<kernel v5.0>
관련 커널 옵션들
CONFIG_KMEMCHECK
- x86 아키텍처에서만 지원되며 할당된 kernel memory를 dynamic하게 tracing할 수 있게하는 커널 옵션이다.
- cmdline에서 “kmemcheck=0” or “kmemcheck=1” early 커널 파라메터를 사용하여 enable/disable 시킬 수 있다.
CONFIG_MEMORY_ISOLATION
- 최근 커널은 CONFIG_{CMA | MEMORY_HOTPLUG | MEMORY_FAILURE} 커널 옵션을 사용하지 않고 CONFIG_MEMORY_ISOLATION 커널 옵션만 사용해도 memory의 isolation 기능을 사용할 수 있도록 하였다.
- rpi2: 이 커널 옵션을 사용한다.
CONFIG_KASAN
- KASAN(Kernel Address Sanitizer) – SLUB에 대한 런타임 메모리 디버거
- 이 기능을 사용하면 최대 3배까지 성능 저하가 발생되고 약 1/8의 free 메모리를 소모한다.
- 더 좋은 에러 감지를 위해 CONFIG_STACKTRACE 및 cmdline에 “slub_debug=U”를 같이 사용한다.
페이지 해지(free)
다음 그림은 free_pages() 함수 이후의 호출 과정을 보여준다.
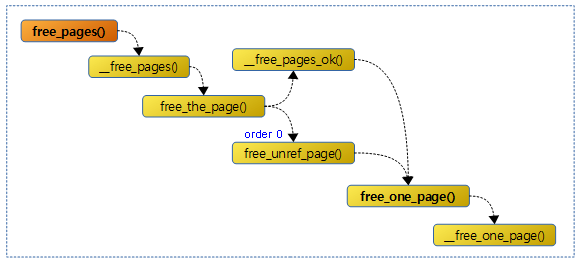
free_pages()
mm/page_alloc.c
void free_pages(unsigned long addr, unsigned int order)
{
if (addr != 0) {
VM_BUG_ON(!virt_addr_valid((void *)addr));
__free_pages(virt_to_page((void *)addr), order);
}
}
EXPORT_SYMBOL(free_pages);
버디 시스템으로 @addr 주소부터 @order 페이지를 할당 해제한다.
__free_pages()
mm/page_alloc.c
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page))
free_the_page(page, order);
}
EXPORT_SYMBOL(__free_pages);
참조 카운터가 감소시키며, 0이 되면 버디 시스템으로 @order 페이지를 할당 해제한다.
free_the_page()
mm/page_alloc.c
static inline void free_the_page(struct page *page, unsigned int order)
{
if (order == 0) /* Via pcp? */
free_unref_page(page);
else
__free_pages_ok(page, order);
}
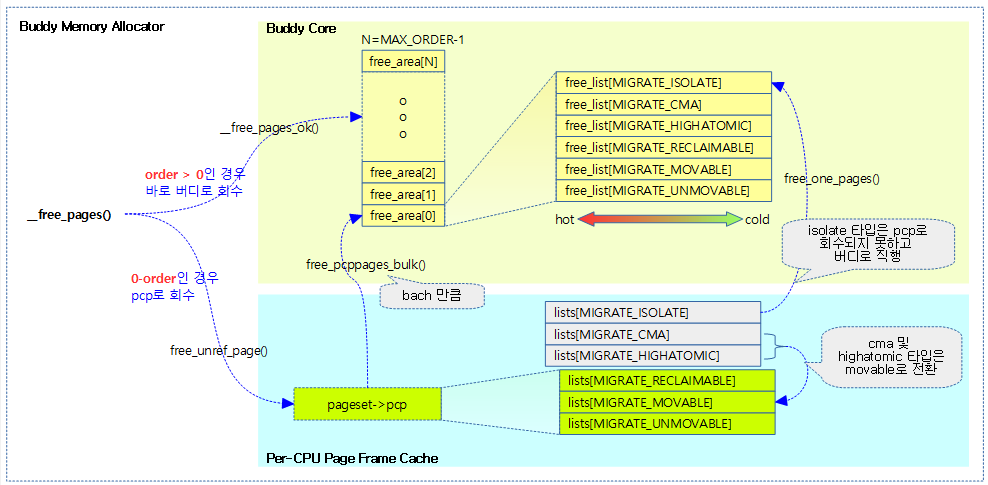
사용이 완료된 2^order 페이지인 경우 free 하되 0-order 페이지의 경우 Per CPU Page Frame Cache로의 free를 시도한다.
