<kernel v5.4>
워커
워커 생성
create_worker()
kernel/workqueue.c
/** * create_worker - create a new workqueue worker * @pool: pool the new worker will belong to * * Create and start a new worker which is attached to @pool. * * CONTEXT: * Might sleep. Does GFP_KERNEL allocations. * * Return: * Pointer to the newly created worker. */
static struct worker *create_worker(struct worker_pool *pool)
{
struct worker *worker = NULL;
int id = -1;
char id_buf[16];
/* ID is needed to determine kthread name */
id = ida_simple_get(&pool->worker_ida, 0, 0, GFP_KERNEL);
if (id < 0)
goto fail;
worker = alloc_worker(pool->node);
if (!worker)
goto fail;
worker->pool = pool;
worker->id = id;
if (pool->cpu >= 0)
snprintf(id_buf, sizeof(id_buf), "%d:%d%s", pool->cpu, id,
pool->attrs->nice < 0 ? "H" : "");
else
snprintf(id_buf, sizeof(id_buf), "u%d:%d", pool->id, id);
worker->task = kthread_create_on_node(worker_thread, worker, pool->node,
"kworker/%s", id_buf);
if (IS_ERR(worker->task))
goto fail;
set_user_nice(worker->task, pool->attrs->nice);
kthread_bind_mask(worker->task, pool->attrs->cpumask);
/* successful, attach the worker to the pool */
worker_attach_to_pool(worker, pool);
/* start the newly created worker */
spin_lock_irq(&pool->lock);
worker->pool->nr_workers++;
worker_enter_idle(worker);
wake_up_process(worker->task);
spin_unlock_irq(&pool->lock);
return worker;
fail:
if (id >= 0)
ida_simple_remove(&pool->worker_ida, id);
kfree(worker);
return NULL;
}
요청한 워커풀에 워커 스레드를 생성한다.
- 코드 라인 8~10에서 워커풀에서 생성할 새로운 워커를 위해 id를 받아온다.
- pool->worker_ida는 워커들의 id의 할당 관리를 위해 IDR Radix tree 기반으로 동작한다.
- 코드 라인 12~17에서 워커 객체를 할당 받은 후 워커풀 및 id를 지정한다.
- 코드 라인 19~23에서 워커풀의 이름을 지정한다.
- cpu로 바운드(지정)된 워커풀은 nice 값에 따라 다음과 같이 표시한다.
- “<cpu>:<worker id>H” – 디폴트 nice 보다 스레드의 nice 우선 순위가 보다 높다.
- “<cpu>:<worker id>” – 디폴트 nice 보다 스레드의 nice 우선 순위가 같거나 낮다.
- 언바운드된 워커풀은 “u<pool id>:<worker id>“와 같이 표현한다.
- cpu로 바운드(지정)된 워커풀은 nice 값에 따라 다음과 같이 표시한다.
- 코드 라인 25~28에서 kthread를 통해 worker_thread() 함수가 호출되는 스레드를 생성하여 워커의 task에 대입한다.
- 코드 라인 30에서 워커 스레드의 static_prio 값을 워커풀 속성에 있는 nice 값을 우선순위로 변환한 값으로 설정한다.
- 코드 라인 31에서 워커 스레드에 cpu mask를 지정한다. 또한 PF_NO_SETAFFINITY 플래그를 추가하여 다른 cpu로 마이그레이션되지 않도록 막는다.
- 코드 라인 34에서 워커 스레드를 워커풀에 지정한다.
- 코드 라인 38에서 워커풀내의 워커 수를 나타내는 nr_workers를 1 증가시킨다.
- 코드 라인 39~40에서 워커 스레드를 idle 상태로 진입하게 한 후 다시 깨운다.
- 코드 라인 43에서 생성한 워크 스레드를 반환한다.
alloc_worker()
kernel/workqueue.c
static struct worker *alloc_worker(int node)
{
struct worker *worker;
worker = kzalloc_node(sizeof(*worker), GFP_KERNEL, node);
if (worker) {
INIT_LIST_HEAD(&worker->entry);
INIT_LIST_HEAD(&worker->scheduled);
INIT_LIST_HEAD(&worker->node);
/* on creation a worker is in !idle && prep state */
worker->flags = WORKER_PREP;
}
return worker;
}
워커 구조체를 할당받고 내부에서 관리하는 리스트들을 초기화한다.
워커를 워커풀에 연결(attach)
worker_attach_to_pool()
kernel/workqueue.c
/** * worker_attach_to_pool() - attach a worker to a pool * @worker: worker to be attached * @pool: the target pool * * Attach @worker to @pool. Once attached, the %WORKER_UNBOUND flag and * cpu-binding of @worker are kept coordinated with the pool across * cpu-[un]hotplugs. */
static void worker_attach_to_pool(struct worker *worker,
struct worker_pool *pool)
{
mutex_lock(&pool->attach_mutex);
/*
* set_cpus_allowed_ptr() will fail if the cpumask doesn't have any
* online CPUs. It'll be re-applied when any of the CPUs come up.
*/
set_cpus_allowed_ptr(worker->task, pool->attrs->cpumask);
/*
* The pool->attach_mutex ensures %POOL_DISASSOCIATED remains
* stable across this function. See the comments above the
* flag definition for details.
*/
if (pool->flags & POOL_DISASSOCIATED)
worker->flags |= WORKER_UNBOUND;
list_add_tail(&worker->node, &pool->workers);
mutex_unlock(&pool->attach_mutex);
}
워커를 워커풀에 연결한다.
- 코드 라인 10에서 워커풀 속성에 있는 cpumask를 워커 스레드에 지정한다.
- 바운드된 워커풀은 특정 cpu만 마스크비트가 설정되어 있다.
- 언바운드된 워커풀은 online된 cpu들에 대해 모두 마스크비트가 설정되어 있다.
- 코드 라인 17~19에서 워커풀이 아직 서비스하지 않는 상태인 경우 워커에 WORKER_UNBOUND 플래그를 설정한다.
- 코드 라인 20에서 워커풀의 workers 리스트에 워커를 추가한다.
워커를 워커풀에서 연결 해제
worker_detach_from_pool()
kernel/workqueue.c
/** * worker_detach_from_pool() - detach a worker from its pool * @worker: worker which is attached to its pool * * Undo the attaching which had been done in worker_attach_to_pool(). The * caller worker shouldn't access to the pool after detached except it has * other reference to the pool. */
static void worker_detach_from_pool(struct worker *worker)
{
struct worker_pool *pool = worker->pool;
struct completion *detach_completion = NULL;
mutex_lock(&pool->attach_mutex);
list_del(&worker->node);
worker->pool = NULL;
if (list_empty(&pool->workers))
detach_completion = pool->detach_completion;
mutex_unlock(&pool->attach_mutex);
/* clear leftover flags without pool->lock after it is detached */
worker->flags &= ~(WORKER_UNBOUND | WORKER_REBOUND);
if (detach_completion)
complete(detach_completion);
}
워커를 워커풀에서 연결해제한다.
- 코드 라인 8~9에서 워커풀의 workers 리스트에서 요청한 워커를 제거한다.
- 코드 라인 11~12에서 워커풀이 빈 경우 워커풀의 detach_completion 상태를 알아온다.
- 코드 라인 16에서 워커의 WORKER_UNBOUND 및 WORKER_REBOUND 플래그를 제거한다.
- 코드 라인 18~19에서 detach 작업이 완료될 때 까지 기다린다.
워커 Idle 진입
worker_enter_idle()
kernel/workqueue.c
/** * worker_enter_idle - enter idle state * @worker: worker which is entering idle state * * @worker is entering idle state. Update stats and idle timer if * necessary. * * LOCKING: * spin_lock_irq(pool->lock). */
static void worker_enter_idle(struct worker *worker)
{
struct worker_pool *pool = worker->pool;
if (WARN_ON_ONCE(worker->flags & WORKER_IDLE) ||
WARN_ON_ONCE(!list_empty(&worker->entry) &&
(worker->hentry.next || worker->hentry.pprev)))
return;
/* can't use worker_set_flags(), also called from create_worker() */
worker->flags |= WORKER_IDLE;
pool->nr_idle++;
worker->last_active = jiffies;
/* idle_list is LIFO */
list_add(&worker->entry, &pool->idle_list);
if (too_many_workers(pool) && !timer_pending(&pool->idle_timer))
mod_timer(&pool->idle_timer, jiffies + IDLE_WORKER_TIMEOUT);
/*
* Sanity check nr_running. Because unbind_workers() releases
* pool->lock between setting %WORKER_UNBOUND and zapping
* nr_running, the warning may trigger spuriously. Check iff
* unbind is not in progress.
*/
WARN_ON_ONCE(!(pool->flags & POOL_DISASSOCIATED) &&
pool->nr_workers == pool->nr_idle &&
atomic_read(&pool->nr_running));
}
요청한 워커 스레드를 idle 상태로 설정하고 idle 카운터를 증가시킨다. 필요 시 idle 카운터를 동작시킨다.
- 코드 라인 5~8에서 워커가 이미 idle 상태이거나 워커가 워커풀의 idle_list에서 대기중면서 busy_hash[] 리스트에서도 존재하는 경우 경고 메시지를 1번 출력 후 함수를 빠져나간다.
- 코드 라인 11~13에서 워커에 WORKER_IDLE 플래그를 설정하고 idle 카운터를 1 증가시킨다. last_active에 현재 시각으로 갱신한다.
