버디 시스템이 연속된 물리 메모리의 할당 관리를 하는 시스x템인데, 그 중 특별히 디바이스들이 사용하는 연속된 물리 메모리에 대해 우선권을 주기 위해 사용하는 시스템이 CMA이다.
디바이스 장치를 위해 특별히 영역을 한정지어 CMA 영역으로 설정을 하면 버디 시스템은 보통 때에는 이 영역을 movable 페이지로 할당 관리한다. 이 영역이 movable 페이지로 가득 찰 때 디바이스가 연속된 물리 메모리를 요청하는 경우 CMA 영역의 일부 페이지들을 CMA 영역이 아닌 다른 영역으로 이주시키고 CMA 메모리 할당자가 디바이스가 필요로 하는 크기만큼의 메모리 페이지를 할당해준다.
- 2010년 삼성이 만든 연속 메모리 할당자이며 IBM 및 LG가 참여하여 발전시켰다.
- CONFIG_CMA 커널 옵션을 사용한다.
- CMA 기능은 주로 DMA 서브시스템에서 필요로하는 물리적으로 연속된 메모리를 커널 실행 시 별도로 reserve하지 않고 할당받아 사용할 수 있도록 관리하기 위해 사용된다.
- CONFIG_DMA_CMA 커널 옵션을 사용한다.
- 그외 powerpc 아키텍처에서는 kvm을 위해서도 사용된다.
- “cma=” 커널 파라메터로 cma 영역을 지정하고 이 영역에는 cma 및 movable 페이지만 사용되도록 제한되며 cma 영역이 부족한 경우 movable 페이지를 다른 곳으로 이주시킨다.
- 버디 할당자와는 다르게 2의 차수 단위의 사이즈로 할당을 제한하지 않는다. (10M 영역 할당 등)
- cma 할당자는 dma 서브 시스템과 완전 통합되어 dma를 사용하는 디바이스 드라이버 개발자가 별도의 cma api를 사용할 필요 없다.
- 참고: Document/DMA-API.txt | kernel.org
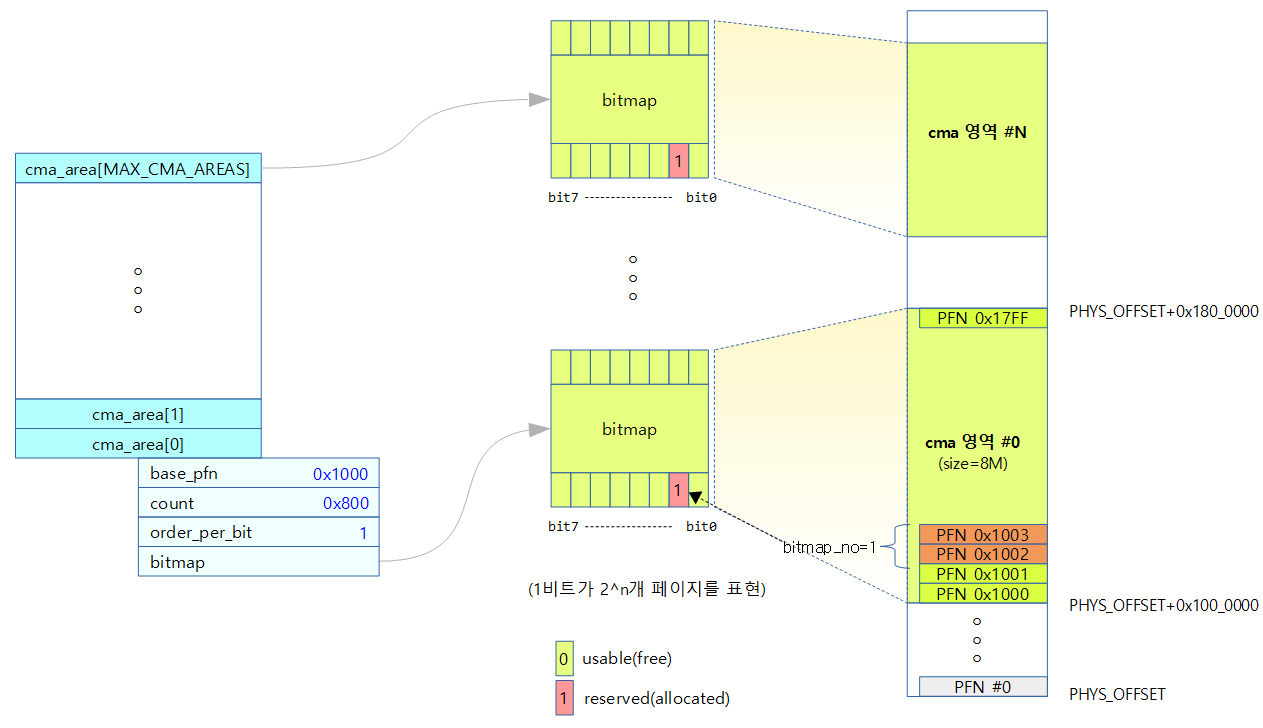
다음 그림은 cma 가 cma_area[] 구조체 배열에서 관리되는 것을 나타내며 각각의 cma area는 비트맵으로 관리되는 것을 나타낸다.
Cache-Coherent 문제
- h/w가 캐시 coherent 기능을 제공하지 않는 경우 s/w 자체적으로 캐시 coherent 기능이 필요한데 이를 위해 페이지 할당 시 dma_alloc_coherent() 함수를 통해 캐시를 사용하지 않는 매핑을 사용한다.
