<kernel v5.4>
Sched Clock
sched_clock은 시간 계산에 사용하는 ns 단위의 카운터를 제공하며 클럭 소스 서브시스템에서 제공하는 고정밀도 카운터를 사용하여 sched_clock으로 등록한다.
- 32비트 일반 타이머로 동작하던 sched_clock을 64비트 hrtimer 구조로 확장하였다. (kernel v3.13-rc1)
- 아키텍트 타이머를 사용하는 arm 및 arm64 시스템
- 56비트 아키텍트 타이머를 사용하는 sched_clock을 등록하기 전까지는 일반 타이머로 갱신되는 jiffies 값을 이용하는 함수를 사용한다.
- CONFIG_GENERIC_SCHED_CLOCK 커널 옵션을 사용한다.
- sched_clock() API를 통해 등록된 스케줄 클럭(ns) 값을 읽을 수 있다.
다음 그림은 jiffies 클럭 카운터에서 56비트 아키텍트 카운터 기반의 스케줄 클럭으로 등록되어 전환되는 과정을 보여준다.
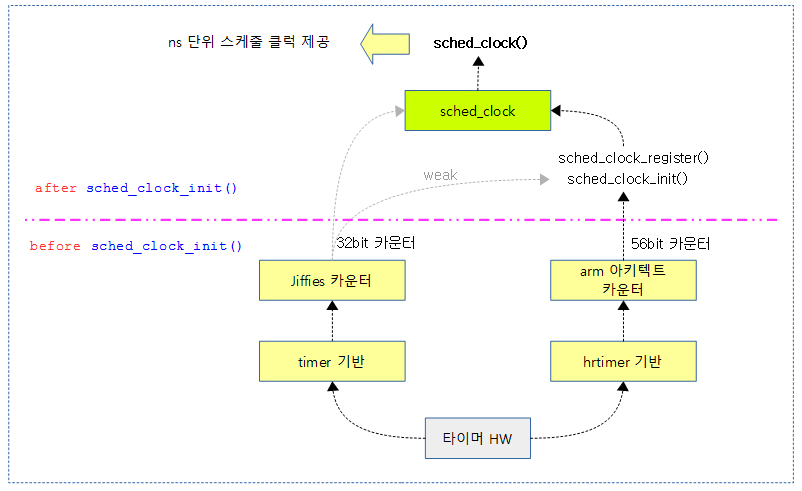
스케줄 클럭 초기화
sched_clock_init()
arm 및 arm64에서는 CONFIG_HAVE_UNSTABLE_SCHED_CLOCK 커널 옵션이 사용되지 않는다. 따라서 이 옵션이 사용되지 않는 함수를 분석한다.
kernel/sched/clock.c
void __init sched_clock_init(void)
{
static_branch_inc(&sched_clock_running);
local_irq_disable();
generic_sched_clock_init();
local_irq_enable();
}
irq를 블럭한 상태에서 generic 스케줄 클럭 초기화를 수행한다.
generic_sched_clock_init()
kernel/time/sched_clock.c
void __init generic_sched_clock_init(void)
{
/*
* If no sched_clock() function has been provided at that point,
* make it the final one one.
*/
if (cd.actual_read_sched_clock == jiffy_sched_clock_read)
sched_clock_register(jiffy_sched_clock_read, BITS_PER_LONG, HZ);
update_sched_clock();
/*
* Start the timer to keep sched_clock() properly updated and
* sets the initial epoch.
*/
hrtimer_init(&sched_clock_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
sched_clock_timer.function = sched_clock_poll;
hrtimer_start(&sched_clock_timer, cd.wrap_kt, HRTIMER_MODE_REL);
}
sched_clock을 초기화한다.
- 코드 라인 7~8에서 시스템에 고정밀도 hw 기반의 스케줄 클럭이 등록되지 않고 여전히 스케줄 클럭의 읽기용 함수가 jiffy 방식인 경우 스케줄 클럭으로 jiffy를 사용한다.
- 코드 라인 10에서 스케줄 클럭을 갱신한다.
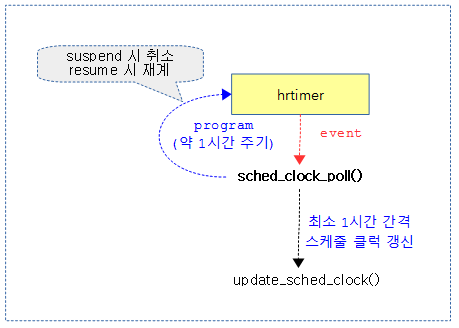
- 코드 라인 16~18에서 hrtimer를 사용하여 약 1시간 주기로 스케줄 클럭을 프로그램하여 sched_clock_poll() 함수를 호출한다. 이 함수에서는 sched_clock을 갱신한다.
