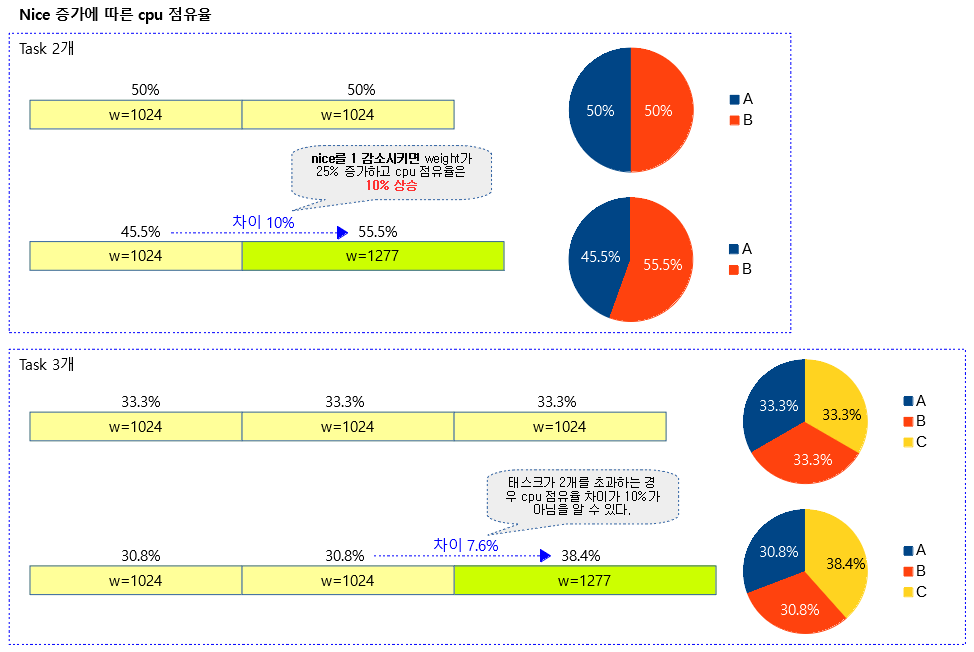
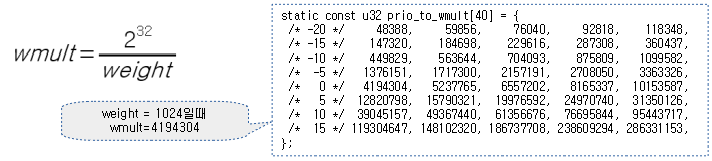
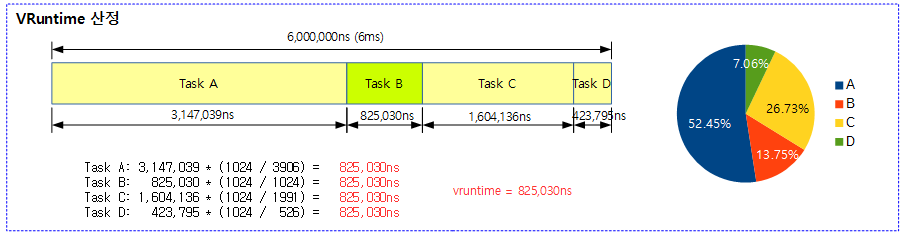
<kernel v5.4>
멀티 태스킹
arm 아키텍처에서 각 cpu core들은 한 번에 하나의 스레드를 동작시킬 수 있다. (특정 아키텍처에서 cpu core 당 2 개 이상의 h/w 스레드를 지원하기도한다. 예: 인텔의 하이퍼스레드 등) 사용자가 요청한 여러 개의 태스크를 동시에 처리하기 위해 각 태스크들을 일정 주기 시간을 분할하여 스케줄하는 방법을 사용한다.
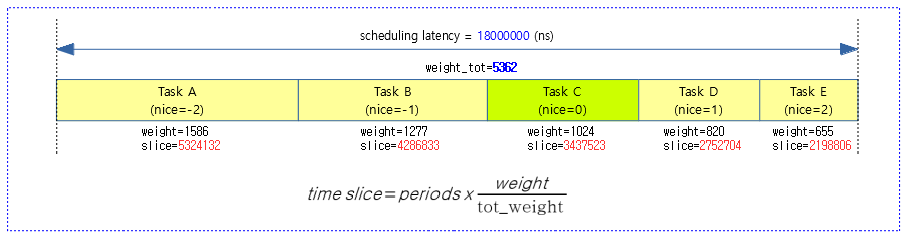
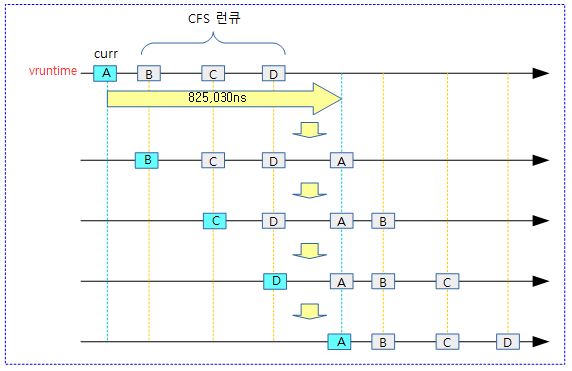
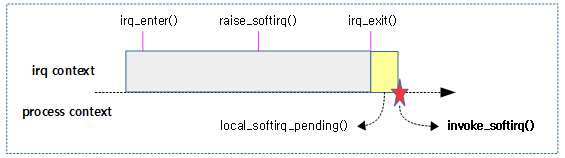
다음 그림과 같이 시간 분할하여 스케줄한 예를 보여준다. (1 core 시스템에서 디폴트 스케줄 레이턴시: 6ms)
- Case A) 3개의 태스크를 구동한 예:
- 3개의 태스크 각 A, B, C 태스크가 각자 지정된 로드 weight 비율로 6ms 스케줄링 레이튼시 간격으로 스케줄 처리하는 것으로 멀티태스킹을 수행한다.
- Case B) 1개의 태스크를 구동한 예:
- 1개의 태스크는 경쟁하는 태스크가 없으므로 계속 동작한다. sleep 하는 구간에서는 idle 태스크가 대신 동작한다.
- Case C) 10개의 태스크를 구동한 예:
- 8개를 초과하는 태스크의 경우 디폴트 스케줄링 레이튼시를 초과하므로 지정된 최소 할당 시간(0.75ms) x 태스크 수를 산출하여 스케줄링 레이턴시를 산출하여 처리한다.
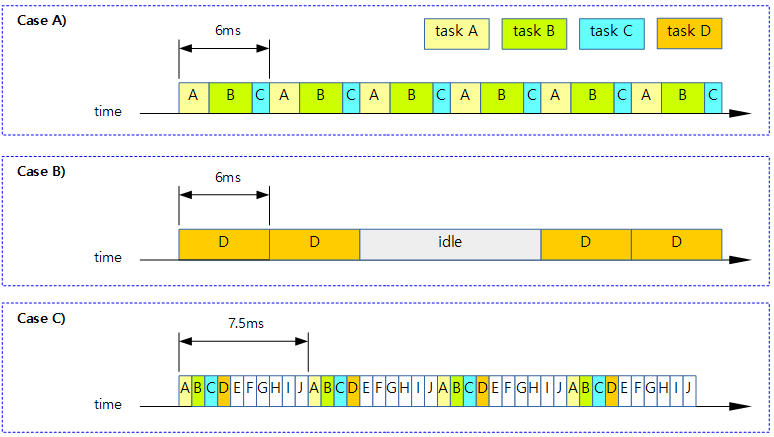
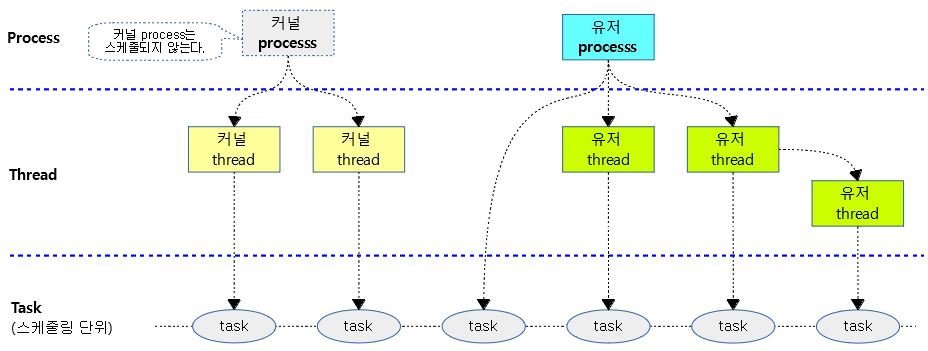
유저 모드 vs 커널 모드
다음 그림과 같이 유저 모드와 커널 모드에서 동작하는 태스크들을 구분해본다.
- 아키텍처에 따라 커널 모드 및 유저 모드의 정확한 명칭이 조금씩 다르다.
- 예) ARM32 및 ARM64 AArch32의 경우 커널 모드는 PL1(Previlidge Level 1)이다. 경우에 따라서는 하이퍼바이저의 PL2도 포함된다. 그리고 유저 모드는 PL0로 동작한다.
- 예) ARM64 AArch64의 경우 커널 모드는 EL1(Exception Level 1)이다. 경우에 따라서는 하이퍼바이저의 EL2도 포함된다. 그리고 유저 모드는 EL0(Exception Level 0)로 동작한다.
- dl, rt, cfs 태스크들은 유저 모드에서 동작시킬 수도 있고, 커널 모드에서 동작시킬 수 있다.
- 예) kthreadd는 커널 모드에서 동작하는 cfs 태스크이고, /sbin/init의 경우 유저 모드에서 동작하는 cfs 태스크이다.
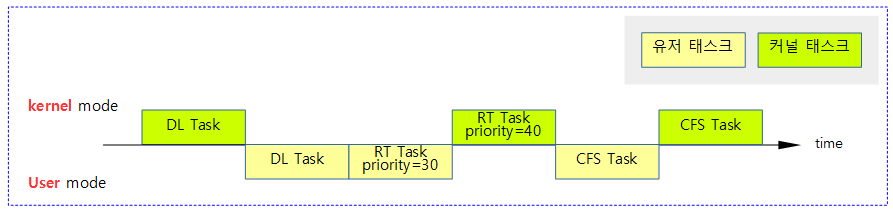
다음 그림과 같이 인터럽트 및 Exception 코드들은 커널 모드에서 동작하는 것을 알 수 있다. 그리고 유저에서 요청한 syscall 역시 커널 모드에서 동작한다.
- 아래 전체 구간에서 리눅스 커널의 preemption 모델에 따라 preemption이 가능한 구간과 불가능한 구간을 파악해내는 것이 중요하다.
Preemption
한 개의 태스크가 cpu 시간을 독차지하지 못하게 제어를 할 필요가 있어 다음과 같은 순간에 다른 태스크의 전환을 수행한다.
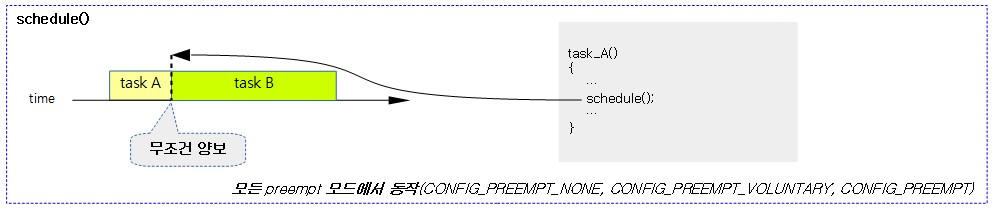
1) 양보
다음 그림과 같이 유저/커널 태스크의 구분 없이 모든 preemption 모드에서 yield() 또는 schedule() 함수가 동작하는 경우 다음 수행하여야 할 태스크를 선택한다.
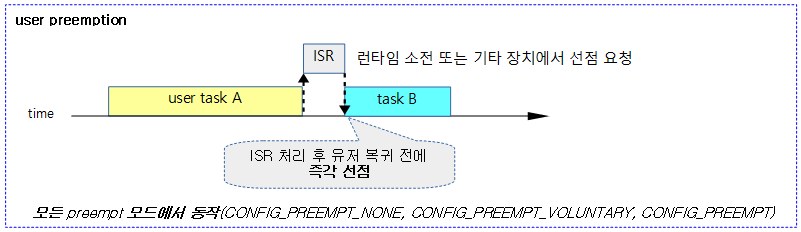
2) 유저 선점
다음 그림과 같이 유저 태스크 동작 중 syscall, exception 및 인터럽트에 의해 선점 요청이 이루어진 경우 유저 모드 복귀 시 리스케줄을 수행한다.
- 타이머 인터럽트에서 현재 태스크의 런타임이 다 소진되었거나, 기타 장치 인터럽트에서 우선 처리할 태스크가 있는 경우 요청된다.
3) 커널 선점
- CONFIG_PREEMPT_NONE
- 커널 스레드가 스스로 양보하지 않으면 preemption되지 않는다. 커널 태스크를 만들어 사용하는 경우 일반적으로 태스크를 설계 시 적절한 위치에서 종종 양보(yield or sleep)를 해야 한다.
- CONFIG_PREEMPT_VOLUNTRY
- 커널 스레드가 양보하지 않으면 preemption되지 않는 것은 동일하다. 단 커널 API의 곳곳에 preemption point를 두었고 이 곳에서 리스케줄 요청 플래그를 확인하고 직접 양보를 수행한다.
- CONFIG_PREEMPT & CONFIG_PREEMPT_RT
- 유저 선점처럼 실시간 선점이 가능하다. 단 다음의 경우엔 즉각 선점을 허용하지 않고 약간 지연된다.
- 인터럽트 처리 중
- 인터럽트가 끝날 때 preemption을 허용하므로 약간의 latency가 발생한다.
- disable_preempt() 처리중
- preemption을 허용하지 않고 있다가, enable_preempt() 명령이 올 때 preemption을 허용하므로 약간의 latency가 발생한다.
- 인터럽트 처리 중
- 유저 선점처럼 실시간 선점이 가능하다. 단 다음의 경우엔 즉각 선점을 허용하지 않고 약간 지연된다.
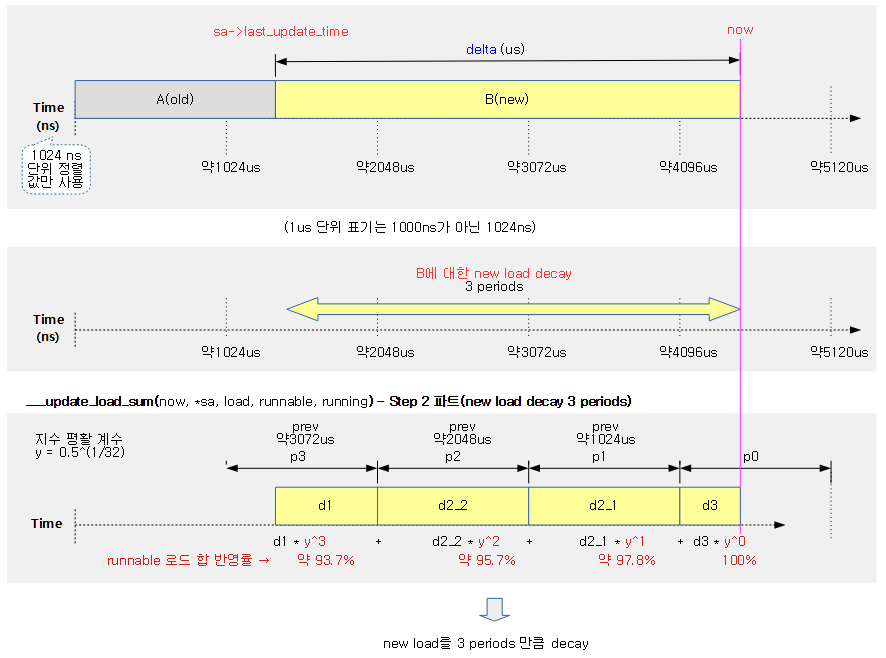
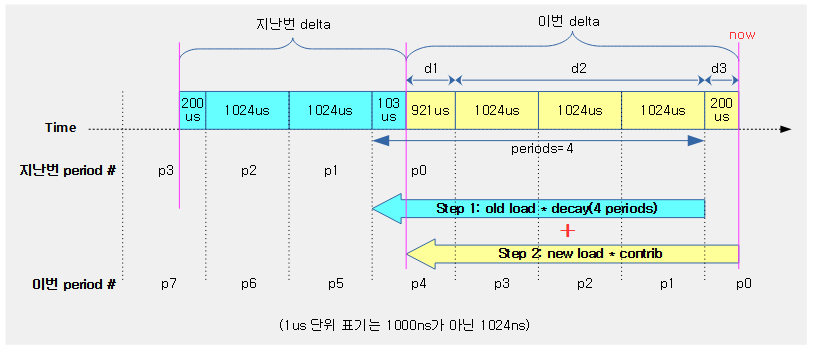
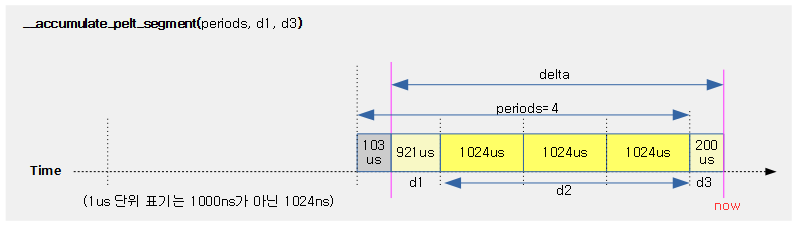
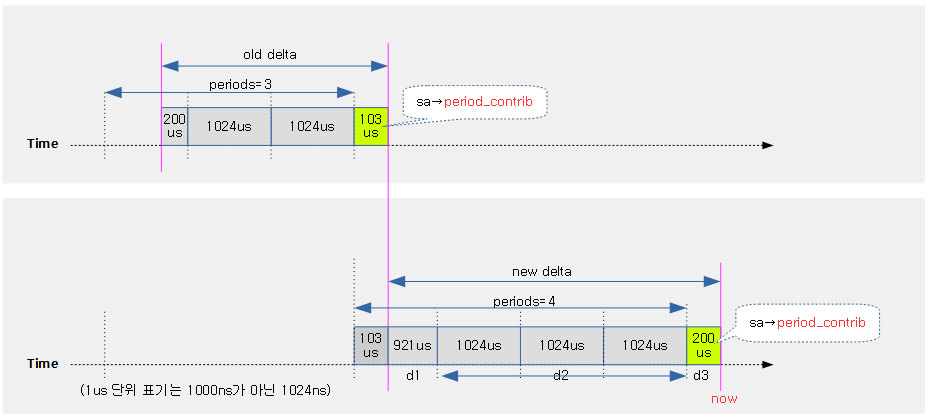
다음 그림은 커널 선점에 대해 4개의 preemption 모델별 처리 차이를 보여준다.

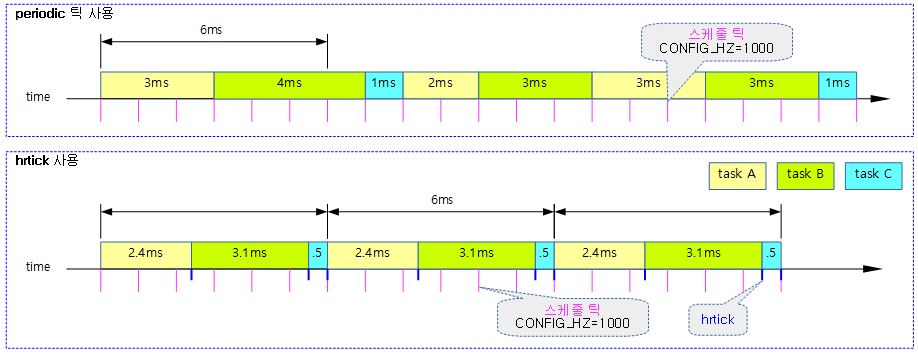
런타임 소진에 따른 스케줄(유저 선점 예)
유저 태스크에 주어진 로드 weight 비율만큼의 산출된 런타임이 다 소진된 경우 이를 체크하기 위해 타이머 인터럽트가 사용된다. 틱은 다음과 같이 두 가지 종류 중 하나 이상을 사용한다.
- hrtick
- hrtick을 사용하는 시스템에서는 산출된 런타임에 맞춰 타이머 인터럽트를 생성하고 그 때마다 런타임 소진을 체크하므로 just하게 스케줄할 수 있다
- CONFIG_SCHED_HRTICK 커널 옵션과 hrtick_feature가 활성화되어야 한다.
- 디폴트: CONFIG_SCHED_HRTICK을 사용한다.
- 디폴트: hrtick feature를 사용하지 않는다.
- 정규 periodic tick
- 정규 periodic tick을 사용하는 시스템에서는 매 틱마다 런타임 소진을 체크한다. 런타임을 초과하여 사용한 런타임은 나중에 그 만큼 빼고 처리된다.
- periodic tick은 엄밀히 런타임 소진 또는 vruntime이 가장 작은 태스크로 스케줄링이된다.
다음 그림은 유저 태스크들을 대상으로 hrtick과 정규 periodic 틱을 사용하는 두 개의 예를 보여준다.
- preemption 체크 여부를 위해 두 틱을 다 사용하게 할 수도 있다. (double tick feature)
CONFIG_PREEMPT 또는 CONFIG_PREEMPT_RT 커널 옵션을 사용한 경우에는 커널 태스크가 동작 시 런타임 소진에 의해 선점 요청을 하면 위의 유저 태스크 상황과 동일하게 동작한다. 그러나 다른 커널 옵션을 사용하는 경우 양보 코드 및 preemption point에 의지하여 선점을 하는 것에 주의해야 한다.
preemption이 일어나는 것을 막아야 할 때?
- preemption은 동기화 문제를 수반한다.
- critical section으로 보호받는 영역에서는 preemption이 발생하면 안되기 때문에 이러한 경우 preempt_disable()을 사용한다.
- preempt_disable() 코드에서는 단순히 preempt 카운터를 증가시킨다.
- 인터럽트 발생 시 preempt 카운터가 0이 아니면 스케쥴링이 일어나지 않도록 즉 다른 스레드로의 context switching이 일어나지 않도록 막는다.
- 물론 interrupt를 원천적으로 disable하는 경우도 preemption 이 일어나지 않는다.
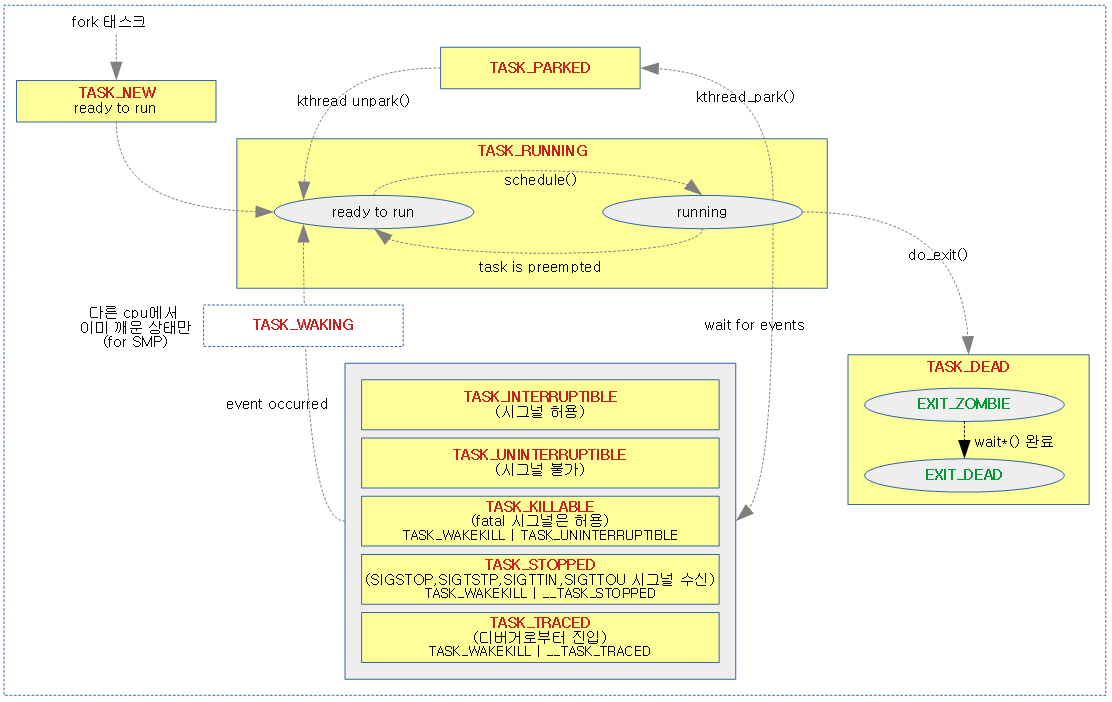
리눅스 preemption 모델의 특징
리눅스는 유저 모드에서는 태스크에 할당받은 time slice에 대해 모두 소진하기 전이라도 다른 태스크에 의해 preemption 되어 현재 태스크가 sleep될 수 있다. 하지만 커널 스레드나 커널 모드에서는 다음과 같이 4가지의 preemption 모델에 따라 동작을 다르게 한다.
