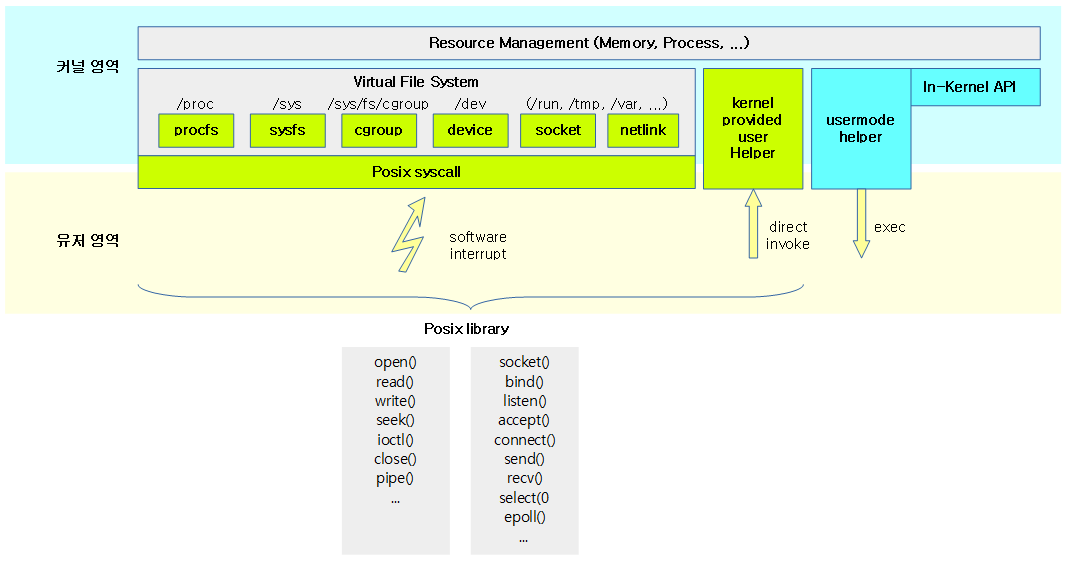
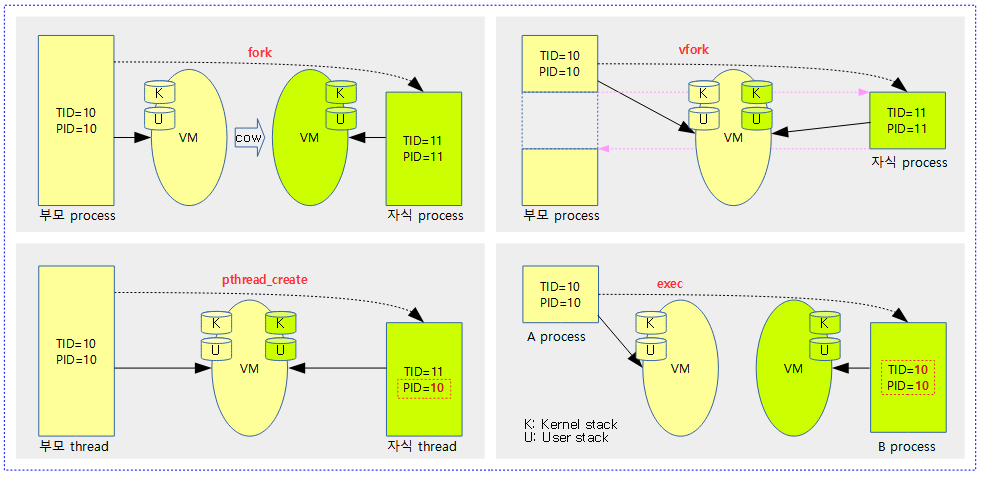
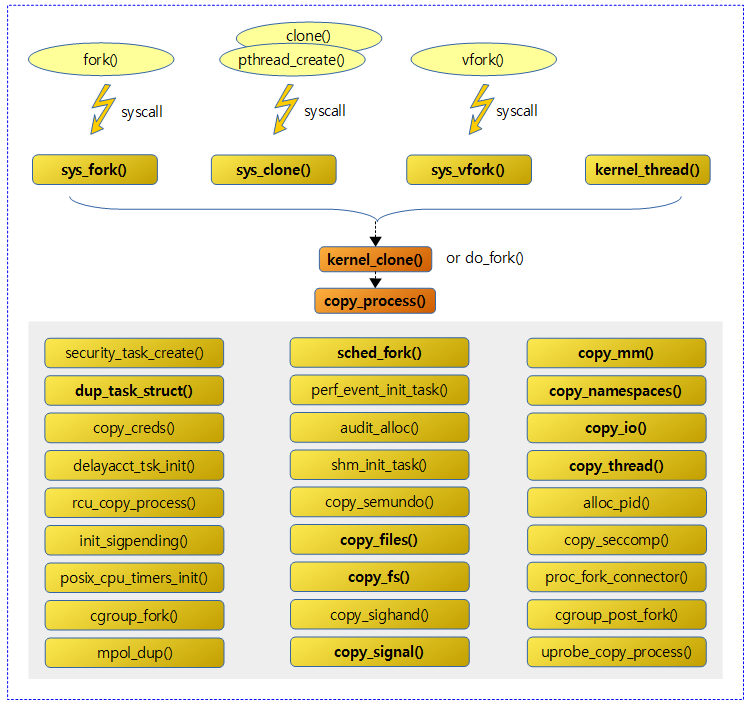
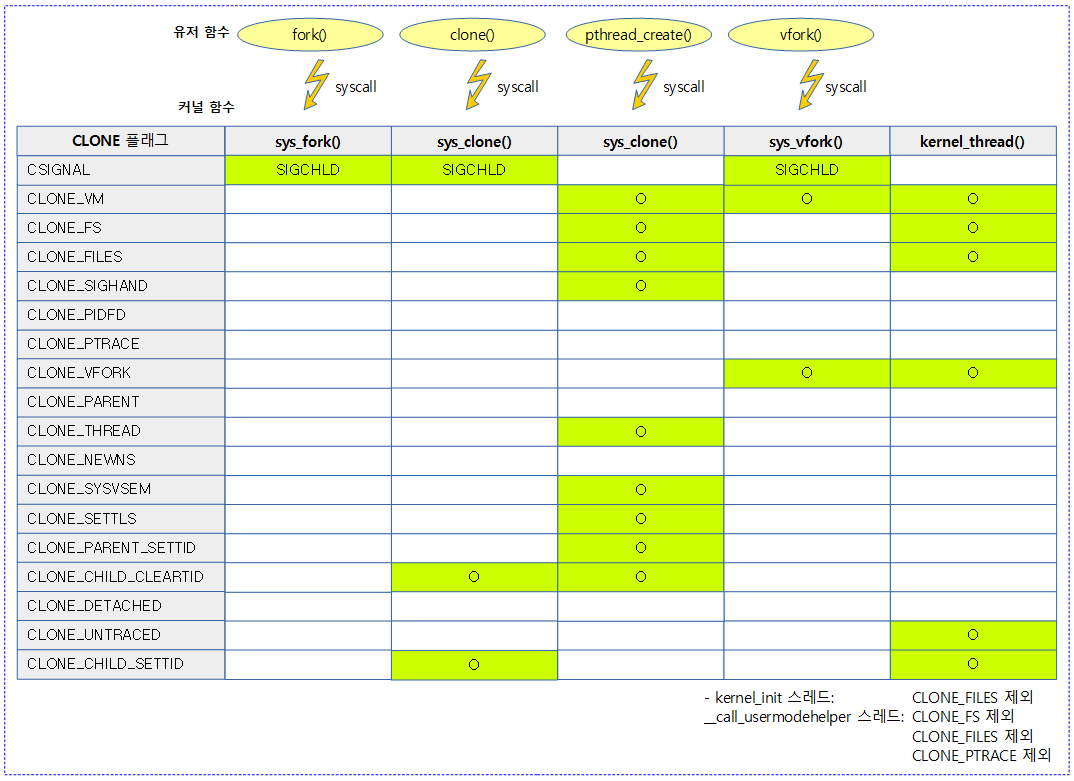
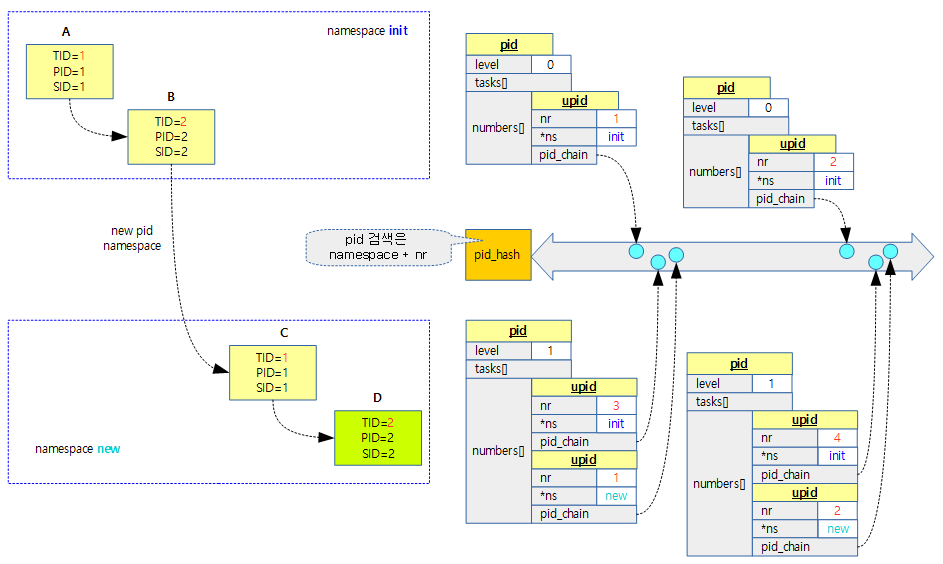
<kernel v5.4>
RCU NO-CB (Offload RCU callback)
rcu의 콜백을 처리하는 유형은 큰 흐름으로 다음과 같이 두 가지로 나뉜다.
- cb 용
- 1) softirq(디폴트)에서 처리하거나, 2) cb용 콜백 처리 커널 스레드에서 처리된다.
- softirq로 처리될 때 interrupt context에서 곧장 호출되어 처리되고 만일 softirq 처리 건 수가 많아져 지연되는 경우 softirqd 커널 스레드에서 호출되어 처리된다.
- softirq로 처리되는 경우 latency가 짧아 빠른 호출이 보장된다.
- no-cb 용
- 전용 no-cb용 콜백 처리 커널 스레드에 위탁(offloaded) 시켜 처리하는 것으로 latency는 약간 저하되지만 절전과 성능을 만족시키는 옵션이다.
- nohz full cpu들을 지정하거나 no-cb cpu들을 지정하는 경우 no-cb용으로 위탁(offloaded)하여 사용한다.
- 예) “nohz_full=3-7”, 예) “rcu_nocbs=3-7”
- no-cb cpu 지정을 위해 CONFIG_RCU_NOCB_CPU 커널 옵션을 사용하고 다음 3가지 중 하나를 선택할 수 있다.
- CONFIG_RCU_NOCB_CPU_NONE
- 디폴트로 nocb 지정된 cpu는 없지만 “nocbs=” 커널 파라메터로 특정 cpu들을 nocb로 지정할 수 있다.
- CONFIG_RCU_NOCB_CPU_ZERO
- 디폴트로 cpu#0을 nocb 지정한다. 추가로 “nocbs=” 커널 파라메터를 사용하여 다른 cpu들을 nocb로 지정할 수 있다.
- CONFIG_RCU_NOCB_CPU_ALL
bypass 콜백 리스트
커널 v5.4-rc1에서 각 cpu에 있는 seg 콜백 리스트에 3 군데 사용처(cb 호출, nocb gp 커널 스레드, nocb 커널 스레드)의 과도한 lock contention을 줄이기 위해 nocb_nobypass_lim_per_jiffy(디폴트: ms당 16개) 개 이상 유입되는 콜백을 등록하는 경우 일시적으로 bypass 콜백 리스트에 추가한 후 nocb_bypass 콜백 수가 qhimark를 초과하거나 새 틱으로 전환될 때 seg 콜백 리스트에 플러시하여 lock contention에 대한 부담을 줄여 성능을 높일 수 있도록 설계되었다.
no-cb용 rcu 초기화
RCU NO-CB 설정
rcu_is_nocb_cpu()
kernel/rcu/tree_plugin.h
/* Is the specified CPU a no-CBs CPU? */
