<kernel v5.0>
Zoned Allocator -12- (Direct Reclaim-Shrink-1)
다음 그림은 페이지 회수를 위해 shrink_zones() 함수 호출 시 처리되는 함수 호출 관계를 보여준다.
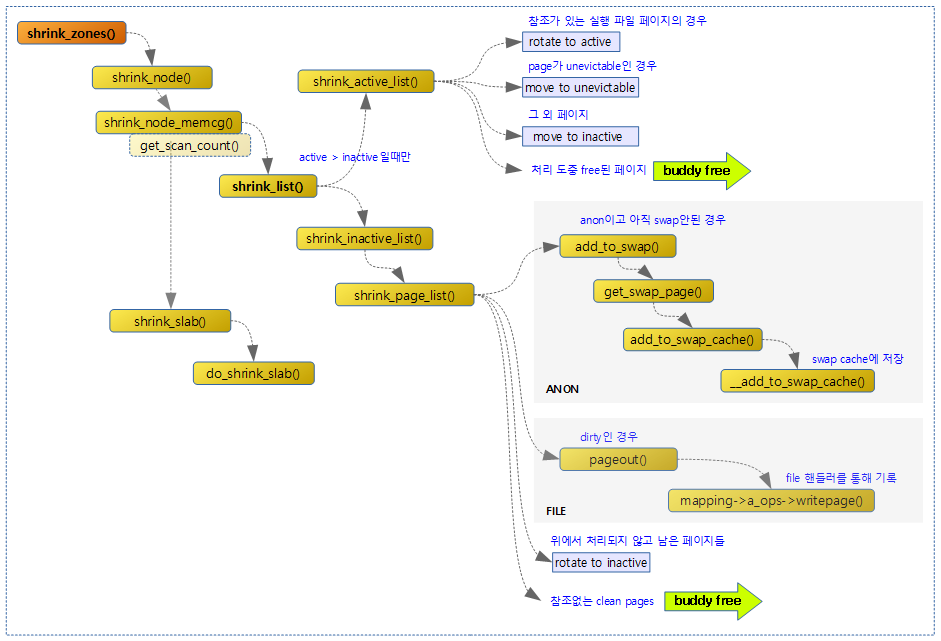
Shrink Zones
shrink_zones()
mm/vmscan.c
/* * This is the direct reclaim path, for page-allocating processes. We only * try to reclaim pages from zones which will satisfy the caller's allocation * request. * * If a zone is deemed to be full of pinned pages then just give it a light * scan then give up on it. */
static void shrink_zones(struct zonelist *zonelist, struct scan_control *sc)
{
struct zoneref *z;
struct zone *zone;
unsigned long nr_soft_reclaimed;
unsigned long nr_soft_scanned;
gfp_t orig_mask;
pg_data_t *last_pgdat = NULL;
/*
* If the number of buffer_heads in the machine exceeds the maximum
* allowed level, force direct reclaim to scan the highmem zone as
* highmem pages could be pinning lowmem pages storing buffer_heads
*/
orig_mask = sc->gfp_mask;
if (buffer_heads_over_limit) {
sc->gfp_mask |= __GFP_HIGHMEM;
sc->reclaim_idx = gfp_zone(sc->gfp_mask);
}
for_each_zone_zonelist_nodemask(zone, z, zonelist,
sc->reclaim_idx, sc->nodemask) {
/*
* Take care memory controller reclaiming has small influence
* to global LRU.
*/
if (global_reclaim(sc)) {
if (!cpuset_zone_allowed(zone,
GFP_KERNEL | __GFP_HARDWALL))
continue;
/*
* If we already have plenty of memory free for
* compaction in this zone, don't free any more.
* Even though compaction is invoked for any
* non-zero order, only frequent costly order
* reclamation is disruptive enough to become a
* noticeable problem, like transparent huge
* page allocations.
*/
if (IS_ENABLED(CONFIG_COMPACTION) &&
sc->order > PAGE_ALLOC_COSTLY_ORDER &&
compaction_ready(zone, sc)) {
sc->compaction_ready = true;
continue;
}
/*
* Shrink each node in the zonelist once. If the
* zonelist is ordered by zone (not the default) then a
* node may be shrunk multiple times but in that case
* the user prefers lower zones being preserved.
*/
if (zone->zone_pgdat == last_pgdat)
continue;
/*
* This steals pages from memory cgroups over softlimit
* and returns the number of reclaimed pages and
* scanned pages. This works for global memory pressure
* and balancing, not for a memcg's limit.
*/
nr_soft_scanned = 0;
nr_soft_reclaimed = mem_cgroup_soft_limit_reclaim(zone->zone_pgdat,
sc->order, sc->gfp_mask,
&nr_soft_scanned);
sc->nr_reclaimed += nr_soft_reclaimed;
sc->nr_scanned += nr_soft_scanned;
/* need some check for avoid more shrink_zone() */
}
/* See comment about same check for global reclaim above */
if (zone->zone_pgdat == last_pgdat)
continue;
last_pgdat = zone->zone_pgdat;
shrink_node(zone->zone_pgdat, sc);
}
/*
* Restore to original mask to avoid the impact on the caller if we
* promoted it to __GFP_HIGHMEM.
*/
sc->gfp_mask = orig_mask;
}
zonelist를 대상으로 필요한 zone에 대해 페이지 회수를 수행한다.
- 코드 라인 15에서 sc->gfp_mask를 백업해둔다.
- 코드 라인 16~19에서 버퍼 헤드의 수가 최대 허락된 레벨을 초과하는 경우 페이지 회수 스캐닝에 highmem zone도 포함시킨다.
- 코드 라인 21~22에서 zonelist에서 요청 zone 이하 및 노드들을 대상으로 루프를 돈다.
- 코드 라인 27에서 global lru를 대상으로 회수하는 경우이다.
- 코드 라인 28~30에서 cpuset이 GFP_KERNEL 및 __GFP_HARDWALL 플래그 요청으로 이 zone에서 허락되지 않는 경우 skip 한다.
- 코드 라인 41~46에서 cosltly order 이면서 compaction 없이 처리할 수 있을거라 판단하면 skip 한다.
- 코드 라인 54~55에서 이미 처리한 노드인 경우 skip 한다.
- 코드 라인 63~68에서 memcg 소프트 제한된 페이지 회수를 시도하여 스캔 및 회수된 페이지를 알아와서 추가한다.
- 코드 라인 73~75에서 이미 처리한 노드인 경우 skip 한다.
- 코드 라인 76에서 노드를 대상으로 페이지 회수를 시도한다.
- 코드 라인 83에서 백업해두었던 gfp_mask를 복구한다.
다음 그림은 shrink_zones() 함수의 처리 흐름을 보여준다.
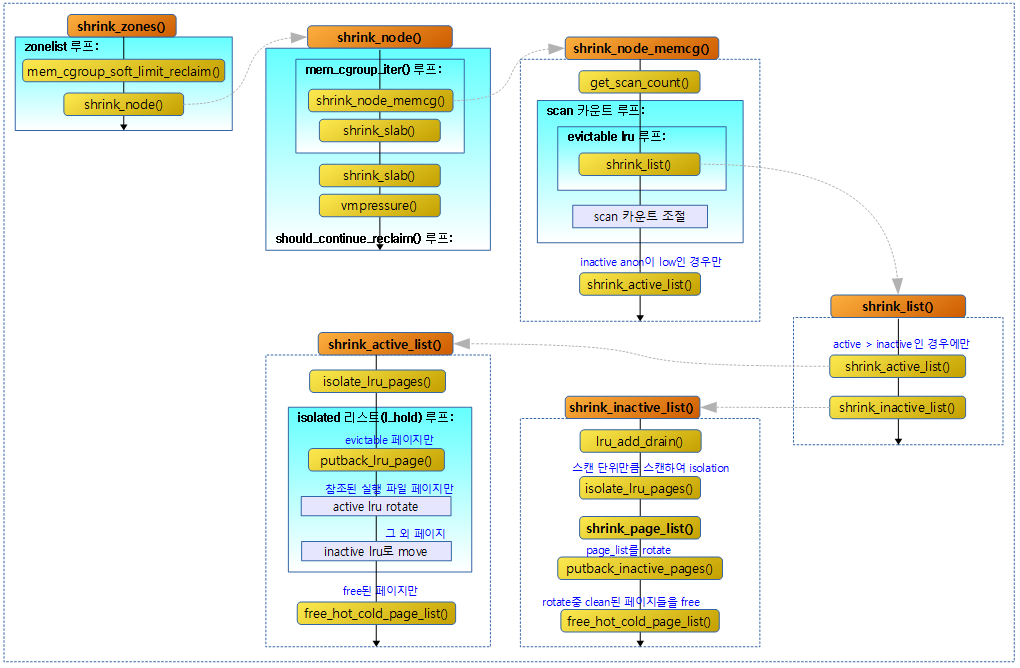
compaction_ready()
mm/vmscan.c
/* * Returns true if compaction should go ahead for a costly-order request, or * the allocation would already succeed without compaction. Return false if we * should reclaim first. */
static inline bool compaction_ready(struct zone *zone, struct scan_control *sc)
{
unsigned long watermark;
enum compact_result suitable;
suitable = compaction_suitable(zone, sc->order, 0, sc->reclaim_idx);
if (suitable == COMPACT_SUCCESS)
/* Allocation should succeed already. Don't reclaim. */
return true;
if (suitable == COMPACT_SKIPPED)
/* Compaction cannot yet proceed. Do reclaim. */
return false;
/*
* Compaction is already possible, but it takes time to run and there
* are potentially other callers using the pages just freed. So proceed
* with reclaim to make a buffer of free pages available to give
* compaction a reasonable chance of completing and allocating the page.
* Note that we won't actually reclaim the whole buffer in one attempt
* as the target watermark in should_continue_reclaim() is lower. But if
* we are already above the high+gap watermark, don't reclaim at all.
*/
watermark = high_wmark_pages(zone) + compact_gap(sc->order);
return zone_watermark_ok_safe(zone, 0, watermark, sc->reclaim_idx);
}
추가적인 compaction 없이 페이지 할당이 가능한지 여부를 반환한다. (true=페이지 할당 가능 상태, false=페이지 회수가 필요한 상태)
- 코드 라인 6에서 compaction 수행이 적합한지 여부를 알아온다.
- 코드 라인 7~9에서 할당에 문제가 없는 경우 페이지 회수를 진행할 필요 없어 true를 반환한다.
- 코드 라인 10~12에서 compaction이 아직 끝나지 않았으므로 페이지 회수가 더 필요하므로 false를 반환한다.
- 코드 라인 23~25에서 compaction이 필요한 상태이나 이미 많은 페이지가 확보되어 있을지 모르므로 high 워터마크 기준에 compact 갭(order 페이지의 두 배)을 추가하여 free 페이지를 비교해본 결과를 반환한다.
Shrink 노드
shrink_node()
mm/vmscan.c -1/2-
static bool shrink_node(pg_data_t *pgdat, struct scan_control *sc)
{
struct reclaim_state *reclaim_state = current->reclaim_state;
unsigned long nr_reclaimed, nr_scanned;
bool reclaimable = false;
do {
struct mem_cgroup *root = sc->target_mem_cgroup;
struct mem_cgroup_reclaim_cookie reclaim = {
.pgdat = pgdat,
.priority = sc->priority,
};
unsigned long node_lru_pages = 0;
struct mem_cgroup *memcg;
memset(&sc->nr, 0, sizeof(sc->nr));
nr_reclaimed = sc->nr_reclaimed;
nr_scanned = sc->nr_scanned;
memcg = mem_cgroup_iter(root, NULL, &reclaim);
do {
unsigned long lru_pages;
unsigned long reclaimed;
unsigned long scanned;
switch (mem_cgroup_protected(root, memcg)) {
case MEMCG_PROT_MIN:
/*
* Hard protection.
* If there is no reclaimable memory, OOM.
*/
continue;
case MEMCG_PROT_LOW:
/*
* Soft protection.
* Respect the protection only as long as
* there is an unprotected supply
* of reclaimable memory from other cgroups.
