3~9에서 smp 시스템인 경우 IPI 용으로 hrtick에 대한 호출되는 함수를 지정하고 인수로는 런큐를 사용하게 한다.
- 코드 라인 11~12에서 hrtick_timer를 초기화하고 hrtick 만료 시 호출되는 함수를 지정한다.
아이들 스레드 초기화
init_idle()
kernel/sched/core.c
/**
* init_idle - set up an idle thread for a given CPU
* @idle: task in question
* @cpu: cpu the idle task belongs to
*
* NOTE: this function does not set the idle thread's NEED_RESCHED
* flag, to make booting more robust.
*/
void init_idle(struct task_struct *idle, int cpu)
{
struct rq *rq = cpu_rq(cpu);
unsigned long flags;
raw_spin_lock_irqsave(&rq->lock, flags);
__sched_fork(0, idle);
idle->state = TASK_RUNNING;
idle->se.exec_start = sched_clock();
do_set_cpus_allowed(idle, cpumask_of(cpu));
/*
* We're having a chicken and egg problem, even though we are
* holding rq->lock, the cpu isn't yet set to this cpu so the
* lockdep check in task_group() will fail.
*
* Similar case to sched_fork(). / Alternatively we could
* use task_rq_lock() here and obtain the other rq->lock.
*
* Silence PROVE_RCU
*/
rcu_read_lock();
__set_task_cpu(idle, cpu);
rcu_read_unlock();
rq->curr = rq->idle = idle;
idle->on_rq = TASK_ON_RQ_QUEUED;
#if defined(CONFIG_SMP)
idle->on_cpu = 1;
#endif
raw_spin_unlock_irqrestore(&rq->lock, flags);
/* Set the preempt count _outside_ the spinlocks! */
init_idle_preempt_count(idle, cpu);
/*
* The idle tasks have their own, simple scheduling class:
*/
idle->sched_class = &idle_sched_class;
ftrace_graph_init_idle_task(idle, cpu);
vtime_init_idle(idle, cpu);
#if defined(CONFIG_SMP)
sprintf(idle->comm, "%s/%d", INIT_TASK_COMM, cpu);
#endif
}
요청 cpu에 대한 idle 스레드를 설정하고 idle 스케줄러에 등록한다.
- 코드 라인 16에서 idle 태스크의 cfs, dl 및 rt 스케줄링 엔티티의 멤버 값들과 numa 밸런싱 관련 값들을 초기화한다.
- 코드 라인 17~18에서 요청 idle 태스크의 상태를 TASK_RUNNING으로 바꾸고 스케줄링 엔티티의 시작 실행 시각을 현재 시각으로 초기화한다.
- 코드 라인 20에서 요청한 idle 태스크는 요청한 cpu만 운영될 수 있도록 제한한다.
- 코드 라인 32에서 idle 태스크의 cfs_rq와 부모 엔티티를 설정한다.
- 코드 라인 35에서 런큐가 현재 동작중인 태스크와 idle 태스크로 인수로 요청한 태스크를 지정한다.
- 코드 라인 36에서 idle 태스크의 on_rq에 TASK_ON_RQ_QUEUED(1)를 대입하여 런큐에 올라가 있는 것을 의미하게 한다.
- 코드 라인 37에서 idle 태스크이 on_cpu에 1을 대입한다.
- 코드 라인 43에서 preempt 카운터를 0으로 설정하여 preemption이 가능하게 한다.
- 코드 라인 48에서 idle 태스크가 idle 스케줄러를 사용하게 설정한다.
- 코드 라인 50에서 디버그 정보를 제공하기 위해 full dynticks cpu 타임을 측정을 목적으로 초기화한다.
다음 그림은 init_idle() 함수가 처리되는 과정을 보여준다.

__sched_fork()
kernel/sched/core.c
/*
* Perform scheduler related setup for a newly forked process p.
* p is forked by current.
