Cache 및 버퍼
문c: “소프트웨어 개발 엔지니어들이 커널을 잘 이해하기 위해 알아야 할 매우 중요한 항목(캐시 및 버퍼, 베리어, atomic 연산) 중 하나입니다. 여러 자료들을 참고하여 여러 방향에서 이해할 수 있도록 하시길 바랍니다.”
캐시 및 버퍼는 메모리 접근 성능과 관련하여 소프트웨어 개발자들이 기술적으로 지원해야 하는 매우 복잡한 테크닉이 필요한 곳이다. 소프트웨어 엔지니어로서 하드웨어 아키텍처와 밀접한 일부 내용을 알아야 이해할 수 있는 내용이 많으므로 앞으로 유의해야 할 몇가지를 다음과 같이 나열해본다.
- 메모리 오더링(in order 및 out of order)에 대한 이해
- 어떠한 경우에 out of order 메모리 접근이 사용되는지에 대한 이해
- 가상 주소 매핑에 의한 제어
- 메모리 베리어
- out of order memory에 접근 시 특정 주소들 간에 반드시 순서를 확정해야 할 때가 있다. 성능에 따라 어떠한 메모리 베리어가 지원되며 어떻게 선택하여 사용하는지에 대한 이해
- Flush
- 어느 시점에 캐시된 메모리를 버리거나 주 메모리에 기록을 시켜야 하는지에 대한 이해
- 공유 메모리 및 DMA
- CPU, GPU, NPU 및 기타 장치와의 공유에 대한 이해
cpu 명령 처리 능력
오늘 날의 cpu는 1 나노초당 십수개의 명령어(instruction)를 처리할 수 있을 정도로 빨라졌다. 순수하게 cpu의 정수(integer) 처리 성능만을 비교하기 위해 사용되는 지표는 DMIPS/Mhz를 사용하며 이에 대해 ARM 아키텍처의 성능을 알아본다.
- ARM Cortex-A7
- dmips@mhz는 1.7로하나의 cpu가 1mhz 클럭으로 환산하여 동작시 1.7 백만 개의 정수 명령어를 처리할 수 있다.
- 1Ghz로 동작하는 하나의 cpu가 1초에 1,700,000,000개(17억개)의 정수 명령어를 처리할 수 있다.
- ARM Cortex-A76
- dmips@mhz는 12.4로 하나의 cpu가 1mhz 클럭으로 환산하여 동작시 12.4 백만 개의 정수 명령어를 처리할 수 있다.
- 3Ghz로 동작하는 하나의 cpu가 1초에 37,200,000,000개(372억개)의 정수 명령어를 처리할 수 있다.
- Intel i9 9900k
- dmips@mhz는 11로 하나의 cpu가 1mhz 클럭으로 환산하여 동작시 11 백만 개의 정수 명령어를 처리할 수 있다.
- 4.7Ghz로 동작하는 하나의 cpu가 1초에 51,700,000,000개(517억개)의 정수 명령어를 처리할 수 있다.
- AMD Ryzen 9 3950X
- dmips@mhz는 10.1로 하나의 cpu가 1mhz 클럭으로 환산하여 동작시 10.1 백만 개의 정수 명령어를 처리할 수 있다.
- 4.6Ghz로 동작하는 하나의 cpu가 1초에 46,460,000,000개(464억개)의 정수 명령어를 처리할 수 있다.
DMIPS(Dhrystone Million Instructions Per Second)
1970년대에 1Mhz로 동작하는 DEC VAX 11/780 미니컴퓨터의 성능이 1초에 100만(1M)개의 명령을 처리하였고, 이를 기준으로 컴퓨터의 성능을 측정하는 단위이다. DMIPS와 DMIPS/Mhz의 의미는 다음과 구분한다.
- DMIPS가 2000
- 비교 컴퓨터의 성능이 DEC VAX 11/780 보다 2000배가 빠르다는 것을 의미한다.
- DMIPS/Mhz가 2
- 비교 컴퓨터를 1Mhz로 동작시켰다고 가정할 때의 성능이 DEC VAX 11/780보다 2배가 빠르다는 것을 의미한다.
다음 그림은 ARM Cortex-A 시리즈의 DMIPS.Mhz 값을 보여준다.
- DMIPS/Mhz는 인텔의 경우 지난 10년간 10번의 generation을 통해 성능이 2배 밖에 오르지 않았으나, ARM 진영은 더 많은 성능 향상이 이루어지고 있다.

DRAM 액세스 능력
그러나 아무리 빠른 cpu라 하더라도 DRAM 메모리에 접근할 때 수십 나노초의 시간이 소요된다. DDR3, DDR4, DDR5와 같이 계속 성능이 향상되긴 하였지만 cpu 발전 성능을 따라가지 못했기 때문에 추가적인 성능 향상을 위해 다음과 같은 추가 수단을 사용한다.
- DRAM 메모리에 접근할 때 수십 나노초의 시간이 소요되므로 한 번에 여러 바이트를 한꺼번에 읽어 온다. 이를 burst 전송이라 한다.
- 한꺼번에 읽는 바이트들 수는 최소 16~256 바이트이고 이를 캐시라인이라고 한다. 보통 SoC 마다 지정된 바이트로 디자인되어 고정된채 사용된다.
- burst 액세스한 캐시 라인 데이터를 캐시 메모리에 유지시킨다.
- 캐시를 위치에 따라 L1, L2, L3, … 등으로 용량을 다르게 나누어 관리한다. 가장 앞단의 L1 캐시가 가장 성능이 높은 캐시이고, 용량이 작다.
- 캐시들은 보통 클 수록 성능이 향상되나 적정 용량 이상 키운 이후에는 큰 성능차가 없는 특성을 가진다
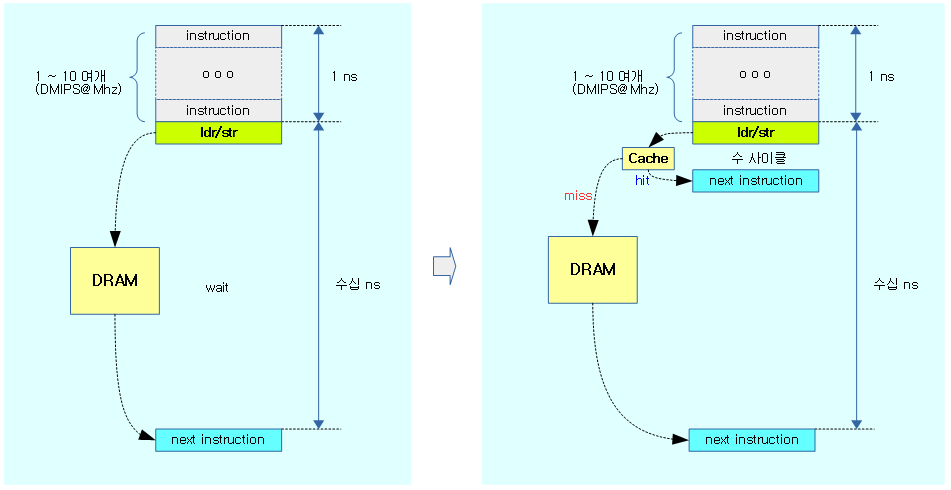
다음은 Load 명령 시 캐시가 hit할 때 사용된 평균 사이클 수이다.

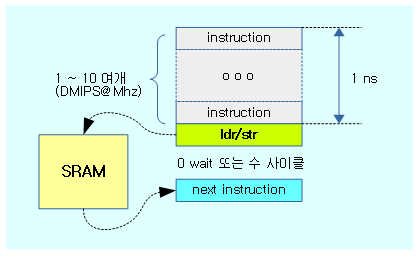
캐시용 메모리(SRAM 등)
캐시는 cost가 비싼 SRAM 등을 사용하여 만들며, 0 사이클 또는 수 사이클 이내에 처리되는 고성능 메모리로 설계된다. 주 메모리를 모두 SRAM으로 만들었다면 캐시가 필요 없을 수 있다. 하지만 매우 비싸기 때문에 주 메모리에는 느린 DRAM을 사용할 수 밖에 없는 상황이다.
캐시 종류
cpu와 DRAM사이에 위치한 캐시들만을 거론할 때 어떠한 종류가 있을까?
- 명령 및 데이터 캐시들
- 버퍼들
- TLB 캐시들
- predict 캐시들
다음 그림은 ARM Cortex-A57 블럭 다이어그램에서 사용된 여러 종류의 캐시들을 적/청색 박스로 표시하였다.
- 청색 박스는 L1 및 L2 캐시(태그 제외)이고, 그 외는 적색 박스로 표시되어 있다.
- 성능이 높은 아키텍처들일 수록 다양한 기능의 predict 캐시들이 추가된다.

명령 캐시 및 데이터 캐시
ARM의 경우 처음 발표 시 캐시가 탑재되지 않은 칩부터 시작하였고, 그 후 순서대로 L1 , L2, 및 L3 캐시가 하나씩 추가되어왔다. L1 레벨의 캐시는 명령 캐시와 데이터 캐시로 나뉘어 사용되는 경우가 많고, L2 레벨 이후부터는 보통 명령과 데이터가 통합된 통합(unification) 캐시가 운용하도록 디자인되었다.
- 최근 ARM Cortex-A77부터 L1 명령 캐시보다 앞단에 L0 캐시인 uOP(Micro Operation) 또는 MOP(Macro OP) 라고 불리는 캐시를 두어 병렬 명령 대역을 높여 디코딩 능력을 최대화한다.
- L3 바깥에 별도의 시스템 캐시를 두는 경우도 있다.
다음 그림과 같이 레벨별 명령 캐시 및 데이터 캐시 또는 통합 캐시의 위치를 알아볼 수 있다.
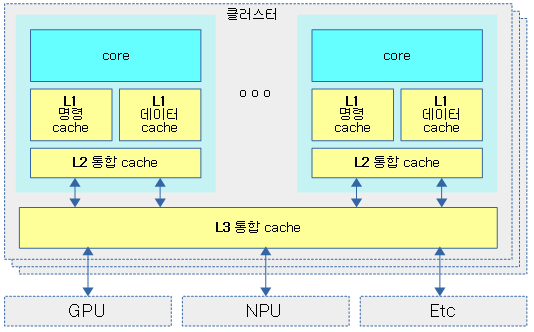
- 아래에서 시스템 캐시는 L2 캐시가 그 역할을 하고 있지만, SoC 디자인에 따라 L3에서 시스템 캐시 역할을 수행할 수도 있다.
- 시스템 캐시는 내부 core 뿐만 아니라 외부 GPU, NPU 및 고속 네트웍 장치등과 공유되어 사용되며, 캐시 코히런트 연동한다.

최근 ARM Cortex-A75 아키텍처부터 L2 캐시 마저도 core 마다 사용되는 private 캐시로 사용되고, L3 캐시부터 shared 캐시로 사용됨을 알 수 있다.
- 기존에 ARM사의 주요 고객사들이 고성능 칩을 디자인하고, ARM은 보급형 칩만 공개했었다. 이러한 전략은 ARM Cortex-A77 아키텍처부터 바꾼다고 한다. 즉 ARM사가 직접 나서서 고성능 서버용 칩으로 사용될 수 있도록 개발하는 전략이다.