PREEMPT_NONE:
- No Forced Preemption (Server)
- 반응 속도(latency)는 최대한 떨어뜨리되 배치 작업을 우선으로 하여 성능에 최적화 시켜 서버에 적합한 모델이다.
- 100hz ~ 250hz의 낮은 타이머 주기를 사용.
- context switching을 최소화
PREEMPT_VOLUNTARY:
- Voluntary Kernel Preemption (Desktop)
- 오래 걸릴만한 api 또는 드라이버에서 중간 중간에 preemption point를 두어 리스케줄 요청한 태스크들을 먼저 수행할 수 있도록 preemption 될 수 있게 한다. (중간 중간 필요한 preemption point에서 스케줄을 변경하게 한다.)
- 어느 정도 반응 속도(latency)를 높여 키보드, 마우스 및 멀티미디어 등의 작업이 가능하도록 하고 성능도 일정부분 보장하게 하도록한 데스크탑에 적합한 모델이다.
- preemption points
- 커널 모드에서 동작하는 여러 코드에 explicit preemption points를 추가하여 종종 reschedule이 필요한지 확인하여 preemption이 사용되어야 하는 빈도를 높힘으로 preemption latency를 작게하였다.
- 이러한 preemption 포인트의 도움을 받아 급한 태스크의 기동에 필요한 latency가 100us 이내로 줄어드는 성과가 있었다.
- preemption point는 보통 1ms(100us) 이상 소요되는 루틴에 보통 추가한다.
- 현재 커널에 거의 천 개에 가까운 preemption point가 존재한다.
PREEMPT:
- Preemptible Kernel (Low-Latency Desktop)
- 커널 모드에서도 다음 몇 가지 상황(PREEMPT_RT도 마찬가지)을 제외하고 언제나 preemption을 허용하여 거의 대부분의 시간동안 우선 순위가 높은 태스크가 먼저 수행되도록 스케줄링 된다. 따라서 이 옵션을 사용하는 경우에는 preemption point가 불필요하므로 빈코드로 대채된다.
-
- 반응 속도(latency) 빨라야 하는 대략 밀리세컨드의 latency가 필요한 네트웍 장치등의 임베디드 시스템에 적합한 모델이다
PREEMPT_RT:
- Fully Preemptible Kernel (Real-Time)
- 최근에 커널 v5.3-rc1부터 정식으로 mainline에 등록되었다.
- sched/rt, Kconfig: Introduce CONFIG_PREEMPT_RT (2019, v5.3-rc1)
- 그 동안 full preempt kernel에 대한 고민이 kernel mainliner들에게 있다. 바로 성능 저하인데 이 때문에 mainline에 올리지 못했던 이유이기도 하다. (참고: Optimizing preemption | LWN.net)
- 대부분의 타이머와 각종 디바이스의 인터럽트 처리를 디폴트로 bottom-half에서 처리하도록 하므로 hardirq 처리로 인해 block되는 시간이 짧아진다. 따라서 이 모델은 실시간 인터럽트 처리가 필요한 시스템에 적합한 모델이다.
- hrtimer에 hard모드와 soft 모드 플래그가 추가되었으며, 디폴트로 soft 모드로 동작한다. soft 모드는 타이머 펑션을 rt 스레드에서 동작하도록 bottom-half 처리하고, hard 모드는 hardirq 처리한다.
- 아키텍처 지원을 받는 시스템만 사용할 수 있다.
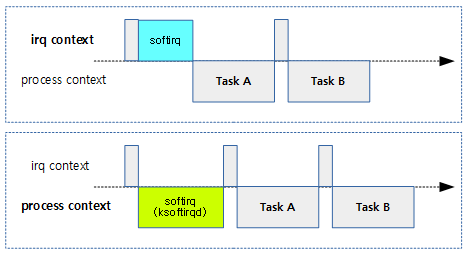
커널의 irq latency를 줄이기 위한 또 다른 기능
- preempt 및 preempt_rt 모델이더라해도 현재 syscall 및 irq를 네스트하여 처리하지 않고, irq를 disable한 채로 hardirq service를 처리하여 irq latency를 커지게 하는 주범이다. 극히 짧은 타이밍에 네스트될 수 있긴 하지만 본격적인 irq 네스팅을 지원하는 것은 아니다.
- 위의 hardirq 서비스 처리 구간 이외에도 커널의 많은 코드에서 동기화를 위해 local_irq_disable()을 많이 사용하여 인터럽트의 빠른 처리를 방해하고 있다. 이들 또한 irq latency를 커지게 만드는데 동조한다.
- ARM 시스템에서는 위의 hardirq 제한을 피해가는 방법으로 fiq를 사용할 수 있다. 이 fiq는 성능을 이유로 irq domain 서브시스템을 사용하지 못하고, 처리 루틴을 비워두었다. 따라서 특정 시스템에서 custom하게 처리할 수 있으며 약간의 제한을 받는다.
- fiq보다 더 강력한 x86의 NMI처럼 local_irq_disable() 시에도 특정 중요 인터럽트를 처리할 수 있는 Pesudo-NMI 방법이 있다. 이는 ARM64 시스템 중 GIC v3.0 이상을 채용하여 ARM64_HAS_IRQ_PRIO_MASKING 기능이 동작하는 시스템에서만 제공된다.
기타 preemption 관련 커널 옵션
CONFIG_PREEMPTION
- CONFIG_PREEMPT_RT 코드가 도입되면서 기존 CONFIG_PREEMPT를 CONFIG_PREEMPT_LL로 변경하였었는데, 이러한 변경이 oldconfig 빌드에 문제를 일으켜 rollback하고, CONFIG_PREEMPTION이 새롭게 만들어 졌다.이 커널 옵션은 CONFIG_PREMPT 및 CONFIG_PREEMPT_RT를 선택하면 enable된다.
- 참고: sched/rt, Kconfig: Unbreak def/oldconfig with CONFIG_PREEMPT=y (2019, v5.3-rc2)
CONFIG_PREEMPT_COUNT
- preempt 옵션으로부터 분리하였다. 이 분리된 기능으로 preempt_none 및 preempt_voluntry 모델에서도 preempt_disable()로 preempt_count를 증가시켜 preemption을 막을 수 있다.
- 참고: sched: Isolate preempt counting in its own config option (2011, v3.1-rc1)
- CONFIG_PREEMPTION이 사용되지 않는 preempt_none 및 preempt_voluntry 모델에서 옵션으로 지정할 수 있다. (디폴트=n)
- CONFIG_PREEMPTION이 사용되는 preempt 및 preempt_rt 모델은 디폴트로 항상 사용된다.
커널 버전에 따른 preemption 기능
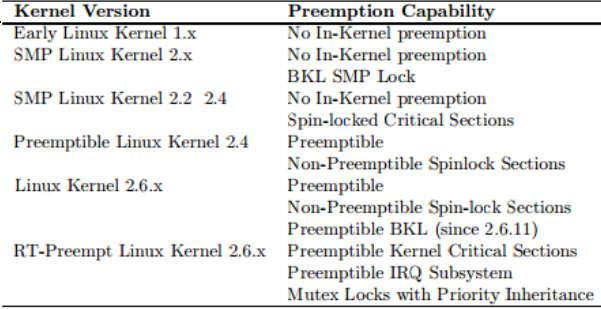
- 커널 버전 2.4까지 user mode만 선점이 가능했었다.
- user mode에서 동작중인 process가 system call API를 호출하여 kernel mode로 진입하여 동작 중인 경우에는 선점 불가능
- 버전 2.6에 이르러 kernel mode도 선점이 가능해졌다.
- 드라이버 수행 중 또는 system call API를 호출하여 kernel mode에 있는 경우에도 다른 태스크로의 선점이 가능해졌다.
- preemption 모델 중 CONFIG_PREEMPT_NONE 제외
- kernel mode에서 선점이 가능해졌지만 리눅스가 원래 Real-Time OS 설계가 아닌 관계로 big kernel lock(2중, 3중 critical section 등 사용)으로 인해 필요한 때 인터럽트 응답성이 빠르지 않았다. 물론 현재는 big kernel lock을 다 제거하여 사용하지 않는다.
- 인터럽트 latency를 줄이기 위해 인터럽트 핸들러를 top-half, bottom-half 두 개의 파트로 나누었다. (Two part interrupt handler | 문c)
- RT-Preempt 리눅스 커널 (RT 패치 적용된 모델)
- critical section 및 인터럽트 수행중에서도 preemption이 지원되었다.
- SMP 환경에서는 spinlock으로 제어되는 critical section에서 CPU들의 동시 접근 효율이 떨어지면서 문제가 되므로 이를 해결하기 위해 spinlock은 preempt_disable을 하지 않도록 RT mutex를 사용한다. 물론 반드시 preemption이 disable되어야 하는 경우를 위해 그러한 루틴을 위해 raw_spin_lock에서 처리되게 이전하였다.
- PREEMPT_RT의 메인라인 커널 적용
- 그 동안 많은 RT-Preempt 리눅스 커널의 기능들이 메인라인에 조금씩 추가되어 왔었다.
- PREEMPT_RT preemption 모델이 v5.3 메인라인에 합류하기 전까지는 별도의 RT 기능이 패치된 RT-Preempt Linux Kernel을 사용하여야 했다.
- 현재 버전은 제한된 RT-Preempt 커널로 인터럽트 수행 및 spinlock 처리 중에서의 preemption은 불가능하다. 대신 hardirq 처리 시의 irq latency를 줄이기 위해 디폴트로 타이머 및 디바이스의 irq 처리를 bottom-half에서 처리하도록 하였다. spinlock 처리 중 preemption을 가능하게 하기 위해 추가 코드의 적용이 필요한 상태이다. 호환되지 않는 드라이버들이 있어 spinlock 처리 중 preemption이 가능하게 하지 않았다.
RT Mutex based PI(Priority Inheritance) Protocol
- 커널 버전 2.6.18 버전에서 소개
- kernel space locking
- user space locking 역시 “futex”를 통해 빠른 lock 지원
- preemption이 일어날 때 critical section 구간에서 또 다른 문제 중 하나인 priority inversion이 발생한다.
- priority inversion을 제거하기 위한 방법으로 priority inheritance protocol을 사용
- 참고:
Preemption Point 구현
might_sleep()
include/linux/kernel.h
# define might_sleep() do { might_resched(); } while (0)
CONFIG_PREEMPT_VOLUNTARY 커널에서 preemption point로 동작한다. 리스케줄 요청이 있고, preemption 카운터가 0이되어 preemption이 가능한 경우 스케줄하여 태스크 선점을 양보한다.
- 현재 태스크는 cpu 선점을 양보하고, 런큐는 다음 실행할 태스크를 선택하고 스케줄하여 실행한다.
- 커널에서 1ms 이상 소요되는 경우 voluntary preemption 모델을 사용하는 커널을 위해 잠시 우선순위가 높은 태스크를 위해 스스로 양보하고 선점당할 수 있는 포인트를 제공하기 위해 사용된다.
might_resched()
include/linux/kernel.h
#ifdef CONFIG_PREEMPT_VOLUNTARY
# define might_resched() _cond_resched()
#else
# define might_resched() do { } while (0)
#endif
CONFIG_PREEMPT_VOLUNTARY 커널에서 preemption point로 동작하여 리스케줄 요청에 대해 리스케줄 가능한 경우 스케줄한다.
다음 그림은 might_sleep() 및 cond_resched() 함수를 호출 할 때 voluntary 커널에서 스케줄 함수를 호출하는 과정을 보여준다.
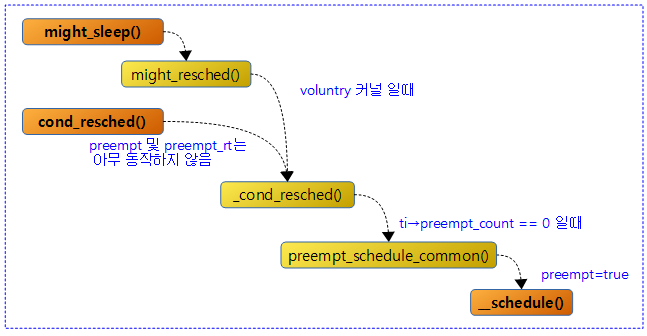
cond_resched()
include/linux/sched.h
#define cond_resched() ({ \
___might_sleep(__FILE__, __LINE__, 0); \
_cond_resched(); \
})
리스케줄 요청에 대해 리스케줄 가능한 경우(preempt count=0) 스케줄을 수행한다. 리스케줄한 경우 1을 반환한다.
- CONFIG_PREEMPT_NONE 또는 CONFIG_PREEMPT_VOLUNTARY 커널에서 사용가능하다.
_cond_resched()
kernel/sched/core.c
int __sched _cond_resched(void)
{
if (should_resched(0)) {
preempt_schedule_common();
return 1;
}
rcu_all_qs();
return 0;
}
EXPORT_SYMBOL(_cond_resched);
리스케줄 요청에 대해 리스케줄 가능한 경우(preempt count=0) 스케줄을 수행한다. 리스케줄한 경우 1을 반환한다.
- 코드 라인 3~6에서 preemption 가능한 경우 스케줄을 수행하고, 1을 반환한다.
- 코드 라인 7에서 RCU의 모든 cpu가 qs 상태를 보고한다.
- 코드 라인 8에서 리스케줄 하지 않았으므로 0을 반환한다.
should_resched() – Generic
include/asm-generic/preempt.h
/* * Returns true when we need to resched and can (barring IRQ state). */
static __always_inline bool should_resched(int preempt_offset)
{
return unlikely(preempt_count() == preempt_offset &&
tif_need_resched());
}
리스케줄 요청에 대해 preempt 카운터가 @preempt_offset과 동일한 경우 true를 반환한다.
should_resched() – ARM64
arch/arm64/include/asm/preempt.h
static inline bool should_resched(int preempt_offset)
{
u64 pc = READ_ONCE(current_thread_info()->preempt_count);
return pc == preempt_offset;
}
리스케줄 요청에 대해 preempt 카운터가 @preempt_offset과 동일한 경우 true를 반환한다.
리스케줄 요청 – TIF_NEED_RESCHED 플래그
32비트 아키텍처에서는 preempt_count와 TIF_NEED_RESCHED 요청을 flags에 저장하여야 하였고 LLSC 방식을 사용하는 아키텍처에서 인터럽트에 의해 위의 두 멤버가 한번에 갱신되지 않은채 읽히는 문제점이 있었다. 그러나 64비트 아키텍처부터 64비트로 확장된 preempt_count의 절반을 원래 목적의 카운터를 담아두고, 나머지 절반에 리스케줄 요청(need_resched)을 추가로 사용하도록하여 이를 한 번에 액세스할 수 있으므로 이러한 문제점을 해결하였다.
- 참고: arm64: preempt: Provide our own implementation of asm/preempt.h (2018, v5.0-rc1)
다음 32비트와 64비트에서코드를 보면 64비트에서 리스케줄 요청이 약간 변형되어 사용하는 것을 알 수 있다.
arch/arm/include/asm/thread_info.h – ARM32
struct thread_info {
unsigned long flags; <- TIF_NEED_RESCHED 플래그 사용
int preempt_count;
(...생략...)
arch/arm64/include/asm/thread_info.h – ARM64
struct thread_info {
unsigned long flags; <- TIF_NEED_RESCHED 플래그 그대로 사용
(...생략...)
union {
u64 preempt_count;
struct {
#ifdef CONFIG_CPU_BIG_ENDIAN
u32 need_resched; <- 빅엔디안 설정 시 사용
u32 count;
#else
u32 count; <- 64비트 나머지 절반은 기존 preempt_count와 동일
u32 need_resched; <- TIF_NEED_RESCHED와 동일한 용도로 여기에 0 설정
. 주의: 리스케줄 요청=0, 초기 값=1
} preempt;
#endif
};
};
need_resched()
include/linux/sched.h
static __always_inline bool need_resched(void)
{
return unlikely(tif_need_resched());
}
현재 스레드에 리스케줄 요청이 기록되어 있는지 여부를 반환한다. 리스케줄 요청=true(1)
tif_need_resched()
include/linux/thread_info.h
#define tif_need_resched() test_thread_flag(TIF_NEED_RESCHED)
현재 스레드에 리스케줄 요청이 기록되어 있는지 여부를 반환한다. 리스케줄 요청=true(1)
test_thread_flag()
include/linux/thread_info.h
#define test_thread_flag(flag) \
test_ti_thread_flag(current_thread_info(), flag)
현재 스레드에 요청 flag 비트가 설정된 경우 true(1)를 반환한다.
리스케줄 Now
resched_curr()
kernel/sched/fair.c
/* * resched_curr - mark rq's current task 'to be rescheduled now'. * * On UP this means the setting of the need_resched flag, on SMP it * might also involve a cross-CPU call to trigger the scheduler on * the target CPU. */
void resched_curr(struct rq *rq)
{
struct task_struct *curr = rq->curr;
int cpu;
lockdep_assert_held(&rq->lock);
if (test_tsk_need_resched(curr))
return;
cpu = cpu_of(rq);
if (cpu == smp_processor_id()) {
set_tsk_need_resched(curr);
set_preempt_need_resched();
return;
}
if (set_nr_and_not_polling(curr))
smp_send_reschedule(cpu);
else
trace_sched_wake_idle_without_ipi(cpu);
}
현재 태스크에 리스케줄 요청 플래그를 설정한다. 만일 런큐의 cpu가 현재 cpu가 아닌 경우 리스케줄 요청 IPI call을 수행한다.
- 코드 라인 8~9에서 런큐에서 동작중인 현재 태스크에 이미 리스케줄 요청 플래그가 설정된 경우 함수를 빠져나간다.
- 코드 라인 11~17에서 런큐의 cpu가 현재 cpu와 동일한 경우 태스크에 리스케줄 요청 플래그를 설정하고 함수를 빠져나간다.
- arm 커널에서 set_preempt_need_resched() 함수는 아무런 동작도 하지 않는다.
- 코드 라인 19~20에서 리스케줄 요청할 태스크가 현재 런큐의 cpu가 아닌 경우이다. 만일 TIF_POLLING_NRFLAG가 설정되지 않은 경우 리스케줄 요청 플래그를 설정하고 리스케줄 요청 IPI 호출을 수행한다.
test_tsk_need_resched()
include/linux/sched.h
static inline int test_tsk_need_resched(struct task_struct *tsk)
{
return unlikely(test_tsk_thread_flag(tsk,TIF_NEED_RESCHED));
}
현재 태스크에 리스케줄 요청 플래그가 설정되었는지 여부를 반환한다. 낮은 확률로 설정된 경우 true를 반환한다.
set_tsk_need_resched()
include/linux/sched.h
static inline void set_tsk_need_resched(struct task_struct *tsk)
{
set_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
}
현재 태스크에 리스케줄 요청 플래그를 설정한다.
set_nr_and_not_polling()
kernel/sched/core.c
#if defined(CONFIG_SMP) && defined(TIF_POLLING_NRFLAG) /* * Atomically set TIF_NEED_RESCHED and test for TIF_POLLING_NRFLAG, * this avoids any races wrt polling state changes and thereby avoids * spurious IPIs. */
static bool set_nr_and_not_polling(struct task_struct *p)
{
struct thread_info *ti = task_thread_info(p);
return !(fetch_or(&ti->flags, _TIF_NEED_RESCHED) & _TIF_POLLING_NRFLAG);
}
#else
static bool set_nr_and_not_polling(struct task_struct *p)
{
set_tsk_need_resched(p);
return true;
}
smp 시스템이면서 TIF_POLLING_NRFLAG가 지원되는 커널 여부에 따라 IPI 호출 여부를 판단하기 위해 다음과 같은 동작을 수행한다.
- 지원되는 경우 현재 태스크가 가리키는 스레드의 플래그에 리스케줄 요청 플래그를 설정한다. 그리고 그 플래그에 _TIF_POLLING_NRFLAG가 설정된 경우 write 폴링 상태 변화 시에 무분별한 IPI 호출이 발생하지 않도록 false를 반환한다.
- 지원되지 않는 경우 태스크에 리스케줄 요청 플래그를 설정하고 true를 반환한다.
smp_send_reschedule()
kernel/smp.c
void smp_send_reschedule(int cpu)
{
smp_cross_call(cpumask_of(cpu), IPI_RESCHEDULE);
}
지정 cpu로 리스케줄 요청 IPI 호출을 수행한다.
Preempt Count
현재 스레드의 preemption 허용 여부를 nest 하여 증/감하는데 이 값이 0이 될 때 preemption 가능한 상태가 된다.
- 참고: Four short stories about preempt_count() (2020) | LWN.net
preempt_count() – Generic
include/asm-generic/preempt.h
static __always_inline int preempt_count(void)
{
return READ_ONCE(current_thread_info()->preempt_count);
}
현재 태스크의 preempt 카운터를 반환한다.
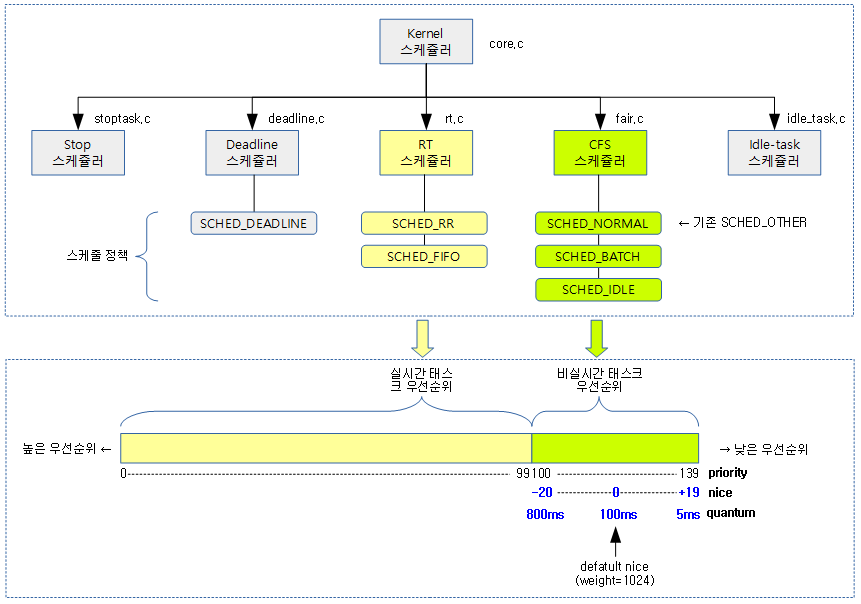
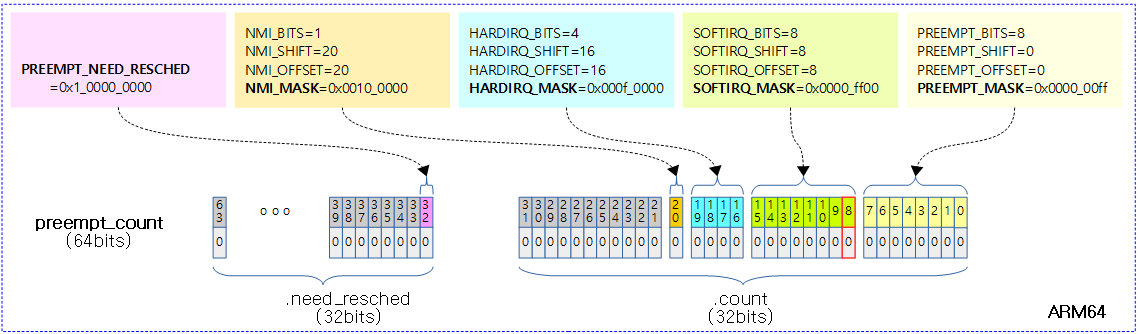
32비트 preemption 카운터가 0이되면 preemption이 가능해진다. preemption 카운터의 각 비트를 묶어 preemption을 mask하는 용도로 나누어 구성한다. 어느 한 필드라도 비트가 존재하면 preemption되지 않는다.
preempt_count() – ARM64
arch/arm64/include/asm/preempt.h
static inline int preempt_count(void)
{
return READ_ONCE(current_thread_info()->preempt.count);
}
현재 태스크의 preempt 카운터를 반환한다. (32비트 preempt.count)
include/linux/preempt_mask.h
/*
* We put the hardirq and softirq counter into the preemption
* counter. The bitmask has the following meaning:
*
* - bits 0-7 are the preemption count (max preemption depth: 256)
* - bits 8-15 are the softirq count (max # of softirqs: 256)
*
* The hardirq count could in theory be the same as the number of
* interrupts in the system, but we run all interrupt handlers with
* interrupts disabled, so we cannot have nesting interrupts. Though
* there are a few palaeontologic drivers which reenable interrupts in
* the handler, so we need more than one bit here.
