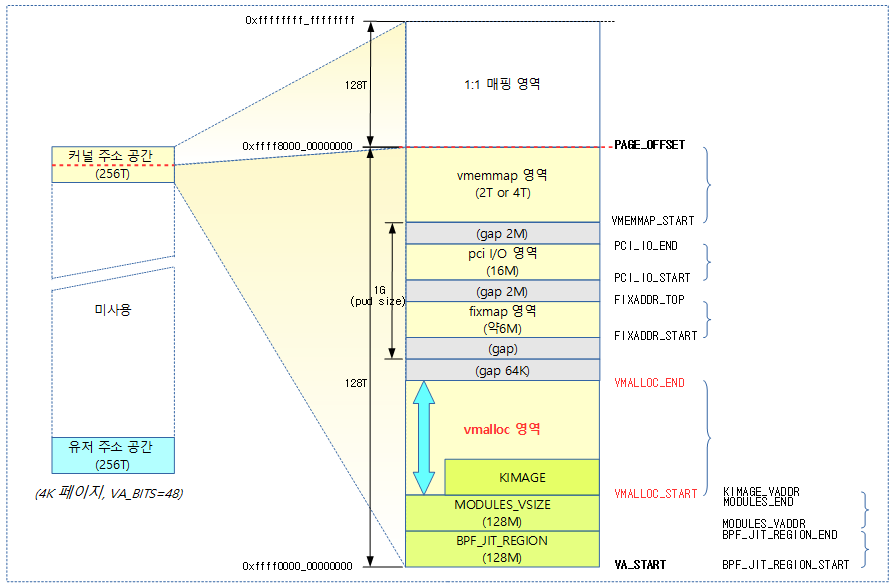
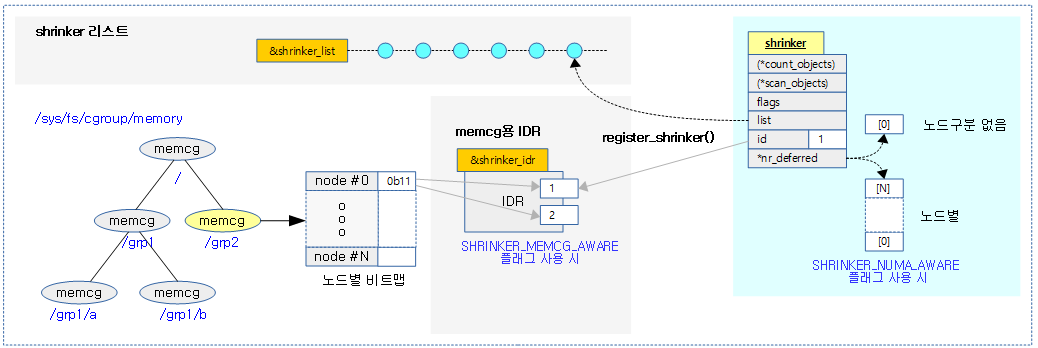
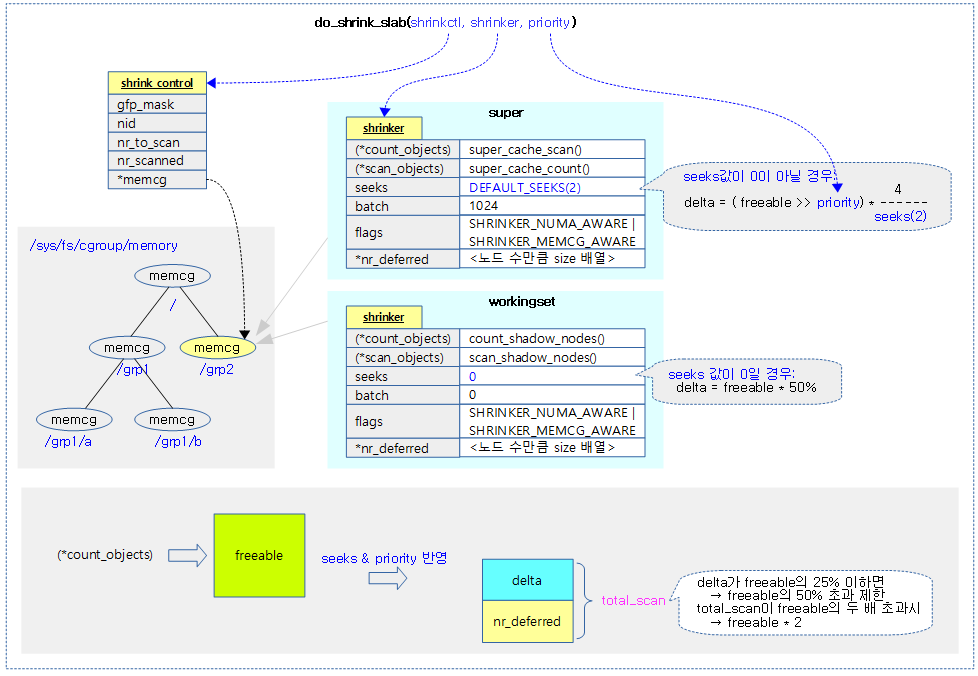
<kernel v5.0>
Vmap
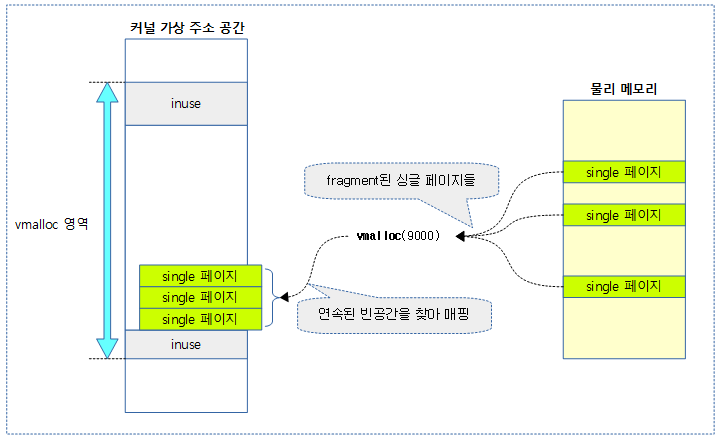
커널에서는 단편화 문제를 유발하는 high order 페이지 할당의 사용을 매우 꺼려한다. 따라서 사이즈가 큰 페이지 할당이 필요하지만 빈번한 할당/해제를 하지 않는 경우에 한해 여러 개의 싱글(order 0) 페이지들을 사용하여 연속된 가상 주소 공간에 모아 매핑하는 방법을 사용한다. 이러한 매핑 방법을 vmap(Virtually contiguous memory area mapping)이라고 한다.
vmap을 사용하여 다음 2가지의 주소 공간에 메모리를 할당하는 api는 다음과 같다.
- vmalloc()
- 요청 size 만큼의 페이지를 할당하여 vmalloc address space 공간에 매핑
- module_alloc()
- 요청 size 만큼의 페이지를 할당하여 module address space 공간에 매핑
VM 영역 관리
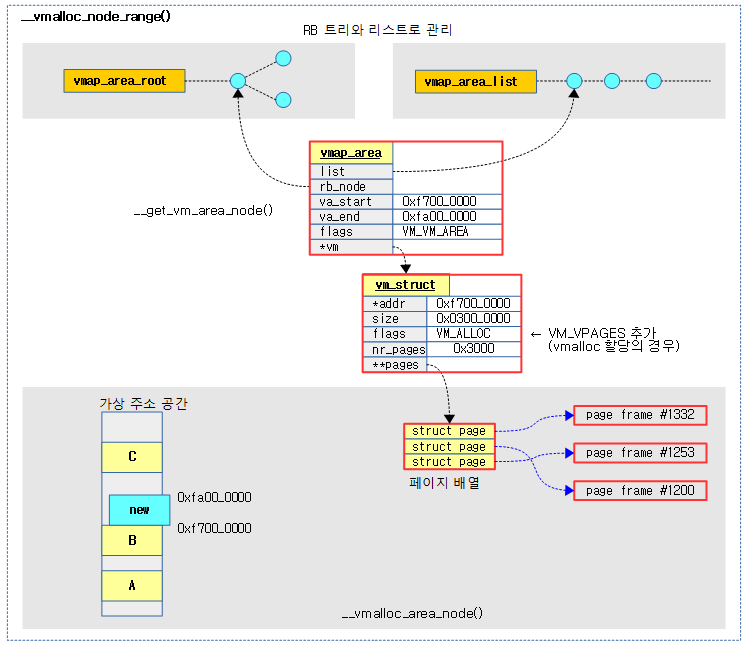
VMALLOC 가상 주소 공간의 빈 공간 검색을 위해 RB 트리 및 리스트 자료 구조를 동시에 사용한다.