- 0-order 페이지를 pcp의 hot 페이지로 이주시킨다.
- pcp 이주 시킬 때 migrate 타입에 따라 처리가 달라진다.
- unmovable, reclaimable, movable 타입인 경우는 그대로 이주된다.
- reserve, cma 타입인 경우는 movable 타입으로 변환하여 이주된다.
- isolate 타입인 경우 pcp로 이주되지 않고 다시 buddy로 보낸다.
아래 그림은 order 비트에 따라 처리되는 모습을 보여준다.
- order=0인 single page를 free할 때
- pcp로 회수되는데 isolate 타입의 경우 페이지를 버디 시스템으로 회수시킨다. 그리고 cma 및 highatomic 타입은 movable 타입의 pcp로 회수시킨다.
- pcp 이주 시 overflow인 경우 batch 수 만큼 버디 시스템으로 회수시킨다.
- order가 0이 아닌 multi page를 free할 때
- pcp를 사용하지 않고 버디 시스템으로 회수시킨다.
__free_pages_ok()
mm/page_alloc.c
static void __free_pages_ok(struct page *page, unsigned int order)
{
unsigned long flags;
int migratetype;
unsigned long pfn = page_to_pfn(page);
if (!free_pages_prepare(page, order, true))
return;
migratetype = get_pfnblock_migratetype(page, pfn);
local_irq_save(flags);
__count_vm_events(PGFREE, 1 << order);
free_one_page(page_zone(page), page, pfn, order, migratetype);
local_irq_restore(flags);
}
사용이 완료된 order 페이지를 버디 시스템으로 회수한다.
- 코드 라인 7~8에서 할당 해제할 페이지를 체크한다.
- 코드 라인 12에서 PGFREE 카운터를 페이지 수 만큼 증가시킨다.
- 코드 라인 13에서 order 페이지를 버디 시스템으로 회수한다.
free_one_page()
mm/page_alloc.c
static void free_one_page(struct zone *zone,
struct page *page, unsigned long pfn,
unsigned int order,
int migratetype)
{
spin_lock(&zone->lock);
if (unlikely(has_isolate_pageblock(zone) ||
is_migrate_isolate(migratetype))) {
migratetype = get_pfnblock_migratetype(page, pfn);
}
__free_one_page(page, pfn, zone, order, migratetype);
spin_unlock(&zone->lock);
}
사용이 완료된 order 페이지를 버디 시스템으로 회수한다.
- 코드 라인 7~10에서 낮은 확률로 zone에 isolate 타입이 존재하거나 인수로 isolate 타입이 지정된 경우 페이지가 속한 페이지블럭의 migratetype을 사용한다.
- 코드 라인 11에서 order 페이지를 버디 시스템의 migrate 타입으로 회수한다.
