<kernel v5.0>
DMA -4- (DMA Mapping)
Coherent 매핑이 아닌 Streaming 매핑을 사용하는 경우 DMA 전송 전/후로 매번 매핑 및 매핑 해제(sync 동작)가 필요하다.
- DMA 전/후로 캐시 sync 동작 및 iommu 매핑/매핑 해제를 수행한다.
- DMA 방향에 따라 캐시를 clean 하거나, invalidate 한다.
- DMA를 사용하는 디바이스가 iommu 사용 시 매핑 및 매핑 해제를 수행한다.
- 시스템 DRAM 보다 DMA 영역이 작은 경우 bounce buffer가 필요하다.
- 이러한 경우에는 데이터 copy가 필요한 swiotlb를 사용한다.
- 디폴트 bounce buffer는 64MB이다.
- 접근 가능한 DMA 주소 범위안에서 bounce buffer가 할당된다.
- ARM64의 경우 ZONE_DMA32를 사용하는 경우 4GB 물리 주소로 제한된다.
DMA 매핑 종류
다음과 같이 두 종류의 dma 매핑 중 하나를 선택하여 사용한다.
- constant dma 매핑
- driver 초기화 때 개별 매핑이 필요 없어 dma 전송 전/후로 매핑을 하지 않는다.
- streaming dma 매핑
- dma 전송 전/후로 매핑이 필요한 경우 사용한다.
스트리밍 DMA 매핑 종류
- Single
- 물리적으로 연속된 하나의 DMA 버퍼를 사용한다.
- Scatter/Gather
- 물리적으로 분산된 DMA 버퍼를 사용한다.
- 한 번의 DMA 동작에 여러 개의 DMA 버퍼에 전송하도록 하는데, 물리적으로 연속된 DMA 버퍼처럼 동작한다.
- 진보된 dma 컨트롤러에서만 이 기능을 사용할 수 있다.
스트리밍 dma – single 매핑/해제
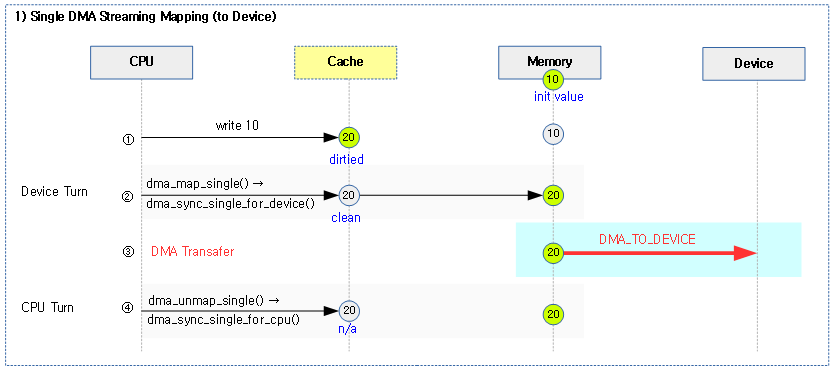
다음 그림은 RAM에서 Device로 DMA 전송할 때의 캐시에 대한 single 스트리밍 매핑/해제 과정을 보여준다.
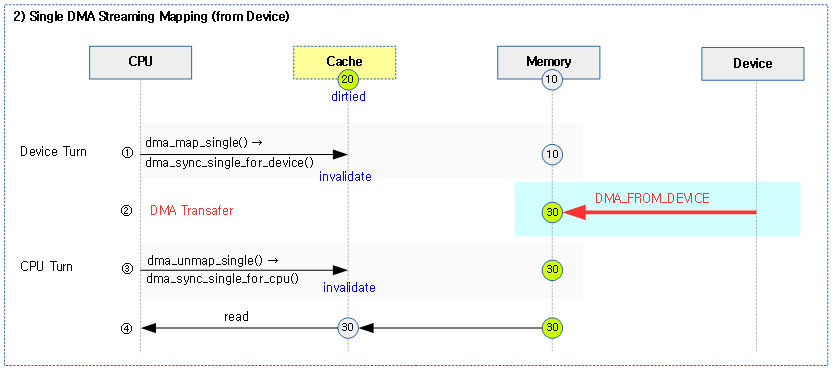
다음 그림은 Device로부터 RAM으로 DMA 전송할 때의 캐시에 대한 single 스트리밍 매핑/해제 과정을 보여준다.
