<kernel v5.0>
Zonned Allocator -3- (Buddy 페이지 할당)
Buddy Memory Allocator는 물리 메모리를 페이지 단위로 나눠 할당 관리하는 시스템으로 연속된(contiguous) 물리 페이지의 할당/해지를 지원한다. 또한 최대한 커다란 연속된 페이지를 확보하도록 단편화 관련 알고리즘들이 사용되고 있다.
- free 메모리 페이지를 2의 차수 페이지 크기로 나누어 관리한다.
- 2^0=1 페이지부터 2^(MAX_ORDER-1)=1024 페이지 까지 총 11 slot으로 나누어 관리한다.
- MAX_ORDER=11
- 커널 2.4.x에서는 defalut로 10을 사용하였었다.
- CONFIG_FORCE_MAX_ZONEORDER 커널 옵션을 사용하여 크기를 바꿀 수 있다.
- MAX_ORDER=11
- 2^0=1 페이지부터 2^(MAX_ORDER-1)=1024 페이지 까지 총 11 slot으로 나누어 관리한다.
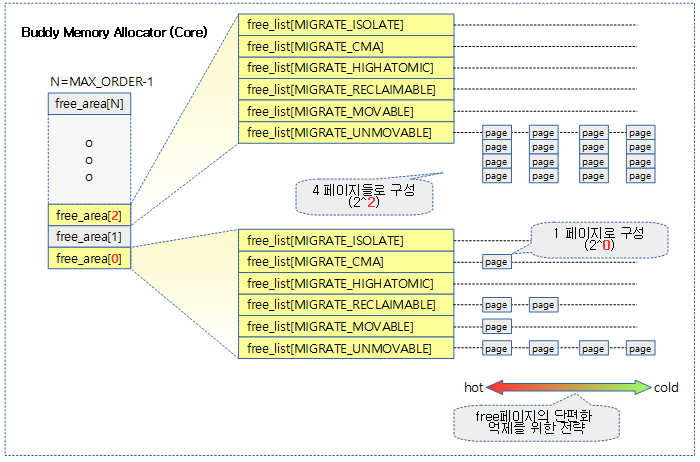
- 각 order slot 또한 단편화 되지 않도록 관리하기 위해 다음과 같은 구조가 준비되어 있다.
- 같은 mobility 속성을 가진 페이지들끼리 가능하면 뭉쳐서 있도록 각 order slot은 migratetype 별로 나뉘어 관리한다.
- 이렇게 나누어 관리함으로 페이지 회수 및 메모리 compaction 과정이 효율을 높일 수 있다.
- NUMA 시스템에서는 특별히 MIGRATE_MOVABLE 타입을 더 도와주기 위해 ZONE_MOVABLE 영역을 만들 수도 있다.
- 각 페이지를 담는 free_list에서 free page 들은 짝(버디)을 이루어 두 개의 짝(버디)이 모이면 더 큰 order로 합병되어 올라가고 필요시 분할하여 하나 더 적은 order로 나뉠 수 있다.
- 이제 더 이상 짝(버디)을 관리할 때 map이라는 이름의 bitmap을 사용하지 않고 free_list라는 이름의 리스트와 페이지 정보만을 사용하여 관리한다.
- free_list는 선두 방향으로 hot 속성을 갖고 후미 방향으로 cold 속성을 갖는다.
- hot, cold 속성은 각각 리스트의 head와 tail의 위치로 대응하여 관리된다.
- hot: 리스트 검색에서 앞부분에 놓인 페이지들은 다시 할당되어 사용될 가능성이 높은 page 이다.
- cold: 리스트 검색에서 뒷부분에 놓인 페이지들은 order가 통합되어 점점 상위 order로 올라갈 가능성이 높은 page 이다. 이를 통해 free 페이지의 단편화를 최대한 억제할 수 있다.
- hot, cold 속성은 각각 리스트의 head와 tail의 위치로 대응하여 관리된다.
- 같은 mobility 속성을 가진 페이지들끼리 가능하면 뭉쳐서 있도록 각 order slot은 migratetype 별로 나뉘어 관리한다.
- migrate 타입이 CMA인 경우 이 영역에는 CMA 페이지와 movable 페이지가 동시에 사용될 수 있다.
- CMA 페이지들이 할당되면 CMA Memory Allocator에서도 별도로 이를 관리한다.
- 버디 시스템의 관리 기법이 계속 버전 업하면서 복잡도는 증가하고 있지만 최대한 버디 시스템의 효율(단편화 방지)이 높아지고 있다
다음 그림은 Buddy 메모리 할당자의 core 부분의 모습을 보여준다.
- 커널 v4.4-rc1부터 바뀐 내용은 다음과 같다.
- MIGRATE_RECLAIMABLE 위치와 MIGRATE_MOVABLE의 위치가 바뀌었다.
- MIGRATE_RESERVE가 없어지고 MIGRATE_HIGHATOMIC로 바뀌었다.
버디 시스템과 관련된 페이지 속성
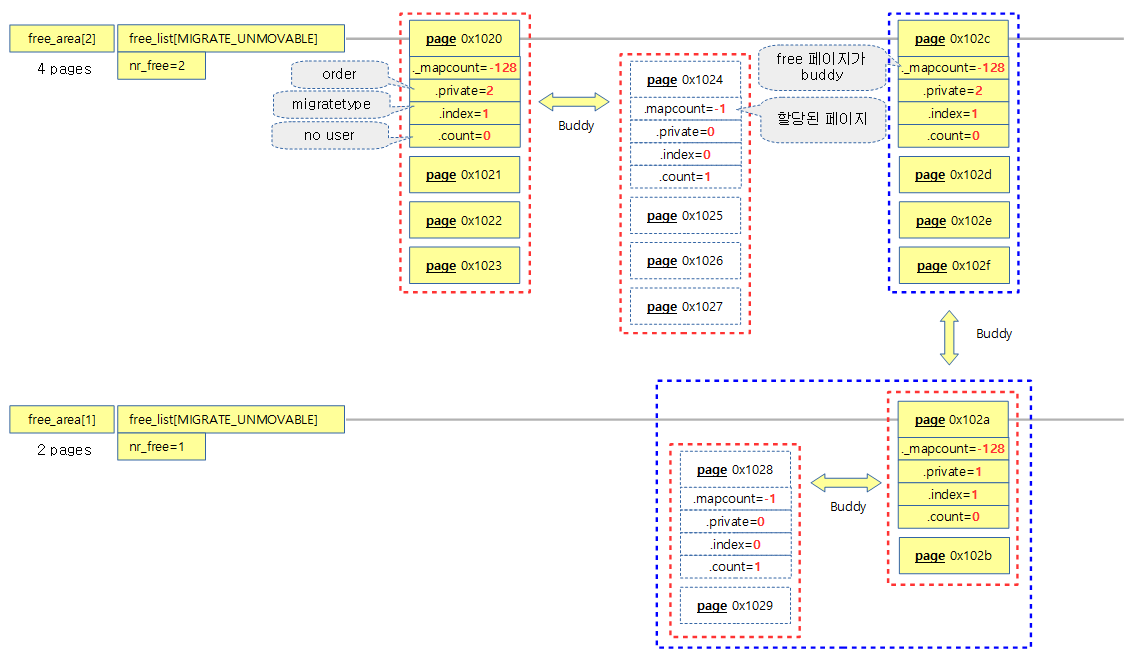
- _mapcount
- 버디 시스템의 free page로 페이지=-128(PAGE_BUDDY_MAPCOUNT_VALUE)
- 할당되어 버디 시스템에서 빠져나간 페이지=-1
- private
- 버디 시스템에서 관리될 때 사용되는 order 값
- 페이지가 할당되어 버디 시스템에서 빠져나갈 때에는 0으로 리셋된다.
