<kernel v5.0>
슬랩 캐시 사이즈 및 order 산출
calculate_sizes()
mm/slub.c -1/2-
/* * calculate_sizes() determines the order and the distribution of data within * a slab object. */
static int calculate_sizes(struct kmem_cache *s, int forced_order)
{
slab_flags_t flags = s->flags;
unsigned int size = s->object_size;
unsigned int order;
/*
* Round up object size to the next word boundary. We can only
* place the free pointer at word boundaries and this determines
* the possible location of the free pointer.
*/
size = ALIGN(size, sizeof(void *));
#ifdef CONFIG_SLUB_DEBUG
/*
* Determine if we can poison the object itself. If the user of
* the slab may touch the object after free or before allocation
* then we should never poison the object itself.
*/
if ((flags & SLAB_POISON) && !(flags & SLAB_TYPESAFE_BY_RCU) &&
!s->ctor)
s->flags |= __OBJECT_POISON;
else
s->flags &= ~__OBJECT_POISON;
/*
* If we are Redzoning then check if there is some space between the
* end of the object and the free pointer. If not then add an
* additional word to have some bytes to store Redzone information.
*/
if ((flags & SLAB_RED_ZONE) && size == s->object_size)
size += sizeof(void *);
#endif
/*
* With that we have determined the number of bytes in actual use
* by the object. This is the potential offset to the free pointer.
*/
s->inuse = size;
if (((flags & (SLAB_TYPESAFE_BY_RCU | SLAB_POISON)) ||
s->ctor)) {
/*
* Relocate free pointer after the object if it is not
* permitted to overwrite the first word of the object on
* kmem_cache_free.
*
* This is the case if we do RCU, have a constructor or
* destructor or are poisoning the objects.
*/
s->offset = size;
size += sizeof(void *);
}
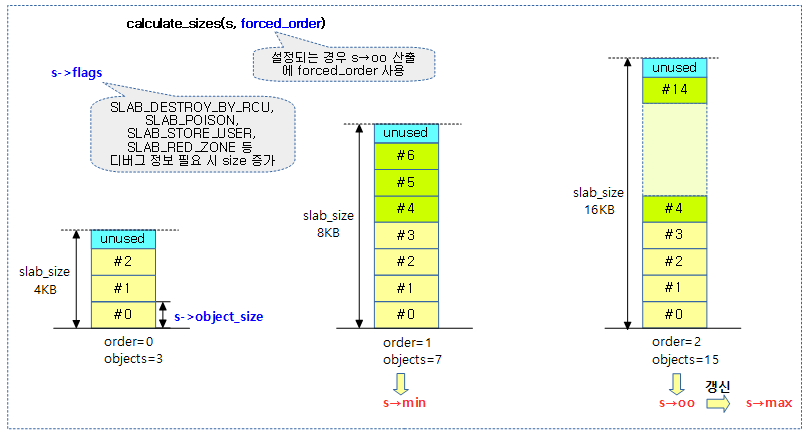
지정된 forced_order 또는 객체 사이즈(s->size)로 적절히 산출된 order 둘 중 하나를 선택하여 slab에 들어갈 최소 객체 수(s->min), 적절한 객체 수(s->oo) 및 최대 객체 수(s->max)를 설정하고 1을 반환한다. 객체 수가 0인 경우 에러로 0을 반환한다.
- 코드 라인 12에서 size를 포인터 사이즈 단위로 올림 정렬한다.
- 코드 라인 20~24에서 poison 디버그를 요청한 경우에 한해 __OBJECT_POISON 플래그를 추가하되 별도의 생성자를 사용하는 슬랩 캐시 또는 RCU를 사용한 슬랩 캐시는 RCU가 우선되므로 poison 디버깅을 지원하지 않는다. RCU를 이용한 free 기능을 사용하는 경우 object의 free 시점이 delay 되므로 원본 object 데이터가 poison 값으로 파괴되면 안되는 상태이다.
- 코드 라인 31~32에서 red-zone 디버깅 시 size와 object_size가 같은 경우 object와 FP(Free Pointer) 사이에 red-zone으로 사용할 패딩 공간이 없어 별도의 red-zone 용도의 패딩 공간을 포인터 길이 만큼 추가한다.
