최근 2~3일간 사이트가 느려져서 불편한 점이 있었습니다.
갑자기 문제를 일으킨 플러그인을 제거하여 정상 복구하였습니다.
– 문c
최근 2~3일간 사이트가 느려져서 불편한 점이 있었습니다.
갑자기 문제를 일으킨 플러그인을 제거하여 정상 복구하였습니다.
– 문c
<kernel v5.4>
rt 태스크들은 cfs 태스크들보다 항상 우선순위가 높아 먼저 실행될 권리를 갖는다. 다만 cpu를 offline 시킬 때 사용하는 stop 스케줄러에서 사용되는 stop 태스크와 deadline 스케줄러에서 사용하는 deadline 태스크들 보다는 우선 순위가 낮다. 스케줄러들 끼리의 우선 순위를 보면 다음과 같다.

rt 태스크들 끼리 경쟁할 때 스케줄링 순서를 알아본다. rt 태스크의 우선 순위는 0(highest priority) ~ 99(lowest priority)로 나뉜다. 이를 RT0 ~ RT99라고 표현하기도 한다. 동시에 RT50 태스크와 RT60 태스크가 경쟁하는 경우 RT50이 우선 순위가 더 높아 먼저 실행된다.
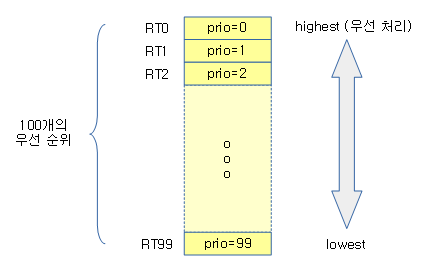
rt 런큐는 cpu 수 만큼 생성된다. 물론 그룹 스케줄링을 사용하는 경우(cgroup의 cpu subsystem) 서브 그룹이 만들어질 때마다 cpu 수 만큼 추가로 만들어지는데 이는 잠시 후에 언급한다. rt 태스크들이 rt 스케줄러에 큐잉되면 rt 런큐에 존재하는 active라는 이름의 큐에 들어가는데 100개의 리스트로 이루어진 array[]에서 관리한다. rt 스케줄러는 2 개 이상의 rt 태스크가 큐에서 관리될 때 우선 순위가 가장 높은 rt 태스크부터 실행시킨다.
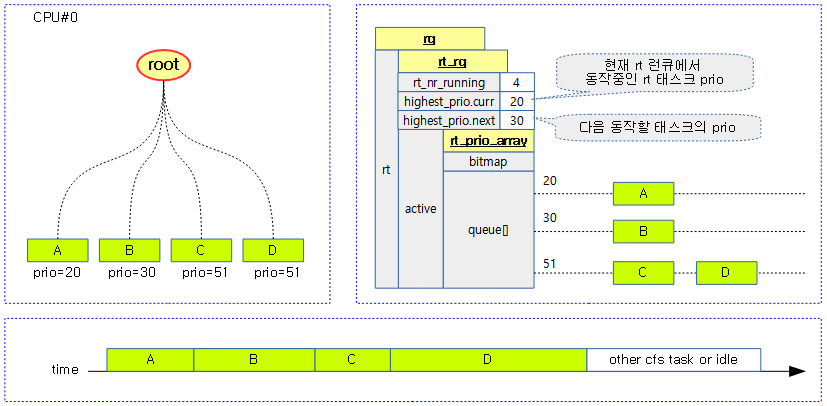
아래 그림은 cpu#0의 rt 런큐에 4개의 rt 태스크들이 큐잉되어 동작하는 모습을 보여준다. 동작하는 순서는 A 태스크부터 D 태스크까지 각 rt 태스크들이 디큐될 때마다 다음 우선 순위의 태스크가 실행된다.
RT 태스크는 한 번 실행되면 다음 조건으로만 멈추거나 다른 태스크로 변경될 수 있다.
RT 태스크의 우선 순위가 같을 때 처리 순서가 바뀌는 다음 2 가지의 RT 스케줄링 정책을 지원한다.
현재 처리하는 RT 태스크의 우선 순위보다 더 높은 우선 순위의 RT 태스크가 RT 런큐에 엔큐되면 당연히 우선 순위가 더 높은 RT 태스크를 실행한다. 하지만 기존 태스크가 커널에서 만들어진 커널용 태스크인 경우에는 커널의 preemption 옵션에 따라 우선 순위가 바뀌지 않을 수도 있고, 약간 지연 또는 즉각 반영되어 바뀔 수도 있다.
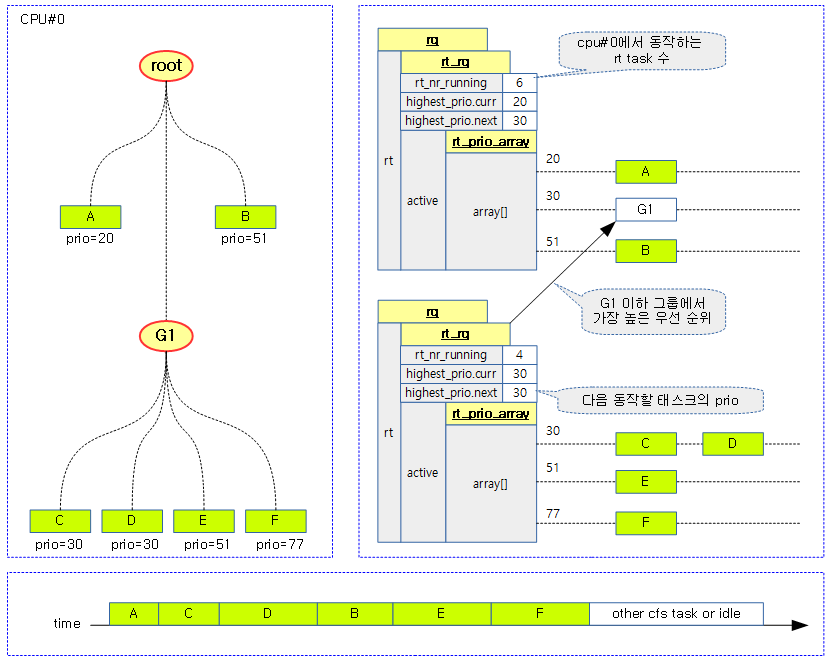
그룹 스케줄링을 사용하는 경우 아래 그림과 같이 관리된다. 우선 순위만 보면 RT 그룹 스케줄링을 사용하는 것과 사용하지 않는 것은 스케줄링에 대해 다른 점을 구별할 수 없다. RT 그룹 스케줄링을 사용할 때에는 RT 밴드위드에서 쓰임새가 달라진다. RT 밴드위드의 동작은 CFS 밴드위드의 동작과 거의 유사하게 동작한다. 그룹에 주기(period)와 런타임(runtime)이 주어지고 주기마다 런타임이 소진되면 rt 런큐가 스로틀되는 형태로 동일하다.
kernel/sched/rt.c
const struct sched_class rt_sched_class = {
.next = &fair_sched_class,
.enqueue_task = enqueue_task_rt,
.dequeue_task = dequeue_task_rt,
.yield_task = yield_task_rt,
.check_preempt_curr = check_preempt_curr_rt,
.pick_next_task = pick_next_task_rt,
.put_prev_task = put_prev_task_rt,
.set_next_task = set_next_task_rt,
#ifdef CONFIG_SMP
.balance = balance_rt,
.select_task_rq = select_task_rq_rt,
.set_cpus_allowed = set_cpus_allowed_common,
.rq_online = rq_online_rt,
.rq_offline = rq_offline_rt,
.task_woken = task_woken_rt,
.switched_from = switched_from_rt,
#endif
.task_tick = task_tick_rt,
.get_rr_interval = get_rr_interval_rt,
.prio_changed = prio_changed_rt,
.switched_to = switched_to_rt,
.update_curr = update_curr_rt,
#ifdef CONFIG_UCLAMP_TASK
.uclamp_enabled = 1,
#endif
};
kernel/sched/rt.c
/* * scheduler tick hitting a task of our scheduling class. * * NOTE: This function can be called remotely by the tick offload that * goes along full dynticks. Therefore no local assumption can be made * and everything must be accessed through the @rq and @curr passed in * parameters. */
static void task_tick_rt(struct rq *rq, struct task_struct *p, int queued)
{
struct sched_rt_entity *rt_se = &p->rt;
update_curr_rt(rq);
update_rt_rq_load_avg(rq_clock_pelt(rq), rq, 1);
watchdog(rq, p);
/*
* RR tasks need a special form of timeslice management.
* FIFO tasks have no timeslices.
*/
if (p->policy != SCHED_RR)
return;
if (--p->rt.time_slice)
return;
p->rt.time_slice = sched_rr_timeslice;
/*
* Requeue to the end of queue if we (and all of our ancestors) are not
* the only element on the queue
*/
for_each_sched_rt_entity(rt_se) {
if (rt_se->run_list.prev != rt_se->run_list.next) {
requeue_task_rt(rq, p, 0);
resched_curr(rq);
return;
}
}
}
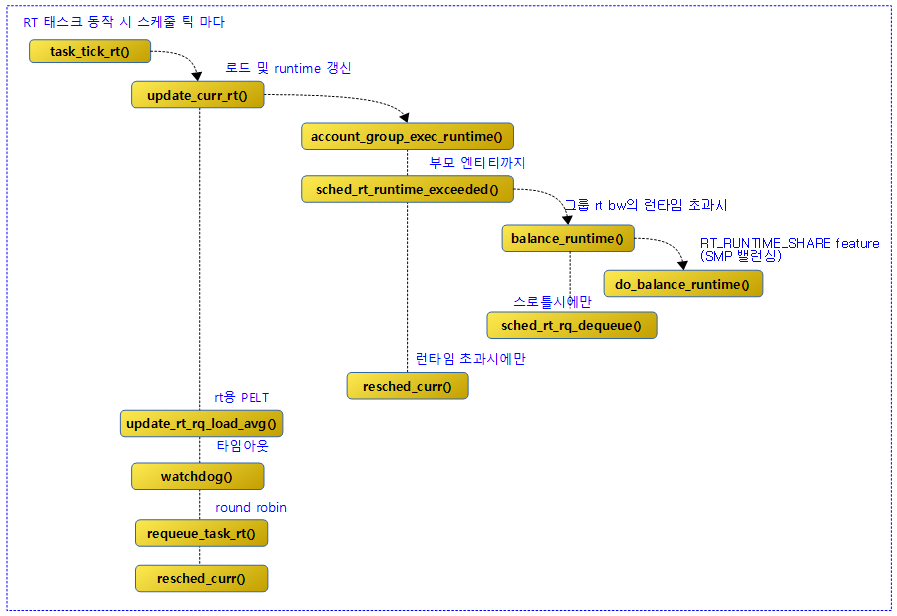
RT 스케줄러에서 스케줄 틱마다 다음과 같은 일들을 수행한다.
다음 그림은 task_tick_rt() 함수 이후의 호출 관계를 보여준다.
kernel/sched/rt.c
static void requeue_task_rt(struct rq *rq, struct task_struct *p, int head)
{
struct sched_rt_entity *rt_se = &p->rt;
struct rt_rq *rt_rq;
for_each_sched_rt_entity(rt_se) {
rt_rq = rt_rq_of_se(rt_se);
requeue_rt_entity(rt_rq, rt_se, head);
}
}
RT 태스크를 라운드 로빈 처리한다. @head=1일 때 리스트의 선두로, 0일 때 후미로 이동시킨다.
다음 그림은 같은 우선 순위를 가진 RT 태스크(R1, A1, A2)들이 라운드 로빈을 하는 모습을 보여준다.
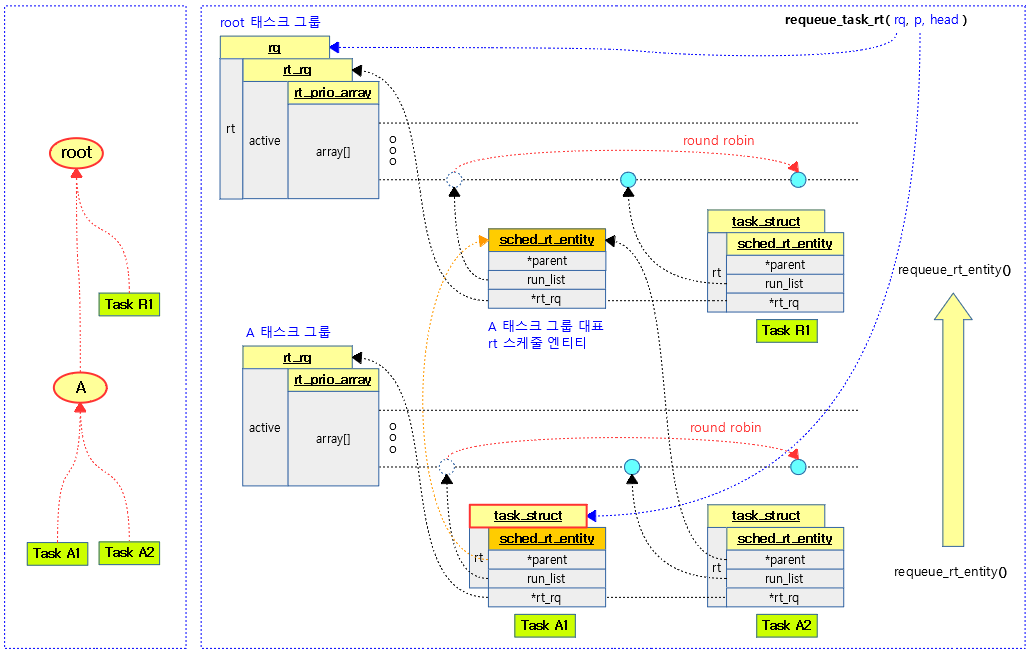
kernel/sched/rt.c
/* * Put task to the head or the end of the run list without the overhead of * dequeue followed by enqueue. */
static void
requeue_rt_entity(struct rt_rq *rt_rq, struct sched_rt_entity *rt_se, int head)
{
if (on_rt_rq(rt_se)) {
struct rt_prio_array *array = &rt_rq->active;
struct list_head *queue = array->queue + rt_se_prio(rt_se);
if (head)
list_move(&rt_se->run_list, queue);
else
list_move_tail(&rt_se->run_list, queue);
}
}
RT 스케줄 엔티티를 라운드 로빈 처리한다. 디큐 및 엔큐 처리로 인한 오버헤드를 없애기 위해 스케줄 엔티티만 이동시킨다.
다음 그림은 요청한 rt 엔티티를 라운드 로빈하는 것을 보여준다.

kernel/sched/rt.c
/* * Update the current task's runtime statistics. Skip current tasks that * are not in our scheduling class. */
static void update_curr_rt(struct rq *rq)
{
struct task_struct *curr = rq->curr;
struct sched_rt_entity *rt_se = &curr->rt;
u64 delta_exec;
u64 now;
if (curr->sched_class != &rt_sched_class)
return;
now = rq_clock_task(rq);
delta_exec = rq_clock_task(rq) - curr->se.exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
schedstat_set(curr->se.statistics.exec_max,
max(curr->se.statistics.exec_max, delta_exec));
curr->se.sum_exec_runtime += delta_exec;
account_group_exec_runtime(curr, delta_exec);
curr->se.exec_start = now;
cpuacct_charge(curr, delta_exec);
if (!rt_bandwidth_enabled())
return;
for_each_sched_rt_entity(rt_se) {
struct rt_rq *rt_rq = rt_rq_of_se(rt_se);
if (sched_rt_runtime(rt_rq) != RUNTIME_INF) {
raw_spin_lock(&rt_rq->rt_runtime_lock);
rt_rq->rt_time += delta_exec;
if (sched_rt_runtime_exceeded(rt_rq))
resched_curr(rq);
raw_spin_unlock(&rt_rq->rt_runtime_lock);
}
}
}
현재 동작 중인 rt 태스크의 런타임을 갱신한다. 그리고 라운드 로빈할 태스크가 있는 경우 리스케줄 요청한다.
다음 예와 같이 태스크 그룹에 대해 커널이 사용한 시간과 유저가 사용한 시간을 틱 수로 보여준다.
$ cat /sys/fs/cgroup/cpu/A/cpuacct.stat
user 47289
system 5
유저용 RT 태스크가 슬립 없이 일정 기간(rlimit) 이상 가동되는 경우 이 RT 태스크에 시그널을 전달한다. 별도의 시그널 처리기가 없으면 태스크가 종료된다.
kernel/sched/rt.c
static void watchdog(struct rq *rq, struct task_struct *p)
{
unsigned long soft, hard;
/* max may change after cur was read, this will be fixed next tick */
soft = task_rlimit(p, RLIMIT_RTTIME);
hard = task_rlimit_max(p, RLIMIT_RTTIME);
if (soft != RLIM_INFINITY) {
unsigned long next;
if (p->rt.watchdog_stamp != jiffies) {
p->rt.timeout++;
p->rt.watchdog_stamp = jiffies;
}
next = DIV_ROUND_UP(min(soft, hard), USEC_PER_SEC/HZ);
if (p->rt.timeout > next)
posix_cputimers_rt_watchdog(&p->posix_cputimers,
p->se.sum_exec_runtime);
}
}
유저용 rt 태스크에 제한시간(RLIMIT_RTTIME)이 설정된 경우 태스크의 cpu 시간 만료를 체크한다.
#include <sys/resource.h>
void main()
{
long long n = 0;
struct rlimit rlim;
rlim.rlim_cur = 2000000; /* us */
rlim.rlim_max = 3000000; /* us */
if (setrlimit(RLIMIT_RTTIME, &rlim) == -1)
return;
while (1)
n++;
}
gcc test.c -o test date +"%Y-%m-%d %H:%M:%S.%N" chrt -f 50 ./test date +"%Y-%m-%d %H:%M:%S.%N"
슬립없이 유저용 rt 태스크를 계속 돌리면 SIGXCPU 시그널이 발생된 후 다음과 같이 메시지를 출력하고 태스크를 종료시킨다.
$ ./run.sh
2020-10-21 20:36:48.014463532
./run.sh: line 3: 8697 CPU time limit exceeded chrt -f 50 ./test
2020-10-21 20:36:50.025738816
RT bandwidth 기능은 CFS 스케줄러와 달리 RT 그룹 스케줄링을 사용하지 않아도 항상 기본 동작하도록 설정되어 있다. 디폴트 값으로 다음과 같은 설정이 되어 있다.
커널이 cgroup을 사용하면서 CONFIG_RT_GROUP_SCHED 커널 옵션을 사용하여 RT 그룹 스케줄링을 동작시키는 경우 태스크 그룹마다 bandwidth 기능을 설정하여 사용할 수 있게 된다.
디폴트 설정을 그대로 사용하는 경우 rt 태스크는 1초 기간 내에 0.95초 만큼 런타임을 사용할 수 있다. 이는 1개의 cpu를 사용하는 시스템을 가정할 때 최대 95%의 cpu를 rt 스케줄러가 점유할 수 있도록 한다.
kernel/sched/rt.c
void init_rt_bandwidth(struct rt_bandwidth *rt_b, u64 period, u64 runtime)
{
rt_b->rt_period = ns_to_ktime(period);
rt_b->rt_runtime = runtime;
raw_spin_lock_init(&rt_b->rt_runtime_lock);
hrtimer_init(&rt_b->rt_period_timer,
CLOCK_MONOTONIC, HRTIMER_MODE_REL);
rt_b->rt_period_timer.function = sched_rt_period_timer;
}
rt period와 runtime 값을 사용하여 초기화한다.
kernel/sched/core.c
static int sched_group_set_rt_runtime(struct task_group *tg, long rt_runtime_us)
{
u64 rt_runtime, rt_period;
rt_period = ktime_to_ns(tg->rt_bandwidth.rt_period);
rt_runtime = (u64)rt_runtime_us * NSEC_PER_USEC;
if (rt_runtime_us < 0)
rt_runtime = RUNTIME_INF;
else if ((u64)rt_runtime_us > U64_MAX / NSEC_PER_USEC)
return -EINVAL;
return tg_set_rt_bandwidth(tg, rt_period, rt_runtime);
}
요청한 태스크 그룹에 rt 런타임(us)을 나노초로 변경하여 설정한다.
kernel/sched/core.c
static int sched_group_set_rt_period(struct task_group *tg, long rt_period_us)
{
u64 rt_runtime, rt_period;
if (tg->rt_bandwidth.rt_runtime == RUNTIME_INF)
return -1;
rt_period = (u64)rt_period_us * NSEC_PER_USEC;
rt_runtime = tg->rt_bandwidth.rt_runtime;
return tg_set_rt_bandwidth(tg, rt_period, rt_runtime);
}
요청한 태스크 그룹에 rt period(us) 값을 나노초로 변경하여 설정한다.
kernel/sched/core.c
static int tg_set_rt_bandwidth(struct task_group *tg,
u64 rt_period, u64 rt_runtime)
{
int i, err = 0;
/*
* Disallowing the root group RT runtime is BAD, it would disallow the
* kernel creating (and or operating) RT threads.
*/
if (tg == &root_task_group && rt_runtime == 0)
return -EINVAL;
/* No period doesn't make any sense. */
if (rt_period == 0)
return -EINVAL;
mutex_lock(&rt_constraints_mutex);
read_lock(&tasklist_lock);
err = __rt_schedulable(tg, rt_period, rt_runtime);
if (err)
goto unlock;
raw_spin_lock_irq(&tg->rt_bandwidth.rt_runtime_lock);
tg->rt_bandwidth.rt_period = ns_to_ktime(rt_period);
tg->rt_bandwidth.rt_runtime = rt_runtime;
for_each_possible_cpu(i) {
struct rt_rq *rt_rq = tg->rt_rq[i];
raw_spin_lock(&rt_rq->rt_runtime_lock);
rt_rq->rt_runtime = rt_runtime;
raw_spin_unlock(&rt_rq->rt_runtime_lock);
}
raw_spin_unlock_irq(&tg->rt_bandwidth.rt_runtime_lock);
unlock:
read_unlock(&tasklist_lock);
mutex_unlock(&rt_constraints_mutex);
return err;
}
kernel/sched/rt.c
static int sched_rt_runtime_exceeded(struct rt_rq *rt_rq)
{
u64 runtime = sched_rt_runtime(rt_rq);
if (rt_rq->rt_throttled)
return rt_rq_throttled(rt_rq);
if (runtime >= sched_rt_period(rt_rq))
return 0;
balance_runtime(rt_rq);
runtime = sched_rt_runtime(rt_rq);
if (runtime == RUNTIME_INF)
return 0;
if (rt_rq->rt_time > runtime) {
struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq);
/*
* Don't actually throttle groups that have no runtime assigned
* but accrue some time due to boosting.
*/
if (likely(rt_b->rt_runtime)) {
rt_rq->rt_throttled = 1;
printk_deferred_once("sched: RT throttling activated\n");
} else {
/*
* In case we did anyway, make it go away,
* replenishment is a joke, since it will replenish us
* with exactly 0 ns.
*/
rt_rq->rt_time = 0;
}
if (rt_rq_throttled(rt_rq)) {
sched_rt_rq_dequeue(rt_rq);
return 1;
}
}
return 0;
}
RT 로컬에서 소모한 런타임이 할당된 런타임을 초과한 경우 밸런싱 작업을 수행한다. 스로틀이 필요한 경우 1을 반환한다.
다음 그림과 같이 소모한 런타임이 초과된 경우 UP 시스템에서 처리되는 모습을 보여준다.
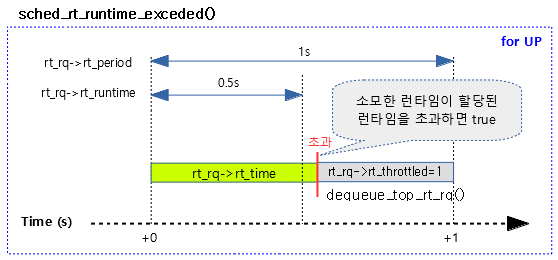
kernel/sched/rt.c
static void sched_rt_rq_dequeue(struct rt_rq *rt_rq)
{
struct sched_rt_entity *rt_se;
int cpu = cpu_of(rq_of_rt_rq(rt_rq));
rt_se = rt_rq->tg->rt_se[cpu];
if (!rt_se) {
dequeue_top_rt_rq(rt_rq);
/* Kick cpufreq (see the comment in kernel/sched/sched.h). */
cpufreq_update_util(rq_of_rt_rq(rt_rq), 0);
}
else if (on_rt_rq(rt_se))
dequeue_rt_entity(rt_se, 0);
}
rt 런큐를 디큐한다.
kernel/sched/rt.c
static void sched_rt_rq_enqueue(struct rt_rq *rt_rq)
{
struct task_struct *curr = rq_of_rt_rq(rt_rq)->curr;
struct rq *rq = rq_of_rt_rq(rt_rq);
struct sched_rt_entity *rt_se;
int cpu = cpu_of(rq);
rt_se = rt_rq->tg->rt_se[cpu];
if (rt_rq->rt_nr_running) {
if (!rt_se)
enqueue_top_rt_rq(rt_rq);
else if (!on_rt_rq(rt_se))
enqueue_rt_entity(rt_se, 0);
if (rt_rq->highest_prio.curr < curr->prio)
resched_curr(rq);
}
}
rt 런큐를 엔큐한다.
kernel/sched/rt.c
static void
dequeue_top_rt_rq(struct rt_rq *rt_rq)
{
struct rq *rq = rq_of_rt_rq(rt_rq);
BUG_ON(&rq->rt != rt_rq);
if (!rt_rq->rt_queued)
return;
BUG_ON(!rq->nr_running);
sub_nr_running(rq, rt_rq->rt_nr_running);
rt_rq->rt_queued = 0;
}
최상위 rt 런큐를 디큐 상태로 바꾸고 동작했던 태스크 수만큼 런큐에서 감소시킨다. (rq->nr_running 갱신)
다음 그림은 rt 런큐의 디큐와 엔큐 처리 과정을 보여준다.