*/
if (!sc->memcg_low_reclaim) {
sc->memcg_low_skipped = 1;
continue;
}
memcg_memory_event(memcg, MEMCG_LOW);
break;
case MEMCG_PROT_NONE:
break;
}
reclaimed = sc->nr_reclaimed;
scanned = sc->nr_scanned;
shrink_node_memcg(pgdat, memcg, sc, &lru_pages);
node_lru_pages += lru_pages;
if (sc->may_shrinkslab) {
shrink_slab(sc->gfp_mask, pgdat->node_id,
memcg, sc->priority);
}
/* Record the group's reclaim efficiency */
vmpressure(sc->gfp_mask, memcg, false,
sc->nr_scanned - scanned,
sc->nr_reclaimed - reclaimed);
/*
* Direct reclaim and kswapd have to scan all memory
* cgroups to fulfill the overall scan target for the
* node.
*
* Limit reclaim, on the other hand, only cares about
* nr_to_reclaim pages to be reclaimed and it will
* retry with decreasing priority if one round over the
* whole hierarchy is not sufficient.
*/
if (!global_reclaim(sc) &&
sc->nr_reclaimed >= sc->nr_to_reclaim) {
mem_cgroup_iter_break(root, memcg);
break;
}
} while ((memcg = mem_cgroup_iter(root, memcg, &reclaim)));
요청 노드의 anon 및 file lru 리스트에서 페이지 회수를 진행한다. 타겟 memcg 이하에서 진행하고 페이지 회수 결과 여부를 반환한다.
- 코드 라인 3에서 현재 태스크의 reclaim 상태를 알아온다.
- 코드 라인 7~19에서 reclaim이 완료되지 못한 경우 다시 반복된다. 회수할 memcg 대상은 sc->target_mem_cgroup 부터 모든 하위 memcg들이다.
- 코드 라인 21~22에서 root 부터 하이라키로 구성된 하위 memcg를 대상으로 순회한다. root가 지정되지 않은 경우 최상위 root memcg를 대상으로 수행한다.
- 코드 라인 27~49에서 memcg에 대한 프로텍션을 확인하고 skip 하거나 진행한다.
- hard 프로텍션이 걸린 memcg의 경우 skip 한다.
- uage < memory.emin
- soft 프로텍션이 걸린 memcg의 경우 memcg low 이벤트를 통지한다. 단 low_reclaim을 허용하지 않은 경우 skip 한다.
- usage < memory.elow
- 어떠한 프로텍션도 없는 memcg의 경우 그대로 진행한다.
- hard 프로텍션이 걸린 memcg의 경우 skip 한다.
- 코드 라인 51~53에서 memcg를 대상으로 shrink 한다.
- 코드 라인 56~59에서 슬랩의 shrink를 요청한 경우 이를 수행한다.
- 코드 라인 62~64에서 memcg에 대한 메모리 압박률을 체크하여 갱신한다.
- 코드 라인 76~80에서 global 회수가 아닌 경우이고 목표를 달성한 경우 루프를 벗어난다.
- 코드 라인 81에서 하이라키로 구성된 다음 memcg를 순회한다.
mm/vmscan.c -2/2-
if (reclaim_state) {
sc->nr_reclaimed += reclaim_state->reclaimed_slab;
reclaim_state->reclaimed_slab = 0;
}
/* Record the subtree's reclaim efficiency */
vmpressure(sc->gfp_mask, sc->target_mem_cgroup, true,
sc->nr_scanned - nr_scanned,
sc->nr_reclaimed - nr_reclaimed);
if (sc->nr_reclaimed - nr_reclaimed)
reclaimable = true;
if (current_is_kswapd()) {
/*
* If reclaim is isolating dirty pages under writeback,
* it implies that the long-lived page allocation rate
* is exceeding the page laundering rate. Either the
* global limits are not being effective at throttling
* processes due to the page distribution throughout
* zones or there is heavy usage of a slow backing
* device. The only option is to throttle from reclaim
* context which is not ideal as there is no guarantee
* the dirtying process is throttled in the same way
* balance_dirty_pages() manages.
*
* Once a node is flagged PGDAT_WRITEBACK, kswapd will
* count the number of pages under pages flagged for
* immediate reclaim and stall if any are encountered
* in the nr_immediate check below.
*/
if (sc->nr.writeback && sc->nr.writeback == sc->nr.taken)
set_bit(PGDAT_WRITEBACK, &pgdat->flags);
/*
* Tag a node as congested if all the dirty pages
* scanned were backed by a congested BDI and
* wait_iff_congested will stall.
*/
if (sc->nr.dirty && sc->nr.dirty == sc->nr.congested)
set_bit(PGDAT_CONGESTED, &pgdat->flags);
/* Allow kswapd to start writing pages during reclaim.*/
if (sc->nr.unqueued_dirty == sc->nr.file_taken)
set_bit(PGDAT_DIRTY, &pgdat->flags);
/*
* If kswapd scans pages marked marked for immediate
* reclaim and under writeback (nr_immediate), it
* implies that pages are cycling through the LRU
* faster than they are written so also forcibly stall.
*/
if (sc->nr.immediate)
congestion_wait(BLK_RW_ASYNC, HZ/10);
}
/*
* Legacy memcg will stall in page writeback so avoid forcibly
* stalling in wait_iff_congested().
*/
if (!global_reclaim(sc) && sane_reclaim(sc) &&
sc->nr.dirty && sc->nr.dirty == sc->nr.congested)
set_memcg_congestion(pgdat, root, true);
/*
* Stall direct reclaim for IO completions if underlying BDIs
* and node is congested. Allow kswapd to continue until it
* starts encountering unqueued dirty pages or cycling through
* the LRU too quickly.
*/
if (!sc->hibernation_mode && !current_is_kswapd() &&
current_may_throttle() && pgdat_memcg_congested(pgdat, root))
wait_iff_congested(BLK_RW_ASYNC, HZ/10);
} while (should_continue_reclaim(pgdat, sc->nr_reclaimed - nr_reclaimed,
sc->nr_scanned - nr_scanned, sc));
/*
* Kswapd gives up on balancing particular nodes after too
* many failures to reclaim anything from them and goes to
* sleep. On reclaim progress, reset the failure counter. A
* successful direct reclaim run will revive a dormant kswapd.
*/
if (reclaimable)
pgdat->kswapd_failures = 0;
return reclaimable;
}
- 코드 라인 1~4에서 reclaim_state가 null이 아닌 경우 회수된 페이지 수에 회수된 slab 페이지 갯수를 더한다.
- 코드 라인 7~9에서 memcg에 대한 메모리 압박률을 체크하여 조건을 만족시키는 vmpressure 리스터들에 이벤트를 통지한다.
- 코드 라인 11~12에서 순회 중에 한 번이라도 회수한 페이지의 변화가 있는 경우 reclimable을 true로 설정한다.
- 코드 라인 14~56에서 kswapd에서 페이지 회수를 해야 하는 경우이다. 노드에 관련 플래그들을 설정한다.
- 코드 라인 62~64에서 글로벌 회수가 아니고, 지정된 memcg를 사용하지 않으면서 writeback으로 인해 지연되는 경우 memcg 노드의 congested를 true로 설정한다.
- 코드 라인 72~74에서 direct-reclaim 중 memcg 노드가 혼잡한 경우 0.1초 슬립한다.
- 코드 라인 76~77에서 페이지 회수를 계속할지 여부에 의해 순회를 한다.
- 코드 라인 85에서 페이지 회수가 된적 있으면 kswapd의 실패 수를 리셋한다.
- 코드 라인 87에서 페이지 회수 여부를 반환한다.
Shrink 노드 memcg
shrink_node_memcg()
mm/vmscan.c -1/2-
/* * This is a basic per-node page freer. Used by both kswapd and direct reclaim. */
static void shrink_node_memcg(struct pglist_data *pgdat, struct mem_cgroup *memcg,
struct scan_control *sc, unsigned long *lru_pages)
{
struct lruvec *lruvec = mem_cgroup_lruvec(pgdat, memcg);
unsigned long nr[NR_LRU_LISTS];
unsigned long targets[NR_LRU_LISTS];
unsigned long nr_to_scan;
enum lru_list lru;
unsigned long nr_reclaimed = 0;
unsigned long nr_to_reclaim = sc->nr_to_reclaim;
struct blk_plug plug;
bool scan_adjusted;
get_scan_count(lruvec, memcg, sc, nr, lru_pages);
/* Record the original scan target for proportional adjustments later */
memcpy(targets, nr, sizeof(nr));
/*
* Global reclaiming within direct reclaim at DEF_PRIORITY is a normal
* event that can occur when there is little memory pressure e.g.
* multiple streaming readers/writers. Hence, we do not abort scanning
* when the requested number of pages are reclaimed when scanning at
* DEF_PRIORITY on the assumption that the fact we are direct
* reclaiming implies that kswapd is not keeping up and it is best to
* do a batch of work at once. For memcg reclaim one check is made to
* abort proportional reclaim if either the file or anon lru has already
* dropped to zero at the first pass.
*/
scan_adjusted = (global_reclaim(sc) && !current_is_kswapd() &&
sc->priority == DEF_PRIORITY);
blk_start_plug(&plug);
while (nr[LRU_INACTIVE_ANON] || nr[LRU_ACTIVE_FILE] ||
nr[LRU_INACTIVE_FILE]) {
unsigned long nr_anon, nr_file, percentage;
unsigned long nr_scanned;
for_each_evictable_lru(lru) {
if (nr[lru]) {
nr_to_scan = min(nr[lru], SWAP_CLUSTER_MAX);
nr[lru] -= nr_to_scan;
nr_reclaimed += shrink_list(lru, nr_to_scan,
lruvec, memcg, sc);
}
}
cond_resched();
if (nr_reclaimed < nr_to_reclaim || scan_adjusted)
continue;
/*
* For kswapd and memcg, reclaim at least the number of pages
* requested. Ensure that the anon and file LRUs are scanned
* proportionally what was requested by get_scan_count(). We
* stop reclaiming one LRU and reduce the amount scanning
* proportional to the original scan target.
*/
nr_file = nr[LRU_INACTIVE_FILE] + nr[LRU_ACTIVE_FILE];
nr_anon = nr[LRU_INACTIVE_ANON] + nr[LRU_ACTIVE_ANON];
/*
* It's just vindictive to attack the larger once the smaller
* has gone to zero. And given the way we stop scanning the
* smaller below, this makes sure that we only make one nudge
* towards proportionality once we've got nr_to_reclaim.
*/
if (!nr_file || !nr_anon)
break;
memcg의 노드별 lruvec에서 anon 및 file lru 리스트의 페이지 회수를 진행한다.
- 코드 라인 4에서 memcg에 대한 lruvec을 알아온다. memcg가 지정되지 않은 경우 노드 lruvec을 알아온다.
- 코드 라인 14에서 요청한 lruvec에 대해 밸런스를 고려하여 스캔할 페이지 비율을 산출한다.
- 코드 라인 17에서 나중에 일부 조정을 위해 산출된 nr[] 배열을 targets[] 배열에 백업해둔다.
- 코드 라인 30~31에서 direct reclaim을 포함하는 global reclaim이 첫 우선 순위로 시도하는지 여부를 scan_adjusted에 대입한다.
- scan_adjusted가 true로 설정된 경우 anon과 file 페이지의 스캔 비율을 재조정되지 않게 한다.
- 코드 라인 33에서 태스크의 plug에 blk_plug를 대입하여 배치 i/o가 시작된 것을 알린다.
- 코드 라인 34~35에서 nr[]배열에서 inactive anon+file 또는 active file이 0보다 큰 경우 루프를 돈다.
- active anon은 제외한다.
- 코드 라인 39~47에서 evictable lru에 대해서 회수를 시도한다. 단 최대 스캔 페이지 수는 32 페이지로 제한한다.
- 코드 라인 51~52에서 회수가 더 필요하거나, scan_adjusted가 설정된 경우 루프를 반복한다.
- 코드 라인 61~62에서 회수한 페이지가 목표치를 초과 달성한 경우이다. scan 비율을 조절하기 위해 먼저 스캔 후 남은 file 페이지 수와 anon 페이지 수를 준비한다.