*
* PREEMPT_MASK: 0x000000ff
* SOFTIRQ_MASK: 0x0000ff00
* HARDIRQ_MASK: 0x000f0000
* NMI_MASK: 0x00100000
* PREEMPT_NEED_RESCHED: 0x80000000 <- 주의: ARM64의 경우 0x1_00000000 이다.
*/
#define PREEMPT_BITS 8 #define SOFTIRQ_BITS 8 #define HARDIRQ_BITS 4 #define NMI_BITS 1 #define PREEMPT_SHIFT 0 #define SOFTIRQ_SHIFT (PREEMPT_SHIFT + PREEMPT_BITS) #define HARDIRQ_SHIFT (SOFTIRQ_SHIFT + SOFTIRQ_BITS) #define NMI_SHIFT (HARDIRQ_SHIFT + HARDIRQ_BITS) #define __IRQ_MASK(x) ((1UL << (x))-1) #define PREEMPT_MASK (__IRQ_MASK(PREEMPT_BITS) << PREEMPT_SHIFT) #define SOFTIRQ_MASK (__IRQ_MASK(SOFTIRQ_BITS) << SOFTIRQ_SHIFT) #define HARDIRQ_MASK (__IRQ_MASK(HARDIRQ_BITS) << HARDIRQ_SHIFT) #define NMI_MASK (__IRQ_MASK(NMI_BITS) << NMI_SHIFT) #define PREEMPT_OFFSET (1UL << PREEMPT_SHIFT) #define SOFTIRQ_OFFSET (1UL << SOFTIRQ_SHIFT) #define HARDIRQ_OFFSET (1UL << HARDIRQ_SHIFT) #define NMI_OFFSET (1UL << NMI_SHIFT) #define SOFTIRQ_DISABLE_OFFSET (2 * SOFTIRQ_OFFSET) #define PREEMPT_DISABLED (PREEMPT_DISABLE_OFFSET + PREEMPT_ENABLED)
다음 그림은 preempt 카운터의 각 비트에 대해 표시하였다. (ARM64기준)
- PREEMPT_NEED_RESCHED 플래그 유무 및 위치는 아키텍처에 따라 다르다.
- 주의: 리스케줄 요청이 있는 경우 이 비트는 0이된다.
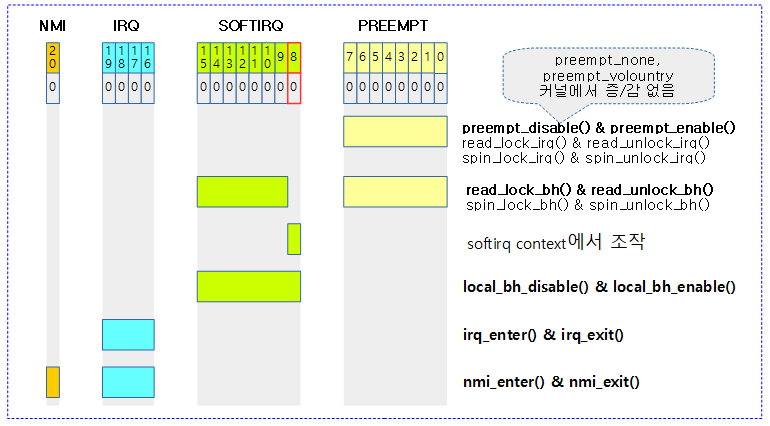
다음 그림은 preempt_count와 관련된 조작 함수들을 보여준다.
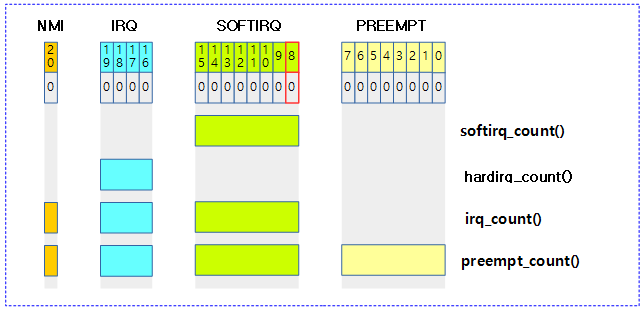
preempt_count 조회 함수들
include/linux/preempt.h
#define hardirq_count() (preempt_count() & HARDIRQ_MASK)
#define softirq_count() (preempt_count() & SOFTIRQ_MASK)
#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK \
| NMI_MASK))
다음 그림은 preempt_count와 관련된 조회 함수 들을 보여준다.
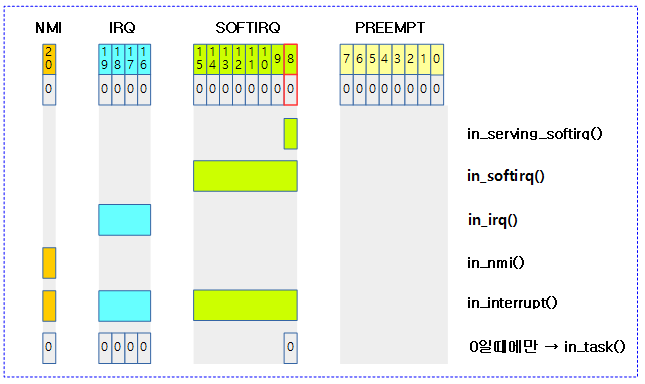
preempt_count 조건 판단 함수들
include/linux/preempt.h
/* * Are we doing bottom half or hardware interrupt processing? * * in_irq() - We're in (hard) IRQ context * in_softirq() - We have BH disabled, or are processing softirqs * in_interrupt() - We're in NMI,IRQ,SoftIRQ context or have BH disabled * in_serving_softirq() - We're in softirq context * in_nmi() - We're in NMI context * in_task() - We're in task context * * Note: due to the BH disabled confusion: in_softirq(),in_interrupt() really * should not be used in new code. */
#define in_irq() (hardirq_count())
#define in_softirq() (softirq_count())
#define in_interrupt() (irq_count())
#define in_serving_softirq() (softirq_count() & SOFTIRQ_OFFSET)
#define in_nmi() (preempt_count() & NMI_MASK)
#define in_task() (!(preempt_count() & \
(NMI_MASK | HARDIRQ_MASK | SOFTIRQ_OFFSET)))
다음 그림은 preempt_count와 관련된 조건 판단에 대한 함수 들을 보여준다.
Preempt Disable & Enable
자료 구조 동기화를 위해 리스케줄링(preemption)을 잠시 막아두어야 할 때 사용하는 기본 API 이다.
- preempt_disable()
- 리스케줄되지 않도록 preempt 카운터를 증가시킨다. preempt 카운터가 0 보다 큰 경우 리스케줄(preemption)을 방지한다.
- preempt_enable()
- 리스케줄을 방지하기 위해 증가시킨 preempt 카운터를 감소시킨다. 0이 되었을 때 리스케줄 요청이 있는 경우 리스케줄한다(현재 태스크를 스케줄-out하고 다음 태스크를 스케줄-in)
그 외에 다음과 같이 여러 가지 형태의 API들이 준비되어 있다.
- preempt_disable_notrace()
- preempt_enable_notrace()
- preempt_enable_no_resched()
- preempt_enable_no_resched_notrace()
- sched_preempt_enable_no_resched()
notrace 옵션
notrace 옵션은 CONFIG_DEBUG_PREEMPT 또는 CONFIG_TRACE_PREEMPT_TOGGLE 커널 옵션이 있는 상태에서도 ftrace 출력을 하지 않게 한다. 주로 타이머 등 내부에서 사용된다.
- 참고: ftrace: add preempt_enable/disable notrace macros (2008, 2.6.27-rc1)
no_resched 옵션
no_resched 옵션은 preempt_enable 후에 preempt 카운터가 0이되고 리스케줄 요청이 있더라도 리스케줄을 하지 않도록 제한한다.
모듈에서의 사용
위의 옵션들은 모듈내에서는 아무런 동작도 하지 않는다.
- 참고: sched/preempt: Take away preempt_enable_no_resched() from modules (2014, v3.14-rc1)
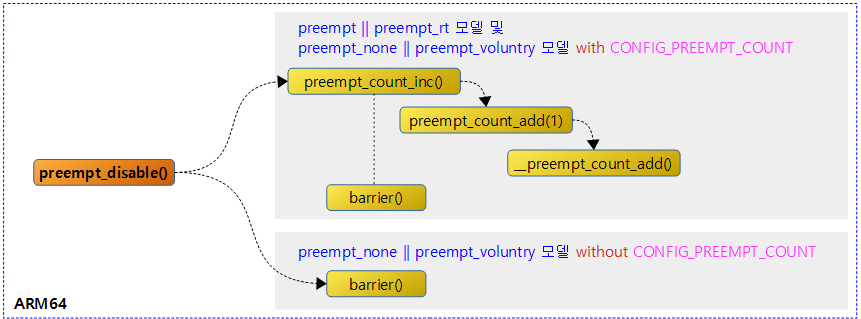
preempt_disable()
include/linux/preempt.h
#ifdef CONFIG_PREEMPT_COUNT
#define preempt_disable() \
do { \
preempt_count_inc(); \
barrier(); \
} while (0)
#else
/*
* Even if we don't have any preemption, we need preempt disable/enable
* to be barriers, so that we don't have things like get_user/put_user
* that can cause faults and scheduling migrate into our preempt-protected
* region.
*/
#define preempt_disable() barrier()
#endif
리스케줄되지 않도록 preempt 카운터를 증가시킨다. preempt 카운터가 0 보다 큰 경우 리스케줄(preemption)을 방지한다. preempt 카운터 및 preemption 모델에 따라 다음과 같이 동작한다.
- CONFIG_PREEMPT_COUNT 사용
- preemption 카운터를 증가시킨다.
- preemption 모델과 관계 없이 이후부터 preemption을 허용하지 않는다.
- CONFIG_PREEMPT_COUNT 미사용
- 커널 모드에서 preemption되지 않으므로 preempt 카운터의 조작이 불필요한 상태이다.
다음 그림은 preempt_disable()이 preempt 카운터 사용 여부에 따라 수행되는 경로를 보여준다.
preempt_count_inc()
include/linux/preempt.h
#define preempt_count_inc() preempt_count_add(1)
preemption 카운터를 1 만큼 증가시킨다.
preempt_count_add()
include/linux/preempt.h
#define preempt_count_add(val) __preempt_count_add(val)
preemption 카운터를 val 값 만큼 증가시킨다.
__preempt_count_add()
include/asm-generic/preempt.h
static __always_inline void __preempt_count_add(int val)
{
*preempt_count_ptr() += val;
}
preemption 카운터를 val 값 만큼 증가시킨다.
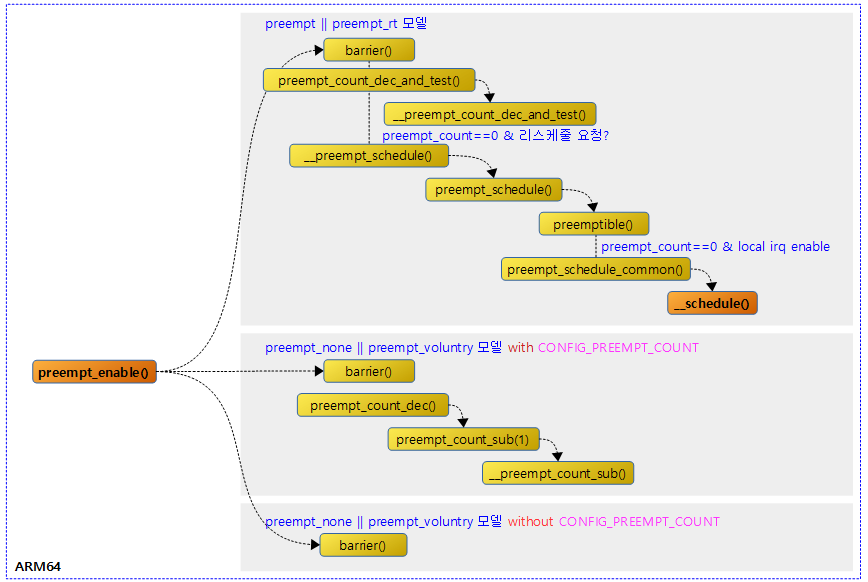
preempt_enable()
include/linux/preempt.h
#ifdef CONFIG_PREEMPT_COUNT
#ifdef CONFIG_PREEMPTION
#define preempt_enable() \
do { \
barrier(); \
if (unlikely(preempt_count_dec_and_test())) \
__preempt_schedule(); \
} while (0)
#else
#define preempt_enable() \
do { \
barrier(); \
preempt_count_dec(); \
} while (0)
#endif
#else
#define preempt_enable() barrier()
#endif
리스케줄을 방지하기 위해 증가시킨 preempt 카운터를 감소시킨다. 0이 되었을 때 리스케줄 요청이 있는 경우 리스케줄한다(현재 태스크를 스케줄-out하고 다음 태스크를 스케줄-in). preemption 모델에 따라 다음과 같이 동작한다.
- preempt & preempt_rt
- preemption 카운터를 감소시키고 그 값이 0이면서 리스케줄 요청이 있으면 리스케줄한다.
- (none 및 voluntry) with CONFIG_PREEMPT_COUNT
- preemption 카운터를 감소시킨다.
- (none 및 voluntry) without CONFIG_PREEMPT_COUNT
- 컴파일러 배리어만 동작한다.
다음 그림은 preempt_enable()이 preemption 모델에 따라 수행되는 경로를 보여준다.
preempt_count_dec_and_test()
include/linux/preempt.h
#define preempt_count_dec_and_test() __preempt_count_dec_and_test()
preemption 카운터를 감소시키고 그 값이 0이 되어 preemption 가능하고 리스케줄 요청이 있는 경우 true를 반환한다.
__preempt_count_dec_and_test() – Generic
include/asm-generic/preempt.h
static __always_inline bool __preempt_count_dec_and_test(void)
{
/*
* Because of load-store architectures cannot do per-cpu atomic
* operations; we cannot use PREEMPT_NEED_RESCHED because it might get
* lost.
*/
return !--*preempt_count_ptr() && tif_need_resched();
}
preemption 카운터를 감소시키고 그 값이 0이며 리스케줄 요청이 있는 경우 true를 반환한다.
__preempt_count_dec_and_test() – ARM64
arch/arm64/include/asm/preempt.h
static inline bool __preempt_count_dec_and_test(void)
{
struct thread_info *ti = current_thread_info();
u64 pc = READ_ONCE(ti->preempt_count);
/* Update only the count field, leaving need_resched unchanged */
WRITE_ONCE(ti->preempt.count, --pc);
/*
* If we wrote back all zeroes, then we're preemptible and in
* need of a reschedule. Otherwise, we need to reload the
* preempt_count in case the need_resched flag was cleared by an
* interrupt occurring between the non-atomic READ_ONCE/WRITE_ONCE
* pair.
*/
return !pc || !READ_ONCE(ti->preempt_count);
}
preemption 카운터를 감소시키고 그 값이 0이며 리스케줄 요청이 있는 경우 true를 반환한다.
- ARM64의 경우 64비트 preempt_count를 사용하고, 절반은 count와 need_resched로 나누어 관리한다.
- 주의: 리스케줄 요청이 있는 경우 need_resched는 0이된다.
- 참고: arm64: preempt: Provide our own implementation of asm/preempt.h (2018, v5.0-rc1)
preempt_count_dec()
include/linux/preempt.h
#define preempt_count_dec() preempt_count_sub(1) #define preempt_count_sub(val) __preempt_count_sub(val)
preemption 카운터를 1 만큼 감소시킨다.
preempt_count_sub()
include/linux/preempt.h
#define preempt_count_sub(val) __preempt_count_sub(val)
preemption 카운터를 val 값 만큼 감소시킨다.
__preempt_count_sub()
include/asm-generic/preempt.h
static __always_inline void __preempt_count_sub(int val)
{
*preempt_count_ptr() -= val;
}
preemption 카운터를 val 값 만큼 감소시킨다.
스케줄
다음과 같이 다양한 형태의 스케줄 함수들이 있다.
- schedule()
- 현재 태스크를 런큐에서 디큐하고 슬립한다. 이후 다음 선정된 태스크가 실행된다.
- 현재 태스크는 런큐에서 디큐한다.
- 재 실행을 위해서는 wake_up_process() 등으로 깨워야 한다.
- preempt_schedule()
- 현재 태스크가 preemption이 가능한 상태인 경우에 한해 러닝 상태로 리스케줄 한다.
- 현재 태스크를 런큐에 그대로 두고 실행 순서만 바꾼다.
- preempt_schedule_notrace()
- preempt_schedule()과 같은 동작을 하되 ftrace 출력을 하지 않는다.
- schedule_user()
- 유저 context 디버깅을 위한 정보를 수집하고, 나머지는 schedule() 함수와 동일하다.
- schedule_idle()
- idle 스케줄러에서 idle에 사용하는 init 태스크를 슬립시킬 용도로 사용한다.
- schedule() API를 호출하지 않는 이유는 내부에서 rcu와 관련된 API동작하는 sched_submit_work() 등이 포함되어 있으므로 이들을 제외하고 순수하게 __schedule(false)만을 호출하게 한다.
- schedule_preempt_disabled()
- mutex 구현에서 사용되며 schedule 후 preempt가 disable된 상태로 리턴한다.
timeout 기능이 포함된 스케줄
타이머를 사용한 상태로 슬립하고, 타이머가 expire되면 태스크를 깨운다.
- schedule_timeout()
- 현재 태스크를 틱(jiffies) 만큼 슬립한다.
- schedule_timeout_uninterruptible()
- 현재 태스크를 uninterruptible 상태로 변경하고 틱(jiffies) 만큼 슬립한다.
- schedule_timeout_interruptible()
- 현재 태스크를 interruptible 상태로 변경하고 틱(jiffies) 만큼 슬립한다.
- schedule_timeout_killable()
- 현재 태스크를 killable(uninterruptible 및 wakekill) 상태로 변경하고 틱(jiffies) 만큼 슬립한다.
- schedule_timeout_idle()
- 현재 태스크를 idle(uninterruptible 및 noload) 상태로 변경하고 틱(jiffies) 만큼 슬립한다.
태스크 슬립
msleep()
kernel/time/timer.c
/** * msleep - sleep safely even with waitqueue interruptions * @msecs: Time in milliseconds to sleep for */
void msleep(unsigned int msecs)
{
unsigned long timeout = msecs_to_jiffies(msecs) + 1;
while (timeout)
timeout = schedule_timeout_uninterruptible(timeout);
}
요청한 밀리세컨드+1 만큼 sleep한다.
- 현재 태스크를 TASK_UNINTERRUPTIBLE 상태로 바꾸고 lowres 타이머에 요청한 밀리세컨드로 타이머를 설정한 후 preemption 하도록 스케줄한다.
schedule_timeout_uninterruptible()
kernel/time/timer.c
signed long __sched schedule_timeout_uninterruptible(signed long timeout)
{
__set_current_state(TASK_UNINTERRUPTIBLE);
return schedule_timeout(timeout);
}
EXPORT_SYMBOL(schedule_timeout_uninterruptible);
현재 태스크를 TASK_UNINTERRUPTIBLE 상태로 바꾸고 lowres 타이머를 사용하여 청한 밀리세컨드로 타이머를 설정한 후 preemption 하도록 스케줄한다.
- 지정된 시간이 지나기 전에 schedule_timeout() 함수가 끝날 수 없다.
schedule_timeout_interruptible()
kernel/time/timer.c
signed long __sched schedule_timeout_interruptible(signed long timeout)
{
__set_current_state(TASK_INTERRUPTIBLE);
return schedule_timeout(timeout);
}
EXPORT_SYMBOL(schedule_timeout_interruptible);
현재 태스크를 TASK_INTERRUPTIBLE 상태로 바꾸고 lowres 타이머를 사용하여 청한 밀리세컨드로 타이머를 설정한 후 preemption 하도록 스케줄한다.
- 지정된 시간이 지나기 전에 schedule_timeout() 함수가 끝나고 돌아올 수 있다.
schedule_timeout()
kernel/time/timer.c – 1/2
/** * schedule_timeout - sleep until timeout * @timeout: timeout value in jiffies * * Make the current task sleep until @timeout jiffies have * elapsed. The routine will return immediately unless * the current task state has been set (see set_current_state()). * * You can set the task state as follows - * * %TASK_UNINTERRUPTIBLE - at least @timeout jiffies are guaranteed to * pass before the routine returns unless the current task is explicitly * woken up, (e.g. by wake_up_process())". * * %TASK_INTERRUPTIBLE - the routine may return early if a signal is * delivered to the current task or the current task is explicitly woken * up. * * The current task state is guaranteed to be TASK_RUNNING when this * routine returns. * * Specifying a @timeout value of %MAX_SCHEDULE_TIMEOUT will schedule * the CPU away without a bound on the timeout. In this case the return * value will be %MAX_SCHEDULE_TIMEOUT. * * Returns 0 when the timer has expired otherwise the remaining time in * jiffies will be returned. In all cases the return value is guaranteed * to be non-negative. */
signed long __sched schedule_timeout(signed long timeout)
{
struct process_timer timer;
unsigned long expire;
switch (timeout)
{
case MAX_SCHEDULE_TIMEOUT:
/*
* These two special cases are useful to be comfortable
* in the caller. Nothing more. We could take
* MAX_SCHEDULE_TIMEOUT from one of the negative value
* but I' d like to return a valid offset (>=0) to allow
* the caller to do everything it want with the retval.
*/
schedule();
goto out;
default:
/*
* Another bit of PARANOID. Note that the retval will be
* 0 since no piece of kernel is supposed to do a check
* for a negative retval of schedule_timeout() (since it
* should never happens anyway). You just have the printk()
* that will tell you if something is gone wrong and where.
*/
if (timeout < 0) {
printk(KERN_ERR "schedule_timeout: wrong timeout "
"value %lx\n", timeout);
dump_stack();
current->state = TASK_RUNNING;
goto out;
}
}
expire = timeout + jiffies;
timer.task = current;
timer_setup_on_stack(&timer.timer, process_timeout, 0);
__mod_timer(&timer.timer, expire, 0);
schedule();
del_singleshot_timer_sync(&timer.timer);
/* Remove the timer from the object tracker */
destroy_timer_on_stack(&timer.timer);
timeout = expire - jiffies;
out:
return timeout < 0 ? 0 : timeout;
}
EXPORT_SYMBOL(schedule_timeout);
lowres 타이머를 사용하여 @timeout(jiffies 틱 단위) 값으로 타이머를 설정한 후 슬립하고 타이머가 expire될 때 깨어난다. 함수를 빠져나갈 때에는 TASK_RUNNING 상태를 보장한다.
