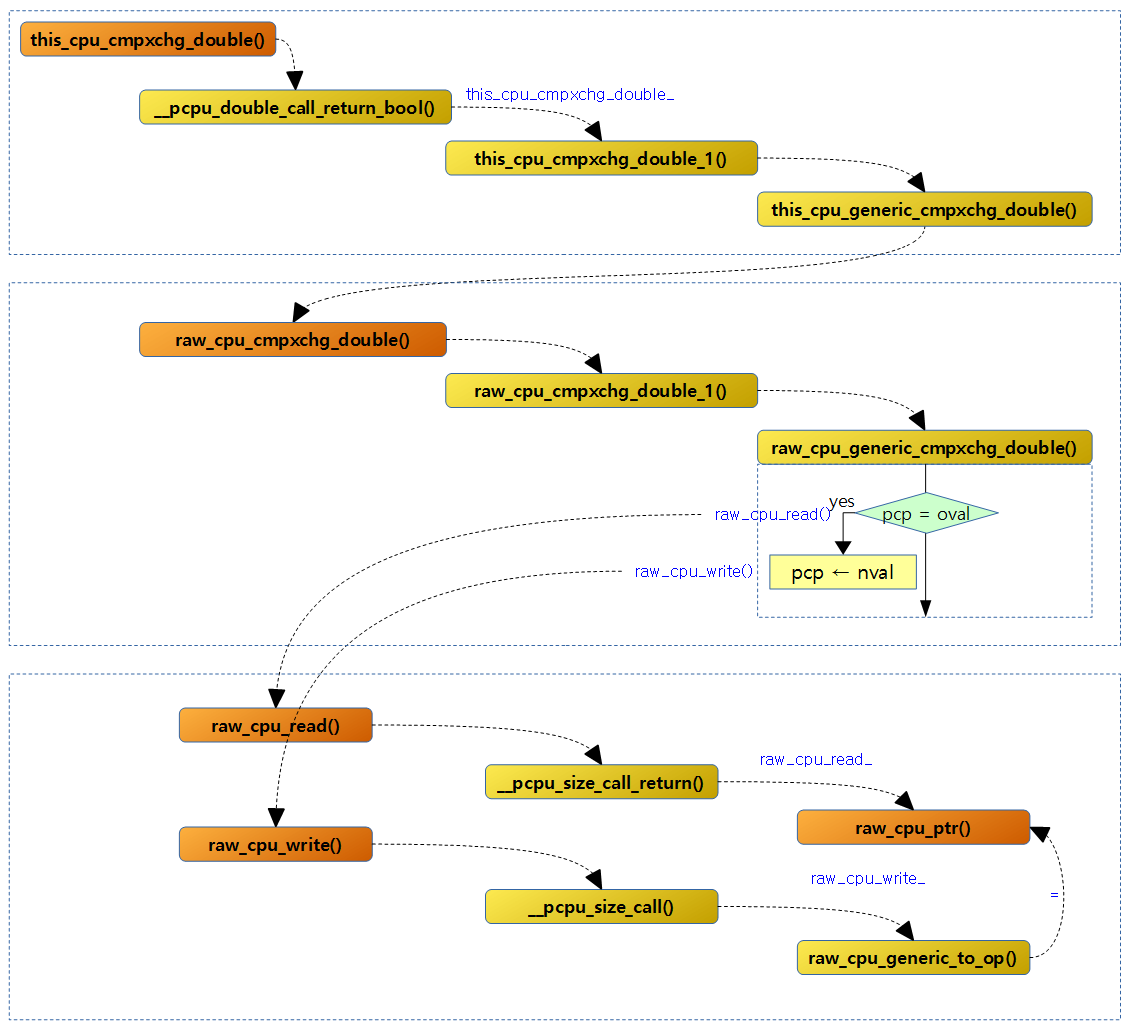
<kernel v5.0>
/proc/slabinfo
$ cat /proc/slabinfo slabinfo - version: 2.1 # name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail> nf_conntrack_1 1035 1035 344 23 2 : tunables 0 0 0 : slabdata 45 45 0 ext4_groupinfo_4k 2112 2112 168 24 1 : tunables 0 0 0 : slabdata 88 88 0 ip6-frags 0 0 248 16 1 : tunables 0 0 0 : slabdata 0 0 0 ip6_dst_cache 126 126 384 21 2 : tunables 0 0 0 : slabdata 6 6 0 RAWv6 104 104 1216 26 8 : tunables 0 0 0 : slabdata 4 4 0 UDPLITEv6 0 0 1216 26 8 : tunables 0 0 0 : slabdata 0 0 0 UDPv6 156 156 1216 26 8 : tunables 0 0 0 : slabdata 6 6 0 tw_sock_TCPv6 0 0 272 30 2 : tunables 0 0 0 : slabdata 0 0 0 request_sock_TCPv6 0 0 328 24 2 : tunables 0 0 0 : slabdata 0 0 0 TCPv6 56 56 2304 14 8 : tunables 0 0 0 : slabdata 4 4 0 cfq_io_cq 216 216 112 36 1 : tunables 0 0 0 : slabdata 6 6 0 bsg_cmd 0 0 312 26 2 : tunables 0 0 0 : slabdata 0 0 0 xfs_icr 0 0 144 28 1 : tunables 0 0 0 : slabdata 0 0 0 xfs_ili 0 0 152 26 1 : tunables 0 0 0 : slabdata 0 0 0 xfs_inode 0 0 1216 26 8 : tunables 0 0 0 : slabdata 0 0 0 xfs_efd_item 0 0 400 20 2 : tunables 0 0 0 : slabdata 0 0 0 xfs_log_item_desc 128 128 32 128 1 : tunables 0 0 0 : slabdata 1 1 0 xfs_da_state 0 0 480 17 2 : tunables 0 0 0 : slabdata 0 0 0 xfs_btree_cur 0 0 208 19 1 : tunables 0 0 0 : slabdata 0 0 0 xfs_log_ticket 0 0 184 22 1 : tunables 0 0 0 : slabdata 0 0 0
각 슬랩 캐시에 대해 다음과 같은 정보가 출력된다.