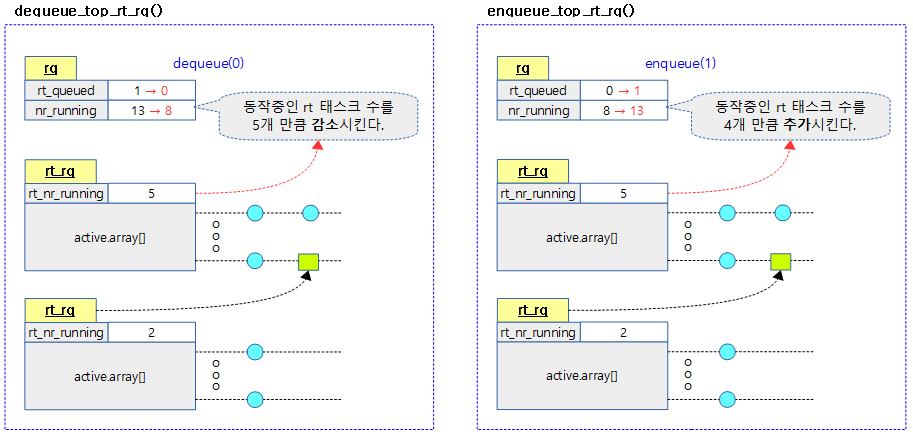
kernel/sched/rt.c
static void
enqueue_top_rt_rq(struct rt_rq *rt_rq)
{
struct rq *rq = rq_of_rt_rq(rt_rq);
BUG_ON(&rq->rt != rt_rq);
if (rt_rq->rt_queued)
return;
if (rt_rq_throttled(rt_rq))
return;
if (rt_rq->rt_nr_running) {
add_nr_running(rq, rt_rq->rt_nr_running);
rt_rq->rt_queued = 1;
}
/* Kick cpufreq (see the comment in kernel/sched/sched.h). */
cpufreq_update_util(rq, 0);
}
최상위 rt 런큐를 엔큐 상태로 바꾸고 최상위 rt 런큐에있는 태스크 수만큼 증가시킨다. (rq->nr_running 갱신)
kernel/sched/rt.c
static void balance_runtime(struct rt_rq *rt_rq)
{
if (!sched_feat(RT_RUNTIME_SHARE))
return;
if (rt_rq->rt_time > rt_rq->rt_runtime) {
raw_spin_unlock(&rt_rq->rt_runtime_lock);
do_balance_runtime(rt_rq);
raw_spin_lock(&rt_rq->rt_runtime_lock);
}
}
요청한 rt 런큐의 할당된 런타임을 모두 소모한 경우 다른 rt 로컬 풀로부터 빌려와서 최대한 rt_period 만큼 더 할당하여 늘리도록 밸런싱을 수행한다.
다음 그림은 RT_RUNTIME_SHARE 기능을 사용하지 않을 때 특정 태스크 그룹의 rt 밴드위드의 동작을 보여준다.
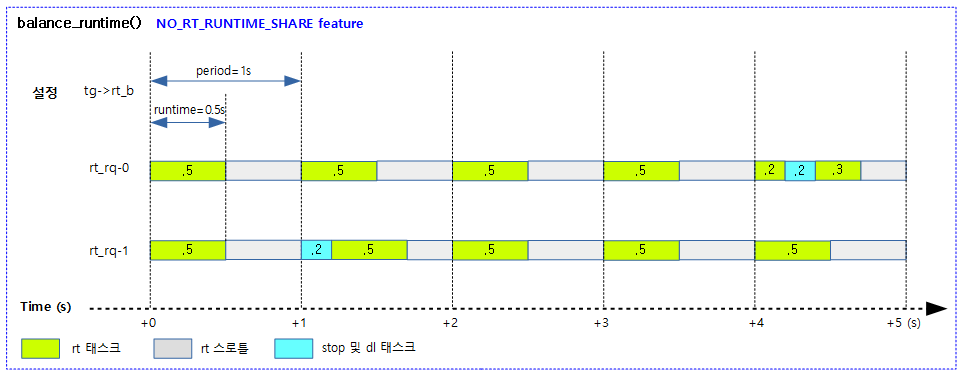
다음 그림은 RT_RUNTIME_SHARE 기능을 사용할 때 특정 태스크 그룹의 rt 밴드위드의 동작을 보여준다.
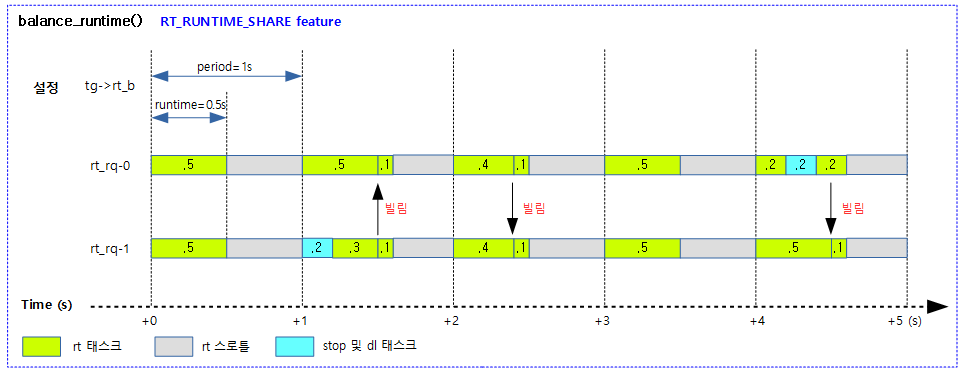
kernel/sched/rt.c
/* * We ran out of runtime, see if we can borrow some from our neighbours. */
static void do_balance_runtime(struct rt_rq *rt_rq)
{
struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq);
struct root_domain *rd = rq_of_rt_rq(rt_rq)->rd;
int i, weight;
u64 rt_period;
weight = cpumask_weight(rd->span);
raw_spin_lock(&rt_b->rt_runtime_lock);
rt_period = ktime_to_ns(rt_b->rt_period);
for_each_cpu(i, rd->span) {
struct rt_rq *iter = sched_rt_period_rt_rq(rt_b, i);
s64 diff;
if (iter == rt_rq)
continue;
raw_spin_lock(&iter->rt_runtime_lock);
/*
* Either all rqs have inf runtime and there's nothing to steal
* or __disable_runtime() below sets a specific rq to inf to
* indicate its been disabled and disalow stealing.
*/
if (iter->rt_runtime == RUNTIME_INF)
goto next;
/*
* From runqueues with spare time, take 1/n part of their
* spare time, but no more than our period.
*/
diff = iter->rt_runtime - iter->rt_time;
if (diff > 0) {
diff = div_u64((u64)diff, weight);
if (rt_rq->rt_runtime + diff > rt_period)
diff = rt_period - rt_rq->rt_runtime;
iter->rt_runtime -= diff;
rt_rq->rt_runtime += diff;
if (rt_rq->rt_runtime == rt_period) {
raw_spin_unlock(&iter->rt_runtime_lock);
break;
}
}
next:
raw_spin_unlock(&iter->rt_runtime_lock);
}
raw_spin_unlock(&rt_b->rt_runtime_lock);
}
요청한 rt 로컬 런큐에 런타임 할당량을 루트 도메인의 다른 rt 로컬 런큐에서 사용하고 남은 만큼 빌려 할당한다.
다음 그림은 enqueue_rt_entity()와 dequeue_rt_entity() 함수의 함수간 처리 흐름도이다.
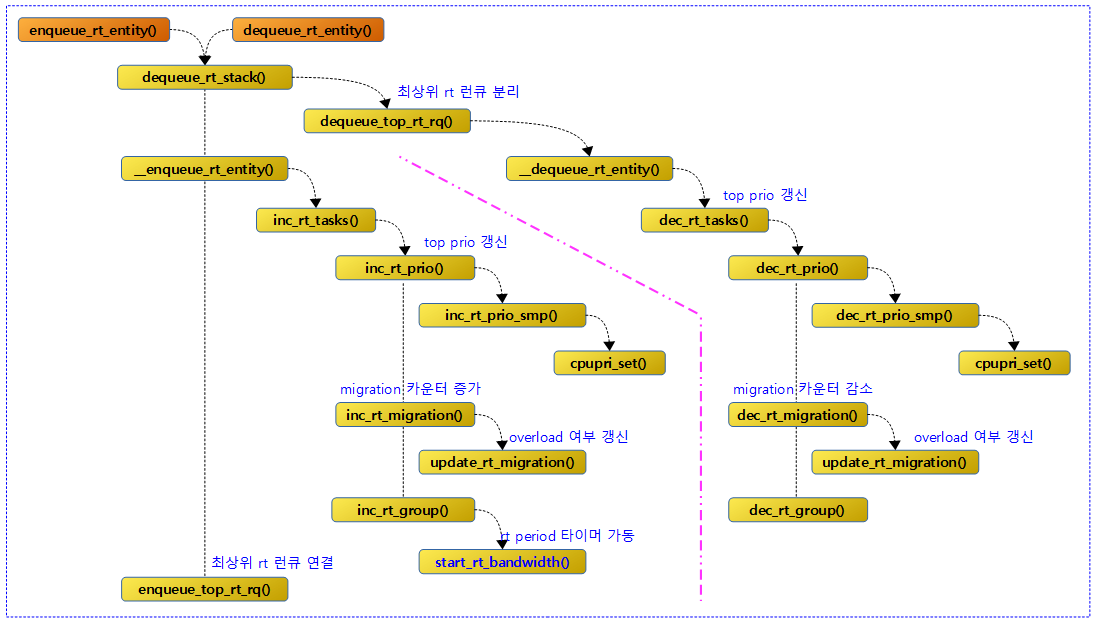
kernel/sched/rt.c
static void enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head)
{
struct rq *rq = rq_of_rt_se(rt_se);
dequeue_rt_stack(rt_se);
for_each_sched_rt_entity(rt_se)
__enqueue_rt_entity(rt_se, head);
enqueue_top_rt_rq(&rq->rt);
}
rt 엔티티를 엔큐한다.
kernel/sched/rt.c
static void dequeue_rt_entity(struct sched_rt_entity *rt_se)
{
struct rq *rq = rq_of_rt_se(rt_se);
dequeue_rt_stack(rt_se);
for_each_sched_rt_entity(rt_se) {
struct rt_rq *rt_rq = group_rt_rq(rt_se);
if (rt_rq && rt_rq->rt_nr_running)
__enqueue_rt_entity(rt_se, false);
}
enqueue_top_rt_rq(&rq->rt);
}
rt 엔티티를 디큐한다.
kernel/sched/rt.c
/* * Because the prio of an upper entry depends on the lower * entries, we must remove entries top - down. */
static void dequeue_rt_stack(struct sched_rt_entity *rt_se)
{
struct sched_rt_entity *back = NULL;
for_each_sched_rt_entity(rt_se) {
rt_se->back = back;
back = rt_se;
}
dequeue_top_rt_rq(rt_rq_of_se(back));
for (rt_se = back; rt_se; rt_se = rt_se->back) {
if (on_rt_rq(rt_se))
__dequeue_rt_entity(rt_se);
}
}
최상위 rt 엔티티부터 요청한 rt 엔티티까지 top-down 방향으로 rt 엔티티들을 디큐한다.
kernel/sched/rt.c
static void __enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head)
{
struct rt_rq *rt_rq = rt_rq_of_se(rt_se);
struct rt_prio_array *array = &rt_rq->active;
struct rt_rq *group_rq = group_rt_rq(rt_se);
struct list_head *queue = array->queue + rt_se_prio(rt_se);
/*
* Don't enqueue the group if its throttled, or when empty.
* The latter is a consequence of the former when a child group
* get throttled and the current group doesn't have any other
* active members.
*/
if (group_rq && (rt_rq_throttled(group_rq) || !group_rq->rt_nr_running))
return;
if (head)
list_add(&rt_se->run_list, queue);
else
list_add_tail(&rt_se->run_list, queue);
__set_bit(rt_se_prio(rt_se), array->bitmap);
inc_rt_tasks(rt_se, rt_rq);
}
rt 엔티티를 rt 런큐에 엔큐한다.
kernel/sched/rt.c
static void __dequeue_rt_entity(struct sched_rt_entity *rt_se)
{
struct rt_rq *rt_rq = rt_rq_of_se(rt_se);
struct rt_prio_array *array = &rt_rq->active;
if (move_entity(flags)) {
WARN_ON_ONCE(!rt_se->on_list);
__delist_rt_entity(rt_se, array);
}
rt_se->on_rq = 0;
dec_rt_tasks(rt_se, rt_rq);
}
rt 엔티티를 rt 런큐에서 디큐한다.
kernel/sched/rt.c
static inline
void inc_rt_tasks(struct sched_rt_entity *rt_se, struct rt_rq *rt_rq)
{
int prio = rt_se_prio(rt_se);
WARN_ON(!rt_prio(prio));
rt_rq->rt_nr_running += rt_se_nr_running(rt_se);
rt_rq->rr_nr_running += rt_se_rr_nr_running(rt_se);
inc_rt_prio(rt_rq, prio);
inc_rt_migration(rt_se, rt_rq);
inc_rt_group(rt_se, rt_rq);
}
엔큐한 rt 엔티티에 대한 후속 작업을 수행한다.
kernel/sched/rt.c
static inline
void dec_rt_tasks(struct sched_rt_entity *rt_se, struct rt_rq *rt_rq)
{
WARN_ON(!rt_prio(rt_se_prio(rt_se)));
WARN_ON(!rt_rq->rt_nr_running);
rt_rq->rt_nr_running -= rt_se_nr_running(rt_se);
rt_rq->rr_nr_running -= rt_se_rr_nr_running(rt_se);
dec_rt_prio(rt_rq, rt_se_prio(rt_se));
dec_rt_migration(rt_se, rt_rq);
dec_rt_group(rt_se, rt_rq);
}
디큐한 rt 엔티티에 대한 후속 작업을 진행한다.
kernel/sched/rt.c
static inline
unsigned int rt_se_nr_running(struct sched_rt_entity *rt_se)
{
struct rt_rq *group_rq = group_rt_rq(rt_se);
if (group_rq)
return group_rq->rt_nr_running;
else
return 1;
}
rt 엔티티와 관련된 태스크 수를 반환한다. rt 엔티티가 태스크이면 1을 반환하고, 태스크 그룹용이면 태스크 그룹을 포함한 그 이하 child 태스크의 수를 반환한다.
kernel/sched/rt.c
static inline
unsigned int rt_se_rr_nr_running(struct sched_rt_entity *rt_se)
{
struct rt_rq *group_rq = group_rt_rq(rt_se);
struct task_struct *tsk;
if (group_rq)
return group_rq->rr_nr_running;
tsk = rt_task_of(rt_se);
return (tsk->policy == SCHED_RR) ? 1 : 0;
}
round robin policy를 가진 rt 엔티티와 관련된 태스크 수를 반환한다. rt 엔티티가 rr 태스크이면 1을 반환하고, 태스크 그룹용이면 태스크 그룹을 포함한 그 이하 child rr 태스크의 수를 반환한다.
다음과 같이 총 102개의 우선 순위를 관리한다.
위의 102 단계의 우선 순위를 다음과 같이 즉각 변환하도록 관리한다.
다음 그림은 cpu와 priority와의 컨버전에 사용되는 배열을 보여준다.
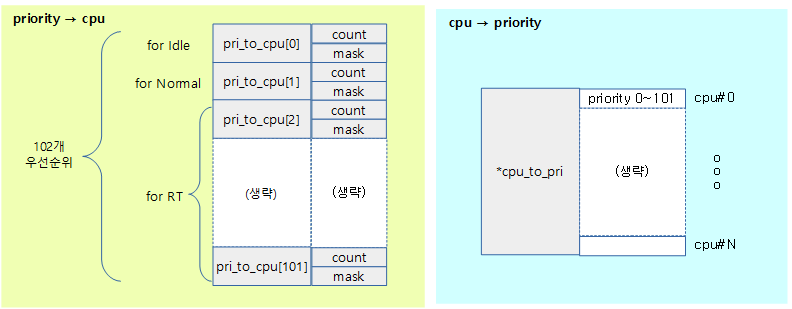
kernel/sched/rt.c
static void
inc_rt_prio(struct rt_rq *rt_rq, int prio)
{
int prev_prio = rt_rq->highest_prio.curr;
if (prio < prev_prio)
rt_rq->highest_prio.curr = prio;
inc_rt_prio_smp(rt_rq, prio, prev_prio);
}
엔큐된 rt 엔티티로 인해 최고 우선 순위가 변경된 경우 이를 갱신하고 cpupri 설정도 수행한다.
kernel/sched/rt.c
static void
dec_rt_prio(struct rt_rq *rt_rq, int prio)
{
int prev_prio = rt_rq->highest_prio.curr;
if (rt_rq->rt_nr_running) {
WARN_ON(prio < prev_prio);
/*
* This may have been our highest task, and therefore
* we may have some recomputation to do
*/
if (prio == prev_prio) {
struct rt_prio_array *array = &rt_rq->active;
rt_rq->highest_prio.curr =
sched_find_first_bit(array->bitmap);
}
} else
rt_rq->highest_prio.curr = MAX_RT_PRIO;
dec_rt_prio_smp(rt_rq, prio, prev_prio);
}
디큐된 rt 엔티티로 인해 최고 우선 순위가 변경된 경우 이를 갱신하고 cpupri 설정도 수행한다.
kernel/sched/rt.c
static void
inc_rt_prio_smp(struct rt_rq *rt_rq, int prio, int prev_prio)
{
struct rq *rq = rq_of_rt_rq(rt_rq);
#ifdef CONFIG_RT_GROUP_SCHED
/*
* Change rq's cpupri only if rt_rq is the top queue.
*/
if (&rq->rt != rt_rq)
return;
#endif
if (rq->online && prio < prev_prio)
cpupri_set(&rq->rd->cpupri, rq->cpu, prio);
}
요청한 rt 런큐에서 가장 높은 우선 순위인 경우 cpu와 우선 순위를 cpupri에 설정한다.
kernel/sched/rt.c
static void
dec_rt_prio_smp(struct rt_rq *rt_rq, int prio, int prev_prio)
{
struct rq *rq = rq_of_rt_rq(rt_rq);
#ifdef CONFIG_RT_GROUP_SCHED
/*
* Change rq's cpupri only if rt_rq is the top queue.
*/
if (&rq->rt != rt_rq)
return;
#endif
if (rq->online && rt_rq->highest_prio.curr != prev_prio)
cpupri_set(&rq->rd->cpupri, rq->cpu, rt_rq->highest_prio.curr);
}
요청한 rt 런큐에서 요청한 우선 순위가 가장 높은 우선 순위인 경우 cpu와 차순위로 갱신된 최고 우선 순위를 cpupri에 설정한다.
요청한 cpu와 현재 동작 중인 스케줄러내에서의 최고 우선 순위를 cpupri에 설정한다.
kernel/sched/cpupri.c – 1/2
/** * cpupri_set - update the cpu priority setting * @cp: The cpupri context * @cpu: The target cpu * @newpri: The priority (INVALID-RT99) to assign to this CPU * * Note: Assumes cpu_rq(cpu)->lock is locked * * Returns: (void) */
void cpupri_set(struct cpupri *cp, int cpu, int newpri)
{
int *currpri = &cp->cpu_to_pri[cpu];
int oldpri = *currpri;
int do_mb = 0;
newpri = convert_prio(newpri);
BUG_ON(newpri >= CPUPRI_NR_PRIORITIES);
if (newpri == oldpri)
return;
/*
* If the cpu was currently mapped to a different value, we
* need to map it to the new value then remove the old value.
* Note, we must add the new value first, otherwise we risk the
* cpu being missed by the priority loop in cpupri_find.
*/
if (likely(newpri != CPUPRI_INVALID)) {
struct cpupri_vec *vec = &cp->pri_to_cpu[newpri];
cpumask_set_cpu(cpu, vec->mask);
/*
* When adding a new vector, we update the mask first,
* do a write memory barrier, and then update the count, to
* make sure the vector is visible when count is set.
*/
smp_mb__before_atomic();
atomic_inc(&(vec)->count);
do_mb = 1;
}
kernel/sched/cpupri.c – 2/2
if (likely(oldpri != CPUPRI_INVALID)) {
struct cpupri_vec *vec = &cp->pri_to_cpu[oldpri];
/*
* Because the order of modification of the vec->count
* is important, we must make sure that the update
* of the new prio is seen before we decrement the
* old prio. This makes sure that the loop sees
* one or the other when we raise the priority of
* the run queue. We don't care about when we lower the
* priority, as that will trigger an rt pull anyway.
*
* We only need to do a memory barrier if we updated
* the new priority vec.
*/
if (do_mb)
smp_mb__after_atomic();
/*
* When removing from the vector, we decrement the counter first
* do a memory barrier and then clear the mask.
*/
atomic_dec(&(vec)->count);
smp_mb__after_atomic();
cpumask_clear_cpu(cpu, vec->mask);
}
*currpri = newpri;
}
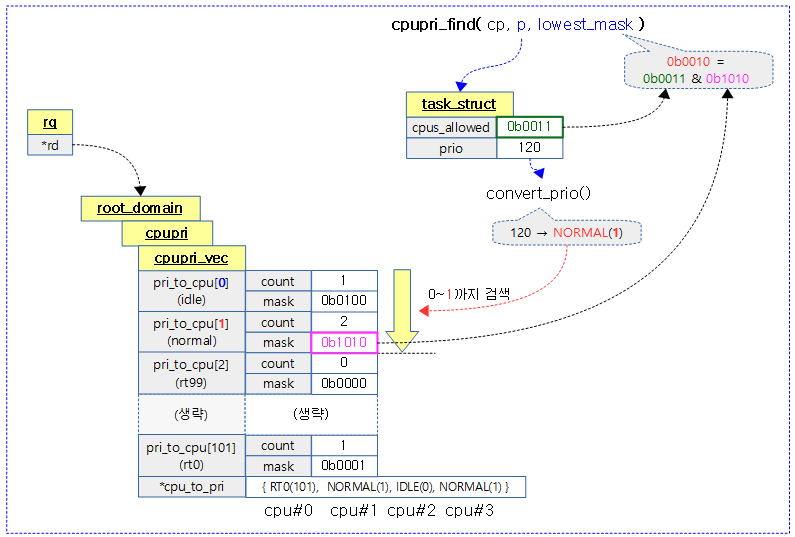
다음 그림은 루트 도메인의 cpupri 내부에 있는 102개의 cpupri 벡터와 cpu_to_pri를 갱신하는 모습을 보여준다.
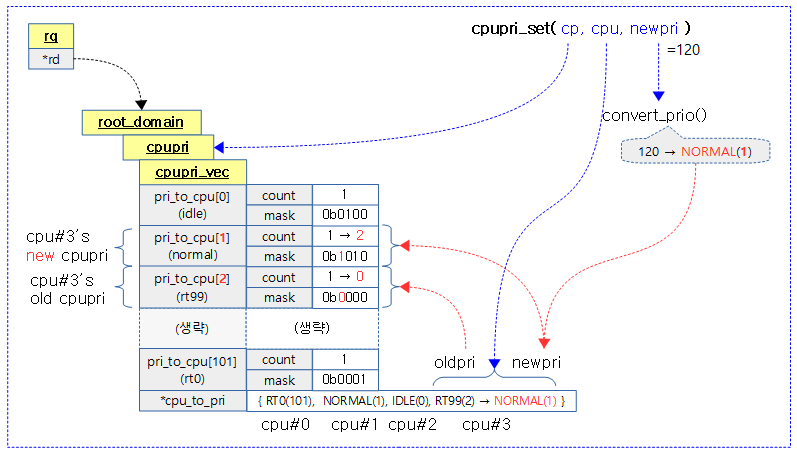
kernel/sched/cpupri.c
/* Convert between a 140 based task->prio, and our 102 based cpupri */
static int convert_prio(int prio)
{
int cpupri;
if (prio == CPUPRI_INVALID)
cpupri = CPUPRI_INVALID;
else if (prio == MAX_PRIO)
cpupri = CPUPRI_IDLE;
else if (prio >= MAX_RT_PRIO)
cpupri = CPUPRI_NORMAL;
else
cpupri = MAX_RT_PRIO - prio + 1;
return cpupri;
}
태스크 기반의 140단계 우선 순위를 102단계의 cpupri로 변환하여 반환한다.
다음 그림은 태스크 기반의 140단계 우선 순위를 102단계의 cpupri로 변경하는 모습을 보여준다.

kernel/sched/cpupri.c
/** * cpupri_find - find the best (lowest-pri) CPU in the system * @cp: The cpupri context * @p: The task * @lowest_mask: A mask to fill in with selected CPUs (or NULL) * * Note: This function returns the recommended CPUs as calculated during the * current invocation. By the time the call returns, the CPUs may have in * fact changed priorities any number of times. While not ideal, it is not * an issue of correctness since the normal rebalancer logic will correct * any discrepancies created by racing against the uncertainty of the current * priority configuration. * * Return: (int)bool - CPUs were found */
int cpupri_find(struct cpupri *cp, struct task_struct *p,
struct cpumask *lowest_mask)
{
int idx = 0;
int task_pri = convert_prio(p->prio);
BUG_ON(task_pri >= CPUPRI_NR_PRIORITIES);
for (idx = 0; idx < task_pri; idx++) {
struct cpupri_vec *vec = &cp->pri_to_cpu[idx];
int skip = 0;
if (!atomic_read(&(vec)->count))
skip = 1;
/*
* When looking at the vector, we need to read the counter,
* do a memory barrier, then read the mask.
*
* Note: This is still all racey, but we can deal with it.
* Ideally, we only want to look at masks that are set.
*
* If a mask is not set, then the only thing wrong is that we
* did a little more work than necessary.
*
* If we read a zero count but the mask is set, because of the
* memory barriers, that can only happen when the highest prio
* task for a run queue has left the run queue, in which case,
* it will be followed by a pull. If the task we are processing
* fails to find a proper place to go, that pull request will
* pull this task if the run queue is running at a lower
* priority.
*/
smp_rmb();
/* Need to do the rmb for every iteration */
if (skip)
continue;
if (cpumask_any_and(&p->cpus_allowed, vec->mask) >= nr_cpu_ids)
continue;
if (lowest_mask) {
cpumask_and(lowest_mask, &p->cpus_allowed, vec->mask);
/*
* We have to ensure that we have at least one bit
* still set in the array, since the map could have
* been concurrently emptied between the first and
* second reads of vec->mask. If we hit this
* condition, simply act as though we never hit this
* priority level and continue on.
*/
if (cpumask_any(lowest_mask) >= nr_cpu_ids)
continue;
}
return 1;
}
return 0;
}
102 단계의 가장 낮은 우선 순위부터 요청한 태스크의 우선순위 범위 이내에서 동작할 수 있는 cpu가 있는지 여부를 찾아 반환한다. cpu를 찾은 경우 1을 반환한다. 또한 출력 인수 lowest_mask에 찾은 best(lowest) 우선순위에서 동작할 수 있는 cpumask를 반환한다.
다음 그림은 102단계의 cpupri 벡터들에서 가장 낮은 우선 순위 0부터 요청한 태스크의 우선순위까지 검색하여 best (lowest) 우선 순위의 cpu들을 찾는 모습을 보여준다.
