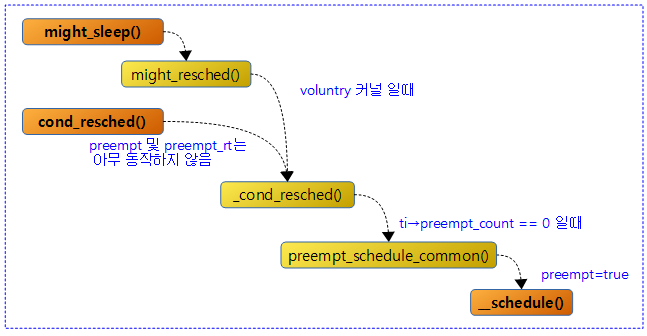
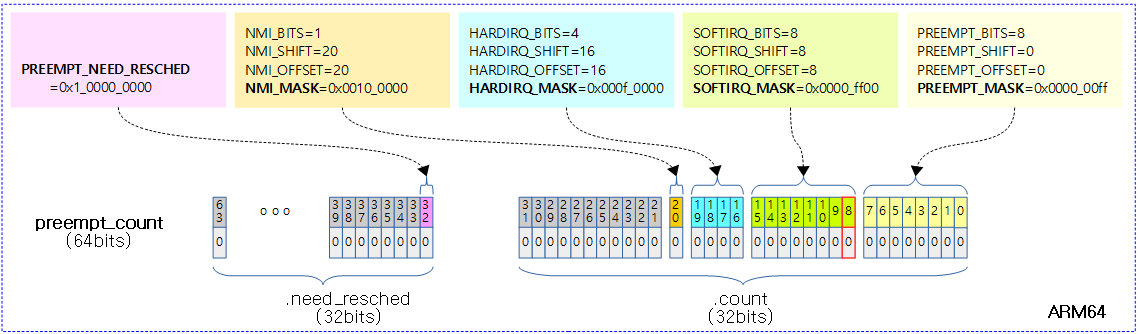
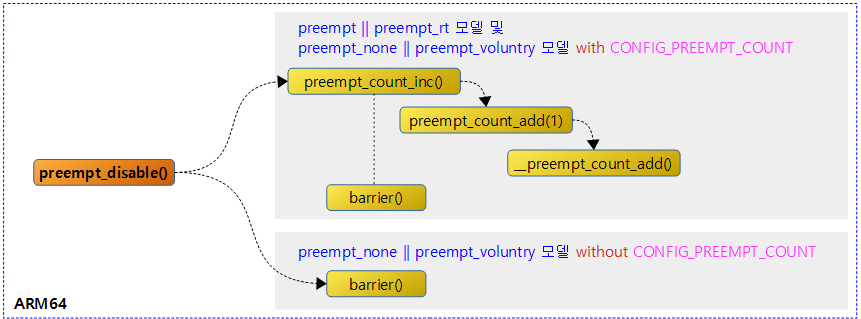
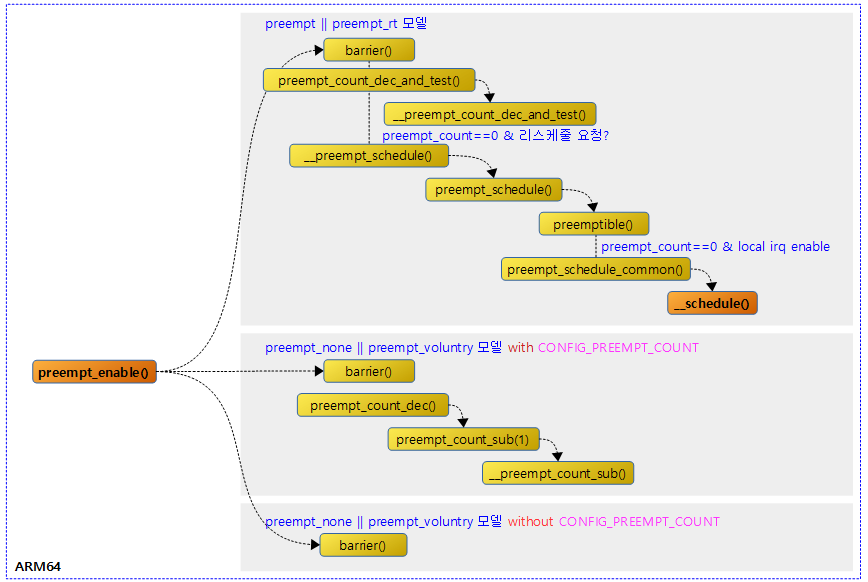
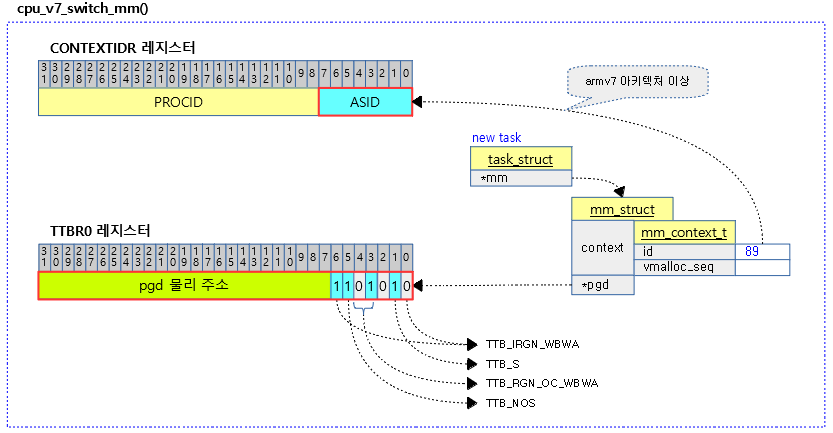
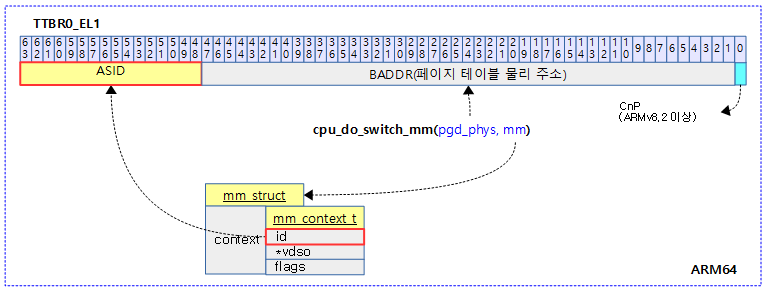
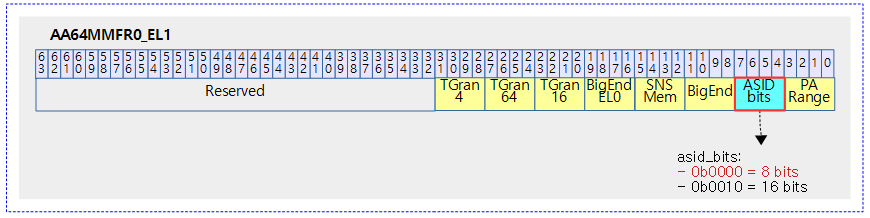
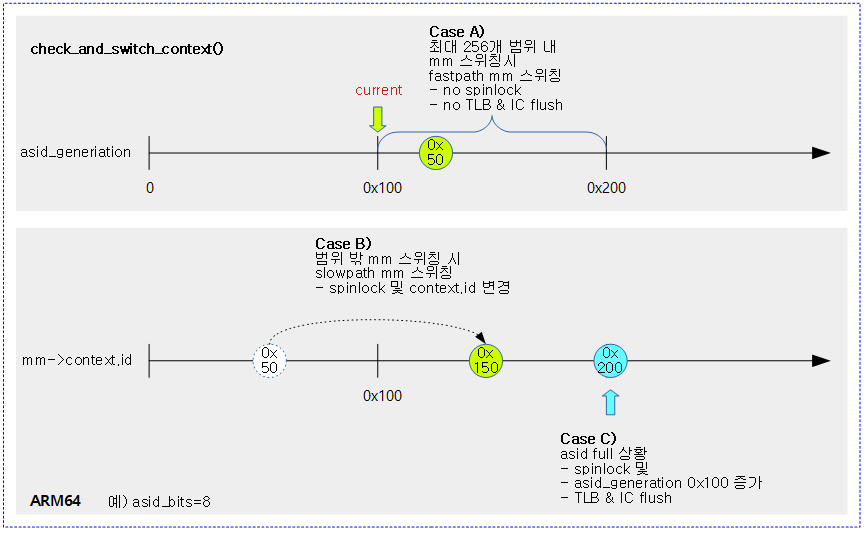
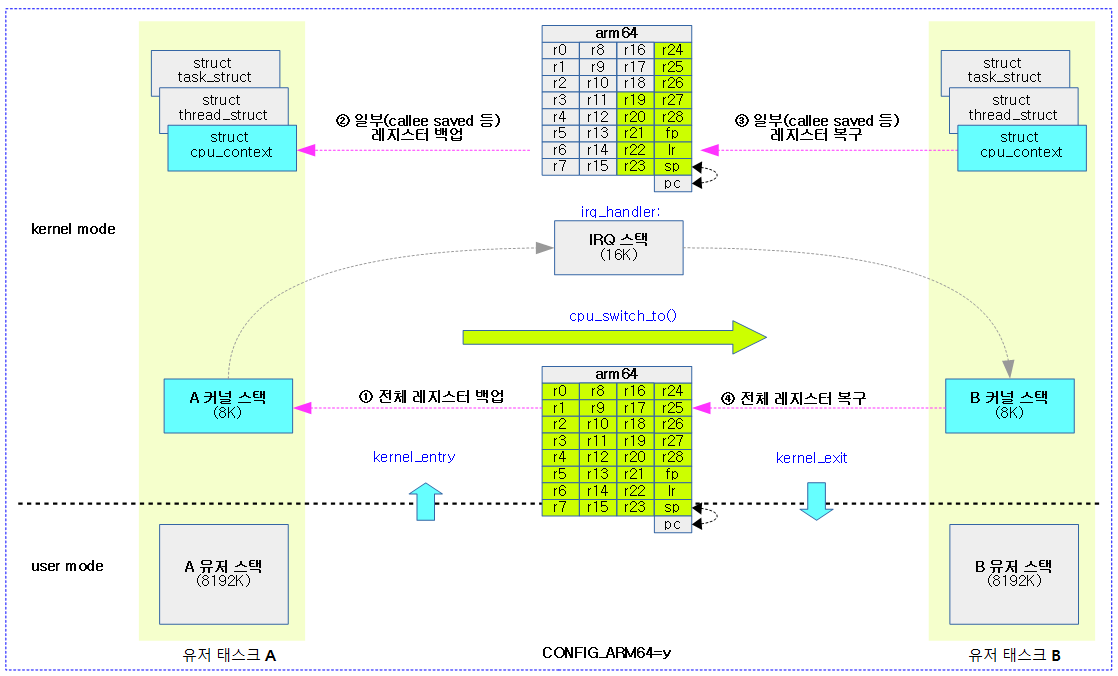
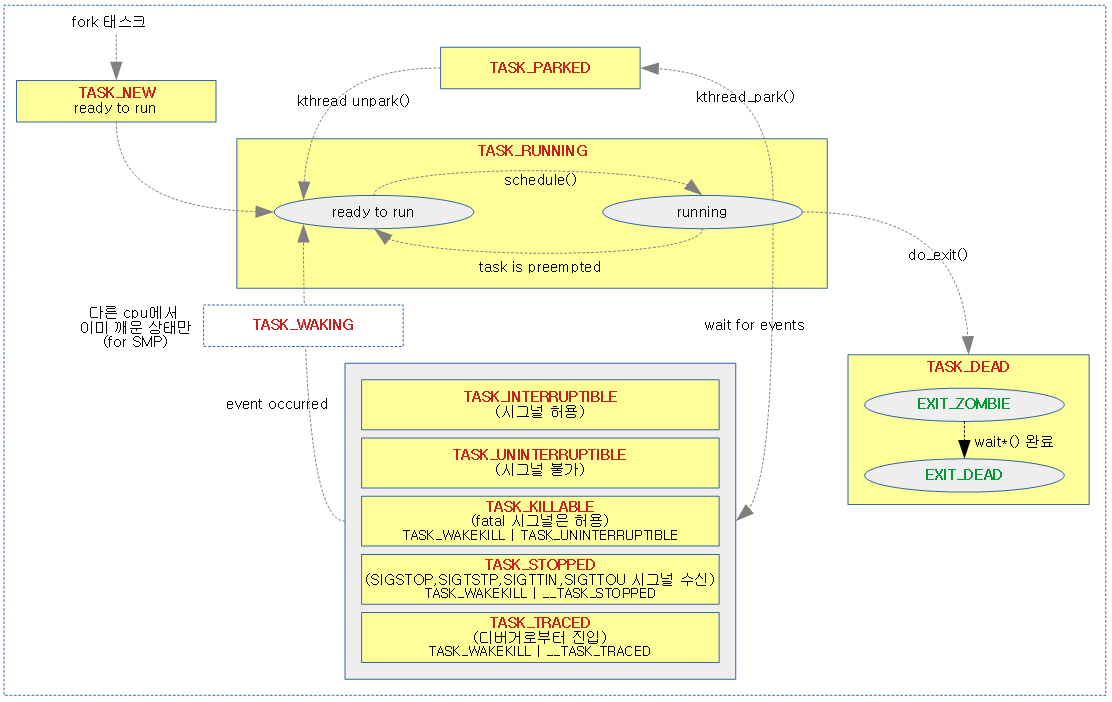
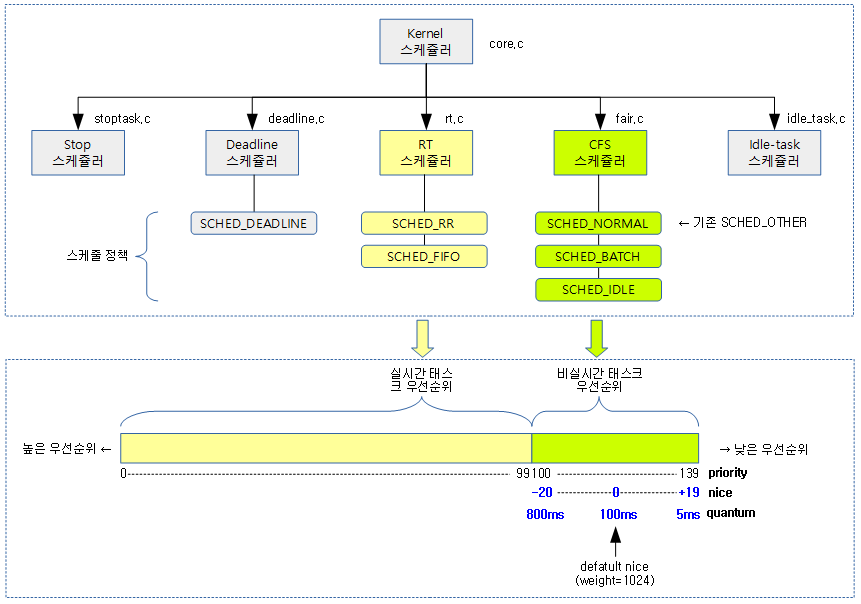
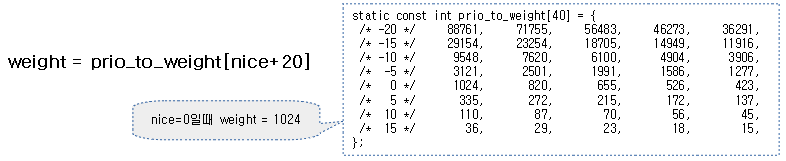
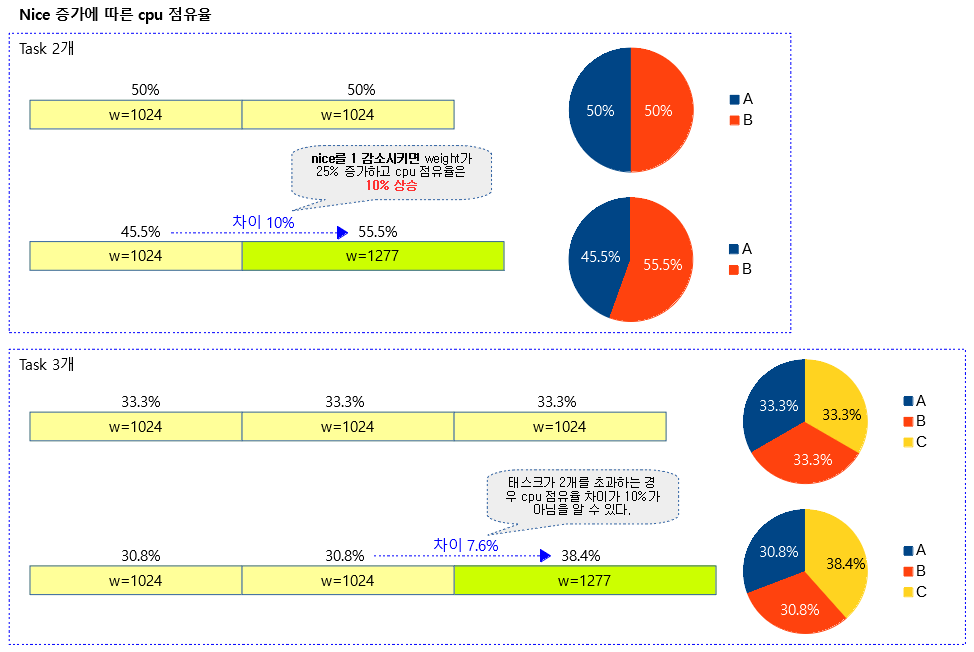
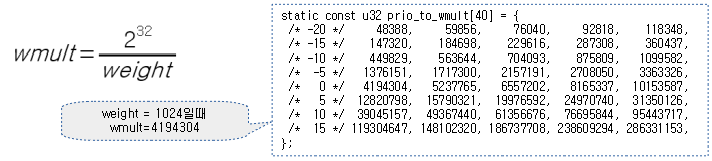
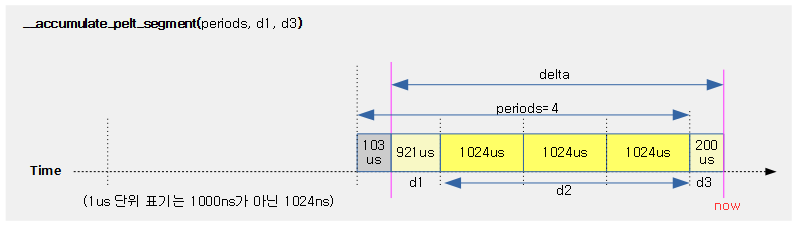
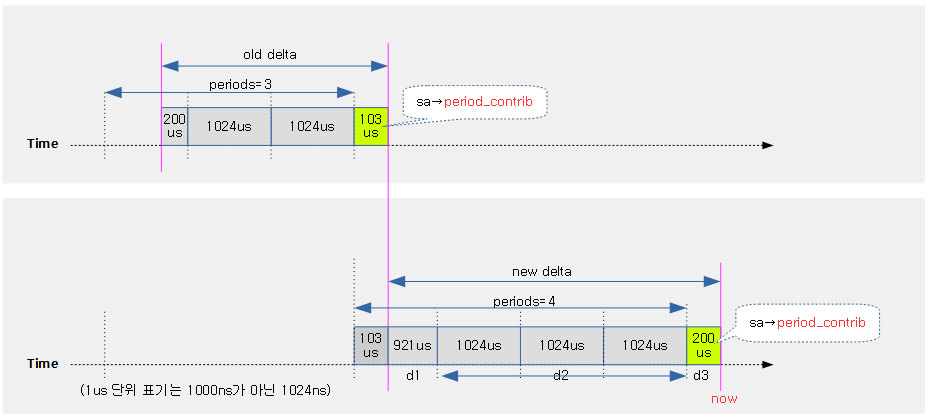
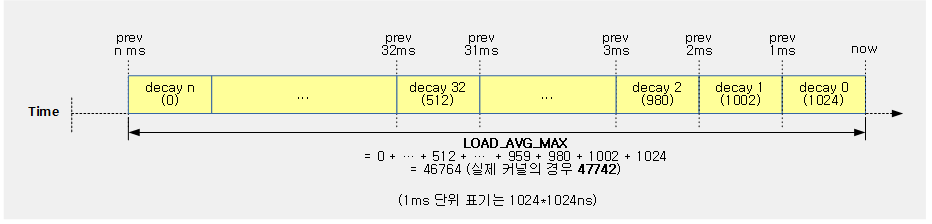
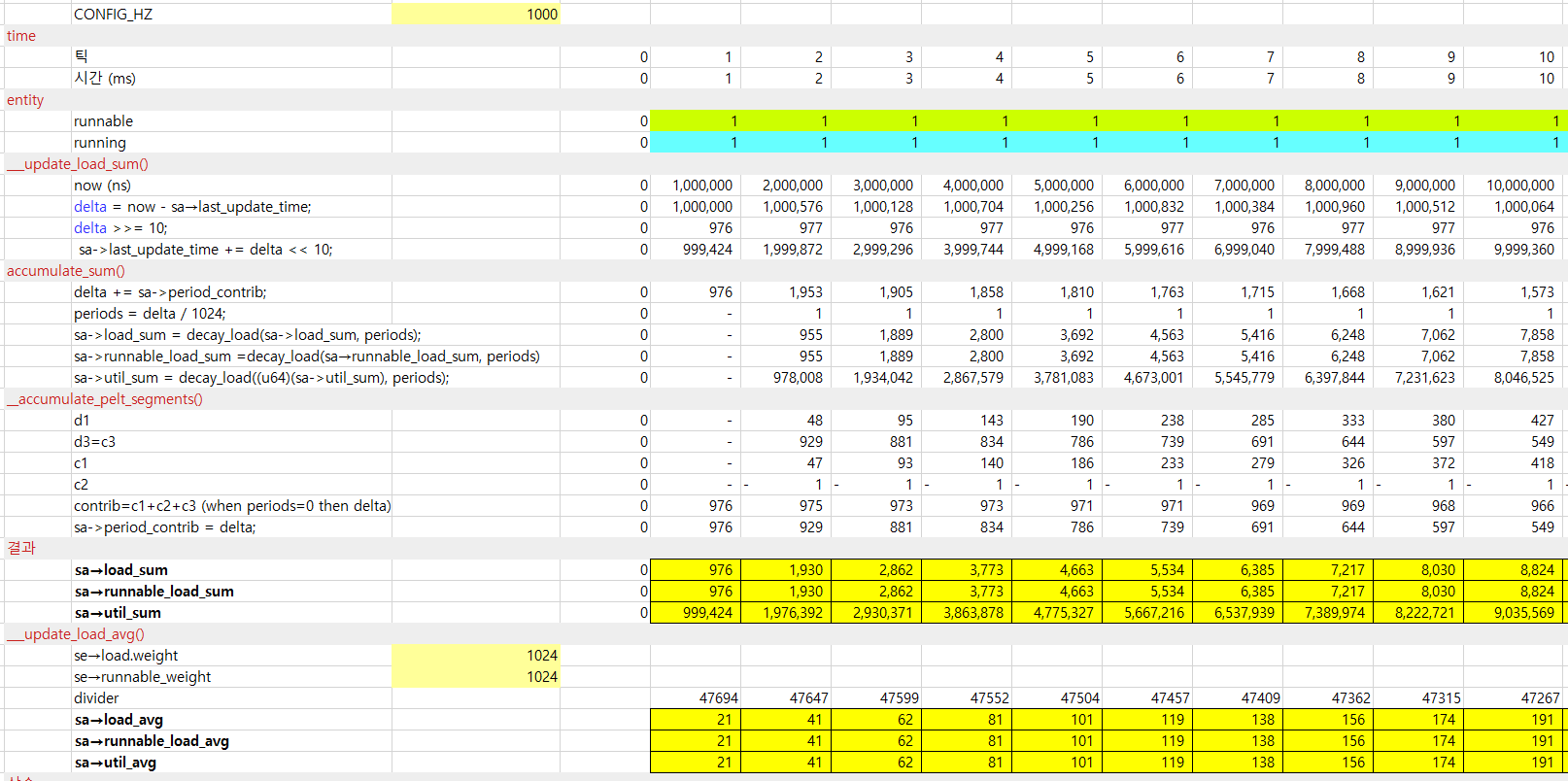
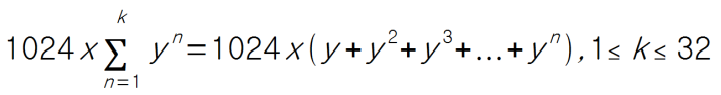<kernel v5.4>
런타임 산출
타임 슬라이스 산출
sched_slice()
kernel/sched/fair.c
/* * We calculate the wall-time slice from the period by taking a part * proportional to the weight. * * s = p*P[w/rw] */
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
u64 slice = __sched_period(cfs_rq->nr_running + !se->on_rq);
for_each_sched_entity(se) {
struct load_weight *load;
struct load_weight lw;
cfs_rq = cfs_rq_of(se);
load = &cfs_rq->load;
if (unlikely(!se->on_rq)) {
lw = cfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
}
slice = __calc_delta(slice, se->load.weight, load);
}
return slice;
}
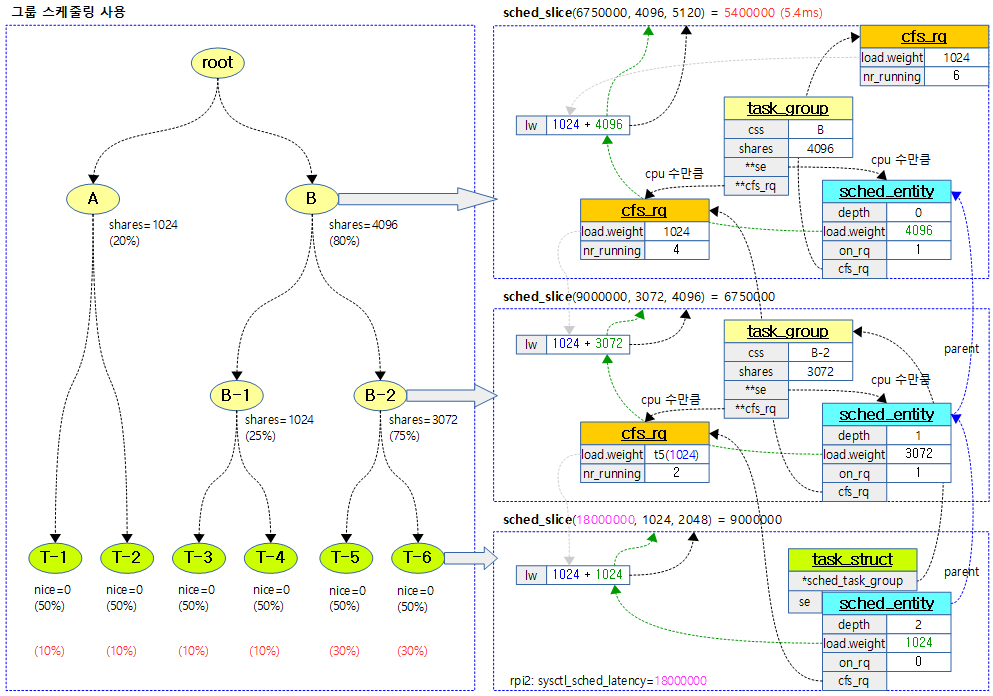
