<kernel v5.4>
Deadline 스케줄러
Deadline 스케줄러는 Dario Faggioli에 의해 2013년 3월 Kernel v3.14 에서 소개되었다.
deadline 스케줄러는 EDF(Earliest Deadline First) + CBS(Constant Bandwidth Server) 알고리즘 기반으로 동작한다. 처음 UP 시스템용으로 구현되었다가 SMP 시스템에서는 이를 더 발전 시켜 각 cpu의 earliest deadline을 관리하고 다른 cpu로 전달하여 더욱 효과적으로 스케줄한다. Linus Tovalds는 Realtime 스케줄러(rt 및 dl 등)에 대해 회의적인 시각이 있어 Mainstream에서는 아직 많이 사용하지 않고 있다. 임베디드 개발자들이 원하는 기능이지만 Linus는 cpu 스케줄러만 가지고 해결할 수 없다고 보는 관점이 있다. 그러나 최근 OS X 에서의 움직임도 있고, 2017 Linaro connect 등을 통해 새 버전의 deadline 스케줄러가 안내되어 어떻게 변해갈지 주목할 듯 하다. 안드로이드를 위해 구글도 Energy Aware 기반의 코드들을 커널 메인 라인에 merge 하였다. 그 동안 추가된 기능은 다음과 같다.
- I/O 스케줄링 알고리즘 중 하나
- CFS 스케줄러 처럼 PELT와 유사한 로드 트래킹을 통한 로드밸런싱
- GRUB (“greedy utilization of unused bandwidth”) 알고리즘을 적용하여 대역폭을 조절
- RT 스케줄러와 연동하여 그룹 스케줄링을 사용하는 방법등이 고려
- Multi-processor Bandwidth Inheritance Protocol 지원
- Clock frequency selection hints
- Energy Aware Scheduling
- GRUB Reclaiming
- Constrained Deadline Task를 지원하고, Revisited Wakeup 기능이 추가
DL 스케줄러 우선 순위
dl 태스크들은 rt 및 cfs 태스크들보다 항상 우선순위가 높아 먼저 실행될 권리를 갖는다. 다만 cpu를 offline 시킬 때 사용하는 stop 스케줄러에서 사용되는 stop 태스크 보다는 우선 순위가 낮다. 스케줄러들 끼리의 우선 순위를 보면 다음과 같다.

DL 밴드위드
dl 태스크는 매 주기마다 실행되는데 보통 매 주기에 잠깐 실행되고 작업이 완료되면 스스로 슬립한다. 그러나 작업이 지연되는 경우 매 주기마다 dl_runtime 만큼 실행된다. 작업이 처리되는 동안 다른 dl 태스크에 의해 preemption될 수 있다. 커널 태스크의 경우 preemption 커널 모델에 따라 순서가 바뀌지 않을 수도 있다. 그러나 dl 스케줄러를 사용한다는 것은 사용자가 real-time 환경을 원하기 때문에 사용하였을 것이며 당연히 커널도 preemption 가능하도록 준비하는 것이 좋다. (CONFIG_PREEMPT)
dl 태스크에 설정하는 파라메터는 다음과 같이 3개이다.
- dl_period
- 설정된 주기 마다 dl 태스크가 깨어나 작업을 해야 할 간격을 설정한다.
- 참고: sched/deadline: Add period support for SCHED_DEADLINE tasks (2014, v3.14-rc1)
- dl_deadline
- 설정된 데드라인 이내에 dl 태스크의 작업이 완료될 수 있도록 한다.
- dl_deadline 이후에는 dl 스로틀이 풀려 다시 실행 가능한 시간으로 설정한다.
- 2 개 이상의 dl 태스크가 경쟁 상황에서 우선 순위 결정에 사용된다. (보통 dl_period와 동일한 값을 사용한다.)
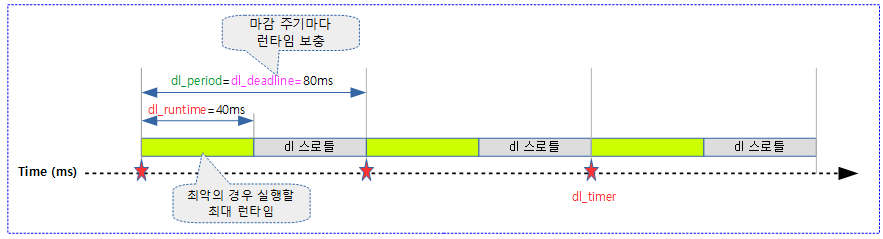
- dl_runtime
- 최악의 경우 매 기간(dl_period) 마다 최대 실행될 수 있는 시간으로 설정한다.
- 최대 런타임 시간으로, WCET(Worst Case Execution Time)로도 불린다.
위 파라메터의 관계는 다음과 같다.
- dl_runtime <= dl_deadline <= dl_period
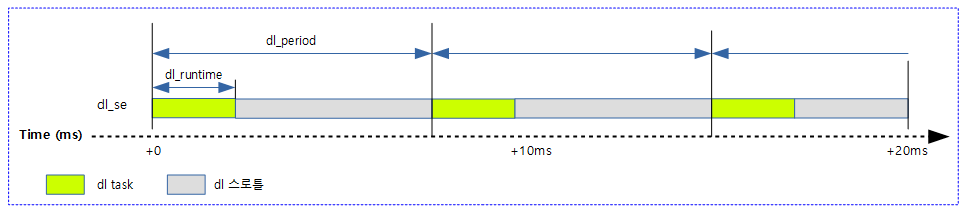
Implicit Deadline Task
- dl_period와 dl_deadline 설정 값이 같다. 즉 deadline task에 dl_runtime과 dl_period만을 설정하여 사용한다.
- 처음 deadline 스케줄러가 지원한 방법으로 매 period 마다 정해진 런타임(dl_runtime)을 보충하여 동작하는 기존 Original CBS를 지원한다.
Constrained Deadline Task
주로 실행 주기(period)를 길게 설정하여 사용해야 하는 deadline 태스크이지만, 마감을 더 빠르게 지정하여 더 빠른 우선 순위를 부여하여 사용하고 싶은 deadline 태스크에 사용되는 모델이다.
- Implicit deadline task의 두 설정값에 추가로 dl_deadline 값을 지정하여 사용한다.
- 단: dl_deadline <= dl_period
- period를 길게하고 deadline을 짧게 하면 태스크는 slow activation으로 동작하고 빠른 스케줄을 할 수 있다.
- Revisited CBS를 지원하는 모델이다.
- implicit dl task와 다르게 deadline을 넘겨 깨어난 dl 태스크에 곧바로 런타임을 제공하지 않고 스로틀시키는 특성이 있다.
- implicit dl task의 경우 deadline을 넘겨서 깨어난 태스크에도 런타임을 제공하여 오버런 하므로 deadline 규칙을 무시한다.
- 깨어난 태스크에 대해 마감 전 판단하여 마감을 넘길것 같은(overflow 판정) 태스크에 대해서는 이 번 period에 한해 비례 설정(runtime/deadline) * 남은 마감 잔량만큼만을 런타임으로 공급한다.
- 참고: sched/deadline: Use the revised wakeup rule for suspending constrained dl tasks (2017, v4.13-rc1)
- implicit dl task와 다르게 deadline을 넘겨 깨어난 dl 태스크에 곧바로 런타임을 제공하지 않고 스로틀시키는 특성이 있다.
DL 태스크의 우선 순위
dl 태스크들 간의 우선 순위는 만료 시각이 먼저 다가 오는 태스크에 우선 처리할 기회가 주어진다. 실제 구현은 아래 그림보다는 복잡하며 conceptual한 시각으로 이해하여야 한다.
- deadline 값은 매 dl_period 마다 설정된다.
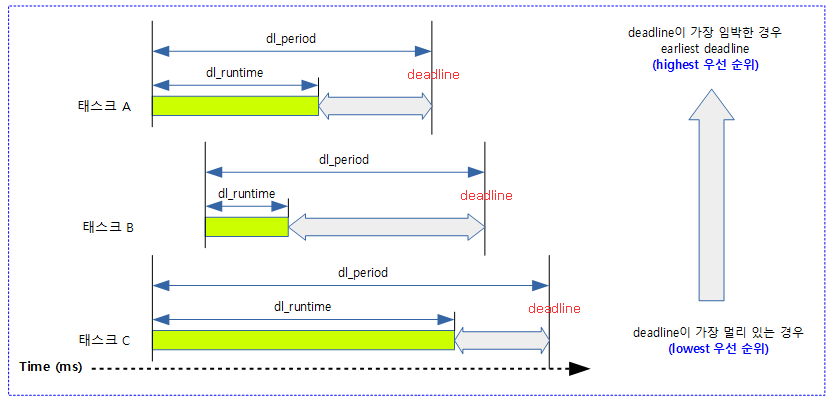
DL 태스크의 Priority Inversion
RT 태스크의 priority inversion과 동일하게 deadline 태스크에서 우선 순위 경쟁은 deadline이 가장 빠른 deadline 태스크가 우선된다. dl 태스크끼리의 rt_mutex 경합에서 priority inversion을 회피하기 위해 deadline이 빠른 태스크의 deadline 값을 상속 받아 처리한다. 이를 dl boost라고 한다.
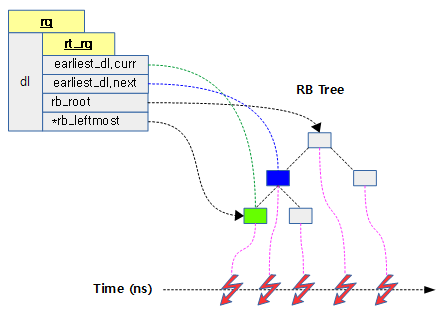
DL 런큐
dl 런큐는 cpu 수 만큼 생성된다. dl 스케줄러는 rt나 cfs 스케줄러와는 다르게 그룹 스케줄링을 지원하지 않는다. dl 태스크들이 dl 스케줄러에 큐잉되면 dl 런큐에 존재하는 RB 트리에서 관리된다. deadline 스케줄러는 2 개 이상의 태스크가 큐에서 관리될 때 만료 시각이 가장 이른 태스크를 찾아 실행시킨다. 아래 그림에서 초록색 -> 파란색 순서로 실행하게된다.
DL 스로틀
DL 밴드위드는 태스크마다 주어진다. 태스크에 매 기간마다 주어진 런타임이 다 소진되면 스로틀(스스로 슬립)한다.
- cfs나 rt 스케줄러에서는 밴드위드 설정이 그룹 스케줄링을 사용하는 경우에 각 태스크 그룹에 대해서 설정되었으나 DL 밴드위드는 태스크 단위로 설정한다.
스로틀링이 발생하면 다음 우선 순위의 대기 태스크에게 기회가 주어진다. 현재 cpu에서 더 이상 수행할 태스크가 없는 경우 idle로 진입한다.
- cfs나 rt 스케줄러에서는 스로틀링이 그룹 스케줄링을 사용하는 경우에 각 태스크 그룹에 대해서 설정되었으나 DL 스케줄러에서는 태스크 단위로 수행된다.
- 아래 그림에서 붉은 색 점선으로 표현된 구간이 되면 dl 스케줄러에서 동작하는 cpu가 스로틀하여 다음 순위의 스케줄러에 있는 태스크를 수행시킬 수 있다. 즉 붉은 색 점선에서 rt, cfs 태스크가 동작할 수 있고 수행시킬 수 있는 태스크가 하나도 없으면 idle 상태로 진입한다.
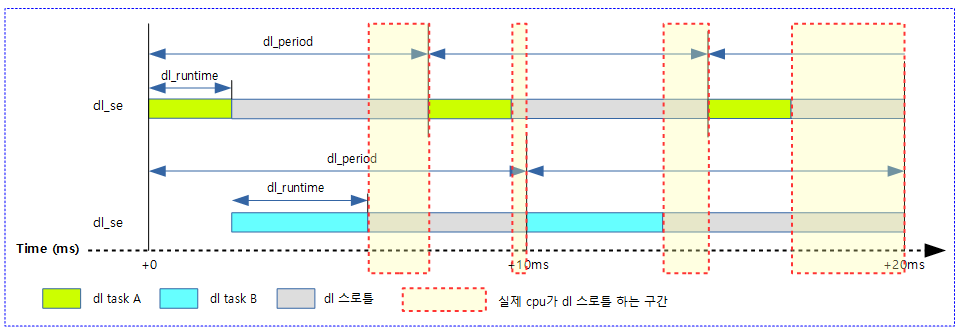
DL 밴드위드에 따른 스로틀 발생과 관련하여 각 타이머들의 동작을 알아본다.
- sched tick: dl 태스크가 현재 동작하고 있을 때 매 스케줄 틱마다 진입하여 런타임 잔량을 체크하여 0 이하가 되면 스로틀링한다.
- hrtick: 태스크가 처음 수행될 때 최대 런타임(dl_runtime) 만큼 타이머를 동작시킨다.
- deadline timer: 런타임 잔량이 다 소모된 후에 스로틀된 dl 태스크를 다음 주기에 깨우기 위해 가동되는 타이머이다. 스로틀할 때 남은 주기(dl_period)만큼 deadline 시간을 정하여 deadline 타이머를 프로그램한다.
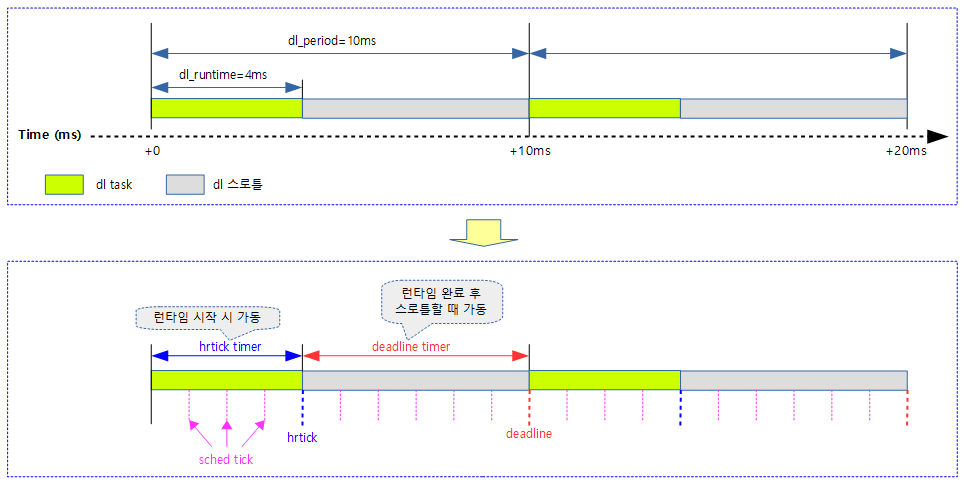
earliest deadline에 따른 우선 순위 변경
만료 시각이 급한 태스크가 동작해야 할 때 우선 순위 바꿈(preemption)이 일어난다. deadline 타이머에 의해 태스크가 곧바로 깨어날지 기존 dl 태스크가 계속 수행할지 여부에 대한 판단은 deadline 우선 순위로 결정한다. 아래 그림에서 처음 Task A -> Task B -> Task A로 수행 순서가 변경되는 과정을 알아본다. Task A가 수행 중에 Task B의 deadline 타이머에 의해 처음 판단을 하게 된다. 그 순간 deadline이 가장 먼저인 Task B를 선택하여 수행하고 런타임 잔량을 모두 소모하면 스로틀링이 발생한다. 다시 자연스럽게 대기하고 있던 Task A로 실행 순서가 바뀐다.
hrtick의 동작은 더 복잡하므로 이에 대해 자세히 알아보자. 아래 그림에서 Task A가 동작할 때 hrtick 타이머를 프로그램한다. Task B의 deadline 타이머 만료 시 Task B의 hrtick 타이머도 프로그램한다. Task A에서 준비한 hrtick 타이머가 만료되어 깨어날 때 현재 동작 태스크는 Task B로 이미 순서가 변경된 후 실행되고 있던 순간이다. 따라서 Task A의 런타임 잔량을 체크하는 것이 아니라 Task B의 런타임 잔량을 체크하고 아직 남아 있기 때문에 남은 기간으로 재조정하여 hrtick 타이머를 재프로그램한다. 재프로그램한 타이머가 만료되어 꺠어나면 Task B의 런타임 잔량이 다 소모되었으므로 스로틀링하고 Task A로의 전환이 발생한다. 그 후 Task A의 남은 런타임 잔량만큼 다시 hrtick을 재프로그램 한다.
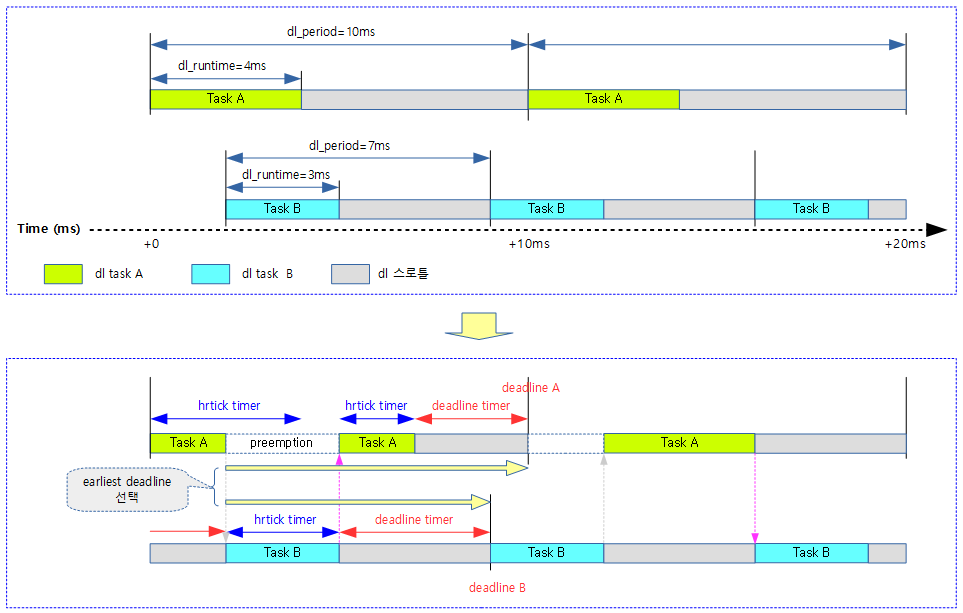
종합하여 보면 earliest deadline 우선 처리하도록 다음과 같이 처리된다.
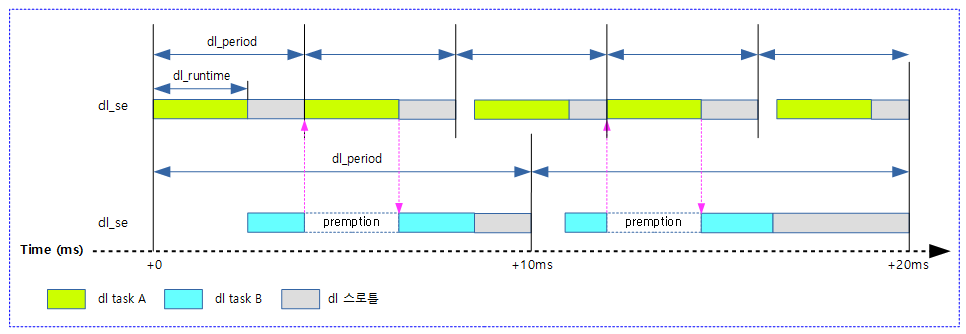
기타
DL 로드밸런스와 관련된 다음 항목들은 코드 분석 중에 보여준다.
- push operation
- pull operation
- overload
- CPU deadline 관리
dl 태스크로 변경하는 방법
다음 코드는 100ms 주기와 데드라인, 그리고 30ms의 최대 런타임을 설정하여 태스크의 속성을 바꾸는 방법을 보여준다. (root 권한이 필요하다)
#include <sched.h>
...
struct sched_attr attr;
attr.size = sizeof(struct attr);
attr.sched_policy = SCHED_DEADLINE;
attr.sched_runtime = 30000000;
attr.sched_period = 100000000;
attr.sched_deadline = attr.sched_period;
...
if (sched_setattr(gettid(), &attr, 0))
perror("sched_setattr()");
다음과 같이 deadline policy로 새 태스크를 동작시킬 수도 있다.
- –pid 옵션을 사용하여 실행 중인 태스크의 policy를 변경할 수도 있다
- 단위는 나노초(ns)를 사용한다.