최상위 rt 런큐에 rt 태스크가 엔큐될 때마다 그 태스크가 2 개 이상이면서 2 개 이상의 cpu로 할당된 경우 오버로드될 수 있다고 판단한다.
kernel/sched/rt.c
static void inc_rt_migration(struct sched_rt_entity *rt_se, struct rt_rq *rt_rq)
{
struct task_struct *p;
if (!rt_entity_is_task(rt_se))
return;
p = rt_task_of(rt_se);
rt_rq = &rq_of_rt_rq(rt_rq)->rt;
rt_rq->rt_nr_total++;
if (p->nr_cpus_allowed > 1)
rt_rq->rt_nr_migratory++;
update_rt_migration(rt_rq);
}
rt 태스크의 수를 증가시킨다. 또한 rt 태스크가 이주 가능한 경우 이주가능한 rt 태스크의 수를 증가시킨다.
kernel/sched/rt.c
static void dec_rt_migration(struct sched_rt_entity *rt_se, struct rt_rq *rt_rq)
{
struct task_struct *p;
if (!rt_entity_is_task(rt_se))
return;
p = rt_task_of(rt_se);
rt_rq = &rq_of_rt_rq(rt_rq)->rt;
rt_rq->rt_nr_total--;
if (p->nr_cpus_allowed > 1)
rt_rq->rt_nr_migratory--;
update_rt_migration(rt_rq);
}
rt 태스크의 수를 감소시킨다. 또한 rt 태스크가 이주 가능한 경우 이주가능한 rt 태스크의 수를 감소시킨다.
이주와 관련된 멤버들
kernel/sched/rt.c
static void update_rt_migration(struct rt_rq *rt_rq)
{
if (rt_rq->rt_nr_migratory && rt_rq->rt_nr_total > 1) {
if (!rt_rq->overloaded) {
rt_set_overload(rq_of_rt_rq(rt_rq));
rt_rq->overloaded = 1;
}
} else if (rt_rq->overloaded) {
rt_clear_overload(rq_of_rt_rq(rt_rq));
rt_rq->overloaded = 0;
}
}
요청한 RT 런큐의 이주와 관련된 상태를 갱신한다. RT 런큐에 2 개 이상의 태스크가 있는 경우 오버로드 상태로 설정한다. 이미 오버로드된 상태라면 클리어한다.
RT 런큐에 2 개 이상의 태스크가 엔큐된 경우 이를 오버로드라 부르고 트래킹하기 위해 사용한다.
참고: sched: add rt-overload tracking
kernel/sched/rt.c
static inline void rt_set_overload(struct rq *rq)
{
if (!rq->online)
return;
cpumask_set_cpu(rq->cpu, rq->rd->rto_mask);
/*
* Make sure the mask is visible before we set
* the overload count. That is checked to determine
* if we should look at the mask. It would be a shame
* if we looked at the mask, but the mask was not
* updated yet.
*
* Matched by the barrier in pull_rt_task().
*/
smp_wmb();
atomic_inc(&rq->rd->rto_count);
}
rt 오버로드 카운터를 증가시키고 rt 오버로드 마스크 중 해당 cpu의 비트를 설정한다.
kernel/sched/rt.c
static inline void rt_clear_overload(struct rq *rq)
{
if (!rq->online)
return;
/* the order here really doesn't matter */
atomic_dec(&rq->rd->rto_count);
cpumask_clear_cpu(rq->cpu, rq->rd->rto_mask);
}
rt 오버로드 카운터를 감소시키고 rt 오버로드 마스크 중 해당 cpu의 비트를 클리어한다.
kernel/sched/rt.c
static void
inc_rt_group(struct sched_rt_entity *rt_se, struct rt_rq *rt_rq)
{
if (rt_se_boosted(rt_se))
rt_rq->rt_nr_boosted++;
if (rt_rq->tg)
start_rt_bandwidth(&rt_rq->tg->rt_bandwidth);
}
요청한 rt 런큐가 부스팅중이면 boosted 카운터를 증가시킨다. 그리고 그룹에 대한 rt period 타이머를 가동시킨다.
kernel/sched/rt.c
static void
dec_rt_group(struct sched_rt_entity *rt_se, struct rt_rq *rt_rq)
{
if (rt_se_boosted(rt_se))
rt_rq->rt_nr_boosted--;
WARN_ON(!rt_rq->rt_nr_running && rt_rq->rt_nr_boosted);
}
요청한 rt 런큐가 부스팅중이면 boosted 카운터를 감소시킨다.
다음 그림은 rt period 타이머에 대한 가동과 호출 함수에 대한 함수간 처리 흐름을 보여준다.
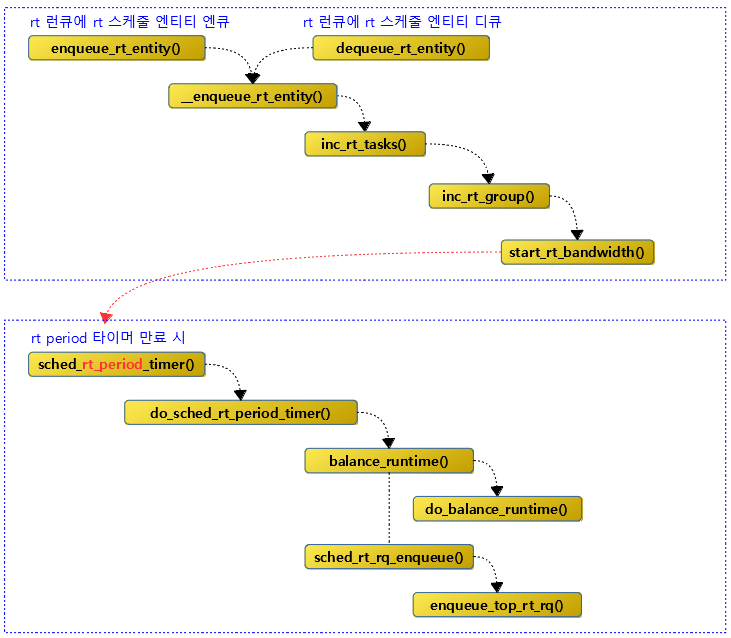
kernel/sched/rt.c
static void start_rt_bandwidth(struct rt_bandwidth *rt_b)
{
if (!rt_bandwidth_enabled() || rt_b->rt_runtime == RUNTIME_INF)
return;
raw_spin_lock(&rt_b->rt_runtime_lock);
if (!rt_b->rt_period_active) {
rt_b->rt_period_active = 1;
/*
* SCHED_DEADLINE updates the bandwidth, as a run away
* RT task with a DL task could hog a CPU. But DL does
* not reset the period. If a deadline task was running
* without an RT task running, it can cause RT tasks to
* throttle when they start up. Kick the timer right away
* to update the period.
*/
hrtimer_forward_now(&rt_b->rt_period_timer, ns_to_ktime(0));
hrtimer_start_expires(&rt_b->rt_period_timer,
HRTIMER_MODE_ABS_PINNED_HARD);
}
raw_spin_unlock(&rt_b->rt_runtime_lock);
}
rt bandwidth용 period 타이머를 동작시킨다.
kernel/sched/rt.c
static enum hrtimer_restart sched_rt_period_timer(struct hrtimer *timer)
{
struct rt_bandwidth *rt_b =
container_of(timer, struct rt_bandwidth, rt_period_timer);
int idle = 0;
int overrun;
raw_spin_lock(&rt_b->rt_runtime_lock);
for (;;) {
overrun = hrtimer_forward_now(timer, rt_b->rt_period);
if (!overrun)
break;
raw_spin_unlock(&rt_b->rt_runtime_lock);
idle = do_sched_rt_period_timer(rt_b, overrun);
raw_spin_lock(&rt_b->rt_runtime_lock);
}
if (idle)
rt_b->rt_period_active = 0;
raw_spin_unlock(&rt_b->rt_runtime_lock);
return idle ? HRTIMER_NORESTART : HRTIMER_RESTART;
}
kernel/sched/rt.c -1/2-
static int do_sched_rt_period_timer(struct rt_bandwidth *rt_b, int overrun)
{
int i, idle = 1, throttled = 0;
const struct cpumask *span;
span = sched_rt_period_mask();
#ifdef CONFIG_RT_GROUP_SCHED
/*
* FIXME: isolated CPUs should really leave the root task group,
* whether they are isolcpus or were isolated via cpusets, lest
* the timer run on a CPU which does not service all runqueues,
* potentially leaving other CPUs indefinitely throttled. If
* isolation is really required, the user will turn the throttle
* off to kill the perturbations it causes anyway. Meanwhile,
* this maintains functionality for boot and/or troubleshooting.
*/
if (rt_b == &root_task_group.rt_bandwidth)
span = cpu_online_mask;
#endif
for_each_cpu(i, span) {
int enqueue = 0;
struct rt_rq *rt_rq = sched_rt_period_rt_rq(rt_b, i);
struct rq *rq = rq_of_rt_rq(rt_rq);
int skip;
/*
* When span == cpu_online_mask, taking each rq->lock
* can be time-consuming. Try to avoid it when possible.
*/
raw_spin_lock(&rt_rq->rt_runtime_lock);
if (!sched_feat(RT_RUNTIME_SHARE) && rt_rq->rt_runtime != RUNTIME_INF)
rt_rq->rt_runtime = rt_b->rt_runtime;
skip = !rt_rq->rt_time && !rt_rq->rt_nr_running;
raw_spin_unlock(&rt_rq->rt_runtime_lock);
if (skip)
continue;
raw_spin_lock(&rq->lock);
update_rq_clock(rq);
rt period 만료 시 해야 할 일을 수행한다
kernel/sched/rt.c -2/2-
if (rt_rq->rt_time) {
u64 runtime;
raw_spin_lock(&rt_rq->rt_runtime_lock);
if (rt_rq->rt_throttled)
balance_runtime(rt_rq);
runtime = rt_rq->rt_runtime;
rt_rq->rt_time -= min(rt_rq->rt_time, overrun*runtime);
if (rt_rq->rt_throttled && rt_rq->rt_time < runtime) {
rt_rq->rt_throttled = 0;
enqueue = 1;
/*
* When we're idle and a woken (rt) task is
* throttled check_preempt_curr() will set
* skip_update and the time between the wakeup
* and this unthrottle will get accounted as
* 'runtime'.
*/
if (rt_rq->rt_nr_running && rq->curr == rq->idle)
rq_clock_cancel_skipupdate(rq);
}
if (rt_rq->rt_time || rt_rq->rt_nr_running)
idle = 0;
raw_spin_unlock(&rt_rq->rt_runtime_lock);
} else if (rt_rq->rt_nr_running) {
idle = 0;
if (!rt_rq_throttled(rt_rq))
enqueue = 1;
}
if (rt_rq->rt_throttled)
throttled = 1;
if (enqueue)
sched_rt_rq_enqueue(rt_rq);
raw_spin_unlock(&rq->lock);
}
if (!throttled && (!rt_bandwidth_enabled() || rt_b->rt_runtime == RUNTIME_INF))
return 1;
return idle;
}
kernel/sched/rt.c
/*
* Preempt the current task with a newly woken task if needed:
*/
static void check_preempt_curr_rt(struct rq *rq, struct task_struct *p, int flags)
{
if (p->prio < rq->curr->prio) {
resched_curr(rq);
return;
}
#ifdef CONFIG_SMP
/*
* If:
*
* - the newly woken task is of equal priority to the current task
* - the newly woken task is non-migratable while current is migratable
* - current will be preempted on the next reschedule
*
* we should check to see if current can readily move to a different
* cpu. If so, we will reschedule to allow the push logic to try
* to move current somewhere else, making room for our non-migratable
* task.
*/
if (p->prio == rq->curr->prio && !test_tsk_need_resched(rq->curr))
check_preempt_equal_prio(rq, p);
#endif
}
현재 태스크보다 더 높은 우선 순위 또는 동등한 우선 순위의 태스크에 리스케줄해야 하는 경우를 체크하여 필요 시 리스케줄 요청 플래그를 설정한다.
kernel/sched/rt.c
static void check_preempt_equal_prio(struct rq *rq, struct task_struct *p)
{
/*
* Current can't be migrated, useless to reschedule,
* let's hope p can move out.
*/
if (rq->curr->nr_cpus_allowed == 1 ||
!cpupri_find(&rq->rd->cpupri, rq->curr, NULL))
return;
/*
* p is migratable, so let's not schedule it and
* see if it is pushed or pulled somewhere else.
*/
if (p->nr_cpus_allowed != 1
&& cpupri_find(&rq->rd->cpupri, p, NULL))
return;
/*
* There appears to be other cpus that can accept
* current and none to run 'p', so lets reschedule
* to try and push current away:
*/
requeue_task_rt(rq, p, 1);
resched_curr(rq);
}
조건에 따라 요청한 태스크를 라운드 로빈하고 리스케줄 요청 플래그를 설정해야 하는지 체크한다.
kernel/sched/rt.c
/* * Adding/removing a task to/from a priority array: */
static void
enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags)
{
struct sched_rt_entity *rt_se = &p->rt;
if (flags & ENQUEUE_WAKEUP)
rt_se->timeout = 0;
enqueue_rt_entity(rt_se, flags);
if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
enqueue_pushable_task(rq, p);
}
rt 태스크를 런큐에 엔큐한다.
kernel/sched/rt.c
static void dequeue_task_rt(struct rq *rq, struct task_struct *p, int flags)
{
struct sched_rt_entity *rt_se = &p->rt;
update_curr_rt(rq);
dequeue_rt_entity(rt_se, flags);
dequeue_pushable_task(rq, p);
}
rt 태스크를 런큐에서 디큐한다.
kernel/sched/rt.c
static void enqueue_pushable_task(struct rq *rq, struct task_struct *p)
{
plist_del(&p->pushable_tasks, &rq->rt.pushable_tasks);
plist_node_init(&p->pushable_tasks, p->prio);
plist_add(&p->pushable_tasks, &rq->rt.pushable_tasks);
/* Update the highest prio pushable task */
if (p->prio < rq->rt.highest_prio.next)
rq->rt.highest_prio.next = p->prio;
}
요청한 태스크를 최상위 런큐의 pushable_tasks 리스트에 추가하고 최상위 rt 런큐의 차순위를 갱신한다.
다음 그림은 태스크를 pushable task 리스트에 추가할 때 차순위(highest_prio.next)를 갱신하는 모습을 보여준다.
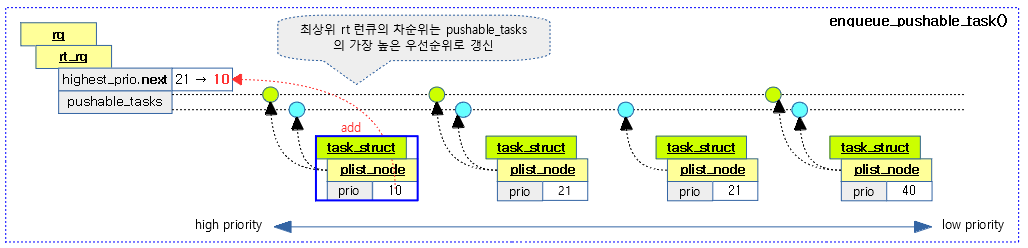
kernel/sched/rt.c
static void dequeue_pushable_task(struct rq *rq, struct task_struct *p)
{
plist_del(&p->pushable_tasks, &rq->rt.pushable_tasks);
/* Update the new highest prio pushable task */
if (has_pushable_tasks(rq)) {
p = plist_first_entry(&rq->rt.pushable_tasks,
struct task_struct, pushable_tasks);
rq->rt.highest_prio.next = p->prio;
} else
rq->rt.highest_prio.next = MAX_RT_PRIO;
}
요청한 태스크를 최상위 런큐의 pushable_tasks 리스트에서 제거하고 최상위 rt 런큐의 차순위를 갱신한다.
다음 그림은 태스크를 pushable task 리스트에서 삭제할 때 차순위(highest_prio.next)를 갱신하는 모습을 보여준다.
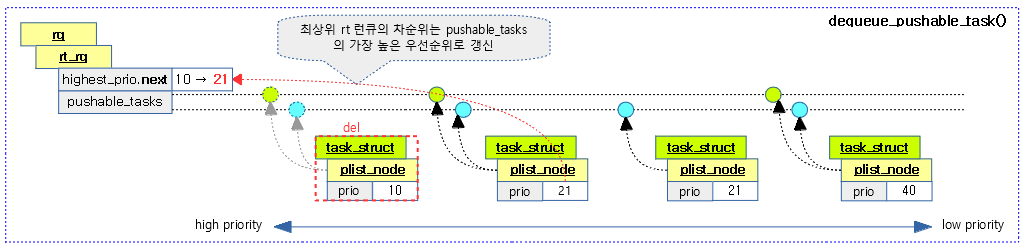
kernel/sched/rt.c
/*
* Return the highest pushable rq's task, which is suitable to be executed
* on the cpu, NULL otherwise
*/
static struct task_struct *pick_highest_pushable_task(struct rq *rq, int cpu)
{
struct plist_head *head = &rq->rt.pushable_tasks;
struct task_struct *p;
if (!has_pushable_tasks(rq))
return NULL;
plist_for_each_entry(p, head, pushable_tasks) {
if (pick_rt_task(rq, p, cpu))
return p;
}
return NULL;
}
pushable tasks 리스트에 연결된 태스크를 순회하며 active 되지 않은 첫 태스크를 알아온다. (높은 우선 순위 -> 낮은 우선 순위로 순회)
kernel/sched/rt.c
static inline int has_pushable_tasks(struct rq *rq)
{
return !plist_head_empty(&rq->rt.pushable_tasks);
}
pushable 태스크 리스트에 태스크가 존재하는지 여부를 반환한다.
kernel/sched/rt.c
static int pick_rt_task(struct rq *rq, struct task_struct *p, int cpu)
{
if (!task_running(rq, p) &&
cpumask_test_cpu(cpu, tsk_cpus_allowed(p)))
return 1;
return 0;
}
요청한 cpu에서 동작 가능하고 active 되지 않은 태스크인지 여부를 반환한다.
kernel/sched/rt.c
static struct task_struct *pick_next_pushable_task(struct rq *rq)
{
struct task_struct *p;
if (!has_pushable_tasks(rq))
return NULL;
p = plist_first_entry(&rq->rt.pushable_tasks,
struct task_struct, pushable_tasks);
BUG_ON(rq->cpu != task_cpu(p));
BUG_ON(task_current(rq, p));
BUG_ON(p->nr_cpus_allowed <= 1);
BUG_ON(!task_on_rq_queued(p));
BUG_ON(!rt_task(p));
return p;
}
요청한 런큐의 pushable tasks 리스트에서 대기 중인 첫 번째 rt 태스크를 반환한다.
우선 순위 기반으로 소팅된 이중 리스트이다. 키에 사용될 우선 순위가 0~99까지 100개로 제한되어 있어서 RB 트리를 사용하는 것보다 더 효율적이다. 따라서 RT 스케줄러에서 이 자료 구조는 overload된 태스크들을 pushable_tasks plist에 추가할 때 소팅에 최적화된 모습을 보여준다.
다음 그림은 plist의 각 노드가 연결되어 있는 모습을 보여준다.
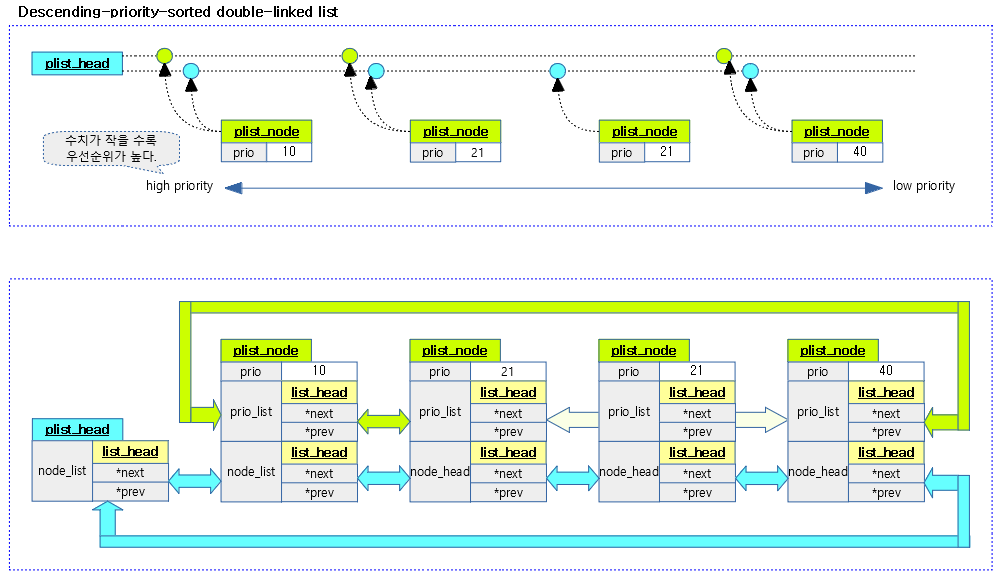
kernel/sched/rt.c
static struct task_struct *
pick_next_task_rt(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct task_struct *p;
WARN_ON_ONCE(prev || rf);
if (!sched_rt_runnable(rq))
return NULL;
p = _pick_next_task_rt(rq);
set_next_task_rt(rq, p);
return p;
}
다음에 스케줄할 가장 높은 우선 순위의 rt 태스크를 알아온다.
kernel/sched/rt.c
static struct task_struct *_pick_next_task_rt(struct rq *rq)
{
struct sched_rt_entity *rt_se;
struct rt_rq *rt_rq = &rq->rt;
do {
rt_se = pick_next_rt_entity(rq, rt_rq);
BUG_ON(!rt_se);
rt_rq = group_rt_rq(rt_se);
} while (rt_rq);
return rt_task_of(rt_se);
}
rt 런큐의 rt 어레이 리스트에서 가장 높은 우선 순위의 rt 태스크를 찾아 반환한다.
다음 그림은 런큐에서 가장 높은 우선 순위의 rt 태스크를 찾아오는 모습을 보여준다.
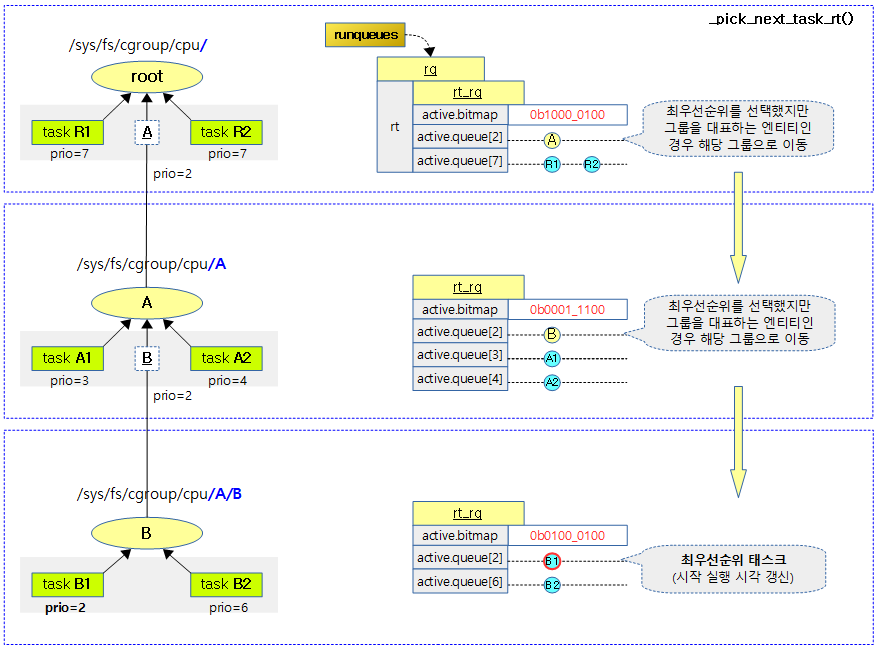
kernel/sched/rt.c
static struct sched_rt_entity *pick_next_rt_entity(struct rq *rq,
struct rt_rq *rt_rq)
{
struct rt_prio_array *array = &rt_rq->active;
struct sched_rt_entity *next = NULL;
struct list_head *queue;
int idx;
idx = sched_find_first_bit(array->bitmap);
BUG_ON(idx >= MAX_RT_PRIO);
queue = array->queue + idx;
next = list_entry(queue->next, struct sched_rt_entity, run_list);
return next;
}
rt 런큐의 rt 어레이 리스트에서 가장 높은 우선 순위의 rt 엔티티를 찾아 반환한다.
kernel/sched/rt.c
static inline void set_next_task_rt(struct rq *rq, struct task_struct *p)
{
p->se.exec_start = rq_clock_task(rq);
/* The running task is never eligible for pushing */
dequeue_pushable_task(rq, p);
/*
* If prev task was rt, put_prev_task() has already updated the
* utilization. We only care of the case where we start to schedule a
* rt task
*/
if (rq->curr->sched_class != &rt_sched_class)
update_rt_rq_load_avg(rq_clock_pelt(rq), rq, 0);
rt_queue_push_tasks(rq);
}
요청한 태스크를 rt 런큐에서 지금 실행할 태스크로 지정한다.
kernel/sched/rt.c
static void put_prev_task_rt(struct rq *rq, struct task_struct *p)
{
update_curr_rt(rq);
/*
* The previous task needs to be made eligible for pushing
* if it is still active
*/
if (on_rt_rq(&p->rt) && p->nr_cpus_allowed > 1)
enqueue_pushable_task(rq, p);
}
rt 런큐내에서 기존 rt 태스크의 수행 완료 처리를 한다.
두 개 이상의 rt 태스크가 하나의 cpu에서 동작을 해야 하는 경우 하나의 rt 태스크를 제외한 나머지를 migration 시킬 수 있도록 다음과 같은 관리를 수행한다.
rt 태스크가 다른 cpu로 migration될 때 다음 함수 호출을 통해서 수행한다. 또한 migration할 cpu를 찾기 위해 cpu별로 102개의 priority를 갱신하여 이를 통해 우선 순위가 가장 낮은 cpu들을 가려낸다.
kernel/sched/rt.c
static int balance_rt(struct rq *rq, struct task_struct *p, struct rq_flags *rf)
{
if (!on_rt_rq(&p->rt) && need_pull_rt_task(rq, p)) {
/*
* This is OK, because current is on_cpu, which avoids it being
* picked for load-balance and preemption/IRQs are still
* disabled avoiding further scheduler activity on it and we've
* not yet started the picking loop.