- name
- 슬랩 이름
- s->name
- <active_objs>
- 사용 중인 object 수 (per-cpu에 있는 free object 조차 사용 중인 object 수에 포함된다)
- 모든 노드의 n->total_objects – (per 노드 partial 리스트에 있는 슬랩 페이지의 page->objects – page->inuse 합계)
- <num_objs>
- 할당된 슬랩 페이지의 모든 object 수(free + inuse)
- 모든 노드의 n->total_objects 합계
- <objsize>
- 슬랩 object 사이즈 (메타 정보 포함)
- s->size
- <objperslab>
- 각 슬랩 페이지에 들어가는 object 수
- s->oo에 기록된 object 수
- <pagesperslab>
- 각 슬랩 페이지에 들어가는 페이지 수
- 2 ^ s->oo에 기록된 order
- <limit>
- 캐시될 최대 object 수 – slub에서 미사용 중(항상 0으로 출력)
- <batchcount>
- 한 번에 refill 가능한 object 수 – slub에서 미사용 중(항상 0으로 출력)
- <sharedfactor>
- slub에서 미사용 중(항상 0으로 출력)
- <active_slabs>
- 사용 중인 슬랩 수 = 전체 슬랩 수와 동일
- 모든 노드의 n->nr_slabs 합계
- <num_slabs>
- 전체 슬랩 수 = 사용 중인 슬랩 수와 동일
- 모든 노드의 n->nr_slabs 합계
- <sharedavail>
- slub에서 미사용 중(항상 0으로 출력)
/sys/kernel/slab 디렉토리
슬랩 캐시들은 /sys/kernel/slab 디렉토리에서 관리하며 다음과 같이 분류한다.
- 병합 불가능한 슬랩 캐시로 슬랩 캐시명을 사용한 디렉토리가 생성된다.
- 예) TCP 디렉토리
- 병합 가능한 슬랩 캐시
- alias 캐시가 가리키는 유니크한 이름으로 자동 생성된 슬랩 캐시로”:”문자열로 시작하는 디렉토리가 생성된다.
- 예) :A-0001088 디렉토리
- 병합된 alias 슬랩 캐시로 오리지널 캐시를 가리키는 링크 파일을 생성한다.
- 예) lrwxrwxrwx 1 root root 0 Nov 19 15:42 UDP -> :A-0001088
병합 가능한 슬랩 캐시명의 규칙은 다음과 같다.
- format
- “:” 문자 + [[d][a][F][A]-] + 유니크한 7자리 숫자
각 옵션 문자에 대한 의미는 다음과 같다.
- d
- DMA 사용 슬랩 캐시
- SLAB_CACHE_DMA 플래그 사용
- D
- DMA32 사용 슬랩 캐시
- SLAB_CAHE_DMA32 플래그 사용 (커널 v5.1-rc3에서 추가)
- a
- reclaimable 슬랩 캐시
- SLAB_RECLAIM_ACCOUNT 플래그 사용
- F
- consistency 체크 허용한 슬랩 캐시
- SLAB_CONSISTENCY_CHECKS 플래그 사용
- A
- memcg 통제 허용한 슬랩 캐시
- SLAB_ACCOUNT 플래그 사용
- t
- SLAB_NOTRACK 플래그 사용 (커널 v.4.15-rc1에서 삭제)
- 참고: kmemcheck: remove whats left of NOTRACK flags
다음과 같이 병합된 슬랩 캐시들은 병합 가능한 오리지널 캐시 디렉토리를 가리킨다.
$ ls /sys/kernel/slab -la ... lrwxrwxrwx 1 root root 0 Nov 19 15:32 PING -> :A-0000960 drwxr-xr-x 2 root root 0 Nov 19 15:32 RAW drwxr-xr-x 2 root root 0 Nov 19 15:32 TCP lrwxrwxrwx 1 root root 0 Nov 19 15:32 UDP -> :A-0001088 lrwxrwxrwx 1 root root 0 Nov 19 15:32 UDP-Lite -> :A-0001088 lrwxrwxrwx 1 root root 0 Nov 19 15:32 UNIX -> :A-0001024 lrwxrwxrwx 1 root root 0 Nov 19 15:32 aio_kiocb -> :0000192 ...
