<kernel v5.4>
Exception -9- (ARM64 Fault Handler)
메모리 fault 처리는 아키텍처 관련 코드를 수행한 후 아키텍쳐 공통 메모리 fault 코드를 수행한다.
- 먼저 do_mem_abort() 함수를 호출하며, 페이지 fault 처리에 대해 do_page_fault() -> __do_page_fault() 함수 순서대로 수행한다.
- 그 후 아키텍처 공통(generic) 메모리 fault 처리 함수인 handle_mm_fault() 함수로 진입한다.
다음 그림은 유저 및 커널 모드 수행 중 sync exception 발생 시 처리되는 함수 흐름이다.
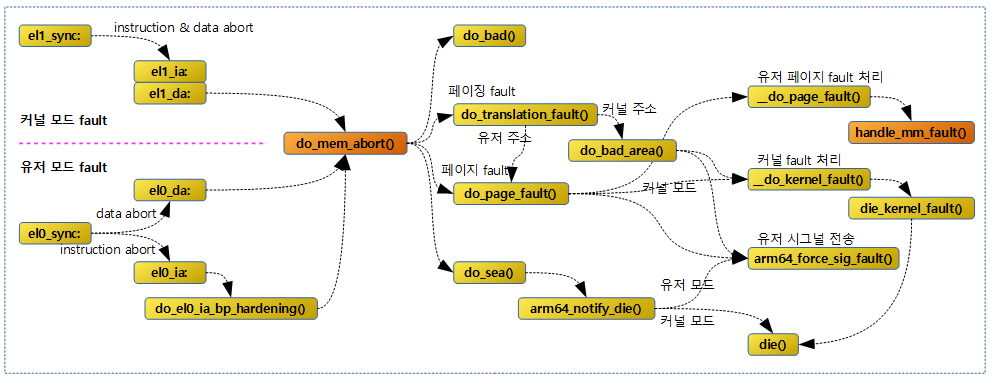
do_mem_abort()
arch/arm64/mm/fault.c
asmlinkage void __exception do_mem_abort(unsigned long addr, unsigned int esr,
struct pt_regs *regs)
{
const struct fault_info *inf = esr_to_fault_info(esr);
if (!inf->fn(addr, esr, regs))
return;
if (!user_mode(regs)) {
pr_alert("Unhandled fault at 0x%016lx\n", addr);
mem_abort_decode(esr);
show_pte(addr);
}
arm64_notify_die(inf->name, regs,
inf->sig, inf->code, (void __user *)addr, esr);
}
가상 주소 @addr에 해당하는 공간에 접근하다 fault가 발생하였고, @esr(Exception Syndrom Register) 값과 스택에 저장한 context(pt_regs)를 인자로 가지고 진입하였다. 해당 가상 메모리 영역에 대한 fault 처리를 수행한다.
- 코드 라인 4에서 @esr 값으로 static하게 정의된 fault_info[] 배열에서 구조체 fault_info를 알아온다.
- 코드 라인 6~7에서 fault_info[] 배열에 미리 static으로 지정해둔 해당 함수를 실행한다.
- 예) “level 1 permission fault”가 발생한 경우 do_page_fault() 함수를 호출한다.
- 코드 라인 9~13에서 유저 영역이 아닌 가상 주소에서 fault가 발생한 경우 다음과 같은 디버그용 정보를 출력한다.
- “Unhandled fault at 0x################” 에러 메시지
- “Mem abort info: ESR=0x########” 등의 메모리 abort 정보
- 데이터 abort 인 경우 “Data abort info:” 정보도 추가
- swapper 또는 user 페이지 테이블 정보
- 코드 라인 15~16에서 유저 영역에서의 fault는 해당 프로세스를 kill하고, 커널 영역에서의 fault인 경우 die 처리한다.
페이지 fault 처리
do_page_fault()
arch/arm64/mm/fault.c -1/3-
static int __kprobes do_page_fault(unsigned long addr, unsigned int esr,
struct pt_regs *regs)
{
const struct fault_info *inf;
struct mm_struct *mm = current->mm;
vm_fault_t fault, major = 0;
unsigned long vm_flags = VM_READ | VM_WRITE;
unsigned int mm_flags = FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_KILLABLE;
if (kprobe_page_fault(regs, esr))
return 0;
/*
* If we're in an interrupt or have no user context, we must not take
* the fault.