bool rcu_is_nocb_cpu(int cpu)
{
if (have_rcu_nocb_mask)
return cpumask_test_cpu(cpu, rcu_nocb_mask);
return false;
}
요청한 cpu가 no-cb(rcu 스레드 사용)으로 설정되었는지 여부를 반환한다.
- have_rcu_nocb_mask 변수는 rcu_nocb_setup() 함수가 호출되어 rcu_nocb_mask라는 cpu 마스크가 할당된 경우 true로 설정된다.
- CONFIG_RCU_NOCB_CPU_ALL 커널 옵션을 사용하는 경우 항상 rcu 스레드에서 동작시키기 위해 true를 반환한다.
- CONFIG_RCU_NOCB_CPU_ALL 및 CONFIG_RCU_NOCB_CPU 커널 옵션 둘 다 사용하지 않는 경우 항상 callback 처리하기 위해 false를 반환한다.
rcu_nocb_setup()
kernel/rcu/tree_plugin.h
/* Parse the boot-time rcu_nocb_mask CPU list from the kernel parameters. */
static int __init rcu_nocb_setup(char *str)
{
alloc_bootmem_cpumask_var(&rcu_nocb_mask);
have_rcu_nocb_mask = true;
cpulist_parse(str, rcu_nocb_mask);
return 1;
}
__setup("rcu_nocbs=", rcu_nocb_setup);
커널 파라메터 “rcu_nocbs=”에 cpu 리스트를 설정한다. 이렇게 설정된 cpu들은 rcu callback 처리를 rcu 스레드에서 처리할 수 있다.
nocb용 gp 및 cb 커널 스레드의 구성
rcu_organize_nocb_kthreads()
kernel/rcu/tree_plugin.h
/*
* Initialize GP-CB relationships for all no-CBs CPU.
*/
static void __init rcu_organize_nocb_kthreads(void)
{
int cpu;
bool firsttime = true;
int ls = rcu_nocb_gp_stride;
int nl = 0; /* Next GP kthread. */
struct rcu_data *rdp;
struct rcu_data *rdp_gp = NULL; /* Suppress misguided gcc warn. */
struct rcu_data *rdp_prev = NULL;
if (!cpumask_available(rcu_nocb_mask))
return;
if (ls == -1) {
ls = nr_cpu_ids / int_sqrt(nr_cpu_ids);
rcu_nocb_gp_stride = ls;
}
/*
* Each pass through this loop sets up one rcu_data structure.