- dma_map_single() 함수를 통해 사용하는 경우 캐시 coherent 없이 빠르게 access하는 버퍼를 만들 수도 있다.
- DMA Pool 할당자를 통해 dma_pool_create() 및 dma_pool_alloc() 함수도 사용할 수 있다.
- dma_map_single() 함수를 통해 사용하는 경우 캐시 coherent 없이 빠르게 access하는 버퍼를 만들 수도 있다.
- 불행하게도 캐시 매핑에 대해 현재 cma 구조가 완전하지 않는 문제가 있다. 캐시 coherent 기능을 위해 언캐시 매핑이 필요한데 이미 커널의 lowmem 영역을 매핑하여 캐시가 사용되게 사용되므로 dma 영역으로 할당하는 언캐시된 메모리 페이지에 대해서 두 개의 매핑이 충돌하는 문제가 있다.
- 이에 대해 2가지 해법으로 진행이되고 있다. 하나는 highmem에 cma 영역을 할당하게 하는 방법이다.(단 메모리가 작거나 64비트 시스템은 highmem이 없음…^^;) 두 번째는 dma-buffer로 할당되어 사용되는 영역은 커널의 리니어 매핑에서 제거하는 방법이다.
- 현재는 두 번째의 방법을 밀고있다. 이 방법을 사용하므로 커널 메모리 영역(lowmem)이 huge 페이지를 사용하여 크게 리니어 매핑되는데 이 영역의 일부가 분할되어 매핑되면서 TLB 캐시 성능이 저하되는 것은 피할 수 없다.
- CMA and ARM | LWN.net
- 이에 대해 2가지 해법으로 진행이되고 있다. 하나는 highmem에 cma 영역을 할당하게 하는 방법이다.(단 메모리가 작거나 64비트 시스템은 highmem이 없음…^^;) 두 번째는 dma-buffer로 할당되어 사용되는 영역은 커널의 리니어 매핑에서 제거하는 방법이다.
CMA 관리 영역 추가
이 함수에서 정의된 cma 관리 영역들은 추후 cma 드라이버가 로드되면서 초기화 된 후 할당 관리를 사용할 수 있다. CONFIG_MODULE 커널 옵션을 사용하지 않을 경우에는 아래의 루틴에 의해 초기화된다.
- core_initcall(cma_init_reserved_areas);
- 등록되는 모든 initcall 함수들은 kernel_init 스레드의 do_initcalls() 함수에서 호출된다.
cma_declare_contiguous()
mm/cma.c
/**
* cma_declare_contiguous() - reserve custom contiguous area
* @base: Base address of the reserved area optional, use 0 for any
* @size: Size of the reserved area (in bytes),
* @limit: End address of the reserved memory (optional, 0 for any).
* @alignment: Alignment for the CMA area, should be power of 2 or zero
* @order_per_bit: Order of pages represented by one bit on bitmap.
* @fixed: hint about where to place the reserved area
* @res_cma: Pointer to store the created cma region.
*
* This function reserves memory from early allocator. It should be
* called by arch specific code once the early allocator (memblock or bootmem)
* has been activated and all other subsystems have already allocated/reserved
* memory. This function allows to create custom reserved areas.
*
* If @fixed is true, reserve contiguous area at exactly @base. If false,
* reserve in range from @base to @limit.
*/
int __init cma_declare_contiguous(phys_addr_t base,
phys_addr_t size, phys_addr_t limit,
phys_addr_t alignment, unsigned int order_per_bit,
bool fixed, struct cma **res_cma)
{
phys_addr_t memblock_end = memblock_end_of_DRAM();
phys_addr_t highmem_start;
int ret = 0;
#ifdef CONFIG_X86
/*
* high_memory isn't direct mapped memory so retrieving its physical
* address isn't appropriate. But it would be useful to check the
* physical address of the highmem boundary so it's justfiable to get
* the physical address from it. On x86 there is a validation check for
* this case, so the following workaround is needed to avoid it.
*/
highmem_start = __pa_nodebug(high_memory);
#else
highmem_start = __pa(high_memory);
#endif
pr_debug("%s(size %pa, base %pa, limit %pa alignment %pa)\n",
__func__, &size, &base, &limit, &alignment);
if (cma_area_count == ARRAY_SIZE(cma_areas)) {
pr_err("Not enough slots for CMA reserved regions!\n");
return -ENOSPC;
}
if (!size)
return -EINVAL;
if (alignment && !is_power_of_2(alignment))
return -EINVAL;
CMA로 관리하고자 하는 메모리 영역을 설정한다. 메모리 영역은 최대 MAX_CMA_AREAS 갯수 이내로 제한된다.
- phys_addr_t memblock_end = memblock_end_of_DRAM();
- memory memblock에 등록된 마지막 항목의 base + size를 하여 끝 주소를 알아온다.
- highmem_start = __pa(high_memory);
- high_memory
- 물리 메모리 사이즈를 최대 lowmem 영역의 사이즈와 비교하여
- 초과하는 경우 high_memory는 max lowmem 영역의 의 끝 가상 주소
- 초과하지 않는 경우 high_memory는 lowmem 영역의 끝 가상 주소
- 물리 메모리 사이즈를 최대 lowmem 영역의 사이즈와 비교하여
- high_memory
- if (cma_area_count == ARRAY_SIZE(cma_areas)) {
- cma_areas 배열이 가득 찬 경우 에러 메시지를 출력하고 에러를 리턴한다.