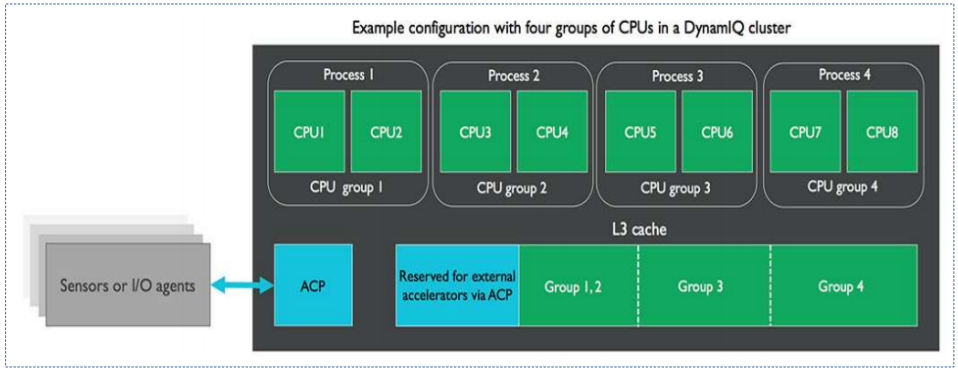
다음 그림은 ARM Cortex A75 이상의 아키텍처에서 L3 캐시를 파티션하여 사용하는 모습을 보여준다.
버퍼
SoC 내부에 많은 종류의 버퍼가 사용되지만 커널 개발자가 주의 깊게 알아야 할 버퍼는 다음 두 종류를 고려하면 된다.
- Load/Store 버퍼
- 다음 챕터에서 자세히 설명한다.
- Queue (Retirement) 버퍼
- 최종 명령/데이터 캐시 및 DRAM에 연결된 버스 사이에서 사용되며 load/store 명령이 순차 처리를 한다.
- smp_mb() 등의 메모리 베리어가 수행될 때 큐 버퍼에 있는 모든 load/store가 모두 완료될 때까지 대기하고, 새로운 load/store가 동작하지 못하게 한다.
- Invalidate 큐로 사용되는 경우 모든 load/store 명령을 빠르게 취소시키는 역할을 수행한다.
TLB 캐시
페이지 테이블 엔트리를 캐시하는 TLB 캐시도 다양하게 구성된다.
- micro TLB
- MMU 내부 cpu와 가장 가까운 위치에서 사용되며 명령어 및 데이터 캐시로 분리하여 사용한다.
- L1 TLB 캐시로도 불리운다.
- main TLB
- MMU 내부 micro TLB 다음에 위치하며 더 큰 크기로 구성한다.
- L2 TLB 통합 캐시로도 불리운다.
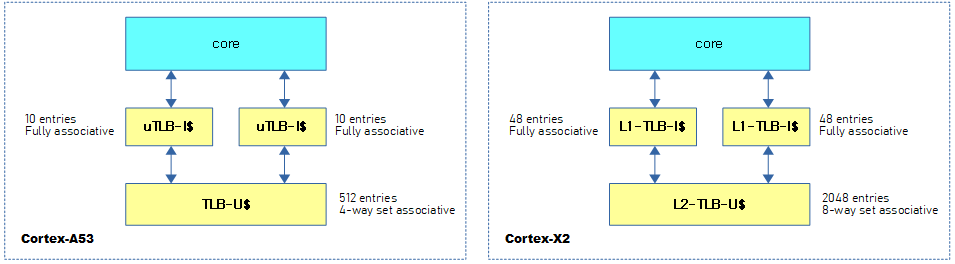
다음 그림은 TLB 캐시의 명칭과 엔트리 수를 보여준다.
- ARM32 시스템의 경우 대부분 1개의 TLB 통합 캐시를 사용한다.
predict 캐시들
out of order 실행 처리와 매우 밀접한 관계를 가진다. 이들은 예측 처리와 관련되어 최근 고성능 cpu의 out-of-order execution 및 Load/Store 버퍼에서 speculative load 등으로 meltdown 및 사이드 채널 공격 보안 이슈가 있었다.
- 참고: Meltdown and Spectre | Redhat – 다운로드 pdf
다음과 같은 예측 캐시들이 있다.
- prefetch 버퍼
- 명령이 실행될 때 마다 예측하여 명령을 미리 로드(speculative load)하며 예측이 실패한 경우 폐기한다.
- branch predict 버퍼
- 다음 브랜치할 또는 리턴될 위치의 명령 또는 데이터를 미리 로드해 놓기 위해 사용되는 캐시이다. (다양한 예측 관련 버퍼들이 사용되고 있다)
- BTB(Branch Target Buffer), nanoBTB, L1-BTB, L2-BTB
- RAS(Return Address Stack)
- 다음 브랜치할 또는 리턴될 위치의 명령 또는 데이터를 미리 로드해 놓기 위해 사용되는 캐시이다. (다양한 예측 관련 버퍼들이 사용되고 있다)
Load/Store 버퍼
위의 캐시 종류에서 간단히 용도를 나타내었지만, 성능을 올리기 위해 사용되는 또 하나의 중요한 버퍼로 load/store 버퍼가 있다. 아키텍처에 따라 load 및 store 버퍼를 별도로 디자인하여 운영할 수도 있고, 통합하여 디자인하기도 한다.
- load buffer
- 가능하면 하나의 캐시 라인에 병합할 수 있는 데이터의 로드 요청을 병합하여 처리한다.
- load 요청 후 그 결과를 사용하는 명령전까지 다른 명령들을 수행할 수 있다.
- store buffer
- 가능하면 하나의 캐시 라인에 병합할 수 있는 데이터의 쓰기 요청을 병합하여 처리한다.
- store 요청 후 그 결과를 사용하는 명령전까지 다른 명령들을 수행할 수 있다.
- 참고로 뒤에 소개하는 write buffer와는 다른 버퍼이다.
- 각 아키텍처 진영에서도 store buffer와 write buffer를 정확히 구분하여 표현하지 않는 경우도 있으므로 주의해야 한다.
- 예) ARM
- 코어가 하나인 UP(Uni Processor) 시스템에서는 Load/Store 버퍼 대신 Write Buffer를 사용하였다.
- 멀티 코어인 SMP 시스템에서는 block diagram 등에서 Store Buffer로 표기하지만 arm 레퍼런스 매뉴얼등 에서는 store buffer라고 하지 않고 통칭적으로 write buffer라고 표현한다.
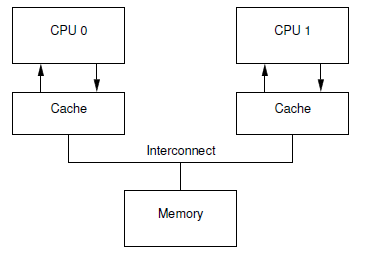
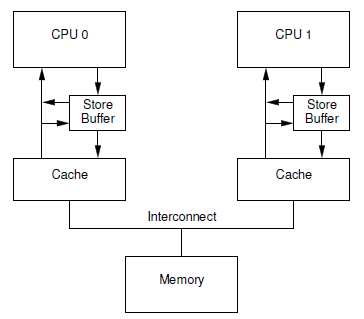
Store 버퍼 미적용 모델
다음 그림은 Store 버퍼 없이 cpu와 캐시가 직접 연결된 모습을 보여준다.
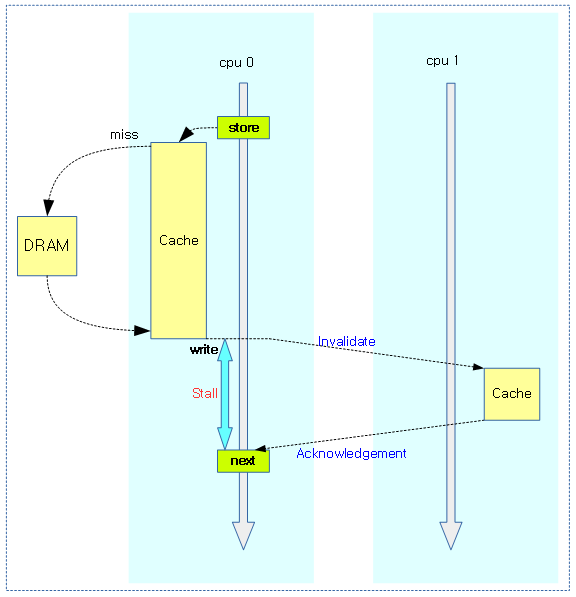
다음 그림과 같이 SMP 시스템에서 첫 store 명령을 사용한 후 다른 cpu의 캐시 연동(코히런스)을 위해 시간을 빼앗겨 대기하는 모습을 보여준다.
- 다른 cpu들의 L1 캐시 invalidate 연동을 위해 대기한다. (DRAM으로 부터 데이터를 가져온 후에도 캐시 동기화를 위해 추가 시간이 더 사용된다.)
- 보통 store 명령에 대해 결과를 알 필요가 없는 경우에는 다른 cpu의 정보 상태와 상관없이 무조건 기록 요청하고 그냥 다음 명령을 수행할 수 있는 메커니즘이 필요해졌다.
- store 명령 후에 곧바로 그 값을 읽어 사용해야 하는 경우 그 값을 읽기 전에 메모리 베리어를 사용하여 store와 load를 완전히 분리해야 오류가 발생하지 않는다.
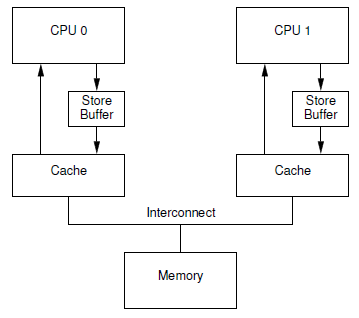
Store 버퍼 적용 모델
다음 그림은 Store 버퍼를 cpu와 캐시 사이에 추가한 모습을 보여준다.
- cpu의 파이프라인 중 마지막 writeback에 위치한다. (L1 캐시 직전)
- cpu0은 store 버퍼에 기록하도록 요청하고, 다음 명령이 그 결과를 사용하지 않는 경우 완료를 기다리지 않고 곧바로 수행한다.
위의 그림과 같이 연속적인 기록에서 훌륭한 성능을 발휘할 수 있으나, 다음 그림과 같이 저장 요청한 값을 곧바로 로드하여 사용하는 상황에서 또 다른 문제가 발생 할 수 있다.
- b의 값이 2가 아닌 1이 저장되는 문제를 발견할 수 있다.
- 처음 a, b 값은 0으로 초기화되어, a는 cpu1 캐시 라인에, b는 cpu 0 캐시라인에 담겨있다.
- (1) 레지스터 w0에 1 값을 담는다.
- (2) cpu 0에서 a에 대한 캐시 라인이 없음을 확인하고, a = 1 명령을 store buffer에 추가한다. (exclusive 오너십을 가진다)
- (3) cpu 1에 있는 a값 0을 읽어온다.
- (4) 읽어온 값 0에 1을 추가한다.
- (5) 값 1을 b에 저장한다.

