<kernel v5.0>
Slowpath
NUMA 메모리 정책에 따른 zonelist에서 fastpath 할당이 실패한 경우 slowpath 단계를 진행한다. 만일 nofail 옵션이 사용된 경우 할당이 성공할 때까지 반복한다. slowpath 단계를 진행하는 동안 요청 옵션에 따라 free 페이지 부족 시 다음과 같은 회수 동작들을 수행한다.
- direct-compaction
- 페이지 할당 시 요청한 order의 페이지가 부족하여 할당 할 수 없는 상황일 때 곧바로(direct) compaction 동작을 수행하여 페이지들을 확보한 후 할당한다.
- direct-reclaim
- 페이지 할당 시 요청한 order의 페이지가 부족하여 할당 할 수 없는 상황일 때 곧바로(direct) reclaim 동작을 수행하여 페이지들을 확보한 후 할당한다.
- reclaim 동작을 수행하면
- OOM killing
- 페이지 할당 시 요청한 order의 페이지가 부족하여 최종적으로 OOM killing을 통해 특정 태스크를 종료시키므로 확보한 페이지들로 할당한다.
- kswapd
- 백그라운드에서 페이지 회수(reclaim) 매커니즘을 동작시켜 Dirty 된 파일 캐시들을 기록하고, Clean된 파일 캐시를 비우고, swap 시스템에 페이지들을 옮기는 등으로 free 페이지들을 확보한다.
- kcompactd
- 백그라운드에서 compaction 동작을 수행하여 파편화된 movable 페이지를 이동시켜 free 페이지들을 병합하는 것으로 더 큰 order free 페이지들을 확보한다.
OOM(Out of Memory) Killing
메모리가 부족한 상황에서 compaction이나 reclaim을 통해 페이지 회수가 모두 실패하여 더 이상 진행할 수 없는 경우 다음 특정 태스크 중 하나를 죽여야 하는 상황이다.
- 현재 태스크가 종료 중인 경우 0 순위
- OOM 상태에서 먼저 처리해야 할 지정된 태스크 1 순위
- 태스크 들 중 일정 연산 기준 이상의 한 태스크 2 순위
다음은 OOM killing을 강제로 수행한 결과를 보여준다.
$ echo f > /proc/sysrq-trigger
$ dmesg
[460767.036092] sysrq: SysRq : Manual OOM execution
[460767.037248] kworker/0:0 invoked oom-killer: gfp_mask=0x24000c0, order=-1, oom_score_adj=0
[460767.038016] kworker/0:0 cpuset=/ mems_allowed=0
[460767.038468] CPU: 0 PID: 8063 Comm: kworker/0:0 Tainted: G W 4.4.103-g94108fb3583f-dirty #4
[460767.039307] Hardware name: ROCK960 - 96boards based on Rockchip RK3399 (DT)
[460767.039948] Workqueue: events moom_callback
[460767.040348] Call trace:
[460767.040603] [<ffffff800808806c>] dump_backtrace+0x0/0x21c
[460767.041104] [<ffffff80080882ac>] show_stack+0x24/0x30
[460767.041583] [<ffffff80083b56f4>] dump_stack+0x94/0xbc
[460767.042064] [<ffffff80081bdd4c>] dump_header.isra.5+0x50/0x15c
[460767.042603] [<ffffff800817f240>] oom_kill_process+0x94/0x3dc
[460767.043128] [<ffffff800817f7fc>] out_of_memory+0x1e4/0x2ac
[460767.043639] [<ffffff800845d9ac>] moom_callback+0x48/0x70
[460767.044128] [<ffffff80080cd264>] process_one_work+0x220/0x378
[460767.044663] [<ffffff80080ce124>] worker_thread+0x2e0/0x3a0
[460767.045176] [<ffffff80080d3004>] kthread+0xe0/0xe8
[460767.045627] [<ffffff80080826c0>] ret_from_fork+0x10/0x50
[460767.046235] Mem-Info:
[460767.046484] active_anon:33752 inactive_anon:6597 isolated_anon:0
active_file:535284 inactive_file:190256 isolated_file:0
unevictable:0 dirty:31 writeback:0 unstable:0
slab_reclaimable:48749 slab_unreclaimable:5217
mapped:25870 shmem:6685 pagetables:894 bounce:0
free:145659 free_pcp:686 free_cma:0
[460767.049564] DMA free:582636kB min:7900kB low:9872kB high:11848kB active_anon:135008kB inactive_anon:26388kB active_file:2141136kB inactive_file:761024kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:4061184kB managed:3903784kB mlocked:0kB dirty:124kB writeback:0kB mapped:103480kB shmem:26740kB slab_reclaimable:194996kB slab_unreclaimable:20868kB kernel_stack:4352kB pagetables:3576kB unstable:0kB bounce:0kB free_pcp:2744kB local_pcp:620kB free_cma:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? no
[460767.053616] lowmem_reserve[]: 0 0 0
[460767.054043] DMA: 997*4kB (UME) 613*8kB (UME) 559*16kB (UME) 482*32kB (UM) 356*64kB (UM) 160*128kB (UME) 77*256kB (UME) 40*512kB (UM) 29*1024kB (ME) 21*2048kB (M) 96*4096kB (M) = 582636kB
[460767.055848] 732229 total pagecache pages
[460767.056242] 0 pages in swap cache
[460767.056559] Swap cache stats: add 0, delete 0, find 0/0
[460767.057065] Free swap = 1048572kB
[460767.057390] Total swap = 1048572kB
[460767.057714] 1015296 pages RAM
[460767.058027] 0 pages HighMem/MovableOnly
[460767.058388] 39350 pages reserved
[460767.058689] [ pid ] uid tgid total_vm rss nr_ptes nr_pmds swapents oom_score_adj name
