<kernel v5.0>
Per-cpu -2- (초기화)
아래의 순서도는 SMP 또는 NUMA 시스템 기반으로 구성되었다.
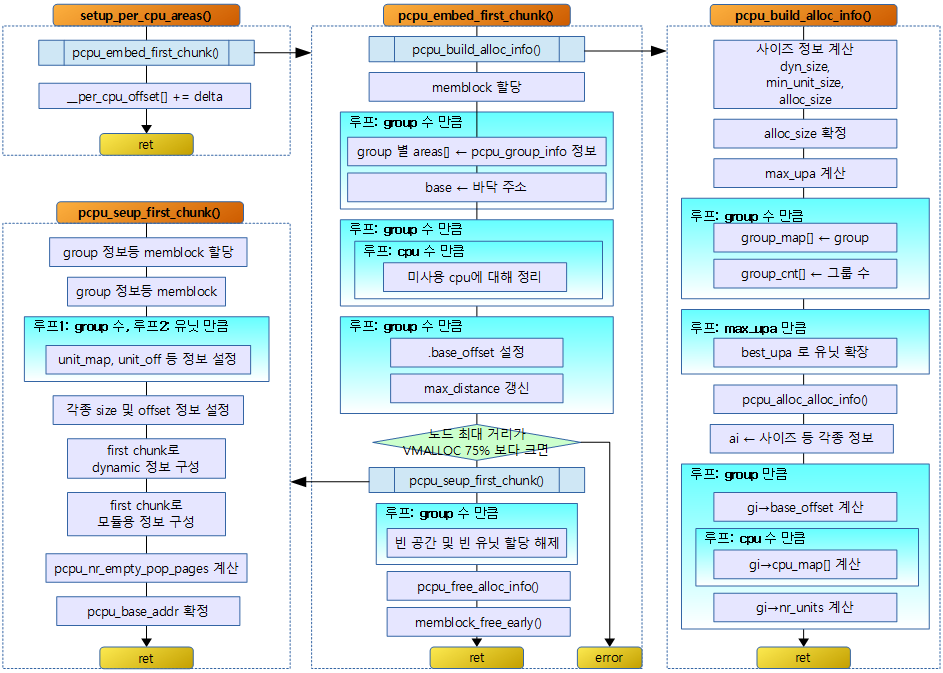
코어 수에 따른 3 가지 per-cpu 구현
per-cpu 셋업에 사용할 setup_per_cpu_areas() 함수의 구현은 3가지로 구분된다.
- UP Generic:
- UP 시스템에서 동작하는 공통 setup_per_cpu_areas() 구현
- SMP Generic:
- SMP 시스템에서 동작하는 공통 setup_per_cpu_areas() 구현
- 아키텍처 고유 구현:
- CONFIG_HAVE_SETUP_PER_CPU_AREA 커널 옵션을 사용하며 각 arch 디렉토리에 별도의 setup_per_cpu_areas() 함수를 제공한다.
- NUMA를 지원하는 ia64, sparc64, powerpc64, x86, arm64 아키텍처에서는 별도의 per-cpu 고유 구현을 사용한다.
- 이렇게 별도의 고유 구현을 사용하는 이유는 아키텍처가 수천개의 cpu도 구성할 수 있고 , NUMA 설계 및 sparse 메모리도 사용하는 시스템이 있어 노드 구성에 따라 per-cpu 데이터를 할당하는 메모리 위치가 다르기 때문에 이를 지원하기 위함이다.
1) UP Generic용 per-cpu 셋업
setup_per_cpu_areas() – UP Generic
mm/percpu.c
/* * UP percpu area setup. * * UP always uses km-based percpu allocator with identity mapping. * Static percpu variables are indistinguishable from the usual static * variables and don't require any special preparation. */
void __init setup_per_cpu_areas(void)
{
const size_t unit_size =
roundup_pow_of_two(max_t(size_t, PCPU_MIN_UNIT_SIZE,
PERCPU_DYNAMIC_RESERVE));
struct pcpu_alloc_info *ai;
void *fc;
ai = pcpu_alloc_alloc_info(1, 1);
fc = memblock_alloc_from_nopanic(unit_size,
PAGE_SIZE,
__pa(MAX_DMA_ADDRESS));
if (!ai || !fc)
panic("Failed to allocate memory for percpu areas.");
/* kmemleak tracks the percpu allocations separately */
kmemleak_free(fc);
ai->dyn_size = unit_size;
ai->unit_size = unit_size;
ai->atom_size = unit_size;
ai->alloc_size = unit_size;
ai->groups[0].nr_units = 1;
ai->groups[0].cpu_map[0] = 0;
if (pcpu_setup_first_chunk(ai, fc) < 0)
panic("Failed to initialize percpu areas.");
pcpu_free_alloc_info(ai);
}
UP 시스템용 per-cpu 할당자를 준비한다. UP 시스템용 per-cpu 데이터형은 성능 향상에 큰 의미가 없지만 1개 그룹(노드) 및 1개 유닛으로 구성된 first 청크를 준비한다.
- 코드 라인 3~5에서 per-cpu 최소 유닛 사이즈인 PCPU_MIN_UNIT_SIZE(32K)와 dynamic 영역 사이즈인 PERCPU_DYNAMIC_RESERVE(32bit=20K, 64bit=28K)와 비교하여 가장 큰 크기로 유닛 크기를 결정한다.
- 코드 라인 9에서 first 청크를 만들기 위해 임시로 사용할 할당 정보를 구성용으로 1개 그룹(노드)과 1개 유닛 수로 pcpu_alloc_info 구조체등을 할당 받아 온다.
- 코드 라인 10~14에서 memblock을 사용하여 1개 유닛을 할당해온다.
- 코드 라인 18~26에서 할당 정보를 설정한 후 pcpu_setup_first_chunk() 함수를 호출하여 first chunk를 구성해온다.
- 코드 라인 27에서 first 청크를 만들기 위해 사용한 할당 정보를 할당 해제한다.
2) SMP Generic용 per-cpu 셋업
setup_per_cpu_areas() – SMP Generic
다음은 SMP Generic 구현 기반의 setup_per_cpu_areas() 함수이다.
mm/percpu.c
/* * Generic SMP percpu area setup. * * The embedding helper is used because its behavior closely resembles * the original non-dynamic generic percpu area setup. This is * important because many archs have addressing restrictions and might * fail if the percpu area is located far away from the previous * location. As an added bonus, in non-NUMA cases, embedding is * generally a good idea TLB-wise because percpu area can piggy back * on the physical linear memory mapping which uses large page * mappings on applicable archs. */
void __init setup_per_cpu_areas(void)
{
unsigned long delta;
unsigned int cpu;
int rc;
/*
* Always reserve area for module percpu variables. That's
* what the legacy allocator did.
*/
rc = pcpu_embed_first_chunk(PERCPU_MODULE_RESERVE,
PERCPU_DYNAMIC_RESERVE, PAGE_SIZE, NULL,
pcpu_dfl_fc_alloc, pcpu_dfl_fc_free);
if (rc < 0)
panic("Failed to initialize percpu areas.");
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
for_each_possible_cpu(cpu)
__per_cpu_offset[cpu] = delta + pcpu_unit_offsets[cpu];
}
SMP 시스템용 per-cpu 할당자를 준비한다.
- 코드 라인 11~15에서 per-cpu 데이터 사용을 위해 embed형 first chunk를 구성한다.
- ARM32에서는 embed형을 사용하고 다른 몇 개 아키텍처에서는 page형 first chunk를 구성한다.
- PERCPU_MODULE_RESERVE
- 모듈에서 사용하는 모든 static용 per-cpu 데이터를 커버할 수 있는 크기로 8K이다.
- PERCPU_DYNAMIC_RESERVE
- first chunk에 dynamic per-cpu 할당을 할 수 있는 크기를 나타낸다.
- 값을 설정할 때 1-2 페이지 정도의 여유가 남아 있을 수 있도록 설정한다.
- default 값은 예전 보다 용량이 조금 더 증가되었고 다음과 같다.
- 32bit 시스템의 경우 20K
- 64bit 시스템의 경우 28K
- 코드 라인 17~19에서 pcpu_base_addr와 __per_cpu_start가 다를 수 있으며 이 때 delta가 발생하는데, __per_cpu_offset[] 값에 delta를 모두 적용한다.
3) 아키텍처 고유 구현 – for ARM64 NUMA
ARM64 시스템은 이제 디폴트 설정으로 NUMA 시스템을 지원한다. NUMA가 아닌 시스템이더라도 1개 노드를 사용하는 NUMA 설정을 사용한다.
setup_per_cpu_areas() – ARM64
arch/arm64/mm/numa.c
void __init setup_per_cpu_areas(void)
{
unsigned long delta;
unsigned int cpu;
int rc;
/*
* Always reserve area for module percpu variables. That's
* what the legacy allocator did.
*/
rc = pcpu_embed_first_chunk(PERCPU_MODULE_RESERVE,
PERCPU_DYNAMIC_RESERVE, PAGE_SIZE,
pcpu_cpu_distance,
pcpu_fc_alloc, pcpu_fc_free);
if (rc < 0)
panic("Failed to initialize percpu areas.");
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
for_each_possible_cpu(cpu)
__per_cpu_offset[cpu] = delta + pcpu_unit_offsets[cpu];
}
ARM64 시스템용 per-cpu 할당자를 준비한다. NUMA 처리를 위해 pcpu_cpu_distance 가 추가 되는 것을 제외하고, SMP Generic과 코드가 동일하다.
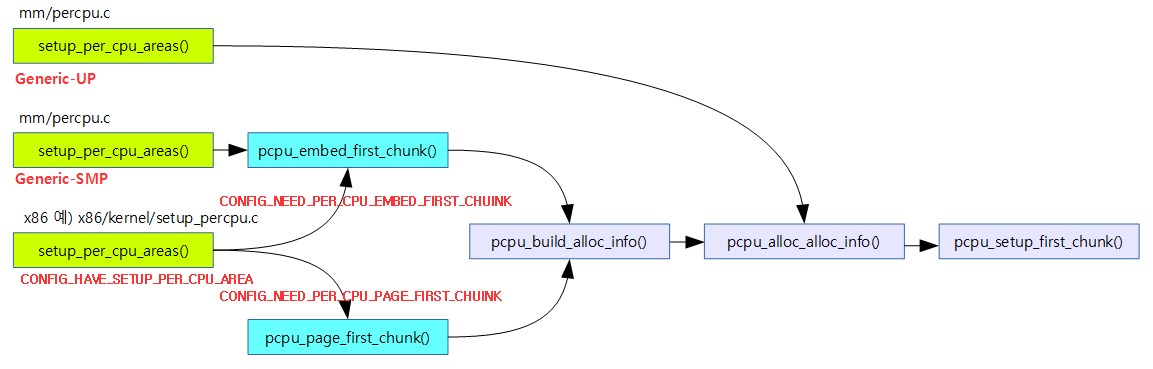
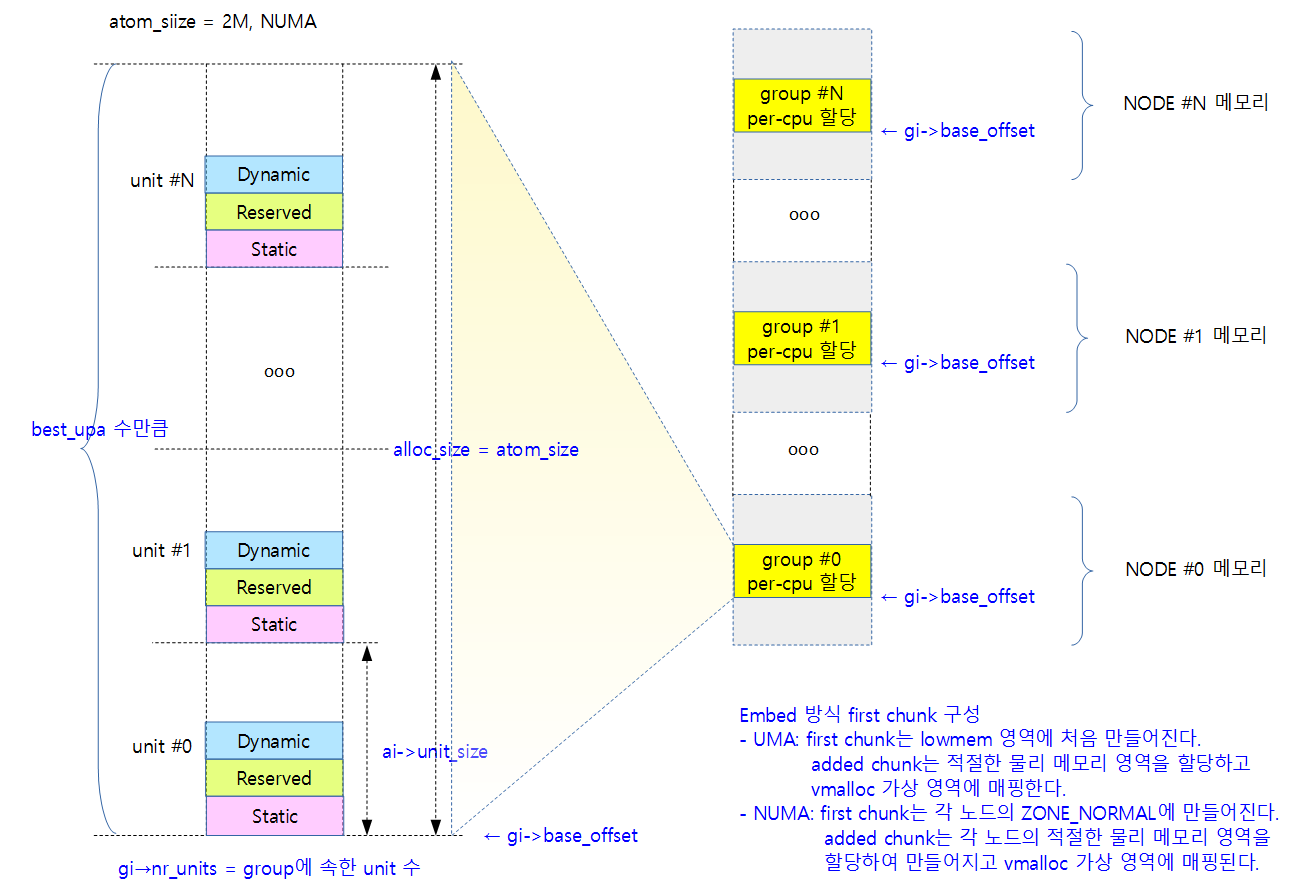
Embed 방식 First Chunk 구성
pcpu_embed_first_chunk()
이 함수에서는first chunk를 생성 시 huge 페이지를 사용할 수 있는 embed 방식으로 구성한다. 이 때 구성된 정보를 가지고 추가 chunk를 만들 때 사용한다. 초기에 설계될 때에는 bootmem에 만들었었는데 지금은 memblock 이라는 early memory allocator에 할당을 한다.
- @reserved_size:
- 모듈 용도의 static per-cpu로 할당할 reserved area 크기를 지정한다.
- ARM에서는 CONFIG_MODULE이 설정되어 있으면 PERCPU_MODULE_REWSERVE(8K)의 크기로 만들고, 그렇지 않으면 0이 지정된다.
- @dyn_size:
- cpu-per 데이터를 다이나믹하게 할당할 수 있도록 dynamic area 크기를 지정한다.
- ARM에서는 PERCPU_DYNAMIC_RESERVER(32bit=20K, 64bit=28K)만큼 만든다.
- @atom_size:
- 할당 최소 사이즈로 주어진 atom_size에 대해 2의 n차수로 할당 영역이 만들어진다.
- ARM에서는 PAGE_SIZE(4K)를 사용한다.
- @cpu_distance_fn:
- CPU간 distance를 알아오는 함수 포인터로 NUMA 아키텍처를 지원해야하는 경우 사용된다.
- NUMA 아키텍처에서는 노드 서로간에 메모리 접근 시간이 다르다.
- 구현된 NUMA 시스템마다 노드와 CPU간의 구성이 복잡하므로 NUMA 시스템을 제공하는 업체에서 이 함수를 제공한다.
- NUMA 아키텍처 구현에 따라 CPU간에 LOCAL_DISTANCE(10), REMOTE_DISTANCE(20)등 distance 값을 알아오게 된다.
- 이 함수에서는 이렇게 알아오는 distance 값으로 그룹(노드)을 구분하는데 사용한다.
- ARM32에서는 null 이다.
- @alloc_fn:
- per-cpu 페이지를 할당할 함수를 지정한다.
