프로세스 생성
리눅스 유저 application에서 fork() 함수를 사용할 때 공유 라이브러리인 glibc를 통해 더 이상 fork syscall을 호출하지 않고 clone syscall을 호출한다. 때문에 clone과 fork는 동일하게 사용한다. 리눅스 커널은 backward 호환을 이유로 fork에 대한 syscall을 열어둔 상태이긴 하지만 거의 사용되지 않는다고 보면된다. 그 동안 fork와 vfork를 많이 비교하는 글들이 있지만 리눅스 커널 버전이 향상되면서 논쟁이 되었던 글들이 조금씩 핀트를 벗어나고 있다. 커널이 v4.x에 이르렀으므로 이제 조금 정리를 해보고자 한다.
최초 리눅스 구현 시 vfork가 fork에 비해 매우 light한 구동을 보여줬다. vfork로 생성되는 자식 프로세스는 부모 프로세스와 파이프 등을 사용하여 교류를 할 수 없고 단지 부모 프로세스가 자식 프로세스에게 argument만 전달하고 반대로 종료(exit) 결과만 부모 프로세스에 알려줄 수 있다. 이제는 과거지만 그러한 점 때문에 심플하게 프로세스를 구동하고자 할 때에는 vfork를 선호하였었다. 그러나 추후 리눅스가 fork에 COW(Copy On Write) 기능을 사용하면서 fork 역시 light한 동작을 갖게되었다. 이로인해 vfork를 사용해야 할 커다란 이유가 없어졌고, vfork의 사용은 추천되지 않게되었다. 최종적으로 vfork가 fork(clone)와 매우 유사하게 되었는데, 정확히 vfork와 fork(clone)의 차이 점을 구별해 낼 수 없다면 그냥 fork(clone)를 사용하여야 한다.
fork vs vfork
- fork와 달리 vfork는부모 프로세스와 파이프를 통한 교류를 할 수 없다.
- vfork는 자식 태스크를 생성시 부모 프로세스를 잠시 블럭한다.
- vfork는 스레드와 같은 동작을 하도록 CLONE_VM을 사용하여 메모리의 사용량을 대폭 줄였다.
- 부모 프로세스가 사용하는 mm 디스크립터 생성하지 않고 공유한다.
- 부모 프로세스가 사용하는 페이지 테이블(pgd)을 공유한다.
- fork는 새 페이지 테이블(pgd)을 사용하여 COW(Copy On Write) 동작으로 필요 시 마다 메모리를 할당하여 사용한다.
- 부모 프로세스가 사용하는 vm 영역을 복사하지 않고 공유한다.
- 예) 부모 프로세스가 20M의 메모리를 사용할 때 자식 프로세스가 사용하는 메모리 비교
- fork: 약 12 ~ 21M
- 처음 fork를 하였을 때에는 COW 동작에 메모리를 복사하지 않지만 write 동작이 가해지면 메모리를 할당하여 사용한다.
- 부모 태스크가 사용했었던 vm을 그대로 상속하기 위해 vma 및 페이지 테이블을 새롭게 복사하여 사용한다.
- vfork: 약 1.5M
- application에 대해서는 동일한 가상 주소 메모리를 공유하여 사용하므로 자식 프로세스 관리에 필요한 메모리만 조금 추가된다.
- fork: 약 12 ~ 21M
- 참고
- fork() gets slower as parent process uses more memory | famzah‘s blog
- A much faster popen() and system() implementation for Linux | famzah‘s blog
스레드 생성
프로세스보다 가벼운 스레드가 필요한 경우에는 커널 v2.6부터 구현되어 현재까지도 사용되는 NPTL 라이브러리(-lpthread)를 사용한 POSIX thread를 사용한다. pthread_create() 함수를 사용 시 CLONE_VM을 추가한 clone syscall을 사용한다. 이를 통해 light한 메모리 사용과 빠른 스레드 생성을 할 수있다.
- 참고:
리눅스 태스크 생성
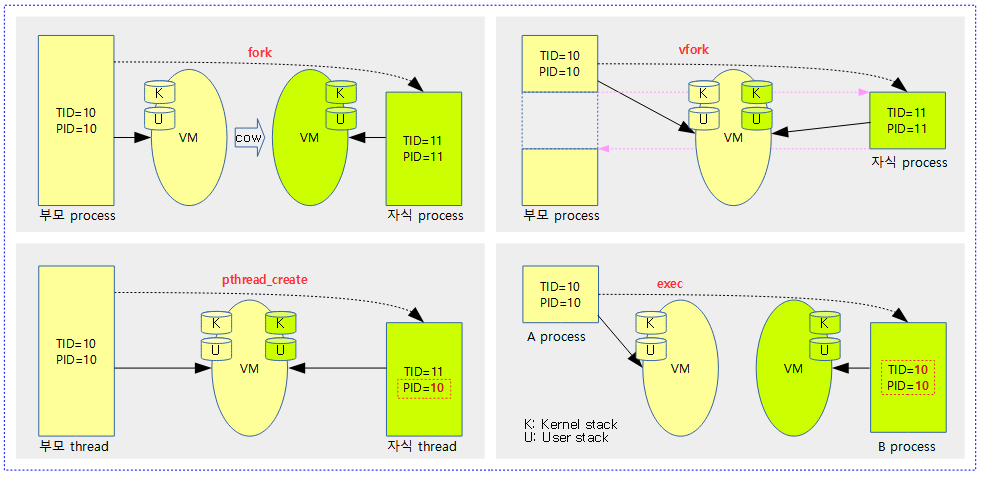
다음 그림은 태스크가 fork, vfork 및 pthread_create 될때의 모습을 보여준다. 추가로 exec에 의해 다른 태스크로 전환되는 과정도 보여준다.
- VM 공유 관련
- fork의 경우 부모 프로세스의 heap 및 user stack을 포함하는 메모리를 읽을 수 있고, 변경 시 CoW(Copy on Write)에 의해 별도로 복제되어 사용된다.
- 나머지의 경우 부모 프로세스(스레드)와 VM(가상 공간)을 공유하므로 읽기 뿐만 아니라 수정도 가능하다.
- vfork 동작 시 부모 process는 잠시 멈추고, 자식 process가 종료되어야 잠시 멈춘 지점부터 동작한다.
- exec 동작 시 A 프로세스가 같은 PID를 사용하면서 B 프로세스로 전환되며 A 프로세스로 복귀는 불가능하다. 이 때 VM은 공유하지 않는다.
do_fork()
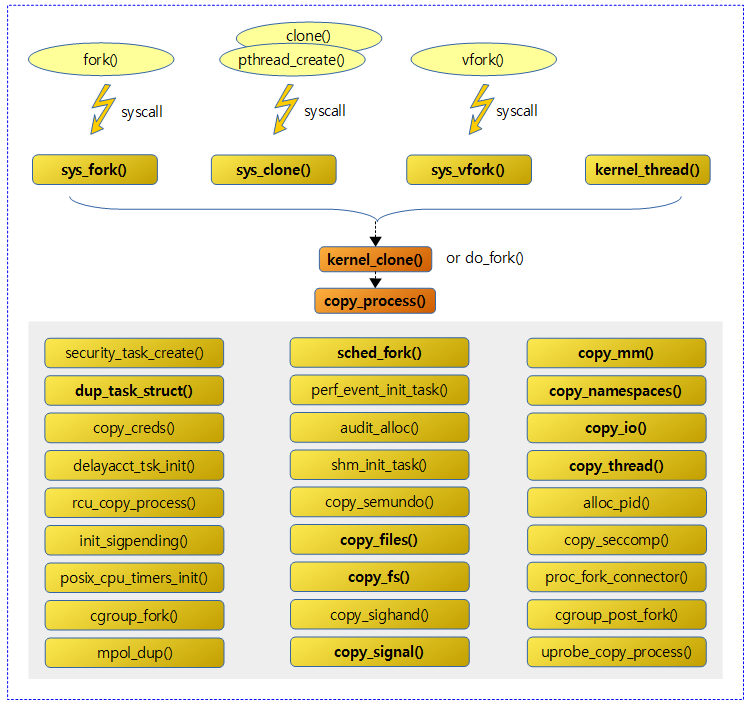
다음 그림은 유저 모드에서 syscall을 통해 프로세스나 스레드를 생성할 때 대응하는 커널 함수와 CLONE 플래그들을 보여준다.
