<kernel v5.0>
Per-cpu -1- (Basic)
동일한 변수에 대해 각 cpu별 독립적인 메모리 공간을 제공하는 것을 per-cpu 변수라 한다. SMP(Symmetry Multi Processing)에서 cpu가 동시에 접근하는 자원에 대해 캐시에 대한 일관성 및 스핀락 같은 동기화 메커니즘이 필요한데, per-cpu 변수를 이용하면 개별 공간에 접근하므로 동기화 메커니즘이 필요 없어 속도가 빠르다.
per-cpu는 변수를 cpu 수만큼 별도로 할당하는 메모리 관리 기법이다. 이렇게 cpu별로 분리된 공간을 사용하면 cpu들 사이에 락 메커니즘이 필요 없어 빠른 성능을 얻을 수 있고, 프로세서의 캐시 히트율(hit rate)을 높일 수 있다는 장점도 있다.
per-cpu의 주요 특징
per-cpu 영역은 커널 2.6에서 추가되었다. 데이터를 per-cpu 영역으로 만들어 각 cpu별로 사본을 갖게 하여 SMP 환경에서 자신의 cpu와 관련된 데이터만 접근하는 경우 동기화에 대해 고려해야 할 것이 줄어든다. 락을 사용하지 않고 빠른 쓰기를 반복하고자 하는 설계에서 사용한다. 태스크 선점 및 인터럽트에 대한 보호는 필요하다.
네트워크 패킷, 디스크 및 커널 객체 등의 카운팅에 많이 사용되는데 초당 수천 번 이상의 갱신이 요구되는 경우 락 메커니즘을 사용하지 않고 수행하므로 빠르다. 각 cpu에서 효과적으로 캐시되며 공유 메모리에서 발생하는 캐시 라인 바운싱 문제가 없어서 빠르다.
초기 설계 시 각 per-cpu 데이터는 캐시 라인 수만큼 바이트 정렬(align)하여 사용했다가 현재 커널에서는 per-cpu 데이터를 선언할 때부터 유형에 맞게 나누어 선언하므로 정렬 없이 다른 per-cpu 데이터와 함께 사용하는 것으로 변경되었다(read-mostly 등).
per-cpu 데이터들은 커널이 사용하는 일반 코드나 데이터 주소 공간이 아닌 별도의 per-cpu 주소 공간에 정의되고, sparse 정적 코드 분석 툴을 사용하는 경우 영역 침범 오류 등을 걸러낼 수 있다. 커널 이미지 내에 static하게 정의된 per-cpu 데이터들은 first chunk에 구성된다. 동적 per-cpu 할당이 2009년도에 패치(patch)로 추가되면서 chunk 방식이 소개되었다. 비동기 chunk population이 2014년도 9월에 커널 3.18-rc1에 추가되었다.
- 참고:
per-cpu 용도
per-cpu가 자주 사용되는 용도를 알아보자.
- 캐시 객체
- 전역에서 사용되는 리스트나 트리 등을 cpu마다 할당해 캐시처럼 사용한다. 이렇게 성능이 빠른 반면에, cpu 개수만큼의 메모리를 사용하므로 메모리의 요구량이 증가된다는 단점이 있다. 이를 보완하기 위해 전체 리스트나 트리를 관리하지 않고 일부만을 제한하여 제공하는 캐시 역할을 한다( 버디 시스템에서의 pcp 캐시, 슬랩 객체에 적용된 per-cpu 캐시, lru 캐시).
- 통계 카운터
- 각종 통계 카운터는 단순 증감이 매우 빈번하다. 통계 카운터 변수를 per-cpu로 사용하면 락 메커니즘 없이 사용하여 각 cpu에서 증감되는 값을 기억하고 있다가 임계치를 초과한다면 전역 통계 카운터 변수에 더해서 사용한다. 카운터 값의 대략치를 사용해도 되는 경우 전역 통계 카운터 변수 값만을 읽어오고 정밀한 값이 필요한 경우에는 각 cpu에서 증감했던 per-cpu 통계 카운터 값을 글로벌 통계 카운터 값에 적용하게 한 후 사용한다. 글로벌 카운터의 정확도를 일정 부분 보장하기 위해 각 cpu에서 증감되는 크기가 일정 임계치를 벗어나는 경우 글로벌 카운터에 갱신시킨다(글로벌 카운터의 갱신은 어토믹 연산을 사용한다).
- 그 외
- RCU infrastructure
- Profiling, Ftrace
- VFS components
다음 그림은 per-cpu 카운터로 사용되는 사례를 보여준다.

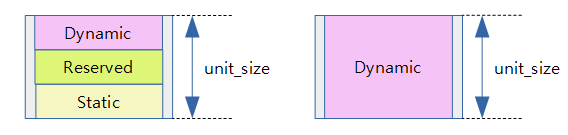
유닛: cpu마다 per-cpu 데이터가 저장되는 공간
유닛(unit)은 cpu 하나에 대응하는 per-cpu 데이터가 저장되는 공간이다. 유닛은 다음 세 가지 타입의 저장 영역으로 나뉘어 관리된다. 유닛의 크기는 아래의 세 영역을 더한 뒤에 페이지 단위로 올림 정렬한 값이다.
- static 영역
- 커널에서 DEFINE_PER_CPU( ) 매크로를 사용한 정적 per-cpu 데이터가 저장된다.
- rpi2: 예) 0x3ec0
- reserved 영역
- 모듈에서 DEFINE_PER_CPU( ) 매크로를 사용한 정적 per-cpu 데이터가 저장된다.
- rpi2: 예) default 0x2000 (8K)
- dynamic 영역
- 커널 또는 모듈에서 alloc_percpu( ) 함수를 통해 동적 per-cpu 데이터가 저장된다.
- rpi2 예) default 0x5000 (20K)
- 64bit 시스템에서는 default 28K
관련된 주요 변수는 다음 두 가지다
- pcpu_unit_pages
- 1개의 유닛이 사용하는 페이지 수가 담겨 있다.
- rpi2: 예) 11
- pcpu_unit_size
- 1개의 유닛이 사용하는 바이트 크기가 담겨 있다.
- rpi2: 예) 0xb000 (44KB = 11 * 4KB(PAGE_SIZE))
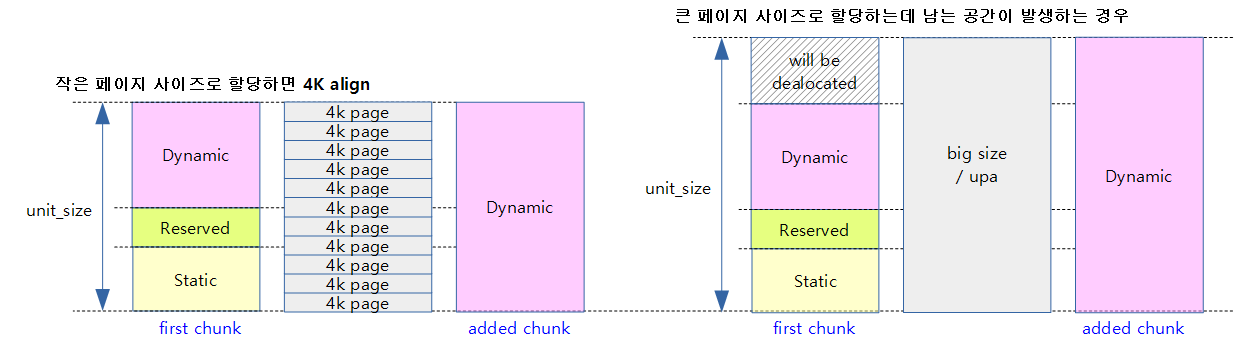
ARM과 같이 4K 작은 페이지를 사용하는 시스템의 경우 per-cpu 영역을 할당할 때는 1개의 유닛에 다수의 페이지들을 사용한다. 그리고 그 영역은 페이지 단위로 정렬하여 사용한다. static_size + reserved_size + dyn_size를 모두 더한 후 4K align하고 남는 공간은 dynamic 영역에 추가한다.
- rpi2: 예) 0x3ec0 + 0x2000 + 0x5000 + 0x140(4K align 하여 남는 공간을 dynamic 영역에 추가한다.)
x86_64 및 ARM64 등 몇몇 아키텍처에서는 2M 페이지 등의 큰 페이지를 사용하여 할당할 수 있다. 이 공간이 크기 때문에 여러 개의 유닛을 하나의 할당 크기에 나누어 배치할 수 있다. 유닛을 배치하는 과정에서 유닛의 마지막 부분에 남는 공간이 발생하는데 이 공간은 메모리 할당에서 해제한다.
다음 그림은 per-cpu 영역을 처음 만들 때 3개의 영역으로 나뉘는 것을 보여준다. 또한 추가 per-cpu 영역을 생성할 때 같은 유닛 크기로 dynamic 영역만을 포함하는 유닛을 보여준다.
다음 그림은 할당 페이지가 작은 경우와 큰 경우 두 가지로 나뉘어 사용하는 것을 보여준다.
- first chunk와 added chunk에서 dynamic 영역을 비교해본다.
- first chunk에만 static 및 reserved 영역이 존재하는 것을 알 수 있다.
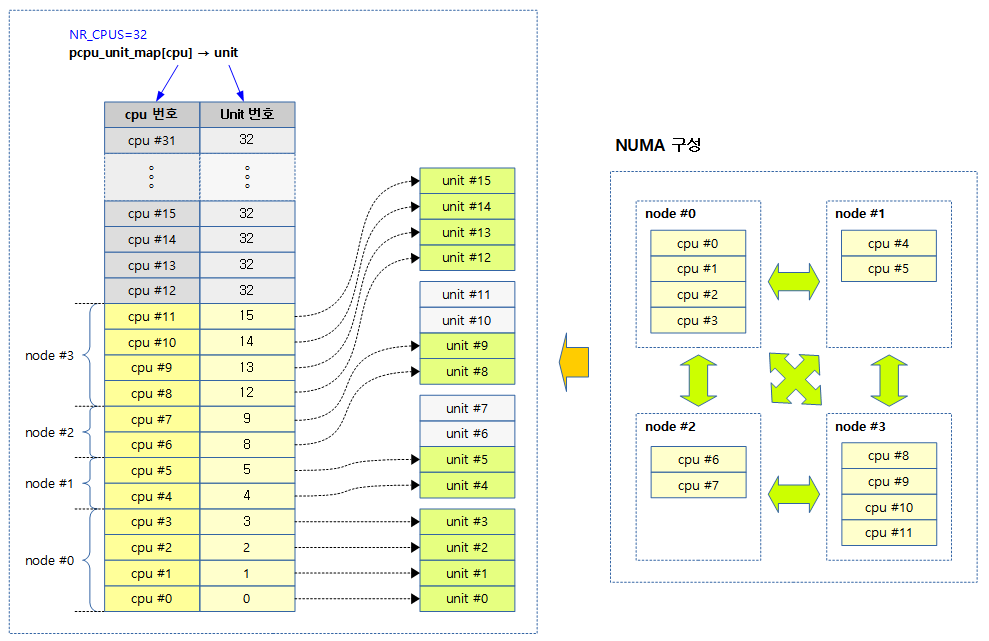
CPU -> Unit 매핑
per-cpu 데이터는 NR_CPUS 수만큼 배열을 사용하기 때문에 실제 존재하는 cpu의 수보다 큰 수를 사용하는 경우에는 메모리가 낭비될 수 있다. 수천 개의 cpu를 지원하도록 설정(NR_CPUS)된 시스템에서 실제 부팅 시 동작될 예정인(possible 상태) cpu가 몇 개 안 될 때가 있기 때문이다.