스케줄 클럭 초기값
kernel/time/sched_clock.c
static struct clock_data cd ____cacheline_aligned = {
.read_data[0] = { .mult = NSEC_PER_SEC / HZ,
.read_sched_clock = jiffy_sched_clock_read, },
.actual_read_sched_clock = jiffy_sched_clock_read,
};
스케줄 클럭은 지정되지 않는 경우 위의 jiffies 후크 함수가 사용된다.
- 커널 부트업 시 초반에는 jiffy_sched_clock_read()를 사용하지만 arm 및 arm64에서는 generic 아키텍트 타이머가 준비되면 56비트 카운터 기반의 다음 함수를 사용한다.
- 예) arch_counter_get_cntvct()
jiffy_sched_clock_read()
kernel/time/sched_clock.c
static u64 notrace jiffy_sched_clock_read(void)
{
/*
* We don't need to use get_jiffies_64 on 32-bit arches here
* because we register with BITS_PER_LONG
*/
return (u64)(jiffies - INITIAL_JIFFIES);
}
커널 부트업 시 초반에는 jiffy_sched_clock_read()를 사용한다.
sched_clock_poll()
kernel/time/sched_clock.c
static enum hrtimer_restart sched_clock_poll(struct hrtimer *hrt)
{
update_sched_clock();
hrtimer_forward_now(hrt, cd.wrap_kt);
return HRTIMER_RESTART;
}
스케줄 클럭을 갱신하고, 다시 hrtimer의 forward 기능을 사용하여 프로그램한다. (약 1시간 주기)
Sched Clock 등록
sched_clock_register()
kernel/time/sched_clock.c
void __init
sched_clock_register(u64 (*read)(void), int bits, unsigned long rate)
{
u64 res, wrap, new_mask, new_epoch, cyc, ns;
u32 new_mult, new_shift;
unsigned long r;
char r_unit;
struct clock_read_data rd;
if (cd.rate > rate)
return;
WARN_ON(!irqs_disabled());
/* Calculate the mult/shift to convert counter ticks to ns. */
clocks_calc_mult_shift(&new_mult, &new_shift, rate, NSEC_PER_SEC, 3600);
new_mask = CLOCKSOURCE_MASK(bits);
cd.rate = rate;
/* Calculate how many nanosecs until we risk wrapping */
wrap = clocks_calc_max_nsecs(new_mult, new_shift, 0, new_mask, NULL);
cd.wrap_kt = ns_to_ktime(wrap);
rd = cd.read_data[0];
/* Update epoch for new counter and update 'epoch_ns' from old counter*/
new_epoch = read();
cyc = cd.actual_read_sched_clock();
ns = rd.epoch_ns + cyc_to_ns((cyc - rd.epoch_cyc) & rd.sched_clock_mask, rd.mult, rd.shift);
cd.actual_read_sched_clock = read;
rd.read_sched_clock = read;
rd.sched_clock_mask = new_mask;
rd.mult = new_mult;
rd.shift = new_shift;
rd.epoch_cyc = new_epoch;
rd.epoch_ns = ns;
update_clock_read_data(&rd);
if (sched_clock_timer.function != NULL) {
/* update timeout for clock wrap */
hrtimer_start(&sched_clock_timer, cd.wrap_kt, HRTIMER_MODE_REL);
}
r = rate;
if (r >= 4000000) {
r /= 1000000;
r_unit = 'M';
} else {
if (r >= 1000) {
r /= 1000;
r_unit = 'k';
} else {
r_unit = ' ';
}
}
/* Calculate the ns resolution of this counter */
res = cyc_to_ns(1ULL, new_mult, new_shift);
pr_info("sched_clock: %u bits at %lu%cHz, resolution %lluns, wraps every %lluns\n",
bits, r, r_unit, res, wrap);
/* Enable IRQ time accounting if we have a fast enough sched_clock() */
if (irqtime > 0 || (irqtime == -1 && rate >= 1000000))
enable_sched_clock_irqtime();
pr_debug("Registered %pS as sched_clock source\n", read);
}
클럭 소스의 카운터 읽기 함수를 sched_clock으로 등록하여 사용한다.
- 코드 라인 10~11에서 이미 등록한 sched_clock의 rate가 요청한 @rate 보다 높은 경우 처리하지 않고 함수를 빠져나간다.
- 요청한 스케줄 클럭이 여러 개인 경우 가장 높은 rate를 사용하는 스케줄 클럭을 사용한다.
- 코드 라인 16에서 요청한 클럭 주파수를 3600초의 ns 단위로 바꾸는데 필요한 mult/shift를 산출한다.
- rpi4 예) rate=54M -> mult=0x250_97b4, shift=21
- rpi2 예) rate=19.2M -> mult=0x682_aaab, shift=21
- 코드 라인 18에서 요청한 bit로 마스크 값을 구한다.