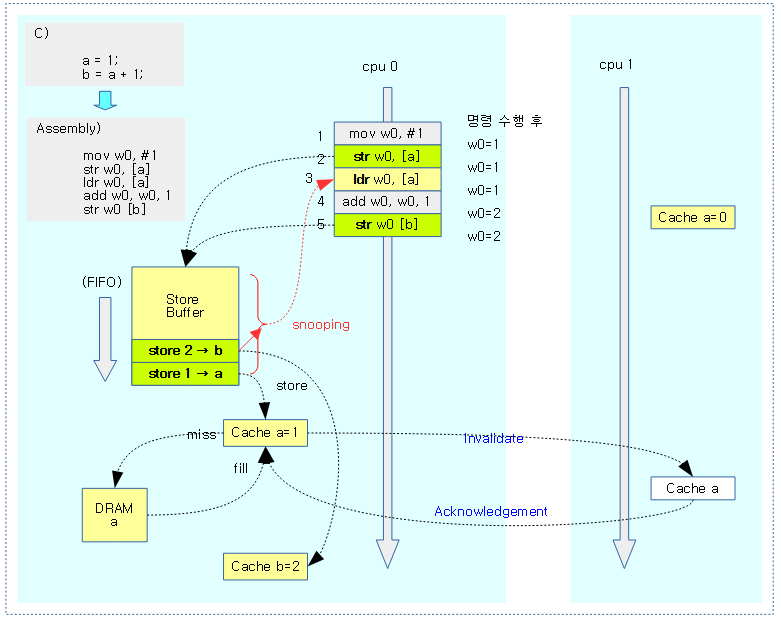
“Store Forwarding” 추가된 Store 버퍼 모델
위의 Store 버퍼 모델은 a의 사본이 캐시와 store 버퍼 양쪽에 있어서 문제가 되었다. 다음 그림은 이를 하드웨어에서 보강하여 로드할 때 Store 버퍼를 스누핑하여 사본이 존재하는지 확인하는 모델을 보여준다. 즉 store 후 load를 하면 store 버퍼에서 먼저 읽어오도록 하였다.
- x86-TSO 모델과 같다.
다음 그림은 store 후 연속된 load에서 store 버퍼를 snooping하여 올바른 값을 읽어오는 과정을 보여준다.
- 처음 a, b 값은 0으로 초기화되어, a는 cpu1 캐시 라인에, b는 cpu 0 캐시라인에 담겨있다.
- (1) 레지스터 w0에 1 값을 담는다.
- (2) cpu 0에서 a에 대한 캐시 라인이 없음을 확인하고, a = 1 명령을 store buffer에 추가한다. (exclusive 오너십을 가진다)
- (3) cpu 1에 있는 a값 0을 읽어오기 전에, store 버퍼를 snooping하여 a 값이 존재하므로 이 값 1을 읽어온다.
- (4) 읽어온 값 1에 1을 추가한다.
- (5) 값 2를 b에 저장한다.
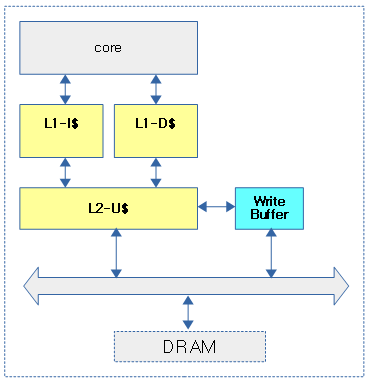
Write Buffer
write buffer 및 write combine buffer 라고 불리는 장치는 버스 사용을 최소화하여 메모리 전송 대역폭을 키우기 위해 적절히 캐시 라인 단위로 merge하여 액세스하는 기능등을 수행한다. store buffer가 거의 cpu 쪽에 위치한 것과 다르게 write buffer는 위치가 메모리 쪽에 가깝다.
- ARM의 경우
- 코어가 하나인 UP(Uni Processor) 시스템에서는 Write Buffer를 사용하였다.
- 코어가 여러 개인 SMP 시스템이 도입되면서 이러한 Write Buffer를 사용하지 않고, cpu 와 L1 캐시에 위치한 Store Buffer를 사용하는 것으로 바뀌었다. 블럭 다이어그램에서는 Store buffer라고 표시하고 있으나, 레퍼런스 매뉴얼 등에서는 그냥 통칭적으로 Write Buffer로 사용한다.
- 기존 Write Buffer 중 일부 기능이 Fill/Evict Buffer에서 사용되고 있다.
- 참고: Cortex A57 block diagram
{kind=link}
다음 그림은 Write Buffer의 위치를 보여준다.
invalidate queue
invalidate queue등은 요즘 아키텍처의 캐시 코히런시에 사용하는 SCU(Snoop Control Unit)등에서 사용된다.
메모리 베리어
1 개의 cpu에서 특정 값을 store 후 곧바로 load를 하는 경우에도 store 버퍼에서 스누핑하는 매커니즘을 통해 올바른 값을 가져올 수 있었다. 그러나 store와 load가 각각 다른 cpu에서 진행되는 경우에는 store 버퍼를 스누핑하는 것만으로는 올바른 데이터를 가져오는 것이 불가능해진다. 이 때에는 load와 store 사이에 메모리 베리어라는 소프트웨어적인 방법을 사용하여 해결해야 한다.
- 참고: Barriers | 문c
Cache 기본 동작
캐시 내부 구조
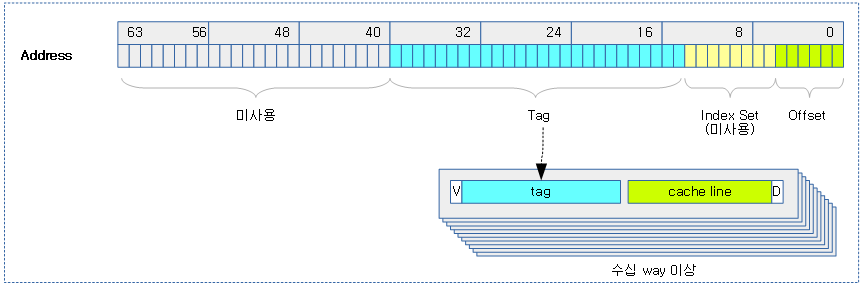
다음 그림과 같이 가장 단순한 캐시가 담고 있는 내부 정보를 보여준다.
- 캐시는 일반적으로 Die의 거의 절반에 가까울 정도로 많은 자리를 차지한다. 따라서 성능을 높이고자 무조건 용량을 키우지 않는다.
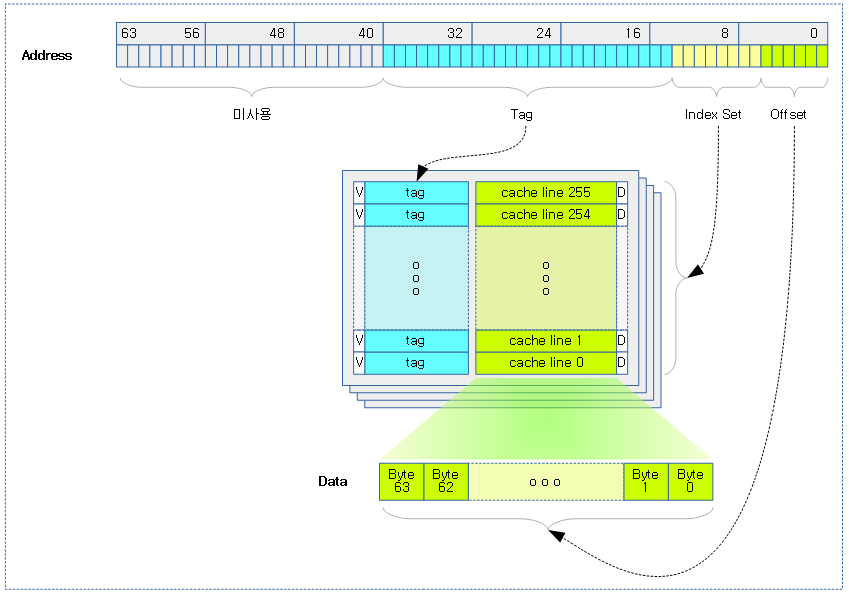
위의 그림에서 각 항목은 다음과 같다.
- Cache lines
- 실제 메모리 데이터의 사본이 보관되며, 메모리와 캐시 사이에 한 번의 전송과 저장에 사용되는 고정 사이즈이다.
- 메모리와의 전송 단위는 워드(4 바이트 기준) 단위 이며, 성능을 위해 한꺼번에 burst 전송한다. 크기 표현은 워드 또는 바이트이다.
- 캐시 라인 크기를 1 워드로 사용하면 캐시 데이터에 비해 태그 데이터가 너무 커 오버헤드가 커진다.
- 캐시 라인 크기는 보통 16, 32, 64, 128 바이트를 사용한다.
- ARMv8 및 ARMv9 아키텍처는 L1-I$, L1-D$ 및 L2-U$ 캐시들 대부분 64 바이트 고정 길이를 사용한다.
- 캐시 라인 크기는 보통 아키텍처 디자인 단계에서 결정된다.
- Index Set
- 캐시를 찾기 위해 사용되는 캐시 라인들에 대한 Y축 인덱스이다.
- PE(Process Entity)가 요청한 주소로 캐시를 찾을 때 주소의 일부를 Index Set으로 사용한다.
- 캐시 타입에 따라 Index Set의 지정에 다음과 같이 둘 중 하나로 동작하도록 설계된다.
- 가상 주소를 사용하여 Index Set을 지정하면 Virtually Indexed
- 물리 주소를 사용하여 Index Set을 지정하면 Physically Indexed
- 캐시 타입에 따라 Index Set의 지정에 다음과 같이 둘 중 하나로 동작하도록 설계된다.
- Offset
- Index Set에 의해 캐시 라인을 찾은 후 바이트를 지정하기 위한 캐시 라인의 X축 위치이다.
- Tag
- 캐시 라인을 보관할 때 실제 데이터의 주소(캐시 타입에 따라 가상 주소 또는 물리 주소)의 일부를 보관한다.
- 캐시 타입에 따라 태그는 다음과 같이 둘 중 하나로 동작하도록 설계된다.
- 가상 주소를 태그에 저장하면 Virtually Tagged
- 물리 주소를 태그에 저장하면 Physically Tagged
- 이렇게 보관된 태그 정보는 PE(Process Entity)가 요청하는 주소로 캐시를 찾을 때 동일한 Index Set 위치에 있는 1 개 이상(최대 way 수 만큼)의 캐시 태그들과 실제 데이터가 보관된 DRAM 주소(가상 주소 또는 물리 주소)를 비교하기 위해 사용된다.
- 태그 데이터에 32비트 또는 64비트 주소 전체를 보관하면 너무 커지므로, 물리 주소를 저장하는 태그 타입인 경우 주소 중 SoC가 실제 물리 메모리의 크기를 제한하여 사용하므로 사용하지 않는 앞부분의 비트들, 그리고 하위 비트들 중 Index Set 이하 비트들을 제외한 비트들만을 보관한다.