이로 인해 낭비되는 per-cpu 배열을 줄이기 위해 몇몇 아키텍처에서 추가 패치(patch)가 적용되어 공간을 효율적으로 사용하기도 한다. NUMA 시스템에서 각 노드마다 cpu 개수가 다르고 large 페이지를 사용하는 경우 하나의 할당 메모리마다 유닛 수가 동일하다. cpu와 유닛이 항상 동일하게 매핑되던 것을 NUMA를 위해 비선형(non-linear/sparse) cpu->unit 매핑했다.
cpu->unit 매핑 배열을 추가하는 것으로 쉽게 구현할 수 있고 매치된 유닛을 찾아 사용할 수 있다. 비대칭 NUMA 시스템으로 구성하는 경우 매핑되지 않는 유닛도 있기 때문에 유닛 수와 cpu 개수는 동일하지 않다.
여기서 주로 사용되는 배열은 다음과 같다.
- pcpu_unit_map[]
- cpu id는 unit index에 매핑된다.
- 모든 chunk에 대해 매핑이 유효하다.
- 예) 0,1,2,3
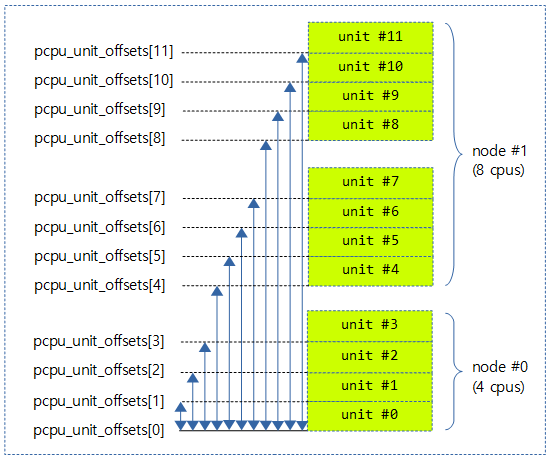
- pcpu_unit_offsets[]
- 해당 chunk의 baseaddr에서 각 unit과의 간격(offset)이 들어있다.
- 모든 chunk에 unit offset이 동일하게 적용된다.
- 예) 0, 0x8000, 0x10000, 0x18000
per-cpu의 NUMA 지원
NUMA를 지원하기 위해 per-cpu는 cpu와 유닛이 항상 동일하게 매핑되던 것에 비선형(non-linear/sparse) cpu->unit 매핑을 추가했다. cpu->unit 매핑 배열을 추가하는 것으로 쉽게 구현할 수 있고 매치된 유닛을 찾아 사용할 수 있다. unit0의 base 주소는 고정되지 않는다. 매핑이 바뀌면 unit0의 base 주소는 바뀐다.
ARM64에서는 아래 그룹 매핑 구조체 정보들은 커널 초기화 후 사용되지 않고 실제 cpu->unit 매핑에 전역 변수를 사용한다. x86 및 sparc64 아키텍처에서는 커널 초기화 후에도 아래의 두 구조체 정보를 활용하여 cpu->unit 매핑을 하게 된다.
다음 그림은 NUMA 시스템에서 사용 가능한 cpu 번호에 매핑된 unit 번호를 보여준다. (32개의 NR_CPUS 중 실제 12개의 possible cpu에 대응하는 16개의 unit가 있다.)
다음 그림은 가장 낮은 주소의 unit으로 부터 각각의 unit의 시작 offset이 지정되는 것을 보여준다.
- pcpu_unit_offset[] 배열의 초기화는 pcpu_setup_first_chunk() 함수를 참고한다.
Chunk
chunk는 모든 cpu에 대응하는 유닛 전체가 모인 단위를 말하며, 특징은 다음과 같다.
- 하나의 chunk는 nr_units 개수로 나뉨
- chunk가 부족해지면 추가 chunk를 만들어 사용함
- first chunk가 아닌 모든 추가된 chunk의 각 유닛에는 dynamic 영역만 존재함
- 모든 chunk는 pcpu_chunk 구조체로 관리됨
- NUMA 시스템에서 1개의 chunk는 각각의 노드(그룹) 메모리를 사용하여 할당됨
여기서 first chunk는 커널 초기화 과정에서 처음 만드는 chunk를 말한다. first chunk의 각 유닛은 static, reserved, dynamic이라는 세 영역으로 나뉜다.
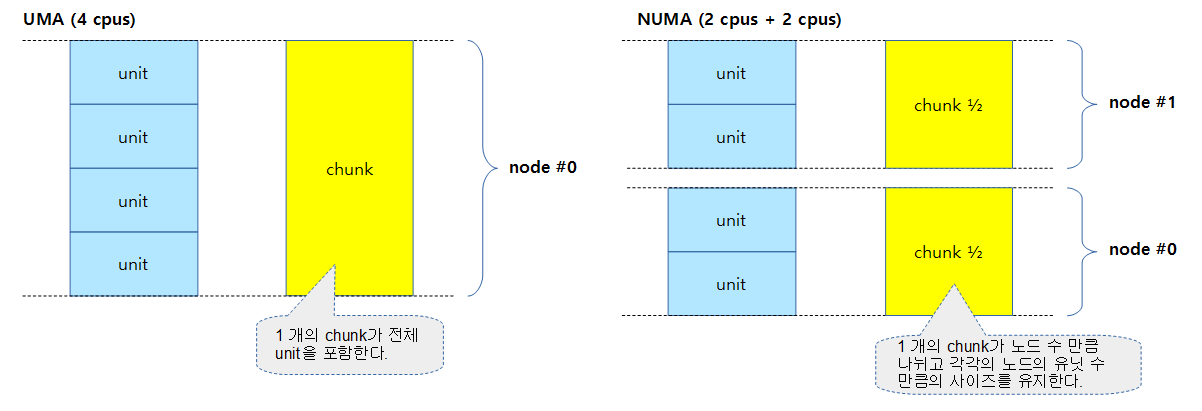
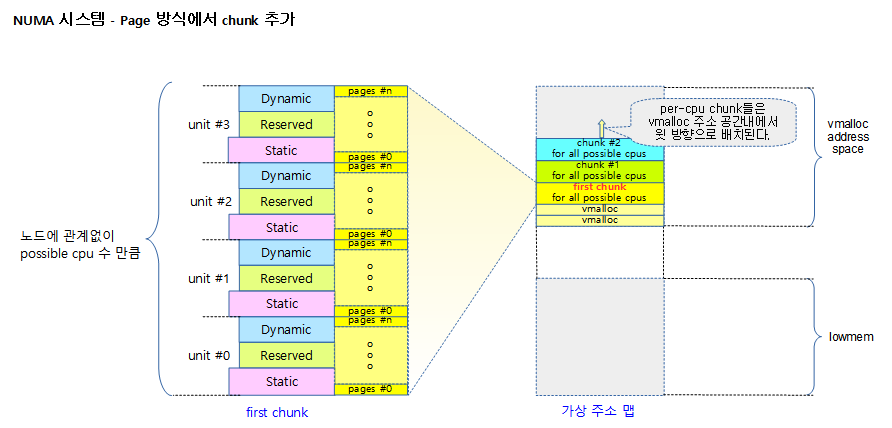
다음 그림은 하나의 chunk가 노드 수 만큼 나뉘어 할당되는 것을 보여준다.
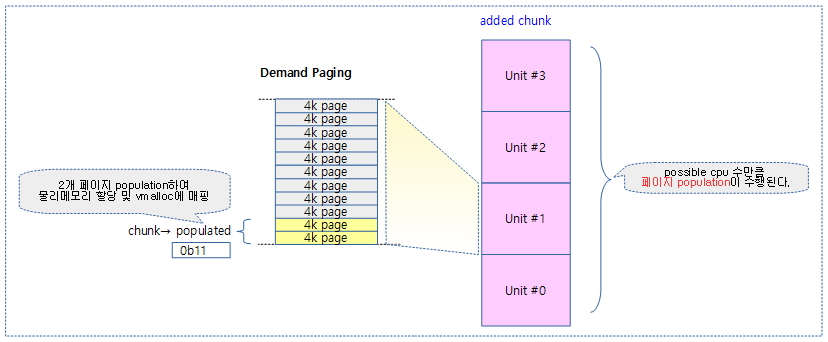
Demand Paging (페이지별 Population)
- 모든 추가되는 chunk들은 Demand Paging 방식을 사용하여 메모리를 절약한다.
- first chunk는 이미 매핑되어 있으므로 제외
- 새 chunk가 할당될 때 모든 유닛에 포함된 페이지를 할당하여 매핑하지 않고, 실제 per-cpu 할당 요청이 있을 때에만 해당 페이지에 대한 물리 메모리를 할당하고 vmalloc 공간에 매핑하여 사용한다. 이를 페이지 population이라 한다.
- chunk 내에 구성된 전체 페이지에 대해 populated 되어 있는지 여부를 비트맵인 populated 멤버 변수로 관리한다.
- per-cpu 데이터를 할당받아 사용하는 경우 chunk의 지정된 영역에 해당하는 페이지들이 populated 비트맵에 설정되어 있지 않은 경우 물리 메모리 페이지의 할당과 vmap에 의한 매핑을 수행한다.
다음 그림은 populated된 페이지들을 보여준다.