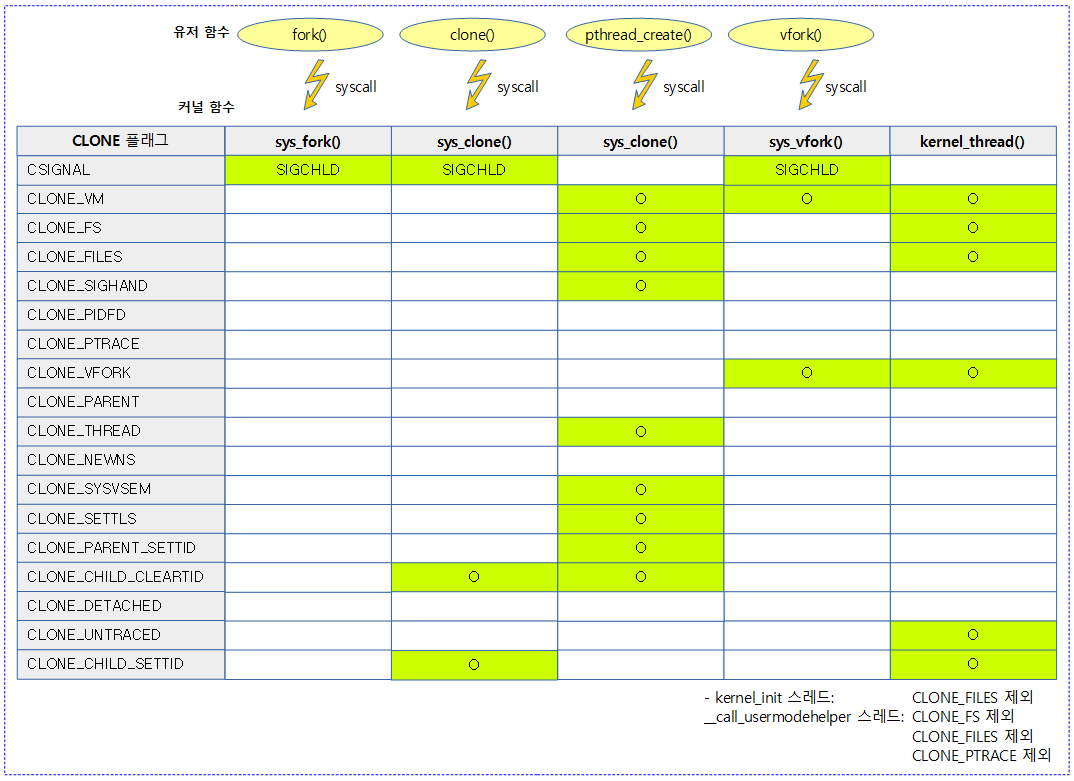
다음 그림은 태스크를 생성 시 CLONE 플래그에 따라 각 루틴이 하는 일들을 보여준다.
- CLONE 플래그에 해당하는 항목이 설정된 경우 함수에서의 동작이 노란 색 항목과 같이 수행된다.
COW(Copy On Write)
fork 및 clone 프로세스의 경우 COW(Copy On Write)을 지원하기 위해 dup_mmap() 함수에서 다음과 같은 함수들을 호출하여 VMA들과 페이지 테이블들을 복사한다.
- vm_area_dup()
- vma_dup_policy()
- anon_vma_fork()
- copy_page_range()
kernel/fork.c -1/2-
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
*/
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
부모 태스크를 복사(fork)한 새 태스크를 스케줄러에서 깨운다. CLONE 플래그 요청에 따라 각각의 리소스에 대해 부모 리소스를 같이 공유하여 사용하거나 별도로 새로 생성된 태스크에 독립적으로 리소스를 사용하도록 배정한다.
- 코드 라인 23~33에서 CLONE_UNTRACED 커널 옵션을 지정하여 요청한 경우 ptreacer로 이벤트를 리포팅하지 않도록 제한시킨다. 또한
- kernel_thread() 함수를 통해 만든 커널 스레드는 항상 CLONE_UNTRACED 커널 옵션을 사용한다.
- 코드 라인 35~36 copy_process() 함수를 호출하여 각 플래그 요청을 기반으로 자원의 공유 여부를 결정하고 부모 태스크를 기반으로 새 태스크를 상속받아 만든다. (clone)
kernel/fork.c -2/2-
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
- 코드 라인 11~12에서 글로벌 pid 값을 가져온다. 참조 카운터를 1 증가시킨다. 태스크가 소속된 namespace에서 upid 번호를 알아온다.
- 코드 라인 14~15에서 유저 모드에서 clone syscall을 통해 즉, sys_clone() 함수를 통해 호출된 경우 부모 태스크의 tid에 child 태스크의 upid 번호를 설정한다.
- 코드 라인 17~21에서 CLONE_VFORK 플래그를 사용하여 요청한 경우 fork 완료 대기를 위해 준비한다.
- 코드 라인 23에서 생성된 새 태스크를 깨워 동작시킨다.
- 코드 라인 29~32에서 CLONE_VFORK 플래그를 사용하여 요청한 경우 태스크가 종료될 때 까지 호출한 부모 태스크는 대기한다.
- 리눅스에서 fork 대신 vfork를 사용하면 부모와 자식간의 race가 발생하지 않도록 부모 태스크는 여기서 잠시 block되어 있다가 자식 task가 fork된 후에야 wakeup한다.
- 코드 라인 34에서 pid의 참조 카운터를 1 감소시킨다.
kernel/fork.c -1/8-
/*
* This creates a new process as a copy of the old one,
* but does not actually start it yet.
*
* It copies the registers, and all the appropriate
* parts of the process environment (as per the clone
* flags). The actual kick-off is left to the caller.
*/
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
if ((clone_flags & (CLONE_NEWUSER|CLONE_FS)) == (CLONE_NEWUSER|CLONE_FS))
return ERR_PTR(-EINVAL);
/*
* Thread groups must share signals as well, and detached threads
* can only be started up within the thread group.
*/
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
/*
* Shared signal handlers imply shared VM. By way of the above,
* thread groups also imply shared VM. Blocking this case allows
* for various simplifications in other code.
*/
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
/*
* Siblings of global init remain as zombies on exit since they are
* not reaped by their parent (swapper). To solve this and to avoid
* multi-rooted process trees, prevent global and container-inits
* from creating siblings.
*/
if ((clone_flags & CLONE_PARENT) &&
current->signal->flags & SIGNAL_UNKILLABLE)
return ERR_PTR(-EINVAL);
/*
* If the new process will be in a different pid or user namespace
* do not allow it to share a thread group or signal handlers or
* parent with the forking task.