[460767.059547] [ 195] 0 195 7917 1596 9 3 0 0 systemd-journal
[460767.060436] [ 229] 0 229 3281 822 9 4 0 -1000 systemd-udevd
[460767.061301] [ 257] 102 257 1952 979 8 4 0 0 systemd-network
[460767.062193] [ 382] 101 382 20508 936 10 5 0 0 systemd-timesyn
[460767.063081] [ 416] 0 416 61035 1826 18 3 0 0 upowerd
[460767.063883] [ 419] 106 419 1676 980 7 3 0 -900 dbus-daemon
[460767.064739] [ 434] 0 434 2481 1120 7 4 0 0 wpa_supplicant
[460767.065614] [ 437] 0 437 1900 1091 9 4 0 0 systemd-logind
[460767.066533] [ 441] 0 441 79590 2400 20 4 0 0 udisksd
[460767.067365] [ 450] 0 450 446 231 5 4 0 0 acpid
[460767.068170] [ 454] 0 454 54453 725 11 3 0 0 rsyslogd
[460767.068973] [ 459] 0 459 88404 4283 28 4 0 0 NetworkManager
[460767.069849] [ 478] 0 478 58975 2351 18 4 0 0 polkitd
[460767.070677] [ 568] 103 568 2102 1141 8 4 0 0 systemd-resolve
[460767.071565] [ 585] 0 585 58528 1963 17 4 0 0 lightdm
[460767.072396] [ 590] 0 590 623 363 6 4 0 0 agetty
[460767.073213] [ 592] 0 592 1841 780 8 4 0 0 login
[460767.073991] [ 603] 0 603 274336 17176 90 5 0 0 Xorg
[460767.074794] [ 630] 110 630 441 92 5 4 0 0 uml_switch
[460767.075645] [ 658] 0 658 2357 1385 8 3 0 0 systemd
[460767.076472] [ 668] 0 668 2994 454 11 4 0 0 (sd-pam)
[460767.077298] [ 673] 0 673 1675 1097 7 3 0 0 bash
[460767.078102] [ 772] 0 772 40489 2052 14 4 0 0 lightdm
[460767.078904] [ 780] 1000 780 2476 1328 9 4 0 0 systemd
[460767.079731] [ 785] 1000 785 2994 454 11 4 0 0 (sd-pam)
[460767.080559] [ 788] 1000 788 61601 3212 23 3 0 0 lxsession
[460767.081398] [ 808] 1000 808 1801 382 7 4 0 0 dbus-launch
[460767.082257] [ 809] 1000 809 1596 681 7 4 0 0 dbus-daemon
[460767.083134] [ 830] 1000 830 984 79 6 4 0 0 ssh-agent
[460767.083948] [ 838] 1000 838 58269 1523 14 3 0 0 gvfsd
[460767.084752] [ 848] 1000 848 13921 3757 19 3 0 0 openbox
[460767.085579] [ 853] 1000 853 196606 6848 44 4 0 0 lxpanel
[460767.086479] [ 854] 1000 854 98755 7408 36 3 0 0 pcmanfm
[460767.087311] [ 859] 1000 859 984 79 7 4 0 0 ssh-agent
[460767.088153] [ 863] 1000 863 92314 13900 46 5 0 0 blueman-applet
[460767.089028] [ 868] 1000 868 112028 14267 67 5 0 0 nm-applet
[460767.089842] [ 869] 1000 869 43274 2728 20 3 0 0 xfce4-power-man
[460767.090729] [ 876] 1000 876 2359 1082 9 4 0 0 xfconfd
[460767.091555] [ 885] 1000 885 123932 2468 19 3 0 0 pulseaudio
[460767.092403] [ 898] 1000 898 39537 1649 13 3 0 0 menu-cached
[460767.093268] [ 905] 0 905 1810 963 7 4 0 0 bluetoothd
[460767.094139] [ 915] 1000 915 67422 2887 21 5 0 0 gvfs-udisks2-vo
[460767.095036] [ 923] 1000 923 77517 2078 19 5 0 0 gvfsd-trash
[460767.095889] [ 933] 1000 933 9809 1559 12 3 0 0 obexd
[460767.096706] [ 5483] 0 5483 3049 1593 11 3 0 0 sshd
[460767.097537] [ 5498] 0 5498 2968 1498 10 3 0 0 sshd
[460767.098351] [ 5511] 0 5511 573 403 5 3 0 0 sftp-server
[460767.099273] [ 5518] 0 5518 1691 1156 7 3 0 0 bash
[460767.100048] [ 5735] 0 5735 3048 1579 11 4 0 0 sshd
[460767.100810] [ 5743] 0 5743 2968 1511 10 4 0 0 sshd
[460767.101580] [ 5766] 0 5766 573 427 6 3 0 0 sftp-server
[460767.102396] [ 5773] 0 5773 1698 1173 7 3 0 0 bash
[460767.103166] [ 5994] 0 5994 3048 1565 9 4 0 0 sshd
[460767.103928] [ 5999] 0 5999 2968 1529 10 4 0 0 sshd
[460767.104697] [ 6021] 0 6021 573 409 5 4 0 0 sftp-server
[460767.105515] [ 6028] 0 6028 1699 1172 7 3 0 0 bash
[460767.106289] [ 7742] 0 7742 2968 1514 10 3 0 0 sshd
[460767.107059] [ 7758] 0 7758 1697 1221 7 3 0 0 bash
[460767.107821] [ 7849] 0 7849 2968 1506 10 4 0 0 sshd
[460767.108591] [ 7863] 0 7863 1699 1201 7 3 0 0 bash
[460767.109360] Out of memory: Kill process 603 (Xorg) score 13 or sacrifice child
[460767.110302] Killed process 603 (Xorg) total-vm:1097344kB, anon-rss:15892kB, file-rss:52812kB
__alloc_pages_slowpath()
다음 그림과 같이 slow-path 페이지 할당 과정을 보여준다.