*/
rq_unpin_lock(rq, rf);
pull_rt_task(rq);
rq_repin_lock(rq, rf);
}
return sched_stop_runnable(rq) || sched_dl_runnable(rq) || sched_rt_runnable(rq);
}
rt 태스크의 로드밸런스가 필요한지 여부를 확인하고 수행한다.
kernel/sched/rt.c
static inline bool need_pull_rt_task(struct rq *rq, struct task_struct *prev)
{
/* Try to pull RT tasks here if we lower this rq's prio */
return rq->rt.highest_prio.curr > prev->prio;
}
요청한 태스크의 우선 순위가 최상위 rt 런큐에서 가장 높은 우선 순위보다 높거나 같은 경우 true를 반환한다.
kernel/sched/rt.c
static inline void rt_queue_push_tasks(struct rq *rq)
{
if (!has_pushable_tasks(rq))
return;
queue_balance_callback(rq, &per_cpu(rt_push_head, rq->cpu), push_rt_tasks);
}
런큐에 pushable 태스크가 있는 경우 콜백함수로 push_rt_tasks() 함수를 지정한다.
kernel/sched/rt.c
static inline void
queue_balance_callback(struct rq *rq,
struct callback_head *head,
void (*func)(struct rq *rq))
{
lockdep_assert_held(&rq->lock);
if (unlikely(head->next))
return;
head->func = (void (*)(struct callback_head *))func;
head->next = rq->balance_callback;
rq->balance_callback = head;
}
런큐의 balance_callback 리스트에 밸런스를 위한 콜백 함수를 추가한다.
kernel/sched/rt.c
tatic void push_rt_tasks(struct rq *rq)
{
/* push_rt_task will return true if it moved an RT */
while (push_rt_task(rq))
;
}
런큐에서 overload된 태스크들을 모두 다른 cpu로 마이그레이션한다.
kernel/sched/rt.c
/* * If the current CPU has more than one RT task, see if the non * running task can migrate over to a CPU that is running a task * of lesser priority. */
static int push_rt_task(struct rq *rq)
{
struct task_struct *next_task;
struct rq *lowest_rq;
int ret = 0;
if (!rq->rt.overloaded)
return 0;
next_task = pick_next_pushable_task(rq);
if (!next_task)
return 0;
retry:
if (WARN_ON(next_task == rq->curr))
return 0;
/*
* It's possible that the next_task slipped in of
* higher priority than current. If that's the case
* just reschedule current.
*/
if (unlikely(next_task->prio < rq->curr->prio)) {
resched_curr(rq);
return 0;
}
/* We might release rq lock */
get_task_struct(next_task);
/* find_lock_lowest_rq locks the rq if found */
lowest_rq = find_lock_lowest_rq(next_task, rq);
if (!lowest_rq) {
struct task_struct *task;
/*
* find_lock_lowest_rq releases rq->lock
* so it is possible that next_task has migrated.
*
* We need to make sure that the task is still on the same
* run-queue and is also still the next task eligible for
* pushing.
*/
task = pick_next_pushable_task(rq);
if (task == next_task) {
/*
* The task hasn't migrated, and is still the next
* eligible task, but we failed to find a run-queue
* to push it to. Do not retry in this case, since
* other CPUs will pull from us when ready.
*/
goto out;
}
if (!task)
/* No more tasks, just exit */
goto out;
/*
* Something has shifted, try again.
*/
put_task_struct(next_task);
next_task = task;
goto retry;
}
deactivate_task(rq, next_task, 0);
set_task_cpu(next_task, lowest_rq->cpu);
activate_task(lowest_rq, next_task, 0);
ret = 1;
resched_curr(lowest_rq);
double_unlock_balance(rq, lowest_rq);
out:
put_task_struct(next_task);
return ret;
}
런큐에서 overload된 태스크 하나를 다른 cpu로 마이그레이션한다.
kernel/sched/rt.c
/* Will lock the rq it finds */
static struct rq *find_lock_lowest_rq(struct task_struct *task, struct rq *rq)
{
struct rq *lowest_rq = NULL;
int tries;
int cpu;
for (tries = 0; tries < RT_MAX_TRIES; tries++) {
cpu = find_lowest_rq(task);
if ((cpu == -1) || (cpu == rq->cpu))
break;
lowest_rq = cpu_rq(cpu);
if (lowest_rq->rt.highest_prio.curr <= task->prio) {
/*
* Target rq has tasks of equal or higher priority,
* retrying does not release any lock and is unlikely
* to yield a different result.
*/
lowest_rq = NULL;
break;
}
/* if the prio of this runqueue changed, try again */
if (double_lock_balance(rq, lowest_rq)) {
/*
* We had to unlock the run queue. In
* the mean time, task could have
* migrated already or had its affinity changed.
* Also make sure that it wasn't scheduled on its rq.
*/
if (unlikely(task_rq(task) != rq ||
!cpumask_test_cpu(lowest_rq->cpu, task->cpus_ptr) ||
task_running(rq, task) ||
!rt_task(task) ||
!task_on_rq_queued(task))) {
double_unlock_balance(rq, lowest_rq);
lowest_rq = NULL;
break;
}
}
/* If this rq is still suitable use it. */
if (lowest_rq->rt.highest_prio.curr > task->prio)
break;
/* try again */
double_unlock_balance(rq, lowest_rq);
lowest_rq = NULL;
}
return lowest_rq;
}
가장 낮은 우선 순위를 가진 cpu의 런큐를 선택한다. 성공 시 요청한 런큐와 찾은 cpu의 런큐 둘 다 락을 건 상태로 리턴한다.
kernel/sched/rt.c
static inline void rt_queue_pull_task(struct rq *rq)
{
queue_balance_callback(rq, &per_cpu(rt_pull_head, rq->cpu), pull_rt_task);
}
런큐에 pushable 태스크가 있는 경우 콜백함수로 pull_rt_task() 함수를 지정한다.
kernel/sched/rt.c -1/2-
static void pull_rt_task(struct rq *this_rq)
{
int this_cpu = this_rq->cpu, cpu;
bool resched = false;
struct task_struct *p;
struct rq *src_rq;
int rt_overload_count = rt_overloaded(this_rq);
if (likely(!rt_overload_count))
return;
/*
* Match the barrier from rt_set_overloaded; this guarantees that if we
* see overloaded we must also see the rto_mask bit.
*/
smp_rmb();
/* If we are the only overloaded CPU do nothing */
if (rt_overload_count == 1 &&
cpumask_test_cpu(this_rq->cpu, this_rq->rd->rto_mask))
return;
#ifdef HAVE_RT_PUSH_IPI
if (sched_feat(RT_PUSH_IPI)) {
tell_cpu_to_push(this_rq);
return;
}
#endif
for_each_cpu(cpu, this_rq->rd->rto_mask) {
if (this_cpu == cpu)
continue;
src_rq = cpu_rq(cpu);
/*
* Don't bother taking the src_rq->lock if the next highest
* task is known to be lower-priority than our current task.
* This may look racy, but if this value is about to go
* logically higher, the src_rq will push this task away.
* And if its going logically lower, we do not care
*/
if (src_rq->rt.highest_prio.next >=
this_rq->rt.highest_prio.curr)
continue;
오버로드된 런큐들에 대해 현재 런큐에서 진행하려고 하는 우선 순위 태스크보다 더 높은 우선 순위 태스크가 있으면 끌어온다. 단 RT_PUSH_IPI feature(디폴트 enable)를 사용 중인 경우 오버로드된 런큐의 cpu로 IPI 호출하여 직접 push 하도록 한다.
kernel/sched/rt.c -2/2-
/*
* We can potentially drop this_rq's lock in
* double_lock_balance, and another CPU could
* alter this_rq
*/
double_lock_balance(this_rq, src_rq);
/*
* We can pull only a task, which is pushable
* on its rq, and no others.
*/
p = pick_highest_pushable_task(src_rq, this_cpu);
/*
* Do we have an RT task that preempts
* the to-be-scheduled task?
*/
if (p && (p->prio < this_rq->rt.highest_prio.curr)) {
WARN_ON(p == src_rq->curr);
WARN_ON(!task_on_rq_queued(p));
/*
* There's a chance that p is higher in priority
* than what's currently running on its CPU.
* This is just that p is wakeing up and hasn't
* had a chance to schedule. We only pull
* p if it is lower in priority than the
* current task on the run queue
*/
if (p->prio < src_rq->curr->prio)
goto skip;
resched = true;
deactivate_task(src_rq, p, 0);
set_task_cpu(p, this_cpu);
activate_task(this_rq, p, 0);
/*
* We continue with the search, just in
* case there's an even higher prio task
* in another runqueue. (low likelihood
* but possible)
*/
}
skip:
double_unlock_balance(this_rq, src_rq);
}
if (resched)
resched_curr(this_rq);
}
다음 그림은 오버로드된 다른 cpu의 런큐에서 현재 런큐에서 수행하려고 하는 태스크의 우선 순위보다 더 높은 우선 순위를 가진 태스크를 끌어오는 과정을 보여준다.
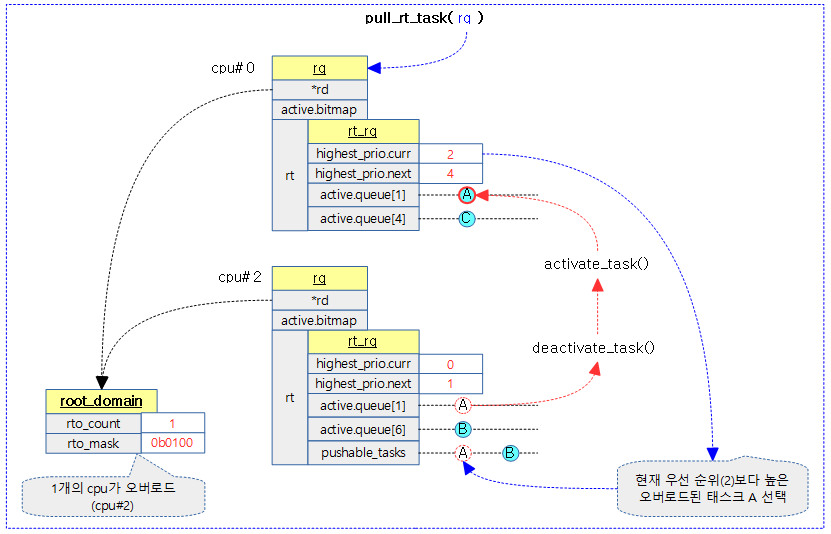
kernel/sched/sched.h
struct sched_rt_entity {
struct list_head run_list;
unsigned long timeout;
unsigned long watchdog_stamp;
unsigned int time_slice;
unsigned short on_rq;
unsigned short on_list;
struct sched_rt_entity *back;
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity *parent;
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq;
/* rq "owned" by this entity/group: */
struct rt_rq *my_q;
#endif
} __randomize_layout;
kernel/sched/sched.h
struct rt_bandwidth {
/* nests inside the rq lock: */
raw_spinlock_t rt_runtime_lock;
ktime_t rt_period;
u64 rt_runtime;
struct hrtimer rt_period_timer;
};
kernel/sched/sched.h
/* Real-Time classes' related field in a runqueue: */
struct rt_rq {
struct rt_prio_array active;
unsigned int rt_nr_running;
unsigned int rr_nr_running;
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED
struct {
int curr; /* highest queued rt task prio */
#ifdef CONFIG_SMP
int next; /* next highest */
#endif
} highest_prio;
#endif
#ifdef CONFIG_SMP
unsigned long rt_nr_migratory;
unsigned long rt_nr_total;
int overloaded;
struct plist_head pushable_tasks;
#endif /* CONFIG_SMP */
int rt_queued;
int rt_throttled;
u64 rt_time;
u64 rt_runtime;
/* Nests inside the rq lock: */
raw_spinlock_t rt_runtime_lock;
#ifdef CONFIG_RT_GROUP_SCHED
unsigned long rt_nr_boosted;
struct rq *rq;
struct task_group *tg;
#endif
};
<kernel v5.4>
태스크 그룹별로 shares 값을 설정하여 cfs 태스크의 스케줄 할당 비율을 조절할 수 있엇다. 여기서 또 다른 cfs 태스크의 스케줄 할당 비율을 조절할 수 있는 cfs bandwidth 방법을 소개한다.
태스크 그룹에 매 cfs_period_us 기간 마다 cfs_quota_us 기간 만큼 런타임을 할당하여 사용한다. 소진되어 런타임 잔량이 0이하가 되면 다음 period가 오기 전까지 남는 시간은 스로틀링 한다.
해당 cfs 런큐가 스로틀 하는 경우 다음과 같이 동작한다.
다음은 루트 태스크 그룹에 설정된 cfs_period_us와 cfs_quota_us 값을 보여준다. 디폴트로 cfs_quota_us 값이 -1이 설정되어 cfs bandwidth가 활성화되어 있지 않음을 알 수 있다.
$ cd /sys/fs/cgroup/cpu $ ls cgroup.clone_children cpu.cfs_period_us cpu.stat cpuacct.usage_percpu system.slice cgroup.procs cpu.cfs_quota_us cpuacct.stat notify_on_release tasks cgroup.sane_behavior cpu.shares cpuacct.usage release_agent user.slice $ cat cpu.cfs_period_us 100000 $ cat cpu.cfs_quota_us -1
다음 용어들이 빈번이 나오므로 먼저 요약한다.
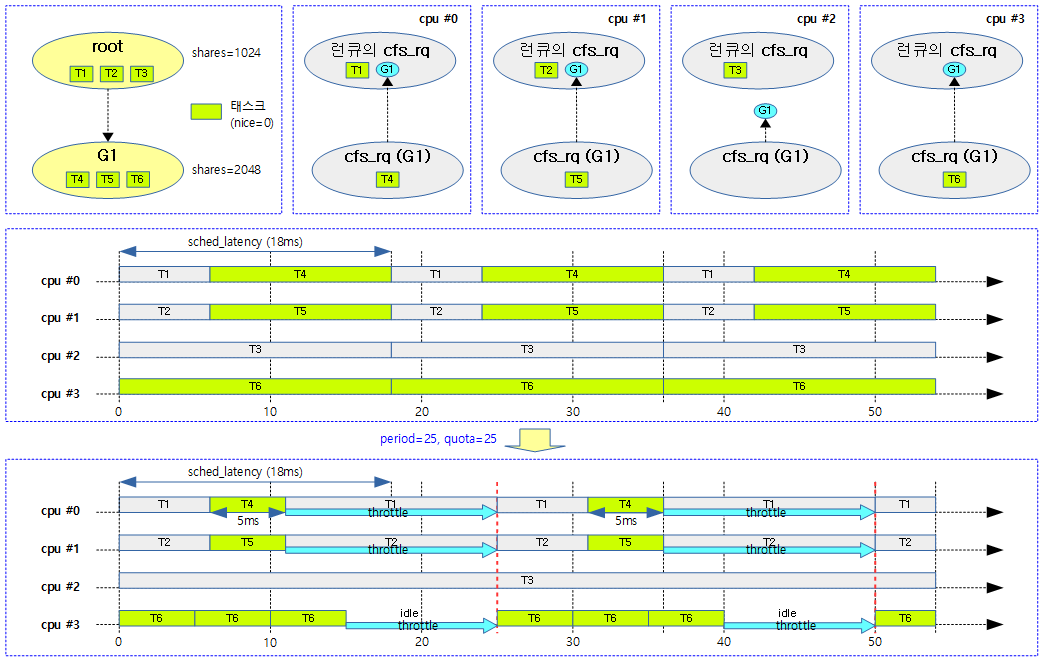
bandwidth가 적용된 사례 3개를 확인해보자.
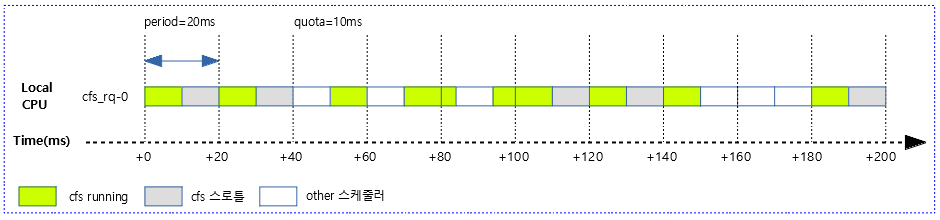
사례 1) 다음 그림은 20ms 주기마다 10ms quota 만큼 cfs 스케줄되는 모습을 보여준다. 남는 시간은 스로틀링 한다.

다음 그림은 위의 사례 1)에서 발생할 수 있는 다양한 케이스를 보여준다.
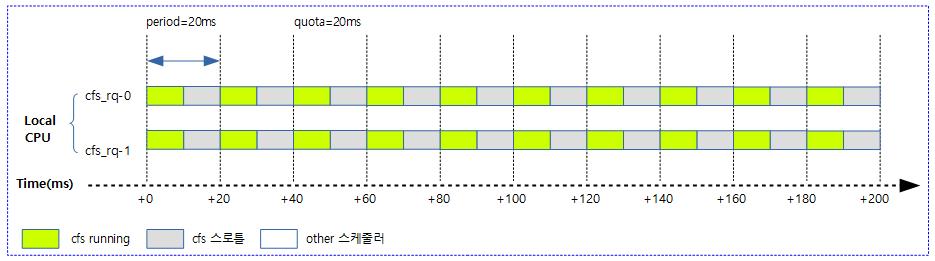
사례 2) 다음 그림은 20ms 주기마다 2개의 cpu에 총 20ms quota 만큼 cfs 스케줄한다.
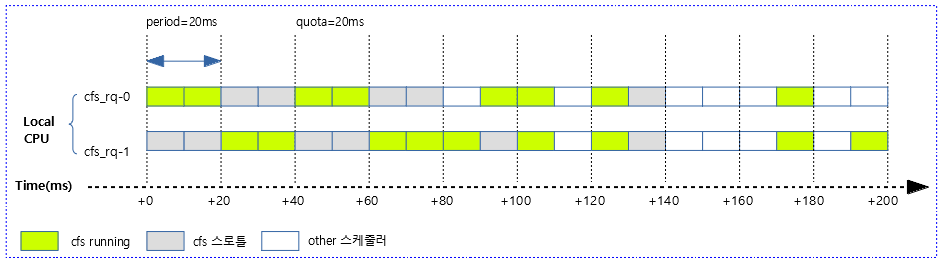
다음 그림은 위의 사례 2)에서 발생할 수 있는 다양한 케이스를 보여준다.
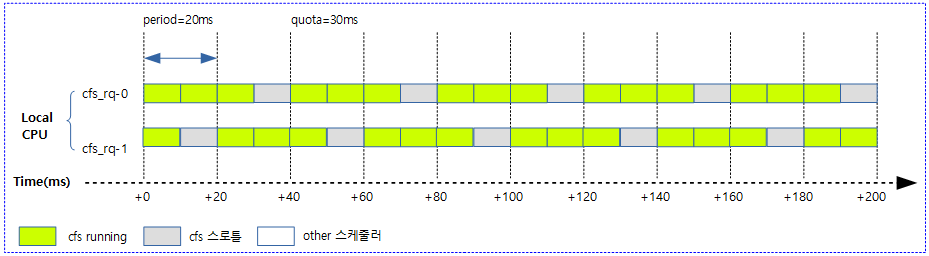
사례 3) 다음 그림은 20ms 주기마다 2개의 cpu에 총 30ms quota 만큼 cfs 스케줄한다.
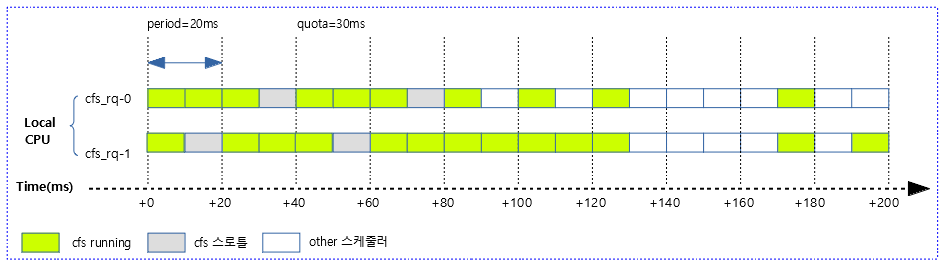
다음 그림은 위의 사례 3)에서 발생할 수 있는 다양한 케이스를 보여준다.
다음 그림은 cfs 밴드 위드를 설정하지 않았을 때와 두 개 그룹 중 G1 태스크 그룹에 period=25, quota=25의 밴드위드를 설정하여 동작시켰을 때의 차이를 비교하였다.
그룹내에서 CFS bandwidth를 사용 시 스로틀링을 위해 남은 quota(runtime) 산출에 사용했던 CFS runtime의 구현 방법들은 다음과 같이 진화하였다.
global runtime으로만 구현하게 되면 cpu가 많이 있는 시스템에서 각 cpu마다 동작하는 cfs 런큐간의 lock contension에 대한 부담이 매우커지는 약점이 있다. 또한 local cpu runtime으로만 구현하더라도 cfs 런큐 간에 남은 quota들을 확인하는 복잡한 relation이 발생하므로 소규모 smp 시스템에서만 적절하다고 볼 수 있다. 따라서 최근에는 성능을 위해 로컬 및 글로벌 두 개 모두를 구현한 하이브리드 버전이 사용되고 있다.
로컬 런타임의 보충은 다음과 같은 사례에서 발생한다. 자세한 것은 각 함수들에서 알아본다.
kernel/sched/fair.c
void init_cfs_bandwidth(struct cfs_bandwidth *cfs_b)
{
raw_spin_lock_init(&cfs_b->lock);
cfs_b->runtime = 0;
cfs_b->quota = RUNTIME_INF;
cfs_b->period = ns_to_ktime(default_cfs_period());
INIT_LIST_HEAD(&cfs_b->throttled_cfs_rq);
hrtimer_init(&cfs_b->period_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
cfs_b->period_timer.function = sched_cfs_period_timer;
hrtimer_init(&cfs_b->slack_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
cfs_b->slack_timer.function = sched_cfs_slack_timer;
cfs_b->distribute_running = 0;
cfs_b->slack_started = false;
}
cfs bandwidth를 초기화한다.
kernel/sched/core.c
int tg_set_cfs_quota(struct task_group *tg, long cfs_quota_us)
{
u64 quota, period;
period = ktime_to_ns(tg->cfs_bandwidth.period);
if (cfs_quota_us < 0)
quota = RUNTIME_INF;
else if ((u64)cfs_quota_us <= U64_MAX / NSEC_PER_USEC)
quota = (u64)cfs_quota_us * NSEC_PER_USEC;
else
return -EINVAL;
return tg_set_cfs_bandwidth(tg, period, quota);
}
요청한 태스크 그룹에 cfs quota 값(us)을 나노초로 변경하여 설정하되 가능한 범위는 1ms ~ 1s 이다.
kernel/sched/core.c
int tg_set_cfs_period(struct task_group *tg, long cfs_period_us)
{
u64 quota, period;
if ((u64)cfs_period_us > U64_MAX / NSEC_PER_USEC)
return -EINVAL;
period = (u64)cfs_period_us * NSEC_PER_USEC;
quota = tg->cfs_bandwidth.quota;
return tg_set_cfs_bandwidth(tg, period, quota);
}
요청한 태스크 그룹에 cfs period 값(us)을 나노초로 변경하여 설정하되 최소 1ms 부터 설정 가능하다.
kernel/sched/core.c
const u64 max_cfs_quota_period = 1 * NSEC_PER_SEC; /* 1s */ const u64 min_cfs_quota_period = 1 * NSEC_PER_MSEC; /* 1ms */
cfs period의 설정은 1ms ~ 1s 범위에서 가능하게 제한된다. cfs quota 값은 1ms 이상 가능하다.
kernel/sched/core.c -1/2-
static int tg_set_cfs_bandwidth(struct task_group *tg, u64 period, u64 quota)
{
int i, ret = 0, runtime_enabled, runtime_was_enabled;
struct cfs_bandwidth *cfs_b = &tg->cfs_bandwidth;
if (tg == &root_task_group)
return -EINVAL;
/*
* Ensure we have at some amount of bandwidth every period. This is
* to prevent reaching a state of large arrears when throttled via
* entity_tick() resulting in prolonged exit starvation.
*/
if (quota < min_cfs_quota_period || period < min_cfs_quota_period)
return -EINVAL;
/*
* Likewise, bound things on the otherside by preventing insane quota
* periods. This also allows us to normalize in computing quota
* feasibility.
*/
if (period > max_cfs_quota_period)
return -EINVAL;
/*
* Prevent race between setting of cfs_rq->runtime_enabled and
* unthrottle_offline_cfs_rqs().
*/
get_online_cpus();
mutex_lock(&cfs_constraints_mutex);
ret = __cfs_schedulable(tg, period, quota);
if (ret)
goto out_unlock;
요청한 태스크 그룹의 bandwidth 기능 유무를 설정한다. 처리되는 항목은 다음과 같다.
kernel/sched/core.c -2/2-
runtime_enabled = quota != RUNTIME_INF;
runtime_was_enabled = cfs_b->quota != RUNTIME_INF;
/*
* If we need to toggle cfs_bandwidth_used, off->on must occur
* before making related changes, and on->off must occur afterwards
*/
if (runtime_enabled && !runtime_was_enabled)
cfs_bandwidth_usage_inc();
raw_spin_lock_irq(&cfs_b->lock);
cfs_b->period = ns_to_ktime(period);
cfs_b->quota = quota;
__refill_cfs_bandwidth_runtime(cfs_b);
/* restart the period timer (if active) to handle new period expiry */
if (runtime_enabled)
start_cfs_bandwidth(cfs_b, true);
raw_spin_unlock_irq(&cfs_b->lock);
for_each_online_cpu(i) {
struct cfs_rq *cfs_rq = tg->cfs_rq[i];
struct rq *rq = cfs_rq->rq;
struct rq_flags rf;
rq_lock_irq(rq, &rf);
cfs_rq->runtime_enabled = runtime_enabled;
cfs_rq->runtime_remaining = 0;
if (cfs_rq->throttled)
unthrottle_cfs_rq(cfs_rq);
rq_unlock_irq(rq, &rf);
}
if (runtime_was_enabled && !runtime_enabled)
cfs_bandwidth_usage_dec();
out_unlock:
mutex_unlock(&cfs_constraints_mutex);
put_online_cpus();
return ret;
}
kernel/sched/core.c
static int __cfs_schedulable(struct task_group *tg, u64 period, u64 quota)
{
int ret;
struct cfs_schedulable_data data = {
.tg = tg,
.period = period,
.quota = quota,
};
if (quota != RUNTIME_INF) {
do_div(data.period, NSEC_PER_USEC);
do_div(data.quota, NSEC_PER_USEC);
}
rcu_read_lock();
ret = walk_tg_tree(tg_cfs_schedulable_down, tg_nop, &data);
rcu_read_unlock();
return ret;
}
최상위 루트 태스크부터 전체 태스크 그룹을 순회하는 동안 위에서 아래로 내려가는 순서로 quota 정수 비율을 설정한다. 성공하면 0을 반환한다.
kernel/sched/core.c
static int tg_cfs_schedulable_down(struct task_group *tg, void *data)
{
struct cfs_schedulable_data *d = data;
struct cfs_bandwidth *cfs_b = &tg->cfs_bandwidth;
s64 quota = 0, parent_quota = -1;
if (!tg->parent) {
quota = RUNTIME_INF;
} else {
struct cfs_bandwidth *parent_b = &tg->parent->cfs_bandwidth;
quota = normalize_cfs_quota(tg, d);
parent_quota = parent_b->hierarchical_quota;
/*
* ensure max(child_quota) <= parent_quota, inherit when no
* limit is set
*/
if (cgroup_subsys_on_dfl(cpu_cgrp_subsys)) {
quota = min(quota, parent_quota);
} else {
if (quota == RUNTIME_INF)
quota = parent_quota;
else if (parent_quota != RUNTIME_INF && quota > parent_quota)
return -EINVAL;
}
}
cfs_b->hierarchical_quota = quota;
return 0;
}
요청한 태스크 그룹에서 period에 대한 quota 정수 비율을 설정한다. 에러가 없으면 0을 반환한다.
kernel/sched/core.c
/* * normalize group quota/period to be quota/max_period * note: units are usecs */
static u64 normalize_cfs_quota(struct task_group *tg,
struct cfs_schedulable_data *d)
{
u64 quota, period;
if (tg == d->tg) {
period = d->period;
quota = d->quota;
} else {
period = tg_get_cfs_period(tg);
quota = tg_get_cfs_quota(tg);
}
/* note: these should typically be equivalent */
if (quota == RUNTIME_INF || quota == -1)
return RUNTIME_INF;
return to_ratio(period, quota);
}
period에 대한 quota 비율을 정수로 반환한다. (예: 정수 1M=100%, 256K=25%)
kernel/sched/core.c
long tg_get_cfs_quota(struct task_group *tg)
{
u64 quota_us;
if (tg->cfs_bandwidth.quota == RUNTIME_INF)
return -1;
quota_us = tg->cfs_bandwidth.quota;
do_div(quota_us, NSEC_PER_USEC);
return quota_us;
}
태스크 그룹의 cfs quota를 us 단위로 반환한다. 무제한 설정된 경우 -1을 반환한다.
kernel/sched/core.c
long tg_get_cfs_period(struct task_group *tg)
{
u64 cfs_period_us;
cfs_period_us = ktime_to_ns(tg->cfs_bandwidth.period);
do_div(cfs_period_us, NSEC_PER_USEC);
return cfs_period_us;
}
태스크 그룹의 cfs period를 us 단위로 반환한다.
kernel/sched/sched.h
/* * Iterate the full tree, calling @down when first entering a node and @up when * leaving it for the final time. * * Caller must hold rcu_lock or sufficient equivalent. */
static inline int walk_tg_tree(tg_visitor down, tg_visitor up, void *data)
{
return walk_tg_tree_from(&root_task_group, down, up, data);
}
태스크 그룹 트리에서 최상위 루트 태스크부터 전체 태스크 그룹을 순회하는 동안 아래로 내려가면 down 함수를 호출하고 위로 올라가면 up 함수를 호출한다. 호출한 함수가 중간에 에러가 발생하면 그 값을 반환하고 처리를 중단한다.