- rpi2 & rpi4 예) bits=56 -> new_mask = 0xff_ffff_ffff_ffff
- 코드 라인 22~23에서 wrap 타임을 구해 ktime으로 변환한 후 cd.wrap_kt에 저장한다.
- clocks_calc_max_nsecs() 함수에서는 카운터로 사용 가능한 wrap 타임의 50%를 적용하였다.
- rpi4 예) rate=54Mhz -> wrap=4398,046,511,102(약 72분) wrap_kt=3,131,746,996,224 (약 52분)
- 코드 라인 28~29에서 요청한 새 클럭 카운터를 읽어 new_epoch에 대입하고 기존 클럭 카운터를 읽어 cyc에 대입한다.
- 코드 라인 30에서 기존 클럭 카운터를 이용한 epoch_ns에 새로 읽은 카운터에 대한 delta ns를 구해 더한 값을 ns에 대입한다.
- 처음 sched_clock을 등록 시 읽어온 jiffies cyc 값은 0이므로 ns 값은 항상 0이다.
- sched_clock으로 사용될 클럭 소스가 더 높은 rate의 클럭 소스가 지정되는 경우 그 동안 소요된 ns 값이 반영된다.
- 코드 라인 31에서 스케줄 클럭에서 읽어들일 새 카운터 읽기 함수를 지정한다.
- rpi2 & rpi4 예) arch_counter_get_cntvct()
- 코드 라인 33~40에서 clock_read_data 구조체에 새 값들을 구성한 후 스케줄 클럭에 갱신한다.
- 코드 라인 42~45에서 wrap_kt 주기(약 1시간)로 동작하는 sched_clock_timer를 동작시킨다.
- rpi4 예) 약 72분 단위
- 코드 라인 47~58에서 출력을 위해 rate 값으로 r과 r_unit을 산출한다. (rate가 4M 이상일 때 M 단위를 사용하고, 그 이하인 경우 k 단위를 사용한다)
- rpi4 예) rate=54000000 -> r=54, r_unit=’M’
- rpi2 예) rate=19200000 -> r=19, r_unit=’M’
- 코드 라인 61에서 1 cycle에 해당하는 ns를 산출하여 res에 대입한다.
- 코드 라인 63~64에서 sched_clock에 대한 정보를 출력한다.
- rpi4 예) “sched_clock: 56 bits at 54MHz, resolution 18ns, wraps every 4398046511102ns”
- rpi2 예) “sched_clock: 56 bits at 19MHz, resolution 52ns, wraps every 3579139424256ns”
- 코드 라인 67~68에서 irqtime 값이 0을 초과하거나 처음 설정한 sched_clock의 rate가 1M 이상일 때 irq 타임 성능 측정을 할 수 있도록 전역 변수 sched_clock_irqtime에 1을 대입한다.
- irqtime의 디폴트 값은 -1이다.
- irq 타임 성능 측정은 NO_HZ_FULL 커널 옵션을 사용하지 않고 IRQ_TIME_ACCOUNTING 커널 옵션이 적용된 커널에서만 동작한다.
- 코드 라인 70에서 스케줄 클럭으로 등록되어 사용되어 사용될 클럭 카운터 함수명을 출력한다.
- rpi4 예) “Registered arch_counter_get_cntvct+0x0/0x10 as sched_clock source”
다음 그림은 rpi4 시스템이 사용하는 56비트 아키텍트 카운터를 스케줄 클럭으로 등록시킨 모습을 보여준다.
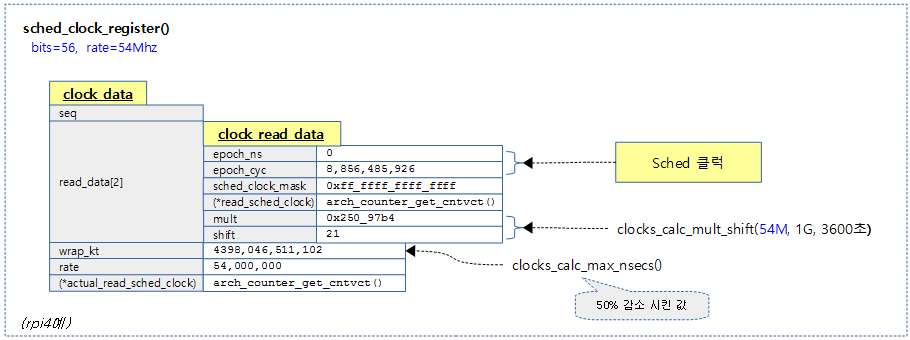
스케줄 클럭 갱신 및 읽기
스케줄 클럭은 nmi 인터럽트 핸들러에서 dead-lock을 없애고 빠르게 읽어낼 수 있도록 시퀀스 카운터를 사용한 lock-less 구현을 사용하였고, 다음과 같이 두 개의 clock_read_data 구조체를 사용하여 관리한다.
