<kernel v5.0>
DMA -2- (DMA Coherent Memory)
DMA coherent 메모리 할당은 아키텍처 및 플랫폼마다 다르다. 다음 몇 가지 예를 들어본다.
- 디바이스 전용 메모리가 구성되어 있고, Custom code 또는 디바이스 트리에서 지정한 reserved 메모리 영역을 DMA 영역으로 지정하고, 이 곳에서 할당하는 방법
- TCM(Tightly Coupled Memory, SRAM)이 제공되는 일부 시스템에서 이 영역을 특정 디바이스의 DMA 영역으로 사용
- 고속 네트워크 디바이스 등이 패킷 퍼버로 SRAM 등을 제공하고, 이 영역을 DMA 영역으로 사용
- 시스템 메모리의 일부를 DMA 영역으로 지정하고 사용
- 시스템 메모리의 CMA 영역 또는 시스템 메모리에서 DMA 메모리를 할당하는 방법
- 시스템 메모리의 HIGHMEM zone의 메모리를 유저 메모리에 할당하고 DMA 용도로 사용하는 방법
DMA coherent 메모리 할당
DMA coherent 메모리를 할당하는 방법은 다음과 같이 3가지 방법으로 나뉜다.
- Generic cohernet per-device memory
- reserved 메모리를 디바이스 전용 coherent 메모리로 사용하는 방법
- Direct DMA
- 시스템 메모리의 물리 주소에 Direct로 연결된 디바이스가 시스템 메모리의 일부를 DMA coherent 메모리로 사용하는 방법
- IOMMU
- IOMMU를 통한 디바이스가 시스템 메모리의 일부를 DMA coherent 메모리로 사용하는 방법
다음 그림은 DMA coherent 메모리 할당에 관련된 함수들의 호출 관계이다.
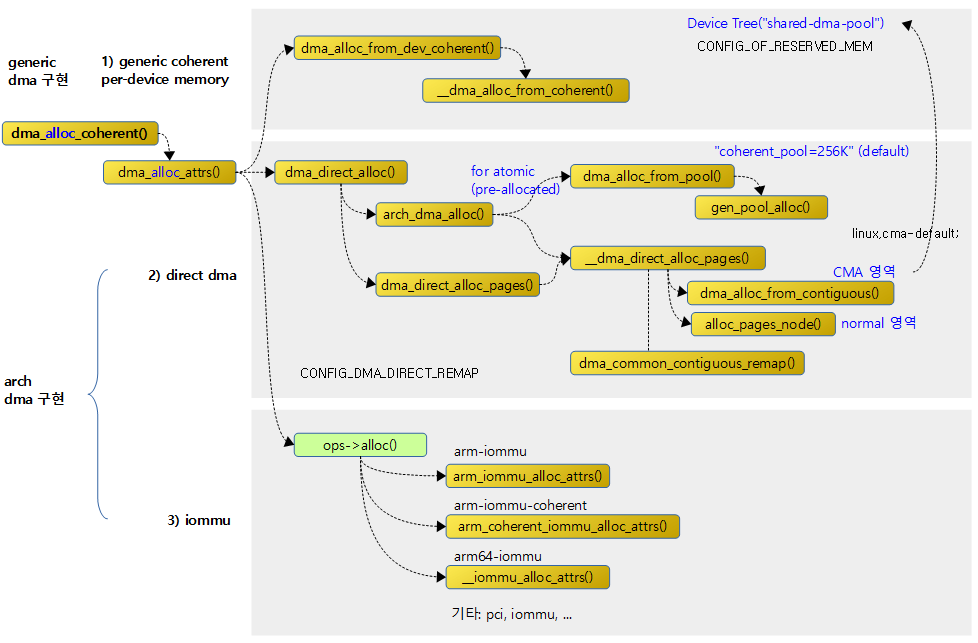
DMA coherent 메모리 할당 API
dma_alloc_coherent()
include/linux/dma-mapping.h
static inline void *dma_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t gfp)
{
return dma_alloc_attrs(dev, size, dma_handle, gfp,
(gfp & __GFP_NOWARN) ? DMA_ATTR_NO_WARN : 0);
}
DMA에 사용하기 위해 coherent 메모리를 size 만큼 할당해온다. 성공하는 경우 할당한 가상 주소가 반환된다.
dma_alloc_attrs()
kernel/dma/mapping.c
void *dma_alloc_attrs(struct device *dev, size_t size, dma_addr_t *dma_handle,
gfp_t flag, unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
void *cpu_addr;
WARN_ON_ONCE(dev && !dev->coherent_dma_mask);
if (dma_alloc_from_dev_coherent(dev, size, dma_handle, &cpu_addr))
return cpu_addr;
/* let the implementation decide on the zone to allocate from: */
flag &= ~(__GFP_DMA | __GFP_DMA32 | __GFP_HIGHMEM);
if (!arch_dma_alloc_attrs(&dev))
return NULL;
if (dma_is_direct(ops))
cpu_addr = dma_direct_alloc(dev, size, dma_handle, flag, attrs);
else if (ops->alloc)
cpu_addr = ops->alloc(dev, size, dma_handle, flag, attrs);
else
return NULL;
debug_dma_alloc_coherent(dev, size, *dma_handle, cpu_addr);
return cpu_addr;
}
EXPORT_SYMBOL(dma_alloc_attrs);
DMA에 사용하기 위해 coherent 메모리를 size 만큼 할당해온다. 디바이스전용 dma pool이 제공되는 경우 우선 할당한다. 없는 경우 시스템 메모리를 DMA direct 또는 IOMMU 매핑을 사용하여 할당해온다. 성공하는 경우 할당한 가상 주소가 반환된다.