single 매핑
다음 그림은 single 매핑에 대해 함수간 호출 관계를 보여준다.
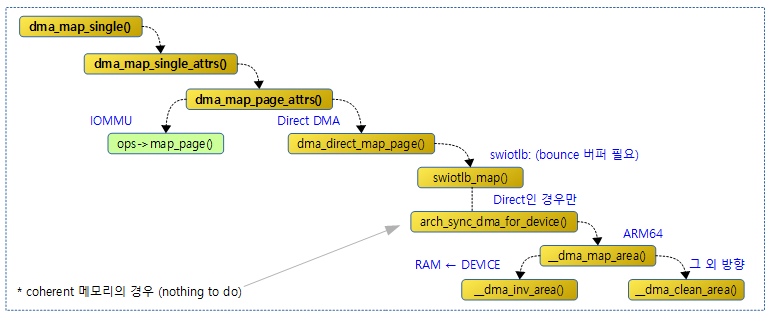
dma_map_single()
include/linux/dma-mapping.h
#define dma_map_single(d, a, s, r) dma_map_single_attrs(d, a, s, r, 0)
single 공간을 대상으로 dma 스트리밍 매핑을 수행한다.
- d: 디바이스
- a: 가상 주소
- s: 사이즈
- r: DMA 방향
dma_map_single_attrs()
include/linux/dma-mapping.h
static inline dma_addr_t dma_map_single_attrs(struct device *dev, void *ptr,
size_t size, enum dma_data_direction dir, unsigned long attrs)
{
debug_dma_map_single(dev, ptr, size);
return dma_map_page_attrs(dev, virt_to_page(ptr), offset_in_page(ptr),
size, dir, attrs);
}
single 공간을 대상으로 dma 스트리밍 매핑을 수행하는데, 옵션으로 속성 값을 지정할 수 있다.
dma_map_page_attrs()
include/linux/dma-mapping.h
static inline dma_addr_t dma_map_page_attrs(struct device *dev,
struct page *page, size_t offset, size_t size,
enum dma_data_direction dir, unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
dma_addr_t addr;
BUG_ON(!valid_dma_direction(dir));
if (dma_is_direct(ops))
addr = dma_direct_map_page(dev, page, offset, size, dir, attrs);
else
addr = ops->map_page(dev, page, offset, size, dir, attrs);
debug_dma_map_page(dev, page, offset, size, dir, addr);
return addr;
}
한 개의 페이지를 대상으로 dma 스트리밍 매핑을 수행하는데, 옵션으로 속성 값을 지정할 수 있다.
- 코드 라인 9~12에서 디바이스에 IOMMU dma 매핑 오퍼레이션이 제공되는 경우 (*map_page) 후크 함수를 호출한다. 그렇지 않은 경우 주소 변환 없이 사용하는 direct 매핑을 하도록 호출한다.
dma_direct_map_page()
kernel/dma/direct.c
dma_addr_t dma_direct_map_page(struct device *dev, struct page *page,
unsigned long offset, size_t size, enum dma_data_direction dir,
unsigned long attrs)
{
phys_addr_t phys = page_to_phys(page) + offset;
dma_addr_t dma_addr = phys_to_dma(dev, phys);
if (unlikely(!dma_direct_possible(dev, dma_addr, size)) &&
!swiotlb_map(dev, &phys, &dma_addr, size, dir, attrs)) {
report_addr(dev, dma_addr, size);
return DMA_MAPPING_ERROR;
}
if (!dev_is_dma_coherent(dev) && !(attrs & DMA_ATTR_SKIP_CPU_SYNC))
arch_sync_dma_for_device(dev, phys, size, dir);
return dma_addr;
}
EXPORT_SYMBOL(dma_direct_map_page);
한 개의 페이지를 대상으로 주소 변환 없는 direct 매핑을 수행한다.