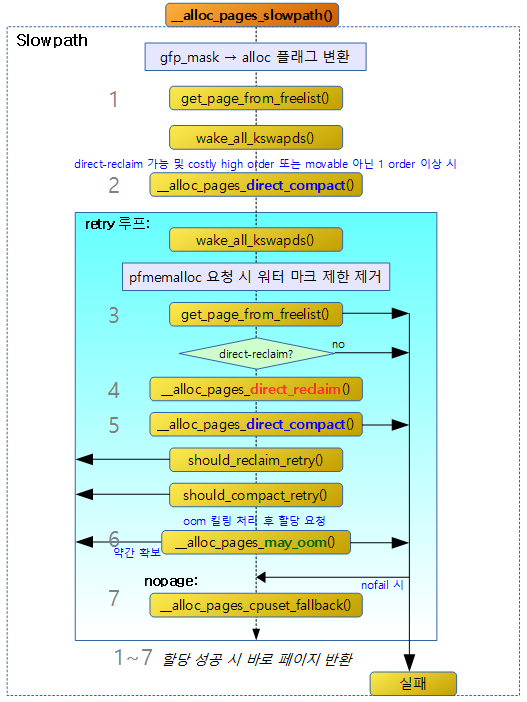
mm/page_alloc.c -1/5-
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;
const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;
struct page *page = NULL;
unsigned int alloc_flags;
unsigned long did_some_progress;
enum compact_priority compact_priority;
enum compact_result compact_result;
int compaction_retries;
int no_progress_loops;
unsigned int cpuset_mems_cookie;
int reserve_flags;
/*
* We also sanity check to catch abuse of atomic reserves being used by
* callers that are not in atomic context.
*/
if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) ==
(__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)))
gfp_mask &= ~__GFP_ATOMIC;
retry_cpuset:
compaction_retries = 0;
no_progress_loops = 0;
compact_priority = DEF_COMPACT_PRIORITY;
cpuset_mems_cookie = read_mems_allowed_begin();
/*
* The fast path uses conservative alloc_flags to succeed only until
* kswapd needs to be woken up, and to avoid the cost of setting up
* alloc_flags precisely. So we do that now.
*/
alloc_flags = gfp_to_alloc_flags(gfp_mask);
/*
* We need to recalculate the starting point for the zonelist iterator
* because we might have used different nodemask in the fast path, or
* there was a cpuset modification and we are retrying - otherwise we
* could end up iterating over non-eligible zones endlessly.
*/
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
if (!ac->preferred_zoneref->zone)
goto nopage;
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
/*
* The adjusted alloc_flags might result in immediate success, so try
* that first
*/
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
- 코드 라인 5에서 페이지 할당 중에 free 페이지가 기준 이하인 경우 직접 적인 페이지 회수(direct-reclaim)가 필요한데 이를 허용하는지 여부를 알아온다. direct-reclaim을 허용하는 요청들은 다음과 같다.
- 커널 메모리 할당에 사용하는 GFP_KERNEL, GFP_KERNEL_ACCOUNT, GFP_NOIO, GFP_NOFS
- 유저 메모리 할당에 사용하는 GFP_USER
- 코드 라인 6에서 order 3 이상이면 높은 order로 판단하여 costly order라고 한다.
- 코드 라인 21~23에서 불합리하게 gfp 마스크에 atomic과 direct-reclaim 요청을 동시에 한 경우 atomic 요청을 무시하도록 gfp 마스크에서 제거한다.
- 코드 라인 25~29에서 디폴트 compact 우선 순위로 준비한다.
- 코드 라인 36에서 gfp 마스크로 할당 플래그를 구한다.
- 코드 라인 44~47에서 노드 마스크와 zonelist에서 리셋하여 다시 첫 zone을 선택한다. 만일 대상 노드 마스크에 가용한 zone이 없는 경우 nopage: 레이블로 이동한다.
- 코드 라인 49~50에서 kswapd reclaim이 허용된 경우 zonelist에 관련된 가용 zone에 대한 노드들에서 free 메모리가 기준 이상 적거나 너무 많은 파편화 상태인 경우 해당 노드의 kswapd를 깨운다.
- 코드 라인 56~58에서 조정된 할당 플래그를 사용하여 첫 번째 slow-path 할당 시도를 수행한다.
mm/page_alloc.c -2/5-
. /*
* For costly allocations, try direct compaction first, as it's likely
* that we have enough base pages and don't need to reclaim. For non-
* movable high-order allocations, do that as well, as compaction will
* try prevent permanent fragmentation by migrating from blocks of the
* same migratetype.
* Don't try this for allocations that are allowed to ignore
* watermarks, as the ALLOC_NO_WATERMARKS attempt didn't yet happen.
*/
if (can_direct_reclaim &&
(costly_order ||
(order > 0 && ac->migratetype != MIGRATE_MOVABLE))
&& !gfp_pfmemalloc_allowed(gfp_mask)) {
page = __alloc_pages_direct_compact(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
if (page)
goto got_pg;
/*
* Checks for costly allocations with __GFP_NORETRY, which
* includes THP page fault allocations
*/
if (costly_order && (gfp_mask & __GFP_NORETRY)) {
/*
* If compaction is deferred for high-order allocations,
* it is because sync compaction recently failed. If
* this is the case and the caller requested a THP
* allocation, we do not want to heavily disrupt the
* system, so we fail the allocation instead of entering
* direct reclaim.
*/
if (compact_result == COMPACT_DEFERRED)
goto nopage;
/*
* Looks like reclaim/compaction is worth trying, but
* sync compaction could be very expensive, so keep
* using async compaction.
*/
compact_priority = INIT_COMPACT_PRIORITY;
}
}
- 코드 라인 10~19에서 다음 3 가지 조건을 동시에 만족시키는 경우 첫 번째 direct-compaction을 수행하고 페이지를 할당한다.
