<kernel v5.15>
존 사이즈 결정 및 초기화
zone_sizes_init()
arch/arm64/mm/init.c
static void __init zone_sizes_init(unsigned long min, unsigned long max)
{
unsigned long max_zone_pfns[MAX_NR_ZONES] = {0};
#ifdef CONFIG_ZONE_DMA
max_zone_pfns[ZONE_DMA] = PFN_DOWN(arm64_dma_phys_limit);
#endif
#ifdef CONFIG_ZONE_DMA32
max_zone_pfns[ZONE_DMA32] = PFN_DOWN(arm64_dma32_phys_limit);
#endif
max_zone_pfns[ZONE_NORMAL] = max;
free_area_init(max_zone_pfns);
}
메모리 모델에 따른 노드, 존의 초기화를 다룬다. (@min에 물리 메모리의 최소 pfn, @max에 물리 메모리의 최대 pfn+1 값. 예: min=0x40000, max=0x80000)
- 코드 라인 6에서 dma 존의 끝(pfn)을 지정한다.
- 코드 라인 9에서 dma32 존의 끝(pfn)을 지정한다.
- 코드 라인 11에서 normal 존의 끝(pfn)을 지정한다.
- 메모리가 dma32 존에 들어갈 정도로 작은 경우 dma32 존과 normal 존에 대한 max_zone_pfns[] 값은 동일하다.
- 예) 1G 메모리
- max_zone_pfns[] = { 0x8_0000, 0x8_0000, 0x8_0000, 0x0 }
- 코드 라인 13에서 max_zone_pfns[] 배열 정보를 사용하여 빈 페이지들을 초기화한다.
다음 그림은 max_zone_pfns[] 값을 산출하는 과정이다.
- DMA 영역은 물리 공간에서 최대 4G 영역을 사용할 수 있으며, 4G 단위의 영역 경계를 넘어가지 못한다.

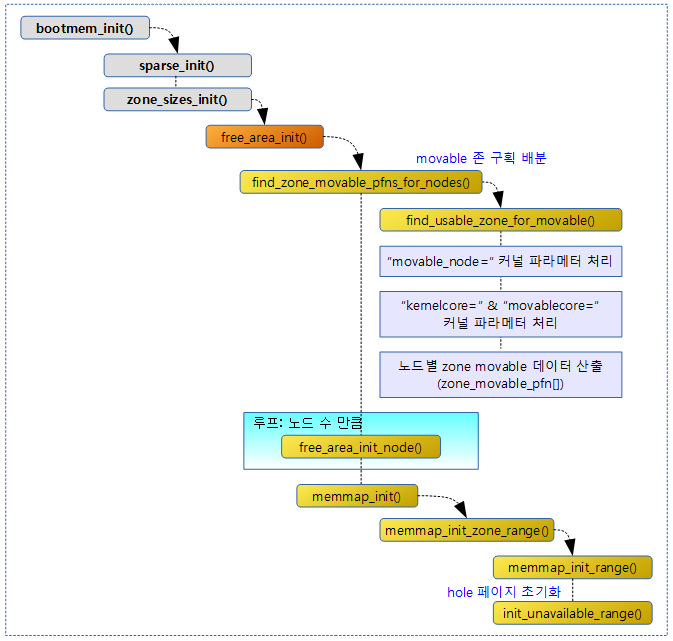
노드 초기화
노드를 초기화하기 사용된 함수명은 free_area_init_nodes()였지만 커널 v5.8-rc1부터 free_area_init() 함수명으로 변경되었다.
- 참고: mm: use free_area_init() instead of free_area_init_nodes() (2020, v5.8-rc1)
다음 그림은 미리 산출된 존 구획 정보를 넘겨받아 각 노드를 초기화하는 흐름을 보여준다.
- NUMA 시스템의 경우 커널 파라미터등을 사용하여 movable 존을 추가할 수 있는데 이 때에는 각 노드의 last 존을 커널 파라미터에서 요청한 사이즈만큼 movable 존으로 분리하여 구획한다.
- 아키텍처 및 메모리의 크기에 따라 last 존은 다르며 highmem -> normal -> dma32 -> dma 순서대로 실제 메모리가 존재하는 가장 마지막 존이 지정된다.
- 예) normal, dma32, dma 존에 실제 메모리가 존재하는 경우 last 존은 normal 존이 된다.
- arm64 아키텍처 커널 v4.7-rc1 부터 NUMA 설정을 지원한다. arm 아키텍처의 경우 별도의 NUMA 패치를 적용해야 한다.
다음 그림은 지정된 노드 정보와 사용 가능한 존 정보들을 초기화하는 흐름을 보여준다.
NUMA 시스템의 노드들 초기화
free_area_init()
mm/page_alloc.c -1/2-
/** * free_area_init - Initialise all pg_data_t and zone data * @max_zone_pfn: an array of max PFNs for each zone * * This will call free_area_init_node() for each active node in the system. * Using the page ranges provided by memblock_set_node(), the size of each * zone in each node and their holes is calculated. If the maximum PFN * between two adjacent zones match, it is assumed that the zone is empty. * For example, if arch_max_dma_pfn == arch_max_dma32_pfn, it is assumed * that arch_max_dma32_pfn has no pages. It is also assumed that a zone * starts where the previous one ended. For example, ZONE_DMA32 starts * at arch_max_dma_pfn. */
void __init free_area_init(unsigned long *max_zone_pfn)
{
unsigned long start_pfn, end_pfn;
int i, nid, zone;
bool descending;
/* Record where the zone boundaries are */
memset(arch_zone_lowest_possible_pfn, 0,
sizeof(arch_zone_lowest_possible_pfn));
memset(arch_zone_highest_possible_pfn, 0,
sizeof(arch_zone_highest_possible_pfn));
start_pfn = find_min_pfn_with_active_regions();
descending = arch_has_descending_max_zone_pfns();
for (i = 0; i < MAX_NR_ZONES; i++) {
if (descending)
zone = MAX_NR_ZONES - i - 1;
else
zone = i;
if (zone == ZONE_MOVABLE)
continue;
end_pfn = max(max_zone_pfn[zone], start_pfn);
arch_zone_lowest_possible_pfn[zone] = start_pfn;
arch_zone_highest_possible_pfn[zone] = end_pfn;
start_pfn = end_pfn;
}
/* Find the PFNs that ZONE_MOVABLE begins at in each node */
memset(zone_movable_pfn, 0, sizeof(zone_movable_pfn));
find_zone_movable_pfns_for_nodes();
시스템내의 모든 active 노드 및 ZONE 정보를 초기화하고 구성한다.
- 코드 라인 13에서 물리 메모리의 시작 pfn을 구해온다.
- 코드 라인 14에서 아키텍처의 존 순서가 거꾸로되어 있는지 여부를 알아온다.
- ARC 아키텍처를 제외하면 모두 false이다.
- 코드 라인 16~30에서 인자로 받은 @max_zone_pfn 배열에서 모든 존을 순회하며 movable 존을 제외하고 각 zone의 경계를 구분한다.
- arch_zone_lowest_possible_pfn[]에 각 존별로 시작 pfn 값이 지정된다.
- arch_zone_highest_possible_pfn[]에 각 존별로 끝 pfn 값이 지정된다.
- 코드 라인 33~34에서 노드별로 movable 존의 시작 pfn 값을 알아와서 zone_movable_pfn[ ]에 담아온다.
mm/page_alloc.c -2/2-
/* Print out the zone ranges */
pr_info("Zone ranges:\n");
for (i = 0; i < MAX_NR_ZONES; i++) {
if (i == ZONE_MOVABLE)
continue;
pr_info(" %-8s ", zone_names[i]);
if (arch_zone_lowest_possible_pfn[i] ==
arch_zone_highest_possible_pfn[i])
pr_cont("empty\n");
else
pr_cont("[mem %#018Lx-%#018Lx]\n",
(u64)arch_zone_lowest_possible_pfn[i]
<< PAGE_SHIFT,
((u64)arch_zone_highest_possible_pfn[i]
<< PAGE_SHIFT) - 1);
}
/* Print out the PFNs ZONE_MOVABLE begins at in each node */
pr_info("Movable zone start for each node\n");
for (i = 0; i < MAX_NUMNODES; i++) {
if (zone_movable_pfn[i])
pr_info(" Node %d: %#018Lx\n", i,
(u64)zone_movable_pfn[i] << PAGE_SHIFT);
}
/*
* Print out the early node map, and initialize the
* subsection-map relative to active online memory ranges to
* enable future "sub-section" extensions of the memory map.
*/
pr_info("Early memory node ranges\n");
for_each_mem_pfn_range(i, MAX_NUMNODES, &start_pfn, &end_pfn, &nid) {
pr_info(" node %3d: [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT,
((u64)end_pfn << PAGE_SHIFT) - 1);
subsection_map_init(start_pfn, end_pfn - start_pfn);
}
/* Initialise every node */
mminit_verify_pageflags_layout();
setup_nr_node_ids();
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid);
free_area_init_node(nid);
/* Any memory on that node */
if (pgdat->node_present_pages)
node_set_state(nid, N_MEMORY);
check_for_memory(pgdat, nid);
}
memmap_init();
}
- 코드 라인 2~16에서 movable 존을 제외한 각 존별 pfn 영역을 출력한다.
- 코드 라인 19~24에서 각 노드에 등록된 movable 존 정보를 출력한다.
- 코드 라인 31~37에서 각 노드에 등록된 early 노드 메모리 정보를 출력한다. 또한 사용하는 서브섹션 메모리를 1과 0으로 표현하는 서브섹션비트맵을 설정한다.
- 코드 라인 40에서 page->flags에 들어갈 섹션 비트 수, 노드 비트 수, 존 비트 수 등을 점검한다.
- 코드 라인 41에서 active 노드 수를 결정하기 위해 마지막 possible 노드 + 1을 전역 nr_node_ids에 설정한다.
- 코드 라인 42~50에서 모든 온라인 노드를 초기화한다.
- 코드 라인 52에서 mem_map을 초기화한다.
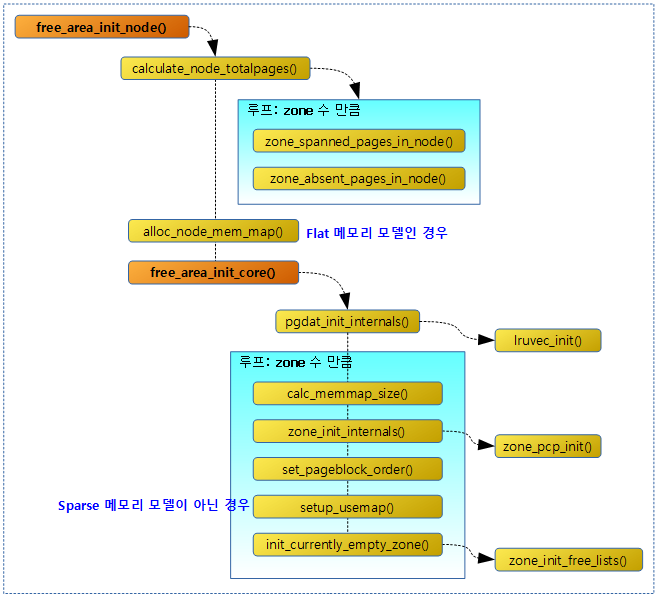
지정한 노드 초기화
free_area_init_node()
mm/page_alloc.c
static void __init free_area_init_node(int nid)
{
pg_data_t *pgdat = NODE_DATA(nid);
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->kswapd_highest_zoneidx);
get_pfn_range_for_nid(nid, &start_pfn, &end_pfn);
pgdat->node_id = nid;
pgdat->node_start_pfn = start_pfn;
pgdat->per_cpu_nodestats = NULL;
pr_info("Initmem setup node %d [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT,
end_pfn ? ((u64)end_pfn << PAGE_SHIFT) - 1 : 0);
calculate_node_totalpages(pgdat, start_pfn, end_pfn);
alloc_node_mem_map(pgdat);
pgdat_set_deferred_range(pgdat);
free_area_init_core(pgdat);
}
요청한 노드 @nid의 모든 ZONE 정보를 초기화하고 구성한다.
- 코드 라인 3 에서 노드에 속한 페이지를 관리하는 구조체 포인터를 알아온다.
- 코드 라인 10에서 지정된 노드의 memory memblock에서 파편화되지 않은 페이지 프레임 시작 번호와 끝 번호를 알아온다.
