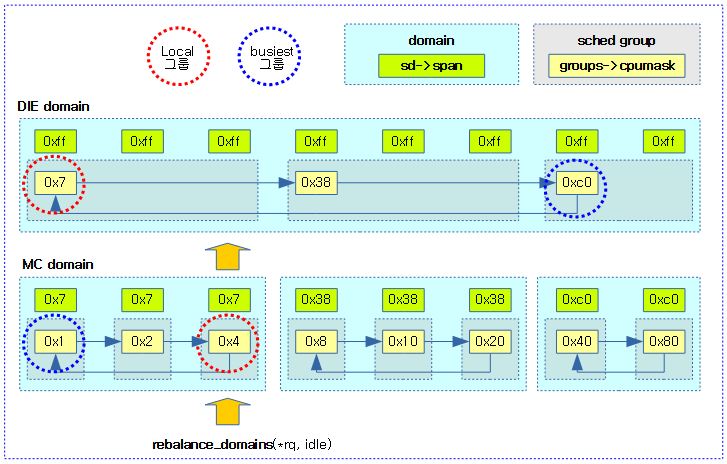
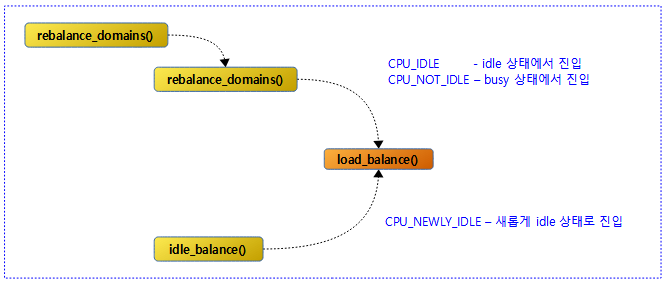
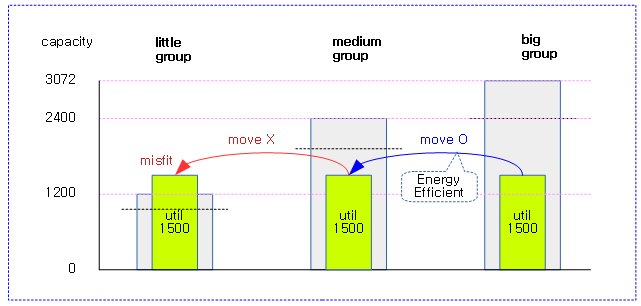
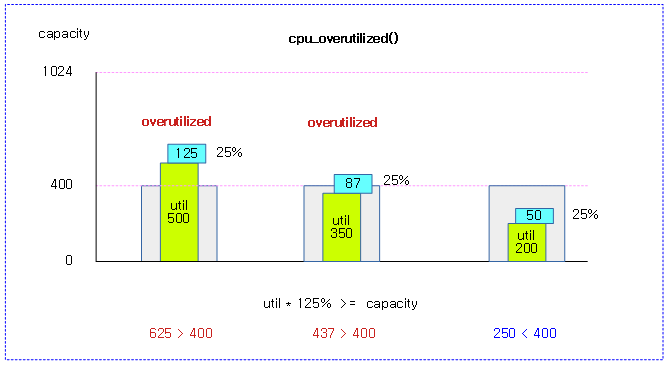
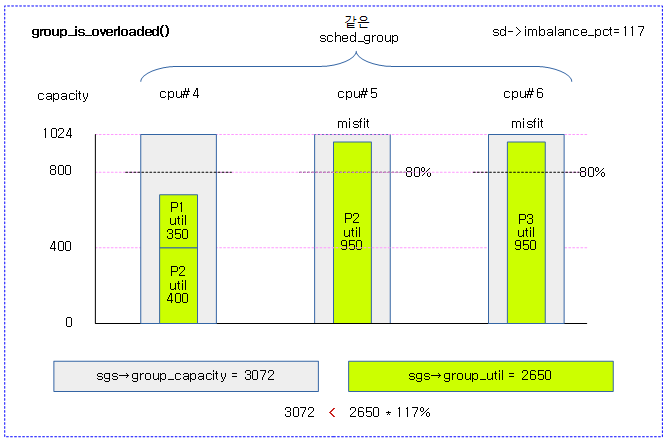
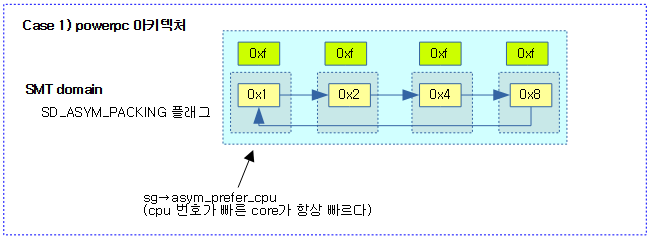
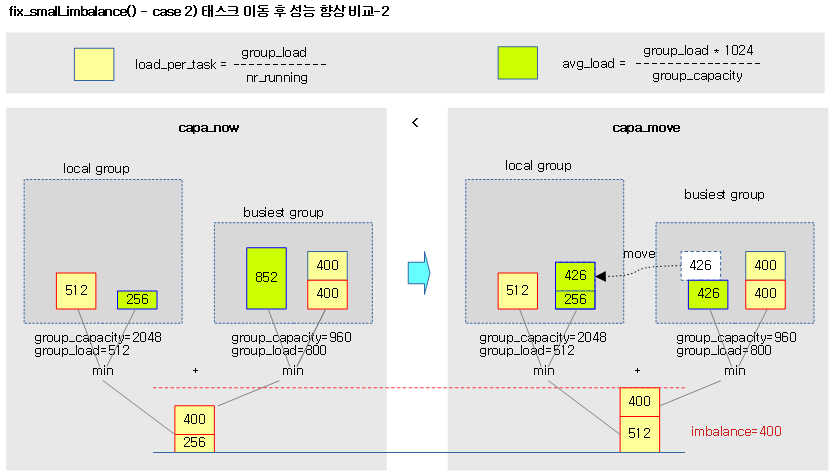
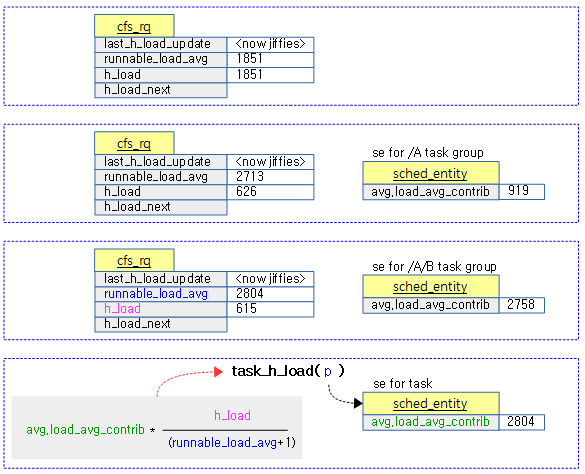
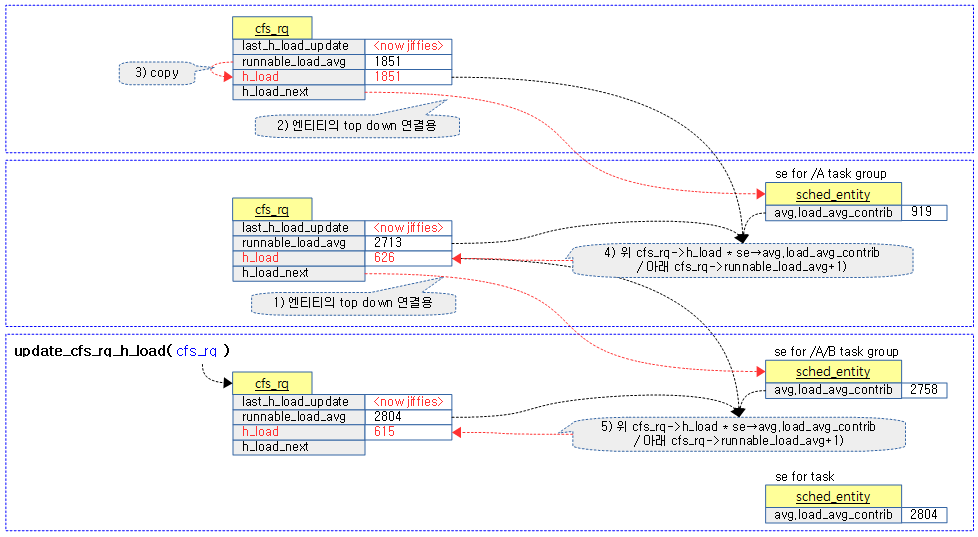
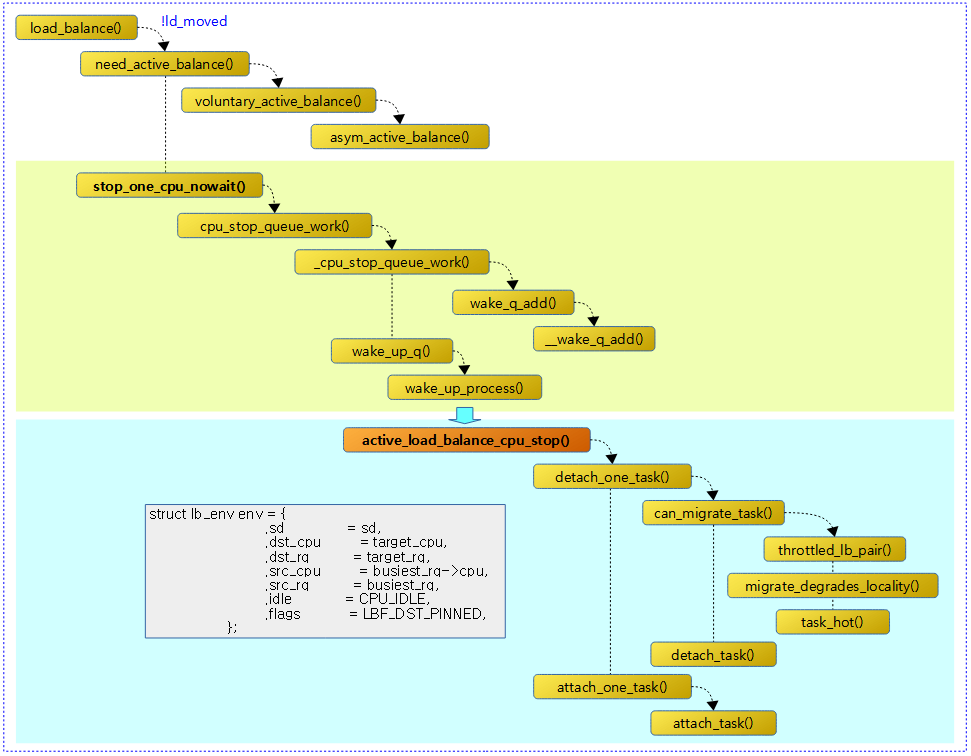
<kernel v5.4>
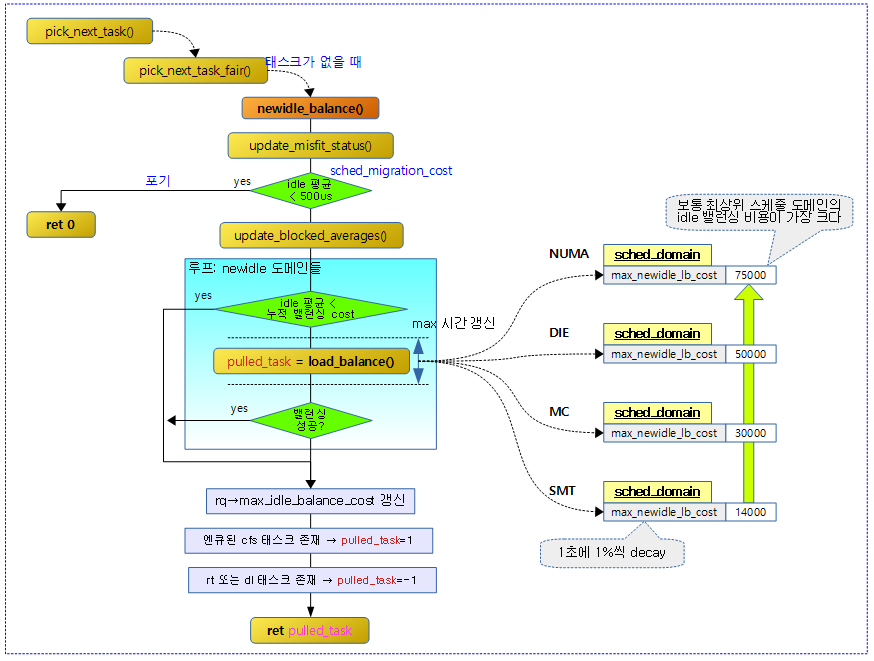
New Idle 밸런싱
현재 cpu의 런큐에서 수행시킬 태스크가 없어서 idle 상태에 진입하는데 그 전에 newidle_balance()함수를 통해 다른 cpu에서 동작하는 태스크를 가져와서 동작시키게 할 수 있다.
newidle_balance() 결과 값에 따라 결과 값이 양수인 경우 cfs 태스크가 있으므로 pick_next_task_fair()를 다시 시도하고 그 외의 결과 값인 경우 다음과 같다.
- 음수인 경우RETRY_TASK를 반환하면 stop -> dl -> rt 순서로 태스크를 찾아 수행한다.
- 0인 경우 NULL 반환하고 pick_next_task_idle()을 호출하여 idle로 진입한다.
newidle_balance()
kernel/sched/fair.c – 1/2
/* * idle_balance is called by schedule() if this_cpu is about to become * idle. Attempts to pull tasks from other CPUs. */
int newidle_balance(struct rq *this_rq, struct rq_flags *rf)
{
unsigned long next_balance = jiffies + HZ;
int this_cpu = this_rq->cpu;
struct sched_domain *sd;
int pulled_task = 0;
u64 curr_cost = 0;
update_misfit_status(NULL, this_rq);
/*
* We must set idle_stamp _before_ calling idle_balance(), such that we
* measure the duration of idle_balance() as idle time.
*/
this_rq->idle_stamp = rq_clock(this_rq);
/*
* Do not pull tasks towards !active CPUs...
*/
if (!cpu_active(this_cpu))
return 0;
/*
* This is OK, because current is on_cpu, which avoids it being picked
* for load-balance and preemption/IRQs are still disabled avoiding
* further scheduler activity on it and we're being very careful to
* re-start the picking loop.
*/
rq_unpin_lock(this_rq, rf);
if (this_rq->avg_idle < sysctl_sched_migration_cost ||
!READ_ONCE(this_rq->rd->overload)) {
rcu_read_lock();
sd = rcu_dereference_check_sched_domain(this_rq->sd);
if (sd)
update_next_balance(sd, &next_balance);
rcu_read_unlock();
nohz_newidle_balance(this_rq);
goto out;
}
raw_spin_unlock(&this_rq->lock);
새롭게 처음 idle 진입 시 newidle 밸런싱을 시도한다. (결과: 0=수행할 태스크가 없다. -1=rt 또는 dl 태스크가 있다. 양수=cfs 태스크가 있다.)
- 코드 라인 9에서 misfit 상태를 갱신한다.
- 코드 라인 14에서 idle 진입 시각을 기록한다.
- 코드 라인 19~20에서 cpu가 이미 active 상태가 아닌 경우 0을 반환한다.
- 코드 라인 30~42에서 평균 idle 시간이 너무 짧거나 오버로드된 상태가 아니면 다음 밸런싱 시각을 갱신하고, nohz_newidle_balance()를 수행 후 out 레이블로 이동하여 idle 밸런싱을 skip 한다.