- 코드 라인 8~12에서 DMA 영역이 제한되어 bounce buffer를 사용하는 sw-iotlb 매핑이 필요한 경우 이를 수행한다.
- 코드 라인 14~15에서 디바이스가 coherent 연동되지 않고 skip cpu sync 속성 요청되지 않은 경우 디바이스의 DMA 전송 전에 아키텍처별로 제공되는 sync를 요청한다.
arch_sync_dma_for_device() – ARM64
arch/arm64/mm/dma-mapping.c
void arch_sync_dma_for_device(struct device *dev, phys_addr_t paddr,
size_t size, enum dma_data_direction dir)
{
__dma_map_area(phys_to_virt(paddr), size, dir);
}
ARM64 아키텍처의 경우 디바이스의 DMA 전송 전에 디바이스 턴을 위해 DMA 방향에 따른 캐시 sync를 요청한다.
__dma_map_area()
arch/arm64/mm/cache.S
/* * __dma_map_area(start, size, dir) * - start - kernel virtual start address * - size - size of region * - dir - DMA direction */
ENTRY(__dma_map_area)
cmp w2, #DMA_FROM_DEVICE
b.eq __dma_inv_area
b __dma_clean_area
ENDPIPROC(__dma_map_area)
ARM64 아키텍처의 경우 디바이스의 DMA 전송 전에 DMA 방향에 따른 캐시 sync를 다음과 같이 수행한다.
- DEVICE -> RAM 방향인 경우 기존 값은 의미가 없으므로 성능 향상을 위해 캐시를 clean 하지 않고 invalidate를 수행한다.
- 그 외의 방향은 clean을 수행한다.
single 매핑 해제
다음 그림은 single 매핑 해제에 대해 함수간 호출 관계를 보여준다.
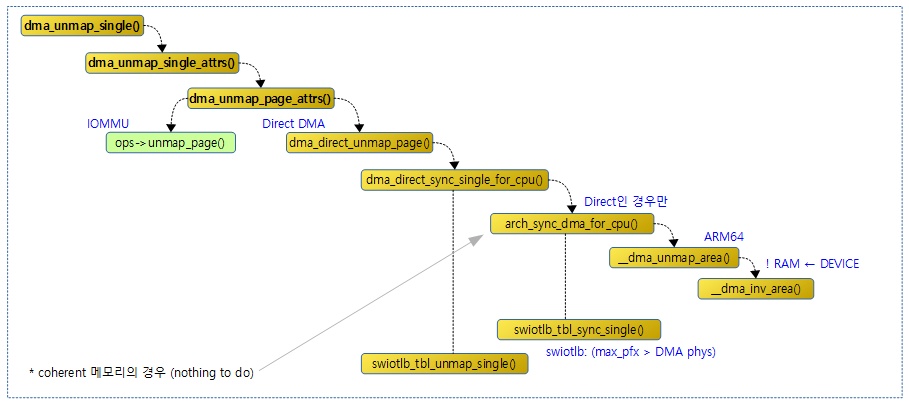
dma_unmap_single()
include/linux/dma-mapping.h
#define dma_unmap_single(d, a, s, r) dma_unmap_single_attrs(d, a, s, r, 0)
single 공간을 대상으로 dma 스트리밍 매핑을 해제한다.
