<kernel v5.0>
버디 시스템의 구조
버디 시스템이라 불리는 버디 페이지 할당자는 페이지 단위의 메모리 할당과 해제를 수행한다. 버디 시스템은 연속으로 할당 가능한 페이지를 2의 승수 단위로 관리한다. 페이지들은 2^0 = 1페이지부터 2^(MAX_ORDER – 1)까지 각 order 슬롯으로 나누어 관리한다.
페이지 할당 order
페이지 할당자에서 사용하는 버디 시스템에서는 오더(order)라는 용어로 페이지 할당을 요청한다. 이것은 2의 제곱승 단위로만 요청을 할 수 있음을 의미한다. 예를 들어, 오더 3에 해당하는 페이지를 요청하는 경우 2^3 = 8페이지를 요청하는 것이다.
다음 그림은 버디 시스템이 할당 요청 받을 수 있는 order 페이지들을 보여준다.
- 0x1234_5000 ~ 0x1236_2000 사이에 연속된 9개의 free 페이지가 존재하지만, order 단위로 align되어 관리하는 버디 시스템에서 할당 가능한 페이지들은 다음과 같다.
- 0 order 페이지 1개
- 1 order 페이지 2개
- 2 order 페이지 1개

MAX_ORDER
버디 시스템에서 한 번에 최대 할당 가능한 페이지 수는 2^(MAX_ORDER-1) 페이지이다.
- 예) PAGE_SIZE=4K, MAX_ORDER=11인 경우 한 번에 최대 할당 가능한 페이지는 1024 페이지이고 바이트로는 4M이다.
- 2^0, 2^1, 2^2, … 2^10 페이지
- 4K, 8K, 16K, …, 4M 페이지
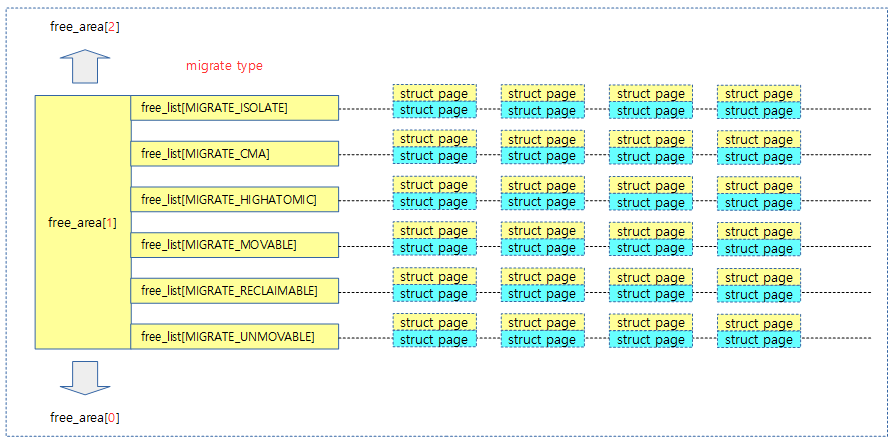
다음 그림은 페이지를 관리하는 order 슬롯이 0 부터 최대 MAX_ORDER-1 까지 free 페이지들을 관리하고 있는 모습을 보여준다.
- 각 free 메모리에 대한 page 구조체들 중 head에 해당하는 page 구조체가 대표 페이지이며 리스트에 연결된다.

ARM32 및 ARM64 커널의 디폴트 설정으로 MAX_ORDER는 11로 정의되어 있다. 또한 CONFIG_FORCE_MAX_ZONEORDER 커널 옵션을 사용하여 크기를 바꿀 수 있다. 각 오더 슬롯 또한 단편화되지 않도록 관리하기 위해 다음과 같은 구조로 이루어져 있다.
- 같은 mobility 속성을 가진 페이지들끼리 가능하면 뭉쳐 있도록 각 오더 슬롯은 마이그레이션 타입별로 나누어 관리한다. 이렇게 나누어 관리함으로써 페이지 회수 및 메모리 컴팩션(compaction) 과정에서 효율을 높일 수 있다. 특별히 MIGRATE_MOVABLE 타입으로만 구성된 ZONE_MOVABLE 영역을 만들 수도 있다.
- 각 페이지를 담는 free_list에서 free 페이지들은 짝(버디)을 이루어 2개의 짝(버디)이 모이면 더 큰 오더로 합병되어 올라가고 필요시 분할하여 하나 더 적은 오더로 나뉠 수 있다. 이제 더 이상 짝(버디)을 관리할 때 map이라는 이름의 bitmap을 사용하지 않고 free_list라는 이름의 리스트와 페이지 정보만을 사용하여 관리한다.
- free_list는 선두 방향으로 hot 속성을 갖고 후미 방향으로 cold 속성을 갖는다. hot, cold 속성은 각각 리스트의 head와 tail의 위치로 대응하여 관리된다. 앞부분에 놓인 페이지들은 다시 할당되어 사용될 가능성이 높은 페이지다. 뒷부분에 놓인 페이지들은 오더가 통합되어 점점 상위 오더로 올라갈 가능성이 높은 페이지다. 이를 통해 free 페이지의 단편화 방지에 도움을 주고 캐시의 지속성을 높여 성능을 올리는 효과도 있다.
버디 시스템의 관리 기법이 계속 발전하면서 복잡도는 증가하고 있지만, 최대한 버디 시스템의 효율(비단편화)을 높이는 쪽으로 발전하고 있다. 그림 4-41은 버디 메모리 할당자의 코어 부분을 보여준다.
페이지 블록과 mobility(migrate) 속성
메모리를 페이지 블록 단위로 나누어 페이지 블록마다 4비트를 사용한 비트맵으로 mobility 속성을 표현한다. 첫 3비트를 사용하여 각 메모리 블록을 마이그레이션 타입으로 구분하여 mobility 속성을 관리한다. 페이지 블록은 2^pageblock_order만큼 페이지를 관리하고 그 페이지들이 가장 많이 사용하는 mobility 속성을 메모리 블록에서 대표 mobility 속성으로 기록하여 관리한다. 나머지 1비트를 사용하여 컴팩션 기능에 의해 스킵할 수 있도록 한다.
migrate 타입
페이지 타입이라고도 불린다. 각 order 페이지는 각각 mobility 속성을 표현하기 위해 migrate 타입을 갖고 있으며, 가능하면 같은 속성을 가진 페이지들끼리 뭉쳐 있도록 하여 연속된 메모리의 단편화를 억제한다. 최대한 커다랗고 연속된 free 메모리를 유지하고자 하는 목적으로 버디 시스템에 설계되었다. 버디 시스템의 free_list는 다음과 같은 migrate 타입별로 관리된다. 단 migrate 타입별로 1 개 이상의 페이지 블럭을 확보하지 못하는 메모리가 극히 적은 시스템(수M ~ 수십M)에서는 모든 페이지를 unmovable로 구성한다.
참고로 버디의 pcp 캐시는 아래 타입 중 가장 많이 사용되는 아래 3가지 타입만을 사용하여 관리한다.
- MIGRATE_UNMOVABLE
- 이동과 메모리 회수가 불가능한 타입이다.
- 용도
- 커널에서 할당한 페이지, 슬랩, I/O 버퍼, 커널 스택, 페이지 테이블 등에 사용되는 타입이다.
- MIGRATE_MOVABLE
- 연속된 큰 메모리가 필요한 경우, 현재 사용되는 페이지를 이동시켜 최대한 단편화를 막기 위해 사용되는 타입이다.
- 용도
- 유저(file, anon) 메모리 할당 시 사용된다.
- MIGRATE_RECLAIMABLE
- 이동은 불가능하지만 메모리 부족 시 메모리 회수가 가능한 경우에 사용되는 타입이며, 자주 사용하는 타입이 아니다.
- 용도
- __GFP_RECLAIMABLE 플래그를 특별히 지정하여 생성한 슬랩 캐시인 경우 이 타입으로 이용한다
- MIGRATE_HIGHATOMIC
- high order 페이지 할당에 대해 atomic 할당 요청 시 실패될 확률을 줄이기 위해 커널은 이 유형의 페이지 타입을 1 블럭씩 미리 준비하고 있다. 이 타입의 메모리는 최대 메모리의 1% 범위까지 확장될 수 있다.
- 용도
- 주로 RT 스케줄러를 사용하는 커널 스레드나 인터럽트 핸들러 등에서 메모리 할당 시 GFP_ATOMIC을 사용하여 메모리 할당을 요청하면, 슬립을 일으킬 수 있는 페이지 회수(reclaim) 없이 처리해야 한다. 그런데 high order 페이지 할당 요청을 하는 경우 페이지 회수 없이 처리하다 보면 메모리가 충분한 경우에도 high order 페이지가 하나도 없어 OOM(Out Of Memory)이 발생할 수 있다. 이러한 경우를 위해 미리 reserve된 MIGRATE_HIGHATOMIC 타입의 페이지를 할당하여 위기를 넘길 수 있다.
- 커널 4.4-rc1에서 MIGRATE_RESERVE 타입이 삭제되었고 대신 high-order atomic allocation을 지원하기 위해 MIGRATE_HIGHATOMIC이 추가되었다.
- MIGRATE_CMA
- CMA 메모리 할당자가 별도로 관리하는 페이지 타입이다. CMA 영역을 버디 시스템에 구성하는 경우 이 영역은 movable 페이지도 할당될 수 있다. CMA 요청 시 이 영역이 부족하면 movable 페이지를 다른 영역으로 이동시킨다. CMA 페이지로 할당되면 각 페이지들의 할당 및 관리는 별도로 CMA 메모리 할당자에서 수행한다.
- 용도
- 커널이 DMA 용도 등으로 사용하기 위한 메모리 할당 시 사용된다.
- MIGRATE_ISOLATE
- 커널이 특정 범위의 사용 중인 movable 페이지들을 다른 곳으로 migration 하기 위해 잠시 이 타입으로 변경하여 관리한다. 그리고 이 타입으로 있는 페이지들에 대해 버디 시스템은 절대 사용하지 않는다.
- 용도
- CMA 영역의 메모리가 부족한 상황에서 free 페이지를 확보하기 위해 CMA 영역에 있는 movable 페이지들을 CMA 영역의 밖으로 이동시켜 확보할 때 사용된다.
- 메모리 hot-remove를 위해 해당 영역의 사용 중인 movable 페이들을 다른 곳으로 옮길 때 사용된다.
다음 그림은 각 order 슬롯마다 6개의 migrate type 별로 free 페이지를 관리하는 리스트의 모습을 보여준다.
page_blockorder
매크로로 정의된 pageblock_order는 페이지 블록을 구성하는 페이지의 개수를 승수 단위로 표현한다.