* Should the corresponding CPU come online in the future, then
* we will spawn the needed set of rcu_nocb_kthread() kthreads.
*/
for_each_cpu(cpu, rcu_nocb_mask) {
rdp = per_cpu_ptr(&rcu_data, cpu);
if (rdp->cpu >= nl) {
/* New GP kthread, set up for CBs & next GP. */
nl = DIV_ROUND_UP(rdp->cpu + 1, ls) * ls;
rdp->nocb_gp_rdp = rdp;
rdp_gp = rdp;
if (!firsttime && dump_tree)
pr_cont("\n");
firsttime = false;
pr_alert("%s: No-CB GP kthread CPU %d:", __func__, cpu);
} else {
/* Another CB kthread, link to previous GP kthread. */
rdp->nocb_gp_rdp = rdp_gp;
rdp_prev->nocb_next_cb_rdp = rdp;
pr_alert(" %d", cpu);
}
rdp_prev = rdp;
}
}
no-cb용 gp 및 cb 커널 스레드를 구성한다.
- 코드 라인 11~12에서 커널 파라미터로 no-cb 지정된 cpu가 없는 경우 함수를 빠져나간다.
- 코드 라인 13~16에서 모듈 파라미터 rcu_nocb_gp_stride (디폴트=-1)가 아직 설정되지 않은 경우 다음과 같이 산출한 후 ls와 rcu_nocb_gp_stride에 대입한다.
- 코드 라인 23~41에서 no-cb용 cpu들을 순회하며 ls로 지정된 단위마다 각 첫 번째 cpu는 gp용 커널 스레드로 지정된다.
다음 그림은 cpu 수에 따라 구성되는 no-cb용 gp 커널 스레드와 cb 커널 스레드들을 보여준다.
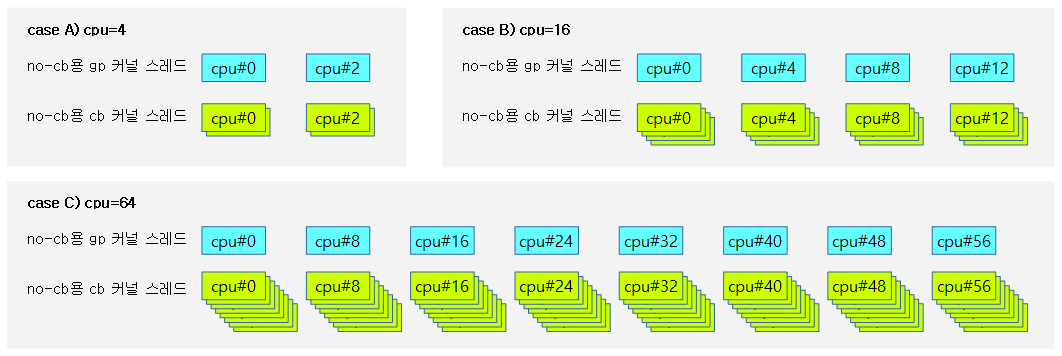
NO-CB용 콜백 처리 커널 스레드
기존 커널에서 no-cb용 콜백 리스트를 별도로 분리 구성하여 사용했었는데 이를 없애고 cb용 세그먼티드 콜백리스트 방식을 사용하는 것으로 바꿔 지연도 없애며 OOM 발생 확률을 줄였다.
rcu_nocb_cb_kthread()
kernel/rcu/tree_plugin.h
/*
* Per-rcu_data kthread, but only for no-CBs CPUs. Repeatedly invoke
* nocb_cb_wait() to do the dirty work.
*/
static int rcu_nocb_cb_kthread(void *arg)
{
struct rcu_data *rdp = arg;
// Each pass through this loop does one callback batch, and,
// if there are no more ready callbacks, waits for them.
for (;;) {
nocb_cb_wait(rdp);
cond_resched_tasks_rcu_qs();
}
return 0;
}
cpu 마다 구성되는 no-cb용 콜백 처리 커널 스레드이다. 무한 루프를 돌며 대기 중인 콜백들을 처리한다.
nocb_cb_wait()
kernel/rcu/tree_plugin.h
/*
* Invoke any ready callbacks from the corresponding no-CBs CPU,
* then, if there are no more, wait for more to appear.
*/
static void nocb_cb_wait(struct rcu_data *rdp)
{
unsigned long cur_gp_seq;
unsigned long flags;
bool needwake_gp = false;
struct rcu_node *rnp = rdp->mynode;
local_irq_save(flags);
rcu_momentary_dyntick_idle();
local_irq_restore(flags);
local_bh_disable();
rcu_do_batch(rdp);
local_bh_enable();
lockdep_assert_irqs_enabled();
rcu_nocb_lock_irqsave(rdp, flags);
if (rcu_segcblist_nextgp(&rdp->cblist, &cur_gp_seq) &&
rcu_seq_done(&rnp->gp_seq, cur_gp_seq) &&
raw_spin_trylock_rcu_node(rnp)) { /* irqs already disabled. */
needwake_gp = rcu_advance_cbs(rdp->mynode, rdp);
raw_spin_unlock_rcu_node(rnp); /* irqs remain disabled. */
}
if (rcu_segcblist_ready_cbs(&rdp->cblist)) {
rcu_nocb_unlock_irqrestore(rdp, flags);
if (needwake_gp)
rcu_gp_kthread_wake();
return;
}
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu, TPS("CBSleep"));
WRITE_ONCE(rdp->nocb_cb_sleep, true);
rcu_nocb_unlock_irqrestore(rdp, flags);
if (needwake_gp)
rcu_gp_kthread_wake();
swait_event_interruptible_exclusive(rdp->nocb_cb_wq,
!READ_ONCE(rdp->nocb_cb_sleep));
if (!smp_load_acquire(&rdp->nocb_cb_sleep)) { /* VVV */
/* ^^^ Ensure CB invocation follows _sleep test. */
return;
}
WARN_ON(signal_pending(current));
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu, TPS("WokeEmpty"));
}
준비 완료된 콜백들을 호출하여 처리한다. 없는 경우 대기한다.
- 코드 라인 8~10에서 irq를 disable한 채로 rcu core가 긴급하게 qs 상태를 알아야 할 때 수행된다.
- 코드 라인 11~13에서 bh를 disable한 채로 준비 완료된 콜백들을 호출한다.
- 코드 라인 16~21에서 콜백리스트에 다음 gp를 기다리는 콜백들이 있고 gp 시퀀스도 완료된 경우해당 노드의 lock을 획득한 채로 콜백들을 advance(cascade) 처리한다.
- 코드 라인 22~27에서 준비 완료된 콜백들이 존재하는 경우 함수를 빠져나가며, 필요 시gp 커널 스레드를 깨운다.
- 코드 라인 30~35에서 rdp->nocb_cb_sleep에 true를 대입한 후 rdp->nocb_cb_sleep을 외부에서 false로 변경시킬 때까지 슬립한다.
- 코드 라인 36~39에서 rdp->nocb_cb_sleep에 대한 메모리 베리어 처리를 수행한다.