__free_one_page()
mm/page_alloc.c -1/2-
/* * Freeing function for a buddy system allocator. * * The concept of a buddy system is to maintain direct-mapped table * (containing bit values) for memory blocks of various "orders". * The bottom level table contains the map for the smallest allocatable * units of memory (here, pages), and each level above it describes * pairs of units from the levels below, hence, "buddies". * At a high level, all that happens here is marking the table entry * at the bottom level available, and propagating the changes upward * as necessary, plus some accounting needed to play nicely with other * parts of the VM system. * At each level, we keep a list of pages, which are heads of continuous * free pages of length of (1 << order) and marked with PageBuddy. * Page's order is recorded in page_private(page) field. * So when we are allocating or freeing one, we can derive the state of the * other. That is, if we allocate a small block, and both were * free, the remainder of the region must be split into blocks. * If a block is freed, and its buddy is also free, then this * triggers coalescing into a block of larger size. * * -- nyc */
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype)
{
unsigned long combined_pfn;
unsigned long uninitialized_var(buddy_pfn);
struct page *buddy;
unsigned int max_order;
max_order = min_t(unsigned int, MAX_ORDER, pageblock_order + 1);
VM_BUG_ON(!zone_is_initialized(zone));
VM_BUG_ON_PAGE(page->flags & PAGE_FLAGS_CHECK_AT_PREP, page);
VM_BUG_ON(migratetype == -1);
if (likely(!is_migrate_isolate(migratetype)))
__mod_zone_freepage_state(zone, 1 << order, migratetype);
VM_BUG_ON_PAGE(pfn & ((1 << order) - 1), page);
VM_BUG_ON_PAGE(bad_range(zone, page), page);
continue_merging:
while (order < max_order - 1) {
buddy_pfn = __find_buddy_pfn(pfn, order);
buddy = page + (buddy_pfn - pfn);
if (!pfn_valid_within(buddy_pfn))
goto done_merging;
if (!page_is_buddy(page, buddy, order))
goto done_merging;
/*
* Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page,
* merge with it and move up one order.
*/
if (page_is_guard(buddy)) {
clear_page_guard(zone, buddy, order, migratetype);
} else {
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
rmv_page_order(buddy);
}
combined_pfn = buddy_pfn & pfn;
page = page + (combined_pfn - pfn);
pfn = combined_pfn;
order++;
}
if (max_order < MAX_ORDER) {
/* If we are here, it means order is >= pageblock_order.
* We want to prevent merge between freepages on isolate
* pageblock and normal pageblock. Without this, pageblock
* isolation could cause incorrect freepage or CMA accounting.
*
* We don't want to hit this code for the more frequent
* low-order merging.
*/
if (unlikely(has_isolate_pageblock(zone))) {
int buddy_mt;
buddy_pfn = __find_buddy_pfn(pfn, order);
buddy = page + (buddy_pfn - pfn);
buddy_mt = get_pageblock_migratetype(buddy);
if (migratetype != buddy_mt
&& (is_migrate_isolate(migratetype) ||
is_migrate_isolate(buddy_mt)))
goto done_merging;
}
max_order++;
goto continue_merging;
}
사용이 완료된 order 페이지를 버디 시스템의 migrate 타입으로 회수한다.
- 코드 라인 11에서 최대 combine할 order 값으로 페이지 블럭 order와 max 오더중 작은 값을 사용한다. 루프에사용하므로 1추가된 값이다.
- 코드 라인 17~18에서 버디 시스템에서 free 페이지 수를 관리할 때 isolate 타입은 free 페이지 수에 추가하지 않는다. 따라서 isolate 타입을 제외한 경우에만 free 페이지 수를 회수될 order 페이지 수만큼 감소시킨다.
- 코드 라인 23~47에서 continue_merging: 레이블이다. max order 직전까지의 order를 증가시키며 페이지를 combine하기위해 가드 페이지가 아닌 버디 페이지를 찾은 경우 해당 order의 엔트리를 제거한다. 더 이상 combine할 버디 페이지가 없는 경우 루프를 벗어나 done_merging 레이블로 이동한다.
