<kernel v5.4>
cgroup에서 사용하는 “그룹 스케줄링”과 로드 밸런싱에서 사용하는 “스케줄 그룹”은 서로 다른 기술을 의미하므로 각별히 주의해야한다.
스케줄링 도메인과 스케줄 그룹
리눅스 커널이 적절한 로드밸런싱을 수행하기 위해 모든 cpu들이 동등한 조건으로 로드밸런싱을 할 수가 없다. 각 cpu들의 성능, 캐시 공유, 노드에 따른 메모리 대역폭이 달라 다른 성능을 나태낸다. 가장 로드밸런싱이 용이한 cpu들끼리 그루핑을하고, 그 다음 레벨의 cpu들과 그루핑하는 식으로 레벨별로 묶어 로드 밸런싱에 대한 우선 순위를 결정하기 위해 cpu 토플로지를 파악하고, 이를 통해 스케줄링 도메인 토플로지 레벨을 구성한다. 그런 후 최종 단계에서 스케줄링 도메인과 스케줄 그룹을 구성하면 로드 밸런싱에서 이들을 이용하게 된다.
스케줄링 도메인 토플로지
1) arm 스케줄링 도메인 토플로지
32bit arm cpu 토플로지를 만들때 다음과 같은 순서로 단계별로 구성한다.
- GMC
- core power 제어 가능한 그룹
- CONFIG_SCHED_MC 커널 옵션 사용
- MC
- 그 다음으로 l2 캐시를 공유하는 클러스터 내의 cpu에 더 우선권을 준다.
- CONFIG_SCHED_MC 커널 옵션 사용
- DIE
- 그 다음으로 (l3 캐시를 공유하는) 같은 die를 사용하는 cpu에 더 우선권을 준다.
- NUMA
- 같은 NUMA 노드를 사용하는 cpu에 더 우선권을 준다.
- NUMA 노드에서 최단 거리 path를 사용하는 cpu에 더 우선권을 준다.
- CONFIG_NUMA 커널 옵션 사용
2) arm64 및 디폴트 스케줄링 도메인 토플로지
ARM64 및 RISC-V 시스템의 토플로지를 만들때 다음과 같은 순서로 단계별로 구성한다.
- SMT
- l1 캐시를 공유하는 cpu에 대해 더 우선권을 준다. (virtual core)
- 캐시를 플러시할 필요가 없으므로 가장 비용이 저렴하다.
- arm64는 아직 활용하지 않는다.
- CONFIG_SCHED_SMT 커널 옵션 사용
- MC
- 그 다음으로 l2 캐시를 공유하는 클러스터 내의 cpu에 더 우선권을 준다.
- big/little 등 클러스터가 존재하는 경우 이 옵션을 사용하여 클러스터 단위로 관리한다.
- CONFIG_SCHED_MC 커널 옵션 사용
- DIE
- 그 다음으로 (l3 캐시를 공유하는) 같은 die를 사용하는 cpu에 더 우선권을 준다.
- 보통 멀티 클러스터가 아닌 대부분의 몇 개 코어 이하의 시스템들은 이 단계만 사용한다.
- NUMA
- NUMA 레벨은 NUMA distance 별로 여러 개의 레벨을 사용할 수 있다.
- NUMA 노드에서 최단 거리 path를 사용하는 cpu에 더 우선권을 준다.
- CONFIG_SCHED_NUMA 커널 옵션 사용
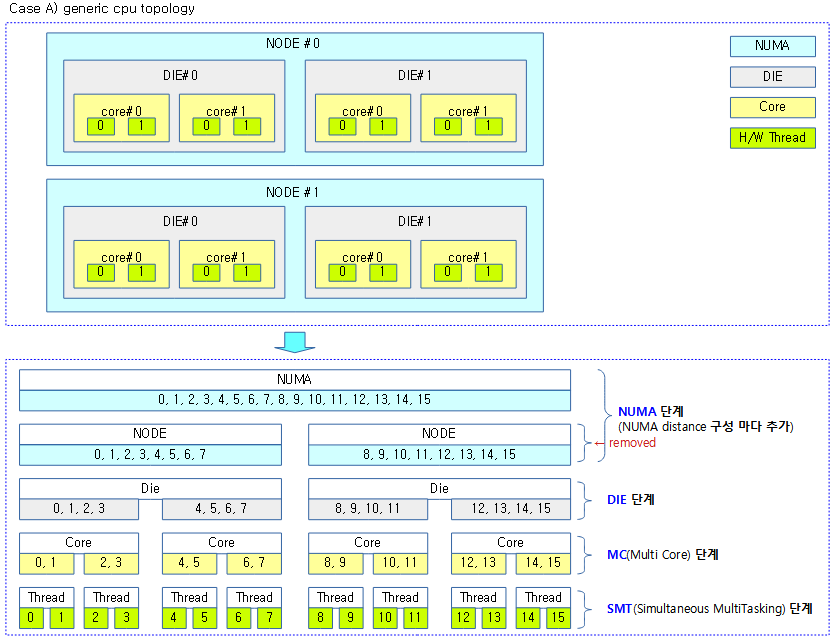
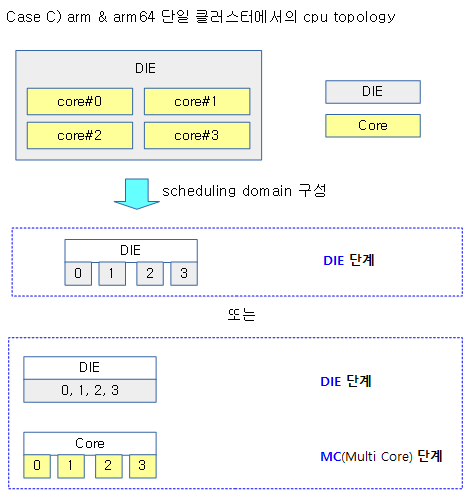
다음 그림 3가지는 시스템 구성에 따른 cpu topology를 나타낸다.
- NODE 단계의 도메인 토플로지는 DIE 단계의 토플로지와 동일한 cpu들로 구성되었고, 그룹도 1개만 포함되었다. 이러한 구성은 로드밸런싱에 불필요하므로 보통 삭제된다.

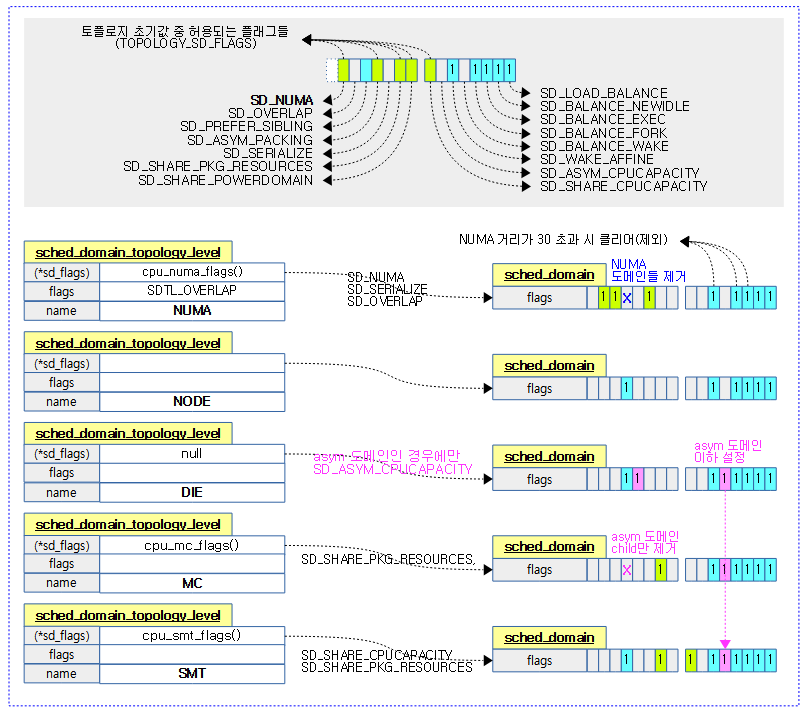
스케줄 도메인 플래그
- SD_LOAD_BALANCE
- 이 도메인에서 로드 밸런싱을 허용한다.
- SD_BALANCE_NEWIDLE
- 이 도메인에서 새롭게 idle로 진입하는 로드 밸런싱을 허용한다. (idle 밸런싱)
- SD_BALANCE_EXEC
- 이 도메인은 실행되는 태스크에 대해 로드 밸런싱을 허용한다. (exec 밸런싱)
- SD_BALANCE_FORK
- 이 도메인은 새롭게 fork한 태스크에 대해 로드 밸런싱을 허용한다. (fork 밸런싱)
- SD_BALANCE_WAKE
- 이 도메인은 idle 상태에서 깨어난 cpu에 대해 로드 밸런싱을 허용한다. (wake 밸런싱)
- SD_WAKE_AFFINE
- 이 도메인은 idle 상태에서 깨어난 cpu가 도메인내의 idle sibling cpu 선택을 허용한다.
- SD_ASYM_CPUCAPACITY
- 도메인 내의 멤버들이 다른 cpu 성능을 가진다.
- SD_SHARE_CPUCAPACITY
- 이 도메인은 cpu 성능을 공유한다.
- 하드웨어 스레드들은 하나의 코어에 대한 성능을 공유한다.
- x86(하이퍼 스레드)이나 powerpc의 SMT 도메인 토플로지 레벨에서 사용한다.
- SD_SHARE_POWERDOMAIN
- 이 도메인에서 파워를 공유한다.
- 절전을 위해 클러스터 단위로 core들의 파워를 제어한다. (빅/리틀 클러스터 등)
- 현재 arm/arm64의 GMC 도메인 토플로지 레벨에서 사용한다.
- SD_SHARE_PKG_RESOURCES
- 이 도메인에서 패키시 내의 각종 캐시 등의 리소스를 공유한다.
- arm, arm64의 경우 보통 한 패키지(DIE) 안에 구성된 단위 클러스터내의 코어들이 캐시를 공유한다. (L2 캐시 등)
- x86이나 powerpc 같은 경우 하드웨어 스레드(SMT)와 코어(MC)가 캐시를 공유한다. (L2 또는 L3 캐시까지)
- SD_SERIALIZE
- 이 도메인은 누마 시스템에서 싱글 로드밸런싱에서만 사용된다.
- SD_ASYM_PACKING
- 낮은 번호의 하드웨어 스레드가 높은 더 성능을 가진다. (비균형)
- powerpc의 SMT 도메인 토플로지 레벨에서 사용한다.
- ITMT(Intel Turbo Boost Max Technology 3.0) 기능을 지원하는 x86 시스템에서 SMT 및 MC 도메인에서 사용된다.
- SD_PREFER_SIBLING
- sibling 도메인내에서 태스크를 수행할 수 있도록 권장한다.
- SD_NUMA, SD_SHARE_PKG_RESOURCES(MC, SMT), SD_SHARE_CPUCAPACITY(SMT)가 설정되지 않은 도메인에서만 사용 가능하므로 주로 DIE 도메인에서 사용된다.
- SD_OVERLAP
- 도메인들 간에 오버랩되는 경우 사용한다.
- SD_NUMA
- 이 도메인이 누마 도메인이다.
- NUMA distance 단계 수 만큼의 도메인 레벨을 구성하여 사용한다.
적절한 로드밸런싱을 위해 태스크의 migration 비용을 고려하여 언제 수행해야 할 지 다음의 항목들을 체크한다.
- 스케줄러 특성에 따른 로드 밸런싱
- cpu 토플로지 레벨에 따른 로드 밸런싱
- cpu affinity별 로드 밸런싱을 수행해야 하기 때문에 단계별 cpu 토플로지를 만들어 사용한다.
- cpu capacity(core 능력치 * freq)를 파악하여 코어별 로드 밸런싱에 사용한다.
- 도메인 그룹 간 균형을 맞추기 위한 active 밸런싱
스케줄러 특성 별 로드 밸런싱
다음과 같이 사용하는 스케줄러에 따라 로드밸런싱을 하는 방법이 달라진다. cpu의 검색 순서는 모든 스케줄러가 스케줄링 도메인 레벨을 차례 대로 사용한다.
- Deadline 스케줄러
- dl 태스크가 2 개 이상 동작해야 하는 경우 그 중 deadline이 가장 급한 dl 태스크를 제외하고 나머지들을 다른 cpu로 옮기려한다.
- 다른 cpu들에서 dl 태스크가 수행되고 있지 않거나 deadline이 가장 큰 dl 태스크가 동작하는 cpu를 찾아 그 cpu로 dl 태스크를 migration 한다.
- RT 스케줄러
- rt 태스크가 2개 이상 동작해야 하는 경우 그 중 우선 순위가 가장 높은 rt 태스크를 제외한 나머지들을 다른 cpu로 옮기려한다.
- 다른 cpu들에서 rt 태스크가 수행되고 있지 않거나 우선 순위가 가장 낮은 rt 태스크가 동작하는 cpu를 찾아 그 cpu로 rt 태스크를 migration 한다.
- CFS 스케줄러
- cpu 로드가 가장 낮은 cpu로 cfs 태스크를 migration 한다.
- cpu 로드가 얼마 이상일 때 수행할지 여부
스케줄링 도메인 토플로지 레벨 with NUMA
kernel_init() -> kernel_init_freeable() -> sched_init_smp() 함수에서 호출된다.
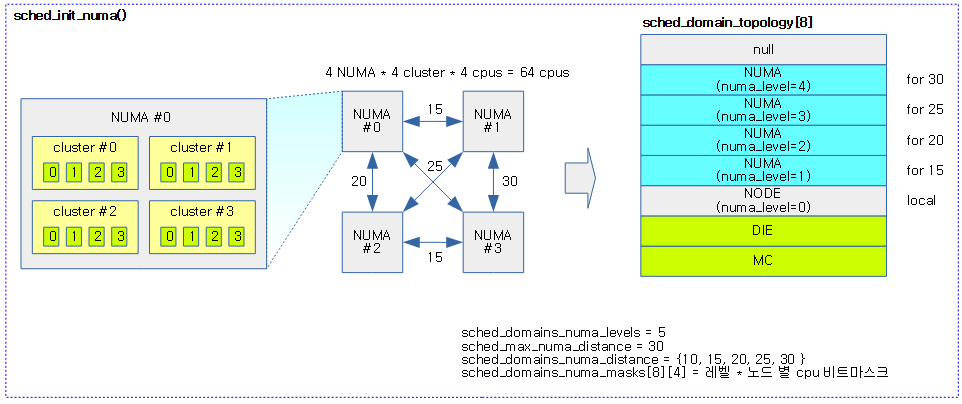
sched_init_numa()
kernel/sched/topology.c -1/3-
void sched_init_numa(void)
{
int next_distance, curr_distance = node_distance(0, 0);
struct sched_domain_topology_level *tl;
int level = 0;
int i, j, k;
sched_domains_numa_distance = kzalloc(sizeof(int) * (nr_node_ids + 1), GFP_KERNEL);
if (!sched_domains_numa_distance)
return;
/* Includes NUMA identity node at level 0. */
sched_domains_numa_distance[level++] = curr_distance;
sched_domains_numa_levels = level;
/*
* O(nr_nodes^2) deduplicating selection sort -- in order to find the
* unique distances in the node_distance() table.
*
* Assumes node_distance(0,j) includes all distances in
* node_distance(i,j) in order to avoid cubic time.
*/
next_distance = curr_distance;
for (i = 0; i < nr_node_ids; i++) {
for (j = 0; j < nr_node_ids; j++) {
for (k = 0; k < nr_node_ids; k++) {
int distance = node_distance(i, k);
if (distance > curr_distance &&
(distance < next_distance ||
next_distance == curr_distance))
next_distance = distance;
/*
* While not a strong assumption it would be nice to know
* about cases where if node A is connected to B, B is not
* equally connected to A.
