메모리 Fault 핸들러
유저 태스크에서 sys_mmap()이나 sys_brk() 등을 통해 커널에 메모리를 요청하면 커널은 곧바로 해당 태스크에 메모리를 할당하여 매핑하지 않는다. 커널은 요청을 받으면 요청한 유저 태스크의 rb 트리(로 관리하는 vma 정보에 메모리 range 및 플래그 등의 정보만을 기록(추가 또는 변경)한다. 그런 후 유저 태스크에서 실제 해당 페이지에 접근하려할 때 fault가 발생하도록 유도한다. fault 핸들러는 이러한 요구에 대한 처리를 수행한다. 요청한 페이지가 처음 0으로 초기화된 메모리를 요청하는 경우 zero 페이지에 매핑을 하거나, 다른 태스크에서 사용중인 페이지로 매핑하여 페이지를 공유하게 하는 방법을 사용한다. 이렇게 처리하게 되면 다음 몇 가지의 장점을 얻게된다.
- 유저 태스크가 요청한 메모리를 할당 받자마자 모두 다 사용하는 것이 아니므로 필요한 메모리에 접근할 때에만 물리 메모리를 할당하면 실제 메모리의 사용을 절약할 수 있다.
- anon 매핑: 파일과 관계 없는 유저 태스크가 요구하는 heap, stack 메모리 요청
- file 매핑: 유저가 파일을 가상 주소 공간에 매핑(memory-mapped 파일) 요청 – mmap 메모리 요청
- 유저 태스크가 요청한 메모리에 대한 처리를 커널이 빠르게 수행할 수 있다. – COW(Copy On Write) 방법
- 부모 태스크가 child 태스크의 생성을 위해 fork 또는 clone등을 수행할 때 child 태스크가 사용할 메모리 할당 요청에 대해 즉각적으로 물리 페이지를 할당하지 않고 부모 태스크가 사용하던 메모리 페이지 테이블을 복사하여 사용한다. 이렇게 하여 빠른 태스크의 생성이 가능해진다.
- h/w 아키텍처가 실제 메모리의 접근에 대한 모니터링을 지원하지 못하는 경우에도 이러한 fault 처리를 통해 리눅스가 알아낼 수 있도록 표식을 남길 수 있다. (young 플래그)
MMU가 TLB를 통해 Table walk를 수행하다 매핑되지 않은 페이지이거나 페이지 fault 핸들러인 do_page_fault() -> __do_page_fault() 함수를 통해 handle_mm_fault() 함수가 호출되었다. 다음 그림에서 그 이후 함수 호출 흐름을 보여준다.
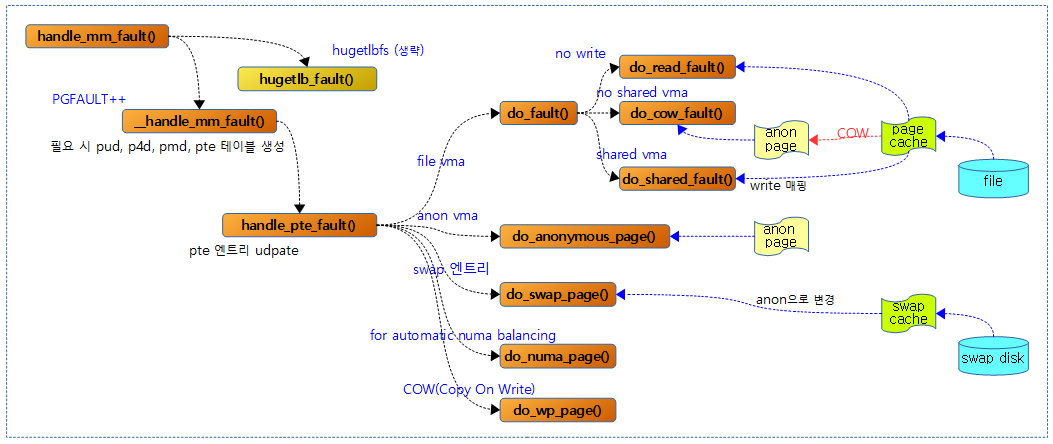
handle_mm_fault()
mm/memory.c
/* * By the time we get here, we already hold the mm semaphore * * The mmap_sem may have been released depending on flags and our * return value. See filemap_fault() and __lock_page_or_retry(). */
vm_fault_t handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
vm_fault_t ret;
__set_current_state(TASK_RUNNING);
count_vm_event(PGFAULT);
count_memcg_event_mm(vma->vm_mm, PGFAULT);
/* do counter updates before entering really critical section. */
check_sync_rss_stat(current);
if (!arch_vma_access_permitted(vma, flags & FAULT_FLAG_WRITE,
flags & FAULT_FLAG_INSTRUCTION,
flags & FAULT_FLAG_REMOTE))
return VM_FAULT_SIGSEGV;
/*
* Enable the memcg OOM handling for faults triggered in user
* space. Kernel faults are handled more gracefully.
*/
if (flags & FAULT_FLAG_USER)
mem_cgroup_enter_user_fault();
if (unlikely(is_vm_hugetlb_page(vma)))
ret = hugetlb_fault(vma->vm_mm, vma, address, flags);
else
ret = __handle_mm_fault(vma, address, flags);
if (flags & FAULT_FLAG_USER) {
mem_cgroup_exit_user_fault();
/*
* The task may have entered a memcg OOM situation but
* if the allocation error was handled gracefully (no
* VM_FAULT_OOM), there is no need to kill anything.
* Just clean up the OOM state peacefully.
*/
if (task_in_memcg_oom(current) && !(ret & VM_FAULT_OOM))
mem_cgroup_oom_synchronize(false);
}
return ret;
}
EXPORT_SYMBOL_GPL(handle_mm_fault);
유저 공간의 vma 영역에 대해 접근하다 fault가 발생하여 진입한 핸들러이다. vma 영역 상태에 따라 처리 방법이 다르다.
- 코드 라인 6에서 현재 태스크를 TASK_RUNNING 상태로 설정한다.
- 코드 라인 8~9에서 PGFAULT vm 카운터를 증가시기고, 현재 태스크가 memcg 통제를 받는 경우 이에 대해서도 증가시킨다.
- 코드 라인 12에서 해당 태스크에서 TASK_RSS_EVENTS_THRESH(64)번 만큼 fault가 발생한 경우 per-cpu rss 관련 메모리 통계를 글로벌에 갱신한다.
- 코드 라인 14~17에서 코드 영역에 기록을 수행하려 할 때 특정 아키텍처가 지원하지 않는 경우 VM_FAULT_SIGSEGV를 반환한다.
- arch_vma_access_permitted() 함수는 x86, powerpc에 해당 코드를 지원하며 그 밖의 경우 항상 true를 반환한다.
- 코드 라인 23~24에서 유저 영역에 대한 fault인 경우 memcg OOM 기능을 동작하도록 enable 한다.
- 코드 라인 26~29에서 hugetlb를 사용하는 영역 여부에 따라 각각의 fault 함수를 호출한다.
- 코드 라인 31~41에서 유저 영역에 대한 fault인 경우 memcg OOM 기능을 disable 한다. 만일 태스크가 memcg oom을 진행중이고 fault 핸들러 결과가 fault OOM이 아닌 경우 oom 동기화도 수행한다.
__handle_mm_fault()
mm/memory.c -1/2-
/* * By the time we get here, we already hold the mm semaphore * * The mmap_sem may have been released depending on flags and our * return value. See filemap_fault() and __lock_page_or_retry(). */
static vm_fault_t __handle_mm_fault(struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
unsigned int dirty = flags & FAULT_FLAG_WRITE;
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
vm_fault_t ret;
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
if (!p4d)
return VM_FAULT_OOM;
vmf.pud = pud_alloc(mm, p4d, address);
if (!vmf.pud)
return VM_FAULT_OOM;
if (pud_none(*vmf.pud) && __transparent_hugepage_enabled(vma)) {
ret = create_huge_pud(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
pud_t orig_pud = *vmf.pud;
barrier();
if (pud_trans_huge(orig_pud) || pud_devmap(orig_pud)) {
/* NUMA case for anonymous PUDs would go here */
if (dirty && !pud_write(orig_pud)) {
ret = wp_huge_pud(&vmf, orig_pud);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
huge_pud_set_accessed(&vmf, orig_pud);
return 0;
}
}
}
p4d, pud, pmd 및 pte 테이블이 필요한 경우 할당하여 연결(population)하고 루틴의 마지막에서 handle_pte_fault() 함수를 호출하여 pte 테이블에서의 fault 처리를 수행한다.
pud population
- 코드 라인 4~10에서 fault 처리를 위해 여러 함수가 사용되는데 필요한 인자가 많아서 이를 쉽게 전달할 구조체 vm_fault에 담는다. 주요 정보로 다음들을 담는다.
- .vma
- fault 발생한 vma 영역
- .address
- fault 발생한 가상 주소 페이지의 시작 주소
- .flags
- .pgoff
- vma 영역내에서 fault 발생한 가상 주소 페이지의 offset 페이지 번호
- .gfp_mask
- 파일 매핑된 경우 fs, io를 포함한 매핑에 사용한 gfp 플래그를 사용하고, 그 외의 경우 GFP_KERNEL에 해당하는 gfp 플래그를 사용한다.
- .vma
- 코드 라인 11에서 write 중에 fault가 발생했는지 여부를 dirty에 대입한다.
- 코드 라인 17에서 fault 가상 주소에 해당하는 pgd 엔트리를 알아온다.
- 코드 라인 18~20에서 pgd 엔트리가 빈 경우 연결을 위해 다음 레벨인 p4d 테이블을 할당한다.
- 코드 라인 22~24에서 p4d 엔트리가 빈 경우 연결을 위해 다음 레벨인 pud 테이블을 할당한다.
- 코드 라인 25~28에서 pud 엔트리가 비어있고, pud 단위의 블록 매핑을 사용할 조건을 만족하면 huge pud를 할당한다.
- ARM64의 경우 pud 단위의 블럭 매핑은 1G에 해당한다.
- 코드 라인 29~46에서 pud_trans_huge() 함수에선 pud 단위의 thp가 가능한 경우에 한해 다음과 같이 처리한다.
- pud 엔트리가 읽기 전용 매핑되었고, write 시도하여 fault가 발생한 경우 파일 매핑된 파일 시스템이 (*huge_fault) 후크를 지원하는 경우 이를 실행한다. 그 외 anonymous 등은 아직 지원하지 않아 VM_FAULT_FALLBACK을 반환받아 오므로 계속 코드를 진행한다.
- 그 외의 경우 pud 엔트리에 읽었음을 의미하는 young 플래그를 기록한다. 또한 write 시도였던 경우 dirty 플래그도 기록한다.
DAX(Direct Access)와 huge pud fault
DAX를 지원하는 파일 시스템이 (*huge_fault) 후크 함수를 지원하면, 이를 통해 이 영역에 접근 하여 fault가 발생하는 경우 pte 단위(4K) 보다 더 큰 pmd(2M) 단위 또는 pud 단위(ARM64에서 1G )로 크게 매핑하면 그 만큼 fault 발생 횟수를 줄이므로 성능을 향상시킨다.
- 현재 리눅스에서 DAX를 지원하는 파일 시스템과 지원하는 fault 매핑 크기는 다음과 같다.
- ext2의 경우 pte(4K) 단위의 fault 매핑을 지원한다.
- ext4의 경우 pte(4K) 및 pmd(2M) 단위의 huge fault 매핑을 지원한다.
- xfs의 경우 pte(4K), pmd(2M) 및 pud(1G) 단위의 huge fault 매핑을 지원한다.
- MS 윈도우 ntfs의 경우에도 dax를 지원하나, 리눅스에서는 아직 지원하지 않는다.
- 참고: Persistent Memory & DAX | 문c
mm/memory.c -2/2-
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
if (!vmf.pmd)
return VM_FAULT_OOM;
if (pmd_none(*vmf.pmd) && __transparent_hugepage_enabled(vma)) {
ret = create_huge_pmd(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
pmd_t orig_pmd = *vmf.pmd;
barrier();
if (unlikely(is_swap_pmd(orig_pmd))) {
VM_BUG_ON(thp_migration_supported() &&
!is_pmd_migration_entry(orig_pmd));
if (is_pmd_migration_entry(orig_pmd))
pmd_migration_entry_wait(mm, vmf.pmd);
return 0;
}
if (pmd_trans_huge(orig_pmd) || pmd_devmap(orig_pmd)) {
if (pmd_protnone(orig_pmd) && vma_is_accessible(vma))
return do_huge_pmd_numa_page(&vmf, orig_pmd);
if (dirty && !pmd_write(orig_pmd)) {
ret = wp_huge_pmd(&vmf, orig_pmd);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
huge_pmd_set_accessed(&vmf, orig_pmd);
return 0;
}
}
}
return handle_pte_fault(&vmf);
}
pmd population
- 코드 라인 1~3에서 pud 엔트리가 빈 경우 연결을 위해 다음 레벨인 pmd 테이블을 할당한다.
- 코드 라인 4~7에서 pmd 엔트리가 비어있고, pmd 단위의 블록 매핑을 사용할 조건을 만족하면 huge pmd를 할당한다.
- ARM64의 경우 pmd 단위의 블럭 매핑은 2M에 해당한다.
- 코드 라인 8~18에서 pmd 엔트리가 존재하는 경우이다. 낮은 확률로 pmd 엔트리가 swap 된 상태에서 fault가 발생한 경우 swap 영역으로 부터 로딩 중이다. 잠시 기다렸다 성공 값 0을 반환한다.
- 코드 라인 19~32에서 pmd_trans_huge() 함수에선 pmd 단위의 thp가 가능하거나 pmd 단위의 디바이스 메모리의 맵이 가능한 경우에 한해 다음과 같이 처리한다.
- vma 영역에 접근이 가능한 상태이면 do_huge_pmd_numa_page() 함수를 통해 huge pmd에 대한 처리를 수행한다.
