<kernel v5.4>
cpu topology
cpu 토플로지로 구성된 정보는 스케줄 도메인을 사용한 로드밸런싱과 PM(Power Management) 시스템에서 사용된다. core.c에 있었던 cpu topology 부분을 topology.c로 분리하였다.
- 코드 위치
- kernel/sched/topology.c
- include/linux/sched/topology.c
cpu 토플로지
cpu 토플로지는 다음 3 종류의 아키텍처가 지원한다. 이를 지원하지 않는 경우 모든 cpu의 성능이 동일하다고 판단한다. cpu 토플로지의 변경은 cpu가 online/offline 됨에 따라 갱신된다.
- ARM32
- armv7 아키텍처에서 CONFIG_ARM_CPU_TOPOLOGY 커널 옵션을 사용할 때 cpu topology를 지원한다.
- MPIDR 레지스터를 통해 3 단계 affinity 레벨을 읽어 cpu_topology[]를 구성한다.
- 최근 일부 시스템은 디바이스 트리를 지원한다.
- ARM64
- 항상 cpu topology를 구성하여 사용한다.
- 부트 타임에 Device Tree의 “cpu-map” 노드 정보를 읽어와서 클러스터 정보들을 추가하며, 디바이스 트리를 통해 구성하지 못한 경우 MPIDR 레지스터를 통해 4 단계 affinity 레벨을 읽어 cpu_topology[]를 구성한다.
- RISC-V
- 항상 cpu topology를 구성하여 사용한다.
- 부트 타임에 Device Tree의 “cpu-map” 노드 정보를 읽어와서 클러스터 정보들을 추가한다.
arch specific cpu topology & cpu capacity
- arm, arm64 아키텍처 전용 cpu topology 및 cpu capacity에 대한 중복 코드들을 다음 위치에 통합한다.
- common 코드 위치
- drivers/base/arch_topology.c
- include/linux/arch_topology.h
- 참고:
- arm,arm64,drivers: move externs in a new header file (2017, v4.13-rc1)
- arm, arm64: factorize common cpu capacity default code (2017, v4.13-rc1)
- common 코드 위치
- 디바이스 트리 관련
- RISC-V & ARM64 시스템의 경우 디바이스 트리에서 “cpu-map” 노드를 읽어 cpu topology를 만들어낸다. 따라서 관련 중복 코드들을 common 위치로 옮긴다. (arm의 일부 코드는 구현이 달라 통합하지 않고 남아있다)
- 참고: cpu-topology: Move cpu topology code to common code (2019, v5.4-rc1)
- ARM32 시스템에서 디바이스 트리를 지원하는 시스템들에 대해서는 위의 common 코드 외에 별도의 디바이스 트리 파싱 소스를 사용하고 있다.
- RISC-V & ARM64 시스템의 경우 디바이스 트리에서 “cpu-map” 노드를 읽어 cpu topology를 만들어낸다. 따라서 관련 중복 코드들을 common 위치로 옮긴다. (arm의 일부 코드는 구현이 달라 통합하지 않고 남아있다)
cpu_topology[]
include/linux/arch_topology.h
struct cpu_topology {
int thread_id;
int core_id;
int package_id;
int llc_id;
cpumask_t thread_sibling;
cpumask_t core_sibling;
cpumask_t llc_sibling;
};
cpu topology 구조체는 모든 아키텍처에서 공통으로 통합되었다. 시스템 레지스터를 읽어 구성하고, 디바이스 트리를 지원하는 경우 이를 통해서도 추가 구성된다.
- thread_id
- h/w 스레드를 구분하기 위한 값이다. 아직 arm에서는 하드웨어 스레드를 지원하지 않아 항상 -1을 담고, 사용하지 않는다.
- powerpc, s390, mips 및 x86의 하이퍼 스레딩 등 멀티 스레딩(hw thread)을 지원하는 시스템에서 CONFIG_SCHED_SMT 커널 옵션과 함께 사용된다.
- core_id
- core(cpu)를 구분하기 위한 값이다.
- package_id
- package(클러스터)를 구분하기 위한 값이다.
- 최근 ARM64 SoC 동향은 빅 클러스터/미디엄 클러스터/리틀 클러스터로 나뉘어 동시에 동작시킬 수 있다.
