<kernel v5.0>
Drain 캐시
per-cpu 슬랩 캐시 페이지 -> n->partial 리스트로 이동
deactivate_slab()
mm/slub.c -1/3-
/* * Remove the cpu slab */
static void deactivate_slab(struct kmem_cache *s, struct page *page,
void *freelist, struct kmem_cache_cpu *c)
{
enum slab_modes { M_NONE, M_PARTIAL, M_FULL, M_FREE };
struct kmem_cache_node *n = get_node(s, page_to_nid(page));
int lock = 0;
enum slab_modes l = M_NONE, m = M_NONE;
void *nextfree;
int tail = DEACTIVATE_TO_HEAD;
struct page new;
struct page old;
if (page->freelist) {
stat(s, DEACTIVATE_REMOTE_FREES);
tail = DEACTIVATE_TO_TAIL;
}
/*
* Stage one: Free all available per cpu objects back
* to the page freelist while it is still frozen. Leave the
* last one.
*
* There is no need to take the list->lock because the page
* is still frozen.
*/
while (freelist && (nextfree = get_freepointer(s, freelist))) {
void *prior;
unsigned long counters;
do {
prior = page->freelist;
counters = page->counters;
set_freepointer(s, freelist, prior);
new.counters = counters;
new.inuse--;
VM_BUG_ON(!new.frozen);
} while (!__cmpxchg_double_slab(s, page,
prior, counters,
freelist, new.counters,
"drain percpu freelist"));
freelist = nextfree;
}
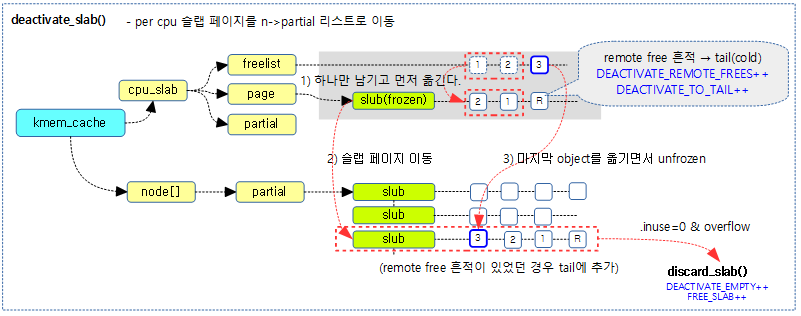
per-cpu 슬랩 페이지를 n->partial 리스트로 이동시킨다.
- 코드 라인 13~16에서 페이지에 free objects들이 있는 경우 DEACTIVASTE_REMOTE_FREES 카운터를 증가시킨다.n->partial 리스트에 추가할 때 후미에 들어가도록 준비한다.
- remote cpu에서 object를 free한 경우 page->freelist에 free object가 존재할 수 있다. 결국 remote cpu가 처리한 페이지 이므로 가능하면 현재 cpu가 접근하게 되는 확률을 늦추게 하기 위해 n->partial 리스트의 마지막에 추가(cold 처리)한다.
Stage 1 – 마지막을 제외한 c->freelist —> page->freelist로 이동
- 코드 라인 26~44에서 @freelist의 마지막 object 하나만 제외하고 순회하며 page->freelist로 옮긴다. 옮긴 object 수 만큼 inuse 카운터를 감소시킨다.
mm/slub.c -2/3-
/*
* Stage two: Ensure that the page is unfrozen while the
* list presence reflects the actual number of objects
* during unfreeze.
*
* We setup the list membership and then perform a cmpxchg
* with the count. If there is a mismatch then the page
* is not unfrozen but the page is on the wrong list.
*
* Then we restart the process which may have to remove
* the page from the list that we just put it on again
* because the number of objects in the slab may have
* changed.
