<kernel v5.0>
Zoned Allocator -13- (Direct Reclaim-Shrink-2)
shrink_page_list()
mm/vmscan.c -1/6-
/* * shrink_page_list() returns the number of reclaimed pages */
static unsigned long shrink_page_list(struct list_head *page_list,
struct pglist_data *pgdat,
struct scan_control *sc,
enum ttu_flags ttu_flags,
struct reclaim_stat *stat,
bool force_reclaim)
{
LIST_HEAD(ret_pages);
LIST_HEAD(free_pages);
int pgactivate = 0;
unsigned nr_unqueued_dirty = 0;
unsigned nr_dirty = 0;
unsigned nr_congested = 0;
unsigned nr_reclaimed = 0;
unsigned nr_writeback = 0;
unsigned nr_immediate = 0;
unsigned nr_ref_keep = 0;
unsigned nr_unmap_fail = 0;
cond_resched();
while (!list_empty(page_list)) {
struct address_space *mapping;
struct page *page;
int may_enter_fs;
enum page_references references = PAGEREF_RECLAIM_CLEAN;
bool dirty, writeback;
cond_resched();
page = lru_to_page(page_list);
list_del(&page->lru);
if (!trylock_page(page))
goto keep;
VM_BUG_ON_PAGE(PageActive(page), page);
sc->nr_scanned++;
if (unlikely(!page_evictable(page)))
goto activate_locked;
if (!sc->may_unmap && page_mapped(page))
goto keep_locked;
/* Double the slab pressure for mapped and swapcache pages */
if ((page_mapped(page) || PageSwapCache(page)) &&
!(PageAnon(page) && !PageSwapBacked(page)))
sc->nr_scanned++;
may_enter_fs = (sc->gfp_mask & __GFP_FS) ||
(PageSwapCache(page) && (sc->gfp_mask & __GFP_IO));
/*
* The number of dirty pages determines if a node is marked
* reclaim_congested which affects wait_iff_congested. kswapd
* will stall and start writing pages if the tail of the LRU
* is all dirty unqueued pages.
*/
page_check_dirty_writeback(page, &dirty, &writeback);
if (dirty || writeback)
nr_dirty++;
if (dirty && !writeback)
nr_unqueued_dirty++;
/*
* Treat this page as congested if the underlying BDI is or if
* pages are cycling through the LRU so quickly that the
* pages marked for immediate reclaim are making it to the
* end of the LRU a second time.
*/
mapping = page_mapping(page);
if (((dirty || writeback) && mapping &&
inode_write_congested(mapping->host)) ||
(writeback && PageReclaim(page)))
nr_congested++;
isolation 후 전달받은 @page_list의 페이지들에 대해 shrink를 수행하고 회수된 페이지의 수를 반환한다.
- 코드 라인 8에서 회수되지 않고 남은 페이지들을 담기위해 임시로 사용되는 ret_pages 리스트를 초기화한다.
- 코드 라인 9에서 회수를 위해 임시로 사용되는 free_pages 리스트를 초기화한다.
- 코드 라인 22~32에서 page_list의 페이지 수 만큼 순회하며 페이지를 가져온다.
- 코드 라인 34~35에서 페이지 lock 획득이 실패하는 경우 다음에 처리하도록 lru로 되돌리기 위해 keep 레이블로 이동한다.
- 코드 라인 41~42에서 작은 확률로 페이지가 evictable 페이지 상태가 아닌 경우 active lru로 되돌리기 위해 activate_locked 레이블로 이동한다.
- 코드 라인 44~45에서 sc->may_unmap 요청인 경우 매핑된 페이지는 처리하지 않고 lru로 되돌리기 위해 keep 레이블로 이동한다.
- 코드 라인 48~50에서 pte 매핑된 페이지 또는 swap 캐시인 경우 nr_scanned를 증가시킨다. 단 swap 영역을 가지지 않는 clean anon 페이지는 제외한다.
- 코드 라인 51~52에서 이 페이지의 처리에 fs 사용 가능 여부를 알아온다. fs 허용하였거나 swap 캐시이면서 IO 사용 가능한 상태도 fs 사용 가능한 상태이다.
- 코드 라인 61~63에서 dirty 및 writeback 페이지인지 여부를 알아오고 nr_dirty 카운터를 증가시킨다.
- 코드 라인 65~66에서 writeback 큐잉되지 않은 dirty 페이지인 경우 nr_unqueued_dirty 카운터를 증가시킨다.
- 코드 라인 74~78에서 write가 혼잡한 상태이거나 페이지가 writeback을 통해 회수가 진행되는 페이지인 경우 nr_congested를 증가시킨다.
mm/vmscan.c -2/6-
. /*
* If a page at the tail of the LRU is under writeback, there
* are three cases to consider.
*
* 1) If reclaim is encountering an excessive number of pages
* under writeback and this page is both under writeback and
* PageReclaim then it indicates that pages are being queued
* for IO but are being recycled through the LRU before the
* IO can complete. Waiting on the page itself risks an
* indefinite stall if it is impossible to writeback the
* page due to IO error or disconnected storage so instead
* note that the LRU is being scanned too quickly and the
* caller can stall after page list has been processed.
*
* 2) Global or new memcg reclaim encounters a page that is
* not marked for immediate reclaim, or the caller does not
* have __GFP_FS (or __GFP_IO if it's simply going to swap,
* not to fs). In this case mark the page for immediate
* reclaim and continue scanning.
*
* Require may_enter_fs because we would wait on fs, which
* may not have submitted IO yet. And the loop driver might
* enter reclaim, and deadlock if it waits on a page for
* which it is needed to do the write (loop masks off
* __GFP_IO|__GFP_FS for this reason); but more thought
* would probably show more reasons.
*
* 3) Legacy memcg encounters a page that is already marked
* PageReclaim. memcg does not have any dirty pages
* throttling so we could easily OOM just because too many
* pages are in writeback and there is nothing else to
* reclaim. Wait for the writeback to complete.
*
* In cases 1) and 2) we activate the pages to get them out of
* the way while we continue scanning for clean pages on the
* inactive list and refilling from the active list. The
* observation here is that waiting for disk writes is more
* expensive than potentially causing reloads down the line.
* Since they're marked for immediate reclaim, they won't put
* memory pressure on the cache working set any longer than it
* takes to write them to disk.
*/
if (PageWriteback(page)) {
/* Case 1 above */
if (current_is_kswapd() &&
PageReclaim(page) &&
test_bit(PGDAT_WRITEBACK, &pgdat->flags)) {
nr_immediate++;
goto activate_locked;
/* Case 2 above */
} else if (sane_reclaim(sc) ||
!PageReclaim(page) || !may_enter_fs) {
/*
* This is slightly racy - end_page_writeback()
* might have just cleared PageReclaim, then
* setting PageReclaim here end up interpreted
* as PageReadahead - but that does not matter
* enough to care. What we do want is for this
* page to have PageReclaim set next time memcg
* reclaim reaches the tests above, so it will
* then wait_on_page_writeback() to avoid OOM;
* and it's also appropriate in global reclaim.