ARM64 커널에서는 huge 페이지를 지원하며 huge 페이지 단위에 맞춰 사용한다. huge 페이지를 사용하지 않는 경우는 버디 시스템이 사용하는 최대 페이지 크기에 맞춰사용한다.
- 예) 4K 페이지 및 huge 페이지 사용 시 pageblock_order=9
- 예) 4K 페이지 및 huge 페이지 미사용 시 pageblock_order=10
include/linux/pageblock-flags.h
#define pageblock_order HUGETLB_PAGE_ORDER
ARM32 커널은 버디 시스템이 사용하는 최대 페이지 크기에 맞춰사용한다.
- 예) 4K 페이지 사용 시 pageblock_order=10
include/linux/pageblock-flags.h
#define pageblock_order (MAX_ORDER-1)
다음 ARM64 시스템은 pageblock_order가 9로 설정되어 있음을 알 수 있고, 각 노드, zone 및 order, migrate 타입별 버디에서 관리되고 있는 free 페이지 수를 보여준다. 또한 각 노드, zone 및 migrate 타입별 페이지 블럭 수를 보여준다.
$ cat /proc/pagetypeinfo Page block order: 9 Pages per block: 512 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 0, zone DMA32, type Unmovable 0 0 168 322 108 6 2 0 0 1 0 Node 0, zone DMA32, type Movable 0 0 31 9 3 4 0 0 0 0 412 Node 0, zone DMA32, type Reclaimable 0 0 1 0 0 1 1 1 1 0 0 Node 0, zone DMA32, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone DMA32, type CMA 0 0 0 0 0 0 1 1 1 1 7 Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Movable Reclaimable HighAtomic CMA Isolate Node 0, zone DMA32 232 1250 38 0 16 0 Number of mixed blocks Unmovable Movable Reclaimable HighAtomic CMA Isolate Node 0, zone DMA32 0 1 1 0 0 0
다음 ARM32 시스템은 pageblock_order가 10으로 설정되어 있음을 알 수 있다.
$ cat /proc/pagetypeinfo Page block order: 10 Pages per block: 1024 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 0, zone Normal, type Unmovable 10 13 9 6 2 2 0 1 0 1 0 Node 0, zone Normal, type Reclaimable 1 2 2 3 0 0 1 0 1 0 0 Node 0, zone Normal, type Movable 6 3 1 1 447 109 4 0 0 1 147 Node 0, zone Normal, type Reserve 0 0 0 0 0 0 0 0 0 0 2 Node 0, zone Normal, type CMA 1 1 1 2 1 2 1 0 1 1 0 Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Reclaimable Movable Reserve CMA Isolate Node 0, zone Normal 4 5 223 2 2 0
- rpi2의 경우 MAX_ORDER=11로 설정되어 있고 pageblock_order 역시 MAX_ORDER-1로 설정되어 있는 것을 알 수 있다.
- 커널 버전에 따라 MAX_ORDER값이 다르다. 기존에는 9, 10 등이 사용되었었다.
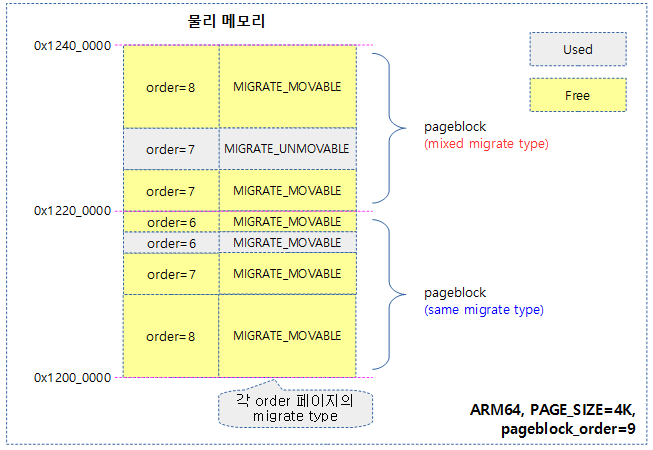
다음 그림은 각 pageblock에 포함된 order 페이지들의 migrate 타입이 하나로 유지된 것과, 그렇지 않고 여러 개가 mix된 사례를 보여준다.
- 커널은 가능하면 같은 블럭내에서 한 가지 migrate 타입을 유지하려 하지만 메모리 부족 등의 상황에서 migrate 타입이 섞일 수도 있다.
- migrate 타입이 섞이지 않게 관리하면 파편화되지 않을 가능성이 높아진다.
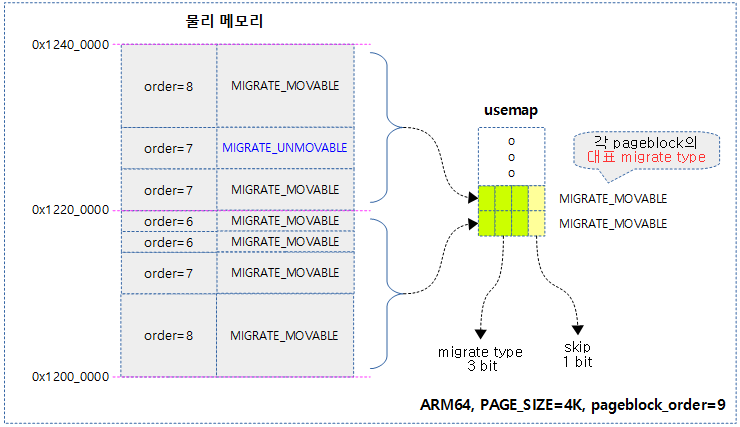
pageblock 별 대표 migrate type
order 페이지들이 migrate 타입으로 관리되는 것과 동일하게, pageblock들도 각각의 migrate 타입을 관리한다. 만일 pageblock 내에서 여러 개의 migrate 타입을 사용하는 order 페이지들이 섞여 사용 중인 경우 그 들중 가장 많이 사용되는 migrate 타입을 해당 블럭의 대표 migrate 타입으로 지정한다. 이러한 대표 migrate 타입 3 비트와 compaction에서 사용하는 1 비트의 skip 비트를 추가하여 usemap에 저장한다.
usemap 각 비트의 용도
- 대표 migrate 타입(3 bits)
- 파편화를 회피하기 위해 페이지 할당 시 요청한 migrate 타입과 동일한 대표 migrate 타입이 있는 pageblock에서 할당하려고 노력한다.
- skip 비트(1bits)
- 메모리 부족 시compaction을 수행할 때 compaction을 skip 하기 위한 비트이다.
다음 그림은 usemap에 표현된 각 pageblock 별 대표 migrate 타입을 보여준다.
PF_MEMALLOC
메모리 회수와 관련한 특수한 커널 스레드 또는 페이지 회수 시 잠시 페이지 할당을 해야 하는 스레드에서 사용하는 플래그 비트이다. 워터마크 기준 이하로 메모리가 부족해진 경우 페이지 회수 시스템이 동작한다. 이 때 페이지를 회수하는 과정에서 네트웍을 이용한 Swap 등을 포함한 몇 개의 특수한 페이지 회수 요청에서 오히려 페이지를 잠시 할당해야 하는 경우가 있다. 예를 들어 페이지 부족 시 네트워크를 사용하여 swap을 해야 할 때 네트웍 처리 시 필요한 skb(소켓버퍼)등이 할당되어야 한다. 이렇게 메모리 할당 요청을 할 때 다시 메모리 부족에 대한 페이지 회수 시스템이 동작하는 등을 반복하게 되는 문제가 있다. 따라서 이러한 재귀적인 문제가 발생하지 않도록 특수한 목적으로 페이지 할당을 해야 하는 경우에 “메모리 부족을 해결하기 위한 임시 메모리 할당 요청”임을 식별하게 하는 PF_MEMALLOC 플래그를 사용한다. 이 플래그를 사용하면 다음과 같은 동작을 수행하게 한다.
- 워터마크 기준 이하의 메모리도 할당한다.
- 페이지 회수가 반복되지 않도록 모든 종류의 페이지 회수를 다시 요청하지 않는다.
PF_MEMALLOC 플래그와 같이 메모리가 부족한 상황에서 임시 메모리를 할당하기 위해 호출될 때 사용하기 위해 아래 두 개의 플래그가 추가되었다.
PF_MEMALLOC_NOIO
- 워터마크 기준 이하의 메모리도 할당한다.
- IO 요청을 동반한 페이지 회수가 반복되지 않게 한다. 즉 IO 요청이 아닌 메모리 내에서만 동작하는 페이지 회수는 동작시킬 수 있다.
PF_MEMALLOC_NOFS
- 워터마크 기준 이하의 메모리도 할당한다.
- 파일 시스템을 이용하는 페이지 회수가 반복되지 않게 한다. 즉 파일 시스템이 아닌 메모리나 다른 종류의 IO를 사용하는 페이지 회수는 동작시킬 수 있다.
- 참고: mm: introduce memalloc_nofs_{save,restore} API
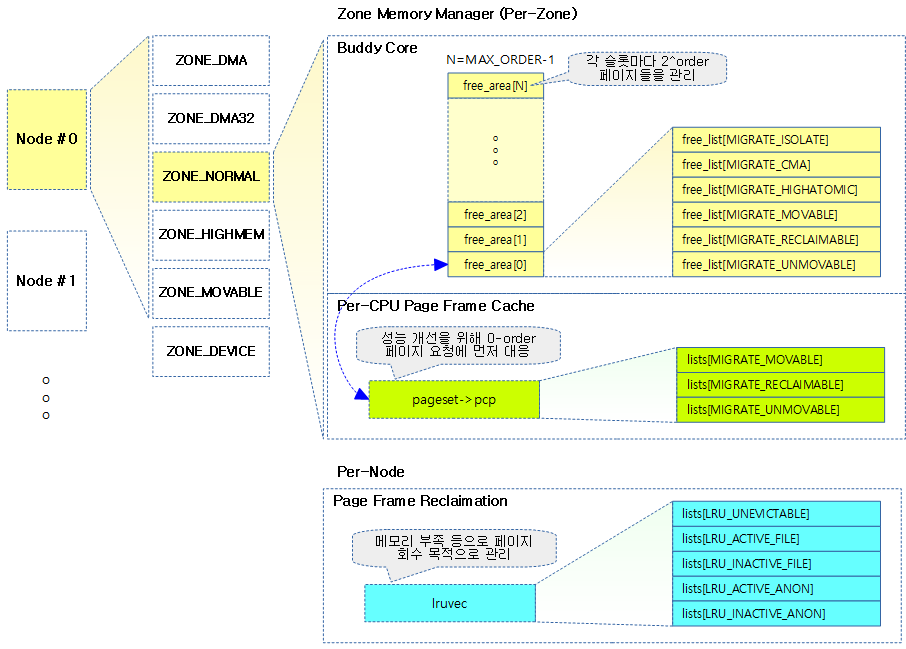
페이지 할당자 구조
다음 그림은 페이지 할당자를 구성하는 주요 항목들을 보여준다.