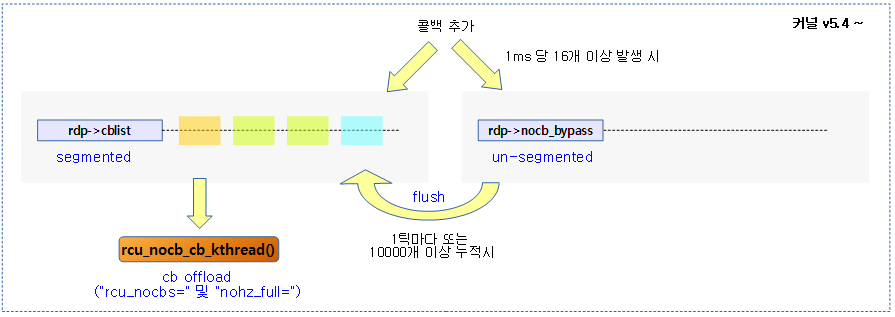
다음 그림은 커널 v5.4부터 no-cb용 콜백 처리 커널 스레드가 cb용 segmented 콜백 리스트를 그대로 사용하여 운영되는 모습을 보여준다.
- 추가로 nocb_bypass 콜백 리스트의 운용도 보여주고 있다.
다음 그림은 기존 커널 v5.3까지에서 no-cb용 콜백 처리 커널 스레드가 leader/follower로 구성되어 동작하는 모습이다.
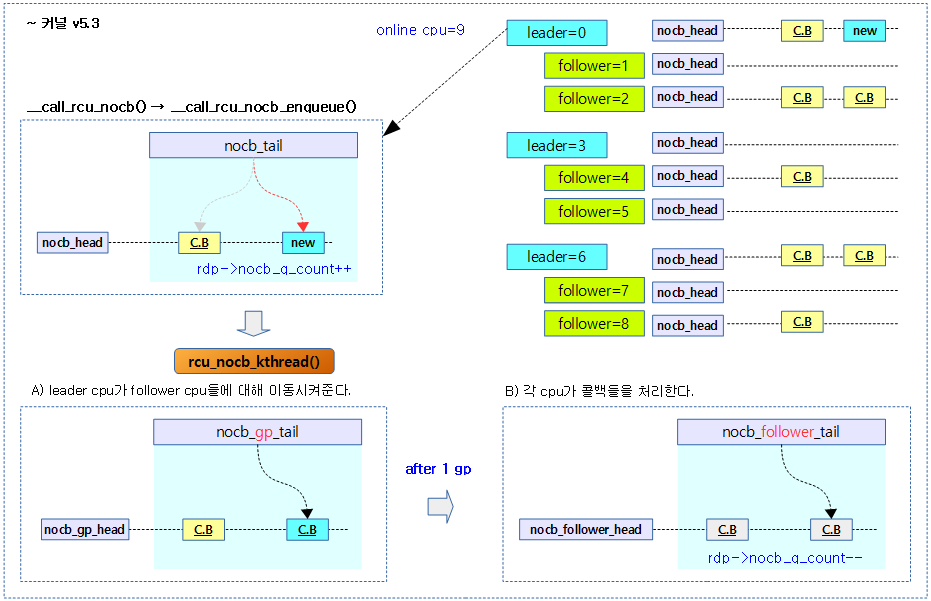
no-cb용 gp 커널 스레드
기존 커널에서 leader 커널 스레드는 콜백과 gp를 관리하고, follower 커널 스레드들은 콜백만을 처리하는 구조였다. 그러나 수 많은 수의 콜백을 leader가 처리해야 하는 상황에서 많은 follower cpu들이 gp 완료까지 대기를 하느라 OOM이 발생하는 현상이 벌어져 새 커널에서는 gp 커널 스레드를 별도의 커널 스레드로 제공한다.
rcu_nocb_gp_kthread()
kernel/rcu/tree_plugin.h
/*
* No-CBs grace-period-wait kthread. There is one of these per group
* of CPUs, but only once at least one CPU in that group has come online
* at least once since boot. This kthread checks for newly posted
* callbacks from any of the CPUs it is responsible for, waits for a
* grace period, then awakens all of the rcu_nocb_cb_kthread() instances
* that then have callback-invocation work to do.
*/
static int rcu_nocb_gp_kthread(void *arg)
{
struct rcu_data *rdp = arg;
for (;;) {
WRITE_ONCE(rdp->nocb_gp_loops, rdp->nocb_gp_loops + 1);
nocb_gp_wait(rdp);
cond_resched_tasks_rcu_qs();
}
return 0;
}
cpu들을 대상으로 cpu수의 제곱근마다 그룹을 분리하고 각 그룹의 첫 번째 cpu에 구성하는 no-cb용 gp 커널 스레드이다. 무한 루프를 돌며 no-cb용 gp를 기다린다.
nocb_gp_wait()
kernel/rcu/tree_plugin.h -1/2-
/*
* No-CBs GP kthreads come here to wait for additional callbacks to show up
* or for grace periods to end.
*/
static void nocb_gp_wait(struct rcu_data *my_rdp)
{
bool bypass = false;
long bypass_ncbs;
int __maybe_unused cpu = my_rdp->cpu;
unsigned long cur_gp_seq;
unsigned long flags;
bool gotcbs;
unsigned long j = jiffies;
bool needwait_gp = false; // This prevents actual uninitialized use.
bool needwake;
bool needwake_gp;
struct rcu_data *rdp;
struct rcu_node *rnp;
unsigned long wait_gp_seq = 0; // Suppress "use uninitialized" warning.
/*
* Each pass through the following loop checks for CBs and for the
* nearest grace period (if any) to wait for next. The CB kthreads
* and the global grace-period kthread are awakened if needed.
*/
for (rdp = my_rdp; rdp; rdp = rdp->nocb_next_cb_rdp) {
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu, TPS("Check"));
rcu_nocb_lock_irqsave(rdp, flags);
bypass_ncbs = rcu_cblist_n_cbs(&rdp->nocb_bypass);
if (bypass_ncbs &&
(time_after(j, READ_ONCE(rdp->nocb_bypass_first) + 1) ||
bypass_ncbs > 2 * qhimark)) {
// Bypass full or old, so flush it.
(void)rcu_nocb_try_flush_bypass(rdp, j);
bypass_ncbs = rcu_cblist_n_cbs(&rdp->nocb_bypass);
} else if (!bypass_ncbs && rcu_segcblist_empty(&rdp->cblist)) {
rcu_nocb_unlock_irqrestore(rdp, flags);
continue; /* No callbacks here, try next. */
}
if (bypass_ncbs) {
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu,
TPS("Bypass"));
bypass = true;
}
rnp = rdp->mynode;
if (bypass) { // Avoid race with first bypass CB.
WRITE_ONCE(my_rdp->nocb_defer_wakeup,
RCU_NOCB_WAKE_NOT);
del_timer(&my_rdp->nocb_timer);
}
// Advance callbacks if helpful and low contention.
needwake_gp = false;
if (!rcu_segcblist_restempty(&rdp->cblist,
RCU_NEXT_READY_TAIL) ||
(rcu_segcblist_nextgp(&rdp->cblist, &cur_gp_seq) &&
rcu_seq_done(&rnp->gp_seq, cur_gp_seq))) {
raw_spin_lock_rcu_node(rnp); /* irqs disabled. */
needwake_gp = rcu_advance_cbs(rnp, rdp);
raw_spin_unlock_rcu_node(rnp); /* irqs disabled. */
}
// Need to wait on some grace period?