- “/proc/sys/kernel/sched_migration_cost_ns”의 디폴트 값은 500,000 (ns)이다.
kernel/sched/fair.c – 2/2
update_blocked_averages(this_cpu);
rcu_read_lock();
for_each_domain(this_cpu, sd) {
int continue_balancing = 1;
u64 t0, domain_cost;
if (!(sd->flags & SD_LOAD_BALANCE))
continue;
if (this_rq->avg_idle < curr_cost + sd->max_newidle_lb_cost) {
update_next_balance(sd, &next_balance);
break;
}
if (sd->flags & SD_BALANCE_NEWIDLE) {
t0 = sched_clock_cpu(this_cpu);
pulled_task = load_balance(this_cpu, this_rq,
sd, CPU_NEWLY_IDLE,
&continue_balancing);
domain_cost = sched_clock_cpu(this_cpu) - t0;
if (domain_cost > sd->max_newidle_lb_cost)
sd->max_newidle_lb_cost = domain_cost;
curr_cost += domain_cost;
}
update_next_balance(sd, &next_balance);
/*
* Stop searching for tasks to pull if there are
* now runnable tasks on this rq.
*/
if (pulled_task || this_rq->nr_running > 0)
break;
}
rcu_read_unlock();
raw_spin_lock(&this_rq->lock);
if (curr_cost > this_rq->max_idle_balance_cost)
this_rq->max_idle_balance_cost = curr_cost;
out:
/*
* While browsing the domains, we released the rq lock, a task could
* have been enqueued in the meantime. Since we're not going idle,
* pretend we pulled a task.
*/
if (this_rq->cfs.h_nr_running && !pulled_task)
pulled_task = 1;
/* Move the next balance forward */
if (time_after(this_rq->next_balance, next_balance))
this_rq->next_balance = next_balance;
/* Is there a task of a high priority class? */
if (this_rq->nr_running != this_rq->cfs.h_nr_running)
pulled_task = -1;
if (pulled_task)
this_rq->idle_stamp = 0;
rq_repin_lock(this_rq, rf);
return pulled_task;
}
- 코드 라인 1에서 블럭드 로드 평균을 갱신한다.
- 코드 라인 3~8에서 요청한 cpu에 대해 최하위 스케줄 도메인부터 최상위 스케줄 도메인까지 순회하며 로드 밸런싱을 허용하지 않는 도메인은 skip 한다.
- 코드 라인 10~13에서 평균 idle 시간(avg_idle)이 하위 도메인부터 누적된 밸런싱 소요 시간 + 현재 도메인에 대한 최대 밸런싱 소요 시간보다 작은 경우에는 밸런싱에 오버헤드가 발생하는 경우를 막기 위해 밸런싱을 하지 않는다. 다음 밸런싱 시각(1틱 ~ 최대 0.1초)을 갱신하고 루프를 벗어난다.
- curr_cost
- 하위 도메인부터 누적된 idle 밸런싱 소요 시간
- domain_cost
- 해당 도메인에 대한 idle 밸런싱 소요 시간
- sd->max_newidle_lb_cost
- 해당 도메인의 최대 idle 밸런싱 소요 시간
- 매 스케줄 틱마다 수행되는 rebalance_domains() 함수를 통해 1초에 1%씩 줄어든다.
- curr_cost
- 코드 라인 15~27에서 순회 중인 스케줄 도메인이 newidle을 허용하는 경우 다음과 같이 처리한다.
- idle 로드밸런싱을 수행하고 마이그레이션을 한 태스크 수를 알아온다.
- 순회 중인 도메인에서 idle 로드밸런싱에서 소요된 시간을 curr_cost에 누적시킨다. 또한 순회 중인 도메인의 idle 밸런싱 시간이 도메인의 max_newidle_lb_cost보다 큰 경우 갱신한다.
- 코드 라인 29에서 다음 밸런싱 시각을 갱신한다.
- 코드 라인 35~36에서 마이그레이션한 태스크가 있거나 현재 동작 중인 엔티티가 1개 이상인 경우 루프를 벗어난다.
- 이 cpu의 런큐에 일감(?)이 생겼으므로 idle 상태로 진입할 필요가 없어졌다.
- 코드 라인 42~43에서 idle 밸런싱에 사용한 시간이 현재 런큐의 max_idle_balance_cost를 초과한 경우 갱신한다.
- 코드 라인 45~52 에서 out: 레이블이다. idle 밸런스를 통해 마이그레이션을 한 태스크가 없지만 그 사이에 새로운 태스크가 cfs 런큐에 엔큐된 경우 idle 상태로 진입할 필요 없으므로 pulled_task=1로 대입한다.
- 코드 라인 55~56에서 런큐에 지정된 다음 밸런싱 시각이 이미 경과한 경우 그 시각으로 갱신한다.
- 코드 라인 59~60에서 현재 런큐에 cfs 태스크보다 빠른 우선 순위를 가진 태스크(stop, rt, dl)가 있는 경우 pulled_task=-1을 대입하여 idle 상태로 진입할 필요를 없앤다.
- 코드 라인 62~63에서 현재 cpu에 수행할 태스크가 있어 idle에 진입할 필요가 없는 경우이다. 러너블 로드 평균을 갱신하고 idle_stamp를 0으로 초기화한다.
- 코드 라인 67에서 마이그레이션된 태스크 수를 반환한다. 0=수행할 태스크가 없다. -1=rt 또는 dl 태스크가 있다. 양수=cfs 태스크가 있다.
다음 그림은 newidle_balance()의 처리 과정을 보여준다.
nohz 밸런싱
다음 플래그들은 nohz 밸런싱과 관련한 플래그들이다.
- NOHZ_STATS_KICK
- nohz 관련 stat을 갱신할 수 있게 한다.
- NOHZ_BALANCE_KICK
- nohz idle 밸런싱을 할 수 있게 한다.
다음 그림은 nohz 밸런싱을 수행하는 과정을 보여준다.
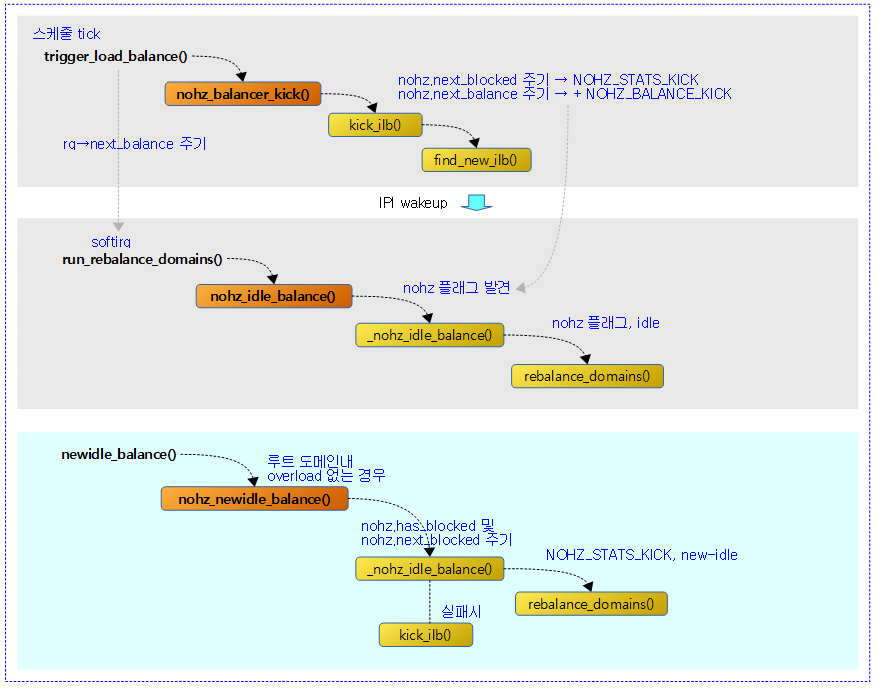
nohz idle 밸런싱 시작
nohz_balancer_kick()
kernel/sched/fair.c -1/2-
/* * Current decision point for kicking the idle load balancer in the presence * of idle CPUs in the system. */
static void nohz_balancer_kick(struct rq *rq)
{
unsigned long now = jiffies;
struct sched_domain_shared *sds;
struct sched_domain *sd;
int nr_busy, i, cpu = rq->cpu;
unsigned int flags = 0;
if (unlikely(rq->idle_balance))
return;
/*
* We may be recently in ticked or tickless idle mode. At the first
* busy tick after returning from idle, we will update the busy stats.
*/
nohz_balance_exit_idle(rq);
/*
* None are in tickless mode and hence no need for NOHZ idle load
* balancing.
*/
if (likely(!atomic_read(&nohz.nr_cpus)))
return;
if (READ_ONCE(nohz.has_blocked) &&
time_after(now, READ_ONCE(nohz.next_blocked)))
flags = NOHZ_STATS_KICK;
if (time_before(now, nohz.next_balance))
goto out;
if (rq->nr_running >= 2) {
flags = NOHZ_KICK_MASK;
goto out;
}
rcu_read_lock();
sd = rcu_dereference(rq->sd);
if (sd) {
/*
* If there's a CFS task and the current CPU has reduced
* capacity; kick the ILB to see if there's a better CPU to run
* on.
*/
if (rq->cfs.h_nr_running >= 1 && check_cpu_capacity(rq, sd)) {
flags = NOHZ_KICK_MASK;
goto unlock;
}
}
sd = rcu_dereference(per_cpu(sd_asym_packing, cpu));
if (sd) {
/*
* When ASYM_PACKING; see if there's a more preferred CPU
* currently idle; in which case, kick the ILB to move tasks
* around.
*/
for_each_cpu_and(i, sched_domain_span(sd), nohz.idle_cpus_mask) {
if (sched_asym_prefer(i, cpu)) {
flags = NOHZ_KICK_MASK;
goto unlock;
}
}
}
nohz idle 동작 중인 cpu를 찾아 nohz 밸런싱을 동작시키게 한다. ipi를 통해 해당 cpu를 깨운다.
- 코드 라인 9~10에서 이미 idle 밸런싱 중인 경우 함수를 빠져나간다.
- 코드 라인 16에서 현재 cpu가 busy 상태로 진입하였다. 이 때 처음 busy tick인 경우 현재 cpu를 nohz idle에서 busy 상태로 변경한다.
- 코드 라인 22~23에서 nohz idle 중인 cpu가 하나도 없으면 함수를 빠져나간다.
- 코드 라인 25~27에서 nohz idle 중인 cpu들 중 blocked 로드를 가진 경우 nohz.next_blocked 시간이 도래하였으면 NOHZ_STATS_KICK 플래그를 지정해둔다.
- 코드 라인 29~30에서 현재 시각이 아직 nohz.next_balance 시각을 넘어서지 않은 경우 out 레이블로 이동한다.
- 코드 라인 32~35에서 현재 cpu의 런큐에서 2 개 이상의 태스크가 동작 중인 경우 NOHZ_KICK_MASK 플래그를 지정한 후 out 레이블로 이동한다.
- 코드 라인 39~50에서 1개 이상의 cfs 태스크가 동작하는데 rt,dl,irq 등의 외부 로드가 높아 cfs capacity가 일정 부분 감소된 경우 NOHZ_KICK_MASK 플래그를 지정한 후 unlock 레이블로 이동한다.
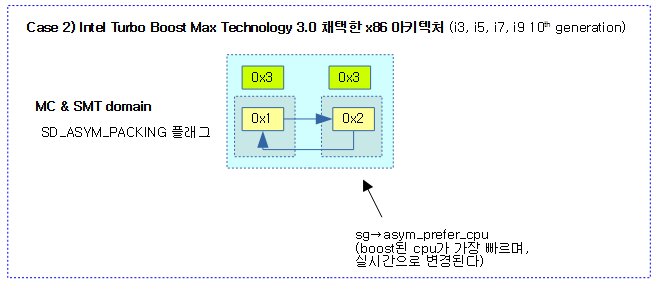
- 코드 라인 52~65에서 power7 또는 x86의 ITMT 처럼 asym packing이 있는 도메인의 cpu들을 대상으로 순회하며 순회 중인 cpu가 현재 cpu보다 더 높은 우선 순위를 가진 경우 NOHZ_KICK_MASK 플래그를 지정한 후 unlock 레이블로 이동한다.
kernel/sched/fair.c -2/2-
sd = rcu_dereference(per_cpu(sd_asym_cpucapacity, cpu));
if (sd) {
/*
* When ASYM_CPUCAPACITY; see if there's a higher capacity CPU
* to run the misfit task on.
*/
if (check_misfit_status(rq, sd)) {
flags = NOHZ_KICK_MASK;
goto unlock;
}
/*
* For asymmetric systems, we do not want to nicely balance
* cache use, instead we want to embrace asymmetry and only
* ensure tasks have enough CPU capacity.
*
* Skip the LLC logic because it's not relevant in that case.
*/
goto unlock;
}
sds = rcu_dereference(per_cpu(sd_llc_shared, cpu));
if (sds) {
/*
* If there is an imbalance between LLC domains (IOW we could
* increase the overall cache use), we need some less-loaded LLC
* domain to pull some load. Likewise, we may need to spread
* load within the current LLC domain (e.g. packed SMT cores but
* other CPUs are idle). We can't really know from here how busy
* the others are - so just get a nohz balance going if it looks
* like this LLC domain has tasks we could move.
*/
nr_busy = atomic_read(&sds->nr_busy_cpus);
if (nr_busy > 1) {
flags = NOHZ_KICK_MASK;
goto unlock;
}
}
unlock:
rcu_read_unlock();
out:
if (flags)
kick_ilb(flags);
}
- 코드 라인 1~20에서 빅/리틀 처럼 asym cpu capacity를 가진 도메인에서 현재 런큐가 misfit 상태이면서 루트 도메인내 다른 cpu보다 낮은 성능을 가졌거나 cpu가 rt/dl/irq 등의 유틸로 인해 cfs capacity 가 압박을 받고 있는 상태인 경우 NOHZ_KICK_MASK 플래그를 지정한 후 unlock 레이블로 이동한다.
- 코드 라인 22~38에서 캐시 공유 도메인에서 busy cpu가 2개 이상인 경우 NOHZ_KICK_MASK 플래그를 지정한 후 unlock 레이블로 이동한다.
- 코드 라인 39~43에서 unlock: 및 out: 레이블이다. nohz idle 상태의 cpu를 알아온 후 nohz 밸런싱을 동작시키게 하기 위해 해당 cpu를 깨운다.
kick_ilb()
kernel/sched/fair.c
/* * Kick a CPU to do the nohz balancing, if it is time for it. We pick any * idle CPU in the HK_FLAG_MISC housekeeping set (if there is one). */
static void kick_ilb(unsigned int flags)
{
int ilb_cpu;
nohz.next_balance++;
ilb_cpu = find_new_ilb();
if (ilb_cpu >= nr_cpu_ids)
return;
flags = atomic_fetch_or(flags, nohz_flags(ilb_cpu));
if (flags & NOHZ_KICK_MASK)
return;
/*
* Use smp_send_reschedule() instead of resched_cpu().
* This way we generate a sched IPI on the target CPU which
* is idle. And the softirq performing nohz idle load balance
* will be run before returning from the IPI.
*/
smp_send_reschedule(ilb_cpu);
}
no idle 상태의 cpu를 알아온 후 해당 cpu에서 nohz 밸런싱을 동작시키게 햐기 위해 cpu를 깨운다.
- 코드 라인 5~10에서 nohz idle 상태의 cpu를 알아온다.
- 코드 라인 12~22에서 해당 cpu의 런큐에 flags를 추가한다. 그 전에 NOHZ_KICK_MASK에 해당하는 플래그가 없으면 해당 cpu를 깨운다.
- 첫 kicking 한 번만 IPI 호출을 한다.
find_new_ilb()
kernel/sched/fair.c
static inline int find_new_ilb(void)
{
int ilb;
for_each_cpu_and(ilb, nohz.idle_cpus_mask,
housekeeping_cpumask(HK_FLAG_MISC)) {
if (idle_cpu(ilb))
return ilb;
}
return nr_cpu_ids;
}
nohz idle cpu 및 HK_FLAG_MISC 플래그를 가진 cpu들 중 idle 상태의 cpu 번호를 반환한다. 못 찾은 경우 nr_cpu_ids를 반환한다.
- HK_FLAG_MISC 플래그는 nohz full 지정된 cpu들에 플래그가 설정된다.
