<kernel v5.10>
list_head 구조체를 사용하는 환형 양방향 연결 리스트를 다루는 함수 내부에서 어느 순간(v4.5 부터) WRITE_ONCE() 매크로가 사용된다. 그 중 INIT_LIST_HEAD()에 왜 WRITE_ONCE() 함수를 추가하였는지 알아본다.
- A: 리스트의 사용 전후로 lock/unlock을 사용하는 SMP 시스템은 WRITE_ONCE()를 사용하지 않아도 무방하다. 그런데 이 양방향 연결 리스트를 lockless로 운영하는 SMP 시스템의 경우 같은 리스트를 공유하여 접근하는 경쟁(contention) 상황에서 WRITE_ONCE() 매크로가 필요해졌다.
- READ_ONCE() 및 WRITE_ONCE()
- 접근 하려는 영역(메모리 및 IO 가상 주소)에 원하는 자료 타입 만큼의 값이 분할되어 읽거나 기록되지 않는 조치가 필요하다.
- Case) 주로 32비트 시스템 등에서 8바이트 포인터등을 다룰 때 4 바이트 단위로 2 번 기록하지 않게한다.
- 접근 하려는 영역(메모리 및 IO 가상 주소)에 원하는 자료 타입 만큼의 값이 분할되어 읽거나 기록되지 않는 조치가 필요하다.
- READ_ONCE() 및 WRITE_ONCE()
먼저 READ_ONCE() 및 WRITE_ONCE()를 알아본 후 SMP core 들간에 경합이 일어나는 상황에서 lockess로 운영되는 리스트와 관련된 코드 위주로 살펴본다. (분석 케이스로 본문에서는 list_del_init() 함수를 살펴본다.)
READ_ONCE() & WRITE_ONCE()
READ_ONCE()
include/asm-generic/rwonce.h
#define READ_ONCE(x) \
({ \
compiletime_assert_rwonce_type(x); \
__READ_ONCE(x); \
})
인자 @x의 타입 사이즈가 1, 2, 4 또는 8 바이트에 해당하고, @x 주소에서 타입 사이즈 만큼의 값을 atomic하게 읽어온다.
- 아래 __READ_ONCE()에 추가적인 설명을 하였다.
compiletime_assert_rwonce_type()
include/asm-generic/rwonce.h
/* * Yes, this permits 64-bit accesses on 32-bit architectures. These will * actually be atomic in some cases (namely Armv7 + LPAE), but for others we * rely on the access being split into 2x32-bit accesses for a 32-bit quantity * (e.g. a virtual address) and a strong prevailing wind. */
#define compiletime_assert_rwonce_type(t) \
compiletime_assert(__native_word(t) || sizeof(t) == sizeof(long long), \
"Unsupported access size for {READ,WRITE}_ONCE().")
타입 @t의 사이즈가 1, 2, 4 또는 8 바이트인 경우가 아닌 경우 컴파일 타임에 에러를 발생시킨다.
include/linux/compiler_types.h
/* Is this type a native word size -- useful for atomic operations */
#define __native_word(t) \
(sizeof(t) == sizeof(char) || sizeof(t) == sizeof(short) || \
sizeof(t) == sizeof(int) || sizeof(t) == sizeof(long))
타입 @t의 사이즈가 1, 2, 4 또는 long(4 또는 8) 타입에 해당하는 바이트인 경우인지 여부를 반환한다.
__READ_ONCE()
include/asm-generic/rwonce.h
/* * Use __READ_ONCE() instead of READ_ONCE() if you do not require any * atomicity. Note that this may result in tears! */
#ifndef __READ_ONCE #define __READ_ONCE(x) (*(const volatile __unqual_scalar_typeof(x) *)&(x)) #endif
인자 @x 주소로부터 @x 타입에 해당하는 사이즈만큼의 값을 atomic하게 읽어온다.