- direct-reclaim이 허용된 상태의 할당 요청
- costly high order 할당 요청이거나 movable이 아닌 1 order 이상의 할당 요청
- 페이지 회수를 위해 일시적으로 할당 요청을 할 때 사용되는 pfmemalloc을 사용하지 않아야 하는 일반 할당 요청
- 코드 라인 25~43에서 첫 번째 direct-compaction 을 통해서도 페이지 할당이 실패한 상황이다. costly order에 대해 noretry 옵션이 사용된 경우 다시 한 번 시도하기 위해 async compaction을 사용한다. 단 compact 결과가 유예상태인 경우 nopage 레이블로 이동한다.
mm/page_alloc.c -3/5-
retry:
/* Ensure kswapd doesn't accidentally go to sleep as long as we loop */
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
reserve_flags = __gfp_pfmemalloc_flags(gfp_mask);
if (reserve_flags)
alloc_flags = reserve_flags;
/*
* Reset the nodemask and zonelist iterators if memory policies can be
* ignored. These allocations are high priority and system rather than
* user oriented.
*/
if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) {
ac->nodemask = NULL;
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
}
/* Attempt with potentially adjusted zonelist and alloc_flags */
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/* Caller is not willing to reclaim, we can't balance anything */
if (!can_direct_reclaim)
goto nopage;
/* Avoid recursion of direct reclaim */
if (current->flags & PF_MEMALLOC)
goto nopage;
/* Try direct reclaim and then allocating */
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
/* Try direct compaction and then allocating */
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
/* Do not loop if specifically requested */
if (gfp_mask & __GFP_NORETRY)
goto nopage;
/*
* Do not retry costly high order allocations unless they are
* __GFP_RETRY_MAYFAIL
*/
if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL))
goto nopage;
if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,
did_some_progress > 0, &no_progress_loops))
goto retry;
- 코드 라인 1~4에서 페이지 할당을 다시 시도하기 위한 retry: 레이블이다. kswapd 깨우기를 할 수 있는 상태로 할당 요청된 경우 메모리 상태를 보고 kswapd를 꺠운다.
- 코드 라인 6~8에서 페이지 회수를 위해 일시적으로 할당 요청을 할 때 사용되는 pfmemalloc을 사용해야 하는 상황인 경우 워터 마크 기준을 사용하지 않도록 할당 플래그를 ALLOC_NO_WATERMARKS로 설정한다.
- 코드 라인 15~24에서 다음 두 가지 조건 중 하나인 경우 메모리 policies 대로 순회 중인 노드와 존 순서를 무시하고 처음 노드와 존으로 바꾼 후 페이지 할당을 시도한다.
- cpuset을 사용하는 페이지 할당 요청이 아닌 커널 할당 요청
- pfmemalloc으로 인해 워터 마크 기준을 사용하지 않아야 하는 할당 요청
- 코드 라인 27~28에서 atomic 할당 요청과 같이 direct-reclaim이 허용되지 않은 할당 요청인 경우 더 이상 페이지 회수를 하지 못하므로 nopage: 레이블로 이동한다.
- 코드 라인 31~32에서 페이지 회수를 위해 일시적으로 할당 요청을 할 때 사용되는 pfmemalloc을 사용해야 하는 상황인 경우 재귀 동작이 수행되지 않도록 페이지 회수를 진행하지 않고 nopage: 레이블로 이동한다.
- 코드 라인 35~38에서 direct-recalim을 시도한다.
- 코드 라인 41~44에서 두 번째 direct-compaction을 시도한다.
- 코드 라인 47~48에서 noretry 요청이 있는 경우 nopage: 레이블로 이동한다.
- 코드 라인 54~55에서 __GFP_RETRY_MAYFAIL 플래그를 사용하지 않는 할당 요청인 경우 costly order에 대해서는 재시도를 하지 않고 nopage: 레이블로 이동한다.
- 코드 라인 57~59에서 reclaim을 재시도할 필요가 있는 경우 retry: 레이블로 이동하여 할당을 재시도한다.
mm/page_alloc.c -4/5-
. /*
* It doesn't make any sense to retry for the compaction if the order-0
* reclaim is not able to make any progress because the current
* implementation of the compaction depends on the sufficient amount
* of free memory (see __compaction_suitable)
*/
if (did_some_progress > 0 &&
should_compact_retry(ac, order, alloc_flags,
compact_result, &compact_priority,
&compaction_retries))
goto retry;
/* Deal with possible cpuset update races before we start OOM killing */
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/* Reclaim has failed us, start killing things */
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
/* Avoid allocations with no watermarks from looping endlessly */
if (tsk_is_oom_victim(current) &&
(alloc_flags == ALLOC_OOM ||
(gfp_mask & __GFP_NOMEMALLOC)))
goto nopage;
/* Retry as long as the OOM killer is making progress */
if (did_some_progress) {
no_progress_loops = 0;
goto retry;
}
- 코드 라인 7~11에서 compaction을 재시도할 필요가 있는 경우 retry: 레이블로 이동하여 재시도한다.
- 코드 라인 15~16에서 cpuset에 변경이 있어 race 상황이 감지되면 retry_cpuset: 레이블로 이동하여 재시도한다.
- 코드 라인 19~21에서 OOM 킬링을 통해 확보한 페이지로 할당을 다시 시도해본다.
- 코드 라인 24~27에서 현재 태스크가 OOM으로 인해 특정 태스크가 killing되고 있는 상태이면 nopage: 레이블로 이동한다.