*/
if (sched_debug() && node_distance(k, i) != distance)
sched_numa_warn("Node-distance not symmetric");
if (sched_debug() && i && !find_numa_distance(distance))
sched_numa_warn("Node-0 not representative");
}
if (next_distance != curr_distance) {
sched_domains_numa_distance[level++] = next_distance;
sched_domains_numa_levels = level;
curr_distance = next_distance;
} else break;
}
/*
* In case of sched_debug() we verify the above assumption.
*/
if (!sched_debug())
break;
}
- 코드 라인 8~10에서 numa distance 배열을 노드 수 + 1(for null finish) 만큼 할당한다.
- 코드 라인 13~14에서 0번 레벨에 대한 값을 지정한다. 0번 레벨에는 from 0 to 0에 대한 distance 값으로 지정한다.
- ARM64의 경우 디바이스 트리를 통한 numa_distance[] 배열의 초기화 및 파싱 함수는 다음과 같다.
- arm64_numa_init() -> numa_init() -> of_numa_init() -> of_numa_parse_distance_map()
- 참고: NUMA -1- (ARM64 초기화) | 문c
- ARM64의 경우 디바이스 트리를 통한 numa_distance[] 배열의 초기화 및 파싱 함수는 다음과 같다.
- 코드 라인 23~57에서 distance 순서대로 정렬하여 sched_domains_numa_distance[]을 구성한다.
- 예) 총 5 레벨: [0]=10, [1]=15, [2]=20, [3]=25, [4]=30
kernel/sched/topology.c -2/3-
. /*
* 'level' contains the number of unique distances
*
* The sched_domains_numa_distance[] array includes the actual distance
* numbers.
*/
/*
* Here, we should temporarily reset sched_domains_numa_levels to 0.
* If it fails to allocate memory for array sched_domains_numa_masks[][],
* the array will contain less then 'level' members. This could be
* dangerous when we use it to iterate array sched_domains_numa_masks[][]
* in other functions.
*
* We reset it to 'level' at the end of this function.
*/
sched_domains_numa_levels = 0;
sched_domains_numa_masks = kzalloc(sizeof(void *) * level, GFP_KERNEL);
if (!sched_domains_numa_masks)
return;
/*
* Now for each level, construct a mask per node which contains all
* CPUs of nodes that are that many hops away from us.
*/
for (i = 0; i < level; i++) {
sched_domains_numa_masks[i] =
kzalloc(nr_node_ids * sizeof(void *), GFP_KERNEL);
if (!sched_domains_numa_masks[i])
return;
for (j = 0; j < nr_node_ids; j++) {
struct cpumask *mask = kzalloc(cpumask_size(), GFP_KERNEL);
if (!mask)
return;
sched_domains_numa_masks[i][j] = mask;
for_each_node(k) {
if (node_distance(j, k) > sched_domains_numa_distance[i])
continue;
cpumask_or(mask, mask, cpumask_of_node(k));
}
}
}
- 코드 라인 17에서sched_domains_numa_leves를 일단 0으로 리셋한다. 이 값은 함수 끝에서 다시 지정된다.
- 코드 라인 19~21에서 sched_domains_numa_masks[]에 먼저 레벨 수 만큼 포인터 배열을 할당한다.
- 코드 라인 27~47에서 sched_domains_numa_masks[][]에 레벨 * 노드 수 만큼 cpu 비트 마스크를 할당하고 소속된 cpu들을 설정한다.
- sched_domains_numa_distance[][] 배열의 각 distance에 해당 distance 뿐만 아니라 그 이하 distance에 속한 cpu 까지도 포함된다.
kernel/sched/topology.c -3/3-
/* Compute default topology size */
for (i = 0; sched_domain_topology[i].mask; i++);
tl = kzalloc((i + level + 1) *
sizeof(struct sched_domain_topology_level), GFP_KERNEL);
if (!tl)
return;
/*
* Copy the default topology bits..
*/
for (i = 0; sched_domain_topology[i].mask; i++)
tl[i] = sched_domain_topology[i];
/*
* Add the NUMA identity distance, aka single NODE.
*/
tl[i++] = (struct sched_domain_topology_level){
.mask = sd_numa_mask,
.numa_level = 0,
SD_INIT_NAME(NODE)
};
/*
* .. and append 'j' levels of NUMA goodness.
*/
for (j = 1; j < level; i++, j++) {
tl[i] = (struct sched_domain_topology_level){
.mask = sd_numa_mask,
.sd_flags = cpu_numa_flags,
.flags = SDTL_OVERLAP,
.numa_level = j,
SD_INIT_NAME(NUMA)
};
}
sched_domain_topology = tl;
sched_domains_numa_levels = level;
sched_max_numa_distance = sched_domains_numa_distance[level - 1];
init_numa_topology_type();
}
- 코드 라인 2~7에서 디폴트 토플로지 수 + numa distance 레벨 수 + 1(for null terminate)만큼 tl(토플로지 레벨)을 할당한다.
- 예) MC + DIE + NUMA(10) + NUMA(15) + NUMA(20) + NUMA(30) + NULL
- 코드 라인 12~13에서 디폴트 토플로지의 값을 새로 할당한 tl로 옮긴다.
- 코드 라인 18~22에서 NUMA 0 레벨을 추가한다.
- 코드 라인 27~35에서 NUMA 1 레벨부터 마지막 레벨까지 초기화한다.
- 코드 라인 37에서 스케줄러용 sched_domain_topology 변수에 새로 구성한 tl을 대입한다.
- 코드 라인 39에서 sched_domains_numa_levels에 NUMA 레벨을 대입한다.
- 예) 10, 15, 20, 30인 경우 레벨 수=4
- 코드 라인 40에서 sched_max_numa_distance에 가장 거리가 먼 distance를 대입한다.
- 코드 라인 42에서 numa topology 타입 3 가지 중 하나를 선택한다.
다음 그림은 NUMA 시스템의 도메인 토플로지 레벨을 구성하는 모습을 보여준다.
init_numa_topology_type()
kernel/sched/topology.c
/* * A system can have three types of NUMA topology: * NUMA_DIRECT: all nodes are directly connected, or not a NUMA system * NUMA_GLUELESS_MESH: some nodes reachable through intermediary nodes * NUMA_BACKPLANE: nodes can reach other nodes through a backplane * * The difference between a glueless mesh topology and a backplane * topology lies in whether communication between not directly * connected nodes goes through intermediary nodes (where programs * could run), or through backplane controllers. This affects * placement of programs. * * The type of topology can be discerned with the following tests: * - If the maximum distance between any nodes is 1 hop, the system * is directly connected. * - If for two nodes A and B, located N > 1 hops away from each other, * there is an intermediary node C, which is < N hops away from both * nodes A and B, the system is a glueless mesh. */
static void init_numa_topology_type(void)
{
int a, b, c, n;
n = sched_max_numa_distance;
if (sched_domains_numa_levels <= 2) {
sched_numa_topology_type = NUMA_DIRECT;
return;
}
for_each_online_node(a) {
for_each_online_node(b) {
/* Find two nodes furthest removed from each other. */
if (node_distance(a, b) < n)
continue;
/* Is there an intermediary node between a and b? */
for_each_online_node(c) {
if (node_distance(a, c) < n &&
node_distance(b, c) < n) {
sched_numa_topology_type =
NUMA_GLUELESS_MESH;
return;
}
}
sched_numa_topology_type = NUMA_BACKPLANE;
return;
}
}
}
다음 3가지 NUMA topology 타입 중 하나를 선택한다.
- NUMA_DIRECT
- 모든 노드 간에 1 hop으로 접근할 수 있는 경우이다.
- NUMA_GLULESS_MESH
- 모든 노드 간에 1 hop으로 접근할 수 없지만, 2 hop 이내에 접근 가능한 경우이다.
- NUMA_BACKPLANE
- 모든 노드 간에 2 hop 이내에서 접근 할 수 없는 경우이다.
다음 그림은 numa topology 타입을 보여준다.

스케줄링 도메인들 초기화
kernel_init() -> kernel_init_freeable() -> sched_init_smp(cpu_active_mask) 함수에서 최종 호출된다.
sched_init_domains() 함수 이후로 다음과 같은 함수들이 호출되어 처리한다.
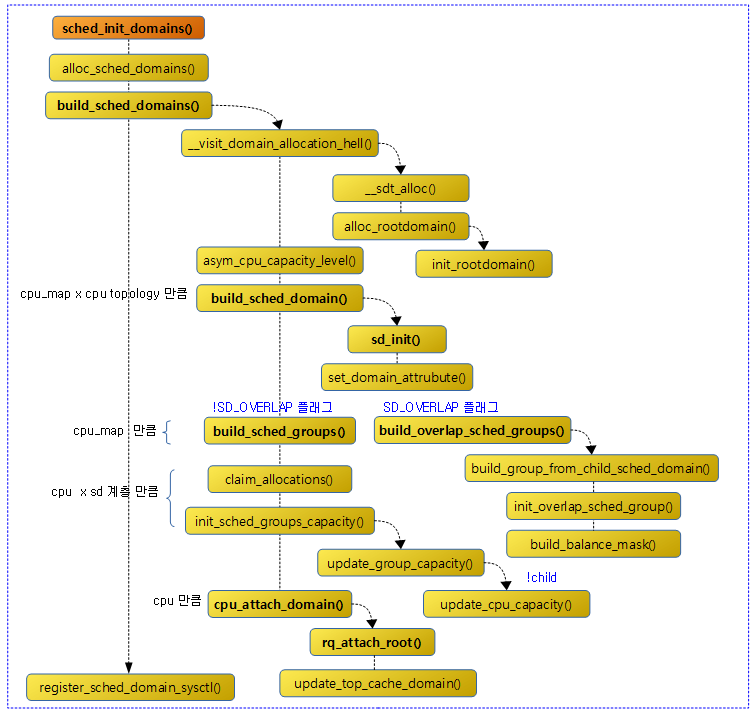
sched_init_domains()
kernel/sched/topology.c
/* * Set up scheduler domains and groups. For now this just excludes isolated * CPUs, but could be used to exclude other special cases in the future. */
int sched_init_domains(const struct cpumask *cpu_map)
{
int err;
zalloc_cpumask_var(&sched_domains_tmpmask, GFP_KERNEL);
zalloc_cpumask_var(&sched_domains_tmpmask2, GFP_KERNEL);
zalloc_cpumask_var(&fallback_doms, GFP_KERNEL);
arch_update_cpu_topology();
ndoms_cur = 1;
doms_cur = alloc_sched_domains(ndoms_cur);
if (!doms_cur)
doms_cur = &fallback_doms;
cpumask_and(doms_cur[0], cpu_map, housekeeping_cpumask(HK_FLAG_DOMAIN));
err = build_sched_domains(doms_cur[0], NULL);
register_sched_domain_sysctl();
return err;
}
요청한 cpu 맵을 사용하여 스케줄 도메인들을 초기화한다.
- 코드 라인 9에서 아키텍처가 지원하는 경우 cpu topology를 갱신한다. (arm, arm64는 지원하지 않음)
- 코드 라인 10~13에서 스케줄 도메인의 수를 1로 지정하고 하나의 스케줄 도메인용 비트마스크를 할당해온다. 할당이 실패한 경우 싱글 cpumask로 이루어진 fallback 도메인을 사용한다.
- 코드 라인 14에서 인수로 전달받은 cpu_map에서 cpu_isolated_map을 제외시킨 cpumask를 doms_cur[0]에 대입한다.
- 코드 라인 15에서 산출된 cpumask 만큼 스케줄 도메인을 구성한다.
- 코드 라인 16에서 스케줄 도메인들을 sysctl에 구성한다.
alloc_sched_domains()
kernel/sched/core.c
cpumask_var_t *alloc_sched_domains(unsigned int ndoms)
{
int i;
cpumask_var_t *doms;
doms = kmalloc(sizeof(*doms) * ndoms, GFP_KERNEL);
if (!doms)
return NULL;
for (i = 0; i < ndoms; i++) {
if (!alloc_cpumask_var(&doms[i], GFP_KERNEL)) {
free_sched_domains(doms, i);
return NULL;
}
}
return doms;
}
요청한 스케줄 도메인 수 만큼의 cpu 비트마스크 어레이를 할당하고 반환한다.
- 코드 라인 6~8에서 요청한 스케줄 도메인 수 만큼 스케줄 도메인용 비트마스크를 할당한다.
- 코드 라인 9~14에서 대단위 cpumask가 필요한 경우 할당받아온다.
- 32bit 시스템에서는 cpu가 32개를 초과하는 경우,
- 64bit 시스템에서는 cpu가 64개를 초과하는 경우 별도의 cpumask를 할당받는다.
“isolcpus=” 커널 파라메터
/* cpus with isolated domains */
static cpumask_var_t cpu_isolated_map;
/* Setup the mask of cpus configured for isolated domains */
static int __init isolated_cpu_setup(char *str)
{
alloc_bootmem_cpumask_var(&cpu_isolated_map);
cpulist_parse(str, cpu_isolated_map);
return 1;
}
__setup("isolcpus=", isolated_cpu_setup);
아이솔레이티드 도메인들을 위해 지정된 cpu리스트들을 마스크한다.
- 지정된 태스크들로 태스크들이 스케줄되지 않도록 분리시킨다. 이렇게 분리된 cpu에서도 인터럽트는 사용될 수 있다.
- “cat /sys/devices/system/cpu/isolated”으로 확인할 수 있다.
- 예) “isolcpus=0,1”
- 참고: how to detect if isolcpus is activated? | Linux & Unix
build_sched_domains()
kernel/sched/topology.c -1/2-
/* * Build sched domains for a given set of CPUs and attach the sched domains * to the individual CPUs */
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
enum s_alloc alloc_state = sa_none;
struct sched_domain *sd;
struct s_data d;
struct rq *rq = NULL;
int i, ret = -ENOMEM;
struct sched_domain_topology_level *tl_asym;
bool has_asym = false;
if (WARN_ON(cpumask_empty(cpu_map)))
goto error;
alloc_state = __visit_domain_allocation_hell(&d, cpu_map);
if (alloc_state != sa_rootdomain)
goto error;
tl_asym = asym_cpu_capacity_level(cpu_map);
/* Set up domains for CPUs specified by the cpu_map: */
for_each_cpu(i, cpu_map) {
struct sched_domain_topology_level *tl;
sd = NULL;
for_each_sd_topology(tl) {
int dflags = 0;
if (tl == tl_asym) {
dflags |= SD_ASYM_CPUCAPACITY;
has_asym = true;
}
sd = build_sched_domain(tl, cpu_map, attr, sd, dflags, i);
if (tl == sched_domain_topology)
*per_cpu_ptr(d.sd, i) = sd;
if (tl->flags & SDTL_OVERLAP)
sd->flags |= SD_OVERLAP;
if (cpumask_equal(cpu_map, sched_domain_span(sd)))
break;
}
}
스케줄 도메인을 구성한다. 이 함수를 호출하는 루틴은 다음 두 개가 있다.
- sched_init_domains() -> 커널 부트업 시 속성값을 null로 진입
- partition_sched_domains() -> cpu on/off 시 진입된다.
- 코드 라인 15~17에서 스케줄 도메인 토플로지의 자료 구조를 할당받고 초기화하고 루트 도메인을 할당받은 후 초기화한다.
- 코드 라인 19에서 동일하지 않은 cpu capacity 성능을 가진 경우 해당 도메인을 알아온다.
- 코드 라인 22에서 cpu_map 비트마스크에 설정된 cpu에 대해 순회한다.
- 코드 라인 26~34에서 스케줄 도메인 계층 구조를 순회하며 스케줄 도메인을 구성한다. 또한 asym 토플로지 레벨에 대해서는 dflags에 SD_ASYM_CPUCAPACITY 플래그를 추가하여 둔다.
- 코드 라인 36~37에서 순회중인 tl이 전역 스케줄 도메인 토플로지인 경우 s_data.sd의 현재 순회중인 cpu에 구성한 스케줄 도메인을 연결한다.
