<kernel v5.4>
CFS Bandwidth
태스크 그룹별로 shares 값을 설정하여 cfs 태스크의 스케줄 할당 비율을 조절할 수 있엇다. 여기서 또 다른 cfs 태스크의 스케줄 할당 비율을 조절할 수 있는 cfs bandwidth 방법을 소개한다.
태스크 그룹에 매 cfs_period_us 기간 마다 cfs_quota_us 기간 만큼 런타임을 할당하여 사용한다. 소진되어 런타임 잔량이 0이하가 되면 다음 period가 오기 전까지 남는 시간은 스로틀링 한다.
- cfs_period_us
- bandwidth 기간 (us)
- cfs_quota_us
- bandwidth 할당 쿼터 (us)
- 디폴트 값으로 -1(무제한)이 설정되어 있으며, 이 때에는 cfs bandwidth가 동작하지 않는다.
cfs 스로틀
해당 cfs 런큐가 스로틀 하는 경우 다음과 같이 동작한다.
- 다른 태스크 그룹에게 시간 할당을 양보한다.
- 예) root 그룹 아래에 A, B 두 태스크 그룹이 동작할 때 A 그룹에 cfs 밴드위드를 걸면 A 그룹이 스로틀 하는 동안 B 그룹이 동작한다.
- 양보할 다른 태스크 그룹도 없는 경우 idle 한다.
다음은 루트 태스크 그룹에 설정된 cfs_period_us와 cfs_quota_us 값을 보여준다. 디폴트로 cfs_quota_us 값이 -1이 설정되어 cfs bandwidth가 활성화되어 있지 않음을 알 수 있다.
$ cd /sys/fs/cgroup/cpu $ ls cgroup.clone_children cpu.cfs_period_us cpu.stat cpuacct.usage_percpu system.slice cgroup.procs cpu.cfs_quota_us cpuacct.stat notify_on_release tasks cgroup.sane_behavior cpu.shares cpuacct.usage release_agent user.slice $ cat cpu.cfs_period_us 100000 $ cat cpu.cfs_quota_us -1
다음 용어들이 빈번이 나오므로 먼저 요약한다.
- cfs runtime
- cfs 런큐에 태스크가 스케줄되어 동작한 시간
- quota 정수 비율 (normalize cfs quota)
- period 기간에 대한 quota 기간의 비율을 정수로 변환한 값이다.
- 100%=1M(1,048,576)이다.
- 예 1) period=10ms, quota=5ms인 경우 50%이며 이 비율을 quota 정수 비율로 표현하면 524,288이다.
- 예 2) period=10ms, quota=20ms인 경우 200%이며 이 비율을 quota 정수 비율로 표현하면 2,097,152이다.
bandwith 적용 사례
bandwidth가 적용된 사례 3개를 확인해보자.
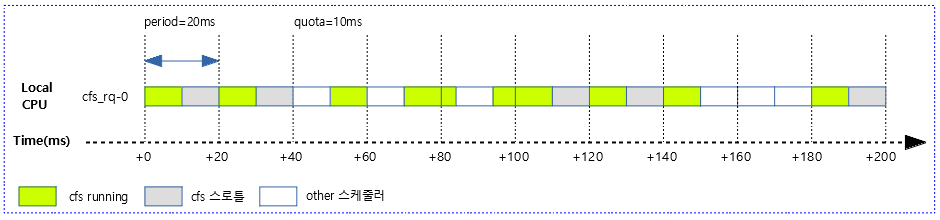
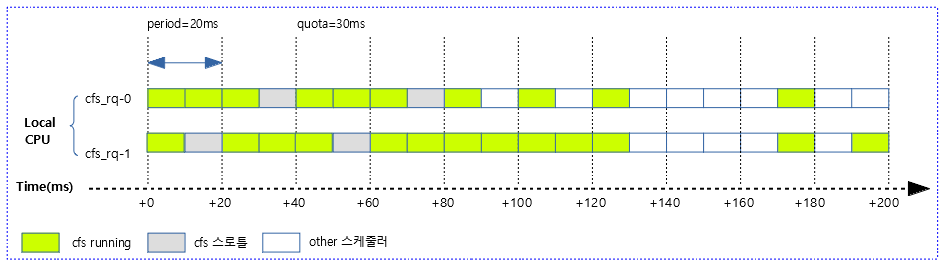
사례 1) 다음 그림은 20ms 주기마다 10ms quota 만큼 cfs 스케줄되는 모습을 보여준다. 남는 시간은 스로틀링 한다.
- 일반적으로는 첫 번째 구간의 반복이다. 하지만 그림에서는 매 구간 마다 발생할 수 있는 케이스를 최대한 담았다.
- 범례 설명
- cfs running
- 해당 태스크 그룹에 소속된 cfs 태스크들이 사용한 런타임 구간이다.
- cfs 스로틀
- 해당 태스크 그룹이 dequeue되어 cfs 스로틀하면 다른 태스크 그룹의 cfs 태스크들이 이 구간에서 동작할 수 있다.
- 동작할 cfs 태스크가 하나도 없는 경우 idle 한다.
- other 스케줄러
- cfs 보다 우선 순위가 높은 stop, dl 및 rt 태스크들이 동작하는 구간이다.
- cfs running

다음 그림은 위의 사례 1)에서 발생할 수 있는 다양한 케이스를 보여준다.
- 1 번째 period 구간은 해당 그룹이 먼저 동작하고 주어진 quota 만큼의 런타임을 다 소진하고 스로틀링 하여 다른 태스크들에게 스케줄링을 넘겼다.
- 2 번째 period 구간이 되면서 다시 quota 만큼 런타임을 재충전(refill) 받아 다시 모두 사용하고 또 스로틀링하였다.
- 3 번째 period 구간에서 other(stop, rt, dl) 스케줄러가 먼저 할당되어 동작하고 끝나면서 해당 그룹의 cfs 태스크가 수행됨을 알 수 있다.
- 9 번째 period 구간에서 other(stop, rt, dl) 스케줄러가 먼저 할당되어 동작하면서 cfs 태스크가 동작할 수 있는 시간이 없었음을 알 수 있다.
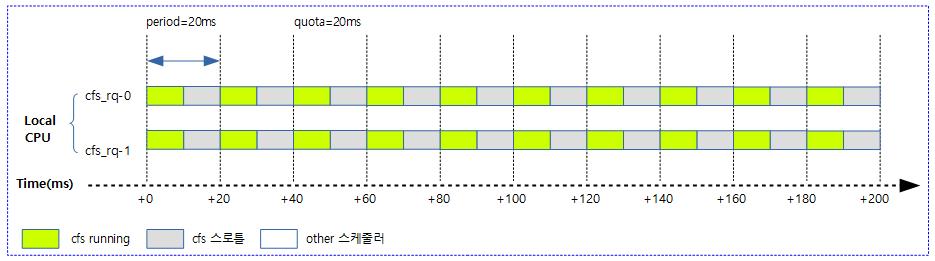
사례 2) 다음 그림은 20ms 주기마다 2개의 cpu에 총 20ms quota 만큼 cfs 스케줄한다.
- period와 quota가 같은 경우 2개의 cpu가 주어지면 일반적으로 매 period 마다 2 개의 cpu가 번갈아 가면서 런타임이 소진된다.
- cpu가 두 개라 period와 quota 기간이 같아도 절반의 여유가 있음을 확인할 수 있다.
- 가능하면 스로틀링한 cpu에 런타임을 우선 할당하여 스로틀링이 교대로 됨을 알 수 있다.
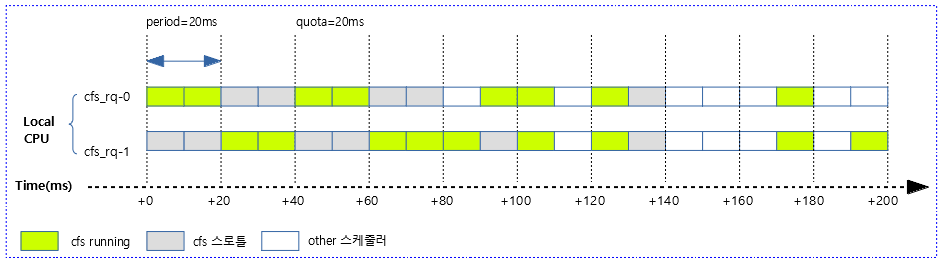
다음 그림은 위의 사례 2)에서 발생할 수 있는 다양한 케이스를 보여준다.
- 8 번째 period 구간에서 other(stop, rt, dl) 스케줄러가 먼저 할당되어 동작하면서 cfs 태스크가 동작할 수 있는 시간이 없었음을 알 수 있다.
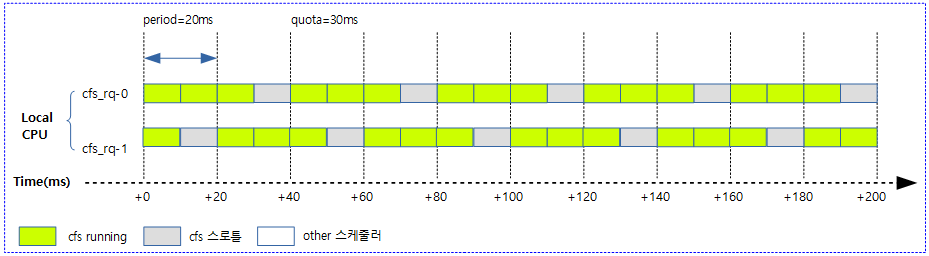
사례 3) 다음 그림은 20ms 주기마다 2개의 cpu에 총 30ms quota 만큼 cfs 스케줄한다.
- 해당 태스크 그룹은 최대 75%의 cfs 런타임 할당을 받는 것을 확인할 수 있다.
다음 그림은 위의 사례 3)에서 발생할 수 있는 다양한 케이스를 보여준다.
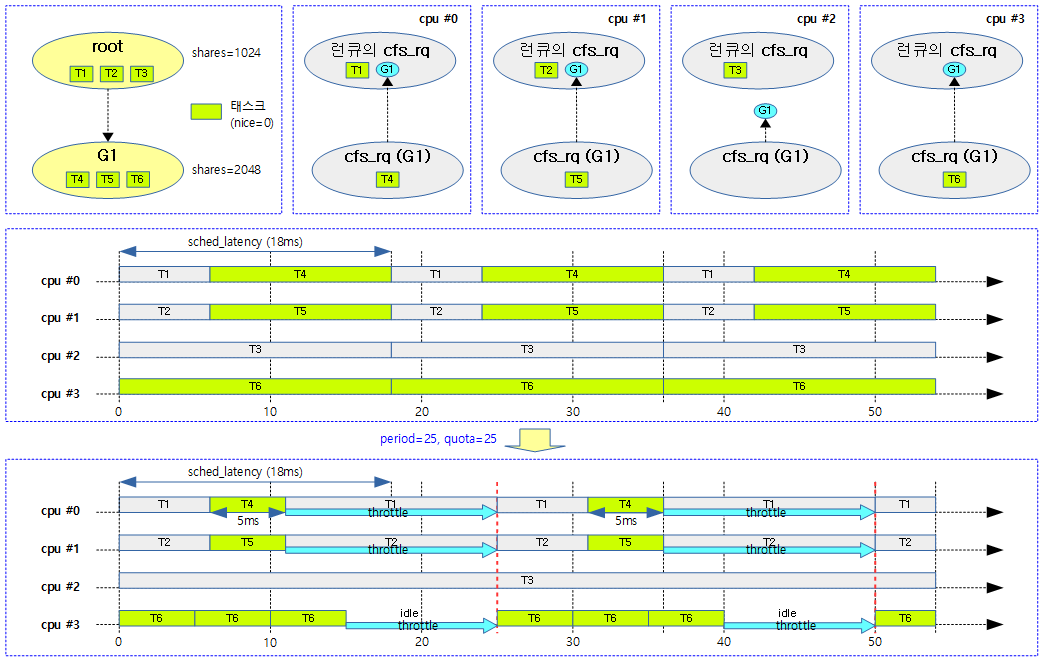
다음 그림은 cfs 밴드 위드를 설정하지 않았을 때와 두 개 그룹 중 G1 태스크 그룹에 period=25, quota=25의 밴드위드를 설정하여 동작시켰을 때의 차이를 비교하였다.