- 코드 라인 12~14에서 노드 정보에 노드 id와 노드의 시작 pfn 등을 설정한다.
- 코드 라인 16~18에서 메모리 정보를 출력한다.
- 예) “Initmem setup node 0 [mem 0x0000000040000000-0x000000007fffffff]“
- 코드 라인 19에서 zones_size[]와 zholes_size[] 정보를 사용하여 노드 정보를 산출한 후 기록한다.
- ZONE_MOVABLE이 있는 경우 메모리가 존재하는 마지막 zone의 영역이 조정된다.
- 코드 라인 21에서 flat 물리 메모리 모델용 mem_map을 할당한다.
- page[] 구조체로 구성된 mem_map을 위해 memblock 할당을 한다
- Spasrse 메모리 모델을 사용하는 경우 mem_map은 이미 sparse_init() 함수에서 section_mem_map[]으로 구성되었다.
- 코드 라인 22에서 메모리가 큰 시스템인 경우 page 구조체를 초기화하려면 많은 시간이 걸린다. 이러한 경우 시스템에 필요한 일부 메모리를 제외한 후 CONFIG_DEFERRED_STRUCT_PAGE_INIT 커널 옵션을 사용하여 별도의 커널 스레드가 동작시켜 나중에 page 구조체를 초기화한다. 즉 page 구조체 초기화를 유예시키는 옵션이다.
- 코드 라인 24에서 노드의 zone 관리를 위해 zone 구조체와 관련된 정보들을 초기화한다. 내부에서 usemap을 할당하고 초기화하며, 버디 시스템에 사용하는 free_area[], lruvec, pcp 등도 초기화한다.
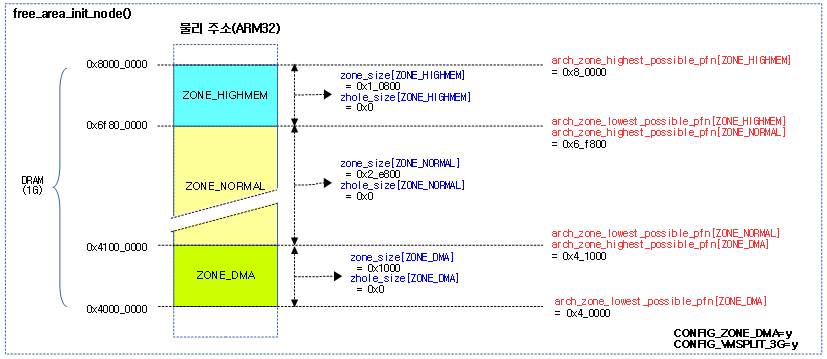
다음 그림은 1G 메모리를 가진 ARM32에서 존 구획이 나뉘는 모습을 보여준다.
- 참고로 4G 이하 메모리를 사용하는 대부분의 ARM32는 ZONE_DMA를 사용하지 않는다.
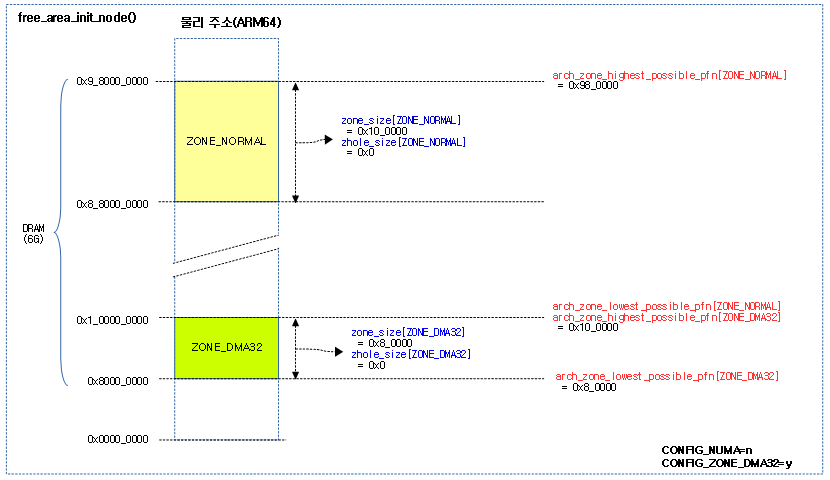
다음 그림은 메모리 영역이 2개로 분리된 6G 메모리를 가진 ARM64에서 존 구획이 나뉘는 모습을 보여준다.
Movable 존 구성
NUMA 시스템에서는 대용량 메모리가 사용된다. 이러한 경우 특정 메모리 노드들에 대해 movable 페이지들만을 할당하도록 제한된 movable 존을 설정할 수 있다. movable 존은 시스템의 last 존의 영역을 나누어 사용한다. ARM32 시스템의 경우 마지막 존인 highmem 영역의 일부를 사용하고, ARM64의 경우 highmem을 사용하지 않으므로 마지막 존인 normal 영역의 일부를 사용한다. 시스템에서 마지막 존과 movable 존의 구획을 나누어 구성하는 다음 방법들을 알아본다.
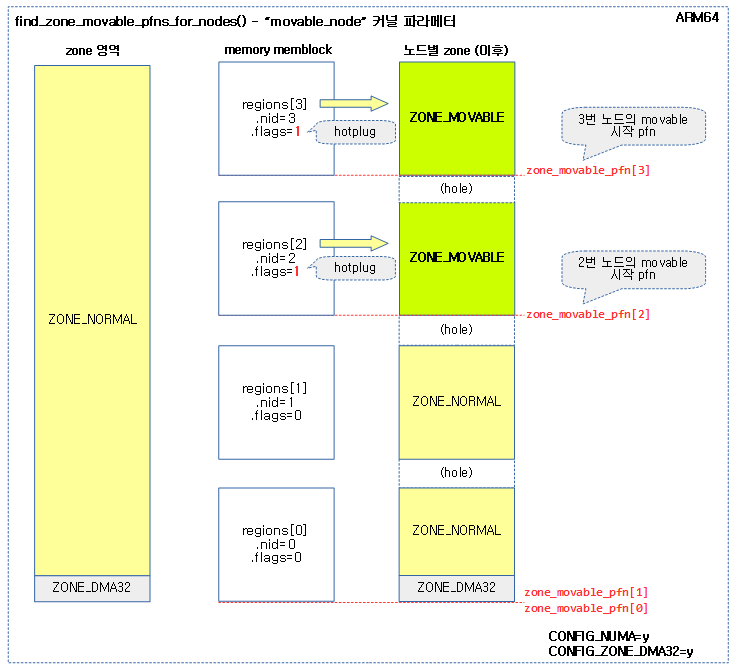
- “movable_node” 커널 파라미터 지정
- hotplug 메모리 설정된 노드들을 모두 movable 존으로 설정한다.
- 0번 노드는 hotplug 설정할 수 없다.
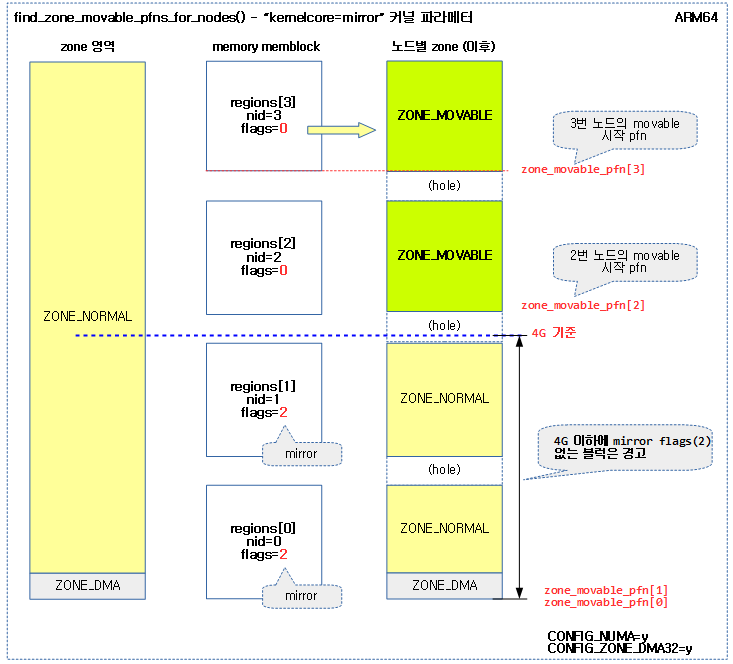
- “kernelcore=mirror” 커널 파라미티 지정
- 고신뢰성 확보를 위해 x86 시스템에서 일부 메모리를 mirror로 사용할 수 있다. 이렇게 신뢰성이 확보되는 영역의 사용에 커널 코어가 사용되도록 할 수 있다. 이런 경우에는 나머지 영역들은 movable zone으로 설정한다.
- 이 옵션을 사용 시 4G 이하의 메모리 영역에 mirror 플래그가 설정되어 있어야 한다.
- “kernelcore=nn” 커널 파라미터 지정
- 전체 페이지에서 kernelcore로 지정된 용량을 제외한 나머지를 movablecore 페이지로 하고 이를 각 노드들에 배분하여 movable 존으로 설정한다.
- “movablecore=nn” 커널 파라미터 지정
- 전체 페이지에서 movablecore로 지정된 용량 만큼의 페이지를 각 노드들에 배분하여 movale 존으로 설정한다.
커널 v4.0 이후 다음과 같은 내용이 추가되었다.
- 커널 v4.6-rc1에서 “kernelcore=mirror” 커널 파라미터 추가
- 커널 v4.17-rc1에서 “kernelcore=nn%” 및 “movablecore=nn%” 커널 파라미터에서 퍼센트(%) 기호 사용 추가
find_zone_movable_pfns_for_nodes()
mm/page_alloc.c -1/4-
/* * Find the PFN the Movable zone begins in each node. Kernel memory * is spread evenly between nodes as long as the nodes have enough * memory. When they don't, some nodes will have more kernelcore than * others */
static void __init find_zone_movable_pfns_for_nodes(void)
{
int i, nid;
unsigned long usable_startpfn;
unsigned long kernelcore_node, kernelcore_remaining;
/* save the state before borrow the nodemask */
nodemask_t saved_node_state = node_states[N_MEMORY];
unsigned long totalpages = early_calculate_totalpages();
int usable_nodes = nodes_weight(node_states[N_MEMORY]);
struct memblock_region *r;
/* Need to find movable_zone earlier when movable_node is specified. */
find_usable_zone_for_movable();
/*
* If movable_node is specified, ignore kernelcore and movablecore
* options.
*/
if (movable_node_is_enabled()) {
for_each_mem_region(r) {
if (!memblock_is_hotpluggable(r))
continue;
nid = memblock_get_region_node(r);
usable_startpfn = PFN_DOWN(r->base);
zone_movable_pfn[nid] = zone_movable_pfn[nid] ?
min(usable_startpfn, zone_movable_pfn[nid]) :
usable_startpfn;
}
goto out2;
}
/*
* If kernelcore=mirror is specified, ignore movablecore option
*/
if (mirrored_kernelcore) {
bool mem_below_4gb_not_mirrored = false;
for_each_mem_region(r) {
if (memblock_is_mirror(r))
continue;
nid = memblock_get_region_node(r);
usable_startpfn = memblock_region_memory_base_pfn(r);
if (usable_startpfn < 0x100000) {
mem_below_4gb_not_mirrored = true;
continue;
}
zone_movable_pfn[nid] = zone_movable_pfn[nid] ?
min(usable_startpfn, zone_movable_pfn[nid]) :
usable_startpfn;
}
if (mem_below_4gb_not_mirrored)
pr_warn("This configuration results in unmirrored kernel memory.\n");
goto out2;
}
노드별 movable 존 구획을 나눈다.
- 코드 라인 8에서 모든 노드의 페이지 수를 알아온다.
- 코드 라인 9에서 메모리가 있는 노드의 수를 알아온다.
- 코드 라인 13에서 모든 zone에서 메모리가 있는 마지막 zone을 알아와서 전역 변수 movable_zone에 대입한다.
- ZONE_MOVABLE은 마지막 zone의 일부 또는 전부를 사용하여 구성하게 된다.
- 코드 라인 19~33에서 Hot-plug용 ZONE_MOVABLE을 구성하기 위해 노드별 zone movable의 시작 주소를 전역 zone_movable_pfn[] 배열에 산출한다.
- CONFIG_MOVABLE_NODE 커널 옵션을 사용하면서 “movable_node” 커널 파라메터를 사용한 경우 true를 반환한다.
