<kernel v5.4>
RCU(Read Copy Update) -3- (RCU threads)
다음과 같은 rcu 커널 스레드들을 알아본다.
- rcu와 관련된 커널 스레드
- “rcu_preempt”
- cb용 gp 관리 커널 스레드
- rcu_gp_kthread()
- cb용 gp 관리 커널 스레드
- “rcuog/N”
- no-cb용 gp 관리 커널 스레드
- rcu_nocb_gp_kthread()
- no-cb용 gp 관리 커널 스레드
- “rcuop/N”
- no-cb용 콜백 처리 커널 스레드
- rcu_nocb_cb_kthread()
- no-cb용 콜백 처리 커널 스레드
- “rcub/N”
- priority boost 커널 스레드
- rcu_boost_kthread()
- priority boost 커널 스레드
- “rcuc/N”
- cb용 콜백 처리 커널 스레드
- rcu_cpu_kthread()
- cb용 콜백 처리 커널 스레드
- “rcu_tasks_kthread”
- srcu API를 사용하고 타스크 기반에서 동작하는 rcu tasks 커널 스레드 (srcu와 관련된 코드분석은 생략)
- rcu_tasks_kthread()
- srcu API를 사용하고 타스크 기반에서 동작하는 rcu tasks 커널 스레드 (srcu와 관련된 코드분석은 생략)
- “rcu_gp”
- synchronize_rcu_expedited() API에서 급행 gp 동기화 및 srcu에서 사용되는 워커 스레드
- wait_rcu_exp_gp()
- srcu_invoke_callbacks()
- synchronize_rcu_expedited() API에서 급행 gp 동기화 및 srcu에서 사용되는 워커 스레드
- “rcu_par_gp”
- 급행 gp에서 선택된 노드들을 기다릴 때 사용되는 워커 스레드
- sync_rcu_exp_select_node_cpus()
- 급행 gp에서 선택된 노드들을 기다릴 때 사용되는 워커 스레드
- “rcu_preempt”
커널 v5.4.-rc1에서 많은 cpu 시스템에서 no-cb 처리관련한 OOM을 개선하기 위해 leader/follow group 기반의 no-cb 구조를 탈피한 nocb gp kthread룰 도입하였다.
- 참고:
RCU-Tasks 서브시스템
rcu-tasks 서브시스템 – call_rcu_tasks() API 함수를 활용하는 커널 코드는 일부((rorture 테스트 및 bpf)를 제외하고 현재까지 극히 드물다.
RCU 관련 스레드 생성
rcu 커널 스레드의 우선 순위
kernel/rcu/tree.c
/* rcuc/rcub kthread realtime priority */ static int kthread_prio = CONFIG_RCU_KTHREAD_PRIO; module_param(kthread_prio, int, 0644);
SCHED_FIFO 정책을 사용하는 RCU 커널 스레드를 위한 우선 순위이다.
- 디폴트 값
- 가장 빠른 우선 순위(0 ~ 2)를 사용
- CONFIG_RCU_BOOST 커널 옵션이 사용되는 경우에는 0번을 비워둔다.
- CONFIG_RCU_TORTURE_TEST 커널 옵션을 사용한 경우 1번을 비워둔다.
- 사용자 설정
- 0 ~ 99까지이다.
다음은 kthread_prio 우선순위가 디폴트 0을 출력한 모습이다.
<pre “>$ cat /sys/module/rcutree/parameters/kthread_prio 0
다음 그림은 rcu 관련 스레드들을 생성시키는 함수들간의 호출 관계를 보여준다.
- srcu 및 워커 스레드는 제외

rcu_spawn_gp_kthread()
kernel/rcu/tree.c
/* * Spawn the kthreads that handle RCU's grace periods. */
static int __init rcu_spawn_gp_kthread(void)
{
unsigned long flags;
int kthread_prio_in = kthread_prio;
struct rcu_node *rnp;
struct sched_param sp;
struct task_struct *t;
/* Force priority into range. */
if (IS_ENABLED(CONFIG_RCU_BOOST) && kthread_prio < 2
&& IS_BUILTIN(CONFIG_RCU_TORTURE_TEST))
kthread_prio = 2;
else if (IS_ENABLED(CONFIG_RCU_BOOST) && kthread_prio < 1)
kthread_prio = 1;
else if (kthread_prio < 0)
kthread_prio = 0;
else if (kthread_prio > 99)
kthread_prio = 99;
if (kthread_prio != kthread_prio_in)
pr_alert("rcu_spawn_gp_kthread(): Limited prio to %d from %d\n",
kthread_prio, kthread_prio_in);
rcu_scheduler_fully_active = 1;
t = kthread_create(rcu_gp_kthread, NULL, "%s", rcu_state.name);
if (WARN_ONCE(IS_ERR(t), "%s: Could not start grace-period kthread, OOM is now expected behavior\n", __func__))
return 0;
if (kthread_prio) {
sp.sched_priority = kthread_prio;
sched_setscheduler_nocheck(t, SCHED_FIFO, &sp);
}
rnp = rcu_get_root();
raw_spin_lock_irqsave_rcu_node(rnp, flags);
rcu_state.gp_kthread = t;
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
wake_up_process(t);
rcu_spawn_nocb_kthreads();
rcu_spawn_boost_kthreads();
return 0;
}
early_initcall(rcu_spawn_gp_kthread);
gp의 시작과 끝을 관리하는 gp kthread를 생성하여 동작시킨다.
- 코드 라인 10~12에서 CONFIG_RCU_BOOST 및 CONFIG_RCU_TORTURE_TEST 커널 옵션이 사용되는 시스템의 경우 rcu 및 rcu를 사용하는 커널 스레드의 우선 순위를 2 미만으로 내려가지 못하게 제한한다.
- rcutorture 스레드가 1번 우선 순위에서 동작하도록 2 미만으로 내려가지 못하게 한다. (0=최상위 우선순위)
- 코드 라인 13~18에서 rcu 커널 스레드의 우선 순위가 0~99 범위를 벗어나지 않도록 조정한다. rcu boost 기능을 사용하는 경우에는 preempt된 rcu가 가장 빠르게 처리될 수 있도록 0번 우선 순위를 사용하므로 rcu 커널 스레드들이 0번 우선 순위를 사용하지 않게 한다.
- rcu boost 기능을 사용하는 경우에는 preempt된 rcu가 가장 빠르게 처리될 수 있도록 0번 우선 순위를 사용하므로 gp 커널 스레드가 0번 우선 순위를 사용하지 않게 한다.
- 코드 라인 20~22에서 kthread_prio로 gp 커널 스레드가 동작하지 못하고 우선 순위가 하향 조정된 경우 이에 대한 alert 메시지를 출력한다.
- 코드 라인 24에서 rcu 스케줄러가 full active 되었음을 알린다.
- 코드 라인 25~36에서 rcu_gp_kthread를 생성하고 깨워 동작시킨다. 생성 시에 주어진 우선 순위로 SCHED_FIFO 정책을 사용하는 RT 스레드를 사용한다.
- rcu_gp_kthread 태스크명: [rcu_preempt]
- 코드 라인 37에서 no-cb 설정된 online cpu 수 만큼 rcu_nocb_kthread를 생성하고 동작시킨다.
- rcu_nocb_gp_kthread 태스크명: [rcuog/<cpu>]
- 예) [rcuog/0]
- rcu_nocb_cb_kthread 태스크명: [rcuop/<cpu>]
- 예) [rcuop/0]
- 코드 라인 38에서 leaf 노드 수 만큼 rcu_boost_kthread를 생성하고 동작시킨다. 이들은 SCHED_FIFO 스레드로 생성시킨다.
- rcu_boost_kthread 태스크명: [rcub/<rcu leaf node 인덱스>]
- 예) [rcub/0], [rcub/1], …
- 코드 라인 39에서 정상 값 0을 반환한다.
rcu_spawn_core_kthreads()
kernel/rcu/tree.c
/* * Spawn per-CPU RCU core processing kthreads. */
static int __init rcu_spawn_core_kthreads(void)
{
int cpu;
for_each_possible_cpu(cpu)
per_cpu(rcu_data.rcu_cpu_has_work, cpu) = 0;
if (!IS_ENABLED(CONFIG_RCU_BOOST) && use_softirq)
return 0;
WARN_ONCE(smpboot_register_percpu_thread(&rcu_cpu_thread_spec),
"%s: Could not start rcuc kthread, OOM is now expected behavior\n", __func__);
return 0;
}
early_initcall(rcu_spawn_core_kthreads);
rcu 콜백 처리를 위한 core 프로세싱 스레드들을 생성하여 동작시킨다. 단 rcu boost 기능을 사용하지 않거나 use_softirq(디폴트=1)가 설정된 경우 core 프로세싱 스레드들을 생성하지 않는다.
- 코드 라인 5~6에서 모든 possible cpu를 순회하며 rcu_data.rcu_cpu_has_work 를 0으로 초기화한다.
- 코드 라인 7~8에서 rcu boost 기능을 사용하지 않거나 use_softirq(디폴트=1)가 설정된 경우 core 프로세싱 스레드들을 생성하지 않고 함수를 빠져나간다.
- 코드 라인 9~10에서 online cpu가 핫플러그될때마다 호출되도록 core 프로세싱 스레드를 등록한다.
- rcu_cpu_kthread 태스크명: [rcuc/<cpu>]
- 예) [rcuc/0], [rcuc/1], …
rcu_spawn_nocb_kthreads()
kernel/rcu/tree_plugin.h
/* * Once the scheduler is running, spawn rcuo kthreads for all online * no-CBs CPUs. This assumes that the early_initcall()s happen before * non-boot CPUs come online -- if this changes, we will need to add * some mutual exclusion. */
static void __init rcu_spawn_nocb_kthreads(void)
{
int cpu;
for_each_online_cpu(cpu)
rcu_spawn_cpu_nocb_kthread(cpu);
}
online cpu들 수 만큼 no-cb용 커널 스레드들을 생성시킨다.
rcu_spawn_cpu_nocb_kthread()
kernel/rcu/tree_plugin.h
/* * If the specified CPU is a no-CBs CPU that does not already have its * rcuo kthreads, spawn them. */
static void rcu_spawn_cpu_nocb_kthread(int cpu)
{
if (rcu_scheduler_fully_active)
rcu_spawn_one_nocb_kthread(rsp, cpu);
}
no-cb용 커널 스레드들을 생성시킨다.
- no-cb용 gp 커널 스레드
- nocb용 콜백 처리 커널 스레드를 생성시킨다.
rcu_spawn_one_nocb_kthread()
kernel/rcu/tree_plugin.h
/* * If the specified CPU is a no-CBs CPU that does not already have its * rcuo CB kthread, spawn it. Additionally, if the rcuo GP kthread * for this CPU's group has not yet been created, spawn it as well. */
static void rcu_spawn_one_nocb_kthread(int cpu)
{
struct rcu_data *rdp = per_cpu_ptr(&rcu_data, cpu);
struct rcu_data *rdp_gp;
struct task_struct *t;
/*
* If this isn't a no-CBs CPU or if it already has an rcuo kthread,
* then nothing to do.
*/
if (!rcu_is_nocb_cpu(cpu) || rdp->nocb_cb_kthread)
return;
/* If we didn't spawn the GP kthread first, reorganize! */
rdp_gp = rdp->nocb_gp_rdp;
if (!rdp_gp->nocb_gp_kthread) {
t = kthread_run(rcu_nocb_gp_kthread, rdp_gp,
"rcuog/%d", rdp_gp->cpu);
if (WARN_ONCE(IS_ERR(t), "%s: Could not start rcuo GP kthread, OOM is now expected behavior\n", __func___
))
return;
WRITE_ONCE(rdp_gp->nocb_gp_kthread, t);
}
/* Spawn the kthread for this CPU. */
t = kthread_run(rcu_nocb_cb_kthread, rdp,
"rcuo%c/%d", rcu_state.abbr, cpu);
if (WARN_ONCE(IS_ERR(t), "%s: Could not start rcuo CB kthread, OOM is now expected behavior\n", __func__))
return;
WRITE_ONCE(rdp->nocb_cb_kthread, t);
WRITE_ONCE(rdp->nocb_gp_kthread, rdp_gp->nocb_gp_kthread);
}
cpu에 해당하는 no-cb용 gp 커널 스레드와 nocb용 콜백 처리 커널 스레드를 생성시킨다.
rcu_spawn_boost_kthreads()
kernel/rcu/tree_plugin.h
/* * Spawn boost kthreads -- called as soon as the scheduler is running. */
static void __init rcu_spawn_boost_kthreads(void)
{
struct rcu_node *rnp;
rcu_for_each_leaf_node(rnp)
rcu_spawn_one_boost_kthread(rnp);
}
leaf 노드 수 만큼 rcu_boost_kthread를 생성하고 동작시킨다. 이들은 SCHED_FIFO 스레드로 생성시킨다.
rcu_spawn_one_boost_kthread()
kernel/rcu/tree_plugin.h
/* * Create an RCU-boost kthread for the specified node if one does not * already exist. We only create this kthread for preemptible RCU. * Returns zero if all is well, a negated errno otherwise. */
static void rcu_spawn_one_boost_kthread(struct rcu_node *rnp)
{
int rnp_index = rnp - rcu_get_root();
unsigned long flags;
struct sched_param sp;
struct task_struct *t;
if (!IS_ENABLED(CONFIG_PREEMPT_RCU))
return 0;
if (!rcu_scheduler_fully_active || rcu_rnp_online_cpus(rnp) == 0)
return 0;
rcu_state.boost = 1;
if (rnp->boost_kthread_task != NULL)
return 0;
t = kthread_create(rcu_boost_kthread, (void *)rnp,
"rcub/%d", rnp_index);
if (WARN_ON_ONCE(IS_ERR(t)))
return;
raw_spin_lock_irqsave_rcu_node(rnp, flags);
rnp->boost_kthread_task = t;
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
sp.sched_priority = kthread_prio;
sched_setscheduler_nocheck(t, SCHED_FIFO, &sp);
wake_up_process(t); /* get to TASK_INTERRUPTIBLE quickly. */
}
rcu boost 기능을 위해 leaf 노드 수 만큼 rcu_boost_kthread 들도 생성하고 동작시킨다. 이들은 SCHED_FIFO 스레드로 생성시킨다.
rcu_spawn_tasks_kthread()
kernel/rcu/update.c
/* Spawn rcu_tasks_kthread() at core_initcall() time. */
static int __init rcu_spawn_tasks_kthread(void)
{
struct task_struct *t;
t = kthread_run(rcu_tasks_kthread, NULL, "rcu_tasks_kthread");
if (WARN_ONCE(IS_ERR(t), "%s: Could not start Tasks-RCU grace-period kthread, OOM is now expected behavior\n", __
_func__))
return 0;
smp_mb(); /* Ensure others see full kthread. */
WRITE_ONCE(rcu_tasks_kthread_ptr, t);
return 0;
}
core_initcall(rcu_spawn_tasks_kthread);
rcu tasks 커널 스레드를 생성하고 동작시킨다. srcu 기반에서 동작한다. (“rcu_tasks_kthread”)
CB용 GP 커널 스레드
CB용 gp 커널 스레드는 다음과 같이 동작한다.
- 다음과 같이 3 함수를 무한 반복한다.
- rcu_gp_init() -> rcu_gp_fqs_loop() -> rcu_gp_cleanup()
- rcu_gp_init()
- 새 gp 요청을 대기한 후 요청이 오는 경우 gp 시퀀스를 증가시켜 새로운 gp를 시작한다.
- 새 gp 요청
- 새로운 콜백이 있는 경우 gp_flag에 RCU_GP_FLAG_INIT 플래그를 기록하고 gp 커널 스레드를 깨우는 것으로 새 gp 요청을 한다.
- 새 gp 요청
- 새 gp 요청을 대기한 후 요청이 오는 경우 gp 시퀀스를 증가시켜 새로운 gp를 시작한다.
- rcu_gp_fqs_loop()
- qs 완료 또는 fqs 요청을 기다린다.
- gp가 시작한 후에는 빠른 시간내에 gp를 완료해야 하므로 수 틱마다 반복하며 qs 완료 체크 및 외부 fqs 요청을 체크하고 fqs를 진행한다.