- llc_id
- last level 캐시를 구분하기 위한 값이다.
- 현재 ACPI를 사용하는 ARM64에서만 지원한다.
- thread_sibling
- core(cpu)에 구성된 h/w 스레드들의 비트 마스크이다.
- hw-thread는 arm64에 출시 계획이 있었으나 지연 후 출시가 보류된 상태이다.
- core_sibling
- package(클러스터)에 구성된 core(cpu)들의 비트 마스크이다.
- 예) 0b11110000 -> 해당 클러스터가 cpu#4 ~ cpu#7 까지를 구성한다.
- llc_sibling
- last level 캐시를 공유하는 패키지들의 비트 마스크이다.
다음은 두 단계의 클러스터를 사용하는 총 4개 클러스터로 구성된 시스템의 예를 보여준다.
- 참고
- CPU topology binding description | Documentation/devicetree/bindings/cpu/cpu-topology.txt
- ARM CPUs bindings | Documentation/devicetree/bindings/arm/cpus.txt
cpus {
#size-cells = <0>;
#address-cells = <2>;
cpu-map {
cluster0 {
cluster0 {
core0 {
thread0 {
cpu = <&CPU0>;
};
thread1 {
cpu = <&CPU1>;
};
};
core1 {
thread0 {
cpu = <&CPU2>;
};
thread1 {
cpu = <&CPU3>;
};
};
};
cluster1 {
core0 {
thread0 {
cpu = <&CPU4>;
};
thread1 {
cpu = <&CPU5>;
};
};
core1 {
thread0 {
cpu = <&CPU6>;
};
thread1 {
cpu = <&CPU7>;
};
};
};
};
cluster1 {
cluster0 {
core0 {
thread0 {
cpu = <&CPU8>;
};
thread1 {
cpu = <&CPU9>;
};
};
core1 {
thread0 {
cpu = <&CPU10>;
};
thread1 {
cpu = <&CPU11>;
};
};
};
cluster1 {
core0 {
thread0 {
cpu = <&CPU12>;
};
thread1 {
cpu = <&CPU13>;
};
};
core1 {
thread0 {
cpu = <&CPU14>;
};
thread1 {
cpu = <&CPU15>;
};
};
};
};
};
CPU0: cpu@0 {
device_type = "cpu";
compatible = "arm,cortex-a53";
reg = <0x0 0x0>; <- core_id
enable-method = "spin-table";
cpu-release-addr = <0 0x20000000>;
capacity-dmips-mhz = <485>; <- raw cpu capacity
};
...
}
CPU Capacity 스케일 관리
코어별로 능력치가 다른 시스템을 위해 상대적 능력치를 저장해두어 로드밸런스에 사용한다.
최근 아키텍처들은 빅/미디엄/리틀 클러스터들이 각각의 성능을 가진 이 기종 아키텍처들을 지원하고 있으며, 이들은 커널에서 서로 다른 성능으로 동작하고 있다. 처음 ARM32 시스템에서는 frequency가 고정된 빅/리틀 클러스터(cortex-a7/a15)에서 먼저 사용되면서 이 기능이 지원되었고 최근에는 ARM64 및 RISC-V 시스템에서 여러 가지 클러스터 들을 사용하여 지원하고 있다. ARM64의 경우 frequency를 제외한 cpu capacity를 관리하고, frequency 관리는 별도로 한다.
Scaled CPU Capacity 산출 – Generic
디바이스 트리를 통해 다음 값을 읽어 산출한다.
- “capacity-dmips-mhz” 속성 값
- raw_capacity[]에 저장한다.
- 최대 값은 capacity_scale 저장한다.
- 다음과 같이 간단히 산출한다.
- cpu_scale[] = raw_capacity[] / capacity_scale
cpu 토플로지 초기화
다음 그림은 cpu 토플로지를 초기화하는 모습을 보여준다. 커널 부트업 및 나머지 cpu들이 on될 때마다 store_cpu_topology() 함수가 호출된다.