*/
SetPageReclaim(page);
nr_writeback++;
goto activate_locked;
/* Case 3 above */
} else {
unlock_page(page);
wait_on_page_writeback(page);
/* then go back and try same page again */
list_add_tail(&page->lru, page_list);
continue;
}
}
- 코드 라인 43에서 writeback 페이지에 대한 처리이다.
- 코드 라인 45~49에서 첫 번째 writeback 케이스: kswapd에서 회수 중인 페이지가 다시 돌아온 경우이다. 이러한 경우 처리 시간을 좀 더 주기위해 nr_immediate 카운터를 증가시키고, activate 처리 후 lru로 되돌리기 위해 activate_locked 레이블로 이동한다.
- 코드 라인 52~67에서 두 번째 writeback 케이스: memcg를 통해 writeback을 하거나 아직 회수 중인 페이지가 아니거나 fs 사용 불가능한 상태인 경우 즉각 회수를 위해 reclaim 플래그를 설정하고, nr_writeback 카운터를 증가시킨다. 그런 후 activate 처리 후 lru로 되돌리기 위해 activate_locked 레이블로 이동한다.
- 코드 라인 70~76에서 세 번째 writeback 케이스: 해당 페이지의 writeback이 완료될 때 까지 기다린 후 page_list에 추가하고 계속한다.
mm/vmscan.c -3/6-
. if (!force_reclaim)
references = page_check_references(page, sc);
switch (references) {
case PAGEREF_ACTIVATE:
goto activate_locked;
case PAGEREF_KEEP:
nr_ref_keep++;
goto keep_locked;
case PAGEREF_RECLAIM:
case PAGEREF_RECLAIM_CLEAN:
; /* try to reclaim the page below */
}
/*
* Anonymous process memory has backing store?
* Try to allocate it some swap space here.
* Lazyfree page could be freed directly
*/
if (PageAnon(page) && PageSwapBacked(page)) {
if (!PageSwapCache(page)) {
if (!(sc->gfp_mask & __GFP_IO))
goto keep_locked;
if (PageTransHuge(page)) {
/* cannot split THP, skip it */
if (!can_split_huge_page(page, NULL))
goto activate_locked;
/*
* Split pages without a PMD map right
* away. Chances are some or all of the
* tail pages can be freed without IO.
*/
if (!compound_mapcount(page) &&
split_huge_page_to_list(page,
page_list))
goto activate_locked;
}
if (!add_to_swap(page)) {
if (!PageTransHuge(page))
goto activate_locked;
/* Fallback to swap normal pages */
if (split_huge_page_to_list(page,
page_list))
goto activate_locked;
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
count_vm_event(THP_SWPOUT_FALLBACK);
#endif
if (!add_to_swap(page))
goto activate_locked;
}
may_enter_fs = 1;
/* Adding to swap updated mapping */
mapping = page_mapping(page);
}
} else if (unlikely(PageTransHuge(page))) {
/* Split file THP */
if (split_huge_page_to_list(page, page_list))
goto keep_locked;
}
/*
* The page is mapped into the page tables of one or more
* processes. Try to unmap it here.
*/
if (page_mapped(page)) {
enum ttu_flags flags = ttu_flags | TTU_BATCH_FLUSH;
if (unlikely(PageTransHuge(page)))
flags |= TTU_SPLIT_HUGE_PMD;
if (!try_to_unmap(page, flags)) {
nr_unmap_fail++;
goto activate_locked;
}
}
- 코드 라인 1~13에서 @force_reclaim이 true인 경우 reclaim을 강제하고, 그렇지 않은 경우 페이지 참조 체크 결과에 따라 다음 중 하나로 진행한다.
- swapback 중인 페이지, 2 번 이상 참조된 페이지, 실행 파일 페이지가 참조된 경우 activate lru로 되돌리기 위해 activate_locked 레이블로 이동한다.
- 기타 페이지가 참조된 경우 inactivate lru로 되돌리기 위해 keep_locked 레이블로 이동한다.
- 그 외의 경우 페이지 회수를 진행하기 위해 코드를 계속 진행한다.
- 코드 라인 20~56에서 swap 영역 사용 가능한 normal anon 페이지를 처리한다. 만일 swap 캐시가 아직 없을 때에 다음과 같이 수행한다.
- io 처리 금지된 상태라면 keep_locked 레이블로 이동시킨다.
- thp인 경우 split이 불가능하면 activate_locked 레이블로 이동시키고, 페이지를 split한 order 0 페이지들을 page_list에 추가하고 activate_locked 레이블로 이동한다.
- 페이지를 swap 큐에 추가한다. 만일 추가할 수 없는 경우 thp이면 split한 order 0페이지를 page_list에 추가한다.
- 코드 라인 57~61에서 swap 영역에 지정된 anon 페이지가 아니면서 thp인 경우 페이지를 split한 order 0 페이지들을 page_list에 추가하고 keep_locked 레이블로 이동한다.
- 코드 라인 67~76에서 매핑된 페이지에 대해 언매핑을 수행한다. 언매핑이 실패한 경우 activate lru로 되돌리기 위해 activate_locked로 이동한다.
mm/vmscan.c -4/6-
. if (PageDirty(page)) {
/*
* Only kswapd can writeback filesystem pages
* to avoid risk of stack overflow. But avoid
* injecting inefficient single-page IO into
* flusher writeback as much as possible: only
* write pages when we've encountered many
* dirty pages, and when we've already scanned
* the rest of the LRU for clean pages and see
* the same dirty pages again (PageReclaim).
*/
if (page_is_file_cache(page) &&
(!current_is_kswapd() || !PageReclaim(page) ||
!test_bit(PGDAT_DIRTY, &pgdat->flags))) {
/*
* Immediately reclaim when written back.
* Similar in principal to deactivate_page()
* except we already have the page isolated
* and know it's dirty
*/
inc_node_page_state(page, NR_VMSCAN_IMMEDIATE);
SetPageReclaim(page);
goto activate_locked;
}
if (references == PAGEREF_RECLAIM_CLEAN)
goto keep_locked;
if (!may_enter_fs)
goto keep_locked;
if (!sc->may_writepage)
goto keep_locked;
/*
* Page is dirty. Flush the TLB if a writable entry
* potentially exists to avoid CPU writes after IO
* starts and then write it out here.
*/
try_to_unmap_flush_dirty();
switch (pageout(page, mapping, sc)) {
case PAGE_KEEP:
goto keep_locked;
case PAGE_ACTIVATE:
goto activate_locked;
case PAGE_SUCCESS:
if (PageWriteback(page))
goto keep;
if (PageDirty(page))
goto keep;
/*
* A synchronous write - probably a ramdisk. Go
* ahead and try to reclaim the page.