- 코드 라인 16에서 워커풀의 idle 리스트에 워커를 추가한다.
- 코드 라인 18~19에서 워커풀에 워커들이 너무 많이 쉬고 있으면 idle 타이머를 현재 시각 기준으로 IDLE_WORKER_TIMEOUT(5분) 후에 동작하도록 설정한다.
- 코드 라인 27~29에서 워커풀이 서비스 중이고 워커들이 모두 idle 상태인데 동작 중인 워커들이 있다고 하는 경우 경고메시지를 출력한다.
- nr_workers(워커풀에 등록된 워커 수) = nr_running(동작중인 워커 수) + nr_idle(idle 상태인 워커 수)
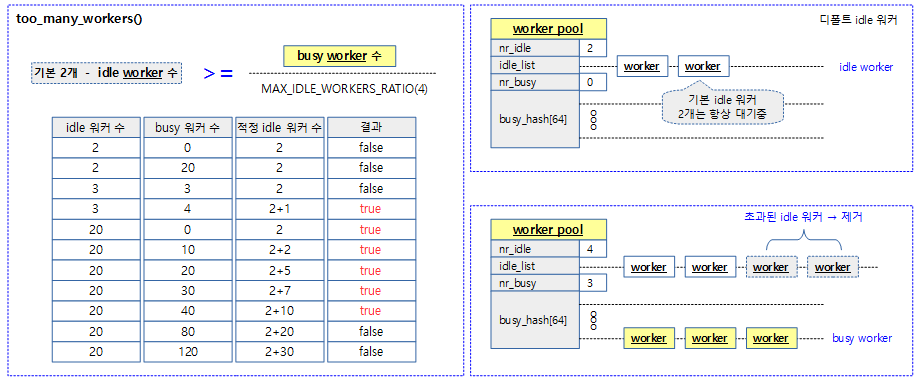
too_many_workers()
kernel/workqueue.c
/* Do we have too many workers and should some go away? */
static bool too_many_workers(struct worker_pool *pool)
{
bool managing = mutex_is_locked(&pool->manager_arb);
int nr_idle = pool->nr_idle + managing; /* manager is considered idle */
int nr_busy = pool->nr_workers - nr_idle;
return nr_idle > 2 && (nr_idle - 2) * MAX_IDLE_WORKERS_RATIO >= nr_busy;
}
워커풀에 idle 워커들이 busy 워커들의 일정 비율 이상 즉, idle 워커 수가 많은지 여부를 반환한다.
- 코드 라인 4~6에서 워커풀에 등록된 워커들에서 idle 워커를 제외한 수를 알아온다.
- 코드 라인 8에서 idle 워커에서 기본 idle 워커 수 2를 뺀 나머지 idle 워커 수가 busy 워커보다 일정 비율(기본 1/4배) 이상인 경우 놀고 있는 idle 워커 수가 많다고 판단하여 true를 반환한다.
- 조건: (idle 워커 – 2) * MAX_IDLE_WORKERS_RATIO(4) > busy 워커
- 이 함수가 true가 되는 조건 예)
- idle=3, busy=0~4
- idle=4, busy=0~8
- idle=5, busy=0~12
- …
다음 그림은 idle 워커가 너무 많은지 여부를 판단한다.
Idle 워커 타임아웃 -> idle 워커 수 줄이기
idle_worker_timeout()
kernel/workqueue.c
static void idle_worker_timeout(struct timer_list *t)
{
struct worker_pool *pool = from_timer(pool, t, idle_timer);
spin_lock_irq(&pool->lock);
while (too_many_workers(pool)) {
struct worker *worker;
unsigned long expires;
/* idle_list is kept in LIFO order, check the last one */
worker = list_entry(pool->idle_list.prev, struct worker, entry);
expires = worker->last_active + IDLE_WORKER_TIMEOUT;
if (time_before(jiffies, expires)) {
mod_timer(&pool->idle_timer, expires);
break;
}
destroy_worker(worker);
}
spin_unlock_irq(&pool->lock);
}
idle 타이머가 만료 시 호출되며 busy 워커에 비해 너무 많은 idle 워커 비율(기본 1/4)가 있다고 판단하면 일정 비율만큼 idle 워커를 줄인다.
- 코드 라인 7에서 워커풀에 idle 워커들이 busy 워커들의 일정 비율 이상 즉, idle 워커 수가 많은 경우에 한하여 반복한다.
- 코드 라인 12~21에서 idle_list에서 하나의 워커를 가져와서 워커의 최종 사용 시각이 현재 시각에 비해 IDLE_WORKER_TIMEOUT(5분)을 지나지 않은 경우 만료 시각을 다시 재설정하고 함수를 빠져간다. 이미 지정된 시간을 초과한 경우 워커를 제거하고 계속 루프를 돈다.

워커 소멸
destroy_worker()
kernel/workqueue.c
/** * destroy_worker - destroy a workqueue worker * @worker: worker to be destroyed * * Destroy @worker and adjust @pool stats accordingly. The worker should * be idle. * * CONTEXT: * spin_lock_irq(pool->lock). */
static void destroy_worker(struct worker *worker)
{
struct worker_pool *pool = worker->pool;
lockdep_assert_held(&pool->lock);
/* sanity check frenzy */
if (WARN_ON(worker->current_work) ||
WARN_ON(!list_empty(&worker->scheduled)) ||
WARN_ON(!(worker->flags & WORKER_IDLE)))
return;
pool->nr_workers--;
pool->nr_idle--;
list_del_init(&worker->entry);
worker->flags |= WORKER_DIE;
wake_up_process(worker->task);
}
워커를 소멸시킨다. 즉 워커 스레드를 소멸시킨다.
- 코드 라인 8~11에서 요청한 워크가 동작 중이거나 이 워커에 스케줄된 워크가 있거나 idle 플래그가 없는 경우 경고 메시지를 출력하고 함수를 빠져나간다.
- 코드 라인 13에서 워커풀에 등록된 워커 수인 nr_workers를 1 감소시킨다.
- 코드 라인 14에서 워커풀에서 idle 중인 워커 수를 나타내는 nr_idle을 1 감소시킨다.
- 코드 라인 16에서 워커를 워커풀의 idle_list 에서 제거한다.
- 코드 라인 17~18에서 워커에 WORKER_DIE 플래그를 설정하고 worker에 연결된 태스크를 깨워 소멸 처리한다.
- 워커풀에서 워커 id를 반납하고 워커풀에서 디태치하며 워커를 제거한다.
- 제거중인 상황에서의 태스크명을 “kworker/dying”으로 변경한다.
워크가 동작했던 워커 찾기
find_worker_executing_work()
kernel/workqueue.c
/** * find_worker_executing_work - find worker which is executing a work * @pool: pool of interest * @work: work to find worker for * * Find a worker which is executing @work on @pool by searching * @pool->busy_hash which is keyed by the address of @work. For a worker * to match, its current execution should match the address of @work and * its work function. This is to avoid unwanted dependency between * unrelated work executions through a work item being recycled while still * being executed. * * This is a bit tricky. A work item may be freed once its execution * starts and nothing prevents the freed area from being recycled for * another work item. If the same work item address ends up being reused * before the original execution finishes, workqueue will identify the * recycled work item as currently executing and make it wait until the * current execution finishes, introducing an unwanted dependency. * * This function checks the work item address and work function to avoid * false positives. Note that this isn't complete as one may construct a * work function which can introduce dependency onto itself through a * recycled work item. Well, if somebody wants to shoot oneself in the * foot that badly, there's only so much we can do, and if such deadlock * actually occurs, it should be easy to locate the culprit work function. * * CONTEXT: * spin_lock_irq(pool->lock). * * Return: * Pointer to worker which is executing @work if found, %NULL * otherwise. */
static struct worker *find_worker_executing_work(struct worker_pool *pool,
struct work_struct *work)
{
struct worker *worker;
hash_for_each_possible(pool->busy_hash, worker, hentry,
(unsigned long)work)
if (worker->current_work == work &&
worker->current_func == work->func)
return worker;
return NULL;
}
동작중인 워커들에서 워크가 동작하는 워커를 찾아온다. 없으면 null을 반환한다.
- busy_hash 리스트를 순회하며 요청한 워크가 현재 동작중인 워커를 찾는다.
need_more_worker()
kernel/workqueue.c
/* * Need to wake up a worker? Called from anything but currently * running workers. * * Note that, because unbound workers never contribute to nr_running, this * function will always return %true for unbound pools as long as the * worklist isn't empty. */
static bool need_more_worker(struct worker_pool *pool)
{
return !list_empty(&pool->worklist) && __need_more_worker(pool);
}
워커가 더 필요한지 여부를 알아온다.
- 워커풀에 작업이 대기되어 있고 워커가 더 필요한 경우 true를 반환한다.
__need_more_worker()
kernel/workqueue.c
/* * Policy functions. These define the policies on how the global worker * pools are managed. Unless noted otherwise, these functions assume that * they're being called with pool->lock held. */
static bool __need_more_worker(struct worker_pool *pool)
{
return !atomic_read(&pool->nr_running);
}
워커풀에서 동작 중인 워커가 없는지 여부를 반환한다. (1=현재 동작중인 워커가 없다.)
wake_up_worker()
kernel/workqueue.c
/** * wake_up_worker - wake up an idle worker * @pool: worker pool to wake worker from * * Wake up the first idle worker of @pool. * * CONTEXT: * spin_lock_irq(pool->lock). */
static void wake_up_worker(struct worker_pool *pool)
{
struct worker *worker = first_idle_worker(pool);
if (likely(worker))
wake_up_process(worker->task);
}
요청한 워커풀의 첫 번째 idle 워커를 깨운다.
first_idle_worker()
kernel/workqueue.c
/* Return the first idle worker. Safe with preemption disabled */
static struct worker *first_idle_worker(struct worker_pool *pool)
{
if (unlikely(list_empty(&pool->idle_list)))
return NULL;
return list_first_entry(&pool->idle_list, struct worker, entry);
}
요청한 워커풀에서 첫 idle 워커를 반환한다.