다음은 전체 슬랩 캐시를 보여준다.
$ ls /sys/kernel/slab :0000024 :a-0000256 files_cache nfs_inode_cache :0000032 :a-0000360 filp nfs_page :0000040 PING fs_cache nfs_read_data :0000048 RAW fsnotify_mark nfs_write_data :0000056 TCP fsnotify_mark_connector nsproxy :0000064 UDP hugetlbfs_inode_cache numa_policy :0000080 UDP-Lite iint_cache p9_req_t :0000088 UNIX inet_peer_cache pde_opener :0000104 aio_kiocb inode_cache pid :0000128 anon_vma inotify_inode_mark pid_namespace :0000192 anon_vma_chain iommu_iova pool_workqueue :0000208 asd_sas_event ip4-frags posix_timers_cache :0000216 audit_buffer ip_dst_cache proc_dir_entry :0000240 audit_tree_mark ip_fib_alias proc_inode_cache :0000256 bdev_cache ip_fib_trie radix_tree_node :0000320 bio-0 isp1760_qh request_queue :0000344 bio-1 isp1760_qtd request_sock_TCP :0000384 bio_integrity_payload isp1760_urb_listitem rpc_buffers :0000448 biovec-128 jbd2_inode rpc_inode_cache :0000464 biovec-16 jbd2_journal_handle rpc_tasks :0000512 biovec-64 jbd2_journal_head sas_task :0000640 biovec-max jbd2_revoke_record_s scsi_data_buffer :0000704 blkdev_ioc jbd2_revoke_table_s sd_ext_cdb :0000768 buffer_head jbd2_transaction_s seq_file :0000896 configfs_dir_cache kernfs_node_cache sgpool-128 :0001024 cred_jar key_jar sgpool-16 :0001088 debug_objects_cache khugepaged_mm_slot sgpool-32 :0001984 dentry kioctx sgpool-64 :0002048 dio kmalloc-128 sgpool-8 :0002112 dmaengine-unmap-128 kmalloc-1k shared_policy_node :0004096 dmaengine-unmap-16 kmalloc-256 shmem_inode_cache :A-0000032 dmaengine-unmap-2 kmalloc-2k sighand_cache :A-0000040 dmaengine-unmap-256 kmalloc-4k signal_cache :A-0000064 dnotify_mark kmalloc-512 sigqueue :A-0000072 dnotify_struct kmalloc-8k skbuff_ext_cache :A-0000080 dquot kmalloc-rcl-128 skbuff_fclone_cache :A-0000128 eventpoll_epi kmalloc-rcl-1k skbuff_head_cache :A-0000192 eventpoll_pwq kmalloc-rcl-256 sock_inode_cache :A-0000256 ext2_inode_cache kmalloc-rcl-2k squashfs_inode_cache :A-0000704 ext4_allocation_context kmalloc-rcl-4k task_delay_info :A-0000960 ext4_extent_status kmalloc-rcl-512 task_group :A-0001024 ext4_free_data kmalloc-rcl-8k task_struct :A-0001088 ext4_groupinfo_4k kmem_cache taskstats :A-0005120 ext4_inode_cache kmem_cache_node tcp_bind_bucket :a-0000016 ext4_io_end ksm_mm_slot tw_sock_TCP :a-0000024 ext4_pending_reservation ksm_rmap_item uid_cache :a-0000032 ext4_prealloc_space ksm_stable_node user_namespace :a-0000040 ext4_system_zone mbcache uts_namespace :a-0000048 fanotify_event_info mm_struct v9fs_inode_cache :a-0000056 fanotify_perm_event_info mnt_cache vm_area_struct :a-0000064 fasync_cache mqueue_inode_cache xfrm_dst_cache :a-0000072 fat_cache names_cache xfrm_state :a-0000104 fat_inode_cache net_namespace :a-0000128 file_lock_cache nfs_commit_data :a-0000144 file_lock_ctx nfs_direct_cache
슬랩 캐시 속성들
$ ls /sys/kernel/slab/TCP aliases destroy_by_rcu objects_partial red_zone slabs_cpu_partial align free_calls objs_per_slab remote_node_defrag_ratio store_user alloc_calls hwcache_align order sanity_checks total_objects cpu_partial min_partial partial shrink trace cpu_slabs object_size poison slab_size usersize ctor objects reclaim_account slabs validate
- aliases
- 병합된 alias 캐시 수
- align
- 슬랩 object에 사용할 align 값
- s->align
- alloc_calls
- alloc 유저 (owner) 트래킹을 사용하여 슬랩 캐시의 할당 내역을 출력한다.
- 예) 1 0xffff000008b8a068 age=2609 pid=3481
- cache_dma
- DMA 존을 사용한 슬랩 캐시인지 여부를 보여준다. (1=dma 존 사용 슬랩 캐시, 0=normal 존 사용 슬랩 캐시)
- SLAB_CACHE_DMA 플래그 사용 유무
- cpu_partial
- per-cpu에서 관리될 최대 슬랩 object 수
- 사이즈(s->size)에 따라 디폴트 값으로 2, 6, 13, 30 중 하나로 지정된다.
