<kernel v5.0>
DMA(Direct Memory Access) -1- (Basic)
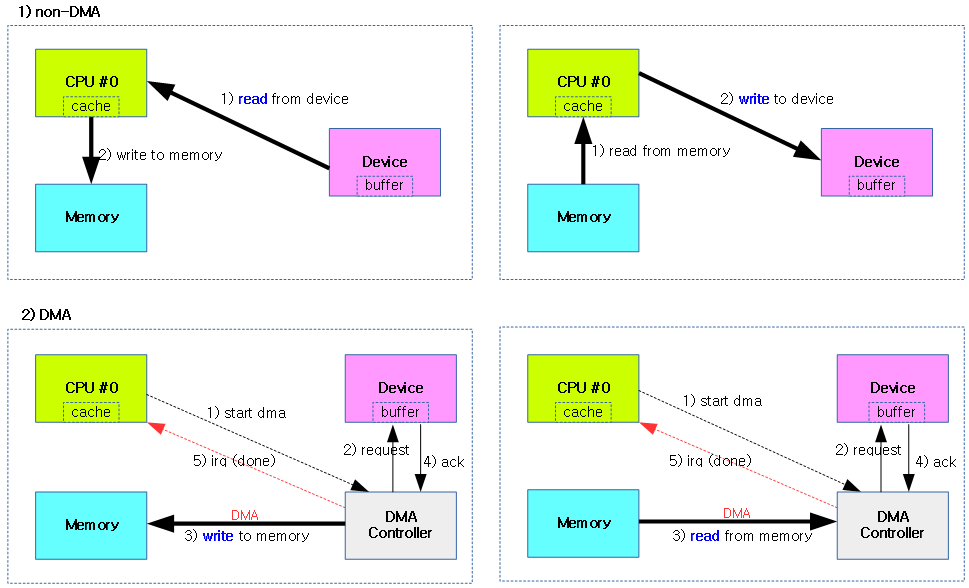
디바이스로 부터 데이터를 메모리에 읽어들일 때 DMA를 사용하지 않는 방법과 DMA를 사용하는 방법을 보여준다.
- non-DMA
- CPU가 디바이스로부터 직접 데이터를 읽거나 기록하는 것을 반복하여 cpu load가 상승한다.
- DMA
- CPU는 디바이스에게 DMA 시작 신호와 DMA 완료 인터럽트만 수신하고, 직접적인 전송에는 참여하지 않으므로 cpu load를 최소화 시킨다. 이 과정에서 디바이스가 직접 메모리에 접근하여 읽거나 기록한다.
- 버스 아키텍처에 DMA 컨트롤러 h/w가 구성되어 있어야 한다.
- ISA, EISA, AXI, AHB, …
- 참고로 PCI 및 PCIe를 통한 DMA는 아래 그림의 DMA 컨트롤러와 동작 방법이 다르다.
- CPU가 관여하지 않고(리눅스 커널 프로그래머가 하지 않고) , pci 디바이스가 pci 컨트롤러에 버스 마스터를 요청하여 버스를 소유한 후 pci 디바이스 내부에 있는 dma 컨트롤러를 통해 주도하여 직접 DMA한다. (많은 pci/pcie 디바이스들은 dma 기능을 내장하고 있다)
참고: DMA를 사용하면 cpu 커널 드라이버가 사용하는 cpu 사용률을 낮춰 유저 application등에 더 많은 cpu를 주어지게 하는데 가장 큰 장점이 있다. 그러나 많은 인터럽트가 발생되는 네트워크 디바이스 등 고성능 처리를 요구하는 디바이스 드라이버들은 NAPI가 사용되고 있는데, 커널 드라이버에서 cpu를 사용해서라도 polling 하여 처리를 하고 있다. 또한 10G 네트웍 및 infiniband 네트워크 장치 등에서 더 빠른 처리를 위해 유저 모드에서 polling하여 동작시킬 수 있는 방법들을 사용하고 있다. (예: DPDK, infiniband)
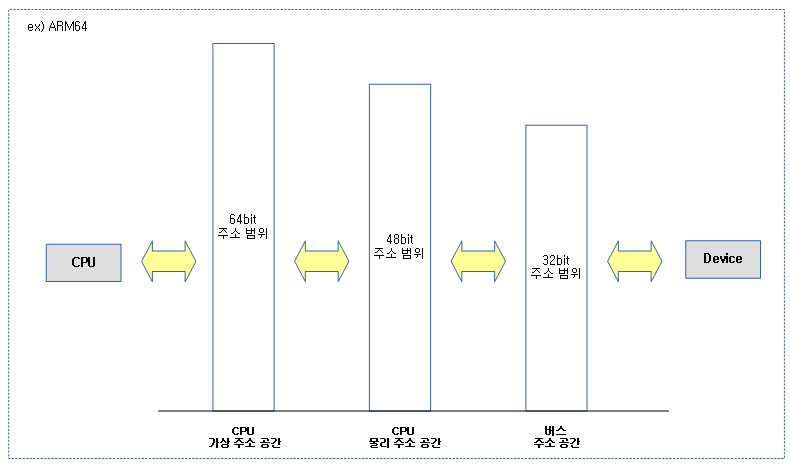
DMA 주소 체계
디바이스가 DMA 방식으로 접근할 메모리(Buffer)와 관련된 세 가지 주소 공간 유형을 알아본다.
- CPU 가상 주소 공간
- CPU가 사용하는 주소 공간
- CPU 물리 주소 공간
- CPU 가상 주소가 MMU에 의해 물리 주소로 변환하여 사용하는 주소 공간
- 버스 주소 공간
- 디바이스가 사용하는 주소 공간
다음 그림과 같이 CPU와 디바이스가 바라보는 주소 공간이 다름을 알 수 있다.
- 64비트 시스템이더라도 전력의 소모를 줄이기 위해 물리 주소 공간의 크기를 보통 줄여 설계한다.
- 버스 주소 공간의 크기도 여러 가지 버스(AXI, AMBA, ISA, PCI,…)가 존재하므로 사용하는 비트 크기는 각각 다르다.
- 특정 디바이스들은 버스 주소의 일부 주소 공간에만 접근하게 제약하기도 한다.
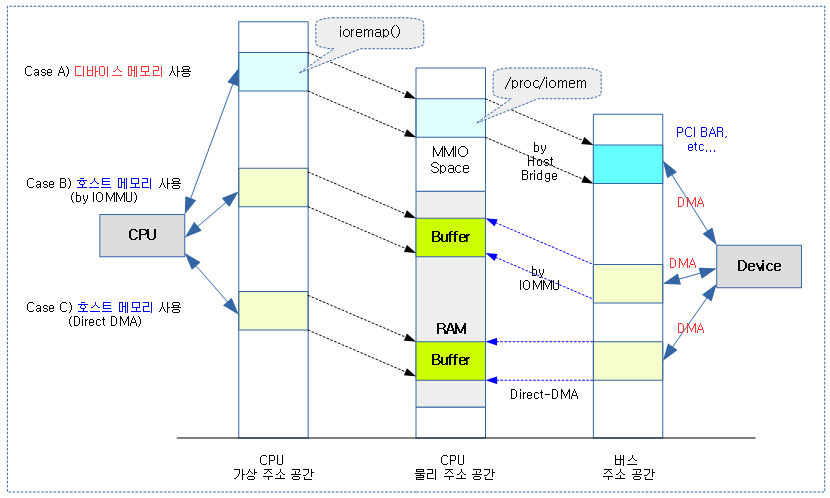
아래 그림은 호스트가 소유한 메모리와 디바이스가 소유한 메모리의 관계를 3 가지 주소 공간을 통해 보여준다.
- Case A) 디바이스 메모리
- 디바이스가 소유한 메모리, 레지스터 또는 PCI BAR 영역이 호스트 브리지에 의해 매핑되어 사용된다.
- 이 영역은 ioremap() 등의 API를 통해 매핑하여 사용한다.
- 대부분 /proc/iomem을 통해 영역을 확인할 수 있다.
- 아래 PCI/PCIe with DMA 글을 참고한다.
- Case B) 호스트 CPU 메모리 – 디바이스가 IOMMU를 통해 접근
- 호스트 CPU의 메모리 영역에 DMA 버퍼 메모리를 제공한다.
- 디바이스가 사용하는 버스 주소 공간은 IOMMU를 통해 호스트 CPU의 물리 주소 공간에 접근할 수 있다.
- IOMMU 매핑을 통해 cpu용 페이지 테이블이 아닌 디바이스용 IOMMU 페이지 테이블이 생성된다.
- Case C) 호스트 CPU 메모리 – 디바이스가 Direct 접근
- 호스트 CPU의 메모리 영역에 DMA 버퍼 메모리를 제공한다.
- 디바이스가 사용하는 버스 주소 공간과 호스트 CPU의 물리 주소 공간이 같거나, 일괄적으로 변경(DTB:”dma-ranges”)되는 경우 디바이스는 주소 변환을 위해 IOMMU를 사용할 필요가 없다. 따라서 디바이스는 Direct로 호스트 CPU의 물리 주소 공간에 위치한 DMA 버퍼에 접근할 수 있다.
- 주소 변환에 대해서 아래의 Case C)와 같이 물리 주소와 dma 주소가 일치하는 것이 일반적이지만, 특정 시스템의 경우 일률적으로 변환되는 경우도 있다.
