<kernel v5.0>
Kswapd & Kcompactd
노드마다 kswapd와 kcompactd가 동작하며 free 메모리가 일정량 이상 충분할 때에는 잠들어(sleep) 있다. 그런데 페이지 할당자가 order 페이지 할당을 시도하다 free 페이지가 부족해 low 워터마크 기준을 충족하지 못하는 순간 kswapd 및 kcompactd를 깨운다. kswapd는 자신의 노드에서 페이지 회수를 진행하고, kcompactd는 compaction을 진행하는데 모든 노드에 대해 밸런스하게 high 워터마크 기준을 충족하게 되면 스스로 sleep 한다.
kswapd 초기화
kswapd_init()
mm/vmscan.c
static int __init kswapd_init(void)
{
int nid, ret;
swap_setup();
for_each_node_state(nid, N_MEMORY)
kswapd_run(nid);
ret = cpuhp_setup_state_nocalls(CPUHP_AP_ONLINE_DYN,
"mm/vmscan:online", kswapd_cpu_online,
NULL);
WARN_ON(ret < 0);
return 0;
}
module_init(kswapd_init)
kswapd를 사용하기 위해 초기화한다.
- 코드 라인 5에서 kswapd 실행 전에 준비한다.
- 코드 라인 6~7에서 모든 메모리 노드에 대해 kswapd를 실행시킨다.
- 코드 라인 8~10에서 cpu가 hot-plug를 통해 CPUHP_AP_ONLINE_DYN 상태로 변경될 때 kswapd_cpu_online() 함수가 호출될 수 있도록 등록한다.
swap_setup()
mm/swap.c
/* * Perform any setup for the swap system */
void __init swap_setup(void)
{
unsigned long megs = totalram_pages >> (20 - PAGE_SHIFT);
/* Use a smaller cluster for small-memory machines */
if (megs < 16)
page_cluster = 2;
else
page_cluster = 3;
/*
* Right now other parts of the system means that we
* _really_ don't want to cluster much more
*/
}
kswapd 실행 전에 준비한다.
- 코드 라인 3~9에서 전역 total 램이 16M 이하이면 page_cluster에 2를 대입하고 그렇지 않으면 3을 대입한다.
kswapd_run()
mm/vmscan.c
/* * This kswapd start function will be called by init and node-hot-add. * On node-hot-add, kswapd will moved to proper cpus if cpus are hot-added. */
int kswapd_run(int nid)
{
pg_data_t *pgdat = NODE_DATA(nid);
int ret = 0;
if (pgdat->kswapd)
return 0;
pgdat->kswapd = kthread_run(kswapd, pgdat, "kswapd%d", nid);
if (IS_ERR(pgdat->kswapd)) {
/* failure at boot is fatal */
BUG_ON(system_state == SYSTEM_BOOTING);
pr_err("Failed to start kswapd on node %d\n", nid);
ret = PTR_ERR(pgdat->kswapd);
pgdat->kswapd = NULL;
}
return ret;
}
kswapd 스레드를 동작시킨다.
- 코드 라인 3~7에서 @nid 노드의 kswapd 스레드가 이미 실행 중인 경우 skip하기 위해 0을 반환한다.
- 코드 라인 9~16에서 kswapd 스레드를 동작시킨다.
kswapd 동작
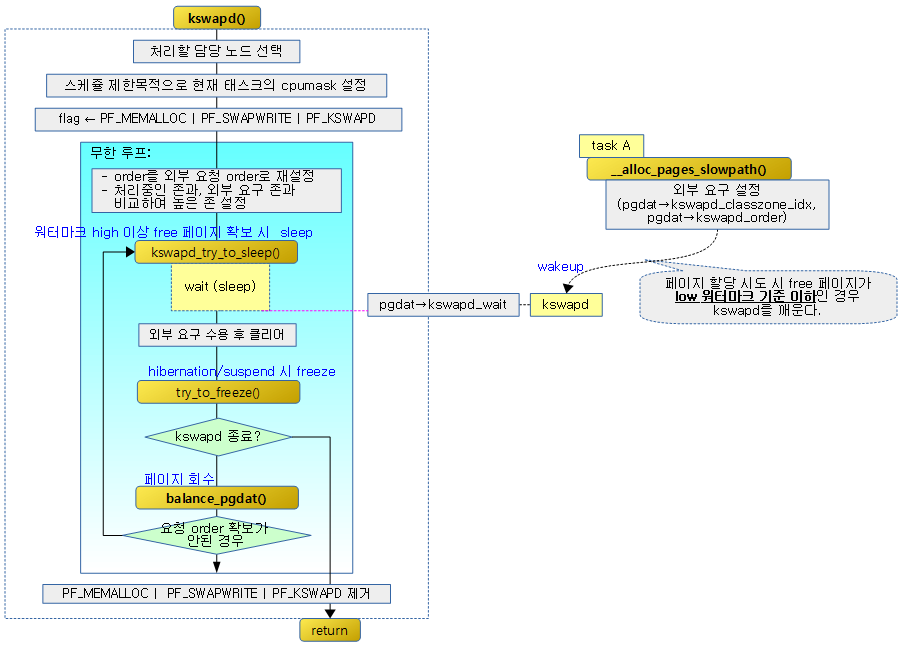
kswapd()
mm/vmscan.c
/* * The background pageout daemon, started as a kernel thread * from the init process. * * This basically trickles out pages so that we have _some_ * free memory available even if there is no other activity * that frees anything up. This is needed for things like routing * etc, where we otherwise might have all activity going on in * asynchronous contexts that cannot page things out. * * If there are applications that are active memory-allocators * (most normal use), this basically shouldn't matter. */
static int kswapd(void *p)
{
unsigned int alloc_order, reclaim_order;
unsigned int classzone_idx = MAX_NR_ZONES - 1;
pg_data_t *pgdat = (pg_data_t*)p;
struct task_struct *tsk = current;
struct reclaim_state reclaim_state = {
.reclaimed_slab = 0,
};
const struct cpumask *cpumask = cpumask_of_node(pgdat->node_id);
if (!cpumask_empty(cpumask))
set_cpus_allowed_ptr(tsk, cpumask);
current->reclaim_state = &reclaim_state;
/*
* Tell the memory management that we're a "memory allocator",
* and that if we need more memory we should get access to it
* regardless (see "__alloc_pages()"). "kswapd" should
* never get caught in the normal page freeing logic.
*
* (Kswapd normally doesn't need memory anyway, but sometimes
* you need a small amount of memory in order to be able to
* page out something else, and this flag essentially protects
* us from recursively trying to free more memory as we're
* trying to free the first piece of memory in the first place).
*/
tsk->flags |= PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD;
set_freezable();
pgdat->kswapd_order = 0;
pgdat->kswapd_classzone_idx = MAX_NR_ZONES;
for ( ; ; ) {
bool ret;
alloc_order = reclaim_order = pgdat->kswapd_order;
classzone_idx = kswapd_classzone_idx(pgdat, classzone_idx);
kswapd_try_sleep:
kswapd_try_to_sleep(pgdat, alloc_order, reclaim_order,
classzone_idx);
/* Read the new order and classzone_idx */
alloc_order = reclaim_order = pgdat->kswapd_order;
classzone_idx = kswapd_classzone_idx(pgdat, 0);
pgdat->kswapd_order = 0;
pgdat->kswapd_classzone_idx = MAX_NR_ZONES;
ret = try_to_freeze();
if (kthread_should_stop())
break;
/*
* We can speed up thawing tasks if we don't call balance_pgdat
* after returning from the refrigerator
*/
if (ret)
continue;
/*
* Reclaim begins at the requested order but if a high-order
* reclaim fails then kswapd falls back to reclaiming for
* order-0. If that happens, kswapd will consider sleeping
* for the order it finished reclaiming at (reclaim_order)
* but kcompactd is woken to compact for the original
* request (alloc_order).
