<kernel v5.0>
Rmap -2- (TTU & Rmap Walk)
Rmap Walk
다음 그림은 유저 페이지 하나에 대해 rmap 워크를 수행하면서 rmap_walk_control 구조체에 담긴 후크 함수를 호출하는 과정을 보여준다.
- 유저 페이지 하나가 여러 개의 가상 주소에 매핑된 경우 관련된 VMA들을 찾아 매핑된 pte 엔트리를 대상으로 언매핑, 마이그레이션, … 등 여러 기능들을 수행할 수 있다.
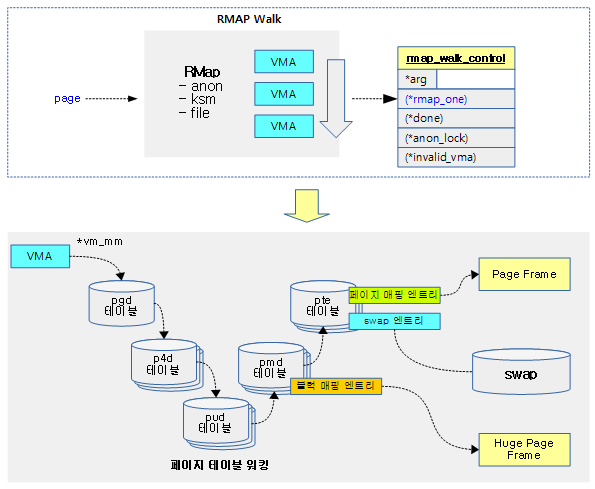
다음 그림은 현재 rmap walk를 사용하는 호출 함수들을 보여주며 사용된 후크 함수들을 보여준다.

TTU(Try To Unmap)
유저 페이지의 매핑을 해제할 때 rmap walk를 통해 매핑을 해제한다.
- 사용자 공간의 매핑을 해제할 때 mmu notifier를 통해 연동된 secondary MMU를 제어한다.
TTU 플래그
TTU 동작 시 사용할 플래그들이다.
- TTU_MIGRATION
- 마이그레이션 모드
- TTU_MUNLOCK
- munlock 모드로 VM_LOCKED되지 않은 vma들은 skip 한다.
- TTU_SPLIT_HUGE_PMD
- 페이지가 huge PMD인 경우 분리(split) 시킨다.
- TTU_IGNORE_MLOCK
- MLOCK 무시
- TTU_IGNORE_ACCESS
- young 페이지가 access된 적이 있으면 pte 엔트리의 액세스 플래그를 클리어하고 TLB 플러시를 하게하는데 이의 조사를 무시하게 한다.
- TTU_IGNORE_HWPOISON
- hwpoison을 무시하고 손상된 페이지라도 사용한다.
- TTU_BATCH_FLUSH
- 가능하면 TLB 플러시를 마지막에 한꺼번에 처리한다.
- TTU_RMAP_LOCKED
- TTU_SPLIT_FREEZE
- thp를 분리(split)할 때 pte를 freeze한다.
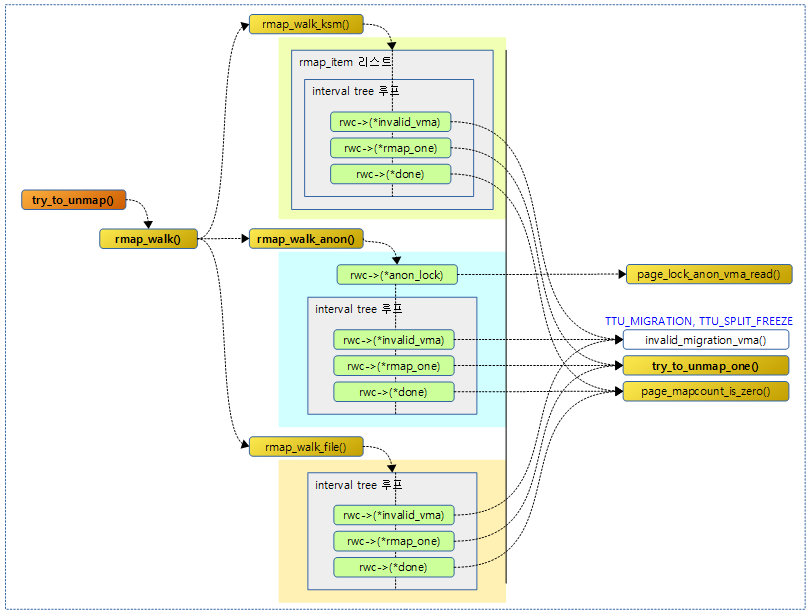
try_to_unmap()
mm/rmap.c
/** * try_to_unmap - try to remove all page table mappings to a page * @page: the page to get unmapped * @flags: action and flags * * Tries to remove all the page table entries which are mapping this * page, used in the pageout path. Caller must hold the page lock. * * If unmap is successful, return true. Otherwise, false. */
bool try_to_unmap(struct page *page, enum ttu_flags flags)
{
struct rmap_walk_control rwc = {
.rmap_one = try_to_unmap_one,
.arg = (void *)flags,
.done = page_mapcount_is_zero,
.anon_lock = page_lock_anon_vma_read,
};
/*
* During exec, a temporary VMA is setup and later moved.
* The VMA is moved under the anon_vma lock but not the
* page tables leading to a race where migration cannot
* find the migration ptes. Rather than increasing the
* locking requirements of exec(), migration skips
* temporary VMAs until after exec() completes.
*/
if ((flags & (TTU_MIGRATION|TTU_SPLIT_FREEZE))
&& !PageKsm(page) && PageAnon(page))
rwc.invalid_vma = invalid_migration_vma;
if (flags & TTU_RMAP_LOCKED)
rmap_walk_locked(page, &rwc);
else
rmap_walk(page, &rwc);
return !page_mapcount(page) ? true : false;
}
rmap 워크를 통해 페이지에 대한 모든 매핑을 해제한다.
- 코드 라인 3~8에서 rwc를 통해 호출될 후크 함수들을 지정한다.
- 코드 라인 18~20에서 thp(TTU_SPLIT_FREEZE)의 분리(split) 또는 마이그레이션(TTU_MIGRATION)에서 사용되었으며 ksm을 제외한 anon 매핑 페이지의 경우 (*invalid_vma) 후크 함수에 invalid_migration_vma() 함수를 지정한다.