- RB 트리
- 리스트
다음 그림은 vmalloc 가상 주소 공간내에서 VM 영역들이 RB 트리 및 리스트에서 관리되고 있는 모습을 보여준다.

관리 항목
위의 자료 구조를 사용하여 vmalloc의 공간을 관리하는 항목은 다음과 같다.
- 사용 공간 관리
- vmap_area_root
- vmap_area_list
- 빈 공간 관리
- ree_vmap_area_root
- free_vmap_area_list
- 이 항목은 커널 v5.2-rc1에서추가되었다.
- 참고: mm/vmalloc.c: keep track of free blocks for vmap allocation (2019, v5.2-rc1)
- lazy free 관리
- purge_vmap_area_root
- purge_vmap_area_list
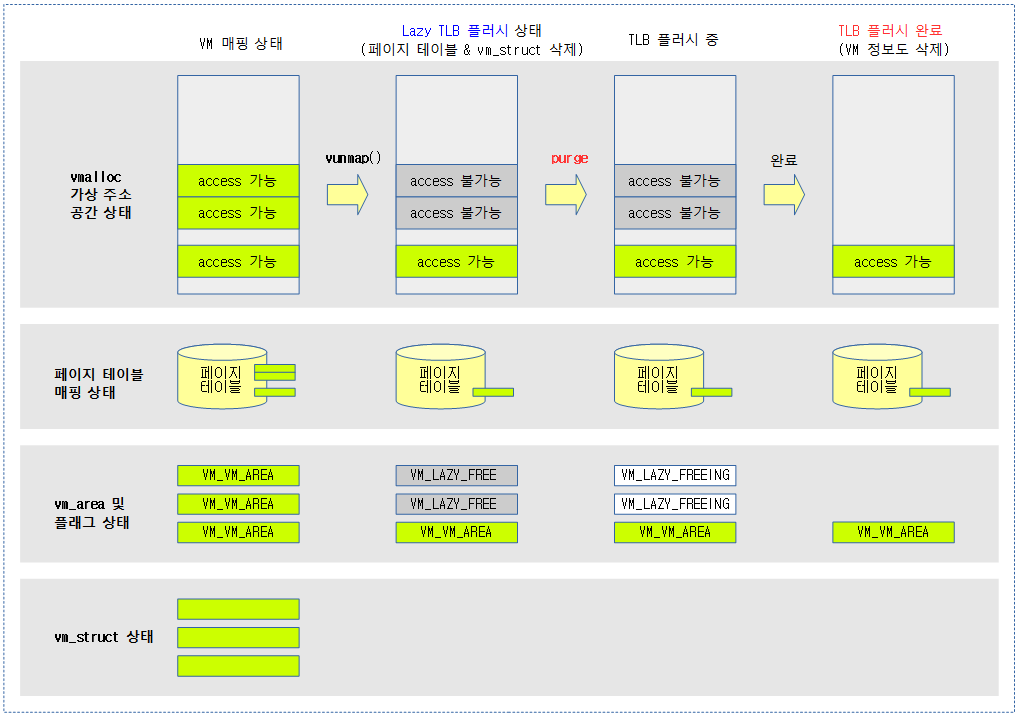
Lazy TLB Flushing(Free)
- vunmap()을 수행하면 다음과 같은 처리항목이 수행되어야 하는데 즉각 처리되는 항목과 나중에 모아 처리할 항목을 분류한다.
- 즉각 처리
- 페이지 테이블에서 매핑 해제
- 캐시 flush
- 지연 처리
- RB tree 및 리스트에서 지연된 vmap_area의 제거
- 모든 cpu의 TLB flush
- cpu가 많은 시스템에서 arm64의 경우 inner 영역의 cpu들에 대해 일괄적으로 TLB flush를 수행하게 할 수 있어 arm32보다는 조금 더 낳은 요건이 있다. 이에 비해 arm32 시스템의 경우 IPI(Inter Process Interrupt) 콜을 사용하여 각 cpu로 인터럽트를 발생시킨 후 처리하게 하여 더욱 처리 성능을 떨어뜨리는 요인이 된다.
- 즉각 처리
- 삭제할 vma를 처리하지 않고 놔두었다가 일정량을 초과하거나 메모리 부족 시 한꺼번에 purge 처리하여 처리 성능을 높인다.
- 이러한 해지를 유보하는 방법을 사용하여 vmap_area의 관리를 약 20배 이상 빠르게 처리를 하는 구현을 적용하였다.
- lazy TLB free 상태를 표현하는 플래그 비트는 다음과 같다.
- VM_LAZY_FREE (0x1)
- 삭제 요청된 상태
- VM_LAZY_FREEING (0x2)
- purge 진행중인 상태
- VM_VM_AREA (0x4)
- 할당 상태
- VM_LAZY_FREE (0x1)
다음 그림은 VM 영역이 vunmap()에 의해 Lazy TLB 플러시 상태로 변화하고, 그 후 purge될 때 실제 TLB 플러시 처리되는 과정을 보여준다.
관련 API
- vmap()
- vunmap()
대체 API
vmap() 대체 api로 per-cpu map 기반의 api들이 소개되었다. 이 API는 아직 많은 드라이버에 적용되어 사용하지는 않고 일부 드라이버들 에서만 사용하고 있다.
- vm_map_ram()
- vm_unmap_ram()
vmap 매핑
vmap() 함수를 사용하기 위해서 매핑에 사용할 싱글(order 0) 페이지 단위의 물리 메모리 정보들을 페이지 디스크립터 배열로 구성하여 요청한다. 그러면 vmalloc 가상 주소 공간의 빈 자리를 찾아 페이지들을 주어진 매핑 속성으로 매핑하고 매핑된 가상 시작 주소를 반환한다.
- 보다 빠른 할당/해제를 위해 캐시 노드와 몇 개의 변수들을 사용한다.
- free_vmap_cache
- 빈 공간에 대한 검색을 빠르게 하기 위해 가장 최근에 등록하여 사용한 vmap_area 또는 가장 최근에 free 한 vmap_area의 이전(prev) vmap_area가 보관된다.
- cached_hole_size
- 캐시의 바로 앞 hole의 크기를 기억한다.
- 이 값이 0이면 캐시를 사용하지 않고 처음부터 검색을 수행한다.
- cached_vstart
- 캐시된 시작 가상 주소
- cached_align
- 캐시된 align 값
- free_vmap_cache
- per-cpu에서 사용하는 변수
- vmap_area_pcpu_hole
- per-cpu의 할당 시작 주소로 vmalloc 공간의 끝 부터 시작한다. (초기값은 VMALLOC_END)
- vmalloc()이 vmalloc 공간의 처음 주소부터 할당하지만, per-cpu는 그 반대이다.
- vmap_area_pcpu_hole
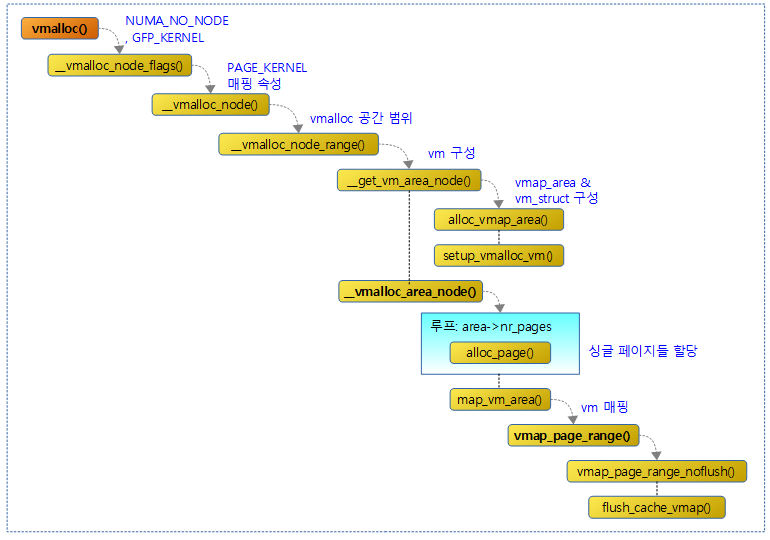
다음 그림은 vmap() 함수에 대해 연관 함수들과의 처리 흐름을 보여준다.