- hotplug 설정이 있는 memblock의 시작 주소를 zone_movable_pfn[]에 대입하되 zone_movable_pfn[] 값보다 큰 경우에 한정 한다.
- 코드 라인 38~63에서 “kernelcore=mirror” 커널 파라미터가 설정된 경우 “movablecore” 커널 파라미터는 무시한다.
- 4G 이하의 메모리에 대해서는 mirror가 설정되어 있지 않은 경우 경고 메시지를 출력한다.
다음 그림은 “movable_node” 커널 파라미터를 사용하여 movable zone을 구성하는 모습을 보여준다.
다음 그림은 “movablecore=mirror” 커널 파라미터를 사용하여 movable zone을 구성하는 모습을 보여준다.
mm/page_alloc.c -2/4-
. /*
* If kernelcore=nn% or movablecore=nn% was specified, calculate the
* amount of necessary memory.
*/
if (required_kernelcore_percent)
required_kernelcore = (totalpages * 100 * required_kernelcore_percent) /
10000UL;
if (required_movablecore_percent)
required_movablecore = (totalpages * 100 * required_movablecore_percent) /
10000UL;
/*
* If movablecore= was specified, calculate what size of
* kernelcore that corresponds so that memory usable for
* any allocation type is evenly spread. If both kernelcore
* and movablecore are specified, then the value of kernelcore
* will be used for required_kernelcore if it's greater than
* what movablecore would have allowed.
*/
if (required_movablecore) {
unsigned long corepages;
/*
* Round-up so that ZONE_MOVABLE is at least as large as what
* was requested by the user
*/
required_movablecore =
roundup(required_movablecore, MAX_ORDER_NR_PAGES);
required_movablecore = min(totalpages, required_movablecore);
corepages = totalpages - required_movablecore;
required_kernelcore = max(required_kernelcore, corepages);
}
/*
* If kernelcore was not specified or kernelcore size is larger
* than totalpages, there is no ZONE_MOVABLE.
*/
if (!required_kernelcore || required_kernelcore >= totalpages)
goto out;
- 코드 라인 5~7에서 퍼센트를 사용한 “kernelcore=nn%” 커널 파라미터에서 전체 페이지로부터 지정한 퍼센트를 커널 코어 페이지로 지정한다.
- 코드 라인 8~10에서 퍼센트를 사용한 “movablecore=nn%” 커널 파라미터에서 전체 페이지로부터 지정한 퍼센트를 movable 코어 페이지로 지정한다.
- 코드 라인 20~33에서”movablecore=” 커널 파라미터가 지정된 경우 “kernelcore=” 보다 우선하여 처리한다. 전체 페이지에서 movable로 지정한 페이지를 제외한 나머지를 커널 코어로 지정한다.
- movable 페이지는 MAX_ORDER_NR_PAGES 단위로 올림 정렬하여 사용한다.
- 코드 라인 39~40에서 커널 코어에 배정한 페이지가 없거나 전체 페이지보다 큰 경우 out 레이블을 통해 빠져나간다.
다음 그림은 “kernelcore=” 보다 “movablecore=” 커널 파라미터의 사용을 우선하는 것을 보여준다.
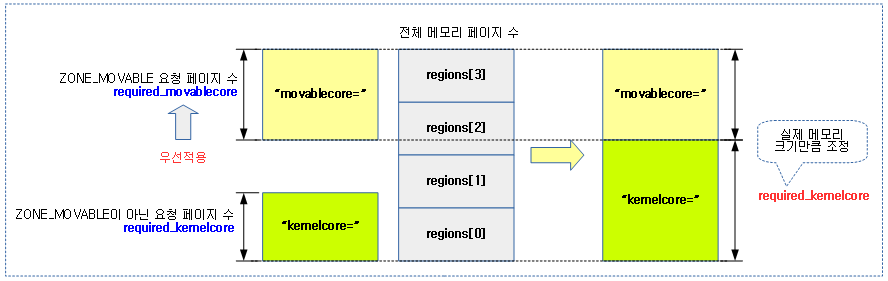
mm/page_alloc.c -3/4-
/* usable_startpfn is the lowest possible pfn ZONE_MOVABLE can be at */
usable_startpfn = arch_zone_lowest_possible_pfn[movable_zone];
restart:
/* Spread kernelcore memory as evenly as possible throughout nodes */
kernelcore_node = required_kernelcore / usable_nodes;
for_each_node_state(nid, N_MEMORY) {
unsigned long start_pfn, end_pfn;
/*
* Recalculate kernelcore_node if the division per node
* now exceeds what is necessary to satisfy the requested
* amount of memory for the kernel
*/
if (required_kernelcore < kernelcore_node)
kernelcore_node = required_kernelcore / usable_nodes;
/*
* As the map is walked, we track how much memory is usable
* by the kernel using kernelcore_remaining. When it is
* 0, the rest of the node is usable by ZONE_MOVABLE
*/
kernelcore_remaining = kernelcore_node;
/* Go through each range of PFNs within this node */
for_each_mem_pfn_range(i, nid, &start_pfn, &end_pfn, NULL) {
unsigned long size_pages;
start_pfn = max(start_pfn, zone_movable_pfn[nid]);
if (start_pfn >= end_pfn)
continue;
/* Account for what is only usable for kernelcore */
if (start_pfn < usable_startpfn) {
unsigned long kernel_pages;
kernel_pages = min(end_pfn, usable_startpfn)
- start_pfn;
kernelcore_remaining -= min(kernel_pages,
kernelcore_remaining);
required_kernelcore -= min(kernel_pages,
required_kernelcore);
/* Continue if range is now fully accounted */
if (end_pfn <= usable_startpfn) {
/*
* Push zone_movable_pfn to the end so
* that if we have to rebalance
* kernelcore across nodes, we will
* not double account here
*/
zone_movable_pfn[nid] = end_pfn;
continue;
}
start_pfn = usable_startpfn;
}
/*
* The usable PFN range for ZONE_MOVABLE is from
* start_pfn->end_pfn. Calculate size_pages as the
* number of pages used as kernelcore
*/
size_pages = end_pfn - start_pfn;
if (size_pages > kernelcore_remaining)
size_pages = kernelcore_remaining;
zone_movable_pfn[nid] = start_pfn + size_pages;
/*
* Some kernelcore has been met, update counts and
* break if the kernelcore for this node has been
* satisfied
*/
required_kernelcore -= min(required_kernelcore,
size_pages);
kernelcore_remaining -= size_pages;
if (!kernelcore_remaining)
break;
}
}
- 코드 라인 2에서 루프를 돌기 전에 가장 아래에 위치한 movable 존의 시작 pfn 값을 usable_startpfn에 지정한다.
- 이 usable_startpfn 보다 아래에 있는 영역들은 커널 코어에 해당한다.
- 코드 라인 4~6에서 restart 레이블을 통해 반복되는 경우 요청 커널 코어 페이지 수를 메모리 노드로 나눈 노드별 커널 코어 페이지 수를 산출한다.
- 코드 라인 7~16에서 메모리 memblock을 순회하며요청 코어 페이지가 노드별 커널 코어 페이지보다 적어진 경우 요청 커널 코어 페이지를 미처리된 메모리 노드로 나눠 노드별 커널 코어 페이지 수를 재산출한다.
- 코드 라인 26~31에서 메모리 memblock을 순회하며 시작 pfn과 끝 pfn을 알아오고, 해당 메모리 영역 사이에 노드의 movable pfn 경계가 없는 경우 movable 영역으로 처리할 필요가 없으므로 skip 한다.
- 노드의 첫 memblock 영역을 처리할 때 zone_movable_pfn[nid] 값은 처음에 0 이므로 이 조건에 걸리지 않는다.
- 코드 라인 34~57에서 커널 코어 영역으로 사용할 페이지 양을 결정한다.
- 코드 라인 64~67에서 현재 진행되고 있는 노드의 movable 존을 산출하기 위해 현재까지 처리한 커널 코어 양의 끝 위치를 zone_movable_pfn[nid]에 저장해둔다.
- 코드 라인 74~78에서 커널 코어 잔량 처리를 수행한다.
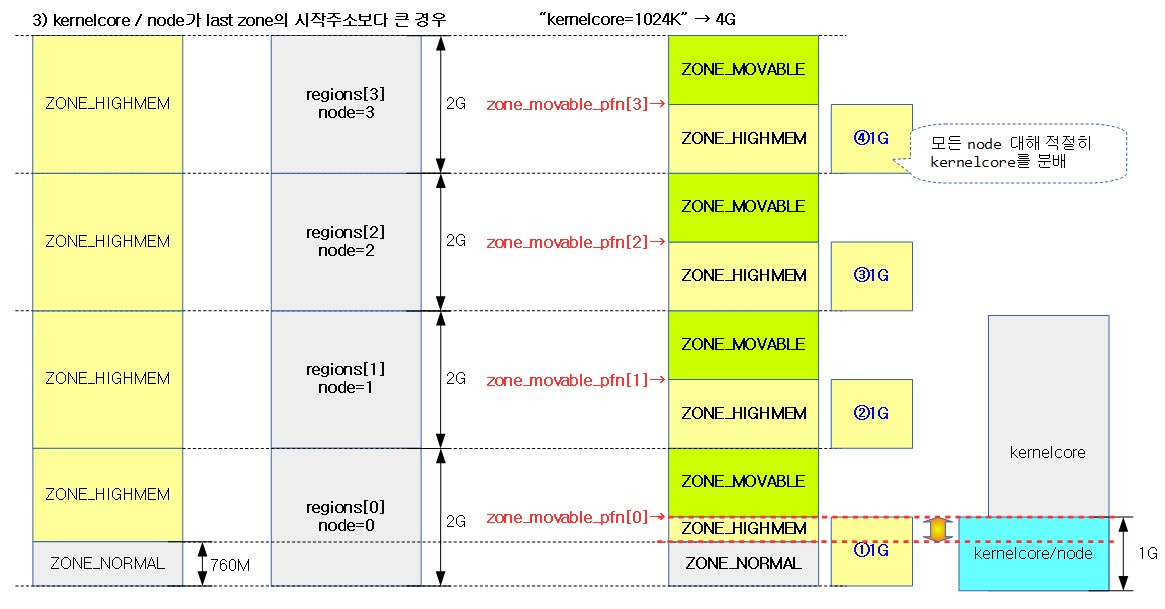
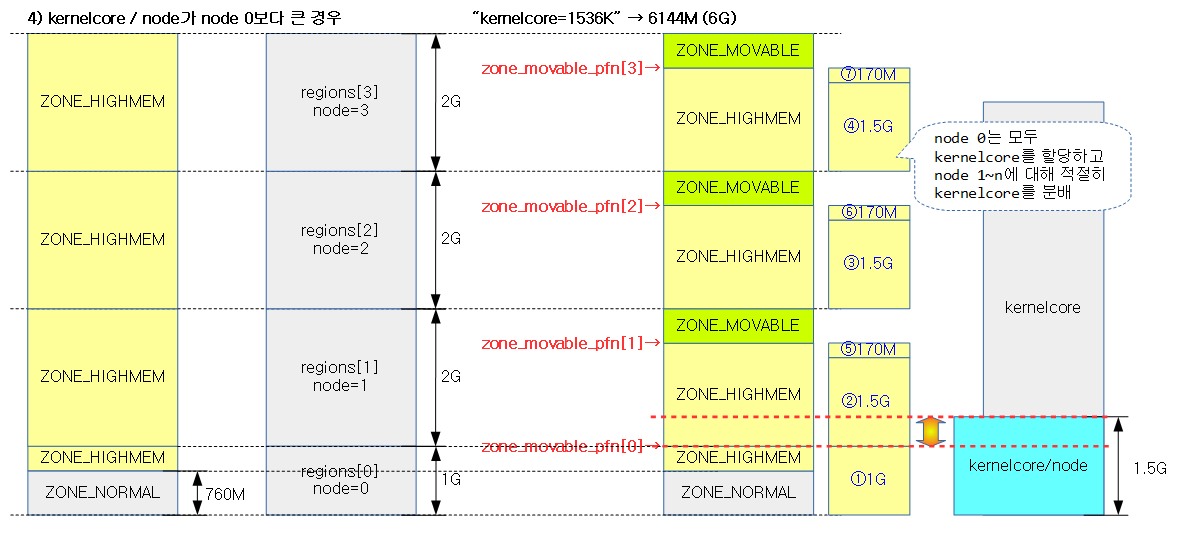
다음 그림은 “kernelcore=nn” 또는 “movablecore” 커널 파라미터를 사용하여 movable zone을 각 노드에 고르게 분배하여 구성하는 모습을 보여준다.