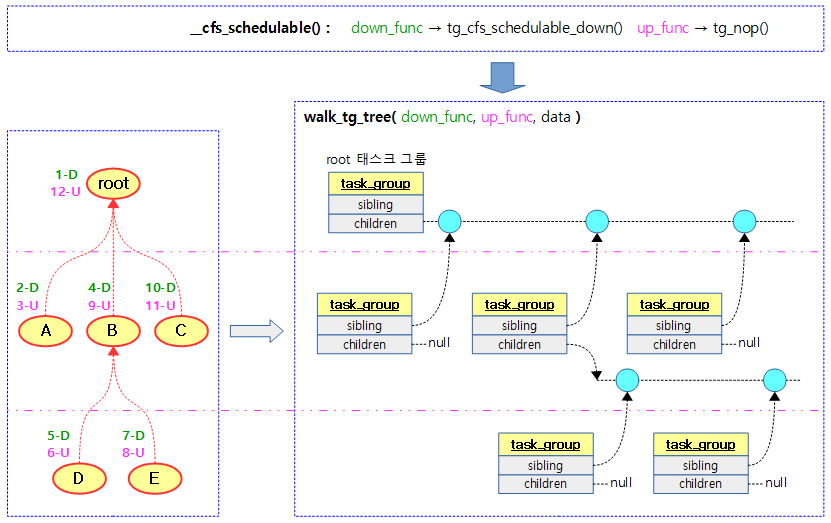
다음 그림은 __cfs_schedulabel() 함수를 호출할 때 각 태스크 그룹을 아래로 내려갈 때마다 tg_cfs_schedulable_down()을 호출하는 모습을 보여준다.
kernel/sched/core.c
/* * Iterate task_group tree rooted at *from, calling @down when first entering a * node and @up when leaving it for the final time. * * Caller must hold rcu_lock or sufficient equivalent. */
int walk_tg_tree_from(struct task_group *from,
tg_visitor down, tg_visitor up, void *data)
{
struct task_group *parent, *child;
int ret;
parent = from;
down:
ret = (*down)(parent, data);
if (ret)
goto out;
list_for_each_entry_rcu(child, &parent->children, siblings) {
parent = child;
goto down;
up:
continue;
}
ret = (*up)(parent, data);
if (ret || parent == from)
goto out;
child = parent;
parent = parent->parent;
if (parent)
goto up;
out:
return ret;
}
태스크 그룹 트리에서 요청한 태스크 그룹 이하의 태스크 그룹을 순회하는 동안 아래로 내려가면 down 함수를 호출하고 위로 올라가면 up 함수를 호출한다. 호출한 함수가 중간에 에러가 발생하면 그 값을 반환하고 처리를 중단한다. 에러가 없으면 0을 반환한다.
다음 그림은 walk_tg_tree_from() 함수가 1번 down 함수 호출부터 12번 up 함수 호출하는 것 까지 트리를 순회하는 모습을 보여준다.

kernel/sched/fair.c
/* * When a group wakes up we want to make sure that its quota is not already * expired/exceeded, otherwise it may be allowed to steal additional ticks of * runtime as update_curr() throttling can not not trigger until it's on-rq. */
static void check_enqueue_throttle(struct cfs_rq *cfs_rq)
{
if (!cfs_bandwidth_used())
return;
/* an active group must be handled by the update_curr()->put() path */
if (!cfs_rq->runtime_enabled || cfs_rq->curr)
return;
/* ensure the group is not already throttled */
if (cfs_rq_throttled(cfs_rq))
return;
/* update runtime allocation */
account_cfs_rq_runtime(cfs_rq, 0);
if (cfs_rq->runtime_remaining <= 0)
throttle_cfs_rq(cfs_rq);
}
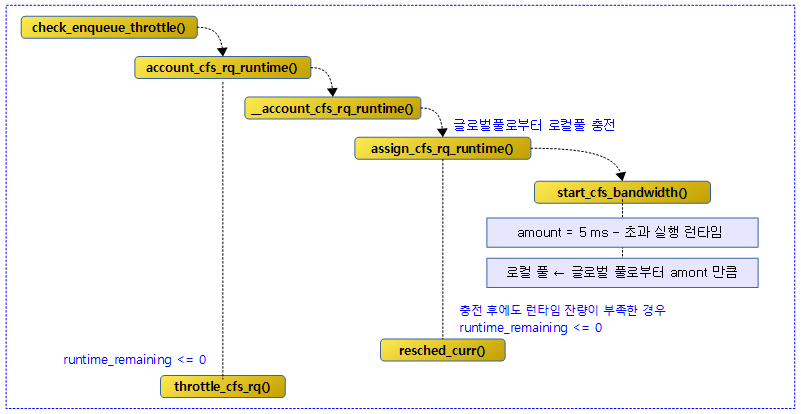
현재 그룹의 cfs 런큐에서 quota 만큼의 실행이 끝나고 남은 런타임이 없으면 스로틀한다.
다음 그림은 check_enqueue_throttle() 함수 이하의 호출 관계를 보여준다.
kernel/sched/fair.c
static void throttle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
long task_delta, dequeue = 1;
se = cfs_rq->tg->se[cpu_of(rq_of(cfs_rq))];
/* freeze hierarchy runnable averages while throttled */
rcu_read_lock();
walk_tg_tree_from(cfs_rq->tg, tg_throttle_down, tg_nop, (void *)rq);
rcu_read_unlock();
task_delta = cfs_rq->h_nr_running;
for_each_sched_entity(se) {
struct cfs_rq *qcfs_rq = cfs_rq_of(se);
/* throttled entity or throttle-on-deactivate */
if (!se->on_rq)
break;
if (dequeue)
dequeue_entity(qcfs_rq, se, DEQUEUE_SLEEP);
qcfs_rq->h_nr_running -= task_delta;
if (qcfs_rq->load.weight)
dequeue = 0;
}
if (!se)
sub_nr_running(rq, task_delta);
cfs_rq->throttled = 1;
cfs_rq->throttled_clock = rq_clock(rq);
raw_spin_lock(&cfs_b->lock);
/*
* Add to the _head_ of the list, so that an already-started
* distribute_cfs_runtime will not see us
*/
list_add_rcu(&cfs_rq->throttled_list, &cfs_b->throttled_cfs_rq);
if (!cfs_b->timer_active)
__start_cfs_bandwidth(cfs_b, false);
raw_spin_unlock(&cfs_b->lock);
}
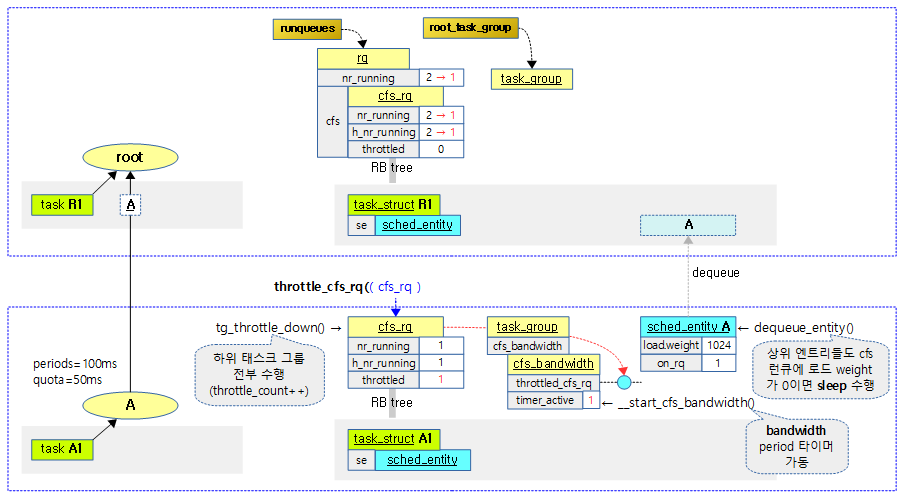
요청한 cfs 런큐를 스로틀링한다.
다음 그림은 요청한 cfs 런큐에 대해 스로틀링을 할 때 처리되는 모습을 보여준다.
kernel/sched/fair.c
static int tg_throttle_down(struct task_group *tg, void *data)
{
struct rq *rq = data;
struct cfs_rq *cfs_rq = tg->cfs_rq[cpu_of(rq)];
/* group is entering throttled state, stop time */
if (!cfs_rq->throttle_count) {
cfs_rq->throttled_clock_task = rq_clock_task(rq);
list_del_leaf_cfs_rq(cfs_rq);
}
cfs_rq->throttle_count++;
return 0;
}
요청 태스크 그룹 및 cpu의 cfs 런큐의 스로틀 카운터를 증가시켜 스로틀 상태로 변경한다.
kernel/sched/fair.c
void unthrottle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
int enqueue = 1;
long task_delta, idle_task_delta;
se = cfs_rq->tg->se[cpu_of(rq)];
cfs_rq->throttled = 0;
update_rq_clock(rq);
raw_spin_lock(&cfs_b->lock);
cfs_b->throttled_time += rq_clock(rq) - cfs_rq->throttled_clock;
list_del_rcu(&cfs_rq->throttled_list);
raw_spin_unlock(&cfs_b->lock);
/* update hierarchical throttle state */
walk_tg_tree_from(cfs_rq->tg, tg_nop, tg_unthrottle_up, (void *)rq);
if (!cfs_rq->load.weight)
return;
task_delta = cfs_rq->h_nr_running;
idle_task_delta = cfs_rq->idle_h_nr_running;
for_each_sched_entity(se) {
if (se->on_rq)
enqueue = 0;
cfs_rq = cfs_rq_of(se);
if (enqueue)
enqueue_entity(cfs_rq, se, ENQUEUE_WAKEUP);
cfs_rq->h_nr_running += task_delta;
cfs_rq->idle_h_nr_running += idle_task_delta;
if (cfs_rq_throttled(cfs_rq))
break;
}
assert_list_leaf_cfs_rq(rq);
if (!se)
add_nr_running(rq, task_delta);
/* determine whether we need to wake up potentially idle cpu */
if (rq->curr == rq->idle && rq->cfs.nr_running)
resched_curr(rq);
}
요청한 cfs 런큐를 언스로틀링한다.
다음 그림은 여러 가지 clock에 대해 동작되는 모습을 보여준다.
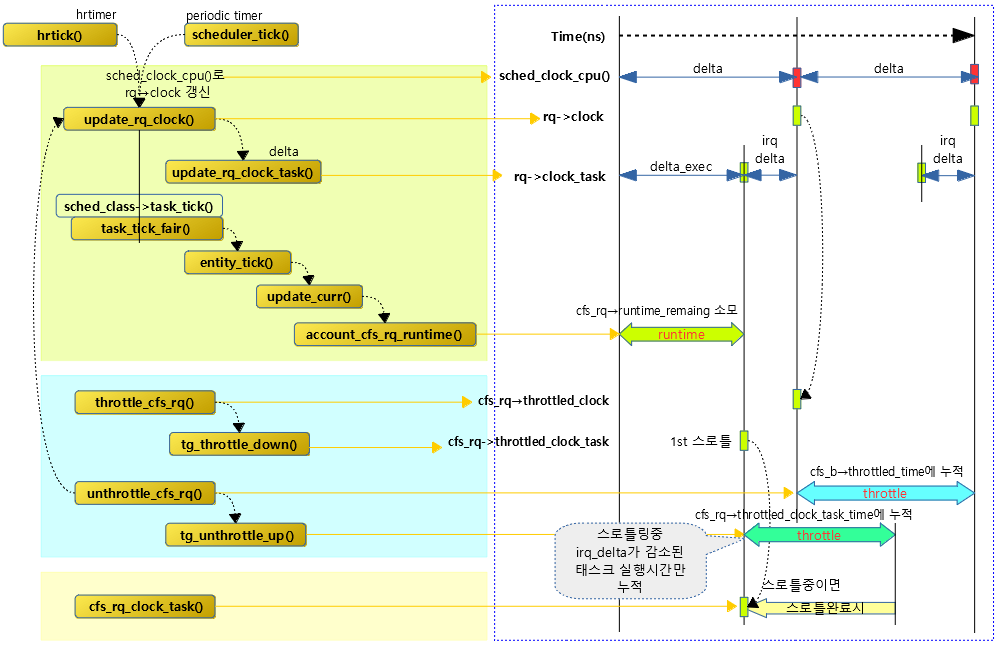
kernel/sched/fair.c
static int tg_unthrottle_up(struct task_group *tg, void *data)
{
struct rq *rq = data;
struct cfs_rq *cfs_rq = tg->cfs_rq[cpu_of(rq)];
cfs_rq->throttle_count--;
if (!cfs_rq->throttle_count) {
/* adjust cfs_rq_clock_task() */
cfs_rq->throttled_clock_task_time += rq_clock_task(rq) -
cfs_rq->throttled_clock_task;
/* Add cfs_rq with already running entity in the list */
if (cfs_rq->nr_running >= 1)
list_add_leaf_cfs_rq(cfs_rq);
}
return 0;
}
요청 태스크 그룹의 cfs 런큐에 스로틀 완료 카운터를 감소시킨다. 이 카운터가 0인 경우 스로틀 상태에서 벗어난다.
kernel/sched/fair.c
static __always_inline
void account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec)
{
if (!cfs_bandwidth_used() || !cfs_rq->runtime_enabled)
return;
__account_cfs_rq_runtime(cfs_rq, delta_exec);
}
로컬 런타임이 모두 소비된 경우 글로벌 런타임에서 최소 slice(디폴트=5 ms) – 초과 소모한 런타임만큼을 차용하여 로컬 런타임을 할당한다. 만일 로컬 런타임이 충분히 할당되지 않은 경우 리스케줄 요청 플래그를 설정한다..
kernel/sched/fair.c
static void __account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec)
{
/* dock delta_exec before expiring quota (as it could span periods) */
cfs_rq->runtime_remaining -= delta_exec;
if (likely(cfs_rq->runtime_remaining > 0))
return;
if (cfs_rq->throttled)
return;
/*
* if we're unable to extend our runtime we resched so that the active
* hierarchy can be throttled
*/
if (!assign_cfs_rq_runtime(cfs_rq) && likely(cfs_rq->curr))
resched_curr(rq_of(cfs_rq));
}
로컬 런타임이 모두 소비된 경우 글로벌 런타임에서 최소 slice(디폴트=5 ms) – 초과 소모한 런타임만큼을 차용하여 로컬 런타임을 할당한다. 로컬 런타임이 충분히 할당되지 않은 경우 리스케줄 요청 플래그를 설정한다..
kernel/sched/fair.c
/* returns 0 on failure to allocate runtime */
static int assign_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
struct task_group *tg = cfs_rq->tg;
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(tg);
u64 amount = 0, min_amount;
/* note: this is a positive sum as runtime_remaining <= 0 */
min_amount = sched_cfs_bandwidth_slice() - cfs_rq->runtime_remaining;
raw_spin_lock(&cfs_b->lock);
if (cfs_b->quota == RUNTIME_INF)
amount = min_amount;
else {
start_cfs_bandwidth(cfs_b);
if (cfs_b->runtime > 0) {
amount = min(cfs_b->runtime, min_amount);
cfs_b->runtime -= amount;
cfs_b->idle = 0;
}
}
raw_spin_unlock(&cfs_b->lock);
cfs_rq->runtime_remaining += amount;
return cfs_rq->runtime_remaining > 0;
}
로컬 런타임이 모두 소비된 경우 글로벌 런타임에서 최소 slice(디폴트=5 ms) – 초과 소모한 런타임만큼을 차용하여 로컬 런타임을 할당한다. 로컬 런타임이 채워진 경우 1을 반환하고, 여전히 부족한 경우 0을 반환한다.
다음 그림은 스케줄 tick이 발생하여 delta 실행 시간을 로컬 런타임 풀에서 소모시키고 소모 시킬 로컬 런타임이 없으면 slice 만큼의 런타임을 글로벌 런타임에서 빌려오는 것을 보여준다.

kernel/sched/fair.c
static inline u64 sched_cfs_bandwidth_slice(void)
{
return (u64)sysctl_sched_cfs_bandwidth_slice * NSEC_PER_USEC;
}
cfs bandwidth slice 값을 나노초 단위로 반환한다.
/* * Amount of runtime to allocate from global (tg) to local (per-cfs_rq) pool * each time a cfs_rq requests quota. * * Note: in the case that the slice exceeds the runtime remaining (either due * to consumption or the quota being specified to be smaller than the slice) * we will always only issue the remaining available time. * * default: 5 msec, units: microseconds */ unsigned int sysctl_sched_cfs_bandwidth_slice = 5000UL;
다음 그림은 cfs bandwidth에 대한 두 개의 타이머에 대한 함수 호출 관계를 보여준다.
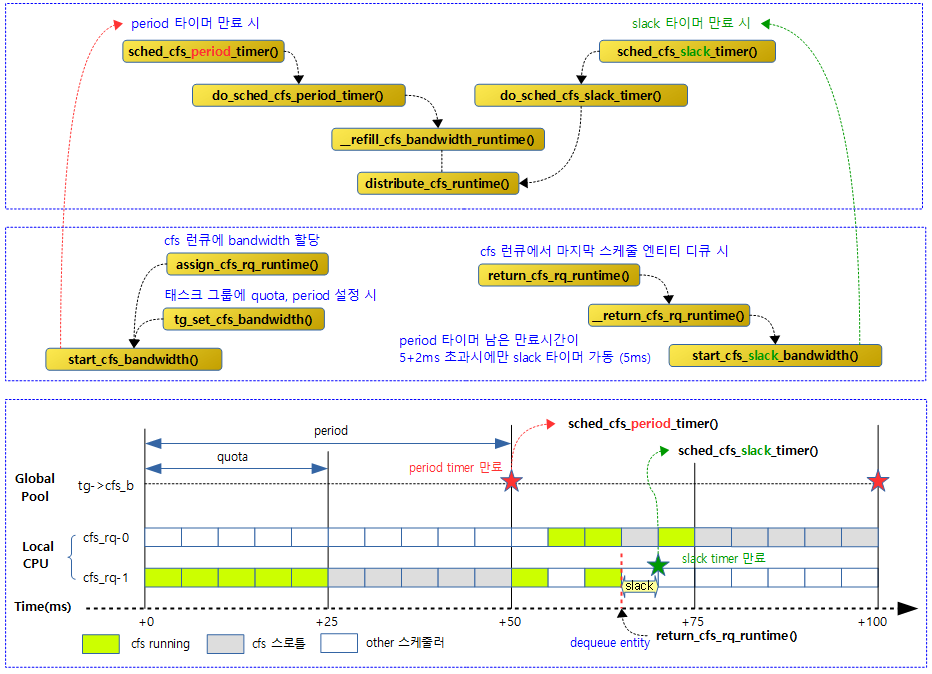
period 타이머를 통해 매 period 시각마다 글로벌 런타임 리필 후 스로틀된 로컬 cfs 런큐를 대상으로 런타임 부족분을 우선 차감 분배한다.
kernel/sched/fair.c
void start_cfs_bandwidth(struct cfs_bandwidth *cfs_b)
{
lockdep_assert_held(&cfs_b->lock);
if (cfs_b->period_active)
return;
cfs_b->period_active = 1;
hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
글로벌 풀의 period 타이머를 가동시킨다.
kernel/sched/fair.c
static enum hrtimer_restart sched_cfs_period_timer(struct hrtimer *timer)
{
struct cfs_bandwidth *cfs_b =
container_of(timer, struct cfs_bandwidth, period_timer);
unsigned long flags;
int overrun;
int idle = 0;
int count = 0;
raw_spin_lock_irqsave(&cfs_b->lock, flags);
for (;;) {
overrun = hrtimer_forward_now(timer, cfs_b->period);
if (!overrun)
break;
if (++count > 3) {
u64 new, old = ktime_to_ns(cfs_b->period);
/*
* Grow period by a factor of 2 to avoid losing precision.
* Precision loss in the quota/period ratio can cause __cfs_schedulable
* to fail.
*/
new = old * 2;
if (new < max_cfs_quota_period) {
cfs_b->period = ns_to_ktime(new);
cfs_b->quota *= 2;
pr_warn_ratelimited(
"cfs_period_timer[cpu%d]: period too short, scaling up (new cfs_period_us = %lld, cfs_quota_us = %lld)\n",
smp_processor_id(),
div_u64(new, NSEC_PER_USEC),
div_u64(cfs_b->quota, NSEC_PER_USEC));
} else {
pr_warn_ratelimited(
"cfs_period_timer[cpu%d]: period too short, but cannot scale up without losing precision (cfs_period_us = %lld, cfs_quota_us = %lld)\n",
smp_processor_id(),
div_u64(old, NSEC_PER_USEC),
div_u64(cfs_b->quota, NSEC_PER_USEC));
}
/* reset count so we don't come right back in here */
count = 0;
}
idle = do_sched_cfs_period_timer(cfs_b, overrun, flags);
}
if (idle)
cfs_b->period_active = 0;
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
return idle ? HRTIMER_NORESTART : HRTIMER_RESTART;
}
period 타이머 만료 시에 호출되며 타이머에 연동된 태스크 그룹의 quota를 글로벌 런타임에 리필하고 추가적으로 필요한 작업들을 수행한다.
태스크 그룹의 quota를 글로벌 런타임에 리필하고 이전 period에서 언스로틀된 cfs 런큐들에 대해 글로벌 런타임을 먼저 차감 분배하고 언스로틀한다.
kernel/sched/fair.c
/* * Responsible for refilling a task_group's bandwidth and unthrottling its * cfs_rqs as appropriate. If there has been no activity within the last * period the timer is deactivated until scheduling resumes; cfs_b->idle is * used to track this state. */
static int do_sched_cfs_period_timer(struct cfs_bandwidth *cfs_b, int overrun, unsigned long flags)
{
u64 runtime;
int throttled;
/* no need to continue the timer with no bandwidth constraint */
if (cfs_b->quota == RUNTIME_INF)
goto out_deactivate;
throttled = !list_empty(&cfs_b->throttled_cfs_rq);
cfs_b->nr_periods += overrun;
/*
* idle depends on !throttled (for the case of a large deficit), and if
* we're going inactive then everything else can be deferred
*/
if (cfs_b->idle && !throttled)
goto out_deactivate;
__refill_cfs_bandwidth_runtime(cfs_b);
if (!throttled) {
/* mark as potentially idle for the upcoming period */
cfs_b->idle = 1;
return 0;
}
/* account preceding periods in which throttling occurred */
cfs_b->nr_throttled += overrun;
/*
* This check is repeated as we are holding onto the new bandwidth while
* we unthrottle. This can potentially race with an unthrottled group
* trying to acquire new bandwidth from the global pool. This can result
* in us over-using our runtime if it is all used during this loop, but
* only by limited amounts in that extreme case.
*/
while (throttled && cfs_b->runtime > 0 && !cfs_b->distribute_running) {
runtime = cfs_b->runtime;
cfs_b->distribute_running = 1;
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
/* we can't nest cfs_b->lock while distributing bandwidth */
runtime = distribute_cfs_runtime(cfs_b, runtime);
raw_spin_lock_irqsave(&cfs_b->lock, flags);
cfs_b->distribute_running = 0;
throttled = !list_empty(&cfs_b->throttled_cfs_rq);
lsub_positive(&cfs_b->runtime, runtime);
}
/*
* While we are ensured activity in the period following an
* unthrottle, this also covers the case in which the new bandwidth is
* insufficient to cover the existing bandwidth deficit. (Forcing the
* timer to remain active while there are any throttled entities.)
*/
cfs_b->idle = 0;
return 0;
out_deactivate:
return 1;
}
다음 그림은 글로벌 런타임을 스로틀된 cfs 런큐에 부족한 런타임만큼 우선 차감 분배하는 과정을 보여준다.
