<kernel v5.0>
Zoned Allocator -11- (Direct Reclaim)
Reclaim 판단
should_continue_reclaim()
mm/vmscan.c
/* * Reclaim/compaction is used for high-order allocation requests. It reclaims * order-0 pages before compacting the zone. should_continue_reclaim() returns * true if more pages should be reclaimed such that when the page allocator * calls try_to_compact_zone() that it will have enough free pages to succeed. * It will give up earlier than that if there is difficulty reclaiming pages. */
static inline bool should_continue_reclaim(struct pglist_data *pgdat,
unsigned long nr_reclaimed,
unsigned long nr_scanned,
struct scan_control *sc)
{
unsigned long pages_for_compaction;
unsigned long inactive_lru_pages;
int z;
/* If not in reclaim/compaction mode, stop */
if (!in_reclaim_compaction(sc))
return false;
/* Consider stopping depending on scan and reclaim activity */
if (sc->gfp_mask & __GFP_RETRY_MAYFAIL) {
/*
* For __GFP_RETRY_MAYFAIL allocations, stop reclaiming if the
* full LRU list has been scanned and we are still failing
* to reclaim pages. This full LRU scan is potentially
* expensive but a __GFP_RETRY_MAYFAIL caller really wants to succeed
*/
if (!nr_reclaimed && !nr_scanned)
return false;
} else {
/*
* For non-__GFP_RETRY_MAYFAIL allocations which can presumably
* fail without consequence, stop if we failed to reclaim
* any pages from the last SWAP_CLUSTER_MAX number of
* pages that were scanned. This will return to the
* caller faster at the risk reclaim/compaction and
* the resulting allocation attempt fails
*/
if (!nr_reclaimed)
return false;
}
/*
* If we have not reclaimed enough pages for compaction and the
* inactive lists are large enough, continue reclaiming
*/
pages_for_compaction = compact_gap(sc->order);
inactive_lru_pages = node_page_state(pgdat, NR_INACTIVE_FILE);
if (get_nr_swap_pages() > 0)
inactive_lru_pages += node_page_state(pgdat, NR_INACTIVE_ANON);
if (sc->nr_reclaimed < pages_for_compaction &&
inactive_lru_pages > pages_for_compaction)
return true;
/* If compaction would go ahead or the allocation would succeed, stop */
for (z = 0; z <= sc->reclaim_idx; z++) {
struct zone *zone = &pgdat->node_zones[z];
if (!managed_zone(zone))
continue;
switch (compaction_suitable(zone, sc->order, 0, sc->reclaim_idx)) {
case COMPACT_SUCCESS:
case COMPACT_CONTINUE:
return false;
default:
/* check next zone */
;
}
}
return true;
}
high order 페이지 요청을 처리하는데 reclaim/compaction이 계속되야 하는 경우 true를 반환한다.
- 코드 라인 11~12에서 reclaim/compaction 모드가 아니면 처리를 중단한다.
- 코드 라인 15~35에서 __GFP_RETRY_MAYFAIL 플래그가 사용된 경우 reclaimed 페이지와 scanned 페이지가 없는 경우 false를 반환한다. 플래그가 사용되지 않은 경우 reclaimed 페이지가 없는 경우 false를 반환한다.
- 코드 라인 41~47에서 reclaimed 페이지가 order 페이지의 두 배보다 작아 compaction을 위해 작지만 inactive lru 페이지 수가 order 페이지의 두 배보다는 커 충분한 경우 true를 반환한다.
- 코드 라인 50~64에서 reclaim_idx만큼 존을 순회하며 compaction이 이미 성공하였거나 계속해야 하는 경우 false를 반환한다.
