<kernel v5.4>
Interrupts -7- (Workqueue 1)
워크큐는 인터럽트 처리 중 bottom-half 처리를 위해 만들어졌다. Device의 top-half 부분의 인터럽트 처리를 수행한 후 bottom-half 부분의 작업을 워크큐에 의뢰하면 워커스레드가 이를 처리한다.
- 워크큐의 우선 순위는일반 태스크와 스케줄 경쟁하도록 디폴트 우선 순위인 nice 를 사용한다.
- 단 highpri 워크큐는 softirq와 같은 nice -20의 우선 순위를 사용하여 일반 태스크들 중 가장 우선 순위가 높게 처리된다.
- softirq 및 tasklet 같은 IRQ용 bottom-half 서브 시스템과는 다르게 처리 루틴에서 sleep 가능하다.
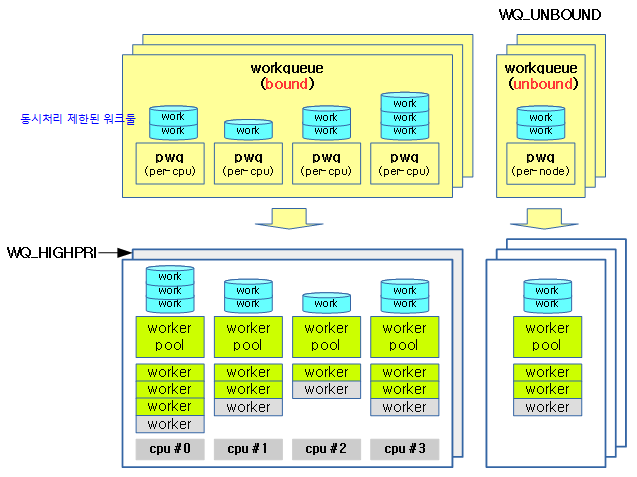
다음 그림은 인터럽트 처리를 워크큐에 의뢰하여 워커 스레드가 해당 work를 처리하는 과정을 보여준다.

워크큐의 구성원들 및 특징에 대해 알아본다.
- 워크큐
- 시스템이 기본 생성하는 시스템 워크큐는 초기 커널에서는 bound 및 unbound 2개의 시스템 워크큐가 있었고, 점점 늘어나 커널 v3.11 ~ v4.12 현재까지 7개를 사용하고 있다.
- 시스템 워크큐의 특징
- system_wq
- Multi-CPU, multi-threaded용으로 오래 걸리지 않는 작업에 사용한다.
- system_highpri_wq
- 가장 높은 nice 우선 순위 -20으로 워커들이 워크를 처리한다.
- system_long_wq
- system_wq과 유사한 환경에서 조금 더 오래 걸리는 작업에 사용한다.
- system_unbound_wq
- 특정 cpu에 연결되지 않고 동일한 작업이 2개 이상 동시 처리하지 않는 성격의 작업에 사용한다.
- 한 번에 하나씩만 처리되고, max_active 제한까지 스레드 수가 커질 수 있어서 요청한 작업은 즉각 동작한다.
- system_freezable
- system_wq과 유사한 환경이지만 suspend되는 경우 freeze 가능한 작업에 사용한다.
- 작업 중 suspend 요청이 오면 다른 워크큐는 마저 다 처리하지만 이 워크큐는 그대로 freeze하고 복구(resume)한 후에 동작을 계속한다.
- system_power_efficient_wq
- 절전 목적으로 성능을 약간 희생하여도 되는 작업에 사용한다.
- system_freezable_power_efficient_wq
- 절전 목적으로 성능을 약간 희생하여도 되고 suspend 시 freeze되어도 되는 작업에 사용한다.
- system_wq
- 워크큐는 1개 이상의 풀별 워크큐(pwq)를 지정하는데 워크큐의 성격에따라 연결되는 워커풀 수가 결정된다.
- cpu bound된 워크큐는 cpu 수 만큼
- unbound된 워크큐는 UMA 시스템에서 1개
- unbound된 워크큐는 NUMA 시스템에서 노드 수만큼
- …
- 풀별 워크큐(pwq)
- 지연된 작업들이 대기되어 관리된다.
- 기존 cwq가 풀워크큐로 이름이 변경되었다.
- 풀워크큐는 1개 이상의 워커풀을 지정하여 사용한다.
- 워커풀
- 커널 부트업 시에 생성되는 바운드용 워커풀은 nice=0, nice=-20(highpri)용으로 나누어 cpu 수 만큼 생성하여 사용한다.
- 바운드용 워크큐들은 highpri 여부 및 cpu 번호로 워커풀을 공유하여 사용한다.
- 언바운드용 워커풀은 워크큐의 속성(nice 및 cpumask)에 따라 필요 시 마다 생성된다.
- 언바운드용 워크큐들은 워크큐 속성이 같은 경우 워커풀을 공유하여 사용한다.
- 커널 부트업 시에 생성되는 바운드용 워커풀은 nice=0, nice=-20(highpri)용으로 나누어 cpu 수 만큼 생성하여 사용한다.
- 워커
- idle 워커 리스트와 busy 워커 리스트로 나뉘어 관리하는데 busy 워커 리스트는 hash로 관리한다.
- idle 상태에 있다가 워크가 주어지면 워커스레드를 깨워 워크를 처리한다.
- 워커 스레드들은 각 워커풀에서 초기 idle 워커가 1개 생성되고 필요에 따라 dynamic 하게 생성되고 소멸된다.
- 워커 스레드의 소멸 주기는 약 5분에 한 번씩 busy 워커의 약 25%가 유지되도록 한다. (최하 2개의 idle 워커를 남겨둔다.)
- 워크
- bottom-half 처리할 함수가 워크큐에 등록된 후 적절한 워커스레드에 전달되어 워크에 등록된 함수가 수행된다.
- delayed 워크인 경우 곧바로 워커풀에 전달하여 처리하지 않고 타이머를 먼저 동작시킨다. 타이머가 만료되면 그 때 워크큐에 등록한다.
- 동일 워크를 반복하여 워크큐에 등록하더라도 동시에 처리되지 않도록 보장한다. (max_active가 1이 아니더라도)
- 워크 큐에 여러 개의 다른 워크들이 등록되는 경우 cpu별 max_active 만큼 동시 처리된다.
다음 그림은 워크큐와 관련된 컴포넌트간의 관계를 보여준다.
History
리눅스 workqueue 서브시스템은 interrupt bottom-half 처리를 위해 준비되었고 다음과 같이 진행되어 왔다.
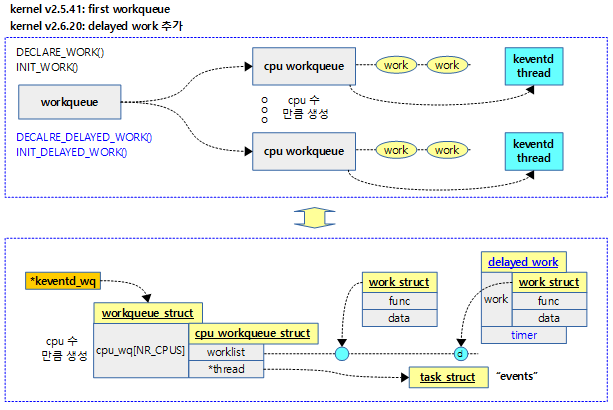
- 커널 v2.5.41에서 처음 소개
- 커널 v2.6.20에서 delayed work API가 추가
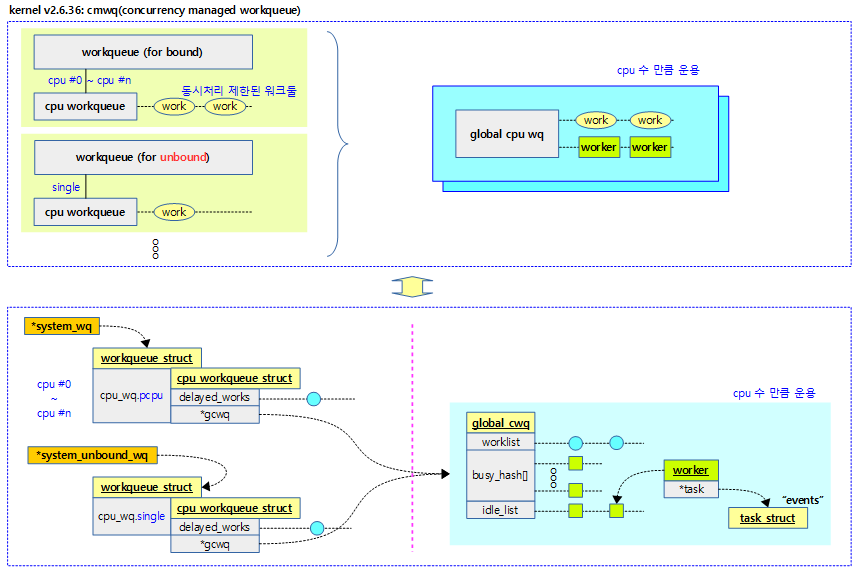
- 커널 v2.6.36에서 오늘날 사용되는 형태의 CMWQ(concurrency managed workqueue)가 소개
- 커널 v3.8에서 워커풀 추가
- 커널 v3.9에서 cwq 등이 없어지고 pool workqueue로 변경
다음 그림은 처음 소개된 워크큐의 모습이다.
다음 그림은 CMWQ(Concurrency Managed WorkQueue) 방식으로 구현이 변경되었을 때의 모습이다.
다음 그림은 워커풀이 추가되었을 때의 모습이다.
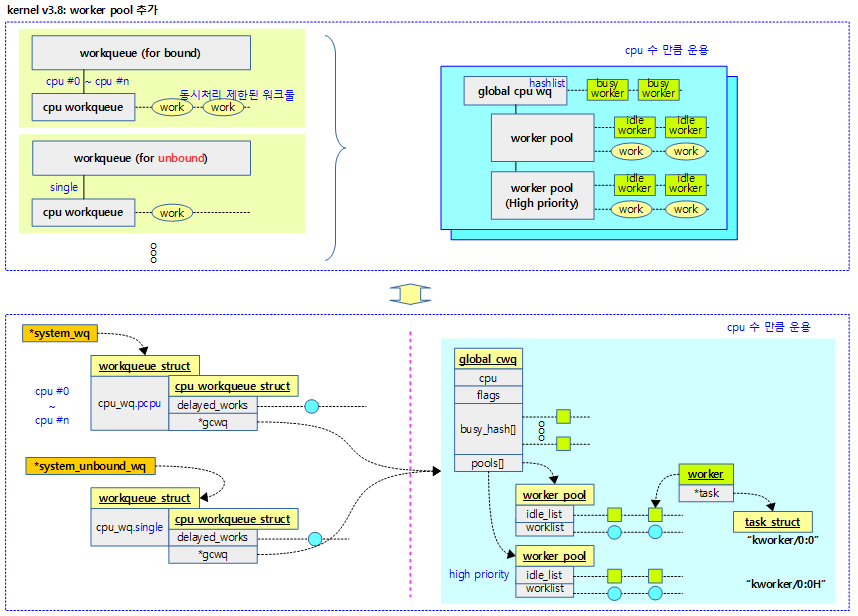
다음 그림은 최근 커널에서 워크큐가 구현된 모습을 보여준다.
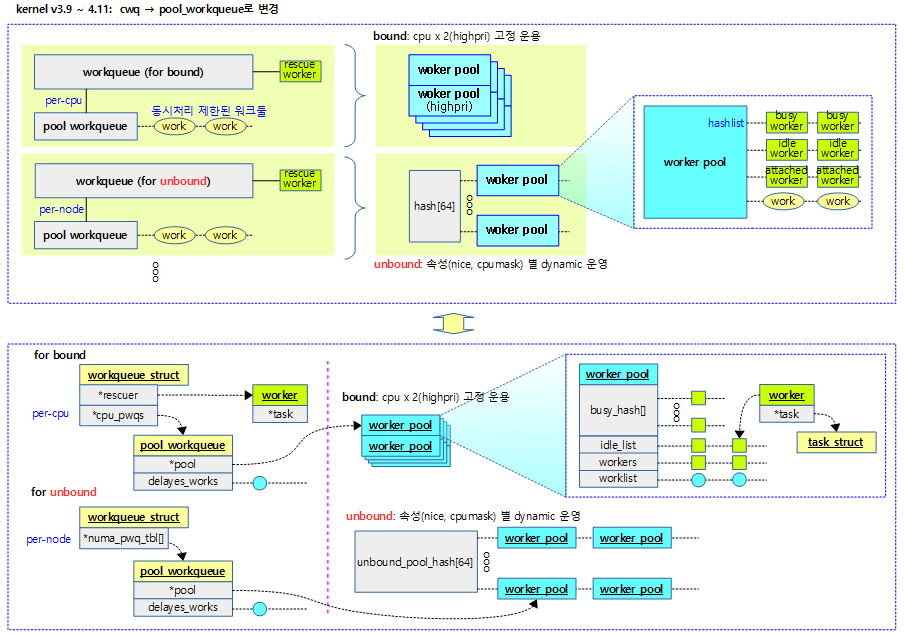
워크큐별 플래그
워크큐에서 사용하는 플래그들을 알아본다.