*/
trace_mm_vmscan_kswapd_wake(pgdat->node_id, classzone_idx,
alloc_order);
reclaim_order = balance_pgdat(pgdat, alloc_order, classzone_idx);
if (reclaim_order < alloc_order)
goto kswapd_try_sleep;
}
tsk->flags &= ~(PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD);
current->reclaim_state = NULL;
return 0;
}
각 노드에서 동작되는 kswapd 스레드는 각 노드에서 동작하는 zone에 대해 free 페이지가 low 워터마크 이하로 내려가는 경우 백그라운드에서 페이지 회수를 진행하고 high 워터마크 이상이 되는 경우 페이지 회수를 멈춘다.
- 코드 라인 5~14에서 요청 노드에서 동작하는 온라인 cpumask를 읽어와서 현재 태스크에 설정한다.
- 요청 노드의 cpumask를 현재 task에 cpus_allowed 등을 설정한다.
- 코드 라인 15에서 현재 태스크의 reclaim_state가 초기화된 reclaim_state 구조체를 가리키게 한다.
- 코드 라인 29에서 현재 태스크의 플래그에 PF_MEMALLOC, PF_SWAPWRITE 및 PF_KSWAPD를 설정한다.
- PF_MEMALLOC
- 메모리 reclaim을 위한 태스크로 워터 마크 제한 없이 할당할 수 있도록 한다.
- PF_SWAPWRITE
- anon 메모리에 대해 swap 기록 요청을 한다.
- PF_KSWAPD
- kswapd task를 의미한다.
- PF_MEMALLOC
- 코드 라인 30에서 현재 태스크를 freeze할 수 있도록 PF_NOFREEZE 플래그를 제거한다.
- 참고: freeze | 문c
- 코드 라인 32~33에서 kswapd_order를 0부터 시작하게 하고 kswapd_classzone_idx는 가장 상위부터 할 수 있도록 MAX_NR_ZONES를 대입해둔다.
- 코드 라인 34~38에서 alloc_order와 reclaim_order를 노드의 kswapd가 진행하는 order를 사용한다. 그리고 대상 존인 classzone_idx를 가져온다.
- 코드 라인 40~42에서 try_sleep: 레이블이다. kswapd가 슬립하도록 시도한다.
- 코드 라인 45~46에서 alloc_order와 reclaim_order를 외부에서 요청한 order와 zone을 적용시킨다.
- 코드 라인 47~48에서 kwapd_order를 0으로 리셋하고, kswapd_classzone_idx는 가장 상위부터 할 수 있도록 MAX_NR_ZONES를 대입해둔다.
- 코드 라인 50에서 현재 태스크 kswapd에 대해 freeze 요청이 있는 경우 freeze 시도한다.
- 코드 라인 51~52에서 현재 태스크의 KTHREAD_SHOULD_STOP 플래그 비트가 설정된 경우 루프를 탈출하고 스레드 종료 처리한다.
- 코드 라인 58~59에서 freeze 된 적이 있으면 빠른 처리를 위해 노드 밸런스를 동작시키지 않고 계속 진행한다.
- 코드 라인 71에서 freeze 한 적이 없었던 경우이다. order 페이지와 존을 대상으로 페이지 회수를 진행한다.
- 코드 라인 72~73에서 요청한 order에서 회수가 실패한 경우 order 0 및 해당 존에서 다시 시도하기 위해 try_sleep: 레이블로 이동한다.
- 코드 라인 74에서 요청한 order에서 회수가 성공한 경우에는 루프를 계속 반복한다.
- 코드 라인 76~79에서 kswapd 스레드의 처리를 완료시킨다.
kswapd_try_to_sleep()
mm/vmscan.c
static void kswapd_try_to_sleep(pg_data_t *pgdat, int alloc_order, int reclaim_order,
unsigned int classzone_idx)
{
long remaining = 0;
DEFINE_WAIT(wait);
if (freezing(current) || kthread_should_stop())
return;
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
/*
* Try to sleep for a short interval. Note that kcompactd will only be
* woken if it is possible to sleep for a short interval. This is
* deliberate on the assumption that if reclaim cannot keep an
* eligible zone balanced that it's also unlikely that compaction will
* succeed.
*/
if (prepare_kswapd_sleep(pgdat, reclaim_order, classzone_idx)) {
/*
* Compaction records what page blocks it recently failed to
* isolate pages from and skips them in the future scanning.
* When kswapd is going to sleep, it is reasonable to assume
* that pages and compaction may succeed so reset the cache.
*/
reset_isolation_suitable(pgdat);
/*
* We have freed the memory, now we should compact it to make
* allocation of the requested order possible.
*/
wakeup_kcompactd(pgdat, alloc_order, classzone_idx);
remaining = schedule_timeout(HZ/10);
/*
* If woken prematurely then reset kswapd_classzone_idx and
* order. The values will either be from a wakeup request or
* the previous request that slept prematurely.
*/
if (remaining) {
pgdat->kswapd_classzone_idx = kswapd_classzone_idx(pgdat, classzone_idx);
pgdat->kswapd_order = max(pgdat->kswapd_order, reclaim_order);
}
finish_wait(&pgdat->kswapd_wait, &wait);
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
}
/*
* After a short sleep, check if it was a premature sleep. If not, then
* go fully to sleep until explicitly woken up.
*/
if (!remaining &&
prepare_kswapd_sleep(pgdat, reclaim_order, classzone_idx)) {
trace_mm_vmscan_kswapd_sleep(pgdat->node_id);
/*
* vmstat counters are not perfectly accurate and the estimated
* value for counters such as NR_FREE_PAGES can deviate from the
* true value by nr_online_cpus * threshold. To avoid the zone
* watermarks being breached while under pressure, we reduce the
* per-cpu vmstat threshold while kswapd is awake and restore
* them before going back to sleep.
*/
set_pgdat_percpu_threshold(pgdat, calculate_normal_threshold);
if (!kthread_should_stop())
schedule();
set_pgdat_percpu_threshold(pgdat, calculate_pressure_threshold);
} else {
if (remaining)
count_vm_event(KSWAPD_LOW_WMARK_HIT_QUICKLY);
else
count_vm_event(KSWAPD_HIGH_WMARK_HIT_QUICKLY);
}
finish_wait(&pgdat->kswapd_wait, &wait);
}
노드에 대해 요청 order 및 zone 까지 free 페이지가 high 워터마크 기준으로 밸런스하게 할당할 수 있는 상태라면 sleep 한다.
- 코드 라인 7~8에서 freeze 요청이 있는 경우 함수를 빠져나간다.
- 코드 라인 10에서 현재 태스크를 kswapd_wait에 추가하여 sleep할 준비를 한다.
- 코드 섹션 19~48에서 요청 zone 까지 그리고 요청 order에 대해 free 페이지가 밸런스된 high 워터마크 기준을 충족하는 경우의 처리이다.
- 최근에 direct-compaction이 완료되어 해당 존에서 compaction을 다시 처음부터 시작할 수 있도록 존에 compact_blockskip_flush이 설정된다. 이렇게 설정된 존들에 대해 skip 블럭 비트를 모두 클리어한다.
- compactd 스레드를 깨운다.
- 0.1초를 sleep 한다. 만일 중간에 깬 경우 노드에 kswapd가 처리중인 zone과 order를 기록해둔다.
- 다시 슬립할 준비를 한다.
- 코드 섹션 54~71에서 중간에 깨어나지 않고 0.1초를 완전히 슬립하였고, 여전히 요청 zone 까지 그리고 요청 order에 대해 free 페이지가 확보되어 밸런스된 high 워터마크 기준을 충족하면 다음과 같이 처리한다.