- 노드별
- NUMA 메모리 정책에 따른 노드 및 zonelist
- 페이지 회수 매커니즘
- 존별
- 버디 코어(심장)
- 버디 캐시(pcp)
페이지 할당 Sequence
페이지 할당자는 크게 다음과 같은 루틴들을 통해 할당된다.
- 가장 먼저 NUMA 메모리 정책을 통해 대상이 되는 노드 또는 노드들을 정한다.
- Memory Control Group 통제 내에서 할당된다.
- 버디 시스템을 통해 할당을 수행한다.
- 1 페이지(0-order) 할당 요청인 경우 버디 캐시 시스템인 pcp를 사용하여 할당한다.
- 메모리 부족 시 인터럽트 여부 또는 요청한 플래그 옵션에 따라 메모리 회수를 동반할 수 있다.
GFP 마스크(gfp_mask)
페이지 할당 요청 시 사용되는 플래그들이다.
- 참고: GFP 플래그 | 문c
할당 플래그(alloc_flags)들
페이지 할당 함수에서 gfp_mask와 별도로 사용되며, 함수 내부(internal) 용도로 사용되는 할당 플래그들이다.
- ALLOC_WMARK_MIN
- 남은 메모리가 min 워터마크 미만으로 내려가는 경우 할당을 제한하도록 하는 기준이다.
- 유저 메모리 할당 요청(GFP_USER), 일반적인 커널 메모리 할당 요청(GFP_KERNEL) 등에서는 이 기준 이하의 할당을 제한한다.
- 단 GFP_ATOMIC으로 할당요청하는 경우 비상용으로 남겨둔 이 기준보다 절반 정도를 더 사용하도록 허락한다.
- ALLOC_WMARK_LOW
- 남은 메모리가 low 워터마크 미만으로 내려가는 경우 kcompactd 및 kswapd 등의 페이지 회수 시스템을 가동시키는 기준으로 사용된다.
- ALLOC_WMARK_HIGH
- 남은 메모리가 high워터마크 이상일 때 kcompactd 및 kswapd 등의 페이지 회수 시스템의 가동을 슬립시켜 정지시키는 기준으로 사용된다.
- ALLOC_NO_WATERMARKS
- 워터마크 기준을 무시하고 할당할 수 있도록 한다.
- PF_MEMALLOC 플래그가 사용되는 태스크(kswapd, kcompactd, … 등의 페이지 회수 스레드들)이 메모리 할당을 요구할 때 워터마크 기준을 무시하고 할당 할 수 있어야 하므로 이러한 플래그가 사용된다.
- ALLOC_HARDER
- 다음과 같은 상황에서 이 플래그가 사용된다.
- GFP_ATOMIC 플래그 사용하여 메모리 할당을 요청하는 경우
- RT 스케줄러를 사용하는 커널 스레드에서 할당을 요청하는 경우
- 이 플래그는 다음과 같은 동작을 수행한다.
- 메모리 부족 시 남은 min 워터마크 기준보다 25% 더 할당을 받게 한다.
- GFP_ATOMIC 사용시 아래 ALLOC_HIGH까지 부터 50% 한 후 추가 25% 적용
- high order 페이지 할당 시 실패하는 경우에 대비하여 높은 order 할당이 실패하지 않도록 예비로 관리하는 MIGRATE_HIGHATOMIC freelist를 사용하게 한다.
- 메모리 부족 시 남은 min 워터마크 기준보다 25% 더 할당을 받게 한다.
- 다음과 같은 상황에서 이 플래그가 사용된다.
- ALLOC_HIGH
- GFP_ATOMIC 플래그를 사용할 때 ALLOC_HARDER와 함께 이 플래그가 사용되며, 메모리 부족 시 남은 min 워터마크 기준보다 50% 더 할당을 받게 한다.
- ALLOC_CPUSET
- 태스크가 요청하는 메모리를 cgroup의 cpuset 서브시스템을 사용하여 제한한다.
- interrupt context에서 요청하는 메모리의 경우 cpuset을 무시하고 할당한다.
- ALLOC_CMA
- movable 페이지에 대한 할당 요청 시 가능하면 cma 영역을 사용하지 않고 할당을 시도하지만, 이 플래그를 사용하면 메모리가 부족 시 cma 영역도 사용하여 할당을 시도한다.
- ALLOC_NOFRAGMENT
- 페이지 할당 시 요청한 migratetype 만으로 구성된 페이지 블럭내에서 할당을 시도한다.
- 단 메모리가 부족한 경우에는 어쩔 수 없이, 이 플래그 요청을 무시하고 fragment 할당을 한다.
- GFP_KERNEL or GFP_ATOMIC 등)과 같이 normal 존을 이용하는 커널 메모리 등을 할당해야 할 때 노드 내에 해당 normal zone 밑에 dma(or dma32)가 구성되어 있는 경우 이러한 플래그를 사용되어 최대한 1 페이지 블럭내에서 여러 migratetype의 페이지가 할당되어 구성되지 않도록 노력한다.
- ALLOC_KSWAPD
- GFP_ATOMIC을 제외한 GFP_KERNEL, GFP_USER, GFP_HIGHUSER 등의 메모리 할당을 요청하는 경우 __GFP_RECLAIM 플래그(direct + kswapd)가 추가되는데 그 중 __GFP_RECLAIM_KSWAPD를 체크하여 이 플래그가 사용된다. 메모리 부족시 즉각 kcompactd 및 kswapd 스레드를 꺄워 동작시키는 기능을 의미한다.
ALLOC_FAIR
ALLOC_FAIR 플래그를 사용한 fair zone 정책은 NUMA 시스템의 메모리 정책을 사용하면서 불필요하게 되어 커널 v4.8-rc1에서 제거되었다.
NUMA 메모리 정책(Policy)
- 참고: NUMA -3- (Memory policy) | 문c
물리 페이지 할당(alloc)
다음 그림은 페이지 할당을 하는 흐름을 보여준다.
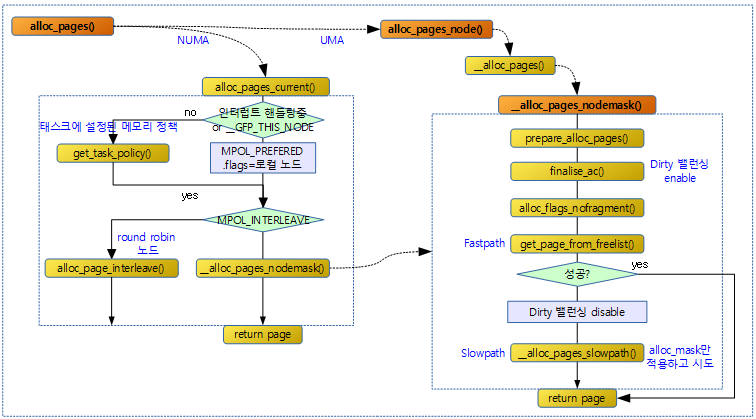
alloc_pages()
include/linux/gfp.h
#ifdef CONFIG_NUMA
static inline struct page * alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
#else
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
#endif
버디 시스템을 통해 연속된 2^order 페이지들을 할당받는다. NUMA 시스템을 사용하는 경우 NUMA 메모리 정책을 반영하기 위해 alloc_pages_current( ) 함수를 통해 노드가 선택되고, 그 후 그 함수 내부에서 alloc_pages_node( ) 함수를 호출하여 페이지를 할당받는다.
alloc_pages_current()
mm/mempolicy.c
/** * alloc_pages_current - Allocate pages. * * @gfp: * %GFP_USER user allocation, * %GFP_KERNEL kernel allocation, * %GFP_HIGHMEM highmem allocation, * %GFP_FS don't call back into a file system. * %GFP_ATOMIC don't sleep. * @order: Power of two of allocation size in pages. 0 is a single page. * * Allocate a page from the kernel page pool. When not in * interrupt context and apply the current process NUMA policy. * Returns NULL when no page can be allocated. */
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);
/*
* No reference counting needed for current->mempolicy
* nor system default_policy
*/
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));
else
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;
}
EXPORT_SYMBOL(alloc_pages_current);
NUMA 시스템에서 메모리 정책에 따라 노드를 선택하고 버디 시스템을 통하여 연속된 2^order 페이지들을 할당 받는다.
- 코드 라인 3~7에서 인터럽트 처리중이거나 현재 노드에서만 할당하라는 요청인 경우에는 디폴트 메모리 정책을 선택한다. 그 외의 경우에는 현재 태스크에 주어진 메모리 정책을 선택한다. 만일 태스크에도 메모리 정책이 설정되지 않은 경우 노드를 지정한 경우 해당 노드에 우선 처리되는 메모리 정책을 사용한다. 노드가 지정되지 않은 경우에는 디폴트 메모리 정책을 선택한다.디폴트 메모리 정책은 로컬 노드를 사용하여 할당한다.
- __GFP_THISNODE 플래그를 사용하여 로컬 노드로 제한한 경우 -> 디폴트 메모리 정책 사용
- 인터럽트 중 -> 디폴트(로컬 노드 preferred) 메모리 정책 사용
- 태스크에 지정된 정책
- 태스크에 지정된 정책이 있으면 -> 태스크에 지정된 메모리 정책
- 지정된 노드가 있으면 -> 노드에 지정된 우선 메모리 정책 사용
- 지정된 노드가 없으면 -> 디폴트(로컬 노드 preferred) 메모리 정책
- 코드 라인 13~14에서 인터리브 메모리 정책을 사용하는 경우 페이지를 노드별로 돌아가며 할당하게 한다.
- 코드 라인 15~16에서 그 외의 정책을 사용하는 경우 요청한 노드 제한내에서 order 페이지를 할당 받는다.
alloc_pages_node()
include/linux/gfp.h
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
/* Unknown node is current node */
if (nid < 0)
nid = numa_node_id();
return __alloc_pages(gfp_mask, order, node_zonelist(nid, gfp_mask));
}
지정된 노드에서 연속된 2^order 페이지들을 할당 받는다. 만일 알 수 없는 노드가 지정된 경우 현재 노드에서 할당 받는다.