- 코드 라인 9~10에서 디바이스 전용 coherent pool이 제공되는 경우 요청한 사이즈만큼 메모리를 할당한다. generic 할당이 성공한 경우 할당한 가상 주소를 결과로 함수를 빠져나간다.
- DMA_MEMORY_EXCLUSIVE 플래그를 사용할 때 디바이스 전용 dma 영역보다 큰 페이지 할당 요청을 하여 할당을 못하는 경우가 있다. 이러한 경우 generic DMA 할당을 시도하도록 유도하게 거짓 성공(1)으로 반환한다. 출력 인자 cpu_addr는 null로 반환한다.
- 코드 라인 13에서 zone 선택 관련 gfp 플래그에서 DMA, DMA32 및 HIGHMEM 영역을 제외한다.
- 코드 라인 15~16에서 아키텍처 specific한 dma 할당이 구현되어 있지 않으면 실패로 함수를 빠져나간다.
- x86 시스템의 경우에만 디바이스별로 판단한다. 그외의 아키텍처는 default로 항상 true이다.
- 코드 라인 18~26에서 direct dma 방식 또는 IOMMU 방식으로 할당해온다.
- IOMMU는 iommu 디바이스 드라이버에 구현된 dma_map_ops 구조체의 멤버 (*alloc) 함수를 호출하여 할당해온다.
Generic per-device DMA coherent 메모리
arm, arm64, x86, mips등 일부 아키텍처는 DMA coherent 메모리 할당을 위해 generic한 구현 코드를 지원한다.
- CONFIG_HAVE_GENERIC_DMA_COHERENT 커널 옵션 사용
- dma_coherent_mem 구조체를 사용하여 구현된다.
- 디바이스 트리를 통해 지정된 reserved-memory 영역을 DMA coherent 메모리로 사용할 수 있다.
- 지정된 영역은 DMA coherent 메모리 영역으로 비트맵으로 관리되며 1비트는 1페이지의 할당 여부를 관리한다.
dma_coherent_mem 구조체
kernel/dma/coherent.c
struct dma_coherent_mem {
void *virt_base;
dma_addr_t device_base;
unsigned long pfn_base;
int size;
int flags;
unsigned long *bitmap;
spinlock_t spinlock;
bool use_dev_dma_pfn_offset;
};
- *virt_base
- per-device DMA coherent 메모리가 매핑된 cpu 가상 주소
- device_base
- per-device DMA coherent 메모리의 cpu 물리 주소
- pfn_base
- per-device DMA coherent 메모리가 위치한 cpu 물리 주소위의 pfn
- size
- 사이즈
- flags
- DMA_MEMORY_EXCLUSIVE
- 디바이스 전용 dma coherent 메모리를 할당
- 그 외 플래그는 해당 드라이버의 custom 플래그
- DMA_MEMORY_EXCLUSIVE
- *bitmap
- 비트맵으로 각 bit는 페이지의 할당 여부를 관리한다.
- spinlock
- dma coherent 메모리 할당/할당 해제 시 동기화를 위하여 사용한다.
- use_dev_dma_pfn_offset
- 디바이스 트리의 reserved-memory 영역 지정을 통해 dma 메모리가 지정된 경우 사용된다.
- 디바이스에 지정된 dma_pfn_offset을 사용한다.
dma_alloc_from_dev_coherent()
kernel/dma/coherent.c
/** * dma_alloc_from_dev_coherent() - allocate memory from device coherent pool * @dev: device from which we allocate memory * @size: size of requested memory area * @dma_handle: This will be filled with the correct dma handle * @ret: This pointer will be filled with the virtual address * to allocated area. * * This function should be only called from per-arch dma_alloc_coherent() * to support allocation from per-device coherent memory pools. * * Returns 0 if dma_alloc_coherent should continue with allocating from * generic memory areas, or !0 if dma_alloc_coherent should return @ret. */
int dma_alloc_from_dev_coherent(struct device *dev, ssize_t size,
dma_addr_t *dma_handle, void **ret)
{
struct dma_coherent_mem *mem = dev_get_coherent_memory(dev);
if (!mem)
return 0;
*ret = __dma_alloc_from_coherent(mem, size, dma_handle);
if (*ret)
return 1;
/*
* In the case where the allocation can not be satisfied from the
* per-device area, try to fall back to generic memory if the
* constraints allow it.