- struct clock_read_data read_data[2];
- 참고: timers, sched/clock: Avoid deadlock during read from NMI (2015, v4.1-rc1)
다음 그림은 두 개의 클럭 데이터로 운영되는 모습을 보여준다.

스케줄 클럭 갱신
update_sched_clock()
kernel/time/sched_clock.c
/* * Atomically update the sched_clock() epoch. */
static void update_sched_clock(void)
{
u64 cyc;
u64 ns;
struct clock_read_data rd;
rd = cd.read_data[0];
cyc = cd.actual_read_sched_clock();
ns = rd.epoch_ns + cyc_to_ns((cyc - rd.epoch_cyc) & rd.sched_clock_mask, rd.mult, rd.shift);
rd.epoch_ns = ns;
rd.epoch_cyc = cyc;
update_clock_read_data(&rd);
}
스케줄 클럭을 읽어 갱신한다.
update_clock_read_data()
kernel/time/sched_clock.c
/* * Updating the data required to read the clock. * * sched_clock() will never observe mis-matched data even if called from * an NMI. We do this by maintaining an odd/even copy of the data and * steering sched_clock() to one or the other using a sequence counter. * In order to preserve the data cache profile of sched_clock() as much * as possible the system reverts back to the even copy when the update * completes; the odd copy is used *only* during an update. */
static void update_clock_read_data(struct clock_read_data *rd)
{
/* update the backup (odd) copy with the new data */
cd.read_data[1] = *rd;
/* steer readers towards the odd copy */
raw_write_seqcount_latch(&cd.seq);
/* now its safe for us to update the normal (even) copy */
cd.read_data[0] = *rd;
/* switch readers back to the even copy */
raw_write_seqcount_latch(&cd.seq);
}
@rd 값을 사용하여 스케줄 클럭을 홀/짝 두 개의 클럭 데이터에 갱신한다.
- read_data[1]을 갱신하고 시퀀스를 증가시켜 홀수가 될 때 read_data[0]을 갱신한다.
스케줄 클럭 읽기
sched_clock()
kernel/time/sched_clock.c
unsigned long long notrace sched_clock(void)
{
u64 cyc, res;
unsigned int seq;
struct clock_read_data *rd;
do {
seq = raw_read_seqcount(&cd.seq);
rd = cd.read_data + (seq & 1);
cyc = (rd->read_sched_clock() - rd->epoch_cyc) &
rd->sched_clock_mask;
res = rd->epoch_ns + cyc_to_ns(cyc, rd->mult, rd->shift);
} while (read_seqcount_retry(&cd.seq, seq));
return res;
}
스케줄 클럭을 읽어 반환한다.
- 시퀀스가 짝수이면 read_data[1]을 갱신할 가능성이 있으므로 read_data[0]의 클럭 데이터를 사용한다.
- 시퀀스가 홀수이면 read_data[0]을 갱신하고 있으므로 read_data[1]의 클럭 데이터를 사용한다.
스케줄 클럭 suspend/resume 핸들러 초기화
다음 그림은 suspend/resume에 대해 스케줄 클럭이 전환되도록 핸들러를 초기화하는 과정을 보여준다.
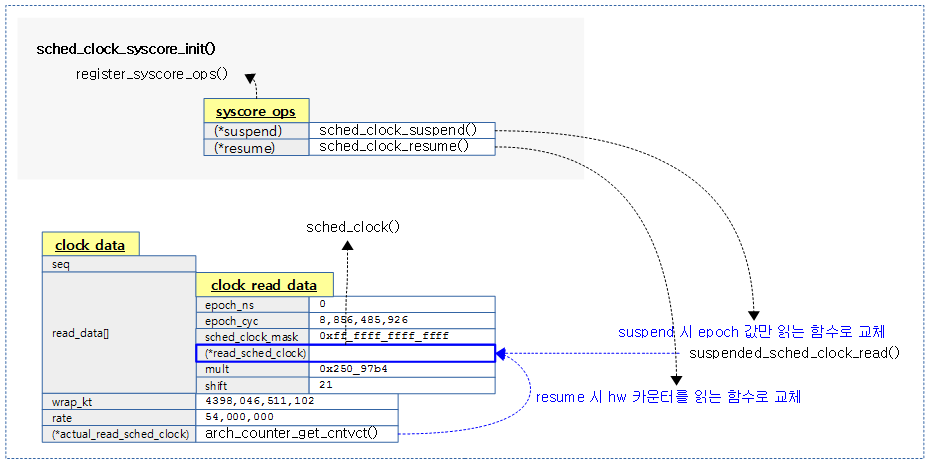
sched_clock_syscore_init()
kernel/time/sched_clock.c
static int __init sched_clock_syscore_init(void)
{
register_syscore_ops(&sched_clock_ops);
return 0;
}
device_initcall(sched_clock_syscore_init);
suspend/resume을 위해 sched_clock_ops를 등록한다.
sched_clock_ops
kernel/time/sched_clock.c
static struct syscore_ops sched_clock_ops = {
.suspend = sched_clock_suspend,
.resume = sched_clock_resume,
};
sched_clock_suspend()
kernel/time/sched_clock.c
int sched_clock_suspend(void)
{
struct clock_read_data *rd = &cd.read_data[0];
update_sched_clock();
hrtimer_cancel(&sched_clock_timer);
rd->read_sched_clock = suspended_sched_clock_read;
return 0;
}
suspend 시 호출되어 스케줄 클럭의 동작 방식을 변경한다.