WARN_ON_ONCE(!rcu_segcblist_restempty(&rdp->cblist,
RCU_NEXT_READY_TAIL));
if (rcu_segcblist_nextgp(&rdp->cblist, &cur_gp_seq)) {
if (!needwait_gp ||
ULONG_CMP_LT(cur_gp_seq, wait_gp_seq))
wait_gp_seq = cur_gp_seq;
needwait_gp = true;
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu,
TPS("NeedWaitGP"));
}
if (rcu_segcblist_ready_cbs(&rdp->cblist)) {
needwake = rdp->nocb_cb_sleep;
WRITE_ONCE(rdp->nocb_cb_sleep, false);
smp_mb(); /* CB invocation -after- GP end. */
} else {
needwake = false;
}
rcu_nocb_unlock_irqrestore(rdp, flags);
if (needwake) {
swake_up_one(&rdp->nocb_cb_wq);
gotcbs = true;
}
if (needwake_gp)
rcu_gp_kthread_wake();
}
no-cb용 gp 커널 스레에서 호출되며 gp를 대기한다.
- 코드 라인 22~35에서 gp 커널 스레드가 관리하는 cpu들을 대상으로 순회하며 ->nocb_bypass 리스트에 콜백들이 있고, 1틱 이상 시간이 지났거나 bypass 대기 중인 콜백들이 qhimark(디폴트=10000)의 2배를 넘는 경우 이들을 flush 한다. 그렇지 않고 bypass 콜백도 없고 세그먼트 콜백 리스트도 비어 있는 경우 skip 한다.
- 코드 라인 36~46에서 여전히 bypass 콜백이 존재하는 경우 bypass를 true로 변경하고, no-cb 타이머를 제거한다.
- 코드 라인 48~56에서 NEXT 구간에 콜백들이 존재하거나 wait 구간에서 대기 중인 콜백의 gp 시퀀스가 이미 만료된 상태인 경우 콜백들을 advance(cascade) 처리한다.
- 코드 라인 60~67에서 대기 중인 콜백이 있는 경우 needwait_gp에 true를 대입한다. wait_gp_seq를 갱신하는데 wait 구간의 gp 시퀀스보다 작을 때에만 갱신한다.
- 코드 라인 68~81에서 준비 완료된 콜백들이 있는 경우 no-cb용 콜백 처리 커널 스레드를 깨우고, nocb_cb_sleep에 false를 대입하여 no-cb용 gp 커널 스레드를 깨운다. 그런 후 계속 다음 cpu를 처리하기 위해 루프를 돈다.
kernel/rcu/tree_plugin.h -2/2-
my_rdp->nocb_gp_bypass = bypass;
my_rdp->nocb_gp_gp = needwait_gp;
my_rdp->nocb_gp_seq = needwait_gp ? wait_gp_seq : 0;
if (bypass && !rcu_nocb_poll) {
// At least one child with non-empty ->nocb_bypass, so set
// timer in order to avoid stranding its callbacks.
raw_spin_lock_irqsave(&my_rdp->nocb_gp_lock, flags);
mod_timer(&my_rdp->nocb_bypass_timer, j + 2);
raw_spin_unlock_irqrestore(&my_rdp->nocb_gp_lock, flags);
}
if (rcu_nocb_poll) {
/* Polling, so trace if first poll in the series. */
if (gotcbs)
trace_rcu_nocb_wake(rcu_state.name, cpu, TPS("Poll"));
schedule_timeout_interruptible(1);
} else if (!needwait_gp) {
/* Wait for callbacks to appear. */
trace_rcu_nocb_wake(rcu_state.name, cpu, TPS("Sleep"));
swait_event_interruptible_exclusive(my_rdp->nocb_gp_wq,
!READ_ONCE(my_rdp->nocb_gp_sleep));
trace_rcu_nocb_wake(rcu_state.name, cpu, TPS("EndSleep"));
} else {
rnp = my_rdp->mynode;
trace_rcu_this_gp(rnp, my_rdp, wait_gp_seq, TPS("StartWait"));
swait_event_interruptible_exclusive(
rnp->nocb_gp_wq[rcu_seq_ctr(wait_gp_seq) & 0x1],
rcu_seq_done(&rnp->gp_seq, wait_gp_seq) ||
!READ_ONCE(my_rdp->nocb_gp_sleep));
trace_rcu_this_gp(rnp, my_rdp, wait_gp_seq, TPS("EndWait"));
}
if (!rcu_nocb_poll) {
raw_spin_lock_irqsave(&my_rdp->nocb_gp_lock, flags);
if (bypass)
del_timer(&my_rdp->nocb_bypass_timer);
WRITE_ONCE(my_rdp->nocb_gp_sleep, true);
raw_spin_unlock_irqrestore(&my_rdp->nocb_gp_lock, flags);
}
my_rdp->nocb_gp_seq = -1;
WARN_ON(signal_pending(current));
}
- 코드 라인 1에서 no-cb용 bypass 콜백이 지난 gp에서 스캔되었느지 여부를 대입한다.
- 코드 라인 2에서 no-cb용 다음 gp를 대기해야 하는지 요청 여부를 지정한다.
- 코드 라인 3에서 no-cb용 gp 시퀀스 번호를 대입한다. 만일 다음 gp 요청이 없는 경우 0을 대입한다.
- 코드 라인 4~10에서 bypass 콜백이 있고 no-cb용 cb 커널 스레드가 폴링을 하지 않는 경우 no-cb용 bypass 타이머를 2틱 뒤의 시각으로 설정한다.
- 코드 라인 11~15에서 no-cb용 cb 커널 스레드가 폴링을 하는 경우 1틱 슬립한다.
- 코드 라인 16~21에서 gp 요청이 없는 경우 rdp->nocb_gp_sleep이 외부에서 false를 대입할 때까지 슬립하며 대기한다.
- 코드 라인 22~30에서 그 외의 경우 대기 중인 gp 시퀀스가 종료되거나 rdp->nocb_gp_sleep이 외부에서 false를 대입할 때까지 슬립하며 대기한다.
- 코드 라인 31~37에서 no-cb용 cb 커널 스레드가 폴링을 하지 않는 경우 ->nocb_gp_sleep에 true를 대입한다. 만일 bypass 콜백이 있는 경우 bypass 타이머를 제거한다.
- 코드 라인 38에서 no-cb용 gp 시퀀스에 -1을 대입한다.
no-cb용 gp wakeup 타이머
do_nocb_deferred_wakeup()
kernel/rcu/tree_plugin.h
/*
* Do a deferred wakeup of rcu_nocb_kthread() from fastpath.
* This means we do an inexact common-case check. Note that if
* we miss, ->nocb_timer will eventually clean things up.