*/
if (!trylock_page(page))
goto keep;
if (PageDirty(page) || PageWriteback(page))
goto keep_locked;
mapping = page_mapping(page);
case PAGE_CLEAN:
; /* try to free the page below */
}
}
- 코드 라인 1에서 dirty 페이지인 경우의 처리이다.
- 코드 라인 12~25에서 dirty된 file 캐시는 kswapd에서만 pageout()을 사용할 예정이다. 따라서 file 캐시 페이지이면서 kswapd가 아닌 경우에는 reclaim 플래그를 설정한 후 activate lru로 되돌리기 위해 activate_locked 레이블로 이동한다.
- 코드 라인 27~32에서 fs를 사용하지 못하거나, write 금지 상황이거나, 페이지 참조 체크가 clean 상태인 경우 lru로 되돌리기 위해 keep_locked 레이블로 이동한다.
- 코드 라인 39에서 writable 페이지의 경우 TLB를 플러시하여 IO 시작 후 cpu가 기록하는 일이 없도록 방지한다.
- 코드 라인 40~62에서 dirty 페이지를 pageout() 함수를 통해 파일 시스템에 기록하도록 요청한다. clean 결과를 얻으면 페이지를 free 하기위해 아래 코드를 계속 진행하고, 나머지는 페이지 상황에 따라 active 또는 inactive lru로 되돌린다.
mm/vmscan.c -5/6-
. /*
* If the page has buffers, try to free the buffer mappings
* associated with this page. If we succeed we try to free
* the page as well.
*
* We do this even if the page is PageDirty().
* try_to_release_page() does not perform I/O, but it is
* possible for a page to have PageDirty set, but it is actually
* clean (all its buffers are clean). This happens if the
* buffers were written out directly, with submit_bh(). ext3
* will do this, as well as the blockdev mapping.
* try_to_release_page() will discover that cleanness and will
* drop the buffers and mark the page clean - it can be freed.
*
* Rarely, pages can have buffers and no ->mapping. These are
* the pages which were not successfully invalidated in
* truncate_complete_page(). We try to drop those buffers here
* and if that worked, and the page is no longer mapped into
* process address space (page_count == 1) it can be freed.
* Otherwise, leave the page on the LRU so it is swappable.
*/
if (page_has_private(page)) {
if (!try_to_release_page(page, sc->gfp_mask))
goto activate_locked;
if (!mapping && page_count(page) == 1) {
unlock_page(page);
if (put_page_testzero(page))
goto free_it;
else {
/*
* rare race with speculative reference.
* the speculative reference will free
* this page shortly, so we may
* increment nr_reclaimed here (and
* leave it off the LRU).
*/
nr_reclaimed++;
continue;
}
}
}
if (PageAnon(page) && !PageSwapBacked(page)) {
/* follow __remove_mapping for reference */
if (!page_ref_freeze(page, 1))
goto keep_locked;
if (PageDirty(page)) {
page_ref_unfreeze(page, 1);
goto keep_locked;
}
count_vm_event(PGLAZYFREED);
count_memcg_page_event(page, PGLAZYFREED);
} else if (!mapping || !__remove_mapping(mapping, page, true))
goto keep_locked;
unlock_page(page);
- 코드 라인 22~41에서 파일 시스템에 별도의 버퍼를 가진 private 페이지인 경우 버퍼를 해제한다. 만일 버퍼 해제가 실패한 경우 다시 active lru로 되돌리기 위해 activate_locked 레이블로 이동한다. 매핑되지 않았거나 사용되지 않으면 페이지를 회수하기 위해 free_it 레이블로 이동한다. 경쟁 상황에서 드물게 이미 free되고 있는 페이지인 경우 nr_reclaimed 카운트를 증가하고 다음 페이지를 처리하도록 한다.
- 코드 라인 43~53에서 swap 영역을 사용하지 못하는 clean anon 페이지인 경우이다. 다음 순서대로 처리한다.
- 사용자가 없으면 참조 카운터를 0으로 변경한다. 만일 아직 사용자가 있으면 keep_locked 레이블로 이동한다.
- dirty 페이지인 경우 참조 카운터를 1로 변경하고, lru로 되돌리기 위해 keep_locked 레이블로 이동한다.
- 마지막으로 PGLAZYFREED 카운터를 증가시킨다. 다음 free_it: 레이블로 이어지는 코드를 통해 회수될 예정이다.
- 코드 라인 54~55에서 swapbacked 되지 않은 anon 페이지도 아니면서 매핑이 없거나 매핑을 제거할 수 없으면 lru로 되돌리기 위해 keep_locked 레이블로 이동한다.
mm/vmscan.c -6/6-
free_it:
nr_reclaimed++;
/*
* Is there need to periodically free_page_list? It would
* appear not as the counts should be low
*/
if (unlikely(PageTransHuge(page))) {
mem_cgroup_uncharge(page);
(*get_compound_page_dtor(page))(page);
} else
list_add(&page->lru, &free_pages);
continue;
activate_locked:
/* Not a candidate for swapping, so reclaim swap space. */
if (PageSwapCache(page) && (mem_cgroup_swap_full(page) ||
PageMlocked(page)))
try_to_free_swap(page);
VM_BUG_ON_PAGE(PageActive(page), page);
if (!PageMlocked(page)) {
SetPageActive(page);
pgactivate++;
count_memcg_page_event(page, PGACTIVATE);
}
keep_locked:
unlock_page(page);
keep:
list_add(&page->lru, &ret_pages);
VM_BUG_ON_PAGE(PageLRU(page) || PageUnevictable(page), page);
}
mem_cgroup_uncharge_list(&free_pages);
try_to_unmap_flush();
free_unref_page_list(&free_pages);
list_splice(&ret_pages, page_list);
count_vm_events(PGACTIVATE, pgactivate);
if (stat) {
stat->nr_dirty = nr_dirty;
stat->nr_congested = nr_congested;
stat->nr_unqueued_dirty = nr_unqueued_dirty;
stat->nr_writeback = nr_writeback;
stat->nr_immediate = nr_immediate;
stat->nr_activate = pgactivate;
stat->nr_ref_keep = nr_ref_keep;
stat->nr_unmap_fail = nr_unmap_fail;
}
return nr_reclaimed;
}
- 코드 라인 1~13에서 free_it: 레이블이다. 이 곳에서는 회수될 페이지를 free_pages 리스트에 추가하고 다음 페이지를 반복한다. 만일 thp의 경우 memcg에도 보고하고 free_transhuge_page() 함수를 호출하여 order 0 페이지로 분해한다.
- 코드 라인 15~25에서 activate_locked: 레이블이다. 이 곳에서는 페이지를 active 설정한다. 만일 swap 캐시 페이지가 memcg swap 공간이 full 상태이거나 mlocked 페이지인 상태인 경우 swap 영역을 비우도록 한다. 그리고 mlocked 페이지가 아닌 경우 actvie 설정하고 아래 keep_locked: 레이블을 계속 진행한다.