- 코드 라인 6~17에서 MAX_SCHEDULE_TIMEOUT 값으로 요청한 경우 타이머 설정없이 슬립한다.
- 외부에서 wakeup_process() 또는 try_to_wake_up()등의 함수에 의해 태스크를 런큐에 다시 엔큐하여 깨어나게한다음 out 레이블로 이동한 후 함수를 빠져나간다.
- 코드 라인 18~32에서 음수 값으로 타이머를 설정한 경우 에러 메시지를 출력하고 태스크를 TASK_RUNNING 상태로 바꾼 후 함수를 빠져나간다.
- 코드 라인 35~40에서 타이머 만료 시각을 설정하고 슬립한다. 타이머 만료 시 프로세스를 깨우도록 process_timeout() 함수를 호출한다.
- 코드 라인 41에서 혹시 만료되지 않은 타이머를 제거한다.
- 코드 라인 44에서 타이머 디버그 용도로 트래킹 중인 오브젝트를 제거한다.
- 코드 라인 46~49에서 남은 jiffies 단위의 타이머 만료 시간을 반환한다. 0 미만인 경우 0을 반환한다.
process_timeout()
kernel/time/timer.c
static void process_timeout(unsigned long __data)
{
wake_up_process((struct task_struct *)__data);
}
태스크를 깨운다.
- 타이머에의 의해 호출되며 interruptible 또는 uninterruptible 상태의 태스크를 깨워 다시 런큐에 엔큐시킨다.
schedule()
kernel/sched/core.c
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
sched_update_worker(tsk);
}
EXPORT_SYMBOL(schedule);
현재 태스크를 런큐에서 디큐하고, 슬립한 후 다음 태스크를 스케줄한다. 재 실행을 위해 슬립 후엔 wake_up_process() 함수 등으로 깨워야 한다.
- 코드 라인 5에서 리스케줄 하기 전에 할 일을 수행한다.
- 워커 스레드인 경우 슬립 상태로 진입함을 알린다.
- 처리 중인 plugged IO 큐를 확실히 전송하여 데드락을 회피한다.
- 코드 라인 7~9에서 현재 실행 중인 태스크를 런큐에서 디큐하고 preempt disable 상태로 슬립한 후, 다음 태스크를 스케줄한다.
- false로 요청하는 경우 현재 태스크를 런큐에서 디큐한다.
- 코드 라인 10에서 리스케줄 요청이 있으면 반복한다.
- 코드 라인 11에서 워커 스레드인 경우 러닝 상태로 변경함을 알린다.
__preempt_schedule()
kernel/sched/core.c
#define __preempt_schedule() preempt_schedule()
현재 태스크가 preemption이 가능한 경우에만 러닝 상태에서 리스케줄한다.
- CONFIG_PREEMPT에서만 사용 가능하다.
preempt_schedule()
kernel/sched/core.c
/* * this is the entry point to schedule() from in-kernel preemption * off of preempt_enable. Kernel preemptions off return from interrupt * occur there and call schedule directly. */
asmlinkage __visible void __sched notrace preempt_schedule(void)
{
/*
* If there is a non-zero preempt_count or interrupts are disabled,
* we do not want to preempt the current task. Just return..
*/
if (likely(!preemptible()))
return;
preempt_schedule_common();
}
NOKPROBE_SYMBOL(preempt_schedule);
EXPORT_SYMBOL(preempt_schedule);
현재 태스크가 preemption이 가능한 경우에만 러닝 상태에서 리스케줄한다.
- preempt 및 preempt_rt 커널에서 사용 가능하다.
- preempt 카운터가 0이고, 인터럽트가 enable된 상태여야 한다.
- 현재 태스크는 런큐에서 실행 순서만 재배치된다
preemptible()
include/linux/preempt_mask.h
#ifdef CONFIG_PREEMPT_COUNT # define preemptible() (preempt_count() == 0 && !irqs_disabled()) #else # define preemptible() 0 #endif
preemption이 가능한 상태인지 여부를 알아온다. true(1)=preemption 가능한 상태
- CONFIG_PREEMPT_COUNT 커널 옵션을 사용하지 않는 경우에는 항상 preemption을 할 수 없다.
preempt_schedule_common()
kernel/sched/core.c
static void __sched notrace preempt_schedule_common(void)
{
do {
/*
* Because the function tracer can trace preempt_count_sub()
* and it also uses preempt_enable/disable_notrace(), if
* NEED_RESCHED is set, the preempt_enable_notrace() called
* by the function tracer will call this function again and
* cause infinite recursion.
*
* Preemption must be disabled here before the function
* tracer can trace. Break up preempt_disable() into two
* calls. One to disable preemption without fear of being
* traced. The other to still record the preemption latency,
* which can also be traced by the function tracer.
*/
preempt_disable_notrace();
preempt_latency_start(1);
__schedule(true);
preempt_latency_stop(1);
preempt_enable_no_resched_notrace();
/*
* Check again in case we missed a preemption opportunity
* between schedule and now.
*/
} while (need_resched());
}
리스케줄 요청이 있는 동안 루프를 돌며 리스케줄을 수행한다.
- 코드 라인 17에서 리스케줄 하기 전에 ftrace 출력 없이 preempt 카운터를 증가시켜 preemption을 막아둔다.
- 코드 라인 18에서 현재 태스크의 스케줄 out을 ftrace 출력한다.
- 코드 라인 19에서 현재 태스크를 러닝 상태로 런큐에 그대로 두고 리스케줄하여 다음 진행할 태스크를 pickup하여 실행시킨다.
- 코드 라인 20에서 pickup한 태스크의 스케줄 in을 ftrace 출력한다.
- 코드 라인 21에서 리스케줄 하기 전에 막아두었던 preemption을 다시 열기 위해 preempt 카운터를 감소시킨다. 이 때 다시 리스케줄되지 않게 하기 위해 no_resched 옵션을 사용하였다.
- 코드 라인 27에서 코드 라인 13에서 리스케줄 요청이 남아 있는 경우 계속 루프를 돈다.
스케줄 메인 함수
__schedule()
kernel/sched/core.c
/* * __schedule() is the main scheduler function. * * The main means of driving the scheduler and thus entering this function are: * * 1. Explicit blocking: mutex, semaphore, waitqueue, etc. * * 2. TIF_NEED_RESCHED flag is checked on interrupt and userspace return * paths. For example, see arch/x86/entry_64.S. * * To drive preemption between tasks, the scheduler sets the flag in timer * interrupt handler scheduler_tick(). * * 3. Wakeups don't really cause entry into schedule(). They add a * task to the run-queue and that's it. * * Now, if the new task added to the run-queue preempts the current * task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets * called on the nearest possible occasion: * * - If the kernel is preemptible (CONFIG_PREEMPT=y): * * - in syscall or exception context, at the next outmost * preempt_enable(). (this might be as soon as the wake_up()'s * spin_unlock()!) * * - in IRQ context, return from interrupt-handler to * preemptible context * * - If the kernel is not preemptible (CONFIG_PREEMPT is not set) * then at the next: * * - cond_resched() call * - explicit schedule() call * - return from syscall or exception to user-space * - return from interrupt-handler to user-space * * WARNING: all callers must re-check need_resched() afterward and reschedule * accordingly in case an event triggered the need for rescheduling (such as * an interrupt waking up a task) while preemption was disabled in __schedule(). */
CONFIG_PREEMPT 및 CONFIG_PREMPT_RT 커널 옵션을 사용하는 preemptible 커널인 경우 커널 모드에서도 preempt가 enable 되어 있는 대부분의 경우 preemption이 가능하다. 그러나 그러한 옵션을 사용하지 않는 커널은 커널 모드에서 preemption이 가능하지 않다. 다만 다음의 경우에 한하여 preemption이 가능하다.
- CONFIG_PREEMPT_VOLUNTARY 커널 옵션을 사용하면서 cond_resched() 호출 시
- 명확히 지정하여 schedule() 함수를 호출 시
- syscall 호출 후 유저 스페이스로 되돌아 갈 때
- 유저 모드에서는 언제나 preemption이 가능하다. 때문에 syscall 호출하여 커널에서 요청한 서비스를 처리한 후 유저로 돌아갔다 preemption이 일어나면 유저 모드와 커널 모드의 왕래만 한 번 더 반복하게 되므로 overhead가 생길 따름이다. 그래서 유저 스페이스로 돌아가기 전에 preemption 처리를 하는 것이 더 빠른 처리를 할 수 있다.
- 인터럽트 핸들러를 처리 후 다시 유저 스페이스로 되돌아 갈 때
- 이 전 syscall 상황과 유사하게 이 상황도 유저 스페이스로 돌아가기 전에 처리해야 더 빠른 처리를 할 수 있다.
kernel/sched/core.c -1/2-
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
schedule_debug(prev, preempt);
if (sched_feat(HRTICK))
hrtick_clear(rq);
local_irq_disable();
rcu_note_context_switch(preempt);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*
* The membarrier system call requires a full memory barrier
* after coming from user-space, before storing to rq->curr.
*/
rq_lock(rq, &rf);
smp_mb__after_spinlock();
/* Promote REQ to ACT */
rq->clock_update_flags <<= 1;
update_rq_clock(rq);
switch_count = &prev->nivcsw;
if (!preempt && prev->state) {
if (signal_pending_state(prev->state, prev)) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);
if (prev->in_iowait) {
atomic_inc(&rq->nr_iowait);
delayacct_blkio_start();
}
}
switch_count = &prev->nvcsw;
}
현재 태스크를 인자 @preempt 요청에 따라 런큐에서 디큐하여 슬립(preempt=false) 시키거나 러닝 상태로 런큐에 그대로 두고 리스케줄 한다.
- 코드 라인 9~11에서 현재 cpu의 런큐에서 동작 중인 태스크를 prev에 알아온다.
- 코드 라인 13에서 스케줄 타임에 체크할 항목과 통계를 수행한다.
- 코드 라인 15~16에서 hrtick 이 동작 중인 경우 현재 태스크에 대한 hrtick이 더 이상 필요 없으므로 클리어한다.
- 코드 라인 18에서 로컬 irq를 disable 한다.
- 코드 라인 19에서 현재 태스크가 스케줄 out되기 전에 필요한 rcu 처리를 수행한다.
- 코드 라인 29~30에서 런큐 락 및 smp 메모리 베리어를 수행한다.
- 런큐 락을 사용하지 않은 곳과의 동기화를 위해 spin_lock을 사용한 런큐 락을 사용한 후 에 smp_mb()를 수행해야 한다.
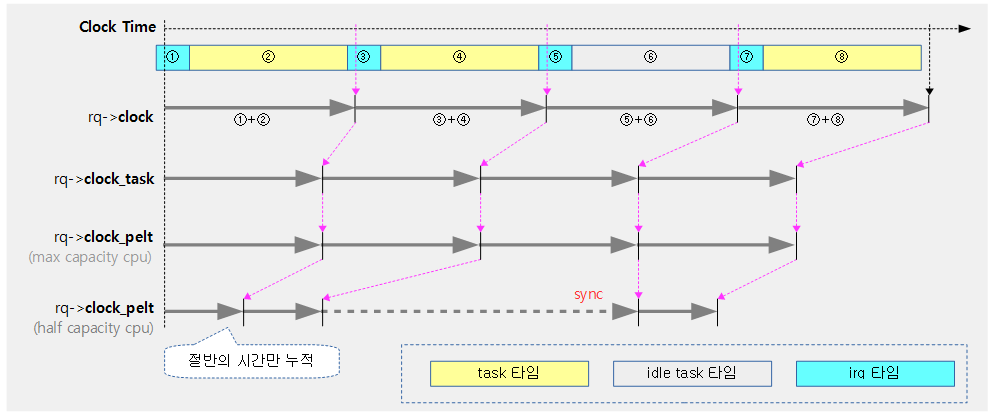
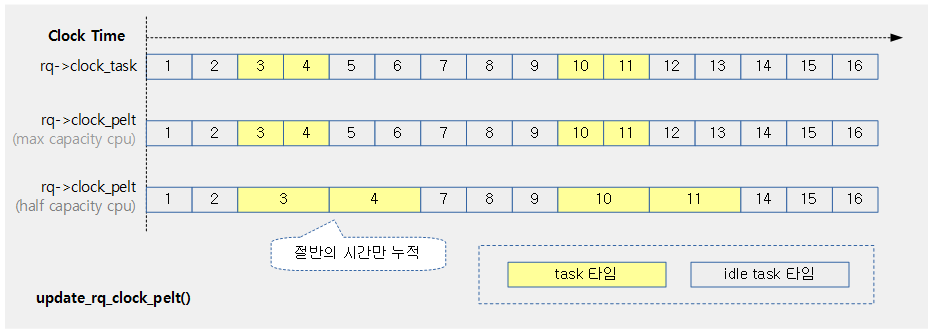
- 코드 라인 33~34에서 런큐의 clock_skip_update에 담긴 RQCF_REQ_SKIP(1) 플래그에서 RQCF_ACT_SKIP(2) 단계로 전환한 후 현재 cpu의 런큐 클럭을 갱신한다.
- 코드 라인 36에서 기존 태스크의 context 스위치 횟수를 알아온다.
- 코드 라인 37~49에서 현재 태스크를 런큐에서 디큐하고 슬립시키기 위해 @preempt=false로 하고 태스크 상태가 TASK_RUNNING(0)이 아닌 경우 태스크를 런큐에서 디큐한다. 단 펜딩 시그널이 있으면 그대로 러닝 상태로 둔다.
- DEQUEUE_SLEEP 플래그를 주어 이 태스크가 cfs 런큐에서 완전히 빠져나가는 것이 아니라 슬립하기 위해 디큐하므로 추후 다시 엔큐됨을 표시하기 위함이다.
kernel/sched/core.c -2/2-
next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
if (likely(prev != next)) {
rq->nr_switches++;
/*
* RCU users of rcu_dereference(rq->curr) may not see
* changes to task_struct made by pick_next_task().
*/
RCU_INIT_POINTER(rq->curr, next);
/*
* The membarrier system call requires each architecture
* to have a full memory barrier after updating
* rq->curr, before returning to user-space.
*
* Here are the schemes providing that barrier on the
* various architectures:
* - mm ? switch_mm() : mmdrop() for x86, s390, sparc, PowerPC.
* switch_mm() rely on membarrier_arch_switch_mm() on PowerPC.
* - finish_lock_switch() for weakly-ordered
* architectures where spin_unlock is a full barrier,
* - switch_to() for arm64 (weakly-ordered, spin_unlock
* is a RELEASE barrier),
*/
++*switch_count;
trace_sched_switch(preempt, prev, next);
/* Also unlocks the rq: */
rq = context_switch(rq, prev, next, &rf);
} else {
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
rq_unlock_irq(rq, &rf);
}
balance_callback(rq);
}
- 코드 라인 1~3에서 다음 처리할 태스크를 가져오고 기존 태스크의 리스케줄 요청(TIF_NEED_RESCHED 플래그)을 클리어한다. LLSC 방식을 사용하는 64비트 시스템의 경우 추가로 ti->preempt.need_resched을 1로 지정하여 리스케줄 요청을 클리어(주의: 0=리스케줄 요청, 1=클리어)한다.
- arm64 시스템의 경우 아키텍처 버전에 따라 ARMv8.0의 경우 LLSC 방식을 사용하고, ARMv8.1부터는 CAS 방식을 사용한다. 그런데 preempt 관련 코드는 그냥 LLSC 방식으로 처리한다.
- 코드 라인 5~31에서 높은 확률로 태스크를 전환한다.
- 코드 라인 32~35에서 태스크 전환을 하지 않는 경우에는 런큐의 clock_skip_update는 다시 클리어 단계로 전환시킨다. 그리고 런큐를 언락한다.
- 코드 라인 37에서 스케줄 완료 후 로드 밸런스와 관련된 일이 있으면 이를 처리한다.
- dl 및 rt 태스크의 경우 2 개 이상 같은 cpu에서 동작하는 경우 이를 다른 cpu로 push 하기 위한 처리가 있다.
schedule_debug()
kernel/sched/core.c
/* * Various schedule()-time debugging checks and statistics: */
static inline void schedule_debug(struct task_struct *prev)
{
#ifdef CONFIG_SCHED_STACK_END_CHECK
if (task_stack_end_corrupted(prev))
panic("corrupted stack end detected inside scheduler\n");
#endif
#ifdef CONFIG_DEBUG_ATOMIC_SLEEP
if (!preempt && prev->state && prev->non_block_count) {
printk(KERN_ERR "BUG: scheduling in a non-blocking section: %s/%d/%i\n",
prev->comm, prev->pid, prev->non_block_count);
dump_stack();
add_taint(TAINT_WARN, LOCKDEP_STILL_OK);
}
#endif
if (unlikely(in_atomic_preempt_off())) {
__schedule_bug(prev);
preempt_count_set(PREEMPT_DISABLED);
}
rcu_sleep_check();
profile_hit(SCHED_PROFILING, __builtin_return_address(0));
schedstat_inc(this_rq(), sched_count);
}
스케줄 타임에 체크할 항목과 통계를 수행한다.
- 코드 라인 3~6에서 스택이 손상되었는지 체크한다.
- 코드 라인 8~15에서 non-blocking 섹션에서 슬립하는 경우를 찾아내기 위한 디버그 코드이다.
- 코드 라인 17~20에서 preempt disable 여부를 체크하여 에러 메시지를 출력한다.
- 코드 라인 21에서 다음 3가지 rcu에 대해 read-side 크리티컬 섹션에서 sleep(context-switch)이 발생하는 경우를 체크한다.
- “Illegal context switch in RCU read-side critical section”
- CONFIG_PREEMPT_RCU 커널 옵션을 사용하는 경우는 rcu preemption를 지원하므로 슬립이 가능하므로 이 경우는 체크하지 않는다.
- “Illegal context switch in RCU-bh read-side critical section”
- “Illegal context switch in RCU-sched read-side critical section”
- “Illegal context switch in RCU read-side critical section”
- 코드 라인 23에서 SCHED_PROFILING을 동작시킨 경우 수행한다.
- 코드 라인 25에서 rq->sched_count를 1 증가시킨다.
task_stack_end_corrupted()
include/linux/sched.h
#define task_stack_end_corrupted(task) \
(*(end_of_stack(task)) != STACK_END_MAGIC)
스택의 마지막 경계에 기록해둔 매직 넘버(0x57AC6E9D)가 깨져서 손상되었는지 여부를 알아온다. true(1)=스택 손상
hrtick_clear()
kernel/sched/core.c
/* * Use HR-timers to deliver accurate preemption points. */
static void hrtick_clear(struct rq *rq)
{
if (hrtimer_active(&rq->hrtick_timer))
hrtimer_cancel(&rq->hrtick_timer);
}
hrtick을 취소시킨다.
- CONFIG_SCHED_HRTICK 커널 옵션을 사용하고, HRTICK feature를 사용하면 hrtick이 active된다.
signal_pending_state()
include/linux/sched.h
static inline int signal_pending_state(long state, struct task_struct *p)
{
if (!(state & (TASK_INTERRUPTIBLE | TASK_WAKEKILL)))
return 0;
if (!signal_pending(p))
return 0;
return (state & TASK_INTERRUPTIBLE) || __fatal_signal_pending(p);
}
TASK_INTERRUPTIBLE 또는 TASK_WAKEKILL 상태인 태스크가 SIGKILL 요청을 받았거나 시그널 처리를 요청받은 경우 true를 반환한다.
- 코드 라인 3~4에서 태스크가 TASK_INTERRUPTIBLE 상태도 아니고 TASK_INTERRUPTIBLE 상태도 아닌 경우 false를 반환한다.
- 코드 라인 5~6에서 태스크가 시그널 펜딩 상태가 아니면 false를 반환한다.
- 코드 라인 8에서 상태가 인터럽터블이거나 요청 태스크로 fatal(SIGKILL) 시그널 요청이 온경우 true를 반환한다.
signal_pending()
include/linux/sched.h
static inline int signal_pending(struct task_struct *p)
{
return unlikely(test_tsk_thread_flag(p,TIF_SIGPENDING));
}
요청 태스크의 TIF_SIGPENDING 플래그 설정 여부를 반환한다.
fatal_signal_pending()
include/linux/sched.h
static inline int fatal_signal_pending(struct task_struct *p)
{
return signal_pending(p) && __fatal_signal_pending(p);
}
요청 태스크로 fatal(SIGKILL) 시그널이 요청되었는지 여부를 반환한다.
__fatal_signal_pending()
include/linux/sched.h
static inline int __fatal_signal_pending(struct task_struct *p)
{
return unlikely(sigismember(&p->pending.signal, SIGKILL));
}
요청 태스크로 SIGKILL 시그널이 요청되었는지 여부를 반환한다.
- SIGKILL 시그널
- 태스크를 죽일 떄 요청한다.
task_on_rq_queued()
kernel/sched/sched.h
static inline int task_on_rq_queued(struct task_struct *p)
{
return p->on_rq == TASK_ON_RQ_QUEUED;
}
태스크가 현재 런큐에서 동작중인지 여부를 반환한다.
clear_tsk_need_resched()
include/linux/sched.h”
static inline void clear_tsk_need_resched(struct task_struct *tsk)
{
clear_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
}
요청 태스크에서 리스케줄 요청 플래그를 클리어한다.
Context Switch
태스크 전환은 다음과 같이 여러 가지 이름으로 불린다. (단 Interrupt Context Switch는 여기서 설명하지 않는다.)
- Process Context Switch
- Thread Context Switch
- Task Context Switch
- CPU Context Switch
- 주의: 소극적인 표현으로는 태스크의 mm 스위칭을 제외한 cpu 레지스터들의 백업/복구를 수행하는 context 전환만을 의미할 수 있다.
context_switch()
kernel/sched/core.c
/* * context_switch - switch to the new MM and the new thread's register state. */
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
prepare_task_switch(rq, prev, next);
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
/*
* kernel -> kernel lazy + transfer active
* user -> kernel lazy + mmgrab() active
*
* kernel -> user switch + mmdrop() active
* user -> user switch
*/
if (!next->mm) { // to kernel
enter_lazy_tlb(prev->active_mm, next);
next->active_mm = prev->active_mm;
if (prev->mm) // from user
mmgrab(prev->active_mm);
else
prev->active_mm = NULL;
} else { // to user
membarrier_switch_mm(rq, prev->active_mm, next->mm);
/*
* sys_membarrier() requires an smp_mb() between setting
* rq->curr / membarrier_switch_mm() and returning to userspace.
*
* The below provides this either through switch_mm(), or in
* case 'prev->active_mm == next->mm' through
* finish_task_switch()'s mmdrop().
*/
switch_mm_irqs_off(prev->active_mm, next->mm, next);
if (!prev->mm) { // from kernel
/* will mmdrop() in finish_task_switch(). */
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}
}
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
prepare_lock_switch(rq, next, rf);
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
새로운 태스크로 context 스위칭한다. 만일 새로운 태스크가 유저 태스크인 경우 가상 공간을 바꾸기 위해 mm 스위칭도 한다.
- 코드 라인 5에서 다음 태스크로 context 스위치하기 전에 할 일을 준비한다.
- 코드 라인 12에서 context 스위치 직전에 아키텍처에서 할 일을 수행한다.
- 현재 x86 아키텍처만 수행한다.
- 코드 라인 21~24에서 스위칭할 다음 태스크가 커널 태스크(mm=null)인 경우 기존 태스크의 active_mm을 사용한다. lazy tlb 모드로 진입한다.
- arm 아키텍처는 lazy_tlb 모드를 사용하지 않는다.
- arm64의 경우 ttbr0를 사용여 PAN 기능을 sw 에뮬레이션 하는 아키텍처에서는 ti->ttbr0에 zero 페이지를 지정한다. HW PAN 기능이 있는 아키텍처의 경우에는 아무런 수행을 하지 않는다.