- 디버그를 사용하는 경우에는 per-cpu 관리를 사용하지 않아 0이 지정된다.
- cpu_slabs
- per-cpu용으로 관리되고 있는 슬랩 페이지 수를 합산하여 보여준다. (c->page + c->partial 페이지 수)
- 노드별로 N[nid]=<per-cpu 슬랩 페이지 수>를 추가로 표기한다.
- 예) 21 N0=21
- ctor
- 생성자가 있는 슬랩 캐시의 생성자 함수명을 보여준다.
- 예) init_once+0x0/0x78
- destroy_by_rcu
- rcu를 사용한 슬랩 object 삭제 기법을 사용하는지 여부를 보여준다.
- lock-less 접근을 통해 빠르게 삭제하는 rcu 방법의 사용 유무 (1=사용, 0=미사용)
- free_calls
- 예) 2 <not-available> age=4295439025 pid=0
- hwcache_align
- L1 하드웨어 캐시 라인에 정렬 유무를 보여준다. (1=사용, 0=미사용)
- SLAB_HWCACHE_ALIGN 플래그 사용 유무
- min_partial
- 노드별 partial 리스트에서 유지할 최소 슬랩 페이지 수를 보여준다.
- 디폴트(s->min_partial) 값은 사이즈에 비례한 5~10 범위의 값을 사용하며 이는 노드별로 적용된다.
- /proc/sys/kernel/
- object_size
- 메타 데이터를 제외한 슬랩 object 사이즈를 보여준다.
- s->object_size
- objects
- 전체 사용중인 슬랩 object 수를 보여준다. (주의: per-cpu에서 관리되는 free object들도 사용 중인 상태로 카운팅된다.)
- 노드별로 N[nid]=<슬랩 object 수>를 추가로 표기한다.
- 예) 1288 N0=1288
- objects_partial
- 노드별 partial 리스트에서 사용중인 슬랩 object 수를 보여준다.
- 노드별로 N[nid]=<슬랩 object 수>를 추가로 표기한다.
- 예) 2 N0=2
- objs_per_slab
- 슬랩 페이지에 사용될 object 수를 보여준다.
- s->oo에 기록된 order 페이지에 포함될 object 수이다.
- order
- 슬랩 페이지 할당에 사용될 order 값이다. (s->oo)
- 이 값은 슬랩 캐시를 생성 시 사이즈에 따라 적절히 산출되었다.
- 메모리 부족 상황에서 슬랩 페이지를 할당하는 경우 위의 order가 아닌 최소 order (s->min)값으로 슬랩 페이지를 할당하기도 한다.
- partial
- 노드 partial 리스트에서 관리되고 있는 슬랩 페이지의 수를 합산하여 보여준다.
- n->nr_partial 합산
- 노드별로 N[nid]=<per-cpu 슬랩 object 수>를 추가로 표기한다.
- 예) 1 N0=1
- 노드 partial 리스트에서 관리되고 있는 슬랩 페이지의 수를 합산하여 보여준다.
- poison
- poison 디버그 사용 유무를 보여준다. (1=사용, 0=미사용)
- SLAB_POISON 플래그 사용 유무
- “slab_debug=FP,<슬랩캐시명>”
- reclaim_account
- reclaimable 슬랩 캐시인지 여부를 보여준다. (1=reclaimable 캐시, 0=일반 unreclaimable 캐시)
- shrinker를 지원하는 슬랩 캐시들을 만들 때 SLAB_RECLAIM_ACCOUNT 플래그를 사용하여 슬랩 캐시를 생성한다.
- red_zone
- red-zone 디버그 사용 유무를 보여준다. (1=사용, 0=미사용)
- SLAB_RED_ZONE 플래그 사용 유무
- “slab_debug=FZ,<슬랩캐시명>”
- remote_node_defrag_ratio
- 로컬 노드의 슬랩 페이지가 부족한 상황인 경우 이 값으로 지정한 백분율만큼 리모트 노드에서 메모리를 허용한다.
- 디폴트 값은 100이고 0~100까지 허용되며, 0을 사용하는 경우 리모트 노드의 슬랩 페이지를 사용하지 못하게 한다.
- sanity_checks
- sanity 체크 디버그 사용 유무를 보여준다. (1=사용, 0=미사용)
- SLAB_CONSISTENCY_CHECKS 플래그 사용 유무
- “slab_debug=F,<슬랩캐시명>”
- shrink
- reclaimable 슬랩 캐시의 메모리 회수를 수행한다.
- 예) echo 1 > /sys/kernel/slab/ext4_inode_cache/shrink
- slab_size
- 메타 데이터를 포함한 슬랩 object 사이즈를 보여준다.
- s->size
- slabs
- 전체 슬랩 페이지 수를 보여준다.
- 노드별로 N[nid]=<슬랩 페이지 수>를 추가로 표기한다.