- 코드 라인 70~71에서 처리 후 남은 file 또는 anon 페이지가 없는 경우 비율을 조절할 필요가 없으므로 루프를 빠져나간다.
mm/vmscan.c -2/2-
if (nr_file > nr_anon) {
unsigned long scan_target = targets[LRU_INACTIVE_ANON] +
targets[LRU_ACTIVE_ANON] + 1;
lru = LRU_BASE;
percentage = nr_anon * 100 / scan_target;
} else {
unsigned long scan_target = targets[LRU_INACTIVE_FILE] +
targets[LRU_ACTIVE_FILE] + 1;
lru = LRU_FILE;
percentage = nr_file * 100 / scan_target;
}
/* Stop scanning the smaller of the LRU */
nr[lru] = 0;
nr[lru + LRU_ACTIVE] = 0;
/*
* Recalculate the other LRU scan count based on its original
* scan target and the percentage scanning already complete
*/
lru = (lru == LRU_FILE) ? LRU_BASE : LRU_FILE;
nr_scanned = targets[lru] - nr[lru];
nr[lru] = targets[lru] * (100 - percentage) / 100;
nr[lru] -= min(nr[lru], nr_scanned);
lru += LRU_ACTIVE;
nr_scanned = targets[lru] - nr[lru];
nr[lru] = targets[lru] * (100 - percentage) / 100;
nr[lru] -= min(nr[lru], nr_scanned);
scan_adjusted = true;
}
blk_finish_plug(&plug);
sc->nr_reclaimed += nr_reclaimed;
/*
* Even if we did not try to evict anon pages at all, we want to
* rebalance the anon lru active/inactive ratio.
*/
if (inactive_list_is_low(lruvec, false, memcg, sc, true))
shrink_active_list(SWAP_CLUSTER_MAX, lruvec,
sc, LRU_ACTIVE_ANON);
}
- 코드 라인 1~5에서 남은 잔량이 file 페이지가 많은 경우 스캔 목표 대비 남은 anon 페이지의 백분율을 산출한다.
- 예) shrink 전 산출하여 백업해둔 anon=200, shrink 후 anon=140
- scan_target=201, percentage=약 70%의 anon 페이지를 스캔하지 못함
- 예) shrink 전 산출하여 백업해둔 anon=200, shrink 후 anon=140
- 코드 라인 6~11에서 남은 잔량이 anon이 많은 경우 스캔 목표 대비 남은 file 페이지의 백뷴율을 산출한다.
- 예) shrink 전 산출하여 백업해둔 file=200, shrink 후 file=140
- scan_target=201, percentage=약 70%의 file 페이지를 스캔하지 못함
- 예) shrink 전 산출하여 백업해둔 file=200, shrink 후 file=140
- 코드 라인 14~15에서 대상(file 또는 anon) lru는 많이 처리되었기 때문에 다음에 스캔하지 않도록 inactive와 active 스캔 카운트를 0으로 설정한다.
- 코드 라인 21~24에서 대상 lru의 반대(file <-> anon) inactive를 선택하고 스캔 목표에서 원래 대상 lru가 스캔한 백분율 만큼의 페이지를 감소 시킨 페이지 수를 nr[]에 대입한다.
- 감소 시킬 때 원래 대상 lru가 스캔한 페이지 수를 초과하지 않도록 조정한다.
- 코드 라인 26~29에서 active anon 또는 file lru를 선택하고 스캔 목표에서 원래 대상 lru가 스캔한 백분율만큼의 페이지를 감소 시킨 페이지 수를 nr[]에 산출한다.
- 감소 시킬 때 원래 대상 lru가 스캔한 페이지 수를 초과하지 않도록 조정한다.
- 코드 라인 31에서 스캔 값이 조절된 후에는 루프내에서 다시 재조정되지 않도록 한다.
- 코드 라인 33에서 태스크의 plug에 null을 대입하여 배치 i/o가 완료된 것을 알린다.
- 코드 라인 34에서 회수된 페이지 수를 갱신한다.
- 코드 라인 40~42에서 inactive anon이 active anon보다 작을 경우 active 리스트에 대해 shrink를 수행하여 active와 inactive간의 밸런스를 다시 잡아준다.
다음 그림은 지정된 memcg의 lru 벡터 리스트를 shrink하는 모습을 보여준다.
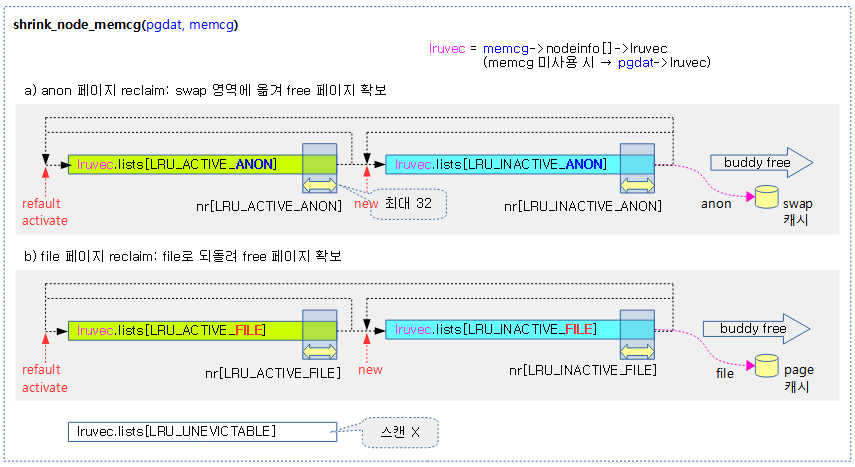
요청 lru shrink
lru shrink
shrink_list()
mm/vmscan.c
static unsigned long shrink_list(enum lru_list lru, unsigned long nr_to_scan,
struct lruvec *lruvec, struct mem_cgroup *memcg,
struct scan_control *sc)
{
if (is_active_lru(lru)) {
if (inactive_list_is_low(lruvec, is_file_lru(lru),
memcg, sc, true))
shrink_active_list(nr_to_scan, lruvec, sc, lru);
return 0;
}
return shrink_inactive_list(nr_to_scan, lruvec, sc, lru);
}
lruvec의 lru 리스트에서 페이지 회수를 진행한다. 단 active lru의 경우 inactive lru보다 페이지 수가 많은 경우만 수행한다.
- active 리스트에 대한 shrink 요청 시 inactive 리스트보다 페이지 수가 적으면 active 리스트에 대해 shrink를 수행하지 않는다.
- inactive 리스트에 대한 shrink 요청은 조건 없이 수행한다.
active lru의 shrink
shrink_active_list()
mm/vmscan.c -1/2-
static void shrink_active_list(unsigned long nr_to_scan,
struct lruvec *lruvec,
struct scan_control *sc,
enum lru_list lru)
{
unsigned long nr_taken;
unsigned long nr_scanned;
unsigned long vm_flags;
LIST_HEAD(l_hold); /* The pages which were snipped off */
LIST_HEAD(l_active);
LIST_HEAD(l_inactive);
struct page *page;
struct zone_reclaim_stat *reclaim_stat = &lruvec->reclaim_stat;
unsigned nr_deactivate, nr_activate;
unsigned nr_rotated = 0;
isolate_mode_t isolate_mode = 0;
int file = is_file_lru(lru);
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
lru_add_drain();
if (!sc->may_unmap)
isolate_mode |= ISOLATE_UNMAPPED;
spin_lock_irq(&pgdat->lru_lock);
nr_taken = isolate_lru_pages(nr_to_scan, lruvec, &l_hold,
&nr_scanned, sc, isolate_mode, lru);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, nr_taken);
reclaim_stat->recent_scanned[file] += nr_taken;
__count_vm_events(PGREFILL, nr_scanned);
count_memcg_events(lruvec_memcg(lruvec), PGREFILL, nr_scanned);
spin_unlock_irq(&pgdat->lru_lock);
while (!list_empty(&l_hold)) {
cond_resched();
page = lru_to_page(&l_hold);
list_del(&page->lru);
if (unlikely(!page_evictable(page))) {
putback_lru_page(page);
continue;
}
if (unlikely(buffer_heads_over_limit)) {
if (page_has_private(page) && trylock_page(page)) {
if (page_has_private(page))
try_to_release_page(page, 0);
unlock_page(page);
}
}
if (page_referenced(page, 0, sc->target_mem_cgroup,
&vm_flags)) {
nr_rotated += hpage_nr_pages(page);
/*
* Identify referenced, file-backed active pages and
* give them one more trip around the active list. So
* that executable code get better chances to stay in
* memory under moderate memory pressure. Anon pages
* are not likely to be evicted by use-once streaming
* IO, plus JVM can create lots of anon VM_EXEC pages,
* so we ignore them here.
*/
if ((vm_flags & VM_EXEC) && page_is_file_cache(page)) {
list_add(&page->lru, &l_active);
continue;
}
}
ClearPageActive(page); /* we are de-activating */
SetPageWorkingset(page);
list_add(&page->lru, &l_inactive);
}
lruvec의 active lru 리스트에서 페이지 회수를 진행한다. active lru 리스트에서 일정 분량의 페이지를 isolation한 후 file 캐시 페이지인 경우 다시 active lru 리스트로 rotate 시키고, 나머지는 inactive lru 리스트로 옮긴다. 단 이들 중 unevictable 페이지는 unevictable lru 리스트로 옮긴다. 그리고 처리하는 동안 사용자가 없어진 페이지들은 버디 시스템에 free 한다.
- 코드 라인 20에서 per cpu lru들을 비우고 lruvec으로 되돌린다.
- 코드 라인 22~23에서 may_unmap 요청이 없는 경우 unmapped 페이지들도 isolation할 수 있도록 모드에 추가한다.
- 코드 라인 27~28에서 지정한 lru 리스트로부터 nr_to_scan 만큼 스캔을 시도하여 분리된 페이지는 l_hold 리스트에 담고 분리된 페이지 수를 반환한다.
- 코드 라인 30에서 NR_ISOLATED_ANON 또는 NR_ISOLATED_FILE 카운터를 분리한 페이지 수 만큼 더한다.
- 코드 라인 31에서 anon/file 스캔 비율 모드를 사용할 때 비율을 산출하기 위해 최근 스캔된 수에 분리한 페이지 수를 더한다.
- 코드 라인 33~34에서 PGREFILL 카운터에 스캔 수 만큼 추가한다.
- 코드 라인 38~41에서 에서 isolation한 페이지들이 있는 l_hold 리스트에서 페이지들을 하나씩 순회하며 삭제한다.
- 코드 라인 43~46에서 만일 페이지가 evitable 가능한 상태가 아니면 다시 원래 lru 리스트로 옮긴다.
- 코드 라인 48~54에서 작은 확률로 buffer_heads_over_limit이 설정되었고 private 페이지에서 lock 획득이 성공한 경우 페이지를 버디 시스템으로 되돌리고 unlock한다.
- 코드 라인 56~72에서 참조된 페이지의경우 nr_rotate 카운터를 페이지 수 만큼 증가시킨다. 그리고 실행 파일 캐시인경우 active lru로 rotate 시키기 위해 l_active로 옮긴다.
- 코드 라인 74~76에서 그 외의 페이지들은 active 플래그를 제거하고, workingset 플래그를 설정한 후 inactive lru로 옮기기 위해 l_inactive로 옮긴다.
mm/vmscan.c -2/2-
/*
* Move pages back to the lru list.
*/
spin_lock_irq(&pgdat->lru_lock);
/*
* Count referenced pages from currently used mappings as rotated,
* even though only some of them are actually re-activated. This
* helps balance scan pressure between file and anonymous pages in
* get_scan_count.
*/
reclaim_stat->recent_rotated[file] += nr_rotated;
nr_activate = move_active_pages_to_lru(lruvec, &l_active, &l_hold, lru);
nr_deactivate = move_active_pages_to_lru(lruvec, &l_inactive, &l_hold, lru - LRU_ACTIVE);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, -nr_taken);
spin_unlock_irq(&pgdat->lru_lock);
mem_cgroup_uncharge_list(&l_hold);
free_unref_page_list(&l_hold);
trace_mm_vmscan_lru_shrink_active(pgdat->node_id, nr_taken, nr_activate,
nr_deactivate, nr_rotated, sc->priority, file);
}
- 코드 라인 11에서 anon/file 스캔 비율 모드를 사용할 때 비율을 산출하기 위해 최근 rotated 카운터에 nr_rotated를 더한다.