- 코드 라인 22~25에서 rwc를 사용하여 페이지에 대한 모든 매핑을 해제하도록 rmap 워크를 수행한다. TTU_RMAP_LOCKED 플래그가 사용된 경우 외부에서 락을 획득한 상황이다.
다음 그림은 try_to_unmap() 함수의 진행 과정을 보여준다.
page_mapcount_is_zero()
mm/rmap.c
static int page_mapcount_is_zero(struct page *page)
{
return !total_mapcount(page);
}
페이지의 매핑 카운터가 0인지 여부를 반환한다.
- rmap_walk_control 구조체의 (*done) 후크 함수에 연결되어 사용될 때 페이지의 언매핑이 완료되면 rmap walk를 완료하도록 하기 위해 사용된다.
total_mapcount()
mm/huge_memory.c
int total_mapcount(struct page *page)
{
int i, compound, ret;
VM_BUG_ON_PAGE(PageTail(page), page);
if (likely(!PageCompound(page)))
return atomic_read(&page->_mapcount) + 1;
compound = compound_mapcount(page);
if (PageHuge(page))
return compound;
ret = compound;
for (i = 0; i < HPAGE_PMD_NR; i++)
ret += atomic_read(&page[i]._mapcount) + 1;
/* File pages has compound_mapcount included in _mapcount */
if (!PageAnon(page))
return ret - compound * HPAGE_PMD_NR;
if (PageDoubleMap(page))
ret -= HPAGE_PMD_NR;
return ret;
}
페이지의 매핑 카운터 값을 반환한다.
page_lock_anon_vma_read()
mm/rmap.c
/* * Similar to page_get_anon_vma() except it locks the anon_vma. * * Its a little more complex as it tries to keep the fast path to a single * atomic op -- the trylock. If we fail the trylock, we fall back to getting a * reference like with page_get_anon_vma() and then block on the mutex. */
struct anon_vma *page_lock_anon_vma_read(struct page *page)
{
struct anon_vma *anon_vma = NULL;
struct anon_vma *root_anon_vma;
unsigned long anon_mapping;
rcu_read_lock();
anon_mapping = (unsigned long)READ_ONCE(page->mapping);
if ((anon_mapping & PAGE_MAPPING_FLAGS) != PAGE_MAPPING_ANON)
goto out;
if (!page_mapped(page))
goto out;
anon_vma = (struct anon_vma *) (anon_mapping - PAGE_MAPPING_ANON);
root_anon_vma = READ_ONCE(anon_vma->root);
if (down_read_trylock(&root_anon_vma->rwsem)) {
/*
* If the page is still mapped, then this anon_vma is still
* its anon_vma, and holding the mutex ensures that it will
* not go away, see anon_vma_free().
*/
if (!page_mapped(page)) {
up_read(&root_anon_vma->rwsem);
anon_vma = NULL;
}
goto out;
}
/* trylock failed, we got to sleep */
if (!atomic_inc_not_zero(&anon_vma->refcount)) {
anon_vma = NULL;
goto out;
}
if (!page_mapped(page)) {
rcu_read_unlock();
put_anon_vma(anon_vma);
return NULL;
}
/* we pinned the anon_vma, its safe to sleep */
rcu_read_unlock();
anon_vma_lock_read(anon_vma);
if (atomic_dec_and_test(&anon_vma->refcount)) {
/*
* Oops, we held the last refcount, release the lock
* and bail -- can't simply use put_anon_vma() because
* we'll deadlock on the anon_vma_lock_write() recursion.
*/
anon_vma_unlock_read(anon_vma);
__put_anon_vma(anon_vma);
anon_vma = NULL;
}
return anon_vma;
out:
rcu_read_unlock();
return anon_vma;
}
anon 페이지에 대한 루트 anon_vma 락을 획득하고, anon_vma를 반환한다.
rmap 워크
rmap_walk()
mm/rmap.c
void rmap_walk(struct page *page, struct rmap_walk_control *rwc)
{
if (unlikely(PageKsm(page)))
rmap_walk_ksm(page, rwc);
else if (PageAnon(page))
rmap_walk_anon(page, rwc, false);
else
rmap_walk_file(page, rwc, false);
}
페이지가 소속된 ksm, anon 및 file 타입에 대한 vma들을 순회하며 rwc의 (*rmap_one) 후크 함수를 동작시킨다.
/* * rmap_walk_anon - do something to anonymous page using the object-based * rmap method * @page: the page to be handled * @rwc: control variable according to each walk type * * Find all the mappings of a page using the mapping pointer and the vma chains * contained in the anon_vma struct it points to. * * When called from try_to_munlock(), the mmap_sem of the mm containing the vma * where the page was found will be held for write. So, we won't recheck * vm_flags for that VMA. That should be OK, because that vma shouldn't be * LOCKED. */
static void rmap_walk_anon(struct page *page, struct rmap_walk_control *rwc,
bool locked)
{
struct anon_vma *anon_vma;
pgoff_t pgoff_start, pgoff_end;
struct anon_vma_chain *avc;
if (locked) {
anon_vma = page_anon_vma(page);
/* anon_vma disappear under us? */
VM_BUG_ON_PAGE(!anon_vma, page);
} else {
anon_vma = rmap_walk_anon_lock(page, rwc);
}
if (!anon_vma)
return;
pgoff_start = page_to_pgoff(page);
pgoff_end = pgoff_start + hpage_nr_pages(page) - 1;
anon_vma_interval_tree_foreach(avc, &anon_vma->rb_root,
pgoff_start, pgoff_end) {
struct vm_area_struct *vma = avc->vma;
unsigned long address = vma_address(page, vma);
cond_resched();
if (rwc->invalid_vma && rwc->invalid_vma(vma, rwc->arg))
continue;
if (!rwc->rmap_one(page, vma, address, rwc->arg))
break;
if (rwc->done && rwc->done(page))
break;
}
if (!locked)
anon_vma_unlock_read(anon_vma);
}
페이지가 소속된 anon vma들을 순회하며 rwc의 (*rmap_one) 후크 함수를 동작시킨다.
- 코드 라인 8~16에서 페이지에 해당하는 anon_vma를 구해온다. @locked가 설정되지 않은 경우 이 함수에서 anon_vma에 대한 lock을 획득해야 한다.
- 코드 라인 18~23에서 pgoff 시작 ~ pgoff 끝에 포함되는 anon_vma에 소속된 vma들을 순회한다.