- 예) 28 N0=28
- slabs_cpu_partial
- per-cpu partial 리스트가 관리하고 있는 free 슬랩 object 수 및 슬랩 페이지 수를 보여준다. (s->page 제외)
- cpu별로 C[cpu] = <cpu partial free 슬랩 object 수>(<cpu partial 슬랩 페이지 수>)를 추가로 표기한다.
- 예) 28(28) C0=6(6) C1=3(3) C2=18(18) C3=1(1)
- store_user
- 유저 트래킹 디버그 사용 유무를 보여준다. (1=사용, 0=미사용)
- SLAB_STORE_USER 플래그 사용 유무
- “slab_debug=FU,<슬랩캐시명>”
- total_objects
- 전체 슬랩 object 수를 보여준다.
- 노드별로 N[nid]=<슬랩 object 수>를 추가로 표기한다.
- 예) 1288 N0=1288
- trace
- 트레이스 디버그 사용 유무를 보여준다. (1=사용, 0=미사용)
- SLAB_TRACE 플래그 사용 유무
- “slab_debug=T,<슬랩캐시명>”
- usersize
- copy to/from user에 사용할 유저 사이즈를 보여준다.
- s->usersize
- validate
- 슬랩 캐시의 유효성 검사를 수행한다. (강제 디버그 체크)
- 예) echo 1 > /sys/kernel/slab/anon_vma/validate
slabinfo 유틸리티
디버깅 툴 빌드
$ gcc -o slabinfo tools/vm/slabinfo.c
사용법
$ sudo ./slabinfo -h slabinfo 4/15/2011. (c) 2007 sgi/(c) 2011 Linux Foundation. slabinfo [-ahnpvtsz] [-d debugopts] [slab-regexp] -a|--aliases Show aliases -A|--activity Most active slabs first -d<options>|--debug=<options> Set/Clear Debug options -D|--display-active Switch line format to activity -e|--empty Show empty slabs -f|--first-alias Show first alias -h|--help Show usage information -i|--inverted Inverted list -l|--slabs Show slabs -n|--numa Show NUMA information -o|--ops Show kmem_cache_ops -s|--shrink Shrink slabs -r|--report Detailed report on single slabs -S|--Size Sort by size -t|--tracking Show alloc/free information -T|--Totals Show summary information -v|--validate Validate slabs -z|--zero Include empty slabs -1|--1ref Single reference Valid debug options (FZPUT may be combined) a / A Switch on all debug options (=FZUP) - Switch off all debug options f / F Sanity Checks (SLAB_DEBUG_FREE) z / Z Redzoning p / P Poisoning u / U Tracking t / T Tracing
슬랩 캐시 리스트
$ sudo ./slabinfo Name Objects Objsize Space Slabs/Part/Cpu O/S O %Fr %Ef Flg :at-0000016 256 16 4.0K 0/0/1 256 0 0 100 *a :at-0000032 3968 32 126.9K 22/0/9 128 0 0 100 *a :at-0000040 408 40 16.3K 0/0/4 102 0 0 99 *a :at-0000064 32128 64 2.0M 454/0/48 64 0 0 100 *a :at-0000104 156 104 16.3K 0/0/4 39 0 0 99 *a :t-0000024 680 24 16.3K 0/0/4 170 0 0 99 * :t-0000032 9472 32 303.1K 12/0/62 128 0 0 100 * :t-0000040 612 40 24.5K 0/0/6 102 0 0 99 * :t-0000064 12483 64 802.8K 128/1/68 64 0 0 99 * :t-0000088 2714 88 241.6K 15/0/44 46 0 0 98 * :t-0000096 168 96 16.3K 0/0/4 42 0 0 98 * :t-0000104 6552 104 688.1K 158/0/10 39 0 0 99 * :t-0000128 2240 128 286.7K 15/0/55 32 0 0 100 * :t-0000192 4305 192 839.6K 152/0/53 21 0 0 98 * :t-0000256 192 256 49.1K 3/0/9 16 0 0 100 * :t-0000320 954 320 335.8K 12/5/29 25 1 12 90 *A :t-0000384 84 384 32.7K 0/0/4 21 1 0 98 *A :t-0000512 720 512 368.6K 26/0/19 16 1 0 100 * :t-0000640 50 640 32.7K 1/0/1 25 2 0 97 *A :t-0000960 187 936 180.2K 1/0/10 17 2 0 97 *A :t-0001024 176 1024 180.2K 4/0/7 16 2 0 100 * :t-0002048 176 2048 360.4K 2/0/9 16 3 0 100 * :t-0004032 153 4032 655.3K 5/2/15 8 3 10 94 * :t-0004096 64 4096 262.1K 0/0/8 8 3 0 100 * anon_vma 2124 104 241.6K 10/0/49 36 0 0 91 bdev_cache 72 848 65.5K 0/0/4 18 2 0 93 Aa biovec-128 84 1536 131.0K 0/0/4 21 3 0 98 A biovec-256 10 3072 32.7K 0/0/1 10 3 0 93 A biovec-64 84 768 65.5K 0/0/4 21 2 0 98 A blkdev_queue 34 1824 65.5K 0/0/2 17 3 0 94 blkdev_requests 204 232 49.1K 0/0/12 17 0 0 96 dentry 20500 200 4.1M 1012/0/13 20 0 0 97 a ext4_groupinfo_4k 253 172 45.0K 10/0/1 23 0 0 96 a ext4_inode_cache 10686 1232 13.4M 400/0/11 26 3 0 97 a fat_cache 170 20 4.0K 0/0/1 170 0 0 83 a fat_inode_cache 60 776 49.1K 1/0/2 20 2 0 94 a file_lock_cache 100 160 16.3K 0/0/4 25 0 0 97 fscache_cookie_jar 32 124 4.0K 0/0/1 32 0 0 96 ftrace_event_file 595 48 28.6K 6/0/1 85 0 0 99 idr_layer_cache 270 1068 294.9K 5/0/4 30 3 0 97 inode_cache 5589 584 3.3M 191/0/16 27 2 0 96 a jbd2_journal_handle 292 56 16.3K 0/0/4 73 0 0 99 a jbd2_transaction_s 189 176 36.8K 0/0/9 21 0 0 90 Aa kmalloc-8192 24 8192 196.6K 1/0/5 4 3 0 100 kmem_cache 128 116 16.3K 1/0/3 32 0 0 90 A kmem_cache_node 128 68 16.3K 1/0/3 32 0 0 53 A mm_struct 112 536 65.5K 0/0/4 28 2 0 91 A mqueue_inode_cache 18 840 16.3K 0/0/1 18 2 0 92 A nfs_commit_data 18 448 8.1K 0/0/1 18 1 0 98 A posix_timers_cache 18 216 4.0K 0/0/1 18 0 0 94 proc_inode_cache 546 616 344.0K 4/0/17 26 2 0 97 a radix_tree_node 2106 304 663.5K 71/0/10 26 1 0 96 a shmem_inode_cache 644 696 458.7K 20/0/8 23 2 0 97 sighand_cache 184 1372 262.1K 0/0/8 23 3 0 96 A sigqueue 112 144 16.3K 0/0/4 28 0 0 98 sock_inode_cache 100 616 65.5K 0/0/4 25 2 0 93 Aa taskstats 24 328 8.1K 0/0/1 24 1 0 96 TCP 68 1816 131.0K 0/0/4 17 3 0 94 A UDP 64 960 65.5K 0/0/4 16 2 0 93 A
- Name
- 슬랩 명
- Objects
- 사용중인(in-use) object 수
- Objsize
- 메타 데이터를 제외한 object 사이즈 (s->obj_size)
- Space
- 전체 슬랩 페이지에 사용된 바이트 사이즈 (단위에 사용된 값들은 1024 단위가 아니라 1000단위이다.)
- Slabs/Part/Cpu
- Slabs
- 전체 슬랩 페이지 수 – Cpu
- = full 슬랩 페이지 수 + Part
- 전체 슬랩 페이지 수 – Cpu
- Part
- 노드별 partial 리스트에서 관리하는 슬랩 페이지 수
- Cpu
- cpu별 슬랩 페이지에서 관리하는 슬랩 페이지 수 (c->page + c->partial 페이지 수)
- Slabs
- O/S
- 슬랩 페이지당 object 수
- s->objs_per_slab
- O
- order 값
- %Fr
- 노드 partial 리스트의 슬랩 페이지 비율
- %Ef
- 사용 중인 object 비율
- Flg
- 플래그 값은 다음과 같다.
- *- alias 캐시
- d – dma
- A – L1 하드웨어 캐시 정렬(hwcache_align)
- p – poison
- a – reclaimable 슬랩 캐시
- Z – red-zone
- F – sanity check
- U – 유저(owner) 트래킹
- T – 트레이스
- 플래그 값은 다음과 같다.