- WQ_UNBOUND
- cpu를 배정하지 않고 현재 cpu에 워크를 배정하게 한다.
- cpu별로 풀워크큐를 만들지 않고 누마 노드별 풀워크큐를 만든다.
- WQ_FREEZABLE
- 시스템이 절전을 위해 suspend 상태로 빠지는 경우 플러싱을 하도록한다.
- 플러시가 진행되면 기존 워크들이 다 처리되고 새로운 워크들을 받아들이지 않는다.
- WQ_MEM_RECLAIM
- 메모리 부족으로 회수가 진행되는 중에도 반드시 동작해야 하는 경우 사용한다.
- idle 워커가 부족하여 새로운 워커를 할당 받아 동작해야 하는 경우 메모리 부족으로 인해 새로운 워커를 할당받지 못하는 이러한 비상 상황에 사용하기 위해 이 플래그가 사용되어 만들어둔 rescue 워커에게 워크 실행을 의뢰한다.
- WQ_HIGH_PRI
- 다른 워크보다 더 빠른 우선 순위를 갖고 처리할 수 있게 한다.
- 이 큐는 FIFO 처리를 보장한다.
- WQ_CPU_INTENSIVE
- 동시성 관리(concurrent management)에 참여하지 않게 한다.
- 워크들이 진입한 순서대로 빠르게 처리하는 WQ_HIGH_PRI와 다르게 순서와 상관없이 빠르게 처리한다.
- WQ_SYSFS
- sysfs 인터페이스를 제공한다.
- WQ_POWER_EFFICIENT
- 절전 옵션에 따라 성능을 희생해도 되는 작업을 위해 사용된다.
- CONFIG_WQ_POWER_EFFICIENT_DEFAULT 커널 옵션을 사용하거나 “power_efficient” 모듈 파라메터를 설정하는 경우 절전을 위해 언바운드 큐로 동작한다.
- __WQ_DRAINING
- (internal) 워크큐가 draining 중이다.
- __WQ_ORDERED
- (internal) 워크풀에서 하나의 워커만 처리하도록 제한하여 워크의 FIFO 처리 순서를 보장한다.
- __WQ_LEGACY
- (internal) create*_workqueue()
- __WQ_ORDERED_EXPLICIT
- (internal) alloc_ordered_workqueue()
컴파일 타임 시스템 생성 워크큐들
max_active는 워커풀에서 동시 처리 가능 워크 수이다.
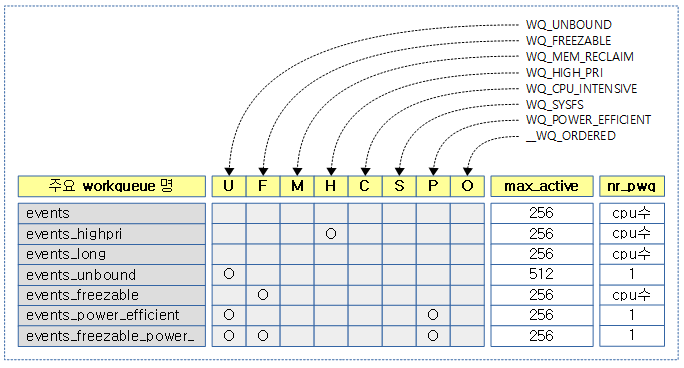
그 외 런타임 생성 워크큐들
워크큐 초기화
워크큐 Early 초기화
workqueue_init_early()
kernel/workqueue.c
/** * workqueue_init_early - early init for workqueue subsystem * * This is the first half of two-staged workqueue subsystem initialization * and invoked as soon as the bare basics - memory allocation, cpumasks and * idr are up. It sets up all the data structures and system workqueues * and allows early boot code to create workqueues and queue/cancel work * items. Actual work item execution starts only after kthreads can be * created and scheduled right before early initcalls. */
int __init workqueue_init_early(void)
{
int std_nice[NR_STD_WORKER_POOLS] = { 0, HIGHPRI_NICE_LEVEL };
int hk_flags = HK_FLAG_DOMAIN | HK_FLAG_WQ;
int i, cpu;
WARN_ON(__alignof__(struct pool_workqueue) < __alignof__(long long));
BUG_ON(!alloc_cpumask_var(&wq_unbound_cpumask, GFP_KERNEL));
cpumask_copy(wq_unbound_cpumask, housekeeping_cpumask(hk_flags));
pwq_cache = KMEM_CACHE(pool_workqueue, SLAB_PANIC);
/* initialize CPU pools */
for_each_possible_cpu(cpu) {
struct worker_pool *pool;
i = 0;
for_each_cpu_worker_pool(pool, cpu) {
BUG_ON(init_worker_pool(pool));
pool->cpu = cpu;
cpumask_copy(pool->attrs->cpumask, cpumask_of(cpu));
pool->attrs->nice = std_nice[i++];
pool->node = cpu_to_node(cpu);
/* alloc pool ID */
mutex_lock(&wq_pool_mutex);
BUG_ON(worker_pool_assign_id(pool));
mutex_unlock(&wq_pool_mutex);
}
}
/* create default unbound and ordered wq attrs */
for (i = 0; i < NR_STD_WORKER_POOLS; i++) {
struct workqueue_attrs *attrs;
BUG_ON(!(attrs = alloc_workqueue_attrs()));
attrs->nice = std_nice[i];
unbound_std_wq_attrs[i] = attrs;
/*
* An ordered wq should have only one pwq as ordering is
* guaranteed by max_active which is enforced by pwqs.
* Turn off NUMA so that dfl_pwq is used for all nodes.
*/
BUG_ON(!(attrs = alloc_workqueue_attrs()));
attrs->nice = std_nice[i];
attrs->no_numa = true;
ordered_wq_attrs[i] = attrs;
}
system_wq = alloc_workqueue("events", 0, 0);
system_highpri_wq = alloc_workqueue("events_highpri", WQ_HIGHPRI, 0);
system_long_wq = alloc_workqueue("events_long", 0, 0);
system_unbound_wq = alloc_workqueue("events_unbound", WQ_UNBOUND,
WQ_UNBOUND_MAX_ACTIVE);
system_freezable_wq = alloc_workqueue("events_freezable",
WQ_FREEZABLE, 0);
system_power_efficient_wq = alloc_workqueue("events_power_efficient",
WQ_POWER_EFFICIENT, 0);
system_freezable_power_efficient_wq = alloc_workqueue("events_freezable_power_efficient",
WQ_FREEZABLE | WQ_POWER_EFFICIENT,
0);
BUG_ON(!system_wq || !system_highpri_wq || !system_long_wq ||
!system_unbound_wq || !system_freezable_wq ||
!system_power_efficient_wq ||
!system_freezable_power_efficient_wq);
return 0;
}
워크큐 서브시스템을 early 초기화한다.
- 코드 라인 3에서 표준 워커풀에서 사용할 nice 우선 순위를 배열로 정의한다. 표준 워커풀은 컴파일 타임에 생성된 기본 2개를 사용하고 디폴트 nice 0과 최고 우선 순위의 nice 20을 사용한다.
- 코드 라인 12에서 pool_workqueue 구조체에 사용할 객체를 slab 캐시로부터 할당 받아온다.
- 코드 라인 15~31에서 모든 possible cpu들에 대하여 순회하며 해당하는 표준 워커풀 수만큼 cpu 바운드용 워커풀을 초기화한다.
- cpu 바운드용 워커풀은 컴파일 타임에 cpu 수 만큼 각각 NR_STD_WORKER_POOLS(2)개가 생성된다.
- 워커풀의 cpu, 워커풀 속성의 cpumask, 워커풀 속성의 nice 우선 순위, 워커풀의 노드를 초기화한다.
- worker_pool_idr 트리에서 워커풀의 id를 할당받아 워크풀에 대입한다.
- 코드 라인 34~50에서 표준 워커풀 수만큼 순회하며 언바운드 표준 워크큐 속성과 순차 실행용(ordered) 워크큐 속성을 할당받고 초기화한다.
- 순차 실행용 워크큐는 pwq를 1개만 생성하여 작업이 순서대로 실행되는 것을 보장한다.
- NUMA 시스템을 사용하지 않는 경우 모든 노드들은 오직 dfl_pwq를 사용한다.
- 코드 라인 52~63에서 다음과 같은 시스템 워크 큐들을 생성한다.
- system_wq
- “events”용 워크큐
- system_highpri_wq
- “events_highpri”용 워크큐를 생성할 때 워크큐에 WQ_HIGHPRI 플래그를 사용하여 high priority 용 워크큐임을 지정한다.
- system_long_wq
- “events_long”용 워크큐
- system_unbound_wq
- “events_unbound”용 워크큐를 생성할 때 워크큐에 WQ_UNBOUND 플래그를 사용하여 최대 WQ_UNBOUND_MAX_ACTIVE(512) 수와 cpu * 4 중 큰 수의 값으로 워커 생성을 제한한다.
- system_freezable_wq
- “events_freezable”용 워크큐를 생성할 때 워크큐에 WQ_FREEZABLE 플래그를 사용하여 suspend 처리 시 freeze 처리가 가능하도록 한다.
- system_power_efficient_wq
- “events_power_efficient”용 워크큐를 생성할 때 워크큐에 WQ_POWER_EFFICENT 플래그를 사용하여 성능보다 전력 효율 우선으로 처리를 하도록 지정한다.
- system_freezable_power_efficient_wq
- “events_freezable_power_efficient”용 워크큐를 생성할 때 WQ_FREEZABLE 및 WQ_POWER_EFFICENT 플래그를 사용하여 성능보다 전력 효율 우선으로 처리를 하도록 지정한다. 추가적으로 suspend 시 처리되지 않고 얼린채로 남아있는 것을 허용한다.
- system_wq
- 코드 라인 69에서 성공 0 값을 반환한다.
워크큐 초기화
workqueue_init()
kernel/workqueue.c
/** * workqueue_init - bring workqueue subsystem fully online * * This is the latter half of two-staged workqueue subsystem initialization * and invoked as soon as kthreads can be created and scheduled. * Workqueues have been created and work items queued on them, but there * are no kworkers executing the work items yet. Populate the worker pools * with the initial workers and enable future kworker creations. */
int __init workqueue_init(void)
{
struct workqueue_struct *wq;
struct worker_pool *pool;
int cpu, bkt;
/*
* It'd be simpler to initialize NUMA in workqueue_init_early() but
* CPU to node mapping may not be available that early on some
* archs such as power and arm64. As per-cpu pools created
* previously could be missing node hint and unbound pools NUMA
* affinity, fix them up.
*
* Also, while iterating workqueues, create rescuers if requested.
*/
wq_numa_init();
mutex_lock(&wq_pool_mutex);
for_each_possible_cpu(cpu) {
for_each_cpu_worker_pool(pool, cpu) {
pool->node = cpu_to_node(cpu);
}
}
list_for_each_entry(wq, &workqueues, list) {
wq_update_unbound_numa(wq, smp_processor_id(), true);
WARN(init_rescuer(wq),
"workqueue: failed to create early rescuer for %s",
wq->name);
}
mutex_unlock(&wq_pool_mutex);
/* create the initial workers */
for_each_online_cpu(cpu) {
for_each_cpu_worker_pool(pool, cpu) {
pool->flags &= ~POOL_DISASSOCIATED;
BUG_ON(!create_worker(pool));
}
}
hash_for_each(unbound_pool_hash, bkt, pool, hash_node)
BUG_ON(!create_worker(pool));
wq_online = true;
wq_watchdog_init();
return 0;
}
워크큐 서브시스템을 초기화한다.