- idle_list에서 있는 첫 번째 워커를 반환한다.
워커 스레드 동작
worker_thread()
kernel/workqueue.c -1/2-
/** * worker_thread - the worker thread function * @__worker: self * * The worker thread function. All workers belong to a worker_pool - * either a per-cpu one or dynamic unbound one. These workers process all * work items regardless of their specific target workqueue. The only * exception is work items which belong to workqueues with a rescuer which * will be explained in rescuer_thread(). * * Return: 0 */
static int worker_thread(void *__worker)
{
struct worker *worker = __worker;
struct worker_pool *pool = worker->pool;
/* tell the scheduler that this is a workqueue worker */
set_pf_worker(true);
woke_up:
spin_lock_irq(&pool->lock);
/* am I supposed to die? */
if (unlikely(worker->flags & WORKER_DIE)) {
spin_unlock_irq(&pool->lock);
WARN_ON_ONCE(!list_empty(&worker->entry));
set_pf_worker(false);
set_task_comm(worker->task, "kworker/dying");
ida_simple_remove(&pool->worker_ida, worker->id);
worker_detach_from_pool(worker);
kfree(worker);
return 0;
}
worker_leave_idle(worker);
recheck:
/* no more worker necessary? */
if (!need_more_worker(pool))
goto sleep;
/* do we need to manage? */
if (unlikely(!may_start_working(pool)) && manage_workers(worker))
goto recheck;
/*
* ->scheduled list can only be filled while a worker is
* preparing to process a work or actually processing it.
* Make sure nobody diddled with it while I was sleeping.
*/
WARN_ON_ONCE(!list_empty(&worker->scheduled));
- 코드 라인 7에서 스케줄러로 하여금 이 태스크가 워커 스레드인 것을 알 수 있게 PF_WQ_WORKER 플래그를 설정한다.
- 코드 라인 12~22에서 워커 스레드의 종료 요청 플래그가 설정된 경우 워커를 워커풀에서 제거하고 할당 해제 후 종료한다.
- 코드 라인 24에서 워커 스레드를 idle 상태로 둔다.
- 코드 라인 27~28에서 추가 적인 워커가 필요하지 않으면 sleep으로 이동한다.
- 동작중인 워커가 하나도 없으면 더 이상 필요한 워커가 없다고 판단한다.
- 코드 라인 31~32에서 워커풀에 idle 워커가 없으면 워커를 생성한다. 만일 워커를 생성하기 위한 락 획득 시도가 실패하는 경우 다시 recheck 레이블로 이동하여 다시 시도한다.
kernel/workqueue.c -2/2-
/*
* Finish PREP stage. We're guaranteed to have at least one idle
* worker or that someone else has already assumed the manager
* role. This is where @worker starts participating in concurrency
* management if applicable and concurrency management is restored
* after being rebound. See rebind_workers() for details.
*/
worker_clr_flags(worker, WORKER_PREP | WORKER_REBOUND);
do {
struct work_struct *work =
list_first_entry(&pool->worklist,
struct work_struct, entry);
pool->watchdog_ts = jiffies;
if (likely(!(*work_data_bits(work) & WORK_STRUCT_LINKED))) {
/* optimization path, not strictly necessary */
process_one_work(worker, work);
if (unlikely(!list_empty(&worker->scheduled)))
process_scheduled_works(worker);
} else {
move_linked_works(work, &worker->scheduled, NULL);
process_scheduled_works(worker);
}
} while (keep_working(pool));
worker_set_flags(worker, WORKER_PREP);
sleep:
/*
* pool->lock is held and there's no work to process and no need to
* manage, sleep. Workers are woken up only while holding
* pool->lock or from local cpu, so setting the current state
* before releasing pool->lock is enough to prevent losing any
* event.
*/
worker_enter_idle(worker);
__set_current_state(TASK_IDLE);
spin_unlock_irq(&pool->lock);
schedule();
goto woke_up;
}
- 코드 라인 8에서 워커에서 WORKER_PREP 및 WORKER_REBOUND 플래그를 제거한다.
- 코드 라인 10~13에서 워커풀에 있는 워크리스트에서 처리할 워크를 가져온다.
- 코드 라인 15에서 watchdog_ts에 현재 시각(jiffies)를 기록한다.
- 코드 라인 17~21에서 높은 확률로 워크에서 linked라는 플래그가 없는 경우 하나의 워크를 처리한다. 그 후 낮은 확률로 워커의 scheduled리스트에 있는 워크도 모두 처리한다.
- 코드 라인 22~25에서 lined라는 플래그가 있는 경우 다음 연결된 워크를 모두 처리한다.
- 코드 라인 26에서 워커풀의 워크리스트가 다 처리되어 empty될 때까지 루프를 반복한다.
- 코드 라인 28에서 워커를 다시 prep 상태로 변경한다.
- 코드 라인 37~38에서 워커를 idle 상태로 설정하고 태스크 상태는 슬립 중 wakeup할 수 있도록 인터럽터블로 변경한다.
- 코드 라인 40~41에서 스케줄 함수를 통해 슬립한다. 그 후 깨어나면 다시 처음 루틴부터 시작하도록 woke_up 레이블로 이동한다.
다음 그림은 워커 스레드가 워크를 처리하는 과정을 보여준다.
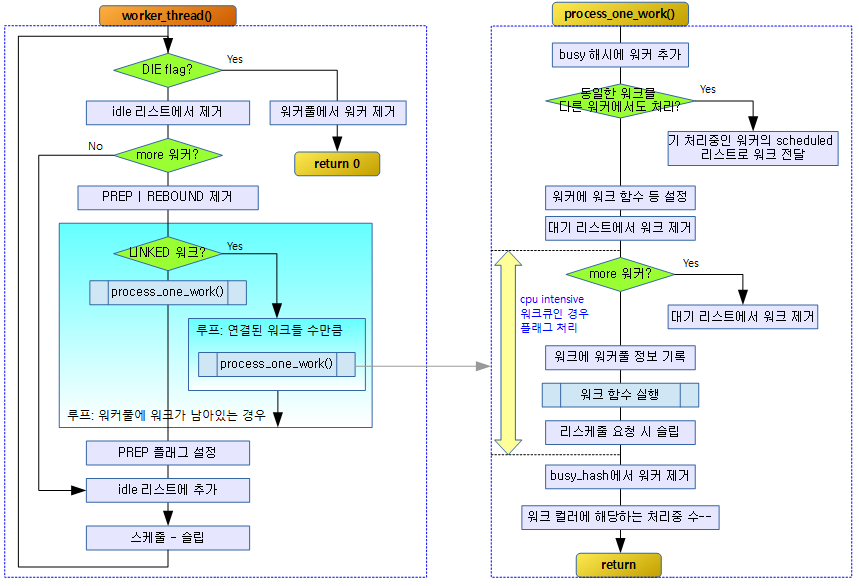
manage_workers()
kernel/workqueue.c
/** * manage_workers - manage worker pool * @worker: self * * Assume the manager role and manage the worker pool @worker belongs * to. At any given time, there can be only zero or one manager per * pool. The exclusion is handled automatically by this function. * * The caller can safely start processing works on false return. On * true return, it's guaranteed that need_to_create_worker() is false * and may_start_working() is true. * * CONTEXT: * spin_lock_irq(pool->lock) which may be released and regrabbed * multiple times. Does GFP_KERNEL allocations. * * Return: * %false if the pool doesn't need management and the caller can safely * start processing works, %true if management function was performed and * the conditions that the caller verified before calling the function may * no longer be true. */
static bool manage_workers(struct worker *worker)
{
struct worker_pool *pool = worker->pool;
if (pool->flags & POOL_MANAGER_ACTIVE)
return false;
pool->flags |= POOL_MANAGER_ACTIVE;
pool->manager = worker;
maybe_create_worker(pool);
pool->manager = NULL;
pool->flags &= ~POOL_MANAGER_ACTIVE;
wake_up(&wq_manager_wait);
return true;
}
필요한 만큼 요청한 워커풀에 워커를 생성한다. 만일 워커를 생성하기 위해 락 획득 시도가 실패하는 경우 false를 반환한다.
maybe_create_worker()
kernel/workqueue.c
/** * maybe_create_worker - create a new worker if necessary * @pool: pool to create a new worker for * * Create a new worker for @pool if necessary. @pool is guaranteed to * have at least one idle worker on return from this function. If * creating a new worker takes longer than MAYDAY_INTERVAL, mayday is * sent to all rescuers with works scheduled on @pool to resolve * possible allocation deadlock. * * On return, need_to_create_worker() is guaranteed to be %false and * may_start_working() %true. * * LOCKING: * spin_lock_irq(pool->lock) which may be released and regrabbed * multiple times. Does GFP_KERNEL allocations. Called only from * manager. */
static void maybe_create_worker(struct worker_pool *pool)
__releases(&pool->lock)
__acquires(&pool->lock)
{
restart:
spin_unlock_irq(&pool->lock);
/* if we don't make progress in MAYDAY_INITIAL_TIMEOUT, call for help */
mod_timer(&pool->mayday_timer, jiffies + MAYDAY_INITIAL_TIMEOUT);
while (true) {
if (create_worker(pool) || !need_to_create_worker(pool))
break;
schedule_timeout_interruptible(CREATE_COOLDOWN);
if (!need_to_create_worker(pool))
break;
}
del_timer_sync(&pool->mayday_timer);
spin_lock_irq(&pool->lock);
/*
* This is necessary even after a new worker was just successfully
* created as @pool->lock was dropped and the new worker might have
* already become busy.