Loss 소팅 순서 (-L)
$ sudo ./slabinfo -L Name Objects Objsize Loss Slabs/Part/Cpu O/S O %Fr %Ef Flg task_struct 92 3456 206.3K 11/9/5 9 3 56 60 kmalloc-512 624 512 147.4K 52/31/5 16 1 54 68 :A-0000192 2317 192 140.8K 112/58/31 21 0 40 75 *A kernfs_node_cache 13230 128 112.8K 432/0/9 30 0 0 93 proc_inode_cache 1114 648 97.3K 96/18/4 12 1 18 88 a dentry 7417 192 70.9K 341/56/24 21 0 15 95 a
사용률 표시 (-D)
$ sudo ./slabinfo -D Name Objects Alloc Free %Fast Fallb O CmpX UL :0000024 170 0 0 0 0 0 0 0 0 :0000040 102 0 0 0 0 0 0 0 0 :0000048 85 0 0 0 0 0 0 0 0 :0000056 73 0 0 0 0 0 0 0 0 :0000064 64 0 0 0 0 0 0 0 0 :0000080 51 0 0 0 0 0 0 0 0 :0000128 32 0 0 0 0 0 0 0 0 :0000192 21 0 0 0 0 0 0 0 0 :0000256 192 0 0 0 0 0 0 0 0 :0000448 36 0 0 0 0 0 1 0 0 :0000896 36 0 0 0 0 0 2 0 0 :0001024 16 0 0 0 0 0 2 0 0 :0002048 16 0 0 0 0 0 3 0 0 :0004096 40 0 0 0 0 0 3 0 0 :a-0000032 128 0 0 0 0 0 0 0 0 :a-0000048 85 0 0 0 0 0 0 0 0 :a-0000056 73 0 0 0 0 0 0 0 0 :A-0000064 1340 0 0 0 0 0 0 0 0 :A-0000072 168 0 0 0 0 0 0 0 0 :A-0000080 255 0 0 0 0 0 0 0 0 :a-0000104 1482 0 0 0 0 0 0 0 0 :A-0000128 320 0 0 0 0 0 0 0 0 :A-0000192 2317 0 0 0 0 0 0 0 0 :a-0000256 16 0 0 0 0 0 0 0 0 :A-0001088 130 0 0 0 0 0 2 0 0 anon_vma 654 0 0 0 0 0 0 0 0 bdev_cache 19 0 0 0 0 0 2 0 0 blkdev_ioc 39 0 0 0 0 0 0 0 0 configfs_dir_cache 46 0 0 0 0 0 0 0 0 ...
alias 슬랩 캐시 리스트 (-A)
$ sudo ./slabinfo -a :at-0000016 <- discard_entry f2fs_inode_entry jbd2_revoke_table_s inmem_page_entry free_nid f2fs_ino_entry sit_entry_set :at-0000024 <- nat_entry nat_entry_set :at-0000032 <- ext4_extent_status jbd2_revoke_record_s :at-0000040 <- ext4_free_data ext4_io_end :at-0000064 <- mmcblk0p6 jbd2_journal_head buffer_head :at-0000104 <- ext4_allocation_context ext4_prealloc_space :t-0000024 <- ip_fib_alias dnotify_struct jbd2_inode nsproxy scsi_data_buffer :t-0000032 <- ftrace_event_field fanotify_event_info dmaengine-unmap-2 secpath_cache anon_vma_chain sd_ext_cdb ip_fib_trie tcp_bind_bucket ext4_system_zone :t-0000040 <- eventpoll_pwq page->ptl :t-0000064 <- nfs_page pid kmalloc-64 kiocb uid_cache fasync_cache file_lock_ctx cfq_io_cq :t-0000088 <- flow_cache vm_area_struct :t-0000096 <- dnotify_mark fsnotify_mark inotify_inode_mark :t-0000104 <- task_delay_info kernfs_node_cache :t-0000128 <- ip_mrt_cache blkdev_ioc sgpool-8 pid_namespace fs_cache inet_peer_cache kmalloc-128 ip_dst_cache eventpoll_epi cred_jar :t-0000192 <- bio-0 key_jar skbuff_head_cache ip4-frags request_sock_TCP rpc_tasks kmalloc-192 biovec-16 :t-0000256 <- mnt_cache sgpool-16 pool_workqueue kmalloc-256 files_cache :t-0000320 <- xfrm_dst_cache filp :t-0000384 <- skbuff_fclone_cache dio :t-0000512 <- sgpool-32 kmalloc-512 :t-0000640 <- nfs_write_data kioctx nfs_read_data :t-0000960 <- RAW PING signal_cache :t-0001024 <- UNIX kmalloc-1024 sgpool-64 :t-0002048 <- kmalloc-2048 sgpool-128 rpc_buffers :t-0004032 <- task_struct net_namespace :t-0004096 <- names_cache kmalloc-4096
슬랩 캐시 요약 (-T)
$ sudo ./slabinfo -T Slabcache Totals ---------------- Slabcaches : 71 Aliases : 118->49 Active: 59 Memory used: 32.5M # Loss : 741.4K MRatio: 2% # Objects : 125.2K # PartObj: 9 ORatio: 0% Per Cache Average Min Max Total --------------------------------------------------------- #Objects 2.1K 10 32.1K 125.2K #Slabs 58 1 1.0K 3.4K #PartSlab 0 0 2 2 %PartSlab 0% 0% 10% 0% PartObjs 0 0 9 9 % PartObj 0% 0% 5% 0% Memory 550.9K 4.0K 13.4M 32.5M Used 538.3K 3.4K 13.1M 31.7M Loss 12.5K 0 302.4K 741.4K Per Object Average Min Max --------------------------------------------- Memory 255 16 8.1K User 253 16 8.1K Loss 1 0 64
슬랩 캐시 세부 정보 (-r)
$ slabinfo -r jake
Slabcache: jake Aliases: 0 Order : 1 Objects: 2
Sizes (bytes) Slabs Debug Memory
------------------------------------------------------------------------
Object : 30 Total : 1 Sanity Checks : On Total: 8192
SlabObj: 392 Full : 0 Redzoning : On Used : 60
SlabSiz: 8192 Partial: 1 Poisoning : On Loss : 8132
Loss : 362 CpuSlab: 0 Tracking : On Lalig: 724
Align : 56 Objects: 20 Tracing : On Lpadd: 352
jake has no kmem_cache operations
jake: Kernel object allocation
-----------------------------------------------------------------------
1 0xffff000008b8a068 age=1174850 pid=3481
1 0xffff000008b8a078 age=1174837 pid=3481
jake: Kernel object freeing
------------------------------------------------------------------------
2 <not-available> age=4296123146 pid=0
jake: No NUMA information available.