- 코드 라인 16에서 NUMA 시스템인 경우 possible cpumask 배열과 워크큐 속성을 할당받고 초기화한다.
- 코드 라인 20~24에서 모든 워커풀들의 노드를 지정한다.
- 코드 라인 26~31에서 모든 워크큐들을 순회하며 NUMA affinity를 갱신한다.
- 코드 라인 36~41에서 모든 워커풀들의 속성에서 POOL_DISASSOCIATED 속성을 제거하고, 각 워커풀에서 동작할 워커를 생성한다.
- 코드 라인 43~44에서 64개 해시로 구성된 언바운드 풀들에서 동작할 워커를 생성한다.
- 코드 라인 46에서 워크큐 서브시스템이 가동되었음을 표시한다.
- 코드 라인 47에서 워크큐 워치독을 초기화한다.
- 코드 라인 49에서 성공 값 0을 반환한다.
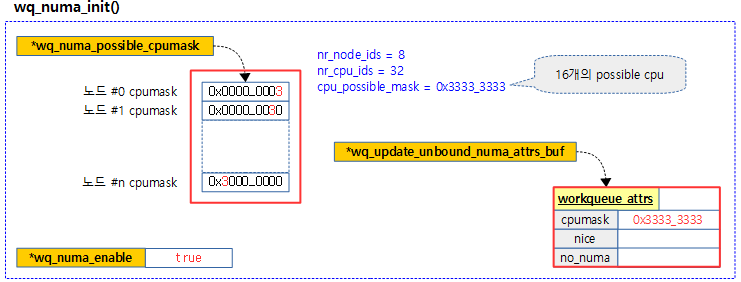
누마에 필요한 설정 준비
wq_numa_init()
kernel/workqueue.c
static void __init wq_numa_init(void)
{
cpumask_var_t *tbl;
int node, cpu;
if (num_possible_nodes() <= 1)
return;
if (wq_disable_numa) {
pr_info("workqueue: NUMA affinity support disabled\n");
return;
}
wq_update_unbound_numa_attrs_buf = alloc_workqueue_attrs(GFP_KERNEL);
BUG_ON(!wq_update_unbound_numa_attrs_buf);
/*
* We want masks of possible CPUs of each node which isn't readily
* available. Build one from cpu_to_node() which should have been
* fully initialized by now.
*/
tbl = kzalloc(nr_node_ids * sizeof(tbl[0]), GFP_KERNEL);
BUG_ON(!tbl);
for_each_node(node)
BUG_ON(!zalloc_cpumask_var_node(&tbl[node], GFP_KERNEL,
node_online(node) ? node : NUMA_NO_NODE));
for_each_possible_cpu(cpu) {
node = cpu_to_node(cpu);
if (WARN_ON(node == NUMA_NO_NODE)) {
pr_warn("workqueue: NUMA node mapping not available for cpu%d, disabling NUMA support\n", cpu);
/* happens iff arch is bonkers, let's just proceed */
return;
}
cpumask_set_cpu(cpu, tbl[node]);
}
wq_numa_possible_cpumask = tbl;
wq_numa_enabled = true;
}
워크큐를 위해 NUMA 시스템인 경우 possible cpumask 배열과 워크큐 속성을 할당받고 초기화한다.
- 코드 라인 6~7에서 멀티 노드가 아닌 경우 함수를 빠져나간다.
- 코드 라인 9~12에서 “workqueue.disable_numa.disable_numa” 커널 파라미터가 사용되면 함수를 빠져나간다.
- “/sys/module/workqueue/parameters/disable_numa” 파일
- 코드 라인 14에서 전역 wq_update_unbound_numa_attrs_buf 변수에 워크큐 속성을 할당받아 저장한다.
- wq_update_unbound_numa() 함수에서 언바운드 워크에 대해 이 속성을 사용한다.
- 코드 라인 25~27에서 노드 수만큼 포인터 변수 어레이를 할당받는다. 그런 후 노드 수만큼 순회하며 cpumask를 각 NUMA 노드에서 할당받아온다.
- 코드 라인 29~37에서 모든 possible cpu 수만큼 순회를 하며 해당 노드 테이블에 해당하는 cpu에 bit를 설정한다.
- 코드 라인 39에서 이렇게 cpumask가 설정된 테이블을 wq_numa_possible_cpumask에 대입한다.
- 코드 라인 40에서 워크큐용 numa 설정이 enable되었음을 알린다.
워크큐 생성 및 삭제
워크큐 생성
alloc_workqueue()
include/linux/workqueue.h
/** * alloc_workqueue - allocate a workqueue * @fmt: printf format for the name of the workqueue * @flags: WQ_* flags * @max_active: max in-flight work items, 0 for default * remaining args: args for @fmt * * Allocate a workqueue with the specified parameters. For detailed * information on WQ_* flags, please refer to * Documentation/core-api/workqueue.rst. * * RETURNS: * Pointer to the allocated workqueue on success, %NULL on failure. */
kernel/workqueue.c – 1/2
__printf(1, 4)
struct workqueue_struct *alloc_workqueue(const char *fmt,
unsigned int flags,
int max_active, ...)
{
size_t tbl_size = 0;
va_list args;
struct workqueue_struct *wq;
struct pool_workqueue *pwq;
/*
* Unbound && max_active == 1 used to imply ordered, which is no
* longer the case on NUMA machines due to per-node pools. While
* alloc_ordered_workqueue() is the right way to create an ordered
* workqueue, keep the previous behavior to avoid subtle breakages
* on NUMA.
*/
if ((flags & WQ_UNBOUND) && max_active == 1)
flags |= __WQ_ORDERED;
/* see the comment above the definition of WQ_POWER_EFFICIENT */
if ((flags & WQ_POWER_EFFICIENT) && wq_power_efficient)
flags |= WQ_UNBOUND;
/* allocate wq and format name */
if (flags & WQ_UNBOUND)
tbl_size = nr_node_ids * sizeof(wq->numa_pwq_tbl[0]);
wq = kzalloc(sizeof(*wq) + tbl_size, GFP_KERNEL);
if (!wq)
return NULL;
if (flags & WQ_UNBOUND) {
wq->unbound_attrs = alloc_workqueue_attrs();
if (!wq->unbound_attrs)
goto err_free_wq;
}
va_start(args, max_active);
vsnprintf(wq->name, sizeof(wq->name), fmt, args);
va_end(args);
max_active = max_active ?: WQ_DFL_ACTIVE;
max_active = wq_clamp_max_active(max_active, flags, wq->name);
워크큐를 @fmt 이름으로 생성하고 최대 active 워크 수를 설정한다.
- 코드 라인 18~19에서 최대 워크가 1개인 active 언바운드용 워크큐를 생성하려는 경우 자동으로 순차처리되도록 __WQ_ORDERED 플래그를 추가한다.
- 코드 라인 22~23에서 power_efficient용 워크큐를 요청한 경우 WQ_UNBOUND 플래그를 추가하여 unbound 워크큐로 만들어 절전을 목적으로 성능을 약간 희생시킨다.
- “/sys/module/workqueue/parameters/power_efficient” 파일 설정 (커널 파라메터를 통해 모듈 변수의 값을 조절할 수도 있다.)
- 코드 라인 26~37에서 워크큐와 워크큐 속성을 할당한다. 언바운드 워크큐인 경우 워크큐에 누마 노드별 풀워크큐 포인터 용도의 어레이를 추가 할당한다. 또한 워크큐 속성을 할당한다.
- 코드 라인 39~41에서 워크큐 이름을 설정한다.
- 코드 라인 43~44에서 최대 active 워크 수를 다음과 같이 결정한다.
- 인자 @max_active가 주어지지 않은 경우 WQ_MAX_ACTIVE(512)의 절반인 WQ_DFL_ACTIVE(256)으로 결정한다.
- 단 결정된 수는 cpu가 많은 시스템에서 언바운드 큐를 생성하는 경우에 한하여 결정된 값을 초과하여 cpu * 4만큼 설정할 수 있다.
kernel/workqueue.c – 2/2
/* init wq */
wq->flags = flags;
wq->saved_max_active = max_active;
mutex_init(&wq->mutex);
atomic_set(&wq->nr_pwqs_to_flush, 0);
INIT_LIST_HEAD(&wq->pwqs);
INIT_LIST_HEAD(&wq->flusher_queue);
INIT_LIST_HEAD(&wq->flusher_overflow);
INIT_LIST_HEAD(&wq->maydays);
wq_init_lockdep(wq);
INIT_LIST_HEAD(&wq->list);
if (alloc_and_link_pwqs(wq) < 0)
goto err_unreg_lockdep;
if (wq_online && init_rescuer(wq) < 0)
goto err_destroy;
if ((wq->flags & WQ_SYSFS) && workqueue_sysfs_register(wq))
goto err_destroy;
/*
* wq_pool_mutex protects global freeze state and workqueues list.
* Grab it, adjust max_active and add the new @wq to workqueues
* list.
*/
mutex_lock(&wq_pool_mutex);
mutex_lock(&wq->mutex);
for_each_pwq(pwq, wq)
pwq_adjust_max_active(pwq);
mutex_unlock(&wq->mutex);
list_add_tail_rcu(&wq->list, &workqueues);
mutex_unlock(&wq_pool_mutex);
return wq;
err_unreg_lockdep:
wq_unregister_lockdep(wq);
wq_free_lockdep(wq);
err_free_wq:
free_workqueue_attrs(wq->unbound_attrs);
kfree(wq);
return NULL;
err_destroy:
destroy_workqueue(wq);
return NULL;
}
EXPORT_SYMBOL_GPL(alloc_workqueue);
- 코드 라인 2~12에서 생성한 워크큐의 멤버 리스트들과 변수들을 초기화한다.
- 코드 라인 14~15에서 풀워크큐를 할당하고 워크큐에 연결한다.
- 코드 라인 17~18에서 메모리 회수시에도 동작을 보장하도록 rescuer_thread 워커를 만들고 실행시킨다. 그리고 이를 워크큐에 특별한 워커로 설정해둔다.
- 코드 라인 20~21에서 sysfs로 노출 요청을 받은 워크큐를 sysfs에 등록한다.
- WQ_SYSFS 플래그를 사용하여 등록한 워크큐는 다음을 통해 확인할 수 있다.
- “/sys/devices/virtual/workqueue/<wq> 디렉토리에 생성된다. (예: writeback 워크큐)
- “/sys/bus/workqueue/devices/<wq>” 노드가 위의 디렉토리에 연결된다.
- 커널에서 이 요청을 사용한 디바이스는 mm/backing-dev.c – default_bdi_init() 함수에 구현되어 있다.
- WQ_SYSFS 플래그를 사용하여 등록한 워크큐는 다음을 통해 확인할 수 있다.
- 코드 라인 31~32에서 풀워크큐 수 만큼 순회하며 max_active를 조정한다.
- 코드 라인 35에서 워크큐를 전역 워크큐 리스트에 추가한다.
- 코드 라인 39에서 생성한 워크큐를 반환한다.
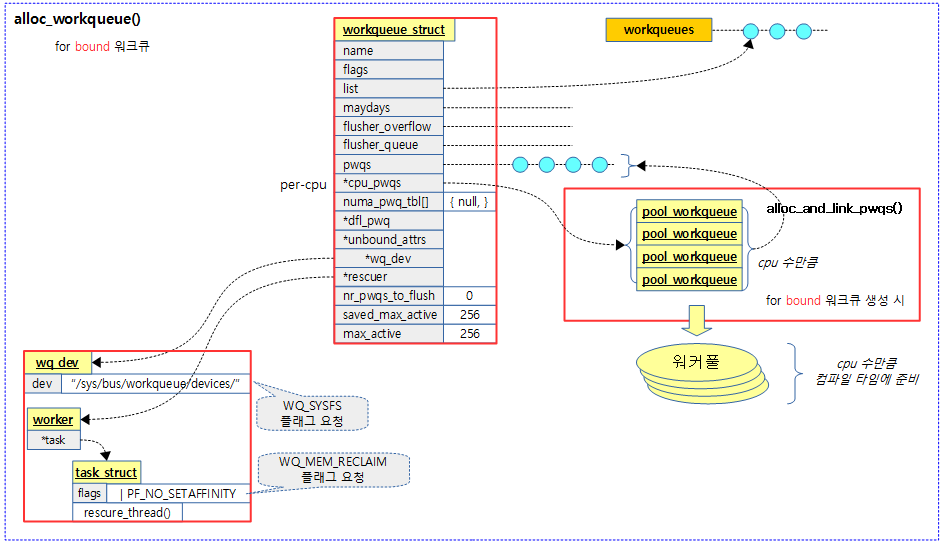
다음 그림은 바운드용 워크큐를 생성했을 때의 모습을 보여준다. 워커풀은 생성되지 않고 컴파일 타임에 생성되었던 워커풀과 연결된다.