- if (alignment && !is_power_of_2(alignment))
- alignment가 지정된 경우 2의 차수가 아닌 경우 그냥 에러를 리턴한다.
/*
* Sanitise input arguments.
* Pages both ends in CMA area could be merged into adjacent unmovable
* migratetype page by page allocator's buddy algorithm. In the case,
* you couldn't get a contiguous memory, which is not what we want.
*/
alignment = max(alignment,
(phys_addr_t)PAGE_SIZE << max(MAX_ORDER - 1, pageblock_order));
base = ALIGN(base, alignment);
size = ALIGN(size, alignment);
limit &= ~(alignment - 1);
if (!base)
fixed = false;
/* size should be aligned with order_per_bit */
if (!IS_ALIGNED(size >> PAGE_SHIFT, 1 << order_per_bit))
return -EINVAL;
/*
* If allocating at a fixed base the request region must not cross the
* low/high memory boundary.
*/
if (fixed && base < highmem_start && base + size > highmem_start) {
ret = -EINVAL;
pr_err("Region at %pa defined on low/high memory boundary (%pa)\n",
&base, &highmem_start);
goto err;
}
- alignment = max(alignment, (phys_addr_t)PAGE_SIZE << max(MAX_ORDER – 1, pageblock_order))
- pageblock_order
- 32bit ARM은 CONFIG_HUGETLB_PAGE 옵션을 지원하지 않는다.
- MAXORDER(11=버디에서 사용)-1과 같다.
- pageblock_order
- alignment와 4M(PAGE_SIZE << 10) 중 큰 수를 대입
- base = ALIGN(base, alignment);
- base를 alignment 단위로round up
- size = ALIGN(size, alignment);
- size를 alignment 단위로 round up
- limit &= ~(alignment – 1);
- limit를 alignment 단위로 round down
- if (!base)
- base가 0이면 인수 fixed 값을 false로 변경한다.
- 결국 fixed를 true로 하여 이 함수를 호출한 경우에도 base가 0일 때만 true로 유지된다.
- if (!IS_ALIGNED(size >> PAGE_SHIFT, 1 << order_per_bit))
- size가 2^order_per_bit 페이지(4K)로 align되지 않으면 에러를 리턴한다.
- if (fixed && base < highmem_start && base + size > highmem_start) {
- fixed가 true이면서 영역이 highmem 영역과 겹치면
- 영역이 low/high 메모리 경계에 정의되었다고 에러 메시지를 출력하고 에러를 리턴한다.
- fixed가 true이면서 영역이 highmem 영역과 겹치면
/*
* If the limit is unspecified or above the memblock end, its effective
* value will be the memblock end. Set it explicitly to simplify further
* checks.
*/
if (limit == 0 || limit > memblock_end)
limit = memblock_end;
/* Reserve memory */
if (fixed) {
if (memblock_is_region_reserved(base, size) ||
memblock_reserve(base, size) < 0) {
ret = -EBUSY;
goto err;
}
} else {
phys_addr_t addr = 0;
/*
* All pages in the reserved area must come from the same zone.
* If the requested region crosses the low/high memory boundary,
* try allocating from high memory first and fall back to low
* memory in case of failure.
*/
if (base < highmem_start && limit > highmem_start) {
addr = memblock_alloc_range(size, alignment,
highmem_start, limit);
limit = highmem_start;
}
if (!addr) {
addr = memblock_alloc_range(size, alignment, base,
limit);
if (!addr) {
ret = -ENOMEM;
goto err;
}
}
/*
* kmemleak scans/reads tracked objects for pointers to other
* objects but this address isn't mapped and accessible
*/
kmemleak_ignore(phys_to_virt(addr));
base = addr;
}
ret = cma_init_reserved_mem(base, size, order_per_bit, res_cma);
if (ret)
goto err;
pr_info("Reserved %ld MiB at %pa\n", (unsigned long)size / SZ_1M,
&base);
return 0;
err:
pr_err("Failed to reserve %ld MiB\n", (unsigned long)size / SZ_1M);
return ret;
}
- if (limit == 0 || limit > memblock_end)
- limit가 0이거나 limit가 memblock_end를 초과하는 경우 limit를 memblock_end로 설정한다.
- CMA에 메모리 만큼의 사이즈를 등록한다.
- if (fixed) {
- 추가 시 lowmem 내에서 고정적으로 base 주소부터 추가를 하려는 경우
- if (memblock_is_region_reserved(base, size) || memblock_reserve(base, size) < 0) {
- 영역이 reserve memblock에 등록되었었거나 영역을 reserve memblock에 등록 에러된 경우 에러를 리턴한다.
fixed가 false인 경우 추가할 영역이 lowmem과 highmem영역의 경계인 경우 먼저 highmem 영역에 할당을 시도하고 실패하는 경우 lowmem 영역에 할당한다.
- if (base < highmem_start && limit > highmem_start) {
- 추가할 영역이 highmem 영역과 lowmem 영역의 경계인 경우
- addr = memblock_alloc_range(size, alignment, highmem_start, limit);
- highmem_start 부터 limit 범위 사이에서 요청 사이즈를 할당한다.
- if (!addr) {
- highmem 영역에 할당을 실패한 경우
- addr = memblock_alloc_range(size, alignment, base, limit);
- base 부터 limit 범위 사이에 요청 사이즈를 할당하고 실패하면 에러를 리턴한다.