- 코드 라인 64에서 순회한 모든 존에서 compaction의 성공이 없는 경우 true를 반환하여 compaction이 계속되어야 함을 알린다.
in_reclaim_compaction()
mm/vmscan.c
/* Use reclaim/compaction for costly allocs or under memory pressure */
static bool in_reclaim_compaction(struct scan_control *sc)
{
if (IS_ENABLED(CONFIG_COMPACTION) && sc->order &&
(sc->order > PAGE_ALLOC_COSTLY_ORDER ||
sc->priority < DEF_PRIORITY - 2))
return true;
return false;
}
reclaim/compaction 모드인 경우 true를 반환한다.
- 0 order 요청을 제외하고 다음 두 조건을 만족하면 true를 반환한다.
- 우선 순위를 2번 이상 높여 반복 수행 중이다. (낮은 priority 번호가 높은 우선 순위)
- costly order 요청이다.(order 4부터)
Direct-Reclaim 수행
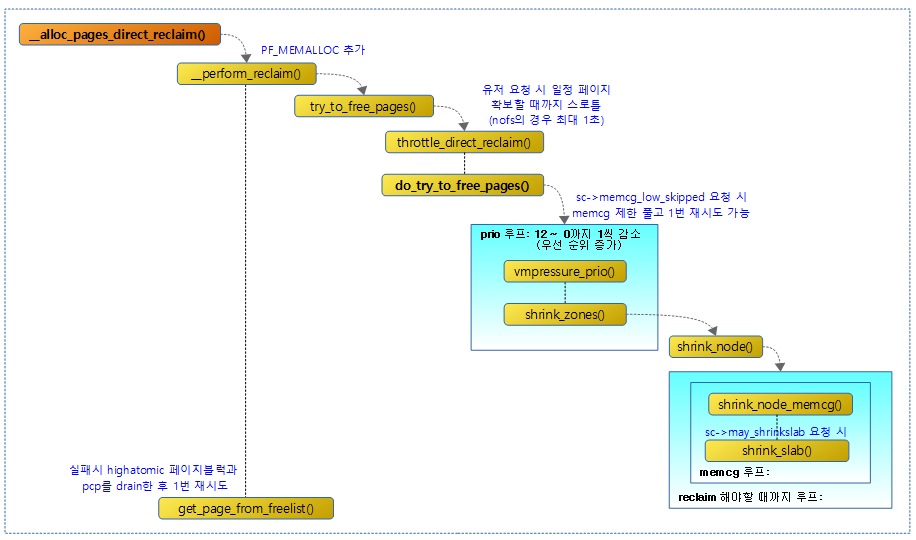
__alloc_pages_direct_reclaim()
mm/page_alloc.c
/* The really slow allocator path where we enter direct reclaim */
static inline struct page *
__alloc_pages_direct_reclaim(gfp_t gfp_mask, unsigned int order,
int alloc_flags, const struct alloc_context *ac,
unsigned long *did_some_progress)
{
struct page *page = NULL;
bool drained = false;
*did_some_progress = __perform_reclaim(gfp_mask, order, ac);
if (unlikely(!(*did_some_progress)))
return NULL;
retry:
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
/*
* If an allocation failed after direct reclaim, it could be because
* pages are pinned on the per-cpu lists. Drain them and try again
*/
if (!page && !drained) {
unreserve_highatomic_pageblock(ac, false);
drain_all_pages(NULL);
drained = true;
goto retry;
}
return page;
}
페이지를 회수한 후 페이지 할당을 시도한다. 만일 처음 실패하는 경우 pcp 캐시를 비워 버디 시스템에 free 페이지를 확보한 후 재시도를 한다.
- 코드 라인 10~12에서 페이지를 회수하며 작은 확률로 회수한 페이지가 없는 경우 null을 반환한다.
- 코드 라인 14~15에서 retry: 레이블에서 order 페이지 할당을 시도한다.
- 코드 라인 21~26에서 페이지 할당이 실패하였고 첫 실패인 경우 highatomic 페이지 블럭을 해제하고, pcp 캐시를 비워 버디시스템에 free 페이지를 확보한 후 재시도 한다.