*/
return mem->flags & DMA_MEMORY_EXCLUSIVE;
}
디바이스 전용 coherent pool에서 요청한 사이즈만큼 메모리를 할당한다. 결과가 0인 경우 할당이 실패한 경우이다.
- 코드 라인 4~7에서 디바이스에 지정된 coherent 메모리를 가져온다.
- 코드 라인 9~11에서 coherent 메모리에서 size 만큼을 할당해온다.
- 코드 라인 18에서 DMA_MEMORY_EXCLUSIVE 옵션을 사용한 경우에 1을 반환한다.
- DMA_MEMORY_EXCLUSIVE
- coherent 메모리 할당 시 디바이스 전용 coherent 영역보다 더 큰 할당을 요구할 때 실패한다. 이 때 fall-back 되어 시스템 메모리를 할당하는데, 이를 금지하게 한다.
- 참고: dma-coherent: Restore dma_alloc_from_coherent() large alloc fall back policy.
- DMA_MEMORY_EXCLUSIVE
__dma_alloc_from_coherent()
kernel/dma/coherent.c
static void *__dma_alloc_from_coherent(struct dma_coherent_mem *mem,
ssize_t size, dma_addr_t *dma_handle)
{
int order = get_order(size);
unsigned long flags;
int pageno;
void *ret;
spin_lock_irqsave(&mem->spinlock, flags);
if (unlikely(size > (mem->size << PAGE_SHIFT)))
goto err;
pageno = bitmap_find_free_region(mem->bitmap, mem->size, order);
if (unlikely(pageno < 0))
goto err;
/*
* Memory was found in the coherent area.
*/
*dma_handle = mem->device_base + (pageno << PAGE_SHIFT);
ret = mem->virt_base + (pageno << PAGE_SHIFT);
spin_unlock_irqrestore(&mem->spinlock, flags);
memset(ret, 0, size);
return ret;
err:
spin_unlock_irqrestore(&mem->spinlock, flags);
return NULL;
}
디바이스 전용 dma coherent 메모리 영역에서 요청한 size 만큼 coherent 메모리를 할당하고 그 가상 주소를 반환한다.
- 코드 라인 4에서 size를 order 페이지로 환산한다.
- 예) size=8192 (페이지=4K)
- order=1
- 예) size=8192 (페이지=4K)
- 코드 라인 11~12에서 dma 메모리 영역을 벗어나는 size 요청인 경우 에러(0)를 결과로 함수를 빠져나간다.
- 코드 라인 14~16에서 dma 메모리 영역을 비트맵으로 관리하는데, 이 비트맵에서 order 페이지 수 만큼의 빈 페이지 공간을 찾는다.
- 비트맵에서 1개의 비트는 1페이지의 할당 여부를 나타낸다.
- 코드 라인 21~25에서 찾은 페이지 번호에 해당하는 가상 주소를 반환한다.
- 예) mem->virt_base=0xffff_fff8_2000_0000, pageno=8 (페이지=4K)
- ret=0xffff_fff8_2000_8000
- 예) mem->virt_base=0xffff_fff8_2000_0000, pageno=8 (페이지=4K)
direct-DMA 메모리 할당
디바이스가 IOMMU를 통해 시스템 메모리에 연결되지 않은 경우에 사용된다.
- 디바이스 트리를 통해 reserved-memory 영역을 CMA 영역으로 선언하고 이를 이용하는 방법도 있고, CMA 영역이 아닌 일반 시스템 메모리를 할당해올 수 있다.
dma_direct_alloc()
kernel/dma/direct.c
void *dma_direct_alloc(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t gfp, unsigned long attrs)
{
if (!dev_is_dma_coherent(dev))
return arch_dma_alloc(dev, size, dma_handle, gfp, attrs);
return dma_direct_alloc_pages(dev, size, dma_handle, gfp, attrs);
}
시스템 메모리에서 주소 변환 없이 direct 매핑된 dma용 메모리를 할당해온다.
- 코드 라인 4~5에서 dma coherent 기능을 사용할 수 있는 디바이스가 아니면 architecture 고유의 dma 할당을 시도하고 coherent 매핑을 수행한다.
- 코드 라인 6에서 dma coherent 기능을 사용할 수 있는 디바이스인 경우이다. atomic 할당이 아닌 경우 cma영역에서 할당을 시도한다. 그렇지 않은 경우 연속된 페이지를 버디 시스템에서 할당해온다.