- 이렇게 제한한 비트 수로 인해 특정 아키텍처에서 VIPT 타입으로 사용된 L1 캐시 데이터에서 부족한 2비트로 인해 주소의 identification을 보증하지 못하는 현상이 벌어진다. 이로 인해 리눅스 커널의 소프트웨어 보완책인 캐시 컬러링을 사용한다.
- 최근 아키텍처에서는 Index Set의 윗 부분의 일부 비트들을 추가 보관하므로, 소프트웨어 보완책인 캐시 컬러링을 사용할 필요없다.
- Valid bit
- 1은 캐시가 유효한 상태임을 의미한다.
- 0은 캐시가 유효하지 않은 상태임을 의미한다.
- Dirty Bit
- 1은 캐시(사본)의 내용이 DRAM(원본)과 다르게 변경되었음을 의미한다.
- 0은 캐시(사본)의 내용이 DRAM(원본)과 다름 없이 동일함을 의미한다.
- 추가 비트들
- Parity Bit
- 최근 아키텍처의 경우 명령 캐시에서 Parity Bit를 추가하여 사용한다.
- ECC Bit
- 최근 아키텍처의 경우 주로 데이터 캐시 또는 통합(명령 + 데이터) 캐시에서 ECC Bit들을 추가하여 사용한다.
- MOESI 캐시 코히런스 프로토콜(MESI, MOESI 등)을 위해 추가 state 필드들을 사용한다.
- Parity Bit
- Way set-associative
- 캐시는 여러 면을 사용하여 운용할 수 있다.
- 몇 면(way)의 캐시들로 구성되어 있는지를 나타내므로 이숫자가 2, 3, 4와 같이 커진다는 것은 캐시 용량도 그 만큼 2배, 3배, 4배로 커진다.
PE(Process Entity)
오늘날 캐시를 검색하고 이용하는 장치는 cpu 뿐만 아니라 gpu, npu 및 기타 장치등이 될 수 있다.
Cache 타입
다음과 같이 3가지의 캐시 타입이 있다.
- Direct-mapped cache
- Fully associative cache
- 예) micro TLB 캐시등에 사용된다.
- N-way skewed associative cache
- 예) L0 MOP(Macro Operation) 캐시에 사용된다. (L1 명령 캐시 관리 분류에 속한다.)
- N-way-set-associative cache
- 예) 명령, 데이터 및 main TLB 캐시등에 사용된다.
참고
- cache_mapping | L님의 블로그
- cache example – Youtube
Fully Associative 캐시
여러 개의 Index Set을 운용하지 않고 1개의 캐시 라인을 다면으로 구성하는 방법이다.
- 장점으로 검색 시간을 줄일 수 있고, 단점으로 회로가 더 많이 구성되어야 하므로 추가 전력 소모가 필요하다.
- 아주 빠르게 동작해야 하는 TLB 캐시등에서 사용한다.
다음 그림은 Index Set을 운용하지 않는 Fully Associative 캐시가 구성된 모습을 보여준다.
캐시 구성 타입
캐시 구성 타입에는 크게 3 종류가 있고, 아키텍처에 따라 세부적으로 조금씩 다른 캐시 타입을 지원한다.
- VIVT (Virtually Indexed Virtually Tagged)
- VIPT (Virtually Indexed Physically Tagged)
- PIPT (Physically Indexed Physically Tagged)
참고: PIVT(Physically Indexed Virtually Tagged) 타입은 cpu 아키텍처에서 사용하지 않는 타입이다.
ARMv8 아키텍처의 경우 데이터 및 통합 캐시에는 PIPT 캐시 타입을 사용한다. 명령 캐시의 경우는 다음 중 하나를 선택하여 구성할 수 있다.
- VIPT (Virtually Indexed Physically Tagged)
- PIPT (Physically Indexed Physically Tagged)
- VPIPT (VMID aware Physically Indexed Physically tagged)
- AIVIVT (ASID-tagged Virtually Indexed Virtually Tagged)
- ARMv8 아키텍처에서 이 타입은 더 이상 지원하지 않아 커널에서도 제거되었다.
- 참고: arm64: cache: Remove support for ASID-tagged VIVT I-caches (2017, v4.12-rc1)
다음과 같이 캐시 인덱스와 태그를 관리하는 4가지 구성 타입의 캐시가 있다. 각각의 장단점을 알아본다.
1) VIVT(Virtually Indexed Virtually Tagged)
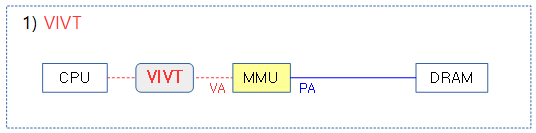
장점
- fast and low power
단점
- 가상주소가 태스크별로 겹치므로 태스크 전환 시마다 TLB 캐시를 flush 해야 한다.
- 최근 cpu에서 거의 사용하지 않는다.
ASID and VMID tagged VIVT instruction cache
ARMv7에서는 VIVT 캐시를 명령 캐시에 채용하고 약간 변형하여 사용하는 방법도 있다.
장점
- VMID, ASID를 추가하여 태스크 전환 시 TLB 캐시를 flush 하지 않고, 필요 시에만 flush를 하므로 유지보수가 줄어듦.
단점
- 다음과 같은 경우에 약간의 유지 보수를 필요로 한다.
- 명령이 바뀌는 경우
- MMU on/off에만 유지보수
- TTBRn, TTBCR, VTTBR, VTCR등이 바뀌는 경우
2) VIPT(Virtually Indexed Physically Tagged)
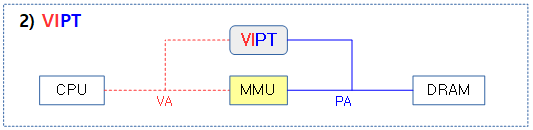
장점
- 가상주소가 겹쳐도 물리메모리가 태그되어 비교되므로 MMU 주소변환에서 자유롭다. (완전히 자유롭진 않다)
단점
- power overhead
- 데이터 캐시에 사용하면 캐시 컬러링을 사용해야 하므로 ARMv7 아키텍처 이후로 명령 캐시에만 사용한다.
IVIPT extension
ARMv7 이상의 아키텍처에 명령 캐시만 VIPT로 구현되는 확장 옵션이 있다.
장점
- 추가된 내용으로 유지보수가 간편해진다.
단점
- 하나의 커널이 여러 종류의 프로세서를 지원해야 하는 경우 프로세서간 호환을 위해서는 이 옵션을 사용하면 안된다.
3) PIPT(Physically Indexed Physically Tagged)
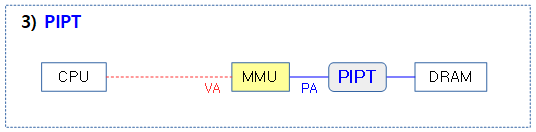
장점
- MMU 주소변환에서 완전히 자유롭다.(free synonym)
단점
- delay and power overhead
VPIPT(VMID-aware PIPT)
ARMv8.2 아키텍처에 추가된 타입으로 명령 캐시에 사용할 수 있다.
장점
- 추가된 내용으로 유지보수가 간편해진다.
단점
- 하나의 커널이 여러 종류의 프로세서를 지원해야 하는 경우 프로세서간 호환을 위해서는 이 옵션을 사용하면 안된다.
L1 캐시 + L2 캐시
대부분의 ARM 아키텍처에서 가장 많이 사용하는 캐시 조합 형태와 하이퍼 바이저를 사용하여 두 개의 MMU를 사용하는 상황도 알아본다.
L1:VIPT+PIPT, L2:PIPT
- cpu 마다 크기가 작은 L1 명령 캐시와 데이터 캐시를 배치하고, 크기가 큰 L2 캐시는 통합하여 메모리 직전에 배치한다.
- L1 명령 캐시에 중간 빠른 VIPT를 채용하고, L1 데이터 캐시와 L2 캐시에는 PIPT를 사용한다.
- ARMv8.2 아키텍처는 L1 명령 캐시에 VPIPT를 지원한다.
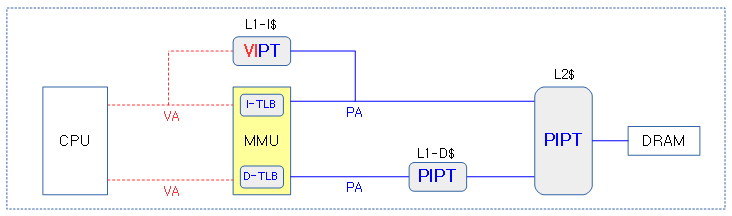
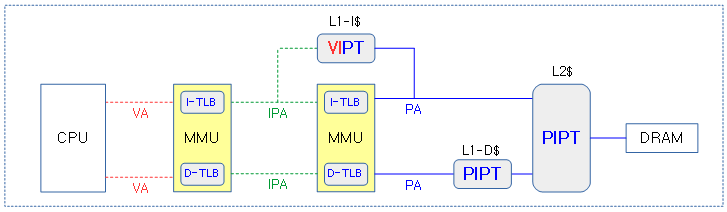
하이퍼바이저
다음 그림은 하이퍼바이저를 사용하여 MMU가 한 번 더 변환되는 상태의 주소 변환을 보여준다.
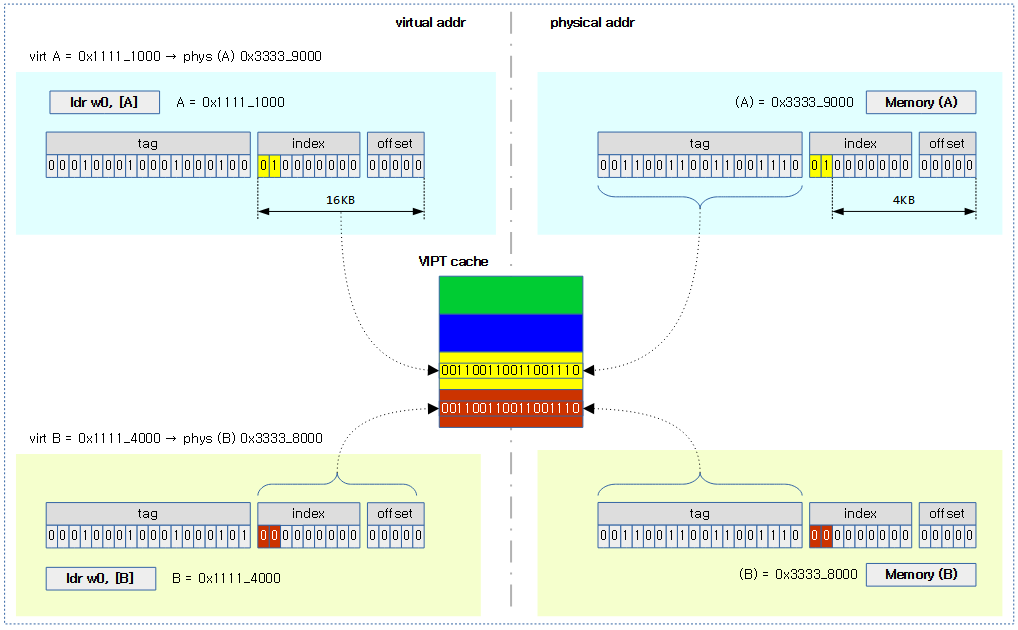
VIPT 캐시 컬러링
VIPT cache aliasing 또는 VIPT 페이지 컬러링이라고도 불린다. L1 데이터 캐시에 VIPT(캐시를 찾을 때의 인덱싱은 가상 주소를 사용하고, 저장된 태그에는 물리 주소를 저장) 타입을 사용하고, 캐시 단면의 사이즈가 가상 주소의 매핑 단위와 크기가 다를 때 캐시 미스 매칭 문제가 발생되므로 이를 해결하기 위해 사용되는 방법이다.