*/
redo:
old.freelist = page->freelist;
old.counters = page->counters;
VM_BUG_ON(!old.frozen);
/* Determine target state of the slab */
new.counters = old.counters;
if (freelist) {
new.inuse--;
set_freepointer(s, freelist, old.freelist);
new.freelist = freelist;
} else
new.freelist = old.freelist;
new.frozen = 0;
if (!new.inuse && n->nr_partial >= s->min_partial)
m = M_FREE;
else if (new.freelist) {
m = M_PARTIAL;
if (!lock) {
lock = 1;
/*
* Taking the spinlock removes the possiblity
* that acquire_slab() will see a slab page that
* is frozen
*/
spin_lock(&n->list_lock);
}
} else {
m = M_FULL;
if (kmem_cache_debug(s) && !lock) {
lock = 1;
/*
* This also ensures that the scanning of full
* slabs from diagnostic functions will not see
* any frozen slabs.
*/
spin_lock(&n->list_lock);
}
}
Stage 2: per-cpu 슬랩 페이지를 n->partial 리스트로 이동.
최초 이 루틴에 진입하는 경우 frozen 상태에서 아직 하나의 object 처리가 남아 있는 상태이다. 기본적으로는 슬랩 페이지를 n->partial 리스트에 이동한다. 단 슬랩 페이지의 모든 object들이 free이면 디버깅을 사용하지 않는 경우에는 그냥 버디로 돌려보낸고, 디버깅을 사용하는 경우엔 n->full 리스트 옮긴다.
- 코드 라인 15에서 redo: 레이블이다. page->freelist에 대해 atomic operation이 실패하면 다시 돌아오게되는 위치이다.
- 코드 라인 17~18에서 old 변수에 현재 슬랩 페이지의 freelist와 카운터(inuse, objects, frozen bit)를 백업해둔다.
- 코드 라인 22~30에서 old 카운터를 복사하여 바뀔 new 카운터를 준비한다. 하나의 object가 남아있는 freelist가 있으면 사용 object 수를 감소시키고 free object들 앞에 마지막 free object를 끼워넣을 준비를 한다. 슬랩 페이지는 unfronzen 상태로 바뀔 예정이다.
- 코드 라인 32~33에서 사용중인 object가 없고 n->partial 리스트가 overflow 상태인 경우 슬랩 페이지를 해제하여 버디 시스템으로 돌리게 하기 위해 현재 모드 상태를 M_FREE로 한다.
- 코드 라인 34~44에서 free object가 하나라도 있는 경우 n->partial 리스트에 추가될 계획으로 현재 모드 상태를 M_PARTIAL로 한다.
- 코드 라인 45~56에서 free object가 하나도 없는 경우 n->full 리스트에 추가될 계획으로 현재 모드를 M_FULL로 한다.
mm/slub.c -3/3-
if (l != m) {
if (l == M_PARTIAL)
remove_partial(n, page);
else if (l == M_FULL)
remove_full(s, n, page);
if (m == M_PARTIAL)
add_partial(n, page, tail);
else if (m == M_FULL)
add_full(s, n, page);
}
l = m;
if (!__cmpxchg_double_slab(s, page,
old.freelist, old.counters,
new.freelist, new.counters,
"unfreezing slab"))
goto redo;
if (lock)
spin_unlock(&n->list_lock);
if (m == M_PARTIAL)
stat(s, tail);
else if (m == M_FULL)
stat(s, DEACTIVATE_FULL);
else if (m == M_FREE) {
stat(s, DEACTIVATE_EMPTY);
discard_slab(s, page);
stat(s, FREE_SLAB);
}
c->page = NULL;
c->freelist = NULL;
}
슬랩 페이지를 unfrozen 시키면서 기존 모드 상태 l과 현재 모드 상태 m에 따라 다음과 같이 슬랩 페이지에 따른 처리를 하되 실패하는 경우 다시 Stage 2 과정부터 돌아가서 처리한다.
- n->partial 리스트에 추가 또는 삭제
- n->full 리스트에 추가 또는 삭제
- 슬랩 페이지를 해제하여 버디 시스템으로 돌려주기
- 코드 라인 1~11에서 슬랩 페이지를 n->partial 또는 n->full에 추가하였던 것을 상태가 바뀌어 다시 제거한 후 적절한 위치로 다시 추가한다.