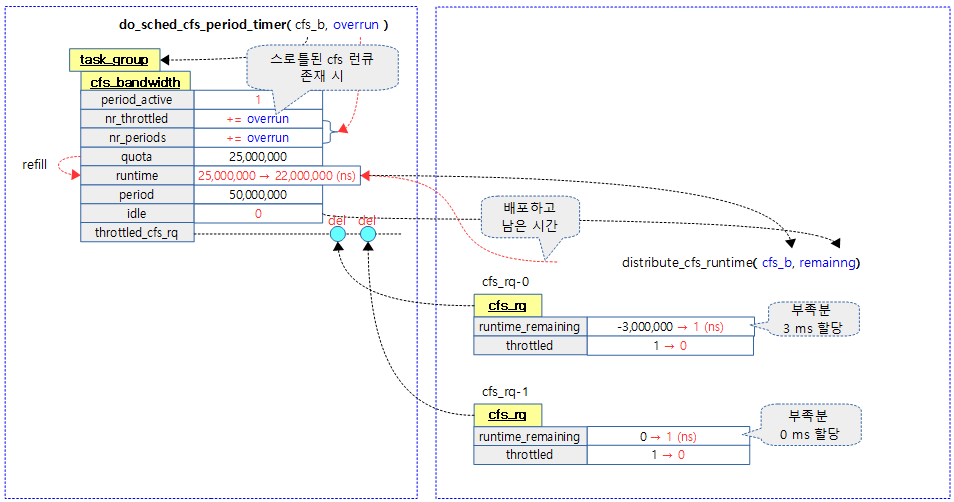
kernel/sched/fair.c
/* * Replenish runtime according to assigned quota. We use sched_clock_cpu * directly instead of rq->clock to avoid adding additional synchronization * around rq->lock. * * requires cfs_b->lock */
void __refill_cfs_bandwidth_runtime(struct cfs_bandwidth *cfs_b)
{
if (cfs_b->quota != RUNTIME_INF)
cfs_b->runtime = cfs_b->quota;
}
글로벌 풀의 런타임을 quota 만큼으로 리필한다.
이 함수는 다음 그림과 같이 period 타이머의 만료 시 마다 호출되어 사용되는 것을 보여준다.

kernel/sched/fair.c
static u64 distribute_cfs_runtime(struct cfs_bandwidth *cfs_b, u64 remaining)
{
struct cfs_rq *cfs_rq;
u64 runtime;
u64 starting_runtime = remaining;
rcu_read_lock();
list_for_each_entry_rcu(cfs_rq, &cfs_b->throttled_cfs_rq,
throttled_list) {
struct rq *rq = rq_of(cfs_rq);
struct rq_flags rf;
rq_lock_irqsave(rq, &rf);
if (!cfs_rq_throttled(cfs_rq))
goto next;
/* By the above check, this should never be true */
SCHED_WARN_ON(cfs_rq->runtime_remaining > 0);
runtime = -cfs_rq->runtime_remaining + 1;
if (runtime > remaining)
runtime = remaining;
remaining -= runtime;
cfs_rq->runtime_remaining += runtime;
/* we check whether we're throttled above */
if (cfs_rq->runtime_remaining > 0)
unthrottle_cfs_rq(cfs_rq);
next:
rq_unlock_irqrestore(rq, &rf);
if (!remaining)
break;
}
rcu_read_unlock();
return starting_runtime - remaining;
}
스로틀된 cfs 런큐들을 순서대로 글로벌 잔량이 남아있는 한 초과 소모한 런타임을 우선 배분하고 언스로틀한다.
다음 그림은 distribute_cfs_runtime() 함수의 동작 시 글로벌 런타임을 기존 스로틀된 cfs 런큐의 초과 소모한 런타임 만큼을 우선 분배하고 언스로틀하는 과정을 보여준다.
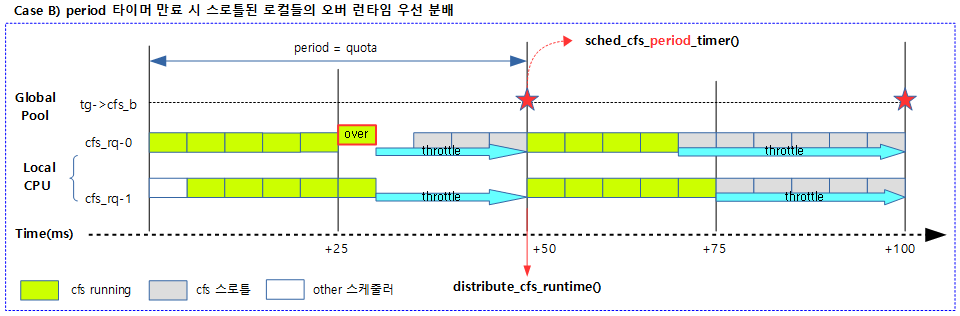
엔티티가 디큐될 때 사용하고 남은 런타임 잔량 중 1ms를 뺀 나머지 모두를 글로벌 런타임에 반납한다. periods 타이머 만료 시각까지 7 ms 이상 충분히 시간이 남아 있으면 스로틀된 cfs 런큐를 깨워 동작시키기 위해 분배 작업을 위해 5ms 슬랙 타이머를 가동 시킨다. 슬랙 타이머의 만료 시각에는 스로틀 중인 로컬 cfs 런큐들에 남은 잔량을 분배한다.
kernel/sched/fair.c
static __always_inline void return_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
if (!cfs_bandwidth_used())
return;
if (!cfs_rq->runtime_enabled || cfs_rq->nr_running)
return;
__return_cfs_rq_runtime(cfs_rq);
}
cfs 스케줄러에서 스케줄 엔티티가 디큐될 때 이 함수가 호출되면 남은 로컬 런타임을 회수하여 글로벌 풀로 반납한다. 그런 후에 5ms 주기의 slack 타이머를 가동시켜서 스로틀된 다른 태스크에게 런타임을 할당해준다.
kernel/sched/fair.c
/* we know any runtime found here is valid as update_curr() precedes return */
static void __return_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
s64 slack_runtime = cfs_rq->runtime_remaining - min_cfs_rq_runtime;
if (slack_runtime <= 0)
return;
raw_spin_lock(&cfs_b->lock);
if (cfs_b->quota != RUNTIME_INF &&
cfs_b->runtime += slack_runtime;
/* we are under rq->lock, defer unthrottling using a timer */
if (cfs_b->runtime > sched_cfs_bandwidth_slice() &&
!list_empty(&cfs_b->throttled_cfs_rq))
start_cfs_slack_bandwidth(cfs_b);
}
raw_spin_unlock(&cfs_b->lock);
/* even if it's not valid for return we don't want to try again */
cfs_rq->runtime_remaining -= slack_runtime;
}
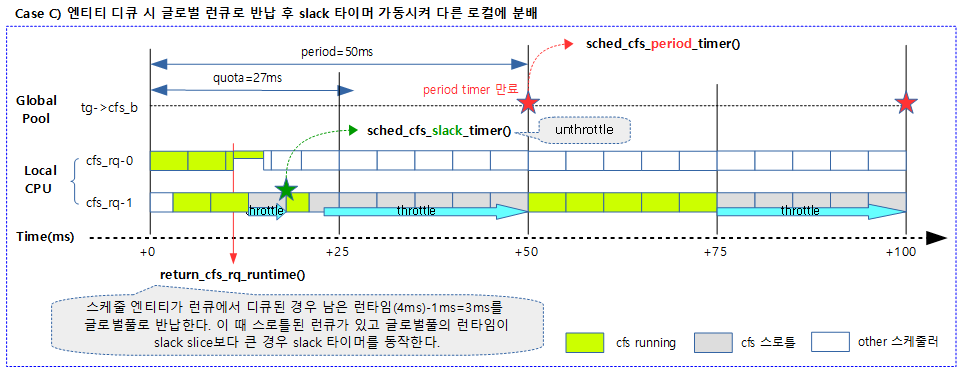
kernel/sched/fair.c
static void start_cfs_slack_bandwidth(struct cfs_bandwidth *cfs_b)
{
u64 min_left = cfs_bandwidth_slack_period + min_bandwidth_expiration;
/* if there's a quota refresh soon don't bother with slack */
if (runtime_refresh_within(cfs_b, min_left))
return;
/* don't push forwards an existing deferred unthrottle */
if (cfs_b->slack_started)
return;
cfs_b->slack_started = true;
hrtimer_start(&cfs_b->slack_timer,
ns_to_ktime(cfs_bandwidth_slack_period),
HRTIMER_MODE_REL);
}
slack 타이머를 slack 주기(디폴트 5ms)로 가동시킨다. 단 period 타이머의 만료 시각이 slack 불필요 범위(디폴트 7ms) 이내인 경우에는 가동시키지 않는다.
kernel/sched/fair.c
/* * Are we near the end of the current quota period? * * Requires cfs_b->lock for hrtimer_expires_remaining to be safe against the * hrtimer base being cleared by __hrtimer_start_range_ns. In the case of * migrate_hrtimers, base is never cleared, so we are fine. */
static int runtime_refresh_within(struct cfs_bandwidth *cfs_b, u64 min_expire)
{
struct hrtimer *refresh_timer = &cfs_b->period_timer;
u64 remaining;
/* if the call-back is running a quota refresh is already occurring */
if (hrtimer_callback_running(refresh_timer))
return 1;
/* is a quota refresh about to occur? */
remaining = ktime_to_ns(hrtimer_expires_remaining(refresh_timer));
if (remaining < min_expire)
return 1;
return 0;
}
글로벌 런타임 리프레쉬 주기가 다가오는지 여부를 확인한다.
kernel/sched/fair.c
static enum hrtimer_restart sched_cfs_slack_timer(struct hrtimer *timer)
{
struct cfs_bandwidth *cfs_b =
container_of(timer, struct cfs_bandwidth, slack_timer);
do_sched_cfs_slack_timer(cfs_b);
return HRTIMER_NORESTART;
}
slack 타이머 만료 시 글로벌 풀로부터 스로틀된 로컬들의 초과 소모 런타임을 우선 분배한다. (디폴트로 slack 타이머는 5ms이다)
kernel/sched/fair.c
/* * This is done with a timer (instead of inline with bandwidth return) since * it's necessary to juggle rq->locks to unthrottle their respective cfs_rqs. */
static void do_sched_cfs_slack_timer(struct cfs_bandwidth *cfs_b)
{
u64 runtime = 0, slice = sched_cfs_bandwidth_slice();
unsigned long flags;
/* confirm we're still not at a refresh boundary */
raw_spin_lock_irqsave(&cfs_b->lock, flags);
cfs_b->slack_started = false;
if (runtime_refresh_within(cfs_b, min_bandwidth_expiration)) {
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
return;
}
if (runtime_refresh_within(cfs_b, min_bandwidth_expiration)) {
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
return;
}
if (cfs_b->quota != RUNTIME_INF && cfs_b->runtime > slice)
runtime = cfs_b->runtime;
if (runtime)
cfs_b->distribute_running = 1;
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
if (!runtime)
return;
runtime = distribute_cfs_runtime(cfs_b, runtime, expires);
raw_spin_lock_irqsave(&cfs_b->lock, flags);
lsub_positive(&cfs_b->runtime, runtime);
cfs_b->distribute_running = 0;
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
}
slack 타이머 만료 시 글로벌 풀로부터 스로틀된 로컬들의 초과 소모한 런타임을 우선 분배한다. (디폴트로 slack 타이머는 5ms이다)
kernel/sched/deadline.c
void init_dl_bandwidth(struct dl_bandwidth *dl_b, u64 period, u64 runtime)
{
raw_spin_lock_init(&dl_b->dl_runtime_lock);
dl_b->dl_period = period;
dl_b->dl_runtime = runtime;
}
dl period와 runtime 값을 사용하여 초기화한다.
kernel/sched/sched.h
struct cfs_bandwidth {
#ifdef CONFIG_CFS_BANDWIDTH
raw_spinlock_t lock;
ktime_t period;
u64 quota;
u64 runtime;
s64 hierarchical_quota;
u8 idle;
u8 period_active;
u8 distribute_running;
u8 slack_started;
struct hrtimer period_timer;
struct hrtimer slack_timer;
struct list_head throttled_cfs_rq;
/* Statistics: */
int nr_periods;
int nr_throttled;
u64 throttled_time;
#endif
};
kernel/sched/sched.
struct cfs_rq {
(...생략...)
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
s64 runtime_remaining;
u64 throttled_clock;
u64 throttled_clock_task;
u64 throttled_clock_task_time;
int throttled;
int throttle_count;
struct list_head throttled_list;
#endif /* CONFIG_CFS_BANDWIDTH */
};
<kernel v5.4>
그룹 스케줄링은 cgroup의 cpu 서브시스템을 사용하여 구현하였고 각 그룹은 태스크 그룹(struct task_group)으로 관리된다.
다음 그림은 태스크 그룹간 계층도를 보여준다.
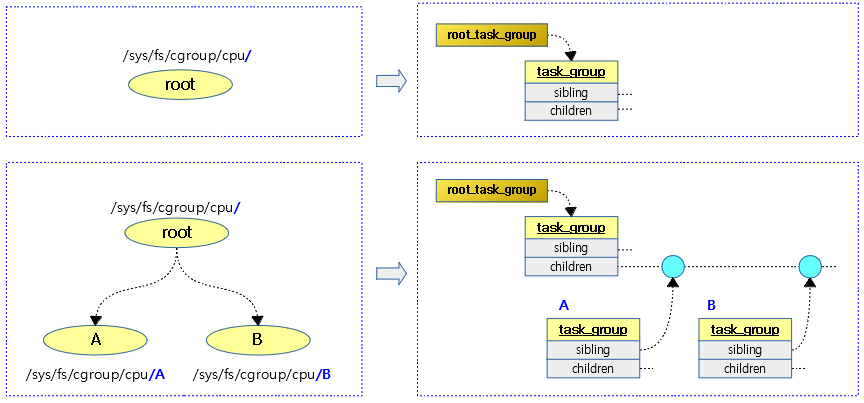
다음 그림은 태스크 그룹에 태스크 및 스케줄 엔티티가 포함된 모습을 보여준다.
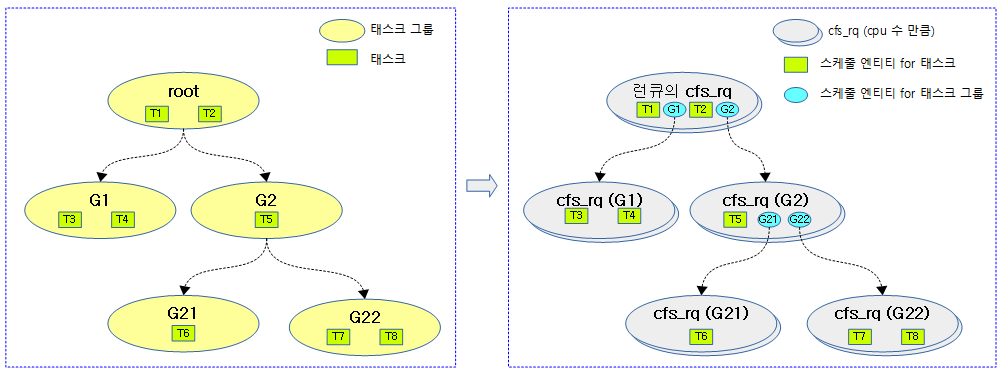
다음 그림은 cfs 런큐들이 cpu 만큼 있음을 보여준다.

다음 그림은 스케줄 엔티티의 부모 관계를 보여준다.

다음 그림은 스케줄 엔티티의 cfs_rq 및 my_q가 어떤 cfs_rq를 가리키는지 보여준다.
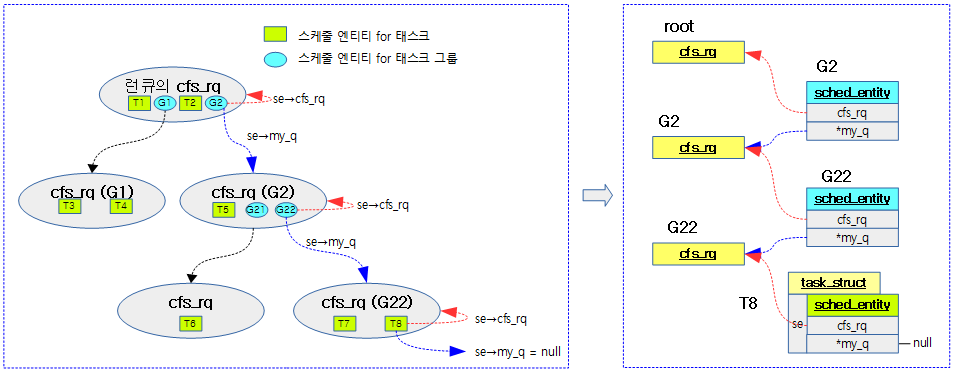
kernel/sched/core.c
static struct cgroup_subsys_state *
cpu_cgroup_css_alloc(struct cgroup_subsys_state *parent_css)
{
struct task_group *parent = css_tg(parent_css);
struct task_group *tg;
if (!parent) {
/* This is early initialization for the top cgroup */
return &root_task_group.css;
}
tg = sched_create_group(parent);
if (IS_ERR(tg))
return ERR_PTR(-ENOMEM);
return &tg->css;
}
요청한 cpu cgroup에 연결된 태스크 그룹의 하위에 새 태스크 그룹을 생성한다.
cpu cgroup 서브시스템이 설정된 커널인 경우 커널이 초기화되면서 cgroup_init_subsys() 함수에서 루트 태스크 그룹은 초기화된다. 그 밑으로 새 태스크 그룹을 생성할 때 다음과 같이 디렉토리를 생성하는 것으로 새 태스크 그룹이 생성된다.
/$ cd /sys/fs/cgroup/cpu /sys/fs/cgroup/cpu$ sudo mkdir A /sys/fs/cgroup/cpu$ ls cgroup.clone_children cpu.rt_runtime_us cpuacct.stat cpuacct.usage_percpu_user cgroup.procs cpu.shares cpuacct.usage cpuacct.usage_sys cpu.cfs_period_us cpu.stat cpuacct.usage_all cpuacct.usage_user cpu.cfs_quota_us cpu.uclamp.max cpuacct.usage_percpu notify_on_release cpu.rt_period_us cpu.uclamp.min cpuacct.usage_percpu_sys tasks
위의 주요 설정 항목들은 다음과 같다. cgroup 공통 항목들의 설명은 제외한다.
다음 그림은 sched_create_group() 함수의 호출 관계를 보여준다.
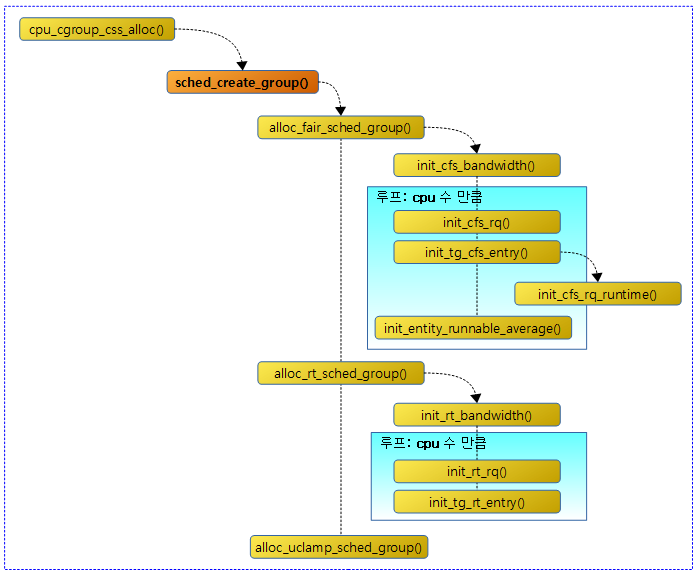
kernel/sched/core.c
/* allocate runqueue etc for a new task group */
struct task_group *sched_create_group(struct task_group *parent)
{
struct task_group *tg;
tg = kmem_cache_alloc(task_group_cache, GFP_KERNEL | __GFP_ZERO);
if (!tg)
return ERR_PTR(-ENOMEM);
if (!alloc_fair_sched_group(tg, parent))
goto err;
if (!alloc_rt_sched_group(tg, parent))
goto err;
alloc_uclamp_sched_group(tg, parent);
return tg;
err:
sched_free_group(tg);
return ERR_PTR(-ENOMEM);
}
요청한 cpu cgroup의 child에 태스크 그룹을 생성하고 그 태스크 그룹에 cfs 스케줄 그룹과 rt 스케줄 그룹을 할당하고 초기화한다.
다음 그림은 sched_create_group() 함수를 호출하여 태스크 그룹을 생성할 때 태스크 그룹에 연결되는 cfs 런큐, 스케줄 엔티티, rt 런큐, rt 스케줄 엔티티를 보여준다.
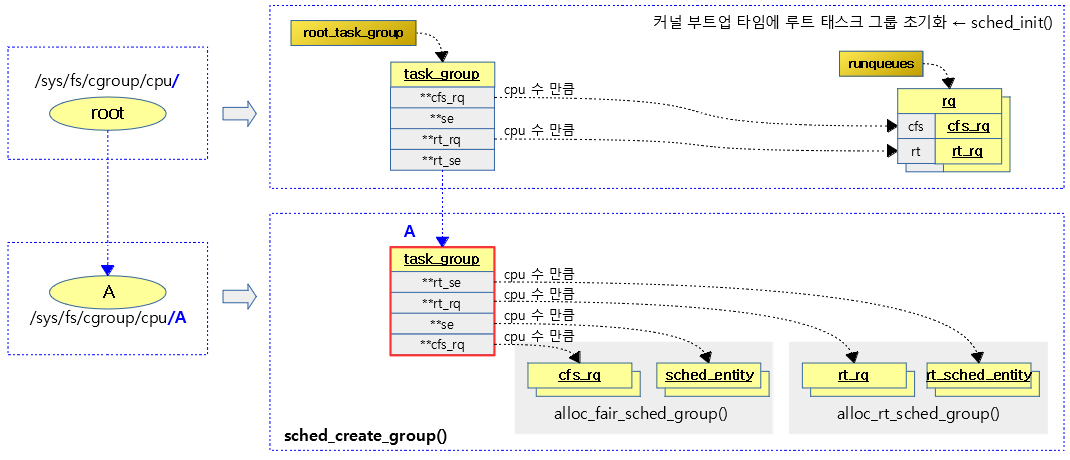
kernel/sched/core.c
int alloc_fair_sched_group(struct task_group *tg, struct task_group *parent)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se;
int i;
tg->cfs_rq = kzalloc(sizeof(cfs_rq) * nr_cpu_ids, GFP_KERNEL);
if (!tg->cfs_rq)
goto err;
tg->se = kzalloc(sizeof(se) * nr_cpu_ids, GFP_KERNEL);
if (!tg->se)
goto err;
tg->shares = NICE_0_LOAD;
init_cfs_bandwidth(tg_cfs_bandwidth(tg));
for_each_possible_cpu(i) {
cfs_rq = kzalloc_node(sizeof(struct cfs_rq),
GFP_KERNEL, cpu_to_node(i));
if (!cfs_rq)
goto err;
se = kzalloc_node(sizeof(struct sched_entity),
GFP_KERNEL, cpu_to_node(i));
if (!se)
goto err_free_rq;
init_cfs_rq(cfs_rq);
init_tg_cfs_entry(tg, cfs_rq, se, i, parent->se[i]);
init_entity_runnable_average(se);
}
return 1;
err_free_rq:
kfree(cfs_rq);
err:
return 0;
}
태스크 그룹에 cfs 스케줄 그룹을 할당하고 초기화한다. 성공인 경우 1을 반환한다.
다음 그림은 alloc_rt_sched_group() 함수를 통해 태스크 그룹이 이 함수에서 생성한 cfs 런큐와 스케줄 엔티티가 연결되고 초기화되는 모습을 보여준다.
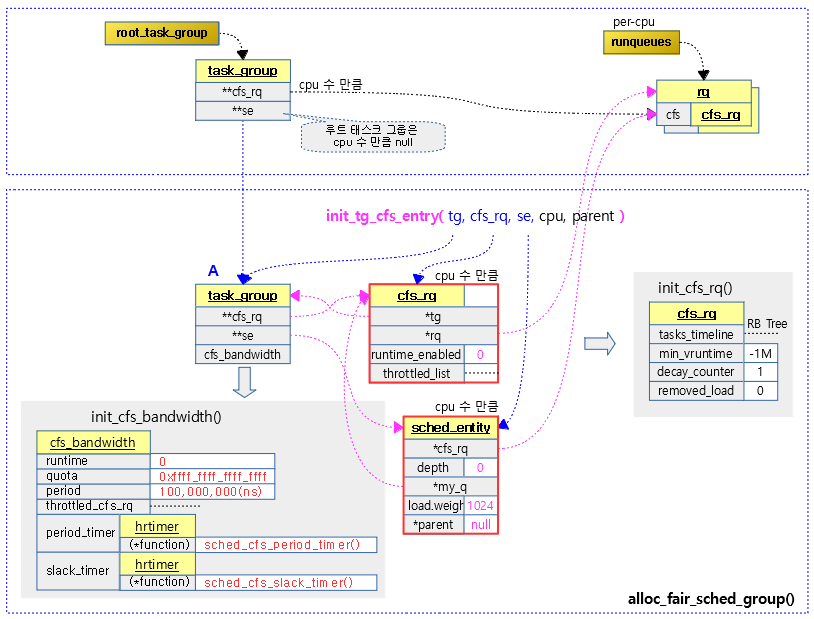
다음 그림은 CFS 런큐 <-> 태스크 그룹 <-> 스케줄 엔티티간의 연관 관계를 보여준다.
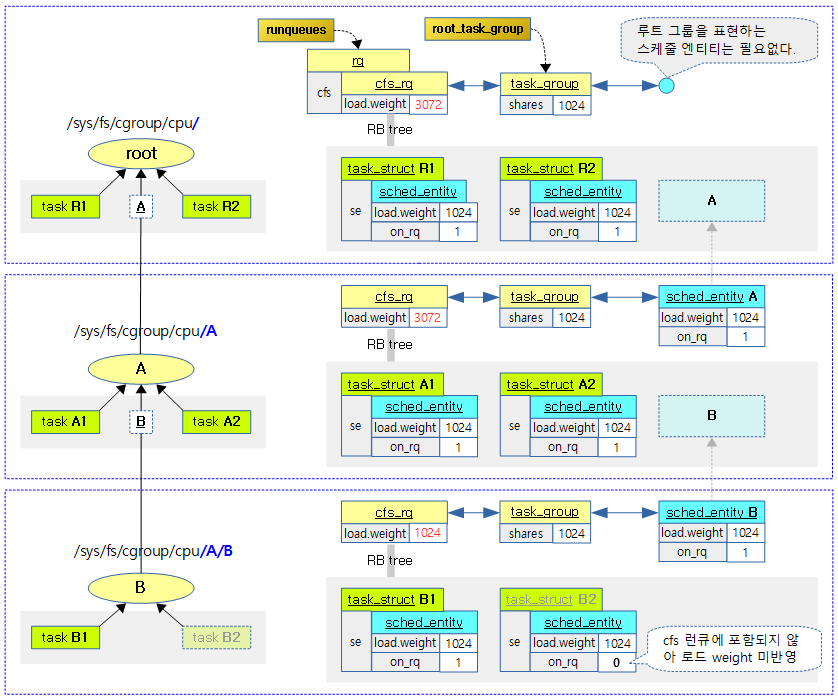
kernel/sched/fair.c
void init_tg_cfs_entry(struct task_group *tg, struct cfs_rq *cfs_rq,
struct sched_entity *se, int cpu,
struct sched_entity *parent)
{
struct rq *rq = cpu_rq(cpu);
cfs_rq->tg = tg;
cfs_rq->rq = rq;
init_cfs_rq_runtime(cfs_rq);
tg->cfs_rq[cpu] = cfs_rq;
tg->se[cpu] = se;
/* se could be NULL for root_task_group */
if (!se)
return;
if (!parent) {
se->cfs_rq = &rq->cfs;
se->depth = 0;
} else {
se->cfs_rq = parent->my_q;
se->depth = parent->depth + 1;
}
se->my_q = cfs_rq;
/* guarantee group entities always have weight */
update_load_set(&se->load, NICE_0_LOAD);
se->parent = parent;
}
태스크 그룹에 cfs 런큐 및 cfs 스케줄 엔티티를 연결시키고 cfs 엔트리들을 초기화한다.