*
* __sched_fork() is basic setup used by init_idle() too:
*/
static void __sched_fork(unsigned long clone_flags, struct task_struct *p)
{
p->on_rq = 0;
p->se.on_rq = 0;
p->se.exec_start = 0;
p->se.sum_exec_runtime = 0;
p->se.prev_sum_exec_runtime = 0;
p->se.nr_migrations = 0;
p->se.vruntime = 0;
#ifdef CONFIG_SMP
p->se.avg.decay_count = 0;
#endif
INIT_LIST_HEAD(&p->se.group_node);
#ifdef CONFIG_SCHEDSTATS
memset(&p->se.statistics, 0, sizeof(p->se.statistics));
#endif
RB_CLEAR_NODE(&p->dl.rb_node);
init_dl_task_timer(&p->dl);
__dl_clear_params(p);
INIT_LIST_HEAD(&p->rt.run_list);
#ifdef CONFIG_PREEMPT_NOTIFIERS
INIT_HLIST_HEAD(&p->preempt_notifiers);
#endif
#ifdef CONFIG_NUMA_BALANCING
if (p->mm && atomic_read(&p->mm->mm_users) == 1) {
p->mm->numa_next_scan = jiffies + msecs_to_jiffies(sysctl_numa_balancing_scan_delay);
p->mm->numa_scan_seq = 0;
}
if (clone_flags & CLONE_VM)
p->numa_preferred_nid = current->numa_preferred_nid;
else
p->numa_preferred_nid = -1;
p->node_stamp = 0ULL;
p->numa_scan_seq = p->mm ? p->mm->numa_scan_seq : 0;
p->numa_scan_period = sysctl_numa_balancing_scan_delay;
p->numa_work.next = &p->numa_work;
p->numa_faults = NULL;
p->last_task_numa_placement = 0;
p->last_sum_exec_runtime = 0;
p->numa_group = NULL;
#endif /* CONFIG_NUMA_BALANCING */
}
fork된 태스크의 cfs, dl 및 rt 스케줄링 엔티티의 멤버 값들과 numa 밸런싱 관련 값들을 초기화한다. 이 태스크는 현재 태스크에서 새롭게 fork되었으며 다음 두 곳 함수에서 호출되어 사용된다.
- kernel/fork.c – copy_process() 함수 -> sched_fork() 함수
- kernel/sched/core.c – init_idle() 함수
- 코드 라인 9에서 on_rq에 0을 대입하여 런큐에 없음을 의미한다.
- 코드 라인 11~20에서 cfs 스케줄링 엔티티 값들을 0으로 초기화하고 group_node 리스트를 초기화한다.
- 코드 라인 26에서 dl 스케줄링 엔티티의 rb_node를 클리어하여 dl 스케줄러의 RB 트리에 태스크가 하나도 대기하지 않음을 의미한다.
- 코드 라인 27에서 dl 태스크 타이머를 초기화한다.
- 코드 라인 28에서 dl 스케줄링 엔티티를 파라메터들을 초기화한다.
- 코드 라인 30에서 rt 스케줄링 엔티티의 run_list를 초기화한다.
- 코드 라인 32~34에서 현재 태스크에서 preemption이 발생되면 preempt_notifiers에 등록된 함수들을 동작시키게 하기 위해 preempt_notifiers 리스트를 초기화한다.
- 코드 라인 36~56에서 numa 밸런싱의 설명은 생략한다.
init_dl_task_timer()
kernel/sched/deadline.c
void init_dl_task_timer(struct sched_dl_entity *dl_se)
{
struct hrtimer *timer = &dl_se->dl_timer;
hrtimer_init(timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
timer->function = dl_task_timer;
}
dl 스케줄링 엔티티의 hrtimer를 초기화하고 만료 시 호출될 함수를 지정한다.
__dl_clear_params()
kernel/sched/core.c
void __dl_clear_params(struct task_struct *p)
{
struct sched_dl_entity *dl_se = &p->dl;
dl_se->dl_runtime = 0;
dl_se->dl_deadline = 0;
dl_se->dl_period = 0;
dl_se->flags = 0;
dl_se->dl_bw = 0;
dl_se->dl_throttled = 0;
dl_se->dl_new = 1;
dl_se->dl_yielded = 0;
}
dl 스케줄링 엔티티를 파라메터들을 초기화한다.
do_set_cpus_allowed()
kernel/sched/core.c
void do_set_cpus_allowed(struct task_struct *p, const struct cpumask *new_mask)
{
if (p->sched_class->set_cpus_allowed)
p->sched_class->set_cpus_allowed(p, new_mask);
cpumask_copy(&p->cpus_allowed, new_mask);
p->nr_cpus_allowed = cpumask_weight(new_mask);
}
요청 태스크가 운영될 수 있는 cpu들을 지정한다. 현재 태스크가 동작 중인 경우 해당 스케줄러에도 통보된다.