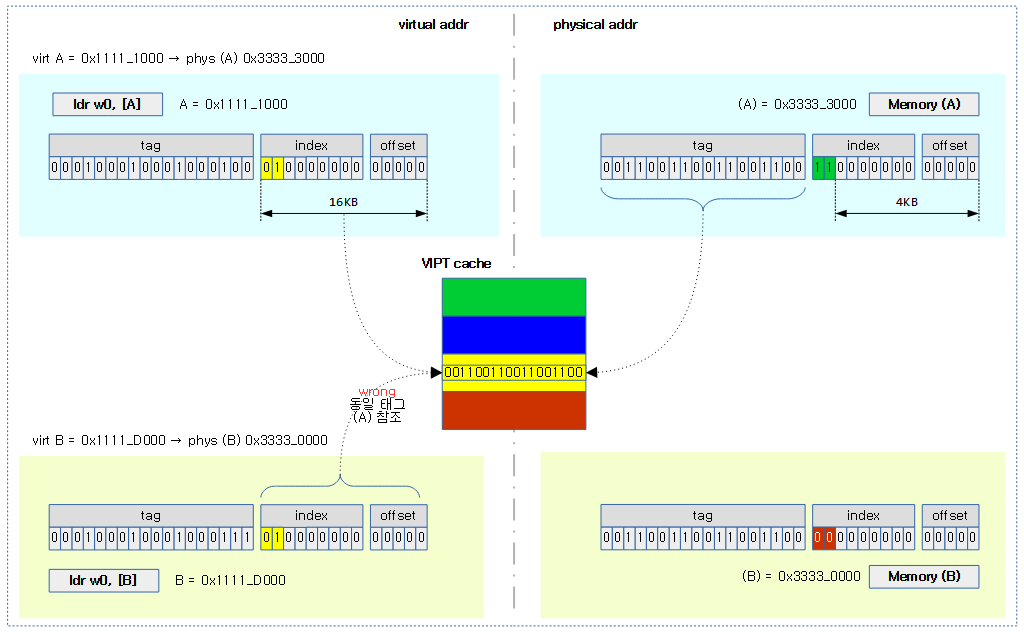
VIPT 타입 데이터 캐시 + 캐시 단면 사이즈 16K
메모리 매핑 단위인 페이지가 12 비트를 사용하는 사이즈이고, 캐시 단면이 14비트를 사용하는 16K 사이즈이다. 두 개 사이즈를 표현하는 비트 사이에 2 비트의 차이가 있다. 리눅스 커널에서 유저 메모리 할당을 할 때 free 메모리의 단편화를 방지하는 목적으로 연속된 가상 주소라도 낱개 단위로 4K 물리 페이지들을 할당한다. 그런데 VIPT 타입의 데이터 캐시를 사용하면 캐시 라인을 찾을 때에는 가상 주소를 사용하고, 캐시 라인에 태그를 저장하는 경우에는 물리 주소를 사용하여 추후 캐시 라인을 검색할 때 2 비트 짧은 태그 정보로 인해 중복된 태그로 인해 잘못된 캐시 라인을 액세스하는 문제가 발생한다.
- 현재 arm에서 캐시 컬러링은 ARMv6 SMP 아키텍처를 사용하는 경우에 발생한다.
- 유저 태스크에 사용되는 페이지들을 할당 받아 매핑 할 때 16K 단위로 align 하여 매핑하여야 한다.
- 참고: User virtual maps (brk) | 문c
VIPT 캐시 컬러링으로 해결
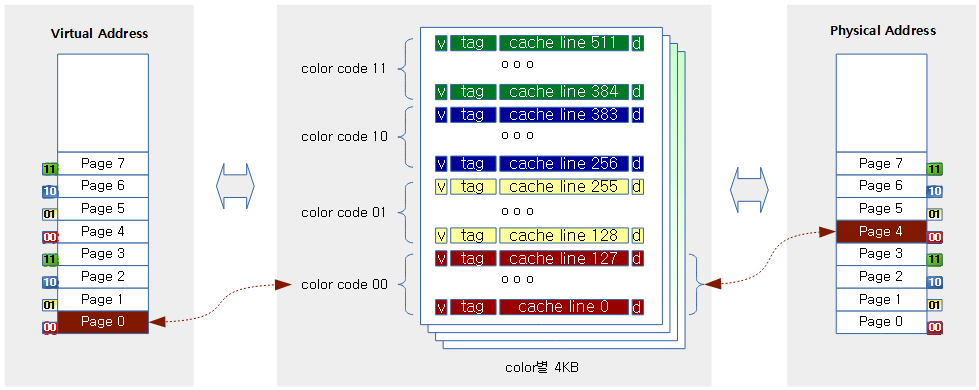
가상 주소 인덱스로 검색한 캐시에 실제 원하는 물리 주소 페이지의 데이터가 저장되었다는 보장을 할 수 있도록 캐시 컬러링 기법을 적용한다. 태그 정보에 기록되지 않는 2 비트에 대해 4 가지 color를(00, 01, 10, 11) 의미적으로 부여하여 가상 주소와 물리 주소가 서로 동일한 컬러로 매핑 연결되도록 한다. 각 컬러에서 16K 단위의 주소 정렬되지 않는 경우의 할당을 피하므로 가상 주소 영역의 낭비가 약간 발생한다.
다음 그림과 같이 가상 주소 페이지와 물리 주소 페이지를 연결하는 매핑시 같은 컬러(2 비트가 동일)를 사용하도록 하는 캐시 컬러링 기법을 적용한다.
다음 그림은 캐시 컬러링을 적용하지 않아 잘못된 캐시 라인을 읽어오는 모습을 보여준다.
다음 그림은 캐시 컬러링 기법을 통해 가상 주소 페이지와 물리 주소 페이지가 각 컬러에 맞게 매핑되어 정상적으로 동작하는 모습을 보여준다.
Cache – Policies
캐시 할당(Allocation) 정책
캐시 할당 정책 중 Read-Allocation은 거의 대부분의 아키텍처에서 기본 정책이라 특별히 기재를 하지 않아도 동작하는 정책이다. WA의 경우는 지정을 하는 경우에만 동작하는 정책이다.
1) WA(Write-Allocation)
쓰기 요청 시 캐시 라인이 할당된다. 즉, 프로세서에서 저장 명령을 실행하면 캐시 라인으로 버스트 읽기가 발생할 수 있다. 쓰기가 수행되기 전에 캐시 라인에 대한 데이터를 얻기위한 라인 필이 발생한다. 캐시는 캐시 라인 내의 단일 바이트에만 쓰는 경우에도 로드 가능한 최소 단위가 캐시 라인이 된다.
2) RA(Read-Allocation)
읽기 요청 시 캐시에서 읽기 실패(miss)한 경우 외부 메모리로 부터 할당된다.
캐시 기록(Write) 정책
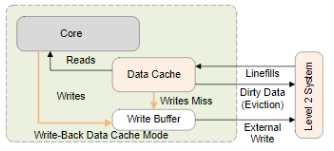
1) WB(Write-Back)
기록 요청 시 캐시만 갱신한다. 그리고 캐시 라인은 Dirty 상태가 된다. 캐시가 eviction이 발생되는 경우 또는 명확히 clean 명령이 내려질 때에만 외부 메모리에 기록하게 된다.
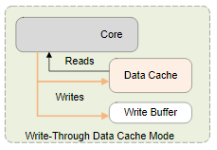
2) WT(Write-Through)
기록 요청 시 캐시와 외부 메모리 둘 다 갱신한다. 캐시 라인은 Dirty 상태가 되지 않는다..
캐시 교체(Replacement) 정책
- RR(Round Robin)
- 캐시 단면(way)별로 돌아가면서 캐시를 교체하는 정책이다.
- Random
- 캐시 단면(way)을 랜덤으로 선택하여 캐시를 교체하는 정책이다.
- LRU(Least Recently Used)
- cpu 아키텍처에서 가장 많이 사용하는 캐시 교체 정책으로 가장 사용 빈도가 가장 낮은 항목을 먼저 삭제한다.
- ARMv8 및 ARMv9 아키텍처에서도 LRU를 사용한다.
- FIFO(First In First Out)
- 전송에 사용되는 Write Buffer 등에서 가장 많이 사용되는 캐시 교체 정책으로 사용 빈도와 관련 없이 가장 먼저 진입한 항목을 먼저 삭제한다.
- 그 외 정책들은 다음을 참고한다.
- 참고: Cache replacement policies | wikipedia
캐시 Policies 상세
WT(Write-Through with no write-allocation)

WB(Write-Back with no write-allocation)

WBWA(Write-Back with Write-Allocation)

캐시 영역(inner vs outer)
다음 그림과 같이 inner 영역에 L1 및 L2 캐시가 같이 존재할 수도 있고, L1 캐시만 inner로 동작하는 경우도 있다.

Branch Predictors
- 1-bit Branch-Prediction
- 2-bit Branch-Prediction
- Correlating Branch Prediction
- Gshare
- Tournament Branch Predictor
- Branch Target Buffer
- Conditionally Executed Instructions
- Return Address Predictors
RAS(Return Address Stack)
- 스택과 같이 리턴 주소를 보관하고 있는 캐시
GShare Predictor
- BHT(Branch History Table): predictors로 구성.
- Predictor: branch 되는 주소로 인덱스 되는 2비트 saturating 카운터
- Fetch phase 에서 make prediction 방식 사용
- update corresponding predictor
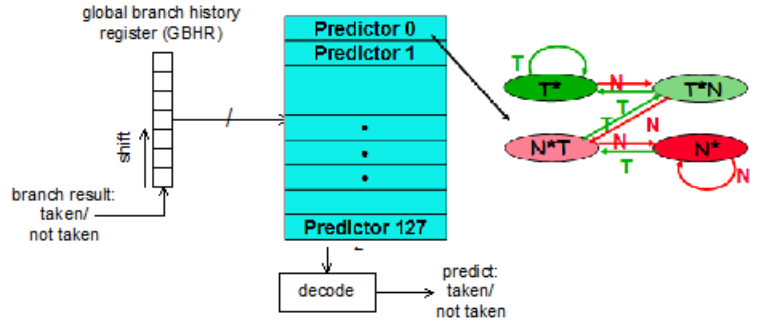
BTB(Branch Target Buffer)
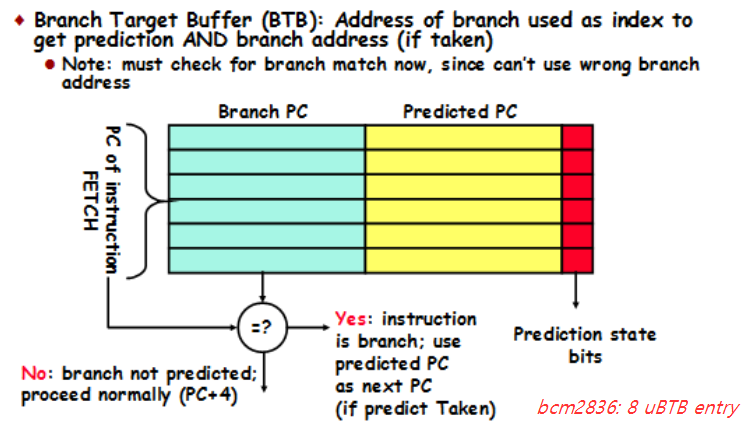
라즈베리파이2의 Branch Predictors
- 8 entry Return Address Stack
- 256 entry branch pattern history table
- 8 uBTB entry
- 4 BTIC(Branch Target Instrunction Cache for Pre Fetch Unit) entry
Cache Coherency
- Cache Coherency가 이루어지려면 모든 프로세스 코어와 버스 마스터간에 데이터를 access할 때 캐시에 있는 데이터가 다른 코어나 버스에게도 같은 상태를 보여줄 수 있어야 한다.