- 코드 라인 38~39에서 토플로지 레벨 tl에 SDTL_OVERLAP 설정된 경우 스케줄 도메인에도 SD_OVERLAP 플래그를 추가한다.
- 코드 라인 40~41에서 cpu_map과 스케줄 도메인의 span 구성이 동일한 경우 루프를 벗어난다.
kernel/sched/topology.c -2/2-
/* Build the groups for the domains */
for_each_cpu(i, cpu_map) {
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
sd->span_weight = cpumask_weight(sched_domain_span(sd));
if (sd->flags & SD_OVERLAP) {
if (build_overlap_sched_groups(sd, i))
goto error;
} else {
if (build_sched_groups(sd, i))
goto error;
}
}
}
/* Calculate CPU capacity for physical packages and nodes */
for (i = nr_cpumask_bits-1; i >= 0; i--) {
if (!cpumask_test_cpu(i, cpu_map))
continue;
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
claim_allocations(i, sd);
init_sched_groups_capacity(i, sd);
}
}
/* Attach the domains */
rcu_read_lock();
for_each_cpu(i, cpu_map) {
rq = cpu_rq(i);
sd = *per_cpu_ptr(d.sd, i);
/* Use READ_ONCE()/WRITE_ONCE() to avoid load/store tearing: */
if (rq->cpu_capacity_orig > READ_ONCE(d.rd->max_cpu_capacity))
WRITE_ONCE(d.rd->max_cpu_capacity, rq->cpu_capacity_orig);
cpu_attach_domain(sd, d.rd, i);
}
rcu_read_unlock();
if (has_asym)
static_branch_inc_cpuslocked(&sched_asym_cpucapacity);
if (rq && sched_debug_enabled) {
pr_info("root domain span: %*pbl (max cpu_capacity = %lu)\n",
cpumask_pr_args(cpu_map), rq->rd->max_cpu_capacity);
}
ret = 0;
error:
__free_domain_allocs(&d, alloc_state, cpu_map);
return ret;
}
- 코드 라인 2~3에서 cpu_map에 설정된 cpu를 순회하고 그 하위 루프에서 해당 cpu의 하위 스케줄 도메인부터 상위 스케줄 도메인까지 순회한다.
- 코드 라인 4에서 스케줄 도메인의 span_weight 멤버에 도메인에 속한 cpu 수를 대입한다.
- 코드 라인 5~7에서 NUMA 스케줄 도메인 단계에서는 overlap 스케줄 그룹을 구성한다.
- 코드 라인 8~11에서 그 외의 경우 일반 스케줄 그룹을 구성한다.
- 코드 라인 16~18에서 cpu 수 만큼 거꾸로 순회하며 cpu_map에 설정되지 않은 cpu는 skip 한다.
- 코드 라인 20~23에서 하위 스케줄 도메인부터 상위 스케줄 도메인까지 순회하며 스케줄링 도메인 토플로지에 구성된 sd, sg, sgc 들에 null을 넣어 함수의 가장 마지막에서 삭제하지 않도록 만든다. 그리고 스케줄링 그룹의 capacity를 초기화한다.
- 코드 라인 28~37에서 cpu_map에 설정된 cpu를 순회하며 도메인을 연결한다.
- 코드 라인 40~41에서 asym cpu capacity가 적용되도록 활성화한다.
- 코드 라인 50~52에서 스케줄링 도메인 토플로지에 구성된 sd, sg, sgc 멤버들에서 사용되지 않는 구조체 할당들을 모두 해제한다.
스케줄 도메인들 할당
__visit_domain_allocation_hell()
kernel/sched/topology.c
static enum s_alloc
__visit_domain_allocation_hell(struct s_data *d, const struct cpumask *cpu_map)
{
memset(d, 0, sizeof(*d));
if (__sdt_alloc(cpu_map))
return sa_sd_storage;
d->sd = alloc_percpu(struct sched_domain *);
if (!d->sd)
return sa_sd_storage;
d->rd = alloc_rootdomain();
if (!d->rd)
return sa_sd;
return sa_rootdomain;
}
요청한 cpu_map 비트마스크를 사용하여 스케줄 도메인 토플로지의 자료 구조를 할당받고 초기화한다. 그리고 루트 도메인을 할당받은 후 초기화한다. 성공한 경우 sa_rootdomain(0)을 반환한다.
__sdt_alloc()
kernel/sched/topology.c
static int __sdt_alloc(const struct cpumask *cpu_map)
{
struct sched_domain_topology_level *tl;
int j;
for_each_sd_topology(tl) {
struct sd_data *sdd = &tl->data;
sdd->sd = alloc_percpu(struct sched_domain *);
if (!sdd->sd)
return -ENOMEM;
sdd->sds = alloc_percpu(struct sched_domain_shared *);
if (!sdd->sds)
return -ENOMEM;
sdd->sg = alloc_percpu(struct sched_group *);
if (!sdd->sg)
return -ENOMEM;
sdd->sgc = alloc_percpu(struct sched_group_capacity *);
if (!sdd->sgc)
return -ENOMEM;
for_each_cpu(j, cpu_map) {
struct sched_domain *sd;
struct sched_domain_shared *sds;
struct sched_group *sg;
struct sched_group_capacity *sgc;
sd = kzalloc_node(sizeof(struct sched_domain) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
if (!sd)
return -ENOMEM;
*per_cpu_ptr(sdd->sd, j) = sd;
sds = kzalloc_node(sizeof(struct sched_domain_shared),
GFP_KERNEL, cpu_to_node(j));
if (!sds)
return -ENOMEM;
*per_cpu_ptr(sdd->sds, j) = sds;
sg = kzalloc_node(sizeof(struct sched_group) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
if (!sg)
return -ENOMEM;
sg->next = sg;
*per_cpu_ptr(sdd->sg, j) = sg;
sgc = kzalloc_node(sizeof(struct sched_group_capacity) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
if (!sgc)
return -ENOMEM;
#ifdef CONFIG_SCHED_DEBUG
sgc->id = j;
#endif
*per_cpu_ptr(sdd->sgc, j) = sgc;
}
}
return 0;
}
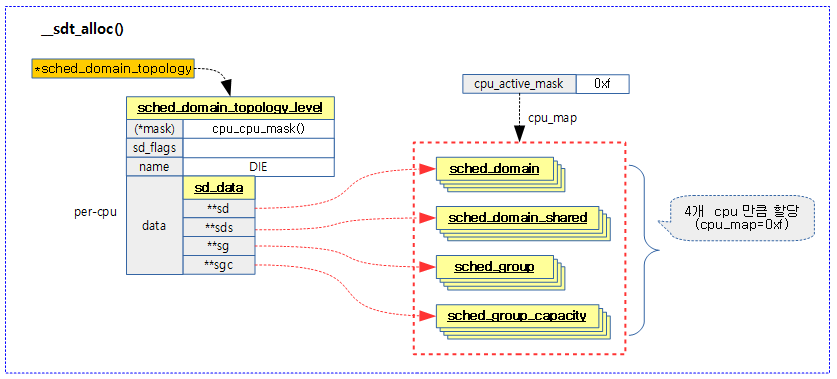
요청한 cpu_map 비트마스크로 스케줄 도메인 토플로지를 초기화한다.
- 코드 라인 6에서 스케줄 도메인 단계만큼 순회한다.
- arm의 경우 보통 1 단계 DIE 만을 구성하여 사용한다. 클러스터를 구성하여 사용하는 경우 2 단계로 구성한 DIE – MC(Multi core)로 구성한다. 또한 클러스터들 끼리 distance가 다른 경우 NUMA 구성을 추가하여 사용한다.
- 코드 라인 9~23에서 스케줄 도메인의 sd_data에 sched_domain, sched_group, sched_group_capacity에 대한 포인터를 per-cpu로 할당하여 구성한다.
- 코드 라인 25~65에서 cpu_map 비트마스크에 포함된 cpu들에 대해 sched_domain, sched_group, sched_group_capacity 구조체를 할당받은 후 sd_data에 연결한다.
- 코드 라인 67에서 성공 값 0을 반환한다.
다음 그림은 cpu_map 비트마스크에 설정된 cpu들에 대해 관련 자료 구조 할당을 받아 스케줄 도메인 토플로지에 연결하는 모습을 보여준다.
for_each_sd_topology()
kernel/sched/core.c
#define for_each_sd_topology(tl) \
for (tl = sched_domain_topology; tl->mask; tl++)
스케줄링 도메인 토플로지 레벨에 따라 순회한다.
- tl->mask가 null인 경우 순회를 정지한다.
asym cpu capacity를 사용하는 토플로지 레벨
asym_cpu_capacity_level()
kernel/sched/topology.c
/* * Find the sched_domain_topology_level where all CPU capacities are visible * for all CPUs. */
static struct sched_domain_topology_level
*asym_cpu_capacity_level(const struct cpumask *cpu_map)
{
int i, j, asym_level = 0;
bool asym = false;
struct sched_domain_topology_level *tl, *asym_tl = NULL;
unsigned long cap;
/* Is there any asymmetry? */
cap = arch_scale_cpu_capacity(cpumask_first(cpu_map));
for_each_cpu(i, cpu_map) {
if (arch_scale_cpu_capacity(i) != cap) {
asym = true;
break;
}
}
if (!asym)
return NULL;
/*
* Examine topology from all CPU's point of views to detect the lowest
* sched_domain_topology_level where a highest capacity CPU is visible
* to everyone.
*/
for_each_cpu(i, cpu_map) {
unsigned long max_capacity = arch_scale_cpu_capacity(i);
int tl_id = 0;
for_each_sd_topology(tl) {
if (tl_id < asym_level)
goto next_level;
for_each_cpu_and(j, tl->mask(i), cpu_map) {
unsigned long capacity;
capacity = arch_scale_cpu_capacity(j);
if (capacity <= max_capacity)
continue;
max_capacity = capacity;
asym_level = tl_id;
asym_tl = tl;
}
next_level:
tl_id++;
}
}
return asym_tl;
}
asymetric cpu capacity를 사용하는 토플로지 레벨을 알아온다.
- 코드 라인 10~20에서 @cpu_map의 첫 번째 cpu에 대한 cpu capacity를 알아온 후 이를 다른 cpu들의 cpu capacity와 비교하여 모두가 같지 않은 경우 asym=true를 설정한다. 모두가 동일한 경우엔 null을 반환한다.
- 코드 라인 27~33에서 @cpu_map cpu들을 대상으로 순회하며 하위 루프에서 도메인 레벨을 순회한다. 그 중 asym 도메인 레벨 미만은 skip 한다.
- 코드 라인 35~46에서 세 번째 루프인 cpu_map을 다시 순회하며 max_capacity를 초과하는 경우 갱신하게 하고, asym 도메인과 레벨도 갱신하게 한다.
- 코드 라인 53에서 발견된 asym 도메인 레벨을 반환한다.
- 예) 빅/리틀 클러스터로 구성된 시스템이 2 단계 MC 및 DIE 도메인을 구성한 경우 aysm 도메인 레벨은 DIE로 지정된다.
루트 도메인 할당 및 초기화
alloc_rootdomain()
kernel/sched/topology.c
static struct root_domain *alloc_rootdomain(void)
{
struct root_domain *rd;
rd = kmalloc(sizeof(*rd), GFP_KERNEL);
if (!rd)
return NULL;
if (init_rootdomain(rd) != 0) {
kfree(rd);
return NULL;
}
return rd;
}
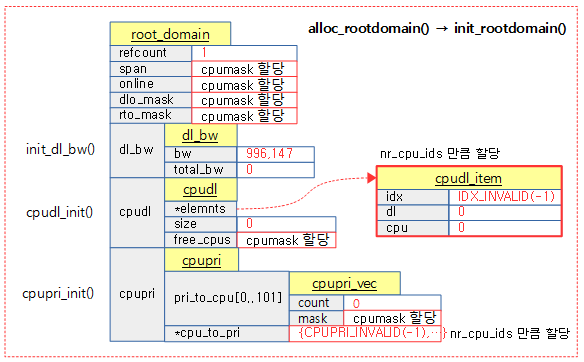
루트 도메인을 할당받고 초기화한다.
다음 그림은 루트도메인을 할당받고 초기화하는 모습을 보여준다.
claim_allocations()
kernel/sched/topology.c
/* * NULL the sd_data elements we've used to build the sched_domain and * sched_group structure so that the subsequent __free_domain_allocs() * will not free the data we're using. */
static void claim_allocations(int cpu, struct sched_domain *sd)
{
struct sd_data *sdd = sd->private;
WARN_ON_ONCE(*per_cpu_ptr(sdd->sd, cpu) != sd);
*per_cpu_ptr(sdd->sd, cpu) = NULL;
if (atomic_read(&(*per_cpu_ptr(sdd->sds, cpu))->ref))
*per_cpu_ptr(sdd->sds, cpu) = NULL;
if (atomic_read(&(*per_cpu_ptr(sdd->sg, cpu))->ref))
*per_cpu_ptr(sdd->sg, cpu) = NULL;
if (atomic_read(&(*per_cpu_ptr(sdd->sgc, cpu))->ref))
*per_cpu_ptr(sdd->sgc, cpu) = NULL;
}
이미 빌드한 할당들에 대해서는 추후 삭제되지 않도록 임시 포인터 배열을 묶어둔 sdd들을 사용하여 null을 대입해둔다.
- 코드 라인 6에서 @cpu에 대한 스케줄링 도메인을 사용하므로 null을 대입한다.
- 코드 라인 8~9에서 @cpu에 대한 sched_domain_share가 사용 중인 경우 null을 대입한다.
- 코드 라인 11~12에서 @cpu에 대한 스케줄링 그룹이 사용 중인 경우 null을 대입한다.
- 코드 라인 14~15에서 @cpu에 대한 스케줄링 그룹 capacity가 사용 중인 경우 null을 대입한다.
스케줄 도메인 구성
kernel/sched/topology.c
/* * Package topology (also see the load-balance blurb in fair.c) * * The scheduler builds a tree structure to represent a number of important * topology features. By default (default_topology[]) these include: * * - Simultaneous multithreading (SMT) * - Multi-Core Cache (MC) * - Package (DIE) * * Where the last one more or less denotes everything up to a NUMA node. * * The tree consists of 3 primary data structures: * * sched_domain -> sched_group -> sched_group_capacity * ^ ^ ^ ^ * `-' `-' * * The sched_domains are per-CPU and have a two way link (parent & child) and * denote the ever growing mask of CPUs belonging to that level of topology. * * Each sched_domain has a circular (double) linked list of sched_group's, each * denoting the domains of the level below (or individual CPUs in case of the * first domain level). The sched_group linked by a sched_domain includes the * CPU of that sched_domain [*]. * * Take for instance a 2 threaded, 2 core, 2 cache cluster part: * * CPU 0 1 2 3 4 5 6 7 * * DIE [ ] * MC [ ] [ ] * SMT [ ] [ ] [ ] [ ] * * - or - * * DIE 0-7 0-7 0-7 0-7 0-7 0-7 0-7 0-7 * MC 0-3 0-3 0-3 0-3 4-7 4-7 4-7 4-7 * SMT 0-1 0-1 2-3 2-3 4-5 4-5 6-7 6-7 * * CPU 0 1 2 3 4 5 6 7 * * One way to think about it is: sched_domain moves you up and down among these * topology levels, while sched_group moves you sideways through it, at child * domain granularity. * * sched_group_capacity ensures each unique sched_group has shared storage. * * There are two related construction problems, both require a CPU that * uniquely identify each group (for a given domain): * * - The first is the balance_cpu (see should_we_balance() and the * load-balance blub in fair.c); for each group we only want 1 CPU to * continue balancing at a higher domain. * * - The second is the sched_group_capacity; we want all identical groups * to share a single sched_group_capacity. * * Since these topologies are exclusive by construction. That is, its * impossible for an SMT thread to belong to multiple cores, and cores to * be part of multiple caches. There is a very clear and unique location * for each CPU in the hierarchy. * * Therefore computing a unique CPU for each group is trivial (the iteration * mask is redundant and set all 1s; all CPUs in a group will end up at _that_ * group), we can simply pick the first CPU in each group. * * * [*] in other words, the first group of each domain is its child domain. */
build_sched_domain()
kernel/sched/topology.c
static struct sched_domain *build_sched_domain(struct sched_domain_topology_level *tl,
const struct cpumask *cpu_map, struct sched_domain_attr *attr,
struct sched_domain *child, int dflags, int cpu)
{
struct sched_domain *sd = sd_init(tl, cpu_map, child, dflags, cpu);
if (child) {
sd->level = child->level + 1;
sched_domain_level_max = max(sched_domain_level_max, sd->level);
child->parent = sd;
if (!cpumask_subset(sched_domain_span(child),
sched_domain_span(sd))) {
pr_err("BUG: arch topology borken\n");
#ifdef CONFIG_SCHED_DEBUG
pr_err(" the %s domain not a subset of the %s domain\n",
child->name, sd->name);
#endif
/* Fixup, ensure @sd has at least @child CPUs. */
cpumask_or(sched_domain_span(sd),
sched_domain_span(sd),
sched_domain_span(child));
}
}
set_domain_attribute(sd, attr);
return sd;
}
요청한 토플로지 레벨에 대한 스케줄 도메인을 구성한다.
