PID 테이블을 해쉬로 구현하여 빠르게 검색하고 처리할 수 있도록 하는데 이 함수를 사용하여 초기화 한다.
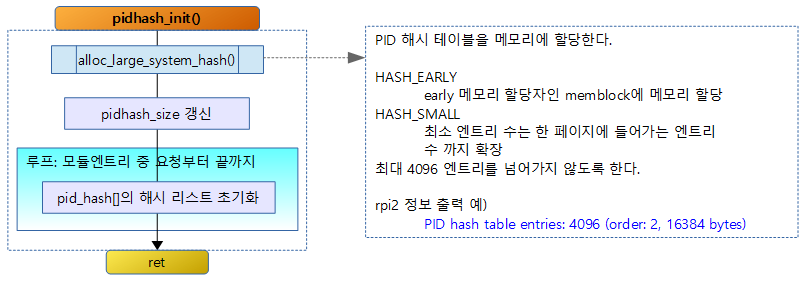
pidhash_init()
kernel/pid.c
/*
* The pid hash table is scaled according to the amount of memory in the
* machine. From a minimum of 16 slots up to 4096 slots at one gigabyte or
* more.
*/
void __init pidhash_init(void)
{
unsigned int i, pidhash_size;
pid_hash = alloc_large_system_hash("PID", sizeof(*pid_hash), 0, 18,
HASH_EARLY | HASH_SMALL,
&pidhash_shift, NULL,
0, 4096);
pidhash_size = 1U << pidhash_shift;
for (i = 0; i < pidhash_size; i++)
INIT_HLIST_HEAD(&pid_hash[i]);
}
pid용 해쉬 테이블을 할당하고 초기화한다.
- pid_hash = alloc_large_system_hash(“PID”, sizeof(*pid_hash), 0, 18, HASH_EARLY | HASH_SMALL, &pidhash_shift, NULL, 0, 4096);
- 커널 초기화 중이므로 early를 사용하여 memblock에 pid용 해쉬테이블 공간을 할당받는다.
- low_limit와 high_limit는 0과 4096개로 제한한다.
- 세 번째 인수로 0이 주어진 경우 커널의 lowmem free 페이지 공간을 확인하여 최대 수의 해시 엔트리 수를 계산해낸다.
- HASH_EARLY
- memblock에 할당 요청
- HASH_SMALL
- 최소 엔트리 수인 경우 확대하도록 한다.
- 해시 엔트리가 최소 2^pidhash_shift 이상 그리고 PAGE_SIZE / pid_hash 사이즈 갯 수 보다 크도록 확대 한다.
- pid_hash_shift
- 초기 값은 4
- rpi2 정보 출력 예)
- PID hash table entries: 4096 (order: 2, 16384 bytes)
- pidhash_size = 1U << pidhash_shift;
- pidhash_size를 2^pidhash_shift로 재조정 한다
- alloc_large_system_hash()를 수행하면서 결정한 해시 엔트리 수에 따라 전역 pidhash_shift 변수가 재조종된다.
- rpi2 예)
- 재조정되어 pidhash_shift=12
- rpi2 예)
- for (i = 0; i < pidhash_size; i++) INIT_HLIST_HEAD(&pid_hash[i]);
- pidhash_size 만큼 pid_hash[]를 초기화한다.
kernel/pid.c
static struct hlist_head *pid_hash;
다음 그림은 pid_hash가 pid 구조체 내부에 있는 upid 구조체들과 연결되는 모습을 보여준다.
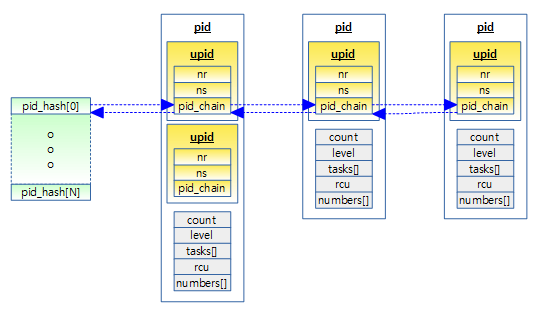
참고
- pid 관리 | 문c
- pidhash_init() | 문c – 현재글
- pidmap_init() | 문c
- alloc_large_system_hash() | 문c
- Linux kernel 3.x와 2.6.11의 PID Hash Table 자료구조 비교(슬라이드) | 양희철
- [Linux] PID 관리 | F/OSS
- PID namespaces in the 2.6.24 kernel | LWN.net