- index
- 버디 시스템에서 구분되는 migratetype
- count
- 사용자 없이 free 된 페이지=0
- 할당되고 사용되는 경우 증가
다음 그림은 12페이지가 버디 시스템의 free page로 등록되어 있고 짝(버디)이 되는 페이지들이 할당되어 사용되는 모습을 보여준다.
- 4 페이지의 연속된 free page 2 건이 free_area[2]에 등록
- 2 페이지의 연속된 free page 1 건이 free_area[1]에 등록
버디 페이지 할당
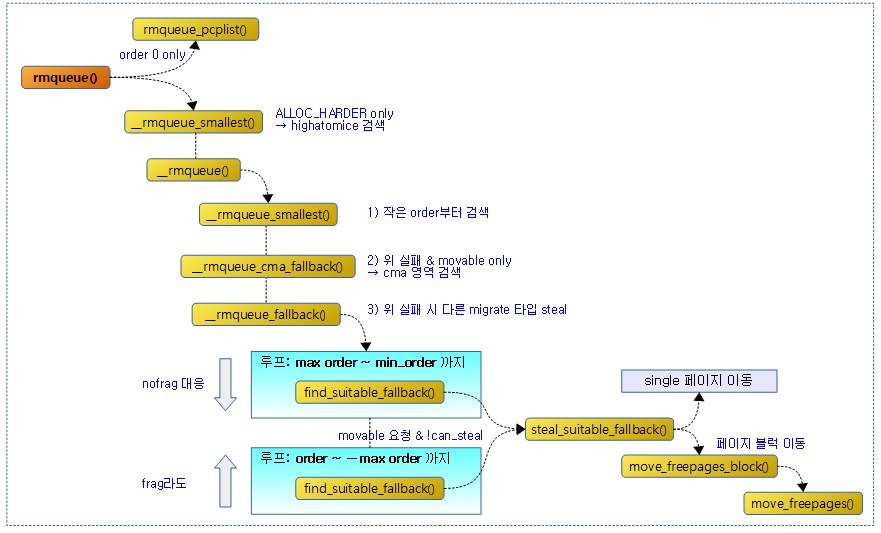
다음 그림은 rmqueue() 함수 이후 호출 과정을 보여준다.
rmqueue()
mm/page_alloc.c
/* * Allocate a page from the given zone. Use pcplists for order-0 allocations. */
static inline
struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
unsigned long flags;
struct page *page;
if (likely(order == 0)) {
page = rmqueue_pcplist(preferred_zone, zone, order,
gfp_flags, migratetype, alloc_flags);
goto out;
}
/*
* We most definitely don't want callers attempting to
* allocate greater than order-1 page units with __GFP_NOFAIL.
*/
WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1));
spin_lock_irqsave(&zone->lock, flags);
do {
page = NULL;
if (alloc_flags & ALLOC_HARDER) {
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
if (page)
trace_mm_page_alloc_zone_locked(page, order, migratetype);
}
if (!page)
page = __rmqueue(zone, order, migratetype, alloc_flags);
} while (page && check_new_pages(page, order));
spin_unlock(&zone->lock);
if (!page)
goto failed;
__mod_zone_freepage_state(zone, -(1 << order),
get_pcppage_migratetype(page));
__count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order);
zone_statistics(preferred_zone, zone);
local_irq_restore(flags);
out:
/* Separate test+clear to avoid unnecessary atomics */
if (test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags)) {
clear_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);
wakeup_kswapd(zone, 0, 0, zone_idx(zone));
}
VM_BUG_ON_PAGE(page && bad_range(zone, page), page);
return page;
failed:
local_irq_restore(flags);
return NULL;
}
요청 zone의 버디 시스템을 통해 @migratype의 @order 페이지를 할당한다. 성공 시 할당한 페이지 디스크립터를 반환하고, 실패하는 경우 null을 반환한다.
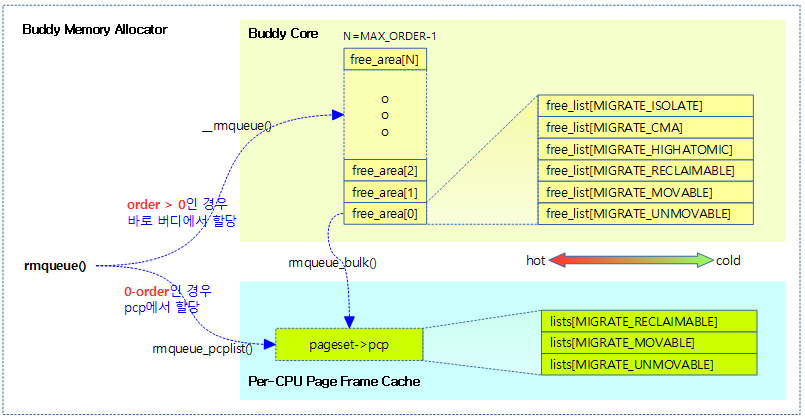
- 코드 라인 10~14에서 높은 확률로 0-order 페이지 할당 요청 시 0 order only 버디 캐시로 동작하는 pcp(Per CPU Page Frame Cache)에서 할당을 받는다.