- 코드 라인 5에서 요청한 스케줄 도메인 토플로지 레벨 tl에 대한 스케줄 도메인을 초기화한다.
- 코드 라인 7~10에서 @child 스케줄 도메인 토플로지 레벨이 있는 경우 현재 스케줄 도메인의 레벨을 child 보다 1 큰 값으로하고 부모 관계를 설정한다.
- 전역 변수 sched_domain_level_max에는 최대 스케줄 도메인 레벨 값을 갱신한다.
- 코드 라인 12~23에서 자식 스케줄 도메인에 속한 cpu가 요청한 스케줄 도메인에 포함되지 않은 경우 경고 메시지를 출력하고 해당 스케줄 도메인에 포함시킨다.
- 코드 라인 26에서 스케줄링 도메인의 레벨이 요청한 relax 도메인 레벨보다 큰 경우 wake 및 newidle 플래그를 클리어하고 그렇지 않은 경우 설정한다. 요청한 relax 도메인 레벨이 없는 경우 디폴트 relax 도메인 레벨 값을 사용하여 판단한다.
- 코드 라인 28에서 스케줄링 도메인을 반환한다.
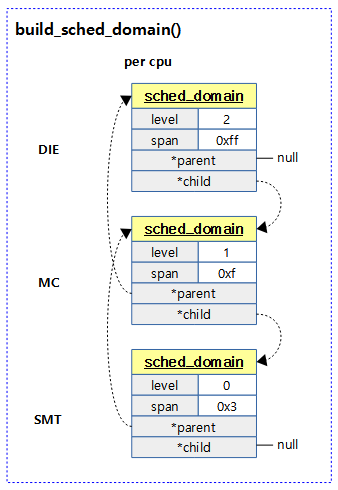
다음 그림은 각 cpu에서 스케줄 도메인간의 계층구조를 보여준다.
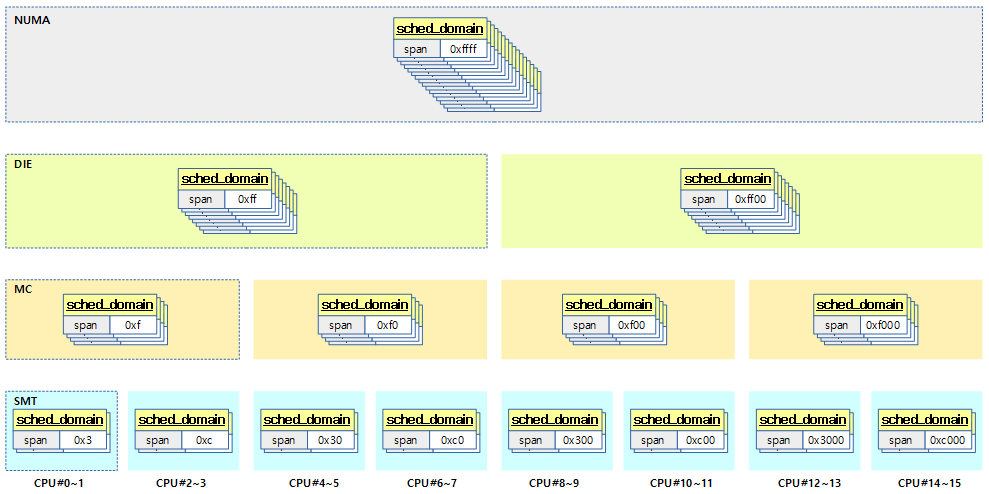
다음 그림은 각 레벨의 스케줄 도메인에 소속된 cpu의 span 값을 표현하였다.

다음 그림도 위의 그림과 동일하지만 스케줄 도메인을 cpu별로 span 값이 같은것들 끼리 뭉쳐 표현하였다.
sd_init()
kernel/sched/topology.c -1/2-
static struct sched_domain *
sd_init(struct sched_domain_topology_level *tl,
const struct cpumask *cpu_map,
struct sched_domain *child, int dflags, int cpu)
{
struct sd_data *sdd = &tl->data;
struct sched_domain *sd = *per_cpu_ptr(sdd->sd, cpu);
int sd_id, sd_weight, sd_flags = 0;
#ifdef CONFIG_NUMA
/*
* Ugly hack to pass state to sd_numa_mask()...
*/
sched_domains_curr_level = tl->numa_level;
#endif
sd_weight = cpumask_weight(tl->mask(cpu));
if (tl->sd_flags)
sd_flags = (*tl->sd_flags)();
if (WARN_ONCE(sd_flags & ~TOPOLOGY_SD_FLAGS,
"wrong sd_flags in topology description\n"))
sd_flags &= ~TOPOLOGY_SD_FLAGS;
/* Apply detected topology flags */
sd_flags |= dflags;
*sd = (struct sched_domain){
.min_interval = sd_weight,
.max_interval = 2*sd_weight,
.busy_factor = 32,
.imbalance_pct = 125,
.cache_nice_tries = 0,
.flags = 1*SD_LOAD_BALANCE
| 1*SD_BALANCE_NEWIDLE
| 1*SD_BALANCE_EXEC
| 1*SD_BALANCE_FORK
| 0*SD_BALANCE_WAKE
| 1*SD_WAKE_AFFINE
| 0*SD_SHARE_CPUCAPACITY
| 0*SD_SHARE_PKG_RESOURCES
| 0*SD_SERIALIZE
| 1*SD_PREFER_SIBLING
| 0*SD_NUMA
| sd_flags
,
.last_balance = jiffies,
.balance_interval = sd_weight,
.max_newidle_lb_cost = 0,
.next_decay_max_lb_cost = jiffies,
.child = child,
#ifdef CONFIG_SCHED_DEBUG
.name = tl->name,
#endif
};
스케줄링 도메인을 초기화한다.
- 코드 라인 19~23에서 요청한 토플로지의 sd_flags() 함수 후크를 수행하여 sd_flags 값을 알아온다. sd_flags 값으로 다음 플래그 값들 이외의 플래그가 설정되어 있는 경우 경고 메시지를 출력하고 제거한다.
- 허용: SD_SHARE_CPUCAPACITY | SD_SHARE_PKG_RESOURCES | SD_NUMA | SD_ASYM_PACKING | SD_SHARE_POWERDOMAIN
- 코드 라인 26에서 토플로지 플래그들을 스케줄링 도메인 플래그에 추가한다.
- 코드 라인 28~57에서 스케줄링 도메인의 초기값을 설정한다.
- 사용자가 지정한 스케줄링 도메인의 초기 플래그 값 sd_flags 이외에 다음 플래그 값은 커널이 기본 플래그로 추가한다.
- 추가: SD_LOAD_BALANCE | SD_BALANCE_NEWIDLE | SD_BALANCE_EXEC | SD_BALANCE_FORK | SD_WAKE_AFFINE | SD_PREFER_SIBLING
kernel/sched/topology.c -2/2-
cpumask_and(sched_domain_span(sd), cpu_map, tl->mask(cpu));
sd_id = cpumask_first(sched_domain_span(sd));
/*
* Convert topological properties into behaviour.
*/
if (sd->flags & SD_ASYM_CPUCAPACITY) {
struct sched_domain *t = sd;
/*
* Don't attempt to spread across CPUs of different capacities.
*/
if (sd->child)
sd->child->flags &= ~SD_PREFER_SIBLING;
for_each_lower_domain(t)
t->flags |= SD_BALANCE_WAKE;
}
if (sd->flags & SD_SHARE_CPUCAPACITY) {
sd->imbalance_pct = 110;
} else if (sd->flags & SD_SHARE_PKG_RESOURCES) {
sd->imbalance_pct = 117;
sd->cache_nice_tries = 1;
#ifdef CONFIG_NUMA
} else if (sd->flags & SD_NUMA) {
sd->cache_nice_tries = 2;
sd->flags &= ~SD_PREFER_SIBLING;
sd->flags |= SD_SERIALIZE;
if (sched_domains_numa_distance[tl->numa_level] > node_reclaim_distance) {
sd->flags &= ~(SD_BALANCE_EXEC |
SD_BALANCE_FORK |
SD_WAKE_AFFINE);
}
#endif
} else {
sd->cache_nice_tries = 1;
}
/*
* For all levels sharing cache; connect a sched_domain_shared
* instance.
*/
if (sd->flags & SD_SHARE_PKG_RESOURCES) {
sd->shared = *per_cpu_ptr(sdd->sds, sd_id);
atomic_inc(&sd->shared->ref);
atomic_set(&sd->shared->nr_busy_cpus, sd_weight);
}
sd->private = sdd;
return sd;
}
- 코드 라인 1~2에서 @cpu_map & tl->mask() 값을 sd->span 비트마스크에 대입하고, sd_id에는 sd->span 중 첫 번째 cpu를 알아온다.
- 코드 라인 8~19에서 arm의 빅/리틀 클러스터처럼 asym cpu capacity를 사용하는 스케줄링 도메인의 경우 다음 두 가지를 실행한다.
- 자식 스케줄링 도메인의 플래그에서 SD_PREFER_SIBLING 플래그를 제거한다.
- 하위 스케줄링 도메인의 플래그에 SD_BALANCE_WAKE 플래그를 추가한다.
- 코드 라인 21~22에서 hw thread를 지원하는 경우 스케줄링 도메인의 경우 imbalance_pct 값을 110으로 조정한다.
- 코드 라인 24~26에서 패키지 리소스(l2 캐시 등)을 공유하는 스케줄링 도메인의 경우 imbalance_pct 값을 117로 조정하고, cache_nice_tries 값을 1로 사용한다.
- 코드 라인 29~38에서 numa 도메인들의 경우 다음과 같이 적용한다.
- cache_nice_tries 값을 2로 사용
- SD_PREFER_SIBLING 플래그 제거
- SD_SERIALIZE 추가
- distance가 멀어 reclaim을 금지 시킨 도메인의 경우 SD_BALANCE_EXEC, SD_BALANCE_FORK, SD_WAKE_AFFINE 플래그를 제거한다.
- 코드 라인 41~43에서 그 외의 스케줄링 도메인의 경우 cache_nice_tries 값을 1로 사용한다.
- 코드 라인 49~53에서 패키지 리소스를 공유하는 도메인의 경우 shared에 shared 도메인의 cpu에 해당하는 sdd->sds 를 지정한다. shared 도메인의 참조 카운트를 1 증가시키고, nr_busy_cpus에 도메인 멤버 cpu 수를 지정한다.
- 코드 라인 55에서 sd->private에 스케줄링 도메인 데이터 sdd를 지정한다.
다음 그림은 스케줄링 도메인을 초기화하는 모습을 보여준다.

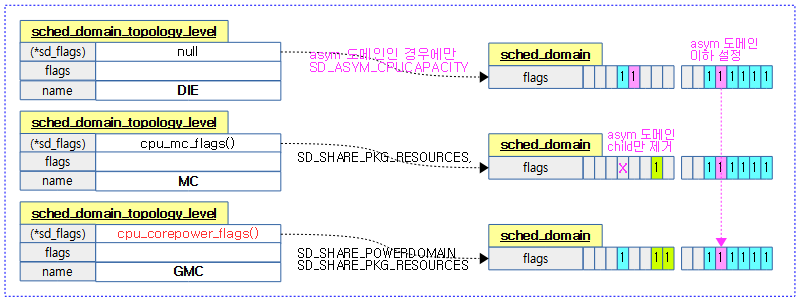
다음 그림은 스케줄 도메인 토플로지 레벨별로 플래그의 변화를 보여준다.

다음 그림은 arm64에서 토플로지에 설정된 sd_flags 값을 읽어 sd_init() 함수 호출 시 스케줄링 도메인의 플래그들 초기값을 보여준다.
다음 그림은 32bit arm 역시 토플로지도 유사함을 보여준다.
- rpi2의 경우 1개의 클러스터만 사용하고, 동등한 cpu capacity를 사용하므로 DIE 레벨만 사용하여도 충분하다.
- ARM32에도 cortex-a15, cortex-a7 아키텍처를 사용하는 빅/리틀 클러스터를 구성하는 경우도 있다. 이 경우 각 클러스터의 cpu capacity가 다르며 CONFIG_SCHED_MC를 설정하여 DIE – MC – GMC의 3 단계를 구성하여 사용한다.
Relax domain 레벨
전역 변수 default_relax_domain_level은 “relax_domain_level=” 커널 파라메터로 변경된다. domain 속성에서 특별히 relax_domain_level 값을 지정하지 않는 경우 default_relax_domain_level을 사용한다.
- relax_domain_level을 초과한 상위의 도메인에서 SD_BALANCE_WAKE, SD_BALANCE_NEWIDLE 플래그를 삭제하여 wakeup 밸런싱과 new idle 밸런싱을 하지 못하도록 한다. 반대로 그 이하의 도에인에는 해당 플래그를 추가한다.
- 보통 원거리(long distance)의 NUMA 시스템에서 태스크가 위의 2 가지 밸런싱을 통해 멀리 migration 되지 않도록 억제한다.
set_domain_attribute()
kernel/sched/topology.c
static void set_domain_attribute(struct sched_domain *sd,
struct sched_domain_attr *attr)
{
int request;
if (!attr || attr->relax_domain_level < 0) {
if (default_relax_domain_level < 0)
return;
else
request = default_relax_domain_level;
} else
request = attr->relax_domain_level;
if (request < sd->level) {
/* turn off idle balance on this domain */
sd->flags &= ~(SD_BALANCE_WAKE|SD_BALANCE_NEWIDLE);
} else {
/* turn on idle balance on this domain */
sd->flags |= (SD_BALANCE_WAKE|SD_BALANCE_NEWIDLE);
}
}
스케줄링 도메인의 레벨이 요청한 relax 도메인 레벨보다 큰 경우 wake 및 newidle 플래그를 클리어하고 그렇지 않은 경우 설정한다. 요청한 relax 도메인 레벨이 없는 경우 디폴트 relax 도메인 레벨 값을 사용하여 판단한다.
- 코드 라인 6~10에서 부트업 과정에서 이 함수에 진입 시에는 attr 값이 null로 진입한다. null로 진입하거나 속성에 부여된 레벨 값이 0보다 작은 경우 default_relax_domain_level 값이 설정되지 않았으면 함수를 빠져나간다. 만일 default_relax_domain_level 값이 이미 설정된 경우 그 값을 기준으로 삼기 위해 request에 대입한다.
- 코드 라인 11~12에서 속성값이 주어진 경우 request에 대입한다.