- 외부 fqs 요청
- gp_flag에 RCU_GP_FLAG_FQS 플래그를 기록하고 gp 커널 스레드를 깨우는 것으로 fqs를 요청한다.
- 외부 fqs 요청
- 반복하는 주기는 첫 체크 시 jiffies_till_first_fqs(디폴트=1~3+@256cpus) 틱 주기를 사용하고, 그 다음 반복시엔 jiffies_till_next_fqs(디폴트=1~3+@256cpus) 틱 주기를 사용한다.
- 장 시간 gp가 hang하는 경우를 막기 위해 rcu_gp_fqs() 함수를 통해 강제로 모든 cpu의 nohz 및 gp 시작 후 1초 경과한 offline cpu들의 qs 상태를 패스시켜 빠르게 gp를 종료할 수 있게 한다.
- rcu_gp_cleanup()
- gp를 종료(gp idle) 처리하고, 다음 gp 시퀀스로 건너띈다.
다음 그림은 rcu_gp_kthread() 함수내에서 사용하는 gp 플래그 요청 및 gp 상태의 변화를 보여준다.
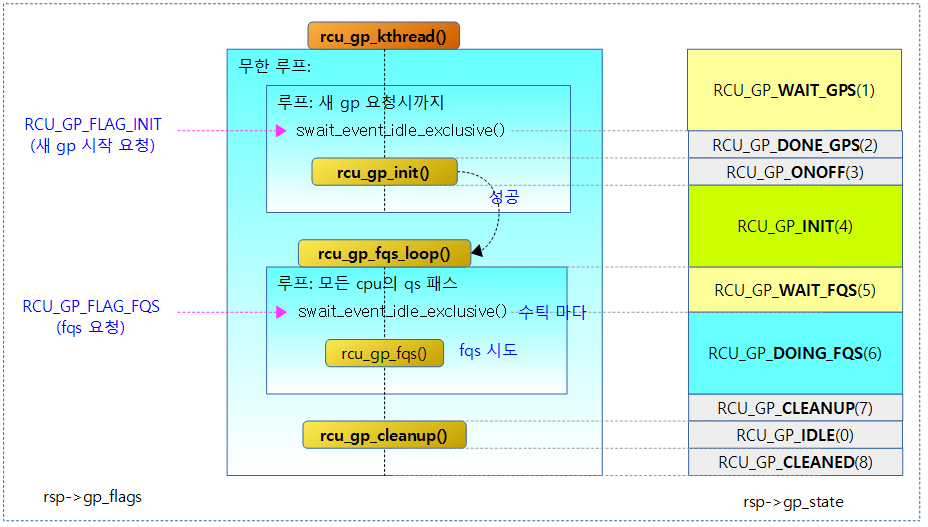
rcu_gp_kthread()
kernel/rcu/tree.c
static int __noreturn rcu_gp_kthread(void *unused)
{
rcu_bind_gp_kthread();
for (;;) {
/* Handle grace-period start. */
for (;;) {
trace_rcu_grace_period(rcu_state.name,
READ_ONCE(rcu_state.gp_seq),
TPS("reqwait"));
rcu_state.gp_state = RCU_GP_WAIT_GPS;
swait_event_idle_exclusive(rcu_state.gp_wq,
READ_ONCE(rcu_state.gp_flags) &
RCU_GP_FLAG_INIT);
rcu_state.gp_state = RCU_GP_DONE_GPS;
/* Locking provides needed memory barrier. */
if (rcu_gp_init())
break;
cond_resched_tasks_rcu_qs();
WRITE_ONCE(rcu_state.gp_activity, jiffies);
WARN_ON(signal_pending(current));
trace_rcu_grace_period(rcu_state.name,
READ_ONCE(rcu_state.gp_seq),
TPS("reqwaitsig"));
}
/* Handle quiescent-state forcing. */
rcu_gp_fqs_loop();
/* Handle grace-period end. */
rcu_state.gp_state = RCU_GP_CLEANUP;
rcu_gp_cleanup();
rcu_state.gp_state = RCU_GP_CLEANED;
}
}
CB용 grace period를 관리하기 위한 커널 스레드로 무한 루프를 돌며 외부에서 깨울 때마다 state 변경을 확인하며 gp의 진행 -> idle을 반복하며 슬립한다.
- 코드 라인 3에서 nohz full 을 위해 현재 gp 커널 스레드를 rcu 처리 가능한 cpu들에서만 동작하도록 제한시킨다.
- 코드 라인 4에서 무한 루프를 반복한다.
- 코드 라인 7에서 gp 시작이 실패하는 경우 다시 시도하기 위한 내부 루프이다.
- 코드 라인 11에서 gp 상태를 RCU_GP_WAIT_GPS(1)로 변경한다.
- 코드 라인 12~14에서 이 스레드는 새 gp 요청을 대기하며 슬립한다. RCU_GP_FLAG_INIT 플래그가 있으면 슬립하지 않고 다음을 진행한다.
- 잠들어 있으므로 외부에서 깨웠을 때 새 gp 요청을 확인한다.
- 코드 라인 15에서 gp 상태를 RCU_GP_DONE_GPS(2)로 변경한다.
- 코드 라인 17~18에서 gp가 정상적으로 시작된 경우 내부 루프를 벗어난다.
- 코드 라인 19~25에서 gp 시작이 실패한 경우 다시 슬립하기 위해 내부 루프를 돈다. 이 때 태스크의 rcu_tasks_holdout 플래그의 클리어 및 gp 상태가 변화에에 따른 변경된 시각을 gp_activity에 기록한다.
- 코드 라인 28에서 qs 완료 시까지 지정된 틱 또는 fqs 요청마다 fqs를 반복하며 처리한다.
- jiffies_till_first_fqs(디폴트=1~3틱+@256cpus), jiffies_till_next_fqs(디폴트=1~3틱+@256cpus)
- 코드 라인 31에서 gp 상태를 RCU_GP_CLEANUP(7)으로 변경한다.
- 코드 라인 32에서 gp를 마감하고 idle 상태로 변경한다.
- 코드 라인 33~34에서 gp 상태를 RCU_GP_CLEANED(8)로 변경하고 다시 새 gp 요청을 대기 하기 위해 반복한다.
rcu_preempt_blocked_readers_cgp()
kernel/rcu/tree_plugin.h
/* * Check for preempted RCU readers blocking the current grace period * for the specified rcu_node structure. If the caller needs a reliable * answer, it must hold the rcu_node's ->lock. */
static int rcu_preempt_blocked_readers_cgp(struct rcu_node *rnp)
{
return rnp->gp_tasks != NULL;
}
rcu 노드 내에서 선점형 rcu 리더가 블러킹되었는지 체크한다.
CB용 GP 시작 처리
rcu_gp_init()
kernel/rcu/tree.c -1/2-
/* * Initialize a new grace period. Return false if no grace period required. */
static bool rcu_gp_init(void)
{
unsigned long flags;
unsigned long oldmask;
unsigned long mask;
struct rcu_data *rdp;
struct rcu_node *rnp = rcu_get_root();
WRITE_ONCE(rcu_state.gp_activity, jiffies);
raw_spin_lock_irq_rcu_node(rnp);
if (!READ_ONCE(rcu_state.gp_flags)) {
/* Spurious wakeup, tell caller to go back to sleep. */
raw_spin_unlock_irq_rcu_node(rnp);
return false;
}
WRITE_ONCE(rcu_state.gp_flags, 0); /* Clear all flags: New GP. */
if (WARN_ON_ONCE(rcu_gp_in_progress())) {
/*
* Grace period already in progress, don't start another.
* Not supposed to be able to happen.
*/
raw_spin_unlock_irq_rcu_node(rnp);
return false;
}
/* Advance to a new grace period and initialize state. */
record_gp_stall_check_time();
/* Record GP times before starting GP, hence rcu_seq_start(). */
rcu_seq_start(&rcu_state.gp_seq);
trace_rcu_grace_period(rcu_state.name, rcu_state.gp_seq, TPS("start"));
raw_spin_unlock_irq_rcu_node(rnp);
/*
* Apply per-leaf buffered online and offline operations to the
* rcu_node tree. Note that this new grace period need not wait
* for subsequent online CPUs, and that quiescent-state forcing
* will handle subsequent offline CPUs.
*/
rcu_state.gp_state = RCU_GP_ONOFF;
rcu_for_each_leaf_node(rnp) {
raw_spin_lock(&rcu_state.ofl_lock);
raw_spin_lock_irq_rcu_node(rnp);
if (rnp->qsmaskinit == rnp->qsmaskinitnext &&
!rnp->wait_blkd_tasks) {
/* Nothing to do on this leaf rcu_node structure. */
raw_spin_unlock_irq_rcu_node(rnp);
raw_spin_unlock(&rcu_state.ofl_lock);
continue;
}
/* Record old state, apply changes to ->qsmaskinit field. */
oldmask = rnp->qsmaskinit;
rnp->qsmaskinit = rnp->qsmaskinitnext;
/* If zero-ness of ->qsmaskinit changed, propagate up tree. */
if (!oldmask != !rnp->qsmaskinit) {
if (!oldmask) { /* First online CPU for rcu_node. */
if (!rnp->wait_blkd_tasks) /* Ever offline? */
rcu_init_new_rnp(rnp);
} else if (rcu_preempt_has_tasks(rnp)) {
rnp->wait_blkd_tasks = true; /* blocked tasks */
} else { /* Last offline CPU and can propagate. */
rcu_cleanup_dead_rnp(rnp);
}
}
/*
* If all waited-on tasks from prior grace period are
* done, and if all this rcu_node structure's CPUs are
* still offline, propagate up the rcu_node tree and
* clear ->wait_blkd_tasks. Otherwise, if one of this
* rcu_node structure's CPUs has since come back online,
* simply clear ->wait_blkd_tasks.
*/
if (rnp->wait_blkd_tasks &&
(!rcu_preempt_has_tasks(rnp) || rnp->qsmaskinit)) {
rnp->wait_blkd_tasks = false;
if (!rnp->qsmaskinit)
rcu_cleanup_dead_rnp(rnp);
}
raw_spin_unlock_irq_rcu_node(rnp);
raw_spin_unlock(&rcu_state.ofl_lock);
}
rcu_gp_slow(gp_preinit_delay); /* Races with CPU hotplug. */
CB용 새로운 GP(grace period)를 시작한다.
- 코드 라인 9에서 gp 상태가 변화됨에 따른 변경된 시각을 gp_activity에 기록한다.
- 코드 라인 10~15에서 노드 락을 획득하고, gp 플래그가 0인 경우 노드 락을 풀고 다시 gp 스레드가 잠들기 위해 false를 반환한다.
- 코드 라인 16에서 새로운 gp를 위해 플래그를 모두 클리어한다.
- 코드 라인 18~25에서 이미 gp가 시작한 경우 다시 시작하지 말고 false로 함수를 빠져나간다.
- 코드 라인 28에서 gp stall 여부 체크를 위해 시간을 gp 시작 시간을 기록해둔다.
- CONFIG_RCU_STALL_COMMON 커널 옵션을 사용하는 경우 장시간(디폴트 21초) 동안 gp가 끝나지 않으면 stall이 된 것으로 판단하여 강제로 gp 종료 처리를 하기 위해 사용한다.
- 코드 라인 30~32에서 gp 시퀀스를 1 증가시켜 gp를 시작시키고 노드 락을 푼다. (홀수)
- 코드 라인 40에서 gp 상태를 RCU_GP_ONOFF(3)로 변경한다. 이 곳에서는 cpu의 online/offline의 변경을 노드에 반영한다.
- 코드 라인 41~43에서 leaf 노드를 순회하며 전역 ofl_lock과 노드 락을 획득한다.
- 코드 라인 44~50에서 online cpu에 변경이 없으면서 순회하는 노드에 블럭드 태스크가 존재하지 않으면 이 노드에서 수행할 일이 없으므로 락들을 풀고 skip 한다.
- 코드 라인 53~54에서 online cpu를 반영하기 위해 rnp->qsmaskinit = <- rnp->qsmaskinitnext 하며, 기존 값은 oldmask에 담는다.
- 코드 라인 57~66에서 만일 노드 구성이 변경된 경우 다음 3 가지 중 하나의 조건을 처리한다.
- 새로운 online cpu가 추가된 경우이고, 노드에 블럭드 태스크가 없는 경우 최상위 노드까지 online을 전파한다.
- 노드에 블럭드 태스크가 존재하는 경우 rnp->wait_blkd_tasks에 true를 대입한다.
- offline cpu가 발생한 경우에 최상위 노드까지 offline을 전파한다.
- 코드 라인 76~81에서 순회 중인 노드에 대기중인 블럭드 태스크가 존재하고,노드에 블럭드 태스크가 없거나 rnp->qsmaskinit가 있는 경우 대기중인 블럭드 태스크를 false로 변경한다. 만일 rnp->qsmaskinit이 0인 경우 최상위 노드까지 offline을 전파한다.
- rcu read-side critical section에서 preemption된 경우 preemption된 태스크가 블럭드 태스크에 추가된다.
- 코드 라인 83~85에서 획득한 락들을 해제한 후 루프를 반복한다.
- 코드 라인 86에서 모듈 파라미터 gp_preinit_delay(디폴트=0)에 지정된 틱 수 만큼 슬립한다.
kernel/rcu/tree.c -2/2-
/*
* Set the quiescent-state-needed bits in all the rcu_node
* structures for all currently online CPUs in breadth-first
* order, starting from the root rcu_node structure, relying on the
* layout of the tree within the rcu_state.node[] array. Note that
* other CPUs will access only the leaves of the hierarchy, thus
* seeing that no grace period is in progress, at least until the
* corresponding leaf node has been initialized.
*
* The grace period cannot complete until the initialization
* process finishes, because this kthread handles both.
*/
rcu_state.gp_state = RCU_GP_INIT;
rcu_for_each_node_breadth_first(rnp) {
rcu_gp_slow(gp_init_delay);
raw_spin_lock_irqsave_rcu_node(rnp, flags);
rdp = this_cpu_ptr(&rcu_data);
rcu_preempt_check_blocked_tasks(rnp);
rnp->qsmask = rnp->qsmaskinit;
WRITE_ONCE(rnp->gp_seq, rcu_state.gp_seq);
if (rnp == rdp->mynode)
(void)__note_gp_changes(rnp, rdp);
rcu_preempt_boost_start_gp(rnp);
trace_rcu_grace_period_init(rcu_state.name, rnp->gp_seq,
rnp->level, rnp->grplo,
rnp->grphi, rnp->qsmask);
/* Quiescent states for tasks on any now-offline CPUs. */
mask = rnp->qsmask & ~rnp->qsmaskinitnext;
rnp->rcu_gp_init_mask = mask;
if ((mask || rnp->wait_blkd_tasks) && rcu_is_leaf_node(rnp))
rcu_report_qs_rnp(mask, rnp, rnp->gp_seq, flags);
else
raw_spin_unlock_irq_rcu_node(rnp);
cond_resched_tasks_rcu_qs();
WRITE_ONCE(rcu_state.gp_activity, jiffies);
}
return true;
}
- 코드 라인 13에서 gp 상태를 RCU_GP_INIT(4)로 변경한다.
- 코드 라인 14~15에서 모든 노드를 순회하며 모듈 파라미터 gp_init_delay(디폴트=0) 에서 지정한 틱 만큼 슬립한다.
- 코드 라인 16~18에서 순회 중인 노드의 노드 락을 획득하고 노드에 블럭드 태스크가 있는지 여부를 체크한다. 블럭드 태스크가 존재하는 경우 이를 경고 덤프한다.
- 코드 라인 19~20에서 qsmask를 qsmaskinit 값으로 대입하고, 노드의 gp 시퀀스를 갱신한다.
- 코드라인 21~22에서 순회 중인 노드가 현재 cpu를 가진 노드인 경우 gp가 끝나고 새로운 gp가 시작되었는지 체크한다.
- 코드 라인 23에서 순회 중인 노드의 boost 타임(디폴트 500ms)을 지정한다.
- 코드 라인 28~33에서 새롭게 offline된 cpu들의 qs를 보고한다.
- 코드 라인 34에서 rcu_tasks_holdout 플래그의 클리어한다.