다음 그림은 direct reclaim을 통해 페이지를 회수하는 과정을 보여준다.
__perform_reclaim()
mm/page_alloc.c
/* Perform direct synchronous page reclaim */
static int
__perform_reclaim(gfp_t gfp_mask, unsigned int order,
const struct alloc_context *ac)
{
struct reclaim_state reclaim_state;
int progress;
unsigned int noreclaim_flag;
unsigned long pflags;
cond_resched();
/* We now go into synchronous reclaim */
cpuset_memory_pressure_bump();
psi_memstall_enter(&pflags);
fs_reclaim_acquire(gfp_mask);
noreclaim_flag = memalloc_noreclaim_save();
reclaim_state.reclaimed_slab = 0;
current->reclaim_state = &reclaim_state;
progress = try_to_free_pages(ac->zonelist, order, gfp_mask,
ac->nodemask);
current->reclaim_state = NULL;
memalloc_noreclaim_restore(noreclaim_flag);
fs_reclaim_release(gfp_mask);
psi_memstall_leave(&pflags);
cond_resched();
return progress;
}
페이지를 회수한다. 반환되는 값은 회수한 페이지 수이다.
- 코드 라인 14에서 전역 cpuset_memory_pressure_enabled가 설정된 경우 현재 태스크 cpuset의 frequency meter를 업데이트한다.
- 루트 cpuset에 있는 memory_pressure_enabled 파일을 1로 설정하여 사용한다.
- 코드 라인 15에서 메모리 압박이 시작되었음을 psi에 알린다.
- 코드 라인 17에서 페이지 회수를 목적으로 잠시 페이지 할당이 필요하다. 이 때 다시 페이지 회수 루틴이 재귀 호출되지 않도록 방지하기 위해 reclaim을 하는 동안 잠시 현재 태스크의 플래그에 PF_MEMALLOC를 설정하여 워터 마크 기준을 없앤 후 할당할 수 있도록 한다.
- 코드 라인 18~19에서 reclaimed_slab 카운터를 0으로 리셋하고, 현재 태스크에 지정한다.
- 코드 라인 21~22에서 페이지를 회수하고 회수한 페이지 수를 알아온다.
- 코드 라인 24에서 태스크에 지정한 reclaim_state를 해제한다.
- 코드 라인 25에서 현재 태스크의 플래그에 reclaim을 하는 동안 잠시 설정해두었던 PF_MEMALLOC을 제거한다.
- 코드 라인 27에서 메모리 압박이 완료되었음을 psi에 알린다.
Scan Control
스캔 컨트롤을 사용하는 루틴들은 다음과 같다.
- reclaim_clean_pages_from_list()
- try_to_free_pages()
- mem_cgroup_shrink_node()
- try_to_free_mem_cgroup_pages()
- balance_pgdat()
- shrink_all_memory()
- __node_reclaim()
페이지 회수로 free 페이지 확보 시도
try_to_free_pages()
mm/vmscan.c
unsigned long try_to_free_pages(struct zonelist *zonelist, int order,
gfp_t gfp_mask, nodemask_t *nodemask)
{
unsigned long nr_reclaimed;
struct scan_control sc = {
.nr_to_reclaim = SWAP_CLUSTER_MAX,
.gfp_mask = current_gfp_context(gfp_mask),
.reclaim_idx = gfp_zone(gfp_mask),
.order = order,
.nodemask = nodemask,
.priority = DEF_PRIORITY,
.may_writepage = !laptop_mode,
.may_unmap = 1,
.may_swap = 1,
.may_shrinkslab = 1,
};
/*
* scan_control uses s8 fields for order, priority, and reclaim_idx.
* Confirm they are large enough for max values.
*/
BUILD_BUG_ON(MAX_ORDER > S8_MAX);
BUILD_BUG_ON(DEF_PRIORITY > S8_MAX);
BUILD_BUG_ON(MAX_NR_ZONES > S8_MAX);
/*
* Do not enter reclaim if fatal signal was delivered while throttled.