- 코드 라인 5에서 sched_clock을 갱신한다.
- 코드 라인 6에서 약 1시간 주기로 동작하는 sched_clock_timer를 취소시킨다.
- 코드 라인 7에서 sched_clock() 함수가 갱신된 sched_clock의 내부 epoch_cyc 값을 읽도록 후크 함수를 변경한다.
sched_clock_resume()
kernel/time/sched_clock.c
void sched_clock_resume(void)
{
struct clock_read_data *rd = &cd.read_data[0];
rd->epoch_cyc = cd.actual_read_sched_clock();
hrtimer_start(&sched_clock_timer, cd.wrap_kt, HRTIMER_MODE_REL);
rd->read_sched_clock = cd.actual_read_sched_clock;
}
resume 시 호출되어 스케줄 클럭의 동작 방식을 변경한다.
- 코드 라인 5에서 sched_clock 을 실제 hw 카운터를 읽어 갱신한다.
- 코드 라인 6에서 약 1시간 주기로 동작하는 sched_clock_timer를 다시 동작시킨다.
- 코드 라인 7에서 sched_clock() 함수가 실제 hw 카운터를 읽도록 후크 함수를 변경한다.
suspended_sched_clock_read()
kernel/time/sched_clock.c
/* * Clock read function for use when the clock is suspended. * * This function makes it appear to sched_clock() as if the clock * stopped counting at its last update. * * This function must only be called from the critical * section in sched_clock(). It relies on the read_seqcount_retry() * at the end of the critical section to be sure we observe the * correct copy of 'epoch_cyc'. */
static u64 notrace suspended_sched_clock_read(void)
{
unsigned int seq = raw_read_seqcount(&cd.seq);
return cd.read_data[seq & 1].epoch_cyc;
}
suspend 시 읽어들일 스케줄 클럭 값을 반환한다.
delay 관련 함수 – ARM64
arm64 시스템에서 cpu는 cfe를 사용한 busy-wait 루프를 사용하여 대기한다. atomic context에서 ndelay() 또는 udelay() API들이 사용된다. 그러나 mdelay() API는 너무 오랫동안 busy-wait을 하므로 권장되지 않으며 가능하면 non-atomic context에서 사용되는 msleep() API를 사용하는 것이 좋다.
다음 그림은 arm64용 delay 관련 함수의 호출 관계를 보여준다.
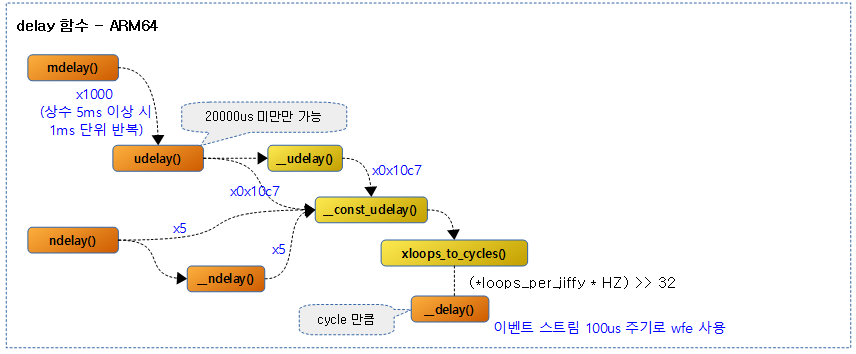
밀리 세컨드 단위 delay
mdelay()
include/linux/delay.h
#define mdelay(n) (\
(__builtin_constant_p(n) && (n)<=MAX_UDELAY_MS) ? udelay((n)*1000) : \
({unsigned long __ms=(n); while (__ms--) udelay(1000);}))
#endif
@n 밀리 세컨드 만큼 delay 한다.
- 상수 @n 값이 MAX_UDELAY_MS(5) 밀리 세컨드 이하에서는 udelay()를 호출 시 1000을 곱해 호출한다.
- 5ms 이하에서는 us단위로 변환하여 udelay() 함수를 한 번만 호출한다.
- 1000, 2000, 3000, 4000 또는 5000
- 5ms 이하에서는 us단위로 변환하여 udelay() 함수를 한 번만 호출한다.
- 그 외의 경우 udelay(1000)을 @n 만큼 호출한다.