- 코드 라인 23~32에서 0-order가 아닌 페이지를 요청한 경우 버디 시스템에서 할당을 수행한다. 만일 ALLOC_HARDER 플래그가 사용된 경우 highatomic 타입 리스트에서 먼저 할당을 시도한다.
- ALLOC_HARDER 플래그는 gfp_mask에서 GFP_ATOMIC 플래그를 사용 시 그 안에 사용되는 __GFP_HIGH 플래그에 의해 설정된다.
- #define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
- check_new_pages() 함수에서는 디버그 사용 시 할당한 페이지의 무결성을 체크한다. (hwpoison 등)
- ALLOC_HARDER 플래그는 gfp_mask에서 GFP_ATOMIC 플래그를 사용 시 그 안에 사용되는 __GFP_HIGH 플래그에 의해 설정된다.
- 코드 라인 36~40에서 할당한 페이지 수만큼 free 페이지 카운터를 감소시키고, PGALLOC 카운터는 증가시킨다. 그리고 처음 요청한 존에서 할당했는지 여부에 대한 hit 및 miss 카운터등을 증/감시킨다.
- 코드 라인 43~51에서 페이지 할당이 성공 또는 실패되어 빠져나가는 out: 레이블이다. 나가기 전에 존에 boost 워터마크를 조사하여 켜진 경우 플래그를 클리어하고 kswapd를 깨운다.
다음 그림은 rmqueue() 함수를 통해 pcp를 포함한 버디시스템에서 페이지 할당이 처리되는 모습을 보여준다.
__rmqueue()
mm/page_alloc.c
/* * Do the hard work of removing an element from the buddy allocator. * Call me with the zone->lock already held. */
static __always_inline struct page *
__rmqueue(struct zone *zone, unsigned int order, int migratetype,
unsigned int alloc_flags)
{
struct page *page;
retry:
page = __rmqueue_smallest(zone, order, migratetype);
if (unlikely(!page)) {
if (migratetype == MIGRATE_MOVABLE)
page = __rmqueue_cma_fallback(zone, order);
if (!page && __rmqueue_fallback(zone, order, migratetype,
alloc_flags))
goto retry;
}
trace_mm_page_alloc_zone_locked(page, order, migratetype);
return page;
}
요청 zone의 버디 시스템을 통해 @migratype의 @order 페이지를 할당한다. 성공 시 할당한 페이지 디스크립터를 반환하고, 실패하는 경우 null을 반환한다.
- 코드 라인 8에서 먼저 요청한 order부터 최대 order까지 즉, 작은 order 부터 검색하여 할당해본다.
- 코드 라인9~11에서 페이지 할당이 실패한 경우 만일 movable 타입 요청인 경우 먼저 cma 공간에서 검색한다.
- 코드 라인 13~15에서 여전히 페이지 할당이 실패한 경우 fallback 타입들을 검색하여 원하는 migrate 타입으로 이주시킨다. 이주가 성공적이면 다시 할당을 재시도한다.
다음 그림은 버디 시스템으로 부터 요청된 migrate type과 order로 free 페이지를 할당 받아올 때 만일 할당이 실패하는 경우 migrate type fallback list를 사용하여 검색을 계속하는 것을 보여준다.

__rmqueue_smallest()
mm/page_alloc.c
/* * Go through the free lists for the given migratetype and remove * the smallest available page from the freelists */
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
page = list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
if (!page)
continue;
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}
요청한 @migratetype으로 요청한 @order 부터 최상위 order 까지, 즉 작은 order부터 free_list를 검색하여 찾은 free 페이지를 반환한다.
- 코드 라인 10~15에서 요청 @order 부터 최상위 order 까지@migratetype의 free_list를 순회하며 free 페이지를 찾는다.
- 코드 라인 16에서 free_list에서 찾은 선두(hot) 페이지를 제거한다.
- 코드 라인 17에서 할당할 페이지의 order 정보를 0으로 리셋하고 buddy 식별 플래그도 없앤다.
- 코드 랑니 18에서 해당 order 슬롯의 nr_free를 감소시킨다.
- 코드 라인 19에서 요청 order에 free 페이지가 없는 경우 큰 order를 가져와 확장한다.
- guard 페이지를 사용하지 않는 한 큰 order 아래로 요청한 order까지 절반씩 분해하여 추가되는 과정을 알 수 있다.
- 예) order=3, current_order=6인 경우
- order=6을 잘라서 order 5, order 4, order 3에 하나씩 추가하고, 남은 order 3 페이지를 반환한다.
- 코드 라인 20에서 migrate 타입을 기록한다.
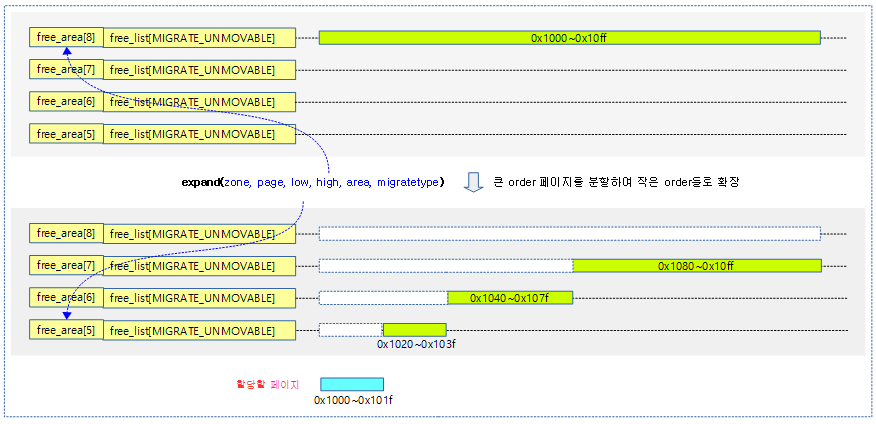
큰 order 페이지 확장(분해)
expand()
/* * The order of subdivision here is critical for the IO subsystem. * Please do not alter this order without good reasons and regression * testing. Specifically, as large blocks of memory are subdivided, * the order in which smaller blocks are delivered depends on the order * they're subdivided in this function. This is the primary factor * influencing the order in which pages are delivered to the IO * subsystem according to empirical testing, and this is also justified * by considering the behavior of a buddy system containing a single * large block of memory acted on by a series of small allocations. * This behavior is a critical factor in sglist merging's success. * * -- nyc */
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
unsigned long size = 1 << high;
while (high > low) {
area--;
high--;
size >>= 1;
VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]);
if (IS_ENABLED(CONFIG_DEBUG_PAGEALLOC) &&
debug_guardpage_enabled() &&
high < debug_guardpage_minorder()) {
/*
* Mark as guard pages (or page), that will allow to
* merge back to allocator when buddy will be freed.