- d: 디바이스
- a: 가상 주소
- s: 사이즈
- r: DMA 방향
dma_unmap_single_attrs()
include/linux/dma-mapping.h
static inline void dma_unmap_single_attrs(struct device *dev, dma_addr_t addr,
size_t size, enum dma_data_direction dir, unsigned long attrs)
{
return dma_unmap_page_attrs(dev, addr, size, dir, attrs);
}
single 공간을 대상으로 dma 스트리밍 매핑을 해제하는데, 옵션으로 속성 값을 지정할 수 있다.
dma_unmap_page_attrs()
include/linux/dma-mapping.h
static inline void dma_unmap_page_attrs(struct device *dev, dma_addr_t addr,
size_t size, enum dma_data_direction dir, unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
BUG_ON(!valid_dma_direction(dir));
if (dma_is_direct(ops))
dma_direct_unmap_page(dev, addr, size, dir, attrs);
else if (ops->unmap_page)
ops->unmap_page(dev, addr, size, dir, attrs);
debug_dma_unmap_page(dev, addr, size, dir);
}
한 개의 페이지를 대상으로 dma 스트리밍 매핑을 해제하는데, 옵션으로 속성 값을 지정할 수 있다.
- 코드 라인 7~10에서 디바이스에 IOMMU dma 매핑 해제 오퍼레이션이 제공되는 경우 (*unmap_page) 후크 함수를 호출한다. 그렇지 않은 경우 주소 변환 없이 사용하는 direct 매핑 해제를 하도록 호출한다.
dma_direct_unmap_page()
kernel/dma/direct.c
void dma_direct_unmap_page(struct device *dev, dma_addr_t addr,
size_t size, enum dma_data_direction dir, unsigned long attrs)
{
phys_addr_t phys = dma_to_phys(dev, addr);
if (!(attrs & DMA_ATTR_SKIP_CPU_SYNC))
dma_direct_sync_single_for_cpu(dev, addr, size, dir);
if (unlikely(is_swiotlb_buffer(phys)))
swiotlb_tbl_unmap_single(dev, phys, size, dir, attrs);
}
EXPORT_SYMBOL(dma_direct_unmap_page);
한 개의 페이지를 대상으로 주소 변환 없는 direct 매핑을 해제한다.
- 코드 라인 6~7에서 skip cpu sync 속성 요청되지 않은 경우 디바이스의 DMA 전송 후에 아키텍처별로 제공되는 sync를 요청한다
- 코드 라인 9~10에서 DMA 영역이 제한되어 bounce buffer를 사용하면 sw-iotlb 매핑 해제를 수행한다.
dma_direct_sync_single_for_cpu()
kernel/dma/direct.c
void dma_direct_sync_single_for_cpu(struct device *dev,
dma_addr_t addr, size_t size, enum dma_data_direction dir)
{
phys_addr_t paddr = dma_to_phys(dev, addr);
if (!dev_is_dma_coherent(dev)) {
arch_sync_dma_for_cpu(dev, paddr, size, dir);
arch_sync_dma_for_cpu_all(dev);
}
if (unlikely(is_swiotlb_buffer(paddr)))
swiotlb_tbl_sync_single(dev, paddr, size, dir, SYNC_FOR_CPU);
}
EXPORT_SYMBOL(dma_direct_sync_single_for_cpu);
디바이스의 DMA 전송 후 cpu 턴을 위해 DMA 방향에 따른 캐시 sync를 요청한다.
- 코드 라인 6~9에서 아키텍처에 따른 sync를 수행한다.
- 코드 라인 11~12에서 DMA 영역이 제한되어 bounce buffer를 사용하면 sw-iotlb 싱크를 수행한다.
arch_sync_dma_for_cpu() – ARM64
arch/arm64/mm/dma-mapping.c
void arch_sync_dma_for_cpu(struct device *dev, phys_addr_t paddr,
size_t size, enum dma_data_direction dir)
{
__dma_unmap_area(phys_to_virt(paddr), size, dir);
}
ARM64 아키텍처의 경우 디바이스의 DMA 전송 후 cpu 턴을 위해 DMA 방향에 따른 캐시 sync를 요청한다.