$ chrt Show or change the real-time scheduling attributes of a process. Set policy: chrt [options][...] chrt [options] --pid Get policy: chrt [options] -p Policy options: -b, --batch set policy to SCHED_BATCH -d, --deadline set policy to SCHED_DEADLINE -f, --fifo set policy to SCHED_FIFO -i, --idle set policy to SCHED_IDLE -o, --other set policy to SCHED_OTHER -r, --rr set policy to SCHED_RR (default) Scheduling options: -R, --reset-on-fork set SCHED_RESET_ON_FORK for FIFO or RR -T, --sched-runtime runtime parameter for DEADLINE -P, --sched-period period parameter for DEADLINE -D, --sched-deadline deadline parameter for DEADLINE Other options: -a, --all-tasks operate on all the tasks (threads) for a given pid -m, --max show min and max valid priorities -p, --pid operate on existing given pid -v, --verbose display status information -h, --help display this help and exit -V, --version output version information and exit For more details see chrt(1). $ chrt --deadline --sched-runtime 300000000 --sched-period 1000000000 0 ./load100 &
DL 스케줄러 ops
kernel/sched/deadline.c
const struct sched_class dl_sched_class = {
.next = &rt_sched_class,
.enqueue_task = enqueue_task_dl,
.dequeue_task = dequeue_task_dl,
.yield_task = yield_task_dl,
.check_preempt_curr = check_preempt_curr_dl,
.pick_next_task = pick_next_task_dl,
.put_prev_task = put_prev_task_dl,
.set_next_task = set_next_task_dl,
#ifdef CONFIG_SMP
.balance = balance_dl,
.select_task_rq = select_task_rq_dl,
.migrate_task_rq = migrate_task_rq_dl,
.set_cpus_allowed = set_cpus_allowed_dl,
.rq_online = rq_online_dl,
.rq_offline = rq_offline_dl,
.task_woken = task_woken_dl,
#endif
.task_tick = task_tick_dl,
.task_fork = task_fork_dl,
.prio_changed = prio_changed_dl,
.switched_from = switched_from_dl,
.switched_to = switched_to_dl,
.update_curr = update_curr_dl,
};
Deadline 스케줄 틱
task_tick_dl()
kernel/sched/deadline.c
/* * scheduler tick hitting a task of our scheduling class. * * NOTE: This function can be called remotely by the tick offload that * goes along full dynticks. Therefore no local assumption can be made * and everything must be accessed through the @rq and @curr passed in * parameters. */
static void task_tick_dl(struct rq *rq, struct task_struct *p, int queued)
{
update_curr_dl(rq);
update_dl_rq_load_avg(rq_clock_pelt(rq), rq, 1);
/*
* Even when we have runtime, update_curr_dl() might have resulted in us
* not being the leftmost task anymore. In that case NEED_RESCHED will
* be set and schedule() will start a new hrtick for the next task.
*/
if (hrtick_enabled(rq) && queued && p->dl.runtime > 0 &&
is_leftmost(p, &rq->dl))
start_hrtick_dl(rq, p);
}
이 함수는 dl 태스크가 수행 중에 스케줄 틱 또는 hrtick 인터럽트가 발생 시 호출된다. hrtick으로 진입한 경우 @queued=1로 호출된다.
- 코드 라인 3에서 dl 런큐에서 스케줄 틱(정규 및 hrtick) 마다 현재 실행 중인 dl 태스크의 런타임을 갱신하고 dl 밴드위드에 따라 필요 시 스로틀한다.
- 코드 라인 5에서 dl 런큐의 PELT를 갱신한다.
- 코드 라인 11~13에서 hrtick 인터럽트에 의해 호출되었으면서 여전히 런타임 잔량이 모두 소모되지 않은 경우 이를 계속 처리하려한다. 단 dl 런큐에서 대기중인 첫 태스크(earliest deadline task)인 경우이면 다시 남은 런타임 잔량 만큼 hrtick 타이머를 재 동작시킨다.
- dl 태스크들은 각자 자신의 hrtick 타이머를 가지고 있다.
다음 그림은 task_tick_dl() 함수 이후 호출 관계를 보여준다.
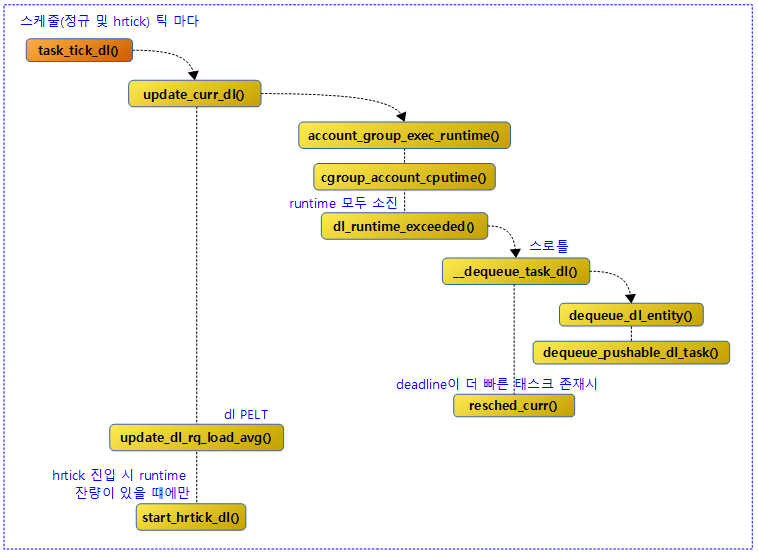
runtime 갱신 및 dl 밴드위드 동작
update_curr_dl()
kernel/sched/deadline.c – 1/2
/* * Update the current task's runtime statistics (provided it is still * a -deadline task and has not been removed from the dl_rq). */
static void update_curr_dl(struct rq *rq)
{
struct task_struct *curr = rq->curr;
struct sched_dl_entity *dl_se = &curr->dl;
u64 delta_exec, scaled_delta_exec;
int cpu = cpu_of(rq);
u64 now;
if (!dl_task(curr) || !on_dl_rq(dl_se))
return;
/*
* Consumed budget is computed considering the time as
* observed by schedulable tasks (excluding time spent
* in hardirq context, etc.). Deadlines are instead
* computed using hard walltime. This seems to be the more
* natural solution, but the full ramifications of this
* approach need further study.
*/
now = rq_clock_task(rq);
delta_exec = now - curr->se.exec_start;
if (unlikely((s64)delta_exec <= 0)) {
if (unlikely(dl_se->dl_yielded))
goto throttle;
return;
}
schedstat_set(curr->se.statistics.exec_max,
max(curr->se.statistics.exec_max, delta_exec));
curr->se.sum_exec_runtime += delta_exec;
account_group_exec_runtime(curr, delta_exec);
curr->se.exec_start = now;
cgroup_account_cputime(curr, delta_exec);
if (dl_entity_is_special(dl_se))
return;
/*
* For tasks that participate in GRUB, we implement GRUB-PA: the
* spare reclaimed bandwidth is used to clock down frequency.
*
* For the others, we still need to scale reservation parameters
* according to current frequency and CPU maximum capacity.
*/
if (unlikely(dl_se->flags & SCHED_FLAG_RECLAIM)) {
scaled_delta_exec = grub_reclaim(delta_exec,
rq,
&curr->dl);
} else {
unsigned long scale_freq = arch_scale_freq_capacity(cpu);
unsigned long scale_cpu = arch_scale_cpu_capacity(cpu);
scaled_delta_exec = cap_scale(delta_exec, scale_freq);
scaled_delta_exec = cap_scale(scaled_delta_exec, scale_cpu);
}
dl_se->runtime -= scaled_delta_exec;
dl 런큐에서 스케줄 틱(정규 및 hrtick) 마다 현재 실행 중인 dl 태스크의 런타임을 갱신하고 dl 밴드위드에 따라 필요 시 스로틀한다.
- 코드 라인 9~10에서 현재 런큐에서 수행중인 태스크가 dl 태스크가 아니거나 dl 엔티티가 dl 런큐에 엔큐되지 않은 경우 함수 처리를 빠져나간다.
- 코드 라인 20~26에서 delta 실행 시간을 구해와서 0 이하인 경우 함수 처리를 빠져나간다. 단 dl 태스크가 스스로 양보(yield)한 경우 throttle 레이블로 이동한다.
- 코드 라인 28~29에서 태스크의 한 틱당 최대 실행 시간을 갱신한다.
- 코드 라인 31에서 구한 delta 실행 시간을 더해 현재 dl 태스크의 총 실행 시간을 갱신한다. (curr->se.sum_exec_runtime)
- 코드 라인 32에서 현재 스레드 그룹용 총 시간 관리를 위해 cpu 타이머가 동작하는 동안 총 실행 시간을 갱신한다.
- posix timer를 통해 만료 시 시그널을 발생한다.
- 한 번에 장시간 dl 태스크가 동작하는 경우 IO 처리에 병목 현상이 발생함을 감지하기 위해 사용된다.
- 코드 라인 34에서 현재 시각(rq->clock_task)으로 현재 dl 태스크의 시작 실행 시각을 갱신한다. (curr->se.exec_start)
- 코드 라인 35에서 현재 태스크의 cpu accounting 그룹용 총 실행 시간을 갱신한다.
- 코드 라인 37~38에서 special 태스크의 경우 가장 우선해서 처리해야 하므로 리스케줄 및 스로틀 하지 않기 위해 그만 함수를 빠져나간다.
- SUGOV(Sched Util Govenor)에 사용되는 kthread 워커 스레드는 cfs 태스크에서 dl 태스크로 변경하였고 한 번 실행되면 stop을 제외하고 preemption 되지 않는다.
- 참고: sched/cpufreq: Change the worker kthread to SCHED_DEADLINE (2018, v4.16-rc1)
- 코드 라인 47~50에서 SCHED_FLAG_RECLAIM 플래그가 설정된 dl 태스크인 경우 GRUB(Greedy
Reclamation of Unused Bandwidth) account 룰에 의해 delta 실행 시간을 산출한다. - 코드 라인 51~57에서 일반 적인 경우 frequency 및 cpu cpu capacity 스케일이 적용된 delta 실행 시간을 산출한다.
- cpu들 중 가장 빠르고, 주파수가 높은 cpu를 100% 상태의 delta 실행 시간을 적용한다.
- 참고: sched/deadline: Make bandwidth enforcement scale-invariant (2018, v4.16-rc1)
- 코드 라인 59에서 런타임을 스케일 적용된 delta 실행 시간 만큼 뺀다.
kernel/sched/deadline.c – 2/2
throttle:
if (dl_runtime_exceeded(dl_se) || dl_se->dl_yielded) {
dl_se->dl_throttled = 1;
/* If requested, inform the user about runtime overruns. */
if (dl_runtime_exceeded(dl_se) &&
(dl_se->flags & SCHED_FLAG_DL_OVERRUN))
dl_se->dl_overrun = 1;
__dequeue_task_dl(rq, curr, 0);
if (unlikely(dl_se->dl_boosted || !start_dl_timer(curr)))
enqueue_task_dl(rq, curr, ENQUEUE_REPLENISH);
if (!is_leftmost(curr, &rq->dl))
resched_curr(rq);
}
/*
* Because -- for now -- we share the rt bandwidth, we need to
* account our runtime there too, otherwise actual rt tasks
* would be able to exceed the shared quota.
*
* Account to the root rt group for now.
*
* The solution we're working towards is having the RT groups scheduled
* using deadline servers -- however there's a few nasties to figure
* out before that can happen.
*/
if (rt_bandwidth_enabled()) {
struct rt_rq *rt_rq = &rq->rt;
raw_spin_lock(&rt_rq->rt_runtime_lock);
/*
* We'll let actual RT tasks worry about the overflow here, we
* have our own CBS to keep us inline; only account when RT
* bandwidth is relevant.
*/
if (sched_rt_bandwidth_account(rt_rq))
rt_rq->rt_time += delta_exec;
raw_spin_unlock(&rt_rq->rt_runtime_lock);
}
}
- 코드 라인 1~10에서 throttle 레이블이다. 런타임 전량이 남아 있지 않는 경우 또는 야보된 태스크인 경우 태스크에 dl_throttled를 1로 설정하고 dl 태스크를 디큐한다. 단 런타임 잔량이 없고 SCHED_FLAG_DL_OVERRUN 플래그가 설정된 dl 태스크에 대해 dl_overrun=1 설정을 한다.
- 코드 라인 11~12에서 낮은 확률로 dl boosted된 태스크는 다시 dl 태스크를 엔큐한다. 또한 deadline을 넘기지 않은 dl 태스크는 다시 deadline 타이머를 가동한다. 단 deadline을 이미 초과한 경우 이 역시 다시 dl 태스크를 엔큐한다.
- 코드 라인 14~15에서 현재 동작 중인 태스크의 deadline이 가장 앞서지 않는 경우 리스케줄 요청한다.
- 코드 라인 29~41에서 rt bandwidth가 설정되었고 rt period 타이머가 동작중이거나 rt 런타임의 잔량이 남아있는 경우 rt 태스크에 delta 시간 만큼 rt 런타임을 소비한다.
- dl 태스크는 rt bandwidth 런타임 할당량을 share 하며 사용한다.
DL 런타임 초과 여부
dl_runtime_exceeded()
kernel/sched/deadline.c
static
int dl_runtime_exceeded(struct rq *rq, struct sched_dl_entity *dl_se)
{
return (dl_se->runtime <= 0);
}
dl 엔티티의 런타임이 모두 소모된 경우 true(1)를 반환한다.
Enqueue & Dequeue DL 태스크
다음 그림은 dl 태스크의 엔큐와 디큐 이후 함수 호출 관계를 보여준다.
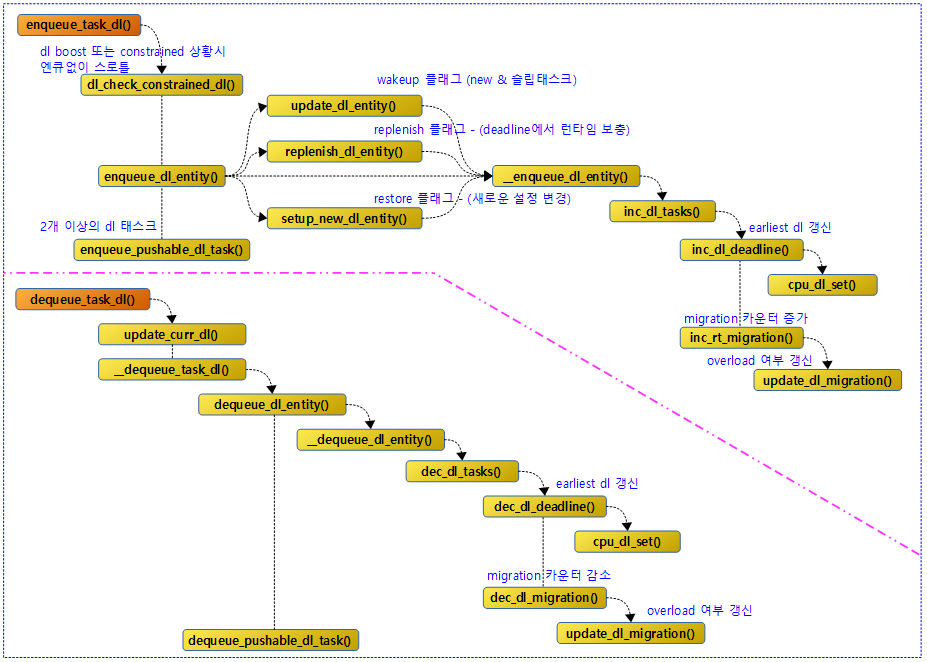
Enqueue DL Task
enqueue_task_dl()
kernel/sched/deadline.c
static void enqueue_task_dl(struct rq *rq, struct task_struct *p, int flags)
{
struct task_struct *pi_task = rt_mutex_get_top_task(p);
struct sched_dl_entity *pi_se = &p->dl;
/*
* Use the scheduling parameters of the top pi-waiter task if:
* - we have a top pi-waiter which is a SCHED_DEADLINE task AND
* - our dl_boosted is set (i.e. the pi-waiter's (absolute) deadline is
* smaller than our deadline OR we are a !SCHED_DEADLINE task getting
* boosted due to a SCHED_DEADLINE pi-waiter).
* Otherwise we keep our runtime and deadline.
*/
if (pi_task && dl_prio(pi_task->normal_prio) && p->dl.dl_boosted) {
pi_se = &pi_task->dl;
} else if (!dl_prio(p->normal_prio)) {
/*
* Special case in which we have a !SCHED_DEADLINE task
* that is going to be deboosted, but exceeds its
* runtime while doing so. No point in replenishing
* it, as it's going to return back to its original
* scheduling class after this.
*/
BUG_ON(!p->dl.dl_boosted || flags != ENQUEUE_REPLENISH);
return;
}
/*
* Check if a constrained deadline task was activated
* after the deadline but before the next period.
* If that is the case, the task will be throttled and
* the replenishment timer will be set to the next period.
*/
if (!p->dl.dl_throttled && !dl_is_implicit(&p->dl))
dl_check_constrained_dl(&p->dl);
if (p->on_rq == TASK_ON_RQ_MIGRATING || flags & ENQUEUE_RESTORE) {
add_rq_bw(&p->dl, &rq->dl);
add_running_bw(&p->dl, &rq->dl);
}
/*
* If p is throttled, we do not enqueue it. In fact, if it exhausted
* its budget it needs a replenishment and, since it now is on
* its rq, the bandwidth timer callback (which clearly has not
* run yet) will take care of this.
* However, the active utilization does not depend on the fact
* that the task is on the runqueue or not (but depends on the
* task's state - in GRUB parlance, "inactive" vs "active contending").
* In other words, even if a task is throttled its utilization must
* be counted in the active utilization; hence, we need to call
* add_running_bw().
*/
if (p->dl.dl_throttled && !(flags & ENQUEUE_REPLENISH)) {
if (flags & ENQUEUE_WAKEUP)
task_contending(&p->dl, flags);
return;
}
enqueue_dl_entity(&p->dl, pi_se, flags);
if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
enqueue_pushable_dl_task(rq, p);
}
dl 태스크를 dl 런큐에 엔큐한다.
- 코드 라인 3에서 요청한 태스크의 rt-mutex에 락 대기 중인 최상위 우선 순위 태스크를 알아온다.
- 참고: RT-mutex subsystem with PI support | Kernel.org
- 코드 라인 14~15에서 rt-mutex 락 대기 중인 dl 태스크가 있고 dl 부스트 되었으면 그 태스크의 dl 엔티티를 알아온다.
- 코드 라인 16~26에서 요청한 태스크가 dl 태스크가 아니면 함수를 빠져나간다.
- 코드 라인 34~35에서 constrained 구간에 엔큐된 태스크이고 dl 부스트 중이 아니면 곧바로 엔큐하지 않기 위해 스로틀 표시하고, dl 타이머를 시작한다.
- 코드 라인 37~40에서 태스크이 migration이 진행 중이거나 설정 변경에 의해 dl 태스크를 잠시 디큐했다가 다시 엔큐한 경우에는 dl 태스크의 런타임을 런큐에 추가한다.
- 코드 라인 54~59에서 태스크가 스로틀 되었으면서 dl 밴드위드의 dl 타이머에 의해 태스크가 다시 엔큐되는 상황이 아닌 경우 함수를 빠져나간다. 만일 wakeup 태스크 상황으로 엔큐한 경우 task contending 상황인 경우 runtime을 런큐에 추가한다.
- 코드 라인 61에서 dl 엔티티 및 pi 엔티티를 사용하여 엔큐한다.
- 코드 라인 63~64에서 요청한 태스크가 런큐에서 실행 중이 아니면서 태스크에 지정된 cpu가 2개 이상인 경우 요청한 dl 태스크를 pushable dl RB 트리에 추가한다.
- 현재 런큐에서 우선 순위에 의해 밀려났으므로 가능하면 다른 cpu에서라도 빠르게 처리되기 위해 push 한다.
Constratined 구간에 엔큐된 경우 계속 스로틀
dl_check_constrained_dl()
kernel/sched/deadline.c
/* * During the activation, CBS checks if it can reuse the current task's * runtime and period. If the deadline of the task is in the past, CBS * cannot use the runtime, and so it replenishes the task. This rule * works fine for implicit deadline tasks (deadline == period), and the * CBS was designed for implicit deadline tasks. However, a task with * constrained deadline (deadine < period) might be awakened after the * deadline, but before the next period. In this case, replenishing the * task would allow it to run for runtime / deadline. As in this case * deadline < period, CBS enables a task to run for more than the * runtime / period. In a very loaded system, this can cause a domino * effect, making other tasks miss their deadlines. * * To avoid this problem, in the activation of a constrained deadline * task after the deadline but before the next period, throttle the * task and set the replenishing timer to the begin of the next period, * unless it is boosted. */
static inline void dl_check_constrained_dl(struct sched_dl_entity *dl_se)
{
struct task_struct *p = dl_task_of(dl_se);
struct rq *rq = rq_of_dl_rq(dl_rq_of_se(dl_se));
if (dl_time_before(dl_se->deadline, rq_clock(rq)) &&
dl_time_before(rq_clock(rq), dl_next_period(dl_se))) {
if (unlikely(dl_se->dl_boosted || !start_dl_timer(p)))
return;
dl_se->dl_throttled = 1;
if (dl_se->runtime > 0)
dl_se->runtime = 0;
}
}
constrained 구간에 엔큐된 태스크이고 dl 부스트 중이 아니면 곧바로 엔큐하지 않기 위해 스로틀 표시하고, dl 타이머를 시작한다.
- 코드 라인 6~7에서 엔큐된 현재 시각이 constrained 구간에 위치한 경우이다.
- 현재 시각이 deadline과 period 사이에 위치한다. (deadline < 현재 < period)
- 코드 라인 8~9에서 낮은 확률로 dl 부스트된 경우가 아니거나 dl 타이머를 동작하지 못한 경우 함수를 빠져나간다.
- dl 부스트 중인 경우 스로틀하면 안된다. 또한 deadline에 거의 인접하여 dl 타이머를 가동시키면 실패할 수 있다.