* 1 is returned so that the page allocator does not OOM kill at this
* point.
*/
if (throttle_direct_reclaim(sc.gfp_mask, zonelist, nodemask))
return 1;
trace_mm_vmscan_direct_reclaim_begin(order,
sc.may_writepage,
sc.gfp_mask,
sc.reclaim_idx);
nr_reclaimed = do_try_to_free_pages(zonelist, &sc);
trace_mm_vmscan_direct_reclaim_end(nr_reclaimed);
return nr_reclaimed;
}
페이지 회수(Reclaim)를 시도하고 회수된 페이지 수를 반환한다. 유저 요청 시 free page가 normal 존 이하에서 min 워터마크 기준의 절반 이상을 확보할 때까지 태스크가 스로틀링(sleep)될 수 있다.
- 코드 라인 5~16에서 페이지 회수를 위한 scan_control 구조체를 준비한다.
- 코드 라인 31~32에서 direct-reclaim을 위해 일정 기준 이상 스로틀링 중 fatal 시그널을 전달 받은 경우 즉각 루틴을 빠져나간다. 단 1을 반환하므로 OOM kill 루틴을 수행하지 못하게 방지한다.
- 코드 라인 39에서 페이지 회수를 시도한다.
유저 요청 시 스로틀링
throttle_direct_reclaim()
mm/vmscan.c
/* * Throttle direct reclaimers if backing storage is backed by the network * and the PFMEMALLOC reserve for the preferred node is getting dangerously * depleted. kswapd will continue to make progress and wake the processes * when the low watermark is reached. * * Returns true if a fatal signal was delivered during throttling. If this * happens, the page allocator should not consider triggering the OOM killer. */
static bool throttle_direct_reclaim(gfp_t gfp_mask, struct zonelist *zonelist,
nodemask_t *nodemask)
{
struct zoneref *z;
struct zone *zone;
pg_data_t *pgdat = NULL;
/*
* Kernel threads should not be throttled as they may be indirectly
* responsible for cleaning pages necessary for reclaim to make forward
* progress. kjournald for example may enter direct reclaim while
* committing a transaction where throttling it could forcing other
* processes to block on log_wait_commit().
*/
if (current->flags & PF_KTHREAD)
goto out;
/*
* If a fatal signal is pending, this process should not throttle.
* It should return quickly so it can exit and free its memory
*/
if (fatal_signal_pending(current))
goto out;
/*
* Check if the pfmemalloc reserves are ok by finding the first node
* with a usable ZONE_NORMAL or lower zone. The expectation is that
* GFP_KERNEL will be required for allocating network buffers when
* swapping over the network so ZONE_HIGHMEM is unusable.
*
* Throttling is based on the first usable node and throttled processes
* wait on a queue until kswapd makes progress and wakes them. There
* is an affinity then between processes waking up and where reclaim
* progress has been made assuming the process wakes on the same node.
* More importantly, processes running on remote nodes will not compete
* for remote pfmemalloc reserves and processes on different nodes
* should make reasonable progress.
*/
for_each_zone_zonelist_nodemask(zone, z, zonelist,
gfp_zone(gfp_mask), nodemask) {
if (zone_idx(zone) > ZONE_NORMAL)
continue;
/* Throttle based on the first usable node */
pgdat = zone->zone_pgdat;
if (allow_direct_reclaim(pgdat))
goto out;
break;
}
/* If no zone was usable by the allocation flags then do not throttle */
if (!pgdat)
goto out;
/* Account for the throttling */
count_vm_event(PGSCAN_DIRECT_THROTTLE);
/*
* If the caller cannot enter the filesystem, it's possible that it
* is due to the caller holding an FS lock or performing a journal
* transaction in the case of a filesystem like ext[3|4]. In this case,
* it is not safe to block on pfmemalloc_wait as kswapd could be
* blocked waiting on the same lock. Instead, throttle for up to a
* second before continuing.