- 코드 라인 39에서 지금 까지 산출된 실제 object에 사용하는 사이즈(actual size)를 s->inuse에 저장한다.
- 코드 라인 41~53에서 object 자리에 FP(Free Pointer)가 기록되는데, rcu를 사용한 object free나 poison 디버깅 및 생성자를 별도로 사용하는 경우 object 위치에 관련 정보를 기록한다. 따라서 FP(Free Pointer)를 뒤로 이동시켜 추가하여야 한다. s->offset은 FP의 위치를 가리킨다.
- RCU는 free 시점이 delay 되므로 원본 object 데이터가 FP 값으로 overwrite되어 파괴되면 안되는 상태이다.
mm/slub.c -2/2-
#ifdef CONFIG_SLUB_DEBUG
if (flags & SLAB_STORE_USER)
/*
* Need to store information about allocs and frees after
* the object.
*/
size += 2 * sizeof(struct track);
#endif
kasan_cache_create(s, &size, &s->flags);
#ifdef CONFIG_SLUB_DEBUG
if (flags & SLAB_RED_ZONE) {
/*
* Add some empty padding so that we can catch
* overwrites from earlier objects rather than let
* tracking information or the free pointer be
* corrupted if a user writes before the start
* of the object.
*/
size += sizeof(void *);
s->red_left_pad = sizeof(void *);
s->red_left_pad = ALIGN(s->red_left_pad, s->align);
size += s->red_left_pad;
}
#endif
/*
* SLUB stores one object immediately after another beginning from
* offset 0. In order to align the objects we have to simply size
* each object to conform to the alignment.
*/
size = ALIGN(size, s->align);
s->size = size;
if (forced_order >= 0)
order = forced_order;
else
order = calculate_order(size);
if ((int)order < 0)
return 0;
s->allocflags = 0;
if (order)
s->allocflags |= __GFP_COMP;
if (s->flags & SLAB_CACHE_DMA)
s->allocflags |= GFP_DMA;
if (s->flags & SLAB_RECLAIM_ACCOUNT)
s->allocflags |= __GFP_RECLAIMABLE;
/*
* Determine the number of objects per slab
*/
s->oo = oo_make(order, size);
s->min = oo_make(get_order(size), size);
if (oo_objects(s->oo) > oo_objects(s->max))
s->max = s->oo;
return !!oo_objects(s->oo);
}
- 코드 라인 2~7에서 SLAB_STORE_USER GFP 플래그가 사용된 경우 alloc/free 호출한 owner 트래킹을 위해 alloc 용 track 구조체와 free용 track 구조체 사이즈를 추가한다.
- 코드 라인 10에서 런타임 디버거인 KASAN을 사용하는 경우 관련 정보들을 추가한다.
- 코드 라인 12~25에서 red-zone 디버깅을 사용하는 경우 좌측에 red_left_pad를 추가하고, 마지막에 red-zone 정보용으로 포인터 사이즈만큼 추가한다.
- 코드 라인 33~34에서 지금까지 산출된 size에 align을 적용한다.
- 코드 라인 35~41에서 forced_order가 지정된 경우를 제외하고 size에 따른 적절한 order를 산출한다. (가능하면 0~3 이내)
- 코드 라인 43~51에서 다음과 같은 요청의 슬랩 캐시인 경우 플래그를 추가한다.
- order가 1 이상인 경우 compound 페이지를 만들기 위해 __GFP_COMP 플래그를 추가한다.
- dma용 슬랩 캐시를 요청한 경우 GFP_DMA 플래그를 추가한다.
- reclaimable 슬랩 캐시를 요청한 경우 __GFP_RECLAIMABLE 플래그를 추가한다.
- migrate type을 reclaimable로 한다.
- 코드 라인 56~59에서 다음 3개의 order 및 object 수를 산출한다.
- s->oo에 산출한 order와 object 수를 대입한다.
- s->min에 최소 order와 object 수를 대입한다.
- s->max에 s->oo의 최고치를 갱신한다.