- 코드 라인 10~12에서 스로틀 중으로 표시하고, 런타임은 모두 제거한다.
enqueue_dl_entity()
kernel/sched/deadline.c
static void
enqueue_dl_entity(struct sched_dl_entity *dl_se,
struct sched_dl_entity *pi_se, int flags)
{
BUG_ON(on_dl_rq(dl_se));
/*
* If this is a wakeup or a new instance, the scheduling
* parameters of the task might need updating. Otherwise,
* we want a replenishment of its runtime.
*/
if (dl_se->dl_new || flags & ENQUEUE_WAKEUP) {
task_contending(dl_se, flags);
update_dl_entity(dl_se, pi_se);
} else if (flags & ENQUEUE_REPLENISH)
replenish_dl_entity(dl_se, pi_se);
} else if ((flags & ENQUEUE_RESTORE) &&
dl_time_before(dl_se->deadline,
rq_clock(rq_of_dl_rq(dl_rq_of_se(dl_se))))) {
setup_new_dl_entity(dl_se);
}
__enqueue_dl_entity(dl_se);
}
dl 엔티티를 dl 런큐에 엔큐한다.
- 코드 라인 12~14에서 new dl 태스크 또는 슬립되었다가 깨어난 dl 태스크의 런타임 및 deadline을 갱신한다.
- 코드 라인 15~16에서 dl 타이머에 의해 엔큐되는 경우(replenish 플래그) 런타임 및 deadline을 새로 보충한다.
- 코드 라인 17~21에서 dl 태스크의 설정이 변경되어 잠시 디큐되었다가 다시 엔큐되는 경우 런타임 및 deadline을 새로 설정한다.
- 코드 라인 23에서 dl 엔티티를 dl 런큐에 엔큐한다.
__enqueue_dl_entity()
kernel/sched/deadline.c
static void __enqueue_dl_entity(struct sched_dl_entity *dl_se)
{
struct dl_rq *dl_rq = dl_rq_of_se(dl_se);
struct rb_node **link = &dl_rq->rb_root.rb_node;
struct rb_node *parent = NULL;
struct sched_dl_entity *entry;
int leftmost = 1;
BUG_ON(!RB_EMPTY_NODE(&dl_se->rb_node));
while (*link) {
parent = *link;
entry = rb_entry(parent, struct sched_dl_entity, rb_node);
if (dl_time_before(dl_se->deadline, entry->deadline))
link = &parent->rb_left;
else {
link = &parent->rb_right;
leftmost = 0;
}
}
rb_link_node(&dl_se->rb_node, parent, link);
rb_insert_color(&dl_se->rb_node, &dl_rq->rb_root);
inc_dl_tasks(dl_se, dl_rq);
}
dl 엔티티를 dl 런큐에 엔큐한다.
- 코드 라인 11~20에서 요청한 dl 엔티티를 RB 트리에 추가할 RB 트리 링크를 찾는다. deadline 시각이 가장 빠르면 좌측에 들어간다.
- 코드 라인 22~23에서 요청한 dl 엔티티를 RB 트리에 추가하고 color를 결정한다.
- 코드 라인 25에서 dl 태스크를 dl 런큐에 추가한 후 각종 갱신할 일들을 수행한다.
- dl 태스크 카운터 갱신, cpu별 earliest deadline 관리, migration을 위한 오버로드 관리
inc_dl_tasks()
kernel/sched/deadline.c
static inline
void inc_dl_tasks(struct sched_dl_entity *dl_se, struct dl_rq *dl_rq)
{
int prio = dl_task_of(dl_se)->prio;
u64 deadline = dl_se->deadline;
WARN_ON(!dl_prio(prio));
dl_rq->dl_nr_running++;
add_nr_running(rq_of_dl_rq(dl_rq), 1);
inc_dl_deadline(dl_rq, deadline);
inc_dl_migration(dl_se, dl_rq);
}
dl 태스크를 dl 런큐에 엔큐한 이후 각종 갱신할 일들을 수행한다.
- 코드 라인 8에서 dl 런큐의 dl 태스크 수를 증가시킨다.
- 코드 라인 9에서 런큐에서 태스크 수를 1 증가시킨다.
- 태스크의 수가 1 -> 2로 증가하면 smp 시스템인 경우 루트 도메인에 오버로드 설정을 하고 nohz full 상태였었던 경우 벗어난다.
- 코드 라인 11에서 dl 태스크가 엔큐될 때 cpu별 earliest deadline을 갱신한다.
- 코드 라인 12에서 dl 태스크가 엔큐되면서 dl 런큐의 오버로드 여부를 갱신한다.
Dequeue DL Task
dequeue_task_dl()
kernel/sched/deadline.c
static void dequeue_task_dl(struct rq *rq, struct task_struct *p, int flags)
{
update_curr_dl(rq);
__dequeue_task_dl(rq, p, flags);
if (p->on_rq == TASK_ON_RQ_MIGRATING || flags & DEQUEUE_SAVE) {
sub_running_bw(&p->dl, &rq->dl);
sub_rq_bw(&p->dl, &rq->dl);
}
/*
* This check allows to start the inactive timer (or to immediately
* decrease the active utilization, if needed) in two cases:
* when the task blocks and when it is terminating
* (p->state == TASK_DEAD). We can handle the two cases in the same
* way, because from GRUB's point of view the same thing is happening
* (the task moves from "active contending" to "active non contending"
* or "inactive")
*/
if (flags & DEQUEUE_SLEEP)
task_non_contending(p);
}
로드 및 런타임을 갱신하고 dl 태스크를 dl 런큐에서 디큐한다.
- 코드 라인 3에서 dl 런큐에서 동작 중인 태스크의 런타임 등을 갱신한다.
- 코드 라인 4에서 요청한 dl 태스크를 dl 런큐에서 디큐한다.
- 코드 라인 6~9에서 migration 중인 태스크이거나 임시로 디큐(sched attribute 변경 등)된 경우 dl 런큐에서 해당 태스크의 밴드위드를 감소시킨다.
- 코드 라인 20~21에서 슬립을 위해 디큐되는 태스크에 대해 active non contending 상태로 변경하고 0-lag 시각에 맞춰 inactive 타이머를 동작시킨다. 만일 현재 시각이 0-lag를 초과한 경우 곧바로 inactive 상태로 변경한다.
__dequeue_task_dl()
kernel/sched/deadline.c
static void __dequeue_task_dl(struct rq *rq, struct task_struct *p, int flags)
{
dequeue_dl_entity(&p->dl);
dequeue_pushable_dl_task(rq, p);
}
dl 태스크를 dl 런큐에서 디큐하고 pushable 리스트에서도 디큐한다.
dequeue_dl_entity()
kernel/sched/deadline.c
static void dequeue_dl_entity(struct sched_dl_entity *dl_se)
{
__dequeue_dl_entity(dl_se);
}
dl 엔티티를 dl 런큐에서 디큐한다.
__dequeue_task_dl()
kernel/sched/deadline.c
static void __dequeue_dl_entity(struct sched_dl_entity *dl_se)
{
struct dl_rq *dl_rq = dl_rq_of_se(dl_se);
if (RB_EMPTY_NODE(&dl_se->rb_node))
return;
rb_erase(&dl_se->rb_node, &dl_rq->rb_root);
RB_CLEAR_NODE(&dl_se->rb_node);
dec_dl_tasks(dl_se, dl_rq);
}
dl 엔티티를 dl 런큐에서 디큐한다.
- 코드 라인 5~6에서 dl 엔티티가 dl 런큐의 RB 트리에 없으면 함수를 빠져나간다.
- 코드 라인 8~9에서 dl 런큐의 RB 트리에서 요청한 dl 엔티티를 제거한다.
- 코드 라인 11에서 dl 태스크를 dl 런큐에 제거하였으므로 그 이후 각종 갱신할 일들을 수행한다.
- dl 태스크 카운터 갱신, cpu별 earliest deadline 관리, migration을 위한 오버로드 관리
dec_dl_tasks()
kernel/sched/deadline.c
static inline
void dec_dl_tasks(struct sched_dl_entity *dl_se, struct dl_rq *dl_rq)
{
int prio = dl_task_of(dl_se)->prio;
WARN_ON(!dl_prio(prio));
WARN_ON(!dl_rq->dl_nr_running);
dl_rq->dl_nr_running--;
sub_nr_running(rq_of_dl_rq(dl_rq), 1);
dec_dl_deadline(dl_rq, dl_se->deadline);
dec_dl_migration(dl_se, dl_rq);
}
dl 태스크를 dl 런큐에 디큐한 이후 각종 갱신할 일들을 수행한다.
- 코드 라인 8에서 dl 런큐의 dl 태스크 수를 1 감소시킨다.
- 코드 라인 9에서 런큐에서 태스크 수를 1 감소시킨다.
- 코드 라인 11에서 dl 태스크가 디큐될 때 dl 런큐에서 earliest deadline인 경우 earliest_dl 및 cpudl을 갱신한다.
- 코드 라인 12에서 dl 태스크가 디큐되면서 dl 런큐의 오버로드 여부를 갱신한다.
엔큐 타입별 deadline 및 런타임 변경
1) new & wakeup 태스크에 대한 DL 엔티티 갱신
update_dl_entity()
kernel/sched/deadline.c
/* * When a deadline entity is placed in the runqueue, its runtime and deadline * might need to be updated. This is done by a CBS wake up rule. There are two * different rules: 1) the original CBS; and 2) the Revisited CBS. * * When the task is starting a new period, the Original CBS is used. In this * case, the runtime is replenished and a new absolute deadline is set. * * When a task is queued before the begin of the next period, using the * remaining runtime and deadline could make the entity to overflow, see * dl_entity_overflow() to find more about runtime overflow. When such case * is detected, the runtime and deadline need to be updated. * * If the task has an implicit deadline, i.e., deadline == period, the Original * CBS is applied. the runtime is replenished and a new absolute deadline is * set, as in the previous cases. * * However, the Original CBS does not work properly for tasks with * deadline < period, which are said to have a constrained deadline. By * applying the Original CBS, a constrained deadline task would be able to run * runtime/deadline in a period. With deadline < period, the task would * overrun the runtime/period allowed bandwidth, breaking the admission test. * * In order to prevent this misbehave, the Revisited CBS is used for * constrained deadline tasks when a runtime overflow is detected. In the * Revisited CBS, rather than replenishing & setting a new absolute deadline, * the remaining runtime of the task is reduced to avoid runtime overflow. * Please refer to the comments update_dl_revised_wakeup() function to find * more about the Revised CBS rule. */
static void update_dl_entity(struct sched_dl_entity *dl_se,
struct sched_dl_entity *pi_se)
{
struct dl_rq *dl_rq = dl_rq_of_se(dl_se);
struct rq *rq = rq_of_dl_rq(dl_rq);
if (dl_time_before(dl_se->deadline, rq_clock(rq)) ||
dl_entity_overflow(dl_se, pi_se, rq_clock(rq))) {
if (unlikely(!dl_is_implicit(dl_se) &&
!dl_time_before(dl_se->deadline, rq_clock(rq)) &&
!dl_se->dl_boosted)){
update_dl_revised_wakeup(dl_se, rq);
return;
}
dl_se->deadline = rq_clock(rq) + pi_se->dl_deadline;
dl_se->runtime = pi_se->dl_runtime;
}
}
new & wakeup dl 태스크의 엔큐시 진입하였다. 이러한 dl 태스크의 경우 현재 시각이 deadline 이후이거나 overflow(남은 시간내 런타임을 모두 처리하지 못할 가능성이 커진 경우)로 판정되는 경우 현재 시각 + dl_deadline으로 deadline을 다시 설정하고, 런타임도 다시 부여받는다. 단 constrained 설정을 사용하고 현재 시각이 deadline을 지나지 않았고, dl boost 태스크가 아닌 경우엔 deadline까지 남은 기간 * dl_densintiy(dl_runtime / dl_deadline) 만큼의 런타임을 부여한다.
- 코드 라인 7~8에서 현재 시각이 이미 deadline을 초과하였거나 overflow(남은 시간내 런타임을 모두 처리하지 못할 가능성이 커진 비율의 경우)로 판정되는 경우이다.
- 코드 라인 10~15에서 constrained 설정을 사용하고 현재 시각이 deadline을 지나지 않았고, dl boost 태스크가 아닌 경우엔 deadline 변경 없이 런타임만 다시 지정하는데, deadline을 초과하여 오버런하지 않도록 deadline까지 남은 기간 * dl_runtime / dl_deadline 비율만큼 런타임을 줄여 설정하고 함수를 빠져나간다.
- 코드 라인 17~18에서 현재 시각 + dl_deadline으로 deadline을 재설정하고, 런타임도 다시 부여받는다.
다음 그림은 dl 태스크가 마감 전에 깨어난 후 overflow 판정 받지 않은 경우 정상적으로 남은 런타임을 실행하는 모습을 보여준다.
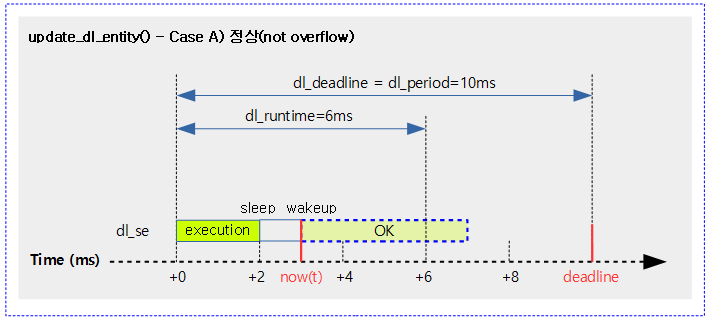
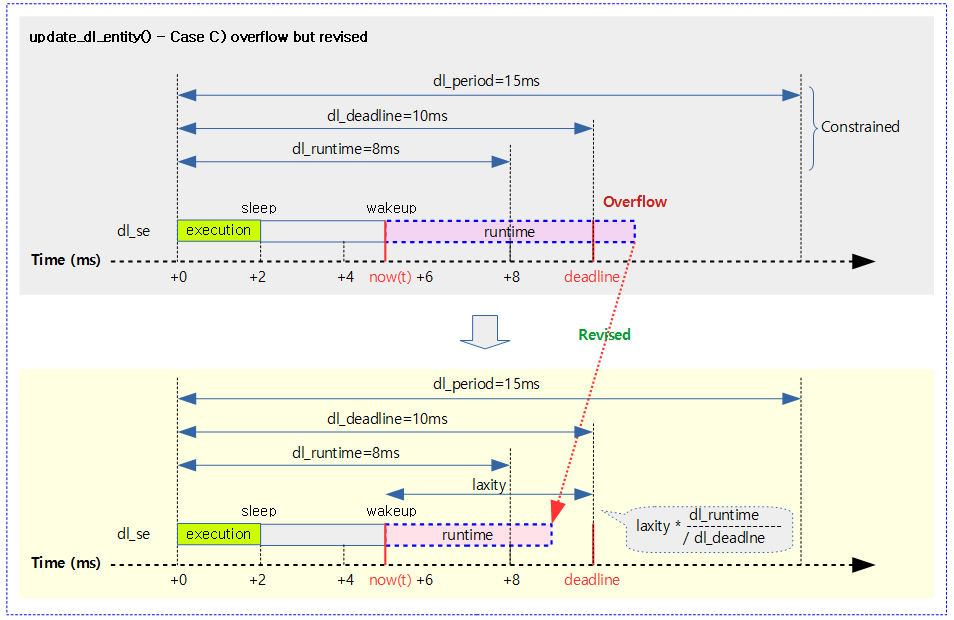
다음 그림은 dl 태스크가 깨어난 후 남은 런타임의 실행이 힘들다고 판단(overflow)한 경우 마감을 다시 설정하고, 런타임을 새롭게 지정한 모습을 보여준다.
- 블록된 시간이 길어 overflow 판정된 경우 이에 대한 런타임을 다시 충전하여 처리할 수 있도록 하였고, 마감도 그 만큼 연장한다.
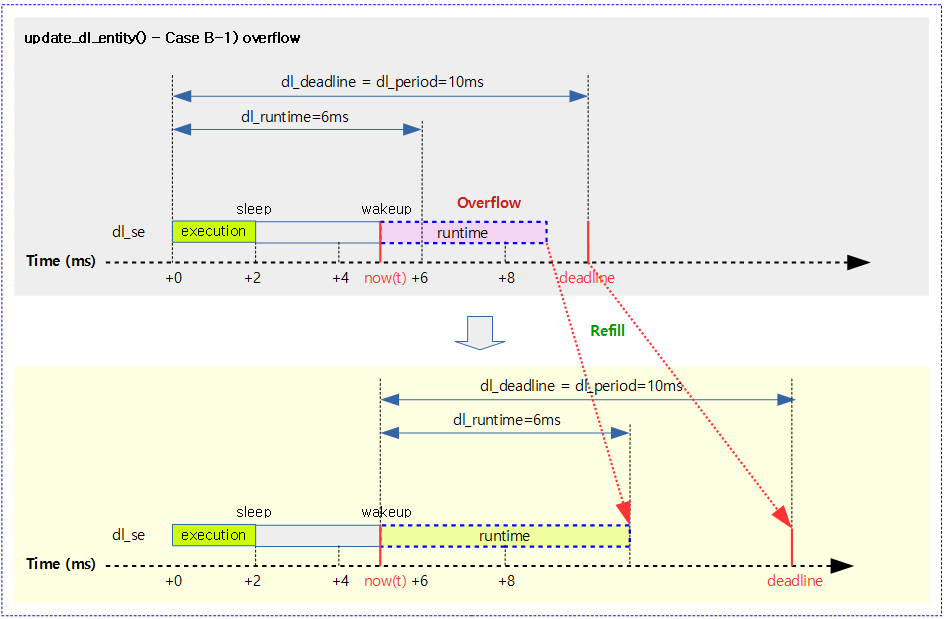
다음 그림은 dl 태스크가 마감을 지나 깨어난 경우 마감을 다시 설정하고, 런타임을 새롭게 지정한 모습을 보여준다.
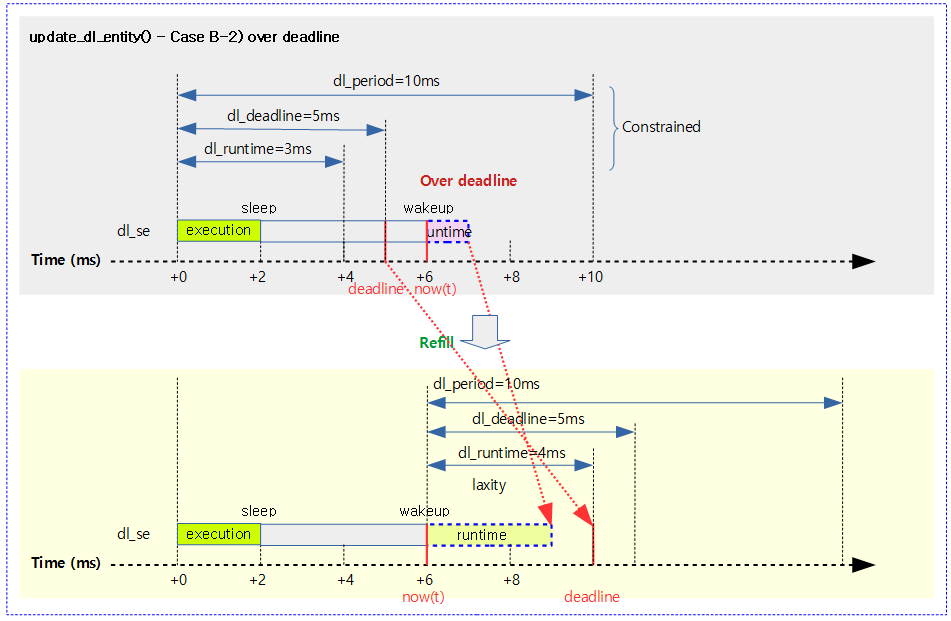
다음 그림은 constrained 설정상태인 dl 태스크가 마감 전 구간에서 깨어났고 overflow 판단 받았지만 남은 마감 시간내에서 dl_runtime/dl_deadline 비율만큼 런타임을 변경하여 오버런하지 않도록 실행되는 모습을 보여준다.