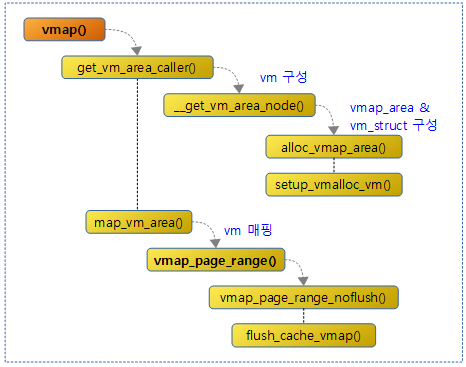
vmap()
mm/vmalloc.c
/** * vmap - map an array of pages into virtually contiguous space * @pages: array of page pointers * @count: number of pages to map * @flags: vm_area->flags * @prot: page protection for the mapping * * Maps @count pages from @pages into contiguous kernel virtual * space. */
void *vmap(struct page **pages, unsigned int count,
unsigned long flags, pgprot_t prot)
{
struct vm_struct *area;
unsigned long size; /* In bytes */
might_sleep();
if (count > totalram_pages())
return NULL;
size = (unsigned long)count << PAGE_SHIFT;
area = get_vm_area_caller(size, flags, __builtin_return_address(0));
if (!area)
return NULL;
if (map_vm_area(area, prot, pages)) {
vunmap(area->addr);
return NULL;
}
return area->addr;
}
EXPORT_SYMBOL(vmap);
연속된 가상 주소 공간에 요청한 물리 페이지들을 매핑하고 매핑한 가상 주소를 반환한다. 실패 시 null을 반환한다.
- 코드 라인 7에서 CONFIG_PREEMPT_VOLUNTARY 커널 옵션을 사용하는 경우 preempt point로 긴급히 리스케쥴링 요청한 태스크가 있는 경우 sleep 한다.
- 코드 라인 9~10에서 전체 메모리 페이지보다 더 많은 페이지를 요구하는 경우 처리를 포기하고 null을 반환한다.
- 코드 라인 12~15에서 VM 할당을 위해, vmap_area 및 vm_struct 정보를 구성한다. 실패하는 경우 null을 반환한다.
- 코드 라인 17~20에서 vm_struct 정보로 페이지들의 매핑을 시도하고 실패한 경우 해제 후 null을 반환한다.
- 코드 라인 22에서 매핑한 가상 주소 공간의 시작 주소를 반환한다.
다음 그림은 요청한 물리 페이지들에 대해 VMALLOC 가상 주소 공간에서 빈 공간을 찾아 매핑을 하는 모습을 보여준다.
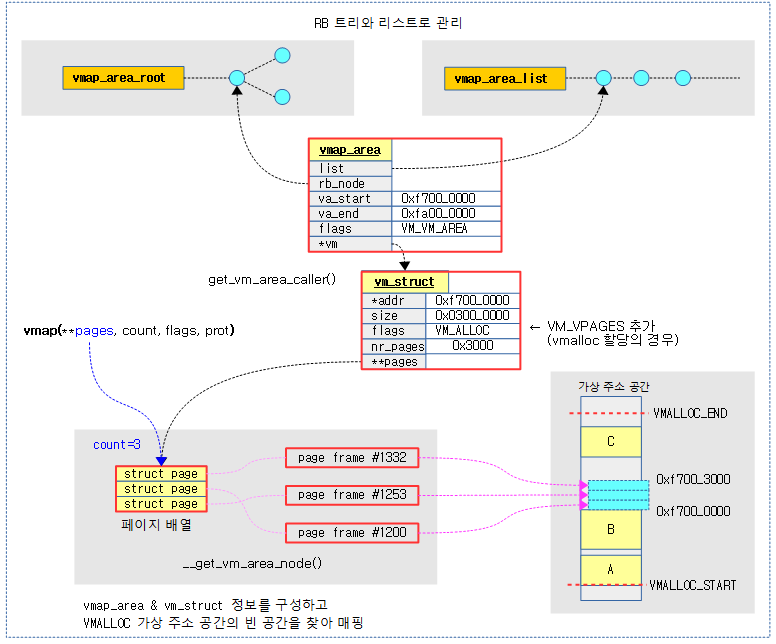
VM(가상 주소 영역) 할당
get_vm_area_caller()
mm/vmalloc.c
struct vm_struct *get_vm_area_caller(unsigned long size, unsigned long flags,
const void *caller)
{
return __get_vm_area_node(size, 1, flags, VMALLOC_START, VMALLOC_END,
NUMA_NO_NODE, GFP_KERNEL, caller);
}
요청한 size(페이지 단위로 정렬된 byte 단위)로 VMALLOC 가상 주소 공간에서 빈 공간을 찾아 VM(vm_area 및 vm_struct) 정보를 구성해온다.
__get_vm_area_node()
mm/vmalloc.c
static struct vm_struct *__get_vm_area_node(unsigned long size,
unsigned long align, unsigned long flags, unsigned long start,
unsigned long end, int node, gfp_t gfp_mask, const void *caller)
{
struct vmap_area *va;
struct vm_struct *area;
BUG_ON(in_interrupt());
size = PAGE_ALIGN(size);
if (unlikely(!size))
return NULL;
if (flags & VM_IOREMAP)
align = 1ul << clamp_t(int, get_count_order_long(size),
PAGE_SHIFT, IOREMAP_MAX_ORDER);
area = kzalloc_node(sizeof(*area), gfp_mask & GFP_RECLAIM_MASK, node);
if (unlikely(!area))
return NULL;
if (!(flags & VM_NO_GUARD))
size += PAGE_SIZE;
va = alloc_vmap_area(size, align, start, end, node, gfp_mask);
if (IS_ERR(va)) {
kfree(area);
return NULL;
}
setup_vmalloc_vm(area, va, flags, caller);
return area;
}
@start ~ @end 가상 주소 공간에서 @align 조건의 @size 만큼의 빈 영역을 찾아 vm을 할당 구성한 후 반환한다.
- 코드 라인 9~11에서 페이지 단위로 사이즈를 정렬한다.
- 코드 라인 13~15에서 ioremap이 요청된 경우 사이즈를 order 단위로 변환한 align 값을 사용한다. 단 ioremap 최대 order 페이지 수 만큼으로 제한한다.
- IOREMAP_MAX_ORDER
- ARM32 pmd 단위(16M) 비트 수 => 24
- ARM64 4K 페이지를 사용하는 경우 pud 단위(1G) 비트 수 => 30
- ARM64 16K 페이지를 사용하는 경우 pmd 단위(32M) 비트 수 => 25
- ARM64, 64K 페이지를 사용하는 경우 pmd 단위 (512M) 비트 수 => 29
- IOREMAP_MAX_ORDER
- 코드 라인 17~19에서 vm_struct를 할당한다.
- 코드 라인 21~22에서 no guard 요청이 없으면 가드 페이지를 위해 1페이지를 추가한다.
- 코드 라인 24~28에서 요청한 가상 주소 범위에서 빈 매핑 공간을 찾아 vmap_area를 할당 구성하고 RB트리 및 리스트에 insert한 후 엔트리 정보를 반환한다.
- 코드 라인 30에서 vm_struct & vm_area 구조체를 구성한다.
- 코드 라인 32에서 구성한 vm_struct 구조체 포인터를 반환한다.
공간 검색 후 vmap_area 할당
alloc_vmap_area()
mm/vmalloc.c -1/2-
/* * Allocate a region of KVA of the specified size and alignment, within the * vstart and vend. */
static struct vmap_area *alloc_vmap_area(unsigned long size,
unsigned long align,
unsigned long vstart, unsigned long vend,
int node, gfp_t gfp_mask)
{
struct vmap_area *va;
struct rb_node *n;
unsigned long addr;
int purged = 0;
struct vmap_area *first;
BUG_ON(!size);
BUG_ON(offset_in_page(size));
BUG_ON(!is_power_of_2(align));
might_sleep();
va = kmalloc_node(sizeof(struct vmap_area),
gfp_mask & GFP_RECLAIM_MASK, node);
if (unlikely(!va))
return ERR_PTR(-ENOMEM);
/*
* Only scan the relevant parts containing pointers to other objects
* to avoid false negatives.