- g1 그룹에 소속된 태스크들이 스로틀링되는 시간을 알아볼 수 있다.
주요 전역 변수 값
- sysctl_sched_cfs_bandwidth_slice
- 디폴트 값은 5000 (us) = 5 (ms)
- “/sys/fs/kernel/sched_cfs_bandwidth_slice_us” 파일로 설정
- 로컬 풀의 요구에 따라 글로벌 풀(tg)로부터 로컬(per cfs_rq) 풀로 런타임을 얻어와서 할당해주는 기간
- min_cfs_rq_runtime
- 디폴트 값은 1,000,000 (ns) = 1 (ms)
- 로컬 풀에서 최소 할당 받을 런타임
- min_bandwidth_expiration
- 디폴트 값은 2,000,000 (ns) = 2 (ms)
- 최소 남은 period 만료 시각으로 이 기간 내에서는 slack 타이머를 활성화시키지 않는다.
- cfs_bandwidth_slack_period
- 디폴트 값은 5,000,000 (ns) = 5 (ms)
- slack 타이머 주기
CFS Runtime
그룹내에서 CFS bandwidth를 사용 시 스로틀링을 위해 남은 quota(runtime) 산출에 사용했던 CFS runtime의 구현 방법들은 다음과 같이 진화하였다.
- 1) cfs hard limits: cfs bandwidth 적용 초기에 구현된 방법
- 2) hybrid global pool: 현재 커널에서 구현된 방법으로 cfs bandwidth v4에서 소개되었다.
Hybrid global pool
global runtime으로만 구현하게 되면 cpu가 많이 있는 시스템에서 각 cpu마다 동작하는 cfs 런큐간의 lock contension에 대한 부담이 매우커지는 약점이 있다. 또한 local cpu runtime으로만 구현하더라도 cfs 런큐 간에 남은 quota들을 확인하는 복잡한 relation이 발생하므로 소규모 smp 시스템에서만 적절하다고 볼 수 있다. 따라서 최근에는 성능을 위해 로컬 및 글로벌 두 개 모두를 구현한 하이브리드 버전이 사용되고 있다.
- global runtime pool
- 글로벌 런타임 풀은 태스크 그룹별로 생성된다.
- cfs bandwidth에서 글로벌 풀로 불리우기도 하며 cfs_bandwidth 구조체에 관련 멤버들을 갖는다.
- 추적이 발생하는 곳이며 period 타이머에 의해 매 period 마다 quota 만큼 런타임을 리필(리프레쉬) 한다.
- local cpu runtime
- 로컬 cpu 런타임은 태스크 그룹의 각 cpu 마다 존재한다.
- cfs bandwidth에서 로컬 풀로 불리우기도 하며 cfs_rq 구조체에 cfs bandwidth 관련 멤버들을 갖는다.
- 로컬 런타임에서 소비가 이루어지며 각각의 local cpu에 있는 cfs 런큐에서 발생하고 성능을 위해 lock을 사용하지 않는 장점이 있다.
- period 만료 시각에 로컬 런타임이 모두 소비된 경우 이전 period 기간에 스로틀한 로컬 풀 위주로 할당을 한다. 할당 할 수 없는 상황에서는 스로틀 한다.
- 로컬 런타임이 모두 소비된 경우 글로벌 런타임 풀에서 적정량(slice) 만큼을 빌려올 수 있다.
로컬 런타임의 보충은 다음과 같은 사례에서 발생한다. 자세한 것은 각 함수들에서 알아본다.
- Case A) period 타이머 만료 시 스로틀된 로컬들에 대해 런타임 부족분 우선 분배
- sched_cfs_period_timer() -> distribute_cfs_runtime()
- Case B) 매 tick 마다 빈 로컬 런타임 분배
- update_curr() -> account_cfs_rq_runtime() -> assign_cfs_rq_runtime()
- Case C) 스케줄 엔티티 디큐 시 로컬 런타임 잔량을 글로벌 런큐로 반납. 조건에 따라 slack 타이머 가동시켜 스로틀된 로컬들에 대해 런타임 부족분 우선 분배
- dequeue_entity() -> return_cfs_rq_runtime()
CFS Bandwidth 초기화
init_cfs_bandwidth()
kernel/sched/fair.c
void init_cfs_bandwidth(struct cfs_bandwidth *cfs_b)
{
raw_spin_lock_init(&cfs_b->lock);
cfs_b->runtime = 0;
cfs_b->quota = RUNTIME_INF;
cfs_b->period = ns_to_ktime(default_cfs_period());
INIT_LIST_HEAD(&cfs_b->throttled_cfs_rq);
hrtimer_init(&cfs_b->period_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
cfs_b->period_timer.function = sched_cfs_period_timer;
hrtimer_init(&cfs_b->slack_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
cfs_b->slack_timer.function = sched_cfs_slack_timer;
cfs_b->distribute_running = 0;
cfs_b->slack_started = false;
}
cfs bandwidth를 초기화한다.
- 코드 라인 4~6에서 글로벌 runtime을 0으로, quota 값은 무한대 값인 RUNTIME_INF(0xffffffff_ffffffff = -1)로, 그리고 period 값은 디폴트 cfs period 값(100,000,000ns=0.1s)를 period에 저장한다.
- 코드 라인 8에서 스로틀드 리스트를 초기화한다.
- 코드 라인 9~10에서 period hrtimer를 초기화하고 만료 시 호출되는 함수를 지정한다.
- 코드 라인 11~12에서 slack hrtimer를 초기화하고 만료 시 호출되는 함수를 지정한다.
- 코드 라인 13~14에서 글로벌 런타임을 스로틀 cpu들에 분배 중이라는 의미의 distribute_running을 0으로 초기화하고, slack 타이머가 진행 중이라는 의미의 slack_started를 false로 초기화한다.
CFS 밴드위드 설정
CFS quota 설정
tg_set_cfs_quota()
kernel/sched/core.c
int tg_set_cfs_quota(struct task_group *tg, long cfs_quota_us)
{
u64 quota, period;
period = ktime_to_ns(tg->cfs_bandwidth.period);
if (cfs_quota_us < 0)
quota = RUNTIME_INF;
else if ((u64)cfs_quota_us <= U64_MAX / NSEC_PER_USEC)
quota = (u64)cfs_quota_us * NSEC_PER_USEC;
else
return -EINVAL;
return tg_set_cfs_bandwidth(tg, period, quota);
}
요청한 태스크 그룹에 cfs quota 값(us)을 나노초로 변경하여 설정하되 가능한 범위는 1ms ~ 1s 이다.
- 코드 라인 5에서 cfs bandwidth에 설정되어 있는 period 값을 나노초 단위로 변환해온다.
- 코드 라인 6~11에서 인수로 받은 us 단위의 quota 값이 0보다 작은 경우 스로틀링 하지 않도록 무제한으로 설정하고, 0보다 큰 경우 quota 값을 나노초 단위로 바꾼다.
- 코드 라인 13에서 요청한 태스크 그룹에 period(ns) 및 quota(ns) 값을 설정한다.
CFS period 설정
tg_get_cfs_period()
kernel/sched/core.c
int tg_set_cfs_period(struct task_group *tg, long cfs_period_us)
{
u64 quota, period;
if ((u64)cfs_period_us > U64_MAX / NSEC_PER_USEC)
return -EINVAL;
period = (u64)cfs_period_us * NSEC_PER_USEC;
quota = tg->cfs_bandwidth.quota;
return tg_set_cfs_bandwidth(tg, period, quota);
}
요청한 태스크 그룹에 cfs period 값(us)을 나노초로 변경하여 설정하되 최소 1ms 부터 설정 가능하다.
- 코드 라인 5~6에서 64비트 나노초로 담을 수 없는 큰 숫자가 주어지면 에러를 반환한다.
- 코드 라인 8에서 인수로 받은 us 단위의 period 값을 나노초 단위로 변환한다.
- 코드 라인 9에서 cfs bandwidth에 설정되어 있는 quota(ns) 값을 알아온다.
- 코드 라인 11에서 요청한 태스크 그룹에 period(ns) 및 quota(ns) 값을 설정한다.
CFS quota 및 period 공통 설정
최대 및 최소 cfs quota 제한
kernel/sched/core.c
const u64 max_cfs_quota_period = 1 * NSEC_PER_SEC; /* 1s */ const u64 min_cfs_quota_period = 1 * NSEC_PER_MSEC; /* 1ms */
cfs period의 설정은 1ms ~ 1s 범위에서 가능하게 제한된다. cfs quota 값은 1ms 이상 가능하다.
tg_set_cfs_bandwidth()
kernel/sched/core.c -1/2-
static int tg_set_cfs_bandwidth(struct task_group *tg, u64 period, u64 quota)
{
int i, ret = 0, runtime_enabled, runtime_was_enabled;
struct cfs_bandwidth *cfs_b = &tg->cfs_bandwidth;
if (tg == &root_task_group)
return -EINVAL;
/*
* Ensure we have at some amount of bandwidth every period. This is
* to prevent reaching a state of large arrears when throttled via
* entity_tick() resulting in prolonged exit starvation.
*/
if (quota < min_cfs_quota_period || period < min_cfs_quota_period)
return -EINVAL;
/*
* Likewise, bound things on the otherside by preventing insane quota
* periods. This also allows us to normalize in computing quota
* feasibility.
*/
if (period > max_cfs_quota_period)
return -EINVAL;
/*
* Prevent race between setting of cfs_rq->runtime_enabled and
* unthrottle_offline_cfs_rqs().
*/
get_online_cpus();
mutex_lock(&cfs_constraints_mutex);
ret = __cfs_schedulable(tg, period, quota);
if (ret)
goto out_unlock;
요청한 태스크 그룹의 bandwidth 기능 유무를 설정한다. 처리되는 항목은 다음과 같다.
- 요청 태스크 그룹에 period(ns) 값이 1ms 이상인 경우에 한하여 설정
- 요청 태스크 그룹에 quota(ns) 값이 1ms ~ 1s 범위내인 경우에 한하여 설정
- 전체 태스크 그룹의 quota 정수 비율을 재설정
- quota 설정에 따라 cfs 밴드폭 기능을 활성화, 비활성화 또는 기존 상태 유지
- 코드 라인 6~7에서 요청한 태스크 그룹이 루트 태스크 그룹인 경우 period 및 quota 밴드폭 설정을 할 수 없어 -EINVAL 에러를 반환한다.
- 코드 라인 14~15에서 요청한 ns 단위의 quota 및 period 값이 최소 값(1ms) 미만인 경우 -EINVAL 에러를 반환한다.
- 코드 라인 22~23에서요청한 ns 단위의 period 값이 최대 값(1s)을 초과하는 경우 -EINVAL 에러를 반환한다.