- 멀티 코어 또는 멀티 프로세스에서 Cache Coherent 동작을 하지 않을 때
- 각기 동작하는 스레드가 동시에 같은 share data를 access시 데이터 불일치 가능
- 각기 동작하는 스레드가 인접 메모리(같은 캐시 라인에 속한)를 access시 데이터 불일치 가능
- coherency 관리 방법
- 캐시 disable: 실제로는 성능 이유로 사용하지 않음
- S/W 관리: 보통 디바이스 드라이버에서 캐시 clean & invalidate를 사용하여 필요시 수행(DMA 등)
- H/W 관리: 가장 완벽한 솔루션(클러스터등에서는 조금 더 복잡하다)
-> 대부분의 ARM SMP 시스템에서는 코어끼리 통신은 H/W 관리를 사용하며, 외부 장치와의 연동에 사용하는 DMA등은 H/W가 지원하는 Cache Coherent 용 포트를 사용할 수도 있지만 대부분의 경우 S/W 관리 방식을 사용한다.
Coherency mechanisms
- Directory-based
- Snooping
- Snarfing
Coherency 프로토콜
아키텍처마다 다양한 캐시 coherency 프로토콜들이 사용되고 있다. 다음은 ARM 및 ARM64 시스템에서 대표적으로 사용되고 있는 프로토콜들이다.
- MSI
- MESI
- MOESI
- ARMv8 아키텍처의 경우 MESI 또는 MOESI 프로토콜을 사용한다.
- 일부 아키텍처의 경우 L1 캐시에 MESI를 사용하고 L2 캐시에만 MOESI를 사용하는 경우도 있다.
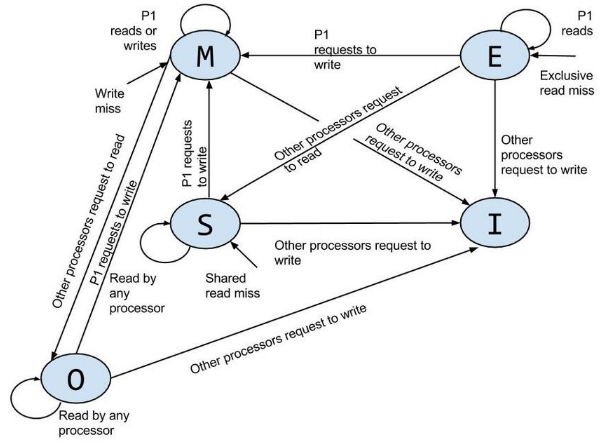
다음 그림은 MSI, MESI, MOESI 3 가지 cache coherency 프로토콜을 보여준다.
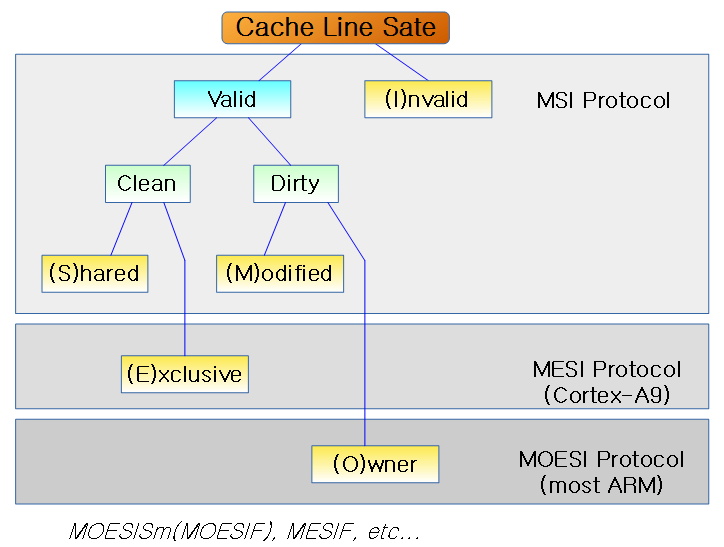
MOESI protocol
캐시라인에 3비트를 사용하여 캐시 상태를 표현한다.
- Valid bit
- Valid(1) 상태와 Invalid(0) 상태를 구분한다.
- Modified bit
- Modified(1) 상태와 Not-Modified(0) 상태를 구분한다.
- Shared bit
- Shared(1) 상태와 Not-Shared(0) 상태를 구분한다.
위의 3비트를 조합하여 5가지의 상태를 나타낸다.
- Modified
- 유일한 캐시 라인에서 데이터가 변경된 상태이다.
- Valid(1) + Modified(1) + Not-Shared(0)
- Owner
- 복제된 캐시 라인에서 데이터가 변경된 상태이고, 독점으로 수정할 수 있는 권한을 가진 상태이다.
- 변경이 가해질 때마다 다른 cpu에 있는 캐시들도 전파되어 변경시킨다.
- Valid(1) + Modifed(1) + Shared(0)
- Exclusive
- 유일 또는 복제된 캐시 라인에서 데이터는 변경되지 않은 클린 상태이다.
- Valid(1) + Not-Modified(0) + Not-Shared(0)
- Shared
- 복제된 캐시 라인에서 데이터는 변경되지 않은 클린 상태이다. 수정 권한은 없는 상태이다.
- Valid(1) + Not-Modified(0) + Shared(1)
- Invalid
- Invalid(0) + 나머지 두 비트와 상관없다.
다음 그림은 MOESI의 비트 상태를 보여주는 그림이다.
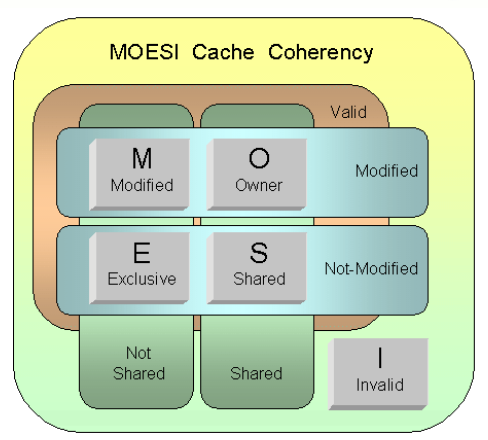
다음 그림은 MOESI 상태 다이어그램을 보여준다.
- Exclusive 상태를 위주로 상태가 변화되는 모습을 알아본다.
- P1(CPU 1)이 처음 데이터를 읽어들였을 때 P1 캐시는 Exclusive이다.
- Exclusive 상태에서 P1이 기록할 때 P1 캐시는 Modified 상태로 변경된다.
- Exclusive 상태에서 다른 CPU가 읽기 요청할 때 P1 캐시는 Shared 상태로 변경된다.
- 다른 CPU의 캐시 상태 역시 Shared 상태로 변경된다.
- Exclusive 상태에서 다른 CPU가 쓰기 요청할 때 P1 캐시는 Invalidate 상태로 변경된다.
- 다른 CPU의 캐시 상태는 Modified 상태로 변경된다.
다음 그림은 MOESI 프로토콜을 사용하는 두 cpu에 연결된 L1 캐시 상태 변화를 보여준다.
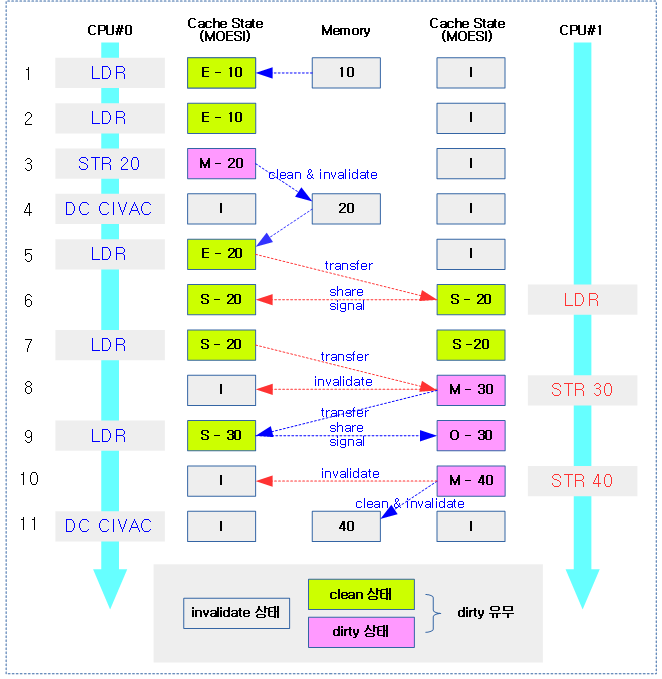
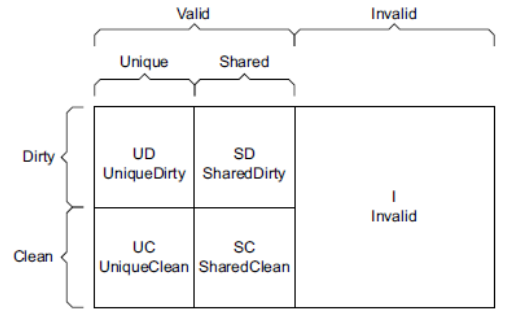
ARM ACE protocol vs MOESI
MOESI coherency 프로토콜과 ARM ACE protocol에서 표현하는 명칭은 다르지만 동일한 동작을 수행한다.
- Modified
- Valid + Unique + Dirty
- Owner
- Valid + Shared + Dirty
- Exclusive
- Valid + Unique + Clean
- Shared
- Valid + Shared + Clean
- Invalid
- Invalid + 나머지 상태와 상관없다.
다음 ARM Ace protocol을 MOESI coherency 프로토콜과 비교하면 다음과 같다.