*/
static void do_nocb_deferred_wakeup(struct rcu_data *rdp)
{
if (rcu_nocb_need_deferred_wakeup(rdp))
do_nocb_deferred_wakeup_common(rdp);
}
no-cb용 gp 커널스레드의 deferred wakeup 요청을 처리한다.
rcu_nocb_need_deferred_wakeup()
kernel/rcu/tree_plugin.h
/* Is a deferred wakeup of rcu_nocb_kthread() required? */
static int rcu_nocb_need_deferred_wakeup(struct rcu_data *rdp)
{
return READ_ONCE(rdp->nocb_defer_wakeup);
}
no-cb용 커널스레드의 deferred wakeup이 요청되었는지 여부를 반환한다.
deferred wakeup 요청 값
kernel/rcu/tree.h”
/* Values for nocb_defer_wakeup field in struct rcu_data. */
#define RCU_NOCB_WAKE_NOT 0
#define RCU_NOCB_WAKE 1
#define RCU_NOCB_WAKE_FORCE 2
- RCU_NOCB_WAKE_NOT
- RCU_NOCB_WAKE
- RCU_NOCB_WAKE_FORCE
deferred wakeup 타이머 핸들러
do_nocb_deferred_wakeup_timer()
kernel/rcu/tree_plugin.h
/* Do a deferred wakeup of rcu_nocb_kthread() from a timer handler. */
static void do_nocb_deferred_wakeup_timer(struct timer_list *t)
{
struct rcu_data *rdp = from_timer(rdp, t, nocb_timer);
do_nocb_deferred_wakeup_common(rdp);
}
no-cb용 커널스레드의 deferred wakeup이 요청된 경우 no-cb용 gp 커널 스레드를 깨운다.
do_nocb_deferred_wakeup_common()
kernel/rcu/tree_plugin.h
/* Do a deferred wakeup of rcu_nocb_kthread(). */
static void do_nocb_deferred_wakeup_common(struct rcu_data *rdp)
{
unsigned long flags;
int ndw;
rcu_nocb_lock_irqsave(rdp, flags);
if (!rcu_nocb_need_deferred_wakeup(rdp)) {
rcu_nocb_unlock_irqrestore(rdp, flags);
return;
}
ndw = READ_ONCE(rdp->nocb_defer_wakeup);
WRITE_ONCE(rdp->nocb_defer_wakeup, RCU_NOCB_WAKE_NOT);
wake_nocb_gp(rdp, ndw == RCU_NOCB_WAKE_FORCE, flags);
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu, TPS("DeferredWake"));
}
no-cb용 커널스레드의 deferred wakeup이 요청된 경우 no-cb용 gp 커널 스레드를 깨운다.
- 코드 라인 7~10에서 no-cb용 커널스레드의 wakeup 유예가 요청된 경우가 아니면 함수를 빠져나간다.
- 코드 라인 11~12용 nocb_defer_wakeup 요청을 RCU_NOCB_WAKE_NOT(0)으로 클리어하고, 기존 값은 ndw로 알아온다.
- 코드 라인 13에서 gp 커널 스레드를 깨운다.
- 기존 값이 RCU_NOCB_WAKE_FORCE(2)인 경우 wakeup을 강제한다.
no-cb용 gp 커널 스레드 깨우기
wake_nocb_gp()
kernel/rcu/tree_plugin.h
/*
* Kick the GP kthread for this NOCB group. Caller holds ->nocb_lock
* and this function releases it.
*/
static void wake_nocb_gp(struct rcu_data *rdp, bool force,
unsigned long flags)
__releases(rdp->nocb_lock)
{
bool needwake = false;
struct rcu_data *rdp_gp = rdp->nocb_gp_rdp;
lockdep_assert_held(&rdp->nocb_lock);
if (!READ_ONCE(rdp_gp->nocb_gp_kthread)) {
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu,
TPS("AlreadyAwake"));
rcu_nocb_unlock_irqrestore(rdp, flags);
return;
}
del_timer(&rdp->nocb_timer);
rcu_nocb_unlock_irqrestore(rdp, flags);
raw_spin_lock_irqsave(&rdp_gp->nocb_gp_lock, flags);
if (force || READ_ONCE(rdp_gp->nocb_gp_sleep)) {
WRITE_ONCE(rdp_gp->nocb_gp_sleep, false);
needwake = true;
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu, TPS("DoWake"));
}
raw_spin_unlock_irqrestore(&rdp_gp->nocb_gp_lock, flags);
if (needwake)
wake_up_process(rdp_gp->nocb_gp_kthread);
}
no-cb용 gp 커널 스레드를 깨운다.
- 코드 라인 6에서 현재 cpu에 대응하여 gp를 관리하는 cpu의 rdp를 알아온다.
- 코드 라인 9~14에서 gp용 cpu의 no-cb용 gp 커널 스레드가 아직 준비되지 않은 경우 함수를 빠져나간다.
- 코드 라인 15에서 no-cb용 타이머를 삭제한다.
- 코드 라인 18~25에서 입력 인자 @force가 요청되었거나 rdp_gp->nocb_gp_sleep이 true로 no-cb용 gp 커널 스레드가 슬립하며 대기 중인 경우 스레드를 깨운다.
no-cb용 gp 커널 스레드 지연시켜 깨우기
wake_nocb_gp_defer()
kernel/rcu/tree_plugin.h
/*
* Arrange to wake the GP kthread for this NOCB group at some future
* time when it is safe to do so.
*/
static void wake_nocb_gp_defer(struct rcu_data *rdp, int waketype,
const char *reason)
{
if (rdp->nocb_defer_wakeup == RCU_NOCB_WAKE_NOT)
mod_timer(&rdp->nocb_timer, jiffies + 1);
if (rdp->nocb_defer_wakeup < waketype)
WRITE_ONCE(rdp->nocb_defer_wakeup, waketype);
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu, reason);
}
no-cb용 gp 커널 스레드를 @waketype에 맞춰 deferred wakeup 요청한다.
- 코드 라인 4~5에서 기존 설정 값(rdp->nocb_defer_wakeup)이 RCU_NOCB_WAKE_NOT(0) 상태에서 요청된 경우 1틱을 지연시켜 no-cb용 gp 커널 스레드를 깨우기 위해 타이머를 변경한다.
- 코드 라인 6~7에서 rdp->nocb_defer_wakeup 보다 @wakeup이 큰 경우에 한해 갱신한다.
no-cb용 bypass 타이머
bypass 타이머 핸들러
do_nocb_bypass_wakeup_timer()
kernel/rcu/tree_plugin.h
/* Wake up the no-CBs GP kthread to flush ->nocb_bypass. */
static void do_nocb_bypass_wakeup_timer(struct timer_list *t)
{
unsigned long flags;
struct rcu_data *rdp = from_timer(rdp, t, nocb_bypass_timer);
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu, TPS("Timer"));
rcu_nocb_lock_irqsave(rdp, flags);
smp_mb__after_spinlock(); /* Timer expire before wakeup. */
__call_rcu_nocb_wake(rdp, true, flags);
}
nocb_bypass 리스트의 콜백들을 모두 처리하기 위해 nocb용 gp kthread를 깨운다.
__call_rcu_nocb_wake()
kernel/rcu/tree_plugin.h
/*
* Awaken the no-CBs grace-period kthead if needed, either due to it
* legitimately being asleep or due to overload conditions.
*
* If warranted, also wake up the kthread servicing this CPUs queues.
*/
static void __call_rcu_nocb_wake(struct rcu_data *rdp, bool was_alldone,
unsigned long flags)
__releases(rdp->nocb_lock)
{
unsigned long cur_gp_seq;
unsigned long j;
long len;
struct task_struct *t;
// If we are being polled or there is no kthread, just leave.
t = READ_ONCE(rdp->nocb_gp_kthread);
if (rcu_nocb_poll || !t) {
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu,
TPS("WakeNotPoll"));
rcu_nocb_unlock_irqrestore(rdp, flags);
return;
}
// Need to actually to a wakeup.