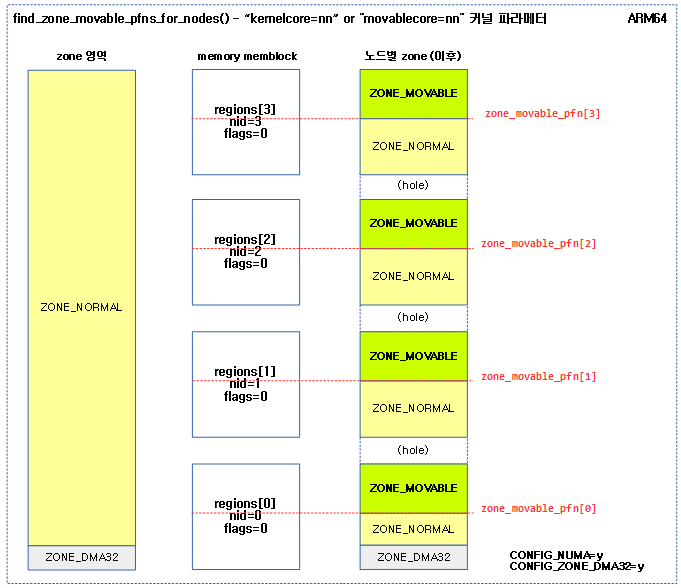
mm/page_alloc.c -4/4-
/*
* If there is still required_kernelcore, we do another pass with one
* less node in the count. This will push zone_movable_pfn[nid] further
* along on the nodes that still have memory until kernelcore is
* satisfied
*/
usable_nodes--;
if (usable_nodes && required_kernelcore > usable_nodes)
goto restart;
out2:
/* Align start of ZONE_MOVABLE on all nids to MAX_ORDER_NR_PAGES */
for (nid = 0; nid < MAX_NUMNODES; nid++)
zone_movable_pfn[nid] =
roundup(zone_movable_pfn[nid], MAX_ORDER_NR_PAGES);
out:
/* restore the node_state */
node_states[N_MEMORY] = saved_node_state;
}
- 코드 라인 7~9에서 커널 코어에 필요한 페이지가 모두 배정되지 않은 경우 다시 한 번 restart 레이블로 이동하여 처리한다.
- 코드 라인 11~15에서 out2: 레이블에서는 zone_movable_pfn[] 배열 값을 MAX_ORDER_NR_PAGES 단위로 올림 정렬하도록 한다.
- 코드 라인 17~19에서 이 함수의 처음에 저장해 둔 메모리 노드 비트맵을 복원한다.
다음 그림은 “kernelcore=”로 지정된 페이지 수를 가용 노드 만큼 나누어 배치를 하고 이에 대한 끝 주소를 zone_movable_pfn[] 배열에 저장하는 모습을 보여준다. 이 값은 추후 각 노드별 ZONE_MOVABLE이 시작되는 주소를 설정하는데 사용된다.
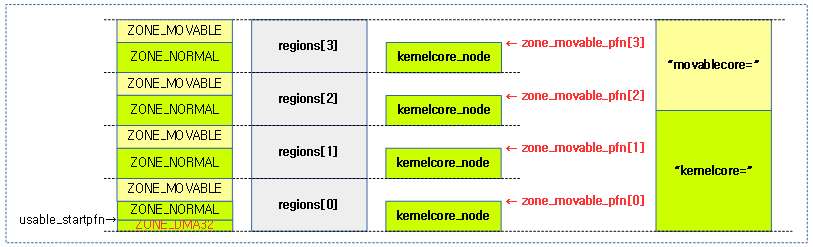
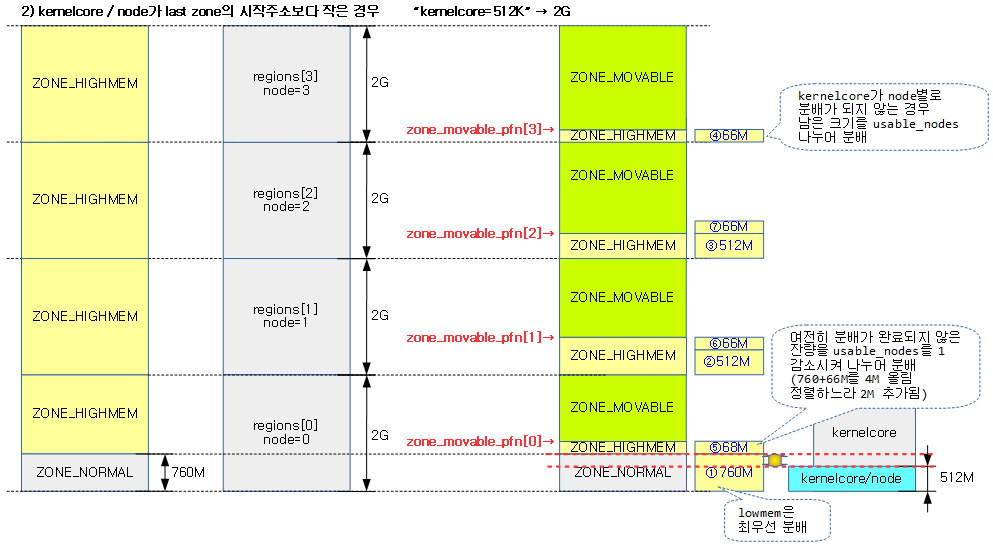
다음 4개의 그림은 NUMA 시스템에서 “kernelcore=” 커널 파라메터 값에 따라 ZONE_MOVABLE 영역이 지정되는 모습을 보여준다.

find_usable_zone_for_movable()
mm/page_alloc.c
/* * This finds a zone that can be used for ZONE_MOVABLE pages. The * assumption is made that zones within a node are ordered in monotonic * increasing memory addresses so that the "highest" populated zone is used */
static void __init find_usable_zone_for_movable(void)
{
int zone_index;
for (zone_index = MAX_NR_ZONES - 1; zone_index >= 0; zone_index--) {
if (zone_index == ZONE_MOVABLE)
continue;
if (arch_zone_highest_possible_pfn[zone_index] >
arch_zone_lowest_possible_pfn[zone_index])
break;
}
VM_BUG_ON(zone_index == -1);
movable_zone = zone_index;
}
가용 zone에서 가장 높이 위치한 zone 인덱스 값을 전역 변수 movable_zone에 저장한다.

get_pfn_range_for_nid()
mm/page_alloc.c
/** * get_pfn_range_for_nid - Return the start and end page frames for a node * @nid: The nid to return the range for. If MAX_NUMNODES, the min and max PFN are returned. * @start_pfn: Passed by reference. On return, it will have the node start_pfn. * @end_pfn: Passed by reference. On return, it will have the node end_pfn. * * It returns the start and end page frame of a node based on information * provided by memblock_set_node(). If called for a node * with no available memory, a warning is printed and the start and end * PFNs will be 0. */
void __init get_pfn_range_for_nid(unsigned int nid,
unsigned long *start_pfn, unsigned long *end_pfn)
{
unsigned long this_start_pfn, this_end_pfn;
int i;
*start_pfn = -1UL;
*end_pfn = 0;
for_each_mem_pfn_range(i, nid, &this_start_pfn, &this_end_pfn, NULL) {
*start_pfn = min(*start_pfn, this_start_pfn);
*end_pfn = max(*end_pfn, this_end_pfn);
}
if (*start_pfn == -1UL)
*start_pfn = 0;
}
해당 노드 @nid의 memory memblock 에서 해당 페이지가 파편화되지 않고 온전히 포함된 페이지 번호만을 찾아 시작 pfn과 끝 pfn으로 알아온다.
- 만일 노드 지정에 MAX_NUMNODES가 지정되면 DRAM의 min_pfn과 max_pfn이 리턴된다.
- 참고: for_each_mem_pfn_range() 함수 -> Memblock – (2) | 문c
노드 및 노드의 모든 존별 spanned 및 present 페이지 산출
calculate_node_totalpages()
mm/page_alloc.c
static void __init calculate_node_totalpages(struct pglist_data *pgdat,
unsigned long node_start_pfn,
unsigned long node_end_pfn)
{
unsigned long realtotalpages = 0, totalpages = 0;
enum zone_type i;
for (i = 0; i < MAX_NR_ZONES; i++) {
struct zone *zone = pgdat->node_zones + i;
unsigned long zone_start_pfn, zone_end_pfn;
unsigned long size, real_size;
size = zone_spanned_pages_in_node(pgdat->node_id, i,
node_start_pfn,
node_end_pfn,
&zone_start_pfn,
&zone_end_pfn);
real_size = size - zone_absent_pages_in_node(pgdat->node_id, i,
node_start_pfn, node_end_pfn);
size = spanned;
real_size = size - absent;
if (size)
zone->zone_start_pfn = zone_start_pfn;
else
zone->zone_start_pfn = 0;
zone->spanned_pages = size;
zone->present_pages = real_size;
#if defined(CONFIG_MEMORY_HOTPLUG)
zone->present_early_pages = real_size;
#endif
totalpages += size;
realtotalpages += real_size;
}
pgdat->node_spanned_pages = totalpages;
pgdat->node_present_pages = realtotalpages;
pr_debug("On node %d totalpages: %lu\n", pgdat->node_id, realtotalpages);
}
요청 노드 및 요청 노드에 대한 모든 존별로 홀을 포함한 spanned_pages와 실제 사용할 수 있는 페이지인 present_pages를 구한다.
- pgdat->node_spanned_pages 및 pgdat->node_present_pages 멤버에 노드에 대해 산출한 spanned 및 present 페이지를 저장한다.
- 존별 zone->spanned_pages 및 zone->present_pages 멤버에 각 존에 대해 산출한 spanned 및 present 페이지를 저장한다.
다음 그림은 0번 노드에서 normal 존과 0번 노드 전체에 대한 spanned 및 present 페이지를 구하는 모습을 보여준다.
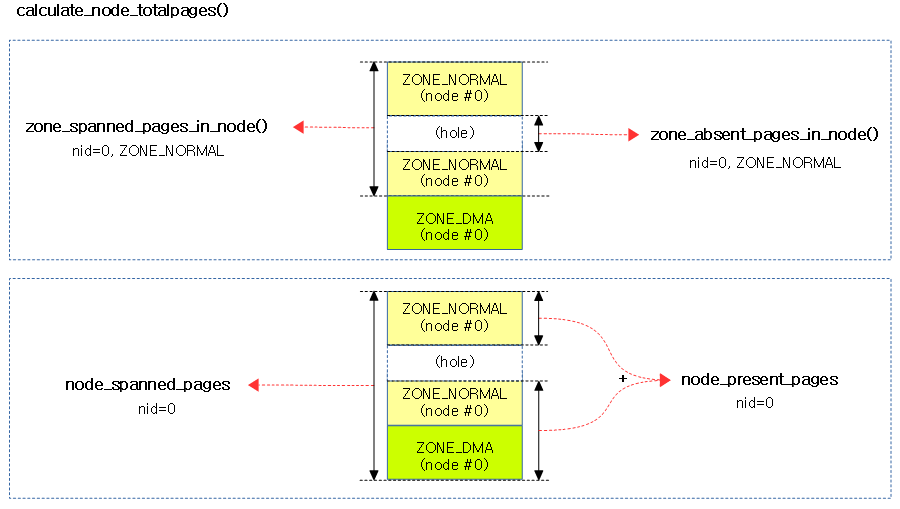
spanned 페이지 산출 – 작업중
zone_spanned_pages_in_node()
mm/page_alloc.c
/* * Return the number of pages a zone spans in a node, including holes * present_pages = zone_spanned_pages_in_node() - zone_absent_pages_in_node() */
static unsigned long __init zone_spanned_pages_in_node(int nid,
unsigned long zone_type,
unsigned long node_start_pfn,
unsigned long node_end_pfn,
unsigned long *zone_start_pfn,
unsigned long *zone_end_pfn)
{
unsigned long zone_low = arch_zone_lowest_possible_pfn[zone_type];
unsigned long zone_high = arch_zone_highest_possible_pfn[zone_type];
/* When hotadd a new node from cpu_up(), the node should be empty */
if (!node_start_pfn && !node_end_pfn)
return 0;
/* Get the start and end of the zone */
*zone_start_pfn = arch_zone_lowest_possible_pfn[zone_type];
*zone_end_pfn = arch_zone_highest_possible_pfn[zone_type];
adjust_zone_range_for_zone_movable(nid, zone_type,
node_start_pfn, node_end_pfn,
zone_start_pfn, zone_end_pfn);
/* Check that this node has pages within the zone's required range */
if (*zone_end_pfn < node_start_pfn || *zone_start_pfn > node_end_pfn)
return 0;
/* Move the zone boundaries inside the node if necessary */
*zone_end_pfn = min(*zone_end_pfn, node_end_pfn);
*zone_start_pfn = max(*zone_start_pfn, node_start_pfn);
/* Return the spanned pages */
return *zone_end_pfn - *zone_start_pfn;
}
해당 노드에 대해 요청 zone의 hole을 포함한 페이지 수를 알아온다. NUMA 시스템에서는 ZONE_MOVABLE을 사용하는 경우가 있으므로 이 때 highest zone의 영역의 일정 양을 나누어 사용하므로 이에 대한 페이지 수 계산을 해야 한다.