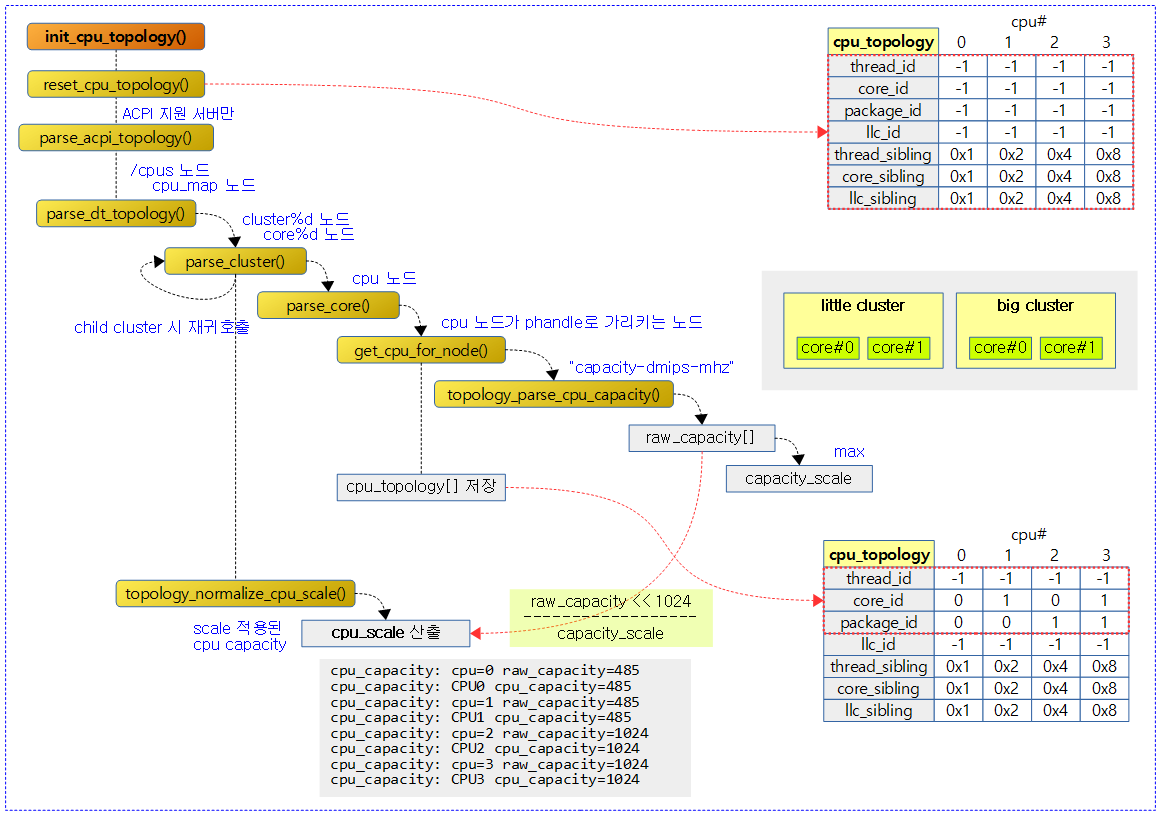
init_cpu_topology() – Generic
drivers/base/arch_topology.c
void __init init_cpu_topology(void)
{
reset_cpu_topology();
/*
* Discard anything that was parsed if we hit an error so we
* don't use partial information.
*/
if (parse_acpi_topology())
reset_cpu_topology();
else if (of_have_populated_dt() && parse_dt_topology())
reset_cpu_topology();
}
cpu_topology[]를 초기화 후 구성한다.
- 코드 라인 3에서 possible cpu 수 만큼 순회하며 cpu_topology[]를 초기화한다.
- 코드 라인 9~10에서 acpi를 파싱하여 cpu topology를 구성한다. 실패하는 경우 다시 초기화한다.
- 코드 라인 11~12에서 디바이스 트리의 cpus 노드를 파싱하여 cpu topology를 구성한다. 실패하는 경우 다시 초기화한다.
reset_cpu_topology()
drivers/base/arch_topology.c
void __init reset_cpu_topology(void)
{
unsigned int cpu;
for_each_possible_cpu(cpu) {
struct cpu_topology *cpu_topo = &cpu_topology[cpu];
cpu_topo->thread_id = -1;
cpu_topo->core_id = -1;
cpu_topo->package_id = -1;
cpu_topo->llc_id = -1;
clear_cpu_topology(cpu);
}
}
cpu_topology[]를 초기화한다.