PCI/PCIe with DMA
1) 호스트 메모리에 DMA
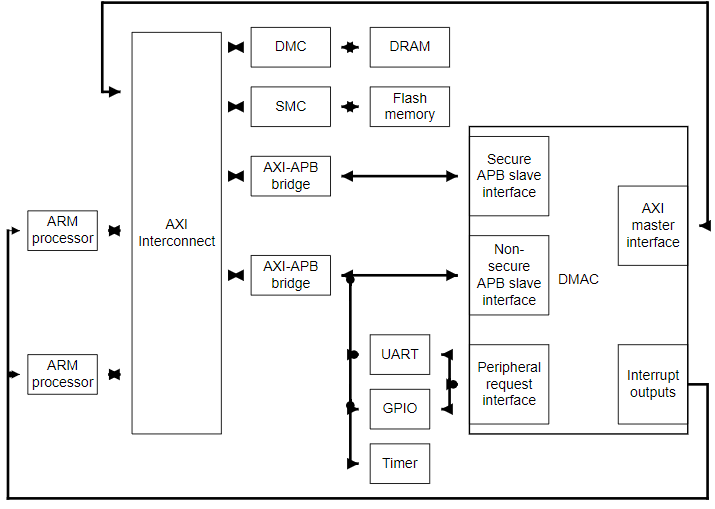
다음 그림은 ARM SoC에 내장된 DMA-330 controlloer를 보여준다.
다음 그림은 pci 디바이스가 내장 메모리 없이 호스트에 위치한 메모리에 DMA하는 전통적인 모습을 보여준다. (인텔 North Bridge 칩셋에 연결되어 있는 DRAM을 사용하여 DMA한다)
- pci/pcie 컨트롤러에 버스 마스터를 요청하여 버스를 점유한 후 시스템에 위치한 dma 컨트롤러릍 통해 pci/pcie 디바이스가 주도하여 호스트 메모리에 직접 DMA한다.
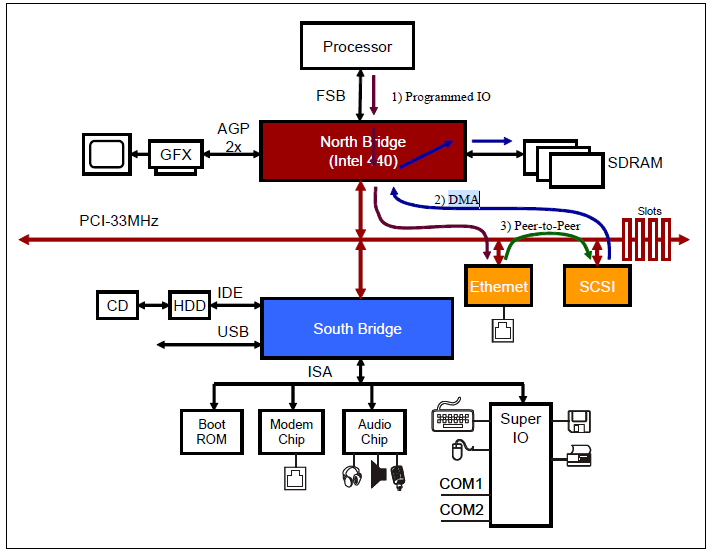
다음 그림은 pcie 장치가 내장 메모리 없이 호스트에 위치한 메모리에 DMA하는 전통적인 모습을 보여준다.

2) 디바이스 메모리에 DMA
- pci/pcie 컨트롤러에 버스 마스터를 요청하여 버스를 점유한 후 pci/pcie 디바이스 내부에 있는 dma 컨트롤러를 통해 pci/pcie 디바이스가 주도하여 내부 메모리에 직접 DMA한다.
다음 그림은 Xilinx사의 DMA IP를 보여주며 자체 메모리에 DMA를 사용하는 1G 네트웍 장치에 대한 사례를 보여준다.
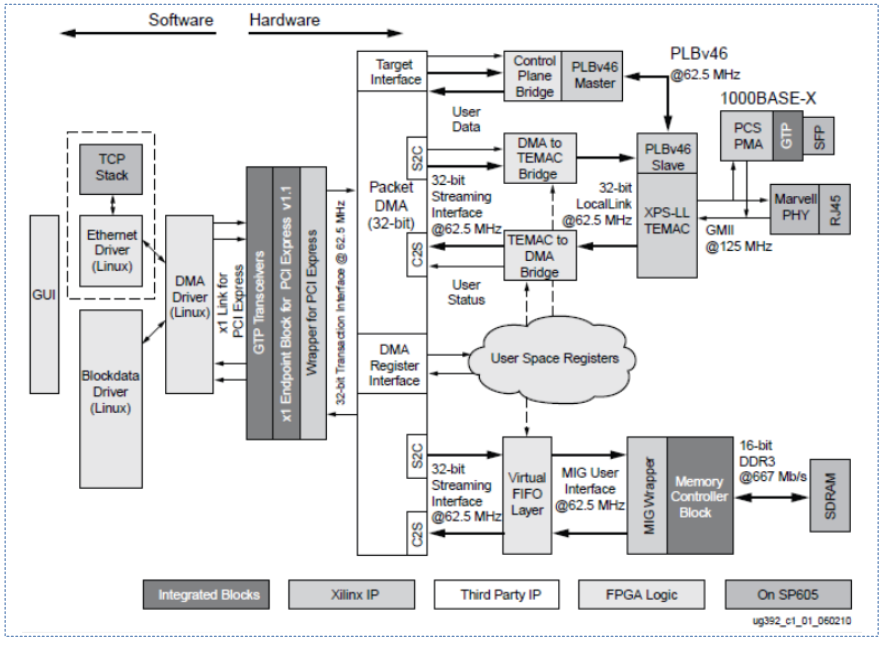
다음 그림은 Altera Megacore사의 레퍼런스 디자인이며, 좌측 슬레이브 측에 있는 메모리를 대상으로 DMA가 사용되고 있는 모습을 보여준다.

DMA 주소 변환
IOMMU 매핑 vs Direct 매핑
디바이스는 다음과 같이 두 가지 io 주소 매핑 방법으로 DMA 영역에 접근한다.
- IOMMU 매핑
- 디바이스가 사용하는 버스 주소를 IOMMU 장치를 통해 CPU의 물리 주소로 변환하는 경우 사용된다.
- 오늘날 CPU와 GPU 및 내장 고속 네트웍 장치등이 포함된 SoC들은 별도의 IOMMU를 가지고 있다. gpu 및 내장 고속 네트웍 장치를 운영할 때 이러한 IOMMU를 사용하여 DMA 접근을 하며, 그 외의 장치들은 아래의 Direct 매핑을 사용한다.
- Direct 매핑
- 디바이스가 사용하는 버스 주소와 CPU의 물리 주소가 일치하거나, 일률적인 변환을 사용하는 경우이다.
- 물리 주소와 dma 주소가 같게 변환하기도 하지만, 오늘날에는 CPU core와 GPU core 등이 통합된 SoC의 경우 DMA 주소와 DRAM 물리 주소의 주소 변환이 부분적으로 특정 영역 몇 개가 일괄적으로 이루어진다.
- legacy x86 시스템에서 디바이스들은 하위 16M 이하의 DMA 영역과 물리 주소가 같이 Direct 접근하였다.
- 디바이스가 사용하는 버스 주소와 CPU의 물리 주소가 일치하거나, 일률적인 변환을 사용하는 경우이다.
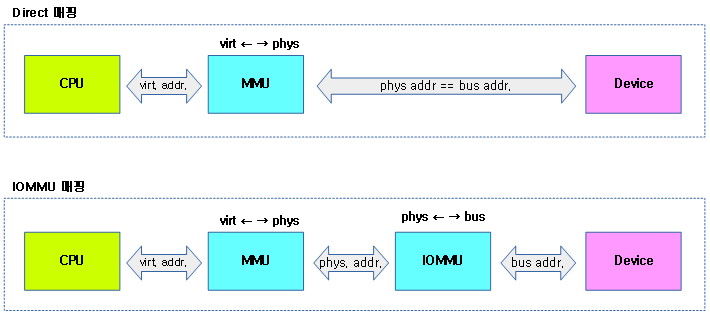
다음 그림은 IOMMU 매핑과 Direct 매핑과의 구성 차이를 보여준다.
- IOMMU를 이용할 수 없는 Device 들은 Direct 매핑을 사용하여 DRAM에 DMA한다.
- 아래 그림에서 물리 주소와 bus 주소가 같은 경우도 있지만 IOMMU 없이도 일괄적으로 변환되기도 한다.
DMA 주소 제한(Limitations)
물리 주소나 버스 주소가 64비트 주소로 표현 가능한 영역을 가진다고 할지라도, 다음과 같은 예와 같이 디바이스의 DMA 주소 지정이 제한되는 경우 가 있다.
- 64bit PCIX 버스에 32bit PCI 디바이스를 사용하는 경우
- legacy x86 시스템에서 ISA 버스를 통해 연결된 디바이스인 경우
- 20bit(1M) 또는 24bit(16M) 주소만을 사용하여 DMA 접근 가능하다.
DMA 주소 제한을 설정할 때 대표적으로 다음 3 가지 API를 사용한다.
- dma_set_mask()
- 스트리밍 매핑을 사용하는 경우에 사용한다.
- 예) 32bit(4G) 제한이 필요한 경우
- mask=0xffff_ffff
- 또는 DMA_BIT_MASK(32)
- dma_set_coherent_mask()
- consistent 매핑에서 사용한다.
- coherent mask는 dma_set_mask()에 사용하는 제한과 같은 mask 값 또는 작은 mask 값을 사용할 수 있다.
- dma_set_mask_and_coherent()
- 위의 두 가지를 같은 mask 값으로 사용하는 구성이다.
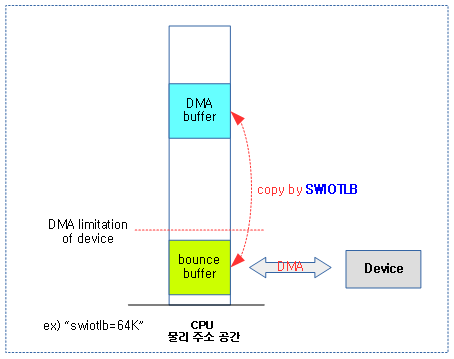
SWIOTLB(SoftWare I/O TransLation Lookaside Buffer) & Bounce Buffer
- hardware IOMMU(IOTLB)를 사용하지 못하는 플랫폼에서 fall-back 용도로 운영한다.