*/
if (faulthandler_disabled() || !mm)
goto no_context;
if (user_mode(regs))
mm_flags |= FAULT_FLAG_USER;
if (is_el0_instruction_abort(esr)) {
vm_flags = VM_EXEC;
mm_flags |= FAULT_FLAG_INSTRUCTION;
} else if (is_write_abort(esr)) {
vm_flags = VM_WRITE;
mm_flags |= FAULT_FLAG_WRITE;
}
if (is_ttbr0_addr(addr) && is_el1_permission_fault(addr, esr, regs)) {
/* regs->orig_addr_limit may be 0 if we entered from EL0 */
if (regs->orig_addr_limit == KERNEL_DS)
die_kernel_fault("access to user memory with fs=KERNEL_DS",
addr, esr, regs);
if (is_el1_instruction_abort(esr))
die_kernel_fault("execution of user memory",
addr, esr, regs);
if (!search_exception_tables(regs->pc))
die_kernel_fault("access to user memory outside uaccess routines",
addr, esr, regs);
}
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, addr);
- 코드 라인 5에서 현재 태크스가 사용중인 메모리 관리에 해당하는 mm을 알아온다.
- 코드 라인 7에서 vm 플래그 초기 값으로 VM_READ와 VM_WRITE플래그를 지정한다.
- 코드 라인 8에서 mm 플래그 초기 값으로 FAULT_FLAG_ALLOW_RETRY와 FAULT_FLAG_KILLABLE 플래그를 지정한다.
- 코드 라인 10~11에서 mm fault 발생 하였으므로 kprobe 디버그를 사용중이면 kprobe 상태에 따라 해당 kprobe fault 함수를 호출한다.
- 코드 라인 17~18에서 irq context에서 fault가 발생하였거나, 해당 태스크의 fault hander를 disable한 경우 유저 fault 처리를 생략하고 곧장 커널에 대한 fault 처리 루틴을 수행하러 no_context: 레이블로 이동한다.
- 코드 라인 20~21에서 유저 모드에서 fault가 발생한 경우 mm 플래그에 FAULT_FLAG_USER 플래그를 추가한다.
- 코드 라인 23~25에서 유저 모드에서 명령어를 수행하다 fault가 발생한 경우 vm 플래그에 VM_EXEC를 대입하고, mm 플래그에 FAULT_FLAG_INSTRUCTION을 추가한다.
- 코드 라인 26~29에서 쓰기 시도 중에 fault가 발생한 경우 vm 플래그에 VM_WRITE를 대입하고, mm 플래그에 FAULT_FLAG_WRITE를 추가한다.
- 코드 라인 31~44에서 커널 모드에서 유저 영역에 접근 시 permission 문제로 fault가 발생한 경우 다음 3 가지 경우에 한하여 die 처리한다.
- 메모리 제한이 없었던 경우
- 커널 모드의 명령어를 처리중 fault가 발생한 경우
- exception 테이블에 등록되지 않은 예외인 경우
- 코드 라인 46에서 perf 디버그를 목적으로 page fault에 대한 카운팅을 알 수 있게 하기 위해 PERF_COUNT_SW_PAGE_FAULTS 카운터를 1 증가시킨다.
arch/arm64/mm/fault.c -2/3-
/*
* As per x86, we may deadlock here. However, since the kernel only
* validly references user space from well defined areas of the code,
* we can bug out early if this is from code which shouldn't.
*/
if (!down_read_trylock(&mm->mmap_sem)) {
if (!user_mode(regs) && !search_exception_tables(regs->pc))
goto no_context;
retry:
down_read(&mm->mmap_sem);
} else {
/*
* The above down_read_trylock() might have succeeded in which
* case, we'll have missed the might_sleep() from down_read().