- pmd 엔트리가 읽기 전용 매핑되었고, write 시도하여 fault가 발생한 경우 파일 매핑된 파일 시스템이 (*huge_fault) 후크를 지원하는 경우 이를 실행한다. 그 외 anonymous 등은 아직 지원하지 않아 VM_FAULT_FALLBACK을 반환받아 오므로 계속 코드를 진행한다.
- 그 외의 경우 pmd 엔트리에 읽었음을 의미하는 young 플래그를 기록한다. 또한 write 시도였던 경우 dirty 플래그도 기록한다.
pte fault 처리
- 코드 라인 34에서 마지막 pte fault를 처리하기 위해 handle_pte_fault() 함수를 호출한다.
handle_pte_fault()
mm/memory.c
/* * These routines also need to handle stuff like marking pages dirty * and/or accessed for architectures that don't do it in hardware (most * RISC architectures). The early dirtying is also good on the i386. * * There is also a hook called "update_mmu_cache()" that architectures * with external mmu caches can use to update those (ie the Sparc or * PowerPC hashed page tables that act as extended TLBs). * * We enter with non-exclusive mmap_sem (to exclude vma changes, but allow * concurrent faults). * * The mmap_sem may have been released depending on flags and our return value. * See filemap_fault() and __lock_page_or_retry(). */
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
if (unlikely(pmd_none(*vmf->pmd))) {
/*
* Leave __pte_alloc() until later: because vm_ops->fault may
* want to allocate huge page, and if we expose page table
* for an instant, it will be difficult to retract from
* concurrent faults and from rmap lookups.
*/
vmf->pte = NULL;
} else {
/* See comment in pte_alloc_one_map() */
if (pmd_devmap_trans_unstable(vmf->pmd))
return 0;
/*
* A regular pmd is established and it can't morph into a huge
* pmd from under us anymore at this point because we hold the
* mmap_sem read mode and khugepaged takes it in write mode.
* So now it's safe to run pte_offset_map().
*/
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
/*
* some architectures can have larger ptes than wordsize,
* e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and
* CONFIG_32BIT=y, so READ_ONCE cannot guarantee atomic
* accesses. The code below just needs a consistent view
* for the ifs and we later double check anyway with the
* ptl lock held. So here a barrier will do.
*/
barrier();
if (pte_none(vmf->orig_pte)) {
pte_unmap(vmf->pte);
vmf->pte = NULL;
}
}
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma))
return do_numa_page(vmf);
vmf->ptl = pte_lockptr(vmf->vma->vm_mm, vmf->pmd);
spin_lock(vmf->ptl);
entry = vmf->orig_pte;
if (unlikely(!pte_same(*vmf->pte, entry)))
goto unlock;
if (vmf->flags & FAULT_FLAG_WRITE) {
if (!pte_write(entry))
return do_wp_page(vmf);
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry,
vmf->flags & FAULT_FLAG_WRITE)) {
update_mmu_cache(vmf->vma, vmf->address, vmf->pte);
} else {
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (vmf->flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(vmf->vma, vmf->address);
}
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
}
요청한 가상 주소에서 fault된 경우 마지막 pte에 엔트리에 대한 처리이다. fault에 의해 처리되는 주요 항목은 다음과 같다.
- file 매핑 타입으로 사용되는 vma 영역에서 fault된 경우 file과 관련한 fault 처리를 수행한다.
- anon 타입으로 사용되는 vma 영역에서 fault된 경우 새 페이지를 매핑하고 reverse anon에 역매핑 관리를 추가한다.
- swap된 anon 페이지에서 fault된 경우 새 페이지를 swap 파일로부터 읽는다.
- write protect 매핑되어 있는 공유메모리에 write 하려다가 fault된 경우 해당 페이지를 새 페이지에 복사한 후 write 매핑한다. (COW)
- numa 페이지 migration
- numa 밸런싱을 위해 fault된 경우에는 페이지를 migration 한다.
- 코드 라인 5~12에서 마지막 pte 테이블을 가리키는 pmd 엔트리가 비어있는 경우이다. vmf->pte에 null을 대입하여 이어지는 루틴에서 이에 대한 처리를 하도록 한다.
- 코드 라인 13~39에서 pmd 엔트리가 존재하는 경우이다. vmf->pte에 pte 엔트리를 알아온다. 단 pmd 단위로 동작하는 디바이스 메모리이거나 pmd 단위로 동작하는 thp인 경우 더 이상 진행할 필요 없으므로 0을 반환한다.
fault에 의해 처리되는 주요 항목들
- 코드 라인 41~46에서 테이블을 pte 엔트리가 매핑되어 있지 않은 경우 fault된 vma 영역이 file 매핑 또는 anon 매핑인지 구분하여 해당 처리 함수를 호출한다.
- anon 매핑을 사용하는 경우 do_anonymous_page() 함수를 호출하여 새로운 페이지를 할당받아 매핑한다. 이 방법을 lazy 페이지 할당이라고 한다.
- file 매핑을 사용하는 경우 file로부터 페이지를 읽어들이기 위해 do_fault() 함수를 호출한다.
- 코드 라인 48~49에서 swap 엔트리인 경우 swap 된 페이지를 불러오기 위해 do_swap_page()를 호출한다.
- 코드 라인 51~52에서 NUMA 밸런싱을 위해 fault가 발생한 경우 페이지를 migration하기 위해 do_numa_page() 함수를 호출한다.
- 코드 라인 54~58에서 지금부터 pte 엔트리 값을 변경하기 위해 페이지 테이블 락을 획득한다.
- pmd 엔트리 값에 해당하는, 즉 pte 페이지 테이블에 대한 페이지의 ptl(page table lock) 값을 가져오고 lock을 수행한다.
- 코드 라인 59~63에서 페이지에 write 요청을 한 경우 엔트리 값에 dirty 설정을 한다. 또한 write protect 엔트리 즉 read-only 공유 페이지에 write 요청이 온 경우 기존 공유페이지를 새 페이지에 복사하기 위해 do_wp_page() 함수를 호출한다.
- 유저가 공유메모리에 대해 write 요청을 하는 경우 기존 공유 페이지를 새 페이지에 COW(Copy-On-Write) 한다.
pte 엔트리 갱신
- 코드 라인 64에서 엔트리 값에 현재 페이지에 acceess 하였음을 표시하는 young 비트 설정을 한다.
- 코드 라인 65~77에서 pte 값과 엔트리 값이 다른 경우 pte 테이블 엔트리 값을 갱신한다. 실제 업데이트가 이루어진 경우 캐시도 업데이트한다. 만일 값이 같아 pte 테이블 엔트리 값을 업데이트 하지 않더라도 write 요청이 있었으면 tlb flush를 진행해야한다.
- update_mmu_cache() 함수
- arm 아키텍처 v6 이상 및 arm64에서는 아무런 동작을 하지 않아도 된다.
- update_mmu_cache() 함수
Page Translation Fault
ARM 및 ARM64의 경우 페이지 테이블 단계별로 엔트리에 접근하는데 이 때 해당 가상 주소에 대한 각 단계별 페이지 테이블의 엔트리 값중 bit0가 0인 경우 fault가 발생한다.
Lazy Page Allocation
유저 프로세스가 malloc() 함수를 호출할 때 Heap 매니저가 메모리가 부족 시 커널로 메모리 할당을 요청하는데 이 때 커널은 물리메모리는 할당하지 않고 가상 주소 영역(vma)만 지정한 후 페이지 테이블에는 null 매핑을 해둔다. 이렇게 비어있는 pte 엔트리를 비워두고 유저가 이 공간에 접근할 때 매핑되지 않은 공간이므로 fault가 발생하게 되는데 이 때에 실제 물리 메모리를 할당하고 해당 가상 주소에 매핑하는 방식을 사용한다.
swap 엔트리
- pte 엔트리 값의 bit0 값이 0이면 매핑되지 않아서 fault가 발생한다. 그 엔트리의 다른 비트들에 어떠한 값이 존재하면 그 pte 엔트리는 swap 엔트리 값으로 사용한다.
- swap 엔트리의 관리 메모리를 절약하기 위해 pte 엔트리를 사용한다.
NUMA 밸런싱 & protnone()
- NUMA 시스템에서 해당 페이지를 읽을 때 accesss 권한 실패로 인해 abort exception이 발생되어 fault된 후 해당 페이지를 사용하는 태스크의 migration을 고려하는 Automatic NUMA balancing을 위해 사용된다. NUMA 밸런싱을 사용하지 않는 UMA 시스템에서는 항상 0을 반환한다.
- ARM64
- return (pte_val(pte) & (PTE_VALID | PTE_PROT_NONE)) == PTE_PROT_NONE;
- none 비트만 설정되고 valid 비트는 없는 상태
- x86
- return (pmd_flags(pmd) & (_PAGE_PROTNONE | _PAGE_PRESENT)) == _PAGE_PROTNONE;
- none 비트만 설정되고 present 비트는 없는 상태
파일 매핑(mmap)된 주소에서의 fault 처리
do_fault()
mm/memory.c
/* * We enter with non-exclusive mmap_sem (to exclude vma changes, * but allow concurrent faults). * The mmap_sem may have been released depending on flags and our * return value. See filemap_fault() and __lock_page_or_retry(). * If mmap_sem is released, vma may become invalid (for example * by other thread calling munmap()). */
static vm_fault_t do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mm_struct *vm_mm = vma->vm_mm;
vm_fault_t ret;
/*
* The VMA was not fully populated on mmap() or missing VM_DONTEXPAND
*/
if (!vma->vm_ops->fault) {
/*
* If we find a migration pmd entry or a none pmd entry, which
* should never happen, return SIGBUS
*/
if (unlikely(!pmd_present(*vmf->pmd)))
ret = VM_FAULT_SIGBUS;
else {
vmf->pte = pte_offset_map_lock(vmf->vma->vm_mm,
vmf->pmd,
vmf->address,
&vmf->ptl);
/*
* Make sure this is not a temporary clearing of pte
* by holding ptl and checking again. A R/M/W update
* of pte involves: take ptl, clearing the pte so that
* we don't have concurrent modification by hardware
* followed by an update.
*/
if (unlikely(pte_none(*vmf->pte)))
ret = VM_FAULT_SIGBUS;
else
ret = VM_FAULT_NOPAGE;
pte_unmap_unlock(vmf->pte, vmf->ptl);
}
} else if (!(vmf->flags & FAULT_FLAG_WRITE))
ret = do_read_fault(vmf);
else if (!(vma->vm_flags & VM_SHARED))
ret = do_cow_fault(vmf);
else
ret = do_shared_fault(vmf);
/* preallocated pagetable is unused: free it */
if (vmf->prealloc_pte) {
pte_free(vm_mm, vmf->prealloc_pte);
vmf->prealloc_pte = NULL;
}
return ret;
}
file 매핑 타입으로 사용되는 vma 영역에서 fault된 경우 다음 3가지 유형으로 처리한다.
- write 권한 요청이 없는 경우 페이지 캐시에 있는 페이지를 읽어와 매핑한다. 만일 페이지 캐시에 없으면 file로 부터 읽어 다시 페이지 캐시에 저장한다.
- read only 비 공유 파일에 대해 write 권한 요청이 있는 경우 file로 부터 읽어 페이지 캐시에 저장한 후 새 페이지에 복사하고 그 페이지에 write 권한을 부여하여 anon 매핑한다.
- read only 공유 파일에 대해 write 권한 요청이 있는 경우 write 권한을 설정한다.
- 코드 라인 10~35에서 매핑된 디바이스나 파일 시스템에 vm_ops->fault 후크 함수가 지원되지 않는 경우의 처리이다.
- pte 엔트리의 unmap을 처리한다.
- 32비트 시스템에서는 pte 엔트리를 highmem에 매핑하는 옵션을 사용할 수 있다. 이러한 경우에 한해 pte 테이블을 사용하지 않을 때 unmap 처리를 해야 한다.
- 64비트 시스템에서는 pte 엔트리가 항상 매핑 상태를 유지하는 normal 메모리를 사용하므로 별도로 언매핑 처리하지 않는다.
- CONFIG_HIGHPTE 커널 옵션을 사용하면 pte 엔트리를 highmem에 할당하여 사용할 수 있다.
- 다음과 같이 fault 처리한다.
- pmd 엔트리가 준비되어 있지 않으면 VM_FAULT_SIGBUS fault를 반환한다.
- fault 주소에 대응하는 pte 엔트리 값이 없으면 VM_FAULT_SIGBUS, 있으면 VM_FAULT_NOPAGE를 반환한다.
- pte 엔트리의 unmap을 처리한다.
- 코드 라인 36~37에서 write 요청이 없는 경우 매핑된 file로부터 페이지를 읽기 위해 do_read_fault() 함수를 호출한다.
- 코드 라인 38~39에서 vma 영역이 공유 설정된 경우 매핑된 file로부터 페이지를 읽은 후에 새 페이지에 복사하고 write 설정하기 위해 do_cow_fault() 함수를 호출한다.
- 코드 라인 40~41에서 그 외의 경우 매핑된 file로부터 페이지를 읽은 후 write 설정하기 위해 do_shared_fault() 함수를 호출한다.
- 코드 라인 44~48에서 사전에 준비한 사용되지 않는 pte 페이지 테이블을 할당해제 한다.
file 매핑
- 디바이스 또는 파일을 vma 공간에 매핑하여 사용한다.
- 페이지 캐시를 검색하여 없으면 새 페이지를 file로부터 읽은 후 페이지 캐시로 등록한다. 페이지 캐시가 검색되는 경우 이 페이지를 가상 공간에 매핑하여 사용한다.
- DAX를 지원하는 파일시스템의 경우 페이지 캐시를 사용하지 않고, 파일 시스템에 연결된 persistent 메모리 등을 직접 가상 공간에 매핑하여 사용한다.
다음 그림은 file 또는 디바이스(pmem 등)를 가상 주소에 mmap() 매핑한 후 해당 영역에서 fault가 발생한 함수 처리 경로를 보여준다.