- 코드 라인 13에서 l_active에 모아둔 페이지들을 active lru에 옮기고 그 와중에 사용자가 없어 free 가능한 페이지들은 l_hold로 옮긴다.
- 코드 라인 14에서 l_inactive에 모아둔 페이지들을 inactive lru에 옮기고 그 와중에 사용자가 없어 free 가능한 페이지들은 l_hold로 옮긴다.
- 코드 라인 15에서 NR_ISOLATED_ANON 또는 NR_ISOLATED_FILE 카운터에서 nr_taken을 뺀다.
- 코드 라인 18에서 memcg에 l_hold 리스트를 uncarge 보고한다.
- 코드 라인 19에서 l_hold에 있는 페이지들 모두를 버디시스템으로 되돌린다.
다음 그림은 anon/file active lru 리스트를 대상으로 shrink하는 모습을 보여준다.
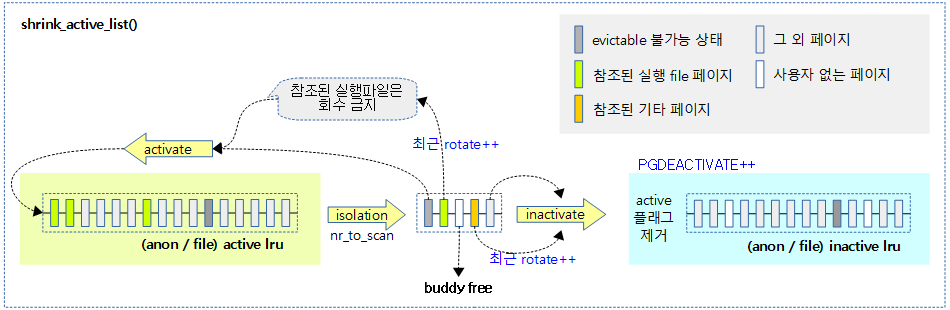
inactive lru의 shrink
shrink_inactive_list()
mm/vmscan.c -1/2-
/* * shrink_inactive_list() is a helper for shrink_node(). It returns the number * of reclaimed pages */
static noinline_for_stack unsigned long
shrink_inactive_list(unsigned long nr_to_scan, struct lruvec *lruvec,
struct scan_control *sc, enum lru_list lru)
{
LIST_HEAD(page_list);
unsigned long nr_scanned;
unsigned long nr_reclaimed = 0;
unsigned long nr_taken;
struct reclaim_stat stat = {};
isolate_mode_t isolate_mode = 0;
int file = is_file_lru(lru);
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
struct zone_reclaim_stat *reclaim_stat = &lruvec->reclaim_stat;
bool stalled = false;
while (unlikely(too_many_isolated(pgdat, file, sc))) {
if (stalled)
return 0;
/* wait a bit for the reclaimer. */
msleep(100);
stalled = true;
/* We are about to die and free our memory. Return now. */
if (fatal_signal_pending(current))
return SWAP_CLUSTER_MAX;
}
lru_add_drain();
if (!sc->may_unmap)
isolate_mode |= ISOLATE_UNMAPPED;
spin_lock_irq(&pgdat->lru_lock);
nr_taken = isolate_lru_pages(nr_to_scan, lruvec, &page_list,
&nr_scanned, sc, isolate_mode, lru);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, nr_taken);
reclaim_stat->recent_scanned[file] += nr_taken;
if (current_is_kswapd()) {
if (global_reclaim(sc))
__count_vm_events(PGSCAN_KSWAPD, nr_scanned);
count_memcg_events(lruvec_memcg(lruvec), PGSCAN_KSWAPD,
nr_scanned);
} else {
if (global_reclaim(sc))
__count_vm_events(PGSCAN_DIRECT, nr_scanned);
count_memcg_events(lruvec_memcg(lruvec), PGSCAN_DIRECT,
nr_scanned);
}
spin_unlock_irq(&pgdat->lru_lock);
if (nr_taken == 0)
return 0;
nr_reclaimed = shrink_page_list(&page_list, pgdat, sc, 0,
&stat, false);
inactive lru 리스트에서 일정 분량의 페이지를 shrink하여 free page를 확보하고, 그 중 active 페이지는 active lru 리스트에 되돌리고 writeback 등의 이유로 처리를 유보한 페이지들은 inactive lru 리스트의 선두로 rotate 시킨다.
- 코드 라인 16~27에서 너무 많은 페이지가 isolation된 경우 0.1초간 슬립한다.
- 코드 라인 29에서 lru cpu 캐시를 lruvec으로 되돌린다.
- 코드 라인 31~32에서 may_unmap 요청이 없는 경우 unmapped 페이지들도 isolation할 수 있도록 모드에 추가한다.
- 코드 라인 36~37에서 isolate_mode에 맞게 lruvec에서 nr_to_scan 만큼 page_list에 분리해온다. 스캔 수는 nr_scanned에 담기고, 처리된 수는 nr_taken에 담겨반환된다.
- 코드 라인 39에서 NR_ISOLATED_ANON 또는 NR_ISOLATED_FILE 카운터를 분리한 페이지 수 만큼 더한다.
- 코드 라인 40에서 anon/file 스캔 비율 모드를 사용할 때 비율을 산출하기 위해 최근 스캔된 수에 분리한 페이지 수를 더한다.
- 코드 라인 42~52에서 kswapd 및 direct-reclaim 스캔 카운터를 증가시킨다.
- 코드 라인 55~56에서 분리되어 처리할 페이지가 없는 경우 처리를 중단한다.
- 코드 라인 58에서 isolation된 페이지들이 담긴 page_list에서 shrink를 수행하고 그 중 회수된 페이지의 수를 알아온다.
mm/vmscan.c -2/2-
spin_lock_irq(&pgdat->lru_lock);
if (current_is_kswapd()) {
if (global_reclaim(sc))
__count_vm_events(PGSTEAL_KSWAPD, nr_reclaimed);
count_memcg_events(lruvec_memcg(lruvec), PGSTEAL_KSWAPD,
nr_reclaimed);
} else {
if (global_reclaim(sc))
__count_vm_events(PGSTEAL_DIRECT, nr_reclaimed);
count_memcg_events(lruvec_memcg(lruvec), PGSTEAL_DIRECT,
nr_reclaimed);
}
putback_inactive_pages(lruvec, &page_list);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, -nr_taken);
spin_unlock_irq(&pgdat->lru_lock);
mem_cgroup_uncharge_list(&page_list);
free_unref_page_list(&page_list);
/*
* If dirty pages are scanned that are not queued for IO, it
* implies that flushers are not doing their job. This can
* happen when memory pressure pushes dirty pages to the end of
* the LRU before the dirty limits are breached and the dirty
* data has expired. It can also happen when the proportion of
* dirty pages grows not through writes but through memory
* pressure reclaiming all the clean cache. And in some cases,
* the flushers simply cannot keep up with the allocation
* rate. Nudge the flusher threads in case they are asleep.
*/
if (stat.nr_unqueued_dirty == nr_taken)
wakeup_flusher_threads(WB_REASON_VMSCAN);
sc->nr.dirty += stat.nr_dirty;
sc->nr.congested += stat.nr_congested;
sc->nr.unqueued_dirty += stat.nr_unqueued_dirty;
sc->nr.writeback += stat.nr_writeback;
sc->nr.immediate += stat.nr_immediate;
sc->nr.taken += nr_taken;
if (file)
sc->nr.file_taken += nr_taken;
trace_mm_vmscan_lru_shrink_inactive(pgdat->node_id,
nr_scanned, nr_reclaimed, &stat, sc->priority, file);
return nr_reclaimed;
}
- 코드 라인 3~13에서 kswapd 및 direct-reclaim PGSTEAL 카운터를 증가시킨다.
- 코드 라인 15에서 남은 page_list에 있는 페이지들을 inactive에 다시 rotate 한다.
- 코드 라인 17에서 isolated lru 건수를 처리한 수 만큼 다시 감소시킨다.
- 코드 라인 21에서 inactive lru 리스트로 돌아가지 않고 free된 페이지에 대해 memcg에 uncharge 보고한다.
- 코드 라인 22에서 inactive lru 리스트로 돌아가지 않고 page_list에 남아있는 page들을 모두 버디 시스템으로 되돌린다.
- 코드 라인 35~36에서 flusher 스레드를 깨운다.
- 코드 라인 38~45에서 처리된 페이지 종류에 따라 스캔 컨트롤에 보고한다.
- 코드 라인 49에서 회수한 페이지 수를 반환한다.
다음 그림은 lru inactive 벡터 리스트를 shrink하는 모습을 보여준다.
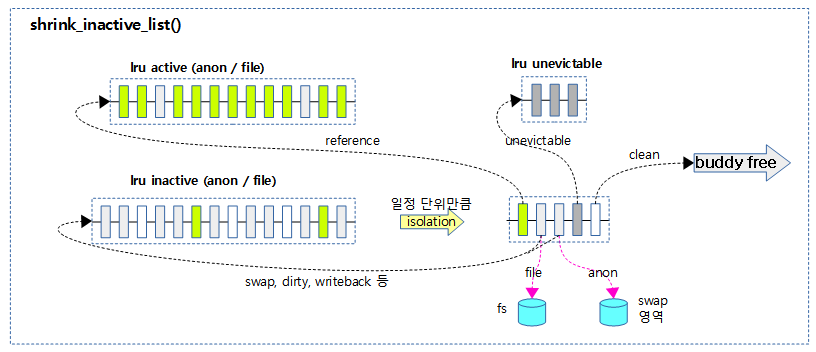
Isolate lru 및 Rotate lru
Isolate 플래그
lru 페이지들을 isolation할 때 다음과 같은 플래그들을 조합하여 사용할 수 있다.
- ISOLATE_UNMAPPED
- 페이지 테이블에 매핑되지 않은 페이지만 isolation 가능하게 제한한다. (unmapping only)
- 페이지 테이블에 매핑된 페이지는 isolation 하지 않게한다.
- ISOLATE_ASYNC_MIGRATE
- async 마이그레이션 모드를 사용하면 메모리 압박이 없을 때 writeback 페이지와 migration이 지원되지 않는 파일 시스템을 사용하는 dirty 페이지를 isolation 하지 않도록 한다.
- ISOLATE_UNEVICTABLE
- unevitable 페이지도 isolation할 수 있게 한다.
- 이 모드는 CMA 영역 또는 Off-line 메모리 영역을 비우기 위해 migration 시 사용된다.
Isolate lru 페이지
isolate_lru_pages()
mm/vmscan.c
/* * zone_lru_lock is heavily contended. Some of the functions that * shrink the lists perform better by taking out a batch of pages * and working on them outside the LRU lock. * * For pagecache intensive workloads, this function is the hottest * spot in the kernel (apart from copy_*_user functions). * * Appropriate locks must be held before calling this function. * * @nr_to_scan: The number of eligible pages to look through on the list. * @lruvec: The LRU vector to pull pages from. * @dst: The temp list to put pages on to. * @nr_scanned: The number of pages that were scanned. * @sc: The scan_control struct for this reclaim session * @mode: One of the LRU isolation modes * @lru: LRU list id for isolating * * returns how many pages were moved onto *@dst. */
static unsigned long isolate_lru_pages(unsigned long nr_to_scan,
struct lruvec *lruvec, struct list_head *dst,
unsigned long *nr_scanned, struct scan_control *sc,
isolate_mode_t mode, enum lru_list lru)
{
struct list_head *src = &lruvec->lists[lru];
unsigned long nr_taken = 0;
unsigned long nr_zone_taken[MAX_NR_ZONES] = { 0 };
unsigned long nr_skipped[MAX_NR_ZONES] = { 0, };
unsigned long skipped = 0;
unsigned long scan, total_scan, nr_pages;
LIST_HEAD(pages_skipped);
scan = 0;
for (total_scan = 0;
scan < nr_to_scan && nr_taken < nr_to_scan && !list_empty(src);
total_scan++) {
struct page *page;
page = lru_to_page(src);
prefetchw_prev_lru_page(page, src, flags);
VM_BUG_ON_PAGE(!PageLRU(page), page);
if (page_zonenum(page) > sc->reclaim_idx) {
list_move(&page->lru, &pages_skipped);
nr_skipped[page_zonenum(page)]++;
continue;
}
/*
* Do not count skipped pages because that makes the function
* return with no isolated pages if the LRU mostly contains
* ineligible pages. This causes the VM to not reclaim any
* pages, triggering a premature OOM.