- 코드 라인 13~15에서 스케줄링 도메인의 레벨이 요청한 레벨보다 큰 경우 이 도메인에서 SD_BALANCE_WAKE와 SD_BALANCE_NEWIDLE 플래그를 제거한다.
- 코드 라인 16~19에서 그 외의 경우 이 도메인에 SD_BALANCE_WAKE와 SD_BALANCE_NEWIDLE 플래그를 설정한다.
setup_relax_domain_level()
kernel/sched/topology.c
static int default_relax_domain_level = -1;
int sched_domain_level_max;
static int __init setup_relax_domain_level(char *str)
{
if (kstrtoint(str, 0, &default_relax_domain_level))
pr_warn("Unable to set relax_domain_level\n");
return 1;
}
__setup("relax_domain_level=", setup_relax_domain_level);
“relax_domain_level=” 값을 파싱하여 전역 변수 default_relax_domain_level에 대입한다. (초기 값은 -1)
DIE 레벨 이하의 스케줄 그룹 구성
build_sched_groups()
kernel/sched/topology.c
/* * build_sched_groups will build a circular linked list of the groups * covered by the given span, will set each group's ->cpumask correctly, * and will initialize their ->sgc. * * Assumes the sched_domain tree is fully constructed */
static int
build_sched_groups(struct sched_domain *sd, int cpu)
{
struct sched_group *first = NULL, *last = NULL;
struct sd_data *sdd = sd->private;
const struct cpumask *span = sched_domain_span(sd);
struct cpumask *covered;
int i;
lockdep_assert_held(&sched_domains_mutex);
covered = sched_domains_tmpmask;
cpumask_clear(covered);
for_each_cpu_wrap(i, span, cpu) {
struct sched_group *sg;
if (cpumask_test_cpu(i, covered))
continue;
sg = get_group(i, sdd);
cpumask_or(covered, covered, sched_group_span(sg));
if (!first)
first = sg;
if (last)
last->next = sg;
last = sg;
}
last->next = first;
sd->groups = first;
return 0;
}
요청한 스케줄 도메인 레벨의 첫 번째 cpu 번호가 주어진 경우 해당 스케줄 그룹들을 구성한다.
- 코드 라인 6에서 요청한 스케줄 도메인의 span cpu 비트마스크를 알아온다.
- 코드 라인 11~13에서 covered 비트마스크를 모두 클리어한다.
- 코드 라인 15~19에서 도메인에 속한 cpu를 cpu 번호부터 순회한다. 단 covered에 이미 설정된 cpu는 skip한다.
- 코드 라인 17에서 순회 중인 i번 cpu에 연결된 스케줄링 그룹을 알아온다.
- 요청한 cpu의 스케줄 도메인을 스케줄그룹과 연결한다.
- 코드 라인 19에서 sg에 해당하는 cpu들을 covered 비트마스크에 추가한다.
- 코드 라인 21~22에서 첫 sg인 경우 시작 sg로 선정한다.
- 코드 라인 23~25에서 마지막 sg가 선정된 경우에 한하여 마지막 sg의 next에 현재 sg를 연결하여 list로 연결해간다.
- 코드 라인 27에서 단방향 환형 리스트로 연결한다.
- 코드 라인 28에서 스케줄 도메인이 첫 sg를 가리키게 한다.
다음 그림은 build_sched_groups() 함수가 각 도메인에 대해 처리되는 모습을 보여준다.
- 예) 2 clusters * 2 cores = 4 cpus
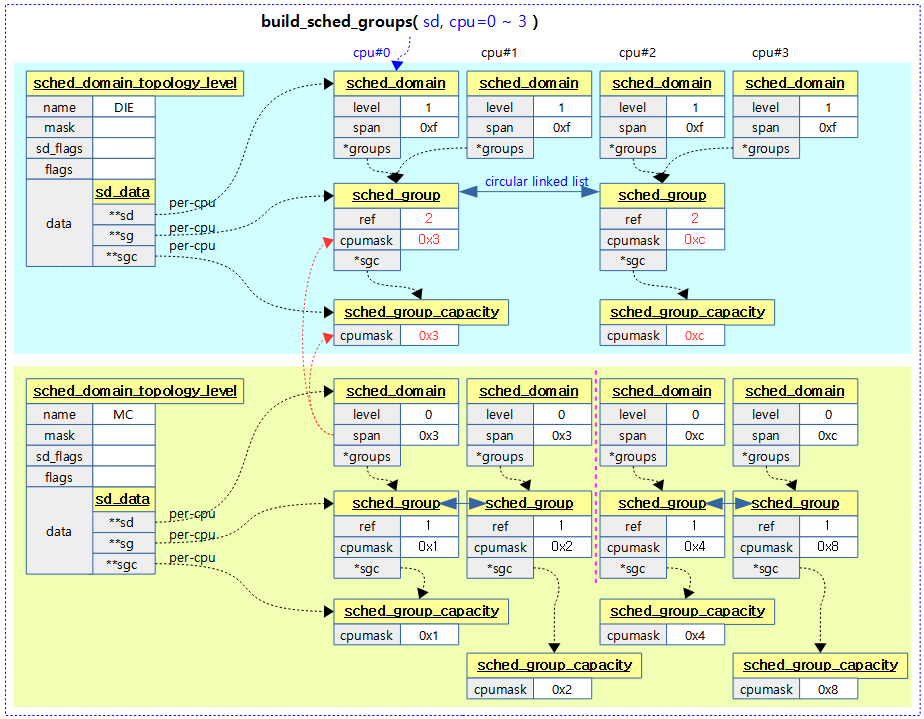
다음 그림은 도메인과 스케줄 그룹간의 관계를 보여준다.
- 예) 2 clusters * 2 cores * 2 hw-threads = 8 cpus

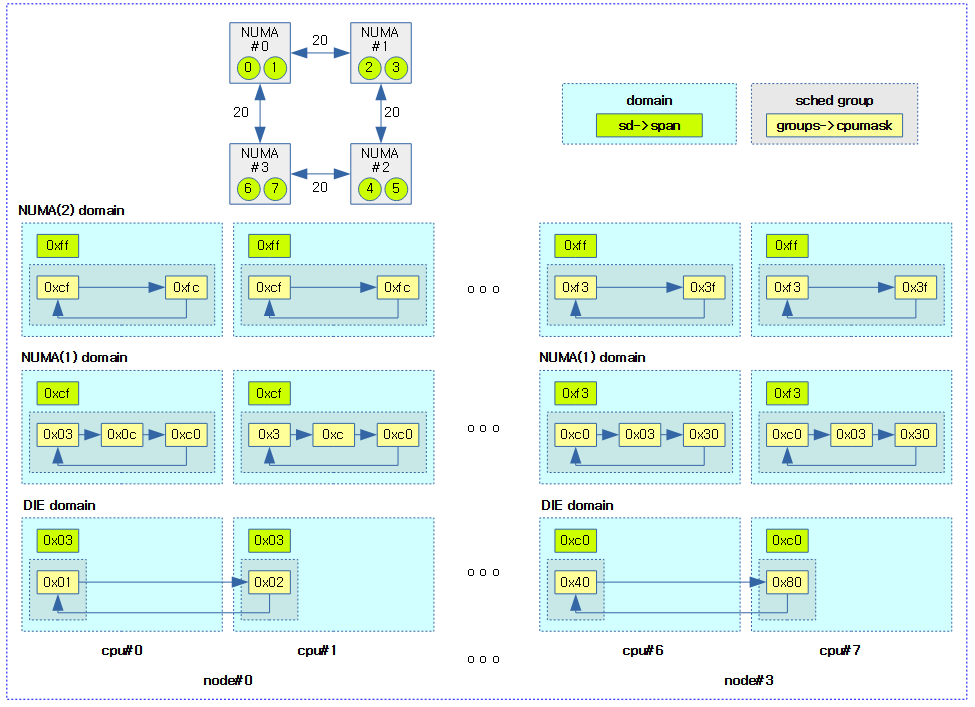
다음 그림은 NUMA 시스템에서의 스케줄링 도메인과 그룹이 생성된 모습을 보여준다.
- NUMA 도메인에서는 per-cpu로 생성한 그룹을 사용하지 않고 overlap되는 cpu들을 표현하기 위해 별도로 필요한 만큼 그룹을 만들어 연결한다.
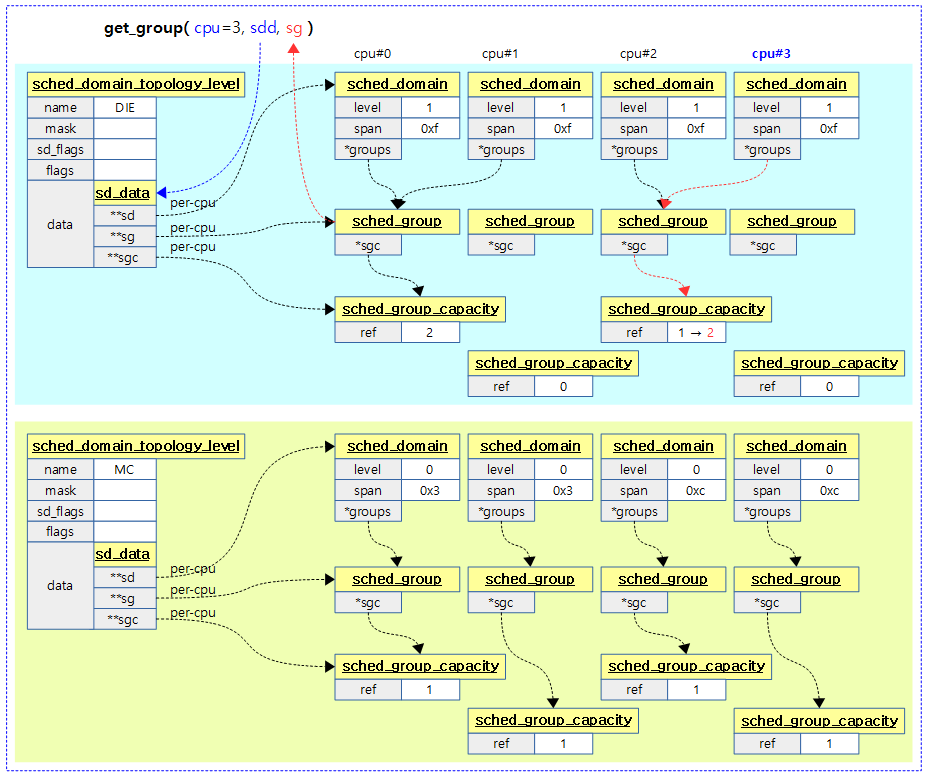
get_group()
kernel/sched/topology.c
static struct sched_group *get_group(int cpu, struct sd_data *sdd)
{
struct sched_domain *sd = *per_cpu_ptr(sdd->sd, cpu);
struct sched_domain *child = sd->child;
struct sched_group *sg;
bool already_visited;
if (child)
cpu = cpumask_first(sched_domain_span(child));
sg = *per_cpu_ptr(sdd->sg, cpu);
sg->sgc = *per_cpu_ptr(sdd->sgc, cpu);
/* Increase refcounts for claim_allocations: */
already_visited = atomic_inc_return(&sg->ref) > 1;
/* sgc visits should follow a similar trend as sg */
WARN_ON(already_visited != (atomic_inc_return(&sg->sgc->ref) > 1));
/* If we have already visited that group, it's already initialized. */
if (already_visited)
return sg;
if (child) {
cpumask_copy(sched_group_span(sg), sched_domain_span(child));
cpumask_copy(group_balance_mask(sg), sched_group_span(sg));
} else {
cpumask_set_cpu(cpu, sched_group_span(sg));
cpumask_set_cpu(cpu, group_balance_mask(sg));
}
sg->sgc->capacity = SCHED_CAPACITY_SCALE * cpumask_weight(sched_group_span(sg));
sg->sgc->min_capacity = SCHED_CAPACITY_SCALE;
sg->sgc->max_capacity = SCHED_CAPACITY_SCALE;
return sg;
}
요청한 @cpu에 해당하는 스케줄 그룹을 알아온다. 첫 참조시에는 child 도메인의 span을 사용하여 스케줄 그룹을 구성하고 단방향 환형 리스트로 연결한다.
- 코드 라인 8~9에서 child 도메인이 있는 경우 child 도메인에 소속된 첫 번째 cpu를 알아온다.
- 코드 라인 11~12에서 cpu에 해당하는 per-cpu용 스케줄링 그룹을 알아온다. 그 후 스케줄링 그룹의 sgc를 연결한다.
- 코드 라인 15에서 스케줄링 그룹에 대한 참조 카운터를 증가시킨다.
- 코드 라인 17에서 sgc에 대한 참조카운터를 증가시킨다.
- 코드 라인 20~21에서 이미 참조된 경우 곧바로 스케줄링 그룹을 반환한다.
- 코드 라인 23~29에서 첫 참조된 경우에는 스케줄링 그룹에 소속될 cpu들과 sgc에 소속될 cpu들을 구성한다. 최하위 인경우 해당 cpu에 대한 비트만을 사용하고, 그 외엔 child의 도메인의 span을 가져와서 동일하게 스케줄링 그룹 및 sgc를 구성한다.
- 코드 라인 31~33에서 sgc에 대한 capacity 값은 1024 * cpu 수 만큼 값으로 초기화한다.
- 코드 라인 32~33에서 sgc에 대한 min, max capacity 값은 1024 값으로 초기화한다.
- 코드 라인 35에서 구성한 스케줄링 그룹을 반환한다.
다음 그림은 2단계의 스케줄 도메인 토플로지가 구성된 상태에서 하위 단계부터 상위 단계까지 get_group()을 모두 호출한 경우를 보여준다.
- 예) 2 clusters * 2 cores = 4 cpus
NUMA 레벨에서 Overlap 스케줄 그룹 구성
/*
* NUMA topology (first read the regular topology blurb below)
*
* Given a node-distance table, for example:
*
* node 0 1 2 3
* 0: 10 20 30 20
* 1: 20 10 20 30
* 2: 30 20 10 20
* 3: 20 30 20 10
*
* which represents a 4 node ring topology like:
*
* 0 ----- 1
* | |
* | |
* | |
* 3 ----- 2
*
* We want to construct domains and groups to represent this. The way we go
* about doing this is to build the domains on 'hops'. For each NUMA level we
* construct the mask of all nodes reachable in @level hops.
*
* For the above NUMA topology that gives 3 levels:
*
* NUMA-2 0-3 0-3 0-3 0-3
* groups: {0-1,3},{1-3} {0-2},{0,2-3} {1-3},{0-1,3} {0,2-3},{0-2}
*
* NUMA-1 0-1,3 0-2 1-3 0,2-3
* groups: {0},{1},{3} {0},{1},{2} {1},{2},{3} {0},{2},{3}
*
* NUMA-0 0 1 2 3
*
*
* As can be seen; things don't nicely line up as with the regular topology.
* When we iterate a domain in child domain chunks some nodes can be
* represented multiple times -- hence the "overlap" naming for this part of
* the topology.
*
* In order to minimize this overlap, we only build enough groups to cover the
* domain. For instance Node-0 NUMA-2 would only get groups: 0-1,3 and 1-3.
*
* Because:
*
* - the first group of each domain is its child domain; this
* gets us the first 0-1,3
* - the only uncovered node is 2, who's child domain is 1-3.
*
* However, because of the overlap, computing a unique CPU for each group is
* more complicated. Consider for instance the groups of NODE-1 NUMA-2, both
* groups include the CPUs of Node-0, while those CPUs would not in fact ever
* end up at those groups (they would end up in group: 0-1,3).
*
* To correct this we have to introduce the group balance mask. This mask
* will contain those CPUs in the group that can reach this group given the
* (child) domain tree.
*
* With this we can once again compute balance_cpu and sched_group_capacity
* relations.
*
* XXX include words on how balance_cpu is unique and therefore can be
* used for sched_group_capacity links.