- kmemleak_ignore(phys_to_virt(addr));
- 이 주소가 scan되고 leak로 리포트되지 않도록 무시하게 한다.
- ret = cma_init_reserved_mem(base, size, order_per_bit, res_cma);
- reserve된 영역을 다시 한 번 sanity check를 수행하고 cma 관리 항목을 설정한다.
- cma 관리 항목(cma area 정보)은 추후 각 항목이 초기화되어야 한다..
- CMA 모듈이 로드될 때 cma_init_reserved_area()가 호출되며 이 때 각 영역이 초기화된다.
cma_init_reserved_mem()
mm/cma.c
/**
* cma_init_reserved_mem() - create custom contiguous area from reserved memory
* @base: Base address of the reserved area
* @size: Size of the reserved area (in bytes),
* @order_per_bit: Order of pages represented by one bit on bitmap.
* @res_cma: Pointer to store the created cma region.
*
* This function creates custom contiguous area from already reserved memory.
*/
int __init cma_init_reserved_mem(phys_addr_t base, phys_addr_t size,
int order_per_bit, struct cma **res_cma)
{
struct cma *cma;
phys_addr_t alignment;
/* Sanity checks */
if (cma_area_count == ARRAY_SIZE(cma_areas)) {
pr_err("Not enough slots for CMA reserved regions!\n");
return -ENOSPC;
}
if (!size || !memblock_is_region_reserved(base, size))
return -EINVAL;
/* ensure minimal alignment requied by mm core */
alignment = PAGE_SIZE << max(MAX_ORDER - 1, pageblock_order);
/* alignment should be aligned with order_per_bit */
if (!IS_ALIGNED(alignment >> PAGE_SHIFT, 1 << order_per_bit))
return -EINVAL;
if (ALIGN(base, alignment) != base || ALIGN(size, alignment) != size)
return -EINVAL;
/*
* Each reserved area must be initialised later, when more kernel
* subsystems (like slab allocator) are available.
*/
cma = &cma_areas[cma_area_count];
cma->base_pfn = PFN_DOWN(base);
cma->count = size >> PAGE_SHIFT;
cma->order_per_bit = order_per_bit;
*res_cma = cma;
cma_area_count++;
totalcma_pages += (size / PAGE_SIZE);
return 0;
}
- if (cma_area_count == ARRAY_SIZE(cma_areas)) {
- cma_areas[]에 더 이상 할당할 공간이 없는 경우 에러를 출력하고 리턴한다.
- if (!size || !memblock_is_region_reserved(base, size))
- size가 0이거나 요청 영역이 reserve memblock에 없는 경우 에러를 리턴한다.
- alignment = PAGE_SIZE << max(MAX_ORDER – 1, pageblock_order);
- pageblock_order
- 32bit ARM은 CONFIG_HUGETLB_PAGE 옵션을 지원하지 않는다.
- MAXORDER(11=버디에서 사용)-1과 같다.
- 4M = PAGE_SIZE(4K) << (MAXORDER(11) – 1)
- pageblock_order
- if (!IS_ALIGNED(alignment >> PAGE_SHIFT, 1 << order_per_bit))
- alignment가 order_per_bit 단위로 align 되어 있지 않은 경우 에러를 리턴한다.
- if (ALIGN(base, alignment) != base || ALIGN(size, alignment) != size)
- 요청 시작 주소와 사이즈가 alignment 단위로 align 되어 있지 않은 경우 에러를 리턴한다.
- cma_areas[]에 요청 항목을 추가, cma_area_count를 1 증가시키고 totalcma_pages에 추가된 페이지 수를 증가시킨다.
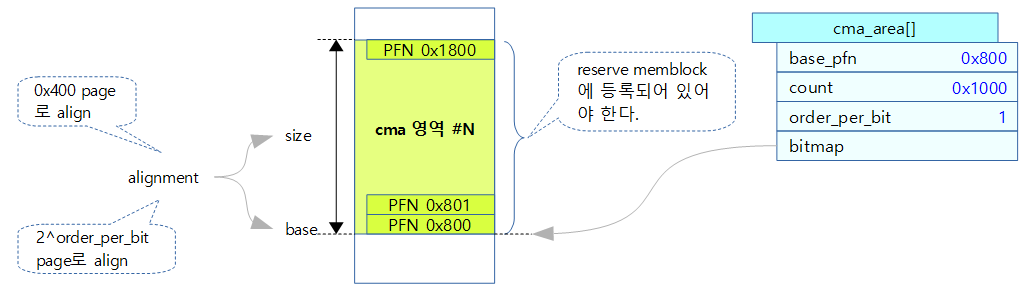
아래 그림은 cma_init_reserved_mem() 함수를 통하여 만들어질 때 영역에 대한 size와 base가 4M 단위 및 2^order_per_bit 페이지로 align되어야 만들어질 수 있는 것을 나타낸다.
cma 할당과 해제
cma_alloc()
mm/cma.c
/**
* cma_alloc() - allocate pages from contiguous area
* @cma: Contiguous memory region for which the allocation is performed.
* @count: Requested number of pages.
* @align: Requested alignment of pages (in PAGE_SIZE order).
*
* This function allocates part of contiguous memory on specific
* contiguous memory area.