- 코드 라인 26~27에서 keep_locked: 레이블이다. 페이지를 unlock 하고 아래 keep: 레이블을 계속 진행한다.
- 코드 라인 28~31에서 keep: 레이블이다. 이 곳에서는 페이지를 ret_pages 리스트에 추가하고 다음 페이지를 반복한다.
- 코드 라인 33~35에서 루프를 모두 완료하면 free_pages 리스트들의 페이지를 memcg에 uncharge 보고하고, pcp에 회수시킨다.
- 코드 라인 37~38에서 ret_pages 리스트는 @page_list의 선두로 다시 되돌리고(rotate) PGACTIVATE 카운트를 증가시킨다.
- 코드 라인 40~50에서 회수와 관련된 카운터들을 갱신하고, 회수된 페이지 수를 반환한다.
다음 그림은 스캔하여 isolation한 page_list를 대상으로 페이지를 회수하여 free page를 확보하는 흐름을 보여준다.
- activate 화살표에서는 페이지에 PG_active 플래그를 설정한 후 lru로 되돌린다.
- keep 화살표에서는 lru로 되돌린다.
- free 화살표에서는 free 페이지를 버디 시스템으로 회수한다.
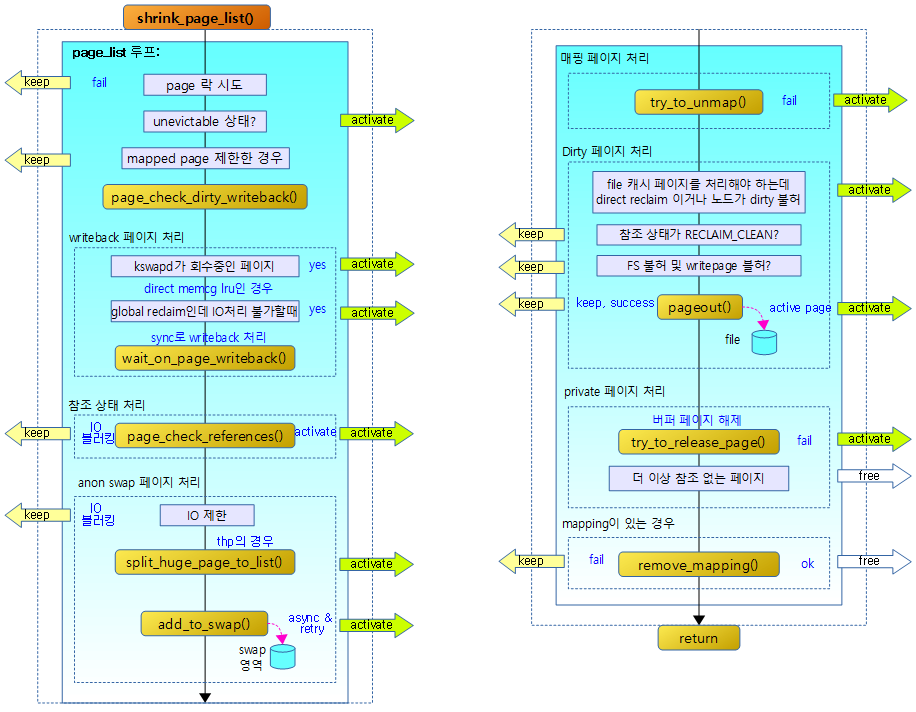
페이지의 dirty & writeback 상태 체크
page_check_dirty_writeback()
mm/vmscan.c
/* Check if a page is dirty or under writeback */
static void page_check_dirty_writeback(struct page *page,
bool *dirty, bool *writeback)
{
struct address_space *mapping;
/*
* Anonymous pages are not handled by flushers and must be written
* from reclaim context. Do not stall reclaim based on them
*/
if (!page_is_file_cache(page) ||
(PageAnon(page) && !PageSwapBacked(page))) {
*dirty = false;
*writeback = false;
return;
}
/* By default assume that the page flags are accurate */
*dirty = PageDirty(page);
*writeback = PageWriteback(page);
/* Verify dirty/writeback state if the filesystem supports it */
if (!page_has_private(page))
return;
mapping = page_mapping(page);
if (mapping && mapping->a_ops->is_dirty_writeback)
mapping->a_ops->is_dirty_writeback(page, dirty, writeback);
}
페이지의 dirty 및 writeback 여부를 알아온다.
- 코드 라인 11~16에서 file 캐시가 아니거나, swap 영역을 사용할 수 없는 anon 페이지인 경우 출력 인수 dirty와 writeback에 false를 담고 함수를 종료한다.
- swapbacked 여부와 상관없는 anon 페이지
- 코드 라인 19~20에서 dirty 및 writeback 플래그 상태를 저장한다.
- 코드 라인23~24에서별도의 버퍼를 갖는 private 페이지가 아닌 경우 함수를 빠져나간다.
- 코드 라인26~28에서 mapping 페이지의 경우 is_dirty_writeback() 핸들러 함수를 통해 dirty 및 writeback 여부를 알아온다.
페이지의 참조 상태 체크
page_check_references()
mm/vmscan.c
static enum page_references page_check_references(struct page *page,
struct scan_control *sc)
{
int referenced_ptes, referenced_page;
unsigned long vm_flags;
referenced_ptes = page_referenced(page, 1, sc->target_mem_cgroup,
&vm_flags);
referenced_page = TestClearPageReferenced(page);
/*
* Mlock lost the isolation race with us. Let try_to_unmap()
* move the page to the unevictable list.
*/
if (vm_flags & VM_LOCKED)
return PAGEREF_RECLAIM;
if (referenced_ptes) {
if (PageSwapBacked(page))
return PAGEREF_ACTIVATE;
/*
* All mapped pages start out with page table
* references from the instantiating fault, so we need
* to look twice if a mapped file page is used more
* than once.
*
* Mark it and spare it for another trip around the
* inactive list. Another page table reference will
* lead to its activation.
*
* Note: the mark is set for activated pages as well
* so that recently deactivated but used pages are
* quickly recovered.
*/
SetPageReferenced(page);
if (referenced_page || referenced_ptes > 1)
return PAGEREF_ACTIVATE;
/*
* Activate file-backed executable pages after first usage.
*/
if (vm_flags & VM_EXEC)
return PAGEREF_ACTIVATE;
return PAGEREF_KEEP;
}
/* Reclaim if clean, defer dirty pages to writeback */
if (referenced_page && !PageSwapBacked(page))
return PAGEREF_RECLAIM_CLEAN;
return PAGEREF_RECLAIM;
}
페이지 참조를 확인하여 그 상태를 다음과 같이 4 가지로 알아온다.