*/
kmemleak_scan_area(&va->rb_node, SIZE_MAX, gfp_mask & GFP_RECLAIM_MASK);
retry:
spin_lock(&vmap_area_lock);
/*
* Invalidate cache if we have more permissive parameters.
* cached_hole_size notes the largest hole noticed _below_
* the vmap_area cached in free_vmap_cache: if size fits
* into that hole, we want to scan from vstart to reuse
* the hole instead of allocating above free_vmap_cache.
* Note that __free_vmap_area may update free_vmap_cache
* without updating cached_hole_size or cached_align.
*/
if (!free_vmap_cache ||
size < cached_hole_size ||
vstart < cached_vstart ||
align < cached_align) {
nocache:
cached_hole_size = 0;
free_vmap_cache = NULL;
}
/* record if we encounter less permissive parameters */
cached_vstart = vstart;
cached_align = align;
/* find starting point for our search */
if (free_vmap_cache) {
first = rb_entry(free_vmap_cache, struct vmap_area, rb_node);
addr = ALIGN(first->va_end, align);
if (addr < vstart)
goto nocache;
if (addr + size < addr)
goto overflow;
} else {
addr = ALIGN(vstart, align);
if (addr + size < addr)
goto overflow;
n = vmap_area_root.rb_node;
first = NULL;
while (n) {
struct vmap_area *tmp;
tmp = rb_entry(n, struct vmap_area, rb_node);
if (tmp->va_end >= addr) {
first = tmp;
if (tmp->va_start <= addr)
break;
n = n->rb_left;
} else
n = n->rb_right;
}
if (!first)
goto found;
}
요청한 가상 주소 범위에서 빈 공간을 찾아 va(vmap_area)를 할당 및 구성하고, RB트리 및 리스트에 insert한 후 va(vmap_area)를 반환한다.
- vmap 캐시에서 먼저 검색하여 재사용할 수 있는지 확인한다.
- 최종 등록한 vm 또는 최종 free한 vm의 이전(prev)vm부터 검색하면 빠른 성공을 기대할 수 있다.
- 캐시에서 찾지 못한 경우 RB 트리로 구성된 전역 vmap_area_root에서 요청 시작 범위 바로 위에 있는 엔트리를 찾고
- 이어서 리스트로 구성한 vmap_area_list에서 빈 공간을 찾는다.
- 찾은 빈 공간에 별도로 메모리 할당 받은 vmap_area를 구성하고 insert 한다.
- 만일 한 번의 검색에서 공간을 찾지 못하는 경우 해지를 유보(lazy)한 vmap_area를 flush한 후 다시 검색하여 공간을 찾는다.
- 코드 라인 18~21에서 vmap_area 구조체를 구성하기 위해 reclaim 관련 플래그만 사용하여 할당을 받고 할당 에러인 경우 -ENOMEM을 반환한다.
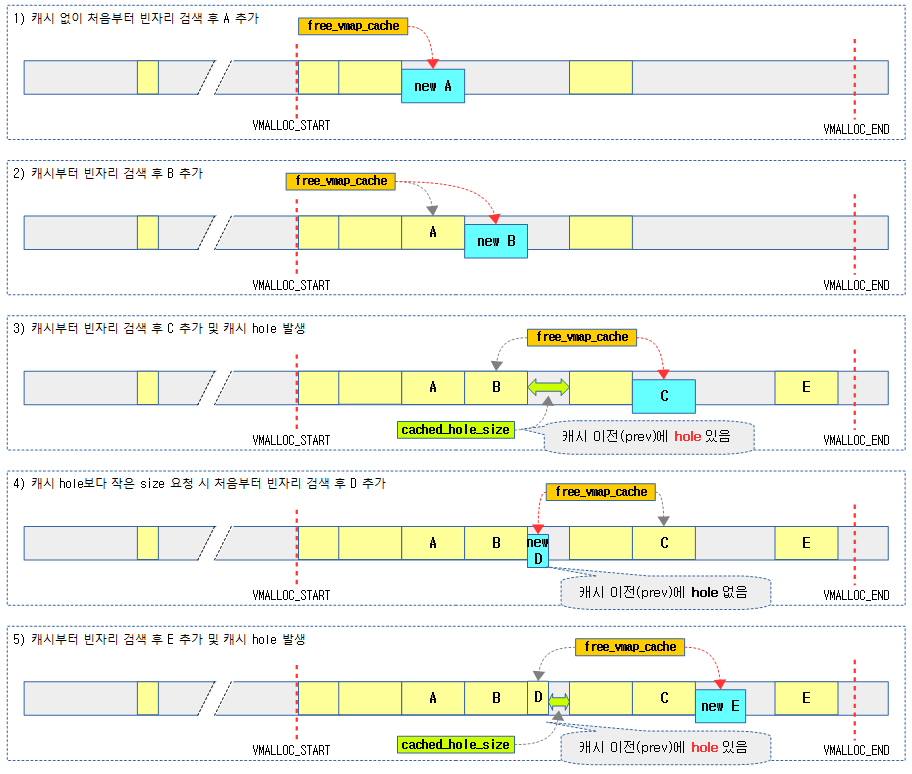
- 코드 라인 29~47에서 retry: 레이블이다. spin-lock을 얻고 캐시된 노드 위치를 사용할 수 없는 조건인 경우 이 번 검색에 캐시를 사용하지 못하게 한다. 조건은 다음과 같다.
- 캐시 바로 이전(prev) 공간에 있는 hole이 새로 요청하는 size를 커버할 수 있는 경우
- 시작 요청 범위가 캐시 사용 시의 요청 범위보다 작은 경우
- 요청 align 값이 캐시된 align 값 보다 작은 경우
- 코드 라인 53~59에서 free_vmap_cache 캐시가 가리키는 rb 노드를 first에 대입하고, 그 노드의 끝 주소를 addr에 대입하여 여기서 부터 검색할 준비를 한다.
- 최종 등록하였거나 최근 free 시킨 va(vmap_area) 이전(prev) va를 보관한 free_vmap_cache에서 vm 엔트리를 가져온다.
- 만일 first 엔트리의 끝 주소가 요청 범위를 벗어난 경우 캐시를 사용하지 않게 하기 위해 nocache 레이블로 이동한다.
- 또한 first 엔트리의 끝 주소에 size를 더해서 범위를 초과한 경우 overflow 레이블로 이동한다.
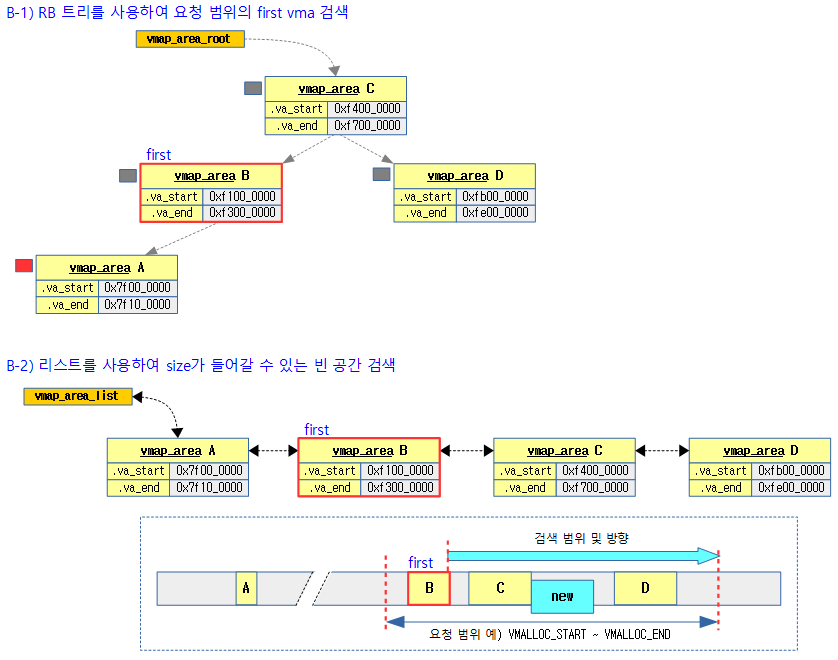
- 코드 라인 61~83에서 free_vmap_cache 캐시에 없는 경우 전역 vmap_area_root RB 트리를 통해 요청 범위에서 가장 첫 va를 찾아 first에 대입한다.