*
*
* Another 'interesting' topology is:
*
* node 0 1 2 3
* 0: 10 20 20 30
* 1: 20 10 20 20
* 2: 20 20 10 20
* 3: 30 20 20 10
*
* Which looks a little like:
*
* 0 ----- 1
* | / |
* | / |
* | / |
* 2 ----- 3
*
* This topology is asymmetric, nodes 1,2 are fully connected, but nodes 0,3
* are not.
*
* This leads to a few particularly weird cases where the sched_domain's are
* not of the same number for each CPU. Consider:
*
* NUMA-2 0-3 0-3
* groups: {0-2},{1-3} {1-3},{0-2}
*
* NUMA-1 0-2 0-3 0-3 1-3
*
* NUMA-0 0 1 2 3
*
*/
build_overlap_sched_groups()
kernel/sched/topology.c
static int
build_overlap_sched_groups(struct sched_domain *sd, int cpu)
{
struct sched_group *first = NULL, *last = NULL, *sg;
const struct cpumask *span = sched_domain_span(sd);
struct cpumask *covered = sched_domains_tmpmask;
struct sd_data *sdd = sd->private;
struct sched_domain *sibling;
int i;
cpumask_clear(covered);
for_each_cpu_wrap(i, span, cpu) {
struct cpumask *sg_span;
if (cpumask_test_cpu(i, covered))
continue;
sibling = *per_cpu_ptr(sdd->sd, i);
/*
* Asymmetric node setups can result in situations where the
* domain tree is of unequal depth, make sure to skip domains
* that already cover the entire range.
*
* In that case build_sched_domains() will have terminated the
* iteration early and our sibling sd spans will be empty.
* Domains should always include the CPU they're built on, so
* check that.
*/
if (!cpumask_test_cpu(i, sched_domain_span(sibling)))
continue;
sg = build_group_from_child_sched_domain(sibling, cpu);
if (!sg)
goto fail;
sg_span = sched_group_span(sg);
cpumask_or(covered, covered, sg_span);
init_overlap_sched_group(sd, sg);
if (!first)
first = sg;
if (last)
last->next = sg;
last = sg;
last->next = first;
}
sd->groups = first;
return 0;
fail:
free_sched_groups(first, 0);
return -ENOMEM;
}
overlap 스케줄링 그룹을 구성한다. NUMA 시스템에서는 overlap되는 cpu들을 표현하기 위해 기존에 미리 만들어 두었던 그룹을 사용하지 않고 별도로 필요한 만큼 그룹을 만들어 사용한다.
- 코드 라인 11에서 coverd 비트마스크를 클리어해둔다.
- 코드 라인 13~17에서 @cpu 번호의 cpu부터 순회한다. 단 이미 covered에 설정된 cpu는 skip 한다.
- 코드 라인 19에서 순회 cpu 번호에 해당하는 스케줄 도메인을 sibling에 알아온다.
- 코드 라인 31~32에서 순회 cpu가 sibling에 속한 cpu가 아닌 경우 skip 한다.
- 코드 라인 34~36에서 child 스케줄 도메인을 참조거나 없으면 현재 도메인을 참조하여 스케줄링 그룹을 구성한다.
- 코드 라인 38~39에서 covered 비트마스크에 스케줄링 그룹의 cpu들을 모두 마크한다.
- 코드 라인 41에서 overlap 스케줄링 그룹을 초기화한다.
- 코드 라인 43~50에서 스케줄링 그룹 끼리 단방향 환형 리스트를 구성한다.
- 코드 라인 52에서 성공 값 0을 반환한다.
참고: 커널 v5.15의 경우 위의 NUMA overlap 모델에서 스케줄 그룹을 생성시 build_group_from_child_sched_domain() 함수를 통해 하위 도메인 span 정보를 사용하는데, 하위 도메인의 span이 현재 도메인내에 포함될 수 없는 경우 더 하위 도메인을 선택하게 하도록 수정되었다.
- 참고: sched/topology: fix the issue groups don’t span domain->span for NUMA diameter > 2 (v5.13-rc1, 2021)
build_group_from_child_sched_domain()
kernel/sched/topology.c
/* * XXX: This creates per-node group entries; since the load-balancer will * immediately access remote memory to construct this group's load-balance * statistics having the groups node local is of dubious benefit. */
static struct sched_group *
build_group_from_child_sched_domain(struct sched_domain *sd, int cpu)
{
struct sched_group *sg;
struct cpumask *sg_span;
sg = kzalloc_node(sizeof(struct sched_group) + cpumask_size(),
GFP_KERNEL, cpu_to_node(cpu));
if (!sg)
return NULL;
sg_span = sched_group_span(sg);
if (sd->child)
cpumask_copy(sg_span, sched_domain_span(sd->child));
else
cpumask_copy(sg_span, sched_domain_span(sd));
atomic_inc(&sg->ref);
return sg;
}
child 스케줄 도메인을 참조거나 없으면 현재 도메인을 참조하여 스케줄링 그룹을 구성한다.
- 코드 라인 7~11에서 스케줄 그룹을 생성한다.
- 코드 라인 13~17에서 child 스케줄 도메인의 cpu 수만큼 스케줄 그룹의 cpu를 동일하게 설정한다. child가 없으면 스케줄링 도메인과 동일한 cpu를 사용하게 설정한다.
- 코드 라인 19~20에서 스케줄링 그룹의 참조 카운터를 1 증가시키고 반환한다.
init_overlap_sched_group()
kernel/sched/topology.c
static void init_overlap_sched_group(struct sched_domain *sd,
struct sched_group *sg)
{
struct cpumask *mask = sched_domains_tmpmask2;
struct sd_data *sdd = sd->private;
struct cpumask *sg_span;
int cpu;
build_balance_mask(sd, sg, mask);
cpu = cpumask_first_and(sched_group_span(sg), mask);
sg->sgc = *per_cpu_ptr(sdd->sgc, cpu);
if (atomic_inc_return(&sg->sgc->ref) == 1)
cpumask_copy(group_balance_mask(sg), mask);
else
WARN_ON_ONCE(!cpumask_equal(group_balance_mask(sg), mask));
/*
* Initialize sgc->capacity such that even if we mess up the
* domains and no possible iteration will get us here, we won't
* die on a /0 trap.
*/
sg_span = sched_group_span(sg);
sg->sgc->capacity = SCHED_CAPACITY_SCALE * cpumask_weight(sg_span);
sg->sgc->min_capacity = SCHED_CAPACITY_SCALE;
sg->sgc->max_capacity = SCHED_CAPACITY_SCALE;
}
overlap 스케줄링 그룹을 초기화한다.
- 코드 라인 9~14에서 밸런스 마스크를 구성해온 후 첫 번째 cpu의 sgc에 대해 첫 참조인 경우 sgc->mask에 알아온 밸런스 마스크를 복사하여 사용한다.
- 코드 라인 23~24에서 sgc에 대햔 capacity 값은 1024 * cpu 수 만큼 값으로 초기화한다.
- 코드 라인 25~26에서 sgc에 대한 min, max capacity 값은 1024 값으로 초기화한다.
build_balance_mask()
kernel/sched/topology.c
/* * Build the balance mask; it contains only those CPUs that can arrive at this * group and should be considered to continue balancing. * * We do this during the group creation pass, therefore the group information * isn't complete yet, however since each group represents a (child) domain we * can fully construct this using the sched_domain bits (which are already * complete). */
static void
build_balance_mask(struct sched_domain *sd, struct sched_group *sg, struct cpumask *mask)
{
const struct cpumask *sg_span = sched_group_span(sg);
struct sd_data *sdd = sd->private;
struct sched_domain *sibling;
int i;
cpumask_clear(mask);
for_each_cpu(i, sg_span) {
sibling = *per_cpu_ptr(sdd->sd, i);
/*
* Can happen in the asymmetric case, where these siblings are
* unused. The mask will not be empty because those CPUs that
* do have the top domain _should_ span the domain.
*/
if (!sibling->child)
continue;
/* If we would not end up here, we can't continue from here */
if (!cpumask_equal(sg_span, sched_domain_span(sibling->child)))
continue;
cpumask_set_cpu(i, mask);
}
/* We must not have empty masks here */
WARN_ON_ONCE(cpumask_empty(mask));
}
밸런스 마스크를 구성한다. 스케줄링 그룹의 cpu들을 순회하며 하위 스케줄링 도메인의 cpu들과 동일한 cpu 비트를 설정해온다.
- 코드 라인 9에서 @mask를 모두 클리어한다.
- 코드 라인 11~20에서 스케줄링 그룹에 속한 cpu들을 대상으로 순회하되 스케줄링 도메인의 child가 없는 경우엔 skip 한다.
- 코드 라인 23~26에서 하위 스케줄링 도메인에 속한 cpu들과 스케줄링 그룹의 cpu들이 동일한 경우에만 @mask에 현재 cpu를 설정해둔다.
스케줄 그룹 Capacity
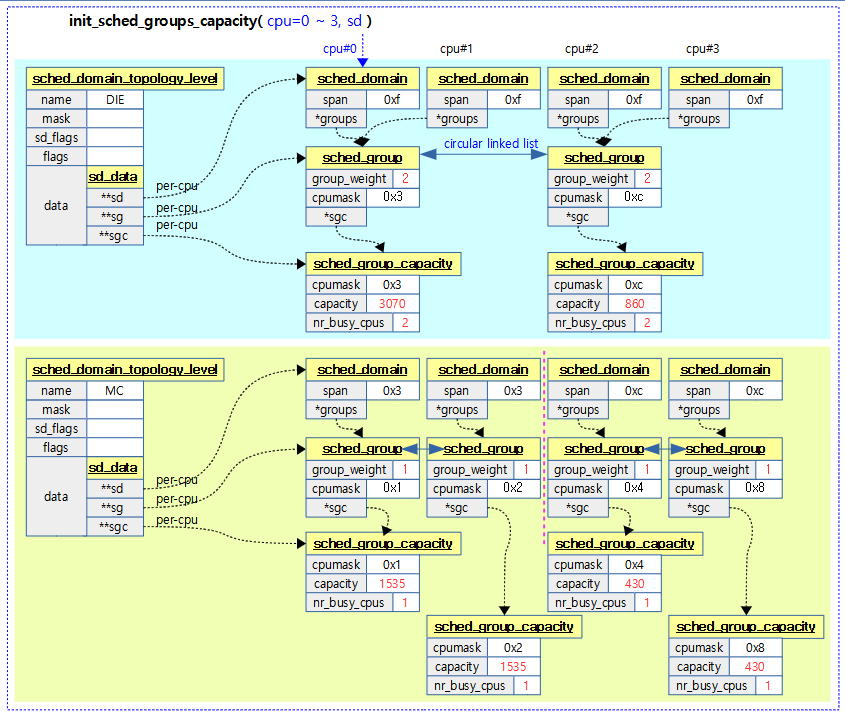
init_sched_groups_capacity()
kernel/sched/topology.c
/* * Initialize sched groups cpu_capacity. * * cpu_capacity indicates the capacity of sched group, which is used while * distributing the load between different sched groups in a sched domain. * Typically cpu_capacity for all the groups in a sched domain will be same * unless there are asymmetries in the topology. If there are asymmetries, * group having more cpu_capacity will pickup more load compared to the * group having less cpu_capacity. */
static void init_sched_groups_capacity(int cpu, struct sched_domain *sd)
{
struct sched_group *sg = sd->groups;
WARN_ON(!sg);
do {
int cpu, max_cpu = -1;
sg->group_weight = cpumask_weight(sched_group_span(sg));
if (!(sd->flags & SD_ASYM_PACKING))
goto next;
for_each_cpu(cpu, sched_group_span(sg)) {
if (max_cpu < 0)
max_cpu = cpu;
else if (sched_asym_prefer(cpu, max_cpu))
max_cpu = cpu;
}
sg->asym_prefer_cpu = max_cpu;
next:
sg = sg->next;
} while (sg != sd->groups);
if (cpu != group_balance_cpu(sg))
return;
update_group_capacity(sd, cpu);
}
요청한 cpu의 스케줄링 도메인에 대한 스케줄링 그룹 capacity를 초기화한다.
- 코드 라인 7~10에서 연결된 스케줄링 그룹들을 순회하며 스케줄링 그룹에 참여하는 cpu들 수를 sg->group_weight에 대입한다.
- 코드 라인 12~13에서 스케줄링 도메인이 asymetric 패킹을 사용하지 않는 경우엔 next: 레이블로 이동한다.
- powerpc의 SMT 토플로지 도메인의 경우 도메인 내 포함된 첫 번째 hw thread 가 더 성능이 좋다.
- 코드 라인 15~21에서 스케줄링 그룹내의 cpu들을 순회하며 가장 성능 좋은 cpu를 찾아 스케줄링 그룹의 asym_prefer_cpu에 지정한다.
- SMT 토플로지 중 asym 패킹을 사용하는 경우 powerpc 등에서 첫 번째 cpu가 가장 성능이 좋다.
- ITMT(Intel Turbo Boost Max Technology 3.0) 기능을 지원하는 x86 시스템의 경우 특정 코어를 boost할 수 있고 SMT 및 MC 토플로지에서 사용할 수 있다.
- 코드 라인 23~25에서 next: 레이블이다. 다음 스케줄링 그룹을 순회한다.
- 코드 라인 27~30에서 밸런스 마스크의 첫 번째 cpu인 경우 스케줄링 그룹 capacity를 갱신한다.
sched_asym_prefer()
kernel/sched/sched.h
tatic inline bool sched_asym_prefer(int a, int b)
{
return arch_asym_cpu_priority(a) > arch_asym_cpu_priority(b);
}
@a cpu가 @b cpu보다 더 성능이 좋은지 여부를 반환한다.
- arch_asym_cpu_priority() 함수는 ITMT(Intel Turbo Boost Max Technology 3.0) 기능을 지원하는 x86 시스템을 위해 추가되었다.
- 위의 기능을 지원하지 않는 아키텍처의 경우 weak 함수를 통해 -cpu 값을 반환한다.
group_balance_cpu()
kernel/sched/topology.c
/* * Return the canonical balance CPU for this group, this is the first CPU * of this group that's also in the balance mask. * * The balance mask are all those CPUs that could actually end up at this * group. See build_balance_mask(). * * Also see should_we_balance(). */
int group_balance_cpu(struct sched_group *sg)
{
return cpumask_first(group_balance_mask(sg));
}
밸런스 마스크 중 첫 번째 cpu를 반환한다.
update_group_capacity()
kernel/sched/fair.c
void update_group_capacity(struct sched_domain *sd, int cpu)
{
struct sched_domain *child = sd->child;
struct sched_group *group, *sdg = sd->groups;
unsigned long capacity, min_capacity, max_capacity;
unsigned long interval;
interval = msecs_to_jiffies(sd->balance_interval);
interval = clamp(interval, 1UL, max_load_balance_interval);
sdg->sgc->next_update = jiffies + interval;
if (!child) {
update_cpu_capacity(sd, cpu);
return;
}
capacity = 0;
min_capacity = ULONG_MAX;
max_capacity = 0;
if (child->flags & SD_OVERLAP) {
/*
* SD_OVERLAP domains cannot assume that child groups
* span the current group.
*/
for_each_cpu(cpu, sched_group_span(sdg)) {
struct sched_group_capacity *sgc;
struct rq *rq = cpu_rq(cpu);
/*
* build_sched_domains() -> init_sched_groups_capacity()
* gets here before we've attached the domains to the
* runqueues.
*
* Use capacity_of(), which is set irrespective of domains
* in update_cpu_capacity().
*
* This avoids capacity from being 0 and
* causing divide-by-zero issues on boot.
*/
if (unlikely(!rq->sd)) {
capacity += capacity_of(cpu);
} else {
sgc = rq->sd->groups->sgc;
capacity += sgc->capacity;
}
min_capacity = min(capacity, min_capacity);
max_capacity = max(capacity, max_capacity);
}
} else {
/*
* !SD_OVERLAP domains can assume that child groups
* span the current group.