- 코드 라인 3~4에서 태스크의 스케줄러가 (*set_cpus_allowed) 후크 함수가 구현된 경우 호출한다.
- 현재 rt 스케줄러에는 set_cpus_allowed_rt() 함수, 그리고 dl 스케줄러에는 set_cpus_allowed_dl() 함수가 구현되어 있다.
- 코드 라인 6에서 태스크의 cpus_allowed에 new_mask를 복사한다.
- 코드 라인 7에서 태스크의 nr_cpus_allowed에 new_mask에 설정된 cpu 수를 기록한다.
__set_task_cpu()
kernel/sched/sched.h
static inline void __set_task_cpu(struct task_struct *p, unsigned int cpu)
{
set_task_rq(p, cpu);
#ifdef CONFIG_SMP
/*
* After ->cpu is set up to a new value, task_rq_lock(p, ...) can be
* successfuly executed on another CPU. We must ensure that updates of
* per-task data have been completed by this moment.
*/
smp_wmb();
task_thread_info(p)->cpu = cpu;
p->wake_cpu = cpu;
#endif
}
태스크의 cfs_rq와 부모 엔티티를 설정한다.
- 코드 3에서 태스크의 cfs_rq와 부모 엔티티를 설정한다.
- 부트업 과정에서는 init_task가 태스크 그룹이 관리하는 cfs 런큐를 가리키게한다.
- 코드 4~13에서 smp 시스템인 경우 현재 스레드의 cpu 멤버와 현재 태스크의 wake_cpu 멤버에 요청한 cpu 번호를 대입한다.
set_task_rq()
kernel/sched/sched.h
/* Change a task's cfs_rq and parent entity if it moves across CPUs/groups */
static inline void set_task_rq(struct task_struct *p, unsigned int cpu)
{
#if defined(CONFIG_FAIR_GROUP_SCHED) || defined(CONFIG_RT_GROUP_SCHED)
struct task_group *tg = task_group(p);
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
p->se.cfs_rq = tg->cfs_rq[cpu];
p->se.parent = tg->se[cpu];
#endif
#ifdef CONFIG_RT_GROUP_SCHED
p->rt.rt_rq = tg->rt_rq[cpu];
p->rt.parent = tg->rt_se[cpu];
#endif
}
태스크의 cfs_rq와 부모 엔티티를 설정한다.
- 코드 라인 4~6에서 cfs 그룹 스케줄링 또는 rt 그룹 스케줄링을 지원하는 경우 태스크 그룹을 알아온다.
- 코드 라인 8~11에서 cfs 그룹 스케줄링을 지원하는 경우 스케줄링 엔티티의 cfs 런큐 및 부모로 태스크 그룹의 cfs 런큐 및 스케줄링 엔티티를 지정하게 한다.
- 코드 라인 13~16에서 rt 그룹 스케줄링을 지원하는 경우 rt 스케줄링 엔티티의 rt 런큐 및 부모로 태스크 그룹의 rt 런큐 및 rt 스케줄링 엔티티를 지정하게 한다.
init_idle_preempt_count()
include/asm-generic/preempt.h
#define init_idle_preempt_count(p, cpu) do { \
task_thread_info(p)->preempt_count = PREEMPT_ENABLED; \
} while (0)
preempt 카운터를 PREEMPT_ENABLED(0)으로 설정하여 preemption이 가능하게 한다.