- 예) “nohz_full=5-8”
nohz idle 밸런스
nohz_idle_balance()
kernel/sched/fair.c
/* * In CONFIG_NO_HZ_COMMON case, the idle balance kickee will do the * rebalancing for all the cpus for whom scheduler ticks are stopped. */
static bool nohz_idle_balance(struct rq *this_rq, enum cpu_idle_type idle)
{
int this_cpu = this_rq->cpu;
unsigned int flags;
if (!(atomic_read(nohz_flags(this_cpu)) & NOHZ_KICK_MASK))
return false;
if (idle != CPU_IDLE) {
atomic_andnot(NOHZ_KICK_MASK, nohz_flags(this_cpu));
return false;
}
/* could be _relaxed() */
flags = atomic_fetch_andnot(NOHZ_KICK_MASK, nohz_flags(this_cpu));
if (!(flags & NOHZ_KICK_MASK))
return false;
_nohz_idle_balance(this_rq, flags, idle);
return true;
}
nohz idle 밸런싱을 통해 현재 cpu가 nohz idle 상태인 경우 다른 바쁜 cpu에서 태스크를 마이그레이션해온다.
- 코드 라인 6~17에서 현재 cpu에 대해 idle 상태로 진입하지 않았거나 NOHZ_KICK_MASK에 해당하는 플래그가 없는 경우 false를 반환한다. NOHZ_KICK_MASK에 해당하는 플래그들은 클리어한다.
- #define NOHZ_KICK_MASK (NOHZ_BALANCE_KICK | NOHZ_STATS_KICK)
- 코드 라인 19~21에서 idle 밸런싱을 수행하고 true를 반환한다.
nohz newidle 밸런스
nohz_newidle_balance()
kernel/sched/fair.c
static void nohz_newidle_balance(struct rq *this_rq)
{
int this_cpu = this_rq->cpu;
/*
* This CPU doesn't want to be disturbed by scheduler
* housekeeping
*/
if (!housekeeping_cpu(this_cpu, HK_FLAG_SCHED))
return;
/* Will wake up very soon. No time for doing anything else*/
if (this_rq->avg_idle < sysctl_sched_migration_cost)
return;
/* Don't need to update blocked load of idle CPUs*/
if (!READ_ONCE(nohz.has_blocked) ||
time_before(jiffies, READ_ONCE(nohz.next_blocked)))
return;
raw_spin_unlock(&this_rq->lock);
/*
* This CPU is going to be idle and blocked load of idle CPUs
* need to be updated. Run the ilb locally as it is a good
* candidate for ilb instead of waking up another idle CPU.
* Kick an normal ilb if we failed to do the update.
*/
if (!_nohz_idle_balance(this_rq, NOHZ_STATS_KICK, CPU_NEWLY_IDLE))
kick_ilb(NOHZ_STATS_KICK);
raw_spin_lock(&this_rq->lock);
}
newidle_balance() 함수에서 newidle 로드밸런싱을 수행하지만 오버로드되지 않은 경우에 한해서는 이 함수를 호출한다. 이 함수에서는 nohz 블럭드 로드만 갱신하고 pull 마이그레이션은 포기한다. 만일 갱신이 실패하는 경우 ipi를 통해 다른 nohz cpu를 통해 nohz 블록드 로드를 갱신하게 한다.
- 코드 라인 9~10에서 현재 cpu가 HK_FLAG_SCHED 플래그를 가지지 않은 경우 함수를 빠져나간다.
- nohz 및 isolcpus 관련하여 미래 사용을 위해 남겨두었다.
- 코드 라인 13~14에서 평균 idle이 sysctl_sched_migration_cost(디폴트 500us) 보다 작은 경우 함수를 빠져나간다.
- 잦은 wakeup / sleep이 발생되는 상황
- 코드 라인 17~19에서 이미 nohz 블럭드 로드 상태(nohz 진입 후)이거나 32ms 주기의 next_blocked 시각이 도래하지 않았으면 함수를 빠져나간다.
- 코드 라인 28~29에서 nohz 블럭드 로드를 갱신하고, 만일 갱신이 실패한 경우 nohz cpu들 중 하나를 선택해서 ipi call을 통해 nohz 블럭드 로드를 갱신하게 한다.
_nohz_idle_balance()
kernel/sched/fair.c -1/2-
/* * Internal function that runs load balance for all idle cpus. The load balance * can be a simple update of blocked load or a complete load balance with * tasks movement depending of flags. * The function returns false if the loop has stopped before running * through all idle CPUs. */
static bool _nohz_idle_balance(struct rq *this_rq, unsigned int flags,
enum cpu_idle_type idle)
{
/* Earliest time when we have to do rebalance again */
unsigned long now = jiffies;
unsigned long next_balance = now + 60*HZ;
bool has_blocked_load = false;
int update_next_balance = 0;
int this_cpu = this_rq->cpu;
int balance_cpu;
int ret = false;
struct rq *rq;
SCHED_WARN_ON((flags & NOHZ_KICK_MASK) == NOHZ_BALANCE_KICK);
/*
* We assume there will be no idle load after this update and clear
* the has_blocked flag. If a cpu enters idle in the mean time, it will
* set the has_blocked flag and trig another update of idle load.
* Because a cpu that becomes idle, is added to idle_cpus_mask before
* setting the flag, we are sure to not clear the state and not
* check the load of an idle cpu.
*/
WRITE_ONCE(nohz.has_blocked, 0);
/*
* Ensures that if we miss the CPU, we must see the has_blocked
* store from nohz_balance_enter_idle().
*/
smp_mb();
for_each_cpu(balance_cpu, nohz.idle_cpus_mask) {
if (balance_cpu == this_cpu || !idle_cpu(balance_cpu))
continue;
/*
* If this CPU gets work to do, stop the load balancing
* work being done for other CPUs. Next load
* balancing owner will pick it up.
*/
if (need_resched()) {
has_blocked_load = true;
goto abort;
}
rq = cpu_rq(balance_cpu);
has_blocked_load |= update_nohz_stats(rq, true);
/*
* If time for next balance is due,
* do the balance.
*/
if (time_after_eq(jiffies, rq->next_balance)) {
struct rq_flags rf;
rq_lock_irqsave(rq, &rf);
update_rq_clock(rq);
rq_unlock_irqrestore(rq, &rf);
if (flags & NOHZ_BALANCE_KICK)
rebalance_domains(rq, CPU_IDLE);
}
if (time_after(next_balance, rq->next_balance)) {
next_balance = rq->next_balance;
update_next_balance = 1;
}
}
nohz ilde (또는 newilde) 밸런싱을 수행한다.
- 코드 라인 6에서 다음 밸런싱 시각으로 현재 시각 + 60초를 준다. 이 값은 최대값으로 갱신될 예정이다.
- 코드 라인 32~34에서 nohz idle 중인 cpu를 순회하며 현재 cpu 및 busy cpu는 skip 한다.
- 코드 라인 41~44에서 리스케줄 요청이 있는 경우 루프를 벗어나 abort 레이블로 이동한다.
- 코드 라인 46~48에서 순회 중인 cpu의 런큐에 대해 블럭드 로드 존재 여부를 알아온다.
- 코드 라인 54~63에서 밸런싱 시각을 넘어선 경우 런큐 클럭을 갱신 한 후 밸런싱을 시도한다.
- 코드 라인 65~68에서 처음 60초로 설정해 두었던 next_balance 시각을 갱신한다.
kernel/sched/fair.c -2/2-
/* Newly idle CPU doesn't need an update */
if (idle != CPU_NEWLY_IDLE) {
update_blocked_averages(this_cpu);
has_blocked_load |= this_rq->has_blocked_load;
}
if (flags & NOHZ_BALANCE_KICK)
rebalance_domains(this_rq, CPU_IDLE);
WRITE_ONCE(nohz.next_blocked,
now + msecs_to_jiffies(LOAD_AVG_PERIOD));
/* The full idle balance loop has been done */
ret = true;
abort:
/* There is still blocked load, enable periodic update */
if (has_blocked_load)
WRITE_ONCE(nohz.has_blocked, 1);
/*
* next_balance will be updated only when there is a need.
* When the CPU is attached to null domain for ex, it will not be
* updated.
*/
if (likely(update_next_balance))
nohz.next_balance = next_balance;
return ret;
}
- 코드 라인 2~5에서 idle 밸런싱인 경우 blocked 평균을 갱신하고, blocked 로드를 가졌는지를 알아온다.
- 코드 라인 7~8에서 nohz 밸런스를 수행한다.
- 코드 라인 10~14에서 다음 idle 밸런싱 주기를 현재 시각 + 32ms로 갱신하고 ret=true를 대입한다.
- 코드 라인 16~19에서 abort: 레이블이다. blocked 로드가 여전히 있는 경우 nohz.has_blocked에 1을 대입하여 계속 갱신될 수 있게 한다.
- 코드 라인 26~27에서 nohz 밸런싱 주기를 갱신한다.
Blocked 로드 갱신
nohz와 관련하여 다음과 같은 주요 멤버들을 알아본다.
- rq->has_blocked_load
- nohz 상태에 진입하여 nohz_balance_enter_idle() 함수를 통해 이 값이 1로 설정된다.
- update_blocked_averages() -> update_blocked_load_status() 함수를 통해 cfs,dl,rt 및 irq 등의 로드 및 유틸이 완전히 없을 때 0으로 클리어된다.
- nohz.has_blocked
- nohz 상태에 진입하여 nohz_balance_enter_idle() 함수를 통해 이 값이 1로 설정된다.
- _nohz_idle_balance() 함수가 수행될 때에는 이 값이 0으로 클리어된 후 nohz idle 밸런싱의 경우에만 update_blocked_averages()를 통해 갱신된 블럭드 로드가 여전히 존재하는 경우 1로 설정된다.
- 이 값이 1인 경우에만 nohz idle 밸런싱을 수행한다.
- 이 값이 1이고 newidle 밸런싱에서 LBF_NOHZ_STATS 플래그를 설정하여 nohz 관련 stat을 갱신하도록 한다.
- 이 값이 1이고 nohz.next_blocked 시각이 지난 경우 NOHZ_STATS_KICK 플래그를 설정하여 nohz 관련 stat을 갱신하도록 한다.
update_blocked_averages()
kernel/sched/fair.c
static void update_blocked_averages(int cpu)
{
struct rq *rq = cpu_rq(cpu);
struct cfs_rq *cfs_rq, *pos;
const struct sched_class *curr_class;
struct rq_flags rf;
bool done = true;
rq_lock_irqsave(rq, &rf);
update_rq_clock(rq);
/*
* update_cfs_rq_load_avg() can call cpufreq_update_util(). Make sure
* that RT, DL and IRQ signals have been updated before updating CFS.
*/
curr_class = rq->curr->sched_class;
update_rt_rq_load_avg(rq_clock_pelt(rq), rq, curr_class == &rt_sched_class);
update_dl_rq_load_avg(rq_clock_pelt(rq), rq, curr_class == &dl_sched_class);
update_irq_load_avg(rq, 0);
/* Don't need periodic decay once load/util_avg are null */
if (others_have_blocked(rq))
done = false;
/*
* Iterates the task_group tree in a bottom up fashion, see
* list_add_leaf_cfs_rq() for details.
*/
for_each_leaf_cfs_rq_safe(rq, cfs_rq, pos) {
struct sched_entity *se;
if (update_cfs_rq_load_avg(cfs_rq_clock_pelt(cfs_rq), cfs_rq))
update_tg_load_avg(cfs_rq, 0);
/* Propagate pending load changes to the parent, if any: */
se = cfs_rq->tg->se[cpu];
if (se && !skip_blocked_update(se))
update_load_avg(cfs_rq_of(se), se, 0);
/*
* There can be a lot of idle CPU cgroups. Don't let fully
* decayed cfs_rqs linger on the list.
*/
if (cfs_rq_is_decayed(cfs_rq))
list_del_leaf_cfs_rq(cfs_rq);
/* Don't need periodic decay once load/util_avg are null */
if (cfs_rq_has_blocked(cfs_rq))
done = false;
}
update_blocked_load_status(rq, !done);
rq_unlock_irqrestore(rq, &rf);
}
런큐의 블럭드 로드 여부를 갱신한다.
- 코드 라인 10~19에서 런큐 클럭을 갱신한 후 cfs 로드 평균을 갱신하기 전에 먼저 dl, rt, irq 로드 평균을 갱신한다.
- 코드 라인 22~23에서 dl, rt, irq 유틸이 남아 있으면 done을 false로 변경한다.
- 코드 라인 29~38에서 런큐에 매달린 모든 leaf cfs 런큐들에 대해 태스크 그룹 및 cfs 런큐 로드 평균을 갱신한다.
- leaf cfs 런큐는 태스크가 연결된 cfs 런큐로 중복되지 않는다.
- 코드 라인 44~45에서 decay되어 로드가 없는 경우 leaf cfs 런큐 리스트에서 제거한다.
- 코드 라인 48~49에서 cfs 런큐에 여전히 로드가 있는 경우 done을 false로 변경한다.
- 코드 라인 52에서 block 로드 상태를 갱신한다.
- 하나의 cfs 런큐라도 로드가 남아 있으면 rq->has_blocked_load=0이 설정된다.
others_have_blocked()
kernel/sched/fair.c
static inline bool others_have_blocked(struct rq *rq)
{
if (READ_ONCE(rq->avg_rt.util_avg))
return true;
if (READ_ONCE(rq->avg_dl.util_avg))
return true;
#ifdef CONFIG_HAVE_SCHED_AVG_IRQ
if (READ_ONCE(rq->avg_irq.util_avg))
return true;
#endif
cfs외 다른(rt, dl 및 irq) 유틸 평균이 조금이라도 남아 있는지 여부를 반환한다. (1=유틸 평균 존재, 0=유틸 평균 없음)
skip_blocked_update()
kernel/sched/fair.c
/* * Check if we need to update the load and the utilization of a blocked * group_entity: */
static inline bool skip_blocked_update(struct sched_entity *se)
{
struct cfs_rq *gcfs_rq = group_cfs_rq(se);
/*
* If sched_entity still have not zero load or utilization, we have to
* decay it:
*/
if (se->avg.load_avg || se->avg.util_avg)
return false;
/*
* If there is a pending propagation, we have to update the load and
* the utilization of the sched_entity:
*/
if (gcfs_rq->propagate)
return false;
/*
* Otherwise, the load and the utilization of the sched_entity is
* already zero and there is no pending propagation, so it will be a
* waste of time to try to decay it:
*/
return true;
}
그룹 엔티티의 유틸이나 로드 평균이 하나도 없어 skip 해도 되는지 여부를 반환한다. (1=skip, 0=로드 평균 또는 유틸이 남아 있어 skip 불가)
cfs_rq_is_decayed()
kernel/sched/fair.c
static inline bool cfs_rq_is_decayed(struct cfs_rq *cfs_rq)
{
if (cfs_rq->load.weight)
return false;
if (cfs_rq->avg.load_sum)
return false;
if (cfs_rq->avg.util_sum)
return false;
if (cfs_rq->avg.runnable_load_sum)
return false;
return true;
}
cfs 런큐가 decay되어 러너블 로드 및 로드, 유틸 하나도 남아 있지 않은지 여부를 반환한다. (1=하나도 남아 있지 않다. 0=일부 남아 있다)
cfs_rq_has_blocked()
kernel/sched/fair.c
static inline bool cfs_rq_has_blocked(struct cfs_rq *cfs_rq)
{
if (cfs_rq->avg.load_avg)
return true;
if (cfs_rq->avg.util_avg)
return true;
return false;
}
cfs 런큐가 블럭드 로드를 가지는지 여부를 반환한다. (1=로드 또는 유틸 존재, 0=로드 및 유틸 없음)
update_blocked_load_status()
kernel/sched/fair.c
static inline void update_blocked_load_status(struct rq *rq, bool has_blocked)
{
rq->last_blocked_load_update_tick = jiffies;
if (!has_blocked)
rq->has_blocked_load = 0;
}
cfs 런큐에 블럭드 로드의 유무 상태를 갱신한다.
- has_blocked_load
- 0=로드 또는 유틸 존재 <- 이 함수에서는 이 상태만 설정한다.
- 1=로드 및 유틸 남아 있지 않음. <- idle 상태 진입 시 1로 설정된다.