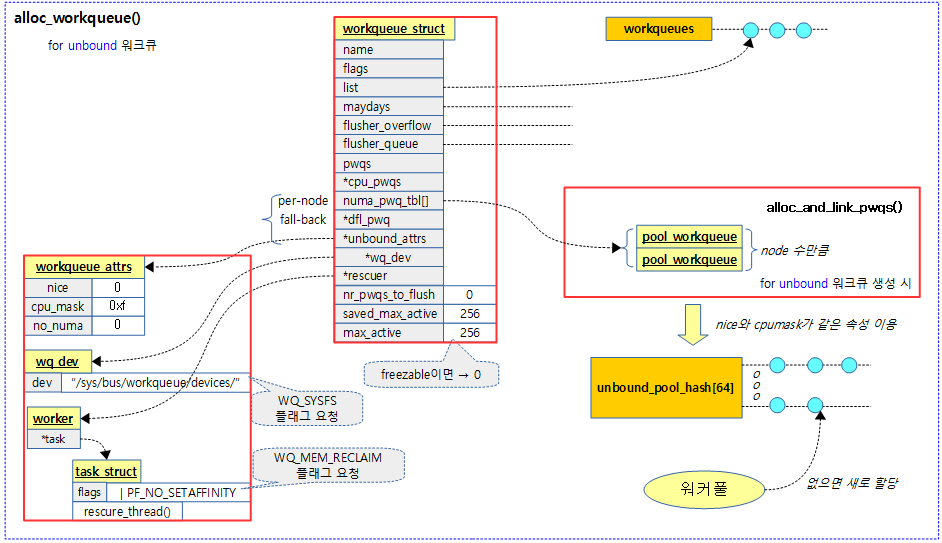
다음 그림은 언바운드용 워크큐를 생성했을 때의 모습을 보여준다. 워커풀은 기존 언바운드용 해시 워커풀에 같은 워크큐 속성을 가진 워커풀이 있으면 같이 공유하여 사용하고 그렇지 않은 경우 생성을 해서 사용한다.
wq_clamp_max_active()
kernel/workqueue.c
static int wq_clamp_max_active(int max_active, unsigned int f lags,
const char *name)
{
int lim = flags & WQ_UNBOUND ? WQ_UNBOUND_MAX_ACTIVE : WQ_MAX_ACTIVE;
if (max_active < 1 || max_active > lim)
pr_warn("workqueue: max_active %d requested for %s is out of range, clamping between %d and %d\n",
max_active, name, 1, lim);
return clamp_val(max_active, 1, lim);
}
max_active는 1~512개로 제한된다. 단 언바운드 워크큐인 경우에 한하여 cpu가 많은 경우 제한을 초과하여 cpu x 4개로 설정할 수 있다.
워크큐 삭제
destroy_workqueue()
워크큐에 등록된 모든 워크들을 처리하고 워크큐를 삭제할 때 소속된 워커풀도 삭제한다.
kernel/workqueue.c – 1/2
/** * destroy_workqueue - safely terminate a workqueue * @wq: target workqueue * * Safely destroy a workqueue. All work currently pending will be done first. */
void destroy_workqueue(struct workqueue_struct *wq)
{
struct pool_workqueue *pwq;
int node;
/* drain it before proceeding with destruction */
drain_workqueue(wq);
/* sanity checks */
mutex_lock(&wq->mutex);
for_each_pwq(pwq, wq) {
int i;
for (i = 0; i < WORK_NR_COLORS; i++) { if (WARN_ON(pwq->nr_in_flight[i])) {
mutex_unlock(&wq->mutex);
show_workqueue_state();
return;
}
}
if (WARN_ON((pwq != wq->dfl_pwq) && (pwq->refcnt > 1)) ||
WARN_ON(pwq->nr_active) ||
WARN_ON(!list_empty(&pwq->delayed_works))) {
mutex_unlock(&wq->mutex);
show_workqueue_state();
return;
}
}
mutex_unlock(&wq->mutex);
/*
* wq list is used to freeze wq, remove from list after
* flushing is complete in case freeze races us.
*/
mutex_lock(&wq_pool_mutex);
list_del_rcu(&wq->list);
mutex_unlock(&wq_pool_mutex);
workqueue_sysfs_unregister(wq);
if (wq->rescuer)
kthread_stop(wq->rescuer->task);
if (!(wq->flags & WQ_UNBOUND)) {
wq_unregister_lockdep(wq);
/*
* The base ref is never dropped on per-cpu pwqs. Directly
* schedule RCU free.
*/
call_rcu(&wq->rcu, rcu_free_wq);
} else {
/*
* We're the sole accessor of @wq at this point. Directly
* access numa_pwq_tbl[] and dfl_pwq to put the base refs.
* @wq will be freed when the last pwq is released.
*/
for_each_node(node) {
pwq = rcu_access_pointer(wq->numa_pwq_tbl[node]);
RCU_INIT_POINTER(wq->numa_pwq_tbl[node], NULL);
put_pwq_unlocked(pwq);
}
/*
* Put dfl_pwq. @wq may be freed any time after dfl_pwq is
* put. Don't access it afterwards.
*/
pwq = wq->dfl_pwq;
wq->dfl_pwq = NULL;
put_pwq_unlocked(pwq);
}
}
EXPORT_SYMBOL_GPL(destroy_workqueue);
- 코드 라인 7에서 이미 등록된 워크들에 대한 드레인(플러시) 처리를 수행한다. 드레인 처리 중에는 워크큐에 새로운 워크 등록을 허용하지 않는다.
- 코드 라인 10~29에서 워크큐에서 사용하는 풀워크큐를 순회하며 처리중인 워크가 있으면 경고 메시지를 출력하고 함수를 빠져나간다. 또한 처리중인 워크가 있거나 delayed 워크들이 있는 경우 경고 메시지를 출력하고 함수를 빠져나간다.
- 코드 라인 35~37에서 전역 워크큐 리스트에서 요청한 워크큐를 제거한다.
- 코드 라인 39에서 sysfs 등록된 경우 sysfs의 관련 워크큐 항목을 제거한다.
- 코드 라인 41~42에서 rescuer 워커가 등록되어 있는 워크큐인 경우 해당 스레드를 정지시키고 제거한다.
- 코드 라인 44~50에서 바운드 워크큐인 경우 cpu별 풀워크큐 및 워크큐를 제거한다.
- 코드 라인 51~70에서 언바운드 워크큐인 경우 노드별 풀워크큐를 제거하고 가리키는 테이블도 rcu 방식으로 제거한다. 디폴트 풀워크큐에 대한 참조 카운터를 1 감소시키고 연결을 제거한다.
워크큐 드레인
drain_workqueue()
kernel/workqueue.c
/** * drain_workqueue - drain a workqueue * @wq: workqueue to drain * * Wait until the workqueue becomes empty. While draining is in progress, * only chain queueing is allowed. IOW, only currently pending or running * work items on @wq can queue further work items on it. @wq is flushed * repeatedly until it becomes empty. The number of flushing is detemined * by the depth of chaining and should be relatively short. Whine if it * takes too long. */
void drain_workqueue(struct workqueue_struct *wq)
{
unsigned int flush_cnt = 0;
struct pool_workqueue *pwq;
/*
* __queue_work() needs to test whether there are drainers, is much
* hotter than drain_workqueue() and already looks at @wq->flags.
* Use __WQ_DRAINING so that queue doesn't have to check nr_drainers.
*/
mutex_lock(&wq->mutex);
if (!wq->nr_drainers++)
wq->flags |= __WQ_DRAINING;
mutex_unlock(&wq->mutex);
reflush:
flush_workqueue(wq);
mutex_lock(&wq->mutex);
for_each_pwq(pwq, wq) {
bool drained;
spin_lock_irq(&pwq->pool->lock);
drained = !pwq->nr_active && list_empty(&pwq->delayed_works);
spin_unlock_irq(&pwq->pool->lock);
if (drained)
continue;
if (++flush_cnt == 10 ||
(flush_cnt % 100 == 0 && flush_cnt <= 1000))
pr_warn("workqueue %s: drain_workqueue() isn't complete after %u tries\n",
wq->name, flush_cnt);
mutex_unlock(&wq->mutex);
goto reflush;
}
if (!--wq->nr_drainers)
wq->flags &= ~__WQ_DRAINING;
mutex_unlock(&wq->mutex);
}
EXPORT_SYMBOL_GPL(drain_workqueue);
워크큐에 있는 워크를 모두 처리하여 비울때까지 기다린다. 드레인 처리 중에는 현재 워크큐로 요청하는 워크들의 등록 요청은 모두 거절된다.
- 코드 라인 12~13에서 드레이너 수가 0인 경우 워크큐 플래그에 __WQ_DRAINING을 추가한다. 드레이너 수를 1 증가시킨다.
- 코드 라인 16에서 워크큐를 플러시한다.
- 코드 라인 20~28에서 워크큐에 소속된 풀워크큐들에 대해 순회하며 처리할 워크가 없는 경우 skip 한다.
- 코드 라인 30~33에서 플러시 카운터를 1증가시키고 플러시 카운터가 10이거나 1000번 미만에 대해 100번마다 경고 메시지를 출력한다.
- 코드 라인 36에서 다시 reflush 레이블로 반복한다.
- 코드 라인 39~40에서 드레이너 수를 1 감소시키고 0이된 경우 워크큐 플래그에서 __WQ_DRAINING을 제거한다.
워크큐 플러시
워크 컬러 & 플러시 컬러
워크큐를 비우는데 사용한 기존 동기화 코드를 모두 지우고 동기화 없이 빠르게 플러시를 할 수 있는 방법으로 대체되었다. 다음 과정을 살펴보자.
- 워크들이 등록될 때 마다 워크 컬러값을 부여한다.
- 플러시 요청이 있는 경우 플러시 컬러에 워크 컬러를 대입하고 다음 워크 컬러로 증가(0 ~ 14 순환)시킨다.
- 마지막 컬러 번호 WORK_NO_COLOR(15)는 사용하지 않는다.
- 플러시(기존 워크 컬러) 컬러값에 해당하는 워크들이 모두 처리되도록 기다린다.
flush_workqueue()
kernel/workqueue.c – 1/3
/** * flush_workqueue - ensure that any scheduled work has run to completion. * @wq: workqueue to flush * * This function sleeps until all work items which were queued on entry * have finished execution, but it is not livelocked by new incoming ones. */
void flush_workqueue(struct workqueue_struct *wq)
{
struct wq_flusher this_flusher = {
.list = LIST_HEAD_INIT(this_flusher.list),
.flush_color = -1,
.done = COMPLETION_INITIALIZER_ONSTACK_MAP(this_flusher.done, wq->lockdep_map),
};
int next_color;
if (WARN_ON(!wq_online))
return;
lock_map_acquire(&wq->lockdep_map);
lock_map_release(&wq->lockdep_map);
mutex_lock(&wq->mutex);
/*
* Start-to-wait phase
*/
next_color = work_next_color(wq->work_color);
if (next_color != wq->flush_color) {
/*
* Color space is not full. The current work_color
* becomes our flush_color and work_color is advanced
* by one.
*/
WARN_ON_ONCE(!list_empty(&wq->flusher_overflow));
this_flusher.flush_color = wq->work_color;
wq->work_color = next_color;
if (!wq->first_flusher) {
/* no flush in progress, become the first flusher */
WARN_ON_ONCE(wq->flush_color != this_flusher.flush_color);
wq->first_flusher = &this_flusher;
if (!flush_workqueue_prep_pwqs(wq, wq->flush_color,
wq->work_color)) {
/* nothing to flush, done */
wq->flush_color = next_color;
wq->first_flusher = NULL;
goto out_unlock;
}
} else {
/* wait in queue */
WARN_ON_ONCE(wq->flush_color == this_flusher.flush_color);
list_add_tail(&this_flusher.list, &wq->flusher_queue);
flush_workqueue_prep_pwqs(wq, -1, wq->work_color);
}
} else {
/*
* Oops, color space is full, wait on overflow queue.