- 코드 라인 8~23에서 movable 존이 사용되는 경우 실제 movable 가능한 페이지 영역을 기준으로 last 존 의 영역을 조정한다.
- 코드 라인 26에서 zone 끝 pfn 값이 노드 끝 pfn 값을 초과하지 않도록 한다.
- 코드 라인 27에서 zone 시작 pfn 값이 노드 시작 pfn 값보다 작지 않도록 한다.
- 코드 라인 30에서 재조정된 zone의 hole을 포함한 페이지 수를 리턴한다.
absent 페이지 산출
zone_absent_pages_in_node()
mm/page_alloc.c
/* Return the number of page frames in holes in a zone on a node */
static unsigned long __init zone_absent_pages_in_node(int nid,
unsigned long zone_type,
unsigned long node_start_pfn,
unsigned long node_end_pfn)
{
unsigned long zone_low = arch_zone_lowest_possible_pfn[zone_type];
unsigned long zone_high = arch_zone_highest_possible_pfn[zone_type];
unsigned long zone_start_pfn, zone_end_pfn;
unsigned long nr_absent;
/* When hotadd a new node from cpu_up(), the node should be empty */
if (!node_start_pfn && !node_end_pfn)
return 0;
zone_start_pfn = clamp(node_start_pfn, zone_low, zone_high);
zone_end_pfn = clamp(node_end_pfn, zone_low, zone_high);
adjust_zone_range_for_zone_movable(nid, zone_type,
node_start_pfn, node_end_pfn,
&zone_start_pfn, &zone_end_pfn);
nr_absent = __absent_pages_in_range(nid, zone_start_pfn, zone_end_pfn);
/*
* ZONE_MOVABLE handling.
* Treat pages to be ZONE_MOVABLE in ZONE_NORMAL as absent pages
* and vice versa.
*/
if (mirrored_kernelcore && zone_movable_pfn[nid]) {
unsigned long start_pfn, end_pfn;
struct memblock_region *r;
for_each_mem_region(r) {
start_pfn = clamp(memblock_region_memory_base_pfn(r),
zone_start_pfn, zone_end_pfn);
end_pfn = clamp(memblock_region_memory_end_pfn(r),
zone_start_pfn, zone_end_pfn);
if (zone_type == ZONE_MOVABLE &&
memblock_is_mirror(r))
nr_absent += end_pfn - start_pfn;
if (zone_type == ZONE_NORMAL &&
!memblock_is_mirror(r))
nr_absent += end_pfn - start_pfn;
}
}
return nr_absent;
}
해당 노드에 대해 요청 zone에서 빈 공간(hole) 페이지 수를 알아온다.
- 코드 라인 15에서 node_start_pfn 값을 zone 영역으로 들어가도록 조정하여 zone 시작 pfn으로 대입한다.
- 코드 라인 16에서 node_end_pfn 값을 zone 영역으로 들어가도록 조정하여 zone 끝 pfn으로 대입한다.
- 코드 라인 18~20에서 실제 movable 가능한 페이지 영역을 기준으로 zone 들의 영역을 조정한다.
- 코드 라인 21에서 지정된 영역내에서 빈 공간(hole) 페이지 수를 알아온다.
- 코드 라인 28~46에서 mirrored 커널 코어를 사용한 경우 movable 페이지들을 absent 페이지로 카운트 한다.
- 코드 라인 48에서 absent 페이지 수를 반환한다.
__absent_pages_in_range()
mm/page_alloc.c
/* * Return the number of holes in a range on a node. If nid is MAX_NUMNODES, * then all holes in the requested range will be accounted for. */
unsigned long __meminit __absent_pages_in_range(int nid,
unsigned long range_start_pfn,
unsigned long range_end_pfn)
{
unsigned long nr_absent = range_end_pfn - range_start_pfn;
unsigned long start_pfn, end_pfn;
int i;
for_each_mem_pfn_range(i, nid, &start_pfn, &end_pfn, NULL) {
start_pfn = clamp(start_pfn, range_start_pfn, range_end_pfn);
end_pfn = clamp(end_pfn, range_start_pfn, range_end_pfn);
nr_absent -= end_pfn - start_pfn;
}
return nr_absent;
}
지정된 영역내에서 빈 공간(hole) 페이지 수를 알아온다.
- 코드 라인 5에서 nr_absent 초기값을 영역에 대한 페이지 수로 한다.
- 코드 라인 9에서 노드 번호에 해당하는 memory memblock에서 파편화된 페이지를 제외한 즉 온전한 페이지가 1개 이상인 경우의 시작 pfn과 끝 pfn 값을 루프를 돌며 하나씩 알아온다.
- 코드 라인 10에서 영역에 들어가게 start_pfn 값을 바꾼다.
- 코드 라인 11에서 영역에 들어가게 end_pfn 값을 바꾼다.
- 코드 라인 12에서 영역에 포함된 페이지 수를 빼면 사용할 수 없는 페이지 수가 계산된다.
- 코드 라인 14에서 absent 페이지를 반환한다.
아래 그림은 함수 처리 예를 보인다. (실제 NUMA 시스템 사용 사례는 아니므로 계산에 참고만 한다.)
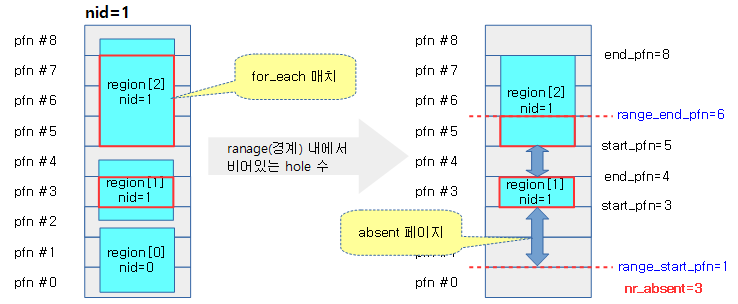
movable 존에 맞춰 각 존 조정
adjust_zone_range_for_zone_movable()
page_alloc.c
/* * The zone ranges provided by the architecture do not include ZONE_MOVABLE * because it is sized independent of architecture. Unlike the other zones, * the starting point for ZONE_MOVABLE is not fixed. It may be different * in each node depending on the size of each node and how evenly kernelcore * is distributed. This helper function adjusts the zone ranges * provided by the architecture for a given node by using the end of the * highest usable zone for ZONE_MOVABLE. This preserves the assumption that * zones within a node are in order of monotonic increases memory addresses */
static void __init adjust_zone_range_for_zone_movable(int nid,
unsigned long zone_type,
unsigned long node_start_pfn,
unsigned long node_end_pfn,
unsigned long *zone_start_pfn,
unsigned long *zone_end_pfn)
{
/* Only adjust if ZONE_MOVABLE is on this node */
if (zone_movable_pfn[nid]) {
/* Size ZONE_MOVABLE */
if (zone_type == ZONE_MOVABLE) {
*zone_start_pfn = zone_movable_pfn[nid];
*zone_end_pfn = min(node_end_pfn,
arch_zone_highest_possible_pfn[movable_zone]);
/* Adjust for ZONE_MOVABLE starting within this range */
} else if (!mirrored_kernelcore &&
*zone_start_pfn < zone_movable_pfn[nid] &&
*zone_end_pfn > zone_movable_pfn[nid]) {
*zone_end_pfn = zone_movable_pfn[nid];
/* Check if this whole range is within ZONE_MOVABLE */
} else if (*zone_start_pfn >= zone_movable_pfn[nid])
*zone_start_pfn = *zone_end_pfn;
}
}
실제 movable 가능한 페이지 영역을 기준으로 현재 zone의 영역을 다음과 같이 조정 한다.
- 처리할 zone이 ZONE_MOVABLE인 경우 실제 movable 가능한 페이지 범위로 조정한다.
- 처리할 zone이 ZONE_MOVABLE이 아닌 경우 movable 가능한 페이지 범위와 겹치지 않도록 조정한다.
- 코드 라인 9에서 해당 노드에 movable 존이 있는 경우
- 코드 라인 11~14에서 현재 zone이 ZONE_MOVABLE인 경우 zone 시작 pfn 에 zone_movable_pfn[nid] 값을 대입하고, zone 끝 pfn을 moveable 가능한 페이지 번호로 줄인다.
- 코드 라인 17~20에서 mirrored 커널 코어가 아니면서 노드의 메모리 일부가 ZONE_MOVABLE로 구성한 경우 last zone의 끝 주소를 조정한다.
- 코드 라인 23~24에서 요청 zone이 movable 영역보다 높은 경우 잘못 요청한 경우 이므로 zone 시작 pfn에 zone 끝 pfn 값을 대입하여 요청 zone의 size가 0이되게 하여 이 zone을 처리하지 않게 한다.
Flat 메모리 모델에서 노드용 mem_map 할당
alloc_node_mem_map()
mm/page_alloc.c
#ifdef CONFIG_FLATMEM
static void __init alloc_node_mem_map(struct pglist_data *pgdat)
{
unsigned long __maybe_unused start = 0;
unsigned long __maybe_unused offset = 0;
/* Skip empty nodes */
if (!pgdat->node_spanned_pages)
return;
start = pgdat->node_start_pfn & ~(MAX_ORDER_NR_PAGES - 1);
offset = pgdat->node_start_pfn - start;
/* ia64 gets its own node_mem_map, before this, without bootmem */
if (!pgdat->node_mem_map) {
unsigned long size, end;
struct page *map;
/*
* The zone's endpoints aren't required to be MAX_ORDER
* aligned but the node_mem_map endpoints must be in order
* for the buddy allocator to function correctly.
*/
end = pgdat_end_pfn(pgdat);
end = ALIGN(end, MAX_ORDER_NR_PAGES);
size = (end - start) * sizeof(struct page);
map = memmap_alloc(size, SMP_CACHE_BYTES, MEMBLOCK_LOW_LIMIT,
pgdat->node_id, false);
if (!map)
panic("Failed to allocate %ld bytes for node %d memory map\n",
size, pgdat->node_id);
pgdat->node_mem_map = map + offset;
}
pr_debug("%s: node %d, pgdat %08lx, node_mem_map %08lx\n",
__func__, pgdat->node_id, (unsigned long)pgdat,
(unsigned long)pgdat->node_mem_map);
#ifndef CONFIG_NUMA
/*
* With no DISCONTIG, the global mem_map is just set as node 0's
*/
if (pgdat == NODE_DATA(0)) {
mem_map = NODE_DATA(0)->node_mem_map;
if (page_to_pfn(mem_map) != pgdat->node_start_pfn)
mem_map -= offset;
}
#endif
}
#else
static inline void alloc_node_mem_map(struct pglist_data *pgdat) { }
#endif /* CONFIG_FLATMEM */
page[] 구조체로 구성된 flat 메모리 모델용 mem_map을 위해 memblock 할당을 한다. (ARM64의 경우 sparse 메모리 모델을 사용한다.)
- 코드 라인 8~9에서 노드에 사용 가능한 메모리 페이지 영역이 없는 경우 리턴한다.
- 코드 라인 11~12에서 노드 시작 pfn을 버디 할당자용 최대 페이지 요청의 절반 단위로 정렬하고, 정렬하여 조정된 만큼을 offset에 저장한다.
- 코드 라인 14~32에서 ia64 시스템에서는 별도의 mem_map이 미리 지정되어 있다. 따라서 나머지 시스템을 위해 flat 메모리 모델용 mem_map을 할당한다.
- 코드 라인 33~35에서 노드에 대한 mem_map 정보를 출력한다.