- 컴파일러의 재배치(optimization) 기능을 사용하지 말고, 반드시 해당 주소 @x로부터 값을 읽어오도록 생략하지 않게 컴파일하여 코드를 생성한다.
- 컴파일러가 두 번에 나눠 읽지 않고, 또한 다른 값과 같이 읽지 않고 정확히 요청 타입의 길이에 맞춰 atomic하게 한번에 읽어오도록 컴파일하여 코드를 생성한다.
- ARM32에서도 long long 타입의 8바이트 값을 읽을 때 4 바이트 값을 읽는 ldr 명령을 사용하지 않고, 8바이트 값을 두 개의 레지스터로 읽는 ldrd 명령을 사용한다.
- 스칼라 타입은 char, int, long 등과 같이 하나의 값만을 가지는 데이터 타입이다. (vs 벡터 타입)
예) 다음은 ARM32 시스템에서 long long 타입의 값을 READ_ONCE()로 읽어들인 예이다.
- ldrd 명령 한번에 8바이트 값을 2 개의 32bit 레지스터에 읽어옮을 알 수 있다.
. long long a = 10;
1042c: e3a0200a mov r2, #10
10430: e3a03000 mov r3, #0
10434: e14b21fc strd r2, [fp, #-28] ; 0xffffffe4
long long *p = &a;
10438: e24b301c sub r3, fp, #28
1043c: e50b3008 str r3, [fp, #-8]
long long b;
b = READ_ONCE(*p);
10440: e51b3008 ldr r3, [fp, #-8]
10444: e1c320d0 ldrd r2, [r3]
10448: e14b21f4 strd r2, [fp, #-20] ; 0xffffffec
예) 다음은 ARM64 시스템에서 long long 타입의 값을 READ_ONCE()로 읽어들인 예이다.
- ARM32와 다르게 ldr 명령 한번으로 8바이트 값을 1 개의 64bit 레지스터에 읽어옮을 알 수 있다.
. long long a = 10;
810: d2800140 mov x0, #10
814: f9000ba0 str x0, [x29, #16]
long long *ap = &a;
818: 910043a0 add x0, x29, #0x10
81c: f9000fa0 str x0, [x29, #24]
long long b;
b = READ_ONCE(*ap);
820: f9400fa0 ldr x0, [x29, #24]
824: f9400000 ldr x0, [x0]
828: f90013a0 str x0, [x29, #32]
__unqual_scalar_typeof()
include/linux/compiler_types.h
/* * __unqual_scalar_typeof(x) - Declare an unqualified scalar type, leaving * non-scalar types unchanged. */
#define __unqual_scalar_typeof(x) typeof( \
_Generic((x), \
char: (char)0, \
__scalar_type_to_expr_cases(char), \
__scalar_type_to_expr_cases(short), \
__scalar_type_to_expr_cases(int), \
__scalar_type_to_expr_cases(long), \
__scalar_type_to_expr_cases(long long), \
default: (x)))
non-scalar 타입으로 주어진 인자 @type의 자료 타입에 따라 다음 중 하나의 타입으로 반환한다. (_Generic() 키워드는 다음 절에서 설명한다)
- signed char
- unsigned char
- signed int
- unsigned int
- signed long
- unsigned long
- signed long long
- unsigned long long
- 기타 타입
참고: compiler_types.h: Optimize __unqual_scalar_typeof compilation time (2020, v5.8-rc1)
WRITE_ONCE()
include/asm-generic/rwonce.h
컴파일러 베리어 volatile을 포함한 WRITE_ONCE() 매크로의 주요 기능은 다음과 같다.
#define WRITE_ONCE(x, val) \
do { \
compiletime_assert_rwonce_type(x); \
__WRITE_ONCE(x, val); \
} while (0)
인자 @x의 타입 사이즈가 1, 2, 4 또는 8 바이트에 해당하고, @x 주소에 @x 타입에 해당하는 사이즈만큼의 @val값을 atomic하게 기록한다.
- 아래 __WRITE_ONCE()에 추가적인 설명을 하였다.