Fork 밸런싱
wake_up_new_task()
kernel/sched/core.c
/* * wake_up_new_task - wake up a newly created task for the first time. * * This function will do some initial scheduler statistics housekeeping * that must be done for every newly created context, then puts the task * on the runqueue and wakes it. */
void wake_up_new_task(struct task_struct *p)
{
struct rq_flags rf;
struct rq *rq;
raw_spin_lock_irqsave(&p->pi_lock, rf.flags);
p->state = TASK_RUNNING;
#ifdef CONFIG_SMP
/*
* Fork balancing, do it here and not earlier because:
* - cpus_ptr can change in the fork path
* - any previously selected CPU might disappear through hotplug
*
* Use __set_task_cpu() to avoid calling sched_class::migrate_task_rq,
* as we're not fully set-up yet.
*/
p->recent_used_cpu = task_cpu(p);
__set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
#endif
rq = __task_rq_lock(p, &rf);
update_rq_clock(rq);
post_init_entity_util_avg(p);
activate_task(rq, p, ENQUEUE_NOCLOCK);
trace_sched_wakeup_new(p);
check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken) {
/*
* Nothing relies on rq->lock after this, so its fine to
* drop it.
*/
rq_unpin_lock(rq, &rf);
p->sched_class->task_woken(rq, p);
rq_repin_lock(rq, &rf);
}
#endif
task_rq_unlock(rq, p, &rf);
}
새로운 태스크에 대해 밸런싱을 수행한다. 새 태스크를 가능하면 idle한 cpu를 찾아 이동시킨다.
- 코드 라인 7에서 태스크를 TASK_RUNNING 상태로 변경한다.
- 코드 라인 17에서 최근에 사용했던 cpu 번호를 p->recent_used_cpu에 보관해둔다. 이렇게 보관된 cpu 번호는 select_idle_sibling() 함수를 사용할 때에 이용된다.
- 코드 라인 18에서 SD_BALANCE_FORK 플래그를 사용하여 태스크가 수행될 가장 적절한 cpu를 찾아 태스크에 설정한다.
- 코드 라인 21~22에서 런큐 클럭을 갱신하고, 새 태스크가 동작할 cfs 런큐의 로드 평균을 사용하여 태스크의 유틸 평균에 대한 초기값을 결정한다.
- 코드 라인 24에서 태스크를 런큐에 엔큐하고 activation 한다.
- 코드 라인 26에서 preemption 여부를 체크한다.
- 코드 라인 28~36에서 해당 태스크의 스케줄러의 (*task_woken) 후크에 등록된 함수를 호출한다. dl 또는 rt 스케줄러의 함수가 동작할 수 있는데, 새 태스크가 우선 순위가 밀려 곧장 동작하지 못할 경우 dl 또는 rt 오버로드 시켜 다른 cpu로의 push 밸런싱을 수행하게 한다.
Exec 밸런싱
sched_exec()
kernel/sched/core.c
/* * sched_exec - execve() is a valuable balancing opportunity, because at * this point the task has the smallest effective memory and cache footprint. */
void sched_exec(void)
{
struct task_struct *p = current;
unsigned long flags;
int dest_cpu;
raw_spin_lock_irqsave(&p->pi_lock, flags);
dest_cpu = p->sched_class->select_task_rq(p, task_cpu(p), SD_BALANCE_EXEC, 0);
if (dest_cpu == smp_processor_id())
goto unlock;
if (likely(cpu_active(dest_cpu))) {
struct migration_arg arg = { p, dest_cpu };
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
stop_one_cpu(task_cpu(p), migration_cpu_stop, &arg);
return;
}
unlock:
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
}
실행될 태스크에 대해 밸런싱을 수행한다.
- 코드 라인 8~10에서 exec 밸런싱을 통해 태스크가 수행될 cpu를 선택한다. 선택한 cpu가 현재 cpu인 경우 마이그레이션 없이 함수를 빠져나간다.
- 코드 라인 12~18에서 현재 태스크를 수행될 cpu로 마이그레이션 하도록 워크큐를 사용하여 워커스레드에 요청한다.
migration_cpu_stop()
kernel/sched/core.c
/* * migration_cpu_stop - this will be executed by a highprio stopper thread * and performs thread migration by bumping thread off CPU then * 'pushing' onto another runqueue. */
static int migration_cpu_stop(void *data)
{
struct migration_arg *arg = data;
struct task_struct *p = arg->task;
struct rq *rq = this_rq();
struct rq_flags rf;
/*
* The original target CPU might have gone down and we might
* be on another CPU but it doesn't matter.
*/
local_irq_disable();
/*
* We need to explicitly wake pending tasks before running
* __migrate_task() such that we will not miss enforcing cpus_ptr
* during wakeups, see set_cpus_allowed_ptr()'s TASK_WAKING test.
*/
sched_ttwu_pending();
raw_spin_lock(&p->pi_lock);
rq_lock(rq, &rf);
/*
* If task_rq(p) != rq, it cannot be migrated here, because we're
* holding rq->lock, if p->on_rq == 0 it cannot get enqueued because
* we're holding p->pi_lock.
*/
if (task_rq(p) == rq) {
if (task_on_rq_queued(p))
rq = __migrate_task(rq, &rf, p, arg->dest_cpu);
else
p->wake_cpu = arg->dest_cpu;
}
rq_unlock(rq, &rf);
raw_spin_unlock(&p->pi_lock);
local_irq_enable();
return 0;
}
런큐에서 wake up 시도 중인 태스크들을 모두 activate 시킨 후 요청한 태스크를 dest cpu의 런큐에 마이그레이션한다.
__migrate_task()
kernel/sched/core.c
/* * Move (not current) task off this CPU, onto the destination CPU. We're doing * this because either it can't run here any more (set_cpus_allowed() * away from this CPU, or CPU going down), or because we're * attempting to rebalance this task on exec (sched_exec). * * So we race with normal scheduler movements, but that's OK, as long * as the task is no longer on this CPU. */
static struct rq *__migrate_task(struct rq *rq, struct rq_flags *rf,
struct task_struct *p, int dest_cpu)
{
/* Affinity changed (again). */
if (!is_cpu_allowed(p, dest_cpu))
return rq;
update_rq_clock(rq);
rq = move_queued_task(rq, rf, p, dest_cpu);
return rq;
}
요청한 태스크를 @dest cpu의 런큐에 마이그레이션한다. 실패한 경우 0을 반환한다.
- 코드 라인 5~6에서 태스크가 @dest_cpu를 지원하지 않는 경우 기존 @rq를 반환한다.
- 코드 라인 8~11에서 런큐 클럭을 갱신하고, @dest_cpu로 태스크를 마이그레이션한 후 @dest_cpu의 런큐를 반환한다.
move_queued_task()
kernel/sched/core.c
/* * This is how migration works: * * 1) we invoke migration_cpu_stop() on the target CPU using * stop_one_cpu(). * 2) stopper starts to run (implicitly forcing the migrated thread * off the CPU) * 3) it checks whether the migrated task is still in the wrong runqueue. * 4) if it's in the wrong runqueue then the migration thread removes * it and puts it into the right queue. * 5) stopper completes and stop_one_cpu() returns and the migration * is done. */ /* * move_queued_task - move a queued task to new rq. * * Returns (locked) new rq. Old rq's lock is released. */
static struct rq *move_queued_task(struct rq *rq, struct rq_flags *rf,
struct task_struct *p, int new_cpu)
{
lockdep_assert_held(&rq->lock);
WRITE_ONCE(p->on_rq, TASK_ON_RQ_MIGRATING);
dequeue_task(rq, p, DEQUEUE_NOCLOCK);
set_task_cpu(p, new_cpu);
rq_unlock(rq, rf);
rq = cpu_rq(new_cpu);
rq_lock(rq, rf);
BUG_ON(task_cpu(p) != new_cpu);
enqueue_task(rq, p, 0);
p->on_rq = TASK_ON_RQ_QUEUED;
check_preempt_curr(rq, p, 0);
return rq;
}
요청한 태스크를 new cpu로 마이그레이션한다.
- 코드 라인 6~8에서 태스크의 on_rq에 마이그레이션 중이라고 상태를 바꾸고, 런큐에서 태스크를 디큐한다. 그런 후 태스크에 @new_cpu를 지정한다.
- 코드 라인 11~16에서 @new_cpu의 런큐에 태스크를 엔큐시키키고, 엔큐 상태도 변경한다.
- 코드 라인 17에서 preemption이 필요한 경우 리스케줄 요청을 설정하도록 체크한다.
- 코드 라인 19에서 @new_cpu의 런큐를 반환한다.
Wake 밸런싱
try_to_wake_up() 함수 내부에서 select_task_rq()를 호출할 떄 SD_BALANCE_WAKE 플래그를 사용하여 wake 밸런싱을 수행한다.
- 참고: Scheduler -5- (Scheduler Core) | 문c
FORK, EXEC 및 WAKE 밸런싱 공통
태스크가 동작할 적절한 cpu 선택
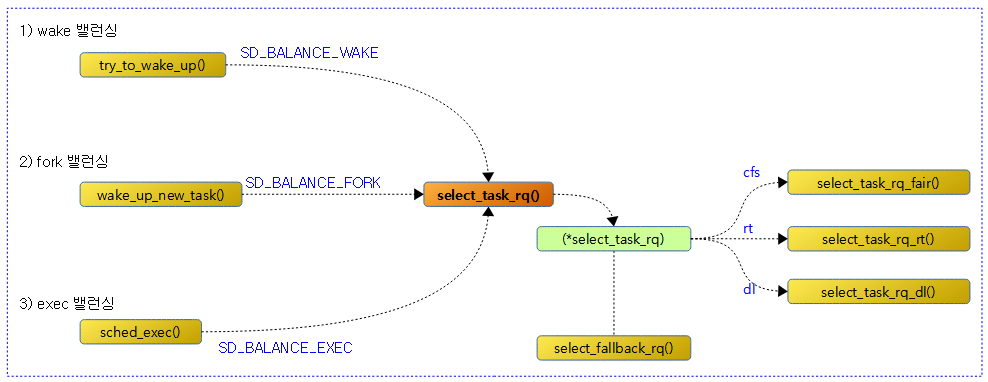
다음 그림은 select_task_rq() 함수 이하의 호출 관계를 보여준다.
select_task_rq()
kernel/sched/core.c
/* * The caller (fork, wakeup) owns p->pi_lock, ->cpus_ptr is stable. */
static inline
int select_task_rq(struct task_struct *p, int cpu, int sd_flags, int wake_flags)
{
lockdep_assert_held(&p->pi_lock);
if (p->nr_cpus_allowed > 1)
cpu = p->sched_class->select_task_rq(p, cpu, sd_flags, wake_flags);
else
cpu = cpumask_any(p->cpus_ptr);
/*
* In order not to call set_task_cpu() on a blocking task we need
* to rely on ttwu() to place the task on a valid ->cpus_ptr
* CPU.
*
* Since this is common to all placement strategies, this lives here.
*
* [ this allows ->select_task() to simply return task_cpu(p) and
* not worry about this generic constraint ]
*/
if (unlikely(!is_cpu_allowed(p, cpu)))
cpu = select_fallback_rq(task_cpu(p), p);
return cpu;
}
@sd_flags 요청에 맞게 태스크가 동작할 적절한 cpu를 찾아 선택한다.
- 코드 라인 6~9에서 태스크가 동작 할 수 있는 cpu가 2개 이상인 경우 스케줄러에 등록된 (*select_task_rq) 후크 함수를 통해 태스크가 동작할 적절한 cpu를 찾아온다. 태스크가 사용할 cpu가 1개로 고정된 경우 태스크에 지정된 cpu를 찾아온다.
- dl 태스크의 경우 select_task_rq_dl() 함수를 호출하며 wake 밸런싱인 경우에만 deadline이 가장 여유 있는 cpu를 선택한다.
- rt 태스크의 경우 select_task_rq_rt() 함수를 호출하며 wake 또는 fork 밸런싱인 경우에만 가장 낮은 우선 순위부터 요청한 태스크의 우선순위 범위 이내에서 동작할 수 있는 cpu cpu를 찾아 선택한다.
- cfs 태스크의 경우 select_task_rq_fair() 함수를 호출하여 적절한 cpu를 선택한다.
- 코드 라인 21~22에서 낮은 확률로 선택된 cpu가 태스크에 허용되지 않는 cpu인 경우 fallback cpu를 찾는다.
- 코드 라인 24에서 찾은 cpu를 반환한다.
fallback cpu 선택
select_fallback_rq()
요청한 cpu와 태스크를 사용하여 fallback cpu를 찾아 반환한다. 다음 순서대로 찾는다.
- 요청한 cpu가 소속된 노드와 태스크가 허용하는 online cpu를 찾아 반환한다.
- 노드와 상관없이 태스크가 허용하는 online cpu를 찾아 반환한다.
- cpuset에 설정된 effective_cpus를 태스크에 설정하고 그 중 online cpu를 찾아 반환한다.
- possible cpu를 태스크에 설정하고 그 중 online cpu를 찾아 반환한다.
kernel/sched/core.c
/* * ->cpus_ptr is protected by both rq->lock and p->pi_lock * * A few notes on cpu_active vs cpu_online: * * - cpu_active must be a subset of cpu_online * * - on CPU-up we allow per-CPU kthreads on the online && !active CPU, * see __set_cpus_allowed_ptr(). At this point the newly online * CPU isn't yet part of the sched domains, and balancing will not * see it. * * - on CPU-down we clear cpu_active() to mask the sched domains and * avoid the load balancer to place new tasks on the to be removed * CPU. Existing tasks will remain running there and will be taken * off. * * This means that fallback selection must not select !active CPUs. * And can assume that any active CPU must be online. Conversely * select_task_rq() below may allow selection of !active CPUs in order * to satisfy the above rules. */
static int select_fallback_rq(int cpu, struct task_struct *p)
{
int nid = cpu_to_node(cpu);
const struct cpumask *nodemask = NULL;
enum { cpuset, possible, fail } state = cpuset;
int dest_cpu;
/*
* If the node that the CPU is on has been offlined, cpu_to_node()
* will return -1. There is no CPU on the node, and we should
* select the CPU on the other node.
*/
if (nid != -1) {
nodemask = cpumask_of_node(nid);
/* Look for allowed, online CPU in same node. */
for_each_cpu(dest_cpu, nodemask) {
if (!cpu_active(dest_cpu))
continue;
if (cpumask_test_cpu(dest_cpu, p->cpus_ptr))
return dest_cpu;
}
}
for (;;) {
/* Any allowed, online CPU? */
for_each_cpu(dest_cpu, p->cpus_ptr) {
if (!is_cpu_allowed(p, dest_cpu))
continue;
goto out;
}
/* No more Mr. Nice Guy. */
switch (state) {
case cpuset:
if (IS_ENABLED(CONFIG_CPUSETS)) {
cpuset_cpus_allowed_fallback(p);
state = possible;
break;
}
/* Fall-through */
case possible:
do_set_cpus_allowed(p, cpu_possible_mask);
state = fail;
break;
case fail:
BUG();
break;
}
}
out:
if (state != cpuset) {
/*
* Don't tell them about moving exiting tasks or
* kernel threads (both mm NULL), since they never
* leave kernel.
*/
if (p->mm && printk_ratelimit()) {
printk_deferred("process %d (%s) no longer affine to cpu%d\n",
task_pid_nr(p), p->comm, cpu);
}
}
return dest_cpu;
}
- 코드 라인 13~23에서 cpu가 포함된 노드에 속한 cpu들을 순회하며 active cpu가 태스크에서 허용하면 해당 cpu를 반환한다.
- 코드 라인 25~32에서 태스크에 허용된 cpu들 중 active cpu를 찾아 반환한다.
- 코드 라인 35~41에서 태스크에 허용된 cpu들을 태스크 그룹의 지정된 cpu들로 바꾼 후 possible 단계로 다시 시도해본다.
- 코드 라인 43~46에서 태스크에 허용된 cp들을 possible cpu로 변경한 후 fail 단계로 다시 시도해본다.
- 코드 라인 48~51에서 fail 단계마저 실패한 경우 BUG() 함수를 호출한다
- 코드 라인 54~65에서 out: 레이블이다. 재시도를 한 경우는 경고 메시지를 출력한다.
- 코드 라인 67에서 최종 선택한 cpu를 반환한다.