- null을 사용하면 vmalloc 영역을 사용한다.
- @free_fn:
- per-cpu 페이지를 회수(free)할 함수를 지정한다.
- null을 함수하면 vmalloc 영역에서 회수(free)한다.
mm/percpu.c -1/2-
#if defined(BUILD_EMBED_FIRST_CHUNK) /** * pcpu_embed_first_chunk - embed the first percpu chunk into bootmem * @reserved_size: the size of reserved percpu area in bytes * @dyn_size: minimum free size for dynamic allocation in bytes * @atom_size: allocation atom size * @cpu_distance_fn: callback to determine distance between cpus, optional * @alloc_fn: function to allocate percpu page * @free_fn: function to free percpu page * * This is a helper to ease setting up embedded first percpu chunk and * can be called where pcpu_setup_first_chunk() is expected. * * If this function is used to setup the first chunk, it is allocated * by calling @alloc_fn and used as-is without being mapped into * vmalloc area. Allocations are always whole multiples of @atom_size * aligned to @atom_size. * * This enables the first chunk to piggy back on the linear physical * mapping which often uses larger page size. Please note that this * can result in very sparse cpu->unit mapping on NUMA machines thus * requiring large vmalloc address space. Don't use this allocator if * vmalloc space is not orders of magnitude larger than distances * between node memory addresses (ie. 32bit NUMA machines). * * @dyn_size specifies the minimum dynamic area size. * * If the needed size is smaller than the minimum or specified unit * size, the leftover is returned using @free_fn. * * RETURNS: * 0 on success, -errno on failure. */
int __init pcpu_embed_first_chunk(size_t reserved_size, size_t dyn_size,
size_t atom_size,
pcpu_fc_cpu_distance_fn_t cpu_distance_fn,
pcpu_fc_alloc_fn_t alloc_fn,
pcpu_fc_free_fn_t free_fn)
{
void *base = (void *)ULONG_MAX;
void **areas = NULL;
struct pcpu_alloc_info *ai;
size_t size_sum, areas_size;
unsigned long max_distance;
int group, i, highest_group, rc;
ai = pcpu_build_alloc_info(reserved_size, dyn_size, atom_size,
cpu_distance_fn);
if (IS_ERR(ai))
return PTR_ERR(ai);
size_sum = ai->static_size + ai->reserved_size + ai->dyn_size;
areas_size = PFN_ALIGN(ai->nr_groups * sizeof(void *));
areas = memblock_alloc_nopanic(areas_size, SMP_CACHE_BYTES);
if (!areas) {
rc = -ENOMEM;
goto out_free;
}
/* allocate, copy and determine base address & max_distance */
highest_group = 0;
for (group = 0; group < ai->nr_groups; group++) {
struct pcpu_group_info *gi = &ai->groups[group];
unsigned int cpu = NR_CPUS;
void *ptr;
for (i = 0; i < gi->nr_units && cpu == NR_CPUS; i++)
cpu = gi->cpu_map[i];
BUG_ON(cpu == NR_CPUS);
/* allocate space for the whole group */
ptr = alloc_fn(cpu, gi->nr_units * ai->unit_size, atom_size);
if (!ptr) {
rc = -ENOMEM;
goto out_free_areas;
}
/* kmemleak tracks the percpu allocations separately */
kmemleak_free(ptr);
areas[group] = ptr;
base = min(ptr, base);
if (ptr > areas[highest_group])
highest_group = group;
}
max_distance = areas[highest_group] - base;
max_distance += ai->unit_size * ai->groups[highest_group].nr_units;
/* warn if maximum distance is further than 75% of vmalloc space */
if (max_distance > VMALLOC_TOTAL * 3 / 4) {
pr_warn("max_distance=0x%lx too large for vmalloc space 0x%lx\n",
max_distance, VMALLOC_TOTAL);
#ifdef CONFIG_NEED_PER_CPU_PAGE_FIRST_CHUNK
/* and fail if we have fallback */
rc = -EINVAL;
goto out_free_areas;
#endif
}
- 코드 라인 14~17에서 주어진 인자 값을 가지고 ai(pcpu_alloc_info 구조체) 값을 구성하고 만들어온다. pcpu_alloc_info 구조체 필드 전체가 설정되어 리턴된다. pcpu_alloc_info 구조체 안에 있는 pcpu_group_info 구조체 정보도 모두 설정되며 cpu_map[ ]도 구성되어 있다.
- 코드 라인 19에서 size_sum을 구한다. size_sum은 unit_size와 다를 수 있다. atom_size가 4K page를 사용할 때는 unit_size와 size_sum이 동일하다. atom_size가 1M, 2M, 16M 등을 사용하는 경우 unit_size는 보통 size_sum보다 크다.
- rpi2: size_sum = 0xb000 = 0x3ec0 + 0x2000 + 0x5140
- dyn_size의 0x5140에서 0x140 은 size_sum의 page align 수행에 의해 추가되었다.
- 코드 라인 20~26에서 그룹(노드)별로 per-cpu 데이터가 위치할 영역의 주소는 areas[ ]라는 배열에서 관리되는데 이 배열을 memblock에서 할당한다. area_size는 그룹(노드) 수의 주소(void *) 크기만큼 필요한 크기이며 페이지 크기로 내림 정렬한다.
- 그룹 수만큼 루프를 돌며 각 그룹의 유닛 수(ai->nr_units) * 유닛 크기(unit_size)만큼 per-cpu 데이터 영역을 memblock에서 할당한다. 처음에 만드는 per-cpu 영역은 버디 시스템 등 정식 메모리 관리자가 동작하기 전에는 memblock을 통해, 즉 각 그룹(노드) 메모리에 할당을 하지 않고 lowmem 영역에 만든다.
- 코드 라인 30~37에서 그룹 수 만큼 순회하며 그룹 내 유닛들 중 unit->cpu 매핑되지않은 cpu를 알아온다.
- cpu_map[]에 처음 매핑되지 않은 유닛들은 NR_CPUS 값으로 초기화되어 있다.
- 코드 라인 40~44에서 할당 크기(그룹에 포함된 유닛 수 * 유닛 크기)만큼 인자로 받은 할당자 함수를 통해 atom_size로 align하여 할당한다.
- 부트 업 중에는 인자로 전달받은 할당자 함수로 memblock을 할당한다.
- generic: pcpu_dfl_fc_alloc()
- arm64: pcpu_fc_alloc()
- 부트 업 중에는 인자로 전달받은 할당자 함수로 memblock을 할당한다.
- 코드 라인 46에서 CONFIG_DEBUG_KMEMLEAK 커널 옵션이 설정된 경우 메모리 누수(leak)를 분석하기 위해 호출한다.
- 코드 라인 47에서 areas[ ] 배열 영역에 해당 그룹(노드)의 per-cpu 데이터 영역으로 할당받은 base 주소를 기록한다.
- 코드 라인 49에서 각 그룹이 할당받은 주소 중 가장 작은 주소를 기억한다. base의 초깃값은 ULONG_MAX이므로 처음 한 번은 반드시 갱신된다.
- 코드 라인 53~65에서 max_distance를 계산하여 VMALLOC_TOTAL의 75%를 초과하는지 검사하고 초과하는 경우 경고를 출력한다. 그런 후 이미 할당 받은 메모리를 해제하고 에러를 반환하기 위해 out_free_areas: 라벨로 이동한다. 추가되는 chunk들은 first chunk를 만들 때의 그룹(노드) offset만큼 간격을 유지하여 vmalloc 영역에 메모리를 할당하고 매핑을 해야 하기 때문에 제약조건이 생기므로 vmalloc 영역의 최대 75%를 초과하는 경우 first chunk를 만들 때 embed 방식을 사용하지 못하게 한다. 참고로 embed 방식을 사용하는 경우 각 그룹 간의 간격을 유지하게 하기 위해 vmalloc 영역의 할당을 반대편에서, 즉 위에서 아래로 빈 공간을 검색하여 사용하게 하여 추가되는 chunk 할당에 대해 실패 확률을 줄여주도록 설계되었다.
- CONFIG_NEED_PER_CPU_PAGE_FIRST_CHUNK 커널 옵션을 사용하는 다른 아키텍처에서는 이 함수가 실패하여 빠져나가게 되면 page 방식으로 다시 한번 준비하게 된다.
- max_distance는 모든 그룹의 base_offset 중 가장 큰 주소를 담고 여기에 유닛 크기만큼 더한다.
mm/percpu.c -2/2-
/*
* Copy data and free unused parts. This should happen after all
* allocations are complete; otherwise, we may end up with
* overlapping groups.
*/
for (group = 0; group < ai->nr_groups; group++) {
struct pcpu_group_info *gi = &ai->groups[group];
void *ptr = areas[group];
for (i = 0; i < gi->nr_units; i++, ptr += ai->unit_size) {
if (gi->cpu_map[i] == NR_CPUS) {
/* unused unit, free whole */
free_fn(ptr, ai->unit_size);
continue;
}
/* copy and return the unused part */
memcpy(ptr, __per_cpu_load, ai->static_size);
free_fn(ptr + size_sum, ai->unit_size - size_sum);
}
}
/* base address is now known, determine group base offsets */
for (group = 0; group < ai->nr_groups; group++) {
ai->groups[group].base_offset = areas[group] - base;
}
pr_info("Embedded %zu pages/cpu @%p s%zu r%zu d%zu u%zu\n",
PFN_DOWN(size_sum), base, ai->static_size, ai->reserved_size,
ai->dyn_size, ai->unit_size);
rc = pcpu_setup_first_chunk(ai, base);
goto out_free;
out_free_areas:
for (group = 0; group < ai->nr_groups; group++)
if (areas[group])
free_fn(areas[group],
ai->groups[group].nr_units * ai->unit_size);
out_free:
pcpu_free_alloc_info(ai);
if (areas)
memblock_free_early(__pa(areas), areas_size);
return rc;
}
#endif /* BUILD_EMBED_FIRST_CHUNK */
- 코드 라인 6~15에서 그룹 수만큼 루프를 돌며 각 그룹의 영역 할당 주소를 ptr에 담고, unit->cpu 매핑이 되지 않은 유닛인 경우에는 해당 유닛에 해당하는 memblock 영역에서 유닛 크기만큼 해제한다.
- 코드 라인 17~18에서 _ _per_cpu_load에 위치한 static per-cpu 데이터를 해당 유닛에 대응하는 주소에 복사하고 해당 유닛 내에서 복사한 크기를 제외한, 즉 사용하지 않는 공간 만큼의 크기를 memblock 영역에서 해제한다
- 유닛 구성에 small 페이지를 사용하는 경우 불필요한 공간이 없으므로 제거할 영역은 없다.
- 코드 라인 23~25에서 각 그룹의 base offset 값을 설정한다.
- 코드 라인 27~29에서 first chunk 구성 정보를 출력한다.
- 코드 라인 31~32에서 first chunk에 대한 관리 정보를 각종 전역변수에 설정하고 out_free: 레이블로 이동하여 임시로 만들었던 정보(ai)들을 해제(free)한다.
- 코드 라인 34~38에서 out_free_areas:레이블이다. 그룹 수만큼 areas[]를 통해 per-cpu 데이터 영역을 할당한 곳의 주소를 알아오고 해당 영역을 memblock에서 할당 해제한다.
- 코드 라인 39~43에서 out_free:레이블이다. per-cpu data를 만들때 사용한 관리정보를 모두 삭제하고, areas 정보도 memblock 영역에서 할당 해제한다.
- 부트 업 중에는 인자로 전달받은 할당자 함수로 memblock을 할당 해제한다.
- generic: pcpu_dfl_fc_free()
- arm64: pcpu_fc_free()
- 부트 업 중에는 인자로 전달받은 할당자 함수로 memblock을 할당 해제한다.
다음 그림은 per-cpu first chunk의 모든 유닛 내의 빈 공간과 사용하지 않는 유닛 공간을 할당 해제하는 모습을 보여준다.
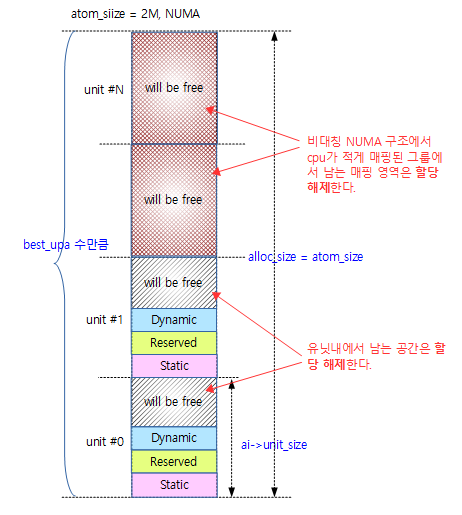
per-cpu 할당 정보로 빌드
하나의 할당에 사용될 유닛 크기를 산출하고 유닛 내부의 영역을 나누는 방법을 알아본다.
유닛내 영역 구분
다음 그림은 first chunk의 한 유닛 내부에서 세 영역을 구분하는 모습을 보여준다.

UPA(Unit Per Alloc) 산출
- 한 번의 할당에 사용할 최대 유닛 수이다. 최적의 upa를 얻기 위해 임시로 max_upa 및 best_upa 값을 산출한다.
- 할당 사이즈가 1 페이지 단위인 경우 보통 1유닛에 수십 KB가 필요하므로 1개의 페이지를 할당받는 경우에는 하나의 유닛도 포함시킬 수 없다.
- ARM32 및 ARM64 디폴트의 경우 1 페이지 단위의 할당을 사용하므로 upa는 항상 1이 산출된다.
- upa를 구하는 이유는 huge 페이지를 사용하는 시스템에서 huge 페이지를 할당할 때마다 큰 사이즈(1, 2M, …)가 할당되므로 이 공간에서의 효과적인 유닛의 수를 계산하는 것이다.
- cpu가 8개인 시스템에서 1개의 huge 페이지를 할당받아 256MB씩 나누어 배치하면 전체 유닛이 하나의 huge 페이지에 배치되므로 upa 값은 그냥 8이다.
- 또한 NUMA 시스템에서는 메모리 노드가 각각의 노드에 배치되어 있어 per-cpu 데이터들도 각각의 노드에서 접근되어야 성능이 빠르므로 upa를 적절히 구해야 하나의 할당 메모리당 유닛 배치가 효과적으로 배치할 수 있다.
아래 그림과 최소 할당 단위로 한 페이지를 사용하는 경우 하나의 페이지에 유닛들이 들어갈 수가 없다. 오히려 한 개의 유닛을 위해 여러 개의 할당이 필요한 상황이다. 이런 경우 upa 값은 최소값으로 1을 사용한다.
- ARM32 예) atom_size=1 페이지(4K), alloc_size=0xb000인 경우
- upa=1
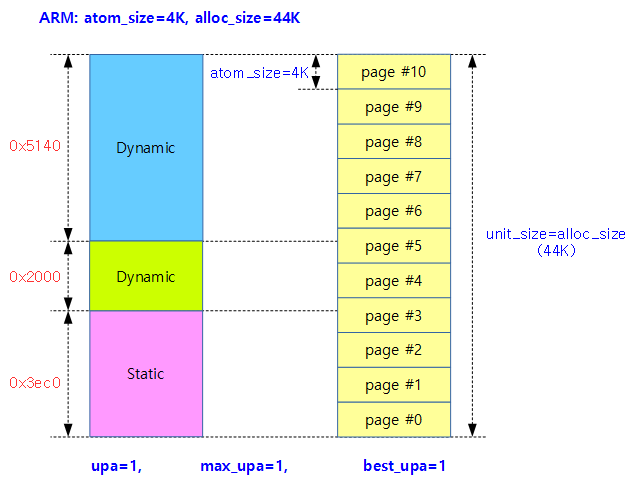
max_upa
- 최소 할당 단위로 huge 페이지와 같이 큰 사이즈를 지원하는 경우 할당 단위당 포함될 수 있는 최대 유닛 수이다.
- 4K 페이지에 대해 2의 n차수로 시작하는 하나의 할당 크기에 최대 할당 가능한 유닛 수가 담긴다.
- ARM32 및 ARM64 메인 스트림 커널의 경우 아직 최소 할당 단위로 huge 페이지의 사용을 적용하지 않았다. 항상 페이지 단위만을 사용한다.
- 예) alloc_size=2M, min_unit_size=0xb000 인경우 처음 upa=46
- 최종 max_upa=32
best_upa
- NUMA 시스템과 같이 멀티 노드 메모리를 사용하는 경우 각 노드에 max_upa를 사용한 메모리 할당은 낭비다. 따라서 max_upa를 노드별로 나누어 배치하여 사용하기 위해 적절한(best) 유닛 수를 산출한다.