- 코드 라인 27~28에서 rwc에 (*invalid_vma) 후크 함수를 수행한 결과가 ture인 경우 해당 vma는 skip 한다.
- 코드 라인 30~31에서 rwc의 (*rmap_one) 후크 함수를 수행한다. 만일 실패한 경우 break 한다.
- 코드 라인 32~33에서 rwc의 (*done) 후크 함수를 수행한 후 결과가 true이면 break 한다.
- 코드 라인 36~37에서 anon_vma에 대한 락을 해제한다.
/* * rmap_walk_file - do something to file page using the object-based rmap method * @page: the page to be handled * @rwc: control variable according to each walk type * * Find all the mappings of a page using the mapping pointer and the vma chains * contained in the address_space struct it points to. * * When called from try_to_munlock(), the mmap_sem of the mm containing the vma * where the page was found will be held for write. So, we won't recheck * vm_flags for that VMA. That should be OK, because that vma shouldn't be * LOCKED. */
static void rmap_walk_file(struct page *page, struct rmap_walk_control *rwc,
bool locked)
{
struct address_space *mapping = page_mapping(page);
pgoff_t pgoff_start, pgoff_end;
struct vm_area_struct *vma;
/*
* The page lock not only makes sure that page->mapping cannot
* suddenly be NULLified by truncation, it makes sure that the
* structure at mapping cannot be freed and reused yet,
* so we can safely take mapping->i_mmap_rwsem.
*/
VM_BUG_ON_PAGE(!PageLocked(page), page);
if (!mapping)
return;
pgoff_start = page_to_pgoff(page);
pgoff_end = pgoff_start + hpage_nr_pages(page) - 1;
if (!locked)
i_mmap_lock_read(mapping);
vma_interval_tree_foreach(vma, &mapping->i_mmap,
pgoff_start, pgoff_end) {
unsigned long address = vma_address(page, vma);
cond_resched();
if (rwc->invalid_vma && rwc->invalid_vma(vma, rwc->arg))
continue;
if (!rwc->rmap_one(page, vma, address, rwc->arg))
goto done;
if (rwc->done && rwc->done(page))
goto done;
}
done:
if (!locked)
i_mmap_unlock_read(mapping);
}
페이지가 소속된 file vma들을 순회하며 rwc의 (*rmap_one) 후크 함수를 동작시킨다.
- 코드 라인 4~17에서 매핑된 파일 페이지가 아닌 경우 함수를 빠져나간다.
- 코드 라인 19~20에서 파일 페이지에서 pgoff 시작과 pgoff 끝을 산출한다.
- 코드 라인 21~22에서 @locked가 설정되지 않은 경우 이 함수에서 i_mmap에 대한 lock을 획득해야 한다.
- 코드 라인 23~24에서 pgoff 시작 ~ pgoff 끝에 포함되는 파일 매핑 공간에 대해 인터벌 트리를 통해 vma들을 순회한다.
- 코드 라인 29~30에서 rwc의 (*invalid_vma) 후크 함수를 수행한 결과가 true인 경우 해당 vma는 skip 한다.
- 코드 라인 32~33에서 rwc의 (*rmap_one) 후크 함수를 수행한다. 수행 결과가 실패한 경우 break 한다.
- 코드 라인 34~35에서 rwc의 (*done) 후크 함수의 수행 결과가 true인 경우 break 한다.
- 코드 라인 38~40에서 done: 레이블이다. i_mmap에 대한 락을 해제한다.
언맵 1개 시도
try_to_unmap_one()
mm/rmap.c -1/6-
/* * @arg: enum ttu_flags will be passed to this argument */
static bool try_to_unmap_one(struct page *page, struct vm_area_struct *vma,
unsigned long address, void *arg)
{
struct mm_struct *mm = vma->vm_mm;
struct page_vma_mapped_walk pvmw = {
.page = page,
.vma = vma,
.address = address,
};
pte_t pteval;
struct page *subpage;
bool ret = true;
struct mmu_notifier_range range;
enum ttu_flags flags = (enum ttu_flags)arg;
/* munlock has nothing to gain from examining un-locked vmas */
if ((flags & TTU_MUNLOCK) && !(vma->vm_flags & VM_LOCKED))
return true;
if (IS_ENABLED(CONFIG_MIGRATION) && (flags & TTU_MIGRATION) &&
is_zone_device_page(page) && !is_device_private_page(page))
return true;
if (flags & TTU_SPLIT_HUGE_PMD) {
split_huge_pmd_address(vma, address,
flags & TTU_SPLIT_FREEZE, page);
}
/*
* For THP, we have to assume the worse case ie pmd for invalidation.
* For hugetlb, it could be much worse if we need to do pud
* invalidation in the case of pmd sharing.
*
* Note that the page can not be free in this function as call of
* try_to_unmap() must hold a reference on the page.
*/
mmu_notifier_range_init(&range, vma->vm_mm, address,
min(vma->vm_end, address +
(PAGE_SIZE << compound_order(page))));
if (PageHuge(page)) {
/*
* If sharing is possible, start and end will be adjusted
* accordingly.
*/
adjust_range_if_pmd_sharing_possible(vma, &range.start,
&range.end);
}
mmu_notifier_invalidate_range_start(&range);
- 코드 라인 4에서 vma가 소속된 가상 주소 공간 관리 mm을 구해온다.
- 코드 라인 5~9에서 매핑 여부를 확인하기 위한 pvmw를 준비한다.
- 코드 라인 17~18에서 VM_LOCKED 설정되지 않은 vma에 TTU_MUNLOCK 요청이 있는 경우 해당 페이지를 skip하기 위해 그냥 성공을 반환한다.
- 코드 라인 20~22에서 migration 매핑 요청 시 hmm이 아닌 zone 디바이스인 경우 skip 하기 위해 true를 반환한다.
- hmm이 아닌 zone 디바이스는 정규 매핑/언매핑 동작을 수행할 수 없다.
- 코드 라인 24~27에서 huge 페이지 split 요청을 수행한다.
- 코드 라인 37~39에서 mmu_notifier_range를 초기화한다.
- 코드 라인 40~47에서 huge 페이지인 경우 위의 range를 조정한다.