*/
if (clone_flags & CLONE_SIGHAND) {
if ((clone_flags & (CLONE_NEWUSER | CLONE_NEWPID)) ||
(task_active_pid_ns(current) !=
current->nsproxy->pid_ns_for_children))
return ERR_PTR(-EINVAL);
}
기존 프로세스의 정보들을 사용하여 새로운 프로세스를 생성한다.
- 코드 라인 19~20에서 새로운 mount namespace로 태스크 생성을 요청했지만 파일 시스템 정보를 공유할 수 없으므로 실패로 함수를 빠져나간다.
- 코드 라인 22~23에서 새로운 user namespace로 태스크 생성을 요청했지만 파일 시스템 정보를 공유할 수 없으므로 실패로 함수를 빠져나간다.
- 코드 라인 29~30에서 thread 생성을 요청했지만 시그널 핸들러의 공유가 필요하다. 그렇지 않은 경우 실패로 함수를 빠져나간다.
- 스레드 그룹끼리는 시그널을 공유해야 한다.
- 코드 라인 37~38에서 시그널 핸들러를 공유할 때 같은 가상 주소(VM)를 사용해야한다. 그렇지 않은 경우 실패로 함수를 빠져나간다.
- 코드 라인 46~48에서 부모 태스크에 SIGNAL_UNKILLABLE 시그널 플래그가 있는 경우 부모 태스크 클론을 요청한 경우 실패로 함수를 빠져나간다.
- 코드 라인 55~60에서 새로운 user namespace 또는 pid namespace로 태스크 생성을 요청한 경우 시그널 핸들러를 공유할 수 없다. 이러한 경우 실패로 함수를 빠져나간다.
kernel/fork.c -2/8-
retval = security_task_create(clone_flags);
if (retval)
goto fork_out;
retval = -ENOMEM;
p = dup_task_struct(current);
if (!p)
goto fork_out;
ftrace_graph_init_task(p);
rt_mutex_init_task(p);
#ifdef CONFIG_PROVE_LOCKING
DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled);
DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled);
#endif
retval = -EAGAIN;
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}
current->flags &= ~PF_NPROC_EXCEEDED;
retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
- 코드 라인 1~3에서 태스크 생성 이전에 태스크 생성 관련 시큐리티 후크 함수를 호출한다. 만일 실패(0이 아닐 때)시 fork_out 레이블로 이동한다.
- CONFIG_SECURITY 커널 옵션을 사용하지 않는 경우 항상 성공(0)이다.
- 참고: LSM(Linux Security Module) -1-
- 코드 라인 5~8에서 태스크를 생성한다.
- current task 디스크립터(task_struct 및 thread_info 포함)를 복제한다. 이 때 커널 스택도 생성된다.
- 코드 라인 10에서 ftrace 추적을 위한 초기화를 수행한다.
- 코드 라인 12에서 priority inheritency 처리 관련 초기화를 수행한다.
- 코드 라인 18~24에서 최대 프로세스 생성 제한치를 초과하고, 태스크 생성을 루트 유저가 하지 않았으면 bad_fork_free 레이블로 이동한다.
- 단 시스템 리소스와 시스템 관리자에 대한 capability가 설정된 경우에는 제한을 무시한다.
- 코드 라인 25~29에서 부모 프로세스의 플래그에서 최대 프로세스 생성 제한 플래그를 클리어하고 인증(credentials)을 복사한다.
kernel/fork.c -3/8-
/*
* If multiple threads are within copy_process(), then this check
* triggers too late. This doesn't hurt, the check is only there
* to stop root fork bombs.
*/
retval = -EAGAIN;
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count;
delayacct_tsk_init(p); /* Must remain after dup_task_struct() */
p->flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER);
p->flags |= PF_FORKNOEXEC;
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock);
init_sigpending(&p->pending);
p->utime = p->stime = p->gtime = 0;
p->utimescaled = p->stimescaled = 0;
#ifndef CONFIG_VIRT_CPU_ACCOUNTING_NATIVE
p->prev_cputime.utime = p->prev_cputime.stime = 0;
#endif
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
seqlock_init(&p->vtime_seqlock);
p->vtime_snap = 0;
p->vtime_snap_whence = VTIME_SLEEPING;
#endif
#if defined(SPLIT_RSS_COUNTING)
memset(&p->rss_stat, 0, sizeof(p->rss_stat));
#endif
p->default_timer_slack_ns = current->timer_slack_ns;
task_io_accounting_init(&p->ioac);
acct_clear_integrals(p);
posix_cpu_timers_init(p);
p->start_time = ktime_get_ns();
p->real_start_time = ktime_get_boot_ns();
p->io_context = NULL;
p->audit_context = NULL;
if (clone_flags & CLONE_THREAD)
threadgroup_change_begin(current);
cgroup_fork(p);
- 코드 라인 6~8에서 스레드 수가 fork_init()함수에서 초기화한 최대 스레드 수(max_threads) 이상인 경우 실패로 bad_fork_cleanup_count 레이블로 이동한다.
- max_threads 디폴트: mempages / (8 * 커널 스택 사이즈 / 페이지 사이즈)
- 코드 라인 10~11에서 현재 태스크의 실행 도메인이 디폴트 실행 도메인이 아니면서 모듈 정보가 없는 경우 bad_fork_cleanup_count 레이블로 이동한다.
- 코드 라인 13에서 delay accounting이 동작 시 초기화를 수행한다.
- 코드 라인 14~15에서 생성된 태스크의 수퍼 유저 권한 및 워커 스레드 플래그를 제거하고 태스크 생성 후 실행되지 않도록 PF_FORKNOEXEC 플래그를 제거한다.
- 코드 라인 16~17에서 생성된 태스크의 자식 및 형제 관련한 리스트를 초기화한다.
- 코드 라인 18에서 생성된 태스크의 rcu 관련 멤버의 초기화를 수행한다.
- 코드 라인 22에서 시그널 펜딩 리스트를 초기화한다.
- 코드 라인 24~25 생성된 프로세스의 각종 실행 타임을 0으로 초기화한다.
- utime: 유저 코드 실행 시간(jiffies)
- stime: 시스템 코드 실행 시간(jiffies)
- 코드 라인 26~33 virtual cpu에 대한 time accounting을 초기화한다.
- 코드 라인 35~37에서 rss 통계 카운터를 초기화한다.
- MM_FILEPAGES 카운터, MM_ANONPAGES 카운터, MM_SWAPENTS 카운터
- 코드 라인 39에서 절전을 위해 사용하는 타이머용 slack 나노초를 부모 값을 상속하여 사용한다.
- 코드 라인 41에서 태스크에 대한 io 통계 카운터를 초기화한다.
- CONFIG_TASK_XACCT 커널 옵션 사용시
- 읽은 바이트 수
- 기록한 바이트 수
- 읽은 syscall 수
- 기록한 syscall 수
- CONFIG_TASK_IO_ACCOUNTING 커널 옵션 사용 시
- 디스크로 부터 읽은 바이트 수
- 디스크에 기록한 비이트 수
- 디스크에 기록 취소한 바이트 수
- CONFIG_TASK_XACCT 커널 옵션 사용시
- 코드 라인 42에서 태스크에 대한 mm 관련 accounting 카운터 정보를 초기화한다.
- 코드 라인 44에서 posix cpu 타이머들을 초기화한다.
- 코드 라인 46~47에서 monotonic 시간(nsec)과 boot based 시간(nsec)을 구해와 대입한다.
- 코드 라인 48~49에서 io 및 audit 컨택스트를 초기화한다.