- 코드 라인 48~71에서 페이지 블럭까지는 다른 migrate 타입을 combine하여도 상관이 없었다. 그러나 isolate 타입은 free 페이지 카운터에 추가되지 않기 때문에 isolation이 진행 중인 존에서는 페이지 블럭 이상의 order에 대해 combine될 buddy 페이지 역시 같은 migrate 타입을 사용하지 않는 경우 combine을 하지 못하게 하였다.
mm/page_alloc.c -2/2-
done_merging:
set_page_order(page, order);
/*
* If this is not the largest possible page, check if the buddy
* of the next-highest order is free. If it is, it's possible
* that pages are being freed that will coalesce soon. In case,
* that is happening, add the free page to the tail of the list
* so it's less likely to be used soon and more likely to be merged
* as a higher order page
*/
if ((order < MAX_ORDER-2) && pfn_valid_within(buddy_pfn)) {
struct page *higher_page, *higher_buddy;
combined_pfn = buddy_pfn & pfn;
higher_page = page + (combined_pfn - pfn);
buddy_pfn = __find_buddy_pfn(combined_pfn, order + 1);
higher_buddy = higher_page + (buddy_pfn - combined_pfn);
if (pfn_valid_within(buddy_pfn) &&
page_is_buddy(higher_page, higher_buddy, order + 1)) {
list_add_tail(&page->lru,
&zone->free_area[order].free_list[migratetype]);
goto out;
}
}
list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);
out:
zone->free_area[order].nr_free++;
}
- 코드 라인 1~2에서 done_merging: 레이블이다. 더 이상 combine할 버디 페이지가 없는 경우에서 진입하였다. free 페이지에 order를 기록한다.
- 코드 라인 12~24에서 2단 combine될 가능성이 있을 때 cold 방향에 추가한다. 회수할 order 페이지의 1 단계 위 order 페이지의 버디 페이지가 존재하는지 체크한다. 회수된 order 페이지의 짝이되는 버디 페이지가 추후 free될 때, 상위 order에서도 한 번 더 combine될 가능성이 커진다. 따라서 곧바로 할당되어 나가지 못하도록 최대한 더 보존하기 위해 tail(cold) 방향에 페이지를 추가한다.
- 코드 라인 26~28에서 head(hot) 방향에 페이지를 추가하고, 해당 order의 엔트리 수를 1 증가시킨다.
다음 그림은 order 3 페이지 하나가 회수되었을 때 해당 페이지의 짝이되는 버디 페이지가 발견되면 상위 order로 병합(combine)되는 과정을 보여준다. 두 번의 병합(combine)을 통해 order 5에 등록되었다.
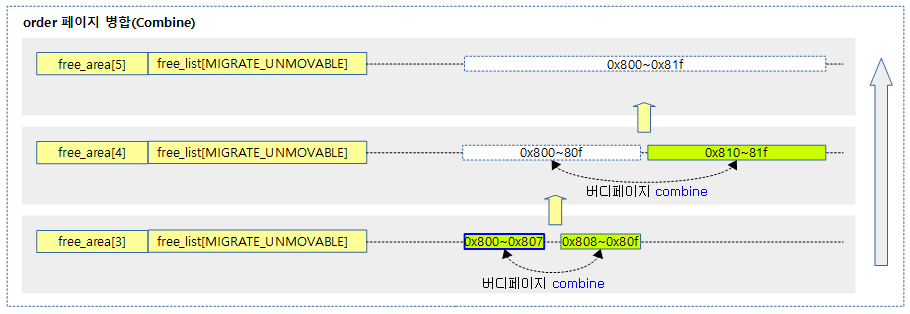
아래 그림은 free할 페이지가 해당 order slot에 추가될 때 상위 slot의 버디 페이지가 존재하면 2단 combine될 가능성이 높아진다. 따라서 free 페이지의 파편화를 최대한 억제하기 위해 방금 회수한 free 페이지를 cold 방향에 추가하는 모습을 보여준다.

has_isolate_pageblock()
include/linux/page-isolation.h
#ifdef CONFIG_MEMORY_ISOLATION
static inline bool has_isolate_pageblock(struct zone *zone)
{
return zone->nr_isolate_pageblock;
}
#else
static inline bool has_isolate_pageblock(struct zone *zone)
{
return false;
}
#endif
지정된 zone에 isolate된 페이지가 존재하는지 여부를 리턴한다.