스케드 도메인용 토플로지
kernel/sched/topology.c
struct sched_domain_topology_level *sched_domain_topology = default_topology;
default_topology[] – Generic
kernel/sched/topology.c
/* * Topology list, bottom-up. */
static struct sched_domain_topology_level default_topology[] = {
#ifdef CONFIG_SCHED_SMT
{ cpu_smt_mask, cpu_smt_flags, SD_INIT_NAME(SMT) },
#endif
#ifdef CONFIG_SCHED_MC
{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
#endif
{ cpu_cpu_mask, SD_INIT_NAME(DIE) },
{ NULL, },
};
디폴트 토플로지는 최대 3단계인 SMT -> MC -> DIE 레벨까지 구성할 수 있다.
- ARM64 및 RISC-V 시스템의 경우 NUMA 레벨은 디바이스 트리를 사용하여 NUMA distance 단계 별로 DIE 레벨 뒤에 추가 구성된다.
arm_topology[] – ARM32
arch/arm/kernel/topology.c
static struct sched_domain_topology_level arm_topology[] = {
#ifdef CONFIG_SCHED_MC
{ cpu_corepower_mask, cpu_corepower_flags, SD_INIT_NAME(GMC) },
{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
#endif
{ cpu_cpu_mask, SD_INIT_NAME(DIE) },
{ NULL, },
};
ARM32에서는 코어 파워 도메인을 구분하는 GMC라는 단계를 추가하여 사용한다.
cpu_coregroup_mask()
drivers/base/arch_topology.c
const struct cpumask *cpu_coregroup_mask(int cpu)
{
const cpumask_t *core_mask = cpumask_of_node(cpu_to_node(cpu));
/* Find the smaller of NUMA, core or LLC siblings */
if (cpumask_subset(&cpu_topology[cpu].core_sibling, core_mask)) {
/* not numa in package, lets use the package siblings */
core_mask = &cpu_topology[cpu].core_sibling;
}
if (cpu_topology[cpu].llc_id != -1) {
if (cpumask_subset(&cpu_topology[cpu].llc_sibling, core_mask))
core_mask = &cpu_topology[cpu].llc_sibling;
}
return core_mask;
}
@cpu의 MC 도메인 단계에 해당하는 cpumask를 반환한다. 라스트 레벨 캐시 정보가 존재하면 해당 core 들에 대한 비트맵을 반환한다. 없으면 요청한 cpu의 노드 및 패키지 내의 core 들에 대한 비트맵을 반환한다. 이 정보도 없는 경우 그냥 cpu가 소속된 노드의 cpu core 들에 대한 비트맵을 반환한다.
- 코드 라인 3에서 cpu가 소속된 노드의 cpu core 들에 대한 비트맵을 구한다.
- 코드 라인 6~9에서 위에서 구한 비트맵에 cpu의 동료 core cpu들이 포함된 경우 이 동료 core cpu들로 비트맵을 구한다.
- 코드 라인 10~13에서 llc 캐시 정보가 구현된 경우 이에 해당하는 core cpu들로 비트맵을 구한다.
- 코드 라인 15에서 최종 구한 비트맵을 반환한다.
cpu_core_flags()
include/linux/topology.h
#ifdef CONFIG_SCHED_MC
static inline int cpu_core_flags(void)
{
return SD_SHARE_PKG_RESOURCES;
}
#endif
SD_SHARE_PKG_RESOURCES 플래그를 반환한다. (MC 도메인 레벨)
cpu_cpu_mask()
include/linux/topology.h
static inline const struct cpumask *cpu_cpu_mask(int cpu)
{
return cpumask_of_node(cpu_to_node(cpu));
}
@cpu의 소속 노드 id에 해당하는 cpumask를 반환한다. (DIE 단계에서 사용된다)
- 예) 2개의 numa 노드 * 4개의 클러스터 * 4개 cpu를 가진 시스템에서 요청 cpu=31
- 0xffff_0000
디바이스 트리 파싱
parse_dt_topology() – Generic, ARM32 별도
drivers/base/arch_topology.c
static int __init parse_dt_topology(void)
{
struct device_node *cn, *map;
int ret = 0;
int cpu;
cn = of_find_node_by_path("/cpus");
if (!cn) {
pr_err("No CPU information found in DT\n");
return 0;
}
/*
* When topology is provided cpu-map is essentially a root
* cluster with restricted subnodes.