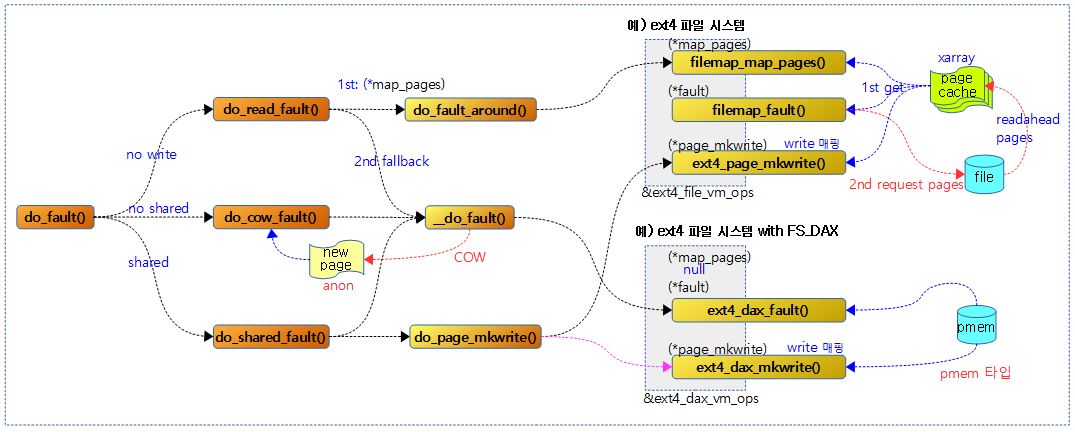
—커널 5.4 코드로 수정 중—
do_read_fault()
mm/memory.c
static int do_read_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd,
pgoff_t pgoff, unsigned int flags, pte_t orig_pte)
{
struct page *fault_page;
spinlock_t *ptl;
pte_t *pte;
int ret = 0;
/*
* Let's call ->map_pages() first and use ->fault() as fallback
* if page by the offset is not ready to be mapped (cold cache or
* something).
*/
if (vma->vm_ops->map_pages && fault_around_bytes >> PAGE_SHIFT > 1) {
pte = pte_offset_map_lock(mm, pmd, address, &ptl);
do_fault_around(vma, address, pte, pgoff, flags);
if (!pte_same(*pte, orig_pte))
goto unlock_out;
pte_unmap_unlock(pte, ptl);
}
ret = __do_fault(vma, address, pgoff, flags, NULL, &fault_page);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
return ret;
pte = pte_offset_map_lock(mm, pmd, address, &ptl);
if (unlikely(!pte_same(*pte, orig_pte))) {
pte_unmap_unlock(pte, ptl);
unlock_page(fault_page);
page_cache_release(fault_page);
return ret;
}
do_set_pte(vma, address, fault_page, pte, false, false);
unlock_page(fault_page);
unlock_out:
pte_unmap_unlock(pte, ptl);
return ret;
}
파일 시스템의 vm_ops의 map_pages 핸들러를 통해 페이지 캐시로부터 exception된 가상 주소의 주변(readahead 기능) 페이지들을 읽어오는데 만일 그러한 핸들러가 필요 없는 블럭 디바이스(FS_DAX)이거나 페이지 캐시로 부터 읽어오지 못한 경우 fallback되어 vm_ops의 fault 핸들러를 통해 파일에서 해당 페이지에 대해서 read I/O 요청을 한다.
- 코드 라인 15~21에서 vma에 map_pages 핸들러가 있고 fault_around_bytes가 2 페이지 이상인 경우 pte 테이블 페이지에 대한 ptl lock을 걸고 fault 주소 주변의 몇 개 페이지들을 불러 온다. pte 값이 변경된 경우 unlock_out 레이블로 이동하여 ptl 락을 풀고 함수를 빠져나간다.
- 이렇게 미리 주변 페이지를 불러오는 경우 fault 처리를 줄이고자 하는데 목적이 있다.
- ext2나 ext4 파일 시스템에서 generic 함수인 filemap_map_pages() 함수가 사용된다.
- DAX(Direct Access eXicting) 기능에서는 앞으로 더 읽을 것이라고 예측하여 주변 페이지를 미리 더 읽어오게 하는 readahead 기능을 사용하지 않으므로 map_pages에 해당하는 핸들러는 제공하지 않는다. 따라서 map_pages 핸들러에서 항상 fallback된다.
- fault_around_bytes
- default 값으로 65536이며 CONFIG_DEBUG_FS 커널 옵션이 사용될 때 “/sys/kernel/debug/fault_around_bytes” 파일을 통해 설정 값을 바꿀 수 있다. (2의 차수 단위가 적용되며 최소 페이지 사이즈이다)
- 참고: [PATCH] mm: make fault_around_bytes configurable | LKML.org
- 코드 라인 23~25에서 페이지 캐시를 통해 페이지들을 가져올 수 없어 fallback된 경우 해당 페이지 들을 파일에서 읽기 위해 __do_fault() 함수를 호출한다. 만일 작은 확률로 errror, nopage 또는 retry 결과를 얻게되면 바로 그 결과를 반환한다.
- 코드 라인 27~33에서 다시 pte 테이블 페이지에 대한 ptl lock을 건다. 만일 pte 값이 orig_pte 값과 다른 경우 fault 페이지를 할당 해제하고 함수를 빠져나간다.
- 코드 라인 34~35 fault 페이지에 대한 pte 매핑을 하고 fault 페이지에 대한 락(PG_locked) 플래그를 클리어한다.
- 코드 라인 37~38에서 pte 테이블 페이지의 ptl 락을 풀고 함수를 빠져나간다.
do_fault_around()
mm/memory.c
/*
* do_fault_around() tries to map few pages around the fault address. The hope
* is that the pages will be needed soon and this will lower the number of
* faults to handle.
*
* It uses vm_ops->map_pages() to map the pages, which skips the page if it's
* not ready to be mapped: not up-to-date, locked, etc.
*
* This function is called with the page table lock taken. In the split ptlock
* case the page table lock only protects only those entries which belong to
* the page table corresponding to the fault address.
*
* This function doesn't cross the VMA boundaries, in order to call map_pages()
* only once.
*
* fault_around_pages() defines how many pages we'll try to map.
* do_fault_around() expects it to return a power of two less than or equal to
* PTRS_PER_PTE.
*
* The virtual address of the area that we map is naturally aligned to the
* fault_around_pages() value (and therefore to page order). This way it's
* easier to guarantee that we don't cross page table boundaries.
*/
static void do_fault_around(struct vm_area_struct *vma, unsigned long address,
pte_t *pte, pgoff_t pgoff, unsigned int flags)
{
unsigned long start_addr, nr_pages, mask;
pgoff_t max_pgoff;
struct vm_fault vmf;
int off;
nr_pages = ACCESS_ONCE(fault_around_bytes) >> PAGE_SHIFT;
mask = ~(nr_pages * PAGE_SIZE - 1) & PAGE_MASK;
start_addr = max(address & mask, vma->vm_start);
off = ((address - start_addr) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1);
pte -= off;
pgoff -= off;
/*
* max_pgoff is either end of page table or end of vma
* or fault_around_pages() from pgoff, depending what is nearest.
*/
max_pgoff = pgoff - ((start_addr >> PAGE_SHIFT) & (PTRS_PER_PTE - 1)) +
PTRS_PER_PTE - 1;
max_pgoff = min3(max_pgoff, vma_pages(vma) + vma->vm_pgoff - 1,
pgoff + nr_pages - 1);
/* Check if it makes any sense to call ->map_pages */
while (!pte_none(*pte)) {
if (++pgoff > max_pgoff)
return;
start_addr += PAGE_SIZE;
if (start_addr >= vma->vm_end)
return;
pte++;
}
vmf.virtual_address = (void __user *) start_addr;
vmf.pte = pte;
vmf.pgoff = pgoff;
vmf.max_pgoff = max_pgoff;
vmf.flags = flags;
vma->vm_ops->map_pages(vma, &vmf);
}
파일에 대해 radix tree로 관리되는 페이지 캐시로부터 요청 가상 주소를 기준으로 fault_around_bytes(64K) 단위로 정렬된 범위 만큼의 페이지를 가져와 매핑한다.
- 코드 라인 32~33에서 fault_around_bytes(default: 64K) 를 페이지 단위로 바꾸고, 이에 대한 mask 값을 산출한다.
- 예 1) fault_around_bytes=64K, PAGE_SIZE=4K
- -> nr_pages=16, mask=0xffff_0000
- 예 1) fault_around_bytes=64K, PAGE_SIZE=4K
- 코드 라인 35에서 요청 가상 주소를 mask하여 절삭 한 값과 vma 영역의 시작 주소 중 가장 큰 주소를 start_addr에 대입한다.
- 코드 라인 36~38에서 start_addr를 기준으로 요청 했던 주소와 차이나는 페이지 수를 산출한 후 off에 대입하고, pte와 pgoff에서 그 차이를 각각 뺀다.
- 코드 라인 44~47에서 start_addr를 기준으로 pte 테이블의 마지막 엔트리에 해당하는 가상 주소에 대한 pgoff 값을 max_pgoff에 대입한다. 그 후 max_pgoff, vma 페이지의 마지막 pgoff 및 fault_around_bytes 단위로 읽고자 하는 마지막 페이지에 대한 pgoff 중 가장 작은 수를 max_pgoff로 대입한다.
- 예) 아래 그림 중 처음 fault된 경우: address=0x1000_5000, pgoff=5
- -> nr_pages=4, mask=0xffff_c000, off=1, 최종 pgoff=4, max_pgoff=7=min(255, 12, 7)
- 예) 아래 그림 중 처음 fault된 경우: address=0x1000_5000, pgoff=5
- 코드 라인 50~57에서 이미 매핑된 페이지들은 skip한다. pgoff 부터 max_pgoff를 벗어나거나 페이지가 vma의 영역의 끝 주소를 넘어가는 경우 이미 다 매핑이 된 경우로 함수를 빠져나간다.
- 코드 라인 59~64에서 매핑되지 않은 pte 엔트리에 대한 가상 주소 start_addr와 이 주소에 대한 pgoff와 max_pgoff 등을 가지고 vm_fault 구조체를 채운 후 마운팅된 파일 시스템의 map_pages 핸들러 함수를 호출한다.
- ext2 및 ext4 파일 시스템에서는 generic 코드인 mapfiles_map_pages() 함수를 호출한다.
아래 그림과 같이 예를 들어 vma 영역이 13개 페이지가 있을 때 매핑된 file에 대해 0x1000_5000 ~ 0x1000_9fff까지 5개 페이지를 읽으려 할 때 2 번의 fault가 발생하는 모습을 보여준다.
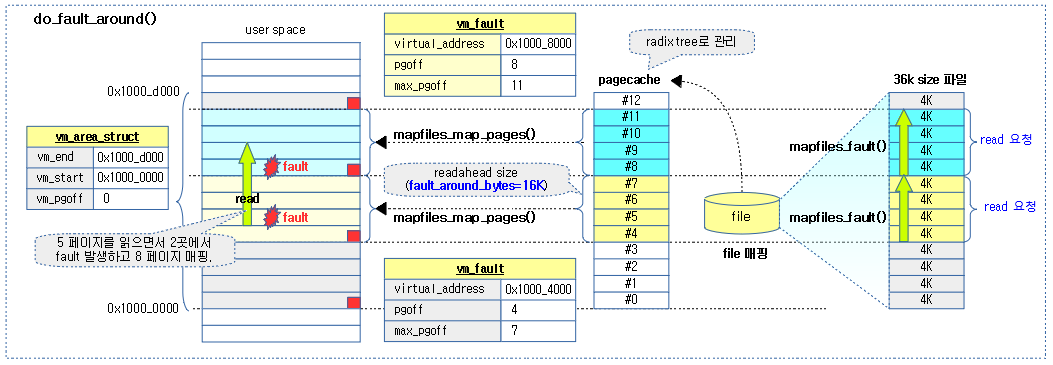
__do_fault()
mm/memory.c
/*
* The mmap_sem must have been held on entry, and may have been
* released depending on flags and vma->vm_ops->fault() return value.
* See filemap_fault() and __lock_page_retry().
*/
static int __do_fault(struct vm_area_struct *vma, unsigned long address,
pgoff_t pgoff, unsigned int flags,
struct page *cow_page, struct page **page)
{
struct vm_fault vmf;
int ret;
vmf.virtual_address = (void __user *)(address & PAGE_MASK);
vmf.pgoff = pgoff;
vmf.flags = flags;
vmf.page = NULL;
vmf.cow_page = cow_page;
ret = vma->vm_ops->fault(vma, &vmf);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
return ret;
if (!vmf.page)
goto out;
if (unlikely(PageHWPoison(vmf.page))) {
if (ret & VM_FAULT_LOCKED)
unlock_page(vmf.page);
page_cache_release(vmf.page);
return VM_FAULT_HWPOISON;
}
if (unlikely(!(ret & VM_FAULT_LOCKED)))
lock_page(vmf.page);
else
VM_BUG_ON_PAGE(!PageLocked(vmf.page), vmf.page);
out:
*page = vmf.page;
return ret;
}
vm_fault 구조체 정보를 채워 vma의 fault 핸들러를 호출한다. 출력 인수 page에 파일로 부터 읽어들인 페이지 정보를 전달한다.
- 코드 라인 13~19에서 인수로 받은 정보를 vm_struct 구조체에 대입하고 vma에 등록한 fault 핸들러 함수를 호출한다.
- 예) ext2 및 ext4 파일 시스템을 사용하는 경우 등록하여 사용하는 핸들러는 다음 둘 중 하나를 사용한다.
- generic mmap fault 핸들러: mm/filemap.c – filemap_fault()
- CONFIG_FS_DAX 커널 옵션이 사용되는 경우 dax mmap fault 핸들러: fs/dax.c – dax_fault()
- DAX(Direct Access eXiciting)
- 블럭 디바이스에 RAM이 장착되어 사용되므로, 리눅스에서 별도로 버퍼를 만들어 핸들링 하지 않도록 한다.
- 실제 마운트 옵션에서 -o dax 옵션을 주어 사용한다.
- arm, mips, sparc 아키텍처에서는 사용하지 않는다.