- 코드 라인 31~33에서 최상위 루트 태스크부터 전체 태스크 그룹을 순회하는 동안 위에서 아래로 내려가는 순서로 각 태스크 그룹의 quota 정수 비율을 설정한다.
kernel/sched/core.c -2/2-
runtime_enabled = quota != RUNTIME_INF;
runtime_was_enabled = cfs_b->quota != RUNTIME_INF;
/*
* If we need to toggle cfs_bandwidth_used, off->on must occur
* before making related changes, and on->off must occur afterwards
*/
if (runtime_enabled && !runtime_was_enabled)
cfs_bandwidth_usage_inc();
raw_spin_lock_irq(&cfs_b->lock);
cfs_b->period = ns_to_ktime(period);
cfs_b->quota = quota;
__refill_cfs_bandwidth_runtime(cfs_b);
/* restart the period timer (if active) to handle new period expiry */
if (runtime_enabled)
start_cfs_bandwidth(cfs_b, true);
raw_spin_unlock_irq(&cfs_b->lock);
for_each_online_cpu(i) {
struct cfs_rq *cfs_rq = tg->cfs_rq[i];
struct rq *rq = cfs_rq->rq;
struct rq_flags rf;
rq_lock_irq(rq, &rf);
cfs_rq->runtime_enabled = runtime_enabled;
cfs_rq->runtime_remaining = 0;
if (cfs_rq->throttled)
unthrottle_cfs_rq(cfs_rq);
rq_unlock_irq(rq, &rf);
}
if (runtime_was_enabled && !runtime_enabled)
cfs_bandwidth_usage_dec();
out_unlock:
mutex_unlock(&cfs_constraints_mutex);
put_online_cpus();
return ret;
}
- 코드 라인 1에서 quota 값이 무제한 설정이 아니면 runtime_enable에 true가 대입된다.
- 코드 라인 2에서 기존 quota 값이 무제한 설정이 아니면 runtime_was_enable에 true가 대입된다.
- 코드 라인 7~8에서 quota가 무제한이었다가 설정된 경우 cfs bandwidth 기능을 enable 한다.
- 코드 라인 10~11에서 cfs bandwidth period와 quota에 요청한 값을 저장한다. (ns 단위)
- 코드 라인 13에서 cfs 밴드폭을 리필(리프레쉬)한다.
- 코드 라인 16~17에서 cfs bandwidth 기능이 enable 되었고 cfs bandwidth 타이머도 enable된 경우 cfs bandwidth 기능을 시작하기 위해 cfs 밴드폭 타이머를 가동한다.
- 코드 라인 21~33에서 cpu 수만큼 루프를 돌며 cfs 런큐에 runtime_enabled를 설정하고 runtime_remaining에 0을 대입하여 초기화한다. cfs 런큐가 이미 스로틀된 경우 언스로틀 한다.
- 코드 라인 34~35에서 quota가 설정되었다가 무제한으로 된 경우 cfs bandwidth 기능을 disable한다.
- 코드 라인 36~40에서 out_unlock: 레이블이다. 뮤텍스를 언락하고, online cpu 시퀀스 락을 해제한 후 ret 값을 반환한다.
__cfs_schedulable()
kernel/sched/core.c
static int __cfs_schedulable(struct task_group *tg, u64 period, u64 quota)
{
int ret;
struct cfs_schedulable_data data = {
.tg = tg,
.period = period,
.quota = quota,
};
if (quota != RUNTIME_INF) {
do_div(data.period, NSEC_PER_USEC);
do_div(data.quota, NSEC_PER_USEC);
}
rcu_read_lock();
ret = walk_tg_tree(tg_cfs_schedulable_down, tg_nop, &data);
rcu_read_unlock();
return ret;
}
최상위 루트 태스크부터 전체 태스크 그룹을 순회하는 동안 위에서 아래로 내려가는 순서로 quota 정수 비율을 설정한다. 성공하면 0을 반환한다.
- 코드 라인 4~8에서 cfs 스케줄 데이터 구조체에 태스크 그룹과 ns 단위의 period와 quota 값을 대입한다.
- 코드 라인 10~13에서 period와 quota 값을 us 단위로 변환한다.
- 코드 라인 15~17에서 최상위 루트 태스크부터 전체 태스크 그룹을 순회하는 동안 위에서 아래로 내려가는 순서로 quota 정수 비율을 설정한다.
태스크 그룹 트리 워크 다운을 통한 quota 정수 비율 설정
tg_cfs_schedulable_down()
kernel/sched/core.c
static int tg_cfs_schedulable_down(struct task_group *tg, void *data)
{
struct cfs_schedulable_data *d = data;
struct cfs_bandwidth *cfs_b = &tg->cfs_bandwidth;
s64 quota = 0, parent_quota = -1;
if (!tg->parent) {
quota = RUNTIME_INF;
} else {
struct cfs_bandwidth *parent_b = &tg->parent->cfs_bandwidth;
quota = normalize_cfs_quota(tg, d);
parent_quota = parent_b->hierarchical_quota;
/*
* ensure max(child_quota) <= parent_quota, inherit when no
* limit is set
*/
if (cgroup_subsys_on_dfl(cpu_cgrp_subsys)) {
quota = min(quota, parent_quota);
} else {
if (quota == RUNTIME_INF)
quota = parent_quota;
else if (parent_quota != RUNTIME_INF && quota > parent_quota)
return -EINVAL;
}
}
cfs_b->hierarchical_quota = quota;
return 0;
}
요청한 태스크 그룹에서 period에 대한 quota 정수 비율을 설정한다. 에러가 없으면 0을 반환한다.
- 코드 라인 3에서 인수 data에서 us 단위의 period 및 quota가 담긴 구조체 포인터를 가져온다.
- 코드 라인 7~8에서 부모가 없는 최상위 태스크 그룹인 경우 스로틀링 하지 않도록 quota에 무제한을 설정한다.
- 코드 라인 12에서 period에 대한 quota 정수 비율을 산출한다. (예: 정수 1M=100%, 256K=25%)
- 코드 라인 13에서 부모 quota 정수 비율을 알아온다.
- 코드 라인 19~20에서 cgroupv2의 경우 quota 값과 부모의 quota 값 중 작은 값을 사용한다.
- 코드 라인 21~23에서 산출된 quota 정수 비율이 무제한인 경우 부모 quota 값을 사용한다.
- 코드 라인 24~25에서 부모 quota 비율이 무제한이 아니고 산출된 quota 비율이 부모 quota 비율보다 큰 경우 -EINVAL 에러를 반환한다.
- 코드 라인 28~30에서 요청한 태스크 그룹의 quota 비율을 설정하고 성공(0)을 반환한다.
- 계층적으로 관리되는 태스크 그룹의 quota 정수 비율은 hierarchical_quota에 저장한다.
CFS quota 정수 비율 산출
normalize_cfs_quota()
kernel/sched/core.c
/* * normalize group quota/period to be quota/max_period * note: units are usecs */
static u64 normalize_cfs_quota(struct task_group *tg,
struct cfs_schedulable_data *d)
{
u64 quota, period;
if (tg == d->tg) {
period = d->period;
quota = d->quota;
} else {
period = tg_get_cfs_period(tg);
quota = tg_get_cfs_quota(tg);
}
/* note: these should typically be equivalent */
if (quota == RUNTIME_INF || quota == -1)
return RUNTIME_INF;
return to_ratio(period, quota);
}
period에 대한 quota 비율을 정수로 반환한다. (예: 정수 1M=100%, 256K=25%)
- 코드 라인 6~8에서 요청한 태스크 그룹과 스케줄 데이터의 태스크 그룹이 동일한 경우 us 단위인 스케줄 데이터의 period와 quota 값을 사용한다.
- 코드 라인 9~12에서 동일하지 않은 경우 태스크 그룹의 period 값과 quota 값을 us 단위로 변환하여 가져온다.
- 코드 라인 15~16에서 quota가 무제한 설정된 경우 무제한(0xffffffff_ffffffff) 값을 반환한다.
- 코드 라인 18에서 quota * 1M(1 << 20) / period 값을 반환한다.
tg_get_cfs_quota()
kernel/sched/core.c
long tg_get_cfs_quota(struct task_group *tg)
{
u64 quota_us;
if (tg->cfs_bandwidth.quota == RUNTIME_INF)
return -1;
quota_us = tg->cfs_bandwidth.quota;
do_div(quota_us, NSEC_PER_USEC);
return quota_us;
}
태스크 그룹의 cfs quota를 us 단위로 반환한다. 무제한 설정된 경우 -1을 반환한다.
tg_get_cfs_period()
kernel/sched/core.c
long tg_get_cfs_period(struct task_group *tg)
{
u64 cfs_period_us;
cfs_period_us = ktime_to_ns(tg->cfs_bandwidth.period);
do_div(cfs_period_us, NSEC_PER_USEC);
return cfs_period_us;
}
태스크 그룹의 cfs period를 us 단위로 반환한다.
태스크 그룹 트리 Walk
walk_tg_tree()
kernel/sched/sched.h
/* * Iterate the full tree, calling @down when first entering a node and @up when * leaving it for the final time. * * Caller must hold rcu_lock or sufficient equivalent. */
static inline int walk_tg_tree(tg_visitor down, tg_visitor up, void *data)
{
return walk_tg_tree_from(&root_task_group, down, up, data);
}
태스크 그룹 트리에서 최상위 루트 태스크부터 전체 태스크 그룹을 순회하는 동안 아래로 내려가면 down 함수를 호출하고 위로 올라가면 up 함수를 호출한다. 호출한 함수가 중간에 에러가 발생하면 그 값을 반환하고 처리를 중단한다.
다음 그림은 __cfs_schedulabel() 함수를 호출할 때 각 태스크 그룹을 아래로 내려갈 때마다 tg_cfs_schedulable_down()을 호출하는 모습을 보여준다.
- 호출 순서는 번호 순이며 하향에 대한 호출 순서만 나열하면 1-D -> 2-D -> 4-D -> 5-D -> 7-D -> 10-D 순서이다.
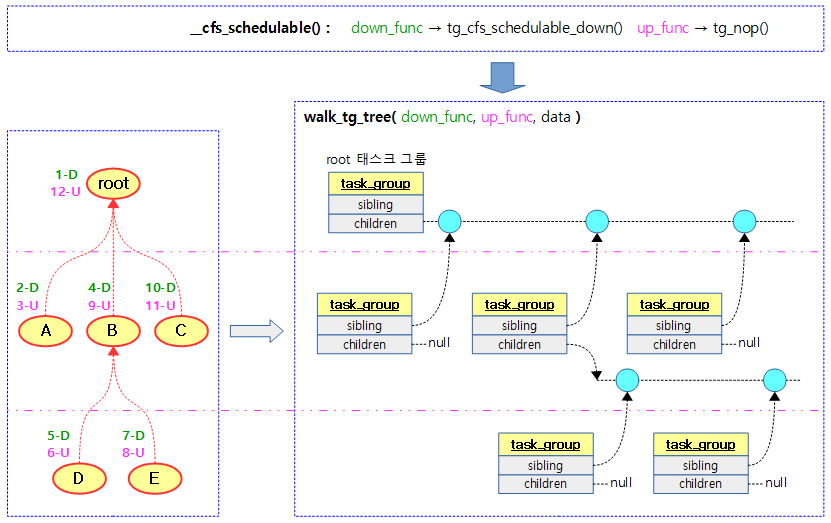
walk_tg_tree_from()
kernel/sched/core.c
/* * Iterate task_group tree rooted at *from, calling @down when first entering a * node and @up when leaving it for the final time. * * Caller must hold rcu_lock or sufficient equivalent. */
int walk_tg_tree_from(struct task_group *from,
tg_visitor down, tg_visitor up, void *data)
{
struct task_group *parent, *child;
int ret;
parent = from;
down:
ret = (*down)(parent, data);
if (ret)
goto out;
list_for_each_entry_rcu(child, &parent->children, siblings) {
parent = child;
goto down;
up:
continue;
}
ret = (*up)(parent, data);
if (ret || parent == from)
goto out;
child = parent;
parent = parent->parent;
if (parent)
goto up;
out:
return ret;
}
태스크 그룹 트리에서 요청한 태스크 그룹 이하의 태스크 그룹을 순회하는 동안 아래로 내려가면 down 함수를 호출하고 위로 올라가면 up 함수를 호출한다. 호출한 함수가 중간에 에러가 발생하면 그 값을 반환하고 처리를 중단한다. 에러가 없으면 0을 반환한다.