*/
map = of_get_child_by_name(cn, "cpu-map");
if (!map)
goto out;
ret = parse_cluster(map, 0);
if (ret != 0)
goto out_map;
topology_normalize_cpu_scale();
/*
* Check that all cores are in the topology; the SMP code will
* only mark cores described in the DT as possible.
*/
for_each_possible_cpu(cpu)
if (cpu_topology[cpu].package_id == -1)
ret = -EINVAL;
out_map:
of_node_put(map);
out:
of_node_put(cn);
}
디바이스 트리를 통해 cpu topology를 구성한다.
- 코드 라인 7~11에서 “/cpus” 노드를 찾는다.
- 코드 라인 17~19에서 찾은 “/cpus” 노드의 하위에서 “cpu-map” 노드를 찾는다.
- 코드 라인 21~23에서 찾은 “cpu-map” 노드의 하위에 있는 “cluster%d” 노드들을 파싱한다.
- 코드 라인 25에서 scale 적용된 cpu capacity를 산출한다.
- 코드 라인 31~33에서 읽어들인 cpu_topology[]에서 package_id가 구성되지 않은 경우 -EINVAL 에러를 반환한다.
parse_cluster()
drivers/base/arch_topology.c
static int __init parse_cluster(struct device_node *cluster, int depth)
{
char name[10];
bool leaf = true;
bool has_cores = false;
struct device_node *c;
static int package_id __initdata;
int core_id = 0;
int i, ret;
/*
* First check for child clusters; we currently ignore any
* information about the nesting of clusters and present the
* scheduler with a flat list of them.
*/
i = 0;
do {
snprintf(name, sizeof(name), "cluster%d", i);
c = of_get_child_by_name(cluster, name);
if (c) {
leaf = false;
ret = parse_cluster(c, depth + 1);
of_node_put(c);
if (ret != 0)
return ret;
}
i++;
} while (c);
/* Now check for cores */
i = 0;
do {
snprintf(name, sizeof(name), "core%d", i);
c = of_get_child_by_name(cluster, name);
if (c) {
has_cores = true;
if (depth == 0) {
pr_err("%pOF: cpu-map children should be clusters\n",
c);
of_node_put(c);
return -EINVAL;
}
if (leaf) {
ret = parse_core(c, package_id, core_id++);
} else {
pr_err("%pOF: Non-leaf cluster with core %s\n",
cluster, name);
ret = -EINVAL;
}
of_node_put(c);
if (ret != 0)
return ret;
}
i++;
} while (c);
if (leaf && !has_cores)
pr_warn("%pOF: empty cluster\n", cluster);
if (leaf)
package_id++;
return 0;
}
“cluster%d” 노드를 파싱한다.
- 코드 라인 16~28에서 0번 부터 순회하며 클러스터 노드가 있는지 확인하고, 확인된 클러스터 노드의 경우 그 밑에 child 클러스터에 대해서도 재귀 호출로 파싱하도록 한다.
- 코드 라인 31~58에서 클러스터의 child가 없는 경우에 도착한다. leaf 클러스터에 소속된 “core%d” 노드 정보를 파싱한다.
- 코드 라인 60~61에서 클러스터에 core 노드가 구성되지 않은 경우 경고 메시지를 출력한다.
- 코드 라인 63~64에서 leaf 클러스터인 경우에 한해 static 변수인 package_id를 증가시킨다.