- PAGEREF_RECLAIM
- 페이지 회수 시작
- PAGEREF_RECLAIM_CLEAN
- 페이지 회수 완료되어 free 하여도 되는 상태
- PAGEREF_KEEP
- 다음에 처리하게 유보
- PAGEREF_ACTIVATE
- 페이지가 active 중이므로 다음에 처리하게 유보
- 코드 라인 7~8에서 pte 매핑된 횟수를 알아온다.
- 참조: Rmap -2- (TTU & Rmap Walk) | 문c
- 코드 라인 9에서 페이지의 reference 플래그를 알아오고 클리어한다.
- 코드 라인 15~16에서 참조된 vma 영역이 VM_LOCKED 상태인 경우 PAGEREF_RECLAIM을 반환하여 페이지 회수를 시작하게 한다.
- 코드 라인 18~47에서 pte 참조 중인 페이지인 경우 PAGEREF_KEEP을 반환하여 해당 lru로 되돌리게 한다. 단 다음 조건인 경우에는 PAGEREF_ACTIVATE를 반환하여 activae lru로 되돌리게 한다.
- swap 영역을 사용할 수 있는 anon 페이지인 경우
- 참조 플래그를 설정하고, 그 전에 참조 플래그가 설정되었었거나, 2 군데 이상에서 pte 참조된 경우
- 실행 파일인 경우
- 코드 라인 50~51에서 기존에 참조 플래그가 설정되었고 swap 영역을 사용할 수 없는 clean anon 페이지인 경우 RECLAIM_CLEAN 상태로 반환하여 곧바로 페이지를 free하게 한다.
- 코드 라인 53에서 그 외의 경우 PAGEREF_RECLAIM을 반환하여 페이지를 회수 시작하도록 한다.
Shrinker
슬랩 캐시를 사용하는 스캔하여 사용되지 않는 슬랩 오브젝트를 제거하여 free 페이지를 확보할 수 있도록 shrinker를 구성할 수 있다. 이러한 shrinker는 캐시를 많이 사용하는 파일 시스템 등에서 주로 많이 사용되며 이들의 등록과 삭제는 다음 api를 통해서 할 수 있다.
- register_shrinker()
- unregister_shrinker()
이를 사용하는 대표적인 서브시스템 및 드라이버등은 다음과 같다.
- zsmalloc
- huge_memory
- kvm
- ubifs
- ext4
- f2fs
- xfs
- nfs
- gpu
- ion
- bcache
- raid5
- virtio_balloon
shrinker 구조체
include/linux/shrinker.h
/* * A callback you can register to apply pressure to ageable caches. * * @count_objects should return the number of freeable items in the cache. If * there are no objects to free, it should return SHRINK_EMPTY, while 0 is * returned in cases of the number of freeable items cannot be determined * or shrinker should skip this cache for this time (e.g., their number * is below shrinkable limit). No deadlock checks should be done during the * count callback - the shrinker relies on aggregating scan counts that couldn't * be executed due to potential deadlocks to be run at a later call when the * deadlock condition is no longer pending. * * @scan_objects will only be called if @count_objects returned a non-zero * value for the number of freeable objects. The callout should scan the cache * and attempt to free items from the cache. It should then return the number * of objects freed during the scan, or SHRINK_STOP if progress cannot be made * due to potential deadlocks. If SHRINK_STOP is returned, then no further * attempts to call the @scan_objects will be made from the current reclaim * context. * * @flags determine the shrinker abilities, like numa awareness */
struct shrinker {
unsigned long (*count_objects)(struct shrinker *,
struct shrink_control *sc);
unsigned long (*scan_objects)(struct shrinker *,
struct shrink_control *sc);
long batch; /* reclaim batch size, 0 = default */
int seeks; /* seeks to recreate an obj */
unsigned flags;
/* These are for internal use */
struct list_head list;
#ifdef CONFIG_MEMCG_KMEM
/* ID in shrinker_idr */
int id;
#endif
/* objs pending delete, per node */
atomic_long_t *nr_deferred;
};
- (*count_objects)
- 캐시안에서 free 가능한 오브젝트 수를 반환한다. 없는 경우 SHRINK_EMPTY를 반환한다.
- (*scan_objects)
- 캐시안에서 free 가능한 오브젝트들을 대상으로 reclaim을 수행한다. 반환되는 수는 할당 해제한 오브젝트 수이다.
- batch
- 배치 수 만큼 reclaim을 수행한다.
- 지정하지 않는 경우 SHRINK_BATCH(128) 만큼 처리한다.
- seeks
- 지정되지 않으면 항상 free 가능한 오브젝트 수의 절반씩 recalim 한다.
- 지정되는 경우 free 가능한 오브젝트 >> priority를 한 후 4/seeks를 곱한 수 만큼 reclaim 한다.
- flags
- 다음과 같은 플래그가 사용된다.
- SHRINKER_NUMA_AWARE
- node 별로 shrink를 할 수 있도록 구성한다.
- SHRINKER_MEMCG_AWARE
- memcg 별로 shrink를 할 수 있도록 구성한다.
- SHRINKER_NUMA_AWARE
- 다음과 같은 플래그가 사용된다.
- list
- shrinker_list에 등록될 때 사용될 노드이다.
- id
- memcg에서 shrinker_idr에 등록할 때 사용되는 id 값이다.
- *nr_deferred
- 이 포인터는 노드 수(per-node)만큼 할당된 정수 배열에 연결되며, 노드별 삭제 지연된 오브젝트 수를 나타낸다.
shrinker 등록
register_shrinker()
mm/vmscan.c
int register_shrinker(struct shrinker *shrinker)
{
int err = prealloc_shrinker(shrinker);
if (err)
return err;
register_shrinker_prepared(shrinker);
return 0;
}
EXPORT_SYMBOL(register_shrinker);
shrinker를 등록한다.
- 코드 라인 3~6에서 shrinker를 등록하기 전에 할당할 항목들을 준비한다.
- 코드 라인 7에서 shrinker를 등록한다.
다음 그림은 register_shrinker() 함수를 통해 shrinker가 등록되는 모습을 보여준다.