__alloc_pages()
include/linux/gfp.h
static inline struct page *
__alloc_pages(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist)
{
return __alloc_pages_nodemask(gfp_mask, order, zonelist, NULL);
}
노드 및 존에 대한 우선순위를 담은 zonelist에서 2^order 페이지 만큼 연속된 물리메모리를 할당 받는다.
버디 할당자의 심장
지정 노드들에서 페이지 할당하기
__alloc_pages_nodemask()
mm/page_alloc.c
/* * This is the 'heart' of the zoned buddy allocator. */
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW;
gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = { };
/*
* There are several places where we assume that the order value is sane
* so bail out early if the request is out of bound.
*/
if (unlikely(order >= MAX_ORDER)) {
WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN));
return NULL;
}
gfp_mask &= gfp_allowed_mask;
alloc_mask = gfp_mask;
if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc__
flags))
return NULL;
finalise_ac(gfp_mask, &ac);
/*
* Forbid the first pass from falling back to types that fragment
* memory until all local zones are considered.
*/
alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp_mask);
/* First allocation attempt */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
/*
* Apply scoped allocation constraints. This is mainly about GFP_NOFS
* resp. GFP_NOIO which has to be inherited for all allocation requests
* from a particular context which has been marked by
* memalloc_no{fs,io}_{save,restore}.
*/
alloc_mask = current_gfp_context(gfp_mask);
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
if (unlikely(ac.nodemask != nodemask))
ac.nodemask = nodemask;
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
out:
if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page &&
unlikely(memcg_kmem_charge(page, gfp_mask, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype);
return page;
}
EXPORT_SYMBOL(__alloc_pages_nodemask);
지정된 노드마스크, zonelist 및 flags 설정을 참고하여 노드와 zone을 선택한 후 2^order 페이지만큼 연속된 물리 메모리 할당을 한다.
- 코드 라인 6에서 할당 플래그의 초기 값으로 low 워터마크를 사용하는 것으로 지정한다.
- 코드 라인 14~17에서 @order 값이 MAX_ORDER 이상을 사용할 수 없다. 이러한 경우 null을 반환한다.
- 버디 시스템에서 연속된 메모리를 한 번에 요청할 수 있는 최대 페이지 수는 2^(MAX_ORDER-1) 이다.
- 코드 라인 19에서 커널 부트업 프로세스가 처리되는 동안은 페이지 할당을 위해 IO 처리를 위한 드라이버나 파일 시스템이 준비되지 않으며, 따라서 메모리 회수 시스템도 구동되지 않고 있는 상태다. 따라서 이러한 요청들이 발생할 때 이 기능을 사용하지 못하게 막기 위해 gfp 플래그에서 _ _GFP_RECLAIM, _ _GFP_IO 및 _ _GFP_FS 비트를 제거한다.
- 부팅 중에는 전역 변수 gfp_allowed_mask에 GFP_BOOT_MASK를 대입한다.
- GFP_BOOT_MASK에는 __GFP_RECLAIM | __GFP_IO | __GFP_FS를 제거한 비트들이 담겨있다.
- 부팅 중에는 전역 변수 gfp_allowed_mask에 GFP_BOOT_MASK를 대입한다.
- 코드 라인 20~23에서 페이지 할당을 시도하기 전에 필요한 할당 context 및 필요한 할당 플래그를 추가하여 준비한다.
- 코드 라인 25에서 마지막으로 alloc 컨텍스트의 추가 멤버를 준비한다.
- 코드 라인 31에서 zone 및 gfp 마스크 요청에 따라 nofragment 등의 alloc 플래그를 추가한다.
- 코드 라인34~36에서 처음 Fast-path 페이지 할당을 시도한다.
- 코드 라인 44~54에서 Fast-path 할당이 실패한 경우 dirty zone 밸런싱을 하지 않도록 설정하고, slow-path 할당을 시도한다.
- 코드 라인 56~61에서 out: 레이블이다. 할당된 페이지를 반환하는데, 메모리 컨트롤 그룹의 리밋을 벗어나는 경우 할당을 포기한다.
할당 context 준비
prepare_alloc_pages()
mm/page_alloc.c
static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order,
int preferred_nid, nodemask_t *nodemask,
struct alloc_context *ac, gfp_t *alloc_mask,
unsigned int *alloc_flags)
{
ac->high_zoneidx = gfp_zone(gfp_mask);
ac->zonelist = node_zonelist(preferred_nid, gfp_mask);
ac->nodemask = nodemask;
ac->migratetype = gfpflags_to_migratetype(gfp_mask);
if (cpusets_enabled()) {
*alloc_mask |= __GFP_HARDWALL;
if (!ac->nodemask)
ac->nodemask = &cpuset_current_mems_allowed;
else
*alloc_flags |= ALLOC_CPUSET;
}
fs_reclaim_acquire(gfp_mask);
fs_reclaim_release(gfp_mask);
might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM);
if (should_fail_alloc_page(gfp_mask, order))
return false;
if (IS_ENABLED(CONFIG_CMA) && ac->migratetype == MIGRATE_MOVABLE)
*alloc_flags |= ALLOC_CMA;
return true;
}
페이지 할당을 시도하기 전에 각 하위 함수들에 전달할 값들을 모아 ac_context 구조체에 준비한다. 그리고 입출력 인자 @alloc_flags에 필요 시 플래그를 추가하여 준비한다. 디버깅 목적으로 강제로 할당을 실패하게 한 경우에만 false를 반환한다.
- 코드 라인 6에서 @gfp_mask에 해당하는 존 인덱스를 알아온다.
- 코드 라인 7에서 @nid 노드에서 @flags 값에 따라 두 zonelist 중 하나를 선택하여 반환한다.
- 참고: build_all_zonelists() | 문c
- 코드 라인 8~9에서 노드 마스크와 할당받을 마이그레이션 타입을 gfp 플래그에서 구한다.
- 코드 라인 11~17에서 컨트롤 그룹의 cpuset 을 사용하는 경우 alloc_mask에 hardwall 플래그를 추가하여, 요청한 태스크에 혹시 cgroup의 현재 cpuset 디렉토리 설정에서 지정한 제한 사항들이 반영되는 상태에서 할당하게 한다. 추후 이러한 제한은 GFP_ATOMIC 같은 할당에서는 제외된다. 또한 할당 함수에서 노드 마스크 지정여부에 따라 다음과 같이 나뉜다.
- hardwall + 할당 함수에서 요청한 노드마스크에 지정된 노드들
- hardwall + 할당 함수에서 요청한 노드마스크 없으면 태스크가 지정한 노드들
- 코드 라인 22에서 direct 회수를 허용한 경우 preempt point를 수행한다.
- 일반적인 유저 및 커널 메모리 할당 요청 시 direct 회수는 허용된다.
- 코드 라인 24~25에서 디버깅 목적으로 실패 상황을 만들 수 있다.
- 코드 라인 27~28에서 movable 페이지인 경우 cma 영역의 사용을 허락한다.
finalise_ac()
mm/page_alloc.c
/* Determine whether to spread dirty pages and what the first usable zone */
static inline void finalise_ac(gfp_t gfp_mask, struct alloc_context *ac)
{
/* Dirty zone balancing only done in the fast path */
ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE);
/*
* The preferred zone is used for statistics but crucially it is
* also used as the starting point for the zonelist iterator. It
* may get reset for allocations that ignore memory policies.
*/
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
}
alloc 컨텍스트의 추가 멤버를 준비하여 마무리한다.
- 코드 라인 5에서 gfp 플래그에 _ _GFP_WRITE 요청이 있다면 fastpath 페이지 할당에서만 더티 존(dirty zone) 밸런싱을 사용한다
- 코드 라인 12~13에서 현재 zonelist의 사용 가능한 가장 첫 번째 존을 preferred_zoneref에 저장한다. 이 값은 나중에 통계에서 사용한다. 또한 첫 존이 없는 경우에는 페이지 할당을 할 수 없으므로 out 레이블로 이동하여 함수를 빠져나간다. ac.nodemask가 지정되지 않아 NULL인 경우에는 현재 태스크에 cpuset으로 지정된 노드마스크를 사용한다.
alloc_flags_nofragment()
mm/page_alloc.c
/* * The restriction on ZONE_DMA32 as being a suitable zone to use to avoid * fragmentation is subtle. If the preferred zone was HIGHMEM then * premature use of a lower zone may cause lowmem pressure problems that * are worse than fragmentation. If the next zone is ZONE_DMA then it is * probably too small. It only makes sense to spread allocations to avoid * fragmentation between the Normal and DMA32 zones. */
static inline unsigned int
alloc_flags_nofragment(struct zone *zone, gfp_t gfp_mask)
{
unsigned int alloc_flags = 0;
if (gfp_mask & __GFP_KSWAPD_RECLAIM)
alloc_flags |= ALLOC_KSWAPD;
#ifdef CONFIG_ZONE_DMA32
if (zone_idx(zone) != ZONE_NORMAL)
goto out;
/*
* If ZONE_DMA32 exists, assume it is the one after ZONE_NORMAL and
* the pointer is within zone->zone_pgdat->node_zones[]. Also assume
* on UMA that if Normal is populated then so is DMA32.
*/
BUILD_BUG_ON(ZONE_NORMAL - ZONE_DMA32 != 1);
if (nr_online_nodes > 1 && !populated_zone(--zone))
goto out;
out:
#endif /* CONFIG_ZONE_DMA32 */
return alloc_flags;
}
zone 및 gfp 마스크 요청에 따라 nofragment 등의 alloc 플래그를 추가한다.
- 코드 라인 6~7에서 gfp 플래그로 __GFP_KSWAPD_RECLAIM이 요청된 경우 alloc 플래그에서 ALLOC_KSWAPD를 추가하여 메모리 부족 시 kswapd를 깨울 수 있게 한다.
- 코드 라인 9~23에서 dma32 존과 normal 존을 모두 운용하는 경우에 normal 존에 할당 요청을 한 경우ALLOC_NOFRAGMENT플래그를추가한다. (단 5.0 코드는 버그)
- ALLOC_NOFRAGMENT 플래그를 추가하지 않는 버그로 인하여 커널 v5.1-rc7에서 패치되었다.
ALLOC_NOFRAGMENT
- 요청한 migratetype의 메모리를 할당 시 메모리가 부족한 경우 다른 타입(fallback migratetype)으로부터 steal 해오는데, 이 때 1 페이지 블럭 단위 이상으로만 steal하도록 하여 페이지 블럭내에 다른 migratetype이 섞이지 않도록 제한한다. 이렇게 migratetype간의 fragment 요소를 배제하도록 한다.
Fastpath 페이지 할당
아래의 함수는 페이지 할당 시 Fastpath와 Slowpath 두 곳에서 호출되어 사용되는데 Fastpath에서 호출될 때에는 인수 gfp_mask에 __GFP_HARDWALL을 추가하여 호출한다.