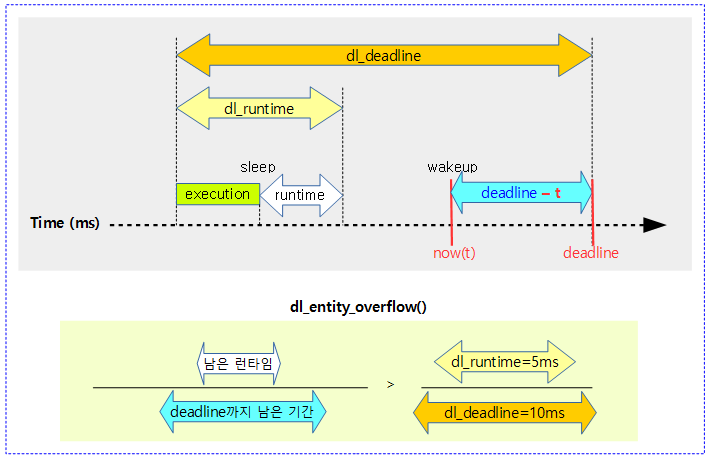
dl_entity_overflow()
kernel/sched/deadline.c
/* * Here we check if --at time t-- an entity (which is probably being * [re]activated or, in general, enqueued) can use its remaining runtime * and its current deadline _without_ exceeding the bandwidth it is * assigned (function returns true if it can't). We are in fact applying * one of the CBS rules: when a task wakes up, if the residual runtime * over residual deadline fits within the allocated bandwidth, then we * can keep the current (absolute) deadline and residual budget without * disrupting the schedulability of the system. Otherwise, we should * refill the runtime and set the deadline a period in the future, * because keeping the current (absolute) deadline of the task would * result in breaking guarantees promised to other tasks (refer to * Documentation/scheduler/sched-deadline.rst for more information). * * This function returns true if: * * runtime / (deadline - t) > dl_runtime / dl_deadline , * * IOW we can't recycle current parameters. * * Notice that the bandwidth check is done against the deadline. For * task with deadline equal to period this is the same of using * dl_period instead of dl_deadline in the equation above. */
static bool dl_entity_overflow(struct sched_dl_entity *dl_se,
struct sched_dl_entity *pi_se, u64 t)
{
u64 left, right;
/*
* left and right are the two sides of the equation above,
* after a bit of shuffling to use multiplications instead
* of divisions.
*
* Note that none of the time values involved in the two
* multiplications are absolute: dl_deadline and dl_runtime
* are the relative deadline and the maximum runtime of each
* instance, runtime is the runtime left for the last instance
* and (deadline - t), since t is rq->clock, is the time left
* to the (absolute) deadline. Even if overflowing the u64 type
* is very unlikely to occur in both cases, here we scale down
* as we want to avoid that risk at all. Scaling down by 10
* means that we reduce granularity to 1us. We are fine with it,
* since this is only a true/false check and, anyway, thinking
* of anything below microseconds resolution is actually fiction
* (but still we want to give the user that illusion >;).
*/
left = (pi_se->dl_deadline >> DL_SCALE) * (dl_se->runtime >> DL_SCALE);
right = ((dl_se->deadline - t) >> DL_SCALE) *
(pi_se->dl_runtime >> DL_SCALE);
return dl_time_before(right, left);
}
이 함수는 태스크가 깨어나거나 엔큐될 때 스케줄링 가능 여부를 타진한다. 남은 런타임 잔량이 남은 만료 기간내에 처리할 수 있는 비율이 기존 설정된 비율(설정 런타임 / 설정 기간)을 초과해 오버플로우되는지 여부를 체크한다. true=오버플로우 된다. false=적절하게 처리할 수 있다.
- 수식은 나눗셈이지만 구현은 곱셈을 사용하였다.
- 수식: 런타임 잔량(runtime) / 남은 만료 시간(deadline – t) > 설정 런타임(dl_runtime) / 설정 만료 시간(dl deadline)
- 구현: 런타임 잔량(runtime) * 설정 만료 시간(dl_deadline) > 설정 런타임(dl_runtime) * 남은 만료 시간(deadline – t)
- 나노초를 DL_SCALE(10) 비트만큼 우측으로 쉬프트하여 us 단위로 바꾸어 연산한다. 사실 us 단위 조차도 픽션 ^^;
다음 그림과 같이 태스크가 다시 깨어나 엔큐될때 남은 런타임을 처리하지 못할(overflow) 가능성을 판단한다. overflow 판정되면 런타임 잔량 및 만료 시각 설정을 다시 설정 런타임(dl_runtime) 및 설정 만료 시간(dl_deadline)으로 새롭게 출발시킨다.
update_dl_revised_wakeup()
kernel/sched/deadline.c
/* * Revised wakeup rule [1]: For self-suspending tasks, rather then * re-initializing task's runtime and deadline, the revised wakeup * rule adjusts the task's runtime to avoid the task to overrun its * density. * * Reasoning: a task may overrun the density if: * runtime / (deadline - t) > dl_runtime / dl_deadline * * Therefore, runtime can be adjusted to: * runtime = (dl_runtime / dl_deadline) * (deadline - t) * * In such way that runtime will be equal to the maximum density * the task can use without breaking any rule. * * [1] Luca Abeni, Giuseppe Lipari, and Juri Lelli. 2015. Constant * bandwidth server revisited. SIGBED Rev. 11, 4 (January 2015), 19-24. */
static void
update_dl_revised_wakeup(struct sched_dl_entity *dl_se, struct rq *rq)
{
u64 laxity = dl_se->deadline - rq_clock(rq);
/*
* If the task has deadline < period, and the deadline is in the past,
* it should already be throttled before this check.
*
* See update_dl_entity() comments for further details.
*/
WARN_ON(dl_time_before(dl_se->deadline, rq_clock(rq)));
dl_se->runtime = (dl_se->dl_density * laxity) >> BW_SHIFT;
}
남은 마감 시간까지 dl_runtime / dl_deadline 비율만큼 줄여서 실행하도록 런타임을 재조정한다.
2) 설정 변경된 태스크의 엔큐에 대한 DL 엔티티 갱신
setup_new_dl_entity()
kernel/sched/deadline.c
/* * We are being explicitly informed that a new instance is starting, * and this means that: * - the absolute deadline of the entity has to be placed at * current time + relative deadline; * - the runtime of the entity has to be set to the maximum value. * * The capability of specifying such event is useful whenever a -deadline * entity wants to (try to!) synchronize its behaviour with the scheduler's * one, and to (try to!) reconcile itself with its own scheduling * parameters. */
static inline void setup_new_dl_entity(struct sched_dl_entity *dl_se)
{
struct dl_rq *dl_rq = dl_rq_of_se(dl_se);
struct rq *rq = rq_of_dl_rq(dl_rq);
WARN_ON(dl_se->dl_boosted);
WARN_ON(dl_time_before(rq_clock(rq), dl_se->deadline));
/*
* We are racing with the deadline timer. So, do nothing because
* the deadline timer handler will take care of properly recharging
* the runtime and postponing the deadline
*/
if (dl_se->dl_throttled)
return;
/*
* We use the regular wall clock time to set deadlines in the
* future; in fact, we must consider execution overheads (time
* spent on hardirq context, etc.).
*/
dl_se->deadline = rq_clock(rq) + dl_se->dl_deadline;
dl_se->runtime = dl_se->dl_runtime;
}
dl 엔티티의 런타임 및 deadline을 새롭게 설정한다.
- 코드 라인 14~15에서 이미 스로틀 중인 경우 함수를 빠져나간다.
- 코드 라인 22~23에서 deadline 을 다시 설정하고, 런타임도 재충전한다.
3) deadline 타이머에 따라 다시 dl 태스크가 엔큐되어 런타임 보충
replenish_dl_entity()
kernel/sched/deadline.c
/* * Pure Earliest Deadline First (EDF) scheduling does not deal with the * possibility of a entity lasting more than what it declared, and thus * exhausting its runtime. * * Here we are interested in making runtime overrun possible, but we do * not want a entity which is misbehaving to affect the scheduling of all * other entities. * Therefore, a budgeting strategy called Constant Bandwidth Server (CBS) * is used, in order to confine each entity within its own bandwidth. * * This function deals exactly with that, and ensures that when the runtime * of a entity is replenished, its deadline is also postponed. That ensures * the overrunning entity can't interfere with other entity in the system and * can't make them miss their deadlines. Reasons why this kind of overruns * could happen are, typically, a entity voluntarily trying to overcome its * runtime, or it just underestimated it during sched_setattr(). */
static void replenish_dl_entity(struct sched_dl_entity *dl_se,
struct sched_dl_entity *pi_se)
{
struct dl_rq *dl_rq = dl_rq_of_se(dl_se);
struct rq *rq = rq_of_dl_rq(dl_rq);
BUG_ON(pi_se->dl_runtime <= 0);
/*
* This could be the case for a !-dl task that is boosted.
* Just go with full inherited parameters.
*/
if (dl_se->dl_deadline == 0) {
dl_se->deadline = rq_clock(rq) + pi_se->dl_deadline;
dl_se->runtime = pi_se->dl_runtime;
}
if (dl_se->dl_yielded && dl_se->runtime > 0)
dl_se->runtime = 0;
/*
* We keep moving the deadline away until we get some
* available runtime for the entity. This ensures correct
* handling of situations where the runtime overrun is
* arbitrary large.
*/
while (dl_se->runtime <= 0) {
dl_se->deadline += pi_se->dl_period;
dl_se->runtime += pi_se->dl_runtime;
}
/*
* At this point, the deadline really should be "in
* the future" with respect to rq->clock. If it's
* not, we are, for some reason, lagging too much!
* Anyway, after having warn userspace abut that,
* we still try to keep the things running by
* resetting the deadline and the budget of the
* entity.
*/
if (dl_time_before(dl_se->deadline, rq_clock(rq))) {
printk_deferred_once("sched: DL replenish lagged too much\n");
dl_se->deadline = rq_clock(rq) + pi_se->dl_deadline;
dl_se->runtime = pi_se->dl_runtime;
}
if (dl_se->dl_yielded)
dl_se->dl_yielded = 0;
if (dl_se->dl_throttled)
dl_se->dl_throttled = 0;
}
deadline 타이머가 만료되어 런타임을 보충하러 진입하였다. 런타임이 0 이하로 오버런한 상황인 경우 dl_period 만큼씩 이동하며 런타임을 시리얼하게 보충한다. 만일 deadline이 경과한 경우엔 다시 full 보충한다.
- 코드 라인 13~16에서 deadline 설정이 없는 경우 full 보충한다.
- full 보충: dl_deadline만큼 지정하고, 런타임은 dl_runtime 만큼 지정한다. 만일 pi boost중인 경우 pi 태스크에 설정된 dl_deadline 및 dl_runtime을 사용한다.
- 코드 라인 18~19에서 이번 타임에 양보(yield) 하는 경우 런타임을 0으로 변경한다.
- 코드 라인 27~30에서 오버런으로 인해 런타임이 0 미만으로 많이 소모될 수 있다. 오버런 상황에서도 정확한 period 관계를 유지하기 위해 런타임이 0을 초과할 때까지 dl_runtime을 증가시키고, deadline은 dl_period만큼 증가시킨다. 만일 pi boost중인 경우 pi 태스크에 설정된 dl_period 및 dl_runtime을 사용한다.
- 코드 라인 41~45에서 현재 시각이 deadline을 이미 지난 경우 full 보충한다.
- 코드 라인 47~50에서 다음 인스턴스를 진행하므로 기존 인스턴스 구간에서 설정된 양보(yield)및 스로틀 설정이 있으면 모두 클리어한다.
cpu별 Deadline 설정
inc_dl_deadline()
kernel/sched/deadline.c
static void inc_dl_deadline(struct dl_rq *dl_rq, u64 deadline)
{
struct rq *rq = rq_of_dl_rq(dl_rq);
if (dl_rq->earliest_dl.curr == 0 ||
dl_time_before(deadline, dl_rq->earliest_dl.curr)) {
dl_rq->earliest_dl.curr = deadline;
cpudl_set(&rq->rd->cpudl, rq->cpu, deadline);
}
}
dl 태스크가 엔큐될 때 dl 런큐에서 earliest deadline을 가진 태스크인 경우 earliest_dl 및 cpu별 earliest deadline을 관리하는 cpudl을 갱신한다.
- 코드 라인 5~6에서 동작 중인 dl 태스크가 없거나, 현재 동작 중인 dl 태스크보다 더 빠른 @deadline 값인 경우이다.
- 코드 라인 7~8에서 earliest_dl.curr에 요청한 deadline으로 갱신하고, cpu별 earliest deadline을 관리하는 cpudl을 갱신한다..
dec_dl_deadline()
kernel/sched/deadline.c
static void dec_dl_deadline(struct dl_rq *dl_rq, u64 deadline)
{
struct rq *rq = rq_of_dl_rq(dl_rq);
/*
* Since we may have removed our earliest (and/or next earliest)
* task we must recompute them.
*/
if (!dl_rq->dl_nr_running) {
dl_rq->earliest_dl.curr = 0;
dl_rq->earliest_dl.next = 0;
cpudl_set(&rq->rd->cpudl, rq->cpu, 0, 0);
} else {
struct rb_node *leftmost = dl_rq->rb_leftmost;
struct sched_dl_entity *entry;
entry = rb_entry(leftmost, struct sched_dl_entity, rb_node);
dl_rq->earliest_dl.curr = entry->deadline;
cpudl_set(&rq->rd->cpudl, rq->cpu, entry->deadline);
}
}
dl 태스크가 디큐될 때 dl 런큐에서 earliest deadline을 가진 태스크인 경우 earliest_dl 및 cpu별 earliest deadline을 관리하는 cpudl을 갱신한다.
- 코드 라인 9~12에서 dl 태스크가 디큐되면서 dl 런큐에 dl 태스크가 하나도 남지 않는 경우 earliest_dl.curr 및 earliest_dl.next를 비운다. 그리고 요청한 dl 런큐의 cpu에 cpudl을 클리어한다.
- 코드 라인 13~18에서 earliest_dl.curr에 dl 런큐의 RB 트리에서 대기중인 가장 빠른 deadline을 대입한다.
- 코드 라인 19에서 요청한 dl 런큐의 cpu에 대한 cpudl을 가장 빠른 deadline으로 갱신한다.
글로벌 CPU deadline 관리
글로벌 cpu deadline 관리는 루트도메인내에서 cpudl 구조체를 통해 관리된다. cpudl 구조체 내에는 cpu 수 만큼의 cpudl_item 구조체가 할당되어 사용된다.

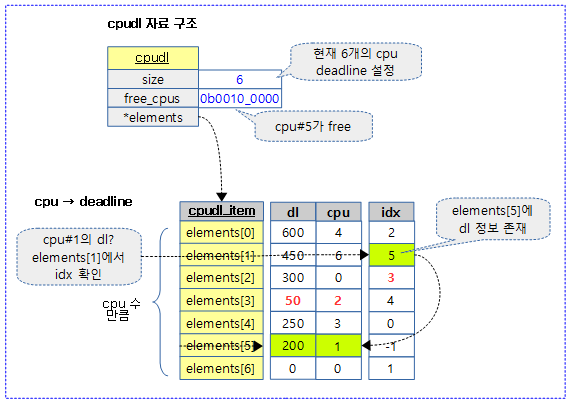
다음 그림은 cpu 번호에 해당하는 deadline 을 찾아올 때 2번 검색으로 deadline 값을 알아오는 모습을 보여준다.
Heapify
Heapify는 배열을 완전 이진 트리 형태로 변환하여 처리하는 과정을 말한다. deadline 스케줄러에서는 가장 큰 deadline 값을 찾기 위해 max-heapify를 사용한다. 이 알고리즘의 특징은 다음과 같다.
- 트리의 최상위에는 가장 큰(max) 값이 배치되어 한 번에 읽어올 수 있다.
- 커널의 경우 각 cpu에 해당하는 earliest deadline들로 관리되는데 그중 가장 느린 latest deadline 값이 가장 위로 배치된다.
- latest deadline을 가진 cpu를 찾을 때 가장 상위(elements[0]) 엘레멘트를 찾는다.
- 완전 이진 트리로 구성된다.
- 부모와 자식간의 관계만 힙 정렬(heap sort)한다.
- 참고
- Building Heap from Array | GeeksforGeeks
- 힙정렬 | 위키백과
아래 그림은 7개의 cpu들 중 6개의 cpu에 deadline이 설정되었다고 가정한 경우의 cpudl 힙트리를 보여준다.
- 같은 값이라도 cpu 갱신 순서에 따라 트리는 달라진다. 단 max 값을 가진 최상위 값은 변함없다.

cpu에 해당하는 deadline 추가 또는 변경
cpudl_set()
kernel/sched/cpudeadline.c
/* * cpudl_set - update the cpudl max-heap * @cp: the cpudl max-heap context * @cpu: the target cpu * @dl: the new earliest deadline for this cpu * * Notes: assumes cpu_rq(cpu)->lock is locked * * Returns: (void) */
void cpudl_set(struct cpudl *cp, int cpu, u64 dl)
{
int old_idx;
unsigned long flags;
WARN_ON(!cpu_present(cpu));
raw_spin_lock_irqsave(&cp->lock, flags);
old_idx = cp->elements[cpu].idx;
if (old_idx == IDX_INVALID) {
int new_idx = cp->size++;
cp->elements[new_idx].dl = dl;
cp->elements[new_idx].cpu = cpu;
cp->elements[cpu].idx = new_idx;
cpudl_heapify_up(cp, new_idx);
cpumask_clear_cpu(cpu, cp->free_cpus);
} else {
cp->elements[old_idx].dl = dl;
cpudl_heapify(cp, old_idx);
}
raw_spin_unlock_irqrestore(&cp->lock, flags);
}
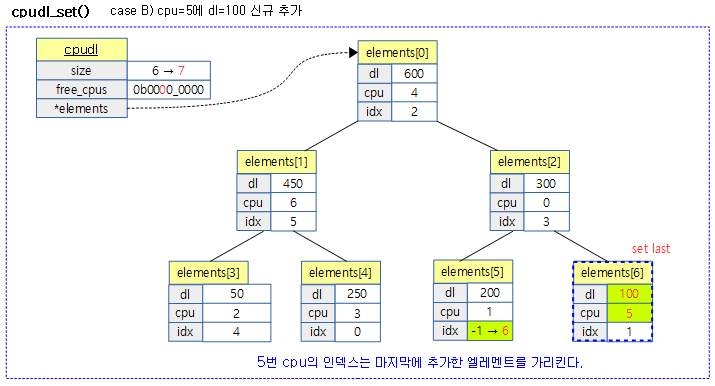
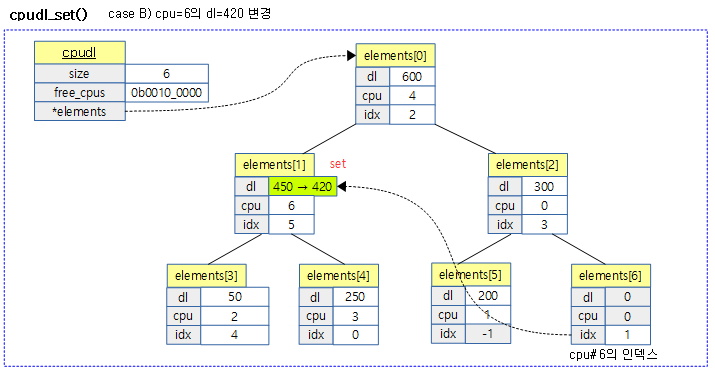
요청 cpu에 가장 먼저 다가오는(earliest) deadline을 설정한다. (cpudl heap tree에는 각 cpu의 earliest deadline 값이 저장된다)
- 코드 라인 10에서 요청한 cpu에 설정된 기존 인덱스 값을 알아온다.
- 코드 라인 11~16에서 해당 cpu에 대한 dl 설정이 없는 경우 새로운 엘레멘트를 사용하기 위해 엘레멘트 사이즈를 증가시키고 새 엘레멘트에 dl, cpu값을 기록하고, idx에는 새 인덱스 값을 기록한다.
- 코드 라인 17에서 새로 추가한 엘레멘트는 가장 마지막에 위치하므로 이진 힙 트리를 윗 방향으로만 비교하며 정렬한다.
- 상위 부모 엔트리의 dl 값과 비교하여 부모 엔트리의 dl 값보다 큰 경우 서로 값을 교환하는 방법으로 최상위 루트까지 정렬한다. (큰 dl 값이 위로 정렬된다)
- 코드 라인 18에서 free_cpus 비트맵에서 요청한 cpu에 해당하는 비트를 클리어하여 해당 cpu에 earliest deadline이 설정되었음을 나타낸다.
- 코드 라인 19~22에서 만일 cpu에 해당하는 dl 정보가 이미 존재하는 경우 이를 갱신하고 위 또는 아래 방향으로 이진 힙 트리를 정렬한다.
다음 그림은 총 7개의 cpu 시스템에서 6개의 cpu에 deadline이 설정되어 동작하는 중에 미설정된 5번 cpu의 deadline이 설정되는 모습을 보여준다.
다음 그림은 총 7개의 cpu 시스템에서 6개의 cpu에 deadline이 설정되어 동작하는 중에 기존에 설정된 6번 cpu의 deadline이 재설정되는 모습을 보여준다.
cpu에 해당하는 deadline 삭제
cpudl_clear()
kernel/sched/cpudeadline.c
/* * cpudl_clear - remove a CPU from the cpudl max-heap * @cp: the cpudl max-heap context * @cpu: the target CPU * * Notes: assumes cpu_rq(cpu)->lock is locked * * Returns: (void) */
void cpudl_clear(struct cpudl *cp, int cpu)
{
int old_idx, new_cpu;
unsigned long flags;
WARN_ON(!cpu_present(cpu));
raw_spin_lock_irqsave(&cp->lock, flags);
old_idx = cp->elements[cpu].idx;
if (old_idx == IDX_INVALID) {
/*
* Nothing to remove if old_idx was invalid.
* This could happen if a rq_offline_dl is
* called for a CPU without -dl tasks running.