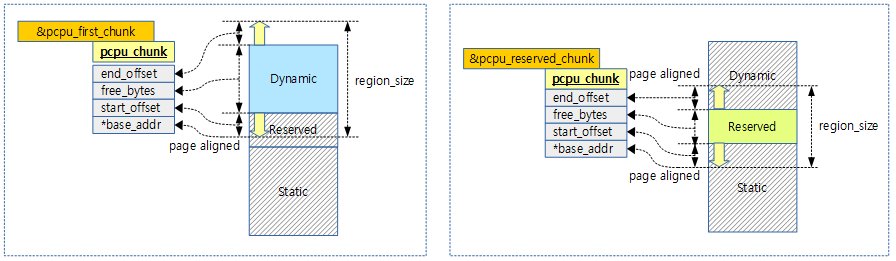
first chunk 구성
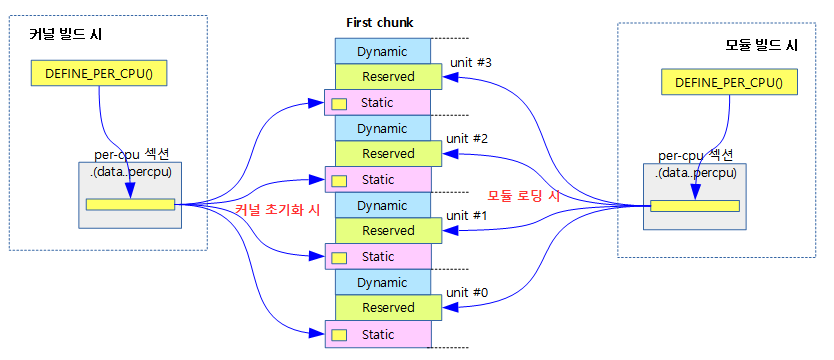
first chunk는 각 그룹 및 유닛의 배치를 결정하는 중요 역할을 하는 chunk로, 특별히 관리된다. 컴파일 시에는 .data..percpu 섹션에 만들어져 있다가 부팅 시 초기화 루틴 setup_per_cpu_areas( )에서 first chunk의 각 static 영역에 복사한다.
reserved 영역은 PERCPU_MODULE_RESERVE 크기로 초기화된다. 모듈을 사용하는 경우 8K, 모듈을 사용하지 않는 경우 0K가 된다. dynamic 영역은 PERCPU_DYNAMIC_RESERVE 크기로 초기화된다. 32비트 시스템에서는 20K, 64비트 시스템에서는 28K가 된다. v3.17 커널까지는 각각 12K, 20K로 현재보다 크기가 더 적었다.
만들어지는 방식은 두 가지가 있고, 부팅 시 percpu_alloc 옵션으로 둘 중 하나를 선택하여 사용한다.
-
- Embed 방식
- 아키텍처가 지원하는 경우 유닛 할당에 huge 페이지 크기를 사용하여 TLB 캐시의 효율을 높인다.
- ARM64는 embed 방식을 사용하지만 per-cpu에서 huge 페이지 사용은 아직 지원하지 않는다.
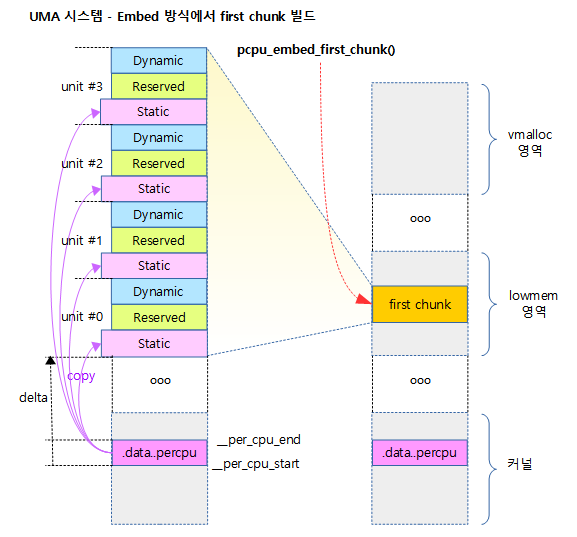
- first chunk를 구성할 때 각 유닛의 dynamic 뒷부분이 공간이 남는다. 이 공간은 할당을 해제(free)하여 다른 용도로 사용할 수 있게 한다
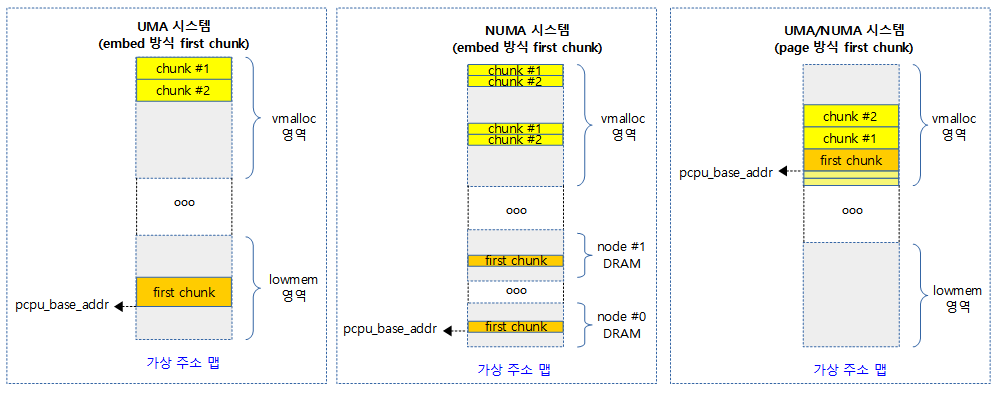
- UMA 시스템의 경우 first chunk를 한 번에 할당하여 사용한다.
- NUMA 시스템의 경우 first chunk를 각 노드 메모리에 나누어 할당하여 구성한다.
- chunk를 추가하는 경우 vmalloc 공간에 first chunk를 만들었을 때의 노드별 구성과 동일한 간격으로 만들기 위해 vmalloc 공간의 위에서 부터 아래로 할당하여 구성한다.
- 32bit NUMA 시스템의 경우 vmalloc 공간이 매우 협소(arm=240M, x86=120M)하기 때문에 Embed 방식으로 사용할 수 없는 경우 Page 방식으로 전환하여 사용한다.
- 추가 chunk의 vmalloc 공간 배치를 고려하기 위해 각 노드에 할당된 chunk의 base 주소간에 가장 멀리 있는 max_distance가 vmalloc 공간의 75%를 초과하는 경우 Embed 방식을 사용하지 못하게 제약한다.
- x86에서는 embed 방식으로 생성할 수 없으면 자동으로 page 방식으로 재시도한다.
- 32bit NUMA 시스템의 경우 vmalloc 공간이 매우 협소(arm=240M, x86=120M)하기 때문에 Embed 방식으로 사용할 수 없는 경우 Page 방식으로 전환하여 사용한다.
- 비어 있는 vmalloc 공간을 위에서 부터 아래로 검색하여 사용한다.
- vmalloc() 및 vmap() 함수에 의해 vmalloc 공간을 할당할 때 vmalloc 공간의 아래에서부터 위로 검색하여 사용하는데 per-cpu의 chunk는 이와 반대로 하여 chunk를 추가 시마다 서로 겹쳐지는 것을 최대한 막는다.
- per-cpu는 NUMA 시스템에서 vmalloc 공간에 할당 할 때 first chunk에서 만들었던 노드(그룹)간의 base offset만큼 똑같이 간격을 유지하며 그 공간을 할당받아 매핑하여 사용해야 하므로 일반 vmalloc 영역과 섞이지 않게 하기 위해 반대 방향에서 생성하여야 빠르게 생성이 가능하고 생성에 대한 실패할 확률이 줄어든다.
- 아키텍처가 지원하는 경우 유닛 할당에 huge 페이지 크기를 사용하여 TLB 캐시의 효율을 높인다.
- Paged 방식
- first chunk를 구성 시 처음 부터 vmalloc 공간에 최소 페이지 단위로 물리 메모리 페이지를 할당받고 매핑하여 사용한다.
- 커널 초기화 시 아직 slub 메모리 할당자가 동작하지 않으므로 vmalloc 영역에 매핑이 불가능하다 따라서 slub 메모리 할당자가 동작한 후에 해당 영역을 등록할 수 있도록 early 등록 방법을 사용한다.
- slub 메모리 할당자가 동작한 후에 percpu_init_late() 함수를 호출하여 기존에 만들었던 chunk map들을 모두 읽어 할당받고 매핑할 수 있게 한다.
- vmalloc 공간에 chunk를 노드별로 나누지 않고 possible cpu 수만큼 유닛을 연달아 한꺼번에 구성한다.
- large 페이지를 사용하지 않기 때문에 Embed 방식에 비해 성능이 느릴 수 있지만 vmalloc 공간이 적은 32bit NUMA 시스템에서도 문제없이 사용될 수 있다.
- 비어 있는 vmalloc 공간을 아래에서 위로 검색하여 사용한다.
- vmalloc 공간에 chunk를 노드 수 만큼 나누어 구성할 필요가 없기 때문에 vmalloc() 및 vmap() 함수에 의해 vmalloc 공간을 할당하는 방식과 동일하게 사용할 수 있다.
- first chunk를 구성 시 처음 부터 vmalloc 공간에 최소 페이지 단위로 물리 메모리 페이지를 할당받고 매핑하여 사용한다.
- Embed 방식
다음 그림은 static per-cpu 데이터를 선언하고 빌드 후 커널이 초기화 될 때 first chunk 각 유닛의 static 영역으로 복사되고, 또한 모듈이 로딩될 때 first chunk 각 유닛의 reserved 영역으로 복사되어 구성되는 것을 보여준다.
다음 그림은 UMA 시스템에서 Embed 방식을 사용하여 first chunk가 만들어지는 공간의 위치를 보여준다.
다음 그림은 UMA 시스템에서 Embed 방식을 사용하여 추가 chunk가 만들어지는 공간의 위치를 보여준다.
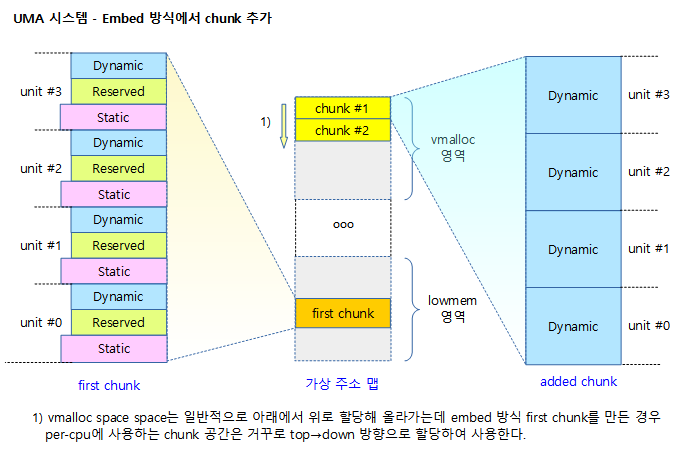
다음 그림은 NUMA 시스템에서 Embed 방식을 사용하여 first chunk가 만들어지는 공간의 위치를 보여준다.