arch_dma_alloc()
kernel/dma/remap.c
void *arch_dma_alloc(struct device *dev, size_t size, dma_addr_t *dma_handle,
gfp_t flags, unsigned long attrs)
{
struct page *page = NULL;
void *ret;
size = PAGE_ALIGN(size);
if (!gfpflags_allow_blocking(flags) &&
!(attrs & DMA_ATTR_NO_KERNEL_MAPPING)) {
ret = dma_alloc_from_pool(size, &page, flags);
if (!ret)
return NULL;
goto done;
}
page = __dma_direct_alloc_pages(dev, size, dma_handle, flags, attrs);
if (!page)
return NULL;
/* remove any dirty cache lines on the kernel alias */
arch_dma_prep_coherent(page, size);
if (attrs & DMA_ATTR_NO_KERNEL_MAPPING) {
ret = page; /* opaque cookie */
goto done;
}
/* create a coherent mapping */
ret = dma_common_contiguous_remap(page, size, VM_USERMAP,
arch_dma_mmap_pgprot(dev, PAGE_KERNEL, attrs),
__builtin_return_address(0));
if (!ret) {
__dma_direct_free_pages(dev, size, page);
return ret;
}
memset(ret, 0, size);
done:
*dma_handle = phys_to_dma(dev, page_to_phys(page));
return ret;
}
architecture 고유의 dma 메모리를 할당하고 디폴트로 coherenet 매핑을 한다.
- 코드 라인 9~15에서 블럭킹되면 안되는 atomic 할당 요청이고, 아직 커널 매핑이 없어 커널 매핑이 필요한 경우이다. 이 경우 빠른 dma 메모리 할당을 위해 atomic dma pool 영역을 사용하여 할당한다.
- DMA_ATTR_NO_KERNEL_MAPPING
- 할당 DMA 버퍼가 이미 매핑되어 DMA 메모리 할당 후 커널 매핑이 필요 없는 경우에 사용한다.
- DMA_ATTR_NO_KERNEL_MAPPING
- 코드 라인 17~19에서 DMA Direct 매핑(버스 주소와 CPU 물리 주소가 같거나 일률적으로 변환가능)된 메모리를 할당해온다.
- 코드 라인 22에서 아키텍처별로 이 DMA 영역을 사용하기 전에 캐시 flush하도록 한다.
- arm64의 경우 해당 페이지들 영역에 대한 명령 및 데이터 캐시에 대해 clean & invalidate를 하도록 한다.
- 코드 라인 24~27에서 DMA_ATTR_NO_KERNEL_MAPPING 속성을 사용한 경우 커널에서 별도의 매핑 동작을 하지 않고 할당된 dma 페이지의 가상 주소를 결과로 함수를 빠져나간다.
- 코드 라인 30~36에서 coherent 매핑을 수행한다. 할당 받은 연속된 페이지의 dma 페이지들을 vmalloc 공간의 연속된 가상 주소로 매핑한다.
- coherent 매핑이 사용된 경우 스트리밍 매핑을 사용하지 않고도 cpu에서 기록한 내용이 device에서도 잘 읽히고, 그 반대도 잘 동작한다.
- 코드 라인 38~41에서 할당받은 메모리를 0으로 초기화하고, dma 주소를 @dma_handle에 저장하고 dma v페이지의 가상 주소를 결과로 함수를 정상 종료한다.
dma_direct_alloc_pages()
kernel/dma/direct.c”
void *dma_direct_alloc_pages(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t gfp, unsigned long attrs)
{
struct page *page;
void *ret;
page = __dma_direct_alloc_pages(dev, size, dma_handle, gfp, attrs);
if (!page)
return NULL;
if (PageHighMem(page)) {
/*
* Depending on the cma= arguments and per-arch setup
* dma_alloc_from_contiguous could return highmem pages.
* Without remapping there is no way to return them here,
* so log an error and fail.
*/
dev_info(dev, "Rejecting highmem page from CMA.\n");
__dma_direct_free_pages(dev, size, page);
return NULL;
}
ret = page_address(page);
if (force_dma_unencrypted()) {
set_memory_decrypted((unsigned long)ret, 1 << get_order(size));
*dma_handle = __phys_to_dma(dev, page_to_phys(page));
} else {
*dma_handle = phys_to_dma(dev, page_to_phys(page));
}
memset(ret, 0, size);
return ret;
}
dma direct 방식으로 페이지를 size 만큼 할당해온다. 할당해온 페이지가 highmem인 경우 할당을 해제하고 null을 반환한다.
- 코드 라인 7~9에서 dma direct 방식으로 페이지를 size 만큼 할당해온다.
- 코드 라인 11~21에서 할당된 페이지가 highmem 페이지인 경우 할당을 해제하고 null을 반환한다.
- 코드 라인 23~31에서 할당 영역의 메모리 decrytion을 수행한다.