- 코드 라인 16~18에서 상위 태스크 그룹부터 인수로 받은 down() 함수를 호출한다.
- throttle_cfs_rq() -> tg_throttle_down() 함수를 호출한다.
- unthrottle_cfs_rq() -> tg_nop() 함수를 호출하여 아무 것도 수행하지 않는다.
- 코드 라인 19에서 parent의 자식들에 대해 좌에서 우로 루프를 돈다. 자식이 없으면 루프를 벗어난다.
- 코드 라인 20~21에서 선택된 자식으로 down 레이블로 이동한다.
- 코드 라인 23~25에서 다시 자식들에 대해 계속 처리한다.
- 코드 라인 26~28에서 하위 태스크 그룹부터 인수로 받은 up() 함수를 호출한다.
- throttle_cfs_rq() -> tg_nop() 함수를 호출하여 아무 것도 수행하지 않는다.
- unthrottle_cfs_rq() -> tg_unthrottle_up() 함수를 호출한다.
- 코드 라인 30~33에서 parent의 부모를 선택하고 부모가 있으면 up 레이블로 이동한다.
다음 그림은 walk_tg_tree_from() 함수가 1번 down 함수 호출부터 12번 up 함수 호출하는 것 까지 트리를 순회하는 모습을 보여준다.

CFS Throttling
스로틀 필요 체크
check_enqueue_throttle()
kernel/sched/fair.c
/* * When a group wakes up we want to make sure that its quota is not already * expired/exceeded, otherwise it may be allowed to steal additional ticks of * runtime as update_curr() throttling can not not trigger until it's on-rq. */
static void check_enqueue_throttle(struct cfs_rq *cfs_rq)
{
if (!cfs_bandwidth_used())
return;
/* an active group must be handled by the update_curr()->put() path */
if (!cfs_rq->runtime_enabled || cfs_rq->curr)
return;
/* ensure the group is not already throttled */
if (cfs_rq_throttled(cfs_rq))
return;
/* update runtime allocation */
account_cfs_rq_runtime(cfs_rq, 0);
if (cfs_rq->runtime_remaining <= 0)
throttle_cfs_rq(cfs_rq);
}
현재 그룹의 cfs 런큐에서 quota 만큼의 실행이 끝나고 남은 런타임이 없으면 스로틀한다.
- 코드 라인 3~4에서 cfs bandwidth 구성이 사용되지 않으면 함수를 빠져나간다.
- 코드 라인 7~8에서 무제한 quota 설정이거나 cfs 런큐에서 동작 중인 태스크가 있으면 함수를 빠져나간다.
- 코드 라인 11~12에서 cfs 런큐가 이미 스로틀된 경우 함수를 빠져나간다.
- 코드 라인 15~17에서 cfs 런큐의 런타임을 산출하고 런타임이 남아 있지 않는 경우 스로틀한다.
다음 그림은 check_enqueue_throttle() 함수 이하의 호출 관계를 보여준다.
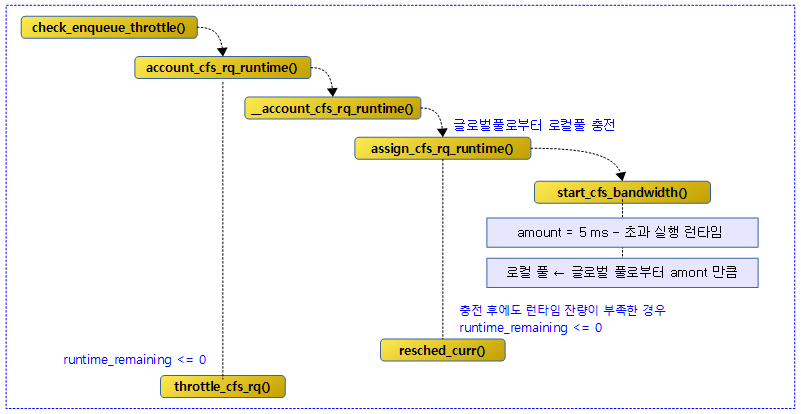
cfs 런큐 스로틀
throttle_cfs_rq()
kernel/sched/fair.c
static void throttle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
long task_delta, dequeue = 1;
se = cfs_rq->tg->se[cpu_of(rq_of(cfs_rq))];
/* freeze hierarchy runnable averages while throttled */
rcu_read_lock();
walk_tg_tree_from(cfs_rq->tg, tg_throttle_down, tg_nop, (void *)rq);
rcu_read_unlock();
task_delta = cfs_rq->h_nr_running;
for_each_sched_entity(se) {
struct cfs_rq *qcfs_rq = cfs_rq_of(se);
/* throttled entity or throttle-on-deactivate */
if (!se->on_rq)
break;
if (dequeue)
dequeue_entity(qcfs_rq, se, DEQUEUE_SLEEP);
qcfs_rq->h_nr_running -= task_delta;
if (qcfs_rq->load.weight)
dequeue = 0;
}
if (!se)
sub_nr_running(rq, task_delta);
cfs_rq->throttled = 1;
cfs_rq->throttled_clock = rq_clock(rq);
raw_spin_lock(&cfs_b->lock);
/*
* Add to the _head_ of the list, so that an already-started
* distribute_cfs_runtime will not see us
*/
list_add_rcu(&cfs_rq->throttled_list, &cfs_b->throttled_cfs_rq);
if (!cfs_b->timer_active)
__start_cfs_bandwidth(cfs_b, false);
raw_spin_unlock(&cfs_b->lock);
}
요청한 cfs 런큐를 스로틀링한다.
- 코드 라인 3~4에서 요청한 cfs 런큐에 해당하는 런큐와 태스크 그룹의 cfs bandwidth을알아온다.
- 코드 라인 8에서 요청한 cfs 런큐에 해당하는 태스크 그룹용 스케줄 엔티티를 알아온다.
- 코드 라인 11~13에서 요청한 cfs 런큐에 해당하는 태스크 그룹부터 하위의 태스크 그룹 전체를 순회하며 스로틀 되는 동안 계층적인 러너블 평균의 산출을 멈추게 한다.
- 각 태스크 그룹의 cfs 런큐의 스로틀 카운터를 증가시키고 처음인 경우 런큐의 clock_task를 cfs 런큐의 throttled_clock_task에 대입한다.
- 코드 라인 15에서 요청한 cfs 런큐의 동작중인 active 태스크의 수를 알아온다.
- 코드 라인 16~20에서 요청한 cfs 런큐용 스케줄 엔티티부터 최상위 스케줄 엔티티까지 순회하며 해당 스케줄 엔티티가 런큐에 올라가 있지 않으면 순회를 멈춘다.
- 코드 라인 22~24에서 dequeue 요청이 있을 때 현재 스케줄 엔티티를 디큐하여 sleep 하게 하고 동작 중인 태스크 수를 1 감소시킨다.
- 코드 라인 26~27에서 현재 스케줄 엔티티를 담고 있는 cfs 런큐의 로드 weight이 0이 아니면 순회 중 다음 부모 스케줄 엔티티에 대해 dequeue를 요청하도록 dequeue에 0을 설정한다.
- 코드 라인 30~31에서 순회가 중단된 적이 없으면 런큐의 active 태스크 수를 task_delta 만큼 감소시킨다.
- sub_nr_running()
- rq->nr_running -= count
- sub_nr_running()
- 코드 라인 33~34에서 cfs 런큐에 스로틀되었음을 알리고 스로틀된 시각을 기록한다.
- 코드 라인 40에서 cfs bandwidth 의 throttled_cfs_rq 리스트에 cfs 런큐의 스로틀된 cfs 런큐를 추가한다.
- 코드 라인 41~42에서 cfs bandwidth 기능이 동작하도록 타이머를 동작시킨다.
다음 그림은 요청한 cfs 런큐에 대해 스로틀링을 할 때 처리되는 모습을 보여준다.
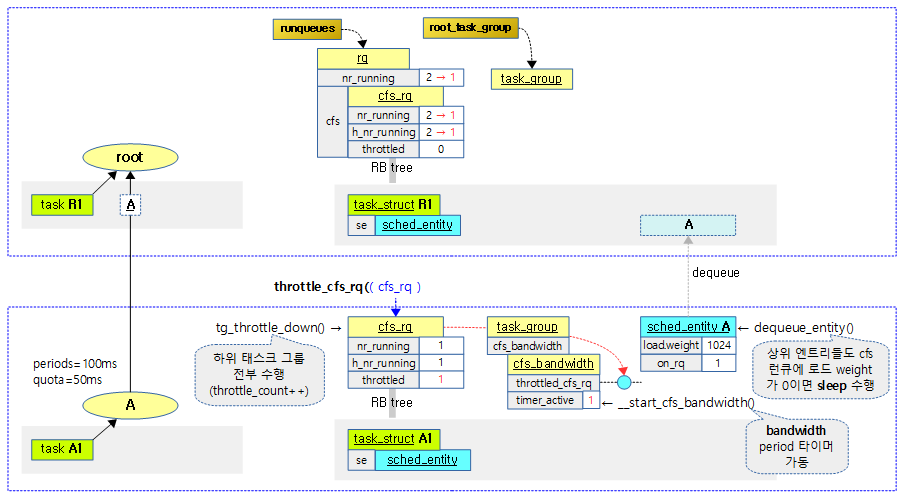
태스크 그룹 워크 다운을 통한 스로틀
tg_throttle_down()
kernel/sched/fair.c
static int tg_throttle_down(struct task_group *tg, void *data)
{
struct rq *rq = data;
struct cfs_rq *cfs_rq = tg->cfs_rq[cpu_of(rq)];
/* group is entering throttled state, stop time */
if (!cfs_rq->throttle_count) {
cfs_rq->throttled_clock_task = rq_clock_task(rq);
list_del_leaf_cfs_rq(cfs_rq);
}
cfs_rq->throttle_count++;
return 0;
}
요청 태스크 그룹 및 cpu의 cfs 런큐의 스로틀 카운터를 증가시켜 스로틀 상태로 변경한다.
- 요청 태스크 그룹의 cfs 런큐의 스로틀 카운터를 증가시키고 처음인 경우 런큐의 clock_task를 cfs 런큐의 throttled_clock_task에 대입한다.
- 코드 라인 3~4에서 두 번째 인수로 받은 런큐의 cpu 번호를 알아와서 요청 태스크 그룹의 cfs 런큐를 알아온다.
- 코드 라인 7~10에서 처음 스로틀링에 들어가는 경우 스로틀 시작 시각을 기록하고, leaf_cfs_rq 리스트에서 이 cfs 런큐가 있으면 제거한다.
- 코드 라인 11에서 cfs 런큐의 스로틀 카운터를 1 증가시킨다.
- 코드 라인 13에서 성공 0을 반환한다.
cfs 런큐 언스로틀
unthrottle_cfs_rq()
kernel/sched/fair.c
void unthrottle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
int enqueue = 1;
long task_delta, idle_task_delta;
se = cfs_rq->tg->se[cpu_of(rq)];
cfs_rq->throttled = 0;
update_rq_clock(rq);
raw_spin_lock(&cfs_b->lock);
cfs_b->throttled_time += rq_clock(rq) - cfs_rq->throttled_clock;
list_del_rcu(&cfs_rq->throttled_list);
raw_spin_unlock(&cfs_b->lock);
/* update hierarchical throttle state */
walk_tg_tree_from(cfs_rq->tg, tg_nop, tg_unthrottle_up, (void *)rq);
if (!cfs_rq->load.weight)
return;
task_delta = cfs_rq->h_nr_running;
idle_task_delta = cfs_rq->idle_h_nr_running;
for_each_sched_entity(se) {
if (se->on_rq)
enqueue = 0;
cfs_rq = cfs_rq_of(se);
if (enqueue)
enqueue_entity(cfs_rq, se, ENQUEUE_WAKEUP);
cfs_rq->h_nr_running += task_delta;
cfs_rq->idle_h_nr_running += idle_task_delta;
if (cfs_rq_throttled(cfs_rq))
break;
}
assert_list_leaf_cfs_rq(rq);
if (!se)
add_nr_running(rq, task_delta);
/* determine whether we need to wake up potentially idle cpu */
if (rq->curr == rq->idle && rq->cfs.nr_running)
resched_curr(rq);
}
요청한 cfs 런큐를 언스로틀링한다.