- 참고: DAX: Page cache bypass for filesystems on memory storage | LWN.net
- DAX(Direct Access eXiciting)
- 예) ext2 및 ext4 파일 시스템을 사용하는 경우 등록하여 사용하는 핸들러는 다음 둘 중 하나를 사용한다.
- 코드 라인 20~21에서 작은 확률로 error, nopage, retry 등의 결과를 얻게되면 그대로 반환한다.
- 코드 라인 22~23에서 vfm.page에 읽어들인 정보를 할당받은 페이지를 가리키는데 지정되지 않은 경우 함수를 빠져나간다.
- 코드 라인 25~30에서 작은 확률로 vmf.page가 hwpoison 된 경우 페이지 할당을 해제한 후 hwpoison 에러를 반환한다.
- HWPOISON
- 메모리 에러를 검출할 수 있는 하드웨어와 이를 지원하는 시스템에서 사용된다. 주로 ECC 메모리에 대한 에러 교정에 사용된다.
- 참고: HWPOISON | LWN.net
- HWPOISON
- 코드 라인 32~33에서 작은 확률로 locked 가 설정되지 않은 경우 다시 lock을 수행한다.
do_cow_fault()
mm/memory.c
static int do_cow_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd,
pgoff_t pgoff, unsigned int flags, pte_t orig_pte)
{
struct page *fault_page, *new_page;
struct mem_cgroup *memcg;
spinlock_t *ptl;
pte_t *pte;
int ret;
if (unlikely(anon_vma_prepare(vma)))
return VM_FAULT_OOM;
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address);
if (!new_page)
return VM_FAULT_OOM;
if (mem_cgroup_try_charge(new_page, mm, GFP_KERNEL, &memcg)) {
page_cache_release(new_page);
return VM_FAULT_OOM;
}
ret = __do_fault(vma, address, pgoff, flags, new_page, &fault_page);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
goto uncharge_out;
if (fault_page)
copy_user_highpage(new_page, fault_page, address, vma);
__SetPageUptodate(new_page);
pte = pte_offset_map_lock(mm, pmd, address, &ptl);
if (unlikely(!pte_same(*pte, orig_pte))) {
pte_unmap_unlock(pte, ptl);
if (fault_page) {
unlock_page(fault_page);
page_cache_release(fault_page);
} else {
/*
* The fault handler has no page to lock, so it holds
* i_mmap_lock for read to protect against truncate.
*/
i_mmap_unlock_read(vma->vm_file->f_mapping);
}
goto uncharge_out;
}
do_set_pte(vma, address, new_page, pte, true, true);
mem_cgroup_commit_charge(new_page, memcg, false);
lru_cache_add_active_or_unevictable(new_page, vma);
pte_unmap_unlock(pte, ptl);
if (fault_page) {
unlock_page(fault_page);
page_cache_release(fault_page);
} else {
/*
* The fault handler has no page to lock, so it holds
* i_mmap_lock for read to protect against truncate.
*/
i_mmap_unlock_read(vma->vm_file->f_mapping);
}
return ret;
uncharge_out:
mem_cgroup_cancel_charge(new_page, memcg);
page_cache_release(new_page);
return ret;
}
파일 시스템의 vm_ops의 map_pages 핸들러를 통해 페이지 캐시로부터 exception된 가상 주소에 대한 페이지를 읽어와서 새 페이지에 복사하고 write 권한으로 anon 매핑한다.
- 코드 라인 11~12에서 요청 vma에 anon_vma가 준비되지 않은 경우 할당하고 준비를 해온다. 만일 준비가 안된 경우 가상 메모리 부족(VM_FAULT_OOM) 에러를 반환한다.
- 코드 라인 14~16에서 하나의 새 유저 페이지를 할당받는다. 만일 할당되지 않으면 가상 메모리 부족 에러를 반환한다.
- highmem이 있는 경우 가능하면 highmem에서 movable 타입으로 한 개 페이지를 할당 받는다.
- 코드 라인 18~21에서 가상 페이지 수가 memcg 설정된 commit 할당량을 벗어난 경우 가상 메모리 부족 에러를 반환한다.
- 주로 memory control group을 사용하여 지정한 태스크의 메모리 사용량을 제어하기 위해 사용한다.
- 코드 라인 23~25에서 파일로부터 읽어온다. 만일 결과가 error, nopage 또는 retry 에러인 경우 uncharge_out 레이블을 통해 함수를 빠져나간다.
- 코드 라인 27~29에서 파일로 부터 요청한 페이지 fault_page를 읽어온 경우 새 페이지에 복사하고 새 페이지에 대해 PG_uptodate 플래그를 설정한다.
- 코드 라인 31~45에서 출력 인수로 받아온 pte와 orig_pte가 다른 경우 매핑 없이 uncharge_out 레이블을 통해 함수를 빠져나간다.
- 코드 라인 46에서 새 페이지를 write 속성으로 매핑하고 anon reverse map에 페이지를 추가한다.
- 코드 라인 47에서 memcg에 한 페이지가 추가되었음을 commit 한다.
- 코드 라인 48에서 새 페이지를 active 설정하고 lru 캐시에 추가한다.
- lru_add_pvec에 추가한다.
- 코드 라인 50~52에서 fault_page에 대해 참조 카운터를 감소시키고 0이되면 할당 해제도 한다.
do_shared_fault()
mm/memory.c
static int do_shared_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd,
pgoff_t pgoff, unsigned int flags, pte_t orig_pte)
{
struct page *fault_page;
struct address_space *mapping;
spinlock_t *ptl;
pte_t *pte;
int dirtied = 0;
int ret, tmp;
ret = __do_fault(vma, address, pgoff, flags, NULL, &fault_page);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
return ret;
/*
* Check if the backing address space wants to know that the page is
* about to become writable
*/
if (vma->vm_ops->page_mkwrite) {
unlock_page(fault_page);
tmp = do_page_mkwrite(vma, fault_page, address);
if (unlikely(!tmp ||
(tmp & (VM_FAULT_ERROR | VM_FAULT_NOPAGE)))) {
page_cache_release(fault_page);
return tmp;
}
}
pte = pte_offset_map_lock(mm, pmd, address, &ptl);
if (unlikely(!pte_same(*pte, orig_pte))) {
pte_unmap_unlock(pte, ptl);
unlock_page(fault_page);
page_cache_release(fault_page);
return ret;
}
do_set_pte(vma, address, fault_page, pte, true, false);
pte_unmap_unlock(pte, ptl);
if (set_page_dirty(fault_page))
dirtied = 1;
/*
* Take a local copy of the address_space - page.mapping may be zeroed
* by truncate after unlock_page(). The address_space itself remains
* pinned by vma->vm_file's reference. We rely on unlock_page()'s
* release semantics to prevent the compiler from undoing this copying.
*/
mapping = fault_page->mapping;
unlock_page(fault_page);
if ((dirtied || vma->vm_ops->page_mkwrite) && mapping) {
/*
* Some device drivers do not set page.mapping but still
* dirty their pages
*/
balance_dirty_pages_ratelimited(mapping);
}
if (!vma->vm_ops->page_mkwrite)
file_update_time(vma->vm_file);
return ret;
}
공유 파일 매핑 영역에서 write 요청으로 fault된 경우 해당 페이지의 매핑을 write로 변경한다. 만일 write로 변경을 할 수 없는 상황인 경우 포기한다.
- 코드 라인 12~14에서 파일 캐시로 부터 fault된 주소의 페이지를 읽어온다. 만일 결과가 error, nopage 또는 retry 에러인 경우 포기하고 그 결과를 반환한다.
- 코드 라인 20~28에서 vma의 오퍼레이션 핸들러 중 page_mkwrite 후크 함수가 설정된 경우 write 설정을 위해 do_page_mkwrite() 함수를 호출한다. 만일 실패하는 경우 fault_page 를 release 하고 함수를 빠져나간다.
- 코드 라인 30~36에서 페이지 테이블 락을 획득해온다. 만일 락 획득 과정에서 pte 엔트리가 다른 cpu와의 경쟁 상황으로 인해 변경된 경우 포기하고 빠져나간다.
- 코드 라인 37에서 pte 엔트리에 대한 매핑을 write로 변경한다.
- 코드 라인 40~41에서 fault_page가 dirty 설정이 되어 있는지 여부를 알아온다.
- dirty 설정이 된 경우 페이지 캐시의 내용이 파일에 기록이 되지 않았음을 알 수 있다.
- 코드 라인 48~56에서 fault_page의 매핑과 vma의 page_mkwrite 핸들러가 설정되었거나 dirty 된 경우 balance_dirty_pages_ratelimited() 함수를 호출한다.
- dirty 페이지가 제한치를 초과하는 경우 밸런싱을 맞추기 위해 블록디바이스가 백그라운드에서 writeback을 수행할 수 있게 요청한다.
- 코드 라인 58~59에서 vma의 page_mkwrite 핸들러가 설정되지 않은 경우 이 루틴에서 파일의 시간을 업데이트 한다.
- inode의 mtime(수정 시각)과 ctime(작성 시각)을 현재 시간으로 업데이트 한다.
anon 매핑된 주소에서의 fault 처리
anon 매핑 주소에서의 fault 처리
do_anonymous_page()
mm/memory.c
/*
* We enter with non-exclusive mmap_sem (to exclude vma changes,
* but allow concurrent faults), and pte mapped but not yet locked.
* We return with mmap_sem still held, but pte unmapped and unlocked.
*/
static int do_anonymous_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags)
{
struct mem_cgroup *memcg;
struct page *page;
spinlock_t *ptl;
pte_t entry;
pte_unmap(page_table);
/* Check if we need to add a guard page to the stack */
if (check_stack_guard_page(vma, address) < 0)
return VM_FAULT_SIGSEGV;
/* Use the zero-page for reads */
if (!(flags & FAULT_FLAG_WRITE) && !mm_forbids_zeropage(mm)) {
entry = pte_mkspecial(pfn_pte(my_zero_pfn(address),
vma->vm_page_prot));
page_table = pte_offset_map_lock(mm, pmd, address, &ptl);
if (!pte_none(*page_table))
goto unlock;
goto setpte;
}
/* Allocate our own private page. */
if (unlikely(anon_vma_prepare(vma)))
goto oom;
page = alloc_zeroed_user_highpage_movable(vma, address);
if (!page)
goto oom;
/*
* The memory barrier inside __SetPageUptodate makes sure that
* preceeding stores to the page contents become visible before
* the set_pte_at() write.
*/
__SetPageUptodate(page);
if (mem_cgroup_try_charge(page, mm, GFP_KERNEL, &memcg))
goto oom_free_page;
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
page_table = pte_offset_map_lock(mm, pmd, address, &ptl);
if (!pte_none(*page_table))
goto release;
inc_mm_counter_fast(mm, MM_ANONPAGES);
page_add_new_anon_rmap(page, vma, address);
mem_cgroup_commit_charge(page, memcg, false);
lru_cache_add_active_or_unevictable(page, vma);
setpte:
set_pte_at(mm, address, page_table, entry);
/* No need to invalidate - it was non-present before */
update_mmu_cache(vma, address, page_table);
unlock:
pte_unmap_unlock(page_table, ptl);
return 0;
release:
mem_cgroup_cancel_charge(page, memcg);
page_cache_release(page);
goto unlock;
oom_free_page:
page_cache_release(page);
oom:
return VM_FAULT_OOM;
}
anon 매핑된 영역에서 exception된 가상 주소에 대한 새 페이지를 할당하고 anon 매핑한다.
- 코드 라인 15에서 pte 테이블이 fixmap에 임시로 매핑되어 있는 경우 매핑을 해제한다.
- 코드 라인 18~19에서 영역이 스택이고 확장 불가능한 경우 VM_FAULT_SIGSEGV 에러를 반환한다.
- 코드 라인 22~29에서 write 요청이 아니고 zero 페이지를 사용할 수 있는 경우 별도로 페이지를 할당하지 않고 기존 zero 페이지를 매핑하도록 준비하고 setpte 레이블로 이동한다.
- 코드 라인 32~33에서 요청 vma에 anon_vma가 준비되지 않은 경우 할당하고 준비를 해온다. 만일 준비가 안된 경우 가상 메모리 부족(VM_FAULT_OOM) 에러를 반환한다.
- 코드 라인 34~36에서 하나의 새 유저 페이지를 할당받는다. 만일 할당되지 않으면 가상 메모리 부족 에러를 반환한다.
- highmem이 있는 경우 가능하면 highmem에서 movable 타입으로 한 개 페이지를 할당 받는다.
- 코드 라인 42에서 새 페이지에 대해 PG_uptodate 플래그를 설정한다.
- 코드 라인 44~45에서 가상 페이지 수가 memcg 설정된 commit 할당량을 벗어난 경우 가상 메모리 부족 에러를 반환한다.
- 주로 memory control group을 사용하여 지정한 태스크의 메모리 사용량을 제어하기 위해 사용한다.
- 코드 라인 47에서 vma 영역에 설정된 페이지 테이블 속성을 사용하여 pte 엔트리의 매핑을 준비한다.
- 코드 라인 48~49에서 vma 영역에 write 속성이 있는 경우 pte 엔트리의 dirty 플래그를 추가하고 read only 플래그를 제거한다.
- 코드 라인 51~53에서 해당 가상주소에 대한 pte 테이블 페이지의 lock을 걸고 pte 엔트리를 알아온다. 만일 엔트리가 이미 설정되어 있는 경우 release 레이블을 통해 함수를 빠져나간다.
- 코드 라인 55에서 MM_ANONPAGES 카운터를 증가시킨다.
- 코드 라인 56에서 anon rmap(reverse map)에 페이지를 추가한다.
- 코드 라인 57에서 memcg에 한 페이지가 추가되었음을 commit 한다.
- 코드 라인 58에서 새 페이지를 active 설정하고 lru 캐시에 추가한다.
- lru_add_pvec에 추가한다.
- 코드 라인 60에서 pte 엔트리에 매핑한다.
- 코드 라인 63에서 tlb 캐시를 업데이트(flush) 한다.