*/
struct page *cma_alloc(struct cma *cma, int count, unsigned int align)
{
unsigned long mask, offset, pfn, start = 0;
unsigned long bitmap_maxno, bitmap_no, bitmap_count;
struct page *page = NULL;
int ret;
if (!cma || !cma->count)
return NULL;
pr_debug("%s(cma %p, count %d, align %d)\n", __func__, (void *)cma,
count, align);
if (!count)
return NULL;
mask = cma_bitmap_aligned_mask(cma, align);
offset = cma_bitmap_aligned_offset(cma, align);
bitmap_maxno = cma_bitmap_maxno(cma);
bitmap_count = cma_bitmap_pages_to_bits(cma, count);
for (;;) {
mutex_lock(&cma->lock);
bitmap_no = bitmap_find_next_zero_area_off(cma->bitmap,
bitmap_maxno, start, bitmap_count, mask,
offset);
if (bitmap_no >= bitmap_maxno) {
mutex_unlock(&cma->lock);
break;
}
bitmap_set(cma->bitmap, bitmap_no, bitmap_count);
/*
* It's safe to drop the lock here. We've marked this region for
* our exclusive use. If the migration fails we will take the
* lock again and unmark it.
*/
mutex_unlock(&cma->lock);
pfn = cma->base_pfn + (bitmap_no << cma->order_per_bit);
mutex_lock(&cma_mutex);
ret = alloc_contig_range(pfn, pfn + count, MIGRATE_CMA);
mutex_unlock(&cma_mutex);
if (ret == 0) {
page = pfn_to_page(pfn);
break;
}
cma_clear_bitmap(cma, pfn, count);
if (ret != -EBUSY)
break;
pr_debug("%s(): memory range at %p is busy, retrying\n",
__func__, pfn_to_page(pfn));
/* try again with a bit different memory target */
start = bitmap_no + mask + 1;
}
pr_debug("%s(): returned %p\n", __func__, page);
return page;
}
- if (!cma || !cma->count)
- cma가 null이거나 cma에 사용할 수 있는 비트가 없는 경우 null 리턴
- if (!count)
- 요청 count(bit)가 없는 경우 null 리턴
- mask = cma_bitmap_aligned_mask(cma, align);
- align이 cma->order_per_bit 보다 큰 경우 그 차이만큼의 비트 수를 마스크 비트 1로 만들어 리턴
- 예) align=4(64K), cma->order_per_bit=2(16K)
- 3 (두 개의 bit를 1로 하여 만든 마스크)
- 예) align=4(64K), cma->order_per_bit=2(16K)
- align이 cma->order_per_bit 보다 큰 경우 그 차이만큼의 비트 수를 마스크 비트 1로 만들어 리턴
- offset = cma_bitmap_aligned_offset(cma, align);
- 시작 주소를 2 ^ align page로 align할 때 사용할 수 없는 사이즈를 offset으로 알아온다.
- bitmap_maxno = cma_bitmap_maxno(cma);
- 비트맵에서 최대 사용할 수 있는 비트 수를 알아온다.
- bitmap_count = cma_bitmap_pages_to_bits(cma, count);
- 요청 count(페이지)에 대해 필요한 비트맵 비트 수
- bitmap_no = bitmap_find_next_zero_area_off(cma->bitmap, bitmap_maxno, start, bitmap_count, mask, offset);
- 비트맵에서 빈자리를 찾아 bitmap_no를 알아온다.
- cma->bitmap 부터 검색을 하여 size만큼의 bit를 mask하여 0이 나오면 빈 자리라 판단하여 bitmap_no를 알아온다. (offset은 할당하지 않는 영역)
- 비트맵에서 빈자리를 찾아 bitmap_no를 알아온다.
- if (bitmap_no >= bitmap_maxno) {
- 추가할 공간이 없으면 null을 return 한다.
- bitmap_set(cma->bitmap, bitmap_no, bitmap_count);
- bitmap_no 위치에 bitmap_count bit 수 만큼 1로 설정한다.
- pfn = cma->base_pfn + (bitmap_no << cma->order_per_bit);
- 할당한 위치에 대한 pfn
- 예) base_pfn=0x1000, bitmap_no=1, order_per_bit=1
- 0x1002 = 0x1000 + (1 << 1)
- ret = alloc_contig_range(pfn, pfn + count, MIGRATE_CMA);
- 필요한 만큼의 페이지들을 모두 MIGRATE_CMA로 할당하고 성공하는 경우 page 구조체 포인터를 리턴한다. 이 영역에 들어가 있는 기존 movable 페이지들은 모두 compaction 과정을 통해 이주시킨다.
- cma_clear_bitmap(cma, pfn, count);
- 할당이 실패한 경우 bitmap을 다시 지운다.
- 만일 실패 사요가 -EBUSY가 아닌 경우 null을 리턴한다.
- start = bitmap_no + mask + 1;
- 다음 비트맵 위치에서 다시 한 번 할당을 시도한다.
아래 그림에서는 align 단위를 다르게 하여 cma_alloc() 함수를 호출하였을 때 페이지가 할당되는 모습을 나타낸다.

cma_bitmap_aligned_mask()
mm/cma.c
static unsigned long cma_bitmap_aligned_mask(struct cma *cma, int align_order)
{
if (align_order <= cma->order_per_bit)
return 0;
return (1UL << (align_order - cma->order_per_bit)) - 1;
}
- align_order와 cma->order_per_bit의 차이만큼의 비트 수를 1로 만들어 리턴
- 해당 cma 항목에서 비트가 관리하는 페이지 단위가 요청한 align_order보다 크거나 같으면 0을 리턴한다.