- 코드 라인 40~44에서 싱글 노드의 경우 mem_map 전역 변수에 할당된 mem_map을 지정한다.
- flat 메모리 모델을 사용하는 2M 이하를 사용하는 arm 보드에 문제가 있어 offset을 제거하는 패치를 사용하였다.
- 커널 v4.4-rc1에서 2M 이하의 flatmem을 사용하는 특정 시스템에서 문제가 있어 패치를 하였다.
다음 그림은 지정된 노드에 대한 mem_map[]을 할당 받아 노드 구조체의 node_mem_map에 연결시키는 모습을 보여준다.
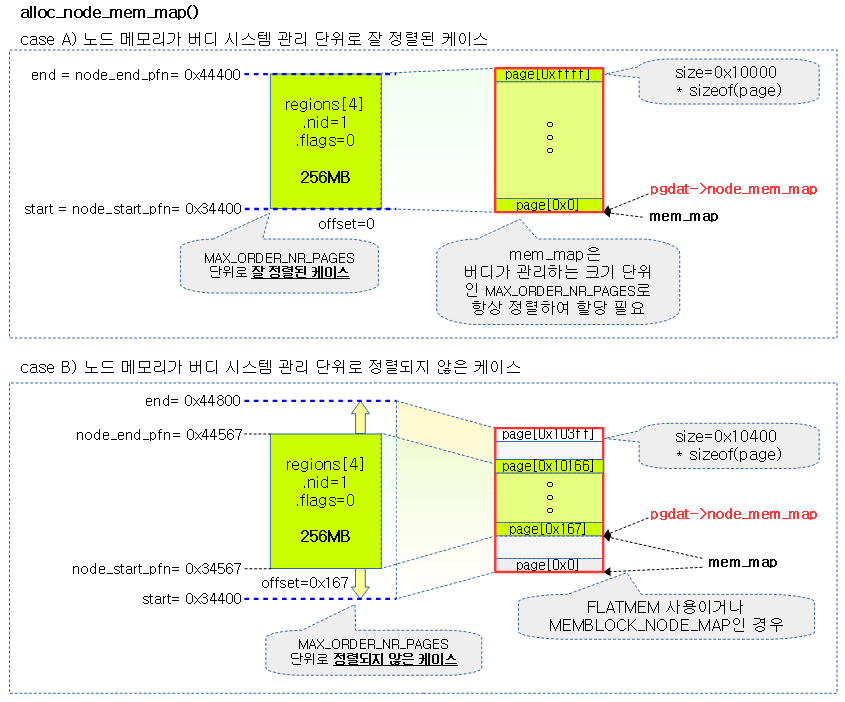
노드 및 노드에 해당하는 존 초기화
free_area_init_core()
mm/page_alloc.c
/* * Set up the zone data structures: * - mark all pages reserved * - mark all memory queues empty * - clear the memory bitmaps * * NOTE: pgdat should get zeroed by caller. * NOTE: this function is only called during early init. */
static void __init free_area_init_core(struct pglist_data *pgdat)
{
enum zone_type j;
int nid = pgdat->node_id;
pgdat_init_internals(pgdat);
pgdat->per_cpu_nodestats = &boot_nodestats;
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, freesize, memmap_pages;
unsigned long zone_start_pfn = zone->zone_start_pfn;
size = zone->spanned_pages;
freesize = zone->present_pages;
/*
* Adjust freesize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = calc_memmap_size(size, freesize);
if (!is_highmem_idx(j)) {
if (freesize >= memmap_pages) {
freesize -= memmap_pages;
if (memmap_pages)
pr_debug(" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
pr_warn(" %s zone: %lu memmap pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
}
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;
pr_debug(" %s zone: %lu pages reserved\n", zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;
nr_all_pages += freesize;
/*
* Set an approximate value for lowmem here, it will be adjusted
* when the bootmem allocator frees pages into the buddy system.
* And all highmem pages will be managed by the buddy system.
*/
zone_init_internals(zone, j, nid, freesize);
if (!size)
continue;
set_pageblock_order();
setup_usemap(zone);
init_currently_empty_zone(zone, zone->zone_start_pfn, size);
}
}
지정된 노드의 zone 관리를 위해 zone 구조체와 관련된 정보들을 설정한다. 그리고 usemap을 할당하고 초기화하며, 버디 시스템에 사용하는 free_area[], lruvec, pcp 등도 초기화한다.
- 코드 라인 6에서 노드에서 사용하는 내부 락 및 큐등을 초기화한다.
- 코드 라인 7에서 per cpu 노드 stat을 지정한다.
- 코드 라인 9~22에서 zone 수 만큼 순회하며, page 구조체 배열이 들어갈 페이지 수를 구한다.
- 코드 라인 23~32에서 highmem 존이 아닌 경우 freesize에서 memmap에 사용될 pages 수 만큼을 감소시킨다.
- 코드 라인 35~38에서 freesize에서 dma_reserve에 사용될 pages 수 만큼을 감소시킨다.
- 코드 라인 40~41에서 highmem 존이 아닌 경우 전역 변수 nr_kernel_pages 에 freesize를 추가한다.
- 코드 라인 43~44에서 nr_kernel_pages가 memmap_pages * 2 보다 큰 경우 nr_kernel_pages에서 memmap_pages 만큼 줄인다.
- memmap은 보통 lowmem 영역에 할당되는데, 메모리가 무척 큰 32 비트 시스템에서는 lowmem 영역이 작아 memmap을 모두 lowmem에 할당하기에는 부담스러워진다. 이렇게 memmap 영역이 lowmem 영역의 절반 이상을 차지 하는 경우 memmap을 highmem에 생성한다.
- 코드 라인 45에서전역 변수 nr_all_pages에 freesize를 추가한다.
- nr_kernel_pages와 nr_all_pages 값은 각 zone의 워터마크를 설정할 때 사용된다.
- nr_kernel_pages=
- lowmem pages – mem_map pages(highmem 제외) – dma_reserve
- 조건: highmem memmap 비중이 lowmem의 절반 이하일 때 – mem_map pages(highmem)
- lowmem pages – mem_map pages(highmem 제외) – dma_reserve
- nr_all_pages=
- lowmem pages – mem_map pages(highmem 제외) – dma_reserve + highmem pages
- 두 개의 변수는 alloc_large_system_hash()에서 해쉬의 크기를 결정할 때 엔트리 크기가 지정되지 않을 경우 메모리의 크기에 비례하여 만들기 위해 사용된다.
- 예) uhash_entries=, ihash_entries=, dhash_entries=, mhash_entries=
- 코드 라인 52에서 존에 대한 내부 정보를 초기화한다.
- 코드 라인 54~55에서 사이즈가 0이 된 경우 다음 존을 처리한다.
- 코드 라인 57에서 CONFIG_HUGETLB_PAGE_SIZE_VARIABLE 커널 옵션을 사용한 경우 런타임에 pageblock_order를 설정한다.
- 코드 라인 58에서 zone별로 usemap을 memblock에 할당 받는다.
- 코드 라인 59에서 wait table에 대한 해시 엔트리 수를 결정하고 관련 메모리를 할당 받은 후 초기화(waitqueue 및 spinlock) 하고 버디시스템에서 사용하는 free_area[].free_list[]를 초기화한다.
다음 그림은 각 zone의 managed_pages와 전역 nr_kernel_pages 및 nr_all_pages를 한눈에 알아볼 수 있도록 도식화하였다
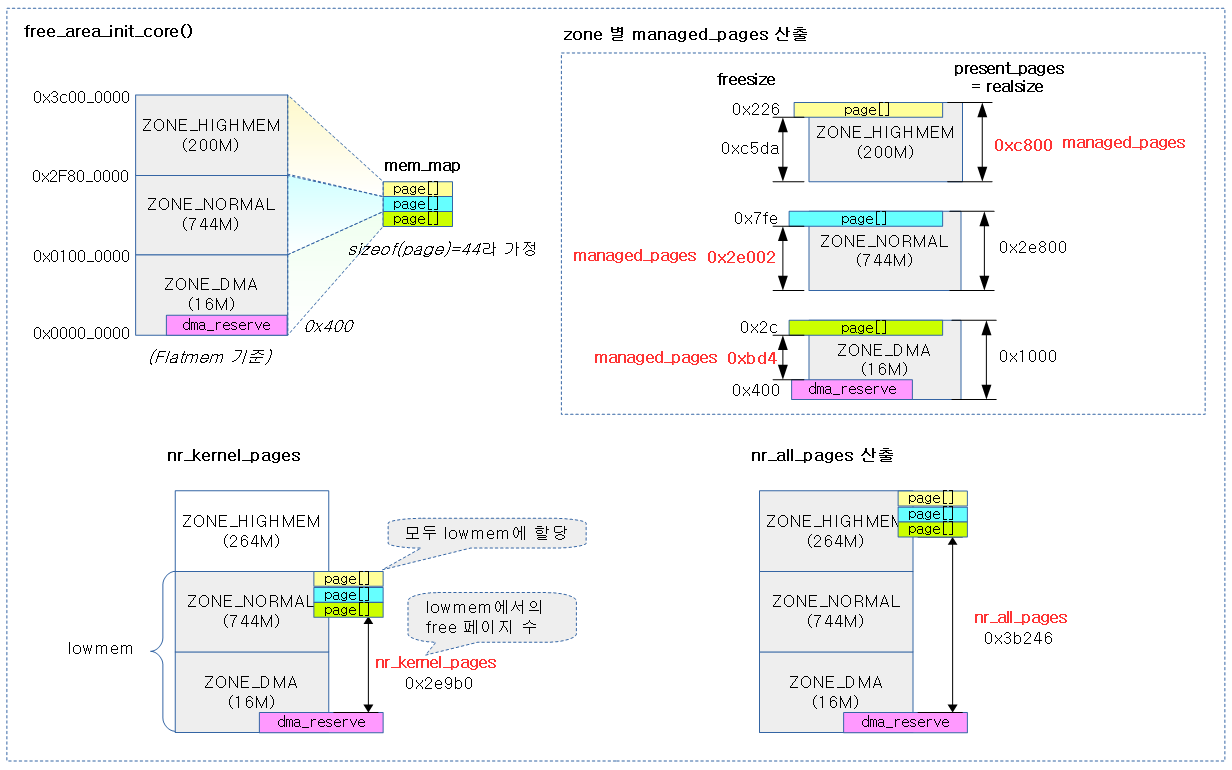
다음 그림은 위에서 산출한 값을 실제 연산과정으로 살펴보았다.
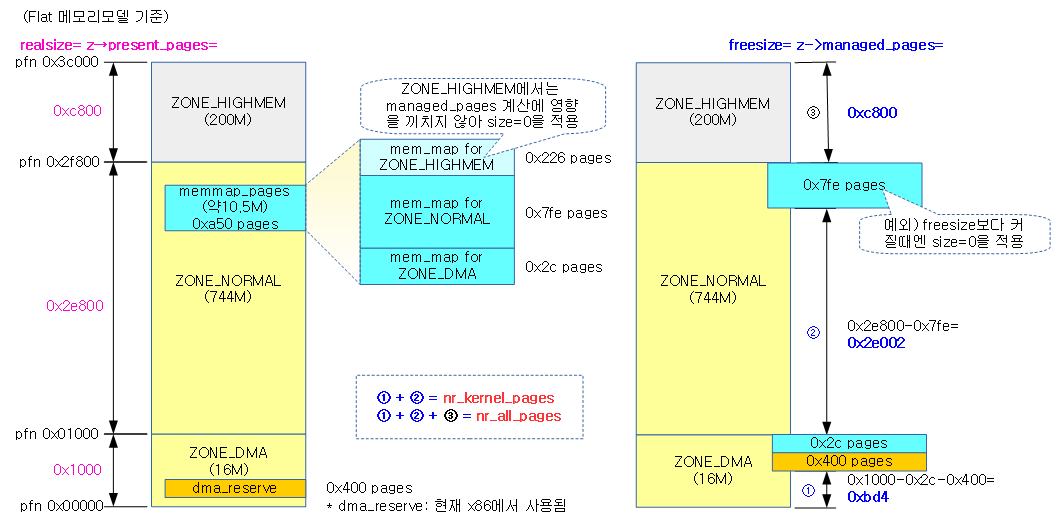
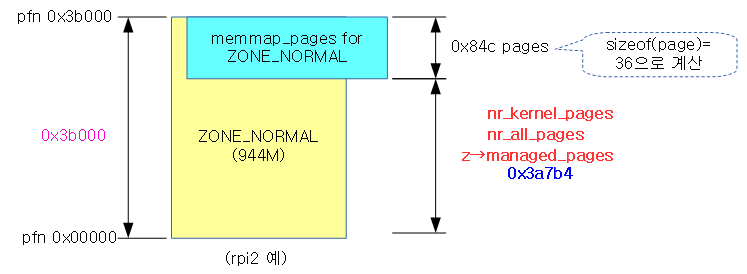
다음은 ZONE_NORMAL만 있는 경우의 예(rpi2)로 산출한 사례이다.