- 비대칭형 NUMA 시스템의 경우 사용하지 않을 유닛이 필요 이상 배치되는 낭비를 방지하기 위해 사용하지 않을 유닛 수가 실제 사용할 유닛(possible cpu 수와 동일)의 1/3을 초과하면 안된다.
- 대칭형 NUMA 시스템 예) alloc_size=2M, min_unit_size=0xb000, max_upa=32, nr_cpu=8, nr_group=2 인경우
- 노드마다 4개를 배치하여 사용하면 되므로 best_upa=4 이다.
- 비대칭형 NUMA 시스템 예) alloc_size=2M, min_unit_size=0xb000, max_upa=32, nr_cpu=8+1, nr_group=2 인경우
- upa를 32, 16, 8, 4, 2, 1와 같이 순서대로 시도할 때 할당 수는 각각 2, 2, 2, 3, 5, 9가 된다. 그리고 사용하지 않는 유닛 수는 55, 23, 7, 3, 1, 0이 된다. 이 결과 중 사용할 유닛(cpu 수=9)의 3/1인 3을 초과하지 않는 best_upa는 4가 됨을 알 수 있다.
- 할당 수 = 그룹 수 만큼 DIV_ROUND_UP(해당 그룹 cpu 수 / upa)을 누적시킨다.
- DIV_ROUND_UP(8 / 32) + DIV_ROUND_UP(1 / 32) = 1 + 1 = 2
- DIV_ROUND_UP(8 / 16) + DIV_ROUND_UP(1 / 16) = 1 + 1 = 2
- DIV_ROUND_UP(8 / 8) + DIV_ROUND_UP(1 / 8) = 1 + 1 = 2
- DIV_ROUND_UP(8 / 4) + DIV_ROUND_UP(1 / 4) = 2 + 1 = 3
- DIV_ROUND_UP(8 / 2) + DIV_ROUND_UP(1 / 2) = 4 + 1 = 5
- DIV_ROUND_UP(8 / 1) + DIV_ROUND_UP(1 / 1) = 8 + 1 = 9
- 낭비되는 유닛 수 산출(wasted) = 할당 수 * upa – 사용할 유닛 수(possible cpu 수=9)이다.
- 2 * 32 – 9 = 55 (55개 미사용 유닛은 9개 cpu의 1/3을 초과하여 낭비 판정)
- 2 * 16 – 9 = 23 (23개 미사용 유닛은 9개 cpu의 1/3을 초과하여 낭비 판정)
- 2 * 8 – 9 = 7 (57개 미사용 유닛은 9개 cpu의 1/3을 초과하여 낭비 판정)
- 3 * 4 – 9 = 3 (3개 미사용 유닛은 9개 cpu의 1/3을 초과하지 않으므로 ok)
- 5 * 2 – 9 = 1 (1개 미사용 유닛은 9개 cpu의 1/3을 초과하지 않으므로 ok)
- 9 * 1 – 9 = 0 (0개 미사용 유닛은 9개 cpu의 1/3을 초과하지 않으므로 ok)
max_upa 및 best_upa 산출
계산 단계는 다음 3단계로 이루어진다.
- 1단계) 최초 upa = 할당 사이즈 / 최소 할당할 유닛 사이즈(min_unit_size)
- 2단계) max_upa = huge 페이지 할당 단위를 upa로 나눌 때 남는 나머지가 없도록 upa 조정
- 3단계) best_upa = 비 균형 NUMA 시스템을 위해 upa 조정하기 위해 미사용 유닛이 실사용 유닛의 1/3을 초과하지 않는 한도내에서 최소 할당 수를 찾아 조정한다.
다음 그림은 2M 할당을 사용하는 대칭형 NUMA 시스템에서 산출된 upa, max_upa 및 best_upa가 산출된 이후 운용되는 모습을 보여준다.
- 할당하고 남는(extra) 공간은 per-cpu 데이터 공간으로 사용하지 않고 할당 해제하여 버디 시스템으로 되돌린다.
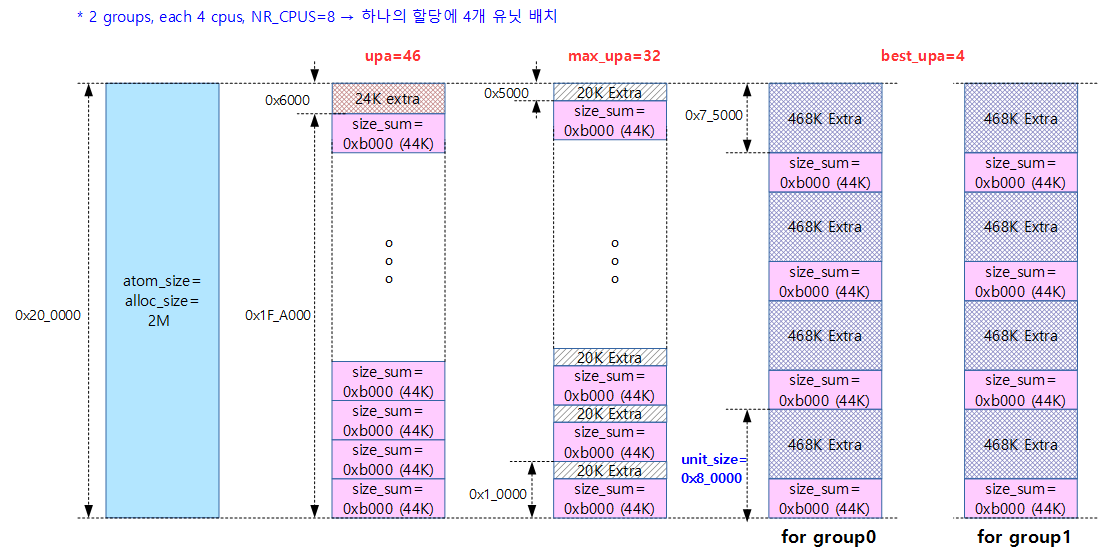
다음 그림은 2M 할당을 사용하는 대칭형 NUMA 시스템에서 산출된 upa, max_upa 및 best_upa가 산출된 이후 운용되는 모습을 보여준다.
- 한 쪽 group(노드)은 8개의 cpu를 사용하였고, 다른 한 쪽 group(노드)이 1개의 cpu를 사용한 경우 3개의 할당을 사용하고, upa(best_upa) 값은 4가 산출된다.
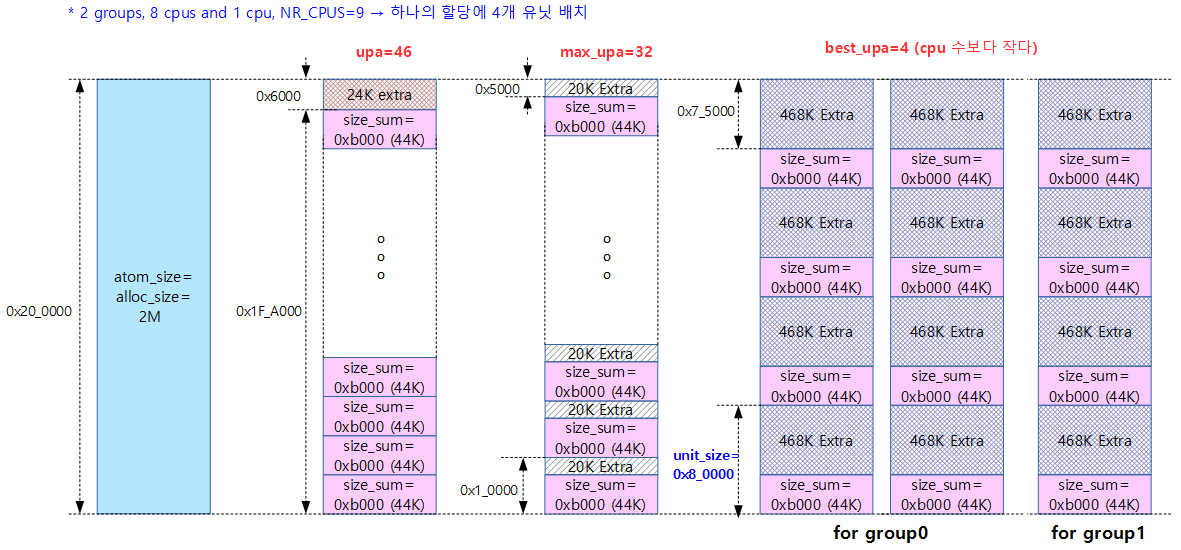
pcpu_build_alloc_info()
mm/percpu.c -1/4-
/* pcpu_build_alloc_info() is used by both embed and page first chunk */ #if defined(BUILD_EMBED_FIRST_CHUNK) || defined(BUILD_PAGE_FIRST_CHUNK) /** * pcpu_build_alloc_info - build alloc_info considering distances between CPUs * @reserved_size: the size of reserved percpu area in bytes * @dyn_size: minimum free size for dynamic allocation in bytes * @atom_size: allocation atom size * @cpu_distance_fn: callback to determine distance between cpus, optional * * This function determines grouping of units, their mappings to cpus * and other parameters considering needed percpu size, allocation * atom size and distances between CPUs. * * Groups are always multiples of atom size and CPUs which are of * LOCAL_DISTANCE both ways are grouped together and share space for * units in the same group. The returned configuration is guaranteed * to have CPUs on different nodes on different groups and >=75% usage * of allocated virtual address space. * * RETURNS: * On success, pointer to the new allocation_info is returned. On * failure, ERR_PTR value is returned. */
static struct pcpu_alloc_info * __init pcpu_build_alloc_info(
size_t reserved_size, size_t dyn_size,
size_t atom_size,
pcpu_fc_cpu_distance_fn_t cpu_distance_fn)
{
static int group_map[NR_CPUS] __initdata;
static int group_cnt[NR_CPUS] __initdata;
const size_t static_size = __per_cpu_end - __per_cpu_start;
int nr_groups = 1, nr_units = 0;
size_t size_sum, min_unit_size, alloc_size;
int upa, max_upa, uninitialized_var(best_upa); /* units_per_alloc */
int last_allocs, group, unit;
unsigned int cpu, tcpu;
struct pcpu_alloc_info *ai;
unsigned int *cpu_map;
/* this function may be called multiple times */
memset(group_map, 0, sizeof(group_map));
memset(group_cnt, 0, sizeof(group_cnt));
/* calculate size_sum and ensure dyn_size is enough for early alloc */
size_sum = PFN_ALIGN(static_size + reserved_size +
max_t(size_t, dyn_size, PERCPU_DYNAMIC_EARLY_SIZE));
dyn_size = size_sum - static_size - reserved_size;
/*
* Determine min_unit_size, alloc_size and max_upa such that
* alloc_size is multiple of atom_size and is the smallest
* which can accommodate 4k aligned segments which are equal to
* or larger than min_unit_size.
*/
min_unit_size = max_t(size_t, size_sum, PCPU_MIN_UNIT_SIZE);
reserved 크기, dynamic 크기, atom 크기 및 cpu 간 거리 인자로 per-cpu chunk 할당 정보를 준비한다. atom_size는 대부분 4K 페이지를 사용하여 할당 영역을 align되게 유도하는데, huge 페이지를 사용하는 몇 개의 아키텍처에서는 1M, 2M, 16M 등을 지원하기도 한다.
- 처음 ARM 32비트 아키텍처 first chunk를 만들기 위해 호출된 경우 지정된 인수는 다음과 같다.
- reserved_size=8K, dyn_size=20K, atom_size=4K
- atom_size는 대부분 4K 페이지를 사용하여 할당 영역을 align되게 유도하는데 huge 페이지를 사용하는 몇 개의 아키텍처에서는 1M, 2M, 16M 등을 지원하기도 한다.
- 코드 라인 8에서 static 크기는 컴파일 타임에 결정되는 __per_cpu_end에서 __per_cpu_start를 빼는 것으로 계산된다.
- rpi2 예) 설정마다 약간씩 다름 -> static_size = 0x3ec0 bytes
- rock960 예) static_size = 0xdad8
- 코드 라인 11에서 초기화되지 않은 로컬 변수 사용 시 컴파일 경고(compile warning)를 없애기 위한 매크로다.
- uninitialized_var(best_upa);
- 초기화 되지 않은 로컬 변수를 사용 시 compile warning을 없애기 위한 매크로이다.
- #define uninitialized_var(x) x = x
- uninitialized_var(best_upa);
- 코드 라인 22~23에서 size_sum은 static 영역 + reserved 영역 + dynamic 영역을 모두 더한 크기를 페이지 단위로 정렬한 크기다. dyn_size는 최소 PERCPU_DYNAMIC_EARLY_SIZE(0x3000=12K)이다. dynamic 크기는 32비트에서 20K 이고, 64비트 시스템에서는 28K이다.
- rpi2 예) size_sum = 0xb000 = PFN_ALIGN(0xaec0)
- rock960 예) size_sum = 0x1_7000 = PFN_ALIGN(0x17ad8)
- 코드 라인 24에서 dyn_size를 재조정한다.
- rpi2 예) dyn_size = 0x5140
- rock960 예) dyn_size=0x7528
- 코드 라인 32에서 min_unit_size를 최소 PCPU_MIN_UNIT_SIZE(0x8000=32K) 이상으로 제한한다.
- rpi2 예) min_unit_size = 0xb000 (0x3ec0(static) + 0x2000 + 0x5000(dynamic) + 0x140(align to dynamic))
- rock960 예) min_unit_size = 0x1_7000 (0xdad8(static) + 0x2000(reserved) + 0x7000(dynamic) + 0x528(align to dynamic))
mm/percpu.c -2/4-
. /* determine the maximum # of units that can fit in an allocation */
alloc_size = roundup(min_unit_size, atom_size);
upa = alloc_size / min_unit_size;
while (alloc_size % upa || (offset_in_page(alloc_size / upa)))
upa--;
max_upa = upa;
/* group cpus according to their proximity */
for_each_possible_cpu(cpu) {
group = 0;
next_group:
for_each_possible_cpu(tcpu) {
if (cpu == tcpu)
break;
if (group_map[tcpu] == group && cpu_distance_fn &&
(cpu_distance_fn(cpu, tcpu) > LOCAL_DISTANCE ||
cpu_distance_fn(tcpu, cpu) > LOCAL_DISTANCE)) {
group++;
nr_groups = max(nr_groups, group + 1);
goto next_group;
}
}
group_map[cpu] = group;
group_cnt[group]++;
}
- 코드 라인 2에서 최소 할당 크기를 atom_size(ARM: 4K) 단위로 roundup한다. roundup( )의 두 번째 인자는 스칼라 타입(scalar type)이어야 한다. 할당 크기(alloc_size)가 계산되었으면 이 할당에 배치될 유닛 수를 계산해야 한다.
- 다른 몇 개의 아키텍처에서 atom_size 1M, 2M, 16M를 지원하는 경우 alloc_size는 atom_size 단위로 만들어진다.
- rpi2: alloc_size = 0xb000
- rock960: alloc_size=0x1_7000
- 코드 라인 3에서 먼저 하나의 할당에 들어갈 수 있는 유닛 수인 upa를 계산한다.
- ARM과 같이 atom_size가 작은 4K 인경우 alloc_size가 항상 4K 보다 같거나 큰 경우가 되므로 upa 값은 항상 1이다.
- 다른 특별한 아키텍처에서는 atom_size를 1M, 2M, 및 16M 등으로 지정할 수도 있고 그런 경우 할당 하나에 여려 개의 유닛이 들어간다.
- 예) atom_size가 2M인 아키텍처: upa=46
- upa(46)=alloc_size(2M) / min_unit_size(44K)
- 코드 라인 4~6에서max_upa를 계산한다(upa보다 같거나 작아진다). alloc_size가 페이지 크기에 대해 2의 n승에서만 루프를 탈출할 기회가 있다. max_upa에는 4K 페이지에 대해 2의 n승으로 시작하는 하나의 할당 크기에 최대 할당 가능한 유닛 수가 담긴다. 즉, max_upa는 2^N 값이다.
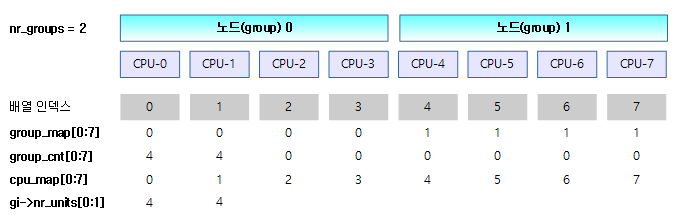
- 코드 라인 9~25에서 그룹 정보 group_map[ ], group_cnt[ ], nr_groups 값을 계산한다.