다음 그림은 루트 태스크 그룹부터 하위 태스크 그룹까지 init_tg_cfs_entry() 함수를 각각 호출할 때 서로 연결되는 모습을 보여준다.
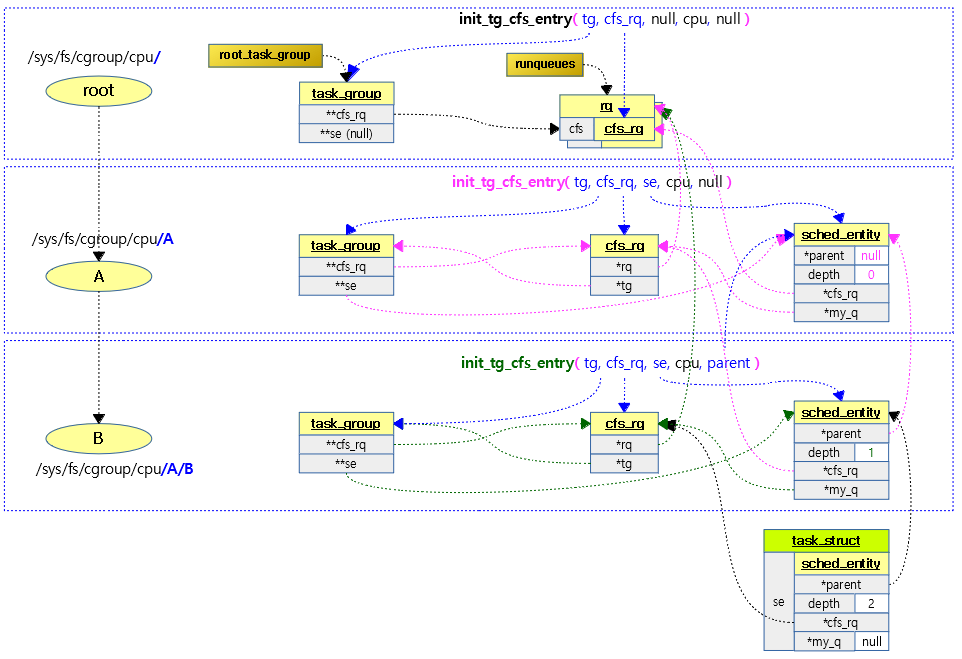
kernel/sched/fair.c
static void init_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
cfs_rq->runtime_enabled = 0;
INIT_LIST_HEAD(&cfs_rq->throttled_list);
}
cfs 런큐의 스로틀링 runtime을 초기화한다.
kernel/sched/fair.c
static inline void update_load_set(struct load_weight *lw, unsigned long w)
{
lw->weight = w;
lw->inv_weight = 0;
}
로드 weight 값을 설정한다. inv_weight 값은 0으로 일단 초기화한다.
kernel/sched/core.c
int alloc_rt_sched_group(struct task_group *tg, struct task_group *parent)
{
struct rt_rq *rt_rq;
struct sched_rt_entity *rt_se;
int i;
tg->rt_rq = kzalloc(sizeof(rt_rq) * nr_cpu_ids, GFP_KERNEL);
if (!tg->rt_rq)
goto err;
tg->rt_se = kzalloc(sizeof(rt_se) * nr_cpu_ids, GFP_KERNEL);
if (!tg->rt_se)
goto err;
init_rt_bandwidth(&tg->rt_bandwidth,
ktime_to_ns(def_rt_bandwidth.rt_period), 0);
for_each_possible_cpu(i) {
rt_rq = kzalloc_node(sizeof(struct rt_rq),
GFP_KERNEL, cpu_to_node(i));
if (!rt_rq)
goto err;
rt_se = kzalloc_node(sizeof(struct sched_rt_entity),
GFP_KERNEL, cpu_to_node(i));
if (!rt_se)
goto err_free_rq;
init_rt_rq(rt_rq, cpu_rq(i));
rt_rq->rt_runtime = tg->rt_bandwidth.rt_runtime;
init_tg_rt_entry(tg, rt_rq, rt_se, i, parent->rt_se[i]);
}
return 1;
err_free_rq:
kfree(rt_rq);
err:
return 0;
}
태스크 그룹에 rt 스케줄 그룹을 할당하고 초기화한다. 성공인 경우 1을 반환한다.
다음 그림은 alloc_rt_sched_group() 함수를 통해 태스크 그룹이 이 함수에서 생성한 rt 런큐와 rt 스케줄 엔티티가 연결되고 초기화되는 모습을 보여준다.
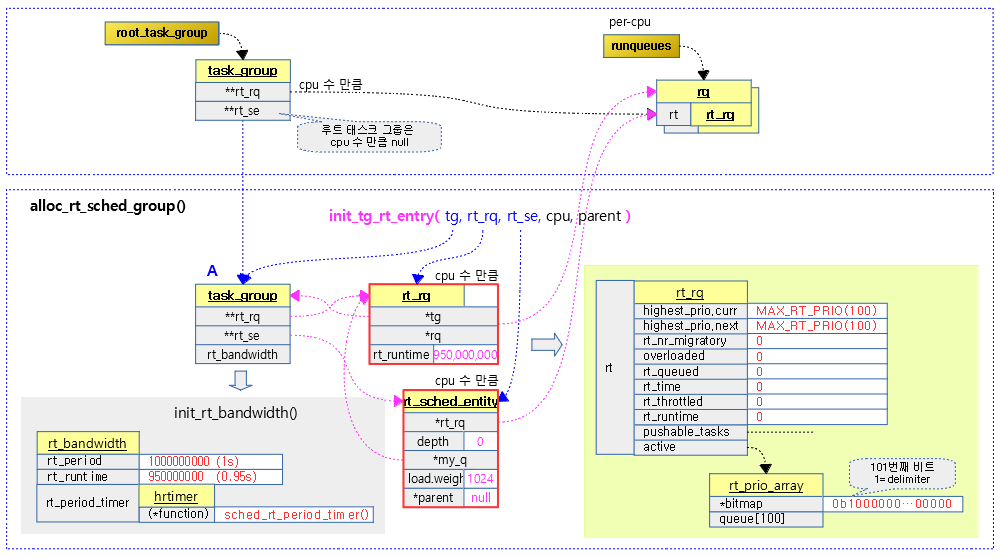
kernel/sched/rt.c
void init_tg_rt_entry(struct task_group *tg, struct rt_rq *rt_rq,
struct sched_rt_entity *rt_se, int cpu,
struct sched_rt_entity *parent)
{
struct rq *rq = cpu_rq(cpu);
rt_rq->highest_prio.curr = MAX_RT_PRIO;
rt_rq->rt_nr_boosted = 0;
rt_rq->rq = rq;
rt_rq->tg = tg;
tg->rt_rq[cpu] = rt_rq;
tg->rt_se[cpu] = rt_se;
if (!rt_se)
return;
if (!parent)
rt_se->rt_rq = &rq->rt;
else
rt_se->rt_rq = parent->my_q;
rt_se->my_q = rt_rq;
rt_se->parent = parent;
INIT_LIST_HEAD(&rt_se->run_list);
}
태스크 그룹에 rt 런큐 및 rt 스케줄 엔티티를 연결시키고 rt 엔트리들을 초기화한다.
다음 그림은 루트 태스크 그룹부터 하위 태스크 그룹까지 init_tg_rt_entry() 함수를 각각 호출할 때 서로 연결되는 모습을 보여준다.
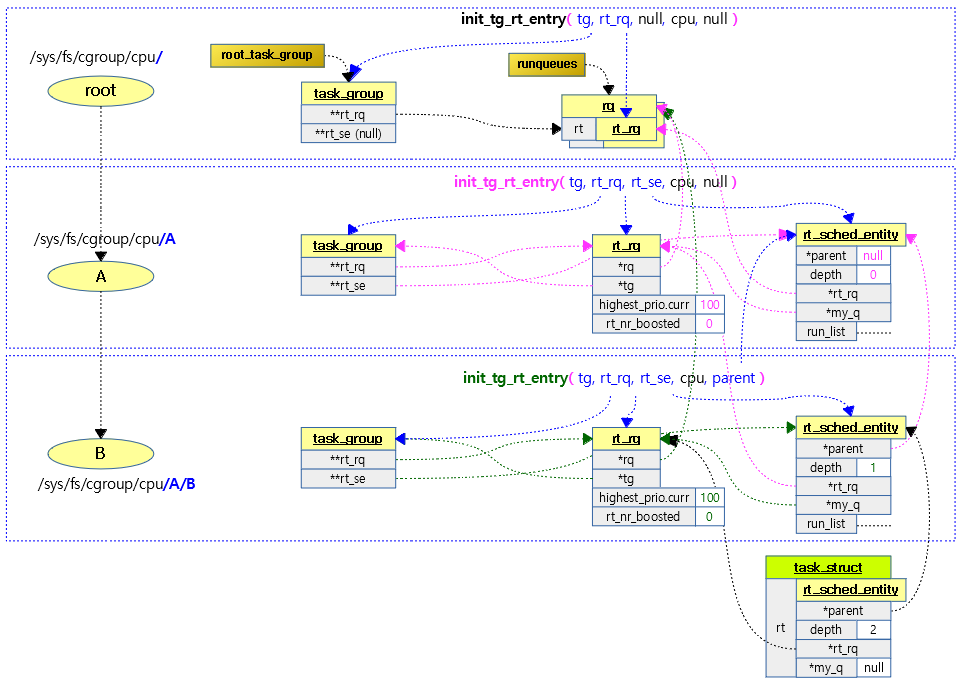
kernel/sched/fair.c
int sched_group_set_shares(struct task_group *tg, unsigned long shares)
{
int i;
/*
* We can't change the weight of the root cgroup.
*/
if (!tg->se[0])
return -EINVAL;
shares = clamp(shares, scale_load(MIN_SHARES), scale_load(MAX_SHARES));
mutex_lock(&shares_mutex);
if (tg->shares == shares)
goto done;
tg->shares = shares;
for_each_possible_cpu(i) {
struct rq *rq = cpu_rq(i);
struct sched_entity *se;
struct rq_flags rf;
/* Propagate contribution to hierarchy */
raw_spin_lock_irqsave(&rq->lock, rf);
update_rq_clock(rq);
for_each_sched_entity(se) {
update_load_avg(cfs_rq_of(se), se, UPDATE_TG);
update_cfs_group(se);
}
raw_spin_unlock_irqrestore(&rq->lock, &rf);
}
done:
mutex_unlock(&shares_mutex);
return 0;
}
요청한 태스크 그룹의 cfs shares 값을 설정한다.
kernel/sched/sched.h
/* * A weight of 0 or 1 can cause arithmetics problems. * A weight of a cfs_rq is the sum of weights of which entities * are queued on this cfs_rq, so a weight of a entity should not be * too large, so as the shares value of a task group. * (The default weight is 1024 - so there's no practical * limitation from this.) */ #define MIN_SHARES (1UL << 1) #define MAX_SHARES (1UL << 18)
CFS shares 값 범위(2 ~ 256K)
다음 그림은 태스크 그룹에 설정한 shares 값이 스케줄 엔트리, cfs 런큐 및 런큐의 로드 weight 값에 재반영되는 모습을 보여준다.
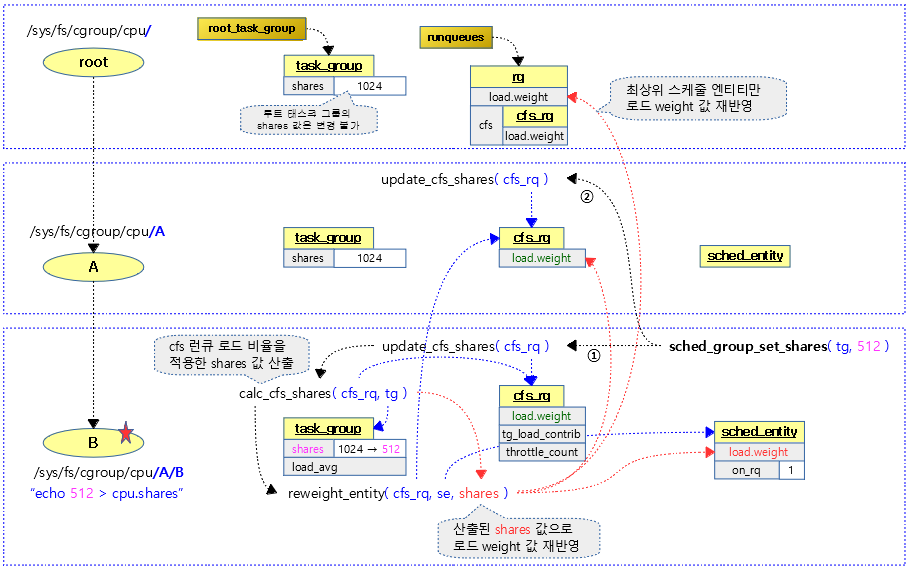
kernel/sched/sched.h
/* Task group related information */
struct task_group {
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each CPU */
struct sched_entity **se;
/* runqueue "owned" by this group on each CPU */
struct cfs_rq **cfs_rq;
unsigned long shares;
#ifdef CONFIG_SMP
/*
* load_avg can be heavily contended at clock tick time, so put
* it in its own cacheline separated from the fields above which
* will also be accessed at each tick.
*/
atomic_long_t load_avg ____cacheline_aligned;
#endif
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
struct task_group *parent;
struct list_head siblings;
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
#ifdef CONFIG_UCLAMP_TASK_GROUP
/* The two decimal precision [%] value requested from user-space */
unsigned int uclamp_pct[UCLAMP_CNT];
/* Clamp values requested for a task group */
struct uclamp_se uclamp_req[UCLAMP_CNT];
/* Effective clamp values used for a task group */
struct uclamp_se uclamp[UCLAMP_CNT];
#endif
};
다음 그림은 sched_init() 함수의 간략한 처리 흐름도이다.
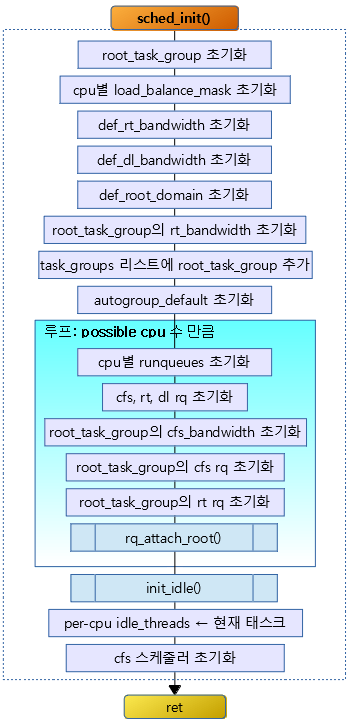
다음 그림은 sched_init() 함수 내부에서 다른 함수들과의 호출 관계 흐름을 보여준다.
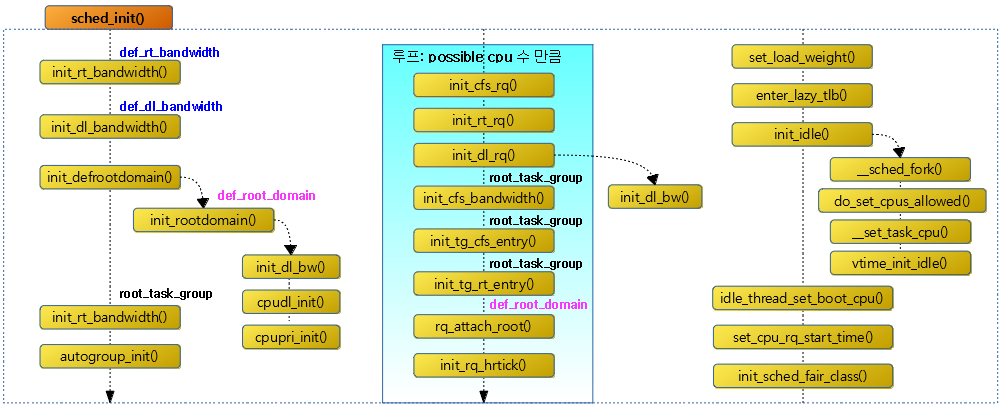
함수의 소스 라인이 길어서 5개로 나누었다.
kernel/sched/core.c – (1/5)
void __init sched_init(void)
{
int i, j;
unsigned long alloc_size = 0, ptr;
#ifdef CONFIG_FAIR_GROUP_SCHED
alloc_size += 2 * nr_cpu_ids * sizeof(void **);
#endif
#ifdef CONFIG_RT_GROUP_SCHED
alloc_size += 2 * nr_cpu_ids * sizeof(void **);
#endif
if (alloc_size) {
ptr = (unsigned long)kzalloc(alloc_size, GFP_NOWAIT);
#ifdef CONFIG_FAIR_GROUP_SCHED
root_task_group.se = (struct sched_entity **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
root_task_group.cfs_rq = (struct cfs_rq **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
#endif /* CONFIG_FAIR_GROUP_SCHED */
#ifdef CONFIG_RT_GROUP_SCHED
root_task_group.rt_se = (struct sched_rt_entity **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
root_task_group.rt_rq = (struct rt_rq **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
#endif /* CONFIG_RT_GROUP_SCHED */
}
#ifdef CONFIG_CPUMASK_OFFSTACK
for_each_possible_cpu(i) {
per_cpu(load_balance_mask, i) = (cpumask_var_t)kzalloc_node(
cpumask_size(), GFP_KERNEL, cpu_to_node(i));
}
#endif /* CONFIG_CPUMASK_OFFSTACK */
init_rt_bandwidth(&def_rt_bandwidth,
global_rt_period(), global_rt_runtime());
init_dl_bandwidth(&def_dl_bandwidth,
global_rt_period(), global_rt_runtime());
cfs 그룹 스케줄링을 위해 cpu 수 만큼 루트 태스크 그룹용 스케줄 엔티티들과 cfs 런큐의 포인터 배열을 할당받아 준비한다. rt 그룹 스케줄링도 동일하게 준비한다. 그리고 디폴트 rt 및 디폴트 dl 밴드폭을 초기화한다.
다음 그림은 루트 태스크 그룹 및 디폴트 rt 밴드폭 및 디폴트 dl 밴드폭을 초기화하는 과정을 보여준다.
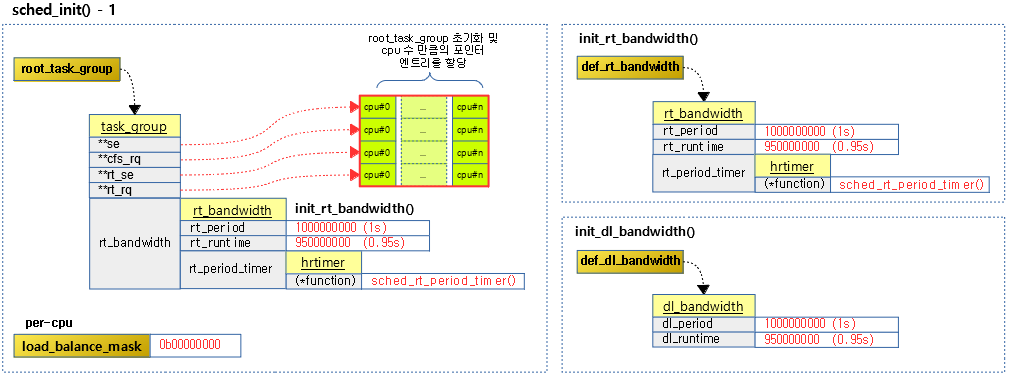
kernel/sched/core.c – (2/5)
#ifdef CONFIG_SMP
init_defrootdomain();
#endif
#ifdef CONFIG_RT_GROUP_SCHED
init_rt_bandwidth(&root_task_group.rt_bandwidth,
global_rt_period(), global_rt_runtime());
#endif /* CONFIG_RT_GROUP_SCHED */
#ifdef CONFIG_CGROUP_SCHED
list_add(&root_task_group.list, &task_groups);
INIT_LIST_HEAD(&root_task_group.children);
INIT_LIST_HEAD(&root_task_group.siblings);
autogroup_init(&init_task);
#endif /* CONFIG_CGROUP_SCHED */
루트 도메인을 초기화한다. rt 그룹 스케줄링을 위해 루트 태스크 그룹의 rt 밴드폭도 초기화한다. 루트 태스크 그룹 및 오토그룹도 초기화한다.
다음 그림은 디폴트 루트 도메인과 오토 그룹을 초기화하는 과정을 보여줍니다.
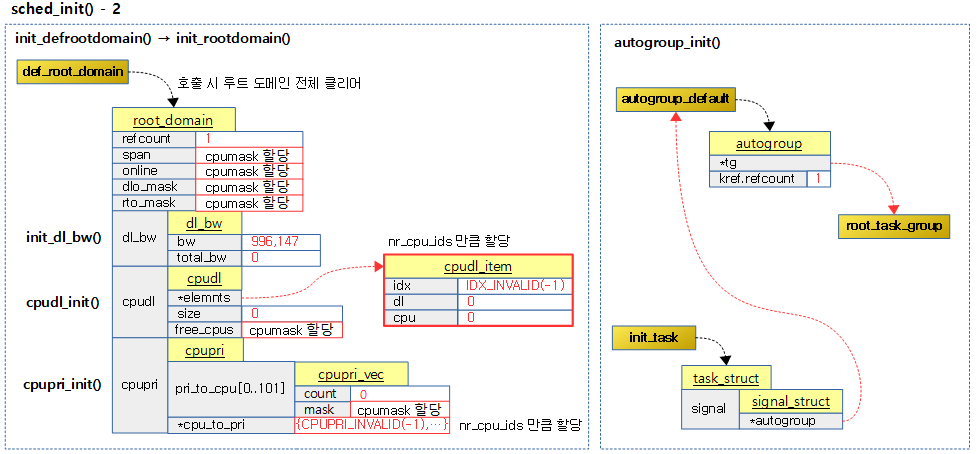
kernel/sched/core.c – (3/5)
. for_each_possible_cpu(i) {
struct rq *rq;
rq = cpu_rq(i);
raw_spin_lock_init(&rq->lock);
rq->nr_running = 0;
rq->calc_load_active = 0;
rq->calc_load_update = jiffies + LOAD_FREQ;
init_cfs_rq(&rq->cfs);
init_rt_rq(&rq->rt, rq);
init_dl_rq(&rq->dl, rq);
cpu 수 만큼 루프를 돌며 cfs 런큐, rt 런큐, dl 런큐들을 초기화한다.
다음 그림은 cpu 수 만큼 루프를 돌며 각각의 런큐를 초기화하고 내부의 cfs, rt 및 dl 런큐를 초기화하는 과정을 보여준다.
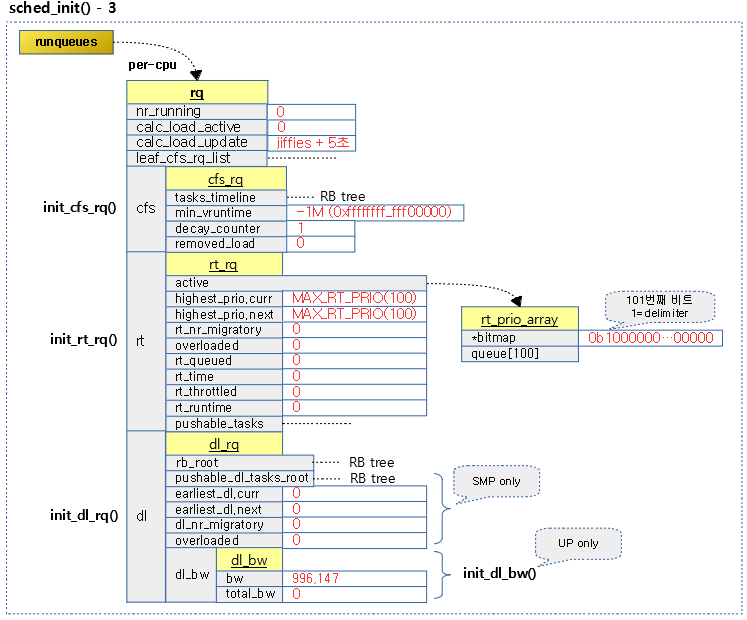
kernel/sched/core.c – (4/5)
#ifdef CONFIG_FAIR_GROUP_SCHED
root_task_group.shares = ROOT_TASK_GROUP_LOAD;
INIT_LIST_HEAD(&rq->leaf_cfs_rq_list);
/*
* How much cpu bandwidth does root_task_group get?
*
* In case of task-groups formed thr' the cgroup filesystem, it
* gets 100% of the cpu resources in the system. This overall
* system cpu resource is divided among the tasks of
* root_task_group and its child task-groups in a fair manner,
* based on each entity's (task or task-group's) weight
* (se->load.weight).
*
* In other words, if root_task_group has 10 tasks of weight
* 1024) and two child groups A0 and A1 (of weight 1024 each),
* then A0's share of the cpu resource is:
*
* A0's bandwidth = 1024 / (10*1024 + 1024 + 1024) = 8.33%
*
* We achieve this by letting root_task_group's tasks sit
* directly in rq->cfs (i.e root_task_group->se[] = NULL).