기타 초기화
set_load_weight()
kernel/sched/core.c
static void set_load_weight(struct task_struct *p)
{
int prio = p->static_prio - MAX_RT_PRIO;
struct load_weight *load = &p->se.load;
/*
* SCHED_IDLE tasks get minimal weight:
*/
if (p->policy == SCHED_IDLE) {
load->weight = scale_load(WEIGHT_IDLEPRIO);
load->inv_weight = WMULT_IDLEPRIO;
return;
}
load->weight = scale_load(prio_to_weight[prio]);
load->inv_weight = prio_to_wmult[prio];
}
태스크에 지정된 static 우선순위를 사용하여 로드 weight를 설정한다. (idle 스레드인 경우는 로드 weight 값으로 가장 느린 3을 사용한다)
- 코드 라인 3에서 nice 40개 우선순위에 있는 weight 값을 사용하기 위해 100~139 사이 값인 태스크의 static 우선순위 – MAX_RT_PRIO(100)을 prio에 대입한다.
- 코드 라인 9~13에서 현재 태스크가 SCHED_IDLE 스케줄 정책을 사용하는 경우 cfs 스케줄링 엔티티의 로드 weight 값으로 WEIGHT_IDLEPRIO(3)을 저장하고 inv_weight 값도 이에 해당하는 WMULT_IDLEPRIO(1431655765) 값을 저장하고 함수를 빠져나간다.
- 코드 라인 15~16에서 0 ~ 39까지 범위인 prio에 해당하는 weight 값과 inv_weight 값을 cfs 스케줄링 엔티티의 로드 값에 저장한다.
set_cpu_rq_start_time()
kernel/sched/core.c
static void __cpuinit set_cpu_rq_start_time(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
rq->age_stamp = sched_clock_cpu(cpu);
}
현재 런큐의 age_stamp에 현재 스케줄 클럭을 대입한다.
init_sched_fair_class()
kernel/sched/fair.c
__init void init_sched_fair_class(void)
{
#ifdef CONFIG_SMP
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
#ifdef CONFIG_NO_HZ_COMMON
nohz.next_balance = jiffies;
zalloc_cpumask_var(&nohz.idle_cpus_mask, GFP_NOWAIT);
cpu_notifier(sched_ilb_notifier, 0);
#endif
#endif /* SMP */
}
smp 시스템인 경우 cfs 스케줄러를 초기화한다.
- 코드 라인 4에서 SCHED_SOFTIRQ가 발생할 때 호출되는 함수로 run_rebalance_domains() 함수를 지정한다.
- 코드 라인 5에서 nohz idle이 지원되는 경우 nohz.next_balance에 현재 시각(jiffies)을 대입하고 idle_cpus_mask에 cpumask를 할당받는다. 마지막으로 cpu notier에 sched_lib_notifer() 함수를 등록한다.
sched_ilb_notifier()
kernel/sched/fair.c
static int sched_ilb_notifier(struct notifier_block *nfb,
unsigned long action, void *hcpu)
{
switch (action & ~CPU_TASKS_FROZEN) {
case CPU_DYING:
nohz_balance_exit_idle(smp_processor_id());
return NOTIFY_OK;
default:
return NOTIFY_DONE;
}
}
cpu 상태가 dying 상태(frozen 제외)가 된 경우 nohz_balance_exit_idle() 함수를 호출하여 해당 cpu가 nohz idle 상태를 벗어나게 한다.
nohz_balance_exit_idle()
kernel/sched/fair.c
static inline void nohz_balance_exit_idle(int cpu)
{
if (unlikely(test_bit(NOHZ_TICK_STOPPED, nohz_flags(cpu)))) {
/*
* Completely isolated CPUs don't ever set, so we must test.
*/
if (likely(cpumask_test_cpu(cpu, nohz.idle_cpus_mask))) {
cpumask_clear_cpu(cpu, nohz.idle_cpus_mask);
atomic_dec(&nohz.nr_cpus);
}
clear_bit(NOHZ_TICK_STOPPED, nohz_flags(cpu));
}
}
해당 cpu가 idle 상태를 벗어나게 한다.
- 코드 라인 3, 11에서 낮은 확률로 현재 cpu의 런큐 멤버 중 nohz_flags에 NOHZ_TICK_STOPPED 플래그가 설정된 경우 이 플래그를 지운다.
- 코드 라인 7~10에서 nohz.idle_cpus_mask에 요청 cpu가 설정된 경우, 즉 현재 cpu가 nohz idle 상태를 지원하는 경우 해당 비트를 클리어하고 nohz.nr_cpus를 1 감소시킨다.
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c – 현재 글
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c