- 예) align_order = 4(64K 단위), cma->order_per_bit = 2(16K 단위)
- 3 (2개의 비트를 1로 설정하여 마스크로 만든다.)
아래 그림은 요청 단위를 2^3 page로 할당하고자 할 때 기존 cma 영역이 2 페이지 단위로 관리되던 것에 대하여 그 비트 차이만큼의 mask 값을 알아온다.

cma_bitmap_aligned_offset()
mm/cma.c
/*
* Find a PFN aligned to the specified order and return an offset represented in
* order_per_bits.
*/
static unsigned long cma_bitmap_aligned_offset(struct cma *cma, int align_order)
{
if (align_order <= cma->order_per_bit)
return 0;
return (ALIGN(cma->base_pfn, (1UL << align_order))
- cma->base_pfn) >> cma->order_per_bit;
}
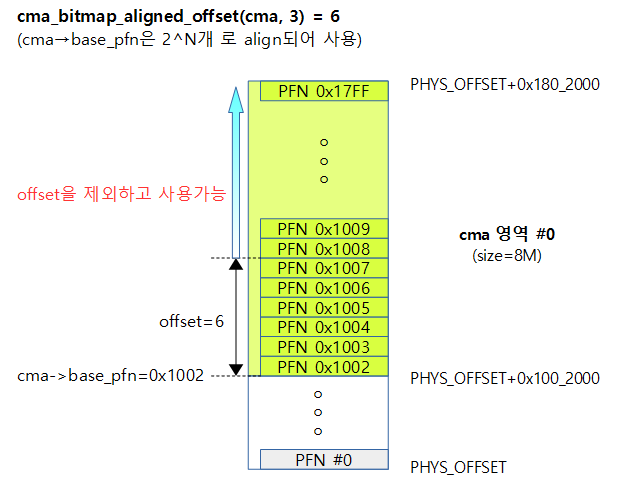
- cma->base_pfn이 요청한 align_order로 되어 있지 않은 경우 align_order 단위의 검색을 위해 필요한 offset를 리턴한다.
- 해당 cma 항목에서 비트가 관리하는 페이지 단위가 요청한 align_order보다 크거나 같으면 0을 리턴한다.
- 시작 pfn을 align_order만큼 좌측으로 shift한 후 시작 pfn을 뺀 후 cma->order_per_bit 만큼 우측 쉬프트
- 예) 0x0001_2344, cma->order_per_bit = 2(16K 단위), align_order = 4(64K 단위)
- 0xC(0x0001_2350 – 0x0001_2344) >> 2 = 3
- 예) 0x0001_2344, cma->order_per_bit = 2(16K 단위), align_order = 4(64K 단위)
아래 그림은 cma->base_pfn이 2^3 page 수 만큼 align이 되어 있지 않을 경우 그 차이만큼 offset을 알아오는 것을 나타낸다.
cma_bitmap_maxno()
mm/cma.c
static unsigned long cma_bitmap_maxno(struct cma *cma)
{
return cma->count >> cma->order_per_bit;
}
- 비트맵에서 사용하는 최대 비트 수
- 예) cma->count=800, cma->order_per_bit=2
- 200개 비트
- 예) cma->count=800, cma->order_per_bit=2
cma_bitmap_pages_to_bits()
mm/cma.c
static unsigned long cma_bitmap_pages_to_bits(struct cma *cma,
unsigned long pages)
{
return ALIGN(pages, 1UL << cma->order_per_bit) >> cma->order_per_bit;
}
- 요청 페이지에 대해 필요한 비트맵에서 사용할 비트 수
- 비트맵이 사용하는 최소 단위의 사이즈로 align하였을 때 필요한 비트 수를 리턴한다.
- 예) pages=5(20K 요청), cma->order_per_bit=2(16K 단위)
- 2(16K x 2) = 8 >> 2
cma_release()
mm/cma.c
/**
* cma_release() - release allocated pages
* @cma: Contiguous memory region for which the allocation is performed.
* @pages: Allocated pages.
* @count: Number of allocated pages.
*
* This function releases memory allocated by alloc_cma().
* It returns false when provided pages do not belong to contiguous area and
* true otherwise.
*/
bool cma_release(struct cma *cma, struct page *pages, int count)
{
unsigned long pfn;
if (!cma || !pages)
return false;
pr_debug("%s(page %p)\n", __func__, (void *)pages);
pfn = page_to_pfn(pages);
if (pfn < cma->base_pfn || pfn >= cma->base_pfn + cma->count)
return false;
VM_BUG_ON(pfn + count > cma->base_pfn + cma->count);
free_contig_range(pfn, count);
cma_clear_bitmap(cma, pfn, count);
return true;
}
- if (!cma || !pages)
- cma가 null이거나 pages 포인터가 null 인경우 false를 리턴한다.
- 요청 페이지의 시작 물리 주소가 cma 영역을 벗어난 경우 false를 리턴한다.
- free_contig_range(pfn, count)
- cma 영역의 pfn 주소에서 count(페이지 수) 만큼 해제한다.