- 코드 라인 48에서 secondary mmu의range에 대한 tlb 무효화를 수행하기 전에 시작됨을 알려주기 위해 mmu notifier가 등록된 (*invalidate_range_start) 함수를 호출한다.
mm/rmap.c -2/6-
while (page_vma_mapped_walk(&pvmw)) {
#ifdef CONFIG_ARCH_ENABLE_THP_MIGRATION
/* PMD-mapped THP migration entry */
if (!pvmw.pte && (flags & TTU_MIGRATION)) {
VM_BUG_ON_PAGE(PageHuge(page) || !PageTransCompound(page), page);
set_pmd_migration_entry(&pvmw, page);
continue;
}
#endif
/*
* If the page is mlock()d, we cannot swap it out.
* If it's recently referenced (perhaps page_referenced
* skipped over this mm) then we should reactivate it.
*/
if (!(flags & TTU_IGNORE_MLOCK)) {
if (vma->vm_flags & VM_LOCKED) {
/* PTE-mapped THP are never mlocked */
if (!PageTransCompound(page)) {
/*
* Holding pte lock, we do *not* need
* mmap_sem here
*/
mlock_vma_page(page);
}
ret = false;
page_vma_mapped_walk_done(&pvmw);
break;
}
if (flags & TTU_MUNLOCK)
continue;
}
/* Unexpected PMD-mapped THP? */
VM_BUG_ON_PAGE(!pvmw.pte, page);
subpage = page - page_to_pfn(page) + pte_pfn(*pvmw.pte);
address = pvmw.address;
if (PageHuge(page)) {
if (huge_pmd_unshare(mm, &address, pvmw.pte)) {
/*
* huge_pmd_unshare unmapped an entire PMD
* page. There is no way of knowing exactly
* which PMDs may be cached for this mm, so
* we must flush them all. start/end were
* already adjusted above to cover this range.
*/
flush_cache_range(vma, range.start, range.end);
flush_tlb_range(vma, range.start, range.end);
mmu_notifier_invalidate_range(mm, range.start,
range.end);
/*
* The ref count of the PMD page was dropped
* which is part of the way map counting
* is done for shared PMDs. Return 'true'
* here. When there is no other sharing,
* huge_pmd_unshare returns false and we will
* unmap the actual page and drop map count
* to zero.
*/
page_vma_mapped_walk_done(&pvmw);
break;
}
}
- 코드 라인 1에서 pvmw를 통해 요청한 정규 매핑 상태가 정상인 경우에 한해 루프를 돈다.
- 코드 라인 4~9에서 pmd 엔트리를 통해 thp 페이지를 migration 엔트리에 매핑하고 루프를 계속 수행 한다.
- 코드 라인 17~33에서 TTU_IGNORE_MLOCK 플래그가 없이 요청한 경우 mlocked 페이지는 swap out할 수 없다. VM_LOCKED vma 영역인 경우 루프를 멈추고 처리도 중단하게 한다.
- 코드 라인 38~67에서 공유되지 않은 huge 페이지인 경우 range 영역에 대해 캐시 및 tlb 캐시를 플러시하고, secondary MMU의 range에 대한 tlb 무효화를 수행한다. 그런 후 루프를 멈추고 처리도 중단하게 한다.
mm/rmap.c -3/6-
. if (IS_ENABLED(CONFIG_MIGRATION) &&
(flags & TTU_MIGRATION) &&
is_zone_device_page(page)) {
swp_entry_t entry;
pte_t swp_pte;
pteval = ptep_get_and_clear(mm, pvmw.address, pvmw.pte);
/*
* Store the pfn of the page in a special migration
* pte. do_swap_page() will wait until the migration
* pte is removed and then restart fault handling.
*/
entry = make_migration_entry(page, 0);
swp_pte = swp_entry_to_pte(entry);
if (pte_soft_dirty(pteval))
swp_pte = pte_swp_mksoft_dirty(swp_pte);
set_pte_at(mm, pvmw.address, pvmw.pte, swp_pte);
/*
* No need to invalidate here it will synchronize on
* against the special swap migration pte.
*/
goto discard;
}
if (!(flags & TTU_IGNORE_ACCESS)) {
if (ptep_clear_flush_young_notify(vma, address,
pvmw.pte)) {
ret = false;
page_vma_mapped_walk_done(&pvmw);
break;
}
}
/* Nuke the page table entry. */
flush_cache_page(vma, address, pte_pfn(*pvmw.pte));
if (should_defer_flush(mm, flags)) {
/*
* We clear the PTE but do not flush so potentially
* a remote CPU could still be writing to the page.
* If the entry was previously clean then the
* architecture must guarantee that a clear->dirty
* transition on a cached TLB entry is written through
* and traps if the PTE is unmapped.
*/
pteval = ptep_get_and_clear(mm, address, pvmw.pte);
set_tlb_ubc_flush_pending(mm, pte_dirty(pteval));
} else {
pteval = ptep_clear_flush(vma, address, pvmw.pte);
}
/* Move the dirty bit to the page. Now the pte is gone. */
if (pte_dirty(pteval))
set_page_dirty(page);
/* Update high watermark before we lower rss */
update_hiwater_rss(mm);
- 코드 라인 1~24에서 존 디바이스 페이지에 TTU_MIGRATION 플래그를 요청한 경우이다. pte 엔트리에 migration 정보를 swap 엔트리 형태로 만들어 매핑한다.
- swap 엔트리를 활용하여 migration 정보를 담아 매핑하여 사용한다. 이 매핑을 통해 fault 발생 시 fault 핸들러 중 swap fault를 담당하는 do_swap_page()에서 migration이 완료될 때까지 기다리게 한다.
- soft dirty 기능은 현재 x86_64, powerpc_64, s390 아키텍처에서만 사용된다.
- 참고: mm/migrate: support un-addressable ZONE_DEVICE page in migration
- 코드 라인 26~33에서 TTU_IGNORE_ACCESS 플래그 요청이 없는 경우 address에 해당하는 secondary MMU의 pte 엔트리의 young/accessed 플래그를 test-and-clearing을 수행한 후 access된 적이 있으면 플러시하고 루틴을 중단하게 한다.
- 코드 라인 36에서 유저 가상 주소에 대한 캐시를 flush한다.
- ARM64 아키텍처는 아무런 동작도 하지 않는다.
- 아키텍처의 캐시 타입이 vivt 또는 vipt aliasing 등을 사용하면 flush 한다.
- 코드 라인 37~51에서 유저 가상 주소에 매핑된 pte 엔트리를 클리어하여 언매핑하고, tlb 플러시한다. 만일 TTU_BATCH_FLUSH 플러그 요청을 받은 경우 tlb flush는 마지막에 모아 처리하는 것으로 성능을 높인다.