* Corresponding page table entries will not be touched,
* pages will stay not present in virtual address space
*/
set_page_guard(zone, &page[size], high, migratetype);
continue;
}
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;
set_page_order(&page[size], high);
}
}
요청한 @low order 보다 큰 @high order에서 페이지를 할당 받은 경우 확장(분해)하여 high-1 부터 low까지의 free 페이지를 등록한다.
- 코드 라인 5에서 @high order 페이지 수를 미리 산출해둔다.
- 코드 라인 7~10에서 @high order가 @low order 보다 큰 경우 area 및 high를 감소시키고 size를 반으로 감소시킨다.
- 코드 라인 13~24에서 디버그용 guard 페이지를 사용하는 경우 max order의 절반 이하(0~5 order)들에 대해서는 skip 한다.
- 코드 라인 25에서 area->free_list[migratetype]에 page[size]를 추가한다.
- 코드 라인 26에서 area의 free 엔트리 수를 증가시킨다.
- 코드 라인 27에서 추가한 페이지에 해당 order 값을 저장한다.
다음 그림은 order 8 페이지를 확장하여 할당 요청한 order 5 페이지를 이외에, 남는 페이지들을 order 7 ~ 5에 해당하는 free_list에 추가한다.
migrate type 부족 시 fallback
CMA 영역 사용
__rmqueue_cma_fallback()
mm/page_alloc.c
static __always_inline struct page *__rmqueue_cma_fallback(struct zone *zone,
unsigned int order)
{
return __rmqueue_smallest(zone, order, MIGRATE_CMA);
}
movable 타입 요청 시 해당 migrate 타입에서 검색이 실패하는 경우 cma 영역에서도 시도한다.
fallback migrate 타입 사용
__rmqueue_fallback()
mm/page_alloc.c
/* * Try finding a free buddy page on the fallback list and put it on the free * list of requested migratetype, possibly along with other pages from the same * block, depending on fragmentation avoidance heuristics. Returns true if * fallback was found so that __rmqueue_smallest() can grab it. * * The use of signed ints for order and current_order is a deliberate * deviation from the rest of this file, to make the for loop * condition simpler. */
static __always_inline bool
__rmqueue_fallback(struct zone *zone, int order, int start_migratetype,
unsigned int alloc_flags)
{
struct free_area *area;
int current_order;
int min_order = order;
struct page *page;
int fallback_mt;
bool can_steal;
/*
* Do not steal pages from freelists belonging to other pageblocks
* i.e. orders < pageblock_order. If there are no local zones free,
* the zonelists will be reiterated without ALLOC_NOFRAGMENT.
*/
if (alloc_flags & ALLOC_NOFRAGMENT)
min_order = pageblock_order;
/*
* Find the largest available free page in the other list. This roughly
* approximates finding the pageblock with the most free pages, which
* would be too costly to do exactly.
*/
for (current_order = MAX_ORDER - 1; current_order >= min_order;
--current_order) {
area = &(zone->free_area[current_order]);
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);
if (fallback_mt == -1)
continue;
/*
* We cannot steal all free pages from the pageblock and the
* requested migratetype is movable. In that case it's better to
* steal and split the smallest available page instead of the
* largest available page, because even if the next movable
* allocation falls back into a different pageblock than this
* one, it won't cause permanent fragmentation.
*/
if (!can_steal && start_migratetype == MIGRATE_MOVABLE
&& current_order > order)
goto find_smallest;
goto do_steal;
}
return false;
find_smallest:
for (current_order = order; current_order < MAX_ORDER;
current_order++) {
area = &(zone->free_area[current_order]);
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);
if (fallback_mt != -1)
break;
}
/*
* This should not happen - we already found a suitable fallback
* when looking for the largest page.
*/
VM_BUG_ON(current_order == MAX_ORDER);
do_steal:
page = list_first_entry(&area->free_list[fallback_mt],
struct page, lru);
steal_suitable_fallback(zone, page, alloc_flags, start_migratetype,
can_steal);
trace_mm_page_alloc_extfrag(page, order, current_order,
start_migratetype, fallback_mt);
return true;
}
요청한 migrate 타입에서 페이지 할당이 실패할 때 호출되는데, migrate 타입 fallback 순서에 의해 다음 migrate 타입을 뺏어온다.(steal). 다른 migrate 타입을 뺏어올 때에는 가장 큰 order 위주로 뺏어온다. 이렇게 큰 페이지를 뺏어와야 다음에 동일한 migrate 타입 요청 시 즉각 대응할 수 있다.
- 코드 라인 17~18에서 ALLOC_NOFRAGMENT 요청이 있는 경우 페이지 블럭내에서 migrate 타입이 섞이지 않도록 min_order 값에 페이지 블럭 order를 대입한다.
- 코드 라인 25~31에서 가장 큰 order 부터 min_order까지 버디 리스트를 역방향으로 순회하며 fallback migrate 타입 순으로 free 페이지가 있는지 여부를 알아온다.
- 코드 라인 41~45에서 요청한 타입이 movable이고, 출력 결과인 can_steal이 false이면 find_smallest 레이블로 이동한다. 그렇지 않은 경우 do_steal 레이블로 이동한다.
- 코드 라인 48에서 루프를 완료할 때까지 fallback migrate 타입에서도 페이지를 찾지 못한 경우 false를 반환한다.
- 코드 라인 50~58에서 find_smallest: 레이블이다. 요청한 migrate 타입이 movable인 경우이므로 페이지 블럭내에서 migrate 타입이 섞이더라도 요청한 order 부터 가장 큰 오더까지, 즉 작은 order 순서부터 시작하여 fallback migrate 타입에 free 페이지가 있으면 루프를 탈출한다.