__dma_unmap_area()
arch/arm64/mm/cache.S
/* * __dma_unmap_area(start, size, dir) * - start - kernel virtual start address * - size - size of region * - dir - DMA direction */
ENTRY(__dma_unmap_area)
cmp w2, #DMA_TO_DEVICE
b.ne __dma_inv_area
ret
ENDPIPROC(__dma_unmap_area)
ARM64 아키텍처의 경우 디바이스의 DMA 전송 후에 DMA 방향에 따른 캐시 sync를 다음과 같이 수행한다.
- DEVICE <- RAM 방향인 경우 디바이스가 캐시에 write 접근을 하지 않은 경우이므로 캐시를 invalidate하거나 clean 할 필요 없다.
- 또한 그 외의 방향에서는 디바이스가 메모리에 기록하였을지도 모르므로 CPU의 캐시들은 모두 invalidate를 하여 메모리에 아무런 변경을 하지 못하게 한다.
스트리밍 dma – scatter/gather 매핑/해제
분산된 물리 메모리를 DMA 버퍼용도로 할당 받은 후 이들의 정보를 scaterlist 구조체에 대입하고 이를 배열로 요청하여 DMA 전송 요청 전/후로 등록된 DMA 버퍼들에 대해 DMA Streaming 매핑을 한꺼번에 수행할 때 scatter/gather 매핑을 사용한다.
- DMA 전송 시 물리메모리가 연속된 것처럼 한꺼번에 이루어진다.
다음 그림은 3개의 DMA 버퍼로 구성된 scatterlist 배열을 보여준다.
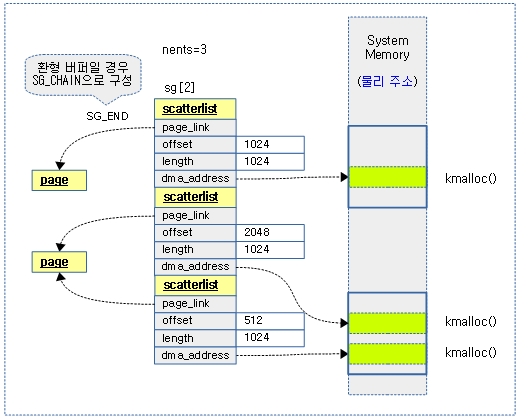
scatter/gather 매핑
DMA 전송할 여러 개의 영역을 한 꺼번에 매핑을 수행한다.
dma_map_sg()
include/linux/dma-mapping.h
#define dma_map_sg(d, s, n, r) dma_map_sg_attrs(d, s, n, r, 0)
여러 개의 공간을 대상으로 dma 스트리밍 매핑을 수행한다.
- d: 디바이스
- s: 여러 영역 정보를 리스트한 scatterlist
- n: 엔트리 수
- r: DMA 방향
dma_map_sg_attrs()
include/linux/dma-mapping.h
/* * dma_maps_sg_attrs returns 0 on error and > 0 on success. * It should never return a value < 0. */
static inline int dma_map_sg_attrs(struct device *dev, struct scatterlist *sg,
int nents, enum dma_data_direction dir,
unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
int ents;
BUG_ON(!valid_dma_direction(dir));
if (dma_is_direct(ops))
ents = dma_direct_map_sg(dev, sg, nents, dir, attrs);
else
ents = ops->map_sg(dev, sg, nents, dir, attrs);
BUG_ON(ents < 0);
debug_dma_map_sg(dev, sg, nents, ents, dir);
return ents;
}
인자 @sg로 전달받은 여러 공간을 대상으로 dma 스트리밍 매핑을 수행하는데, 옵션으로 속성 값을 지정할 수 있다.