- 코드 라인 30~33에서 OOM 킬링을 통해 페이지가 회수될 가능성이 있는 경우 retry: 레이블로 이동하여 재시도한다.
mm/page_alloc.c -5/5-
nopage:
/* Deal with possible cpuset update races before we fail */
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/*
* Make sure that __GFP_NOFAIL request doesn't leak out and make sure
* we always retry
*/
if (gfp_mask & __GFP_NOFAIL) {
/*
* All existing users of the __GFP_NOFAIL are blockable, so warn
* of any new users that actually require GFP_NOWAIT
*/
if (WARN_ON_ONCE(!can_direct_reclaim))
goto fail;
/*
* PF_MEMALLOC request from this context is rather bizarre
* because we cannot reclaim anything and only can loop waiting
* for somebody to do a work for us
*/
WARN_ON_ONCE(current->flags & PF_MEMALLOC);
/*
* non failing costly orders are a hard requirement which we
* are not prepared for much so let's warn about these users
* so that we can identify them and convert them to something
* else.
*/
WARN_ON_ONCE(order > PAGE_ALLOC_COSTLY_ORDER);
/*
* Help non-failing allocations by giving them access to memory
* reserves but do not use ALLOC_NO_WATERMARKS because this
* could deplete whole memory reserves which would just make
* the situation worse
*/
page = __alloc_pages_cpuset_fallback(gfp_mask, order, ALLOC_HARDER, ac);
if (page)
goto got_pg;
cond_resched();
goto retry;
}
fail:
warn_alloc(gfp_mask, ac->nodemask,
"page allocation failure: order:%u", order);
got_pg:
return page;
}
- 코드 라인 1~4에서 페이지를 할당하지 못하고 포기 직전인 nopage: 레이블이다. 만일 cpuset에 변경이 있어 race 상황이 감지되면 retry_cpuset: 레이블로 이동하여 재시도한다.
- 코드 라인 10~45에서 nofail 옵션을 사용한 경우 페이지가 할당될 때 까지 재시도한다. 단 direct-reclaim 이 허용되지 않는 상황이면 fail 처리한다.
GFP 마스크 -> 할당 플래그 변환
gfp_to_alloc_flags()
mm/page_alloc.c
static inline unsigned int
gfp_to_alloc_flags(gfp_t gfp_mask)
{
unsigned int alloc_flags = ALLOC_WMARK_MIN | ALLOC_CPUSET;
/* __GFP_HIGH is assumed to be the same as ALLOC_HIGH to save a branch. */
BUILD_BUG_ON(__GFP_HIGH != (__force gfp_t) ALLOC_HIGH);
/*
* The caller may dip into page reserves a bit more if the caller
* cannot run direct reclaim, or if the caller has realtime scheduling
* policy or is asking for __GFP_HIGH memory. GFP_ATOMIC requests will
* set both ALLOC_HARDER (__GFP_ATOMIC) and ALLOC_HIGH (__GFP_HIGH).
*/
alloc_flags |= (__force int) (gfp_mask & __GFP_HIGH);
if (gfp_mask & __GFP_ATOMIC) {
/*
* Not worth trying to allocate harder for __GFP_NOMEMALLOC even
* if it can't schedule.
*/
if (!(gfp_mask & __GFP_NOMEMALLOC))
alloc_flags |= ALLOC_HARDER;
/*
* Ignore cpuset mems for GFP_ATOMIC rather than fail, see the
* comment for __cpuset_node_allowed().
*/
alloc_flags &= ~ALLOC_CPUSET;
} else if (unlikely(rt_task(current)) && !in_interrupt())
alloc_flags |= ALLOC_HARDER;
if (gfp_mask & __GFP_KSWAPD_RECLAIM)
alloc_flags |= ALLOC_KSWAPD;
#ifdef CONFIG_CMA
if (gfpflags_to_migratetype(gfp_mask) == MIGRATE_MOVABLE)
alloc_flags |= ALLOC_CMA;
#endif
return alloc_flags;
}
@gfp_mask 값으로 할당 플래그를 구성하여 반환한다. 반환되는 할당 플래그와 조건 들은 다음과 같다.
- ALLOC_WMARK_MIN(0)
- 디폴트
- ALLOC_NO_WATERMARKS
- pfmemalloc 요청인 경우
- ALLOC_CPUSET
- atomic 요청이 아닌 경우
- ALLOC_HIGH
- high 요청이 있는 경우
- ALLOC_HARDER
- rt 태스크 요청인 경우
- atomic 요청이 있으면서 nomemalloc이 없는 경우
- ALLOC_CMA
- movable 페이지 타입인 할당 요청인 경우
- ALLOC_KSWAPD
- swapd_reclaim 요청이 있는 경우
- 코드 라인 4에서 할당 플래그에 min 워터마크 할당과 cpuset 사용을 하도록 한다.
- 코드 라인 15에서 할당 플래그에 high 요청 여부를 추가한다.
- 코드 라인 17~28에서 atomic 요청인 경우 할당 플래그에서 cpuset을 제거한다. 또한 nomemalloc 요청이 아닌 한 harder 플래그를 추가한다.
- 코드 라인 29~30에서 rt 태스크에서 요청한 경우에도 harder 플래그를 추가한다.
- 코드 라인 32~33에서 swapd_reclaim 요청이 있는 경우 kswpd 플래그를 추가한다.
- 코드 라인 36~37에서 removable 요청이 있는 경우 cma 플래그를 추가한다.
gfp 플래그 -> migrate 타입 변환
gfpflags_to_migratetype()
include/linux/gfp.h
static inline int gfpflags_to_migratetype(const gfp_t gfp_flags)
{
VM_WARN_ON((gfp_flags & GFP_MOVABLE_MASK) == GFP_MOVABLE_MASK);
BUILD_BUG_ON((1UL << GFP_MOVABLE_SHIFT) != ___GFP_MOVABLE);
BUILD_BUG_ON((___GFP_MOVABLE >> GFP_MOVABLE_SHIFT) != MIGRATE_MOVABLE);
if (unlikely(page_group_by_mobility_disabled))
return MIGRATE_UNMOVABLE;
/* Group based on mobility */
return (gfp_flags & GFP_MOVABLE_MASK) >> GFP_MOVABLE_SHIFT;
}
GFP 플래그에 대응하는 migrate 타입을 다음 중 하나로 변환한다.