CFS 태스크가 동작할 적절한 cpu 선택
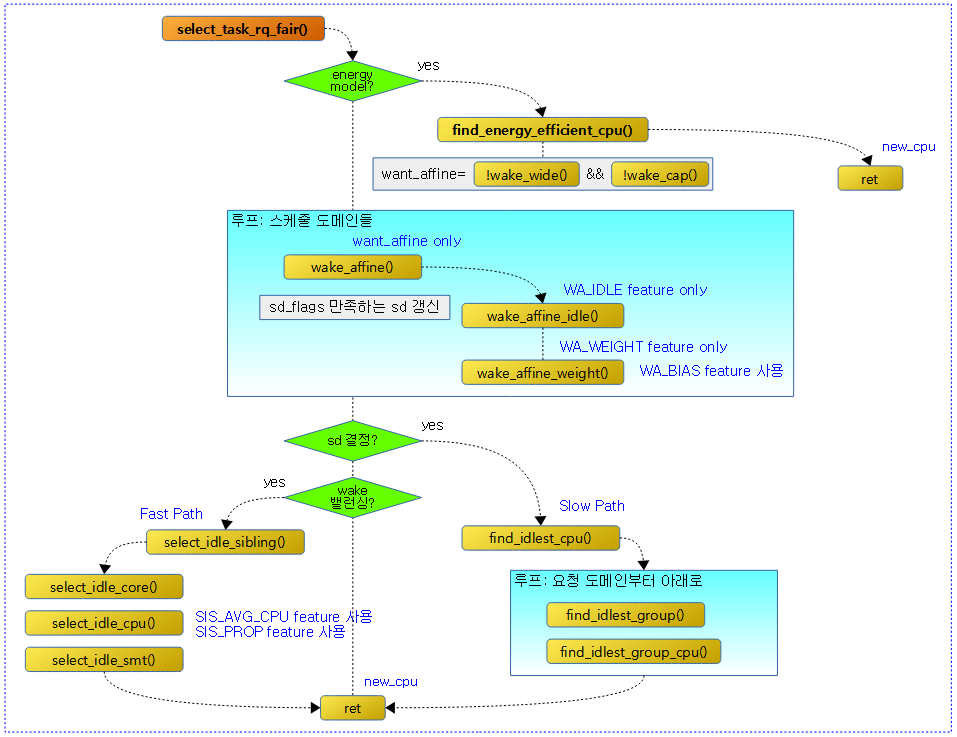
다음 그림은 select_task_rq_fair() 함수 이하의 호출 관계를 보여준다.
select_task_rq_fair()
kernel/sched/fair.c
/* * select_task_rq_fair: Select target runqueue for the waking task in domains * that have the 'sd_flag' flag set. In practice, this is SD_BALANCE_WAKE, * SD_BALANCE_FORK, or SD_BALANCE_EXEC. * * Balances load by selecting the idlest CPU in the idlest group, or under * certain conditions an idle sibling CPU if the domain has SD_WAKE_AFFINE set. * * Returns the target CPU number. * * preempt must be disabled. */
static int
select_task_rq_fair(struct task_struct *p, int prev_cpu, int sd_flag, int wake_flags)
{
struct sched_domain *tmp, *sd = NULL;
int cpu = smp_processor_id();
int new_cpu = prev_cpu;
int want_affine = 0;
int sync = (wake_flags & WF_SYNC) && !(current->flags & PF_EXITING);
if (sd_flag & SD_BALANCE_WAKE) {
record_wakee(p);
if (sched_energy_enabled()) {
new_cpu = find_energy_efficient_cpu(p, prev_cpu);
if (new_cpu >= 0)
return new_cpu;
new_cpu = prev_cpu;
}
want_affine = !wake_wide(p) && !wake_cap(p, cpu, prev_cpu) &&
cpumask_test_cpu(cpu, p->cpus_ptr);
}
rcu_read_lock();
for_each_domain(cpu, tmp) {
if (!(tmp->flags & SD_LOAD_BALANCE))
break;
/*
* If both 'cpu' and 'prev_cpu' are part of this domain,
* cpu is a valid SD_WAKE_AFFINE target.
*/
if (want_affine && (tmp->flags & SD_WAKE_AFFINE) &&
cpumask_test_cpu(prev_cpu, sched_domain_span(tmp))) {
if (cpu != prev_cpu)
new_cpu = wake_affine(tmp, p, cpu, prev_cpu, sync);
sd = NULL; /* Prefer wake_affine over balance flags */
break;
}
if (tmp->flags & sd_flag)
sd = tmp;
else if (!want_affine)
break;
}
if (unlikely(sd)) {
/* Slow path */
new_cpu = find_idlest_cpu(sd, p, cpu, prev_cpu, sd_flag);
} else if (sd_flag & SD_BALANCE_WAKE) { /* XXX always ? */
/* Fast path */
new_cpu = select_idle_sibling(p, prev_cpu, new_cpu);
if (want_affine)
current->recent_used_cpu = cpu;
}
rcu_read_unlock();
return new_cpu;
}
@sd_flag에 SD_BALANCE_WAKE, SD_BALANCE_FORK 또는 SD_BALANCE_EXEC를 가지고 이 함수에 진입하였다. 이 함수에서는 wake, fork 또는 exec 밸런싱을 통해 가장 에너지 및 성능 효과적인 cpu를 찾아 반환한다.
- 코드 라인 8에서 종료 중인 태스크가 아닌 경우이면서 @wake_flags에 WF_SYNC 플래그를 사용 여부를 sync에 대입해둔다.
- WF_SYNC 플래그는 waker와 wakee 태스크가 캐시 바운싱으로 인해 성능 하락되지 않도록 가능하면 하나의 cpu즉, waker가 있는 cpu에서 wakee 태스크가 동작되도록 동기화시킬 때 사용한다.
- 코드 라인 10~18에서 wake 밸런싱인 경우 wakee 태스크 @p와 waker와의 wake 스위칭 비율이 비슷하고 현재 cpu가 태스크가 허용하는 cpu에 포함되었는지 여부를 알아와서 want_affine에 대입한다. 만일 모바일 기기 처럼 EM(에너지 모델)을 사용하는 경우 EAS(Energy Aware Scheduler)를 통해 에너지 및 성능 효과적인 cpu를 찾아 반환한다.
- 코드 라인20~21에서 wake 밸런싱에서 EAS를 통해 new cpu를 결정하지 못한 경우 태스크에 대한 현재 cpu 및 태스크가 마지막으로 잠들기 전 동작했었던 기존 cpu에 대해 캐시 친화 여부를 알아온다.
- wake_wide() 및 wake_cap()이 false가 되어야 wake_affine() 함수를 통해 태스크를 동작시킬 cpu를 결정하는데, 현재 cpu 또는 태스크가 동작하던 기존 cpu 둘 중 가장 캐시 친화적인 cpu를 고려하여 결정한다.
- 코드 라인 25~27에서 현재 cpu의 최하위 도메인에서 최상위 도메인까지 순회하며 밸런싱을 허용하지 않는 도메인이 나타나는 경우 break 한다.
- 코드 라인 33~40에서 want_affine이 설정되었고, SD_WAKE_AFFINE 플래그가 있는 도메인이면서 현재 cpu가 도메인에 포함된 경우 sd에 null을 대입하고, 루프를 벗어나다. 만일 현재 cpu가 wakeup 전에 돌던 cpu가 아니면 wake_affine() 함수를 통해 새 cpu를 알아온다.
- SD_WAKE_AFFINE 플래그가 있는 도메인
- 이 도메인은 idle 상태에서 깨어난 cpu가 도메인내의 idle sibling cpu 선택을 허용한다.
- NUMA distance가 30이상 되는 원거리에 있는 누마 노드에 wake된 태스크가 밸런싱하지 못하게 하려면 이 플래그를 사용하지 않아야 한다.
- SD_WAKE_AFFINE 플래그가 있는 도메인
- 코드 라인 42~45에서 순회 중인 도메인에 sd_flag가 있는 경우 sd에 현재 순회중인 도메인을 대입한다. 그렇지 않고 want_affine 값이 있으면 계속 순회하고, 0인 경우 루프를 벗어난다.
- 코드 라인 48~50에서 낮은 확률로 도메인이 결정된 경우 slow path로써 도메인에서 가장 idle한 cpu를 찾아온다.
- 코드 라인 51~58에서 wak 밸런싱인 경우 fast path로써 가장 idle한 cpu를 찾아온다.
- 코드 라인 61에서 결정된 cpu 번호를 반환한다.
캐시 친화를 고려한 wakeup
wake 스위칭 수 기록
record_wakee()
kernel/sched/fair.c
static void record_wakee(struct task_struct *p)
{
/*
* Only decay a single time; tasks that have less then 1 wakeup per
* jiffy will not have built up many flips.
*/
if (time_after(jiffies, current->wakee_flip_decay_ts + HZ)) {
current->wakee_flips >>= 1;
current->wakee_flip_decay_ts = jiffies;
}
if (current->last_wakee != p) {
current->last_wakee = p;
current->wakee_flips++;
}
}
현재(current) 동작 중인 waker 태스크에 깨울 wakee 태스크 @p를 last_wakee로 기록하고, wake 스위칭 수(wakee_flips)를 증가시킨다.
- 코드 라인 7~10에서 1초마다 햔제 동작 중인 태스크의 wakee_flips 값을 절반으로 decay 한다.
- 코드 라인 12~15에서 현재 동작 중인 태스크의 last_wakee를 @p로 갱신하고, wakee_flips를 증가시킨다.
waker/wakee의 빈번한 wake 스위칭 판단
wake_wide()
kernel/sched/fair.c
/* * Detect M:N waker/wakee relationships via a switching-frequency heuristic. * * A waker of many should wake a different task than the one last awakened * at a frequency roughly N times higher than one of its wakees. * * In order to determine whether we should let the load spread vs consolidating * to shared cache, we look for a minimum 'flip' frequency of llc_size in one * partner, and a factor of lls_size higher frequency in the other. * * With both conditions met, we can be relatively sure that the relationship is * non-monogamous, with partner count exceeding socket size. * * Waker/wakee being client/server, worker/dispatcher, interrupt source or * whatever is irrelevant, spread criteria is apparent partner count exceeds * socket size. */
static int wake_wide(struct task_struct *p)
{
unsigned int master = current->wakee_flips;
unsigned int slave = p->wakee_flips;
int factor = this_cpu_read(sd_llc_size);
if (master < slave)
swap(master, slave);
if (slave < factor || master < slave * factor)
return 0;
return 1;
}
현재 동작 중인 태스크 waker와 wakee @p에 대해 wake 스위칭이 어느 한 쪽이 더 빈번한 경우 1을 반환한다. (캐시 친화가 없는 것으로 간주한다.)
- 코드 라인 3~4에서 waker 태스크와 wakee 태스크 @p의 wake 스위칭 횟수를 각각 가져와 master와 slave에 대입한다.
- 코드 라인 5에서 패키지 내에서 캐시를 공유하는 cpu 수를 알아와서 factor에 대입한다.
- SD_SHARE_PKG_RESOURCES 플래그가 있는 스케줄 도메인(복수개인 경우 상위 도메인)에 소속된 cpu 수
- 코드 라인 7~11에서 master와 slave 횟수가 factor보다 크고 작은 쪽과 큰 쪽의 횟수가 factor 비율만큼 차이가 벌어진 경우 1을 반환한다.
- 태스크 @p의 wake 스위칭(wakee_flips) 횟수 slave가 오히려 master보다 큰 경우 현재 동작 중인 태스크의 횟수보다 큰 경우에 한해 서로 값을 swap 하여 항상 master가 더 크게 만들어 둔다.
- wake 스위칭(wake_flips) 작은 쪽이 factor 보다 더 작거나, 작은쪽에 factor 배율을 적용하여 오히려 커지는 경우 0을 반환하고, 그렇지 않은 경우 1을 반환한다.
- 예) 캐시 공유 cpu 수=4, 현재 태스크가 9번 스위칭, 밸런스 요청한 태스크가 2번인 경우
- 9 > (4 x 2) = 1
- Facebook 개발자가 더 빠른 로직으로 대체하여 기존 wake_wide() 함수의 결과가 약간 변했다.
- 기존: sched: Implement smarter wake-affine logic (2013, v3.12-rc1)
- 변경: sched/fair: Beef up wake_wide() (2017, v4.15-rc1)
다음 그림은 waker 태스크와 wakee 태스크간의 wake 스위칭 비율이 일정 배수(factor) 이상되는지 여부를 알아온다.
- dispacher/worker 스레드 모델의 경우 dispacher가 여러 개의 worker 스레드를 한번 씩 깨우므로 dispacher의 wake 스위칭 수가 더 많다. 이렇게 wake 스위칭 비율이 큰 경우 캐시 친화적이지 않은 것으로 판단한다.
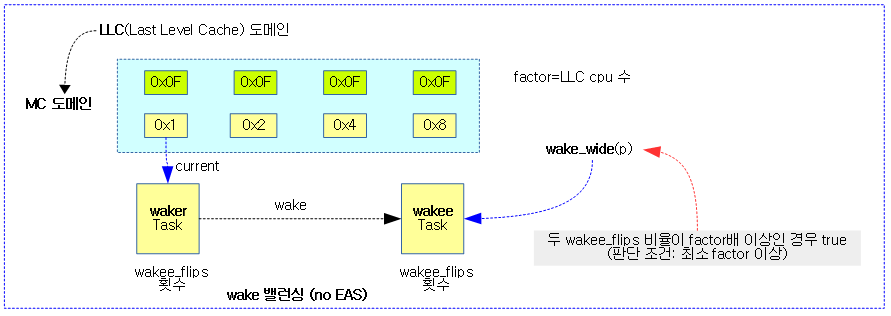
다음 그림은 wake_wide() 함수를 통해 wake 스위칭 비율을 비교하여 캐시 친화 판단을 결정하는 과정을 보여준다.
- dispatcher와 worker가 서로 할 일을 하고 깨운다고 가정한다.

wake_cap()
kernel/sched/fair.c
/* * Disable WAKE_AFFINE in the case where task @p doesn't fit in the * capacity of either the waking CPU @cpu or the previous CPU @prev_cpu. * * In that case WAKE_AFFINE doesn't make sense and we'll let * BALANCE_WAKE sort things out. */
static int wake_cap(struct task_struct *p, int cpu, int prev_cpu)
{
long min_cap, max_cap;
if (!static_branch_unlikely(&sched_asym_cpucapacity))
return 0;
min_cap = min(capacity_orig_of(prev_cpu), capacity_orig_of(cpu));
max_cap = cpu_rq(cpu)->rd->max_cpu_capacity;
/* Minimum capacity is close to max, no need to abort wake_affine */
if (max_cap - min_cap < max_cap >> 3)
return 0;
/* Bring task utilization in sync with prev_cpu */
sync_entity_load_avg(&p->se);
return !task_fits_capacity(p, min_cap);
}
빅/리틀같은 asym cpu capacity가 적용된 시스템에서 태스크 @p의 기존 cpu와 요청한 @cpu간의 capacity가 차이를 비교하여 적절한지 여부를 판단한다.
- 커널 v5.7에서 select_idle_sibling() 함수가 이를 대체하므로 이 로직이 불필요하다 판단되어 제거된다.
- 참고: sched/fair: Remove wake_cap() (2020, v5.7-rc1)
Wake시 idle, 캐시 및 로드 고려한 cpu 선택
wake_affine()
kernel/sched/fair.c
static int wake_affine(struct sched_domain *sd, struct task_struct *p,
int this_cpu, int prev_cpu, int sync)
{
int target = nr_cpumask_bits;
if (sched_feat(WA_IDLE))
target = wake_affine_idle(this_cpu, prev_cpu, sync);
if (sched_feat(WA_WEIGHT) && target == nr_cpumask_bits)
target = wake_affine_weight(sd, p, this_cpu, prev_cpu, sync);
schedstat_inc(p->se.statistics.nr_wakeups_affine_attempts);
if (target == nr_cpumask_bits)
return prev_cpu;
schedstat_inc(sd->ttwu_move_affine);
schedstat_inc(p->se.statistics.nr_wakeups_affine);
return target;
}
태스크가 동작할 때 @this_cpu와 @prev_cpu 둘 중 어떤 cpu에서 동작해야 캐시(cache hot) 활용에 더 도움이 되는지 판단하여 해당 cpu를 반환한다.
- 코드 라인 4에서 target cpu를 선택하지 못한 상태로 둔다.