*/
if (!(gfp_mask & __GFP_FS)) {
wait_event_interruptible_timeout(pgdat->pfmemalloc_wait,
allow_direct_reclaim(pgdat), HZ);
goto check_pending;
}
/* Throttle until kswapd wakes the process */
wait_event_killable(zone->zone_pgdat->pfmemalloc_wait,
allow_direct_reclaim(pgdat));
check_pending:
if (fatal_signal_pending(current))
return true;
out:
return false;
}
유저 태스크에서 direct-reclaim 요청 시 필요한 만큼 스로틀링한다. 파일 시스템을 사용하지 않는(nofs) direct-reclaim 요청인 경우 스로틀링은 1초로 제한된다. 스로틀링 중 sigkill 시그널 수신 여부를 반환한다.
- 코드 라인 15~16에서 커널 스레드에서 요청한 경우 스로틀링을 하지 않기 위해 처리를 중단하고 false를 반환한다.
- 코드 라인 22~23에서 SIGKILL 시그널이 처리되고 있는 태스크의 경우도 역시 처리를 중단하고 false를 반환한다.
- 코드 라인 39~49에서 요청한 노드의 lowmem 존들의 direct-reclaim이 허용 기준 이상인 경우 스로틀링을 포기한다.
- 코드 라인 52~53에서 사용할 수 있는 노드가 없는 경우 처리를 포기한다.
- 코드 라인 56에서 스로틀링이 시작되는 구간이다. PGSCAN_DIRECT_THROTTLE stat을 증가시킨다.
- 코드 라인 66~71에서 파일 시스템을 사용하지 않는 direct-reclaim 요청인 경우 direct-reclaim을 허락할 때까지 최대 1초간 스로틀링 후 check_pending 레이블로 이동한다.
- 코드 라인74~75에서 파일 시스템을 사용하는 direct-reclaim의 경우 kswapd를 깨워 free page를 확보하며 direct-reclaim을 허락할 때까지 슬립한다.
- 코드 라인 77~82에서 현재 태스크에 SIGKILL 시그널이 요청된 경우 true를 반환하고 그렇지 않은 경우 false를 반환한다.
다음 그림은 유저 요청 direct-reclaim 시 파일 시스템 사용 여부에 따라 direct-reclaim을 사용하기 위해 스로틀링하는 과정을 보여준다.

direct-reclaim 허락 여부
allow_direct_reclaim()
mm/vmscan.c
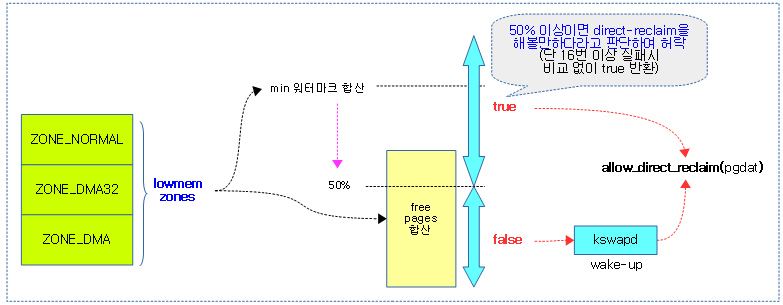
static bool allow_direct_reclaim(pg_data_t *pgdat)
{
struct zone *zone;
unsigned long pfmemalloc_reserve = 0;
unsigned long free_pages = 0;
int i;
bool wmark_ok;
if (pgdat->kswapd_failures >= MAX_RECLAIM_RETRIES)
return true;
for (i = 0; i <= ZONE_NORMAL; i++) {
zone = &pgdat->node_zones[i];
if (!managed_zone(zone))
continue;
if (!zone_reclaimable_pages(zone))
continue;
pfmemalloc_reserve += min_wmark_pages(zone);
free_pages += zone_page_state(zone, NR_FREE_PAGES);
}
/* If there are no reserves (unexpected config) then do not throttle */
if (!pfmemalloc_reserve)
return true;
wmark_ok = free_pages > pfmemalloc_reserve / 2;
/* kswapd must be awake if processes are being throttled */
if (!wmark_ok && waitqueue_active(&pgdat->kswapd_wait)) {
pgdat->kswapd_classzone_idx = min(pgdat->kswapd_classzone_idx,
(enum zone_type)ZONE_NORMAL);
wake_up_interruptible(&pgdat->kswapd_wait);
}
return wmark_ok;
}
요청한 노드에서 direct-reclaim을 허락하는지 여부를 반환한다. 만일 lowmem 존들의 free 페이지가 min 워터마크 50% 이하인 경우 현재 태스크를 슬립하고, kswapd를 깨운 뒤 false를 반환한다. 그리고 그 이상인 경우 direct-reclaim을 시도해도 좋다고 판단하여 true를 반환한다.