*/
if (need_to_create_worker(pool))
goto restart;
}
필요한 만큼 요청한 워커풀에 워커를 생성한다.
- 코드 라인 9에서 mayday 타이머를 현재 시각 기준으로 만료 시각을 다시 조정한다.
- 코드 라인 11~19에서 반복하며 필요한 수 만큼 워커를 생성한다.
- 코드 라인 21에서 mayday 타이머를 제거한다.
- 코드 라인 28~29에서 다시 한 번 워커를 추가해야 하는지 확인하여 재시도할지 결정한다.
need_to_create_worker()
kernel/workqueue.c
/* Do we need a new worker? Called from manager. */
static bool need_to_create_worker(struct worker_pool *pool)
{
return need_more_worker(pool) && !may_start_working(pool);
}
요청한 워커풀에 워커가 더 필요하지만 준비된 idle 워커가 없어서 곧바로 동작할 수 없는 경우 워커를 만들 필요가 있는지 여부를 반환한다.
연결된(스케줄된) 워크들 처리
move_linked_works()
kernel/workqueue.c
/** * move_linked_works - move linked works to a list * @work: start of series of works to be scheduled * @head: target list to append @work to * @nextp: out paramter for nested worklist walking * * Schedule linked works starting from @work to @head. Work series to * be scheduled starts at @work and includes any consecutive work with * WORK_STRUCT_LINKED set in its predecessor. * * If @nextp is not NULL, it's updated to point to the next work of * the last scheduled work. This allows move_linked_works() to be * nested inside outer list_for_each_entry_safe(). * * CONTEXT: * spin_lock_irq(pool->lock). */
static void move_linked_works(struct work_struct *work, struct list_head *head,
struct work_struct **nextp)
{
struct work_struct *n;
/*
* Linked worklist will always end before the end of the list,
* use NULL for list head.
*/
list_for_each_entry_safe_from(work, n, NULL, entry) {
list_move_tail(&work->entry, head);
if (!(*work_data_bits(work) & WORK_STRUCT_LINKED))
break;
}
/*
* If we're already inside safe list traversal and have moved
* multiple works to the scheduled queue, the next position
* needs to be updated.
*/
if (nextp)
*nextp = n;
}
연결된 워크들을 두 번째 head 리스트로 옮긴다.
- 코드 라인 10~14에서 워크들을 순회하며 head로 옮긴다. 만일 워크에 linked 속성 플래그가 없는 경우 루프를 벗어난다.
- 코드 라인 21~22에서 출력 인수 nextp에 처리된 워크를 반환한다.
process_scheduled_works()
kernel/workqueue.c
/** * process_scheduled_works - process scheduled works * @worker: self * * Process all scheduled works. Please note that the scheduled list * may change while processing a work, so this function repeatedly * fetches a work from the top and executes it. * * CONTEXT: * spin_lock_irq(pool->lock) which may be released and regrabbed * multiple times. */
static void process_scheduled_works(struct worker *worker)
{
while (!list_empty(&worker->scheduled)) {
struct work_struct *work = list_first_entry(&worker->scheduled,
struct work_struct, entry);
process_one_work(worker, work);
}
}
모든 스케줄된 워크를 처리한다.
- 워커의 스케줄드 리스트에 있는 워크들 수 만큼 순회하며 워크를 처리한다.
하나의 워크 처리
process_one_work()
워커에서 워크를 하나 처리한다.
kernel/workqueue.c – 1/4
/** * process_one_work - process single work * @worker: self * @work: work to process * * Process @work. This function contains all the logics necessary to * process a single work including synchronization against and * interaction with other workers on the same cpu, queueing and * flushing. As long as context requirement is met, any worker can * call this function to process a work. * * CONTEXT: * spin_lock_irq(pool->lock) which is released and regrabbed. */
static void process_one_work(struct worker *worker, struct work_struct *work)
__releases(&pool->lock)
__acquires(&pool->lock)
{
struct pool_workqueue *pwq = get_work_pwq(work);
struct worker_pool *pool = worker->pool;
bool cpu_intensive = pwq->wq->flags & WQ_CPU_INTENSIVE;
int work_color;
struct worker *collision;
#ifdef CONFIG_LOCKDEP
/*
* It is permissible to free the struct work_struct from
* inside the function that is called from it, this we need to
* take into account for lockdep too. To avoid bogus "held
* lock freed" warnings as well as problems when looking into
* work->lockdep_map, make a copy and use that here.
*/
struct lockdep_map lockdep_map;
lockdep_copy_map(&lockdep_map, &work->lockdep_map);
#endif
/* ensure we're on the correct CPU */
WARN_ON_ONCE(!(pool->flags & POOL_DISASSOCIATED) &&
raw_smp_processor_id() != pool->cpu);
- 코드 라인 7에서 워크큐에 cpu intensive 플래그가 사용되었는지 여부를 알아온다.
kernel/workqueue.c – 2/4
. /*
* A single work shouldn't be executed concurrently by
* multiple workers on a single cpu. Check whether anyone is
* already processing the work. If so, defer the work to the
* currently executing one.
*/
collision = find_worker_executing_work(pool, work);
if (unlikely(collision)) {
move_linked_works(work, &collision->scheduled, NULL);
return;
}
/* claim and dequeue */
debug_work_deactivate(work);
hash_add(pool->busy_hash, &worker->hentry, (unsigned long)work);
worker->current_work = work;
worker->current_func = work->func;
worker->current_pwq = pwq;
work_color = get_work_color(work);
/*
* Record wq name for cmdline and debug reporting, may get
* overridden through set_worker_desc().
*/
strscpy(worker->desc, pwq->wq->name, WORKER_DESC_LEN);
list_del_init(&work->entry);
/*
* CPU intensive works don't participate in concurrency management.
* They're the scheduler's responsibility. This takes @worker out
* of concurrency management and the next code block will chain
* execution of the pending work items.
*/
if (unlikely(cpu_intensive))
worker_set_flags(worker, WORKER_CPU_INTENSIVE);
/*
* Wake up another worker if necessary. The condition is always
* false for normal per-cpu workers since nr_running would always
* be >= 1 at this point. This is used to chain execution of the
* pending work items for WORKER_NOT_RUNNING workers such as the
* UNBOUND and CPU_INTENSIVE ones.
*/
if (need_more_worker(pool))
wake_up_worker(pool);
- 코드 라인 7~11에서 워터풀내에서 요청한 워크가 이미 처리중인 경우 처리중인 워커의 스케줄드 리스트에 추가하고 함수를 빠져나간다.
- 같은 워크 요청은 하나의 cpu에서 여러 개의 워커에서 동작못하게 막는다.
- 코드 라인 15~18에서 busy_hash에 work를 키로 인덱스를 결정하고 워커를 추가한다. 추가할 때 워커에 처리중인 함수와 워크 및 풀워크큐를 지정한다.
- 코드 라인 19에서 현재 작업의 워크 컬러를 알아온다.
- 코드 라인 25에서 워커 스레드의 이름을 워크큐명으로 지정한다.
- 코드 라인 27에서 워크를 기존 리스트에서 제거한다.
- 코드 라인 35~36에서 cpu intensive 워크큐를 이용하는 경우 워커에 cpu intensive 플래그를 설정한다.
- 코드 라인 45~46에서 워커가 더 필요한 경우 대기중인 첫 번째 idle 워커를 깨운다.
kernel/workqueue.c – 3/4
. /*
* Record the last pool and clear PENDING which should be the last
* update to @work. Also, do this inside @pool->lock so that
* PENDING and queued state changes happen together while IRQ is
* disabled.
*/
set_work_pool_and_clear_pending(work, pool->id);
spin_unlock_irq(&pool->lock);
lock_map_acquire_read(&pwq->wq->lockdep_map);
lock_map_acquire(&lockdep_map);
/*
* Strictly speaking we should mark the invariant state without holding
* any locks, that is, before these two lock_map_acquire()'s.
*
* However, that would result in:
*
* A(W1)
* WFC(C)
* A(W1)
* C(C)
*
* Which would create W1->C->W1 dependencies, even though there is no
* actual deadlock possible. There are two solutions, using a
* read-recursive acquire on the work(queue) 'locks', but this will then
* hit the lockdep limitation on recursive locks, or simply discard
* these locks.
*
* AFAICT there is no possible deadlock scenario between the
* flush_work() and complete() primitives (except for single-threaded
* workqueues), so hiding them isn't a problem.
*/
lockdep_invariant_state(true);
trace_workqueue_execute_start(work);
worker->current_func(work);
/*
* While we must be careful to not use "work" after this, the trace
* point will only record its address.