- 코드 라인 3~4에서 요청한 cfs 런큐에 해당하는 런큐와 태스크 그룹의 cfs bandwidth을알아온다.
- 코드 라인 9에서 cfs 런큐를 대표하는 엔티티를 알아온다.
- 코드 라인 11에서 cfs 런큐의 throttled를 0으로 하여 스로틀링을 해제한 것으로 설정한다.
- 코드 라인 13~18에서 런큐 클럭을 갱신하고, cfs 밴드위드 락을 획득한 채로 스로틀된 시간을 갱신한다. 그런 후 스로틀 리스트에서 제거한다.
- 코드 라인 21에서 각 태스크 그룹의 하위 그룹들에 대해 bottom-up 방향으로 각 로컬 풀을 언스로틀하도록 요청한다.
- 코드 라인 23~24에서 현재 로컬 풀의 로드 weight이 0이면 부모에 영향을 끼치지 않으므로 더이상 처리하지 않고 함수를 빠져나간다.
- 코드 라인 26~27에서 task_delta에 요청한 cfs 런큐 이하에서 동작중인 active 태스크 수를 알아온다. idle_task_delta에는 idle policy를 사용하는 cfs 태스크 수를 알아온다.
- 코드 라인 28~30에서 요청한 cfs 런큐용 스케줄 엔티티부터 최상위 스케줄 엔티티까지 순회하며 해당 스케줄 엔티티가 런큐에 올라가 있는 상태이면 enqueue에 0을 대입하여 엔큐를 못하게 설정한다.
- 코드 라인 32~34에서 enqueue가 필요한 상태인 경우 엔티티를 엔큐한다.
- 코드 라인 35~36에서 순회 중인 cfs 런큐들 마다 cfs active 태스크 수와 idle 태스크 수를 추가하여 반영한다.
- 코드 라인 38~39에서 cfs 런큐가 스로틀된 적 있으면 루프를 빠져나간다.
- 코드 라인 44~45에서 최상위 스케줄 엔티티(루트 태스크 그룹에 연결된)까지 루프를 다 돌은 경우 런큐의 nr_running에도 active 태스크 수를 추가하여 반영한다.
- 코드 라인 48~49에서 현재 태스크가 idle 중이면서 최상위 cfs 런큐에서 동작중인 스케줄 엔티티가 있으면 리스케줄 요청 플래그를 설정한다.
다음 그림은 여러 가지 clock에 대해 동작되는 모습을 보여준다.
- 스로틀링 시간 역시 rq->clock에 동기되는 time 누적과 rq->clock_task를 사용한 task_time 누적으로 나뉘어 관리된다.
- rq->clock에서 irq 처리 부분만 제외시킨 부분이 rq->clock_task 이다.
- 그러나 CONFIG_IRQ_TIME_ACCOUNTING 커널 옵션을 사용하지 않으면 irq 소요시간을 측정하지 않으므로 이러한 경우에는 rq->clock과 rq->clock_task가 동일하게 된다.
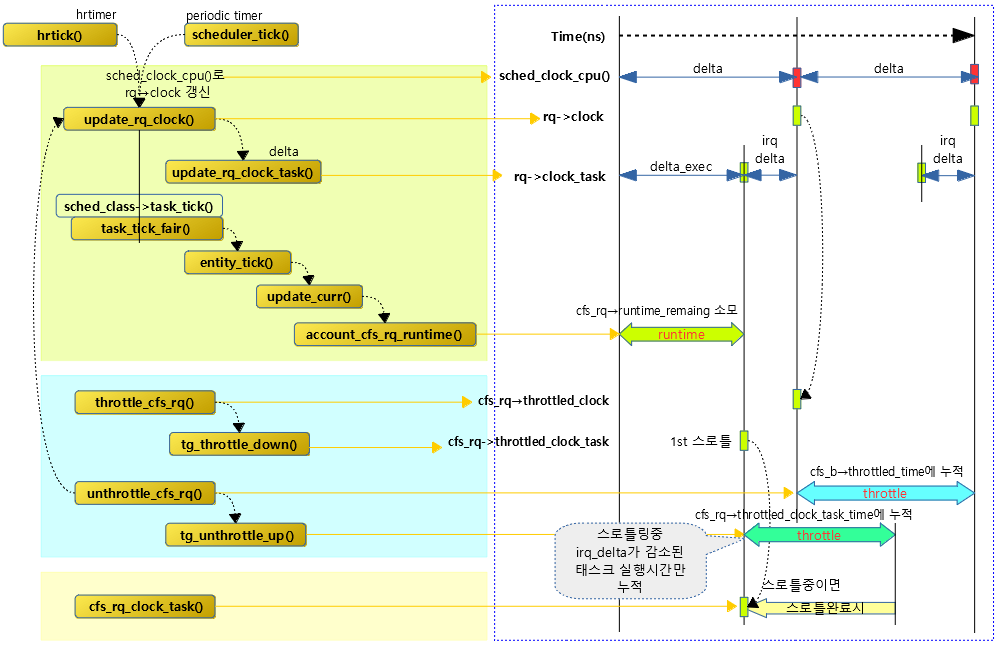
태스크 그룹 워크 업을 통한 언스로틀
tg_unthrottle_up()
kernel/sched/fair.c
static int tg_unthrottle_up(struct task_group *tg, void *data)
{
struct rq *rq = data;
struct cfs_rq *cfs_rq = tg->cfs_rq[cpu_of(rq)];
cfs_rq->throttle_count--;
if (!cfs_rq->throttle_count) {
/* adjust cfs_rq_clock_task() */
cfs_rq->throttled_clock_task_time += rq_clock_task(rq) -
cfs_rq->throttled_clock_task;
/* Add cfs_rq with already running entity in the list */
if (cfs_rq->nr_running >= 1)
list_add_leaf_cfs_rq(cfs_rq);
}
return 0;
}
요청 태스크 그룹의 cfs 런큐에 스로틀 완료 카운터를 감소시킨다. 이 카운터가 0인 경우 스로틀 상태에서 벗어난다.
- 요청 태스크 그룹의 cfs 런큐의 스로틀 카운터를 감소시키고 처음인 경우 런큐의 clock_task를 cfs 런큐의 throttled_clock_task에 대입한다.
- 코드 라인 3~4에서 두 번째 인수로 받은 런큐의 cpu 번호를 알아와서 요청 태스크 그룹의 cfs 런큐를 알아온다.
- 코드 라인 6에서 cfs 런큐의 스로틀 카운터를 1 감소시킨다.
- 코드 라인 7~15에서 smp 시스템에서 스로틀 카운터가 0인 경우 스로틀된 시간 총합을 갱신한다. 또한 cfs 런큐에 동작 중인 엔티티가 1개 이상있는 경우 leaf cfs 런큐 리스트에 추가한다.
CFS Runtime 최소 slice 할당
account_cfs_rq_runtime()
kernel/sched/fair.c
static __always_inline
void account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec)
{
if (!cfs_bandwidth_used() || !cfs_rq->runtime_enabled)
return;
__account_cfs_rq_runtime(cfs_rq, delta_exec);
}
로컬 런타임이 모두 소비된 경우 글로벌 런타임에서 최소 slice(디폴트=5 ms) – 초과 소모한 런타임만큼을 차용하여 로컬 런타임을 할당한다. 만일 로컬 런타임이 충분히 할당되지 않은 경우 리스케줄 요청 플래그를 설정한다..
__account_cfs_rq_runtime()
kernel/sched/fair.c
static void __account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec)
{
/* dock delta_exec before expiring quota (as it could span periods) */
cfs_rq->runtime_remaining -= delta_exec;
if (likely(cfs_rq->runtime_remaining > 0))
return;
if (cfs_rq->throttled)
return;
/*
* if we're unable to extend our runtime we resched so that the active
* hierarchy can be throttled
*/
if (!assign_cfs_rq_runtime(cfs_rq) && likely(cfs_rq->curr))
resched_curr(rq_of(cfs_rq));
}
로컬 런타임이 모두 소비된 경우 글로벌 런타임에서 최소 slice(디폴트=5 ms) – 초과 소모한 런타임만큼을 차용하여 로컬 런타임을 할당한다. 로컬 런타임이 충분히 할당되지 않은 경우 리스케줄 요청 플래그를 설정한다..
- 코드 라인 4에서 매 스케줄 틱마다 update_curr() 함수를 통해 이 루틴이 불리는데 실행되었던 시간 만큼을 로컬 런타임에서 소모시킨다.
- 코드 라인 6~7에서 로컬 런타임이 아직 남아 있으면 함수를 빠져나간다.
- 코드 라인 9~10에서 이미 스로틀 중인 경우 함수를 빠져나간다.
- 코드 라인 15~16에서 로컬 런타임이 충분히 할당되지 않고 높은 확률로 cfs 런큐에서 태스크가 동작 중인 경우 리스케줄 요청 플래그를 설정하여 cfs 스로틀을 시작 한다.
assign_cfs_rq_runtime()
kernel/sched/fair.c
/* returns 0 on failure to allocate runtime */
static int assign_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
struct task_group *tg = cfs_rq->tg;
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(tg);
u64 amount = 0, min_amount;
/* note: this is a positive sum as runtime_remaining <= 0 */
min_amount = sched_cfs_bandwidth_slice() - cfs_rq->runtime_remaining;
raw_spin_lock(&cfs_b->lock);
if (cfs_b->quota == RUNTIME_INF)
amount = min_amount;
else {
start_cfs_bandwidth(cfs_b);
if (cfs_b->runtime > 0) {
amount = min(cfs_b->runtime, min_amount);
cfs_b->runtime -= amount;
cfs_b->idle = 0;
}
}
raw_spin_unlock(&cfs_b->lock);
cfs_rq->runtime_remaining += amount;
return cfs_rq->runtime_remaining > 0;
}
로컬 런타임이 모두 소비된 경우 글로벌 런타임에서 최소 slice(디폴트=5 ms) – 초과 소모한 런타임만큼을 차용하여 로컬 런타임을 할당한다. 로컬 런타임이 채워진 경우 1을 반환하고, 여전히 부족한 경우 0을 반환한다.
- 코드 라인 9에서 로컬 런타임이 다 소진된 상태에서 글로벌 런타임 풀에서 가져올 런타임을 결정한다.
- 로컬 잔여 런타임이 다 소진되어 0이거나 초과 소모하여 음수인 경우에만 이 함수에 진입되었다.
- 글로벌 런타임에서 차용할 런타임은 slice(디폴트 5ms)에서 초과 소모한 런타임양을 뺀 값이다.
- 차용할 런타임 = 5 ms – 초과 소모 런타임
- 코드 라인 12~13에서 quota 설정이 무한대인 경우 빌려올 양은 위에서 산출한 값을 그대로 적용한다.
- 코드 라인 14~22에서 quota 설정이 있는 경우 cfs 밴드위드를 동작시킨다. 그리고 위에서 산출한 런타임 만큼 글로벌 런타임에서 차감한다. 글로벌 런타임은 0 미만으로 떨어지지디 않도록 제한된다.
- 코드 라인 25에서 로컬 런타임 잔량에 글로벌 런타임에서 가져온 양을 추가한다.
- 코드 라인 27에서 로컬 풀의 잔여 런타임이 있는지 여부를 반환한다.