- 코드 라인 54~55에서 언매핑(클리어) 하기 전 기존 pte 엔트리가 dirty 상태인 경우 페이지를 dirty 상태로 설정한다.
- 코드 라인 58에서 mm의 hiwater_rss 카운터를 최고 값인 경우 갱신한다.
- mm의 file 페이지 수 + anon 페이지 수 + shmem 페이지 수
mm/rmap.c -4/6-
. if (PageHWPoison(page) && !(flags & TTU_IGNORE_HWPOISON)) {
pteval = swp_entry_to_pte(make_hwpoison_entry(subpage));
if (PageHuge(page)) {
int nr = 1 << compound_order(page);
hugetlb_count_sub(nr, mm);
set_huge_swap_pte_at(mm, address,
pvmw.pte, pteval,
vma_mmu_pagesize(vma));
} else {
dec_mm_counter(mm, mm_counter(page));
set_pte_at(mm, address, pvmw.pte, pteval);
}
} else if (pte_unused(pteval) && !userfaultfd_armed(vma)) {
/*
* The guest indicated that the page content is of no
* interest anymore. Simply discard the pte, vmscan
* will take care of the rest.
* A future reference will then fault in a new zero
* page. When userfaultfd is active, we must not drop
* this page though, as its main user (postcopy
* migration) will not expect userfaults on already
* copied pages.
*/
dec_mm_counter(mm, mm_counter(page));
/* We have to invalidate as we cleared the pte */
mmu_notifier_invalidate_range(mm, address,
address + PAGE_SIZE);
} else if (IS_ENABLED(CONFIG_MIGRATION) &&
(flags & (TTU_MIGRATION|TTU_SPLIT_FREEZE))) {
swp_entry_t entry;
pte_t swp_pte;
if (arch_unmap_one(mm, vma, address, pteval) < 0) {
set_pte_at(mm, address, pvmw.pte, pteval);
ret = false;
page_vma_mapped_walk_done(&pvmw);
break;
}
/*
* Store the pfn of the page in a special migration
* pte. do_swap_page() will wait until the migration
* pte is removed and then restart fault handling.
*/
entry = make_migration_entry(subpage,
pte_write(pteval));
swp_pte = swp_entry_to_pte(entry);
if (pte_soft_dirty(pteval))
swp_pte = pte_swp_mksoft_dirty(swp_pte);
set_pte_at(mm, address, pvmw.pte, swp_pte);
/*
* No need to invalidate here it will synchronize on
* against the special swap migration pte.
*/
- 코드 라인 1~12에서 hwpoison 페이지이면서 TTU_IGNORE_HWPOISON 플래그를 사용하지 않는 요청인 경우이다. 관련 mm 카운터(anon, file, shm)를 페이지 수 만큼 감소시킨다. 그런 후 pte 엔트리에 swap 엔트리 값을 매핑시킨다.
- 코드 라인 14~28에서 userfaultfd vma의 사용되지 않는 pte 값인 경우 관련 mm 카운터(anon, file, shm)를 페이지 수 만큼 감소시킨다. 그런 후 secondary MMU도 가상 주소에 대한 TLB 무효화(invalidate)를 수행하게 한다.
- 코드 라인 29~51에서 TTU_MIGRATION 또는 TTU_SPLIT_FREEZE 플래그 요청을 받은 경우이다. migration할 swap 엔트리를 매핑한다. 기존 매핑에 soft dirty가 설정된 경우 swap 엔트리에도 포함시킨다.
mm/rmap.c -5/6-
. } else if (PageAnon(page)) {
swp_entry_t entry = { .val = page_private(subpage) };
pte_t swp_pte;
/*
* Store the swap location in the pte.
* See handle_pte_fault() ...
*/
if (unlikely(PageSwapBacked(page) != PageSwapCache(page))) {
WARN_ON_ONCE(1);
ret = false;
/* We have to invalidate as we cleared the pte */
mmu_notifier_invalidate_range(mm, address,
address + PAGE_SIZE);
page_vma_mapped_walk_done(&pvmw);
break;
}
/* MADV_FREE page check */
if (!PageSwapBacked(page)) {
if (!PageDirty(page)) {
/* Invalidate as we cleared the pte */
mmu_notifier_invalidate_range(mm,
address, address + PAGE_SIZE);
dec_mm_counter(mm, MM_ANONPAGES);
goto discard;
}
/*
* If the page was redirtied, it cannot be
* discarded. Remap the page to page table.
*/
set_pte_at(mm, address, pvmw.pte, pteval);
SetPageSwapBacked(page);
ret = false;
page_vma_mapped_walk_done(&pvmw);
break;
}
if (swap_duplicate(entry) < 0) {
set_pte_at(mm, address, pvmw.pte, pteval);
ret = false;
page_vma_mapped_walk_done(&pvmw);
break;
}
if (arch_unmap_one(mm, vma, address, pteval) < 0) {
set_pte_at(mm, address, pvmw.pte, pteval);
ret = false;
page_vma_mapped_walk_done(&pvmw);
break;
}
if (list_empty(&mm->mmlist)) {
spin_lock(&mmlist_lock);
if (list_empty(&mm->mmlist))
list_add(&mm->mmlist, &init_mm.mmlist);
spin_unlock(&mmlist_lock);
}
dec_mm_counter(mm, MM_ANONPAGES);
inc_mm_counter(mm, MM_SWAPENTS);
swp_pte = swp_entry_to_pte(entry);
if (pte_soft_dirty(pteval))
swp_pte = pte_swp_mksoft_dirty(swp_pte);
set_pte_at(mm, address, pvmw.pte, swp_pte);
/* Invalidate as we cleared the pte */
mmu_notifier_invalidate_range(mm, address,
address + PAGE_SIZE);
- 코드 라인 1~16에서 anon 페이지에 대한 처리이다. 낮은 확률로 페이지가 swapbacked와 swapcache 플래그 설정이 일치하지 않은 경우 secondary mmu의 tlb 무효화를 수행하고, 루틴을 중단하게 한다.
- 코드 라인 19~37에서 SwapBacked 페이지가 아닌 경우 다시 페이지를 매핑하고, 루틴을 중단하게 한다. 단 dirty 페이지가 아닌 경우 secondary mmu의 tlb 무효화를 수행하고 anon mm 카운터를 감소시킨 후 discard 레이블로 이동하여 다음을 진행하게 한다.