__WRITE_ONCE()
include/asm-generic/rwonce.h
#define __WRITE_ONCE(x, val) \
do { \
*(volatile typeof(x) *)&(x) = (val); \
} while (0)
인자 @x 주소에 @x 타입에 해당하는 사이즈만큼 val 값을 atomic하게 기록한다.
- 컴파일러의 재배치(optimization) 기능을 사용하지 말고, 반드시 해당 주소 @x에 @val값을 기록하도록 생략하지 않게 컴파일하여 코드를 생성한다.
- 컴파일러가 두 번에 나눠 기록하지 않고, 또한 다른 값과 같이 기록하지 않고 정확히 요청 타입의 길이에 맞춰 atomic하게 한번에 기록하도록 컴파일하여 코드를 생성한다.
- ARM32에서도 long long 타입의 8바이트 값을 기록할 때 4 바이트 값을 기록하는 str 명령을 사용하지 않고, 8바이트 값을 두 개의 레지스터로 기록하는 strd 명령을 사용한다.
_Generic() keyword
/* * Prefer C11 _Generic for better compile-times and simpler code. Note: 'char' * is not type-compatible with 'signed char', and we define a separate case. */
C11 표준을 따르는 컴파일러에 추가된 새 키워드로 인자 하나의 데이터 타입을 기준으로 함수의 컴파일 타임 오버로딩을 지원한다.
- 참고:
- C11 _Generic usage | Stack overflow
- _Generic keyword in C ? 1: 20 | Tutorials Point
__scalar_type_to_expr_cases()
include/linux/compiler_types.h
#define __scalar_type_to_expr_cases(type) \
unsigned type: (unsigned type)0, \
signed type: (signed type)0
인자 @type의 부호 여부에 따라 한쌍식의 0 값을 반환한다.
- 이는 _Generic()에서 사용된다.
연결 리스트
리눅스 커널에서 자주 사용되는 두 가지 연결 리스트를 알아본다.
- 환형 양방향 연결 리스트(A Circular Doubly Linked List)
- 엔트리 노드의 추가/삭제를 수행하고, 삽입(insert)등은 하지 않는 단순한 연결 리스트이다. 리스트의 접합/분리/회전에 강점이 있다.
- list_head 구조체 하나만을 사용하여 리스트 헤드와 리스트 노드 엔트리를 표현한다.
- list_*로 시작하는 함수들 (본문에서 사용하는 리스트 함수)
- list_add(), list_add_tail(), list_del()
- 양방향 연결 리스트(A Doubly Linked List)
- 엔트리 노드의 추가/삭제/삽입(insert)을 수행하는 리눅스 커널의 대표적인 연결 리스트이다.
- hlist_head와 hlist_node 구조체를 각각 사용하여 리스트 헤드와 리스트 노드 엔트리를 표현한다.
- hlist_*로 시작하는 함수들
- hlist_add_head(), hlist_add_before(), hlist_behind(), hlist_del()
- 단방형 연결 리스트(A Singly Linked List)
- 엔트리 노드의 추가/삭제를 수행하는 단방향 연결 리스트로 일부 조건에 따라 완전한 lockless로 사용된다.
- 예) 공급자로 llist_add()를 사용하고, 소비자로 llist_del_all()을 사용하는 조합 등이다.
- llist_head와 llist_node 구조체를 각각 사용하여 리스트 헤드와 리스트 노드 엔트리를 표현한다.
- llist_*로 시작하는 함수들
- llist_add(), llist_del_first(), llist_del_all()
- 엔트리 노드의 추가/삭제를 수행하는 단방향 연결 리스트로 일부 조건에 따라 완전한 lockless로 사용된다.
다음 그림은 세 가지 연결 리스트들의 실제 구조체 내부의 연결 상태를 비교하여 보여준다.