최상위 그룹 엔티티까지 엔티티의 가중치 비율을 적용하여 타임 슬라이스를 구한다.
- 코드 라인 3에서 cfs 런큐에서 동작 중인 태스크들 + 1(해당 엔티티가 런큐에 포함되지 않은 경우)의 개수로 스케줄링 latency를 구한다.
- 코드 라인 5에서 최상위 그룹 엔티티까지 순회한다.
- 코드 라인 9~10에서 엔티티가 소속된 cfs 런큐의 로드 값을 load 포인터 변수가 가리키게 한다.
- 코드 라인 12~17에서 낮은 확률로 엔티티가 cfs 런큐에 포함되지 않은 경우 cfs 런큐의 로드에 이 엔티티의 로드도 포함하여 load에 산출한다.
- 코드 라인 18에서 타임 슬라이스 값에 cfs 런큐 가중치 대비 엔티티의 가중치 비율을 곱한 값을 slice에 구해온다.
- 코드 라인 20에서 최종 산출한 타임 슬라이스 값을 반환한다.
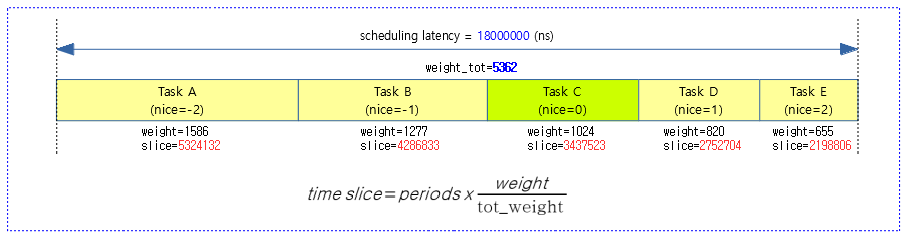
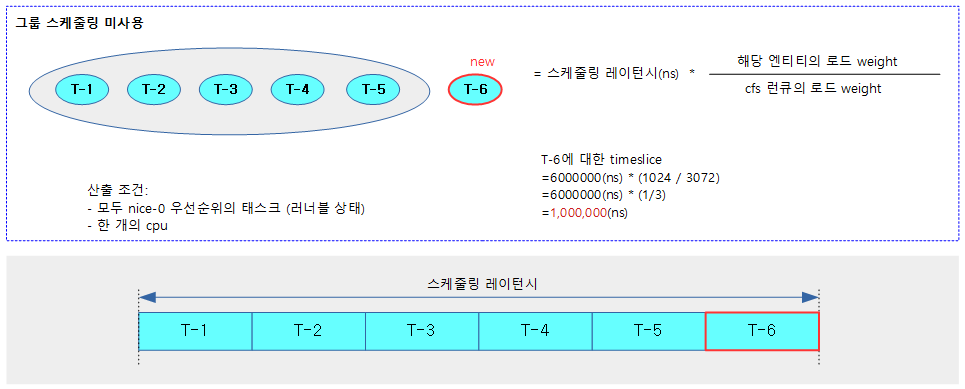
다음 그림은 그룹 스케줄링 없이 추가할 엔티티에 대한 타임 슬라이스를 산출하는 과정을 보여준다.
- 런큐에 5개 스케줄 엔티티의 load weight가 더해있고 아직 런큐에 올라가지 않은 스케줄 엔티티를 더해서 타임 슬라이스를 산출한다.
- 엔티티 및 cfs 런큐의 로드 weight은 64비트 시스템에서 추가로 scale up (10비트)되어 사용된다.
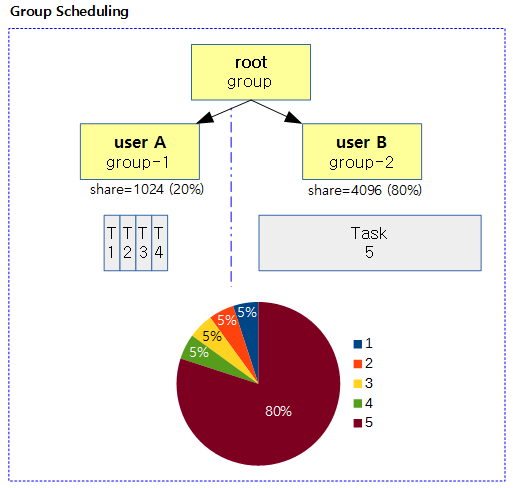
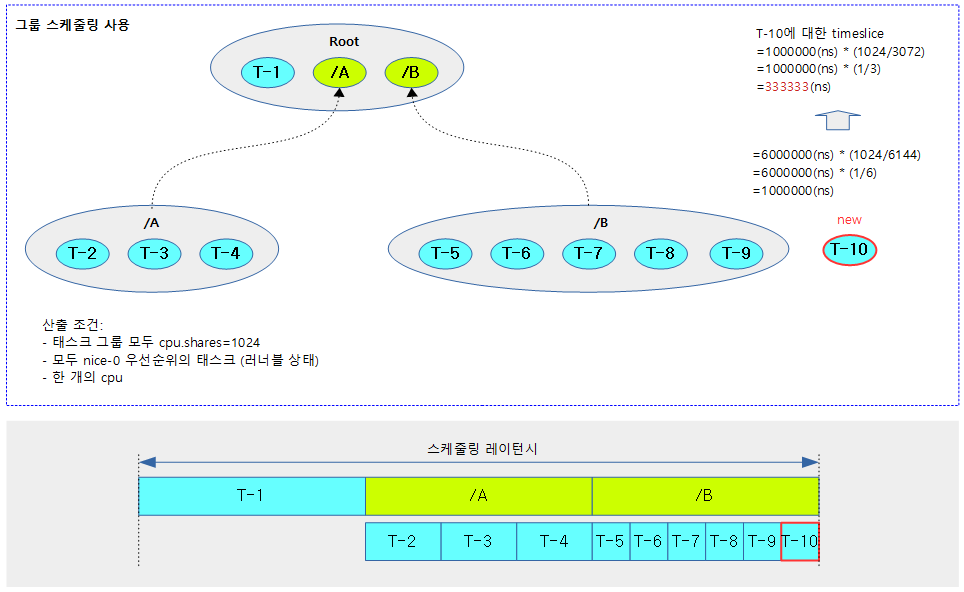
다음 그림은 하위 그룹 스케줄링 A, B를 사용하였고, 그 중 추가 할 엔티티에 대한 타임 슬라이스를 산출하는 과정을 보여준다.
다음 그림은 그룹 스케줄링을 사용할 때 태스크들의 타임 슬라이스 분배를 자세히 보여준다.
__sched_period()
kernel/sched/fair.c
/* * The idea is to set a period in which each task runs once. * * When there are too many tasks (sched_nr_latency) we have to stretch * this period because otherwise the slices get too small. * * p = (nr <= nl) ? l : l*nr/nl */
static u64 __sched_period(unsigned long nr_running)
{
if (unlikely(nr_running > sched_nr_latency))
return nr_running * sysctl_sched_min_granularity;
else
return sysctl_sched_latency;
}
태스크 스케줄에 사용할 스케줄링 latency를 산출한다.