- 코드 라인 25~28에서 이전 태스크가 유저 태스크인지 여부에 따라 다음과 같이 동작한다.
- 유저 태스크인 경우 기존 유저 태스크의 가상 공간을 계속 사용할 계획이므로 mm 참조 카운터를 1 증가시킨다.
- 커널 태스크인 경우 prev->active_mm을 null로 대입시킨다.
- 코드 라인 29~39에서 스위칭할 다음 유저 태스크의 가상 공간을 사용하기 위해 mm 스위칭을 한다.
- mm 스위칭을 하기전에 메모리 베리어 관련 동작을 수행한다.
- mm 스위칭을 위해 TTBR0 레지스터를 새 태스크의 mm을 사용하여 설정한다.
- ASID generation이 같거나 이동 가능한 경우 TLB flush 없이 빠르게 스위칭하고, ASID 부여할 공간이 없는 경우 높은 cost가 발생하는 TLB flush도 수행해야 한다.
- 코드 라인 41~45에서 이전 태스크가 커널 태스크인 경우 rq->prev_mm에 이전 태스크의 active_mm을 백업해두고, prev->active_mm에 null을 대입한다.
- 코드 라인 48에서 런큐의 클럭 갱신 플래그에서 RQCF_ACT_SKIP와 RQCF_REQ_SKIP 모두 지운다.
- 코드 라인 50에서 태스크 스위칭 전에 런큐 락을 스위칭한다.
- 코드 라인 53에서 다음 태스크로 context 스위칭을 수행한다.
- 코드 라인 56에서 기존 태스크에 대해 context 스위치 완료 후 할 일을 수행한다
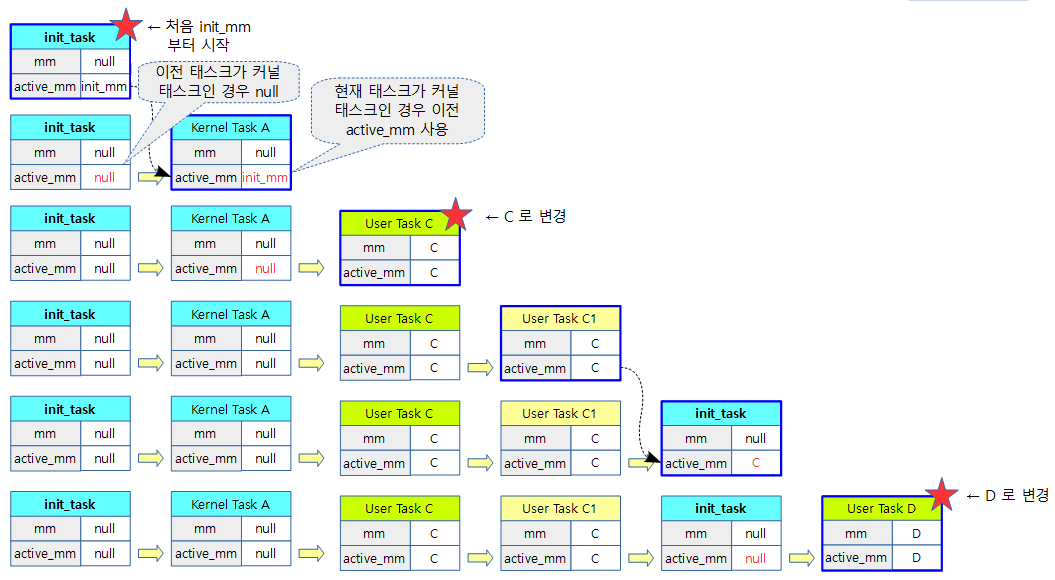
active_mm을 별도로 사용하는 이유
유저 프로세스는 유저 가상 영역을 표현한 mm을 가지고 있다(유저 스레드들은 유저 프로세스의 mm을 공유). 그런데 커널 스레드는 유저 프로세스 영역을 이용할 이유가 없으므로 유저 가상 영역을 포현한 mm을 사용하지 않으며 그 값은 null이다. 그런데 active_mm은 어디에 사용할까?
- 먼저 context swing에는 mm 스위칭이 포함되어 있는데 mm 스위칭이 일어날때마다 매우 높은 cost가 발생한다. 따라서 커널 스레드가 스케쥴 될 경우에는 mm 스위칭을 하지 않아도 된다.
- 따라서 커널 스레드가 동작 중인 경우 active_mm은 기존 유저 프로세스의 mm을 전달받아 사용한다.
- 즉 active_mm은 현재 진행중인 current task(프로세스 및 스레드)가 mm을 사용 중이든 아니든. active_mm 말 표현과 동일하게 현재 활성화된 mm 환경을 가리킨다.
두 개의 속성을 정리해본다.
- mm
- 유저 프로세스인 경우 자신의 mm을 가리킨다.
- 유저 스레드인 경우 해당 부모 프로세스의 mm을 가리킨다.
- 커널 스레드의 경우 null
- active_mm
- 유저 프로세스인 경우 자신의 mm을 가리킨다.
- 유저 스레드인 경우 해당 부모 프로세스의 mm을 가리킨다.
- 커널 스레드의 경우 이전 유저 프로세스의 mm을 전달받아 사용한다.
다음 그림과 같이 6개의 초기 태스크가 생성되었다고 가정한다.

다음 그림과 같이 초기 태스크인 init_task부터 각 커널 태스크들과 유저 태스크들이 스케줄링 되면서 active_mm이 변화하는 모습과 각 별표에서 mm 스위칭이 발생하는 것을 알 수 있다.
- 참고로 가장 주소 환경은 처음 init_task를 제외하고 항상 유저 태스크인 경우만 mm 스위칭이 발생하는데 이 때 mm을 사용한다.
- 커널 태스크로 전환된 경우 이전에 사용했던 유저 가상 주소를 active_mm을 통해 전달받아 사용한다.
- 처음 init_mm 제외
Context 스위치 전에 준비할 일과 종료 후 할 일
prepare_task_switch()
kernel/sched/core.c
/** * prepare_task_switch - prepare to switch tasks * @rq: the runqueue preparing to switch * @prev: the current task that is being switched out * @next: the task we are going to switch to. * * This is called with the rq lock held and interrupts off. It must * be paired with a subsequent finish_task_switch after the context * switch. * * prepare_task_switch sets up locking and calls architecture specific * hooks. */
static inline void
prepare_task_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
kcov_prepare_switch(prev);
sched_info_switch(rq, prev, next);
perf_event_task_sched_out(prev, next);
rseq_preempt(prev);
fire_sched_out_preempt_notifiers(prev, next);
prepare_task(next);
prepare_arch_switch(next);
}
다음 태스크로 context 스위치하기 전에 할일을 준비한다.
- 코드 라인 5에서 kcov(Kernel Code Coverage Randomize Test Tool)를 위해 스케줄 out할 태스크에 대한 정보를 기록한다.
- 참고: kernel: add kcov code coverage (2016) | LWN.net
- 코드 라인 6에서 스케줄러 통계 정보를 수집한다.
- 코드 라인 7에서 스케줄 out 태스크에 대한 perf event 정보를 출력한다.
- 코드 라인 8에서 스케줄 out 태스크의 preempt_notifier에 등록한 함수들을 콜백 함수들을 호출한다.
- 코드 라인 9에서 다음 태스크가 런큐에서 동작함을 알린다. (next->on_cpu = 1)
- 코드 라인 10에서 아키텍처에서 지원하는 경우 context 스위치 전에 할 일을 수행하게 한다.
- arm, arm64 아키텍처는 해당 사항 없다.
다음은 perf 툴을 사용하여 태스크들에 대해 스케줄 레이턴시를 분석하였다.
- 단순한 연산을 반복하는 load100 태스크가 실행하였고, 백그라운드에서는 커널을 빌드중이다
$ perf sched record ./load100 ^C [ perf record: Woken up 2 times to write data ] [ perf record: Captured and wrote 10.035 MB perf.data (88881 samples) ] $ perf sched latency ----------------------------------------------------------------------------------------------------------------- Task | Runtime ms | Switches | Average delay ms | Maximum delay ms | Maximum delay at | ----------------------------------------------------------------------------------------------------------------- rm:(5) | 19.912 ms | 7 | avg: 5.079 ms | max: 13.957 ms | max at: 255594.701006 s sh:(45) | 176.899 ms | 71 | avg: 4.153 ms | max: 20.318 ms | max at: 255593.822963 s recordmcount:(5) | 32.081 ms | 7 | avg: 3.589 ms | max: 14.293 ms | max at: 255592.467954 s fixdep:(6) | 312.116 ms | 36 | avg: 3.232 ms | max: 12.683 ms | max at: 255594.611009 s cc1:(11) | 24455.216 ms | 4283 | avg: 1.071 ms | max: 20.005 ms | max at: 255594.251001 s gcc:(10) | 60.107 ms | 41 | avg: 0.938 ms | max: 11.545 ms | max at: 255593.861169 s make:(8) | 150.007 ms | 64 | avg: 0.802 ms | max: 10.033 ms | max at: 255595.552049 s load100:9169 | 5440.106 ms | 40 | avg: 0.706 ms | max: 4.055 ms | max at: 255590.765890 s lxpanel:992 | 8.397 ms | 17 | avg: 0.601 ms | max: 3.316 ms | max at: 255594.839685 s perf_4.9:9154 | 44.080 ms | 2 | avg: 0.256 ms | max: 0.483 ms | max at: 255590.709552 s as:(6) | 1609.065 ms | 2505 | avg: 0.214 ms | max: 20.093 ms | max at: 255594.555090 s ... ----------------------------------------------------------------------------------------------------------------- TOTAL: | 32729.581 ms | 15537 | ---------------------------------------------------
finish_task_switch()
kernel/sched/core.c
/** * finish_task_switch - clean up after a task-switch * @prev: the thread we just switched away from. * * finish_task_switch must be called after the context switch, paired * with a prepare_task_switch call before the context switch. * finish_task_switch will reconcile locking set up by prepare_task_switch, * and do any other architecture-specific cleanup actions. * * Note that we may have delayed dropping an mm in context_switch(). If * so, we finish that here outside of the runqueue lock. (Doing it * with the lock held can cause deadlocks; see schedule() for * details.) * * The context switch have flipped the stack from under us and restored the * local variables which were saved when this task called schedule() in the * past. prev == current is still correct but we need to recalculate this_rq * because prev may have moved to another CPU. */
static struct rq *finish_task_switch(struct task_struct *prev)
__releases(rq->lock)
{
struct rq *rq = this_rq();
struct mm_struct *mm = rq->prev_mm;
long prev_state;
/*
* The previous task will have left us with a preempt_count of 2
* because it left us after:
*
* schedule()
* preempt_disable(); // 1
* __schedule()
* raw_spin_lock_irq(&rq->lock) // 2
*
* Also, see FORK_PREEMPT_COUNT.
*/
if (WARN_ONCE(preempt_count() != 2*PREEMPT_DISABLE_OFFSET,
"corrupted preempt_count: %s/%d/0x%x\n",
current->comm, current->pid, preempt_count()))
preempt_count_set(FORK_PREEMPT_COUNT);
rq->prev_mm = NULL;
/*
* A task struct has one reference for the use as "current".
* If a task dies, then it sets TASK_DEAD in tsk->state and calls
* schedule one last time. The schedule call will never return, and
* the scheduled task must drop that reference.
*
* We must observe prev->state before clearing prev->on_cpu (in
* finish_task), otherwise a concurrent wakeup can get prev
* running on another CPU and we could rave with its RUNNING -> DEAD
* transition, resulting in a double drop.
*/
prev_state = prev->state;
vtime_task_switch(prev);
perf_event_task_sched_in(prev, current);
finish_task(prev);
finish_lock_switch(rq);
finish_arch_post_lock_switch();
kcov_finish_switch(current);
fire_sched_in_preempt_notifiers(current);
/*
* When switching through a kernel thread, the loop in
* membarrier_{private,global}_expedited() may have observed that
* kernel thread and not issued an IPI. It is therefore possible to
* schedule between user->kernel->user threads without passing though
* switch_mm(). Membarrier requires a barrier after storing to
* rq->curr, before returning to userspace, so provide them here:
*
* - a full memory barrier for {PRIVATE,GLOBAL}_EXPEDITED, implicitly
* provided by mmdrop(),
* - a sync_core for SYNC_CORE.
*/
if (mm) {
membarrier_mm_sync_core_before_usermode(mm);
mmdrop(mm);
}
if (unlikely(prev_state == TASK_DEAD)) {
if (prev->sched_class->task_dead)
prev->sched_class->task_dead(prev);
/*
* Remove function-return probe instances associated with this
* task and put them back on the free list.
*/
kprobe_flush_task(prev);
/* Task is done with its stack. */
put_task_stack(prev);
put_task_struct_rcu_user(prev);
}
tick_nohz_task_switch();
return rq;
}
기존 태스크 @prev에 대해 context 스위치 완료 후 할 일을 수행한다. (prepare_task_switch() 함수와 한 쌍을 이룬다.)
- 코드 라인 4~24에서 런큐의 prev_mm 정보를 mm에 가져온 후 null을 대입하여 클리어한다.
- 코드 라인 37에서 기존 태스크의 state를 알아온다.
- 코드 라인 38에서 CONFIG_VIRT_CPU_ACCOUNTING 커널 옵션이 사용되는 경우 idle 및 system 타임으로 나누어 기존 태스크에 대한 vtime을 갱신한다.
- 코드 라인 39에서 스케줄 in 태스크에 대한 perf event 정보를 출력한다.
- 코드 라인 40~42에서 기존 태스크의 스위칭 완료 시 수행할 일, 런큐에 대한 락 전환 및 아키텍처별로 수행할 일을 한다.
- 코드 라인 43에서 kcov(Kernel Code Coverage Randomize Test Tool)를 위해 스케줄 in할 태스크에 대한 정보를 기록한다.
- 코드 라인 45에서 스케줄 in 되는 태스크의 preempt_notifiers 체인 리스트에 등록된 notifier 콜백 함수를 호출한다.
- 코드 라인 58~61에서 기존 태스크가 유저 태스크인 경우 가상 공간 mm을 사용하지 않으므로 mm 참조 카운터를 감소시킨다. (참조 카운터가 0이되면 할당 해제한다.)
- 코드 라인 62~76에서 낮은 확률로 기존 태스크 상태가 TASK_DEAD 인 경우 기존 태스크를 사용하지 않는다. (참조 카운터가 0이되면 할당 해제한다) 만일 기존 태스크의 스케줄러에 (*task_dead)가 준비된 경우 호출한다.
- dl 스케줄러를 사용하는 경우 task_dead_dl() 함수를 호출하여 total_bw에서 dl_bw를 감소시키고 dl 타이머를 중지시킨다.
- 코드 라인 78에서 시스템이 nohz full로 동작하고 있는 경우 nohz 지속 여부에 대한 판단 결과 지속할 필요가 없음녀 다시 tick 스케줄링을 재개한다.
- 코드 라인 79에서 런큐를 반환한다.
fire_sched_in_preempt_notifiers()
kernel/sched/core.c
static __always_inline void fire_sched_in_preempt_notifiers(struct task_struct *curr)
{
if (static_branch_unlikely(&preempt_notifier_key))
__fire_sched_in_preempt_notifiers(curr);
}
스케줄 in 되는 경우 현재 태스크의 preempt_notifiers 체인 리스트에 등록된 notifier 함수를 호출한다.
__fire_sched_out_preempt_notifiers()
kernel/sched/core.c
static void fire_sched_in_preempt_notifiers(struct task_struct *curr)
{
struct preempt_notifier *notifier;
hlist_for_each_entry(notifier, &curr->preempt_notifiers, link)
notifier->ops->sched_in(notifier, raw_smp_processor_id());
}
다음 그림은 현재 태스크의 preempt_notifiers 체인리스트에 virt/kvm/kvm_main.c – vcpu_load() 함수가 등록되어 호출되는 것을 보여준다.
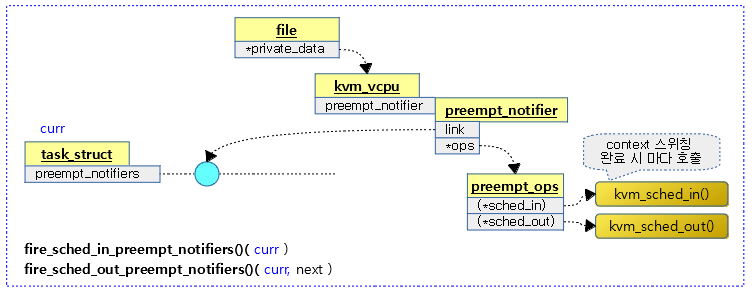
가상 메모리 관리(mm) 제거
mmdrop()
include/linux/sched.h
/* mmdrop drops the mm and the page tables */
static inline void mmdrop(struct mm_struct * mm)
{
if (unlikely(atomic_dec_and_test(&mm->mm_count)))
__mmdrop(mm);
}
메모리 디스크립터 mm의 참조 카운터를 감소시키고 0인 경우 mm을 할당 해제한다.
__mmdrop()
kernel/fork.c
/* * Called when the last reference to the mm * is dropped: either by a lazy thread or by * mmput. Free the page directory and the mm. */
void __mmdrop(struct mm_struct *mm)
{
BUG_ON(mm == &init_mm);
WARN_ON_ONCE(mm == current->mm);
WARN_ON_ONCE(mm == current->active_mm);
mm_free_pgd(mm);
destroy_context(mm);
mmu_notifier_mm_destroy(mm);
check_mm(mm);
put_user_ns(mm->user_ns);
free_mm(mm);
}
EXPORT_SYMBOL_GPL(__mmdrop);
메모리 디스크립터 mm을 할당 해제한다.
- 코드 라인 6에서 mm에 연결된 페이지 테이블을 할당 해제한다.
- 코드 라인 7에서 mm의 context 정보를 해제한다.
- arm 아키텍처는 아무것도 수행하지 않는다.
- 코드 라인 8에서 mm->mmu_notifier_mm을 할당 해제한다.
- 코드 라인 9에서 mm에 문제가 있는지 체크하고 문제가 있는 경우 alert 메시지를 출력한다
- 코드 라인 10에서 유저 네임스페이스 참조 카운터를 1 감소시킨다. (0이되면 유저 네임스페이스를 제거한다)
- 코드 라인 11에서 mm을 할당 해제한다.
mm_free_pgd()
kernel/fork.c
static inline void mm_free_pgd(struct mm_struct *mm)
{
pgd_free(mm, mm->pgd);
}
check_mm()
kernel/fork.c
static void check_mm(struct mm_struct *mm)
{
int i;
BUILD_BUG_ON_MSG(ARRAY_SIZE(resident_page_types) != NR_MM_COUNTERS,
"Please make sure 'struct resident_page_types[]' is updated as well");
for (i = 0; i < NR_MM_COUNTERS; i++) {
long x = atomic_long_read(&mm->rss_stat.count[i]);
if (unlikely(x))
pr_alert("BUG: Bad rss-counter state mm:%p type:%s val:%ld\n",
mm, resident_page_types[i], x);
}
if (mm_pgtables_bytes(mm))
pr_alert("BUG: non-zero pgtables_bytes on freeing mm: %ld\n",
mm_pgtables_bytes(mm));
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
VM_BUG_ON_MM(mm->pmd_huge_pte, mm);
#endif
}
mm에 문제가 있는지 체크하고 문제가 있는 경우 alert 메시지를 출력한다.
- 코드 라인 5~6에서 mm 카운터 수가 맞는지 체크한다.
- 코드 라인 8~14에서 3개의 mm 카운터 수만큼 루프를 돌며 rss_stat 카운터 값이 0 보다 큰 경우 alert 메시지를 출력한다.
- 코드 라인 16~18에서 mm에 사요된 페이지 테이블 바이트 수가 여전히 0 보다 큰 경우 alert 메시지를 출력한다.
- 코드 라인 20~22에서 mm->pmd_huge_pte 수가 0 보다 큰 경우 emergency 메시지를 덤프한다.
mm 카운터
include/linux/mm_types.h
enum {
MM_FILEPAGES,
MM_ANONPAGES,
MM_SWAPENTS,
NR_MM_COUNTERS
};
free_mm()
kernel/fork.c
#define free_mm(mm) (kmem_cache_free(mm_cachep, (mm)))
mm 슬랩 캐시에 메모리 디스크립터 mm을 할당 해제 한다.
가상 메모리 관리(mm) 체계 스위칭
ARM32 mm 스위칭
switch_mm() – ARM32
arch/arm/include/asm/mmu_context.h
/* * This is the actual mm switch as far as the scheduler * is concerned. No registers are touched. We avoid * calling the CPU specific function when the mm hasn't * actually changed. */
static inline void
switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
#ifdef CONFIG_MMU
unsigned int cpu = smp_processor_id();
/*
* __sync_icache_dcache doesn't broadcast the I-cache invalidation,
* so check for possible thread migration and invalidate the I-cache
* if we're new to this CPU.
*/
if (cache_ops_need_broadcast() &&
!cpumask_empty(mm_cpumask(next)) &&
!cpumask_test_cpu(cpu, mm_cpumask(next)))
__flush_icache_all();
if (!cpumask_test_and_set_cpu(cpu, mm_cpumask(next)) || prev != next) {
check_and_switch_context(next, tsk);
if (cache_is_vivt())
cpumask_clear_cpu(cpu, mm_cpumask(prev));
}
#endif
}
지정한 태스크의 가상 메모리 관리 체계로 전환하기 위해 mm 스위칭을 수행한다.
- 코드 라인 13~16에서 캐시 작업에 브로드캐스트가 필요한 아키텍처이고 태스크에 대한 cpu 비트맵이 비어 있지 않고 해당 cpu 비트만 클리어 되어 있는 경우 명령 캐시 전체를 flush 한다.
- arm 아키텍처에서 UP 시스템이나 armv7 이상인 경우 해당 사항 없다.
- 코드 라인 18~22에서 태스크에 대한 cpu 비트맵이 클리어된 상태이거나 다음 태스크에 사용할 mm이 기존 태스크의 mm과 동일하지 않은 경우 mm 스위칭을 수행한다. 캐시가 vivt 타입인 경우 기존 태스크에 대한 cpu 비트맵에서 현재 cpu 비트를 클리어한다.
cache_ops_need_broadcast() – ARM32
arch/arm/include/asm/smp_plat.h
#if !defined(CONFIG_SMP) || __LINUX_ARM_ARCH__ >= 7
#define cache_ops_need_broadcast() 0
#else
static inline int cache_ops_need_broadcast(void)
{
if (!is_smp())
return 0;
return ((read_cpuid_ext(CPUID_EXT_MMFR3) >> 12) & 0xf) < 1;
}
#endif
캐시 작업에 브로드캐스트가 필요한 아키텍처인지 여부를 알아온다. true(1)=브로드캐스트 필요
- 다음과 같이 armv6 이하 SMP 아키텍처에서 브로드캐스트가 필요한 SMP 아키텍처가 있다.
- MMFR3.Maintenance broadcast가 레지스터는 다음과 같다.
- 0b0000: 캐시, TLB 및 BP 조작 모두 local cpu에만 적용된다.
- 0b0001: 캐시, BP 조작은 명령에 따라 share cpu들에 적용되지만 TLB는 local cpu에만 적용된다.
- 0b0010: 캐시, TLB 및 BP 조작 모두 명령에 따라 share cpu들에 적용된다.
cpu_set_reserved_ttbr0() – ARM32
arch/arm/mm/context.c
static void cpu_set_reserved_ttbr0(void)
{
u32 ttb;
/*
* Copy TTBR1 into TTBR0.
* This points at swapper_pg_dir, which contains only global
* entries so any speculative walks are perfectly safe.