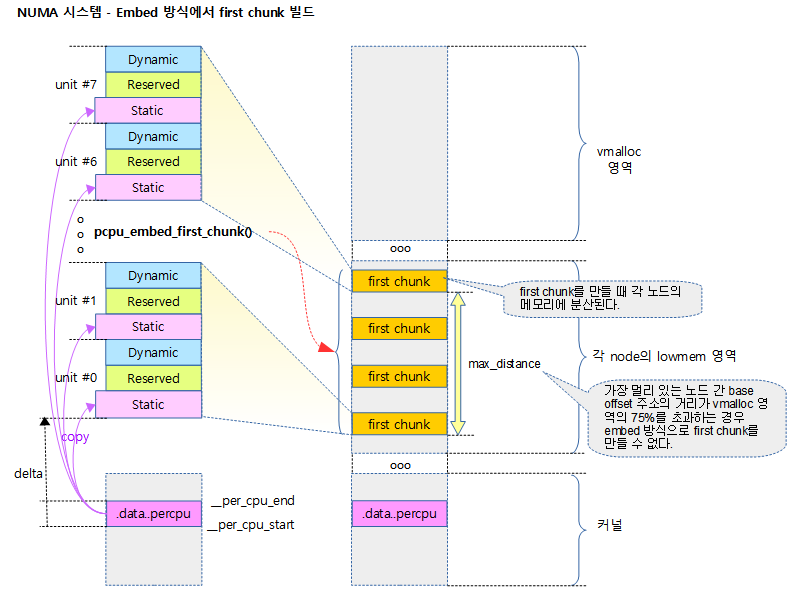
다음 그림은 NUMA 시스템에서 Embed 방식을 사용하여 추가 chunk가 만들어지는 공간의 위치를 보여준다.
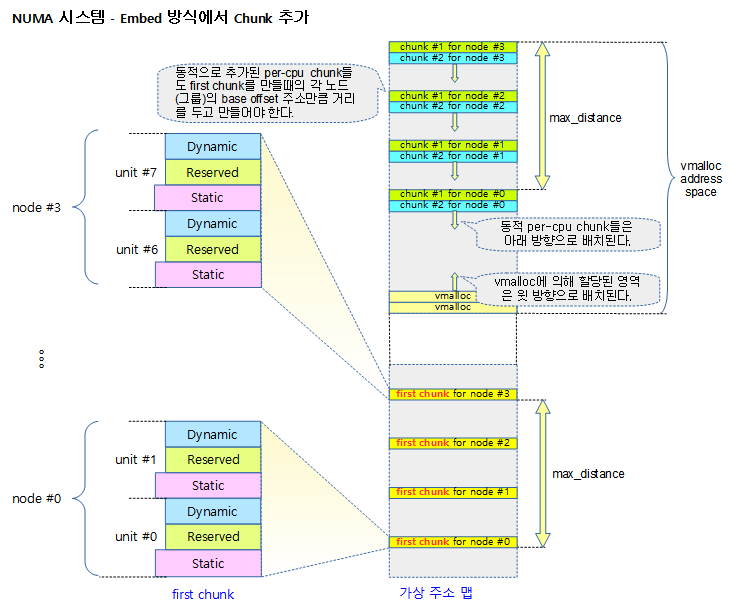
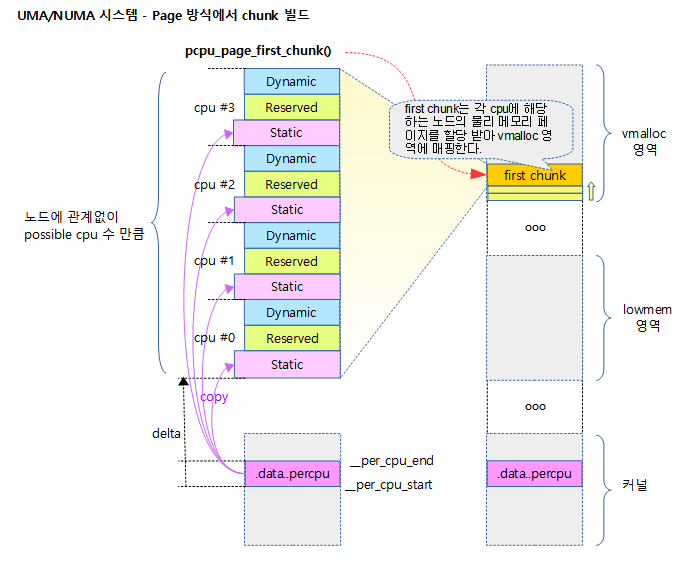
다음 그림은 Paged 방식을 사용하여 first chunk가 만들어지는 공간의 위치를 보여준다.
다음 그림은 Paged 방식을 사용하여 추가 chunk가 만들어지는 공간의 위치를 보여준다.
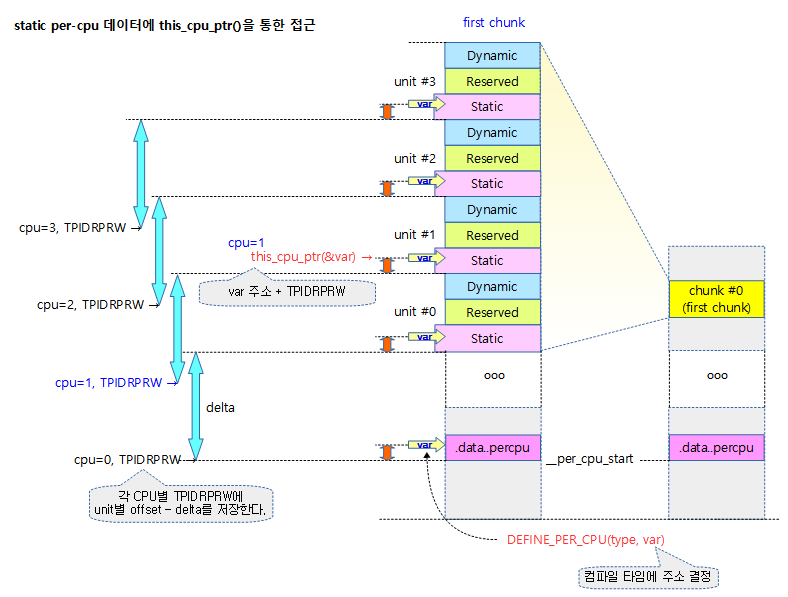
다음 그림은 this_cpu_ptr()함수를 통하여 static per-cpu 데이터에 접근하는 모습을 보여준다.
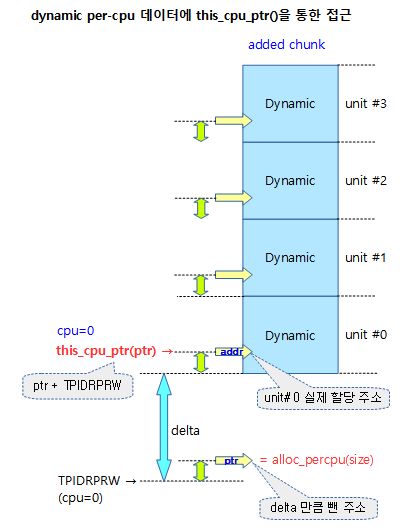
다음 그림은 this_cpu_ptr()함수를 통하여 추가된 chunk의 dynamic per-cpu 데이터에 접근하는 모습을 보여준다.
pcpu_base_addr
다음 그림과 같이 pcpu_base_addr은 first chunk의 base 주소를 담고 있다.
- 아키텍처에 따라 vmalloc 공간이 lowmem 영역 아래에 위치할 수도 있다. 참고로 ARM32는 vmalloc 공간이 lowmem보다 위에 위치하고, ARM64는 vmalloc 공간이 lowmem보다 아래에 위치한다.
First Chunk의 맵 엔트리 관리
First chunk의 매핑 관리
이 chunk는 각 그룹 및 유닛의 배치를 결정하는 중요 역할을 하는 chunk로, 특별히 관리된다. first chunk 1개의 할당 영역에 대해 관리 chunk 맵은 1개 또는 2개로 구성될 수 있다. pcpu_first_chunk는 다른 chunk들과 동일하게 dynamic 공간을 관리하며 pcpu_slot[ ]에 추가되어 사용한다. pcpu_reserved_chunk는 pcpu_slot[ ]에 추가되지 않고 모듈 관리 메커니즘에서 사용한다.
커널에서 모듈을 사용하는 경우 pcpu_reserved_chunk 전역 변수를 통해 first chunk의 reserved 영역 맵 엔트리를 관리하게 한다. 커널 모듈이 로드되거나 언로드될 때마다 커널 모듈에서 사용한 DEFINE_PER_CPU( ) 매크로의 per-cpu 데이터를 reserved 영역에 추가한다.
다음 그림은 커널 모듈을 사용하는 경우와 그렇지 않은 경우에 따라 first chunk의 관리 구조를 1개 또는 2개로 관리하는 모습을 보여준다.
per-cpu 영역 저장 섹션
_per_cpu_load는 per-cpu 영역이 메모리에 로드되는 가상 주소다. 성능 향상을 위해 여러 영역에 per-cpu 데이터를 저장할 수 있도록 다음 그림과 같은 다양한 매크로가 준비되어 있다.

per-cpu 섹션 위치
다음 vmlinux.lds.S 링커 스크립트를 통해 per-cpu 섹션이 .init.data 섹션 아래에 위치하는 것을 확인할 수 있다.
for ARM32
arch/arm/kernel/vmlinux.lds.S – ARM32
.init.data : {
INIT_DATA
INIT_SETUP(16)
INIT_CALLS
CON_INITCALL
INIT_RAM_FS
*(.init.rodata.* .init.bss) /* from the EFI stub */
}
.exit.data : {
ARM_EXIT_KEEP(EXIT_DATA)
}
PERCPU_SECTION(L1_CACHE_BYTES)
for ARM64
arch/arm64/kernel/vmlinux.lds.S – ARM64
INIT_DATA_SECTION(16)
.exit.data : {
ARM_EXIT_KEEP(EXIT_DATA)
}
#ifdef CONFIG_SMP
PERCPU_SECTION(L1_CACHE_BYTES)
#endif
PERCPU_SECTION()
include/asm-generic/vmlinux.lds.h
/**
* PERCPU_SECTION - define output section for percpu area, simple version
* @cacheline: cacheline size
*
* Align to PAGE_SIZE and outputs output section for percpu area. This
* macro doesn't manipulate @vaddr or @phdr and __per_cpu_load and
* __per_cpu_start will be identical.