- 코드 라인 35~36에서 gp 상태가 변화됨에 따른 변경된 시각을 gp_activity에 기록하고 루프를 반복한다.
- 코드 라인 38에서 true를 반환한다.
CB용 모든 QS 완료 및 FQS 처리
rcu_gp_fqs_loop()
kernel/rcu/tree.c
/* * Loop doing repeated quiescent-state forcing until the grace period ends. */
static void rcu_gp_fqs_loop(void)
{
bool first_gp_fqs;
int gf;
unsigned long j;
int ret;
struct rcu_node *rnp = rcu_get_root();
first_gp_fqs = true;
j = READ_ONCE(jiffies_till_first_fqs);
ret = 0;
for (;;) {
if (!ret) {
rcu_state.jiffies_force_qs = jiffies + j;
WRITE_ONCE(rcu_state.jiffies_kick_kthreads,
jiffies + (j ? 3 * j : 2));
}
trace_rcu_grace_period(rcu_state.name,
READ_ONCE(rcu_state.gp_seq),
TPS("fqswait"));
rcu_state.gp_state = RCU_GP_WAIT_FQS;
ret = swait_event_idle_timeout_exclusive(
rcu_state.gp_wq, rcu_gp_fqs_check_wake(&gf), j);
rcu_state.gp_state = RCU_GP_DOING_FQS;
/* Locking provides needed memory barriers. */
/* If grace period done, leave loop. */
if (!READ_ONCE(rnp->qsmask) &&
!rcu_preempt_blocked_readers_cgp(rnp))
break;
/* If time for quiescent-state forcing, do it. */
if (ULONG_CMP_GE(jiffies, rcu_state.jiffies_force_qs) ||
(gf & RCU_GP_FLAG_FQS)) {
trace_rcu_grace_period(rcu_state.name,
READ_ONCE(rcu_state.gp_seq),
TPS("fqsstart"));
rcu_gp_fqs(first_gp_fqs);
first_gp_fqs = false;
trace_rcu_grace_period(rcu_state.name,
READ_ONCE(rcu_state.gp_seq),
TPS("fqsend"));
cond_resched_tasks_rcu_qs();
WRITE_ONCE(rcu_state.gp_activity, jiffies);
ret = 0; /* Force full wait till next FQS. */
j = READ_ONCE(jiffies_till_next_fqs);
} else {
/* Deal with stray signal. */
cond_resched_tasks_rcu_qs();
WRITE_ONCE(rcu_state.gp_activity, jiffies);
WARN_ON(signal_pending(current));
trace_rcu_grace_period(rcu_state.name,
READ_ONCE(rcu_state.gp_seq),
TPS("fqswaitsig"));
ret = 1; /* Keep old FQS timing. */
j = jiffies;
if (time_after(jiffies, rcu_state.jiffies_force_qs))
j = 1;
else
j = rcu_state.jiffies_force_qs - j;
}
}
}
qs 완료를 대기하며, fqs 타임아웃 또는 fqs 요청이 있는 경우엔 fqs를 수행한다.
- 코드 라인 7에서 모든 qs 완료 체크는 최상위 노드에서 수행하므로 루트 노드를 알아온다.
- 코드 라인 9에서 fqs를 진행할 때 처음 시도시엔 true를 전달하고, 다음 시도시엔 false로 바뀔 예정이다.
- 코드 라인 10에서 fqs 대기 시간(jiffies_till_first_fqs 틱)을 j로 읽어온다. 이 값은 변화된다.
- jiffies_till_first_fqs 값은 초기 값으로 1~3(250hz 이하=1틱, 500hz 이하=2틱, 500hz 초과=3틱) + cpu 256개마다 1틱을 사용한다.
- 예) rpi4, 250hz인 경우 1틱이다.
- 코드 라인 12~17에서 fqs 체크 결과 ret(처음엔 0)가 false(0)인 경우 루프를 돌며 다음 fqs 대기 시간을 준비하고, jiffies_kick_kthreads에 j 값의 3배를 준다.
- 코드 라인 21에서 gp 상태를 RCU_GP_WAIT_FQS(5)로 변경한다.
- 코드 라인 22~23에서 j 타임아웃으로 깨어나거나 외부에서 깨울 때 마다 fqs를 체크한 결과를 ret로 알아온다.
- 코드 라인 24에서 gp 상태를 RCU_GP_DOING_FQS(6)로 변경한다.
- 코드 라인 27~29에서 qs가 모두 체크되어 완료된 경우이면서 preempt된 rcu 리더 태스크가 없는 경우 루프를 벗어나서 함수를 빠져나간다.
- 코드 라인 31~44에서 현재 시각이 fqs 대기 시간을 지난 경우이거나 fqs 플래그가 수신된 경우 fqs를 시작한다. 또한 gp 상태가 변화됨에 따른 변경된 시각을 gp_activity에 기록한다.
- 코드 라인 45~59에서 signal이 수신된 경우 gp 상태가 변화됨에 따른 변경된 시각을 gp_activity에 기록하고 계속 루프를 돈다.
CB용 GP 종료 처리
rcu_gp_cleanup()
kernel/rcu/tree.c – 1/2
/* * Clean up after the old grace period. */
static void rcu_gp_cleanup(void)
{
unsigned long gp_duration;
bool needgp = false;
unsigned long new_gp_seq;
bool offloaded;
struct rcu_data *rdp;
struct rcu_node *rnp = rcu_get_root();
struct swait_queue_head *sq;
WRITE_ONCE(rcu_state.gp_activity, jiffies);
raw_spin_lock_irq_rcu_node(rnp);
rcu_state.gp_end = jiffies;
gp_duration = rcu_state.gp_end - rcu_state.gp_start;
if (gp_duration > rcu_state.gp_max)
rcu_state.gp_max = gp_duration;
/*
* We know the grace period is complete, but to everyone else
* it appears to still be ongoing. But it is also the case
* that to everyone else it looks like there is nothing that
* they can do to advance the grace period. It is therefore
* safe for us to drop the lock in order to mark the grace
* period as completed in all of the rcu_node structures.
*/
raw_spin_unlock_irq_rcu_node(rnp);
/*
* Propagate new ->gp_seq value to rcu_node structures so that
* other CPUs don't have to wait until the start of the next grace
* period to process their callbacks. This also avoids some nasty
* RCU grace-period initialization races by forcing the end of
* the current grace period to be completely recorded in all of
* the rcu_node structures before the beginning of the next grace
* period is recorded in any of the rcu_node structures.
*/
new_gp_seq = rcu_state.gp_seq;
rcu_seq_end(&new_gp_seq);
rcu_for_each_node_breadth_first(rnp) {
raw_spin_lock_irq_rcu_node(rnp);
if (WARN_ON_ONCE(rcu_preempt_blocked_readers_cgp(rnp)))
dump_blkd_tasks(rnp, 10);
WARN_ON_ONCE(rnp->qsmask);
WRITE_ONCE(rnp->gp_seq, new_gp_seq);
rdp = this_cpu_ptr(&rcu_data);
if (rnp == rdp->mynode)
needgp = __note_gp_changes(rnp, rdp) || needgp;
/* smp_mb() provided by prior unlock-lock pair. */
needgp = rcu_future_gp_cleanup(rnp) || needgp;
sq = rcu_nocb_gp_get(rnp);
raw_spin_unlock_irq_rcu_node(rnp);
rcu_nocb_gp_cleanup(sq);
cond_resched_tasks_rcu_qs();
WRITE_ONCE(rcu_state.gp_activity, jiffies);
rcu_gp_slow(gp_cleanup_delay);
}
현재 gp의 종료 처리를 수행하며 모든 노드에 반영시킨다.
- 코드 라인 11에서 gp 상태가 변화됨에 따른 변경된 시각을 gp_activity에 기록한다.
- 코드 라인 12~26에서 최상위 노드 락을 획득한 채로, gp 만료 시간을 gp_end에 기록하고, gp 최대 duration인 gp_max를 갱신한다.
- 코드 라인 37~38에서 gp 시퀀스를 만료시킨다. (gp idle 상태) 만료 전의 gp 시퀀스 값을 new_gp_seq에 담아둔다.
- 코드 라인 39~42에서 모든 노드를 대상으로 순회하며 순회 중인 노드에 블럭드 태스크가 있는 경우 경고 덤프 출력을 한다.
- 코드 라인 43에서 qs가 완료되지 않은 노드에 대해서 경고 출력을 한다.
- 코드 라인 44에서 노드에 gp 완료 전의 gp 시퀀스 값인 new_gp_seq 값으로 복사한다.
- 코드 라인 45~47에서 순회 중인 노드가 현재 cpu를 소유한 leaf 노드인 경우 gp가 끝나고 새로운 gp가 시작되었는지 체크한다.
- 코드 라인 49에서 기존 gp 요청을 클리어하고, 새로운 gp 요청이 있는지를 알아온다.
- 코드 라인 50~52에서 gp 클린업을 위해 no-cb용 gp 커널 스레드를 모두 wakeup 시킨다.
- 코드 라인 53에서 태스크의 rcu_tasks_holdout 플래그를 클리어한다.
- 코드 라인 54에서 gp 상태가 변화됨에 따른 변경된 시각을 gp_activity에 기록한다.
- 코드 라인 55에서 모듈 파라미터 gp_cleanup_delay(디폴트=0) 에서 지정한 틱 만큼 슬립한다.
kernel/rcu/tree.c – 2/2
rnp = rcu_get_root();
raw_spin_lock_irq_rcu_node(rnp); /* GP before ->gp_seq update. */
/* Declare grace period done, trace first to use old GP number. */
trace_rcu_grace_period(rcu_state.name, rcu_state.gp_seq, TPS("end"));
rcu_seq_end(&rcu_state.gp_seq);
rcu_state.gp_state = RCU_GP_IDLE;
/* Check for GP requests since above loop. */
rdp = this_cpu_ptr(&rcu_data);
if (!needgp && ULONG_CMP_LT(rnp->gp_seq, rnp->gp_seq_needed)) {
trace_rcu_this_gp(rnp, rdp, rnp->gp_seq_needed,
TPS("CleanupMore"));
needgp = true;
}
/* Advance CBs to reduce false positives below. */
offloaded = IS_ENABLED(CONFIG_RCU_NOCB_CPU) &&
rcu_segcblist_is_offloaded(&rdp->cblist);
if ((offloaded || !rcu_accelerate_cbs(rnp, rdp)) && needgp) {
WRITE_ONCE(rcu_state.gp_flags, RCU_GP_FLAG_INIT);
rcu_state.gp_req_activity = jiffies;
trace_rcu_grace_period(rcu_state.name,
READ_ONCE(rcu_state.gp_seq),
TPS("newreq"));
} else {
WRITE_ONCE(rcu_state.gp_flags,
rcu_state.gp_flags & RCU_GP_FLAG_INIT);
}
raw_spin_unlock_irq_rcu_node(rnp);
}
- 코드 라인 1~2에서 최상위 루트 노드 락을 획득한다.
- 코드 라인 6~7에서 gp 시퀀스를 종료시키고 gp 상태를 RCU_GP_IDLE(0)로 변경한다.
- 코드 라인 9~14에서 노드에서 새 gp가 요구된 경우 needgp를 true로 설정한다.
- 코드 라인 16~27에서 새 gp가 요청된 상태에서 콜백 처리를 offload 하였거나 acceleration 되지 않은 경우 gp 플래그에 RCU_GP_FLAG_INIT(1) 를 대입하고, gp 요청 시각을 현재 시각으로 갱신한다. 그렇지 않은 경우 gp 플래그에서 RCU_GP_FLAG_INIT(1) 비트만 제거한다.
- 코드 라인 28에서 노드 락을 해제한다.
rcu_future_gp_cleanup()
kernel/rcu/tree.c
/* * Clean up any old requests for the just-ended grace period. Also return * whether any additional grace periods have been requested. */
static bool rcu_future_gp_cleanup(struct rcu_node *rnp)
{
bool needmore;
struct rcu_data *rdp = this_cpu_ptr(&rcu_data);
needmore = ULONG_CMP_LT(rnp->gp_seq, rnp->gp_seq_needed);
if (!needmore)
rnp->gp_seq_needed = rnp->gp_seq; /* Avoid counter wrap. */
trace_rcu_this_gp(rnp, rdp, rnp->gp_seq,
needmore ? TPS("CleanupMore") : TPS("Cleanup"));
return needmore;
}
노드에 기존 gp 요청은 클리어(gp_seq와 같은 값으로)하고 새 gp가 요구 여부를 반환한다.
gp 시작 요청
rcu_start_this_gp()
kernel/rcu/tree.c
/* * rcu_start_this_gp - Request the start of a particular grace period * @rnp_start: The leaf node of the CPU from which to start. * @rdp: The rcu_data corresponding to the CPU from which to start. * @gp_seq_req: The gp_seq of the grace period to start. * * Start the specified grace period, as needed to handle newly arrived * callbacks. The required future grace periods are recorded in each * rcu_node structure's ->gp_seq_needed field. Returns true if there * is reason to awaken the grace-period kthread. * * The caller must hold the specified rcu_node structure's ->lock, which * is why the caller is responsible for waking the grace-period kthread. * * Returns true if the GP thread needs to be awakened else false. */
static bool rcu_start_this_gp(struct rcu_node *rnp_start, struct rcu_data *rdp,
unsigned long gp_seq_req)
{
bool ret = false;
struct rcu_node *rnp;
/*
* Use funnel locking to either acquire the root rcu_node
* structure's lock or bail out if the need for this grace period
* has already been recorded -- or if that grace period has in
* fact already started. If there is already a grace period in
* progress in a non-leaf node, no recording is needed because the
* end of the grace period will scan the leaf rcu_node structures.
* Note that rnp_start->lock must not be released.
*/
raw_lockdep_assert_held_rcu_node(rnp_start);
trace_rcu_this_gp(rnp_start, rdp, gp_seq_req, TPS("Startleaf"));
for (rnp = rnp_start; 1; rnp = rnp->parent) {
if (rnp != rnp_start)
raw_spin_lock_rcu_node(rnp);
if (ULONG_CMP_GE(rnp->gp_seq_needed, gp_seq_req) ||
rcu_seq_started(&rnp->gp_seq, gp_seq_req) ||
(rnp != rnp_start &&
rcu_seq_state(rcu_seq_current(&rnp->gp_seq)))) {
trace_rcu_this_gp(rnp, rdp, gp_seq_req,
TPS("Prestarted"));
goto unlock_out;
}
rnp->gp_seq_needed = gp_seq_req;
if (rcu_seq_state(rcu_seq_current(&rnp->gp_seq))) {
/*
* We just marked the leaf or internal node, and a
* grace period is in progress, which means that
* rcu_gp_cleanup() will see the marking. Bail to
* reduce contention.
*/
trace_rcu_this_gp(rnp_start, rdp, gp_seq_req,
TPS("Startedleaf"));
goto unlock_out;
}
if (rnp != rnp_start && rnp->parent != NULL)
raw_spin_unlock_rcu_node(rnp);
if (!rnp->parent)
break; /* At root, and perhaps also leaf. */
}
/* If GP already in progress, just leave, otherwise start one. */
if (rcu_gp_in_progress()) {
trace_rcu_this_gp(rnp, rdp, gp_seq_req, TPS("Startedleafroot"));
goto unlock_out;
}
trace_rcu_this_gp(rnp, rdp, gp_seq_req, TPS("Startedroot"));
WRITE_ONCE(rcu_state.gp_flags, rcu_state.gp_flags | RCU_GP_FLAG_INIT);
rcu_state.gp_req_activity = jiffies;
if (!rcu_state.gp_kthread) {
trace_rcu_this_gp(rnp, rdp, gp_seq_req, TPS("NoGPkthread"));
goto unlock_out;
}
trace_rcu_grace_period(rcu_state.name, READ_ONCE(rcu_state.gp_seq), TPS("newreq"));
ret = true; /* Caller must wake GP kthread. */
unlock_out:
/* Push furthest requested GP to leaf node and rcu_data structure. */
if (ULONG_CMP_LT(gp_seq_req, rnp->gp_seq_needed)) {
rnp_start->gp_seq_needed = rnp->gp_seq_needed;
rdp->gp_seq_needed = rnp->gp_seq_needed;
}
if (rnp != rnp_start)
raw_spin_unlock_rcu_node(rnp);
return ret;
}
새 gp 시작을 요청한다. gp 시작이 성공한 경우 1을 반환하고 이미 시작되었거나 기존 gp가 진행 중인 경우 0을 반환한다.