- GFP_KERNEL
- (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
- __GFP_RECLAIM은 ___GFP_DIRECT_RECLAIM 과 ___GFP_KSWAPD_RECLAIM 두 플래그를 가진다.
- GFP_USER
- (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
- user space에서 페이지를 할당 요청시 __GFP_HARDWALL을 설정하여 현재 태스크의 cpuset이 허락하는 메모리 노드가 아닌 곳에서 할당되는 것을 허용하지 않게 한다.
다음 그림은 페이지 할당 시 사용되는 Fastpath 루틴과 Slowpath 루틴에서 사용되는 함수를 구분하여 보여준다.
- 단 get_page_from_freelist() 함수가 __alloc_pages_slowpath() 함수에서 호출되는 경우에는 Slowpath의 일부분이다.
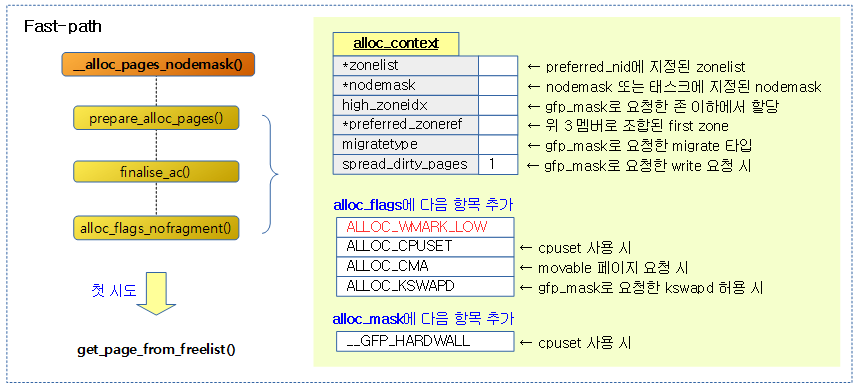
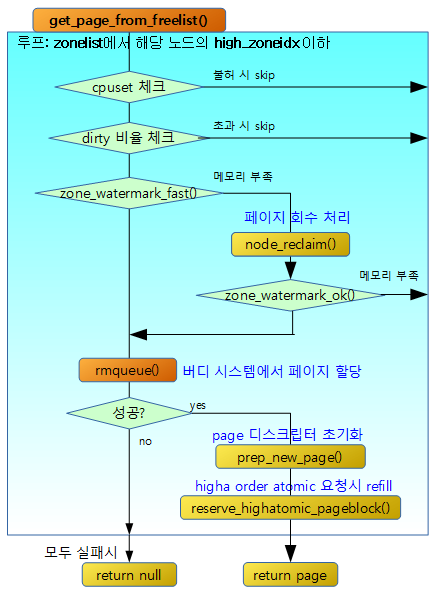
get_page_from_freelist()
mm/page_alloc.c -1/2-
/* * get_page_from_freelist goes through the zonelist trying to allocate * a page. */
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z;
struct zone *zone;
struct pglist_data *last_pgdat_dirty_limit = NULL;
bool no_fallback;
retry:
/*
* Scan zonelist, looking for a zone with enough free.
* See also __cpuset_node_allowed() comment in kernel/cpuset.c.
*/
no_fallback = alloc_flags & ALLOC_NOFRAGMENT;
z = ac->preferred_zoneref;
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!__cpuset_zone_allowed(zone, gfp_mask))
continue;
/*
* When allocating a page cache page for writing, we
* want to get it from a node that is within its dirty
* limit, such that no single node holds more than its
* proportional share of globally allowed dirty pages.
* The dirty limits take into account the node's
* lowmem reserves and high watermark so that kswapd
* should be able to balance it without having to
* write pages from its LRU list.
*
* XXX: For now, allow allocations to potentially
* exceed the per-node dirty limit in the slowpath
* (spread_dirty_pages unset) before going into reclaim,
* which is important when on a NUMA setup the allowed
* nodes are together not big enough to reach the
* global limit. The proper fix for these situations
* will require awareness of nodes in the
* dirty-throttling and the flusher threads.
*/
if (ac->spread_dirty_pages) {
if (last_pgdat_dirty_limit == zone->zone_pgdat)
continue;
if (!node_dirty_ok(zone->zone_pgdat)) {
last_pgdat_dirty_limit = zone->zone_pgdat;
continue;
}
}
if (no_fallback && nr_online_nodes > 1 &&
zone != ac->preferred_zoneref->zone) {
int local_nid;
/*
* If moving to a remote node, retry but allow
* fragmenting fallbacks. Locality is more important
* than fragmentation avoidance.
*/
local_nid = zone_to_nid(ac->preferred_zoneref->zone);
if (zone_to_nid(zone) != local_nid) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
}
할당 context 정보를 토대로 요청한 2^@order 페이지들을 할당한다. 할당을 성공하면 해당 페이지를 반환하고, 실패하면 null을 반환한다.
- 코드 라인 15에서 처음 할당 시도 시 페이지 블럭 내에서 fragment 되지 않도록 할당 플래그에 ALLOC_NOFRAGMENT 플래그가 있는 경우 no_fallback 여부를 지정한다.
- 페이지 블럭내에서 여러 mobility 타입이 혼재될 수 있다.
- 파편화를 방지하기 위해서 메모리에 여유가 있으면 각 페이지 블럭에서 한 가지 mobility 타입으로 유도하는 것이 좋다.
- 코드 라인 16~18에서 요청한 노드와 zonelist에서 [선호 존, high_zoneidx]의 존에 대해 순서대로 zone을 순회한다.
- 코드 라인 22~25에서 현재 태스크가 control group의 cpuset이 지원하는 존을 지원하지 않는 경우 제외하기 위해 skip 한다.
- 코드 라인 45~53에서 노드 별로 dirty limit이 제한되어 있다. 모든 노드의 dirty limit을 초과한 경우가 아니라면 dirty limit을 초과한 노드는 skip 하기 위함이다. slowpath 할당 시에는 spread_dirty_pages 값은 false로 호출되어 dirty limit 제한을 받지 않는다.
- 코드 라인 55~69에서 페이지 할당 시 리모트 노드에서 nofragment 요청 보다 fragment 되더라도 로컬 노드에서 할당하는 것이 더 중요한 상황이다. 만일 2개 이상의 노드를 가진 시스템에서 nofragment 요청을 가졌지만 다른 노드에서 할당을 해야 하는 상황이라면 nofragment 요청을 제거하고 로컬 노드에서 할당할 수 있도록 retry 레이블로 이동한다.
mm/page_alloc.c -2/2-
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);
if (!zone_watermark_fast(zone, order, mark,
ac_classzone_idx(ac), alloc_flags)) {
int ret;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* Watermark failed for this zone, but see if we can
* grow this zone if it contains deferred pages.
*/
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
if (node_reclaim_mode == 0 ||
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))
continue;
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
case NODE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case NODE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
if (zone_watermark_ok(zone, order, mark,
ac_classzone_idx(ac), alloc_flags))
goto try_this_zone;
continue;
}
}
try_this_zone:
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
prep_new_page(page, order, gfp_mask, alloc_flags);
/*
* If this is a high-order atomic allocation then check
* if the pageblock should be reserved for the future
*/
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))
reserve_highatomic_pageblock(page, zone, order);
return page;
} else {
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/* Try again if zone has deferred pages */
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
}
}
/*
* It's possible on a UMA machine to get through all zones that are
* fragmented. If avoiding fragmentation, reset and try again.
*/
if (no_fallback) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
return NULL;
}
- 코드 라인 1~3에서 빠른 산출을 위해 대략적으로 추산한 남은 free 페이지 수와 할당 플래그로 요청 받은 3가지 high, low, min 워터마크 값 중 하나와 비교하여 기준 이하의 메모리 부족 상태인 경우이다.
- 코드 라인 11~14에서 x86 시스템 등의 대용량 메모리 시스템에서 부트업 중에 일부 메모리의 초기화를 유예시킨다. 현재 그러한 상황이라 현재 존의 page들이 초기화되지 않은 상태라면 진짜 메모리 부족이 아닌 경우이므로 이 존에서 할당을 시도하게 한다.
- 코드 라인 18~19에서 워터 마크 기준이 설정되지 않은 경우에도 이 존에서 할당을 시도하게 한다.
- 코드 라인 21~23에서 “/sys/vm/zone_reclaim_mode” 설정이 0(디폴트) 이거나 로컬 또는 근거리의 리모트 노드가 아니면 이 존에서 할당을 skip 한다.
- 코드 라인 25~32에서 노드에 대한 페이지 회수를 위해 scan을 하지 않은 경우이거나, 이미 full scan 하여 더 이상 효과가 없는 상태인 경우 이 존을 skip 한다.
- 코드 라인 33~40에서 노드에 대해 페이지 회수를 한 결과가 일부 있거나 성공적이면 다시 한 번 정확히 추산하여 남은 free 페이지 수와 할당 플래그로 요청 받은 3가지 high, low, min 워터마크 값 중 하나와 비교하여 기준을 넘어 메모리 부족 상태가 아니면 이 존에서 할당을 시도한다. 그렇지 않고 메모리가 여전히 부족한 상태이면 이 존을 skip 한다.
- 코드 라인 43~45에서 try_this_zone: 레이블에서는 실제 버디 시스템을 통해 order 페이지를 할당해본다.
- 코드 라인 46~56에서 메모리가 정상적으로 할당된 경우 새 페이지 구조체에 대한 준비를 수행한 후 해당 페이지를 반환한다.
- 코드 라인 57~65에서 초기화 유예된 상태인 경우 다시 한번 이 존에서 페이지 할당을 시도한다.
- 코드 라인 72~75에서 첫 번째 할당 시도가 실패한 경우 블럭 내에서 migrate 타입이 달라도 할당을 할 수 있도록, nofragment 속성을 제거후 다시 시도한다.
- 코드 라인 77에서 두 번째 할당 시도도 실패한 경우 null을 반환한다.
다음 그림은 get_page_from_freelist() 함수를 통해 처리되는 과정을 보여준다.
zone_reclaim_mode
- NUMA 시스템을 지원하는 커널에서 “proc/sys/fs/zone_reclaim_mode” 파일 값으로 설정한다
- RECLAIM_OFF(0)
- 워터마크 기준 이하인 경우 현재 zone의 회수 처리 없이 다음 zone으로 skip
- RECLAIM_ZONE(1)
- inactive LRU list를 대상으로 회수 처리한다.
- RECLAIM_WRITE(2)
- 수정된 파일 페이지에 대해 writeout 과정을 통해 회수 처리한다.