- 코드 라인 3~4에서 태스크 수 @nr_running이 sched_nr_latency를 초과하는 경우 스케줄링 레이턴시는 다음과 같이 늘어난다.
- nr_running * 최소 태스크 스케줄 단위(0.75ms * factor)
- 디폴트 factor = log2(cpu 수) + 1
- sched_nr_latency
- sysctl_sched_latency / sysctl_sched_min_granularity
- 디폴트 값은 8이다.
- 코드 라인 5~6에서 적정 수 이내인 경우 스케줄링 레이턴시 값을 반환한다.
- 디폴트 스케줄링 레이턴시 = 6,000,000(ns) * factor
- 예) rpi2, 3, 4의 경우 cpu가 4개 이므로 6,000,000(ns) * factor(3) = 18,000,000(ns)
다음은 rpi2, 3, 4 시스템에서 스케줄링 레이턴시 산출 관련 디폴트 설정 값이다.
$ cat /proc/sys/kernel/sched_latency_ns 18000000 $ cat /proc/sys/kernel/sched_min_granularity_ns 2250000
update_load_add()
kernel/sched/fair.c
static inline void update_load_add(struct load_weight *lw, unsigned long inc)
{
lw->weight += inc;
lw->inv_weight = 0;
}
로드 값을 inc 만큼 추가하고 inv_weight 값은 0으로 리셋한다.
__calc_delta()
kernel/sched/fair.c
/* * delta_exec * weight / lw.weight * OR * (delta_exec * (weight * lw->inv_weight)) >> WMULT_SHIFT * * Either weight := NICE_0_LOAD and lw \e prio_to_wmult[], in which case * we're guaranteed shift stays positive because inv_weight is guaranteed to * fit 32 bits, and NICE_0_LOAD gives another 10 bits; therefore shift >= 22. * * Or, weight =< lw.weight (because lw.weight is the runqueue weight), thus * weight/lw.weight <= 1, and therefore our shift will also be positive. */
static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw)
{
u64 fact = scale_load_down(weight);
int shift = WMULT_SHIFT;
__update_inv_weight(lw);
if (unlikely(fact >> 32)) {
while (fact >> 32) {
fact >>= 1;
shift--;
}
}
/* hint to use a 32x32->64 mul */
fact = (u64)(u32)fact * lw->inv_weight;
while (fact >> 32) {
fact >>= 1;
shift--;
}
return mul_u64_u32_shr(delta_exec, fact, shift);
}
스케줄링 기간을 산출하여 반환한다. (delta_exec * weight / lw.weight)
- 코드 라인 3에서 weight 값을 scale 로드 다운하여 fact에 대입한다. 32bit 아키텍처는 scale 로드 다운하지 않는다.
- 커널 v4.7-rc1에서 64bit 아키텍처에 대해 weight에 대한 해상도를 높여서 사용할 수 있게 변경되었다.
- 코드 라인 6에서 0xfff_ffff / lw->weight 값을 lw->inv_weight 값으로 대입한다.
- 코드 라인 8~13에서 작은 확률로 fact가 32bit 값 이상인 경우 상위 32bit에서 사용하는 bit 수만큼을 기존 shift(32) 값에서 빼고 그 횟수만큼 fact를 우측 시프트한다.
- 32bit 아키텍처는 fact 값이 32bit 값을 넘어가지 않아 이 루틴은 건너뛴다.
- 예) 0x3f_ffff_ffff -> shift=32-6=26
- 코드 라인 16에서 나눗셈을 피하기 위해 계산된 inv_wieght 값을 fact에 곱한다.
- delta_exec * weight / lw.weight = (delta_exec * weight * lw.inv_weight) >> 32
- 코드 라인 18~21에서 32bit 시프트 중 남은 시프트 수를 구한다. 또한 루프 반복 횟수 만큼 fact를 시프트한다.
- 코드 라인 23에서 (delta_exec * fact) >> shift 한 값을 반환한다.
- 결국: (delta_exec * weight * lw.inv_weight) >> 32와 같은 결과를 반환하게 된다.
kernel/sched/fair.c
#define WMULT_CONST (~0U) #define WMULT_SHIFT 32
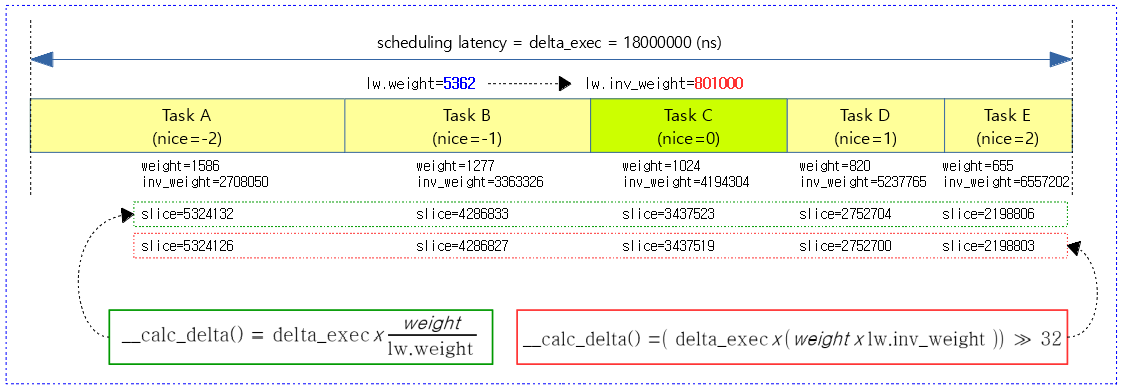
다음 그림은 5개의 태스크가 스케줄되어 산출된 각각의 time slice 값을 알아본다.
- 녹색 박스 수식은 나눗셈을 사용한 산출 방법이다. (수학 모델)
- 적색 박스 수식은 더 빠른 처리를 위해 나눗셈 없이 곱셈과 시프트만 사용한 방법이다. (구현 모델)
- weight 값은 scale down 하였다. (64비트 시스템)
__update_inv_weight()
kernel/sched/fair.c
static void __update_inv_weight(struct load_weight *lw)
{
unsigned long w;
if (likely(lw->inv_weight))
return;
w = scale_load_down(lw->weight);
if (BITS_PER_LONG > 32 && unlikely(w >= WMULT_CONST))
lw->inv_weight = 1;
else if (unlikely(!w))
lw->inv_weight = WMULT_CONST;
else
lw->inv_weight = WMULT_CONST / w;
}
0xfff_ffff / lw->weight 값을 lw->inv_weight 값으로 대입한다.
- 산출된 inv_weight 값은 weight 값으로 나눗셈을 하는 대신 이 값으로 곱하기 위해 반전된 weight 값을 사용한다. 그 후 32bit 우측 쉬프트를 하여 사용한다.
- ‘delta_exec / weight =’ 과 같이 나눗셈이 필요 할 때 나눗셈 대신 ‘delta_exec * wmult >> 32를 사용하는 방법이 있다.
- wmult 값을 만들기 위해 ‘2^32 / weight’ 값을 사용한다.
- 코드 5~6에서 이미 lw->inv_weight 값이 설정된 경우 함수를 빠져나간다.
- 코드 8에서 arm 아키텍처는 sched_load 비율을 적용하지 않으므로 그대로 lw->weight 값을 사용한다.
- 코드 10~15에서 w 값에 따라서 lw->inv_weight 값을 다음 중 하나로 갱신한다.
- 시스템이 64비트이고 낮은 확률로 w 값이 32bit 값을 넘어선 경우 1
- 낮은 확률로 w 값이 0인 경우 0xffff_ffff
- 그 외의 경우 0xffff_ffff / weight
mul_u64_u32_shr()
include/linux/math64.h
#if defined(CONFIG_ARCH_SUPPORTS_INT128) && defined(__SIZEOF_INT128__)
#ifndef mul_u64_u32_shr
static inline u64 mul_u64_u32_shr(u64 a, u32 mul, unsigned int shift)
{
return (u64)(((unsigned __int128)a * mul) >> shift);
}
#endif /* mul_u64_u32_shr */
#else
#ifndef mul_u64_u32_shr
static inline u64 mul_u64_u32_shr(u64 a, u32 mul, unsigned int shift)
{
u32 ah, al;
u64 ret;
al = a;
ah = a >> 32;
ret = ((u64)al * mul) >> shift;
if (ah)
ret += ((u64)ah * mul) << (32 - shift);
return ret;
}
#endif /* mul_u64_u32_shr */
#endif
a * mul >> shift 결과를 반환한다.
- 계산의 중간에 a * mul 연산에서 128비트를 사용하는데 아키텍처가 128비트 정수 연산을 지원하는 경우와 그렇지 않은 경우에 대해 함수가 구분되어 있다.
스케줄링 latency 와 스케일 정책
다음 그림은 update_sysctl() 함수를 호출하는 경로를 보여준다.
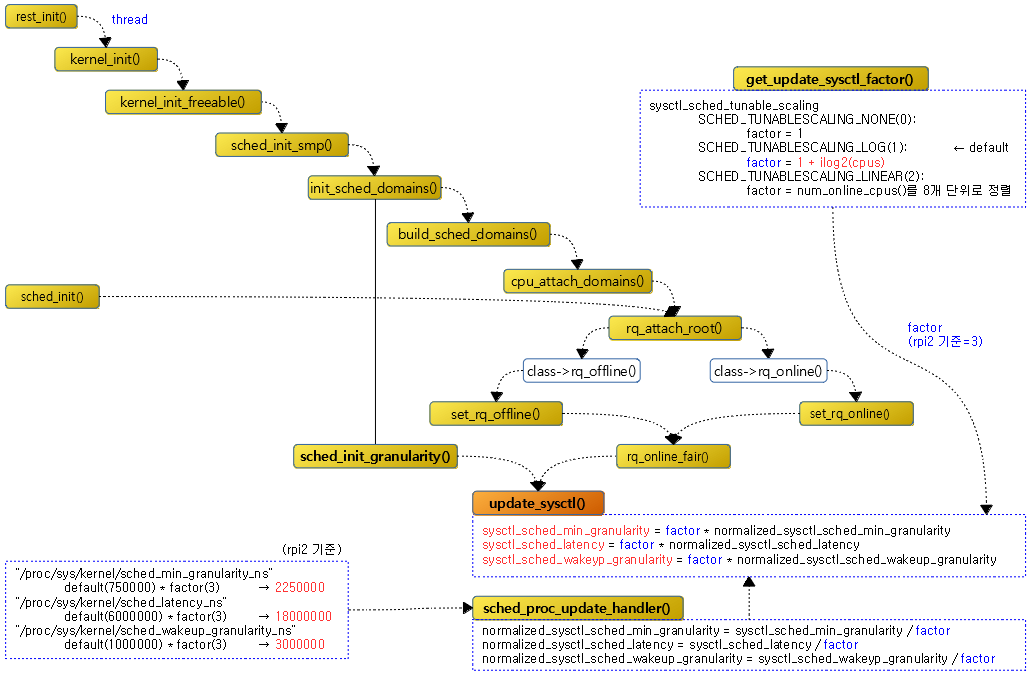
sched_proc_update_handler()
kernel/sched/fair.c
int sched_proc_update_handler(struct ctl_table *table, int write,
void __user *buffer, size_t *lenp,
loff_t *ppos)
{
int ret = proc_dointvec_minmax(table, write, buffer, lenp, ppos);
int factor = get_update_sysctl_factor();
if (ret || !write)
return ret;
sched_nr_latency = DIV_ROUND_UP(sysctl_sched_latency,
sysctl_sched_min_granularity);
#define WRT_SYSCTL(name) \
(normalized_sysctl_##name = sysctl_##name / (factor))
WRT_SYSCTL(sched_min_granularity);
WRT_SYSCTL(sched_latency);
WRT_SYSCTL(sched_wakeup_granularity);
#undef WRT_SYSCTL
return 0;
}
다음 4 가지 중 하나의 스케줄링 옵션을 바꾸게될 때 호출되어 CFS 스케줄러의 스케줄링 latency 산출에 영향을 준다.
- “/proc/sys/kernel/sched_min_granularity_ns”
- min: 100000, max: 1000000000 (range: 100us ~ 1s)
- “/proc/sys/kernel/sched_latency_ns”
- min: 100000, max: 1000000000 (range: 100us ~ 1s)
- “/proc/sys/kernel/sched_wakeup_granularity_ns”
- min: 0, max: 1000000000 (range: 0 ~ 1s)
- “/proc/sys/kernel/sched_tunable_scaling”
- min:0, max: 2 (range: 0 ~ 2)
- 코드 라인 5에서 kern_table[] 배열에서 해당 항목의 min/max에 적용된 범위 이내에서 관련 proc 파일 값을 읽는다.
- 코드 라인 6~9에서 스케줄링 latency에 반영할 factor 값을 산출해온다. 만일 실패하는 경우 함수를 빠져나간다.
- 코드 라인 11~12에서 스케줄링 latency 값을 태스크 최소 스케줄 단위로 나누면 스케쥴 latency 값으로 적용할 수 있는 최대 태스크의 수가 산출된다.
- 코드 라인 14~15에서 WRT_SYSCTL() 매크로를 정의한다.
- 코드 라인 16에서 normalized_sysctl_sched_min_granularity <- sysctl_sched_min_granularity / factor 값을 대입한다.
- 코드 라인 17에서 normalized_sysctl_sched_latency <- sysctl_sched_latency / factor 값을 대입한다.
- 코드 라인 18에서 normalized_sysctl_sched_wakeup_granularity <- sysctl_sched_wakeup_granularity / factor 값을 대입한다.
get_update_sysctl_factor()
kernel/sched/fair.c
/* * Increase the granularity value when there are more CPUs, * because with more CPUs the 'effective latency' as visible * to users decreases. But the relationship is not linear, * so pick a second-best guess by going with the log2 of the * number of CPUs. * * This idea comes from the SD scheduler of Con Kolivas: */
static int get_update_sysctl_factor(void)
{
unsigned int cpus = min_t(int, num_online_cpus(), 8);
unsigned int factor;
switch (sysctl_sched_tunable_scaling) {
case SCHED_TUNABLESCALING_NONE:
factor = 1;
break;
case SCHED_TUNABLESCALING_LINEAR:
factor = cpus;
break;
case SCHED_TUNABLESCALING_LOG:
default:
factor = 1 + ilog2(cpus);
break;
}
return factor;
}
스케일링 정책에 따른 비율을 반환한다. 이 값은 사용하는 정책에 따라 cpu 수에 따른 스케일 latency에 변화를 주게된다.
- “/proc/sys/kernel/sched_tunable_scaling” 을 사용하여 스케일링 정책을 바꿀 수 있다.
- SCHED_TUNABLESCALING_NONE(0)
- 항상 1을 사용한다.
- SCHED_TUNABLESCALING_LOG(1)
- 1 + ilog2(cpus)과 같이 cpu 수에 따라 변화된다.
- rpi2: cpu=4개이고 이 옵션을 사용하므로 factor=3가 된다.
- SCHED_TUNABLESCALING_LINEAR(2)
- online cpu 수로 8 단위로 정렬하여 사용한다. (8, 16, 24, 32, …)
- SCHED_TUNABLESCALING_NONE(0)
update_sysctl()
kernel/sched/fair.c
static void update_sysctl(void)
{
unsigned int factor = get_update_sysctl_factor();
#define SET_SYSCTL(name) \
(sysctl_##name = (factor) * normalized_sysctl_##name)
SET_SYSCTL(sched_min_granularity);
SET_SYSCTL(sched_latency);
SET_SYSCTL(sched_wakeup_granularity);
#undef SET_SYSCTL
}
스케줄 도메인의 초기화 또는 구성이 바뀌는 경우와 cpu가 on/off 될 때에 한하여 다음 3가지의 값을 갱신한다.
- sysctl_sched_min_granularity = factor * normalized_sysctl_sched_min_granularity
- sysctl_sched_latency = factor * normalized_sysctl_sched_latency
- sysctl_sched_wakeup_granularity = factor * normalized_sysctl_sched_wakeup_granularity
vruntime 산출
sched_vslice()
kernel/sched/fair.c
/* * We calculate the vruntime slice of a to-be-inserted task. * * vs = s/w */
static u64 sched_vslice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
return calc_delta_fair(sched_slice(cfs_rq, se), se);
}
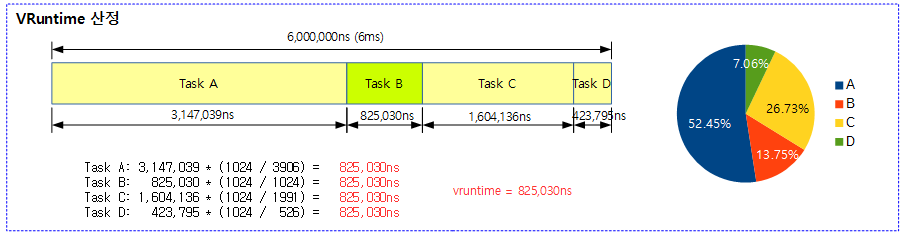
스케줄 엔티티의 로드에 해당하는 time slice 값을 산출하고 이를 통해 vruntime 을 구한다.