*/
scan++;
switch (__isolate_lru_page(page, mode)) {
case 0:
nr_pages = hpage_nr_pages(page);
nr_taken += nr_pages;
nr_zone_taken[page_zonenum(page)] += nr_pages;
list_move(&page->lru, dst);
break;
case -EBUSY:
/* else it is being freed elsewhere */
list_move(&page->lru, src);
continue;
default:
BUG();
}
}
/*
* Splice any skipped pages to the start of the LRU list. Note that
* this disrupts the LRU order when reclaiming for lower zones but
* we cannot splice to the tail. If we did then the SWAP_CLUSTER_MAX
* scanning would soon rescan the same pages to skip and put the
* system at risk of premature OOM.
*/
if (!list_empty(&pages_skipped)) {
int zid;
list_splice(&pages_skipped, src);
for (zid = 0; zid < MAX_NR_ZONES; zid++) {
if (!nr_skipped[zid])
continue;
__count_zid_vm_events(PGSCAN_SKIP, zid, nr_skipped[zid]);
skipped += nr_skipped[zid];
}
}
*nr_scanned = total_scan;
trace_mm_vmscan_lru_isolate(sc->reclaim_idx, sc->order, nr_to_scan,
total_scan, skipped, nr_taken, mode, lru);
update_lru_sizes(lruvec, lru, nr_zone_taken);
return nr_taken;
}
지정한 @lruvec으로부터 nr_to_scan 만큼 스캔을 시도하여 분리한 페이지를 @dst 리스트에 담고 분리 성공한 페이지 수를 반환한다.
- 코드 라인 6에서 작업할 lru 리스트를 선택한다.
- 코드 라인 15~29에서 lru 리스트에서 nr_to_scan 수 만큼 페이지 스캔을 한다. 해당 페이지의 존이 요청한 존을 초과하는 경우 스킵하기 위해 pages_skipped 리스트로 옮긴다.
- 코드 라인 38~53에서 한 페이지를 분리하여 @dst 리스트에 옮긴다. 만일 당장 분리할 수 없는 상태(-EBUSY)인 경우 원래 요청한 lru 리스트의 선두로 옮긴다(rotate).
- 코드 라인 63~74에서 pages_skipped 리스트의 페이지들을 원래 요청한 lru 리스트의 선두로 옮긴다. (rotate)
- 코드 라인 75~79에서 출력 인자 @nr_scanned에 스캔한 수를 대입하고, lru 사이즈를 갱신한 다음, isolation 성공한 페이지의 수를 반환한다.
다음 그림은 lru 리스트에서 isolation 시도 시 일부 페이지는 rotate되고, 나머지는 isolation 되는 모습을 보여준다.
- isolation 여부는 isolation 모드와 각 페이지의 상태에 따라 다르다.
- 메모리 압박이 심하거나 CMA 영역같은 곳을 반드시 비워야 할 때에는 여러 가지 isolation 모드를 설정(set/clear)하여 rotate 되지 않도록 할 수 있다.
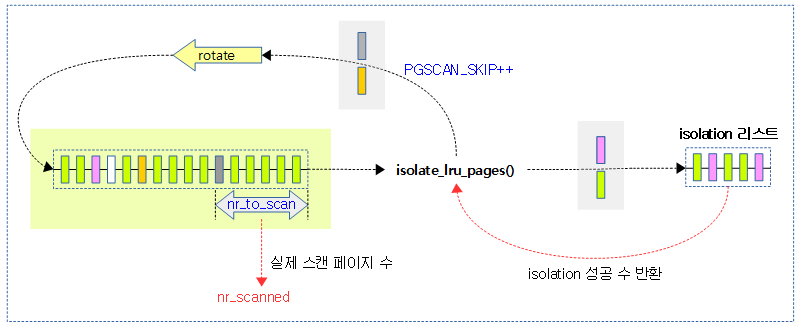
__isolate_lru_page()
mm/vmscan.c
/* * Attempt to remove the specified page from its LRU. Only take this page * if it is of the appropriate PageActive status. Pages which are being * freed elsewhere are also ignored. * * page: page to consider * mode: one of the LRU isolation modes defined above * * returns 0 on success, -ve errno on failure. */
int __isolate_lru_page(struct page *page, isolate_mode_t mode)
{
int ret = -EINVAL;
/* Only take pages on the LRU. */
if (!PageLRU(page))
return ret;
/* Compaction should not handle unevictable pages but CMA can do so */
if (PageUnevictable(page) && !(mode & ISOLATE_UNEVICTABLE))
return ret;
ret = -EBUSY;
/*
* To minimise LRU disruption, the caller can indicate that it only
* wants to isolate pages it will be able to operate on without
* blocking - clean pages for the most part.
*
* ISOLATE_ASYNC_MIGRATE is used to indicate that it only wants to pages
* that it is possible to migrate without blocking
*/
if (mode & ISOLATE_ASYNC_MIGRATE) {
/* All the caller can do on PageWriteback is block */
if (PageWriteback(page))
return ret;
if (PageDirty(page)) {
struct address_space *mapping;
bool migrate_dirty;
/*
* Only pages without mappings or that have a
* ->migratepage callback are possible to migrate
* without blocking. However, we can be racing with
* truncation so it's necessary to lock the page
* to stabilise the mapping as truncation holds
* the page lock until after the page is removed
* from the page cache.
*/
if (!trylock_page(page))
return ret;
mapping = page_mapping(page);
migrate_dirty = !mapping || mapping->a_ops->migratepage;
unlock_page(page);
if (!migrate_dirty)
return ret;
}
}
if ((mode & ISOLATE_UNMAPPED) && page_mapped(page))
return ret;
if (likely(get_page_unless_zero(page))) {
/*
* Be careful not to clear PageLRU until after we're
* sure the page is not being freed elsewhere -- the
* page release code relies on it.
*/
ClearPageLRU(page);
ret = 0;
}
return ret;
}
lru 리스트에서 요청 페이지를 분리하고 성공 시 0을 반환한다. 만일 관련 없는 페이지의 분리를 시도하는 경우 -EINVAL을 반환하고, 모드 조건에 따라 당장 분리할 수 없는 경우 -EBUSY를 반환한다.
- 코드 라인 6~7에서 lru 페이지가 아닌 경우 분리를 포기한다. (-EINVAL)
- 코드 라인 10~11에서 unevictable 페이지이면서 모드에 unevictable의 분리를 허용하지 않은 경우 분리를 포기한다. (-EINVAL)
- 코드 라인 23~50에서 비동기 migration 모드인 경우이다. writeback 페이지는 분리를 포기한다. 또한 dirty 페이지도 페이지의 lock 획득 시도가 실패하거나, 매핑 드라이버의 (*migratepage) 후크가 지원되지 않는 경우 분리를 포기한다. (-EBUSY)
- 코드 라인 52~53에서 모드에 unmapped를 요청한 경우 mapped 페이지는 분리를 포기한다. (-EBUSY)
- 코드 라인 55~63에서 참조카운터가 0이 아니면 1을 증가시킨다. lru 플래그 비트를 클리어하고 성공적으로 리턴한다.
다음 그림은 isolation 모드에 따른 각 페이지 상태 및 종류에 따라 isolation 여부를 결정하는 과정을 보여준다.
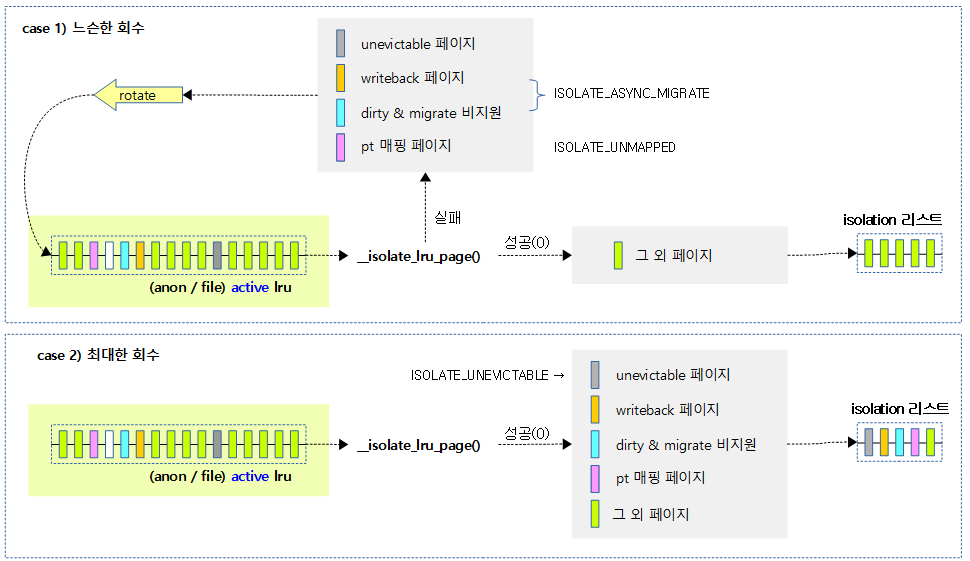
update_lru_sizes()
mm/vmscan.c
/* * Update LRU sizes after isolating pages. The LRU size updates must * be complete before mem_cgroup_update_lru_size due to a santity check. */
static __always_inline void update_lru_sizes(struct lruvec *lruvec,
enum lru_list lru, unsigned long *nr_zone_taken)
{
int zid;
for (zid = 0; zid < MAX_NR_ZONES; zid++) {
if (!nr_zone_taken[zid])
continue;
__update_lru_size(lruvec, lru, zid, -nr_zone_taken[zid]);
#ifdef CONFIG_MEMCG
mem_cgroup_update_lru_size(lruvec, lru, zid, -nr_zone_taken[zid]);
#endif
}
}
isolation된 페이지 수만큼 lru 사이즈를 갱신한다. 입력 인자 @nr_zone_taken에는 각 존별 isolation 성공 페이지 수가 담긴다.
- 코드 라인 6~8에서 zone 수만큼 순회하며 isolation된 페이지가 없는 존은 skip 한다.
- 코드 라인 10에서 lruvec의 지정한 lru 리스트의 사이즈를 갱신한다.
- 코드 라인 12에서 memcg의 노드별로 구성된 존 사이즈를 갱신한다.
LRU로 rotate
move_active_pages_to_lru()
mm/vmscan.c
/* * This moves pages from the active list to the inactive list. * * We move them the other way if the page is referenced by one or more * processes, from rmap. * * If the pages are mostly unmapped, the processing is fast and it is * appropriate to hold zone->lru_lock across the whole operation. But if * the pages are mapped, the processing is slow (page_referenced()) so we * should drop zone->lru_lock around each page. It's impossible to balance * this, so instead we remove the pages from the LRU while processing them. * It is safe to rely on PG_active against the non-LRU pages in here because * nobody will play with that bit on a non-LRU page. * * The downside is that we have to touch page->_count against each page. * But we had to alter page->flags anyway. */
static void move_active_pages_to_lru(struct lruvec *lruvec,
struct list_head *list,
struct list_head *pages_to_free,
enum lru_list lru)
{
struct zone *zone = lruvec_zone(lruvec);
unsigned long pgmoved = 0;
struct page *page;
int nr_pages;
while (!list_empty(list)) {
page = lru_to_page(list);
lruvec = mem_cgroup_page_lruvec(page, zone);
VM_BUG_ON_PAGE(PageLRU(page), page);
SetPageLRU(page);
nr_pages = hpage_nr_pages(page);
mem_cgroup_update_lru_size(lruvec, lru, nr_pages);
list_move(&page->lru, &lruvec->lists[lru]);
pgmoved += nr_pages;
if (put_page_testzero(page)) {
__ClearPageLRU(page);
__ClearPageActive(page);
del_page_from_lru_list(page, lruvec, lru);
if (unlikely(PageCompound(page))) {
spin_unlock_irq(&zone->lru_lock);
mem_cgroup_uncharge(page);
(*get_compound_page_dtor(page))(page);
spin_lock_irq(&zone->lru_lock);
} else
list_add(&page->lru, pages_to_free);
}
}
__mod_zone_page_state(zone, NR_LRU_BASE + lru, pgmoved);
if (!is_active_lru(lru))
__count_vm_events(PGDEACTIVATE, pgmoved);
}
리스트(@list)에 있는 페이지를 lru 리스트(active 또는 inactive)로 옮긴다. 만일 이 과정에 이미 해제되어 사용자가 없는 페이지인 경우 @pages_to_free 리스트에 옮긴다.