*/
group = child->groups;
do {
struct sched_group_capacity *sgc = group->sgc;
capacity += sgc->capacity;
min_capacity = min(sgc->min_capacity, min_capacity);
max_capacity = max(sgc->max_capacity, max_capacity);
group = group->next;
} while (group != child->groups);
}
sdg->sgc->capacity = capacity;
sdg->sgc->min_capacity = min_capacity;
sdg->sgc->max_capacity = max_capacity;
}
요청한 cpu의 스케줄링 도메인에 해당하는 스케줄 그룹 capacity를 갱신한다.
- 코드 라인 8~10에서 스케줄링 도메인의 로드 밸런싱 주기(ms)를 jiffies 단위로 변환하고 이 값이 1 ~ 0.1초에 해당하는 jiffies 범위로 제한시킨 후 다음 갱신 주기로 설정한다.
- 코드 라인 12~15에서 child 없는 최하위 스케줄링 도메인의 경우 cpu capacity를 갱신하고 함수를 빠져나간다.
- 코드 라인 21~51에서 child 스케줄링 도메인에 SD_OVERLAP 플래그가 설정된 경우(NUMA) 스케줄링 그룹의 cpu들을 대상으로 순회하며 capacity 값들을 더하면서 min,/max capacity를 갱신한다.
- 코드 라인 52~67에서 !SD_OVERLAP 도메인의 경우 child 스케줄링 그룹을 순회하며 해당 cpu의 capacity를 더하면서 min/max capacity를 갱신한다.
- 코드 라인 69~71에서 누적한 capacity 값을 스케줄링 그룹 capacity에 대입하고, min/max capacity도 대입한다.
update_cpu_capacity()
kernel/sched/fair.c
static void update_cpu_capacity(struct sched_domain *sd, int cpu)
{
unsigned long capacity = scale_rt_capacity(sd, cpu);
struct sched_group *sdg = sd->groups;
cpu_rq(cpu)->cpu_capacity_orig = arch_scale_cpu_capacity(cpu);
if (!capacity)
capacity = 1;
cpu_rq(cpu)->cpu_capacity = capacity;
sdg->sgc->capacity = capacity;
sdg->sgc->min_capacity = capacity;
sdg->sgc->max_capacity = capacity;
}
cpu의 capacity를 갱신한다.
- 코드 라인 3에서 요청한 @cpu의 cfs 태스크를 위한 capacity로 rt에 사용한 시간 비율 만큼을 줄인 스케일을 적용한다.
- rt 타임: irq 처리에 사용한 시간 + rt 태스크 수행 시간 + deadline 태스크 수행시간
- 코드 라인 6에서 런큐의 cpu_capacity_orig에 rt 스케일이 적용되지 않은 오리지날 cpu capacity 값을 대입한다.
- 코드 라인 8~14에서 런큐의 cpu_capacity, 스케줄링 그룹의 capacity, min/max capacity에 rt 스케일된 capacity 값을 대입한다. 단 이 값이 0인 경우 최소 값 1을 사용한다.
- 1로 나눌 때 방지하기 위한 값이다.
scale_rt_capacity()
kernel/sched/fair.c
static unsigned long scale_rt_capacity(struct sched_domain *sd, int cpu)
{
struct rq *rq = cpu_rq(cpu);
unsigned long max = arch_scale_cpu_capacity(cpu);
unsigned long used, free;
unsigned long irq;
irq = cpu_util_irq(rq);
if (unlikely(irq >= max))
return 1;
used = READ_ONCE(rq->avg_rt.util_avg);
used += READ_ONCE(rq->avg_dl.util_avg);
if (unlikely(used >= max))
return 1;
free = max - used;
return scale_irq_capacity(free, irq, max);
}
rt를 제외한 여유(free) 유틸 로드 값을 반환한다.
- 코드 라인 4에서 해당 cpu의 capacity 값을 알아와서 max에 대입한다.
- 최대 값은 1024이다.
- 코드 라인 8~11에서 irq에 대한 util 값을 알아온다. 만일 이 값이 max를 초과하는 경우 모든 util을 irq가 사용하였으므로 cfs 태스크에 줄 수 있는 capacity는 없다. 따라서 최소 값 1을 반환한다. (0으로 나누기 방지용)
- 코드 라인 13~17에서 rt와 dl 태스크가 사용한 util 값을 알아와서 used에 대입한다. 이 값들도 max를 초과하는 경우 모든 util을 rt 및 dl 태스크가 사용하였으므로 cfs 태스크에 줄 수 있는 capacity는 없다. 따라서 이 경우도 최소 값 1을 반환한다. (0으로 나누기 방지용)
- 코드 라인 19에서 오리지날 capacity 값에서 used(rt + dl)에서 사용한 util을 뺀 나머지 값을 산출한다.
- 코드 라인 21에서 산출한 나머지 값을 전체 성능에서 irq util 비율을 제외한 값을 반환한다.
다음 그림은 rt+dl을 제외한 여유 유틸 로드 값을 알아내는 모습을 보여준다
- scale이 적용된 rt 및 dl 유틸로드와 다르게 irq 유틸로드는 scale 되지 않은 시간이다. 따라서 rt와 dl 태스크 시간을 제외한 전체 cpu capacity에서 irq 타임을 제외하고, 스케일 조정 후 cfs에 사용된 cpu capacity를 알아낸다.
- 이 방법은 커널 v4.19-rc1 부터 rt에 대해 PELT 트래킹이 적용되면서 변경되었다.
- 참고:
- sched/core: Use PELT for scale_rt_capacity() (2018, v4.19-rc1)
- sched/core: Remove the rt_avg code (2018, v4.19-rc1)
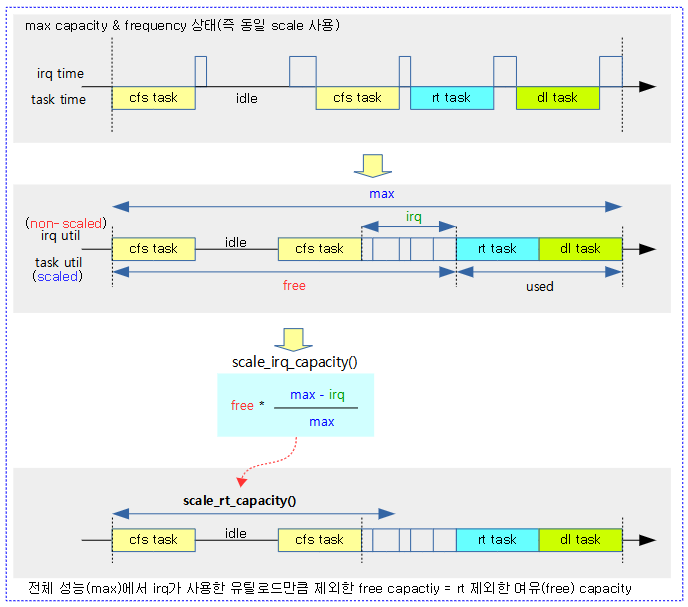
scale_irq_capacity()
kernel/sched/sched.h
static inline
unsigned long scale_irq_capacity(unsigned long util, unsigned long irq, unsigned long max)
{
util *= (max - irq);
util /= max;
return util;
}
다음과 같이 max capacity에 대해 irq 유틸로드가 사용한만큼 제외한 비율만큼을 util 값에 적용하여 반환한다.
- (@max – @irq)
- @util * —————–
- @max
- 예) max 성능이 1024이고, 그 중 약 10%를 irq가 사용하였고, dl과 rt를 제외한 util에 약 70%인 경우
- max=1024, irq=100, util=700
- util 700에서 irq가 사용한 10%를 제외한 63% 값이 반환된다. (return 632)
cpu를 스케줄 도메인에 연결
cpu_attach_domain()
kernel/sched/topology.c
/* * Attach the domain 'sd' to 'cpu' as its base domain. Callers must * hold the hotplug lock. */
static void
cpu_attach_domain(struct sched_domain *sd, struct root_domain *rd, int cpu)
{
struct rq *rq = cpu_rq(cpu);
struct sched_domain *tmp;
/* Remove the sched domains which do not contribute to scheduling. */
for (tmp = sd; tmp; ) {
struct sched_domain *parent = tmp->parent;
if (!parent)
break;
if (sd_parent_degenerate(tmp, parent)) {
tmp->parent = parent->parent;
if (parent->parent)
parent->parent->child = tmp;
/*
* Transfer SD_PREFER_SIBLING down in case of a
* degenerate parent; the spans match for this
* so the property transfers.
*/
if (parent->flags & SD_PREFER_SIBLING)
tmp->flags |= SD_PREFER_SIBLING;
destroy_sched_domain(parent);
} else
tmp = tmp->parent;
}
if (sd && sd_degenerate(sd)) {
tmp = sd;
sd = sd->parent;
destroy_sched_domain(tmp);
if (sd)
sd->child = NULL;
}
sched_domain_debug(sd, cpu);
rq_attach_root(rq, rd);
tmp = rq->sd;
rcu_assign_pointer(rq->sd, sd);
dirty_sched_domain_sysctl(cpu);
destroy_sched_domains(tmp);
update_top_cache_domain(cpu);
}
요청한 도메인 트리에서 스케줄링에 참여할 필요가 없는 스케줄링 도메인들은 해제하고 루트 도메인에 현재 cpu의 런큐를 연결한다.
- 코드 라인 8~11에서 요청한 스케줄 도메인부터 최상위 스케줄 도메인까지 순회한다.
- 코드 라인 13~24에서 부모 스케줄 도메인이 필요 없는 구성일 때 부모 스케줄 도메인을 skip 하도록 연결을 변경하고 제거한다. 부모 스케줄 도메인 플래그에 SD_PREFER_SIBLING이 있는 경우 자식에게 물려준다.
- 코드 라인 25~27에서 부모 스케줄 도메인이 필요한 경우 계속 순회한다.
- 코드 라인 29~35에서 마지막 최상위 부모 스케줄 도메인이 필요 없는 구성일 때 연결을 변경하고 제거한다.
- 코드 라인 39에서 요청한 cpu의 런큐를 루트 도메인에 연결한다.
- 참고: sched_init() | 문c
- 코드 라인 40~41에서 기존 런큐에 연결되어 있었던 스케줄 도메인을 tmp에 대입하고 요청한 스케줄 도메인을 런큐에 연결한다.
- 코드 라인 42에서 해당 cpu를 sysctl에 등록할 수 있도록 sd_sysctl_cpus 비트마스크에서 해당 cpu 비트를 설정한다.
- 코드 라인 43에서 기존 런큐에 연결되어 있었던 스케줄 도메인부터 최상위까지 모두 rcu 방법으로 제거한다.
- 코드 라인 45에서 최상위 캐시 도메인을 갱신한다.
부모 도메인 삭제 가능 여부 체크
sd_parent_degenerate()
kernel/sched/topology.c
static int
sd_parent_degenerate(struct sched_domain *sd, struct sched_domain *parent)
{
unsigned long cflags = sd->flags, pflags = parent->flags;
if (sd_degenerate(parent))
return 1;
if (!cpumask_equal(sched_domain_span(sd), sched_domain_span(parent)))
return 0;
/* Flags needing groups don't count if only 1 group in parent */
if (parent->groups == parent->groups->next) {
pflags &= ~(SD_LOAD_BALANCE |
SD_BALANCE_NEWIDLE |
SD_BALANCE_FORK |
SD_BALANCE_EXEC |
SD_SHARE_CPUCAPACITY |
SD_SHARE_PKG_RESOURCES |
SD_PREFER_SIBLING |
SD_SHARE_POWERDOMAIN);
if (nr_node_ids == 1)
pflags &= ~SD_SERIALIZE;
}
if (~cflags & pflags)
return 0;
return 1;
}
요청한 스케줄 도메인 또는 부모 스케줄 도메인이 스케줄링에 참여할 필요가 없는 경우 true(1)를 반환한다. (true인 경우 바깥 루틴에서 이 스케줄링 도메인을 제거한다)
- 코드 라인 4에서 자식 스케줄 도메인의 플래그와, 부모 스케줄 도메인의 플래그를 알아온다.
- 코드 라인 6~7에서 부모 스케줄 도메인이 스케줄링에 참여할 필요가 없는 경우 true(1)를 반환한다.
- 코드 라인 9~10에서 부모 스케줄 도메인과 자식 스케줄 도메인에 참여한 cpu 들이 같은 경우 false(0)를 반환한다.
- 코드 라인 13~21에서 부모 스케줄 도메인에 그룹이 하나밖에 없는 경우 부모 플래그에서 밸런싱에 관련된 플래그를 모두 제거한다.
- 코드 라인 22~23에서 그리고 노드가 1개인 경우 NUMA 로드밸런싱에서 사용하는 SD_SERIALIZE 플래그도 제거한다.
- 코드 라인 25~26에서 자식 스케줄 도메인용 플래그에 없는 설정이 부모 플래그에 있는 경우 false(0)를 반환한다.
- 코드 라인 28에서 true(1)를 반환한다.
도메인 삭제 가능 여부 체크
sd_degenerate()
kernel/sched/topology.c
static int sd_degenerate(struct sched_domain *sd)
{
if (cpumask_weight(sched_domain_span(sd)) == 1)
return 1;
/* Following flags need at least 2 groups */
if (sd->flags & (SD_LOAD_BALANCE |
SD_BALANCE_NEWIDLE |
SD_BALANCE_FORK |
SD_BALANCE_EXEC |
SD_SHARE_CPUCAPACITY |
SD_ASYM_CPUCAPACITY |
SD_SHARE_PKG_RESOURCES |
SD_SHARE_POWERDOMAIN)) {
if (sd->groups != sd->groups->next)
return 0;
}
/* Following flags don't use groups */
if (sd->flags & (SD_WAKE_AFFINE))
return 0;
return 1;
}
스케줄 도메인에 속한 cpu가 1개이거나 스케줄링에 참여를 할 수 없는 상태인 경우 true(1)를 반환한다. (true인 경우 바깥 루틴에서 이 스케줄링 도메인을 제거한다)
- 코드 라인 3~4에서 요청한 스케줄링 도메인에 속한 cpu가 1개뿐이면 true(1)를 반환한다.
- 코드 라인 7~17에서 스케줄 도메인의 플래그가 밸런싱을 요구하는데 다음 그룹이 있으면 false(0)을 반환한다.
- 코드 라인 20~21에서 스케줄 도메인에서 SD_WAKE_AFFINE 플래그가 사용된 경우 false(0)을 반환한다.
- 코드 라인 23에서 true(1)를 반환한다.