*/
asm volatile(
" mrc p15, 0, %0, c2, c0, 1 @ read TTBR1\n"
" mcr p15, 0, %0, c2, c0, 0 @ set TTBR0\n"
: "=r" (ttb));
isb();
}
커널 페이지 테이블(pgd)의 물리 주소가 담겨 있는 TTBR1 레지스터를 읽어 TTBR0에 복사한다.
cpu_switch_mm() – ARM32
arch/arm/include/asm/proc-fns.h
#define cpu_switch_mm(pgd,mm) cpu_do_switch_mm(virt_to_phys(pgd),mm)
cpu_do_switch_mm() – ARM32
arch/arm/include/asm/proc-fns.h & arch/arm/include/asm/glue-proc.h
#ifdef MULTI_CPU #define cpu_do_switch_mm processor.switch_mm #else #define cpu_do_switch_mm __glue(CPU_NAME,_switch_mm) #endif
- armV7 아키텍처는 MULTI_CPU를 사용하고 processor.switch_mm 후크는 cpu_v7_switch_mm() 함수를 가리킨다.
cpu_v7_switch_mm() – ARM32
arch/arm/mm/proc-v7-2level.S
/* * cpu_v7_switch_mm(pgd_phys, tsk) * * Set the translation table base pointer to be pgd_phys * * - pgd_phys - physical address of new TTB * * It is assumed that: * - we are not using split page tables * * Note that we always need to flush BTAC/BTB if IBE is set * even on Cortex-A8 revisions not affected by 430973. * If IBE is not set, the flush BTAC/BTB won't do anything. */
ENTRY(cpu_v7_switch_mm)
#ifdef CONFIG_MMU
mmid r1, r1 @ get mm->context.id
ALT_SMP(orr r0, r0, #TTB_FLAGS_SMP)
ALT_UP(orr r0, r0, #TTB_FLAGS_UP)
#ifdef CONFIG_PID_IN_CONTEXTIDR
mrc p15, 0, r2, c13, c0, 1 @ read current context ID
lsr r2, r2, #8 @ extract the PID
bfi r1, r2, #8, #24 @ insert into new context ID
#endif
#ifdef CONFIG_ARM_ERRATA_754322
dsb
#endif
mcr p15, 0, r1, c13, c0, 1 @ set context ID
isb
mcr p15, 0, r0, c2, c0, 0 @ set TTB 0
isb
#endif
bx lr
ENDPROC(cpu_v7_switch_mm)
mm 스위칭을 위해 CONTEXTIDR.ASID를 mm->context.id로 갱신하고 TTBR0 레지스터에는 pgd_phys + TTB 속성 플래그를 기록한다.
- 코드 라인 3에서 mm->context.id 값을 읽어 r1에 대입한다.
- 코드 라인 4~5에서 pgd 물리 주소가 담긴 r0에 TTB 플래그를 추가한다.
- 코드 라인 6~10에서 CONTEXTIDR 레지스터값 >> 8 비트한 값이 PROCID이고 이 값을 r1의 상위 24비트에 대입한다.
- r1 bits[31:8] <- CONTEXTIDR.PROCID
- 코드 라인 11~13에서 ARMv7 아키텍처에서 ASID 스위칭을 하는 경우 잘못된 MMU 변환이 가능하여 erratum을 위해 dsb 명령을 수행한다.
- 코드 라인 14~15에서 CONTEXTIDR에서 ASID 값이 교체된 r1 값을 CONTEXTIDR에 기록하고 isb 명령을 통해 명령 파이프를 비운다.
- 코드 라인 16~17에서 TTBR0 레지스터에 pgd 주소 및 TTB 플래그가 담긴 r0 레지스터를 기록하고 isb 명령을 통해 명령 파이프를 비운다.
arch/arm/mm/proc-v7-2level.S – ARM32
/* PTWs cacheable, inner WB not shareable, outer WB not shareable */
#define TTB_FLAGS_UP TTB_IRGN_WB|TTB_RGN_OC_WB
/* PTWs cacheable, inner WBWA shareable, outer WBWA not shareable */
#define TTB_FLAGS_SMP TTB_IRGN_WBWA|TTB_S|TTB_NOS|TTB_RGN_OC_WBWA
- TTBR0 레지스터에 pgd 물리 주소를 지정할 때 위의 플래그와 같이 지정하여 사용한다.
#define TTB_S (1 << 1) #define TTB_RGN_NC (0 << 3) #define TTB_RGN_OC_WBWA (1 << 3) #define TTB_RGN_OC_WT (2 << 3) #define TTB_RGN_OC_WB (3 << 3) #define TTB_NOS (1 << 5) #define TTB_IRGN_NC ((0 << 0) | (0 << 6)) #define TTB_IRGN_WBWA ((0 << 0) | (1 << 6)) #define TTB_IRGN_WT ((1 << 0) | (0 << 6)) #define TTB_IRGN_WB ((1 << 0) | (1 << 6))
다음 그림은 armv7 아키텍처의 context 스위칭 시 CONTEXTIDR 레지스터와 TTBR0 레지스터가 변경되는 모습을 보여준다
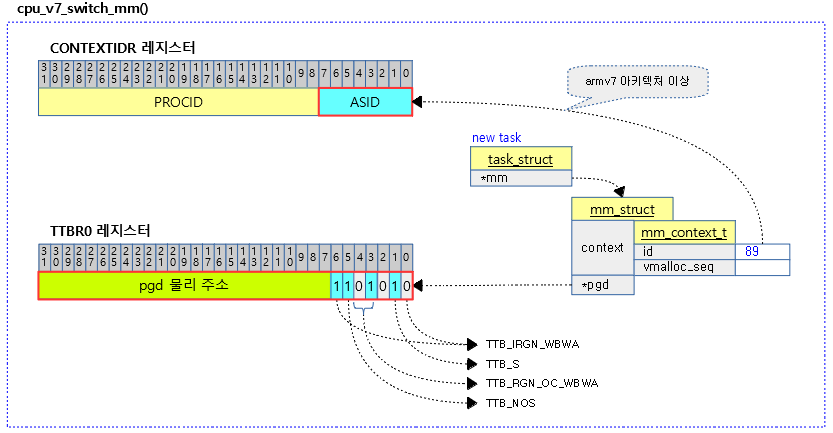
mmid 매크로 – ARM32
arch/arm/mm/proc-macros.S
/* * mmid - get context id from mm pointer (mm->context.id) * note, this field is 64bit, so in big-endian the two words are swapped too. */
.macro mmid, rd, rn
#ifdef __ARMEB__
ldr \rd, [\rn, #MM_CONTEXT_ID + 4 ]
#else
ldr \rd, [\rn, #MM_CONTEXT_ID]
#endif
.endm
mm->context.id를 rd에 반환한다. (rn에 mm)
ARM64 mm 스위칭
switch_mm() – ARM64
arch/arm64/include/asm/mmu_context.h
static inline void
switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
if (prev != next)
__switch_mm(next);
/*
* Update the saved TTBR0_EL1 of the scheduled-in task as the previous
* value may have not been initialised yet (activate_mm caller) or the
* ASID has changed since the last run (following the context switch
* of another thread of the same process).
*/
update_saved_ttbr0(tsk, next);
}
지정한 태스크의 가상 메모리 관리 체계로 전환하기 위해 mm 스위칭을 수행한다.
- 코드 라인 5~6에서 @prev 가상 메모리 관리(mm)과 @next 가상 메모리 관리(mm)가 다른 경우 mm 스위칭을 수행한다.
- 코드 라인 14에서 유저 가상 주소를 담당하는 ti->ttbr0에 기록할 ttbr 디스크립터를 기록한다. ttbr 디스크립터는 다음과 같이 구성된다.
- 16바이트의 ASID
- 48비트의 pgd 테이블에 대한 물리 주소
__switch_mm() – ARM64
arch/arm64/include/asm/mmu_context.h
static inline void __switch_mm(struct mm_struct *next)
{
unsigned int cpu = smp_processor_id();
/*
* init_mm.pgd does not contain any user mappings and it is always
* active for kernel addresses in TTBR1. Just set the reserved TTBR0.
*/
if (next == &init_mm) {
cpu_set_reserved_ttbr0();
return;
}
check_and_switch_context(next, cpu);
}
@next mm으로 mm 스위칭을 수행한다.
- 코드 라인 9~12에서 커널 가상 메모리 관리로 전환되는 경우 ttbr0를 zero 페이지를 가리키게 하여 유저 가상 주소를 액세스하지 못하게 막고 함수를 빠져나간다. ARM64 시스템의 경우 커널 가상 메모리 관리는 ttbr1을 통해 항상 active되어 있다.
- 코드 라인 14에서 asid를 체크하여 TLB 캐시 플러시 없는 mm 스위칭을 수행한다. 단 asid 부족 시엔 TLB 캐시를 플러시한다.
cpu_set_reserved_ttbr0() – ARM64
arch/arm64/include/asm/mmu_context.h
/* * Set TTBR0 to empty_zero_page. No translations will be possible via TTBR0. */
static inline void cpu_set_reserved_ttbr0(void)
{
unsigned long ttbr = phys_to_ttbr(__pa_symbol(empty_zero_page));
write_sysreg(ttbr, ttbr0_el1);
isb();
}
유저 페이지 테이블을 가리키는 ttbr0에 zero 페이지를 연결하여 유저 가상 주소 영역에 접근하지 못하게 막는다.
cpu_switch_mm() – ARM64
arch/arm64/include/asm/mmu_context.h
static inline void cpu_switch_mm(pgd_t *pgd, struct mm_struct *mm)
{
BUG_ON(pgd == swapper_pg_dir);
cpu_set_reserved_ttbr0();
cpu_do_switch_mm(virt_to_phys(pgd),mm);
}
TTBR0에 @mm->context.id와 @pgd 물리주소를 기록하여 mm 스위칭을 수행한다.
cpu_do_switch_mm() – ARM64
arch/arm64/mm/proc.S
/* * cpu_do_switch_mm(pgd_phys, tsk) * * Set the translation table base pointer to be pgd_phys. * * - pgd_phys - physical address of new TTB */
ENTRY(cpu_do_switch_mm)
mmid x1, x1 // get mm->context.id
bfi x0, x1, #48, #16 // set the ASID
msr ttbr0_el1, x0 // set TTBR0
isb
alternative_if_not ARM64_WORKAROUND_CAVIUM_27456
ret
nop
nop
nop
alternative_else
ic iallu
dsb nsh
isb
ret
alternative_endif
ENDPROC(cpu_do_switch_mm)
64비트의 ttbr0_el1 레지스터에 페이지 테이블의 물리주소(pgd_phys)를 대입하되 최상위 16비트는 asid를 지정한다. (16비트의 asid + 48비트의 pgd_phys)
- 코드 라인 2에서 x1레지스터에 mm을 담고 있고, 이를 이용하여 mm->context.id를 다시 x1 레지스터로 읽어온다.
- 코드 라인 3에서 pgd 물리 주소가 담긴 x0 레지스터의 bit[63:48] ASID 위치에 읽어온 mm->context.id를 대입한다.
- 코드 라인 4에서 ttbr0_el1에 기록한다.
- 코드 라인 5~16에서 명령어 배리어를 수행한 후 리턴한다.
- 단 CAVIUM_27456 SoC에 대해서는 워크어라운드로 명령어 캐시를 비우고 dsb 베리어 및 명령어 베리어를 한 번 더 수행한다.
mmid 매크로
include/asm/assembler.h
/* * mmid - get context id from mm pointer (mm->context.id) */
. .macro mmid, rd, rn
ldr \rd, [\rn, #MM_CONTEXT_ID]
.endm
mm_struct 구조체 포인터인 @rn->context.id 값을 @rd 레지스터에 읽어온다.
다음 그림은 pgd 페이지 테이블 주소와 ASID 값을 기록하여 mm 스위칭을 하는 모습을 보여준다.
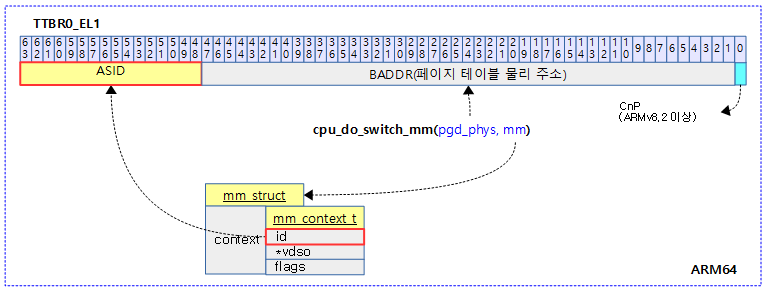
ASID 관리
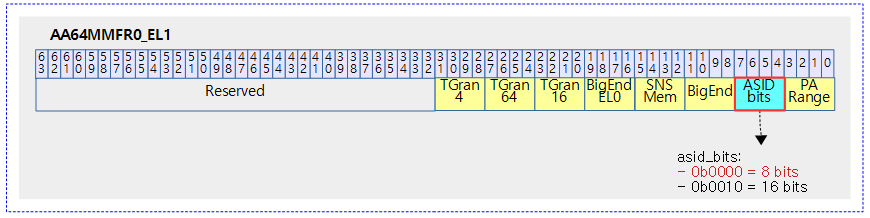
mm 스위칭 후 TLB 캐시 및 명령 캐시에 대한 플러시를 수행하는데 이는 높은 코스트를 유지한다. ARMv7 아키텍처 이후부터 TLB 캐시에 ASID를 이용한 가상 주소의 중복을 허용하게 하였다. 이를 이용하여 각각의 태스크 마다 아키텍처가 유니크하게 식별할 수 있도록 ASID를 발급하여 구분한다. 그런데 이 ASID는 ARM32의 경우 8 bit 만을 허용하고, ARM64의 경우 8 bit 또는 16 bit를 지원한다. 이 때문에 리눅스 커널에서 태스크의 식별에 사용하는 pid를 사용하지 못하고 별도로 ASID 발급 관리를 수행한다.
ARM 아키텍처에서의 ASID 운용
다음 그림은 TLB 캐시내에서 VMID + ASID + 주소로 엔트리를 구분하고 있는 모습을 보여준다.
- ARMv7 이상에서 지원한다.

다음 그림은 ARM64 시스템에서 아키텍처가 지원하는 ASID 비트 수를 알아오기 위한 레지스터를 보여준다.
ASID 대역(generation) 관리 범위
ASID generiation 관리 범위와 관련하여 태스크들의 mm 스위칭 시 다음과 같이 동작한다.
- Fastpath mm스위칭
- 다음 태스크로의 mm 스위칭 시 context.id의 하위 8비트를 제외한 값이 현재 asid_generation 값과 동일하다.
- 스핀락을 사용하지 않고, cost 높은 TLB 캐시 플러시를 수행하지 않는다.
- Slowpath mm 스위칭
- 다음 태스크로의 mm 스위칭 시 context.id의 하위 8비트를 제외한 값이 현재 asid_generation 값과 다르다.
- 스핀락을 사용하며 mm->context.id 값을 변경한다.
- asid 대역을 모두 사용한 경우 다음과 같이 동작한다.
- asid generation을 증가시킨다.
- asid_map 비트맵을 한꺼번에 클리어한다.
- 모든 cpu의 TLB 캐시를 플러시 한다.
asid_map 비트맵
2^asid_bits 수만큼의 비트를 관리하는 비트맵으로 현재 사용 중인 asid 값들을 마크하고 있다.
- 가상 메모리 mm이 필요 없어져 삭제되었다 하더라도 TLB 캐시를 플러시하지 않을 계획이므로 한 번 마크된 asid들은 계속 사용하는 것처럼 유지한다.
- ASID generation을 증가시키고 비트맵을 한꺼번에 클리어한다. 그리고 mm 스위칭 시 모든 cpu에 대한 TLB 캐시를 플러시하도록 예약한다.
ASID generation의 증가
asid 값들이 모두 다 사용되어 더 이상 asid를 발급받지 못하는 경우 다음과 같이 처리한다.
- asid_generation 값을 2^asid_bits 수 만큼 증가시킨 새로운 대역으로 이동한다.
- TLB 캐시를 플러시한다. 이 때 asid_map 비트맵도 한꺼번에 클리어한다.
check_and_switch_context() – ARM32
arch/arm/mm/context.c
void check_and_switch_context(struct mm_struct *mm, struct task_struct *tsk)
{
unsigned long flags;
unsigned int cpu = smp_processor_id();
u64 asid;
if (unlikely(mm->context.vmalloc_seq != init_mm.context.vmalloc_seq))
__check_vmalloc_seq(mm);
/*
* We cannot update the pgd and the ASID atomicly with classic
* MMU, so switch exclusively to global mappings to avoid
* speculative page table walking with the wrong TTBR.
*/
cpu_set_reserved_ttbr0();
asid = atomic64_read(&mm->context.id);
if (!((asid ^ atomic64_read(&asid_generation)) >> ASID_BITS)
&& atomic64_xchg(&per_cpu(active_asids, cpu), asid))
goto switch_mm_fastpath;
raw_spin_lock_irqsave(&cpu_asid_lock, flags);
/* Check that our ASID belongs to the current generation. */
asid = atomic64_read(&mm->context.id);
if ((asid ^ atomic64_read(&asid_generation)) >> ASID_BITS) {
asid = new_context(mm, cpu);
atomic64_set(&mm->context.id, asid);
}
if (cpumask_test_and_clear_cpu(cpu, &tlb_flush_pending)) {
local_flush_bp_all();
local_flush_tlb_all();
}
atomic64_set(&per_cpu(active_asids, cpu), asid);
cpumask_set_cpu(cpu, mm_cpumask(mm));
raw_spin_unlock_irqrestore(&cpu_asid_lock, flags);
switch_mm_fastpath:
cpu_switch_mm(mm->pgd, mm);
}
asid를 체크하여 TLB 캐시 플러시 없는 mm 스위칭을 수행한다. 단 asid 부족 시엔 TLB 캐시를 플러시한다.
- 코드 라인 7~8에서 커널 매핑 정보가 갱신된 경우 해당 커널 페이지 테이블로 부터 변경된 부분을 유저 페이지 테이블의 커널 영역에 복사하는 것으로 커널 매핑을 갱신한다.
- init_mm의 vmalloc 정보가 갱신되어 현재 태스크의 vmalloc 시퀀스와 다른 경우 init_mm의 페이지 테이블 중 vmalloc 주소 공간에 해당하는 매핑 테이블 엔트리들만 현재 태스크의 vmalloc 영역을 가리키는 엔트리에 복사한다.
- 코드 라인 15에서 classic MMU를 사용하면서 atomic하게 유저 페이지 테이블 지정 및 ASID 설정을 atomic하게 갱신할 수 없다. 따라서 먼저 커널 페이지 테이블로 전환한다. 이렇게 커널 페이지 테이블로 전환하면 유저 페이지와 관계 없는 글로벌 매핑 페이지만을 사용하므로 ASID의 효력이 없게하여 잘못된 페이지 테이블 워킹을 방지하는 효과가 있다.
- 코드 라인 17~20에서 mm 스위칭할 태스크의 32bit asid 값을 읽어 asid의 256 발급(generation) 단위(0, 0x100, 0x200, 0x300, …)에 속하면 switch_mm_fast로 이동한다.
- asid를 atomic하게 읽어온 값의 최하위 8비트를 제외한 값이 최근에 발급한 대역과 같은 경우 fastpath 처리한다.
- 예) asid_generation=0x300, mm->context.id=0x340
- 각각 8비트를 우측 shift한 결과가 같으므로 fastpath
- 예) asid_generation=0x400, mm->context.id=0x3f0
- 각각 8비트를 우측 shift한 결과가 다르므로 slowpath
- 코드 라인 22~28에서 스핀락을 걸고 다시 한 번 asid 값을 읽었을 때 최하위 8비트를 제외한 값이 최근에 발급한 번호 대역과 다른 경우 새로운 asid를 발급해와서 mm->context.id에 기록하여 변경한다.
- 예) asid_generation=0x400, mm->context.id=0x3f0인 경우 보통 mm->context.id는 0x4f0으로 변경된다.
- 0xf0이 이미 사용되고 있으면 빈 번호를 발급받는다.
- 예) asid_generation=0x400, mm->context.id=0x3f0인 경우 보통 mm->context.id는 0x4f0으로 변경된다.
- 코드 라인 30~33에서 현재 cpu에 대해 tlb 플러시가 펜딩된 상태인 경우 TLB 및 명령 캐시의 플러시 처리를 수행한다.
- 코드 라인 35~37에서 현재 cpu의 active_asids에 asid 값을 저장해두고 mm->cpu_vm_mask_var에 현재 cpu 비트를 설정한다.
- 코드 라인 40에서 mm 스위칭을 수행한다.
- TTBR0 레지스터에 pgd를 대입하고 CONTEXTIDR에서 8비트의 asid 값만 변경한다.
check_and_switch_context() – ARM64
arch/arm64/mm/context.c
void check_and_switch_context(struct mm_struct *mm, unsigned int cpu)
{
unsigned long flags;
u64 asid, old_active_asid;
if (system_supports_cnp())
cpu_set_reserved_ttbr0();
asid = atomic64_read(&mm->context.id);
/*
* The memory ordering here is subtle.
* If our active_asids is non-zero and the ASID matches the current
* generation, then we update the active_asids entry with a relaxed
* cmpxchg. Racing with a concurrent rollover means that either:
*
* - We get a zero back from the cmpxchg and end up waiting on the
* lock. Taking the lock synchronises with the rollover and so
* we are forced to see the updated generation.
*
* - We get a valid ASID back from the cmpxchg, which means the
* relaxed xchg in flush_context will treat us as reserved
* because atomic RmWs are totally ordered for a given location.
*/
old_active_asid = atomic64_read(&per_cpu(active_asids, cpu));
if (old_active_asid &&
!((asid ^ atomic64_read(&asid_generation)) >> asid_bits) &&
atomic64_cmpxchg_relaxed(&per_cpu(active_asids, cpu),
old_active_asid, asid))
goto switch_mm_fastpath;
raw_spin_lock_irqsave(&cpu_asid_lock, flags);
/* Check that our ASID belongs to the current generation. */
asid = atomic64_read(&mm->context.id);
if ((asid ^ atomic64_read(&asid_generation)) >> asid_bits) {
asid = new_context(mm);
atomic64_set(&mm->context.id, asid);
}
if (cpumask_test_and_clear_cpu(cpu, &tlb_flush_pending))
local_flush_tlb_all();
atomic64_set(&per_cpu(active_asids, cpu), asid);
raw_spin_unlock_irqrestore(&cpu_asid_lock, flags);
switch_mm_fastpath:
arm64_apply_bp_hardening();
/*
* Defer TTBR0_EL1 setting for user threads to uaccess_enable() when
* emulating PAN.
*/
if (!system_uses_ttbr0_pan())
cpu_switch_mm(mm->pgd, mm);
}
asid를 체크하여 TLB 캐시 플러시 없는 mm 스위칭을 수행한다. 단 asid 부족 시엔 TLB 캐시를 플러시한다.
- 코드 라인 6~7에서 ARMv8.2 이상 아키텍처에서 CnP를 지원하는데 이러한 경우 TTBR0_EL1에 zero 페이지를 연결하여 유저 가상 주소에 접근하지 못하게 한다.
- CnP를 사용하면 페이지 테이블 변환이 다른 cpu들에게도 동일한 효과를 발휘한다. 0으로 기록하면 CnP가 disable되어 다른 cpu들에는 영향을 주지 않게 한다.
- 참고: arm64: mm: Support Common Not Private translations (2018, v4.20-rc1)
- 코드 라인 9에서 mm->context.id를 asid 값으로 읽어온다.
- 코드 라인 25~30에서 old_active_asid가 0이 아니고 읽어온 asid가 현재 asid_generation 대역 범위에 있으면 active_asids에 atomice 하게 기록한 후 switch_mm_fastpath 레이블로 이동한다.
- 다음 상황에선 slowpath를 진행한다.
- active_asids가 0인 경우
- asid가 asid_generation 대역 범위를 벗어나는 경우
- 레이스로 인하여 atomic 기록이 실패하는 경우
- active_asids는 atomic 연산을 통해 race 상황을 감시하기 위해서만 사용된다.
- 다음 상황에선 slowpath를 진행한다.
- 코드 라인 32~38에서 스핀락을 획득한채로 다시 asid를 읽어온 값이 asid_generation 대역 범위를 벗어나면 asid를 새로운 generation 범위내에 있는 값으로 재발급해온다. 이 값을 mm->context.id에 기록한다.