1) 내부 노드 데이터 초기화
pgdat_init_internals()
mm/page_alloc.c
static void __meminit pgdat_init_internals(struct pglist_data *pgdat)
{
pgdat_resize_init(pgdat);
pgdat_init_split_queue(pgdat);
pgdat_init_kcompactd(pgdat);
init_waitqueue_head(&pgdat->kswapd_wait);
init_waitqueue_head(&pgdat->pfmemalloc_wait);
pgdat_page_ext_init(pgdat);
lruvec_init(&pgdat->__lruvec);
}
노드에서 사용하는 내부 락 및 큐등을 초기화한다.
- 코드 라인 3에서 node_size_lock 초기화
- 코드 라인 5에서 split 큐를 초기화한다.
- 코드 라인 6에서 kcompactd용 대기큐를 초기화한다.
- 코드 라인 8에서 kswapd용 대기큐를 초기화한다.
- 코드 라인 9에서 pfmemalloc용 대기큐를 초기화한다.
- 코드 라인 11에서 CONFIG_SPARSEMEM 커널 옵션이 설정되어 있지 않으면 pgdat->node_page_ext에 NULL을 대입한다.
- 코드 라인 12에서 __lruvec 리스트를 초기화한다.
lruvec_init()
mm/mmzone.c
void lruvec_init(struct lruvec *lruvec)
{
enum lru_list lru;
memset(lruvec, 0, sizeof(struct lruvec));
for_each_lru(lru)
INIT_LIST_HEAD(&lruvec->lists[lru]);
}
lruvec 리스트를 초기화한다.
2) mem_map 사이즈 산출
calc_memmap_size()
mm/page_alloc.c
static unsigned long __paginginit calc_memmap_size(unsigned long spanned_pages,
unsigned long present_pages)
{
unsigned long pages = spanned_pages;
/*
* Provide a more accurate estimation if there are holes within
* the zone and SPARSEMEM is in use. If there are holes within the
* zone, each populated memory region may cost us one or two extra
* memmap pages due to alignment because memmap pages for each
* populated regions may not naturally algined on page boundary.
* So the (present_pages >> 4) heuristic is a tradeoff for that.
*/
if (spanned_pages > present_pages + (present_pages >> 4) &&
IS_ENABLED(CONFIG_SPARSEMEM))
pages = present_pages;
return PAGE_ALIGN(pages * sizeof(struct page)) >> PAGE_SHIFT;
}
spanned size 수 만큼 page 구조체 배열이 들어갈 페이지 수를 구한다.
- 다만 CONFIG_SPARSEMEM 커널 옵션을 사용하는 경우에는 spanned size가 real size 수의 125% 만큼 보다 큰 경우 spanned size 대신 real size를 대신 사용한다.
3) 내부 존 데이터 초기화
zone_init_internals()
mm/page_alloc.c
static void __meminit zone_init_internals(struct zone *zone, enum zone_type idx, int nid,
unsigned long remaining_pages)
{
atomic_long_set(&zone->managed_pages, remaining_pages);
zone_set_nid(zone, nid);
zone->name = zone_names[idx];
zone->zone_pgdat = NODE_DATA(nid);
spin_lock_init(&zone->lock);
zone_seqlock_init(zone);
zone_pcp_init(zone);
}
zone 내부에서 사용하는 락 및 리스트 등을 초기화한다.
- 코드 라인 4에서 managed_pages 값에 remaining_pages를 대입한다.
- 코드 라인 5에서 존에 노드 id를 설정한다.
- 코드 라인 6에서 존 이름을 지정한다.
- 코드 라인 7에서 존에 해당하는 노드를 지정한다.
- 코드 라인 8~9에서 존 관리용 락을 초기화한다.
- 코드 라인 10에서 0 오더 페이지 전용 버디 캐시인 pcp를 준비한다.
zone_pcp_init()
mm/page_alloc.c
static __meminit void zone_pcp_init(struct zone *zone)
{
/*
* per cpu subsystem is not up at this point. The following code
* relies on the ability of the linker to provide the
* offset of a (static) per cpu variable into the per cpu area.
*/
zone->per_cpu_pageset = &boot_pageset;
zone->per_cpu_zonestats = &boot_zonestats;
zone->pageset_high = BOOT_PAGESET_HIGH;
zone->pageset_batch = BOOT_PAGESET_BATCH;
if (populated_zone(zone))
pr_debug(" %s zone: %lu pages, LIFO batch:%u\n", zone->name,
zone->present_pages, zone_batchsize(zone));
}
0 오더 페이지 전용 버디 캐시인 pcp를 준비한다.
- zone->pageset에 boot_pageset per-cpu 데이터의 주소를 대입한다.
4) 페이지 블럭 order 지정
set_pageblock_order()
mm/page_alloc.c
#ifdef CONFIG_HUGETLB_PAGE_SIZE_VARIABLE
/* Initialise the number of pages represented by NR_PAGEBLOCK_BITS */
void __init set_pageblock_order(void)
{
unsigned int order;
/* Check that pageblock_nr_pages has not already been setup */
if (pageblock_order)
return;
if (HPAGE_SHIFT > PAGE_SHIFT)
order = HUGETLB_PAGE_ORDER;
else
order = MAX_ORDER - 1;
/*
* Assume the largest contiguous order of interest is a huge page.
* This value may be variable depending on boot parameters on IA64 and
* powerpc.
*/
pageblock_order = order;
}
#else /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
/*
* When CONFIG_HUGETLB_PAGE_SIZE_VARIABLE is not set, set_pageblock_order()
* is unused as pageblock_order is set at compile-time. See
* include/linux/pageblock-flags.h for the values of pageblock_order based on
* the kernel config
*/
void __init set_pageblock_order(void)
{
}
#endif /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
페이지 블럭 order 값을 설정한다.
- huge 페이지를 지원하면 HUGETLB_PAGE_ORDER를 사용하고 그렇지 않은 경우 MAX_ORDER(11)-1 값으로 지정할 수 있다.
- HUGETLB_PAGE_ORDER는 PMD_SHIFT – PAGE_SHIFT 값으로 사용한다.
- 예) 4K 페이지 + 2M huge 페이지를 사용하는 경우 HUGETLB_PAGE_ORDER=21-12=9 이다.
5) usemap 할당
setup_usemap()
이 함수는 SPARSEMEM 메모리 모델이 아닌 경우에 한해 요청한 노드의 usemap을 할당받는다.
mm/page_alloc.c
static void __ref setup_usemap(struct zone *zone)
{
unsigned long usemapsize = usemap_size(zone->zone_start_pfn,
zone->spanned_pages);
zone->pageblock_flags = NULL;
if (usemapsize) {
zone->pageblock_flags =
memblock_alloc_node(usemapsize, SMP_CACHE_BYTES,
zone_to_nid(zone));
if (!zone->pageblock_flags)
panic("Failed to allocate %ld bytes for zone %s pageblock flags on node %d\n",
usemapsize, zone->name, zone_to_nid(zone));
}
}
요청한 노드용 usemap을 할당받고 지정한다.
- usemap은 partial 페이지 관리를 위해 블록 단위로 mobility를 관리한다.
usemap_size()
SPARSE 메모리 모델을 사용하는 경우와 아닌 경우 두 가지 구현이 있지만 다음은 sparse 메모리 모델이 아닌 경우의 구현을 소개한다.
mm/page_alloc.c
/* * Calculate the size of the zone->blockflags rounded to an unsigned long * Start by making sure zonesize is a multiple of pageblock_order by rounding * up. Then use 1 NR_PAGEBLOCK_BITS worth of bits per pageblock, finally * round what is now in bits to nearest long in bits, then return it in * bytes. */
#ifndef CONFIG_SPARSEMEM
static unsigned long __init usemap_size(unsigned long zone_start_pfn, unsigned long zonesize)
{
unsigned long usemapsize;
zonesize += zone_start_pfn & (pageblock_nr_pages-1);
usemapsize = roundup(zonesize, pageblock_nr_pages);
usemapsize = usemapsize >> pageblock_order;
usemapsize *= NR_PAGEBLOCK_BITS;
usemapsize = roundup(usemapsize, 8 * sizeof(unsigned long));
return usemapsize / 8;
}
#endif
SPARSEMEM 메모리 모델이 아닌 경우의 usemap 사이즈를 산출한다.
- 코드 라인 6에서 zonesize를 페이지 블럭 단위로 반올림한다.
- 코드 라인 7~12에서 usemap 사이즈를 산출하여 반환한다.
- 페이지 블럭 당 사용할 usemap 비트는 NR_PAGEBLOCK_BITS(4)이다.
- 산출된 usemap 사이즈는 unsingned long 사이즈 단위로 정렬한다.
6) empty 존 초기화
init_currently_empty_zone()
mm/page_alloc.c
void __meminit init_currently_empty_zone(struct zone *zone,
unsigned long zone_start_pfn,
unsigned long size)
{
struct pglist_data *pgdat = zone->zone_pgdat;
int zone_idx = zone_idx(zone) + 1;
if (zone_idx > pgdat->nr_zones)
pgdat->nr_zones = zone_idx;
zone->zone_start_pfn = zone_start_pfn;
mminit_dprintk(MMINIT_TRACE, "memmap_init",
"Initialising map node %d zone %lu pfns %lu -> %lu\n",
pgdat->node_id,
(unsigned long)zone_idx(zone),
zone_start_pfn, (zone_start_pfn + size));
zone_init_free_lists(zone);
zone->initialized = 1;
}
현재 비어 있는 존에 대한 초기화를 수행한다. 이 때 해당 존의 버디 리스트도 초기화한다.
- 코드 라인 5~9에서 현재 노드에서 사용할 zone 수를 지정한다.
- 코드 라인 11에서 zone의시작 pfn을 지정한다.
- 코드 라인 19에서 zone용 버디 리스트를 초기화한다.
- 코드 라인 20에서 존이 초기화되었음을 식별하게 한다.
zone_init_free_lists()
mm/page_alloc.c
static void __meminit zone_init_free_lists(struct zone *zone)
{
unsigned int order, t;
for_each_migratetype_order(order, t) {
INIT_LIST_HEAD(&zone->free_area[order].free_list[t]);
zone->free_area[order].nr_free = 0;
}
}
zone에 해당하는 버디 시스템을 초기화한다.
- free_area[] 배열의 초기화를 수행한다.
7) mem_map 초기화
memmap_init()
mm/page_alloc.c
static void __init memmap_init(void)
{
unsigned long start_pfn, end_pfn;
unsigned long hole_pfn = 0;
int i, j, zone_id = 0, nid;
for_each_mem_pfn_range(i, MAX_NUMNODES, &start_pfn, &end_pfn, &nid) {
struct pglist_data *node = NODE_DATA(nid);
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = node->node_zones + j;
if (!populated_zone(zone))
continue;
memmap_init_zone_range(zone, start_pfn, end_pfn,
&hole_pfn);
zone_id = j;
}
}
#ifdef CONFIG_SPARSEMEM
/*
* Initialize the memory map for hole in the range [memory_end,
* section_end].
* Append the pages in this hole to the highest zone in the last
* node.
* The call to init_unavailable_range() is outside the ifdef to
* silence the compiler warining about zone_id set but not used;
* for FLATMEM it is a nop anyway
*/
end_pfn = round_up(end_pfn, PAGES_PER_SECTION);
if (hole_pfn < end_pfn)
#endif
init_unavailable_range(hole_pfn, end_pfn, zone_id, nid);
}
할당받은 mem_map(page 디스크립터 배열)을 초기화한다.
- 코드 라인 7~20에서 memory memblock을 순회하며 메모리가 존재하는 존의 mem_map을 초기화한다.