- NR_FREE_PAGES 등의 vmstat을 정밀하게 계산할 필요 여부를 per-cpu 스레졸드라고 하는데, 이를 일반적인 기준의 스레졸드로 지정하도록 노드에 포함된 각 zone에 대해 normal한 스레졸드 값을 지정한다.
- 스레드 종료 요청이 아닌 경우 sleep한다.
- kswapd가 깨어났다는 이유는 메모리 압박 상황이 되었다라는 의미이다. 따라서 이번에는 per-cpu 스레졸드 값으로 pressure한 스레졸드 값을 사용하기 지정한다.
- 코드 섹션 72~77에서 메모리 부족 상황이 빠르게 온 경우이다. 슬립하자마자 깨어났는데 조건에 따라 관련 카운터를 다음과 같이 처리한다.
- 0.1초간 잠시 sleep 하는 와중에 다시 메모리 부족을 이유로 현재 스레드인 kswapd가 깨어난 경우에는 KSWAPD_LOW_WMARK_HIT_QUICKLY 카운터를 증가시킨다.
- 0.1초 슬립한 후에도 high 워터마크 기준을 충족할 만큼 메모리가 확보되지 못해 슬립하지 못하는 상황이다. 이러한 경우 KSWAPD_HIGH_WMARK_HIT_QUICKLY 카운터를 증가시킨다.
- 코드 섹션 78에서 kswapd_wait 에서 현재 태스크를 제거한다.
다음 그림은 kswapd_try_to_sleep() 함수를 통해 kswapd가 high 워터마크 기준을 충족하면 슬립하는 과정을 보여준다.
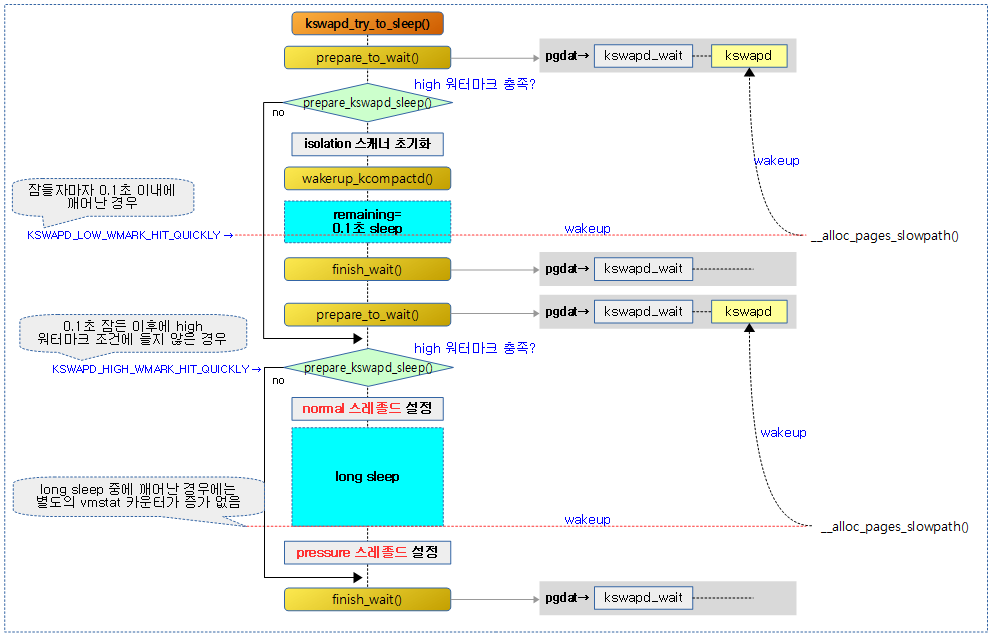
밸런스될 때까지 페이지 회수
balance_pgdat()
mm/vmscan.c -1/3-
/* * For kswapd, balance_pgdat() will reclaim pages across a node from zones * that are eligible for use by the caller until at least one zone is * balanced. * * Returns the order kswapd finished reclaiming at. * * kswapd scans the zones in the highmem->normal->dma direction. It skips * zones which have free_pages > high_wmark_pages(zone), but once a zone is * found to have free_pages <= high_wmark_pages(zone), any page is that zone * or lower is eligible for reclaim until at least one usable zone is * balanced. */
static int balance_pgdat(pg_data_t *pgdat, int order, int classzone_idx)
{
int i;
unsigned long nr_soft_reclaimed;
unsigned long nr_soft_scanned;
unsigned long pflags;
unsigned long nr_boost_reclaim;
unsigned long zone_boosts[MAX_NR_ZONES] = { 0, };
bool boosted;
struct zone *zone;
struct scan_control sc = {
.gfp_mask = GFP_KERNEL,
.order = order,
.may_unmap = 1,
};
psi_memstall_enter(&pflags);
__fs_reclaim_acquire();
count_vm_event(PAGEOUTRUN);
/*
* Account for the reclaim boost. Note that the zone boost is left in
* place so that parallel allocations that are near the watermark will
* stall or direct reclaim until kswapd is finished.
*/
nr_boost_reclaim = 0;
for (i = 0; i <= classzone_idx; i++) {
zone = pgdat->node_zones + i;
if (!managed_zone(zone))
continue;
nr_boost_reclaim += zone->watermark_boost;
zone_boosts[i] = zone->watermark_boost;
}
boosted = nr_boost_reclaim;
restart:
sc.priority = DEF_PRIORITY;
do {
unsigned long nr_reclaimed = sc.nr_reclaimed;
bool raise_priority = true;
bool balanced;
bool ret;
sc.reclaim_idx = classzone_idx;
/*
* If the number of buffer_heads exceeds the maximum allowed
* then consider reclaiming from all zones. This has a dual
* purpose -- on 64-bit systems it is expected that
* buffer_heads are stripped during active rotation. On 32-bit
* systems, highmem pages can pin lowmem memory and shrinking
* buffers can relieve lowmem pressure. Reclaim may still not
* go ahead if all eligible zones for the original allocation
* request are balanced to avoid excessive reclaim from kswapd.
*/
if (buffer_heads_over_limit) {
for (i = MAX_NR_ZONES - 1; i >= 0; i--) {
zone = pgdat->node_zones + i;
if (!managed_zone(zone))
continue;
sc.reclaim_idx = i;
break;
}
}
우선 순위를 12부터 1까지 높여가며 페이지 회수 및 compaction을 진행하여 free 페이지가 요청 order 및 zone까지 밸런스하게 high 워터마크 기준을 충족할 때까지 진행한다.
- 코드 라인 11~15에서 준비한 scan_control 구조체에 매핑된 페이지를 언맵할 수 있게 may_unmap=1로 설정한다.
- 코드 라인 17에서 메모리 부족으로 인한 현재 태스크의 psi 산출을 시작하는 지점이다.
- 참고: PSI – Pressure Stall Information | kernel.org
- 코드 라인 20에서 PAGEOUTRUN 카운터를 증가시킨다.
- 코드 라인 27~36에서 요청한 classzone_idx 이하의 존들을 순회하며 워터마크 부스트 값을 합산하여 boosted 및 nr_boost_reclaim에 대입한다. 그리고 존별 부스트 값도 zone_boosts[]에 대입한다.
- 코드 라인 38~40에서 restart: 레이블이다. 우선 순위를 초가값(12)으로 한 후 다시 시도한다.
- 코드 라인 46~67에서 reclaim할 존 인덱스 값으로 classzone_idx를 사용하되, buffer_heads_over_limit가 설정된 경우 가용한 최상위 존을 대입한다.
mm/vmscan.c -2/3-
. /*
* If the pgdat is imbalanced then ignore boosting and preserve
* the watermarks for a later time and restart. Note that the
* zone watermarks will be still reset at the end of balancing
* on the grounds that the normal reclaim should be enough to
* re-evaluate if boosting is required when kswapd next wakes.