- 코드 라인 11~20에서 @list에 있는 페이지를 순회하며, 해당 lruvec의 lru 리스트로 되돌린다. (rotate)
- 코드 라인 23~35에서 페이지의 사용이 완료되었으므로 참조 카운터를 감소시킨다. 만일 이미 사용자가 없는 페이지인 경우 버디시스템으로 되돌린다.
- 코드 라인 38~39에서 inactive lru인 경우 PGDEACTIVATE 카운터를 옮긴 수 만큼 증가시킨다.
lru별 스캔 수 산정
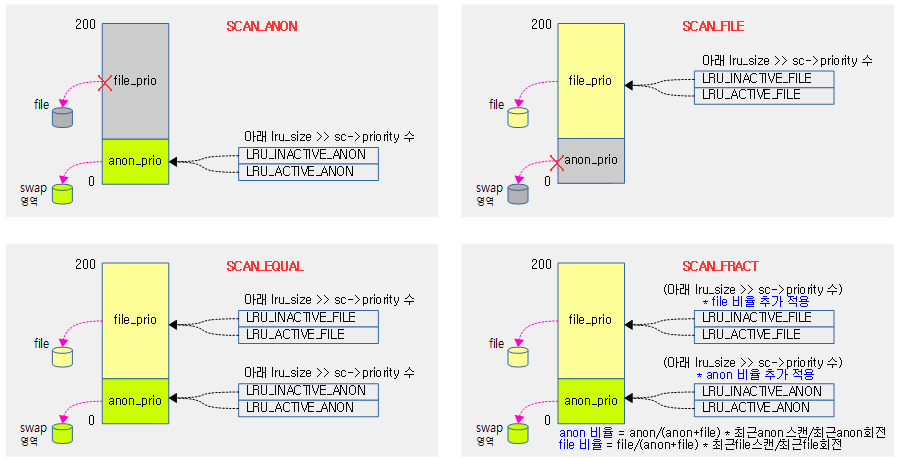
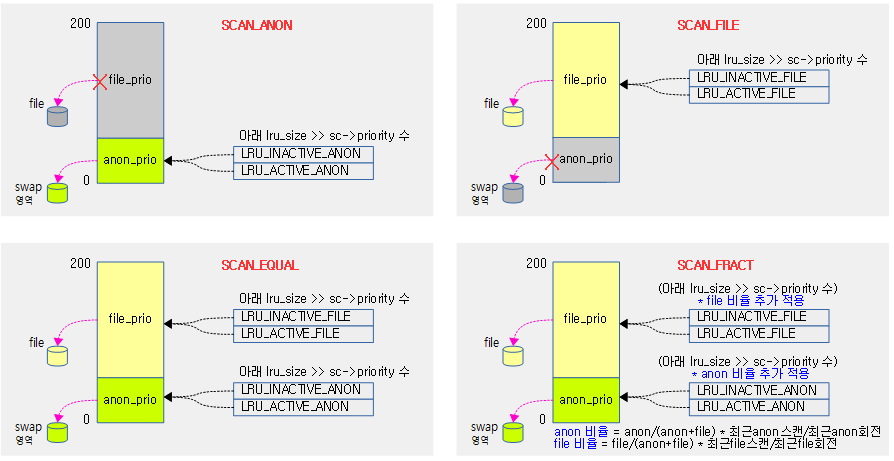
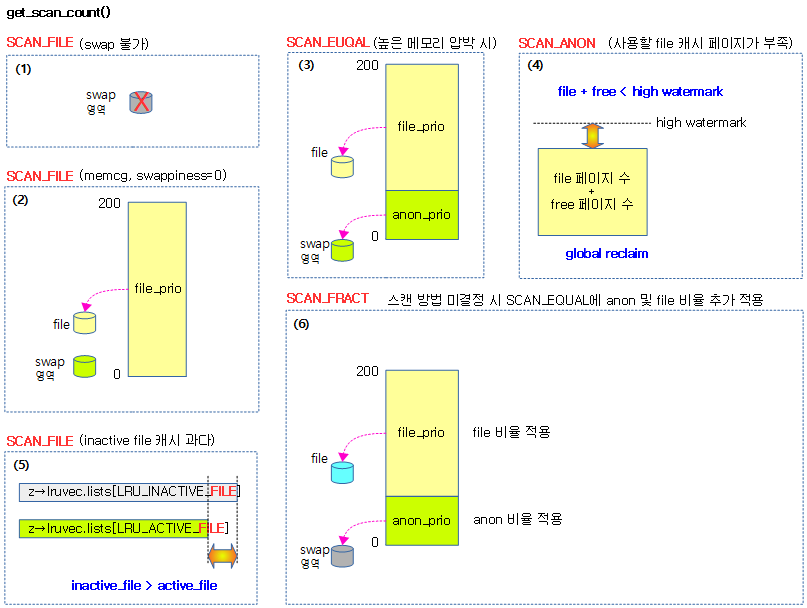
스캔 밸런스 모드
lru별 스캔 수를 산정하기 위해 4가지의 모드를 사용한다. 우선 순위(sc->priority)가 점점 줄어들면서 scan 수가 줄어든다. 단 한번에 최대 스캔 가능한 수는 SWAP_CLUSTER_MAX(32) 개로 제한된다.
- SCAN_ANON
- anon 페이지만 스캔한다.
- SCAN_FILE
- file 페이지만 스캔한다.
- SCAN_EQUAL
- anon 및 file 페이지를 동시에 스캔한다.
- SCAN_FRACT
- 위의 SCAN_EQUAL로 결정한 스캔 수에 다음 anon/file 비율을 추가 적용한다.
- anon 비율 = anon/(anon+file) 비율 * 최근 anon 스캔 수 / 최근 anon 회전 비율
- file 비율 = file/(anon+file) 비율 * 최근 file 스캔 수 / 최근 file 회전 비율
- 위의 SCAN_EQUAL로 결정한 스캔 수에 다음 anon/file 비율을 추가 적용한다.
다음 그림은 4가지 스캔 밸런스 모드에 따라 lru별 스캔 수를 대략적으로 결정하는 과정을 보여준다.
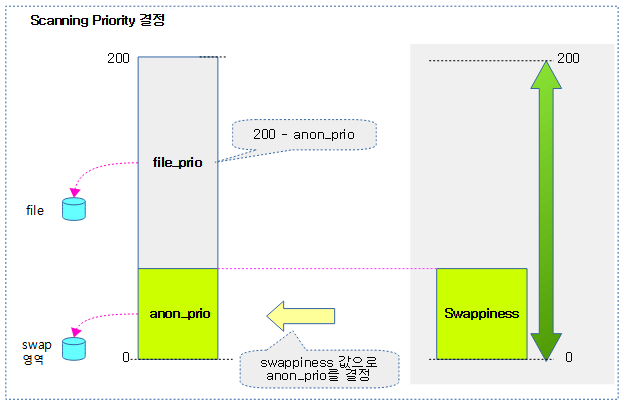
Scanning Priority 설정
anon 및 file 페이지의 priority를 설정한다.
- anon priority는 swappiness 값과 동일한 값으로 0 ~ 100까지이며, 디폴트 값은 60이다.
- 최근 커널의 경우 swap 영역에 SSD 등의 고성능 블럭디스크를 사용하여 reclaim 성능을 끌어올릴 수 있어 swappiness 값을 최대 200까지 사용할 수 있도록 허용하였다.
-
참고: mm: allow swappiness that prefers reclaiming anon over the file workingset (2020, v5.8-rc1)
-
- 최근 커널의 경우 swap 영역에 SSD 등의 고성능 블럭디스크를 사용하여 reclaim 성능을 끌어올릴 수 있어 swappiness 값을 최대 200까지 사용할 수 있도록 허용하였다.
- file priority는 200 – anon priority 값을 사용한다.
다음 그림은 swappiness 값으로 Scanning Prioirty(file_prio 및 anon_prio)가 결정되는 모습을 보여준다.
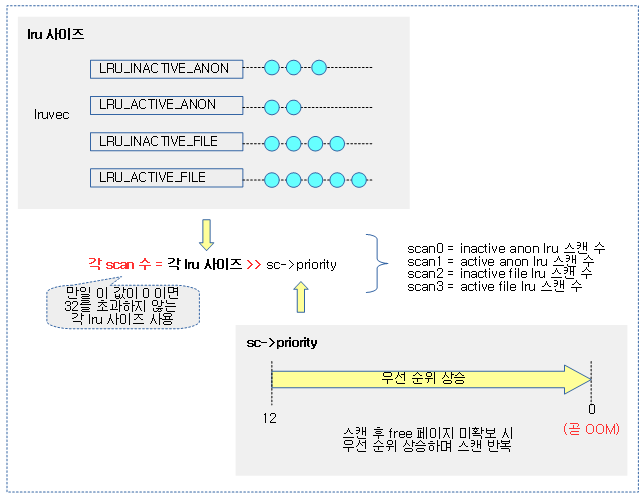
1차 lru 별 스캔 수 결정
lru 별 스캔할 수는 스캔 컨트롤을 통해 요청한 우선순위(sc->priority)만큼 우측 시프트하여 결정한다. 단 이 값이 0이면 32를 초과하지 않는 lru 사이즈를 사용한다. OOM 직전에는 최고 우선 순위에 다다르는데 이 때에는 swapness 비율을 사용하던 SCAN_FRACT의 사용을 멈추고, swapness 비율과 상관 없는 SCAN_EQUAL을 사용하여 최대한 모든 lru를 스캔하려한다.
아래 그림은 우선 순위가 적용된 lru 별 스캔 수를 산출하는 과정을 보여준다.
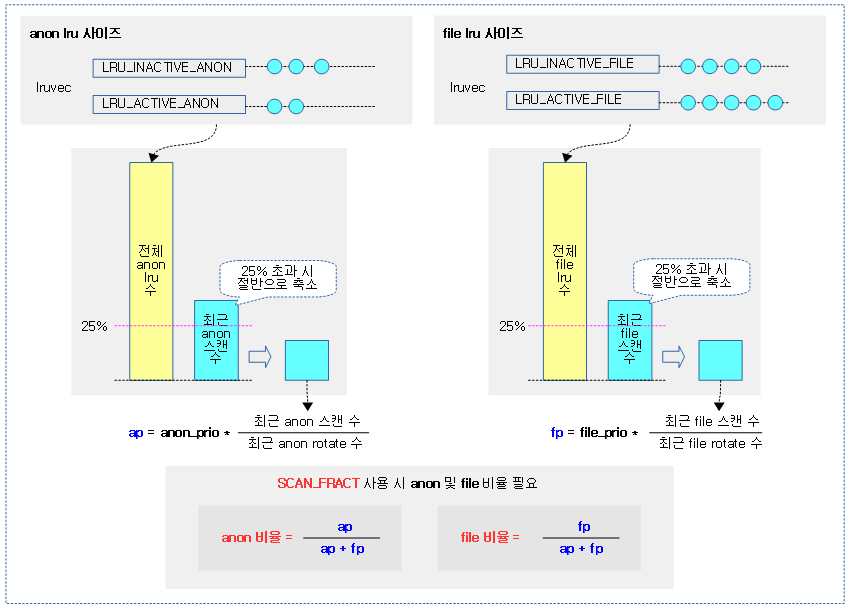
anon 및 lru 비율 산출
SCAN_FRACT 모드에서는 추가로 anon 및 lru 비율을 산정하여야 한다.
- 최근 커널 v5.8-rc1 부터는 recent_rotated[] 및 recent_scaned[] 대신 anon_cost 와 file_cost 모델을 채용하였다.
- active된적이 있었던 refault(workingset detection) 페이지의경우 cost를 추가하여 이를 스캔 밸런싱에 사용하였다.