- 코드 라인 50~51에서 스레드 생성 요청 시 스레드 그룹 변경에 대한 락을 건다.
- 코드 라인 52에서 cgroup 관련 초기화를 수행한다.
kernel/fork.c -4/8-
#ifdef CONFIG_NUMA
p->mempolicy = mpol_dup(p->mempolicy);
if (IS_ERR(p->mempolicy)) {
retval = PTR_ERR(p->mempolicy);
p->mempolicy = NULL;
goto bad_fork_cleanup_threadgroup_lock;
}
#endif
#ifdef CONFIG_CPUSETS
p->cpuset_mem_spread_rotor = NUMA_NO_NODE;
p->cpuset_slab_spread_rotor = NUMA_NO_NODE;
seqcount_init(&p->mems_allowed_seq);
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
p->irq_events = 0;
p->hardirqs_enabled = 0;
p->hardirq_enable_ip = 0;
p->hardirq_enable_event = 0;
p->hardirq_disable_ip = _THIS_IP_;
p->hardirq_disable_event = 0;
p->softirqs_enabled = 1;
p->softirq_enable_ip = _THIS_IP_;
p->softirq_enable_event = 0;
p->softirq_disable_ip = 0;
p->softirq_disable_event = 0;
p->hardirq_context = 0;
p->softirq_context = 0;
#endif
#ifdef CONFIG_LOCKDEP
p->lockdep_depth = 0; /* no locks held yet */
p->curr_chain_key = 0;
p->lockdep_recursion = 0;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
p->blocked_on = NULL; /* not blocked yet */
#endif
#ifdef CONFIG_BCACHE
p->sequential_io = 0;
p->sequential_io_avg = 0;
#endif
- 코드 라인 1~8에서 누마 시스템에서 메모리 정책을 복제한다.
- 코드 라인 9~13에서 cpuset 관련 멤버들을 초기화한다.
- 코드 라인 14~28에서 irq 시작과 끝에 대한 trace 정보 및 조작 관련 멤버를 초기화한다.
- 코드 라인 29~33에서 lockdep 디버깅 관련 멤버를 초기화한다.
- 코드 라인 35~37에서 뮤텍스 블럭 디버깅 멤버를 초기화한다.
- 코드 라인 38~41에서 블럭 디바이스를 다른 디바이스의 캐시 대용으로 사용할 때 관련된 멤버들을 초기화한다.
kernel/fork.c -5/8-
/* Perform scheduler related setup. Assign this task to a CPU. */
retval = sched_fork(clone_flags, p);
if (retval)
goto bad_fork_cleanup_policy;
retval = perf_event_init_task(p);
if (retval)
goto bad_fork_cleanup_policy;
retval = audit_alloc(p);
if (retval)
goto bad_fork_cleanup_perf;
/* copy all the process information */
shm_init_task(p);
retval = copy_semundo(clone_flags, p);
if (retval)
goto bad_fork_cleanup_audit;
retval = copy_files(clone_flags, p);
if (retval)
goto bad_fork_cleanup_semundo;
retval = copy_fs(clone_flags, p);
if (retval)
goto bad_fork_cleanup_files;
retval = copy_sighand(clone_flags, p);
if (retval)
goto bad_fork_cleanup_fs;
retval = copy_signal(clone_flags, p);
if (retval)
goto bad_fork_cleanup_sighand;
retval = copy_mm(clone_flags, p);
if (retval)
goto bad_fork_cleanup_signal;
retval = copy_namespaces(clone_flags, p);
if (retval)
goto bad_fork_cleanup_mm;
retval = copy_io(clone_flags, p);
if (retval)
goto bad_fork_cleanup_namespaces;
retval = copy_thread(clone_flags, stack_start, stack_size, p);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
if (!pid)
goto bad_fork_cleanup_io;
}
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL;
/*
* Clear TID on mm_release()?
*/
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr : NULL;
#ifdef CONFIG_BLOCK
p->plug = NULL;
#endif
#ifdef CONFIG_FUTEX
p->robust_list = NULL;
#ifdef CONFIG_COMPAT
p->compat_robust_list = NULL;
#endif
INIT_LIST_HEAD(&p->pi_state_list);
p->pi_state_cache = NULL;
#endif
- 코드 라인 1~4에서 태스크의 스케줄러 관련 멤버들을 초기화한다.
- p->state: TAKS_RUNNING 상태로 바꾼다.
- p->prio: normal_prio로 설정한다. (pi boost에 의해 priority가 변경되어 있을 수도 있다)
- p->sched_class: prio를 보고 rt 또는 cfs 스케줄러로 설정한다. (deadline인 경우 에러)
- thread_info->cpu: cpu 설정
- p->on_cpu: 0으로 초기화
- p->pushable_tasks: rt 오버로드용 리스트 초기화
- p->pusjable_dl_tasks: dl 오버로드용 RB 트리 초기화
- thread_info->preempt_count: PREEMPT_ENABLE로 초기화
- 코드 라인 6~8에서 perf 이벤트 관련한 context 들을 모두 초기화한다.
- 코드 라인 9~11에서 audit 기능이 동작하는 경우 audit context 블럭을 할당한다.
- 참고: 리눅스 Audit 시스템 소개 | Techint
- 코드 라인 13에서 시스템V IPC용 공유 메모리(shm)에 관련 리스트의 초기화를 수행한다.
- 코드 라인 14~16에서 부모 태스크에서 사용중인 시스템V IPC용 세마포어들에 대해 공유(CLONE_SYSVSEM)하거나 새로 초기화하여 사용한다.
- 공유하여 사용하면 참조 카운터는 1을 증가시키고, 그렇지 않은 경우 초기화하여 사용한다.
- 코드 라인 17~19에서 부모 태스크에서 열고 사용하고 있는 파일 정보를 공유(CLONE_FILES)하거나 복사하여 사용한다.
- 공유하여 사용하면 참조 카운터는 1을 증가시키고, 그렇지 않은 경우 해당 파일들의 참조 카운터를 1부터 시작한다.
- 코드 라인 20~22에서 부모 태스크에서 사용하는 루트 파일 시스템을 공유(CLONE_FS)하거나 복사하여 사용한다.
- 공유하여 사용하면 참조 카운터는 1을 증가시키고, 그렇지 않은 경우 참조 카운터를 1부터 시작한다.
- 코드 라인 23~25에서 부모 태스크에서 사용하는 시그널 핸들러 정보를 공유(CLONE_SIGHAND)하거나 복사하여 사용한다.
- 공유하여 사용하면 참조 카운터는 1을 증가시키고, 그렇지 않은 경우 참조 카운터를 1부터 시작한다.
- 코드 라인 26~28에서 부모 태스크에서 사용하는 시그널 rlimit 정보를 알아와서 시그널 디스크립터를 생성하여 초기화한다. 단 생성되는 태스크가 스레드인 경우에는 아무일도 하지 않고 성공(0)으로 함수를 빠져나간다.
- 코드 라인 29~31에서 커널 스레드인경우 거의 아무일도 수행하지 않고, pthread, vfork를 통해 진입한 경우 별도의 mm을 만들지 않고 부모의 mm을 공유한다. 유저 프로세스(fork & clone)를 생성한 경우 자신의 vm을 만들되 부모의 mm 정보를 상속받아 사용한다. 부모가 사용하는 vma 정보와 페이지 테이블 정보를 복사하여 사용한다. (COW)
- COW 방식을 사용하여 실제 사용메모리는 할당하지 않고, 부모 태스크가 사용하던 vma 및 페이지 테이블만 복사하여 자신의 vm을 구성하고, 유저 태스크가 추후 실제 페이지에 수정을 위해 접근하려 할 때 fault 되어 기존 페이지를 새로 할당받은 곳에 복사하여 사용하는 방식을 사용한다.