- IOMMU(IOTLB)는 버스 주소와 cpu 물리 주소간의 주소 변환 매핑을 수행한다.
- SWIOTLB는 io 가상 주소와 io 물리 주소간의 주소 변환 매핑이 되는 것처럼 보이도록 software 기법을 사용하여 두 영역간의 데이터를 복사하는 방법을 사용한다.
- 디바이스가 좁은 범위의 주소 영역에만 접근할 수 있는 경우 사용된다.
- 커널 부트업 과정중에 디바이스가 접근할 수 있는 범위안의 일정량의 Bounce Buffer를 할당받아 운용한다.
- 커널 파라메터 예) “swiotlb=64K”
- 디바이스가 DMA를 통해 bounce 버퍼에 기록하면 이를 swiotlb 드라이버가 디바이스의 버퍼에 복사하여 운영된다.
- 바운스 버퍼를 DMA window로 사용한다.
- software 방법으로 운영하기 때문에 성능이 저하되는 단점이 있다.
- 이러한 Bounce 버퍼 운영을 통해 디바이스가 접근하지 못하는 highmem에 있는 유저 매핑 메모리에 복사하여 사용하는 사례도 있다.
다음 그림은 bounce buffer로 64K를 사용하여 디바이스가 DMA 전송을 수행하는 모습을 보여준다.
PCI DAC(Dual Address Cycle)
x86 PCI-X 디바이스는 64비트 주소를 사용한다. 특정 플랫폼에서 IOMMU가 32비트 이하의 주소만을 지원할 때 PCI-X 디바이스에 32비트 주소를 두 번 보내는 방법이 있다.
DMA coherent 디바이스
dma coherent 디바이스는 h/w 차원에서 캐시와 연동되어 동작하므로 dma 전송 전/후로 캐시 sync 작업을 수행할 필요가 없다.
- ARM/ARM64의 경우 CCI(Cache Coherent Interface)에 연결된 ACP 포트 등에 연결된 디바이스가 코히런트 디바이스이다.
- 예) gpu
- 주의: coherent device와 coherent memory는 coherent 동작을 똑같이 수행하지만 서로 동작하는 방식이 다르다.
- coherent device는 캐시와 연동되어 동작하는 device이고, coherent memory는 캐시 없이 동작하는 메모리이다.
DMA coherent 디바이스 예)
enet: ethernet@340000{
compatible = "brcm,amac";
reg = <0x00340000 0x1000>;
reg-names = "amac_base";
dma-coherent;
interrupts = <GIC_SPI 213 IRQ_TYPE_LEVEL_HIGH>;
status= "disabled";
};
DMA용 버퍼 메모리
리눅스 커널은 여러 가지 메모리 할당자를 제공한다. DMA 버퍼 메모리를 위해서 커널에서 제공하는 메모리 영역의 사용 가부를 알아본다.
DMA 메모리 할당 가능
- 캐시를 사용하는 일반 커널 메모리
- 이 메모리를 사용하는 일반적인 디바이스들은 dma 전송 전/후로 캐시 sync 작업이 필요하다. 단 dma coherent 디바이스는 dma 전송 전/후로 캐시 sync 작업을 수행할 필요가 없다.
- API들
- __get_free_page()
- 페이지 할당자(버디 시스템)으로 부터 2의 제곱승 단위의 페이지 할당
- kmalloc()
- 슬랩 할당자를 사용하여 작은 사이즈부터 할당 가능
- kmem_cache_alloc()
- 많은 양의 반복되는 슬랩 할당이 예상되는 경우 슬랩 캐시 할당
- __get_free_page()
- dma coherent 메모리
- dma 디바이스 전용 dma coherent 메모리로 선언하여 사용한다. 이렇게 할당한 메모리는 consistent dma 매핑 방법으로 사용할 수 있다.
- coherent 메모리
- sram 전용 메모리를 사용하는 경우 캐시를 사용할 필요 없이 빠르므로 캐시를 사용하는 매핑을 하지 않는다.
- contiguous 메모리
- 일반 커널 메모리를 캐시 사용 없이 사용하도록, 커널 메모리의 일부를 write-combine 매핑으로 바꾸어 dma 버퍼로 사용한다.
- coherent 메모리
- API들
- dma_alloc_coherent()
- 큰 영역의 dma coherent 메모리를 한 번에 할당한다.
- dma_pool_create() & dma_pool_alloc()
- dma coherent 메모리에서 메모리 pool을 만든 후 조금씩 할당하여 사용한다.
- dma_alloc_coherent()
- dma 디바이스 전용 dma coherent 메모리로 선언하여 사용한다. 이렇게 할당한 메모리는 consistent dma 매핑 방법으로 사용할 수 있다.
DMA 메모리 할당 불가능
- 커널 이미지 주소
- 컴파일 타임에 static하게 할당
- 이 영역들은 ARM, ARM64의 경우 섹션 페이지 매핑되어 있다.
- 모듈 이미지 주소
- 모듈의 로드 타임에 할당
- 이 영역들은 ARM, ARM64의 경우 섹션 페이지 매핑되어 있다.
- 스택 주소
- 현재 스택의 일부를 할당
- vmalloc()
- vmalloc(연속된 가상 주소 공간이지만 연속되지 않은 물리 주소 공간) 영역의 할당
Cache Coherent vs Non-Coherent
디바이스가 액세스할 수 있도록 물리적으로 연속된 메모리이다.
Cache Coherent
- 캐시 효과에 대해 걱정할 필요없이 장치 또는 프로세서에서 기록한 내용이 또 다른 프로세서 또는 디바이스에 의해 언제든 읽을 수 있다.
- 캐시를 사용하는 메모리 시스템에서 cpu, 캐시, 메모리(DRAM) 및 디바이스가 Cache Coherent Inter-connect 장치를 통해 연동된다.
- 디바이스가 DMA를 수행하기 전/후로 hardware가 알아서 캐시의 invalidate 및 clean 등을 수행한다.
- 예) ARM, ARM64에서 ACP(Accelerator Coherency Port)를 사용하는 디바이스의 경우 L1/L2 캐시와 h/w coherent 작용을 한다.
- 캐시를 사용하지 않아도 될 정도로 빠른 메모리(SRAM)의 경우 캐시 없이 cpu, 메모리 및 디바이스가 버스와 연결된다.
- SRAM 등의 고속 메모리는 DRAM에 비해 매우 cost가 높기 때문에 고속 네트웍 디바이스 전용의 버퍼 메모리로 종종 사용된다.
- 리눅스 커널에서는 캐시를 사용하지 않도록 write-combine 매핑을 활용한다.
Non-Coherent
- 디바이스 또는 프로세서가 기록한 데이터가 캐시 효과로 인해 양쪽에 동시에 업데이트된 데이터가 sync되지 않는다. 이의 sync 보정를 위해 software적으로 추가적인 조작이 필요한다.
- cpu, 캐시, 메모리 및 디바이스 중 하나라도 Cache Coherent Inter-connect 장치에 연동하지 못한 경우이다.
- 디바이스가 DMA를 수행하기 전/후로 software가 캐시의 invalidate 및 clean 등을 수행해야 한다. (그 외의 버퍼등)
- 예) ARM에서 디바이스가 Cache Coherent Inter-connect 장치에 연동되지 않는 사례들이 많이 있다.
Consistent(coherent) DMA 매핑 vs Streaming DMA 매핑
리눅스 커널의 DMA 버퍼 메모리를 사용하기 전에 매핑하는 두 가지 방법에 대해 알아본다.
1. Consistent(coherent) DMA 매핑
DMA 요청 시 마다 매핑하지 않고, 보통 드라이버 초기화 시 한 번만 consistent(coherent) DMA 매핑을 수행한다. cpu와 디바이스가 동시에 접근이 가능한 상태이고, 명시적인 software flush 없이 서로 갱신된 값을 볼 수 있다. consistent DMA 매핑을 위해 사용되는 메모리 할당은 dma_alloc_coherent() API를 사용하며, 아래 3 가지 중 한 가지 방법으로 coherent 메모리를 할당한다.
1) generic coherent per-device memory
- Reserved DMA 영역으로 지정된 디바이스 전용 메모리 영역을사용한다.
- 디바이스 트리를 사용하여 정의하는 경우 compatible = “shared-dma-pool”을 지정하고, reusable 속성을 사용하지 않아야 한다.
- ARM32의 경우 no-map 속성도 사용해야 한다.
- 아주 일부의 시스템에서 “linux,dma-default” 속성을 사용하여 이 영역을 default dma coherent 메모리로 동작하게 한다.
- 커널 cmdline 파라메터의 경우 “memmap=nn[KMG]$ss[KMG]”
- 동적으로 선언하는 경우(for legacy) dma_declare_coherent_memory() 함수를 사용하여 영역을 지정한다.
- 부팅 시 커널 로그 예)
- Reserved memory: created DMA memory pool at 0x0000000060000000, size 16 MiB
- 디바이스별로 비트맵을 통해 관리된다.
- 비트맵의 1 비트는 1 페이지의 할당 여부를 관리한다.
- 디바이스 트리를 사용하여 정의하는 경우 compatible = “shared-dma-pool”을 지정하고, reusable 속성을 사용하지 않아야 한다.
- 보통 다음과 같은 메모리를 사용한다. 이들은 캐시를 사용하지 않고 write 버퍼만 사용가능한 write-combine 매핑을 사용한다.
- SRAM 등의 고속 메모리를 DMA 메모리로 사용
- 호스트 메모리의 일부를 DMA 메모리로 사용
디바이스 트리 예) bman 디바이스가 bman-fbpr 영역의 메모리를 지정하여 사용한다.
arch/arm64/boot/dts/freescale/fsl-ls1046a.dtsi
reserved-memory {
#address-cells = <2>;
#size-cells = <2>;
ranges;
bman_fbpr: bman-fbpr {
compatible = "shared-dma-pool";
size = <0 0x1000000>;
alignment = <0 0x1000000>;
no-map;
};
...
soc: soc {
bman: bman@1890000 {
compatible = "fsl,bman";
reg = <0x0 0x1890000 0x0 0x10000>;
interrupts = <GIC_SPI 45 IRQ_TYPE_LEVEL_HIGH>;
memory-region = <&bman_fbpr>;
};
...