- 참고:
- mm: base LRU balancing on an explicit cost model (2020, v5.8-rc1)
- mm: vmscan: reclaim writepage is IO cost (2020, v5.8-rc1)
- 참고:
다음 그림은 비율을 적용한 SCAN_FRACT 모드인 경우에 사용될 anon 및 lru 비율을 산정하는 과정을 보여준다.
최종 lru별 스캔 수 산출
다음 그림은 4가지 모드 각각의 스캔 카운터를 구하는 모습을 보여준다.
- 숫자 0~3은 inactive anon lru(0)부터 active file lru(3)까지를 의미한다.
get_scan_count()
mm/vmscan.c -1/3-
/* * Determine how aggressively the anon and file LRU lists should be * scanned. The relative value of each set of LRU lists is determined * by looking at the fraction of the pages scanned we did rotate back * onto the active list instead of evict. * * nr[0] = anon inactive pages to scan; nr[1] = anon active pages to scan * nr[2] = file inactive pages to scan; nr[3] = file active pages to scan */
static void get_scan_count(struct lruvec *lruvec, struct mem_cgroup *memcg,
struct scan_control *sc, unsigned long *nr,
unsigned long *lru_pages)
{
int swappiness = mem_cgroup_swappiness(memcg);
struct zone_reclaim_stat *reclaim_stat = &lruvec->reclaim_stat;
u64 fraction[2];
u64 denominator = 0; /* gcc */
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
unsigned long anon_prio, file_prio;
enum scan_balance scan_balance;
unsigned long anon, file;
unsigned long ap, fp;
enum lru_list lru;
/* If we have no swap space, do not bother scanning anon pages. */
if (!sc->may_swap || mem_cgroup_get_nr_swap_pages(memcg) <= 0) {
scan_balance = SCAN_FILE;
goto out;
}
/*
* Global reclaim will swap to prevent OOM even with no
* swappiness, but memcg users want to use this knob to
* disable swapping for individual groups completely when
* using the memory controller's swap limit feature would be
* too expensive.
*/
if (!global_reclaim(sc) && !swappiness) {
scan_balance = SCAN_FILE;
goto out;
}
/*
* Do not apply any pressure balancing cleverness when the
* system is close to OOM, scan both anon and file equally
* (unless the swappiness setting disagrees with swapping).
*/
if (!sc->priority && swappiness) {
scan_balance = SCAN_EQUAL;
goto out;
}
/*
* Prevent the reclaimer from falling into the cache trap: as
* cache pages start out inactive, every cache fault will tip
* the scan balance towards the file LRU. And as the file LRU
* shrinks, so does the window for rotation from references.
* This means we have a runaway feedback loop where a tiny
* thrashing file LRU becomes infinitely more attractive than
* anon pages. Try to detect this based on file LRU size.
*/
if (global_reclaim(sc)) {
unsigned long pgdatfile;
unsigned long pgdatfree;
int z;
unsigned long total_high_wmark = 0;
pgdatfree = sum_zone_node_page_state(pgdat->node_id, NR_FREE_PAGES);
pgdatfile = node_page_state(pgdat, NR_ACTIVE_FILE) +
node_page_state(pgdat, NR_INACTIVE_FILE);
for (z = 0; z < MAX_NR_ZONES; z++) {
struct zone *zone = &pgdat->node_zones[z];
if (!managed_zone(zone))
continue;
total_high_wmark += high_wmark_pages(zone);
}
if (unlikely(pgdatfile + pgdatfree <= total_high_wmark)) {
/*
* Force SCAN_ANON if there are enough inactive
* anonymous pages on the LRU in eligible zones.
* Otherwise, the small LRU gets thrashed.
*/
if (!inactive_list_is_low(lruvec, false, memcg, sc, false) &&
lruvec_lru_size(lruvec, LRU_INACTIVE_ANON, sc->reclaim_idx)
>> sc->priority) {
scan_balance = SCAN_ANON;
goto out;
}
}
}
anon & file lru 리스트에서 얼마큼 스캔해야 하는지를 결정한다. lru 리스트 셋의 각 상대 값은 eviction 대신 active list로 다시 rotate back을 수행해야 하는 페이지의 비율을 찾는 것에 의해 결정된다.
- 코드 라인 5에서 memcg에 대해 swappiness 값을 알아온다.
- 코드 라인 17~20에서 swap이 필요 없거나 swap space가 없는 경우 anon 페이지의 swap을 할 수 없다. 따라서 이러한 경우 file 페이지만 스캔하도록 결정하고 out 레이블로 이동한다.
- 코드 라인 29~32에서 글로벌 reclaim이 아니고 swappiness 값이 0인 경우 file 페이지만 스캔하도록 결정하고 out 레이블로 이동한다.
- 코드 라인 39~42에서 최우선 순위(OOM이 가까와진)이고 swappiness 값이 주어진 경우 동등한 밸런스를 하도록 결정하고 out 레이블로 이동한다.
- 코드 라인 53~84에서 글로벌 reclaim인 경우 노드의 free 페이지와 file 페이지 수를 알아온다. 그리고 해당 노드에 포함된 존들의 high 워터마크 합산 값을 알아온다. 낮은 확률로 다음 조건을 만족하는 경우 anon 페이지만 스캔하도록 결정하고 out 레이블로 이동한다.
- free 페이지와 file 페이지 수가 high 워터마크 합산 값 이하이다.
- inactive anon 페이지 수가 0 이상이고 active anon 페이지 수보다 크다.
mm/vmscan.c -2/3-
. /*
* If there is enough inactive page cache, i.e. if the size of the
* inactive list is greater than that of the active list *and* the
* inactive list actually has some pages to scan on this priority, we
* do not reclaim anything from the anonymous working set right now.
* Without the second condition we could end up never scanning an
* lruvec even if it has plenty of old anonymous pages unless the
* system is under heavy pressure.
*/
if (!inactive_list_is_low(lruvec, true, memcg, sc, false) &&
lruvec_lru_size(lruvec, LRU_INACTIVE_FILE, sc->reclaim_idx) >> sc->priority) {
scan_balance = SCAN_FILE;
goto out;
}
scan_balance = SCAN_FRACT;
/*
* With swappiness at 100, anonymous and file have the same priority.
* This scanning priority is essentially the inverse of IO cost.
*/
anon_prio = swappiness;
file_prio = 200 - anon_prio;
/*
* OK, so we have swap space and a fair amount of page cache
* pages. We use the recently rotated / recently scanned
* ratios to determine how valuable each cache is.
*
* Because workloads change over time (and to avoid overflow)
* we keep these statistics as a floating average, which ends
* up weighing recent references more than old ones.
*
* anon in [0], file in [1]
*/
anon = lruvec_lru_size(lruvec, LRU_ACTIVE_ANON, MAX_NR_ZONES) +
lruvec_lru_size(lruvec, LRU_INACTIVE_ANON, MAX_NR_ZONES);
file = lruvec_lru_size(lruvec, LRU_ACTIVE_FILE, MAX_NR_ZONES) +
lruvec_lru_size(lruvec, LRU_INACTIVE_FILE, MAX_NR_ZONES);
spin_lock_irq(&pgdat->lru_lock);
if (unlikely(reclaim_stat->recent_scanned[0] > anon / 4)) {
reclaim_stat->recent_scanned[0] /= 2;
reclaim_stat->recent_rotated[0] /= 2;
}
if (unlikely(reclaim_stat->recent_scanned[1] > file / 4)) {
reclaim_stat->recent_scanned[1] /= 2;
reclaim_stat->recent_rotated[1] /= 2;
}
/*
* The amount of pressure on anon vs file pages is inversely
* proportional to the fraction of recently scanned pages on
* each list that were recently referenced and in active use.
*/
ap = anon_prio * (reclaim_stat->recent_scanned[0] + 1);
ap /= reclaim_stat->recent_rotated[0] + 1;
fp = file_prio * (reclaim_stat->recent_scanned[1] + 1);
fp /= reclaim_stat->recent_rotated[1] + 1;
spin_unlock_irq(&pgdat->lru_lock);
fraction[0] = ap;
fraction[1] = fp;
denominator = ap + fp + 1;
- 코드 라인 10~14에서 inactive file 페이지 수가 0 이상이고 active file 페이지 수보다 크면 file 페이지만 스캔하도록 결정하고 out 레이블로 이동한다.
- 코드 라인 16에서 anon 페이지와 file 페이지를 산출된 비율로 스캔을 하는 것으로 결정한다.
- 코드 라인 22~23에서 첫 번째, anon과 file에 해당하는 scanning priority(anon_prio와 file_prio)를 결정한다. anon_prio에 해당하는 swappiness 값은 0 ~ 100이다. file_prio는 200 – anon_prio 값을 사용한다. 참고로 swappiness가 100일 경우 anon_prio와 file_prio가 동일하다. 이 값은 다음 fs를 통해서 바꿀 수 있다.
- /proc/sys/vm/swappiness (for global)
- /sys/fs/cgroup/memory/memory.swappiness (for each memcg.)
- swappiness가 0일 때 문제가되는 경우도 있으니 주의해야 한다.
- 코드 라인 37~40에서 anon 페이지 수와 file 페이지 수를 알아온다.
- 코드 라인 43~46에서 작은 확률로 최근 anon scan 페이지 수가 anon의 25%보다 큰 경우 최근 anon scan 페이지 수와 최근 anon rotate 수를 절반으로 줄인다.
- 코드 라인 48~51에서 작은 확률로 최근 file scan 페이지 수가 file의 25%보다 큰 경우 최근 file scan 페이지 수와 최근 file rotate 수를 절반으로 줄인다.
- 코드 라인 58~67에서 scan 페이지 수를 비율로 산출하기 위해 두 번째, 비율 적용 시 anon 및 file 비율이 담기는 fraction[]에 대입한다. 비율 산출 시 분모로 사용할 값으로 그 두 값을 더해 denominator에 대입한다.(+1을 추가하는 이유는 나눗셈 연산에서 에러가 발생하지 않도록 추가하였다.)
- fraction[0] = ap = anon_prio(0~200) * 최근 anon rotate에 비해 최근 scan된 비율
- fraction[1] = fp = file_prio(200-anon_prio) * 최근 file rotate에 비해 최근 scan된 비율
- denominator = ap + fp + 1
mm/vmscan.c -3/3-
out:
*lru_pages = 0;
for_each_evictable_lru(lru) {
int file = is_file_lru(lru);
unsigned long size;
unsigned long scan;
size = lruvec_lru_size(lruvec, lru, sc->reclaim_idx);
scan = size >> sc->priority;
/*
* If the cgroup's already been deleted, make sure to
* scrape out the remaining cache.
*/
if (!scan && !mem_cgroup_online(memcg))
scan = min(size, SWAP_CLUSTER_MAX);
switch (scan_balance) {
case SCAN_EQUAL:
/* Scan lists relative to size */
break;
case SCAN_FRACT:
/*
* Scan types proportional to swappiness and
* their relative recent reclaim efficiency.
* Make sure we don't miss the last page
* because of a round-off error.
*/
scan = DIV64_U64_ROUND_UP(scan * fraction[file],
denominator);
break;
case SCAN_FILE:
case SCAN_ANON:
/* Scan one type exclusively */
if ((scan_balance == SCAN_FILE) != file) {
size = 0;
scan = 0;
}
break;
default:
/* Look ma, no brain */
BUG();
}
*lru_pages += size;
nr[lru] = scan;
}
}
- 코드 라인 1~3에서 lru 별로 최종 스캔할 수를 산출할 out: 레이블이다. evictable lru 만큼 순회한다.
- 코드 라인 8~9에서 스캔 할 수는 해당 lru 사이즈를 우선 순위 만큼 우측 시프트하여 결정한다.
- 우선 순위가 가장 높은 경우 sc->priority 값이 0이므로 해당 lru 사이즈를 모두 사용한다.
- 코드 라인 14~15에서 스캔 수가 0이거나 memcg가 이미 삭제된 경우 스캔 수를 lru 사이즈로 결정한다. 단 최대 수는 32로 제한한다.
- 코드 라인 17~42에서 결정된 다음 4 가지 스캔 밸런스 방법에 따라 lru 별로 scan 수를 결정한다.
- SCAN_EQUAL
- 산출된 scan 값을 그대로 사용한다.