- 코드 라인 66~76에서 do_steal: 레이블이다. 찾은 fallback migrate 타입의 free 페이지를 요청한 migrate 타입의 free_list로 뺏어온다. 그런 후 true를 반환한다.
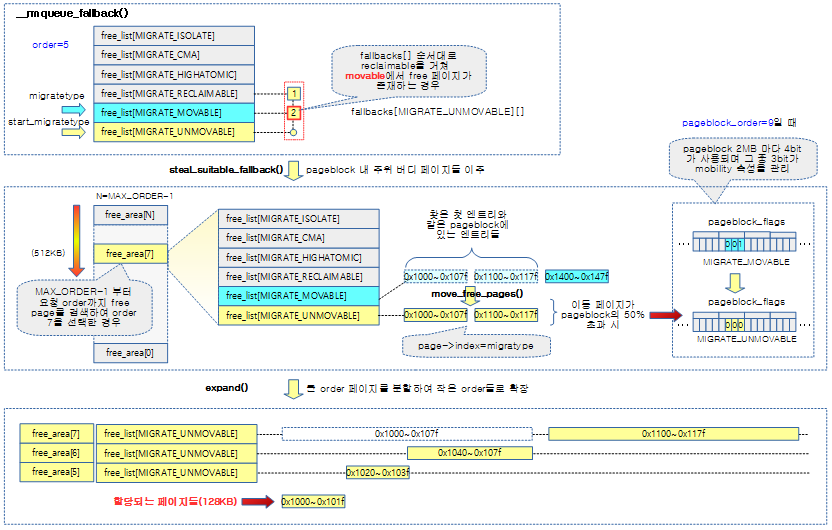
아래 그림은 unmovable 타입으로 5-order page를 할당 받으려는데 unmovable 타입의 free_list에서 free 페이지를 확보하지 못한 경우 fallback migrate 타입순으로 free_list의 free 페이지를 검색하여 steal 하는 모습을 보여준다.
- unmovable에 대한 첫 번째 fallback migrate 타입인 reclaimable migrate 타입의 free_list를 검색하고, 그 다음 두 번째 movable migrate 타입의 free_list를 검색한다.
적합한 fallback migrate 타입 찾기
find_suitable_fallback()
mm/page_alloc.c
/* * Check whether there is a suitable fallback freepage with requested order. * If only_stealable is true, this function returns fallback_mt only if * we can steal other freepages all together. This would help to reduce * fragmentation due to mixed migratetype pages in one pageblock. */
int find_suitable_fallback(struct free_area *area, unsigned int order,
int migratetype, bool only_stealable, bool *can_steal)
{
int i;
int fallback_mt;
if (area->nr_free == 0)
return -1;
*can_steal = false;
for (i = 0;; i++) {
fallback_mt = fallbacks[migratetype][i];
if (fallback_mt == MIGRATE_TYPES)
break;
if (list_empty(&area->free_list[fallback_mt]))
continue;
if (can_steal_fallback(order, migratetype))
*can_steal = true;
if (!only_stealable)
return fallback_mt;
if (*can_steal)
return fallback_mt;
}
return -1;
}
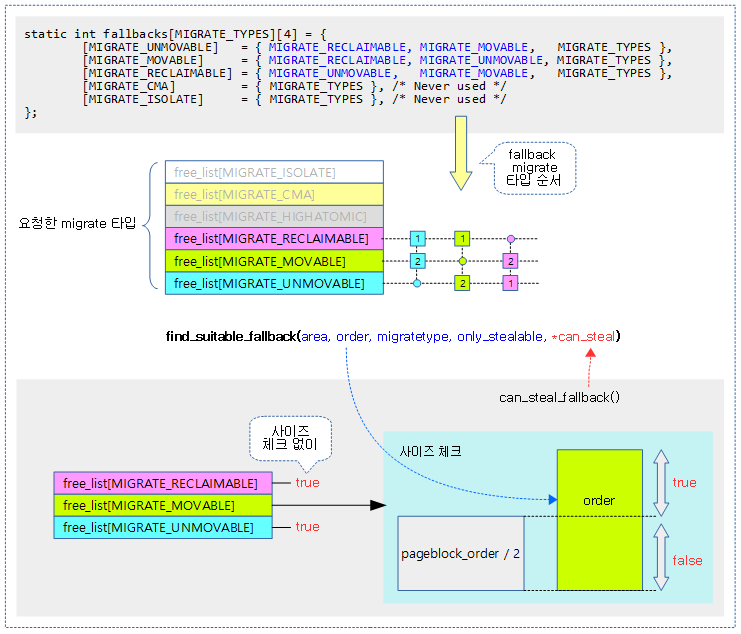
order 페이지가 fallback migrate 타입을 사용하는 free_list에 존재하고 steal 할 수 있는 fallback migrate 타입을 알아온다. fallback migrate 타입에서도 더 이상 찾지못한 경우 -1을 반환한다. @only_stealable에 true를 사용한 경우 반드시 1 페이지 블럭 전체를 steal해야 경우에 사용한다.(compaction 루틴에서 호출할 때 true로 요청한다) 출력 인자 @can_steal이 true이면 해당 페이지 이외에 해당 페이지가 소속된 페이지 블럭에 포함된 나머지 free 페이지들을 모두 steal 가능한 상태라고 알려주고, false이면 해당 페이지에 대해서만 steal 가능한 상태라고 알려준다.
- 코드 라인 7~8에서 해당 order에 어떠한 free 엔트리가 없는 경우 -1을 반환한다.
- 코드 라인 11~17에서 요청한 migrate 타입의 fallback migrate 타입 순서대로 순회한다.
- 코드 라인 19~26에서 1 페이지 블럭을 모두 steal 해야 하는지 여부를 판단해온다.
- 한 페이지 블럭 전체의 steal이 가능한 경우 출력 인자 *can_steal에 true를 대입하고 순회 중인 해당 migrate 타입을 반환한다.
- 만일 only_stealable이 false인 경우 *can_stean 여부와 관계 없이 더 이상 순회하지 않고 해당 migrate 타입을 반환한다.
- 코드 라인 29에서 순회가 완료되도록 steal 가능한 migrate 타입이 없는 경우 -1을 반환한다.