- 공유하여 사용하면 참조 카운터는 1을 증가시키고, 그렇지 않은 경우 참조 카운터를 1부터 시작한다.
- 코드 라인 32~34에서 부모 태스크에서 사용하는 namespace를 사용하거나 공유(CLONE_NEWNS, CLONE_NEWUTS | CLONE_NEWIPC, CLONE_NEWPID, CLONE_NEWNET) 요청이 있는 경우 부모 태스크의 namespace 정보를 사용하여 새로운 namespace를 생성한다.
- 유저가 CAP_SYS_ADMIN 권한이 없는 경우 -EPERM 에러로 함수를 빠져나간다.
- 코드 라인 35~37에서 부모 태스크가 사용하는 io context 정보를 공유(CLONE_IO)하거나 새로 생성하여 사용한다.
- 코드 라인 38~40에서 부모 태스크가 사용하는 스레드 레지스터 정보를 사용하여 초기화한다. 부모 태스크가 사용하는 TLS 정보를 공유(CLONE_SETTLS)할 수도 있다.
- 코드 라인 42~47에서 인자로 받은 pid 디스크립터가 &init_struct_pid가 아닌 경우 pid 디스크립터를 새로 할당받는다.
- fork_idle() 함수를 통해 copy_process() 함수를 호출할 때 인자로 &init_struct_pid 디스크립터가 주어진다.
kernel/fork.c -6/8-
/*
* sigaltstack should be cleared when sharing the same VM
*/
if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM)
p->sas_ss_sp = p->sas_ss_size = 0;
/*
* Syscall tracing and stepping should be turned off in the
* child regardless of CLONE_PTRACE.
*/
user_disable_single_step(p);
clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE);
#ifdef TIF_SYSCALL_EMU
clear_tsk_thread_flag(p, TIF_SYSCALL_EMU);
#endif
clear_all_latency_tracing(p);
/* ok, now we should be set up.. */
p->pid = pid_nr(pid);
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
p->group_leader = current->group_leader;
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
p->group_leader = p;
p->tgid = p->pid;
}
p->nr_dirtied = 0;
p->nr_dirtied_pause = 128 >> (PAGE_SHIFT - 10);
p->dirty_paused_when = 0;
p->pdeath_signal = 0;
INIT_LIST_HEAD(&p->thread_group);
p->task_works = NULL;
/*
* Make it visible to the rest of the system, but dont wake it up yet.
* Need tasklist lock for parent etc handling!
*/
write_lock_irq(&tasklist_lock);
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
- 코드 라인 4~5에서 vfork가 아닌 fork 또는 clone을 통해 VM을 공유하는 경우 시그널 보조 스택을 초기화한다.
- 코드 라인 11에서 gdb 등이 사용하는 ptrace 디버그용 유저 모드 싱글 스텝을 disable한다.
- arm 및 arm64 아키텍처는 하드웨어 디버거를 지원받아 사용한다.
- 참고: ptrace
- 코드 라인 12에서 trace용 syscall 플래그를 제거한다.
- 코드 라인 13~15에서 emulator용 syscall 플래그를 제거한다.
- 코드 라인 16에서 latency tracing을 위한 정보를 초기화한다.
- 코드 라인 20~23에서 스레드를 생성한 경우 이 스레드의 그룹 리더와 스레드 그룹 리더(tgid)는 부모 태스크가 가리키는 그룹리더와 스레드 그룹 리더를 그대로 사용한다.
- 코드 라인 24~31에서 스레드가 아닌 프로세스를 생성한 경우 그룹 리더와 스레드 그룹 리더는 자신이된다.
kernel/fork.c -7/8-
spin_lock(¤t->sighand->siglock);
/*
* Copy seccomp details explicitly here, in case they were changed
* before holding sighand lock.
*/
copy_seccomp(p);
/*
* Process group and session signals need to be delivered to just the
* parent before the fork or both the parent and the child after the
* fork. Restart if a signal comes in before we add the new process to
* it's process group.
* A fatal signal pending means that current will exit, so the new
* thread can't slip out of an OOM kill (or normal SIGKILL).
*/
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_free_pid;
}
if (likely(p->pid)) {
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
init_task_pid(p, PIDTYPE_PID, pid);
if (thread_group_leader(p)) {
init_task_pid(p, PIDTYPE_PGID, task_pgrp(current));
init_task_pid(p, PIDTYPE_SID, task_session(current));
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE;
}
p->signal->leader_pid = pid;
p->signal->tty = tty_kref_get(current->signal->tty);
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
attach_pid(p, PIDTYPE_PGID);
attach_pid(p, PIDTYPE_SID);
__this_cpu_inc(process_counts);
} else {
current->signal->nr_threads++;
atomic_inc(¤t->signal->live);
atomic_inc(¤t->signal->sigcnt);
list_add_tail_rcu(&p->thread_group,
&p->group_leader->thread_group);
list_add_tail_rcu(&p->thread_node,
&p->signal->thread_head);
}
attach_pid(p, PIDTYPE_PID);
nr_threads++;
}
- 코드 라인 7에서 부모 태스크에서 사용하는 secure computing mode를 가져와서 새 태스크에 복사하여 사용한다.
- 프로세스에 이미 열린 파일 디스크립터에 대해 exit(), sigreturn(), read() 그리고 write()를 제외한 모든 시스템 호출을 할 수 없게 보호한다. 만일 시도시 SIGKILL이 발생한다.
- 참고: seccomp(2) – Linux manual page – man7.org
- 코드 라인 17~23에서 부모 태스크의 시그널 상태를 재평가하여 펜딩된 경우 에러로 함수를 빠져나간다. 그렇지 않은 경우 플래그에서 시그널 펜딩 플래그를 제거한다.
- 코드 라인 25~28에서 높은 확률로 생성된 태스크에 pid 디스크립터가 지정된 경우 이 태스크의 PIDTYPE_PID에 pid 디스크립터를 지정한다.
- 코드 라인 29~31에서 생성된 태스크가 스레드 그룹의 리더인 경우 이 태스크의 PIDTYPE_PGID에 부모 태스크의 프로세스 그룹 리더의 pid 디스크립터를 지정한다. 또한 PIDTYPE_SID에 부모 태스크의 세션 id의 pid 디스크립터를 지정한다.
- 코드 라인 33~36에서 이 태스크가 child reaper인 경우 이 pid namespace의 child_reaper에 생성 태스크를 지정한다. 또한 시그널 플래그에 SIGNAL_UNKILLABLE 플래그를 추가한다.
- 코드 라인 38~39에서 시그널 리더 pid에 이 pid를 지정하고, 시그널에 지정된 tty도 부모 tty를 지정한다.
- 코드 라인 40~41에서 init_tasks.tasks 리스트에 생성된 스레드 그룹 리더 태스크를 추가하고, 부모 태스크의 자식으로 이 태스크를 추가한다.
- 코드 라인 42~43에서 생성된 태스크에 지정된 PIDTYPE_PGID 타입과 PIDTYPE_SID에 이 pid를 연결한다.
- 코드 라인 44에서 전역 per-cpu 변수인 process_counts 카운터를 1 증가시킨다.