- frozen 상태의 슬랩 페이지에 free object들의 할당 및 해제가 경쟁 상태에서 계속되고 있다.
- 예) n->partial에 추가하고 atomic 처리를 시도 했는데 실패하였다. 다시 반복하여 처리하려 보니까 슬랩 페이지가 full 상태가 되면 n->partial에 추가하였던 것을 취소하고 다시 n->full에 추가한다.
- 코드 라인 13~18에서 모드를 동일하게 하고, 슬랩 페이지를 다음과 같이 처리한다. 만일 atomic operation이 실패하는 경우 redo: 레이블로 이동하여 다시 시도한다.
- if page->freelist == old.freelist & page->counters == old.counters
- page->freelist = new.freelist
- page->counters = new.counters
- if page->freelist == old.freelist & page->counters == old.counters
- 코드 라인 20~21에서 그 동안 lock이 걸린 경우 해제한다.
- 코드 라인 23~31에서 최종 결정된 모드에 다음과 같이 수행한다.
- 최종 n->partial 리스트에 추가한 경우 DEACTIVATE_TO_HEAD 또는 DEACTIVATE_TO_TAIL 카운터를 증가시킨다.
- 최종 n->full 리스트에 추가한 경우 DEACTIVATE_FULL 카운터를 증가시킨다.
- 최종 버디 시스템으로 돌려보내야 하는 경우 DEACTIVATE_EMPTY 카운터 및 FREE_SLAB 카운터를 증가시키고 버디 시스템으로 돌려보낸다.
- 코드 라인 33~34에서 c->page 및 c->freelist를 비운다.
아래 그림은 per cpu frozen된 슬랩 페이지를 n->partial 리스토 옮기는 과정을 보여준다.
Flush 캐시
flush_all()
mm/slub.c
static void flush_all(struct kmem_cache *s)
{
on_each_cpu_cond(has_cpu_slab, flush_cpu_slab, s, 1, GFP_ATOMIC);
}
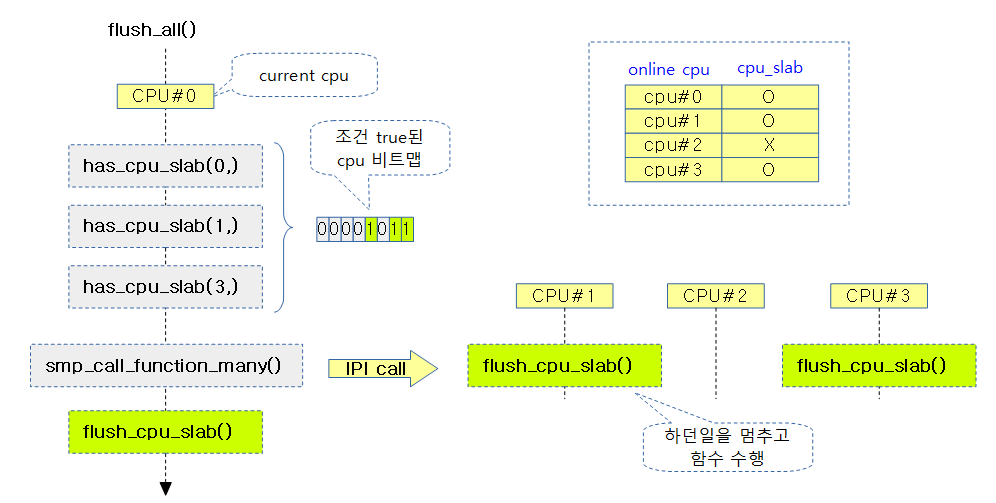
online된 cpu들에서 요청한 슬랩 캐시의 per-cpu 슬랩 페이지들이 존재하는 경우 이를 flush 하여 n->partial 리스트에 옮기도록 각 cpu에 요청하고 완료될 때 까지 기다린다.