회수한 order 페이지 체크
free_pages_prepare()
mm/page_alloc.c
static __always_inline bool free_pages_prepare(struct page *page,
unsigned int order, bool check_free)
{
int bad = 0;
VM_BUG_ON_PAGE(PageTail(page), page);
trace_mm_page_free(page, order);
/*
* Check tail pages before head page information is cleared to
* avoid checking PageCompound for order-0 pages.
*/
if (unlikely(order)) {
bool compound = PageCompound(page);
int i;
VM_BUG_ON_PAGE(compound && compound_order(page) != order, page);
if (compound)
ClearPageDoubleMap(page);
for (i = 1; i < (1 << order); i++) {
if (compound)
bad += free_tail_pages_check(page, page + i);
if (unlikely(free_pages_check(page + i))) {
bad++;
continue;
}
(page + i)->flags &= ~PAGE_FLAGS_CHECK_AT_PREP;
}
}
if (PageMappingFlags(page))
page->mapping = NULL;
if (memcg_kmem_enabled() && PageKmemcg(page))
memcg_kmem_uncharge(page, order);
if (check_free)
bad += free_pages_check(page);
if (bad)
return false;
page_cpupid_reset_last(page);
page->flags &= ~PAGE_FLAGS_CHECK_AT_PREP;
reset_page_owner(page, order);
if (!PageHighMem(page)) {
debug_check_no_locks_freed(page_address(page),
PAGE_SIZE << order);
debug_check_no_obj_freed(page_address(page),
PAGE_SIZE << order);
}
arch_free_page(page, order);
kernel_poison_pages(page, 1 << order, 0);
kernel_map_pages(page, 1 << order, 0);
kasan_free_nondeferred_pages(page, order);
return true;
}
order 페이지를 버디 시스템으로 회수하기 전에 각 페이지의 플래그들을 확인하여 bad 요건이 있는지 모두 확인한다. true=이상 없음, false=bad 페이지
- 코드 라인 14~21에서 compound 페이지인 경우 두번째 페이지의 PG_double_map을 클리어한다.
- 코드 라인 22~30에서 두번째 페이지부터 order 페이지의 마지막까지 순회하며 bad 페이지 여부를 확인한다. 그리고 PAGE_FLAGS_CHECK_AT_PREP 플래그를 제거한다.
- 코드 라인 32~33에서 페이지 매핑을 null로 초기화한다.
- 코드 라인 34~35에서 kmemcg 페이지인 경우 order 페이지 만큼 uncharge한다.
- 코드 라인 36~37에서 @check_free가 설정된 경우
- 코드 라인 38~39에서 bad 페이지가 결과인 경우 false를 반환한다.
- 코드 라인 41~43에서 페이지에서 cpupid 정보를 리셋하고, PAGE_FLAGS_CHECK_AT_PREP 플래그도 제거하고, 페이지 owner를 리셋한다.
- 코드 라인 45~50에서 highmem 페이지인 경우 디버그용 체크를 수행한다.
- 코드 라인 51에서 아키텍처에서 free 페이지에 대한 검사를 지원하는 경우 수행한다.
- 코드 라인 52에서 poison 디버그 기능을 사용하는 경우 free 페이지에 대해 poison 처리한다.
- 코드 라인 53에서 pagealloc 디버그 기능을 사용하는 경우 메모리의 valid 여부를 확인한다.
- 코드 라인 54에서 kasan 디버그 기능을 사용하는 경우의 처리이다.
- 코드 라인 56에서 페이지에 이상이 없으므로 true를 반환한다.
버디 페이지 확인
__find_buddy_pfn()
mm/internal.h
/* * Locate the struct page for both the matching buddy in our * pair (buddy1) and the combined O(n+1) page they form (page). * * 1) Any buddy B1 will have an order O twin B2 which satisfies * the following equation: * B2 = B1 ^ (1 << O) * For example, if the starting buddy (buddy2) is #8 its order * 1 buddy is #10: * B2 = 8 ^ (1 << 1) = 8 ^ 2 = 10 * * 2) Any buddy B will have an order O+1 parent P which * satisfies the following equation: * P = B & ~(1 << O) * * Assumption: *_mem_map is contiguous at least up to MAX_ORDER */
static inline unsigned long
__find_buddy_pfn(unsigned long page_pfn, unsigned int order)
{
return page_pfn ^ (1 << order);
}
요청한 order의 pfn과 짝을 이루는 버디 페이지의 pfn을 반환한다.