2) direct DMA memory -fall-back
- 디바이스가 IOMMU를 사용하지 않아 주소 변환 없이 시스템 메모리에 DMA 전송할 메모리이다.
- CMA 영역에서 할당 받은 페이지 또는 일반 버디시스템에서 할당 받은 페이지를 사용한다.
- CMA 영역 지정은 시스템 메모리 내에서 사용된다.
- 디바이스 트리의 경우 compatible = “shared-dma-pool”을 지정하고 reusable 속성을 사용해야 한다.
- linux,cma-default 속성을 사용하면 defaul cma 영역으로 지정한다.
- no-map 속성은 사용하면 안된다.
- 커널 cmdline 파라메터의 경우 “cma=nn[MG]@[start[MG][-end[MG]]]”
- 부팅 시 커널 로그 예)
- Reserved memory: created CMA memory pool at 0x0000000048000000, size 16 MiB
- 디바이스 트리의 경우 compatible = “shared-dma-pool”을 지정하고 reusable 속성을 사용해야 한다.
- CMA 영역 지정은 시스템 메모리 내에서 사용된다.
- 할당 받은 후 DMA coherent 디바이스가 아닌 경우 아키텍처가 지원하는 매핑 방법을 사용하여 다시 매핑한다.
- ARM64의 경우 write-combine 매핑을 사용하고, 그 외의 경우 no-cache 매핑을 사용한다.
디바이스 트리 예) DMA를 사용하는 디바이스가 특정 메모리를 지정하지 않는 경우 cma 메모리 사용할 수 있다.
arch/arm64/boot/amlogic/meson-gx.dtsi
reserved-memory {
#address-cells = <2>;
#size-cells = <2>;
ranges;
linux,cma {
compatible = "shared-dma-pool";
reusable;
size = <0x0 0x10000000>;
alignment = <0x0 0x400000>;
linux,cma-default;
};
...
3) IOMMU memory – fall-back
- 디바이스가 IOMMU를 사용하여 주소 변환 과정을 통해 시스템 메모리에 DMA 전송한다.
- CMA 영역에서 할당 받은 페이지 또는 일반 버디시스템에서 할당 받은 페이지를 사용한다.
- 할당 받은 후 IOMMU가 지원하는 매핑 방법을 사용하여 다시 매핑한다.
IOMMU를 사용하는 DMA controller와 MMC Nand controller 디바이스 트리 예)
arch/arm64/boot/dts/broadcom/stingray/stingray.dtsi
scr {
smmu: mmu@3000000 {
compatible = "arm,mmu-500";
reg = <0x03000000 0x80000>;
#global-interrupts = <1>;
interrupts = <GIC_SPI 704 IRQ_TYPE_LEVEL_HIGH>,
...
<GIC_SPI 774 IRQ_TYPE_LEVEL_HIGH>;
#iommu-cells = <2>;
};
hsls {
dma0: dma@310000 {
compatible = "arm,pl330", "arm,primecell";
reg = <0x00310000 0x1000>;
interrupts = <GIC_SPI 193 IRQ_TYPE_LEVEL_HIGH>,
<GIC_SPI 194 IRQ_TYPE_LEVEL_HIGH>,
<GIC_SPI 195 IRQ_TYPE_LEVEL_HIGH>,
<GIC_SPI 196 IRQ_TYPE_LEVEL_HIGH>,
<GIC_SPI 197 IRQ_TYPE_LEVEL_HIGH>,
<GIC_SPI 198 IRQ_TYPE_LEVEL_HIGH>,
<GIC_SPI 199 IRQ_TYPE_LEVEL_HIGH>,
<GIC_SPI 200 IRQ_TYPE_LEVEL_HIGH>,
<GIC_SPI 201 IRQ_TYPE_LEVEL_HIGH>;
#dma-cells = <1>;
#dma-channels = <8>;
#dma-requests = <32>;
clocks = <&hsls_div2_clk>;
clock-names = "apb_pclk";
iommus = <&smmu 0x6000 0x0000>;
};
sdio0: sdhci@3f1000 {
compatible = "brcm,sdhci-iproc";
reg = <0x003f1000 0x100>;
interrupts = <GIC_SPI 204 IRQ_TYPE_LEVEL_HIGH>;
bus-width = <8>;
clocks = <&sdio0_clk>;
iommus = <&smmu 0x6002 0x0000>;
status = "disabled";
};
DMA 버퍼 할당 및 consistent(coherent) DMA 매핑
- 큰 페이지 할당 및 매핑
- dma_alloc_coherent() API를 사용하여 페이지 단위의 큰 DMA 버퍼를 할당하고 cosistent 매핑한다.
- 작은 페이지 할당 및 매핑
- dma_alloc_coherent() API를 사용하여 할당 받은 DMA 버퍼를 여러 개로 나누어 사용하거나,
- 자주 반복되어 사용되는 작은 블럭 사이즈의 DMA 버퍼를 위해 dma_pool_create() API로 DMA pool을 생성하고, dma_pool_alloc() API로 블럭을 할당 받아 사용한다.
페이지 매핑 타입
다음은 페이지를 매핑할 때 사용하는 방법에 대해 잠시 기억해본다.
- WC(Write Combine) 매핑
- 캐시는 사용하지 않고 쓰기 버퍼만 사용 가능하다. 이 때 weekly(in) 오더 메모리도 가능하다.
- WT(Write Through) 매핑
- 캐시 hit되는 경우 캐시와 메모리를 동시에 기록한다. 캐시 hit하지 않는 경우는 곧바로 메모리에 기록하게 한다.
- WB(Write Back) 매핑
- 캐시를 사용하도록 매핑한다. (커널이 사용하는 일반 DRAM 영역)
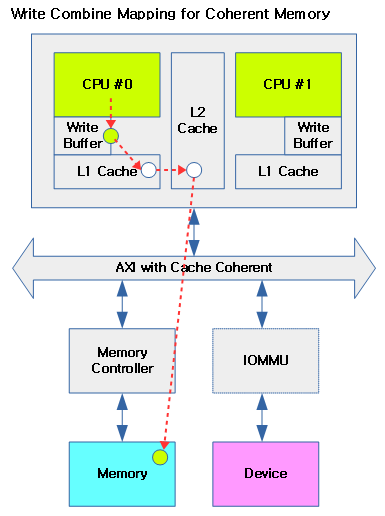
다음 그림은 cpu가 write-combine 매핑된 coherent(contiguous) 메모리에 데이터를 기록하는 모습을 보여준다.
- L1, L2 캐시를 사용하지 않는다.
2. Streaming DMA 매핑
디바이스가 DMA를 수행하기 전에 매핑(map)을 하고 DMA 수행한 후에 매핑 해제(unmap)를 한다. 이 매핑들은 interrupt context에서 사용될 수 있다.
- consistent DMA 매핑은 드라이버 로드 시 한 번만 수행하는 것과 다르게, Streaming DMA 매핑과 매핑 해제는 매번 DMA를 하기 전/후에 수행하여야 한다.
map & unmap
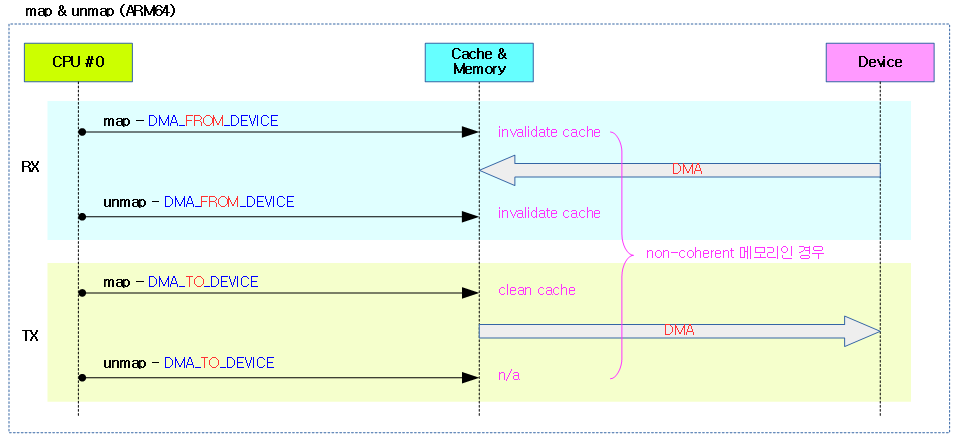
아키텍처 및 시스템 설계에 따라 cpu와 디바이스간에 공유된 메모리를 동시에 양쪽에서 업데이트를 하는 경우 서로 데이터가 싱크되지 않아 올바르게 보여지지 않을 수 있다. 따라서 cpu와 디바이스간의 데이터 일관성을 위해 DMA를 사용하기 전에 DMA 방향을 지정하고 DMA 전송 전/후로 다음 특별한 조작 등을 수행할 필요가 있다. 이러한 동작은 아키텍처마다 조금씩 다르다.
- map
- 디바이스가 메모리에 DMA 전송(read/write)을 하기 전에 처리해야 할 일을 수행한다.
- 아키텍처 및 시스템에 따라 다양한 조작이 있을 수 있는데 그러한 조작은 다음과 같은 것들이 있다.
- 캐시 조작(clean 또는 invalidate)
- 버퍼 조작(flush)
- IOMMU 사용 시 TLB 관련 매핑 레지스터 조작
- SWIOTLB 사용 시 orginal DMA 버퍼와 디바이스가 실제 DMA 전송하는 Bounce 버퍼와의 데이터 복사(copy)
- ARM64 캐시 조작 예)
- coherent 메모리를 사용하는 경우 캐시 조작을 할 필요없다.
- coherent 메모리를 사용하지 않는 경우 캐시 조작이 필요하다.