- 코드 라인 18~20에서 @rnp_start 노드부터 최상위 노드까지 순회하며 노드 스핀락을 획득한다. 인자로 전달받은 시작 노드는 이미 락을 획득한 상태로 진입하였다.
- 코드 라인 21~28에서 순회 중인 노드의 gp 시퀀스 요청(gp_seq_needed)이 인자로 전달받은 @gp_seq_req 보다 더 큰 경우이거나 gp가 이미 시작된 경우 gp가 이미 시작한 상태이므로 unlock_out: 레이블로 이동한다.
- 코드 라인 29에서 순회하는 노드의 gp 시퀀스 요청(gp_seq_needed)을 @gp_seq_req 값으로 갱신한다.
- 코드 라인 30~40에서 순회 중인 노드의 gp가 이미 시작하여 진행 중인 경우 unlock_out: 레이블로 이동한다.
- 코드 라인 41~45에서 다음 노드를 처리하기 위해 현재 순회 중인 노드의 스핀락을 해제한다. 그런 후 상위 노드를 계속 처리한다.
- 코드 라인 48~51에서 글로벌 gp가 이미 시작되어 진행 중인 경우 unlock_out: 레이블로 이동한다.
- 코드 라인 53에서 gp가 이제 시작되었으므로 gp 플래그에 RCU_GP_FLAG_INIT(1) 플래그를 추가한다.
- 코드 라인 54에서 gp 요청 시각을 현재 시각으로 갱신한다.
- 코드 라인 55~58에서 cb용 gp 커널 스레드가 아직 동작하지 않는 경우 unlock_out: 레이블로 이동한다.
- 코드 라인 60에서 성공적으로 gp가 시작된 것을 반환한기 위해 ret에 true를 미리 대입해둔다.
- 코드 라인 61~69에서 unlock_out: 레이블이다. 노드 및 cpu의 gp 시퀀스 요청(gp_seq_needed) 값을 갱신하고, 노드의 스핀락을 해제한 후 함수를 빠져나간다.
Quiscent State 체크, 기록 및 보고
QS 상태가 패스되었는지 확인하는 방법은 여러 가지가 사용되며 특히 preemption 커널 모델에 따라 조금씩 상이하다. qs는 다음과 같은 순서대로 진행된다.
- qs 체크 -> qs 기록 -> qs 보고
Q.S 체크 및 기록
RCU non-preemptible 커널
- context switch
- context switch 발생 시 해당 cpu는 q.s로 기록된다.
- __schedule() -> rcu_note_context_switch() -> rcu_qs()
- 유저 모드 또는 idle에서 스케줄 틱
- 유저 태스크 수행 중이거나 idle 중인 경우 해당 cpu는 q.s로 기록된다.
- update_process_times() -> rcu_sched_clock_irq() -> rcu_flavor_sched_clock_irq() -> rcu_qs()
- 유저 태스크 수행 중이거나 idle 중인 경우 해당 cpu는 q.s로 기록된다.
- softirqd 실행 중
- 현재 cpu에서 동작 중인 태스크가 softirqd인 경우 qs로 기록된다.
- __do_softirq() -> rcu_softirq_qs() -> rcu_qs()
- 참고: rcu: Apply RCU-bh QSes to RCU-sched and RCU-preempt when safe (2018, v4.20-rc1)
- voluntry 커널에서 cond_resched() 사용
- cond_resched_tasks_rcu_qs() -> cond_resched() -> _cond_resched() -> rcu_all_qs() -> rcu_qs()
- 참고: Make cond_resched() provide RCU quiescent state (2017, v4.15-rc1)
- voluntry 커널에서 cond_resched_tasks_rcu_qs() 사용
- cb용 gp 커널 스레드 또는 nocb용 콜백 처리 루틴에서 long loop 에서 이 함수를 사용 시 qs로 기록된다.
- 참고: Provide cond_resched_rcu_qs() to force quiescent states in long loops (2014, v3.18-rc1)
RCU preemtible 커널
- Context Switch
- context switch 발생 시 해당 cpu는 q.s로 기록된다.
- __schedule() -> rcu_note_context_switch() -> rcu_qs()
- context switch 발생 시 해당 cpu는 q.s로 기록된다.
- 유저 모드 또는 idle 중 스케줄 틱
- 가장 바깥 쪽 rcu read-side critical section을 벗어났고(rcu_read_lock_nesting 카운터가 0), preempt 및 bh 등이 enable된 경우 해당 cpu는 q.s로 보고된다.
- update_process_times() -> rcu_sched_clock_irq() -> rcu_flavor_sched_clock_irq() -> rcu_qs()
- 가장 바깥 쪽 rcu read-side critical section을 벗어났고(rcu_read_lock_nesting 카운터가 0), preempt 및 bh 등이 enable된 경우 해당 cpu는 q.s로 보고된다.
- deferred qs에서 스케줄 틱
- gp 시작 후 1초 이상 지난 deferred qs의 경우 해당 cpu는 q.s로 기록한다.
- update_process_times() -> rcu_sched_clock_irq() -> rcu_flavor_sched_clock_irq() -> rcu_preempt_deferred_qs() -> rcu_preempt_deferred_qs_irqrestore() -> rcu_qs()
- gp 시작 후 1초 이상 지난 deferred qs의 경우 해당 cpu는 q.s로 기록한다.
- softirqd 실행 중
- 현재 cpu에서 동작 중인 태스크가 softirqd인 경우 qs로 기록된다.
- __do_softirq() -> rcu_softirq_qs() -> rcu_qs()
- 참고: rcu: Apply RCU-bh QSes to RCU-sched and RCU-preempt when safe (2018, v4.20-rc1)
- rcu_read_unlock()의 special 케이스
- rcu_read_unlock_special() -> rcu_preempt_deferred_qs_irqrestore() -> rcu_qs()
QS 보고
기록된 qs를 보고하는 곳은 다음과 같다.
정규 체크 시 보고
- rcu 코어의 qs 체크 루틴을 통해 기록된 qs의 정규 보고
- rcu_core() -> rcu_check_quiescent_state() -> rcu_report_qs_rdp() -> rcu_report_qs_rnp()
deferred qs 시 보고
irq/bh/preempt 모두 enable 된 상태인 경우 deferred qs를 해제하고, 태스크가 blocked 상태인 경우 blocked 상태도 해제하고 qs를 보고한다. 함수 처리는 다음과 같다.
- rcu_preempt_deferred_qs() -> rcu_preempt_deferred_qs_irqrestore() -> rcu_report_unblock_qs_rnp()
deferred qs를 처리하는 곳은 다음과 같이 여러 곳에서 수행된다.
- rcu 코어
- rcu_core() -> rcu_preempt_deferred_qs()
- 스케줄 틱
- rcu_flavor_sched_clock_irq() -> rcu_preempt_deferred_qs()
- rcu_read_unlock()의 special 케이스
- rcu_read_unlock_special() -> rcu_preempt_deferred_qs_irqrestore()
- softirqd에서 softirq 처리후
- rcu_softirq_qs() -> rcu_preempt_deferred_qs()
- context switch의 heavy_qs
- rcu_momentary_dyntick_idle() -> rcu_preempt_deferred_qs()
- voluntry 커널에서 cond_resched() 사용
- rcu_momentary_dyntick_idle() -> rcu_preempt_deferred_qs()
- nocb용 cb 커널 스레드의 콜백 처리
- rcu_momentary_dyntick_idle() -> rcu_preempt_deferred_qs()
- eqs 진입
- rcu_eqs_enter() -> rcu_preempt_deferred_qs()
- cpu offline 시
- rcu_report_dead() -> rcu_preempt_deferred_qs()
- 급행 IPI 핸들러
- rcu_exp_handler() -> rcu_preempt_deferred_qs()
- context switch
- rcu_note_context_switch() -> rcu_preempt_deferred_qs()
- 태스크 종료 시
- exit_rcu() -> rcu_preempt_deferred_qs()
qs 기록 함수
rcu_qs()
kernel/rcu/tree_plugin.h
/* * Record a preemptible-RCU quiescent state for the specified CPU. * Note that this does not necessarily mean that the task currently running * on the CPU is in a quiescent state: Instead, it means that the current * grace period need not wait on any RCU read-side critical section that * starts later on this CPU. It also means that if the current task is * in an RCU read-side critical section, it has already added itself to * some leaf rcu_node structure's ->blkd_tasks list. In addition to the * current task, there might be any number of other tasks blocked while * in an RCU read-side critical section. * * Callers to this function must disable preemption. */
static void rcu_qs(void)
{
RCU_LOCKDEP_WARN(preemptible(), "rcu_qs() invoked with preemption enabled!!!\n");
if (__this_cpu_read(rcu_data.cpu_no_qs.s)) {
trace_rcu_grace_period(TPS("rcu_preempt"),
__this_cpu_read(rcu_data.gp_seq),
TPS("cpuqs"));
__this_cpu_write(rcu_data.cpu_no_qs.b.norm, false);
barrier(); /* Coordinate with rcu_flavor_sched_clock_irq(). */
WRITE_ONCE(current->rcu_read_unlock_special.b.need_qs, false);
}
}
preemptible RCU에서 현재 cpu의 QS를 보고한다.
- 코드 라인 4~11에서 아직 현재 cpu의 qs가 체크되어 있지 않은 경우 cpu_no_qs의 norm 비트를 클리어하는 것으로 현재 cpu에 대한 qs를 체크한다. 또한 현재 태스크의 unlock special의 need_qs 비트도 클리어한다.
qs 정규 체크 및 보고
qs 체크 시 qs가 기록된 후 qs의 보고 순서는 다음 그림과 같다.
- local cpu qs 체크 -> local cpu qs 기록: rdp(rcu_data) -> 노드로 qs 보고: rnp(rcu_node) -> 글로벌로 qs 보고: rsp(rcu_state) -> gp 커널 스레드(current gp 종료)
- rnp(rcu_node)는 하이라키 구조로되어 있으므로 최상위 루트 노드까지 qs가 보고 완료되면 rsp(rcu_state)에 보고한다.
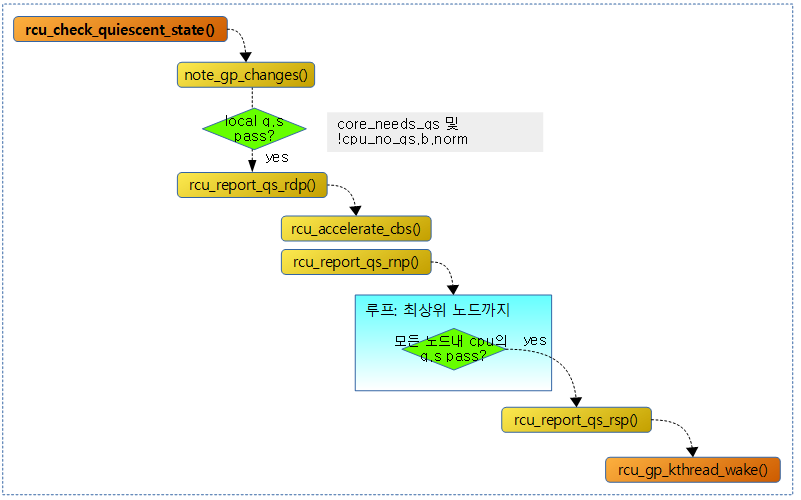
다음 그림에서는 36개의 cpu에 대한 rnp(rcu_node) 보고와 관련된 멤버 변수의 상태를 알 수 있다.
- grpmask: 현재 노드에 대응하는 상위 노드 비트
- qsmaskinit: 현재 노드가 취급하는 online cpu 비트마스크로 qs 시작할 때 마다 이 값은 qsmask에 복사된다.
- qsmask: 노드에 포함된 online cpu 비트마스크로 qs가 pass된 cpu는 0으로 클리어된다.
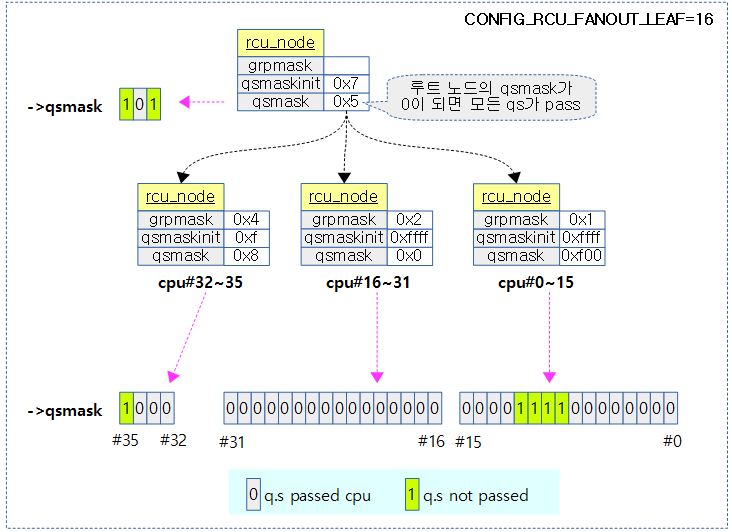
qs 체크 및 보고
rcu_check_quiescent_state()
kernel/rcu/tree.c
/* * Check to see if there is a new grace period of which this CPU * is not yet aware, and if so, set up local rcu_data state for it. * Otherwise, see if this CPU has just passed through its first * quiescent state for this grace period, and record that fact if so. */
static void
rcu_check_quiescent_state(struct rcu_data *rdp)
{
/* Check for grace-period ends and beginnings. */
note_gp_changes(rdp);
/*
* Does this CPU still need to do its part for current grace period?
* If no, return and let the other CPUs do their part as well.
*/
if (!rdp->core_needs_qs)
return;
/*
* Was there a quiescent state since the beginning of the grace
* period? If no, then exit and wait for the next call.
*/
if (rdp->cpu_no_qs.b.norm)
return;
/*
* Tell RCU we are done (but rcu_report_qs_rdp() will be the
* judge of that).
*/
rcu_report_qs_rdp(rdp->cpu, rdp);
}
현재 cpu에 대해 새 gp가 시작되었는지 체크한다. 또한 qs 상태를 체크하고 패스된 경우 rdp에 기록하여 상위 노드로 보고하게 한다.
- 코드 라인 5에서 gp가 끝나고 새로운 gp가 시작되었는지 체크한다.
- 코드 라인 11~12에서 현재 cpu에 대한 qs 체크가 필요 없으면 함수를 빠져나간다.
- 코드 라인 18~19에서 gp 시작 이후 일반 qs가 감지되지 않은 경우 함수를 빠져나간다.
- 코드 라인 25에서 현재 cpu의 qs를 보고한다.
새 gp 변화(시작) 체크
note_gp_changes()
kernel/rcu/tree.c
static void note_gp_changes(struct rcu_data *rdp)
{
unsigned long flags;
bool needwake;
struct rcu_node *rnp;
local_irq_save(flags);
rnp = rdp->mynode;
if ((rdp->gp_seq == rcu_seq_current(&rnp->gp_seq) &&
!unlikely(READ_ONCE(rdp->gpwrap))) || /* w/out lock. */
!raw_spin_trylock_rcu_node(rnp)) { /* irqs already off, so later. */
local_irq_restore(flags);
return;
}
needwake = __note_gp_changes(rnp, rdp);
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
if (needwake)
rcu_gp_kthread_wake();
}
gp가 끝나고 새로운 gp가 시작되었는지 체크한다.
- 코드 라인 9~14에서 gp 오버플로우(gpwrap) 없이 gp 시퀀스가 이미 갱신된 상태이거나 노드 락을 획득하지 못하는 경우 다음 기회를 위해 함수를 빠져나간다.
- 코드 라인 15~18에서 gp가 끝나고 새로운 gp가 시작되었는지 체크한다. 그러한 경우 gp kthread를 깨운다.