*/
init_cfs_bandwidth(&root_task_group.cfs_bandwidth);
init_tg_cfs_entry(&root_task_group, &rq->cfs, NULL, i, NULL);
#endif /* CONFIG_FAIR_GROUP_SCHED */
rq->rt.rt_runtime = def_rt_bandwidth.rt_runtime;
#ifdef CONFIG_RT_GROUP_SCHED
init_tg_rt_entry(&root_task_group, &rq->rt, NULL, i, NULL);
#endif
for (j = 0; j < CPU_LOAD_IDX_MAX; j++)
rq->cpu_load[j] = 0;
rq->last_load_update_tick = jiffies;
#ifdef CONFIG_SMP
rq->sd = NULL;
rq->rd = NULL;
rq->cpu_capacity = SCHED_CAPACITY_SCALE;
rq->post_schedule = 0;
rq->active_balance = 0;
rq->next_balance = jiffies;
rq->push_cpu = 0;
rq->cpu = i;
rq->online = 0;
rq->idle_stamp = 0;
rq->avg_idle = 2*sysctl_sched_migration_cost;
rq->max_idle_balance_cost = sysctl_sched_migration_cost;
INIT_LIST_HEAD(&rq->cfs_tasks);
rq_attach_root(rq, &def_root_domain);
#ifdef CONFIG_NO_HZ_COMMON
rq->nohz_flags = 0;
#endif
#ifdef CONFIG_NO_HZ_FULL
rq->last_sched_tick = 0;
#endif
#endif
init_rq_hrtick(rq);
atomic_set(&rq->nr_iowait, 0);
}
계속해서 cpu 수 만큼 루프를 돌며 런큐 및 다음 항목들을 초기화한다.
다음 그림은 계속하여 cpu 수 만큼 루프를 돌며 각각의 런큐를 초기화하고 cfs 밴드폭, 태스크 그룹 cfs 엔트리, 태스크 그룹 rt 엔트리 및 디폴트 루트 도메인을 초기화하는 모습을 보여보여준다.
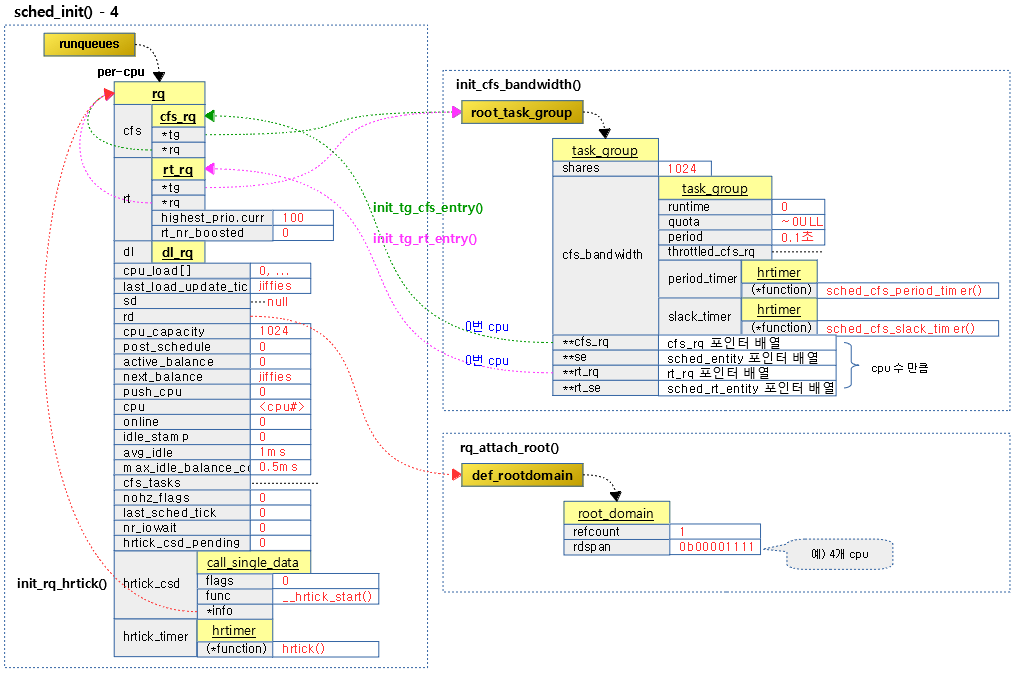
kernel/sched/core.c – (5/5)
set_load_weight(&init_task);
#ifdef CONFIG_PREEMPT_NOTIFIERS
INIT_HLIST_HEAD(&init_task.preempt_notifiers);
#endif
/*
* The boot idle thread does lazy MMU switching as well:
*/
atomic_inc(&init_mm.mm_count);
enter_lazy_tlb(&init_mm, current);
/*
* During early bootup we pretend to be a normal task:
*/
current->sched_class = &fair_sched_class;
/*
* Make us the idle thread. Technically, schedule() should not be
* called from this thread, however somewhere below it might be,
* but because we are the idle thread, we just pick up running again
* when this runqueue becomes "idle".
*/
init_idle(current, smp_processor_id());
calc_load_update = jiffies + LOAD_FREQ;
#ifdef CONFIG_SMP
zalloc_cpumask_var(&sched_domains_tmpmask, GFP_NOWAIT);
/* May be allocated at isolcpus cmdline parse time */
if (cpu_isolated_map == NULL)
zalloc_cpumask_var(&cpu_isolated_map, GFP_NOWAIT);
idle_thread_set_boot_cpu();
set_cpu_rq_start_time();
#endif
init_sched_fair_class();
scheduler_running = 1;
}
현재 부트업 태스크를 초기화하고 마지막으로 cfs 스케줄러를 준비하는 것으로 스케줄러가 준비되었다.
kernel/sched/core.c
static void init_defrootdomain(void)
{
init_rootdomain(&def_root_domain);
atomic_set(&def_root_domain.refcount, 1);
}
디폴트 루트 도메인을 초기화하고 참조 카운터를 1로 설정한다.
kernel/sched/core.c
static int init_rootdomain(struct root_domain *rd)
{
memset(rd, 0, sizeof(*rd));
if (!alloc_cpumask_var(&rd->span, GFP_KERNEL))
goto out;
if (!alloc_cpumask_var(&rd->online, GFP_KERNEL))
goto free_span;
if (!alloc_cpumask_var(&rd->dlo_mask, GFP_KERNEL))
goto free_online;
if (!alloc_cpumask_var(&rd->rto_mask, GFP_KERNEL))
goto free_dlo_mask;
init_dl_bw(&rd->dl_bw);
if (cpudl_init(&rd->cpudl) != 0)
goto free_dlo_mask;
if (cpupri_init(&rd->cpupri) != 0)
goto free_rto_mask;
return 0;
free_rto_mask:
free_cpumask_var(rd->rto_mask);
free_dlo_mask:
free_cpumask_var(rd->dlo_mask);
free_online:
free_cpumask_var(rd->online);
free_span:
free_cpumask_var(rd->span);
out:
return -ENOMEM;
}
요청한 루트 도메인을 초기화한다.
kernel/sched/deadline.c
void init_dl_bw(struct dl_bw *dl_b)
{
raw_spin_lock_init(&dl_b->lock);
raw_spin_lock(&def_dl_bandwidth.dl_runtime_lock);
if (global_rt_runtime() == RUNTIME_INF)
dl_b->bw = -1;
else
dl_b->bw = to_ratio(global_rt_period(), global_rt_runtime());
raw_spin_unlock(&def_dl_bandwidth.dl_runtime_lock);
dl_b->total_bw = 0;
}
cpu가 1개 밖에 없는 up 시스템에서는 dl 스케줄러 요청 사항에 대해 100% cpu 밴드폭을 할당하지 않고 제한을 시키기 위해 디폴트 dl 밴드폭 사용 비율을 설정한다. (정수 1M=100%이며, 디폴트 비율은 95%가 설정된다.)
kernel/sched/sched.h
static inline u64 global_rt_runtime(void)
{
if (sysctl_sched_rt_runtime < 0)
return RUNTIME_INF;
return (u64)sysctl_sched_rt_runtime * NSEC_PER_USEC;
}
글로벌 rt 런타임 값을 나노초 단위로 반환한다.
kernel/sched/sched.h
static inline u64 global_rt_period(void)
{
return (u64)sysctl_sched_rt_period * NSEC_PER_USEC;
}
글로벌 rt 런타임 값을 나노초 단위로 반환한다.
kernel/sched/core.c
unsigned long to_ratio(u64 period, u64 runtime)
{
if (runtime == RUNTIME_INF)
return 1ULL << 20;
/*
* Doing this here saves a lot of checks in all
* the calling paths, and returning zero seems
* safe for them anyway.
*/
if (period == 0)
return 0;
return div64_u64(runtime << 20, period);
}
runtime 비율을 1M 곱한 정수로 반환한다. (runtime / period 비율 결과를 1M를 곱한 정수로 바꿔서 반환한다.)
kernel/sched/cpudeadline.c
/*
* cpudl_init - initialize the cpudl structure
* @cp: the cpudl max-heap context
*/
int cpudl_init(struct cpudl *cp)
{
int i;
memset(cp, 0, sizeof(*cp));
raw_spin_lock_init(&cp->lock);
cp->size = 0;
cp->elements = kcalloc(nr_cpu_ids,
sizeof(struct cpudl_item),
GFP_KERNEL);
if (!cp->elements)
return -ENOMEM;
if (!zalloc_cpumask_var(&cp->free_cpus, GFP_KERNEL)) {
kfree(cp->elements);
return -ENOMEM;
}
for_each_possible_cpu(i)
cp->elements[i].idx = IDX_INVALID;
return 0;
}
dl 스케줄러에서 로드밸런스 관리를 위해 cpudl 구조체를 초기화한다.
kernel/sched/cpupri.c
/**
* cpupri_init - initialize the cpupri structure
* @cp: The cpupri context
*
* Return: -ENOMEM on memory allocation failure.
*/
int cpupri_init(struct cpupri *cp)
{
int i;
memset(cp, 0, sizeof(*cp));
for (i = 0; i < CPUPRI_NR_PRIORITIES; i++) {
struct cpupri_vec *vec = &cp->pri_to_cpu[i];
atomic_set(&vec->count, 0);
if (!zalloc_cpumask_var(&vec->mask, GFP_KERNEL))
goto cleanup;
}
cp->cpu_to_pri = kcalloc(nr_cpu_ids, sizeof(int), GFP_KERNEL);
if (!cp->cpu_to_pri)
goto cleanup;
for_each_possible_cpu(i)
cp->cpu_to_pri[i] = CPUPRI_INVALID;
return 0;
cleanup:
for (i--; i >= 0; i--)
free_cpumask_var(cp->pri_to_cpu[i].mask);
return -ENOMEM;
}
rt 스케줄러에서 로드밸런스 관리를 위해 cpupri 구조체를 초기화한다.
kernel/sched/core.c
static void rq_attach_root(struct rq *rq, struct root_domain *rd)
{
struct root_domain *old_rd = NULL;
unsigned long flags;
raw_spin_lock_irqsave(&rq->lock, flags);
if (rq->rd) {
old_rd = rq->rd;
if (cpumask_test_cpu(rq->cpu, old_rd->online))
set_rq_offline(rq);
cpumask_clear_cpu(rq->cpu, old_rd->span);
/*
* If we dont want to free the old_rd yet then
* set old_rd to NULL to skip the freeing later
* in this function:
*/
if (!atomic_dec_and_test(&old_rd->refcount))
old_rd = NULL;
}
atomic_inc(&rd->refcount);
rq->rd = rd;
cpumask_set_cpu(rq->cpu, rd->span);
if (cpumask_test_cpu(rq->cpu, cpu_active_mask))
set_rq_online(rq);
raw_spin_unlock_irqrestore(&rq->lock, flags);
if (old_rd)
call_rcu_sched(&old_rd->rcu, free_rootdomain);
}
런큐에 루트 도메인을 연결한다.
다음 그림은 런큐의 루트도메인이 교체되는 모습을 보여준다.
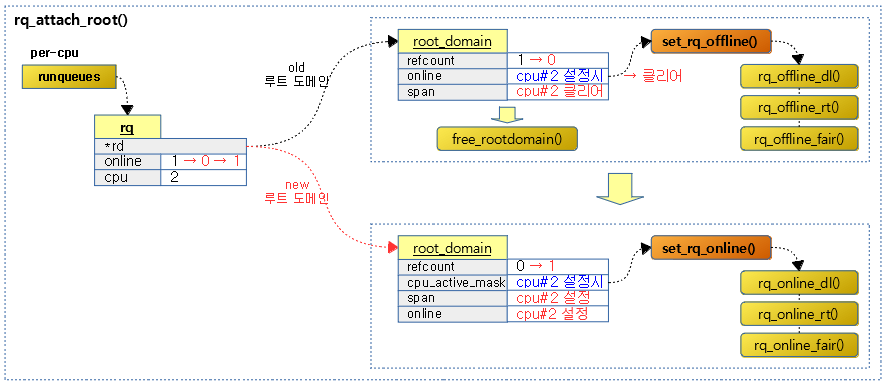
free_rootdomain()
kernel/sched/core.c
static void free_rootdomain(struct rcu_head *rcu)
{
struct root_domain *rd = container_of(rcu, struct root_domain, rcu);
cpupri_cleanup(&rd->cpupri);
cpudl_cleanup(&rd->cpudl);
free_cpumask_var(rd->dlo_mask);
free_cpumask_var(rd->rto_mask);
free_cpumask_var(rd->online);
free_cpumask_var(rd->span);
kfree(rd);
}
rcu에 연결된 루트 도메인을 할당 해제한다.
kernel/sched/cpupri.c
/**
* cpupri_cleanup - clean up the cpupri structure
* @cp: The cpupri context
*/
void cpupri_cleanup(struct cpupri *cp)
{
int i;
kfree(cp->cpu_to_pri);
for (i = 0; i < CPUPRI_NR_PRIORITIES; i++)
free_cpumask_var(cp->pri_to_cpu[i].mask);
}
cpupri 멤버 cpu_to_pri에 할당된 메모리를 할당해제하고 102번 루프를 돌며 pri_to_cpu[].mask에 할당된 cpu 마스크를 를 할당 해제한다.
kernel/sched/cpudeadline.c
/*
* cpudl_cleanup - clean up the cpudl structure
* @cp: the cpudl max-heap context
*/
void cpudl_cleanup(struct cpudl *cp)
{
free_cpumask_var(cp->free_cpus);
kfree(cp->elements);
}
cpudl 멤버 free_cpus에 할당된 cpu 마스크를 할당해제하고 elements에 할당된 메모리도 할당 해제한다.
kernel/sched/auto_group.c
void __init autogroup_init(struct task_struct *init_task)
{
autogroup_default.tg = &root_task_group;
kref_init(&autogroup_default.kref);
init_rwsem(&autogroup_default.lock);
init_task->signal->autogroup = &autogroup_default;
}
자동 그룹 스케줄링을 지원하는 커널에서 디폴트 오토 그룹으로 루트 태스크 그룹을 지정한다.
kernel/sched/fair.c
void init_cfs_rq(struct cfs_rq *cfs_rq)
{
cfs_rq->tasks_timeline = RB_ROOT;
cfs_rq->min_vruntime = (u64)(-(1LL << 20));
#ifndef CONFIG_64BIT
cfs_rq->min_vruntime_copy = cfs_rq->min_vruntime;
#endif
#ifdef CONFIG_SMP
atomic64_set(&cfs_rq->decay_counter, 1);
atomic_long_set(&cfs_rq->removed_load, 0);
#endif
}
cfs 런큐의 구조체를 초기화한다.
kernel/sched/rt.c
void init_rt_rq(struct rt_rq *rt_rq, struct rq *rq)
{
struct rt_prio_array *array;
int i;
array = &rt_rq->active;
for (i = 0; i < MAX_RT_PRIO; i++) {
INIT_LIST_HEAD(array->queue + i);
__clear_bit(i, array->bitmap);
}
/* delimiter for bitsearch: */
__set_bit(MAX_RT_PRIO, array->bitmap);
#if defined CONFIG_SMP
rt_rq->highest_prio.curr = MAX_RT_PRIO;
rt_rq->highest_prio.next = MAX_RT_PRIO;
rt_rq->rt_nr_migratory = 0;
rt_rq->overloaded = 0;
plist_head_init(&rt_rq->pushable_tasks);
#endif
/* We start is dequeued state, because no RT tasks are queued */
rt_rq->rt_queued = 0;
rt_rq->rt_time = 0;
rt_rq->rt_throttled = 0;
rt_rq->rt_runtime = 0;
raw_spin_lock_init(&rt_rq->rt_runtime_lock);
}
rt 런큐의 구조체를 초기화한다.
kernel/sched/deadline.c
void init_dl_rq(struct dl_rq *dl_rq, struct rq *rq)
{
dl_rq->rb_root = RB_ROOT;
#ifdef CONFIG_SMP
/* zero means no -deadline tasks */
dl_rq->earliest_dl.curr = dl_rq->earliest_dl.next = 0;
dl_rq->dl_nr_migratory = 0;
dl_rq->overloaded = 0;
dl_rq->pushable_dl_tasks_root = RB_ROOT;
#else
init_dl_bw(&dl_rq->dl_bw);
#endif
}
dl 런큐의 구조체를 초기화한다.
kernel/sched/core.c
static void init_rq_hrtick(struct rq *rq)
{
#ifdef CONFIG_SMP
rq->hrtick_csd_pending = 0;
rq->hrtick_csd.flags = 0;
rq->hrtick_csd.func = __hrtick_start;
rq->hrtick_csd.info = rq;
#endif
hrtimer_init(&rq->hrtick_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
rq->hrtick_timer.function = hrtick;
}
런큐용 hrtick을 초기화한다.
kernel/sched/core.c
/**
* init_idle - set up an idle thread for a given CPU
* @idle: task in question
* @cpu: cpu the idle task belongs to
*
* NOTE: this function does not set the idle thread's NEED_RESCHED
* flag, to make booting more robust.
*/
void init_idle(struct task_struct *idle, int cpu)
{
struct rq *rq = cpu_rq(cpu);
unsigned long flags;
raw_spin_lock_irqsave(&rq->lock, flags);
__sched_fork(0, idle);
idle->state = TASK_RUNNING;
idle->se.exec_start = sched_clock();
do_set_cpus_allowed(idle, cpumask_of(cpu));
/*
* We're having a chicken and egg problem, even though we are
* holding rq->lock, the cpu isn't yet set to this cpu so the
* lockdep check in task_group() will fail.
*
* Similar case to sched_fork(). / Alternatively we could
* use task_rq_lock() here and obtain the other rq->lock.
*
* Silence PROVE_RCU
*/
rcu_read_lock();
__set_task_cpu(idle, cpu);
rcu_read_unlock();
rq->curr = rq->idle = idle;
idle->on_rq = TASK_ON_RQ_QUEUED;
#if defined(CONFIG_SMP)
idle->on_cpu = 1;
#endif
raw_spin_unlock_irqrestore(&rq->lock, flags);
/* Set the preempt count _outside_ the spinlocks! */
init_idle_preempt_count(idle, cpu);
/*
* The idle tasks have their own, simple scheduling class:
*/
idle->sched_class = &idle_sched_class;
ftrace_graph_init_idle_task(idle, cpu);
vtime_init_idle(idle, cpu);
#if defined(CONFIG_SMP)
sprintf(idle->comm, "%s/%d", INIT_TASK_COMM, cpu);
#endif
}
요청 cpu에 대한 idle 스레드를 설정하고 idle 스케줄러에 등록한다.
다음 그림은 init_idle() 함수가 처리되는 과정을 보여준다.

kernel/sched/core.c
/*
* Perform scheduler related setup for a newly forked process p.
* p is forked by current.
*
* __sched_fork() is basic setup used by init_idle() too:
*/
static void __sched_fork(unsigned long clone_flags, struct task_struct *p)
{
p->on_rq = 0;
p->se.on_rq = 0;
p->se.exec_start = 0;
p->se.sum_exec_runtime = 0;
p->se.prev_sum_exec_runtime = 0;
p->se.nr_migrations = 0;
p->se.vruntime = 0;
#ifdef CONFIG_SMP
p->se.avg.decay_count = 0;
#endif
INIT_LIST_HEAD(&p->se.group_node);
#ifdef CONFIG_SCHEDSTATS
memset(&p->se.statistics, 0, sizeof(p->se.statistics));
#endif
RB_CLEAR_NODE(&p->dl.rb_node);
init_dl_task_timer(&p->dl);
__dl_clear_params(p);
INIT_LIST_HEAD(&p->rt.run_list);
#ifdef CONFIG_PREEMPT_NOTIFIERS
INIT_HLIST_HEAD(&p->preempt_notifiers);
#endif
#ifdef CONFIG_NUMA_BALANCING
if (p->mm && atomic_read(&p->mm->mm_users) == 1) {
p->mm->numa_next_scan = jiffies + msecs_to_jiffies(sysctl_numa_balancing_scan_delay);
p->mm->numa_scan_seq = 0;
}
if (clone_flags & CLONE_VM)
p->numa_preferred_nid = current->numa_preferred_nid;
else
p->numa_preferred_nid = -1;
p->node_stamp = 0ULL;
p->numa_scan_seq = p->mm ? p->mm->numa_scan_seq : 0;
p->numa_scan_period = sysctl_numa_balancing_scan_delay;
p->numa_work.next = &p->numa_work;
p->numa_faults = NULL;
p->last_task_numa_placement = 0;
p->last_sum_exec_runtime = 0;
p->numa_group = NULL;
#endif /* CONFIG_NUMA_BALANCING */
}
fork된 태스크의 cfs, dl 및 rt 스케줄링 엔티티의 멤버 값들과 numa 밸런싱 관련 값들을 초기화한다. 이 태스크는 현재 태스크에서 새롭게 fork되었으며 다음 두 곳 함수에서 호출되어 사용된다.
kernel/sched/deadline.c
void init_dl_task_timer(struct sched_dl_entity *dl_se)
{
struct hrtimer *timer = &dl_se->dl_timer;
hrtimer_init(timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
timer->function = dl_task_timer;
}
dl 스케줄링 엔티티의 hrtimer를 초기화하고 만료 시 호출될 함수를 지정한다.
kernel/sched/core.c
void __dl_clear_params(struct task_struct *p)
{
struct sched_dl_entity *dl_se = &p->dl;
dl_se->dl_runtime = 0;
dl_se->dl_deadline = 0;
dl_se->dl_period = 0;
dl_se->flags = 0;
dl_se->dl_bw = 0;
dl_se->dl_throttled = 0;
dl_se->dl_new = 1;
dl_se->dl_yielded = 0;
}
dl 스케줄링 엔티티를 파라메터들을 초기화한다.
kernel/sched/core.c
void do_set_cpus_allowed(struct task_struct *p, const struct cpumask *new_mask)
{
if (p->sched_class->set_cpus_allowed)
p->sched_class->set_cpus_allowed(p, new_mask);
cpumask_copy(&p->cpus_allowed, new_mask);
p->nr_cpus_allowed = cpumask_weight(new_mask);
}
요청 태스크가 운영될 수 있는 cpu들을 지정한다. 현재 태스크가 동작 중인 경우 해당 스케줄러에도 통보된다.
kernel/sched/sched.h
static inline void __set_task_cpu(struct task_struct *p, unsigned int cpu)
{
set_task_rq(p, cpu);
#ifdef CONFIG_SMP
/*
* After ->cpu is set up to a new value, task_rq_lock(p, ...) can be
* successfuly executed on another CPU. We must ensure that updates of
* per-task data have been completed by this moment.
*/
smp_wmb();
task_thread_info(p)->cpu = cpu;
p->wake_cpu = cpu;
#endif
}
태스크의 cfs_rq와 부모 엔티티를 설정한다.
kernel/sched/sched.h
/* Change a task's cfs_rq and parent entity if it moves across CPUs/groups */
static inline void set_task_rq(struct task_struct *p, unsigned int cpu)
{
#if defined(CONFIG_FAIR_GROUP_SCHED) || defined(CONFIG_RT_GROUP_SCHED)
struct task_group *tg = task_group(p);
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
p->se.cfs_rq = tg->cfs_rq[cpu];
p->se.parent = tg->se[cpu];
#endif
#ifdef CONFIG_RT_GROUP_SCHED
p->rt.rt_rq = tg->rt_rq[cpu];
p->rt.parent = tg->rt_se[cpu];
#endif
}
태스크의 cfs_rq와 부모 엔티티를 설정한다.
include/asm-generic/preempt.h
#define init_idle_preempt_count(p, cpu) do { \
task_thread_info(p)->preempt_count = PREEMPT_ENABLED; \
} while (0)
preempt 카운터를 PREEMPT_ENABLED(0)으로 설정하여 preemption이 가능하게 한다.
kernel/sched/core.c
static void set_load_weight(struct task_struct *p)
{
int prio = p->static_prio - MAX_RT_PRIO;
struct load_weight *load = &p->se.load;
/*
* SCHED_IDLE tasks get minimal weight:
*/
if (p->policy == SCHED_IDLE) {
load->weight = scale_load(WEIGHT_IDLEPRIO);
load->inv_weight = WMULT_IDLEPRIO;
return;
}
load->weight = scale_load(prio_to_weight[prio]);
load->inv_weight = prio_to_wmult[prio];
}
태스크에 지정된 static 우선순위를 사용하여 로드 weight를 설정한다. (idle 스레드인 경우는 로드 weight 값으로 가장 느린 3을 사용한다)
kernel/sched/core.c
static void __cpuinit set_cpu_rq_start_time(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
rq->age_stamp = sched_clock_cpu(cpu);
}
현재 런큐의 age_stamp에 현재 스케줄 클럭을 대입한다.
kernel/sched/fair.c
__init void init_sched_fair_class(void)
{
#ifdef CONFIG_SMP
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
#ifdef CONFIG_NO_HZ_COMMON
nohz.next_balance = jiffies;
zalloc_cpumask_var(&nohz.idle_cpus_mask, GFP_NOWAIT);
cpu_notifier(sched_ilb_notifier, 0);
#endif
#endif /* SMP */
}
smp 시스템인 경우 cfs 스케줄러를 초기화한다.
kernel/sched/fair.c
static int sched_ilb_notifier(struct notifier_block *nfb,
unsigned long action, void *hcpu)
{
switch (action & ~CPU_TASKS_FROZEN) {
case CPU_DYING:
nohz_balance_exit_idle(smp_processor_id());
return NOTIFY_OK;
default:
return NOTIFY_DONE;
}
}
cpu 상태가 dying 상태(frozen 제외)가 된 경우 nohz_balance_exit_idle() 함수를 호출하여 해당 cpu가 nohz idle 상태를 벗어나게 한다.
kernel/sched/fair.c
static inline void nohz_balance_exit_idle(int cpu)
{
if (unlikely(test_bit(NOHZ_TICK_STOPPED, nohz_flags(cpu)))) {
/*
* Completely isolated CPUs don't ever set, so we must test.
*/
if (likely(cpumask_test_cpu(cpu, nohz.idle_cpus_mask))) {
cpumask_clear_cpu(cpu, nohz.idle_cpus_mask);
atomic_dec(&nohz.nr_cpus);
}
clear_bit(NOHZ_TICK_STOPPED, nohz_flags(cpu));
}
}
해당 cpu가 idle 상태를 벗어나게 한다.