- sched_slice() 함수를 통해 스케줄 엔티티의 로드에 해당하는 기간인 time slice를 구한다.
- 예) rpi2: 스케줄 기간 18ms에서 6개의 태스크 중 현재 태스크가 로드 weight으로 기여한 시간이 3ms라고 할 때
- 그런 후 calc_delta_fair() 함수를 통해 스케줄 엔티티의 로드 weight과 반비례한 time slice 값을 반환한다.
- 예) 2개의 태스크에 대해 각각 1024, 3072의 로드 weight이 주어졌을 때
- 6ms의 스케줄 주기를 사용한 경우 각각의 로드 weight에 따라 1.5ms와 4.5ms의 time slice를 할당받는다.
- 이 기간으로 calc_delta_fair() 함수를 통한 경우 각각 ‘1.5ms * (1024/1024)’ , ‘4.5ms * (1024/3072)=1.5ms’ 수식으로 동일하게 1.5ms의 시간이 산출된다.
- 산출된 이 값을 기존 vruntime에 누적하여 사용한다.
- 예) 2개의 태스크에 대해 각각 1024, 3072의 로드 weight이 주어졌을 때
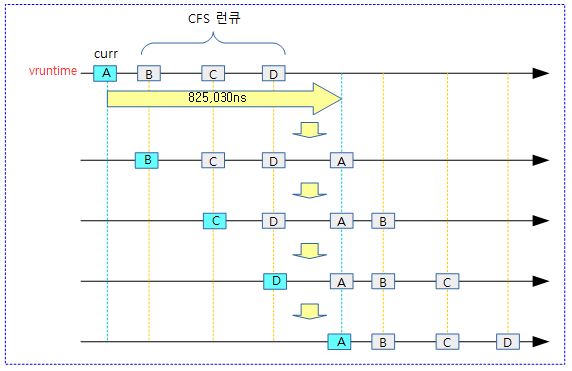
댜음 그림은 4개의 태스크에 대해 vruntime 값이 누적되는 모습을 보여준다.
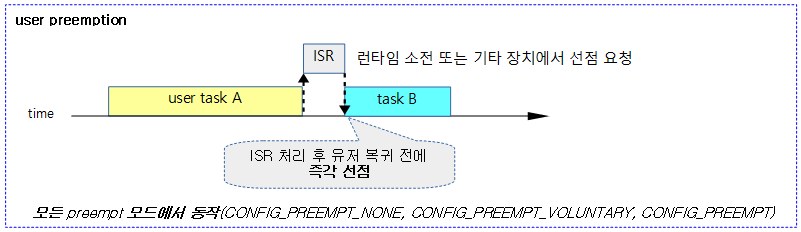
- high-resolution timer를 사용한 HRTICK인 경우 아래 그림과 같이 태스크별 할당 시간을 다 소모한 후 preemption 한다. 그러나 hrtick을 사용하지 않는 경우 매 정규 틱마다 태스크별 할당 시간과 vruntime을 비교하여 스케줄링된다. 그러한 경우 태스크는 자신의 할당 시간을 다 소모하지 못하고 중간에 vruntime이 더 작은 대기중인 태스크에게 선점될 수 있다.
- 아래 vruntime 값은 실제와는 다른 임의의 값으로 실전에서 아래와 같은 수치를 만들기는 어렵다.
- RB 트리에 엔큐된 스케줄링 엔티티들은 vruntime 값이 가장 작은 RB 트리의 가장 좌측부터 vruntime 값이 가장 큰 가장 우측 스케줄 엔티티까지의 vruntime 범위가 아래와 같이 산출된 vruntime 값 범위 이내로 모여드는 특성을 가지고 있다.

calc_delta_fair()
kernel/sched/fair.c
/* * delta /= w */
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}
time slice 값에 해당하는 vruntime 값을 산출한다.
- vruntime = time slice * wieght-0 / weight
CFS 태스크 틱 – (*task_tick)
다음 그림과 같이 스케줄 틱과 hrtick으로부터 호출되어 cfs 스케줄러에서 틱을 처리하는 흐름을 보여준다.

CFS 스케줄러에서 스케줄 틱 처리
task_tick_fair()
kernel/sched/fair.c
/* * scheduler tick hitting a task of our scheduling class. * * NOTE: This function can be called remotely by the tick offload that * goes along full dynticks. Therefore no local assumption can be made * and everything must be accessed through the @rq and @curr passed in * parameters. */
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
if (static_branch_unlikely(&sched_numa_balancing))
task_tick_numa(rq, curr);
update_misfit_status(curr, rq);
update_overutilized_status(task_rq(curr));
}
CFS 스케줄러 틱 호출 시마다 수행해야 할 일을 처리한다.
- 코드라인 6~9에서 요청 태스크에서 부터 최상위 태스크 그룹까지 각 스케줄링 엔티티들에 대해 스케줄 틱을 처리하도록 호출한다.
- 실행 시간 갱신. 만료 시 리스케줄 요청 처리
- 엔티티 로드 평균 갱신
- 블럭드 로드 갱신
- 태스크 그룹의 shares 갱신
- preemption 요청이 필요한 경우를 체크하여 설정
- 코드라인 11~12에서 numa 밸런싱이 enable된 경우 numa 로드 밸런싱을 수행한다.
- 코드 라인 14에서 ARM의 big/little cpu처럼 서로 다른(asynmetric) cpu capacity를 사용하는 cpu에서 misfit 상태를 갱신한다.
- 참고: sched/fair: Add ‘group_misfit_task’ load-balance type (2018, v4.20-rc1)
- 코드 라인 15에서 런큐 루트 도메인의 overutilized 상태를 갱신한다.
- 참고: sched/fair: Add over-utilization/tipping point indicator (2018, v5.0-rc1)
다음 그림은 entity_tick()에 대한 함수 흐름을 보여준다.
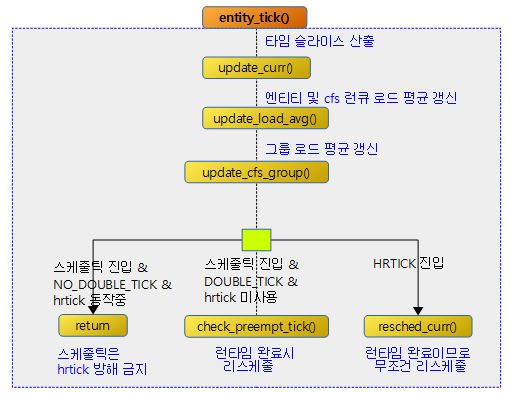
entity_tick()
kernel/sched/fair.c
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq);
/*
* Ensure that runnable average is periodically updated.
*/
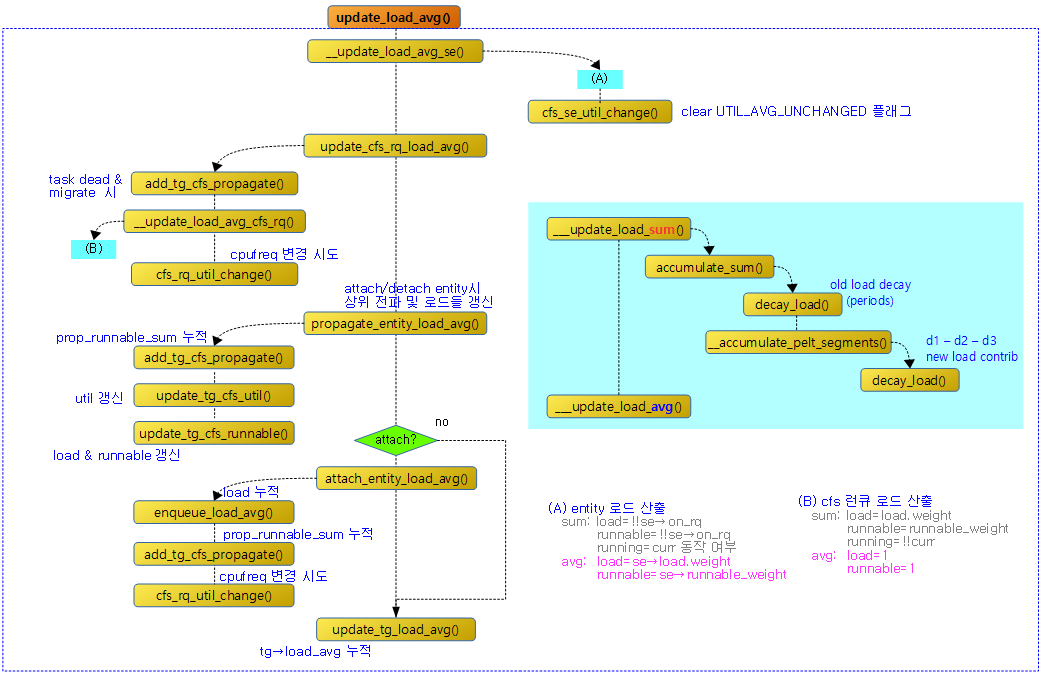
update_load_avg(cfs_rq, curr, UPDATE_TG);
update_cfs_group(curr);
#ifdef CONFIG_SCHED_HRTICK
/*
* queued ticks are scheduled to match the slice, so don't bother
* validating it and just reschedule.
*/
if (queued) {
resched_curr(rq_of(cfs_rq));
return;
}
/*
* don't let the period tick interfere with the hrtick preemption
*/
if (!sched_feat(DOUBLE_TICK) &&
hrtimer_active(&rq_of(cfs_rq)->hrtick_timer))
return;
#endif
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr);
}
CFS 스케줄러의 스케줄 엔티티 틱 호출 시 다음과 같이 처리한다.
- 코드 라인 7에서 현재 스케줄 엔티티의 런타임을 갱신한다. 이미 런타임이 다 소모된 경우에는 다음 태스크를 스케줄 하도록 리스케줄 요청을 한다.
- 코드 라인 12에서 엔티티 로드 평균 등을 산출하여 갱신한다.
- 코드 라인 13에서 그룹 엔티티 및 cfs 런큐의 로드 평균 등을 갱신한다.
- 코드 라인 20~23에서 스케줄러용 hrtick()을 통해 진입한 경우 인자 @queue=1이며, 이 경우 런타임만큼 타이머가 expire 되었으므로 다음 태스크를 위해 리스케줄링 요청한다.
- 코드 라인 27~29에서 더블 틱 기능을 사용하지 않고 고정 스케줄 틱으로 진입하였다. 이 경우 hrtick이 운영중인 경우 hrtick을 방해하지 않게 하기 위해 그냥 함수를 빠져나간다.
- 코드 라인 32~33에서 cfs 런큐에 2 개 이상의 태스크가 동작하는 경우 런타임 소모로 인한 태스크 스위칭(preemption)이 필요한지를 체크한다. 필요시 리스케줄 요청 플래그가 설정된다.
주기적 태스크 preemption 체크
check_preempt_tick()
kernel/sched/fair.c
/* * Preempt the current task with a newly woken task if needed: */
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
ideal_runtime = sched_slice(cfs_rq, curr);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
/*
* The current task ran long enough, ensure it doesn't get
* re-elected due to buddy favours.
*/
clear_buddies(cfs_rq, curr);
return;
}
/*
* Ensure that a task that missed wakeup preemption by a
* narrow margin doesn't have to wait for a full slice.
* This also mitigates buddy induced latencies under load.
*/
if (delta_exec < sysctl_sched_min_granularity)
return;
se = __pick_first_entity(cfs_rq);
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}
다음 상황이 포함된 경우 리스케줄 요청 플래그를 설정한다.
- 실행 시간이 다 소모된 경우
- 더 실행해야 할 시간은 남아 있지만 더 빠르게 동작시켜야 할 cfs 런큐에 엔큐된 태스크가 있는 경우
- 현재 태스크의 vruntime이 다음 수행할 태스크의 vruntime보다 크고 현재 태스크의 time slice 값을 초과하는 경우이다.
- 코드 라인 8에서 현재 태스크가 동작해야 할 time slice 값을 구해 ideal_runtime에 대입한다.
- 코드 라인 9에서 총 실행 시간에서 기존 실행 시간을 빼면 delta 실행 시간이 산출된다.
- 코드 라인 10~18에서 delta 실행 시간이 ideal_runtime을 초과한 경우 태스크에 주어진 시간을 다 소모한 것이다. 이러한 경우 리스케줄 요청 플래그를 설정하고 3개의 버디(skip, last, next) 엔티티에 curr 엔티티가 있으면 클리어하고 함수를 빠져나간다.
- 코드 라인 25~26에서 delta 실행 시간이 최소 preemption에 필요한 시간(0.75ms) 값보다 작은 경우 현재 태스크가 계속 실행될 수 있도록 함수를 빠져나간다.
- 코드 라인 28~29에서 cfs 런큐에서 다음 실행할 첫 엔티티를 가져와서 현재 스케줄링 엔티티의 vruntime에서 다음 스케줄링 엔티티의 vruntime을 뺀 delta 시간을 구한다.
- 코드 라인 31~32에서 delta 시간이 0보다 작은 경우 즉, 다음 스케줄링 엔티티의 vruntime이 현재 스케줄링 엔티티보다 더 큰 일반적인 경우 함수를 빠져나간다.
- 코드 라인 34~35에서 delta 시간이 ideal_runtime보다 큰 경우 리스케줄 요청 플래그를 설정한다.
현재 태스크에 대한 런타임, PELT 및 통계 들 갱신 – (*udpate_curr)
update_curr_fair()
kernel/sched/fair.c
static void update_curr_fair(struct rq *rq)
{
update_curr(cfs_rq_of(&rq->curr->se));
}
현재 태스크의 런타임, PELT 및 통계들을 갱신한다. 그리고 현재 태스크의 실행 시간을 다 소모하였으면 리스케줄 요청한다.
update_curr()
kernel/sched/fair.c
/* * Update the current task's runtime statistics. */
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq->exec_clock, delta_exec);
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cgroup_account_cputime(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
현재 태스크의 런타임, PELT 및 통계들을 갱신한다. 그리고 현재 태스크의 실행 시간을 다 소모하였으면 리스케줄 요청한다.
- 코드 라인 3~8에서 cfs 런큐에 러닝 중인 엔티티가 없으면 함수를 빠져나간다.
- 코드 라인 10~12에서 이번 갱신 시간까지 동작한 엔티티의 런타임을 delta_exec에 대입하고, 혹시 0 이하인 경우 함수를 빠져나간다.
- x86의 unstable 클럭등을 사용할 때 일시적으로 음수가 나올 수 있다.
- 코드 라인 14에서 다음 갱신에 대한 런타임 산출을 위해 미리 현재 시각으로 갱신한다.
- 코드 라인 16~17에서 갱신 중 최대 런타임을 갱신한다.
- 코드 라인 19에서 엔티티의 런타임 총합을 갱신한다.
- 코드 라인 20에서 cfs 런큐의 런타임 총합을 갱신한다.
- 코드 라인 22에서 실행된 런타임으로 vruntime 값을 구해 엔티티의 vruntime 값에 추가한다.
- curr->vruntime += delta_exec * wieght-0 / curr->load.weight
- 코드 라인 23에서 cfs 런큐의 min_vruntime 값을 갱신한다.
- 코드 라인 25~31에서 현재 엔티티가 태스크인 경우 실행된 런타임을 cgroup과 cputimer 통계에 추가하여 갱신하게 한다.
- 코드 라인 33에서 cfs 밴드위드를 사용하여 cfs 런큐의 런타임 잔량을 다 소모한 경우 스로틀 한다.