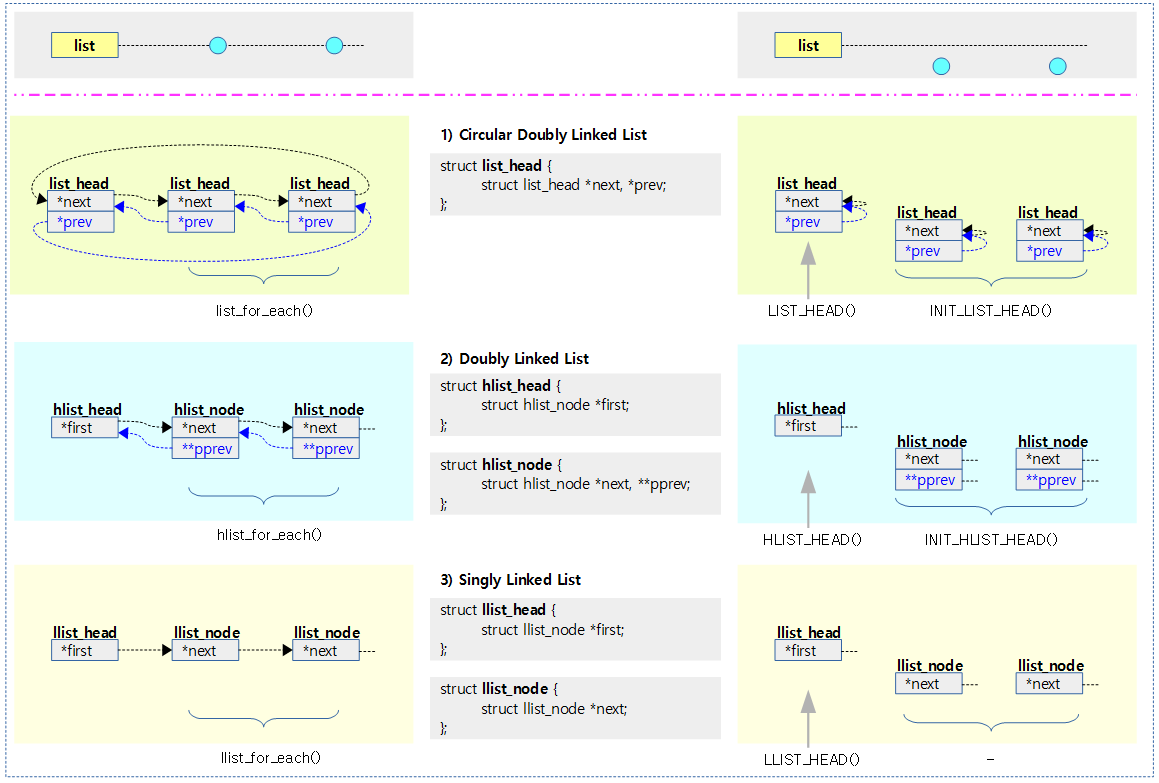
환형 양방향 연결 리스트(A Circular Doubly Linked Lists)
list_del_init()
include/linux/list.h
/** * list_del_init - deletes entry from list and reinitialize it. * @entry: the element to delete from the list. */
static inline void list_del_init(struct list_head *entry)
{
__list_del_entry(entry);
INIT_LIST_HEAD(entry);
}
리스트에서 인자로 요청한 @entry를 삭제하고 엔트리를 초기화한다.
- list_del_init() 함수는 리스트 엔트리를 하나 삭제하고 삭제한 엔트리를 초기화하기 위해 내부에서 INIT_LIST_HEAD()를 호출한다.
다음 그림과 같이 list_del_init() 함수는 __list_del_entry() 함수와 INIT_LIST_HEAD() 함수를 차례대로 호출한다.