- 코드 라인 32~35에서 hole에 대응하는 page 구조체를 Reserved 플래그를 추가한 채로 초기화한다.
memmap_init_zone_range()
mm/page_alloc.c
static void __init memmap_init_zone_range(struct zone *zone,
unsigned long start_pfn,
unsigned long end_pfn,
unsigned long *hole_pfn)
{
unsigned long zone_start_pfn = zone->zone_start_pfn;
unsigned long zone_end_pfn = zone_start_pfn + zone->spanned_pages;
int nid = zone_to_nid(zone), zone_id = zone_idx(zone);
start_pfn = clamp(start_pfn, zone_start_pfn, zone_end_pfn);
end_pfn = clamp(end_pfn, zone_start_pfn, zone_end_pfn);
if (start_pfn >= end_pfn)
return;
memmap_init_range(end_pfn - start_pfn, nid, zone_id, start_pfn,
zone_end_pfn, MEMINIT_EARLY, NULL, MIGRATE_MOVABLE);
if (*hole_pfn < start_pfn)
init_unavailable_range(*hole_pfn, start_pfn, zone_id, nid);
*hole_pfn = end_pfn;
}
존의 mem_map을 초기화한다.
- 코드 라인 6~8에서 zone의 시작과 끝 pfn을 및 노드 id를 구한다.
- 코드 라인 10~11에서 초기화할 pfn의 시작과 끝을 zone 영역 범위 이내로 제한한다.
- 코드 라인 13~14에서 진행할 영역이 없으면 함수를 빠져나간다.
- 코드 라인 16~17에서 존의 mem_map을 초기화한다.
- 코드 라인 19~20에서 page 구조체에 대응하는 메모리가 hole인 경우 Reserved 플래그를 설정한다.
- 코드 라인 22에서 hole_pfn의 처리가 완료하였으므로 end_pfn으로 대입한다.
memmap_init_range()
mm/page_alloc.c -1/2-
/* * Initially all pages are reserved - free ones are freed * up by memblock_free_all() once the early boot process is * done. Non-atomic initialization, single-pass. * * All aligned pageblocks are initialized to the specified migratetype * (usually MIGRATE_MOVABLE). Besides setting the migratetype, no related * zone stats (e.g., nr_isolate_pageblock) are touched. */
void __meminit memmap_init_range(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, unsigned long zone_end_pfn,
enum meminit_context context,
struct vmem_altmap *altmap, int migratetype)
{
unsigned long pfn, end_pfn = start_pfn + size;
struct page *page;
if (highest_memmap_pfn < end_pfn - 1)
highest_memmap_pfn = end_pfn - 1;
#ifdef CONFIG_ZONE_DEVICE
/*
* Honor reservation requested by the driver for this ZONE_DEVICE
* memory. We limit the total number of pages to initialize to just
* those that might contain the memory mapping. We will defer the
* ZONE_DEVICE page initialization until after we have released
* the hotplug lock.
*/
if (zone == ZONE_DEVICE) {
if (!altmap)
return;
if (start_pfn == altmap->base_pfn)
start_pfn += altmap->reserve;
end_pfn = altmap->base_pfn + vmem_altmap_offset(altmap);
}
#endif
할당받은 mem_map(page 디스크립터 배열)을 초기화한다.
- 코드 라인 9~10에서 end_pfn – 1 보다 작으면, highest_memmap_pfn의 값을 end_pfn – 1로 초기화한다.
- 코드 라인 20~27에서 zone 디바이스의 경우 메모리 크기가 매우 크므로 전체 페이지 디스크립터의 초기화를 일부 제한한다.
mm/page_alloc.c -2/2-
for (pfn = start_pfn; pfn < end_pfn; ) {
/*
* There can be holes in boot-time mem_map[]s handed to this
* function. They do not exist on hotplugged memory.
*/
if (context == MEMINIT_EARLY) {
if (overlap_memmap_init(zone, &pfn))
continue;
if (defer_init(nid, pfn, zone_end_pfn))
break;
}
page = pfn_to_page(pfn);
__init_single_page(page, pfn, zone, nid);
if (context == MEMINIT_HOTPLUG)
__SetPageReserved(page);
/*
* Usually, we want to mark the pageblock MIGRATE_MOVABLE,
* such that unmovable allocations won't be scattered all
* over the place during system boot.
*/
if (IS_ALIGNED(pfn, pageblock_nr_pages)) {
set_pageblock_migratetype(page, migratetype);
cond_resched();
}
pfn++;
}
}
- 코드 라인 1~11에서 시작 pfn 부터 끝 pfn 까지 루프를 돌며 인자 @context가 MEMMAP_EARLY(0)로 진입한 경우 overlap된 페이지는 skip 하고, 노드 내 마지막 존이 큰 영역은 유예시킨다.
- 대용량 메모리가 장착된 시스템에서 한꺼번에 페이지 디스크립터를 초기화하는 것은 매우 긴 시간이 소요된다. 따라서 부트 후 병렬로 처리하기 위해 초기화를 유예시킨다.
- 코드 라인 13~14에서 pfn 번호에 해당하는 페이지 디스크립터를 초기화한다.
- 코드 라인 15~16에서 인자 @context가 MEMMAP_HOTPLUG(1)로 진입한 경우 페이지에 Reserved 플래그를 추가한다.
- 코드 라인 23~26에서 페이지 블럭 단위로 migrattype을 지정한다.
- 코드 라인 27~28에서 pfn을 증가시켜고 반복한다.
init_unavailable_range()
mm/page_alloc.c
/* * Only struct pages that correspond to ranges defined by memblock.memory * are zeroed and initialized by going through __init_single_page() during * memmap_init_zone_range(). * * But, there could be struct pages that correspond to holes in * memblock.memory. This can happen because of the following reasons: * - physical memory bank size is not necessarily the exact multiple of the * arbitrary section size * - early reserved memory may not be listed in memblock.memory * - memory layouts defined with memmap= kernel parameter may not align * nicely with memmap sections * * Explicitly initialize those struct pages so that: * - PG_Reserved is set * - zone and node links point to zone and node that span the page if the * hole is in the middle of a zone * - zone and node links point to adjacent zone/node if the hole falls on * the zone boundary; the pages in such holes will be prepended to the * zone/node above the hole except for the trailing pages in the last * section that will be appended to the zone/node below. */
static void __init init_unavailable_range(unsigned long spfn,
unsigned long epfn,
int zone, int node)
{
unsigned long pfn;
u64 pgcnt = 0;
for (pfn = spfn; pfn < epfn; pfn++) {
if (!pfn_valid(ALIGN_DOWN(pfn, pageblock_nr_pages))) {
pfn = ALIGN_DOWN(pfn, pageblock_nr_pages)
+ pageblock_nr_pages - 1;
continue;
}
__init_single_page(pfn_to_page(pfn), pfn, zone, node);
__SetPageReserved(pfn_to_page(pfn));
pgcnt++;
}
if (pgcnt)
pr_info("On node %d, zone %s: %lld pages in unavailable ranges",
node, zone_names[zone], pgcnt);
}
page 구조체에 대응하는 메모리가 hole인 경우 Reserved 플래그를 설정한다.
__init_single_page()
mm/page_alloc.c
static void __meminit __init_single_page(struct page *page, unsigned long pfn,
unsigned long zone, int nid)
{
mm_zero_struct_page(page);
set_page_links(page, zone, nid, pfn);
init_page_count(page);
page_mapcount_reset(page);
page_cpupid_reset_last(page);
page_kasan_tag_reset(page);
INIT_LIST_HEAD(&page->lru);
#ifdef WANT_PAGE_VIRTUAL
/* The shift won't overflow because ZONE_NORMAL is below 4G. */
if (!is_highmem_idx(zone))
set_page_address(page, __va(pfn << PAGE_SHIFT));
#endif
}
요청한 페이지 디스크립터 하나를 초기화한다.
- 코드 라인 4에서 페이지 디스크립터를 0으로 채운다.
- 코드 라인 5에서 페이지 디스크립터에 존과 노드 및 섹션 정보를 기록한다.
- 코드 라인 6에서 페이지 참조 카운터를 1로 초기화한다.
- 코드 라인 7에서 페이지 매핑 카운터를 -1로 초기화한다.
- 코드 라인 8에서 last_cpuid에 해당하는 비트를 1로 채워 초기화한다.
- 코드 라인 9에서 KASAN(Kernel Address SANitizer)용 플래그 비트를 초기화한다.
- 코드 라인 11에서 페이지의 lru 연결용 노드를 초기화한다.
- 코드 라인 12~16에서 zone이 highmem이 아니면 page->virtual에 pfn을 가상주소로 바꾼 주소로 설정한다.
참고
- Memory Model -1- (Basic) | 문c
- Memory Model -2- (mem_map) | 문c
- Memory Model -3- (Sparse Memory) | 문c
- Memory Model -4- (APIs) | 문c
- ZONE 타입 | 문c
- bootmem_init()-ARM64 | 문c
- zone_sizes_init() | 문c – 현재 글
- NUMA -1- (ARM64 초기화) | 문c
- build_all_zonelists() | 문c
안녕하세요.
”’다음 4개의 그림은 NUMA 시스템에서 “kernelcore=” 커널 파라메터 값에 따라 ZONE_MOVABLE 영역이 지정되는 모습을 보여준다.”’ 의
2번째 예시 ”’2)kernelcore / node가 last zone 의 시작주소보다 작은 경우 kernelcore=512k -> 2G”’ 그림에 대한 질문입니다.
2G 에 대하여 노드 숫자(4) 만큼 나누어 512M 을 노드별로 분배하는데 lowmem는 우선 분배하도록 되어 있으니 1. 760M, 2. 512M, 3. 512M
를 할당하게 됩니다. 4번에서 88M 으로 되어 있는데 이 부분에서 제가 이해한 부분과 다릅니다.
kernelcore_node = required_kernelcore / usable_nodes 부분이 for 문의 안쪽과 바깥쪽에 모두 존재하는데 4번 루프를
돌때면 조건에 부합하게 됩니다. (required_kernelcore 2. 512M -> 3. 512M -> 4. 66M -> 5. 66M -> 6. 66M -> 7.66M
이렇게 되어야 한다고 생각하는데 제가 잘못 이해한 건가요?
항상 감사드립니다.
글 이 이상하게 올라가서 수정하려니 수정이 안되네요.
부등호 기호가 들어가서 그런지 중간에 글이 모두 삭제 되었어요 ;;
질문이 제대로 전달안 된 것 같아 다시 올려요
정리하면
1.512M 2. 512M -> 3. 512M -> 4. 66M -> 5. 66M -> 6. 66M -> 7.66M
이렇게 되어야 한다고 생각하는데 제가 잘못 이해한 건가요?
항상 감사드립니다.
복사 붙이기 하다 또 오타났네요. 죄송해요.
1. 760M -> 2. 512M -> 3. 512M -> 4. 66M -> 5. 66M -> 6. 66M -> 7. 66M
이 순서가 아닌지 문의 드렸습니다.
안녕하세요?
권용범님께서 계산한 것이 정확합니다. 따라서 2번 그림을 아래와 같이 수정하였습니다.
——————————————————————————–
(4)에서 남은 잔량 / 4개 노드 = 66M로 그림을 수정하였습니다.
(5)에서 남은 잔량 / 3개 노드 = 66M가 산출되고, 함수를 빠져나가기 전 out2 레이블에서 roundup(760M+66M, 4M) 정렬하므로 추가된 블럭을 68M로 그림을 수정하였습니다.
(6)에서 남은 잔량 / 3개 노드 = 66M로 그림을 수정하였습니다.
(7)에서 남은 잔량 / 3개 노드 = 66M로 그림을 수정하였습니다.
정확히 찾아주셔서 감사합니다.
감사합니다.
항상 여기에서 정확하고 예리한 분석에 감탄하며 많은 걸 배워가고 있습니다. ^^
감사합니다. 좋은 하루 되세요.
안녕하세요, 문영일 님.
문영일 님의 책과 블로그를 통해 많은 것을 배우고 있어 항상 감사한 마음이 듭니다.
중요한 내용이라 생각되진 않지만, 블로그에 contribution을 하고 싶어 답글 남깁니다!
memmap_init_range() 함수의 코드 라인 9-10에 대한 설명으로
“highest_memmap_pfn이 end_pfn – 1을 초과하지 않도록 한다.” 라고 적혀있는데,
“end_pfn – 1 보다 작으면, highest_memmap_pfn의 값을 end_pfn – 1로 초기화한다”가 맞는 표현이라고 생각합니다.
감사합니다.
안녕하세요? 민호님.
말씀하신 바와 같이 제 착각으로 인해 설명을 잘못 달아, 교정하였습니다. ^^
좋은 하루 되시길 바랍니다.
감사합니다.