- DMA_FROM_DEVICE 방향을 사용하는 경우 캐시를 invalidate 한다.
- 그 외의 경우 캐시를 clean 한다.
- unmap
- 디바이스가 메모리에 DMA 전송(read/write)을 한 후에 처리해야 할 일을 수행한다.
- ARM64 캐시 조작 예)
- coherent 메모리를 사용하는 경우 캐시 조작을 할 필요없다.
- coherent 메모리를 사용하지 않는 경우 DMA 방향에 따라 캐시 조작이 필요한 경우가 있다.
- DMA_TO_DEVICE 방향을 사용하는 경우 아무런 동작을 하지 않는다.
- 그 외의 경우 캐시를 invalidate 한다.
다음 그림은 ARM64 시스템에서 DMA 사용 전 후로 map/unmap 시 시스템 메모리의 캐시에 관여를 하는 모습을 보여준다.
DMA directions
다음과 같이 DMA 전송 시 데이터가 움직이는 방향을 지정할 수 있다.
- DMA_BIDIRECTIONAL
- 메인 메모리 및 디바이스 양방향
- 정확한 방향을 모를 때 양방향 보낼 수 있도록 지정한다. 다만 단방향 지정보다 cost가 더 높다.
- DMA_TO_DEVICE
- 메인 메모리에서 디바이스 방향
- DMA_FROM_DEVICE
- 디바이스에서 메인 메모리 방향
- DMA_NONE
- 디버그 시 사용
single vs sg(scatter/gather)
스트리밍 매핑은 DMA 요청 시 마다(one-shot) 매핑과 매핑 해제를 수행하고, 다음과 같이 두 가지 버전을 지원한다.
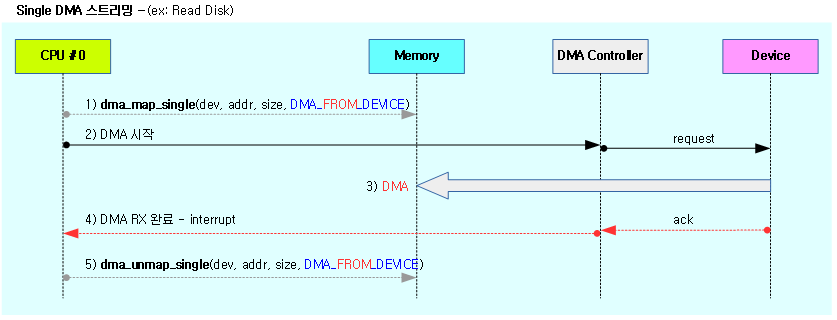
- single map/unmap
- 물리적으로 연속된(contiguous) 하나의 영역을 대상으로 DMA 전송 시 사용
- 예) large 영역으로 구성된 ring 버퍼
- 제약: highmem 영역은 사용하지 못한다.
- DMA 전송 시작 전에 dma_map_single()을 호출하고 DMA 전송이 완료되면 dma_unmap_single()을 호출한다.
- 물리적으로 연속된(contiguous) 하나의 영역을 대상으로 DMA 전송 시 사용
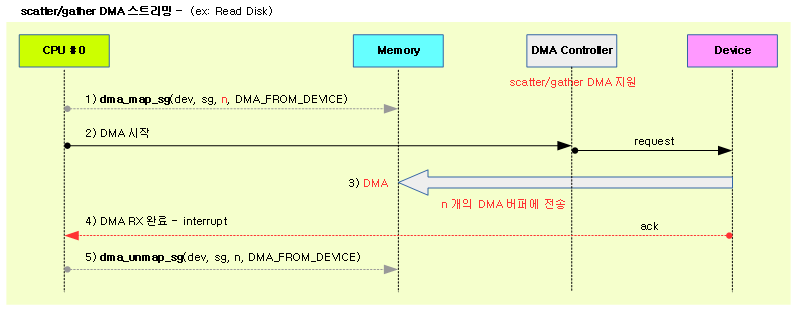
- scatter/gather map/unmap
- 물리적으로 연속되지 않고 fragment된 여러 버퍼를 대상으로 한꺼번에 DMA 전송 시 사용
- 물리적으로 연속된 대용량의 DMA 버퍼를 준비하지 않아도되는 장점이 있다.
- scatterlist에서 지정한 개개의 메모리 영역은 물리적으로 연속된 메모리를 사용해야 하지만, 전체 DMA 버퍼가 연속되지 않고 fragment 되었다.
- scatterlist 배열에 DMA 버퍼로 사용할 영역의 offset 및 길이 정보등을 담아 요청한다.
- DMA 전송 시작 전에 dma_map_sg()를 호출하고 DMA 전송이 완료되면 dma_unmap_sg()를 호출한다.
- 물리적으로 연속되지 않고 fragment된 여러 버퍼를 대상으로 한꺼번에 DMA 전송 시 사용
다음 그림은 single DMA 스트리밍과 scatter/gather DMA 스트리밍의 모습을 보여준다.

다음 그림은 연속된(contiguous) single 메모리 영역을 대상으로 디바이스에서 메모리 방향의 스트리밍 DMA 매핑을 보여준다.
다음 그림은 fragment된 여러 개의 메모리 영역을 대상으로 디바이스에서 메모리 방향의 스트리밍 DMA 매핑을 보여준다.
DMA 관련 헤더 파일 구성
arm 아키텍처는 dma 영역 설정 및 dma 할당을 위해 arm 아키텍처 전용 코드가 많이 남아 있다. arm64 아키텍처는 일부에 전용 코드를 사용하고 대부분 디바이스 트리 및 generic 구현을 통해 구성된다. x86 아키텍처는 대부분 generic 코드로 구현되어 있다. 다음은 DMA 관련한 주요 구현 파일들이다.
- 기본 파일
- include/linux/dma-buf.h
- include/linux/dma-contiguous.h
- include/linux/dma-direct.h
- include/linux/dma-fence.h
- include/linux/dma-fence-array.h
- include/linux/dma-iommu.h
- include/linux/dma-noncoherent.h
- include/linux/dmaengine.h
- include/linux/dmapool.h
- include/linux/dmar.h
- include/linux/dma-mapping.h
- include/linux/dma-direction.h
- include/linux/scatterlist.h
- mm/dmapool.c
- kernel/dma/coherent.c
- kernel/dma/contiguous.c
- kernel/dma/direct.c
- kernel/dma/mapping.c
- kernel/dma/remap.c
- Generic 헤더 파일
- include/asm-generic/dma-mapping.h
- include/asm-generic/dma-contiguous.h
- include/asm-generic/dma.h
- 아키텍처별 헤더 파일
- arm
- arch/arm/include/asm/dma-contiguous.h
- arch/arm/include/asm/dma-iommu.h
- arch/arm/include/asm/dma.h
- arch/arm/include/asm/dma-direct.h
- arch/arm/include/asm/dma-mapping.h
- arch/arm/mm/dma-mapping.c
- arm64
- arch/arm/include/asm/dma-mapping.h
- arch/arm/mm/dma-mapping.c
- x86
- arch/x86/include/asm/dma-mapping.h
- arm
DMA 메모리 할당/해제
DMA 메모리를 사용하기 위한 할당/해제 관리를 알아본다.
- 디바이스 트리를 사용하면서 reserved-memory 영역을 대상으로 dma 또는 cma 영역으로 지정하여 관리할 수 있게 되었다.
- default cma 영역을 의미하는 “linux,cma-default” 속성을 사용할 수 있다.
- 잘 사용되지는 않지만 ARM 아키텍처에서는 default dma 영역을 의미하는 “linux,dma-default” 속성도 사용할 수 있다.
- 디바이스 트리를 사용하지 않는 PC 서버의 경우도 ACPI를 통해 dma 또는 cma 영역을 지정하여 관리할 수 있다.
- 그 외 디바이스 트리 및 ACPI를 사용하지 않는 경우 아키텍처 및 드라이버 specific한 custom 코드를 통해 수행될 수 있다.
- 페이지 단위의 DMA coherent 메모리 할당을 원할때에는 dma_alloc_coherent()를 사용하고, 더 작은 단위의 할당을 반복하여 사용하고자 할 때에는 dma pool을 만든 후 dma_pool_alloc() 함수를 사용하여 할당 할 수 있다.
- dma 영역은 coherent 메모리로 사용하기 위해 no-map 속성을 사용하는 경우 별도의 write-combine 매핑을 사용하여 이용할 수 있다.
다음 그림은 전체적인 DMA 관리체계와 주요 API를 한 눈에 보여준다.
- DMA가 버스와 연동하여 사용되지만 PCI 같은 버스 specific API를 사용하는 것보다 버스 독립적인 DMA-API를 사용해야 한다.
- 예) pci_map_*() 보다 dma_map_*()을 사용한다.