- cma_clear_bitmap(cma, pfn, count);
- 해당 영역의 페이지를 비트맵에서 clear한다.
free_contig_range()
mm/page_alloc.c
void free_contig_range(unsigned long pfn, unsigned nr_pages)
{
unsigned int count = 0;
for (; nr_pages--; pfn++) {
struct page *page = pfn_to_page(pfn);
count += page_count(page) != 1;
__free_page(page);
}
WARN(count != 0, "%d pages are still in use!\n", count);
}
- pfn부터 요청한 페이지 수 만큼 루프를 돌며 페이지를 해제 한다.
cma_clear_bitmap()
mm/cma.c
static void cma_clear_bitmap(struct cma *cma, unsigned long pfn, int count)
{
unsigned long bitmap_no, bitmap_count;
bitmap_no = (pfn - cma->base_pfn) >> cma->order_per_bit;
bitmap_count = cma_bitmap_pages_to_bits(cma, count);
mutex_lock(&cma->lock);
bitmap_clear(cma->bitmap, bitmap_no, bitmap_count);
mutex_unlock(&cma->lock);
}
- bitmap_no = (pfn – cma->base_pfn) >> cma->order_per_bit;
- bitmap 번호를 구한다.
- bitmap_count = cma_bitmap_pages_to_bits(cma, count)
- count(페이지)로 필요한 비트 수를 구한다.
- bitmap_clear(cma->bitmap, bitmap_no, bitmap_count);
- 비트맵에서 bitmap_no 위치부터 bitmap_count bit 수 만큼 clear 한다.
CMA 영역 초기화
cma_init_reserved_areas()
mm/cma.c
static int __init cma_init_reserved_areas(void)
{
int i;
for (i = 0; i < cma_area_count; i++) {
int ret = cma_activate_area(&cma_areas[i]);
if (ret)
return ret;
}
return 0;
}
core_initcall(cma_init_reserved_areas);
- core_initcall(cma_init_reserved_areas);
- CONFIG_MODULE 커널 옵션에 따라 호출되는 위치가 달라진다.
- CONFIG_MODULE 설정이 없는 경우
- 등록되는 모든 initcall 함수들은 kernel_init 스레드의 do_initcalls() 함수에서 호출된다.
- CONFIG_MODULE 설정이 있는 경우
- 드라이버들 내부에 있는 module_init(cma_init_reserved_areas) 선언과 동일하다. 따라서 cma 드라이버 모듈이 로드되는 경우 cma_init_reserved_areas() 함수가 호출된다.
- CONFIG_MODULE 설정이 없는 경우
- CONFIG_MODULE 커널 옵션에 따라 호출되는 위치가 달라진다.
cma_activate_area()
mm/cma.c
static int __init cma_activate_area(struct cma *cma)
{
int bitmap_size = BITS_TO_LONGS(cma_bitmap_maxno(cma)) * sizeof(long);
unsigned long base_pfn = cma->base_pfn, pfn = base_pfn;
unsigned i = cma->count >> pageblock_order;
struct zone *zone;
cma->bitmap = kzalloc(bitmap_size, GFP_KERNEL);
if (!cma->bitmap)
return -ENOMEM;
WARN_ON_ONCE(!pfn_valid(pfn));
zone = page_zone(pfn_to_page(pfn));
do {
unsigned j;
base_pfn = pfn;
for (j = pageblock_nr_pages; j; --j, pfn++) {
WARN_ON_ONCE(!pfn_valid(pfn));
/*
* alloc_contig_range requires the pfn range
* specified to be in the same zone. Make this
* simple by forcing the entire CMA resv range
* to be in the same zone.
*/
if (page_zone(pfn_to_page(pfn)) != zone)
goto err;
}
init_cma_reserved_pageblock(pfn_to_page(base_pfn));
} while (--i);
mutex_init(&cma->lock);
return 0;
err:
kfree(cma->bitmap);
cma->count = 0;
return -EINVAL;
}
모듈 관련
아래 매크로 코드들은 2015년 5월 커널 v4.2-rc3에서 include/linux/init.h -> include/linux/module.h 로 옮겼다.
core_initcall()
include/linux/init.h
#define core_initcall(fn) module_init(fn)
- CONFIG_MODULE이 선언되어 있는 경우 module_init()을 호출한다.
module_init()
include/linux/init.h
/* Each module must use one module_init(). */
#define module_init(initfn) \
static inline initcall_t __inittest(void) \
{ return initfn; } \
int init_module(void) __attribute__((alias(#initfn)));
- initcall_t
- 다음과 같이 인수 없는 함수 포인터이다.
- typedef int (*initcall_t)(void);
- 인수 initfn 함수를 호출하고 결과를 int 타입으로 리턴한다.
- int init_module(void) __attribute__((alias(#initfn)));
- alias 컴파일러 속성을 사용하여 init_module() 함수명을 alias명으로 사용할 때 인수 initfn을 호출한다.
구조체 및 주요 변수
struct cma
mm/cma.c
struct cma {
unsigned long base_pfn;
unsigned long count;
unsigned long *bitmap;
unsigned int order_per_bit; /* Order of pages represented by one bit */
struct mutex lock;
};
- base_pfn
- 시작 물리 주소의 pfn 번호
- count
- 관리 페이지 수
- bitmap
- 비트맵 데이터
- order_per_bit
- 비트맵의 1비트가 표현하는 order 페이지(2^N 페이지, 0=1페이지, 1=2페이지, 2=4페이지, …)
- lock
- 비트맵 조작시 동기화를 위해 사용
전역 변수
mm/cma.c
static struct cma cma_areas[MAX_CMA_AREAS]; static unsigned cma_area_count; static DEFINE_MUTEX(cma_mutex);
- cma_areas[]
- CONFIG_CMA_AREAS 커널 옵션이 설정된 경우 (1 + CONFIG_CMA_AREAS), 그렇지 않은 경우 0 이다.