다음 그림은 스케줄 tick이 발생하여 delta 실행 시간을 로컬 런타임 풀에서 소모시키고 소모 시킬 로컬 런타임이 없으면 slice 만큼의 런타임을 글로벌 런타임에서 빌려오는 것을 보여준다.

sched_cfs_bandwidth_slice()
kernel/sched/fair.c
static inline u64 sched_cfs_bandwidth_slice(void)
{
return (u64)sysctl_sched_cfs_bandwidth_slice * NSEC_PER_USEC;
}
cfs bandwidth slice 값을 나노초 단위로 반환한다.
/* * Amount of runtime to allocate from global (tg) to local (per-cfs_rq) pool * each time a cfs_rq requests quota. * * Note: in the case that the slice exceeds the runtime remaining (either due * to consumption or the quota being specified to be smaller than the slice) * we will always only issue the remaining available time. * * default: 5 msec, units: microseconds */ unsigned int sysctl_sched_cfs_bandwidth_slice = 5000UL;
- 매번 cfs 런큐가 요청하는 quota 마다 태스크 그룹의 글로벌에서 로컬 cfs 런큐 풀로 할당해줄 수 있는 runtime
- “/proc/sys/kernel/sched_cfs_bandwidth_slice_us” -> 디폴트 값은 5000 (us)
두 개의 CFS Bandwidth 타이머
- period 타이머 주요 기능
- period 주기마다 만료되어 호출된다.
- 글로벌 런타임을 재충전(refill) 한다.
- 스로틀된 로컬 cfs 런큐들에 초과 소모한 런타임을 우선 분배한다.
- slack 타이머 주요 기능
- 태스크 dequeue 시 5ms 후에 만료되어 호출된다.
- 남은 로컬 잔량을 글로벌 런타임에 반납하여 스로틀된 로컬 cfs 런큐들에 초과 소모한 런타임을 우선 분배한다.
다음 그림은 cfs bandwidth에 대한 두 개의 타이머에 대한 함수 호출 관계를 보여준다.
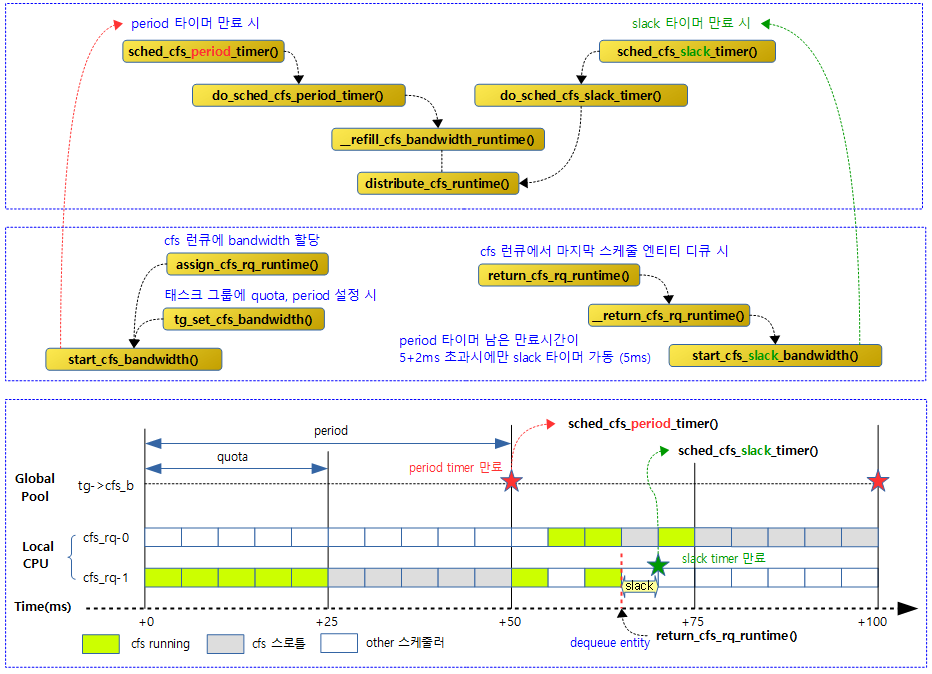
정규 period 시각마다 분배
period 타이머를 통해 매 period 시각마다 글로벌 런타임 리필 후 스로틀된 로컬 cfs 런큐를 대상으로 런타임 부족분을 우선 차감 분배한다.
CFS Period Timer – (1) 활성화
start_cfs_bandwidth()
kernel/sched/fair.c
void start_cfs_bandwidth(struct cfs_bandwidth *cfs_b)
{
lockdep_assert_held(&cfs_b->lock);
if (cfs_b->period_active)
return;
cfs_b->period_active = 1;
hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
글로벌 풀의 period 타이머를 가동시킨다.
- 코드 라인 5~6에서 이미 period 타이머가 동작 중인 경우 함수를 빠져나간다.
- 코드 라인 8에서 period 타이머가 동작 중임을 알린다.
- 코드 라인 9~10에서 period 타이머를 동작시킨다.
CFS Period Timer – (2) 만료 시 호출
sched_cfs_period_timer()
kernel/sched/fair.c
static enum hrtimer_restart sched_cfs_period_timer(struct hrtimer *timer)
{
struct cfs_bandwidth *cfs_b =
container_of(timer, struct cfs_bandwidth, period_timer);
unsigned long flags;
int overrun;
int idle = 0;
int count = 0;
raw_spin_lock_irqsave(&cfs_b->lock, flags);
for (;;) {
overrun = hrtimer_forward_now(timer, cfs_b->period);
if (!overrun)
break;
if (++count > 3) {
u64 new, old = ktime_to_ns(cfs_b->period);
/*
* Grow period by a factor of 2 to avoid losing precision.
* Precision loss in the quota/period ratio can cause __cfs_schedulable
* to fail.
*/
new = old * 2;
if (new < max_cfs_quota_period) {
cfs_b->period = ns_to_ktime(new);
cfs_b->quota *= 2;
pr_warn_ratelimited(
"cfs_period_timer[cpu%d]: period too short, scaling up (new cfs_period_us = %lld, cfs_quota_us = %lld)\n",
smp_processor_id(),
div_u64(new, NSEC_PER_USEC),
div_u64(cfs_b->quota, NSEC_PER_USEC));
} else {
pr_warn_ratelimited(
"cfs_period_timer[cpu%d]: period too short, but cannot scale up without losing precision (cfs_period_us = %lld, cfs_quota_us = %lld)\n",
smp_processor_id(),
div_u64(old, NSEC_PER_USEC),
div_u64(cfs_b->quota, NSEC_PER_USEC));
}
/* reset count so we don't come right back in here */
count = 0;
}
idle = do_sched_cfs_period_timer(cfs_b, overrun, flags);
}
if (idle)
cfs_b->period_active = 0;
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
return idle ? HRTIMER_NORESTART : HRTIMER_RESTART;
}
period 타이머 만료 시에 호출되며 타이머에 연동된 태스크 그룹의 quota를 글로벌 런타임에 리필하고 추가적으로 필요한 작업들을 수행한다.
- 코드 라인 3~4에서 태스크 그룹의 cfs bandwidth를 알아온다.
- 코드 라인 11~14에서 period 타이머를 인터벌 기간 뒤로 forward 한다. 오버런한 적이 없으면 즉 forward할 필요가 없으면 함수를 빠져나간다.
- 참고: Timer -2- (HRTimer) | 문c
- 코드 라인 16~44에서 period와 quota 값이 너무 작아 오버런이 되는 상황인 경우 3회 마다 period와 quota 값을 1초 범위 이내에서 2배씩 늘려나가고 경고 메시지를 출력한다.
- 코드 라인 46에서 period 타이머의 만료에 따른 작업을 수행하고 period 타이머의 종료 여부(idle=1)를 알아온다.
- 태스크 그룹의 quota를 글로벌 런타임에 리필하고 스로틀된 cfs 런큐에 런타임을 분배하는 등을 수행한다.
- 코드 라인 4849에서 idle 상태가 되는 경우 period 타이머가 비활성화되었음을 알린다.
- 코드 라인 52에서 period 타이머의 재시작 여부를 반환한다.
- HRTIMER_RESTART=1
- HRTIMER_NORESTART=0
do_sched_cfs_period_timer()
태스크 그룹의 quota를 글로벌 런타임에 리필하고 이전 period에서 언스로틀된 cfs 런큐들에 대해 글로벌 런타임을 먼저 차감 분배하고 언스로틀한다.
kernel/sched/fair.c
/* * Responsible for refilling a task_group's bandwidth and unthrottling its * cfs_rqs as appropriate. If there has been no activity within the last * period the timer is deactivated until scheduling resumes; cfs_b->idle is * used to track this state. */
static int do_sched_cfs_period_timer(struct cfs_bandwidth *cfs_b, int overrun, unsigned long flags)
{
u64 runtime;
int throttled;
/* no need to continue the timer with no bandwidth constraint */
if (cfs_b->quota == RUNTIME_INF)
goto out_deactivate;
throttled = !list_empty(&cfs_b->throttled_cfs_rq);
cfs_b->nr_periods += overrun;
/*
* idle depends on !throttled (for the case of a large deficit), and if
* we're going inactive then everything else can be deferred
*/
if (cfs_b->idle && !throttled)
goto out_deactivate;
__refill_cfs_bandwidth_runtime(cfs_b);
if (!throttled) {
/* mark as potentially idle for the upcoming period */
cfs_b->idle = 1;
return 0;
}
/* account preceding periods in which throttling occurred */
cfs_b->nr_throttled += overrun;
/*
* This check is repeated as we are holding onto the new bandwidth while
* we unthrottle. This can potentially race with an unthrottled group
* trying to acquire new bandwidth from the global pool. This can result
* in us over-using our runtime if it is all used during this loop, but
* only by limited amounts in that extreme case.
*/
while (throttled && cfs_b->runtime > 0 && !cfs_b->distribute_running) {
runtime = cfs_b->runtime;
cfs_b->distribute_running = 1;
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
/* we can't nest cfs_b->lock while distributing bandwidth */
runtime = distribute_cfs_runtime(cfs_b, runtime);
raw_spin_lock_irqsave(&cfs_b->lock, flags);
cfs_b->distribute_running = 0;
throttled = !list_empty(&cfs_b->throttled_cfs_rq);
lsub_positive(&cfs_b->runtime, runtime);
}
/*
* While we are ensured activity in the period following an
* unthrottle, this also covers the case in which the new bandwidth is
* insufficient to cover the existing bandwidth deficit. (Forcing the
* timer to remain active while there are any throttled entities.)
*/
cfs_b->idle = 0;
return 0;
out_deactivate:
return 1;
}
- 코드 라인 7~8에서 태스크 그룹에 cfs quota 설정을 안한 경우 cfs bandwidth 설정이 안된 것이므로 out_deactivate 레이블로 이동한다.
- 코드 라인 10에서 태스크 그룹에 스로틀된 cfs 런큐가 있는지 여부를 throttled에 대입한다.
- 코드 라인 11에서 nr_periods를 overrun 횟수만큼 증가시킨다.
- 코드 라인 17~18에서 idle 상태이면서 스로틀된 cfs 런큐가 없으면 out_deactivate 레이블로 이동한다.
- 코드 라인 20에서 글로벌 런타임을 quota 설정만큼 리필한다.
- 코드 라인 22~26에서 스로틀된 cfs 런큐가 없는 경우 idle=1로 설정하고 period 타이머를 재시작하기 위해 0을 반환한다.
- 코드 라인 29에서 스로틀된 횟수를 overrun 만큼 증가시킨다.
- 코드 라인 38~50에서 스로틀된 cfs 런큐가 있고 글로벌 런타임이 남아 있으며 다른 곳에서 분배 중이지 않은 경우에 한해 반복하며 다음과 같이 분배를 수행한다.