*/
might_sleep();
#ifdef CONFIG_DEBUG_VM
if (!user_mode(regs) && !search_exception_tables(regs->pc)) {
up_read(&mm->mmap_sem);
goto no_context;
}
#endif
}
fault = __do_page_fault(mm, addr, mm_flags, vm_flags);
major |= fault & VM_FAULT_MAJOR;
if (fault & VM_FAULT_RETRY) {
/*
* If we need to retry but a fatal signal is pending,
* handle the signal first. We do not need to release
* the mmap_sem because it would already be released
* in __lock_page_or_retry in mm/filemap.c.
*/
if (fatal_signal_pending(current)) {
if (!user_mode(regs))
goto no_context;
return 0;
}
/*
* Clear FAULT_FLAG_ALLOW_RETRY to avoid any risk of
* starvation.
*/
if (mm_flags & FAULT_FLAG_ALLOW_RETRY) {
mm_flags &= ~FAULT_FLAG_ALLOW_RETRY;
mm_flags |= FAULT_FLAG_TRIED;
goto retry;
}
}
up_read(&mm->mmap_sem);
mm->mmap_sem 읽기 락을 획득한 채로 __do_page_fault() 함수를 수행한다.
- 코드 라인 6에서 현재 태스크의 mm에서 read 락을 획득 시도한다.
- 코드 라인 7~8에서 만일 락을 획득하지 못했고, fault 발생한 곳이 유저 모드가 아니면서 exception 테이블에 등록된 예외도 없으면 곧장 커널에 대한 fault 처리 루틴을 수행하러 no_context: 레이블로 이동한다.
- 코드 라인 9~10에서 retry: 레이블이다. 여기서 read 락을 획득한다.
- 코드 라인 11~23에서 만일 읽기 락을 획득 시도하다 정상적으로 획득한 경우, 즉 race 컨디션 없이 락을 획득한 경우에 먼저 premption point를 수행해준다.
- preemption 옵션 중 하나인 voluntry 커널 설정인 경우 더 높은 우선 순위의 다른 태스크를 먼저 처리하기 위해 sleep 할 수 있다.
- 코드 라인 25에서 __do_page_fault() 함수를 호출하여 페이지 fault에 대한 처리를 수행한 후 fault 결과를 알아온다.
- 코드 라인 26에서 fault 결과 중 VM_FAULT_MAJOR 플래그가 있는 경우 major에도 추가한다.
- 코드 라인 28~50에서 fault 결과에 retry 요청이 있는 경우이다.
- fatal 시그널이 존재하는 경우 유저 모드에서 fault가 발생한 경우이면 0을 반환하고, 커널 모드에서 fault가 발생한 경우 no_context: 레이블로 이동한다.
- mm 플래그에 retry를 허용하는 경우에 한하여 mm 플래그에서 FAULT_FLAG_ALLOW_RETRY 플래그를 제거하고, retry를 시도했다는 뜻의 FAULT_FLAG_TRIED를 추가한 후 retry 레이블로 이동한다.
- 코드 라인 51에서 fault 처리를 위해 획득했었던 read 락을 풀어준다.
arch/arm64/mm/fault.c -3/3-
/*
* Handle the "normal" (no error) case first.
*/
if (likely(!(fault & (VM_FAULT_ERROR | VM_FAULT_BADMAP |
VM_FAULT_BADACCESS)))) {
/*
* Major/minor page fault accounting is only done
* once. If we go through a retry, it is extremely
* likely that the page will be found in page cache at
* that point.
*/
if (major) {
current->maj_flt++;
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MAJ, 1, regs,
addr);
} else {
current->min_flt++;
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MIN, 1, regs,
addr);
}
return 0;
}
/*
* If we are in kernel mode at this point, we have no context to
* handle this fault with.
*/
if (!user_mode(regs))
goto no_context;
if (fault & VM_FAULT_OOM) {
/*
* We ran out of memory, call the OOM killer, and return to
* userspace (which will retry the fault, or kill us if we got
* oom-killed).
*/
pagefault_out_of_memory();
return 0;
}
inf = esr_to_fault_info(esr);
set_thread_esr(addr, esr);
if (fault & VM_FAULT_SIGBUS) {
/*
* We had some memory, but were unable to successfully fix up
* this page fault.