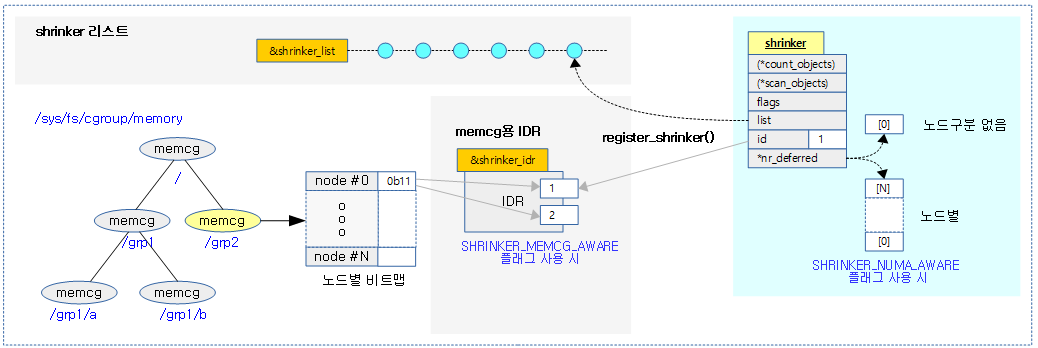
prealloc_shrinker()
mm/vmscan.c
/* * Add a shrinker callback to be called from the vm. */
int prealloc_shrinker(struct shrinker *shrinker)
{
size_t size = sizeof(*shrinker->nr_deferred);
if (shrinker->flags & SHRINKER_NUMA_AWARE)
size *= nr_node_ids;
shrinker->nr_deferred = kzalloc(size, GFP_KERNEL);
if (!shrinker->nr_deferred)
return -ENOMEM;
if (shrinker->flags & SHRINKER_MEMCG_AWARE) {
if (prealloc_memcg_shrinker(shrinker))
goto free_deferred;
}
return 0;
free_deferred:
kfree(shrinker->nr_deferred);
shrinker->nr_deferred = NULL;
return -ENOMEM;
}
shrinker를 등록하기 전에 할당할 항목들을 준비한다.
- 코드 라인 3~10에서 SHRINKER_NUMA_AWARE 플래그를 사용한 경우에 노드 수 만큼 size 배열을 할당하여 shrinker->nr_deferred에 연결한다. 그렇지 않은 경우 1 개의 size 배열을 사용한다.
- 코드 라인 12~15에서 SHRINKER_MEMCG_AWARE 플래그를 사용한 경우에 shrinker를 memcg에 등록하도록 idr을 준비한다.
prealloc_memcg_shrinker()
mm/vmscan.c
static int prealloc_memcg_shrinker(struct shrinker *shrinker)
{
int id, ret = -ENOMEM;
down_write(&shrinker_rwsem);
/* This may call shrinker, so it must use down_read_trylock() */
id = idr_alloc(&shrinker_idr, SHRINKER_REGISTERING, 0, 0, GFP_KERNEL);
if (id < 0)
goto unlock;
if (id >= shrinker_nr_max) {
if (memcg_expand_shrinker_maps(id)) {
idr_remove(&shrinker_idr, id);
goto unlock;
}
shrinker_nr_max = id + 1;
}
shrinker->id = id;
ret = 0;
unlock:
up_write(&shrinker_rwsem);
return ret;
}
shrinker를 memcg에 등록하도록 idr을 준비한다.
- 코드 라인 7~9에서 shrinker_idr에서 id를 발급받는다.
- 코드 라인 11~18에서 새로 발급 받은 id 값이 shrinker_nr_max 보다 크면 shrinker_nr_max를 id + 1 값으로 갱신하고, shrinker 비트맵도 확장한다.
- 코드 라인 19에서 shrinker에 id를 지정한다.
register_shrinker_prepared()
mm/vmscan.c
void register_shrinker_prepared(struct shrinker *shrinker)
{
down_write(&shrinker_rwsem);
list_add_tail(&shrinker->list, &shrinker_list);
#ifdef CONFIG_MEMCG_KMEM
if (shrinker->flags & SHRINKER_MEMCG_AWARE)
idr_replace(&shrinker_idr, shrinker, shrinker->id);
#endif
up_write(&shrinker_rwsem);
}
shrinker를 등록한다.
- 코드 라인 4에서 전역 shrinker_list에 @shrinker를 등록한다.
- 코드 라인 6~7에서 SHRINKER_MEMCG_AWARE 플래그를 사용하는 shrinker인 경우 발급받은 id 자리에 @shrinker 포인터를 저정한다.
shrinker 등록 해제
unregister_shrinker()
mm/vmscan.c
/* * Remove one */
void unregister_shrinker(struct shrinker *shrinker)
{
if (!shrinker->nr_deferred)
return;
if (shrinker->flags & SHRINKER_MEMCG_AWARE)
unregister_memcg_shrinker(shrinker);
down_write(&shrinker_rwsem);
list_del(&shrinker->list);
up_write(&shrinker_rwsem);
kfree(shrinker->nr_deferred);
shrinker->nr_deferred = NULL;
}
EXPORT_SYMBOL(unregister_shrinker);
shrinker의 등록을 해제한다.
등록된 shrinker들을 대상으로 슬랩 캐시를 shrink
shrink_slab()
mm/vmscan.c
/** * shrink_slab - shrink slab caches * @gfp_mask: allocation context * @nid: node whose slab caches to target * @memcg: memory cgroup whose slab caches to target * @priority: the reclaim priority * * Call the shrink functions to age shrinkable caches. * * @nid is passed along to shrinkers with SHRINKER_NUMA_AWARE set, * unaware shrinkers will receive a node id of 0 instead. * * @memcg specifies the memory cgroup to target. Unaware shrinkers * are called only if it is the root cgroup. * * @priority is sc->priority, we take the number of objects and >> by priority * in order to get the scan target. * * Returns the number of reclaimed slab objects. */
tatic unsigned long shrink_slab(gfp_t gfp_mask, int nid,
struct mem_cgroup *memcg,
int priority)
{
unsigned long ret, freed = 0;
struct shrinker *shrinker;
if (!mem_cgroup_is_root(memcg))
return shrink_slab_memcg(gfp_mask, nid, memcg, priority);
if (!down_read_trylock(&shrinker_rwsem))
goto out;
list_for_each_entry(shrinker, &shrinker_list, list) {
struct shrink_control sc = {
.gfp_mask = gfp_mask,
.nid = nid,
.memcg = memcg,
};
ret = do_shrink_slab(&sc, shrinker, priority);
if (ret == SHRINK_EMPTY)
ret = 0;
freed += ret;
/*
* Bail out if someone want to register a new shrinker to
* prevent the regsitration from being stalled for long periods
* by parallel ongoing shrinking.
*/
if (rwsem_is_contended(&shrinker_rwsem)) {
freed = freed ? : 1;
break;
}
}
up_read(&shrinker_rwsem);
out:
cond_resched();
return freed;
}
등록된 shrinker를 대상으로 슬랩 캐시를 shirnk 하여 free 페이지를 확보하게 할 수 있다.
- 코드 라인 8~9에서 root memcg가 아닌 경우 다른 memcg를 사용하는 경우 슬랩 캐시를 shrink 한다.
- 코드 라인 14~34에서 등록된 shrinker 리스트를 대상으로 루프를 돌며 슬랩 캐시를 shrink 한다.
- shrinker는 register_shrinker_prepared() 함수를 통해 등록된다.