len = rcu_segcblist_n_cbs(&rdp->cblist);
if (was_alldone) {
rdp->qlen_last_fqs_check = len;
if (!irqs_disabled_flags(flags)) {
/* ... if queue was empty ... */
wake_nocb_gp(rdp, false, flags);
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu,
TPS("WakeEmpty"));
} else {
wake_nocb_gp_defer(rdp, RCU_NOCB_WAKE,
TPS("WakeEmptyIsDeferred"));
rcu_nocb_unlock_irqrestore(rdp, flags);
}
} else if (len > rdp->qlen_last_fqs_check + qhimark) {
/* ... or if many callbacks queued. */
rdp->qlen_last_fqs_check = len;
j = jiffies;
if (j != rdp->nocb_gp_adv_time &&
rcu_segcblist_nextgp(&rdp->cblist, &cur_gp_seq) &&
rcu_seq_done(&rdp->mynode->gp_seq, cur_gp_seq)) {
rcu_advance_cbs_nowake(rdp->mynode, rdp);
rdp->nocb_gp_adv_time = j;
}
smp_mb(); /* Enqueue before timer_pending(). */
if ((rdp->nocb_cb_sleep ||
!rcu_segcblist_ready_cbs(&rdp->cblist)) &&
!timer_pending(&rdp->nocb_bypass_timer))
wake_nocb_gp_defer(rdp, RCU_NOCB_WAKE_FORCE,
TPS("WakeOvfIsDeferred"));
rcu_nocb_unlock_irqrestore(rdp, flags);
} else {
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu, TPS("WakeNot"));
rcu_nocb_unlock_irqrestore(rdp, flags);
}
return;
}
nocb_bypass 리스트의 콜백들을 모두 처리하기 위해 nocb용 gp kthread를 깨운다.
- 코드 라인 11~17에서 아직 해당 cpu의 no-cb용 gp 커널 스레드가 지정되지 않은 경우 그냥 함수를 빠져나간다.
- 코드 라인 19에서 세그먼트 콜백 리스트의 전체 콜백 수를 len에 알아온다.
- 코드 라인 20~31에서 두 번째 인자 @was_alldone이 설정된 경우 nocb용 gp 커널 스레드를 깨운다. irq disable 상태에서는 1 틱 만큼 지연시켜 깨운다.
- 코드 라인 32~48에서 너무 많은 콜백이 처리를 기다리고 있는 중인 경우이다. nocb_gp_adv_time 틱이 흘러 변경되었거나 다음(wait) 구간의 gp 시퀀스가 완료된 경우 nocb_gp_adv_time 을 현재 시각으로 갱신하고 콜백을 advance(cascade) 처리한다. 만일 no-cb용 gp 커널 스레드가 슬립하여 대기중이거나 세그먼트 콜백 리스트에 완료된 콜백이 없는 경우이면서 bypass 타이머가 설정되어 있지 않은 경우 no-cb용 gp 커널 스레드를 wakeup 강제(force)한다.
- 코드 라인 49~52에서 그 외의 경우 nocb 언락한다.
bypass 리스트에 콜백 추가 시도
rcu_nocb_try_bypass()
kernel/rcu/tree_plugin.h -1/2-
/*
* See whether it is appropriate to use the ->nocb_bypass list in order
* to control contention on ->nocb_lock. A limited number of direct
* enqueues are permitted into ->cblist per jiffy. If ->nocb_bypass
* is non-empty, further callbacks must be placed into ->nocb_bypass,
* otherwise rcu_barrier() breaks. Use rcu_nocb_flush_bypass() to switch
* back to direct use of ->cblist. However, ->nocb_bypass should not be
* used if ->cblist is empty, because otherwise callbacks can be stranded
* on ->nocb_bypass because we cannot count on the current CPU ever again
* invoking call_rcu(). The general rule is that if ->nocb_bypass is
* non-empty, the corresponding no-CBs grace-period kthread must not be
* in an indefinite sleep state.
*
* Finally, it is not permitted to use the bypass during early boot,
* as doing so would confuse the auto-initialization code. Besides
* which, there is no point in worrying about lock contention while
* there is only one CPU in operation.
*/
static bool rcu_nocb_try_bypass(struct rcu_data *rdp, struct rcu_head *rhp,
bool *was_alldone, unsigned long flags)
{
unsigned long c;
unsigned long cur_gp_seq;
unsigned long j = jiffies;
long ncbs = rcu_cblist_n_cbs(&rdp->nocb_bypass);
if (!rcu_segcblist_is_offloaded(&rdp->cblist)) {
*was_alldone = !rcu_segcblist_pend_cbs(&rdp->cblist);
return false; /* Not offloaded, no bypassing. */
}
lockdep_assert_irqs_disabled();
// Don't use ->nocb_bypass during early boot.
if (rcu_scheduler_active != RCU_SCHEDULER_RUNNING) {
rcu_nocb_lock(rdp);
WARN_ON_ONCE(rcu_cblist_n_cbs(&rdp->nocb_bypass));
*was_alldone = !rcu_segcblist_pend_cbs(&rdp->cblist);
return false;
}
// If we have advanced to a new jiffy, reset counts to allow
// moving back from ->nocb_bypass to ->cblist.
if (j == rdp->nocb_nobypass_last) {
c = rdp->nocb_nobypass_count + 1;
} else {
WRITE_ONCE(rdp->nocb_nobypass_last, j);
c = rdp->nocb_nobypass_count - nocb_nobypass_lim_per_jiffy;
if (ULONG_CMP_LT(rdp->nocb_nobypass_count,
nocb_nobypass_lim_per_jiffy))
c = 0;
else if (c > nocb_nobypass_lim_per_jiffy)
c = nocb_nobypass_lim_per_jiffy;
}
WRITE_ONCE(rdp->nocb_nobypass_count, c);
// If there hasn't yet been all that many ->cblist enqueues
// this jiffy, tell the caller to enqueue onto ->cblist. But flush
// ->nocb_bypass first.
if (rdp->nocb_nobypass_count < nocb_nobypass_lim_per_jiffy) {
rcu_nocb_lock(rdp);
*was_alldone = !rcu_segcblist_pend_cbs(&rdp->cblist);
if (*was_alldone)
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu,
TPS("FirstQ"));
WARN_ON_ONCE(!rcu_nocb_flush_bypass(rdp, NULL, j));
WARN_ON_ONCE(rcu_cblist_n_cbs(&rdp->nocb_bypass));
return false; // Caller must enqueue the callback.
}
no-cb용 bypass 리스트에 콜백을 추가한다. 만일 성공하는 경우 true를 반환한다.
- 코드 라인 7에서 nocb_bypass 리스트에 존재하는 콜백들의 수를 ncbs에 알아온다.
- 코드 라인 9~12에서 오프로드되지 않은 경우 false를 반환한다. 또한 펜딩 콜백이 없는지 여부를 출력 인자 @was_alldone에 대입한다.
- 코드 라인 16~21에서 rcu 스케줄러가 아직 준비되지 않은 경우 false를 반환한다. 또한 펜딩 콜백이 없는지 여부를 출력 인자 @was_alldone에 대입한다.
- 코드 라인 25~36에서 새 틱에 진입할 때마다 틱당 nobypass 카운터 제한 수(nocb_nobypass_lim_per_jiffy) 이하로 제한한다.
- 틱 변화가 없는 경우엔 +1 증가시킨다.
- 새 틱에 진입한 경우 nocb_nobypass_count 를 0 ~ nocb_nobypass_lim_per_jiffy 값으로 제한하여 갱신한다.
- 코드 라인 41~50에서 nocb_nobypass_count 수가 틱당 제한 수 미만으로 적게 유입되는 경우 nocb_bypass 리스트에서 처리하지 않고 원래의 세그먼트 콜백 리스트에 추가하기 위해 false를 반환한다. 또한 펜딩 콜백이 없는지 여부를 출력 인자 @was_alldone에 대입한다.