마이크로 세컨드 단위 delay
udelay()
include/asm-generic/delay.h
/* * The weird n/20000 thing suppresses a "comparison is always false due to * limited range of data type" warning with non-const 8-bit arguments. */ /* 0x10c7 is 2**32 / 1000000 (rounded up) */
#define udelay(n) \
({ \
if (__builtin_constant_p(n)) { \
if ((n) / 20000 >= 1) \
__bad_udelay(); \
else \
__const_udelay((n) * 0x10c7ul); \
} else { \
__udelay(n); \
} \
})
@n 마이크로 세컨드 만큼 delay 한다.
- 상수 @n 값이 20000 이상인 경우 즉, 20ms 이상인 경우 컴파일 타임에 에러를 출력한다.
- 상수 @n 값이 20000 미만인 경우 즉, 20ms 미만인 경우 @n 값에 0x10c7을 곱한 값으로 __const_udelay()를 호출한다.
- 그 외의 경우 __udelay()를 그대로 호출한다.
__udelay()
arch/arm64/lib/delay.c
void __udelay(unsigned long usecs)
{
__const_udelay(usecs * 0x10C7UL); /* 2**32 / 1000000 (rounded up) */
}
EXPORT_SYMBOL(__udelay);
@usec 마이크로 세컨드 만큼 delay 한다.
- @usec 값에 0x10c7을 곱한 값으로 __const_udelay()를 호출한다.
루프 단위 delay
__const_udelay()
arch/arm64/lib/delay.c
inline void __const_udelay(unsigned long xloops)
{
__delay(xloops_to_cycles(xloops));
}
EXPORT_SYMBOL(__const_udelay);
@xloops 루프 만큼 delay 한다.
- 루프 단위 @xloops 값을 사이클 단위로 변환한 값으로 __delay() 함수를 호출한다.
나노 세컨드 단위 delay
ndelay()
include/asm-generic/delay.h
/* 0x5 is 2**32 / 1000000000 (rounded up) */
#define ndelay(n) \
({ \
if (__builtin_constant_p(n)) { \
if ((n) / 20000 >= 1) \
__bad_ndelay(); \
else \
__const_udelay((n) * 5ul); \
} else { \
__ndelay(n); \
} \
})
#endif /* __ASM_GENERIC_DELAY_H */
@n 나노 세컨드 만큼 delay 한다.
- 상수 @n 값이 20000 이상인 경우 즉, 20us 이상인 경우 컴파일 타임에 에러를 출력한다.
- 상수 @n 값이 20000 미만인 경우 즉, 20us 미만인 경우 @n 값에 5를 곱한 값으로 __const_udelay()를 호출한다.
- 1us 당 5 루프
- 그 외의 경우 __ndelay()를 그대로 호출한다.
__ndelay()
arch/arm64/lib/delay.c
void __ndelay(unsigned long nsecs)
{
__const_udelay(nsecs * 0x5UL); /* 2**32 / 1000000000 (rounded up) */
}
EXPORT_SYMBOL(__ndelay);
@nsec 나노 세컨드 만큼 delay 한다.
- @nsec 값에 5를 곱한 값으로 __const_udelay()를 호출한다.
사이클 단위 delay
xloops_to_cycles()
arch/arm64/lib/delay.c
static inline unsigned long xloops_to_cycles(unsigned long xloops)
{
return (xloops * loops_per_jiffy * HZ) >> 32;
}
@xloops 루프 단위를 사이클 단위로 변환하여 반환한다.
__delay()
arch/arm64/lib/delay.c
void __delay(unsigned long cycles)
{
cycles_t start = get_cycles();
if (arch_timer_evtstrm_available()) {
const cycles_t timer_evt_period =
USECS_TO_CYCLES(ARCH_TIMER_EVT_STREAM_PERIOD_US);
while ((get_cycles() - start + timer_evt_period) < cycles)
wfe();
}
while ((get_cycles() - start) < cycles)
cpu_relax();
}
EXPORT_SYMBOL(__delay);
@cycles 사이클 단위의 수 만큼 delay 한다.
- 코드 라인 5~11에서 아키텍트 타이머에 이벤트 스트림이 동작하는 경우 요청한 사이클 수 만큼 100us 단위로 wfe를 수행하여 대기하여 cpu 로드를 줄이고 절전할 수 있다.
- 코드 라인 13~14에서 사이클 수 만큼 delay하고, 사이클 수를 초과한 경우 루프를 탈출한다.
delay 관련 함수 – ARM32
arm32 시스템에서는 busy-wait 기반의 delay 타이머를 사용한다.
다음 그림은 arm32용 delay 관련 함수의 호출 관계를 보여준다.