- 코드 라인 39~44에서 swap 엔트리의 참조 카운터를 1 증가시킨다. 에러인 경우 다시 페이지를 매핑하고 루틴을 중단하게 한다.
- 코드 라인 45~50에서 아키텍처 고유의 unmap 수행 시 에러가 발생하면 다시 페이지를 매핑하고 루틴을 중단하게 한다.
- 현재 sparc_64 아키텍처만 지원한다.
- 코드 라인 51~56에서 현재 mm의 mmlist가 비어있는 경우 init_mm의 mmlist에 추가한다.
- 코드 라인 57~65에서 anon, swap mm 카운터를 증가시키고 swap 엔트리를 매핑한 후 secondary mmu의 tlb 무효화를 수행한다.
mm/rmap.c -6/6-
} else {
/*
* This is a locked file-backed page, thus it cannot
* be removed from the page cache and replaced by a new
* page before mmu_notifier_invalidate_range_end, so no
* concurrent thread might update its page table to
* point at new page while a device still is using this
* page.
*
* See Documentation/vm/mmu_notifier.rst
*/
dec_mm_counter(mm, mm_counter_file(page));
}
discard:
/*
* No need to call mmu_notifier_invalidate_range() it has be
* done above for all cases requiring it to happen under page
* table lock before mmu_notifier_invalidate_range_end()
*
* See Documentation/vm/mmu_notifier.rst
*/
page_remove_rmap(subpage, PageHuge(page));
put_page(page);
}
mmu_notifier_invalidate_range_end(&range);
return ret;
}
- 코드 라인 1~13에서 그 밖(file-backed 페이지)의 경우 file 관련 mm 카운터(file, shm)를 감소시킨다.
- 코드 라인 14~23에서 discard: 레이블이다. 페이지의 rmap 매핑을 제거한 후 페이지 사용을 완료한다.
- 코드 라인 26에서 primary MMU의 range 영역에 대한 invalidate가 완료되었다. 따라서 이 함수를 호출해 secondary MMU를 위해 mmu notifier에 등록된 (*invalidate_range_end) 후크 함수를 호출해준다.
- (*invalidate_range_start) 후크 함수와 항상 pair로 동작한다.
ptep_clear_flush_young_notify()
include/linux/mmu_notifier.h
#define ptep_clear_flush_young_notify(__vma, __address, __ptep) \
({ \
int __young; \
struct vm_area_struct *___vma = __vma; \
unsigned long ___address = __address; \
__young = ptep_clear_flush_young(___vma, ___address, __ptep); \
__young |= mmu_notifier_clear_flush_young(___vma->vm_mm, \
___address, \
___address + \
PAGE_SIZE); \
__young; \
})
페이지가 access된 적이 있으면 access 플래그를 클리어하고 플러시를 수행한다. access 여부가 있거나 mnu_notifier에 등록된 (*clear_flush_young) 후크 함수의 결과를 반환한다.
- 코드 라인 6에서 pte 엔트리에 액세스 플래그 설정 유무를 알아오고 클리어한다. 액세스된 적이 있으면 tlb 플러시한다.
- 코드 라인 7에서 mnu notifier에 등록된 (*clear_flush_young) 후크 함수를 호출한 결과를 더한다.
- 다음 함수에서 사용되고 있다.
- virt/kvm/kvm_main.c – kvm_mmu_notifier_clear_flush_young()
- drivers/iommu/amd_iommu_v2.c – mn_clear_flush_young()
- 다음 함수에서 사용되고 있다.
MMU Notifier
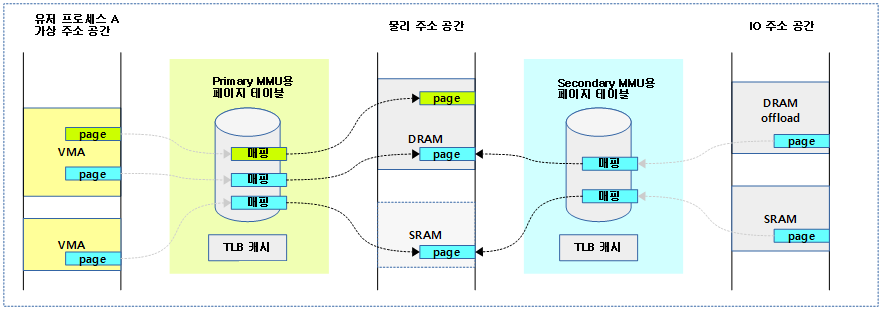
가상 주소 영역에 매핑된 물리 주소와 관련된 secondary MMU(KVM, IOMMU, …)의 mmu 관련 operation 함수를 동작시킨다. mmu notifier를 사용할 드라이버들은 mmu_notifier_ops를 포함한 mmu_notifier 구조체를 준비하여 mmu_notifer_register()를 통해 등록하여 사용한다.
다음 그림은 유저 가상 주소 공간에 매핑된 물리 주소 공간의 페이지의 매핑이 변경되었을 때 Secondary MMU도 같이 영향 받는 모습을 보여준다.
mmu_notifier 구조체
include/linux/mmu_notifier.h
/* * The notifier chains are protected by mmap_sem and/or the reverse map * semaphores. Notifier chains are only changed when all reverse maps and * the mmap_sem locks are taken. * * Therefore notifier chains can only be traversed when either * * 1. mmap_sem is held. * 2. One of the reverse map locks is held (i_mmap_rwsem or anon_vma->rwsem). * 3. No other concurrent thread can access the list (release) */
struct mmu_notifier {
struct hlist_node hlist;
const struct mmu_notifier_ops *ops;
};
IOMMU 드라이버가 준비한 mmu_notifier_ops를 관련 가상 주소 공간을 관리하는 mm의 mmu_notifier_mm 리스트에 추가하여 등록하는 구조체이다.
- hlist
- mm_struct의 멤버 mmu_notifier_mm->list에 등록할 때 사용하는 노드 엔트리이다.
- *ops
- 준비한 mmu_notifier_ops 구조체를 가리킨다.
mmu_notifier_ops 구조체
include/linux/mmu_notifier.h -1/2-
struct mmu_notifier_ops {
/*
* Called either by mmu_notifier_unregister or when the mm is
* being destroyed by exit_mmap, always before all pages are
* freed. This can run concurrently with other mmu notifier
* methods (the ones invoked outside the mm context) and it
* should tear down all secondary mmu mappings and freeze the
* secondary mmu. If this method isn't implemented you've to
* be sure that nothing could possibly write to the pages
* through the secondary mmu by the time the last thread with
* tsk->mm == mm exits.