- 코드 라인 6~7에서 WA_IDLE feture를 사용하는 경우 두 idle cpu 중 캐시 친화 cpu를 찾아온다.
- @this_cpu가 idle이고 두 cpu가 캐시 공유된 상태라면 @this_cpu를 선택하지만 @prev_cpu 역시 idle 상태라면 migration을 포기하고 @prev_cpu를 선택한다.
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. 태스크의 기존 cpu가 캐시 친화 idle인 경우 약간의 성능을 개선하기 위해 밸런싱을 방지한다.
- 참고: sched/core: Fix wake_affine() performance regression (2017, v4.14-rc5)
- 코드 라인 9~10에서 WA_WEIGHT feature를 사용하고 아직 target cpu가 선택되지 않은 상태라면 @this_cpu의 로드가 @prev_cpu 보다 낮은 경우 @this_cpu를 반환한다.
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. 태스크의 기존 cpu와 현재 cpu간의 러너블 로드가 작은 쪽으로 밸런싱을 수행하게 한다. 이렇게 하여 약간의 성능을 개선한다.
- 참고: sched/core: Address more wake_affine() regressions (2017, v4.14-rc5)
- 코드 라인 12에서 캐시 친화 wakeup 시도를 하므로 nr_wakeups_affine_attempts 카운터를 증가시킨다.
- 코드 라인 13~14에서 target cpu가 결정되지 않은 경우 @prev_cpu를 반환한다.
- 코드 라인 16~17에서 캐시 친화 wakeup을 하므로 ttwu_move_affine 및 nr_wakeups_affine 카운터를 1 증가시킨다.
- 코드 라인 18에서 선택한 target cpu를 반환한다.
다음 그림은 태스크를 현재 cpu에서 동작시킬지 아니면 기존 cpu에서 동작 시킬지 캐시 친화도 및 로드를 고려하여 결정하는 모습을 보여준다.
- WA_IDLE, WA_WEIGHT, WA_BIAS features는 디폴트로 true이다.
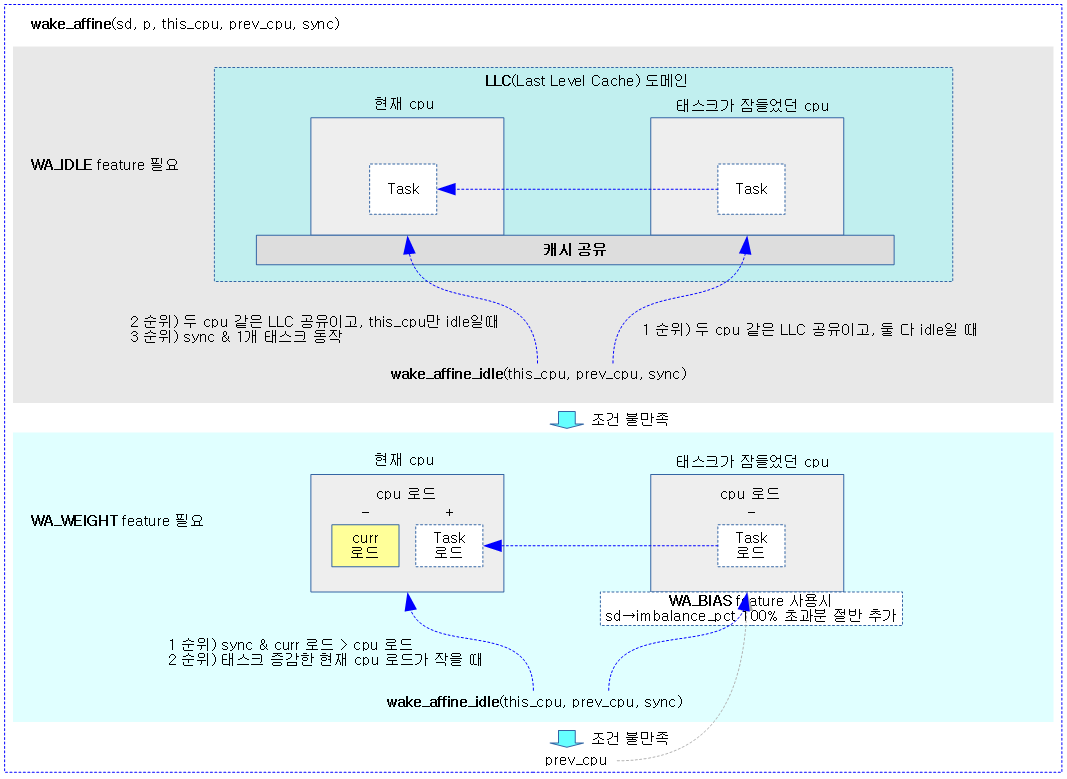
idle 및 캐시 친화력을 고려한 cpu 선택
wake_affine_idle()
kernel/sched/fair.c
/* * The purpose of wake_affine() is to quickly determine on which CPU we can run * soonest. For the purpose of speed we only consider the waking and previous * CPU. * * wake_affine_idle() - only considers 'now', it check if the waking CPU is * cache-affine and is (or will be) idle. * * wake_affine_weight() - considers the weight to reflect the average * scheduling latency of the CPUs. This seems to work * for the overloaded case. */
static int
wake_affine_idle(int this_cpu, int prev_cpu, int sync)
{
/*
* If this_cpu is idle, it implies the wakeup is from interrupt
* context. Only allow the move if cache is shared. Otherwise an
* interrupt intensive workload could force all tasks onto one
* node depending on the IO topology or IRQ affinity settings.
*
* If the prev_cpu is idle and cache affine then avoid a migration.
* There is no guarantee that the cache hot data from an interrupt
* is more important than cache hot data on the prev_cpu and from
* a cpufreq perspective, it's better to have higher utilisation
* on one CPU.
*/
if (available_idle_cpu(this_cpu) && cpus_share_cache(this_cpu, prev_cpu))
return available_idle_cpu(prev_cpu) ? prev_cpu : this_cpu;
if (sync && cpu_rq(this_cpu)->nr_running == 1)
return this_cpu;
return nr_cpumask_bits;
}
@this_cpu가 idle 상태이고 @perv_cpu와 캐시를 공유한 경우 @this_cpu를 선택한다. 단 @prev_cpu도 idle인 경우 태스크가 수행했었던 @prev_cpu를 선택한다. 그 외의 경우 실패 값으로 nr_cpumask_bits를 반환하는데, 만일 @sync가 설정된 경우 @this_cpu에 태스크가 1개만 동작하면 @this_cpu를 선택한다.
- 코드 라인 16~17에서 @this_cpu와 @prev_cpu가 같은 캐시를 공유하는 경우 @prev_cpu가 idle이면 기존 cpu를 선택하도록 @prev_cpu를 반환한다. 그렇지 않고 @this_cpu가 idle인 경우 @this_cpu를 반환한다.
- 코드 라인 19~20에서 @sync가 주어졌고, @this_cpu에 1개의 태스크만 동작하는 상태이면 @this_cpu를 반환한다.
- 코드 라인 22에서 cpu를 결정하지 못한 경우 nr_cpumask_bits를 반환한다.
available_idle_cpu()
kernel/sched/core.c
/** * available_idle_cpu - is a given CPU idle for enqueuing work. * @cpu: the CPU in question. * * Return: 1 if the CPU is currently idle. 0 otherwise. */
int available_idle_cpu(int cpu)
{
if (!idle_cpu(cpu))
return 0;
if (vcpu_is_preempted(cpu))
return 0;
return 1;
}
@cpu가 idle 상태인지 여부를 반환한다.
cpus_share_cache()
kernel/sched/core.c
bool cpus_share_cache(int this_cpu, int that_cpu)
{
return per_cpu(sd_llc_id, this_cpu) == per_cpu(sd_llc_id, that_cpu);
}
@this_cpu와 @that_cpu 가 캐시를 공유하는지 여부를 반환한다.
태스크 이동을 고려한 this cpu 로드가 작을 때 this cpu 선택
wake_affine_weight()
kernel/sched/fair.c
static int
wake_affine_weight(struct sched_domain *sd, struct task_struct *p,
int this_cpu, int prev_cpu, int sync)
{
s64 this_eff_load, prev_eff_load;
unsigned long task_load;
this_eff_load = cpu_runnable_load(cpu_rq(this_cpu));
if (sync) {
unsigned long current_load = task_h_load(current);
if (current_load > this_eff_load)
return this_cpu;
this_eff_load -= current_load;
}
task_load = task_h_load(p);
this_eff_load += task_load;
if (sched_feat(WA_BIAS))
this_eff_load *= 100;
this_eff_load *= capacity_of(prev_cpu);
prev_eff_load = cpu_runnable_load(cpu_rq(prev_cpu));
prev_eff_load -= task_load;
if (sched_feat(WA_BIAS))
prev_eff_load *= 100 + (sd->imbalance_pct - 100) / 2;
prev_eff_load *= capacity_of(this_cpu);
/*
* If sync, adjust the weight of prev_eff_load such that if
* prev_eff == this_eff that select_idle_sibling() will consider
* stacking the wakee on top of the waker if no other CPU is
* idle.
*/
if (sync)
prev_eff_load += 1;
return this_eff_load < prev_eff_load ? this_cpu : nr_cpumask_bits;
}
두 cpu 중 스케일 적용된 capacity를 반영하여 @this_cpu의 러너블 로드가 낮은 경우 @this_cpu를 반환한다. 실패 시 nr_cpumask_bits를 반환한다.
- 코드 라인 8에서 @this_cpu의 러너블 로드 평균을 알아와서 this_eff_load에 대입한다.
- 코드 라인 10~17에서 this_eff_load 보다 현재 동작 중인 태스크(waker)의 로드 평균이 큰 경우 @this_cpu를 선택한다. 그렇지 않은 경우 this_eff_load을 동작 중인 태스크의 로드만큼 감소시킨다.
- 코드 라인 19~24에서 this_eff_load에서 태스크 @p의 로드 평균을 더하고 두 cpu의 capacity가 적용된 비율을 비교하기 위해 반대쪽 @prev_cpu의 capacity를 곱한다. WA_BIAS feature가 적용된 경우 100%를 곱해 적용한다.
- 코드 라인 26~30에서 @prev_cpu의 러너블 로드 평균을 알아와서 태스크 @p의 로드 평균을 감소시키고 두 cpu의 capacity가 적용된 비율을 비교하기 위해 반대쪽 @this_cpu의 capacity를 곱한다. WA_BIAS feature가 적용된 경우 100%+ imbalance_pct의 절반을 추가로 곱해 적용한다.
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. 위의 WA_WEIGHT 기능을 사용할 때 태스크의 기존 cpu 로드에 약간의 바이어스(sd->imbalance_pct의 100% 초과분 절반)를 추가하여 this cpu 쪽으로 조금 더 유리한 선택이되게 한다.
- 코드 라인 38~41에서 두 로드 평균을 비교하여 @this_cpu의 로드가 더 낮은 경우 @this_cpu를 반환하고, 그렇지 않은 경우 마이그레이션을 하지 않기 위해 nr_cpumask_bits를 반환한다.
- @sync가 주어지지 않은 일반적인 경우 두 로드 평균이 동일할 때 this_cpu로 마이그레이션을 하지 않는 것이 유리하다고 판단한다.
- 참고: Do not migrate on wake_affine_weight() if weights are equal (2018, v4.17-rc1)
- 단 @sync가 주어진 경우 동일 로드 값 비교 시 prev_eff_load에 더 불리한 판정을 주기위해 1을 더해 this_cpu로 마이그레이션을 하도록 한다.
- waker 태스크와 wakee 태스크가 캐시 바운싱으로 성능 저하가 예상될 때 동기화 시켜 가능하면 waker 태스크가 있는 this_cpu에서 wakee 태스크를 깨우도록하는데 이 때에는 prev_cpu에 최소한의(1 만큼)의 불리함을 준다.
- @sync가 주어지지 않은 일반적인 경우 두 로드 평균이 동일할 때 this_cpu로 마이그레이션을 하지 않는 것이 유리하다고 판단한다.
Wake 밸런싱의 Fast-Path
select_idle_sibling()
kernel/sched/fair.c
/* * Try and locate an idle core/thread in the LLC cache domain. */
static int select_idle_sibling(struct task_struct *p, int prev, int target)
{
struct sched_domain *sd;
int i, recent_used_cpu;
if (available_idle_cpu(target) || sched_idle_cpu(target))
return target;
/*
* If the previous CPU is cache affine and idle, don't be stupid:
*/
if (prev != target && cpus_share_cache(prev, target) &&
(available_idle_cpu(prev) || sched_idle_cpu(prev)))
return prev;
/* Check a recently used CPU as a potential idle candidate: */
recent_used_cpu = p->recent_used_cpu;
if (recent_used_cpu != prev &&
recent_used_cpu != target &&
cpus_share_cache(recent_used_cpu, target) &&
(available_idle_cpu(recent_used_cpu) || sched_idle_cpu(recent_used_cpu)) &&
cpumask_test_cpu(p->recent_used_cpu, p->cpus_ptr)) {
/*
* Replace recent_used_cpu with prev as it is a potential
* candidate for the next wake:
*/
p->recent_used_cpu = prev;
return recent_used_cpu;
}
sd = rcu_dereference(per_cpu(sd_llc, target));
if (!sd)
return target;
i = select_idle_core(p, sd, target);
if ((unsigned)i < nr_cpumask_bits)
return i;
i = select_idle_cpu(p, sd, target);
if ((unsigned)i < nr_cpumask_bits)
return i;
i = select_idle_smt(p, target);
if ((unsigned)i < nr_cpumask_bits)
return i;
return target;
}
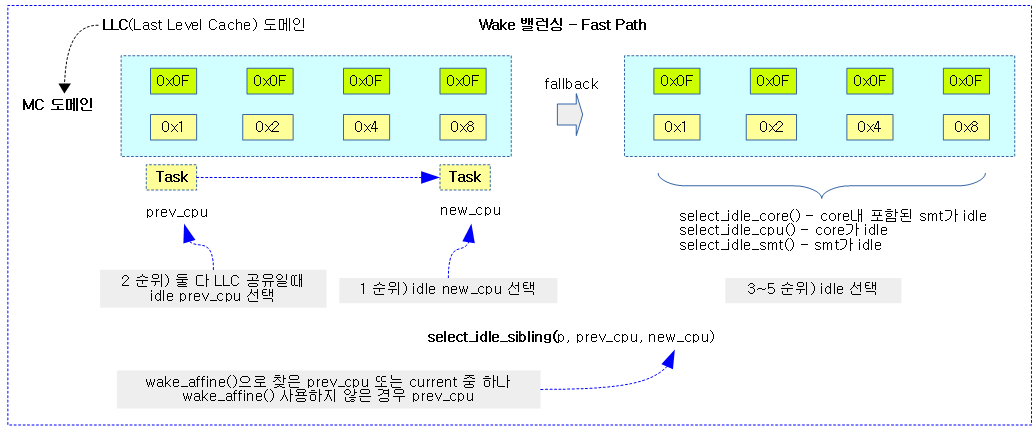
태스크가 깨어날 현재 cpu와 태스크가 잠들었었던 기존 cpu 둘 중 idle한 cpu 하나를 선택한다. 만일 idle cpu가 없으면 LLC 도메인내에서 idle한 cpu를 찾는다. 다음과 같은 순서로 찾아본다.
- 1) @target cpu가 idle
- 2) @prev cpu가 캐시 공유 사용 및 idle
- 3) 태스크가 최근에 사용했었던 cpu가 캐시 공유 사용 및 idle
- 4) 캐시 공유 도메인에서 idle core/cpu/smt
- @target cpu 부터 순회하며 hw thread들 모두 idle cpu인 core 선택
- @target cpu 부터 제한된 스캔 내에서 idle cpu 선택
- @target cpu의 hw thread들 중 idle인 hw thread 선택
- 5) 캐시 친화 포기하고 그냥 @target
- 참고: sched/core: Rewrite and improve select_idle_siblings() (2016, v4.9-rc1)
- 코드 라인 6~7에서 @target cpu가 idle이거나 SCHED_IDLE policy 태스크만 동작하는 경우 @target cpu를 반환한다.