- RECLAIM_UNMAP(3)
- 매핑된 파일 페이지에 대해 unmap 과정을 통해 회수 처리한다.
- RECLAIM_OFF(0)
zone_allows_reclaim()
mm/page_alloc.c
static bool zone_allows_reclaim(struct zone *local_zone, struct zone *zone)
{
return node_distance(zone_to_nid(local_zone), zone_to_nid(zone)) <
RECLAIM_DISTANCE;
}
local_zone과 요청 zone이 RECLAIM_DISTANCE(30) 이내의 거리에 있는 경우 true를 반환한다.
- 페이지 회수는 가까운 리모트 zone에서만 가능하게 한다.
새 페이지 할당 후 초기화
prep_new_page()
page_alloc.c
static void prep_new_page(struct page *page, unsigned int order, gfp_t gfp_flags,
unsigned int alloc_flags)
{
int i;
post_alloc_hook(page, order, gfp_flags);
if (!free_pages_prezeroed() && (gfp_flags & __GFP_ZERO))
for (i = 0; i < (1 << order); i++)
clear_highpage(page + i);
if (order && (gfp_flags & __GFP_COMP))
prep_compound_page(page, order);
/*
* page is set pfmemalloc when ALLOC_NO_WATERMARKS was necessary to
* allocate the page. The expectation is that the caller is taking
* steps that will free more memory. The caller should avoid the page
* being used for !PFMEMALLOC purposes.
*/
if (alloc_flags & ALLOC_NO_WATERMARKS)
set_page_pfmemalloc(page);
else
clear_page_pfmemalloc(page);
}
할당 받은 2^order 페이지 사이즈 메모리에 해당하는 모든 페이지 디스크립터를 초기화한다.
- 코드 라인 6에서 할당받은 2^order 페이지 사이즈 메모리에 해당하는 첫 번째 페이지 디스크립터를 초기화한다.
- 코드 라인 8~10에서 zero 초기화 요청을 받은 경우 할당 받은 메모리를 0으로 모두 초기화한다.
- 32bit 시스템의 highmem 영역에 속한 메모리들은 임시 매핑하여 0으로 초기화한 후 다시 매핑해제한다.
- 코드 라인 12~13에서 compound 페이지인 경우 페이지 디스크립터들을 compound 페이지로 초기화한다.
- 모든 tail 페이지들은 head 페이지를 가리킨다.
- 코드 라인 21~24에서 no watermark 기준으로 할당 요청한 경우 해당 페이지 디스크립터의 index 멤버에 -1을 대입하여 pfmemalloc 상태에서 할당 받았다는 표식을 한다.
post_alloc_hook()
mm/page_alloc.c
inline void post_alloc_hook(struct page *page, unsigned int order,
gfp_t gfp_flags)
{
set_page_private(page, 0);
set_page_refcounted(page);
arch_alloc_page(page, order);
kernel_map_pages(page, 1 << order, 1);
kernel_poison_pages(page, 1 << order, 1);
kasan_alloc_pages(page, order);
set_page_owner(page, order, gfp_flags);
}
할당받은 2^order 페이지 사이즈 메모리에 해당하는 첫 번째 페이지 디스크립터를 초기화한다.
- 코드 라인 4에서 페이지 디스크립터의 private 멤버를 0으로 초기화한다.
- 코드 라인 5에서 참조 카운터를 1로 초기화한다.
- 코드 라인 7에서 아키텍처에 대응하는 페이지 할당 후크를 호출한다.
- ARM, ARM64는 해당 호출 함수가 없다.
- 코드 라인 8에서 디버그용 페이지 할당을 호출한다.
- 코드 라인 9에서 poison을 사용한 디버깅을 수행한다. 할당된 메모리에 미리 표식된 poison이 이상 없는지 체크한다.
- 코드 라인 10에서 KASAN 디버깅을 위해 호출한다.
- 코드 라인 11에서 디버그용 페이지 오너 트래킹을 위해 호출한다.
CPUSET 관련
cpuset_zone_allowed()
include/linux/cpuset.h
static inline int cpuset_zone_allowed(struct zone *z, gfp_t gfp_mask)
{
if (cpusets_enabled())
return __cpuset_zone_allowed(z, gfp_mask);
return true;
}
요청 zone의 노드가 현재 cpu가 지원하는 노드인 경우 true를 반환한다. 그 외에 우선되는 경우는 인터럽트 수행중에 호출되었거나 __GFP_THISNODE 플래그가 설정되었거나 현재 태스크가 이미 허락하는 노드이거나 태스크가 TIF_MEMDIE 플래그 또는 PF_EXITING 플래그가 설정된 경우는 true를 반환하고 __GFP_HARDWALL이 설정된 경우 현재 태스크의 cpuset이 허락한 메모리 노드가 아닌 노드에 기회를 주지않게 하기 위해 false를 반환한다.
cpuset_node_allowed()
include/linux/cpuset.h
static inline int cpuset_node_allowed(int node, gfp_t gfp_mask)
{
return __cpuset_node_allowed(zone_to_nid(z), gfp_mask);
}
아래 함수 호출
__cpuset_node_allowed()
kernel/cpuset.c
/** * cpuset_node_allowed - Can we allocate on a memory node? * @node: is this an allowed node? * @gfp_mask: memory allocation flags * * If we're in interrupt, yes, we can always allocate. If @node is set in * current's mems_allowed, yes. If it's not a __GFP_HARDWALL request and this * node is set in the nearest hardwalled cpuset ancestor to current's cpuset, * yes. If current has access to memory reserves as an oom victim, yes. * Otherwise, no. * * GFP_USER allocations are marked with the __GFP_HARDWALL bit, * and do not allow allocations outside the current tasks cpuset * unless the task has been OOM killed. * GFP_KERNEL allocations are not so marked, so can escape to the * nearest enclosing hardwalled ancestor cpuset. * * Scanning up parent cpusets requires callback_lock. The * __alloc_pages() routine only calls here with __GFP_HARDWALL bit * _not_ set if it's a GFP_KERNEL allocation, and all nodes in the * current tasks mems_allowed came up empty on the first pass over * the zonelist. So only GFP_KERNEL allocations, if all nodes in the * cpuset are short of memory, might require taking the callback_lock. * * The first call here from mm/page_alloc:get_page_from_freelist() * has __GFP_HARDWALL set in gfp_mask, enforcing hardwall cpusets, * so no allocation on a node outside the cpuset is allowed (unless * in interrupt, of course). * * The second pass through get_page_from_freelist() doesn't even call * here for GFP_ATOMIC calls. For those calls, the __alloc_pages() * variable 'wait' is not set, and the bit ALLOC_CPUSET is not set * in alloc_flags. That logic and the checks below have the combined * affect that: * in_interrupt - any node ok (current task context irrelevant) * GFP_ATOMIC - any node ok * tsk_is_oom_victim - any node ok * GFP_KERNEL - any node in enclosing hardwalled cpuset ok * GFP_USER - only nodes in current tasks mems allowed ok. */
bool __cpuset_node_allowed(int node, gfp_t gfp_mask)
{
struct cpuset *cs; /* current cpuset ancestors */
int allowed; /* is allocation in zone z allowed? */
unsigned long flags;
if (in_interrupt())
return true;
if (node_isset(node, current->mems_allowed))
return true;
/*
* Allow tasks that have access to memory reserves because they have
* been OOM killed to get memory anywhere.
*/
if (unlikely(tsk_is_oom_victim(current)))
return true;
if (gfp_mask & __GFP_HARDWALL) /* If hardwall request, stop here */
return false;
if (current->flags & PF_EXITING) /* Let dying task have memory */
return true;
/* Not hardwall and node outside mems_allowed: scan up cpusets */
spin_lock_irqsave(&callback_lock, flags);
rcu_read_lock();
cs = nearest_hardwall_ancestor(task_cs(current));
allowed = node_isset(node, cs->mems_allowed);
rcu_read_unlock();
spin_unlock_irqrestore(&callback_lock, flags);
return allowed;
}
요청 노드가 현재 cpu가 지원하는 노드인 경우 true를 반환한다. 그 외에 우선되는 경우는 인터럽트 수행중에 호출되었거나 __GFP_THISNODE 플래그가 설정되었거나 현재 태스크가 이미 허락하는 노드이거나 태스크가 TIF_MEMDIE 플래그 또는 PF_EXITING 플래그가 설정된 경우는 true를 반환하고 __GFP_HARDWALL이 설정된 경우 현재 태스크의 cpuset이 허락한 메모리 노드가 아닌 노드에 기회를 주지않게 하기 위해 false를 반환한다.
- 코드 라인 7~8에서 인터럽트 핸들러에서 호출된 경우 true를 반환한다.
- 코드 라인 9~10에서 현재 태스크가 허락하는 노드인 경우 true를 반환한다.
- 코드 라인 15~16에서 낮은 확률로 현재 태스크가 메모리 부족으로 인해 종료되고 있는 중이면 true를 반환한다.
- 코드 라인 17~18에서 hardwall 요청인 경우 false를 반환한다.
- 코드 라인 20~21에서 현재 태스크가 종료 중인 경우 true를 반환한다.
- 코드 라인 24~32에서 hardwall 요청이 없고, 현재 태스크가 허락하지 않는 노드인 경우이다. 이러한 경우 현재 태스크의 cpuset에서 가장 가까운 hardwall 부모 cpuset을 알아와서 cpuset에 허락된 메모리 노드의 여부를 반환한다.
__GFP_HARDWALL 플래그를 사용하는 케이스는 다음 3가지이다.
- fastpath 페이지 할당 요청
- 사용자 태스크에서 페이지 할당 요청
- 슬랩(slab) 페이지 할당 요청
커널이 메모리를 할당 요청할 때엔 슬랩(slab) 페이지를 위한 할당 등의 특수한 경우를 제외하고 __GFP_HARDWALL 플래그를 사용하지 않는다.
- __GFP_HARDWALL 플래그를 사용하지 않으면 cgroup을 사용한다.
- cgroup의 cpuset 서브시스템에서 현재 태스크가 포함된 그룹을 기점으로 부모 방향으로 hardwall 또는 exclusive 설정이 된 가장 가까운 상위 그룹을 찾아 사용한다.
- cgroup의 cpuset 서브시스템에 있는 cpuset.mem_exclusive와 cpuset.mem_hardwall의 값을 각각 1로 변경하는 것으로 해당 그룹의 hardwall 및 exclusive가 설정된다.