*
* This macro is equivalent to ALIGN(PAGE_SIZE); PERCPU_VADDR(@cacheline,,)
* except that __per_cpu_load is defined as a relative symbol against
* .data..percpu which is required for relocatable x86_32 configuration.
*/
#define PERCPU_SECTION(cacheline) \
. = ALIGN(PAGE_SIZE); \
.data..percpu : AT(ADDR(.data..percpu) - LOAD_OFFSET) { \
__per_cpu_load) = .; \
PERCPU_INPUT(cacheline) \
}
per-cpu 영역을 위한 출력 섹션을 정의한다.
- LOAD_OFFSET
- asm-generic에서 정의된 값은 0이고 ARM 아키텍처에서도 변경없이 사용된다.
PERCPU_INPUT()
include/asm-generic/vmlinux.lds.h
/**
* PERCPU_INPUT - the percpu input sections
* @cacheline: cacheline size
*
* The core percpu section names and core symbols which do not rely
* directly upon load addresses.
*
* @cacheline is used to align subsections to avoid false cacheline
* sharing between subsections for different purposes.
*/
#define PERCPU_INPUT(cacheline) \
__per_cpu_start = .; \
*(.data..percpu..first) \
. = ALIGN(PAGE_SIZE); \
*(.data..percpu..page_aligned) \
. = ALIGN(cacheline); \
*(.data..percpu..read_mostly) \
. = ALIGN(cacheline); \
*(.data..percpu) \
*(.data..percpu..shared_aligned) \
PERCPU_DECRYPTED_SECTION \
__per_cpu_end = .;
per-cpu 영역을 위한 입력 섹션을 정의한다.
per-cpu 데이터 할당 API
Static per-cpu 데이터 할당
컴파일 타임에 per-cpu 데이터를 할당하고 사용하기 위해 선언하는 API를 알아본다.
DEFINE_PER_CPU()
include/linux/percpu-defs.h
#define DEFINE_PER_CPU(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "")
per_cpu 데이터를 사용하기 위해 선언한다. 커널 코어에서 선언된 per-cpu 데이터는 first chunk의 static 영역을 사용한다.
- type에 array를 사용할 수도 있다.
- 예) DEFINE_PER_CPU(int[3], my_percpu_array);
DEFINE_PER_CPU_SECTION()
include/linux/percpu-defs.h
#define DEFINE_PER_CPU_SECTION(type, name, sec) \
__PCPU_ATTRS(sec) __typeof__(type) name
__PCPU_ATTRS()
include/linux/percpu-defs.h
/*
* Base implementations of per-CPU variable declarations and definitions, where
* the section in which the variable is to be placed is provided by the
* 'sec' argument. This may be used to affect the parameters governing the
* variable's storage.
*
* NOTE! The sections for the DECLARE and for the DEFINE must match, lest
* linkage errors occur due the compiler generating the wrong code to access
* that section.
*/
#define __PCPU_ATTRS(sec) \
__percpu __attribute__((section(PER_CPU_BASE_SECTION sec))) \
PER_CPU_ATTRIBUTES
per-cpu 데이터가 저장될 섹션 위치를 지정한다.
#ifndef PER_CPU_BASE_SECTION #ifdef CONFIG_SMP #define PER_CPU_BASE_SECTION ".data..percpu" #else #define PER_CPU_BASE_SECTION ".data" #endif #endif
per-cpu 데이터 선언시 저장되는 섹션이다.
- SMP 머신에서는 .data..percpu 섹션에 저장된다.
- UP 머신에서는 per-cpu 데이터가 일반 데이터와 차이가 없으므로 .data 섹션에 저장된다.
Static per-cpu 데이터 extern 선언
다른 파일에서 static per-cpu 데이터를 참조하기 위해서는 다음 API를 사용한다.
include/linux/percpu-defs.h”
#define DECLARE_PER_CPU(type, name) \
DECLARE_PER_CPU_SECTION(type, name, "")
include/linux/percpu-defs.h”
#define DECLARE_PER_CPU_SECTION(type, name, sec) \
extern __PCPU_ATTRS(sec) __typeof__(type) name
Dynamic 생성/해제
런 타임에 dynamic하게 per-cpu 데이터를 할당 및 할당 해제 하는 API를 알아본다.
- alloc_percpu()
- free_percpu()
alloc_percpu()
include/linux/percpu.h
#define alloc_percpu(type) \
(typeof(type) __percpu *)__alloc_percpu(sizeof(type), \
__alignof__(type))
지정된 타입 크기만큼 per-cpu 데이터 영역을 할당한다. 처음엔 first chunk의 dynamic을 사용하여 할당하고, first chunk의 dynamic 영역이 모자라면 추가 chunk를 생성하여 사용한다. 추가된 chunk는 전체가 dynamic 영역이다.
__alloc_percpu()
mm/percpu.c
/** * __alloc_percpu - allocate dynamic percpu area * @size: size of area to allocate in bytes * @align: alignment of area (max PAGE_SIZE) * * Equivalent to __alloc_percpu_gfp(size, align, %GFP_KERNEL). */
void __percpu *__alloc_percpu(size_t size, size_t align)
{
return pcpu_alloc(size, align, false, GFP_KERNEL);
}
EXPORT_SYMBOL_GPL(__alloc_percpu);
요청한 @size로 @align하여 per-cpu 데이터 영역을 할당한다.
모듈에서 per-cpu 데이터 사용
모듈에서 per-cpu를 사용하는 방법은 커널 내부 처리에서 약간 다르게 처리된다.
- dynamic 할당
- 기존 dynamic 영역에서 할당하여 관리하는 방법이 동일하다.
- static 할당
- first chunk의 static 영역에 할당되지 않고, reserve 영역에 동적으로 할당 관리를 수행한다.
per-cpu data access API
preemption을 고려하여 설계하였고, per-cpu 데이터는 실제 per-cpu 데이터의 주소를 가리키지 않으므로 직접 접근하여 사용하지 않고 반드시 적절한 API를 통해서 per-cpu 데이터를 접근해야 한다.
1) l-value 조작
다음 예와 같이 get_cpu_var() 함수를 사용하여 per-cpu 데이터를 증가시킨다. 사용 후에 반드 시 put_cpu_var() 함수를 호출하여야 한다.
- get_cpu_var(sockets_in_use)++;
- put_cpu_var(sockets_in_use);
get_cpu_var()
include/linux/percpu-defs.h
/*
* Must be an lvalue. Since @var must be a simple identifier,
* we force a syntax error here if it isn't.
*/
#define get_cpu_var(var)
(*({ \
preempt_disable(); \
this_cpu_ptr(&var); \
}))
- SMP 머신에서는 값을 얻고자 할 때 preempt_disable()한 후 사용한다.
- 인수는 l-value이어야 한다.
put_cpu_var()
include/linux/percpu-defs.h
/*
* The weird & is necessary because sparse considers (void)(var) to be
* a direct dereference of percpu variable (var).
*/
#define put_cpu_var(var) \
do { \
(void)&(var); \
preempt_enable(); \
} while (0)
- SMP 머신에서 값을 기록한 후 preempt_enable()한다.
2) 포인터 조작
다음 예와 같이 포인터로 접근을 해야 하는 경우 먼저 현재 cpu id를 알아오고 per_cpu_ptr() 함수를 사용하여 포인터를 알아온 후 이 포인터로 원하는 사용자 작업을 한다. per-cpu data의 작업이 완료되면 반드시 put_cpu()를 사용해야 한다.
int cpu; cpu = get_cpu( ) ptr = per_cpu_ptr(per_cpu_var, cpu); /* work with ptr */ put_cpu( );
per_cpu_ptr()
include/linux/percpu-defs.h
#define per_cpu_ptr(ptr, cpu) \
({ \
__verify_pcpu_ptr(ptr); \
SHIFT_PERCPU_PTR((ptr), per_cpu_offset((cpu))); \
})
Sparse 정적 코드 분석툴을 사용 시 __verify_pcpu_ptr()를 통해 ptr(포인터)이 문제 없는지 확인한다. 그 후 ptr과 해당 cpu의 offset을 더한 주소를 리턴한다.
per_cpu_offset()
include/asm-generic/percpu.h
/* * per_cpu_offset() is the offset that has to be added to a * percpu variable to get to the instance for a certain processor. * * Most arches use the __per_cpu_offset array for those offsets but * some arches have their own ways of determining the offset (x86_64, s390). */ #ifndef __per_cpu_offset extern unsigned long __per_cpu_offset[NR_CPUS]; #define per_cpu_offset(x) (__per_cpu_offset[x]) #endif
요청한 cpu @x 번호에 대한 per-cpu offset 값을 반환한다.
- __per_cpu_offset[]
- per-cpu 데이터를 접근하려면 cpu 번호마다 지정된 offset 값을 더해야 하는데 그 offset 값 들이 저장된 전역 변수 배열이다.
this_cpu_ptr()
include/linux/percpu-defs.h
#ifdef CONFIG_DEBUG_PREEMPT
#define this_cpu_ptr(ptr) \
({ \
__verify_pcpu_ptr(ptr); \
SHIFT_PERCPU_PTR(ptr, my_cpu_offset); \
})
#else
#define this_cpu_ptr(ptr) raw_cpu_ptr(ptr)
#endif
현재 cpu에 대한 per-cpu offset 값이 적용된 포인터를 반환한다.
- raw_cpu_ptr() 매크로 함수를 호출하여 ptr에 현재 cpu의 offset를 더한 주소를 리턴한다.
__verify_pcpu_ptr()
include/linux/percpu-defs.h
/*
* __verify_pcpu_ptr() verifies @ptr is a percpu pointer without evaluating
* @ptr and is invoked once before a percpu area is accessed by all
* accessors and operations. This is performed in the generic part of
* percpu and arch overrides don't need to worry about it; however, if an
* arch wants to implement an arch-specific percpu accessor or operation,
* it may use __verify_pcpu_ptr() to verify the parameters.
*
* + 0 is required in order to convert the pointer type from a
* potential array type to a pointer to a single item of the array.
*/
#define __verify_pcpu_ptr(ptr) \
do { \
const void __percpu *__vpp_verify = (typeof((ptr) + 0))NULL; \
(void)__vpp_verify; \
} while (0)
이 매크로는 Sparse 정적 코드 분석툴을 위한 것으로 ptr(포인터)이 per-cpu address space용 포인터로 사용되는지 검사한다.