- 코드 라인 61에서 적절한 order의 산출 여부를 반환한다. (성공 시 1)
다음 그림은 slab에 사용할 최소 order와 적절한 order 및 최대 order가 산출된 모습을 보여준다.
order 산출
calculate_order()
mm/slub.c
static inline int calculate_order(unsigned int size)
{
unsigned int order;
unsigned int min_objects;
unsigned int max_objects;
/*
* Attempt to find best configuration for a slab. This
* works by first attempting to generate a layout with
* the best configuration and backing off gradually.
*
* First we increase the acceptable waste in a slab. Then
* we reduce the minimum objects required in a slab.
*/
min_objects = slub_min_objects;
if (!min_objects)
min_objects = 4 * (fls(nr_cpu_ids) + 1);
max_objects = order_objects(slub_max_order, size);
min_objects = min(min_objects, max_objects);
while (min_objects > 1) {
unsigned int fraction;
fraction = 16;
while (fraction >= 4) {
order = slab_order(size, min_objects,
slub_max_order, fraction);
if (order <= slub_max_order)
return order;
fraction /= 2;
}
min_objects--;
}
/*
* We were unable to place multiple objects in a slab. Now
* lets see if we can place a single object there.
*/
order = slab_order(size, 1, slub_max_order, 1);
if (order <= slub_max_order)
return order;
/*
* Doh this slab cannot be placed using slub_max_order.
*/
order = slab_order(size, 1, MAX_ORDER, 1);
if (order < MAX_ORDER)
return order;
return -ENOSYS;
}
slub 할당을 위해 @size에 따른 적절한 order를 산출한다. 가능하면 커널 파라미터의 “slub_min_order=”(디폴트=0) ~ “slub_max_order=”(디폴트=3) 범위 내에서 적절한 order를 산출한다. 그러나 size가 slub_max_order 페이지 크기보다 큰 경우 버디 시스템 최대 order 범위내에서 산출한다.
- 코드 라인 15~17에서 슬랩 페이지당 관리할 최소 object 수를 지정하기 위해 다음 중 하나를 사용한다.
- “slub_min_order=” 커널 파라메터로 설정된 값(디폴트=0)을 사용한다.
- cpu 수에 비례한 수를 산출한다.
- 수식: 4 * (2log(cpu 수) + 1 + 1)
- rpi2 예) 4 * (2 + 1 + 1) = 16
- 코드 라인 18에서 “slub_max_order=”(default=3) 사이즈에 들어갈 수 있는 최대 object 수를 구한다.
- 코드 라인 19에서 위의 두 값 중 가장 작은 값으로 min_objects 수를 갱신한다.
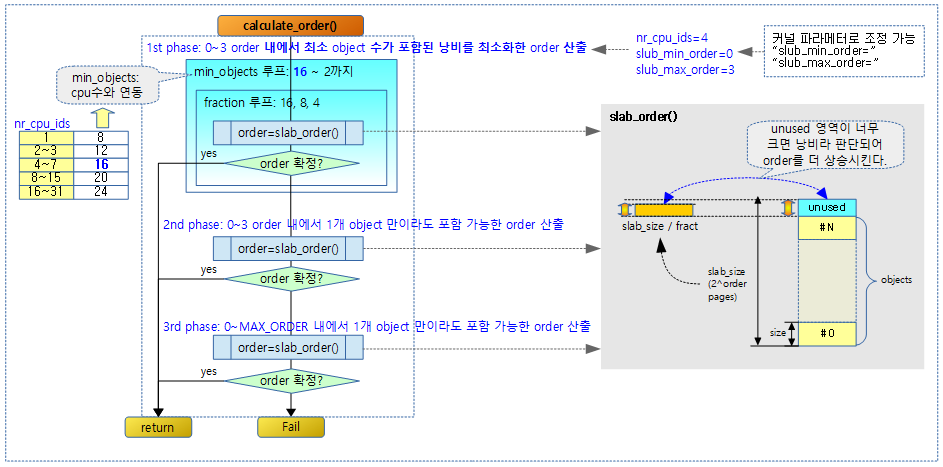
1st phase: slab order 범위 내 적절한 order 산출
위에서 산출된 min_objects 수를 포함 시킬 수 있는 최소 order 부터 시작하되 “slub_min_order=”(디폴트=0) ~ “slub_max_order=”(디폴트=3) 범위 order 순으로 순회하며 @size에 따른 object들을 배치시키고 남은 나머지 공간이 낭비가 적은 order를 반환한다. 남은 나머지 공간이 진행 중인 order 페이지 사이즈의 1/16보다 큰 경우 낭비가 있다고 판단하여 다음 order로 넘어간다. 만일 1/16으로 안되면 1/8로 시도하고, 마지막으로 1/4로 시도한다. 마지막 시도마저 안되면 min_objects 수를 1씩 줄여가며 다시 처음 부터 시도하고, min_objects가 마지막 2가 될 때까지 시도한다.