- cgroup에 있는 모든 서브시스템의 형상은 트리 구조로 관리가 되며 특별히 값을 설정하지 않아도 부모의 값을 자식이 상속하는 구조로 구성된다. 이 때 hardwall 기능을 사용하면 자신의 그룹과 부모 그룹을 막는 벽이 생기는 것이다
nearest_hardwall_ancestor()
kernel/cpuset.c
/*
* nearest_hardwall_ancestor() - Returns the nearest mem_exclusive or
* mem_hardwall ancestor to the specified cpuset. Call holding
* callback_lock. If no ancestor is mem_exclusive or mem_hardwall
* (an unusual configuration), then returns the root cpuset.
*/
static struct cpuset *nearest_hardwall_ancestor(struct cpuset *cs)
{
while (!(is_mem_exclusive(cs) || is_mem_hardwall(cs)) && parent_cs(cs))
cs = parent_cs(cs);
return cs;
}
cpuset이 메모리를 베타적으로 사용하거나 부모 cpuset이 hardwall인 경우 cpuset을 반환한다. 조건을 만족하지 못하면 만족할 때 까지 부모 cpuset을 계속 찾는다.
read_mems_allowed_begin()
include/linux/cpuset.h
/* * read_mems_allowed_begin is required when making decisions involving * mems_allowed such as during page allocation. mems_allowed can be updated in * parallel and depending on the new value an operation can fail potentially * causing process failure. A retry loop with read_mems_allowed_begin and * read_mems_allowed_retry prevents these artificial failures. */
static inline unsigned int read_mems_allowed_begin(void)
{
if (!static_branch_unlikely(&cpusets_pre_enable_key))
return 0;
return read_seqcount_begin(¤t->mems_allowed_seq);
}
현재 태스크의 mems_allowed_seq 시퀀스 락 값을 알아온다.
- 현재 태스크에 대한 cpuset 설정이 바뀐 경우(/sys/fs/cpuset 디렉토리에 있는 설정) current->mems_allowed_seq 값이 변경된다.
Dirty 노드 밸런싱
dirty(파일에 기록하였지만 파일 캐시 메모리에 상주된 상태로 지연(lazy) 기록되는 상태) limit을 지정하여 사용하는데, 이러한 파일 기록을 요청한 노드를 대상으로 dirty limit을 초과하는 경우 다른 노드에 할당하여 dirty 파일들이 분산되도록 한다.
- 만일 모든 노드에서 dirty limit을 초과하여 할당을 실패하는 경우 그냥 dirty limit을 풀고 다시 시도하여 할당한다.
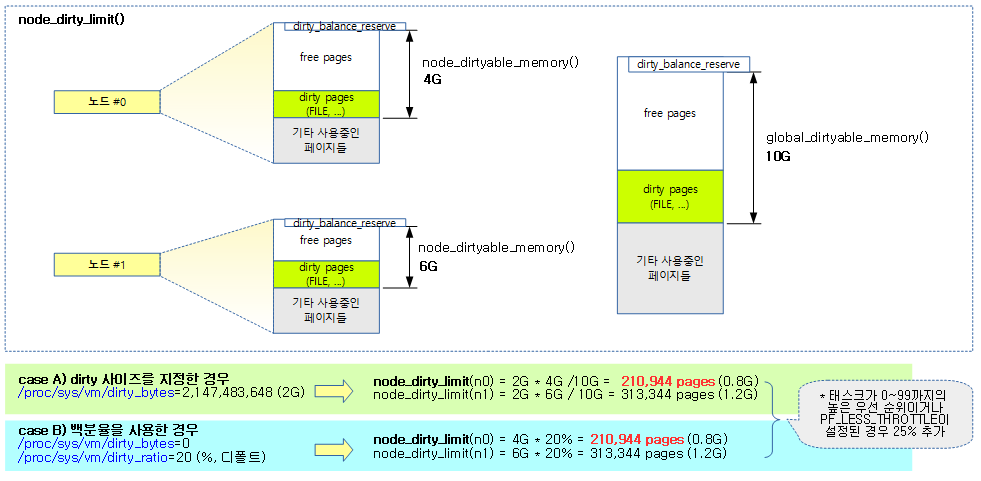
다음 그림은 dirty 페이지 할당 요청들로부터 20%의 dirty 제한을 초과하지 않게 운영되는 모습을 보여준다.
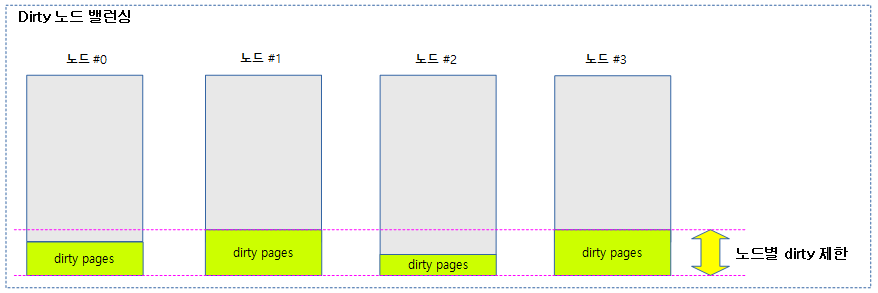
node_dirty_ok()
mm/page-writeback.c
/** * node_dirty_ok - tells whether a node is within its dirty limits * @pgdat: the node to check * * Returns %true when the dirty pages in @pgdat are within the node's * dirty limit, %false if the limit is exceeded. */
bool node_dirty_ok(struct pglist_data *pgdat)
{
unsigned long limit = node_dirty_limit(pgdat);
unsigned long nr_pages = 0;
nr_pages += node_page_state(pgdat, NR_FILE_DIRTY);
nr_pages += node_page_state(pgdat, NR_UNSTABLE_NFS);
nr_pages += node_page_state(pgdat, NR_WRITEBACK);
return nr_pages <= limit;
}
요청한 노드가 dirty 제한 이하인지 여부를 반환한다. 1=dirty 제한 범위 이하, 0=dirty 제한 범위 초과
- 노드의 NR_FILE_DRITY + NR_UNSTABLE_NFS + NR_WRITEBACK 페이지들이 노드의 dirty(write buffer) 한계 이하인 경우 true를 반환한다.
- zone 카운터들 대한 수치 확인은
다음과 같이 “cat /proc/zoneinfo” 명령을 통해 노드별 카운터 정보를 확인할 수 있다.
- nodeinfo 파일이 아니라 zoneinfo 파일인 이유: 기존에는 노드별 정보가 아니라 존별 정보를 출력 하였었다.
$ cat /proc/zoneinfo
Node 0, zone DMA32
per-node stats
nr_inactive_anon 2162
nr_active_anon 4186
nr_inactive_file 8415
nr_active_file 5303
nr_unevictable 0
nr_slab_reclaimable 3490
nr_slab_unreclaimable 6347
nr_isolated_anon 0
nr_isolated_file 0
workingset_nodes 0
workingset_refault 0
workingset_activate 0
workingset_restore 0
workingset_nodereclaim 0
nr_anon_pages 4141
nr_mapped 6894
nr_file_pages 15924
nr_dirty 91 <-----
nr_writeback 0 <-----
nr_writeback_temp 0
nr_shmem 2207
nr_shmem_hugepages 0
nr_shmem_pmdmapped 0
nr_anon_transparent_hugepages 0
nr_unstable 0 <-----
nr_vmscan_write 0
nr_vmscan_immediate_reclaim 0
nr_dirtied 330
nr_written 239
nr_kernel_misc_reclaimable 0
pages free 634180
min 5632
low 7040
high 8448
spanned 786432
present 786432
managed 765785
protection: (0, 0, 0)
nr_free_pages 634180
nr_zone_inactive_anon 2162
nr_zone_active_anon 4186
nr_zone_inactive_file 8415
nr_zone_active_file 5303
nr_zone_unevictable 0
nr_zone_write_pending 91
nr_mlock 0
nr_page_table_pages 233
nr_kernel_stack 1472
nr_bounce 0
nr_free_cma 8128
numa_hit 97890
numa_miss 0
numa_foreign 0
numa_interleave 6202
numa_local 97890
numa_other 0
pagesets
cpu: 0
count: 320
high: 378
batch: 63
vm stats threshold: 24
cpu: 1
count: 275
high: 378
batch: 63
vm stats threshold: 24
node_unreclaimable: 0
start_pfn: 262144
Node 0, zone Normal
pages free 0
min 0
low 0
high 0
spanned 0
present 0
managed 0
protection: (0, 0, 0)
Node 0, zone Movable
pages free 0
min 0
low 0
high 0
spanned 0
present 0
managed 0
protection: (0, 0, 0)
node_dirty_limit()
mm/page-writeback.c
/** * node_dirty_limit - maximum number of dirty pages allowed in a node * @pgdat: the node * * Returns the maximum number of dirty pages allowed in a node, based * on the node's dirtyable memory. */
static unsigned long node_dirty_limit(struct pglist_data *pgdat)
{
unsigned long node_memory = node_dirtyable_memory(pgdat);
struct task_struct *tsk = current;
unsigned long dirty;
if (vm_dirty_bytes)
dirty = DIV_ROUND_UP(vm_dirty_bytes, PAGE_SIZE) *
node_memory / global_dirtyable_memory();
else
dirty = vm_dirty_ratio * node_memory / 100;
if (tsk->flags & PF_LESS_THROTTLE || rt_task(tsk))
dirty += dirty / 4;
return dirty;
}
노드에 허락된 dirty 가능한 페이지 수의 일정 비율만큼으로 제한한 페이지 수를 반환한다. 만일 태스크에 PF_LESS_THROTTLE가 설정되어 있거나 우선 순위가 user task보다 높은 태스크인 경우 25%를 추가한다.
- vm_dirty_bytes가 설정된 경우 노드가 사용하는 dirty 페이지의 비율만큼 배정한다.
- vm_dirty_bytes가 설정되지 않은 경우 vm_dirty_ratio 백분율로 배정한다.
- 태스크 우선 순위
- 0~139중 rt_task는 100이하의 높은 우선 순위를 가진다.
- 100~139는 유저 태스크의 우선순위를 가진다.
- 낮은 숫자가 가장 높은 우선순위를 가진다.