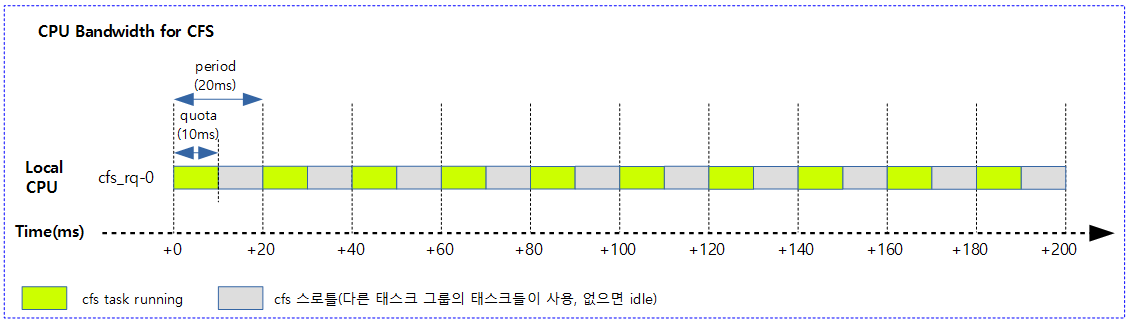
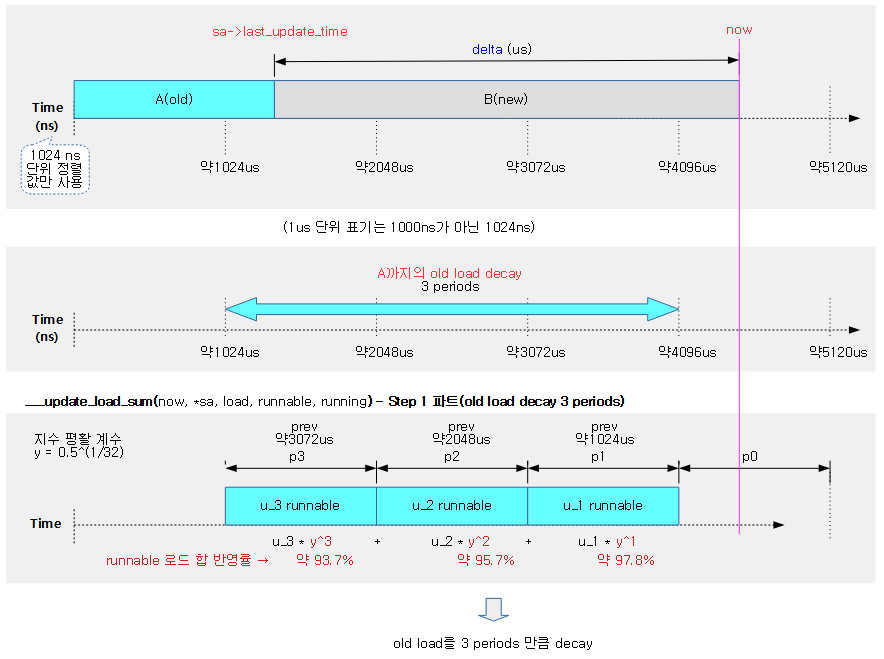
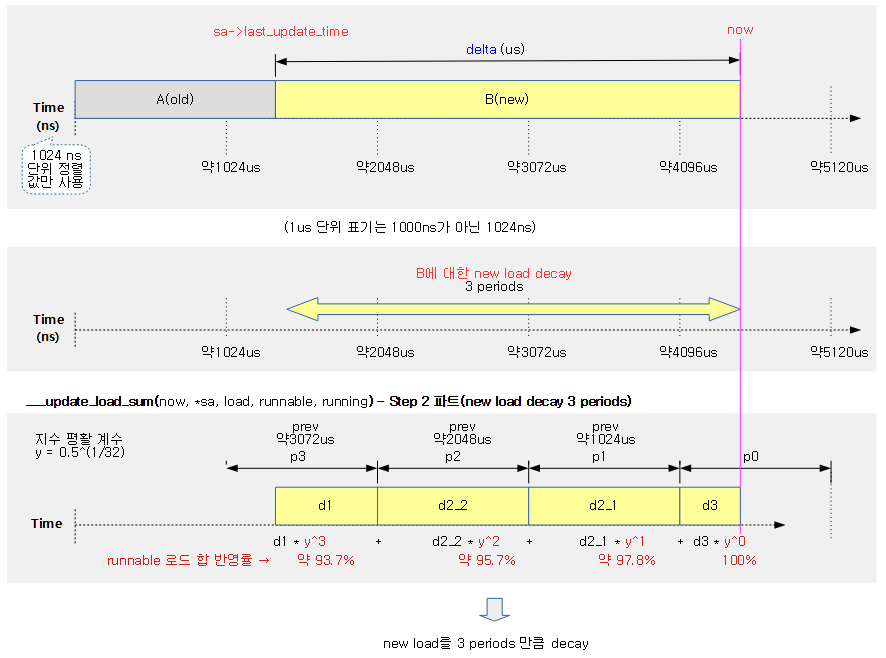
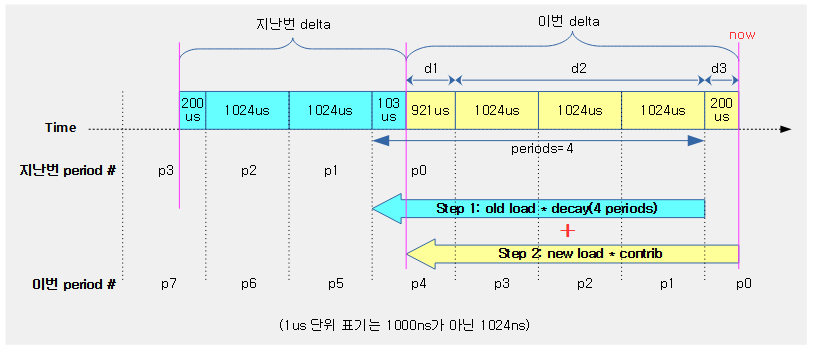
다음 그림은 cfs 런큐에서 동작 중인 엔티티의 런타임 값으로 vruntime, min_vruntime을 갱신한다. 그리고 cfs 밴드위드를 사용하는 경우 cfs 런큐의 런타임 잔량이 다 소모된 경우 리스줄되는 과정을 보여준다.
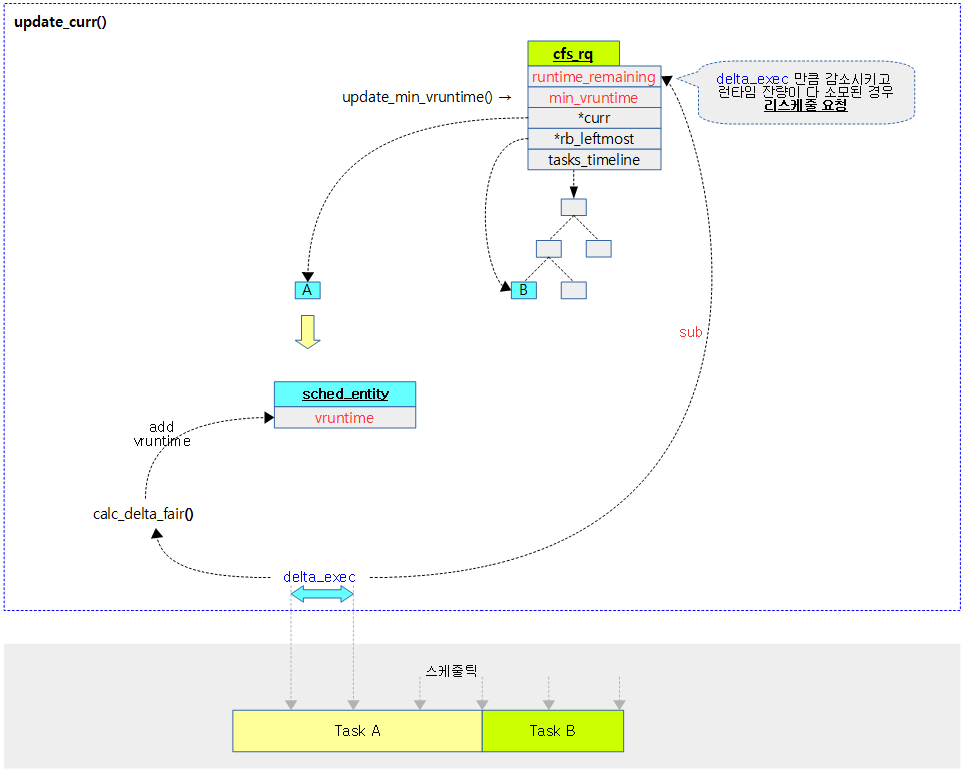
min_vruntime 갱신
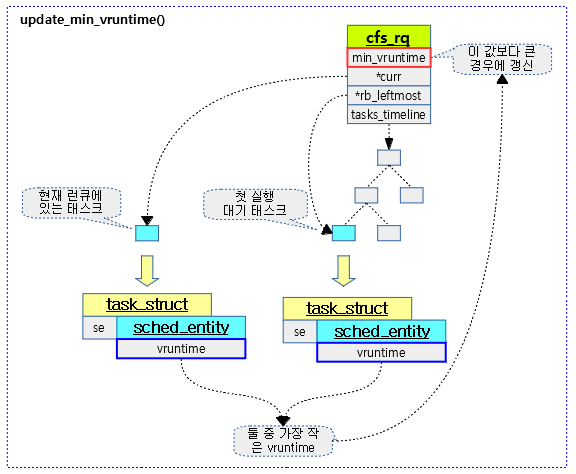
update_min_vruntime()
kernel/sched/fair.c
static void update_min_vruntime(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
struct rb_node *leftmost = rb_first_cached(&cfs_rq->tasks_timeline);
u64 vruntime = cfs_rq->min_vruntime;
if (curr) {
if (curr->on_rq)
vruntime = curr->vruntime;
else
curr = NULL;
}
if (leftmost) { /* non-empty tree */
struct sched_entity *se;
se = rb_entry(leftmost, struct sched_entity, run_node);
if (!curr)
vruntime = se->vruntime;
else
vruntime = min_vruntime(vruntime, se->vruntime);
}
/* ensure we never gain time by being placed backwards. */
cfs_rq->min_vruntime = max_vruntime(cfs_rq->min_vruntime, vruntime);
#ifndef CONFIG_64BIT
smp_wmb();
cfs_rq->min_vruntime_copy = cfs_rq->min_vruntime;
#endif
}
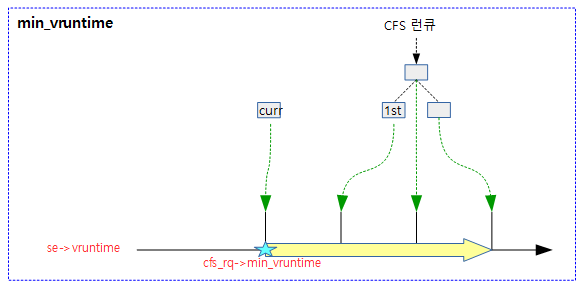
cfs 런큐의 min_vruntime 값을 갱신한다. 현재 태스크와 첫 번째 대기 중인 태스크 둘 중 작은 vruntime 값을 cfs 런큐의 min_vruntime 값보다 큰 경우에만 갱신한다.
- 코드 라인 6에서 cfs 런큐의 min_vruntime 값을 vruntime에 저장한다.
- 코드 라인 8~13에서 현재 동작 중인 엔티티가 cfs 런큐에 엔큐되어 있는 경우 이 엔티티의 vruntime으로 대체한다.
- 코드 라인 15~23에서 cfs 런큐에 대기중인 엔티티가 있는 경우 가장 먼저 실행될 엔티티의 vruntime과 비교하여 가장 작은 것을 산출한다.
- 코드 라인 26에서 위에서 산출된 가장 작은 vruntime 값이 cfs 런큐의 min_vruntime 값보다 큰 경우에만 갱신한다.
- cfs 런큐의 min_vruntime을 새로운 min_vruntime으로 갱신하는데 새로 갱신하는 값은 기존 보다 더 큰 값이 된다.
- 코드 라인 29에서 32bit 시스템인 경우에만 min_vruntime을 min_vruntime_copy에도 복사한다.
다음 그림은 update_min_vruntime()에 대한 동작을 보여준다.
CFS 버디
리스케줄시 특정 태스크의 순서를 변경할 때 사용하기 위해 다음과 같은 버디가 있다.
- skip 버디
- 리스케줄 할 때 현재 태스크를 skip 버디에 지정하여 가능하면 자기 자신을 다음 태스크로 선택하지 못하게 한다.
- last 버디
- 캐시 지역성을 향상시키기 위해 웨이크 업 preemption이 성공하면 preemption 직전에 실행된 작업 옆에 둔다.
- next 버디
- 캐시 지역성을 높이기 위해 깨어난 태스크를 다음 스케줄 시 곧바로 동작시킨다.
- 리스케줄 할 때 지정된 태스크를 next 버디에 지정하여 리스케줄 시 다음 태스크에서 선택하도록 한다.
버디들 모두 클리어
clear_buddies()
kernel/sched/fair.c
static void clear_buddies(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
if (cfs_rq->last == se)
__clear_buddies_last(se);
if (cfs_rq->next == se)
__clear_buddies_next(se);
if (cfs_rq->skip == se)
__clear_buddies_skip(se);
}
다음에 이 스케줄링 엔티티가 재선택되지 않도록 계층적 정리한다.
- 코드 라인 3~4에서 cfs 런큐의 last가 요청한 스케줄링 엔티티와 동일한 경우 last에 대한 계층적 정리를 수행한다.
- 코드 라인 6~7에서 cfs 런큐의 next가 요청한 스케줄링 엔티티와 동일한 경우 next에 대한 계층적 정리를 수행한다.
- 코드 라인 9~10에서 cfs 런큐의 skip이 요청한 스케줄링 엔티티와 동일한 경우 skip에 대한 계층적 정리를 수행한다.
__clear_buddies_last()
kernel/sched/fair.c
static void __clear_buddies_last(struct sched_entity *se)
{
for_each_sched_entity(se) {
struct cfs_rq *cfs_rq = cfs_rq_of(se);
if (cfs_rq->last != se)
break;
cfs_rq->last = NULL;
}
}
최상위 태스크 그룹까지 루프를 돌며 cfs 런큐의 last가 요청한 스케줄링 엔티티인 경우 null을 대입하여 클리어한다.
__clear_buddies_next()
kernel/sched/fair.c
static void __clear_buddies_next(struct sched_entity *se)
{
for_each_sched_entity(se) {
struct cfs_rq *cfs_rq = cfs_rq_of(se);
if (cfs_rq->next != se)
break;
cfs_rq->next = NULL;
}
}
최상위 태스크 그룹까지 루프를 돌며 cfs 런큐의 next가 요청한 스케줄링 엔티티인 경우 null을 대입하여 클리어한다.
__clear_buddies_skip()
kernel/sched/fair.c
static void __clear_buddies_skip(struct sched_entity *se)
{
for_each_sched_entity(se) {
struct cfs_rq *cfs_rq = cfs_rq_of(se);
if (cfs_rq->skip != se)
break;
cfs_rq->skip = NULL;
}
}
최상위 태스크 그룹까지 루프를 돌며 cfs 런큐의 skip이 요청한 스케줄링 엔티티인 경우 null을 대입하여 클리어한다.
태스크 Fork (*task_fork)
task_fork_fair()
sched/fair.c
/* * called on fork with the child task as argument from the parent's context * - child not yet on the tasklist * - preemption disabled */
static void task_fork_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se, *curr;
struct rq *rq = this_rq();
struct rq_flags rf;
rq_lock(rq, &rf);
update_rq_clock(rq);
cfs_rq = task_cfs_rq(current);
curr = cfs_rq->curr;
if (curr) {
update_curr(cfs_rq);
se->vruntime = curr->vruntime;
}
place_entity(cfs_rq, se, 1);
if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) {
/*
* Upon rescheduling, sched_class::put_prev_task() will place
* 'current' within the tree based on its new key value.
*/
swap(curr->vruntime, se->vruntime);
resched_curr(rq);
}
se->vruntime -= cfs_rq->min_vruntime;
rq_unlock(rq, &rf);
}
부모 context로 부터 fork된 새 child 태스크의 vruntime을 결정한다. (cfs 런큐의 RB 트리의 위치를 결정한다)
- 코드 라인 8~9에서 런큐 락을 획득한 후 런큐 클럭을 갱신한다.
- 코드 라인 11~16에서 현재 처리중인 cfs 태스크의 런큐에 대해 런타임, PELT 및 stat 등을 갱신하고, 현재 엔티티의 vruntime을 새 엔티티에도 사용한다.
- 코드 라인 17에서 cfs 런큐에서 엔티티의 위치를 지정한다.
- 새 엔티티의 vruntime을 지정한다. (cfs 런큐의 RB 트리에 넣을 위치가 결정된다)
- 코드 라인 19~26에서 sysctl_sched_child_runs_first가 true이면 새 child를 먼저 동작시켜야 한다.
- 현재 동작중인 스케줄링 엔티티가 새 스케줄링 엔티티의 vruntime보다 더 우선인 경우 vruntime 값을 서로 교환하여 자리를 바꾼다. 그런 후 리스케줄 요청한다.
- “/proc/sys/kernel/sched_child_runs_first”의 default 값은 0으로 1로 설정되는 경우 새 child가 가장 먼저 동작하도록 한다.
- 코드 라인 28에서 새 엔티티는 아직 런큐되지 않았으므로 min_vruntim을 제거해야 한다.
- 코드 라인 29에서 런큐 락을 해제한다.
RB 트리에서의 스케줄 엔티티의 위치 설정(vruntime)
place_entity()
kernel/sched/fair.c
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
u64 vruntime = cfs_rq->min_vruntime;
/*
* The 'current' period is already promised to the current tasks,
* however the extra weight of the new task will slow them down a
* little, place the new task so that it fits in the slot that
* stays open at the end.
*/
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
/* sleeps up to a single latency don't count. */
if (!initial) {
unsigned long thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh;
}
/* ensure we never gain time by being placed backwards. */
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
스케줄 엔티티의 vruntime 값을 갱신한다. (vruntime 값이 RB 트리내에서 앞으로 전진하지는 못하고 뒤로 후진만 가능하다)
- 코드 라인 4에서 cfs 런큐의 min_vruntime 값을 알아온다.
- 태스크가 cfs 런큐되는 상황이 다음과 같이 있다.
- 처음 fork 된 태스크
- 다른 태스크 그룹에서 넘어온 태스크
- 슬립/스로틀 되었다가 다시 깨어난 태스크 또는 그룹 엔티티
- 다른 클래스에 있다가 넘어온 태스크
- place_entity() 함수가 호출되는 case
- 처음 fork 된 태스크 -> task_fork_fair() -> place_entity(initial=1)
- 슬립/스로틀되었다가 다시 깨어난 태스크 또는 그룹 엔티티 -> unthrottle_cfs_rq(ENQUEUE_WAKEUP) -> enqueue_entity() -> place_entity(initial=0)
- 다른 클래스로 넘어가려는 태스크 -> switched_from_fair() -> detach_task_cfs_rq() -> place_entity(initial=0)
- 다른 태스크 그룹에서 넘어온 태스크 -> task_move_group_fair() -> detach_task_cfs_rq() -> place_entity(initial=0)
- 태스크가 다시 cfs 런큐에 들어올 때 min_vruntime을 가지고 시작한다.