- 코드 라인 12~14에서 @prev_cpu가 idle 또는 SCHED_IDLE policy 태스크만 동작하고 @target cpu와 캐시를 공유하는 cpu인 경우 당연히 @prev_cpu를 반환한다.
- target_cpu로 마이그레이션하지 못하게 해야 한다.
- 코드 라인 17~29에서 최근에 태스크가 동작했었던 cpu가 코드 라인 12~14와 같은 조건이라면 최근에 사용했었던 cpu를 반환한다.
- 코드 라인 31~45에서 캐시 공유 스케줄 도메인이 있는 경우 idle core, idle cpu, idle smt 순서대로 진행하되 cpu가 선택되면 그 cpu를 반환한다.
- 코드 라인 47에서 어떠한 조건에도 만족하지 못하는 경우 캐시 친화와 관련 없이 그냥 @target cpu를 반환한다.
다음 그림은 Wake 밸런싱의 Fast Path 동작으로 select_idle_sibling() 함수를 통해 idle cpu를 찾는 과정을 보여준다.
idle SMT core 선택
select_idle_core()
kernel/sched/fair.c
/* * Scan the entire LLC domain for idle cores; this dynamically switches off if * there are no idle cores left in the system; tracked through * sd_llc->shared->has_idle_cores and enabled through update_idle_core() above. */
static int select_idle_core(struct task_struct *p, struct sched_domain *sd, int target)
{
struct cpumask *cpus = this_cpu_cpumask_var_ptr(select_idle_mask);
int core, cpu;
if (!static_branch_likely(&sched_smt_present))
return -1;
if (!test_idle_cores(target, false))
return -1;
cpumask_and(cpus, sched_domain_span(sd), p->cpus_ptr);
for_each_cpu_wrap(core, cpus, target) {
bool idle = true;
for_each_cpu(cpu, cpu_smt_mask(core)) {
__cpumask_clear_cpu(cpu, cpus);
if (!available_idle_cpu(cpu))
idle = false;
}
if (idle)
return core;
}
/*
* Failed to find an idle core; stop looking for one.
*/
set_idle_cores(target, 0);
return -1;
}
캐시 공유 도메인의 SMT core들 중 L1 캐시를 공유하는 cpu들 모두 idle인 core를 찾아 반환한다. @target 코어부터 시작하여 검색한다.
- 코드 라인 6~7에서 hw thread가 없는 !SMT 시스템의 경우 -1을 반환한다.
- 코드 라인 9~10에서 @target cpu의 L1 캐시를 공유하는 hw thread들 중 idle thread가 없으면 -1을 반환한다.
- 코드 라인 12~14에서 도메인의 cpu들과 태스크가 허용하는 cpu들을 포함하는 cpu들을 @target 부터 순회한다.
- 코드 라인 15~24에서 순회 중인 cpu의 L1 캐시를 공유하는 smt thrad들 중 하나라도 busy 상태인지를 체크한다. 만일 모두 idle한 경우 순회 중인 core 번호를 반환한다.
- 코드 라인 29에서 idle core를 못찾은 경우 @target cpu 내의 hw 스레드들에 idle 코어가 없다고 기록한 후 -1을 반환한다.
test_idle_cores()
kernel/sched/fair.c
static inline bool test_idle_cores(int cpu, bool def)
{
struct sched_domain_shared *sds;
sds = rcu_dereference(per_cpu(sd_llc_shared, cpu));
if (sds)
return READ_ONCE(sds->has_idle_cores);
return def;
}
@cpu에 포함된 hw thread들이 모두 idle 상태인지 여부를 반환한다. 캐시 공유 도메인이 없는 경우 @def 값을 반환한다.
set_idle_cores()
kernel/sched/fair.c
static inline void set_idle_cores(int cpu, int val)
{
struct sched_domain_shared *sds;
sds = rcu_dereference(per_cpu(sd_llc_shared, cpu));
if (sds)
WRITE_ONCE(sds->has_idle_cores, val);
}
@cpu에 연관된 모든 hw thread들의 idle 상태 @val을 기록한다. (@val: 0=하나라도 idle이 아닌 hw thread가 있다. 1=해당 core의 hw thread들이 모두 idle이다.)
Idle cpu 선택
select_idle_cpu()
kernel/sched/fair.c
/* * Scan the LLC domain for idle CPUs; this is dynamically regulated by * comparing the average scan cost (tracked in sd->avg_scan_cost) against the * average idle time for this rq (as found in rq->avg_idle). */
static int select_idle_cpu(struct task_struct *p, struct sched_domain *sd, int target)
{
struct sched_domain *this_sd;
u64 avg_cost, avg_idle;
u64 time, cost;
s64 delta;
int this = smp_processor_id();
int cpu, nr = INT_MAX, si_cpu = -1;
this_sd = rcu_dereference(*this_cpu_ptr(&sd_llc));
if (!this_sd)
return -1;
/*
* Due to large variance we need a large fuzz factor; hackbench in
* particularly is sensitive here.
*/
avg_idle = this_rq()->avg_idle / 512;
avg_cost = this_sd->avg_scan_cost + 1;
if (sched_feat(SIS_AVG_CPU) && avg_idle < avg_cost)
return -1;
if (sched_feat(SIS_PROP)) {
u64 span_avg = sd->span_weight * avg_idle;
if (span_avg > 4*avg_cost)
nr = div_u64(span_avg, avg_cost);
else
nr = 4;
}
time = cpu_clock(this);
for_each_cpu_wrap(cpu, sched_domain_span(sd), target) {
if (!--nr)
return si_cpu;
if (!cpumask_test_cpu(cpu, p->cpus_ptr))
continue;
if (available_idle_cpu(cpu))
break;
if (si_cpu == -1 && sched_idle_cpu(cpu))
si_cpu = cpu;
}
time = cpu_clock(this) - time;
cost = this_sd->avg_scan_cost;
delta = (s64)(time - cost) / 8;
this_sd->avg_scan_cost += delta;
return cpu;
}
도메인 내에서 산정된 횟수 이내에서 cpu를 순회하며 idle cpu를 찾아 반환한다. 산정된 횟수가 이내에서 idle cpu를 찾지 못한 경우 대안으로 idle policy 태스크만을 돌리는 cpu라도 반환한다.
- 참고: sched/core: Implement new approach to scale select_idle_cpu() (2017, v4.13-rc1)
- 코드 라인 8에서 스캔할 cpu 수로 무제한 값을 대입한다.
- 코드 라인 10~12에서 캐시 공유 도메인이 없는 경우 -1을 반환한다.
- 코드 라인 18~22에서 SIS_AVG_CPU(디폴트 false) feture를 사용하는 경우 평균 스캔 코스트에 비해 너무 짧은 시간이 사용된 wakeup 밸런싱인 경우 -1을 반환한다.
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. wake 밸런싱에서 cpu의 평균 idle 시간(rq->avg_idle)이 스케줄 도메인의 wakeup cost(sd->avg_scan_cost)에 비해 너무 짧은 경우 밸런싱을 방지한다.
- 참고: sched/fair: Make select_idle_cpu() more aggressive (2017, v4.11)
- 코드 라인 24~30에서 SIS_PROP(디폴트 true) feature를 사용하는 경우 스캔할 cpu 수를 다음과 같이 결정하고 최소 4 이상으로 한다.
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. wake 밸런싱에서 sibling cpu를 스캔할 수를 제한한다.
- span_avg(avg_idle * 도메인 소속 cpu 수) / avg_cost
- 참고: sched/core: Implement new approach to scale select_idle_cpu() (2017, v4.13-rc1)
- wake 밸런싱의 캐시 친화 cpu 관련 기능이다. wake 밸런싱에서 sibling cpu를 스캔할 수를 제한한다.
- 코드 라인 34~43에서 도메인 내의 cpu들을 @target 번호부터 순회하며 idle cpu를 찾아 루프를 벗어난다. idle policy 태스크만을 동작중인 cpu는 si_cpu에 기록해두고, 스캔 cpu 수 만큼 루프를 돌아도 idle cpu를 못찾은 경우 대안으로 이 si_cpu를 사용한다.
- 코드 라인 45~48에서 위의 idle cpu를 찾는 스캔 시간을 평균 스캔 코스트와의 차이의 1/8만큼을 도메인의 평균 스캔 코스트에 누적시킨다.
- 코드 라인 50에서 결정한 cpu를 반환한다.
Idle hw thread 선택
select_idle_smt()
kernel/sched/fair.c
/* * Scan the local SMT mask for idle CPUs. */
static int select_idle_smt(struct task_struct *p, int target)
{
int cpu, si_cpu = -1;
if (!static_branch_likely(&sched_smt_present))
return -1;
for_each_cpu(cpu, cpu_smt_mask(target)) {
if (!cpumask_test_cpu(cpu, p->cpus_ptr))
continue;
if (available_idle_cpu(cpu))
return cpu;
if (si_cpu == -1 && sched_idle_cpu(cpu))
si_cpu = cpu;
}
return si_cpu;
}
@target cpu의 hw thread들 중 idle cpu를 찾아 반환한다. 차선으로 idle cpu가 없는 경우 idle policy 만을 동작시키는 cpu를 반환한다. 그마저도 없으면 -1을 반환한다.
- 코드 라인 5~6에서 hw thread가 없는 !SMT 시스템의 경우 -1을 반환한다.
- 코드 라인 8~15에서 @target cpu와 같은 L1 캐시를 공유하는 hw thread들을 순회하며 태스크가 허용하지 않는 cpu들은 skip 하고, idle cpu를 찾아 반환한다. idle policy 태스크만을 돌리는 cpu는 차선으로 선택해둔다.
- 코드 라인 17에서 idle cpu를 못찾은 경우 차선으로 지정해둔 cpu를 반환한다.
Wake 밸런싱의 Slow-Path
idlest cpu 찾기
find_idlest_cpu()
kernel/sched/fair.c
static inline int find_idlest_cpu(struct sched_domain *sd, struct task_struct *p,
int cpu, int prev_cpu, int sd_flag)
{
int new_cpu = cpu;
if (!cpumask_intersects(sched_domain_span(sd), p->cpus_ptr))
return prev_cpu;
/*
* We need task's util for capacity_spare_without, sync it up to
* prev_cpu's last_update_time.
*/
if (!(sd_flag & SD_BALANCE_FORK))
sync_entity_load_avg(&p->se);
while (sd) {
struct sched_group *group;
struct sched_domain *tmp;
int weight;
if (!(sd->flags & sd_flag)) {
sd = sd->child;
continue;
}
group = find_idlest_group(sd, p, cpu, sd_flag);
if (!group) {
sd = sd->child;
continue;
}
new_cpu = find_idlest_group_cpu(group, p, cpu);
if (new_cpu == cpu) {
/* Now try balancing at a lower domain level of 'cpu': */
sd = sd->child;
continue;
}
/* Now try balancing at a lower domain level of 'new_cpu': */
cpu = new_cpu;
weight = sd->span_weight;
sd = NULL;
for_each_domain(cpu, tmp) {
if (weight <= tmp->span_weight)
break;
if (tmp->flags & sd_flag)
sd = tmp;
}
}
return new_cpu;
}
- 코드 라인 6~7에서 도메인에 소속된 cpu들이 태스크에서 허용된 cpu들과 하나도 일치하지 않는 경우 @prev_cpu를 반환한다.
- 코드 라인 13~14에서 fork 밸런싱이 아니 경우에 진입한 경우 엔티티의 로드 평균을 갱신하여 동기화한다.
- 코드 라인 16~24에서 요청한 도메인부터 시작하여 child 도메인으로 내려가며 @sd_flag가 도메인에서 지원하지 않는 경우 skip 한다.
- 코드 라인 26~30에서 idlest 그룹을 찾고 없으면 skip 한다.
- 코드 라인 32~37에서 idlest 그룹에서 cpu를 찾고, @cpu와 동일한 경우 skip 한다.
- 코드 라인 40~48에서 찾은 idlest cpu의 가장 낮은 도메인부터 다시 순회하며 @sd_flags가 지원되는 가장 높은 도메인을 찾는다. 단 순회 중인 도메인의 cpu 수가 요청한 도메인보다 크거나 같은 경우 더 이상 진행할 필요 없으므로 루프를 벗어난다.
- 전체 도메인에서 idle cpu의 분산을 위해 찾은 cpu를 그대로 사용하지 않고, 한 단계 스케줄 도메인을 내려서 다시 시도하면서 찾은 cpu가 그 전에 찾은 cpu가 동일할때까지 반복하는 개념이다.
- 코드 라인 51에서 idlest cpu를 반환한다. 찾지 못한 경우 @cpu가 반환된다.
idlest 그룹 찾기
find_idlest_group()
kernel/sched/fair.c -1/2-
/* * find_idlest_group finds and returns the least busy CPU group within the * domain. * * Assumes p is allowed on at least one CPU in sd. */
static struct sched_group *
find_idlest_group(struct sched_domain *sd, struct task_struct *p,
int this_cpu, int sd_flag)
{
struct sched_group *idlest = NULL, *group = sd->groups;
struct sched_group *most_spare_sg = NULL;
unsigned long min_runnable_load = ULONG_MAX;
unsigned long this_runnable_load = ULONG_MAX;
unsigned long min_avg_load = ULONG_MAX, this_avg_load = ULONG_MAX;
unsigned long most_spare = 0, this_spare = 0;
int imbalance_scale = 100 + (sd->imbalance_pct-100)/2;
unsigned long imbalance = scale_load_down(NICE_0_LOAD) *
(sd->imbalance_pct-100) / 100;
do {
unsigned long load, avg_load, runnable_load;
unsigned long spare_cap, max_spare_cap;
int local_group;
int i;
/* Skip over this group if it has no CPUs allowed */
if (!cpumask_intersects(sched_group_span(group),
p->cpus_ptr))
continue;
local_group = cpumask_test_cpu(this_cpu,
sched_group_span(group));
/*
* Tally up the load of all CPUs in the group and find
* the group containing the CPU with most spare capacity.
*/
avg_load = 0;
runnable_load = 0;
max_spare_cap = 0;
for_each_cpu(i, sched_group_span(group)) {
load = cpu_runnable_load(cpu_rq(i));
runnable_load += load;
avg_load += cfs_rq_load_avg(&cpu_rq(i)->cfs);
spare_cap = capacity_spare_without(i, p);
if (spare_cap > max_spare_cap)
max_spare_cap = spare_cap;
}
/* Adjust by relative CPU capacity of the group */
avg_load = (avg_load * SCHED_CAPACITY_SCALE) /
group->sgc->capacity;
runnable_load = (runnable_load * SCHED_CAPACITY_SCALE) /
group->sgc->capacity;
if (local_group) {
this_runnable_load = runnable_load;
this_avg_load = avg_load;
this_spare = max_spare_cap;
} else {
if (min_runnable_load > (runnable_load + imbalance)) {
/*
* The runnable load is significantly smaller
* so we can pick this new CPU:
*/
min_runnable_load = runnable_load;
min_avg_load = avg_load;
idlest = group;
} else if ((runnable_load < (min_runnable_load + imbalance)) &&
(100*min_avg_load > imbalance_scale*avg_load)) {
/*
* The runnable loads are close so take the
* blocked load into account through avg_load:
*/
min_avg_load = avg_load;
idlest = group;
}
if (most_spare < max_spare_cap) {
most_spare = max_spare_cap;
most_spare_sg = group;
}
}
} while (group = group->next, group != sd->groups);
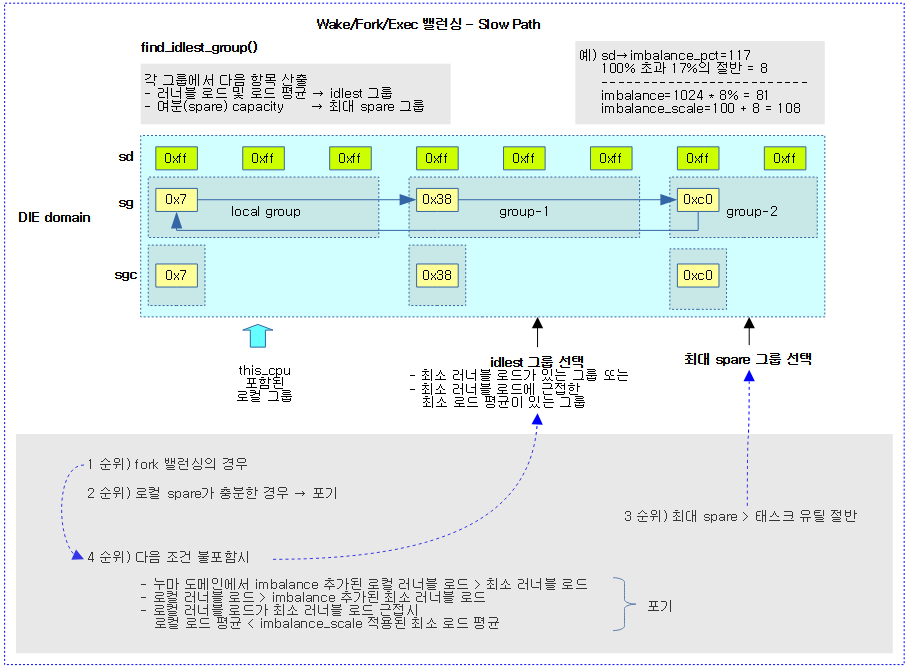
스케줄링 도메인내에서 cpu 로드가 가장 낮은 idlest 스케줄 그룹을 찾아 반환한다.