- 코드 라인 45~48에서 생성된 태스크가 스레드인 경우 부모 태스크의 시그널 카운터들을 1씩 증가시킨다.
- 코드 라인 49~53에서 프로세스 그룹리더의 스레드 그룹 리스트와 시그널에 생성된 스레드를 추가한다.
- 코드 라인 54~55에서 생성된 태스크에 지정된 PIDTYPE_PID 타입에 이 pid를 연결한다. 그런 후 전역 변수인 스레드 수(nr_threads)를 증가시킨다.
kernel/fork.c -8/8-
total_forks++;
spin_unlock(¤t->sighand->siglock);
syscall_tracepoint_update(p);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
cgroup_post_fork(p);
if (clone_flags & CLONE_THREAD)
threadgroup_change_end(current);
perf_event_fork(p);
trace_task_newtask(p, clone_flags);
uprobe_copy_process(p, clone_flags);
return p;
bad_fork_free_pid:
if (pid != &init_struct_pid)
free_pid(pid);
bad_fork_cleanup_io:
if (p->io_context)
exit_io_context(p);
bad_fork_cleanup_namespaces:
exit_task_namespaces(p);
bad_fork_cleanup_mm:
if (p->mm)
mmput(p->mm);
bad_fork_cleanup_signal:
if (!(clone_flags & CLONE_THREAD))
free_signal_struct(p->signal);
bad_fork_cleanup_sighand:
__cleanup_sighand(p->sighand);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup_semundo:
exit_sem(p);
bad_fork_cleanup_audit:
audit_free(p);
bad_fork_cleanup_perf:
perf_event_free_task(p);
bad_fork_cleanup_policy:
#ifdef CONFIG_NUMA
mpol_put(p->mempolicy);
bad_fork_cleanup_threadgroup_lock:
#endif
if (clone_flags & CLONE_THREAD)
threadgroup_change_end(current);
delayacct_tsk_free(p);
module_put(task_thread_info(p)->exec_domain->module);
bad_fork_cleanup_count:
atomic_dec(&p->cred->user->processes);
exit_creds(p);
bad_fork_free:
free_task(p);
fork_out:
return ERR_PTR(retval);
}
- 코드 라인 1에서 fork된 태스크의 수를 증가시킨다. (전역 변수 total_forks)
- 코드 라인 3에서 syscall_tracepoint 관련하여 부모 태스크에 설정된 TIF_SYSCALL_TRACEPOINT 플래그 유무를 현재 태스크에 복사하여 설정한다.
- 코드 라인 6에서 fork가 발생하였으므로 1개 이상의 대기중인 프로세스 이벤트 리스너들에게 넷링크를 통해 전송한다.
- 참고
- Process Events Connector | LWN.net
- The Proc Connector and Socket Filters | SCOTT JAMES REMNANT
- 참고
- 코드 라인 7에서 새 태스크 생성 후 cgroup이 처리할 일을 수행한다.
- cgroup 태스크 리스트에 추가하고 에서 처리할 일을 수행한다.
- cgroup 서브시스템에 등록된 fork 후크 함수를 호출한다.
- 코드 라인 8~9에서 스레드 생성 요청(CLONE_THREAD)인 경우 스레드 그룹 변경에 대한 락을 닫는다.
- 코드 라인 10에서 fork에 대한 perf 이벤트 처리를 수행한다.
- 코드 라인 13에서 부모 태스크에서 사용하던 Uprobe 기반 이벤트 트레이스에서 사용하는 context들을 vfork로 만들어진 새 유저 태스크에만 복사한다.
- 참고
- Uprobe-tracer: Uprobe-based Event Tracing | Kernel.org
- Linux uprobe: User-Level Dynamic Tracing | Brendan Gregg’s Blog
- 참고
새 유저 태스크를 위한 mm 공유 또는 복제
copy_mm()
kernel/fork.c
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
int retval;
tsk->min_flt = tsk->maj_flt = 0;
tsk->nvcsw = tsk->nivcsw = 0;
#ifdef CONFIG_DETECT_HUNG_TASK
tsk->last_switch_count = tsk->nvcsw + tsk->nivcsw;
#endif
tsk->mm = NULL;
tsk->active_mm = NULL;
/*
* Are we cloning a kernel thread?
*
* We need to steal a active VM for that..
*/
oldmm = current->mm;
if (!oldmm)
return 0;
/* initialize the new vmacache entries */
vmacache_flush(tsk);
if (clone_flags & CLONE_VM) {
atomic_inc(&oldmm->mm_users);
mm = oldmm;
goto good_mm;
}
retval = -ENOMEM;
mm = dup_mm(tsk);
if (!mm)
goto fail_nomem;
good_mm:
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
fail_nomem:
return retval;
}
새 태스크를 위해 부모 mm 디스크립터 및 페이지 테이블을 공유 또는 복사해온다. 다음 조건에 따라 동작이 구분된다.
- kernel_thread() 함수를 통해 커널 스레드의 생성이 요청된 경우
- 커널 스레드는 vm 정보 구성을 하지 않으므로 아무런 처리를 하지 않는다.
- pthread_create() 또는 vfork() 함수를 통해 유저 스레드 또는 유저 태스크의 생성이 요청된 경우
- 부모가 사용하는 mm 디스크립터 정보를 그대로 공유한다.
- fork() 또는 clone() 함수를 통해 유저 태스크의 생성이 요청된 경우
- 생성된 태스크용으로 mm 디스크립터와 페이지 테이블을 새롭게 할당한 후 부모가 사용하는 mm 디스크립터와 페이지 테이블을 복사하여 구성한다. (COW)
참고:
- tsk->mm
- 커널 스레드인 경우 null
- 유저 태스크(유저 프로세스 및 유저 스레드)인 경우 mm 디스크립터를 가리킨다.
- tsk->active_mm
- 커널 스레드인 경우 마지막에 사용했었던 mm을 가리킨다.
- 최초 init_mm을 제외하곤 항상 마지막 유저 프로세스의 mm 디스크립터를 가리킨다.
- 유저 프로세스가 사용하는 mm 디스크립터를 가리킨다.
- 유저 스레드들은 자신이 소속된 유저 프로세스의 mm 디스크립터를 가리킨다.
- 커널 스레드인 경우 마지막에 사용했었던 mm을 가리킨다.
dup_mm()
kernel/fork.c
/*
* Allocate a new mm structure and copy contents from the
* mm structure of the passed in task structure.
*/
static struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;
int err;
mm = allocate_mm();
if (!mm)
goto fail_nomem;
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk))
goto fail_nomem;
dup_mm_exe_file(oldmm, mm);
err = dup_mmap(mm, oldmm);
if (err)
goto free_pt;
mm->hiwater_rss = get_mm_rss(mm);
mm->hiwater_vm = mm->total_vm;
if (mm->binfmt && !try_module_get(mm->binfmt->module))
goto free_pt;
return mm;
free_pt:
/* don't put binfmt in mmput, we haven't got module yet */
mm->binfmt = NULL;
mmput(mm);
fail_nomem:
return NULL;
}
새 유저 태스크를 위해 mm 디스크립터와 페이지 테이블을 할당한 후, 부모 태스크가 사용하던 mm 정보와 페이지 테이블을 복사한다.
- 코드 라인 10~12에서 mm 디스크립터용 kmem 캐시를 통해 새 mm 디스크립터를 할당받아온다.
- 코드 라인 14에서 부모 mm(oldmm) 디스크립터를 할당받은 mm 디스크립터에 모두 복사한다.