아래 그림은 online된 cpu 4개에 대해 슬랩 캐시의 per-cpu 슬랩 페이지가 존재하는 경우 flush하는 flush_cpu_slab() 함수를 호출하는 과정을 보여준다.
has_cpu_slab()
mm/slub.c
static bool has_cpu_slab(int cpu, void *info)
{
struct kmem_cache *s = info;
struct kmem_cache_cpu *c = per_cpu_ptr(s->cpu_slab, cpu);
return c->page || c->partial;
}
슬랩 캐시의 per-cpu 슬랩 페이지들의 유무를 반환한다.
flush_cpu_slab()
mm/slub.c
static void flush_cpu_slab(void *d)
{
struct kmem_cache *s = d;
__flush_cpu_slab(s, smp_processor_id());
}
슬랩 캐시의 현재 cpu에 대한 per-cpu 슬랩 페이지들을 비워 n->partial 리스트로 보낸다.
- c->page 및 c->partial 리스트의 슬랩 페이지들을 n->partial 리스트로 이동시킨다.
- 이 함수는 각 CPU의 IPI 핸들러가 호출되고 수행되어지는 함수이며 반드시 인터럽트는 disable된 채로 호출되야 한다.
__flush_cpu_slab()
mm/slub.c
/* * Flush cpu slab. * * Called from IPI handler with interrupts disabled. */
static inline void __flush_cpu_slab(struct kmem_cache *s, int cpu)
{
struct kmem_cache_cpu *c = per_cpu_ptr(s->cpu_slab, cpu);
if (likely(c)) {
if (c->page)
flush_slab(s, c);
unfreeze_partials(s, c);
}
}
슬랩 캐시의 @cpu에 대한 per-cpu 슬랩 페이지들을 비워 n->partial 리스트로 보낸다.
flush_slab()
mm/slub.c
static inline void flush_slab(struct kmem_cache *s, struct kmem_cache_cpu *c)
{
stat(s, CPUSLAB_FLUSH);
deactivate_slab(s, c->page, c->freelist, c);
c->tid = next_tid(c->tid);
}
슬랩 캐시의 per-cpu 슬랩 페이지를 unfrozen하여 n->partial 리스트로 보낸다. 그리고 CPUSLAB_FLUSH 카운터를 증가시킨다.
SMP 관련 API
on_each_cpu_cond()
kernel/smp.c
void on_each_cpu_cond(bool (*cond_func)(int cpu, void *info),
smp_call_func_t func, void *info, bool wait,
gfp_t gfp_flags)
{
on_each_cpu_cond_mask(cond_func, func, info, wait, gfp_flags,
cpu_online_mask);
}
EXPORT_SYMBOL(on_each_cpu_cond);
online된 cpu들에서 cpu_slab이 존재하는 경우 cpu_slab을 flush 하도록 각 cpu에 요청하고 완료될 때 까지 기다린다.
on_each_cpu_cond_mask()
kernel/smp.c
/* * on_each_cpu_cond(): Call a function on each processor for which * the supplied function cond_func returns true, optionally waiting * for all the required CPUs to finish. This may include the local * processor. * @cond_func: A callback function that is passed a cpu id and * the the info parameter. The function is called * with preemption disabled. The function should * return a blooean value indicating whether to IPI * the specified CPU. * @func: The function to run on all applicable CPUs. * This must be fast and non-blocking. * @info: An arbitrary pointer to pass to both functions. * @wait: If true, wait (atomically) until function has * completed on other CPUs. * @gfp_flags: GFP flags to use when allocating the cpumask * used internally by the function. * * The function might sleep if the GFP flags indicates a non * atomic allocation is allowed. * * Preemption is disabled to protect against CPUs going offline but not online. * CPUs going online during the call will not be seen or sent an IPI. * * You must not call this function with disabled interrupts or * from a hardware interrupt handler or from a bottom half handler. */
void on_each_cpu_cond_mask(bool (*cond_func)(int cpu, void *info),
smp_call_func_t func, void *info, bool wait,
gfp_t gfp_flags, const struct cpumask *mask)
{
cpumask_var_t cpus;
int cpu, ret;
might_sleep_if(gfpflags_allow_blocking(gfp_flags));
if (likely(zalloc_cpumask_var(&cpus, (gfp_flags|__GFP_NOWARN)))) {
preempt_disable();
for_each_cpu(cpu, mask)
if (cond_func(cpu, info))
__cpumask_set_cpu(cpu, cpus);
on_each_cpu_mask(cpus, func, info, wait);
preempt_enable();
free_cpumask_var(cpus);
} else {
/*
* No free cpumask, bother. No matter, we'll
* just have to IPI them one by one.