__note_gp_changes()
kernel/rcu/tree.c
/* * Update CPU-local rcu_data state to record the beginnings and ends of * grace periods. The caller must hold the ->lock of the leaf rcu_node * structure corresponding to the current CPU, and must have irqs disabled. * Returns true if the grace-period kthread needs to be awakened. */
static bool __note_gp_changes(struct rcu_node *rnp, struct rcu_data *rdp)
{
bool ret = false;
bool need_gp;
const bool offloaded = IS_ENABLED(CONFIG_RCU_NOCB_CPU) &&
rcu_segcblist_is_offloaded(&rdp->cblist);
raw_lockdep_assert_held_rcu_node(rnp);
if (rdp->gp_seq == rnp->gp_seq)
return false; /* Nothing to do. */
/* Handle the ends of any preceding grace periods first. */
if (rcu_seq_completed_gp(rdp->gp_seq, rnp->gp_seq) ||
unlikely(READ_ONCE(rdp->gpwrap))) {
if (!offloaded)
ret = rcu_advance_cbs(rnp, rdp); /* Advance CBs. */
trace_rcu_grace_period(rcu_state.name, rdp->gp_seq, TPS("cpuend"));
} else {
if (!offloaded)
ret = rcu_accelerate_cbs(rnp, rdp); /* Recent CBs. */
}
/* Now handle the beginnings of any new-to-this-CPU grace periods. */
if (rcu_seq_new_gp(rdp->gp_seq, rnp->gp_seq) ||
unlikely(READ_ONCE(rdp->gpwrap))) {
/*
* If the current grace period is waiting for this CPU,
* set up to detect a quiescent state, otherwise don't
* go looking for one.
*/
trace_rcu_grace_period(rcu_state.name, rnp->gp_seq, TPS("cpustart"));
need_gp = !!(rnp->qsmask & rdp->grpmask);
rdp->cpu_no_qs.b.norm = need_gp;
rdp->core_needs_qs = need_gp;
zero_cpu_stall_ticks(rdp);
}
rdp->gp_seq = rnp->gp_seq; /* Remember new grace-period state. */
if (ULONG_CMP_LT(rdp->gp_seq_needed, rnp->gp_seq_needed) || rdp->gpwrap)
rdp->gp_seq_needed = rnp->gp_seq_needed;
WRITE_ONCE(rdp->gpwrap, false);
rcu_gpnum_ovf(rnp, rdp);
return ret;
}
gp가 끝나고 새로운 gp가 시작되었는지 체크한다. 결과가 1인 경우 새 gp 시작이 필요하다는 의미이다.
- 코드 라인 5~6에서 콜백 오프로드 상태인지 여부를 알아온다.
- 코드 라인 10~11에서 해당 cpu의 gp 시퀀스가 이미 갱신된 상태인 경우 함수를 빠져나간다.
- 코드 라인 14~22에서 해당 cpu의 gp 시퀀스가 이미 완료된 경우 오프로드되지 않은 경우에 대해 미리 advance(cascade) 또는 acceleration 처리를 수행한다.
- 코드 라인 27~39에서 해당 cpu의 gp 시퀀스가 새롭게 시작하거나 오버플로우(gpwrap)된 경우 현재 cpu의 qs 필요 및 상태를 갱신한다.
- 코드 라인 40에서 해당 cpu의 gp 시퀀스를 갱신한다.
- 코드 라인 41~42에서 해당 cpu의 gp 시퀀스 요청을 갱신한다.
- 코드 라인 43에서 gp 시퀀스 오버플로우(gpwrap)을 false로 클리어한 후 다시 한 번 오버플로우 체크를 수행한다.
gp 시퀀스 오버플로우 체크
rcu_gpnum_ovf()
kernel/rcu/tree.c
/* * We are reporting a quiescent state on behalf of some other CPU, so * it is our responsibility to check for and handle potential overflow * of the rcu_node ->gp_seq counter with respect to the rcu_data counters. * After all, the CPU might be in deep idle state, and thus executing no * code whatsoever. */
static void rcu_gpnum_ovf(struct rcu_node *rnp, struct rcu_data *rdp)
{
raw_lockdep_assert_held_rcu_node(rnp);
if (ULONG_CMP_LT(rcu_seq_current(&rdp->gp_seq) + ULONG_MAX / 4,
rnp->gp_seq))
WRITE_ONCE(rdp->gpwrap, true);
if (ULONG_CMP_LT(rdp->rcu_iw_gp_seq + ULONG_MAX / 4, rnp->gp_seq))
rdp->rcu_iw_gp_seq = rnp->gp_seq + ULONG_MAX / 4;
}
해당 cpu의 gp 시퀀스와 노드 간에 간격이 너무 넓어 오버플로우 여부를 확인한다.
- 코드 라인 4~6에서 해당 cpu의 gp 시퀀스가 노드의 gp 시퀀스보다 ulong/4 이상 느린 경우 오버플로우를 설정한다.
- nohz로 인해 cpu의 gp 시퀀스는 갱신을 오랫동안 하지 못할 수 있다. 그래도 64 비트 시스템에서는 gp 시퀀스가 64비트를 사용하므로 발생할 일이 거의 없다고 봐야 한다.
- 코드 라인 7~8에서 rcu_iw_gp_seq 에는 gp 시퀀스가 오버플로우될 예정인 한계 값이 담겨있다. 노드의 gp 시퀀스가 이를 넘어서는 경우 이 값을 갱신한다.
rdp(cpu)에 qs 보고
rcu_report_qs_rdp()
kernel/rcu/tree.c
/* * Record a quiescent state for the specified CPU to that CPU's rcu_data * structure. This must be called from the specified CPU. */
static void
rcu_report_qs_rdp(int cpu, struct rcu_data *rdp)
{
unsigned long flags;
unsigned long mask;
bool needwake = false;
const bool offloaded = IS_ENABLED(CONFIG_RCU_NOCB_CPU) &&
rcu_segcblist_is_offloaded(&rdp->cblist);
struct rcu_node *rnp;
rnp = rdp->mynode;
raw_spin_lock_irqsave_rcu_node(rnp, flags);
if (rdp->cpu_no_qs.b.norm || rdp->gp_seq != rnp->gp_seq ||
rdp->gpwrap) {
/*
* The grace period in which this quiescent state was
* recorded has ended, so don't report it upwards.
* We will instead need a new quiescent state that lies
* within the current grace period.
*/
rdp->cpu_no_qs.b.norm = true; /* need qs for new gp. */
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
return;
}
mask = rdp->grpmask;
rdp->core_needs_qs = false;
if ((rnp->qsmask & mask) == 0) {
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
} else {
/*
* This GP can't end until cpu checks in, so all of our
* callbacks can be processed during the next GP.
*/
if (!offloaded)
needwake = rcu_accelerate_cbs(rnp, rdp);
rcu_report_qs_rnp(mask, rnp, rnp->gp_seq, flags);
/* ^^^ Released rnp->lock */
if (needwake)
rcu_gp_kthread_wake();
}
}
로컬 qs 상태가 pass된 경우 노드에 보고한다.
- 코드 라인 7~8에서 콜백 오프로드 상태인지 여부를 알아온다.
- 코드 라인 11~25에서 해당 cpu의 노드 락을 획득하고 다음 3 조건 중 하나에 해당하는 경우 qs를 계속 체크해야 하는 상황이다. qs를 클리어한 후 함수를 빠져나간다.
- 아직 일반 qs가 체크되지 않은 경우
- cpu의 gp 시퀀스가 갱신되지 않은 경우(새 gp 시작)
- gp 시퀀스가 오버플로우 상태인 경우
- 코드 라인 27에서 해당 cpu의 qs 체크가 완료되어 보고할 예정이므로 rdp->core_needs_qs에 false를 대입하여 다음엔 qs 체크 및 보고를 하지 않도록 한다.
- 코드 라인 28~29에서 해당 cpu의 qs가 이미 노드에 보고된 경우엔 노드락을 풀고 함수를 빠져나간다.
- 코드 라인 30~42에서 콜백 오프로드가 아닌 경우 acceleration 처리를 한 후 노드에 qs를 보고한다. 그 후 필요 시 gp 스레드를 깨운다.
rnp(노드)에 qs 보고
rcu_report_qs_rnp()
kernel/rcu/tree.c
/* * Similar to rcu_report_qs_rdp(), for which it is a helper function. * Allows quiescent states for a group of CPUs to be reported at one go * to the specified rcu_node structure, though all the CPUs in the group * must be represented by the same rcu_node structure (which need not be a * leaf rcu_node structure, though it often will be). The gps parameter * is the grace-period snapshot, which means that the quiescent states * are valid only if rnp->gp_seq is equal to gps. That structure's lock * must be held upon entry, and it is released before return. * * As a special case, if mask is zero, the bit-already-cleared check is * disabled. This allows propagating quiescent state due to resumed tasks * during grace-period initialization. */
static void rcu_report_qs_rnp(unsigned long mask, struct rcu_node *rnp,
unsigned long gps, unsigned long flags)
__releases(rnp->lock)
{
unsigned long oldmask = 0;
struct rcu_node *rnp_c;
raw_lockdep_assert_held_rcu_node(rnp);
/* Walk up the rcu_node hierarchy. */
for (;;) {
if ((!(rnp->qsmask & mask) && mask) || rnp->gp_seq != gps) {
/*
* Our bit has already been cleared, or the
* relevant grace period is already over, so done.
*/
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
return;
}
WARN_ON_ONCE(oldmask); /* Any child must be all zeroed! */
WARN_ON_ONCE(!rcu_is_leaf_node(rnp) &&
rcu_preempt_blocked_readers_cgp(rnp));
rnp->qsmask &= ~mask;
trace_rcu_quiescent_state_report(rcu_state.name, rnp->gp_seq,
mask, rnp->qsmask, rnp->level,
rnp->grplo, rnp->grphi,
!!rnp->gp_tasks);
if (rnp->qsmask != 0 || rcu_preempt_blocked_readers_cgp(rnp)) {
/* Other bits still set at this level, so done. */
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
return;
}
rnp->completedqs = rnp->gp_seq;
mask = rnp->grpmask;
if (rnp->parent == NULL) {
/* No more levels. Exit loop holding root lock. */
break;
}
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
rnp_c = rnp;
rnp = rnp->parent;
raw_spin_lock_irqsave_rcu_node(rnp, flags);
oldmask = rnp_c->qsmask;
}
/*
* Get here if we are the last CPU to pass through a quiescent
* state for this grace period. Invoke rcu_report_qs_rsp()
* to clean up and start the next grace period if one is needed.
*/
rcu_report_qs_rsp(flags); /* releases rnp->lock. */
}
현재 cpu의 qs가 완료되어 소속된 노드부터 최상위 노드까지 보고한다. 최상위 노드에서 모든 cpu의 qs가 완료되었음을 인식하면 gp 커널 스레드를 깨워 새로운 gp를 시작하게 한다.
- 코드 라인 11~20에서 최상위 노드까지 루프를 돌며, 노드에 이미 qs 체크되었거나 새 gp 시퀀스가 시작된 경우 루프를 벗어난다.
- 코드 라인 24에서 순회중인 노드의 qsmask에서 @mask에 해당하는 비트를 클리어한다.
- 코드 라인 29~34에서 순회 중인 노드의 qsmask에서 비트 클리어 후 아직 남아있는 비트가 있거나 노드에 블럭된 rcu reader 태스크가 있는 경우 노드 락을 풀고 함수를 벗어난다.
- 코드 라인 35에서 노드의 완료 시퀀스 rnp->completedqs를 갱신한다.
- 코드 라인 36에서 상위 노드에서 사용하기 위해 현재 노드의 그룹 마스크 rnp->grpmask를 mask에 대입해둔다.
- 코드 라인 37~42에서 상위 노드가 없는 경우 루프를 벗어난다.
- 코드 라인 43~48에서 순회 중인 노드 락을 해제하고, 상위 노드를 선택하여 루프를 계속한다.
- 코드 라인 55에서 최상위 노드까지 모든 qs가 끝났으므로 rsp에 보고한다.
rsp에 qs 보고
rcu_report_qs_rsp()
kernel/rcu/tree.c
/*
* Report a full set of quiescent states to the specified rcu_state
* data structure. This involves cleaning up after the prior grace
* period and letting rcu_start_gp() start up the next grace period
* if one is needed. Note that the caller must hold rnp->lock, which
* is released before return.
*/
static void rcu_report_qs_rsp(unsigned long flags)
__releases(rcu_get_root(rsp)->lock)
{
raw_lockdep_assert_held_rcu_node(rcu_get_root());
WARN_ON_ONCE(!rcu_gp_in_progress());
WRITE_ONCE(rcu_state.gp_flags,
READ_ONCE(rcu_state.gp_flags) | RCU_GP_FLAG_FQS);
raw_spin_unlock_irqrestore_rcu_node(rcu_get_root(), flags);
rcu_gp_kthread_wake();
}
모든 qs가 pass되었으므로 gp를 갱신하기 위해 gp 커널 스레드를 깨워 새로운 gp를 시작하게 한다.
- gp_flags에 RCU_GP_FLAG_FQS(2)를 추가한 후 cb용 gp 커널 스레드를 깨운다.
Force Quiescent State
대기 중인 콜백이 제한된 수(디폴트=10000) 이상으로 너무 많은 상태에서 gp 시퀀스가 변화가 없으면 다음 상황을 qs로 강제(forcing) 처리한다.
- eqs(extended qs) 상태에 있는 cpu
- nohz idle 진입 상태인 cpu
- nohz full 유저 태스크가 동작 중인 cpu
- gp 시작 후 1초 이상 지난 offline cpu
fqs 요청
force_quiescent_state()
kernel/rcu/tree.c
/* * Force quiescent states on reluctant CPUs, and also detect which * CPUs are in dyntick-idle mode. */
void rcu_force_quiescent_state(void)
{
unsigned long flags;
bool ret;
struct rcu_node *rnp;
struct rcu_node *rnp_old = NULL;
/* Funnel through hierarchy to reduce memory contention. */
rnp = __this_cpu_read(rcu_data.mynode);
for (; rnp != NULL; rnp = rnp->parent) {
ret = (READ_ONCE(rcu_state.gp_flags) & RCU_GP_FLAG_FQS) ||
!raw_spin_trylock(&rnp->fqslock);
if (rnp_old != NULL)
raw_spin_unlock(&rnp_old->fqslock);
if (ret)
return;
rnp_old = rnp;
}
/* rnp_old == rcu_get_root(), rnp == NULL. */
/* Reached the root of the rcu_node tree, acquire lock. */
raw_spin_lock_irqsave_rcu_node(rnp_old, flags);
raw_spin_unlock(&rnp_old->fqslock);
if (READ_ONCE(rcu_state.gp_flags) & RCU_GP_FLAG_FQS) {
raw_spin_unlock_irqrestore_rcu_node(rnp_old, flags);
return; /* Someone beat us to it. */
}
WRITE_ONCE(rcu_state.gp_flags,
READ_ONCE(rcu_state.gp_flags) | RCU_GP_FLAG_FQS);
raw_spin_unlock_irqrestore_rcu_node(rnp_old, flags);
rcu_gp_kthread_wake();
}
EXPORT_SYMBOL_GPL(rcu_force_quiescent_state);
force quiescent state를 진행시켜 기존 gp를 종료시키고 새로운 gp를 시작하기 위해 시도한다.
- 코드 라인 9~18에서 요청한 cpu에 해당하는 노드에서 최상위 루트 노드까지 상위로 올라가면서 fqs 락 획득과 해제를 시도한다. 만일 다른 cpu로부터 노드에 이미 fqs 락을 걸어 로컬 cpu에서 락의 획득이 실패하였거나 다른 cpu에서 RCU_GP_FLAG_FQS 플래그를 이미 설정하여 Force Quiescent State를 처리하고 있는 경우 함수를 빠져나간다.
- 코드 라인 22~23에서 최상위 루트 노드에서 스핀락을 얻은 후 fqs 락을 푼다.
- 코드 라인 24~27에서 다시 한 번 최종 확인하는 것으로 최상위 노드에 이미 RCU_GP_FLAG_FQS 비트가 설정된 경우 함수를 빠져나간다.