*/
arm64_force_sig_fault(SIGBUS, BUS_ADRERR, (void __user *)addr,
inf->name);
} else if (fault & (VM_FAULT_HWPOISON_LARGE | VM_FAULT_HWPOISON)) {
unsigned int lsb;
lsb = PAGE_SHIFT;
if (fault & VM_FAULT_HWPOISON_LARGE)
lsb = hstate_index_to_shift(VM_FAULT_GET_HINDEX(fault));
arm64_force_sig_mceerr(BUS_MCEERR_AR, (void __user *)addr, lsb,
inf->name);
} else {
/*
* Something tried to access memory that isn't in our memory
* map.
*/
arm64_force_sig_fault(SIGSEGV,
fault == VM_FAULT_BADACCESS ? SEGV_ACCERR : SEGV_MAPERR,
(void __user *)addr,
inf->name);
}
return 0;
no_context:
__do_kernel_fault(addr, esr, regs);
return 0;
}
- 코드 라인 4~23에서 fault 처리 결과 에러도 없고, 매핑도 정상이고 접근에 문제가 없었던 경우 major 변수 값에 따른 perf 카운터를 증가시키고, 정상 결과(0)를 반환한다.
- 코드 라인 29~30에서 fault가 커널에서 발생한 경우는 커널을 계속 진행할 수 없어 no_context로 이동한다.
- 코드 라인 32~40에서 OOM(메모리 부족) 상황인 경우 OOM 킬을 수행하고 정상 결과(0)를 반환한다.
- OOM score가 높은 유저 태스크를 죽여 메모리를 확보한다.
- 코드 라인 42에서 esr 값으로 fault_info를 알아온다.
- 코드 라인 43에서 현재 태스크에 esr 값(내부 함수에서 조건에 따라 esr 값이 변경된다)을 기록한다.
- 코드 라인 44~69에서 fault 주소에 접근하려 했던 프로세스에 다음과 같은 시그널을 전송한다. 참고로 해당 프로세스는 시그널을 받아 처리할 수 있는 핸들러를 추가할 수 있다. SIGBUS 및 SIGSEGV 시그널 등에 대한 처리 핸들러가 설치되지 않은 프로세스는 디폴트로 kill 된다.
- SIGBUS fault인 경우 해당 프로세스에 SIGBUS 시그널을 전송한다.
- HWPOISON fault 검출인 경우 메모리 에러로 프로세스에 SIGBUS 시그널을 전송한다.
- 그 외 fault인 경우 해당 프로세스에 SIGSEGV 시그널을 전송한다.
- 코드 라인 71에서 정상 결과(0)를 반환한다.
- 코드 라인 73~75에서 no_context: 레이블이다. 커널이 더 이상 처리를 수행할 수 없어 fault에 대한 메시지를 출력하고 커널을 die 처리한다. 단 exception이 설치된 명령은 die 처리하지 않는다.
유저 페이지 fault 처리
__do_page_fault()
arch/arm64/mm/fault.c
static vm_fault_t __do_page_fault(struct mm_struct *mm, unsigned long addr,
unsigned int mm_flags, unsigned long vm_flags)
{
struct vm_area_struct *vma = find_vma(mm, addr);
if (unlikely(!vma))
return VM_FAULT_BADMAP;
/*
* Ok, we have a good vm_area for this memory access, so we can handle
* it.
*/
if (unlikely(vma->vm_start > addr)) {
if (!(vma->vm_flags & VM_GROWSDOWN))
return VM_FAULT_BADMAP;
if (expand_stack(vma, addr))
return VM_FAULT_BADMAP;
}
/*
* Check that the permissions on the VMA allow for the fault which
* occurred.
*/
if (!(vma->vm_flags & vm_flags))
return VM_FAULT_BADACCESS;
return handle_mm_fault(vma, addr & PAGE_MASK, mm_flags);
}
유저 주소에 대한 페이지 fault 처리이다.
- 코드 라인 4~7에서 현재 태스크의 mm내에서 fault 주소로 vma 영역을 찾는다.
- 코드 라인 13~18에서 vma 영역이 스택인 경우 스택을 확장 시도한다.
- 코드 라인 24~25에서 vma 영역이 요청한 속성을 허용하지 않는 경우 VM_FAULT_BADACCESS 결과를 반환한다.
- vma 공간이 vm 플래그(VM_READ, VM_WRITE, VM_EXEC 등)를 지원하지 않은 경우이다.