- 코드 라인 40~41에서 현재 cpu에 대한 tlb 플러싱을 요구하는 비트가 설정된 경우 로컬 플러시를 수행한다.
- 이 요청은 asid가 모두 발급되어 부족해진 경우 다음 mm 스위칭에서 tlb를 플러시하도록 설정한다.
- 코드 라인 43~44에서 최종 사용할 asid 값을 active_asids 기록하고 스핀락을 해제한다.
- 코드 라인 46~48에서 switch_mm_fastpath: 레이블이다. ARM64_HARDEN_BRANCH_PREDICTOR 기능(capability)을 가진 시스템에서 workround가 필요한 경우 호출된다.
- 코드 라인 54~55에서 sw 에뮬레이션 방식의 PAN을 사용하는 시스템이 아니면 mm 스위칭을 수행한다.
- sw 에뮬레이션 방식의 PAN을 사용하는 시스템의 경우 uaccess_enable()에서 TTBR0를 기록하므로 이때 mm 스위칭을 하게되도록 유예시킨다.
다음 그림은 태스크의 mm 스위칭 시 asid_generation 범위내와 범위 밖에서 운용될 때의 변화를 3가지 케이스 형태로 보여준다.
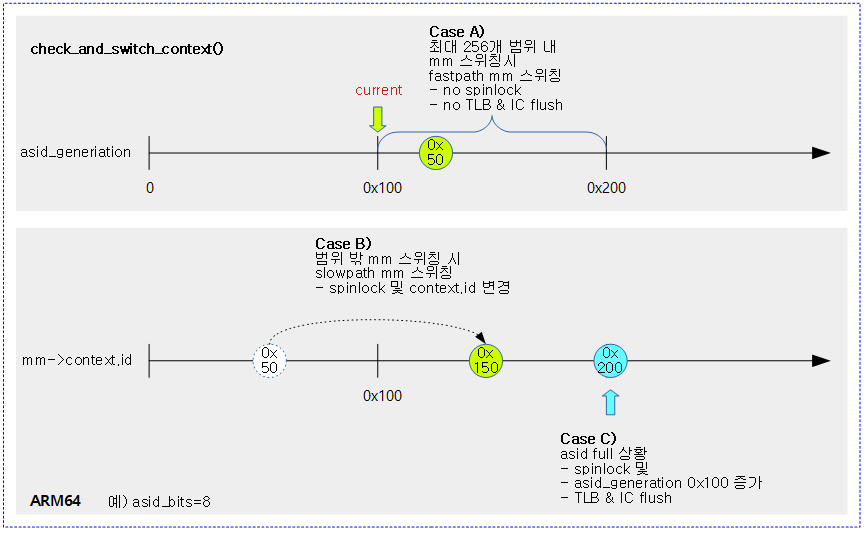
새 ASID 번호 발급
다음 그림은 새롭게 이동한 asid_generation 대역의 빈 asid 번호로 기존 context.id를 변경하는 모습을 보여준다.
- asid들은 context.id의 하위 asid_bits 수 만큼의 비트를 사용하여 asid_map에서 비트맵으로 관리된다. 단 중복되는 경우 빈 번호를 사용한다.

new_context() – ARM32
arch/arm/mm/context.c
static u64 new_context(struct mm_struct *mm, unsigned int cpu)
{
static u32 cur_idx = 1;
u64 asid = atomic64_read(&mm->context.id);
u64 generation = atomic64_read(&asid_generation);
if (asid != 0) {
u64 newasid = generation | (asid & ~ASID_MASK);
/*
* If our current ASID was active during a rollover, we
* can continue to use it and this was just a false alarm.
*/
if (check_update_reserved_asid(asid, newasid))
return newasid;
/*
* We had a valid ASID in a previous life, so try to re-use
* it if possible.,
*/
asid &= ~ASID_MASK;
if (!__test_and_set_bit(asid, asid_map))
return newasid;
}
/*
* Allocate a free ASID. If we can't find one, take a note of the
* currently active ASIDs and mark the TLBs as requiring flushes.
* We always count from ASID #1, as we reserve ASID #0 to switch
* via TTBR0 and to avoid speculative page table walks from hitting
* in any partial walk caches, which could be populated from
* overlapping level-1 descriptors used to map both the module
* area and the userspace stack.
*/
asid = find_next_zero_bit(asid_map, NUM_USER_ASIDS, cur_idx);
if (asid == NUM_USER_ASIDS) {
generation = atomic64_add_return(ASID_FIRST_VERSION,
&asid_generation);
flush_context(cpu);
asid = find_next_zero_bit(asid_map, NUM_USER_ASIDS, 1);
}
__set_bit(asid, asid_map);
cur_idx = asid;
cpumask_clear(mm_cpumask(mm));
return asid | generation;
}
현재 asid 발급 대역에서 태스크에 사용할 새로운 asid를 찾아 반환한다. 만일 256개를 모두 사용한 경우 tlb 플러싱을 예약한 후 새로운 대역에서 발급한다. 대역은 256 단위로 증가한다.
- 코드 라인 4~23에서 asid는 256개 비트를 관리하는 asid_map에서 asid의 사용 유무를 관리한다. mm->context_id에서 읽어온 asid 값과, 이 값과 asid_generation 값을 합쳐 만든 newasid를 다음과 같이 비교하여 처리한다.
- 읽어온 asid 값이 reserve_asid와 동일한 경우에 newasid 값을 반환한다.
- reserve_asid는 미리 asid_map에 비트를 설정하여 할당해둔 asid이므로 비트 설정이 따로 필요 없다.
- asid의 하위 8비트 만큼의 비트에 해당하는 인덱스 값으로 asid_map이 비어있는 경우 이의 비트틀 설정하고 asid 값을 반환한다.
- 읽어온 asid 값이 reserve_asid와 동일한 경우에 newasid 값을 반환한다.
- 코드 라인 34에서 asid가 0이거나 asid_map에서 이미 사용된 경우 직전에 보관해둔 cur_idx 번호부터 빈 번호를 찾아 asid 값으로 알아온다.
- 코드 라인 35~40에서 모두 할당되어 비어 있는 번호가 없으면 asid_generation을 ASID_FIRST_VERSION 값 만큼 추가하여 증가시킨다. 그런 후 asid_map의 모든 비트들을 클리어하고, 다음 mm 스위칭 시에 모든 cpu에 대해 tlb 및 명령 캐시를 플러시 하도록 예약한다. 마지막으로 asid_map의 1번에 해당하는 비트를 설정하고 asid를 발급해온다.
- 코드 라인 42~43에서 asid_map에서 asid에 해당하는 비트를 설정하고, 다음 검색을 위해 asid 값을 cur_idx에도 저장한다.
- 코드 라인 44에서 mm->cpu_bitmap을 클리어한다.
- 코드 라인 45에서 asid 인덱스 값과 generation을 조합하여 반환한다.
new_context() – ARM64
arch/arm64/mm/context.c
static u64 new_context(struct mm_struct *mm)
{
static u32 cur_idx = 1;
u64 asid = atomic64_read(&mm->context.id);
u64 generation = atomic64_read(&asid_generation);
if (asid != 0) {
u64 newasid = generation | (asid & ~ASID_MASK);
/*
* If our current ASID was active during a rollover, we
* can continue to use it and this was just a false alarm.
*/
if (check_update_reserved_asid(asid, newasid))
return newasid;
/*
* We had a valid ASID in a previous life, so try to re-use
* it if possible.
*/
if (!__test_and_set_bit(asid2idx(asid), asid_map))
return newasid;
}
/*
* Allocate a free ASID. If we can't find one, take a note of the
* currently active ASIDs and mark the TLBs as requiring flushes. We
* always count from ASID #2 (index 1), as we use ASID #0 when setting
* a reserved TTBR0 for the init_mm and we allocate ASIDs in even/odd
* pairs.
*/
asid = find_next_zero_bit(asid_map, NUM_USER_ASIDS, cur_idx);
if (asid != NUM_USER_ASIDS)
goto set_asid;
/* We're out of ASIDs, so increment the global generation count */
generation = atomic64_add_return_relaxed(ASID_FIRST_VERSION,
&asid_generation);
flush_context();
/* We have more ASIDs than CPUs, so this will always succeed */
asid = find_next_zero_bit(asid_map, NUM_USER_ASIDS, 1);
set_asid:
__set_bit(asid, asid_map);
cur_idx = asid;
return idx2asid(asid) | generation;
}
현재 asid 발급 대역에서 태스크에 사용할 새로운 asid를 찾아 반환한다. 만일 asid generation 대역을 모두 모두 사용한 경우 tlb 플러싱을 예약하고 새로운 대역에서 발급한다. 대역은 2^asid_bits 만큼 단위로 증가한다. (시스템에 따라 asid_bits=8 또는 16)
- 코드 라인 4~23에서 asid는 2^asid_bits 만큼의 사이즈를 가진 asid_map에서 asid의 사용 유무를 관리한다. mm->context_id에서 읽어온 asid 값과, 이 값과 asid_generation 값을 합쳐 만든 newasid를 다음과 같이 비교하여 처리한다.
- 읽어온 asid 값이 reserve_asid와 동일한 경우에 newasid 값을 반환한다.
- reserve_asid는 미리 asid_map에 비트를 설정하여 할당해둔 asid이므로 비트 설정이 따로 필요 없다.
- asid의 하위 asid_bits 만큼의 비트에 해당하는 인덱스 값으로 asid_map이 비어있는 경우 이의 비트틀 설정하고 asid 값을 반환한다.
- 읽어온 asid 값이 reserve_asid와 동일한 경우에 newasid 값을 반환한다.
- 코드 라인 32~34에서 asid가 0이거나 asid_map에서 이미 사용된 경우 직전에 보관해둔 cur_idx 번호부터 빈 번호를 찾아 asid 값으로 알아온 후 정상적으로 발급된 경우 set_asid 레이블로 이동한다.
- 성능을 위해 1번 비트부터 검색하지 않고 cur_idx 번호부터 검색한다.
- 코드 라인 37~38에서 모두 할당되어 비어 있는 번호가 없으면 asid_generation을 ASID_FIRST_VERSION 값 만큼 추가하여 증가시킨다.
- 코드 라인 39~42에서 asid_map의 모든 비트들을 클리어하고, 다음 mm 스위칭 시에 모든 cpu에 대해 tlb 및 명령 캐시를 플러시 하도록 예약한다. 마지막으로 asid_map의 1번에 해당하는 비트를 설정하고 asid를 발급해온다.
- 코드 라인 44~46에서 set_asid 레이블이다. asid_map에서 asid에 해당하는 비트를 설정하고, 다음 검색을 위해 asid 값을 cur_idx에도 저장한다.
- 코드 라인 47에서 asid 인덱스 값과 generation을 조합하여 반환한다.
flush_context()
arch/arm64/mm/context.c
static void flush_context(void)
{
int i;
u64 asid;
/* Update the list of reserved ASIDs and the ASID bitmap. */
bitmap_clear(asid_map, 0, NUM_USER_ASIDS);
for_each_possible_cpu(i) {
asid = atomic64_xchg_relaxed(&per_cpu(active_asids, i), 0);
/*
* If this CPU has already been through a
* rollover, but hasn't run another task in
* the meantime, we must preserve its reserved
* ASID, as this is the only trace we have of
* the process it is still running.
*/
if (asid == 0)
asid = per_cpu(reserved_asids, i);
__set_bit(asid2idx(asid), asid_map);
per_cpu(reserved_asids, i) = asid;
}
/*
* Queue a TLB invalidation for each CPU to perform on next
* context-switch
*/
cpumask_setall(&tlb_flush_pending);
}
TLB 플러시를 예약한다.
- 코드 라인 7에서 asid_map의 모든 비트들을 클리어한다.
- 코드 라인 9~10에서 모든 possible cpu들을 순회하며 active_asids 값을 asid로 읽어오고 0으로 클리어한다.
- 코드 라인 18~19에서 읽어온 asid가 0인 경우 reserved_asids에 다시 읽어온다.
- 코드 라인 20에서 asid_map에 asid에 해당하는 비트를 설정한다.
- 코드 라인 21에서 reserved_asids에 asid를 기록한다.
- 코드 라인 28에서 tlb_flush_pending 비트에 모두 1을 기록하여 다음 context-switch에서 TLB flush를 수행하게 한다.
mm 스위칭 전 vmalloc 복제 – ARM32
__check_vmalloc_seq()
arch/arm/mm/ioremap.c
void __check_vmalloc_seq(struct mm_struct *mm)
{
unsigned int seq;
do {
seq = init_mm.context.vmalloc_seq;
memcpy(pgd_offset(mm, VMALLOC_START),
pgd_offset_k(VMALLOC_START),
sizeof(pgd_t) * (pgd_index(VMALLOC_END) -
pgd_index(VMALLOC_START)));
mm->context.vmalloc_seq = seq;
} while (seq != init_mm.context.vmalloc_seq);
}
init_mm의 vmalloc 정보가 갱신되었기 때문에 다음 태스크로 스위칭 되기 전에 init_mm->pgd의 vmalloc 엔트리들을 mm->pgd로 갱신한다.
- 코드 라인 6에서 init_mm의 vmalloc 시퀀스 번호를 알아온다.
- 코드 라인 7~10에서 vmalloc address space에 해당하는 init_mm의 페이지 테이블 엔트리들을 mm의 페이지 테이블로 복사한다.
- 코드 라인 11~12에서 vmalloc 시퀀스 번호도 갱신한다. 이렇게 갱신하는 동안 또 변경이 일어나면 루프를 돌며 다시 갱신한다.
다음 그림은 갱신된 커널의 vmalloc 엔트리들을 내 태스크의 페이지 테이블로 갱신하는 모습을 보여준다.
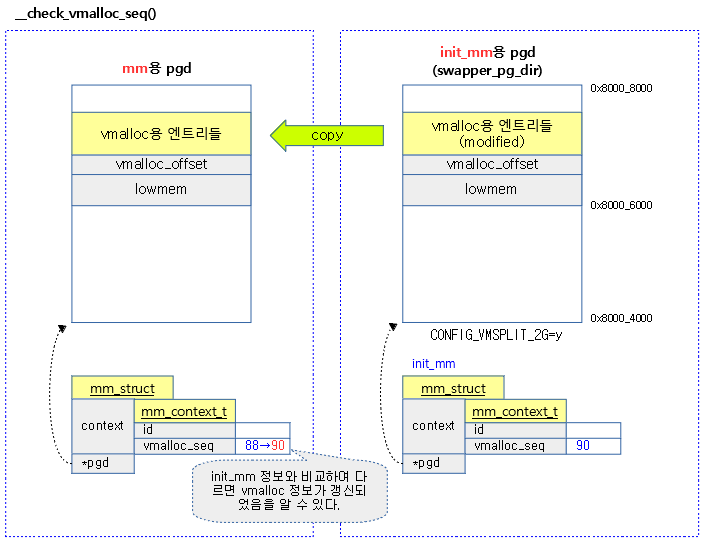
태스크 스위칭
switch_to()
include/asm-generic/switch_to.h
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to((prev), (next))); \
} while (0)
#endif
태스크 context 스위칭을 통해 다음 태스크로 전환한다.
다음 그림과 같이 태스크가 생성되는 경우 할당되는 context 관련된 컴포넌트들을 알아본다.
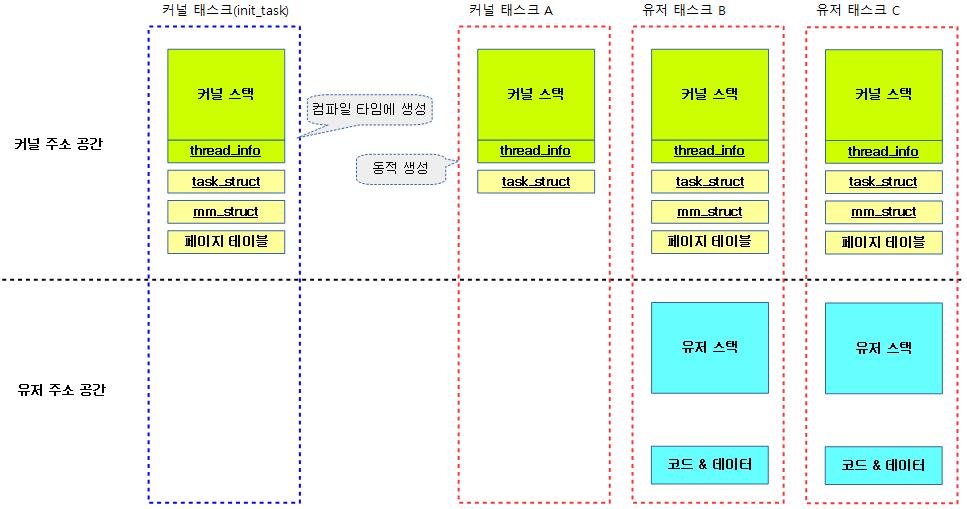
태스크 스위칭 – ARM32
__switch_to() – ARM32
arch/arm/kernel/entry-armv.S – THUMB 코드 제거
/* * Register switch for ARMv3 and ARMv4 processors * r0 = previous task_struct, r1 = previous thread_info, r2 = next thread_info * previous and next are guaranteed not to be the same. */
ENTRY(__switch_to)
UNWIND(.fnstart )
UNWIND(.cantunwind )
add ip, r1, #TI_CPU_SAVE
ARM( stmia ip!, {r4 - sl, fp, sp, lr} ) @ Store most regs on stack
ldr r4, [r2, #TI_TP_VALUE]
ldr r5, [r2, #TI_TP_VALUE + 4]
#ifdef CONFIG_CPU_USE_DOMAINS
mrc p15, 0, r6, c3, c0, 0 @ Get domain register
str r6, [r1, #TI_CPU_DOMAIN] @ Save old domain register
ldr r6, [r2, #TI_CPU_DOMAIN]
#endif
switch_tls r1, r4, r5, r3, r7
#if defined(CONFIG_STACKPROTECTOR) && !defined(CONFIG_SMP)
ldr r7, [r2, #TI_TASK]
ldr r8, =__stack_chk_guard
.if (TSK_STACK_CANARY > IMM12_MASK)
add r7, r7, #TSK_STACK_CANARY & ~IMM12_MASK
.endif
ldr r7, [r7, #TSK_STACK_CANARY & IMM12_MASK]
#endif
#ifdef CONFIG_CPU_USE_DOMAINS
mcr p15, 0, r6, c3, c0, 0 @ Set domain register
#endif
mov r5, r0
add r4, r2, #TI_CPU_SAVE
ldr r0, =thread_notify_head
mov r1, #THREAD_NOTIFY_SWITCH
bl atomic_notifier_call_chain
#if defined(CONFIG_STACKPROTECTOR) && !defined(CONFIG_SMP)
str r7, [r8]
#endif
mov r0, r5
ARM( ldmia r4, {r4 - sl, fp, sp, pc} ) @ Load all regs saved previously
UNWIND(.fnend )
ENDPROC(__switch_to)
태스크 context 스위칭을 통해 다음 태스크로 전환한다.
- 코드 라인 4~5에서 기존 ti->cpu_context에 r4 레지스터 부터 대부분의 레지스터들을 백업한다.
- struct thread_info -> ti
- 코드 라인 6~12에서 레지스터 r4, r5, r6에 순서대로 thread_info의 tp_value[0], tp_value[1] 및 cpu_domain 값을 가져온다.
- 코드 라인 14에서 process context 스위칭을 위해 TLS 스위칭을 한다.
- r1: &prev->thread_info
- r4: &tp_value[0]
- r5: &tp_value[1]
- r3: tmp1 레지스터
- r7: tmp2 레지스터
- 코드 라인 15~22에서 SMP가 아닌 시스템에서 CONFIG_STACKPROTECTOR 커널 옵션을 사용하는 경우 다음 태스크의 stack_canary 값을 r7 레지스터에 읽어오고 r8 레지스터에는 __stack_chk_guard 주소 값을 읽어온다.
- 코드 라인 23~25에서 도메인 레지스터에 cpu_domain 값을 설정한다.
- 코드 라인 26에서 r5 레지스터에 이전 태스크를 가리키는 r0 레지스터를 잠시 백업해둔다.
- 코드 라인 27에서 r4 레지스터에 다음 ti->cpu_context 값을 대입한다.
- 코드 라인 28~30에서 thread_notify_head 리스트에 등록된 notify 블럭의 모든 함수들을 호출한다. 호출 시 THREAD_NOTIFY_SWITCH 명령과 다음 struct thread_info 포인터 값을 전달한다.
- 코드 라인 31~33에서 다음 태스크의 stack_canary 값을 __stack_chk_guard 전역 변수에 저장한다.
- 코드 라인 34에서 r5에 보관해둔 이전 태스크 포인터 값을 다시 r0에 대입한다.
- 코드 라인 35에서 다음 ti->cpu_context 값을 가리키는 r4를 통해서 r4 레지스터 부터 대부분의 레지스터들을 복구한다.
- 마지막에 읽은 pc 레지스터로 점프하게 된다.
switch_tls 매크로 – ARM32
arch/arm/include/asm/tls.h
#define switch_tls switch_tls_v6k
armv6 및 armv7 아키텍처 이상의 경우 tls 레지스터를 가지고 있고 switch_tls_v68 매크로 함수를 호출한다.
switch_tls_v6k 매크로 – ARM32
arch/arm/include/asm/tls.h
. .macro switch_tls_v6k, base, tp, tpuser, tmp1, tmp2
ldr \tmp1, =elf_hwcap
ldr \tmp1, [\tmp1, #0]
mov \tmp2, #0xffff0fff
tst \tmp1, #HWCAP_TLS @ hardware TLS available?
streq \tp, [\tmp2, #-15] @ set TLS value at 0xffff0ff0
mrcne p15, 0, \tmp2, c13, c0, 2 @ get the user r/w register
mcrne p15, 0, \tp, c13, c0, 3 @ yes, set TLS register
mcrne p15, 0, \tpuser, c13, c0, 2 @ set user r/w register
strne \tmp2, [\base, #TI_TP_VALUE + 4] @ save it
mrc p15, 0, \tmp2, c13, c0, 2 @ get the user r/w register
mcr p15, 0, \tp, c13, c0, 3 @ set TLS register
mcr p15, 0, \tpuser, c13, c0, 2 @ and the user r/w register
str \tmp2, [\base, #TI_TP_VALUE + 4] @ save it
.endm
process context 스위칭을 위해 TLS 스위칭을 한다.
- Thread ID 레지스터를 읽어서 이전 thread_info.tp_value[1]에 백업하고 TLS 레지스터에 tp 값과 Thread ID 레지스터에 tpuser 값을 설정한다.
- 코드 라인 2~3에서 elf_hwcap 값을 읽어온다.
- 코드 라인 3~5에서 하드웨어 TLS 기능이 있으면 0xfff_0ff0을 @tp에 저장한다.
- 코드 라인 6에서 하드웨어 TLS 기능이 없으면 다음과 같이 처리한다.
- Thread ID 레지스터 용도의 TPIDRURW(User 읽기/쓰기) 레지스터 값을 tmp2에 대입한다. (tmp2 <- ThreadID)
- TLS 레지스터 용도의 TPIDRURO(User 읽기 전용) 레지스터에 tp 값을 저장한다. (TLS <- tp)
- Thread ID 레지스터 용도의 TPIDRURW(User 읽기/쓰기) 레지스터에 tpuser 값을 저장한다. (ThreadID <- tpuser)
- 기존 Thread ID 값을 thread_info->tp_value[1]에 저장한다.
다음 그림은 process context 스위칭을 위해 TLS를 스위칭하는 모습을 보여준다.