*/
balanced = pgdat_balanced(pgdat, sc.order, classzone_idx);
if (!balanced && nr_boost_reclaim) {
nr_boost_reclaim = 0;
goto restart;
}
/*
* If boosting is not active then only reclaim if there are no
* eligible zones. Note that sc.reclaim_idx is not used as
* buffer_heads_over_limit may have adjusted it.
*/
if (!nr_boost_reclaim && balanced)
goto out;
/* Limit the priority of boosting to avoid reclaim writeback */
if (nr_boost_reclaim && sc.priority == DEF_PRIORITY - 2)
raise_priority = false;
/*
* Do not writeback or swap pages for boosted reclaim. The
* intent is to relieve pressure not issue sub-optimal IO
* from reclaim context. If no pages are reclaimed, the
* reclaim will be aborted.
*/
sc.may_writepage = !laptop_mode && !nr_boost_reclaim;
sc.may_swap = !nr_boost_reclaim;
sc.may_shrinkslab = !nr_boost_reclaim;
/*
* Do some background aging of the anon list, to give
* pages a chance to be referenced before reclaiming. All
* pages are rotated regardless of classzone as this is
* about consistent aging.
*/
age_active_anon(pgdat, &sc);
/*
* If we're getting trouble reclaiming, start doing writepage
* even in laptop mode.
*/
if (sc.priority < DEF_PRIORITY - 2)
sc.may_writepage = 1;
/* Call soft limit reclaim before calling shrink_node. */
sc.nr_scanned = 0;
nr_soft_scanned = 0;
nr_soft_reclaimed = mem_cgroup_soft_limit_reclaim(pgdat, sc.order,
sc.gfp_mask, &nr_soft_scanned);
sc.nr_reclaimed += nr_soft_reclaimed;
/*
* There should be no need to raise the scanning priority if
* enough pages are already being scanned that that high
* watermark would be met at 100% efficiency.
*/
if (kswapd_shrink_node(pgdat, &sc))
raise_priority = false;
- 코드 라인 8~12에서 노드가 밸런스 상태가 아니고, 부스트 중이면 nr_boost_reclaim을 리셋한 후 restart: 레이블로 이동하여 다시 시작한다.
- 코드 라인 19~20에서 노드가 이미 밸런스 상태이고 부스트 중이 아니면 더이상 페이지 확보를 할 필요 없으므로 out 레이블로 이동한다.
- 코드 라인 23~24에서 부스트 중에는 priority가 낮은 순위(12~10)는 상관없지만 높은 순위(9~1)부터는 더 이상 우선 순위가 높아지지 않도록 raise_priority에 false를 대입한다.
- 가능하면 낮은 우선 순위에서는 writeback을 허용하지 않는다.
- 코드 라인 32~34에서 랩톱(절전 지원) 모드가 아니고 부스트 중이 아니면 may_writepage를 1로 설정하여 writeback을 허용한다. 그리고 부스트 중이 아니면 may_swap 및 may_shrinkslab을 1로 설정하여 swap 및 슬랩 shrink를 지원한다.
- 코드 라인 42에서 swap이 활성화된 경우 inactive anon이 active anon보다 작을 경우 active 리스트에 대해 shrink를 수행하여 active와 inactive간의 밸런스를 다시 잡아준다.
- 코드 라인 48~49에서 높은 우선 순위(9~1)에서는 may_writepage를 1로 설정하여 writeback을 허용한다.
- 코드 라인 52~56에서 노드를 shrink하기 전에 memcg soft limit reclaim을 수행한다. 스캔한 수는 nr_soft_scanned에 대입되고, nr_reclaimed에는 soft reclaim된 페이지 수가 추가된다.
- 코드 라인 63~64에서 free 페이지가 high 워터마크 기준을 충족할 만큼 노드를 shrink 한다. 만일 shrink가 성공한 경우 순위를 증가시키지 않도록 raise_priority를 false로 설정한다.
mm/vmscan.c -3/3-
/*
* If the low watermark is met there is no need for processes
* to be throttled on pfmemalloc_wait as they should not be
* able to safely make forward progress. Wake them
*/
if (waitqueue_active(&pgdat->pfmemalloc_wait) &&
allow_direct_reclaim(pgdat))
wake_up_all(&pgdat->pfmemalloc_wait);
/* Check if kswapd should be suspending */
__fs_reclaim_release();
ret = try_to_freeze();
__fs_reclaim_acquire();
if (ret || kthread_should_stop())
break;
/*
* Raise priority if scanning rate is too low or there was no
* progress in reclaiming pages
*/
nr_reclaimed = sc.nr_reclaimed - nr_reclaimed;
nr_boost_reclaim -= min(nr_boost_reclaim, nr_reclaimed);
/*
* If reclaim made no progress for a boost, stop reclaim as
* IO cannot be queued and it could be an infinite loop in
* extreme circumstances.
*/
if (nr_boost_reclaim && !nr_reclaimed)
break;
if (raise_priority || !nr_reclaimed)
sc.priority--;
} while (sc.priority >= 1);
if (!sc.nr_reclaimed)
pgdat->kswapd_failures++;
out:
/* If reclaim was boosted, account for the reclaim done in this pass */
if (boosted) {
unsigned long flags;
for (i = 0; i <= classzone_idx; i++) {
if (!zone_boosts[i])
continue;
/* Increments are under the zone lock */
zone = pgdat->node_zones + i;
spin_lock_irqsave(&zone->lock, flags);
zone->watermark_boost -= min(zone->watermark_boost, zone_boosts[i]);
spin_unlock_irqrestore(&zone->lock, flags);
}
/*
* As there is now likely space, wakeup kcompact to defragment
* pageblocks.
*/
wakeup_kcompactd(pgdat, pageblock_order, classzone_idx);
}
snapshot_refaults(NULL, pgdat);
__fs_reclaim_release();
psi_memstall_leave(&pflags);
/*
* Return the order kswapd stopped reclaiming at as
* prepare_kswapd_sleep() takes it into account. If another caller
* entered the allocator slow path while kswapd was awake, order will
* remain at the higher level.
*/
return sc.order;
}
- 코드 라인 6~8에서 페이지 할당 중 메모리가 부족하여 direct reclaim 시도 중 대기하고 있는 태스크들이 pfmemalloc_wait 리스트에 존재하고, 노드가 direct reclaim을 해도 된다고 판단하면 대기 중인 태스크들을 모두 깨운다.
- allow_direct_reclaim(): normal 존 이하의 free 페이지 합이 min 워터마크를 더한 페이지의 절반보다 큰 경우 true.
- 코드 라인 12~15에서 freeze 하였다가 깨어났었던 경우 또는 kswapd 스레드 정지 요청이 있는 경우 루프를 빠져나간다.
- 코드 라인 21~30에서 reclaimed 페이지와 nr_boost_reclaim을 산출한 후 부스트 중이 아니면서 회수된 페이지가 없으면 루프를 벗어난다.
- 코드 라인 32~34에서 우선 순위를 높이면서 최고 우선 순위까지 루프를 반복한다. 만일 회수된 페이지가 없거나 우선 순위 상승을 원하지 않는 경우에는 우선 순위 증가없이 루프를 반복한다.
- 코드 라인 36~37에서 루프 완료 후까지 회수된 페이지가 없으면 kswapd_failures 카운터를 증가시킨다.
- 코드 라인 39~60에서 out: 레이블이다. 처음 시도 시 부스트된 적이 있었으면 kcompactd를 깨운다. 또한 워터마크 부스트 값을 갱신한다.
- 코드 라인 64에서 메모리 부족으로 인한 현재 태스크의 psi 산출을 종료하는 지점이다.