- MIGRATE_UNMOVABLE
- MIGRATE_RECLAIMABLE
- MIGRATE_MOVABLE
모든 kswapd 깨우기
wake_all_kswapds()
mm/page_alloc.c
static void wake_all_kswapds(unsigned int order, gfp_t gfp_mask,
const struct alloc_context *ac)
{
struct zoneref *z;
struct zone *zone;
pg_data_t *last_pgdat = NULL;
enum zone_type high_zoneidx = ac->high_zoneidx;
for_each_zone_zonelist_nodemask(zone, z, ac->zonelist, high_zoneidx,
ac->nodemask) {
if (last_pgdat != zone->zone_pgdat)
wakeup_kswapd(zone, gfp_mask, order, high_zoneidx);
last_pgdat = zone->zone_pgdat;
}
}
high_zoneidx 이하의 zonelist에서 high_zoneidx 이하의 zone이면서 노드 마스크에 설정된 노드들인 존을 순회하며 해당 노드의 kswapd를 모두 깨운다.
reclaim 재시도 필요 체크
should_reclaim_retry()
mm/page_alloc.c
/* * Checks whether it makes sense to retry the reclaim to make a forward progress * for the given allocation request. * * We give up when we either have tried MAX_RECLAIM_RETRIES in a row * without success, or when we couldn't even meet the watermark if we * reclaimed all remaining pages on the LRU lists. * * Returns true if a retry is viable or false to enter the oom path. */
static inline bool
should_reclaim_retry(gfp_t gfp_mask, unsigned order,
struct alloc_context *ac, int alloc_flags,
bool did_some_progress, int *no_progress_loops)
{
struct zone *zone;
struct zoneref *z;
bool ret = false;
/*
* Costly allocations might have made a progress but this doesn't mean
* their order will become available due to high fragmentation so
* always increment the no progress counter for them
*/
if (did_some_progress && order <= PAGE_ALLOC_COSTLY_ORDER)
*no_progress_loops = 0;
else
(*no_progress_loops)++;
/*
* Make sure we converge to OOM if we cannot make any progress
* several times in the row.
*/
if (*no_progress_loops > MAX_RECLAIM_RETRIES) {
/* Before OOM, exhaust highatomic_reserve */
return unreserve_highatomic_pageblock(ac, true);
}
/*
* Keep reclaiming pages while there is a chance this will lead
* somewhere. If none of the target zones can satisfy our allocation
* request even if all reclaimable pages are considered then we are
* screwed and have to go OOM.
*/
for_each_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,
ac->nodemask) {
unsigned long available;
unsigned long reclaimable;
unsigned long min_wmark = min_wmark_pages(zone);
bool wmark;
available = reclaimable = zone_reclaimable_pages(zone);
available += zone_page_state_snapshot(zone, NR_FREE_PAGES);
/*
* Would the allocation succeed if we reclaimed all
* reclaimable pages?
*/
wmark = __zone_watermark_ok(zone, order, min_wmark,
ac_classzone_idx(ac), alloc_flags, available);
trace_reclaim_retry_zone(z, order, reclaimable,
available, min_wmark, *no_progress_loops, wmark);
if (wmark) {
/*
* If we didn't make any progress and have a lot of
* dirty + writeback pages then we should wait for
* an IO to complete to slow down the reclaim and
* prevent from pre mature OOM
*/
if (!did_some_progress) {
unsigned long write_pending;
write_pending = zone_page_state_snapshot(zone,
NR_ZONE_WRITE_PENDING);
if (2 * write_pending > reclaimable) {
congestion_wait(BLK_RW_ASYNC, HZ/10);
return true;
}
}
ret = true;
goto out;
}
}
out:
/*
* Memory allocation/reclaim might be called from a WQ context and the
* current implementation of the WQ concurrency control doesn't
* recognize that a particular WQ is congested if the worker thread is
* looping without ever sleeping. Therefore we have to do a short sleep
* here rather than calling cond_resched().
*/
if (current->flags & PF_WQ_WORKER)
schedule_timeout_uninterruptible(1);
else
cond_resched();
return ret;
}
회수 가능한 페이지와 남은 free 페이지를 확인하여 reclaim 시도를 계속할 지 여부를 체크한다.( true=계속, false=스탑) costly high order 초과 요청 시 MAX_RECLAIM_RETRIES(16)번 이내에서 반복 가능하며 마지막 시도 시에는 atomic 요청으로 high order 처리를 위해 남겨둔(reserve) highatomic 타입의 free 페이지를 모두 요청한 페이지 타입으로 변경하여 활용하도록 한다.
- 코드 라인 15~27에서 이 함수 호출 전에 수행한 direct-reclaim에서 페이지 회수가 있었고 high order를 초과하는 요청인 경우 direct-reclaim을 재시도한 회수를 저장하기 위해 출력 인자 no_progress_loops를 1 증가 시킨다. 이 값이 최대 reclaim 시도 수를 초과하면 OOM 직전의 상황이므로 atomic 요청으로 high order 처리를 위해 남겨둔(reserve) highatomic 타입의 free 페이지를 모두 회수하여 요청한 페이지 타입으로 변환한다. 기존 direct-reclaim 처리 시 회수한 페이지가 하나도 없거나, costly high order 이하의 요청인 경우에는 retry 카운터를 0으로 지정한다.
- 코드 라인 35~43에서 zonelist에서 노드 마스크를 대상으로하는 high_zoneidx 이하의 존을 순회하며 해당 존의 최대 회수 가능한 페이지를 더한 free 페이지 수를 산출한다.