* The next flush completion will assign us
* flush_color and transfer to flusher_queue.
*/
list_add_tail(&this_flusher.list, &wq->flusher_overflow);
}
check_flush_dependency(wq, NULL);
mutex_unlock(&wq->mutex);
wait_for_completion(&this_flusher.done);
- 코드 라인 3~7에서 워크큐 플러셔 구조체를 준비한다.
- 코드 라인 20에서 다음 워크큐 컬러를 가져온다.
- 0 ~ 14번의 컬러 범위이다.
- 코드 라인 22에서 다음 컬러가 워크큐의 플러시 컬러와 다른 경우 컬러 스페이스가 풀되지 않았음을 의미한다.
- 코드 라인 29~30에서 요청한 워크큐의 워크 컬러는 현재 플러셔의 플러시 컬러에 백업한 후 다음 컬러를 지정한다.
- 코드 라인 32~36에서 요청한 워크큐의 first_flusher가 지정되지 않은 경우 지금 진행되는 플러셔를 대입한다.
- 코드 라인 38~44에서 워크큐 플러시를 위해 풀워크큐들도 준비하는데 완료되어 wakeup stage를 갈 필요 없을 경우 워크큐의 플러시 컬러를 다음 컬러로 대입하고 first_flusher에 null을 대입하고 함수를 빠져나간다.
- 코드 라인 45~50에서 요청한 워크큐에 first_flusher가 있는 경우워크큐의 flusher_queue 리스트에 현재 플러시 요청을 추가하고 워크큐 플러시를 위해 풀워크큐들도 준비한다. 이 때 플러시컬러는 지정하지 않는다.
- 코드 라인 51~58에서 다음 컬러 공간이 부족하면 워크큐의 flusher_overflow 리스트에 현재 플러쉬 요청을 추가한다.
- 플러시 컬러가 한 바퀴를 돌아 현재 진행하는 워커 컬러번호가 되면 오버플로우된다.
- 코드 라인 60에서 플러시 디펜던시 sanity 체크를 수행한다.
- 코드 라인 63에서 현재 플러시 요청이 완료될 때까지 기다린다. 다음 두 가지 함수에서 완료를 체크하여 이곳 first 플러셔를 깨운다.
- flush_workqueue_prep_pwqs() 함수
- 플워크큐들에서 요청한 플러시 컬러로 처리중인 워크가 없으면 완료처리한다.
- pwq_dec_nr_in_flight() 함수
- 마지막 워크가 처리된 경우 완료처리한다.
- 이 함수의 2nd phase
- 같은 플러시 번호를 사용하는 경우 같이 처리되어 완료된다.
- flush_workqueue_prep_pwqs() 함수
kernel/workqueue.c – 2/3
. /*
* Wake-up-and-cascade phase
*
* First flushers are responsible for cascading flushes and
* handling overflow. Non-first flushers can simply return.
*/
if (wq->first_flusher != &this_flusher)
return;
mutex_lock(&wq->mutex);
/* we might have raced, check again with mutex held */
if (wq->first_flusher != &this_flusher)
goto out_unlock;
wq->first_flusher = NULL;
WARN_ON_ONCE(!list_empty(&this_flusher.list));
WARN_ON_ONCE(wq->flush_color != this_flusher.flush_color);
while (true) {
struct wq_flusher *next, *tmp;
/* complete all the flushers sharing the current flush color */
list_for_each_entry_safe(next, tmp, &wq->flusher_queue, list) {
if (next->flush_color != wq->flush_color)
break;
list_del_init(&next->list);
complete(&next->done);
}
WARN_ON_ONCE(!list_empty(&wq->flusher_overflow) &&
wq->flush_color != work_next_color(wq->work_color));
/* this flush_color is finished, advance by one */
wq->flush_color = work_next_color(wq->flush_color);
- 코드 라인 7~8에서 first 플러셔가 완료 요청을 받은 경우가 아니면 함수를 빠져나간다.
- 코드 라인 13~14에서 다시 한 번 락을 건 후 first 플러셔가 완료 요청을 받은 경우가 아니면 함수를 빠져나간다.
- 코드 라인 16에서 워크큐의 first 플러셔에 null을 대입한다.
- 코드 라인 21~30에서 대기중인 플러셔들 중에 같은 플러시 번호로 대기중인 플러셔가 있으면 그 플러셔를 제거하고 완료 요청을 보낸다.
- 코드 라인 36에서 워크큐에 다음 플러시 컬러를 준비한다.
kernel/workqueue.c – 3/3
/* one color has been freed, handle overflow queue */
if (!list_empty(&wq->flusher_overflow)) {
/*
* Assign the same color to all overflowed
* flushers, advance work_color and append to
* flusher_queue. This is the start-to-wait
* phase for these overflowed flushers.
*/
list_for_each_entry(tmp, &wq->flusher_overflow, list)
tmp->flush_color = wq->work_color;
wq->work_color = work_next_color(wq->work_color);
list_splice_tail_init(&wq->flusher_overflow,
&wq->flusher_queue);
flush_workqueue_prep_pwqs(wq, -1, wq->work_color);
}
if (list_empty(&wq->flusher_queue)) {
WARN_ON_ONCE(wq->flush_color != wq->work_color);
break;
}
/*
* Need to flush more colors. Make the next flusher
* the new first flusher and arm pwqs.
*/
WARN_ON_ONCE(wq->flush_color == wq->work_color);
WARN_ON_ONCE(wq->flush_color != next->flush_color);
list_del_init(&next->list);
wq->first_flusher = next;
if (flush_workqueue_prep_pwqs(wq, wq->flush_color, -1))
break;
/*
* Meh... this color is already done, clear first
* flusher and repeat cascading.
*/
wq->first_flusher = NULL;
}
out_unlock:
mutex_unlock(&wq->mutex);
}
EXPORT_SYMBOL_GPL(flush_workqueue);
- 코드 라인 2~12에서 flusher_overflow 리스트에 플러시 요청이 있는 경우 순회하며 플러시 컬러를 모두 워크큐의 워크 컬러로 치환하고 워크큐는 다음 워크컬러로 갱신한다.
- 코드 라인 14~17에서 오버플로우 리스트에 연결된 플러시 요청들을 flusher_queue 리스트에 옮긴다. 그런 후 워크큐 플러시를 위해 풀워크큐들도 준비하는데 플러시 컬러는 지정하지 않는다.
- 코드 라인 19~22에서 처리할 플러시 요청이 없는 경우 루프를 벗어난다.
- 코드 라인 31~32에서 현재 처리한 플러시 요청을 리스트에서 제거하고 워크큐의 first_flusher로 옮겨 지정한다.
- 코드 라인 34~35에서 워크큐 플러시를 위해 풀워크큐들도 준비하는데 워크큐 컬러는 지정하지 않는다. 처리 후 true이면 함수를 빠져나간다.
- 코드 라인 41~42에서 워크큐의 first_flusher에 null을 대입한 후 계속 루프를 돈다.
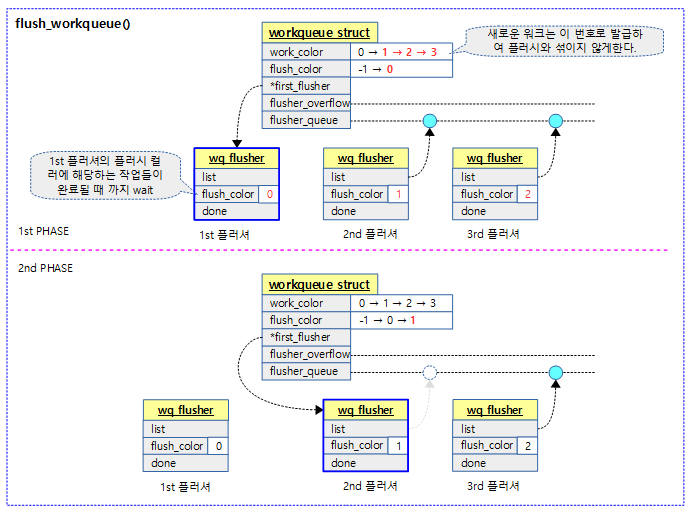
다음 그림은 워크큐 플러시 처리과정을 보여준다.
- 항상 첫 번째 플러시 요청자인 1st 플러셔에 대한 요청을 처리한다.
- 2 개 이상의 플러시 요청이 있을 경우 두 번째 요청자 부터 (2nd 플러셔 부터) 플러셔 큐에서 대기시킨다.
풀워크큐
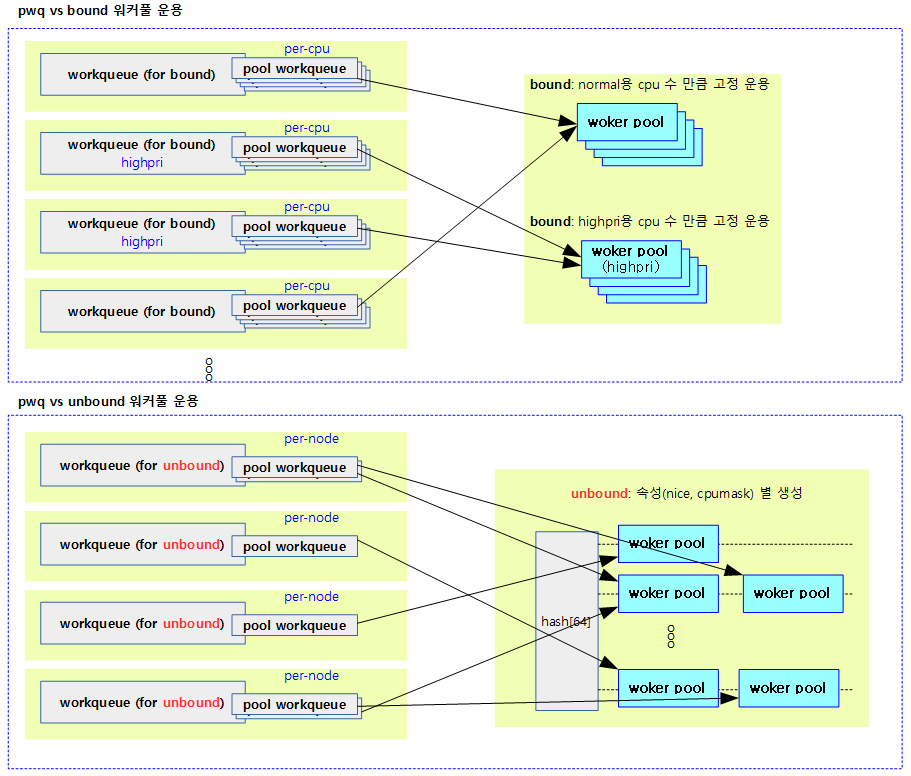
풀워크큐는 워크큐를 워커풀에 연결하는 용도로 사용한다.
pool_workqueue 참조
get_pwq()
kernel/workqueue.c
/** * get_pwq - get an extra reference on the specified pool_workqueue * @pwq: pool_workqueue to get * * Obtain an extra reference on @pwq. The caller should guarantee that * @pwq has positive refcnt and be holding the matching pool->lock. */
static void get_pwq(struct pool_workqueue *pwq)
{
lockdep_assert_held(&pwq->pool->lock);
WARN_ON_ONCE(pwq->refcnt <= 0);
pwq->refcnt++;
}
pwq 참조 카운터를 증가시킨다.
put_pwq()
kernel/workqueue.c
/** * put_pwq - put a pool_workqueue reference * @pwq: pool_workqueue to put * * Drop a reference of @pwq. If its refcnt reaches zero, schedule its * destruction. The caller should be holding the matching pool->lock. */
static void put_pwq(struct pool_workqueue *pwq)
{
lockdep_assert_held(&pwq->pool->lock);
if (likely(--pwq->refcnt))
return;
if (WARN_ON_ONCE(!(pwq->wq->flags & WQ_UNBOUND)))
return;
/*
* @pwq can't be released under pool->lock, bounce to
* pwq_unbound_release_workfn(). This never recurses on the same
* pool->lock as this path is taken only for unbound workqueues and
* the release work item is scheduled on a per-cpu workqueue. To
* avoid lockdep warning, unbound pool->locks are given lockdep
* subclass of 1 in get_unbound_pool().