- 코드 라인 21에서 산출된 min_objects가 2개 이상인 경우에만 루프를 돈다.
- min_objects가 16으로 산출된 경우 예) 16, 15, 14, … 2까지 루프를 돈다.
- 코드 라인 24~25에서 낭비 여부를 판단하기 위해 진행 중인 order 페이지 사이즈의 1/16, 1/8, 1/4로 변경하며 시도한다.
- 코드 라인 26~29에서 min_objects 수가 포함된 order 부터 “slub_min_order=”(디폴트=0) ~ “slub_max_order=”(디폴트=3) 범위 order 순으로 순회하며 fraction(1/16, 1/8, 1/4)으로 지정된 낭비 사이즈 이내에 배치가능한 order를 반환한다.
- 코드 라인30~31에서fraction을 반으로 줄이고 다시 반복한다.
- 코드 라인 32~33에서 min_objects를 1 감소시키고 다시 반복한다.
2nd phase: 1개 object가 들어갈 수 있는 slab order 범위 내 산출
- 코드 라인 39~41에서 “slub_max_order=”(디폴트=3) 범위 order 까지 순회하며 낭비 사이즈 범위를 고려하지 않고, 1개의 object라도 들어갈 수 있는 order를 산출한다.
3rd phase: 1개 object가 들어갈 수 있는 order 산출 (order 무제한)
- 코드 라인 46~48에서 버디 시스템의 최대 order 까지 순회하며 낭비 사이즈 범위를 고려하지 않고, 1개의 object라도 들어갈 수 있는 order를 산출한다.
다음 그림은 slab 할당을 위해 적절한 order를 산출하는 모습을 보여준다.
order_objects()
mm/slub.c
static inline unsigned int order_objects(unsigned int order, unsigned int size)
{
return ((unsigned int)PAGE_SIZE << order) / size;
}
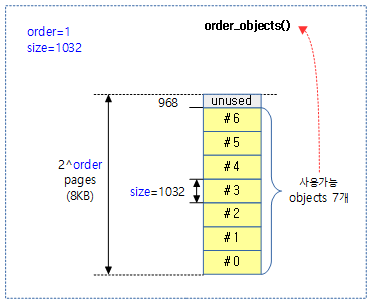
요청된 order 페이지에서 생성할 수 있는 최대 object 수를 구한다.
- 객체가 할당되는 2^order 페이지에서 size로 나눈 수를 반환한다.
다음 그림은 order 만큼의 페이지에서 생성할 수 있는 최대 object의 수를 알아오는 것을 보여준다.