- SCAN_FRACT
- 산출된 scan 값에 비율(fraction )을 적용한다.
- SCAN_FILE
- anon lru의 경우 스캔 수를 0으로 변경한다.
- SCAN_ANON
- file lru의 경우 스캔 수를 0으로 변경한다.
- SCAN_EQUAL
- 코드 라인 44~45에서 결정된 사이즈는 출력 인자 @lru_pages에 대입하고, 스캔 수는 출력 인자 @nr[lru]에 대입한다.
다음 그림은 get_scan_coun() 함수를 통해 각 스캔 모드를 결정하는 이유를 보여준다.
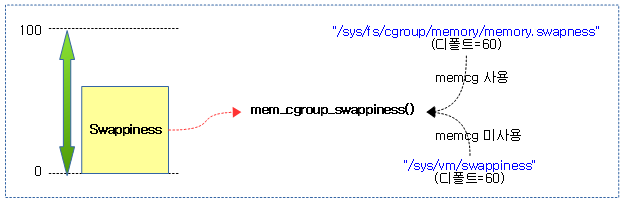
Swappiness
mem_cgroup_swappiness()
include/linux/swap.h
static inline int mem_cgroup_swappiness(struct mem_cgroup *memcg)
{
/* Cgroup2 doesn't have per-cgroup swappiness */
if (cgroup_subsys_on_dfl(memory_cgrp_subsys))
return vm_swappiness;
/* root ? */
if (mem_cgroup_disabled() || !memcg->css.parent)
return vm_swappiness;
return memcg->swappiness;
}
memcg의 “memory.swappiness” 값을 알아온다. 이 값의 디폴트 값은 60이며 0~100까지 사용된다. memcg가 사용되지 않는 경우 vm_swappiness(0..100, 디폴트: 60)를 반환한다.
다음 그림은 swappiness 값을 알아오는 과정을 보여준다.
기타
zone_reclaimable()
mm/vmscan.c
bool zone_reclaimable(struct zone *zone)
{
return zone_page_state(zone, NR_PAGES_SCANNED) <
zone_reclaimable_pages(zone) * 6;
}
zone에서 스캔된 페이지 수가 회수할 수 있는 페이지의 6배 보다 작은 경우 회수가 가능하다고 판단한다.
zone_reclaimable_pages()
mm/vmscan.c
static unsigned long zone_reclaimable_pages(struct zone *zone)
{
int nr;
nr = zone_page_state(zone, NR_ACTIVE_FILE) +
zone_page_state(zone, NR_INACTIVE_FILE);
if (get_nr_swap_pages() > 0)
nr += zone_page_state(zone, NR_ACTIVE_ANON) +
zone_page_state(zone, NR_INACTIVE_ANON);
return nr;
}
요청 zone의 최대 회수 가능한 페이지 수를 알아온다.
- active file + inactive file 건 수를 더한 수를 반환환다. 만일 swap 페이지가 있는 경우 active anon과 inactive anon 건 수도 더해 반환한다.
get_nr_swap_pages()
include/linux/swap.h
static inline long get_nr_swap_pages(void)
{
return atomic_long_read(&nr_swap_pages);
}
swap 페이지 수를 반환한다.
구조체
scan_control 구조체
mm/vmscan.c
struct scan_control {
/* How many pages shrink_list() should reclaim */
unsigned long nr_to_reclaim;
/*
* Nodemask of nodes allowed by the caller. If NULL, all nodes
* are scanned.
*/
nodemask_t *nodemask;
/*
* The memory cgroup that hit its limit and as a result is the
* primary target of this reclaim invocation.
*/
struct mem_cgroup *target_mem_cgroup;
/* Writepage batching in laptop mode; RECLAIM_WRITE */
unsigned int may_writepage:1;
/* Can mapped pages be reclaimed? */
unsigned int may_unmap:1;
/* Can pages be swapped as part of reclaim? */
unsigned int may_swap:1;
/* e.g. boosted watermark reclaim leaves slabs alone */
unsigned int may_shrinkslab:1;
/*
* Cgroups are not reclaimed below their configured memory.low,
* unless we threaten to OOM. If any cgroups are skipped due to
* memory.low and nothing was reclaimed, go back for memory.low.
*/
unsigned int memcg_low_reclaim:1;
unsigned int memcg_low_skipped:1;
unsigned int hibernation_mode:1;
/* One of the zones is ready for compaction */
unsigned int compaction_ready:1;
/* Allocation order */
s8 order;
/* Scan (total_size >> priority) pages at once */
s8 priority;
/* The highest zone to isolate pages for reclaim from */
s8 reclaim_idx;
/* This context's GFP mask */
gfp_t gfp_mask;
/* Incremented by the number of inactive pages that were scanned */
unsigned long nr_scanned;
/* Number of pages freed so far during a call to shrink_zones() */
unsigned long nr_reclaimed;
struct {
unsigned int dirty;
unsigned int unqueued_dirty;
unsigned int congested;
unsigned int writeback;
unsigned int immediate;
unsigned int file_taken;
unsigned int taken;
} nr;
};
- nr_to_reclaim
- shrink_list()에서 회수할 페이지 수
- *nodemask
- 스캔할 노드 마스크 비트맵. null인 경우 모든 노드에서 스캔
- *target_mem_cgroup
- 타겟 memcg가 주어진 경우 하이라키로 구성된 이 memcg 이하의 memcg를 대상으로 한정한다.
- may_writepage
- dirty된 file 캐시 페이지를 write 시킨 후 회수 가능
- may_unmap
- mapped 페이지를 unmap 시킨 후 회수 가능
- may_swap
- 스웝을 사용하여 페이지 회수 가능
- may_shrinkslab
- e.g. boosted watermark reclaim leaves slabs alone
- memcg_low_reclaim:1
- memcg_low_skipped:1
- hibernation_mode:1
- 절전모드
- compaction_ready:1
- zone 들 중 하나가 compaction 준비가 된 경우
- order
- 할당 order
- priority
- 한 번에 스캔할 페이지 수 (total_size >> priority)
- reclaim_idx
- 이 존 이하를 대상으로 스캔한다. (이 보다 높은 존은 대상에서 제외)
- gfp_mask
- GFP mask
- nr_scanned
- 스캔한 inactive 페이지의 수
- nr_reclaimed
- shrink_zones()을 호출하고 회수된 free 페이지의 수
참고
- Zoned Allocator -1- (물리 페이지 할당-Fastpath) | 문c
- Zoned Allocator -2- (물리 페이지 할당-Slowpath) | 문c
- Zoned Allocator -3- (Buddy 페이지 할당) | 문c
- Zoned Allocator -4- (Buddy 페이지 해지) | 문c
- Zoned Allocator -5- (Per-CPU Page Frame Cache) | 문c
- Zoned Allocator -6- (Watermark) | 문c
- Zoned Allocator -7- (Direct Compact) | 문c
- Zoned Allocator -8- (Direct Compact-Isolation) | 문c
- Zoned Allocator -9- (Direct Compact-Migration) | 문c
- Zoned Allocator -10- (LRU & pagevec) | 문c
- Zoned Allocator -11- (Direct Reclaim) | 문c
- Zoned Allocator -12- (Direct Reclaim-Shrink-1) | 문c – 현재 글
- Zoned Allocator -13- (Direct Reclaim-Shrink-2) | 문c
- Zoned Allocator -14- (Kswapd) | 문c
안녕하세요 좋은 글 감사합니다.
글을 읽다가 궁금한 점이 생겼는데욥
만약에 dirty page를 free page로 만들어주기 위해서
balance_dirty_pages() 함수에서
storage로 I/O를 발생시켜서 해당 내용을 write해야 하는 경우,
해당 dirty page의 상태가 clean page로 바뀌어서 free page로 관리가 되려면, storage에서 실제로 그 내용을 써서 I/O completion까지 하고 나서야 가능한 것인가요?
아니면 혹시 실제 storage에 쓰지 않더라도, block layer에 있는 큐로 I/O 요청을 던지기만 해도(예를 들면) dirty page의 상태가 clean으로 변하게 되는 것인지 궁금합니다
안녕하세요?
write-back이 완료될 때 까지 Dirty 상태가 유지됩니다.
따라서 블럭 레이어의 큐가 아니라 완전히 파일시스템에 기록이 완료되면 write-back 플래그가 클리어되고, 그 후 Dirty 플래그도 클리어됩니다.
감사합니다.
아.. 제가 잘못 대답했습니다.
pageout() 함수를 보니까 dirty 플래그를 지운 후에 I/O 요청을 하네요. ^^;
답변 감사합니다.
pageout함수내에 clear_page_dirty_for_io()가 호출이 되네요.
그렇다면 좀 의문이 드는 점이 있는데요, free page를 만들기 위해 dirty page를 pageout()을 하는 경우(file cache에 있던 dirty page),
아직 storage와 dirty page가 서로 동기화가 되지 않았는데도 불구하고 이미 free page가 되어
free page로서 관리가 된다는 건가요?
lru 리스트내에서 페이지 캐시가 완전히 클린이 된 상태에서만 버디에 되돌립니다.
writeback 작업을 비동기로 요청만한 후 writeback 및 reclaim 플래그를 설정한 채로 계속 lru에 둡니다.
다시 한 번 lru inactive 리스트를 돌면서 언젠가 자기 페이지 턴이 왔을 때마다 체크를 합니다.
이 때 기록이 완료되어 writeback이 없어진 클린 상태가 되면 reclaim 플래그도 제거하고 버디 시스템으로 페이지를 보내 페이지를 회수 합니다.
다음은 이해를 돕기 위한 스텝별 플래그입니다. (lock 플래그는 표현에서 제외)
lru,dirty 상태-> 회수시작(lru,reclaim) -> 기록중(lru,reclaim,writeback) -> 기록완료(lru,reclaim) -> 클린(lru) -> 버디회수(buddy)
친절한 답변 감사합니다.
네. 열공하세요. ^^
안녕하세요, 글을 읽다가 궁금한 점이 생겨 질문을 남깁니다.
shrink_page_list() 에서 dirty file page 는 pageout() 이 되고 그 나머지는 inactive list로 rotate 한다라고 하셨는데요.
여기서 pageout() 되는 dirty file page 는 tmpfs 와 관련된 file page 만 해당되는 것인가요? 아니면 정규 파일의 dirty data page 도 포함되는 것인가요?
관련 부분이 궁금하여 gdb로 breakpoint를 해봤을 경우에는 pageout() 은 swap_writepage를 호출하는 것 같아 여쭤봅니다.
안녕하세요?
가상 메모리에 매핑되어 있는 메모리에 dirty 플래그가 있다는 말은 어디엔가 원본이 있다는 말입니다.
그런데 그 원본이 swap 데이터에 있을 수도 있고, 매핑된 파일(tmpfs, 정규 파일 등)에 있을 수도 있습니다.
때문에 pageout()을 하게되면 swap 데이터(anon)에서 온 매핑인 경우 swap하고, 그렇지 않은 tmpfs나 정규 파일들은 저장을 하는 동작으로 진행합니다.
(즉 질문의 두 tmpfs 및 정규 파일 모두 해당합니다,)
감사합니다.
네 답변 감사합니다.!
좋은 하루되시길 바랍니다. 즐공하세요.
안녕하세요,
좋은 정보 얻어갑니다.
질문이 있어서 댓글을 쓰게 되었는데요.
Fileserver로 intensive하게 pagecache를 사용하는 경우, perf로 page reclamation count를 측정해보니 direct reclaim과 kswapd는 불리지만
실제 writepage는 불리지 않는 것으로 측정되었습니다.
하지만 이와중에 blktrace를 확인해보면 실제 I/O는 내려가는 것으로 확인되는데요.
pageout쪽 코드를 보니 write가 non-blocking일때만 write를 한다고 나와있는데, 이와 관련된 것인지 궁금합니다.
혹시 실제 writepage 함수가 요청되지 않는다면, 어떤 방식을 통해 dirty file backed pages들을 스토리지와 동기화 시키고 해제를 하나요?
감사합니다…
실제로 동작시킨 방법과, 확인한 내용들을 알려주시겠습니까?
확인할 때 cat /proc/vmstat 내용도요.
내용이 많으면 메일(jakeisname@gmail.com)로 주셔도 됩니다.