SHIFT_PERCPU_PTR()
include/linux/percpu-defs.h
/*
* Add an offset to a pointer but keep the pointer as-is. Use RELOC_HIDE()
* to prevent the compiler from making incorrect assumptions about the
* pointer value. The weird cast keeps both GCC and sparse happy.
*/
#define SHIFT_PERCPU_PTR(__p, __offset) \
RELOC_HIDE((typeof(*(__p)) __kernel __force *)(__p), (__offset))
__p에 __offset을 단순히 더하여 커널 address space로 강제 캐스트되어 리턴한다.
RELOC_HIDE()
include/linux/compiler-gcc.h
/*
* This macro obfuscates arithmetic on a variable address so that gcc
* shouldn't recognize the original var, and make assumptions about it.
*
* This is needed because the C standard makes it undefined to do
* pointer arithmetic on "objects" outside their boundaries and the
* gcc optimizers assume this is the case. In particular they
* assume such arithmetic does not wrap.
*
* A miscompilation has been observed because of this on PPC.
* To work around it we hide the relationship of the pointer and the object
* using this macro.
*
* Versions of the ppc64 compiler before 4.1 had a bug where use of
* RELOC_HIDE could trash r30. The bug can be worked around by changing
* the inline assembly constraint from =g to =r, in this particular
* case either is valid.
*/
#define RELOC_HIDE(ptr, off) \
({ unsigned long __ptr; \
__asm__ ("" : "=r"(__ptr) : "0"(ptr)); \
(typeof(ptr)) (__ptr + (off)); })
- __ptr에 off를 더한 주소를 리턴한다.
- 위 주석을 직역하면 이 매크로가 한 변수에 대한 산술연산을 모호하게 만들어 gcc가 원래 값을 인식할 수 없도록 하여 그것에 대해 가정을 할 수 없게 한다라고 하였는데 달리 말하면 그 변수의 type과 관계없이 그 변수의 주소만을 가지고 거기에 offset을 더한 후 원래 변수의 타입으로 캐스트하여 보낸다.
- gcc 4.1 이전 버전의 컴파일러가 ppc64 아키텍처에 대해 버그가 발생하여 이 워크어라운드를 적용하여 해결하였다.
raw_cpu_ptr()
include/linux/percpu-defs.h
#define raw_cpu_ptr(ptr) \
({ \
__verify_pcpu_ptr(ptr); \
arch_raw_cpu_ptr(ptr); \
})
@ptr에 현재 cpu에 대한 per-cpu offset을 더한 포인터 주소를 반환한다.
- Sparse 정적 코드 분석을 위해 __verify_pcpu_ptr()를 통해 ptr(포인터)이 문제 없는지 확인한다. 그 후 arch_raw_cpu_ptre() 매크로 함수를 호출하여 ptr에 현재 cpu의 per-cpu offset을 더한 주소를 리턴한다.
arch_raw_cpu_ptr()
include/asm-generic/percpu.h”
/* * Arch may define arch_raw_cpu_ptr() to provide more efficient address * translations for raw_cpu_ptr(). */ #ifndef arch_raw_cpu_ptr #define arch_raw_cpu_ptr(ptr) SHIFT_PERCPU_PTR(ptr, __my_cpu_offset) #endif
@ptr에 현재 cpu에 대한 per-cpu offset을 더한 포인터 주소를 반환한다.
__my_cpu_offset() – ARM32
arch/arm/include/asm/percpu.h
#define __my_cpu_offset __my_cpu_offset()
static inline unsigned long __my_cpu_offset(void)
{
unsigned long off;
/*
* Read TPIDRPRW.
* We want to allow caching the value, so avoid using volatile and
* instead use a fake stack read to hazard against barrier().
*/
asm("mrc p15, 0, %0, c13, c0, 4" : "=r" (off)
: "Q" (*(const unsigned long *)current_stack_pointer));
return off;
}
TPIDRPRW 레지스터에 저장된 cpu에 해당하는 offset 값을 읽어온다.
- 이 값은 per-cpu ptr 주소에 더해 per-cpu 데이터에 접근하는데 사용한다.
- arm 아키텍처에서는 cpu별 offset 보관에 CP15 레지스터중 사용하지 않는 TPIDRPRW 레지스터를 사용하여 per-cpu 연산 성능을 상승시켰다.
__my_cpu_offset() – ARM64
arch/arm64/include/asm/percpu.h
#define __my_cpu_offset __my_cpu_offset()
static inline unsigned long __my_cpu_offset(void)
{
unsigned long off;
/*
* We want to allow caching the value, so avoid using volatile and
* instead use a fake stack read to hazard against barrier().
*/
asm(ALTERNATIVE("mrs %0, tpidr_el1",
"mrs %0, tpidr_el2",
ARM64_HAS_VIRT_HOST_EXTN)
: "=r" (off) :
"Q" (*(const unsigned long *)current_stack_pointer));
return off;
}
TPIDR 레지스터에 저장된 cpu에 해당하는 per-cpu offset 값을 읽어온다.
기타 주요 함수
__percpu 속성 매크로
include/linux/compiler_types.h
# define __percpu __attribute__((noderef, address_space(3)))
Sparse 정적 코드 분석툴에서 지정한 속성이다.
- address_space(3):
- per-cpu address_space를 지정하여 사용하게 규정한다.
- noderef
- dereferencing pointer를 사용할 수 없도록 규정한다.
- 일반 포인터 변수 *ptr 등은 사용할 수 없고 변수의 주소를 직접 제공하는 &val 형태는 사용할 수 있다.
- dereferencing pointer를 사용할 수 없도록 규정한다.
pcpu_addr_in_first_chunk()
mm/percpu.c – 커널 v4.14부터 삭제됨
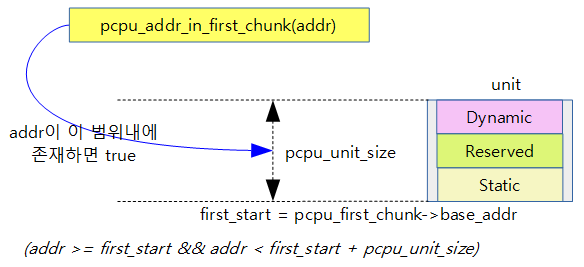
- 주어진 주소가 first chunk 범위에 있는 주소인지 여부를 리턴한다.
pcpu_addr_in_reserved_chunk()
mm/percpu.c – 커널 v4.14부터 삭제됨
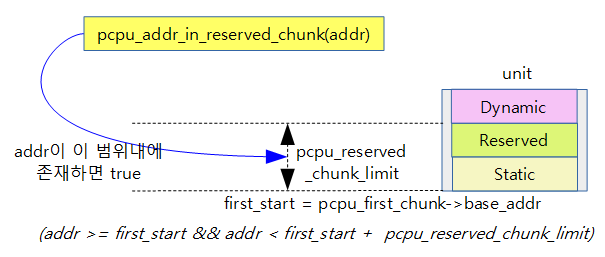
- 주어진 주소가 Static 영역 및 Reserved 영역에 포함되는지 여부를 리턴한다.
- Reserved chunk가 주어지지 않았을 때 즉, Reserved 영역이 없는 경우 pcpu_reserved_chunk_limit 값은 0이다.
pcpu_chunk_addr()

- 주어진 chunk 번호, cpu 번호 및 페이지 번호로 해당 페이지의 시작 주소를 얻어온다.
slub 객체의 카운팅에 활용된 per-cpu 데이터 사용 예제
include/linux/slub_def.h
/*
* Slab cache management.
*/
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
struct page *partial; /* Partially allocated frozen slabs */
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
static inline void flush_slab(struct kmem_cache *s, struct kmem_cache_cpu *c)
{
stat(s, CPUSLAB_FLUSH);
deactivate_slab(s, c->page, c->freelist);
c->tid = next_tid(c->tid);
c->page = NULL;
c->freelist = NULL;
}
static inline void stat(const struct kmem_cache *s, enum stat_item si)
{
#ifdef CONFIG_SLUB_STATS
/*
* The rmw is racy on a preemptible kernel but this is acceptable, so
* avoid this_cpu_add()'s irq-disable overhead.
*/
raw_cpu_inc(s->cpu_slab->stat[si]);
#endif
}
include/linux/slub_def.h
enum stat_item {
ALLOC_FASTPATH, /* Allocation from cpu slab */
ALLOC_SLOWPATH, /* Allocation by getting a new cpu slab */
FREE_FASTPATH, /* Free to cpu slab */
FREE_SLOWPATH, /* Freeing not to cpu slab */
FREE_FROZEN, /* Freeing to frozen slab */
FREE_ADD_PARTIAL, /* Freeing moves slab to partial list */
FREE_REMOVE_PARTIAL, /* Freeing removes last object */
ALLOC_FROM_PARTIAL, /* Cpu slab acquired from node partial list */
ALLOC_SLAB, /* Cpu slab acquired from page allocator */
ALLOC_REFILL, /* Refill cpu slab from slab freelist */
ALLOC_NODE_MISMATCH, /* Switching cpu slab */
FREE_SLAB, /* Slab freed to the page allocator */
CPUSLAB_FLUSH, /* Abandoning of the cpu slab */
(..생략..)
include/linux/percpu-defs.h
#define raw_cpu_inc(pcp) raw_cpu_add(pcp, 1)
#define raw_cpu_add(pcp, val) __pcpu_size_call(raw_cpu_add_, pcp, val)
#define __pcpu_size_call(stem, variable, ...) \
do { \
__verify_pcpu_ptr(&(variable)); \
switch(sizeof(variable)) { \
case 1: stem##1(variable, __VA_ARGS__);break; \
case 2: stem##2(variable, __VA_ARGS__);break; \
case 4: stem##4(variable, __VA_ARGS__);break; \
case 8: stem##8(variable, __VA_ARGS__);break; \
default: \
__bad_size_call_parameter();break; \
} \
} while (0)
include/asm-generic/percpu.h
#ifndef raw_cpu_add_4 #define raw_cpu_add_4(pcp, val) raw_cpu_generic_to_op(pcp, val, +=) #endif
#define raw_cpu_generic_to_op(pcp, val, op) \
do { \
*raw_cpu_ptr(&(pcp)) op val; \
} while (0)
per-cpu 관련 구조체
pcpu_chunk 구조체
mm/percpu-internal.h
struct pcpu_chunk {
#ifdef CONFIG_PERCPU_STATS
int nr_alloc; /* # of allocations */
size_t max_alloc_size; /* largest allocation size */
#endif
struct list_head list; /* linked to pcpu_slot lists */
int free_bytes; /* free bytes in the chunk */
int contig_bits; /* max contiguous size hint */
int contig_bits_start; /* contig_bits starting
offset */
void *base_addr; /* base address of this chunk */
unsigned long *alloc_map; /* allocation map */
unsigned long *bound_map; /* boundary map */
struct pcpu_block_md *md_blocks; /* metadata blocks */
void *data; /* chunk data */
int first_bit; /* no free below this */
bool immutable; /* no [de]population allowed */
int start_offset; /* the overlap with the previous
region to have a page aligned
base_addr */
int end_offset; /* additional area required to
have the region end page
aligned */
int nr_pages; /* # of pages served by this chunk */
int nr_populated; /* # of populated pages */
int nr_empty_pop_pages; /* # of empty populated pages */
unsigned long populated[]; /* populated bitmap */
};
- nr_alloc
- 이 청크에 요청된 할당 수
- max_alloc_size
- 이 청크에 할당 요청 시 마다 요청한 할당 사이즈 중 최대 할당 사이즈가 갱신된다.