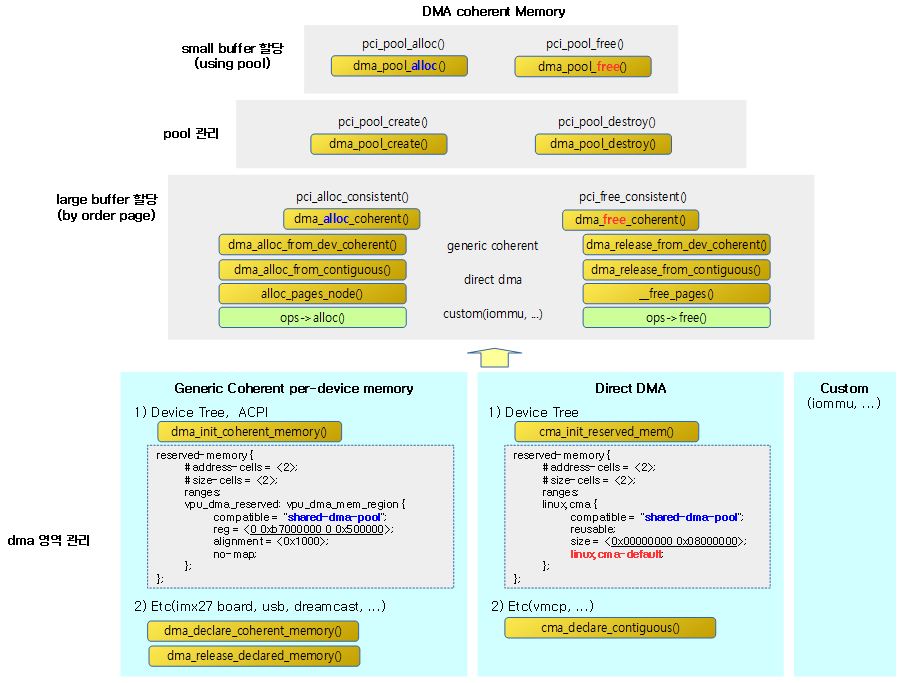
Generic DMA Coherent per-device Memory 영역 선언
주로 성능이 빠른 SRAM 등의 디바이스 전용 메모리로 coherent 메모리 영역을 선언하는데 사용한다. 이렇게 선언된 메모리 영역은 디바이스가 dma 메모리의 할당/해제를 위해 비트맵으로 관리하며, 비트맵 1비트는 1개 페이지에 해당한다.
- dma_declare_coherent_memory()
- dmam_declare_coherent_memory() – Managed API
- dma_release_declared_memory()
- dmam_release_declared_memory() – Managed API
- dma_mark_declared_memory_occupied()
메모리 페이지 할당/해제 API
DMA Coherent 메모리 페이지 할당/해제 API
위에서 선언한 coherent 메모리를 order 페이지 단위로 할당/해제한다. interrupt context에서 사용해야 하는 경우 GFP_ATOMIC gfp 플래그를 지정하여 사용할 수 있다.
- dma_alloc_coherent()
- dmam_alloc_coherent() – Managed API
- dma_free_coherent()
- dmam_free_coherent() – Managed API
DMA Contiguous 메모리 페이지 할당/해제 API
dma 메모리에서 order 페이지 단위로 할당/해제하되, write-combine 매핑 속성을 사용한다.
- dma_alloc_wc()
- dma_free_wc()
다양한 종류의 옵션 속성을 제공하는 DMA 메모리 페이지 할당/헤제 API
dma_alloc_coherent() 및 dma_alloc_wc() API를 사용할 수 없는 특수한 메모리 환경에서 옵션 속성을 주어 DMA 메모리 페이지 할당/해제를 수행할 수 있다.
- dma_alloc_attrs()
- dma_alloc_coherent()와 dma_alloc_wc()도 직접 호출한다.
- dma_alloc_coherent()와 dma_alloc_wc()도 직접 호출한다.
- dma_free_attrs()
- dma_free_coherent()와 dma_free_wc()가 호출하는 함수이다.
DMA Attributes
메모리 할당 시 옵션 속성을 지정할 수 있다.
- 무속성: fully coherent 메모리를 할당한다.
- DMA_ATTR_WRITE_COMBINE
- ARM과 ARM64 및 일부 mips(avr32) 아키텍처에서 제공된다.
- dma_alloc_wc()에서 호출할 때 사용한다.
- DMA_ATTR_WEAK_ORDERING
- powerpc(cell), sparc 등의 아키텍처에서 read 및 write 들이 weakly order될 수 있다고 알려준다.
- DMA_ATTR_NON_CONSISTENT
- non-coherent 메모리를 사용해도 sync 포인트를 통해 적절히 DMA를 수행할 수 있게된다.
- DMA_ATTR_WRITE_BARRIER
- 지연된 DMA write가 완료될 때까지 기다린다.
- 현재 ia64의 infiniband/core/umem.c에서 사용되고 있다.
- DMA_ATTR_FORCE_CONTIGUOUS
- ARM, ARM64의 특정 gpu 디바이스에서 반드시 물리 주소 및 가상 주소 모두 contiguous 메모리 매핑을 사용해야할 때 요청된다.
- DMA_ATTR_ALLOC_SINGLE_PAGES
- 1 페이지만 할당할 때 사용된다.
- ARM에서만 지원하는 기능이다.
유저 매핑 속성.
- DMA_ATTR_NO_KERNEL_MAPPING
기타
- DMA_ATTR_SKIP_CPU_SYNC
- DMA 전/후에 cpu에서 sync 작업을 할 필요가 없는 경우이다.
- DMA_ATTR_NO_WARN
- 메모리 할당 실패 경고를 출력하지 못하게 한다.
- 현재 powerpc 에서만 적용되어 있다.
- DMA_ATTR_PRIVILEGED
- 유저 및 커널 레벨 양쪽에서 접근 가능하도록 요청한다.
- arm의 pl330 DMA 컨트롤러 드라이버에서만 사용되고 있다.
DMA Pool 종류
- DMA Pool
- 현재 가장 많이 사용하는 dma pool 자료 구조이며, 실제 우선 할당되는 메모리는 device가 지정한 coherent 메모리이며, 지정한 coherent 메모리가 없는 경우 아래 dma coherent pool로 생성된 메모리 영역을 이용한다.
- DMA Coherent pool (atomic pool)
- kernel/dma/pool.c
- 커널 파라미터로 preallocated 용량을 지정할 수 있으며, 지정하지 않는 경우 디폴트로 메모리 용량 1G당 128KB를 선택하되, 128~4MB 범위를 사용한다.
- kernel parameter ex) “coherent_pool=1M”
- log) DMA: preallocated 1024 KiB pool for atomic allocations
- DMA Global pool
- 거의 사용하지 않는다.
- “linux,dma-default” with arm & !MMU
- kernel/dma/coherent.c
- 기타 custom dma pool
- dma pool의 관리는 다양한 각사의 방법들을 사용하여 왔다.
DMA Coherent Memory Pool API
페이지 단위가 아닌 작은 용량의 dma coherent 메모리를 반복하여 사용하고자 할 때 DMA coherent 메모리 풀을 생성한 후 그 풀 내부에서 작은 메모리 할당을 할 필요성이 생겼다. 다음은 풀을 생성하고 해제하는데 사용하는 API이다.
- dma_pool_create()
- 이 함수 내부에서 dma_alloc_coherent() 함수를 호출하여 요청한 크기의 dma coherent pool을 생성한다.
- dmam_pool_create() – Managed API
- dma_pool_destroy()
- dmam_pool_destroy() – Managed API
다음은 지정한 dma coherent pool에서 1개의 작은 블럭 메모리를 할당/해제하는 API 이다.
- dma_pool_alloc()
- dma_pool_free()
DMA Mask
DMA 영역 제한용 마스크를 설정하는 API 이다.
- dma_set_mask()
- streaming dma 매핑을 위해 사용되는 dma 제한이다.
- dma_set_coherent_mask()
- consistent dma 매핑을 위해 사용되는 dma 제한이다.
- dma_set_mask_and_coherent()
- 위의 두 가지 매핑을 한꺼번에 설정한다.
DMA 유저스페이스 매핑
유저 스페이스에서 사용할 수 있는 매핑도 지원한다.
- dma_mmap_attrs()
- dma_mmap_coherent()
- dma_mmap_writecombine()
DMA 매핑
두 매핑 중 하나의 전략을 사용한다.
- consistent dma 매핑
- 디바이스 드라이버 초기화 시 dma 매핑(iommu 및 캐시 sync)이 필요한 경우 미리 매핑을 한다.
- 드라이버 종료까지 개별 dma 매핑을 수행할 필요 없다
- 스트리밍 dma 매핑
- iommu 사용 시 매핑/언매핑을 동반한다.
- 코히런트 메모리를 사용하지 않는 경우 캐시 sync 함수를 동반한다.
스트리밍 dma 매핑
dma 버퍼를 활용하는 다음 방법들이 제공된다.
- 싱글 매핑
- 하나의 영역에 대한 요청이고,
- 페이지 매핑
- 한 페이지에 대한 요청이다.
- scatter/gather 매핑
- fragment된 여러 영역에 대한 요청이다.
for_cpu
DMA 전에 sync가 필요한 경우
- dma_sync_*_for_cpu() 함수를 사용할 수 있고,
for_device
DMA 후에 sync가 필요한 경우
- dma_sync_*_for_device() 함수를 사용할 수 있다.
- dma_map_single_attrs()
- dma_unmap_single_attrs()
- dma_map_single()
- dma_unmap_single()
- dma_map_page()
- dma_unmap_page()
- dma_map_sg_attrs()
- dma_unmap_sg_attrs()
- dma_map_sg()
- dma_unmap_sg()
- dma_mapping_error()
- dma_sync_single_for_cpu()
- dma_sync_single_for_device()
- dma_sync_single_range_for_cpu()
- dma_sync_single_range_for_device()
- dma_sync_sg_for_cpu()
- dma_sync_sg_for_device()
IOMMU
iommu 도메인을 할당하고 이를 이용하는 디바이스를 붙인 후 매핑을 지원하는 API이다.
- iommu_domain_alloc()
- iommu_domain_free()
- iommu_attach_device()
- iommu_detach_device()
- iommu_map()
- iommu_unmap()
참고
- DMA -1- (Basic) | 문c – 현재 글
- DMA -2- (DMA Coherent Memory) | 문c
- DMA -3- (DMA Pool) | 문c
- DMA -4- (DMA Mapping) | 문c
- DMA -5- (IOMMU) | 문c
- DMA -6- (DMAEngine Subsystem) | 문c
- IOMMU | 문c
- Mastering the DMA and IOMMU APIs (2014) | Laurent Pinchart – 다운로드 pdf
- An Overview of the DMAEngine Subsystem (2015) | Free Electrons – 다운로드 pdf
- Write Combining Memory Implementation Guidelines (1998) | Intel – 다운로드 pdf
- DMA safety in buffers for Linux Kernel device drivers (2018) | Wolfram Sang, Consultant / Renesas – 다운로드 pdf
- Linux Kernel Network Subsystem (2006) | Chih-che Lin – 다운로드 pdf
- What is Direct Memory Access (DMA) and Why Should We Know About it? | John Franco – 다운로드 pdf
- Contiguous memory on ARM and cache coherency (2015) | A else B
임베디드 환경에서 DMA 사용시 캐쉬 컨트롤 관련 디버깅하는데 많은 도움이 되었습니다.