- free_vmap_cache를 사용할 수 없는 경우 first 엔트리의 끝 주소에 size를 더해서 범위를 초과한 경우 overflow 레이블로 이동한다.
mm/vmalloc.c -2/2-
/* from the starting point, walk areas until a suitable hole is found */
while (addr + size > first->va_start && addr + size <= vend) {
if (addr + cached_hole_size < first->va_start)
cached_hole_size = first->va_start - addr;
addr = ALIGN(first->va_end, align);
if (addr + size < addr)
goto overflow;
if (list_is_last(&first->list, &vmap_area_list))
goto found;
first = list_next_entry(first, list);
}
found:
if (addr + size > vend)
goto overflow;
va->va_start = addr;
va->va_end = addr + size;
va->flags = 0;
__insert_vmap_area(va);
free_vmap_cache = &va->rb_node;
spin_unlock(&vmap_area_lock);
BUG_ON(!IS_ALIGNED(va->va_start, align));
BUG_ON(va->va_start < vstart);
BUG_ON(va->va_end > vend);
return va;
overflow:
spin_unlock(&vmap_area_lock);
if (!purged) {
purge_vmap_area_lazy();
purged = 1;
goto retry;
}
if (gfpflags_allow_blocking(gfp_mask)) {
unsigned long freed = 0;
blocking_notifier_call_chain(&vmap_notify_list, 0, &freed);
if (freed > 0) {
purged = 0;
goto retry;
}
}
if (!(gfp_mask & __GFP_NOWARN) && printk_ratelimit())
pr_warn("vmap allocation for size %lu failed: use vmalloc=<size> to increase size\n",
size);
kfree(va);
return ERR_PTR(-EBUSY);
}
- 코드 라인 2~13에서 전역 first va(vmap_area)부터 리스트의 끝까지 요청 범위 내에서 size가 들어갈 수 있는 빈 공간을 찾는다.
- 코드 라인 15~30에서 found: 레이블이다. 적절한 공간을 찾은 경우 RB 트리 및 리스트에 insert 하고, 영역을 반환한다.
- 코드 라인 32~47에서 overflow: 레이블이다. 빈 공간을 찾을 수 없는 경우 lazy TLB flush 된 상태의 free 상태의 vm 엔트리들을 모두 purge 처리하여 삭제한 후 한 번만 다시 시도한다.
다음 그림은 매핑을 위해 요청 가상 주소 범위내에서 빈 공간을 찾을 때 먼저 free_vmap_cache 부터 size가 들어갈 빈공간을 검색하는 모습을 보여준다.

다음 그림은 매핑을 위해 요청 가상 주소 범위내에서 빈 공간을 찾을 때 RB 트리로 first vmap_area를 찾고 다시 리스트를 사용하여 size가 들어갈 빈공간을 검색하는 모습을 보여준다.
다음 그림은 free_vmap_cache와 cached_hole_size의 변화를 보여준다.
- cached_hole_size는 캐시의 바로 앞 hole의 크기만을 기억한다.
vmap_area 추가
__insert_vmap_area()
mm/vmalloc.c
static void __insert_vmap_area(struct vmap_area *va)
{
struct rb_node **p = &vmap_area_root.rb_node;
struct rb_node *parent = NULL;
struct rb_node *tmp;
while (*p) {
struct vmap_area *tmp_va;
parent = *p;
tmp_va = rb_entry(parent, struct vmap_area, rb_node);
if (va->va_start < tmp_va->va_end)
p = &(*p)->rb_left;
else if (va->va_end > tmp_va->va_start)
p = &(*p)->rb_right;
else
BUG();
}
rb_link_node(&va->rb_node, parent, p);
rb_insert_color(&va->rb_node, &vmap_area_root);
/* address-sort this list */
tmp = rb_prev(&va->rb_node);
if (tmp) {
struct vmap_area *prev;
prev = rb_entry(tmp, struct vmap_area, rb_node);
list_add_rcu(&va->list, &prev->list);
} else
list_add_rcu(&va->list, &vmap_area_list);
}
전역 vmap_area_root RB 트리와 전역 vmap_area_list에 vmap_area 엔트리를 insert 한다.
- 코드 라인 7~18에서 vmap_area_root RB 트리에서 insert 할 leaf 노드를 찾는다.
- 코드 라인 20~21에서 leaf 노드에 엔트리를 연결하고, RB 트리의 밸런스를 균형있게 맞춘다.
- 코드 라인 24~30에서 마지막으로 rcu를 사용하여 vmap_area_list에 vmap_area 엔트리를 끼워 넣는다.
- RB 트리에 insert한 엔트리를 RB 트리를 이용하여 rb_prev()를 사용하는 경우 바로 앞에 있는 노드를 알아내어 리스트 연결에 끼워넣을 수 있다.
다음 그림은 vmap_area 엔트리를 추가할 때의 모습을 보여준다.

vm_area 매핑
map_vm_area()
mm/vmalloc.c
int map_vm_area(struct vm_struct *area, pgprot_t prot, struct page **pages)
{
unsigned long addr = (unsigned long)area->addr;
unsigned long end = addr + get_vm_area_size(area);
int err;
err = vmap_page_range(addr, end, prot, pages);
return err > 0 ? 0 : err;
}
EXPORT_SYMBOL_GPL(map_vm_area);
요청한 vm_struct 정보에 담긴 가상 주소 범위에 매핑한다.
get_vm_area_size()
include/linux/vmalloc.h
static inline size_t get_vm_area_size(const struct vm_struct *area)
{
if (!(area->flags & VM_NO_GUARD))
/* return actual size without guard page */
return area->size - PAGE_SIZE;
else
return area->size;
}
영역이 사용하는 페이지 수를 반환한다.
vmap_page_range()
mm/vmalloc.c
static int vmap_page_range(unsigned long start, unsigned long end,
pgprot_t prot, struct page **pages)
{
int ret;
ret = vmap_page_range_noflush(start, end, prot, pages);
flush_cache_vmap(start, end);
return ret;
}
요청한 가상 주소 범위를 매핑하고 그 공간을 flush한다.
vmap_page_range_noflush()
mm/vmalloc.c
/* * Set up page tables in kva (addr, end). The ptes shall have prot "prot", and * will have pfns corresponding to the "pages" array. * * Ie. pte at addr+N*PAGE_SIZE shall point to pfn corresponding to pages[N] */
static int vmap_page_range_noflush(unsigned long start, unsigned long end,
pgprot_t prot, struct page **pages)
{
pgd_t *pgd;
unsigned long next;
unsigned long addr = start;
int err = 0;
int nr = 0;
BUG_ON(addr >= end);
pgd = pgd_offset_k(addr);
do {
next = pgd_addr_end(addr, end);
err = vmap_p4d_range(pgd, addr, next, prot, pages, &nr);
if (err)
return err;
} while (pgd++, addr = next, addr != end);
return nr;
}
요청 가상 주소 범위에 해당하는 커널 페이지 테이블을 **pages 와 속성 정보를 사용하여 매핑한다.
- pgd -> p4d -> pud -> pmd -> pte 테이블 순으로 population해가며 마지막 pte 테이블의 해당 엔트리에 매핑한다.
flush_cache_vmap() – ARM32
arch/arm/include/asm/cacheflush.h()
/*
* flush_cache_vmap() is used when creating mappings (eg, via vmap,
* vmalloc, ioremap etc) in kernel space for pages. On non-VIPT
* caches, since the direct-mappings of these pages may contain cached
* data, we need to do a full cache flush to ensure that writebacks
* don't corrupt data placed into these pages via the new mappings.
*/
static inline void flush_cache_vmap(unsigned long start, unsigned long end)
{
if (!cache_is_vipt_nonaliasing())
flush_cache_all();
else
/*
* set_pte_at() called from vmap_pte_range() does not
* have a DSB after cleaning the cache line.
*/
dsb(ishst);
}
요청한 가상 주소 범위에 대해 flush를 한다.