*/
} else {
new_cpu = cp->elements[cp->size - 1].cpu;
cp->elements[old_idx].dl = cp->elements[cp->size - 1].dl;
cp->elements[old_idx].cpu = new_cpu;
cp->size--;
cp->elements[new_cpu].idx = old_idx;
cp->elements[cpu].idx = IDX_INVALID;
cpudl_heapify(cp, old_idx);
cpumask_set_cpu(cpu, cp->free_cpus);
}
raw_spin_unlock_irqrestore(&cp->lock, flags);
}
요청 cpu의 deadline 값을 제거한다.
- 코드 라인 10에서 요청한 cpu의 정보가 담긴 엘레멘트를 찾기 위해 인덱스 값을 알아온다.
- 코드 라인 11~16에서 이미 삭제된 엘레멘트인 경우 아무런 처리를 하지 않는다.
- 코드 라인 17~20에서 마지막(size) 엔트리의 dl, cpu 정보를 삭제할 cpu가 가리키는 인덱스의 엘레멘트에 복사한다.
- 코드 라인 21에서 엘레멘트 사이즈를 1 감소시킨다.
- 코드 라인 22에서 마지막 엔트리에 저장되었었던 cpu 번호를 사용하는 엘레멘트의 인덱스에 삭제된 cpu의 인덱스에 저장되었었던 값을 복사한다.
- 코드 라인 23에서 삭제한 cpu 엘레멘트의 인덱스 값은 invalid 표시(-1) 한다.
- 코드 라인 24에서 해당 cpu에 대한 엘레멘트를 기준으로 부모 또는 자식 엘레멘트와 힙 정렬한다.
- 코드 라인 26에서 free_cpus에서 삭제한 cpu 번호의 비트에 1을 설정하여 free 상태임을 표시한다.
다음 그림은 총 7개의 cpu 시스템에서 6개의 cpu에 deadline이 설정되어 동작하는 중에 2번 cpu의 deadline이 클리어되는 모습을 보여준다.
![]()
상위 또는 하위 방향 힙 정렬
cpudl_heapify()
kernel/sched/cpudeadline.c
static void cpudl_heapify(struct cpudl *cp, int idx)
{
if (idx > 0 && dl_time_before(cp->elements[parent(idx)].dl,
cp->elements[idx].dl))
cpudl_heapify_up(cp, idx);
else
cpudl_heapify_down(cp, idx);
}
요청한 인덱스의 엘레멘트 정보를 이진 힙 트리에서 위아래 방향으로만 정렬한다.
- 코드 라인 3~5에서 요청한 인덱스의 엘레멘트 정보를 바로 위 부모와 비교하여 부모의 dl 값보다 더 큰 dl 값을 가진 경우 상위 방향으로 이진 힙 트리 정렬을 수행한다.
- 코드 라인 6~7에서 그렇지 않은 경우 자식 방향으로 이진 힙 트리 정렬을 수행한다.
상위 방향 힙 정렬
cpudl_heapify_up()
kernel/sched/cpudeadline.c
static void cpudl_heapify_up(struct cpudl *cp, int idx)
{
int p;
int orig_cpu = cp->elements[idx].cpu;
u64 orig_dl = cp->elements[idx].dl;
if (idx == 0)
return;
do {
p = parent(idx);
if (dl_time_before(orig_dl, cp->elements[p].dl))
break;
/* pull parent onto idx */
cp->elements[idx].cpu = cp->elements[p].cpu;
cp->elements[idx].dl = cp->elements[p].dl;
cp->elements[cp->elements[idx].cpu].idx = idx;
idx = p;
} while (idx != 0);
/* actual push up of saved original values orig_* */
cp->elements[idx].cpu = orig_cpu;
cp->elements[idx].dl = orig_dl;
cp->elements[cp->elements[idx].cpu].idx = idx;
}
요청한 인덱스의 엘레멘트 정보부터 상위 방향 부모와 비교하여 max-heapify 방식으로 정렬해 올라가며 정렬이 필요 없을 때 정지한다.
- 코드 라인 5~6에서 인덱스에 해당하는 오리지날 엘레멘트의 정보를 잠시 보관한다.
- 코드 라인 8~9에서 인덱스 0은 루트이므로 정렬할 필요 없어서 함수를 빠져나간다.
- 코드 라인 11~14에서 부모의 dl 값보다 작은 값인 경우 그만 정렬하기 위해 루프를 탈출한다.
- 코드 라인 16~18에서 부모 엘레멘트 정보를 현재 진행 중인 아래 엘레멘트로 복사한다.
- 코드 라인 19~20에서 루트 엘레멘트 직전까지 부모 방향으로 순회한다.
- 코드 라인 22~24에서 최종 결정된 엘레멘트 위치에 잠시 기억해 두었던 오리지날 값을 기록한다.
다음 그림은 3번 엘레멘트를 max-heapify up 방향 정렬하는 과정을 보여준다.

하위 방향 힙 정렬
cpudl_heapify_down()
kernel/sched/cpudeadline.c
static void cpudl_heapify_down(struct cpudl *cp, int idx)
{
int l, r, largest;
int orig_cpu = cp->elements[idx].cpu;
u64 orig_dl = cp->elements[idx].dl;
if (left_child(idx) >= cp->size)
return;
/* adapted from lib/prio_heap.c */
while (1) {
u64 largest_dl;
l = left_child(idx);
r = right_child(idx);
largest = idx;
largest_dl = orig_dl;
if ((l < cp->size) && dl_time_before(orig_dl,
cp->elements[l].dl)) {
largest = l;
largest_dl = cp->elements[l].dl;
}
if ((r < cp->size) && dl_time_before(largest_dl,
cp->elements[r].dl))
largest = r;
if (largest == idx)
break;
/* pull largest child onto idx */
cp->elements[idx].cpu = cp->elements[largest].cpu;
cp->elements[idx].dl = cp->elements[largest].dl;
cp->elements[cp->elements[idx].cpu].idx = idx;
idx = largest;
}
/* actual push down of saved original values orig_* */
cp->elements[idx].cpu = orig_cpu;
cp->elements[idx].dl = orig_dl;
cp->elements[cp->elements[idx].cpu].idx = idx;
}
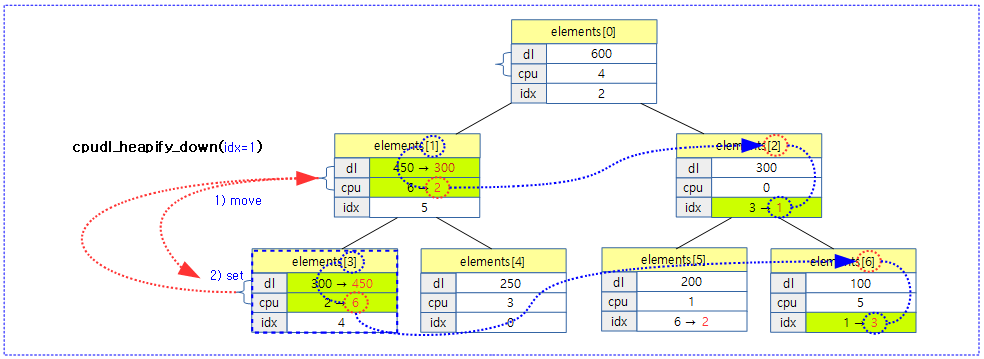
요청한 인덱스 엘레멘트부터 하위 방향 두 개 child 엘레멘트와 비교하여 max-heapify 방식으로 정렬해 내려가며 정렬이 필요 없을 때 정지한다.
- 코드 라인 5~6에서 인덱스에 해당하는 오리지날 엘레멘트의 정보를 잠시 보관한다.
- 코드 라인 8~9에서 요청한 인덱스 엘레멘트의 자식 엘레멘트가 없으면 더 이상 정렬할 필요가 없으므로 함수를 빠져나간다.
- 코드 라인 12~16에서 요청한 인덱스부터 하위 방향으로 루프를 도는데 현재 인덱스의 좌/우측 자식 인덱스 값을 산출한다.
- 예) 인덱스 5의 좌측 인덱스 = (5 << 1) + 1 = 11
- 예) 인덱스 5의 우측 인덱스 = (5 << 1) + 2 = 12
- 코드 라인 17~18에서 largest에 오리지날 값을 지정한다.
- 코드 라인 20~24에서 순회중인 인덱스와 좌측 자식과 비교하여 자식 deadline이 큰 경우 largest에 지정한다.
- 코드 라인 25~27에서 largest dl과 우측 자식의 deadline을 비교하여 자식의 deadline이 큰 경우 largest에 지정한다.
- 코드 라인 29~30에서 더 이상 정렬이 필요 없는 경우 루프를 벗어난다.
- 코드 라인 33~35에서 deadline이 큰 자식의 값을 위로 올린다.
- 코드 라인 36~37에서 largest 자식쪽 하위 방향으로 순회한다.
- 코드 라인 39~41에서 최종 결정된 엘레멘트 위치에 잠시 기억해 두었던 오리지날 값을 기록한다.
다음 그림은 1번 엘레멘트를 max-heapify down 방향 정렬하는 과정을 보여준다.
latest deadline을 가진 best cpu 검색
cpudl_find()
kernel/sched/cpudeadline.c
/* * cpudl_find - find the best (later-dl) CPU in the system * @cp: the cpudl max-heap context * @p: the task * @later_mask: a mask to fill in with the selected CPUs (or NULL) * * Returns: int - CPUs were found */
int cpudl_find(struct cpudl *cp, struct task_struct *p,
struct cpumask *later_mask)
{
const struct sched_dl_entity *dl_se = &p->dl;
if (later_mask &&
cpumask_and(later_mask, cp->free_cpus, p->cpus_ptr)) {
return 1;
} else {
int best_cpu = cpudl_maximum(cp);
WARN_ON(best_cpu != -1 && !cpu_present(best_cpu));
if (cpumask_test_cpu(best_cpu, p->cpus_ptr) &&
dl_time_before(dl_se->deadline, cp->elements[0].dl)) {
if (later_mask)
cpumask_set_cpu(best_cpu, later_mask);
return 1;
}
}
return 0;
}
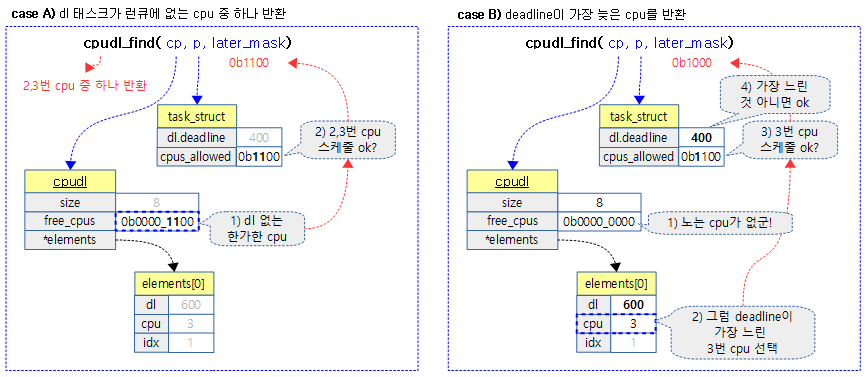
cpu들 중 latest deadline을 가진 best cpu를 찾아 출력 인자 @later_mask에 기록한다. 성공한 경우 1을 반환하고, 찾지 못한 경우 0을 반환한다.
- 코드 라인 6~8에서 dl 태스크가 동작하지 않는 cpu들 중 태스크의 마이그레이션이 가능한 cpu들과의 교집합을 출력 인자 @later_mask에 기록하고 성공(1)을 반환한다.
- 코드 라인 9~10에서 latest deadline을 사용하는 cpu 하나를 찾아온다.
- 코드 라인 14~19에서 찾아온 best cpu가 태스크에서 허용된 cpu이고, 적어도 요청한 dl 태스크의 deadline보다 더 느리거나 같으면 성공 1을 반환한다. later_mask에는 best cpu에 해당하는 비트가 설정된다.
- 코드 라인 21에서 실패 0을 반환한다.
다음 그림은 dl 태스크를 스케줄하기 가장 알맞은 cpu를 찾는 모습을 보여준다.
GRUB Reclaim
GRUB (Greedy Reclaimation of Unused Bandwidt) 기반의 cpu reclaim 기능은 다른 cpu에서 사용하지 않고 남는 런타임을 회수하여 사용할 수 있게 하는 알고리즘으로 동작한다.
- user-space 기반의 dl 태스크에 스케줄러 파라미터로 SCHED_FLAG_RECLAIM 플래그를 사용하면 GRUB 기반의 cpu reclaim 기능을 사용할 수 있다.
- 참고: sched/deadline: Implement GRUB accounting (2017, v4.13-rc1)
- 이 알고리즘은 non realtime 태스크에 대한 기아(starvation) 현상을 막기 위해 약간의 confugurable spare 마진의 cpu bandwidtn를 운용한다.
- 참고: CPU reclaiming for SCHED_DEADLINE (2016) | LWN.net
- 다음 참고 문서에서 GRUB reclaim에 대하여 자세하게 알려준다.
- 참고: SCHED_DEADLINE: It’s Alive! (2017) | ARM – 다운로드 pdf
- 다음 참고 문서는 절전 기반의 실시간 스케줄러를 위해 GRUB-PA 알고리즘에 대해 설명한다.
- 참고: Energy-Aware Real-Time Scheduling in the Linux Kernel (2018) | Claudio Scordino, Luca Abeni, Juri Lelli – 다운로드 pdf
grub_reclaim()
kernel/sched/deadline.c
/*
* This function implements the GRUB accounting rule:
* according to the GRUB reclaiming algorithm, the runtime is
* not decreased as "dq = -dt", but as
* "dq = -max{u / Umax, (1 - Uinact - Uextra)} dt",
* where u is the utilization of the task, Umax is the maximum reclaimable
* utilization, Uinact is the (per-runqueue) inactive utilization, computed
* as the difference between the "total runqueue utilization" and the
* runqueue active utilization, and Uextra is the (per runqueue) extra
* reclaimable utilization.
* Since rq->dl.running_bw and rq->dl.this_bw contain utilizations
* multiplied by 2^BW_SHIFT, the result has to be shifted right by
* BW_SHIFT.
* Since rq->dl.bw_ratio contains 1 / Umax multipled by 2^RATIO_SHIFT,
* dl_bw is multiped by rq->dl.bw_ratio and shifted right by RATIO_SHIFT.
* Since delta is a 64 bit variable, to have an overflow its value
* should be larger than 2^(64 - 20 - 8), which is more than 64 seconds.
* So, overflow is not an issue here.
*/
static u64 grub_reclaim(u64 delta, struct rq *rq, struct sched_dl_entity *dl_se)
{
u64 u_inact = rq->dl.this_bw - rq->dl.running_bw; /* Utot - Uact */
u64 u_act;
u64 u_act_min = (dl_se->dl_bw * rq->dl.bw_ratio) >> RATIO_SHIFT;
/*
* Instead of computing max{u * bw_ratio, (1 - u_inact - u_extra)},
* we compare u_inact + rq->dl.extra_bw with
* 1 - (u * rq->dl.bw_ratio >> RATIO_SHIFT), because
* u_inact + rq->dl.extra_bw can be larger than
* 1 * (so, 1 - u_inact - rq->dl.extra_bw would be negative
* leading to wrong results)
*/
if (u_inact + rq->dl.extra_bw > BW_UNIT - u_act_min)
u_act = u_act_min;
else
u_act = BW_UNIT - u_inact - rq->dl.extra_bw;
return (delta * u_act) >> BW_SHIFT;
}
@delta 런타임에 GRUB account 룰을 적용하여 반환한다.
- 코드 라인 3에서 전체에서 active 유틸을 뺴서 inactive 유틸을 구한다.
- u_inact = rq->dl.this_bw – rq->dl.running_bw
- Uinacct = Utot – Uact
- 코드 라인 5에서 엔티티의 유틸에 해당하는 최소 active 유틸을 구해 놓는다.
- 코드 라인 15~18에서 active 유틸 값은 1 – inact – extra 유틸이다. 단 active 유틸 값은 최소 active 유틸 이상으로 제한한다.
- 코드 라인 20에서 @delta 런타임에 active 유틸을 적용한 값을 반환한다.
Task Non Contending
task_non_contending()
kernel/sched/deadline.c
/* * The utilization of a task cannot be immediately removed from * the rq active utilization (running_bw) when the task blocks. * Instead, we have to wait for the so called "0-lag time". * * If a task blocks before the "0-lag time", a timer (the inactive * timer) is armed, and running_bw is decreased when the timer * fires. * * If the task wakes up again before the inactive timer fires, * the timer is cancelled, whereas if the task wakes up after the * inactive timer fired (and running_bw has been decreased) the * task's utilization has to be added to running_bw again. * A flag in the deadline scheduling entity (dl_non_contending) * is used to avoid race conditions between the inactive timer handler * and task wakeups. * * The following diagram shows how running_bw is updated. A task is * "ACTIVE" when its utilization contributes to running_bw; an * "ACTIVE contending" task is in the TASK_RUNNING state, while an * "ACTIVE non contending" task is a blocked task for which the "0-lag time" * has not passed yet. An "INACTIVE" task is a task for which the "0-lag" * time already passed, which does not contribute to running_bw anymore. * +------------------+ * wakeup | ACTIVE | * +------------------>+ contending | * | add_running_bw | | * | +----+------+------+ * | | ^ * | dequeue | | * +--------+-------+ | | * | | t >= 0-lag | | wakeup * | INACTIVE |<---------------+ | * | | sub_running_bw | | * +--------+-------+ | | * ^ | | * | t < 0-lag | | * | | | * | V | * | +----+------+------+ * | sub_running_bw | ACTIVE | * +-------------------+ | * inactive timer | non contending | * fired +------------------+ * * The task_non_contending() function is invoked when a task * blocks, and checks if the 0-lag time already passed or * not (in the first case, it directly updates running_bw; * in the second case, it arms the inactive timer). * * The task_contending() function is invoked when a task wakes * up, and checks if the task is still in the "ACTIVE non contending" * state or not (in the second case, it updates running_bw). */
static void task_non_contending(struct task_struct *p)
{
struct sched_dl_entity *dl_se = &p->dl;
struct hrtimer *timer = &dl_se->inactive_timer;
struct dl_rq *dl_rq = dl_rq_of_se(dl_se);
struct rq *rq = rq_of_dl_rq(dl_rq);
s64 zerolag_time;
/*
* If this is a non-deadline task that has been boosted,
* do nothing
*/
if (dl_se->dl_runtime == 0)
return;
if (dl_entity_is_special(dl_se))
return;
WARN_ON(dl_se->dl_non_contending);
zerolag_time = dl_se->deadline -
div64_long((dl_se->runtime * dl_se->dl_period),
dl_se->dl_runtime);
/*
* Using relative times instead of the absolute "0-lag time"
* allows to simplify the code
*/
zerolag_time -= rq_clock(rq);
/*
* If the "0-lag time" already passed, decrease the active
* utilization now, instead of starting a timer
*/
if ((zerolag_time < 0) || hrtimer_active(&dl_se->inactive_timer)) {
if (dl_task(p))
sub_running_bw(dl_se, dl_rq);
if (!dl_task(p) || p->state == TASK_DEAD) {
struct dl_bw *dl_b = dl_bw_of(task_cpu(p));
if (p->state == TASK_DEAD)
sub_rq_bw(&p->dl, &rq->dl);
raw_spin_lock(&dl_b->lock);
__dl_sub(dl_b, p->dl.dl_bw, dl_bw_cpus(task_cpu(p)));
__dl_clear_params(p);
raw_spin_unlock(&dl_b->lock);
}
return;
}
dl_se->dl_non_contending = 1;
get_task_struct(p);
hrtimer_start(timer, ns_to_ktime(zerolag_time), HRTIMER_MODE_REL_HARD);
}
태스크가 sleep 하면서 디큐될 때 잠시 active non contending 상태로 전환할지 여부를 결정한다.
- 코드 라인 13~14에서 엔티티의 런타임이 남아있지 않은 경우 함수를 빠져나간다.
- 코드 라인 16~17에서 special 타입 엔티티의 경우도 함수를 빠져나간다.
- 코드 라인 21~23에서 deadline – (period * 남은 런타임 잔량 비율) 값으로 0-lag 시각을 산출한다.
- 남은 런타임 잔량
- 0-lag = deadline – ( ———————— * dl_period )
- 전체 런타임
- 코드 라인 29에서 0-lag에 현재 시각을 빼 상대 값으로 만든다.
- 코드 라인 35~50에서 0-lag 타임이 이미 지난 경우 inactive 상태이다. 먼저 함수를 빠져나가기 전에 다음과 같이 처리한다.
- dl 엔티티의 유틸을 dl 런큐의 러닝 유틸에서 감소시킨다.
- dl 엔티티가 아니거나 종료된 태스크이 경우 dl 런큐의 전체 유틸에서 엔티티의 유틸을 뺀다.
- 해당 cpu에 대한 유틸에서 dl 엔티티의 유틸을 뺀다.
- 코드 라인 52~54에서 태스크를 non contending 상태로 변경하고, 0-lag 에 맞춰 inactive 타이머를 가동한다.