- 코드 라인 9~10에서 reclaim 실패 횟수가 MAX_RECLAIM_RETRIES(16)번 이상일 때 스로틀을 하지못하게 곧바로 true를 반환한다.
- 코드 라인 12~22에서 lowmem 존들의 min 워터마크를 합산한 pfmemalloc_reserve 값 및 free 페이지 수의 합산 값을 구한다.
- 코드 라인 25~26에서 pfmemalloc_reserve 값이 0인 경우 스로틀을 하지 못하게 곧바로 true를 반환한다.
- 코드 라인 28~35에서 free 페이지 합산 수가 lowmem 존들의 min 워터마크 합산 값의 50% 이하이면 현재 태스크를 슬립시키고 kswapd를 깨운 뒤 false를 반환한다.
다음 그림은 direct-reclaim 허락 여부를 알아오는 과정을 보여준다.
do_try_to_free_pages()
mm/vmscan.c
/* * This is the main entry point to direct page reclaim. * * If a full scan of the inactive list fails to free enough memory then we * are "out of memory" and something needs to be killed. * * If the caller is !__GFP_FS then the probability of a failure is reasonably * high - the zone may be full of dirty or under-writeback pages, which this * caller can't do much about. We kick the writeback threads and take explicit * naps in the hope that some of these pages can be written. But if the * allocating task holds filesystem locks which prevent writeout this might not * work, and the allocation attempt will fail. * * returns: 0, if no pages reclaimed * else, the number of pages reclaimed */
static unsigned long do_try_to_free_pages(struct zonelist *zonelist,
struct scan_control *sc)
{
int initial_priority = sc->priority;
pg_data_t *last_pgdat;
struct zoneref *z;
struct zone *zone;
retry:
delayacct_freepages_start();
if (global_reclaim(sc))
__count_zid_vm_events(ALLOCSTALL, sc->reclaim_idx, 1);
do {
vmpressure_prio(sc->gfp_mask, sc->target_mem_cgroup,
sc->priority);
sc->nr_scanned = 0;
shrink_zones(zonelist, sc);
if (sc->nr_reclaimed >= sc->nr_to_reclaim)
break;
if (sc->compaction_ready)
break;
/*
* If we're getting trouble reclaiming, start doing
* writepage even in laptop mode.
*/
if (sc->priority < DEF_PRIORITY - 2)
sc->may_writepage = 1;
} while (--sc->priority >= 0);
last_pgdat = NULL;
for_each_zone_zonelist_nodemask(zone, z, zonelist, sc->reclaim_idx,
sc->nodemask) {
if (zone->zone_pgdat == last_pgdat)
continue;
last_pgdat = zone->zone_pgdat;
snapshot_refaults(sc->target_mem_cgroup, zone->zone_pgdat);
set_memcg_congestion(last_pgdat, sc->target_mem_cgroup, false);
}
delayacct_freepages_end();
if (sc->nr_reclaimed)
return sc->nr_reclaimed;
/* Aborted reclaim to try compaction? don't OOM, then */
if (sc->compaction_ready)
return 1;
/* Untapped cgroup reserves? Don't OOM, retry. */
if (sc->memcg_low_skipped) {
sc->priority = initial_priority;
sc->memcg_low_reclaim = 1;
sc->memcg_low_skipped = 0;
goto retry;
}
return 0;
}
direct-reclaim 요청을 통해 페이지를 회수하여 free 페이지를 확보를 시도한다.