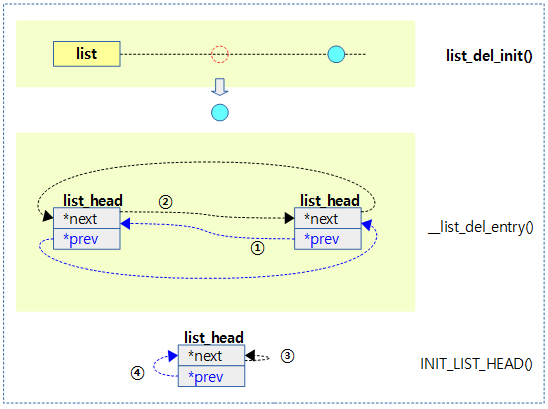
__list_del_entry()
include/linux/list.h
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}
리스트에서 인자로 요청한 @entry를 삭제한다.
- 코드 라인 3~4에서 CONFIG_DEBUG_LIST 커널 옵션이 사용되는 경우 __list_del_entry_valid() 함수는 poison 기록 여부를 살펴보고 두 번 삭제되는 등을 알아내어 경고 메시지를 출력하고 false를 반환한다. 해당 커널 옵션을 사용하지 않는 경우 항상 true를 반환한다.
- 코드 라인 6에서 리스트에서 인자로 요청한 @entry를 삭제한다.
__list_del()
include/linux/list.h
/* * Delete a list entry by making the prev/next entries * point to each other. * * This is only for internal list manipulation where we know * the prev/next entries already! */
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
리스트에서 인자로 요청한 @entry를 삭제한다.
INIT_LIST_HEAD()
include/linux/list.h
/** * INIT_LIST_HEAD - Initialize a list_head structure * @list: list_head structure to be initialized. * * Initializes the list_head to point to itself. If it is a list header, * the result is an empty list. */
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
list->prev = list;
}
@list를 초기화한다.
- 환형 연결 리스트의 경우 next와 prev가 자기 자신을 가리키게 하는 것으로 초기화한다.
lockless 연결 리스트
lockless 환형 양방향 연결 리스트와 WRITE_ONCE()
본문에서 READ_ONCE()와 WRITE_ONCE()를 먼저 알아보았다. 이제 위에서 살펴본 list_del_init() 함수를 모두 인라인으로 연결하여 분석해본다.
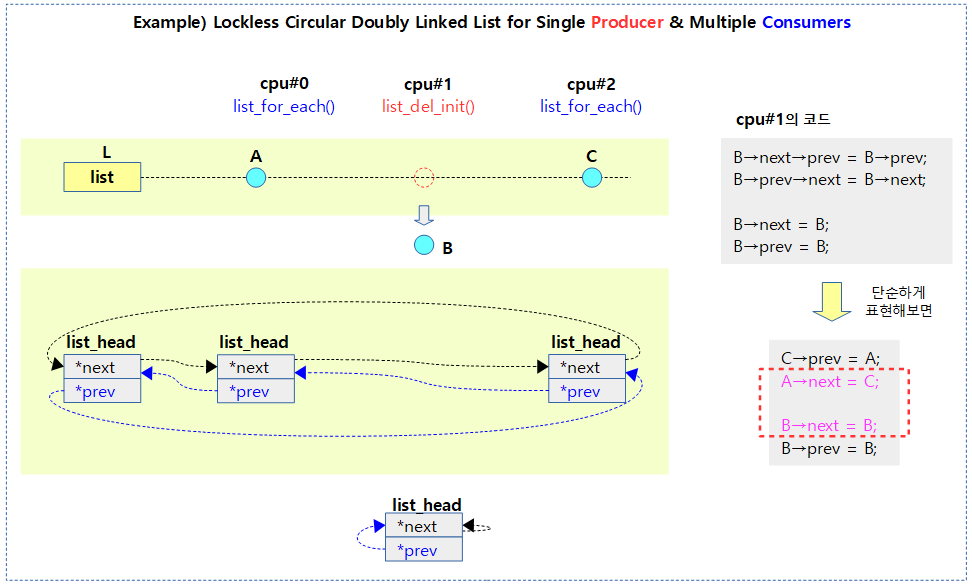
inline 처리한 list_del_init()
static inline void list_del_init(struct list_head *entry)
{
/* 현재 엔트리를 제거하고 뒷쪽 및 앞쪽 엔트리 연결을 갱신 */
entry->next->prev = entry->prev; // (1)
WRITE_ONCE(entry->prev->next) = entry->next; // (2)
/* 엔트리의 next, prev 모두 자신을 가리키게 한다 */
WRITE_ONCE(entry->next, entry); // (3)
entry->prev = entry; // (4)
}
다음 그림은 세 개의 cpu에서 동시에 같은 리스트에 접근하고 있다. 그 중 하나의 cpu가 엔트리를 삭제할 때 다른 두 cpu와 경합(contention)이 발생하는 모습을 보여준다. lockless 방식으로 리스트를 사용하는 경우 리스트 엔트리의 포인터 엔트리인 next가 atomic하게 한 번에 교체되어야 한다. (믈론 lockless 환경이 아닌 경우에는 WRITE_ONCE를 사용하지 않아도 상관 없다)