- group_map[]
- ARM 같이 UMA 시스템에서는 하나의 group(노드)을 사용하므로 값이 0이다.
- NUMA 시스템에서는 아래 그림과 같이 group(노드)끼리 묶어진다.
- CPU간 distance 값이 LOCAL_DISTANCE(10)보다 큰 경우는 서로 다른 group(노드)이라 인식한다.
- group_cnt[]
- ARM 같이 UMA 시스템에서는 group(노드)이 하나이므로 group_cnt[0]에만 cpu 수가 들어간다.
- NUMA 시스템에서는 아래 그림과 같이 각 group(노드)이 소유한 cpu 수가 들어간다. 아래 그림과 같이 두 개의 그룹에 각각 4개씩의 cpu 수가 입력되었다.
- nr_groups
- 그룹(노드) 수
- group_map[]
아래 그림은 대칭형 NUMA 시스템으로 각각의 그룹(노드)에 4개씩 cpu가 배치된 경우이다.

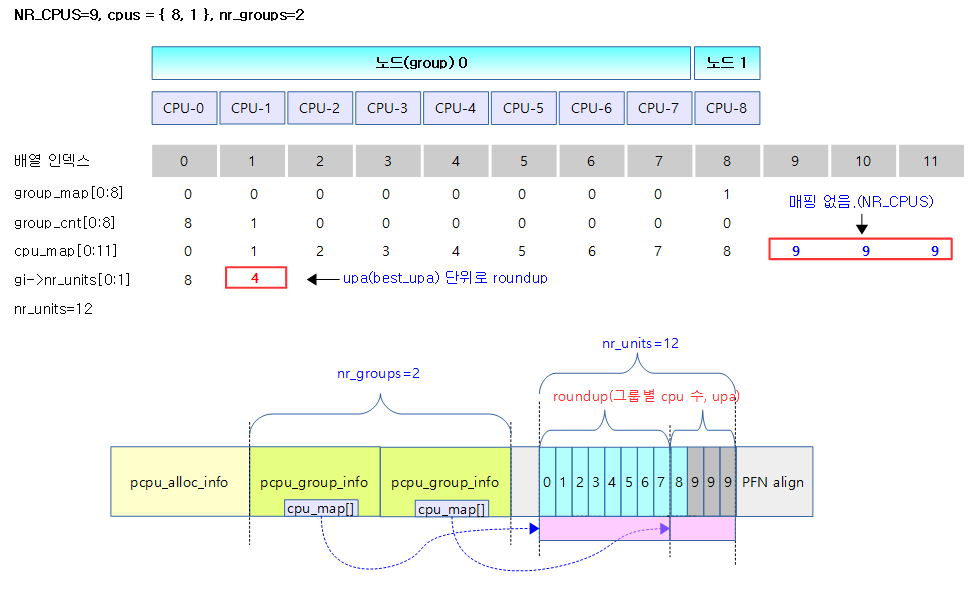
아래 그림은 비대칭형 NUMA 시스템으로 첫 번째 그룹(노드)에 4개, 두 번째 그룹(노드)에 2개의 cpu가 배치된 경우이다.

mm/percpu.c -3/4-
. /*
* Wasted space is caused by a ratio imbalance of upa to group_cnt.
* Expand the unit_size until we use >= 75% of the units allocated.
* Related to atom_size, which could be much larger than the unit_size.
*/
last_allocs = INT_MAX;
for (upa = max_upa; upa; upa--) {
int allocs = 0, wasted = 0;
if (alloc_size % upa || (offset_in_page(alloc_size / upa)))
continue;
for (group = 0; group < nr_groups; group++) {
int this_allocs = DIV_ROUND_UP(group_cnt[group], upa);
allocs += this_allocs;
wasted += this_allocs * upa - group_cnt[group];
}
/*
* Don't accept if wastage is over 1/3. The
* greater-than comparison ensures upa==1 always
* passes the following check.
*/
if (wasted > num_possible_cpus() / 3)
continue;
/* and then don't consume more memory */
if (allocs > last_allocs)
break;
last_allocs = allocs;
best_upa = upa;
}
upa = best_upa;
- 코드 라인 7~11에서 max_upa~1까지 루프를 돌며 페이지에 대해 2의 n승이 아니면 스킵한다.
- 예) upa 값이 32(max_upa) -> 16 -> 8 -> 4 -> 2 -> 1 까지 점점 낮아지며 시도한다.
- 코드 라인 13~17에서 그룹 수만큼 루프(group = 0, 1)를 돌며 this_allocs, allocs, wasted 값을 계산한다.
- this_allocs
- 그룹별로 필요한 할당 수
- allocs
- 전체 그룹에 필요한 할당 수
- 그룹 수 만큼 DIV_ROUND_UP(해당 그룹 cpu 수 / upa)을 누적시킨다.
- wasted
- 낭비되는 유닛 수 산출
- 할당 수 * 할당마다 배치할 유닛 수(upa) – 사용할 유닛 수(possible cpu 수=9) 이다.
- this_allocs
- 코드 라인 24~25에서 남는 유닛이 실제 사용하는 유닛의 1/3을 초과하면 낭비가 많다고 판단해서 스킵한다.
- 코드 라인 28~33에서 계산된 할당 크기가 기존 할당 크기보다 큰 경우 루프를 탈출하여 best_upa를 결정한다.
아래 표는 대칭형 NUMA 시스템에서 min_unit_size=44K를 적용하고 다음과 같은 다양한 조건을 사용하여 best_upa값을 추적하였다.
- X축 조건: 할당 사이즈
- Y축 조건: group별 cpu 수, 그룹 수, 전체 cpu 수

아래 표 역시 대칭형 NUMA 시스템에서 min_unit_size=44K를 적용하고 다음과 같은 다양한 조건을 사용하여 allocs, wasted 값들을 추적하였다.
- X축 조건: upa
- Y축 조건: group
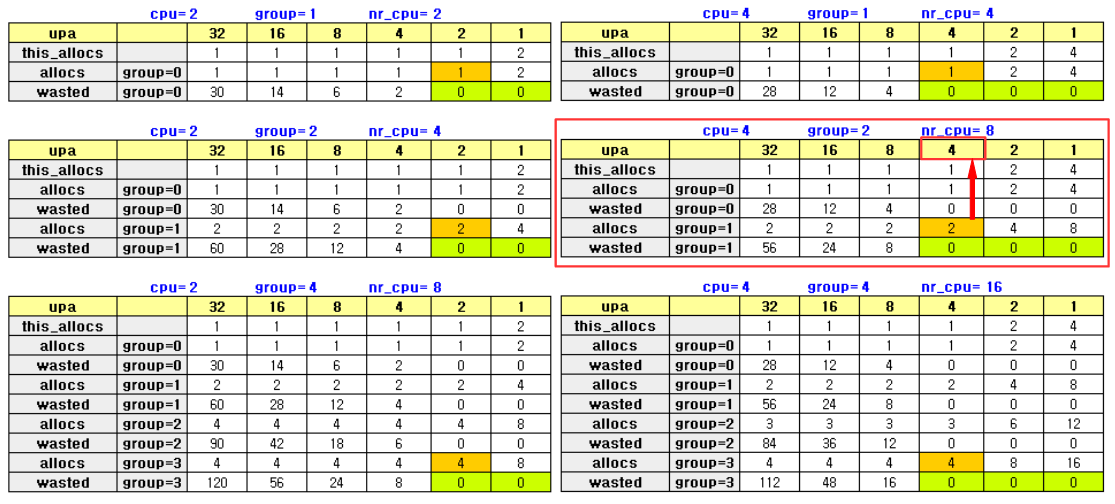
아래 표와 같이 비대칭형 NUMA 시스템에서 다음 2 가지 사례로 체크해 보았다.
- 1) group-0에는 4개의 cpu, group-1에는 2개의 cpu, 그리고 max_upa=32일 때
- allocs=2, best_upa=4
- 할당은 2개, 하나의 할당 공간에 유닛을 4개.
- 그룹당 최대 cpu 수만큼 4개의 best_upa가 나온 사례이다.
- allocs=2, best_upa=4
- 2) group-0에는 8개의 cpu, group-1에는 1개의 cpu, 그리고 max_upa=32일 때
- allocs=3, best_upa=4
- 할당은 3개, 하나에 할당 공간에 유닛을 4개.
- 보통은 그룹당 최대 cpu 수만큼 8개의 best_upa가 나오는데 이런 경우 1개의 cpu가 배정받는 할당 영역이 너무 많이 남는 공간이 생기므로 낭비가 생기지 않을 때 까지 할당 수를 더 늘리고 best_upa는 절반씩 줄여 나간다.
- allocs=3, best_upa=4

mm/percpu.c -4/4-
/* allocate and fill alloc_info */
for (group = 0; group < nr_groups; group++)
nr_units += roundup(group_cnt[group], upa);
ai = pcpu_alloc_alloc_info(nr_groups, nr_units);
if (!ai)
return ERR_PTR(-ENOMEM);
cpu_map = ai->groups[0].cpu_map;
for (group = 0; group < nr_groups; group++) {
ai->groups[group].cpu_map = cpu_map;
cpu_map += roundup(group_cnt[group], upa);
}
ai->static_size = static_size;
ai->reserved_size = reserved_size;
ai->dyn_size = dyn_size;
ai->unit_size = alloc_size / upa;
ai->atom_size = atom_size;
ai->alloc_size = alloc_size;
for (group = 0, unit = 0; group_cnt[group]; group++) {
struct pcpu_group_info *gi = &ai->groups[group];
/*
* Initialize base_offset as if all groups are located
* back-to-back. The caller should update this to
* reflect actual allocation.
*/
gi->base_offset = unit * ai->unit_size;
for_each_possible_cpu(cpu)
if (group_map[cpu] == group)
gi->cpu_map[gi->nr_units++] = cpu;
gi->nr_units = roundup(gi->nr_units, upa);
unit += gi->nr_units;
}
BUG_ON(unit != nr_units);
return ai;
}
#endif /* BUILD_EMBED_FIRST_CHUNK || BUILD_PAGE_FIRST_CHUNK */
- 코드 라인 2~3에서 그룹 수만큼 루프를 돌며 nr_units를 계산한다. nr_units에는 만들게 될 총 유닛 수가 담긴다. 그룹 수만큼 루프를 돌며 그룹당 cpu 개수를 upa 크기 단위로 자리 올림한 후 더한다.
- 만일 NUMA 노드가 2개가 있고 비대칭 형태로 디자인되어 한쪽 그룹(노드)은 8개의 cpu를 사용했고, 다른 한쪽 그룹(노드)이 1개의 cpu를 사용한 경우 upa(best_upa) 값이 4라고 가정할 때 총 nr_units 수는 8 + 4 = 12가 된다.
- 코드 라인 5~7에서 pcpu_alloc_info 구조체를 memblock 영역에 만들고 리턴한다. pcpu_alloc_info 구조체 안에는 pcpu_group_info[ ] 구조체 배열과 그 안에 cpu_map[ ] 배열도 구성한다.
- 코드 라인 8~13에서 그룹별 cpu_map[ ] 배열에 각 그룹에 속한 cpu_map 영역을 지정한다. 그리고 그룹에 속한 cpu 수를 upa 단위로 올림 정렬한다.
- 예) nr_groups = 4, NR_CPUS = 16, nr_units = 4인 경우에는 다음과 같이 배당된다. 매핑 정보에는 NR_CPUS 값으로 초기화되어 있는 상태다.
- ai->groups[0].cpu_map[0~3] -> 0번 group의 unit->cpu 매핑 배열
- ai->groups[1].cpu_map[0~3] -> 1번 group의 unit->cpu 매핑 배열
- ai->groups[2].cpu_map[0~3] -> 2번 group의 unit->cpu 매핑 배열
- ai->groups[3].cpu_map[0~3] -> 3번 group의 unit->cpu 매핑 배열
- 코드 라인 15~20에서 ai(pcpu_alloc_info 구조체) 내부의 필드에 크기 등을 지정한다.
- 코드 라인 22~37에서 그룹 수만큼 루프를 돌며 base_offset, cpu_map, nr_units 필드를 설정한다.
- base_offset: 그룹별 base 주소
- cpu_map: unit->cpu 매핑 값, 매핑되지 않은 값은 NR_CPUS 값이 들어감
- nr_units: 그룹별 유닛 수(비대칭 NUMA 시스템에서는 매핑이 되지 않는 빈 유닛도 포함됨)
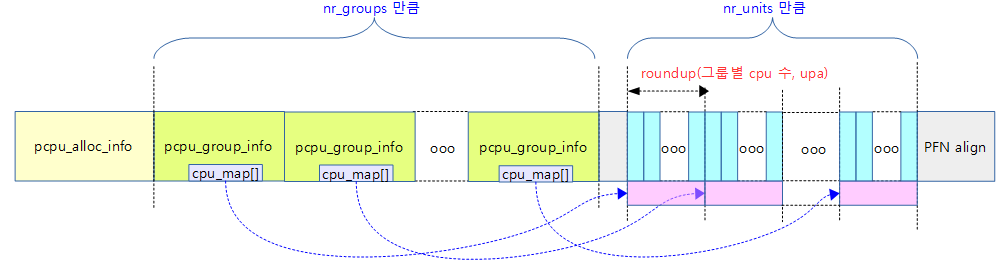
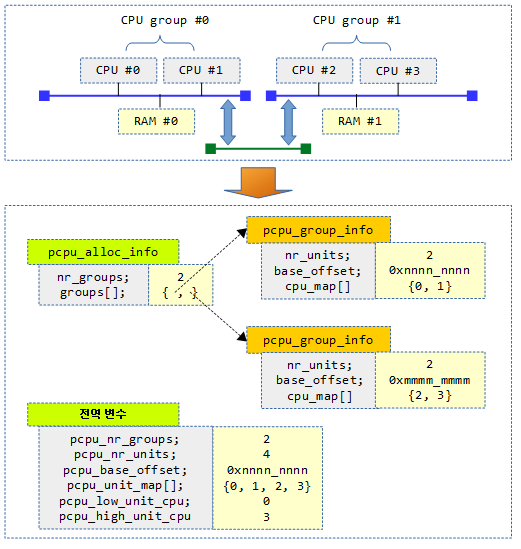
다음 그림은 pcpu 할당 정보를 나타내는 pcpu_alloc_info 구조체 구성을 보여준다.
아래 그림은 NUMA 시스템이면서 huge 페이지 메모리를 지원하는 경우 per-cpu 데이터 할당을 각각의 노드 메모리에 나누어서 한 경우를 표현하였다.
아래 표는 2개의 노드를 가진 대칭형 NUMA 시스템에서 cpu_map[]을 배치한 모습이다.
- 예) NR_CPUS=8, cpus={ 4, 4 }, max_upa=32
- allocs(할당 수)=2, nr_units=8, best_upa=4
아래 표와 그림은 2개의 노드를 가진 비대칭형 NUMA 시스템에서 cpu_map[]을 배치한 모습이다.
- 예) NR_CPUS=9, cpus = { 8, 1 }, max_upa=32, best_upa=4
- allocs(할당 수)=3, nr_units=12, best_upa=4
per-cpu 할당 정보 구성
pcpu_alloc_alloc_info()
mm/percpu.c
/** * pcpu_alloc_alloc_info - allocate percpu allocation info * @nr_groups: the number of groups * @nr_units: the number of units * * Allocate ai which is large enough for @nr_groups groups containing * @nr_units units. The returned ai's groups[0].cpu_map points to the * cpu_map array which is long enough for @nr_units and filled with * NR_CPUS. It's the caller's responsibility to initialize cpu_map * pointer of other groups. * * RETURNS: * Pointer to the allocated pcpu_alloc_info on success, NULL on * failure. */
struct pcpu_alloc_info * __init pcpu_alloc_alloc_info(int nr_groups,
int nr_units)
{
struct pcpu_alloc_info *ai;
size_t base_size, ai_size;
void *ptr;
int unit;
base_size = ALIGN(sizeof(*ai) + nr_groups * sizeof(ai->groups[0]),
__alignof__(ai->groups[0].cpu_map[0]));
ai_size = base_size + nr_units * sizeof(ai->groups[0].cpu_map[0]);
ptr = memblock_alloc_nopanic(PFN_ALIGN(ai_size), 0);
if (!ptr)
return NULL;
ai = ptr;
ptr += base_size;
ai->groups[0].cpu_map = ptr;
for (unit = 0; unit < nr_units; unit++)
ai->groups[0].cpu_map[unit] = NR_CPUS;
ai->nr_groups = nr_groups;
ai->__ai_size = PFN_ALIGN(ai_size);
return ai;
}
per-cpu의 그룹, 유닛 등의 구성 정보를 pcpu_alloc_info 구조체에 만들어서 반환한다.