- 코드 라인 26에서 아키텍처 mm fault 처리는 완료되었다. 이 다음부터는 아키텍처와 무관한 코드로 작성된 generic mm fault 루틴을 수행한다.
커널 페이지 fault 처리
__do_kernel_fault()
arch/arm64/mm/fault.c
static void __do_kernel_fault(unsigned long addr, unsigned int esr,
struct pt_regs *regs)
{
const char *msg;
/*
* Are we prepared to handle this kernel fault?
* We are almost certainly not prepared to handle instruction faults.
*/
if (!is_el1_instruction_abort(esr) && fixup_exception(regs))
return;
if (WARN_RATELIMIT(is_spurious_el1_translation_fault(addr, esr, regs),
"Ignoring spurious kernel translation fault at virtual address %016lx\n", addr))
return;
if (is_el1_permission_fault(addr, esr, regs)) {
if (esr & ESR_ELx_WNR)
msg = "write to read-only memory";
else
msg = "read from unreadable memory";
} else if (addr < PAGE_SIZE) {
msg = "NULL pointer dereference";
} else {
msg = "paging request";
}
die_kernel_fault(msg, addr, esr, regs);
}
커널 페이지에 대한 fault 처리를 수행한다.
- 코드 라인 10~11에서 커널 명령(instruction)에서 fault가 발생하지 않았거나, 커널 명령에서 fault가 발생했어도 이에 대응하는 exception 테이블이 등록되어 있는 경우 커널 페이지에 대한 fault가 아니므로 그냥 함수를 빠져나간다.
- 코드 라인 13~15에서 거짓(spurious) 커널 페이지 변환 fault인 경우 경고 메시지를 출력한다.
- ratelimit 방식을 사용하여 디폴트로 최대 5초 이내에 10번만 메시지를 출력하도록 제한한다.
- 코드 라인 17~21에서 커널 permission fault인 경우의 메시지를 선택한다.
- 코드 라인 22~23에서 첫 페이지에 대한 접근의 경우의 메시지를 선택한다.
- 코드 라인 24~26에서 그 외의 경우 메시지를 선택한다.
- 코드 라인 28에서 커널 context를 덤프하고 die 처리를 한다.
die_kernel_fault()
arch/arm64/mm/fault.c
static void die_kernel_fault(const char *msg, unsigned long addr,
unsigned int esr, struct pt_regs *regs)
{
bust_spinlocks(1);
pr_alert("Unable to handle kernel %s at virtual address %016lx\n", msg,
addr);
mem_abort_decode(esr);
show_pte(addr);
die("Oops", regs, esr);
bust_spinlocks(0);
do_exit(SIGKILL);
}
커널 context를 덤프하고 die 처리를 한다. 다음과 같은 내용들을 출력한다.
- 메모리 abort 정보
- 데이터 abort 정보
- 페이지 테이블 정보
- 레지스터 덤프
- 커널 스택 덤프
다음은 0x00003fc8에 접근하다 발생한 커널 fault 예제이다.