- armv6 이전 아키텍처는 tlb 캐시를 flush한다.
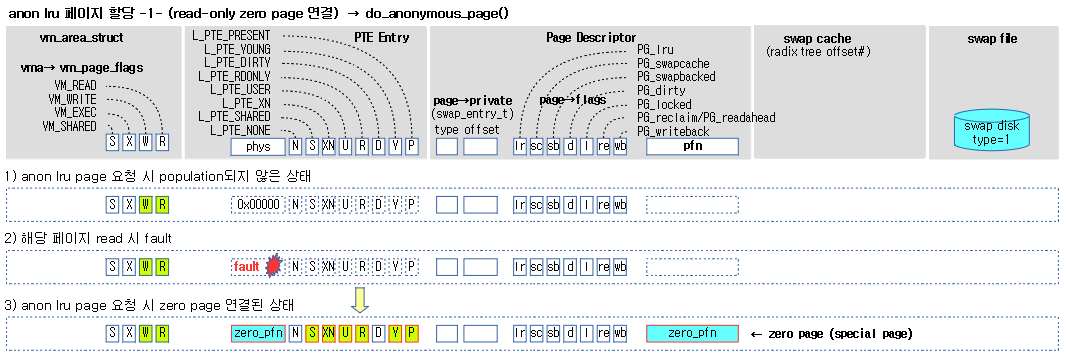
anon 매핑에서 swap 페이지의 fault 처리
do_swap_page()
mm/memory.c
/*
* We enter with non-exclusive mmap_sem (to exclude vma changes,
* but allow concurrent faults), and pte mapped but not yet locked.
* We return with pte unmapped and unlocked.
*
* We return with the mmap_sem locked or unlocked in the same cases
* as does filemap_fault().
*/
static int do_swap_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags, pte_t orig_pte)
{
spinlock_t *ptl;
struct page *page, *swapcache;
struct mem_cgroup *memcg;
swp_entry_t entry;
pte_t pte;
int locked;
int exclusive = 0;
int ret = 0;
if (!pte_unmap_same(mm, pmd, page_table, orig_pte))
goto out;
entry = pte_to_swp_entry(orig_pte);
if (unlikely(non_swap_entry(entry))) {
if (is_migration_entry(entry)) {
migration_entry_wait(mm, pmd, address);
} else if (is_hwpoison_entry(entry)) {
ret = VM_FAULT_HWPOISON;
} else {
print_bad_pte(vma, address, orig_pte, NULL);
ret = VM_FAULT_SIGBUS;
}
goto out;
}
delayacct_set_flag(DELAYACCT_PF_SWAPIN);
page = lookup_swap_cache(entry);
if (!page) {
page = swapin_readahead(entry,
GFP_HIGHUSER_MOVABLE, vma, address);
if (!page) {
/*
* Back out if somebody else faulted in this pte
* while we released the pte lock.
*/
page_table = pte_offset_map_lock(mm, pmd, address, &ptl);
if (likely(pte_same(*page_table, orig_pte)))
ret = VM_FAULT_OOM;
delayacct_clear_flag(DELAYACCT_PF_SWAPIN);
goto unlock;
}
/* Had to read the page from swap area: Major fault */
ret = VM_FAULT_MAJOR;
count_vm_event(PGMAJFAULT);
mem_cgroup_count_vm_event(mm, PGMAJFAULT);
} else if (PageHWPoison(page)) {
/*
* hwpoisoned dirty swapcache pages are kept for killing
* owner processes (which may be unknown at hwpoison time)
*/
ret = VM_FAULT_HWPOISON;
delayacct_clear_flag(DELAYACCT_PF_SWAPIN);
swapcache = page;
goto out_release;
}
swapcache = page;
locked = lock_page_or_retry(page, mm, flags);
delayacct_clear_flag(DELAYACCT_PF_SWAPIN);
if (!locked) {
ret |= VM_FAULT_RETRY;
goto out_release;
}
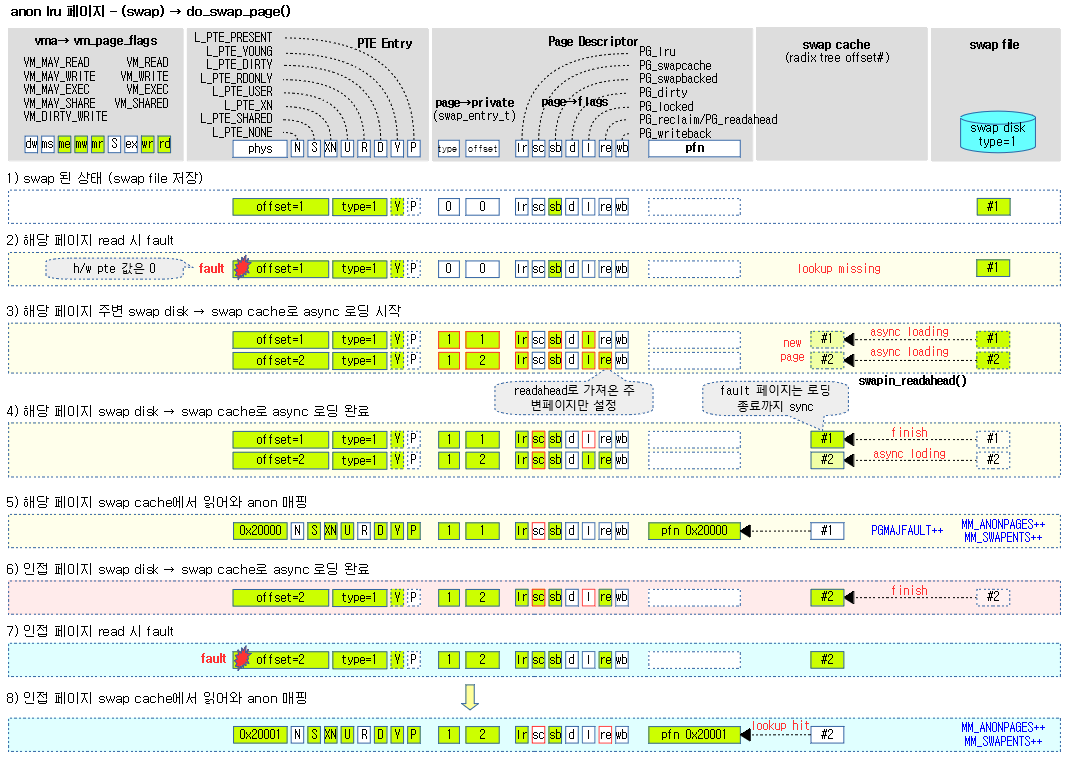
swap 되어 있는 페이지에 접근했을 때 fault 되어 진입한 경우 swap 캐시 또는 swap file로 부터 페이지를 읽어들인다.
- 코드 라인 22~23에서 pte 엔트리 값과 orig_pte 엔트리 값이 다른 경우 out 레이블로 이동한 후 함수를 빠져나간다.
- 코드 라인 24에서 orig_pte 엔트리에 대한 swap 엔트리를 구해온다.
- 코드 라인 25~36에서 작은 확률로 swap 엔트리가 아닌 경우 다음을 처리한 후 out 레이블로 이동하고 함수를 빠져나간다.
- 코드 라인 27~28에서 실제 swap 정보로 구성된 swap 엔트리가 아니라 migration 정보가 담긴 swap 엔트리인 경우 해당 페이지의 migration이 완료되어 page가 unlock될 때까지 기다린다.
- 해당 페이지의 migration이 완료되어 PG_locked가 클리어될 때까지 대기한다.
- 코드 라인 29~30에서 엔트리가 hwpoison 엔트리인 경우 에러 코드로 hwpoison을 담는다.
- 코드 라인 31~34에서 pte 정보를 출력하고 에러 코드로 sigbus를 담는다.
- 코드 라인 27~28에서 실제 swap 정보로 구성된 swap 엔트리가 아니라 migration 정보가 담긴 swap 엔트리인 경우 해당 페이지의 migration이 완료되어 page가 unlock될 때까지 기다린다.
- 코드 라인 37에서 현재 태스크의 delay 플래그에 delay accounting을 위해 DELAYACCT_PF_SWAPIN 플래그를 설정한다.
- 코드 라인 38에서 swap 엔트리로 swap 캐시 페이지를 알아온다.
- 코드 라인 39~41에서 페이지를 알아올 수 없으면 swapin_readahead() 함수를 호출하여 swap file로 부터 요청 페이지를 포함한 일정량의 페이지를 읽어온다.
- 코드 라인 42~52에서 그래도 페이지를 가져올 수 없으면 설정해둔 DELAYACCT_PF_SWAPIN 플래그를 제거하고 unlock 레이블을 통해 함수를 빠져나간다.
- swap file을 블럭 디바이스에서 비동기로 읽어들여 바로 가져오지 못할 확률이 크다. 그래서 delay를 발생시킬 목적으로 그냥 함수를 빠져나간다.
- 코드 라인 55~57에서 에러 코드로 major fault로 대입하고, PGMAJFAULT 카운터를 증가시키고 memcg 설정된 경우에서도 PGMAJFAULT 카운터를 증가시킨다.
- fault된 페이지가 swap 캐시에서 검색되지 않은 경우 swap file에서 페이지를 읽어온 경우 pgmajfault 카운터가 증가된다.
- 코드 라인 58~67에서 hwpoison 페이지인 경우 hwpoison 에러 코드를 설정하고 설정해둔 DELAYACCT_PF_SWAPIN 플래그도 제거하며 out_release 레이블을 통해 함수를 빠져나간다.
- 참고:
- What is hwpoison? | kernel.org
- HWPOISON | LWN.net
- 참고:
- 코드 라인 69~76에서 가져온 페이지에 대해 lock을 시도하고 안되면 retry 에러를 추가하여 out_release 레이블을 통해 함수를 빠져나간다.
. /*
* Make sure try_to_free_swap or reuse_swap_page or swapoff did not
* release the swapcache from under us. The page pin, and pte_same
* test below, are not enough to exclude that. Even if it is still
* swapcache, we need to check that the page's swap has not changed.
*/
if (unlikely(!PageSwapCache(page) || page_private(page) != entry.val))
goto out_page;
page = ksm_might_need_to_copy(page, vma, address);
if (unlikely(!page)) {
ret = VM_FAULT_OOM;
page = swapcache;
goto out_page;
}
if (mem_cgroup_try_charge(page, mm, GFP_KERNEL, &memcg)) {
ret = VM_FAULT_OOM;
goto out_page;
}
/*
* Back out if somebody else already faulted in this pte.
*/
page_table = pte_offset_map_lock(mm, pmd, address, &ptl);
if (unlikely(!pte_same(*page_table, orig_pte)))
goto out_nomap;
if (unlikely(!PageUptodate(page))) {
ret = VM_FAULT_SIGBUS;
goto out_nomap;
}
/*
* The page isn't present yet, go ahead with the fault.
*
* Be careful about the sequence of operations here.
* To get its accounting right, reuse_swap_page() must be called
* while the page is counted on swap but not yet in mapcount i.e.
* before page_add_anon_rmap() and swap_free(); try_to_free_swap()
* must be called after the swap_free(), or it will never succeed.
*/
inc_mm_counter_fast(mm, MM_ANONPAGES);
dec_mm_counter_fast(mm, MM_SWAPENTS);
pte = mk_pte(page, vma->vm_page_prot);
if ((flags & FAULT_FLAG_WRITE) && reuse_swap_page(page)) {
pte = maybe_mkwrite(pte_mkdirty(pte), vma);
flags &= ~FAULT_FLAG_WRITE;
ret |= VM_FAULT_WRITE;
exclusive = 1;
}
flush_icache_page(vma, page);
if (pte_swp_soft_dirty(orig_pte))
pte = pte_mksoft_dirty(pte);
set_pte_at(mm, address, page_table, pte);
if (page == swapcache) {
do_page_add_anon_rmap(page, vma, address, exclusive);
mem_cgroup_commit_charge(page, memcg, true);
} else { /* ksm created a completely new copy */
page_add_new_anon_rmap(page, vma, address);
mem_cgroup_commit_charge(page, memcg, false);
lru_cache_add_active_or_unevictable(page, vma);
}
- 코드 라인 7~8에서 작은 확률로 swap 캐시 페이지가 아니거나 private 페이지의 private 값이 entry 값과 다른 경우 out_page 레이블로 이동하여 함수를 빠져나간다.
- 코드 라인 10~15에서 ksm 페이지인 경우 새 페이지를 할당 받고 기존 ksm 페이지로 부터 복사하고, 그렇지 않으면 기존 페이지를 그대로 반환한다. 만일 새 페이지 할당이 실패하는 경우 oom 에러를 반환한다.
- 코드 라인 17~20에서 가상 페이지 수가 memcg 설정된 commit 할당량을 벗어난 경우 가상 메모리 부족 에러를 반환한다.
- 주로 memory control group을 사용하여 지정한 태스크의 메모리 사용량을 제어하기 위해 사용한다.
- 코드 라인 25~27에서 해당 가상주소에 대한 pte 테이블 페이지의 lock을 걸고 pte 엔트리를 알아와서 orig_pte와 다른 경우 누군가 이미 매핑한 경우이므로 내버려 두고 함수를 빠져나간다. 다시 fault될지 모르지만…
- 코드 라인 29~32에서 작은 확률로 uptodate 플래그가 설정되지 않은 경우 sigbus 에러를 반환한다.
- 코드 라인 44~45에서 anon 페이지가 추가되었고 swap 페이지가 감소되었으므로 MM_ANONPAGES 카운터를 증가시키고 MM_SWAPENTS 카운터를 감소시킨다.
- 코드 라인 46에서 해당 페이지에 대해 vma 영역에 설정된 권한 속성을 더해 pte 엔트리를 만든다.
- 코드 라인 47~52에서 write 요청이 있으면서 swap 캐시를 재 사용할 수 있는 상황인 경우 COW 없이 그냥 swap 캐시에서 제거하고 그 페이지를 그대로 anon 페이지로 전환한다. 그런 후 pte 속성 에서 read only를 제거하고 dirty를 설정하여 준비하고 write 플래그는 제거한다. 반환 값에 VM_FAULT_WRITE를 추가하고 exclusive를 1로 설정한다.