- 코드 라인 28~31에서 fqs를 하기 위해 RCU_GP_FLAG_FQS 비트를 설정하고 최상위 노드의 스핀락을 해제한 후 gp 커널 스레드를 깨워 fqs를 진행하도록 요청한다.
fqs 진행(by cb용 gp kthread)
rcu_gp_fqs()
kernel/rcu/tree.c
/* * Do one round of quiescent-state forcing. */
static void rcu_gp_fqs(bool first_time)
{
struct rcu_node *rnp = rcu_get_root();
WRITE_ONCE(rcu_state.gp_activity, jiffies);
rcu_state.n_force_qs++;
if (first_time) {
/* Collect dyntick-idle snapshots. */
force_qs_rnp(dyntick_save_progress_counter);
} else {
/* Handle dyntick-idle and offline CPUs. */
force_qs_rnp(rcu_implicit_dynticks_qs);
}
/* Clear flag to prevent immediate re-entry. */
if (READ_ONCE(rcu_state.gp_flags) & RCU_GP_FLAG_FQS) {
raw_spin_lock_irq_rcu_node(rnp);
WRITE_ONCE(rcu_state.gp_flags,
READ_ONCE(rcu_state.gp_flags) & ~RCU_GP_FLAG_FQS);
raw_spin_unlock_irq_rcu_node(rnp);
}
}
모든 처리되지 않은 qs들을 강제로 qs 패스된 것으로 처리한다. 두 가지 용도로 함수를 사용하는데
- 코드 라인 5에서 gp 상태가 변화됨에 따른 변경된 시각을 gp_activity에 기록한다.
- 코드 라인 6에서 fqs 카운터인 n_force_qs를 1 증가시킨다.
- 코드 라인 7~9에서 인자 @first_time이 true인 경우 qs 완료되지 않은 cpu에서 dyntick_save_progress_counter() 함수를 통해 eqs(extended qs)가 확인된 경우 qs를 보고한다.
- 코드 라인 10~13에서 그렇지 않은 경우 qs 완료되지 않은 cpu에서 rcu_implicit_dynticks_qs() 함수를 통해 다음 조건이 확인된 경우 qs를 보고한다.
- cpu가 eqs(extended qs) 상태인 경우
- offline cpu에서 gp 시작 후 1초 이상 경과한 경우
- 코드 라인 15~20에서 RCU_GP_FLAG_FQS 플래그를 제거한다.
다음 그림은 rcu_gp_fqs() 함수를 통해 fqs가 처리되는 과정을 보여준다.
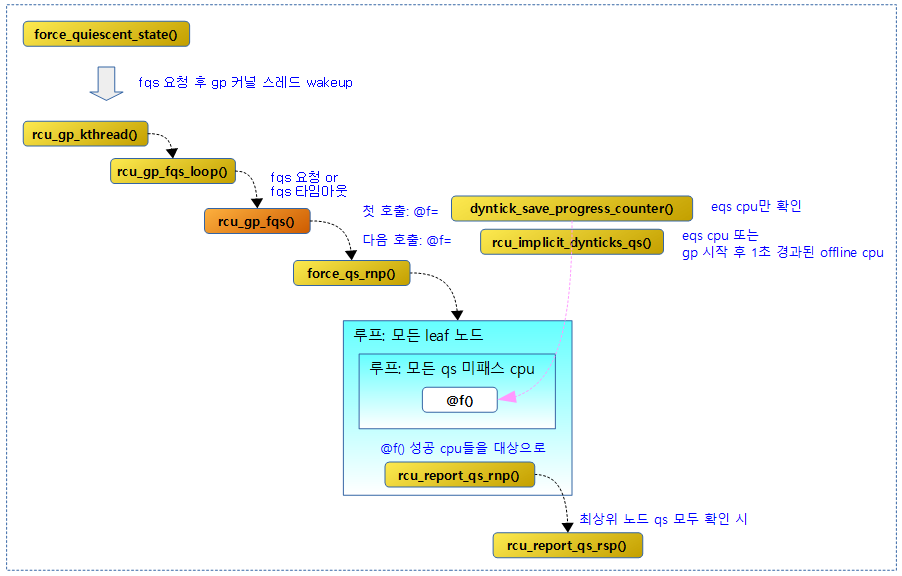
force_qs_rnp()
kernel/rcu/tree.c
/* * Scan the leaf rcu_node structures. For each structure on which all * CPUs have reported a quiescent state and on which there are tasks * blocking the current grace period, initiate RCU priority boosting. * Otherwise, invoke the specified function to check dyntick state for * each CPU that has not yet reported a quiescent state. */
static void force_qs_rnp(int (*f)(struct rcu_data *rdp))
{
int cpu;
unsigned long flags;
unsigned long mask;
struct rcu_node *rnp;
rcu_for_each_leaf_node(rnp) {
cond_resched_tasks_rcu_qs();
mask = 0;
raw_spin_lock_irqsave_rcu_node(rnp, flags);
if (rnp->qsmask == 0) {
if (!IS_ENABLED(CONFIG_PREEMPTION) ||
rcu_preempt_blocked_readers_cgp(rnp)) {
/*
* No point in scanning bits because they
* are all zero. But we might need to
* priority-boost blocked readers.
*/
rcu_initiate_boost(rnp, flags);
/* rcu_initiate_boost() releases rnp->lock */
continue;
}
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
continue;
}
for_each_leaf_node_possible_cpu(rnp, cpu) {
unsigned long bit = leaf_node_cpu_bit(rnp, cpu);
if ((rnp->qsmask & bit) != 0) {
if (f(per_cpu_ptr(&rcu_data, cpu)))
mask |= bit;
}
}
if (mask != 0) {
/* Idle/offline CPUs, report (releases rnp->lock). */
rcu_report_qs_rnp(mask, rnp, rnp->gp_seq, flags);
} else {
/* Nothing to do here, so just drop the lock. */
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
}
}
}
leaf 노드들의 qs 미완료 cpu들을 대상으로 인자로 전달 받은 함수를 호출하여 결과가 true인 cpu들을 강제로 qs 체크된 것으로 보고한다. 인자로 따라오는 함수는 다음과 같다.
- dyntick_save_progress_counter()
- fqs 처리를 위해 처음 호출될 때 이 함수가 지정되는데 이는 idle(eqs) cpu 여부를 반환하는 함수이다.
- rcu_implicit_dynticks_qs()
- fqs 처리를 위해 그 다음부터 호출될 때 이 함수가 지정되는데 이는 idle(eqs) 또는 offline cpu 여부를 반환하는 함수이다.
- 코드 라인 8~9에서 모든 leaf 노드들을 대상으로 순회하며 현재 태스크의 rcu_tasks_holdout 플래그를 클리어한다.
- 우선 리스케줄링 요청이 없는 경우 현재 cpu의 rcu_qs_ctr을 1 증가시킨다. 또한 nohz idle을 위해 qs가 pass된 상태이면 rcu core가 알 수 있도록 한다.
- 코드 라인 12~26에서 이미 qs가 모두 처리된 노드는 skip 한다. 또한 non-preemption 커널 모델이거나 순회 중인 노드에 rcu reader에서 블럭된 태스크들이 있는 경우 boost 한다.
- 코드 라인 27~33에서 순회 중인 노드에 포함된 possible cpu들에 대해 순회하며 인자로 전달받은 함수 @f를 호출하여 결과가 true인 경우 mask에 해당 cpu 비트를 추가한다.
- 코드 라인 34~40에서 qs 완료로 판정한(@f() 결과가 true) cpu들을 노드에 보고한다.
idle, user, nmi, irq 진출입에서의 rcu 처리
idle & user 진출입에서의 rcu 처리 관련
다음 그림은 idle 및 유저 모드 진출입시 rcu를 처리하기 위한 함수 호출 관계를 보여준다.
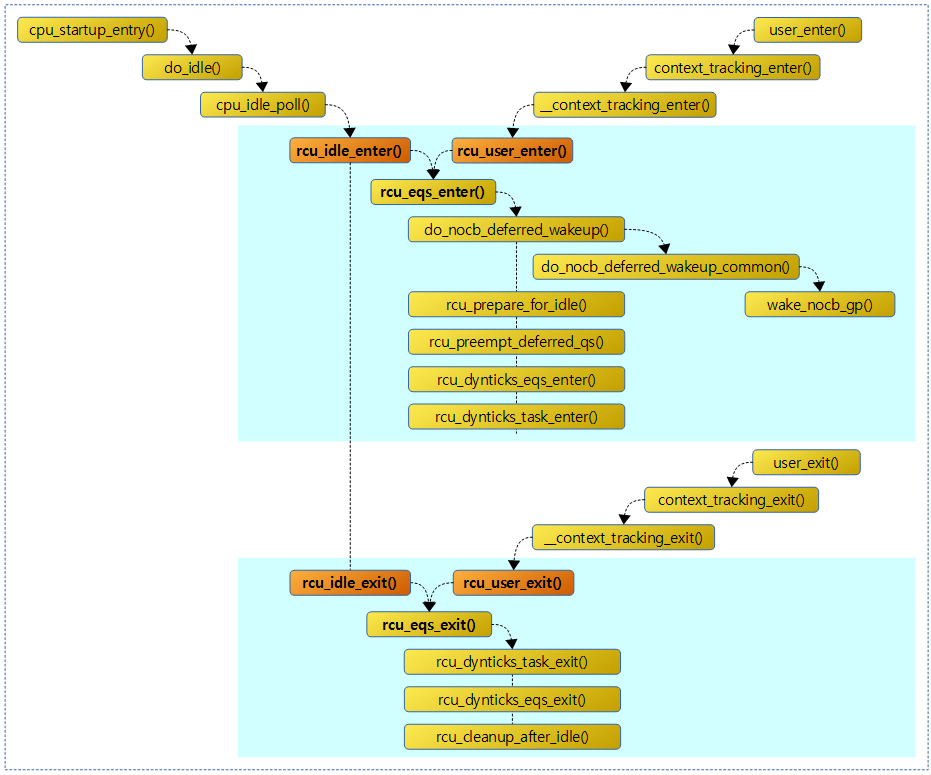
rcu_idle_enter()
kernel/rcu/tree.c
/** * rcu_idle_enter - inform RCU that current CPU is entering idle * * Enter idle mode, in other words, -leave- the mode in which RCU * read-side critical sections can occur. (Though RCU read-side * critical sections can occur in irq handlers in idle, a possibility * handled by irq_enter() and irq_exit().) * * If you add or remove a call to rcu_idle_enter(), be sure to test with * CONFIG_RCU_EQS_DEBUG=y. */
void rcu_idle_enter(void)
{
lockdep_assert_irqs_disabled();
rcu_eqs_enter();
}
해당 cpu가 idle 모드에 진입할 때의 rcu 처리를 수행한다.
- idle 스케줄러: cpu_startup_entry() -> do_idle()
- -> cpu_idle_poll() -> rcu_idle_enter()
- -> cpuidle_idle_call() -> rcu_idle_enter()
rcu_idle_exit()
kernel/rcu/tree.c
/** * rcu_idle_exit - inform RCU that current CPU is leaving idle * * Exit idle mode, in other words, -enter- the mode in which RCU * read-side critical sections can occur. * * If you add or remove a call to rcu_idle_exit(), be sure to test with * CONFIG_RCU_EQS_DEBUG=y. */
void rcu_idle_exit(void)
{
unsigned long flags;
local_irq_save(flags);
rcu_eqs_exit(false);
local_irq_restore(flags);
}
해당 cpu가 idle 모드에서 벗어날 때의 rcu 처리를 수행한다.
- idle 스케줄러: cpu_startup_entry() -> do_idle()
- -> cpu_idle_poll() -> rcu_idle_exit()
- -> cpuidle_idle_call() -> rcu_idle_exit()
rcu_user_enter() – nohz full
kernel/rcu/tree.c
/** * rcu_user_enter - inform RCU that we are resuming userspace. * * Enter RCU idle mode right before resuming userspace. No use of RCU * is permitted between this call and rcu_user_exit(). This way the * CPU doesn't need to maintain the tick for RCU maintenance purposes * when the CPU runs in userspace. * * If you add or remove a call to rcu_user_enter(), be sure to test with * CONFIG_RCU_EQS_DEBUG=y. */
void rcu_user_enter(void)
{
lockdep_assert_irqs_disabled();
rcu_eqs_enter(true);
}
해당 cpu가 user 모드에 진입할 때의 rcu 처리를 수행한다.
- ct_user_enter() -> context_tracking_user_enter() -> user_enter() -> context_tracking_enter() -> __context_tracking_enter() -> rcu_user_enter()
rcu_user_exit() – nohz full
kernel/rcu/tree.cㄷ
/** * rcu_user_exit - inform RCU that we are exiting userspace. * * Exit RCU idle mode while entering the kernel because it can * run a RCU read side critical section anytime. * * If you add or remove a call to rcu_user_exit(), be sure to test with * CONFIG_RCU_EQS_DEBUG=y. */
void rcu_user_exit(void)
{
rcu_eqs_exit(1);
}
해당 cpu가 user 모드에서 벗어날 때의 rcu 처리를 수행한다.
- ct_user_exit() -> context_tracking_user_exit() -> user_exit() -> context_tracking_exit() -> __context_tracking_exit() -> rcu_user_exit()
인터럽트에서의 rcu 처리 관련
다음 그림은 인터럽트 진출입에서 rcu를 처리하기 위한 함수 호출 관계를 보여준다.
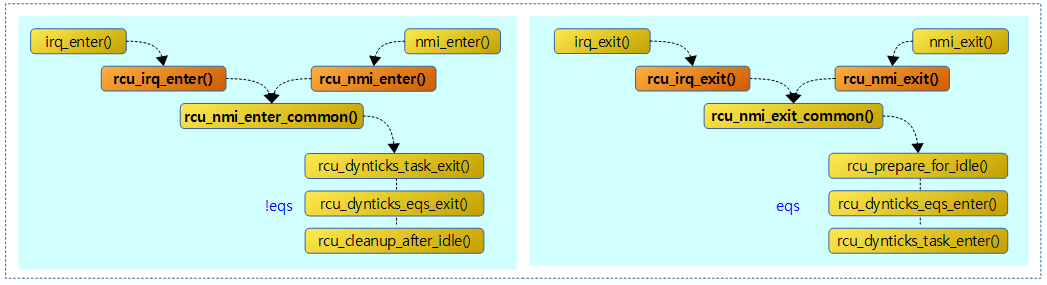
rcu_nmi_enter()
kernel/rcu/tree.c
/** * rcu_nmi_enter - inform RCU of entry to NMI context */
void rcu_nmi_enter(void)
{
rcu_nmi_enter_common(false);
}
NOKPROBE_SYMBOL(rcu_nmi_enter);
cpu가 nmi에 진입 시 rcu에서 할 일을 처리한다.
rcu_nmi_exit()
kernel/rcu/tree.c
/** * rcu_nmi_exit - inform RCU of exit from NMI context * * If you add or remove a call to rcu_nmi_exit(), be sure to test * with CONFIG_RCU_EQS_DEBUG=y. */
void rcu_nmi_exit(void)
{
rcu_nmi_exit_common(false);
}
cpu가 nmi로부터 복귀 전에 rcu에서 할 일을 처리한다.
rcu_irq_enter()
kernel/rcu/tree.c
/** * rcu_irq_enter - inform RCU that current CPU is entering irq away from idle * * Enter an interrupt handler, which might possibly result in exiting * idle mode, in other words, entering the mode in which read-side critical * sections can occur. The caller must have disabled interrupts. * * Note that the Linux kernel is fully capable of entering an interrupt * handler that it never exits, for example when doing upcalls to user mode! * This code assumes that the idle loop never does upcalls to user mode. * If your architecture's idle loop does do upcalls to user mode (or does * anything else that results in unbalanced calls to the irq_enter() and * irq_exit() functions), RCU will give you what you deserve, good and hard. * But very infrequently and irreproducibly. * * Use things like work queues to work around this limitation. * * You have been warned. * * If you add or remove a call to rcu_irq_enter(), be sure to test with * CONFIG_RCU_EQS_DEBUG=y. */
void rcu_irq_enter(void)
{
lockdep_assert_irqs_disabled();
rcu_nmi_enter_common(true);
}
cpu가 인터럽트에 진입 시 rcu에서 할 일을 처리한다.
rcu_irq_exit()
kernel/rcu/tree.c
/** * rcu_irq_exit - inform RCU that current CPU is exiting irq towards idle * * Exit from an interrupt handler, which might possibly result in entering * idle mode, in other words, leaving the mode in which read-side critical * sections can occur. The caller must have disabled interrupts. * * This code assumes that the idle loop never does anything that might * result in unbalanced calls to irq_enter() and irq_exit(). If your * architecture's idle loop violates this assumption, RCU will give you what * you deserve, good and hard. But very infrequently and irreproducibly. * * Use things like work queues to work around this limitation. * * You have been warned. * * If you add or remove a call to rcu_irq_exit(), be sure to test with * CONFIG_RCU_EQS_DEBUG=y. */
void rcu_irq_exit(void)
{
lockdep_assert_irqs_disabled();
rcu_nmi_exit_common(true);
}
cpu가 인터럽트로부터 복귀 전에 rcu에서 할 일을 처리한다.
rcu_nmi_enter_common()
kernel/rcu/tree.c
/** * rcu_nmi_enter_common - inform RCU of entry to NMI context * @irq: Is this call from rcu_irq_enter? * * If the CPU was idle from RCU's viewpoint, update rdp->dynticks and * rdp->dynticks_nmi_nesting to let the RCU grace-period handling know * that the CPU is active. This implementation permits nested NMIs, as * long as the nesting level does not overflow an int. (You will probably * run out of stack space first.) * * If you add or remove a call to rcu_nmi_enter_common(), be sure to test * with CONFIG_RCU_EQS_DEBUG=y. */
static __always_inline void rcu_nmi_enter_common(bool irq)
{
struct rcu_data *rdp = this_cpu_ptr(&rcu_data);
long incby = 2;
/* Complain about underflow. */
WARN_ON_ONCE(rdp->dynticks_nmi_nesting < 0);
/*
* If idle from RCU viewpoint, atomically increment ->dynticks
* to mark non-idle and increment ->dynticks_nmi_nesting by one.