- 스로틀된 cfs 런큐들을 순서대로 부족한 런타임만큼 우선 배분하고 언스로틀한다.
- 배분한 런타임은 글로벌 런타임 잔량에서 차감한다.
- 코드 라인 58~60에서 글로벌 풀의 idle에 0을 대입하고 period 타이머를 재시작하기 위해 0을 반환한다.
- 코드 라인 62~63에서 out_deactivate: 레이블이다. period 타이머를 재시작하지 않도록 1을 반환한다.
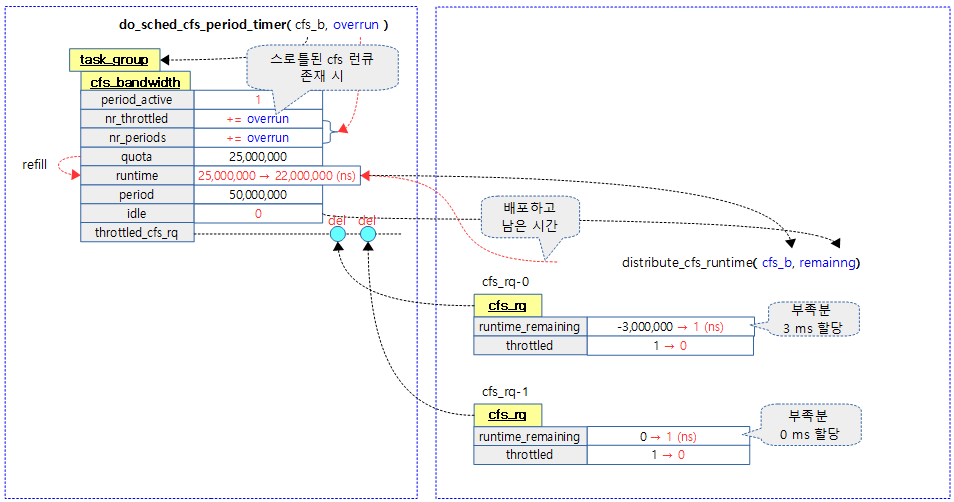
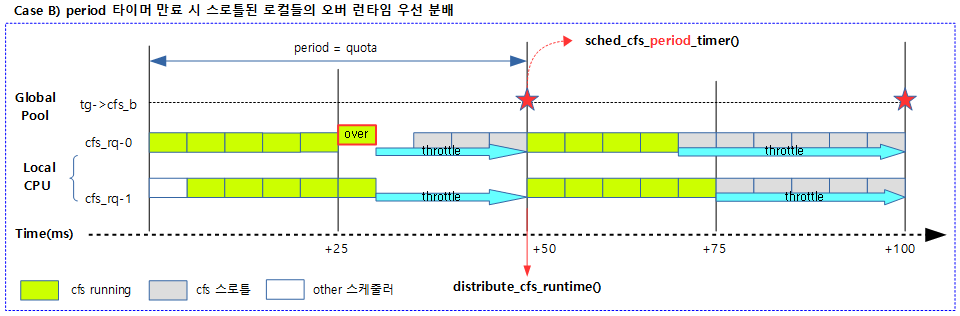
다음 그림은 글로벌 런타임을 스로틀된 cfs 런큐에 부족한 런타임만큼 우선 차감 분배하는 과정을 보여준다.
글로벌 런타임 재충전
__refill_cfs_bandwidth_runtime()
kernel/sched/fair.c
/* * Replenish runtime according to assigned quota. We use sched_clock_cpu * directly instead of rq->clock to avoid adding additional synchronization * around rq->lock. * * requires cfs_b->lock */
void __refill_cfs_bandwidth_runtime(struct cfs_bandwidth *cfs_b)
{
if (cfs_b->quota != RUNTIME_INF)
cfs_b->runtime = cfs_b->quota;
}
글로벌 풀의 런타임을 quota 만큼으로 리필한다.
이 함수는 다음 그림과 같이 period 타이머의 만료 시 마다 호출되어 사용되는 것을 보여준다.

스로틀된 cfs 런큐에 초과 소모한 런타임 분배
distribute_cfs_runtime()
kernel/sched/fair.c
static u64 distribute_cfs_runtime(struct cfs_bandwidth *cfs_b, u64 remaining)
{
struct cfs_rq *cfs_rq;
u64 runtime;
u64 starting_runtime = remaining;
rcu_read_lock();
list_for_each_entry_rcu(cfs_rq, &cfs_b->throttled_cfs_rq,
throttled_list) {
struct rq *rq = rq_of(cfs_rq);
struct rq_flags rf;
rq_lock_irqsave(rq, &rf);
if (!cfs_rq_throttled(cfs_rq))
goto next;
/* By the above check, this should never be true */
SCHED_WARN_ON(cfs_rq->runtime_remaining > 0);
runtime = -cfs_rq->runtime_remaining + 1;
if (runtime > remaining)
runtime = remaining;
remaining -= runtime;
cfs_rq->runtime_remaining += runtime;
/* we check whether we're throttled above */
if (cfs_rq->runtime_remaining > 0)
unthrottle_cfs_rq(cfs_rq);
next:
rq_unlock_irqrestore(rq, &rf);
if (!remaining)
break;
}
rcu_read_unlock();
return starting_runtime - remaining;
}
스로틀된 cfs 런큐들을 순서대로 글로벌 잔량이 남아있는 한 초과 소모한 런타임을 우선 배분하고 언스로틀한다.
- 코드 라인 8~15에서 태스크 그룹의 스로틀된 cfs 런큐 리스트를 순회하며 cfs 런큐가 스로틀되지 않은 경우 cfs 런큐가 발견되면 skip 처리하기 위해 next 레이블로 이동한다.
- 코드 라인 20~25에서 글로벌 런타임에서 스로틀된 cfs 런큐의 런타임 부족분 + 1만큼을 차감 분배한다.글로벌 런타임값은 0미만으로 떨어지지 않도록 제한된다.
- cfs 런큐가 스로틀되었다는 의미는 cfs 런큐의 잔여 런타임은 0이 되었거나 초과 수행되어 음수 값인 상태이다.
- 코드 라인 28~29에서 cfs 런큐의 잔여 런타임이 0보다 큰 경우 언스로틀한다.
- 코드 라인 31~35에서 next: 레이블이다. remaing 값이 0인 경우 루프를 벗어난다.
- 코드 라인 39에서 분배한 런타임만큼을 반환한다.
다음 그림은 distribute_cfs_runtime() 함수의 동작 시 글로벌 런타임을 기존 스로틀된 cfs 런큐의 초과 소모한 런타임 만큼을 우선 분배하고 언스로틀하는 과정을 보여준다.
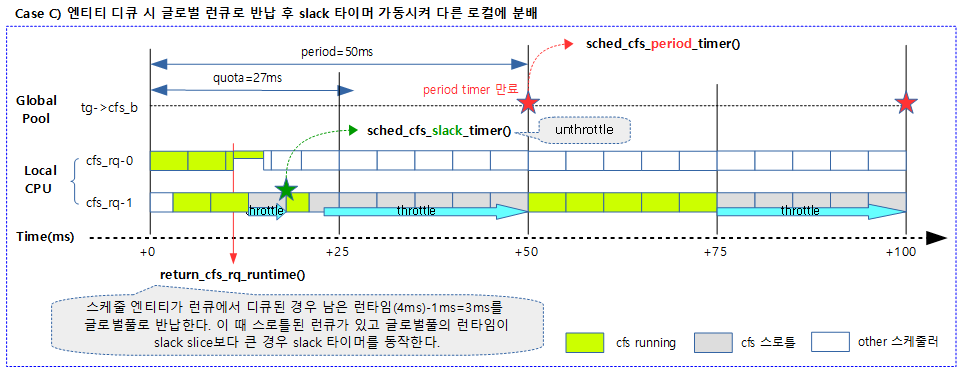
엔티티 디큐 시 남은 런타임 반납
엔티티가 디큐될 때 사용하고 남은 런타임 잔량 중 1ms를 뺀 나머지 모두를 글로벌 런타임에 반납한다. periods 타이머 만료 시각까지 7 ms 이상 충분히 시간이 남아 있으면 스로틀된 cfs 런큐를 깨워 동작시키기 위해 분배 작업을 위해 5ms 슬랙 타이머를 가동 시킨다. 슬랙 타이머의 만료 시각에는 스로틀 중인 로컬 cfs 런큐들에 남은 잔량을 분배한다.
- 7 ms가 필요한 이유
- 다음 두 가지 기간을 더한 값이 period 타이머의 만료 시간보다 작으면 어짜피 period 타이머로 글로벌 런타임이 리필될 예정이고, 각 로컬 풀도 다시 할당 받을 수 있게 된다. 따라서 period 타이머 만료 시각에 가까와 지면 남은 로컬 런타임 잔량을 반납할 이유가 없어진다.
- 슬랙 타이머용으로 5 ms
- period 타이머 만료 시간 전 2 ms의 여유가 필요하다.
- 다음 두 가지 기간을 더한 값이 period 타이머의 만료 시간보다 작으면 어짜피 period 타이머로 글로벌 런타임이 리필될 예정이고, 각 로컬 풀도 다시 할당 받을 수 있게 된다. 따라서 period 타이머 만료 시각에 가까와 지면 남은 로컬 런타임 잔량을 반납할 이유가 없어진다.
return_cfs_rq_runtime()
kernel/sched/fair.c
static __always_inline void return_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
if (!cfs_bandwidth_used())
return;
if (!cfs_rq->runtime_enabled || cfs_rq->nr_running)
return;
__return_cfs_rq_runtime(cfs_rq);
}
cfs 스케줄러에서 스케줄 엔티티가 디큐될 때 이 함수가 호출되면 남은 로컬 런타임을 회수하여 글로벌 풀로 반납한다. 그런 후에 5ms 주기의 slack 타이머를 가동시켜서 스로틀된 다른 태스크에게 런타임을 할당해준다.
__return_cfs_rq_runtime()
kernel/sched/fair.c
/* we know any runtime found here is valid as update_curr() precedes return */
static void __return_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
s64 slack_runtime = cfs_rq->runtime_remaining - min_cfs_rq_runtime;
if (slack_runtime <= 0)
return;
raw_spin_lock(&cfs_b->lock);
if (cfs_b->quota != RUNTIME_INF &&
cfs_b->runtime += slack_runtime;
/* we are under rq->lock, defer unthrottling using a timer */
if (cfs_b->runtime > sched_cfs_bandwidth_slice() &&
!list_empty(&cfs_b->throttled_cfs_rq))
start_cfs_slack_bandwidth(cfs_b);
}
raw_spin_unlock(&cfs_b->lock);
/* even if it's not valid for return we don't want to try again */
cfs_rq->runtime_remaining -= slack_runtime;
}
- 코드 라인 5~8에서 로컬 런타임으로부터 글로벌 풀로 반납할 잔량을 구한다. 반납할 량이 0보다 적으면 함수를 빠져나간다.
- 반납할 런타임 = 런타임의 잔량 – 최소 런타임(1 ms)
- 코드 라인 11~12에서 반납할 런타임을 글로벌 풀에 반납한다.
- 코드 라인 15~17에서 글로벌 풀의 런타임이 slice(디폴트 5ms) 보다 크고 스로틀되어 있는 로컬 풀이 있으면 slack 타이머를 가동한다.
- 코드 라인 22에서 로컬 런타임 잔량을 반납한 양 만큼 빼서 갱신한다.