- Object
- 메타 데이터를 제외한 object 사이즈
- SlabObj
- 메타 데이터를 포함한 object 사이즈
- SlabSiz
- 1 개의 슬렙 페이지 사이즈
- Loss
- 1 개의 슬랩 페이지에서 사용할 수 없는 공간 사이즈(remain)
- Align
- align 단위
- Total
- 전체 슬랩 페이지 수
- Full
- 전체 object가 모두 사용 중인 슬랩 페이지 수
- Partial
- 노드별 슬랩 페이지 수
- CpuSlab
- per-cpu 슬랩 페이지 수
- Objects
- 1 개의 슬랩 페이지당 object 수
- Sanity Checks
- Sanity 체크 디버그 사용 여부
- Redzoning
- Red-zone 디버그 사용 여부
- Poisoning
- poison 디버그 사용 여부
- Tracking
- 유저 트래킹 디버그 사용 여부
- Tracing
- 트레이스 디버그 사용 여부
- Total
- 전체 슬렙 페이지에 사용 중인 메모리 사이즈
- Used
- 메타 데이터를 제외한 사용(in-use) 중인 슬랩 object가 점유한 메모리 사이즈
- Loss
- Toal – Used
- Lalig
- (메타 데이터를 포함한 object 사이즈 – 메타 데이터를 제외한 object 사이즈) * 사용 중인 object 수
- (SlabObj – Object) * 사용 중인 object 수
- Lpadd
- 슬랩 페이지의 남는(remain) 영역을 모두 합산한 메모리 사이즈
slabtop 유틸리티
$ slabtop Active / Total Objects (% used) : 514911 / 563284 (91.4%) Active / Total Slabs (% used) : 30238 / 30238 (100.0%) Active / Total Caches (% used) : 89 / 121 (73.6%) Active / Total Size (% used) : 198611.59K / 205849.01K (96.5%) Minimum / Average / Maximum Object : 0.02K / 0.37K / 12.00K OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME 114156 110759 0% 0.19K 5436 21 21744K dentry 86895 84904 0% 1.04K 13611 30 435552K ext4_inode_cache 56589 45405 0% 0.10K 1451 39 5804K buffer_head 46512 19299 0% 0.04K 456 102 1824K ext4_extent_status 44832 43854 0% 0.12K 1401 32 5604K kmalloc-128 41300 39940 0% 0.57K 1475 28 23600K radix_tree_node 25664 25664 100% 0.06K 401 64 1604K anon_vma_chain 23070 22810 0% 0.13K 769 30 3076K kernfs_node_cache 18774 18489 0% 0.57K 783 28 12528K inode_cache 14344 14234 0% 0.18K 652 22 2608K vm_area_struct 13110 13110 100% 0.09K 285 46 1140K anon_vma 8816 8696 0% 0.25K 551 16 2204K filp 4752 4057 0% 0.64K 198 24 3168K proc_inode_cache 4386 4386 100% 0.04K 43 102 172K pde_opener 3825 3825 100% 0.05K 45 85 180K ftrace_event_field 3616 3616 100% 0.12K 113 32 452K pid 3549 3549 100% 0.19K 169 21 676K cred_jar 3125 3125 100% 0.62K 125 25 2000K squashfs_inode_cache 2896 2877 0% 0.50K 181 16 1448K kmalloc-512 2496 2496 100% 0.06K 39 64 156K dmaengine-unmap-2 2408 2408 100% 0.14K 86 28 344K ext4_groupinfo_4k 2304 2292 0% 1.00K 144 16 2304K kmalloc-1024 2192 2140 0% 0.25K 137 16 548K kmalloc-256 2075 2075 100% 0.62K 83 25 1328K sock_inode_cache ...
참고
- Slab Memory Allocator -1- (구조) | 문c
- Slab Memory Allocator -2- (캐시 초기화) | 문c
- Slub Memory Allocator -3- (캐시 생성) | 문c
- Slub Memory Allocator -4- (Order 계산) | 문c
- Slub Memory Allocator -5- (Slub 할당) | 문c
- Slub Memory Allocator -6- (Object 할당) | 문c
- Slub Memory Allocator -7- (Object 해제) | 문c
- Slub Memory Allocator -8- (Drain/Flash 캐시) | 문c
- Slub Memory Allocator -9- (캐시 Shrink) | 문c
- Slub Memory Allocator -10- (Slub 해제) | 문c
- Slub Memory Allocator -11- (캐시 삭제) | 문c
- Slub Memory Allocator -12- (Slub 디버깅) | 문c
- Slub Memory Allocator -13- (slabinfo) | 문c – 현재 글