- for x86 SME(Secure Memory Encryption)
- 참고 x86/mm: Add Secure Memory Encryption (SME) support
__dma_direct_alloc_pages()
kernel/dma/direct.c
struct page *__dma_direct_alloc_pages(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t gfp, unsigned long attrs)
{
unsigned int count = PAGE_ALIGN(size) >> PAGE_SHIFT;
int page_order = get_order(size);
struct page *page = NULL;
u64 phys_mask;
if (attrs & DMA_ATTR_NO_WARN)
gfp |= __GFP_NOWARN;
/* we always manually zero the memory once we are done: */
gfp &= ~__GFP_ZERO;
gfp |= __dma_direct_optimal_gfp_mask(dev, dev->coherent_dma_mask,
&phys_mask);
again:
/* CMA can be used only in the context which permits sleeping */
if (gfpflags_allow_blocking(gfp)) {
page = dma_alloc_from_contiguous(dev, count, page_order,
gfp & __GFP_NOWARN);
if (page && !dma_coherent_ok(dev, page_to_phys(page), size)) {
dma_release_from_contiguous(dev, page, count);
page = NULL;
}
}
if (!page)
page = alloc_pages_node(dev_to_node(dev), gfp, page_order);
if (page && !dma_coherent_ok(dev, page_to_phys(page), size)) {
__free_pages(page, page_order);
page = NULL;
if (IS_ENABLED(CONFIG_ZONE_DMA32) &&
phys_mask < DMA_BIT_MASK(64) &&
!(gfp & (GFP_DMA32 | GFP_DMA))) {
gfp |= GFP_DMA32;
goto again;
}
if (IS_ENABLED(CONFIG_ZONE_DMA) &&
phys_mask < DMA_BIT_MASK(32) && !(gfp & GFP_DMA)) {
gfp = (gfp & ~GFP_DMA32) | GFP_DMA;
goto again;
}
}
return page;
}
dma direct 방식으로 페이지를 size 만큼 할당해온다. atomic 할당 요청이 아닌 경우 cma 영역에서 할당한다. 그렇지 못한 경우 버디 시스템을 통해 할당해온다. 할당이 실패한 경우 null을 반환한다.
- 코드 라인 9-10에서 DMA_ATTR_NO_WARN 속성을 사용한 메모리 요청 시 warnning 에러를 발생하지 않게한다.
- 코드 라인 13에서GFP_ZERO 플래그를 제거한다.
- 코드 라인 14~15에서 dma 할당을 위해 offset과 해당 zone 선택 비트를 추가한 gfp를 얻어온다.
- 코드 라인 18~25에서 atomic 할당이 요청이 아니어서 blocking 가능한 경우 cma 영역에서 페이지 할당을 해온다. 만일 할당받은 해당 페이지가 coherent가 가능하지 않은 경우 cma 영역에서 할당한 페이지들을 다시 되돌린다.
- 코드 라인 26~27에서 마지막으로 시도할 곳은 버디 시스템이다.
- 코드 라인 29~31에서 버디 시스템에서 할당한 페이지가 coherent가 가능하지 않은 경우 다시 버디 시스템으로 되돌린다.
- 코드 라인 33~45에서 zone DMA32 또는 zone DMA 에서 다시 시도해본다.
per-device DMA coherent 메모리 영역 지정
디바이스 전용 DMA coherent 메모리 영역을 지정하는 방법은 다음 그림과 같이 두 가지가 있다.
- 1) Custom 드라이버에서 dma_declare_coherent_memory() 함수를 사용하여 등록한다.
- 2) 디바이스 트리를 통해 등록한다.
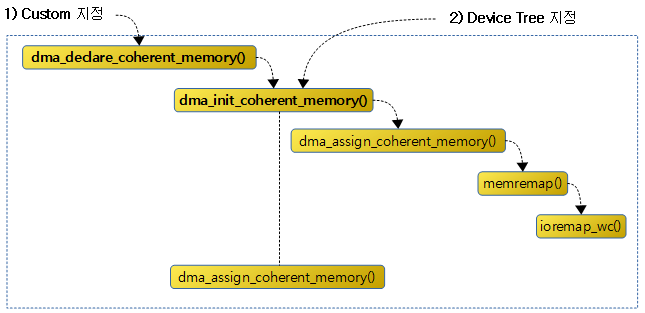
dma_declare_coherent_memory()
kernel/dma/coherent.c
int dma_declare_coherent_memory(struct device *dev, phys_addr_t phys_addr,
dma_addr_t device_addr, size_t size, int flags)
{
struct dma_coherent_mem *mem;
int ret;
ret = dma_init_coherent_memory(phys_addr, device_addr, size, flags, &mem);
if (ret)
return ret;
ret = dma_assign_coherent_memory(dev, mem);
if (ret)
dma_release_coherent_memory(mem);
return ret;
}
EXPORT_SYMBOL(dma_declare_coherent_memory);
디바이스 전용 dma coherent 메모리 영역을 지정하는 generic 코드이다.
- 코드 라인 7~9에서 인자로 전달받은 물리 주소 영역을 write combine 매핑하고, 관리할 수 있도록 dma_coherent_mem 구조체를 할당하고 설정한다.
- 코드 라인 11~13에서 매핑과 dma_coherent_mem 할당이 성공한 경우 디바이스에 할당된 정보를 지정한다.