slab_order()
mm/slub.c
/* * Calculate the order of allocation given an slab object size. * * The order of allocation has significant impact on performance and other * system components. Generally order 0 allocations should be preferred since * order 0 does not cause fragmentation in the page allocator. Larger objects * be problematic to put into order 0 slabs because there may be too much * unused space left. We go to a higher order if more than 1/16th of the slab * would be wasted. * * In order to reach satisfactory performance we must ensure that a minimum * number of objects is in one slab. Otherwise we may generate too much * activity on the partial lists which requires taking the list_lock. This is * less a concern for large slabs though which are rarely used. * * slub_max_order specifies the order where we begin to stop considering the * number of objects in a slab as critical. If we reach slub_max_order then * we try to keep the page order as low as possible. So we accept more waste * of space in favor of a small page order. * * Higher order allocations also allow the placement of more objects in a * slab and thereby reduce object handling overhead. If the user has * requested a higher mininum order then we start with that one instead of * the smallest order which will fit the object. */
static inline unsigned int slab_order(unsigned int size,
unsigned int min_objects, unsigned int max_order,
unsigned int fract_leftover)
{
unsigned int min_order = slub_min_order;
unsigned int order;
if (order_objects(min_order, size) > MAX_OBJS_PER_PAGE)
return get_order(size * MAX_OBJS_PER_PAGE) - 1;
for (order = max(min_order, (unsigned int)get_order(min_objects * size));
order <= max_order; order++) {
unsigned int slab_size = (unsigned int)PAGE_SIZE << order;
unsigned int rem;
rem = slab_size % size;
if (rem <= slab_size / fract_leftover)
break;
}
return order;
}
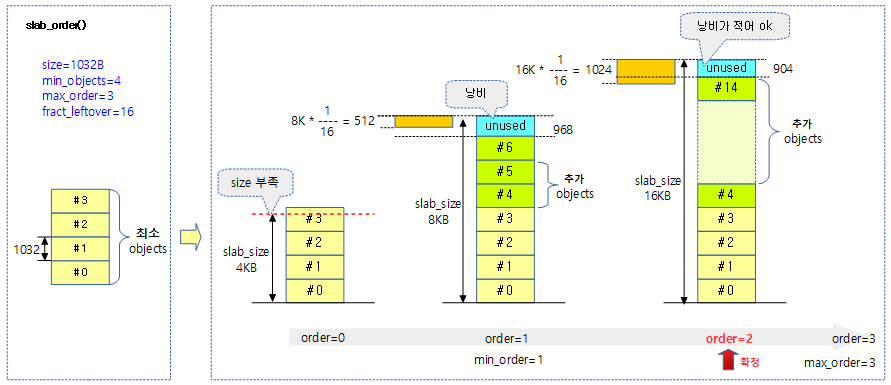
slab 페이지 생성에 필요한 order를 산출한다. @size로 @min_objects 만큼 배치 가능해야 하고, 최대 @max_order 범위내에서 object를 배치하고 남은 공간이 슬랩 페이지의 1/fract_leftover 보다 크면 안된다.
- 코드 라인 5에서 “slub_min_order=”(디폴트=0) 값을 min_order에 대입한다.
- 코드 라인 8~9에서 min_order 페이지에 포함 가능한 object 수가 MAX_OBJS_PER_PAGE(32767)를 초과하는 경우 size * MAX_OBJS_PER_PAGE(32767)를 처리할 수 있는 order 값 – 1을 반환한다.
- 코드 라인 11~12에서 min_order 또는 @min_objects * @size 만큼 포함 가능한 order 둘 중 큰 order 부터 @max_order 까지 순회한다.
- 코드 라인 14~20에서 순회 중인 order 페이지에 object들을 배치하고 남은 공간이 슬랩 페이지의 1/@fract_leftover 보다 작은 경우만 낭비가 적다 판단하여 루프를 벗어나서 order를 반환한다.
다음 그림은 최대 3 order 페이지 범위내에서 object의 사이즈가 1032이고, 최소 4개 이상을 배치하여 남은 사이즈 공간이 슬랩 페이지의 1/16보다 작은 order를 산출하는 모습을 보여준다.
get_order()
include/asm-generic/getorder.h
/** * get_order - Determine the allocation order of a memory size * @size: The size for which to get the order * * Determine the allocation order of a particular sized block of memory. This * is on a logarithmic scale, where: * * 0 -> 2^0 * PAGE_SIZE and below * 1 -> 2^1 * PAGE_SIZE to 2^0 * PAGE_SIZE + 1 * 2 -> 2^2 * PAGE_SIZE to 2^1 * PAGE_SIZE + 1 * 3 -> 2^3 * PAGE_SIZE to 2^2 * PAGE_SIZE + 1 * 4 -> 2^4 * PAGE_SIZE to 2^3 * PAGE_SIZE + 1 * ... * * The order returned is used to find the smallest allocation granule required * to hold an object of the specified size. * * The result is undefined if the size is 0. * * This function may be used to initialise variables with compile time * evaluations of constants. */
#define get_order(n) \
( \
__builtin_constant_p(n) ? ( \
((n) == 0UL) ? BITS_PER_LONG - PAGE_SHIFT : \
(((n) < (1UL << PAGE_SHIFT)) ? 0 : \
ilog2((n) - 1) - PAGE_SHIFT + 1) \
) : \
__get_order(n) \
)
@n 사이즈에 따른 order 값을 산출한다.