*/
preempt_disable();
for_each_cpu(cpu, mask)
if (cond_func(cpu, info)) {
ret = smp_call_function_single(cpu, func,
info, wait);
WARN_ON_ONCE(ret);
}
preempt_enable();
}
}
EXPORT_SYMBOL(on_each_cpu_cond_mask);
@mask cpu들에서 인수로 받은 @cond_func() 함수 결과가 true인 경우 인수로 받은 @func() 함수를 수행하게 한다. 그리고 @wait이 true인 경우 현재 cpu에서 각 cpu로 보낸 함수의 실행 요청에 대한 완료를 기다린다.
- 코드 라인 8에서 __GFP_DIRECT_RECLAIM 플래그가 요청된 경우 preemption pointer를 수행한다.
- 코드 라인 10~17에서 cpu 비트맵을 클리어하고, @mask cpu 수 만큼 루프를 돌며 인수로 전달받은 @cond_func() 함수가 결과 값이 true인 경우 cpus 비트맵의 현재 cpu 비트를 설정한다. 그런 후 cpus 비트맵에 설정된 모든 cpu에서 IPI call을 통해 @func 함수를 수행한다. @wait이 true인 경우 각 함수의 실행 완료를 기다린다.
- 코드 라인 18~31에서 zalloc_cpumask_var()를 통해 메모리 할당이 안된 경우 online된 cpu에 대해 루프를 돌며 인수로 전달받은 @cond_func() 함수 결과 값이 true인 경우 해당 cpu에서 @func 함수를 동작시키게 IPI call을 통해 요청한다.
CONFIG_CPUMASK_OFFSTACK 커널 옵션
- CPU 디버깅을 위해 DEBUG_PER_CPU_MAPS 커널 옵션을 사용하는 경우에 사용할 수 있는 커널 옵션이다.
- 이 옵션은 CPU 마스크를 stack을 이용하지 않고 dynamic하게 별도의 메모리 할당을 받아 사용하므로 zalloc_cpumask_var() 함수로 인해서 stack overflow가 발생하지 않는 장점이 있으나 단점으로는 속도가 저하된다.
on_each_cpu_mask()
kernel/smp.c
/** * on_each_cpu_mask(): Run a function on processors specified by * cpumask, which may include the local processor. * @mask: The set of cpus to run on (only runs on online subset). * @func: The function to run. This must be fast and non-blocking. * @info: An arbitrary pointer to pass to the function. * @wait: If true, wait (atomically) until function has completed * on other CPUs. * * If @wait is true, then returns once @func has returned. * * You must not call this function with disabled interrupts or from a * hardware interrupt handler or from a bottom half handler. The * exception is that it may be used during early boot while * early_boot_irqs_disabled is set. */
void on_each_cpu_mask(const struct cpumask *mask, smp_call_func_t func,
void *info, bool wait)
{
int cpu = get_cpu();
smp_call_function_many(mask, func, info, wait);
if (cpumask_test_cpu(cpu, mask)) {
unsigned long flags;
local_irq_save(flags);
func(info);
local_irq_restore(flags);
}
put_cpu();
}
EXPORT_SYMBOL(on_each_cpu_mask);
@mask에 설정된 모든 cpu에서 @func 함수를 수행한다. @wait이 true인 경우 각 함수의 실행 완료를 기다린다.
- 코드 라인 6에서 현재 cpu를 제외한 리모트 cpu 모두에서 @func 함수가 실행되게 한다. @wait 인수를 true로 지정하는 경우 현재 cpus는 각 cpu의 함수 실행이 완료될 때 까지 기다린다.