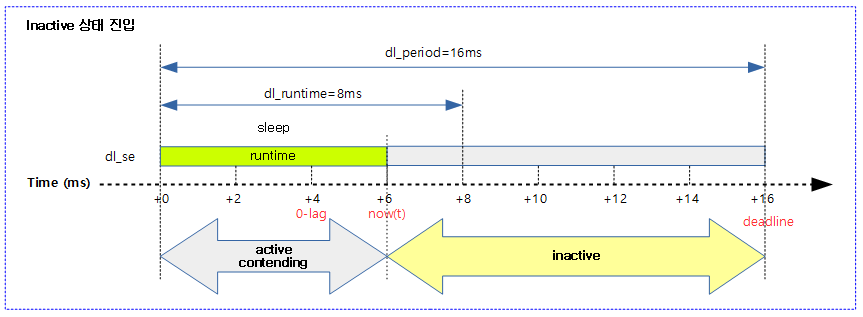
다음 그림은 태스크가 0-leg 시각에 맞춰 inactive 타이머를 설정하고 active non contending 상태에 들어간 모습을 보여준다.
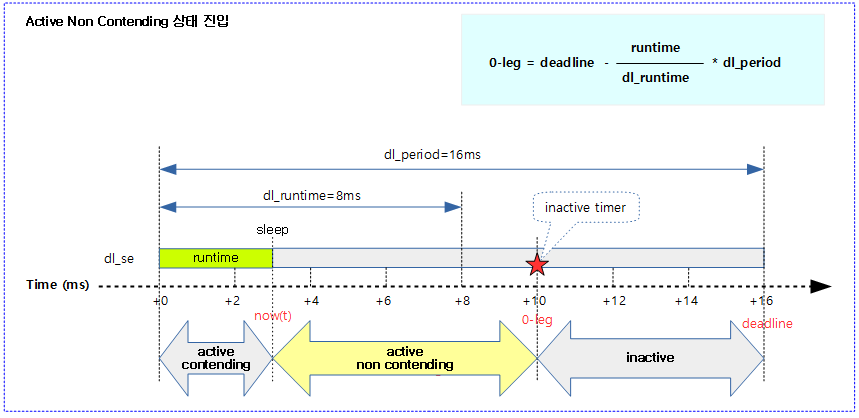
다음 그림은 산출한 0-leg 시각이 현재보다 과거이므로 태스크를 active non contending 상태를 무시하고 곧바로 inactive 상태에 들어간 모습을 보여준다.
Task Contending
task_contending()
kernel/sched/deadline.c
static void task_contending(struct sched_dl_entity *dl_se, int flags)
{
struct dl_rq *dl_rq = dl_rq_of_se(dl_se);
/*
* If this is a non-deadline task that has been boosted,
* do nothing
*/
if (dl_se->dl_runtime == 0)
return;
if (flags & ENQUEUE_MIGRATED)
add_rq_bw(dl_se, dl_rq);
if (dl_se->dl_non_contending) {
dl_se->dl_non_contending = 0;
/*
* If the timer handler is currently running and the
* timer cannot be cancelled, inactive_task_timer()
* will see that dl_not_contending is not set, and
* will not touch the rq's active utilization,
* so we are still safe.
*/
if (hrtimer_try_to_cancel(&dl_se->inactive_timer) == 1)
put_task_struct(dl_task_of(dl_se));
} else {
/*
* Since "dl_non_contending" is not set, the
* task's utilization has already been removed from
* active utilization (either when the task blocked,
* when the "inactive timer" fired).
* So, add it back.
*/
add_running_bw(dl_se, dl_rq);
}
}
태스크가 동작 중에 있을 때에 active contending 상태가 되도록 갱신한다.
- 코드 라인 9~10에서 런타임이 설정되지 않은 경우 함수를 빠져나간다.
- 코드 라인 12~13에서 cpu가 이동되어 엔큐된 태스크인 경우 엔티티의 유틸을 dl 런큐에 추가한다.
- 코드 라인 15~25에서 non contending 상태였었던 경우 inactive 타이머를 취소시키고 non contending 상태를 해제한다.
- 코드 라인 26~35에서 non contending 상태가 아닌 경우엔 엔티티의 유틸을 dl 런큐의 러닝 유틸에 추가한다.
init_dl_inactive_task_timer()
kernel/sched/deadline.c
void init_dl_inactive_task_timer(struct sched_dl_entity *dl_se)
{
struct hrtimer *timer = &dl_se->inactive_timer;
hrtimer_init(timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL_HARD);
timer->function = inactive_task_timer;
}
dl 태스크의 inactive 타이머를 초기화한다. 동작시 수행할 함수를 미리 지정해둔다.
inactive_task_timer()
kernel/sched/deadline.c
static enum hrtimer_restart inactive_task_timer(struct hrtimer *timer)
{
struct sched_dl_entity *dl_se = container_of(timer,
struct sched_dl_entity,
inactive_timer);
struct task_struct *p = dl_task_of(dl_se);
struct rq_flags rf;
struct rq *rq;
rq = task_rq_lock(p, &rf);
sched_clock_tick();
update_rq_clock(rq);
if (!dl_task(p) || p->state == TASK_DEAD) {
struct dl_bw *dl_b = dl_bw_of(task_cpu(p));
if (p->state == TASK_DEAD && dl_se->dl_non_contending) {
sub_running_bw(&p->dl, dl_rq_of_se(&p->dl));
sub_rq_bw(&p->dl, dl_rq_of_se(&p->dl));
dl_se->dl_non_contending = 0;
}
raw_spin_lock(&dl_b->lock);
__dl_sub(dl_b, p->dl.dl_bw, dl_bw_cpus(task_cpu(p)));
raw_spin_unlock(&dl_b->lock);
__dl_clear_params(p);
goto unlock;
}
if (dl_se->dl_non_contending == 0)
goto unlock;
sub_running_bw(dl_se, &rq->dl);
dl_se->dl_non_contending = 0;
unlock:
task_rq_unlock(rq, p, &rf);
put_task_struct(p);
return HRTIMER_NORESTART;
}
non contending 상태의 태스크로부터 inactive 타이머가 expire되어 호출되면 non contending 상태를 취소한다.
- 코드 라인 13에서 런큐 클럭을 갱신한다.
- 코드 라인 15~30에서 dl 태스크가 아니거나 종료된 태스크인 경우 다음과 같이 처리한다.
- non contending 상태이면서 종료된 태스크인 경우 dl 엔티티의 유틸을 dl 런큐의 러닝 유틸에서 감소시키고, dl 런큐의 전체 유틸에서 엔티티의 유틸을 뺀 후 non contending 상태를 해제한다.
- 해당 cpu에 대한 유틸에서 dl 엔티티의 유틸을 뺀다.
- 코드 라인 31~32에서 이미 non contending 상태가 해제된 경우 unlock 레이블로 이동 후 함수를 빠져나간다.
- 코드 라인 34~35에서 dl 런큐의 러닝 유틸에서 dl 엔티티의 유틸만큼 감소시키고 non contending 상태를 해제한다.
- 코드 라인 36~40에서 unlock: 레이블이다. 런큐를 언락 후 함수를 빠져나간다.
DL Migration, Overload
DL Migration
inc_dl_migration()
kernel/sched/deadline.c
static void inc_dl_migration(struct sched_dl_entity *dl_se, struct dl_rq *dl_rq)
{
struct task_struct *p = dl_task_of(dl_se);
if (p->nr_cpus_allowed > 1)
dl_rq->dl_nr_migratory++;
update_dl_migration(dl_rq);
}
dl 태스크에 2개 이상의 cpu가 할당된 경우 dl_nr_migratory를 증가시키고 migration 가능 여부를 갱신한다.
dec_dl_migration()
kernel/sched/deadline.c
static void dec_dl_migration(struct sched_dl_entity *dl_se, struct dl_rq *dl_rq)
{
struct task_struct *p = dl_task_of(dl_se);
if (p->nr_cpus_allowed > 1)
dl_rq->dl_nr_migratory--;
update_dl_migration(dl_rq);
}
dl 태스크에 2개 이상의 cpu가 할당된 경우 dl_nr_migratory를 감소시키고 migration 가능 여부를 갱신한다.
update_dl_migration()
kernel/sched/deadline.c
static void update_dl_migration(struct dl_rq *dl_rq)
{
if (dl_rq->dl_nr_migratory && dl_rq->dl_nr_running > 1) {
if (!dl_rq->overloaded) {
dl_set_overload(rq_of_dl_rq(dl_rq));
dl_rq->overloaded = 1;
}
} else if (dl_rq->overloaded) {
dl_clear_overload(rq_of_dl_rq(dl_rq));
dl_rq->overloaded = 0;
}
}
런큐의 migration 가능 여부를 갱신한다.
- 코드 라인 3~7에서 dl 런큐의 dl_nr_migratory가 1 이상이고 dl 런큐에 dl 태스크의 수가 2개 이상인 경우 런큐를 overload 설정한다.
- 코드 라인 8~11에서 런큐가 이미 오버로드된 경우 클리어한다.
DL Overload
dl_set_overload()
kernel/sched/deadline.c
static inline void dl_set_overload(struct rq *rq)
{
if (!rq->online)
return;
cpumask_set_cpu(rq->cpu, rq->rd->dlo_mask);
/*
* Must be visible before the overload count is
* set (as in sched_rt.c).
*
* Matched by the barrier in pull_dl_task().
*/
smp_wmb();
atomic_inc(&rq->rd->dlo_count);
}
요청한 런큐를 overload 설정한다
- 코드 라인 3~4에서 런큐가 offline 상태면 함수를 빠져나간다.
- 코드 라인 6에서 런큐의 루트 도메인에 있는 dlo_mask에 런큐가 동작하는 cpu에 해당하는 비트를 설정한다.
- 코드 라인 13에서 dlo_mask 및 dlo_count 의 기록을 명확히 순서대로 하기 위해 메모리 베리어를 수행한다.
- 코드 라인 14에서 런큐의 루트 도메인에 있는 dlo_count를 1 증가시킨다.
dl_clear_overload()
kernel/sched/deadline.c
static inline void dl_clear_overload(struct rq *rq)
{
if (!rq->online)
return;
atomic_dec(&rq->rd->dlo_count);
cpumask_clear_cpu(rq->cpu, rq->rd->dlo_mask);
}
요청한 런큐를 overload 클리어한다
- 코드 라인 3~4에서 런큐가 offline 상태면 함수를 빠져나간다.
- 코드 라인 6에서 런큐의 루트 도메인에 있는 dlo_count를 1 감소시킨다.
- 코드 라인 7에서 런큐의 루트 도메인에 있는 dlo_mask에 런큐가 동작하는 cpu에 해당하는 비트를 클리어한다.
Pushable DL tasks
Enqueue & Dequeue
enqueue_pushable_dl_task()
kernel/sched/deadline.c
/*
* The list of pushable -deadline task is not a plist, like in
* sched_rt.c, it is an rb-tree with tasks ordered by deadline.
*/
static void enqueue_pushable_dl_task(struct rq *rq, struct task_struct *p)
{
struct dl_rq *dl_rq = &rq->dl;
struct rb_node **link = &dl_rq->pushable_dl_tasks_root.rb_node;
struct rb_node *parent = NULL;
struct task_struct *entry;
int leftmost = 1;
BUG_ON(!RB_EMPTY_NODE(&p->pushable_dl_tasks));
while (*link) {
parent = *link;
entry = rb_entry(parent, struct task_struct,
pushable_dl_tasks);
if (dl_entity_preempt(&p->dl, &entry->dl))
link = &parent->rb_left;
else {
link = &parent->rb_right;
leftmost = 0;
}
}
if (leftmost)
dl_rq->earliest_dl.next = p->dl.deadline;
rb_link_node(&p->pushable_dl_tasks, parent, link);
rb_insert_color(&p->pushable_dl_tasks,
&dl_rq->pushable_dl_tasks_root);
}
요청한 dl 태스크를 pushable dl 태스크 RB 트리에 추가한다.
- 코드 라인 8에서 요청한 런큐의 dl 런큐에 있는 pushable_dl_tasks_root RB 트리를 알아온다.
- 코드 라인 15~25에서 요청한 dl 태스크가 위치할 노드를 찾아간다.
- 코드 라인 27~28에서 dl 태스크의 deadline이 가장 먼저(early)인 경우 next에 연결한다.
- 코드 라인 30~32에서 dl 태스크를 pushable dl 태스크 RB 트리에 추가하고 color를 갱신한다.
dequeue_pushable_dl_task()
kernel/sched/deadline.c
static void dequeue_pushable_dl_task(struct rq *rq, struct task_struct *p)
{
struct dl_rq *dl_rq = &rq->dl;
if (RB_EMPTY_NODE(&p->pushable_dl_tasks))
return;
if (dl_rq->pushable_dl_tasks_leftmost == &p->pushable_dl_tasks) {
struct rb_node *next_node;
next_node = rb_next(&p->pushable_dl_tasks);
if (next_node) {
dl_rq->earliest_dl.next = rb_entry(next_node,
struct task_struct, pushable_dl_tasks)->dl.deadline;
}
}
rb_erase(&p->pushable_dl_tasks, &dl_rq->pushable_dl_tasks_root);
RB_CLEAR_NODE(&p->pushable_dl_tasks);
}
요청한 dl 태스크를 pushable dl 태스크 RB 트리에서 제거한다.
- 코드 라인 5~6에서 RB 트리가 이미 비어 있는 경우 함수를 빠져나간다.
- 코드 라인 8~16에서 제거할 태스크의 deadline이 가장 먼저(early)인 경우 다음으로 deadline이 빠른 태스크를 next에 대입한다.
- 코드 라인 18~19에서 dl 태스크를 pushable dl 태스크 RB 트리에서 제거하고 color를 갱신한다.
Push Operations
has_pushable_dl_tasks()
kernel/sched/deadline.c
static inline int has_pushable_dl_tasks(struct rq *rq)
{
return !RB_EMPTY_ROOT(&rq->dl.pushable_dl_tasks_root);
}
요청한 런큐의 pushable dl 태스크 RB 트리에 태스크가 존재하는지 여부를 반환한다. 1=존재, 0=비존재
push_dl_task()
kernel/sched/deadline.c – 1/2
/* * See if the non running -deadline tasks on this rq * can be sent to some other CPU where they can preempt * and start executing. */
static int push_dl_task(struct rq *rq)
{
struct task_struct *next_task;
struct rq *later_rq;
int ret = 0;
if (!rq->dl.overloaded)
return 0;
next_task = pick_next_pushable_dl_task(rq);
if (!next_task)
return 0;
retry:
if (WARN_ON(next_task == rq->curr))
return 0;
}
/*
* If next_task preempts rq->curr, and rq->curr
* can move away, it makes sense to just reschedule
* without going further in pushing next_task.
*/
if (dl_task(rq->curr) &&
dl_time_before(next_task->dl.deadline, rq->curr->dl.deadline) &&
rq->curr->nr_cpus_allowed > 1) {
resched_curr(rq);
return 0;
}
/* We might release rq lock */
get_task_struct(next_task);
요청한 런큐에서 오버로드되어 현재 동작하지 않는 dl 태스크에 대해 다른 여유있는 cpu로 migration 시키고 해당 런큐에서 동작중인 태스크에 preemption 요청 플래그를 설정한다. push가 성공한 경우 1을 반환하고, 실패한 경우 0을 반환한다.
- 코드 라인 7~8에서 요청한 런큐가 오버로드되지 않은 경우 0을 반환한다.
- 코드 라인 10~12에서 요청한 런큐에서 가장 deadline이 빠른 태스크를 알아온다. 만일 발견하지 못하면 0을 반환한다.
- 코드 라인 14~17에서 retry: 레이블이다. 이미 처리할 태스크가 요청한 런큐에서 이미 동작중인 경우 경고 메시지를 출력하고 0을 반환한다.
- 코드 라인 24~29에서 요청한 런큐에서 동작중인 dl 태스크의 deadline보다 다음 태스크의 deadline이 더 먼저이면서 현재 동작중인 dl 태스크에 할당된 cpu가 2개 이상인 경우 리스케줄 요청 플래그를 설정하고 0을 반환한다.
- 현재 dl 태스크보다 더 deadline이 빠른 dl 태스크가 있는 경우 리스케줄한다.
- 코드 라인 32에서 다음 태스크의 참조 카운터를 증가시킨다.
kernel/sched/deadline.c – 2/2
/* Will lock the rq it'll find */
later_rq = find_lock_later_rq(next_task, rq);
if (!later_rq) {
struct task_struct *task;
/*
* We must check all this again, since
* find_lock_later_rq releases rq->lock and it is
* then possible that next_task has migrated.
*/
task = pick_next_pushable_dl_task(rq);
if (task_cpu(next_task) == rq->cpu && task == next_task) {
/*
* The task is still there. We don't try
* again, some other cpu will pull it when ready.
*/
goto out;
}
if (!task)
/* No more tasks */
goto out;
put_task_struct(next_task);
next_task = task;
goto retry;
}
deactivate_task(rq, next_task, 0);
set_task_cpu(next_task, later_rq->cpu);
/*
* Update the later_rq clock here, because the clock is used
* by the cpufreq_update_util() inside __add_running_bw().
*/
update_rq_clock(later_rq);
activate_task(later_rq, next_task, 0);
ret = 1;
resched_curr(later_rq);
double_unlock_balance(rq, later_rq);
out:
put_task_struct(next_task);
return ret;
}
- 코드 라인 2에서 요청한 dl 태스크를 돌릴만한 여유있는 later 런큐를 알아온다.
- 코드 라인 3~11에서 찾아온 적절한 later 런큐가 없는 경우 pushable dl 태스크 RB 트리에 있는 다음 태스크를 가져온다.
- 코드 라인 12~18에서 다음 태스크의 cpu가 현재 런큐의 cpu와 같으면서 알아온 태스크가 다음 태스크와 동일한 경우 null을 반환한다.
- 코드 라인 20~22에서 알아온 태스크가 없으면 null을 반환한다.
- 코드 라인 24~27에서 알아온 태스크를 다음 태스크에 대입하고 반복한다.
- 코드 라인 29~37에서 다음 태스크를 런큐에서 디큐하고 태스크에 later 런큐의 cpu를 설정하고 later 런큐에 엔큐한다.
- 코드 라인 40~47에서 later 런큐에서 동작중인 태스크에 리스케줄 요청 플래그를 설정한 후 1을 반환한다.
pick_next_pushable_dl_task()
kernel/sched/deadline.c
static struct task_struct *pick_next_pushable_dl_task(struct rq *rq)
{
struct task_struct *p;
if (!has_pushable_dl_tasks(rq))
return NULL;
p = rb_entry(rq->dl.pushable_dl_tasks_leftmost,
struct task_struct, pushable_dl_tasks);
BUG_ON(rq->cpu != task_cpu(p));
BUG_ON(task_current(rq, p));
BUG_ON(p->nr_cpus_allowed <= 1);
BUG_ON(!task_on_rq_queued(p));
BUG_ON(!dl_task(p));
return p;
}
요청한 런큐에서 가장 deadline이 빠른 태스크를 반환한다.
find_lock_later_rq()
kernel/sched/deadline.c
/* Locks the rq it finds */
static struct rq *find_lock_later_rq(struct task_struct *task, struct rq *rq)
{
struct rq *later_rq = NULL;
int tries;
int cpu;
for (tries = 0; tries < DL_MAX_TRIES; tries++) {
cpu = find_later_rq(task);
if ((cpu == -1) || (cpu == rq->cpu))
break;
later_rq = cpu_rq(cpu);
if (later_rq->dl.dl_nr_running &&
!dl_time_before(task->dl.deadline,
later_rq->dl.earliest_dl.curr)) {
/*
* Target rq has tasks of equal or earlier deadline,
* retrying does not release any lock and is unlikely
* to yield a different result.
*/
later_rq = NULL;
break;
}
/* Retry if something changed. */
if (double_lock_balance(rq, later_rq)) {
if (unlikely(task_rq(task) != rq ||
!cpumask_test_cpu(later_rq->cpu, task->cpus_ptr) ||
task_running(rq, task) ||
!dl_task(task) ||
!task_on_rq_queued(task))) {
double_unlock_balance(rq, later_rq);
later_rq = NULL;
break;
}
}
/*
* If the rq we found has no -deadline task, or
* its earliest one has a later deadline than our
* task, the rq is a good one.
*/
if (!later_rq->dl.dl_nr_running ||
dl_time_before(task->dl.deadline,
later_rq->dl.earliest_dl.curr))
break;
/* Otherwise we try again. */
double_unlock_balance(rq, later_rq);
later_rq = NULL;
}
return later_rq;
}
요청한 dl 태스크를 돌릴만한 여유있는 later 런큐를 찾아 반환한다.
- 코드 라인 8~9에서 최대 3회 이내를 반복하며 later_mask에 있는 cpu들 중 deadline이 가장 여유있는 cpu 또는 적절한 cpu를 찾아온다.
- 코드 라인 11~12에서 찾은 cpu가 없거나 현재 런큐의 cpu인 경우 null을 반환한다.
- 코드 라인 14에서 결정한 cpu의 런큐를 later_rq에 대입한다.
- 코드 라인 16~26에서 만일 later 런큐에서 동작 중인 dl 태스크의 deadline이 요청한 태스크의 deadline보다 더 빠른 경우 이 later 런큐를 포기하고 함수를 빠져나간다.
- 코드 라인 29~39에서 런큐와 later 런큐 락을 획득한다. 락을 건후 다시 한 번 다음 조건에 해당하면 포기하고 null을 반환한다.