- 코드 라인 53에서 해당 페이지에 대해 instruction 캐시를 flush 한다.
- 특정 아키텍처에서 사용되며, arm, arm64, x86 아키텍처 등에서는 아무런 동작도 하지 않는다.
- 코드 라인 54~55에서 orig_pte 값에 soft-dirty 플래그가 설정된 경우 pte 엔트리에도 soft-dirty 설정을 한다.
- CONFIG_MEM_SOFT_DIRTY
- 메모리 변경 시 트래킹을 하기 위해 사용하며 현재는 x86 아키텍처에만 구현되어 있는 커널 옵션이다.
- 참고: SOFT-DIRTY PTEs – vm/soft-dirty.txt
- CONFIG_MEM_SOFT_DIRTY
- 코드 라인 56에서 page_table 엔트리를 pte 값으로 설정하여 매핑한다.
- 코드 라인 57~59에서 swap 캐시페이지를 anon 페이지로 그대로 활용한 경우 그 페이지를 anon reverse map에 추가하고 memcg에 에 페이지가 추가되었음을 commit 한다.
- 코드 라인 60~64에서 swap 캐시 페이지를 새 페이지에 복사하여 사용하게 된 경우 anon reverse map에 새 페이지를 추가하고 memcg에 에 한 페이지가 추가되었음을 commit 하며 lru 캐시에 추가한다.
- 페이지는 PG_SwapBacked 플래그 설정하고 _mapcount=0(-1부터 시작)으로 초기화한다.
. swap_free(entry);
if (vm_swap_full() || (vma->vm_flags & VM_LOCKED) || PageMlocked(page))
try_to_free_swap(page);
unlock_page(page);
if (page != swapcache) {
/*
* Hold the lock to avoid the swap entry to be reused
* until we take the PT lock for the pte_same() check
* (to avoid false positives from pte_same). For
* further safety release the lock after the swap_free
* so that the swap count won't change under a
* parallel locked swapcache.
*/
unlock_page(swapcache);
page_cache_release(swapcache);
}
if (flags & FAULT_FLAG_WRITE) {
ret |= do_wp_page(mm, vma, address, page_table, pmd, ptl, pte);
if (ret & VM_FAULT_ERROR)
ret &= VM_FAULT_ERROR;
goto out;
}
/* No need to invalidate - it was non-present before */
update_mmu_cache(vma, address, page_table);
unlock:
pte_unmap_unlock(page_table, ptl);
out:
return ret;
out_nomap:
mem_cgroup_cancel_charge(page, memcg);
pte_unmap_unlock(page_table, ptl);
out_page:
unlock_page(page);
out_release:
page_cache_release(page);
if (page != swapcache) {
unlock_page(swapcache);
page_cache_release(swapcache);
}
return ret;
}
- 코드 라인 1에서 엔트리를 swap 캐시에서 제거한다.
- 코드 라인 2~3에서 swap 캐시가 50% 이상 가득 차거나 locked vma 영역이거나 mlock 설정된 페이지인 경우 좀 더 swap 캐시를 비우려고 시도한다.
- 코드 라인 4에서 페이지를 unlock한다.
- 코드 라인 5~16에서 swap 캐시페이지를 새 페이지에 COW한 경우 swapcache 페이지도 unlock하고 release 한다.
- 코드 라인 18~23에서 write 요청이 있는 경우 새 페이지를 할당받고 COW 하기 위해 do_wp_page() 함수를 호출하고 빠져나간다.
- 코드 라인 26에서 tlb 캐시를 업데이트(flush) 한다.
- armv6 이전 아키텍처는 tlb 캐시를 flush한다.
- 코드 라인 28~30에서 page_table 페이지에 대한 ptl 언락을 하고 함수를 마친다.

swapin_readahead()
mm/swap_state.c
/**
* swapin_readahead - swap in pages in hope we need them soon
* @entry: swap entry of this memory
* @gfp_mask: memory allocation flags
* @vma: user vma this address belongs to
* @addr: target address for mempolicy
*
* Returns the struct page for entry and addr, after queueing swapin.
*
* Primitive swap readahead code. We simply read an aligned block of
* (1 << page_cluster) entries in the swap area. This method is chosen
* because it doesn't cost us any seek time. We also make sure to queue
* the 'original' request together with the readahead ones...
*
* This has been extended to use the NUMA policies from the mm triggering
* the readahead.
*
* Caller must hold down_read on the vma->vm_mm if vma is not NULL.
*/
struct page *swapin_readahead(swp_entry_t entry, gfp_t gfp_mask,
struct vm_area_struct *vma, unsigned long addr)
{
struct page *page;
unsigned long entry_offset = swp_offset(entry);
unsigned long offset = entry_offset;
unsigned long start_offset, end_offset;
unsigned long mask;
struct blk_plug plug;
mask = swapin_nr_pages(offset) - 1;
if (!mask)
goto skip;
/* Read a page_cluster sized and aligned cluster around offset. */
start_offset = offset & ~mask;
end_offset = offset | mask;
if (!start_offset) /* First page is swap header. */
start_offset++;
blk_start_plug(&plug);
for (offset = start_offset; offset <= end_offset ; offset++) {
/* Ok, do the async read-ahead now */
page = read_swap_cache_async(swp_entry(swp_type(entry), offset),
gfp_mask, vma, addr);
if (!page)
continue;
if (offset != entry_offset)
SetPageReadahead(page);
page_cache_release(page);
}
blk_finish_plug(&plug);
lru_add_drain(); /* Push any new pages onto the LRU now */
skip:
return read_swap_cache_async(entry, gfp_mask, vma, addr);
}
swap 파일로 부터 swap 캐시로 요청 offset 페이지에 대한 readahead(한 번에 미리 읽어올 적정 페이지 수)페이지들을 읽어오도록 비동기 요청한다. 단 해당 offset 페이지는 읽혀올 때까지 블럭된다.
- 코드 라인24에서 swap 엔트리 값에서 offset을 추출한다.
- 코드 라인 30~32에서 swap 파일에서 swap 캐시로 읽어올 readahead(한 번에 미리 읽어올 적정 페이지 수) 페이지 수에서 -1을 하여 mask 값을 구한다. 만일 mask 값이 0인 경우 skip 레이블로 이동한다.
- 코드 라인 35~36에서 offset을 mask를 사용하여 시작 offset과 끝 offset을 구한다.
- 예) mask=7, offset=30
- start_offset=24, end_offset=31
- 예) mask=7, offset=30
- 코드 라인 37~38에서 start_offset이 0인 경우 1부터 시작하게 한다.
- 특별히 0에는 swap 헤더가 존재한다.
- 코드 라인 40에서 태스크에서 blk_plug를 초기화 하고 pending I/O에 의한 데드락 트래킹하도록 구성한다.
- 코드 라인 41~50에서 swap 파일에서 해당 offset에 대한 페이지를 읽어오도록 비동기 요청을 한다. 이미 요청 offset이 아닌 다른 offset 페이지에는 PG_readahead 플래그를 설정한다.
- 코드 라인 51에서 태스크에 설정해 둔 blk_plug를 flush한다.
- 코드 라인 53~55에서 per cpu lru들을 lruvec으로 이동시키고 다시 swap 파일에서 해당 offset에 대한 페이지를 읽어오도록 비동기 요청을 한다.
- 두 번째 호출 시 내부에서는 swap file로 부터 해당 페이지를 불러오는데 완료될 때까지 블럭된다.
swap 캐시용 raadahead 페이지 산출
swapin_nr_pages()
mm/swap_state.c
static unsigned long swapin_nr_pages(unsigned long offset)
{
static unsigned long prev_offset;
unsigned int pages, max_pages, last_ra;
static atomic_t last_readahead_pages;
max_pages = 1 << ACCESS_ONCE(page_cluster);
if (max_pages <= 1)
return 1;
/*
* This heuristic has been found to work well on both sequential and
* random loads, swapping to hard disk or to SSD: please don't ask
* what the "+ 2" means, it just happens to work well, that's all.
*/
pages = atomic_xchg(&swapin_readahead_hits, 0) + 2;
if (pages == 2) {
/*
* We can have no readahead hits to judge by: but must not get
* stuck here forever, so check for an adjacent offset instead
* (and don't even bother to check whether swap type is same).
*/
if (offset != prev_offset + 1 && offset != prev_offset - 1)
pages = 1;
prev_offset = offset;
} else {
unsigned int roundup = 4;
while (roundup < pages)
roundup <<= 1;
pages = roundup;
}
if (pages > max_pages)
pages = max_pages;
/* Don't shrink readahead too fast */
last_ra = atomic_read(&last_readahead_pages) / 2;
if (pages < last_ra)
pages = last_ra;
atomic_set(&last_readahead_pages, pages);
return pages;
}
swap 파일에서 swap 캐시로 읽어올 readahead(한 번에 미리 읽어올 적정 페이지 수) 페이지 수를 산출한다.
- readahead 페이지 수는 swap 캐시 hit 를 기반으로 huristic 하게 관리된다.
- readahead 수는 유지, 증가, 감소가 가능하되 증가 시엔 항상 2배씩 증가하고, 감소 시에는 절반씩 감소한다.
- 범위는 최소 1 ~ 최대 클러스터 당 페이지 수이며 2의 차수 단위이다.
- 예) 4 -> 8(증가) -> 8(유지) -> 16(증가) -> 32(증가) -> 16(감소) -> 16(유지) -> 8(감소) -> 4(감소) -> 2(감소) -> 1(감소)
- 범위는 최소 1 ~ 최대 클러스터 당 페이지 수이며 2의 차수 단위이다.
- 코드 라인 7~9에서 2^page_cluster 값을 max_pages에 대입한다.
- 클러스터 단위가 최대 처리할 수 있는 페이지이다.
- 코드 라인 16에서 swapin_readahead_hits +2를 하여 pages에 대입하고 swapin_readahead_hits 값은 0으로 초기화한다.
- swapin_readahead_hits
- default 값은 4부터 출발하고 통계 기반으로 적중률이 높아지면 증가된다.
- swap 캐시가 hit되면 1씩 증가한다.
- swap 캐시가 miss되어 이 함수가 호출되면 0으로 리셋된다.
- default 값은 4부터 출발하고 통계 기반으로 적중률이 높아지면 증가된다.
- swapin_readahead_hits
- 코드 라인 17~25에서 기존 swapin_readahead_hits 값이 0인 경우 즉, 이전에도 swap 캐시에서 페이지 lookup이 실패한 경우 이전 offset 요청이 현재 offset 요청과 +1/-1 차이로 연속된 번호가 아닌 경우 pages에 1을 대입한다. 그리고 현재 offset을 기억해둔다.
- 코드 라인 26~31에서 초기화 전 swapin_readahead_hits 값이 0이 아닌 경우 즉, 이전에 swap 캐시에서 페이지 lookup이 실패하지 않았던 경우 pages 값을 최소 4부터 시작하여 2의 차수 단위로 올림 정렬한다.
- 코드 라인 33~34에서 결정된 pages 값이 max_pages를 초과하는 경우 max_pages로 변경한다.
- 코드라인 37~42에서 페이지가 마지막에 읽었던 readhead 페이지의 절반보다 작으면 그 절반 값을 last_readahead_pages에 대입하고 반환한다.
- last_readahead_pages
- 가장 마지막에 사용한 swap 사용 시 readahead 페이지 수를 보관한다.
- last_readahead_pages
radix tree로 구성된 swap 캐시 검색
lookup_swap_cache()
mm/swap_state.c
/*
* Lookup a swap entry in the swap cache. A found page will be returned
* unlocked and with its refcount incremented - we rely on the kernel
* lock getting page table operations atomic even if we drop the page
* lock before returning.
*/
struct page * lookup_swap_cache(swp_entry_t entry)
{
struct page *page;
page = find_get_page(swap_address_space(entry), entry.val);
if (page) {
INC_CACHE_INFO(find_success);
if (TestClearPageReadahead(page))
atomic_inc(&swapin_readahead_hits);
}
INC_CACHE_INFO(find_total);
return page;
}
swap 엔트리로 radix tree로 구성된 swap 캐시에서 페이지를 구해 반환한다.
- 코드 라인 11에서 swap 엔트리로 radix tree로 구성된 swap 캐시에서 페이지를 구해 반환한다.
- #define swap_address_space(entry) (&swapper_spaces[swp_type(entry)])
- 코드 라인 13~17에서 만일 페이지가 발견되면 swap_cache_info.find_success 카운터를 증가시킨다. 그리고 readahead 플래그가 설정되어 있으면 클리어하고 swapin_readahead_hits 값을 증가시킨다.
- 이 값은 swap 캐시에서의 lookup이 계속 성공할 때마다 증가되고 실패하는 순간 0으로 초기화된다.
- 코드 라인 19에서 swap_cache_info.find_total 카운터를 증가시킨다.
anon 매핑에서 protnone 페이지의 fault 처리 (numa migration for automatic numa balancing)
do_numa_page()
mm/memory.c
static int do_numa_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long addr, pte_t pte, pte_t *ptep, pmd_t *pmd)
{
struct page *page = NULL;
spinlock_t *ptl;
int page_nid = -1;
int last_cpupid;
int target_nid;
bool migrated = false;
bool was_writable = pte_write(pte);
int flags = 0;
/* A PROT_NONE fault should not end up here */
BUG_ON(!(vma->vm_flags & (VM_READ | VM_EXEC | VM_WRITE)));
/*
* The "pte" at this point cannot be used safely without
* validation through pte_unmap_same(). It's of NUMA type but
* the pfn may be screwed if the read is non atomic.
*
* We can safely just do a "set_pte_at()", because the old
* page table entry is not accessible, so there would be no
* concurrent hardware modifications to the PTE.