- 참고: IPI cross call – 소프트 인터럽트 | 문c
- 코드 라인 7~12에서 현재 cpu도 마스크 되어 있는 경우 @func 함수를 실행한다.
참고
- Slab Memory Allocator -1- (구조) | 문c
- Slab Memory Allocator -2- (캐시 초기화) | 문c
- Slub Memory Allocator -3- (캐시 생성) | 문c
- Slub Memory Allocator -4- (Order 계산) | 문c
- Slub Memory Allocator -5- (Slub 할당) | 문c
- Slub Memory Allocator -6- (Object 할당) | 문c
- Slub Memory Allocator -7- (Object 해제) | 문c
- Slub Memory Allocator -8- (Drain/Flash 캐시) | 문c – 현재 글
- Slub Memory Allocator -9- (캐시 Shrink) | 문c
- Slub Memory Allocator -10- (Slub 해제) | 문c
- Slub Memory Allocator -11- (캐시 삭제) | 문c
- Slub Memory Allocator -12- (Slub 디버깅) | 문c
- Slub Memory Allocator -13- (slabinfo) | 문c
안녕하세요, 문영일님~
아이엠루트 16차 이파란입니다~
연이어 질문 하나 더 드리겠습니다.. ^^;
** 아래 그림은 per cpu frozen된 슬랩 페이지를 n->partial 리스토 옮기는 과정을 보여준다.
// deactivate_slab-1a.png
Drain c->freelist 에 마지막을 제외하고 하는 이유가 무엇일까요?
음, 하나를 제외하고 옮기는 목적은 무엇일까요?
p.s.
앗 그리고 스터디 관련해서 12월에 크리스마스, 신정 빼면 2주 정도의 시간이 남아있는데요.
슬럽은 1 ~ 13 까지 다 보았구, 2년여의 시간동안 메모리 서브시스템 + cgroup 기초까지 전반적으로 본 것 같습니다.
이제 어떤 주제부터 스터디 하면 좋을까요? 후보로 생각나는 항목은
(1) start_kernel -> mm_init -> kem cache init 이후에 코드를 순서대로 분석하는게 좋을까요?
(2) 코드로 알아보는 ARM 리눅스 커널 슬랩 이후의 순서대로 보는게 좋을까요?
(3) 리눅스 커널의 이해에 특정 챕터를 볼까요? 프로세스? fork ?
(4) cpu 매뉴얼?
12월에 말부터 연속으로 2주를 쉬어서
그 전에는 어떤 항목을 보면 좋을지 고민 중입니다.
루프를 돌면서 c->freelist의 object들을 frozen 상태를 유지하며 page->freelist로 옮기고, 마지막에 노드의 partial 리스트로 옮긴 후 마지막 object와 unfrozen을 동시에 atomic하게 처리하기 위해 로직 구성상 마지막 1개의 object는 따로 처리합니다.
다음과 같은 시퀀스로 처리합니다.
1) c->freelist에 있는 n-1 object들을 page->freelist로 옮기기
2) 위의 페이지를 n->partial로 옮기기
3) c->freelist에 있는 마지막 1개의 object를 page->freelist로 옮기면서 unfreeze를 동시에 하기.
————–
메모리 관리 이후 스터디 코스는 다음과 같이 제안합니다.
1) 클럭 -> 카운터/타이머 -> 타임 관리 -> 인터럽트/gic -> 스케줄러들 -> 프로세스/태스크 관리(fork)
향후 드라이버 관련된 메모리 관리에 대해서는 cma, dma(coherent), iommu 등도 관심을 갖으시면 됩니다.
감사합니다.
앗 해당 그림 3) 동작에 나와있었는데, 놓치고 있었네요!
정말 감사합니다!
p.s
답변 해주셔서 감사합니다! 스터디 멤버들과 공유하고
현재 문C 블로그 기준으로 클록 관련하여 아래 순서대로 봐야하겠네요!
– Common Clock Framework -1, 2
– Timer 시리즈
– time_init()
자세하게 설명해주셔서, 항상 감사드립니다!