- 코드 라인 9~12에서 디바이스에 IOMMU dma 매핑 오퍼레이션이 제공되는 경우 (*map_sg) 후크 함수를 호출한다. 그렇지 않은 경우 주소 변환 없이 사용하는 direct sg 매핑을 하도록 호출한다.
dma_direct_map_sg()
kernel/dma/direct.c
int dma_direct_map_sg(struct device *dev, struct scatterlist *sgl, int nents,
enum dma_data_direction dir, unsigned long attrs)
{
int i;
struct scatterlist *sg;
for_each_sg(sgl, sg, nents, i) {
sg->dma_address = dma_direct_map_page(dev, sg_page(sg),
sg->offset, sg->length, dir, attrs);
if (sg->dma_address == DMA_MAPPING_ERROR)
goto out_unmap;
sg_dma_len(sg) = sg->length;
}
return nents;
out_unmap:
dma_direct_unmap_sg(dev, sgl, i, dir, attrs | DMA_ATTR_SKIP_CPU_SYNC);
return 0;
}
EXPORT_SYMBOL(dma_direct_map_sg);
인자 @sgl로 전달받은 여러 공간을 대상으로 엔트리 수(@nents)만큼 dma 페이지 매핑을 수행하는데, 옵션으로 속성 값을 지정할 수 있다.
scatter/gather 매핑 해제
DMA 전송할 여러 개의 영역을 한 꺼번에 매핑해제를 수행한다.
dma_unmap_sg()
include/linux/dma-mapping.h
#define dma_unmap_sg(d, s, n, r) dma_unmap_sg_attrs(d, s, n, r, 0)
여러 개의 공간을 대상으로 dma 스트리밍 매핑 해제를 수행한다.
- d: 디바이스
- s: 여러 영역 정보를 리스트한 scatterlist
- n: 엔트리 수
- r: DMA 방향
dma_unmap_sg_attrs()
include/linux/dma-mapping.h
static inline void dma_unmap_sg_attrs(struct device *dev, struct scatterlist *sg,
int nents, enum dma_data_direction dir,
unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
BUG_ON(!valid_dma_direction(dir));
debug_dma_unmap_sg(dev, sg, nents, dir);
if (dma_is_direct(ops))
dma_direct_unmap_sg(dev, sg, nents, dir, attrs);
else if (ops->unmap_sg)
ops->unmap_sg(dev, sg, nents, dir, attrs);
}
인자 @sg로 전달받은 여러 공간을 대상으로 dma 스트리밍 매핑 해제를 수행하는데, 옵션으로 속성 값을 지정할 수 있다.
- 코드 라인 9~12에서 디바이스에 IOMMU dma 매핑 오퍼레이션이 제공되는 경우 (*unmap_sg) 후크 함수를 호출한다. 그렇지 않은 경우 주소 변환 없이 사용하는 direct sg 매핑 해제를 호출한다.
dma_direct_unmap_sg()
kernel/dma/direct.c
void dma_direct_unmap_sg(struct device *dev, struct scatterlist *sgl,
int nents, enum dma_data_direction dir, unsigned long attrs)
{
struct scatterlist *sg;
int i;
for_each_sg(sgl, sg, nents, i)
dma_direct_unmap_page(dev, sg->dma_address, sg_dma_len(sg), dir,
attrs);
}
EXPORT_SYMBOL(dma_direct_unmap_sg);
인자 @sgl로 전달받은 여러 공간을 대상으로 엔트리 수(@nents)만큼 dma 페이지 매핑 해제를 수행하는데, 옵션으로 속성 값을 지정할 수 있다.
scatter/gather 테이블
sg_kmalloc()
lib/scatterlist.c
/* * The default behaviour of sg_alloc_table() is to use these kmalloc/kfree * helpers. */
static struct scatterlist *sg_kmalloc(unsigned int nents, gfp_t gfp_mask)
{
if (nents == SG_MAX_SINGLE_ALLOC) {
/*
* Kmemleak doesn't track page allocations as they are not
* commonly used (in a raw form) for kernel data structures.