- 코드 라인 8~9에서 retry: 레이블이다. 페이지 회수에 소요되는 시간을 계량하기 위해 시작한다.
- 참고: delayacct_init() | 문c
- 코드 라인 11~12에서 global reclaim을 사용해야하는 경우 ALLOCSTALL stat을 증가시킨다.
- 코드 라인 14~16에서 루프를 돌며 우선 순위가 높아져 스캔 depth가 깊어지는 경우 vmpressure 정보를 갱신한다.
- 참고: vmpressure | 문c
- 코드 라인 17~18에서 스캔 건 수를 리셋시키고 페이지를 회수하고 회수한 건 수를 알아온다.
- 코드 라인 20~21에서 회수 건 수가 회수해야 할 건 수보다 큰 경우 처리를 위해 루프에서 벗어난다.
- 코드 라인 23~24에서 compaction이 준비된 경우 처리를 위해 루프에서 벗어난다.
- 코드 라인 30~31에서 우선 순위를 2 단계 더 높여 처리하는 경우 writepage 기능을 설정한다.
- 코드 라인 32에서 우선 순위를 최고까지 높여가며(0으로 갈수록 높아진다) 루프를 돈다.
- 코드 라인 34~42에서 zonelist를 순회하며 노드에 대해 노드 또는 memcg lru의 refaults를 갱신하고 memcg 노드의 congested를 false로 리셋한다.
- 코드 라인 44에서 페이지 회수에 소요되는 시간을 계량한다.
- 코드 라인 46~47네거 회수한 적이 있는 경우 그 값을 반환한다.
- 코드 라인 50~51에서 compaction이 준비된 경우 1을 반환한다.
- 코드 라인 54~59에서 sc->memcg_low_skipped가 설정된 경우 처음 재시도에 한해 priority를 다시 원래 요청 priority로 바꾸고 재시도한다.
global_reclaim()
mm/vmscan.c
#ifdef CONFIG_MEMCG
static bool global_reclaim(struct scan_control *sc)
{
return !sc->target_mem_cgroup;
}
#else
static bool global_reclaim(struct scan_control *sc)
{
return true;
}
#endif
CONFIG_MEMCG 커널 옵션을 사용하여 Memory Control Group을 사용하는 경우 scan_control의 target_mem_cgroup이 정해진 경우 false를 반환한다. 그렇지 않은 경우 global reclaim을 위해 true를 반환한다. CONFIG_MEMCG를 사용하지 않는 경우 항상 true이다.
Memory Pressure (per-cpuset reclaims)
cpuset_memory_pressure_bump()
include/linux/cpuset.h
#define cpuset_memory_pressure_bump() \
do { \
if (cpuset_memory_pressure_enabled) \
__cpuset_memory_pressure_bump(); \
} while (0)
현재 태스크 cpuset의 frequency meter를 업데이트한다.