- 코드 라인 9~10에서 base_size 값에 pcpu_alloc_info 구조체 하나의 크기 + nr_groups만큼의 pcpu_group_info 구조체 크기를 ai->groups[0].cpu_map[0]의 타입인 unsigned int의 크기로 정렬한다.
- 코드 라인 11에서 ai_size 값으로 base_size에 cpu_map[nr_units] 크기를 더한다.
- 코드 라인 13~15에서 ai_size를 페이지 크기로 정렬하여 memblock으로부터 할당한 영역의 주소를 ptr에 설정한다.
- 코드 라인 16~22에서 첫 번째 그룹에만 cpu_map[ ] 공간을 연결한다. 그리고 첫 번째 그룹의 unit->cpu 매핑의 모든 값을 아무것도 매핑하지 않ㅇ느 초기값(NR_CPUS)으로 설정한다.
- 코드 라인 24~25에서 그룹 수와 ai 할당 사이즈를 대입한다.
다음 그림은 pcpu_alloc_info 구조체에 그룹 수 만큼의 pcpu_group_info 구조체 배열과 이어지는 전체 유닛 수 만큼의 cpu_map 정수 배열 정보가 구성된 모습을 보여준다.
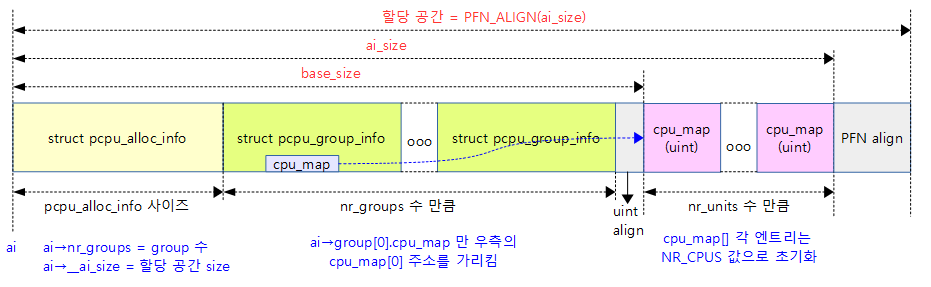
다음 그림은 두 개의 노드 각각에 2개의 cpu가 있는 경우 group(노드) 정보를 구성하는 것을 보여준다.
아키텍처별 per-cpu용 First Chunk 생성시 사용한 memblock 할당자들
pcpu_dfl_fc_alloc() – Generic (ARM32, …)
mm/percpu.c
static void * __init pcpu_dfl_fc_alloc(unsigned int cpu, size_t size,
size_t align)
{
return memblock_alloc_from_nopanic(
size, align, __pa(MAX_DMA_ADDRESS));
}
memblock을 통해 @size 만큼의 @align 정렬한 메모리 할당 요청을 한다. 할당된 메모리의 가상 주소 가 반환된다.
pcpu_dfl_fc_free() – Generic (ARM32, …)
mm/percpu.c
static void __init pcpu_dfl_fc_free(void *ptr, size_t size)
{
memblock_free_early(__pa(ptr), size);
}
memblock을 통해 할당된 가상 주소 @ptr로부터 @size 만큼의 메모리 할당 해제를 요청 한다.
pcpu_fc_alloc() – for ARM64
arch/arm64/mm/numa.c
static void * __init pcpu_fc_alloc(unsigned int cpu, size_t size,
size_t align)
{
int nid = early_cpu_to_node(cpu);
return memblock_alloc_try_nid(size, align,
__pa(MAX_DMA_ADDRESS), MEMBLOCK_ALLOC_ACCESSIBLE, nid);
}
memblock을 통해 @size 만큼의 @align 정렬한 메모리 할당 요청을 한다. 할당된 메모리의 가상 주소 가 반환된다.
pcpu_fc_alloc() – for ARM64
arch/arm64/mm/numa.c
static void __init pcpu_fc_free(void *ptr, size_t size)
{
memblock_free_early(__pa(ptr), size);
}
memblock을 통해 할당된 가상 주소 @ptr로부터 @size 만큼의 메모리 할당 해제를 요청 한다.
First Chunk 구성
First chunk의 두 가지 관리 맵
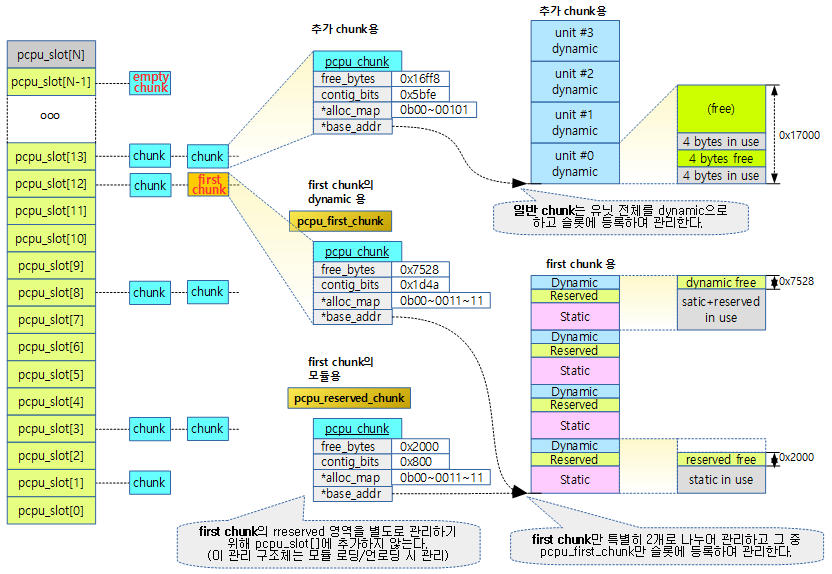
새로 추가되는 일반 chunk 들은 dynamic 영역만 관리하지만 First chunk의 경우는 3 영역이(static, reserved, dynamic) 존재하므로 이에 대한 관리들이 다르다.
- static 영역
- 컴파일 타임에 결정되어 증감되지 않아 부트업 완료 후에는 별도의 할당 관리가 필요 없다.
- reserved 영역
- 모듈이 로드될 때 할당 관리가 필요하며 pcpu_chunk 구조체를 사용하여 reserved 영역의 할당 관리를 수행한다.
- 모듈이 사용되지 않는 경우에는 reserved 영역의 관리가 필요 없다.
- dynamic 영역
- dynamic 영역은 런타임 시 항상 할당 관리가 필요하며 pcpu_chunk 구조체를 사용하여 dynamic 영역의 할당 관리를 수행한다.
다음 그림은 한 개의 first chunk의 두 영역을 두 개의 pcpu_chunk 구조체에서 관리하는 모습을 보여준다.
- 관리할 영역의 base 주소는 페이지 정렬하여 사용하므로 정렬된 offset 만큼 추가하여 사용한다.
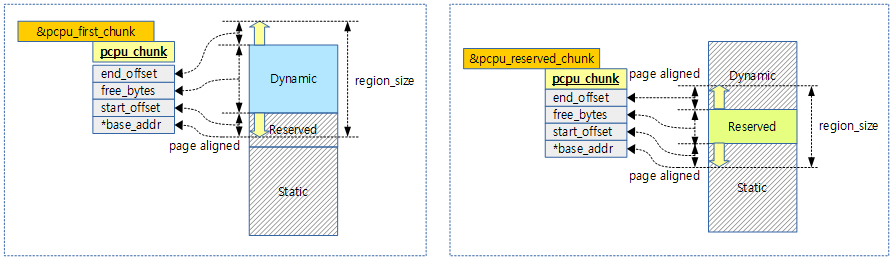
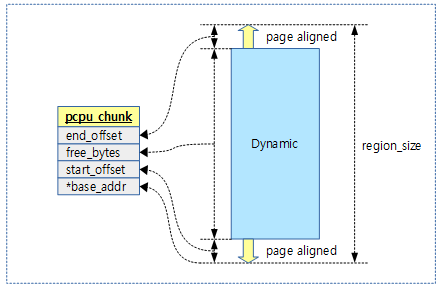
일반 chunk는 다음과 같이 dynamic 영역만 관리하므로 하나의 pcpu_chunk 구조체로 관리하는 것을 알 수 있다.
pcpu_setup_first_chunk()
mm/percpu.c -1/3-
/** * pcpu_setup_first_chunk - initialize the first percpu chunk * @ai: pcpu_alloc_info describing how to percpu area is shaped * @base_addr: mapped address * * Initialize the first percpu chunk which contains the kernel static * perpcu area. This function is to be called from arch percpu area * setup path. * * @ai contains all information necessary to initialize the first * chunk and prime the dynamic percpu allocator. * * @ai->static_size is the size of static percpu area. * * @ai->reserved_size, if non-zero, specifies the amount of bytes to * reserve after the static area in the first chunk. This reserves * the first chunk such that it's available only through reserved * percpu allocation. This is primarily used to serve module percpu * static areas on architectures where the addressing model has * limited offset range for symbol relocations to guarantee module * percpu symbols fall inside the relocatable range. * * @ai->dyn_size determines the number of bytes available for dynamic * allocation in the first chunk. The area between @ai->static_size + * @ai->reserved_size + @ai->dyn_size and @ai->unit_size is unused. * * @ai->unit_size specifies unit size and must be aligned to PAGE_SIZE * and equal to or larger than @ai->static_size + @ai->reserved_size + * @ai->dyn_size. * * @ai->atom_size is the allocation atom size and used as alignment * for vm areas. * * @ai->alloc_size is the allocation size and always multiple of * @ai->atom_size. This is larger than @ai->atom_size if * @ai->unit_size is larger than @ai->atom_size. * * @ai->nr_groups and @ai->groups describe virtual memory layout of * percpu areas. Units which should be colocated are put into the * same group. Dynamic VM areas will be allocated according to these * groupings. If @ai->nr_groups is zero, a single group containing * all units is assumed. * * The caller should have mapped the first chunk at @base_addr and * copied static data to each unit. * * The first chunk will always contain a static and a dynamic region. * However, the static region is not managed by any chunk. If the first * chunk also contains a reserved region, it is served by two chunks - * one for the reserved region and one for the dynamic region. They * share the same vm, but use offset regions in the area allocation map. * The chunk serving the dynamic region is circulated in the chunk slots * and available for dynamic allocation like any other chunk. * * RETURNS: * 0 on success, -errno on failure. */
int __init pcpu_setup_first_chunk(const struct pcpu_alloc_info *ai,
void *base_addr)
{
size_t size_sum = ai->static_size + ai->reserved_size + ai->dyn_size;
size_t static_size, dyn_size;
struct pcpu_chunk *chunk;
unsigned long *group_offsets;
size_t *group_sizes;
unsigned long *unit_off;
unsigned int cpu;
int *unit_map;
int group, unit, i;
int map_size;
unsigned long tmp_addr;
#define PCPU_SETUP_BUG_ON(cond) do { \
if (unlikely(cond)) { \
pr_emerg("failed to initialize, %s\n", #cond); \
pr_emerg("cpu_possible_mask=%*pb\n", \
cpumask_pr_args(cpu_possible_mask)); \
pcpu_dump_alloc_info(KERN_EMERG, ai); \
BUG(); \
} \
} while (0)
/* sanity checks */
PCPU_SETUP_BUG_ON(ai->nr_groups <= 0);
#ifdef CONFIG_SMP
PCPU_SETUP_BUG_ON(!ai->static_size);
PCPU_SETUP_BUG_ON(offset_in_page(__per_cpu_start));
#endif
PCPU_SETUP_BUG_ON(!base_addr);
PCPU_SETUP_BUG_ON(offset_in_page(base_addr));
PCPU_SETUP_BUG_ON(ai->unit_size < size_sum);
PCPU_SETUP_BUG_ON(offset_in_page(ai->unit_size));
PCPU_SETUP_BUG_ON(ai->unit_size < PCPU_MIN_UNIT_SIZE);
PCPU_SETUP_BUG_ON(!IS_ALIGNED(ai->unit_size, PCPU_BITMAP_BLOCK_SIZE));
PCPU_SETUP_BUG_ON(ai->dyn_size < PERCPU_DYNAMIC_EARLY_SIZE);
PCPU_SETUP_BUG_ON(!ai->dyn_size);
PCPU_SETUP_BUG_ON(!IS_ALIGNED(ai->reserved_size, PCPU_MIN_ALLOC_SIZE));
PCPU_SETUP_BUG_ON(!(IS_ALIGNED(PCPU_BITMAP_BLOCK_SIZE, PAGE_SIZE) ||
IS_ALIGNED(PAGE_SIZE, PCPU_BITMAP_BLOCK_SIZE)));
PCPU_SETUP_BUG_ON(pcpu_verify_alloc_info(ai) < 0);
/* process group information and build config tables accordingly */
group_offsets = memblock_alloc(ai->nr_groups * sizeof(group_offsets[0]),
SMP_CACHE_BYTES);
group_sizes = memblock_alloc(ai->nr_groups * sizeof(group_sizes[0]),
SMP_CACHE_BYTES);
unit_map = memblock_alloc(nr_cpu_ids * sizeof(unit_map[0]),
SMP_CACHE_BYTES);
unit_off = memblock_alloc(nr_cpu_ids * sizeof(unit_off[0]),
SMP_CACHE_BYTES);
for (cpu = 0; cpu < nr_cpu_ids; cpu++)
unit_map[cpu] = UINT_MAX;
per-cpu 데이터의 first chunk를 초기화한다.
- @ai: 이 곳에 초기화는데 사용할 모든 정보가 담겨있다.
- @base_addr: 매핑할 주소
- 이 함수를 진입하기 전에 이미 per-cpu 영역의 메모리는 할당되어 있고 이 함수에서는 매핑을 관리할 구조체가 준비된다.
- 코드 라인 46~53에서 다음과 같이 매핑에 필요한 그룹 정보 및 unit->cpu 매핑 테이블을 할당받고 초기화한다.
- group_offsets[]
- 그룹 수(nr_groups)만큼의 group_offsets 변수를 가진 배열을 할당한다.
- group_sizes[]
- 그룹 수(nr_groups)만큼의 group_sizes 변수를 가진 배열을 할당한다.
- unit_map[]
- cpu 수(nr_cpu_ids)만큼의 unit->cpu 매핑에 사용할 unit_map을 가진 배열을 할당한다.
- unit_off[]
- cpu 수(nr_cpu_ids)만큼의 unit_off를 가진 배열을 할당한다
- group_offsets[]
- 코드 라인 55~56에서 unit->cpu 매핑 배열의 내용을 언매핑(UINT_MAX) 값으로 초기화한다.
mm/percpu.c -2/3-
pcpu_low_unit_cpu = NR_CPUS;
pcpu_high_unit_cpu = NR_CPUS;
for (group = 0, unit = 0; group < ai->nr_groups; group++, unit += i) {
const struct pcpu_group_info *gi = &ai->groups[group];
group_offsets[group] = gi->base_offset;
group_sizes[group] = gi->nr_units * ai->unit_size;
for (i = 0; i < gi->nr_units; i++) {
cpu = gi->cpu_map[i];
if (cpu == NR_CPUS)
continue;
PCPU_SETUP_BUG_ON(cpu >= nr_cpu_ids);
PCPU_SETUP_BUG_ON(!cpu_possible(cpu));
PCPU_SETUP_BUG_ON(unit_map[cpu] != UINT_MAX);
unit_map[cpu] = unit + i;
unit_off[cpu] = gi->base_offset + i * ai->unit_size;
/* determine low/high unit_cpu */
if (pcpu_low_unit_cpu == NR_CPUS ||
unit_off[cpu] < unit_off[pcpu_low_unit_cpu])
pcpu_low_unit_cpu = cpu;
if (pcpu_high_unit_cpu == NR_CPUS ||
unit_off[cpu] > unit_off[pcpu_high_unit_cpu])
pcpu_high_unit_cpu = cpu;
}
}
pcpu_nr_units = unit;
for_each_possible_cpu(cpu)
PCPU_SETUP_BUG_ON(unit_map[cpu] == UINT_MAX);
/* we're done parsing the input, undefine BUG macro and dump config */
#undef PCPU_SETUP_BUG_ON
pcpu_dump_alloc_info(KERN_DEBUG, ai);
pcpu_nr_groups = ai->nr_groups;
pcpu_group_offsets = group_offsets;
pcpu_group_sizes = group_sizes;
pcpu_unit_map = unit_map;
pcpu_unit_offsets = unit_off;
/* determine basic parameters */
pcpu_unit_pages = ai->unit_size >> PAGE_SHIFT;
pcpu_unit_size = pcpu_unit_pages << PAGE_SHIFT;
pcpu_atom_size = ai->atom_size;
pcpu_chunk_struct_size = sizeof(struct pcpu_chunk) +
BITS_TO_LONGS(pcpu_unit_pages) * sizeof(unsigned long);
pcpu_stats_save_ai(ai);
- 코드 라인 1-2에서 초깃값으로 pcpu_low_unit_cpu와 pcpu_high_unit_cpu 변수에 NR_CPUS를 설정한다.