* As we chain together a list of pages and then a normal
* kmalloc (tracked by kmemleak), in order to for that last
* allocation not to become decoupled (and thus a
* false-positive) we need to inform kmemleak of all the
* intermediate allocations.
*/
void *ptr = (void *) __get_free_page(gfp_mask);
kmemleak_alloc(ptr, PAGE_SIZE, 1, gfp_mask);
return ptr;
} else
return kmalloc_array(nents, sizeof(struct scatterlist),
gfp_mask);
}
@nents개의 scatterlist 배열을 담을 메모리를 할당받는다.
- 보통 1페이지를 채워서 받을 수 있도록 @nents=SG_MAX_SINGLE_ALLOC을 지정할 수 있다.
- sg_kfree()
- 할당 해제 API
sg_init_table()
lib/scatterlist.c
/** * sg_init_table - Initialize SG table * @sgl: The SG table * @nents: Number of entries in table * * Notes: * If this is part of a chained sg table, sg_mark_end() should be * used only on the last table part. * **/
void sg_init_table(struct scatterlist *sgl, unsigned int nents)
{
memset(sgl, 0, sizeof(*sgl) * nents);
sg_init_marker(sgl, nents);
}
EXPORT_SYMBOL(sg_init_table);
sg 테이블을 초기화한다. 마지막 엔트리는 SG_END 마킹을 한다.
/** * sg_init_marker - Initialize markers in sg table * @sgl: The SG table * @nents: Number of entries in table * **/
static inline void sg_init_marker(struct scatterlist *sgl,
unsigned int nents)
{
sg_mark_end(&sgl[nents - 1]);
}
sgl의 마지막 엔트리를 SG_END 마킹 한다.
/** * sg_mark_end - Mark the end of the scatterlist * @sg: SG entryScatterlist * * Description: * Marks the passed in sg entry as the termination point for the sg * table. A call to sg_next() on this entry will return NULL. * **/
static inline void sg_mark_end(struct scatterlist *sg)
{
/*
* Set termination bit, clear potential chain bit
*/
sg->page_link |= SG_END;
sg->page_link &= ~SG_CHAIN;
}
요청한 sg를 SG_END 마킹한다. (SG_CHAIN이 있는 경우 제거)
기타 Scatter/Gather API
- sg_next()
- sg_next_ptr()
- sg_chain()
- sg_nents()
- sg_nents_for_len()
- sg_last()
- sg_set_page()
- sg_set_buf()
- sg_mark_end()
Chained Scatter/Gather Table
- sg 테이블을 여러 개 할당받아 chain으로 연결하여 대규모 전송을 통한 성능 향상을 위해 사용한다.
- block io 전송에 사용되고 있다.
- 관련 API
- sg_alloc_table()
- __sg_alloc_table()
- sg_alloc_table_from_pages()
- __sg_alloc_table_from_pages()
- sgl_alloc()
- sgl_alloc_order()
- sgl_free()
- sgl_free_order()
- sgl_free_n_order()
- sgl_free_order()
- sg_copy_from_buffer()
- sg_copy_buffer()
- sg_miter_start()
- sg_miter_skip()
- sg_miter_stop()
- sg_copy_buffer()
- sg_copy_to_buffer()
- sg_zero_buffer()
- sg_alloc_table()
- 참고
- The chained scatterlist API (2007) | LWN.net
- Rationalizing scatter/gather chains (2007) | LWN.net
참고
- DMA -1- (Basic) | 문c
- DMA -2- (DMA Coherent Memory) | 문c
- DMA -3- (DMA Pool) | 문c
- DMA -4- (DMA Mapping) | 문c – 현재 글
- DMA -5- (IOMMU) | 문c
- DMA -6- (DMAEngine Subsystem) | 문c
- IOMMU | 문c