*/
schedule_work(&pwq->unbound_release_work);
}
pwq 참조 카운터를 감소시킨다. 만일 참조 카운터가 0이되면 unbound_release_work 작업을 스케줄한다.
- pwq_unbound_release_workfn() 함수를 실행시켜 pwq를 제거한다.
pwq_unbound_release_workfn()
kernel/workqueue.c
/* * Scheduled on system_wq by put_pwq() when an unbound pwq hits zero refcnt * and needs to be destroyed. */
static void pwq_unbound_release_workfn(struct work_struct *work)
{
struct pool_workqueue *pwq = container_of(work, struct pool_workqueue,
unbound_release_work);
struct workqueue_struct *wq = pwq->wq;
struct worker_pool *pool = pwq->pool;
bool is_last;
if (WARN_ON_ONCE(!(wq->flags & WQ_UNBOUND)))
return;
mutex_lock(&wq->mutex);
list_del_rcu(&pwq->pwqs_node);
is_last = list_empty(&wq->pwqs);
mutex_unlock(&wq->mutex);
mutex_lock(&wq_pool_mutex);
put_unbound_pool(pool);
mutex_unlock(&wq_pool_mutex);
call_rcu_sched(&pwq->rcu, rcu_free_pwq);
/*
* If we're the last pwq going away, @wq is already dead and no one
* is gonna access it anymore. Free it.
*/
if (is_last) {
free_workqueue_attrs(wq->unbound_attrs);
kfree(wq);
}
}
언바운드 풀워크큐를 제거한다. 만일 워크큐에 등록된 풀워크큐가 하나도 없는 경우 워크큐도 제거한다.
- 코드 라인 9~10에서 unbound 워크큐와 연결된 풀워크큐인 경우 경고 메시지를 출력한 후 함수를 빠져나간다.
- 코드 라인 13에서 워크큐에 등록된 풀워크큐를 rcu를 사용하여 제거요청을 한다.
- 코드 라인 14에서 삭제한 풀워크큐가 워크큐에서 마지막이었던 경우 true, 아니면 false를 대입한다.
- 코드 라인 18에서 언바운드 워크풀의 참조카운터를 1 감소시키고 0이되면 언바운드 워커풀을 소멸시킨다.
- 코드 라인 21에서 rcu를 사용하여 풀워크큐에 사용한 pool_workqueue 객체를 pwq 캐시에서 할당 해제한다.
- 코드 라인 27~30에서 제거한 풀워크큐가 마지막 이었으면 워크큐 속성과 워크큐 마저도 할당 해제한다.
flush_workqueue_prep_pwqs()
kernel/workqueue.c
/** * flush_workqueue_prep_pwqs - prepare pwqs for workqueue flushing * @wq: workqueue being flushed * @flush_color: new flush color, < 0 for no-op * @work_color: new work color, < 0 for no-op * * Prepare pwqs for workqueue flushing. * * If @flush_color is non-negative, flush_color on all pwqs should be * -1. If no pwq has in-flight commands at the specified color, all * pwq->flush_color's stay at -1 and %false is returned. If any pwq * has in flight commands, its pwq->flush_color is set to * @flush_color, @wq->nr_pwqs_to_flush is updated accordingly, pwq * wakeup logic is armed and %true is returned. * * The caller should have initialized @wq->first_flusher prior to * calling this function with non-negative @flush_color. If * @flush_color is negative, no flush color update is done and %false * is returned. * * If @work_color is non-negative, all pwqs should have the same * work_color which is previous to @work_color and all will be * advanced to @work_color. * * CONTEXT: * mutex_lock(wq->mutex). * * Return: * %true if @flush_color >= 0 and there's something to flush. %false * otherwise. */
static bool flush_workqueue_prep_pwqs(struct workqueue_struct *wq,
int flush_color, int work_color)
{
bool wait = false;
struct pool_workqueue *pwq;
if (flush_color >= 0) {
WARN_ON_ONCE(atomic_read(&wq->nr_pwqs_to_flush));
atomic_set(&wq->nr_pwqs_to_flush, 1);
}
for_each_pwq(pwq, wq) {
struct worker_pool *pool = pwq->pool;
spin_lock_irq(&pool->lock);
if (flush_color >= 0) {
WARN_ON_ONCE(pwq->flush_color != -1);
if (pwq->nr_in_flight[flush_color]) {
pwq->flush_color = flush_color;
atomic_inc(&wq->nr_pwqs_to_flush);
wait = true;
}
}
if (work_color >= 0) {
WARN_ON_ONCE(work_color != work_next_color(pwq->work_color));
pwq->work_color = work_color;
}
spin_unlock_irq(&pool->lock);
}
if (flush_color >= 0 && atomic_dec_and_test(&wq->nr_pwqs_to_flush))
complete(&wq->first_flusher->done);
return wait;
}
워크큐 플러싱을 위해 소속된 풀워크큐들 플러시 준비를 한다.
- 코드 라인 7~10에서 플러시 컬러가 지정된 경우 워크큐가 플러시중임을 알 수 있도록 nr_pwqs_to_flush를 1로 설정한다.
- 코드 라인 12~13에서 워크큐에 등록된 모든 풀워크큐를 순회하며 연결된 워커풀을 가져온다.
- 코드 라인 17~25에서 플러시 컬러가 지정된 경우 플러시 컬러에 해당하는 nr_in_flight가 있을 때 풀워크큐의 플러시 컬러를 갱신한다. 그런 후 워크큐의 nr_pwqs_to_flush도 증가시킨다.
- 코드 라인 27~30에서 워크 컬러가 지정된 경우 풀워크큐의 워크컬러도 갱신한다.
- 코드 라인 35~36에서 플러시 컬러가 지정된 경우 nr_pwqs_to_flush를 감소시키고 그 전 값이 0인 경우 워크큐의 첫 플러싱이 완료될 때가지 기다린다.
pwq_adjust_max_active()
kernel/workqueue.c
/** * pwq_adjust_max_active - update a pwq's max_active to the current setting * @pwq: target pool_workqueue * * If @pwq isn't freezing, set @pwq->max_active to the associated * workqueue's saved_max_active and activate delayed work items * accordingly. If @pwq is freezing, clear @pwq->max_active to zero. */
static void pwq_adjust_max_active(struct pool_workqueue *pwq)
{
struct workqueue_struct *wq = pwq->wq;
bool freezable = wq->flags & WQ_FREEZABLE;
unsigned long flags;
/* for @wq->saved_max_active */
lockdep_assert_held(&wq->mutex);
/* fast exit for non-freezable wqs */
if (!freezable && pwq->max_active == wq->saved_max_active)
return;
/* this function can be called during early boot w/ irq disabled */
spin_lock_irq(&pwq->pool->lock, flags);
/*
* During [un]freezing, the caller is responsible for ensuring that
* this function is called at least once after @workqueue_freezing
* is updated and visible.
*/
if (!freezable || !workqueue_freezing) {
pwq->max_active = wq->saved_max_active;
while (!list_empty(&pwq->delayed_works) &&
pwq->nr_active < pwq->max_active)
pwq_activate_first_delayed(pwq);
/*
* Need to kick a worker after thawed or an unbound wq's
* max_active is bumped. It's a slow path. Do it always.
*/
wake_up_worker(pwq->pool);
} else {
pwq->max_active = 0;
}
spin_unlock_irq(&pwq->pool->lock, flags);
}
풀워크큐의 max_active를 조정한다. (max_active는 최대 동시 처리할 수 있는 워크 수이다.)
- 코드 라인 4에서 WQ_FREEZABLE 플래그가 사용된 워크큐인지 여부를 알아온다.
- 코드 라인 11~12에서 freezable 설정되지 않았으면서 워크큐와 워커풀이 동일한 max_active 설정이 된 경우 함수를 빠져나간다.
- 코드 라인 22~23에서 freezable 설정되지 않았거나 절전이 시작되어(suspend로 인해) 워크큐가 현재 프리징이 진행중인 경우가 아니면 워크큐의 saved_max_active를 그대로 풀워크큐에도 사용한다.
- 코드 라인 25~33에서 delayed 리스트에 워크들이 있으면서 풀워크큐의 동시 처리수(max_active)가 여유가 있으면 첫 번째 delayed 리스트의 워크를 워커풀로 옮긴 후 워커풀의 워커를 꺠운다. (max_active 제한 및 suspend 처리로 인해 지연된 작업을 워커풀에 옮겨 처리하게 한다)
- 코드 라인 34~36에서 freezable 기능으로 인해 풀워크큐의 max_active는 0으로 설정된다.
- 풀워크큐의 max_active를 0으로 처리하는 경우 모든 워크 요청은 곧바로 처리하지 않고 delayed 리스트에 등록한다.
풀워크큐들 할당 및 연결
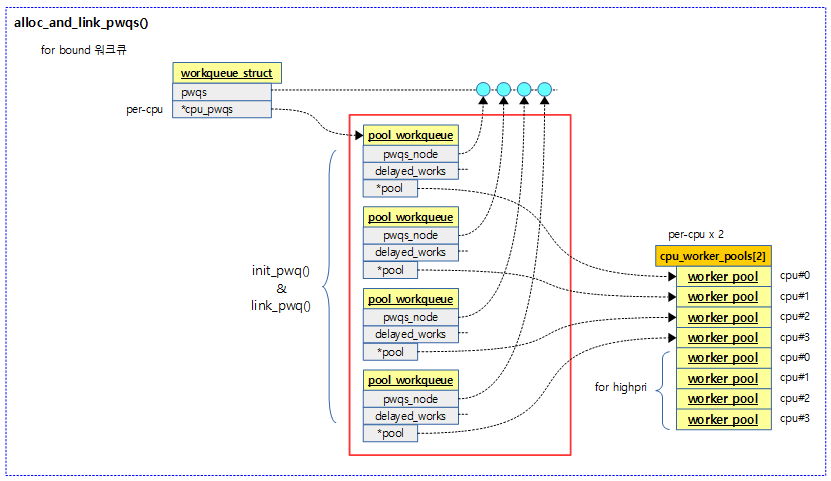
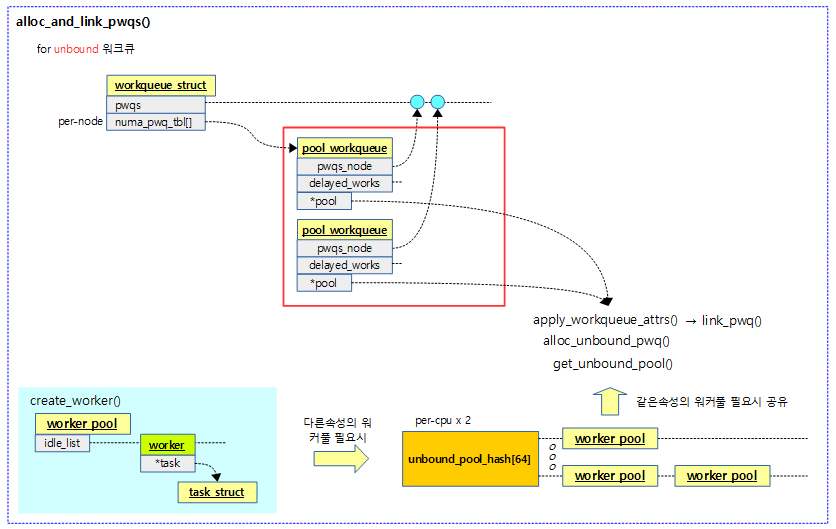
alloc_and_link_pwqs()
kernel/workqueue.c
static int alloc_and_link_pwqs(struct workqueue_struct *wq)
{
bool highpri = wq->flags & WQ_HIGHPRI;
int cpu, ret;
if (!(wq->flags & WQ_UNBOUND)) {
wq->cpu_pwqs = alloc_percpu(struct pool_workqueue);
if (!wq->cpu_pwqs)
return -ENOMEM;
for_each_possible_cpu(cpu) {
struct pool_workqueue *pwq =
per_cpu_ptr(wq->cpu_pwqs, cpu);
struct worker_pool *cpu_pools =
per_cpu(cpu_worker_pools, cpu);
init_pwq(pwq, wq, &cpu_pools[highpri]);
mutex_lock(&wq->mutex);
link_pwq(pwq);
mutex_unlock(&wq->mutex);
}
return 0;
}
get_online_cpus();
if (wq->flags & __WQ_ORDERED) {
ret = apply_workqueue_attrs(wq, ordered_wq_attrs[highpri]);
/* there should only be single pwq for ordering guarantee */
WARN(!ret && (wq->pwqs.next != &wq->dfl_pwq->pwqs_node ||
wq->pwqs.prev != &wq->dfl_pwq->pwqs_node),
"ordering guarantee broken for workqueue %s\n", wq->name);
return ret;
} else {
return apply_workqueue_attrs(wq, unbound_std_wq_attrs[highpri]);
}
put_online_cpus();
return ret;
}
풀워크큐들을 할당하고 워커풀에 연결한다.