*/
ptl = pte_lockptr(mm, pmd);
spin_lock(ptl);
if (unlikely(!pte_same(*ptep, pte))) {
pte_unmap_unlock(ptep, ptl);
goto out;
}
/* Make it present again */
pte = pte_modify(pte, vma->vm_page_prot);
pte = pte_mkyoung(pte);
if (was_writable)
pte = pte_mkwrite(pte);
set_pte_at(mm, addr, ptep, pte);
update_mmu_cache(vma, addr, ptep);
page = vm_normal_page(vma, addr, pte);
if (!page) {
pte_unmap_unlock(ptep, ptl);
return 0;
}
/*
* Avoid grouping on RO pages in general. RO pages shouldn't hurt as
* much anyway since they can be in shared cache state. This misses
* the case where a mapping is writable but the process never writes
* to it but pte_write gets cleared during protection updates and
* pte_dirty has unpredictable behaviour between PTE scan updates,
* background writeback, dirty balancing and application behaviour.
*/
if (!(vma->vm_flags & VM_WRITE))
flags |= TNF_NO_GROUP;
/*
* Flag if the page is shared between multiple address spaces. This
* is later used when determining whether to group tasks together
*/
if (page_mapcount(page) > 1 && (vma->vm_flags & VM_SHARED))
flags |= TNF_SHARED;
last_cpupid = page_cpupid_last(page);
page_nid = page_to_nid(page);
target_nid = numa_migrate_prep(page, vma, addr, page_nid, &flags);
pte_unmap_unlock(ptep, ptl);
if (target_nid == -1) {
put_page(page);
goto out;
}
/* Migrate to the requested node */
migrated = migrate_misplaced_page(page, vma, target_nid);
if (migrated) {
page_nid = target_nid;
flags |= TNF_MIGRATED;
} else
flags |= TNF_MIGRATE_FAIL;
out:
if (page_nid != -1)
task_numa_fault(last_cpupid, page_nid, 1, flags);
return 0;
}
참고: Automatic NUMA Balancing | redhat – 다운로드 pdf
write protect 페이지의 fault 처리
do_wp_page()
mm/memory.c
/*
* This routine handles present pages, when users try to write
* to a shared page. It is done by copying the page to a new address
* and decrementing the shared-page counter for the old page.
*
* Note that this routine assumes that the protection checks have been
* done by the caller (the low-level page fault routine in most cases).
* Thus we can safely just mark it writable once we've done any necessary
* COW.
*
* We also mark the page dirty at this point even though the page will
* change only once the write actually happens. This avoids a few races,
* and potentially makes it more efficient.
*
* We enter with non-exclusive mmap_sem (to exclude vma changes,
* but allow concurrent faults), with pte both mapped and locked.
* We return with mmap_sem still held, but pte unmapped and unlocked.
*/
static int do_wp_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
spinlock_t *ptl, pte_t orig_pte)
__releases(ptl)
{
struct page *old_page, *new_page = NULL;
pte_t entry;
int ret = 0;
int page_mkwrite = 0;
bool dirty_shared = false;
unsigned long mmun_start = 0; /* For mmu_notifiers */
unsigned long mmun_end = 0; /* For mmu_notifiers */
struct mem_cgroup *memcg;
old_page = vm_normal_page(vma, address, orig_pte);
if (!old_page) {
/*
* VM_MIXEDMAP !pfn_valid() case, or VM_SOFTDIRTY clear on a
* VM_PFNMAP VMA.
*
* We should not cow pages in a shared writeable mapping.
* Just mark the pages writable as we can't do any dirty
* accounting on raw pfn maps.
*/
if ((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))
goto reuse;
goto gotten;
}
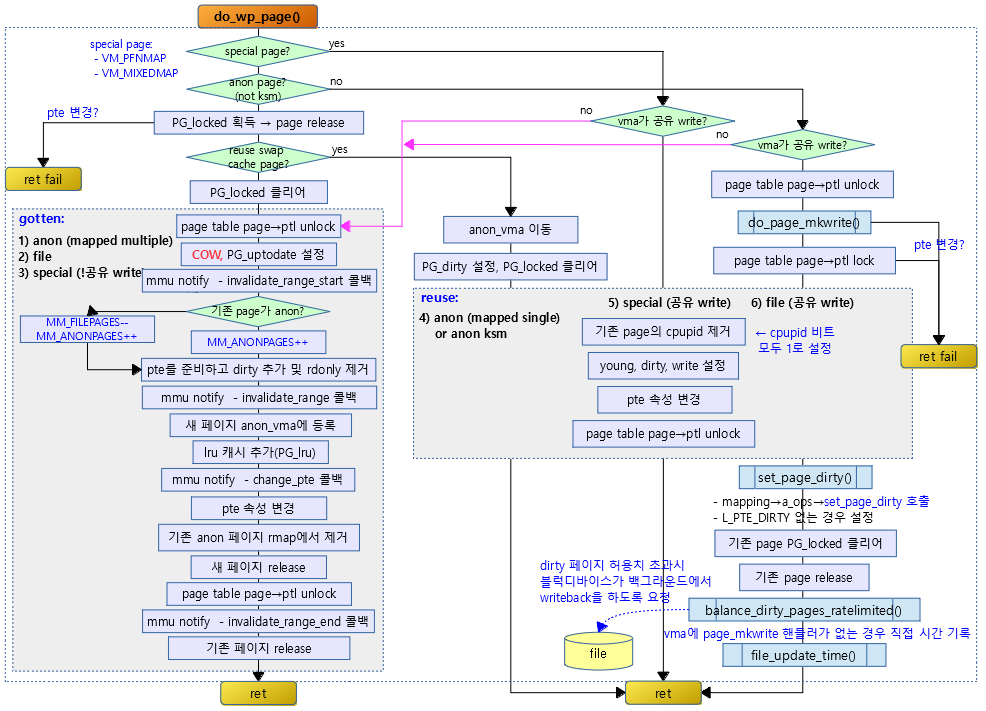
write 권한이 없어 fault된 페이지에 대해 해당 페이지 또는 COW(Copy On Write) anon 페이지에 write 권한 매핑을 한다.
- 코드 라인 33~47에서 special 페이지인 경우 vma가 공유 write 매핑된 경우 재사용하기 위해 reuse: 레이블로 이동하고, 그렇지 않은 경우 COW를 위해 gotten: 레이블로 이동한다.
- null을 반환하는 경우 VM_PFMMAP 또는 VM_MIXEDMAP에서 사용하는 special 페이지이다.
. /*
* Take out anonymous pages first, anonymous shared vmas are
* not dirty accountable.
*/
if (PageAnon(old_page) && !PageKsm(old_page)) {
if (!trylock_page(old_page)) {
page_cache_get(old_page);
pte_unmap_unlock(page_table, ptl);
lock_page(old_page);
page_table = pte_offset_map_lock(mm, pmd, address,
&ptl);
if (!pte_same(*page_table, orig_pte)) {
unlock_page(old_page);
goto unlock;
}
page_cache_release(old_page);
}
if (reuse_swap_page(old_page)) {
/*
* The page is all ours. Move it to our anon_vma so
* the rmap code will not search our parent or siblings.
* Protected against the rmap code by the page lock.
*/
page_move_anon_rmap(old_page, vma, address);
unlock_page(old_page);
goto reuse;
}
unlock_page(old_page);
} else if (unlikely((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))) {
page_cache_get(old_page);
/*
* Only catch write-faults on shared writable pages,
* read-only shared pages can get COWed by
* get_user_pages(.write=1, .force=1).
*/
if (vma->vm_ops && vma->vm_ops->page_mkwrite) {
int tmp;
pte_unmap_unlock(page_table, ptl);
tmp = do_page_mkwrite(vma, old_page, address);
if (unlikely(!tmp || (tmp &
(VM_FAULT_ERROR | VM_FAULT_NOPAGE)))) {
page_cache_release(old_page);
return tmp;
}
/*
* Since we dropped the lock we need to revalidate
* the PTE as someone else may have changed it. If
* they did, we just return, as we can count on the
* MMU to tell us if they didn't also make it writable.
*/
page_table = pte_offset_map_lock(mm, pmd, address,
&ptl);
if (!pte_same(*page_table, orig_pte)) {
unlock_page(old_page);
goto unlock;
}
page_mkwrite = 1;
}
dirty_shared = true;
- 코드 라인 5에서 anon 페이지이면서 KSM(Kernel Same Merge) 페이지가 아닌 경우
- 코드 라인 6~17에서 페이지의 PG_locked를 획득(설정)하고 페이지를 release 한다. 만일 락 획득 과정에서 pte 엔트리가 다른 cpu와의 경쟁 상황으로 인해 변경된 경우 포기하고 빠져나간다.
- 코드 라인 18~27에서 swap 페이지를 재사용할 수 있는 경우 PG_dirty 설정을 하고 기존 reserve map을 재배치하고 PG_locked를 해제한다. 그리고 계속 reuse: 레이블을 진행한다.
- swap 캐시가 참조되지 않았으면서 PG_writeback이 없는 경우 swap 캐시를 지우고 PG_dirty 설정을 한다.
- 코드 라인 28에서 페이지의 PG_locked를 해제한다.
- 코드 라인 29~31에서 낮은 확률로 vma가 공유 write 설정된 경우(file) old 페이지의 참조 카운터를 증가시킨다.
- 코드 라인 37~46에서 vma의 ops 핸들러에 page_mkwrite가 설정된 경우 pte 엔트리가 있는 페이지 테이블 락을 해제하고 do_page_mkwrite()를 수행하여 write 설정을 한다. 이 과정에서 mkwrite 수행 시 에러가 있는 경우 페이지를 release하고 빠져나간다.
- 코드 라인 53~58에서 다시 페이지 테이블 락을 얻는다. 이 과정에서 pte 엔트리가 다른 cpu와의 경쟁 상황으로 인해 변경된 경우 포기하고 빠져나간다.
- 코드 라인 59에서 page_mkwrite를 설정하여 아래 reuse: 레이블의 코드에서 vma의 ops 핸들러에 page_mkwrite 핸들러가 없는 경우에만 동작시킬 코드를 구분하기 위한 플래그이다.
- 코드 라인 62에서 아래 reuse: 레이블의 코드를 3군데에서 호출하여 사용하는데, 특별히 위의 조건에서만 진행할 코드를 수행할 수 있도록 이를 판단하기 위해 dirty_shared를 설정한다.
reuse:
/*
* Clear the pages cpupid information as the existing
* information potentially belongs to a now completely
* unrelated process.
*/
if (old_page)
page_cpupid_xchg_last(old_page, (1 << LAST_CPUPID_SHIFT) - 1);
flush_cache_page(vma, address, pte_pfn(orig_pte));
entry = pte_mkyoung(orig_pte);
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
if (ptep_set_access_flags(vma, address, page_table, entry,1))
update_mmu_cache(vma, address, page_table);
pte_unmap_unlock(page_table, ptl);
ret |= VM_FAULT_WRITE;
if (dirty_shared) {
struct address_space *mapping;
int dirtied;
if (!page_mkwrite)
lock_page(old_page);
dirtied = set_page_dirty(old_page);
VM_BUG_ON_PAGE(PageAnon(old_page), old_page);
mapping = old_page->mapping;
unlock_page(old_page);
page_cache_release(old_page);
if ((dirtied || page_mkwrite) && mapping) {
/*
* Some device drivers do not set page.mapping
* but still dirty their pages
*/
balance_dirty_pages_ratelimited(mapping);
}
if (!page_mkwrite)
file_update_time(vma->vm_file);
}
return ret;
}
- 코드 라인 7~8에서 old 페이지의 플래그 중 cpupid 정보를 제거하기 위해 모든 해당 비트를 1로 설정한다.
- 코드 라인 10에서 해당 페이지에 대한 캐시를 각 아키텍처의 고유한 방법으로 flush한다.
- 코드 라인 11~14에서 young, dirty, write 비트를 설정하고 pte 엔트리를 업데이트한다. 또한 해당 페이지에 대한 캐시를 각 아키텍처의 고유한 방법으로 update 한다.
- 코드 라인 15에서 페이지 테이블 락(pte 페이지 테이블에 대한 page->ptl)을 해제한다.
- 코드 라인 16에서 결과 코드에 VM_FAULT_WRITE 플래그를 설정한다.
- 코드 라인 18~23에서 dirty_shared가 설정된 경우 (vma가 공유 파일 write 설정) vma의 page_mkwrite 핸들러가 별도로 지정되지 않은 경우 페이지의 락을 획득한다. (PG_locked)
- 코드 라인 25~29에서 페이지에 PG_dirty 설정을하고 페이지 락을 다시 해제한 후 페이지를 release 한다.
- 코드 라인 31~37에서 file 매핑된 페이지가 기존에 PG_dirty 설정이 있었거나 vma에 page_mkwrite 핸들러가 있으면 balance_dirty_pages_ratelimited() 함수를 호출한다.
- dirty 페이지가 제한치를 초과하는 경우 밸런싱을 맞추기 위해 블록디바이스가 백그라운드에서 writeback을 수행할 수 있게 요청한다.
- 코드 라인 39~40에서 vma에 page_mkwrite 핸들러 함수가 없는 경우 file_update_time() 함수를 호출하여 파일에 update 시간을 기록한다.
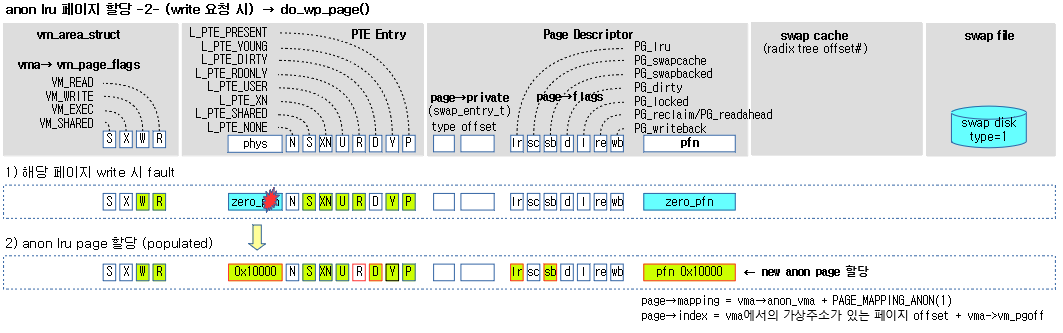
/*
* Ok, we need to copy. Oh, well..