- 코드 라인 4~8에서 그룹 수만큼 루프를 돌며 그룹에 대한 정보를 설정한다.
- group_offsets에는 기존 그룹 정보에 있는 base_offset 값을 저장한다.
- group_sizes에는 기존 그룹 정보에 있는 nr_units 수만큼 유닛 크기를 곱한 값을 저장한다.
- 코드 라인 10~13에서 그룹의 유닛 수만큼 루프를 돌며 unit->cpu 매핑되지 않은 유닛은 스킵한다.
- 코드 라인 19~28에서 cpu->unit 매핑을 수행한다. 여기서 설정하는 내용은 다음과 같다.
- unit_map에 cpu 인덱스로 unit 번호를 나타내는 테이블을 구성함
- unit_off에 cpu마다 접근 시 필요한 offset 값(그룹의 base_offset + 유닛 크기)을 설정함
- pcpu_low_unit_cpu
- 모든 cpu 중에서 가장 낮은 base 주소를 저장함
- pcpu_high_unit_cpu
- 모든 cpu 중에서 가장 높은 base 주소를 저장함
- 코드 라인 31에서 전역 pcpu_nr_units에 각 그룹의 유닛 수를 더한 수를 설정한다.
- 비대칭 NUMA 시스템의 경우 매핑되지 않은 유닛도 포함된다.
- 예) 2개 그룹에 대한 cpu 수가 각각 cpus = {8, 1}인 경우이면서 best_upa = 4일 때 각 그룹의 nr_units 수는 8과 4이다.
- 코드 라인 38에서 per-cpu 할당에 관련된 디버깅용 정보를 콘솔에 출력한다.
- 코드 라인 40~51에서 pcpu 관련 전역 변수들을 초기화한다.
mm/percpu.c -3/3-
/*
* Allocate chunk slots. The additional last slot is for
* empty chunks.
*/
pcpu_nr_slots = __pcpu_size_to_slot(pcpu_unit_size) + 2;
pcpu_slot = memblock_alloc(pcpu_nr_slots * sizeof(pcpu_slot[0]),
SMP_CACHE_BYTES);
for (i = 0; i < pcpu_nr_slots; i++)
INIT_LIST_HEAD(&pcpu_slot[i]);
/*
* The end of the static region needs to be aligned with the
* minimum allocation size as this offsets the reserved and
* dynamic region. The first chunk ends page aligned by
* expanding the dynamic region, therefore the dynamic region
* can be shrunk to compensate while still staying above the
* configured sizes.
*/
static_size = ALIGN(ai->static_size, PCPU_MIN_ALLOC_SIZE);
dyn_size = ai->dyn_size - (static_size - ai->static_size);
/*
* Initialize first chunk.
* If the reserved_size is non-zero, this initializes the reserved
* chunk. If the reserved_size is zero, the reserved chunk is NULL
* and the dynamic region is initialized here. The first chunk,
* pcpu_first_chunk, will always point to the chunk that serves
* the dynamic region.
*/
tmp_addr = (unsigned long)base_addr + static_size;
map_size = ai->reserved_size ?: dyn_size;
chunk = pcpu_alloc_first_chunk(tmp_addr, map_size);
/* init dynamic chunk if necessary */
if (ai->reserved_size) {
pcpu_reserved_chunk = chunk;
tmp_addr = (unsigned long)base_addr + static_size +
ai->reserved_size;
map_size = dyn_size;
chunk = pcpu_alloc_first_chunk(tmp_addr, map_size);
}
/* link the first chunk in */
pcpu_first_chunk = chunk;
pcpu_nr_empty_pop_pages = pcpu_first_chunk->nr_empty_pop_pages;
pcpu_chunk_relocate(pcpu_first_chunk, -1);
/* include all regions of the first chunk */
pcpu_nr_populated += PFN_DOWN(size_sum);
pcpu_stats_chunk_alloc();
trace_percpu_create_chunk(base_addr);
/* we're done */
pcpu_base_addr = base_addr;
return 0;
}
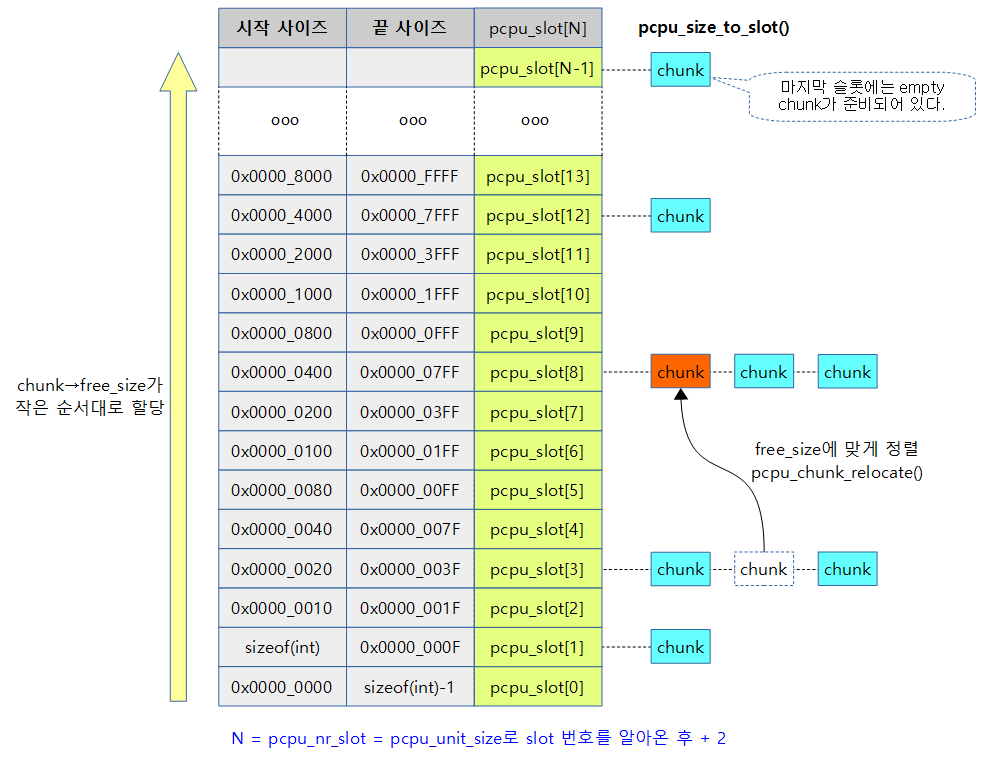
- 코드 라인 5~7에서 unit 크기로 chunk 리스트를 관리하는 최대 슬롯 수 + 2를 계산하고 그 수만큼 pcpu_slot[ ]을 memblock으로부터 할당받는다.
- __pcpu_size_to_slot()
- 유닛 사이즈로 slot을 알아온다.
- PCPU_SLOT_BASE_SHIFT=5
- 예) size에 따른 slot 값
- 32K -> 13번 slot
- 64K -> 12번 slot
- 1M -> 8번 slot
- 2M -> 7번 slot
- 처음 0번 슬롯은 할당할 공간이 없는 chunk를 위한 슬롯이다.
- 마지막 슬롯은 항상 1개의 빈 chunk가 대기하는 슬롯이다.
- 2개 이상 대기할 때도 있지만 스케줄 웍에 의해 정리되어 한 개를 유지한다.
- __pcpu_size_to_slot()
- 코드 라인 8~9에서 할당받은 슬롯 개수만큼 pcpu_slot[ ]의 list 구조를 초기화한다.
- 코드 라인 19~20에서 static 영역의 사이즈는 최소 4바이트 단위로 정렬되어야 한다. 이에 맞춰 dynamic 영역의 사이즈도 재 산출한다.
- 코드 라인 30~32에서 first chunk 관리용 pcpu_chunk를 할당하고 초기화한다.
- 코드 라인 35~42에서 만일 모듈이 지원되어 reserved 영역이 필요한 경우 기존 할당한 chunk를 reserved용으로 지정하고, 새로 first chunk 관리용 pcpu_chunk를 하나 더 할당하고 초기화한다.
- 코드 라인 45~47에서 할당 받은 first chunk를 dynamic용으로 지정한 후 chunk 리스트를 관리하는 슬롯에 추가한다.
- 코드 라인 50에서 first chunk에 위치한 페이지들은 모두 population된 상태이므로 카운터를 pcpu_nr_populated 카운터를 그만큼 증가시킨다.
- 코드 라인 52에서 chunk 추가에 대한 stat 카운터들을 증가시킨다.
Chunk 관리
First Chunk용 두 chunk의 할당 및 매핑 초기화
pcpu_alloc_first_chunk()
mm/percpu.c
/** * pcpu_alloc_first_chunk - creates chunks that serve the first chunk * @tmp_addr: the start of the region served * @map_size: size of the region served * * This is responsible for creating the chunks that serve the first chunk. The * base_addr is page aligned down of @tmp_addr while the region end is page * aligned up. Offsets are kept track of to determine the region served. All * this is done to appease the bitmap allocator in avoiding partial blocks. * * RETURNS: * Chunk serving the region at @tmp_addr of @map_size. */
static struct pcpu_chunk * __init pcpu_alloc_first_chunk(unsigned long tmp_addr,
int map_size)
{
struct pcpu_chunk *chunk;
unsigned long aligned_addr, lcm_align;
int start_offset, offset_bits, region_size, region_bits;
/* region calculations */
aligned_addr = tmp_addr & PAGE_MASK;
start_offset = tmp_addr - aligned_addr;
/*
* Align the end of the region with the LCM of PAGE_SIZE and
* PCPU_BITMAP_BLOCK_SIZE. One of these constants is a multiple of
* the other.
*/
lcm_align = lcm(PAGE_SIZE, PCPU_BITMAP_BLOCK_SIZE);
region_size = ALIGN(start_offset + map_size, lcm_align);
/* allocate chunk */
chunk = memblock_alloc(sizeof(struct pcpu_chunk) +
BITS_TO_LONGS(region_size >> PAGE_SHIFT),
SMP_CACHE_BYTES);
INIT_LIST_HEAD(&chunk->list);
chunk->base_addr = (void *)aligned_addr;
chunk->start_offset = start_offset;
chunk->end_offset = region_size - chunk->start_offset - map_size;
chunk->nr_pages = region_size >> PAGE_SHIFT;
region_bits = pcpu_chunk_map_bits(chunk);
chunk->alloc_map = memblock_alloc(BITS_TO_LONGS(region_bits) * sizeof(chunk->alloc_map[0]),
SMP_CACHE_BYTES);
chunk->bound_map = memblock_alloc(BITS_TO_LONGS(region_bits + 1) * sizeof(chunk->bound_map[00
]),
SMP_CACHE_BYTES);
chunk->md_blocks = memblock_alloc(pcpu_chunk_nr_blocks(chunk) * sizeof(chunk->md_blocks[0]),
SMP_CACHE_BYTES);
pcpu_init_md_blocks(chunk);
/* manage populated page bitmap */
chunk->immutable = true;
bitmap_fill(chunk->populated, chunk->nr_pages);
chunk->nr_populated = chunk->nr_pages;
chunk->nr_empty_pop_pages =
pcpu_cnt_pop_pages(chunk, start_offset / PCPU_MIN_ALLOC_SIZE,
map_size / PCPU_MIN_ALLOC_SIZE);
chunk->contig_bits = map_size / PCPU_MIN_ALLOC_SIZE;
chunk->free_bytes = map_size;
if (chunk->start_offset) {
/* hide the beginning of the bitmap */
offset_bits = chunk->start_offset / PCPU_MIN_ALLOC_SIZE;
bitmap_set(chunk->alloc_map, 0, offset_bits);
set_bit(0, chunk->bound_map);
set_bit(offset_bits, chunk->bound_map);
chunk->first_bit = offset_bits;
pcpu_block_update_hint_alloc(chunk, 0, offset_bits);
}
if (chunk->end_offset) {
/* hide the end of the bitmap */
offset_bits = chunk->end_offset / PCPU_MIN_ALLOC_SIZE;
bitmap_set(chunk->alloc_map,
pcpu_chunk_map_bits(chunk) - offset_bits,
offset_bits);
set_bit((start_offset + map_size) / PCPU_MIN_ALLOC_SIZE,
chunk->bound_map);
set_bit(region_bits, chunk->bound_map);
pcpu_block_update_hint_alloc(chunk, pcpu_chunk_map_bits(chunk)
- offset_bits, offset_bits);
}
return chunk;
}
first chunk의 맵을 초기화한다.
- 코드 라인 9~11에서 관리할 영역의 base 주소는 페이지 정렬하여 사용하므로 정렬된 offset 만큼 추가하여 사용한다.
- 코드 라인 18~19에서 map_size에 offset을 더한 값을 페이지 크기와 PCPU_BITMAP_BLOCK_SIZE 두 값의 최소 공배수로 정렬한다.
- 현재 커널에서 PCPU_BITMAP_BLOCK_SIZE 값은 페이지 사이즈와 동일하다. 따라서 최소 공배수 값은 항상 페이지 사이즈이다.
- 코드 라인 22~24에서 pcpu_chunk 정보를 위해 메모리를 할당한다. 이 안에 populated 비트맵에 사용할 메모리도 포함된다.
- 코드 라인28~30에서 align된 시작 주소와 시작 offset 및 끝 offset을 지정한다.
- 코드 라인 32~33에서 재 산정된 영역의 페이지 수와 지정하고, chunk에 필요한 비트 수를 산출한다.
- 워드 단위로 산출한다.
- 예) nr_pages=10, 4K 페이지인 경우
- region_bits=10K
- 코드 라인 35~39에서 워드 단위로 관리되는 alloc_map, bound_map에 사용될 비트 수를 할당받는다.
- 코드 라인 40~42에서 1024 바이트 블럭단위 당 관리되는 메타데이터를 할당하고 초기화한다.
- 코드 라인 45~50에서 first chunk는 이미 활성화되어 있으므로 이에 대한 처리를 한다.
- 코드 라인 52~53에서 실제 @map_size를 free 바이트로 지정하고, contig_bits에는 free 워드 수를 지정한다.
- 코드 라인 55~65에서 start_offset 구간은 관리할 필요가 없으므로 맵에 설정하여 숨긴다.
- 코드 라인 67~79에서 end_offset 구간은 관리할 필요가 없으므로 맵에 설정하여 숨긴다.
Chunk내 Per-cpu 메모리 할당맵
다음 그림과 같이 chunk 들을 관리하기 위해 슬롯 리스트를 사용한다.
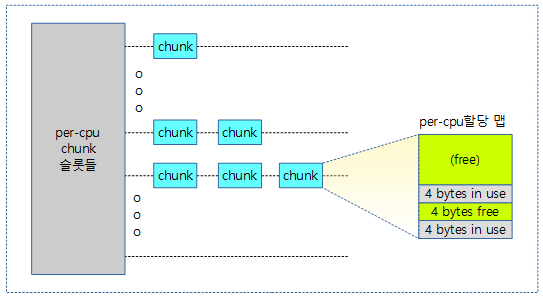
위의 chunk 들을 관리하는 방법은 뒷 부분에서 설명하기로 하고, 먼저 한 chunk 내부의 per-cpu 할당 맵의 동작을 파악해보자.
1) bitmap 방식 할당자
- 커널 v4.14-rc1에 적용된 방식으로 per-cpu 데이터의 할당이 많을 때 scalable 문제가 발생한다. 이를 해결하기 위해 비트맵 방식으로 관리하는 chunk 영역 맵 할당자로 변경되었다.
- 참고
다음 그림은 chunk가 관리하는 per-cpu 영역이 2 개의 비트맵과, per-cpu 블럭 단위로 메타 데이터가 관리되는 모습을 보여준다.