아래 그림은 task A에서 direct 페이지 회수를 진행 중에 pfmemalloc 워터마크 기준 이하로 떨어진 경우 kswapd에 의해 페이지 회수가 될 때까지스로틀링 즉, direct 페이지 회수를 잠시 쉬게 하여 cpu 부하를 줄인다.
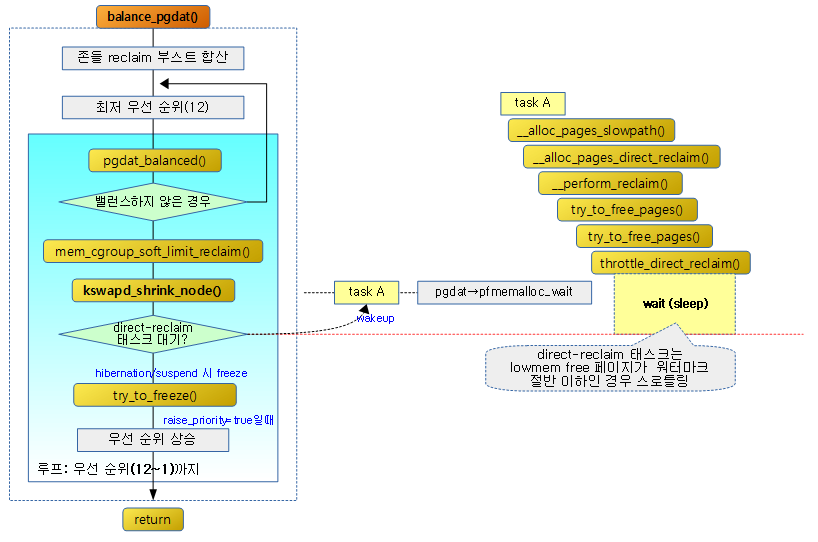
Kswapd 깨우기
wake_all_kswapds()
mm/page_alloc.c
static void wake_all_kswapds(unsigned int order, gfp_t gfp_mask,
const struct alloc_context *ac)
{
struct zoneref *z;
struct zone *zone;
pg_data_t *last_pgdat = NULL;
enum zone_type high_zoneidx = ac->high_zoneidx;
for_each_zone_zonelist_nodemask(zone, z, ac->zonelist, high_zoneidx,
ac->nodemask) {
if (last_pgdat != zone->zone_pgdat)
wakeup_kswapd(zone, gfp_mask, order, high_zoneidx);
last_pgdat = zone->zone_pgdat;
}
}
alloc context가 가리키는 zonelist 중 관련 노드의 kswpad를 깨운다.
wakeup_kswapd()
mm/vmscan.c
/* * A zone is low on free memory or too fragmented for high-order memory. If * kswapd should reclaim (direct reclaim is deferred), wake it up for the zone's * pgdat. It will wake up kcompactd after reclaiming memory. If kswapd reclaim * has failed or is not needed, still wake up kcompactd if only compaction is * needed. */
void wakeup_kswapd(struct zone *zone, gfp_t gfp_flags, int order,
enum zone_type classzone_idx)
{
pg_data_t *pgdat;
if (!managed_zone(zone))
return;
if (!cpuset_zone_allowed(zone, gfp_flags))
return;
pgdat = zone->zone_pgdat;
pgdat->kswapd_classzone_idx = kswapd_classzone_idx(pgdat,
classzone_idx);
pgdat->kswapd_order = max(pgdat->kswapd_order, order);
if (!waitqueue_active(&pgdat->kswapd_wait))
return;
/* Hopeless node, leave it to direct reclaim if possible */
if (pgdat->kswapd_failures >= MAX_RECLAIM_RETRIES ||
(pgdat_balanced(pgdat, order, classzone_idx) &&
!pgdat_watermark_boosted(pgdat, classzone_idx))) {
/*
* There may be plenty of free memory available, but it's too
* fragmented for high-order allocations. Wake up kcompactd
* and rely on compaction_suitable() to determine if it's
* needed. If it fails, it will defer subsequent attempts to
* ratelimit its work.
*/
if (!(gfp_flags & __GFP_DIRECT_RECLAIM))
wakeup_kcompactd(pgdat, order, classzone_idx);
return;
}
trace_mm_vmscan_wakeup_kswapd(pgdat->node_id, classzone_idx, order,
gfp_flags);
wake_up_interruptible(&pgdat->kswapd_wait);
}
지정된 zone에서 order 페이지를 할당하려다 메모리가 부족해지면 kswapd 태스크를 깨운다.
- 코드 라인 6~7에서 유효한 존이 아닌 경우 처리할 페이지가 없으므로 함수를 빠져나간다.
- 코드 라인 9~10에서 요청한 zone의 노드가 cgroup cpuset을 통해 허가되지 않은 경우 처리를 포기하고 빠져나간다.
- 코드 라인 11~14에서 kswapd에 존과 order를 지정하여 요청한다.
- 코드 라인 15~16에서 kswapd가 이미 동작 중이면 함수를 빠져나간다.
- 코드 라인 19~32에서 다음 조건을 만족하고 direct-reclaim을 허용하지 않는 경우에 한해 kcompactd만 깨우고 함수를 빠져나간다.
- kswad를 통한 페이지 회수 실패가 MAX_RECLAIM_RETRIES(16)번 이상인 경우
- 노드가 이미 밸런스 상태이고 부스트 중이 아닌 경우
- 코드 라인 36에서 kswapd 태스크를 깨운다.
current_is_kswapd()
include/linux/swap.h
static inline int current_is_kswapd(void)
{
return current->flags & PF_KSWAPD;
}
현재 태스크가 kswapd 인 경우 true를 반환한다.
kcompactd
kcompactd 초기화
kcompactd_init()
static int __init kcompactd_init(void)
{
int nid;
int ret;
ret = cpuhp_setup_state_nocalls(CPUHP_AP_ONLINE_DYN,
"mm/compaction:online",
kcompactd_cpu_online, NULL);
if (ret < 0) {
pr_err("kcompactd: failed to register hotplug callbacks.\n");
return ret;
}
for_each_node_state(nid, N_MEMORY)
kcompactd_run(nid);
return 0;
}
subsys_initcall(kcompactd_init)
kcompactd를 사용하기 위해 초기화한다.
- 코드 라인 6~12에서 cpu가 hot-plug를 통해 CPUHP_AP_ONLINE_DYN 상태로 변경될 때 kcompactd_cpu_online() 함수가 호출될 수 있도록 등록한다.
- 코드 라인 14~15에서 모든 메모리 노드에 대해 kcompactd를 실행시킨다.
kcompactd_run()
mm/compaction.c
/* * This kcompactd start function will be called by init and node-hot-add. * On node-hot-add, kcompactd will moved to proper cpus if cpus are hot-added. */
int kcompactd_run(int nid)
{
pg_data_t *pgdat = NODE_DATA(nid);
int ret = 0;
if (pgdat->kcompactd)
return 0;
pgdat->kcompactd = kthread_run(kcompactd, pgdat, "kcompactd%d", nid);
if (IS_ERR(pgdat->kcompactd)) {
pr_err("Failed to start kcompactd on node %d\n", nid);
ret = PTR_ERR(pgdat->kcompactd);
pgdat->kcompactd = NULL;
}
return ret;
}
kcompactd 스레드를 동작시킨다.
- 코드 라인 3~7에서 @nid 노드의 kcompactd 스레드가 이미 실행 중인 경우 skip 하기 위해 0을 반환한다.