*/
page_cache_get(old_page);
gotten:
pte_unmap_unlock(page_table, ptl);
if (unlikely(anon_vma_prepare(vma)))
goto oom;
if (is_zero_pfn(pte_pfn(orig_pte))) {
new_page = alloc_zeroed_user_highpage_movable(vma, address);
if (!new_page)
goto oom;
} else {
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address);
if (!new_page)
goto oom;
cow_user_page(new_page, old_page, address, vma);
}
__SetPageUptodate(new_page);
if (mem_cgroup_try_charge(new_page, mm, GFP_KERNEL, &memcg))
goto oom_free_new;
mmun_start = address & PAGE_MASK;
mmun_end = mmun_start + PAGE_SIZE;
mmu_notifier_invalidate_range_start(mm, mmun_start, mmun_end);
- 코드 라인 4에서 기존 페이지를 복사하기 위해 페이지 참조 카운터를 증가시킨다.
- 코드 라인 6에서 페이지 테이블 페이지의 ptl 락을 해제한다.
- 코드 라인 8~9에서 낮은 확률로 메모리가 부족하여 anon_vma를 준비하지 못하면 oom 레이블로 이동한다.
- 코드 라인 11~14에서 zero 페이지가 매핑되어 있었던 경우 0으로 초기화된 새로운 페이지를 준비한다. 메모리 부족으로 새 페이지가 준비되지 않으면 oom 레이블로 이동한다.
- 코드 라인 15~20에서 zero 페이지가 아닌 경우 새로운 페이지를 준비하고 기존 페이지로부터 복사한다. 만일 메모리 부족으로 새 페이지가 준비되지 않으면 oom 레이블로 이동한다.
- 코드 라인 21에서 새 페이지의 PG_uptodate 플래그를 설정한다.
- 코드 라인 23~24에서 memcg에 새 페이지의 할당 한계가 초과되었는지 알아보고 초과한 경우 oom_free_new 레이블로 이동한다.
- 코드 라인 26~28에서 새 가상 주소 페이지의 주소 범위를 인수로 mmu notifier 리스트에 등록한 invalidate_range_start 콜백 함수들을 호출한다.
- mm->mmu_notifier_mm 리스트에 등록한 mn ops 핸들러에 연결된 invalidate_range_start 콜백 함수들
- virt/kvm/kvm_main.c – kvm_mmu_notifier_invalidate_range_start()
- drivers/gpu/drm/radeon/radeon_mn.c – radeon_mn_invalidate_range_start()
- drivers/infiniband/core/umem_odp.c – ib_umem_notifier_invalidate_range_start()
- drivers/misc/mic/scif/scif_dma.c – scif_mmu_notifier_invalidate_range_start()
- mmu notifier
- CONFIG_MMU_NOTIFIER 커널 옵션을 사용하는 경우 CONFIG_SRCU 커널 옵션이 자동 선택되며 read-side 크리티컬 섹션에서 슬립이 가능한 SRCU(Sleepable RCU)를 사용할 수 있다.
- mm이 변경되는 경우 notify 하는 메커니즘을 제공하는데 리스트 탐색 시 SRCU를 사용한다.
- mm->mmu_notifier_mm 리스트에 등록한 mn ops 핸들러에 연결된 invalidate_range_start 콜백 함수들
. /*
* Re-check the pte - we dropped the lock
*/
page_table = pte_offset_map_lock(mm, pmd, address, &ptl);
if (likely(pte_same(*page_table, orig_pte))) {
if (old_page) {
if (!PageAnon(old_page)) {
dec_mm_counter_fast(mm, MM_FILEPAGES);
inc_mm_counter_fast(mm, MM_ANONPAGES);
}
} else
inc_mm_counter_fast(mm, MM_ANONPAGES);
flush_cache_page(vma, address, pte_pfn(orig_pte));
entry = mk_pte(new_page, vma->vm_page_prot);
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
/*
* Clear the pte entry and flush it first, before updating the
* pte with the new entry. This will avoid a race condition
* seen in the presence of one thread doing SMC and another
* thread doing COW.
*/
ptep_clear_flush_notify(vma, address, page_table);
page_add_new_anon_rmap(new_page, vma, address);
mem_cgroup_commit_charge(new_page, memcg, false);
lru_cache_add_active_or_unevictable(new_page, vma);
/*
* We call the notify macro here because, when using secondary
* mmu page tables (such as kvm shadow page tables), we want the
* new page to be mapped directly into the secondary page table.
*/
set_pte_at_notify(mm, address, page_table, entry);
update_mmu_cache(vma, address, page_table);
if (old_page) {
/*
* Only after switching the pte to the new page may
* we remove the mapcount here. Otherwise another
* process may come and find the rmap count decremented
* before the pte is switched to the new page, and
* "reuse" the old page writing into it while our pte
* here still points into it and can be read by other
* threads.
*
* The critical issue is to order this
* page_remove_rmap with the ptp_clear_flush above.
* Those stores are ordered by (if nothing else,)
* the barrier present in the atomic_add_negative
* in page_remove_rmap.
*
* Then the TLB flush in ptep_clear_flush ensures that
* no process can access the old page before the
* decremented mapcount is visible. And the old page
* cannot be reused until after the decremented
* mapcount is visible. So transitively, TLBs to
* old page will be flushed before it can be reused.
*/
page_remove_rmap(old_page);
}
/* Free the old page.. */
new_page = old_page;
ret |= VM_FAULT_WRITE;
} else
mem_cgroup_cancel_charge(new_page, memcg);
- 코드 라인 4~5에서 페이지 테이블 페이지의 ptl 락을 획득한 후에도 pte 엔트리 값이 변경된 적이 없으면 해당 pte 엔트리에 대해 다른 cpu와의 경쟁이 없었거나 경쟁 상황에서 이긴 경우이다.
- 코드 라인 6~12에서 기존 페이지가 anon 페이지가 아닌 경우 MM_FILEPAGES 카운터를 줄이고 MM_ANONPAGES 카운터를 증가시킨다. 기존 페이지가 없었던 경우는 MM_ANONPAGES만 증가시킨다.
- 코드 라인 13에서 orig_pte에 해당하는 페이지 영역을 캐시 flush 한다.
- 코드 라인 14~15에서 새 페이지에 해당하는 pte 엔트리 속성을 준비하고 L_PTE_DIRTY를 추가하고 vma에 write 설정된 경우 L_PTE_RDONLY를 제거한다.
- 코드 라인 22에서 pte 엔트리를 언매핑(0) 한 후 아키텍처에 따라 해당 페이지에 대해 TLB 캐시를 flush한다. 그런 후 mmu notifier 리스트에 등록한 invalidate_range 콜백 함수들을 호출한다.
- mm->mmu_notifier_mm 리스트에 등록한 mn ops 핸들러에 연결된 invalidate_range 콜백 함수들
- drivers/infiniband/hw/mlx5/odp.c – mlx5_ib_invalidate_range()
- drivers/net/ethernet/adi/bfin_mac.c – blackfin_dcache_invalidate_range()
- drivers/iommu/amd_iommu_v2.c – mn_invalidate_range()
- mm->mmu_notifier_mm 리스트에 등록한 mn ops 핸들러에 연결된 invalidate_range 콜백 함수들
- 코드 라인 23~25에서 anon reverse map에 새 페이지를 추가하고, memcg에 새 페이지 추가를 commit 한 후 lru 캐시에 추가한다.
- 코드 라인 31~32에서 mmu notifier 리스트에 등록한 change_pte 콜백 함수들을 호출한 후 pte 엔트리를 변경한다.
- mm->mmu_notifier_mm 리스트에 등록한 mn ops 핸들러에 연결된 change_pte 콜백 함수
- virt/kvm/kvm_main.c – kvm_mmu_notifier_change_pte()
- mm->mmu_notifier_mm 리스트에 등록한 mn ops 핸들러에 연결된 change_pte 콜백 함수
- 코드 라인 33~57에서 기존 페이지가 있는 경우 anon reverse map에서 제거한다.
- 코드 라인 62~63에서 pte 엔트리가 다른 cpu와의 경쟁 상황으로 인해 변경된 경우 memcg에 새 페이지를 commit 계량하지 않게 취소 요청한다.
if (new_page)
page_cache_release(new_page);
unlock:
pte_unmap_unlock(page_table, ptl);
if (mmun_end > mmun_start)
mmu_notifier_invalidate_range_end(mm, mmun_start, mmun_end);
if (old_page) {
/*
* Don't let another task, with possibly unlocked vma,
* keep the mlocked page.
*/
if ((ret & VM_FAULT_WRITE) && (vma->vm_flags & VM_LOCKED)) {
lock_page(old_page); /* LRU manipulation */
munlock_vma_page(old_page);
unlock_page(old_page);
}
page_cache_release(old_page);
}
return ret;
oom_free_new:
page_cache_release(new_page);
oom:
if (old_page)
page_cache_release(old_page);
return VM_FAULT_OOM;
}
- 코드 라인 1~2에서 새 페이지가 있는 경우 페이지 참조를 release 한다.
- 코드 라인 4에서 페이지 테이블 락을 해제한다.
- pte 엔트리가 있는 페이지 테이블 페이지의 ptl 락을 해제한다.
- 코드 라인 5~6에서 mmu notifier 리스트에 등록한 invalidate_range_end 콜백 함수들을 호출한다.
- mm->mmu_notifier_mm 리스트에 등록한 mn ops 핸들러에 연결된 invalidate_range_end 콜백 함수들
- virt/kvm/kvm_main.c – kvm_mmu_notifier_invalidate_range_end()
- drivers/misc/sgi-gru/grutlbpurge.c – gru_invalidate_range_end()
- drivers/infiniband/core/umem_odp.c – ib_umem_notifier_invalidate_range_end()
- mm->mmu_notifier_mm 리스트에 등록한 mn ops 핸들러에 연결된 invalidate_range_end 콜백 함수들
- 코드 라인 7~18에서 old 페이지가 있는 경우 페이지의 참조 카운터를 감소시키고 0이되는 경우 할당 해제한다. 만일 mlocked 페이지에서 COW 하였었던 경우 기존 페이지에 lock을 걸고 PG_mlocked 을 제거하고 NR_MLOCK 카운터를 감소시킨다. 또한 lru 페이지인 경우 PG_lru를 제거하고, lru 리스트에서도 제거한다. 마지막으로 다시 old 페이지에서 lock을 해제한다.(PG_locked 해제)
빠른 RSS 카운팅을 위해 분리
SPLIT_RSS_COUNTING
include/linux/mm_types.h
#if USE_SPLIT_PTE_PTLOCKS && defined(CONFIG_MMU)
#define SPLIT_RSS_COUNTING
/* per-thread cached information, */
struct task_rss_stat {
int events; /* for synchronization threshold */
int count[NR_MM_COUNTERS];
};
#endif /* USE_SPLIT_PTE_PTLOCKS */
USE_SPLIT_PTE_PTLOCKS와 MMU가 설정된 경우 빠른 RSS 카운팅을 위해 RSS 카운팅을 이원화 시킨다.
- 2개의 rss_stat으로 나뉘어 운영한다.
- mm->rss_stat.count[] (RSS 통계값 원본)
- task->rss_stat.count[] (이원화할 때 빠른 카운터로 추가)
- sync는 task->stat_envents를 증가시키다 TASK_RSS_EVENTS_THRESH(64) 값에 도달하면 sync를 위해 task의 카운터들을 mm에 옮긴다.
USE_SPLIT_PTE_PTLOCKS
include/linux/mm_types.h
#define USE_SPLIT_PTE_PTLOCKS (NR_CPUS >= CONFIG_SPLIT_PTLOCK_CPUS)
USE_SPLIT_PTE_PTLOCKS은 CONFIG_SPLIT_PTLOCK_CPUS이상의 NR_CPUS가 설정된 경우 동작한다.
- rpi2: NR_CPUS=4, CONFIG_SPLIT_PTLOCK_CPUS=4로 설정되어 USE_SPLIT_PTE_PTLOCKS가 운용된다.
check_sync_rss_stat()
mm/memory.c
static void check_sync_rss_stat(struct task_struct *task)
{
if (unlikely(task != current))
return;
if (unlikely(task->rss_stat.events++ > TASK_RSS_EVENTS_THRESH))
sync_mm_rss(task->mm);
}
요청 태스크가 현재 태스크인 경우에 한해 task의 sync 카운터인 rss_stat.events를 증가시킨다. 만일 sync 카운터가 스레졸드(64)를 초과하는 경우 다시 0으로 설정하고 이원화된 rss 카운터를 동기화하도록 요청 한다.
sync_mm_rss()
mm/memory.c
void sync_mm_rss(struct mm_struct *mm)
{
int i;
for (i = 0; i < NR_MM_COUNTERS; i++) {
if (current->rss_stat.count[i]) {
add_mm_counter(mm, i, current->rss_stat.count[i]);
current->rss_stat.count[i] = 0;
}
}
current->rss_stat.events = 0;
}
현재 태스크의 rss_stat.count[]의 값들을 모두 원래 카운터 값인 메모리 디스크립터의 rss_stat.count[]에 옮기고 sync 카운터를 다시 0으로 한다.
참고
- Exception -1- (ARM32 Vector) | 문c
- Exception -2- (ARM32 Handler 1) | 문c
- Exception -3- (ARM32 Handler 2) | 문c
- Exception -4- (ARM32 VFP & FPE) | 문c
- Exception -5- (Extable) | 문c
- Exception -6- (MM Fault Handler) | 문c – 현재 글
- Exception -7- (ARM64 Vector) | 문c
- Exception -8- (ARM64 Handler) | 문c
- Exception -9- (ARM64 Fault Handler) | 문c
- Swap 엔트리 | 문c
- User-space page fault handling | LWN.net
- fault() | LWN.net
- Faulting out populate(), nopfn(), and nopage() | LWN.net