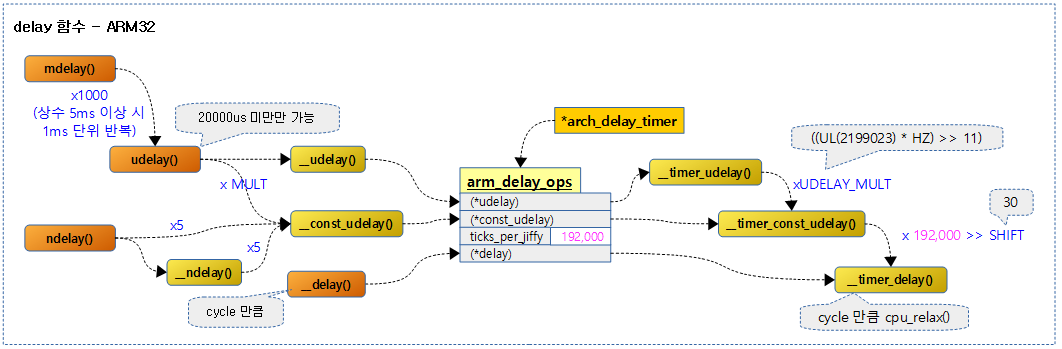
Delay 타이머 등록 (generic 타이머) – ARM32
arch_timer_delay_timer_register()
arch/arm/kernel/arch_timer.c
static void __init arch_timer_delay_timer_register(void)
{
/* Use the architected timer for the delay loop. */
arch_delay_timer.read_current_timer = arch_timer_read_counter_long;
arch_delay_timer.freq = arch_timer_get_rate();
register_current_timer_delay(&arch_delay_timer);
}
armv7 아키텍처에 내장된 generic 타이머를 delay 타이머로 사용할 수 있도록 등록한다.
다음 그림은 100hz로 구성된 generic 타이머를 딜레이 타이머로 등록하는 과정을 보여준다.
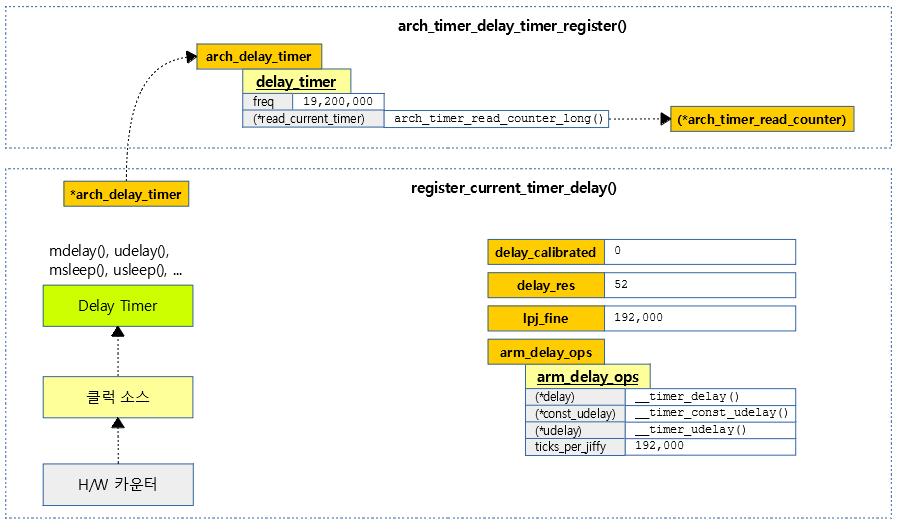
register_current_timer_delay() – ARM32
arch/arm/lib/delay.c
void __init register_current_timer_delay(const struct delay_timer *timer)
{
u32 new_mult, new_shift;
u64 res;
clocks_calc_mult_shift(&new_mult, &new_shift, timer->freq,
NSEC_PER_SEC, 3600);
res = cyc_to_ns(1ULL, new_mult, new_shift);
if (!delay_calibrated && (!delay_res || (res < delay_res))) {
pr_info("Switching to timer-based delay loop, resolution %lluns\n", res);
delay_timer = timer;
lpj_fine = timer->freq / HZ;
delay_res = res;
/* cpufreq may scale loops_per_jiffy, so keep a private copy */
arm_delay_ops.ticks_per_jiffy = lpj_fine;
arm_delay_ops.delay = __timer_delay;
arm_delay_ops.const_udelay = __timer_const_udelay;
arm_delay_ops.udelay = __timer_udelay;
} else {
pr_info("Ignoring duplicate/late registration of read_current_timer delay\n");
}
}
딜레이 타이머를 등록하고 calibration 한다. 처음 설정 시에는 반드시 calibration을 한다.
- 코드 라인 6~7에서 1시간에 해당하는 정확도로 1 cycle에 소요되는 nano초를 산출할 수 있도록 new_mult/new_shift 값을 산출한다.