- 코드 라인 9~14에서 kcompactd 스레드를 동작시킨다.
kcompactd 동작
kcompactd()
mm/compaction.c
/* * The background compaction daemon, started as a kernel thread * from the init process. */
static int kcompactd(void *p)
{
pg_data_t *pgdat = (pg_data_t*)p;
struct task_struct *tsk = current;
const struct cpumask *cpumask = cpumask_of_node(pgdat->node_id);
if (!cpumask_empty(cpumask))
set_cpus_allowed_ptr(tsk, cpumask);
set_freezable();
pgdat->kcompactd_max_order = 0;
pgdat->kcompactd_classzone_idx = pgdat->nr_zones - 1;
while (!kthread_should_stop()) {
unsigned long pflags;
trace_mm_compaction_kcompactd_sleep(pgdat->node_id);
wait_event_freezable(pgdat->kcompactd_wait,
kcompactd_work_requested(pgdat));
psi_memstall_enter(&pflags);
kcompactd_do_work(pgdat);
psi_memstall_leave(&pflags);
}
return 0;
}
각 메모리 노드에서 동작되는 kcompactd 스레드는 슬립한 상태에 있다가 kswapd가 페이지 회수를 진행한 후 호출되어 깨어나면 백그라운드에서 compaction을 진행하고 다시 슬립한다.
- 코드 라인 3~9에서 현재 kcompactd 스레드를 요청 노드에 포함된 cpu들에서만 동작할 수 있도록 cpu 비트마스크를 지정한다.
- 코드 라인11에서 태스크를 freeze할 수 있도록 PF_NOFREEZE 플래그를 제거한다.
- 참고: freeze | 문c
- 코드 라인 13~14에서 kcompactd의 최대 order와 존을 리셋한다.
- 코드 라인 16~26에서 종료 요청이 없는 한 계속 루프를 돌며 슬립한 후 외부 요청에 의해 깨어나면 compaction을 수행한다.
다음 그림은 kcompactd 스레드가 동작하는 과정을 보여준다.
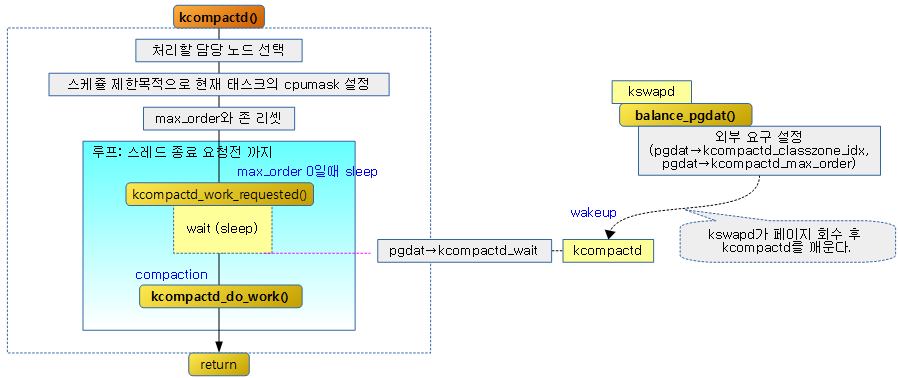
kcompactd_do_work()
mm/compaction.c
static void kcompactd_do_work(pg_data_t *pgdat)
{
/*
* With no special task, compact all zones so that a page of requested
* order is allocatable.
*/
int zoneid;
struct zone *zone;
struct compact_control cc = {
.order = pgdat->kcompactd_max_order,
.total_migrate_scanned = 0,
.total_free_scanned = 0,
.classzone_idx = pgdat->kcompactd_classzone_idx,
.mode = MIGRATE_SYNC_LIGHT,
.ignore_skip_hint = false,
.gfp_mask = GFP_KERNEL,
};
trace_mm_compaction_kcompactd_wake(pgdat->node_id, cc.order,
cc.classzone_idx);
count_compact_event(KCOMPACTD_WAKE);
for (zoneid = 0; zoneid <= cc.classzone_idx; zoneid++) {
int status;
zone = &pgdat->node_zones[zoneid];
if (!populated_zone(zone))
continue;
if (compaction_deferred(zone, cc.order))
continue;
if (compaction_suitable(zone, cc.order, 0, zoneid) !=
COMPACT_CONTINUE)
continue;
cc.nr_freepages = 0;
cc.nr_migratepages = 0;
cc.total_migrate_scanned = 0;
cc.total_free_scanned = 0;
cc.zone = zone;
INIT_LIST_HEAD(&cc.freepages);
INIT_LIST_HEAD(&cc.migratepages);
if (kthread_should_stop())
return;
status = compact_zone(zone, &cc);
if (status == COMPACT_SUCCESS) {
compaction_defer_reset(zone, cc.order, false);
} else if (status == COMPACT_PARTIAL_SKIPPED || status == COMPACT_COMPLETE) {
/*
* Buddy pages may become stranded on pcps that could
* otherwise coalesce on the zone's free area for
* order >= cc.order. This is ratelimited by the
* upcoming deferral.
*/
drain_all_pages(zone);
/*
* We use sync migration mode here, so we defer like
* sync direct compaction does.
*/
defer_compaction(zone, cc.order);
}
count_compact_events(KCOMPACTD_MIGRATE_SCANNED,
cc.total_migrate_scanned);
count_compact_events(KCOMPACTD_FREE_SCANNED,
cc.total_free_scanned);
VM_BUG_ON(!list_empty(&cc.freepages));
VM_BUG_ON(!list_empty(&cc.migratepages));
}
/*
* Regardless of success, we are done until woken up next. But remember
* the requested order/classzone_idx in case it was higher/tighter than
* our current ones
*/
if (pgdat->kcompactd_max_order <= cc.order)
pgdat->kcompactd_max_order = 0;
if (pgdat->kcompactd_classzone_idx >= cc.classzone_idx)
pgdat->kcompactd_classzone_idx = pgdat->nr_zones - 1;
}
노드에 지정된 kcompactd_classzone_idx 존까지 kcompactd_max_order로 compaction을 수행한다.
- 코드 라인 9~17에서 kcompactd에서 사용할 compact_control을 다음과 같이 준비한다.
- .order에 외부에서 요청한 오더를 지정한다.
- .classzone_idx에 외부에서 요청한 존 인덱스를 지정한다.
- .mode에 MIGRATE_SYNC_LIGHT를 사용한다.
- skip 힌트를 사용하도록 한다.
- 코드 라인 20에서 KCOMPACTD_WAKE 카운터를 증가시킨다.
- 코드 라인 22~27에서 가장 낮은 존부터 요청한 존까지 순회하며 유효하지 않은 존은 스킵한다.
- 코드 라인 29~30에서 compaction 유예 조건인 존의 경우 스킵한다.
- 코드 라인 32~34에서 존이 compaction 하기 적절하지 않은 경우 스킵한다.
- 코드 라인 36~42에서 compaction을 하기 위해 compaction_control 결과를 담을 멤버들을 초기화한다.
- 코드 라인 44~45에서 스레드 종료 요청인 경우 함수를 빠져나간다.
- 코드 라인 46에서 존에 대해 compaction을 수행하고 결과를 알아온다.
- 코드 라인 48~49에서 만일 compaction이 성공한 경우 유예 카운터를 리셋한다.
- 코드 라인 50~64에서 만일 compaction이 완료될 때까지 원하는 order가 없는 경우 per-cpu 캐시를 회수하고, 유예 한도를 증가시킨다.
- 코드 라인 66~69에서 KCOMPACTD_MIGRATE_SCANNED 카운터 및 KCOMPACTD_FREE_SCANNED 카운터를 갱신한다.
- 코드 라인 80~81에서 진행 order보다 외부 요청 order가 작거나 동일하면 다음에 wakeup 하지 않도록 max_order를 0으로 리셋한다.
- 코드 라인 82~83에서 진행 존보다 외부 요청 존이 더 크거나 동일하면 다음에 시작할 존을 가장 높은 존으로 리셋한다.