* Otherwise, increment ->dynticks_nmi_nesting by two. This means
* if ->dynticks_nmi_nesting is equal to one, we are guaranteed
* to be in the outermost NMI handler that interrupted an RCU-idle
* period (observation due to Andy Lutomirski).
*/
if (rcu_dynticks_curr_cpu_in_eqs()) {
if (irq)
rcu_dynticks_task_exit();
rcu_dynticks_eqs_exit();
if (irq)
rcu_cleanup_after_idle();
incby = 1;
}
trace_rcu_dyntick(incby == 1 ? TPS("Endirq") : TPS("++="),
rdp->dynticks_nmi_nesting,
rdp->dynticks_nmi_nesting + incby, rdp->dynticks);
WRITE_ONCE(rdp->dynticks_nmi_nesting, /* Prevent store tearing. */
rdp->dynticks_nmi_nesting + incby);
barrier();
}
cpu가 nmi 및 irq 진입 후 rcu에서 할 일을 처리한다.
- 코드 라인 17~28에서 cpu가 eqs 상태인 경우 eqs를 벗어난다. 단 nmi가 아닌 irq에서 진입한 경우 eqs를 벗어나기 전에 현재 태스크의 rcu_tasks_idle_cpu 멤버에서 cpu 지정을 클리어하기 위해 -1을 대입한다.
- 코드 라인 32~33에서 cpu가 eqs 상태였었던 경우 rdp->dynticks_nmi_nesting 값을 1 증가시키고, 그렇지 않은 경우 2 증가시킨다.
rcu_nmi_exit_common()
kernel/rcu/tree.c
/* * If we are returning from the outermost NMI handler that interrupted an * RCU-idle period, update rdp->dynticks and rdp->dynticks_nmi_nesting * to let the RCU grace-period handling know that the CPU is back to * being RCU-idle. * * If you add or remove a call to rcu_nmi_exit_common(), be sure to test * with CONFIG_RCU_EQS_DEBUG=y. */
static __always_inline void rcu_nmi_exit_common(bool irq)
{
struct rcu_data *rdp = this_cpu_ptr(&rcu_data);
/*
* Check for ->dynticks_nmi_nesting underflow and bad ->dynticks.
* (We are exiting an NMI handler, so RCU better be paying attention
* to us!)
*/
WARN_ON_ONCE(rdp->dynticks_nmi_nesting <= 0);
WARN_ON_ONCE(rcu_dynticks_curr_cpu_in_eqs());
/*
* If the nesting level is not 1, the CPU wasn't RCU-idle, so
* leave it in non-RCU-idle state.
*/
if (rdp->dynticks_nmi_nesting != 1) {
trace_rcu_dyntick(TPS("--="), rdp->dynticks_nmi_nesting, rdp->dynticks_nmi_nesting - 2, rdp->dynticks);
WRITE_ONCE(rdp->dynticks_nmi_nesting, /* No store tearing. */
rdp->dynticks_nmi_nesting - 2);
return;
}
/* This NMI interrupted an RCU-idle CPU, restore RCU-idleness. */
trace_rcu_dyntick(TPS("Startirq"), rdp->dynticks_nmi_nesting, 0, rdp->dynticks);
WRITE_ONCE(rdp->dynticks_nmi_nesting, 0); /* Avoid store tearing. */
if (irq)
rcu_prepare_for_idle();
rcu_dynticks_eqs_enter();
if (irq)
rcu_dynticks_task_enter();
}
cpu가 nmi 및 irq 복귀 전 rcu에서 할 일을 처리한다.
- 코드 라인 17~22에서 rdp->dynticks_nmi_nesting이 1이 아닌 경우 2만 큼 감소시키고 함수를 빠져나간다.
- 코드 라인 26에서 rdp->dynticks_nmi_nesting을 0으로 초기화한다.
- 코드 라인 28~34에서 irq 복귀전인 경우 cpu가 idle 진입 전에 남은 non-lazy rcu 콜백들을 호출하여 처리한다.
- 코드 라인 31에서 cpu를 eqs 상태로 변경한다.
- 코드 라인 33~34에서 irq 복귀전인 경우 현재 태스크의 rcu_tasks_idle_cpu 멤버에 현재 cpu를 기록한다.
Extended QS
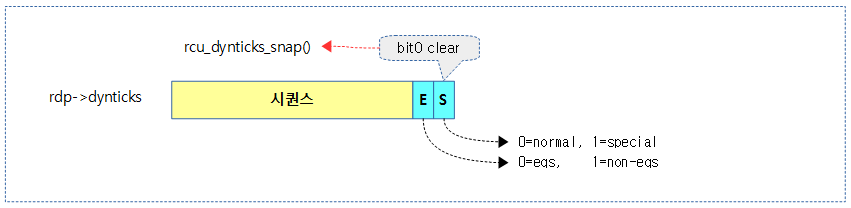
다음 그림은 idle(eqs)의 시퀀스 값 및 하위 두 비트를 보여준다.
rcu_eqs_enter()
kernel/rcu/tree.c
/* * Enter an RCU extended quiescent state, which can be either the * idle loop or adaptive-tickless usermode execution. * * We crowbar the ->dynticks_nmi_nesting field to zero to allow for * the possibility of usermode upcalls having messed up our count * of interrupt nesting level during the prior busy period. */
static void rcu_eqs_enter(bool user)
{
struct rcu_data *rdp = this_cpu_ptr(&rcu_data);
WARN_ON_ONCE(rdp->dynticks_nmi_nesting != DYNTICK_IRQ_NONIDLE);
WRITE_ONCE(rdp->dynticks_nmi_nesting, 0);
WARN_ON_ONCE(IS_ENABLED(CONFIG_RCU_EQS_DEBUG) &&
rdp->dynticks_nesting == 0);
if (rdp->dynticks_nesting != 1) {
rdp->dynticks_nesting--;
return;
}
lockdep_assert_irqs_disabled();
trace_rcu_dyntick(TPS("Start"), rdp->dynticks_nesting, 0, rdp->dynticks);
WARN_ON_ONCE(IS_ENABLED(CONFIG_RCU_EQS_DEBUG) && !user && !is_idle_task(current));
rdp = this_cpu_ptr(&rcu_data);
do_nocb_deferred_wakeup(rdp);
rcu_prepare_for_idle();
rcu_preempt_deferred_qs(current);
WRITE_ONCE(rdp->dynticks_nesting, 0); /* Avoid irq-access tearing. */
rcu_dynticks_eqs_enter();
rcu_dynticks_task_enter();
}
확장 qs 상태로 진입한다. @user가 true인 경우 nohz full user 모드 진입을 의미하며, false인 경우 nohz idle 모드 진입을 의미한다.
- 코드 라인 6에서 rdp->dynticks_nmi_nesting을 클리어한다.
- 코드 라인 9~12에서 이미 2 번 이상 네스팅된 경우 rdp->dynticks_nesting 값을 1 감소시키고 함수를 빠져나간다.
- 코드 라인 18에서 rdp->nocb_defer_wakeup 설정이 있는 경우 rcu_nocb_kthread를 깨운다.
- 코드 라인 19에서 cpu가 idle 진입 전에 남은 non-lazy rcu 콜백들을 호출하여 처리한다.
- 코드 라인 20에서 deferred qs를 처리한다.
- deferred qs를 해제하고, blocked 상태인 경우 blocked 해제 후 qs를 보고한다.
- 코드 라인 21에서 rdp->dynticks_nesting 값을 0으로 클리어한다.
- 코드 라인 22에서 확장 qs 상태로 기록한다.
- 코드 라인 23에서 현재 태스크의 rcu_tasks_idle_cpu 멤버에 현재 cpu를 기록한다.
rcu_eqs_exit()
kernel/rcu/tree.c
/* * Exit an RCU extended quiescent state, which can be either the * idle loop or adaptive-tickless usermode execution. * * We crowbar the ->dynticks_nmi_nesting field to DYNTICK_IRQ_NONIDLE to * allow for the possibility of usermode upcalls messing up our count of * interrupt nesting level during the busy period that is just now starting. */
static void rcu_eqs_exit(bool user)
{
struct rcu_data *rdp;
long oldval;
lockdep_assert_irqs_disabled();
rdp = this_cpu_ptr(&rcu_data);
oldval = rdp->dynticks_nesting;
WARN_ON_ONCE(IS_ENABLED(CONFIG_RCU_EQS_DEBUG) && oldval < 0);
if (oldval) {
rdp->dynticks_nesting++;
return;
}
rcu_dynticks_task_exit();
rcu_dynticks_eqs_exit();
rcu_cleanup_after_idle();
trace_rcu_dyntick(TPS("End"), rdp->dynticks_nesting, 1, rdp->dynticks);
WARN_ON_ONCE(IS_ENABLED(CONFIG_RCU_EQS_DEBUG) && !user && !is_idle_task(current));
WRITE_ONCE(rdp->dynticks_nesting, 1);
WARN_ON_ONCE(rdp->dynticks_nmi_nesting);
WRITE_ONCE(rdp->dynticks_nmi_nesting, DYNTICK_IRQ_NONIDLE);
}
확장 qs 상태를 빠져나온다. @user가 true인 경우 nohz full user 모드 퇴출을 의미하며, false인 경우 nohz idle 모드 퇴출을 의미한다.
- 코드 라인 8~13에서 이미 네스팅 중인경우 rdp->dynticks_nesting 값을 1 증가시키고 함수를 빠져나간다.
- 코드 라인 14에서 현재 태스크의 rcu_tasks_idle_cpu 멤버에서 cpu 지정을 클리어하기 위해 -1을 대입한다.
- 코드 라인 15에서 확장 qs 상태를 클리어한다.
- 코드 라인 16에서 idle에서 빠져나온 후 rcu 처리를 수행한다. 현재 빈 함수이다.
- 코드 라인 19에서 rdp->dynticks_nesting을 0에서 1로 설정한다.
- 코드 라인 21에서 rdp->dynticks_nmi_nesting 값을 DYNTICK_IRQ_NONIDLE(long max / 2 + 1)으로 설정한다.
rcu_dynticks_eqs_enter()
kernel/rcu/tree.c
/* * Record entry into an extended quiescent state. This is only to be * called when not already in an extended quiescent state. */
static void rcu_dynticks_eqs_enter(void)
{
struct rcu_data *rdp = this_cpu_ptr(&rcu_data);
int seq;
/*
* CPUs seeing atomic_add_return() must see prior RCU read-side
* critical sections, and we also must force ordering with the
* next idle sojourn.
*/
seq = atomic_add_return(RCU_DYNTICK_CTRL_CTR, &rdp->dynticks);
/* Better be in an extended quiescent state! */
WARN_ON_ONCE(IS_ENABLED(CONFIG_RCU_EQS_DEBUG) &&
(seq & RCU_DYNTICK_CTRL_CTR));
/* Better not have special action (TLB flush) pending! */
WARN_ON_ONCE(IS_ENABLED(CONFIG_RCU_EQS_DEBUG) &&
(seq & RCU_DYNTICK_CTRL_MASK));
}
확장 qs 상태로 기록한다.
- 코드 라인 11에서 rdp->dynticks += 2를 수행한다. 이 때 시퀀스 파트는 1 증가되고, ilde(eqs) 상태를 나타내는 bit1은 클리어된다.
- 코드 라인 13~14에서 변경 후 bit1은 클리어 상태여야 한다.
- 코드 라인 16~17 에서 변경 후 special 비트인 bit0은 클리어된 상태여야 한다.
다음 그림은 idle(eqs)의 진출입시 rdp->dynticks의 시퀀스 및 하위 두 비트의 변화를 보여준다.

rcu_dynticks_eqs_exit()
kernel/rcu/tree.c
/* * Record exit from an extended quiescent state. This is only to be * called from an extended quiescent state. */
static void rcu_dynticks_eqs_exit(void)
{
struct rcu_data *rdp = this_cpu_ptr(&rcu_data);
int seq;
/*
* CPUs seeing atomic_add_return() must see prior idle sojourns,
* and we also must force ordering with the next RCU read-side
* critical section.
*/
seq = atomic_add_return(RCU_DYNTICK_CTRL_CTR, &rdp->dynticks);
WARN_ON_ONCE(IS_ENABLED(CONFIG_RCU_EQS_DEBUG) &&
!(seq & RCU_DYNTICK_CTRL_CTR));
if (seq & RCU_DYNTICK_CTRL_MASK) {
atomic_andnot(RCU_DYNTICK_CTRL_MASK, &rdp->dynticks);
smp_mb__after_atomic(); /* _exit after clearing mask. */
/* Prefer duplicate flushes to losing a flush. */
rcu_eqs_special_exit();
}
}
확장 qs 상태를 클리어한다.
- 코드 라인 11에서 rdp->dynticks += 2를 수행한다. 이 때 시퀀스 파트는 변경 없이 bit1이 설정되어 non-eqs 상태로 변경한다.
- 코드 라인 12~13에서 변경 후 bit1은 설정 상태여야 한다.
- 코드 라인 14~19 에서 만일 special 비트가 설정된 경우 special 비트를 제거한 후 rcu_eqs_special_exit() 함수를 호출한다.
rcu_dynticks_curr_cpu_in_eqs()
kernel/rcu/tree.c
/* * Is the current CPU in an extended quiescent state? * * No ordering, as we are sampling CPU-local information. */
bool rcu_dynticks_curr_cpu_in_eqs(void)
{
struct rcu_data *rdp = this_cpu_ptr(&rcu_data);
return !(atomic_read(&rdp->dynticks) & RCU_DYNTICK_CTRL_CTR);
}
현재 cpu가 eqs 상태인지 여부를 알아온다. (true=eqs, false=none eqs)
- rdp->dynticks의 bit1이 0일때 true (eqs)
rcu_dynticks_eqs_online()
kernel/rcu/tree.c
/* * Reset the current CPU's ->dynticks counter to indicate that the * newly onlined CPU is no longer in an extended quiescent state. * This will either leave the counter unchanged, or increment it * to the next non-quiescent value. * * The non-atomic test/increment sequence works because the upper bits * of the ->dynticks counter are manipulated only by the corresponding CPU, * or when the corresponding CPU is offline. */
static void rcu_dynticks_eqs_online(void)
{
struct rcu_data *rdp = this_cpu_ptr(&rcu_data);
if (atomic_read(&rdp->dynticks) & RCU_DYNTICK_CTRL_CTR)
return;
atomic_add(RCU_DYNTICK_CTRL_CTR, &rdp->dynticks);
}
새롭게 online된 cpu가 eqs가 아니도록 리셋한다.