- dev->dma_mem = <할당된 dma_coherent_mem 구조체 주소>
dma_init_coherent_memory()
kernel/dma/coherent.c
static int dma_init_coherent_memory(
phys_addr_t phys_addr, dma_addr_t device_addr, size_t size, int flags,
struct dma_coherent_mem **mem)
{
struct dma_coherent_mem *dma_mem = NULL;
void __iomem *mem_base = NULL;
int pages = size >> PAGE_SHIFT;
int bitmap_size = BITS_TO_LONGS(pages) * sizeof(long);
int ret;
if (!size) {
ret = -EINVAL;
goto out;
}
mem_base = memremap(phys_addr, size, MEMREMAP_WC);
if (!mem_base) {
ret = -EINVAL;
goto out;
}
dma_mem = kzalloc(sizeof(struct dma_coherent_mem), GFP_KERNEL);
if (!dma_mem) {
ret = -ENOMEM;
goto out;
}
dma_mem->bitmap = kzalloc(bitmap_size, GFP_KERNEL);
if (!dma_mem->bitmap) {
ret = -ENOMEM;
goto out;
}
dma_mem->virt_base = mem_base;
dma_mem->device_base = device_addr;
dma_mem->pfn_base = PFN_DOWN(phys_addr);
dma_mem->size = pages;
dma_mem->flags = flags;
spin_lock_init(&dma_mem->spinlock);
*mem = dma_mem;
return 0;
out:
kfree(dma_mem);
if (mem_base)
memunmap(mem_base);
return ret;
}
인자로 전달받은 물리 주소 영역을 write combine 매핑하고, 관리할 수 있도록 dma coherent_mem 구조체를 할당하고 설정한다.
- 코드 라인 11~14에서 size가 0인 경우 -EINVAL 결과로 함수를 빠져나간다.
- 코드 라인 16~20에서 인자로 전달받은 물리 주소 영역을 write combine 매핑을 한다.
- 코드 라인 21~30에서 dma_coherent_mem 구조체를 할당받고, 멤버 bitmap에 각 1비트가 1페이지를 관리할 수 있는 비트맵을 할당받아 대입한다.
- 코드 라인 32~40에서 나머지 멤버 변수들을 대입하고 정상 결과(0)를 반환한다.
디바이스 트리의 DMA reserved 메모리 지원
- CONFIG_OF_RESERVED_MEM 커널 옵션 사용
- compatible = “shared-dma-pool”; 명시
- ARM 아키텍처에서는 “linux,dma-default” 속성을 쓰면 이 영역을 per-device가 아닌 디폴트 영역으로 사용하게 할 수도 있다.
- 거의 사용하지 않는다.
- no-map 속성을 지정하여야 하며, 이 영역을 초기화할 때 coherent 메모리 속성을 얻을 수 있도록 write-combine 매핑을 이용한다.
다음 그림은 지정된 특정 영역을 DMA coherent 메모리 영역으로 등록하는 모습을 보여준다.
- reserved-memory의 dma 메모리 영역이 no-map으로 되어 있음을 알 수 있으며, 이 메모리를 사용하는 사용자 디바이스 드라이버에서 이 메모리를 사용하기 전에 of_reserved_mem_device_init() 함수 등을 통해 write-combine 매핑하여 초기화한다.
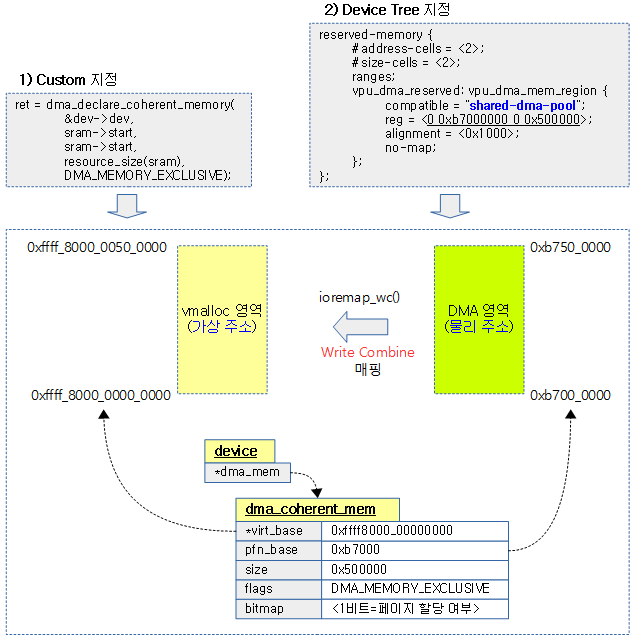
사용자 Device Driver에서 전용(per-device) coherent 메모리 사용
디바이스 트리 샘플
foo.dts
...