- nocb_nobypass_lim_per_jiffy
- 틱 당 유입되는 콜백 수로 이 값을 초과하는 경우에만 nocb_bypass 리스트에 추가한다.
kernel/rcu/tree_plugin.h -2/2-
// If ->nocb_bypass has been used too long or is too full,
// flush ->nocb_bypass to ->cblist.
if ((ncbs && j != READ_ONCE(rdp->nocb_bypass_first)) ||
ncbs >= qhimark) {
rcu_nocb_lock(rdp);
if (!rcu_nocb_flush_bypass(rdp, rhp, j)) {
*was_alldone = !rcu_segcblist_pend_cbs(&rdp->cblist);
if (*was_alldone)
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu,
TPS("FirstQ"));
WARN_ON_ONCE(rcu_cblist_n_cbs(&rdp->nocb_bypass));
return false; // Caller must enqueue the callback.
}
if (j != rdp->nocb_gp_adv_time &&
rcu_segcblist_nextgp(&rdp->cblist, &cur_gp_seq) &&
rcu_seq_done(&rdp->mynode->gp_seq, cur_gp_seq)) {
rcu_advance_cbs_nowake(rdp->mynode, rdp);
rdp->nocb_gp_adv_time = j;
}
rcu_nocb_unlock_irqrestore(rdp, flags);
return true; // Callback already enqueued.
}
// We need to use the bypass.
rcu_nocb_wait_contended(rdp);
rcu_nocb_bypass_lock(rdp);
ncbs = rcu_cblist_n_cbs(&rdp->nocb_bypass);
rcu_segcblist_inc_len(&rdp->cblist); /* Must precede enqueue. */
rcu_cblist_enqueue(&rdp->nocb_bypass, rhp);
if (!ncbs) {
WRITE_ONCE(rdp->nocb_bypass_first, j);
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu, TPS("FirstBQ"));
}
rcu_nocb_bypass_unlock(rdp);
smp_mb(); /* Order enqueue before wake. */
if (ncbs) {
local_irq_restore(flags);
} else {
// No-CBs GP kthread might be indefinitely asleep, if so, wake.
rcu_nocb_lock(rdp); // Rare during call_rcu() flood.
if (!rcu_segcblist_pend_cbs(&rdp->cblist)) {
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu,
TPS("FirstBQwake"));
__call_rcu_nocb_wake(rdp, true, flags);
} else {
trace_rcu_nocb_wake(rcu_state.name, rdp->cpu,
TPS("FirstBQnoWake"));
rcu_nocb_unlock_irqrestore(rdp, flags);
}
}
return true; // Callback already enqueued.
}
- 코드 라인 3~22에서 첫 콜백이 추가된 후 1 틱이 지났거나 nocb_bypas 콜백들이 qhimark(디폴트=10000) 보다 많은 경우 이들을 한꺼번에 세그먼트 콜백리스트에 플러시하고 함수를 true로 빠져나가는 것으로 매 콜백 건마다 수행되는 lock 컨텐션을 줄인다.
- 코드 라인 25~26에서 no-cb 락 contention이 없어질때까지 스핀하며 대기한 후 락을 획득한다.
- 코드 라인 27~34에서 nocb_bypass 리스트에 콜백을 하나 추가하고 언락한다. 만일 nocb_bypass 리스트에 콜백이 처음 추가된 경우 nocb_bypass_first에 현재 시각을 갱신한다.
- 코드 라인 36~50에서 nocb_bypass 리스트가 비어있는 상태에서 첫 콜백으로 추가되었고 세그먼트 콜백 리스트에서 대기중인 콜백이 없는 경우 no-cb용 gp 커널 스레드를 깨운다.
- 코드 라인 51에서 true를 반환한다.
다음 그림은 콜백을 offload 하여 운영하는 경우 과도하게 유입되는 콜백을 nocb_bypass 리스트에 추가하고, 1틱이 지났거나 10000개 이상 누적되는 경우 flush 하는 것으로 lock contention을 줄여 성능을 올리기 위해 사용하는 모습을 보여준다.

rcu_nocb_flush_bypass()
kernel/rcu/tree_plugin.h
/*
* Flush the ->nocb_bypass queue into ->cblist, enqueuing rhp if non-NULL.
* However, if there is a callback to be enqueued and if ->nocb_bypass
* proves to be initially empty, just return false because the no-CB GP
* kthread may need to be awakened in this case.
*
* Note that this function always returns true if rhp is NULL.
*/
static bool rcu_nocb_flush_bypass(struct rcu_data *rdp, struct rcu_head *rhp,
unsigned long j)
{
if (!rcu_segcblist_is_offloaded(&rdp->cblist))
return true;
rcu_lockdep_assert_cblist_protected(rdp);
rcu_nocb_bypass_lock(rdp);
return rcu_nocb_do_flush_bypass(rdp, rhp, j);
}
nocb_bypass 리스트의 콜백들을 모두 세그먼트 콜백리스트에 옮긴다.
- 코드 라인 4~5에서 콜백 오프로드되지 않은 경우 true를 반환한다.
- 코드 라인 8에서 nocb_bypass 리스트의 콜백들을 모두 세그먼트 콜백리스트에 옮긴다. 성공한 경우 true를 반환한다.
rcu_nocb_do_flush_bypass()
kernel/rcu/tree_plugin.h
/*
* Flush the ->nocb_bypass queue into ->cblist, enqueuing rhp if non-NULL.
* However, if there is a callback to be enqueued and if ->nocb_bypass
* proves to be initially empty, just return false because the no-CB GP
* kthread may need to be awakened in this case.
*
* Note that this function always returns true if rhp is NULL.
*/
static bool rcu_nocb_do_flush_bypass(struct rcu_data *rdp, struct rcu_head *rhp,
unsigned long j)
{
struct rcu_cblist rcl;
WARN_ON_ONCE(!rcu_segcblist_is_offloaded(&rdp->cblist));
rcu_lockdep_assert_cblist_protected(rdp);
lockdep_assert_held(&rdp->nocb_bypass_lock);
if (rhp && !rcu_cblist_n_cbs(&rdp->nocb_bypass)) {
raw_spin_unlock(&rdp->nocb_bypass_lock);
return false;
}
/* Note: ->cblist.len already accounts for ->nocb_bypass contents. */
if (rhp)
rcu_segcblist_inc_len(&rdp->cblist); /* Must precede enqueue. */
rcu_cblist_flush_enqueue(&rcl, &rdp->nocb_bypass, rhp);
rcu_segcblist_insert_pend_cbs(&rdp->cblist, &rcl);
WRITE_ONCE(rdp->nocb_bypass_first, j);
rcu_nocb_bypass_unlock(rdp);
return true;
}
nocb_bypass 리스트의 콜백들을 모두 세그먼트 콜백리스트에 옮긴다. 성공한 경우 true를 반환한다.
- 코드 라인 9~12에서 nocb_bypass 리스트에 콜백들이 하나도 없는 경우 false를 반환한다.
- 코드 라인 14~15에서 인자로 주어진 콜백 @rhp가 있는 경우 콜백 수를 1 증가시킨다.
- 코드 라인 16에서 nocb_bypass 리스트의 콜백을 내부 임시 리스트에 옮긴다. 이 때 콜백도 하나 추가한다.
- 코드 라인 17에서 내부 임시 리스트에 옮겨진 콜백들을 세그먼트 콜백리스트의 next 구간에 추가한다.
- 코드 라인 18에서 nocb_bypass_first에 현재 시각을 갱신한다.
- 코드 라인 20에서 정상적으로 옮겼으므로 true를 반환한다.
참고