- 예) 4K 페이지, n=1025 ~ 2048
- -> 1
__get_order()
include/asm-generic/getorder.h
/* * Runtime evaluation of get_order() */
static inline __attribute_const__
int __get_order(unsigned long size)
{
int order;
size--;
size >>= PAGE_SHIFT;
#if BITS_PER_LONG == 32
order = fls(size);
#else
order = fls64(size);
#endif
return order;
}
@size를 버디 시스템의 order로 표현할 때의 값을 구한다.
- size에서 1을 뺀 값을 페이지 수로 변경하고 이를 표현할 수 있는 필요 비트 수를 구한다.
- fls()
- lsb -> msb로 검색하여 가장 마지막에 발견되는 1로된 비트 번호 + 1
- 예) 0xf000_0000 -> 32
- lsb -> msb로 검색하여 가장 마지막에 발견되는 1로된 비트 번호 + 1
- fls()
- 예) size=0x10_0000 (1MB)
- -> 8
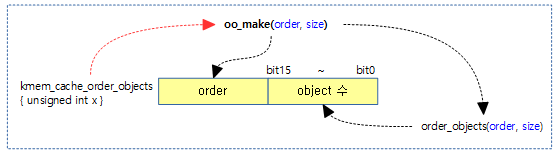
oo_make()
mm/slub.c
static inline struct kmem_cache_order_objects oo_make(unsigned int order,
unsigned int size)
{
struct kmem_cache_order_objects x = {
(order << OO_SHIFT) + order_objects(order, size)
};
return x;
}
@order 및 @size를 사용하여 kmem_cache_order_objects 구조체 객체에 담고 그 값을 반환한다.
- 객체는 하나의 unsigned int 값을 사용하는데 lsb 16bit에 객체 수를 담고 나머지 bits에 order 값을 담는다.
- OO_SHIFT=16
아래 그림은 oo_make() 인라인 함수를 사용하여 order 값과 산출된 객체 수를 kmem_cache_order_objects라는 내부 규조체 객체에 담아 반환을 하는 모습을 보여준다.
oo_objects()
mm/slub.c
static inline unsigned int oo_objects(struct kmem_cache_order_objects x)
{
return x.x & OO_MASK;
}
@x 값에서 object 수 만을 반환한다.
- x 값의 lsb 16bit를 반환한다.
다음 그림은 kmem_cache_order_objects 구조체 객체에서 객체 수 값만을 반환받는 모습을 보여준다.
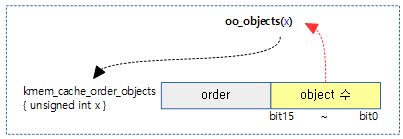
참고
- Slab Memory Allocator -1- (구조) | 문c
- Slab Memory Allocator -2- (캐시 초기화) | 문c
- Slub Memory Allocator -3- (캐시 생성) | 문c
- Slub Memory Allocator -4- (Order 계산) | 문c – 현재 글
- Slub Memory Allocator -5- (Slub 할당) | 문c
- Slub Memory Allocator -6- (Object 할당) | 문c
- Slub Memory Allocator -7- (Object 해제) | 문c
- Slub Memory Allocator -8- (Drain/Flash 캐시) | 문c
- Slub Memory Allocator -9- (캐시 Shrink) | 문c
- Slub Memory Allocator -10- (Slub 해제) | 문c
- Slub Memory Allocator -11- (캐시 삭제) | 문c
- Slub Memory Allocator -12- (Slub 디버깅) | 문c
- Slub Memory Allocator -13- (slabinfo) | 문c