*/
trace_workqueue_execute_end(work);
lock_map_release(&lockdep_map);
lock_map_release(&pwq->wq->lockdep_map);
if (unlikely(in_atomic() || lockdep_depth(current) > 0)) {
pr_err("BUG: workqueue leaked lock or atomic: %s/0x%08x/%d\n"
" last function: %pf\n",
current->comm, preempt_count(), task_pid_nr(current),
worker->current_func);
debug_show_held_locks(current);
dump_stack();
}
- 코드 라인 7에서 워크에 워커풀 id를 기록하고 pending 비트를 포함한 나머지 플래그들도 모두 지운다.
- 코드 라인 36에서 워커에 지정된 처리 함수를 호출한다. (워크에 지정된 함수)
- 코드 라인 45~52에서 PREEMPT_ACTIVE를 뺀 preempt 카운터가 0이 아니면 즉, preempt가 disable된 경우 에러 메시지를 출력하고 스택을 덤프한다.
kernel/workqueue.c – 4/4
/*
* The following prevents a kworker from hogging CPU on !PREEMPT
* kernels, where a requeueing work item waiting for something to
* happen could deadlock with stop_machine as such work item could
* indefinitely requeue itself while all other CPUs are trapped in
* stop_machine. At the same time, report a quiescent RCU state so
* the same condition doesn't freeze RCU.
*/
cond_resched();
spin_lock_irq(&pool->lock);
/* clear cpu intensive status */
if (unlikely(cpu_intensive))
worker_clr_flags(worker, WORKER_CPU_INTENSIVE);
/* tag the worker for identification in schedule() */
worker->last_func = worker->current_func;
/* we're done with it, release */
hash_del(&worker->hentry);
worker->current_work = NULL;
worker->current_func = NULL;
worker->current_pwq = NULL;
worker->desc_valid = false;
pwq_dec_nr_in_flight(pwq, work_color);
}
- 코드 라인 9에서 리스케줄 요청이 있는 경우 슬립한다.
- 코드 라인 14~15에서 cpu_intensive가 설정된 경우 워커에서 cpu intensive 플래그를 제거한다.
- 코드 라인 18에서 마지막 수행한 함수를 기록해둔다.
- 코드 라인 21에서 busy_hash에서 워커를 제거한다.
- 코드 라인 22~25에서 워커에 설정한 워크 정보를 초기화한다.
- 코드 라인 26에서 워크 컬러에 해당하는 현재 처리 중인 워크 수를 1 감소시킨다.
워크
static 워크 생성
컴파일 타임 워크 생성 및 초기화 매크로
- DECLARE_WORK()
- DECLARE_DELAYED_WORK()
- DECLARE_DEFERABLE_WORK()
DECLARE_WORK()
include/linux/workqueue.h
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f)
컴파일 타임에 워크를 static 하게 선언하고 워크 함수를 지정한다.
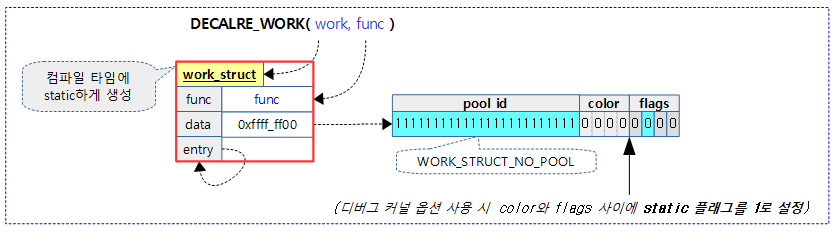
include/linux/workqueue.h
#define __WORK_INITIALIZER(n, f) { \
.data = WORK_DATA_STATIC_INIT(), \
.entry = { &(n).entry, &(n).entry }, \
.func = (f), \
__WORK_INIT_LOCKDEP_MAP(#n, &(n)) \
}
워크 구조체의 주요 멤버를 설정하고 초기화한다.
- data 멤버의 초기 설정 값으로 아직 워크풀이 지정되지 않았고 컴파일 타임에 static하게 생성되었음을 알린다.
- entry 멤버는 아직 워크풀에 등록되지 않았으므로 자기 자신을 가리키게 초기화한다.
- func 멤버는 실행될 함수를 지정한다.
include/linux/workqueue.h
#define WORK_DATA_STATIC_INIT() \
ATOMIC_LONG_INIT(WORK_STRUCT_NO_POOL | WORK_STRUCT_STATIC)
워크의 data 멤버의 초기 설정 값으로 아직 워크풀이 지정되지 않았고 컴파일 타임에 static하게 생성되었음을 알린다.
- WORK_STRUCT_NO_POOL 값은 플래그들이 있는 lsb 몇 비트를 제외하고 pool id에 해당하는 모든 비트가 1로 설정된다.
- WORK_STRUCT_STATIC 플래그는 CONFIG_DEBUG_OBJECT 커널 옵션을 사용하는 경우에만 bit4에 해당하는 플래그가 추가되고 1로 설정된다.
dynamic 워크 생성
동적으로 사용되며 기존 워크 구조체를 초기화한다.
- INIT_WORK()
- INIT_WORK_ONSTACK()
- INIT_DELAYED_WORK()
- INIT_DELAYED_WORK_ONSTACK()
- INIT_DEFERRABLE_WORK()
- INIT_DEFERRABLE_WORK_ONSTACK()
INIT_WORK()
include/linux/workqueue.h
#define INIT_WORK(_work, _func) \
__INIT_WORK((_work), (_func), 0)
요청한 워크에 워크 함수를 지정하고 초기화한다. (런타임에 사용)

include/linux/workqueue.h
#define __INIT_WORK(_work, _func, _onstack) \
do { \
__init_work((_work), _onstack); \
(_work)->data = (atomic_long_t) WORK_DATA_INIT(); \
INIT_LIST_HEAD(&(_work)->entry); \
(_work)->func = (_func); \
} while (0)
#endif
런타임에 요청한 워크에 함수를 지정하고 초기화한다.
- data 멤버에는초기 설정 값으로 아직 워크풀이 지정되지 않았음을 알린다.
- entry 멤버는 아직 워크풀에 등록되지 않았으므로 자기 자신을 가리키게 초기화한다.
- func 멤버는 실행될 함수를 지정한다.
include/linux/workqueue.h
#define WORK_DATA_INIT() ATOMIC_LONG_INIT(WORK_STRUCT_NO_POOL)
워크의 data 멤버 초기값으로 pool id 필드를 WORK_STRUCT_NO_POOL로 설정하여 아직 워크풀이 지정되지 않았음을 알린다.
- WORK_STRUCT_NO_POOL 값은 플래그들이 있는 lsb 몇 비트를 제외하고 pool id에 해당하는 모든 비트가 1로 설정된다.
워크 엔큐
워크(work)를 글로벌(시스템) 워크큐 또는 지정된 워크큐에 엔큐할 수 있다.
- schedule_work()
- 글로벌(시스템) 워크큐에 워크를 엔큐한다.
- queue_work()
- 지정한 워크큐에 워크를 엔큐한다.
지연 워크(delayed work)를 글로벌(시스템) 워크큐 또는 지정된 워크큐에 엔큐할 수 있다. 지연 시간은 틱(jiffies) 단위를 사용한다.
- schedule_delayed_work()
- 글로벌(시스템) 워크큐에 지연 워크를 엔큐한다.
- queue_delayed_work()
- 지정한 워크큐에 워크를 엔큐한다.
위의 4가지 api 명칭의 마지막에 _on을 추가하는 경우 특정 cpu를 지정(bound)하여 동작하게 할 수 있다.
- schedule_work_on()
- queue_work_on()
- schedule_delayed_work_on()
- queue_delayed_work_on()
워크를 글로벌 워크큐에 엔큐
schedule_work()
include/linux/workqueue.h
/** * schedule_work - put work task in global workqueue * @work: job to be done * * Returns %false if @work was already on the kernel-global workqueue and * %true otherwise. * * This puts a job in the kernel-global workqueue if it was not already * queued and leaves it in the same position on the kernel-global * workqueue otherwise. */
static inline bool schedule_work(struct work_struct *work)
{
return queue_work(system_wq, work);
}
워크를 시스템 워크큐에 엔큐한다.
워크를 지정한 워크큐에 엔큐
queue_work()
include/linux/workqueue.h
/** * queue_work - queue work on a workqueue * @wq: workqueue to use * @work: work to queue * * Returns %false if @work was already on a queue, %true otherwise. * * We queue the work to the CPU on which it was submitted, but if the CPU dies * it can be processed by another CPU. */
static inline bool queue_work(struct workqueue_struct *wq,
struct work_struct *work)
{
return queue_work_on(WORK_CPU_UNBOUND, wq, work);
}
워크큐 @wq에 워크를 엔큐한다. 가능하면 현재 cpu에 작업을 시키도록 요청한다. 이미 워크큐에 등록되어 있는 상태이면 실패를 반환한다.
queue_work_on()
kernel/workqueue.c
/** * queue_work_on - queue work on specific cpu * @cpu: CPU number to execute work on * @wq: workqueue to use * @work: work to queue * * We queue the work to a specific CPU, the caller must ensure it * can't go away. * * Return: %false if @work was already on a queue, %true otherwise. */
bool queue_work_on(int cpu, struct workqueue_struct *wq,
struct work_struct *work)
{
bool ret = false;
unsigned long flags;
local_irq_save(flags);
if (!test_and_set_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))) {
__queue_work(cpu, wq, work);
ret = true;
}
local_irq_restore(flags);
return ret;
}
EXPORT_SYMBOL(queue_work_on);
워크가 이미 등록된 상태가 아니면 워크큐에 워크를 엔큐한다. 가능하면 현재 cpu에 작업을 시키도록 요청한다. 이미 워크큐에 등록되어 있는 상태이면 실패를 반환한다.