다음 그림은 fallback 하여 사용할 migrate 타입을 알아오는 과정을 보여준다.
can_steal_fallback()
mm/page_alloc.c
/* * When we are falling back to another migratetype during allocation, try to * steal extra free pages from the same pageblocks to satisfy further * allocations, instead of polluting multiple pageblocks. * * If we are stealing a relatively large buddy page, it is likely there will * be more free pages in the pageblock, so try to steal them all. For * reclaimable and unmovable allocations, we steal regardless of page size, * as fragmentation caused by those allocations polluting movable pageblocks * is worse than movable allocations stealing from unmovable and reclaimable * pageblocks. */
static bool can_steal_fallback(unsigned int order, int start_mt)
{
/*
* Leaving this order check is intended, although there is
* relaxed order check in next check. The reason is that
* we can actually steal whole pageblock if this condition met,
* but, below check doesn't guarantee it and that is just heuristic
* so could be changed anytime.
*/
if (order >= pageblock_order)
return true;
if (order >= pageblock_order / 2 ||
start_mt == MIGRATE_RECLAIMABLE ||
start_mt == MIGRATE_UNMOVABLE ||
page_group_by_mobility_disabled)
return true;
return false;
}
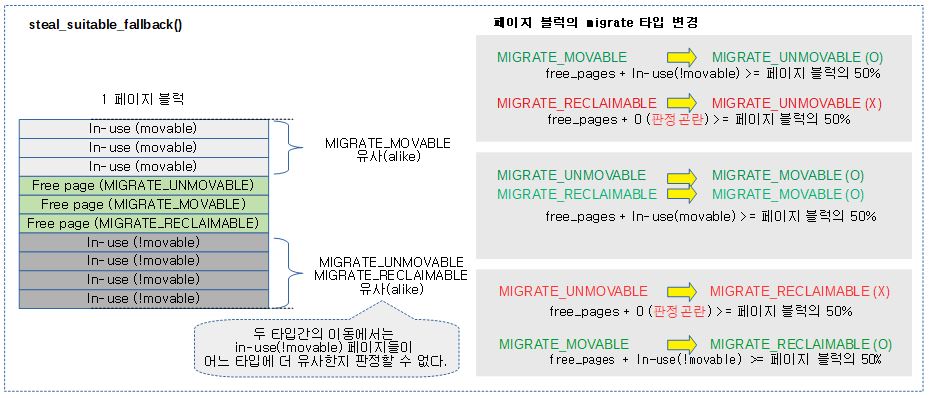
1 페이지 블럭을 모두 steal 해야 하는지 여부를 판단해온다. 할당 시 원하던 migratetype의 freelist에서 할당이 불가능한 경우 fallback migratetype을 사용한다. 만일 이러한 fallback을 통한 할당을 사용하는 경우 steal할 페이지의 같은 페이지 블럭내의 나머지 free 페이지들을 모두 steal해 오면 다가오는 미래의 추가 할당을 안전하게 수행할 수 있고, 이를 통해 페이지블럭들의 오염(많은 페이지 블럭들이 unmovable로 여러군데에 퍼짐)을 막는 효과가 있다. 이렇게 1 페이지 블럭내의 free 페이지들을 모두 steal 해올지 여부의 판단은 다음과 같이 한다.
- 어느 정도 큰 order 요청
- x86, arm, arm64 시스템등이 사용하는 huge page를 사용할 때 pageblock_order는 대체로 9이므로 이의 절반 4.5에서 소숫점 이하를 버리고 4 이상의 order 요청이다.
- reclaimable 타입이나 unmovable 타입 방향이 목적지(dest)인 경우 이러한 타입의 오염을 막아야 하므로 무조건 요청
- freelist를 migratetype으로 나누어 관리할 만큼의 주 메모리가 너무 적은 경우
fallback migrate 타입에서 steal 하기
steal_suitable_fallback()
mm/page_alloc.c
/* * This function implements actual steal behaviour. If order is large enough, * we can steal whole pageblock. If not, we first move freepages in this * pageblock to our migratetype and determine how many already-allocated pages * are there in the pageblock with a compatible migratetype. If at least half * of pages are free or compatible, we can change migratetype of the pageblock * itself, so pages freed in the future will be put on the correct free list. */
static void steal_suitable_fallback(struct zone *zone, struct page *page,
unsigned int alloc_flags, int start_type, bool whole_block)
{
unsigned int current_order = page_order(page);
struct free_area *area;
int free_pages, movable_pages, alike_pages;
int old_block_type;
old_block_type = get_pageblock_migratetype(page);
/*
* This can happen due to races and we want to prevent broken
* highatomic accounting.
*/
if (is_migrate_highatomic(old_block_type))
goto single_page;
/* Take ownership for orders >= pageblock_order */
if (current_order >= pageblock_order) {
change_pageblock_range(page, current_order, start_type);
goto single_page;
}
/*
* Boost watermarks to increase reclaim pressure to reduce the
* likelihood of future fallbacks. Wake kswapd now as the node
* may be balanced overall and kswapd will not wake naturally.
*/
boost_watermark(zone);
if (alloc_flags & ALLOC_KSWAPD)
set_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);
/* We are not allowed to try stealing from the whole block */
if (!whole_block)
goto single_page;
free_pages = move_freepages_block(zone, page, start_type,
&movable_pages);
/*
* Determine how many pages are compatible with our allocation.
* For movable allocation, it's the number of movable pages which
* we just obtained. For other types it's a bit more tricky.
*/
if (start_type == MIGRATE_MOVABLE) {
alike_pages = movable_pages;
} else {
/*
* If we are falling back a RECLAIMABLE or UNMOVABLE allocation
* to MOVABLE pageblock, consider all non-movable pages as
* compatible. If it's UNMOVABLE falling back to RECLAIMABLE or
* vice versa, be conservative since we can't distinguish the
* exact migratetype of non-movable pages.
*/
if (old_block_type == MIGRATE_MOVABLE)
alike_pages = pageblock_nr_pages
- (free_pages + movable_pages);
else
alike_pages = 0;
}
/* moving whole block can fail due to zone boundary conditions */
if (!free_pages)
goto single_page;
/*
* If a sufficient number of pages in the block are either free or of
* comparable migratability as our allocation, claim the whole block.
*/
if (free_pages + alike_pages >= (1 << (pageblock_order-1)) ||
page_group_by_mobility_disabled)
set_pageblock_migratetype(page, start_type);
return;
single_page:
area = &zone->free_area[current_order];
list_move(&page->lru, &area->free_list[start_type]);
}
- 코드 라인 9에서 현재 페이지가 속한 페이지 블럭의 변경 되기 전 migrate 타입을 알아온다.