- idlest 스케줄 그룹의 cpu 로드에 imbalance_pct의 100% 초과분은 절반만 적용하여 로컬 그룹의 cpu 로드보다 오히려 커지는 경우 null을 반환한다.
- 코드 라인 11에서 요청한 도메인의 imbalance_pct의 100% 초과분의 절반만 적용한 값을 imbalance_scale로 사용한다.
- 예) imbalance_pct=117인 경우 100을 넘어서는 값 17의 절반인 8을 100과 더해 imbalance_scale=108이 된다.
- 코드 라인 12~13에서 요청한 도메인의 imbalance_pct의 100% 초과분의 절반을 nice 0 태스크에 해당하는 로드 weight 값과 곱한 후 100으로 나눈 값을 imbalance에 대입한다.
- 예) imbalance_pct=117인 경우 nice-0 load weight에 해당하는 1024 * 100% 초과분 17의 절반 값 8%를 적용한 imbalance=81
- 코드 라인 15~24에서 그룹을 순회하며 그룹의 cpu들이 태스크가 허용하는 cpu들에 하나도 포함되지 않은 경우 skip 한다.
- 코드 라인 26~27에서 @this_cpu가 포함된 로컬 그룹을 알아온다.
- 코드 라인 33~47에서 순회 중인 그룹의 cpu들을 대상으로 재차 순회하며 다음을 계산해둔다.
- 러너블 로드 합을 runnable_load에 대입
- cfs 런큐의 로드 평균 합을 avg_load에 대입
- 순회 중인 cpu에서 여분의 capacity 중 최대 값을 max_spare_cap에 대입
- 코드 라인 50~51에서 그룹 capacity를 스케일 적용한 평균 로드를 산출한다.
- 코드 라인 52~53에서 그룹 capacity를 스케일 적용한 러너블 로드를 산출한다.
- 코드 라인 55~58에서 순회 중인 그룹이 로컬 그룹인 경우의 값들을 보관한다.
- 코드 라인 59~82에서 순회 중인 그룹의 러너블 로드가 가장 작은 idlest 그룹을 찾아 갱신한다.
- imbalance 값이 추가된 러너블 로드가 min_runnable_load 보다 충분히 작은 경우이다.
- 이 때 min_runnable_load 값도 갱신해둔다.
- 러너블 로드가 imbalace 값이 추가된 min_runnable_load 보다 작으면서 imbalance_scale 비율이 적용된 평균 로드가 min_avg_load보다 작은 경우이다.
- 이 때 min_runnable_load는 갱신하지 않는다.
- 그룹들 중 가장 여분의 capacity가 있는 그룹을 most_spare_sg에 대입하고, capacity 값은 most_spare에 대입한다.
- imbalance 값이 추가된 러너블 로드가 min_runnable_load 보다 충분히 작은 경우이다.
- 코드 라인 83에서 단방향 원형 리스트로 연결된 스케줄 그룹이 한 바퀴 돌 때까지 계속한다.
kernel/sched/fair.c -2/2-
/*
* The cross-over point between using spare capacity or least load
* is too conservative for high utilization tasks on partially
* utilized systems if we require spare_capacity > task_util(p),
* so we allow for some task stuffing by using
* spare_capacity > task_util(p)/2.
*
* Spare capacity can't be used for fork because the utilization has
* not been set yet, we must first select a rq to compute the initial
* utilization.
*/
if (sd_flag & SD_BALANCE_FORK)
goto skip_spare;
if (this_spare > task_util(p) / 2 &&
imbalance_scale*this_spare > 100*most_spare)
return NULL;
if (most_spare > task_util(p) / 2)
return most_spare_sg;
skip_spare:
if (!idlest)
return NULL;
/*
* When comparing groups across NUMA domains, it's possible for the
* local domain to be very lightly loaded relative to the remote
* domains but "imbalance" skews the comparison making remote CPUs
* look much more favourable. When considering cross-domain, add
* imbalance to the runnable load on the remote node and consider
* staying local.
*/
if ((sd->flags & SD_NUMA) &&
min_runnable_load + imbalance >= this_runnable_load)
return NULL;
if (min_runnable_load > (this_runnable_load + imbalance))
return NULL;
if ((this_runnable_load < (min_runnable_load + imbalance)) &&
(100*this_avg_load < imbalance_scale*min_avg_load))
return NULL;
return idlest;
}
- 코드 라인 12~13에서 fork 밸런싱으로 진입한 경우 skip_spare 레이블로 이동한다.
- 코드 라인 15~17에서 로컬의 여분 capacity가 태스크 유틸의 절반 보다 크고, imbalance_scale이 적용된 로컬의 여분 capacity 또한 most_spare보다 큰 경우 migration할 필요 없으므로 null을 반환한다.
- 코드 라인 19~20에서 그룹들 중 가장 큰 여분 capacity가 태스크 유틸의 절반보다 큰 경우 가장 큰 여분을 가진 그룹을 반환한다.
- 코드 라인 22~24에서 skip_spare: 레이블이다. idlest 그룹을 찾지 못한 경우 null을 반환한다.
- 코드 라인 34~43에서 다음 3가지 조건에 해당하면 migration할 필요 없으므로 null을 반환한다.
- 누마 도메인에서 imbalance가 추가된 최소 러너블 로드가 로컬 그룹의 러너블 로드보다 큰 경우
- imbalance가 추가된 로컬 그룹의 러너블 로드보다 최소 러너블 로드가 더 큰 경우
- imbalance가 추가된 최소 러너블 로드가 로컬 그룹의 러너블 로드보다 크면서 imbalnce_scale이 적용된 최소 평균 로드보다 로컬 그룹의 평균 로드보다 작은 경우
- 코드 라인 45에서 결정한 idlest 그룹을 반환한다.
다음 그림은 wake/fork/exec 밸런싱의 Slow Path로 동작하는 find_idlest_group() 함수를 통해 최대 여유 capacity 그룹 또는 최소 로드 그룹을 찾는 과정을 보여준다.
idlest 그룹내 idlest cpu 찾기
find_idlest_group_cpu()
kernel/sched/fair.c
/* * find_idlest_group_cpu - find the idlest CPU among the CPUs in the group. */
static int
find_idlest_group_cpu(struct sched_group *group, struct task_struct *p, int this_cpu)
{
unsigned long load, min_load = ULONG_MAX;
unsigned int min_exit_latency = UINT_MAX;
u64 latest_idle_timestamp = 0;
int least_loaded_cpu = this_cpu;
int shallowest_idle_cpu = -1, si_cpu = -1;
int i;
/* Check if we have any choice: */
if (group->group_weight == 1)
return cpumask_first(sched_group_span(group));
/* Traverse only the allowed CPUs */
for_each_cpu_and(i, sched_group_span(group), p->cpus_ptr) {
if (available_idle_cpu(i)) {
struct rq *rq = cpu_rq(i);
struct cpuidle_state *idle = idle_get_state(rq);
if (idle && idle->exit_latency < min_exit_latency) {
/*
* We give priority to a CPU whose idle state
* has the smallest exit latency irrespective
* of any idle timestamp.
*/
min_exit_latency = idle->exit_latency;
latest_idle_timestamp = rq->idle_stamp;
shallowest_idle_cpu = i;
} else if ((!idle || idle->exit_latency == min_exit_latency) &&
rq->idle_stamp > latest_idle_timestamp) {
/*
* If equal or no active idle state, then
* the most recently idled CPU might have
* a warmer cache.
*/
latest_idle_timestamp = rq->idle_stamp;
shallowest_idle_cpu = i;
}
} else if (shallowest_idle_cpu == -1 && si_cpu == -1) {
if (sched_idle_cpu(i)) {
si_cpu = i;
continue;
}
load = cpu_runnable_load(cpu_rq(i));
if (load < min_load) {
min_load = load;
least_loaded_cpu = i;
}
}
}
if (shallowest_idle_cpu != -1)
return shallowest_idle_cpu;
if (si_cpu != -1)
return si_cpu;
return least_loaded_cpu;
}
그룹내에서 가장 idle한 cpu를 다음 순서대로 찾아 반환한다. 단 그룹내 1개의 cpu만 동작 중인 경우 해당 cpu를 반환한다.
- 1) 가장 짧은 latency를 가진 idle cpu (동일한 경우 가장 최근에 idle 진입한 cpu)
- 2) 차선으로 idle policy 태스크만 동작중인 cpu
- 3) 마지막으로 가장 낮은 로드를 사용하는 cpu
- 코드 라인 12~13에서 그룹 내 cpu가 하나만 지원하는 경우 해당 cpu를 반환한다.
- 코드 라인 16에서 그룹에 포함된 cpu들 중 태스크가 허용하는 cpu들에 대해 순회한다.
- 코드 라인 17~38에서 순회 중인 cpu가 idle cpu인 경우 런큐에 연결된 cpuidle_state를 알아온다. 그리고 idle 상태에서 깨어나는데 걸리는 시간(exit_latency)가 가장 작은 cpu를 찾아 shallowest_idle_cpu에 대입하고 cpu idle PM에서 지정해둔 exit_latency 시간을 min_exit_latency에 대입한다.
- cpuidle_state
- cpu idle 상태를 관리하고 cpu idle PM을 위한 generic 프레임워크와 연결된다. 여기서 cpu idle 드라이버와 연결하여 사용한다.
- idle->exit_latency (us 단위)
- arm에서 사용하는 대부분의 idle 드라이버는 cpu idle과 클러스터 idle의 2단계의 상태 정도로 나누어 관리한다. 그 중 클러스터 idle의 경우 idle로 진입한 후 다시 wake될 때까지 사이클에 소요되는 시간이 크므로 이를 exit_latency에 대입하여 관리한다.
- 이 값은 초기 커널에서는 하드 코딩하여 각 시스템에 지정하였는데 최근에는 디바이스 트리에서 지정한 값으로도 관리된다. 보통 수 us 부터 수십 ms까지 전원 관리를 얼마나 깊게 하는가에 따라 다르다.
- idle cpu가 wake하기 위해 걸리는 시간이 작은 cpu를 선택하여 더욱 성능 효율을 낼 수 있다.
- exit_latency가 서로 동일한 경우 idle 진입한 시각이 얼마되지 않은 cpu를 선택한다.
- 최근에 idle 상태에 진입한 cpu를 선택하는 것으로 L2 이상의 share 캐시에 데이터가 남아있을 가능성이 크다. (더 높은 성능을 위해)
- cpuidle_state
- 코드 라인 39~50에서 순회 중인 cpu가 idle이 아니고 shallowest_idle_cpu와 si_cpu 모두 아직 지정되지 않은 경우 idle policy를 사용하는 태스크만 동작중인 cpu인 경우에는 si_cpu에 대입하고 skip 한다. 그렇지 않은 경우 순회 중인 cpu의 최소 러너블 로드를 갱신하고 해당 cpu를 least_loaded_cpu에 대입한다.
- 코드 라인 53~54에서 가장 짧은 latency를 가진 idle cpu를 찾은 경우 이 cpu를 반환한다.
- 코드 라인 55~56에서 차선으로 idle policy 태스크만 동작중인 cpu를 찾은 경우 이 cpu를 반환한다.
- 코드 라인 57에서 마지막으로 가장 낮은 로드를 사용하는 cpu를 반환한다.
다음 4 개의 그림은 스케줄 그룹내에서 태스크가 허용하면서 가장 idlest한 cpu를 찾는 과정을 보여준다.
- exit_latency는 WFI로 인해 shallow 슬립하는 cpu에서는 1과 같이 작은 값이고, 클러스터의 전원을 끄는 deep 슬립하는 cpu는 큰 값을 사용한다.
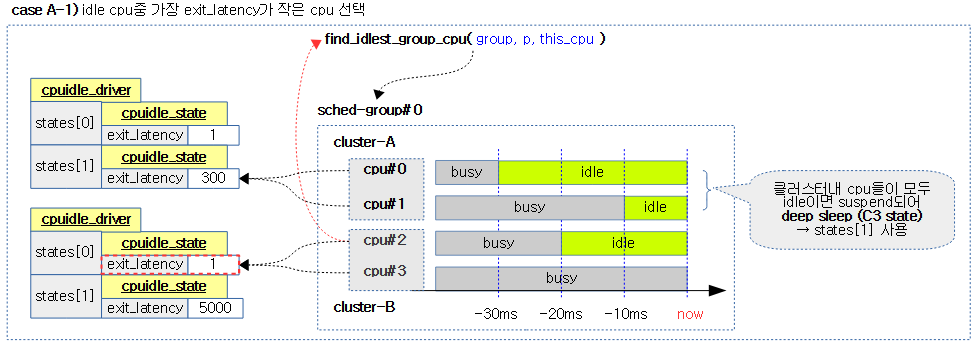

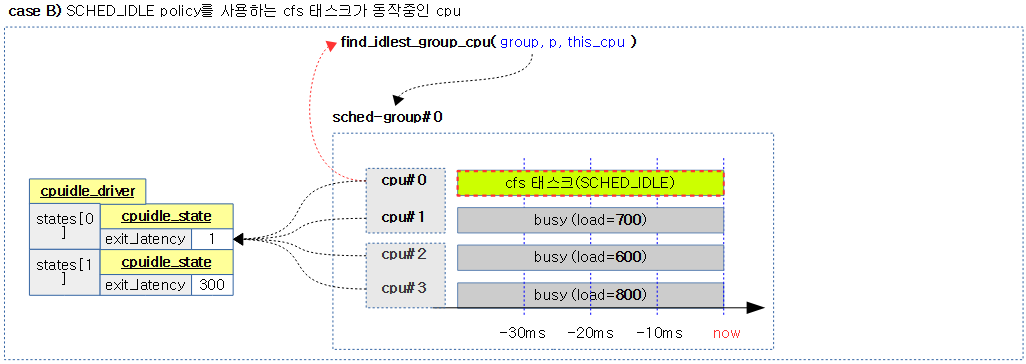
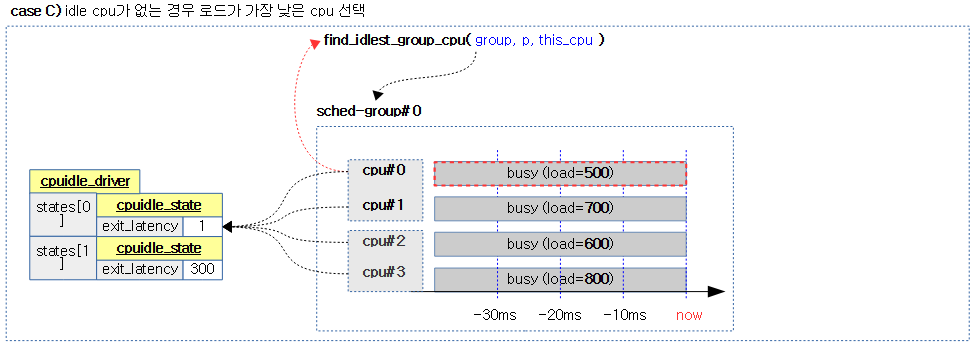
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c – 현재 글
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c