include/asm/mmu.h
#ifdef CONFIG_CPU_HAS_ASID #define ASID_BITS 8 #define ASID_MASK ((~0ULL) << ASID_BITS) #define ASID(mm) ((unsigned int)((mm)->context.id.counter & ~ASID_MASK)) #else #define ASID(mm) (0) #endif
- ASID_MASK=0xffff_ff00
태스크 스위칭 – ARM64
__switch_to() – ARM64
arch/arm64/kernel/process.c
/* * Thread switching. */
__notrace_funcgraph struct task_struct *__switch_to(struct task_struct *prev,
struct task_struct *next)
{
struct task_struct *last;
fpsimd_thread_switch(next);
tls_thread_switch(next);
hw_breakpoint_thread_switch(next);
contextidr_thread_switch(next);
entry_task_switch(next);
uao_thread_switch(next);
ptrauth_thread_switch(next);
ssbs_thread_switch(next);
/*
* Complete any pending TLB or cache maintenance on this CPU in case
* the thread migrates to a different CPU.
* This full barrier is also required by the membarrier system
* call.
*/
dsb(ish);
/* the actual thread switch */
last = cpu_switch_to(prev, next);
return last;
}
태스크 context 스위칭을 통해 다음 태스크로 전환한다.
- 코드 라인 6~13에서 다음 항목들도 context 전환을 수행한다.
- floating 포인트 처리기 및 SIMD 전환
- tls 레지스터 전환
- hw 디버거를 위한 break point 정보 전환
- contextidr_el1 정보 백업
- __entry_task에 @next 태스크 백업
- PSTATE에서 uao 플래그 설정(다음 태스크가 커널=1, 유저=0)
- 다음 유저 태스크인 경우 보안 관련 ssbs 플래그 처리
- 코드 라인 21에서 아직 완료되지 않은 TLB 및 캐시 조작의 완료를 기다린다.
- 코드 라인 24에서 @next 태스크로의 실제 context 스위칭을 수행한다.
- 코드 라인 26에서 전환 전 태스크 last를 반환한다.
- last == @prev
cpu_switch_to() – ARM64
arch/arm64/kernel/entry.S
/* * Register switch for AArch64. The callee-saved registers need to be saved * and restored. On entry: * x0 = previous task_struct (must be preserved across the switch) * x1 = next task_struct * Previous and next are guaranteed not to be the same. * */
ENTRY(cpu_switch_to)
mov x10, #THREAD_CPU_CONTEXT
add x8, x0, x10
mov x9, sp
stp x19, x20, [x8], #16 // store callee-saved registers
stp x21, x22, [x8], #16
stp x23, x24, [x8], #16
stp x25, x26, [x8], #16
stp x27, x28, [x8], #16
stp x29, x9, [x8], #16
str lr, [x8]
add x8, x1, x10
ldp x19, x20, [x8], #16 // restore callee-saved registers
ldp x21, x22, [x8], #16
ldp x23, x24, [x8], #16
ldp x25, x26, [x8], #16
ldp x27, x28, [x8], #16
ldp x29, x9, [x8], #16
ldr lr, [x8]
mov sp, x9
msr sp_el0, x1
ret
ENDPROC(cpu_switch_to)
NOKPROBE(cpu_switch_to)
@x0 -> @x1 태스크로의 context 스위칭을 수행한다.
- 코드 라인 2~11에서 &prev->thread_info.cpu_context에 x19~x29, x9, lr 레지스터를 백업한다.
- 코드 라인 12~19에서 &next->thread_info.cpu_context로부터 x19~x29, x9, lr 레지스터를 로드한다.
- 코드 라인 30~32에서 잠시 x9 레지스터에 보관해두었던 sp를 다시 복구하고, 유저 스택 sp_el0에 @x1(next) 태스크 주소를 기록한다.
다음 그림은 스케줄 틱이 발생했을 때 스케줄링을 통해 유저 태스크간의 전환에 interrupt 및 process의 두 가지 context switch가 진행되는 모습을 보여준다.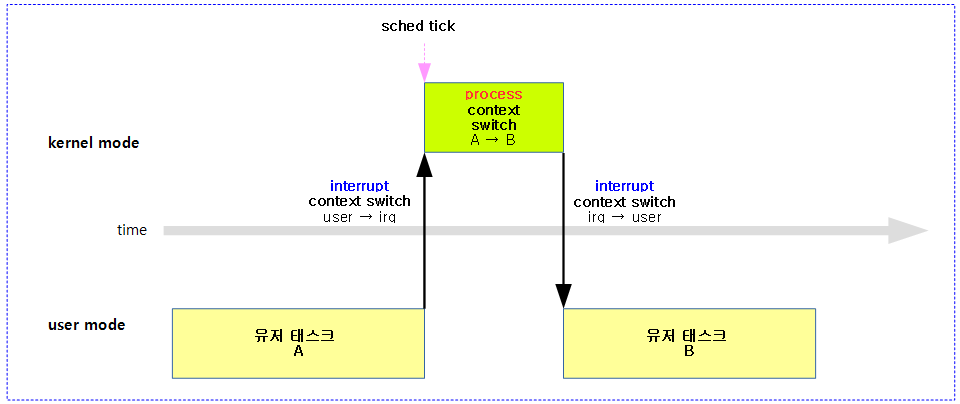
다음 그림은 32bit ARM 시스템에서 interrupt 및 process의 두 가지 context switch가 발생할 때 cpu 레지스터들이 백업/복구되는 과정을 보여준다.
- 유저 태스크에서 사용하던 모든 레지스터들은 인터럽트 발생 시 모두 태스크 A의 커널 스택에 모두 백업한다.
- 커널의 __switch_to() 함수에서 사용중인 일부 레지스터들을 태스크 A의 cpu_context_save 구조체에 백업한다.
- r0~r3, ip 레지스터는 scratch 레지스터로 함수로 부터 리턴될 때 내용이 깨져도 상관이 없다.
- AAPCS 참고: Procedure Call Standard for the ARM® Architecture | ARM – 다운로드 pdf
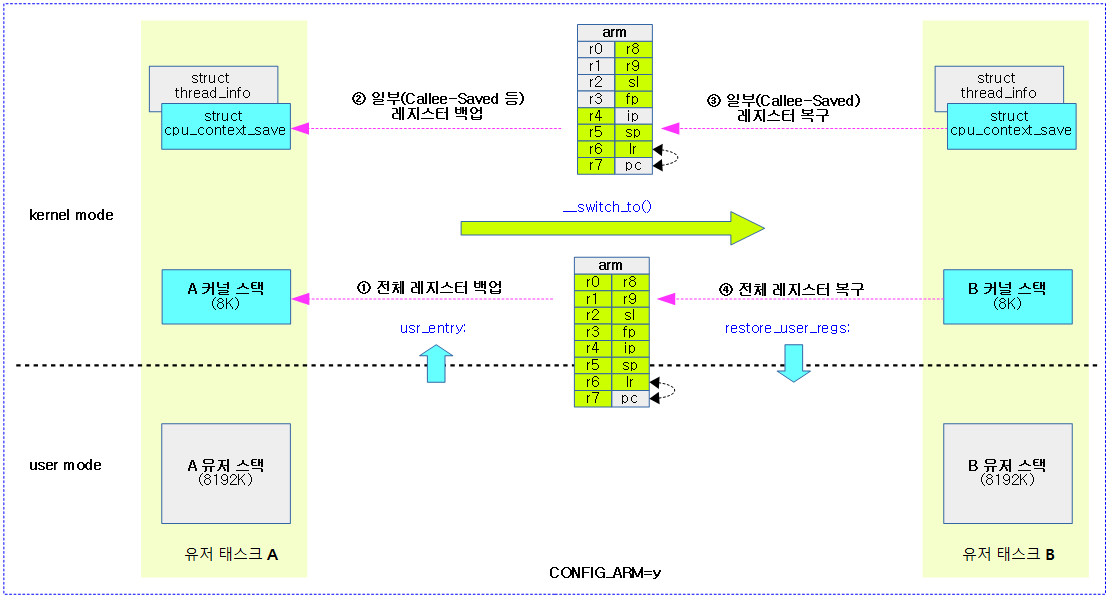
다음 그림은 ARM64 시스템에서 interrupt 및 process의 두 가지 context switch가 발생할 때 cpu 레지스터들이 백업/복구되는 과정을 보여준다.
- 유저 태스크에서 사용하던 모든 레지스터들은 인터럽트 발생 시 모두 태스크 A의 커널 스택에 모두 백업한다.
- 커널의 cpu_switch_to() 함수에서 사용중인 일부 레지스터들을 태스크 A의 cpu_context 구조체에 백업한다.
- Callee Saved 레지스터는 r19~r28이며 이 레지스터들은 호출된(callee) 함수가 스스로 레지스터를 보호해야하는 규약을 가지고 있으므로 변경하여 사용한 후에는 반드시 복귀전에 이를 복원해야 한다.
- AAPCS64 참고: Procedure Call Standard for the Arm® 64-bit Architecture | ARM
- ARM64 시스템에서는 전용 IRQ 스택을 지원하며, 커널 스택의 전환 사이에 인터럽트 처리를 위해 irq 핸들러에서 이를 중간에 이용한다.
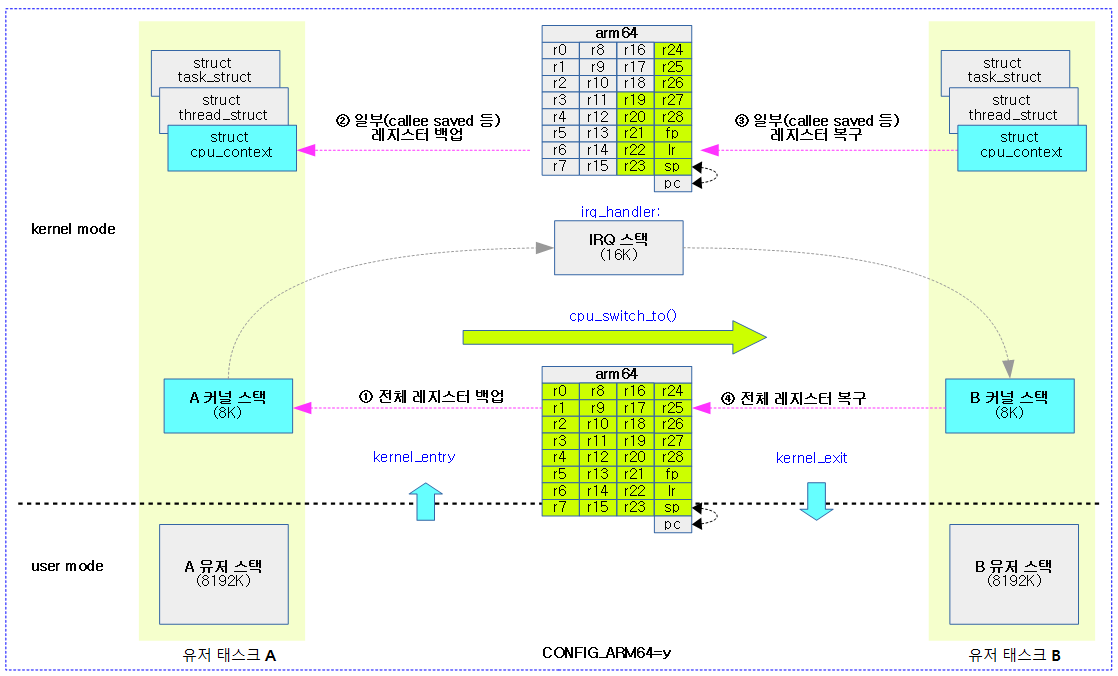
스레드 Notifier
atomic_notifier_call_chain()
kernel/notifier.c
int atomic_notifier_call_chain(struct atomic_notifier_head *nh,
unsigned long val, void *v)
{
return __atomic_notifier_call_chain(nh, val, v, -1, NULL);
}
EXPORT_SYMBOL_GPL(atomic_notifier_call_chain);
NOKPROBE_SYMBOL(atomic_notifier_call_chain);
notify 체인 리스트에 등록된 notify 블럭의 모든 함수들을 호출한다.
__atomic_notifier_call_chain()
/** * __atomic_notifier_call_chain - Call functions in an atomic notifier chain * @nh: Pointer to head of the atomic notifier chain * @val: Value passed unmodified to notifier function * @v: Pointer passed unmodified to notifier function * @nr_to_call: See the comment for notifier_call_chain. * @nr_calls: See the comment for notifier_call_chain. * * Calls each function in a notifier chain in turn. The functions * run in an atomic context, so they must not block. * This routine uses RCU to synchronize with changes to the chain. * * If the return value of the notifier can be and'ed * with %NOTIFY_STOP_MASK then atomic_notifier_call_chain() * will return immediately, with the return value of * the notifier function which halted execution. * Otherwise the return value is the return value * of the last notifier function called. */
int __atomic_notifier_call_chain(struct atomic_notifier_head *nh,
unsigned long val, void *v,
int nr_to_call, int *nr_calls)
{
int ret;
rcu_read_lock();
ret = notifier_call_chain(&nh->head, val, v, nr_to_call, nr_calls);
rcu_read_unlock();
return ret;
}
EXPORT_SYMBOL_GPL(__atomic_notifier_call_chain);
NOKPROBE_SYMBOL(__atomic_notifier_call_chain);
rcu로 보호받으며 notify 체인 리스트에 등록된 notify 블럭의 모든 함수들을 nr_to_call 수 만큼 호출하고 성공적으로 호출된 횟수를 출력 인수 nr_calls에 저장한다.
- val 값과 v 포인터 값이 notifier_call 함수에 전달된다.
contextidr_notifier_init() – ARM32
arch/arm/mm/context.c
static int __init contextidr_notifier_init(void)
{
return thread_register_notifier(&contextidr_notifier_block);
}
arch_initcall(contextidr_notifier_init);
Context 스위치마다 CONTEXTID.ASID 레지스터에 pid 값을 알아와서 기록하게 하도록 notify 블럭을 등록한다.
thread_register_notifier() – ARM32
arch/arm/include/asm/thread_notify.h
static inline int thread_register_notifier(struct notifier_block *n)
{
extern struct atomic_notifier_head thread_notify_head;
return atomic_notifier_chain_register(&thread_notify_head, n);
}
스레드 notify 체인 블럭에 notify 블럭을 등록한다.
- 다음 커널 코드에서 notify 블럭을 등록하여 사용하고 있다.
- mm/context.c – contextidr_notifier_init() <- THREAD_NOTIFY_SWITCH 명령
- arch/arm/nwfpe/fpmodule.c – fpe_init() <- THREAD_NOTIFY_FLUSH 명령
- vfp/vfpmodule.c – vfp_init() <- THREAD_NOTIFY_SWITCH, FLUSH, EXIT, COPY 명령
- 그 외 xscale 아키텍처 및 thumbee에서도 사용한다.
arch/arm/mm/context.c
static struct notifier_block contextidr_notifier_block = {
.notifier_call = contextidr_notifier,
};
contextidr_notifier() – ARM32
arch/arm/mm/context.c
#ifdef CONFIG_PID_IN_CONTEXTIDR
static int contextidr_notifier(struct notifier_block *unused, unsigned long cmd,
void *t)
{
u32 contextidr;
pid_t pid;
struct thread_info *thread = t;
if (cmd != THREAD_NOTIFY_SWITCH)
return NOTIFY_DONE;
pid = task_pid_nr(thread->task) << ASID_BITS;
asm volatile(
" mrc p15, 0, %0, c13, c0, 1\n"
" and %0, %0, %2\n"
" orr %0, %0, %1\n"
" mcr p15, 0, %0, c13, c0, 1\n"
: "=r" (contextidr), "+r" (pid)
: "I" (~ASID_MASK));
isb();
return NOTIFY_OK;
}
#endif
커널에서 하드웨어 트레이스 툴을 사용할 때 사용되며 CONTEXTID.ASID 레지스터에 pid 값을 알아와서 기록한다.
- 코드 라인 9~10에서 THREAD_NOTIFY_SWITCH 명령이 아니면 이 루틴과는 해당 사항이 없으므로 NOTIFY_DONE을 반환한다.
- 코드 라인 12에서 두 번째 인수로 받은 t 값을 사용하여 thread_info->task->pid 값을 읽어온다.
- 코드 라인 13~19에서 CONTEXTID 레지스터의 ASID 필드(bits[7:0])만 클리어하고 pid 값을 더해 기록한다.
arch/arm/include/asm/thread_notify.h
/* * These are the reason codes for the thread notifier. */ #define THREAD_NOTIFY_FLUSH 0 #define THREAD_NOTIFY_EXIT 1 #define THREAD_NOTIFY_SWITCH 2 #define THREAD_NOTIFY_COPY 3
task_pid_nr()
include/linux/sched.h
static inline pid_t task_pid_nr(struct task_struct *tsk)
{
return tsk->pid;
}
태스크의 pid 값을 반환한다.
구조체
태스크(process 또는 cpu) context switch 관련
thread_info 구조체 – ARM64
arch/arm64/include/asm/thread_info.h
/* * low level task data that entry.S needs immediate access to. */
struct thread_info {
unsigned long flags; /* low level flags */
mm_segment_t addr_limit; /* address limit */
#ifdef CONFIG_ARM64_SW_TTBR0_PAN
u64 ttbr0; /* saved TTBR0_EL1 */
#endif
union {
u64 preempt_count; /* 0 => preemptible, <0 => bug */
struct {
#ifdef CONFIG_CPU_BIG_ENDIAN
u32 need_resched;
u32 count;
#else
u32 count;
u32 need_resched;
#endif
} preempt;
};
};
- flags
- 플래그들
- addr_limit
- 접근 제한 주소
- ttbr0
- sw 에뮬레이션 방식의 PAN 기능을 위해 사용하는 ttbr0 값을 백업할 때 사용한다.
- preempt_count
- preemption 카운터로 이 값이 0일 경우에만 preemption이 가능하다.
- 아래 preempt 값을 union으로 사용
- preempt.count
- 64비트 나머지 절반은 기존 preempt_count와 동일
- preempt.need_resched
- TIF_NEED_RESCHED와 동일한 용도로 여기에 0 설정 . 주의: 리스케줄 요청=0, 초기 값=1
thread_info 구조체 – ARM32
arch/arm/include/asm/thread_info.h
/* * low level task data that entry.S needs immediate access to. * __switch_to() assumes cpu_context follows immediately after cpu_domain. */
struct thread_info {
unsigned long flags; /* low level flags */
int preempt_count; /* 0 => preemptable, <0 => bug */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
__u32 cpu; /* cpu */
__u32 cpu_domain; /* cpu domain */
#ifdef CONFIG_STACKPROTECTOR_PER_TASK
unsigned long stack_canary;
#endif
struct cpu_context_save cpu_context; /* cpu context */
__u32 syscall; /* syscall number */
__u8 used_cp[16]; /* thread used copro */
unsigned long tp_value[2]; /* TLS registers */
#ifdef CONFIG_CRUNCH
struct crunch_state crunchstate;
#endif
union fp_state fpstate __attribute__((aligned(8)));
union vfp_state vfpstate;
#ifdef CONFIG_ARM_THUMBEE
unsigned long thumbee_state; /* ThumbEE Handler Base register */
#endif
};
- flags
- 플래그들
- preempt_count
- preemption 카운터로 이 값이 0일 경우에만 preemption이 가능하다.
- addr_limit
- 접근 제한 주소
- task
- 현재 태스크
- exec_domain
- 실행 도메인
- cpu
- 동작 중인 cpu 번호
- cpu_domain
- cpu 도메인
- DACR 레지스터 참고
- 0=no access, 1=user, 3=manager
- stack_canary
- 스택 오버플로우 감지를 위해 저장한 값
- cpu_context
- cpu context 시 사용하는 cpu 레지스터 정보 저장 장소
- 아키텍처에 대한 정보가 담기므로 아키텍처 별로 다르다.
- syscall
- 시스템 콜(swi) 시 사용하는 syscall 번호
- used_cp[]
- 코프로세서 인스트럭션 체크 시 사용
- tp_value[]
- TLS 주소 저장
- fpstate
- undefined 명령 처리 시 사용하는 fp(부동 소숫점 처리기) 상태
- 이 값을 사용하여 FP 모듈의 USR 시작 주소로 진입할 수 있게한다.
- vfpstate
- undefined 명령 처리 시 사용하는 vfp(부동소숫점 연산 처리기) 상태
- 이 값을 사용하여 VFP 모듈의 USR 시작 주소로 진입할 수 있게한다.
thread_struct 구조체 – ARM64
arch/arm64/include/asm/processor.h
struct thread_struct {
struct cpu_context cpu_context; /* cpu context */
/*
* Whitelisted fields for hardened usercopy:
* Maintainers must ensure manually that this contains no
* implicit padding.
*/
struct {
unsigned long tp_value; /* TLS register */
unsigned long tp2_value;
struct user_fpsimd_state fpsimd_state;
} uw;
unsigned int fpsimd_cpu;
void *sve_state; /* SVE registers, if any */
unsigned int sve_vl; /* SVE vector length */
unsigned int sve_vl_onexec; /* SVE vl after next exec */
unsigned long fault_address; /* fault info */
unsigned long fault_code; /* ESR_EL1 value */
struct debug_info debug; /* debugging */
#ifdef CONFIG_ARM64_PTR_AUTH
struct ptrauth_keys_user keys_user;
struct ptrauth_keys_kernel keys_kernel;
#endif
#ifdef CONFIG_ARM64_MTE
u64 sctlr_tcf0;
u64 gcr_user_incl;
#endif
};
thread_struct 구조체 – ARM32
arch/arm/include/asm/processor.h
struct thread_struct {
/* fault info */
unsigned long address;
unsigned long trap_no;
unsigned long error_code;
/* debugging */
struct debug_info debug;
};
cpu_context 구조체 – ARM64
arch/arm64/include/asm/processor.h
struct cpu_context {
unsigned long x19;
unsigned long x20;
unsigned long x21;
unsigned long x22;
unsigned long x23;
unsigned long x24;
unsigned long x25;
unsigned long x26;
unsigned long x27;
unsigned long x28;
unsigned long fp;
unsigned long sp;
unsigned long pc;
};
cpu context 스위치시 레지스터의 일부가 저장되는 장소
cpu_context_save 구조체 – ARM32
arch/arm/include/asm/thread_info.h
struct cpu_context_save {
__u32 r4;
__u32 r5;
__u32 r6;
__u32 r7;
__u32 r8;
__u32 r9;
__u32 sl;
__u32 fp;
__u32 sp;
__u32 pc;
__u32 extra[2]; /* Xscale 'acc' register, etc */
};
cpu context 스위치시 레지스터의 일부가 저장되는 장소
인터럽트 context switch 관련
pt_regs 구조체 – ARM64
arch/arm64/include/uapi/asm/ptrace.h
/* * This struct defines the way the registers are stored on the stack during an * exception. Note that sizeof(struct pt_regs) has to be a multiple of 16 (for * stack alignment). struct user_pt_regs must form a prefix of struct pt_regs. */
struct pt_regs {
union {
struct user_pt_regs user_regs;
struct {
u64 regs[31];
u64 sp;
u64 pc;
u64 pstate;
};
};
u64 orig_x0;
#ifdef __AARCH64EB__
u32 unused2;
s32 syscallno;
#else
s32 syscallno;
u32 unused2;
#endif
u64 orig_addr_limit;
/* Only valid when ARM64_HAS_IRQ_PRIO_MASKING is enabled. */
u64 pmr_save;
u64 stackframe[2];
/* Only valid for some EL1 exceptions. */
u64 lockdep_hardirqs;
u64 exit_rcu;
};
interrupt context switch시 저장되는 레지스터 및 기타 정보들
svc_pt_regs 구조체 – ARM64
arch/arm/include/asm/ptrace.h
struct svc_pt_regs {
struct pt_regs regs;
u32 dacr;
u32 addr_limit;
};
interrupt context switch시 저장되는 레지스터 및 기타 정보들
pt_regs 구조체 – ARM32
arch/arm/include/asm/ptrace.h
struct pt_regs {
unsigned long uregs[18];
};
user_pt_regs 구조체 – ARM64
arch/arm64/include/uapi/asm/ptrace.h
/* * User structures for general purpose, floating point and debug registers. */
struct user_pt_regs {
__u64 regs[31];
__u64 sp;
__u64 pc;
__u64 pstate;
};
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c – 현재 글
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- The Evolution of Real-Time Linux – download pdf
- A realtime preemption overview | LWN.net
- Optimizing preemption | LWN.net