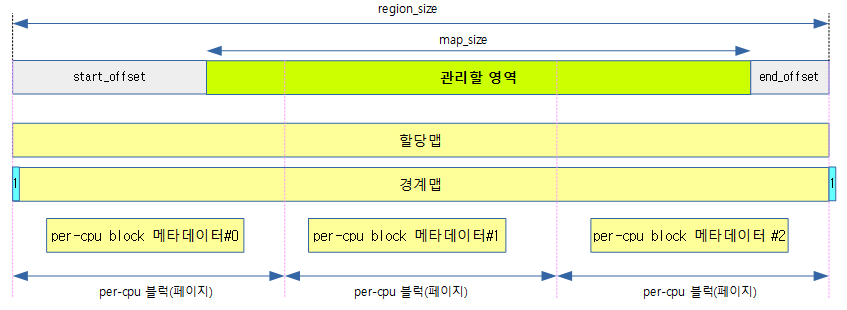
다음 그림은 관리 대상 맵 영역에 대해 할당 맵(alloc_map)과 경계 맵(bound_map)의 자세한 표현 방법을 보여준다.
- 할당 맵과 경계 맵은 비트맵으로 구성되며, 비트맵 크기는 region_size를 워드 단위로 관리한다.
- 4K 페이지 기준으로 1 페이지의 관리에 사용되는 비트, 즉 1 블럭의 관리에 사용되는 비트 수는 0x400개의 비트가 사용된다.
- 예) 0x5520 바이트 영역 -> 페이지 정렬하여 0x6000 바이트를 대상으로 관리하기 위해 필요한 비트맵은 0x1800 비트이다.
- 할당 맵(alloc_map)
- 1 개의 비트는 4바이트로 구성된 1워드의 할당 여부를 표현한다. (0=free, 1=used)
- 경계 맵(bound_map)
- 1 개의 비트는 4바이트로 구성된 1워드에 대응하지만 시작 비트에만 1을 설정한다.
- 경계 맵은 할당 맵보다 1브트를 더 사용한다. 데이터의 마지막을 표현하기 위해 마지막 1 비트가 추가 구성된다.
- 4K 페이지 기준으로 1 페이지의 관리에 사용되는 비트, 즉 1 블럭의 관리에 사용되는 비트 수는 0x400개의 비트가 사용된다.

다음 그림은 관리 대상 맵 영역에 대해 비트맵 표현 방법을 더 자세히 알아본다.
- 맵 영역은 페이지 단위로 정렬하여 사용하므로 start_offset 부분과 end_offset에 대해 hide하여 처리하기 위해 모두 할당된 것으로 하기 위해 1로 설정한다.
- chunk 내에서 가장 큰 free 영역의 비트 수는 chunk->conting_bits에 저장된다.
- chunk 내에서 가장 큰 free 영역의 시작 비트는 chunk->contig_bits_start에 저장된다.
- chunk 내에서 첫 번째 free 영역을 가리키는 시작 비트는 chunk->first_free에 저장된다.

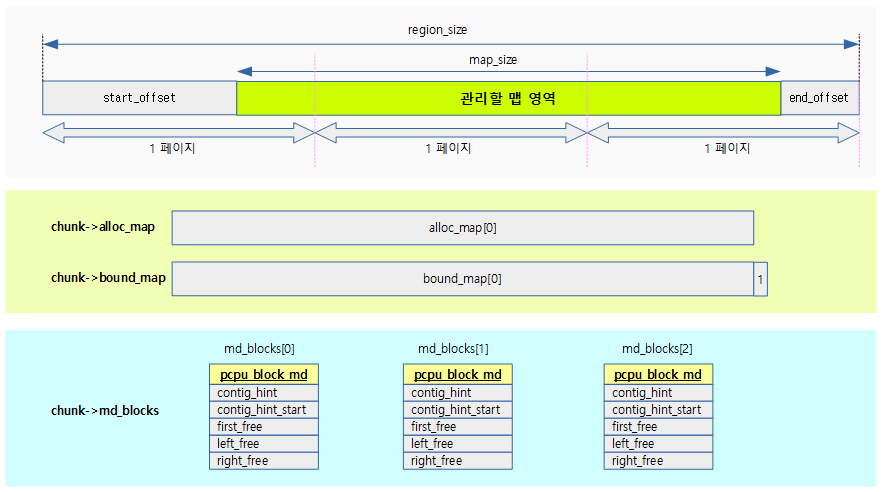
chunk 내의 관리할 맵 영역의 크기는 per-cpu 블럭(default 페이지) 단위로 관리되는데, 다음 그림은 3 개의 per-cpu 블럭을 사용하는 예이다.
- per-cpu 블럭 메타 데이터들은 pcpu_block_md 구조체 배열과 연결되어 관리된다.
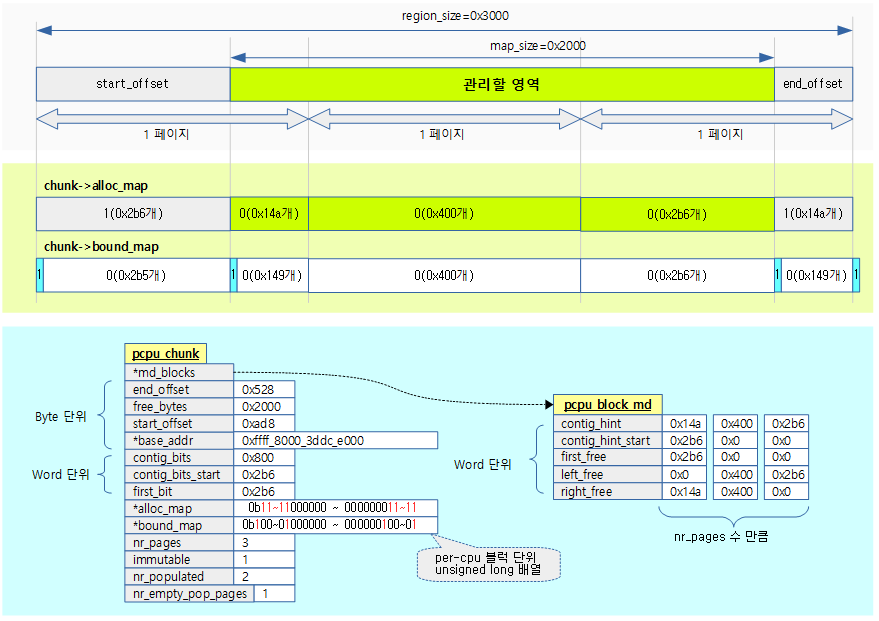
다음 그림은 first chunk의 reserve 영역 2 페이지(8K)에 대한 chunk의 초기화 및 각 블럭의 맵을 관리하기 위해 초기화되는 값들을 보여준다.
다음 그림은 각 블럭의 맵에서 left_free와 right_free에 대한 여러 사례를 보여준다.
- free 영역이 좌측 끝에 붙어 있거나 우측 끝에 붙어 있는 경우에 한해 해당 영역의 비트 수를 각각 left_free 및 right_free에 사용한다.

2) Area map 방식 할당자
커널 v4.13 까지 관리하던 방식이다.
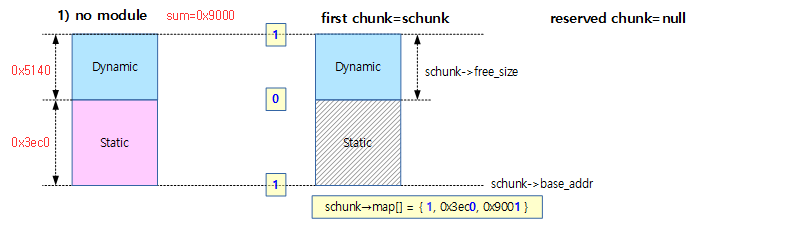
아래 그림은 Area map 방식으로 초기화할 때 reserved(module) 영역을 요청하지 않은 경우에 할당된 map[]의 예이다.
-
- rpi2: dyn_size=0x5140, static_size=0x3ec0
- map 값의 lsb 1비트는 in-use(1=사용중)과 0비트는 free(0=사용 가능)의 표시이다.
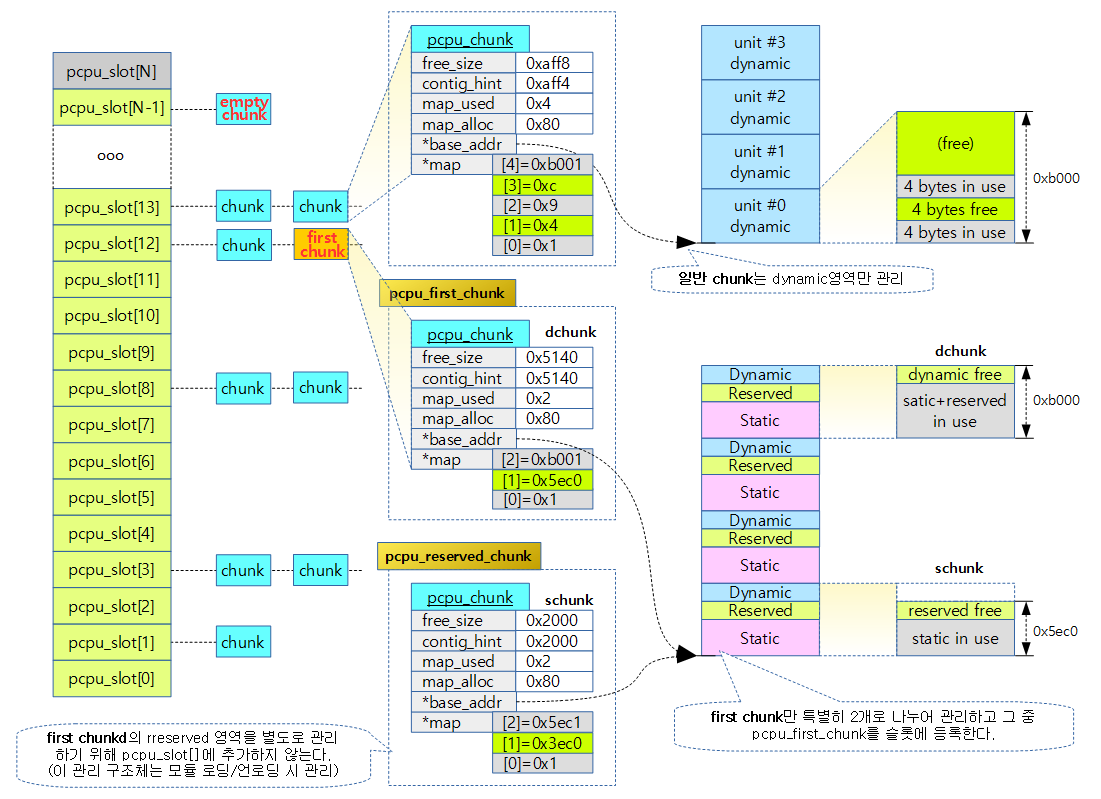
- 아래와 같이 0x0~0x3ec0 전 까지 in-use이며, 0x3ec0~0x9000까지 free 상태라고 매핑되었다.
- first chunk에 schunk가 선택되었고, reserved chunk는 영역이 없어 null이 대입된다.
- schunk->free_size는 dyn_size 와 같다.
- first chunk를 사용하여 dynamic 할당의 매핑 관리가 이루어진다.
- rpi2: dyn_size=0x5140, static_size=0x3ec0
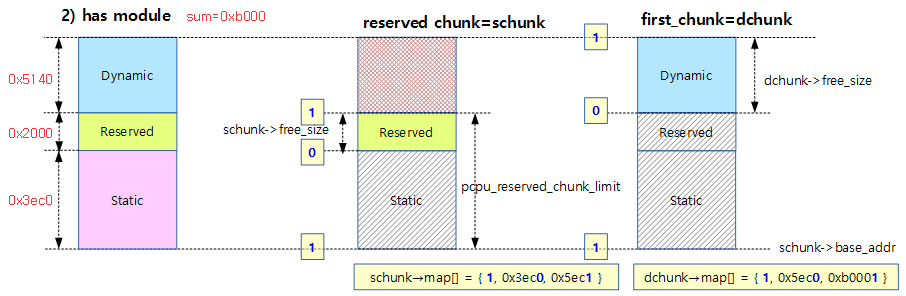
아래 그림은 Area map 방식으로 초기화할 때 reserved(module) 영역을 요청한 경우 schunk와 dchunk의 두 개로 나누어 관리를 하며 그 에 따른 할당 map[]의 예이다.
- rpi2: dyn_size=0x5140, static_size=0x3ec0, reserved=0x2000
- schunk에서의 매핑은 0x0~0x3ec0 전까지 in-use이며, 0x3ec0~0x5ec0까지 free 상태라고 매핑되었다.
- dchunk에서의 매핑은 0x0~0x5ec0 전까지 in-use이며, 0x5ec0~0xb000까지 free 상태라고 매핑되었다.
- first chunk에 dynamic 영역에 대한 매핑 관리를 위해 dchunk가 선택되었고, reserved chunk는 schunk를 대입하여 관리한다.
- schunk->free_size는 reserved_size 와 같다.
- dchunk->free_size는 dyn_size와 같다.
할당에 대한 per-cpu 블럭 hint 갱신
pcpu_block_update_hint_alloc()
mm/percpu.c -1/2-
/** * pcpu_block_update_hint_alloc - update hint on allocation path * @chunk: chunk of interest * @bit_off: chunk offset * @bits: size of request * * Updates metadata for the allocation path. The metadata only has to be * refreshed by a full scan iff the chunk's contig hint is broken. Block level * scans are required if the block's contig hint is broken. */
static void pcpu_block_update_hint_alloc(struct pcpu_chunk *chunk, int bit_off,
int bits)
{
struct pcpu_block_md *s_block, *e_block, *block;
int s_index, e_index; /* block indexes of the freed allocation */
int s_off, e_off; /* block offsets of the freed allocation */
/*
* Calculate per block offsets.
* The calculation uses an inclusive range, but the resulting offsets
* are [start, end). e_index always points to the last block in the
* range.
*/
s_index = pcpu_off_to_block_index(bit_off);
e_index = pcpu_off_to_block_index(bit_off + bits - 1);
s_off = pcpu_off_to_block_off(bit_off);
e_off = pcpu_off_to_block_off(bit_off + bits - 1) + 1;
s_block = chunk->md_blocks + s_index;
e_block = chunk->md_blocks + e_index;
/*
* Update s_block.
* block->first_free must be updated if the allocation takes its place.
* If the allocation breaks the contig_hint, a scan is required to
* restore this hint.
*/
if (s_off == s_block->first_free)
s_block->first_free = find_next_zero_bit(
pcpu_index_alloc_map(chunk, s_index),
PCPU_BITMAP_BLOCK_BITS,
s_off + bits);
if (s_off >= s_block->contig_hint_start &&
s_off < s_block->contig_hint_start + s_block->contig_hint) {
/* block contig hint is broken - scan to fix it */
pcpu_block_refresh_hint(chunk, s_index);
} else {
/* update left and right contig manually */
s_block->left_free = min(s_block->left_free, s_off);
if (s_index == e_index)
s_block->right_free = min_t(int, s_block->right_free,
PCPU_BITMAP_BLOCK_BITS - e_off);
else
s_block->right_free = 0;
}
per-ccpu 할당 후 연속된 가장 큰 free 영역 및 관련 멤버들을 갱신한다. 참고로 할당 해제 후에 호출되는 함수는 pcpu_block_update_hint_free() 이다.
- 코드 라인 14~17에서 시작 offset 및 끝 offset에 해당하는 각각의 블럭 인덱스 및 블럭 offset 값을 알아온다.
- 코드 라인 19~20에서 시작 및 끝 블럭 인덱스 값으로 시작 블럭과 끝 블럭을 산출한다.
- 코드 라인 28~32에서 처음에 위치한 free 공간에서 할당하는 경우 할당하는 공간을 제외시키고 그 다음 free 공간 위치를 찾아 first_free를 갱신한다.
- 코드 라인 34~37에서 가장 큰 free 공간 범위내에서 할당하는 경우 contig_hint를 갱신한다.
- 코드 라인 38~46에서 가장 큰 free 공간 범위내가 아닌 곳에서 할당하는 경우이다. 가장 좌측의 free 공간에서 할당하는 경우 left_free를 갱신한다. 그리고 할당할 영역이 한 개 per-cpu 블럭이내이면서 우측의 free 공간에서 할당하는 경우 각각 right_free를 갱신한다. 영역이 두 개 이상의 per-cpu 블럭으로 나뉘어 관리되는 경우 right_free는 0 이된다.
mm/percpu.c -2/2-
/*
* Update e_block.