- 코드 라인 66에서 해당 클러스터가 분석 완료되어 0을 반환한다.
parse_core()
drivers/base/arch_topology.c
static int __init parse_core(struct device_node *core, int package_id,
int core_id)
{
char name[10];
bool leaf = true;
int i = 0;
int cpu;
struct device_node *t;
do {
snprintf(name, sizeof(name), "thread%d", i);
t = of_get_child_by_name(core, name);
if (t) {
leaf = false;
cpu = get_cpu_for_node(t);
if (cpu >= 0) {
cpu_topology[cpu].package_id = package_id;
cpu_topology[cpu].core_id = core_id;
cpu_topology[cpu].thread_id = i;
} else {
pr_err("%pOF: Can't get CPU for thread\n",
t);
of_node_put(t);
return -EINVAL;
}
of_node_put(t);
}
i++;
} while (t);
cpu = get_cpu_for_node(core);
if (cpu >= 0) {
if (!leaf) {
pr_err("%pOF: Core has both threads and CPU\n",
core);
return -EINVAL;
}
cpu_topology[cpu].package_id = package_id;
cpu_topology[cpu].core_id = core_id;
} else if (leaf) {
pr_err("%pOF: Can't get CPU for leaf core\n", core);
return -EINVAL;
}
return 0;
}
“core%d” 노드를 파싱한다.
- 코드 라인 10~29에서 하위 노드에서 “thread%d” 노드들을 찾아 발견된 경우 스레드 노드의 “cpu” 속성이 phandle로 연결한 cpu 노드를 파싱하여 “capacity-dmips-mhz” 속성 값을 읽어 cpu capacity를 저장하고, package_id, core_id 및 thread_id를 모두 사용하는 3 단계 cpu_topology를 구성한다.
- cpu 노드를 파싱하여
- 코드 라인 31~44에서 현재 노드에서 “cpu” 속성을 찾아 phandle로 연결된 cpu 노드가 존재하는 경우에 한해 “capacity-dmips-mhz” 속성 값을 읽어 cpu capacity를 저장하고 package_id와 core_id 만을 사용하는 2 단계 cpu_topology를 구성한다.
- 코드 라인 46에서 core 노드의 파싱이 정상 완료되어 0을 반환한다.
get_cpu_for_node()
drivers/base/arch_topology.c
static int __init get_cpu_for_node(struct device_node *node)
{
struct device_node *cpu_node;
int cpu;
cpu_node = of_parse_phandle(node, "cpu", 0);
if (!cpu_node)
return -1;
cpu = of_cpu_node_to_id(cpu_node);
if (cpu >= 0)
topology_parse_cpu_capacity(cpu_node, cpu);
else
pr_crit("Unable to find CPU node for %pOF\n", cpu_node);
of_node_put(cpu_node);
return cpu;
}
“cpu” 속성에서 읽은 phandle에 연결된 cpu 노드의 “capacity-dmips-mhz” 값을 읽어 저장하고, “reg” 속성 값을 cpu 번호로 반환한다.
- 코드 라인 6~8에서 “cpu” 속성에서 읽은 phandle에 연결된 cpu 노드를 알아온다.
- 코드 라인 10~14에서 알아온 cpu 노드에서 “capacity-dmips-mhz” 값을 읽어 저장한다.
- 코드 라인 17에서 알아온 cpu 노드의 “reg” 속성에 기록된 cpu 번호를 반환한다.
CPU Capacity
topology_parse_cpu_capacity()
drivers/base/arch_topology.c
bool __init topology_parse_cpu_capacity(struct device_node *cpu_node, int cpu)
{
static bool cap_parsing_failed;
int ret;
u32 cpu_capacity;
if (cap_parsing_failed)
return false;
ret = of_property_read_u32(cpu_node, "capacity-dmips-mhz",
&cpu_capacity);
if (!ret) {
if (!raw_capacity) {
raw_capacity = kcalloc(num_possible_cpus(),
sizeof(*raw_capacity),
GFP_KERNEL);
if (!raw_capacity) {
cap_parsing_failed = true;
return false;
}
}
capacity_scale = max(cpu_capacity, capacity_scale);
raw_capacity[cpu] = cpu_capacity;
pr_debug("cpu_capacity: %pOF cpu_capacity=%u (raw)\n",
cpu_node, raw_capacity[cpu]);
} else {
if (raw_capacity) {
pr_err("cpu_capacity: missing %pOF raw capacity\n",
cpu_node);
pr_err("cpu_capacity: partial information: fallback to 1024 for all CPUs\n");
}
cap_parsing_failed = true;
free_raw_capacity();
}
return !ret;
}
@cpu_node에서 “capacity-dmips-mhz” 값을 읽어 저장한다. 성공 시 0을 반환한다.