reserved-memory {
#address-cells = <2>;
#size-cells = <2>;
ranges;
linux,cma {
compatible = "shared-dma-pool";
reusable;
reg = <0x0 0x50000000 0x0 0x01000000>;
linux,cma-default;
};
foo_mem: foo_mem {
compatible = "shared-dma-pool";
reg = <0x0 0x60000000 0x0 0x01000000>;
alignment = <0 0x1000000>;
no-map;
};
};
/* foo_dev use foo_mem */
foo_dev: foo_dev {
compatible = "foo,foo-dev";
memory-region = <&foo_mem>;
};
};
사용자 드라이버 샘플
foo.c
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/string.h>
#include <linux/version.h> /* LINUX_VERSION_CODE & KERNEL_VERSION() */
#include <linux/platform_device.h>
#include <linux/of.h>
#include <linux/dma-mapping.h>
#include <linux/dma-direct.h>
#include <linux/of_reserved_mem.h>
#define DMA_ALLOC_SIZE (2 * 4096)
struct foo {
struct platform_device *pdev;
void *virt_addr;
phys_addr_t phys_addr;
dma_addr_t dma_addr;
};
typedef struct foo foo_t;
static int foo_probe(struct platform_device *pdev)
{
foo_t *foo;
foo = devm_kzalloc(&pdev->dev, sizeof(foo_t), GFP_KERNEL);
if (foo == NULL)
return -1;
/* set private data */
foo->pdev = pdev;
platform_set_drvdata(pdev, foo);
/* select foo-dev's memory */
of_reserved_mem_device_init(&pdev->dev);
/* test for dma buffer allocation */
foo->virt_addr = dmam_alloc_coherent(&pdev->dev, DMA_ALLOC_SIZE,
&foo->dma_addr, GFP_KERNEL);
if (foo->virt_addr == NULL)
return -2;
foo->phys_addr = dma_to_phys(&pdev->dev, foo->dma_addr);
printk("%s: dma=%llx, xphys=%llx, virt=%llx\n", __func__,
(uint64_t) foo->dma_addr, (uint64_t) foo->phys_addr,
(uint64_t) foo->virt_addr);
return 0;
}
static int foo_remove(struct platform_device *pdev)
{
foo_t *foo = (foo_t *)platform_get_drvdata(pdev);
dmam_free_coherent(&pdev->dev, DMA_ALLOC_SIZE,
foo->virt_addr, foo->dma_addr);
printk("%s\n", __func__);
return 0;
}
static const struct of_device_id of_foo_match[] = {
{ .compatible = "foo,foo-dev", },
{},
};
MODULE_DEVICE_TABLE(of, of_foo_match);
static struct platform_driver foo_driver = {
.driver = {
.name = "foo_driver",
.of_match_table = of_match_ptr(of_foo_match),
},
.probe = foo_probe,
.remove = foo_remove,
};
module_platform_driver(foo_driver);
MODULE_LICENSE("GPL");
- of_reserved_mem_device_init() 명령을 사용하면 해당 디바이스가 디바이스 트리의 memory-region = <&foo_mem>;을 파싱하여 해당 foo_mem 노드 정보를 찾아 해당 메모리를 사용할 수 있게 한다.
- dma_alloc_coherent() API를 사용하여도 되지만, managed API인 dmam_alloc_coherent()를 사용하면 드라이버 unload 시에 실수로 free 되지 않은 메모리도 자동으로 할당 해제되지 사용하기 편하다. 결국 위 코드에서 dmam_free_coherent()를 삭제해도 된다.
실행 예)
$ insmod foo.ko
foo_driver foo_dev: assigned reserved memory node foo_mem
foo_probe: dma=60000000, xphys=60000000, virt=ffff800015000000
$ rmmod foo
foo_remove
RESERVEDMEM_OF_DECLARE() 매크로
RESERVEDMEM_OF_DECLARE() 매크로를 사용한 소스들은 다음과 같고, 그 중 “shared-dma-pool”을 사용한 곳은 rmem_dma_setup()과 rmem_cma_setup() 함수이다.
./drivers/soc/fsl/qbman/bman_ccsr.c:156:RESERVEDMEM_OF_DECLARE(bman_fbpr, "fsl,bman-fbpr", bman_fbpr); ./drivers/soc/fsl/qbman/qman_ccsr.c:480:RESERVEDMEM_OF_DECLARE(qman_fqd, "fsl,qman-fqd", qman_fqd); ./drivers/soc/fsl/qbman/qman_ccsr.c:491:RESERVEDMEM_OF_DECLARE(qman_pfdr, "fsl,qman-pfdr", qman_pfdr); ./drivers/memory/tegra/tegra210-emc-table.c:89:RESERVEDMEM_OF_DECLARE(tegra210_emc_table, "nvidia,tegra210-emc-table", ./kernel/dma/coherent.c:477:RESERVEDMEM_OF_DECLARE(dma, "shared-dma-pool", rmem_dma_setup); ./kernel/dma/swiotlb.c:888:RESERVEDMEM_OF_DECLARE(dma, "restricted-dma-pool", rmem_swiotlb_setup); ./kernel/dma/contiguous.c:598:RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
kernel/dma/coherent.c
RESERVEDMEM_OF_DECLARE(dma, "shared-dma-pool", rmem_dma_setup);
위의 RESERVEDMEM_OF_DECLARE() 매크로는 compatible 명으로 “shared-dma-pool”과 rmem_dma_setup() 함수를 __reservedmem_of_table에 등록한다.