- list
- chunk들을 관리하기 위한 용도로 사용되는 pcpu_slot 맵 리스트이다.
- 모든 chunk들은 pcpu_slot 맵 리스트에 연결되어 dynamic 공간을 관리하기 위해 사용되며 각 chunk 내의 여유(free) 공간의 크기 순으로 정렬하여 여유 공간이 가장 적은 chunk에서부터 할당을 한다.
- free_bytes
- chunk 내의 여유(free) 공간의 합이다. 단위는 바이트이다.
- 할당과 해제시 마다 free_size가 바뀌고 소속된 chunk slot으로 부터 free_size에 따라 다른 적절한 slot으로 옮겨다닌다.
- contig_bits (이전에는 contig_hints로불렸고, 사이즈가 바이트 단위였다.)
- chunk 내에서 가장 큰 연속된 free 공간의 크기이다. (비트당 4 바이트)
- contig_bits_start
- contig_bits가 시작되는 offset 비트이다.
- *alloc_map
- 할당을 표현하는 비트맵으로 각각의 비트는 4 바이트 단위로 할당 여부를 표현한다.
- *bound_map
- 경계를 표현하는 비트맵으로 각각의 비트는 4 바이트 단위로 관리되며 할당된 데이터의 시작 비트를 1로 표현한다.
- bound_map의 가장 마지막 비트도 1로 표현되어야 하므로 alloc_map의 사이즈보다 항상 1 비트가 더 크다.
- *md_blocks
- per-cpu 블럭 단위로 관리되는 메타데이터들을 가리킨다.
- chunk 내에서 이 메터 데이터를 사용하여 각 per-cpu 블럭별로 할당 가능 여부를 빠르게 스캔한다.
- data
- chunk가 할당된 페이지들을 가리키는 page 구조체 포인터 배열의 주소가 저장된다.
- immutable
- 해당 chunk가 변경될 수 있는지 여부를 나타낸다.
- base_addr
- chunk가 할당된 영역들 중 가장 낮은 가상 시작 주소이며 페이지 단위로 align된 주소를 사용한다.
- 페이지 단위로 align 되므로 align된 만큼의 offset 주소가 아래 start_offset에 담긴다.
- 예) 4K 페이지 단위를 사용하고, 시작 주소가 0x1_2340이고, 사이즈가 0x1000인 경우
- base_addr=0x1_2000, start_offset=0x340, end_offset=0xcb0
- 예) 4K 페이지 단위를 사용하고, 시작 주소가 0x1_2340이고, 사이즈가 0x1000인 경우
- start_offset
- chunk가 관리할 영역의 시작 주소와 페이지 단위로 내림 정렬된 시작 주소간의 차이(gap)이다.
- end_offset
- chunk가 관리할 영역의 끝 주소와 페이지 단위로 올림 정렬된 끝 주소간의 차이(gap)이다.
- nr_pages
- 청크가 사용할 수 있는 페이지 수 이다.
- nr_populated
- chunk 내에서 실제 물리 페이지가 할당되어 매핑되었고, 현재 사용중인 페이지 수이다.
- 새로운 chunk를 할당한 경우 실제 페이지가 매핑되지 않았으므로 이 값은 0이다.
- nr_empty_pop_pages
- chunk 내에서 실제 물리 페이지가 할당되어 매핑되었지만 현재 사용하지 않은 상태의 페이지 수이다.
- 새로운 chunk를 할당한 경우 실제 페이지가 매핑되지 않았으므로 이 값은 0이다.
- populated[]
- chunk 내에서 페이지 할당이 이루어진 영역과 아닌 영역을 관리하기 위한 배열이다.
- first chunk는 실제 페이지가 할당되었고 매핑도 이미 되어 있는 메모리를 사용하므로 모든 페이지가 1로 설정된다.
- 추가된 chunk는 실제 영역을 할당하여 사용하기 전에는 모든 페이지가 0으로 설정되어 있다.
- vmalloc 공간은 사용 중으로 관리되지만 물리 페이지가 할당되지 않고 매핑도 되어 있지 않은 상태이다.
기존(legacy) Areamap 방식에서 사용하던 멤버
- contig_hints (X)
- chunk 내에서 가장 큰 연속된 공간의 크기이다.
- 처음 만들어진 chunk의 경우 contig_hint는 free_size와 동일한 사이즈이다.
- 할당이 필요할 때 이 값 보다 큰 사이즈는 이 chunk에서 불가능하다.
- map_used (X)
- chunk 내에서 map[] 배열에서 사용하고 있는 항목 수를 가리킨다.
- 여기서 가리키는 수+1의 엔트리에는 가장 마지막 주소 offset+1(in-use flag)을 담고있다.
- 예) map_used=4인 경우 4+1개 엔트리를 사용한다.
- map_alloc (X)
- chunk 내에서 할당된 map 배열의 최대 항목 수이다. (처음 기본 값은 128개부터 시작하여 부족한 경우 확장된다.)
- map[] (X)
- map[] 배열은 런타임에 동적 확장되는 가변 배열이다.
- map 배열 크기가 확장되면 map_alloc 수가 그 만큼 증가된다.
- early memory allocator가 동작하는 중에는 맵 배열에 PERCPU_DYNAMIC_EARLY_SLOTS(128)개의 배열이 초기 선언되어 있다.
- slub memory allocator가 동작한 후에는 맵이 더 필요한 경우 커질 수 있다.
- map 배열 값의 구별
- old 배열 값 구분 방법(기존 방법)
- 양수는 unit 내에서 비어있는 공간의 크기이다.
- 음수는 사용중인 공간의 크기이다.
- new 배열 값 구분 방법이 2014년 3월 kernel v3.15-rc1에 적용되었다.
- 참고: percpu: store offsets instead of lengths in ->map[]
- 각 바이트는 사이즈를 의미하고 sizeof(int)로 align된 수치가 사용된다. 다만 사이즈의 마지막 다른 용도로 사용하므로 절삭하여 사용해야 한다.
- 마지막 비트는 할당 상태를 구분:
- 1=in-use(사용중) 상태
- 0=free(할당 가능) 상태
- 마지막 비트는 할당 상태를 구분:
- 예) 4 bytes free, 8 in use, 4 in use, 4 free, 12 in use, 100 free, 전체 유닛 크기=132, map_used=3
- old 방법: map[]= {4, -8, -4, 4, -12, 100, 0, }
- new 방법: map[]= {0, 5, 13, 16, 21, 32, 133, 0, }
- <0,0>, <4,1>, <12,1>, <16,0>, <20,1>, <32,0>, <132,1>와 같은 페어를 이루며 <offset, in-use flag>를 의미하고 실제 저장시 에는 offset의 1바이트를 in-use flag로 이용한다.
- 0~3까지 4 bytes free, 4~11까지 8 in use, 12~15까지 4 in use, 16~19까지 4 free, 20~31까지 32 in use, 32~131까지 100 free
- old 배열 값 구분 방법(기존 방법)
- map[] 배열은 런타임에 동적 확장되는 가변 배열이다.
pcpu_block_md 구조체
mm/percpu-internal.h
/* * pcpu_block_md is the metadata block struct. * Each chunk's bitmap is split into a number of full blocks. * All units are in terms of bits. */
struct pcpu_block_md {
int contig_hint; /* contig hint for block */
int contig_hint_start; /* block relative starting
position of the contig hint */
int left_free; /* size of free space along
the left side of the block */
int right_free; /* size of free space along
the right side of the block */
int first_free; /* block position of first free */
};
chunk 내의 비트맵으로 관리하는 맵에 대해 per-cpu 블럭(1 페이지를 4바이트 단위로 비트맵 표현) 단위로 관리하는데 이에 해당하는 메타 데이터이다.
- contig_hint
- 블럭 내에서 최대 free 영역에 대한 비트 수를 담고 있다.
- 예) contig_hint=16인 경우 이 블럭내에 16 x 4 bytes = 64 bytes의 최대 free 영역이 있음을 의미한다.
- 블럭 내에서 최대 free 영역에 대한 비트 수를 담고 있다.
- conting_hint_start
- 블럭 내에서 최대 free 영역이 시작하는 비트 위치
- left_free
- 이 블럭의 시작이 free 영역인 경우 free 영역의 비트 수를 담고 있다.
- right_free
- 이 블럭의 끝이 free 영역인 경우 free 영역의 비트 수를 담고 있다.
- first_free
- 이 블럭의 첫 free 영역을 가리키는 offset 비트를 담고 있다.
- 주의: left_free나 right_free와는 다르게 개 수가 아닌 포지션을 담고 있다.
pcpu_group_info 구조체
include/linux/percpu.h
struct pcpu_group_info {
int nr_units; /* aligned # of units */
unsigned long base_offset; /* base address offset */
unsigned int *cpu_map; /* unit->cpu map, empty
* entries contain NR_CPUS */
};
NUMA 시스템의 노드는 여기서 group으로 관리되며 각 그룹은 해당 노드에 속한 cpu들을 관리한다. UMA 시스템은 단일 노드이므로 1개의 그룹을 사용한다.