- 코드 라인 8에서 해상도 res 값을 구한다. (1 cycle에 해당하는 nano 초)
- rpi2: 100hz, 19.2Mhz clock -> res=52
- 코드 라인 10~20에서 calibration이 완료되지 않았고 처음이거나 요청한 타이머가 더 고해상도 타이머인 경우 딜레이 타이머에 대한 설정을 한다.
- res 값이 작으면 작을 수록 고해상도 타이머이다.
- 클럭 소스가 여러 개가 등록되는 경우 딜레이 타이머에 가장 좋은 고해상도 타이머를 선택하게 한다.
- calivrate_delay() 함수에서 calibration을 완료하고 나면 더 이상 클럭 소스로 부터 더 이상 딜레이 카운터의 등록을 할 수 없게 한다.
- rpi2 예) “Switching to timer-based delay loop, resolution 52ns”
sleep 관련 함수
non-atomic context에서 사용할 수 있는 함수들은 다음과 같다. 10us ~ 20ms까지는 usleep() 보다 atomic context 사용 가능한 udelay()를 사용하길 권장한다.
- hrtimer로 동작
- usleep_range()
- jiffies 및 legacy timer로 동작
- msleep()
- msleep_interruptible()
다음 그림은 sleep 관련 함수의 호출 관계를 보여준다.
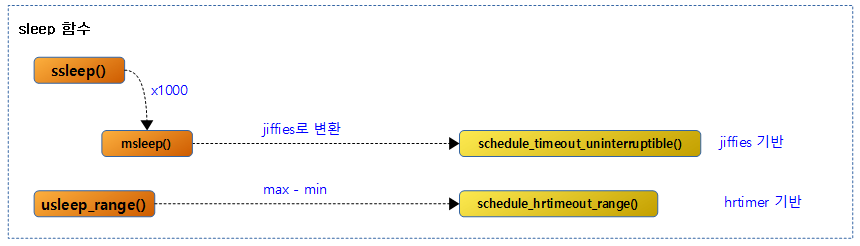
세컨드 단위 sleep
ssleep()
include/linux/delay.h
static inline void ssleep(unsigned int seconds)
{
msleep(seconds * 1000);
}
@seconds 세컨드만큼 슬립한다.
밀리 세컨드 단위 sleep
msleep()
kernel/time/timer.c
/** * msleep - sleep safely even with waitqueue interruptions * @msecs: Time in milliseconds to sleep for */
void msleep(unsigned int msecs)
{
unsigned long timeout = msecs_to_jiffies(msecs) + 1;
while (timeout)
timeout = schedule_timeout_uninterruptible(timeout);
}
EXPORT_SYMBOL(msleep);
@msec 밀리 세컨드만큼 jiffies 스케줄 틱 기반으로 슬립한다.
마이크로 세컨드 단위 sleep
usleep_range()
kernel/time/timer.c
/** * usleep_range - Sleep for an approximate time * @min: Minimum time in usecs to sleep * @max: Maximum time in usecs to sleep * * In non-atomic context where the exact wakeup time is flexible, use * usleep_range() instead of udelay(). The sleep improves responsiveness * by avoiding the CPU-hogging busy-wait of udelay(), and the range reduces * power usage by allowing hrtimers to take advantage of an already- * scheduled interrupt instead of scheduling a new one just for this sleep. */
void __sched usleep_range(unsigned long min, unsigned long max)
{
ktime_t exp = ktime_add_us(ktime_get(), min);
u64 delta = (u64)(max - min) * NSEC_PER_USEC;
for (;;) {
__set_current_state(TASK_UNINTERRUPTIBLE);
/* Do not return before the requested sleep time has elapsed */
if (!schedule_hrtimeout_range(&exp, delta, HRTIMER_MODE_ABS))
break;
}
}
EXPORT_SYMBOL(usleep_range);
@max – @min 마이크로 세컨드만큼 jiffies 스케줄 틱 기반으로 슬립한다.
참고
- Timer -1- (Lowres Timer) | 문c
- Timer -2- (HRTimer) | 문c
- Timer -3- (Clock Sources Subsystem) | 문c
- Timer -4- (Clock Sources Watchdog) | 문c
- Timer -5- (Clock Events Subsystem) | 문c
- Timer -6- (Clock Source & Timer Driver) | 문c
- Timer -7- (Sched Clock & Delay Timers) | 문c – 현재 글
- Timer -8- (Timecounter) | 문c
- Timer -9- (Tick Device) | 문c
- Timer -10- (Timekeeping) | 문c
- Timer -11- (Posix Clock & Timers) | 문c
- time_init() | 문c
- sched_clock_postinit() | 문c
- tick_init() | 문c
- timekeeping_init() | 문c
- calibrate_delay() | 문c
- delays – Information on the various kernel delay / sleep mechanisms (Documentation/timers/timers-howto) | Kernel.org
- [Linux:Kernel] 지연시간 – 다양한 커널 딜레이(delay) / 슬립(sleep) 메카니즘의 정보 | 다솜돌이