Kcompatd 깨우기
wakeup_kcompactd()
mm/compaction.c
void wakeup_kcompactd(pg_data_t *pgdat, int order, int classzone_idx)
{
if (!order)
return;
if (pgdat->kcompactd_max_order < order)
pgdat->kcompactd_max_order = order;
if (pgdat->kcompactd_classzone_idx > classzone_idx)
pgdat->kcompactd_classzone_idx = classzone_idx;
/*
* Pairs with implicit barrier in wait_event_freezable()
* such that wakeups are not missed.
*/
if (!wq_has_sleeper(&pgdat->kcompactd_wait))
return;
if (!kcompactd_node_suitable(pgdat))
return;
trace_mm_compaction_wakeup_kcompactd(pgdat->node_id, order,
classzone_idx);
wake_up_interruptible(&pgdat->kcompactd_wait);
}
kcompactd 스레드를 깨운다.
- 코드 라인 3~4에서 order 값이 0인 경우 kcompactd를 깨우지 않고 함수를 빠져나간다.
- 코드 라인 6~7에서 @order가 kcompactd_max_order 보다 큰 경우 kcompactd_max_order를 갱신한다.
- 코드 라인 9~10에서 @classzone_idx가 kcompactd_classzone_idx보다 작은 경우 kcompactd_classzone_idx를 갱신한다.
- 코드 라인 16~17에서 kcompactd가 이미 깨어있으면 함수를 빠져나간다.
- 코드 라인 19~20에서 compaction을 진행해도 효과가 없을만한 노드의 경우 함수를 빠져나간다.
- 코드 라인 24에서 kcompactd를 깨운다.
kcompactd_node_suitable()
mm/compaction.c
static bool kcompactd_node_suitable(pg_data_t *pgdat)
{
int zoneid;
struct zone *zone;
enum zone_type classzone_idx = pgdat->kcompactd_classzone_idx;
for (zoneid = 0; zoneid <= classzone_idx; zoneid++) {
zone = &pgdat->node_zones[zoneid];
if (!populated_zone(zone))
continue;
if (compaction_suitable(zone, pgdat->kcompactd_max_order, 0,
classzone_idx) == COMPACT_CONTINUE)
return true;
}
return false;
}
kcompactd를 수행하기 위해 요청한 노드의 가용한 존들에 대해 하나라도 compaction 효과가 있을만한 존이 있는지 여부를 반환한다.
- 코드 라인 5~11에서 요청한 노드의 kcompactd_classzone_idx 까지 가용한 존들에 대해 순회한다.
- 코드 라인 13~15에서 순회 중인 존들 중 하나라도 kcompactd_max_order 값을 사용하여 compaction 효과가 있다고 판단하면 true를 반환한다.
- 코드 라인 18에서 해당 노드의 모든 존들에 대해 compaction 효과를 볼 수 없어 false를 반환한다.
기타
swapper_spaces[] 배열
mm/swap_state.c
struct address_space swapper_spaces[MAX_SWAPFILES];
swap_aops
mm/swap_state.c
/*
* swapper_space is a fiction, retained to simplify the path through
* vmscan's shrink_page_list.
*/
static const struct address_space_operations swap_aops = {
.writepage = swap_writepage,
.set_page_dirty = swap_set_page_dirty,
#ifdef CONFIG_MIGRATION
.migratepage = migrate_page,
#endif
};
address_space_operations 구조체
include/linux/fs.h
struct address_space_operations {
int (*writepage)(struct page *page, struct writeback_control *wbc);
int (*readpage)(struct file *, struct page *);
/* Write back some dirty pages from this mapping. */
int (*writepages)(struct address_space *, struct writeback_control *);
/* Set a page dirty. Return true if this dirtied it */
int (*set_page_dirty)(struct page *page);
/*
* Reads in the requested pages. Unlike ->readpage(), this is
* PURELY used for read-ahead!.
*/
int (*readpages)(struct file *filp, struct address_space *mapping,
struct list_head *pages, unsigned nr_pages);
int (*write_begin)(struct file *, struct address_space *mapping,
loff_t pos, unsigned len, unsigned flags,
struct page **pagep, void **fsdata);
int (*write_end)(struct file *, struct address_space *mapping,
loff_t pos, unsigned len, unsigned copied,
struct page *page, void *fsdata);
/* Unfortunately this kludge is needed for FIBMAP. Don't use it */
sector_t (*bmap)(struct address_space *, sector_t);
void (*invalidatepage) (struct page *, unsigned int, unsigned int);
int (*releasepage) (struct page *, gfp_t);
void (*freepage)(struct page *);
ssize_t (*direct_IO)(struct kiocb *, struct iov_iter *iter);
/*
* migrate the contents of a page to the specified target. If
* migrate_mode is MIGRATE_ASYNC, it must not block.
*/
int (*migratepage) (struct address_space *,
struct page *, struct page *, enum migrate_mode);
bool (*isolate_page)(struct page *, isolate_mode_t);
void (*putback_page)(struct page *);
int (*launder_page) (struct page *);
int (*is_partially_uptodate) (struct page *, unsigned long,
unsigned long);
void (*is_dirty_writeback) (struct page *, bool *, bool *);
int (*error_remove_page)(struct address_space *, struct page *);
/* swapfile support */
int (*swap_activate)(struct swap_info_struct *sis, struct file *file,
sector_t *span);
void (*swap_deactivate)(struct file *file);
};
참고
- Zoned Allocator -1- (물리 페이지 할당-Fastpath) | 문c
- Zoned Allocator -2- (물리 페이지 할당-Slowpath) | 문c
- Zoned Allocator -3- (Buddy 페이지 할당) | 문c
- Zoned Allocator -4- (Buddy 페이지 해지) | 문c
- Zoned Allocator -5- (Per-CPU Page Frame Cache) | 문c
- Zoned Allocator -6- (Watermark) | 문c
- Zoned Allocator -7- (Direct Compact) | 문c
- Zoned Allocator -8- (Direct Compact-Isolation) | 문c
- Zoned Allocator -9- (Direct Compact-Migration) | 문c
- Zoned Allocator -10- (LRU & pagevec) | 문c
- Zoned Allocator -11- (Direct Reclaim) | 문c
- Zoned Allocator -12- (Direct Reclaim-Shrink-1) | 문c
- Zoned Allocator -13- (Direct Reclaim-Shrink-2) | 문c
- Zoned Allocator -14- (Kswapd & Kcompactd) | 문c – 현재 글
상세한 설명 감사합니다
제 스터디가 조금이라도 도움이 되셨길 바랍니다. 새해 복 많이 받으세요.
큰 도움이 되었습니다. 한글로 이렇게 잘 설명된 사이트는 오랜만이네요.
염치불구하고 한가지 질문드립니다.
kzalloc(alloc_size, GFP_KERNEL);의 결과가 null이 반환되는 경우가 발생하는데, zoneinfo를 보면 아래와 같습니다. (모바일기기이고 RAM 2G입니다)
Node 0, zone DMA
pages free 6985
min 1342
low 4204
high 4540
—————————————-
cat proc/sys/vm/min_free_kbytes : 읽은값 5368
질문.
1. 아래와 같이 변경하면 malloc에러가 개선되는데 이렇게 수동으로 늘려주는게 올바른지요.
echo 107216 > /proc/sys/vm/min_free_kbytes
2. 맞지않는다면 malloc메모리 여유를 주려면 무슨 방법이 좋을까요.
감사합니다.
반갑습니다.
kzalloc() 함수에서 GFP_KERNEL 플래그를 사용한 경우 커널 메모리 할당을 위해 다음과 같이 동작합니다.
alloc_size에 따라
– 8K 이하이면 2의 제곱승 단위로 kmalloc용 슬랩(slub) 메모리를 할당하고,
– 8K를 초과하는 경우 곧바로 버디 시스템에서 페이지를 할당합니다.