- 요청한 런큐와 태스크가 있는 런큐가 다르거나
- 태스크에 허락된 cpu들 중 later 런큐의 cpu가 없거나
- 이미 태스크가 현재 cpu에서 동작중이거나
- 요청한 태스크가 dl 태스크가 아니거나
- 태스크가 런큐에 없는 경우 null을 반환한다.
- 코드 라인 46~49에서 later 런큐에 dl 태스크가 하나도 없거나 요청한 태스크의 deadline이 later 런큐에서 동작중인 dl 태스크의 deadline보다 더 먼저인 경우 루프를 탈출하고 later_rq를 반환한다.
- 이 later 런큐에 dl 태스크가 하나도 없거나 현재 동작 중인 dl 태스크의 deadline 보다 먼저인 경우 이 later 런큐가 적절하다.
- 코드 라인 52~53에서 런큐와 later 런큐 락을 해제하고, later_rq를 다시 찾기 위해 루프를 반복한다.
find_later_rq()
later_mask에 있는 cpu들 중 deadline이 가장 여유있는 적절한 cpu 또는 적절한 cpu를 찾아 반환한다.
kernel/sched/deadline.c – 1/2
static int find_later_rq(struct task_struct *task)
{
struct sched_domain *sd;
struct cpumask *later_mask = this_cpu_cpumask_var_ptr(local_cpu_mask_dl);
int this_cpu = smp_processor_id();
int best_cpu, cpu = task_cpu(task);
/* Make sure the mask is initialized first */
if (unlikely(!later_mask))
return -1;
if (task->nr_cpus_allowed == 1)
return -1;
/*
* We have to consider system topology and task affinity
* first, then we can look for a suitable cpu.
*/
if (!cpudl_find(&task_rq(task)->rd->cpudl, task, later_mask))
return -1;
/*
* If we are here, some target has been found,
* the most suitable of which is cached in best_cpu.
* This is, among the runqueues where the current tasks
* have later deadlines than the task's one, the rq
* with the latest possible one.
*
* Now we check how well this matches with task's
* affinity and system topology.
*
* The last cpu where the task run is our first
* guess, since it is most likely cache-hot there.
*/
if (cpumask_test_cpu(cpu, later_mask))
return cpu;
/*
* Check if this_cpu is to be skipped (i.e., it is
* not in the mask) or not.
*/
if (!cpumask_test_cpu(this_cpu, later_mask))
this_cpu = -1;
- 코드 라인 4에서 전역 per-cpu local_cpu_mask_dl에서 현재 cpu에 대한 비트마스크를 알아와서 later_mask에 대입한다.
- 코드 라인 9~10에서 later_mask에 아무것도 설정된 cpu가 없으면 -1을 반환한다.
- 코드 라인 12~13에서 현재 태스크에 할당된 cpu가 1개 밖에 없으면 -1을 반환한다.
- 코드 라인 19~20에서 later_mask에 있는 cpu들 중 가장 여유 있는 deadline을 가진 best_cpu를 알아오고 없으면 -1을 반환한다.
- 코드 라인 35~36에서 later_mask에서 태스크의 cpu에 해당하는 비트가 설정된 경우 태스크의 cpu를 반환한다.
- 코드 라인 41~42에서 later_mask에서 현재 cpu에 해당하는 비트가 설정되지 않은 경우 this_cpu에 -1을 설정한다.
kernel/sched/deadline.c – 2/2
rcu_read_lock();
for_each_domain(cpu, sd) {
if (sd->flags & SD_WAKE_AFFINE) {
/*
* If possible, preempting this_cpu is
* cheaper than migrating.
*/
if (this_cpu != -1 &&
cpumask_test_cpu(this_cpu, sched_domain_span(sd))) {
rcu_read_unlock();
return this_cpu;
}
best_cpu = cpumask_first_and(later_mask,
sched_domain_span(sd));
/*
* Last chance: if best_cpu is valid and is
* in the mask, that becomes our choice.
*/
if (best_cpu < nr_cpu_ids) {
rcu_read_unlock();
return best_cpu;
}
}
}
rcu_read_unlock();
/*
* At this point, all our guesses failed, we just return
* 'something', and let the caller sort the things out.
*/
if (this_cpu != -1)
return this_cpu;
cpu = cpumask_any(later_mask);
if (cpu < nr_cpu_ids)
return cpu;
return -1;
}
- 코드 라인 2~3에서 cpu가 소속된 스케줄 도메인들을 순회하며, wakeup 태스크의 캐시 affinity를 지원하는 도메인만을 순회하고자 하는 경우이다.
- 코드 라인 9~13에서 later_mask에 현재 cpu가 없고 순회중인 스케줄 도메인에서는 포함된 경우 현재 cpu를 반환한다.
- 현재 cpu를 사용하는 것이 migration하는 것보다 비용이 저렴하다.
- 코드 라인 15~16에서 순회 중인 스케줄 도메인의 cpu들 중 later_mask와 교집합이 되는 cpu 중 첫 번째 cpu를 best cpu로 선정한다.
- 코드 라인 21~24에서 best cpu를 반환한다.
- 코드 라인 33~34에서 later_mask에 현재 cpu가 없는 경우 이 시점에서는 그냥 현재 cpu를 사용한다.
- 코드 라인 36~38에서 later_mask 중 랜덤으로 하나를 골라 반환한다.
- 코드 라인 40에서 찾지못한 경우 -1을 반환한다.
Pull Operations
need_pull_dl_task()
kernel/sched/deadline.c
static inline bool need_pull_dl_task(struct rq *rq, struct task_struct *prev)
{
return dl_task(prev);
}
dl 태스크 여부를 반환한다.
dl_task()
include/linux/sched/deadline.h
static inline int dl_task(struct task_struct *p)
{
return dl_prio(p->prio);
}
dl 태스크 여부를 반환한다.
dl_prio()
include/linux/sched/deadline.h
static inline int dl_prio(int prio)
{
if (unlikely(prio < MAX_DL_PRIO))
return 1;
return 0;
}
dl 태스크 여부를 반환한다.
include/linux/sched/deadline.h
#define MAX_DL_PRIO 0
pull_dl_task()
kernel/sched/deadline.c -1/2-
static void pull_dl_task(struct rq *this_rq)
{
int this_cpu = this_rq->cpu, cpu;
struct task_struct *p;
bool resched = false;
struct rq *src_rq;
u64 dmin = LONG_MAX;
if (likely(!dl_overloaded(this_rq)))
return;
/*
* Match the barrier from dl_set_overloaded; this guarantees that if we
* see overloaded we must also see the dlo_mask bit.
*/
smp_rmb();
for_each_cpu(cpu, this_rq->rd->dlo_mask) {
if (this_cpu == cpu)
continue;
src_rq = cpu_rq(cpu);
/*
* It looks racy, abd it is! However, as in sched_rt.c,
* we are fine with this.
*/
if (this_rq->dl.dl_nr_running &&
dl_time_before(this_rq->dl.earliest_dl.curr,
src_rq->dl.earliest_dl.next))
continue;
/* Might drop this_rq->lock */
double_lock_balance(this_rq, src_rq);
/*
* If there are no more pullable tasks on the
* rq, we're done with it.
*/
if (src_rq->dl.dl_nr_running <= 1)
goto skip;
p = pick_earliest_pushable_dl_task(src_rq, this_cpu);
모든 오버로드된 cpu들에서 대기중인 dl 태스크들 중 가장 급한 태스크를 알아온다.
- 코드 라인 9~10에서 높은 확률로 요청한 런큐가 오버로드되지 않은 경우 0을 반환한다.
- 코드 라인 16에서 위에서 읽은 dlo_count와 아래의 dlo_mask 값을 읽기 전에 그 가운데에서 메모리 배리어를 수행한다.
- 코드 라인 18~20에서 요청한 런큐에 루트 도메인에 있는 dlo_mask에 설정된 cpu들에 대해 요청한 cpu를 제외하고 순회를 한다.
- 코드 라인 22에서 순회중인 cpu에 대한 런큐를 src_rq에 대입한다.
- 코드 라인 28~31에서 요청한 런큐에서 동작중인 dl 태스크의 deadline이 dl 런큐에서 대기중인 태스크의 deadline보다 더 우선적으로 요구되는 일반적인 경우 skip 한다.
- 코드 라인 34에서 순회 중인 런큐의 태스크를 pull 마이그레이션 하기 위해 요청한 런큐와 순회 중인 런큐 두 런큐에 대해 더블락을 획득한다.
- 코드 라인 40~41에서 락을 건 후 다시 확인해 본다. 요청한 런큐에서 동작중인 dl 태스크가 1개 이하인 경우 skip 한다.
- 코드 라인 43에서 순회 중인 이 런큐의 pushable 태스크 중 가장 이른(earliest) deadline을 가진 태스크를 알아온다.
kernel/sched/deadline.c -2/2-
/*
* We found a task to be pulled if:
* - it preempts our current (if there's one),
* - it will preempt the last one we pulled (if any).
*/
if (p && dl_time_before(p->dl.deadline, dmin) &&
(!this_rq->dl.dl_nr_running ||
dl_time_before(p->dl.deadline,
this_rq->dl.earliest_dl.curr))) {
WARN_ON(p == src_rq->curr);
WARN_ON(!task_on_rq_queued(p));
/*
* Then we pull iff p has actually an earlier
* deadline than the current task of its runqueue.
*/
if (dl_time_before(p->dl.deadline,
src_rq->curr->dl.deadline))
goto skip;
resched = true;
deactivate_task(src_rq, p, 0);
set_task_cpu(p, this_cpu);
activate_task(this_rq, p, 0);
dmin = p->dl.deadline;
/* Is there any other task even earlier? */
}
skip:
double_unlock_balance(this_rq, src_rq);
}
if (resched)
resched_curr(this_rq);
}
- 코드 라인 6~19에서 락을 얻은 이후이므로 다시 한 번 pull 마이그레이션을 위한 조건을 다음과 같이 체크해본다.
- 순회 시 마이그레이션 성공한 태스크의 deadline 보다 더 빠른 태스크에 한정한다.
- pull 마이그레이션 할 태스크의 deadline이 현재 런큐에서 동작하는 태스크보다 deadline이 빨라야 한다.
- pull 마이그레이션할 태스크의 deadline이 해당 런큐에서 동작 중인 태스크의 deadline보다 빠른 경우는 해당 cpu에서 스스로 곧 리스케줄하여 돌리게되므로 제외한다.
- 코드 라인 21~25에서 pull 마이그레이션 할 태스크를 디큐하고 요청한 런큐에 엔큐한다.
- 코드 라인 26~29에서 pull 마이그레이션에 성공한 태스크의 deadline 값을 보관하여 다음 런큐 순회 시 이 deadline 보다 더 빠른 태스크에서만 마이그레이션 하도록 한다.
- 코드 라인 30~32에서 skip: 레이블이다. 더블 런큐 락을 해제한 후 계속 런큐를 순회한다.
- 코드 라인 34~35에서 resched가 설정된 경우 리스케줄 요청한다.
pick_dl_task()
kernel/sched/deadline.c
static int pick_dl_task(struct rq *rq, struct task_struct *p, int cpu)
{
if (!task_running(rq, p) &&
cpumask_test_cpu(cpu, p->cpus_ptr))
return 1;
return 0;
}
요청한 태스크가 런큐에서 동작하지 않은 태스크이며 요청한 cpu에 할당 가능하면 true(1)를 반환한다.
Deadline 타이머

deadline 타이머 시작
start_dl_timer()
kernel/sched/deadline.c
/* * If the entity depleted all its runtime, and if we want it to sleep * while waiting for some new execution time to become available, we * set the bandwidth replenishment timer to the replenishment instant * and try to activate it. * * Notice that it is important for the caller to know if the timer * actually started or not (i.e., the replenishment instant is in * the future or in the past). */
static int start_dl_timer(struct task_struct *p)
{
struct sched_dl_entity *dl_se = &p->dl;
struct hrtimer *timer = &dl_se->dl_timer;
struct rq *rq = task_rq(p);
ktime_t now, act;
s64 delta;
lockdep_assert_held(&rq->lock);
/*
* We want the timer to fire at the deadline, but considering
* that it is actually coming from rq->clock and not from
* hrtimer's time base reading.
*/
act = ns_to_ktime(dl_next_period(dl_se));
now = hrtimer_cb_get_time(timer);
delta = ktime_to_ns(now) - rq_clock(rq);
act = ktime_add_ns(act, delta);
/*
* If the expiry time already passed, e.g., because the value
* chosen as the deadline is too small, don't even try to
* start the timer in the past!
*/
if (ktime_us_delta(act, now) < 0)
return 0;
/*
* !enqueued will guarantee another callback; even if one is already in
* progress. This ensures a balanced {get,put}_task_struct().
*
* The race against __run_timer() clearing the enqueued state is
* harmless because we're holding task_rq()->lock, therefore the timer
* expiring after we've done the check will wait on its task_rq_lock()
* and observe our state.
*/
if (!hrtimer_is_queued(timer)) {
get_task_struct(p);
hrtimer_start(timer, act, HRTIMER_MODE_ABS_HARD);
}
return 1;
}
dl 타이머를 가동시킨다. 가동 상태에 있으면 1을 반환한다.
- 코드 라인 16~19에서 런큐 클럭 기반의 dl 엔티티의 deadline은 hrtimer의 현재 시각과는 약간의 갭(런큐 클럭은 스케줄 틱 등 필요시 마다 갱신)이 있다. 이 갭을 보정하여 hrtimer에 사용할 실제 만료 시각을 구해 act에 대입한다.
- 코드 라인 26~27에서 만료 시각이 지난 경우 0을 반환한다.
- 코드 라인 38~41에서 dl 타이머가 가동되지 않고 있을 때에만 act 시각으로 dl 타이머의 만료 시각을 설정하고 가동한다.
- 코드 라인 43에서dl 타이머가 가동 중임을 알리는 1을 반환한다.
deadline 타이머 만료 시 동작
dl_task_timer()
kernel/sched/deadline.c -1/2-
/* * This is the bandwidth enforcement timer callback. If here, we know * a task is not on its dl_rq, since the fact that the timer was running * means the task is throttled and needs a runtime replenishment. * * However, what we actually do depends on the fact the task is active, * (it is on its rq) or has been removed from there by a call to * dequeue_task_dl(). In the former case we must issue the runtime * replenishment and add the task back to the dl_rq; in the latter, we just * do nothing but clearing dl_throttled, so that runtime and deadline * updating (and the queueing back to dl_rq) will be done by the * next call to enqueue_task_dl(). */
static enum hrtimer_restart dl_task_timer(struct hrtimer *timer)
{
struct sched_dl_entity *dl_se = container_of(timer,
struct sched_dl_entity,
dl_timer);
struct task_struct *p = dl_task_of(dl_se);
struct rq_flags rf;
struct rq *rq;
rq = task_rq_lock(p, &rf);
/*
* The task might have changed its scheduling policy to something
* different than SCHED_DEADLINE (through switched_from_dl()).
*/
if (!dl_task(p))
goto unlock;
/*
* The task might have been boosted by someone else and might be in the
* boosting/deboosting path, its not throttled.
*/
if (dl_se->dl_boosted)
goto unlock;
/*
* Spurious timer due to start_dl_timer() race; or we already received
* a replenishment from rt_mutex_setprio().
*/
if (!dl_se->dl_throttled)
goto unlock;
sched_clock_tick();
update_rq_clock(rq);
/*
* If the throttle happened during sched-out; like:
*
* schedule()
* deactivate_task()
* dequeue_task_dl()
* update_curr_dl()
* start_dl_timer()
* __dequeue_task_dl()
* prev->on_rq = 0;
*
* We can be both throttled and !queued. Replenish the counter
* but do not enqueue -- wait for our wakeup to do that.
*/
if (!task_on_rq_queued(p)) {
replenish_dl_entity(dl_se, dl_se);
goto unlock;
}
dl 타이머가 동작되어 호출되는 함수이다. 스로틀 중인 경우 스로틀을 해제하고 런타임과 deadline을 보충한 후 태스크를 엔큐한다. 런큐 내에서 가장 빠른 deadline으로 등극하는 경우 리스케줄 요청도 한다.
- 코드 라인 10에서 태스크가 소속된 런큐 락을 획득한다.
- 코드 라인 16~17에서 dl 태스크가 아닌 경우 함수를 빠져나간다.
- 코드 라인 23~24에서 부스트 중인 경우 함수를 빠져나간다. 부스트 중에는 빠른 시간내에 락을 벗어나야 하므로 dl 밴드위드에 상관없이 항상 동작한다.
- 코드 라인 30~31에서 스로틀된 경우가 런타임 보충 후 엔큐를 하는 동작이 필요 없으므로 함수를 빠져나간다.
- 코드 라인 33~34에서 런큐 클럭을 갱신한다.
- 코드 라인 50~53에서 태스크가 런큐에 없는 경우 런타임을 보충하고 deadline을 다시 설정한 후 unlock: 레이블로 이동 후 함수를 빠져나간다.
kernel/sched/deadline.c -2/2-
#ifdef CONFIG_SMP
if (unlikely(!rq->online)) {
/*
* If the runqueue is no longer available, migrate the
* task elsewhere. This necessarily changes rq.
*/
lockdep_unpin_lock(&rq->lock, rf.cookie);
rq = dl_task_offline_migration(rq, p);
rf.cookie = lockdep_pin_lock(&rq->lock);
update_rq_clock(rq);
/*
* Now that the task has been migrated to the new RQ and we
* have that locked, proceed as normal and enqueue the task
* there.
*/
}
#endif
enqueue_task_dl(rq, p, ENQUEUE_REPLENISH);
if (dl_task(rq->curr))
check_preempt_curr_dl(rq, p, 0);
else
resched_curr(rq);
#ifdef CONFIG_SMP
/*
* Queueing this task back might have overloaded rq, check if we need
* to kick someone away.
*/
if (has_pushable_dl_tasks(rq)) {
/*
* Nothing relies on rq->lock after this, so its safe to drop
* rq->lock.
*/
rq_unpin_lock(rq, &rf);
push_dl_task(rq);
rq_repin_lock(rq, &rf);
}
#endif
unlock:
task_rq_unlock(rq, p, &rf);
/*
* This can free the task_struct, including this hrtimer, do not touch
* anything related to that after this.
*/
put_task_struct(p);
return HRTIMER_NORESTART;
}
- 코드 라인 2~17에서 낮은 확률로 offline 상태의 런큐인 경우 현재 태스크를 급하게 적절한 마이그레이션 할 런큐를 찾아온다.
- 코드 라인 19에서 태스크를 dl 런큐에 추가한다.
- 코드 라인 20~24에서 엔큐된 dl 태스크의 deadline 값이 가장 빠른 경우 리스케줄 요청한다.
- 코드 라인 31~39에서 pushable 태스크가 있는 경우 해당 태스크를 적절한 cpu를 찾아 push 밸런싱을 수행한다.
- 코드 라인 42~51에서 unlock: 레이블이다. 런큐 락을 해제하고 함수를 빠져나간다.
태스크 선택
select_task_rq_dl()
kernel/sched/deadline.c
static int
select_task_rq_dl(struct task_struct *p, int cpu, int sd_flag, int flags)
{
struct task_struct *curr;
struct rq *rq;
if (sd_flag != SD_BALANCE_WAKE)
goto out;
rq = cpu_rq(cpu);
rcu_read_lock();
curr = READ_ONCE(rq->curr); /* unlocked access */
/*
* If we are dealing with a -deadline task, we must
* decide where to wake it up.
* If it has a later deadline and the current task
* on this rq can't move (provided the waking task
* can!) we prefer to send it somewhere else. On the
* other hand, if it has a shorter deadline, we
* try to make it stay here, it might be important.
*/
if (unlikely(dl_task(curr)) &&
(curr->nr_cpus_allowed < 2 ||
!dl_entity_preempt(&p->dl, &curr->dl)) &&
(p->nr_cpus_allowed > 1)) {
int target = find_later_rq(p);
if (target != -1 &&
(dl_time_before(p->dl.deadline,
cpu_rq(target)->dl.earliest_dl.curr) ||
(cpu_rq(target)->dl.dl_nr_running == 0)))
cpu = target;
}
rcu_read_unlock();
out:
return cpu;
}
wakeup 태스크에 적절한 cpu를 찾아 반환한다.
- 코드 라인 7~8에서 스케줄 도메인이 wakeup에 참여하지 않는 경우 요청한 cpu를 그대로 반환한다.
- 코드 라인 24~35에서 다음 조건을 모두 만족하는 경우 deadline이 가장 여유있는 적절한 cpu 또는 적절한 cpu를 찾아 반환한다.
- 낮은 확률로 현재 런큐에서 동작중인 태스크가 dl 태스크인 경우
- 허락된 cpu가 1개 이하이거나 요청 태스크의 deadline이 더 급해 preemption이 필요한 경우가 아닌 경우
- 요청한 태스크에 허락된 cpu가 2개 이상인 경우
Check Preempt
check_preempt_curr_dl()
kernel/sched/deadline.c
/* * Only called when both the current and waking task are -deadline * tasks. */
static void check_preempt_curr_dl(struct rq *rq, struct task_struct *p,
int flags)
{
if (dl_entity_preempt(&p->dl, &rq->curr->dl)) {
resched_curr(rq);
return;
}
#ifdef CONFIG_SMP
/*
* In the unlikely case current and p have the same deadline
* let us try to decide what's the best thing to do...