- bound용인 경우 cpu 수 만큼 풀워크큐를 할당하고 워커풀에 연결한다.
- unbound용인 경우 node 수 만큼 풀워크큐를 할당하고 언바운드 해시 워커풀에서 같은 속성의 워커풀을 가져와서 공유한다. 단 같은 속성을 사용하는 워커풀이 없는 경우 워커풀과 소속된 워커를 새로 할당하여 사용한다.
- 코드 라인 3에서 워크큐가 WQ_HIGHPRI 속성을 가지고 있는지 확인한다.
- 코드 라인 6~24에서 바운드용 워크큐인 경우 cpu 수 만큼 풀워크큐를 할당받은 후 컴파일 타임에 만들어진 cpu별 워커풀과 연결하고 생성한 풀워크큐를 초기화하고 워커풀과 연결한 후 정상적으로 함수를 빠져나간다.
- 코드 라인 27~33에서 워크큐가 __WQ_ORDERED 플래그가 설정된 경우 워크들이 병렬처리되면 안된다. 따라서 1개의 풀워크큐와 워커풀이 연결되게 한다.
- 코드 라인 34~36에서 그 밖의 언바운드용 워크큐인 경우 노드 수 만큼 풀워크큐를 할당받은 후 언바운드 해시 워커풀에서 같은 속성의 워커풀과 연결한다. 만일 같은 속성의 워커풀이 없는 경우 새로운 워커풀과 워커풀용 워커를 할당하여 사용한다.
다음 그림은 cpu 수 만큼 bound용 풀워크큐를 할당하고 cpu별 워커풀을 연결하는 모습을 보여준다.
다음 그림은 노드 수 만큼 풀워크큐를 할당하고 unbound용 해시 워커풀에서 같은 속성을 사용하는 워커풀에 연결되는 모습을 보여준다.
풀워크큐 초기화
init_pwq()
kernel/workqueue.c
/* initialize newly alloced @pwq which is associated with @wq and @pool */
static void init_pwq(struct pool_workqueue *pwq, struct workqueue_struct *wq,
struct worker_pool *pool)
{
BUG_ON((unsigned long)pwq & WORK_STRUCT_FLAG_MASK);
memset(pwq, 0, sizeof(*pwq));
pwq->pool = pool;
pwq->wq = wq;
pwq->flush_color = -1;
pwq->refcnt = 1;
INIT_LIST_HEAD(&pwq->delayed_works);
INIT_LIST_HEAD(&pwq->pwqs_node);
INIT_LIST_HEAD(&pwq->mayday_node);
INIT_WORK(&pwq->unbound_release_work, pwq_unbound_release_workfn);
}
풀워크큐를 초기화한다.
- 코드 라인 7에서 풀워크큐 구조체 내용을 모두 0으로 초기화한다.
- 코드 라인 9~10에서 풀워크큐에 요청한 워커풀 및 워크큐를 대입한다.
- 코드 라인 11에서 플러시 컬러를 -1로 지정하여 초기화한다.
- 코드 라인 12에서 이 풀워크큐의 참조 카운터를 1로 하여 사용중으로 한다.
- 코드 라인 13~15에서 각 리스트를 초기화한다.
- 코드 라인 16에서 풀워크큐를 삭제하는 시스템 전용의 특수한 워크를 풀워크큐에 등록한다.
- 마지막 풀워크큐가 삭제되면 워크큐도 삭제한다.
풀워크큐를 워크큐에 연결
link_pwq()
kernel/workqueue.c
/* sync @pwq with the current state of its associated wq and link it */
static void link_pwq(struct pool_workqueue *pwq)
{
struct workqueue_struct *wq = pwq->wq;
lockdep_assert_held(&wq->mutex);
/* may be called multiple times, ignore if already linked */
if (!list_empty(&pwq->pwqs_node))
return;
/* set the matching work_color */
pwq->work_color = wq->work_color;
/* sync max_active to the current setting */
pwq_adjust_max_active(pwq);
/* link in @pwq */
list_add_rcu(&pwq->pwqs_node, &wq->pwqs);
}
풀워크큐를 워크큐에 연결한다.
- 코드 라인 9~10에서 풀워크큐가 이미 워크큐의 풀워크큐 리스트에 등록된 경우 함수를 빠져나간다.
- 코드 라인 13에서 워크큐의 워크 컬러 값을 풀워크큐에 대입한다.
- 코드 라인 16에서 워크큐의 saved_max_active를 반영하여 풀워크큐의 max_active를 조정한다.
- 코드 라인 19에서 rcu 방식으로 워크큐의 풀워크큐 리스트에 풀워크큐를 추가한다.
언바운드 풀워크큐 할당
alloc_unbound_pwq()
kernel/workqueue.c
/* obtain a pool matching @attr and create a pwq associating the pool and @wq */
static struct pool_workqueue *alloc_unbound_pwq(struct workqueue_struct *wq,
const struct workqueue_attrs *attrs)
{
struct worker_pool *pool;
struct pool_workqueue *pwq;
lockdep_assert_held(&wq_pool_mutex);
pool = get_unbound_pool(attrs);
if (!pool)
return NULL;
pwq = kmem_cache_alloc_node(pwq_cache, GFP_KERNEL, pool->node);
if (!pwq) {
put_unbound_pool(pool);
return NULL;
}
init_pwq(pwq, wq, pool);
return pwq;
}
언바운드 풀워크큐를 할당한다. (워커풀 및 초기 워커까지 준비한다.)
- 코드 라인 10~12에서 언바운드 워커풀을 얻어온다. (기존에 같은 속성을 가진 워커풀을 공유하거나 새로 할당 받아온다)
- 코드 라인 14~18에서 풀워크큐를 할당받아온다.
- 코드 라인 20~21에서 풀워크큐를 초기화한 후 반환한다.
워커풀
워커풀 초기화
init_worker_pool()
kernel/workqueue.c
/** * init_worker_pool - initialize a newly zalloc'd worker_pool * @pool: worker_pool to initialize * * Initiailize a newly zalloc'd @pool. It also allocates @pool->attrs. * * Return: 0 on success, -errno on failure. Even on failure, all fields * inside @pool proper are initialized and put_unbound_pool() can be called * on @pool safely to release it. */
static int init_worker_pool(struct worker_pool *pool)
{
spin_lock_init(&pool->lock);
pool->id = -1;
pool->cpu = -1;
pool->node = NUMA_NO_NODE;
pool->flags |= POOL_DISASSOCIATED;
pool->watchdog_ts = jiffies;
INIT_LIST_HEAD(&pool->worklist);
INIT_LIST_HEAD(&pool->idle_list);
hash_init(pool->busy_hash);
timer_setup(&pool->idle_timer, idle_worker_timeout, TIMER_DEFERRABLE);
timer_setup(&pool->mayday_timer, pool_mayday_timeout, 0);
INIT_LIST_HEAD(&pool->workers);
ida_init(&pool->worker_ida);
INIT_HLIST_NODE(&pool->hash_node);
pool->refcnt = 1;
/* shouldn't fail above this point */
pool->attrs = alloc_workqueue_attrs();
if (!pool->attrs)
return -ENOMEM;
return 0;
}
워커풀들을 초기화한다.
- 코드 라인 4에서 워커풀의 id를 -1로 설정한다.
- 코드 라인 5에서 연결된 cpu가 없는 -1로 설정한다.
- 코드 라인 6에서 누마 적용되지 않은 상태(-1)로 설정한다.
- 코드 라인 7에서 어떠한 워커와 연결되지 않은 상태로 설정한다.
- 코드 라인 8에서 워치독 시각을 현재 시각(jiffies)으로 설정한다.
- 코드 라인 10~11에서 worklist와 idle_list 리스트를 초기화한다.
- 코드 라인 12에서 해시용 busy_hash 리스트들을 초기화한다.
- 코드 라인 13에서 idle_timer를 유예 타이머로 초기화한다.
- 만료 시 idle_worker_timerout() 함수가 호출된다.
- 코드 라인 14에서 mayday_timer를 초기화한다.
- 만료 시 pool_mayday_timerout() 함수가 호출된다.
- 코드 라인 16에서 워크들이 등록될 worker 리스트를 초기화한다.
- 코드 라인 18에서 워커들을 ida radix 트리 구조로 관리하기 위해 worker_ida를 초기화한다.
- 코드 라인 19에서 hash_node를 초기화한다.
- 코드 라인 20에서 워커풀의 참조 카운터를 1로 설정한다.
- 코드 라인 23~25에서 워크큐 속성을 할당받아 풀에 지정한다.
- 코드 라인 26에서 성공 값 0을 반환한다.
for_each_cpu_worker_pool()
kernel/workqueue.c
#define for_each_cpu_worker_pool(pool, cpu) \
for ((pool) = &per_cpu(cpu_worker_pools, cpu)[0]; \
(pool) < &per_cpu(cpu_worker_pools, cpu)[NR_STD_WORKER_POOLS]; \
(pool)++)
요청한 cpu에 해당하는 워커풀을 순회한다.
- cpu 워커풀은 컴파일 타임에 NR_STD_WORKER_POOLS(2) 만큼 생성된다.
워커풀 속성
alloc_workqueue_attrs()
kernel/workqueue.c
/** * alloc_workqueue_attrs - allocate a workqueue_attrs * @gfp_mask: allocation mask to use * * Allocate a new workqueue_attrs, initialize with default settings and * return it. * * Return: The allocated new workqueue_attr on success. %NULL on failure. */
struct workqueue_attrs *alloc_workqueue_attrs(gfp_t gfp_mask)
{
struct workqueue_attrs *attrs;
attrs = kzalloc(sizeof(*attrs), gfp_mask);
if (!attrs)
goto fail;
if (!alloc_cpumask_var(&attrs->cpumask, gfp_mask))
goto fail;
cpumask_copy(attrs->cpumask, cpu_possible_mask);
return attrs;
fail:
free_workqueue_attrs(attrs);
return NULL;
}
워크큐 속성을 할당받아 반환한다.
- 코드 라인 5~7에서 워크큐 속성을 할당받아온다.
- 코드 라인 8~9에서 워크큐 속성의 cpumask도 할당받거나 준비한다.
- 코드 라인 11에서 possible cpu들에 대한 cpumask를 속성에 복사한다.
- 코드 라인 12에서 할당한 속성을 반환한다.
워커풀 id 할당
worker_pool_assign_id()
kernel/workqueue.c
/** * worker_pool_assign_id - allocate ID and assing it to @pool * @pool: the pool pointer of interest * * Returns 0 if ID in [0, WORK_OFFQ_POOL_NONE) is allocated and assigned * successfully, -errno on failure. */
static int worker_pool_assign_id(struct worker_pool *pool)
{
int ret;
lockdep_assert_held(&wq_pool_mutex);
ret = idr_alloc(&worker_pool_idr, pool, 0, WORK_OFFQ_POOL_NONE,
GFP_KERNEL);
if (ret >= 0) {
pool->id = ret;
return 0;
}
return ret;
}
IDR Radix 트리인 전역 worker_pool_idr에서 워커풀의 id를 할당받은 후 워커풀의 id에 지정한다. 성공한 경우 0을 반환한다.