- 코드 라인 15~16에서 highatomic 타입인 경우 single_page 레이블로 이동한다.
- 코드 라인 19~22에서 페이지 블럭보다 큰 order 요청인 경우 페이지 블럭들내에서 migrate 타입이 섞이지 않는다. 따라서 single_page 레이블로 이동한다.
- 코드 라인 29~31에서 페이지 블럭보다 작은 fallback order가 동작하면 watermark_boost_factor 비율(디폴트=15000, 150%)이 적용된 워터마크 boost를 지정하고, ALLOC_KSWAPD 요청이 있는 경우 존의 boost 워터마크 플래그를 설정한다.
- 코드 라인 34~35에서 @whole_block 요청이 없으면 해당 페이지만을 처리하기 위해 single_page 레이블로 이동한다.
- 코드 라인 37~38에서 해당 페이지가 포함된 페이지 블럭의 모든 free 페이지들이 있는 버디 시스템의 migrate 타입을 @start_type으로 이동시킨다.
- 코드 라인 44~59에서 요청 migrate 타입별로 호환되는 migrate 타입 페이지들을 다음과 같이 산출하여 alike_pages에 대입한다.
- 사용중인 페이지는 각 타입에 동조하는 유사 페이지(alike_pages)로 인정한다.
- 그러나 사용중인 페이지는 정확히 3가지 migratetype으로 구분하지 못하고 movable과 !movable로만 구분할 수 있다.
- 따라서 MIGRATE_UNMOVABLE과 MIGRATE_RECLAIMABLE간의 migration에는 alike 페이지에 참여할 수 없다.
- 코드 라인 62~63에서 free 페이지가 없는 경우 single_page 레이블로 이동한다.
- 코드 라인 69~71에서 호환되는 페이지를 포함한 free 페이지가 페이지 블럭의 절반 이상인 경우 해당 페이지 블럭의 migrate 타입을 변경한다.
- 코드 라인 75~77에서 single_page: 레이블이다. 해당 페이지만 free_list의 @start_type 으로 옮긴다.
다음 그림은 steal_suitable_fallback() 함수에서 페이지 블럭을 steal 할지, 아니면 해당 페이지만 steal 할지 여부를 판단하여 동작하는 모습을 보여준다.
change_pageblock_range()
mm/page_alloc.c
static void change_pageblock_range(struct page *pageblock_page,
int start_order, int migratetype)
{
int nr_pageblocks = 1 << (start_order - pageblock_order);
while (nr_pageblocks--) {
set_pageblock_migratetype(pageblock_page, migratetype);
pageblock_page += pageblock_nr_pages;
}
}
요청한 order 내에 있는 모든 페이지 블럭의 수 만큼 각 페이지 블럭에 대해 migratetype을 설정한다.
- 코드 라인 4에서 start_order내에 들어갈 수 있는 pageblock의 수를 산출한다.
- 코드 라인 6~9에서 페이지 블럭 수 만큼 순회하며 페이지 블럭의 migrate 타입을 설정한다.
페이지 블럭내 모든 free 페이지의 migrate 타입 이동
move_freepages_block()
mm/page_alloc.c
int move_freepages_block(struct zone *zone, struct page *page,
int migratetype)
{
unsigned long start_pfn, end_pfn;
struct page *start_page, *end_page;
start_pfn = page_to_pfn(page);
start_pfn = start_pfn & ~(pageblock_nr_pages-1);
start_page = pfn_to_page(start_pfn);
end_page = start_page + pageblock_nr_pages - 1;
end_pfn = start_pfn + pageblock_nr_pages - 1;
/* Do not cross zone boundaries */
if (!zone_spans_pfn(zone, start_pfn))
start_page = page;
if (!zone_spans_pfn(zone, end_pfn))
return 0;
return move_freepages(zone, start_page, end_page, migratetype);
}
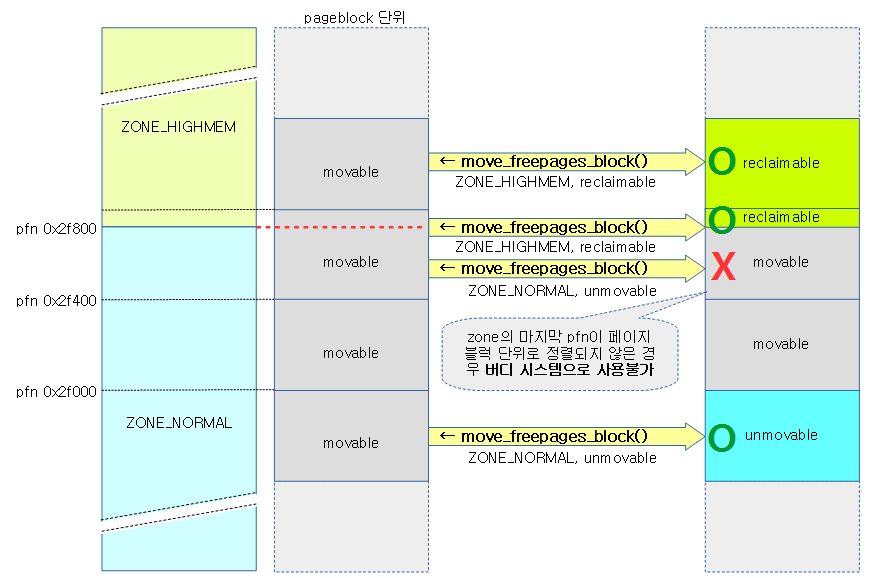
지정된 zone의 요청 page가 있는 pageblock내의 모든 free page들을 요청 migrate 타입으로 변경하고 버디 시스템에서 요청 migrate 타입으로 이동하고 이동된 페이지 수를 반환한다. 단 존 경계를 이유로 페이지블럭의 끝 부분이 partial된 경우 move 시킬 수 없다.