- 예) pfn=0x1000, order=3
- =0x1008
- 예) page_idx=0x1008, order=3
- =0x1000
page_is_buddy()
mm/page_alloc.c
/* * This function checks whether a page is free && is the buddy * we can coalesce a page and its buddy if * (a) the buddy is not in a hole (check before calling!) && * (b) the buddy is in the buddy system && * (c) a page and its buddy have the same order && * (d) a page and its buddy are in the same zone. * * For recording whether a page is in the buddy system, we set PageBuddy. * Setting, clearing, and testing PageBuddy is serialized by zone->lock. * * For recording page's order, we use page_private(page). */
static inline int page_is_buddy(struct page *page, struct page *buddy,
unsigned int order)
{
if (page_is_guard(buddy) && page_order(buddy) == order) {
if (page_zone_id(page) != page_zone_id(buddy))
return 0;
VM_BUG_ON_PAGE(page_count(buddy) != 0, buddy);
return 1;
}
if (PageBuddy(buddy) && page_order(buddy) == order) {
/*
* zone check is done late to avoid uselessly
* calculating zone/node ids for pages that could
* never merge.
*/
if (page_zone_id(page) != page_zone_id(buddy))
return 0;
VM_BUG_ON_PAGE(page_count(buddy) != 0, buddy);
return 1;
}
return 0;
}
같은 존에 포함된 @page와 @buddy 페이지가 짝이면 1을 반환하고 그렇지 않으면 0을 반환한다.
- 코드 라인 4~11에서 @buddy 페이지가 가드 페이지로 사용되고 있고, order도 동일한 경우 1을 반환한다. 단 @page와 @buddy 페이지가 같은 존에 위치하지 않은 경우 0을 반환한다.
- 코드 라인 13~25에서 @buddy 페이지가 PG_buddy 플래그가 설정되어 있고, order도 동일한 경우 1을 반환한다. 단 @page와 @buddy 페이지가 같은 존에 위치하지 않은 경우 0을 반환한다.
- 코드 라인 26에서 @page와 @buddy 페이지가 짝이 아니므로 0을 반환한다.
order 값 삭제
rmv_page_order()
mm/page_alloc.c
static inline void rmv_page_order(struct page *page)
{
__ClearPageBuddy(page);
set_page_private(page, 0);
}
페이지의 PG_buddy 플래그 클리어하고 order bit를 나타내는 페이지의 private에 0을 대입한다.
include/linux/mm.h
#define set_page_private(page, v) ((page)->private = (v))
참고
- Zoned Allocator -1- (물리 페이지 할당-Fastpath) | 문c
- Zoned Allocator -2- (물리 페이지 할당-Slowpath) | 문c
- Zoned Allocator -3- (Buddy 페이지 할당) | 문c
- Zoned Allocator -4- (Buddy 페이지 해지) | 문c – 현재 글
- Zoned Allocator -5- (Per-CPU Page Frame Cache) | 문c
- Zoned Allocator -6- (Watermark) | 문c
- Zoned Allocator -7- (Direct Compact) | 문c
- Zoned Allocator -8- (Direct Compact-Isolation) | 문c
- Zoned Allocator -9- (Direct Compact-Migration) | 문c
- Zoned Allocator -10- (LRU & pagevec) | 문c
- Zoned Allocator -11- (Direct Reclaim) | 문c
- Zoned Allocator -12- (Direct Reclaim-Shrink-1) | 문c
- Zoned Allocator -13- (Direct Reclaim-Shrink-2) | 문c
- Zoned Allocator -14- (Kswapd) | 문c
- page_alloc_init() | 문c