- 아키텍처가 pipt 캐시를 사용하고나 vipt nonaliasing을 지원하는 경우 flush를 할 필요가 없어서 성능이 크게 개선된다.
flush_cache_vmap() – ARM64
arch/arm64/include/asm/cacheflush.h
/* * Not required on AArch64 (PIPT or VIPT non-aliasing D-cache). */
static inline void flush_cache_vmap(unsigned long start, unsigned long end)
{
}
ARM64 에서는 vmap 매핑을 위해 캐시를 flush하지 않는다.
vm_struct 설정
setup_vmalloc_vm()
mm/vmalloc.c
static void setup_vmalloc_vm(struct vm_struct *vm, struct vmap_area *va,
unsigned long flags, const void *caller)
{
spin_lock(&vmap_area_lock);
vm->flags = flags;
vm->addr = (void *)va->va_start;
vm->size = va->va_end - va->va_start;
vm->caller = caller;
va->vm = vm;
va->flags |= VM_VM_AREA;
spin_unlock(&vmap_area_lock);
}
vm_struct 및 vmap_area에 정보를 설정한다.
vmap 매핑 해제
vunmap()
mm/vmalloc.c
/** * vunmap - release virtual mapping obtained by vmap() * @addr: memory base address * * Free the virtually contiguous memory area starting at @addr, * which was created from the page array passed to vmap(). * * Must not be called in interrupt context. */
void vunmap(const void *addr)
{
BUG_ON(in_interrupt());
might_sleep();
if (addr)
__vunmap(addr, 0);
}
EXPORT_SYMBOL(vunmap);
vmap() 함수로 vmalloc 주소 공간에 매핑한 가상 주소 영역의 매핑을 해제한다. 다만 물리 페이지는 할당 해제하지 않는다.
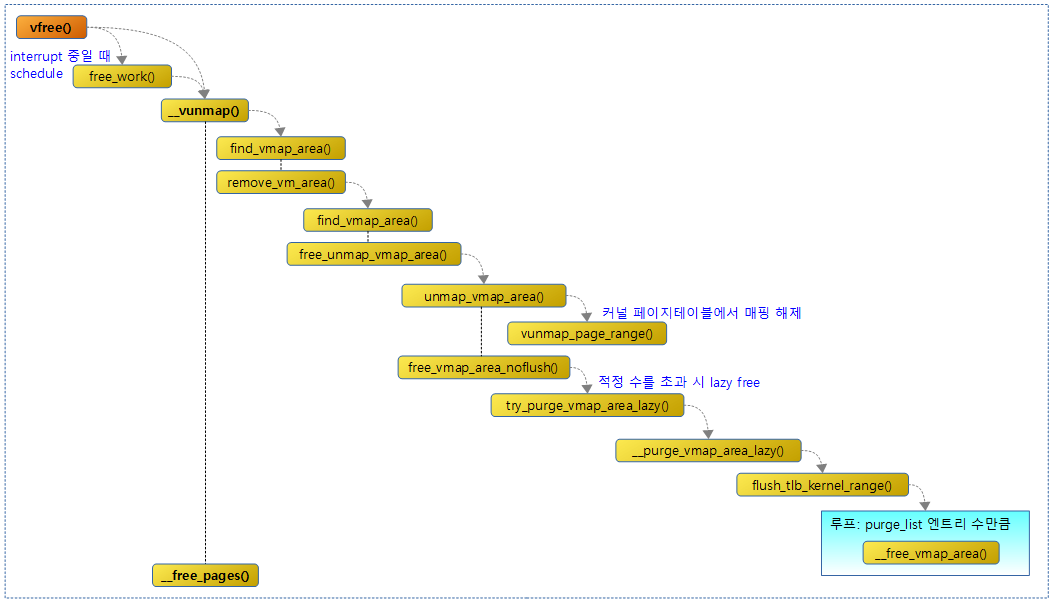
다음 그림은 vunmap() 함수에 대해 연관 함수들과의 처리 흐름을 보여준다.
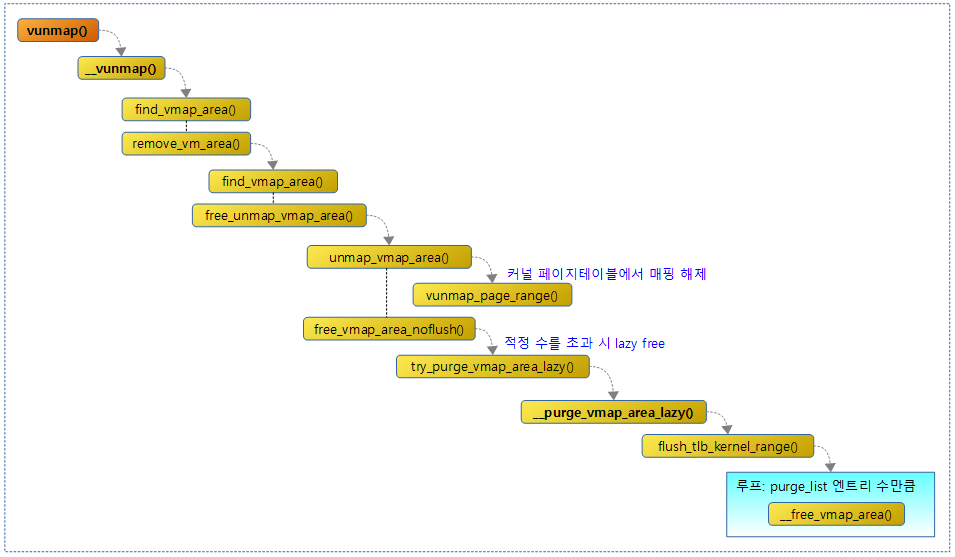
다음 그림은 vummap() 함수가 요청한 가상 주소로 vmap_area()를 찾아 그에 해당하는 매핑을 삭제하는 모습을 보여준다.
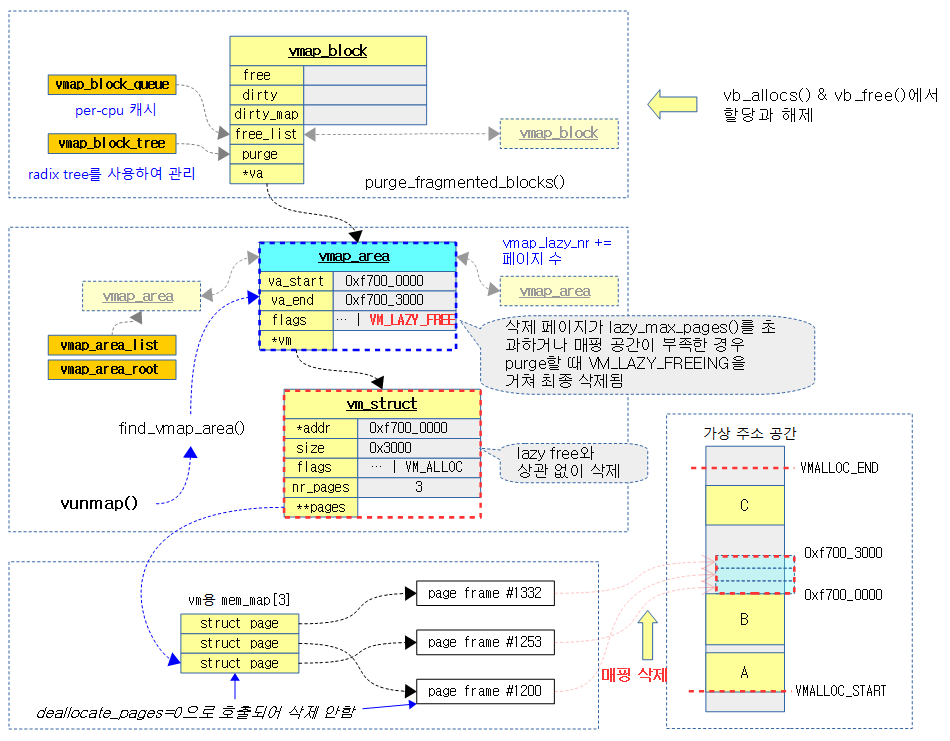
__vunmap()
mm/vmalloc.c
static void __vunmap(const void *addr, int deallocate_pages)
{
struct vm_struct *area;
if (!addr)
return;
if (WARN(!PAGE_ALIGNED(addr), "Trying to vfree() bad address (%p)\n",
addr))
return;
area = find_vmap_area((unsigned long)addr)->vm;
if (unlikely(!area)) {
WARN(1, KERN_ERR "Trying to vfree() nonexistent vm area (%p)\n",
addr);
return;
}
debug_check_no_locks_freed(area->addr, get_vm_area_size(area));
debug_check_no_obj_freed(area->addr, get_vm_area_size(area));
remove_vm_area(addr);
if (deallocate_pages) {
int i;
for (i = 0; i < area->nr_pages; i++) {
struct page *page = area->pages[i];
BUG_ON(!page);
__free_pages(page, 0);
}
kvfree(area->pages);
}
kfree(area);
return;
}
요청 가상 주소로 vm 정보를 찾아 매핑을 제거하고 요청에 따라 각 페이지들을 해제하여 버디 시스템으로 돌려준다.