- 코드 라인 37~39에서 out: 레이블에서는 free된 슬랩 오브젝트의 수를 반환한다.
shrink_slab_memcg()
mm/vmscan.c
static unsigned long shrink_slab_memcg(gfp_t gfp_mask, int nid,
struct mem_cgroup *memcg, int priority)
{
struct memcg_shrinker_map *map;
unsigned long ret, freed = 0;
int i;
if (!memcg_kmem_enabled() || !mem_cgroup_online(memcg))
return 0;
if (!down_read_trylock(&shrinker_rwsem))
return 0;
map = rcu_dereference_protected(memcg->nodeinfo[nid]->shrinker_map,
true);
if (unlikely(!map))
goto unlock;
for_each_set_bit(i, map->map, shrinker_nr_max) {
struct shrink_control sc = {
.gfp_mask = gfp_mask,
.nid = nid,
.memcg = memcg,
};
struct shrinker *shrinker;
shrinker = idr_find(&shrinker_idr, i);
if (unlikely(!shrinker || shrinker == SHRINKER_REGISTERING)) {
if (!shrinker)
clear_bit(i, map->map);
continue;
}
ret = do_shrink_slab(&sc, shrinker, priority);
if (ret == SHRINK_EMPTY) {
clear_bit(i, map->map);
/*
* After the shrinker reported that it had no objects to
* free, but before we cleared the corresponding bit in
* the memcg shrinker map, a new object might have been
* added. To make sure, we have the bit set in this
* case, we invoke the shrinker one more time and reset
* the bit if it reports that it is not empty anymore.
* The memory barrier here pairs with the barrier in
* memcg_set_shrinker_bit():
*
* list_lru_add() shrink_slab_memcg()
* list_add_tail() clear_bit()
* <MB> <MB>
* set_bit() do_shrink_slab()
*/
smp_mb__after_atomic();
ret = do_shrink_slab(&sc, shrinker, priority);
if (ret == SHRINK_EMPTY)
ret = 0;
else
memcg_set_shrinker_bit(memcg, nid, i);
}
freed += ret;
if (rwsem_is_contended(&shrinker_rwsem)) {
freed = freed ? : 1;
break;
}
}
unlock:
up_read(&shrinker_rwsem);
return freed;
}
memcg에 등록된 shrinker를 대상으로 슬랩 캐시를 shirnk 하여 free 페이지를 확보하게 할 수 있다.
- 코드 라인 8~9에서 요청한 memcg가 online 상태가 아니면 처리를 포기하고 0을 반환한다.
- 코드 라인 14~17에서 lock-less rcu 방식을 사용하여 shrinker_map을 수정하기 위해 준비한다.
- 코드 라인 19~34에서 비트맵인 shrinker_map에서 비트가 설정된 항목만큼 순회하며 해당 비트 인덱스를 키로 shrinker_idr 에서 등록된 shrinker를 대상으로 슬랩 캐시를 shrink한다.
- 코드 라인 35~58에서 shrink 결과가 empty인 경우 shrinker_map의 해당 비트를 클리어한다. 그 후 다시 한번 슬랩 캐시를 shrink 하고, 두 번째 수행 결과가 empty가 아닌 경우에는 shrinker_map의 해당 비트를 다시 설정한다.
- 코드 라인 59~64에서 shirnk된 슬랩 캐시 오브젝트 수를 더한 후 계속 반복한다.
- 코드 라인 66~68에서 unlock: 레이블에서는 free된 슬랩 오브젝트의 수를 반환한다.
do_shrink_slab()
mm/vmscan.c -1/2-
static unsigned long do_shrink_slab(struct shrink_control *shrinkctl,
struct shrinker *shrinker, int priority)
{
unsigned long freed = 0;
unsigned long long delta;
long total_scan;
long freeable;
long nr;
long new_nr;
int nid = shrinkctl->nid;
long batch_size = shrinker->batch ? shrinker->batch
: SHRINK_BATCH;
long scanned = 0, next_deferred;
if (!(shrinker->flags & SHRINKER_NUMA_AWARE))
nid = 0;
freeable = shrinker->count_objects(shrinker, shrinkctl);
if (freeable == 0 || freeable == SHRINK_EMPTY)
return freeable;
/*
* copy the current shrinker scan count into a local variable
* and zero it so that other concurrent shrinker invocations
* don't also do this scanning work.
*/
nr = atomic_long_xchg(&shrinker->nr_deferred[nid], 0);
total_scan = nr;
if (shrinker->seeks) {
delta = freeable >> priority;
delta *= 4;
do_div(delta, shrinker->seeks);
} else {
/*
* These objects don't require any IO to create. Trim
* them aggressively under memory pressure to keep
* them from causing refetches in the IO caches.
*/
delta = freeable / 2;
}
total_scan += delta;
if (total_scan < 0) {
pr_err("shrink_slab: %pF negative objects to delete nr=%ld\n",
shrinker->scan_objects, total_scan);
total_scan = freeable;
next_deferred = nr;
} else
next_deferred = total_scan;
/*
* We need to avoid excessive windup on filesystem shrinkers
* due to large numbers of GFP_NOFS allocations causing the
* shrinkers to return -1 all the time. This results in a large
* nr being built up so when a shrink that can do some work
* comes along it empties the entire cache due to nr >>>
* freeable. This is bad for sustaining a working set in
* memory.
*
* Hence only allow the shrinker to scan the entire cache when
* a large delta change is calculated directly.
*/
if (delta < freeable / 4)
total_scan = min(total_scan, freeable / 2);
/*
* Avoid risking looping forever due to too large nr value:
* never try to free more than twice the estimate number of
* freeable entries.
*/
if (total_scan > freeable * 2)
total_scan = freeable * 2;
trace_mm_shrink_slab_start(shrinker, shrinkctl, nr,
freeable, delta, total_scan, priority);
shrink_control을 통해 요청한 글로벌 또는 memcg에 등록된 shrinker를 대상으로 슬랩 캐시를 shirnk 하여 free 페이지를 확보 한다.
- 코드 라인 11~12에서 shrinker에 한 번에 처리할 슬랩 오브젝트 수가 지정되지 않는 경우 SHRINK_BATCH(128) 개를 대입한다.
- 코드 라인 15~16에서 SHRINKER_NUMA_AWARE 플래그가 사용된 경우가 아니면 nid를 0으로 고정한다.
- 코드 라인 18~20에서 shrinker에서 free 가능한 object 수를 알아오기 위해 (*count_object)의 결과 값을 알아와서 freeable에 대입한다. 처리할 free 가능한 오브젝트가 없는 경우 함수를 빠져나간다.
- 코드 라인 27~29에서 삭제 지연 중인 오브젝트 수(nr_deferred)를 이번에 처리하기 위해 total_scan에 대입하고, 기존 값은 atomic하게 0으로 리셋하여 다른 곳과 동시에 호출되는 것을 막는다.
- 코드 라인 30~50에서 freeable 값에 seeks와 priority를 적용하여 산출한 delta를 total_scan에 더한다. 만일 total_scan 값이 0 미만인 경우 freeable 값을 모두 적용한다.