- 윗줄 2개가 왼쪽부터 순서대로 Modified, Owner
- 아랫줄 2개가 왼쪽부터 순서대로 Exclusive, Shared
- 가장 우측 Invalid
ARM H/W Cache Coherency 메카니즘
- SCU(Snoop Control Unit):
- AMBA AXI 3에서 소개
- ARM 각 코어의 L1-Data cache 끼리 coherency 가능
- ARM에서 L1-Instruction cache는 s/w 관리가 필요함 (self-modifing-code)
- 1개의 클러스터 내 inner shareable 영역만 가능
- MSI 프로토콜 기반
- ACP(Accelerator Coherency Port)를 사용한 H/W 주변장치도 cache coherent 동작 사용 가능
- ACP를 사용하지 않는 디바이스들은 cache coherent를 위해 s/w 관리가 필요함(DMA).
- AMBA 4 with ACE(AXI Coherency Extensions)
- AMBA AXI 4에서 소개
- 2개 이상의 클러스터에서도 cache coherent 가능
- MOESI 프로토콜 기반
- 멀티 코어 뿐 아니라 ACE Lite를 사용한 디바이스의 cache coherent 동작 사용 가능
- SCU 버스를 사용하지 않고 AMBA 4 버스를 확장시켜 5개의 AXI 채널 + 3개의 ACE 전용 채널을 사용
- AMBA 5 with CHI
- AMBA AXI 5에서 소개
- 대역폭이 큰 초고속 버스를 사용
- 그 외 AMBA 4 with ACE와 유사
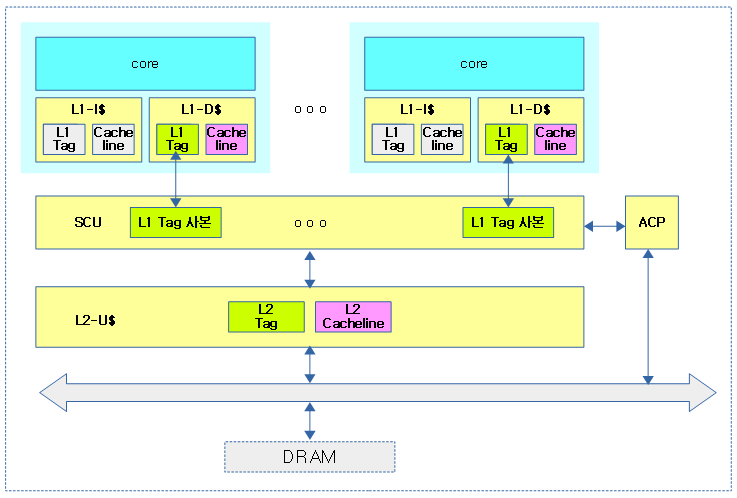
멀티 클러스터에서의 ACE
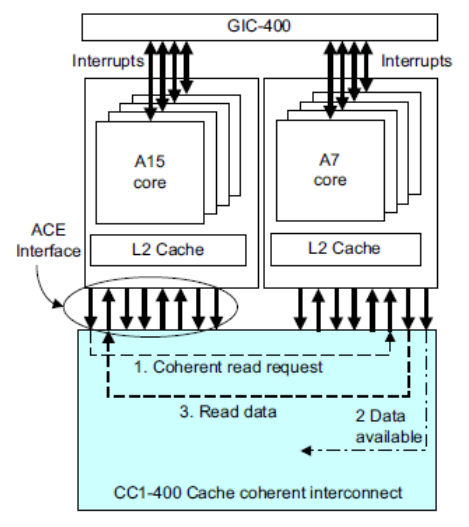
다음 그림은 SCU(Snoop Control Unit)을 통해 캐시 코히런시가 동작하는 모습을 보여준다.
캐시 Operation
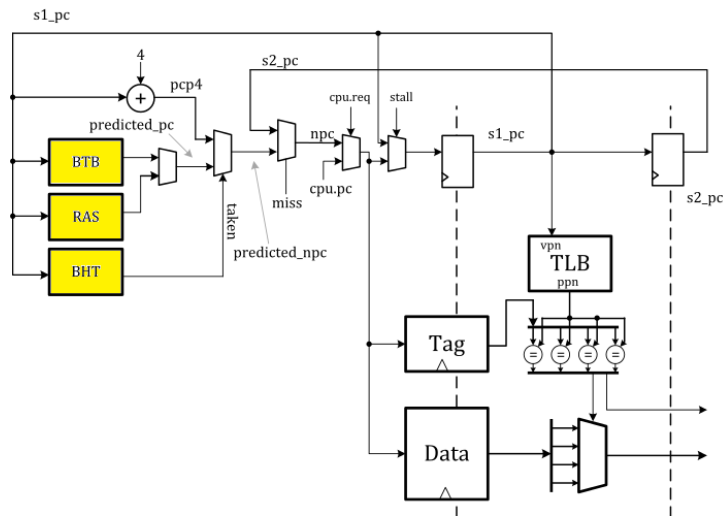
ARM Cache Identification
- CTR(Cache Type Register)를 읽어서 Level 1 명령어 캐시의 정책(VIPT)과 cache line을 알아온다.
- CLIDR(Cache Level ID Register)를 통해 7개의 캐시 타입필드를 읽는다. 각 단계의 캐시의 종류(I, D, I+D)를 알아내고 LoU 및 LoC를 알아온다.
- CCSSR(Cache Sizae Selection Register)를 사용해 요청받은 캐시레벨을 선택하고 캐시 종류를 선택한 후 CCSIDR(Cache Size ID Register)를 읽어 캐시 정보를 획득한다.
- 참고:
- ARM 시스템 주요 레지스터 | 문c
- ARM64 시스템 주요 레지스터 | 문c
계층별 캐시
ARMv8 및 ARMv9 캐시는 레벨별로 다음과 같이 구성된다.
- L1
- 명령 캐시와 데이터 캐시가 분리되어 있는 하버드 타입의 캐시이다.
- L2
- 통합 캐시로 구성된다.
- L3
- 통합 캐시로 구성되며 옵션이다.
포함 관계
- L1 명령어 캐시 및 L2 통합 캐시간에는 약하게 포함되어 있다.
- L2 캐시에서 invalidate 하여도 L1 캐시는 invalidate 하지 않는다.
- L1 데이터 캐시에 존재하는 데이터는 L2 캐시에 없을 수도 있다.
- L1 데이터 캐시 및 L2 통합 캐시간에는 강하게 포함되어 있다.
- L2 캐시에서 invalidate 하면 L1 데이터 캐시도 invalidate 된다.
- L1 데이터 캐시에 존재하는 데이터는 L2 캐시에도 존재한다.
캐시 조작 명령 Flush
Flush라는 용어는 여러 아키텍처에서 다음 3가지 항목과 동일하게 혼용되어 사용되어 구현 의도를 파악하기 어렵게 만든다. 따라서 ARM 매뉴얼에서는 flush라는 용어를 사용하지 않고 다음 아래와 같은 표기를 사용한다.
- Clean
- 현재 레벨의 캐시 라인을 다음 레벨의 캐시나 메모리에 기록한다.
- Invalidate
- 현재 레벨의 캐시 라인을 비운다.
- Clean & Invalidate
- 현재 레벨의 캐시 라인을 다음 레벨의 캐시나 메모리에 기록한 후 비운다.
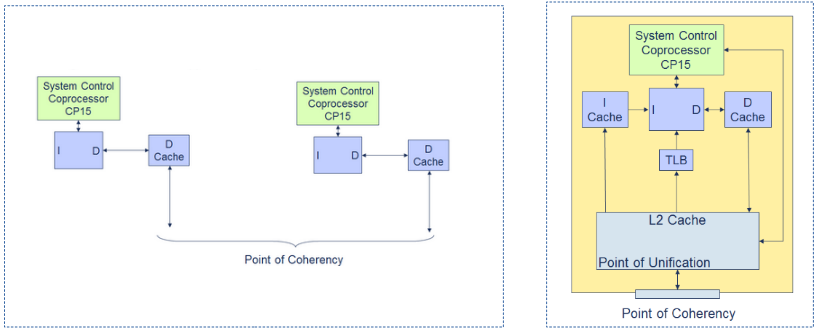
PoC(Point of Coherency)
특정한 VA(MVA)를 위해 PoC는 접근하는 모든 agent(cores, bus(dma, mmio))들이 메모리 위치의 동일한 사본 값을 access할 수 있게 보장하는 포인트이다.
- PoC는 대부분 BUS에 연결된 DRAM이 위치한 곳이다. 이 위치에서 Core, DSP 및 DMA 엔진 등이 같은 데이터를 access할 수 있도록 보장한다.
- ARM v7 아키텍처는 최대 7단계 까지의 캐시를 지원하며 PoC 명령으로 처리할 수 있는 캐시 레벨은 다음 레지스터에 기록되어 있다.
- CLIDR 레지스터의 LoC(Level of Coherency) 필드에 기록되어 있다.
- 예) rpi2에서 사용된 BCM2709 SoC에는 LoC(PoC를 캐시 구현 레벨로 표현) 값이 2(L2 캐시)이다. 즉 PoC 명령을 사용 시 SoC가 캐시 레벨 2까지 처리한다.
- Cache Coherency H/W Unit
- SMP 시스템을 위해 Data 캐시들 끼리의 coherent를 보장하게 하는 하드웨어 장치이다.
- Data 캐시와 메모리의 coherent는 자동으로 하지 않고 PoC 명령 등을 통해 수동으로 수행한다.
- ARM사는 Cache Coherency를 하드웨어로 보장하게 하는 장치를 IP block으로 제공한다. (SCU, Corelink series… 등).
- 보통 SoC 제조사들은 ARM사의 IP block 중 하나를 선택하여 cache coherent 장치를 구성하는데 일부 SoC 제조사는 자사가 가지고 있는 cache coherency 장치를 사용하는 경우도 있다.
- Cache Coherency H/W 장치를 사용하는 cpu-캐시, GPU, ACP(Accelerator Coherency Port) 및 ACP-lite 에 연결된 장치들은 특별히 PoC 관련 명령을 수행하지 않아도 하드웨어가 지원하는 기능에 의해 자동적으로 coherency를 보장하게 한다. 그러나 이러한 cache coherent DMA(ACP, ACP-Lite 등) 하드웨어 장치를 사용하지 않는 구형 DMA 디바이스 등에서는 드라이버를 구현할 때에 반드시 PoC 명령 등을 사용하여야 한다.
- SMP 시스템을 위해 Data 캐시들 끼리의 coherent를 보장하게 하는 하드웨어 장치이다.
- 추가 캐시 컨트롤러
- CP15를 통해 처리하지 못하는 캐시 컨트롤러에 대해서는 공급사가 관련 캐시 명령들을 제공하여야 한다.