워크에 pending 플래그를 보고 워크가 이미 워크큐에 엔큐되어 있다는 것을 알 수 있다.
__queue_work()
워크를 워크큐에 엔큐한다.
kernel/workqueue.c – 1/2
static void __queue_work(int cpu, struct workqueue_struct *wq,
struct work_struct *work)
{
struct pool_workqueue *pwq;
struct worker_pool *last_pool;
struct list_head *worklist;
unsigned int work_flags;
unsigned int req_cpu = cpu;
/*
* While a work item is PENDING && off queue, a task trying to
* steal the PENDING will busy-loop waiting for it to either get
* queued or lose PENDING. Grabbing PENDING and queueing should
* happen with IRQ disabled.
*/
lockdep_assert_irqs_disabled();
debug_work_activate(work);
/* if draining, only works from the same workqueue are allowed */
if (unlikely(wq->flags & __WQ_DRAINING) &&
WARN_ON_ONCE(!is_chained_work(wq)))
return;
rcu_read_lock()
retry:
if (req_cpu == WORK_CPU_UNBOUND)
cpu = wq_select_unbound_cpu(raw_smp_processor_id());
/* pwq which will be used unless @work is executing elsewhere */
if (!(wq->flags & WQ_UNBOUND))
pwq = per_cpu_ptr(wq->cpu_pwqs, cpu);
else
pwq = unbound_pwq_by_node(wq, cpu_to_node(cpu));
/*
* If @work was previously on a different pool, it might still be
* running there, in which case the work needs to be queued on that
* pool to guarantee non-reentrancy.
*/
last_pool = get_work_pool(work);
if (last_pool && last_pool != pwq->pool) {
struct worker *worker;
spin_lock(&last_pool->lock);
worker = find_worker_executing_work(last_pool, work);
if (worker && worker->current_pwq->wq == wq) {
pwq = worker->current_pwq;
} else {
/* meh... not running there, queue here */
spin_unlock(&last_pool->lock);
spin_lock(&pwq->pool->lock);
}
} else {
spin_lock(&pwq->pool->lock);
}
코드 라인 21~23에서 draining 플래그가 있는 워크큐이면서 워크큐의 워커가 현재 실행중이 아니면 경고 메시지를 출력하고 함수를 빠져나간다.
코드 라인 26~27에서 WORK_CPU_UNBOUND cpu로 요청한 경우 일단 현재 cpu로 설정한다.
코드 라인 30~33에서 unbound 워크큐가 아닌 경우 요청 cpu에 대한 풀워크큐를 알아온다. unbound 워크큐인 경우 현재 cpu 노드의 풀워크큐를 알아온다.
- wq->cpu_pwqs:
- cpu 바운드 워크큐인 경우 cpu별로 사용
- wq->numa_pwq_tbl[node]:
- unbound 워크큐이면 노드별로 사용
코드 라인 40~46에서 워크가 마지막으로 동작했었던 워커풀이 조금전에 알아온 풀워크큐가 가리키는 워커풀과 다른 경우 워크가 동작했었던 마지막 풀에서 요청한 워크가 현재 동작중인 워커를 알아온다.
코드 라인 48~54에서 워커가 현재 동작중인 풀워크큐의 워커인 경우 워커에서 현재 동작하는 풀워크큐를 그대로 사용한다.
- 워크의 재진입을 허용하지 않게 하는 것을 보장하기 위해 기존 워크가 수행되었던 워커의 풀워크큐를 그대로 사용한다.
- 워크가 이미 동작 중인 경우 다른 cpu를 사용하는 워커풀로 전달되지 않도록 현재 동작 중인 워커가 있는 워커풀로 워크를 보낸다. 동일 워크들은 절대 동시 처리되지 않게 한다.
kernel/workqueue.c – 2/2
/*
* pwq is determined and locked. For unbound pools, we could have
* raced with pwq release and it could already be dead. If its
* refcnt is zero, repeat pwq selection. Note that pwqs never die
* without another pwq replacing it in the numa_pwq_tbl or while
* work items are executing on it, so the retrying is guaranteed to
* make forward-progress.
*/
if (unlikely(!pwq->refcnt)) {
if (wq->flags & WQ_UNBOUND) {
spin_unlock(&pwq->pool->lock);
cpu_relax();
goto retry;
}
/* oops */
WARN_ONCE(true, "workqueue: per-cpu pwq for %s on cpu%d has 0 refcnt",
wq->name, cpu);
}
/* pwq determined, queue */
trace_workqueue_queue_work(req_cpu, pwq, work);
if (WARN_ON(!list_empty(&work->entry)))
goto out;
pwq->nr_in_flight[pwq->work_color]++;
work_flags = work_color_to_flags(pwq->work_color);
if (likely(pwq->nr_active < pwq->max_active)) {
trace_workqueue_activate_work(work);
pwq->nr_active++;
worklist = &pwq->pool->worklist;
if (list_empty(worklist))
pwq->pool->watchdog_ts = jiffies;
} else {
work_flags |= WORK_STRUCT_DELAYED;
worklist = &pwq->delayed_works;
}
insert_work(pwq, work, worklist, work_flags);
out:
spin_unlock(&pwq->pool->lock);
rcu_read_unlock();
}
코드 라인 9~18에서 풀워크큐의 참조 카운터가 0인 경우 경고 메시지를 출력한다. 단 unbound 워크큐인경우 retry 한다.
- 풀워크큐가 race 상황에서 release되었을 수도 있다. 그런 경우 다시 풀워크큐를 알아온다.
코드 라인 23~24에서 워크가 아무 곳에도 등록되지 않은 경우 함수를 빠져나간다.
코드 라인 26~27에서 워크 컬러에 해당하는 처리중인 워크 수를 증가시키고 워크 컬러 값을 플래그 값으로 변환한다.
코드 라인 29~40에서 풀워크큐에 등록된 워크의 수가 최대 제한에 걸리지 않았으면 워커 수 카운터인 nr_active를 1 증가시키고 풀워크큐가 가리키는 워커풀의 워크리스트에 워크를 추가한다. 만일 최대 제한을 초과한 경우 워크에 delay 플래그를 추가한 후 풀워크큐의 delayed_works 리스트에 추가한다.
- 최대 제한 수는 512이며 unbound 워크큐인 경우 512와 cpu*4 중 큰 수를 사용한다.
insert_work()
kernel/workqueue.c
/** * insert_work - insert a work into a pool * @pwq: pwq @work belongs to * @work: work to insert * @head: insertion point * @extra_flags: extra WORK_STRUCT_* flags to set * * Insert @work which belongs to @pwq after @head. @extra_flags is or'd to * work_struct flags. * * CONTEXT: * spin_lock_irq(pool->lock). */
static void insert_work(struct pool_workqueue *pwq, struct work_struct *work,
struct list_head *head, unsigned int extra_flags)
{
struct worker_pool *pool = pwq->pool;
/* we own @work, set data and link */
set_work_pwq(work, pwq, extra_flags);
list_add_tail(&work->entry, head);
get_pwq(pwq);
/*
* Ensure either wq_worker_sleeping() sees the above
* list_add_tail() or we see zero nr_running to avoid workers lying
* around lazily while there are works to be processed.
*/
smp_mb();
if (__need_more_worker(pool))
wake_up_worker(pool);
}
요청한 리스트에 워크를 추가한다.
코드 라인 7에서 워크 데이터가 풀워크큐를 가리키게 하고 요청한 플래그들을 추가한다.
코드 라인 8에서 요청한 리스트의 후미에 워크를 추가한다.
코드 라인 9에서 풀워크큐의 참조카운터를 1 증가시킨다.
코드 라인 18~19에서 워커풀에서 동작중인 워커가 없는 경우 idle 워커를 깨운다.
set_work_pwq()
kernel/workqueue.c
static void set_work_pwq(struct work_struct *work, struct pool_workqueue *pwq,
unsigned long extra_flags)
{
set_work_data(work, (unsigned long)pwq,
WORK_STRUCT_PENDING | WORK_STRUCT_PWQ | extra_flags);
}
워크에 풀워크큐를 지정하고 요청한 플래그 이외에도 기본적으로 WORK_STRUCT_PENDING 및 WORK_STRUCT_PWQ 를 추가한다.
set_work_data()
kernel/workqueue.c
/* * While queued, %WORK_STRUCT_PWQ is set and non flag bits of a work's data * contain the pointer to the queued pwq. Once execution starts, the flag * is cleared and the high bits contain OFFQ flags and pool ID. * * set_work_pwq(), set_work_pool_and_clear_pending(), mark_work_canceling() * and clear_work_data() can be used to set the pwq, pool or clear * work->data. These functions should only be called while the work is * owned - ie. while the PENDING bit is set. * * get_work_pool() and get_work_pwq() can be used to obtain the pool or pwq * corresponding to a work. Pool is available once the work has been * queued anywhere after initialization until it is sync canceled. pwq is * available only while the work item is queued. * * %WORK_OFFQ_CANCELING is used to mark a work item which is being * canceled. While being canceled, a work item may have its PENDING set * but stay off timer and worklist for arbitrarily long and nobody should * try to steal the PENDING bit. */
static inline void set_work_data(struct work_struct *work, unsigned long data,
unsigned long flags)
{
WARN_ON_ONCE(!work_pending(work));
atomic_long_set(&work->data, data | flags | work_static(work));
}
워크에 data(풀워크큐 또는 pool id)와 플래그를 더해 설정한다.