CFS Slack Timer – (1) 활성화
start_cfs_slack_bandwidth()
kernel/sched/fair.c
static void start_cfs_slack_bandwidth(struct cfs_bandwidth *cfs_b)
{
u64 min_left = cfs_bandwidth_slack_period + min_bandwidth_expiration;
/* if there's a quota refresh soon don't bother with slack */
if (runtime_refresh_within(cfs_b, min_left))
return;
/* don't push forwards an existing deferred unthrottle */
if (cfs_b->slack_started)
return;
cfs_b->slack_started = true;
hrtimer_start(&cfs_b->slack_timer,
ns_to_ktime(cfs_bandwidth_slack_period),
HRTIMER_MODE_REL);
}
slack 타이머를 slack 주기(디폴트 5ms)로 가동시킨다. 단 period 타이머의 만료 시각이 slack 불필요 범위(디폴트 7ms) 이내인 경우에는 가동시키지 않는다.
- 코드 라인 3~7에서 런타임 리필(리프레쉬) 주기가 다가온 경우 slack 타이머를 활성화할 필요 없으므로 함수를 빠져나간다.
- 최소 만료 시간과 slack 주기를 더해 min_left(디폴트=2+5=7ms)보다 런타임 리필 주기가 커야 한다.
- 코드 라인 10~11에서 이미 슬랙 타이머가 동작 중인 경우 함수를 빠져나간다.
- 코드 라인 12에서 슬랙 타이머가 동작 했음을 알린다.
- 코드 라인 14~16에서 slack 타이머를 cfs_bandwidth_slack_period(디폴트 5ms) 주기로 활성화한다.
runtime_refresh_within()
kernel/sched/fair.c
/* * Are we near the end of the current quota period? * * Requires cfs_b->lock for hrtimer_expires_remaining to be safe against the * hrtimer base being cleared by __hrtimer_start_range_ns. In the case of * migrate_hrtimers, base is never cleared, so we are fine. */
static int runtime_refresh_within(struct cfs_bandwidth *cfs_b, u64 min_expire)
{
struct hrtimer *refresh_timer = &cfs_b->period_timer;
u64 remaining;
/* if the call-back is running a quota refresh is already occurring */
if (hrtimer_callback_running(refresh_timer))
return 1;
/* is a quota refresh about to occur? */
remaining = ktime_to_ns(hrtimer_expires_remaining(refresh_timer));
if (remaining < min_expire)
return 1;
return 0;
}
글로벌 런타임 리프레쉬 주기가 다가오는지 여부를 확인한다.
- 코드 라인 3~8에서 hrtimer가 만료되어 콜백이 진행중이면 1을 반환한다. 현재 리프레시 진행 중이므로 굳이 slack 타이머를 가동시킬 필요 없다.
- 코드 라인 11~15에서 만료될 시간이 인수로 받은 min_expire 기준 시간 보다 작은 경우 곧 리프레쉬 주기가 다가오므로 1을 반환하고 그 외의 경우 slack 타이머가 동작하도록 0을 반환한다.
CFS Slack Timer – (2) 만료 시 호출
sched_cfs_slack_timer()
kernel/sched/fair.c
static enum hrtimer_restart sched_cfs_slack_timer(struct hrtimer *timer)
{
struct cfs_bandwidth *cfs_b =
container_of(timer, struct cfs_bandwidth, slack_timer);
do_sched_cfs_slack_timer(cfs_b);
return HRTIMER_NORESTART;
}
slack 타이머 만료 시 글로벌 풀로부터 스로틀된 로컬들의 초과 소모 런타임을 우선 분배한다. (디폴트로 slack 타이머는 5ms이다)
- 디큐된 태스크의 남은 런타임 잔량을 글로벌에 반납하면서 slack 타이머를 통해 할당을 못받고 스로틀되고 있는 로컬 풀에 오버 소모한 런타임을 준 후 언스로틀한다.
do_sched_cfs_slack_timer()
kernel/sched/fair.c
/* * This is done with a timer (instead of inline with bandwidth return) since * it's necessary to juggle rq->locks to unthrottle their respective cfs_rqs. */
static void do_sched_cfs_slack_timer(struct cfs_bandwidth *cfs_b)
{
u64 runtime = 0, slice = sched_cfs_bandwidth_slice();
unsigned long flags;
/* confirm we're still not at a refresh boundary */
raw_spin_lock_irqsave(&cfs_b->lock, flags);
cfs_b->slack_started = false;
if (runtime_refresh_within(cfs_b, min_bandwidth_expiration)) {
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
return;
}
if (runtime_refresh_within(cfs_b, min_bandwidth_expiration)) {
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
return;
}
if (cfs_b->quota != RUNTIME_INF && cfs_b->runtime > slice)
runtime = cfs_b->runtime;
if (runtime)
cfs_b->distribute_running = 1;
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
if (!runtime)
return;
runtime = distribute_cfs_runtime(cfs_b, runtime, expires);
raw_spin_lock_irqsave(&cfs_b->lock, flags);
lsub_positive(&cfs_b->runtime, runtime);
cfs_b->distribute_running = 0;
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
}
slack 타이머 만료 시 글로벌 풀로부터 스로틀된 로컬들의 초과 소모한 런타임을 우선 분배한다. (디폴트로 slack 타이머는 5ms이다)
- 코드 라인 3에서 cfs bandwidth의 slice를 구해온다.
- slice: 글로벌 풀에서 로컬로 빌려올 수 있는 런타임 시간 단위(디폴트=5 ms)
- 코드 라인 7~12에서 cfs 밴드위드 락을 획득한 채로 슬랙 타이머가 동작 중임을 알리는 slack_started를 false로 한다. 만일 다른 곳(다른 cpu의 periods 타이머에서 분배 중)에서 이미 분배를 진행하고 있는 경우 cfs 밴드위드 락을 해제하고 함수를 빠져나간다.
- 코드 라인 14~17에서 period 타이머의 만료 시각이 최소 만료 시각(디폴트 2 ms)이내로 곧 다가오는 경우 처리하지 않고 cfs 밴드위드 락을 해제하고 함수를 빠져나간다.
- 코드 라인 19~20에서 quota 설정이 되었으면서 글로벌 풀의 런타임이 slice 보다 큰 경우 분배할 런타임으로 글로벌 런타임을 사용한다.
- 코드 라인 22~23에서 런타임이 있으면 분배 중임을 알리기 위해 distribute_running에 1을 대입한다.
- 코드 라인 25에서 cfs 밴드위드 락을 해제한다.
- 코드 라인 27~28에서 분해할 런타임이 없으면 함수를 빠져나간다.
- 코드 라인 30에서 스로틀된 cfs 런큐들을 순서대로 글로벌 잔량이 남아있는 한 초과 소모한 런타임을 우선 배분하고 언스로틀한다.
- 코드 라인 32~35에서 글로벌 풀의 런타임에서 분배에 소진한 런타임을 뺀다. 글로벌 런타임이 0 미만이 되지 않도록 0으로 제한한다.
DL Bandwidth 초기화
init_dl_bandwidth()
kernel/sched/deadline.c
void init_dl_bandwidth(struct dl_bandwidth *dl_b, u64 period, u64 runtime)
{
raw_spin_lock_init(&dl_b->dl_runtime_lock);
dl_b->dl_period = period;
dl_b->dl_runtime = runtime;
}
dl period와 runtime 값을 사용하여 초기화한다.
- 코드 라인 4에서 인수로 전달받은 us 단위의 period 값을 나노초 단위로 바꾸어 dl_period에 저장한다.
- 코드 라인 5에서 인수로 전달받은 us 단위의 runtime 값을 나노초 단위로 바꾸어 dl_runtime에 저장한다.
구조체
cfs_bandwidth 구조체
kernel/sched/sched.h
struct cfs_bandwidth {
#ifdef CONFIG_CFS_BANDWIDTH
raw_spinlock_t lock;
ktime_t period;
u64 quota;
u64 runtime;
s64 hierarchical_quota;
u8 idle;
u8 period_active;
u8 distribute_running;
u8 slack_started;
struct hrtimer period_timer;
struct hrtimer slack_timer;
struct list_head throttled_cfs_rq;
/* Statistics: */
int nr_periods;
int nr_throttled;
u64 throttled_time;
#endif
};
- lock
- spin 락
- period
- 태스크 그룹의 cpu 사용량을 제어하기 위한 주기로 ns 단위로 저장된다.
- 1ms ~ 1s까지 설정가능하며 디폴트 값=100ms
- “/sys/fs/cgroup/cpu/<태스크그룹>/cpu.cfs_period_us”에서 설정하고 ns 단위로 변환하여 저장된다.
- quota
- 태스크 그룹이 period 동안 수행 할 쿼터로 ns 단위로 저장된다.
- 1ms~ 부터 설정 가능
- 0xffffffff_ffffffff 또는 -1인 경우 무제한(bandwidth 설정 없음)
- “/sys/fs/cgroup/cpu/<태스크그룹>/cpu.cfs_quota_us”에서 설정하고 ns 단위로 변환하여 저장된다.
- runtime
- 글로벌 런타임(ns)
- period 타이머 주기마다 quota 시간으로 refill(refresh) 된다.
- 로컬 풀에서 디폴트 5ms 씩 런타임을 분배하면서 점점 줄어든다.
- 디큐되는 엔티티에서 반납되어 커지는 경우도 있다.
- 그 외 매 period 타이머 주기 및 slack 타이머가 동작하는 하여 스로틀된 로컬에 런타임을 분배하면서 줄어들기도 한다.
- hierarchical_quota
- 계층적으로 관리되는 태스크 그룹의 period에 대한 quota 정수 비율이다.
- 정수 값은 1M(1 << 20)가 100%이고 512K는 50%에 해당한다.
- idle
- idle(1) 상태인 경우 로컬에 런타임 할당이 필요 없는 상태로 만들고 다음 주기에 스로틀되도록 하려는 목적이다.
- 로컬에 런타임 할당을 하거나 스로틀링을 한 경우는 idle 상태에서 해제(0)된다.
- period_active
- period 타이머의 가동 여부
- distribute_running
- 스로틀된 로컬 cfs 런큐에 분배 중인 경우 1이된다.
- slack_timer
- 슬랙 타이머 (디폴트 5ms)
- 태스크가 dequeue되어 남는 로컬 런타임 잔량이 있을 때 반납하고, 슬랙 타이머를 동작시킨다.
- 슬랙 타이머가 동작하면 스로틀된 로컬 cfs 런큐에 분배한다.
- throttled_cfs_rq
- 스로틀된 cfs 런큐 리스트
- 참고: sched: Add support for throttling group entities
- nr_periods
- 주기가 반복 진행된 횟수
- nr_throttled
- 스로틀링된 횟수
- throttled_time
- 스로틀링된 시간 총합(태스크 및 irq 처리 타임을 포함한 시간)
cfs_rq 구조체 (bandwidth 멤버만)
kernel/sched/sched.
struct cfs_rq {
(...생략...)
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
s64 runtime_remaining;
u64 throttled_clock;
u64 throttled_clock_task;
u64 throttled_clock_task_time;
int throttled;
int throttle_count;
struct list_head throttled_list;
#endif /* CONFIG_CFS_BANDWIDTH */
};
- runtime_enabled
- period 타이머 활성화 여부
- runtime_remaining
- 로컬 잔여 런타임
- 글로벌 풀로부터 필요한 만큼 분배 받아서 설정된다.
- throttled_clock
- 스로틀된 시작 시각으로 irq 처리 타임을 포함한 rq->clock으로 산출된다.
- throttled_clock_task
- 스로틀된 시작 시각으로 irq 처리 타임을 뺸 태스크 실행시간만으로 rq->clock_task를 사용하여 산출된다.
- throttled_clock_task_time
- 스로틀된 시간 총합(irq 처리 타임을 뺀 태스크 스로틀링된 시간만 누적)
- throttled
- 스로틀된 적이 있었는지 여부(1=스로틀된 적이 있는 경우)
- throttle_count
- 스로틀 횟수
- throttled_list
- 태스크 그룹에 있는 cfs_bandwidth의 throttled_cfs_rq 리스트에 추가할 때 사용하는 링크 노드
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c – 현재 글
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
very good paper, can you write it in English ?
Sorry, There’s not planned.