- cfs 런큐는 글로벌 런큐에도 위치하고 태스크 그룹이 설정된 경우 각각의 태스크 그룹에도 설정되어 사용된다.
- 태스크가 cfs 런큐되는 상황이 다음과 같이 있다.
- 코드 라인 12~13에서 태스크에 대한 초기 태스크인 경우이고 START_DEBIT 기능을 사용하는 경우 vruntime 기준 한 타임 더 늦게 실행되도록 유도한다.
- initial
- 새로 fork된 태스크가 스케줄링될 때 이 값이 1로 요청된다.
- 경로: copy_process() -> sched_fork() —->sched_class->task_fork(p)–> task_fork_fair() -> place_entity()
- 새로 fork된 태스크가 스케줄링될 때 이 값이 1로 요청된다.
- START_DEBIT & GENTLE_FAIR_SLEEPERS
- 참고: Scheduler -15- (Core) | 문c
- “/proc/sys/kernel/sched_child_runs_first”
- 이 기능을 사용하는 경우 이 함수를 빠져나간 후에 현재 실행 중인 태스크보다 fork된 자식 태스크를 먼저 실행 시키기 위해 현재 태스크의 vruntime과 swap 시킨다.
- initial
- 코드 라인 16~27에서 초기 태스크 생성시 호출된 경우가 아니면 스케줄 latency 만큼 vruntime을 줄인다. 단 GENTLE_FAIR_SLEEPERS 기능을 사용하는 경우 절반만 줄인다.
- 코드 라인 30에서 산출된 vruntime 값이 스케줄 엔티티의 vruntime 값보다 큰 경우 갱신한다.
- cfs_rq->min_vruntime <= se->vruntime
태스크 엔큐 – (*enqueue_task)
enqueue_task_fair()
kernel/sched/fair.c -1/2-
/* * The enqueue_task method is called before nr_running is * increased. Here we update the fair scheduling stats and * then put the task into the rbtree: */
static void
enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
int idle_h_nr_running = task_has_idle_policy(p);
/*
* The code below (indirectly) updates schedutil which looks at
* the cfs_rq utilization to select a frequency.
* Let's add the task's estimated utilization to the cfs_rq's
* estimated utilization, before we update schedutil.
*/
util_est_enqueue(&rq->cfs, p);
/*
* If in_iowait is set, the code below may not trigger any cpufreq
* utilization updates, so do it here explicitly with the IOWAIT flag
* passed.
*/
if (p->in_iowait)
cpufreq_update_util(rq, SCHED_CPUFREQ_IOWAIT);
for_each_sched_entity(se) {
if (se->on_rq)
break;
cfs_rq = cfs_rq_of(se);
enqueue_entity(cfs_rq, se, flags);
/*
* end evaluation on encountering a throttled cfs_rq
*
* note: in the case of encountering a throttled cfs_rq we will
* post the final h_nr_running increment below.
*/
if (cfs_rq_throttled(cfs_rq))
break;
cfs_rq->h_nr_running++;
cfs_rq->idle_h_nr_running += idle_h_nr_running;
flags = ENQUEUE_WAKEUP;
}
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
cfs_rq->h_nr_running++;
cfs_rq->idle_h_nr_running += idle_h_nr_running;
if (cfs_rq_throttled(cfs_rq))
break;
update_load_avg(cfs_rq, se, UPDATE_TG);
update_cfs_group(se);
}
태스크를 cfs 런큐에 추가하고 로드 weight 및 runtime 통계들을 갱신한다. cgroup을 사용하여 태스크(스케줄링) 그룹이 구성되어 운영되는 경우 각 태스크 그룹의 cfs 런큐에 각각의 스케줄 엔티티를 큐잉하고 역시 로드 weight 및 runtime 통계들을 갱신한다.
- 코드 라인 14에서 util_est 엔큐를 갱신한다.
- 참고: sched/fair: Add util_est on top of PELT (2018, v4.17-rc1)
- 코드 라인 21~22에서 in_iowait 중인 태스크는 cpu frequency를 조절하도록 진입한다.
- 코드 라인 24~26에서 요청 태스크의 엔티티들에 대해 루프를 돌며 현재의 엔티티가 런큐에 이미 존재하면 루프를 탈출한다.
- 코드 라인 27~28에서 cfs 런큐에 엔티티를 엔큐한다.
- 코드 라인 36~37에서 cfs 런큐가 스로틀된 경우 루프를 탈출한다.
- 코드 라인 38에서 cfs 런큐 이하 동작 중인 cfs 태스크 수를 의미하는 h_r_running을 증가시킨다.
- 코드 라인 39에서 cfs 런큐 이하 동작 중인 idle policy를 가진 cfs 태스크 수를 의미하는 idle_h_r_running를 idle cfs 태스크인 경우에 한해 증가시킨다.
- 코드 라인 41에서 플래그에 ENQUEUE_WAKEUP을 기록한다.
- 코드 라인 44에서 위의 루프가 중간에서 멈춘 경우 그 중간 부터 계속 하여 루프를 돈다.
- 코드 라인 45~47에서 h_nr_running을 증가시키고, idle_h_nr_running도 idle policy를 가진 태스크의 경우 증가시킨다.
- 코드 라인 49~50에서 cfs 런큐가 스로틀된 경우 루프를 탈출한다.
- 코드 라인 52~53에서 cfs 런큐의 로드 평균과 그룹의 로드 평균을 갱신한다.
kernel/sched/fair.c -2/2-
if (!se) {
add_nr_running(rq, 1);
/*
* Since new tasks are assigned an initial util_avg equal to
* half of the spare capacity of their CPU, tiny tasks have the
* ability to cross the overutilized threshold, which will
* result in the load balancer ruining all the task placement
* done by EAS. As a way to mitigate that effect, do not account
* for the first enqueue operation of new tasks during the
* overutilized flag detection.
*
* A better way of solving this problem would be to wait for
* the PELT signals of tasks to converge before taking them
* into account, but that is not straightforward to implement,
* and the following generally works well enough in practice.
*/
if (flags & ENQUEUE_WAKEUP)
update_overutilized_status(rq);
}
if (cfs_bandwidth_used()) {
/*
* When bandwidth control is enabled; the cfs_rq_throttled()
* breaks in the above iteration can result in incomplete
* leaf list maintenance, resulting in triggering the assertion
* below.
*/
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
if (list_add_leaf_cfs_rq(cfs_rq))
break;
}
}
assert_list_leaf_cfs_rq(rq);
hrtick_update(rq);
}
- 코드 라인 1~20에서 위의 두 번쨰 루프에서 cfs 런큐가 스로틀하여 중간에 루프를 벗어난 경우 런큐의 태스크 수를 증가시킨다. 첫 번째 루프를 통해 태스크가 한 번이라도 엔큐한 적이 있으면 루트 도메인의 overutilized 상태를 갱신한다.
- 코드 라인 22~35에서 cfs 밴드위드를 사용하는 경우 엔티티 루프를 돌며 런큐의 leaf_cfs_rq_list에 cfs 런큐를 추가한다.
- 코드 라인 39에서 hrtick이 사용 중인 경우 런타임이 남아 있는 경우에 한해 남은 런타임만큼 타이머를 동작시킨다.
다음 그림은 enqueue_task_fair() 함수에서 태스크를 추가할 때 각 태스크 그룹의 cfs 런큐에 큐잉되는 모습을 보여준다.
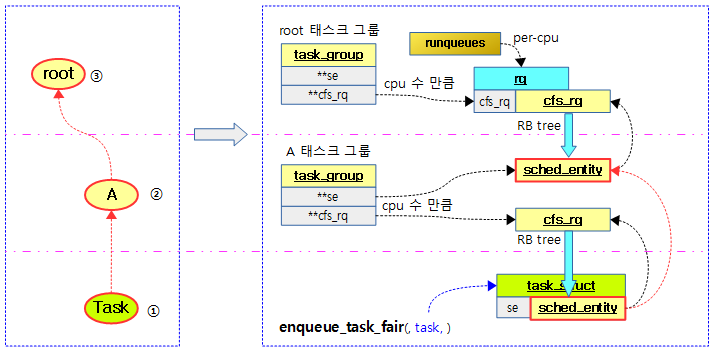
for_each_sched_entity() 매크로
kernel/sched/fair.c
/* Walk up scheduling entities hierarchy */
#define for_each_sched_entity(se) \
for (; se; se = se->parent)
스케줄 엔티티의 최상위 부모까지 루프를 돈다.
- cgroup을 사용하여 태스크(스케줄링) 그룹을 계층적으로 만들어서 운영하는 경우 스케줄 엔티티는 태스크가 있는 하위 스케줄 엔티티부터 루트 태스크 그룹까지 부모로 연결된다.
- 그러나 태스크(스케줄링) 그룹을 운영하지 않는 경우 태스크는 태스크 구조체 내부에 임베드된 스케줄 엔티티 하나만을 갖게되어 루프를 돌지 않는다.

cfs 런큐에 엔티티 엔큐
enqueue_entity()
kernel/sched/fair.c
/* * MIGRATION * * dequeue * update_curr() * update_min_vruntime() * vruntime -= min_vruntime * * enqueue * update_curr() * update_min_vruntime() * vruntime += min_vruntime * * this way the vruntime transition between RQs is done when both * min_vruntime are up-to-date. * * WAKEUP (remote) * * ->migrate_task_rq_fair() (p->state == TASK_WAKING) * vruntime -= min_vruntime * * enqueue * update_curr() * update_min_vruntime() * vruntime += min_vruntime * * this way we don't have the most up-to-date min_vruntime on the originating * CPU and an up-to-date min_vruntime on the destination CPU. */
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
bool renorm = !(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_MIGRATED);
bool curr = cfs_rq->curr == se;
/*
* If we're the current task, we must renormalise before calling
* update_curr().
*/
if (renorm && curr)
se->vruntime += cfs_rq->min_vruntime;
update_curr(cfs_rq);
/*
* Otherwise, renormalise after, such that we're placed at the current
* moment in time, instead of some random moment in the past. Being
* placed in the past could significantly boost this task to the
* fairness detriment of existing tasks.
*/
if (renorm && !curr)
se->vruntime += cfs_rq->min_vruntime;
/*
* When enqueuing a sched_entity, we must:
* - Update loads to have both entity and cfs_rq synced with now.
* - Add its load to cfs_rq->runnable_avg
* - For group_entity, update its weight to reflect the new share of
* its group cfs_rq
* - Add its new weight to cfs_rq->load.weight
*/
update_load_avg(cfs_rq, se, UPDATE_TG | DO_ATTACH);
update_cfs_group(se);
enqueue_runnable_load_avg(cfs_rq, se);
account_entity_enqueue(cfs_rq, se);
if (flags & ENQUEUE_WAKEUP)
place_entity(cfs_rq, se, 0);
check_schedstat_required();
update_stats_enqueue(cfs_rq, se, flags);
check_spread(cfs_rq, se);
if (!curr)
__enqueue_entity(cfs_rq, se);
se->on_rq = 1;
if (cfs_rq->nr_running == 1) {
list_add_leaf_cfs_rq(cfs_rq);
check_enqueue_throttle(cfs_rq);
}
}
스케줄 엔티티를 RB 트리에 큐잉하고 런타임 통계를 갱신한다.
- 코드 라인 4에서 vruntim에 대한 renormalization의 필요 여부를 알아온다.
- wakeup 플래그가 지정되지 않았거나 migrate 플래그가 지정된 경우 vruntim에 대한 renormalization이 필요하다.
- 코드 라인 11~23에서 @se 엔티티가 renormalization이 필요하면 엔티티의 vruntime에 min_vruntime을 추가한다. 단 @se가 현재 동작 중인 엔티티인지 여부에 따라 다음과 같이 처리한다.
- @se==curr인 경우 min_vruntime을 먼저 더한 후 cfs 런큐에 대한 런타임, PELT 및 stat을 갱신한다.
- @se!=curr인 경우 cfs 런큐에 대한 런타임, PELT 및 stat을 갱신한 후 min_vruntime을 추가한다.
- 코드 라인 22~23에서 @se 엔티티가 renormalization이 필요하고 현재 동작 중인 엔티티가 아닌 경우 vruntime에 min_vruntime을 더한다.
- update_curr() 후에 min_vruntime만 추가한다.
- 코드 라인 33에서 엔티티의 로드를 갱신한다.
- 새 엔티티의 추가를 고려해야 하므로 DO_ATTACH 플래그를 추가하였고, 태스크 그룹도 같이 갱신하도록 UPDATE_TG 플래그도 추가하였다.
- 코드 라인 34에서 그룹 엔티티 및 cfs 런큐의 로드 평균을 갱신한다.
- 코드 라인 35에서 cfs 런큐의 러너블 로드 평균을 갱신한다.
- 코드 라인 36에서 엔티티 엔큐에 대한 account를 갱신한다.
- cfs 런큐에서 로드 weight를 증가시키고 nr_running등을 증가시킨다
- 코드 라인 38~39에서 ENQUEUE_WAKEUP 플래그가 요청된 경우스케줄 엔티티의 위치를 갱신한다.
- 코드 라인 42에서 enque된 스케줄 엔티티가 cfs 런큐에서 현재 돌고 있지 않은 경우 wait_start를 현재 런큐 시각으로 설정한다.
- 코드 라인 43에서 디버깅을 위해 nr_spread_over를 갱신한다.
- 코드 라인 44~45에서 스케줄 엔티티가 cfs 런큐에서 현재 러닝중이지 않으면 RB 트리에 추가한다.
- cfs 런큐에 curr 엔티티가 하나만 동작하는 경우엔 RB 트리는 비어있다.
- 즉 RB 트리에 1개의 엔티티가 있다는 것은 2개의 cfs 엔티티가 러너블 상태임을 뜻한다.
- 코드 라인 46에서 on_rq에 1을 대입하여 현재 엔티티가 cfs 런큐에서 동작함을 알린다.
- 코드 라인 48~51에서 cfs 런큐에서 동작 중인 active 태스크가 1개 뿐인 경우 런큐의 leaf cfs 리스트에 cfs 런큐를 추가하고 필요한 경우 스로틀 한다.
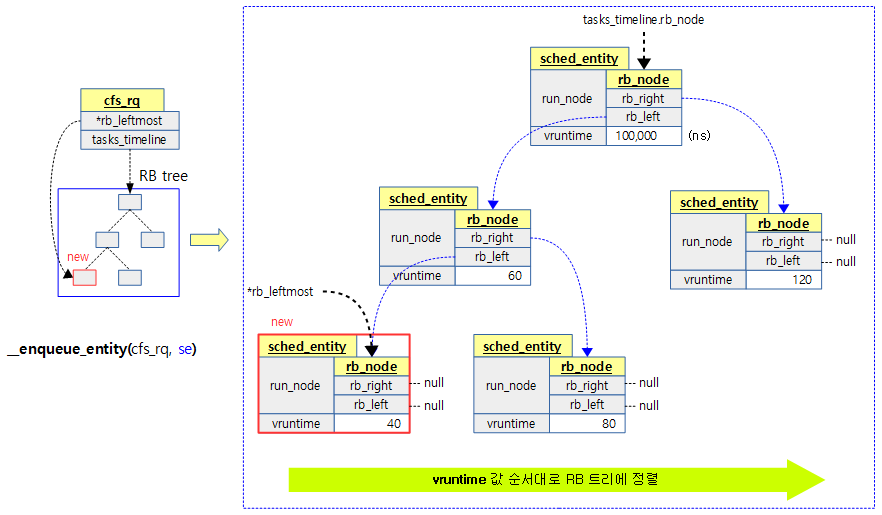
__enqueue_entity()
kernel/sched/fair.c
/* * Enqueue an entity into the rb-tree: */
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
struct rb_node **link = &cfs_rq->tasks_timeline.rb_root.rb_node;
struct rb_node *parent = NULL;
struct sched_entity *entry;
bool leftmost = true;
/*
* Find the right place in the rbtree:
*/
while (*link) {
parent = *link;
entry = rb_entry(parent, struct sched_entity, run_node);
/*
* We dont care about collisions. Nodes with
* the same key stay together.
*/
if (entity_before(se, entry)) {
link = &parent->rb_left;
} else {
link = &parent->rb_right;
leftmost = false;
}
}
rb_link_node(&se->run_node, parent, link);
rb_insert_color_cached(&se->run_node,
&cfs_rq->tasks_timeline, leftmost);
}
엔티티 @se를 cfs 런큐의 RB 트리에 추가한다.
- 코드 라인 3에서 처음 비교할 노드로 RB 트리 루트 노드를 선택한다.
- 코드 라인 11에서 루프를 돌며 노드가 있는 동안 루프를 돈다. (null이되면 끝)
- 코드 라인 12~13에서 parent에 현재 비교할 노드를 보관하고 이 노드에 담긴 스케줄 엔티티를 entry에 대입한다.