*/
if ((p->dl.deadline == rq->curr->dl.deadline) &&
!test_tsk_need_resched(rq->curr))
check_preempt_equal_dl(rq, p);
#endif /* CONFIG_SMP */
}
preemption 할지 여부를 체크하여 필요 시 리스케줄 요청 플래그를 설정한다.
- 코드 라인 4~7에서 요청한 dl 태스크의 deadline이 현재 런큐에서 동작중인 dl 태스크의 deadline 보다 만료 시간이 빨라 더 급한 경우 현재 태스크에 리스케줄 요청 플래그를 설정하고 함수를 빠져나간다.
- 코드 라인 14~16에서 요청한 dl 태스크의 deadline이 런큐에서 동작중인 dl 태스크의 deadline과 동일하고 런큐에서 동작 중인 태스크에 리스케줄 요청이 없었던 경우 cpudl의 deadline과 비교하여 best cpu가 있는 경우 리스케줄 요청 플래그를 설정한다.
dl_entity_preempt()
kernel/sched/sched.h
/* * Tells if entity @a should preempt entity @b. */
static inline bool
dl_entity_preempt(struct sched_dl_entity *a, struct sched_dl_entity *b)
{
return dl_entity_is_special(a) ||
dl_time_before(a->deadline, b->deadline);
}
a dl 엔티티의 deadline이 b dl 엔티티의 deadline보다 빨라 더 급한 경우 true(1)를 반환한다. 단 special 태스크의 경우 모든 dl 태스크보다 더 빨리 동작해야 하므로 항상 1을 반환한다.
- b를 preemption 시키고 a가 동작해야 하는 경우 true
check_preempt_equal_dl()
kernel/sched/deadline.c
static void check_preempt_equal_dl(struct rq *rq, struct task_struct *p)
{
/*
* Current can't be migrated, useless to reschedule,
* let's hope p can move out.
*/
if (rq->curr->nr_cpus_allowed == 1 ||
!cpudl_find(&rq->rd->cpudl, rq->curr, NULL))
return;
/*
* p is migratable, so let's not schedule it and
* see if it is pushed or pulled somewhere else.
*/
if (p->nr_cpus_allowed != 1 &&
cpudl_find(&rq->rd->cpudl, p, NULL))
return;
resched_curr(rq);
}
런큐에서 동작중인 태스크와 요청한 태스크가 동일 deadline을 가졌을 때 preemption 할지 여부를 체크하여 필요 시 리스케줄 요청 플래그를 설정한다.
- 코드 라인 7~9에서 요청한 런큐에서 동작중인 태스크에 할당된 cpu가 1개 뿐이거나 런큐에서 동작중인 태스크의 deadline 보다 빠른 cpudl에서 찾은 적절한 cpu가 없으면 함수를 빠져나간다.
- 코드 라인 15~17에서 요청한 태스크의 cpu가 2개 이상의 cpu가 할당되었으면서 요청한 태스크의 deadline보다 빠른 cpudl에서 찾은 best cpu가 없으면 함수를 빠져나간다.
- 코드 라인 19에서 요청한 런큐의 현재 태스크에 리스케줄 요청 플래그를 설정한다.
다음 태스크 픽업
다음 그림은 pick_next_task_dl() 함수의 흐름을 보여준다.
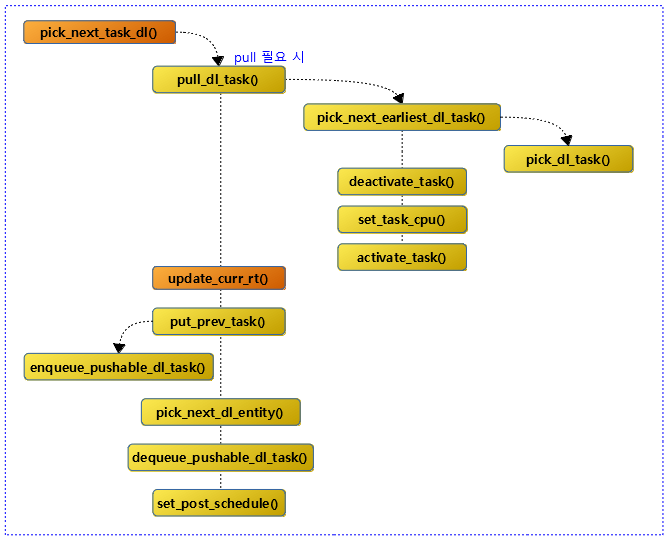
pick_next_task_dl()
kernel/sched/deadline.c
static struct task_struct *
pick_next_task_dl(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct sched_dl_entity *dl_se;
struct dl_rq *dl_rq = &rq->dl;
struct task_struct *p;
WARN_ON_ONCE(prev || rf);
if (!sched_dl_runnable(rq))
return NULL;
dl_se = pick_next_dl_entity(rq, dl_rq);
BUG_ON(!dl_se);
p = dl_task_of(dl_se);
set_next_task_dl(rq, p);
return p;
}
다음 실행해야할 dl 태스크를 알아온다.
- 코드 라인 10~11에서 동작 중인 dl 태스크가 없는 경우 null을 반환한다.
- 코드 라인 13~17에서 deadline이 가장 빠른 dl 태스크를 next 태스크로 지정하고 반환한다.
pick_next_dl_entity()
kernel/sched/deadline.c
static struct sched_dl_entity *pick_next_dl_entity(struct rq *rq,
struct dl_rq *dl_rq)
{
struct rb_node *left = dl_rq->rb_leftmost;
if (!left)
return NULL;
return rb_entry(left, struct sched_dl_entity, rb_node);
}
요청한 dl 런큐에서 가장 deadline이 빠른 dl 엔티티를 반환한다. 없으면 null을 반환한다.
다음 태스크 지정
set_next_task_dl()
kernel/sched/deadline.c
static void set_next_task_dl(struct rq *rq, struct task_struct *p)
{
p->se.exec_start = rq_clock_task(rq);
/* You can't push away the running task */
dequeue_pushable_dl_task(rq, p);
if (hrtick_enabled(rq))
start_hrtick_dl(rq, p);
if (rq->curr->sched_class != &dl_sched_class)
update_dl_rq_load_avg(rq_clock_pelt(rq), rq, 0);
deadline_queue_push_tasks(rq);
}
요청한 태스크를 다음에 동작시킬 태스크로 지정한다.
- 코드 라인 3에서 태스크의 시작 시각을 기록한다.
- 코드 라인 6에서 pushable 태스크 rb 트리에 존재할 지도 모르므로 디큐한다.
- 코드 라인 8~9에서 hrtick을 사용 중인 경우 해당 태스크의 남은 런타임 잔량에 맞춰 hrtick을 시작시킨다.
- 코드 라인 11~12에서 런큐에서 동작 중인 태스크가 dl 태스크가 아닌 경우 dl 런큐의 로드를 갱신한다.
- 코드 라인 14에서 push 마이그레이션을 할 수 있게 콜백을 지정해둔다.
- __sechdule() 함수의 마지막에 이 콜백이 수행된다.
구조체
sched_dl_entity 구조체
include/linux/sched.h
struct sched_dl_entity {
struct rb_node rb_node;
/*
* Original scheduling parameters. Copied here from sched_attr
* during sched_setattr(), they will remain the same until
* the next sched_setattr().
*/
u64 dl_runtime; /* Maximum runtime for each instance */
u64 dl_deadline; /* Relative deadline of each instance */
u64 dl_period; /* Separation of two instances (period) */
u64 dl_bw; /* dl_runtime / dl_period */
u64 dl_density; /* dl_runtime / dl_deadline */
/*
* Actual scheduling parameters. Initialized with the values above,
* they are continuously updated during task execution. Note that
* the remaining runtime could be < 0 in case we are in overrun.
*/
s64 runtime; /* Remaining runtime for this instance */
u64 deadline; /* Absolute deadline for this instance */
unsigned int flags; /* Specifying the scheduler behaviour */
/*
* Some bool flags:
*
* @dl_throttled tells if we exhausted the runtime. If so, the
* task has to wait for a replenishment to be performed at the
* next firing of dl_timer.
*
* @dl_boosted tells if we are boosted due to DI. If so we are
* outside bandwidth enforcement mechanism (but only until we
* exit the critical section);
*
* @dl_yielded tells if task gave up the CPU before consuming
* all its available runtime during the last job.
*
* @dl_non_contending tells if the task is inactive while still
* contributing to the active utilization. In other words, it
* indicates if the inactive timer has been armed and its handler
* has not been executed yet. This flag is useful to avoid race
* conditions between the inactive timer handler and the wakeup
* code.
*
* @dl_overrun tells if the task asked to be informed about runtime
* overruns.
*/
unsigned int dl_throttled : 1;
unsigned int dl_boosted : 1;
unsigned int dl_yielded : 1;
unsigned int dl_non_contending : 1;
unsigned int dl_overrun : 1;
/*
* Bandwidth enforcement timer. Each -deadline task has its
* own bandwidth to be enforced, thus we need one timer per task.
*/
struct hrtimer dl_timer;
/*
* Inactive timer, responsible for decreasing the active utilization
* at the "0-lag time". When a -deadline task blocks, it contributes
* to GRUB's active utilization until the "0-lag time", hence a
* timer is needed to decrease the active utilization at the correct
* time.
*/
struct hrtimer inactive_timer;
};
- rb_node
- dl 런큐의 RB 트리에 엔큐될때 사용하는 노드
- dl_runtime
- 할당된 런타임
- dl_deadline
- 할당된 deadline 기간
- dl_period
- 할당된 dl 태스크의 기간
- dl_bw
- dl_runtime / dl_deadline 비율
- dl_density
- dl_runtime / dl_deadline 비율
- runtime
- 런타임 잔량
- 실행된 시간 만큼 점점 줄어들고 0 이하일 때 런타임이 다 소비된 상태이다.
- deadline
- 스케줄된 deadline (절대 시각)
- flags
- 플래그들
- dl_throttled
- 현재 period 구간 내에서 런타임을 모두 소모한 후 스로틀된 경우를 나타낸다.
- dl_boosted
- 현재 period 구간 내에서 DI(deadline inversion or priority inversion)을 회피하기 위해 critical 섹션을 벗어나기 전까지 최상위 dl 태스크의 deadline을 상속받아 부스트되었는지 여부를 나타낸다.
- dl_yielded
- 현재 period 구간 내에서 남은 런타임을 모두 포기하고 cpu 시간을 양보(yield)한 태스크인지 여부를 나타낸다.
- 한 period를 보낸 후에는 런타임을 보충하고 이 플래그는 클리어된다.
- dl_non_contending
- inactive 타이머에 의해 inactive 상태 직전까지 유틸을 누적하는 상태를 나타낸다. (active non-contending)
- dl_overrun
- 런타임 이상으로 동작하는 경우 설정된다.
- dl_timer
- dl 태스크마다 사용하는 bandwidth 타이머로 deadline 시각에 맞춰 동작한다.
- inactive_timer
- dl 태스크가 슬립하면 곧바로 inactive 상태로 바꾸지 않고, active non-contending 상태로 변경하고 유틸을 누적하는 상태로 둔다. 그 후 타이머가 만료될 때 태스크를 inactive 상태로 변경한다.
dl_rq 구조체
kernel/sched/sched.h
/* Deadline class' related fields in a runqueue */
struct dl_rq {
/* runqueue is an rbtree, ordered by deadline */
struct rb_root_cached root;
unsigned long dl_nr_running;
#ifdef CONFIG_SMP
/*
* Deadline values of the currently executing and the
* earliest ready task on this rq. Caching these facilitates
* the decision whether or not a ready but not running task
* should migrate somewhere else.
*/
struct {
u64 curr;
u64 next;
} earliest_dl;
unsigned long dl_nr_migratory;
int overloaded;
/*
* Tasks on this rq that can be pushed away. They are kept in
* an rb-tree, ordered by tasks' deadlines, with caching
* of the leftmost (earliest deadline) element.
*/
struct rb_root_cached pushable_dl_tasks_root;
#else
struct dl_bw dl_bw;
#endif
/*
* "Active utilization" for this runqueue: increased when a
* task wakes up (becomes TASK_RUNNING) and decreased when a
* task blocks
*/
u64 running_bw;
/*
* Utilization of the tasks "assigned" to this runqueue (including
* the tasks that are in runqueue and the tasks that executed on this
* CPU and blocked). Increased when a task moves to this runqueue, and
* decreased when the task moves away (migrates, changes scheduling
* policy, or terminates).
* This is needed to compute the "inactive utilization" for the
* runqueue (inactive utilization = this_bw - running_bw).
*/
u64 this_bw;
u64 extra_bw;
/*
* Inverse of the fraction of CPU utilization that can be reclaimed
* by the GRUB algorithm.
*/
u64 bw_ratio;
};
- rb_root
- DL 런큐의 RB 트리로 dl 엔티티가 엔큐되어 등록된다.
- dl_nr_running
- dl 런큐이하 child 그룹 모두를 합친 dl 태스크의 수
- earliest_dl.curr
- dl 런큐에서 현재 동작 중인 deadline 값
- earliest_dl.next
- dl 런큐에서 대기중인 가장 첫 dl 엔티티의 deadline 값
- dl_nr_migratory
- dl 런큐에서 migration이 가능한 상태의 태스크 수
- overloaded
- dl 런큐가 오버로드되었는지 여부
- pushable_dl_tasks_root
- pushable 태스크들이 큐잉되는 RB 트리 루트
- *pushable_dl_tasks_leftmost
- pushable 태스크들이 큐잉되는 RB 트리 루트에서 가장 빠른 dl 태스크
- dl_bw
- UP 시스템에서만 사용하며 dl 태스크들이 최대 동작될 수 있는 비율이 정수형으로 등록된다.
dl_bandwidth 구조체
kernel/sched/sched.h
/* * To keep the bandwidth of -deadline tasks and groups under control * we need some place where: * - store the maximum -deadline bandwidth of the system (the group); * - cache the fraction of that bandwidth that is currently allocated. * * This is all done in the data structure below. It is similar to the * one used for RT-throttling (rt_bandwidth), with the main difference * that, since here we are only interested in admission control, we * do not decrease any runtime while the group "executes", neither we * need a timer to replenish it. * * With respect to SMP, the bandwidth is given on a per-CPU basis, * meaning that: * - dl_bw (< 100%) is the bandwidth of the system (group) on each CPU; * - dl_total_bw array contains, in the i-eth element, the currently * allocated bandwidth on the i-eth CPU. * Moreover, groups consume bandwidth on each CPU, while tasks only * consume bandwidth on the CPU they're running on. * Finally, dl_total_bw_cpu is used to cache the index of dl_total_bw * that will be shown the next time the proc or cgroup controls will * be red. It on its turn can be changed by writing on its own * control. */
struct dl_bandwidth {
raw_spinlock_t dl_runtime_lock;
u64 dl_runtime;
u64 dl_period;
};
- rt_runtime
- dl bandwidth의 런타임 (ns)
- dl_period
- dl bandwidth의 period (ns)
dl_bw 구조체
struct dl_bw {
raw_spinlock_t lock;
u64 bw, total_bw;
};
- bw
- deadline 스케줄러를 위해 사용하는 bandwidth 비율을 정수로 표현한 수
- SMP 시스템에서는 디폴트로 100%에 해당하는 정수 1M(1,048,576)가 설정된다.
- cpu가 1개 밖에 없는 UP 시스템에서는 디폴트로 95%에 해당하는 정수 996,147이 설정된다.
- 996,147 / 1M(1,048,576) = 95%
- deadline 스케줄러를 위해 사용하는 bandwidth 비율을 정수로 표현한 수
- total_bw
cpudl 구조체
kernel/sched/cpudeadline.h
struct cpudl {
raw_spinlock_t lock;
int size;
cpumask_var_t free_cpus;
struct cpudl_item *elements;
};
- size
- deadline이 설정된 cpu의 수 (초기 값은 0)
- free_cpus
- deadline이 설정되지 않은 cpu들이 설정된 비트마스크
- *elements
- cpudl 엘레멘트들로 cpudl_item 구조체 배열이다.
cpudl_item 구조체
kernel/sched/cpudeadline.h
struct cpudl_item {
u64 dl;
int cpu;
int idx;
};
- dl
- 현재 cpu에서 가장 빠른 deadline
- cpu
- cpu 번호
- idx
- 엘레멘트 어레이 중 현재 배열 인덱스 번호를 cpu 번호라고 가정하고 이에 해당하는 cpu가 위치한 엘레멘트의 인덱스 번호를 가리킨다.
- 예) elements[3].idx = 2 인 경우 3번 cpu는 elements[2] 위치에 존재한다.
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c – 현재 글
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- Deadline scheduling for Linux (2009) | LWN.net
- A new deadline scheduler patch (2010) | LWN.net
- Adding periods to SCHED_DEADLINE (2010) | LWN.net
- The IRMOS realtime scheduler (2010) | LWN.net
- KS2010: Deadline scheduling (2010) | LWN.net
- A deadline scheduler update (2017) | LWN.net
- Deadline scheduling part 1 — overview and theory (2018)| LWN.net
- Deadline scheduling part 2 — details and usage (2018)| LWN.net
- Deadline Task Scheduling | kernel.org
- Real Time System – Deadline Scheduling | Ted Baker, Florida State University
- Improvement of Scheduling Granularity for Deadline Scheduler | Toshiba – 다운로드 pdf
- Design and development of deadline based scheduling mechanisms for multiprocessor systems | Juri Lelli – 다운로드 pdf
- SCHED_DEADLINE (How to use it, 2014) – Juri Lelli, etis – 다운로드 pdf
- SCHED_DEADLINE (a status update, 2016) | Juri Lelli, ARM – 다운로드 pdf
- SCHED_DEADLINE (Ongoing development and new features, Linaro Connect 2017) – Juri Lelli, ARM – 다운로드 pdf
세세한 내용에 정말 감사드립니다.
Deadline Scheduler를 공부하다가 궁금한 점이 생겨 댓글을 남겨드립니다.
리눅스의 데드라인 태스크는 특성 상 CPU에서 수행되는 고정 런타임만 정의하는데,
어떻게 태스크의 내용과 런타임을 동기화를 시킬 수 있을까요?
안녕하세요?
태스크의 내용과 런타임 동기화라는 질문의 의도를 제가 정확히 파악을 할 수 없네요.
답변에서 도움되지 않으면 다시 설명해주시기 바랍니다.
dl 태스크는 두 가지 의도로 동작시킬 수 있습니다.
첫 번째는, 비디오 fram과 같이 규칙적으로 정해진 일을 수행한 후 스스로 슬립합니다. 그러면 커널이 정기적으로 wakeup 하여 dl 태스크를 동작시킵니다.
아래 예와 같이 프레임을 출력하고 그냥 슬립합니다. dl 태스크는 주기적으로 꺠어납니다.
while (1) {
disp_frame();
schedule();
};
두 번째는, 사용자가 의도적으로 슬립시키지 않고 동작을 시키지만 최대 런타임이 되면 커널이 스스로 슬립합니다. 그 후 주어진 시간이 지난 후 wakeup을 합니다.
아래 예와 같이 슬립없이 동작시킵니다. 슬립과 wakeup이 반복됩니다.
while (1) {
do_work();
};
감사합니다.
빠른 답변에 정말 감사드립니다!
달아주신 답변으로 해결되었습니다.
schedule() 함수 등을 통해 태스크를 슬립할 수 있음을 깨달았습니다.
정말 감사합니다.
정확합니다. ^^
좋은 하루 되시기 바랍니다.
안녕하세요. 꼼꼼히 살펴볼수록 놀라운 정리에 다시 한번 정말 감사드립니다.
그러나 이 부분은 아무리 생각을 하고 테스트를 해봐도 deadline 스케줄러의 구현에 대하여 납득이 안되는 부분이 있어 의견을 구하고 싶습니다.
“다음 그림은 dl 태스카가 깨어난 후 남은 런타임의 실행이 힘들다고 판단(overflow)한 경우 마감을 다시 설정하고, 런타임을 새롭게 지정한 모습을 보여준다.”는 부분입니다.
그렇다면 deadline의 의미가 없지 않은가 싶습니다. 물론 해당 스케줄러의 결과물은 soft real-time 이라는 글을 몇번 접해본 적은 있습니다. 하지만, deadline을 넘기면 실제로 치명적인 결과를 낳는 작업들에 대해서는 사용할 수 없지 않을까 싶습니다.
혹시 이 부분은 커널 개발자들 사이에서 아직까지 고려되지 않은 부분일까요?
아니면 이미 잘 구현되어 있는데 제가 못 찾고 있는건지 궁금합니다……
안녕하세요?
dl 태스크는 우선 순위가 가장 높습니다. 따라서 지정된 런타임을 모두 사용하지 못할 가능성은 거의 없습니다.
그런데 두 개 이상의 dl 태스크끼리 같은 cpu 내에서 경쟁해야 하는 과정에서, 두 dl 태스크의 deadline 및 런타임 설정을 매우 타이트하게 하면 두 태스크 중 하나의 deadline을 만족시킬 수 없는 경우가 있을 수 있습니다. 그러한 경우 overflow가 발생할 수도 있습니다.
감사합니다.
그럼 확률이 낮은데다가 overflow에 대한 명확한 대안이 없어서 이렇게 구현된거군요.
감사합니다!
네. 생각하시는 바가 맞습니다. 감사합니다.