*
* As side note: the pages freed after ->release returns could
* be immediately reallocated by the gart at an alias physical
* address with a different cache model, so if ->release isn't
* implemented because all _software_ driven memory accesses
* through the secondary mmu are terminated by the time the
* last thread of this mm quits, you've also to be sure that
* speculative _hardware_ operations can't allocate dirty
* cachelines in the cpu that could not be snooped and made
* coherent with the other read and write operations happening
* through the gart alias address, so leading to memory
* corruption.
*/
void (*release)(struct mmu_notifier *mn,
struct mm_struct *mm);
/*
* clear_flush_young is called after the VM is
* test-and-clearing the young/accessed bitflag in the
* pte. This way the VM will provide proper aging to the
* accesses to the page through the secondary MMUs and not
* only to the ones through the Linux pte.
* Start-end is necessary in case the secondary MMU is mapping the page
* at a smaller granularity than the primary MMU.
*/
int (*clear_flush_young)(struct mmu_notifier *mn,
struct mm_struct *mm,
unsigned long start,
unsigned long end);
/*
* clear_young is a lightweight version of clear_flush_young. Like the
* latter, it is supposed to test-and-clear the young/accessed bitflag
* in the secondary pte, but it may omit flushing the secondary tlb.
*/
int (*clear_young)(struct mmu_notifier *mn,
struct mm_struct *mm,
unsigned long start,
unsigned long end);
/*
* test_young is called to check the young/accessed bitflag in
* the secondary pte. This is used to know if the page is
* frequently used without actually clearing the flag or tearing
* down the secondary mapping on the page.
*/
int (*test_young)(struct mmu_notifier *mn,
struct mm_struct *mm,
unsigned long address);
/*
* change_pte is called in cases that pte mapping to page is changed:
* for example, when ksm remaps pte to point to a new shared page.
*/
void (*change_pte)(struct mmu_notifier *mn,
struct mm_struct *mm,
unsigned long address,
pte_t pte);
- (*release)
- mm이 제거되거나, mmu_notifer_unregister() 호출 시 동작되는 후크 함수이다.
- (*clear_flush_young)
- pte 엔트리에 있는 young/accessed 비트 플래그에 대해 test-and-clearing 사용 후 호출되는 후크 함수이다.
- Secondary MMU에서 start ~ end 주소 범위에 관련된 young/accessed 비트 플래그의 test-and-clearing을 수행 후 secondary MMU의 tlb 플러시를 수행하게 한다.
- (*clear_young)
- 위의 (*clear_flush_young)의 light 버전으로 secondary MMU의 tlb 플러시를 수행하지 않는다.
- (*test_young)
- Secondary MMU에서 start ~ end 주소 범위에 관련된 young/accessed 비트 플래그 상태를 반환한다.
- (*change_pte)
- Secondary MMU에서 address 주소에 관련된 pte를 교체한다.
include/linux/mmu_notifier.h -2/2-
/*
* invalidate_range_start() and invalidate_range_end() must be
* paired and are called only when the mmap_sem and/or the
* locks protecting the reverse maps are held. If the subsystem
* can't guarantee that no additional references are taken to
* the pages in the range, it has to implement the
* invalidate_range() notifier to remove any references taken
* after invalidate_range_start().
*
* Invalidation of multiple concurrent ranges may be
* optionally permitted by the driver. Either way the
* establishment of sptes is forbidden in the range passed to
* invalidate_range_begin/end for the whole duration of the
* invalidate_range_begin/end critical section.
*
* invalidate_range_start() is called when all pages in the
* range are still mapped and have at least a refcount of one.
*
* invalidate_range_end() is called when all pages in the
* range have been unmapped and the pages have been freed by
* the VM.
*
* The VM will remove the page table entries and potentially
* the page between invalidate_range_start() and
* invalidate_range_end(). If the page must not be freed
* because of pending I/O or other circumstances then the
* invalidate_range_start() callback (or the initial mapping
* by the driver) must make sure that the refcount is kept
* elevated.
*
* If the driver increases the refcount when the pages are
* initially mapped into an address space then either
* invalidate_range_start() or invalidate_range_end() may
* decrease the refcount. If the refcount is decreased on
* invalidate_range_start() then the VM can free pages as page
* table entries are removed. If the refcount is only
* droppped on invalidate_range_end() then the driver itself
* will drop the last refcount but it must take care to flush
* any secondary tlb before doing the final free on the
* page. Pages will no longer be referenced by the linux
* address space but may still be referenced by sptes until
* the last refcount is dropped.
*
* If blockable argument is set to false then the callback cannot
* sleep and has to return with -EAGAIN. 0 should be returned
* otherwise. Please note that if invalidate_range_start approves
* a non-blocking behavior then the same applies to
* invalidate_range_end.
*
*/
int (*invalidate_range_start)(struct mmu_notifier *mn,
const struct mmu_notifier_range *range);
void (*invalidate_range_end)(struct mmu_notifier *mn,
const struct mmu_notifier_range *range);
/*
* invalidate_range() is either called between
* invalidate_range_start() and invalidate_range_end() when the
* VM has to free pages that where unmapped, but before the
* pages are actually freed, or outside of _start()/_end() when
* a (remote) TLB is necessary.
*
* If invalidate_range() is used to manage a non-CPU TLB with
* shared page-tables, it not necessary to implement the
* invalidate_range_start()/end() notifiers, as
* invalidate_range() alread catches the points in time when an
* external TLB range needs to be flushed. For more in depth
* discussion on this see Documentation/vm/mmu_notifier.rst
*
* Note that this function might be called with just a sub-range
* of what was passed to invalidate_range_start()/end(), if
* called between those functions.
*/
void (*invalidate_range)(struct mmu_notifier *mn, struct mm_struct *mm,
unsigned long start, unsigned long end);
};
- (*invalidate_range_start)
- (*invalidate_range_end)
- 위 두 개의 후크 함수는 페어로 동작한다. VM들에 대해 primary MMU의 해당 range에 대해 TLB를 무효화할 때, secondary MMU도 따라서 TLB 무효화를 수행하는데, rmap walk를 통해 한꺼번에 조작하는 루틴 전후에 이 후크 함수들을 호출한다.