- 코드 라인 18~23에서 스케줄 엔티티의 vruntime이 비교 entry의 vruntime보다 작은 경우 좌측 노드 방향을 선택하고 그렇지 않은 경우 우측 노드 방향을 선택한다.
- 요청한 스케줄 엔티티의 vruntime 값이 RB 트리에서 가장 작은 수인 경우 루프 안에서 한 번도 우측 방향을 선택하지 않았던 경우 이다. 이러한 경우 cfs 런큐의 rb_leftmost는 이 스케줄 엔티티를 가리키게 한다. cfs 런큐에서 다음에 스케줄 엔티티를 pickup할 경우 가장 먼저 선택된다.
- 코드 라인 26~28에서 RB 트리에 추가하고 color를 갱신한다.
다음 그림은 스케줄 엔티티를 cfs 런큐에 큐잉하는 모습을 보여준다.
list_add_leaf_cfs_rq()
kernel/sched/fair.c
static inline bool list_add_leaf_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
int cpu = cpu_of(rq);
if (cfs_rq->on_list)
return rq->tmp_alone_branch == &rq->leaf_cfs_rq_list;
cfs_rq->on_list = 1;
/*
* Ensure we either appear before our parent (if already
* enqueued) or force our parent to appear after us when it is
* enqueued. The fact that we always enqueue bottom-up
* reduces this to two cases and a special case for the root
* cfs_rq. Furthermore, it also means that we will always reset
* tmp_alone_branch either when the branch is connected
* to a tree or when we reach the top of the tree
*/
if (cfs_rq->tg->parent &&
cfs_rq->tg->parent->cfs_rq[cpu]->on_list) {
/*
* If parent is already on the list, we add the child
* just before. Thanks to circular linked property of
* the list, this means to put the child at the tail
* of the list that starts by parent.
*/
list_add_tail_rcu(&cfs_rq->leaf_cfs_rq_list,
&(cfs_rq->tg->parent->cfs_rq[cpu]->leaf_cfs_rq_list));
/*
* The branch is now connected to its tree so we can
* reset tmp_alone_branch to the beginning of the
* list.
*/
rq->tmp_alone_branch = &rq->leaf_cfs_rq_list;
return true;
}
if (!cfs_rq->tg->parent) {
/*
* cfs rq without parent should be put
* at the tail of the list.
*/
list_add_tail_rcu(&cfs_rq->leaf_cfs_rq_list,
&rq->leaf_cfs_rq_list);
/*
* We have reach the top of a tree so we can reset
* tmp_alone_branch to the beginning of the list.
*/
rq->tmp_alone_branch = &rq->leaf_cfs_rq_list;
return true;
}
/*
* The parent has not already been added so we want to
* make sure that it will be put after us.
* tmp_alone_branch points to the begin of the branch
* where we will add parent.
*/
list_add_rcu(&cfs_rq->leaf_cfs_rq_list, rq->tmp_alone_branch);
/*
* update tmp_alone_branch to points to the new begin
* of the branch
*/
rq->tmp_alone_branch = &cfs_rq->leaf_cfs_rq_list;
return false;
}
요청한 cfs 런큐를 leaf 리스트에 추가한다. (leaf 리스트 선두는 항상 태스크를 소유한 스케줄 엔티티의 가장 아래 cfs 런큐가 있어야 한다.)
- 코드 라인 3에서 요청한 cfs 런큐가 이미 leaf 리스트에 있는 경우 다음에 따른 결과를 반환한다.
- rq->tmp_alone_branch == &rq->leaf_cfs_rq_list
- on_list
- cfs 런큐가 leaf_cfs_rq_list에 추가 되어 있는 경우 true가 된다.
- 코드 라인 20~37에서 부모 cfs 런큐도 leaf 리스트에 이미 올라가 있는 경우 현재 leaf cfs 런큐 리스트를 부모 leaf cfs 런큐 리스트에 추가하고 1을 반환한다.
- 코드 라인 39~52에서 부모 그룹이 없는 경우 런큐의 leaf cfs 런큐 리스트에 현재 leaf cfs 런큐 리스트를 추가한다.
- 코드 라인 60~66에서 현재 leaf cfs 런큐 리스트를 rq->tmp_alone_branch에 추가하고, false를 반환한다.
다음 그림은 list_add_leaf_cfs_rq() 함수가 패치되기 전/후의 동작을 보여준다.
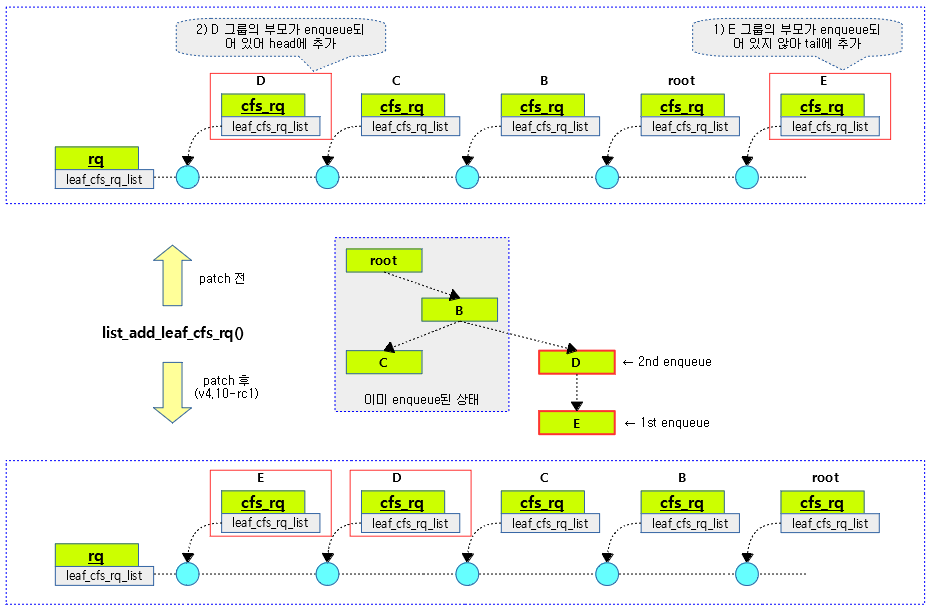
add_nr_running()
kernel/sched/sched.h
static inline void add_nr_running(struct rq *rq, unsigned count)
{
unsigned prev_nr = rq->nr_running;
rq->nr_running = prev_nr + count;
#ifdef CONFIG_SMP
if (prev_nr < 2 && rq->nr_running >= 2) {
if (!READ_ONCE(rq->rd->overload))
WRITE_ONCE(rq->rd->overload, 1);
}
#endif
sched_update_tick_dependency(rq);
}
런큐에서 돌고있는 active 태스크의 수를 count 만큼 추가한다.
- 코드 라인 3~5에서 런큐에서 돌고있는 active 태스크의 수를 count 만큼 추가한다.
- 코드 라인 8~11에서 기존 active 태스크 수가 2개 미만이었지만 추가한 태스크를 포함하여 active 태스크가 2개 이상이 된 경우 smp 시스템이면 런큐의 루트 도메인에 있는 overload를 true로 변경한다.
- 코드 라인 14에서 nohz full을 지원하는 커널인 경우 현재 런큐가 nohz full을 지원하는 상태이면 nohz full 상태에서 빠져나와 tick을 발생하게 한다.
hrtimer를 사용한 hrtick
hrtick 갱신
hrtick_update()
kernel/sched/fair.c
/* * called from enqueue/dequeue and updates the hrtick when the * current task is from our class and nr_running is low enough * to matter. */
static void hrtick_update(struct rq *rq)
{
struct task_struct *curr = rq->curr;
if (!hrtick_enabled(rq) || curr->sched_class != &fair_sched_class)
return;
if (cfs_rq_of(&curr->se)->nr_running < sched_nr_latency)
hrtick_start_fair(rq, curr);
}
다음 hrtick 만료 시각을 갱신한다. 이 함수는 스케줄 엔티티가 엔큐/디큐될 때마다 호출된다.
- 코드 라인 5~6에서 high-resolution 모드의 hitimer를 사용하는 hrtick이 사용되지 않거나 현재 태스크가 cfs 스케줄러를 사용하지 않으면 함수를 빠져나간다.
- 코드 라인 8~9에서 현재 태스크의 스케줄 엔티티의 cfs 런큐에서 동작하는 active 태스크가 sched_nr_latency(디폴트 8) 미만인 경우 다음 hrtick 만료 시각을 설정한다.
hrtick_enabled()
kernel/sched/sched.h
/* * Use hrtick when: * - enabled by features * - hrtimer is actually high res */>
static inline int hrtick_enabled(struct rq *rq)
{
if (!sched_feat(HRTICK))
return 0;
if (!cpu_active(cpu_of(rq)))
return 0;
return hrtimer_is_hres_active(&rq->hrtick_timer);
}
high-resolution 모드의 hitimer를 사용하는 hrtick 동작 여부를 반환한다.
- hrtimer_is_hres_active()
- return timer->base->cpu_base->hres_active
hrtick_start_fair()
kernel/sched/fair.c
static void hrtick_start_fair(struct rq *rq, struct task_struct *p)
{
struct sched_entity *se = &p->se;
struct cfs_rq *cfs_rq = cfs_rq_of(se);
WARN_ON(task_rq(p) != rq);
if (cfs_rq->nr_running > 1) {
u64 slice = sched_slice(cfs_rq, se);
u64 ran = se->sum_exec_runtime - se->prev_sum_exec_runtime;
s64 delta = slice - ran;
if (delta < 0) {
if (rq->curr == p)
resched_curr(rq);
return;
}
hrtick_start(rq, delta);
}
}
태스크에 주어진 weight로 타임 슬라이스를 산출하여 hrtick을 설정한다. 단 타임 슬라이스가 이미 소진된 경우 함수를 빠져나간다.
- 코드 라인 8~9에서 최상위 cfs 런큐에서 동작 중인 태스크가 1개 이상인 경우 요청한 태스크에 배정할 타임 슬라이스를 산출해온다.
- 코드 라인 10~11에서 산출한 타임 슬라이스에서 기존에 오버런한 시간을 뺀다.
- 코드 라인 13~17에서 만일 배정할 타임 슬라이스가 없는 경우 함수를 빠져나간다. 또한 런큐에 설정된 curr가 현재 태스크인 경우 리스케줄 요청한다.
- 코드 라인 11에서 delta 만료 시간으로 런큐의 hrtick 타이머를 가동시킨다.
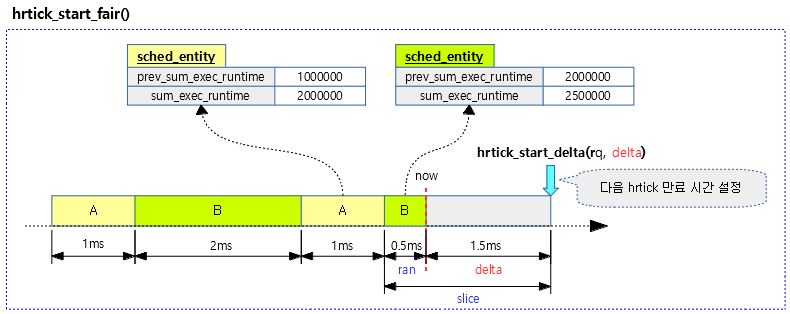
다음 그림은 hrtick 만료 시각을 설정하는 모습을 보여준다.
다음 태스크 선택 – (*pick_next_task)
다음 실행시킬 태스크를 선택해서 반환한다. 만일 hrtick을 사용하고 있으면 해당 타임 슬라이스를 산출하여 타이머를 가동시킨다.
pick_next_task_fair()
kernel/sched/fair.c -1/2-
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
int new_tasks;
again:
if (!sched_fair_runnable(rq))
goto idle;
#ifdef CONFIG_FAIR_GROUP_SCHED
if (!prev || prev->sched_class != &fair_sched_class)
goto simple;
/*
* Because of the set_next_buddy() in dequeue_task_fair() it is rather
* likely that a next task is from the same cgroup as the current.
*
* Therefore attempt to avoid putting and setting the entire cgroup
* hierarchy, only change the part that actually changes.
*/
do {
struct sched_entity *curr = cfs_rq->curr;
/*
* Since we got here without doing put_prev_entity() we also
* have to consider cfs_rq->curr. If it is still a runnable
* entity, update_curr() will update its vruntime, otherwise
* forget we've ever seen it.
*/
if (curr) {
if (curr->on_rq)
update_curr(cfs_rq);
else
curr = NULL;
/*
* This call to check_cfs_rq_runtime() will do the
* throttle and dequeue its entity in the parent(s).
* Therefore the nr_running test will indeed
* be correct.
*/
if (unlikely(check_cfs_rq_runtime(cfs_rq))) {
cfs_rq = &rq->cfs;
if (!cfs_rq->nr_running)
goto idle;
goto simple;
}
}
se = pick_next_entity(cfs_rq, curr);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
- 코드 라인 9~11에서 again: 레이블이다. 동작시킬 cfs 태스크가 없는 경우 idle 레이블로 이동한다.
- 코드 라인 14~15에서 기존 태스크가 없거나 cfs 스케줄러에서 동작하지 않은 경우 simple 레이블로 이동한다.
- 코드 라인 25~38에서 최상위 cfs 런큐부터 하위로 순회하며 cfs 런큐의 curr 엔티티의 런타임, PELT 및 stat등을 갱신한다.
- 코드 라인 46~53에서 현재 그룹 엔티티가 스로틀해야 하는 경우 siple 레이블로 이동한다. 단 동작 중인 엔티티가 없으면 idle 레이블로 이동한다.
- 코드 라인 56~58에서 다음 엔티티를 구하고, 하위 cfs 런큐로 순회한다.
- 코드 라인 60에서 루프가 만료된 후 엔티티는 실제 런타임을 가지는 태스크형 엔티티가 된다.
kernel/sched/fair.c -2/2-
/*
* Since we haven't yet done put_prev_entity and if the selected task
* is a different task than we started out with, try and touch the
* least amount of cfs_rqs.
*/
if (prev != p) {
struct sched_entity *pse = &prev->se;
while (!(cfs_rq = is_same_group(se, pse))) {
int se_depth = se->depth;
int pse_depth = pse->depth;
if (se_depth <= pse_depth) {
put_prev_entity(cfs_rq_of(pse), pse);
pse = parent_entity(pse);
}
if (se_depth >= pse_depth) {
set_next_entity(cfs_rq_of(se), se);
se = parent_entity(se);
}
}
put_prev_entity(cfs_rq, pse);
set_next_entity(cfs_rq, se);
}
goto done;
simple:
#endif
if (prev)
put_prev_task(rq, prev);
do {
se = pick_next_entity(cfs_rq, NULL);
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
done: __maybe_unused;
#ifdef CONFIG_SMP
/*
* Move the next running task to the front of
* the list, so our cfs_tasks list becomes MRU
* one.
*/
list_move(&p->se.group_node, &rq->cfs_tasks);
#endif
if (hrtick_enabled(rq))
hrtick_start_fair(rq, p);
update_misfit_status(p, rq);
return p;
idle:
if (!rf)
return NULL;
new_tasks = newidle_balance(rq, rf);
/*
* Because newidle_balance() releases (and re-acquires) rq->lock, it is
* possible for any higher priority task to appear. In that case we
* must re-start the pick_next_entity() loop.
*/
if (new_tasks < 0)
return RETRY_TASK;
if (new_tasks > 0)
goto again;
/*
* rq is about to be idle, check if we need to update the
* lost_idle_time of clock_pelt
*/
update_idle_rq_clock_pelt(rq);
return NULL;
}
- 코드 라인 6~7에서 러닝할 태스크가 변경된 경우이다.
- 코드 라인 9~21에서 이전 실행 했었던 태스크에 대한 엔티티와 현재 실행할 태스크에 대한 엔티티가 위로 이동하면서 그룹 엔티티가 만나기 직전까지 다음과 같이 처리한다.
- 현재 스케줄 엔티티가 기존 스케줄 엔티티보다 상위에 있는 경우(depth 값 0이 최상위) 기존 스케줄 엔티티를 해당 cfs 런큐에 put하고 부모 스케줄 엔티티를 지정한다.
- 현재 스케줄 엔티티가 기존 스케줄 엔티티보다 같거나 하위에 있는 경우 현재 스케줄 엔티티를 현재 cfs 런큐에 curr로 설정하고 부모 스케줄 엔티티를 지정한다.
- 코드 라인 23~24에서 그룹 엔티티가 같아진 경우 cfs 런큐에 기존 스케줄 엔티티를 put하고 현재 스케줄 엔티티를 curr로 설정한다.
- 코드 라인 27에서 done 레이블로 이동한다.
- 코드 라인 28~31에서 simple: 레이블이다. 만일 prev 태스크가 있었으면 put_prev_task() 처리를 한다.
- 코드 라인 33~37에서 최상위 cfs 런큐부터 실행할 태스크가 있는 cfs 런큐를 내려오면서 순회한다.
- 코드 라인 39에서 여기 까지 오면 다음 실행할 최종 태스크가 구해진다.
- 코드 라인 41~48에서 done: 레이블이다. 런큐의 cfs_tasks 리스트에 러닝 태스크를 추가한다.