- 부모 태스크가 사용했었던 모든 vm 정보들이 복사된다. (물론 여기에서는 페이지 테이블은 제외)
- 코드 라인 16~17에서 부모 태스크의 mm 정보를 사용할 필요가 없는 새 태스크용 mm 디스크립터의 멤버를 일부 초기화시킨다. 이 때 함수내에서 유저 태스크용 페이지 테이블을 할당받아 mm->pgd에 대입한다.
- 코드 라인 19에서 실행 파일 정보를 복제한다.
- 코드 라인 21~23에서 부모 태스크가 사용하던 vma 정보들과 페이지 테이블에서 매핑된 유저 엔트리들을 복사한다.
- COW(Copy On Write) 처리를 위해 실제 부모 태스크가 사용하던 페이지(코드, 데이터 등)을 복사하지 않고 vma 정보와 페이지 테이블만 복사한다. 추후 유저 태스크가 활성화되어 부모 태스크가 사용하던 해당 코드 또는 데이터를 공유하여 접근하는데 만일 쓰기 작업이 수행되는 일이 발생할 때에만 해당 페이지를 복사하는 방식으로 실제 메모리를 지연할당한다. -> 태스크 생성이 빨라지고, 실제 물리 메모리 소모가 줄어든다.
mm_init()
kernel/fork.c
static struct mm_struct *mm_init(struct mm_struct *mm, struct task_struct *p)
{
mm->mmap = NULL;
mm->mm_rb = RB_ROOT;
mm->vmacache_seqnum = 0;
atomic_set(&mm->mm_users, 1);
atomic_set(&mm->mm_count, 1);
init_rwsem(&mm->mmap_sem);
INIT_LIST_HEAD(&mm->mmlist);
mm->core_state = NULL;
atomic_long_set(&mm->nr_ptes, 0);
mm_nr_pmds_init(mm);
mm->map_count = 0;
mm->locked_vm = 0;
mm->pinned_vm = 0;
memset(&mm->rss_stat, 0, sizeof(mm->rss_stat));
spin_lock_init(&mm->page_table_lock);
mm_init_cpumask(mm);
mm_init_aio(mm);
mm_init_owner(mm, p);
mmu_notifier_mm_init(mm);
clear_tlb_flush_pending(mm);
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
mm->pmd_huge_pte = NULL;
#endif
if (current->mm) {
mm->flags = current->mm->flags & MMF_INIT_MASK;
mm->def_flags = current->mm->def_flags & VM_INIT_DEF_MASK;
} else {
mm->flags = default_dump_filter;
mm->def_flags = 0;
}
if (mm_alloc_pgd(mm))
goto fail_nopgd;
if (init_new_context(p, mm))
goto fail_nocontext;
return mm;
fail_nocontext:
mm_free_pgd(mm);
fail_nopgd:
free_mm(mm);
return NULL;
}
mm 디스크립터를 초기화하고 유저용 pgd 테이블도 할당한다.
- 코드 라인 1~33에서 mm 디스크립터를 초기화한다.
- 코드 라인 35~36에서 유저용 pgd 테이블도 할당하고 mm->pgd에 대입한다.
- 코드 라인 38~39에서 context id를 0으로 초기화한다.
유저용 pgd 테이블 할당
arm 커널에서는 하나의 pgd 테이블을 커널 영역과 유저 영역을 같이 공유하여 사용되고, 각 영역을 분리(split)하는 사이즈는 커널 컴파일 옵션(rpi2: CONFIG_VMSPLIT_2G=y)에 따라 다르다. 유저용 pgdb 페이지 테이블을 만들때 arm 아키텍처는 다음과 같은 일을 수행한다.
- init_mm->pgd 테이블에서 커널 영역에 해당하는 pgd 엔트리들을 내 pgd 테이블에 복사한다.
- 커널 영역: CONFIG_VMSPLIT_2G + 16M(모듈 영역)
- 유저 영역에 해당하는 pgd 엔트리들은 null(0)으로 초기화한다.
- 만일 low exception 벡터를 사용하는 경우에는 low 벡터 주소가 유저 영역에 위치하므로 이를 access 할 수 있도록 low exception 벡터에 대한 pte 엔트리들도 할당하고 준비해야 한다.
32bit arm with LPAE 에서는 3개의 페이지 테이블을 구성하는 것이 달라지고, arm64에서는 커널용 페이지 테이블과 유저용 페이지 테이블이 아예 별도로 구성되어 있으므로 간단히 유저용 pgd 페이지 테이블만 할당 한다.
mm_alloc_pgd()
kernel/fork.c
static inline int mm_alloc_pgd(struct mm_struct *mm)
{
mm->pgd = pgd_alloc(mm);
if (unlikely(!mm->pgd))
return -ENOMEM;
return 0;
}
페이지 테이블을 할당한 후 mm->pgd에 지정한다.
- 사용하는 아키텍처 및 커널 옵션 구성에 따라 페이지 테이블 할당 구현이 약간씩 다르다.
pgd_alloc() – for arm
arch/arm/mm/pgd.c
/*
* need to get a 16k page for level 1
*/
pgd_t *pgd_alloc(struct mm_struct *mm)
{
pgd_t *new_pgd, *init_pgd;
pud_t *new_pud, *init_pud;
pmd_t *new_pmd, *init_pmd;
pte_t *new_pte, *init_pte;
new_pgd = __pgd_alloc();
if (!new_pgd)
goto no_pgd;
memset(new_pgd, 0, USER_PTRS_PER_PGD * sizeof(pgd_t));
/*
* Copy over the kernel and IO PGD entries
*/
init_pgd = pgd_offset_k(0);
memcpy(new_pgd + USER_PTRS_PER_PGD, init_pgd + USER_PTRS_PER_PGD,
(PTRS_PER_PGD - USER_PTRS_PER_PGD) * sizeof(pgd_t));
clean_dcache_area(new_pgd, PTRS_PER_PGD * sizeof(pgd_t));
#ifdef CONFIG_ARM_LPAE
/*
* Allocate PMD table for modules and pkmap mappings.
*/
new_pud = pud_alloc(mm, new_pgd + pgd_index(MODULES_VADDR),
MODULES_VADDR);
if (!new_pud)
goto no_pud;
new_pmd = pmd_alloc(mm, new_pud, 0);
if (!new_pmd)
goto no_pmd;
#endif
arm 아키텍처용 pgd 페이지 테이블을 할당한 후 반환한다.
- 코드 라인 11~13에서 pgd 페이지 테이블을 할당해온다.
- 3레벨을 사용하는 LPAE 시스템인 경우에는 4개 엔트리 * 8 바이트 = 32 바이트를 pgd 전용 kmem cache를 통해 할당한다.
- 2레벨을 사용하는 경우에는 버디 시스템을 통해 4개 페이지 * 4K = 16K 페이지를 할당한다.
- 코드 라인 15에서 pgd 테이블에서 유저 영역에 해당하는 부분만 0으로 초기화한다.
- rpi2 예) 2048개의 리눅스 pgd 엔트리에서 하위 유저 영역에 해당하는 부분은 1024(하위 2G 해당)-8(16M 모듈)=1018개의 8바이트 엔트리를 0으로 초기화한다.
- 코드 라인 20~22에서 커널용 pgd 테이블에서 커널 영역에 해당하는 부분만 새로 할당한 페이지의 커널 영역에 복사한다.
- 주의: 커널 영역 사이즈는 커널 쪽 vm_split 영역 사이즈와 모듈 영역을 더해야 한다.
- 코드 라인 24에서 할당받은 pgd 테이블 주소와 사이즈만큼에 해당하는 영역에 대해 data 캐시를 클린한다.