기타 API
- flush_workqueue()
- 워크큐에 엔큐된 워크를 모두 처리하여 비운다.
- flush_schedule_work()
- 워크큐에 엔큐된 지연 워크를 모두 처리하여 비운다.
- cancel_work_sync()
- 워크큐에 엔큐된 워크를 취소하고 완료될 때까지 기다린다.
- cancel_delayed_work()
- 워크큐에 엔큐된 지연 워크를 취소한다.
- cancel_delayed_work_sync()
- 워크큐에 엔큐된 지연 워크를 취소하고 완료될 때까지 기다린다.
- destroy_workqueue()
- 생성했던 워크큐를 소멸시킨다.
구조체
workqueue_struct 구조체
kernel/workqueue.c
/* * The externally visible workqueue. It relays the issued work items to * the appropriate worker_pool through its pool_workqueues. */
struct workqueue_struct {
struct list_head pwqs; /* WR: all pwqs of this wq */
struct list_head list; /* PL: list of all workqueues */
struct mutex mutex; /* protects this wq */
int work_color; /* WQ: current work color */
int flush_color; /* WQ: current flush color */
atomic_t nr_pwqs_to_flush; /* flush in progress */
struct wq_flusher *first_flusher; /* WQ: first flusher */
struct list_head flusher_queue; /* WQ: flush waiters */
struct list_head flusher_overflow; /* WQ: flush overflow list */
struct list_head maydays; /* MD: pwqs requesting rescue */
struct worker *rescuer; /* I: rescue worker */
int nr_drainers; /* WQ: drain in progress */
int saved_max_active; /* WQ: saved pwq max_active */
struct workqueue_attrs *unbound_attrs; /* PW: only for unbound wqs */
struct pool_workqueue *dfl_pwq; /* PW: only for unbound wqs */
#ifdef CONFIG_SYSFS
struct wq_device *wq_dev; /* I: for sysfs interface */
#endif
#ifdef CONFIG_LOCKDEP
char *lock_name;
struct lock_class_key key;
struct lockdep_map lockdep_map;
#endif
char name[WQ_NAME_LEN]; /* I: workqueue name */
/*
* Destruction of workqueue_struct is RCU protected to allow walking
* the workqueues list without grabbing wq_pool_mutex.
* This is used to dump all workqueues from sysrq.
*/
struct rcu_head rcu;
/* hot fields used during command issue, aligned to cacheline */
unsigned int flags ____cacheline_aligned; /* WQ: WQ_* flags */
struct pool_workqueue __percpu *cpu_pwqs; /* I: per-cpu pwqs */
struct pool_workqueue __rcu *numa_pwq_tbl[]; /* PWR: unbound pwqs indexed by node */
};
pwqs
- 워크큐에 소속된 풀워크큐들
list
- 모든 워크큐가 전역 workqueues 리스트에 연결될 떄 사용하는 list 노드이다.
work_color
- 현재 워크 컬러
flush_color
- 현재 플러시 컬러
nr_pwqs_to_flush
- 플러시될 풀워크큐 수로 플러시가 진행중일 때 사용된다.
*first_flusher
- 처음 플러셔(플러시 요청)
flusher_queue
- 플러셔 리스트에 플러시 요청이 쌓이며 하나씩 처리하기 위해 first_flusher로 옮긴다.
- 플러시가 완료되면 first_flusher는 null이 되고 flusher_queue 리스트도 비게된다.
flusher_overflow
- 플러시 오버플로 리스트로 플러시 컬러 공간이 부족할 때 플러시 요청을 이 리스트에 추가한다.
maydays
- 구조 요청한 풀워크큐 리스트
nr_drainers
- 진행중인 drainer 수로 워크큐를 비워달라고 요청받으면 1 증가되고 드레이닝이 시작하고 완료되면 1 감소된다.
saved_max_active
- 등록할 수 있는 최대 active 워크 수로 이 수를 초과하는 워크의 경우 워커풀로 배포하지 않고 풀워크큐의 delayed_works 리스트에서 대기하게 한다.
*unbound_attrs
- 언바운드 워크큐 속성
*dfl_pwq
- 디폴트 언바운드 풀워크큐를 가리키며 cpu on/off 시 numa_pwq_tbl[]의 이용이 힘들 때 잠시 fall-back용으로 사용한다.
wq_dev
- sysfs 인터페이스
name[]
- 워크큐명
rcu
- 워크큐가 제거될 때 rcu에 의해 보호되어 제거된다.
flags
- 플래그들
*cpu_pwqs
- per-cpu 풀워크큐들
*numa_pwq_tbl[]
- 노드별 언바운드 풀워크큐
workqueue_attrs 구조체
include/linux/workqueue.h
/** * struct workqueue_attrs - A struct for workqueue attributes. * * This can be used to change attributes of an unbound workqueue. */
struct workqueue_attrs {
/**
* @nice: nice level
*/
int nice;
/**
* @cpumask: allowed CPUs
*/
cpumask_var_t cpumask;
/**
* @no_numa: disable NUMA affinity
*
* Unlike other fields, ``no_numa`` isn't a property of a worker_pool. It
* only modifies how :c:func:`apply_workqueue_attrs` select pools and thus
* doesn't participate in pool hash calculations or equality comparisons.
*/
bool no_numa;
};
nice
- nice 우선순위
cpumask
- 허락된 cpu들
no_numa
- NUMA 노드 정보를 disable
wq_flusher 구조체
kernel/workqueue.c
/* * Structure used to wait for workqueue flush. */
struct wq_flusher {
struct list_head list; /* WQ: list of flushers */
int flush_color; /* WQ: flush color waiting for */
struct completion done; /* flush completion */
};
list
- 플러셔(플러시 요청)를 플러셔 리스트에 추가할 때 사용되는 연결 노드
flush_color
- 플러시 컬러
done
- 플러시 완료(completion) 대기를 위해 사용
pool_workqueue 구조체
kernel/workqueue.c
/* * The per-pool workqueue. While queued, the lower WORK_STRUCT_FLAG_BITS * of work_struct->data are used for flags and the remaining high bits * point to the pwq; thus, pwqs need to be aligned at two's power of the * number of flag bits. */
struct pool_workqueue {
struct worker_pool *pool; /* I: the associated pool */
struct workqueue_struct *wq; /* I: the owning workqueue */
int work_color; /* L: current color */
int flush_color; /* L: flushing color */
int refcnt; /* L: reference count */
int nr_in_flight[WORK_NR_COLORS];
/* L: nr of in_flight works */
int nr_active; /* L: nr of active works */
int max_active; /* L: max active works */
struct list_head delayed_works; /* L: delayed works */
struct list_head pwqs_node; /* WR: node on wq->pwqs */
struct list_head mayday_node; /* MD: node on wq->maydays */
/*
* Release of unbound pwq is punted to system_wq. See put_pwq()
* and pwq_unbound_release_workfn() for details. pool_workqueue
* itself is also RCU protected so that the first pwq can be
* determined without grabbing wq->mutex.
*/
struct work_struct unbound_release_work;
struct rcu_head rcu;
} __aligned(1 << WORK_STRUCT_FLAG_BITS);
*pool
- 연결된 워커풀
*wq
- 워크큐
work_color
- 워크 컬러로 새 워크마다 이 컬러의 워크 컬러를 사용한다.
- 플러시 요청이 발생한 경우 다음 워크 컬러를 선택한다. (0 ~ 14이내에서 순환 증가)
flush_color
- 플러시 컬러로 플러시 요청이 있는 경우 현재 사용한 워크 컬러를 지정한다. 그리고 이 플러시 컬러에 해당하는 워크들의 작업이 끝날때까지 기다린다. (플러시)
refcnt
- 참조카운터
nr_in_flight[]
- 컬러별 현재 워커가 처리중인 워크 수를 담는다.
nr_active
- active 워크 수
- 지연된 워크는 포함되지 않는다.
max_active
- 동시 처리 제한(최대 active 워크 수)
delayed_works
- 동시 처리 제한(max_active)을 초과한 워크 요청이 대기하는 리스트이다.
- suspend PM 기능이 동작하는 경우 모든 인입되는 워크도 이 곳에서 대기된다.
pwqs_node
- 노드별 풀워크큐
mayday_node
- 워크큐의 maydays 리스트에 추가될 때 연결되는 리스트 노드
unbound_release_work
- 풀워크큐가 내장하여 사용하는 워크이다. 언바운드 워커풀을 제거할 때 사용한다.