- 코드 라인 5~6에서 만일 rdp->dyntics의 bit1이 이미 설정되어 있는 경우 함수를 빠져나간다.
- 코드 라인 7에서 rdp->dyntics의 bit1이 클리어된 상태에서 rdp->dyntics += 2를 수행하여 카운터 파트를 증가시키고 bit1을 클리어한다.
rcu_dynticks_snap()
kernel/rcu/tree.c
/* * Snapshot the ->dynticks counter with full ordering so as to allow * stable comparison of this counter with past and future snapshots. */
int rcu_dynticks_snap(struct rcu_data *rdp)
{
int snap = atomic_add_return(0, &rdp->dynticks);
return snap & ~RCU_DYNTICK_CTRL_MASK;
}
dynticks 카운터의 스냡샷을 반환한다.
- dynticks 카운터에서 스페셜 비트인 bit0를 클리어한 값을 반환한다.
rcu_dynticks_in_eqs()
kernel/rcu/tree.c
/* * Return true if the snapshot returned from rcu_dynticks_snap() * indicates that RCU is in an extended quiescent state. */
static bool rcu_dynticks_in_eqs(int snap)
{
return !(snap & RCU_DYNTICK_CTRL_CTR);
}
dynticks 스냡샷 값이 eqs 상태인지 여부를 반환한다.
- @snap 값의 bit1이 0일 때 eqs 상태이다.
rcu_dynticks_in_eqs_since()
kernel/rcu/tree.c
/* * Return true if the CPU corresponding to the specified rcu_data * structure has spent some time in an extended quiescent state since * rcu_dynticks_snap() returned the specified snapshot. */
static bool rcu_dynticks_in_eqs_since(struct rcu_data *rdp, int snap)
{
return snap != rcu_dynticks_snap(rdp);
}
eqs 상태가 변경되었는지 여부를 반환한다.
rcu_momentary_dyntick_idle()
kernel/rcu/tree.c
/* * Let the RCU core know that this CPU has gone through the scheduler, * which is a quiescent state. This is called when the need for a * quiescent state is urgent, so we burn an atomic operation and full * memory barriers to let the RCU core know about it, regardless of what * this CPU might (or might not) do in the near future. * * We inform the RCU core by emulating a zero-duration dyntick-idle period. * * The caller must have disabled interrupts and must not be idle. */
static void __maybe_unused rcu_momentary_dyntick_idle(void)
{
int special;
raw_cpu_write(rcu_data.rcu_need_heavy_qs, false);
special = atomic_add_return(2 * RCU_DYNTICK_CTRL_CTR,
&this_cpu_ptr(&rcu_data)->dynticks);
/* It is illegal to call this from idle state. */
WARN_ON_ONCE(!(special & RCU_DYNTICK_CTRL_CTR));
rcu_preempt_deferred_qs(current);
}
rcu core가 긴급하게 qs 상태를 알아야 할 때 수행된다.
- 코드 라인 5에서 긴급 qs 요청 플래그(rdp->rcu_need_heavy_qs)를 클리어한다.
- 이 플래그는 force_qs_rnp() -> rcu_implicit_dynticks_qs() 함수를 통해 설정된다.
- 코드 라인 6~9에서 dynticks 카운터에 4를 더하며, 더하기 전의 dynticks 카운터의 bit1이 0인 경우 경고 메시지를 출력한다.
- 코드 라인 10에서 deferred qs를 처리한다.
- deferred qs를 해제하고, blocked 상태인 경우 blocked 해제 후 qs를 보고한다.
rcu_is_cpu_rrupt_from_idle()
kernel/rcu/tree.c
/** * rcu_is_cpu_rrupt_from_idle - see if interrupted from idle * * If the current CPU is idle and running at a first-level (not nested) * interrupt from idle, return true. The caller must have at least * disabled preemption. */
static int rcu_is_cpu_rrupt_from_idle(void)
{
/* Called only from within the scheduling-clock interrupt */
lockdep_assert_in_irq();
/* Check for counter underflows */
RCU_LOCKDEP_WARN(__this_cpu_read(rcu_data.dynticks_nesting) < 0,
"RCU dynticks_nesting counter underflow!");
RCU_LOCKDEP_WARN(__this_cpu_read(rcu_data.dynticks_nmi_nesting) <= 0,
"RCU dynticks_nmi_nesting counter underflow/zero!");
/* Are we at first interrupt nesting level? */
if (__this_cpu_read(rcu_data.dynticks_nmi_nesting) != 1)
return false;
/* Does CPU appear to be idle from an RCU standpoint? */
return __this_cpu_read(rcu_data.dynticks_nesting) == 0;
}
idle 모드에서 인터럽트가 발생하여 진입하였는지 여부를 반환한다.
CB용 콜백 처리 커널 스레드
“rcutree.use_softirq” 모듈 파라미터 값에 따라 cb용 콜백을 처리하는 곳이 달라진다.
- 1
- softirq에서 호출하여 처리한다. (디폴트)
- 0
- cb용 콜백 처리 커널 스레드에서 한다.
rcu_cpu_kthread()
kernel/rcu/tree.c
/* * Per-CPU kernel thread that invokes RCU callbacks. This replaces * the RCU softirq used in configurations of RCU that do not support RCU * priority boosting. */
static void rcu_cpu_kthread(unsigned int cpu)
{
unsigned int *statusp = this_cpu_ptr(&rcu_data.rcu_cpu_kthread_status);
char work, *workp = this_cpu_ptr(&rcu_data.rcu_cpu_has_work);
int spincnt;
for (spincnt = 0; spincnt < 10; spincnt++) {
trace_rcu_utilization(TPS("Start CPU kthread@rcu_wait"));
local_bh_disable();
*statusp = RCU_KTHREAD_RUNNING;
local_irq_disable();
work = *workp;
*workp = 0;
local_irq_enable();
if (work)
rcu_core();
local_bh_enable();
if (*workp == 0) {
trace_rcu_utilization(TPS("End CPU kthread@rcu_wait"));
*statusp = RCU_KTHREAD_WAITING;
return;
}
}
*statusp = RCU_KTHREAD_YIELDING;
trace_rcu_utilization(TPS("Start CPU kthread@rcu_yield"));
schedule_timeout_interruptible(2);
trace_rcu_utilization(TPS("End CPU kthread@rcu_yield"));
*statusp = RCU_KTHREAD_WAITING;
}
cb용 콜백 처리 커널 스레드가 동작하는 경우 rdp->rcu_cpu_has_work 가 1인 경우 최대 10회에 한해 완료된 rcu 콜백을 호출한다.
다음 그림은 cb용 콜백 처리 커널 스레드가 동작하는 과정과 상태를 보여준다.
RCU Boost 커널 스레드
preemptible rcu를 사용하는 경우 rcu read-side critical section에서도 preemption될 수 있다. 다음과 같은 경우 요청에 의해 스레드 B를 부스트하여 처리하도록 백그라운드에서 rcu 부스트 커널 스레드가 동작한다. 이렇게 부스트된 스레드 B는 빠르게 스레드 A로 되돌아 가는 것으로 gp가 지연되는 것을 방지한다. rcu 부스트 커널 스레드는 rcu leaf 노드별로 하나씩 운영된다.
- 스레드 A (rcu reader) ——-(preempt)——> 스레드 B
rcu_boost_kthread()
kernel/rcu/tree_plugin.h
/* * Priority-boosting kthread, one per leaf rcu_node. */
static int rcu_boost_kthread(void *arg)
{
struct rcu_node *rnp = (struct rcu_node *)arg;
int spincnt = 0;
int more2boost;
trace_rcu_utilization(TPS("Start boost kthread@init"));
for (;;) {
rnp->boost_kthread_status = RCU_KTHREAD_WAITING;
trace_rcu_utilization(TPS("End boost kthread@rcu_wait"));
rcu_wait(rnp->boost_tasks || rnp->exp_tasks);
trace_rcu_utilization(TPS("Start boost kthread@rcu_wait"));
rnp->boost_kthread_status = RCU_KTHREAD_RUNNING;
more2boost = rcu_boost(rnp);
if (more2boost)
spincnt++;
else
spincnt = 0;
if (spincnt > 10) {
rnp->boost_kthread_status = RCU_KTHREAD_YIELDING;
trace_rcu_utilization(TPS("End boost kthread@rcu_yield"));
schedule_timeout_interruptible(2);
trace_rcu_utilization(TPS("Start boost kthread@rcu_yield"));
spincnt = 0;
}
}
/* NOTREACHED */
trace_rcu_utilization(TPS("End boost kthread@notreached"));
return 0;
}
rcu용 부스트 커널스레드는 leaf 노드당 하나가 동작하며 노드의 rt 뮤텍스를 사용하는 태스크를 부스트한다.
- 코드 라인 8에서 무한 반복하여 수행한다.
- 코드 라인 9에서 부스트 커널 스레드 상태를 RCU_KTHREAD_WAITING(2)로 변경한다.
- 코드 라인 11에서 노드에 급행 태스크나 부스트 태스크가 발생할 때까지 슬립하며 기다린다.
- 코드 라인 13에서 부스트 커널 스레드 상태를 RCU_KTHREAD_RUNNING(1)으로 변경한다.
- 코드 라인 14에서 노드에서 기존에 rt 뮤텍스를 선점하여 사용중인 rcu 태스크의 priority를 최대한도로 상승시킨다. 부스트할 태스크가 더 있는지 여부를 알아온다.
- 코드 라인 15~18에서 부스트를 반복할 카운터를 증가시킨다. 만일 부스트할 태스크가 없는 경우 0을 지정한다.
- 코드 라인 19~25에서 10회 이상 반복한 경우 부스트 커널 스레드 상태를 RCU_KTHREAD_YIELDING(4)로 변경한다. 2틱을 슬립하고 다시 반복한다.
다음 그림은 rcu 부스트 커널 스레드가 동작하는 과정과 상태를 보여준다.

rcu_wait()
kernel/rcu/tree.h
#define rcu_wait(cond) \
do { \
for (;;) { \
set_current_state(TASK_INTERRUPTIBLE); \
if (cond) \
break; \
schedule(); \
} \
__set_current_state(TASK_RUNNING); \
} while (0)
태스크의 상태를 슬립(interrutible)로 바꾸고 슬립한다. 깨어날때마다 @cond 값을 확인하여 true인 경우 태스크 상태를 러닝으로 변경한 후 함수를 빠져나온다.
rcu_boost()
kernel/rcu/tree_plugin.h
/* * Carry out RCU priority boosting on the task indicated by ->exp_tasks * or ->boost_tasks, advancing the pointer to the next task in the * ->blkd_tasks list. * * Note that irqs must be enabled: boosting the task can block. * Returns 1 if there are more tasks needing to be boosted. */
static int rcu_boost(struct rcu_node *rnp)
{
unsigned long flags;
struct task_struct *t;
struct list_head *tb;
if (READ_ONCE(rnp->exp_tasks) == NULL &&
READ_ONCE(rnp->boost_tasks) == NULL)
return 0; /* Nothing left to boost. */
raw_spin_lock_irqsave_rcu_node(rnp, flags);
/*
* Recheck under the lock: all tasks in need of boosting
* might exit their RCU read-side critical sections on their own.
*/
if (rnp->exp_tasks == NULL && rnp->boost_tasks == NULL) {
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
return 0;
}
/*
* Preferentially boost tasks blocking expedited grace periods.
* This cannot starve the normal grace periods because a second
* expedited grace period must boost all blocked tasks, including
* those blocking the pre-existing normal grace period.
*/
if (rnp->exp_tasks != NULL)
tb = rnp->exp_tasks;
else
tb = rnp->boost_tasks;
/*
* We boost task t by manufacturing an rt_mutex that appears to
* be held by task t. We leave a pointer to that rt_mutex where
* task t can find it, and task t will release the mutex when it
* exits its outermost RCU read-side critical section. Then
* simply acquiring this artificial rt_mutex will boost task
* t's priority. (Thanks to tglx for suggesting this approach!)
*
* Note that task t must acquire rnp->lock to remove itself from
* the ->blkd_tasks list, which it will do from exit() if from
* nowhere else. We therefore are guaranteed that task t will
* stay around at least until we drop rnp->lock. Note that
* rnp->lock also resolves races between our priority boosting
* and task t's exiting its outermost RCU read-side critical
* section.
*/
t = container_of(tb, struct task_struct, rcu_node_entry);
rt_mutex_init_proxy_locked(&rnp->boost_mtx, t);
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
/* Lock only for side effect: boosts task t's priority. */
rt_mutex_lock(&rnp->boost_mtx);
rt_mutex_unlock(&rnp->boost_mtx); /* Then keep lockdep happy. */
return READ_ONCE(rnp->exp_tasks) != NULL ||
READ_ONCE(rnp->boost_tasks) != NULL;
}
기존에 rt 뮤텍스를 선점하여 사용중인 rcu 태스크의 priority를 최대한도로 상승시킨다.
- 코드 라인 7~9에서 노드에 지정된 급행 태스크 및 부스트 태스크가 모두 없는 경우 할 일이 없으므로 0을 반환한다.
- 코드 라인 11~20에서 노드 스핀락을 획득한 후 다시 한 번 노드에 지정된 급행 태스크 및 부스트 태스크가 모두 없는지 체크하여 없으면 노드 스핀락을 풀고 0을 반환한다.
- 코드 라인 28~31에서 급행 태스크를 선택한다. 만일 없는 경우 부스트 태스크를 선택한다.
- 코드 라인 49~50에서 노드의 rt 뮤텍스(boost_mtx)를 초기화하고, 선택한 태스크를 뮤텍스의 owner 태스크로 지정한다.
- rt 뮤텍스에 대기 태스크가 있는 경우 owner 태스크를 지정하고 하위 비트에 RT_MUTEX_HAS_WAITERS 비트를 추가한다.
- 코드 라인 51에서 노드 스핀락을 해제한다.
- 코드 라인 53~54에서 노드의 rt 뮤텍스 락을 획득한 후 다시 푼다.
- rt 뮤텍스를 먼저 선점하여 사용중인 rcu 태스크의 priority를 최대한도로 상승시키는 역할을 한다.
- 코드 라인 54~55에서 노드에 여전히 급행 태스크 또는 부스트 태스크가 존재하는지 여부를 반환한다.
boost 요청
rcu_initiate_boost()
kernel/rcu/tree.c
/* * Check to see if it is time to start boosting RCU readers that are * blocking the current grace period, and, if so, tell the per-rcu_node * kthread to start boosting them. If there is an expedited grace * period in progress, it is always time to boost. * * The caller must hold rnp->lock, which this function releases. * The ->boost_kthread_task is immortal, so we don't need to worry * about it going away. */
static void rcu_initiate_boost(struct rcu_node *rnp, unsigned long flags)
__releases(rnp->lock)
{
raw_lockdep_assert_held_rcu_node(rnp);
if (!rcu_preempt_blocked_readers_cgp(rnp) && rnp->exp_tasks == NULL) {
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
return;
}
if (rnp->exp_tasks != NULL ||
(rnp->gp_tasks != NULL &&
rnp->boost_tasks == NULL &&
rnp->qsmask == 0 &&
ULONG_CMP_GE(jiffies, rnp->boost_time))) {
if (rnp->exp_tasks == NULL)
rnp->boost_tasks = rnp->gp_tasks;
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
rcu_wake_cond(rnp->boost_kthread_task,
rnp->boost_kthread_status);
} else {
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
}
}
boost 처리해야 할 rcu 리더가 있는지 확인하고, 존재 시 부스트한다.
참고
- RCU(Read Copy Update) -1- (Basic) | 문c
- RCU(Read Copy Update) -2- (Callback process) | 문c
- RCU(Read Copy Update) -3- (RCU threads) | 문c – 현재글
- RCU(Read Copy Update) -4- (NOCB process) | 문c
- RCU(Read Copy Update) -5- (Callback list) | 문c
- RCU(Read Copy Update) -6- (Expedited GP) | 문c
- RCU(Read Copy Update) -7- (Preemptible RCU) | 문c
- rcu_init() | 문c
- wait_for_completion() | 문c