__cpuset_memory_pressure_bump()
kernel/cpuset.c
/** * cpuset_memory_pressure_bump - keep stats of per-cpuset reclaims. * * Keep a running average of the rate of synchronous (direct) * page reclaim efforts initiated by tasks in each cpuset. * * This represents the rate at which some task in the cpuset * ran low on memory on all nodes it was allowed to use, and * had to enter the kernels page reclaim code in an effort to * create more free memory by tossing clean pages or swapping * or writing dirty pages. * * Display to user space in the per-cpuset read-only file * "memory_pressure". Value displayed is an integer * representing the recent rate of entry into the synchronous * (direct) page reclaim by any task attached to the cpuset. **/
void __cpuset_memory_pressure_bump(void)
{
rcu_read_lock();
fmeter_markevent(&task_cs(current)->fmeter);
rcu_read_unlock();
}
현재 태스크 cpuset의 frequency meter를 업데이트한다.
fmeter_markevent()
kernel/cpuset.c
/* Process any previous ticks, then bump cnt by one (times scale). */
static void fmeter_markevent(struct fmeter *fmp)
{
spin_lock(&fmp->lock);
fmeter_update(fmp);
fmp->cnt = min(FM_MAXCNT, fmp->cnt + FM_SCALE);
spin_unlock(&fmp->lock);
}
요청한 frequency meter를 업데이트하고 다음 계산을 위해 이벤트 수에 1,000을 대입하되 최대 1,000,000을 넘기지 않게 한다.
fmeter_update()
kernel/cpuset.c
/* Internal meter update - process cnt events and update value */
static void fmeter_update(struct fmeter *fmp)
{
time_t now = get_seconds();
time_t ticks = now - fmp->time;
if (ticks == 0)
return;
ticks = min(FM_MAXTICKS, ticks);
while (ticks-- > 0)
fmp->val = (FM_COEF * fmp->val) / FM_SCALE;
fmp->time = now;
fmp->val += ((FM_SCALE - FM_COEF) * fmp->cnt) / FM_SCALE;
fmp->cnt = 0;
}
요청한 frequency meter로 val 값을 계산하고 이벤트 수를 0으로 리셋한다.
- 코드 라인 4~8에서 fmeter에 기록된 초(second)로부터 경과한 초를 알아온다.
- 코드 라인 10~12에서 ticks는 최대 99까지로 제한하고, ticks 만큼 fmp->val *= 93.3%를 반복한다.
- 코드 라인 13에서 다음 계산을 위해 현재 초로 갱신한다.
- 코드 라인 15~16에서 fmp->val에 fmp->cnt x 6.7%를 더한 후 이벤트 수를 0으로 리셋한다.
fmeter 구조체
kernel/cgroup/cpuset.c
struct fmeter {
int cnt; /* unprocessed events count */
int val; /* most recent output value */
time_t time; /* clock (secs) when val computed */
spinlock_t lock; /* guards read or write of above */
};
- cnt
- 처리되지 않은 이벤트 수
- val
- 최근 fmeter 업데이트 시 계산된 값
- time
- val 값이 계산될 때의 clock(secs)
참고
- Zoned Allocator -1- (물리 페이지 할당-Fastpath) | 문c
- Zoned Allocator -2- (물리 페이지 할당-Slowpath) | 문c
- Zoned Allocator -3- (Buddy 페이지 할당) | 문c
- Zoned Allocator -4- (Buddy 페이지 해지) | 문c
- Zoned Allocator -5- (Per-CPU Page Frame Cache) | 문c
- Zoned Allocator -6- (Watermark) | 문c
- Zoned Allocator -7- (Direct Compact) | 문c
- Zoned Allocator -8- (Direct Compact-Isolation) | 문c
- Zoned Allocator -9- (Direct Compact-Migration) | 문c
- Zoned Allocator -10- (LRU & pagevec) | 문c
- Zoned Allocator -11- (Direct Reclaim) | 문c – 현재 글
- Zoned Allocator -12- (Direct Reclaim-Shrink-1) | 문c
- Zoned Allocator -13- (Direct Reclaim-Shrink-2) | 문c
- Zoned Allocator -14- (Kswapd) | 문c
- Overview of Memory Reclaim in the Current Upstream Kernel (2021) | SUSE – 다운로드 pdf
- Optimizing Linux Memory Management for Low-latency / High-throughput Databases