현재 시스템 메모리 상태를 보니 남은 메모리 여분이 약 28M이고, 약 20M 미만으로 내려가면 kswapd를 통해 백그라운드에서 메모리를 확보하라고 한 상태입니다.
위의 상태라면 보통 alloc_size가 약간 큰 페이지를 할당하려고 한 것 같습니다.
28M의 여분이 있다 하더라도 버디시스템에서 연속된 큰 페이지들이 모자란 상태인 듯 합니다.
..
메모리를 지속적으로 할당하고 다시 풀어주고를 반복하는 경우 황일섭님이 설정하신 것 같이 워터마크 기준을 높이면 메모리가 shortage 나기 전에 compaction 및 reclaim 등을 통해 메모리가 다시 확보되니 대부분 해결이 됩니다. (물론 지속적으로 할당을 시도하는 상황에서 할당 해제되는 메모리가 계속 모자라지는 버그 또는 설계가 잘못된 demon이 없다는 가정입니다)
그런데 휴대폰이라면 사용자가 메모리가 큰 게임 등을 구동하는 경우 메모리 관리 앱을 사용하여 정리하곤 하는데 그 와는 다른 상황인가 보네요?
참고로 휴대폰이 아니고 1년 365일 계속 동작해야 하는 임베디드 시스템인 경우에는 메모리가 줄어들지 않도록 충분히 잘 설계하는 것으로 회피합니다.
감사합니다.
답변 감사합니다.
좋은 글 감사합니다.
근데 하나 궁금한 게 있습니다.
메모리를 회수하고 나서 storage device로 swap partition(예를 들어 /swap)으로 보내줘야 할 것 같은데
이와 관련된 동작이 언제 어디서 일어나는지 알 수 있을까요??
swap_writepage()를 통해 swap partition으로 쓰여지는 것으로 이해되는데요, 문제는 이 함수에 printk()를 심어놔도 trigger되는 경우가 없다는 것입니다.
제 컴퓨터에 swap partition이 따로 잡혀있지는 않고 swapfile만 존재하고 커널 버전은 5.0.5입니다.
fio benchmark를 통해 약 20gb를 쓰는데도(제 DRAM용량은 16GB입니다) trigger되는 경우가 없습니다. 혹시 조언을 받을 수 있을까요?
혹시, mmap()등을 통해 anonymous로 매핑 후에 실험을 해야 할까요?
안녕하세요?
swap을 동작시키려면 유저 레벨에서 할당하는 anon 메모리에 기록을 해야 합니다.
그냥 유저 레벨 application을 작성할 때 반복 루프 내에서 malloc()을 사용하시고 memset()으로 아무 값이나 기록해보시면 알 수 있을 것입니다.
참고: https://linuxize.com/post/create-a-linux-swap-file
감사합니다.
안녕하세요.
오타로 보이는 부분입니다.
1. “코드 라인 3~7에서 @nid 노드의 kswapd 태스크가 지정되지 않은 경우 0을 반환한다” (지정되지 않은 -> 지정된, 이미 실행중인)
2. “코드 라인 3~7에서 @nid 노드의 kcompactd 태스크가 지정되지 않은 경우 0을 반환한다.” (지정되지 않은 -> 지정된, 이미 실행중인)
3. “다음 그림은 kswapd_try_to_sleep() 함수를 통해 kswapd가 high 워터마크 기준을 충족하면 슬립하는 과정을 보여준다” 그림에서
0.1초 잠든 이후에 high 워터마크 조건에 들지 않은 경우 (KSWAPD_LOW_WMARK_HIT_QUICKLY -> KSWAPD_HIGH_WMARK_HIT_QUICKLY)
4. “그리고 부트트 중이 아니면” (부트트 -> 부스트)
5. “아래 그림은 task A에서 direct 페이지 회수를 진행 중에 pfmemalloc 워터마크 기준 이하로…” 그림에서
“밸런스 하지 않은 경우” 의 화살표 목적지가 “존들 reclaim 부스트 합산 아래”, “최저 우선 순위” 위가 되어야 할 것 같습니다.
그리고 질문이 있습니다.
“요청한 order에서 회수가 실패한 경우 order 0 및 해당 존에서 다시 시도하기 위해 try_sleep: 레이블로 이동한다”
balance_pgdat의 반환값이 sc.order 인데 이 부분을 변경하는 코드가 kswapd_shrink_node 함수에서 nr_reclaimed 가 compact_gap 반환값이상
일때 order를 0으로 변경하는 경우이고 이 경우는 실패라기 보다는 order의 2배 이상으로 충분히 회수해서 reclaim 보다는 compaction을
수행하려는 의도처럼 보여지는데요. 제가 뭘 놓친건가요?
안녕하세요? 권용범님.
1번부터 5번까지 잘못된 오자는 모두 수정하였습니다. 세심히 봐주셔서 감사합니다. ^^
잘 아시는 것처럼 kswapd는 보통 슬립상태에 있다가, 메모리 부족 상황에서 깨어나서 동작합니다. 그런 후 메모리 확보가 완료되면 다시 잠들게됩니다.
if (reclaim_order < alloc_order) 코드에서 alloc_order는 사용자가 최근에 할당을 원하는 order 페이지이고, reclaim_order는 kswapd에 의해 회수한 페이지 order 중 가장 큰 order 입니다. 이를 비교하는 이유는 당연히 원하는 만큼 order를 확보했는지 비교하고, 확보가 완료된 경우 새로운 alloc order 요청을 수행하기 위해 다시 루프를 돌것이고, 확보를 실패한 경우 kswapd_try_sleep: 레이블로 다시 back 하여 기존 요청을 계속 수행합니다. 루프 내에서 0.1초씩 sleep 하는 이유는 reclaim 반복만으로는 빠르게 회수되지 않는 페이지를 계속 시도하여 cpu performance를 떨어뜨리므로, kswap를 잠시 슬립하고, 이 때 compaction에 의해 확보가 될 수 있는 기대 역시 합니다. 감사합니다.
“reclaim_order는 kswapd에 의해 회수한 페이지 order 중 가장 큰 order 입니다” 이 부분에서 헤매고 있습니다. 원래 질문의 요지이기도 하구요.
코드상에서 reclaim_order는 balance_pgdat 가 반환하는 sc.order인데 alloc_order로 설정된 sc.order 가 변경되는 부분을 위질문에서 언급한 부분외에서는
못찾고 있습니다. 회수한 페이지 order중 가장 큰 order로 reclaim_order를 설정하는 부분이 코드상 어느 부분인가요?
감사합니다.
권용범님이 고심하는 부분을 코드를 다시 살펴보니 제가 reclaim_order에 대해 잘못 해석했다는 것을 알았습니다.
reclaim_order는 회수 페이지 order 중 가장 큰 order라고 했는데, 이를 정정합니다. ^^;
direct-reclaim과 kswapd는 워터마크를 기준으로 서로 경쟁하는 관계입니다.
kswapd가 회수한 페이지가 compact_gap() 만큼 즉 워터마크(high) + 원하는 alloc_order의 2배 이상 충분히 확보한 경우 sc->order를 0으로 낮춥니다.
이렇게 0으로 낮추고 kswapd_try_sleep: 레이블을 통해 kswapd_try_to_sleep()으로 진행할 때 의미가 있군요.
kswapd는 cost가 높으므로 direct-reclaim 쪽과 경쟁을 회피하기 위해 일부러 order를 0으로 내리면 밸런스 기준이 낮아지므로 곧바로 sleep하도록 도움을 주는 상황입니다.
감사합니다.
친절한 답변 감사합니다.