감사합니다.
도움이 되셨다니 반갑고 힘이 납니다. 감사합니다.
와우 대박입니다 이걸 어떻게 다 정리하셨어요?
하다보니 여기까지 왔네요. ^^;
즐거운 하루 되세요.
머릿속에 뭔가 정리가 안되어있을때 마다, 항상 감탄하여 글을 읽고 있습니다.
정말 최곱니다!!
감사합니다.
즐거운 하루 되세요.
좋은 블로그덕분에 리눅스 이해도가 높아지네요 감사합니다.
자주들어와서 좋은 정보 많이 얻어가고, 책도 덤으로 사겠습니다 🙂
그리고 위에 SWIOTLB에서 Lookaside 가 빠진듯 합니다.
IOMMU SWIOTLB : Input Output Memory Management Unit and the Software Input Output Translation Lookaside Buffer
말씀하시는 내용만으로도제가 즐겁습니다.
즐거운 하루 되세요.
감사합니다.
안녕하세요~ 좋은글 잘 읽어보고 있습니다.
‘버스 아키텍처에 DMA 컨트롤러 h/w가 구성되어 있어야 한다 예) PCI, PCIe, AXI, AHB, …’ 이부분이 잘 이해가 가지 않습니다.
예에서 말씀하신 PCI, AXI, AHB는 DMA 컨트롤러 h/w가 아니라 버스 프로토콜을 말씀하신게 아닌지요?
DMA나 CPU의 특징은 Bus의 Transaction을 시작할 수 있는 Bus Master로 동작 할 수 있는게 특징으로 알고 있습니다.
디바이스가 interrupt는 발생 할 수 있으나, Bus Master가 아닌한 스스로 메모리에 뭔가를 Read/Write하는 동작을 할 수 없으며, CPU나 DMA가 이를 시작해야지만 Read/Write 절차가 시작 되는 것으로 알고 있습니다. 이를 위해 “PCI, AXI등의 버스 프로토콜에 DMA 컨트롤러가 연결되어 있어야 한다”는 것을 언급하신게 아닌지요?
안녕하세요?
한철희님께서 생각하시는 부분이 맞습니다.
‘버스 아키텍처에 DMA 컨트롤러 h/w가 구성되어 있어야 한다” 라는 말은
“버스를 제공하는 버스 컨트롤러에 DMA 컨트롤러 역시 연결되어 있어야 한다.”라는 의미입니다.
예를 들어 x86 시스템 등에서 메인 버스가 ISA -> EISA -> MCA/PCI 버스로 진화할 때
주 버스에는 DMA 컨트롤러가 기본적으로 사용되고 있습니다.
그리고 주 버스에 연결된 하위(sub) 버스를 제공하는 컨트롤러들이 DMA 요청을 할 수 있는 기능을 가질 수 있습니다.
x86의 8237 DMA 컨트롤러를 사용한 그림은 다음 URL 페이지를 참고하시면 그림으로 확인할 수 있습니다.
참고: An overview of direct memory access – https://geidav.wordpress.com/2014/04/27/an-overview-of-direct-memory-access
———————————-
최근 arm/arm64 시스템으로 설명드리면,
메인 버스가 AXI 버스이고 DMA 컨트롤러(arm cortex-a9등에서 pl330 컨트롤러가 사용되었었는데
지금은 어떤 컨트롤러가 내장되어 사용되는지 식별이 잘안되고 있습니다)가 사용되고 있습니다.
참고: CoreLink DMA-330 DMA Controller Technical Reference Manual – http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dai0224c/index.html
그리고 주 장치와 연결된 버스는 하위의 PCI/PCIe와 연결되고
그 PCI/PCIe 컨트롤러 내부에도 DMA 요청 기능이 내장되어 있습니다.
참고로 SPI, serial 등은 너무 느려 보통 AXI 다음의 중간 레벨 버스를 거쳐 연결됩니다.
결국 상위 버스에는 DMA 컨트롤러가 연결되어 있어도 하위 버스에 연결된 컨트롤러가
DMA 컨트롤러와 연동하는 기능을 가졌는지 여부에 따라
DMA 기능을 사용할 수 있기도하고 사용할 수 없기도 합니다.
예) DMA 기능이 없는 SPI 컨트롤러, DMA 기능이 DMA 기능을 가진 SPI 컨트롤러
PCI/PCIe의 경우 PCI 슬레이브 디바이스 조차도 DMA Master 기능을 사용할 수 있어서,
DMA 기능이 매우 복잡하게 구현됩니다. AXI 버스와 PCI/PCIe 버스 사이에 DMA Controller를 연결하는데
다음을 참고하시기 바랍니다.
참고: DMA Controller FPGA IP – https://www.omnitek.tv/dma_controller-ip
설명이 더 복잡해지는 군요. ^^;
감사합니다.
DMA 관련 질문이 하나 있어 글 씁니다.
혹시 여러개의 DMA를 하나의 마스터와 버스를 통해 컨트롤 할 때, DMA가 서로 버스를 사용하기 위해 경쟁하는 경우 어떻게 처리하나요?
1) 1 개의 버스에서는 동시에 1개의 DMA를 처리합니다. 즉 여러 디바이스가 bus를 동시에 요청하면 그 중 하나가 bus arbitrator를 통해 먼저 진입한 디바이스에 우선권을 주어 DMA를 처리합니다. 이렇게 여러 개의 디바이스가 동시에 버스 사용 요청을 하는 것을 여러 개의 DMA라고 말씀하신것인가요? 이러한 경우라면 복수의 디바이스들의 버스 사용 요청이고, 이를 통해 사용하는 DMA는 1개의 채널만을 사용합니다.
질문에서 여러 개의 DMA이며, 하나의 마스터라고 말씀하셔서 조금 헷갈립니다.
(i2c, spi 같은 버스에서는 컨트롤러가 bus 마스터가되고, slave 디바이스들은 마스터가 아닙니다.
그리고 pci 버스 같은 경우 pci 디바이스들은 dma 요청을 직접할 수 있습니다. 이 경우 pci 디바이스들이 마스터가 됩니다)
하나의 버스에서 디바이스들이 동시에 요청하면 bus arbtrator가 통제를 하기 때문에 각각의 요청에 대한 처리를 수행할 때 DMA를 동시간에 한 번만 사용되므로 한 개의 DMA를 사용합니다. 그런데 질문에는 여러 개의 DMA라고 해서 다른 상황을 질문할 수도 있다고 판단됩니다.
2) 혹시 여러 버스에서 요청하는 다수의 DMA 들을 처리하는 DMA 채널 컨트롤러를 말씀하시는 거라면 또 다른 이야기입니다.
보통 DMA 컨트롤러 안에 복수의 DMA를 처리할 수 있게 DMA 채널로 구성하고, 이들은 경쟁 없이 동시에 처리가 가능합니다.
예를 들어 4개의 i2c 버스에서 나오는 요청을 4개의 DMA 채널에 연결하여 동시에 처리합니다.
위의 두 가지 모두 arbitration에 대해 sw 개입 없이 hw가 처리합니다.
감사합니다.
안녕하세요 문영일님. 저는 운영체제 개발 관련 서적을 집필중인 박주항이라고 합니다.
다름이 아니오라 공유해 주신 글이 큰 도움이 되어서 집필 서적에서 참조를 하려고 합니다.
그래서 허락을 받고자 이렇게 글을 남깁니다.
답변주시면 정말 감사하겠습니다.
좋은 하루 되십시오.
박주항님 안녕하세요?
제 글이 박주항님의 집필에 도움이 되신다니 매우 흥미롭고 즐겁습니다.
제 글은 얼마든지 참조하여 사용하시길 바랍니다.
감사합니다.
허락해 주셔서 정말 감사드립니다.
지금 집필하고 있는 책은 “C++로 나만의 운영체제 만들기”의 후속편으로 출간되면 다시 연락드리겠습니다.
좋은 하루 되십시오.
독자들의 기억에 남을 좋은 책 만들어 주시길 바랍니다. 기대됩니다.
좋은 하루 되세요.
안녕하세요 이번 내용 보다 질문이 있어 남겨봅니다.
DMA Streaming을 위한 ‘DMA 시작’ 이라는 오퍼레이션을 어떻게 수행시킬 수 있는건지 궁금합니다.
감사합니다.
안녕하세요?
아직 dmaengine subsystem에 대한 posting을 하지 않아서 자세한 내용이 없습니다만
‘DMA 시작’에 대해 dmaengine sybsystem을 사용한 dma 전송을 사용한가고 가정합니다.
‘DMA 시작’ 전에 드라이버에서는 rx/tx에 대한 dma 채널 설정과 dma용 버퍼가 이미 구성되어있다고 가정합니다. (예: dma_request_chan(), dmaengine_slave_config(), …)
‘DMA 시작’은 dma 매핑 방법에 따라 다릅니다. 다음은 그 중 single 매핑한 예를 보여줍니다.
예)
– dma_map_single() – dma single 방법으로 매핑 준비
– dmaengine_prep_slave_single() – dma_async_tx_descriptor 구조체 준비
– dmaengine_submit() – dma pending 큐에 전송
– dma_async_issue_pending() – dma pending 큐를 모두 전송(flush)
감사합니다.
답변주셔서 정말 감사합니다!!
추가 질문으로 dmaengine 을 pci host controller와 같은 레벨로 볼 수 있을까요?
그렇다면 pci 로도 예를 들어 주실 수 있을지 부탁드려봅니다.
감사합니다.
dmaengine은 pci host controller와 같은 레벨로 볼 수 있기도 하고 없기도 합니다.
dmaengine subsystem은 dma host controller들을 위한 드라이버입니다.