- cma_area_count
- cma_areas[] 배열에서 사용하는 항목 수
- cma_mutex
- cma 영역 할당 시 동기화를 위해 사용
mm/page_alloc.c
unsigned long totalcma_pages __read_mostly;
- totalcma_pages
- cma에 사용된 페이지 수
참고
- CMA: generalize CMA reserved area management functionality
- CMA(Contiguous Memory Allocator) for DMA | 문c
- Contiguous Memory Allocator | LWN.net
- A reworked contiguous memory allocator | LWN.net
- CMA and ARM | LWN.net
- Contiguous memory allocation for drivers | LWN.net
- CMA documentation file | LWN.net
- A deep dive into CMA | LWN.net
- Linux Kernel CMA | Mark Veltzer – odf file 다운로드
- Document/DMA-API-HOWTO.txt | kernel.org
- Document/DMA-API.txt | kernel.org
- Guaranteed Contiguous Memory Allocator | 박성재 – 다운로드 pdf
Hello Author,
Could you please explain more detail about two things:
– what is the purpose of mask (cma_bitmap_aligned_mask). ?
– Why do we need align when allocate?
Thank you in advance!
The CMA allocator allocates memory for the device to use for DMA purposes, which usually requires alignment due to DMA HW start address constraints.
case 1) Example of 8M buffer allocation aligned in 4M units according to user’s intention
Memory range allocated: 0x10C0_0000 to 0x1140_0000
case 2) Example of 8M buffer allocation that the device cannot use because of misalignment
Memory range allocated: 0x1022_2000 to 0x10A2_2000
Thank you.
thank you so much
It is a very helpful post and thank you.
Could you kindly give answer to questions?
1. Is there any way (API) to figure out the offset and size of CMA, which is displayed at the dmesg.
– In kernel module
– In user program
2. Is it possible to make non-cacheable for the CMA area?
– I want to fill the CAM by PCIe DMA and want to disable while DMA fills the CMA memory.
3. Is it possible to allocate a huge one such as 20GByte or ore (of course, there is sufficient main memory, e.g., 36GByte on board)
4. Is it possible to refer the CMA from user program using mmap() on /dev/mem.
Hi ANDO KI,
I answered your question as follows:
1.Is there any way (API) to figure out the offset and size of CMA, which is displayed at the dmesg.
– In kernel module
– In user program
-> There are two ways. Let’s check each method.
1) use “cma=xxM” command line kernel parameter
Example) “cma=16M”
* If you use dmsg, you can see the following log.
cma: Reserved 16 MiB at 0x000000007f000000
Kernel command line: cma = 16M root = / dev / vda rw rootwait
2) use device tree
Example)
reserved-memory {
# address-cells = <2>;
# size-cells = <2>;
ranges;
linux, cma {
compatible = “shared-dma-pool”;
reusable;
size = <0 0x02000000>;
linux, cma-default;
};
};
* If you use dmsg, you can see the following log.
Reserved memory: created CMA memory pool at 0x000000007e000000, size 32 MiB
OF: reserved mem: initialized node linux, cma, compatible id shared-dma-pool
* There is also a way to check the device tree after booting the Linux kernel.
$ cd /sys/firmware/devicetree/base/reserved-memory/linux,cma
$ ls
compatible linux, cma-default name reusable size
$ xxd size
00000000: 0000 0000 0200 0000 ……..
2. Is it possible to make non-cacheable for the CMA area?
– I want to fill the CAM by PCIe DMA and want to disable while DMA fills the CMA memory.
-> yes. You can use dma_alloc_coherent() or dma_alloc_wc() api.
3.Is it possible to allocate a huge one such as 20GByte or ore (of course, there is sufficient main memory, e.g., 36GByte on board)
-> case ARM64)
When CONFIG_ZONE_DMA32 is declared for compatibility with 32-bit pci dma devices, the maximum dma area is limited to 4G.
When using a pcie device that supports 64-bit, the cma area can be largely captured without 4G limitation.
4. Is it possible to refer the CMA from user program using mmap () on / dev / mem.
-> I have never used it, but it will be possible.
Look for the DMA_ATTR_NO_KERNEL_MAPPING attribute in dma_mmap_attrs().
More details on DMA can also be found in my blog.
DMA -1- (Basic)
DMA -2- (DMA Coherent Memory)
DMA -3- (DMA Pool)
DMA -4- (DMA Mapping)
DMA -5- (IOMMU)
One more things to know about DMA performace
1) Using SRAM buffer – Bestest performance
If the system uses a dedicated SRAM buffer as fast as the cache for DMA, no cache mapping is required, so no cache coherent is needed.
2) HW DMA cache coherent – Best performance
If the system supports HW DMA cache coherent (eg CCI-500 and DMA devices using it), using cached (L1, L2, …) system memory as a DMA buffer is no problem.
3) Use dma mapping API – High performance
If you need to use DMA at high speed, you should use dma_alloc_contiguous () instead of dma_alloc_cohernet () or dma_alloc_wc () to use cache. However, dma mapping (sync) API should be used in this case.
4) Use Write combine mapping – Slow performance
When the system memory is changed to the memory mapping for write combine using the dma_alloc_coherent () or dma_alloc_wc () command, the cache cohent problem does not occur because the cache is not used and only the buffer is used. Instead, the cache is not used, so performance is sacrificed.