- (*invalidate_range)
- VM에서 primary MMU의 주어진 범위를 invalidate 한 후 secondary MMU도 같이 호출된다.
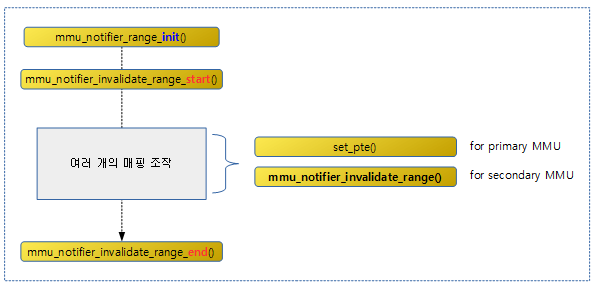
다음 그림은 mmu notifier를 사용 시 secondary MMU에 대해 init, start, end 등의 위치를 확인할 수 있다.
MM 카운터
- RSS(Resident Set Size)
- 프로세스에 실제 물리 메모리가 매핑되어 사용중인 페이지 수를 말한다.
- swap out된 페이지는 제외하고, 스택 및 힙 메모리 등이 포함된다.
- VSZ(Virutal memory SiZe)
- 프로세스가 사용중인 가상 주소 페이지 수이다.
- RSS보다 크며 swap out된 페이지들도 포함되고, 공간에 할당되었지만 한 번도 액세스되지 않아 실제 메모리가 매핑되지 않은 페이지들을 포함한다.
다음과 같이 bash(pid=5831) 프로세스가 사용하는 RSS 및 VSZ 카운터를 확인할 수 있다.
$ cat /proc/5831/status Name: bash State: S (sleeping) Tgid: 5831 Ngid: 0 Pid: 5831 PPid: 5795 TracerPid: 0 Uid: 0 0 0 0 Gid: 0 0 0 0 FDSize: 256 Groups: 0 NStgid: 5831 NSpid: 5831 NSpgid: 5831 NSsid: 5831 VmPeak: 6768 kB <--- hiwater VSZ VmSize: 6704 kB <--- VSZ VmLck: 0 kB VmPin: 0 kB VmHWM: 4552 kB <--- hiwater RSS (file + anon + shm) VmRSS: 3868 kB <--- RSS VmData: 1652 kB VmStk: 132 kB VmExe: 944 kB VmLib: 1648 kB VmPTE: 28 kB VmPMD: 12 kB VmSwap: 0 kB Threads: 1 SigQ: 0/15244 SigPnd: 0000000000000000 ShdPnd: 0000000000000000 SigBlk: 0000000000000000 SigIgn: 0000000000380004 SigCgt: 000000004b817efb CapInh: 0000000000000000 CapPrm: 0000003fffffffff CapEff: 0000003fffffffff CapBnd: 0000003fffffffff CapAmb: 0000000000000000 Seccomp: 0 Cpus_allowed: 3f Cpus_allowed_list: 0-5 Mems_allowed: 1 Mems_allowed_list: 0 voluntary_ctxt_switches: 50 nonvoluntary_ctxt_switches: 29
페이지 참조 확인
page_referenced()
mm/rmap.c
/** * page_referenced - test if the page was referenced * @page: the page to test * @is_locked: caller holds lock on the page * @memcg: target memory cgroup * @vm_flags: collect encountered vma->vm_flags who actually referenced the page * * Quick test_and_clear_referenced for all mappings to a page, * returns the number of ptes which referenced the page. */
int page_referenced(struct page *page,
int is_locked,
struct mem_cgroup *memcg,
unsigned long *vm_flags)
{
int we_locked = 0;
struct page_referenced_arg pra = {
.mapcount = total_mapcount(page),
.memcg = memcg,
};
struct rmap_walk_control rwc = {
.rmap_one = page_referenced_one,
.arg = (void *)&pra,
.anon_lock = page_lock_anon_vma_read,
};
*vm_flags = 0;
if (!page_mapped(page))
return 0;
if (!page_rmapping(page))
return 0;
if (!is_locked && (!PageAnon(page) || PageKsm(page))) {
we_locked = trylock_page(page);
if (!we_locked)
return 1;
}
/*
* If we are reclaiming on behalf of a cgroup, skip
* counting on behalf of references from different
* cgroups
*/
if (memcg) {
rwc.invalid_vma = invalid_page_referenced_vma;
}
rmap_walk(page, &rwc);
*vm_flags = pra.vm_flags;
if (we_locked)
unlock_page(page);
return pra.referenced;
}
page_referenced_one()
mm/rmap.c
/* * arg: page_referenced_arg will be passed */
static bool page_referenced_one(struct page *page, struct vm_area_struct *vma,
unsigned long address, void *arg)
{
struct page_referenced_arg *pra = arg;
struct page_vma_mapped_walk pvmw = {
.page = page,
.vma = vma,
.address = address,
};
int referenced = 0;
while (page_vma_mapped_walk(&pvmw)) {
address = pvmw.address;
if (vma->vm_flags & VM_LOCKED) {
page_vma_mapped_walk_done(&pvmw);
pra->vm_flags |= VM_LOCKED;
return false; /* To break the loop */
}
if (pvmw.pte) {
if (ptep_clear_flush_young_notify(vma, address,
pvmw.pte)) {
/*
* Don't treat a reference through
* a sequentially read mapping as such.
* If the page has been used in another mapping,
* we will catch it; if this other mapping is
* already gone, the unmap path will have set
* PG_referenced or activated the page.
*/
if (likely(!(vma->vm_flags & VM_SEQ_READ)))
referenced++;
}
} else if (IS_ENABLED(CONFIG_TRANSPARENT_HUGEPAGE)) {
if (pmdp_clear_flush_young_notify(vma, address,
pvmw.pmd))
referenced++;
} else {
/* unexpected pmd-mapped page? */
WARN_ON_ONCE(1);
}
pra->mapcount--;
}
if (referenced)
clear_page_idle(page);
if (test_and_clear_page_young(page))
referenced++;
if (referenced) {
pra->referenced++;
pra->vm_flags |= vma->vm_flags;
}
if (!pra->mapcount)
return false; /* To break the loop */
return true;
}
참고
- Rmap -1- (Reverse Mapping) | 문c
- Rmap -2- (TTU & Rmap Walk) | 문c – 현재 글
- Rmap -3- (PVMW) | 문c