- nr_units
- 해당 그룹에서 사용하는 units 수
- base_offset
- 해당 그룹에서 사용하는 base_offset 주소
- *cpu_map[]
- 해당 그룹에서 사용하는 unit->cpu 매핑
pcpu_alloc_info 구조체
include/linux/percpu.h
struct pcpu_alloc_info {
size_t static_size;
size_t reserved_size;
size_t dyn_size;
size_t unit_size;
size_t atom_size;
size_t alloc_size;
size_t __ai_size; /* internal, don't use */
int nr_groups; /* 0 if grouping unnecessary */
struct pcpu_group_info groups[];
};
이 구조체는 setup_per_cpu_areas() 함수에서 per-cpu 데이터를 처음 초기화 작업을 하는 동안 함수 내에서 로컬 변수로 저장되고 사용된다. 초기화 후에는 없어지는 정보이므로 전역변수를 사용해야 한다. (예: unit->cpu 매핑을 할 때 등…)
- static_size
- 1개 유닛 내에서의 static 영역 사이즈
- rpi2: 예) 0x3ec0
- reserved_size
- 1개 유닛 내에서의 reserved 영역 사이즈로 CONFIG_MODULE 커널 옵션이 사용될 때 그 크기를 사용할 수 있다.
- rpi2: 8K.
- dyn_size
- 1개 유닛 내에서의 dyn_size 영역 사이즈로 아키텍첨마다 다르다.
- ARM도 값이 이전 보다 조금 더 커져서 32bit의 경우 20K, 64bit의 경우 28K를 기본 요청하게 되는데 static_size + reserved_size + dyn_size를 모두 합쳐서 4K align을 하게 되면 남는 공간이 생기는데 이를 dyn_size에 추가하였다.
- rpi2: 0x5140 (초기 요청 값은 32K로 0x5000)
- atom_size
- 최소 할당 사이즈
- ARM은 4K
- alloc_size
- 할당할 사이즈
- rpi2: 0xb000 x 4 = 0x3_c000
- nr_groups
- 그룹(노드) 수
- rpi2: 1
주요 전역 변수
- pcpu_unit_pages
- 1개 유닛에 포함된 페이지 수
- rpi2: 예) 0xb (1개 유닛 페이지=11개 페이지)
- 1개 유닛에 포함된 페이지 수
- pcpu_unit_size
- 1개 유닛 사이즈
- rpi2: 예) 0xb000 (1개 유닛 사이즈=44K)
- 1개 유닛 사이즈
- pcpu_nr_units
- 전체 유닛 수
- rpi2: 4 개
- 전체 유닛 수
- pcpu_atom_size
- 할당에 사용할 최소 페이지 사이즈로 ARM 및 ARM64에서는 PAGE_SIZE를 사용한다.
- x86-64비트 시스템 및 몇 개의 아키텍처에서는 huge 페이지인 2M page 등을 사용한다.
- pcpu_nr_slots
- 관리를 위한 슬롯 수
- 유닛 사이즈에 대응하는 슬롯 번호로 바꾸고 2를 더한 값
- rpi2: 유닛 사이즈가 44K 인 경우 슬롯 번호는 13, 따라서 2를 더하면 pcpu_nr_slots=15
- pcpu_chunk_struct_size
- first chunk를 만들 때 설정되는 값으로 chunk 구조체 사이즈 + populated 비트맵 바이트 수(unit 사이즈에 따라 결정된다.)
- pcpu_low_unit_cpu
- base addr가 가장 하단에 위치한 cpu 번호
- rpi2: 0
- pcpu_high_unit_cpu
- base_addr가 가장 상단에 위치한 cpu 번호
- rpi2: 3
- pcpu_base_addr
- first chunk가 할당된 가상 시작 주소
- pcpu_unit_map[]
- cpu -> unit 매핑
- rpi2: { 0, 1, 2, 3 }
- pcpu_unit_offsets[]
- 각 unit의 시작 offset을 저장한 배열
- rpi2: { 0, 0xb000, 0x1_6000, 0x2_1000 }
- 각 unit의 시작 offset을 저장한 배열
- pcpu_nr_groups
- group 수 (NUMA node 수)
- rpi2: 1
- group 수 (NUMA node 수)
- pcpu_group_offsets[]
- 각 group의 시작 offset을 저장한 배열
- rpi2: 0
- 각 group의 시작 offset을 저장한 배열
- pcpu_group_sizes[]
- 각 group의 크기를 저장한 배열
- rpi2: { 0x2_c000 }
- 각 group의 크기를 저장한 배열
- pcpu_first_chunk
- first chunk에서 dynamic 영역 맵을 관리하는 pcpu_chunk 구조체 포인터
- pcpu_reserved_chunk
- first chunk에서 reserved 영역 맵을 관리하는 pcpu_chunk 구조체 포인터
- 모듈을 사용하지 않을 때 null
- pcpu_reserved_chunk_limit
- reserved 영역이 있는 경우 static size와 reserved_size를 더한 값
- pcpu_slot[]
- pcpu_nr_slots로 배열 크기를 관리하고 각 배열에는 chunk를 가리키는 list_head가 담긴다.
- 마지막 슬롯은 empty 청크를 위한 슬롯이다.
- 이 슬롯 배열은 dynamic area를 사용하는 chunk들을 관리한다.
- rpi2: static_size=0x3ec0, reserved_size=0x2000, dyn_size=0x5140 예)
- first chunk의 free_size=0x5140이며, 슬롯은 12번 슬롯이다.
- reserved chunk의 free_size=0x5ec0이지만 reserved chunk는 모듈을 로드할 때 할당되므로 dynamic 영역을 관리하는 pcpu_slot[]에서 관리하지 않는다.
- 따라서 처음 per-cpu 데이터가 초기화될 때 pcpu_slot[12]에는 1 개의 first chunk가 리스트로 연결되어 구성되고 추후 마지막 slot에 예비 empty chunk가 추가된다.
- pcpu_nr_empty_pop_pages
- dynamic 영역만을 관리하는 추가된 chunk에서 비어있는 populated pages의 수를 나타낸다.
- 이 때 first chunk의 reserve 영역을 관리하는 reserved chunk는 당연히 영향을 끼치지 않는다.
- pcpu_async_enabled
- per-cpu 영역의 free에 대한 async를 허용하는 경우 pcpu_balance_workfn() 함수가 스케쥴되어 late하게 동작된다.
- 커널이 초기화되고 initcall이 호출되는 시점에서 enable 된다.
- pcpu_atomic_alloc_failed
- atomic allocation이 실패한 경우 true로 바뀐다.
참고
- Per-cpu -1- (Basic) | 문c – 현재글
- Per-cpu -2- (초기화) | 문c
- Per-cpu -3- (동적 할당) | 문c
- Per-cpu -4- (atomic operations) | 문c
- Per-CPU Variables
- robust per_cpu allocation for modules | LWN.net
- per-CPU 메모리 관리 (1) | F/OSS
- per-CPU 메모리 관리 (2) | F/OSS
- Documentation/preempt-locking.txt | kernel.org
- Better per-CPU variables | LWN.net
- What every programmer should know about memory, Part 1 | LWN.net
- ARM: implement optimized percpu variable access | LWN.net
안녕하세요. 항상 잘 보고 있어서 감사드립니다~
오늘 다시 복습 중에 보다가
# CPU -> Unit 매핑
per-cpu 데이터는 NR_CPUS 수만큼 배열을 사용하기 때문에
<>에는 메모리가 낭비될 수 있다.
수천 개의 cpu를 지원하도록 설정(NR_CPUS)된 시스템에서 실제 부팅 시 동작될 예정인(possible 상태) cpu가 몇 개 안 될 때가 있기 때문이다.
<> 친 부분이 제가 이해를 잘못하는 건지 아래 줄이랑 의미가 차이가 있는 것 같아서
“부팅 이후 시스템이 사용할 cpu 의 수가 NR_CPUS 보다 작을 경우”
제가 이해한 내용이 맞나요?
[[실제 존재하는 cpu 의 수보다 큰 수를 사용하는 경우]]
[[ … ]] 친 부분이 제가 이해를 잘못하는 건지 아래 줄이랑 의미가 차이가 있는 것 같아서
“부팅 이후 시스템이 사용할 cpu 의 수가 NR_CPUS 보다 작을 경우”
안녕하세요?
조금 풀어 설명드리면 다음과 같이 동일한 의미입니다.
per-cpu 데이터는 NR_CPUS 수만큼 배열을 사용하기 때문에
1) 실제 존재하는 cpu의 수보다 큰 수 -> 실제 존재하는 cpu의 수보다 NR_CPUS의 수가 더 클 경우
2) 실제 존재하는 cpu의 수보다 큰 수 -> 빌드된 커널이 사용한 NR_CPUS는 큰 수인데, 부팅한 시스템이 그 보다 적은 수의 cpu를 가진 경우
3) 실제 존재하는 cpu의 수보다 큰 수 -> 부팅 이후 시스템이 사용할 cpu 의 수가 NR_CPUS 보다 작을 경우 (이파란님)
참고로 CONFIG_NR_CPUS 커널 옵션은 arm64 디폴트의 경우 몇 번 바뀌어 왔고, 커널 v5.1부터 64개에서 256개로 상향하였습니다. 그 이후 최근 v5.12까지 변동없습니다.
감사합니다.
질문으로 더 깊은 지식을 얻어가네요! 항상 감사드립니다~
댓글에 추가적으로 말씀해주신 내용에서
CONFIG_NR_CPUS 관련 호기심이 생겨서 질문하나 추가로 드려도 될까요?
제가 만약에 CPU 코어가 4000개 짜리 프로세서가 있으면,
직접 수정해서 NR_CPUS 값을 4000개로 만들어주어야 per-cpu 데이터를 효과적으로 쓸 수 있나요?
CONFIG_NR_CPUS 값은 빌드할 커널이 지원하는 최대 수의 cpu를 의미합니다.
디폴트 값이 4096일 때 4000개의 cpu를 가진 경우 수정할 필요 없습니다.
만일 8000개의 cpu를 가진 경우 8000개 이상으로 수정해야 시스템이 동작할 수 있습니다.
물론 시스템의 cpu 수와 동일한 CONFIG_NR_CPUS 값을 사용하면 메모리 낭비가 없어 좋긴 하지만,
하나의 커널 이미지로 여러 시스템에서 돌릴 수 있게 하기 위해 조금 큰 수를 사용합니다.
감사합니다.
네 초보적인 질문인데도 잘 설명해주셔서 감사합니다!
좋은 하루되세요~
항상 감사드립니다.
다음 그림은 가장 낮은 주소의 unit으로 부터 각각의 unit의 시작 offset이 지정되는 것을 보여준다.
pcpu_unit_offset[] 배열의 초기화는 pcpu_setup_first_chunk() 함수를 참고한다.
percpu-3a.png 그림에서
예) node #0 -> 2 cpu
[[ 2 cpu ]] -> [[ 4 cpu ]] 인가요?
지적해주신 것 처럼 첫 번째 노드의 cpu 수는 2가 아니라 4입니다. 오타입니다. ^^;
node #0 -> 4 cpus로 수정합니다.
감사합니다.