*/
if (s_index != e_index) {
/*
* When the allocation is across blocks, the end is along
* the left part of the e_block.
*/
e_block->first_free = find_next_zero_bit(
pcpu_index_alloc_map(chunk, e_index),
PCPU_BITMAP_BLOCK_BITS, e_off);
if (e_off == PCPU_BITMAP_BLOCK_BITS) {
/* reset the block */
e_block++;
} else {
if (e_off > e_block->contig_hint_start) {
/* contig hint is broken - scan to fix it */
pcpu_block_refresh_hint(chunk, e_index);
} else {
e_block->left_free = 0;
e_block->right_free =
min_t(int, e_block->right_free,
PCPU_BITMAP_BLOCK_BITS - e_off);
}
}
/* update in-between md_blocks */
for (block = s_block + 1; block < e_block; block++) {
block->contig_hint = 0;
block->left_free = 0;
block->right_free = 0;
}
}
/*
* The only time a full chunk scan is required is if the chunk
* contig hint is broken. Otherwise, it means a smaller space
* was used and therefore the chunk contig hint is still correct.
*/
if (bit_off >= chunk->contig_bits_start &&
bit_off < chunk->contig_bits_start + chunk->contig_bits)
pcpu_chunk_refresh_hint(chunk);
}
- 코드 라인 4~11에서 할당 영역이 두 개 이상의 per-cpu 블럭으로 나뉘는 경우 마지막 블럭에 해당하는 멤버들을 갱신할 예정이다. 먼저 마지막 블럭에서 할당 영역 이후에 처음 시작되는 free 영역을 찾아 갱신한다.
- 코드 라인 13~15에서 만일 마지막 블럭의 끝까지 할당한 경우 다음 블럭을 가리키도록 한다.
- 코드 라인 16~19에서 할당 위치가 가장 큰 free 공간 이내이면 블럭에 관련된 hint를 갱신한다.
- 코드 라인 20~25에서 다른 위치인 경우 left_free는 0으로 하고, right_free를 갱신한다.
- 코드 라인 29~33에서 시작과 끝 블럭 사이에 위치한 블럭들의 값들은 모두 사용 중으로 변경한다.
- 코드 라인 41~43에서 할당 요청이 chunk 내의 가장 큰 free 공간 이내인 경우 chunk에 관련된 hint를 갱신한다.
pcpu_block_refresh_hint()
mm/percpu.c
/** * pcpu_block_refresh_hint * @chunk: chunk of interest * @index: index of the metadata block * * Scans over the block beginning at first_free and updates the block * metadata accordingly. */
static void pcpu_block_refresh_hint(struct pcpu_chunk *chunk, int index)
{
struct pcpu_block_md *block = chunk->md_blocks + index;
unsigned long *alloc_map = pcpu_index_alloc_map(chunk, index);
int rs, re; /* region start, region end */
/* clear hints */
block->contig_hint = 0;
block->left_free = block->right_free = 0;
/* iterate over free areas and update the contig hints */
pcpu_for_each_unpop_region(alloc_map, rs, re, block->first_free,
PCPU_BITMAP_BLOCK_BITS) {
pcpu_block_update(block, rs, re);
}
}
@chunk내 요청한 @index 번째 메타 데이터 블럭의 hint 정보를 갱신한다.
- 코드 라인 4에서 요청한 메타 데이터에 해당하는 alloc_map 시작 위치를 알아온다.
- 코드 라인 8~9에서 먼저 hint 정보를 모두 클리어한다.
- 코드 라인 12~14에서 블럭 내에서 first_free 부터 free 영역을 순회하며 hint 정보를 갱신한다.
free 영역에 따른 블럭 메타데이터 갱신
pcpu_block_update()
mm/percpu.c
/** * pcpu_block_update - updates a block given a free area * @block: block of interest * @start: start offset in block * @end: end offset in block * * Updates a block given a known free area. The region [start, end) is * expected to be the entirety of the free area within a block. Chooses * the best starting offset if the contig hints are equal. */
static void pcpu_block_update(struct pcpu_block_md *block, int start, int end)
{
int contig = end - start;
block->first_free = min(block->first_free, start);
if (start == 0)
block->left_free = contig;
if (end == PCPU_BITMAP_BLOCK_BITS)
block->right_free = contig;
if (contig > block->contig_hint) {
block->contig_hint_start = start;
block->contig_hint = contig;
} else if (block->contig_hint_start && contig == block->contig_hint &&
(!start || __ffs(start) > __ffs(block->contig_hint_start))) {
/* use the start with the best alignment */
block->contig_hint_start = start;
}
}
per-cpu 블럭 메터 데이터 @block의 [@start, @end) 범위가 free 영역일 때 free 영역에 관련된 값들을 갱신한다.
- 코드 라인 3~7에서 블럭내의 첫 번째 free 영역의 시작을 지정하고, 시작부터 free 영역인 경우에 한해 left_free에 사이즈를 기록한다.
- 코드 라인 9~10에서 블럭의 끝 부분이 free 영역과 인접한 경우에 한해 right_free에 사이즈를 기록한다.
- 코드 라인 12~19에서 블럭 내의 가장 큰 연속된 free 영역을 갱신한다.
Chunk에 대한 hint 갱신
pcpu_chunk_refresh_hint()
mm/percpu.c
/** * pcpu_chunk_refresh_hint - updates metadata about a chunk * @chunk: chunk of interest * * Iterates over the metadata blocks to find the largest contig area. * It also counts the populated pages and uses the delta to update the * global count. * * Updates: * chunk->contig_bits * chunk->contig_bits_start * nr_empty_pop_pages (chunk and global) */
tatic void pcpu_chunk_refresh_hint(struct pcpu_chunk *chunk)
{
int bit_off, bits, nr_empty_pop_pages;
/* clear metadata */
chunk->contig_bits = 0;
bit_off = chunk->first_bit;
bits = nr_empty_pop_pages = 0;
pcpu_for_each_md_free_region(chunk, bit_off, bits) {
pcpu_chunk_update(chunk, bit_off, bits);
nr_empty_pop_pages += pcpu_cnt_pop_pages(chunk, bit_off, bits);
}
/*
* Keep track of nr_empty_pop_pages.
*
* The chunk maintains the previous number of free pages it held,
* so the delta is used to update the global counter. The reserved
* chunk is not part of the free page count as they are populated
* at init and are special to serving reserved allocations.
*/
if (chunk != pcpu_reserved_chunk)
pcpu_nr_empty_pop_pages +=
(nr_empty_pop_pages - chunk->nr_empty_pop_pages);
chunk->nr_empty_pop_pages = nr_empty_pop_pages;
}
chunk의 최대 연속된 free 사이즈의 검색을 돕는 hint를 갱신한다.
- 코드 라인 6에서 일단 최대 연속된 free 사이즈를 0으로 한다.
- 코드 라인 8~11에서 bit_off부터 bits에 해당하는 블럭 메타 데이터들을 순회하며 각 블럭의 최대 연속된 free 사이즈의 검색을 돕는 hint를 갱신한다.
- 코드 라인 13에서 populate된 빈 페이지 수를 산출한다.
- 코드 라인 24~26에서 chunk가 모듈용이 아니면 전체 pupulate된 빈 페이지 수를 산출한다.
- 코드 라인 28에서 chunk내 멤버에 populate된 빈 페이지 수를 대입한다.
pcpu_chunk_update()
mm/percpu.c
/** * pcpu_chunk_update - updates the chunk metadata given a free area * @chunk: chunk of interest * @bit_off: chunk offset * @bits: size of free area * * This updates the chunk's contig hint and starting offset given a free area. * Choose the best starting offset if the contig hint is equal. */
static void pcpu_chunk_update(struct pcpu_chunk *chunk, int bit_off, int bits)
{
if (bits > chunk->contig_bits) {
chunk->contig_bits_start = bit_off;
chunk->contig_bits = bits;
} else if (bits == chunk->contig_bits && chunk->contig_bits_start &&
(!bit_off ||
__ffs(bit_off) > __ffs(chunk->contig_bits_start))) {
/* use the start with the best alignment */
chunk->contig_bits_start = bit_off;
}
}
free 영역 @bit_off 부터 @bits 만큼 chunk에서 최대 연속된 free 사이즈의 검색을 돕는 hint를 갱신한다.
- 코드 라인 3~5에서 free 할 @bits가 chunk내에서 가장 큰 연속된 free 영역을 초과하는 경우 이 값들을 갱신한다.
- 코드 라인 6~11에서 free 할 공간이 chunk의 연속된 free 영역의 길이가 일치하는 경우 연속된 공간의 시작 위치를 갱신한다.
페이지 활성화(Population)
NUMA 아키텍처 중 NR_CPUS가 수 천 개등 매우 큰 시스템에서는 모든 possible cpu에 실제 할당을 하기가 힘들기 떄문에 lazy allocation을 사용한다.
- 새로 할당된 per-cpu chunk들은 활성화되지 않은 페이지 상태이므로 활성화 과정을 거쳐 사용될 수 있다.
Chunk들의 관리
per-cpu 메모리를 동적으로 할당하기 위해 필요한 chunk를 선택하는 방법은 다음과 같다.
- 1) 할당할 사이즈에 적합한 슬롯 번호 산출
- 2) 해당 슬롯에 있는 chunk들에서 할당할 사이즈를 커버할 수 있는 최대 연속된 빈 공간(contig_hint)을 가진 chunk를 찾는다.
- 3) 빈 공간이 없으면 상위 슬롯으로 이동한 후 2) 번을 반복한다.
- 최상위에 슬롯은 항상 1 개의 빈 chunk가 대기하고 있다.
- 최하위 0번 슬롯은 할당할 공간이 없는 chunk가 있는 곳이다.
- 아래 그림은 chunk의 사이즈별 pcpu_slot 리스트에서 관리를 하는 위치를 나타낸다.
- pcpu_chunk_relocate() 함수를 사용해서 chunk를 relocation 시킬 수 있다.
- rpi2: first chunk의 free_size가 0x5140일 때 nslot=12이므로 first chunk는 pcpu_slot[12] 리스트에 처음 추가된다.
다음 그림은 새로운 비트맵 방식으로 관리되는 맵으로 동작하는 per-cpu chunk들을 슬롯에서 관리하는 모습을 보여준다.
다음 그림은 기존 area 맵 방식으로 관리되는 맵으로 동작하는 per-cpu chunk들을 슬롯에서 관리하는 모습을 보여준다.
Chunk 재배치
pcpu_chunk_relocate()
mm/percpu.c
/** * pcpu_chunk_relocate - put chunk in the appropriate chunk slot * @chunk: chunk of interest * @oslot: the previous slot it was on * * This function is called after an allocation or free changed @chunk. * New slot according to the changed state is determined and @chunk is * moved to the slot. Note that the reserved chunk is never put on * chunk slots. * * CONTEXT: * pcpu_lock. */
static void pcpu_chunk_relocate(struct pcpu_chunk *chunk, int oslot)
{
int nslot = pcpu_chunk_slot(chunk);
if (chunk != pcpu_reserved_chunk && oslot != nslot) {
if (oslot < nslot)
list_move(&chunk->list, &pcpu_slot[nslot]);
else
list_move_tail(&chunk->list, &pcpu_slot[nslot]);
}
}
chunk의 슬롯 이동이 필요한 경우 재 배치한다.
- 코드 라인 3에서 chunk내의 사이즈에 해당하는 새 슬롯을 알아온다. 다 쓴 chunk는 슬롯 번호가 0이 된다.
- 코드 라인 5~10에서 요청 chunk가 모듈용 chunk도 아닌 경우이면서 chunk의 free 사이즈 변경에 따른 슬롯 이동이 필요한 경우 기존 슬롯 리스트에서 chunk를 제거하고 새 슬롯으로 이동시킨다.
- first chunk를 만들면서 이 함수에 진입한 경우 chunk가 first chunk이고, oslot=-1이므로 항상 조건 성립한다.
free 영역 사이즈로 슬롯 번호 산출
pcpu_chunk_slot()
mm/percpu.c
static int pcpu_chunk_slot(const struct pcpu_chunk *chunk)
{
if (chunk->free_bytes < PCPU_MIN_ALLOC_SIZE || chunk->contig_bits == 0)
return 0;
return pcpu_size_to_slot(chunk->free_bytes);
}
chunk내의 빈 공간 사이즈를 커버하는 슬롯을 알아온다.
- 코드 라인 3~4에서 chunk내에 sizeof(int)만큼의 사이즈도 할당할 공간이 없으면 nslot은 0이 된다.
- 코드 라인 6에서 pcpu_size_to_slot()의 결과는 항상 1 이상이다.
- free_bytes가 4~0xF까지 slot 번호는 1이다.
- rpi2: chunk->free_size=0x5140이라 할 경우 nslot=12이다.
pcpu_size_to_slot()
mm/percpu.c
static int pcpu_size_to_slot(int size)
{
if (size == pcpu_unit_size)
return pcpu_nr_slots - 1;
return __pcpu_size_to_slot(size);
}
size에 따른 슬롯 번호를 반환한다. 만일 size가 유닛 사이즈와 동일한 경우 최상위 슬롯 번호를 반환한다.
__pcpu_size_to_slot()
mm/percpu.c
static int __pcpu_size_to_slot(int size)
{
int highbit = fls(size); /* size is in bytes */
return max(highbit - PCPU_SLOT_BASE_SHIFT + 2, 1);
}
size에 따른 슬롯 번호를 반환한다.
- 1~15까지 1번 슬롯에 배정된다.
- 버그로 보이며 +2 -> -1로 수정되어야 할 것 같다.
PCPU_SLOT_BASE_SHIFT
아래 코드에 보여진 주석과 같이 원래 설계자의 목적은 31바이트까지 같은 슬롯인 1번 슬롯에 chunk들을 모으려고 의도 했었던것 같다. 그러나 위의 코드 버그로 인해 1~15 바이트를 1번 슬롯에 배정하였다.
mm/percpu.c
/* the slots are sorted by free bytes left, 1-31 bytes share the same slot */ #define PCPU_SLOT_BASE_SHIFT 5
pcpu_free_alloc_info()
mm/percpu.c
/**
* pcpu_free_alloc_info - free percpu allocation info
* @ai: pcpu_alloc_info to free
*
* Free @ai which was allocated by pcpu_alloc_alloc_info().
*/
void __init pcpu_free_alloc_info(struct pcpu_alloc_info *ai)
{
memblock_free_early(__pa(ai), ai->__ai_size);
}
- memblock_free_early() 함수를 호출하여 memblock에서 pcpu_alloc_info 구조체를 전부 지운다.
- ai->__ai_size:
- pcpu_alloc_info 하위에 존재하는 그룹 정보 및 매핑 정보를 모두 포함한 사이즈
- 함수 내부에서는 memblock_remove_range() 함수를 사용한다.
- ai->__ai_size:
pcpu_schedule_balance_work()
mm/percpu.c
/*
* Balance work is used to populate or destroy chunks asynchronously. We
* try to keep the number of populated free pages between
* PCPU_EMPTY_POP_PAGES_LOW and HIGH for atomic allocations and at most one
* empty chunk.
*/
static void pcpu_balance_workfn(struct work_struct *work);
static DECLARE_WORK(pcpu_balance_work, pcpu_balance_workfn);
static bool pcpu_async_enabled __read_mostly;
static bool pcpu_atomic_alloc_failed;
static void pcpu_schedule_balance_work(void)
{
if (pcpu_async_enabled)
schedule_work(&pcpu_balance_work);
}
pcpu_async_enable 플래그가 설정되어 있으면 schedule_work()를 수행한다.
- 스케쥴러를 사용하여 pcpu_balance_workfn() 호출하여 free chunk 및 페이지 할당(populate) 수를 관리한다.
- 빈 chunk 회수(reclaim)
- 하나만 빼고 완전히 빈 chunk 모두를 이 루틴에서 회수한다.
- 몇 개의 free populated page 유지
- atomic allocation을 위해 항상 약간의 free populated page를 유지하려 한다.
- 페이지 수: PCPU_EMPTY_POP_PAGES_LOW(2) ~ PCPU_EMPTY_POP_PAGES_HIGH(4) 범위
- 이전에 atomic allocation이 실패한 경우에는 최대 값(PCPU_EMPTY_POP_PAGES_HIGH)을 사용한다.
참고
- Per-cpu -1- (Basic) | 문c
- Per-cpu -2- (초기화) | 문c – 현재 글
- Per-cpu -3- (동적 할당) | 문c
- Per-cpu -4- (atomic operations) | 문c