- RB 트리 vmap_area_root에 등록되어 있는 vmap_area 정보에서 요청 가상 주소를 검색하여 매치된 vmap_area 및 vm_struct 정보를 제거하고 매핑을 해제한 다. 만일 @deallocate_pages 인수의 요청 여부에 따라 물리 페이지들을 해제한다.
- 코드 라인 12~17에서 RB 트리 vmap_area_root에 등록되어 있는 vmap_area 정보에서 요청 가상 주소로 vm을 검색한다.
- 코드 라인 22에서 vm을 RB 트리 및 리스트에서 제거하고, 매핑 해제 요청한 후 vm을 반환한다.
- 코드 라인 23~34에서 @deallocate_pages 인수 요청이 설정된 경우 등록된 모든 페이지들을 해제하여 버디 시스템으로 돌려준다.
- 코드 라인 36~37에서 vm_area 구조체 정보를 할당 해제한다.
vmap_area 삭제 및 매핑 해제 요청
remove_vm_area()
mm/vmalloc.c
/** * remove_vm_area - find and remove a continuous kernel virtual area * @addr: base address * * Search for the kernel VM area starting at @addr, and remove it. * This function returns the found VM area, but using it is NOT safe * on SMP machines, except for its size or flags. */
struct vm_struct *remove_vm_area(const void *addr)
{
struct vmap_area *va;
might_sleep();
va = find_vmap_area((unsigned long)addr);
if (va && va->flags & VM_VM_AREA) {
struct vm_struct *vm = va->vm;
spin_lock(&vmap_area_lock);
va->vm = NULL;
va->flags &= ~VM_VM_AREA;
va->flags |= VM_LAZY_FREE;
spin_unlock(&vmap_area_lock);
kasan_free_shadow(vm);
free_unmap_vmap_area(va);
return vm;
}
return NULL;
}
요청 가상 주소를 RB 트리 vmap_area_root에 등록되어 있는 vmap_area 정보에서 검색하여 매치된 vmap_area 정보를 제거하고 매핑을 해제 요청한 후 vm_struct 정보를 알아온다.
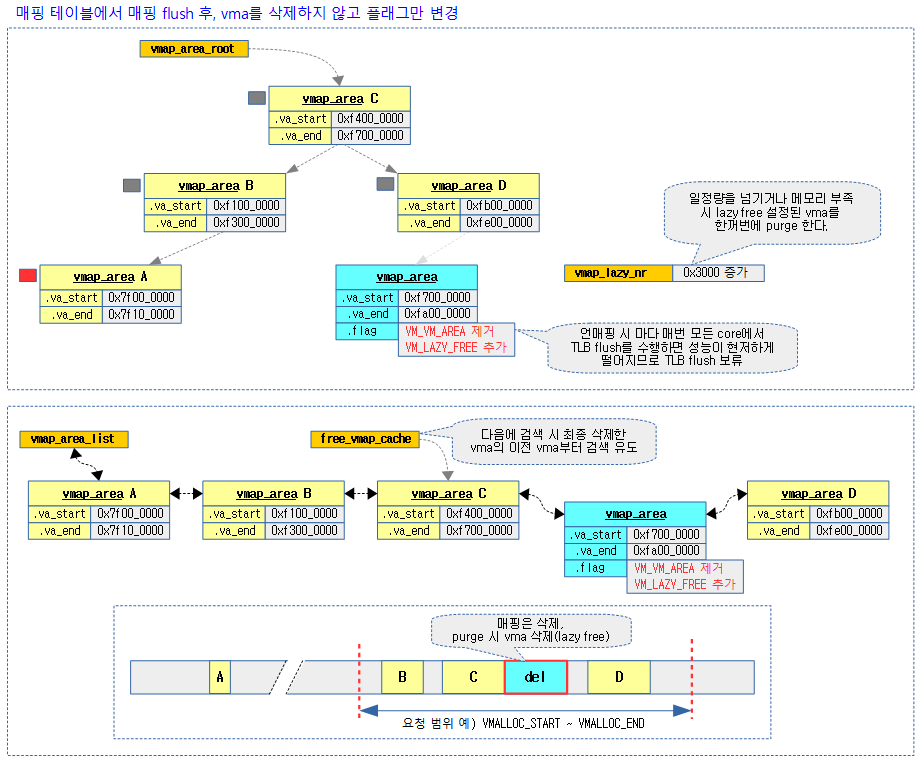
- 메모리 매핑은 해제하는데 vm_area는 VM_VM_AREA 플래그를 삭제하고 VM_LAZY_FREE 플래그를 추가하기만 한다.
- 실제 삭제는 vmap_lazy_nr 갯수가 일정량을 초과하거나 메모리 부족 시 VM_LAZY_FREE 설정된 vma들을 한꺼번에 purge 처리한다.
- vmalloc address space의 매핑이 해지되거나 수정되는 경우 모든 core에서 TLB 플러쉬가 발생되어야 하는데 이를 매 번 수행하는 경우 성능이 현저하게 저하되므로 삭제될 항목을 모아 두었다가 한꺼번에 삭제하는 방식을 취한다. 이를 Lazy TLB flushing이라 부른다.
vmap_area 검색
find_vmap_area()
mm/vmalloc.c
static struct vmap_area *find_vmap_area(unsigned long addr)
{
struct vmap_area *va;
spin_lock(&vmap_area_lock);
va = __find_vmap_area(addr);
spin_unlock(&vmap_area_lock);
return va;
}
vmap_area lock으로 보호한 후 요청 가상 주소로 vmap_area 정보를 찾아온다. 못찾은 경우 null을 반환한다.
__find_vmap_area()
mm/vmalloc.c
static struct vmap_area *__find_vmap_area(unsigned long addr)
{
struct rb_node *n = vmap_area_root.rb_node;
while (n) {
struct vmap_area *va;
va = rb_entry(n, struct vmap_area, rb_node);
if (addr < va->va_start)
n = n->rb_left;
else if (addr >= va->va_end)
n = n->rb_right;
else
return va;
}
return NULL;
}
요청 가상 주소로 vmap_area 정보를 찾아온다. 못찾은 경우 null을 반환한다.
- 요청 가상 주소를 RB 트리 vmap_area_root에 등록되어 있는 vmap_area 정보에서 검색하여 매치된 vmap_area 정보를 찾아온다.
vmap_area 매핑 해제
free_unmap_vmap_area()
mm/vmalloc.c
/* * Free and unmap a vmap area */
static void free_unmap_vmap_area(struct vmap_area *va)
{
flush_cache_vunmap(va->va_start, va->va_end);
unmap_vmap_area(va);
if (debug_pagealloc_enabled())
flush_tlb_kernel_range(va->va_start, va->va_end);
free_vmap_area_noflush(va);
}
아키텍처에 따라 지정된 가상 주소 범위의 데이타 캐시를 비운후 해당 영역의 매핑을 해제한다.
flush_cache_vunmap() – ARM32
arch/arm/include/asm/cacheflush.h
static inline void flush_cache_vunmap(unsigned long start, unsigned long end)
{
if (!cache_is_vipt_nonaliasing())
flush_cache_all();
}
아키텍처의 데이타 캐시가 vivt 타입이거나 vipt aliasing인 경우 캐시를 모두 비우게 한다.