- pwq_unbound_release_workfn() 함수를 호출하여 워커풀을 제거하는데 모든 워커풀이 제거된 워크큐도 함께 제거된다.
rcu
- 풀워크큐 구조체를 rcu 방식으로 풀워크큐 slab 캐시로 free할 때 사용하는 rcu 노드이다.
worker_pool 구조체
kernel/workqueue.c
/* * Structure fields follow one of the following exclusion rules. * * I: Modifiable by initialization/destruction paths and read-only for * everyone else. * * P: Preemption protected. Disabling preemption is enough and should * only be modified and accessed from the local cpu. * * L: pool->lock protected. Access with pool->lock held. * * X: During normal operation, modification requires pool->lock and should * be done only from local cpu. Either disabling preemption on local * cpu or grabbing pool->lock is enough for read access. If * POOL_DISASSOCIATED is set, it's identical to L. * * A: pool->attach_mutex protected. * * PL: wq_pool_mutex protected. * * PR: wq_pool_mutex protected for writes. RCU protected for reads. * * PW: wq_pool_mutex and wq->mutex protected for writes. Either for reads. * * PWR: wq_pool_mutex and wq->mutex protected for writes. Either or * RCU for reads. * * WQ: wq->mutex protected. * * WR: wq->mutex protected for writes. RCU protected for reads. * * MD: wq_mayday_lock protected. */ /* struct worker is defined in workqueue_internal.h */
struct worker_pool {
spinlock_t lock; /* the pool lock */
int cpu; /* I: the associated cpu */
int node; /* I: the associated node ID */
int id; /* I: pool ID */
unsigned int flags; /* X: flags */
unsigned long watchdog_ts; /* L: watchdog timestamp */
struct list_head worklist; /* L: list of pending works */
int nr_workers; /* L: total number of workers */
int nr_idle; /* L: currently idle workers */
struct list_head idle_list; /* X: list of idle workers */
struct timer_list idle_timer; /* L: worker idle timeout */
struct timer_list mayday_timer; /* L: SOS timer for workers */
/* a workers is either on busy_hash or idle_list, or the manager */
DECLARE_HASHTABLE(busy_hash, BUSY_WORKER_HASH_ORDER);
/* L: hash of busy workers */
struct worker *manager; /* L: purely informational */
struct list_head workers; /* A: attached workers */
struct completion *detach_completion; /* all workers detached */
struct ida worker_ida; /* worker IDs for task name */
struct workqueue_attrs *attrs; /* I: worker attributes */
struct hlist_node hash_node; /* PL: unbound_pool_hash node */
int refcnt; /* PL: refcnt for unbound pools */
/*
* The current concurrency level. As it's likely to be accessed
* from other CPUs during try_to_wake_up(), put it in a separate
* cacheline.
*/
atomic_t nr_running ____cacheline_aligned_in_smp;
/*
* Destruction of pool is RCU protected to allow dereferences
* from get_work_pool().
*/
struct rcu_head rcu;
} ____cacheline_aligned_in_smp;
cpu
- cpu 번호
node
- 노드번호
id
- 워커풀 id
flags
- 워커풀의 플래그
watchdog_ts
- 워치독 타임스탬프
worklist
- 처리할 워크가 담기는 리스트
nr_workers
- 워커풀에 등록된 워커 수
nr_idle
- 워커풀에 대기중인 워커 수
idle_list
- idle 워커 리스트
idle_timer
- idle 타이머
- 5분 간격으로 너무 많이 대기중인 워커들을 소멸시킨다.
mayday_timer
- mayday 타이머
- 0.1초 간격으로 워크들의 데드락 상황을 파악하여 rescuer_thread를 깨운다.
busy_hash[]
- busy 워커들이 있는 해시 리스트
*manager
workers
- 연결된 워커들 리스트
*detach_completion
- 모든 워커들을 detach할 때 사용
worker_ida
- 워커들 id를 발급하는 IDA 트리
*attrs
- 워크큐 속성(nice 및 cpumask)
- 언바운드 워크큐는 같은 속성을 사용하는 경우 워커풀을 공유하여 사용한다.
hash_node
- 언바운드 풀 해시 노드
refcnt
- 참조 카운터
nr_running
- 워크를 처리중인 워커 수
- 다른 cpu들에서 try_to_wake_up() 함수를 통해 atomic하게 접근되는 변수로 이용되고 캐시 라인 바이트 수만큼 정렬되어 사용된다.
rcu
- 워커풀을 소멸시킬 때 rcu를 사용하여 수행한다.
work_struct 구조체
include/linux/workqueue.h
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
data
- 풀워크큐 주소 또는 pool id가 저장되고 하위 플래그들이 구성된다. (본문참고)
entry
- 리스트에 연결될 때 사용하는 리스트 노드
func
- 작업 호출 함수
delayed_work 구조체
include/linux/workqueue.h
struct delayed_work {
struct work_struct work;
struct timer_list timer;
/* target workqueue and CPU ->timer uses to queue ->work */
struct workqueue_struct *wq;
int cpu;
};
work
- 워크 구조체가 포함된다.
timer
- 지연 타이머
*wq
- 타이머가 만료되어 워크가 등록될 워크큐를 가리킨다.
cpu
- 워크가 동작할 cpu 지정
참고
- Interrupts -1- (Interrupt Controller) | 문c
- Interrupts -2- (irq chip) | 문c
- Interrupts -3- (irq domain) | 문c
- Interrupts -4- (Top-Half & Bottom-Half) | 문c
- Interrupts -5- (Softirq) | 문c
- Interrupts -6- (IPI Cross-call) | 문c
- Interrupts -7- (Workqueue 1) | 문c
- Interrupts -8- (Workqueue 2) | 문c – 현재 글
- Interrupts -9- (GIC v3 Driver) | 문c
- Interrupts -10- (irq partition) | 문c
- Interrupts -11- (RPI2 IC Driver) | 문c
- Interrupts -12- (irq desc) | 문c
- Driver porting: the workqueue interface. | LWN.net
- [Linux] concurrency managed workqueue (cmwq) | F/OSS
- 지연 가능 함수, 커널 태스크릿 및 작업 큐 (BOTTOM HALF) | 신불사
- Multitasking in the Linux Kernel. Workqueues | Vita Loginova
- Details of the workqueue interface (2002) | LWN.net
안녕하세요! 항상 감사드립니다.
16차 이파란입니다.
아래 iamroot 게시판 말씀해주신 내용에 궁금한 점이 생겼는데요!
http://www.iamroot.org/xe/index.php?document_srl=211957&mid=Programming#4
1) 자동으로 irq-disable 상태로 진입
2) irq-handler 처리
3) irq-enable
4) hard-irq에서 동작하는 softirq 처리
위와 같이 2)번 구간에서는 irq-handler 처리가 완료될 때까지 irq nesting을 하지 않습니다.
다만 4)번 구간에서는 irq를 enable하므로 irq-nesting이 가능합니다.
[질문 1] 드라이버 소스코드에서 실질적으로 irq-nesting 이 가능한 구간 예시
$ pinout
Raspberry Pi 400 Rev 1.0
Revision : c03130
SoC : BCM2711
$ ethtool -i eth0
driver: bcmgenet
version: 5.15.32-v8+
(3) irq-enable
// ~ irq-nesting이 가능 구간 ~ //
(4) hard-irq에서 동작하는 softirq 처리
라즈베리파이 400 보드의 이더넷 드라이버 bcmgenet 기준으로 예를 들면
drivers/net/ethernet/broadcom/genet/bcmgenet.c 소스 코드 안에
irqreturn_t bcmgenet_isr0(int irq, void *dev_id) 함수의 해당 라인에서 irq-nesting 이 가능할까요?
https://github.com/raspberrypi/linux/blob/6f921e98008589258f97243fb6658d09750f0a2f/drivers/net/ethernet/broadcom/genet/bcmgenet.c#L3190
(3) spin_unlock_irqrestore(); // 인터럽트 라인 활성화
// 여기서 irq nesting 이 가능할까요?
(4) schedule_work(); // hard-irq 코드에서 워크큐로 큐잉
[질문 2] 네트워크 드라이버는 보통 워크큐로 Bottom Half,
하나는 hardirq 로 Top Half 로 처리하는지 궁금합니다!
irqreturn_t 리턴 타입의 핸들러 함수는 스터디하면서
봤던 드라이버 하나에 보통 1개만 있었습니다.
하지만 bcmgenet 드라이버는 request_irq 2개를 등록하고,
2개가 다른 방식의 irq 기법을 사용하는점을 확인했습니다.
1. bcmgenet_isr0: handle Rx and Tx default queues + other stuff
(1) request_irq 등록
https://github.com/raspberrypi/linux/blob/6f921e98008589258f97243fb6658d09750f0a2f/drivers/net/ethernet/broadcom/genet/bcmgenet.c#L3365
(2) bcmgenet_isr0 함수 (Bottom Half – 워크큐)
https://github.com/raspberrypi/linux/blob/6f921e98008589258f97243fb6658d09750f0a2f/drivers/net/ethernet/broadcom/genet/bcmgenet.c#L3141
2. bcmgenet_isr1: handle Rx and Tx priority queues
(1) request_irq 등록
https://github.com/raspberrypi/linux/blob/6f921e98008589258f97243fb6658d09750f0a2f/drivers/net/ethernet/broadcom/genet/bcmgenet.c#L3372
(2) bcmgenet_isr1 함수 (Top Half)
https://github.com/raspberrypi/linux/blob/6f921e98008589258f97243fb6658d09750f0a2f/drivers/net/ethernet/broadcom/genet/bcmgenet.c#L3093
bcmgenet 드라이버처럼 네트워크 드라이버에서는
하나는 워크큐로 Bottom Half,
하나는 hardirq 로 Top Half 로 처리하는 전형적인 예시인지 궁금합니다!
아래 URL에서 답변을 대신하였습니다.
http://www.iamroot.org/xe/index.php?document_srl=211957&mid=Programming&rnd=218099#comment_218099
감사합니다! 확인했습니다~
네트워크 드라이버가 어떻게 동작하는지 궁금했었는데,
제가 좀 더 공부하려면 어떤 항목을 봐야하는지 많은 도움을 얻었습니다~
항상 감사드립니다~! 좋은 하루되세요~
이파란 드림.
즐거운 공부되시길 바라며, 오늘도 행복한 하루되세요. ^^