아래 그림은 node_dirty_limit() 값을 산출 시 dirty_bytes 또는 dirty_ratio를 사용할 때 달라지는 모습을 보여준다.
node_dirtyable_memory()
mm/page-writeback.c
/* * In a memory zone, there is a certain amount of pages we consider * available for the page cache, which is essentially the number of * free and reclaimable pages, minus some zone reserves to protect * lowmem and the ability to uphold the zone's watermarks without * requiring writeback. * * This number of dirtyable pages is the base value of which the * user-configurable dirty ratio is the effictive number of pages that * are allowed to be actually dirtied. Per individual zone, or * globally by using the sum of dirtyable pages over all zones. * * Because the user is allowed to specify the dirty limit globally as * absolute number of bytes, calculating the per-zone dirty limit can * require translating the configured limit into a percentage of * global dirtyable memory first. */ /** * node_dirtyable_memory - number of dirtyable pages in a node * @pgdat: the node * * Returns the node's number of pages potentially available for dirty * page cache. This is the base value for the per-node dirty limits. */
static unsigned long node_dirtyable_memory(struct pglist_data *pgdat)
{
unsigned long nr_pages = 0;
int z;
for (z = 0; z < MAX_NR_ZONES; z++) {
struct zone *zone = pgdat->node_zones + z;
if (!populated_zone(zone))
continue;
nr_pages += zone_page_state(zone, NR_FREE_PAGES);
}
/*
* Pages reserved for the kernel should not be considered
* dirtyable, to prevent a situation where reclaim has to
* clean pages in order to balance the zones.
*/
nr_pages -= min(nr_pages, pgdat->totalreserve_pages);
nr_pages += node_page_state(pgdat, NR_INACTIVE_FILE);
nr_pages += node_page_state(pgdat, NR_ACTIVE_FILE);
return nr_pages;
}
해당 노드의 dirty 가능한 페이지 수를 반환한다. (노드의 free 페이지 + 사용된 파일 캐시 페이지 – totalreserve_pages)
- 코드 라인 6~13에서 노드의 모든 populate 존의 free 페이지를 산출한다.
- 코드 라인 20에서 산출된 페이지에서 totalreserve_pages는 제외한다.
- 코드 라인 22~23에서 노드의 모든(inactive+active) 파일 캐시 페이지를 추가한다.
global_dirtyable_memory()
mm/page-writeback.c
/** * global_dirtyable_memory - number of globally dirtyable pages * * Returns the global number of pages potentially available for dirty * page cache. This is the base value for the global dirty limits. */
static unsigned long global_dirtyable_memory(void)
{
unsigned long x;
x = global_zone_page_state(NR_FREE_PAGES);
/*
* Pages reserved for the kernel should not be considered
* dirtyable, to prevent a situation where reclaim has to
* clean pages in order to balance the zones.
*/
x -= min(x, totalreserve_pages);
x += global_node_page_state(NR_INACTIVE_FILE);
x += global_node_page_state(NR_ACTIVE_FILE);
if (!vm_highmem_is_dirtyable)
x -= highmem_dirtyable_memory(x);
return x + 1; /* Ensure that we never return 0 */
}
시스템에서 dirty 가능한 페이지 수를 반환한다. (시스템의 free 페이지 + file 캐시 페이지 – totalreserve_pages)
- free 페이지 + file 캐시로 사용 중인 페이지 – dirty_balance_reserve 값을 반환한다.
- 만일 highmem을 dirty 페이지로 사용되지 못하게 한 경우 highmem의 dirty 페이지 부분을 제외시킨다.
highmem_dirtyable_memory()
mm/page-writeback.c
static unsigned long highmem_dirtyable_memory(unsigned long total)
{
#ifdef CONFIG_HIGHMEM
int node;
unsigned long x = 0;
int i;
for_each_node_state(node, N_HIGH_MEMORY) {
for (i = ZONE_NORMAL + 1; i < MAX_NR_ZONES; i++) {
struct zone *z;
unsigned long nr_pages;
if (!is_highmem_idx(i))
continue;
z = &NODE_DATA(node)->node_zones[i];
if (!populated_zone(z))
continue;
nr_pages = zone_page_state(z, NR_FREE_PAGES);
/* watch for underflows */
nr_pages -= min(nr_pages, high_wmark_pages(z));
nr_pages += zone_page_state(z, NR_ZONE_INACTIVE_FILE);
nr_pages += zone_page_state(z, NR_ZONE_ACTIVE_FILE);
x += nr_pages;
}
}
/*
* Unreclaimable memory (kernel memory or anonymous memory
* without swap) can bring down the dirtyable pages below
* the zone's dirty balance reserve and the above calculation
* will underflow. However we still want to add in nodes
* which are below threshold (negative values) to get a more
* accurate calculation but make sure that the total never
* underflows.
*/
if ((long)x < 0)
x = 0;
/*
* Make sure that the number of highmem pages is never larger
* than the number of the total dirtyable memory. This can only
* occur in very strange VM situations but we want to make sure
* that this does not occur.
*/
return min(x, total);
#else
return 0;
#endif
}
high memory에 대한 dirty 페이지 가능한 수를 알아온다. (64비트 시스템은 사용하지 않는다.)
구조체
alloc_context 구조체
mm/internal.h
/* * Structure for holding the mostly immutable allocation parameters passed * between functions involved in allocations, including the alloc_pages* * family of functions. * * nodemask, migratetype and high_zoneidx are initialized only once in * __alloc_pages_nodemask() and then never change. * * zonelist, preferred_zone and classzone_idx are set first in * __alloc_pages_nodemask() for the fast path, and might be later changed * in __alloc_pages_slowpath(). All other functions pass the whole strucure * by a const pointer. */
struct alloc_context {
struct zonelist *zonelist;
nodemask_t *nodemask;
struct zone *preferred_zone;
int migratetype;
enum zone_type high_zoneidx;
bool spread_dirty_pages;
};
alloc_pages* 패밀리 함수들에서 여러 가지 파라미터를 전달하기 위한 목적으로 사용되는 구조체이다.
- zonelist
- 페이지 할당 시 사용하는 zonelist
- nodemask
- zonelist의 노드들 중 지정한 노드들에서만 할당 가능하도록 제한한다.
- 지정하지 않으면 모든 노드가 대상이 된다.
- preferred_zone
- fastpath에서 가장 우선 할당할 존이 지정된다.
- slowpath에서는 zonelist의 가용한 첫 존이 지정된다.
- migratetype
- 할당할 migrate(페이지) 타입 유형
- high_zoneidx
- zonelist의 존들 중 지정한 high zone 이하에서만 할당 가능하도록 제한한다.
- spread_dirty_pages
- 더티 존(dirty zone) 밸런싱 여부로 다음과 같이 사용된다.
- fastpath 할당 요청 시 1로 설정
- slowpath 할당 요청 시 0으로 설정
- 더티 존(dirty zone) 밸런싱 여부로 다음과 같이 사용된다.
참고
- Zoned Allocator -1- (물리 페이지 할당-Fastpath) | 문c – 현재 글
- Zoned Allocator -2- (물리 페이지 할당-Slowpath) | 문c
- Zoned Allocator -3- (Buddy 페이지 할당) | 문c
- Zoned Allocator -4- (Buddy 페이지 해지) | 문c
- Zoned Allocator -5- (Per-CPU Page Frame Cache) | 문c
- Zoned Allocator -6- (Watermark) | 문c
- Zoned Allocator -7- (Direct Compact) | 문c
- Zoned Allocator -8- (Direct Compact-Isolation) | 문c
- Zoned Allocator -9- (Direct Compact-Migration) | 문c
- Zoned Allocator -10- (LRU & pagevec) | 문c
- Zoned Allocator -11- (Direct Reclaim) | 문c
- Zoned Allocator -12- (Direct Reclaim-Shrink-1) | 문c
- Zoned Allocator -13- (Direct Reclaim-Shrink-2) | 문c
- Zoned Allocator -14- (Kswapd) | 문c
- Tunable watermark | LWN.net
- 메모리 재할당과 커널 파라미터 | 강진우
- Memory compaction | LWN.net
- [LWN 번역] Memory Compaction | Daeseok’s Blog
- mm, compaction: introduce kcompactd
- Page migration | www.kernel.org
- 리눅스커널의이해 16장 스와핑 – 메모리 해제 방법 | 한남대 최성자 – ppt 다운로드
- Controlling Memory Fragmentation and Higher Order Allocation Failure: Analysis, Observations and Results | Pintu Kumar – pdf 다운로드
- ZONE 비트맵 (API) | 문c
안녕하세요?
말씀하신 내용으로 오타를 수정하였습니다.
2pageblock_order -> 2^pageblock_order
감사합니다. ^^
안녕하세요,
좋은 글을 써주셔서 감사합니다. 도움이 정말 많이 됐습니다.
공부하다가 한가지 궁금한 점이 생겨서 글 작성합니다.
우선 제가 이해한 바로는 fast path 할당 과정에서 local node의 dirty limit이 넘었을 경우, remote node에 우선 할당을 시도하는 것으로 이해하였는데,
이게 맞다면 remote node에 할당하면서까지 dirty page cache를 밸런싱하는 이유가 무엇인 지 궁금합니다.
커널 뉴비라 질문이 어색하더라도 양해 부탁드립니다..!
감사합니다.
안녕하세요? 김민호님,
get_page_from_freelist() 코드 설명 본문에서 존 별 -> 노드 별로 수정하였습니다.
이 기능이 처음 개발되었을 때엔 “mm: try to distribute dirty pages fairly across zones”라는 제목으로
dirty page에 대한 존 밸런싱이 동작하도록 개발되었었습니다. 그런데 이후 어느 커널 버전에서
새롭게 존 별로 메모리 회수 시스템이 동작하던 것을 노드 단위로 변경하였는데 이 코드도 마찬가지로 영향을 받아
노드 별로 dirty limit을 제어하는데, 제가 설명을 미쳐 바꾸지 못했습니다.
다행히 김민호님꼐선 잘 알아채시고, 질문을 노드 별로 하셨네요. ^^;
이 기능을 사용하는 이유는 메모리가 부족해졌을 때 너무 한쪽 노드에 dirty 페이지가 몰려 있으면
그 만큼 회수 시스템이 오랜 시간이 걸려 메모리를 회수하게 됩니다.
즉 dirty 페이지들은 디스크에 기록한 후에야 회수를 할 수 있으므로 많이 느립니다.
그래서 메모리가 부족하지기 전까지는 쓰기 가능한 메모리를 할당 요청할 때엔,
커널은 노드별로 dirty 페이지들을 분산하도록 노드 별 dirty limit을 초과하면 다른 노드를 선택하도록 합니다.
감사합니다.
아하 그렇군요, 이해하였습니다.
상세한 답변 감사드립니다.
민호님도 즐거운 하루되세요. 감사합니다.
안녕하세요. 문영일님.
0x1234_5000 ~ 0x1236_2000 사이에 연속된 9개의 fee 페이지가 존재하지만,
=>0x1234_5000 ~ 0x1236_2000 사이에 연속된 9개의 free 페이지가 존재하지만,(fee에서 r이 빠진것 같습니다)
감사합니다.
오타 수정하였습니다. 감사합니다. ^^