- 데이타 캐시가 pipt 타입이거나 vipt nonaliasing 타입인 경우 캐시를 비우지 않아도 되므로 성능이 향상된다.
flush_cache_vunmap() – ARM64
arch/arm64/include/asm/cacheflush.h
static inline void flush_cache_vunmap(unsigned long start, unsigned long end)
{
}
ARM64 에서는 vmap 매핑 해제를 위해 캐시를 flush하지 않는다.
free_unmap_vmap_area_noflush()
mm/vmalloc.c
/* * Free and unmap a vmap area, caller ensuring flush_cache_vunmap had been * called for the correct range previously. */
static void free_unmap_vmap_area_noflush(struct vmap_area *va)
{
unmap_vmap_area(va);
free_vmap_area_noflush(va);
}
vmap_area가 사용하는 가상 주소 영역의 매핑을 커널 페이지 테이블에서 해제한다. 그런 후 vmap_area를 곧바로 삭제하지 않고 purge_list에 추가한다.
- vmap_area가 재활용되는 경우 시간 소모가 큰 TLB 캐시를 flush 하지 않아도 되기 때문에 성능이 매우 좋아진다.
페이지 테이블 매핑 해제
unmap_vmap_area()
mm/vmalloc.c
/* * Clear the pagetable entries of a given vmap_area */
static void unmap_vmap_area(struct vmap_area *va)
{
vunmap_page_range(va->va_start, va->va_end);
}
vmap_area의 가상 주소 영역의 매핑을 커널 페이지 테이블에서 해제한다.
vunmap_page_range()
mm/vmalloc.c
static void vunmap_page_range(unsigned long addr, unsigned long end)
{
pgd_t *pgd;
unsigned long next;
BUG_ON(addr >= end);
pgd = pgd_offset_k(addr);
do {
next = pgd_addr_end(addr, end);
if (pgd_none_or_clear_bad(pgd))
continue;
vunmap_p4d_range(pgd, addr, next);
} while (pgd++, addr = next, addr != end);
}
요청 가상 주소 범위의 매핑을 커널 페이지 테이블에서 해제한다.
- pgd -> p4d -> pud -> pmd -> pte 테이블 순으로 찾아가면 마지막 pte 테이블의 해당 엔트리를 언매핑한다.
lazy TLB Flush 요청
free_vmap_area_noflush()
mm/vmalloc.c
/* * Free a vmap area, caller ensuring that the area has been unmapped * and flush_cache_vunmap had been called for the correct range * previously. */
static void free_vmap_area_noflush(struct vmap_area *va)
{
int nr_lazy;
nr_lazy = atomic_add_return((va->va_end - va->va_start) >> PAGE_SHIFT,
&vmap_lazy_nr);
/* After this point, we may free va at any time */
llist_add(&va->purge_list, &vmap_purge_list);
if (unlikely(nr_lazy > lazy_max_pages()))
try_purge_vmap_area_lazy();
}
vmap_area를 곧바로 삭제하지 않고 VM_LAZY_FREE 플래그를 설정하여 lazy TLB 플러시 요청한다. 그 후 페이지 수가 일정량을 초과하는 경우 purge 처리를 수행한다.
lazy_max_pages()
mm/vmalloc.c
/* * lazy_max_pages is the maximum amount of virtual address space we gather up * before attempting to purge with a TLB flush. * * There is a tradeoff here: a larger number will cover more kernel page tables * and take slightly longer to purge, but it will linearly reduce the number of * global TLB flushes that must be performed. It would seem natural to scale * this number up linearly with the number of CPUs (because vmapping activity * could also scale linearly with the number of CPUs), however it is likely * that in practice, workloads might be constrained in other ways that mean * vmap activity will not scale linearly with CPUs. Also, I want to be * conservative and not introduce a big latency on huge systems, so go with * a less aggressive log scale. It will still be an improvement over the old * code, and it will be simple to change the scale factor if we find that it * becomes a problem on bigger systems. */
static unsigned long lazy_max_pages(void)
{
unsigned int log;
log = fls(num_online_cpus());
return log * (32UL * 1024 * 1024 / PAGE_SIZE);
}
TLB lazy된 페이지들의 purge 처리를 위해 필요한 페이지 수를 산출한다.
- 32M에 해당하는 페이지 수 * log2(online cpu) + 1에 비례하는 페이지 수를 반환한다.
- cpu가 많아지는 경우 TLB flush는 시스템의 전체적인 성능을 떨어뜨리므로 cpu 수가 많아질 수록 lazy_max_pages 수는 더 커져야 한다.
lazy TLB vmap_area들의 Purge 처리
try_purge_vmap_area_lazy()
mm/vmalloc.c
/* * Kick off a purge of the outstanding lazy areas. Don't bother if somebody * is already purging. */
static void try_purge_vmap_area_lazy(void)
{
if (mutex_trylock(&vmap_purge_lock)) {
__purge_vmap_area_lazy(ULONG_MAX, 0);
mutex_unlock(&vmap_purge_lock);
}
}
Lazy TLB 플러시 요청된 vmap_area들을 제거하고 전체 가상 주소 범위의 TLB flush를 수행한다.
__purge_vmap_area_lazy()
mm/vmalloc.c
/* * Purges all lazily-freed vmap areas. */
static bool __purge_vmap_area_lazy(unsigned long start, unsigned long end)
{
struct llist_node *valist;
struct vmap_area *va;
struct vmap_area *n_va;
bool do_free = false;
lockdep_assert_held(&vmap_purge_lock);
valist = llist_del_all(&vmap_purge_list);
llist_for_each_entry(va, valist, purge_list) {
if (va->va_start < start)
start = va->va_start;
if (va->va_end > end)
end = va->va_end;
do_free = true;
}
if (!do_free)
return false;
flush_tlb_kernel_range(start, end);
spin_lock(&vmap_area_lock);
llist_for_each_entry_safe(va, n_va, valist, purge_list) {
int nr = (va->va_end - va->va_start) >> PAGE_SHIFT;
__free_vmap_area(va);
atomic_sub(nr, &vmap_lazy_nr);
cond_resched_lock(&vmap_area_lock);
}
spin_unlock(&vmap_area_lock);
return true;
}
Lazy TLB 플러시 요청된 vmap_area들을 모두 제거하고 @start ~ @end 범위의 TLB flush를 수행한다.
- 코드 라인 10~17에서 purge 리스트에 있는 vmap_area 들의 최초 시작 주소와 마지막 끝 주소를 반영하여 flush할 시작 주소와 끝 주소를 갱신한다.
- 코드 라인 22에서 갱신된 start ~ end 범위의 가상 주소 영역에 대해 TLB 플러시를 수행한다.
- 코드 라인 24~32에서 purge 리스트에 있는 모든 vmap_area들을 할당 해제한다.
- 코드 라인 33에서 성공 true를 반환한다.
vmap_area 삭제
__free_vmap_area()
mm/vmalloc.c
static void __free_vmap_area(struct vmap_area *va)
{
BUG_ON(RB_EMPTY_NODE(&va->rb_node));
if (free_vmap_cache) {
if (va->va_end < cached_vstart) {
free_vmap_cache = NULL;
} else {
struct vmap_area *cache;
cache = rb_entry(free_vmap_cache, struct vmap_area, rb_node);
if (va->va_start <= cache->va_start) {
free_vmap_cache = rb_prev(&va->rb_node);
/*
* We don't try to update cached_hole_size or
* cached_align, but it won't go very wrong.
*/
}
}
}
rb_erase(&va->rb_node, &vmap_area_root);
RB_CLEAR_NODE(&va->rb_node);
list_del_rcu(&va->list);
/*
* Track the highest possible candidate for pcpu area
* allocation. Areas outside of vmalloc area can be returned
* here too, consider only end addresses which fall inside
* vmalloc area proper.
*/
if (va->va_end > VMALLOC_START && va->va_end <= VMALLOC_END)
vmap_area_pcpu_hole = max(vmap_area_pcpu_hole, va->va_end);
kfree_rcu(va, rcu_head);
}
요청한 vmap_area를 RB 트리 vmap_area_root와 vmap_area_list에서 제거한 후 해제한다.
참고
- Kmalloc vs Vmalloc | 문c
- Kmalloc | 문c
- Vmalloc | 문c
- Vmap() | 문c – 현재 글
- Red–black tree | wikipedia
- Reworking vmap() | LWN.net
- mm: rewrite vmap layer
- mm:rewrite vmap layer | Barrios