캐시 스케줄링 도메인 갱신
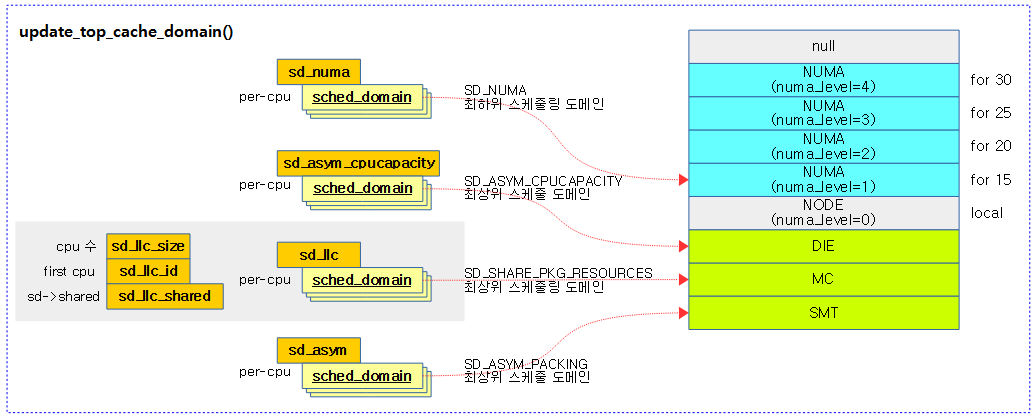
update_top_cache_domain()
kernel/sched/topology.c
static void update_top_cache_domain(int cpu)
{
struct sched_domain_shared *sds = NULL;
struct sched_domain *sd;
int id = cpu;
int size = 1;
sd = highest_flag_domain(cpu, SD_SHARE_PKG_RESOURCES);
if (sd) {
id = cpumask_first(sched_domain_span(sd));
size = cpumask_weight(sched_domain_span(sd));
sds = sd->shared;
}
rcu_assign_pointer(per_cpu(sd_llc, cpu), sd);
per_cpu(sd_llc_size, cpu) = size;
per_cpu(sd_llc_id, cpu) = id;
rcu_assign_pointer(per_cpu(sd_llc_shared, cpu), sds);
sd = lowest_flag_domain(cpu, SD_NUMA);
rcu_assign_pointer(per_cpu(sd_numa, cpu), sd);
sd = highest_flag_domain(cpu, SD_ASYM_PACKING);
rcu_assign_pointer(per_cpu(sd_asym_packing, cpu), sd);
sd = lowest_flag_domain(cpu, SD_ASYM_CPUCAPACITY);
rcu_assign_pointer(per_cpu(sd_asym_cpucapacity, cpu), sd);
}
캐시 스케줄링 도메인들을 갱신한다. (sd_busy, sd_llc, sd_numa, sd_asym)
- 코드 라인 8~18에서 해당 cpu의 스케줄 도메인들 중 SD_SHARE_PKG_RESOURCES 플래그가 설정된 가장 상위의 스케줄링 도메인을 알아와서 llc(last level cache) 정보를 저장한다.
- 코드 라인 20~21에서 해당 cpu의 스케줄 도메인들 중 SD_NUMA 플래그가 설정된 가장 하위의 스케줄 도메인을 알아와서 numa 도메인 정보를 저장한다.
- 코드 라인 23~24에서 해당 cpu의 스케줄 도메인들 중 SD_ASYM_PACKING 플래그가 설정된 가장 상위의 스케줄 도메인을 알아와서 asym 도메인 정보를 저장한다.
- 코드 라인 26~27에서 해당 cpu의 스케줄 도메인들 중 SD_ASYM_CPUCAPACITY 플래그가 설정된 가장 하위의 스케줄 도메인을 알아와서 asym cpu capacity 도메인 정보를 저장한다.
다음 그림은 llc(last level cache) 등의 스케줄링 도메인 정보를 갱신하는 모습을 보여준다.
highest_flag_domain()
kernel/sched/sched.h
/** * highest_flag_domain - Return highest sched_domain containing flag. * @cpu: The cpu whose highest level of sched domain is to * be returned. * @flag: The flag to check for the highest sched_domain * for the given cpu. * * Returns the highest sched_domain of a cpu which contains the given flag. */
static inline struct sched_domain *highest_flag_domain(int cpu, int flag)
{
struct sched_domain *sd, *hsd = NULL;
for_each_domain(cpu, sd) {
if (!(sd->flags & flag))
break;
hsd = sd;
}
return hsd;
}
요청한 플래그가 설정된 가장 상위의 스케줄 도메인을 반환한다.
lowest_flag_domain()
kernel/sched/sched.h
static inline struct sched_domain *lowest_flag_domain(int cpu, int flag)
{
struct sched_domain *sd;
for_each_domain(cpu, sd) {
if (sd->flags & flag)
break;
}
return sd;
}
요청한 플래그가 설정된 가장 하위의 스케줄 도메인을 반환한다.
sysctl for sched_domain
다음은 rock960(4 little + 2 big) 보드가 2 단계 MC+DIE 스케줄 도메인 토플로지 레벨을 사용한 모습을 알아볼 수 있다.
$ cd /proc/sys/kernel/sched_domain $ ls -la total 0 dr-xr-xr-x 1 root root 0 Nov 27 21:39 . dr-xr-xr-x 1 root root 0 Nov 4 2016 .. dr-xr-xr-x 1 root root 0 Nov 27 21:39 cpu0 dr-xr-xr-x 1 root root 0 Nov 27 21:39 cpu1 dr-xr-xr-x 1 root root 0 Nov 27 21:39 cpu2 dr-xr-xr-x 1 root root 0 Nov 27 21:39 cpu3 dr-xr-xr-x 1 root root 0 Nov 27 21:39 cpu4 dr-xr-xr-x 1 root root 0 Nov 27 21:39 cpu5 $ cd cpu0 $ ls -la total 0 dr-xr-xr-x 1 root root 0 Nov 27 21:39 . dr-xr-xr-x 1 root root 0 Nov 27 21:39 .. dr-xr-xr-x 1 root root 0 Nov 27 21:39 domain0 dr-xr-xr-x 1 root root 0 Nov 27 21:39 domain1 $ cd domain0 $ ls -la total 0 dr-xr-xr-x 1 root root 0 Nov 27 21:39 . dr-xr-xr-x 1 root root 0 Nov 27 21:39 .. -rw-r--r-- 1 root root 0 Nov 27 21:39 busy_factor -rw-r--r-- 1 root root 0 Nov 27 21:39 busy_idx -rw-r--r-- 1 root root 0 Nov 27 21:39 cache_nice_tries -rw-r--r-- 1 root root 0 Nov 27 21:39 flags -rw-r--r-- 1 root root 0 Nov 27 21:39 forkexec_idx dr-xr-xr-x 1 root root 0 Nov 27 21:39 group0 dr-xr-xr-x 1 root root 0 Nov 27 21:39 group1 dr-xr-xr-x 1 root root 0 Nov 27 21:39 group2 dr-xr-xr-x 1 root root 0 Nov 27 21:39 group3 -rw-r--r-- 1 root root 0 Nov 27 21:39 idle_idx -rw-r--r-- 1 root root 0 Nov 27 21:39 imbalance_pct -rw-r--r-- 1 root root 0 Nov 27 21:39 max_interval -rw-r--r-- 1 root root 0 Nov 27 21:39 max_newidle_lb_cost -rw-r--r-- 1 root root 0 Nov 27 21:39 min_interval -r--r--r-- 1 root root 0 Nov 27 21:39 name -rw-r--r-- 1 root root 0 Nov 27 21:39 newidle_idx -rw-r--r-- 1 root root 0 Nov 27 21:39 wake_idx $ cat name MC $ cat ../domain1/name DIE
다음은 rpi4(4 big) 보드가 1 단계 DIE 스케줄 도메인 토플로지 레벨만을 사용한 모습을 알아볼 수 있다.
- rpi2~4 보드와 같이 동일한 cpu capacity를 사용하는 경우 CONFIG_SCHED_MC 커널 옵션에 따라 다음과 같다.
- 사용하지 않는 경우 DIE 단계만을 구성한다.
- 사용한 경우 MC 단계만을 구성한다.
$ cd /proc/sys/kernel/sched_domain $ ls -la total 0 dr-xr-xr-x 1 root root 0 Nov 27 21:52 . dr-xr-xr-x 1 root root 0 Jan 29 2018 .. dr-xr-xr-x 1 root root 0 Nov 27 21:52 cpu0 dr-xr-xr-x 1 root root 0 Nov 27 21:52 cpu1 dr-xr-xr-x 1 root root 0 Nov 27 21:52 cpu2 dr-xr-xr-x 1 root root 0 Nov 27 21:52 cpu3 $ ls -la total 0 dr-xr-xr-x 1 root root 0 Nov 27 21:52 . dr-xr-xr-x 1 root root 0 Nov 27 21:52 .. dr-xr-xr-x 1 root root 0 Nov 27 21:52 domain0 $ ls -la total 0 dr-xr-xr-x 1 root root 0 Nov 27 21:52 . dr-xr-xr-x 1 root root 0 Nov 27 21:52 .. -rw-r--r-- 1 root root 0 Nov 27 21:52 busy_factor -rw-r--r-- 1 root root 0 Nov 27 21:52 busy_idx -rw-r--r-- 1 root root 0 Nov 27 21:52 cache_nice_tries -rw-r--r-- 1 root root 0 Nov 27 21:52 flags -rw-r--r-- 1 root root 0 Nov 27 21:52 forkexec_idx -rw-r--r-- 1 root root 0 Nov 27 21:52 idle_idx -rw-r--r-- 1 root root 0 Nov 27 21:52 imbalance_pct -rw-r--r-- 1 root root 0 Nov 27 21:52 max_interval -rw-r--r-- 1 root root 0 Nov 27 21:52 max_newidle_lb_cost -rw-r--r-- 1 root root 0 Nov 27 21:52 min_interval -r--r--r-- 1 root root 0 Nov 27 21:52 name -rw-r--r-- 1 root root 0 Nov 27 21:52 newidle_idx -rw-r--r-- 1 root root 0 Nov 27 21:52 wake_idx $ cat name DIE
구조체
sched_domain_topology_level 구조체
include/linux/sched/topology.h
struct sched_domain_topology_level {
sched_domain_mask_f mask;
sched_domain_flags_f sd_flags;
int flags;
int numa_level;
struct sd_data data;
#ifdef CONFIG_SCHED_DEBUG
char *name;
#endif
};
- (*mask)
- cpumask 값을 읽어오는 함수
- (*sd_flags)
- 스케줄 도메인 플래그를 읽어오는 함수
- flags
- 플래그
- numa_level
- 누마 레벨. NUMA가 아닌 경우 0
- 로컬 노드도 0이며, 노드 간 distance 작은 노드부터 1씩 증가한다.
- data
- sd_data 구조체
- *name
- arm 도메인 단계명(“GMC” -> “MC” -> “DIE” -> “NODE” -> “NUMA”, …)
- arm64 등 generic 도메인 단계명(“SMT” -> “MC” -> “DIE” -> “NODE” -> “NUMA”, …)
sched_domain 구조체
include/linux/sched.h
struct sched_domain {
/* These fields must be setup */
struct sched_domain __rcu *parent; /* top domain must be null terminated */
struct sched_domain __rcu *child; /* bottom domain must be null terminated */
struct sched_group *groups; /* the balancing groups of the domain */
unsigned long min_interval; /* Minimum balance interval ms */
unsigned long max_interval; /* Maximum balance interval ms */
unsigned int busy_factor; /* less balancing by factor if busy */
unsigned int imbalance_pct; /* No balance until over watermark */
unsigned int cache_nice_tries; /* Leave cache hot tasks for # tries */
int nohz_idle; /* NOHZ IDLE status */
int flags; /* See SD_* */
int level;
/* Runtime fields. */
unsigned long last_balance; /* init to jiffies. units in jiffies */
unsigned int balance_interval; /* initialise to 1. units in ms. */
unsigned int nr_balance_failed; /* initialise to 0 */
/* idle_balance() stats */
u64 max_newidle_lb_cost;
unsigned long next_decay_max_lb_cost;
u64 avg_scan_cost; /* select_idle_sibling */
#ifdef CONFIG_SCHEDSTATS
/* load_balance() stats */
unsigned int lb_count[CPU_MAX_IDLE_TYPES];
unsigned int lb_failed[CPU_MAX_IDLE_TYPES];
unsigned int lb_balanced[CPU_MAX_IDLE_TYPES];
unsigned int lb_imbalance[CPU_MAX_IDLE_TYPES];
unsigned int lb_gained[CPU_MAX_IDLE_TYPES];
unsigned int lb_hot_gained[CPU_MAX_IDLE_TYPES];
unsigned int lb_nobusyg[CPU_MAX_IDLE_TYPES];
unsigned int lb_nobusyq[CPU_MAX_IDLE_TYPES];
/* Active load balancing */
unsigned int alb_count;
unsigned int alb_failed;
unsigned int alb_pushed;
/* SD_BALANCE_EXEC stats */
unsigned int sbe_count;
unsigned int sbe_balanced;
unsigned int sbe_pushed;
/* SD_BALANCE_FORK stats */
unsigned int sbf_count;
unsigned int sbf_balanced;
unsigned int sbf_pushed;
/* try_to_wake_up() stats */
unsigned int ttwu_wake_remote;
unsigned int ttwu_move_affine;
unsigned int ttwu_move_balance;
#endif
#ifdef CONFIG_SCHED_DEBUG
char *name;
#endif
union {
void *private; /* used during construction */
struct rcu_head rcu; /* used during destruction */
};
struct sched_domain_shared *shared;
unsigned int span_weight;
/*
* Span of all CPUs in this domain.
*
* NOTE: this field is variable length. (Allocated dynamically
* by attaching extra space to the end of the structure,
* depending on how many CPUs the kernel has booted up with)
*/
unsigned long span[0];
};
- *parent
- 부모 스케줄 도메인. 더 이상 부모가 없는 최상위는 null
- *child
- 자식 스케줄 도메인. 더 이상 자식이 없는 최하위는 null
- *groups
- 로드 밸런싱에 참여하는 스케줄 그룹들
- min_interval
- 최소 밸런싱 주기(ms)
- max_interval
- 최대 밸런싱 주기(ms)
- busy_factor
- 디폴트로 32를 사용한다.
- imbalance_pct
- 로컬과 기존 cpu의 로드 비교 시 둘 중 하나의 cpu 로드에 imbalance_pct 가중치를 부여한다. 밸런싱 목적에 따라 imbalance_pct 가중치가 붙는 cpu가 달라진다.
- 디폴트로 125(%)를 사용하며 다음과 같은 도메인에 대해 밸런싱에 대한 benefit을 주기 위해 이 값을 조금 줄인다.
- SD_SHARE_CPUCAPACITY 플래그를 사용하는 SMT 도메인에서 110(%)을 사용한다.
- SD_SHARE_PKG_RESOURCES 플래그를 사용하여 패키지 내에서 캐시를 공유하는 MC 도메인에서 117(%)을 사용한다.
- 커널 v5.10-rc1 부터 125%를 117%로 줄였다.
- 참고: sched/fair: Reduce minimal imbalance threshold (2020, v5.10-rc1)
- cache_nice_tries
- NUMA 시스템에선 최대 값 2를 사용하고, 그 보다 밸런싱이 용이한 NODE, DIE, MC 레벨은 1 그리고 SMT 레벨은 최소 값 0을 사용한다.
- nohz_idle
- nohz idle 밸런싱에 사용한다. nohz idle인 경우 1이고 그 외의 경우 0이다.
- flags
- 도메인 특성을 나타내는 플래그들로 이 글의 앞 부분에서 별도로 설명하였다.
- level
- 최하위 도메인은 0부터 시작. (SMT -> MC -> DIE -> NODE -> NUMA, …)
- last_balance
- 밸런싱을 수행한 마지막 시각(jiffies)
- balance_interval
- 밸런싱 인터벌. 초기값 1(ms)
- nr_balance_failed
- 실패한 밸런싱 수
- max_newidle_lb_cost
- 도메인에 대해 idle 밸런싱을 시도 할 때마다 소요된 최대 idle 밸런싱 시간이 갱신된다.
- 이 값은 1초에 1%씩 감소(decay) 한다.
- 평균 idle 시간이 이 값보다 작은 경우 밸런싱을 시도하지 않게한다.
- next_decay_max_lb_cost
- 1초에 한 번씩 max_newidle_lb_cost를 decay를 하게 하기 위해 사용한다.
- avg_scan_cost
- *name
- 도메인 명
- *private
- 생성 시 sd_data를 가리킨다.
- *rcu
- 해제 시 rcu 링크로 사용한다.
- *shared
- shared 정보를 가진 sched_domain_shared 구조체를 가리킨다.
- span_weight
- 도메인에 포함된 cpu 수
- span[0]
- 도메인에 포함된 cpu 비트마스크
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c – 현재 글
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- Scheding Domains | LWN.net
- [CFS] scheduling domain | NZCV
- sched-domains.txt | Kernel.org – 번역
- Overview of the Current Approaches to Enhance the Linux Scheduler | IBM