- 코드 라인 7~8에서 cap_parsing_failed가 한 번이라도 설정된 경우 false를 반환한다.
- 코드 라인 10~34에서 “capacity-dmips-mhz” 값을 읽어 raw_capacity[]에 저장한다. 그 중 가장 큰 값을 capacity_scale에 갱신한다.
- 코드 라인 36에서 cpu capacity 값을 저장 여부를 반환한다. 0=저장 성공
topology_normalize_cpu_scale()
drivers/base/arch_topology.c
void topology_normalize_cpu_scale(void)
{
u64 capacity;
int cpu;
if (!raw_capacity)
return;
pr_debug("cpu_capacity: capacity_scale=%u\n", capacity_scale);
for_each_possible_cpu(cpu) {
pr_debug("cpu_capacity: cpu=%d raw_capacity=%u\n",
cpu, raw_capacity[cpu]);
capacity = (raw_capacity[cpu] << SCHED_CAPACITY_SHIFT)
/ capacity_scale;
topology_set_cpu_scale(cpu, capacity);
pr_debug("cpu_capacity: CPU%d cpu_capacity=%lu\n",
cpu, topology_get_cpu_scale(cpu));
}
}
모든 possible cpu에서 읽어 들인 raw cpu capacity 값을 스케일 적용하여 cpu_scale에 저장한다.
cpu_scale
drivers/base/arch_topology.c
DEFINE_PER_CPU(unsigned long, cpu_scale) = SCHED_CAPACITY_SCALE;
전역 per-cpu 변수 cpu_scale에서는 cpu capacity 값을 담고있다. cpu topology를 사용하지 않을 때에 이 값은 디폴트 값 1024를 담고 있다.
topology_set_cpu_scale()
drivers/base/arch_topology.c
void topology_set_cpu_scale(unsigned int cpu, unsigned long capacity)
{
per_cpu(cpu_scale, cpu) = capacity;
}
전역 per-cpu 변수 cpu_scale에 요청한 스케일 적용한 cpu capacity 값을 저장한다.
부팅된 cpu의 토플로지 적용
store_cpu_topology() – ARM64
arch/arm64/kernel/topology.c
void store_cpu_topology(unsigned int cpuid)
{
struct cpu_topology *cpuid_topo = &cpu_topology[cpuid];
u64 mpidr;
if (cpuid_topo->package_id != -1)
goto topology_populated;
mpidr = read_cpuid_mpidr();
/* Uniprocessor systems can rely on default topology values */
if (mpidr & MPIDR_UP_BITMASK)
return;
/* Create cpu topology mapping based on MPIDR. */
if (mpidr & MPIDR_MT_BITMASK) {
/* Multiprocessor system : Multi-threads per core */
cpuid_topo->thread_id = MPIDR_AFFINITY_LEVEL(mpidr, 0);
cpuid_topo->core_id = MPIDR_AFFINITY_LEVEL(mpidr, 1);
cpuid_topo->package_id = MPIDR_AFFINITY_LEVEL(mpidr, 2) |
MPIDR_AFFINITY_LEVEL(mpidr, 3) << 8;
} else {
/* Multiprocessor system : Single-thread per core */
cpuid_topo->thread_id = -1;
cpuid_topo->core_id = MPIDR_AFFINITY_LEVEL(mpidr, 0);
cpuid_topo->package_id = MPIDR_AFFINITY_LEVEL(mpidr, 1) |
MPIDR_AFFINITY_LEVEL(mpidr, 2) << 8 |
MPIDR_AFFINITY_LEVEL(mpidr, 3) << 16;
}
pr_debug("CPU%u: cluster %d core %d thread %d mpidr %#016llx\n",
cpuid, cpuid_topo->package_id, cpuid_topo->core_id,
cpuid_topo->thread_id, mpidr);
topology_populated:
update_siblings_masks(cpuid);
}
디바이스 트리를 통해 cpu topology를 구성하지 못한 경우에 한 해 시스템 레지스터 중 mpidr 레지스터값을 읽어 cpu_topology를 구성한다.
- 코드 라인 6~7에서 package_id가 이미 설정된 경우 sibling cpu 마스크들을 갱신만 하고 함수를 빠져나가기 위해 topology_populated: 레이블로 이동한다.