- 코드 라인 51~52에서 hrtick을 사용하는 경우 해당 스케줄 엔티티의 남은 타임 슬라이스 만큼 만료 시각을 hrtick 타이머에 설정한다.
- 코드 라인 54~56에서 misfit 상태를 갱신하고 실행할 태스크를 반환한다.
- 코드 라인 58~60에서 idle: 레이블이다. 런큐 플래그가 없으면 null을 반환한다.
- 코드 라인 62에서idle 밸런스를 통해 실행할 태스크를 가져온다.
- 현재 cpu가 로드가 없으므로 다른 로드 높은 cpu로부터 태스크를 pull해온다.
- 코드 라인 69~70에서 결과가 0보다 작으면 RETRY_TASK를 반환한다.
- 코드 라인 72~73에서 가져온 태스크가 있는 경우 again 레이블로 이동한다.
- 코드 라인 79~81에서 가져온 태스크가 없는 경우 런큐의 lost_idle_time을 갱신하고 null을 반환한다.
pick_next_entity()
kernel/sched/fair.c
/* * Pick the next process, keeping these things in mind, in this order: * 1) keep things fair between processes/task groups * 2) pick the "next" process, since someone really wants that to run * 3) pick the "last" process, for cache locality * 4) do not run the "skip" process, if something else is available */
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
struct sched_entity *left = __pick_first_entity(cfs_rq);
struct sched_entity *se;
/*
* If curr is set we have to see if its left of the leftmost entity
* still in the tree, provided there was anything in the tree at all.
*/
if (!left || (curr && entity_before(curr, left)))
left = curr;
se = left; /* ideally we run the leftmost entity */
/*
* Avoid running the skip buddy, if running something else can
* be done without getting too unfair.
*/
if (cfs_rq->skip == se) {
struct sched_entity *second;
if (se == curr) {
second = __pick_first_entity(cfs_rq);
} else {
second = __pick_next_entity(se);
if (!second || (curr && entity_before(curr, second)))
second = curr;
}
if (second && wakeup_preempt_entity(second, left) < 1)
se = second;
}
/*
* Prefer last buddy, try to return the CPU to a preempted task.
*/
if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1)
se = cfs_rq->last;
/*
* Someone really wants this to run. If it's not unfair, run it.
*/
if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1)
se = cfs_rq->next;
clear_buddies(cfs_rq, se);
return se;
}
cfs 런큐에서 다음 스케줄 엔티티를 선택해서 반환하는데 cfs 런큐에 설정된 3개의 버디 엔티티를 참고한다.
- 코드 라인 4에서 cfs 런큐의 rb 트리에서 대기 중인 엔티티들 중 가장 처음(leftmost) 엔티티를 알아온다.
- 코드 라인 14에서 알아온 엔티티가 없거나 curr보다 vruntime이 많은 경우 그대로 curr를 엔티티로 선택한다.
- 코드 라인 20~29에서 cfs 런큐에 skip 버디로 설정된 엔티티인 경우 다음 우선 순위의 second 엔티티를 찾는다. 알아온 엔티티 역시 curr보다 vruntime이 많은 경우 그대로 curr를 second 엔티티로 선택한다.
- 코드 라인 31~32에서 second 엔티티가 처음 선택해 두었던 left 엔티티의 vruntime보다 작거나 gran이 적용된 left의 vruntime보다 작은 경우 스케줄 엔티티로 second 엔티티를 선택한다.
- gran:
- cfs 런큐에서 sysctl_sched_wakeup_granularity(디폴트 1000000 ns) 기간에서 해당 스케줄 엔티티의 weight에 해당하는 vruntime으로 변환한 기간
- 이 값을 벗어나는 경우 preemption을 막는다.
- gran:
- 코드 라인 38~39에서 cfs 런큐에 last 버디가 준비된 경우 last 엔티티가 현재 선정된 second 엔티티의 vruntime보다 작거나 gran이 적용된 second의 vruntime보다 작은 경우 스케줄 엔티티로 last 엔티티를 선택한다.
- 코드 라인 44~45에서 cfs 런큐에 next 버디가 준비된 경우 next 엔티티가 현재 선정된 스케줄 엔티티의 vruntime보다 작거나 gran이 적용된 스케줄 엔티티의 vruntime보다 작은 경우 스케줄 엔티티로 next 엔티티를 선택한다.
- 코드 라인 47에서 cfs 런큐에 있는 3개의 버디(skip, next, last) 설정들을 모두 클리어한다.
- 코드 라인 49에서 최종 선택된 스케줄 엔티티를 반환한다.
wakeup_preempt_entity()
kernel/sched/fair.c
/* * Should 'se' preempt 'curr'. * * |s1 * |s2 * |s3 * g * |<--->|c * * w(c, s1) = -1 * w(c, s2) = 0 * w(c, s3) = 1 * */
static int
wakeup_preempt_entity(struct sched_entity *curr, struct sched_entity *se)
{
s64 gran, vdiff = curr->vruntime - se->vruntime;
if (vdiff <= 0)
return -1;
gran = wakeup_gran(curr, se);
if (vdiff > gran)
return 1;
return 0;
}
se 엔티티가 curr 엔티티를 누르고 preemption할 수 있는지 상태를 알아온다. 1=가능, 0=gran 범위 이내이므로 불가능, -1=불가능
- 코드 라인 4~7에서 curr의 vruntime <= se의 vruntime인 경우 preemption 하지 못하도록 -1을 반환한다.
- 코드 라인 9~11에서 se의 vruntime + gran < curr의 vruntime인 경우 se가 preemption 할 수 있도록 1을 반환한다.
- 코드 라인 13에서 preemption을 하지 못하게 도록 0을 반환한다. preemption 해봤자 스위칭하다가 순서가 곧 바뀔만큼의 작은 시간 차이밖에 안날 때이다.
wakeup_gran()
kernel/sched/fair.c
static unsigned long
wakeup_gran(struct sched_entity *curr, struct sched_entity *se)
{
unsigned long gran = sysctl_sched_wakeup_granularity;
/*
* Since its curr running now, convert the gran from real-time
* to virtual-time in his units.
*
* By using 'se' instead of 'curr' we penalize light tasks, so
* they get preempted easier. That is, if 'se' < 'curr' then
* the resulting gran will be larger, therefore penalizing the
* lighter, if otoh 'se' > 'curr' then the resulting gran will
* be smaller, again penalizing the lighter task.
*
* This is especially important for buddies when the leftmost
* task is higher priority than the buddy.
*/
return calc_delta_fair(gran, se);
}
스케줄 엔티티의 wakeup에 필요한 최소 시간을 반환한다. (gran)
- sysctl_sched_wakeup_granularity(디폴트 1000000 ns) 기간을 스케줄 엔티티의 vruntime으로 환산하여 반환한다.
set_next_entity()
kernel/sched/fair.c
static void
set_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
/* 'current' is not kept within the tree. */
if (se->on_rq) {
/*
* Any task has to be enqueued before it get to execute on
* a CPU. So account for the time it spent waiting on the
* runqueue.
*/
update_stats_wait_end(cfs_rq, se);
__dequeue_entity(cfs_rq, se);
update_load_avg(cfs_rq, se, UPDATE_TG);
}
update_stats_curr_start(cfs_rq, se);
cfs_rq->curr = se;
/*
* Track our maximum slice length, if the CPU's load is at
* least twice that of our own weight (i.e. dont track it
* when there are only lesser-weight tasks around):
*/
if (schedstat_enabled() &&
rq_of(cfs_rq)->cfs.load.weight >= 2*se->load.weight) {
schedstat_set(se->statistics.slice_max,
max((u64)schedstat_val(se->statistics.slice_max),
se->sum_exec_runtime - se->prev_sum_exec_runtime));
}
se->prev_sum_exec_runtime = se->sum_exec_runtime;
}
cfs 런큐에 요청한 스케줄 엔티티를 동작하도록 설정한다. (curr에 설정)
- 코드 라인 5~14에서 엔티티를 curr에 넣기 전에 RB tree에서 꺼내고 로드 평균을 갱신한다.
- 코드 라인 16~17에서 시작과 관련한 통계 값들을 설정하고 엔티티를 curr에 설정한다.
- 코드 라인 24~29에서 최대 slice 타임을 갱신한다.
- 코드 라인 31에서 기존 실행 시간 총합을 갱신한다.
구조체
load_weight 구조체
include/linux/sched.h
struct load_weight {
unsigned long weight;
u32 inv_weight;
};
- weight
- CFS 스케줄러에서 사용하는 유저 태스크에 주어진 우선순위 nice에 대한 태스크 로드 값
- default nice 값 0인 경우 weight=1024
- inv_weight
- prio_to_wmult[] 배열에 이미 만들어진 nice값에 해당하는 2^32/weight 값
sched_entity 구조체
include/linux/sched.h
struct sched_entity {
/* For load-balancing: */
struct load_weight load;
unsigned long runnable_weight;
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
struct sched_statistics statistics;
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth;
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
#endif
#ifdef CONFIG_SMP
/*
* Per entity load average tracking.
*
* Put into separate cache line so it does not
* collide with read-mostly values above.
*/
struct sched_avg avg;
#endif
};
- load
- 엔티티의 로드 weight 값
- runnable_weight
- 엔티티의 러너블 로드 weight 값
- run_node
- cfs 런큐의 RB 트리에 연결될 때 사용되는 노드
- group_node
- cfs 런큐의 cfs_tasks 리스트에 연결될 떄 사용되는 노드
- on_rq
- cfs 런큐의 자료 구조인 RB Tree에 엔큐 여부
- curr 엔티티는 on_rq==0이다.
- exec_start
- 엔티티의 실행 시각(ns)
- sum_exec_runtime
- 엔티티가 실행한 총 시간(ns)
- vruntime
- 가상 런타임 값으로 이 시간을 기준으로 cfs 런큐의 RB 트리에서 정렬된다.
- prev_sum_exec_runtime
- 이전 산출에서 엔티티가 실행한 총 시간(ns)
- nr_migrations
- 마이그레이션 횟수
- statistics
- 스케줄 통계
- depth
- 태스크 그룹의 단계별 depth로 루트 그룹이 0이다.
- *parent
- 부모 엔티티
- 태스크 그룹이 구성되면 엔티티가 계층 구조로 구성된다.
- *cfs_rq
- 엔티티가 소속된 cfs 런큐
- *my_q
- 그룹 엔티티가 관리하는 cfs 런큐
- avg
- 스케줄 엔티티의 로드 평균(PELT)
cfs_rq 구조체
kernel/sched/sched.h
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load;
unsigned long runnable_weight;
unsigned int nr_running;
unsigned int h_nr_running; /* SCHED_{NORMAL,BATCH,IDLE} */
unsigned int idle_h_nr_running; /* SCHED_IDLE */
u64 exec_clock;
u64 min_vruntime;
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root_cached tasks_timeline;
/*
* 'curr' points to currently running entity on this cfs_rq.
* It is set to NULL otherwise (i.e when none are currently running).
*/
struct sched_entity *curr;
struct sched_entity *next;
struct sched_entity *last;
struct sched_entity *skip;
#ifdef CONFIG_SCHED_DEBUG
unsigned int nr_spread_over;
#endif
#ifdef CONFIG_SMP
/*
* CFS load tracking
*/
struct sched_avg avg;
#ifndef CONFIG_64BIT
u64 load_last_update_time_copy;
#endif
struct {
raw_spinlock_t lock ____cacheline_aligned;
int nr;
unsigned long load_avg;
unsigned long util_avg;
unsigned long runnable_sum;
} removed;
#ifdef CONFIG_FAIR_GROUP_SCHED
unsigned long tg_load_avg_contrib;
long propagate;
long prop_runnable_sum;
/*
* h_load = weight * f(tg)
*
* Where f(tg) is the recursive weight fraction assigned to
* this group.
*/
unsigned long h_load;
u64 last_h_load_update;
struct sched_entity *h_load_next;
#endif /* CONFIG_FAIR_GROUP_SCHED */
#endif /* CONFIG_SMP */
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq; /* CPU runqueue to which this cfs_rq is attached */
/*
* leaf cfs_rqs are those that hold tasks (lowest schedulable entity in
* a hierarchy). Non-leaf lrqs hold other higher schedulable entities
* (like users, containers etc.)
*
* leaf_cfs_rq_list ties together list of leaf cfs_rq's in a CPU.
* This list is used during load balance.
*/
int on_list;
struct list_head leaf_cfs_rq_list;
struct task_group *tg; /* group that "owns" this runqueue */
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
s64 runtime_remaining;
u64 throttled_clock;
u64 throttled_clock_task;
u64 throttled_clock_task_time;
int throttled;
int throttle_count;
struct list_head throttled_list;
#endif /* CONFIG_CFS_BANDWIDTH */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};
- load
- cfs 런큐의 로드 weight 값
- runnable_weight
- cfs 런큐의 러너블 로드 weight 값
- nr_running
- 해당 cfs 런큐에서 동작중인 엔티티 수이다. (스로틀링된 그룹 엔티티 제외)
- 타임 slice 계산에 참여할 엔티티 수이다.
- h_nr_running
- cfs 런큐를 포함한 하위 cfs 런큐에서 동작중인 active 태스크 수이다. (스로틀링된 하위 그룹들 모두 제외)
- exec_clock
- 실행 시각
- min_vruntime
- 최소 가상 런타임
- RB 트리에서 엔큐된 스케줄 엔티티의 vruntime에서 이 값을 빼서 사용한다.
- min_vruntime_copy
- 32비트 시스템에서 사용
- tasks_timeline
- cfs 런큐의 RB 트리 루트
- *rb_leftmost
- cfs 런큐의 RB 트리에 있는 가장 좌측의 노드를 가리킨다.
- RB 트리내에서 가장 작은 vruntime 값을 가지는 스케줄 엔티티 노드
- *curr
- cfs 런큐에서 동작 중인 현재 스케줄 엔티티
- RB 트리에 존재하지 않고 밖으로 빠져나와 있다.
- *next
- next 버디
- *last
- last 버디
- *skip
- skip 버디
- avg
- PELT 기반 로드 평균
- h_load
- last_h_load_update
- *h_load_next
- *rq
- cfs 런큐가 속한 런큐를 가리킨다.
- on_list
- leaf cfs 런큐 리스트에 포함 여부
- leaf_cfs_rq_list
- 태스크가 포함된 cfs_rq가 추가된다.
- *tg
- cfs 런큐가 속한 태스크 그룹
- runtime_enabled
- cfs 런큐에서 cfs 밴드폭 구성 사용
- quota가 설정된 경우 사용
- runtime_remaing
- 남은 런타임
- throttled_clock
- 스로틀 시작 시각
- throttled_clock_task
- 스로틀 태스크 시작 시각(irq 처리 시간을 제외한 태스크 시간)
- throttled_clock_task_time
- 스로틀된 시간 총합(irq 처리 시간을 제외하고 스로틀된 태스크 시간)
- throttled
- cfs 런큐가 스로틀된 경우 true
- throttle_count
- cfs 런큐가 스로틀된 횟수로 계층 구조의 스케줄 엔티티에 대해 child 부터 시작하여 스로된 cfs 런큐가 있는 경우 카운터가 증가되다.
- throttled_list
- cfs_bandwidth의 throttled_cfs_rq 리스트에 추가할 때 사용하는 cfs 런큐의 스로틀 리스트
참고
- Scheduler -1- (Basic) | 문c
- Scheduler -2- (Global Cpu Load) | 문c
- Scheduler -3- (PELT) | 문c
- Scheduler -4- (Group Scheduling) | 문c
- Scheduler -5- (Scheduler Core) | 문c
- Scheduler -6- (CFS Scheduler) | 문c – 현재 글
- Scheduler -7- (Preemption & Context Switch) | 문c
- Scheduler -8- (CFS Bandwidth) | 문c
- Scheduler -9- (RT Scheduler) | 문c
- Scheduler -10- (Deadline Scheduler) | 문c
- Scheduler -11- (Stop Scheduler) | 문c
- Scheduler -12- (Idle Scheduler) | 문c
- Scheduler -13- (Scheduling Domain 1) | 문c
- Scheduler -14- (Scheduling Domain 2) | 문c
- Scheduler -15- (Load Balance 1) | 문c
- Scheduler -16- (Load Balance 2) | 문c
- Scheduler -17- (Load Balance 3 NUMA) | 문c
- Scheduler -18- (Load Balance 4 EAS) | 문c
- Scheduler -19- (초기화) | 문c
- PID 관리 | 문c
- do_fork() | 문c
- cpu_startup_entry() | 문c
- 런큐 로드 평균(cpu_load[]) – v4.0 | 문c
- PELT(Per-Entity Load Tracking) – v4.0 | 문c
- CPU bandwidth control for CFS | Google Paul Turner, IBM Bharata B Rao, Google Nikhil Rao – 다운로드 pdf
- CFS bandwidth control | LWN.net – 한글 번역 | KERNELMSG
- CFS Bandwidth Control | kernel.org
- cfs scheduling 1 & cfs group scheduling (1) | 솔개가하늘을가르네
- Linux 3.2 – CFS CPU bandwidth (english version) | Christophe Blaess
- integrating the scheduler and cpufreq | Linaro connect – 다운로드 pdf
- CFS 소스 코드 분석 | 어린아이