- 이렇게 등록된 테이블 정보는 fdt_init_reserved_mem() 함수에 의해 등록한 compatible 명이 디바이스 트리 노드에 존재하는 경우 대응하는 rmem_dma_setup() 함수를 호출한다.
kernel/dma/contiguous.c
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
위의 RESERVEDMEM_OF_DECLARE() 매크로는 compatible 명으로 “shared-dma-pool”과 rmem_cma_setup() 함수를 __reservedmem_of_table에 등록한다.
- 이렇게 등록된 테이블 정보는 fdt_init_reserved_mem() 함수에 의해 등록한 compatible 명이 디바이스 트리 노드에 존재하는 경우 대응하는 rmem_dma_setup() 함수를 호출한다.
- rmem_cma_setup() 함수의 분석은 다음 문서의 후반부를 참고한다.
- 참고: arm_memblock_init() | 문c
rmem_dma_setup()
디바이스 트리의 reserved-memory 노드에 등록된 child 노드들 중 compatible = “shared-dma-pool”; 으로 등록된 child 노드가 있는 경우 rmem_dma_setup()과 rmem_cma_setup() 함수가 호출된다.
kernel/dma/coherent.c
static int __init rmem_dma_setup(struct reserved_mem *rmem)
{
unsigned long node = rmem->fdt_node;
if (of_get_flat_dt_prop(node, "reusable", NULL))
return -EINVAL;
#ifdef CONFIG_ARM
if (!of_get_flat_dt_prop(node, "no-map", NULL)) {
pr_err("Reserved memory: regions without no-map are not yet supported\n");
return -EINVAL;
}
if (of_get_flat_dt_prop(node, "linux,dma-default", NULL)) {
WARN(dma_reserved_default_memory,
"Reserved memory: region for default DMA coherent area is redefined\n");
dma_reserved_default_memory = rmem;
}
#endif
rmem->ops = &rmem_dma_ops;
pr_info("Reserved memory: created DMA memory pool at %pa, size %ld MiB\n",
&rmem->base, (unsigned long)rmem->size / SZ_1M);
return 0;
}
reserved 메모리의 ops에 아래 rmem_dma_ops를 추가한다.
- 코드 라인 5~6에서 reserved memory 노드에서 “reusable” 속성은 허용하지 않는다.
- 코드 라인 8~19에서 32비트 ARM 아키텍처에서는 “no-map” 속성이 없는 경우는 아직 지원하지 않는다. 또한 “linux,dma-default” 속성이 있는 경우 default로 지정한다.
- 코드 라인 21에서 reserved 메모리의 ops에 아래 rmem_dma_ops를 추가한다.
아래의 reserved-memory에 대한 operation은 사용자 디바이스 드라이버 코드에서 of_reserved_mem_device_init() 함수 등에 의해 호출된다.
kernel/dma/coherent.c
static const struct reserved_mem_ops rmem_dma_ops = {
.device_init = rmem_dma_device_init,
.device_release = rmem_dma_device_release,
};
rmem_dma_device_init()
kernel/dma/coherent.c
static int rmem_dma_device_init(struct reserved_mem *rmem, struct device *dev)
{
struct dma_coherent_mem *mem = rmem->priv;
int ret;
if (!mem) {
ret = dma_init_coherent_memory(rmem->base, rmem->base,
rmem->size,
DMA_MEMORY_EXCLUSIVE, &mem);
if (ret) {
pr_err("Reserved memory: failed to init DMA memory pool at %pa, size %ld MiBB
\n",
&rmem->base, (unsigned long)rmem->size / SZ_1M);
return ret;
}
}
mem->use_dev_dma_pfn_offset = true;
rmem->priv = mem;
dma_assign_coherent_memory(dev, mem);
return 0;
}
인자로 전달받은 reserved 메모리 정보에 있는 dma_coherent_mem 정보를 사용하여 generic per-device dma coherent 메모리 영역을 지정한다.
dma_init_reserved_memory()
kernel/dma/coherent.c
static int __init dma_init_reserved_memory(void)
{
const struct reserved_mem_ops *ops;
int ret;
if (!dma_reserved_default_memory)
return -ENOMEM;
ops = dma_reserved_default_memory->ops;
/*
* We rely on rmem_dma_device_init() does not propagate error of
* dma_assign_coherent_memory() for "NULL" device.
*/
ret = ops->device_init(dma_reserved_default_memory, NULL);
if (!ret) {
dma_coherent_default_memory = dma_reserved_default_memory->priv;
pr_info("DMA: default coherent area is set\n");
}
return ret;
}
core_initcall(dma_init_reserved_memory);
dma_reserved_default_memory가 설정된 경우에만 호출되는 함수이다.
- 현재 32비트 ARM 시스템에서 default 옵션을 사용할 수 있게 하였는데, 거의 사용되지 않는다.
참고
- DMA -1- (Basic) | 문c
- DMA -2- (DMA Coherent Memory) | 문c – 현재 글
- DMA -3- (DMA Pool) | 문c
- DMA -4- (DMA Mapping) | 문c
- DMA -5- (IOMMU) | 문c
- DMA -6- (DMAEngine Subsystem) | 문c
- IOMMU | 문c