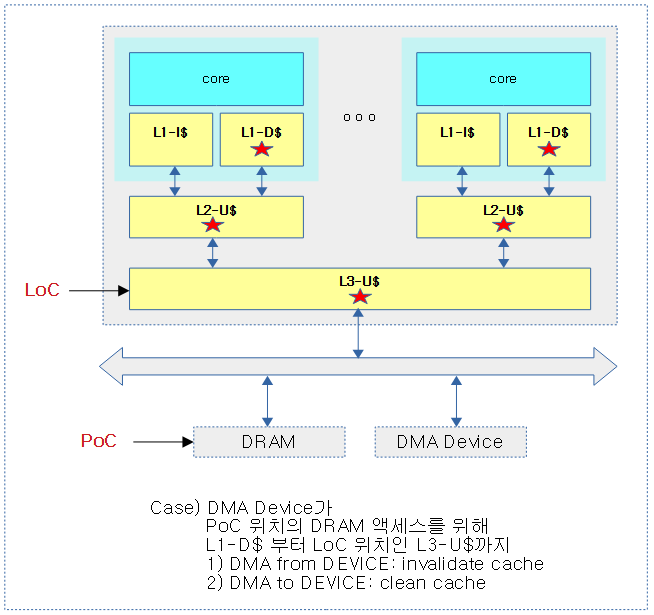
LoC(Level of Coherency for the cache hierarchy)
PoC를 위해 cache hierarchical을 지원하는 캐시 구성에서 core에 가까운 첫 레벨의 캐시부터 LoC가 지정한 캐시 레벨까지 캐시 조작 명령을 수행해야 하는 레벨을 가리킨다.
- 예) rpi2: PoC=DRAM, LoC=2(L2)
- L1 ~ L2 캐시까지 cache operation 명령을 수행한다.
다음 그림은 DMA 디바이스를 위해 LoC까지 캐시 작업을 수행하는 모습을 보여준다.
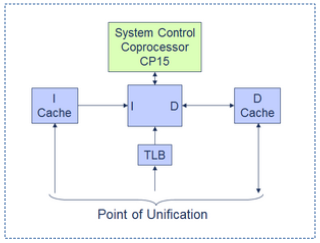
PoU(Point of Unification)
Process에서의 PoU는 instruction 캐시와 data 캐시 그리고 TLB 캐시가 동일한 데이터를 바라보는 것을 보장하는 포인트이다.
- ARM v7 아키텍처는 최대 7단계 까지의 캐시를 지원하며 PoU 명령으로 처리할 수 있는 캐시 레벨은 다음 레지스터에 기록되어 있다. 보통 통합 캐시를 지정하거나 DRAM 메모리 위치가 된다.
- CLIDR 레지스터의 LoUU(Level of Unification Uniprocessor) 및 LoUIS(Level of Unification Inner Shareable) 필드에 기록되어 있다.
- 용도
- Self-modifing 코드
- ARM에서 명령과 데이터 캐시가 분리된 하버드 캐시를 사용하는 캐시 레벨들에 대해서는 instruction 코드를 변경한 후 재 사용하기 위해 h/w가 자동으로 cache coherency를 처리하지 못하므로 이러한 캐시 영역은 PoU 관련 명령을 사용하여 직접 처리해야 한다.
- LoU(LoUU|LoUIS) 까지의 data 캐시를 먼저 clean한 후, 다시 instruction 캐시를 invalidate 하여 data 캐시와 instruction 캐시의 coherency를 PoU 에서 보장한다.
- Self-modifing 코드
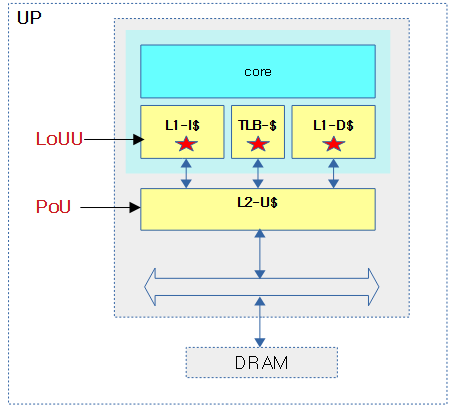
LoUU(Level of Unification Uniprocessor for the cache hierachy)
UP 시스템에서 PoU를 위해 cache hierarchical을 지원하는 캐시 구성에서 core에 가까운 첫 레벨의 캐시부터 LoUU가 지정한 캐시 레벨까지 캐시 조작 명령을 수행하여 PoU 위치에서 데이터 캐시와 instruction 캐시의 coherency를 보장하게 한다.
- 예) rpi2: PoU=L2, LoUU=1(L2 통합 캐시)
- L1 캐시까지 cache operation 명령을 수행한다.
LoUIS(Level of Unification Inner Shareable for the cache hierarchy)
SMP 에서만 구현되며 PoU를 위해 cache hierachical을 지원하는 캐시 구성에서 Inner shareable domain을 위해 core에 가까운 첫 레벨의 캐시부터 LoUIS가 지정한 캐시 레벨까지 캐시 조작 명령을 수행하여 PoU 위치에서 데이터 캐시와 instruction 캐시의 coherency를 보장하게 한다.
- 예) rpi2: PoU=L2, LoUIS=1(L2 통합 캐시)
- L1 캐시까지 cache operation 명령을 수행한다.
다음 그림은 SMP 시스템에서 self-modification code 적용을 위해 LoUIS까지 캐시 작업을 수행하는 모습을 보여준다.

다음 그림은 UP 시스템에서 LoUU와 PoU의 위치를 보여준다.
PoP(Point of Persistence)
Process에서의 PoP는 메모리 시스템에서 시스템 전원이 제거될 때 메모리에 대한 쓰기가 유지되고 메모리의 영향을 받는 위치에 전원이 복구될 때 안정적으로 복구되는 일관성 지점(Point of Coherency)으로 보통 비휘발성 메모리 또는 storage-class 메모리가 위치한다.
PoC vs PoU
- 메모리 계층 구조의 한 지점을 프로세서에 구애받지 않고 참조할 수 있는 방법을 마련하기 위한 것이 PoU와 PoC의 기본 개념이다.
- PoU는 메모리 시스템에서 이 코어의 데이터, 명령어 및 테이블 워크(MMU) 인터페이스가 동일한 위치의 복사본을 보는 지점이다.
- PoC는 이 코어와 다른 마스터(예: DMA)가 동일한 복사본을 보는 지점이다.
- 왜 그냥 L2와 L3라고 하지 않고 PoU와 PoC를 사용할까? 모든 프로세서의 캐시 계층 구조가 동일하지 않기 때문이다. PoU/PoC를 사용하면 캐시의 계층 구조나 캐시 레벨을 정확히 알 필요 없이 프로세서에 무엇을 하려는지 알 수 있다.
- 참고: What is the difference between PoC and PoU for Cortex-A7 MPCore? | ARM community
ARM64 (AArch64) Cache 조작 명령
캐시 조작 명령들은 1개 코어에 영향을 주거나, IS(Inner Shareable) 영역 들의 코어 또는 ALL 처럼 모든 코어들에 broadcast 하여 영향을 줄 수 있다. 또한 가상 주소로 지정한 경우엔 해당 가상 주소가 공유 페이지인 경우에 broadcast 한다.
데이터 캐시
- DC CISW
- Clean and invalidate by Set/Way
- 현재 코어의 Set/Way를 지정하여 데이터 캐시의 clean & invalidate
- DC CIVAC
- Clean and Invalidate by Virtual Address to Point of Coherency
- 지정한 주소의 데이터 캐시를 PoC까지 clean & invalidate (주소가 공유 페이지인 경우 broadcast)
- DC CSW
- Clean by Set/Way
- 현재 코어의 Set/Way를 지정하여 데이터 캐시의 clean
- DC CVAC
- Clean by Virtual Address to Point of Coherency
- 지정한 주소의 데이터 캐시를 PoC까지 clean (주소가 공유 페이지인 경우 broadcast)
- DC CVAU
- Clean by Virtual Address to Point of Unification
- 지정한 주소의 데이터 캐시를 PoU까지 clean (주소가 공유 페이지인 경우 broadcast)
- DC CVAP
- Clean by Virtual Address to Point of Persistence
- 지정한 주소의 데이터 캐시를 PoP까지 clean (주소가 공유 페이지인 경우 broadcast)
- DC ISW
- Invalidate by Set/Way
- 현재 코어의 Set/Way를 지정하여 데이터 캐시의 invalidate
- DC IVAC
- Invalidate by Virtual Address, to Point of Coherency
- 지정한 주소의 데이터 캐시를 PoC까지 invalidate (주소가 공유 페이지인 경우 broadcast)
- DC ZVA
- Cache zero by Virtual Address
- 지정한 주소의 데이터 캐시라인을 zero(0)로 채운다.
명령 캐시
- IC IALLUIS
- Invalidate all, to Point of Unification, Inner Sharable
- Inner share 코어들의 모든 명령 캐시를 PoU까지 invalidate
- IC IALLU
- Invalidate all, to Point of Unification
- 현재 코어의 모든 명령 캐시를 PoU까지 invalidate
- IC IVAU
- Invalidate by Virtual Address to Point of Unification
- 지정한 주소의 명령 캐시를 PoU까지 invalidate (주소가 공유 페이지인 경우 broadcast)
ARM32 캐시 조작 명령
ARMv7 아키텍처에는 CP15 레지스터를 사용하여 PoC를 지원하는 명령이 다음과 같이 3가지가 지원되며 이 명령을 사용하여 PoC 에서 Coherency를 만족하게 할 수 있다.
- DCIMVAC (Data Cache Invalidate MVA to poC)
- PoC 까지 하나의 Data 캐시 라인을 버림으로서 PoC 위치에서 동일한 메모리 데이터의 사본을 access할 수 있다.
- DCCMVAC (Data Cache Clean VMA to poC)
- PoC 까지 하나의 Data 캐시 라인을 저장하게 함으로서 PoC 위치에서 동일한 메모리 데이터의 사본을 access할 수 있다.
- DCCIMVAC(Data Cache Clean & Invalidate VMA to poC)
- PoC 까지 하나의 Data 캐시 라인을 저장하게 하고 버림으로서 PoC 위치에서 동일한 메모리 데이터의 사본을 access할 수 있다.
ARMv7 아키텍처에서는 CP15 레지스터를 사용하여 PoU를 지원하는 명령이 다음과 같이 4가지가 제공된다.
- DCCMVAU(Data Cache Clean MVA to poU)
- PoU 직전까지 dirty된 하나의 data 캐시 라인을 PoU 위치로 기록하게 한다.
- ICIALLUIS(Instruction Cache Invalidate ALL to poU Inner Shareable)
- Inner shareable 캐시 중 PoU 직전 캐시까지 전체 instruction 캐시를 비운다.
- ICIALLU(Instruction Cache Invalidate ALL to poU)
- PoU 직전까지 전체 instruction 캐시를 비운다.
- ICIMVAU(Instruction Cache Invalidate VMA to poU)
- PoU 직전까지 하나의 instruction 캐시 라인을 비운다.
참고
- CPU cache | wikipedia
- Cache (computing) | wikipedia
- 캐시가 동작하는 아주 구체적인 원리 (2019) | 박성범
- cache_mapping | L님의 블로그
- cache example – Youtube
- Stale data, or how we (mis-)manage modern caches (2016) | ARM – 다운로드 pdf
- ARM’s processor lines (2018) | Dezső Sima – 다운로드 pdf
- Cache Attacks on ARM | Graz, University Of Technology – 다운로드 pdf
- Memory in Embedded Systems | Tajana Simunic Rosing – 다운로드 pdf
- Meltdown and Spectre | Redhat – 다운로드 pdf
항상 좋은 글 감사합니다 🙂
이름이 멋지시네요.
응원 감사합니다. 좋은 하루 보내세요.