- 코드 라인 49~74에서 availble 페이지 수가 min 워터마크 기준을 상회하는 경우 reclaim을 다시 시도할 수 있도록 true를 반환하기 위해 out: 레이블로 이동한다. 만일 기존 시도 했던 reclaim 페이지 수가 0이고 회수 가능한 페이지의 50% 이상이 write 지연 상태이면 곧바로 재시도해도 페이지 회수 가능성이 낮기 때문에 0.1초간 대기한 후 true를 곧바로 반환한다.
- 코드 라인 77~89에서 out: 레이블에서는 함수를 빠져나가기 전에 슬립 여부를 결정한다. 워커 스레드에서 페이지 할당을 요청한 경우 congestion 상태에서 슬립없이 루프를 도는 일이 발생하므로 최소 1틱을 쉬며 다른 태스크에게 실행을 양보한다. 그 외의 경우는 premption 요청이 있으면 슬립하고 그렇지 않으면 슬립하지 않고 곧바로 함수를 빠져나간다.
compaction 재시도 필요 체크
should_compact_retry()
mm/page_alloc.c
static inline bool
should_compact_retry(struct alloc_context *ac, int order, int alloc_flags,
enum compact_result compact_result,
enum compact_priority *compact_priority,
int *compaction_retries)
{
int max_retries = MAX_COMPACT_RETRIES;
int min_priority;
bool ret = false;
int retries = *compaction_retries;
enum compact_priority priority = *compact_priority;
if (!order)
return false;
if (compaction_made_progress(compact_result))
(*compaction_retries)++;
/*
* compaction considers all the zone as desperately out of memory
* so it doesn't really make much sense to retry except when the
* failure could be caused by insufficient priority
*/
if (compaction_failed(compact_result))
goto check_priority;
/*
* make sure the compaction wasn't deferred or didn't bail out early
* due to locks contention before we declare that we should give up.
* But do not retry if the given zonelist is not suitable for
* compaction.
*/
if (compaction_withdrawn(compact_result)) {
ret = compaction_zonelist_suitable(ac, order, alloc_flags);
goto out;
}
/*
* !costly requests are much more important than __GFP_RETRY_MAYFAIL
* costly ones because they are de facto nofail and invoke OOM
* killer to move on while costly can fail and users are ready
* to cope with that. 1/4 retries is rather arbitrary but we
* would need much more detailed feedback from compaction to
* make a better decision.
*/
if (order > PAGE_ALLOC_COSTLY_ORDER)
max_retries /= 4;
if (*compaction_retries <= max_retries) {
ret = true;
goto out;
}
/*
* Make sure there are attempts at the highest priority if we exhausted
* all retries or failed at the lower priorities.
*/
check_priority:
min_priority = (order > PAGE_ALLOC_COSTLY_ORDER) ?
MIN_COMPACT_COSTLY_PRIORITY : MIN_COMPACT_PRIORITY;
if (*compact_priority > min_priority) {
(*compact_priority)--;
*compaction_retries = 0;
ret = true;
}
out:
trace_compact_retry(order, priority, compact_result, retries, max_retries, ret);
return ret;
}
compaction을 재시도할 필요가 있는지 여부를 반환한다. (true=재시도 필요, false=재시도 불필요)
- 코드 라인 13~14에서 0 오더 할당 요청에 대해서는 compaction 시도가 필요 없으므로 false를 반환한다.
- 코드 라인 16~17에서 지난 compaction 과정에서 migrate한 페이지가 있는 경우 compaction_retries 카운터를 증가시킨다.
- 코드 라인 24~25에서 지난 compaction 과정이 완전히 완료된 경우 check_priority: 레이블로 이동한다.
- 코드 라인 33~36에서 지난 compaction 과정이 몇 가지 이유로 완료되지 않은 경우이다. 다시 compaction을 시도해도 적절할지 판단 여부를 반환한다.
- 코드 라인 46~51에서 최대 compaction 재시도 수 만큼 반복하기 위해 true를 반환한다. 단 costly high order를 초과하는 할당 요청인 경우 16번의 재시도를 1/4로 줄여 4번까지만 재시도하게 한다.
- 코드 라인 57~65에서 check_priority: 레이블이다. compact 우선 순위가 높은 경우에 대해 재시도 기회를 더 부여하고자 한다. 따라서 compact 우선순위가 최소 priority를 초과한 경우 compact 우선 순위를 1 저하시킨 후 재시도 수를 0으로 리셋하고 true를 반환한다.
OOM 킬링을 통한 페이지 할당
__alloc_pages_may_oom()
mm/page_alloc.c
static inline struct page *
__alloc_pages_may_oom(gfp_t gfp_mask, unsigned int order,
const struct alloc_context *ac, unsigned long *did_some_progress)
{
struct oom_control oc = {
.zonelist = ac->zonelist,
.nodemask = ac->nodemask,
.memcg = NULL,
.gfp_mask = gfp_mask,
.order = order,
};
struct page *page;
*did_some_progress = 0;
/*
* Acquire the oom lock. If that fails, somebody else is
* making progress for us.
*/
if (!mutex_trylock(&oom_lock)) {
*did_some_progress = 1;
schedule_timeout_uninterruptible(1);
return NULL;
}
/*
* Go through the zonelist yet one more time, keep very high watermark
* here, this is only to catch a parallel oom killing, we must fail if
* we're still under heavy pressure. But make sure that this reclaim
* attempt shall not depend on __GFP_DIRECT_RECLAIM && !__GFP_NORETRY
* allocation which will never fail due to oom_lock already held.