- 코드 라인 9에서 cpu affinity 레벨을 파악하기 위해 mpidr 레지스터 값을 읽어온다.
- 코드 라인 12~13에서 uni processor 시스템인 경우 함수를 빠져나간다.
- 코드 라인 16~21에서 mpidr 값에서 hw 스레드를 지원하는 시스템인 경우 4단계 affinity 값들을 모두 반영한다.
- arm 및 arm64는 아직 h/w 멀티스레드가 적용되지 않았다. (cortex-a72,73,75까지도)
- 코드 라인 22~29에서 3단계 affinity 값들을 반영한다.
- 코드 라인 31~33에서 로그 정보를 출력한다.
- 코드 라인 35~46에서 topology_populated: 레이블이다. 요청 cpu에 대한 각 sibling cpumask를 갱신한다.
다음 그림은 mpidr 값을 읽어 core_id, package_id를 갱신하고 관련 시블링 cpu 마스크도 갱신하는 모습을 보여준다.
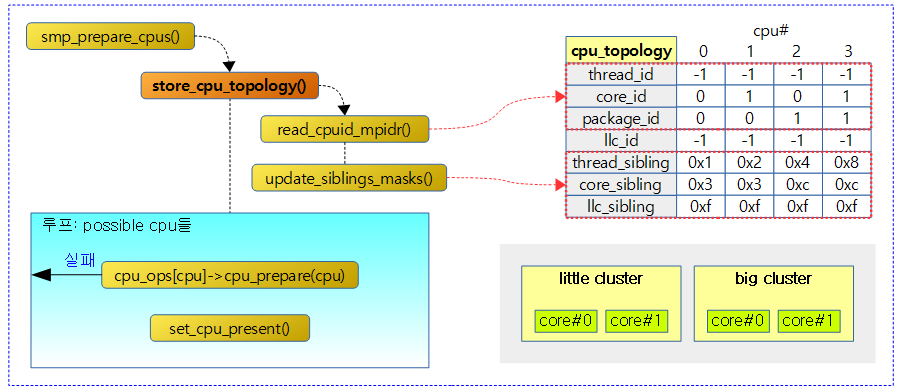
update_siblings_masks()
drivers/base/arch_topology.c
static void update_siblings_masks(unsigned int cpuid)
{
struct cputopo_arm *cpu_topo, *cpuid_topo = &cpu_topology[cpuid];
int cpu;
/* update core and thread sibling masks */
for_each_possible_cpu(cpu) {
cpu_topo = &cpu_topology[cpu];
if (cpuid_topo->llc_id == cpu_topo->llc_id) {
cpumask_set_cpu(cpu, &cpuid_topo->llc_sibling);
cpumask_set_cpu(cpuid, &cpu_topo->llc_sibling);
}
if (cpuid_topo->package_id!= cpu_topo->package_id)
continue;
cpumask_set_cpu(cpuid, &cpu_topo->core_sibling);
cpumask_set_cpu(cpu, &cpuid_topo->core_sibling);
if (cpuid_topo->core_id != cpu_topo->core_id)
continue;
cpumask_set_cpu(cpuid, &cpu_topo->thread_sibling);
cpumask_set_cpu(cpu, &cpuid_topo->thread_sibling);
}
}
요청 cpu에 대한 sibling cpu 마스크들을 갱신한다.
- 코드 라인 7~13에서 possible cpu 수 만큼 순회하며 순회 중인 cpu의 llc_id가 요청한 cpu의 llc_id와 동일한 경우 두 cpu의 llc_sibling 비트를 설정한다.
- 코드 라인 15~16에서 순회 중인 cpu의 package_id와 요청한 cpu의 package_id가 다른 경우 skip 한다.
- 코드 라인 18~19에서 순회 중인 cpu와 요청한 cpu에 대한 core_sibling 비트를 설정한다.
- 코드 라인 21~22에서 순회 중인 cpu의 core_id와 요청한 cpu의 core_id가 다른 경우 skip 한다.
- 코드 라인 24~25에서 순회 중인 cpu와 요청한 cpu에 대한 thread_sibling 비트를 설정한다.
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c – 현재 글
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- Scheding Domains | LWN.net