그리고 dma를 사용하려는 slave 디바이스들이 dmaengine에서 제공하는 slave 디바이스용 API를 사용하여 채널 할당을 하고, DMA 요청할 수 있습니다.
pci host controller는 다른 장치를 위해 dma host controller 역할을 하지 않습니다.
물론 pci host conroller는 자신의 버스에 연결된 pci 디바이스들만을 위해 DMA와 유사한 동작인 “버스 마스터링”을 통해 DMA 기능을 수행합니다.
따라서 pci host conroller는 현재 dmaengine subsystem을 사용하지 않고 pci host controller의 자체 기능을 통해 DMA가 구현됩니다.
(예: ARM에서는 pci host controlelr가 AXI 버스에서 마스터 권한을 얻어 pci 디바이스로 부터 받은 데이터를 직접 메모리에 DMA할 수 있게 합니다.)
감사합니다.
안녕하세요, 좋은 글을 공유해주셔서 감사합니다.
질문이 있어서 댓글을 작성하게 되었는데요,
연속적이지 않은 Physical Memory 공간을 갖는 DMA Buffer를
Scatter/Gather DMA 하기 위해서는 반드시 IOMMU를 사용해야 하는 것인가요?
안녕하세요?
Scatter/Gather API는 dma 버퍼에 사용할 물리 메모리가 분산된 곳을 이용하고자 할 때,
디바이스 입장에서 연속된 메모리로 보이도록 분산된 물리 메모리 들을 scatter/gather lists로 지정하고,
이를 IOMMU를 통해 매핑하여 performance를 상승시키는 기법입니다.
물론 물리 메모리를 분산 시키지 않은 버퍼를 사용하는 경우에 한해
IOMMU 없이 Scatter/Gather API를 사용하여 여러 개를 한꺼번에 받을 수도 있습니다.
질문에 대해서 연속적이지 않은 물리 메모리 공간을 갖는 dma 버퍼에 대해
Scatter/Gather DMA 하기 위해서는 반드시 IOMMU를 사용해야 합니다.
(혹여나 이러한 사래에 위배된 케이스가 있으면 알려주시기 바랍니다. ^^;)
감사합니다.
http://jake.dothome.co.kr/iommu/
IOMMU(Input Output Memory Management Unit)
– IOMMU는 다음과 같은 일들을 할 수 있다.
1. Transalation
– …
– “DMA에 사용하는 버퍼는 연속된 물리 주소”이어야 하는데, IOMMU를 사용하는 경우 그러한 제한이 없어진다.
-> IOMMU를 사용하지 않는다면, DMA 버퍼는 반드시 연속된 물리 주소여야 하는 것인지와 같은 질문인 것 같습니다.
감사합니다.
안녕하세요. 포스팅하신 글을 통해 많은 것을 배웁니다.
dmaengine subsystem에 대해 한가지 질문글을 올립니다.
FPGA로 구현되는 PCIe End-Point 장치가 있고 호스트가 x86일 때, FPGA DMA IP를 사용하여 호스트와 PCIe 장치간에 데이터 Read/Write를 기능을 구현하고자 할때,
dmaengine subsystem 사용 필요성이 있을까요?
안녕하세요?
먼저 답변을 말씀드리면 dmaengine subsystem을 전혀 사용할 필요가 없습니다.
pci가 아닌 다른 장치들이 dma를 이용하려면 dma controller(보통 여러 채널 운영)에게 채널을 요청하고,
이를 통해 dma를 할 수 있습니다. 이 때 dmaengine 서브시스템 API도 사용할 수 있습니다.
그러나 PCI/PCIe 장치들은 시스템에 있는 dma controller를 전혀 이용하지 않습니다.
자신이 버스 마스터가 될 수 있도록 PCI 컨트롤러에 요청하고, 획득한 후 직접 호스트 메모리에 액세스합니다.
그럼 좋은 하루되세요.
존경하는 문영일 선생님, 저는 이 분야의 초짜 연구원입니다.
이 분야에 이렇게 잘 설명된 글을 만들어 주셔서 정말 감사합니다.
PCIe 로 DMA 연결을 하는데 많은 도움이 될 것 같습니다.
집필하고 계시는 책 역시 어떻게 서술해 나가실지 흥미가 생기는군요.
하시는 일 모두 잘 되시길 바랍니다.
감사합니다.
오 이런 윗 댓글을 잘못 이해했군요. 그래도 관련 지식을 참고해갈 정도니 정말 대단하신 것 같습니다.
안녕하세요? 이세연님.
제 글로 도움이 된다면 저로선 기분이 좋아지는 일입니다.
좋은 공부되시고 좋은 하루되시길 바랍니다.
감사합니다.
안녕하세요. 좋은 자료 항상 잘 보고 있습니다.
다름이 아니라 DMA 관련해서 질문이 있어 댓글 남겼습니다.
DMA에 대한 설명 중 Case A, B, C에 대해서 다음과 같은 질문이 있습니다.
1) Case A) MMIO 방식으로 맵핑된 영역에 대해서 DMA가 접근하는 경우가 있는지?
– 그림에서는 DMA가 MMIO 맵핑된 영역을 접근하는 것처럼 보이는데, 대부분의 다른 자료에서는 MMIO 방식은 CPU가 직접 접근하는 거로 대부분 알려져 있습니다. 이 부분에 대해서, MMIO 맵핑된 영역에 대해서 DMA가 직접 접근하는 경우가 있는지, 있다면 어떠한 상황이 있는지 예시를 들어서 설명해주시면 감사하겠습니다.
2) Case B, C) IOMMU 방식 또는 Direct DMA 방식에서는 ioremap()이 사용되지 않는지?
– ioremap()이 아니면 어떠한 함수가 호출되어 해당 영역을 버퍼로 사용할 수 있게 해주는지 궁금합니다. 또는 ioremap()으로도 버퍼를 설정할 수 있는 것인지 궁금합니다.
긴 질문 끝까지 읽어주셔서 감사드리며, 항상 좋은 자료 잘 보고 있습니다.
감사합니다.
안녕하세요?
Q1) Case A) MMIO 방식으로 맵핑된 영역에 대해서 DMA가 접근하는 경우가 있는지?
A -> 이승학 님께서 생각하시는 것과 같이 대부분은 cpu가 취급합니다. 빨간색으로 DMA라고 되어 있는 부분은 이 부분이 항상 DMA로 동작한다는 것이 아니라 이렇게 매핑된 영역이 어떠한 경우에는 DMA 방식으로도 접근할 수 있다는 것을 표현한 것이며 이러한 사례는 다음과 같습니다.
PCI 디바이스내에 대용량 DRAM 버퍼를 가지는 네트웍 장치를 예로 설명합니다. 이들은 수백K ~ 수M의 내장 메모리를 가지고 있고, pci 장치이므로 BAR 형태로 표출되어 pci_ioremap_bar() 또는 ioremap API 등을 사용하여 시스템의 가상 주소에 매핑합니다. 이렇게 매핑된 BAR 메모리 중 하나는 컨트롤 레지스터로 전송 및 수신과 관련한 DMA 컨트롤에 사용합니다. 일부는 PCI 장치의 버퍼 메모리로 사용합니다. DMA 시작과 종료는 BAR에 표출된 레지스터로 컨트롤하고 전송 및 수신에는 BAR에 연결된 버퍼 메모리를 사용합니다. DMA가 끝나면 인터럽트를 발생시키고, 결과 등은 레지스터에 기록됩니다.
물론 PCI가 엄밀히 우리가 아는 DMA(cpu initiate) 또는 Bus Mastering(device initiate) 등의 용어로 분리하여 설명하곤 합니다. – 여기에 대해서는 생략합니다 –
2) Case B, C) IOMMU 방식 또는 Direct DMA 방식에서는 ioremap()이 사용되지 않는지?
A -> Case B)와 C)는 DMA에 시스템이 소유한 메모리를 사용하는 케이스입니다. 시스템이 소유한 메모리가 DRAM일 수도 있고, 내부에 별도의 고속 SRAM을 사용하기도 합니다. 어느 케이스이든 캐시 코히런스 문제를 피하기 위해 DMA Coherent 메모리로 할당하여 사용을 해야 하는데(물론 캐시를 사용하는 DRAM 버퍼를 DMA 버퍼로 바로 사용하기 위해 dma sync api들과 같이 협업하여 사용하는 방법도 있습니다), CMA 영역을 이용하는 방법, DMA 존 영역을 이용하는 방법 및 reserve 영역을 이용하는 방법 여러 개가 있습니다. 일반 DRAM인 경우 이미 커널에 매핑이 되어 있고, 이를 커널 내부에서 캐시 코히런시를 피하기 위해 ioremap_wc()등으로 리맵하여 보통 사용합니다. 그리고 별도의 고속 SRAM 등을 사용한 경우에는 커널 부팅 시 이 영역을 reserve하여 매핑을 피하고, 나중에 SRAM을 사용하는 드라이버 쪽에서 DMA 코히런트 메모리로 등록하여 사용합니다.
어떤 메모리 형태이든 memremap() 또는 ioremap() 형태의 API를 통해 가상 주소에 매핑된 메모리를 DMA로 다루어져야 합니다. 다만 이 메모리가 시스템에 있는 DRAM인 경우 성능을 목적으로 캐시가 활성화된 상태에서 이용할지 아니면 성능이 떨어지더라도 캐시 코히런트 메모리로 매핑(write combine 등으로)을 변경하여 캐시 없이 사용할지 여부를 판단하여 사용해야 합니다. 이에 관련하여 더 자세한 것은 제 블로그의 DMA -2- (DMA Coherent Memory) 편을 참고하시기 바랍니다.
문영일 드림.
항상 큰 도움이 되고 있습니다. 간결하고 명확한 답변해주셔서 진심으로 감사드립니다.
네. 본문에 몇 가지 사례에 대한 그림을 찾아 추가하였으니 참고하시기 바랍니다. 감사합니다.