- 요청 zone의 시작 페이지가 pageblock 단위로 정렬되지 않은 경우에도 zone의 시작 주소부터 move 적용가능 (partial)
- 요청 zone의 끝 페이지가 pageblock 단위로 정렬되지 않은 경우 그 pageblock은 사용할 수 없음
아래 그림은 지정된 zone의 페이지블럭에 있는 free page들의 migrate type을 요청한 타입으로 변경하는 모습을 보여준다.
zone_spans_pfn()
include/linux/mmzone.h
static inline bool zone_spans_pfn(const struct zone *zone, unsigned long pfn)
{
return zone->zone_start_pfn <= pfn && pfn < zone_end_pfn(zone);
}
pfn이 zone의 영역에 들어있는지 여부를 반환한다.
move_freepages()
mm/page_alloc.c
/* * Move the free pages in a range to the free lists of the requested type. * Note that start_page and end_pages are not aligned on a pageblock * boundary. If alignment is required, use move_freepages_block() */
static int move_freepages(struct zone *zone,
struct page *start_page, struct page *end_page,
int migratetype, int *num_movable)
{
struct page *page;
unsigned int order;
int pages_moved = 0;
#ifndef CONFIG_HOLES_IN_ZONE
/*
* page_zone is not safe to call in this context when
* CONFIG_HOLES_IN_ZONE is set. This bug check is probably redundant
* anyway as we check zone boundaries in move_freepages_block().
* Remove at a later date when no bug reports exist related to
* grouping pages by mobility
*/
VM_BUG_ON(pfn_valid(page_to_pfn(start_page)) &&
pfn_valid(page_to_pfn(end_page)) &&
page_zone(start_page) != page_zone(end_page));
#endif
for (page = start_page; page <= end_page;) {
if (!pfn_valid_within(page_to_pfn(page))) {
page++;
continue;
}
/* Make sure we are not inadvertently changing nodes */
VM_BUG_ON_PAGE(page_to_nid(page) != zone_to_nid(zone), page);
if (!PageBuddy(page)) {
/*
* We assume that pages that could be isolated for
* migration are movable. But we don't actually try
* isolating, as that would be expensive.
*/
if (num_movable &&
(PageLRU(page) || __PageMovable(page)))
(*num_movable)++;
page++;
continue;
}
order = page_order(page);
list_move(&page->lru,
&zone->free_area[order].free_list[migratetype]);
page += 1 << order;
pages_moved += 1 << order;
}
return pages_moved;
}
요청 zone의 시작 페이지부터 끝 페이지까지 모든 free page들에 대해 migrate 타입을 이동시키고, 이동시킨 페이지 수를 반환한다.
- 코드 라인 21~25에서 시작 페이지부터 끝 페이지까지 순회하며 페이지가 hole 영역인 경우 skip 한다.
- 코드 라인 30~42에서 버디 시스템에서 free되어 관리되는 페이지가 아니면 skip 한다.
- 사용 중인 페이지가 lru movable 또는 non-lru movable에 포함된 경우 출력 인자 *num_movable을 증가시킨다.
- 코드 라인44~48에서 현재 order에 해당하는 free_list의 지정한 migratetype으로 이동 시킨다.
- 코드 라인 51에서 이동 시킨 페이지 수를 반환한다.
다음 그림은 요청 범위에 있는 페이지들을 찾아 버디 시스템의 지정된 migratetype으로 이주시키는 모습을 보여준다.

참고
- Zoned Allocator -1- (물리 페이지 할당-Fastpath) | 문c
- Zoned Allocator -2- (물리 페이지 할당-Slowpath) | 문c
- Zoned Allocator -3- (Buddy 페이지 할당) | 문c – 현재 글
- Zoned Allocator -4- (Buddy 페이지 해지) | 문c
- Zoned Allocator -5- (Per-CPU Page Frame Cache) | 문c
- Zoned Allocator -6- (Watermark) | 문c
- Zoned Allocator -7- (Direct Compact) | 문c
- Zoned Allocator -8- (Direct Compact-Isolation) | 문c
- Zoned Allocator -9- (Direct Compact-Migration) | 문c
- Zoned Allocator -10- (LRU & pagevec) | 문c
- Zoned Allocator -11- (Direct Reclaim) | 문c
- Zoned Allocator -12- (Direct Reclaim-Shrink-1) | 문c
- Zoned Allocator -13- (Direct Reclaim-Shrink-2) | 문c
- Zoned Allocator -14- (Kswapd) | 문c
블로그 잘 보고 있습니다.
slab allocator와 buddy memory allocator 보면서 궁금한 점이 생겨 이렇게 댓글을 남깁니다.
slab allocator도 page내부에 cleaning기능(partial list의 경우 각각의 slab내부에 object들이 다 사용해 full slab으로 가지 않고 여러 partial slab에 object들이 분배되어 효율적으로 쓰지 않았을때, partial이 많아지는 문제에 대하여 클리닝이나 compaction기능)이 있는지 궁금합니다.
감사합니다!! 글 항상 잘 보고 있습니다
안녕하세요?
kmem 캐시를 생성하면 내부 관리는 partial이 너무 많아지지 않도록 최소 slub ~ 최대 slub 범위가 지정되어 항상 동작하고 있습니다.
(/sys/kernel/slab,< 캐시명> 디렉토리에서 각 캐시 상태를 파악할 수 있습니다.)
예를 들어 partial 범위가 10 ~ 30 개로 지정되었는데, 현재 partial slub이 30개에 있다가 1개 더 늘어나면 일단 31개의 partial이 되는 것 처럼 완전 강제하지는 않습니다.
10개 이하가 되면 refill을 해서 10개로 만들고, 30개를 초과하는 경우 slub 내에 object가 모두 비어있는 slub이 있는 경우에만 해당 slub을 free 하는 로직이 수행됩니다.
아무래도 버디시스템의 compaction이나 migration과는 동작이 다릅니다.
감사합니다. 문영일 드림.
아 정말 감사합니다 ㅜㅜ 해결됬습니다 !!
해결하시는 것도 본인의 실력입니다. 계속 행운이 있길 빕니다. ^^
안녕하세요. 블로그 보면 항상 이미지로 정리가 매우 잘 되어 있는데요, 어떤 툴 사용하시는지 알 수 있을까요?
다이어그램을 그리는 노하우가 있으신지요? 항상 처음부터 그리는지 아니면 템플릿같은걸 사용하시는지도 궁금합니다.
안녕하세요? 제가 사용하는 툴은 MS Office의 파워포인트와 유사한 LibreOffice의 Impress 입니다.
여러번 그리다 보니 숙달된 경우이고요. 조금 더 빠르게 그리기 위해,
보통 기존에 그렸던 도형들을 옮겨서 사용합니다. 그러면 약간 시간을 줄여줍니다.
감사합니다.
답변 감사합니다!