- 코드 라인 26~38에서 3레벨 페이지 테이블을 구성해야 하는 LPAE 시스템에서는 pud는 pgd를 그대로 사용하여 패스시키고 pmd 테이블도 추가로 할당하여 구성한다.
if (!vectors_high()) {
/*
* On ARM, first page must always be allocated since it
* contains the machine vectors. The vectors are always high
* with LPAE.
*/
new_pud = pud_alloc(mm, new_pgd, 0);
if (!new_pud)
goto no_pud;
new_pmd = pmd_alloc(mm, new_pud, 0);
if (!new_pmd)
goto no_pmd;
new_pte = pte_alloc_map(mm, NULL, new_pmd, 0);
if (!new_pte)
goto no_pte;
init_pud = pud_offset(init_pgd, 0);
init_pmd = pmd_offset(init_pud, 0);
init_pte = pte_offset_map(init_pmd, 0);
set_pte_ext(new_pte + 0, init_pte[0], 0);
set_pte_ext(new_pte + 1, init_pte[1], 0);
pte_unmap(init_pte);
pte_unmap(new_pte);
}
return new_pgd;
no_pte:
pmd_free(mm, new_pmd);
mm_dec_nr_pmds(mm);
no_pmd:
pud_free(mm, new_pud);
no_pud:
__pgd_free(new_pgd);
no_pgd:
return NULL;
}
- 코드 라인 1~26에서 low exception 벡터를 사용하는 시스템에서는 벡터가 유저 영역에 위치하므로 이를 위한 별도의 매핑을 추가로 만들어줘야 한다.
- 코드 라인 28에서 정상적으로 할당받은 pgd 테이블의 시작 주소를 반환한다.
pgd_alloc() – for arm64
arch/arm64/mm/pgd.c
pgd_t *pgd_alloc(struct mm_struct *mm)
{
if (PGD_SIZE == PAGE_SIZE)
return (pgd_t *)__get_free_page(PGALLOC_GFP);
else
return kmem_cache_alloc(pgd_cache, PGALLOC_GFP);
}
arm64에서는 커널용 페이지 테이블과 유저용 페이지 테이블이 아예 별도로 구성되어 있으므로 간단히 유저용 pgd 페이지 테이블만 할당 한다.
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c – 현재 글
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- kernel_thread() | 문c
- Namespace | 문c
- MM(Mapped Memory) Fault Handler | 문c
- fork()와 exec() | Laonbud
다음 그림은 유저 모드에서 syscall을 통해 프로세스나 스레드를 생성할 때 대응하는 커널 함수와 CLONE 플래그들을 보여준다. 그림에서 질문있습니다.
fork 와 clone에서 전부 sys_clone함수를 호출하고 CLONE 플래그가 같다면 둘이 같은 함수로 봐야하는거 아닌가요?
둘간 구분해서 clone 플래그를 다르게 하는게 맞는지 궁금합니다.
안녕하세요?
오래된 버전의 커널에서는 fork와 clone이 달랐습니다만 요즘 커널 버전에서는 같습니다.
기존 명령 호환을 위해 기존 호출 syscall 들은 그대로 유지를 하고 있습니다.
그러나 기능은 같으므로 같은 함수를 호출하게된 형식입니다.
엄밀히 말해 fork와 clone이 내부 커널 코드에서는 clone 플래그 하나가 다르긴 합니다.
clone 플래그 안에는 0x100부터 시작하는 clone 플래그 비트들 이외에도 하위 8비트에 signal 번호가 따라가는데,
fork에서만 SIGCHLD 시그널이 따라갑니다. 이는 내부적으로 trace 관련한 동작만 약간 다르고 주요 기능은 같습니다.
도움이 되시길 바랍니다.
정성스러운 답변 정말 감사합니다.
그러면 기존의 fork에서는 메모리 공유를 안하고, clone에서는 메모리 공유를 하는 feature는 하위 8비트에 signal 번호로 인해서 되는거라고 생각하면 될까요?
질문에 대한 답변은 그렇지 않다 입니다. 하위 8비트는 trace 밖에 영향을 끼치지 않습니다. 그러니 fork와 clone은 동일하다고 판단하시면 됩니다.
현재 커널에 있어서 fork와 clone은 동일합니다.
fork 와 clone으로 만들어진 하위 태스크는 둘 다 부모 태스크의 페이지 테이블을 공유하지 않고, 별도의 페이지 테이블을 생성합니다. 즉 부모 태스크의 메모리 공유를 하지 않습니다.
user application에서 pthread를 사용하여 스레드를 만들면 부모 태스크의 페이지 테이블을 스레드도 사용할 수 있게 공유합니다. 즉 유저 메모리가 공유됩니다. 이 때에 VM_CLONE이 사용됩니다.
안녕히세요
fork(clone)의 차이 점을 구별해 낼 수 없다면 그냥 fork(clone)를 사용하여야 한다.
라고 적혀있는데 더 읽어내려가다보면 여전히
vfork가 메모리 등이 훨씬적어서 fork보다 더 나아보이는데 어째서 fork를 써야하는지 잘 모르겠네요
그리고
fork와 달리 vfork는부모 프로세스와 파이프를 통한 교류를 할 수 없다.
이건 exec 를 호출했을때는 적용이 되지않는거죠?
만약 exec 실행을 위해 fork나 vfork를 쓴다면
뭐가 더 나은 선택인지 알수 있을까요?
전 여전히 vfork가 더 나아보이는데
책을 찾아보면 vfork는 exec 실패에 대한 처리가 불가능하니 fork를 쓰라는데 잘 이해가 안가더라구요;;
제가 공부했던 Oracle, PostgresSQL, MySQL 등의 RDBMS 에서는 fork 를 사용합니다.
vfork: 약 1.5M
application에 대해서는 ” 메모리”를 공유하여 사용
저는 처음에 왜? 오버헤드가 큰 fork 를 사용하지? 시스템에 오버헤드가 적어야지 서비스가 운용이 잘 되지 않을까?
저는 오라클 DBA 분께 여쭤봐서 그때 친절히 알려주셨었는데요.
클라이언트 SQL 쿼리 한번에 fork 된 프로세스가 디스크의 데이터를 메모리로 올리는 워크로드를 가정하면,
첫번째, 단일 프로세스 동적 할당 OOM (대용량 쿼리로 순간적으로 메모리를 피크치는 이슈)
두번째, fork 했기 때문에 부모 프로세스의 안정성 (자식 프로세스에서 쿼리를 수행하다가 만약 에러가 발생해 죽더라도, 혼자 죽음)
do_fork-4c.png 그림에 잘 설명되어 있는 것 같아요!
말씀해주신대로 안정성 측면에서 생각을 하면 fork를 쓰는게 맞군요
감사합니다 ㅎㅎ
추가로 RDBMS 가 아니더라도 빅 데이터 등(구글의 검색 엔진 인덱싱, 집계 처리 작업)에서 배치성 프로세스는 실무에서 모두 fork 기반으로 작업하더라구요.
PARAN LEE 님께서 잘 설명해주셨습니다.
리눅스에서는 시스템 프로그래밍시 안정성을 위해 가상 주소 공간을 각각 사용하도록 보통 process를 분리하여 사용하기에 fork를 사용합니다. 그 외에의 경우에도 vfork 보다는 pthread_create를 사용하는 것이 메모리 및 성능 상 더 효율적이라 vfork를 사용하는 일이 더 적어진것 같습니다.
감사합니다.