*/
page = get_page_from_freelist((gfp_mask | __GFP_HARDWALL) &
~__GFP_DIRECT_RECLAIM, order,
ALLOC_WMARK_HIGH|ALLOC_CPUSET, ac);
if (page)
goto out;
/* Coredumps can quickly deplete all memory reserves */
if (current->flags & PF_DUMPCORE)
goto out;
/* The OOM killer will not help higher order allocs */
if (order > PAGE_ALLOC_COSTLY_ORDER)
goto out;
/*
* We have already exhausted all our reclaim opportunities without any
* success so it is time to admit defeat. We will skip the OOM killer
* because it is very likely that the caller has a more reasonable
* fallback than shooting a random task.
*/
if (gfp_mask & __GFP_RETRY_MAYFAIL)
goto out;
/* The OOM killer does not needlessly kill tasks for lowmem */
if (ac->high_zoneidx < ZONE_NORMAL)
goto out;
if (pm_suspended_storage())
goto out;
/*
* XXX: GFP_NOFS allocations should rather fail than rely on
* other request to make a forward progress.
* We are in an unfortunate situation where out_of_memory cannot
* do much for this context but let's try it to at least get
* access to memory reserved if the current task is killed (see
* out_of_memory). Once filesystems are ready to handle allocation
* failures more gracefully we should just bail out here.
*/
/* The OOM killer may not free memory on a specific node */
if (gfp_mask & __GFP_THISNODE)
goto out;
/* Exhausted what can be done so it's blame time */
if (out_of_memory(&oc) || WARN_ON_ONCE(gfp_mask & __GFP_NOFAIL)) {
*did_some_progress = 1;
/*
* Help non-failing allocations by giving them access to memory
* reserves
*/
if (gfp_mask & __GFP_NOFAIL)
page = __alloc_pages_cpuset_fallback(gfp_mask, order,
ALLOC_NO_WATERMARKS, ac);
}
out:
mutex_unlock(&oom_lock);
return page;
}
OOM 킬링을 통해 페이지 확보를 시도한다. 이를 통해 확보가 가능할 수 있는 경우 did_some_progress에 1이 출력된다.
- 코드 라인 20~24에서 oom lock 획득이 실패하는 경우 1 틱 동안 스케줄하여 다른 태스크에게 실행을 양보한다.
- 코드 라인 33~37에서 hardwall 및 cpuset 추가하고, direct-reclaim은 제외한 상태로 high 워터마크를 기준으로 페이지 할당을 다시 한 번 시도한다.
- OOM 킬링이 발생하면서 메모리 압박이 풀릴 가능성이 있기 때문이다.
- 코드 라인 40~41에서 이미 현재 태스크가 코어 덤프 중인 경우 out: 레이블로 이동한다.
- 코드 라인 43~44에서 costly high order를 초과한 요청인 경우 OOM 킬러로 극복하지 못하므로 out 레이블로 이동한다.
- 코드 라인 51~52에서 __GFP_RETRY_MAYFAIL 요청인 경우 이미 많은 reclaim 기회를 다 소진하였고, 합리적인 fallback을 가질 가능성이 있기 때문에 OOM 킬링을 skip 하기위해 out:레이블로 이동한다.
- migrate_pages() -> new_page()를 통해 할당 요청 시 __GFP_RETRY_MAYFILE이 사용된다.
- 코드 라인 54~55에서 DMA32 이하의 존에서 할당을 요청한 경우 OOM 킬링을 skip 하기 위해 out:레이블로 이동한다.
- 코드 라인 56~57에서 io 및 fs를 사용하지 못하는 경우 OOM 킬링을 skip 하기 위해 out: 레이블로 이동한다.
- 코드 라인 69~70에서 로컬 노드에서만 할당하라는 요청인 경우 OOM 킬링을 skip 하기 위해 out: 레이블로 이동한다.
- 코드 라인 73~83에서 OOM 킬링을 수행하여 페이지 회수가 되었거나 nofail 옵션을 사용한 경우 출력 인수 did_some_progress에 1을 대입한다. 만일 nofail 옵션이 사용된 경우 cpuset fallback을 통해 할당을 시도해본다.
- 코드 라인 84~86에서 out: 레이블에서는 oom 락을 풀고 페이지를 반환한다.
OOM 킬링 후 cpuset fallback
__alloc_pages_cpuset_fallback()
mm/page_alloc.c
static inline struct page *
__alloc_pages_cpuset_fallback(gfp_t gfp_mask, unsigned int order,
unsigned int alloc_flags,
const struct alloc_context *ac)
{
struct page *page;
page = get_page_from_freelist(gfp_mask, order,
alloc_flags|ALLOC_CPUSET, ac);
/*
* fallback to ignore cpuset restriction if our nodes
* are depleted
*/
if (!page)
page = get_page_from_freelist(gfp_mask, order,
alloc_flags, ac);
return page;
}
alloc 플래그에 cpuset을 적용한 후 페이지 할당을 먼저 해본 후 할당이 실패하면 cpuset을 제외하고 다시 할당을 시도한다.
참고
- Zoned Allocator -1- (물리 페이지 할당-Fastpath) | 문c
- Zoned Allocator -2- (물리 페이지 할당-Slowpath) | 문c – 현재 글
- Zoned Allocator -3- (Buddy 페이지 할당)) | 문c
- Zoned Allocator -4- (Buddy 페이지 해지) | 문c
- Zoned Allocator -5- (Per-CPU Page Frame Cache) | 문c
- Zoned Allocator -6- (Watermark) | 문c
- Zoned Allocator -7- (Direct Compact) | 문c
- Zoned Allocator -8- (Direct Compact-Isolation) | 문c
- Zoned Allocator -9- (Direct Compact-Migration) | 문c
- Zoned Allocator -10- (LRU & pagevec) | 문c
- Zoned Allocator -11- (Direct Reclaim) | 문c
- Zoned Allocator -12- (Direct Reclaim-Shrink-1) | 문c
- Zoned Allocator -13- (Direct Reclaim-Shrink-2) | 문c
- Zoned Allocator -14- (Kswapd) | 문c