[ 110.965771] Unable to handle kernel paging request at virtual address 00003fc8 [ 110.968799] Mem abort info: [ 110.969351] Exception class = DABT (current EL), IL = 32 bits [ 110.969828] SET = 0, FnV = 0 [ 110.969988] EA = 0, S1PTW = 0 [ 110.970142] Data abort info: [ 110.970560] ISV = 0, ISS = 0x00000006 [ 110.970758] CM = 0, WnR = 0 [ 110.971357] user pgtable: 4k pages, 39-bit VAs, pgd = ffffffc06527e000 [ 110.972077] [0000000000003fc8] *pgd=00000000a6761003, *pud=00000000a6761003, *pmd=0000000000000000 [ 110.972846] Internal error: Oops: 96000006 [#1] PREEMPT SMP [ 110.973711] Modules linked in: [ 110.974527] CPU: 3 PID: 1034 Comm: sleep Not tainted 4.14.67-v8-qemu+ #74 [ 110.974840] Hardware name: linux,dummy-virt (DT) [ 110.975749] task: ffffffc0650bd700 task.stack: ffffff800b0d8000 [ 110.976622] PC is at cpuacct_charge+0x34/0xa8 [ 110.977911] LR is at update_curr+0x98/0x228 [ 110.978260] pc : [<ffffff80080ec54c>] lr : [<ffffff80080d5030>] pstate: a00001c5 [ 110.978803] sp : ffffff800b0dba60 [ 110.978985] x29: ffffff800b0dba60 x28: ffffffc06ffb0480 [ 110.979768] x27: ffffff80092aa7c0 x26: ffffffc06d57d780 [ 110.980104] x25: ffffff80092aa000 x24: 0000000000000008 [ 110.980295] x23: ffffffc06ffb0480 x22: 0000000001c8e1f0 [ 110.980460] x21: 0000000000000001 x20: 0000000001c8e1f0 [ 110.980858] x19: ffffffc0650b9d00 x18: 0000000000000000 [ 110.981157] x17: 0000000000000000 x16: ffffff8008111500 [ 110.981402] x15: 0000000000000000 x14: 00000000004bb6d4 [ 110.981611] x13: 00000000ff9cea5c x12: 0000000000000000 [ 110.981902] x11: 00000000ff9cea94 x10: 00000000004ce000 [ 110.982104] x9 : 000000000000075a x8 : 0000000000000400 [ 110.982268] x7 : 000000000000075a x6 : 0000000002739d7c [ 110.982424] x5 : 00ffffffffffffff x4 : 0000000000000015 [ 110.983490] x3 : 0000000000000000 x2 : ffffffffff76abc0 [ 110.983734] x1 : 0000000000003ec0 x0 : 0000000000003ec0 [ 110.983940] Process sleep (pid: 1034, stack limit = 0xffffff800b0d8000) [ 110.984213] Call trace: [ 110.984388] Exception stack(0xffffff800b0db920 to 0xffffff800b0dba60) [ 110.984723] b920: 0000000000003ec0 0000000000003ec0 ffffffffff76abc0 0000000000000000 [ 110.984970] b940: 0000000000000015 00ffffffffffffff 0000000002739d7c 000000000000075a [ 110.985185] b960: 0000000000000400 000000000000075a 00000000004ce000 00000000ff9cea94 [ 110.985396] b980: 0000000000000000 00000000ff9cea5c 00000000004bb6d4 0000000000000000 [ 110.985624] b9a0: ffffff8008111500 0000000000000000 0000000000000000 ffffffc0650b9d00 [ 110.985878] b9c0: 0000000001c8e1f0 0000000000000001 0000000001c8e1f0 ffffffc06ffb0480 [ 110.986092] b9e0: 0000000000000008 ffffff80092aa000 ffffffc06d57d780 ffffff80092aa7c0 [ 110.986308] ba00: ffffffc06ffb0480 ffffff800b0dba60 ffffff80080d5030 ffffff800b0dba60 [ 110.986528] ba20: ffffff80080ec54c 00000000a00001c5 0000000000000003 ffffffc06d553e00 [ 110.986825] ba40: 0000007fffffffff ffffff80092a9b20 ffffff800b0dba60 ffffff80080ec54c [ 110.987497] [<ffffff80080ec54c>] cpuacct_charge+0x34/0xa8 [ 110.987842] [<ffffff80080d5030>] update_curr+0x98/0x228 [ 110.988085] [<ffffff80080d6108>] dequeue_task_fair+0x68/0x528 [ 110.988251] [<ffffff80080ce440>] deactivate_task+0xa8/0xf0 [ 110.988406] [<ffffff80080da9f4>] load_balance+0x454/0x960 [ 110.988693] [<ffffff80080db2a4>] pick_next_task_fair+0x3a4/0x6c8 [ 110.988987] [<ffffff8008b00bac>] __schedule+0x104/0x898 [ 110.989226] [<ffffff8008b01374>] schedule+0x34/0x98 [ 110.989459] [<ffffff8008b05084>] do_nanosleep+0x7c/0x168 [ 110.989739] [<ffffff80081113f4>] hrtimer_nanosleep+0xa4/0x128 [ 110.990058] [<ffffff8008111570>] compat_SyS_nanosleep+0x70/0x90 [ 110.990300] Exception stack(0xffffff800b0dbec0 to 0xffffff800b0dc000) [ 110.990825] bec0: 00000000ff9cea6c 0000000000000000 00000000f7b82590 00000000ff9cea6c [ 110.991237] bee0: 0000000005f5e100 0000000000000000 00000000004b8e80 00000000000000a2 [ 110.991768] bf00: 0000000000000000 0000000000000000 00000000004ce000 00000000ff9cea94 [ 110.992084] bf20: 0000000000000000 00000000ff9cea5c 00000000004bb6d4 0000000000000000 [ 110.992521] bf40: 0000000000000000 0000000000000000 0000000000000000 0000000000000000 [ 110.993118] bf60: 0000000000000000 0000000000000000 0000000000000000 0000000000000000 [ 110.993655] bf80: 0000000000000000 0000000000000000 0000000000000000 0000000000000000 [ 110.994227] bfa0: 0000000000000000 0000000000000000 0000000000000000 0000000000000000 [ 110.995517] bfc0: 00000000f7ab4a10 0000000060040010 00000000ff9cea6c 00000000000000a2 [ 110.995998] bfe0: 0000000000000000 0000000000000000 0000000000000000 0000000000000000 [ 110.996235] [<ffffff8008083b18>] __sys_trace_return+0x0/0x4 [ 110.996618] Code: 52800035 f9401260 8b010000 b4000080 (f9408400) [ 110.997850] ---[ end trace cdf6df9c4e5b5c95 ]--- [ 110.998316] note: sleep[1034] exited with preempt_count 2
테이블 변환 fault 처리
do_translation_fault()
arch/arm64/mm/fault.c
static int __kprobes do_translation_fault(unsigned long addr,
unsigned int esr,
struct pt_regs *regs)
{
if (is_ttbr0_addr(addr))
return do_page_fault(addr, esr, regs);
do_bad_area(addr, esr, regs);
return 0;
}
가상 주소를 물리 주소로 변환하는 페이지 테이블을 사용한 변환에 fault가 발생하였을 수행을 한다.
- 코드 라인 5~6에서 fault 발생 주소가 유저 영역에 접근하는 경우 페이지 fault 처리로 이동한다.
- 코드 라인 8에서 영역 침범과 관련한 fault 처리를 수행하도록 이동한다.
영역 침범 fault 처리
do_bad_area()
arch/arm64/mm/fault.c
static void do_bad_area(unsigned long addr, unsigned int esr, struct pt_regs *regs)
{
/*
* If we are in kernel mode at this point, we have no context to
* handle this fault with.
*/
if (user_mode(regs)) {
const struct fault_info *inf = esr_to_fault_info(esr);
set_thread_esr(addr, esr);
arm64_force_sig_fault(inf->sig, inf->code, (void __user *)addr,
inf->name);
} else {
__do_kernel_fault(addr, esr, regs);
}
}
영역 침범에 대한 fault 처리를 수행한다.
- 코드 라인 7~12에서 유저 모드에서 동작 중에 fault 발생한 경우 해당 프로세스에 시그널을 전송한다.
- 해당 프로세스가 die 한다. 만일 프로세스에 시그널 핸들러가 설치된 경우 해당 핸들러 코드가 동작하다.
- 코드 라인 13~15에서 커널 fault 처리를 수행하고 die 한다.
정렬 fault 처리
do_alignment_fault()
arch/arm64/mm/fault.c
static int do_alignment_fault(unsigned long addr, unsigned int esr,
struct pt_regs *regs)
{
do_bad_area(addr, esr, regs);
return 0;
}
정렬 fault가 발생한 겨우 영역 침범과 동일한 코드를 호출하여 처리한다.
참고
- Exception -1- (ARM32 Vector) | 문c
- Exception -2- (ARM32 Handler 1) | 문c
- Exception -3- (ARM32 Handler 2) | 문c
- Exception -4- (ARM32 VFP & FPE) | 문c
- Exception -5- (Extable) | 문c
- Exception -6- (MM Fault Handler) | 문c – 현재 글
- Exception -7- (ARM64 Vector) | 문c
- Exception -8- (ARM64 Handler) | 문c
- Exception -9- (ARM64 Fault Handler) | 문c