- shrinker에 seeks가 지정된 경우
- delta = (freeable >> priority) * 4 / shrinker->seeks
- shrinker에 seeks가 지정되지 않은 경우
- delta = freeable / 2
- shrinker에 seeks가 지정된 경우
- 코드 라인 64~65에서 delta가 freeable의 25% 미만인 경우 total_scan 수가 freeable의 절반을 초과하지 않도록 제한한다.
- 코드 라인 72~73에서 total_scan이 freeable의 두 배를 초과하지 않도록 제한한다.
mm/vmscan.c -2/2-
/*
* Normally, we should not scan less than batch_size objects in one
* pass to avoid too frequent shrinker calls, but if the slab has less
* than batch_size objects in total and we are really tight on memory,
* we will try to reclaim all available objects, otherwise we can end
* up failing allocations although there are plenty of reclaimable
* objects spread over several slabs with usage less than the
* batch_size.
*
* We detect the "tight on memory" situations by looking at the total
* number of objects we want to scan (total_scan). If it is greater
* than the total number of objects on slab (freeable), we must be
* scanning at high prio and therefore should try to reclaim as much as
* possible.
*/
while (total_scan >= batch_size ||
total_scan >= freeable) {
unsigned long ret;
unsigned long nr_to_scan = min(batch_size, total_scan);
shrinkctl->nr_to_scan = nr_to_scan;
shrinkctl->nr_scanned = nr_to_scan;
ret = shrinker->scan_objects(shrinker, shrinkctl);
if (ret == SHRINK_STOP)
break;
freed += ret;
count_vm_events(SLABS_SCANNED, shrinkctl->nr_scanned);
total_scan -= shrinkctl->nr_scanned;
scanned += shrinkctl->nr_scanned;
cond_resched();
}
if (next_deferred >= scanned)
next_deferred -= scanned;
else
next_deferred = 0;
/*
* move the unused scan count back into the shrinker in a
* manner that handles concurrent updates. If we exhausted the
* scan, there is no need to do an update.
*/
if (next_deferred > 0)
new_nr = atomic_long_add_return(next_deferred,
&shrinker->nr_deferred[nid]);
else
new_nr = atomic_long_read(&shrinker->nr_deferred[nid]);
trace_mm_shrink_slab_end(shrinker, nid, freed, nr, new_nr, total_scan);
return freed;
}
- 코드 라인 16~33에서 batch_size 또는 freeable 만큼 반복하며 shrinker에 등록한 scan_objects() 핸들러 함수를 호출하여 free 가능한 오브젝트 들을 reclaim한다. free된 object 수를 알아와서 freed에 추가한다. 만일 결과가 SHRINK_STOP인 경우 루프를 벗어난다.
- 코드 라인 35~48에서 삭제 처리되지 않고 남은 오브젝트 수를 다음에 처리하기 위해 다시 shrinker->nr_deferred[nid]에 대입한다.
- 코드 라인 51에서 정상 삭제 처리된 오브젝트 수를 반환한다.
다음 그림은 do_shrink_slab()을 통하여 memcg(없으면 글로벌)에 등록된 등록된 shrinker들을 대상으로 각각 산출된 total_scan만큼씩 shrink 하는 과정을 보여준다.
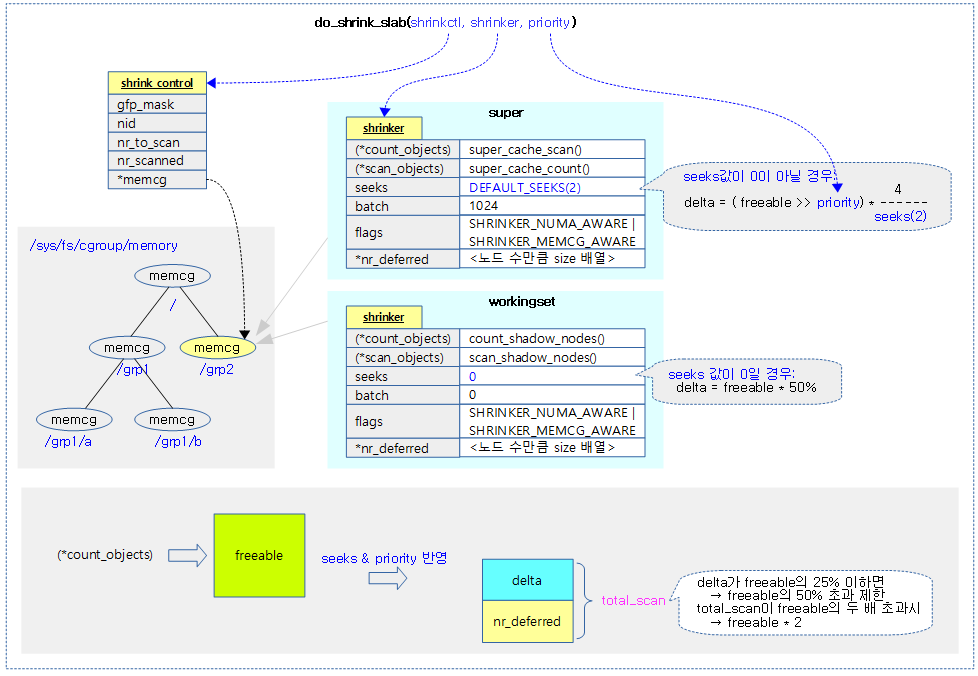
참고
- Zoned Allocator -1- (물리 페이지 할당-Fastpath) | 문c
- Zoned Allocator -2- (물리 페이지 할당-Slowpath) | 문c
- Zoned Allocator -3- (Buddy 페이지 할당) | 문c
- Zoned Allocator -4- (Buddy 페이지 해지) | 문c
- Zoned Allocator -5- (Per-CPU Page Frame Cache) | 문c
- Zoned Allocator -6- (Watermark) | 문c
- Zoned Allocator -7- (Direct Compact) | 문c
- Zoned Allocator -8- (Direct Compact-Isolation) | 문c
- Zoned Allocator -9- (Direct Compact-Migration) | 문c
- Zoned Allocator -10- (LRU & pagevec) | 문c
- Zoned Allocator -11- (Direct Reclaim) | 문c
- Zoned Allocator -12- (Direct Reclaim-Shrink-1) | 문c
- Zoned Allocator -13- (Direct Reclaim-Shrink-2) | 문c – 현재 글
- Zoned Allocator -14- (Kswapd) | 문c
- Smarter shrinkers (2013) | LWN
안녕하세요. 문영일님.
항상 잘 감사하며 열심히 보고 있는 16차 이파란입니다.
이제 페이지 회수 진도도 얼마 안 남은 것 같아요.
@ 코드 라인 48~50에서 pte 매핑된 페이지 또는 swap 캐시인 경우 nr_scanned를 증가시킨다. [단 swap 영역을 자지지 않는] clean anon 페이지는 제외한다.
[단 swap 영역을 가지지 않는 clean anon 페이지]
“가지지 않는” 맞나요?
감사합니다~
축하드립니다. ^^
철자는 수정하였습니다. 감사합니다. ^^