- 참고
- list: Use WRITE_ONCE() when initializing list_head structures (2015, v4.5-rc1)
- list: Use READ_ONCE() when testing for empty lists (2015, v4.5-rc1)
- list: Use WRITE_ONCE() when adding to lists and hlists (2015, v4.5-rc1)
- rculist: Use WRITE_ONCE() when deleting from reader-visible list (2015, v4.5-rc1)
참고
- Play with kernel list_head, three examples of super cattle | FatalErrors
- [Linux Kernel 5] Linked List | Art of PrOgr4m
- WRITE_ONCE in linux kernel lists | Stack Overflow
안녕하세요 16기 양원혁입니다.
READ_ONCE와 WRITE_ONCE에 관련한 디테일한 설명들 정말 잘 읽었습니다!
다만, 하단부의 “lockless 리스트와 WRITE_ONCE()” 에 나오는 예제는 물음표가 생깁니다.
그림의 상황은 lock 없이 consumer가 2명인 케이스로 해석하였습니다.
제 생각에는 이런 상황에서 WRITE_ONCE만으로는 데이터의 일관성이 유지되지 않을 것 같습니다.
CPU:0 CPU:1
B->next->prev = B->prev
A->next->prev = A->prev
위와 같이 실행이 된다면, WRITE_ONCE와 관련없이 해당 리스트의 링크 구조는 깨져버리지 않을까요?
그렇다면, “WRITE_ONCE는 왜 사용되었느냐?”라는 질문에 저도 올려주신 커밋을 읽으며 나름대로 생각을 해봤습니다.
1) list: Use WRITE_ONCE() when initializing list_head structures (2015, v4.5-rc1)
2) list: Use READ_ONCE() when testing for empty lists (2015, v4.5-rc1)
3) list: Use WRITE_ONCE() when adding to lists and hlists (2015, v4.5-rc1)
위 커밋들의 내용에 따르면 list_empty 함수는 lock없이 사용되는 경우가 있는데, head의 next 링크가 부분적으로
load/store되면 문제가 되므로, atomic하게 읽고 저장하는 것으로 변경한 것 같습니다.
4) rculist: Use WRITE_ONCE() when deleting from reader-visible list (2015, v4.5-rc1)
위 커밋에서는 list_del_rcu()에서도 next에 대한 링크가 atomic하게 업데이트 하려고 처리한 것 같습니다.
단방향 리스트 조차도 완벽하게 조건 없이 lockless로 운영을 할 수 없고, 조건에 따라 lockless를 운영할 수 있습니다.
그런데 하물며 양방향 리스트의 경우는 더욱 그러합니다. 그러고 보니 양원혁님 의견이 맞는것 같습니다.
lockless로 양방향 리스트에서 multiple producers가 삭제를 하면 안될 듯 합니다.
샘플을 바꿔서 하나의 공급자가 삭제를 하고, multiple consumers 형태의 그림으로 바꿔야 하겠네요.
좋은 의견 주셔서 감사합니다.