워크가 등록된 워커풀 찾기
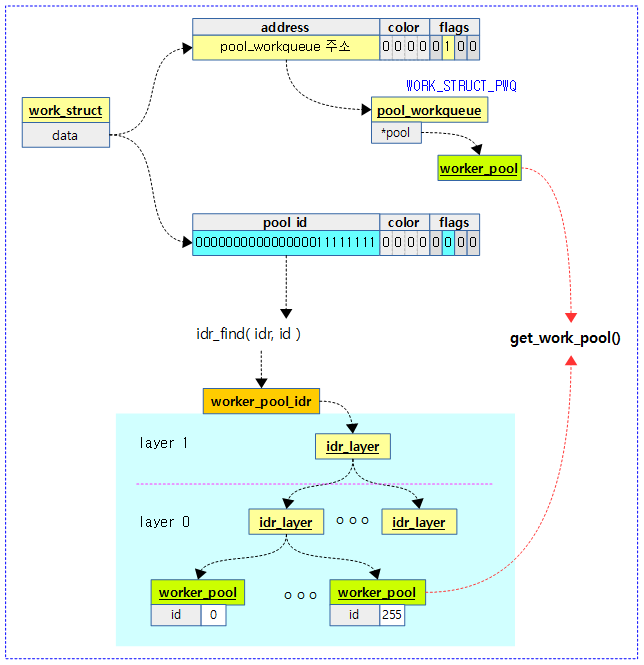
get_work_pool()
kernel/workqueue.c
/** * get_work_pool - return the worker_pool a given work was associated with * @work: the work item of interest * * Pools are created and destroyed under wq_pool_mutex, and allows read * access under sched-RCU read lock. As such, this function should be * called under wq_pool_mutex or with preemption disabled. * * All fields of the returned pool are accessible as long as the above * mentioned locking is in effect. If the returned pool needs to be used * beyond the critical section, the caller is responsible for ensuring the * returned pool is and stays online. * * Return: The worker_pool @work was last associated with. %NULL if none. */
static struct worker_pool *get_work_pool(struct work_struct *work)
{
unsigned long data = atomic_long_read(&work->data);
int pool_id;
assert_rcu_or_pool_mutex();
if (data & WORK_STRUCT_PWQ)
return ((struct pool_workqueue *)
(data & WORK_STRUCT_WQ_DATA_MASK))->pool;
pool_id = data >> WORK_OFFQ_POOL_SHIFT;
if (pool_id == WORK_OFFQ_POOL_NONE)
return NULL;
return idr_find(&worker_pool_idr, pool_id);
}
요청한 워크가 등록된 워크풀을 찾아 반환한다.
- 코드 라인 3~10에서 data 멤버를 통해 풀별 워크큐를 알아낸 후 연결된 워커풀을 반환한다.
- 코드 라인 12~14에서 풀 id를 알아오고 그 값이 지정되지 않은 경우 null을 반환한다.
- 코드 라인 16에서 풀 id로 워커풀을 찾아 반환한다.
- 전역 IDR 트리인 worker_pool_idr에서 pool_id로 검색하여 등록된 worker_pool을 알아온다.
다음 그림은 get_work_pool() 함수가 2 가지의 방법을 사용해서 워커풀을 알아오는 모습을 보여준다.
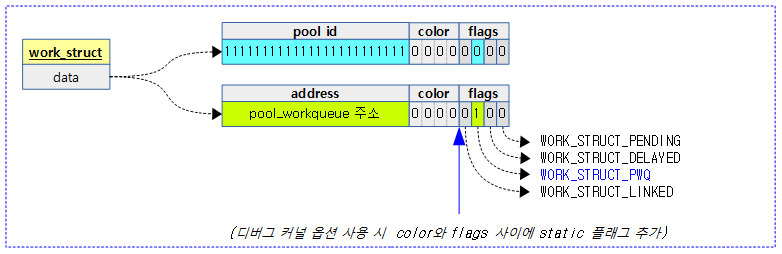
다음 그림에서 워크의 data 멤버는 아래 그림과 같은 정보들을 표현하며 다음의 2 가지 정보 중 하나를 가지고 있다.
- WORK_STRUCT_PWQ_BIT가 설정되지 않은 경우 WORK_OFFQ_POOL_SHIFT 만큼 우측으로 쉬프트한 값을 pool id 값으로 사용한다.
- WORK_STRUCT_PWQ_BIT가 설정된 경우 pool_workqueue 구조체 주소를 지정한다.
언바운드 워커풀
get_unbound_pool()
kernel/workqueue.c
/** * get_unbound_pool - get a worker_pool with the specified attributes * @attrs: the attributes of the worker_pool to get * * Obtain a worker_pool which has the same attributes as @attrs, bump the * reference count and return it. If there already is a matching * worker_pool, it will be used; otherwise, this function attempts to * create a new one. * * Should be called with wq_pool_mutex held. * * Return: On success, a worker_pool with the same attributes as @attrs. * On failure, %NULL. */
static struct worker_pool *get_unbound_pool(const struct workqueue_attrs *attrs)
{
u32 hash = wqattrs_hash(attrs);
struct worker_pool *pool;
int node;
int target_node = NUMA_NO_NODE;
lockdep_assert_held(&wq_pool_mutex);
/* do we already have a matching pool? */
hash_for_each_possible(unbound_pool_hash, pool, hash_node, hash) {
if (wqattrs_equal(pool->attrs, attrs)) {
pool->refcnt++;
return pool;
}
}
/* if cpumask is contained inside a NUMA node, we belong to that node */
if (wq_numa_enabled) {
for_each_node(node) {
if (cpumask_subset(attrs->cpumask,
wq_numa_possible_cpumask[node])) {
target_node = node;
break;
}
}
}
/* nope, create a new one */
pool = kzalloc_node(sizeof(*pool), GFP_KERNEL, target_node);
if (!pool || init_worker_pool(pool) < 0)
goto fail;
lockdep_set_subclass(&pool->lock, 1); /* see put_pwq() */
copy_workqueue_attrs(pool->attrs, attrs);
pool->node = target_node;
/*
* no_numa isn't a worker_pool attribute, always clear it. See
* 'struct workqueue_attrs' comments for detail.
*/
pool->attrs->no_numa = false;
if (worker_pool_assign_id(pool) < 0)
goto fail;
/* create and start the initial worker */
if (wq_online && !create_worker(pool))
goto fail;
/* install */
hash_add(unbound_pool_hash, &pool->hash_node, hash);
return pool;
fail:
if (pool)
put_unbound_pool(pool);
return NULL;
}
속성 @attrs에 매치되는 언바운드 워커풀을 찾아 공유하고, 없는 경우 생성해온다.
- 코드 라인 3에서 요청한 속성 값으로 hash 인덱스를 알아온다.
- 코드 라인 11~16에서 언바운드 해시 워커풀의 hash에 해당하는 인덱스의 리스트를 순회하며 워커풀에 등록된 워크큐 속성이 요청한 워크큐 속성과 동일(nice와 cpumask 비교)한 경우 그 워커풀의 참조 카운터를 1 증가시키고 반환한다. 워크큐 속성이 같은 경우 새로운 워커풀을 생성하지 않고 기존 워커풀을 공유한다.
- 코드 라인 19~27에서 numa 워크큐가 활성화된 경우 노드를 순회하며 속성들이 wq_numa_possible_cpumask[node]에 속한 경우 해당 노드를 target_node로 지정한다.
- 코드 라인 30~32에서 언바운드용 워커풀을 할당 받은 후 초기화한다.
- 코드 라인 35에서 요청한 워크큐 속성을 워커풀에 복사한다. (nice, cpumask, no_numa)
- 코드 라인 36에서 워커풀에 찾은 노드를 지정한다.
- 코드 라인 42에서 워커풀의 속성 중 no_numa는 워커풀의 속성이 아니다 항상 생성 후 먼저 false로 클리어한다.
- 코드 라인 44~45 에서 워커풀에 노드 번호를 지정한다.
- 코드 라인 48~49에서 워커풀내에 초기 워커를 생성한다.
- 코드 라인 52에서 언바운드 해시 워커풀의 해시에 생성한 워커풀을 추가한다.
- 코드 라인 54에서 생성한 언바운드 워커풀을 반환한다.
put_unbound_pool()
kernel/workqueue.c
/** * put_unbound_pool - put a worker_pool * @pool: worker_pool to put * * Put @pool. If its refcnt reaches zero, it gets destroyed in sched-RCU * safe manner. get_unbound_pool() calls this function on its failure path * and this function should be able to release pools which went through, * successfully or not, init_worker_pool(). * * Should be called with wq_pool_mutex held. */
static void put_unbound_pool(struct worker_pool *pool)
{
DECLARE_COMPLETION_ONSTACK(detach_completion);
struct worker *worker;
lockdep_assert_held(&wq_pool_mutex);
if (--pool->refcnt)
return;
/* sanity checks */
if (WARN_ON(!(pool->cpu < 0)) || WARN_ON(!list_empty(&pool->worklist)))
return;
/* release id and unhash */
if (pool->id >= 0)
idr_remove(&worker_pool_idr, pool->id);
hash_del(&pool->hash_node);
/*
* Become the manager and destroy all workers. This prevents
* @pool's workers from blocking on attach_mutex. We're the last
* manager and @pool gets freed with the flag set.
*/
spin_lock_irq(&pool->lock);
wait_event_lock_irq(wq_manager_wait,
!(pool->flags & POOL_MANAGER_ACTIVE), pool->lock);
pool->flags |= POOL_MANAGER_ACTIVE;
while ((worker = first_idle_worker(pool)))
destroy_worker(worker);
WARN_ON(pool->nr_workers || pool->nr_idle);
spin_unlock_irq(&pool->lock);
mutex_lock(&wq_pool_attach_mutex);
if (!list_empty(&pool->workers))
pool->detach_completion = &detach_completion;
mutex_unlock(&wq_pool_attach_mutex);
if (pool->detach_completion)
wait_for_completion(pool->detach_completion);
/* shut down the timers */
del_timer_sync(&pool->idle_timer);
del_timer_sync(&pool->mayday_timer);
/* RCU protected to allow dereferences from get_work_pool() */
call_rcu(&pool->rcu, rcu_free_pool);
}
언바운드 워커풀의 사용을 해제한다.
- 코드 라인 8~9에서 워커풀의 참조카운터를 1 감소시키고 0이 아니면 함수를 빠져나간다.
- 코드 라인 12~13에서 워커풀의 cpu가 지정되어 있지 않거나 워커풀에 워크리스트가 비어 있지 않은 경우 경고 메시지 출력과 함께 함수를 빠져나간다.
- 코드 라인 16~18에서 worker_pool_idr 트리에서 워커풀의 id를 제거하고 언바운드 해시 워커풀에서도 제거한다.
- 코드 라인 25~33에서 idle 워커들을 모두 제거한다.
- 코드 라인 35~41에서 워커풀에 워커리스트가 비어 있지 않은 경우 워커풀의 워커들이 모두 제거될 때까지 대기한다.
- 코드 라인 44~45에서 idle 타이머와 mayday 타이머를 제거한다.
- 코드 라인 48에서 rcu 방식으로 rcu_free_pool() 함수를 호출하여 워커풀을 제거한다.
may_start_working()
kernel/workqueue.c
/* Can I start working? Called from busy but !running workers. */
static bool may_start_working(struct worker_pool *pool)
{
return pool->nr_idle;
}
요청한 워커풀에 idle 워커가 준비되어 작업을 처리할 수 있는지 여부를 알아온다. (idle 워커 수를 반환한다.)
rcu_free_pool()
kernel/workqueue.c
static void rcu_free_pool(struct rcu_head *rcu)
{
struct worker_pool *pool = container_of(rcu, struct worker_pool, rcu);
ida_destroy(&pool->worker_ida);
free_workqueue_attrs(pool->attrs);
kfree(pool);
}
워커풀을 제거한다.
- 코드 라인 5에서 워커풀의 worker_ida 트리를 제거한다.
- 코드 라인 6~7에서 워커풀의 워크큐 속성 및 워커풀을 할당 해제한다.
참고
- Interrupts -1- (Interrupt Controller) | 문c
- Interrupts -2- (irq chip) | 문c
- Interrupts -3- (irq domain) | 문c
- Interrupts -4- (Top-Half & Bottom-Half) | 문c
- Interrupts -5- (Softirq) | 문c
- Interrupts -6- (IPI Cross-call) | 문c
- Interrupts -7- (Workqueue 1) | 문c – 현재 글
- Interrupts -8- (Workqueue 2) | 문c
- Interrupts -9- (GIC v3 Driver) | 문c
- Interrupts -10- (irq partition) | 문c
- Interrupts -11- (RPI2 IC Driver) | 문c
- Interrupts -12- (irq desc) | 문c
- Driver porting: the workqueue interface. | LWN.net
- [Linux] concurrency managed workqueue (cmwq) | F/OSS
- 지연 가능 함수, 커널 태스크릿 및 작업 큐 (BOTTOM HALF) | 신불사
- Multitasking in the Linux Kernel. Workqueues | Vita Loginova
- Details of the workqueue interface (2002) | LWN.net